the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 25 May 2020
| 25 May 2020
Soil moisture: variable in space but redundant in time
Sibylle K. Hassler
Theresa Blume
Markus Weiler
Erwin Zehe
Soil moisture at the catchment scale exhibits a huge spatial variability. This suggests that even a large amount of observation points would not be able to capture soil moisture variability.
We present a measure to capture the spatial dissimilarity and its change over time. Statistical dispersion among observation points is related to their distance to describe spatial patterns. We analyzed the temporal evolution and emergence of these patterns and used the mean shift clustering algorithm to identify and analyze clusters. We found that soil moisture observations from the 19.4 km2 Colpach catchment in Luxembourg cluster in two fundamentally different states. On the one hand, we found rainfall-driven data clusters, usually characterized by strong relationships between dispersion and distance. Their spatial extent roughly matches the average hillslope length in the study area of about 500 m. On the other hand, we found clusters covering the vegetation period. In drying and then dry soil conditions there is no particular spatial dependence in soil moisture patterns, and the values are highly similar beyond hillslope scale.
By combining uncertainty propagation with information theory, we were able to calculate the information content of spatial similarity with respect to measurement uncertainty (when are patterns different outside of uncertainty margins?). We were able to prove that the spatial information contained in soil moisture observations is highly redundant (differences in spatial patterns over time are within the error margins). Thus, they can be compressed (all cluster members can be substituted by one representative member) to only a fragment of the original data volume without significant information loss.
Our most interesting finding is that even a few soil moisture time series bear a considerable amount of information about dynamic changes in soil moisture. We argue that distributed soil moisture sampling reflects an organized catchment state, where soil moisture variability is not random. Thus, only a small amount of observation points is necessary to capture soil moisture dynamics.
- Article
(4681 KB) - Full-text XML
- BibTeX
- EndNote





Although soil water is by far the smallest freshwater stock on earth, it plays a key role in the functioning of terrestrial ecosystems. Soil moisture controls (preferential) infiltration and runoff generation and is a limiting factor for vegetation growth. Plant-available soil water affects the Bowen ratio, i.e., the partitioning of net radiation energy in latent and sensible heat, and last but not least it is an important control for soil respiration and related trace gas emissions. Technologies and experimental strategies to observe soil water dynamics across scales have been at the core of the hydrological research agenda for more than 20 years (Topp et al., 1982, 1984). Since these early studies published by Topp, spatially and temporally distributed time domain reflectometry (TDR) and frequency domain reflectometry (FDR) measurements have been widely used to characterize soil moisture dynamics at the transect (e.g., Blume et al., 2009), hillslope (e.g., Starr and Timlin, 2004; Brocca et al., 2007) and catchment scale (e.g., Western et al., 2004; Bronstert et al., 2012). A common conclusion for the catchment scale is that soil moisture exhibits pronounced spatial variability and that distributed point sampling often does not yield representative data for the catchment (see, e.g., Zehe et al., 2010; Brocca et al., 2012, or numerous studies given in Sect. 2.2 of Vereecken et al., 2008).
Although large spatial variability seems to be a generic feature of soil moisture, there is also evidence that ranks of distributed soil moisture observations are largely stable in time, as observed at the plot (Rolston et al., 1991; Zehe et al., 2010), hillslope (Brocca et al., 2007, 2009; Blume et al., 2009), and even catchment scale (Martínez-Fernández and Ceballos, 2003; Grayson et al., 1997). This rank stability, which is also often referred to as temporal stability (Vanderlinden et al., 2012), can, i.e., be used to improve sensor networks (e.g., Heathman et al., 2009) or select the most representative observation site in terms of soil moisture dynamics (e.g., Teuling et al., 2006). In both cases rank stability assumes some kind of organization in the catchment, otherwise this representativity would not be observed.
Soil moisture dynamics have been subject to numerous review works (e.g., Daly and Porporato, 2005; Vereecken et al., 2008). More specifically, the temporal stability of soil moisture was reviewed by Vanderlinden et al. (2012). The authors analyzed a large number of studies with respect to the controls on time stability of soil water content (TS SWC), yet “the basic question about TS SWC and its controls remain unanswered. Moreover, the evidence found in literature with respect to TS SWC controls remains contradictory” (Vanderlinden et al., 2012, p. 2, l. 2 ff.). We want to contribute by proposing a method that helps to understand how and when spatial soil moisture patterns are persistent.
Soil moisture responds to two main forcing regimes, namely rainfall-driven wetting or radiation-driven drying. The related controlling factors and processes differ strongly and operate at different spatial and temporal scales, and the soil moisture pattern reflects thus the multitude of these influences (Bárdossy and Lehmann, 1998). Hence, we hypothesize that periods in which different controlling factors were dominant are reflected in fundamentally different soil moisture patterns. This can manifest itself in changes in the spatial covariance structure (Lark, 2012; Schume et al., 2003), either in the form of changing nugget-to-sill ratios (spatially explained variance) (Zehe et al., 2010) or state-dependent variogram ranges (spatial extent of correlation) (Western et al., 2004). In a homogeneous, flat and non-vegetated landscape the soil moisture pattern shortly after a rainfall event would be the imprint of the precipitation pattern and provide predictive information about its spatial covariance. In contrast, in a heterogeneous landscape driven by spatially uniform block rain events, the spatial pattern of soil moisture would be a largely stable imprint of different landscape properties controlling throughfall, infiltration as well as vertical and lateral soil water redistribution. Without further forcing, the spatial pattern will gradually dissipate due to soil water potential depletion and by lateral soil water flows. We therefore hypothesize that differences in soil moisture (across space) are higher shortly after a rainfall event and are dissipated afterwards.
Landscape heterogeneity is thus a perquisite for temporarily persistent spatial patterns found in a set of soil moisture time series. While most catchments are strongly heterogeneous, it is striking how spatially organized they are (Dooge, 1986; Sivapalan, 2003; McDonnell et al., 2007; Zehe et al., 2014; Bras, 2015). Spatial organization manifests for instance through systematic and structured patterns of catchment properties, such as a catena. This might naturally lead to a systematic variability of those processes controlling wetting and drying of the soil. One approach to diagnose and model systematic variability is based on the covariance between observations in relation to their separating distance (Burgess and Webster, 1980) and geostatistical interpolation or simulation methods (Kitanidis and Vomvoris, 1983; Ly et al., 2011; Pool et al., 2015).
A spatial covariance function describes how linear statistical dependence of observations declines with increasing separating distance up to the distance of statistical independence. This is often expressed as an experimental variogram. Geostatistics relies on several assumptions, such as second-order stationarity (see, e.g., Lark, 2012 or Burgess and Webster, 1980), which are ultimately important for interpolation. Due to the above-mentioned dynamic nature of soil moisture observations, the most promising avenue for interpolation would be a spatio-temporal geostatistical modeling of our data (Ma, 2002, 2003; De Cesare et al., 2002; Snepvangers et al., 2003; Jost et al., 2005).
However, here we take a different avenue, as we do not intend to interpolate. One of our goals is to detect dynamic changes in the spatial soil moisture pattern. Following Sampson and Guttorp (1992) we relate the statistical dispersion of soil moisture observations to their separating distance to characterize how their similarity and predictive information decline with this distance (see Sect. 2). More specifically, we analyze temporal changes in the spatial dispersion of distributed soil moisture data and hypothesize that a grouping of the data is possible solely based on the changes in spatial dispersion. We want to find out whether typical patterns emerge in time, how those relate to the different forcing regimes and whether those patterns are recurrent in time. The latter is an indicator of predictability and (self-)organization in dynamic systems (Wendi and Marwan, 2018; Wendi et al., 2018).
Zehe et al. (2014) argued that spatial organization manifests through a similar hydrological functioning. This is in line with the idea of Wagener et al. (2007) on catchment classification or the early idea of a geomorphological unit hydrograph (Rodríguez‐Iturbe et al., 1979; Sivapalan et al., 2011; Patil and Stieglitz, 2012). Recently, Loritz et al. (2018) corroborated the idea of Zehe et al. (2014) and showed that hydrological similarity of discharge time series implies that they are redundant. Redundancy in our context means that new observations (over time) do not add significant new information to the data set of spatial dispersion. Thus, they can be compressed without information loss (Weijs et al., 2013). This combination of compression rate and information loss is understood to be a measure of spatial organization in our work. More specifically, Loritz et al. (2018) showed that a set of 105 hillslope models yielded, despite their strong differences in topography, a strongly redundant runoff response. Using Shannon entropy (Shannon, 1948), Loritz et al. (2018) showed that the ensemble could be compressed to a set of six to eight typical hillslopes without performance loss. Here we adopt this idea and investigate the redundancy of patterns in spatially distributed soil moisture data along with their compressibility.
The core objective of this study is to provide evidence that distributed soil moisture time series provide, despite their strong spatial variability, representative information on soil moisture dynamics. More specifically, we test the following hypotheses.
-
H1: radiation-driven drying and rainfall-driven wetting leave different fingerprints in the soil moisture pattern.
-
H2: both forcing regimes and their seasonal variability may be identified through temporal clustering of dispersion functions.
-
H3: spatial dispersion is more pronounced during and shortly after rainfall-driven wetting conditions.
-
H4: soil moisture time series are redundant, which implies they are compressible without information loss. However, the degree of compressibility is changing over time.
We test these hypotheses using a distributed soil moisture data set collected in the Colpach catchment in Luxembourg. In Sect. 2 we give an overview of the study site and our method. The results section consists of three parts: spatial dispersion functions, temporal patterns in their emergence and some insights into generalization (or compressibility) of these functions, followed by a discussion and summary.
2.1 Study area and soil moisture data set
We base our analyses on the CAOS data set, which was collected in the Attert experimental watershed between 2012 and 2017 and is explained in Zehe et al. (2014). The Attert catchment is situated in western Luxembourg and Belgium (Fig. 1). Mean monthly temperatures range from 18 ∘C in July to 0 ∘C in January. Mean annual precipitation is approximately 850 mm (Pfister et al., 2000). The catchment covers three geological formations, Devonian schists of the Ardennes massif in the north-west, a mixture of Triassic sandy marls in the center and a small area on Luxembourg Sandstone on the southern catchment border (Martinez-Carreras et al., 2012). The respective soils in the three areas are haplic Cambisols in the schist, different types of Stagnosols in the marls area and Arenosols in the sandstone (IUSS Working Group WRB, 2006; Sprenger et al., 2016). The distinct differences in geology are also reflected in topography and land use. In the schist area, land use is mainly forest on steep slopes of the valleys, which intersect plateaus that are used for agriculture and pastures. The marls area has very gentle slopes and is mainly used for pastures and agriculture, while the sandstone area is forested on steep topography.
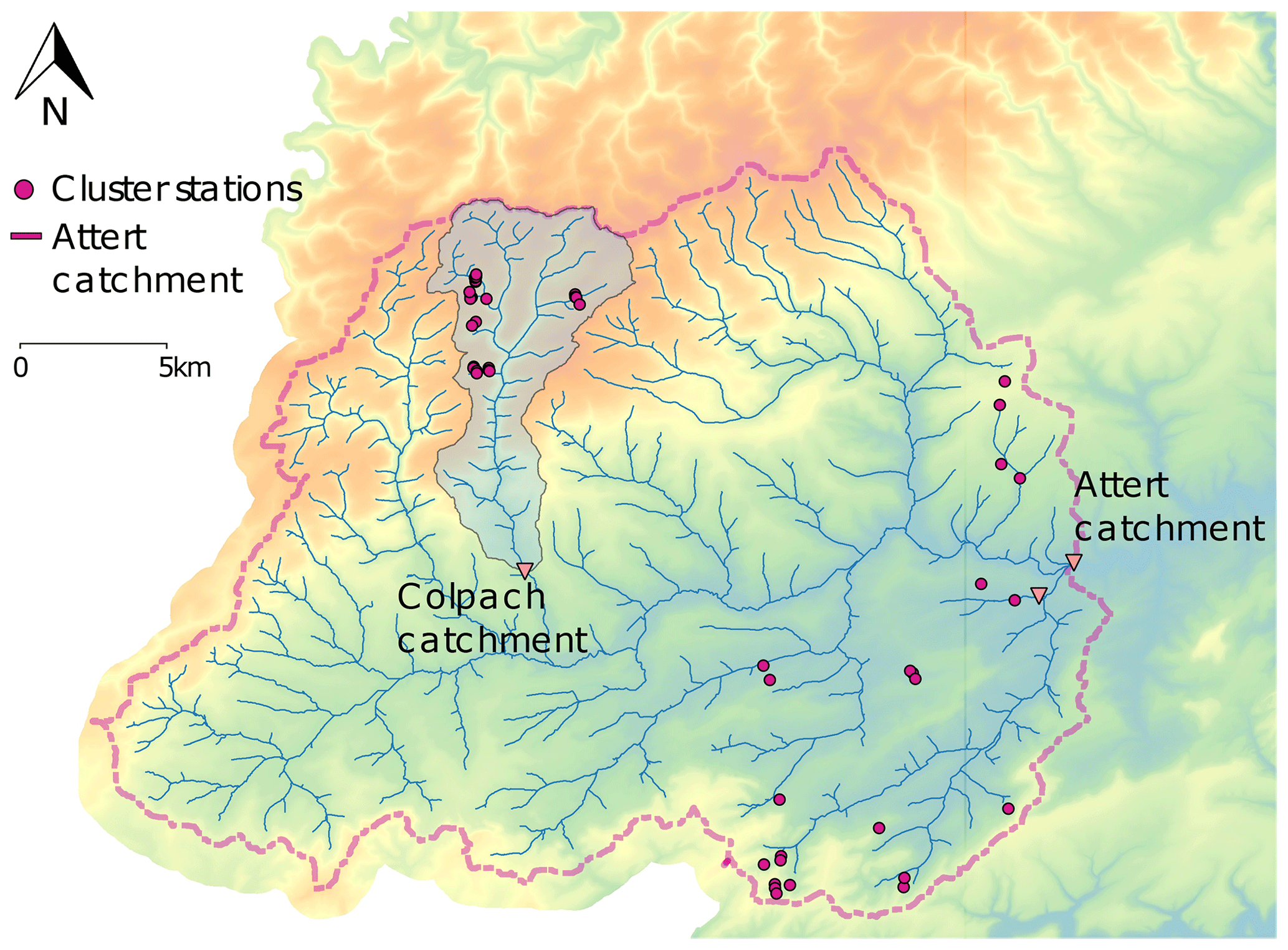
Figure 1Attert experimental catchment in Luxembourg and Belgium. The purple dots show the sensor cluster stations installed during the CAOS project. Here we focus on those cluster stations within the Colpach catchment. Figure adapted after Loritz et al. (2017).
The experimental design is based on spatially distributed, clustered point measurements within replicated hillslopes. Typical hillslope lengths vary between 400 and 600 m, showing maximum elevations of 50 to 100 m above stream level. For further details on the hillslopes, we refer the reader to Fig. 6a in Loritz et al. (2017) and a detailed description in Sect. 3.1.1 of the same publication. Sensor clusters were installed on hillslopes at the top, midslope and hill foot sectors along the anticipated flow paths. Within each of those clusters, soil moisture was recorded in three profiles at 10, 30 and 50 cm depth using Decagon 5TE sensors. While the entire design was stratified to sample different geological settings (schist, marls, sandstone), different aspects and land use (deciduous forest and pasture), we focus here on those sensors installed in the Colpach catchment. In total we used 19 sensor cluster locations and thus 57 soil moisture profiles consisting of 171 time series.
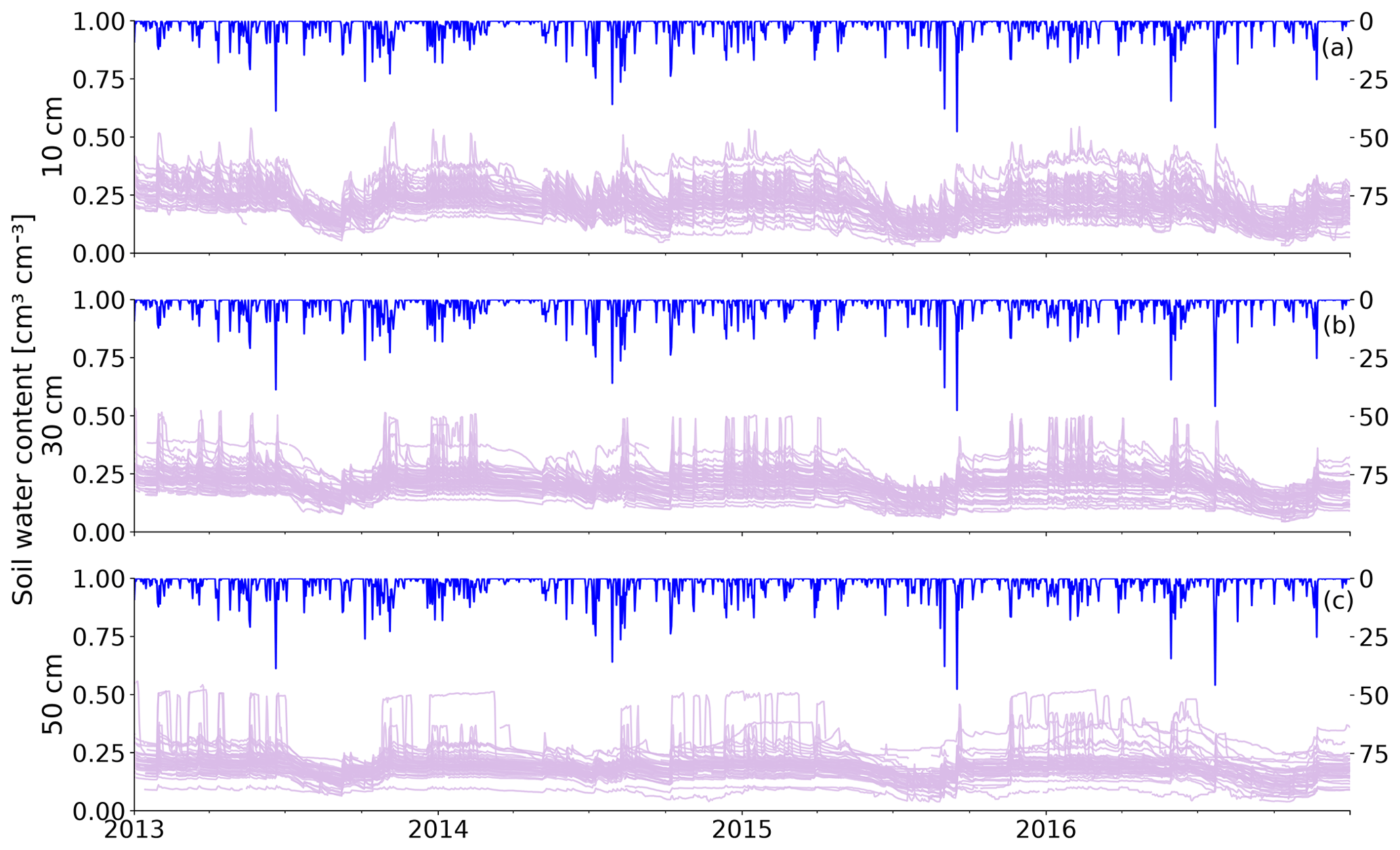
Figure 2Soil moisture data overview. Soil moisture observations in 10 cm (a), 30 cm (b) and 50 cm (c).
Soil moisture in the 19.4 km2 Colpach catchment exhibits high but temporally persistent spatial variability (Fig. 2). For each point in time a wide range of water content values can be observed across the catchment. The range of soil moisture observations is generally wider in winter than in summer. From visual inspection it seems that the heterogeneity in observations is not purely random but systematic, as the measurements are rank stable over long periods. One has to note that the different cluster locations differ in aspect, slope and land use. From the data shown in Fig. 2, two sensors have been removed. Both measured in 50 cm and can be seen in the figure at the very bottom. Both recorded values close to or even below 0.1 cm3 cm−3 for the whole period of 4 years. Additionally, the plateaus lasting for a couple of days at constant 0.5 cm3 cm−3 in 50 and 30 cm were removed.
2.2 Dispersion of soil moisture observations as a function of their distance
We focus on spatial patterns of soil moisture and how they change over time. For our analysis the data set was aggregated to mean daily soil moisture values θ. Each time series is further aggregated using a moving window of 1 month as described by Eq. (1).
This is calculated for each observation location x and time step t=1, 2, …, (L−b), with a time series length of L in days and a window size of b=301.
To estimate the spatial dependence structure between observations, we relate their pairwise separation distance to a measure of pairwise similarity. Here, we further define the statistical spatial dispersion as a measure of spatial similarity. We compare the empirical distribution of pairwise value differences at different distances. Statistically, a more dispersed empirical distribution is less well described by its mean value. Thus, observations taken at a specific distance are more similar in value if they are less dispersed.
To estimate the dispersion, we use the Cressie–Hawkins estimator (Cressie and Hawkins, 1980). This estimator is more robust to extreme values and the contained power transformation handles skewed data better than estimators based on the arithmetic mean (Bárdossy and Kundzewicz, 1990; Cressie and Hawkins, 1980). The estimator is given by Eq. (2):
for each moving window position t with zt(xi,j) given by Eq. (1) for each pair of observation locations xi, xj. h is the separating distance lag between these point pairs and N(h) the number of point pairs formed at the given lag h. Ten classes were formed with a maximum separation distance of 1200 m2. The lag classes are not equidistant, but with a fixed N(h) for all classes. This is further discussed in Sect. 2.3.
2.3 Clustering of dispersion functions
We analyzed how and whether meaningful spatial dispersion functions emerge and whether those converge into stable configurations. To tackle the hypotheses formulated in the introduction, a clustering is applied to the dispersion functions derived for each window. The clustering algorithm should form groups of functions that are more similar to each other than to members of other clusters. The similarity between two dispersion functions is calculated by the Euclidean vector distance between the dispersion values forming the function. This distance is defined by Eq. (3):
with u, v being two dispersion function vectors. This is the Euclidean distance of two points in the (higher-dimensional) value space of the dispersion function's distance lags. Two identical dispersion functions are represented by the same point in this value space, and hence their distance is zero. Thus, distance lags are not equidistant, as this could lead to empty lag classes. Empty lag classes result in an undefined position in the value space, which has to be avoided. The clustering algorithm cannot use the number of clusters as a parameter, as this can hardly be determined a priori. One clustering algorithm meeting these requirements is the mean shift algorithm (Fukunaga and Hostetler, 1975). The actual code implementation is taken from Pedregosa et al. (2011), which follows the Comaniciu and Meer (2002) variant of mean shift. A detailed description of the mean shift algorithm can be found in the Appendix (see Sect. A).
2.4 Cluster compression based on the cluster centroids
The next step is to generate a representative dispersion function for each cluster. The straightforward representative function is the cluster centroid (the dispersion function closest to the point of highest cluster member density; see Sect. A for a detailed explanation). All dispersion functions are calculated with the same parameters, including the maximum separating distance of 1200 m. At larger lags we found instances of declining dispersion values, because we then paired points located on different hillslopes but otherwise in similar landscape units (i.e., same hillslope position or land use). To facilitate the comparison of the dispersion functions we decided to monotonize them. In geostatistics this is usually done through fitting of a theoretical variogram model to the experimental variogram, which ensures monotony and positive definiteness. Here we do not force a specific shape by a fitting a model function. Instead we use the technique of monotonizing the cluster centroid as suggested by Hinterding (2003) using the PAVA algorithm (Barlow et al., 1972). The implementation is from Pedregosa et al. (2011). This way the final compressed dispersion functions are monotonically increasing while still reflecting the shape properties of the cluster members. If dispersion functions are monotonically increasing, they also provide information about the characteristic length of the soil moisture pattern. Similarly to the semi-variogram in geostatistics, this characteristic length corresponds to the lag distance where the dispersion function reaches its first local maximum.
We suggest that the number of clusters needed to represent all observed spatial dispersion functions over a calendar year can be used as a measure of spatial organization (fewer clusters needed means a higher degree of organization, because dispersion functions are redundant in time). Additionally, it is insightful to judge the information loss that goes along with this compression, as a high compression with little information loss is understood as a manifestation of spatial and temporal organization of soil moisture dynamics.
In line with Loritz et al. (2018) we use the Shannon entropy as a measure of the compression without information loss. It requires treatment of the clusters as discrete probability density functions, which in turn implies a careful selection of an appropriate classification of the data. Motivated by Loritz et al. (2018), we use the uncertainty in the dispersion function as a minimal class size for this classification, as described in Sect. 2.5.1.
2.5 Uncertainty propagation and compression quality
2.5.1 Uncertainty propagation
Soil moisture measurements have a considerable measurement uncertainty of 1–3 cm3 cm−3 as reported by manufacturers. For our uncertainty propagation we assume an absolute uncertainty/measurement error Δθ of 0.02 cm3 cm−3.
Next we propagate these uncertainties into the dispersion functions and the distances among those. As we assume the measurement uncertainties to be statistically independent, we use the Gaussian uncertainty propagation to calculate error bands/margins. In a general form, for any function f(z) and an absolute error Δz the propagated error Δf can be calculated. In our case z is itself a function of x, the observation location, and the general form is given by Eq. (4).
To apply Eq. (4) for our method, the measurement uncertainty Δθ is propagated into the dispersion estimator given by Eq. (2). The dispersion estimator is derived with respect to z(x) and, following Eq. (1), the uncertainty in z(x), Δz, is denoted as cm3 cm−3. Then, with a given Δz, we can propagate the uncertainty into the dispersion function. As the dispersion function is a function of the spatial lag h, we need to propagate the uncertainty Δa (uncertainty of the dispersion estimator) for each value of h. At the same time, following Eq. (2), for each h, is a fixed set of point pairs. Instead of propagating uncertainty through Eq. (2), we can substitute by δ, the pairwise differences, for each value of h. The uncertainty Δδ is given by Eq. (5):
The uncertainty of dispersion Δa is then defined by Eq. (6):
where the factors from Eq. (2) that stay constant in the derivative are denoted as c and defined in Eq. (7). In line with Eq. (2) N is the number of observation pairs available for a given lag class h and therefore constant for a single calculation. Δδ and δ are the substitutes for z, as described above (see Eq. 5).
The last step is to propagate the uncertainty into the distance function as defined in Eq. (3). The Euclidean distance is used as a measure of proximity by mean shift, as it groups dispersion functions at short distances together (for more details, see Sect. A). At the same time, we use the uncertainty propagated into the Euclidean distance between two dispersion functions to assess compression quality (as further described in Sect. 2.5.2). Following Eq. (4) the propagated uncertainty Δd can be calculated by the derivative of Eq. (3) with respect to each of the vectors multiplied by the corresponding value of Δa, which results in Eq. (8):
where u, v are two spatial dispersion function vectors as defined and used in Eq. (3). Δu,Δv are the vectors of uncertainties for u, v, where Δvi is the uncertainty propagated into the ith lag class as shown in Eq. (6). n is the number of lag classes and thus the length of each vector u, v, Δu, Δv.
Equation (8) is applied to all possible combinations of dispersion functions u, v to get all possible uncertainties in dispersion function distances.
2.5.2 Compression quality
The Shannon entropy (Shannon, 1948) of all pairwise dispersion function distances is used as a measure of information content. The Shannon entropy of a discrete probability density function of states (patterns in this case) is maximized for the uniform distribution. It corresponds to the number of yes/no questions one has to ask to determine the state of a system. The minimum entropy is zero, which corresponds to the deterministic case where the system state is always known. A common way to define spatial organization of a physical system is through its distance from the maximum entropy state (Kondepudi and Prigogine, 1998; Kleidon, 2012). The deviation of the entropy of the dispersion functions in a cluster from its maximum value is thus a measure of their redundancy and thus similarity.
For a discrete frequency distribution of n bins, the information entropy H is defined as
where pn is the relative probability of the nth bin. H is calculated for each depth in each year individually to compare the information content across years and depths. Note that the term bin is also used in the literature to refer to the binning of pairwise data, e.g., in geostatistics. For this kind of binning, although technically the same thing, we used the term lag classes here to distinguish it from the binning as shown in Eq. (9). Thus, when we write bin or binning we refer to the classification of distances between dispersion functions, not observation points.
To ensure comparability, we use one binning for all calculations of H (across years and depths). To achieve this, all pairwise distances between all spatial dispersion functions of all 4 years in all three depths are calculated. The discrete frequency distribution is formed from 0 up to the global maximum distance (between two dispersion functions) calculated using Eq. (3). The bins are formed equidistantly using a width of the maximum function distance that still lies within the error margins calculated using Eq. (8). Thus, the information content of the spatial heterogeneity is calculated with respect to the expected uncertainties. This way we can be sure to distinguish exclusively those spatial dispersion functions that lie outside of the error margins.
The Kullback–Leibler divergence (Kullback and Leibler, 1951) is a measure of the difference between two empirical, discrete probability distributions. Usually, one distribution is considered to be the population and the other one a sample from it. The Kullback–Leibler divergence DKL then quantifies the uncertainty introduced (e.g., in an statistical model) using a sample as a substitute for the population.
We use the Kullback–Leibler divergence to measure and quantify the information loss due to compression. To compress the series of dispersion functions, each cluster member is expressed by its centroid function. Now, we need to calculate the amount of information lost in this process. To calculate the mean information content of the compressed series, each cluster member is substituted by the respective cluster centroid. This substitution is obviously not a compression in a technical sense, but it is necessary to calculate the Kullback–Leibler divergence. Then a frequency distribution for the compressed series X and the uncompressed series Y can be calculated. The Kullback–Leibler divergence DKL of X, Y is given in Eq. (10):
where is the cross entropy of X and Y and defined by Eq. (11):
where p(x) is the empirical non-exceedance probability of the frequency distribution X and p(y) of Y, respectively.
3.1 Dispersion functions over time
Figure 3a shows the spatial dispersion functions for all moving window positions in 2016 for the 30 cm sensors. The position of the moving window in time can be retraced by the line color: darker red means a later Julian day. Each of the spatial dispersion functions relates the dispersion for all pairwise observations to their separating distance in the corresponding lag class. Dispersion increases with separating distance, as small values correspond to observations which have similar values, while large values suggest the opposite. As expected, the dispersion is a suitable metric for similarity/dependency of observations.
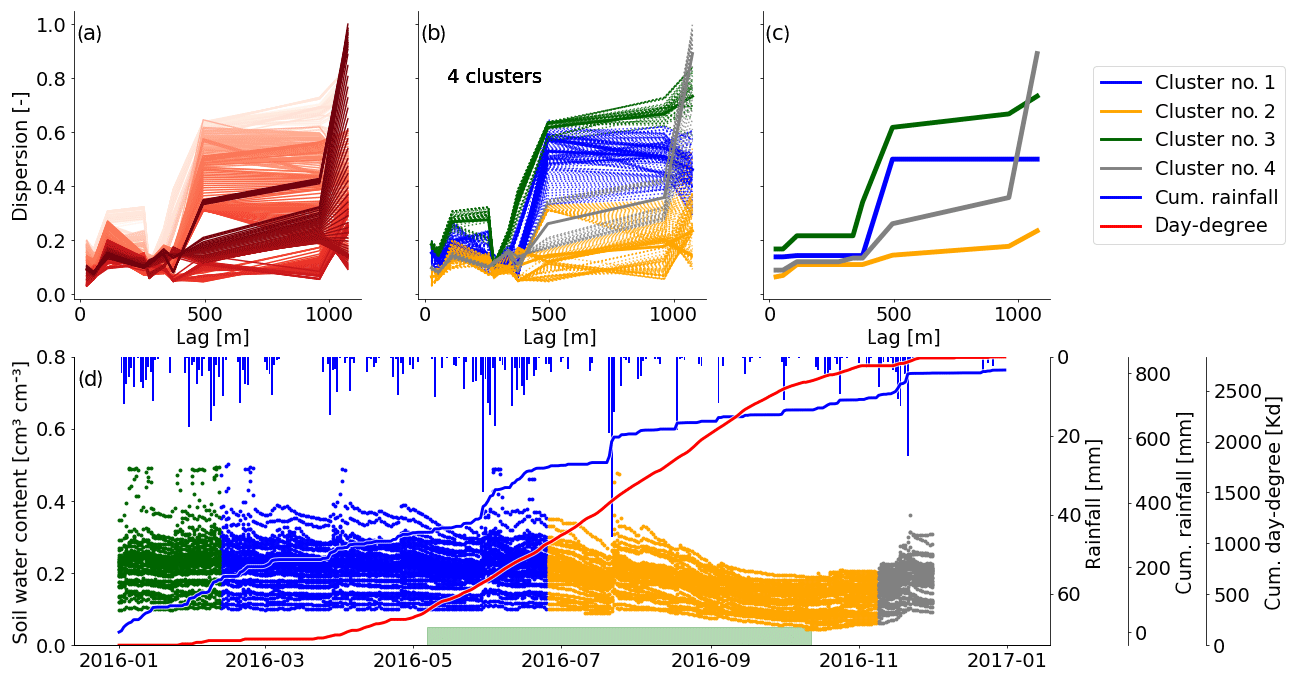
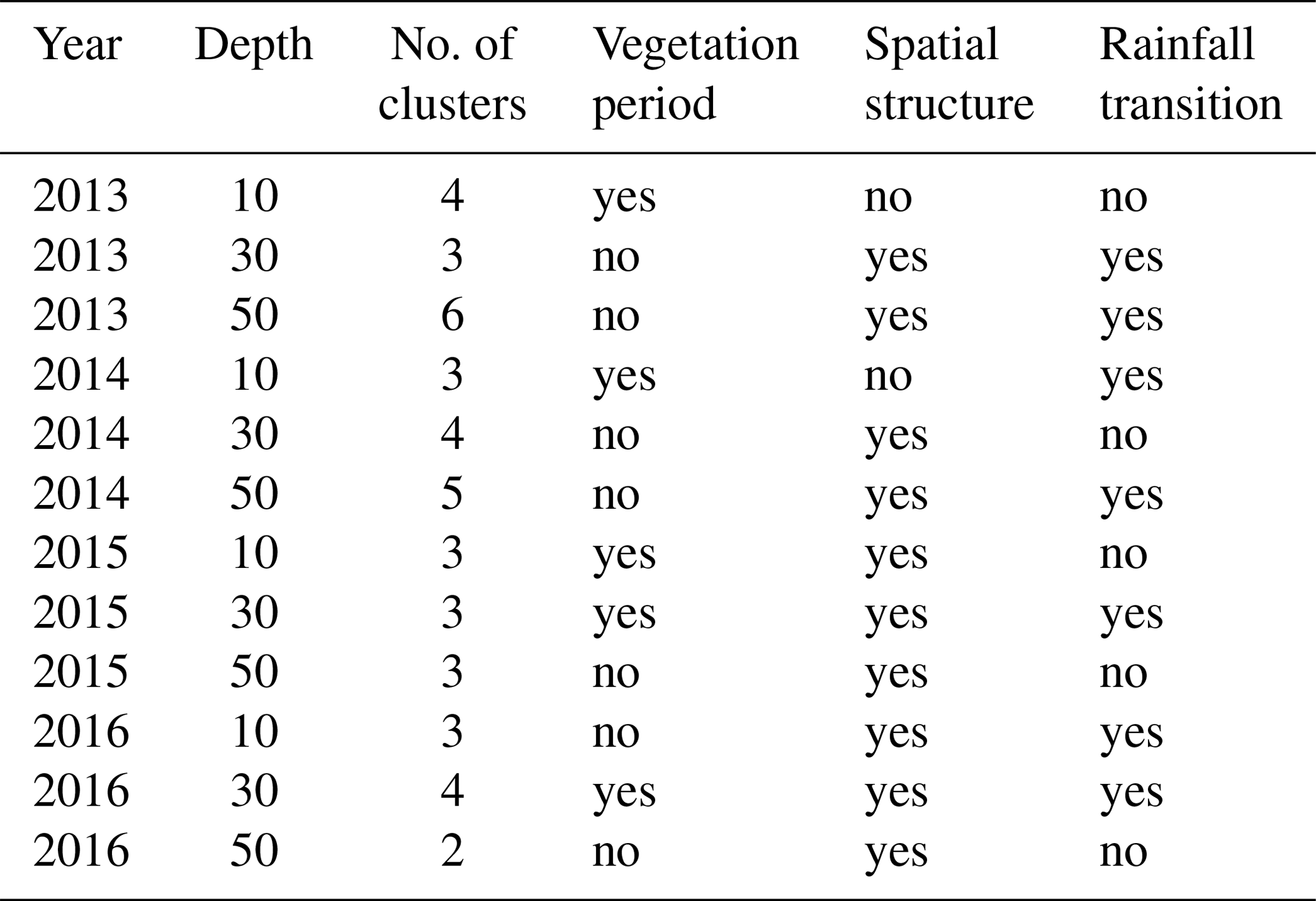
Figure 3Spatial dispersion functions in 30 cm for 2016 based on a window size of 30 d. (a) Spatial dispersion function for each position of the moving window. The red color saturation indicates the window position. The darker the red, the later in the year. (b) The same dispersion functions as presented in (a). Here the color indicates cluster membership as identified by the mean shift algorithm. (c) Compressed spatial dispersion information represented by corrected cluster centroids. The colors match the clusters as presented in (b). (d) Soil moisture time series of 2016 in 30 cm depth. The colors identify the cluster membership of the spatial dispersion function of the current window location and match the colors in (b) and (c). The bars on the top show the daily precipitation sums. The solid blue line is the cumulative daily precipitation sum and the red line the cumulative sum of all mean daily temperatures > 5 ∘C. The green bar marks the assumed vegetation period. It covers the dates where the cumulative day-degree sum is >15 % and <90 % of the maximum.
The spatial dispersion functions take several distinct shapes, with each of these shapes occurring during a certain period in time. More specifically, from Fig. 3a one can identify groups of functions of similar reds plotting close to each other. Dispersion functions of similar red saturation, which reflects proximity in time, are also similar in shape, and this in turn reflects similar spatial patterns. Similar dispersion functions were grouped using the mean shift clustering algorithm (Fig. 3b); here, the color indicates the cluster membership.
To provide further insight into the temporal occurrence of cluster members, we colored the soil moisture time series according to the color codes of the identified clusters (Fig. 3d). The blue parts of the soil moisture time series were classified into Cluster no. 1, while the orange part was classified into Cluster no. 2. Note that cluster memberships are constant for long periods of time, which means that the soil moisture patterns are also persistent over these periods. Exact cluster lifespans can be found in Table B1. We could identify four clusters in 30 cm, with the orange cluster roughly occurring during the vegetation period and the other three the remaining time of the year. As new observations did not change the patterns during these periods, they were redundant in time.
As the spatial dispersion functions in the presented example are redundant in time, we compressed the information by replacing the dispersion function within one cluster by the cluster centroid. All four representative functions shown in Fig. 3c exhibit increasing dispersion with separating distance. For the blue and green clusters this happens step-wise at a characteristic distance of 500 m. That reminds us of a Gaussian variogram, which can also show a step-wise characteristic. The small grey cluster shows an increase at 500 and another one at 1000 m separating distance. In contrast, the orange cluster, however, shows only a gentle increase with distance.
In the vegetation period observations are similar even at large separating distances. Interestingly, dispersion functions in the orange cluster start with small values that only gently increase with separating distance. That means soil moisture becomes more homogeneous. Outside of the vegetation period, different spatial patterns can be observed, with increasing dissimilarity with separating distances. The part of the blue cluster overlapping with the vegetation period shows still higher soil moisture values. The transition to the orange cluster sets in as the soil moisture drops (Fig. 3d). This suggests that vegetation influences, such as root water uptake, smooth out variability in soil water content, leading to a more homogeneous pattern in space, as further discussed in Sect. 4.3.
3.2 Dispersion time series as a function of depth
Figure 4 shows the time series of the dispersion functions for all depths. Note that the coloring between the sub-figure is arbitrary, due to mean shift, which means there is no connection between the orange cluster between the three figures.
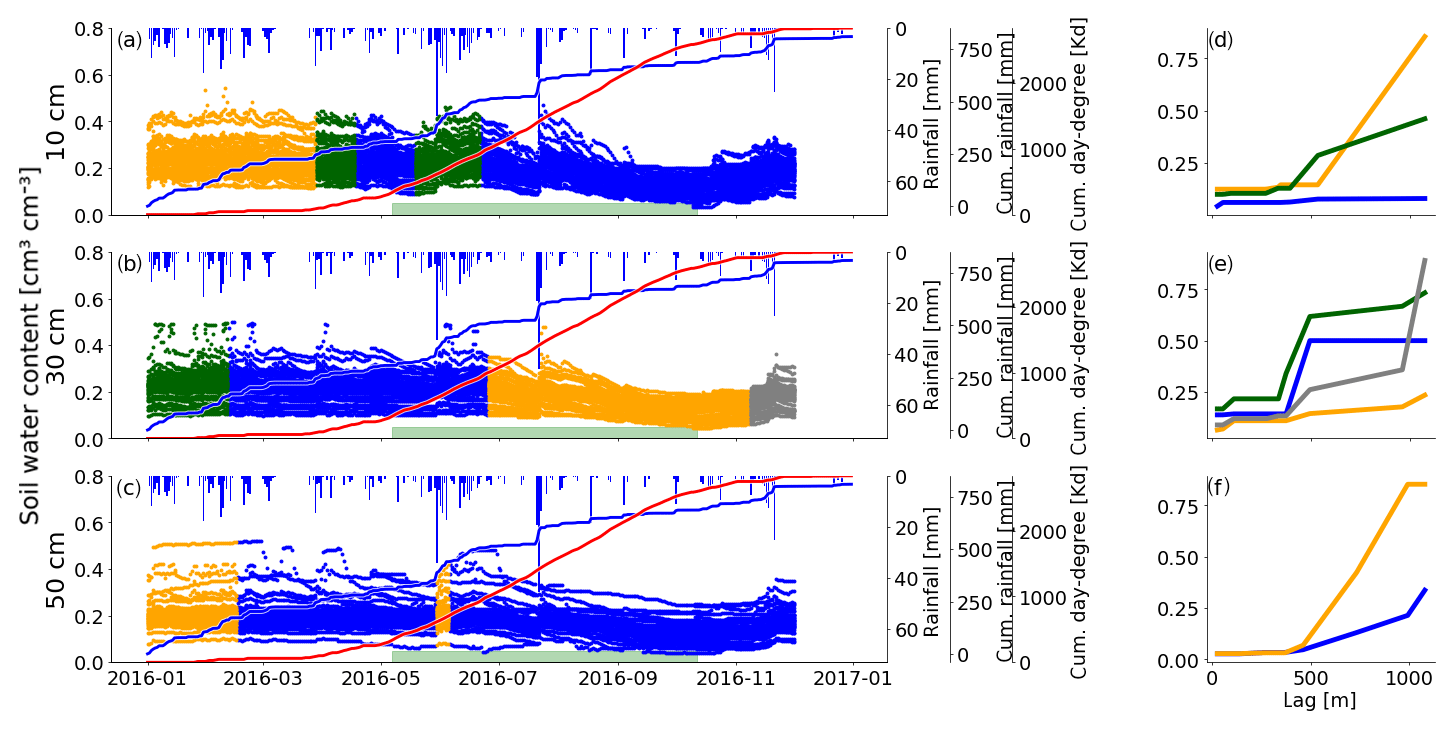
Figure 4Soil moisture time series of 2016 in all three depths with respective cluster centroids. The three rows show the data from 10 cm (a), 30 cm (b) and 50 cm (c). The colors indicate the cluster membership of the corresponding dispersion function of the respective window position. The green bar marks the assumed vegetation period. It covers the dates where the cumulative day-degree sum is >15 % and <90 % of the maximum. The cluster centroids for each depth are shown in (d–f).
In comparison to the dispersion functions in 30 cm (Fig. 4b) the soil moisture signal in 10 cm (Fig. 4a) is more variable in time. A look at the centroid of the orange cluster (Fig. 4d) reveals a higher spatial heterogeneity in winter and spring at large separating distances. At the same time the observations get spatially more homogeneous in summer, particularly when the blue cluster emerges; i.e., the dispersion at large lags decreases significantly. We can still find a summer-recession cluster in 10 cm, but compared to the depth of 30 cm we also find this spatial footprint of continuous drying earlier in the year around May. This is likely due to a higher sensitivity to rising temperatures. Note that during May there was only little rainfall and the soil moisture is already declining. This blue cluster shows very small dispersion values for all separating distance classes (Fig. 4d), just as the orange cluster in 30 cm depth.
The green clusters emerge with strong rainfall events after longer previous dry spells (Fig. 4a and d). We would have expected a third occurrence at the beginning of August, but the soil may already be too dry to bear a detectable dependency on separating distance (remember that the blue cluster does not show increasing dispersion with distance).
Observations at 50 cm depth show a clear spatial dependency throughout the whole year. We cannot identify a summer cluster, mean shift yielded two clusters and rainfall forcing does not have a clear influence on their occurrence or transition. The two 50 cm dispersion functions (Fig. 4f) show a clear dependence on distance, but they differ in their dispersion value at large lags. At 10 and 30 cm we found dispersion functions of fundamentally different shapes, like the flat, blue function (Fig. 4,d) or the step-wise blue and green functions (Fig. 4e). At 50 cm depth the characteristic length is 500 m and the blue cluster persists throughout most of the year (282 d; see Table B1). The orange cluster occurs during the cool and wet start of the year, showing a larger dispersion and thus stronger dissimilarity at larger lags (Fig. 4f). Interestingly this cluster occurs again in early June after an intense rainfall period. However, a similar rainfall period in August does not trigger the emergence of this orange cluster as the topsoil above 50 cm is so dry, so that even this strong wetting signal does not reach the depth of 50 cm (Fig. 4c). This behavior reveals the low-pass behavior of the topsoil, which causes a strong decoupling of the soil moisture pattern at 50 cm depth from event-scale changes.
3.3 Recurring spatial dispersion over the years
Table 1 summarizes the most important features of the clustering for all observation depths. Soil moisture patterns and their clustering appear generally to be clearer for 2015 and 2016. The vegetation period is more often characterized by a typical cluster and dispersion functions more often reveal a clear spatial dependency. In some cases (10 cm, 2013 and 2014) no spatial dependency of dispersion functions could be observed throughout the whole year. Less clusters were formed in 2015 and 2016. Note that annual rainfall sums were higher in 2013 and 2014, while 2015 and 2016 had significantly more precipitation in the first half of the year, followed by a dry summer (compared to 2013 and 2014).
Table 1Qualitative description of method success in all years and depths. The results from years other than 2016 and all depths were inspected visually and are summarized here for the sake of completeness. The first three columns identify the year, sensor depth and number of clusters found by mean shift. The remaining three columns state whether specific features existed in the given result. Vegetation period marks whether or not the vegetation period was characterized by a single, or two, clusters. Spatial structure: does a dependency of dispersion on distance exist outside the vegetation period? Rainfall transition: were cluster transitions accompanied by a rainfall event in close (temporal) proximity? This feature is marked “yes” if it was more often the case than it was not.
To further illuminate interannual changes in soil moisture patterns, we present the time series of cluster memberships for the sensors in 30 cm for the entire monitoring period in Fig. 5. From this example it becomes obvious that patterns are recurring. Years 2013 and 2014 cluster centroids look different from the following 2 years. Dispersion values increase with distance in all centroids in 2013 and 2014, while 2015 and 2016 show a sudden increase at 400–500 m (Fig. 5a–d). Years 2015 and 2016 are segmented by mean shift in a similar way, and cluster centroids reveal that the green clusters in both years are actually the same. This green cluster emerges with the occurrence of the largest rainfall event in the observation period and lasts for around 5 months. All dispersion functions within this cluster look nearly identical (see Fig. C2b). Similar observations can be made between 2014 and 2015. Here, the green and blue clusters seem to be an interannual cluster. However, in contrast to 2015/2016, the dispersion functions here are of a different shape (see Fig. C1b). Hence, the cluster transition indicated between 2014 and 2015 is indeed a real transition. When looking at cluster memberships throughout the whole period, the division into calendar years is rather meaningless, while the division into hydrological years is much more appropriate, as is reflected by the cluster membership and its changes.
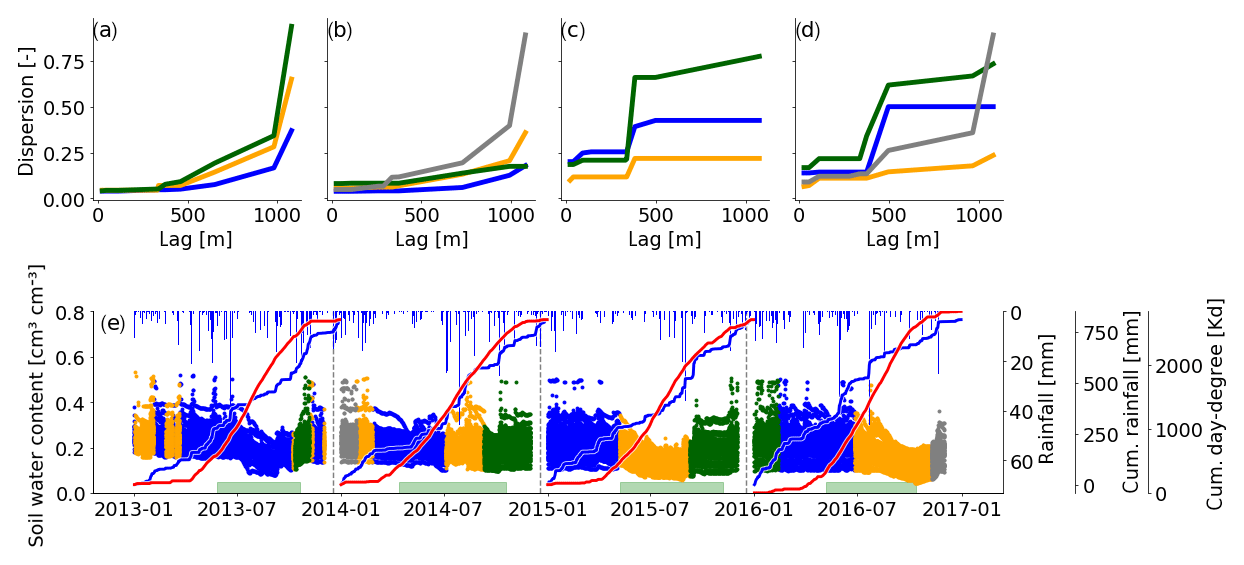
Figure 5Soil moisture time series of all years in 30 cm depth (e) and the respective cluster centroids (a–d). The colors of the soil moisture data indicate the cluster membership of the corresponding dispersion function of the respective window position and correspond to the color of the cluster centroid (in a–d). The cumulative rainfalls (blue) and cumulative temperature sums (red) are shown for each year individually. The green bar marks the assumed vegetation period. It covers the dates where the cumulative day-degree sum is >15 % and <90 % of the maximum.
Distinct summer recessions in soil moisture are only identified in 2015 and 2016. Evapotranspiration (indicated by the cumulative temperature curves in Fig. 5e) dominates over rainfall input (blue sum curve) in the soil moisture signal. Mean shift could identify a significantly distinct spatial dependency in dispersion, as shown by the two orange centroids in Fig. 5c and d. They are both distinct from the other centroids in the same period by showing only a gentle increase in dispersion. A likely reason for the absence of a distinct summer recession in 2014 is the rather wet and cold spring and summer, as can be seen from the steep cumulative rainfall curve during that period (Fig. 5e). In 2013 this identification did not work. Possible reasons are provided in the discussion Sect. 4.5.
3.4 Redundant spatial dispersion functions
We calculated the Shannon entropy for all soil moisture time series for all years and depths (Table 2). As explained in Sect. 2.5.2 this reflects the intrinsic uncertainty of the clusters. Most entropy values are within a range of . The maximum possible entropy for a uniform distribution of the used binning is 3.55. The Kullback–Leibler divergence DKL is a measure of the information loss due to the compression of the cluster onto the centroid dispersion function. In the overwhelming majority of the cases, the information loss is 1 magnitude smaller than the intrinsic uncertainty and the range is . Hence, the information loss due to compression is negligible. There is one exception in 2016 (50 cm).
Table 2Information content and information loss due to compression. The information content is given as Shannon entropy H, which is the expectation value of information in information theory. 2H gives the number of distinct states the underlying distribution can resolve. The information loss after compression is given by the Kullback–Leibler divergence DKL between the compressed and uncompressed series of dispersion functions. The last column relates DKL to H.
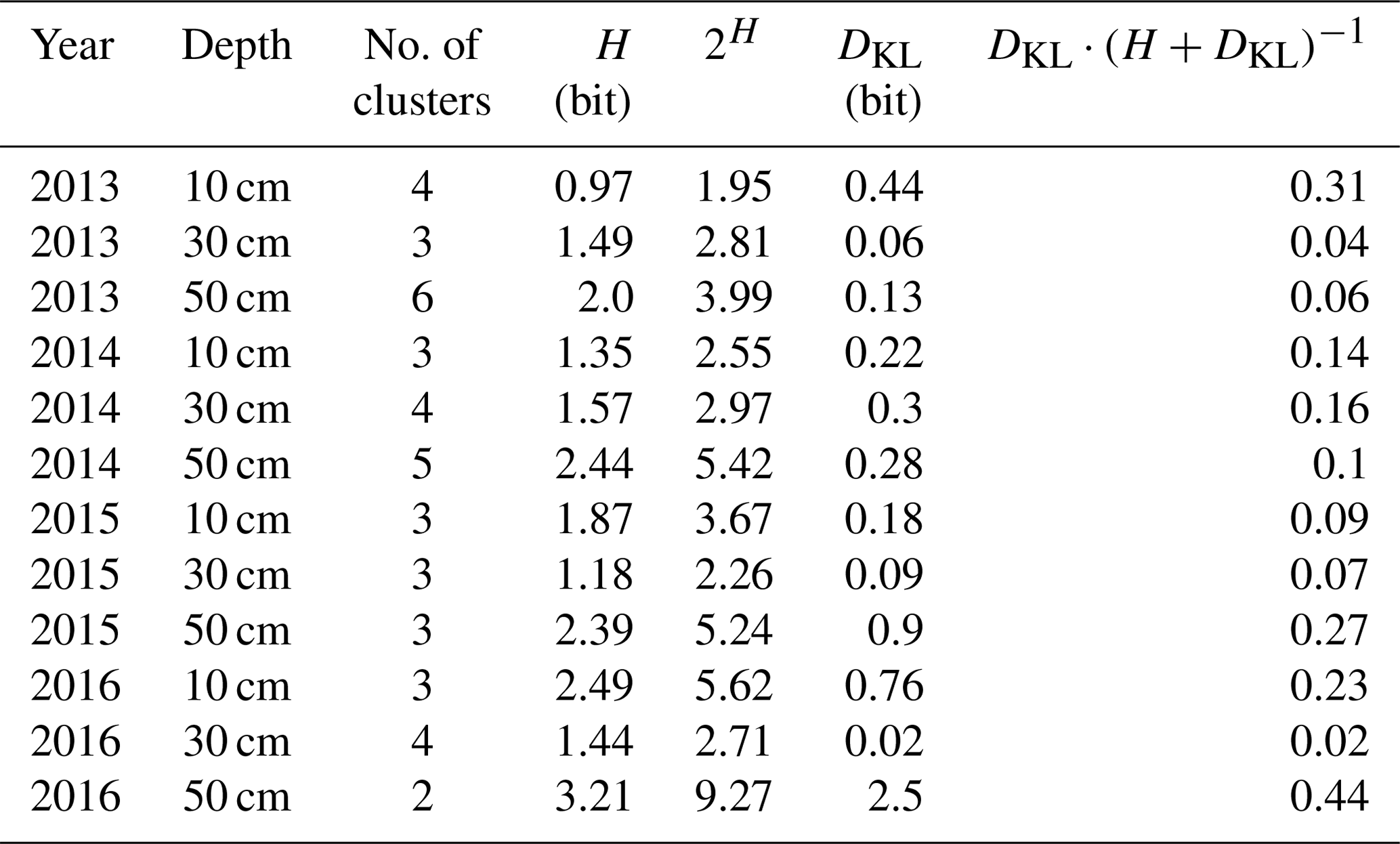
The clusters obtained in 30 cm for the year 2016 (compare Sect. 3.1) showed an entropy of 1.44. Compared to this value, the Kullback–Leibler divergence caused by compression of only 0.02 is small, if not negligible. The last column of Table 2 relates DKL to the overall uncertainty. It contributes less than one-third in almost all cases (2016; 50 cm is the only exception). In the majority of the cases it does not contribute more than 20 %.
According to Eq. (9) the Shannon entropy is derived from a discrete, empirical probability distribution. As it is calculated using the binary logarithm, 2H gives the amount of discriminable states in this discrete distribution. This number of states is deemed to be a reasonable upper limit for the number of clusters for mean shift. A higher number of clusters than 2H appears meaningless, and this ensures that only those clusters are separated which are separated by a distance larger than the margin of uncertainty.
In line with our central hypothesis H1 – that radiation-driven drying and rainfall-driven wetting leave different fingerprints in the soil moisture pattern which manifests in temporal changes in the dispersion functions – we found strong evidence that soil water dynamics is organized in space and time. Our findings reveal that this organization is not static but exhibits dynamic changes which are closely related to seasonal changes in forcing regimes. A direct consequence is that soil moisture observations are quite predictable in time despite their strong spatial heterogeneity. This is in line with conclusions of, e.g., Mittelbach and Seneviratne (2012) or Teuling et al. (2006), who also found characteristic spatial patterns to persist in time. We used the statistical dispersion of soil moisture observations in dependence of their separating distance to describe spatial patterns. The vector distance of these dispersion functions was used to cluster them. As a measure of the degree of organization we used the information loss that goes along with the compression of the entire cluster, i.e., the replacement of the cluster by the most representative cluster member. Here we found that this compression adds negligible uncertainty compared to the intrinsic uncertainty, caused by propagation of measurement uncertainties. We thus conclude that soil moisture is heterogeneous but temporally persistent over several months.
In the following we will discuss our main findings that similarity in space leads to dynamic similarity in time, the way we utilized the measurement uncertainty to determine the information content and how two different processes forcing soil moisture dynamics induce two fundamentally different spatial patterns.
4.1 Spatial similarity persists in time
We related the dispersion of pairwise point observations to their separating distance. For brevity and due to their shape we called these relationships dispersion functions. We emphasize that this term is not meant in a strict sense, and no mathematical functional relationship, analogous to a theoretical model, has been fitted to the experimental dispersion functions. Despite the fact that the presented functions are empirical, they show clear, recurrent shapes on many occasions.
We found spatial similarity to persist in time. This is reflected in the temporal stability in cluster membership. In line with H2 – that both forcing regimes and their seasonal variability may be identified through temporal clustering of dispersion functions – the results (Figs. 3–5) provided evidence that similar dispersion functions emerge in fact very closely in time. Generally they appeared in continuous periods or blocks in time and their changes coincided with changes or a switch in the forcing regimes. In case we can relate the emergence of such a cluster more quantitatively to the nature and strength of a specific forcing event/process, we can analyze for how long this event/process imprints the spatial pattern of soil moisture observations. Or in other words: we can analyze how long a catchment state remembers a disturbance. However, an attempt to relate cluster transitions to rainfall sums and frequencies within the respective moving windows (see Fig. B1) did not yield clear dependencies.
Although cluster memberships occur in temporally continuous blocks in all depths throughout all years, for a few cases we could not relate their emergence to distinct changes in forcing. This implies that H2 needs to be partly revised.
Dispersion functions in 50 cm show a clear spatial dependency throughout the year, with distinct differences within and outside the vegetation period. In 50 cm of 2016 this is different. We find essentially two clusters that do not separate the data series by vegetation period. The shape of the two centroids (Fig. 4f) is similar, only at large distances they differ in value. This means that from the orange to blue clusters observations became more similar at large separating distances. Heavy rainfall disturbs this pattern leading to stronger dissimilarity at larger distances and that pattern lasted for a couple of weeks. Then, evapotranspiration-driven drying smooths out soil moisture variability and during a similarly strong rainfall event in summer, the cluster can not emerge again as the soil is already too dry. The soil acts as a low-pass filter here, which filters out any change in state above a specific frequency. This happens mainly due to dispersion of the infiltrating and percolating water through the soil, or due to storage in the soil matrix. By the time it reaches the deep layers, spatial differences are eliminated. This kind of behaviour is well known and was already reported in the early 1990s (Entekhabi et al., 1992; Wu et al., 2002). More recently Rosenbaum et al. (2012) “found large variations in spatial soil moisture patterns in the topsoil, mostly related to meteorological forcing. In the subsoil, temporal dynamics were diminished due to soil water redistribution processes and root water uptake”. In the same year, Takagi and Lin (2012) analyzed a data set of 106 locations in a forested catchment in the US for spatial organization in soil moisture patterns. They found a seasonal change in more shallow depths (30 cm), controlled by rainfall and evapotranspiration. In deeper depths patterns became more temporally persistent. All these findings are in line with our results and conclusions.
Mittelbach and Seneviratne (2012) decomposed a long-term (15-month) soil moisture time series into time-invariant and dynamic contributions to the spatial variance. Their data set spanned 14 sites from Switzerland at a clearly different scale (150×210 km). The study quantified the time-invariant contribution on average to 94 %, which leads to “a smaller spatial variability of the temporal dynamics than possibly inferred from the spatial variability of the mean soil moisture” (Mittelbach and Seneviratne, 2012, p. 2177, l. 14 ff.). This is comparable to the instances where we find long-lasting clusters, while the absolute soil moisture changes considerably (e.g., Fig. 3d), early April or mid-July).
4.2 Uncertainty analysis
We related the evaluation of compression quality directly to the measurement uncertainty. This was achieved by Gaussian error propagation of measurement uncertainty into the dispersion functions and their distances. The latter allowed definition of a minimum separable vector distance between two dispersion functions that are different with respect to the error margin. We based the bin width for calculating the Shannon entropy on this minimum distance, because this ensured that the Shannon entropy gives the information content of each cluster with respect to the uncertainty. On this basis it was possible to assess compression quality not only by the number of meaningful clusters found, but also based on the information lost due to compression with respect to uncertainty.
In line with H4, spatial patterns of soil moisture were found to be persistent over weeks, if not months. In many instances we found only two to four clusters within 1 year, and compression was possible with small if not negligible information loss. That means that during one cluster period an entire set of dispersion functions does not contain substantially more information than the centroid function. Hence, the whole cluster can be represented by only the centroid function. We conclude that this is a manifestation of a strongly organized state which persists for a considerable time, as most observations were redundant during these periods.
Teuling et al. (2006) concluded that picking a random soil moisture observation location and deriving the temporal dynamics from this single sensor is more accurate than using the spatial mean of many soil moisture time series. This conclusion was true for all three data sets they tested (Teuling et al., 2006). This representativity of a single sensor to our understanding is a manifestation of a persistent spatial pattern in soil moisture dynamics, which also enables us to compress clusters without information loss.
From Eq. (9) it can be seen that the Shannon entropy changes substantially with the binning. Therefore, it is of crucial importance to define a meaningful binning based on objective criteria. We suggest that only a discrimination into bins larger than the error margins makes sense, because smaller differences cannot be resolved based on the precision of the sensors. For the application presented in this work, this is important because otherwise one could not compare the compression quality between depths or years, as different binnings lead to different Shannon entropy values, even for the same data. Hence, it would be difficult to analyze effects or differences of spatial dispersion in depth or over the years. We thus conclude that the Shannon entropy should only be used if the measurement uncertainties of the data are properly propagated.
We provided an example of how the quality of a compression can be assessed. Instead of considering the number of clusters (compression rate) only, we linked the compression rate to the resulting information loss. We could show that in the majority of the cases substantial compression rates could be achieved, which are accompanied by negligible information losses. We thus suggest that the trade-off between compression rate and information loss should be used as a compression quality measure.
4.3 Different dominant processes lead to different patterns
Outside of the vegetation period, we found a recurring picture of spatial dispersion functions with characteristic lengths clearly smaller than the typical extent of hillslopes. Dispersion functions were calculated in three depths for every day throughout 4 years. In most cases there is an characteristic length at which the dispersion function shows a sudden rise in dispersion. For spatial lags smaller than this distance the dispersion is usually very small. Higher lags show much higher and more variable dispersion values. This characteristic length is approx. 500 m. This corresponds to a common hillslope length for the Colpach catchment. During the vegetation period variability at a large separating distance was smoothed out. Dispersion was low also at large distances, suggesting similarity even at distances larger than the typical slope length. We thus conclude that there is dependence of the dispersion on the rainfall pattern, which is reflected in the dispersion function's shape and characteristic length. This confirms H2 and suggests that vegetation is a possible dominant factor in smoothing out soil moisture variability. A similar conclusion is drawn by Meyles et al. (2003), who identified “preferred states in soil moisture” (Grayson et al., 1997; Western and Grayson, 1998; Western et al., 1999) and could relate the state transition to a significant change in the characteristic length of their geostatistical analysis. We generally found more than two clusters, but we still consider these results to be comparable. Most of the clusters identified during the vegetation period are more similar to each other than to the clusters outside of the vegetation period (and vice versa). This can be related to the “wet” and “dry” states in Meyles et al. (2003). Although conducted in a very different climate, McNamara et al. (2005) also widened the separation of two preferred states into five, which they found to be explanatory for runoff generation. Interestingly they found the seasonal interplay of precipitation and evapotranspiration responsible for transitions between states. Vanderlinden et al. (2012) further reference Gómez-Plaza et al. (2001) as an example study, which identified vegetation as the dominant factor. Plant root activity is changing the temporal stability of soil moisture in the upper 20 cm of the soil considerably.
Outside the vegetation period we observed multiple cluster transitions. Although more than one cluster was identified, the clusters were more similar in shape to each other than to the clusters in the “dry” summer period. In many cases these cluster transitions coincided with a shift in rainfall regimes. Either the first stronger rainfall event after a longer period without rainfall sets in, or one of the heaviest rainfall events of that year occurs. There are also instances with recurring clusters that develop more than once (e.g., Figs. 3, 4a, c and 5e). As these periods are controlled by rainfall, either different rainfall patterns or different hydrological processes are dominating. Depending on antecedent wetness, rainfall amounts and rainfall intensity, infiltration and subsurface flow processes can change and thus also alter the soil moisture pattern. Although this may only be a coincidence, we found the green cluster in 2016 (Fig. 3) to form with strong rainfall input setting in after a period of little rainfall. Similar observations can be made for other years, unfortunately not in all cases. Consequently, we can neither confirm nor reject H3 – that spatial dispersion is more pronounced during and shortly after rainfall-driven wetting conditions.
Many other works also tried to link soil moisture pattern to forcing. Teuling and Troch (2005) report for soil moisture measurements taken on an agricultural field in Belgium that the first rainfall events in the late growing season even out the variability, which arose due to heterogeneous transpiration. Although the soil moisture pattern became more homogeneous in summer in our case, we also suspect rainfall events after the vegetation period to be responsible for cluster transitions. Similarly, Albertson and Montaldo (2003) present a set of examples of modeled experiments, in which precipitation is consistently “producing” variability in soil moisture dynamics and transpiration is reducing variability. The question of how spatial patterns or their variability change is also contradictory in the literature. Vanderlinden et al. (2012) present two studies in their review. Both investigated the variability of time-persistent soil moisture patterns over depth. While Pachepsky et al. (2005) found no difference in depth, Choi and Jacobs (2011) reported a decrease in variability with depth. During the vegetation period no spatial dependence is detectable. For the vegetation period, we found usually only one or at maximum two clusters (Table 2). These clusters are characterized by showing no dependence of dispersion on separating distance. This means that evapotranspiration forcing the system to drier states is doing this in a (spatially) homogeneous manner. Dispersion is not only low when the catchment is dry, it is also low while the system is drying. Similar observations have been reported for the Tarrawarra catchment in Australia (Grayson et al., 1997; Western and Grayson, 1998; Western et al., 1999). Although these works focused on the relation of spatial organization to topographic indices, no spatial correlation of soil moisture observations could be found for the dry period. This is comparable to our findings about dispersion functions during the vegetation period. It has to be noted that the lowest soil moisture values, i.e., residual moisture, are only observed for very short periods in time. At residual soil moisture all sensors show essentially the same absolute value (which leads to small dispersion as well).
We conclude that cluster transitions were often triggered by rainfall events. Not all of the strongest rainfall events caused a cluster transition and not every cluster transition could be related to a rainfall sum or frequency within the window of the transition. The characteristics provided in Sect. B provide a good starting point, but further investigations of the rainfall events, their spatial characteristics and relation to the moisture state are needed.
4.4 Mean shift as a diagnostic tool
We used mean shift mainly as a diagnostic tool to cluster dispersion functions based on their similarity. Similarity is measured by the Euclidean distance between two dispersion function vectors. This Euclidean distance does, however, not provide information on the underlying cause of dissimilarity, and thus a minor difference in the values of the dispersion functions, even though characterized by a very similar shape, could result in the same level of dissimilarity as a change in the shape of the dispersion function. We observed some cluster separations that were caused by minor differences in mean dispersion, while essentially describing the same spatial dependency.
It is possible to train better mean shift algorithm instances. As described in the methods, we selected the bandwidth parameter for mean shift to yield meaningful results for the entire data set. The same parameter was used for all subsets to cluster dispersion functions on the same basis. This makes the clustering procedure itself comparable and, thus, the number of identified clusters can support result interpretation. Nevertheless, it is likely that better bandwidth parameters can be found for each data subset individually and overcome misclassifications as described above. Our objective, however, was to find clustering results that can directly be compared to each other (instead of comparing hyper-parameters).
Dispersion functions operate in a higher-dimensional space and might be affected by the curse of dimensionality. Mean shift clusters data points based on their distance to each other. Following the theory of the curse of dimensionality, with each added dimension (of these points), the difference of maximum and minimum distance between points becomes less significant (Beyer et al., 1999). On the one hand, we wish to resolve dispersion functions on as many distance lag classes as possible to gain more insight into spatial dependencies. On the other hand, each additional lag class possibly decreases the performance of mean shift (or any other clustering algorithm) and makes the results less meaningful. We calculated dispersion functions using a 30-day aggregation window and therefore end up with 335 points for mean shift. However, despite the limited number of points and the resulting uncertainty of cluster identification, the clusters identified here seem plausible.
Mean shift is sensitive for the bandwidth parameter. As described in the methods (Sect. 2.3), the bandwidth parameter has to be specified and has direct influence on the amount of clusters formed by the algorithm. We found a suitable parameter through trial-and-error. It would be more satisfactory to infer this crucial parameter from the data or supplementary information gathered at field campaigns. However, to our knowledge there is no such method or procedure to infer bandwidth parameters for mean shift from a data sample.
4.5 Limitations of the proposed method
Successful clustering does not point out spatial dependency. Mean shift can cluster functions without spatial dependency, as it uses their distance and no actual covariance between the functions. In this case the clustering is based on differences in the mean, which may not even be statistically significant. The mean shift algorithm is not meant to test clusters for statistical independence. Whether two groups of points are separated or not depends only on the bandwidth parameter. Therefore the centroid functions of each cluster have to be checked for their shape and the information on spatial dependency that follows from that shape.
Our approach to find suitable bins to calculate the Shannon entropy is sensitive to outliers. We decided to rather define the width of a bin instead of their number. The reasons and necessity to do so were discussed in detail in Sect. 4.2. As a width we used the uncertainty propagated into dispersion function distances. From all distances within uncertainty margins, we used the maximum value. In cases where this maximum distance is an outlier, it will influence the whole entropy calculation. This is a limitation to our method but an acceptable one, as it is still superior to other approaches from our point of view. Choosing the maximum distance within each year or depth (or both) will yield more bins for entropy calculations and therefore a wider range of values, but it would be very hard to compare these values.
From the point of view of the monitoring network, it has to be mentioned that the analysis of the 2013 data is likely to be less reliable, as during this period of installation the number of sensors was still lower than in the following years.
Due to the sampling design and the amount of observation points, we did not systematically test for differences of forest vs. pasture plots, but ran our analyses across the two land covers. The fundamentally different shapes of cluster centroids in the summer clusters and, thus, the strong effect of vegetation-altering soil moisture patterns might be partly more pronounced due to the sampling design and not easy transferable to other sites. In our opinion, we would have made the same observations with a more stratified sampling design, as this is systematic catchment behavior, but we can neither confirm nor reject this.
We presented a new method to identify periods of similar spatial dispersion present in a data set. While soil moisture observations might be spatially heterogeneous, spatial patterns are much more persistent in time. We found two fundamentally different states: on the one hand, rainfall-driven cluster formations, usually characterized by strong relationships between dispersion and separating distance and a characteristic length roughly matching the hillslope scale. On the other hand, we found clusters forming during the vegetation period. A drying and then dry soil exhibits dispersion functions which are much flatter, indicating homogeneity across space. Interestingly, these functions flatten out by minimizing the dispersion on large distance lags, which implies that dissimilarities do not increase with separating distance. We can thus see how the soil acts as a low-pass filter.
While these long-lasting periods of similar spatial patterns help us to understand how and when the soil is wetting or dying in an organized manner, there are possible applications beyond this. One could use the identification of clusters to stratify data based on spatial dispersion for combined modeling. Then, for example, a set of spatio-temporal geostatistical models or hydrological models applied to each period separately might in combination return reasonable catchment responses.
Our most interesting finding is that even a few soil moisture time series bear a considerable amount of predictive information about dynamic changes in soil moisture. We argue that distributed soil moisture reflects an organized catchment state, where soil moisture variability is not random and only a small amount of observation points is necessary to capture soil moisture dynamics.
Mean shift starts by forming a cluster for each sample on its own. Here, a sample corresponds to one dispersion function. We will illustrate the fundamental mechanism of the algorithm for the two-dimensional case, as the samples can easily be plotted in ℝ2 (see Fig. A1a and b). Mean shift works iteratively. In each iteration, a window is shifted over all samples, which can be thought of as coordinate points in the two-dimensional case (see Fig. A1a). This window is called a kernel that is controlled by a size parameter called bandwidth, which is the Euclidean distance between two samples. In the two-dimensional case, this can be thought of as a circle with a radius set to the given bandwidth as shown in Fig. A1a. In each kernel position, the center of sample density is calculated and the current sample is shifted onto this point, which is the new cluster mean, called the cluster centroid. In the next iteration, the newly created cluster centroids are used as the new (input) samples, as shown in Fig. A1b. Hence, with the bandwidth, we define a maximum Euclidean distance at which two samples are still considered to belong to the same group. The iterations stop when the shifting means converge (centroids do not change their position anymore). We substitute the centroids calculated on the last iteration by the original sample closest to this point. Thus, we choose the most representative dispersion function for the cluster.
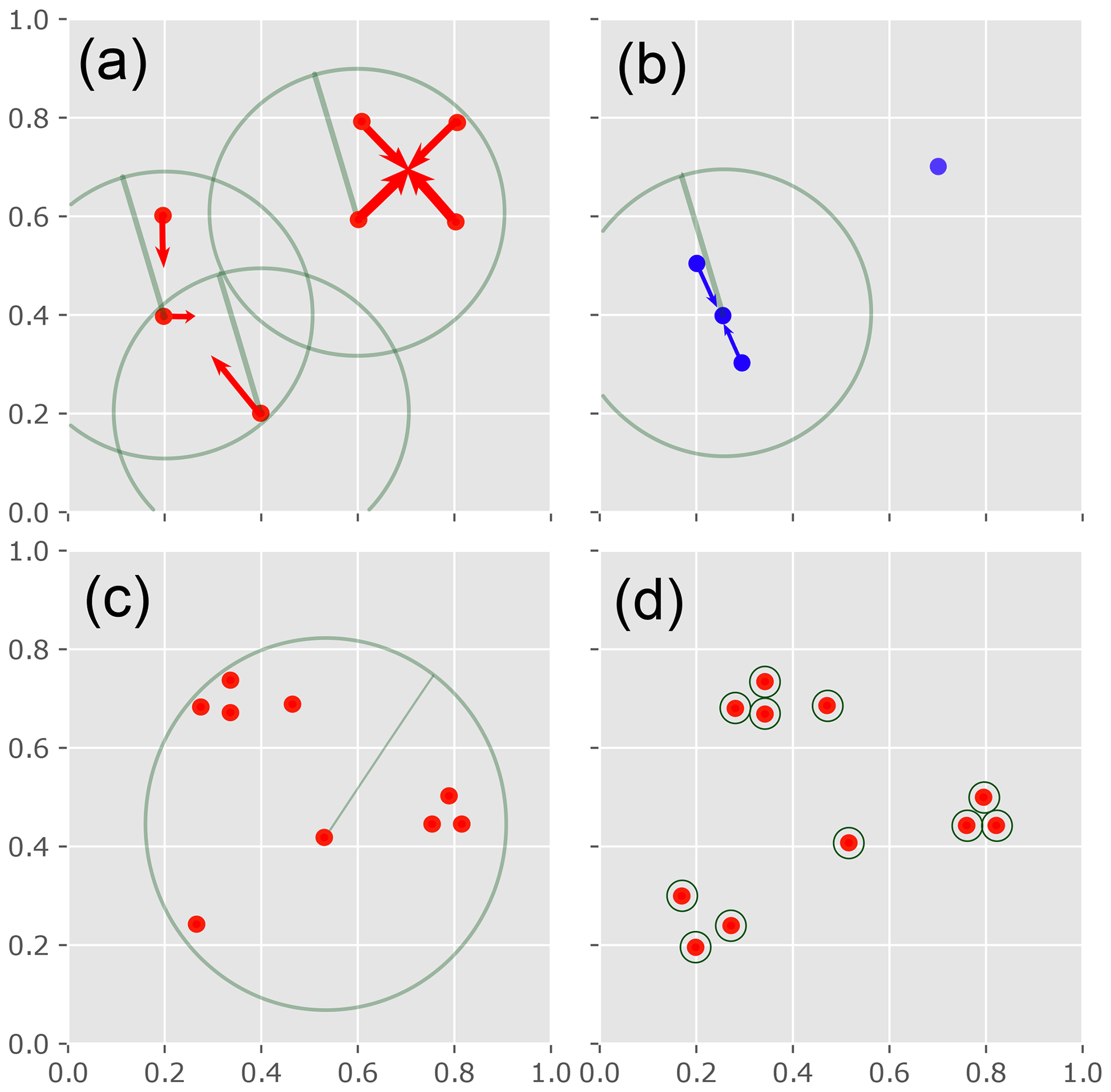
Figure A1Schematic procedure of the mean shift algorithm in ℝ2. (a) Red dots indicate hypothetical samples to be clustered. The circles illustrate the flat kernel of the centered sample at first iteration. The bandwidth parameter is illustrated by the radius. The red arrows indicate the shift of the respective sample onto the geometric mean of all samples inside the current kernel. Note that three points on the left-hand side are shifted differently, as the upper and lower points do not lie in each other's kernel. (b) Second iteration step after (a). The blue dots are the shifted means from (a) and will be used as the input sample for the next iteration. The procedure finishes when no points can be “shifted” anymore. (c) Example of a large bandwidth (radius), which will result in only one cluster at convergence. (d) Example of a too small bandwidth, where no point will be shifted at all.
Mean shift is sensitive to the selected bandwidth. Two clusters whose centroids are within one bandwidth length will be shifted into a combined cluster before convergence is met. As a result a bandwidth parameter chosen too big might classify all samples as a single cluster as indicated in Fig. A1c. In case the bandwidth is chosen too small, many tiny clusters with just a few members will be the result. Figure A1d shows an extreme example, where no sample will shift anywhere. We tested different bandwidth parameters at a few examples and set the bandwidth to the 30 % percentile of all pairwise Euclidean vector distances between the dispersion functions of 1 year and depth. We chose the so-called flat kernel as a kernel, which would result in a circle in the two-dimensional case and a N-dimensional sphere in ℝN, where N is the number of lag classes used for the dispersion function.
Table B1Quantitative results summary. For each depth and cluster of 2016 different cluster characteristics were calculated. The duration of each cluster is given in the third column. To compare rainfall forcing with the emergence of clusters, the rainfall characteristics were based on the same moving window as the clusters. The mean rainfall frequency f30 within each window is given in the fourth column. The mean 30 d sum over the whole cluster in the fifth column. To assess the variability of dispersion functions within each cluster, different measures are given. γ is the dispersion, as calculated in Eq. (2). This describes the dispersion of dispersion functions within one cluster. H is the entropy of the distribution of all cluster members within each cluster. Both measures are calculated for the distribution of each distance lag class individually.
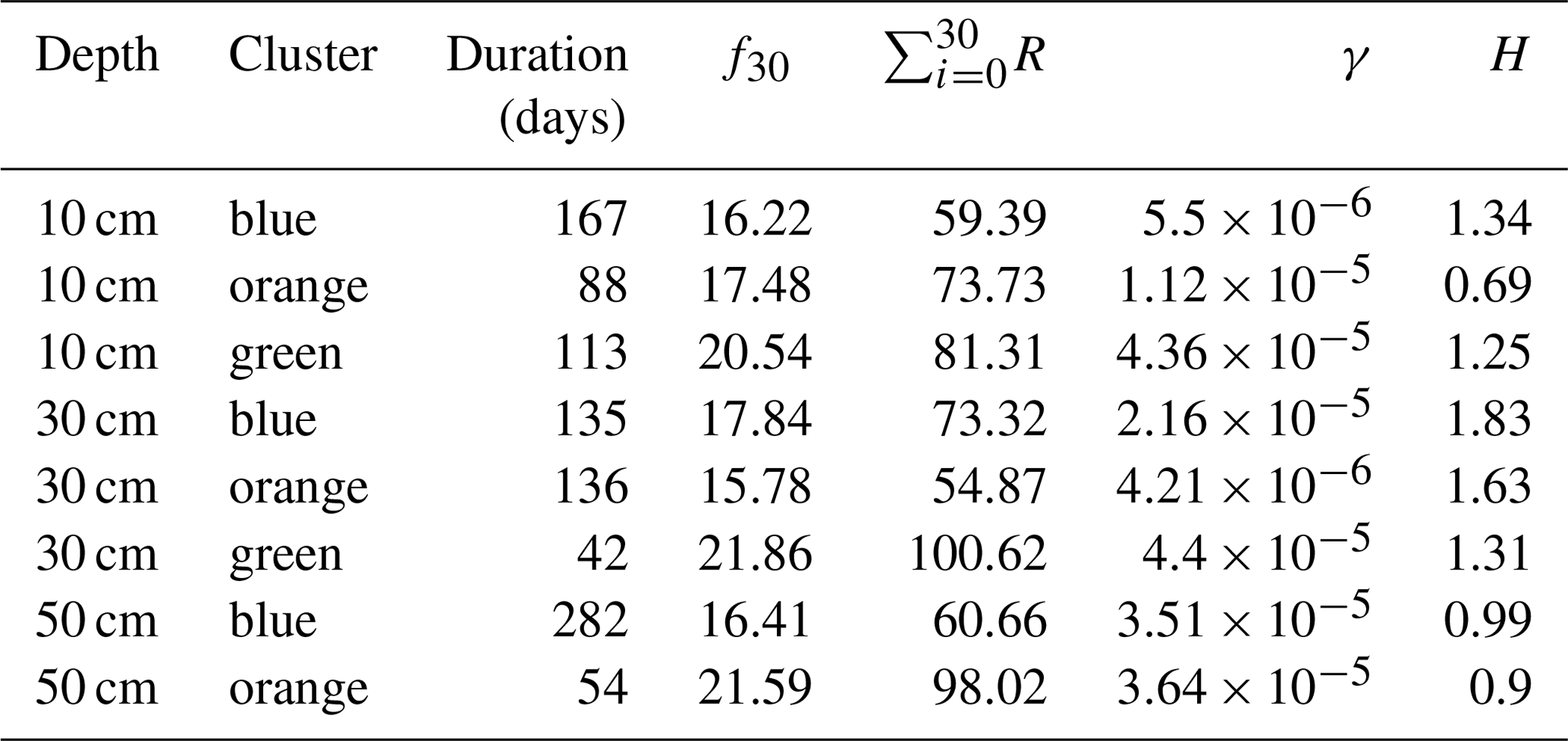

Figure B1Mean rolling rainfall sum (a) and rainfall frequency (b) for 2016. The colored boxes indicate the current cluster as shown in Fig. 3d. Both values were calculated for the same windows as the dispersion functions by using Eq. (1) for the daily rainfall sums, with the total rainfall sum in the window in (a) and the number of days of rainfall occurring in (b).
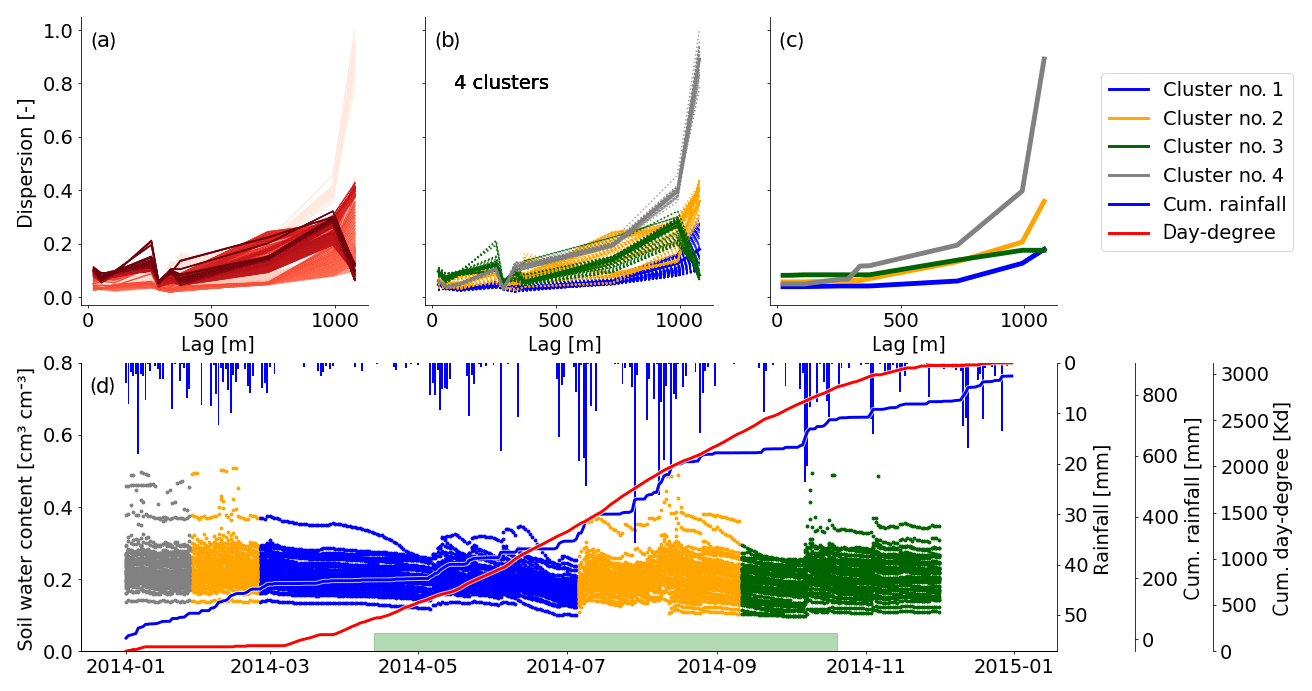
Figure C1Spatial dispersion functions in 30 cm for 2014 based on a window size of 30 d. (a) Spatial dispersion function for each position of the moving window. The red color saturation indicates the window position. The darker the red, the higher in the year. (b) The same dispersion functions as presented in (a). Here the color indicates cluster membership as identified by the mean shift algorithm. (c) Compressed spatial dispersion information represented by corrected cluster centroids. The colors match the clusters as presented in (b). (d) Soil moisture time series of 2014 in 30 cm depth. The colors identify the cluster membership of the spatial dispersion function of the current window location and match the colors in (b) and (c). The bars on the top show the daily precipitation sums. The solid blue line is the cumulative daily precipitation sum and the red line the cumulative sum of all mean daily temperatures > 5 ∘C. The green bar marks the assumed vegetation period. It covers the dates where the cumulative day-degree sum is >15 % and <90 % of the maximum.
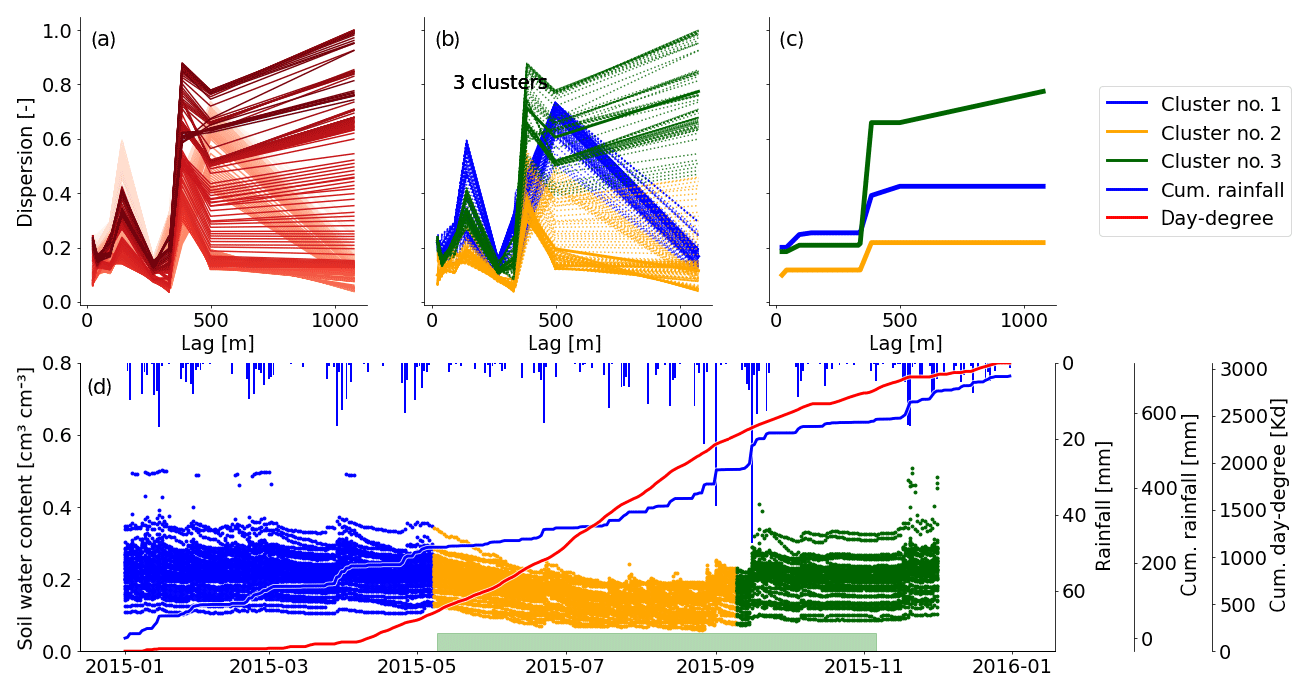
Figure C2Spatial dispersion functions in 30 cm for 2015 based on a window size of 30 d. (a) Spatial dispersion function for each position of the moving window. The red color saturation indicates the window position. The darker the red, the later in the year. (b) The same dispersion functions as presented in (a). Here the color indicates cluster membership as identified by the mean shift algorithm. (c) Compressed spatial dispersion information represented by corrected cluster centroids. The colors match the clusters as presented in (b). (d) Soil moisture time series of 2015 in 30 cm depth. The colors identify the cluster membership of the spatial dispersion function of the current window location and match the colors in (b) and (c). The bars on the top show the daily precipitation sums. The solid blue line is the cumulative daily precipitation sum and the red line the cumulative sum of all mean daily temperatures > 5 ∘C. The green bar marks the assumed vegetation period. It covers the dates where the cumulative day-degree sum is >15 % and <90 % of the maximum.
Major parts of the analysis are based on the scipy (Virtanen et al., 2020), scikit-learn (Pedregosa et al., 2011) and scikit-gstat package (Mälicke and Schneider, 2019). All plots were generated using the matplotlib package (Hunter, 2007). The full analyses of Python scripts are published on Github (https://github.com/mmaelicke/soil-moisture-dynamics-companion-code, last access: 28 April 2020) (Mälicke, 2019). The data are available upon request.
The methodology was developed by MM, supervised by EZ and discussed with SKH. The data were provided by TB and MW. All the code was developed by MM. The manuscript was written by MM, with contributions by EZ in the introduction, discussion and formulas. SKH supplied the field and data descriptions. The structure, narrative and language of the manuscript were revised and significantly improved by TB.
The authors declare that they have no conflict of interest.
We thank the German Ministerium für Wissenschaft, Forschung und Kunst, Baden-Württemberg, for funding the V-FOR-WaTer project. We thank the German Research Foundation (DFG) for funding of CAOS research unit FOR 1598. We especially thank Britta Kattenstroth and Tobias Vetter, the technicians in charge of the maintenance of the monitoring network. The authors also acknowledge support by the Deutsche Forschungsgemeinschaft and the Open Access Publishing Fund of the Karlsruhe Institute of Technology (KIT).
The article processing charges for this open-access publication were covered by a Research Centre of the Helmholtz Association.
This paper was edited by Alberto Guadagnini and reviewed by two anonymous referees.
Albertson, J. D. and Montaldo, N.: Temporal dynamics of soil moisture variability: 1. Theoretical basis, Water Resour. Res., 39, 1274, https://doi.org/10.1029/2002WR001616, 2003. a
Bárdossy, A. and Kundzewicz, Z. W.: Geostatistical methods for detection of outliers in groundwater quality spatial fields, J. Hydrol., 115, 343–359, https://doi.org/10.1016/0022-1694(90)90213-H, 1990. a
Bárdossy, A. and Lehmann, W.: Spatial distribution of soil moisture in a small catchment. Part 1: Geostatistical analysis, J. Hydrol., 206, 1–15, https://doi.org/10.1016/S0022-1694(97)00152-2, 1998. a
Barlow, R. E., Bartholomew, D., Bremner, J., and Brunk, H.: Statistical Inference Under Order Restrictions: Theory and Application of Isotonic Regression, Tech. rep., Dept. of Statistics, Missouri Univ., Comumbia, 1972. a
Beyer, K., Goldstein, J., Ramakrishnan, R., and Shaft, U.: When Is “Nearest Neighbor” Meaningful?, in: International conference on database theory, Springer, Berlin, Heidelberg, 217–235, https://doi.org/10.1007/3-540-49257-7_15, 1999. a
Blume, T., Zehe, E., and Bronstert, A.: Use of soil moisture dynamics and patterns at different spatio-temporal scales for the investigation of subsurface flow processes, Hydrol. Earth Syst. Sci., 13, 1215–1233, https://doi.org/10.5194/hess-13-1215-2009, 2009. a, b
Bras, R. L.: Complexity and organization in hydrology: A personal view, Water Resour. Res., 51, 6532–6548, https://doi.org/10.1002/2015WR016958, 2015. a
Brocca, L., Morbidelli, R., Melone, F., and Moramarco, T.: Soil moisture spatial variability in experimental areas of central Italy, J. Hydrol., 333, 356–373, https://doi.org/10.1016/j.jhydrol.2006.09.004, 2007. a, b
Brocca, L., Melone, F., Moramarco, T., and Morbidelli, R.: Soil moisture temporal stability over experimental areas in Central Italy, Geoderma, 148, 364–374, https://doi.org/10.1016/j.geoderma.2008.11.004, 2009. a
Brocca, L., Tullo, T., Melone, F., Moramarco, T., and Morbidelli, R.: Catchment scale soil moisture spatial-temporal variability, J. Hydrol., 422–423, 63–75, https://doi.org/10.1016/j.jhydrol.2011.12.039, 2012. a
Bronstert, A., Creutzfeldt, B., Graeff, T., Hajnsek, I., Heistermann, M., Itzerott, S., Jagdhuber, T., Kneis, D., Lück, E., Reusser, D., and Zehe, E.: Potentials and constraints of different types of soil moisture observations for flood simulations in headwater catchments, Nat. Hazards, 60, 879–914, https://doi.org/10.1007/s11069-011-9874-9, 2012. a
Burgess, T. M. and Webster, R.: Optimal interpolation and isarithmic mapping of soil properties. I. The semi-variogram and punctual kriging, J. Soil Sci., 31, 315–331, https://doi.org/10.1111/j.1365-2389.1980.tb02084.x, 1980. a, b
Choi, W. and Jacobs, R. L.: Influences of formal learning, personal learning orientation, and supportive learning environment on informal learning, Human Resour. Dev. Quart., 22, 239–257, 2011. a
Comaniciu, D. and Meer, P.: Mean shift: A robust approach toward feature space analysis, IEEE T. Pattern Anal. Mach. Intel., 24, 603–619, 2002. a
Cressie, N. and Hawkins, D. M.: Robust estimation of the variogram: I, J. Int. Asso. Math. Geol., 12, 115–125, https://doi.org/10.1007/BF01035243, 1980. a, b
Daly, E. and Porporato, A.: A review of soil moisture dynamics: from rainfall infiltration to ecosystem response, Environ. Eng. Sci., 22, 9–24, 2005. a
De Cesare, L., Myers, D., and Posa, D.: FORTRAN programs for space-time modeling, Comput. Geosci., 28, 205–212, 2002. a
Dooge, J. C.: Looking for hydrologic laws, Water Resour. Res., 22, 46S–58S, https://doi.org/10.1029/WR022i09Sp0046S, 1986. a
Entekhabi, D., Rodriguez-Iturbe, I., and Bras, R. L.: Variability in large-scale water balance with land surface–atmosphere interaction, J. Climate, 5, 798–813, 1992. a
Fukunaga, K. and Hostetler, L.: The estimation of the gradient of a density function, with applications in pattern recognition, IEEE T. Inform. Theor., 21, 32–40, 1975. a
Gómez-Plaza, A., Martínez-Mena, M., Albaladejo, J., and Castillo, V.: Factors regulating spatial distribution of soil water content in small semiarid catchments, J. Hydrol., 253, 211–226, 2001. a
Grayson, R. B., Western, A. W., Chiew, F. H. S., and Blöschl, G.: Preferred states in spatial soil moisture patterns: Local and nonlocal controls, Water Resour. Res., 33, 2897–2908, https://doi.org/10.1029/97WR02174, 1997. a, b, c
Heathman, G. C., Larose, M., Cosh, M. H., and Bindlish, R.: Surface and profile soil moisture spatio-temporal analysis during an excessive rainfall period in the Southern Great Plains, USA, Catena, 78, 159–169, 2009. a
Hinterding, A.: Entwicklung hybrider Interpolationsverfahren für den automatisierten Betrieb am Beispiel meteorologischer Größen, PhD thesis, Institut für Geoinformatik, Universität Münster, Münster, Germany, 2003. a
Hunter, J. D.: Matplotlib: A 2D graphics environment, Comput. Sci. Eng., 9, 90–95, https://doi.org/10.1109/MCSE.2007.55, 2007. a
IUSS Working Group WRB: World Reference Base for Soil Resources 2006, in: A Framework for International Classification, Correlation and Communication, World Soil Resour. Rep., Food and Agric. Organ. of the UN, Rome, available at: http://www.fao.org/3/a-a0510e.pdf (last access: 20 May 2020), 2006. a
Jost, G., Heuvelink, G., and Papritz, A.: Analysing the space–time distribution of soil water storage of a forest ecosystem using spatio-temporal kriging, Geoderma, 128, 258–273, 2005. a
Kitanidis, P. K. and Vomvoris, E. G.: A geostatistical approach to the inverse problem in groundwater modeling (steady state) and one-dimensional simulations, Water Resour. Res., 19, 677–690, https://doi.org/10.1029/WR019i003p00677, 1983. a
Kleidon, A.: How does the Earth system generate and maintain thermodynamic disequilibrium and what does it imply for the future of the planet?, Philos. T. Roy. Soc. A, 370, 1012–1040, 2012. a
Kondepudi, D. and Prigogine, I.: From heat engines to dissipative structures, in: Modern Thermodynamics, John Wiley & Sons, Chichester, 1998. a
Kullback, S. and Leibler, R. A.: On information and sufficiency, Ann. Math. Stat., 22, 79–86, 1951. a
Lark, R. M.: Towards soil geostatistics, Spatial Stat., 1, 92–99, https://doi.org/10.1016/j.spasta.2012.02.001, 2012. a, b
Loritz, R., Hassler, S. K., Jackisch, C., Allroggen, N., van Schaik, L., Wienhöfer, J., and Zehe, E.: Picturing and modeling catchments by representative hillslopes, Hydrol. Earth Syst. Sci., 21, 1225–1249, https://doi.org/10.5194/hess-21-1225-2017, 2017. a, b
Loritz, R., Gupta, H., Jackisch, C., Westhoff, M., Kleidon, A., Ehret, U., and Zehe, E.: On the dynamic nature of hydrological similarity, Hydrol. Earth Syst. Sci., 22, 3663–3684, https://doi.org/10.5194/hess-22-3663-2018, 2018. a, b, c, d, e
Ly, S., Charles, C., and Degré, A.: Geostatistical interpolation of daily rainfall at catchment scale: The use of several variogram models in the Ourthe and Ambleve catchments, Belgium, Hydrol. Earth Syst. Sci., 15, 2259–2274, https://doi.org/10.5194/hess-15-2259-2011, 2011. a
Ma, C.: Spatio-temporal covariance functions generated by mixtures, Math. Geol., 34, 965–975, 2002. a
Ma, C.: Spatio-temporal stationary covariance models, J. Multivar. Anal., 86, 97–107, 2003. a
Mälicke, M.: Companion Code for: Soil moisture: variable in space but redundant in time. (10.5194/hess-2019-574), Zenodo, https://doi.org/10.5281/zenodo.3773110, 2019. a
Mälicke, M. and Schneider, H. D.: Scikit-GStat 0.2.7: A scipy flavoured geostatistical analysis toolbox written in Python, Zenodo, https://doi.org/10.5281/zenodo.3552235, 2019. a
Martinez-Carreras, N., Krein, A., Gallart, F., Iffly, J.-F., Hissler, C., Pfister, L., Hoffmann, L., and Owens, P. N.: The influence of sediment sources and hydrologic events on the nutrient and metal content of fine-grained sediments (attert river basin, Luxembourg), Water Air Soil Poll., 223, 5685–5705, 2012. a
Martínez-Fernández, J. and Ceballos, A.: Temporal stability of soil moisture in a large-field experiment in Spain, Soil Sci. Soc. Am. J., 67, 1647–1656, 2003. a
McDonnell, J. J., Roderick, M. L., Selker, J., Vaché, K., Hinz, C., Hooper, R., Grant, G., Sivapalan, M., Kirchner, J., Weiler, M., Dunn, S., and Haggerty, R.: Moving beyond heterogeneity and process complexity: A new vision for watershed hydrology, Water Resour. Res., 43, W07301, https://doi.org/10.1029/2006wr005467, 2007. a
McNamara, J. P., Chandler, D., Seyfried, M., and Achet, S.: Soil moisture states, lateral flow, and streamflow generation in a snowmelt-driven catchment, Hydrol. Process., 19, 4023–4038, 2005. a
Meyles, E., Williams, A., Ternan, L., and Dowd, J.: Runoff generation in relation to soil moisture patterns in a small Dartmoor catchment, Southwest England, Hydrol. Process., 17, 251–264, https://doi.org/10.1002/hyp.1122, 2003. a, b
Mittelbach, H. and Seneviratne, S. I.: A new perspective on the spatio-temporal variability of soil moisture: temporal dynamics versus time-invariant contributions, Hydrol. Earth Syst. Sci., 16, 2169–2179, https://doi.org/10.5194/hess-16-2169-2012, 2012. a, b, c
Pachepsky, Y. A., Guber, A., and Jacques, D.: Temporal persistence in vertical distributions of soil moisture contents, Soil Sci. Soc. Am. J., 69, 347–352, 2005. a
Patil, S. and Stieglitz, M.: Controls on hydrologic similarity: Role of nearby gauged catchments for prediction at an ungauged catchment, Hydrol. Earth Syst. Sci., 16, 551–562, https://doi.org/10.5194/hess-16-551-2012, 2012. a
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E.: Scikit-learn: Machine Learning in Python, J. Mach. Learn. Res., 12, 2825–2830, 2011. a, b, c
Pfister, L., Humbert, J., and Hoffmann, L.: Recent trends in rainfall-runoff characteristics in the Alzette river basin, Luxembourg, Climatic Change, 45, 323–337, 2000. a
Pool, M., Carrera, J., Alcolea, A., and Bocanegra, E. M.: A comparison of deterministic and stochastic approaches for regional scale inverse modeling on the Mar del Plata aquifer, J. Hydrol., 531, 214–229, https://doi.org/10.1016/j.jhydrol.2015.09.064, 2015. a
Rodríguez‐Iturbe, I., Devoto, G., and Valdés, J. B.: Discharge response analysis and hydrologic similarity: The interrelation between the geomorphologic IUH and the storm characteristics, Water Resour. Res., 15, 1435–1444, https://doi.org/10.1029/WR015i006p01435, 1979. a
Rolston, D. E., Biggar, J. W., and Nightingale, H. I.: Temporal persistence of spatial soil-water patterns under trickle irrigation, Irrig. Sci., 12, 181–186, https://doi.org/10.1007/BF00190521, 1991. a
Rosenbaum, U., Bogena, H. R., Herbst, M., Huisman, J. A., Peterson, T. J., Weuthen, A., Western, A. W., and Vereecken, H.: Seasonal and event dynamics of spatial soil moisture patterns at the small catchment scale, Water Resour. Res., 48, W10544, https://doi.org/10.1029/2011WR011518, 2012. a
Sampson, P. D. and Guttorp, P.: Nonparametric Estimation of Nonstationary Spatial Covariance Structure, J. Am. Stat. Assoc., 87, 108–119, https://doi.org/10.1080/01621459.1992.10475181, 1992. a
Schume, H., Jost, G., and Katzensteiner, K.: Spatio-temporal analysis of the soil water content in a mixed Norway spruce (Picea abies (L.) Karst.) – European beech (Fagus sylvatica L.) stand, Geoderma, 112, 273–287, https://doi.org/10.1016/S0016-7061(02)00311-7, 2003. a
Shannon, C. E.: A mathematical theory of communication, Bell Syst. Tech. J., 27, 379–423, 1948. a, b
Sivapalan, M.: Process complexity at hillslope scale, process simplicity at the watershed scale: is there a connection?, Hydrol. Process., 17, 1037–1041, https://doi.org/10.1002/hyp.5109, 2003. a
Sivapalan, M., Yaeger, M. A., Harman, C. J., Xu, X., and Troch, P. A.: Functional model of water balance variability at the catchment scale: 1. Evidence of hydrologic similarity and space-time symmetry, Water Resour. Res., 47, W02522, https://doi.org/10.1029/2010WR009568, 2011. a
Snepvangers, J., Heuvelink, G., and Huisman, J.: Soil water content interpolation using spatio-temporal kriging with external drift, Geoderma, 112, 253–271, 2003. a
Sprenger, M., Seeger, S., Blume, T., and Weiler, M.: Travel times in the vadose zone: Variability in space and time, Water Resour. Res., 52, 5727–5754, 2016. a
Starr, J. L. and Timlin, D. J.: Using High‐Resolution Soil Moisture Data to Assess Soil Water Dynamics in the Vadose Zone, Vadose Zone J., 3, 926–935, https://doi.org/10.2136/vzj2004.0926, 2004. a
Takagi, K. and Lin, H. S.: Changing controls of soil moisture spatial organization in the Shale Hills Catchment, Geoderma, 173-174, 289–302, https://doi.org/10.1016/j.geoderma.2011.11.003, 2012. a
Teuling, A. J. and Troch, P. A.: Improved understanding of soil moisture variability dynamics, Geophys. Res. Lett., 32, L05404, https://doi.org/10.1029/2004GL021935, 2005. a
Teuling, A. J., Uijlenhoet, R., Hupet, F., van Loon, E. E., and Troch, P. A.: Estimating spatial mean root-zone soil moisture from point-scale observations, Hydrol. Earth Syst. Sci., 10, 755–767, https://doi.org/10.5194/hess-10-755-2006, 2006. a, b, c, d
Topp, G., Davis, J., and Annan, A.: Electromagnetic Determination of Soil Water Content Using TDR: I. Applications to Wetting Fronts and Steep Gradients 1, Soil Sci. Soc. Am. J., 46, 672–678, 1982. a
Topp, G., Zebchuk, W., Davis, J., and Bailey, W.: The measurement of soil water content using a portable TDR hand probe, Can. J. Soil Sc., 64, 313–321, 1984. a
Vanderlinden, K., Vereecken, H., Hardelauf, H., Herbst, M., Martínez, G., Cosh, M. H., and Pachepsky, Y. A.: Temporal Stability of Soil Water Contents: A Review of Data and Analyses, Vadose Zone J., 11, vzj2011.0178, https://doi.org/10.2136/vzj2011.0178, 2012. a, b, c, d, e
Vereecken, H., Huisman, J. A., Bogena, H., Vanderborght, J., Vrugt, J. A., and Hopmans, J. W.: On the value of soil moisture measurements in vadose zone hydrology: A review, Water Resour. Res., 44, W00D06, https://doi.org/10.1029/2008WR006829, 2008. a, b
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, İ., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., and SciPy 1.0 Contributors: SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python, Nature Methods, in press, 2020. a
Wagener, T., Sivapalan, M., Troch, P., and Woods, R.: Catchment Classification and Hydrologic Similarity, Geogr. Compass, 1, 901–931, https://doi.org/10.1111/j.1749-8198.2007.00039.x, 2007. a
Weijs, S. V., Van De Giesen, N., and Parlange, M. B.: Data compression to define information content of hydrological time series, Hydrol. Earth Syst. Sci., 17, 3171–3187, https://doi.org/10.5194/hess-17-3171-2013, 2013. a
Wendi, D. and Marwan, N.: Extended recurrence plot and quantification for noisy continuous dynamical systems, Chaos, 28, 085722, https://doi.org/10.1063/1.5025485, 2018. a
Wendi, D., Marwan, N., and Merz, B.: In Search of Determinism-Sensitive Region to Avoid Artefacts in Recurrence Plots, Int. J. Bifurcat. Chaos, 28, 1850007, https://doi.org/10.1142/s0218127418500074, 2018. a
Western, A. W. and Grayson, R. B.: The Tarrawarra data set: Soil moisture patterns, soil characteristics, and hydrological flux measurements, Water Resour. Res., 34, 2765–2768, 1998. a, b
Western, A. W., Grayson, R. B., Blöschl, G., Willgoose, G. R., and McMahon, T. A.: Observed spatial organization of soil moisture and its relation to terrain indices, Water Resour. Res., 35, 797–810, https://doi.org/10.1029/1998WR900065, 1999. a, b
Western, A. W., Zhou, S. L., Grayson, R. B., McMahon, T. A., Blöschl, G., and Wilson, D. J.: Spatial correlation of soil moisture in small catchments and its relationship to dominant spatial hydrological processes, J. Hydrol., 286, 113–134, https://doi.org/10.1016/j.jhydrol.2003.09.014, 2004. a, b
Wu, W., Geller, M. A., and Dickinson, R. E.: The response of soil moisture to long-term variability of precipitation, J. Hydrometeorol., 3, 604–613, 2002. a
Zehe, E., Graeff, T., Morgner, M., Bauer, A., and Bronstert, A.: Plot and field scale soil moisture dynamics and subsurface wetness control on runoff generation in a headwater in the Ore Mountains, Hydrol. Earth Syst. Sci., 14, 873–889, https://doi.org/10.5194/hess-14-873-2010, 2010. a, b, c
Zehe, E., Ehret, U., Pfister, L., Blume, T., Schröder, B., Westhoff, M., Jackisch, C., Schymanski, S. J., Weiler, M., Schulz, K., Allroggen, N., Tronicke, J., van Schaik, L., Dietrich, P., Scherer, U., Eccard, J., Wulfmeyer, V., and Kleidon, A.: HESS Opinions: From response units to functional units: a thermodynamic reinterpretation of the HRU concept to link spatial organization and functioning of intermediate scale catchments, Hydrol. Earth Syst. Sci., 18, 4635–4655, https://doi.org/10.5194/hess-18-4635-2014, 2014. a, b, c, d
We tested different window sizes, as we expect that different processes control the emergence of spatial dependence at different temporal scales. The chosen window size was most suitable for detecting seasonal effects.
Observation point pairs further apart than 1200 m are most likely located on different hillslopes. These points might share similar soil, topographic and terrain aspect characteristics. Soil moisture dynamics might thus be similar, although they are located at rather large separating distances
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Mean shift algorithm
- Appendix B: Auxiliary quantitative results
- Appendix C: Detailed result plots of 30 cm in 2014 and 2015
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Mean shift algorithm
- Appendix B: Auxiliary quantitative results
- Appendix C: Detailed result plots of 30 cm in 2014 and 2015
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References