the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 17 Sep 2025
| 17 Sep 2025
Combining recurrent neural networks with variational mode decomposition and multifractals to predict rainfall time series
Daniel Schertzer
Ioulia Tchiguirinskaia
Rainfall time series prediction is essential for monitoring urban hydrological systems, but it is challenging and complex due to the extreme variability of rainfall. A hybrid deep learning model (VMD-RNN) is used in order to improve prediction performance. In this study, variational mode decomposition (VMD) is first applied to decompose the original rainfall time series into several sub-sequences according to the frequency domain, where the number of decomposed sub-sequences is determined by power spectral density (PSD) analysis. To prevent the disclosure of forthcoming data, non-training time series are sequentially appended for generating the decomposed testing samples. Following that, different recurrent neural network (RNN) variant models are used to predict individual sub-sequences, and the final prediction is reconstructed by summing the prediction results of sub-sequences. These RNN variants are long short-term memory (LSTM), gated recurrent unit (GRU), and bidirectional LSTM (BiLSTM) and bidirectional GRU (BiGRU), which are optimal for sequence prediction. In addition to three common evaluation criteria, mean absolute error (MAE), root mean square error (RMSE), and mean absolute percentage error (MAPE), the framework of universal multifractals (UMs) is also introduced to assess the performance of predictions, which enables the extreme variability of predicted rainfall time series to be characterized. The study employs two rainfall time series with daily and hourly resolutions, respectively. The results indicate that the hybrid VMD-RNN model provides a reliable one-step-ahead prediction, with better performance in predicting high and low values than the pure LSTM model without decomposition.
- Article
(4469 KB) - Full-text XML
- BibTeX
- EndNote




Prediction of rainfall time series plays an important role in monitoring urban hydrological systems and their geophysical environment. Accurate and trustworthy predictions can serve as an early warning of floods and other extreme events, as well as a guide for water resource allocation. Although predicting rainfall time series is not a novel concept, it has remained fundamentally difficult due to the extreme variability, in fact intermittency, of rainfall over a wide range of space–time scales; i.e., increasingly heavy precipitation is concentrated over smaller and smaller fractions of the space–time.
Classical forecast models are either process-driven physical models or data-driven statistical models. The former represents the most important physical processes and numerically solves the governing equations based on initial and boundary conditions (Lynch, 2008). Due to the fact that rainfall depends on a variety of land, ocean, and atmospheric processes and their complex interactions, physical models are developed based on simplifications of those processes, in particular by truncating the scales and introducing rather ad hoc parameterizations. This greatly increases their unpredictability (Bauer et al., 2015). On the contrary, data-driven models strive to establish a link between input and output data to predict time series without regard to underlying physical processes (Reichstein et al., 2019). In general, they therefore provide a unique output with no information on the uncertainty generated by the nonlinearity of the involved processes. A sort of hybrid approach has been developed using stochastic models physically based on the cascade paradigm (e.g., Schertzer and Lovejoy, 1987; Marsan et al., 1996; Schertzer and Lovejoy, 2004, 2011). This ensures that intermittency is directly taken into account, including in the generation of uncertainty.
The explosion of supercomputing and data availability offers immense potential for data-driven models to significantly contribute to prediction (Schultz et al., 2021). There are several methods available for predicting rainfall time series, including linear and nonlinear models. The traditional linear data-driven model is the autoregressive integrated moving average (ARIMA) (Chattopadhyay and Chattopadhyay, 2010), which ignores the nonlinearity of the relationship between input and output time series, leading to poor prediction ability. Because of increased data availability and computing power, various deep learning (DL) models have been proposed and applied in predicting nonlinear time series (Lara-Benítez et al., 2021).
Recurrent neural network (RNN) models are a subset of deep learning models, which have been specifically designed to solve sequential prediction problems (Elman, 1990). However, standard RNN struggles with long-term dependence and exhibits the gradient vanishing or exploding problems (Hochreiter and Schmidhuber, 1997). RNN variants, such as long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM), and bidirectional GRU (BiGRU), are intended to alleviate the limitations of standard RNN. These variant models have been employed in various fields (e.g., Graves et al., 2013; Cho et al., 2014; Su et al., 2020; Lin et al., 2022), including time series prediction (e.g., Ma et al., 2015; Ding et al., 2019; Gauch et al., 2021). In particular, great efforts have been devoted to predicting rainfall time series (e.g., Ni et al., 2020; Barrera-Animas et al., 2022; He et al., 2022), as shown in Table 1.
However, these pure variant models are not always capable of efficiently handling extremely nonlinear time series with several noisy components without the need for appropriate preprocessing (Liu et al., 2020; Huang et al., 2021; Zhang et al., 2021; Lv and Wang, 2022; Ruan et al., 2022). Decomposition is a typical preprocessing method in time series analysis, which can extract hidden information to aid in the comprehension of the complex original time series. For decomposition approaches, wavelet decomposition (Pati et al., 1993), empirical mode decomposition (EMD) (Huang et al., 1998), and variational mode decomposition (VMD) (Dragomiretskiy and Zosso, 2013) are commonly used to decompose original data. Relevant studies on time series prediction by combining a decomposition technique with deep learning models are also presented in Table 1. Because wavelet decomposition is highly dependent on the choice of the mother wavelet function, its adaptability in decomposing time series is limited (Hadi and Tombul, 2018). Meanwhile, EMD suffers from boundary effects, mode mixing, and a lack of exact mathematical foundations (Devi et al., 2020). In comparison, VMD, which is theoretically sound, presents the advantage of solving the mode overlap problem.
Table 1Relevant studies on time series prediction using deep learning models.
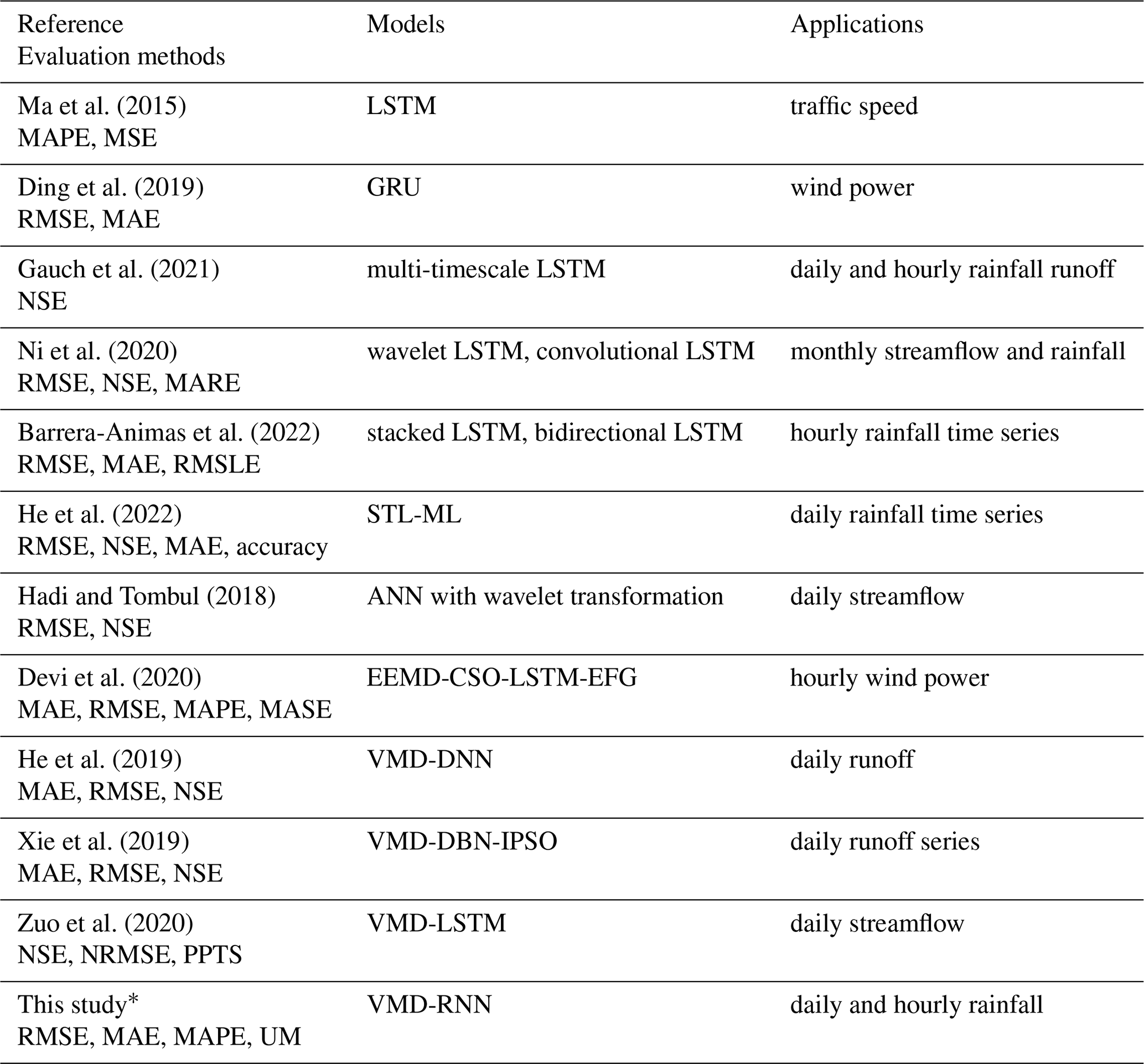
∗ This study incorporates four RNN models, namely LSTM, GRU, bidirectional LSTM, and bidirectional GRU. The RNN model with superior architecture was selected for each sub-sequence.
The inherent variability of rainfall typically results in limited prediction performance for single RNN-variant models. In response to this situation, integrated forecasting paradigms have been widely employed to improve the precision and robustness of time series forecasting. The hybrid VMD-RNN model is based on the fundamental concept of considering the dominant characteristics of VMD in decomposing nonlinear time series and the beneficial performance of variant RNN models in predicting complex sequential problems.
The main purpose of this study is to provide a reliable one-step-ahead rainfall prediction for hydrological applications, particularly urban flood forecasting and water resource management. This addresses the fundamental challenge in operational hydrology where accurate short-term precipitation forecasts are essential for timely flood warnings and infrastructure management. In order to achieve this objective, it is essential to fully extract the underlying patterns of rainfall time series while preserving their intermittency structure – a critical requirement for hydrological modeling where extreme events often dominate system response. An additional crucial point is to develop prediction models with a satisfactory level of accuracy for practical implementation in operational hydrological systems. According to the aforementioned two factors, this study implements a hybrid approach known as VMD-RNN, which combines different RNN-variant models with VMD decomposition for predicting rainfall time series.
The effectiveness and reliability of the employed VMD-RNN approach are extensively validated by applying this method to forecast the following step's rainfall in both daily and hourly resolution, representing different temporal scales relevant to hydrological practice. Furthermore, a comparison study is carried out to further demonstrate the superiority of the adopted VMD-RNN model in comparison to the baseline method, the pure LSTM model without decomposition, and the linear regression method. In addition, the universal multifractal (UM) technique is used to confirm the ability of the predicted time series to accurately describe rainfall variability, ensuring that the predicted series maintain the multifractal properties essential for accurate hydrological modeling and flood risk assessment.
Given the growing usage of deep learning in hydrological research, it is important to bridge the knowledge gap for readers who are not familiar with deep learning models. The pedagogical aspect of our work has the potential to contribute to the hydrology community by providing a deeper understanding of the application of deep learning models and multifractal techniques in short-term rainfall prediction that remains a fundamental problem of hydrology starting with one-step-ahead prediction. This work specifically addresses the need in the Hydrology and Earth System Sciences (HESS) community for accessible methodological advances that maintain strong connections to hydrological theory and practice, demonstrating how modern deep learning techniques can enhance traditional approaches to precipitation forecasting while preserving the physical understanding of rainfall processes essential for water resource management.
The rest of this article is organized as follows. In Sect. 2, the corresponding methodologies are presented in detail, including VMD, RNN variants, and UM. Two rainfall time series with daily and hourly resolutions are created by VMD-RNN in Sect. 3. The results are discussed and analyzed in Sect. 4. Finally, conclusions and future work are given in Sect. 5.
2.1 Variational mode decomposition
The primary process of variational mode decomposition (VMD) is constructing and solving the variational problem (Dragomiretskiy and Zosso, 2013). For rainfall time series f(t), the variation problem is described as identifying K sub-sequences uk(t) with center frequency ωk to minimize the sum value of the estimated bandwidth of each uk(t). The constrained condition is that the aggregation of the sub-sequences uk(t) should be equal to the original sequence f(t). The constrained variational problem can be expressed as follows:
where and are shorthand notations for decomposed sub-sequences and their center frequencies, respectively; δ(t) is the Dirac distribution, the symbol ∗ denotes convolution, and is a phasor describing the rotation of the complex signal in time, with .
The variational problem is addressed efficiently using the alternate direction method of multipliers (ADMMs). The modes uk(t) are updated by Wiener filtering in the Fourier domain with a filter tuned to the current center frequency; see Eq. (2). Then the center frequencies ωk are updated as the center of gravity of the corresponding mode's power spectrum, expressed as Eq. (3), and finally the Lagrangian multiplier λ enforcing exact constraints is updated as the dual ascent by Eq. (4). The updating procedure is repeated until the convergence condition is satisfied, as in Eq. (5).
Here, , , and represent the Fourier transforms of , f(t), and λn+1(t), respectively; n is the iteration, θ is a quadratic penalty term, τ is the iterative factor that indicates VMD's noise tolerance, and ϵ denotes the convergence tolerance.
2.2 Recurrent neural network
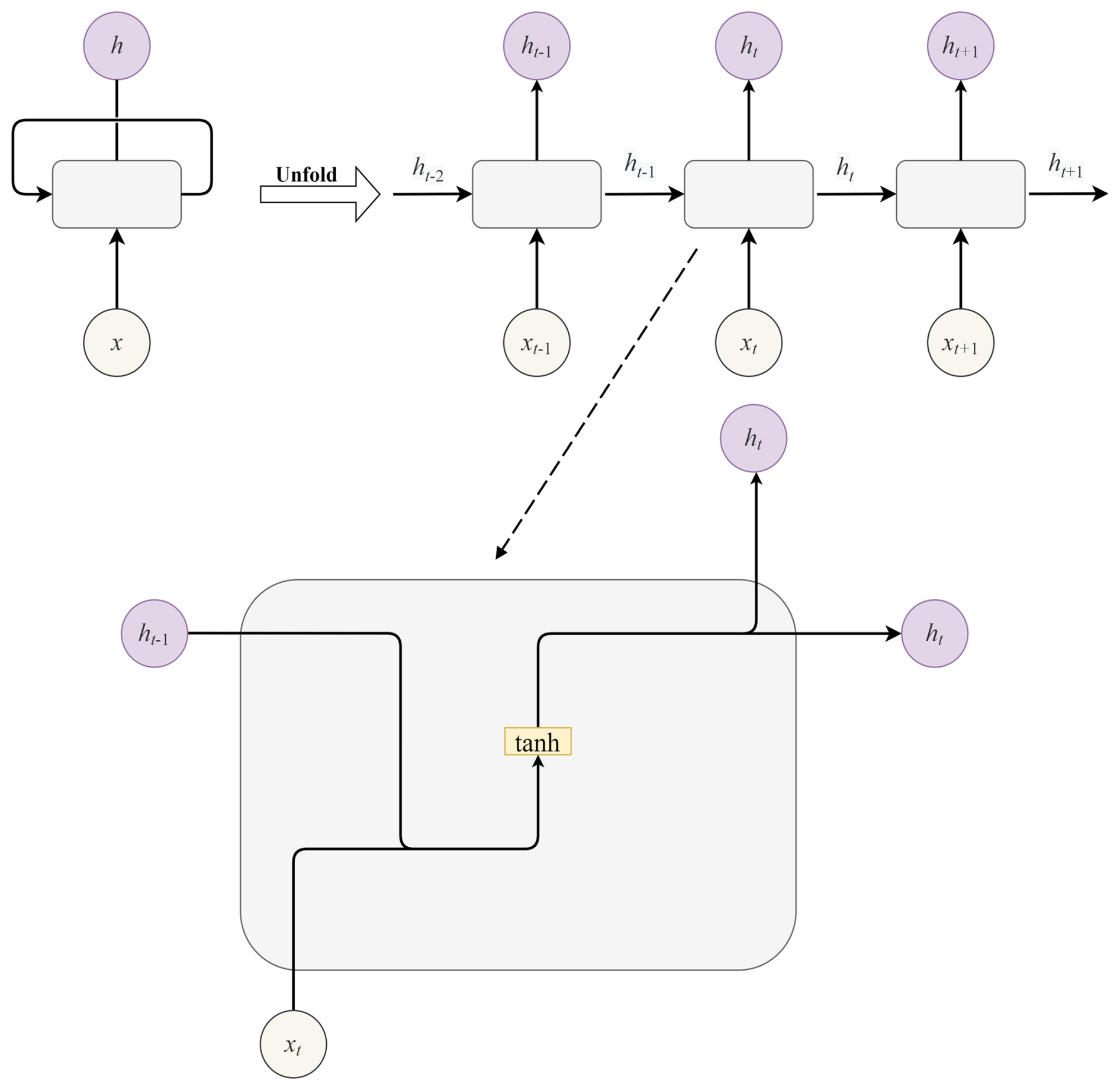
Recurrent neural network models perform deep learning through a unique recurrent structure (Elman, 1990), as illustrated in Fig. 1. In terms of time series predicting, the recurrent units remember earlier information, processing not only new data but also previous outputs to generate an up-to-date prediction. However, RNN models have difficulty dealing with long-term information. Additionally, standard RNN suffers from the gradient vanishing or exploding problem. To overcome the constraints of standard RNN, long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM) and bidirectional GRU (BiGRU), as variants of RNN, are designed. Their working principles are explained in detail as follows.
2.2.1 Long short-term memory
LSTM models are explicitly constructed with special recurrent structures to remember information for long periods, and they have three gates to control the cell state that stores and conveys information (Hochreiter and Schmidhuber, 1997), which is depicted in Fig. 2. The forget gate ft determines how much information should be forgotten from the cell state, which constructs the long-term memory, as represented in Eq. (6). The input gate it is responsible for deciding what new information should be stored in the cell, and the corresponding equations are Eqs. (7) and (8). The output gate ot is to generate outputs (Eq. 9) and update the cell states Ct and the hidden states ht, expressed as Eqs. (10) and (11), respectively.
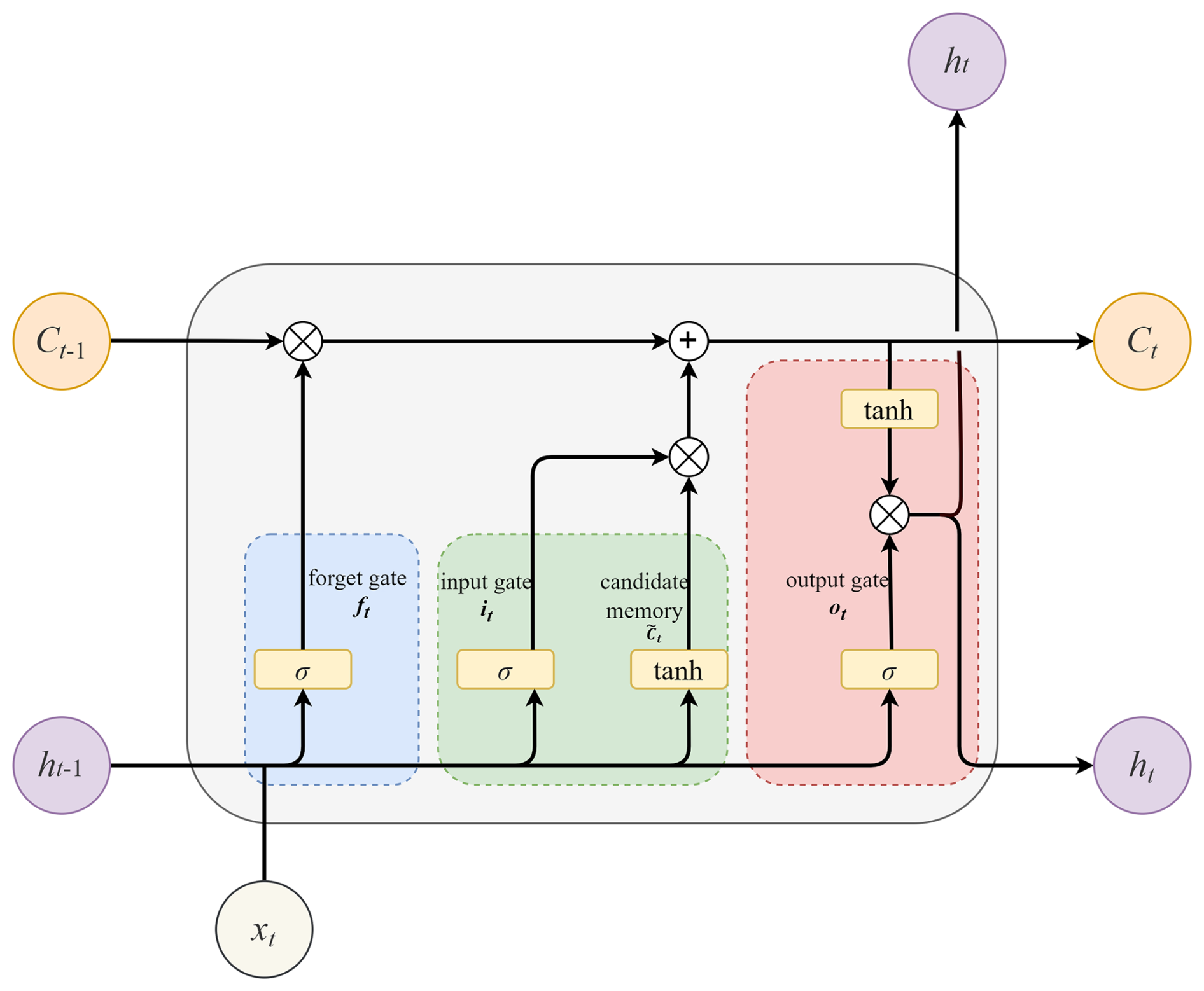
Here, σ and tanh are activation functions, denoting the sigmoid function and hyperbolic tangent function, respectively; xt is the input and is candidate memory; Wxf, Wxi, WxC, and Wxo and Whf, Whi, WhC, and Who represent the corresponding weights to xt and ht−1; bf, bi, bC, and bo are the related bias; and ⊗ indicates element-wise multiplication.
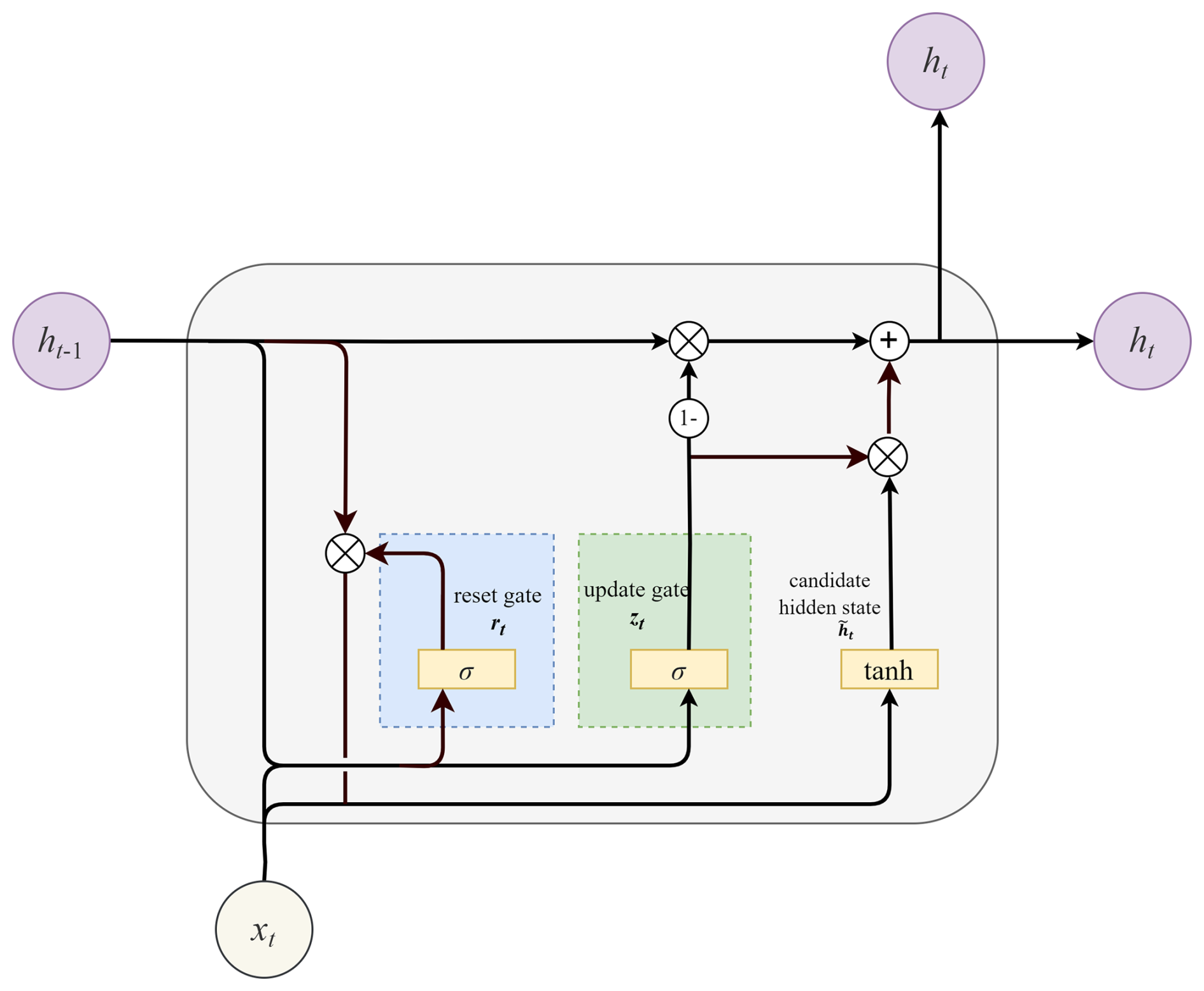
2.2.2 Gated recurrent unit
GRU also overcomes the drawbacks of standard RNN. Unlike LSTM, however, it only has two gates: a reset gate and an update gate (Cho et al., 2014). The rest gate rt is accountable for the short-term dependencies by determining which historical data should be forgotten, represented as Eq. (12). The update gate zt manages the long-term dependencies by controlling what information is delivered to the future (Eq. 13). The hidden state ht is then updated according to Eqs. (4) and (15). The update gate performs functions similar to the forget and input gates of LSTM, so the recurrent structure of GRU (Fig. 3) is less complex, which makes it more efficient computationally from a theoretical standpoint (Chung et al., 2014).
2.2.3 Bidirectional recurrent neural network
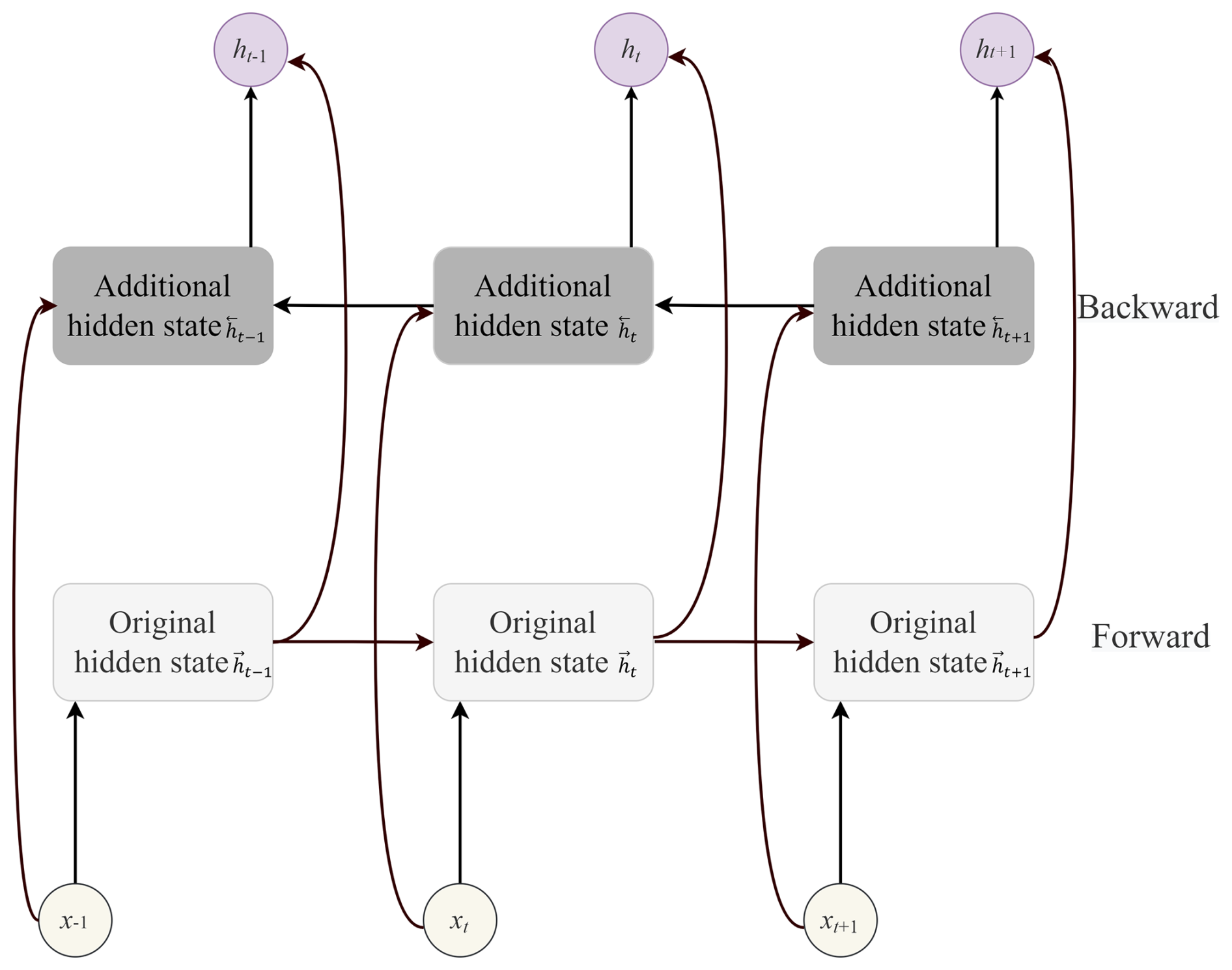
Bidirectional RNN (BiRNN) is an RNN-variant model that takes into account both past and future information to predict the target (Schuster and Paliwal, 1997; Graves and Schmidhuber, 2005). The architecture of a bidirectional RNN is seen in Fig. 4. It adds an additional hidden layer to the RNN construction so that information can be conveyed backward. The hidden state ht is obtained by concatenating the forward and backward hidden states, and , implying that the output is generated by combining information from two hidden layers. To avoid the limitations of standard RNN, BiLSTM and BiGRU are used instead of BiRNN, which have excellent performance in time series prediction.
2.3 Universal multifractals
Universal multifractals (UMs) have been widely used to describe nonlinear phenomena that have a multiplicative structure, such as rainfall. The core principle of the framework of UM is briefly explained here, and interested readers could refer to references (e.g., Schertzer and Lovejoy, 1987, 2011; Lovejoy and Schertzer, 2007) for more details. Let us denote ελ as a conservative field at resolution λ (, the ratio between the outer scale of the phenomenon L and the observation scale l), and the statistical moment of order q can be defined as
where K(q) is the moment scaling function characterizing the variability of the field at all scales.
In the UM framework, the moment scaling function K(q) can be determined by two scale-invariant parameters C1 and α in the conservative field, expressed as Eq. (17) (Schertzer and Lovejoy, 2011). C1 is the mean intermittency co-dimension, which measures the average sparseness of the field. α is the multifractality index (), which indicates how fast the intermittency evolves when considering singularities slightly different from the average field singularity.
The trace moment (TM) technique can be used to estimate UM parameters (Schertzer and Lovejoy, 2011; Gires et al., 2013). The steps in the technique are as follows: first, calculate the empirical statistical moment (corresponding to the trace moment of fluxes) of order q for each resolution λ and then plot the logarithm of the average field versus the logarithm of λ; later perform linear regression to obtain the slope K(q), and finally, according to the theoretical expression of K(q) (Eq. 17), C1 is given by and α by because , i.e., K(1)=0 for the conservative field.
An alternative method for directly estimating the UM parameters C1 and α is the double trace moment (DTM) (Lavallée et al., 1993; Gires et al., 2012). Based on the assumption that the conservative field is renormalized by upscaling the η power of the field at maximum resolution, the statistical moment K(qη) of order q is defined as with . In the specific framework of UM, the statistical moment K(qη) can be expressed as K(qη)=ηαK(q). Therefore, UM parameters C1 and α are obtained according to the slope and intercept of the linear portion of the log–log plot K(qη) vs. η.
When a multifractal field ϕλ is non-conservative (〈ϕλ〉≠1), it is usually assumed that it can be written as
where ελ is a conservative field (〈ελ〉=1) of the moment scaling function Kc(q) depending only on C1 and α; H is the non-conservation parameter (H=0 for the conservative field).
The moment scaling function K(q) of ϕλ is given by
H can be estimated using the following formula (Tessier et al., 1993):
where β is the spectral slope that characterizes the power spectrum of a scaling field, which follows a power law over a wide range of wave numbers,
Theoretically, a fractional integration of order H (equivalent to a multiplication by kH in the Fourier space) is performed to retrieve ελ from ϕλ. A common approximation is to take εΛ as the absolute value of the fluctuation of ϕΛ at the maximum resolution of Λ and renormalizing it, shown as Eq. (22) in one dimension (Lavallée et al., 1993). Then, ελ is obtained by upscaling εΛ.
3.1 Study area and datasets
Two rainfall time series with daily and hourly resolutions in Champs-sur-Marne (48.8425° N, 2.5886° E) were collected from the MERRA-2 (Modern-Era Retrospective analysis for Research and Applications, Version 2) precipitation dataset that is produced by NASA's Global Modeling and Assimilation Office (GMAO); refer to the POWER Project (https://power.larc.nasa.gov, last access: 10 September 2025). The corrected MERRA-2 precipitation dataset is a reanalysis product that integrates various observational data types (like radar, tipping bucket gauges, and satellite) through sophisticated data assimilation techniques into a climate model (Reichle et al., 2017).
One could worry about the model's applicability beyond the chosen study area, i.e., its transportability, because the model only has to be trained once. In principle, a new dataset from different regions or time periods can be fed directly into the well-trained model without repeating the training process to obtain the prediction on the new dataset.
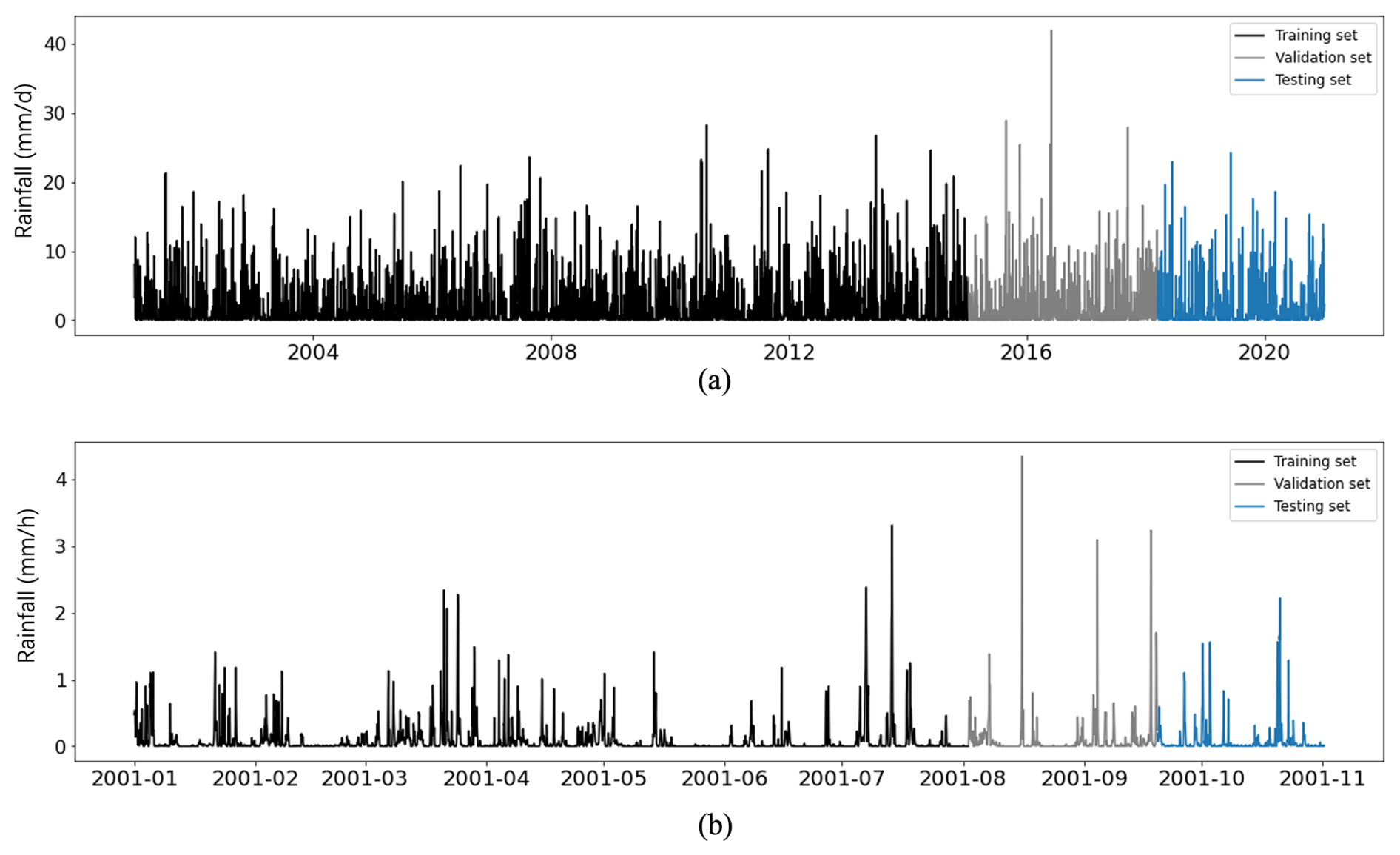
The daily time series covered 1 January 2001 to 31 December 2020 (a total of 7305 data points). The period from 1 January 2001 to 7 January 2015 (5120 data points, accounting for 70 % of the total dataset) was selected as the training set, while the remaining dates were used as the non-training set. The non-training set was further divided into a validation set to tune hyperparameters according to loss changes and a testing set (1024 data points, from 14 March 2018 to 31 December 2020) to evaluate the predicting performance, as presented in Fig. 5a. In addition, the rainfall time series with hourly resolution for the period between 1 January 2001 and 1 November 2001 (a total of 7305 data points) was also studied and divided into three sets: a training set (5120 data points), a validation set (1161 data points), and a testing set (1024 data points), as shown in Fig. 5b.
3.2 Model process
3.2.1 The implementation of VMD-RNN
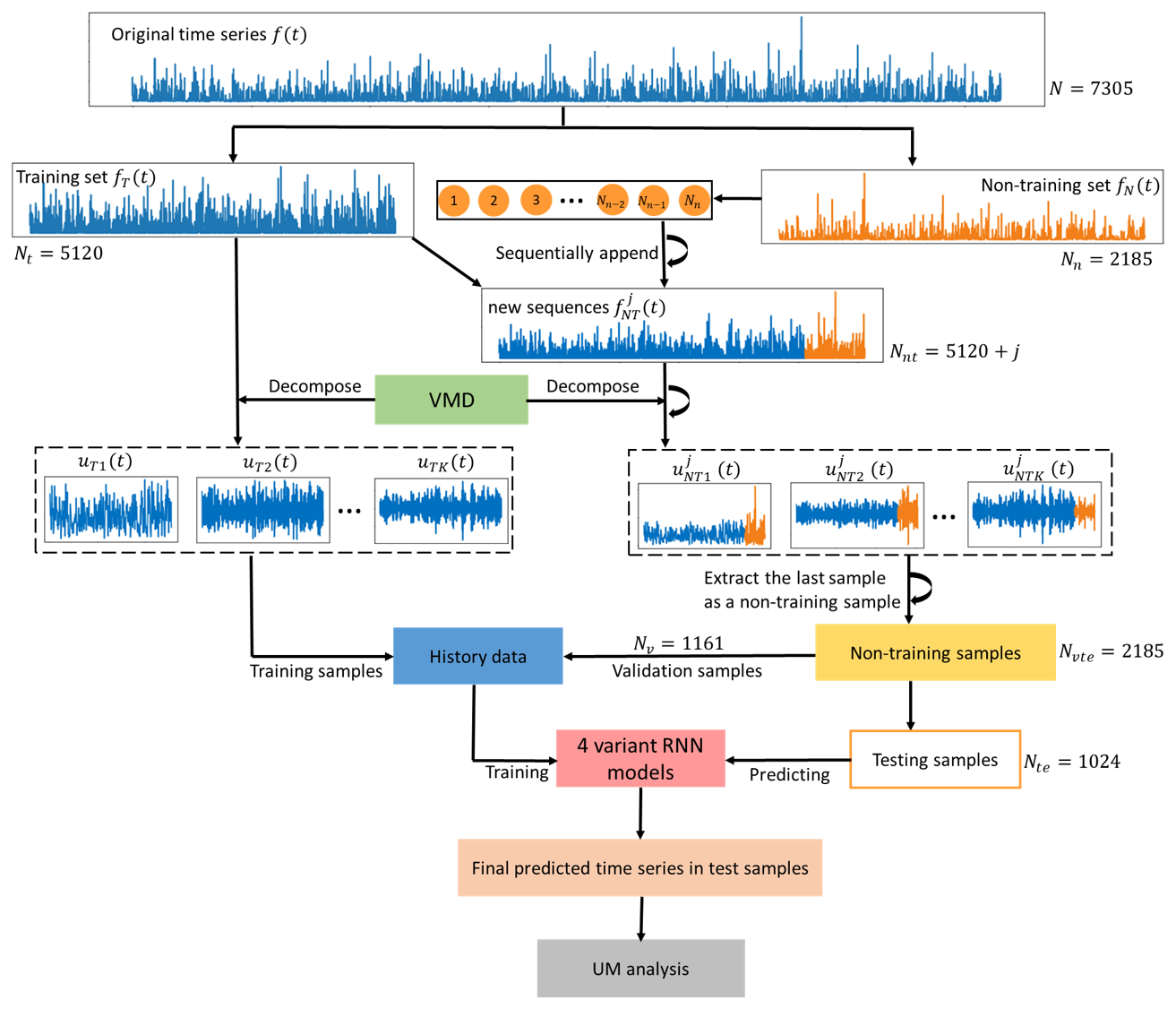
In order to avoid using information from the future, the original rainfall time series was first divided into the training and non-training sets, and then the training set was decomposed into several sub-sequences and applied to train the models (Zhang et al., 2015; Zuo et al., 2020). To predict in the testing set, time series from the non-training set were sequentially appended to the training set, and the decomposition process was repeated with the rainfall time series of the next step appended. Following that, four variant RNN models were used to predict individual sub-sequences. The root mean square error (RMSE) was used to select the ideal RNN model with the optimal parameters for each sub-sequence. In addition to RMSE, UM was also employed to evaluate prediction performances, characterizing the extreme variability of time series. The implementation of the hybrid deep learning model (VMD-RNN) is summarized as follows and presented in Fig. 6.
Step 1. Divide the original rainfall time series f(t) (t=1,2, …, N, where N is the length of total data) into a training set fT(t) (t=1,2,…,Nt, where Nt is the training set length) and a non-training set fN(t) (t=1, 2, …, Nn, where Nn is the non-training set length).
Step 2. Use VMD to decompose the training set fT(t) into sub-sequences uTi(t) (i=1, 2, …, K).
Step 3. Sequentially append the non-training data fN(t) to the training set to generate Nn new appended sequences (j=1, 2, …, Nn and t=1, 2, …, Nt+j), and repeat decomposing each appended sequence into K sets of appended sub-sequences (i=1, 2, …, K).
Step 4. Extract the last sample of each set of appended sub-sequences as a non-training sample and divide the generated non-training samples Nvte=Nn into two subsets: validation samples Nv and testing samples Nte.
Step 5. For each sub-sequence, combine data from the training set and validation samples as history data, which are then used to train four variant RNN models and tune hyperparameters to find an ideal predicting model with optimal parameters.
Step 6. For each sub-sequence, input testing samples into the corresponding predicting models and obtain an individual predicted result yi(t) (i=1, 2, …, K).
Step 7. Aggregate the predicted results of each sub-sequence to generate the final predicted result .
Step 8. Use the framework of UM to analyze the predicted and actual time series in the testing set.
To minimize the possibility of exposing future data during the decomposition of non-training time series, a precautionary approach (Step 3 and Step 4) has been implemented. This approach differs from the direct way of decomposing the testing time series using VMD. The non-training data were added to the training set in a sequential manner to create a new time series, and the number of new generated time series was equal to the number of non-training data points. The VMD technique was thereafter used to decompose the aforementioned new time series into several sub-sequences. Subsequently, the final data point of each newly generated sub-sequence was retrieved and designated as non-training data, which were then used to build validation and testing samples.
3.2.2 Parameters of VMD
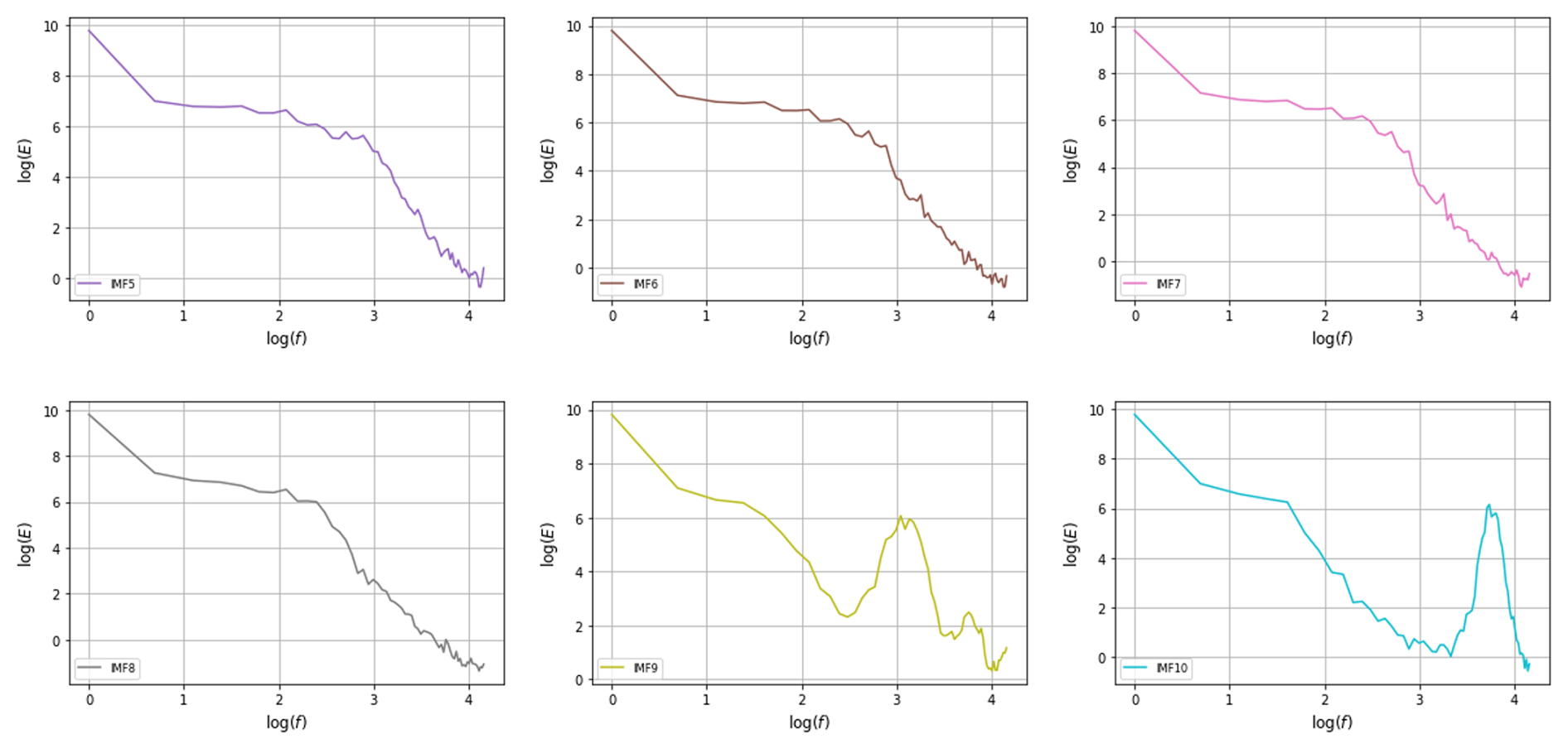
The decomposition performance of VMD is affected by the decomposition level K, the quadratic penalty term θ, the convergence tolerance ε, and the noise tolerance τ. In this study, the number of K was identified by observing the power spectral density (PSD) of the last sub-sequence. The value of K was determined on the training set with 5120 data points. First, an initial K value was given, such as K=5, and there were five sub-sequences (IMFs) with the same length of training set. Then, each sub-sequence was divided into 40 samples with 128 data points to perform the spectral analysis and plot the corresponding PSD of sub-sequences. After that, K was increased by 1 and the plotting PSD was repeated until the PSD of the last sub-sequence exhibited an evident change compared with the previous last sub-sequence. For daily time series, the optimal number of K was 8, which is depicted in Fig. 7, whereas K=6 for hourly time series. Based on the trial and error, other parameters of VMD were suggested as θ=100, , and τ=0.
3.2.3 Parameters of RNN
In the process of training, hyperparameters such as the number of inputs, epoch, hidden layers, and hidden units all influence the performance of models. Without loss of generality, the first sub-sequence (IMF1) is taken as an example to describe the determination of the ideal RNN structure with the optimal hyperparameters. The specific process is as follows: first, initialize a single hidden layer model with 5, 10, and 15 input neurons and 1 output neuron and run different variants of the RNN model (LSTM, GRU, BiLSTM, BiGRU) for various hidden neurons (32, 64, and 128). All experiments were intended to run for 10 000 epochs (one epoch is defined as when an entire dataset is passed forward and backward through the neural network only once), but early stopping with a large patience value (=200) was applied to prevent unnecessary overfitting, which means the model will stop the training if the performance on the validation dataset does not improve after 200 epochs. After adjusting hyperparameters, the ideal model with optimal parameters was found for the first sub-sequence (IMF1) where MAE and RMSE are the lowest.
Table 2Results of the VMD-RNN model with one hidden layer for IMF1 predicting. The best value is marked in bold.
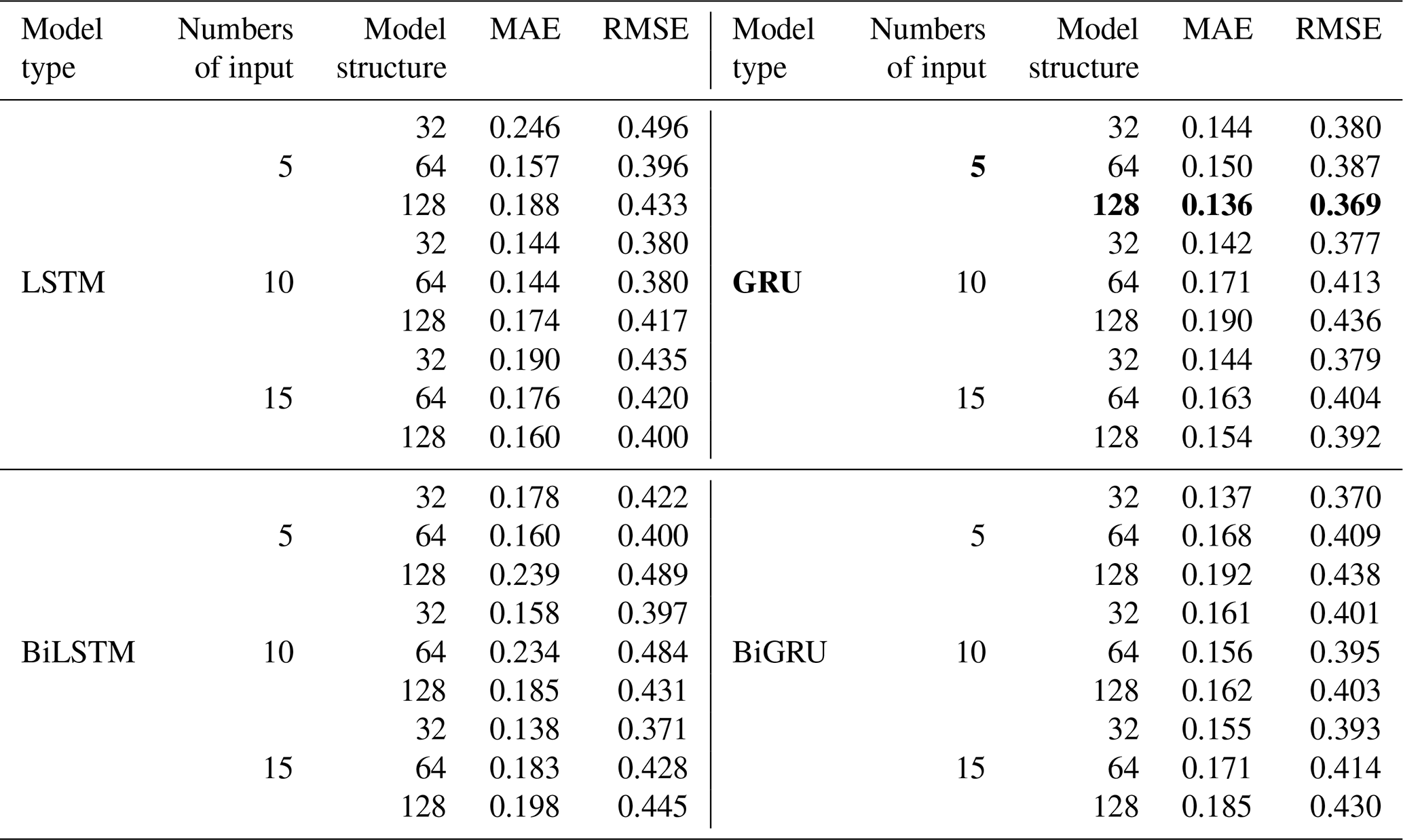
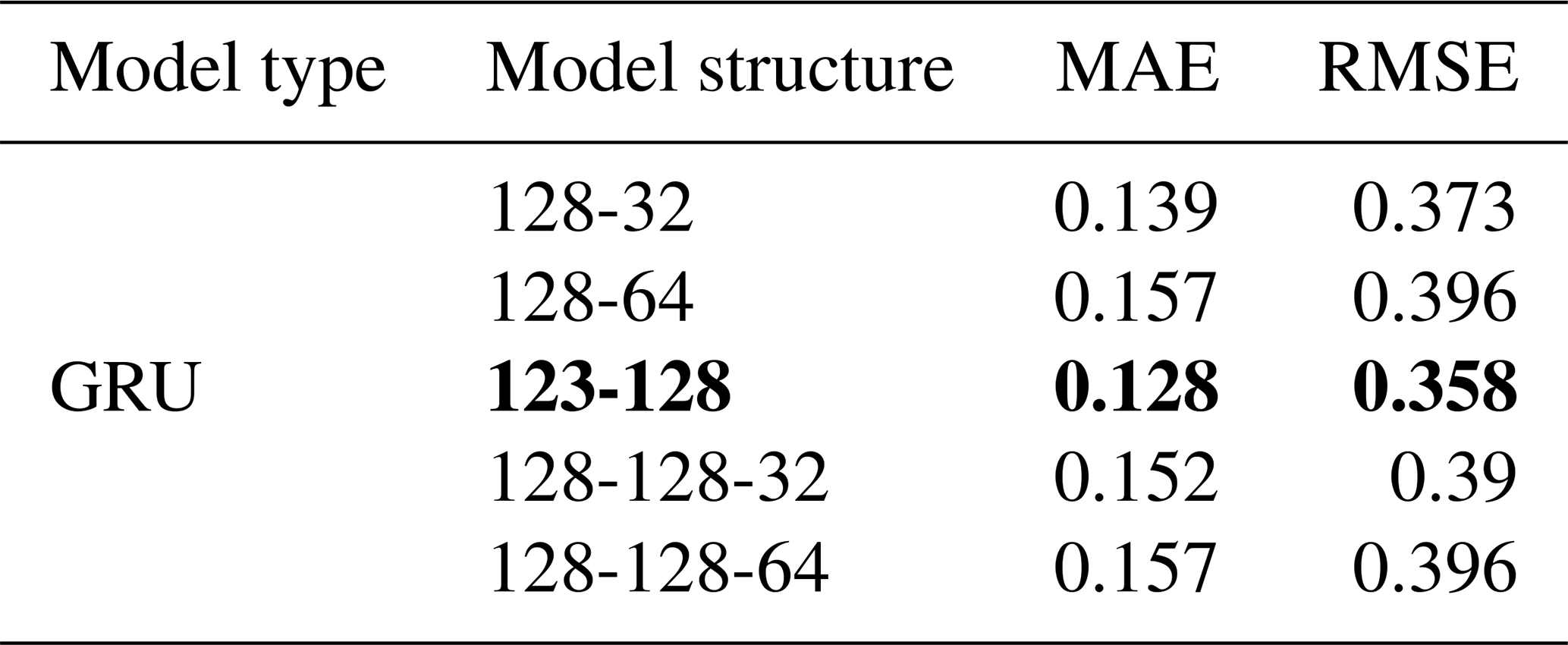
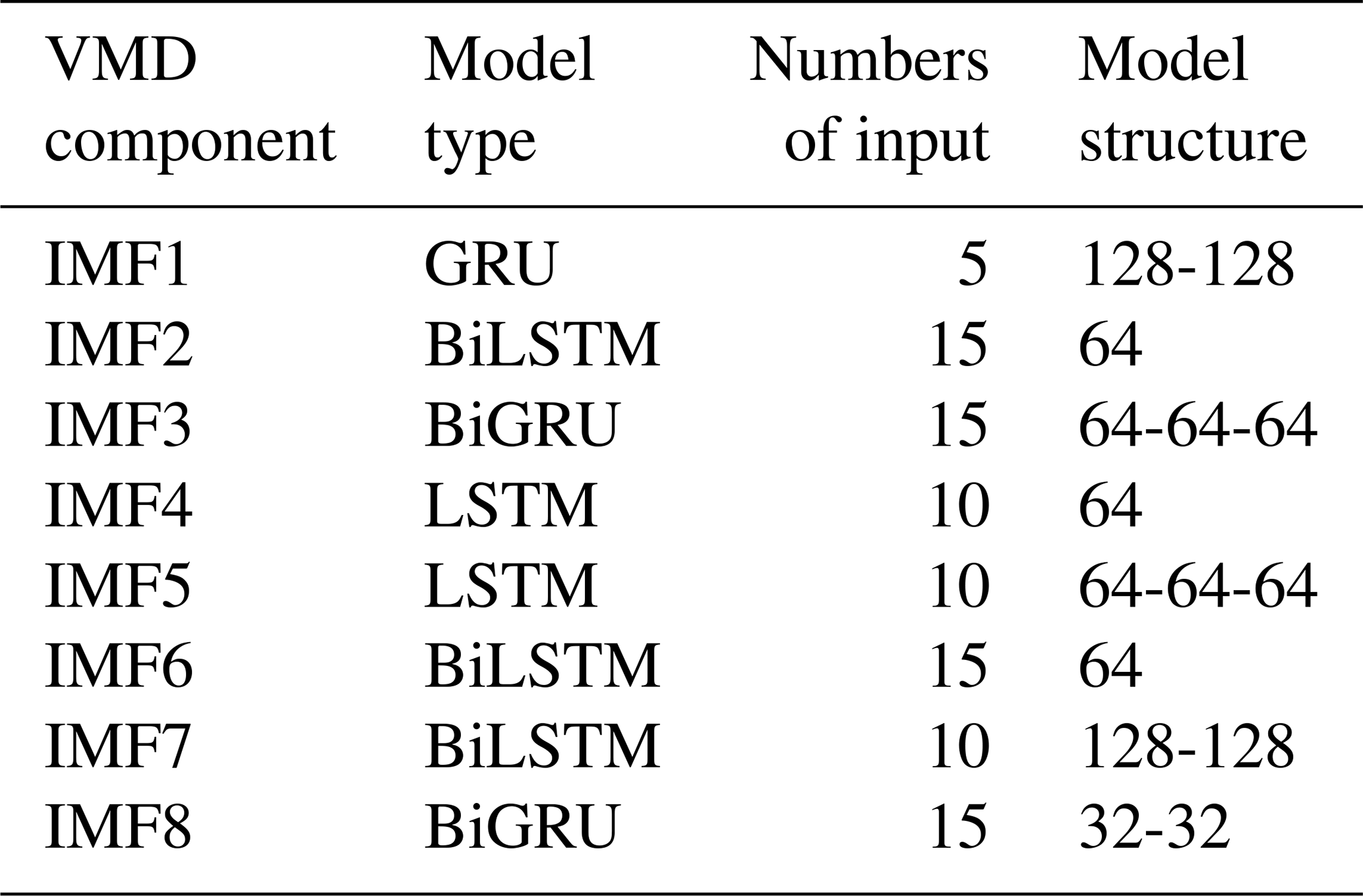
The results of the model with one hidden layer for IMF1 predicting are shown in Table 2, where the best value is marked in bold. Then, different second hidden layers with hidden neurons (32, 64, and 128) were added to the first hidden layer with optimal parameters in order to discover the optimal parameters for the second hidden layer. By analogy, a third hidden layer was added. Table 3 shows the results of the optimal model with second and third hidden layers for IMF1 predicting. Through the above method, the variant RNN model structures of IMF1–IMF8 components were obtained, as shown in Table 4.
Table 3Results of the optimal model with second and third hidden layers for IMF1 predicting.
3.3 Open-source software
This study made extensive use of open-source software. Python 3.8 was the programming language. The packages Numpy (Van Der Walt et al., 2011), Pandas (McKinney, 2011), and Scikit-Learn (Pedregosa et al., 2011) were used to preprocess data. Tensorflow (Abadi et al., 2016) and Keras (Chollet, 2018) were the deep learning frameworks used to analyze time series, and Matplotlib (Hunter, 2007) was used to create all the resulting figures. The decomposition of time series by VMD was implemented based on the package vmdpy (Carvalho et al., 2020), which is derived from the original VMD MATLAB toolbox (Dragomiretskiy and Zosso, 2013). TM and DTM analysis were performed to calculate UM parameters according to the Multifractal toolbox that was provided by the website (https://hmco.enpc.fr/portfolio-archive/multifractals-toolbox, last access: 10 September 2025) (Gires et al., 2011, 2012, 2013).
To verify the effectiveness of the hybrid VMD-RNN model, the benchmark methods, the pure LSTM model without decomposition, and the linear regression (LR) method were introduced. The benchmark also used the previous 5 d rainfall values to predict the next day's rainfall. The parameters for the pure LSTM were adjusted by trial and error. Qualitative and quantitative analyses of one-step-ahead predicted rainfall time series from two different models were conducted.
4.1 Daily rainfall series
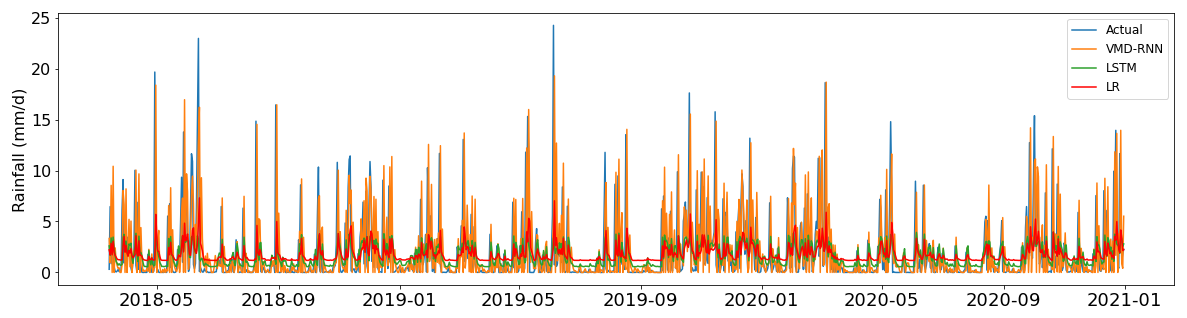
Figure 8 shows the predicted daily time series in the testing set. It compares the predicted results of the VMD-RNN hybrid model, the pure LSTM model, and the linear regression method with the actual data. It can be clearly observed that the hybrid model has a better fit for most of the points, particularly during periods of high-intensity rainfall events that are critical for flood forecasting applications. The VMD-RNN model demonstrates enhanced capability to capture rainfall variability patterns, including the temporal clustering of precipitation events that characterizes real rainfall processes.
The comparison of prediction performance with and without VMD for daily time series in the testing set can be seen in Fig. 9. The scatter plot demonstrates that the VMD-RNN model has superior performance in predicting both high and low values for daily time series, whereas the baseline models with LSTM and linear regression exhibit systematic biases. Notably, the VMD-RNN model shows improved performance in predicting extreme rainfall events, which are crucial for urban flood warning systems. The predicted values obtained by the baseline models exhibit considerable deviation from the best linear fitting line (blue dotted line), with a tendency to underestimate high-intensity events – a critical limitation for hydrological applications where accurate prediction of extreme events directly impacts flood risk assessment and emergency response effectiveness.
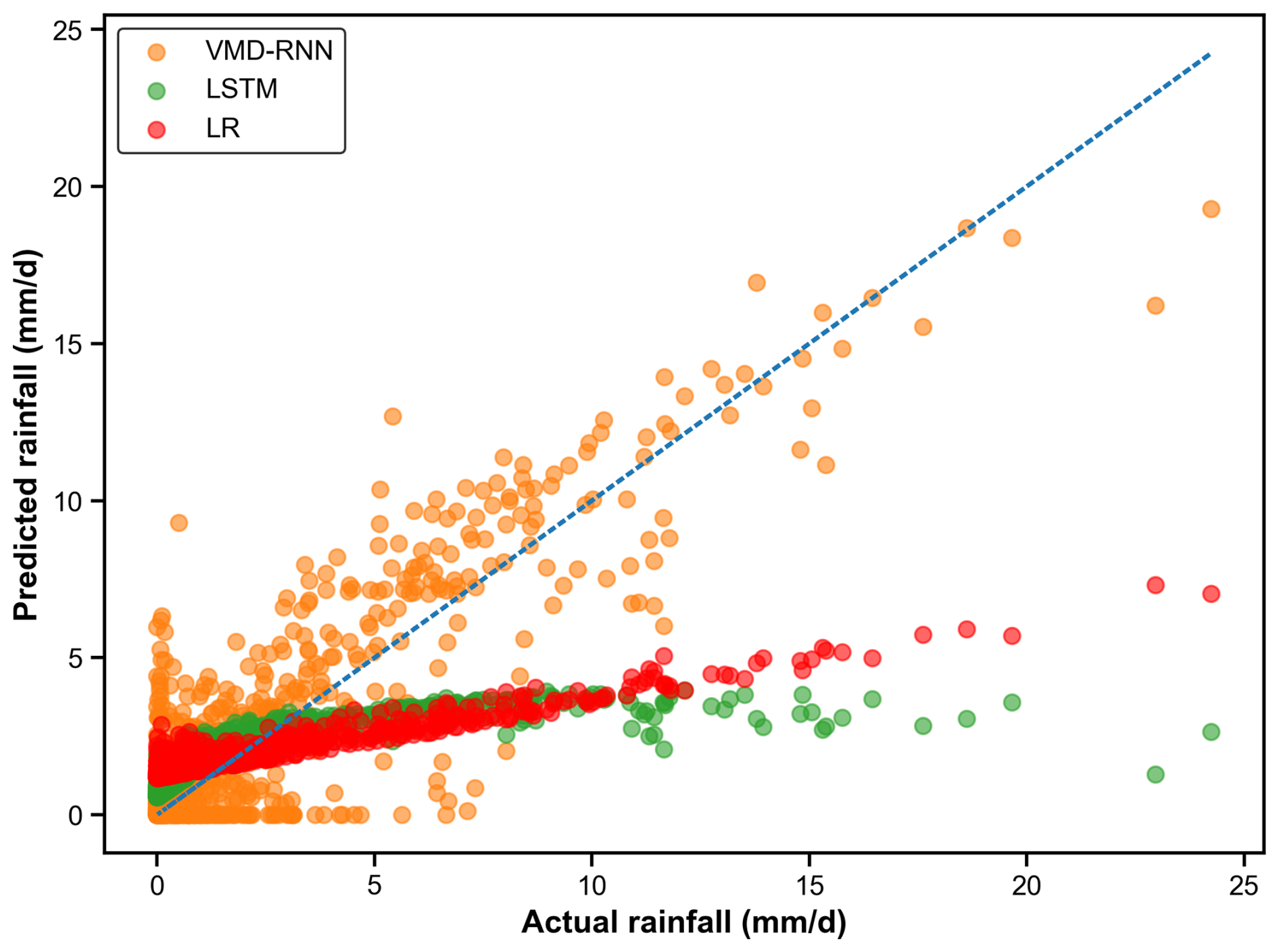
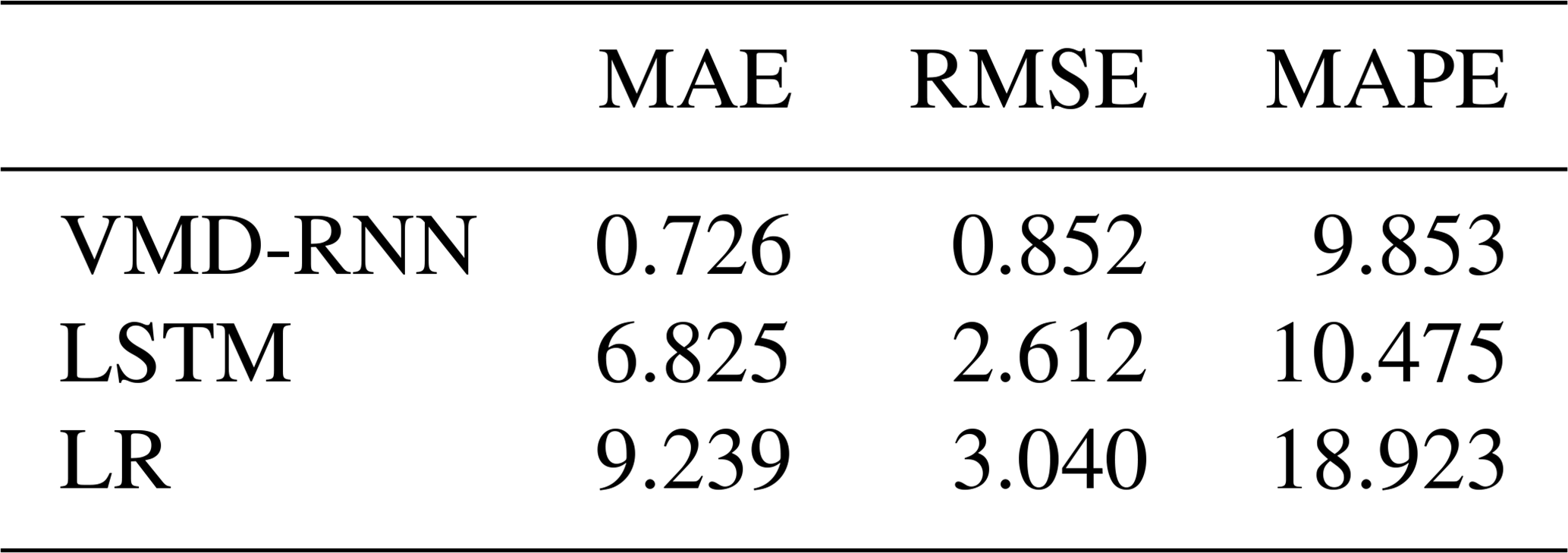
It was also necessary to know which model performed better on quantitative aspects. Table 5 compares the results of three widely used criteria: RMSE, MAE, and MAPE. It can be seen that the three criteria of VMD-RNN are plainly lower, so the hybrid model outperforms the pure model. It further confirms the strong capability of the hybrid model in rainfall prediction.
Table 5Prediction errors for daily time series in the testing set.
In addition to calculating the prediction error, the UM technique was also introduced to evaluate prediction performance since it enables the extreme variability of rainfall time series to be characterized. According to Tessier et al. (1996), the rainfall series in France exhibits a rough scaling break phenomenon between 16 and 30 d. Therefore, the analysis of UM starts with a range of scales from 1 d, increasing in powers of 2 to an outer scale of 16 d. Figure 10 presents versus log λ over the range of q between 0.3 and 2.5 with a coefficient of determination greater than 0.99, the log–log plot of vs. λ for q=1.5, and the corresponding log–log plot of K(qη) vs. η.
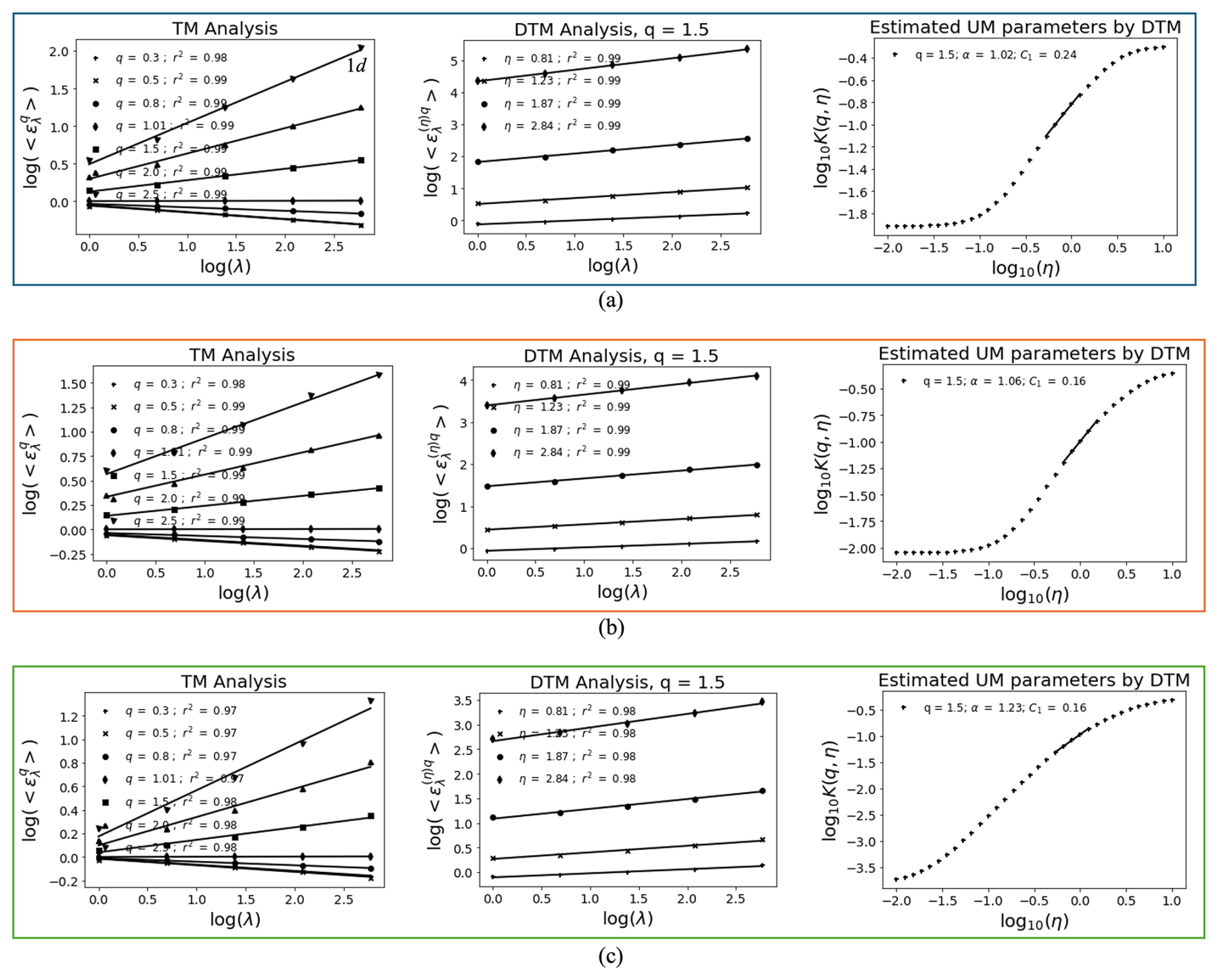
Figure 10UM results for daily time series in the testing set: (a) actual time series, (b) predicted time series by VMD-RNN, (c) predicted time series by LSTM without decomposition.
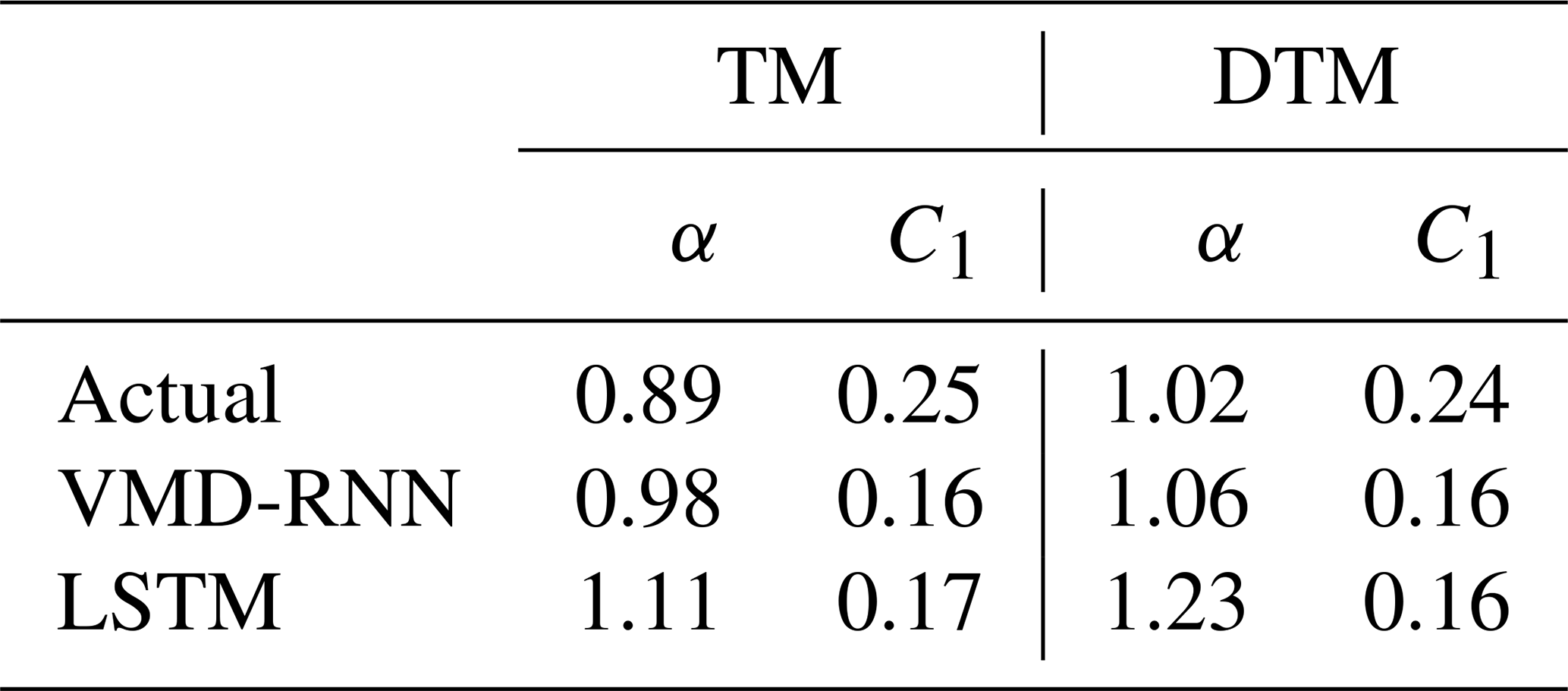
All the parameter values estimated using the TM and DTM methods are listed in Table 6. The values of α and C1 obtained using the DTM technique show slight differences from those estimated by TM but remain within acceptable ranges for multifractal analysis. Importantly, the VMD-RNN-predicted time series preserves multifractal properties more effectively than LSTM without decomposition, as evidenced by UM parameters that are closer to those of actual rainfall. This preservation of scaling properties is crucial for hydrological applications where the multifractal structure of rainfall directly influences runoff generation, infiltration processes, and the temporal distribution of streamflow in urban catchments.
Table 6Estimated UM parameters for daily time series in the testing set.
4.2 Hourly rainfall series
Figure 11 displays the hourly time series in the testing set with 1024 data points. The qualitative analysis reveals that the predictive performance differences between VMD-RNN, pure LSTM, and linear regression are less pronounced for hourly rainfall time series compared to daily predictions. This reduced benefit of decomposition for hourly data can be attributed to the inherently higher noise level and lower signal-to-noise ratio characteristic of high-frequency precipitation measurements, which limits the effectiveness of decomposition techniques in extracting meaningful frequency components.
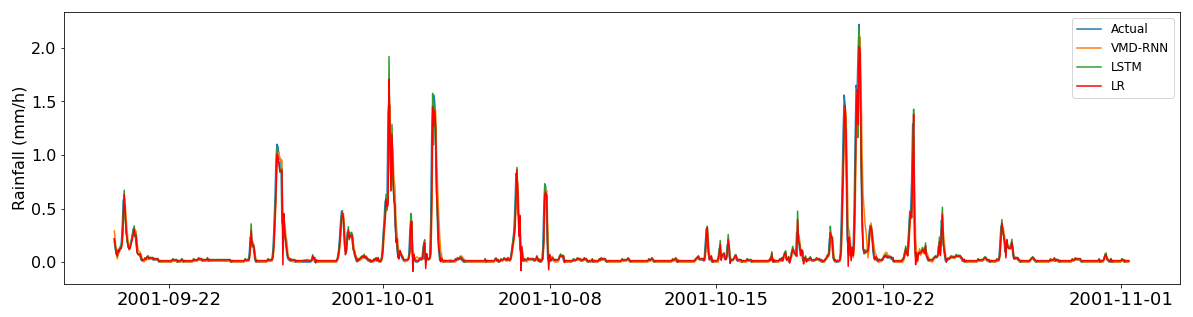
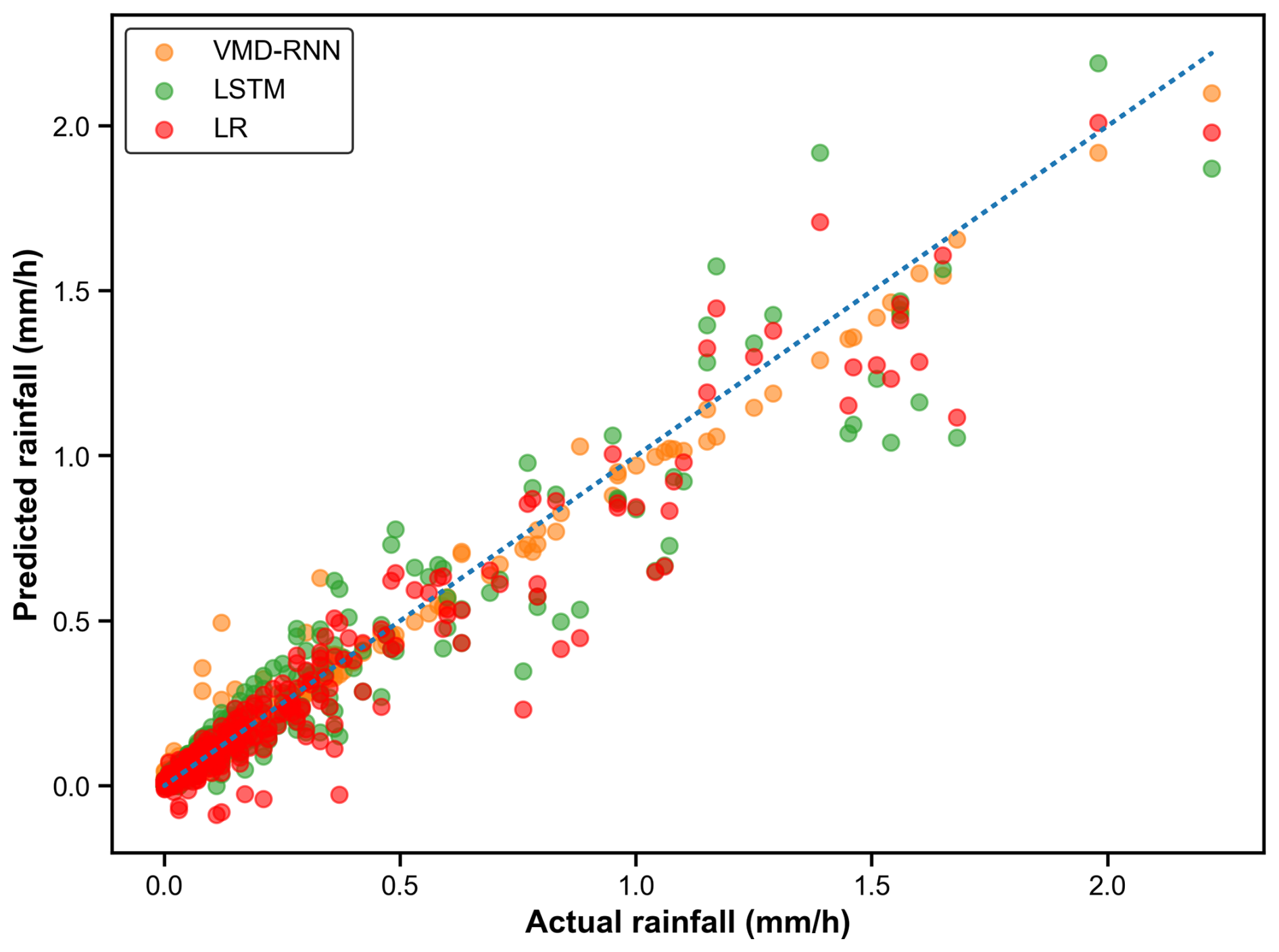
Figure 12 depicts the comparison between predicted and actual hourly rainfall values. The scatter plot reveals that the predicted values from VMD-RNN basically agree with the corresponding actual values, but the values predicted from the baseline LSTM model do not yield the same level of alignment. While the VMD-RNN model shows reasonable agreement with actual values for moderate to high rainfall intensities, significant challenges become apparent for low-intensity precipitation events.
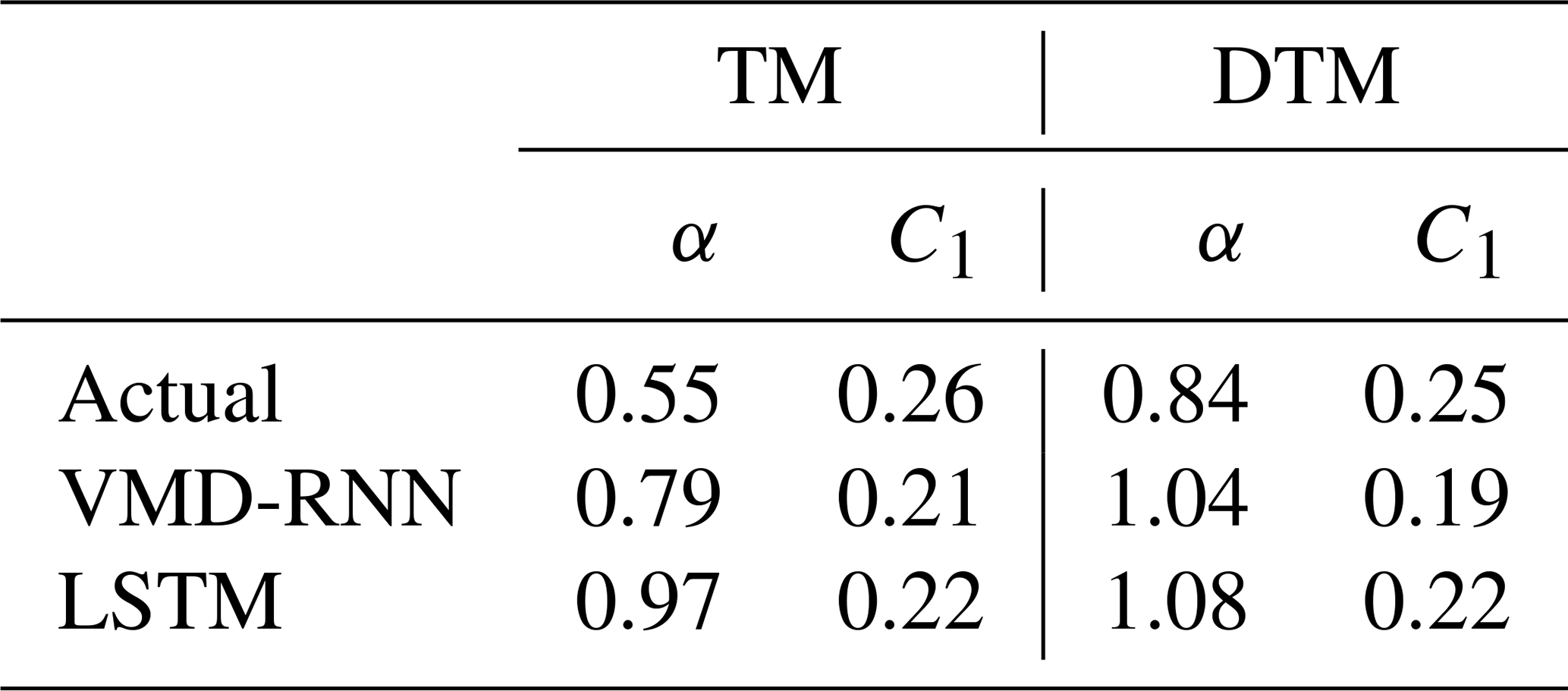
The UM analysis results for hourly time series (Fig. 13) and estimated parameters (Table 7) indicate that the predictive performance of VMD-RNN is comparable to pure LSTM for hourly data, without demonstrating the substantial benefits observed for daily predictions. The UM parameters α and C1 show similar values between VMD-RNN and LSTM predictions, suggesting that both approaches preserve multifractal properties to a similar degree at hourly resolution. This finding reflects the scale-dependent effectiveness of decomposition techniques, where the benefits become more apparent at longer timescales where signal-to-noise ratios are higher and frequency separation is more pronounced.
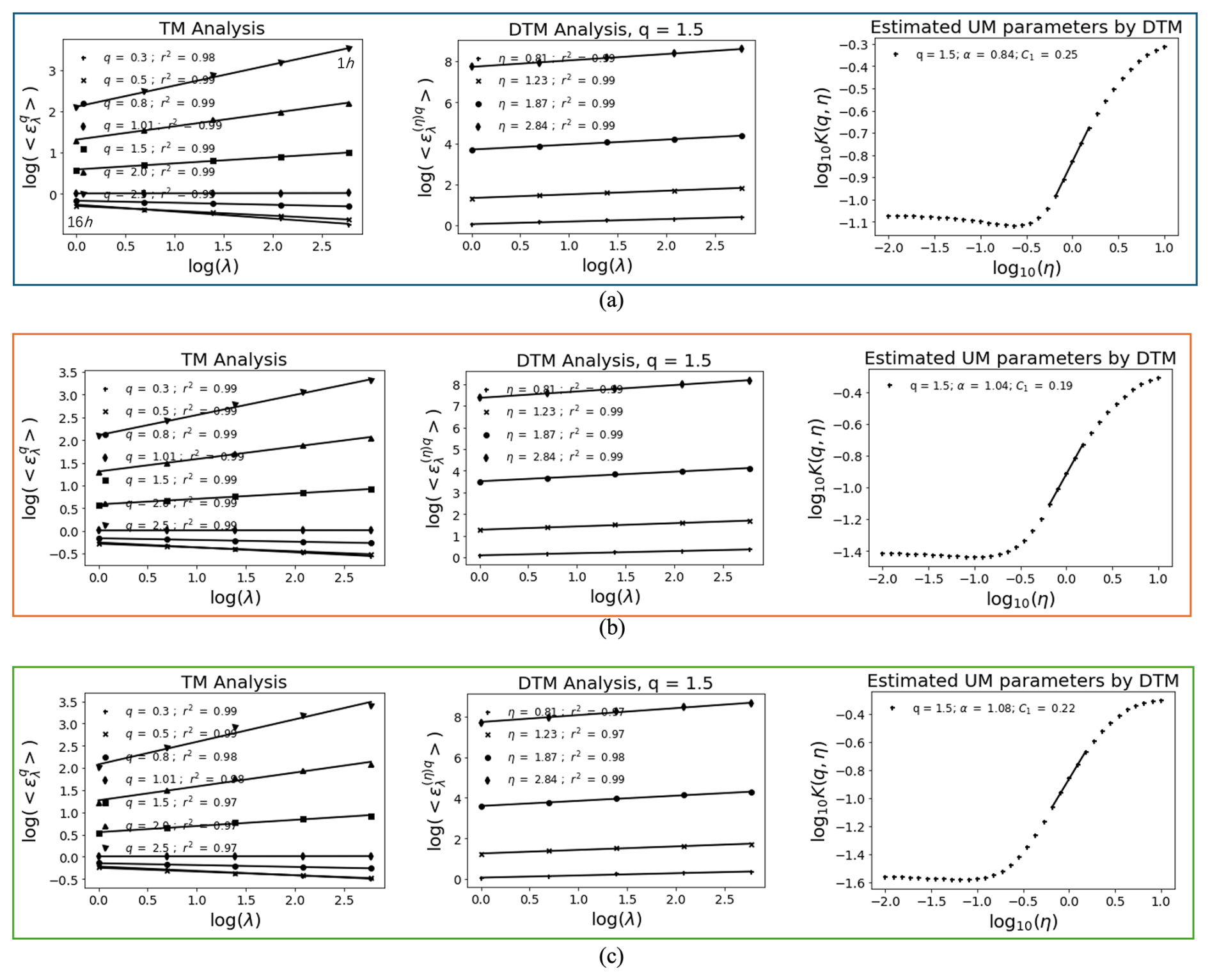
Figure 13UM results for hourly time series in the testing set: (a) actual time series, (b) predicted time series by VMD-RNN, (c) predicted time series by LSTM without decomposition.
Table 7Estimated UM parameters for hourly time series in the testing set.
4.3 Discussion
4.3.1 Comparison with existing approaches
The hybrid VMD-RNN approach addresses several limitations of traditional hydrological forecasting methods. Compared to physically based numerical weather prediction models, data-driven approaches like VMD-RNN can provide more computationally efficient solutions for short-term rainfall prediction, particularly for local-scale applications where high-resolution atmospheric models may not be practical or cost-effective (Wilks, 2011). However, it is important to note that these models complement rather than replace physical understanding of hydrological processes.
Nowcasting systems, which typically rely on radar observations and numerical weather prediction models, face challenges in accurately predicting the timing and intensity of precipitation events (Hess and Boers, 2022). The VMD-RNN approach could potentially be integrated with existing nowcasting frameworks to improve short-term precipitation forecasts, particularly when combined with radar-based observations and ensemble forecasting techniques.
The multifractal analysis using universal multifractals provides additional insights into the scaling properties of rainfall that are not captured by traditional error metrics. The closer agreement of VMD-RNN predictions with observed multifractal parameters suggests that the model better preserves the natural variability structure of rainfall processes across scales (Schertzer et al., 1997). This is particularly important for hydrological applications where the temporal distribution and intensity patterns of rainfall can significantly affect runoff generation and flood risk.
4.3.2 Hydrological significance and applications
The results of this study demonstrate that the VMD-RNN hybrid approach offers significant advantages for rainfall prediction in hydrological contexts, particularly at daily timescales. This improvement has important implications for operational hydrology and water resource management.
The enhanced performance of VMD-RNN in capturing extreme rainfall events is particularly valuable for flood early warning systems. Extreme precipitation events are the primary drivers of flash floods and urban flooding, and their accurate prediction can provide crucial lead time for emergency response and flood mitigation measures (Berne et al., 2004; Beven, 2012). The improved prediction of high-intensity events could enhance the reliability of flood forecasting systems and reduce false alarm rates, which are critical factors in maintaining public trust and ensuring effective emergency response (Demeritt et al., 2007).
4.3.3 Model limitations and uncertainties
Despite the promising results, several limitations must be acknowledged. The systematic overestimation of low-intensity rainfall represents a significant challenge for practical applications. This bias could lead to overestimation of cumulative precipitation over extended periods, affecting water balance calculations and long-term hydrological planning (Gardiya Weligamage et al., 2023). The issue of false positives in low-intensity predictions is a common challenge in precipitation forecasting and requires careful consideration in operational applications.
The temporal scale dependency observed in our results, where VMD decomposition shows greater benefits for daily compared to hourly predictions, suggests that the approach may be most suitable for applications requiring daily to weekly rainfall forecasts. This scale dependence may be related to the frequency content of rainfall signals, where longer timescales contain more distinct frequency components that can be effectively separated by VMD.
The current study focuses on a single location with a temperate climate. The performance of VMD-RNN may vary significantly across different climatic regions, particularly in areas with distinct wet and dry seasons and monsoon climates or arid regions where rainfall patterns differ markedly from those observed in our study area. Further validation across diverse climatic conditions is essential for establishing the general applicability of the approach.
In this study, the hybrid VMD-RNN model was used as a methodology for forecasting rainfall with a one-step lead time. The integration of variational mode decomposition with recurrent neural networks demonstrates significant potential for improving rainfall time series prediction accuracy, particularly for extreme events that are critical for flood risk assessment.
VMD was first used to extract hidden information to understand the complex original time series. Then variants of RNN were applied to handle problems involving sequential prediction. By combining the dominant characteristics of VMD in decomposing nonlinear time series and the favorable performance of variant RNN models in predicting complex sequential problems, the hybrid model based on VMD and RNN was employed to predict rainfall time series with daily and hourly resolution. The framework of UM was subsequently introduced to evaluate the performance of predicting rainfall time series.
According to the above study, the following conclusions could be drawn: (1) the VMD-RNN hybrid approach successfully addresses the challenge of predicting highly variable rainfall time series by decomposing the signal into frequency-specific components. The determination of optimal decomposition levels through power spectral density analysis provides a systematic approach for model configuration. (2) For daily rainfall prediction, the VMD-RNN model significantly outperforms pure LSTM models, particularly in capturing extreme rainfall events that are crucial for flood forecasting applications. The improvement in prediction accuracy has direct implications for early warning systems and flood risk management. (3) The closer agreement of VMD-RNN predictions with observed universal multifractal parameters demonstrates that the model better preserves the natural scaling variability of rainfall processes. This validation using C1 and α parameters provides additional confidence in the model's ability to represent the complex intermittent nature of precipitation. (4) The benefits of VMD decomposition are more pronounced at daily compared to hourly timescales, suggesting that the approach may be most effective for applications requiring daily to weekly rainfall forecasts rather than sub-daily nowcasting.
However, there are still some limits to this study, and corresponding improvements will be implemented in future work. First, extending the approach to multi-step-ahead predictions would significantly enhance its practical utility for hydrological applications. Second, incorporating spatial information through the development of spatially distributed VMD-RNN models could improve rainfall prediction for catchment-scale applications. Third, the integration of physics-informed constraints into the VMD-RNN framework could help address some of the observed limitations, particularly the overestimation of low-intensity rainfall. Finally, the development of ensemble forecasting capabilities would provide valuable uncertainty information for decision-making.
The source Python code of VMD is available at https://github.com/vrcarva/vmdpy (last access: 10 September 2025) (Carvalho et al., 2020). The Multifractal toolbox is provided by the website (https://hmco.enpc.fr/portfolio-archive/multifractals-toolbox, last access: 10 September 2025) (Gires et al., 2013, 2012, 2011). Two rainfall time series with daily and hourly resolutions in Champs-sur-Marne are collected from the POWER Project (https://power.larc.nasa.gov, last access: 10 September 2025) (White et al., 2011).
HZ, DS, and IT developed the concept for the paper; HZ was responsible for conducting the data analysis, coding the hybrid model, and writing the first draft. DS and IT supervised the entire research process and assisted with answering questions. All authors reviewed and edited the paper.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The first author is funded by the China Scholarship Council (grant no. 202006120045). We would like to express our sincere gratitude to the editor and anonymous reviewers for their professional comments and helpful suggestions.
This research has been supported by the China Scholarship Council (grant no. 202006120045).
This paper was edited by Thom Bogaard and reviewed by three anonymous referees.
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., Kudlur, M., Levenberg, J., Monga, R., Moore, S., Murray, D. G., Steiner, B., Tucker, P., Vasudevan, V., Warden, P., Wicke, M., Yu, Y., Zheng, X.: {TensorFlow}: A System for {Large-Scale} Machine Learning, in: 12th USENIX symposium on operating systems design and implementation (OSDI 16), 265–283, https://doi.org/10.48550/arXiv.1605.08695, 2016.
Barrera-Animas, A. Y., Oyedele, L. O., Bilal, M., Akinosho, T. D., Delgado, J. M. D., and Akanbi, L. A.: Rainfall prediction: A comparative analysis of modern machine learning algorithms for time-series forecasting, Machine Learning with Applications, 7, 100204, https://doi.org/10.1016/j.mlwa.2021.100204, 2022.
Bauer, P., Thorpe, A., and Brunet, G.: The quiet revolution of numerical weather prediction, Nature, 525, 47–55, https://doi.org/10.1038/nature14956, 2015.
Berne, A., Delrieu, G., Creutin, J.-D., and Obled, C.: Temporal and spatial resolution of rainfall measurements required for urban hydrology, J. Hydrol., 299, 166–179, https://doi.org/10.1016/j.jhydrol.2004.08.002, 2004.
Beven, K. J.: Rainfall-runoff modelling: the primer, John Wiley & Sons, https://doi.org/10.1002/9781119951001, 2012.
Carvalho, V. R., Moraes, M. F., Braga, A. P., and Mendes, E. M.: Evaluating five different adaptive decomposition methods for EEG signal seizure detection and classification, Biomed. Signal Proces., 62, 102 073, https://doi.org/10.1016/j.bspc.2020.102073, 2020.
Chattopadhyay, S. and Chattopadhyay, G.: Univariate modelling of summer-monsoon rainfall time series: comparison between ARIMA and ARNN, Comptes Rendus Geoscience, 342, 100–107, https://doi.org/10.1016/j.crte.2009.10.016, 2010.
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y.: Learning phrase representations using RNN encoder-decoder for statistical machine translation, In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1724–1734, Doha, Qatar. Association for Computational Linguistics, https://doi.org/10.3115/v1/D14-1179, 2014.
Chollet, F.: Keras: The python deep learning library, Astrophysics source code library, ascl–1806, https://github.com/fchollet/keras (last access: 14 September 2025), 2018.
Chung, J., Gulcehre, C., Cho, K., and Bengio, Y.: Empirical evaluation of gated recurrent neural networks on sequence modeling, arXiv [preprint], arXiv:1412.3555, https://doi.org/10.48550/arXiv.1412.3555, 2014.
Demeritt, D., Cloke, H., Pappenberger, F., Thielen, J., Bartholmes, J., and Ramos, M.-H.: Ensemble predictions and perceptions of risk, uncertainty, and error in flood forecasting, Environ. Hazards, 7, 115–127, https://doi.org/10.1016/j.envhaz.2007.05.001, 2007.
Devi, A. S., Maragatham, G., Boopathi, K., and Rangaraj, A.: Hourly day-ahead wind power forecasting with the EEMD-CSO-LSTM-EFG deep learning technique, Soft Comput., 24, 12391–12411, https://doi.org/10.1007/s00500-020-04680-7, 2020.
Ding, M., Zhou, H., Xie, H., Wu, M., Nakanishi, Y., and Yokoyama, R.: A gated recurrent unit neural networks based wind speed error correction model for short-term wind power forecasting, Neurocomputing, 365, 54–61, https://doi.org/10.1016/j.neucom.2019.07.058, 2019.
Dragomiretskiy, K. and Zosso, D.: Variational mode decomposition, IEEE T. Signal Proces., 62, 531–544, 2013.
Elman, J. L.: Finding structure in time, Cognitive Sci., 14, 179–211, https://doi.org/10.1207/s15516709cog1402_1, 1990.
Gardiya Weligamage, H., Fowler, K., Peterson, T. J., Saft, M., Peel, M. C., and Ryu, D.: Partitioning of precipitation into terrestrial water balance components under a drying climate, Water Resour. Res., 59, e2022WR033538, https://doi.org/10.1029/2022WR033538, 2023.
Gauch, M., Kratzert, F., Klotz, D., Nearing, G., Lin, J., and Hochreiter, S.: Rainfall–runoff prediction at multiple timescales with a single Long Short-Term Memory network, Hydrol. Earth Syst. Sci., 25, 2045–2062, https://doi.org/10.5194/hess-25-2045-2021, 2021.
Gires, A., Tchiguirinskaia, I., Schertzer, D., and Lovejoy, S.: Analyses multifractales et spatio-temporelles des précipitations du modèle Méso-NH et des données radar, Hydrol. Sci. J., 56, 380–396, https://doi.org/10.1080/02626667.2011.564174, 2011.
Gires, A., Tchiguirinskaia, I., Schertzer, D., and Lovejoy, S.: Influence of the zero-rainfall on the assessment of the multifractal parameters, Adv. Water Resour., 45, 13–25, https://doi.org/10.1016/j.advwatres.2012.03.026, 2012.
Gires, A., Tchiguirinskaia, I., Schertzer, D., and Lovejoy, S.: Development and analysis of a simple model to represent the zero rainfall in a universal multifractal framework, Nonlin. Processes Geophys., 20, 343–356, https://doi.org/10.5194/npg-20-343-2013, 2013.
Graves, A. and Schmidhuber, J.: Framewise phoneme classification with bidirectional LSTM and other neural network architectures, Neural networks, 18, 602–610, https://doi.org/10.1016/j.neunet.2005.06.042, 2005.
Graves, A., Jaitly, N., and Mohamed, A.-r.: Hybrid speech recognition with deep bidirectional LSTM, in: 2013 IEEE workshop on automatic speech recognition and understanding, 8–12 December 2013, Olomouc, Czech Republic, 273–278, IEEE, https://doi.org/10.1109/ASRU.2013.6707742, 2013.
Hadi, S. J. and Tombul, M.: Streamflow forecasting using four wavelet transformation combinations approaches with data-driven models: a comparative study, Water Resour. Manage., 32, 4661–4679, https://doi.org/10.1007/s11269-018-2077-3, 2018.
He, R., Zhang, L., and Chew, A. W. Z.: Modeling and predicting rainfall time series using seasonal-trend decomposition and machine learning, Knowledge-Based Systems, 251, 109125, https://doi.org/10.1016/j.knosys.2022.109125, 2022.
He, X., Luo, J., Zuo, G., and Xie, J.: Daily runoff forecasting using a hybrid model based on variational mode decomposition and deep neural networks, Water Resour. Manage., 33, 1571–1590, https://doi.org/10.1007/s11269-019-02212-z, 2019.
Hess, P. and Boers, N.: Deep learning for improving numerical weather prediction of heavy rainfall, J. Adv. Model. Earth Sy., 14, e2021MS002765, https://doi.org/10.1029/2021MS002765, 2022.
Hochreiter, S. and Schmidhuber, J.: Long short-term memory, Neural Computation, 9, 1735–1780, https://doi.org/10.1162/neco.1997.9.8.1735, 1997.
Huang, H., Chen, J., Huo, X., Qiao, Y., and Ma, L.: Effect of multi-scale decomposition on performance of neural networks in short-term traffic flow prediction, IEEE Access, 9, 50994–51004, https://doi.org/10.1109/ACCESS.2021.3068652, 2021.
Huang, N. E., Shen, Z., Long, S. R., Wu, M. C., Shih, H. H., Zheng, Q., Yen, N.-C., Tung, C. C., and Liu, H. H.: The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis, P. Roy. Soc. Lond. A, 454, 903–995, https://doi.org/10.1098/rspa.1998.0193, 1998.
Hunter, J. D.: Matplotlib: A 2D graphics environment, Comput. Sci. Eng., 9, 90–95, https://doi.org/10.1109/MCSE.2007.55, 2007.
Lara-Benítez, P., Carranza-García, M., and Riquelme, J. C.: An experimental review on deep learning architectures for time series forecasting, Int. J. Neur. Syst., 31, 2130001, https://doi.org/10.1142/S0129065721300011, 2021.
Lavallée, D., Lovejoy, S., Schertzer, D., and Ladoy, P.: Nonlinear variability and landscape topography: analysis and simulation, Fractals in geography, edited by: De Cola, L., and Lam, N., PTR, Prentice Hall, 8, 158–192, 1993.
Lin, J., Zhong, S.-h., and Fares, A.: Deep hierarchical LSTM networks with attention for video summarization, Comput. Electr. Eng., 97, 107618, https://doi.org/10.1016/j.compeleceng.2021.107618, 2022.
Liu, Y., Yang, C., Huang, K., and Gui, W.: Non-ferrous metals price forecasting based on variational mode decomposition and LSTM network, Knowledge-Based Systems, 188, 105006, https://doi.org/10.1016/j.knosys.2019.105006, 2020.
Lovejoy, S. and Schertzer, D.: Scale, scaling and multifractals in geophysics: twenty years on, in: Nonlinear dynamics in geosciences, 311–337, Springer, https://doi.org/10.1007/978-0-387-34918-3_18, 2007.
Lv, S.-X. and Wang, L.: Deep learning combined wind speed forecasting with hybrid time series decomposition and multi-objective parameter optimization, Appl. Energ., 311, 118674, https://doi.org/10.1016/j.apenergy.2022.118674, 2022.
Lynch, P.: The origins of computer weather prediction and climate modeling, J. Computat. Phys., 227, 3431–3444, https://doi.org/10.1016/j.jcp.2007.02.034, 2008.
Ma, X., Tao, Z., Wang, Y., Yu, H., and Wang, Y.: Long short-term memory neural network for traffic speed prediction using remote microwave sensor data, Transport. Res. C-Emer., 54, 187–197, https://doi.org/10.1016/j.trc.2015.02.014, 2015.
Marsan, D., Schertzer, D., and Lovejoy, S.: Causal space-time multifractal processes: Predictability and forecasting of rain fields, J. Geophys. Res.-Atmos., 101, 26333–26346, https://doi.org/10.1029/96JD02033, 1996.
McKinney, W.: pandas: a foundational Python library for data analysis and statistics, Python for high performance and scientific computing, 14, 1–9, 2011.
Ni, L., Wang, D., Singh, V. P., Wu, J., Wang, Y., Tao, Y., and Zhang, J.: Streamflow and rainfall forecasting by two long short-term memory-based models, J. Hydrol., 583, 124296, https://doi.org/10.1016/j.jhydrol.2020.124296, 2020.
Pati, Y. C., Rezaiifar, R., and Krishnaprasad, P. S.: Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition, in: Proceedings of 27th Asilomar conference on signals, systems and computers, 1–3 November 1993, Pacific Grove, CA, USA, 40–44, IEEE, https://doi.org/10.1109/ACSSC.1993.342465, 1993.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, É.: Scikit-learn: Machine learning in Python, the Journal of machine Learning research, 12, 2825–2830, https://doi.org/10.48550/arXiv.1201.0490, 2011.
Reichle, R. H., Liu, Q., Koster, R. D., Draper, C. S., Mahanama, S. P., and Partyka, G. S.: Land surface precipitation in MERRA-2, J. Climate, 30, 1643–1664, https://doi.org/10.1175/JCLI-D-16-0570.1, 2017.
Reichstein, M., Camps-Valls, G., Stevens, B., Jung, M., Denzler, J., and Carvalhais, N.: Deep learning and process understanding for data-driven Earth system science, Nature, 566, 195–204, https://doi.org/10.1038/s41586-019-0912-1, 2019.
Ruan, Y., Wang, G., Meng, H., and Qian, F.: A hybrid model for power consumption forecasting using VMD-based the long short-term memory neural network, Front. Energ. Res., 9, 772508, https://doi.org/10.3389/fenrg.2021.772508, 2022.
Schertzer, D. and Lovejoy, S.: Physical modeling and analysis of rain and clouds by anisotropic scaling multiplicative processes, J. Geophys. Res.-Atmos., 92, 9693–9714, https://doi.org/10.1029/JD092iD08p09693, 1987.
Schertzer, D. and Lovejoy, S.: Space–time complexity and multifractal predictability, Physica A, 338, 173–186, https://doi.org/10.1016/j.physa.2004.04.032, 2004.
Schertzer, D. and Lovejoy, S.: Multifractals, generalized scale invariance and complexity in geophysics, Int. J. Bifurcat. Chaos, 21, 3417–3456, https://doi.org/10.1142/S0218127411030647, 2011.
Schertzer, D., Lovejoy, S., Schmitt, F., Chigirinskaya, Y., and Marsan, D.: Multifractal cascade dynamics and turbulent intermittency, Fractals, 5, 427–471, https://doi.org/10.1142/S0218348X97000371, 1997.
Schultz, M., Betancourt, C., Gong, B., Kleinert, F., Langguth, M., Leufen, L., Mozaffari, A., and Stadtler, S.: Can deep learning beat numerical weather prediction?, Philos. T. Roy. Soc. A, 379, 20200097, https://doi.org/10.1098/rsta.2020.0097, 2021.
Schuster, M. and Paliwal, K. K.: Bidirectional recurrent neural networks, IEEE T. Signal Proces., 45, 2673–2681, https://doi.org/10.1109/78.650093, 1997.
Su, C., Huang, H., Shi, S., Jian, P., and Shi, X.: Neural machine translation with Gumbel Tree-LSTM based encoder, J. Vis. Commun. Image R., 71, 102811, https://doi.org/10.1016/j.jvcir.2020.102811, 2020.
Tessier, Y., Lovejoy, S., and Schertzer, D.: Universal multifractals: Theory and observations for rain and clouds, J. Appl. Meteorol. Climatol., 32, 223–250, https://doi.org/10.1175/1520-0450(1993)032<0223:UMTAOF>2.0.CO;2, 1993.
Tessier, Y., Lovejoy, S., Hubert, P., Schertzer, D., and Pecknold, S.: Multifractal analysis and modeling of rainfall and river flows and scaling, causal transfer functions, J. Geophys. Res.-Atmos., 101, 26427–26440, https://doi.org/10.1029/96JD01799, 1996.
Van Der Walt, S., Colbert, S. C., and Varoquaux, G.: The NumPy array: a structure for efficient numerical computation, Comput. Sci. Eng., 13, 22–30, https://doi.org/10.1109/MCSE.2011.37, 2011.
White, J. W., Hoogenboom, G., Wilkens, P. W., Stackhouse, P. W., and Hoel, J. M.: Evaluation of Satellite-Based, Modeled-Derived Daily Solar Radiation Data for the Continental United States, Agronomy Journal, 103, 1242–1251, https://doi.org/10.2134/agronj2011.0038, 2011.
Wilks, D. S.: Statistical methods in the atmospheric sciences, vol. 100, International Geophysics, Academic press, https://doi.org/10.1016/B978-0-12-385022-5.00007-5, 2011.
Xie, T., Zhang, G., Hou, J., Xie, J., Lv, M., and Liu, F.: Hybrid forecasting model for non-stationary daily runoff series: a case study in the Han River Basin, China, J. Hydrol., 577, 123915, https://doi.org/10.1016/j.jhydrol.2019.123915, 2019.
Zhang, X., Peng, Y., Zhang, C., and Wang, B.: Are hybrid models integrated with data preprocessing techniques suitable for monthly streamflow forecasting? Some experiment evidences, J. Hydrol., 530, 137–152, https://doi.org/10.1016/j.jhydrol.2015.09.047, 2015.
Zhang, Z., Zeng, Y., and Yan, K.: A hybrid deep learning technology for PM 2.5 air quality forecasting, Environ. Sci. Pollut. R., 28, 39409–39422, https://doi.org/10.1007/s11356-021-14186-w, 2021.
Zuo, G., Luo, J., Wang, N., Lian, Y., and He, X.: Decomposition ensemble model based on variational mode decomposition and long short-term memory for streamflow forecasting, J. Hydrol., 585, 124776, https://doi.org/10.1016/j.jhydrol.2020.124776, 2020.