the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 09 Aug 2023
| 09 Aug 2023
A genetic particle filter scheme for univariate snow cover assimilation into Noah-MP model across snow climates
Yuanhong You
Zuo Wang
Jinliang Hou
Ying Zhang
Peipei Xu
Accurate snowpack simulations are critical for regional hydrological predictions, snow avalanche prevention, water resource management, and agricultural production, particularly during the snow ablation period. Data assimilation methodologies are increasingly being applied for operational purposes to reduce the uncertainty in snowpack simulations and to enhance their predictive capabilities. This study aims to investigate the feasibility of using a genetic particle filter (GPF) as a snow data assimilation scheme designed to assimilate ground-based snow depth (SD) measurements across different snow climates. We employed the default parameterization scheme combination within the Noah-MP (with multi-parameterization) model as the model operator in the snow data assimilation system to evolve snow variables and evaluated the assimilation performance of the GPF using observational data from sites with different snow climates. We also explored the impact of measurement frequency and particle number on the filter updating of the snowpack state at different sites and the results of generic resampling methods compared to the genetic algorithm used in the resampling process. Our results demonstrate that a GPF can be used as a snow data assimilation scheme to assimilate ground-based measurements and obtain satisfactory assimilation performance across different snow climates. We found that particle number is not crucial for the filter's performance, and 100 particles are sufficient to represent the high dimensionality of the point-scale system. The frequency of measurements can significantly affect the filter-updating performance, and dense ground-based snow observational data always dominate the accuracy of assimilation results. Compared to generic resampling methods, the genetic algorithm used to resample particles can significantly enhance the diversity of particles and prevent particle degeneration and impoverishment. Finally, we concluded that the GPF is a suitable candidate approach for snow data assimilation and is appropriate for different snow climates.
- Article
(1821 KB) - Full-text XML
- BibTeX
- EndNote




Understanding snowpack dynamics is crucial for water resource management, agricultural production, avalanche prevention, and flood preparedness in snow-dominated regions (Piazzi et al., 2019; Pulliainen et al., 2020). As a special land surface type, seasonal snow cover is highly sensitive to climate change and has a significant impact on energy and hydrological processes (Barnett et al., 2005; Takala et al., 2011; Kwon et al., 2017; Che et al., 2014). On one hand, the high albedo of snow-covered surfaces can significantly reduce shortwave radiation absorption, leading to adjustments in the energy exchange between the land surface and atmosphere (You et al., 2020a, b). On the other hand, the low thermal conductivity of snow cover can insulate the underlying soil, which results in reduced temperature variability and a more stable environment (Zhang, 2005; Piazzi et al., 2019). In addition, snowmelt is a vital source of water that plays a critical role in soil moisture, runoff, and groundwater recharge (Dettinger, 2014; Griessinger et al., 2016; Oaida et al., 2019). Therefore, comprehending snow dynamics is essential for predicting snowmelt runoff, atmospheric circulation, hydrological predictions, and climate change.
Currently, there is a growing effort to investigate the potential of data assimilation (DA) schemes to improve snow simulations and to obtain the optimal posterior estimate of the snowpack state (Bergeron et al., 2016; Piazzi et al., 2018; Smyth et al., 2020; Abbasnezhadi et al., 2021). Various DA methodologies with different degrees of complexity have been developed, resulting in diverse performance levels. Sequential DA techniques, including basic direct insertion, optimal interpolation schemes, the ensemble-based Kalman filter, and particle filters, have been widely employed in real-time applications. The greatest strength of sequential DA techniques is that the model state can be sequentially updated when observational data become available (Piazzi et al., 2018). However, the direct-insertion method, which replaces model predictions with observations when available, is based on the assumption that the observation is perfect and the model prior is wrong (Malik et al., 2012). This method can potentially result in model shocks due to physical inconsistencies among state variables (Magnusson et al., 2017). Although the optimal interpolation method is more advanced and takes into account observational uncertainty, it still has great limitations and is rarely used in real-time operational systems (Dee et al., 2011; Balsamo et al., 2015).
At a higher level are the Kalman filter and ensemble-based Kalman filter, which are most commonly used in various real-time applications. The ensemble Kalman filter (EnKF), which was first introduced by Evensen (2003), uses a Monte Carlo approach to approximate error estimates based on an ensemble of model predictions. This approach does not require model linearization, making it particularly advantageous. Precisely due to this advantage, the EnKF has been widely used in snowpack prediction. For example, EnKF has been used to assimilate MODIS snow cover extent and AMSR-E (Advanced Microwave Scanning Radiometer-Earth Observing System) snow water equivalent (SWE) into a hydrological model to improve modeled SWE (Andreadis et al., 2006), as well as to assimilate MODIS fractional snow cover into a land surface model (Su et al., 2008). Moreover, the EnKF method has been used to enhance snow water equivalent estimation by assimilating ground-based snowfall and snowmelt rates, as well as both D-InSAR (differential interferometric synthetic aperture radar) and manually measured snow depth data simultaneously (Yang and Li, 2021). Even though there are numerous studies that have generally stated that the EnKF has an excellent assimilation performance, enabling it to consistently improve snow simulations, some constraining limitations hinder the filter performance (Chen, 2003). One of the main limitations is that the EnKF assumes that the model states follow a Gaussian distribution and only considers the first- and second-order moments, thereby losing relevant information contained in higher-order moments (Moradkhani et al., 2005). Unfortunately, the dynamical system usually has strong nonlinearity, and the involved probability distribution of system state variables is not supposed to follow a Gaussian distribution (Weerts and El Serafy, 2006). Additionally, the filter performance of the EnKF is significantly influenced by the linear updating procedure, and the state-averaging operations can be particularly challenging for highly detailed, complex snowpack models.
In order to overcome these limitations, the particle filter (PF), which is also based on the Monte Carlo method, has been developed for non-Gaussian, nonlinear dynamic models (Gordon et al., 1993). The greatest strength of the PF technique is that it is free from the constraints of model linearity and error that come with following a Gaussian distribution. This enables the successful application of the PF technique to nonlinear dynamical systems with non-Gaussian errors. Additionally, the PF technique gives weights to individual particles but leaves model states untouched, which makes PF more computationally efficient than the ensemble Kalman filter and smoother techniques (Margulis et al., 2015). Thanks to these advantages, there is an increasing interest in applying the PF technique in snow data assimilation. For example, remotely sensed microwave radiance data were assimilated into a snow model to update model states using the PF technique, and the results demonstrated that the SWE simulations have great improvements (Dechant and Moradkhani, 2011; Deschamps-Berger et al., 2022). A new PF approach proposed by Margulis et al. (2015) was used to improve SWE estimation through assimilating remotely sensed fractional snow-covered area. At the basin scale, the PF technique was implemented with the objective of obtaining high-resolution retrospective SWE estimates (Cortes et al., 2016). The PF technique was also used to assimilate daily snow depth observations within a multi-layer energy balance snow model to improve SWE and snowpack runoff simulations (Magnusson et al., 2017). The studies indicated above demonstrated that the assimilated snow-related in situ measurements or the remotely sensed observation data through the PF technique can successfully update predicted snowpack dynamics and that the PF scheme is a well-performing data assimilation technique that enables the consistent improvement of model simulations. Nevertheless, particle degeneracy is still a potential limitation of the PF technique. It occurs when most particles have negligible weight and when only a few particles carry significant weights, which hinders a realistic sampling of the underlying probability distribution of the state (Parrish et al., 2012; Abbaszadeh et al., 2018). The particle resampling has been considered to be an efficient approach that can effectively mitigate the problem of particle degeneracy. However, it may result in a sample containing many repeated points and a lack of diversity among the particles, which is referred to as sample impoverishment (Rings et al., 2012; Zhu et al., 2018). The sample impoverishment was a tricky problem for generic resampling methods. Using intelligent search and optimization methods to mitigate the degeneracy problem may be a good choice because it can effectively avoid sample impoverishment (Park et al., 2009; Ahmadi et al., 2012; Abbaszadeh et al., 2018). The genetic algorithm (GA) as an intelligent search and optimization method has been known to be an effective approach to mitigate the degeneracy problem and has received more attention (Kwok et al., 2005; Park et al., 2009; Mechri et al., 2014). The GA applied in the particle filter, which is referred to as the genetic particle filter (GPF), has been successfully implemented to estimate parameters or states in nonlinear models (Van Leeuwen, 2010; Snyder, 2011). The GPF was also used as a data assimilation scheme applied to land surface models which simulate prior subpixel temperature, and the results showed that the GPF outperformed prior model estimations (Mechri et al., 2014). Despite a series of studies having proven that the GPF is an effective data assimilation approach, however, few studies have investigated the performance of GPF as a snow data assimilation scheme, especially in different snow climates. In view of the promising performances of GPF as a snow data assimilation scheme, this paper aims to investigate the potential of GPF in performing snow data assimilation, and the main goal of this research is to address the following issues: (1) can the GPF be employed as a snow data assimilation scheme? (2) What is the assimilation performance of GPF in snow data assimilation across different snow climates? (3) What is the sensitivity of DA simulations to the frequency of the assimilated measurements and the particle number?
This paper is organized as follows. Section 2 introduces the study sites, the meteorological dataset, the snow module within the Noah-MP (with multi-parameterization) model, the calculation flow of the GPF scheme, and the design of the numerical experiments. Section 3 explains the simulation results of SD using the open-loop ensemble and explores the sensitivity of the measurement frequency and ensemble size. Finally, Sect. 4 summarizes the findings of this study.
2.1 Study sites and data
With consideration of the filtering performance, which may vary in snow climates, eight seasonally snow-covered study sites with different snow climates were selected to implement numerical experiments in this study (Sturm et al., 1995; Trujillo and Molotch, 2014). These sites are distributed at different latitudes in the Northern Hemisphere, and the sites included the Arctic Sodankylä site (SDA, 179 m), located beside the Kitinen River in Finland, with the upper 2 m being frozen (Rautiainen et al., 2014); the Snoqualmie site (SNQ, 921 m) with a rain–snow transitional climate in the Washington Cascades of the USA, where the SD measured by snow stakes was employed (Wayand et al., 2015); the maritime Col de Porte (CDP, 1330 m) site in the Chartreuse Range in the Rhone-Alpes region of France; the Mediterranean-climate Refugio Poqueira site (ROPA, 2510 m) in the Sierra Nevada Mountains of Spain, which has a high evaporation rate (Herrero et al., 2009); the Weissfluhjoch site (WFJ, 2540 m) in Davos of Switzerland, with automatic SD observations being used at this site (Wever et al., 2015); the continental Swamp Angel Study Plot (SASP, 3370 m) site in the San Juan Mountains of Colorado, USA; and two sites from typical snow-covered regions in China, namely the Altay meteorological observation site (ATY, 735.3 m) in northern Xinjiang, China, where there is less wind in the winter season, and the Mohe meteorological observation site (MOHE, 438.5 m) in a county of northeast China, which has a cold temperate continental climate and is the northernmost part of China. Serially complete meteorological measurements are available and can certainly be used as forcing data in these sites; the downward longwave and shortwave radiation values of MOHE were extracted from the China Meteorological Forcing Dataset (CMFD) (Chen et al., 2011) since there are no radiation measurements at this site.
It is noteworthy that the spatial variance of the performance of the model is negligible since these sites themselves are flat and the surrounding vegetation types are uniform. We have used this dataset to examine the sensitivity of simulated SD to physics options, and the results show that the dataset has a reliable quality. In addition, the location, the detailed information of snow climates, and details about the dataset processing for the eight sites can be also referenced in You et al. (2020a).
2.2 Snow module within Noah-MP model
The snow partial module within Noah-MP model can be divided up into to three layers depending on the depth of the snow (Niu et al., 2011). The SD hsnow is calculated by
where Ps,g is the snowfall rate at the ground surface, dt is the time step, and ρsf is the bulk density of the snowfall. When hsnow< 0.025 m, the snowpack is combined with the top soil layer, and no dependent snow layer exists. When 0.05 m, a snow layer is created with a thickness equal to SD. When m, the snowpack will be divided into two layers, each with a thickness of . When m, the thickness of the first layer is m, and the thickness of the second layer is m. When m, a third layer is created, and the three thickness are m and m. When hsnow>0.45 m, the layer thickness of the three snow layers are m, m, and m. Certainly, the snow cover is highly influenced by air and ground temperature, and the snow layer combines with the neighboring layer due to sublimation or melting and is redivided depending on the total SD. The snow module of the Noah-MP model provides an estimate of snow-related variables using energy and mass balance. This computing process requires a series of meteorological forcing data, such as near-surface air temperature, precipitation, and downward solar radiation. The snow accumulation or ablation parameterization of the Noah-MP model is based on the mass and energy balance of the snowpack, and the snow water equivalent can be calculated using the following equation:
where Ws is the snow water equivalent (mm), Ps,g is the solid precipitation (mm s−1), Ms is the snowmelt rate (mm s−1), and E is the snow sublimation rate (mm s−1).
A snow interception model was implemented into the Noah-MP model to describe the process of snowfall intercepted by the vegetation canopy (Niu and Yang, 2004). Within this model, the snowfall rate at the ground surface Ps,g is then calculated by
where Ps,drip (mm s−1) is the drip rate of snow, and Ps,throu (mm s−1) is the through-fall rate of snow. In the Noah-MP model, the ground surface albedo is parameterized as an area-weighted average of the albedos of snow and bare soil, and the snow cover fraction of the canopy is used to calculate the ground surface albedo, as shown in Eq. (4):
where αsoil and αsnow are the albedo of bare soil and snow, respectively. fsnow,g is the snow cover fraction on the ground and is parameterized as a function of snow depth, ground roughness length, and snow density (Niu and Yang, 2006).
2.3 Genetic particle filter data assimilation scheme
The Bayesian recursive estimation problem is solved by the Monte Carlo approach within the PF technique, making this scheme appropriate for a nonlinear system with a non-Gaussian probability distribution (Magnusson et al., 2017). The basic concept of the PF technique is to use a large number of randomly generated realizations (i.e., particles) of the system state to represent the posterior distribution. Meanwhile, the particles are propagated forward in time as the model evolves. The weights associated with the particles are updated based on the likelihood of each particle's simulated proximity to the real observation. The weight of the particles can be updated as follows:
where is the weight of ith particle at time t−1, and the weight is updated by the likelihood function , which measures the likelihood of a given model state with respect to the observation zt. The observation errors are generally assumed to follow a Gaussian distribution, and the chosen likelihood function represents this assumption. In this study, we employed a normal probability distribution to serve as the likelihood function:
where N represents the normal probability distribution of the residuals between observed zt and simulated xt. Finally, the weights of the updated model state would be normalized, and the assimilated value of the model state is the weighted average of all particles at time t. Although the particle filter has been widely applied in various nonlinear systems, the particle degeneracy and impoverishment in the particle filter are still the fatal limitations that need to be urgently addressed. To address the degeneration problem in the PF technique, traditional resampling methods like multinominal resampling and systematic resampling were employed to resample the particles if the effective sample size,
fell below a specified number. In the above equation, N is the ensemble size, and is the normalized weight defined in Eq. (5). To be honest, traditional resampling methods can effectively mitigate the problem of particle degeneracy by resampling high-quality particles. However, after multiple iterations, these methods often lead to a serious lack of diversity among particles, which is known as the particle impoverishment problem. To mitigate both of these issues simultaneously, we employed the genetic algorithm (GA) to resample the particles, resulting in the genetic particle filter algorithm (GPF). The GA is inspired by Darwin's theory of evolution and emphasizes the principle of survival of the fittest. In fact, in the resampling phase, the fitness of particles should be reselected according to the theory of particle filtering. Selection, crossover, and mutation are major steps used to simulate population evolution. As shown in Fig. 1, these three operators are utilized to produce better offspring and improve the overall population fitness, with the aim of preventing particle degeneracy and impoverishment. These operators will be used to improve particle fitness when it falls below a threshold value. The three operators are described below.
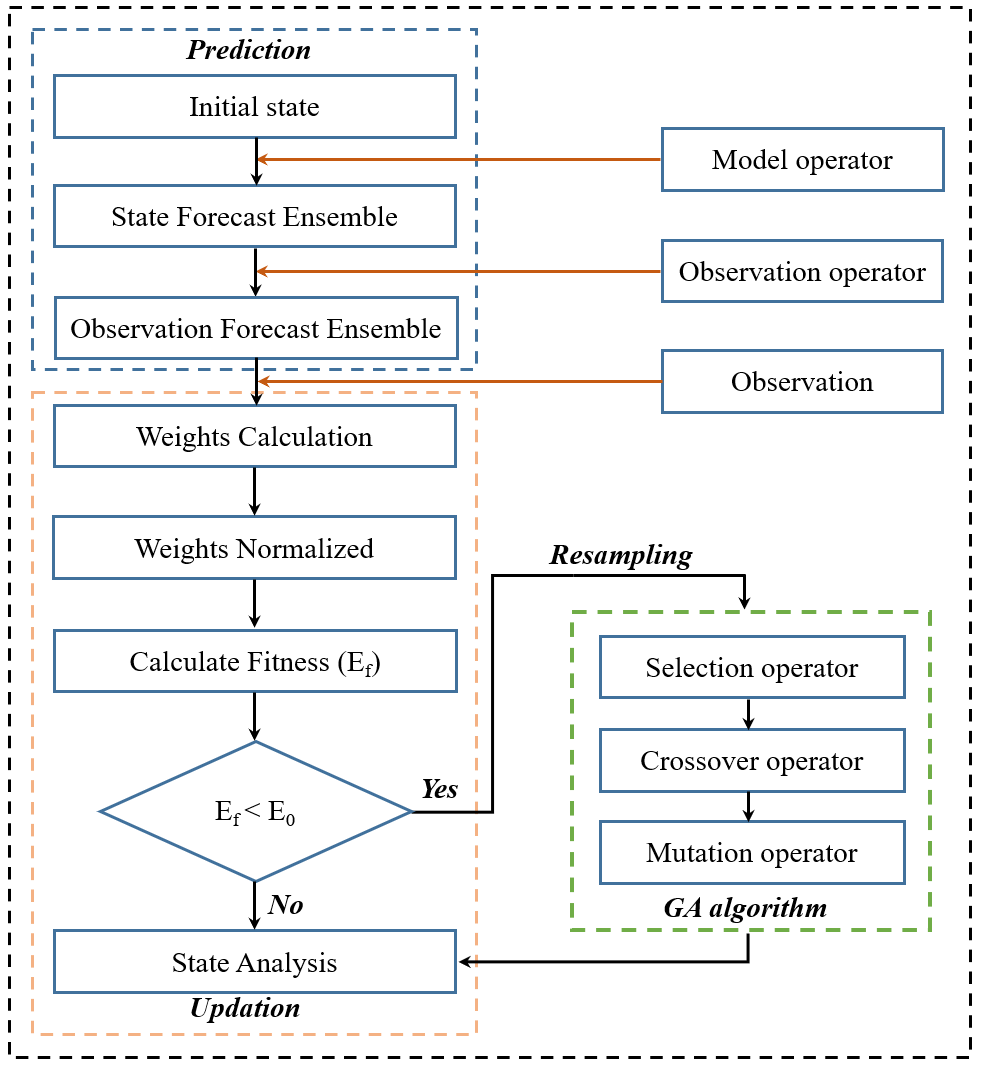
2.3.1 Selection mechanism
At the time of assimilation, the selection operator will preferentially select the particles that are close to the observed SD. This process is usually achieved by sorting the fitness value of all particles and selecting a certain proportion of particles. Here, we calculated the survival rate of all individuals and sorted them in ascending order. The top fifth percentile of particles was considered to be high-quality particles, and these were selected as parents in the genetic algorithm. This ensures that fit individuals can be delivered to the next generation group. The survival rate of particles can be calculated using the following equation:
where Rk is the observation error at time k, with 0.01 m having been set in this study; zk represents the observed SD.
2.3.2 Crossover mechanism
The purpose of the crossover operator is to exchange some genes for two or more chromosomes in a specified way, creating new individuals. GA mainly generates new individuals through this process, which determines the capability of global search. In this study, the arithmetic crossover method was used as the crossover operator to generate new individuals. Two particles were randomly selected from the resampled particle group and combined linearly to form a new particle. Assuming the two selected particles are {xm,xn}, the following equations were used to form the new particles:
where α and β are the empirical crossover coefficients, and α=0.45 and β=0.55 in this study. In order to ensure diversity among particles, newly formed particles will be discarded when occurs, and parent individuals will be re-selected from the particle group.
2.3.3 Mutation mechanism
The mutation in GA refers to replacing the gene values at some loci with other alleles to form a new individual. The mutation mechanism can be considered to be a supplement to the crossover mechanism, which can increase the diversity of the population. Assuming that the randomly selected particle from the crossed particle set is xk, the mutation operation is performed on the particle using the following equation:
where Uniform refers to a random number from a uniform distribution; and η is an empirical coefficient, with 0.01 having been set in this study.
It is noteworthy that a large number of particles may lead to filter collapse. In this study, we set the number of particles to be equal to 100 based on previous references (Mechri et al., 2014; Magnusson et al., 2017; Piazzi et al., 2018). Moreover, to prevent the particle ensemble from being unable to represent the prior model state due to structural deficiencies, a Gaussian-type model error, N(μ,σ), was added to the ensemble members. The μ was obtained from the mean value of residuals between simulation and observation, and the variance σ was set to 0.01.
2.4 DA experimental design
2.4.1 Perturbation of meteorological input data
The accuracy of models' output largely depends on the input meteorological-forcing dataset for land surface models, and meteorological forcing is one of the major sources of uncertainty affecting simulation results (Raleigh et al., 2015). The precipitation and air temperature are the most important input elements for snow simulations due to their roles in determining the quantity of rainfall and snowfall.
To produce the forcing data ensemble, the air temperature and precipitation were perturbed following the method of Lei et al. (2014). In this study, the precipitation was assumed to have an error with a log-normal distribution, and it is expressed as follows:
where Pt and are the observed and perturbed precipitation at time t, respectively. The log transformation of is a Gaussian distribution with a mean (μln P) and a standard deviation (σln P); αP is the variance-scaling factor of the precipitation, which was set to 0.5 in this study; and φP,i is a normally distributed random number. Meanwhile, the ensemble of the air temperature was obtained as follows:
where Tt and are the observed and perturbed air temperatures at time t, respectively; γ is the variance-scaling factor of the temperature with a value of 2.0; and wi is the random noise with a uniform distribution between 0 and 1. A forcing ensemble containing 100 particles was obtained through the above perturbation method in this study.
2.4.2 Evaluation metrics
In order to properly quantify the filter performance, each experiment is evaluated by statistical analysis based on the daily mean values of simulations and observations. In this study, we used the Kling–Gupta efficiency (KGE) coefficient (Gupta et al., 2009) to evaluate the filter performance, which allows the analysis of how the assimilation of snow observations succeeds in properly updating the model simulations on average.
In the above equation, r is the linear correlation coefficient between the simulated and observed SD; a is the ratio of the standard deviation of simulated SD to the standard deviation of the observed ones; and b is the ratio of the mean of simulated SD to the mean of observed ones – here, the simulated SD is the mean of the SD ensemble simulations. Theoretically, when r=1, a=1, and b=1 in Eq. (16), the KGE will obtain the optimal value which is equal to 1, and this illustrates that the simulated SD is highly consistently with the observed ones.
The time series of SD obtained from the assimilation scenarios was compared to observations for evaluating the performance of the assimilation, and the root-mean-square error (RMSE) was employed:
where N is the total number of observations, sim(i) is the simulated value at time i, and obs(i) is the observed value at time i.
Another statistical index is the continuous ranked probability skill score (CRPSS), which is evaluated to assess changes to the overall accuracy of the ensemble simulations of each experiment (CRPS, continuous ranked probability score) by considering the open-loop ensemble control run as the reference one (CRPSref), and the calculation scheme is shown in the following formula:
where CRPS is the continuous ranked probability score which can measure the difference between continuous probability distribution and deterministic observation samples (detail in Hersbach, 2000). A smaller CRPS value indicates better probabilistic simulation, and the CRPS score of a perfect simulation would be equal to 0. Therefore, the changes in the overall accuracy of the SD ensemble simulations can be measured by CRPSS. However, unlike the CRPS score, the optimal CRPSS score is equal to 1, and negative values indicate a negative improvement with respect to the reference control run.
3.1 Open-loop ensemble simulations
In order to investigate the impact of meteorological perturbations on snow simulations, an ensemble containing 100 SD simulations derived from as many different meteorological conditions was analyzed. For the sake of concision and clarity, we considered only one winter season for implementing snow simulation experiments at each site, and the results are shown in Fig. 2. As shown in Fig. 2, the possible overestimation and underestimation of SD simulations produced by the perturbation forcing data were contained within the ensemble spread, which is a direct consequence of the perturbation of the forcing data. Since the meteorological perturbations are unbiased, the physical processes with nonlinear characteristics within the model are supposed to be the main reason for the uncertainty (Piazzi et al., 2018). During the winter season in the Northern Hemisphere, precipitation and air temperature are the primary factors that can determine the total amount of snow.
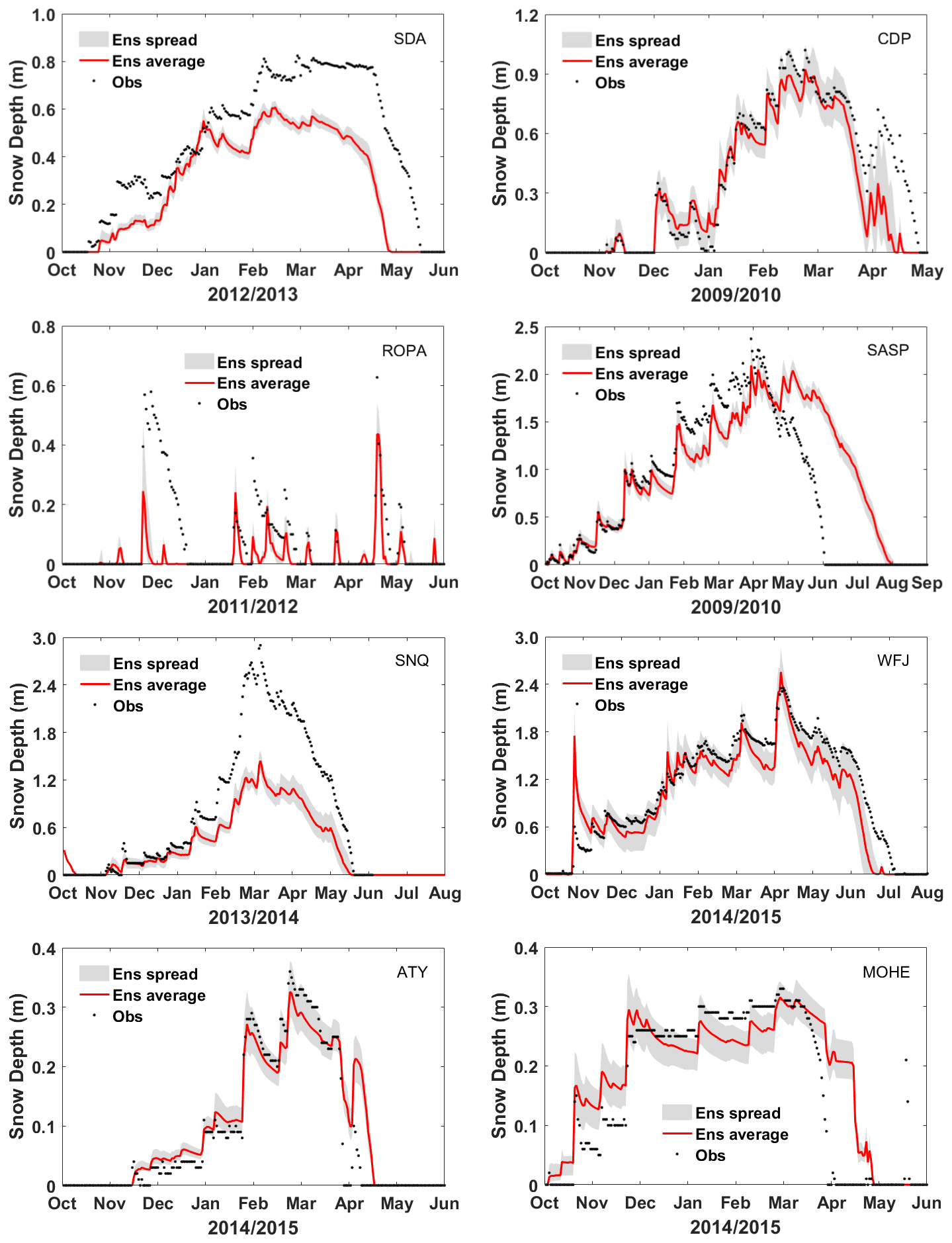
As Fig. 2 shows, the intervals of the SD ensemble are significantly different at different sites, although an identical meteorological perturbation method was used. At some sites, such as ATY, MOHE, WFJ, and CDP, larger SD ensemble spreads were obtained, and most of the SD observations were covered by the ensemble spread. In this case, high-quality particles can be directly selected from the ensemble. However, at some other sites, such as ROPA, SDA, and SASP, narrow SD ensemble spreads were obtained, and the uncertainty interval of simulated SD can hardly cover the observations. In this case, the so-called high-quality particles cannot even be found in the ensemble, and the model prior error becomes a prerequisite for successful assimilation at this time. Especially at the ROPA site, the snow cover was extremely unstable, resulting in difficulty in figuring out any variation rules of the SD. The narrow SD ensemble spread at this site also demonstrates that precipitation and air temperature were not the main factors causing snow change. According to the literature, sublimation losses at ROPA ranged from 24 % to 33 % of total annual ablation and occurred 60 % of the time during which snow was present. A high sublimation rate may be the main reason for snow instability (Herrero et al., 2016; You et al., 2020a). This directly leads to a perfect ensemble spread that can cover all observations and that cannot be produced by perturbing the air temperature and precipitation. Generally speaking, the ensemble produced by perturbing air temperature and precipitation does not contain high-quality particles at this site. It was found that the spread of SD ensembles increases when a snowfall event occurs because the perturbation in precipitation would provide different input snow rates for model realization at all sites. Despite this, we still found that the simulated SD deviated significantly from the observation. For example, at the SNQ site, the maximum value of simulated SD was almost half the maximum value of observed SD. In this case, it is impossible to obtain a simulated SD ensemble spread that can cover or nearly cover the observation through perturbing the meteorological-forcing data. On the one hand, precipitation and air temperature are not the dominant factors affecting snow cover change, which leads to a narrowed ensemble spread at these sites. On the other hand, although the variation trend of snow cover can be accurately expressed by the Noah-MP model, serious underestimation of the simulated SD shows that the snow simulation performance of Noah-MP is poor at these sites. Nonetheless, the simulated ensembles will be improved whenever the prior error of the model state is considered.
3.2 DA simulations with perturbed forcing data
Generally, the ability of a model to simulate autonomously can be limited if observation data are assimilated too frequently, resulting in assimilation results that are essentially the same as the observations and do not reflect the differences among models. To address this, the site's SD measurements were assimilated into the Noah-MP model with an observation frequency of 5 d in this study, enabling the GPF to perform differently at distinct sites. Figure 3 shows the SD assimilation results across snow climates, indicating a substantial improvement in the SD simulations with satisfactory assimilation performance at all sites. The GPF algorithm can handle not only serious underestimations, such as at SNQ and SDA, but also overestimations during the snow ablation period, as seen at the CDP, SASP, ATY, and MOHE sites. These results demonstrate the effectiveness of the GPF algorithm as a snow data assimilation scheme and its ability to significantly improve SD simulations despite the numerous overestimations and underestimations that may occur in the Noah-MP model's snow simulation results across snow climates.
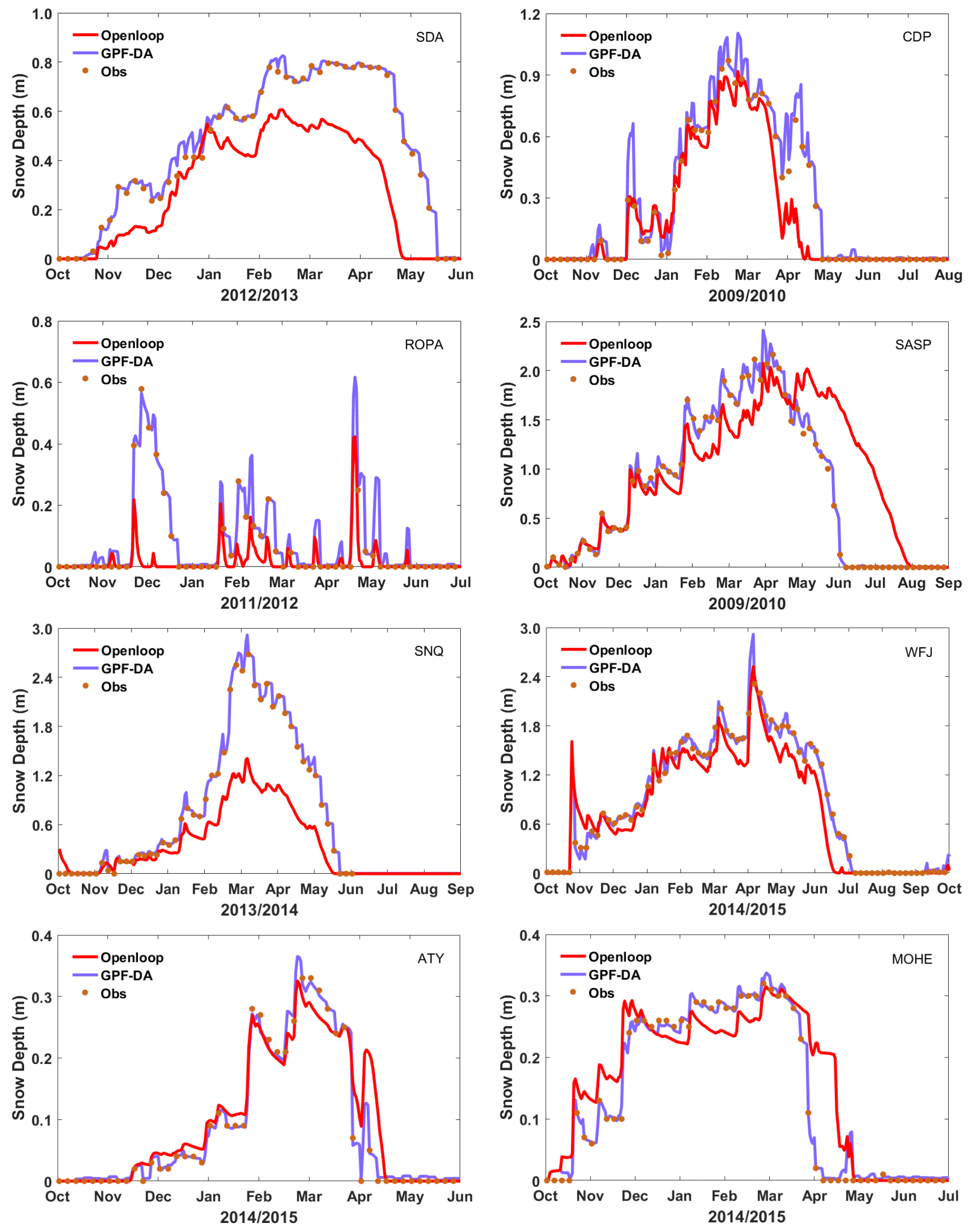
Figure 3Evaluation of the SD at eight sites from mean ensemble simulation and assimilation with the measurements.
The effectiveness of GPF in updating SD simulations is demonstrated by the KGE values of the DA simulations with perturbed meteorological-forcing data, as shown in Fig. 4. Although the mean ensemble simulations of SD exhibit substantial improvement at all sites, not all ensemble members were improved, as per the distribution of GPF-DA KGE values. Some ensemble members achieved significant improvement at sites like SDA, SASP, MOHE, and SNQ, while others showed only slight improvement at sites like ATY and WFJ. Figure 4 also reveals that updating SD model simulations at the ROPA and WFJ sites is more challenging. Snow simulation performance at the ROPA site is known to be poor due to the high sublimation rate. Certainly, the median value of SD ensemble prediction KGE values is expected to be below zero at this site, indicating that there are few qualified simulations in the prediction ensemble. While the GPF succeeds in enhancing the SD simulations at ROPA, the distribution of GPF-DA KGE values is not concentrated enough, with the 25th percentile being at approximately 0.2 and the 75th percentile at about 0.7, indicating that the GPF assimilation algorithm cannot enhance all members but can raise the mean level and obtain an approximation of the optimal posterior estimation. Conversely, the assimilation of snow measurements at the CDP site resulted in a poor quality of the SD simulations compared to the open-loop ensemble simulations. The median value of the GPF-DA KGE was lower than the median value of the open-loop (OL) KGE, indicating that a considerable number of ensemble simulations failed to capture the observed values after assimilating snow measurements. However, Fig. 3 shows that the mean ensemble simulations after assimilating snow measurements are much closer to SD observations. Thus, it underscores the importance of the ensemble mean in characterizing the filter effectiveness and the approximate value of the optimal posterior estimation of model state. Additionally, the scale of the model ensemble spread was found to be the determinant factor that significantly affects assimilation results. A large ensemble spread can adjust the simulations toward the observed system state even if the model predictions are heavily biased.
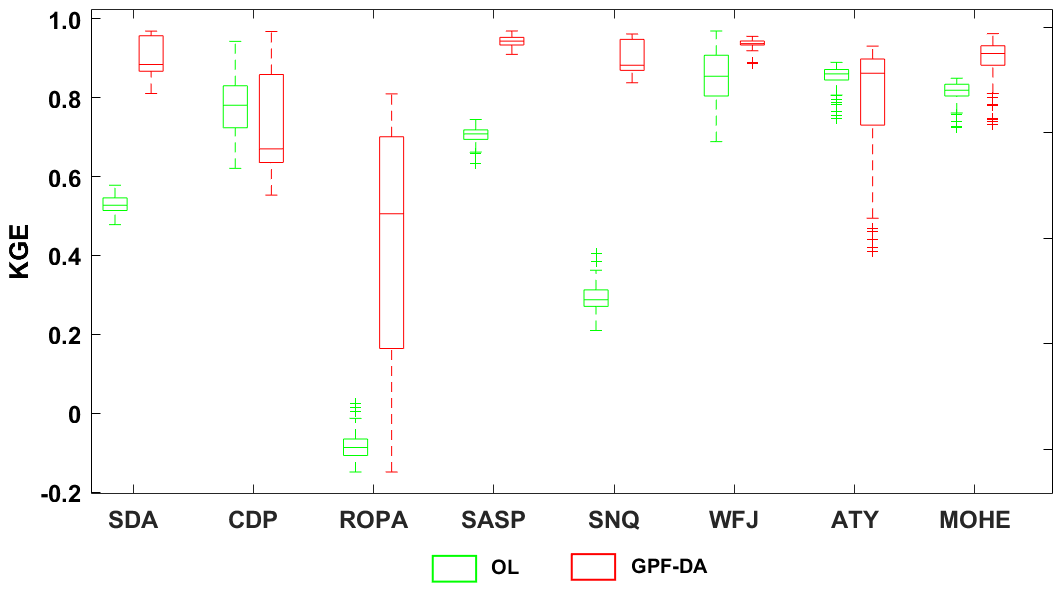
Figure 4The KGE values of SD simulations; the OL and GPF-DA are in green, red, respectively. The bottom and top edges of each box indicate the 25th and 75th percentiles, respectively. The line in the middle of each box is the median.
Figure 5 displays the CRPSS value of GPF-DA at different sites. The smaller the CRPSS value, the worse the probabilistic simulation (with an optimal score of 1). The highest CRPSS score of 0.91 was achieved at SASP, while the lowest score of 0.44 was observed at CDP. These results indicate that the GPF enhances the overall accuracy of ensemble simulations most at SASP and least at CDP with respect to the open-loop ensemble simulation. Certainly, this cannot be illustrated by the mean ensemble simulations (Fig. 3) but is consistent with the KGE statistical results (Fig. 4). Although the open-loop simulations at SNQ exhibited serious underestimation, a satisfactory assimilation result was obtained at this site with a CRPSS score of 0.87. At the SNQ site, the snow simulation performance of the Noah-MP model is poor, and the model shows serious underestimation during the snow stable phase. Implementing a data assimilation experiment in this case is a tricky business since it is difficult to obtain a suitable simulated ensemble by perturbing the meteorological forcings. However, since the model prior error was considered in the GPF algorithm, the overall accuracy of the ensemble simulations will be substantially enhanced, and this is the reason why a satisfactory assimilation result at the SNQ site can be obtained. ROPA was found to be a difficult site to enhance the overall accuracy of the ensemble simulations, with a CRPSS score of only 0.58. The snow cover was highly unstable, and the variation of SD exhibited extreme irregularity; these may be the main obstacles to snow data assimilation at this site.
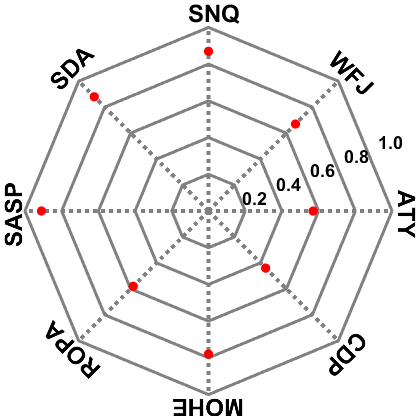
Based on these findings, we conclude that the effectiveness of GPF varied among snow climates: it can be employed as a snow data assimilation scheme across snow climates; however, its performance varied across different sites. It is necessary to explore the sensitivity of the measurement frequency and ensemble size for the GPF assimilation scheme at various sites.
3.3 Sensitivity analysis of DA scheme to SD measurement frequency
For complex land–snow process models, model errors can gradually lead to the system deviating from the true value. Therefore, it is necessary to continuously incorporate observations into the model framework to adjust the operating trajectory of the state. Obviously, the frequency of incorporating observations, that is, the assimilation interval, has an important impact on the assimilation system. To investigate the effect of the SD measurement frequency on the performance of GPF, we conducted a sensitivity experiment at eight sites. We aimed to determine how reducing the frequency of SD measurements affects the DA simulations. As expected, a decrease in SD measurement frequency led to a reduction in the impact of the GPF updating on the model simulations, resulting in a gradual increase in the mean RMSE value. Figure 6 illustrates the RMSE ensembles of SD simulations resulting from assimilating different-frequency SD measurements over the snow period at each site. Higher-frequency SD assimilation improves the accuracy of the simulated SD, as shown by the lower RMSE value achieved when the frequency of the SD measurements was set to 5 d. This means that more frequent SD measurements improve the accuracy of the model, which is particularly useful in regions where snow conditions can change rapidly. The range of RMSE values at different sites varied significantly as it was related to the maximum value of SD. For instance, thick snow at the SNQ and WFJ sites during the snow period led to larger RMSEs of SD simulations. Notably, an increase in the length of the assimilation window generally resulted in a significant increase in the RMSE value. However, an abnormal occurrence was observed at the SDA site, where the assimilation effect of 20 d of SD measurements was significantly better than that of 15 d. Although the RMSE distribution of SD assimilation results with 20 d of observations appeared to be superior to that of 15 d, the RMSE mean values of the two were very close: 0.08 and 0.07 m, respectively. Therefore, this anomaly can be ignored. These results indicate that the frequency of SD observations has a significant impact on the effectiveness of the GPF algorithm and that a dense amount of observational data can effectively improve the assimilation results.

Figure 6The RMSE values of SD simulations at different sites; from left to right in each subfigure are the assimilation observation frequencies of 5, 10, 15, and 20 d, respectively, indicated with different colors.
3.4 Sensitivity analysis of DA scheme to ensemble size
The results of the experiment aimed at evaluating the impact of particle number on the assimilation performance of GPF are presented in Fig. 7. As expected, increasing the particle number up to the threshold leads to a significant improvement in the percent effective sample size. However, the filter performance does not improve significantly when the particle number exceeds the threshold. Figure 7 shows that the GPF algorithm yields the minimum error at all sites when the particle number is set to 100, indicating that 100 particles can optimize the performance of the GPF algorithm. Although a large particle number can enhance particle diversity and prevent filter divergence, it increases the computation burden without reducing the system error. As illustrated in Fig. 7, the RMSEs are generally at the same level when the particle number equals 120 and 160, and they are significantly larger than the RMSE when the particle number is equal to 100. The slight impact of the change in the particle number on the performance of GPF when the particle number is below the threshold indicates low system sensitivity to the ensemble size, and this is observed at all sites. Essentially, blindly increasing the particle number does not guarantee a better DA performance of the GPF algorithm. As demonstrated in Fig. 7, the RMSEs of simulated snow depth are virtually unchanged at all sites despite an increase in the particle number from 120 to 160. This suggests that blindly increasing the ensemble size only increases the computational burden without improving the performance of the GPF.
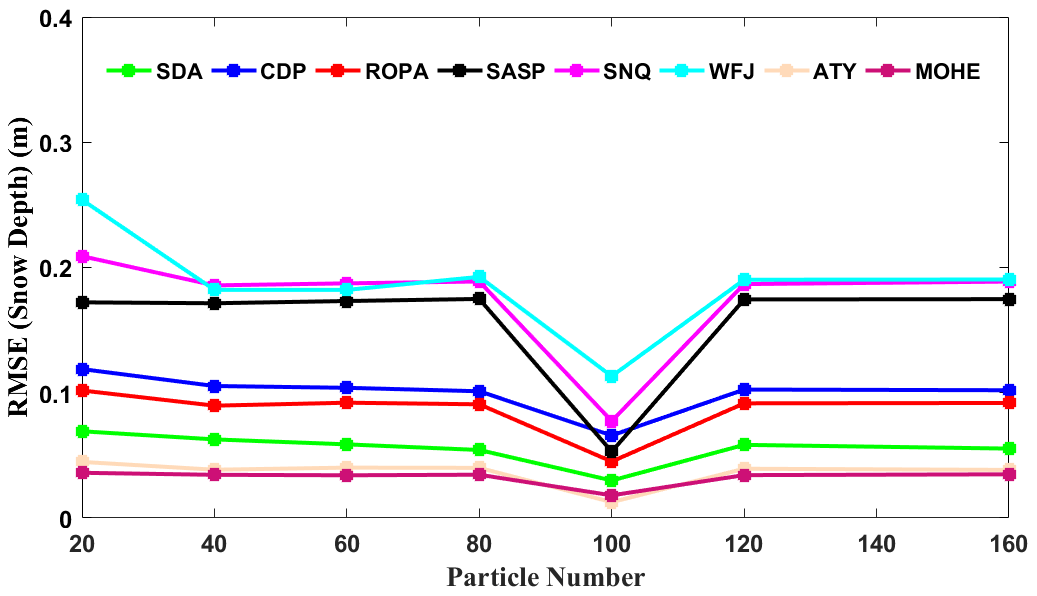
Figure 7Sensitivity analysis of the GPF snow DA scheme to particle number at eight sites during different snow periods.
3.5 Compared to traditional resampling methods
To demonstrate the effectiveness of using genetic algorithms for particle resampling, we compared the results of our genetic algorithm (PF-G) to those of traditional resampling methods: systematic resampling (PF-S) and multinomial resampling (PF-M), which are both commonly used in particle resampling. The calculation process for these methods is detailed in the references of the particle filter introduction. Figure 8 shows the RMSE values for SD simulations obtained using these three methods. We found that the PF-G outperforms PF-M and PF-S at all sites, as evidenced by the significantly smaller mean and median RMSE values. This indicates that the PF-G is suitable for snow data assimilation in various snow climates and is somewhat superior to traditional particle filters. At most sites (MOHE, ATY, SDA, and ROPA), PF-M and PF-S showed similar performance, meaning that these methods did not produce a significant difference in the assimilation results. This is because these traditional resampling methods can only mitigate particle degeneration by resampling particles but are unable to prevent particle impoverishment. Therefore, they are unable to select high-quality particles and keep the particles that have variety. Significantly, the mean and median RMSE values for PF-G were lower than those of PF-M and PF-S at several sites (SASP, SNQ, and WFJ) where the snow cover was relatively thick, with maximum SD during the snow period reaching 2.45, 2.95, and 2.40 m, respectively. This suggests that PF-G performs better in assimilating data from thick snow covers.
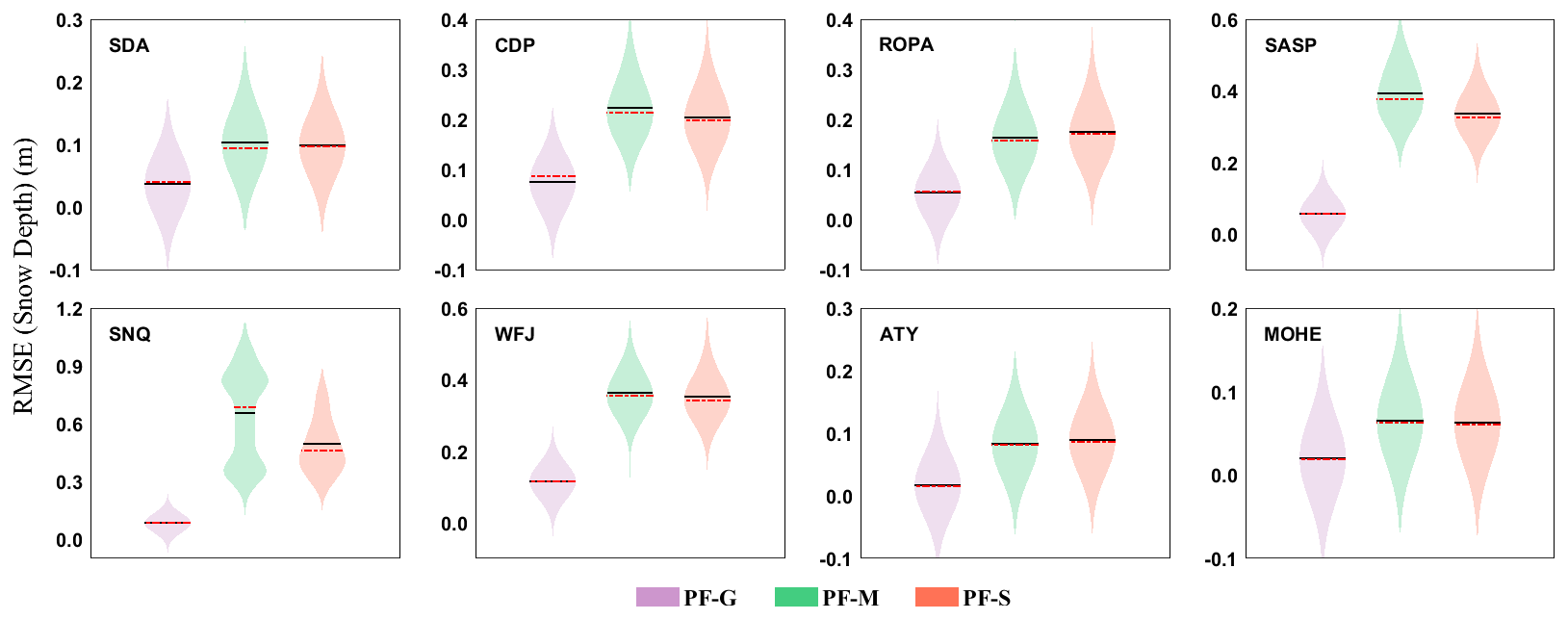
Figure 8The RMSE values of SD simulations by three different resampling methods. For each subfigure, from left to right are the particles resampled by genetic algorithm, multinominal method, and systematic method, respectively, and with different colors – specifically, the black line indicates the mean, and the red line indicates the median; the kernel bandwidth was 0.05.
The multinomial and systematic resampling methods select particles from the original particle set at different levels or based on the accumulation of particle weights. Both of the resampling methods extract particles from the entire particle set, and the corresponding particle values do not undergo any essential changes. However, when compared to the two traditional particle resampling methods, the genetic algorithm first uses the fitness function to calculate the survival rate of each particle one by one and then performs crossover, mutation, and other operations on the selected particles. This approach ensures that the resampled particles are high-quality particles, which is the main reason why genetic particle filtering has an advantage in the snow data assimilation experiments. As Fig. 8 shows, the assimilation error of the genetic particle filter is the smallest at all sites. From the results of the real assimilation experiment, it can be seen that genetic particle filtering has more advantages over the other two methods.
In this study, we investigated the potential of using GPF as a snow data assimilation scheme across eight sites with varying snow climates. We addressed the problem of degeneration and impoverishment in the PF algorithm by using the genetic algorithm to resample particles. We also examined the sensitivity of the GPF scheme to measurement frequency and ensemble size. The main findings of this study are outlined below.
The GPF was an effective snow data assimilation scheme and can be used across different snow climates. The genetic algorithm effectively addressed the problem of particle degeneration and impoverishment in the PF algorithm.
Our experiment showed that the system has low sensitivity to the particle number, and 100 particles can achieve a better assimilation result across different snow climates. This indicates that 100 particles are suitable for representing the high dimensionality of the system.
We found that perturbations in meteorological-forcing data were not sufficient to provide ensemble spread, resulting in poor filter performance. Particle inflation can make up for this deficiency. Moreover, we observed that the RMSE of simulated SD decreased significantly with the increase of the frequency of SD measurement, indicating that dense observational data can improve the assimilation results.
Compared to the two classic resampling methods, the particle filter with the genetic algorithm as the resampling method shows a better assimilation performance, especially in a thick snow cover; the distributed RMSEs are more centralized, and a smaller mean error will be obtained.
Our experiments were based on forcing data and snow observations from various sites with different snow climates. While our results provide a reference for applying GPF to snow data assimilation, further research is needed to investigate the performance of GPF on a regional scale and to explore the assimilation of snow observational data from remote sensing or wireless sensor networks into land surface models using GPF. In summary, our study demonstrates the feasibility of using GPF for snow data assimilation and provides valuable insights for future research in this area.
The Noah-MP model code can be downloaded online (https://ral.ucar.edu/model/high-resolution-land-data-assimilation-system-hrldas, NCAR, 2015). The code of the genetic particle filter algorithm supports the findings of this study and is available from the corresponding author upon request.
The China Meteorological Forcing Dataset can be downloaded online (https://data.tpdc.ac.cn/zh-hans/data/8028b944-daaa-4511-8769-965612652c49, TPDC, 2021). The dataset download sites in the United States and Europe have been explicitly stated in the paper or can be found in the corresponding reference. The dataset of two sites in China is provided by the China Meteorological Administration (CMA) (http://data.cma.cn/data/cdcindex/cid/f0fb4b55508804ca.html, The China Meteorological Administration, 2016).
CLH proposed the study idea. CLH and YHY designed the study. YHY conducted all experiments and prepared the original manuscript under the supervision of CLH. JLH and YZ provided a lot of very good suggestions for the analysis section of the paper. All the authors contributed to the manuscript revision.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the special issue “Experiments in Hydrology and Hydraulics”. It is not associated with a conference.
The authors are grateful to the editor Carla Ferreira and five anonymous reviewers for their constructive comments.
This research has been supported by the National Natural Science Foundation of China (grant nos. 42101361, 42130113, 41871251, and 41971326), the scientific research project of higher education institutions in Anhui province, and the Key Technologies Research and Development Program of Anhui Province (grant no. 2022107020028).
This paper was edited by Carla Ferreira and reviewed by five anonymous referees.
Abbasnezhadi, K., Rousseau, A. N., Foulon, E., and Savary, S.: Verification of regional deterministic precipitation analysis products using snow data assimilation for application in meteorological network assessment in sparsely gauged Nordic basins, J. Hydrometeorol., 22, 859–876, https://doi.org/10.1175/JHM-D-20-0106.1, 2021.
Abbaszadeh, P., Moradkhani, H., and Yan, H. X.: Enhancing hydrologic data assimilation by evolutionary particle filter and Markov Chain Monte Carlo, Adv. Water Resour., 111, 192–204, https://doi.org/10.1016/j.advwatres.2017.11.011, 2018.
Ahmadi, M., Mojallali, H., and Izadi-Zamanabadi, R.: State estimation of nonlinear stochastic systems using a novel meta-heuristic particle filter, Swarm Evol. Comput., 4, 44–53, https://doi.org/10.1016/j.swevo.2011.11.004, 2012.
Andreadis, K. M. and Lettenmaier, D. P.: Assimilating remotely sensed snow observations into a macroscale hydrology model, Adv. Water Resour., 29, 872–886, https://doi.org/10.1016/j.advwatres.2005.08.004, 2006.
Barnett, T. P., Adam, J. C., and Lettenmaier, D. P.: Potential impacts of a warming climate on water availability in snow-dominated regions, Nature, 438, 303–309, https://doi.org/10.1038/nature04141, 2005.
Balsamo, G., Albergel, C., Beljaars, A., Boussetta, S., Brun, E., Cloke, H., Dee, D., Dutra, E., Muñoz-Sabater, J., Pappenberger, F., de Rosnay, P., Stockdale, T., and Vitart, F.: ERA-Interim/Land: a global land surface reanalysis data set, Hydrol. Earth Syst. Sci., 19, 389–407, https://doi.org/10.5194/hess-19-389-2015, 2015.
Bergeron, J. M., Trudel, M., and Leconte, R.: Combined assimilation of streamflow and snow water equivalent for mid-term ensemble streamflow forecasts in snow-dominated regions, Hydrol. Earth Syst. Sci., 20, 4375–4389, https://doi.org/10.5194/hess-20-4375-2016, 2016.
Che, T., Li, X., Jin, R., and Huang, C. L.: Assimilating passive microwave remote sensing data into a land surface model to improve the estimation of snow depth, Remote Sens. Environ., 143, 54–63, https://doi.org/10.1016/j.rse.2013.12.009, 2014.
Chen, Y. Y., Yang, K., He, J., Qin, J., Shi, J. C., Du, J. Y., and He, Q.: Improving land surface temperature modeling for dry land of China, J. Geophys. Res.-Atmos., 116, D20104, https://doi.org/10.1029/2011JD015921, 2011.
Chen, Z.: Bayesian filtering: From Kalman filters to particle filters, and beyond, Adaptive Systems Laboratory Technical Report, McMaster University, Hamilton, 25 pp., 2003.
Cortes, G., Girotto, M., and Margulis, S.: Snow process estimation over the extratropical Andes using a data assimilation framework integrating MERRA data and Landsat imagery, Water Resour. Res., 52, 2582–2600, https://doi.org/10.1002/2015WR018376, 2016.
Dee, D. P., Uppala, S. M., Simmons, A. J., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Balmaseda, M. A., Balsamo, G., Bauer, P., Bechtold, P., Beljaars, A. C. M., van de Berg, L., Bidlot, J., Bormann, N., Delsol, C., Dragani, R., Fuentes, M., Geer, A. J., Haimberger, L., Healy, S. B., Hersbach, H., Holm, E. V., Isaksen, L., Kallberg, P., Koehler, M., Matricardi, M., McNally, A. P., Monge-Sanz, B. M., Morcrette, J. J., Park, B.-K., Peubey, C., de Rosnay, P., Tavolato, C., Thepaut, J. N., and Vitart, F.: The ERA-Interim reanalysis: configuration and performance of the data assimilation system, Q. J. Roy. Meteor. Soc., 137, 553–597, https://doi.org/10.1002/qj.828, 2011.
Dechant, C. and Moradkhani, H.: Radiance data assimilation for operational snow and streamflow forecasting, Adv. Water Resour., 34, 351–364, https://doi.org/10.1016/j.advwatres.2010.12.009, 2011.
Deschamps-Berger, C., Cluzet, B., Dumont, M., Lafaysse, M., Berthier, E., Fanise, P., and Gascoin, S.: Improving the Spatial Distribution of Snow Cover Simulations by Assimilation of Satellite Stereoscopic Imagery, Water Resour. Res., 58, e2021WR030271, https://doi.org/10.1029/2021WR030271, 2022.
Dettinger, M.: Climate change impacts in the third dimension, Nat. Geosci., 7, 166–167, https://doi.org/10.1038/ngeo2096, 2014.
Evensen, G.: The ensemble Kalman filter: Theorical formulation and practical implementation, Ocean Dynam., 53, 343–367, https://doi.org/10.1007/s10236-003-0036-9, 2003.
Gordon, N. J., Salmond, D. J., and Smith, A. F. M.: Novel-Approach to nonlinear non-Gaussian bayesian state estimation, IEE Proc.-F, 140, 107–113, https://doi.org/10.1049/ip-f-2.1993.0015, 1993.
Griessinger, N., Seibert, J., Magnusson, J., and Jonas, T.: Assessing the benefit of snow data assimilation for runoff modeling in Alpine catchments, Hydrol. Earth Syst. Sci., 20, 3895–3905, https://doi.org/10.5194/hess-20-3895-2016, 2016.
Gupta, H. V., Kling, H., Yilmaz, K. K., and Martinez, G. F.: Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling, J. Hydrol., 377, 80–91, https://doi.org/10.1016/j.jhydrol.2009.08.003, 2009.
Herrero, J., Polo, M. J., Monino, A., and Losada, M. A.: An energy balance snowmelt model in a Mediterranean site, J. Hydrol., 371, 98–107, https://doi.org/10.1016/j.jhydrol.2009.03.021, 2009.
Herrero, J., Polo, M. J., Pimentel, R., and Pérez-Palazón, M. J.: Meteorology and snow depth at Refugio Poqueira (Sierra Nevada, Spain) at 2510 m 2008–2015, PANGEA, https://doi.org/10.1594/PANGAEA.867303, 2016.
Hersbach, H.: Decomposition of the continuous ranked probability score for ensemble prediction systems, Weather Forecast., 15, 559–570, https://doi.org/10.1175/1520-0434(2000)015<0559:DOTCRP>2.0.CO;2, 2000.
Kwok, N., Fang, G., and Zhou, W.: Evolutionary particle filter: resampling from the genetic algorithm perspective, in: Proceedings of International Conference on Intelligent Robots and Systems, Shaw Conference Centre, Edmonton, Alberta, Canada, 2–6 August 2005, 2935–2940 pp., 2005.
Kwon, Y., Yang, Z. L., Hoar, T. J., and Toure, A. M.: Improving the radiance assimilation performance in estimating snow water storage across snow and land-cover types in North America, J. Hydrometeorol., 18, 651–668, https://doi.org/10.1175/JHM-D-16-0102.1, 2017.
Lei, F. N., Huang, C. L., Shen, H. F., and Li, X.: Improving the estimation of hydrological states in the SWAT model via the ensemble Kalman smoother: Synthetic experiments for the Heihe River Basin in northwest China, Adv. Water Resour., 67, 32–45, https://doi.org/10.1016/j.advwatres.2014.02.008, 2014.
Malik, M. J., van der Velde, R., Vekerdy, Z., and Su, Z. B.: Assimilation of Satellite-Observed Snow Albedo in a Land Surface Model, J. Hydrometeorol., 13, 1119–1130, https://doi.org/10.1175/JHM-D-11-0125.1, 2012.
Magnusson, J., Winstral, A., Stordal, A. S., Essery, R., and Jonas, T.: Improving physically based snow simulations by assimilating snow depths using the particle filter, Water Resour. Res., 53, 1125–1143, https://doi.org/10.1002/2016WR019092, 2017.
Margulis, S. A., Girotto, M., Cortes, G., and Durand, M.: A particle batch smoother approach to snow water equivalent estimation, J. Hydrometeorol., 16, 1752–1772, https://doi.org/10.1175/JHM-D-14-0177.1, 2015.
Moradkhani, H., Hsu, K. L., Gupta, H., and Sorooshian, S.: Uncertainty assessment of hydrologic model states and parameters: Sequential data assimilation using the particle filter, Water Resour. Res., 41, W05012, https://doi.org/10.1029/2004WR003604, 2005.
Mechri, R., Ottle, C., Pannekoucke, O., and Kallel, A.: Genetic particle filter application to land surface temperature downscaling, J. Geophys. Res.-Atmos., 119, 2131–2146, https://doi.org/10.1002/2013JD020354, 2014.
NCAR: High-Resolution Land Data Assimilation System (HRLDAS), The National Center for Atmospheric Research [code], https://ral.ucar.edu/model/high-resolution-land-data-assimilation-system-hrldas, last access: 10 June 2015.
Niu, G. Y. and Yang, Z. L.: Effects of vegetation canopy processes on snow surface energy and mass balances, J. Geophys. Res.-Atmos., 109, D23111, https://doi.org/10.1029/2004JD004884, 2004.
Niu, G. Y. and Yang, Z. L.: Effects of frozen soil on snowmelt runoff and soil water storage at a continental scale, J. Hydrometeorol., 7, 937–952, https://doi.org/10.1175/JHM538.1, 2006.
Niu, G. Y., Yang, Z. L., Mitchell, K. E., Chen, F., Ek, M. B., Barlage, M., Kumar, A., Manning, K., Niyogi, D., Rosero, E., Tewari, M., and Xia, Y. L.: The community Noah land surface model with multiparameterization options (Noah-MP): 1. Model description and evaluation with local-scale measurements, J. Geophys. Res.-Atmos., 116, D12109, https://doi.org/10.1029/2010JD015139, 2011.
Oaida, C. M., Reager, J. T., Andreadis, K. M., David, C. H., Levoe, S. R., Painter, T. H., Bormann, K. J., Trangsrud, A. R., Girotto, M., and Famiglietti, J. S.: A high-resolution data assimilation framework for snow water equivalent estimation across the western United States and validation with the airborne snow observatory, J. Hydrometeorol., 20, 357–378, https://doi.org/10.1175/JHM-D-18-0009.1, 2019.
Park, S., Hwang, J. P., Kim, E., and Kang, H. J.: A new evolutionary particle filter for the prevention of sample impoverishment, IEEE T. Evolut. Comput., 13, 801–809, https://doi.org/10.1109/TEVC.2008.2011729, 2009.
Parrish, M. A., Moradkhani, H., and DeChant, C. M.: Toward reduction of model uncertainty: Integration of Bayesian model averaging and data assimilation, Water Resour. Res., 48, W03519, https://doi.org/10.1029/2011WR011116, 2012.
Piazzi, G., Thirel, G., Campo, L., and Gabellani, S.: A particle filter scheme for multivariate data assimilation into a point-scale snowpack model in an Alpine environment, The Cryosphere, 12, 2287–2306, https://doi.org/10.5194/tc-12-2287-2018, 2018.
Piazzi, G., Campo, L., Gabellani, S., Castelli, F., Cremonese, E., di Cella, U. M., Stevenin, H., and Ratto, S. M.: An EnKF-based scheme for snow multivariable data assimilation at an Alpine site, J. Hydrol. Hydromech., 67, 4–19, https://doi.org/10.2478/johh-2018-0013, 2019.
Pulliainen, J., Luojus, K., Derksen, C., Mudryk, L., Lemmetyinen, J., Salminen, M., Ikonen, J., Takala, M., Cohen, J., Smolander, T., and Norberg, J.: Patterns and trends of Northern Hemisphere snow mass from 1980 to 2018, Nature, 581, 294–298, https://doi.org/10.1038/s41586-020-2258-0, 2020.
Raleigh, M. S., Lundquist, J. D., and Clark, M. P.: Exploring the impact of forcing error characteristics on physically based snow simulations within a global sensitivity analysis framework, Hydrol. Earth Syst. Sci., 19, 3153–3179, https://doi.org/10.5194/hess-19-3153-2015, 2015.
Rautiainen, K., Lemmetyinen J., Schwank, M., Kontu, A., Menard, C. B., Matzler, C., Drusch, M., Wiesmann, A., Ikonen, J., and Pulliainen, J.: Detection of soil freezing from L-band passive microwave observations, Remote Sens. Environ., 147, 206–218, https://doi.org/10.1016/j.rse.2014.03.007, 2014.
Rings, J., Vrugt, J. A., Schoups, G., Huisman, J. A., and Vereecken, H.: Bayesian model averaging using particle filtering and Gaussian mixture modeling: Theory, concepts, and simulation experiments, Water Resour. Res., 48, W05520, https://doi.org/10.1029/2011WR011607, 2012.
Smyth, E. J., Raleigh, M. S., and Small, E. E.: Improving SWE estimation with data assimilation: the influence of snow depth observation timing and uncertainty, Water Resour. Res., 56, e2019WR026853, https://doi.org/10.1029/2019WR026853, 2020.
Snyder, C.: Particle filters, the optimal proposal and high-dimensional systems, ECMWF Seminar on Data Assimilation for Atmosphere and Ocean, Reading, UK, 6–9 September 2011, 161–170, 2011.
Sturm, M., Holmgren, J., and Liston, G. E.: A seasonal snow cover classification system for local to global applications, J. Climate, 8, 1261–1283, https://doi.org/10.1175/1520-0442(1995)008<1261:ASSCCS>2.0.CO;2, 1995.
Su, H., Yang, Z. L., Niu, G. Y., and Dickinson, R. E.: Enhancing the estimation of continental-scale snow water equivalent by assimilating MODIS snow cover with the ensemble Kalman filter, J. Geophys. Res.-Atmos., 113, D08120, https://doi.org/10.1029/2007JD009232, 2008.
Takala, M., Luojus, K., Pulliainen, J., Derksen, C., Lemmetyinen, J., Karna, J. P., Koskinen, J., and Bojkov, B.: Estimating northern hemisphere snow water equivalent for climate research through assimilation of space-borne radiometer data and ground-based measurements, Remote Sens. Environ., 115, 3517–3529, https://doi.org/10.1016/j.rse.2011.08.014, 2011.
The China Meteorological Administration: Meteorological Station Observation Dataset, CMA [data set], http://data.cma.cn/data/cdcindex/cid/f0fb4b55508804ca, last access: 1 January 2016.
TPDC: China meteorological forcing dataset (1979–2018), TPDC [data set], https://data.tpdc.ac.cn/zh-hans/data/8028b944-daaa-4511-8769-965612652c49, last access: 20 April 2021.
Trujillo, E. and Molotch, N. P.: Snowpack regimes of the Western United States, Water Resour. Res., 50, 5611–5623, https://doi.org/10.1002/2013WR014753, 2014.
Van Leeuwen, P. J.: Nonlinear data assimilation in geosciences: An extremely efficient particle filter, Q. J. Roy. Meteor. Soc., 136, 1991–1999, https://doi.org/10.1002/qj.699, 2010.
Wayand, N. E., Massmann, A., Butler, C., Keenan, E., Stimberis, J., and Lundquist, J. D.: A meteorological and snow observational data set from Snoqualmie Pass (921 m), Washington Cascades, USA, Water Resour. Res., 51, 10092–10103, https://doi.org/10.1002/2015WR 017773, 2015.
Weerts, A. H. and El Serafy, G. Y. H.: Particle filtering and ensemble Kalman filtering for state updating with hydrological conceptual rainfall-runoff models, Water Resour. Res., 42, W09403, https://doi.org/10.1029/2005WR004093, 2006.
Wever, N., Schmid, L., Heilig, A., Eisen, O., Fierz, C., and Lehning, M.: Verification of the multi-layer SNOWPACK model with different water transport schemes, The Cryosphere, 9, 2271–2293, https://doi.org/10.5194/tc-9-2271-2015, 2015.
Yang, J. M. and Li, C. Z.: Assimilation of D-InSAR snow depth data by an ensemble Kalman filter, Arab. J. Geosci., 14, 1–14, https://doi.org/10.1007/s12517-021-06699-y, 2021.
You, Y. H., Huang, C. L., Yang, Z. L., Zhang, Y., Bai, Y. L., and Gu, J.: Assessing Noah-MP parameterization sensitivity and uncertainty interval across snow climates, J. Geophys. Res.-Atmos., 125, e2019JD030417, https://doi.org/10.1029/2019JD030417, 2020a.
You, Y. H., Huang, C. L., Gu, J., Li, H. Y., Hao, X. H., and Hou, J. L.: Assessing snow simulation performance of typical combination schemes within Noah-MP in northern Xinjiang, China, J. Hydrol., 581, 124380, https://doi.org/10.1016/j.jhydrol.2019.124380, 2020b.
Zhang, T. J.: Influence of the seasonal snow cover on the ground thermal regime: An overview, Rev. Geophys., 43, RG4002, https://doi.org/10.1029/2004RG000157, 2005.
Zhu, G. F., Li, X., Ma, J.Z., Wang, Y. Q., Liu, S. M., Huang, C. L., Zhang, K., and Hu, X. L.: A new moving strategy for the sequential Monte Carlo approach in optimizing the hydrological model parameters, Adv. Water Resour., 114, 164–179, https://doi.org/10.1016/j.advwatres.2018.02.007, 2018.