the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 29 Apr 2022
| 29 Apr 2022
Detecting hydrological connectivity using causal inference from time series: synthetic and real karstic case studies
Damien Delforge
Olivier de Viron
Marnik Vanclooster
Michel Van Camp
Arnaud Watlet
We investigate the potential of causal inference methods (CIMs) to reveal hydrological connections from time series. Four CIMs are selected from two criteria, linear or nonlinear and bivariate or multivariate. A priori, multivariate, and nonlinear CIMs are best suited for revealing hydrological connections because they fit nonlinear processes and deal with confounding factors such as rainfall, evapotranspiration, or seasonality. The four methods are applied to a synthetic case and a real karstic case study. The synthetic experiment confirms our expectation: unlike the other methods, the multivariate nonlinear framework has a low false-positive rate and allows for ruling out a connection between two disconnected reservoirs forced with similar effective precipitation. However, for the real case study, the multivariate nonlinear method was unstable because of the uneven distribution of missing values affecting the final sample size for the multivariate analyses, forcing us to cope with the results' robustness. Nevertheless, if we recommend a nonlinear multivariate framework to reveal actual hydrological connections, all CIMs bring valuable insights into the system's dynamics, making them a cost-effective and recommendable comparative tool for exploring data. Still, causal inference remains attached to subjective choices, operational constraints, and hypotheses challenging to test. As a result, the robustness of the conclusions that the CIMs can draw always deserves caution, especially with real, imperfect, and limited data. Therefore, alongside research perspectives, we encourage a flexible, informed, and limit-aware use of CIMs without omitting any other approach that aims at the causal understanding of a system.
- Article
(3975 KB) - Full-text XML
-
Supplement
(1295 KB) - BibTeX
- EndNote





Causal inference methods (CIMs) aim at identifying causal interactions between variables from data only (Spirtes et al., 2000; Pearl, 2009). When applied to time series, these empirical methods are built upon the principle of priority of the cause, which goes back to Hume (1748): CIMs infer causation from the expected time dependencies, i.e., the causes preceding the effects. They evolved throughout the 20th century to go beyond the well-known correlation, or cross-correlation, between two time series (see Runge et al., 2019a, for a broad review). Although widely used, the correlation or cross-correlation method cannot identify nonlinear causal relationships or discriminate actual causal links from dependencies resulting from confounding factors. Indeed, the common cause's principle (Reichenbach, 1956; Runge et al., 2019a) tells us that dependencies between two variables could result from a third confounding cause influencing both. Nowadays, many CIMs have been developed, differing in hypotheses or application fields. Some CIMs explicitly deal with, either or both, nonlinear dependencies or confounding factors through multivariate analyses. These new CIMs are of growing interest in Earth, land, and hydrological sciences (Meyfroidt, 2016; Runge et al., 2019a; Goodwell et al., 2020). In hydrology, applications of CIMs remain rare and cover, for example, the potential causal feedbacks between soil moisture and precipitation (Salvucci et al., 2002; Tuttle and Salvucci, 2017; Wang et al., 2018), the differential effects of environmental drivers of evapotranspiration (Ombadi et al., 2020), interactions across rainfall timescales (Molini et al., 2010), the ecohydrological feedback processes (Ruddell and Kumar, 2009), or the study of hydrological connectivity (Sendrowski and Passalacqua, 2017; Rinderer et al., 2018).
Our study compares four CIMs on hydrological case studies in the spirit of other recent comparative studies (Rinderer et al., 2018; Ombadi et al., 2020). Our application differs in the choice of CIMs and the research questions. We selected four CIMs, all operating on the time domain following the principle of priority up to a maximum causal delay dmax. We use two bivariate CIMs, the linear cross-correlation function (CCF) and the nonlinear convergent cross-mapping (CCM) method (Sugihara et al., 2012; Ye et al., 2015), together with two multivariate methods, one linear testing for partial correlation (ParCorr) and one nonlinear testing for conditional mutual information (CMI). The multivariate CIMs are parts of the same causal inference framework, PCMCI, a sequential procedure based on the PC (Peter–Clark) algorithm (Spirtes and Glymour, 1991), followed by a test for momentary conditional independence (MCI) (Runge et al., 2019b).
Like Rinderer et al. (2018), we discuss whether CIMs are suitable for studying hydrological connectivity, which aims at identifying the paths taken or that could be taken by water (Bracken et al., 2013). We align with the Rinderer et al. (2018) terminology inspired by the field of neurology and brain connectivity (Friston, 2011). Accordingly, there are three types of connectivity: (i) structural, (ii) functional, and (iii) effective connectivity. The structural connectivity is derived from the medium and highlights the potential, static, and time-invariant water flow paths from the geological environment's topography, spatial adjacency, or contiguity. The functional connectivity is dynamic and retrieved from statistical time dependencies between local hydrological variables. Functional connectivity is a matter of cross-predictability and reflects dynamic links between the variables. These dynamic links are potential connections subject to confounding factors; i.e., they may or may not be related to a flow process between variables. Effective connectivity precisely refers to actual connections linked through hydrological processes and flows.
Rinderer et al. (2018) reviewed a broad ensemble of CIMs from the literature and tested them to assess groundwater connectivity. Like Ombadi et al. (2020), they report spurious effective connections (or false positives), highlighting the imperfect yet variable detection performances of CIMs. To deal with false positives, Rinderer et al. (2018) proposed constraining or limiting the results by an assessment of structural connectivity. However, our concern is the hydrological connectivity in the vadose zone of karst systems. Assessing structural connectivity in karst systems is a challenging task because of their hidden and heterogeneous structure (Bakalowicz, 2005). Thus, without structural connectivity assessment, we investigate hydrological connectivity from CIMs alone. Besides, karst systems are known for their nonlinear behavior, which could be imputed to nonlinear hydrological processes, e.g., taking the form of power laws, or threshold effects triggering flows (Bakalowicz, 2005; Blöschl and Zehe, 2005).
As a result, by design, multivariate nonlinear CIMs (e.g., PCMCI–CMI) would seem best suited to retrieving effective hydrological connections: they account for nonlinear dependencies and deal with confounding effects, e.g., seasonality or the forcing of precipitation and evapotranspiration, through a multivariate framework. Following a theoretical introduction of the different CIMs, we test this assertion and get hands-on the CIMs using a toy model to conduct a virtual experiment reproducing a simple case of two parallel hydrological reservoirs forced by the same effective precipitation. In a real case study, we apply the CIMs to data acquired at the Lorette cave (Rochefort, southern Belgium). This dataset includes rainfall and potential evapotranspiration data, electrical resistivity time series patterns from the subsurface obtained from a geophysical monitoring experiment using time-lapse electrical resistivity tomography (ERT) (Watlet et al., 2018b; Delforge et al., 2020c), and drip discharge time series with distinct dynamical patterns monitoring percolation at three spots within the cave. In particular, previous dye tracing tests have revealed fast connected preferential flow between the surface and a particular spot in the cave (Poulain et al., 2018). We expect CIMs to reveal this specific connection. Time series also have different numbers of missing values, unevenly distributed over time, allowing a discussion of the impact of temporal gaps or short sample sizes on the analysis.
2.1 CIMs
2.1.1 CCF
With CCF, we consider that a variable Xt is said to be a cause of variable Yt if Pearson’s correlation coefficient ρ between Yt and Xt−d is significant on their overlapping domain for at least one value of d up to dmax. The significance is assessed with a Student's t test (see Sect. S1 in the Supplement for more details on the CIMs' implementation).
Usually, the CCF method is not explicitly presented as a CIM. Nevertheless, we consider it to be such because the method is simple, intelligible and linearly interpretable, and, in practice, widely used for the implicit purpose of making causal inference, despite its limits as a bivariate linear method, in most scientific domains like hydrology (e.g., Angelini, 1997; Larocque et al., 1998; Labat et al., 2000; Mathevet et al., 2004; Bailly-Comte et al., 2008; Watlet et al., 2018b). In general, linear methods have been popular in hydrology and attractive for their computational efficiency (Dooge, 1973). Besides, as a result of CCF popularity, the outcomes of any other CIMs are best appreciated when benchmarked against the well-known CCF method.
2.1.2 CCM
CCM is primarily designed to reveal weak nonlinear interactions between time series (Sugihara et al., 2012; Ye et al., 2015). CCM is a nearest-neighbor forecasting approach. It tests whether dynamic trajectories between two variables behave consistently, i.e., with some cross-predictive skills, while the system revisits the same states (dynamic recurrence). The system states are usually unknown; they are approximated by trajectory segments found in a trajectory matrix MY given by Takens' embedding theorem (Takens, 1981):
where m is the embedding dimension. In this case, with unit lags between time series, m corresponds to the length of the segments and can be optimized using self-forecasting performance while predicting points in Yt from their nearest neighbors in MY (Sugihara and May, 1990; Delforge et al., 2020a). This length m is set to 2 d in this study due to the overall good performance of this value during our preliminary testing, i.e., .
For a causal analysis and to check whether Xt is a cause of Yt, CCM makes forecasts of the points in Xt from other values in Xt, whose time indices are identified from Yt as similar states in MY for a given forecast time of reference. The algorithm is detailed and illustrated in the Supplement (Sect. S1.2). Our CCM implementation is found in Delforge et al. (2020a). CCM is an ensemble method, i.e., producing many (NSAM) forecasts of the time series at a given lag from NSAM bootstrapped samples of size L from the trajectory matrix MY to identify similar states. In our case, we measure the predictive skills as suggested in Sugihara et al. (2012) with the average Pearson correlation between time series and their forecasts. Like CCF, the significance of the mean Pearson correlation is appreciated with a Student's t test.
There are few recent applications of CCM in hydrology (Wang et al., 2018; Medina et al., 2019; Ombadi et al., 2020). We chose the approach of Ye et al. (2015) over the original one of Sugihara et al. (2012). The latter infers causality without predictive delays (dmax=0) and investigates convergence instead of time dependencies. The convergence criterion for causality suggests that predictive skills must increase by considering larger sample sizes L in MY to identify similar states until a plateau is reached. However, Sugihara et al. (2012) recognized that convergence could be met when variables are subject to strong forcing or seasonality, a case referred to as synchrony, which could yield spurious bidirectional causal relationships, in particular regarding hydrological variables (e.g., Sugihara et al., 2017). Although the parallel is not explicit in the literature, we considered that synchrony relates to confounding and adopted the approach of Ye et al. (2015), which attempts to overcome synchrony by investigating the asymmetric patterns of time dependencies and to solve causality from the principle of priority up to dmax, i.e., like CCF but considering nonlinear dependencies (see also Wang et al., 2018). We do not check for convergence and apply CCM with L=100 based on our preliminary testing (similarly to Ombadi et al., 2020), assuming that convergence is occurring if is significantly high for this given L. Secondly, we use a Theiler window (Theiler, 1986), tw, which is not considered in most applications of CCM (e.g., Wang et al., 2018; Ombadi et al., 2020) but well in applications related to chaos theory, from which CCM is derived (see Huffaker et al., 2018). The Theiler window is a time window that forces similar states to be sampled outside its range, for a time of reference. It prevents undesired predictive skills from being imputed to auto-correlation rather than based on the consistency of dynamic recurrent trajectories, i.e., what CCM is supposed to test. Given the auto-correlated nature of hydrological series, we consider its use recommendable, especially for short time series (Theiler, 1986), although the effect of tw on predictive skills is expected to be marginal if the time series are long enough (Delforge et al., 2020a). In our case, we systematically consider tw=10 d such that similar states are most likely to be separated by one rainfall event.
Finally, since CCM is rooted in chaos theory, it could be argued that CCM applies under the strict assumptions of its parent theory built on deterministic mathematical models, i.e., on low-dimensional systems with infinite length, noiseless, and with non-cyclic and non-intermittent series or relations (Kantz and Schreiber, 2003; Sugihara et al., 2012; Sivakumar, 2017; Huffaker et al., 2018; Runge et al., 2019a). While we acknowledge that these hypotheses are not met with real hydrological time series (Koutsoyiannis, 2006), CCM and its underlying framework were introduced as capable of operating on short and noisy series as a nearest-neighbor regressor combined with its bootstrapping strategy (Sugihara and May, 1990; Sugihara et al., 1994, 2012), and the interest of any CIM is ultimately to be applied to real data while raising awareness about potential problems related to the real context. CCM, as well as other CIMs (see Runge et al., 2019a; Ombadi et al., 2020) or any statistical methods, meets issues with sample length, noise, cycles, dynamic intermittency, as well as stationarity or significance testing (Huffaker et al., 2018; Medina et al., 2019), which should be considered in the result interpretation.
2.1.3 PCMCI: the ParCorr and CMI tests
PCMCI is based on a stochastic framework testing conditional independence (Spirtes et al., 2000; Pearl, 2009), adapted to account for highly time-dependent time series and implemented in the Tigramite Python package (Runge et al., 2019b). It follows a two-step procedure: PC and MCI. The PC abbreviation refers to its authors Peter Spirtes and Clark Glymour (1991). PCMCI's grounding lies in a multivariate definition of the Wiener–Granger causality (Wiener, 1956; Granger, 1969), here referred to as MCI (Runge et al., 2019b, a): a lagged variable Xt−d is said to be a cause of Yt if Xt−d has a significant dependence or predictive power over Yt while removing the effect of all other potential variables influencing Xt−d or Yt, except Xt−d. These potential variables are called parents and are symbolized by 𝒫(Xt−d) and . Conditioning the analysis on the parents allows one to deal with confounding variables.
Parents are subset variables found in the dataset that includes delayed variables up to 2dmax, as 𝒫(Xt−d) has to be estimated beyond the maximum causal lag dmax. Parents are estimated during the conditions' selection step performed with PC. The resulting estimates are noted as and . PC removes irrelevant conditions from the full set of variables and delays by iterative independence testing until there is no more condition to drop out (see Runge et al., 2019b). The resulting sizes of the parents' set are controlled by αPC, a liberal parameter varying between 0 and 1, with the latter being the less restrictive case that includes all possible variables. Then, MCI is defined as
To assert that Xt−d causes Yt, MCI must be rejected by a given independence test. PCMCI is paired with the linear ParCorr and nonlinear CMI tests. ParCorr is estimated by ordinary least squares by regressing the variables against their covariates considering a multivariate linear model. Then, the dependency between the residuals is tested using Pearson's correlation and a Student's t test for the significance. For the PC step with ParCorr, Tigramite optimizes αPC between 0.05 and 0.5 based on Akaike's information criterion (Akaike, 1974). In information theory, CMI, or for possibly multivariate and continuous random variables X, Y, and Z, is defined as the mutual information I between X and Y conditioned to Z (Runge, 2018b):
If , X and Y are conditionally independent of Z, and, therefore, not directly causally related, assuming that the probability densities are correctly estimated, among other assumptions (Runge, 2018a). This is not a trivial task, especially in the case of high dimensionality or small sample sizes. Regarding PCMCI, dimensionality varies between variables according to the size of the sets of parents (Eq. 2), hence depending on dmax, αPC, the independence test, and its parameters. Based on numerical experiments covering sample sizes from 50 to 2000 and dimensions up to 10, Runge (2018b) recommends using nearest-neighbor estimators of CMI (Frenzel and Pompe, 2007; Vejmelka and Paluš, 2008) for small sample sizes (<1000). As no analytical significance test is available, like the Student's t test used in the other cases, Runge (2018b) provides a shuffling significance test that is, in return, computationally demanding. Because of this computational requirement, PC with CMI has no implemented procedure for the selection of αPC, and we limited ourselves to two values among suggested ones: the default αPC=0.2 and a more restrictive αPC=0.05 given the strong interdependence of hydrological series.
PCMCI is based on a strict framework of assumptions: faithfulness, causal sufficiency, the absence of contemporaneous dependencies, the causal Markov condition, stationarity, and the assumptions behind the selected independence tests such as linearity or nonlinear constraints, or hyperparameters related to the estimators (see Runge, 2018a). In this study, we are mainly concerned with the first three. Faithfulness relates the absence of causality to conditional independence and requires that a time series contains noise signals to test it. Causal sufficiency implies that the monitored variables include all common causes, following the principle (Reichenbach, 1956). Finally, contemporaneous links are related to the principle of priority, as some time lags are desired to infer the direction of causal relationships.
Given its flexibility, PCMCI is comparable to several other CIMs found in the literature. First, the PC algorithm itself is a CIM (Spirtes and Glymour, 1991), evaluated in hydrology as well (Ombadi et al., 2020). However, in comparison, the sequential PCMCI procedure is expected to reduce the number of false positives (Runge et al., 2019b). PCMCI–ParCorr is also related to Granger causality (GC) (Granger, 1969), which has several applications in hydrology (e.g., Salvucci et al., 2002; Tuttle and Salvucci, 2017), including karst (Kadić et al., 2018). Still, there are substantial differences. GC relies on multivariate vector autoregressive models, which do not account for contemporaneous dependencies. PCMCI reports significant contemporaneous dependencies, although without any causal direction since it cannot be inferred from the principle of priority. Also, GC relies on an F test checking for significant reductions of the variance in the models' residuals. Besides, GC is not a sequential procedure like PCMCI. The GC conditioning is performed on all possible past variables, as if αPC=1. As a result, GC suffers from the curse of dimensionality, lowering its detection performance (Runge et al., 2019b, a). For this reason, GC is often applied in a bivariate way, considering only Xt and Yt's past. The transfer entropy (TE) method (Schreiber, 2000) is the nonlinear and information theory equivalent of bivariate GC (Barnett et al., 2009), making PCMCI–CMI a multivariate and sequential extension of TE. In hydrology, there are some applications of TE (e.g., Ruddell and Kumar, 2009; Sendrowski and Passalacqua, 2017; Rinderer et al., 2018; Ombadi et al., 2020). Regarding PCMCI–CMI, Goodwell et al. (2020) review information theory approaches and their potential applications in hydrology. Jiang and Kumar (2019) provide a framework built upon PCMCI–CMI to characterize short- and long-term dependencies of observed stream chemistry data.
2.2 Study site and data
The karstic study site is the Lorette cave, next to the city of Rochefort in southern Belgium (Fig. 1a) (Watlet et al., 2018b; Poulain et al., 2018, and references therein). At 3 km from the study site, a PAMESEB agrometeorological station provides estimates of daily potential evapotranspiration data (ET, Fig. 1c) with the Penman–Monteith FAO-56 method (Allen et al., 1998). At the Lorette site, at the Rochefort cave laboratory, daily rainfall data (RF, Fig. 1a) are aggregated from a Lufft tipping bucket rain gauge with a 1 min sample rate located at the surface (elevation ∼225 m above ordnance datum (AOD). Inside the cave (elevation ∼190 m AOD), two drip discharge monitoring devices (P1, P2, Fig. 1a) are installed within the main chamber accessible from a sinkhole, which constitutes the cave entrance. In particular, P1 monitors an active dripping point due to a visible fracture on the chamber's ceiling (see Triantafyllou et al., 2019, for a 3D model). Based on dye injection at the surface and in-cave tracing, a connection and preferential flow path between the dye injection point (DT, Fig. 1a) and P1 was identified (Poulain et al., 2018). The breakthrough curve showed an initial arrival time of 3.75 h, a sustained peak for 80 h, and a tail lasting up to 120 d. However, sporadic peaks in concentration were observed after every rainfall event, reacting after 1.48 h, peaking after 7.2 h, and lasting up to 30 h on average. P2 monitors a dripping spot draining a porous limestone area. The last one, P3, located in the northern gallery, monitors the slow discharge from drops falling from one single stalactite below a massive limestone layer. P1, P2, and P3 (Fig. 1c) are daily means of the percolation rate.
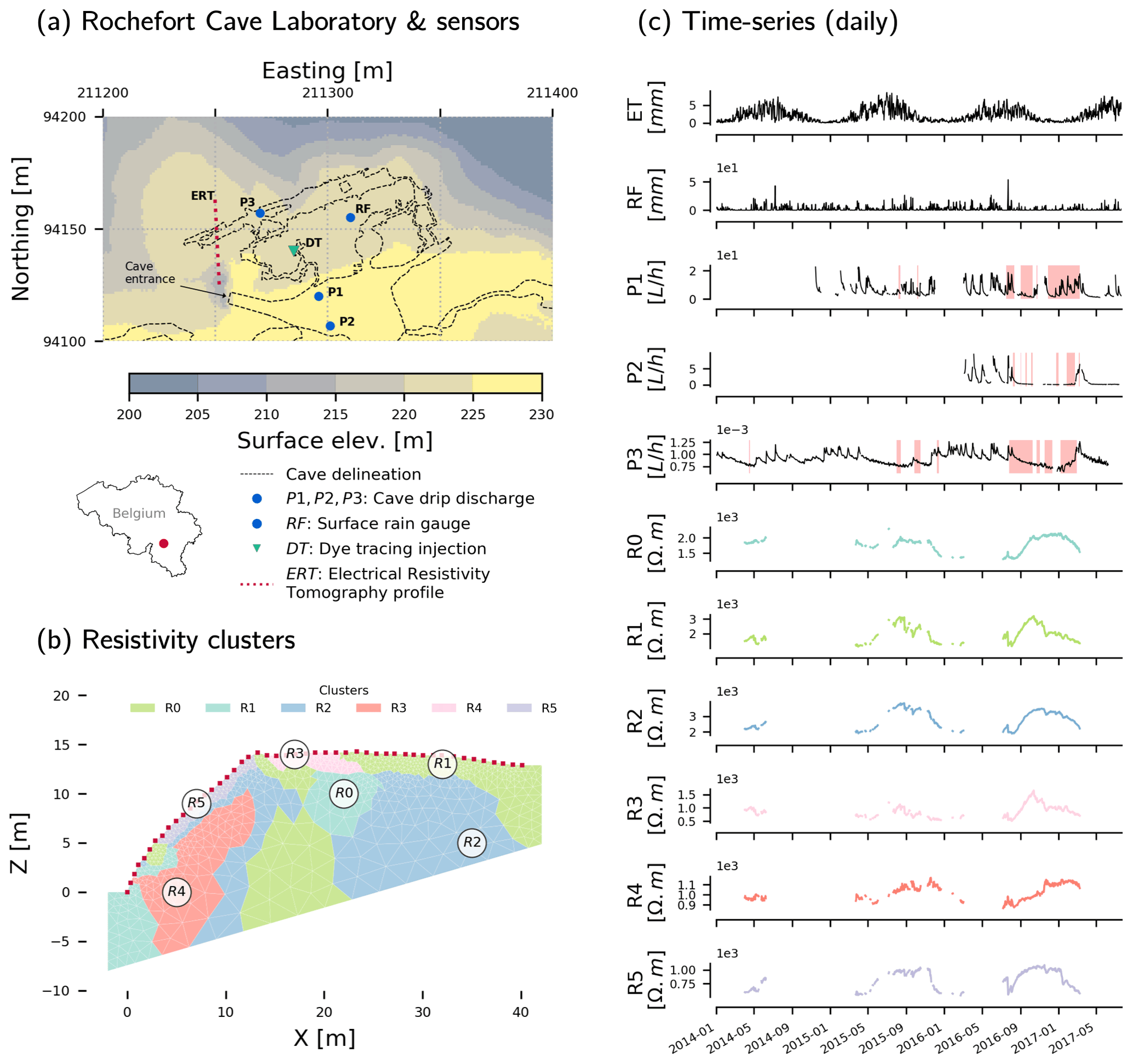
Figure 1Study site and data: (a) Rochefort cave laboratory and sensors (EPSG: 31370), (b) resistivity clusters obtained from hierarchical agglomerative clustering of standardized resistivity data (Watlet et al., 2018b; Delforge et al., 2020c), and (c) daily time series dataset. Resistivity time series (R0 to R5) are the mean resistivity variations per cluster. Potential evapotranspiration data (ET) are obtained from an agrometeorological station (PAMESEB) located 3 km from the site. The red background areas in panel (c) show the time domain resulting from the conditioning on past delays with dmax=5 d while considering, respectively, P1, P2, and P3 only in the causal dataset. A hydrological connection was identified by dye injection and tracing from the surface (DT) to P1 (Poulain et al., 2018). Source: digital elevation model from the Service Public de Wallonie, cave delineation from Watlet et al. (2018b).
An ERT profile was installed to investigate the hydrology of the subsurface and potential connections above the cave (Watlet et al., 2018b). ERT is a geophysical monitoring tool to study various types of hydrological processes (see Slater and Binley, 2021, and references therein). The ERT profile is not flat and starts from the depression of a sinkhole where the entrance to the cave is located (ERT, Fig. 1a). The ERT experiment allowed collection of ERT data daily between 2014 and 2017, which represents the longest high-resolution ERT monitoring experiment conducted in a karst environment to our knowledge (see Watlet et al., 2018b, for details). This dataset consists of processed ERT data, defined over 1558 spatial cells and 465 daily time steps. As a necessary prior step to causal inference, the 1558 time series were dimensionally reduced to six time series clusters (R0 to R5, Fig. 1b and c). We used hierarchical agglomerative clustering with the Ward linkage method to minimize the squared distance between time series within clusters. This algorithm is similar to k means. As clustering was applied to the standardized ERT dataset, clusters represent groups of linearly correlated resistivity dynamics. The optimal number of clusters of six was selected using the optimal silhouette index as a clustering evaluation metric (Rousseeuw, 1987). The methodological aspects associated with clustering are extensively covered in another issue (Delforge et al., 2020c).
R0 is associated with a dense limestone area in the model's center (Fig. 1b, X=22 m, Z=10 m). R1 covers responsive resistivity dynamics at the plateau's surface (Fig. 1b, X=32 m, Z=13 m) and a fractured area around coordinate X=15 m below the surface pattern R3. R2 is rather representative of the resistivity patterns of the limestone matrix. R4 is associated with a clayey limestone layer located below the pattern of slope surface R5 (Watlet et al., 2018b; Delforge et al., 2020c). We expect causal links to appear primarily between P1 and the near-surface resistivity patterns R1 or R3.
Time series of Fig. 1c are the 11 inputs for the four selected CIMs. Table 1 shows their statistics. Bivariate CIMs (CCF and CCM) are applied between each pair of time series on their overlapping time domain with a maximum causal delay dmax=5 d. We considered this delay for our final results as it covers the span of bivariate dependencies (Figs. S3, S4) and the full time span of preferential flow peaks lasting up to 80 h (Poulain et al., 2018). For the same reason, we use the same dmax for the multivariate methods. In general, large dmax values are recommended to satisfy the hypothesis of causal sufficiency, while PCMCI sequential procedures deal with the potentially high dimension resulting from dmax (Sect. 2.1.3). Still, dmax cannot be higher than 5 d because of our uneven time distribution of missing data. Indeed, PCMCI dismisses all time slices of samples where missing values occur in any variable and their lags up to 2dmax, which limits the overall overlapping time domain to 48 d, mostly because of the short time domain of P2 (Fig. 1c, Table 1). Concerned that this number would impact the robustness of the analysis, we also applied PCMCI while considering one percolation datum at a time. In this way, P1, P2, and P3 are considered separate and independent drainage systems, and the overlap domains become larger while keeping dmax=5 d: 184, 62, and 218 d, respectively. These domains are shown in red for P1, P2, and P3 in Fig. 1c.

3.1 Conceptual model
We aim at assessing CIM performances for the detection of effective hydrological connectivity, in particular, the assertion that multivariate nonlinear methods are best suited for that purpose. To this end, we built a simple hydrological reservoir model, inspired by the common cause problem (Fig. 2). Two separate and independent reservoirs, A and B, and their discharges QA and QB, are forced with the same effective precipitation Peff (i.e., precipitation minus evapotranspiration). Then, without any effective connection, they will nevertheless show a temporal dependence. If A and B are disconnected, the ideal CIM would then reject the effective connection between QA and QB if Peff is included in the multivariate analysis. However, B responds systematically 1 d later than A to Peff. Hence, with bivariate methods and the priority principle only, QA would seemingly cause QB. For comparison, we consider a case where QA is effectively connected to another series , as they were contributing to the same drainage network, with QA upstream of . Notably, this experiment does not cover the case of nonlinearities arising from threshold effects and intermittent processes. Instead, we assume sustained causal interactions and no intermittency over time, as the CIMs do.
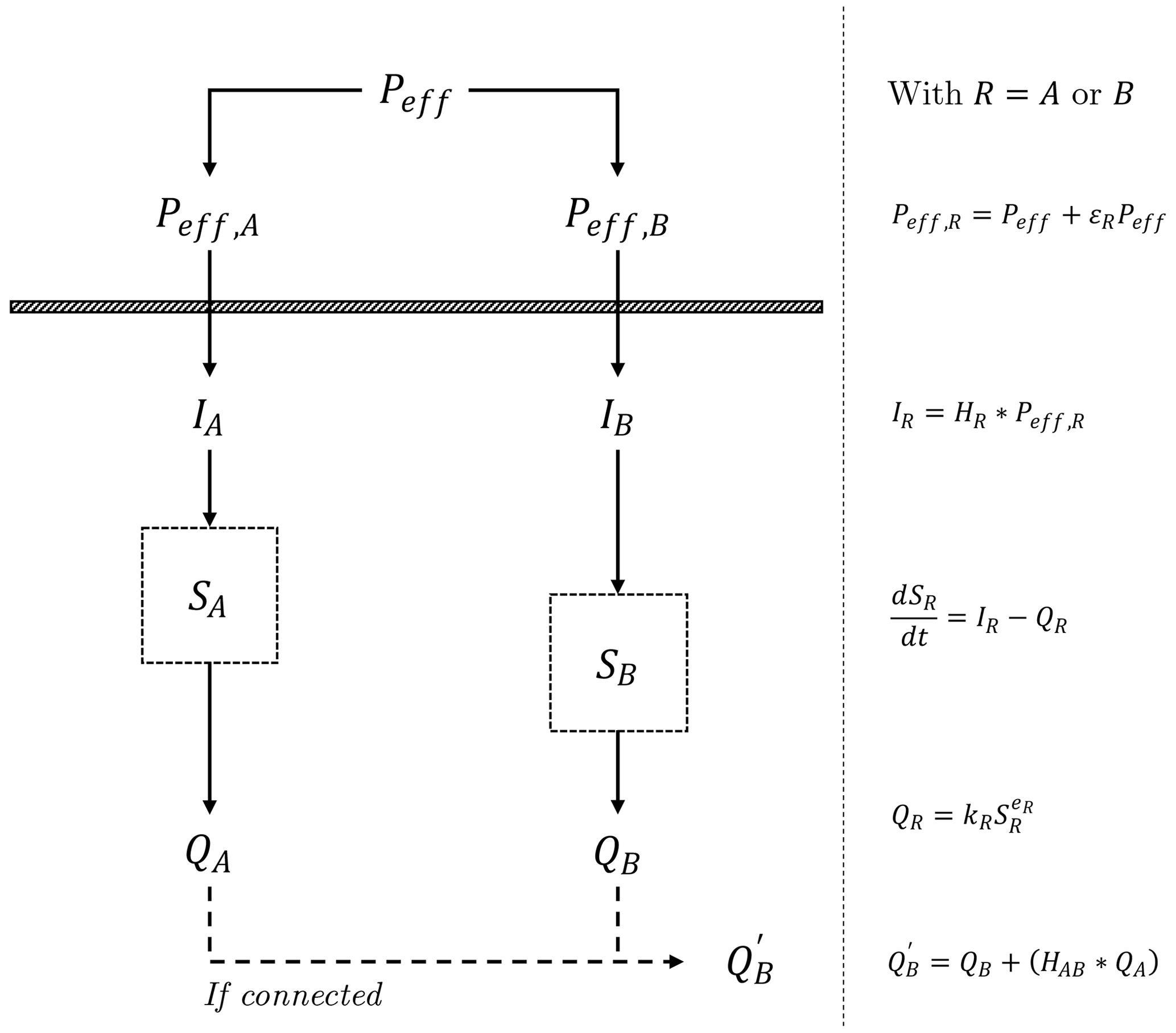
Figure 2The conceptual and mathematical model for the synthetic case study. Two reservoirs A and B are forced by inflows IA or IB resulting from the unit hydrograph HA and HB forward convolution on noisy variants Peff, A and Peff, B of the same effective precipitation Peff computed from real data (Sect. 2.2). The storage SA and SB dynamics follows a typical continuity equation , where the discharges QA and QB follow a nonlinear power law Q=kSe with two parameters k and e. Reservoir B responds mainly 1 d after A, which introduced a systematic time dependency between the reservoir suggesting causation. is a flow downstream of QB draining QA and transferred considering the unit hydrograph HAB. The causal analysis involves either the disconnected case QA and QB or the connected case QA and . Multivariate methods include Peff within the analysis.
The model is forced by real effective precipitation data Peff monitored at the study site (Sect. 2.2). Both reservoirs take as input a net inflow term IA and IB resulting from the application of the unit hydrographs HR, with R either A or B, as linear transfer functions convolved forwardly on a noisy precipitation input ( with ∗ the convolution operator). Adding some noise is mandatory to check for conditional independence (faithfulness, Sect. 2.1.3). A multiplicative noise term is preferred as hydrological variables are often characterized by multiplicative noise (e.g., Rodriguez‐Iturbe et al., 1991). Accordingly, , with εR being randomly generated from a normal distribution with zero mean and standard deviation equal to εlvl times the standard deviation of Peff. The parameter εlvl is always identical for A and B, such that εA and εB have the same distribution. The continuity equation gives the reservoirs' storage dynamics: . The outflow QR introduces some nonlinearities through a typical nonlinear storage–discharge relationship , with kR and eR the discharge coefficient and the nonlinear exponent. Such power-law formulations are typical in hydrology (Dooge, 1973) and common while modeling karsts as well (Hartmann et al., 2014; Jourde et al., 2015).
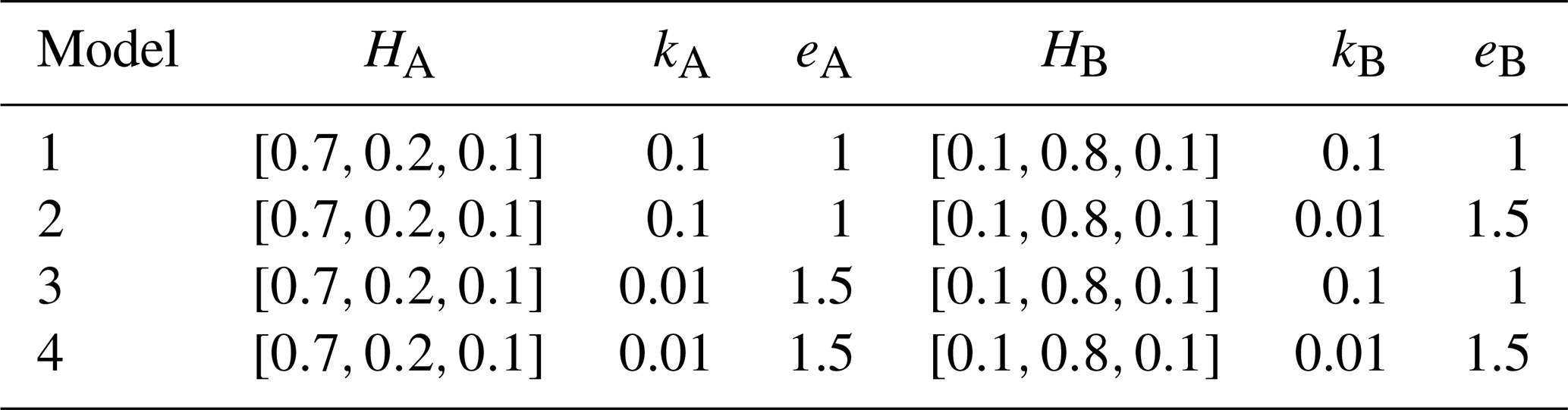
For the synthetic cases, we derived four models based on Table 2. The unit hydrographs HA and HB are constant, with their maxima differing by one daily time step. This lag introduces the desired constant time dependencies between the two reservoirs despite the absence of a connection. The recession parameters allow generation of distinct dynamic patterns with various degrees of nonlinearity thanks to eR. In addition, we also considered 14 stochastic noise level . With such noise levels, the correlation between two generated QA with model configuration 1 (Table 2) should vary on average between 0.96 (εlvl=0.05) and 0.24 (εlvl=0.7). With the four combinations of Table 2 and the 14 noise levels, 56 datasets were generated from 4 years of effective precipitation data Peff (2014–2018) and initial storages SA and SB equal to 30 mm. Only the last years of the three variables Peff, QA, and QB were considered for the causal inference experiment, the first three being considered a warming-up period. The data generation is repeated to produce 56 additional datasets with an effective connection. QA and QB are causally related by overwriting QB such that , where is a linear transfer function convolved forwardly on QA. Finally, the whole synthesis process is repeated to generate first-order differenced datasets (i.e., ), that is, a total of 224 datasets with 4 model combinations and 14 noise levels, connected or not and differenced or not. The primary purpose of the differenced data is to simply illustrate the effect and value of removing past dependencies (auto-correlation, seasonality) on the CIM results.
3.2 Results
Figure 3 depicts the average and interquartile range of QA–QB time dependencies, or QA– if connected, obtained with the four CIMs (panels a–d) on the synthetic datasets for a maximum delay dmax=5 d. The multivariate analysis includes Peff. We distinguish between cases where the reservoirs are connected or not and where the data are differenced or not. Regarding the bivariate methods (panels a and b), CCF and CCM both exhibit sustained time dependencies for non-differenced data due to the auto-correlation and seasonal patterns left in the series. For differenced data, the results better screen the expected peak at lag 1 d, including disconnected reservoirs. This illustrates that bivariate CIMs cannot deal with the confounding effect related to the common forcing of reservoirs. This is not an effective connection but a functional and apparent one resulting from their delayed responses. The sustained time dependency of CCM over the lag of 2 d is an artifact of the embedding dimension, m=2 (Eq. 1), defining the length of trajectory segments, which is 2 d in this case (see Sect. S1.2).
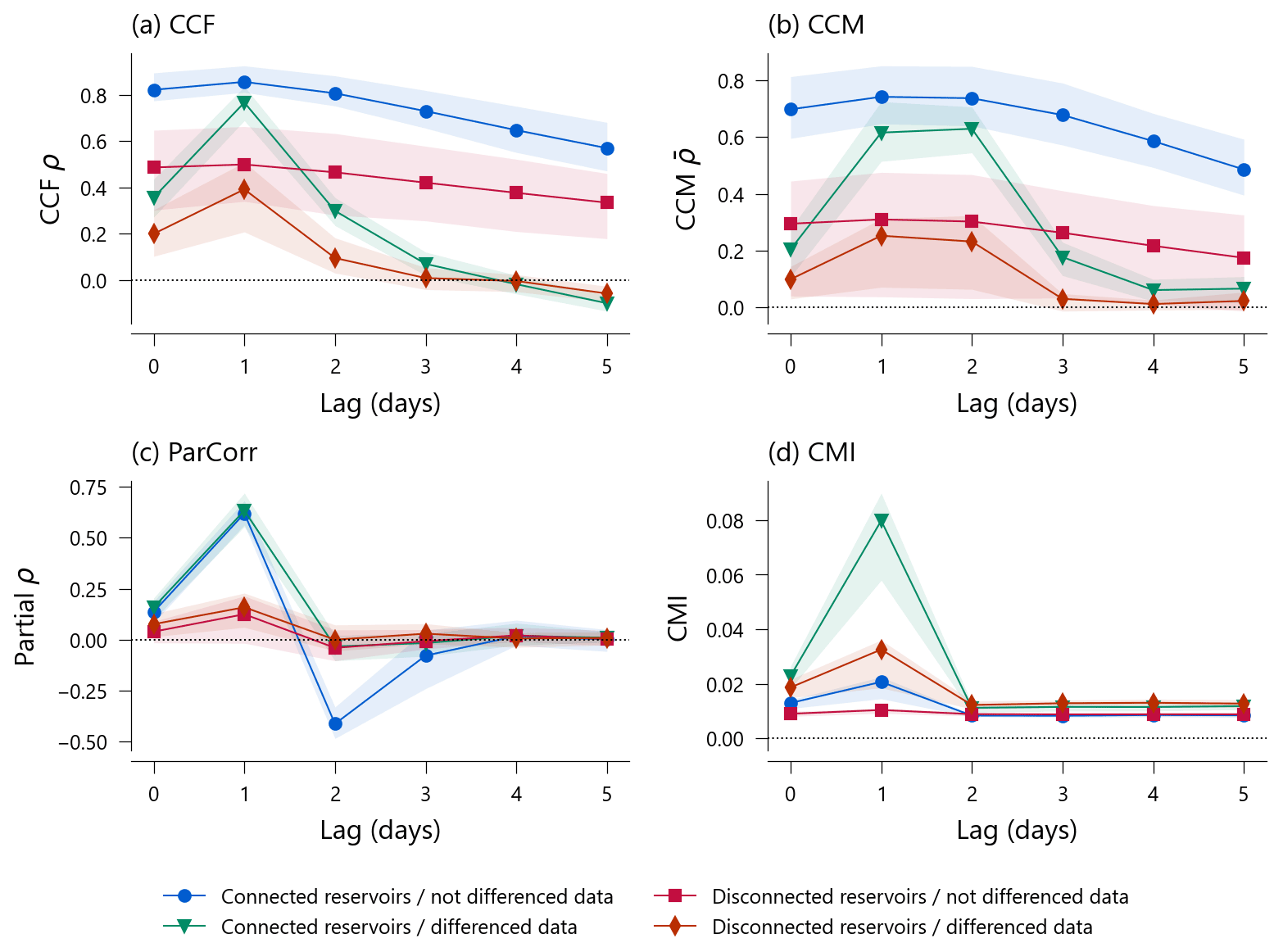
Figure 3Patterns of statistical time dependencies between QA and Qb ( if connected) for the four CIMs (a–d). Lines are the average statistics for 56 synthetic datasets obtained from four different model structures (Table 3) and 14 distinct noise levels. The envelope represents the interquartile range of the statistics. In general, connected reservoirs show causal dependencies at a lag of 1 d. However, except for CMI on the non-differenced data, disconnected reservoirs show a non-causal yet significant statistical dependency QA→QB at lag 1 d, since reservoir A mostly reacts 1 d before B to the effective precipitation.
Regarding the multivariate CIMs (panels c and d), differencing time series is theoretically useless as PCMCI already conditions on the past variables (Eq. 2) and can deal with auto-correlation and seasonality. The linear ParCorr method seems to discriminate the connected case from the disconnected case. Still, it always shows a peak at lag 1 d, whatever the cases, which could be misinterpreted as an effective connection. Only the nonlinear CMI method applied to the non-differenced data seems to reject the idea of connection when it is effectively absent. This finding supports our theoretical assertion: the multivariate nonlinear method is best suited to addressing effective hydrological connectivity. Furthermore, the method appears to perform better if seasonality is left present in the time series. Still, Fig. 3 shows the pattern of the statistics, not the result of a causality test and its p value.
Since we know for each simulation whether or not there is a causal link between A and B, Table 3 reports true positives (TPs), false positives (FPs), true negatives (TNs), and false negatives (FNs) for the problematic lag of 1 d. We consider the multivariate PCMCI methods ParCorr and CMI, with the latter having two different αPC for preselection of parents (PC stage). Two levels of significance are considered at 99 % and 95 % based on the p values obtained by the tests. Table 3 shows that, for a similar level of accuracy, CMI for non-differenced data has higher precision and a lower false-positive rate, meaning that positive tests are likely to detect actual causal relations. Differencing increased the PCMCI–CMI false-positive rate. The low false-positive rate for non-differenced data is particularly contrasting with other methods and provides a valuable piece of information. However, the high precision comes at the cost of a low recall (as reported in Runge, 2020): CMI misses about half of the actual causal links. By contrast, ParCorr misses none but has a bad precision, i.e., many false positives. This analysis thus provides an overview of the contrasts between methods. Of course, this virtual three-variable configuration is far from representative of the great variety of natural hydrological systems and their spatiotemporal organizations.
Table 3Causal test statistics for the synthetic cases at lag 1 d.
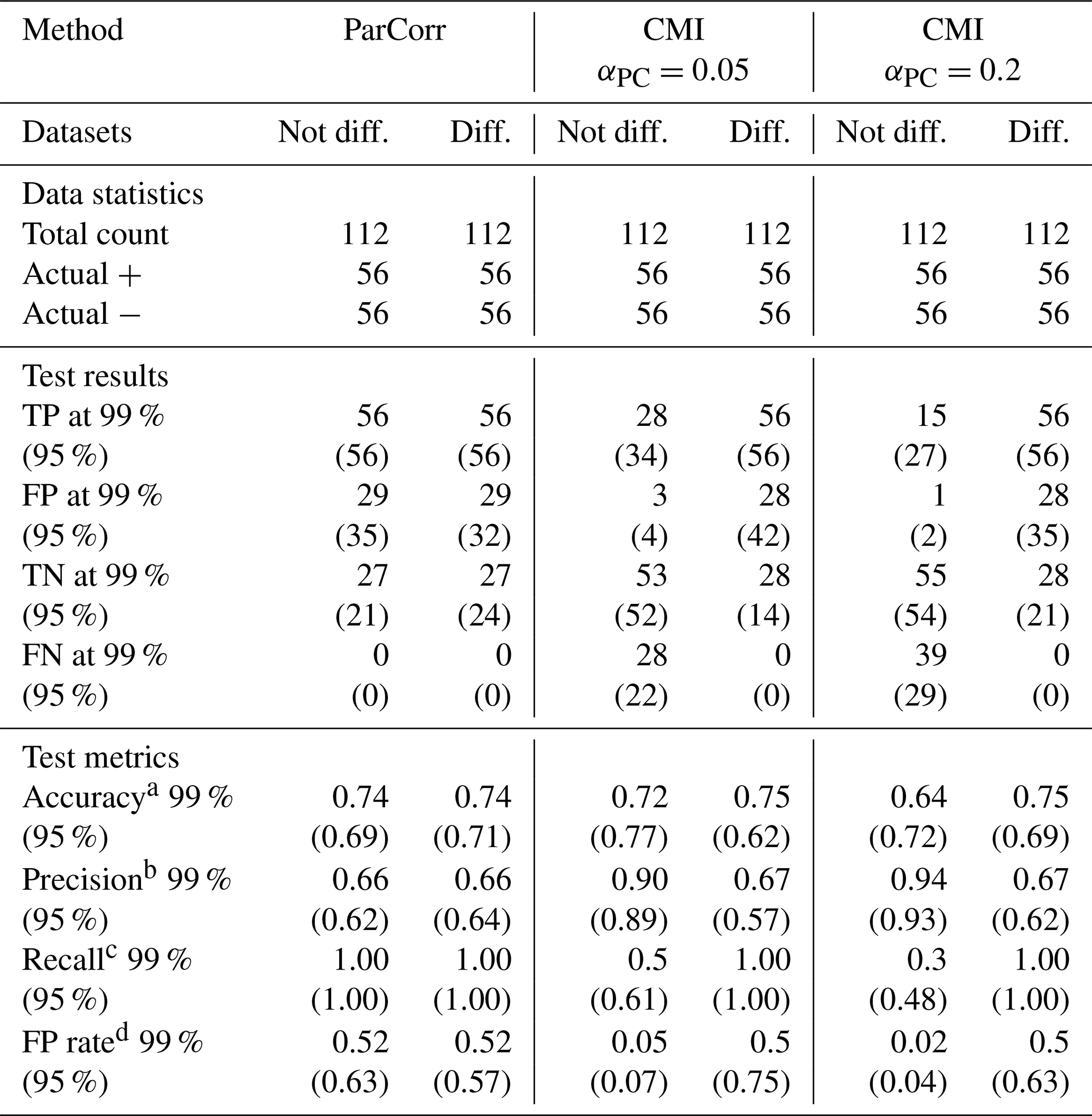
a . b .
c . d .
TP: true positive. FP: false positive. TN: true negative. FN: false negative.
4.1 Bivariate methods
Figure 4 reports the causal graphs for significant pairwise dependencies between first-order differenced time series, for a better screening of time dependencies using bivariate methods (Fig. 3). Detailed time dependencies are also reported in the Supplement (Sect. S2.1, S2.2), allowing us to consider that dmax=5 d is sufficient. The CCF method (Fig. 4a) reports many potential linear causal associations (arrows), in red for positive correlations and in blue for negative ones. Delayed dependencies are represented with curved arrows with the delay d (d) printed in the middle. Contemporaneous dependencies (d=0) are represented by straight links, with no direction since it cannot be inferred from the principle of priority. For CCM (Fig. 4b), significant dependencies are fewer, unsigned as nonlinear, and, therefore, only represented in red. The results and their meaningfulness are appreciated in their dedicated discussion sections.
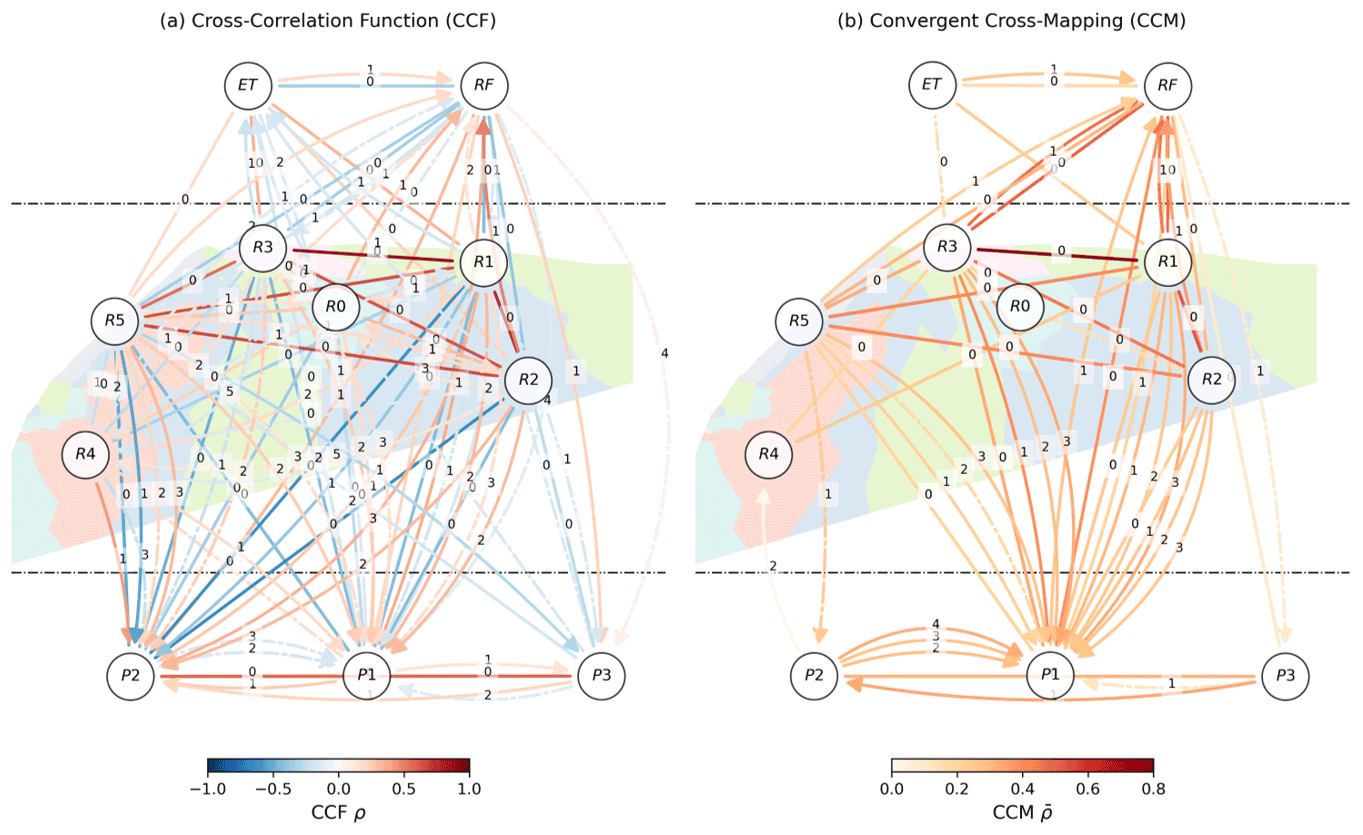
Figure 4Graph of pairwise cross-dependencies: (a) with the linear cross-correlation function (CCF) and (b) with the nonlinear convergent cross-mapping (CCM) method. An undirected line represents contemporaneous dependencies. Delayed dependencies are shown using directed curved arrows. All corresponding delays d are displayed in the middle of its corresponding arrow. The colors of the arrows map to the strengths of dependencies. Solid and dash-dotted arrows represent, respectively, significant dependencies with p value <0.001 and <0.01.
4.2 Multivariate methods
For multivariate methods, we chose to report causal graphs for the raw (non-differenced) data since differencing is theoretically unnecessary and reduced the precision of CMI in the virtual experiment (Table 3). Hence, Fig. 5 shows linear conditional dependencies (ParCorr) obtained from the raw time series for the full dataset (all data, Fig. 5a) and considering the discharge series one by one (P1, P2, and P3, Fig. 5b to d). The P1, P2, and P3 datasets allow the analysis to be performed over larger time domains (Fig. 1c). Except for R4, the dominant relationships between resistivity and meteorological variables are maintained between the graphs, demonstrating stability in the ParCorr results despite differences in the considered time domain.
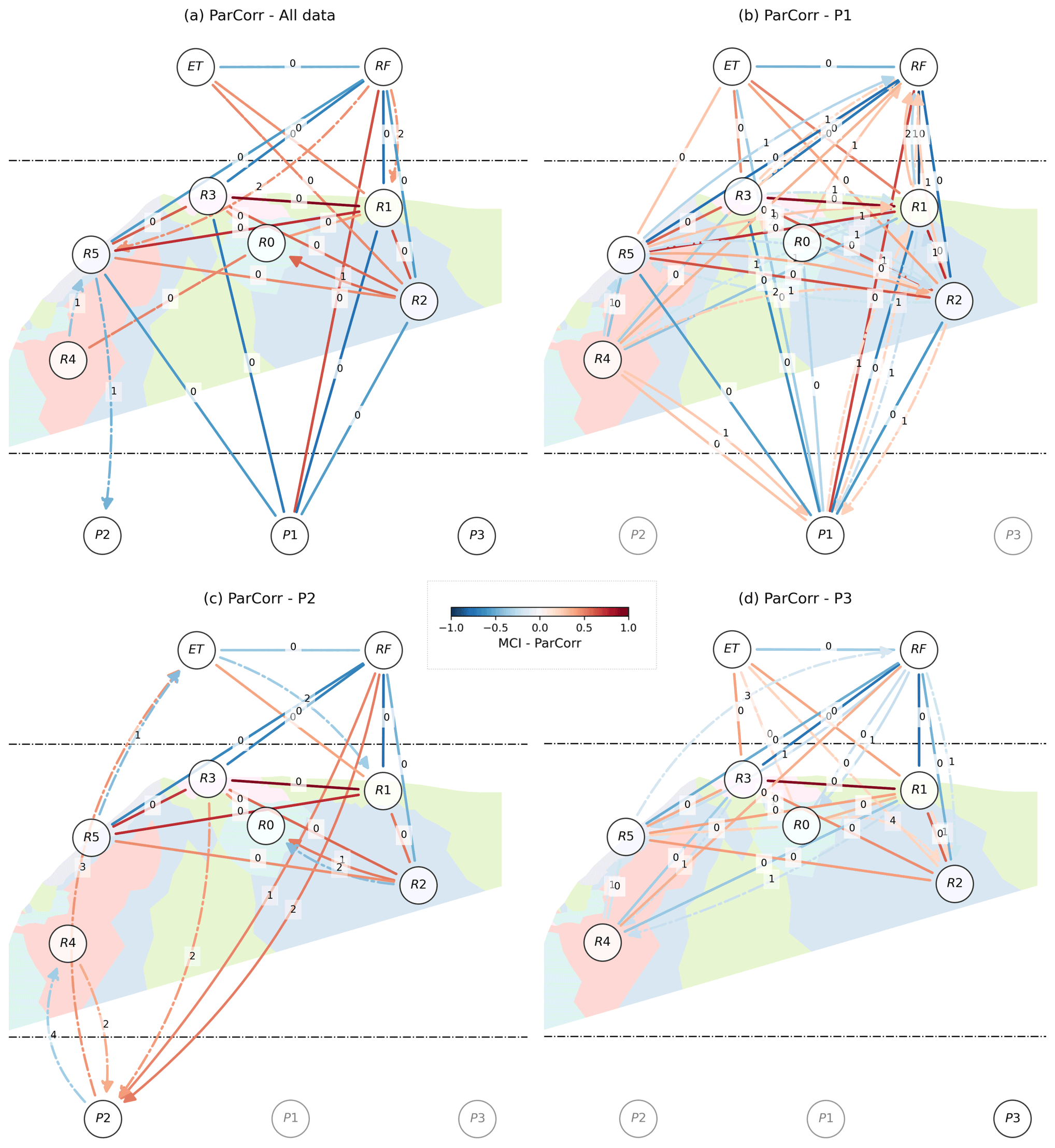
Figure 5Graph of ParCorr cross-dependencies: considering (a) all data or one unique discharge series (b) P1, (c) P2, or (d) P3. An undirected line represents contemporaneous dependencies. Delayed dependencies are shown using directed curved arrows. All corresponding delays d are displayed in the middle of its corresponding arrow. The colors of the arrows map to the strength of dependencies. Solid and dash-dotted arrows represent, respectively, significant dependencies with p value <0.001 and <0.01. For each graph, the size of the overlapping time domain between the variables changes as follows: 48 d (a), 184 d (b), 62 d (c), and 218 d (d).
Regarding PCMCI–CMI, we found unstable results on all datasets: all data, P1, P2, and P3 (see Sect. S2.3). The causal graphs varied substantially when we repeated the analysis with the same parameters due to the stochastic nature of the independence test (Runge, 2018b). Consequently, we developed a sensitivity analysis by varying the hyperparameters of the method, hoping to isolate more stable configurations (Sect. S2.3). Whatever the configuration, the results remained unstable. Consequently, to achieve a causal representation of the system with the nonlinear multivariate method, we had to adopt another logic, that of the consensus brought by the set of models from the sensitivity analysis. We considered all simulations done for the sensitivity analysis to be an ensemble of models rendering each a causal graph. Figure 6 reports the links achieving majority (50 % considering a p value of 0.05) among the ensemble of causal graphs from the sensitivity analysis.
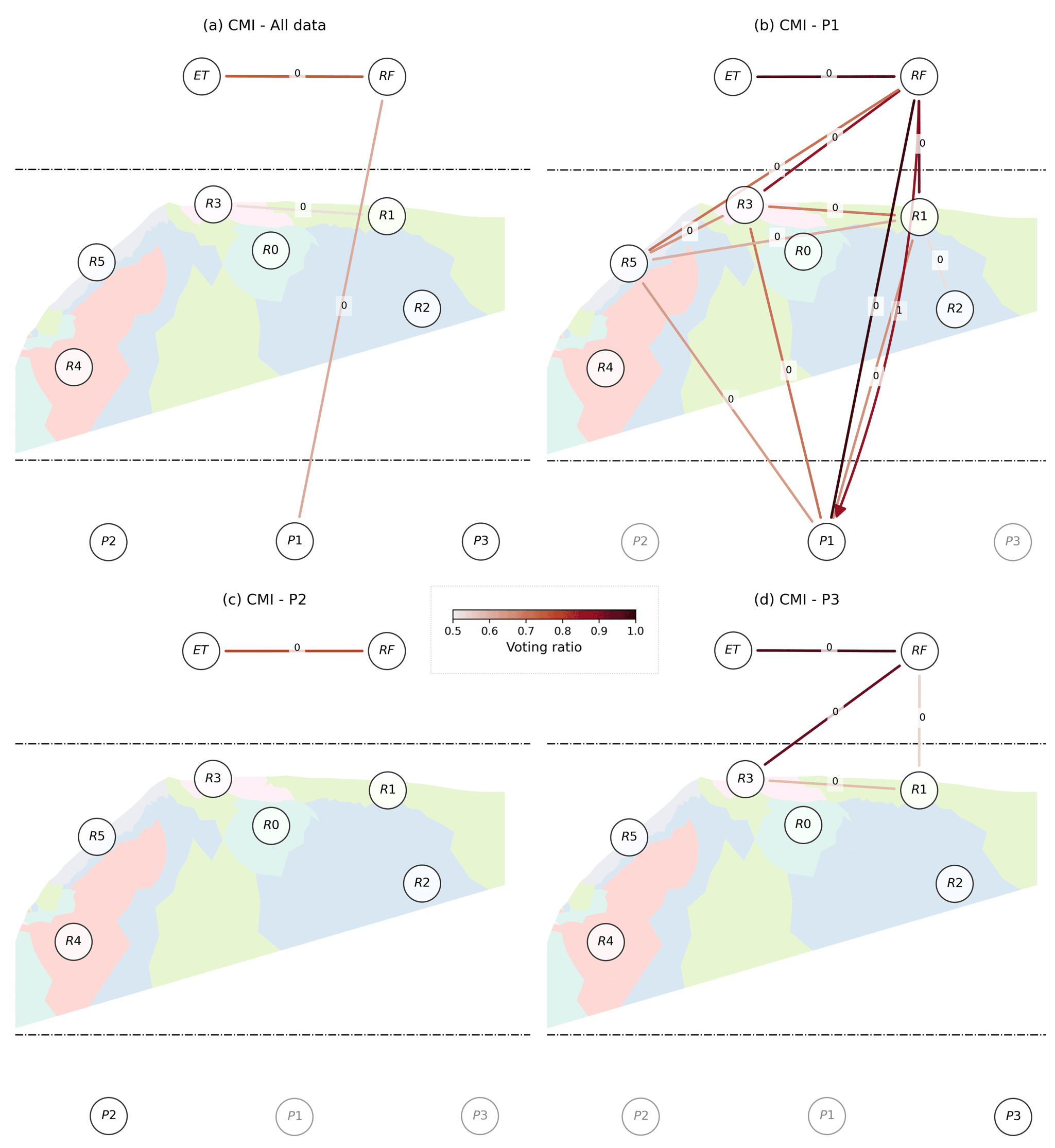
Figure 6Consensual graph of CMI cross-dependencies obtained from the ensemble of simulations performed in the sensitivity analysis, considering (a) all data or one unique discharge series (b) P1, (c) P2, or (d) P3. An undirected line represents the contemporaneous dependencies. Delayed dependencies are shown using directed curved arrows. All corresponding delays d are displayed in the middle of its corresponding arrow. The links displayed are those reaching the majority (50 %) for all causal graphs where the connections are established with a p value of significance at 0.05. The colors of the arrows map to the strength of the voting ratio. For each graph, the size of the overlapping time domain between the variables changes as follows: 48 d (a), 184 d (b), 62 d (c), and 218 d (d).
5.1 CIM-specific discussion
5.1.1 CCF
The CCF results for the real case, on the differenced data, show a dubiously high number of significant connections; we interpret those as an indication that the method does not only reveal effective hydrological connections and reflects the complexity of inferring connectivity from CIMs with strongly correlated, synchronous series forced by common drivers. As a result, statistical dependencies, or functional connections, are ubiquitous. A corollary would be that one could commonly build a point-to-point model based on two time series and their statistical dependencies (functional connections) in hydrology. Somehow, it explains why hydrological systems may be modeled with simple functional lumped model or linear transfer functions (Dooge, 1973). However, when effective connections matter, e.g., to predict the spread of a pollutant, it might become problematic. Similarly, Rinderer et al. (2018) reported many connections with the CCF method and bivariate Granger causality. Our primary explanation is that CCF on differenced data, i.e., with seasonality roughly removed, does not account for the common forcing by rainfall, evapotranspiration, or residual harmonic signals. This failure leads to dependencies despite the absence of causal links or effective connections (as in Fig. 3a), and the system's variables remain highly correlated and synchronized.
Besides, we see that our results contain many false positives reasonably identified from the sign of the dependencies (Fig. 4a). The fact that linear methods report signed dependencies makes it easier to interpret the results and potential false positives. For instance, positive relationships between resistivity and drip discharge are unexpected if water transfers from low-resistivity areas to the drip outlets. Often, positive relationships, e.g., R5 → P2 with , follow negative ones that are more interpretable as a transfer (e.g., R5 → P2 with ). This pattern is rather a phasing artifact captured by CCF interpretable as “after the rain, the good weather”, and vice versa. In general, we observe strong linear dependencies between resistivity series (except R4, the clayey limestone), which may be a problem for PCMCI–CMI (see Sect. 5.1.4). Some links are more intriguing and are hardly interpreted as a causal relationship, e.g., R5 causing RF.
From this latter observation, we recall that dependencies can appear by chance, in particular if the series are short, hence the importance of significance tests. As suggested in Rinderer et al. (2018), we could have further controlled the number of links by considering lower p values, but these were already as low as 0.001, or by comparing the dependencies obtained with those obtained with surrogates (Ebisuzaki, 1997). Surrogates are random substitutes for the original data that share statistical or dynamic properties with the original data, for example, auto-correlation patterns (Schreiber and Schmitz, 2000). In our opinion, these approaches are convenient for ruling out many connections that prevent us from focusing on the most significant ones. They will, however, not overcome the method drawback that is imputed to its design. As a bivariate method, CCF may fail to retrieve effective connections due to confounding factors (Runge et al., 2019a, and Sect. 3.2).
Though clearly not perfect, CCF is simple, linearly interpretable, and widespread or popular. Considering that other CIMs carry their own imperfection, we do not discourage using CCF while knowing its limitations, testing for linearity, removing harmonics (or the use of suitable surrogates' comparisons), or confounding factors using either a statistical or physical model. Manual handling of confounding factors is close to assessing connectivity/causality in a multivariate framework, although not automated but supervised by our knowledge and expertise. Here, we only removed the seasonal signal by differencing, which is not sufficient and results in many dependencies.
5.1.2 CCM
CCM results present fewer connections (Fig. 4b), with many connections pointing from RF or resistivity series (except for R4, the clayey limestone) to P1. In particular, this result is encouraging as we expect a fast preferential flow and effective connection between the surface and P1 (Poulain et al., 2018, and Fig. 1). Still, even when applied to deterministic time series (Runge et al., 2019a), for a system not subject to synchrony (Sugihara et al., 2012, 2017), or, in such cases, by using the time-delayed approach of Ye et al. (2015), CCM can be deceptive because it cannot deal with confounding factors, by design, as a bivariate method. Our result in the synthetic experiment tends to confirm this (Fig. 3b). CCM identifies sustained significant dependencies with the non-differenced data imputed to slow seasonal variations. As for CCF, some of these dependencies may have been ruled out if we had considered surrogate significance testing with a surrogate model that accounts for seasonality (as seen in Nes et al., 2015; Huffaker et al., 2018; Medina et al., 2019). However, on the differenced data removing most of the seasonal signal, CCM captures significant time dependencies at delays reflecting the response time of the reservoirs and not effective connections since they are disconnected. Besides, for the real experiment (Fig. 4b), we found dependencies between drip discharge data (e.g., P2 and P1), which cannot be interpreted as effective connections, since they represent different outlets, similarly to the virtual experiment. In parallel, Ombadi et al. (2020) reported a high false-positive rate while using the original CCM approach (Sugihara et al., 2012), whatever the sample length, explained by CCM's inability to deal with confounding and synchrony.
In addition, noise is expected to reduce both the CCM's true- and false-positive rates, i.e., the general mapping skills (see Ombadi et al., 2020). Regarding our experiment as well, although hidden in the interquartile range shown in Fig. 3b, we found that higher noise levels led to lower . Theoretically, however, this decrease in performance might not be systematic. It may, in some cases, depend on the auto-correlated nature of noise and deterministic signals, the sample length, and the size of a Theiler window (Theiler, 1986). In general, we consider the idea of CCM being restricted to strictly deterministic systems (Runge et al., 2019a) to be overly conservative, potentially misleading, and impractical for real case studies. The theory does not impose anything on the practitioners, but it raises awareness of potential problems if the assumptions are not tested or violated, which is why it deserves careful considerations (further developed in Kantz and Schreiber, 2003; Sivakumar, 2017; Huffaker et al., 2018).
Currently, we consider CCM to be best suited to testing whether or not there is a functional connection between two points, similarly to CCF but considering nonlinear dependencies. Therefore, our recommendations align with those of CCF. However, if CCM has better predictive capabilities than CCF, it can be concluded that the dependency is nonlinear.
5.1.3 PCMCI: ParCorr
ParCorr is linearly interpretable and computationally efficient. As with CCM, the ParCorr results for the real experiment (Fig. 5) seem promising because they generally favor the expected preferential flow and effective connection between the surface and P1 (Poulain et al., 2018, and Fig. 1). ParCorr did not experience any stability problem, first, because ParCorr always provides the same results for the same dataset. Secondly, we deemed the most significant connections to remain between the results from the dataset variations that we tested (Fig. 5a–d). Although there are a few differences between the links that are evaluated in the four variations, these are often related to relationships of lesser significance or magnitude. Some of them are alarming, such as R5 → RF at lag d=1 in Fig. 5b or d=3 in Fig. 5d. They are even more alarming because the whole causal graph can be affected by conditioning on an irrelevant variable (Eq. 2).
Based on the results of the synthetic experiment (Fig. 3 and Table 3), PCMCI–ParCorr, or its variant multivariate GC, may suffer from a relatively high false-positive rate (>50 % in Table 3), most likely due to the inability to deal with direct nonlinear dependencies. Similarly, Ombadi et al. (2020) reported a high false-positive rate for GC in their synthetic experiment, although below CCM's one. A high rate was also observed in Rinderer et al. (2018), although using bivariate GC. Accordingly, claiming an effective hydrological connection based on PCMCI–ParCorr requires caution because of the high false-positive rate reported here and in the literature. We consider that its applications would require deeper testing to ensure that a multivariate linear model fits the data.
5.1.4 PCMCI: CMI
The result of the virtual experiment (Fig. 3 and Table 3) confirmed our general expectation that a multivariate nonlinear method is best suited for assessing effective connectivity. PCMCI–CMI had the lowest false-positive rate (Table 3), which is particularly desired given the confounding problem in hydrological systems. However, it had a low recall relative to other approaches, meaning that the results contain false negatives. Ombadi et al. (2020) also reported a relatively low false-positive rate using different methods, PC (Spirtes and Glymour, 1991) and the bivariate conditional TE method (Schreiber, 2000). Still, according to Runge et al. (2019b), PCMCI–CMI is supposed to perform better than PC thanks to its sequential procedure and TE by being multivariate and accounting for confounding effects.
In the real case study, PCMCI–CMI was found to be unstable, providing different results across consecutive runs (see Figs. S5 and S6). Two main reasons might explain this instability. First, PCMCI conditions dependencies on the parents (Eq. 2) and, therefore, builds a dataset containing the initial variables and their delayed versions up to 2dmax. The overlapping time domain over which all variables and delays are defined is small (see Fig. 1). It covers only 48 up to 218 time stamps (P3). Ruddell and Kumar (2009) reported that 500 to 1000 samples are generally sufficient to obtain a qualitatively robust estimate of the TE, estimated using a binning approach. The nearest-neighbor approach that we used (Runge, 2018b) is more suited for short datasets. However, we found that our final sample sizes, accounting for missing data, are lower and the dimensionality is potentially higher, though variable and depending on the size of the parents' sets (Eq. 2), than those tested in the evaluation of the CMI estimator (Runge, 2018b). This could be the main reason for the instability. In addition, we applied our analysis to highly correlated data from a smooth inverted electrical resistivity model (Fig. 4a). PCMCI–CMI encountered highly interdependent anomalies regarding resistivity (reported in Figs. S5 and S6). We suspect that these anomalies may be related to a violation of the faithfulness hypothesis (Runge, 2018a). PCMCI–CMI may fail because the resistivity series (R1 to R6) are overly deterministically related while accounting for nonlinear dependencies, i.e., without a sufficient stochastic variability. This complementary reason for the instability is further illustrated and detailed in the Supplement (Sect. S2.3).
For short datasets, or with unevenly distributed missing values, we consider that building a consensual graph from multiple runs is a good strategy as our results suggested a fast preferential flow in the case of P1 only (Fig. 6a and b), as expected (Poulain et al., 2018, and Fig. 1). This is, however, computationally expensive. Reducing the number of variables involved in the analysis is another option. It reduces the dimensionality and limits the reduction of the overlapping time domain due to missing values. Considering a bivariate and nonlinear conditional case (i.e., TE), the low false-positive rate obtained by Ombadi et al. (2020) is encouraging in that regard. Besides, regarding multivariate approaches, Rinderer et al. (2018) performed the conditioning on the main confounding variables, i.e., effective precipitation, only. This strategy would deserve further consideration, since it makes the study of effective connectivity from multivariate CIMs between two points in the system a systematic and potentially efficient “three-body problem” representation.
We generally consider that multivariate nonlinear CIMs are preferred to assess effective connectivity based on the theoretical background and the results obtained from our synthetic and real experiments. Still, PCMCI–CMI may miss effective connections because of its low recall, evidenced by the virtual case (Table 3) and the low number of arrows reported in our consensual graph (Fig. 6). In addition, other assumptions may be violated (Runge, 2018a). In particular, for a real case study, one cannot test the hypothesis of causal sufficiency; that is, all common drivers should be included in the analysis. In short, we consider causal sufficiency to be challenging to test and conceptualize since hydrological variables can also be represented in a spatially explicit manner in a high-dimensional continuum. CIMs go hand in hand with a dimension reduction task like ours (Delforge et al., 2020c). In the end, there remain conceptual uncertainties and a risk that these CIMs may provide relationships or connections that are spurious and not effective.
5.2 Further limitations, recommendations, and perspectives
For our comparative study, we limited ourselves to specific methods and set aside some of their hypotheses to focus on fewer relevant elements for potential CIMs' users in hydrology. More details can be found regarding the underlying frameworks of the newly introduced CIMs, for CCM and/or chaos theory (Kantz and Schreiber, 2003; Sugihara et al., 2012; Sivakumar, 2017; Huffaker et al., 2018), the PCMCI framework (Runge, 2018a; Goodwell et al., 2020), or both (Runge et al., 2019a). In particular, we assumed but did not discuss stationarity and its various definitions depending on the framework. We did not test the significance of our results using a surrogate data test, which stands as a common practice (e.g., Schreiber and Schmitz, 2000; Huffaker et al., 2018). We did not address the impact of noise quantitatively (see Ombadi et al., 2020, for that matter). Also, we hypothesized sustained interactions between variables and did not discuss dynamic intermittency, which could be explicitly visible, such as zero values in rainfall time series (Sivakumar, 2017), or hidden and imputed to threshold effects (Blöschl and Zehe, 2005). Arguably, hydrological connectivity is highly dynamic and potentially intermittent, with some portion of the hydrological system getting connected and disconnected depending on its state (Bracken et al., 2013). To explore dynamic intermittency, applying the CIMs to hydrograph segments (e.g., high or low flows; see also Delforge et al., 2020a) or for different seasons (e.g., (Ombadi et al., 2020)) gives two potential options provided that the sample size requirements are met.
Besides, the selected CIMs operate on the time domain, limiting us to studying close temporal connections. However, hydrological connections and processes can be spread over much longer timescales. This further questions our tacit assumption of causal sufficiency. Accordingly, studying methods that operate on the frequency domain or that couple the frequency domain with the time domain may deserve particular interest (e.g., Granger, 1969; Molini et al., 2010; Rinderer et al., 2018).
The PCMCI algorithm is still being actively developed. A more recent implementation of PCMCI is now available in the new version of the Tigramite Python package (v4.2), with refined default parameters and improved computational performance. In particular, a new algorithm, PCMCI+, deals with contemporaneous links and strong auto-correlation in series, with the promises of stronger recall and a well-controlled false-positive rate (Runge, 2020). Besides auto-correlation, we found that contemporaneous links are numerous and compromise the recovery of causal direction based on the principle of priority. As contemporaneous links may concern hydrological systems at all spatiotemporal scales, we recommend exploring PCMCI+ for future studies. In particular, while using PCMCI–CMI or any CIM rooted in information theory, specific attention should be paid to the issue of small sample size (or temporal gaps from missing values). We did not provide any heuristic values linking robustness and the sample size. Such an indicator is contextually linked to the case study and depends on many elements. From the scope of statistical inference with PCMCI, it depends on the parents' preselection procedure (PC and its parameter αPC), the CMI estimator and its parameters, the number of variables, the maximum causal delay dmax, the nature of the dependencies through their joint probability distributions, or signal/noise characteristics and ratios. From the scope of the hydrological system, it relates to its complexity reflected in the spatiotemporal scale of the hydrological problem, the heterogeneity of its geomorphology (or the patterns of structural connectivity), the nonlinearity of hydrological interactions, and their number and spatial organization. Hence, we instead recommend testing the robustness of the results for each particular case study. Potentially, combining any CIM with virtual models mimicking the dynamic properties of the data while knowing the actual causal graph may help select the right CIM, its related estimator, and adequate parametrization. However, our toy model (Fig. 2) was not meant for that purpose but to evaluate different CIMs with a parsimonious representation of the confounding problem in hydrology.
A final consideration is more epistemological: should hydrological connectivity (or causality) be studied from a purely empirical and single automated perspective, as with CIMs? We remind the reader that all types of methods can contribute to our causal understanding of environmental systems, e.g., dye tracing tests or spatially detailed inverse resistivity models (Bakalowicz, 2005; Watlet et al., 2018b; Poulain et al., 2018). However, the potential sensitivity of CIMs to their assumptions, parameters, or conceptual uncertainties makes them hazardous to use alone, despite their recent noticeable improvements. For this reason, even if PCMCI–CMI appeared to stand out, we recommend comparative studies using several CIMs. Linear CIMs may remain attractive for their intelligibility and computational efficiency. Bivariate methods remain helpful for realizing which functional connections multivariate CIMs exclude. We further consider that CIMs complement other methods beyond time series analysis, e.g., field experiments or physically based approaches, and they could be combined to narrow the range of possible causal representations of the system under study.
Regarding CIMs only, Klemeš (1982) was particularly critical of letting the data speak for themselves. Two avenues are possible and should be kept in mind. As mentioned for CCF in Sect. 5.1.1, we see no issues with applying a bivariate method, with awareness of its limits and appropriate hypothesis testing, in a sequential way, e.g., while removing confounding factors using either a statistical or physically based model. That is a supervised causal inference. Another option is to integrate physical constraints in the causal inference algorithm. Here, we adopted the CIM's philosophy of letting the causal graphs be inferred from the data alone. For PCMCI, we have not prescribed any constraint on the conditioning of variables. However, physically irrelevant parents (Eq. 2) may negatively impact the causal graph. Constraining must be framed to prevent us from forcing CIMs on perceptually biased assumptions about the systems' functioning. In particular, this could be done by reintroducing some physical concerns or spatial dimensions into the analysis. Rinderer et al. (2018) already proposed constraining CIMs with structural connectivity. However, structural connectivity is unknown, hidden, or too complex to be hypothesized for most karst systems (Bakalowicz, 2005; Hartmann et al., 2014). Still, mass balances, energy potentials, or spatial attributes such as distances or flow path lengths, none currently matter in CIMs. The spatial dimension is initially present in Hume's contiguity principle in time and space (Hume, 1748). To Schrödinger, the spatial continuum is also a causal paradigm in physics (Schrödinger, 1954). Then, we recommend research avenues in reconciling CIMs with space and physics in geosciences.
The results highlighted that the nonlinear multivariate method, PCMCI coupled with the conditional mutual information test (PCMCI–CMI), shines by its low false-positive rate relative to the other three methods. Hence, statistical dependencies revealed by PCMCI–CMI are more likely to be effective hydrological connections. This advantage is particularly valuable since hydrological systems present highly interdependent time series (or functional connections), favoring a high false-positive rate. This finding confirms our introduced expectation that multivariate nonlinear CIMs are best suited to inferring effective connectivity while dealing with nonlinear dependencies and confounding factors resulting from seasonality or meteorological forcing. However, PCMCI–CMI has a low recall, i.e., it misses effective connections, and particular attention should be paid to the robustness of the outcome for small sample sizes or temporal gaps in the data, as evidenced in our real case study. Furthermore, PCMCI–CMI relies on challenging hypotheses to test (Runge, 2018a). Given these uncertainties, PCMCI–CMI, like any other CIM, would always present a risk of spurious results. For this reason, we do not discourage the use of other CIMs as well, for a comparison purpose, with awareness of their limits. Alongside other limitations, recommendations, and perspectives, we remind the reader that framing the causality of hydrological systems is not restricted to the use of the strictly empirical CIMs but benefits from the vast panel of scientific investigation techniques (e.g., Bakalowicz, 2005; Bracken et al., 2013). In line with Rinderer et al. (2018), hybrid approaches could be developed by reintroducing the physical aspects of the problem to exclude or control the risk of CIMs' physically irrelevant outcomes.
CCF and the Student's t test are computed using the Scipy Python package (Virtanen et al., 2020; https://doi.org/10.1038/s41592-019-0686-2). The CCM Python implementation is available from Delforge et al. (2020a; https://doi.org/10.1029/2019WR025771). The official R implementation is available from the CRAN repository: https://CRAN.R-project.org/package=rEDM (last access: 22 April 2022; Park et al., 2022). PCMCI and independence tests are implemented within the Tigramite (v.4.1 in this case) Python package: https://jakobrunge.github.io/tigramite/ (last access: 22 April 2022; Runge et al., 2019b, https://doi.org/10.1126/sciadv.aau4996). Evapotranspiration data were obtained from the agrometeorological PAMESEB network for the station of Jemelle: https://agromet.be (last access: 22 April 2022; CRA-W, 2022). All other environmental time series can be obtained from Watlet et al. (2018b; https://doi.org/10.5194/hess-22-1563-2018) and the related repository: https://zenodo.org/record/1158631 (Watlet et al., 2018a). Resistivity-clustered time series can be reconstructed following Delforge et al. (2020c) (https://doi.org/10.1016/j.jappgeo.2020.104203) and the example available from the repository: http://dx.doi.org/10.17632/zh5b88vn78.2 (Delforge et al., 2020b).
The supplement related to this article is available online at: https://doi.org/10.5194/hess-26-2181-2022-supplement.
DD conceptualized the research questions and formulated the ideas and the methodology within the frame of his PhD thesis, supervised by MV and MVC. Together with DD, OdV contributed to the methodology and formal analysis. AW was involved in investigating, collecting, modeling, and curating ERT data. DD wrote the original draft manuscript. All authors have contributed to reviewing and editing the manuscript. All authors have read and agreed to the published version of the manuscript.
At least one of the (co-)authors is a member of the editorial board of Hydrology and Earth System Sciences. The peer-review process was guided by an independent editor, and the authors also have no other competing interests to declare.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We are thankful to Michel Van Ruymbeke, who designed and constructed drip discharge sensors utilized in this study, and to Olivier Kaufmann, who also constructed drip discharge sensors, maintained the underground monitoring system, and conceptualized the time-lapse ERT experiment. The authors would like to thank the four anonymous reviewers whose insightful comments significantly improved the quality of the manuscript. Arnaud Watlet publishes with the permission of the Executive Director, British Geological Survey (UKRI-NERC).
This research has been supported by the “Fonds pour la Formation à la Recherche dans l’Industrie et dans l’Agriculture” (FRIA). Damien Delforge is FRIA grantee of the “Fonds de la Recherche Scientifique” (FNRS). The publication in an open access journal has been supported by the sector of science and technology of UCLouvain.
This paper was edited by Nunzio Romano and reviewed by four anonymous referees.
Akaike, H.: A new look at the statistical model identification, IEEE T. Automat. Contr., 19, 716–723, https://doi.org/10.1109/TAC.1974.1100705, 1974. a
Allen, R. G., Pereira, L. S., Raes, D., and Smith, M.: Crop evapotranspiration: guidelines for computing crop water requirements, no. 56, in: FAO irrigation and drainage paper, Food and Agriculture Organization of the United Nations, Rome, ISBN 92-5-104219-5, 1998. a
Angelini, P.: Correlation and spectral analysis of two hydrogeological systems in Central Italy, Hydrolog. Sci. J., 42, 425–438, https://doi.org/10.1080/02626669709492038, 1997. a
Bailly-Comte, V., Jourde, H., Roesch, A., Pistre, S., and Batiot-Guilhe, C.: Time series analyses for Karst/River interactions assessment: Case of the Coulazou river (southern France), J. Hydrol., 349, 98–114, https://doi.org/10.1016/j.jhydrol.2007.10.028, 2008. a
Bakalowicz, M.: Karst groundwater: a challenge for new resources, Hydrogeol. J., 13, 148–160, https://doi.org/10.1007/s10040-004-0402-9, 2005. a, b, c, d, e
Barnett, L., Barrett, A. B., and Seth, A. K.: Granger Causality and Transfer Entropy Are Equivalent for Gaussian Variables, Phys. Rev. Lett., 103, 238701, https://doi.org/10.1103/PhysRevLett.103.238701, 2009. a
Blöschl, G. and Zehe, E.: On hydrological predictability, Hydrol. Process., 19, 3923–3929, https://doi.org/10.1002/hyp.6075, 2005. a, b
Bracken, L. J., Wainwright, J., Ali, G. A., Tetzlaff, D., Smith, M. W., Reaney, S. M., and Roy, A. G.: Concepts of hydrological connectivity: Research approaches, pathways and future agendas, Earth-Sci. Rev., 119, 17–34, https://doi.org/10.1016/j.earscirev.2013.02.001, 2013. a, b, c
CRA-W: Agrometeorological data for the Jemelle station, Wallonia, https://agromet.be/, last access: 22 April 2022. a
Delforge, D., Muñoz‐Carpena, R., Van Camp, M., and Vanclooster, M.: A Parsimonious Empirical Approach to Streamflow Recession Analysis and Forecasting, Water Resour. Res., 56, e2019WR025771, https://doi.org/10.1029/2019WR025771, 2020a. a, b, c, d, e
Delforge, D., Watlet, A., Kaufmann, O., Van Camp, M., and Vanclooster, M.: “Data for: Time-series clustering approaches for subsurface zonation and hydrofacies detection using a real time-lapse electrical resistivity dataset”, V2, Mendeley Data [data set], https://doi.org/10.17632/zh5b88vn78.2, 2020b. a
Delforge, D., Watlet, A., Kaufmann, O., Van Camp, M., and Vanclooster, M.: Time-series clustering approaches for subsurface zonation and hydrofacies detection using a real time-lapse electrical resistivity dataset, J. Appl. Geophys., 184, 104203, https://doi.org/10.1016/j.jappgeo.2020.104203, 2020c. a, b, c, d, e, f
Dooge, J.: Linear Theory of Hydrologic Systems, Agricultural Research Service, U.S. Department of Agriculture, https://books.google.be/books?id=6acoAAAAYAAJ (last access: 14 April 2022), 1973. a, b, c
Ebisuzaki, W.: A Method to Estimate the Statistical Significance of a Correlation When the Data Are Serially Correlated, J. Climate, 10, 2147–2153, https://doi.org/10.1175/1520-0442(1997)010<2147:AMTETS>2.0.CO;2, 1997. a
Frenzel, S. and Pompe, B.: Partial mutual information for coupling analysis of multivariate time series, Phys. Rev. Lett., 99, 204101, https://doi.org/10.1103/PhysRevLett.99.204101, 2007. a
Friston, K. J.: Functional and Effective Connectivity: A Review, Brain Connectivity, 1, 13–36, https://doi.org/10.1089/brain.2011.0008, 2011. a
Goodwell, A. E., Jiang, P., Ruddell, B. L., and Kumar, P.: Debates—Does Information Theory Provide a New Paradigm for Earth Science? Causality, Interaction, and Feedback, Water Resour. Res., 56, e2019WR024940, https://doi.org/10.1029/2019WR024940, 2020. a, b, c
Granger, C. W. J.: Investigating Causal Relations by Econometric Models and Cross-spectral Methods, Econometrica, 37, 424–438, https://doi.org/10.2307/1912791, 1969. a, b, c
Hartmann, A., Goldscheider, N., Wagener, T., Lange, J., and Weiler, M.: Karst water resources in a changing world: Review of hydrological modeling approaches, Rev. Geophys., 52, 218–242, https://doi.org/10.1002/2013RG000443, 2014. a, b
Huffaker, R., Bittelli, M., and Rosa, R.: Nonlinear Time Series Analysis with R, vol. 1, Oxford University Press, https://doi.org/10.1093/oso/9780198782933.001.0001, 2018. a, b, c, d, e, f, g
Hume, D.: Philosophical Essays Concerning Human Understanding, A. Millar, 1748. a, b
Jiang, P. and Kumar, P.: Using Information Flow for Whole System Understanding From Component Dynamics, Water Resour. Res., 55, 8305–8329, https://doi.org/10.1029/2019WR025820, 2019. a
Jourde, H., Mazzilli, N., Lecoq, N., Arfib, B., and Bertin, D.: KARSTMOD: A Generic Modular Reservoir Model Dedicated to Spring Discharge Modeling and Hydrodynamic Analysis in Karst, in: Hydrogeological and Environmental Investigations in Karst Systems, edited by: Andreo, B., Carrasco, F., Durán, J. J., Jiménez, P., and LaMoreaux, J. W., Springer Berlin Heidelberg, Environmental Earth Sciences, 1, 339–344, https://doi.org/10.1007/978-3-642-17435-3_38, 2015. a
Kadić, A., Denić-Jukić, V., and Jukić, D.: Revealing hydrological relations of adjacent karst springs by partial correlation analysis, Hydrol. Res., 49, 616–633, https://doi.org/10.2166/nh.2017.064, 2018. a
Kantz, H. and Schreiber, T.: Nonlinear Time Series Analysis, Cambridge University Press, 2 edn., https://doi.org/10.1017/CBO9780511755798, 2003. a, b, c
Klemeš, V.: Empirical and causal models in hydrology, in: Scientific Basis of Water-Resource Management, Washinton D.C., http://www.itia.ntua.gr/en/docinfo/1075/ (last access: 14 April 2022), 1982. a
Koutsoyiannis, D.: On the quest for chaotic attractors in hydrological processes, Hydrolog. Sci. J., 51, 1065–1091, https://doi.org/10.1623/hysj.51.6.1065, 2006. a
Labat, D., Ababou, R., and Mangin, A.: Rainfall–runoff relations for karstic springs. Part I: convolution and spectral analyses, J. Hydrol., 238, 123–148, https://doi.org/10.1016/S0022-1694(00)00321-8, 2000. a
Larocque, M., Mangin, A., Razack, M., and Banton, O.: Contribution of correlation and spectral analyses to the regional study of a large karst aquifer (Charente, France), J. Hydrol., 205, 217–231, https://doi.org/10.1016/S0022-1694(97)00155-8, 1998. a
Mathevet, T., Lepiller, M. I., and Mangin, A.: Application of time-series analyses to the hydrological functioning of an Alpine karstic system: the case of Bange-L'Eau-Morte, Hydrol. Earth Syst. Sci., 8, 1051–1064, https://doi.org/10.5194/hess-8-1051-2004, 2004. a
Medina, M., Huffaker, R., Jawitz, J. W., and Muñoz-Carpena, R.: Nonlinear Dynamics in Treatment Wetlands: Identifying Systematic Drivers of Nonequilibrium Outlet Concentrations in Everglades STAs, Water Resour. Res., 55, 11101–11120, https://doi.org/10.1029/2018WR024427, 2019. a, b, c
Meyfroidt, P.: Approaches and terminology for causal analysis in land systems science, Journal of Land Use Science, 11, 501–522, https://doi.org/10.1080/1747423X.2015.1117530, 2016. a
Molini, A., Katul, G. G., and Porporato, A.: Causality across rainfall time scales revealed by continuous wavelet transforms, J. Geophys. Res., 115, D14123, https://doi.org/10.1029/2009JD013016, 2010. a, b
Nes, E. H. v., Scheffer, M., Brovkin, V., Lenton, T. M., Ye, H., Deyle, E., and Sugihara, G.: Causal feedbacks in climate change, Nat. Clim. Change, 5, 445–448, https://doi.org/10.1038/nclimate2568, 2015. a
Ombadi, M., Nguyen, P., Sorooshian, S., and Hsu, K.: Evaluation of Methods for Causal Discovery in Hydrometeorological Systems, Water Resour. Res., 56, e2020WR027251, https://doi.org/10.1029/2020WR027251, 2020. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p
Park, J., Smith, C., Sugihara, G., Deyle, E., Saberski, E., Ye, H., and The Regents of the University of California: rEDM: Empirical Dynamic Modeling ('EDM'), https://CRAN.R-project.org/package=rEDM, last access: 22 April 2022. a
Pearl, J.: Causality: Models, Reasoning, and Inference, Cambridge University Press, Cambridge, 2 edn., https://doi.org/10.1017/CBO9780511803161, 2009. a, b
Poulain, A., Watlet, A., Kaufmann, O., Van Camp, M., Jourde, H., Mazzilli, N., Rochez, G., Deleu, R., Quinif, Y., and Hallet, V.: Assessment of groundwater recharge processes through karst vadose zone by cave percolation monitoring, Hydrol. Process., 32, 2069–2083, https://doi.org/10.1002/hyp.13138, 2018. a, b, c, d, e, f, g, h, i
Reichenbach, H.: The Direction of Time, California library reprint series, University of California Press, https://books.google.be/books?id=f6kNAQAAIAAJ (last access: 14 April 2022), 1956. a, b
Rinderer, M., Ali, G., and Larsen, L. G.: Assessing structural, functional and effective hydrologic connectivity with brain neuroscience methods: State-of-the-art and research directions, Earth-Sci. Rev., 178, 29–47, https://doi.org/10.1016/j.earscirev.2018.01.009, 2018. a, b, c, d, e, f, g, h, i, j, k, l, m, n
Rodriguez‐Iturbe, I., Entekhabi, D., and Bras, R. L.: Nonlinear Dynamics of Soil Moisture at Climate Scales: 1. Stochastic Analysis, Water Resour. Res., 27, 1899–1906, https://doi.org/10.1029/91WR01035, 1991. a
Rousseeuw, P. J.: Silhouettes: A graphical aid to the interpretation and validation of cluster analysis, J. Comput. Appl. Math., 20, 53–65, https://doi.org/10.1016/0377-0427(87)90125-7, 1987. a
Ruddell, B. L. and Kumar, P.: Ecohydrologic process networks: 1. Identification, Water Resour. Res., 45, W03419, https://doi.org/10.1029/2008WR007279, 2009. a, b, c
Runge, J.: Causal network reconstruction from time series: From theoretical assumptions to practical estimation, Chaos: An Interdisciplinary J. Nonlinear Sci., 28, 075310, https://doi.org/10.1063/1.5025050, 2018a. a, b, c, d, e, f
Runge, J.: Conditional independence testing based on a nearest-neighbor estimator of conditional mutual information, in: International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Canary Islands, 9–11 April 2018, edited by: Storkey, A. and Perez-Cruz, F., Proceedings of Machine Learning Research, 84, 938–947, http://proceedings.mlr.press/v84/runge18a.html (last access: 14 April 2022), 2018b. a, b, c, d, e, f
Runge, J.: Discovering contemporaneous and lagged causal relations in autocorrelated nonlinear time series datasets, in: Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI), edited by: Peters, J. and Sontag, D., Proceedings of Machine Learning Research (PMLR), 124, 1388–1397, https://proceedings.mlr.press/v124/runge20a.html (last access: 14 April 2022), 2020. a, b
Runge, J., Bathiany, S., Bollt, E., Camps-Valls, G., Coumou, D., Deyle, E., Glymour, C., Kretschmer, M., Mahecha, M. D., Muñoz-Marí, J., van Nes, E. H., Peters, J., Quax, R., Reichstein, M., Scheffer, M., Schölkopf, B., Spirtes, P., Sugihara, G., Sun, J., Zhang, K., and Zscheischler, J.: Inferring causation from time series in Earth system sciences, Nat. Commun., 10, 2553, https://doi.org/10.1038/s41467-019-10105-3, 2019a. a, b, c, d, e, f, g, h, i, j, k
Runge, J., Nowack, P., Kretschmer, M., Flaxman, S., and Sejdinovic, D.: Detecting and quantifying causal associations in large nonlinear time series datasets, Science Advances, 5, eaau4996, https://doi.org/10.1126/sciadv.aau4996, 2019b (data available at: https://jakobrunge.github.io/tigramite/, last access: 22 April 2022). a, b, c, d, e, f, g, h
Salvucci, G. D., Saleem, J. A., and Kaufmann, R.: Investigating soil moisture feedbacks on precipitation with tests of Granger causality, Adv. Water Resour., 25, 1305–1312, https://doi.org/10.1016/S0309-1708(02)00057-X, 2002. a, b
Schreiber, T.: Measuring Information Transfer, Phys. Rev. Lett., 85, 461–464, https://doi.org/10.1103/PhysRevLett.85.461, 2000. a, b
Schreiber, T. and Schmitz, A.: Surrogate time series, Physica D, 142, 346–382, https://doi.org/10.1016/S0167-2789(00)00043-9, 2000. a, b
Schrödinger, E.: Nature and the Greeks, Shearman lectures, 1948, University Press, https://books.google.be/books?id=H7sAAAAAMAAJ (last access: 14 April 2022), 1954. a
Sendrowski, A. and Passalacqua, P.: Process connectivity in a naturally prograding river delta, Water Resour. Res., 53, 1841–1863, https://doi.org/10.1002/2016WR019768, 2017. a, b
Sivakumar, B.: Chaos in Hydrology, Springer Netherlands, Dordrecht, https://doi.org/10.1007/978-90-481-2552-4, 2017. a, b, c, d
Slater, L. and Binley, A.: Advancing hydrological process understanding from long-term resistivity monitoring systems, WIREs Water, 8, e1513, https://doi.org/10.1002/wat2.1513, 2021. a
Spirtes, P. and Glymour, C.: An Algorithm for Fast Recovery of Sparse Causal Graphs, Soc. Sci. Comput. Rev., 9, 62–72, https://doi.org/10.1177/089443939100900106, 1991. a, b, c, d
Spirtes, P., Glymour, C. N., and Scheines, R.: Causation, prediction, and search, Adaptive computation and machine learning, 2nd edn., MIT Press, Cambridge, Mass, ISBN 0-262-19440-6, 2000. a, b
Sugihara, G. and May, R. M.: Nonlinear forecasting as a way of distinguishing chaos from measurement error in time series, Nature, 344, 734–741, https://doi.org/10.1038/344734a0, 1990. a, b
Sugihara, G., Grenfell, B. T., May, R. M., and Tong, H.: Nonlinear forecasting for the classification of natural time series, Philos. T. Roy. Soc. A, 348, 477–495, https://doi.org/10.1098/rsta.1994.0106, 1994. a
Sugihara, G., May, R., Ye, H., Hsieh, C.-H., Deyle, E., Fogarty, M., and Munch, S.: Detecting Causality in Complex Ecosystems, Science, 338, 496–500, https://doi.org/10.1126/science.1227079, 2012. a, b, c, d, e, f, g, h, i, j
Sugihara, G., Deyle, E. R., and Ye, H.: Reply to Baskerville and Cobey: Misconceptions about causation with synchrony and seasonal drivers, P. Natl. Acad. Sci. USA, 114, E2272–E2274, https://doi.org/10.1073/pnas.1700998114, 2017. a, b
Takens, F.: Detecting strange attractors in turbulence, Lecture Notes in Mathematics, Berlin Springer Verlag, 898, 366–381, https://doi.org/10.1007/BFb0091924, 1981. a
Theiler, J.: Spurious dimension from correlation algorithms applied to limited time-series data, Phys. Rev. A-Gen. Phys., 34, 2427–2432, 1986. a, b, c
Triantafyllou, A., Watlet, A., Le Mouélic, S., Camelbeeck, T., Civet, F., Kaufmann, O., Quinif, Y., and Vandycke, S.: 3-D digital outcrop model for analysis of brittle deformation and lithological mapping (Lorette cave, Belgium), J. Struct. Geol., 120, 55–66, https://doi.org/10.1016/j.jsg.2019.01.001, 2019. a
Tuttle, S. E. and Salvucci, G. D.: Confounding factors in determining causal soil moisture-precipitation feedback, Water Resour. Res., 53, 5531–5544, https://doi.org/10.1002/2016WR019869, 2017. a, b
Vejmelka, M. and Paluš, M.: Inferring the directionality of coupling with conditional mutual information, Phys. Rev. E, 77, 026214, https://doi.org/10.1103/PhysRevE.77.026214, 2008. a
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, I., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., and SciPy 1.0 Contributors: SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python, Nat. Methods, 17, 261–272, https://doi.org/10.1038/s41592-019-0686-2, 2020. a
Wang, Y., Yang, J., Chen, Y., De Maeyer, P., Li, Z., and Duan, W.: Detecting the Causal Effect of Soil Moisture on Precipitation Using Convergent Cross Mapping, Scientific Reports, 8, 12171, https://doi.org/10.1038/s41598-018-30669-2, 2018. a, b, c, d
Watlet, A., Kaufmann, O., Triantafyllou, A., Poulain, A., Chambers, J. E., Meldrum, P. I., Wilkinson, P. B., Hallet, V., Quinif, Y., Van Ruymbeke, M., and Van Camp, M.: Data and results for manuscript “Imaging groundwater infiltration dynamics in karst vadose zone with long-term ERT monitoring”, Version 1, Zenodo [data set], https://doi.org/10.5281/zenodo.1158631, 2018a. a
Watlet, A., Kaufmann, O., Triantafyllou, A., Poulain, A., Chambers, J. E., Meldrum, P. I., Wilkinson, P. B., Hallet, V., Quinif, Y., Van Ruymbeke, M., and Van Camp, M.: Imaging groundwater infiltration dynamics in the karst vadose zone with long-term ERT monitoring, Hydrol. Earth Syst. Sci., 22, 1563–1592, https://doi.org/10.5194/hess-22-1563-2018, 2018b. a, b, c, d, e, f, g, h, i, j
Wiener, N.: The theory of prediction, in: Modern Mathematics for the Engineer, edited by: Beckenbach, E. F., McGraw-Hill, New York, https://books.google.be/books?id=OGe4AAAAIAAJ (last access: 14 April 2022), 1956. a
Ye, H., Deyle, E. R., Gilarranz, L. J., and Sugihara, G.: Distinguishing time-delayed causal interactions using convergent cross mapping, Scientific Reports, 5, 14750, https://doi.org/10.1038/srep14750, 2015. a, b, c, d, e