the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 10 May 2021
| 10 May 2021
Global ecosystem-scale plant hydraulic traits retrieved using model–data fusion
Nataniel M. Holtzman
Alexandra G. Konings
Droughts are expected to become more frequent and severe under climate change, increasing the need for accurate predictions of plant drought response. This response varies substantially, depending on plant properties that regulate water transport and storage within plants, i.e., plant hydraulic traits. It is, therefore, crucial to map plant hydraulic traits at a large scale to better assess drought impacts. Improved understanding of global variations in plant hydraulic traits is also needed for parameterizing the latest generation of land surface models, many of which explicitly simulate plant hydraulic processes for the first time. Here, we use a model–data fusion approach to evaluate the spatial pattern of plant hydraulic traits across the globe. This approach integrates a plant hydraulic model with data sets derived from microwave remote sensing that inform ecosystem-scale plant water regulation. In particular, we use both surface soil moisture and vegetation optical depth (VOD) derived from the X-band Japan Aerospace Exploration Agency (JAXA) Advanced Microwave Scanning Radiometer for Earth Observing System (EOS; collectively AMSR-E). VOD is proportional to vegetation water content and, therefore, closely related to leaf water potential. In addition, evapotranspiration (ET) from the Atmosphere–Land Exchange Inverse (ALEXI) model is also used as a constraint to derive plant hydraulic traits. The derived traits are compared to independent data sources based on ground measurements. Using the K-means clustering method, we build six hydraulic functional types (HFTs) with distinct trait combinations – mathematically tractable alternatives to the common approach of assigning plant hydraulic values based on plant functional types. Using traits averaged by HFTs rather than by plant functional types (PFTs) improves VOD and ET estimation accuracies in the majority of areas across the globe. The use of HFTs and/or plant hydraulic traits derived from model–data fusion in this study will contribute to improved parameterization of plant hydraulics in large-scale models and the prediction of ecosystem drought response.
- Article
(7399 KB) - Full-text XML
-
Supplement
(5874 KB) - BibTeX
- EndNote





Water stress during drought restricts photosynthesis, thus weakening the strength of the terrestrial carbon sink (Ma et al., 2012; Wolf et al., 2016; Konings et al., 2017) and possibly causing plant mortality under severe conditions (McDowell et al., 2016; Adams et al., 2017; Choat et al., 2018). The plant response to water stress also directly controls regional water resources and drought propagation by modulating water flux and energy partitioning between the land surface and the atmosphere (Goulden and Bales, 2014; Manoli et al., 2016; Anderegg et al., 2019). However, how plants regulate water, carbon, and energy fluxes and plant mortality under drought could vary considerably depending on plant properties, particularly plant hydraulic traits (Sack et al., 2016; Hartmann et al., 2018; McDowell et al., 2019). Understanding this variation is therefore crucial for the accurate prediction of ecosystem dynamics under changing climate.
Plant hydraulic traits at both stem (e.g., ψ50,x; the xylem water potential under 50 % loss of xylem conductivity) and stomatal (e.g, g1; the sensitivity parameter of stomatal conductance to vapor pressure deficit) levels control plant water uptake and the extent of stomatal closure under water stress (Martin-StPaul et al., 2017; Feng et al., 2017; Meinzer et al., 2017; Anderegg et al., 2017). Distinct hydraulic traits across species and plant communities define hydraulic strategies, which lead to different responses of leaf water potential and gas exchange during drought (Matheny et al., 2017; Barros et al., 2019). Plant hydraulic traits play critical roles in predicting stomatal response to stress (Sperry et al., 2017; Liu et al., 2020a), plant water storage (Huang et al., 2017), leaf desiccation (Blackman et al., 2019), and drought-driven tree mortality risk (Anderegg et al., 2016; Powell et al., 2017; Liu et al., 2017; De Kauwe et al., 2020). As a result of their effect on the surface energy balance, plant hydraulic traits also impact the magnitude of land–atmosphere feedbacks (Anderegg et al., 2019). In dry tropical forests, leaf water potential – which is directly influenced by hydraulic traits – has also been shown to affect leaf phenology (Xu et al., 2016). As a result, it has been increasingly recognized that plant hydraulic traits are important for mediating ecosystem drought response and hydroclimatic feedbacks at regional to global scales (Choat et al., 2012; Anderegg, 2015; Choat et al., 2018; Hartmann et al., 2018).
Understanding how plant hydraulic traits modulate large-scale drought responses requires mapping these traits. At large scales, plant traits are often parameterized based on plant functional types (PFTs), such as evergreen needleleaf forests, evergreen broadleaf forests, deciduous broadleaf forests, mixed forests, shrublands, grasslands, and croplands. However, plant hydraulic traits can vary as much across PFTs as within them (Anderegg, 2015; Konings and Gentine, 2017). Finding alternative ways to scale up in situ measurements using a bottom-up approach is challenging because the spatial coverage of such measurements is often limited and biased towards temperate regions. Furthermore, plant hydraulic traits are highly variable within species (Anderegg, 2015) and even between different components of a single plant and across vertical gradients within individual trees (Johnson et al., 2016). Alternatively, because microwave remote sensing observations of vegetation optical depth (VOD) are sensitive to leaf water potential (Momen et al., 2017; Konings et al., 2019; Holtzman et al., 2021), they may carry implicit information that can be used to disentangle plant hydraulic traits, without the need for explicit upscaling.
Konings and Gentine (2017) first derived plant hydraulic trait variations at large scales by using VOD to calculate the effective ecosystem-scale isohydricity. The isohydricity reflects the response of leaf water potential as soil water potential dries down (Tardieu and Simonneau, 1998). At a stand scale, this plant physiological metric has been used to explain photosynthesis variations (Roman et al., 2015) and drought mortality risk (McDowell et al., 2008) across species. At a global scale, remote-sensing-derived isohydricity patterns have been used to explain photosynthesis sensitivity to vapor pressure deficit and soil moisture in North American grasslands (Konings et al., 2017) and the Amazon (Giardina et al., 2018), to explore the interannual variability in isohydricity (Wu et al., 2020) and to explain the relationship between drought resistance and resilience in gymnosperms (Li et al., 2020). However, because isohydricity is an emergent rather than intrinsic property, it is subject to change with environmental conditions (Hochberg et al., 2018; Novick et al., 2019; Feng et al., 2019; Mrad et al., 2019). Furthermore, isohydricity is influenced by both stomatal and xylem traits (Martínez-Vilalta et al., 2014), which do not always co-vary (Manzoni et al., 2013; Martínez-Vilalta et al., 2014; Bartlett et al., 2016; Martínez-Vilalta and Garcia-Forner, 2017). Estimating intrinsic xylem and stomatal traits separately is, therefore, necessary for better assessment of plant drought response.
From a modeling perspective, as plant hydraulics has been increasingly recognized as a central link connecting hydroclimatic processes and ecosystem ecology (Sack et al., 2016; McDowell et al., 2019), land surface and dynamic vegetation models that explicitly incorporate plant hydraulics are becoming more common (e.g., Xu et al., 2016; Christoffersen et al., 2016; Kennedy et al., 2019; De Kauwe et al., 2020; Eller et al., 2020). However, explicit plant hydraulic representation also requires parameterization choices for the associated plant hydraulic traits. As discussed above, a bottom-up scaling of in situ measurements is likely to miss significant fractions of the spatial variability in these parameters. Alternatively, Liu et al. (2020a) took a top-down inversion approach by integrating a plant hydraulic model with ET data observed at FLUXNET sites. This model–data fusion approach identifies the most likely traits generating modeled dynamics consistent with observations, thus providing effective hydraulic traits that represent ecosystem-scale behaviors. Similar model–data fusion approaches have been previously applied in carbon cycle models (e.g. Wang et al., 2009; Dietze et al., 2013; Quetin et al., 2020). Not surprisingly, many of these applications suggest that integrating informative observations is among the keys to effectively constraining model parameters.
Here, we use the model–data fusion approach to evaluate the global pattern of ecosystem-scale plant hydraulic traits. Specifically, we determined global maps of five plant hydraulic traits (see Sect. 2). To effectively constrain the traits, we use several data sets derived from microwave remote sensing observations, each of which is affected by plant hydraulic behavior. Specifically, we used VOD, surface soil moisture, and ET estimates from a microwave implementation of the Atmosphere–Land Exchange Inverse (ALEXI) framework. The resulting retrieved ecosystem-scale plant hydraulic traits are then compared to available in situ observations. Having derived spatial maps of variations in plant hydraulic traits, we explore whether simple alternatives to PFTs can be built to facilitate parameterizing land surface models. We derive several so-called hydraulic functional types (HFTs) based on the clustering of retrieved hydraulic traits and examine their spatial patterns.
2.1 Plant hydraulics model
For the model underlying the model–data fusion system, we used a soil–plant system model adapted from Liu et al. (2020a) that incorporates plant hydraulics. The soil is characterized by two layers, i.e., a hydraulically active rooting zone extending to the maximum rooting depth, topped by a surface layer with a fixed depth of 5 cm. Soil moisture in both layers is modeled based on the soil water balance, as follows:
where Z1 (=5 cm) and Z2 are the thickness of the two soil layers, and s1 and s2 are the volumetric soil moisture of the two layers. P is the precipitation rate, E is the soil evaporation rate, and J is plant water uptake. The L12 and L23 are vertical fluxes between the two soil layers and out of the rooting zone, respectively. Both are calculated based on Darcy's law. A constant soil moisture below the rooting zone is assumed as the boundary condition for the L23 calculation. The soil evaporation rate E is calculated as the potential evaporation from the Penman equation multiplied by a stress factor of , where n is the soil porosity. The potential evaporation is driven by the fraction of total net radiation that penetrates through the canopy to the ground surface based on Beer's law (Campbell and Norman, 1998). The remaining fraction of total net radiation is absorbed by the leaves and drives transpiration (Eq. 7). Plant water uptake J is determined as the product of the whole-plant conductance (gp) and the water potential gradient between the soil (ψs) and the leaf (ψl), as follows:
where the soil water potential is calculated from s2 based on the empirical soil water retention curve by Clapp and Hornberger (1978).
Above, ψs,sat is the saturated soil water potential, n is the soil porosity, and b0 is the shape parameter. Plant water uptake from the thin surface layer is assumed to be negligible. The whole-plant conductance varies with leaf water potential, following a linear vulnerability curve as follows:
where gp,max is the maximum xylem conductance, and ψ50,x is the water potential at which xylem conductance drops to half of its maximum. A linear vulnerability curve is used because the nonlinearity of the vulnerability curve can hardly be identified using the model–data fusion approach, even at a much finer scale of a flux tower footprint (Liu et al., 2020a). The linearized form here keeps the number of parameters minimal.
The model assumes a single water storage pool in the canopy. The size of this pool is recharged by plant water uptake (J) and reduced by transpiration (T), with a vegetation capacitance parameter C determining the proportionality between that water flux and the corresponding change in plant water potential.
Transpiration is computed using the Penman–Monteith equation.
where Δ is the rate of change of saturated vapor pressure with air temperature, Rnl is the fraction of net radiation absorbed by the leaves, ρa is the air density, cp is the specific heat capacity of air, ga is the aerodynamic conductance, D is the vapor pressure deficit, λ is the latent heat of vaporization, γ is the psychrometric constant, and gs is the stomatal conductance to water vapor per unit ground area. The stomatal conductance is calculated using the Medlyn stomatal conductance model (Medlyn et al., 2011), while omitting cuticular and epidermal losses by assuming zero minimum stomatal conductance.
where a0=1.6 is the relative diffusivity of water vapor with respect to CO2, LAI is the leaf area index, and g1 is the slope parameter, inversely proportional to the square root of marginal water use efficiency (Medlyn et al., 2011; Lin et al., 2015). A is the biochemical demand for CO2 calculated using the photosynthesis model (Farquhar et al., 1980), and ca is the atmospheric CO2 concentration. Photosynthesis is limited by either ribulose-1, 5-bisphosphate (RuBP) regeneration or by the carboxylation rate. Water stress is assumed to restrict photosynthesis under the carboxylation-limited regime through a down-regulated maximum carboxylation rate (Vcmax), following Kennedy et al. (2019) and Fisher et al. (2019).
where ψ50,s is the leaf water potential when Vcmax drops to half of its maximum value under well-watered conditions (Vcmax,w).
The model was driven by climate conditions at a 3 h scale. To temporally integrate the model, a forward Euler method was used for computational efficiency, except for the calculation of plant water uptake, for which Eqs. (2) through (6) were linearized at each time step and then solved analytically to ensure numerical stability. The modeled time series of ET (E+T), surface soil moisture (s1), and VOD were compared with the microwave remote sensing observations as described below.
2.2 Microwave remote sensing constraints
To derive plant hydraulic traits, the model in Sect. 2.1 was constrained by microwave remote sensing products of VOD and surface soil moisture, as well as by remote-sensing-derived ET, all with a spatial resolution of 0.25∘.
2.2.1 VOD
We used VOD and surface soil moisture derived from the Japan Aerospace Exploration Agency (JAXA) Advanced Microwave Scanning Radiometer for Earth Observing System (EOS; collectively AMSR-E) retrieved by the land parameter retrieval model (LPRM; Owe et al., 2008; Vrije Universiteit Amsterdam and NASA GSFC, 2016). This data set is based on observations at X-band frequency (10.7 GHz), which is primarily sensitive to the water content of the upper canopy layers (Frappart et al., 2020). Here, we used an X-band record rather than lower microwave frequencies to reduce errors associated with potential sensitivities of these lower frequencies to xylem water potential, which might deviate from leaf water potential. Data for 2003–2011 were used. Outliers that are more than three scaled median absolute deviations away from the median were filtered out and attributed to high-frequency noise in the retrievals common to VOD data sets (Konings et al., 2015, 2016). A 5 d moving average method was applied to midday and midnight VOD, respectively, to further diminish noise in the raw data. Both ascending (01:30 local time – LT) and descending (13:30 LT) observations were used, to enable them to constrain subdaily variations in plant hydraulic dynamics.
To relate VOD and leaf water potential, we noted that VOD is proportional to vegetation water content (VWC). In turn, VWC is determined by the product of aboveground biomass (AGB) and plant relative water content (RWC).
where β is the scaling parameter depending on the structure and dielectric properties of plants (Kirdiashev et al., 1979). As in Momen et al. (2017), AGB is represented using linearized relationships of LAI and ψl respectively. The relationship between RWC and ψl usually follows a Weibull pressure–volume curve. However, it has been successfully linearized in previous theoretical and observational applications (Manzoni et al., 2014; Momen et al., 2017; Konings and Gentine, 2017). Thus, VOD is modeled as follows:
where a and b are the scaling parameters from LAI to βAGB, and c is the linearized slope of the pressure–volume curve. The a, b, and c parameters vary across pixels and were retrieved as additional inversion parameters as part of the model–data fusion process.
2.2.2 Soil moisture
We also used the associated surface soil moisture retrievals from the LPRM as additional constraints. Instead of performing a direct comparison between modeled and retrieved soil moisture, we followed the widely used approach of assimilating retrieved soil moisture only after matching its cumulative distribution function (cdf) to the modeled soil moisture (Reichle and Koster, 2004; Su et al., 2013; Parrens et al., 2014). Because the magnitudes of both retrieved and modeled soil moisture are highly dependent on the retrieval algorithm and specific model structure (Koster et al., 2009), this cdf-matching approach reduces the effect of bias in either the model or observations on the ability of the soil moisture observations to act as useful constraints. Unlike VOD, surface soil moisture does not have a strong diurnal cycle. Additionally, because the canopy and soil often reach thermal equilibrium at night, AMSR-E retrievals at 13:30 have greater retrieval errors than at 01:30 (Parinussa et al., 2016). Therefore, only 01:30 surface soil moisture was included as a model constraint here.
2.2.3 Evapotranspiration
The model was also constrained by weekly ET during 2003–2011. ET was estimated using the Atmosphere–Land Exchange Inverse (ALEXI) algorithm (Anderson et al., 1997, 2007; Holmes et al., 2018). Most remote-sensing-based ET data sets assume prior values of stomatal parameters (Kalma et al., 2008; Wang and Dickinson, 2012), which would make it circular to retrieve plant traits based on these data sets. By contrast, the ALEXI framework is relatively independent of prior assumptions on vegetation properties. To achieve this independence, ALEXI uses a two-source energy balance method and is constrained to be consistent with the boundary layer evolution (Anderson et al., 2007; Holmes et al., 2018). We further used a version of ALEXI based on microwave-derived land surface temperatures rather than optical ones as in the classic ALEXI implementations. When compared to in situ observations, microwave–ALEXI and optical–ALEXI performed similarly (Holmes et al., 2018), but the microwave-based version has the advantage of having more observations because, unlike optically derived estimates, it is not limited by cloud cover. The 0.25∘ resolution of the microwave–ALEXI product is also more consistent with the other components of our model–data fusion system.
2.3 Model–data fusion
Plant hydraulic traits and several other model parameters controlling plant hydraulic behavior were retrieved using a Markov chain Monte Carlo (MCMC) method, which determined the parameter values that yield model output most consistent with observed constraints. A total of 13 parameters were retrieved, including five plant hydraulic traits (g1, ψ50,s, C, gp,max, and ψ50,x), three scaling parameters relating VOD to ψl (a, b, and c in Eq. 11), two soil properties (including b0 in Eq. 4 and the subsurface boundary condition of soil moisture in the deepest layer), and three uncertainty values, describing the standard deviation of the observational noise of VOD (σVOD), surface soil moisture (σSM), and ET (σET), respectively. An adaptive metropolized independence sampler was used to generate posterior samples (Ji and Schmidler, 2013). This sampling method was designed to facilitate convergence especially for nonlinear models and has been shown to be effective for retrieving plant hydraulic traits at flux tower sites (Liu et al., 2020a). To reduce the dimensionality of the parameter space and facilitate convergence, the MCMC jointly sampled all parameters, except the three scaling parameters of VOD. For these parameters, the optimal values were determined conditional on the rest of the parameters after each sampling step based on least squared error. That is, after each sampling step, the three values were optimized so as to minimize the least-squares difference between observed VOD and the predicted VOD conditional on simulated ψl and the optimized parameter values for a, b, and c.
The MCMC also incorporated prior information about parameter ranges and constraints on their realistic combinations. For ψ50,x, a generalized extreme value distribution was used as the prior for the corresponding PFT. The distribution was fitted using measurements of species belonging to each PFT in the TRY database (Kattge et al., 2011). The corresponding PFT of each species was determined based on the PLANTS database (USDA, NRCS, 2020) and the Encyclopedia of Life (Parr et al., 2014). For PFTs not included in the TRY database, a distribution fitted using measurements for all species was used as the prior (Fig. S1). We also incorporated a physiological constraint from meta-analysis suggesting stomatal conductance is downregulated before substantial xylem embolism occurs (Martin-StPaul et al., 2017; Anderegg et al., 2017), as follows:
The physiological constraint, which was also used in Liu et al. (2020a), avoids unrealistic combinations of parameters that nevertheless match the data. For other parameters, uniform noninformative priors spanning realistic ranges were used (Table S1).
The cost function in the MCMC (i.e., the reverse of the likelihood function multiplied by the prior) determines the estimated posterior distribution of parameters. The likelihood function was calculated by comparing the modeled VOD, surface soil moisture, and ET with the three categories of observations. Observations on rainy (daily cumulative precipitation > 1 cm) or freezing (daily minimum air temperature < 0 ∘C) days were removed. Each of the remaining observations was considered independent, following a Gaussian distribution with a mean of the modeled value and the standard deviation of the corresponding category (i.e., one of σVOD, σSM, and σET). The likelihood of all observations were then combined after reweighting each constraint based on its number of observations. That is, in the following:
where L is likelihood of observed VOD (yv), ET (ye), and surface soil moisture (ys) under given parameters θ (including all the 13 parameters to be retrieved). nv, ne, and ns are the number of valid data of VOD, ET and surface soil moisture, respectively. Due to the unbalanced number of observations among the measurement types, renormalizing the weights in each category based on its number of observations avoids overweighting of semidaily VOD and surface soil moisture over weekly ET observations.
For the global retrievals, pixels classified by MODIS land cover data as wetland, urban area, barren area, snow/ice covered, or tundra dominated were excluded from the analysis. Pixels for which VOD is below 0.15 or above 0.8 were also excluded to remove sparsely vegetated pixels and extremely dense vegetation areas, respectively. The most densely vegetated areas were removed because low microwave transmissivity significantly reduces the accuracy of VOD and soil moisture retrievals there (Kumar et al., 2020), and low VOD pixels were removed to reduce inaccuracies due to ground volume scattering and low vegetation density. For the remaining pixels, parameters were retrieved using observations in 2004 and 2005, during which the El Niño event and the elevated tropical North Atlantic sea surface temperatures induced drought stress in many regions across the globe (Phillips et al., 2009; FAO, 2014). Here, we used only 2 years of observations, rather than the entire period, to reduce the computational load of model–data fusion. The remaining 7 years were used for testing. Separating retrieval and testing periods also helped to (potentially) identify overfitting.
For each pixel, four MCMC chains were used. Each started randomly within the prior parameter ranges, and each generated 50 000 samples. Within- and among-chain convergences were diagnosed by Gelman–Rubin (< 1.2) and Geweke values (< 0.2; Brooks and Gelman, 1998). Across the studied pixels, all parameters converged for 79 % of pixels, while at least half of the parameters converged for 97 % of pixels. The remaining 3 % of pixels that did not converge were removed from the analysis. For each pixel, 200 samples were randomly selected from the chains after step 40 000 as posterior samples of parameters. Ensemble means of VOD, surface soil moisture, and ET modeled using posterior samples were compared to observations during the period 2003–2011. Posterior means of the hydraulic traits in each pixel were used for analysis below.
2.4 Climate forcing and ancillary properties
The model–data fusion system was run at 0.25∘ resolution. Meteorological drivers at this spatial resolution and the 3 h temporal resolution used by the model were derived from the Global Land Data Assimilation System (GLDAS; Rodell et al., 2004; Beaudoing and Rodell, 2020). In particular, GLDAS-derived forcings include net shortwave radiation, air temperature, precipitation, surface atmospheric pressure, specific humidity, and aerodynamic conductance calculated using the ratio between the sensible heat net flux and the difference between air and surface skin temperatures. LAI data from the MODIS (Moderate Resolution Imaging Spectroradiometer) product MCD15A3H v006 (Myneni et al., 2015), with a 500 m resolution, were aggregated to a 0.25∘ scale, using a Google Earth Engine, to be consistent with the GLDAS climatic drivers. Missing data were linearly interpolated, and a Savitzky–Golay filter (Savitzky and Golay, 1964) was applied to diminish high-frequency noise in the LAI time series. To estimate Vcmax,w, a PFT map from the GLDAS land cover map derived from MODIS was used (Fig. S2). The Vcmax,w of each PFT was set as the static PFT-average from Walker et al. (2017) and corrected by temperature, following Medlyn et al. (2002). The maximum rooting depth was obtained from a global map synthesized from in situ observations (Fan et al., 2017). Soil texture from the Harmonized World Soil Database (FAO/IIASA/ISRIC/ISSCAS/JRC, 2012) was used to calculate soil drainage parameters based on empirical relations (Clapp and Hornberger, 1978).
2.5 Analyses
2.5.1 Observing system simulation experiment
To test the capability of the model–data fusion approach to correctly retrieve parameters under the presence of observational noise, we conducted an observing system simulation experiment (OSSE) for 50 pixels. The 50 pixels were randomly distributed across the globe. The OSSE uses synthetic rather than real observations to test data assimilation uncertainty, among other objectives (Arnold and Dey, 1986; Nearing et al., 2012; Errico et al., 2013). At each pixel, the time series of VOD, surface soil moisture, and ET were generated by using the model (Sect. 2.1) with prescribed parameters. To mimic the presence of observational noise in real observational estimates, white noise was then added to the simulated values of VOD, surface soil moisture, and ET. The prescribed standard deviations of noise in VOD, surface soil moisture,, and ET, i.e., 0.05, 0.08, and 0.5 mm d−1, respectively, were chosen to be within the mid-50 % ranges retrieved using real data. The parameters retrieved using the model–data fusion approach were then compared with the prescribed values.
2.5.2 Comparison between derived traits and in situ measurements
Because hydraulic traits are often measured at a single plant or a segment scale that is much smaller than the ecosystem scale used in model–data fusion, and because of the relatively coarse spatial resolution of the remote sensing data used as constraints here, a one-to-one comparison between in situ data and model–data-fusion-derived values is likely to be dominated by representativeness error. Instead, we aggregated both in situ measurements and the traits derived here by PFTs to evaluate whether across-PFT patterns can be captured. Among the most ecologically important and widely measured traits are g1 and ψ50,x, which indicate stomatal marginal water use efficiency and vulnerability to xylem cavitation, respectively. Synthesized data sets of g1 from Lin et al. (2015) and ψ50,x from Kattge et al. (2011), based on in situ measurements covering a variety of species and climate types, were used for comparison. In addition, Trugman et al. (2020) derived a map of tree ψ50,x across the continental United States at a 1∘ resolution, which integrated measurements in the Xylem Functional Traits Database and the US Forest Service Forest Inventory and Analysis (FIA) long-term permanent plot network. This map was used for a pixel-wise comparison with the ψ50,x retrieved here in US areas dominated by forests. To perform this comparison, our model–data-fusion-derived traits were first aggregated from 0.25∘ to the 1∘ resolution of the estimates by Trugman et al. (2020).
2.5.3 Clustering analysis
To understand the global pattern of retrieved plant hydraulic traits, we constructed hydraulic functional types (HFTs) using the K-means clustering method (MacQueen, 1967). This method classifies each pixel to the nearest mean, i.e., the cluster center in the five-dimensional space spanned by the modeled hydraulic traits. To find the optimal number of clusters, we calculated the ratio between the variance within cluster traits across three to 20 clusters. The elbow method was used to derive the optimal number of clusters (Kodinariya and Makwana, 2013). That is, the optimal number of clusters was chosen based on the inflection point (elbow) of the curve relating the above ratio and the number of clusters. The global pattern of these HFTs were examined. To provide insight into whether HFTs could be used as an alternative to PFTs, we evaluated how much the accuracy of estimated VOD and ET would degrade if VOD and ET were modeled using hydraulic traits based on an HFT-based clustering rather than a more typical PFT-based clustering. That is, we calculated the simulated VOD and ET by assigning hydraulic traits as the center values for the HFT present at each pixel, rather than by using the average derived value across each PFT as the PFT-wide value. Several factors differ between this calculation and the potential reduced error from using HFTs in land surface models. For example, land surface models often use subgrid-scale tiling systems that are more complex than the pixel-scale calculations performed here. The calculation here also did not account for uncertainties in determining the optimal PFT-wide or HFT-wide values or, indeed, the mapping of PFTs or HFTs to begin with (Poulter et al., 2011; Hartley et al., 2017). Nevertheless, this analysis provides first-order insight into the capacity of HFT-based parameterization to improve over a PFT-based approach.
3.1 Parameter retrieval in the OSSE
Across the 50 pixels tested in the OSSE, the prescribed traits can be recovered using model–data fusion, with high Pearson correlations between the assumed and retrieved values (Fig. 1). The hydraulic traits of g1, ψ50,x, and gp,max, along with the soil parameters (b0 in Eq. 4 and the boundary condition bc), are accurately recovered (r≥0.77). The C and the ratio between ψ50,s and ψ50,x showed larger discrepancies and greater uncertainty ranges due to the presence of (simulated) observational noise. For all parameters, the residual errors are randomly distributed rather than scaling the true parameter value. Overall, the OSSE supports the effectiveness of the model–data fusion approach.
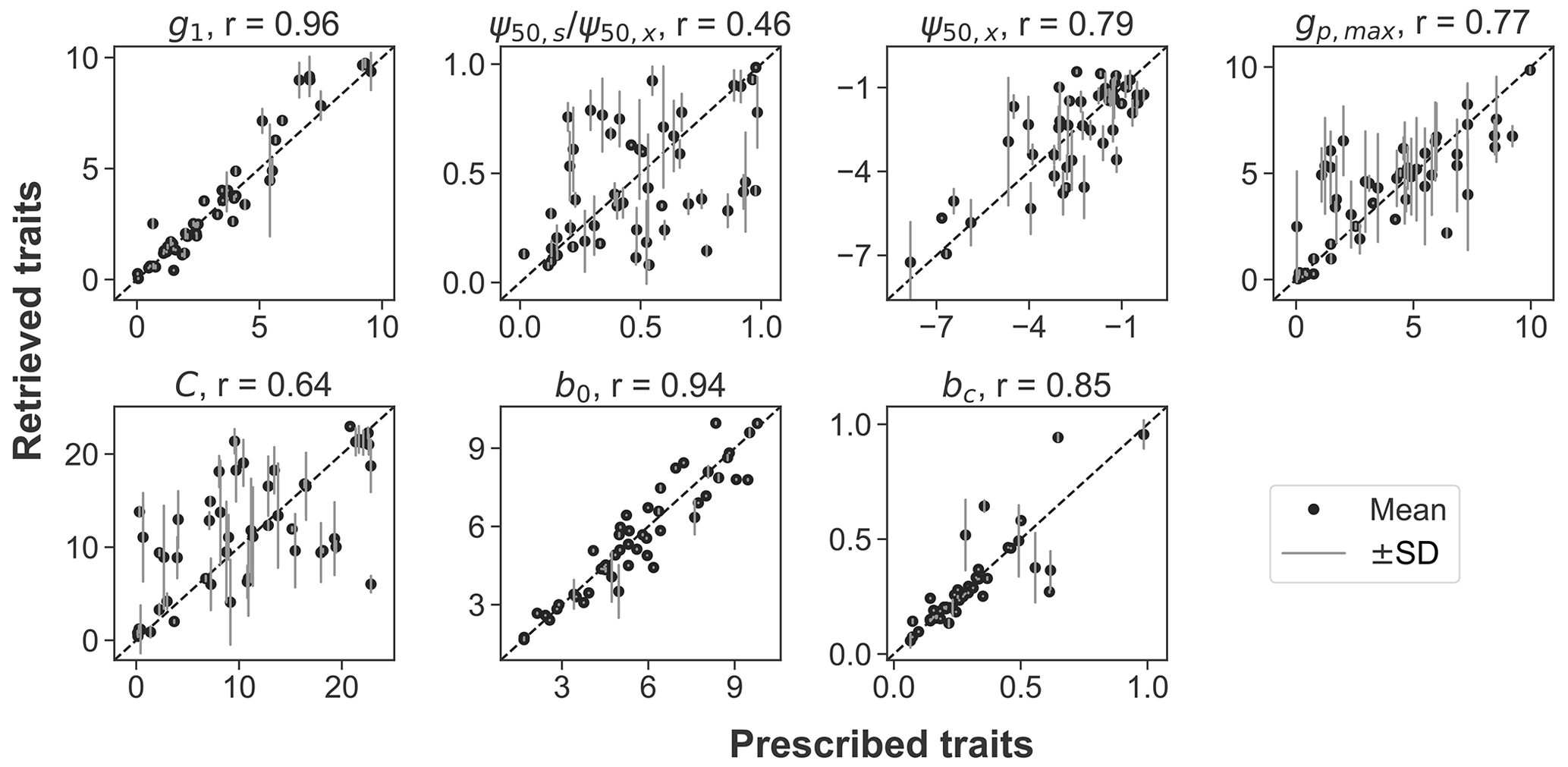
Figure 1Comparison between the prescribed and retrieved plant hydraulic traits (g1, , ψ50,x, gp,max, and C) and soil properties (b0 and bc) in the observing system simulation experiment. The black dots and gray lines represent the mean and range of 1 standard deviation of the retrieved posterior distributions. The diagonal dashed line is the 1:1 line. Pearson correlation coefficient (r) between the prescribed and retrieved parameters is noted.
3.2 Accuracy of modeled VOD, ET, and surface soil moisture
Over the entire study period of 2003–2011, the coefficient of determination (R2) between estimated and observed VOD has a median of 0.38 and a mid-50 % range of (0.22,0.55) across the globe (Fig. 2a). The estimated VOD is highly correlated with observations in northern and southwestern Australia, northeastern China, India, central Europe, Africa, and eastern South America. The high VOD accuracy in these areas is likely partially a result of the large contribution of biomass to VOD due to strong biomass seasonality in these areas (Liu et al., 2011; Momen et al., 2017). Notably, however, even in areas where VOD has been shown to be less correlated with LAI, including central Australia, central Asia, southern Africa, and the western US (Momen et al., 2017), the estimated VOD accounting for the signature of leaf water potential is also able to capture observed VOD. The model also accurately estimates observed ET with a median R2 of 0.60 and a mid-50 % range of (0.36,0.78; Fig. 2b). Unlike in the majority of the world, the R2 of ET is relatively lower in central Australia, southern South America, and the southwestern US, where highly heterogeneous vegetation cover such as savannas and coexisting grass and shrubs within a pixel could undermine model accuracy. The median and mid-50 % range of surface soil moisture R2 is 0.22 and (0.08,0.42), respectively. Modeled surface soil moisture is less accurate in croplands (likely due to irrigation) and in boreal regions, eastern China, Europe, and the mid-western and eastern US. These regions largely overlap with those where the observed soil moisture from AMSR-E is weakly correlated with the reanalysis product of ERA-Interim that integrates ground observations (Parinussa et al., 2015), suggesting greater uncertainties of surface soil moisture from AMSR-E compared to other regions. The overall accuracy of estimated VOD, ET, and surface soil moisture both within (Fig. S3) and outside (Fig. 2) the training period 2004–2005 suggest that the model and the derived traits effectively represent plant hydraulic dynamics.
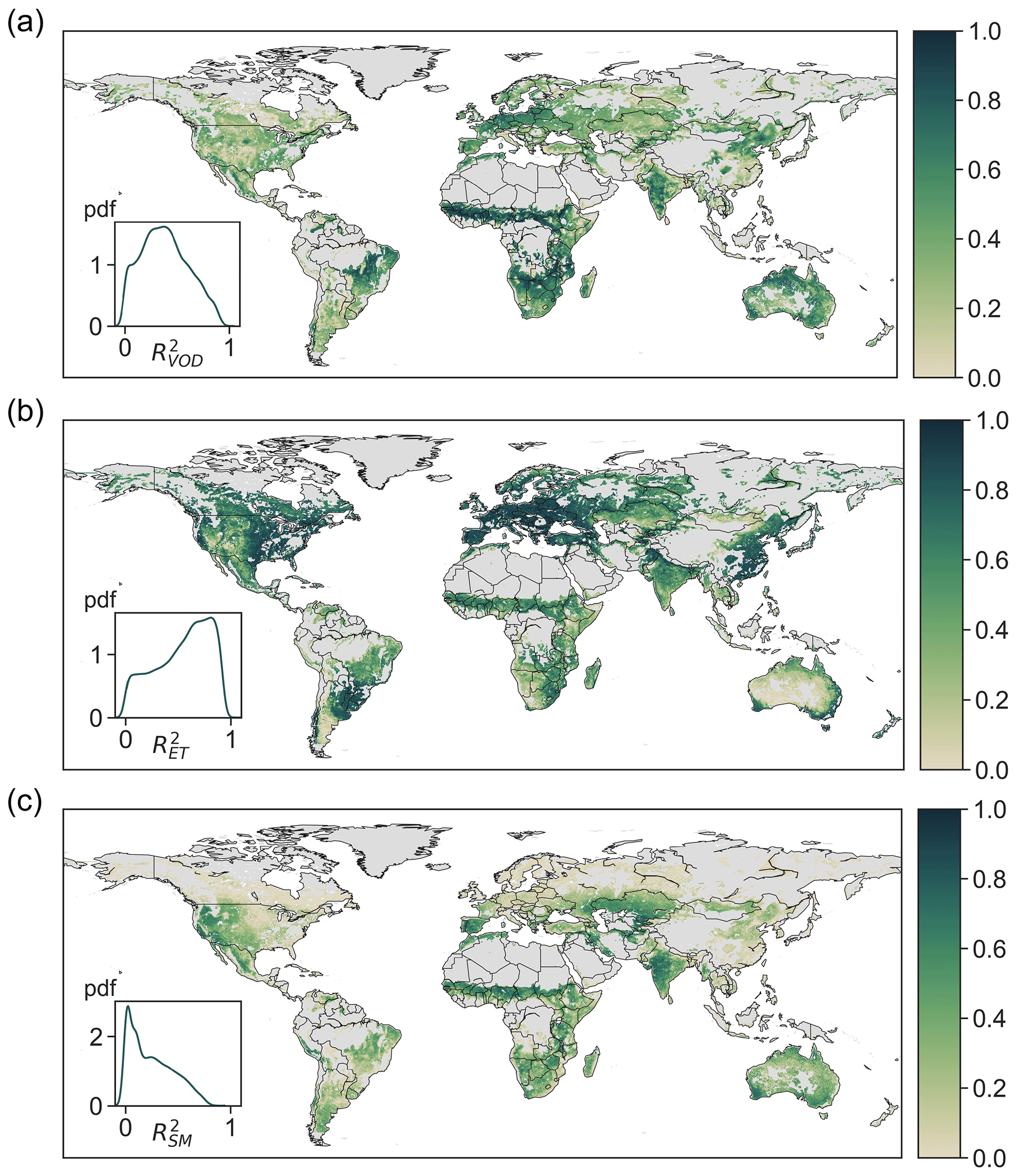
Figure 2Assimilation accuracy (R2) of (a) VOD, (b) ET, and (c) soil moisture during the entire study period (2003–2011). Insets show the probability distribution (pdf) of R2 across the entire study area. The gray shaded area is not included in analysis.
3.3 Global pattern of plant hydraulic traits
The retrieved stomatal conductance slope parameter g1, which is inversely proportional to marginal water use efficiency (Eq. 6), exhibits clear spatial patterns (Fig. 3a). High g1 values arise in areas covered by grasses and savannas, such as the western US, the Sahel, central Asia, northern Mongolia, and inner Australia. This pattern is consistent with predictions from experimental data and optimality theory that herbaceous species – given the low cost of stem wood construction per unit water transport – should have the largest g1, i.e., be the least water-use efficient (Manzoni et al., 2011; Lin et al., 2015). In addition, croplands in India and eastern China also show high g1, consistent with the high isohydricity of these regions (Konings and Gentine, 2017). Consistent with ground measurements that suggest g1 increases with biome average temperature (Lin et al., 2015), the g1 derived here is also (on average) lower in boreal ecosystems than in temperate and tropical ecosystems.
Highly negative ψ50,x values are found in boreal evergreen needleleaf forests and in arid or seasonally dry biomes covered by forests, shrubs or savannas, such as the western US, central America, eastern south America, southeastern Africa, and Australia (Fig. 3b). However, ψ50,x is more spatially scattered than g1. This could partially arise from the greater coefficient of variation across ensembles of ψ50,x (Fig. 4), suggesting ψ50,x is less tightly constrained compared to g1 (consistent with site-scale model–data fusion efforts in Liu et al. (2020a) and the uncertainty estimates in the OSSE; Fig. 1). This additional uncertainty might translate to more noise in the ensemble medians for ψ50,x than that for g1. Maps of other hydraulic traits are shown in Fig. S4. The patterns of hydraulic traits exhibit greater variability beyond PFT distribution (Fig. S2) and only limited correlation with soil and climate conditions (Fig. S5).
Among the plant hydraulic traits, we found strong coordination between the vulnerability of stomata and the xylem (ψ50,s and ψ50,x) across space (Fig. S5), consistent with existing evidence from ground measurements (Anderegg et al., 2017). Other hydraulic traits are only weakly correlated, including gp,max and ψ50,x (Fig. S5), which is consistent with the previous finding suggesting the safety–efficiency trade-off of xylem traits is weak across >400 species (Gleason et al., 2016).
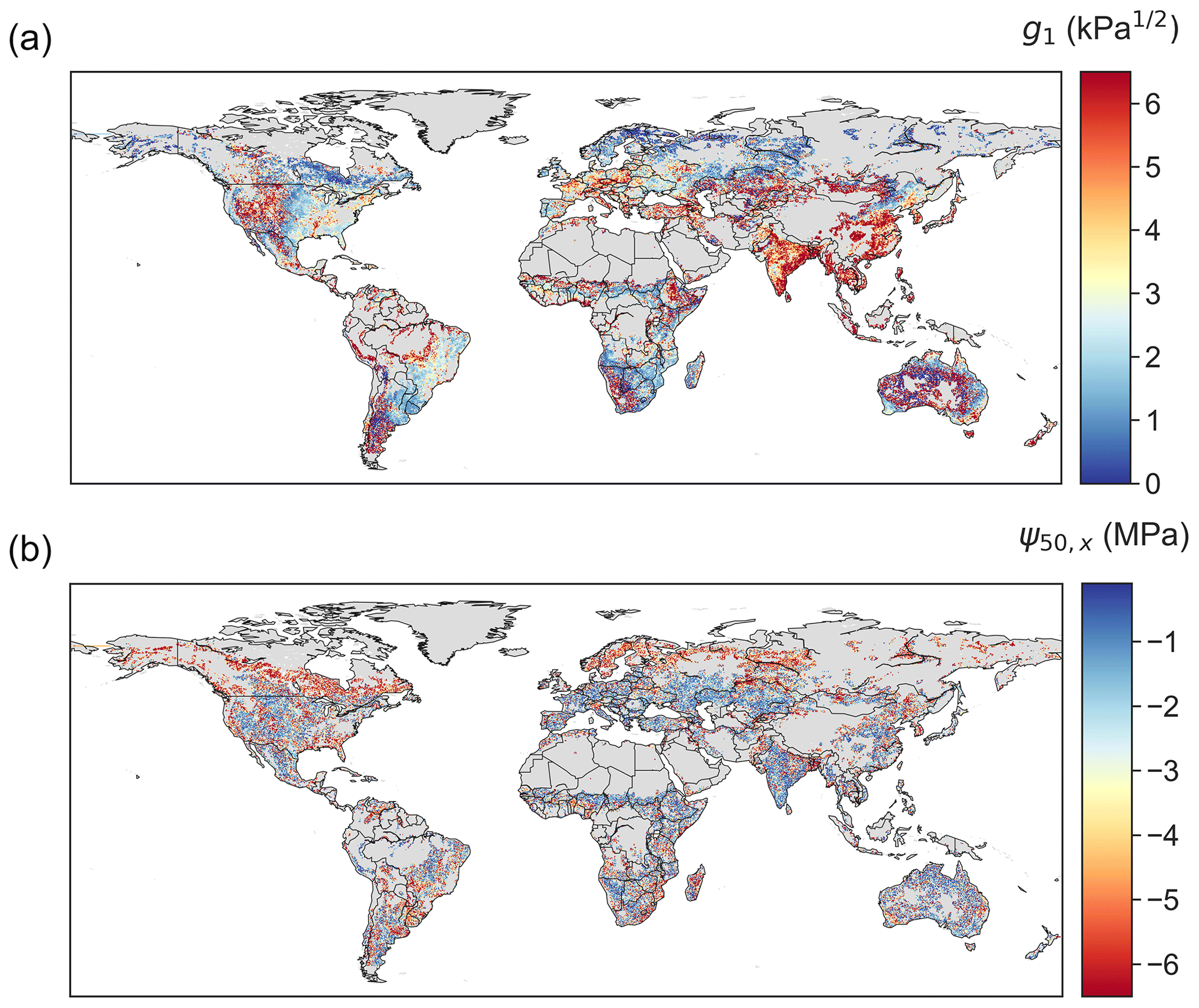
Figure 3Global maps of (a) g1 and (b) ψ50,x retrieved using model–data fusion. The posterior mean of each pixel is plotted.
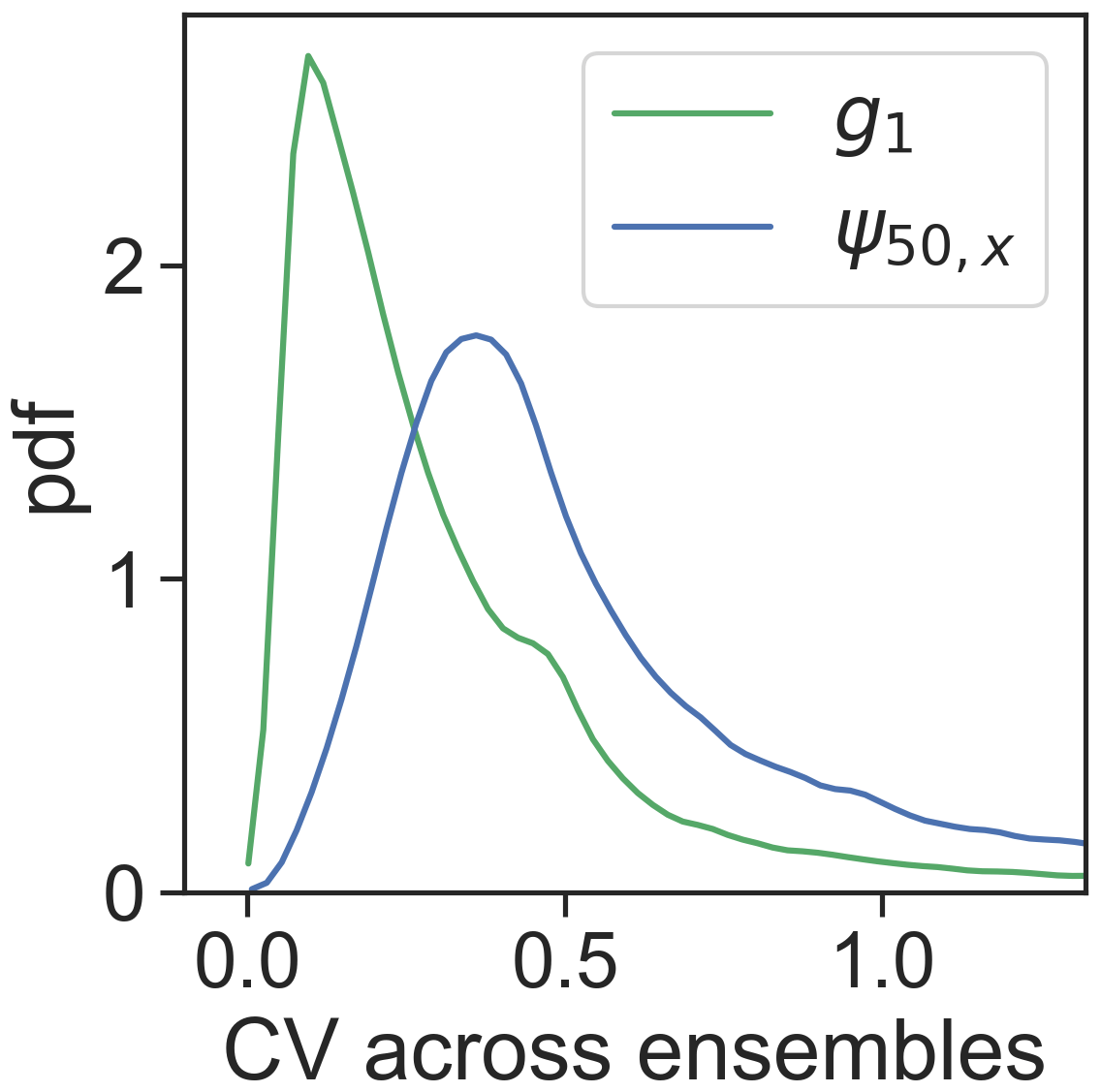
Figure 4Empirical distribution across pixels of the coefficient of variation (CV) of g1 and ψ50,x calculated across ensembles.
Across PFTs, evergreen needleleaf forests have the lowest g1, followed by deciduous broadleaf forests and shrublands (Fig. 5a). Grasslands and croplands have the highest g1. This trend follows the across-PFT pattern found by Lin et al. (2015). The estimated across-PFT pattern of mean ψ50,x is also consistent with measurements included in the TRY database (Kattge et al., 2011), i.e., lowest in grasslands and highest in evergreen needleleaf forests (Fig. 5b). However, across the globe, we found that the average standard deviation within PFTs is 3.6 and 2.3 times the standard deviation across PFTs for g1 and ψ50,x, respectively. The large within-PFT variation is consistent with in situ observations (Anderegg, 2015), indicating that PFTs are not informative of plant hydraulic traits.
We further compared the retrieved ψ50,x for specific locations to an alternative estimate upscaled from Forest Inventory and Analysis (FIA) surveys (Fig. 6). Consistent with the FIA-based estimate, the retrieved ψ50,x are overall lower in pixels dominated by evergreen needleleaf forests than in evergreen and deciduous broadleaf forests and mixed forests. However, across pixels, the ecosystem-scale ψ50,x derived from remote sensing vary significantly more than the estimates from the Trugman et al. (2020) data set. Some fraction of this discrepancy might be due to intra-species variability in ψ50,x, which is not accounted for in the FIA-based estimate, and due to the uncertainty in the kriging-based interpolation used for upscaling from the sparse FIA plots to each 1∘ pixel. Nevertheless, this discrepancy highlights the scale gap between traits measured for a single plant and those derived for an ecosystem.
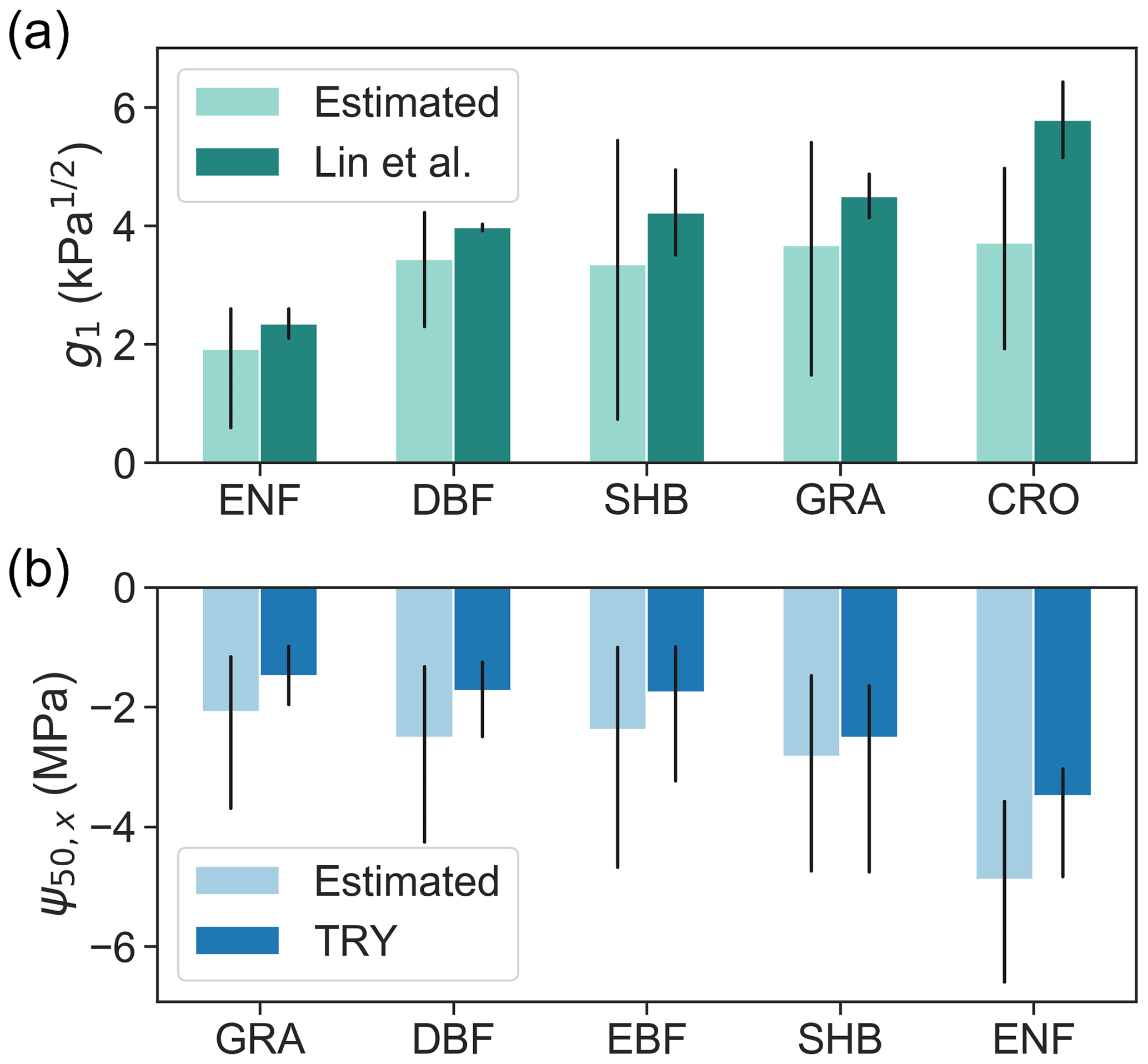
Figure 5Retrieved (a) g1 and (b) ψ50,x using model–data fusion (light colored bars), grouped by PFTs, in comparison with values derived from in situ measurements (dark colored bars) reported in Lin et al. (2015) and the TRY database (Kattge et al., 2011). Compared PFTs include evergreen needleleaf forest (ENF), deciduous broadleaf forest (DBF), evergreen broadleaf forest (EBF), shrubland (SHB), grassland (GRA), and cropland (CRO). Bars represent medians of each PFT, and black lines indicate the 25th–75th percentile ranges. The g1 averaged across gymnosperm trees and angiosperm trees from Lin et al. (2015) were compared to retrieved g1 in pixels dominated by ENF and DBF, respectively.

Figure 6Aggregated ψ50,x from upscaling the Forest Inventory and Analysis (FIA) plots, based on Trugman et al. (2020), and ψ50,x retrieved here for corresponding pixels. The point size is scaled by number of plots used in aggregation for each pixel.
3.4 Hydraulic functional types (HFTs)
We built six HFTs (termed H1 to H6) using the K-means clustering method. The number of clusters (six) was chosen, using the elbow method, based on the inflection point of the ratio of within- to across-cluster variance (Fig. S6). Across the six HFTs, the across-cluster variance is 1.7 times as large as the within-cluster variance. The HFTs explain 57 % of the total variance in hydraulic traits across the globe. The cluster centers of the six HFTs are characterized by distinct combinations of hydraulic traits (Fig. 7a). Specifically, H1 and H2 feature low ψ50,s and ψ50,x and are mainly distributed in boreal forest and arid or seasonally dry biomes, including the western US, central America, southeastern Africa, central Asia, and Australia (Fig. 7b). H3 and H4 are characterized by low and high vegetation capacitance (C), respectively, though both have low gp,max. H3 is mainly but not exclusively distributed in grasslands and savannas in the central US, the Nordeste region in Brazil, eastern and southern Africa, and eastern Australia, as well as in the Miombo woodlands. H4 is distributed in shrublands in the southwestern US, Argentina, southern Africa, northwestern India, and northeastern Australia. H5, often found in tropical and subtropical regions, is characterized by large gp,max and capacitance. H6 is characterized primarily by high g1, which includes croplands in India, southeastern Asia, and central and eastern China. Note that the pattern of HFTs (Fig. 7b) is substantially distinct from the distribution of PFTs (Fig. S2), illustrating the limitations of parameterizing plant hydraulics based on PFTs.
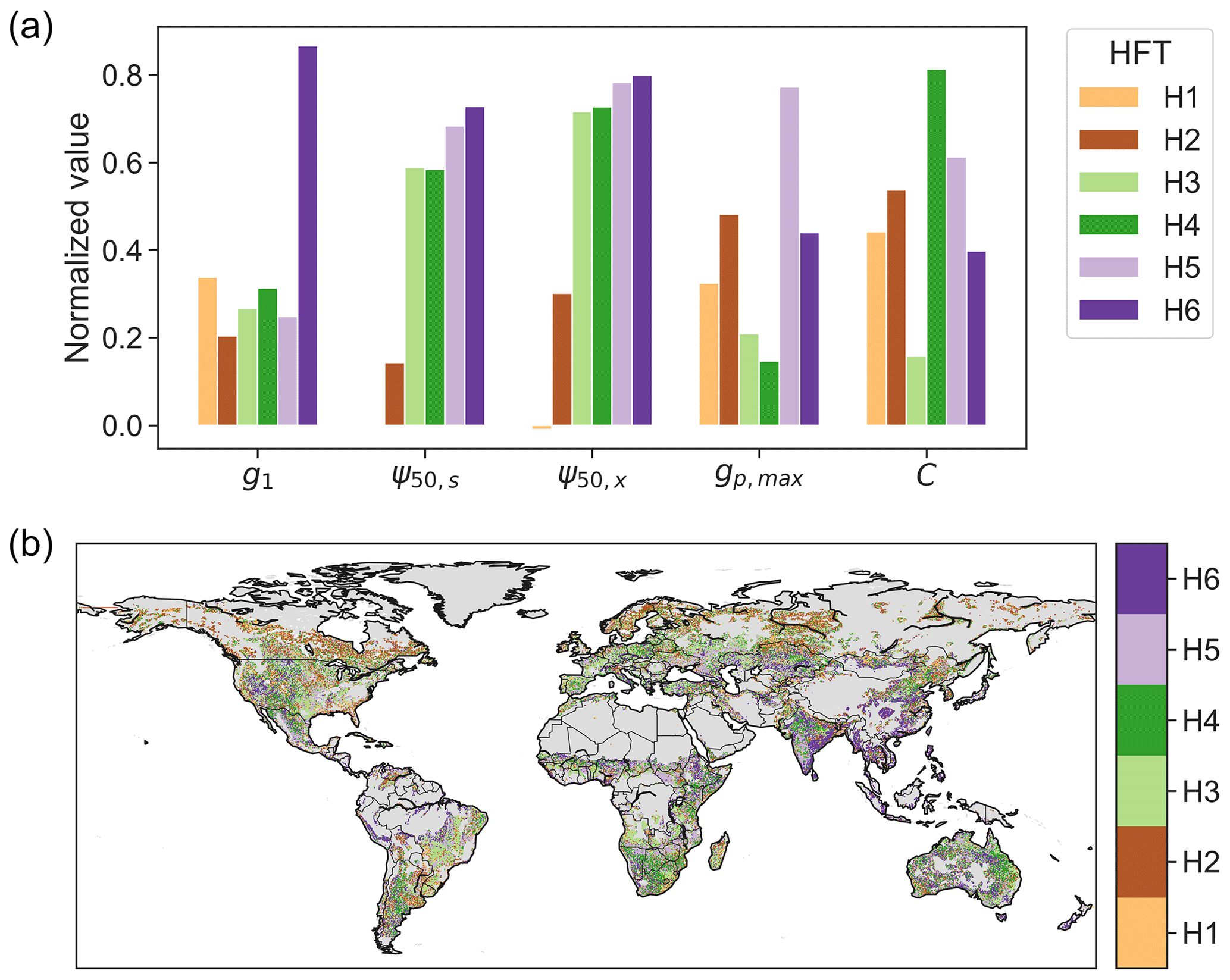
Figure 7(a) Plant hydraulic traits of the centers of six hydraulic functional types and (b) their spatial pattern. Each trait of cluster centers is normalized using , where V is the trait magnitude, and V5 and V95 are the 5th and 95th percentiles of the corresponding trait across the study area.
Using averaged traits per PFT, instead of pixel-specific traits to calculate VOD and ET, led to a median increase in normalized root mean square error (nRMSE, with the long-term average used for normalization) of 0.82 and 0.58, respectively. This degradation of accuracy is unsurprising given the high spatial variability in hydraulic traits and the fact that PFTs are not categorized specifically to distinguish plant hydraulic functions. However, using the hydraulic traits averaged per HFT instead improves prediction accuracy over the PFT-based predictions. When compared to using pixel-specific values, using average traits based on HFTs increases the nRMSE by 0.65 and 0.42 for VOD and ET, respectively. In each case, this is less than the degradation when PFT-based averages are used. Indeed, when PFT-based instead of HFT-based model estimates are compared, the nRMSE of ET increases by more than 0.1 in 58 % of the analyzed area (Fig. 8a). ET is mainly improved in arid or seasonally dry biomes, including the western US, southern South America, southern and eastern Africa, central Asia, and Australia. In addition, the nRMSE of VOD is also improved by more than 0.5 in 37 % of the analyzed area using HFTs rather than PFTs (Fig. 8b). Areas exhibiting reduced error are mainly located in the southwestern US, central America, eastern South America, the Mediterranean, Africa, and Australia, where variation in leaf water potential has a strong signature on VOD (Momen et al., 2017). These findings suggest the importance of the appropriate parameterization of hydraulic traits on capturing leaf water potential and ET variations at an ecosystem scale.

Figure 8Normalized root mean square error (nRMSE) of estimated (a) ET and (b) VOD, using traits averaged by plant PFTs minus those using traits averaged by HFTs. The insets show the areal frequency of the nRMSE difference.
4.1 Contribution of VOD to informing plant hydraulic behavior
The fact that VOD varies with plant water content allows the investigation of plant physiological dynamics at large scales. Although VOD has often been used as a proxy of aboveground biomass (e.g., Liu et al., 2015; Tian et al., 2017; Brandt et al., 2018; Teubner et al., 2019), it is in fact determined by both biomass and plant water status (Konings et al., 2019). VOD variations within a day (Konings and Gentine, 2017; Li et al., 2017; Anderegg et al., 2018) and during soil drydowns (Feldman et al., 2018; Zhang et al., 2019; Feldman et al., 2020) highlight the sensitivity of VOD to relative water content. At seasonal and interannual scales, VOD has also been found to be modulated by leaf water potential or relative water content, thus deviating from biomass signals (Momen et al., 2017; Tian et al., 2018; Tong et al., 2019). Here, after parsing out the impact of biomass through LAI, VOD provides information about leaf water potential variation and, therefore, contributes to constraining the underlying hydraulic traits. Kumar et al. (2020) previously assimilated VOD into a land surface model as a constraint on biomass, which led to improvements in modeled ET. Our findings suggest that, when assimilated into models with an explicit representation of plant hydraulics, VOD can act to constrain both water and carbon dynamics and their respective climatic responses. Although not explored in detail in this study, note also that, by determining optimal values for a, b, and c (the parameters relating VOD to ψl in Eq. 11), the model–data fusion system introduced here also allows the determination of ψl from VOD, which may be of interest for a variety of studies of plant responses to drought. However, additional research is needed to understand the effect of the choice of retrieval algorithm and specific VOD product (Li et al., 2021) on any inferred VOD–ψl relationships. For this reason, any such efforts would also benefit from explicit uncertainty quantification.
Our previous study (Liu et al., 2020a) at the stand scale has shown that stomatal traits are well constrained using ET alone, whereas xylem traits, including ψ50,x, remain largely under-constrained, in part due to lack of information on leaf water potential. Incorporating VOD among the constraints here contributes to the separation of xylem and stomatal behavior. As a result, the model–data fusion approach here is, to our knowledge, the first to be able to retrieve both stomatal and xylem traits across the globe. Nevertheless, ψ50,x is still less well resolved across ensembles compared to other traits (Fig. 4). This could result from trade-offs among hydraulic traits and the lack of constraints on the scaling from leaf water potential to VOD, which varies across space. More prior information about these two factors will likely contribute to improved retrieval of plant hydraulic traits. Additionally, the use of solar-induced fluorescence or other constraints on photosynthesis may allow for independent information about stomatal closure that could be used to improve the accuracy and certainty of the retrieved hydraulic traits. However, care should be taken that the uncertainty introduced by coupling to a photosynthesis model does not outweigh the added advantage of this additional constraint.
4.2 Bridging the spatial scale gap of hydraulic traits
Plant hydraulic traits vary among segments from root to shoot even for a single tree, causing the hydraulic sensitivity at a whole-tree scale to be distinct from that measured at a segment scale (Johnson et al., 2016). Similarly, species diversity, canopy structure, and demographic composition can cause large variability in hydraulic traits. As a result, a community-weighted average of a trait may not well represent the integrated hydraulic behavior at an ecosystem scale, as evidenced, for example, by the significant effect of plant hydraulic diversity on evapotranspiration responses to drought (Anderegg et al., 2018). Here, we also found a substantial discrepancy between community-weighted ψ50,x and the ecosystem-scaled value derived from representing the property of the entire pixel, even in the most extensively surveyed pixels available (biggest dots in Fig. 6). This highlights the challenge of scaling up ground measurements of plant hydraulic traits to a scale relevant to land surface modeling from the bottom up. The model–data fusion used here provides an approach to help address this challenge. However, further study is needed to explore how stand and ecosystem characteristics shape the ecosystem-scale hydraulic traits, as well as the effective relationship between leaf water potential and remote-sensing-scale water content.
4.3 Implications for land surface models
Because they are able to predict ET and VOD better than PFTs (Fig. 8), the HFTs point to the potential for a better parameterization scheme of plant hydraulics in land surface models. Because HFTs require fewer clusters than PFTs do to model ET with the same or better accuracy, parameterizing plant hydraulics by HFTs in land surface models may contribute to higher model accuracy. However, because the magnitude of state variables may differ between models, even as their temporal dynamics do not (Koster et al., 2009), including between a given land surface model and the model used here, using the exact values derived here may cause errors. Instead, the map of HFTs and their relative magnitude of traits can be used as a baseline for model-specific calibration. Moreover, moving beyond fixed values for each HFT, hydraulic traits within each type may be further related to landscape features such as climate, topography, canopy height, and stand age using the environmental filtering approach (Butler et al., 2017). As demonstrated for photosynthetic traits (Verheijen et al., 2013; Smith et al., 2019), such relationships allow practical flexibility to account for trait variations across space, thus improving the performance of large-scale models. They may also allow improved compatibility with subgrid tiling schemes used by land surface schemes. As land surface models that explicitly represent plant hydraulics are becoming more common, our results demonstrate the possibility of alternative, computationally efficient approaches to parameterizing plant hydraulic behavior, which will contribute to improved prediction of natural resources and climate feedbacks.
This study derived ecosystem-scale plant hydraulic traits across the globe using a model–data fusion approach. The retrieved traits enable our hydraulic model to capture the dynamics of leaf water potential and ET, based on a comparison to remote sensing observations. While the traits derived here are consistent with across-PFT patterns based on in situ measurements, they also exhibit large within-PFT variations (as expected). There is some discrepancy between our derived ψ50,x and the values derived from interpolating between forest inventory plots, though it is unclear if this discrepancy is caused by errors in the model–data fusion retrievals, errors in the upscaled inventory data due to intra-specific variability and spatial interpolation imperfections, or both. Uncertainty is also induced by whether or not our retrievals represent the same effective values as a community-weighted average (see Sect. 4.2). Nevertheless, reasonable correspondence between the across-PFT variations in our derived traits compared to in situ measurements add confidence to the data set introduced here.
As an alternative to PFTs, we constructed hydraulic functional types based on clustering of the derived hydraulic traits. Using the hydraulic functional types, rather than PFTs, to drive averaged traits by functional types improves the accuracy of estimated ET and VOD, even as the number of functional types is reduced relative to a PFT-based representation. This suggests that hydraulic functional types may form a computationally efficient yet promising approach for representing the diversity of plant hydraulic behavior in large-scale land surface models. We note that the exact values of the derived hydraulic traits depend on the specific data and model representation used here and, therefore, are subject to model and data uncertainties. However, our findings highlight opportunities and challenges for further investigation of plant hydraulics at a global scale.
The maps of retrieved ensemble mean and standard deviation of plant hydraulic traits are publicly available on Figshare https://doi.org/10.6084/m9.figshare.13350713.v2 (Liu et al., 2020). The source code of the used plant hydraulic model and the model–data fusion algorithm is available at https://github.com/YanlanLiu/VOD_hydraulics (Liu et al., 2020b). All the assimilation and forcing data sets used in this study are publicly available from the referenced sources, except for the microwave-based ALEXI ET, which was obtained upon request from Thomas R. Holmes and Christopher R. Hain on 28 January 2020.
The supplement related to this article is available online at: https://doi.org/10.5194/hess-25-2399-2021-supplement.
YL, NMH, and AGK conceived the study. YL and NMH set up the model. YL prepared the data and conducted the analyses, with all authors providing input. YL led the writing of the paper. All authors contributed to the editing of the paper.
The authors declare that they have no conflict of interest.
This article is part of the special issue “Microwave remote sensing for improved understanding of vegetation–water interactions (BG/HESS inter-journal SI)”. It is not associated with a conference.
We thank Thomas R. Holmes and Christopher R. Hain for providing the ALEXI ET data. The authors have been supported by a NASA Terrestrial Ecology award (grant no. 80NSSC18K0715) through the New Investigator Program. Alexandra G. Konings has also been supported by NOAA (grant no. NA17OAR4310127). Nataniel M. Holtzman has been supported by NASA through FINESST (Future Investigators in NASA Earth and Space Science and Technology; grant no. 19-EARTH20-0078).
This research has been supported by the National Aeronautics and Space Administration (grant nos. 80NSSC18K0715 and 19-EARTH20-0078) and the National Oceanic and Atmospheric Administration (grant no. NA17OAR4310127).
This paper was edited by Matthias Forkel and reviewed by two anonymous referees.
Adams, H. D., Zeppel, M. J. B., Anderegg, W. R. L., Hartmann, H., Landhäusser, S. M., Tissue, D. T., Huxman, T. E., Hudson, P. J., Franz, T. E., Allen, C. D., Anderegg, L. D. L., Barron-Gafford, G. A., Beerling, D. J., Breshears, D. D., Brodribb, T. J., Bugmann, H., Cobb, R. C., Collins, A. D., Dickman, L. T., Duan, H., Ewers, B. E., Galiano, L., Galvez, D. A., Garcia-Forner, N., Gaylord, M. L., Germino, M. J., Gessler, A., Hacke, U. G., Hakamada, R., Hector, A., Jenkins, M. W., Kane, J. M., Kolb, T. E., Law, D. J., Lewis, J. D., Limousin, J.-M., Love, D. M., Macalady, A. K., Martínez-Vilalta, J., Mencuccini, M., Mitchell, P. J., Muss, J. D., O'Brien, M. J., O'Grady, A. P., Pangle, R. E., Pinkard, E. A., Piper, F. I., Plaut, J. A., Pockman, W. T., Quirk, J., Reinhardt, K., Ripullone, F., Ryan, M. G., Sala, A., Sevanto, S., Sperry, J. S., Vargas, R., Vennetier, M., Way, D. A., Xu, C., Yepez, E. A., and McDowell, N. G.: A multi-species synthesis of physiological mechanisms in drought-induced tree mortality, Nat. Ecol. Evol., 1, 1285–1291, 2017. a
Anderegg, W. R. L.: Spatial and temporal variation in plant hydraulic traits and their relevance for climate change impacts on vegetation, New Phytol., 205, 1008–1014, 2015. a, b, c, d
Anderegg, W. R. L., Klein, T., Bartlett, M., Sack, L., Pellegrini, A. F. A., Choat, B., and Jansen, S.: Meta-analysis reveals that hydraulic traits explain cross-species patterns of drought-induced tree mortality across the globe, P. Natl. Acad. Sci. USA, 113, 5024–5029, 2016. a
Anderegg, W. R. L., Wolf, A., Arango-Velez, A., Choat, B., Chmura, D. J., Jansen, S., Kolb, T., Li, S., Meinzer, F., Pita, P., Resco de Dios, V., Sperry, J. S., Wolfe, B. T., and Pacala, S.: Plant water potential improves prediction of empirical stomatal models, PLoS One, 12, e0185481, https://doi.org/10.1371/journal.pone.0185481, 2017. a, b, c
Anderegg, W. R. L., Konings, A. G., Trugman, A. T., Yu, K., Bowling, D. R., Gabbitas, R., Karp, D. S., Pacala, S., Sperry, J. S., Sulman, B. N., and Zenes, N.: Hydraulic diversity of forests regulates ecosystem resilience during drought, Nature, 561, 538–541, 2018. a, b
Anderegg, W. R. L., Trugman, A. T., Bowling, D. R., Salvucci, G., and Tuttle, S. E.: Plant functional traits and climate influence drought intensification and land–atmosphere feedbacks, P. Natl. Acad. Sci. USA, 116, 14071–14076, 2019. a, b
Anderson, M. C., Norman, J. M., Diak, G. R., Kustas, W. P., and Mecikalski, J. R.: A two-source time-integrated model for estimating surface fluxes using thermal infrared remote sensing, Remote Sens. Environ., 60, 195–216, 1997. a
Anderson, M. C., Norman, J. M., Mecikalski, J. R., Otkin, J. A., and Kustas, W. P.: A climatological study of evapotranspiration and moisture stress across the continental United States based on thermal remote sensing: 1. Model formulation, J. Geophys. Res., 112, D10117, https://doi.org/10.1029/2006JD007506, 2007. a, b
Arnold, C. P. and Dey, C. H.: Observing-Systems Simulation Experiments: Past, Present, and Future, B. Am. Meteorol. Soc., 67, 687–695, 1986. a
Barros, F. d. V., Bittencourt, P. R. L., Brum, M., Restrepo‐Coupe, N., Pereira, L., Teodoro, G. S., Saleska, S. R., Borma, L. S., Christoffersen, B. O., Penha, D., Alves, L. F., Lima, A. J. N., Carneiro, V. M. C., Gentine, P., Lee, J., Aragão, L. E. O. C., Ivanov, V., Leal, L. S. M., Araujo, A. C., and Oliveira, R. S.: Hydraulic traits explain differential responses of Amazonian forests to the 2015 El Niño‐induced drought, New Phytol., 223, 1253–1266, 2019. a
Bartlett, M. K., Klein, T., Jansen, S., Choat, B., and Sack, L.: The correlations and sequence of plant stomatal, hydraulic, and wilting responses to drought, P. Natl. Acad. Sci. USA, 113, 13098–13103, 2016. a
Beaudoing, H. and Rodell, M.: GLDAS Noah Land Surface Model L4 3 hourly 0.25 × 0.25 degree V2.1, nASA/GSFC/HSL, Greenbelt, Maryland, USA, Goddard Earth Sciences Data and Information Services Center (GES DISC), https://doi.org/10.5067/E7TYRXPJKWOQ, 2020. a
Blackman, C. J., Creek, D., Maier, C., Aspinwall, M. J., Drake, J. E., Pfautsch, S., O'Grady, A., Delzon, S., Medlyn, B. E., Tissue, D. T., and Choat, B.: Drought response strategies and hydraulic traits contribute to mechanistic understanding of plant dry-down to hydraulic failure, Tree Physiol., 39, 910–924, 2019. a
Brandt, M., Wigneron, J.-P., Chave, J., Tagesson, T., Penuelas, J., Ciais, P., Rasmussen, K., Tian, F., Mbow, C., Al-Yaari, A., Rodriguez-Fernandez, N., Schurgers, G., Zhang, W., Chang, J., Kerr, Y., Verger, A., Tucker, C., Mialon, A., Rasmussen, L. V., Fan, L., and Fensholt, R.: Satellite passive microwaves reveal recent climate-induced carbon losses in African drylands, Nat. Ecol. Evol., 2, 827–835, 2018. a
Brooks, S. P. and Gelman, A.: General Methods for Monitoring Convergence of Iterative Simulations, J. Comput. Graph. Stat., 7, 434–455, 1998. a
Butler, E. E., Datta, A., Flores-Moreno, H., Chen, M., Wythers, K. R., Fazayeli, F., Banerjee, A., Atkin, O. K., Kattge, J., Amiaud, B., Blonder, B., Boenisch, G., Bond-Lamberty, B., Brown, K. A., Byun, C., Campetella, G., Cerabolini, B. E. L., Cornelissen, J. H. C., Craine, J. M., Craven, D., de Vries, F. T., Díaz, S., Domingues, T. F., Forey, E., González-Melo, A., Gross, N., Han, W., Hattingh, W. N., Hickler, T., Jansen, S., Kramer, K., Kraft, N. J. B., Kurokawa, H., Laughlin, D. C., Meir, P., Minden, V., Niinemets, Ü., Onoda, Y., Peñuelas, J., Read, Q., Sack, L., Schamp, B., Soudzilovskaia, N. A., Spasojevic, M. J., Sosinski, E., Thornton, P. E., Valladares, F., van Bodegom, P. M., Williams, M., Wirth, C., and Reich, P. B.: Mapping local and global variability in plant trait distributions, P. Natl. Acad. Sci. USA, 114, E10937–E10946, 2017. a
Campbell, G. S. and Norman, J.: An Introduction to Environmental Biophysics, Springer Science & Business Media, Springer, New York, NY, 1998. a
Choat, B., Jansen, S., Brodribb, T. J., Cochard, H., Delzon, S., Bhaskar, R., Bucci, S. J., Feild, T. S., Gleason, S. M., Hacke, U. G., Jacobsen, A. L., Lens, F., Maherali, H., Martínez-Vilalta, J., Mayr, S., Mencuccini, M., Mitchell, P. J., Nardini, A., Pittermann, J., Pratt, R. B., Sperry, J. S., Westoby, M., Wright, I. J., and Zanne, A. E.: Global convergence in the vulnerability of forests to drought, Nature, 491, 752–755, 2012. a
Choat, B., Brodribb, T. J., Brodersen, C. R., Duursma, R. A., López, R., and Medlyn, B. E.: Triggers of tree mortality under drought, Nature, 558, 531–539, 2018. a, b
Christoffersen, B. O., Gloor, M., Fauset, S., Fyllas, N. M., Galbraith, D. R., Baker, T. R., Kruijt, B., Rowland, L., Fisher, R. A., Binks, O. J., Sevanto, S., Xu, C., Jansen, S., Choat, B., Mencuccini, M., McDowell, N. G., and Meir, P.: Linking hydraulic traits to tropical forest function in a size-structured and trait-driven model (TFS v.1-Hydro), Geosci. Model Dev., 9, 4227–4255, https://doi.org/10.5194/gmd-9-4227-2016, 2016. a
Clapp, R. B. and Hornberger, G. M.: Empirical equations for some soil hydraulic properties, Water Resour. Res., 14, 601–604, 1978. a, b
De Kauwe, M. G., Medlyn, B. E., Ukkola, A. M., Mu, M., Sabot, M. E. B., Pitman, A. J., Meir, P., Cernusak, L. A., Rifai, S. W., Choat, B., Tissue, D. T., Blackman, C. J., Li, X., Roderick, M., and Briggs, P. R.: Identifying areas at risk of drought-induced tree mortality across South-Eastern Australia, Glob. Change Biol., 26, 5716–5733, https://doi.org/10.1111/gcb.15215, 2020. a, b
Dietze, M. C., Lebauer, D. S., and Kooper, R.: On improving the communication between models and data, Plant Cell Environ., 36, 1575–1585, 2013. a
Eller, C. B., Rowland, L., Mencuccini, M., Rosas, T., Williams, K., Harper, A., Medlyn, B. E., Wagner, Y., Klein, T., Teodoro, G. S., Oliveira, R. S., Matos, I. S., Rosado, B. H. P., Fuchs, K., Wohlfahrt, G., Montagnani, L., Meir, P., Sitch, S., and Cox, P. M.: Stomatal optimization based on xylem hydraulics (SOX) improves land surface model simulation of vegetation responses to climate, New Phytol., 226, 1622–1637, 2020. a
Errico, R. M., Yang, R., Privé, N. C., Tai, K.-S., Todling, R., Sienkiewicz, M. E., and Guo, J.: Development and validation of observing-system simulation experiments at NASA's Global Modeling and Assimilation Office, Q. J. Roy. Meteorol. Soc., 139, 1162–1178, 2013. a
Fan, Y., Miguez-Macho, G., Jobbágy, E. G., Jackson, R. B., and Otero-Casal, C.: Hydrologic regulation of plant rooting depth, P. Natl. Acad. Sci. USA, 114, 10572–10577, 2017. a
FAO: Understanding the drought impact of El Niño on the global agricultural areas: An assessment using FAO’s Agricultural Stress Index (ASI), available at: http://www.fao.org/resilience/resources/resources-detail/en/c/1114447/ (last access: 8 October 2020), 2014. a
FAO/IIASA/ISRIC/ISSCAS/JRC: Harmonized World Soil Database (version 1.2), fAO, Rome, Italy and IIASA, Laxenburg, Austria, available at: http://www.fao.org/soils-portal/data-hub/en/ (last access: 22 June 2016), 2012. a
Farquhar, G. D., von Caemmerer, S., and Berry, J. A.: A biochemical model of photosynthetic CO2 assimilation in leaves of C3 species, Planta, 149, 78–90, 1980. a
Feldman, A. F., Short Gianotti, D. J., Konings, A. G., McColl, K. A., Akbar, R., Salvucci, G. D., and Entekhabi, D.: Moisture pulse-reserve in the soil-plant continuum observed across biomes, Nat. Plants, 4, 1026–1033, 2018. a
Feldman, A. F., Short Gianotti, D. J., Trigo, I. F., Salvucci, G. D., and Entekhabi, D.: Land‐Atmosphere Drivers of Landscape‐Scale Plant Water Content Loss, Geophys. Res. Lett., 47, e2020GL090331, https://doi.org/10.1029/2020GL090331, 2020. a
Feng, X., Dawson, T. E., Ackerly, D. D., Santiago, L. S., and Thompson, S. E.: Reconciling seasonal hydraulic risk and plant water use through probabilistic soil-plant dynamics, Glob. Change Biol., 23, 3758–3769, 2017. a
Feng, X., Ackerly, D. D., Dawson, T. E., Manzoni, S., McLaughlin, B., Skelton, R. P., Vico, G., Weitz, A. P., and Thompson, S. E.: Beyond isohydricity: The role of environmental variability in determining plant drought responses, Plant Cell Environ., 42, 1104–1111, 2019. a
Liu, Y., Holtzman, N. M., and Konings, A. G.: Global ecosystem-scale plant hydraulic traits retrieved using model-data fusion, Figshare [dataset], https://doi.org/10.6084/m9.figshare.13350713.v2, 2020. a
Fisher, R. A., Wieder, W. R., Sanderson, B. M., Koven, C. D., Oleson, K. W., Xu, C., Fisher, J. B., Shi, M., Walker, A. P., and Lawrence, D. M.: Parametric Controls on Vegetation Responses to Biogeochemical Forcing in the CLM5, J. Adv. Model. Earth Sy., 11, 2879–2895, 2019. a
Frappart, F., Wigneron, J.-P., Li, X., Liu, X., Al-Yaari, A., Fan, L., Wang, M., Moisy, C., Le Masson, E., Lafkih, Z. A., et al.: Global monitoring of the vegetation dynamics from the Vegetation Optical Depth (VOD): A review, Remote Sensing, 12, 2915, https://doi.org/10.3390/rs12182915, 2020. a
Giardina, F., Konings, A. G., Kennedy, D., Alemohammad, S. H., Oliveira, R. S., Uriarte, M., and Gentine, P.: Tall Amazonian forests are less sensitive to precipitation variability, Nat. Geosci., 11, 405–409, 2018. a
Gleason, S. M., Westoby, M., Jansen, S., Choat, B., Hacke, U. G., Pratt, R. B., Bhaskar, R., Brodribb, T. J., Bucci, S. J., Cao, K.-F., Cochard, H., Delzon, S., Domec, J.-C., Fan, Z.-X., Feild, T. S., Jacobsen, A. L., Johnson, D. M., Lens, F., Maherali, H., Martínez-Vilalta, J., Mayr, S., McCulloh, K. A., Mencuccini, M., Mitchell, P. J., Morris, H., Nardini, A., Pittermann, J., Plavcová, L., Schreiber, S. G., Sperry, J. S., Wright, I. J., and Zanne, A. E.: Weak tradeoff between xylem safety and xylem-specific hydraulic efficiency across the world's woody plant species, New Phytol., 209, 123–136, 2016. a
Goulden, M. L. and Bales, R. C.: Mountain runoff vulnerability to increased evapotranspiration with vegetation expansion, P. Natl. Acad. Sci. USA, 111, 14071–14075, 2014. a
Hartley, A. J., MacBean, N., Georgievski, G., and Bontemps, S.: Uncertainty in plant functional type distributions and its impact on land surface models, Remote Sens. Environ., 203, 71–89, 2017. a
Hartmann, H., Moura, C. F., Anderegg, W. R. L., Ruehr, N. K., Salmon, Y., Allen, C. D., Arndt, S. K., Breshears, D. D., Davi, H., Galbraith, D., Ruthrof, K. X., Wunder, J., Adams, H. D., Bloemen, J., Cailleret, M., Cobb, R., Gessler, A., Grams, T. E. E., Jansen, S., Kautz, M., Lloret, F., and O'Brien, M.: Research frontiers for improving our understanding of drought-induced tree and forest mortality, New Phytol., 218, 15–28, 2018. a, b
Hochberg, U., Rockwell, F. E., Holbrook, N. M., and Cochard, H.: Iso/Anisohydry: A Plant-Environment Interaction Rather Than a Simple Hydraulic Trait, Trends Plant Sci., 23, 112–120, 2018. a
Holmes, T. R. H., Hain, C. R., Crow, W. T., Anderson, M. C., and Kustas, W. P.: Microwave implementation of two-source energy balance approach for estimating evapotranspiration, Hydrol. Earth Syst. Sci., 22, 1351–1369, https://doi.org/10.5194/hess-22-1351-2018, 2018. a, b, c
Holtzman, N. M., Anderegg, L. D. L., Kraatz, S., Mavrovic, A., Sonnentag, O., Pappas, C., Cosh, M. H., Langlois, A., Lakhankar, T., Tesser, D., Steiner, N., Colliander, A., Roy, A., and Konings, A. G.: L-band vegetation optical depth as an indicator of plant water potential in a temperate deciduous forest stand, Biogeosciences, 18, 739–753, https://doi.org/10.5194/bg-18-739-2021, 2021. a
Huang, C.-W., Domec, J.-C., Ward, E. J., Duman, T., Manoli, G., Parolari, A. J., and Katul, G. G.: The effect of plant water storage on water fluxes within the coupled soil-plant system, New Phytol., 213, 1093–1106, 2017. a
Ji, C. and Schmidler, S. C.: Adaptive Markov Chain Monte Carlo for Bayesian Variable Selection, J. Comput. Graph. Stat., 22, 708–728, 2013. a
Johnson, D. M., Wortemann, R., McCulloh, K. A., Jordan-Meille, L., Ward, E., Warren, J. M., Palmroth, S., and Domec, J.-C.: A test of the hydraulic vulnerability segmentation hypothesis in angiosperm and conifer tree species, Tree Physiol., 36, 983–993, 2016. a, b
Kalma, J. D., McVicar, T. R., and McCabe, M. F.: Estimating Land Surface Evaporation: A Review of Methods Using Remotely Sensed Surface Temperature Data, Surv. Geophys., 29, 421–469, 2008. a
Kattge, J., Díaz, S., Lavorel, S., Prentice, I. C., Leadley, P., Bönisch, G., Garnier, E., Westoby, M., Reich, P. B., Wright, I. J., Cornelissen, J. H. C., Violle, C., Harrison, S. P., Van BODEGOM, P. M., Reichstein, M., Enquist, B. J., Soudzilovskaia, N. A., Ackerly, D. D., Anand, M., Atkin, O., Bahn, M., Baker, T. R., Baldocchi, D., Bekker, R., Blanco, C. C., Blonder, B., Bond, W. J., Bradstock, R., Bunker, D. E., Casanoves, F., Cavender-Bares, J., Chambers, J. Q., Chapin, Iii, F. S., Chave, J., Coomes, D., Cornwell, W. K., Craine, J. M., Dobrin, B. H., Duarte, L., Durka, W., Elser, J., Esser, G., Estiarte, M., Fagan, W. F., Fang, J., Fernández-Méndez, F., Fidelis, A., Finegan, B., Flores, O., Ford, H., Frank, D., Freschet, G. T., Fyllas, N. M., Gallagher, R. V., Green, W. A., Gutierrez, A. G., Hickler, T., Higgins, S. I., Hodgson, J. G., Jalili, A., Jansen, S., Joly, C. A., Kerkhoff, A. J., Kirkup, D., Kitajima, K., Kleyer, M., Klotz, S., Knops, J. M. H., Kramer, K., Kühn, I., Kurokawa, H., Laughlin, D., Lee, T. D., Leishman, M., Lens, F., Lenz, T., Lewis, S. L., Lloyd, J., Llusià, J., Louault, F., Ma, S., Mahecha, M. D., Manning, P., Massad, T., Medlyn, B. E., Messier, J., Moles, A. T., Müller, S. C., Nadrowski, K., Naeem, S., Niinemets, Ü., Nöllert, S., Nüske, A., Ogaya, R., Oleksyn, J., Onipchenko, V. G., Onoda, Y., Ordoñez, J., Overbeck, G., Ozinga, W. A., Patiño, S., Paula, S., Pausas, J. G., Peñuelas, J., Phillips, O. L., Pillar, V., Poorter, H., Poorter, L., Poschlod, P., Prinzing, A., Proulx, R., Rammig, A., Reinsch, S., Reu, B., Sack, L., Salgado-Negret, B., Sardans, J., Shiodera, S., Shipley, B., Siefert, A., Sosinski, E., Soussana, J.-F., Swaine, E., Swenson, N., Thompson, K., Thornton, P., Waldram, M., Weiher, E., White, M., White, S., Wright, S. J., Yguel, B., Zaehle, S., Zanne, A. E., and Wirth, C.: TRY – a global database of plant traits, Glob. Change Biol., 17, 2905–2935, 2011. a, b, c, d
Kennedy, D., Swenson, S., Oleson, K. W., Lawrence, D. M., Fisher, R., Lola da Costa, A. C., and Gentine, P.: Implementing Plant Hydraulics in the Community Land Model, Version 5, J. Adv. Model. Earth Syst., 11, 485–513, 2019. a, b
Kirdiashev, K. P., Chukhlantsev, A. A., and Shutko, A. M.: Microwave radiation of the earth's surface in the presence of vegetation cover, Radiotekh. Elektron.+, 24, 256–264, 1979. a
Kodinariya, T. M. and Makwana, P. R.: Review on determining number of Cluster in K-Means Clustering, Int. J., 1, 90–95, 2013. a
Konings, A. G. and Gentine, P.: Global variations in ecosystem‐scale isohydricity, Glob. Change Biol., 23, 891–905, https://doi.org/10.1111/gcb.13389, 2017. a, b, c, d, e
Konings, A. G., McColl, K. A., Piles, M., and Entekhabi, D.: How Many Parameters Can Be Maximally Estimated From a Set of Measurements?, IEEE Geosci. Remote S., 12, 1081–1085, 2015. a
Konings, A. G., Piles, M., Rötzer, K., McColl, K. A., Chan, S. K., and Entekhabi, D.: Vegetation optical depth and scattering albedo retrieval using time series of dual-polarized L-band radiometer observations, Remote Sens. Environ., 172, 178–189, 2016. a
Konings, A. G., Williams, A. P., and Gentine, P.: Sensitivity of grassland productivity to aridity controlled by stomatal and xylem regulation, Nat. Geosci., 10, 284–288, 2017. a, b
Konings, A. G., Rao, K., and Steele-Dunne, S. C.: Macro to micro: microwave remote sensing of plant water content for physiology and ecology, New Phytol., 223, 1166–1172, 2019. a, b
Koster, R. D., Guo, Z., Yang, R., Dirmeyer, P. A., Mitchell, K., and Puma, M. J.: On the Nature of Soil Moisture in Land Surface Models, J. Climate, 22, 4322–4335, 2009. a, b
Kumar, S. V., Holmes, T. R., Bindlish, R., de Jeu, R., and Peters-Lidard, C.: Assimilation of vegetation optical depth retrievals from passive microwave radiometry, Hydrol. Earth Syst. Sci., 24, 3431–3450, https://doi.org/10.5194/hess-24-3431-2020, 2020. a, b
Li, X., Piao, S., Wang, K., Wang, X., Wang, T., Ciais, P., Chen, A., Lian, X., Peng, S., and Peñuelas, J.: Temporal trade-off between gymnosperm resistance and resilience increases forest sensitivity to extreme drought, Nat. Ecol. Evol., 4, 1075–1083, 2020. a
Li, X., Wigneron, J.-P., Frappart, F., Fan, L., Ciais, P., Fensholt, R., Entekhabi, D., Brandt, M., Konings, A. G., Liu, X., Wang, M., Al-Yaari, A., and Moisy, C.: Global-scale assessment and inter-comparison of recently developed/reprocessed microwave satellite vegetation optical depth products, Remote Sens. Environ., 253, 112208, https://doi.org/10.1016/j.rse.2020.112208, 2021. a
Li, Y., Guan, K., Gentine, P., Konings, A. G., Meinzer, F. C., Kimball, J. S., Xu, X., Anderegg, W. R. L., McDowell, N. G., Martinez-Vilalta, J., Long, D. G., and Good, S. P.: Estimating Global Ecosystem Isohydry/Anisohydry Using Active and Passive Microwave Satellite Data, J. Geophys. Res.-Biogeo., 122, 3306–3321, 2017. a
Lin, Y.-S., Medlyn, B. E., Duursma, R. A., Prentice, I. C., Wang, H., Baig, S., Eamus, D., de Dios, V. R., Mitchell, P., Ellsworth, D. S., de Beeck, M. O., Wallin, G., Uddling, J., Tarvainen, L., Linderson, M.-L., Cernusak, L. A., Nippert, J. B., Ocheltree, T. W., Tissue, D. T., Martin-StPaul, N. K., Rogers, A., Warren, J. M., De Angelis, P., Hikosaka, K., Han, Q., Onoda, Y., Gimeno, T. E., Barton, C. V. M., Bennie, J., Bonal, D., Bosc, A., Löw, M., Macinins-Ng, C., Rey, A., Rowland, L., Setterfield, S. A., Tausz-Posch, S., Zaragoza-Castells, J., Broadmeadow, M. S. J., Drake, J. E., Freeman, M., Ghannoum, O., Hutley, L. B., Kelly, J. W., Kikuzawa, K., Kolari, P., Koyama, K., Limousin, J.-M., Meir, P., Lola da Costa, A. C., Mikkelsen, T. N., Salinas, N., Sun, W., and Wingate, L.: Optimal stomatal behaviour around the world, Nat. Clim. Change, 5, 459–464, 2015. a, b, c, d, e, f, g
Liu, Y., Parolari, A. J., Kumar, M., Huang, C.-W., Katul, G. G., and Porporato, A.: Increasing atmospheric humidity and CO2 concentration alleviate forest mortality risk, P. Natl. Acad. Sci. USA, 114, 9918–9923, 2017. a
Liu, Y., Kumar, M., Katul, G. G., Feng, X., and Konings, A. G.: Plant hydraulics accentuates the effect of atmospheric moisture stress on transpiration, Nat. Clim. Change, 10, 691–695, https://doi.org/10.1038/s41558-020-0781-5, 2020a. a, b, c, d, e, f, g, h
Liu, Y., Holtzman, N. M., Konings, A. G., Model-data fusion to retrieve global ecosystem-scale plant hydraulic traits, GitHub [code], available at: https://github.com/YanlanLiu/VOD_hydraulics, last access: 8 December 2020b. a
Liu, Y. Y., de Jeu, R. A. M., McCabe, M. F., Evans, J. P., and van Dijk, A. I. J. M.: Global long-term passive microwave satellite-based retrievals of vegetation optical depth, Geophys. Res. Lett., 38, L18402, https://doi.org/10.1029/2011GL048684, 2011. a
Liu, Y. Y., van Dijk, A. I. J. M., de Jeu, R. A. M., Canadell, J. G., McCabe, M. F., Evans, J. P., and Wang, G.: Recent reversal in loss of global terrestrial biomass, Nat. Clim. Change, 5, 470–474, 2015. a
Ma, Z., Peng, C., Zhu, Q., Chen, H., Yu, G., Li, W., Zhou, X., Wang, W., and Zhang, W.: Regional drought-induced reduction in the biomass carbon sink of Canada's boreal forests, P. Natl. Acad. Sci. USA, 109, 2423–2427, 2012. a
MacQueen, J.: Some methods for classification and analysis of multivariate observations, in: Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, The Regents of the University of California, Oakland, CA, USA, 1967. a
Manoli, G., Domec, J.-C., Novick, K., Oishi, A. C., Noormets, A., Marani, M., and Katul, G.: Soil–plant–atmosphere conditions regulating convective cloud formation above southeastern US pine plantations, Glob. Change Biol., 22, 2238–2254, 2016. a
Manzoni, S., Vico, G., Katul, G., Fay, P. A., Polley, W., Palmroth, S., and Porporato, A.: Optimizing stomatal conductance for maximum carbon gain under water stress: a meta-analysis across plant functional types and climates, Funct. Ecol., 25, 456–467, 2011. a
Manzoni, S., Vico, G., Porporato, A., and Katul, G.: Biological constraints on water transport in the soil–plant–atmosphere system, Adv. Water Resour., 51, 292–304, 2013. a
Manzoni, S., Katul, G., and Porporato, A.: A dynamical system perspective on plant hydraulic failure, Water Resour. Res., 50, 5170–5183, 2014. a
Martin-StPaul, N., Delzon, S., and Cochard, H.: Plant resistance to drought depends on timely stomatal closure, Ecol. Lett., 20, 1437–1447, 2017. a, b
Martínez-Vilalta, J. and Garcia-Forner, N.: Water potential regulation, stomatal behaviour and hydraulic transport under drought: deconstructing the iso/anisohydric concept, Plant Cell Environ., 40, 962–976, 2017. a
Martínez-Vilalta, J., Poyatos, R., Aguadé, D., Retana, J., and Mencuccini, M.: A new look at water transport regulation in plants, New Phytol., 204, 105–115, 2014. a, b
Matheny, A. M., Fiorella, R. P., Bohrer, G., Poulsen, C. J., Morin, T. H., Wunderlich, A., Vogel, C. S., and Curtis, P. S.: Contrasting strategies of hydraulic control in two codominant temperate tree species, Ecohydrol., 10, e1815, https://doi.org/10.1002/eco.1815, 2017. a
McDowell, N., Pockman, W. T., Allen, C. D., Breshears, D. D., Cobb, N., Kolb, T., Plaut, J., Sperry, J., West, A., Williams, D. G., and Yepez, E. A.: Mechanisms of plant survival and mortality during drought: why do some plants survive while others succumb to drought?, New Phytol., 178, 719–739, 2008. a
McDowell, N. G., Williams, A. P., Xu, C., Pockman, W. T., Dickman, L. T., Sevanto, S., Pangle, R., Limousin, J., Plaut, J., Mackay, D. S., Ogee, J., Domec, J. C., Allen, C. D., Fisher, R. A., Jiang, X., Muss, J. D., Breshears, D. D., Rauscher, S. A., and Koven, C.: Addendum: Multi-scale predictions of massive conifer mortality due to chronic temperature rise, Nat. Clim. Change, 6, 1048–1048, 2016. a
McDowell, N. G., Brodribb, T. J., and Nardini, A.: Hydraulics in the 21st century, New Phytol., 224, 537–542, 2019. a, b
Medlyn, B. E., Dreyer, E., Ellsworth, D., Forstreuter, M., Harley, P. C., Kirschbaum, M. U. F., Le Roux, X., Montpied, P., Strassemeyer, J., Walcroft, A., Wang, K., and Loustau, D.: Temperature response of parameters of a biochemically based model of photosynthesis. II. A review of experimental data, Plant Cell Environ., 25, 1167–1179, 2002. a
Medlyn, B. E., Duursma, R. A., Eamus, D., Ellsworth, D. S., Prentice, I. C., Barton, C. V. M., Crous, K. Y., de Angelis, P., Freeman, M., and Wingate, L.: Reconciling the optimal and empirical approaches to modelling stomatal conductance, Glob. Change Biol., 17, 2134–2144, https://doi.org/10.1111/j.1365-2486.2010.02375.x, 2011. a, b
Meinzer, F. C., Smith, D. D., Woodruff, D. R., Marias, D. E., McCulloh, K. A., Howard, A. R., and Magedman, A. L.: Stomatal kinetics and photosynthetic gas exchange along a continuum of isohydric to anisohydric regulation of plant water status, Plant Cell Environ., 40, 1618–1628, 2017. a
Momen, M., Wood, J. D., Novick, K. A., Pangle, R., Pockman, W. T., McDowell, N. G., and Konings, A. G.: Interacting effects of leaf water potential and biomass on vegetation optical depth, J. Geophys. Res.-Biogeo., 122, 3031–3046, 2017. a, b, c, d, e, f, g
Mrad, A., Sevanto, S., Domec, J.-C., Liu, Y., Nakad, M., and Katul, G.: A Dynamic Optimality Principle for Water Use Strategies Explains Isohydric to Anisohydric Plant Responses to Drought, Frontiers in Forests and Global Change, 2, 49, https://doi.org/10.3389/ffgc.2019.00049, 2019. a
Myneni, R., Knyazikhin, Y., and Park, T.: MCD15A3H MODIS/Terra+Aqua Leaf Area Index/FPAR 4-day L4 Global 500m SIN Grid V006, nASA EOSDIS Land Processes DAAC, NASA EOSDIS Land Processes DAAC, https://doi.org/10.5067/MODIS/MCD15A3H.006, 2015. a
Nearing, G. S., Crow, W. T., Thorp, K. R., Moran, M. S., Reichle, R. H., and Gupta, H. V.: Assimilating remote sensing observations of leaf area index and soil moisture for wheat yield estimates: An observing system simulation experiment, Water Resour. Res., 48, 687, https://doi.org/10.1029/2011WR011420, 2012. a
Novick, K. A., Konings, A. G., and Gentine, P.: Beyond soil water potential: An expanded view on isohydricity including land–atmosphere interactions and phenology, Plant Cell Environ., 42, 1802–1815, 2019. a
Owe, M., de Jeu, R., and Holmes, T.: Multisensor historical climatology of satellite-derived global land surface moisture, J. Geophys. Res.-Earth, 113, F01002, https://doi.org/10.1029/2007jf000769, 2008. a
Parinussa, R. M., Holmes, T. R. H., Wanders, N., Dorigo, W. A., and de Jeu, R. A. M.: A Preliminary Study toward Consistent Soil Moisture from AMSR2, J. Hydrometeorol., 16, 932–947, 2015. a
Parinussa, R. M., De Jeu, R. A. M., Van der Schalie, R., Crow, W. T., Lei, F., and Holmes, T. R. H.: A Quasi-Global Approach to Improve Day-Time Satellite Surface Soil Moisture Anomalies through the Land Surface Temperature Input, Climate, 4, 50, https://doi.org/10.3390/cli4040050, 2016. a
Parr, C. S., Wilson, N., Leary, P., Schulz, K. S., Lans, K., Walley, L., Hammock, J. A., Goddard, A., Rice, J., Studer, M., Holmes, J. T. G., and Corrigan Jr., R. J.: The Encyclopedia of Life v2: Providing Global Access to Knowledge About Life on Earth, Biodivers Data J., 2, e1079, https://doi.org/10.3897/BDJ.2.e1079, 2014. a
Parrens, M., Mahfouf, J.-F., Barbu, A. L., and Calvet, J.-C.: Assimilation of surface soil moisture into a multilayer soil model: design and evaluation at local scale, Hydrol. Earth Syst. Sci., 18, 673–689, https://doi.org/10.5194/hess-18-673-2014, 2014. a
Phillips, O. L., Aragão, L. E. O. C., Lewis, S. L., Fisher, J. B., Lloyd, J., López-González, G., Malhi, Y., Monteagudo, A., Peacock, J., Quesada, C. A., van der Heijden, G., Almeida, S., Amaral, I., Arroyo, L., Aymard, G., Baker, T. R., Bánki, O., Blanc, L., Bonal, D., Brando, P., Chave, J., de Oliveira, A. C. A., Cardozo, N. D., Czimczik, C. I., Feldpausch, T. R., Freitas, M. A., Gloor, E., Higuchi, N., Jiménez, E., Lloyd, G., Meir, P., Mendoza, C., Morel, A., Neill, D. A., Nepstad, D., Patiño, S., Peñuela, M. C., Prieto, A., Ramírez, F., Schwarz, M., Silva, J., Silveira, M., Thomas, A. S., Steege, H. T., Stropp, J., Vásquez, R., Zelazowski, P., Alvarez Dávila, E., Andelman, S., Andrade, A., Chao, K.-J., Erwin, T., Di Fiore, A., Honorio C, E., Keeling, H., Killeen, T. J., Laurance, W. F., Peña Cruz, A., Pitman, N. C. A., Núñez Vargas, P., Ramírez-Angulo, H., Rudas, A., Salamão, R., Silva, N., Terborgh, J., and Torres-Lezama, A.: Drought sensitivity of the Amazon rainforest, Science, 323, 1344–1347, 2009. a
Poulter, B., Ciais, P., Hodson, E., Lischke, H., Maignan, F., Plummer, S., and Zimmermann, N. E.: Plant functional type mapping for earth system models, Geosci. Model Dev., 4, 993–1010, https://doi.org/10.5194/gmd-4-993-2011, 2011. a
Powell, T. L., Wheeler, J. K., de Oliveira, A. A. R., da Costa, A. C. L., Saleska, S. R., Meir, P., and Moorcroft, P. R.: Differences in xylem and leaf hydraulic traits explain differences in drought tolerance among mature Amazon rainforest trees, Glob. Change Biol., 23, 4280–4293, 2017. a
Quetin, G. R., Bloom, A. A., Bowman, K. W., and Konings, A. G.: Carbon Flux Variability From a Relatively Simple Ecosystem Model With Assimilated Data Is Consistent With Terrestrial Biosphere Model Estimates, J. Adv. Model. Earth Sy., 12, e2019MS001889, https://doi.org/10.1029/2019MS001889, 2020. a
Reichle, R. H. and Koster, R. D.: Bias reduction in short records of satellite soil moisture, Geophys. Res. Lett., 31, L1590, https://doi.org/10.1029/2004gl020938, 2004. a
Rodell, M., Houser, P. R., Jambor, U., Gottschalck, J., Mitchell, K., Meng, C.-J., Arsenault, K., Cosgrove, B., Radakovich, J., Bosilovich, M., Entin, J. K., Walker, J. P., Lohmann, D., and Toll, D.: The Global Land Data Assimilation System, B. Am. Meteorol. Soc., 85, 381–394, 2004. a
Roman, D. T., Novick, K. A., Brzostek, E. R., Dragoni, D., Rahman, F., and Phillips, R. P.: The role of isohydric and anisohydric species in determining ecosystem-scale response to severe drought, Oecologia, 179, 641–654, 2015. a
Sack, L., Ball, M. C., Brodersen, C., Davis, S. D., Des Marais, D. L., Donovan, L. A., Givnish, T. J., Hacke, U. G., Huxman, T., Jansen, S., Jacobsen, A. L., Johnson, D. M., Koch, G. W., Maurel, C., McCulloh, K. A., McDowell, N. G., McElrone, A., Meinzer, F. C., Melcher, P. J., North, G., Pellegrini, M., Pockman, W. T., Brandon Pratt, R., Sala, A., Santiago, L. S., Savage, J. A., Scoffoni, C., Sevanto, S., Sperry, J., Tyerman, S. D., Way, D., and Michele Holbrook, N.: Plant hydraulics as a central hub integrating plant and ecosystem function: meeting report for “Emerging Frontiers in Plant Hydraulics” (Washington, DC, May 2015), Plant Cell Environ., 39, 2085–2094, 2016. a, b
Savitzky, A. and Golay, M. J. E.: Smoothing and Differentiation of Data by Simplified Least Squares Procedures, Anal. Chem., 36, 1627–1639, 1964. a
Smith, N. G., Keenan, T. F., Colin Prentice, I., Wang, H., Wright, I. J., Niinemets, Ü., Crous, K. Y., Domingues, T. F., Guerrieri, R., Yoko Ishida, F., Kattge, J., Kruger, E. L., Maire, V., Rogers, A., Serbin, S. P., Tarvainen, L., Togashi, H. F., Townsend, P. A., Wang, M., Weerasinghe, L. K., and Zhou, S.-X.: Global photosynthetic capacity is optimized to the environment, Ecol. Lett., 22, 506–517, 2019. a
Sperry, J. S., Venturas, M. D., Anderegg, W. R. L., Mencuccini, M., Mackay, D. S., Wang, Y., and Love, D. M.: Predicting stomatal responses to the environment from the optimization of photosynthetic gain and hydraulic cost, Plant Cell Environ., 40, 816–830, 2017. a
Su, C.-H., Ryu, D., Young, R. I., Western, A. W., and Wagner, W.: Inter-comparison of microwave satellite soil moisture retrievals over the Murrumbidgee Basin, southeast Australia, Remote Sens. Environ., 134, 1–11, 2013. a
Tardieu, F. and Simonneau, T.: Variability among species of stomatal control under fluctuating soil water status and evaporative demand: modelling isohydric and anisohydric behaviours, J. Exp. Bot., 49, 419–432, 1998. a
Teubner, I. E., Forkel, M., Camps-Valls, G., Jung, M., Miralles, D. G., Tramontana, G., van der Schalie, R., Vreugdenhil, M., Mösinger, L., and Dorigo, W. A.: A carbon sink-driven approach to estimate gross primary production from microwave satellite observations, Remote Sens. Environ., 229, 100–113, 2019. a
Tian, F., Brandt, M., Liu, Y. Y., Rasmussen, K., and Fensholt, R.: Mapping gains and losses in woody vegetation across global tropical drylands, Glob. Change Biol., 23, 1748–1760, 2017. a
Tian, F., Wigneron, J.-P., Ciais, P., Chave, J., Ogée, J., Peñuelas, J., Ræbild, A., Domec, J.-C., Tong, X., Brandt, M., Mialon, A., Rodriguez-Fernandez, N., Tagesson, T., Al-Yaari, A., Kerr, Y., Chen, C., Myneni, R. B., Zhang, W., Ardö, J., and Fensholt, R.: Coupling of ecosystem-scale plant water storage and leaf phenology observed by satellite, Nat. Ecol. Evol., 2, 1428–1435, 2018. a
Tong, X., Tian, F., Brandt, M., Liu, Y., Zhang, W., and Fensholt, R.: Trends of land surface phenology derived from passive microwave and optical remote sensing systems and associated drivers across the dry tropics 1992–2012, Remote Sens. Environ., 232, 111307, https://doi.org/10.1016/j.rse.2019.111307, 2019. a
Trugman, A. T., Anderegg, L. D. L., Shaw, J. D., and Anderegg, W. R. L.: Trait velocities reveal that mortality has driven widespread coordinated shifts in forest hydraulic trait composition, P. Natl. Acad. Sci. USA, 117, 8532–8538, 2020. a, b, c, d
USDA, NRCS: The PLANTS Database, national Plant Data Team, Greensboro, NC 27401-4901 USA, available at: http://plants.usda.gov, last access: 10 September 2020. a
Verheijen, L. M., Brovkin, V., Aerts, R., Bönisch, G., Cornelissen, J. H. C., Kattge, J., Reich, P. B., Wright, I. J., and van Bodegom, P. M.: Impacts of trait variation through observed trait–climate relationships on performance of an Earth system model: a conceptual analysis, Biogeosciences, 10, 5497–5515, https://doi.org/10.5194/bg-10-5497-2013, 2013. a
Vrije Universiteit Amsterdam and NASA GSFC: AMSR-E/Aqua surface soil moisture (LPRM) L3 1 day 25 km × 25 km descending V002, edited by Goddard Earth Sciences Data and Information Services Center (GES DISC), Greenbelt, MD, USA, Goddard Earth Sciences Data and Information Services Center (GES DISC), https://doi.org/10.5067/MXL0MFDHWP07, 2016. a
Walker, A. P., Quaife, T., van Bodegom, P. M., De Kauwe, M. G., Keenan, T. F., Joiner, J., Lomas, M. R., MacBean, N., Xu, C., Yang, X., and Woodward, F. I.: The impact of alternative trait-scaling hypotheses for the maximum photosynthetic carboxylation rate (Vcmax) on global gross primary production, New Phytol., 215, 1370–1386, 2017. a
Wang, K. and Dickinson, R. E.: A review of global terrestrial evapotranspiration: Observation, modeling, climatology, and climatic variability, Rev. Geophys., 50, RG2005, https://doi.org/10.1029/2011RG000373, 2012. a
Wang, Y.-P., Trudinger, C. M., and Enting, I. G.: A review of applications of model–data fusion to studies of terrestrial carbon fluxes at different scales, Agr. Forest Meteorol., 149, 1829–1842, 2009. a
Wolf, S., Keenan, T. F., Fisher, J. B., Baldocchi, D. D., Desai, A. R., Richardson, A. D., Scott, R. L., Law, B. E., Litvak, M. E., Brunsell, N. A., Peters, W., and van der Laan-Luijkx, I. T.: Warm spring reduced carbon cycle impact of the 2012 US summer drought, P. Natl. Acad. Sci. USA, 113, 5880–5885, 2016. a
Wu, G., Guan, K., Li, Y., Novick, K. A., Feng, X., McDowell, N. G., Konings, A. G., Thompson, S. E., Kimball, J. S., De Kauwe, M. G., Ainsworth, E. A., and Jiang, C.: Interannual variability of ecosystem iso/anisohydry is regulated by environmental dryness, New Phytol., 229, 2562–2575, https://doi.org/10.1111/nph.17040, 2020. a
Xu, X., Medvigy, D., Powers, J. S., Becknell, J. M., and Guan, K.: Diversity in plant hydraulic traits explains seasonal and inter-annual variations of vegetation dynamics in seasonally dry tropical forests, New Phytol., 212, 80–95, 2016. a, b
Zhang, Y., Zhou, S., Gentine, P., and Xiao, X.: Can vegetation optical depth reflect changes in leaf water potential during soil moisture dry-down events?, Remote Sens. Environ., 234, 111451, https://doi.org/10.1016/j.rse.2019.111451, 2019. a