the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 21 Aug 2020
| 21 Aug 2020
Estimation of annual runoff by exploiting long-term spatial patterns and short records within a geostatistical framework
Ingelin Steinsland
Kolbjørn Engeland
In this article, we present a Bayesian geostatistical framework that is particularly suitable for interpolation of hydrological data when the available dataset is sparse and includes both long and short records of runoff. A key feature of the proposed framework is that several years of runoff are modelled simultaneously with two spatial fields: one that is common for all years under study that represents the runoff generation due to long-term (climatic) conditions and one that is year-specific. The climatic spatial field captures how short records of runoff from partially gauged catchments vary relative to longer time series from other catchments, and transfers this information across years. To make the Bayesian model computationally feasible and fast, we use integrated nested Laplace approximations (INLAs) and the stochastic partial differential equation (SPDE) approach to spatial modelling.
The geostatistical framework is demonstrated by filling in missing values of annual runoff and by predicting mean annual runoff for around 200 catchments in Norway. The predictive performance is compared to top-kriging (interpolation method) and simple linear regression (record augmentation method). The results show that if the runoff is driven by processes that are repeated over time (e.g. orographic precipitation patterns), the value of including short records in the suggested model is large. For partially gauged catchments the suggested framework performs better than comparable methods, and one annual observation from the target catchment can lead to a 50 % reduction in root mean squared error (RMSE) compared to when no observations are available from the target catchment. We also find that short records safely can be included in the framework regardless of the spatial characteristics of the underlying climate, and down to record lengths of 1 year.
- Article
(7590 KB) - Full-text XML
- BibTeX
- EndNote





Characteristic values for streamflow are used for various purposes in water resource management. High-flow indices or design flood estimates are needed for flood risk assessments and design of infrastructure and dams, low-flow indices are needed for assessment of environmental flow and reliability assessment of water supply, while mean annual flow is an important basis for water resource management and a key for design of water supply systems and allocation of water resources between stakeholders. Mean annual flow can also be used as a predictor for low-flow and high-flow indices (Sælthun et al., 1997; Engeland and Hisdal, 2009).
At locations with measurements, the streamflow indices can be estimated based on observations. However, streamflow is only measured at a limited number of locations, and in many applications we need to predict the streamflow indices at ungauged locations. This is a central problem in hydrology and known as the Prediction in Ungauged Basins problem (Blöschl et al., 2013). Often it is of interest to estimate flow indices that represent the long-term average behaviour in a catchment. If this is the case, using only a few years of data from the target catchment might lead to biased estimates. The reason is climate variability over short timescales combined with sample uncertainty. Often a minimum record length is recommended for estimation of long-term indices, but a substantial part of the available streamflow gauges in the world have too short records to provide reliable estimates. These short data series can, however, provide useful information if they are used together with longer time series from other catchments (Laaha and Blöschl, 2005). Motivated by this, we propose a framework for runoff interpolation particularly suitable for datasets including data series of this type, more specifically runoff datasets including a mix of fully gauged catchments (with data available from the whole study period) and partially gauged catchments (with data available from a subset of the study period). We suggest a framework for runoff interpolation that unifies two commonly used statistical approaches for runoff estimation: geostatistical approaches and approaches for exploiting short records of data.
Within the geostatistical framework, Gaussian random fields (GRFs) are often used to model hydrological phenomena that are continuous in space and/or time. The hydrological variable of interest is a GRF if a vector containing a random sample of length n from the process follows a Gaussian distribution with mean vector μ and covariance matrix Σ (Cressie, 1993). The elements in the covariance matrix are typically determined by a covariance function that is specified based on the pairwise distances between the n target locations. For most environmental variables it is straightforward to compute these distances. However, for runoff-related variables the measure of distance is ambiguous because the observations are related to catchment areas, some of them nested, and not to point locations in space. Traditionally, this challenge has been solved by simply interpreting runoff as a point-referenced process linked to the catchment centroids or stream outlets (see e.g. Merz and Blöschl, 2005; Skøien et al., 2003; Adamowski and Bocci, 2001). The problem with these methods is that they can lead to a violation of basic conservation laws, and several alternatives approaches are suggested for making an interpolation scheme that takes the nested structure of catchments into account (Sauquet et al., 2000; Gottschalk, 1993; Skøien et al., 2006). In particular, the top-kriging approach suggested by Skøien et al. (2006) has shown promising results for interpolation of hydrological variables (Viglione et al., 2013). In the top-kriging approach, information from a subcatchment is weighted more than information from a nearby non-overlapping catchment when performing runoff predictions for an ungauged catchment.
In the literature, there exist several techniques to exploit short records of runoff, and these are known as record augmentation techniques. The first step in a record augmentation procedure is often to find one or several donor catchments with longer time series of runoff. The donor catchments are typically selected based on runoff correlation, catchment similarity, or proximity in space. By applying e.g. linear regression approaches and/or computing the correlation between time series, a relationship between the target catchment and the donor catchments is developed. Next, the longer time series from the donor catchment(s) are used to perform predictions for the target catchments for years/months/days without measurements (see e.g. Fiering, 1963, Hirsch, 1982, Matalas and Jacobs, 1964, Vogel and Stedinger, 1985 or Laaha and Blöschl, 2005). The regression and/or correlation analysis is performed based on runoff observations that are of the same type as the target flow index; i.e. for annual runoff, short records of annual runoff are used (Blöschl et al., 2013).
In this paper, we suggest a geostatistical Bayesian framework that represents a new way of exploiting short records of data. The framework is constructed to exploit long-term spatial patterns stored in sparse datasets, i.e. hydrological datasets with several missing values. A key feature of the suggested framework is that it simultaneously models several years of runoff. This is done by using two statistical spatial components or GRFs in the hydrological model: the first GRF is common for all years under study and models the long-term spatial variability of runoff. We denote this the climatic GRF as it represents the spatial variability over time, or what we refer to as the climate in the study area. In this context the term climate also includes the runoff generation due to catchment characteristics that are static, like elevation and slope. The other GRF is year-specific and models the annual discrepancy from the climate, and we denote this the annual or year-specific GRF. If we have a study area for which the spatial variability of runoff is stable over time, the climatic GRF will capture this tendency. Hence, it will also capture how short records of runoff vary relative to longer data series from other catchments. On the other hand, if there are no strong long-term trends present in the data, the year-specific GRF will dominate over the climatic GRF. For this scenario, short records from the target catchment(s) will have less impact on the final results. By adjusting the two spatial fields relative to each other, our method represents a way for detecting long-term trends and uses this to exploit short records in the runoff interpolation.
The framework we suggest is flexible and can be used for any hydrological variable. However, its benefits are linked to exploiting long-term spatial trends in the data, and in order to work better than other interpolation methods, the hydrological variable of interest should be driven by processes that are repeated over time. For this reason, we develop our methodology for annual runoff. This is a flow index that often has a prominent spatial pattern over years, for example due to orographic precipitation and topography that creates weather divides. To describe study areas and/or variables like this, we hereby introduce the terms hydrologically spatially stable and hydrological spatial stability. For hydrologically spatially stable areas, the difference in runoff between two locations for a given year is close to the difference in runoff between these two locations any other year. Be aware that a hydrologically spatially stable area can both have large differences in annual runoff between two close locations and have large variability in annual runoff over years for a given location. The key property is that the underlying spatial pattern is preserved over time.
While annual runoff represents a hydrologically spatially stable variable for many countries, the spatial pattern for monthly runoff is typically less stable. This is due to local weather patterns and the variability in the seasonality of snow accumulation and snowmelt. To demonstrate our methodology for a variable with less hydrological spatial stability, we therefore fit the framework to annual time series of monthly runoff. These predictions allow us to discuss how the approach might work in different regions.
In the following presentation, we introduce two versions of our framework, i.e. two geostatistical models. The first model we propose is denoted the areal model and is particularly suitable for mass-conserved hydrological variables. It ensures that the water balance is preserved for the predicted runoff for any point in the landscape and defines the average runoff in a catchment as the average point runoff integrated over (nested) catchment areas. This way, the nested structure of catchments is taken into account, and the interpretation of covariance between two catchments is similar to the one of top-kriging. The areal model for annual runoff is already presented in Roksvåg et al. (2020), where its mass-conserving properties were demonstrated through an example from Voss in western Norway. The model's ability to exploit short data records was also indicated in Roksvåg et al. (2020), but the property was not tested for a larger dataset or compared to any existing methods. This is a key contribution of this article.
As an alternative to the areal model, we also propose a model that defines runoff as a point-referenced process for which distances are measured between the catchment centroids. This model does not consider preservation of water balance, but on the other hand it can be used for any point-referenced environmental variable, and it is computationally faster than the areal model. This model is more similar to models that have been used traditionally in hydrology, and we denote this the centroid model. Both the areal model and the centroid model have the ability to exploit hydrological spatial stability but have different benefits, drawbacks and hence also areas of use. These are discussed and highlighted throughout the article.
The main objective of this work is to present and evaluate the new geostatistical framework for exploiting short records and to compare its performance to top-kriging (interpolation method) and simple linear regression (record augmentation technique). In particular our goals are to
-
assess the two spatial models' ability to fill in missing annual observations of runoff for ungauged and partially gauged catchments; and
-
assess the two spatial models' ability to predict mean annual runoff for a longer time period for catchments with varying record lengths.
Through (1) and (2) we also aim to
- 3.
demonstrate the potential added value of including short records in the modelling, compared to when not using them or compared to when using traditional methods.
The framework is evaluated by using annual and monthly runoff data from catchments in Norway. This dataset is presented in the section that follows (Sect. 2). Next, in Sect .3, we briefly introduce relevant statistical background theory and notation. In Sect. 4 the suggested model for annual runoff is presented, before evaluation scores and experimental set-up are presented in Sect. 5. Here, we have one experimental set-up for annual predictions (Sect. 5.1) and one set-up for mean annual predictions (Sect. 5.2). In Sect. 6, the results are presented before they are discussed in Sect. 7. Finally, we conclude in Sect. 8.
The study is carried out by using a dataset from Norway provided by the Norwegian Water Resources and Energy Directorate (NVE). It originally consisted of daily runoff data from 1981 to 2010. To make the data suitable for an analysis, a data preparation procedure was performed to construct datasets for two purposes: for assessing the framework's ability to fill in missing annual data and for assessing the framework's ability to predict mean annual runoff.
To make a cross-validation dataset for the experiments related to infill of missing annual data, the daily runoff data were aggregated to annual runoff data for hydrological years that start on 1 September and end on 31 August. We chose to consider a study period from 1996 to 2005: for this period we had the maximum number of fully gauged catchments, i.e. 180 catchments. These 180 fully gauged catchments have areas ranging from 13 to 15 500 km2 and median elevations from 85 to 1562 m a.s.l. Among these, none were significantly influenced by human activities in the time period of interest. Regulated catchments were removed from the original dataset.
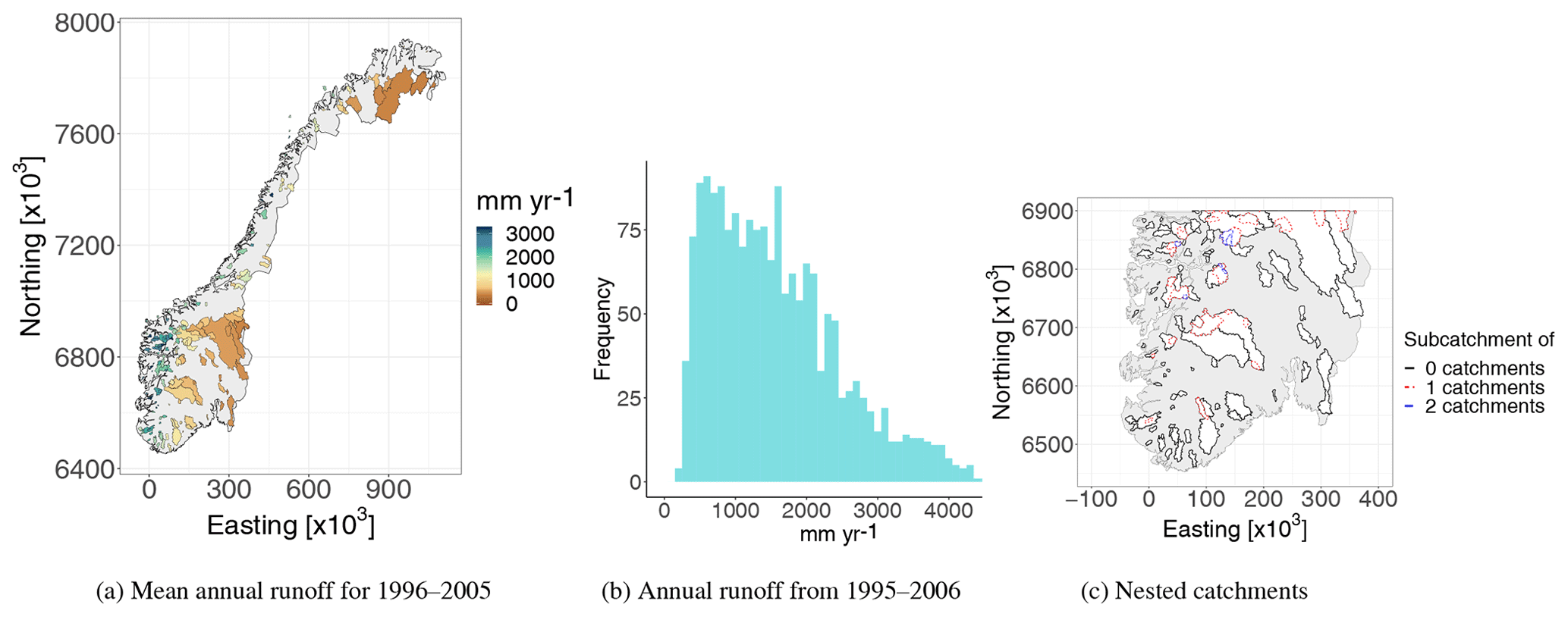
Figure 1Mean annual runoff (1996–2005) from 180 fully gauged catchments in Norway (a) and annual runoff observations from all 180 catchments and years (b). These data are used to evaluate the framework's ability to fill in missing values for individual years. Thirty percent of the involved catchments are nested and most of these are located in southern Norway as visualized in (c). In (c), coloured catchments are subcatchments of at least one larger catchment, while the black catchments are not subcatchments of any larger catchments (but might contain one or two smaller catchments). In the visualization in (a), subcatchments are plotted on top of larger catchments, and this is done throughout the article. The coordinate system used is EUREF89 – UTM33N (EPSG 25833). See Fig. 7 for a closer image of the observed mean annual runoff in southern Norway (1996–2005).
Figure 1a and b show two visualizations of the annual data from the 180 Norwegian target catchments. We see a large spatial variability of runoff. The annual runoff (for individual years) ranges from 170 to 5050 mm yr−1, whereas the mean annual runoff ranges from 350 to 4230 mm yr−1, with the highest values of runoff in western Norway and more moderate values in the east and north. In total 53 of the 180 catchments were nested with at least one other catchment; i.e. the degree of nestedness is 30 %. Most of these are located in southern Norway, and the nested structure here is shown in Fig. 1c. The remaining 127 catchments did not overlap with any other catchment.

Figure 2Seven catchments located in western Norway (a) and their annual runoff (b). The seven time series in (b) are almost parallel (and barely cross), indicating that most of the spatial variability can be explained by long-term spatial patterns. This represents a good example of what we mean by hydrological spatial stability.
In the Norwegian annual data in Fig. 1a we see an east–west pattern of runoff. This is mainly caused by orographic enhancement of frontal precipitation formed around extratropical cyclones. The orographic enhancement is driven by the steep mountains in western Norway that create a topographic barrier for the western wind belt, which transports moist air across the North Atlantic (Stohl et al., 2008). Due to the orographic enhancement, the maximum precipitation is observed at distances 30–70 km from the coast (Førland, 1979) and not necessarily at the highest elevations since the air dries out due to precipitation. The topography results in a spatial pattern of runoff that is stable over years, which means that there exist long-term spatial patterns in the data that can be exploited.
Figure 2 shows time series of annual runoff from seven catchments in the south-western part of the country. We see a year-to-year variation for all catchments that is quite large. However, the seven time series are almost parallel (and almost never cross), indicating that the difference in annual runoff between stations is approximately constant over time. Hence, this is a good example of what we mean by hydrological spatial stability. The tendency we see in Fig. 2 is typical for the annual runoff in many of the areas in Norway.
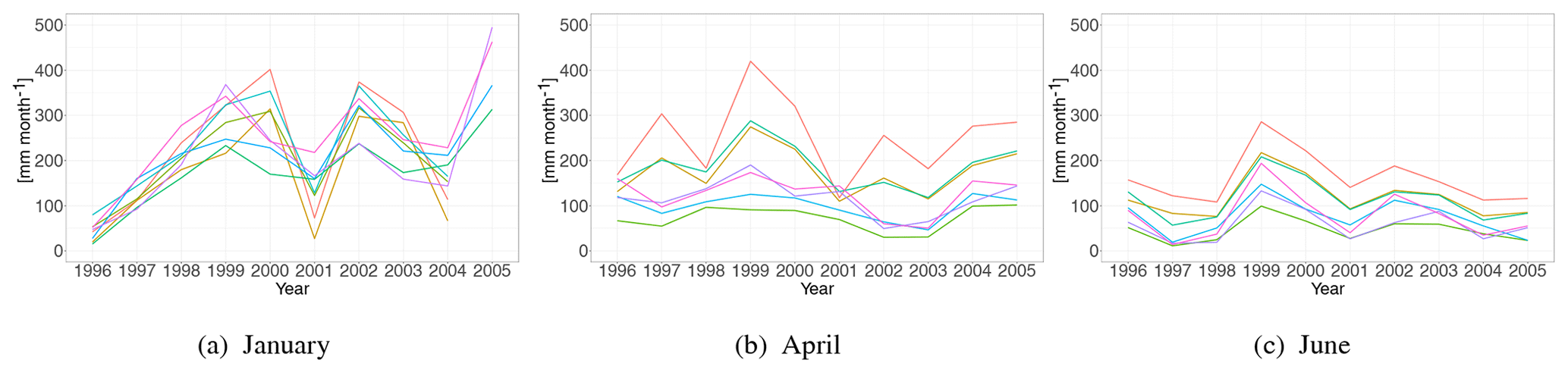
Figure 3Annual series of monthly runoff for January, April and June for the 7 catchments in Fig. 2a. The time series for January and April are less parallel compared to the time series for June and to the annual runoff (Fig. 2b). This suggests that the datasets from January and April represent a more hydrologically spatially unstable setting.
To illustrate the framework's properties for study areas and/or variables that are driven by more unstable weather patterns or hydrological processes, we also aggregated the daily runoff data to monthly runoff for the 180 catchments in Fig. 1a. From this we made annual time series of monthly runoff for 1996–2005 for 3 months: a winter month dominated by snow accumulation (January), a spring month with snowmelt (April) and a summer month dominated by rain (June). The annual observations of monthly runoff for the selected months are presented in Fig. 4, and we see that January has the lowest average runoff, whereas June has the highest. The variation in average monthly runoff describes a runoff regime, and in Norway the combination of snow accumulation, snowmelt, and evapotranspiration processes controls this regime (Gottschalk et al., 1979). Along the western coast, the winter weather is typically rainy with temperatures above the freezing point. In these regions the highest monthly runoff is observed in October–December. The colder areas are found in the interior of the country with winters dominated by snow accumulation. In these regions the highest monthly runoff is observed for the snowmelt season (May–June).
Annual time series of monthly runoff from the seven selected catchments from Fig. 2a are shown in Fig. 3. We see that the spatial pattern is less stable on a monthly scale compared to the annual scale, particularly for January: the difference in monthly runoff between stations over time is not approximately constant for January, and the runoff in January hence represents a more hydrologically spatially unstable variable in Norway. For June, however, the hydrological spatial stability is higher.
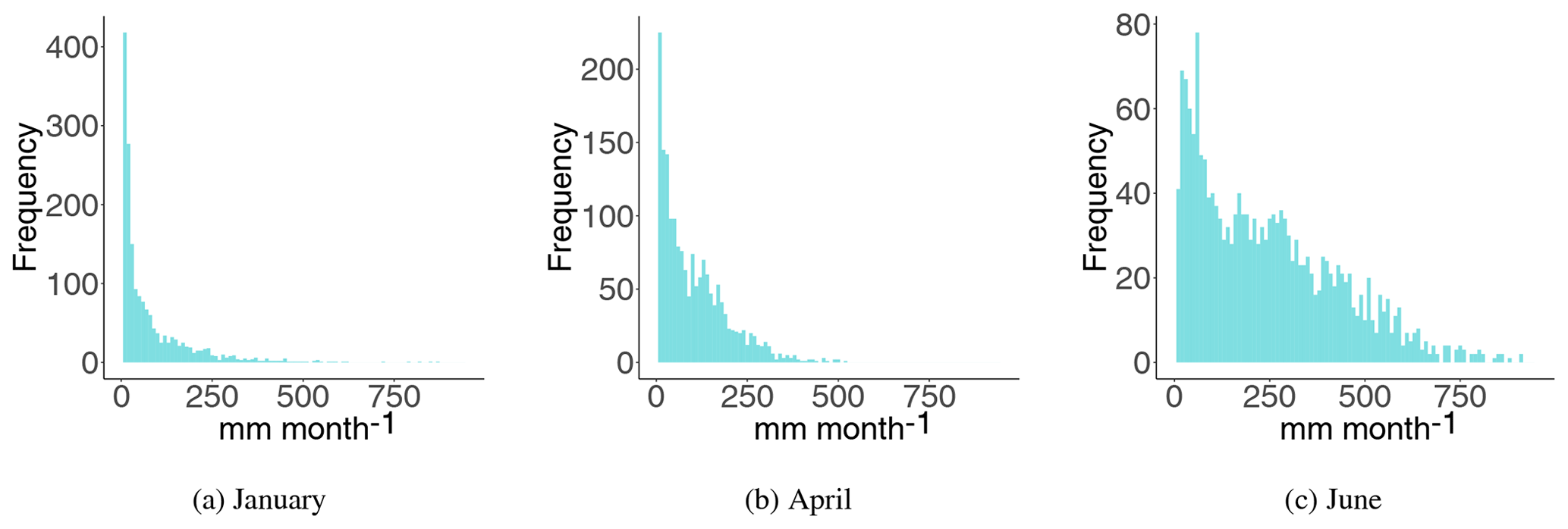
Figure 4Monthly runoff data (1996–2005) from 180 catchments in Norway for January, April and June. These are used to evaluate the framework's ability to fill in missing values for hydrological variables and/or study areas that are driven by more unstable weather patterns.
The cross-validation datasets described so far are used to assess the framework's ability to fill in missing annual observations for a 10-year period and to illustrate how the models behave for different hydrological settings. In addition, we also evaluate the framework's ability to predict mean annual runoff, which is a key hydrological signature. This is done for a 30-year period from 1981 to 2010. As we consider a longer time period for this assessment, a different subset of the original dataset was used: more specifically, annual data from 260 catchments located in southern Norway. These are shown in Fig. 5. Each of the 260 catchments in Fig. 5 have at least one observation of annual runoff between 1981 and 2010, but only 83 of them are fully gauged in the time period of interest (i.e. have annual observations for all 30 years). Among the partially gauged catchments, the mean record length is 15, while the median record length is 13. Furthermore, 20 of the involved catchments only have one, two or three annual observations. As for the previously described datasets, we removed regulated catchments that were significantly influenced by human activity. Also note that we in this experiment only consider catchments from southern Norway. This is done to reduce the computational complexity of fitting 30 years of runoff simultaneously in a cross-validation setting.

Figure 5Mean annual runoff for 1981–2010 for 260 catchments in southern Norway, where only 83 of them are fully gauged (i.e. have annual data for each year in the study period). The 83 fully gauged catchments have black borders in the above plot. In addition, there are data available from 177 so-called partially gauged catchments. These have at least one annual observation between 1981 and 2010 and are visible as catchments without borders in the above figure. Among the 83 fully gauged catchments, 44 catchments are nested (53 %), while 39 catchments do not overlap with any other catchment in the dataset. Data from the catchments in this figure are used to evaluate the framework's ability to estimate mean annual runoff.
When using the data in Fig. 5 to predict mean annual runoff, we do predictions by cross-validation for the 83 fully gauged catchments. However, data from both partially gauged and fully gauged catchments are included in the observation sample (see Sect. 5.2). For the 83 fully gauged catchments in Fig. 5, 53 % of the catchments were nested with a fully gauged or partially gauged catchment.
In Sect. 4 we present two Bayesian geostatistical models for runoff interpolation particularly suitable for sparse datasets containing several missing values. First, some statistical background is necessary.
3.1 Bayesian statistics and hierarchal modelling
The goal in hydrology is to learn about processes related to hydrological variables like daily rainfall, annual runoff or the 5th percentile flow. To gain knowledge about the different hydrological processes, relevant data are collected. There are always uncertainties related to the data that must be accounted for in an analysis, and which make a statistical analysis appropriate.
Assuming is a vector consisting of hydrological variables of interest, e.g. the annual runoff at several locations for a specific year, the observation likelihood π(y|x) expresses how the data are connected to the truth x. In the classical frequentist statistical approach, the variables in x are considered unknown but fixed. In the Bayesian approach, however, x is considered to be a quantity whose variation can be described by a probability distribution (see e.g. Casella and Berger, 1990). Prior to the analysis, this probability distribution is expressed through what is called a prior distribution π(x). This is constructed based on expert knowledge about the variable(s) of interest. The goal of the Bayesian analysis is to update the prior distribution by using data. Through Bayes' formula, the so-called posterior distribution of x is obtained:
Next, the marginal distribution π(xi|y) for xi∈x can be integrated out, and a prediction of xi can be summarized through e.g. the mean, median or the mode of the posterior distribution π(xi|y).
If a complex process is under study, it is sometimes easier to model it by thinking of its mechanisms in a hierarchy of underlying processes or distributions (Banerjee et al., 2004). The annual runoff x can e.g. be thought of as a process that depends on some parameters θ that express the spatial correlation between locations. Here, both x and θ are stochastic variables with prior (and posterior) distributions. A Bayesian model of this type is typically expressed as a three-stage hierarchical model where the first stage consists of the observation likelihood , the second stage is the prior distribution π(x|θ), often referred to as the latent model or process model, while the third stage is the prior distribution of the model parameters π(θ). As before, Bayes' formula can be used to make inference about the variables of interest x but also about the model parameters θ given the set of observations y. In this study we use a three-stage hierarchical Bayesian model to model annual runoff.
3.2 Gaussian random fields
GRFs are commonly used to model environmental variables like precipitation, runoff and temperature or other phenomena that are continuous in space and/or time. In this analysis, the second stage of the Bayesian hierarchical model consists of GRFs that model the spatial dependency of runoff between catchments. A continuous field defined on a spatial domain 𝒟∈ℛ2 is a GRF if for any collection of locations the vector follows a multivariate normal distribution (Cressie, 1993), i.e. where μ is a vector of expected values and Σ is the covariance matrix. The covariance matrix Σ defines the dependency structure in the spatial domain, and element (i,j) is typically constructed from a covariance function C(ui,uj). The dependency structure for a spatial process is often characterized by two parameters: the marginal variance σ2 and the range ρ. The marginal variance provides information about the spatial variability of the process of interest, while the range gives information about how the covariance between the process at two locations decays with distance. The range is defined as the distance at which the correlation between two locations in space has dropped to almost 0. If the range and the marginal variance are constant over the spatial domain, we have a stationary GRF.
In this study, the involved GRFs have their dependency structure specified by a stationary Matérn covariance function that is given by
Here, is the Euclidean distance between two locations , Kν is the modified Bessel function of the second kind and order ν>0, Γ(⋅) is the gamma function and σ2 is the marginal variance that controls the spatial variability (Guttorp and Gneiting, 2006). The parameter κ is a scale parameter, and it can be shown empirically that the spatial range can be expressed as , where ρ is defined as the distance at which the correlation between two locations has dropped to 0.1. Using a Matérn GRF is convenient for computational reasons because it makes it possible to use the stochastic partial differential equation (SPDE) approach to spatial modelling from Lindgren et al. (2011) which is briefly described in Sect. 4.3.
3.3 Kriging and top-kriging
Within the geostatistical framework, kriging approaches have shown promising results for interpolation of hydrological variables (see e.g. Gottschalk, 1993, Sauquet et al., 2000 or Merz and Blöschl, 2005). In kriging methods, the target variable is represented as a random field, typically a Gaussian random field x(u) defined through a covariance structure and some unknown parameters. The process of interest is observed at n locations , and any unknown parameters can be estimated based on e.g. maximum likelihood procedures. Furthermore, to estimate the value of the variable at an unobserved location u0 a weighted average of the observations is used, i.e.
where λi are interpolation weights and x(ui) for are observed values. The interpolation weights are computed by assuming that is the best linear unbiased estimator (BLUE) of x(u0). That is, we determine by finding the weights that both minimize the mean squared error and that give zero mean expected error (Cressie, 1993). Note that the consequence of the latter is that the kriging weights are restricted to sum to 1, i.e. if we assume that the process is homogeneous in space.
Further, to minimize the mean squared error of the kriging predictor in Eq. (3), the covariance function (or variogram) must be estimated and evaluated. The covariance function typically depends on the distance between the observations and the target locations, such that observations measured close to the target location u0 are weighted more than observations further away. In many hydrological applications, the centroids of the catchments are used to compute the catchment distances (Merz and Blöschl, 2005; Skøien et al., 2003), but as mentioned in the introduction this can lead to a violation of basic mass conservation laws. The reason is that streamflow variables are connected to (catchment) areas, not single point locations. Catchments are also organized into subcatchments, and this should be considered when computing the kriging weights.
The top-kriging approach suggested by Skøien et al. (2006) is an example of a kriging method that takes the nested structure of catchments into account. In this method, the streamflow observations are interpreted as areal referenced, and the covariance is computed based on the pairwise distances between all grid nodes in a discretization of the involved catchments. This way, observations from a subcatchment can be weighted more than observations from nearby, non-overlapping catchments. Top-kriging is currently one of the leading methods for interpolation of hydrological variables (Viglione et al., 2013) and is therefore chosen as a benchmark when we evaluate our new interpolation approach.
3.4 Methods for exploiting short records (record augmentation techniques)
The framework we suggest is both a framework for spatial interpolation and a framework for record augmentation. There exist several approaches for record augmentation for which many of them are based on developing a linear relationship between the target catchment and one or several catchments with longer time series of runoff (Fiering, 1963; Laaha and Blöschl, 2005; Matalas and Jacobs, 1964). One class of approaches is the maintenance of variance extension (MOVE) methods. MOVE methods are based on developing a linear relationship between the target catchment and the donor(s) catchment(s) by assuming that the sample mean and sample variance of runoff are maintained over time for the target catchment (Hirsch, 1982). There are different ways the sample mean and sample variance can be estimated, giving different estimators for the predicted runoff. Another way to develop a linear relationship between a donor and a target catchment is to use simple linear regression (Hirsch, 1982). In this article, we use simple linear regression as a benchmark method, in addition to top-kriging.
Assume annual runoff is observed for year in the target catchment and that there exist annual runoff data from some other catchments for year . Simple linear regression is performed by first finding a so-called donor catchment for the catchment of interest. This can be e.g. the closest catchment in space or a catchment with similar catchment characteristics (elevation, annual precipitation, vegetation). Next, it is assumed that there is a linear relationship between the annual runoff in the target catchment and the donor catchment, for , where yi is the annual runoff in the target catchment, xi is the annual runoff in the donor catchment, ϵi is normal distributed measurement error 𝒩(0,σ2) with fixed (but typically unknown) variance σ2, and β0 and β1 are coefficients that must be estimated. The linear relationship between the two catchments is developed by estimating β0 and β1 by minimizing the sum of least squares, . Next, the linear relationship can be used to estimate the runoff in the target catchment based on with corresponding uncertainty estimates.
In this section we present the suggested Bayesian geostatistical framework for runoff interpolation. We start by developing a three-stage hierarchical model for annual runoff consisting of a process model, an observation likelihood and prior distributions as described in Sect. 3.1. Next, we highlight two model properties that make the suggested framework different from most other methods used for interpolation in hydrology (Sect. 4.2) and explain how the framework is made computationally feasible (Sect. 4.3).
4.1 Hierarchical model for annual runoff
4.1.1 True annual runoff (process models)
Let the spatial process denote the runoff-generating process at a point location u in the spatial domain 𝒟∈ℛ2 in year j. The true annual runoff generated at point location u in year j is modelled as
where βc is an intercept common for all years that models the average runoff in the study area over time, while βj is a year-specific intercept that models the annual discrepancy from the long-term average runoff. Likewise is c(u) a spatial effect that models the long-term spatial variability of runoff that is caused by climatic conditions in the study area, while xj(u) is a year-specific spatial effect that models the spatial variability due to annual discrepancy from the climate. We emphasize that, in this context, climate is for simplicity used as a collective term that describes both runoff generation caused by long-term weather patterns and the runoff generation due to static catchment characteristics like e.g. elevation and slope. The two spatial effects are modelled as GRFs with zero mean and stationary Matérn covariance functions with ν=1, given a range and a marginal variance parameter; c(u) with range parameter ρc and marginal variance ; and xj(u) with range parameter ρx and marginal variance . Furthermore, the spatial fields xj(u) for are assumed to be independent realizations, or replicates, of the same underlying field to increase the identifiability of the model parameters (Ingebrigtsen et al., 2015). The same applies for the year-dependent intercepts βj that are all assigned a Gaussian prior given the variance parameter . The intercept βc is assigned the weakly informative wide Gaussian prior .
So far, runoff has been defined for point locations in space. However, runoff observations are linked to catchment areas, and we need to define the true annual runoff generated inside a catchment 𝒜. We suggest two alternative models: the first model is denoted the areal model. For the areal model, the true annual runoff in catchment 𝒜 in year j is given by the average point runoff over the catchment area, i.e.
where is the catchment area and qj(u) is the point runoff from Eq. (4). Interpreting annual runoff as an integral of point runoff ensures that the water balance is approximately preserved for the posterior mean runoff for any point in the landscape. Thus, the areal model is a model for mass-conserved hydrological variables. It also gives a realistic representation of distances and hence also the correlation between the catchments under study (see Eq. 2).
The second model for the annual runoff generated inside a catchment area is denoted the centroid model. For the centroid model, the true annual runoff inside a catchment 𝒜 in year j is given by
where qj(u𝒜) is the point runoff from Eq. (4), and u𝒜 is the centroid of catchment 𝒜. This alternative does not provide a preservation of the water balance for the posterior mean predicted runoff and can be used for any point-referenced environmental variable. Distances are measured between catchment centroids, such that this method is more similar to the traditional kriging methods described in Sect. 3.3.
4.1.2 Observation likelihood
The true annual runoff from Sect. 4.1.1 is observed with uncertainty through streamflow data from n catchments which we denote . We use the following model for the observed runoff yij in catchment 𝒜i in year j:
Here, Qj(𝒜i) is the true runoff from Eq. (5) if we use the areal model, or the true runoff from Eq. (6) if we use the centroid model. The error terms ϵij are identically, independently distributed as given the parameter , and we assume that each observation has its own uncertainty by scaling the variance parameter with a fixed factor sij that is further specified in Sect. 4.1.3.
Through the observation likelihood and the areal formulation of annual runoff from Eq. (5), the areal model puts (soft) constraints on the annual runoff over the catchment areas of the gauged catchments. This way the areal model is able to influence the model to distribute the observed annual runoff within the catchment areas and not only at certain gauging points which is what the centroid model does. This represents a potential benefit for the areal model compared to the centroid model when modelling runoff. However, imposing constraints on areas also comes with a computational cost.
4.1.3 Prior models
According to the model specification in Sect. 4.1.1 and 4.1.2, there are six model parameters in the suggested hierarchical model for annual runoff, i.e. . As we apply the Bayesian framework, these have to be given prior distributions, and we use knowledge based priors for most parameters. Note that since the priors are based on expert opinions about the study area, they are specific for the Norwegian dataset and should be modified before further use for other countries or environmental variables.
In the observation model for runoff in Eq. (7), each observation is allowed to have its own measurement uncertainty by scaling the variance parameter , with a fixed scale sij. This makes sense because the spatial variability of mean annual runoff in Norway is large, with values ranging from around 400 to 4000 mm yr−1, and heteroscedastic errors can be expected (Petersen-Øverleir, 2004). In the specification of the prior standard deviation , we assume that the measurement uncertainty for runoff increases with the magnitude of the observed value yij. Based on this we suggest the following scaling factors:
where yij is the observed runoff in catchment i in year j in mm yr−1. The scaling factors are chosen based on what the data provider NVE believes are realistic standard deviations for the observed values, around 2.5 % of the observed runoff. They are scaled down by 1000 to achieve appropriate values for . For the variance parameter , we use the penalized complexity prior (PC prior) suggested by Simpson et al. (2017). The PC prior is a prior constructed for the precision, i.e. the inverse of the variance, and the PC prior for the precision τ of a Gaussian effect has density
where λ is a parameter that determines the penalty of deviating from a simpler base model. The parameter λ can be specified through a quantile u and a probability α by , where u>0, and . Here, is the standard deviation of this Gaussian distribution. In our case, we specify the PC prior for σy as
Recall that σy is scaled with sij in the final uncertainty model such that a prior 95 % credible interval for the standard deviation for the observed runoff in catchment 𝒜i year j becomes (0.04,6) % of the observed value yij. This is a quite strict prior that is chosen in order to influence the posterior observation uncertainty to be as low as possible. The reason behind this modelling choice is further described in Sect. 4.2. However, an observation uncertainty of 0.04 %–6 % of the observed value also corresponds quite well to what NVE knows about the measurement uncertainty for runoff in the study area. Percentages around 2.5 % are as mentioned realistic.
For the spatial ranges ρx and ρc and the marginal variances and for the Gaussian random fields xj(u) and c(u), we use the joint informative PC prior suggested in Fuglstad et al. (2019). It is specified through the following probabilities and quantiles:
The percentages and quantiles are chosen based on expert knowledge about the spatial variability in the area of interest. It is reasonable to assume that locations that are less than 20 km apart are correlated when it comes to runoff generation. In Norway the annual runoff varies from around 300 to 6000 mm yr−1 such that a marginal standard deviation that is below 2000 mm yr−1 is reasonable. The parameters of the climatic GRF c(u) and the year-dependent GRF xj(u) are given the same prior as it is difficult to identify whether the spatial variability mainly comes from climatic processes or from annual variations. We also want the data to decide which of the two effects that dominates in the study area, and in this way detect hydrological spatial stability or instability. Recall that the phrase hydrological spatial stability here is used to describe a variable and/or a study area that is characterized by an underlying spatial pattern that is repeated over time.
As specified in Sect. 4.1.1, the year-specific intercepts βj for are all assigned the same Gaussian prior given the standard deviation parameter σβ. The standard deviation σβ is given the PC prior from Eq. (9) specified by the wide prior . With this prior, the prior 95 % credible interval is approximately for the standard deviation σβ of βj.
4.1.4 Feasible computation of catchment runoff for the areal model
In the areal model in Eq. (5), the true runoff is modelled as the integral of point runoff over a catchment. To make the areal model computationally feasible, the integral is calculated by a finite sum over a discretization of the target catchment. More specifically, if ℒi denotes the discretization of catchment 𝒜i, the annual runoff in catchment 𝒜i in year j is calculated as
where Ni is the number of grid nodes in the discretization ℒi. In the discretization of the catchments it is important that a subcatchment shares grid nodes with its overlapping catchment(s) such that the water balance can be preserved. In our analysis, we use a regular grid with 4 km spacing. It is also important that the discretization of the study area is fine enough to capture the rapid changes in annual runoff in the study area. Otherwise, non-realistic results such as negative runoff can occur.
4.1.5 Full model specification
Assuming that we observe runoff at n stream gauges for years and that ℒ𝒟 contains all grid nodes in the discretization of the catchments for , the areal model in Sect. 4.1.1–4.1.4 can be summarized as the following hierarchical geostatistical model:
where y is a vector containing all runoff observations yij from all catchments i and years j, x is a vector containing all latent variables, i.e. the intercepts βc, βj and the GRFs c(u⋅) and xj(u⋅) for all combinations of grid nodes and years j=1, …, r. Furthermore, Qj(𝒜i) is the true annual runoff that is modelled as a function of the latent field x, while I(⋅) is an indicator function that is equal to 1 if its argument is true and 0 otherwise, allowing for missing data and short records of runoff. Finally, . Together with σy it contains all model parameters.
The centroid model is summarized as a hierarchical model similarly, except that the true annual runoff Qj(𝒜i) is given by Eq. (6) instead of Eq. (11). This also means that the grid nodes in the above hierarchical model must be replaced by , i.e. the locations of the centroids of the n catchments under study.
The purpose of Bayesian inference is to estimate the posterior distributions of the latent variables x and the parameters θ based on the observations y as described in Sect. 3.1. In this study, the resulting distributions are used to quantify the variable of interest, the catchment runoff Qj(𝒜). By Eq. (6) and Eq. (11) we see that the catchment runoff is determined by the point runoff which is again determined by the latent field x through Eq. (4). This means that in the process of estimating the catchment runoff Qj(𝒜) we always estimate the point runoff qj(u) and the latent field x first. To clarify this process, consider Fig. 10 that is presented later in the article. This shows the posterior mean runoff qj(u), or π(x|y) implicitly, for all points in the study area. From these point estimates, predictions for the areal model Qj(𝒜) are obtained by taking the average of qj(u) over relevant grid nodes according to Eq. (11). For the centroid model, a catchment areal prediction Qj(𝒜) is obtained by simply extracting the value of qj(u𝒜) at the catchment centroid u𝒜 according to Eq. (6). From the point-referenced predictions in Fig. 10 we this way obtain catchment predictions like the ones presented later in e.g. Fig. 7.
From the hierarchical formulation in Eq. (12) we also note that the framework takes the time dimension into account through multiplying the likelihood for annual runoff over different years . These years do not need to be consecutive, which allows for e.g. combining old measurements from closed stations with more recent data. Different years of data are connected through the constant climatic component (c(u)+βc). Apart from this, there is no temporal dependency in the model that assumes correlation over time, and routing is not taken into account. This makes sense for our suggested application, as there is no prominent time dependency for annual runoff in Norway (see e.g. Fig. 2b). Routing effects can typically be neglected for time-aggregated runoff variables for longer timescales. For shorter timescales for which routing has an impact, other spatio-temporal models should be considered, for example the one in Skøien and Blöschl (2007).
4.2 Two model properties and contributions
In this section we highlight and describe two of the model properties that make the suggested framework different from top-kriging and other geostatistical interpolation methods that are used for hydrological applications.
4.2.1 Exploiting short records
The first property we highlight is how the model is particularly suitable for exploiting short records of runoff, and this holds for both the areal model and the centroid model. This property is already briefly addressed in the introduction and is enabled because we simultaneously model several years of data with a spatial component c(u) that is common for all years under study. The GRF c(u) represents the long-term spatial variability of runoff. If most of the spatial variability can be explained by long-term patterns, the marginal variance parameter will dominate over the marginal variance parameter of the annual GRF xj(u) (and the other model variances), i.e. σc≫σx. Thus, a short record of runoff from an otherwise ungauged catchment will have a large impact also for predictions in years without data through c(u). On the other hand, if most of the annual runoff is explained by year-specific effects, xj(u) will dominate over c(u) and short records will not have a large impact on the final model. Hence, it is safe to include short records in the model regardless of the weather patterns in the study area.
Existing methods for exploiting short records are typically based on linear regression or computing the correlation between the runoff in the target catchment and one or several donor catchments, and in order to perform these procedures the short record must be of length larger than 1 (Fiering, 1963; Laaha and Blöschl, 2005). In the method we suggest it is possible to include a short record of length 1, and it is already shown for a smaller case study that this often is enough to see a large improvement in the predictability of (annual) runoff for certain climates (Roksvåg et al., 2020).
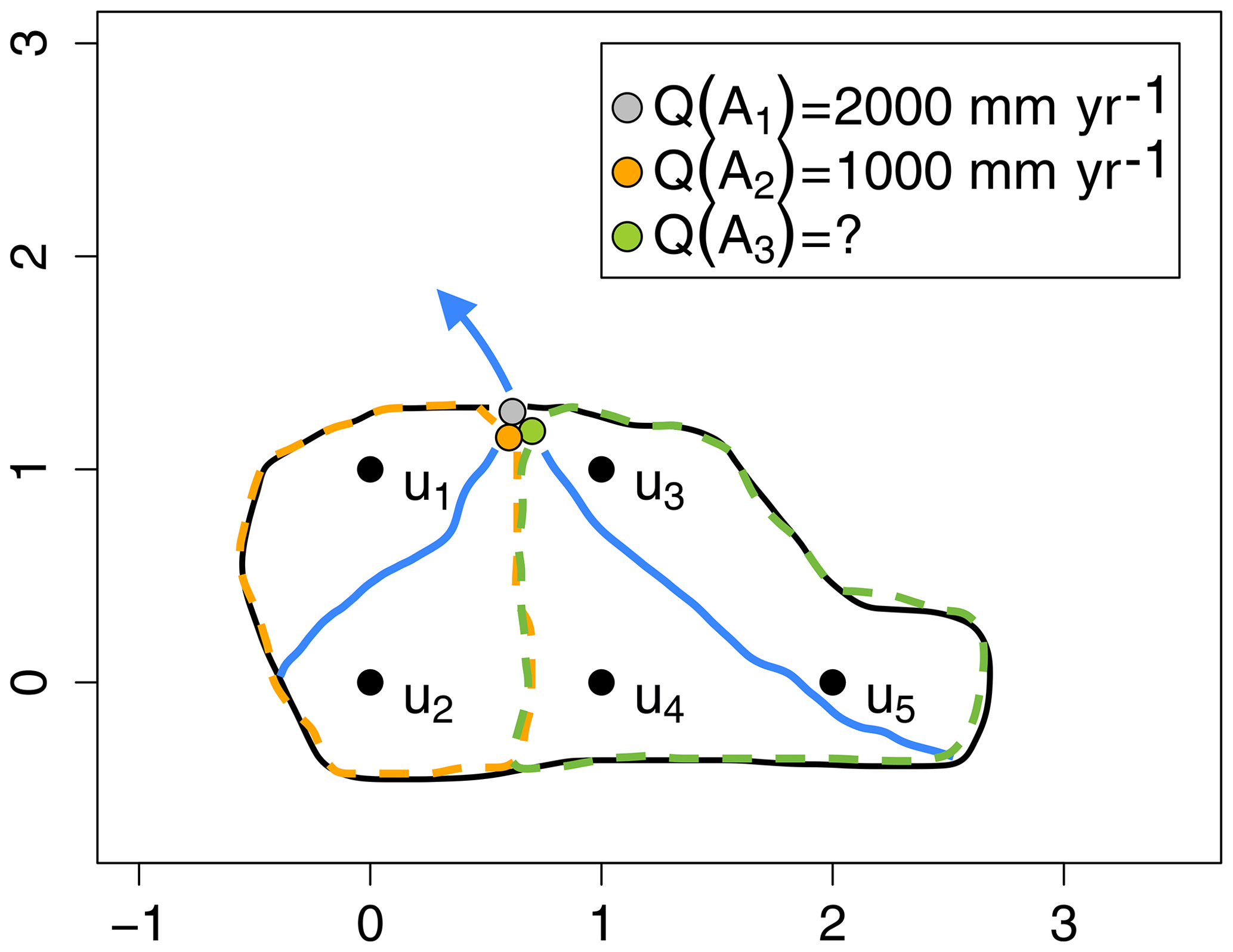
Figure 6Conceptual, simplified figure of a river network, for which the involved catchments are discretized by 5 grid nodes , and each grid node represent one areal unit. Catchment 𝒜1 contains all grid nodes , Catchment 𝒜2 consists of grid nodes u1 and u2, while Catchment 𝒜3 consists of grid nodes u3,u4 and u5. Hence, this is a system of nested catchments where 𝒜1 covers 𝒜2 and 𝒜3. Assume that there are observations of annual runoff at the outlet of catchment 𝒜1 and catchment 𝒜2: Q(𝒜1)=2000 mm yr−1 and Q(𝒜2)=1000 mm yr−1. Catchment 𝒜3 is ungauged. In order to fulfill water balance constraints of the areal model from Eq. (11), imposed by the likelihood in Eq. (7), the predicted mean annual runoff in catchment 𝒜3 must be around 2667 mm yr−1 if we assume a low observation uncertainty.
4.2.2 The water balance constraints of the areal model
The second property we highlight only holds for the areal model and is related to its mass-conserving properties and its ability to do more than smoothing: runoff is in Eq. (11) defined as a weighted sum of point runoff. Through Eq. (11) and the likelihood defined in Eq. (7), a (soft) constraint is put on the predicted annual runoff for the catchments for which we have observations. This also has the consequence that the suggested model allows us to predict values that are larger than any of the observed values in the area of interest. As a conceptual example, consider the river network in Fig. 6, where each black node represents one areal unit in the discretization of the catchments. The observed runoff is 1000 mm yr−1 in the subcatchment and 2000 mm yr−1 in the surrounding larger catchment. That means that the constraints imposed by the observation likelihood and Eq. (11) are the following:
As described in Sect. 4.1.3 we use a quite strict prior on the observation uncertainty. This is done to try to force the above soft constraints to be stronger. By solving this system of equations, it can be shown that the predicted value in the ungauged catchment 𝒜3 must be
where the above uncertainty term is determined by the observation uncertainties for a fixed set of ranges and marginal variances. Hence, as long as the observation uncertainties are sufficiently low, the predicted runoff in the unobserved area 𝒜3 in Fig. 6 is close to 2667 mm yr−1 which is larger than any of the observed values. This example illustrates that the areal model is able to go beyond smoothing through its runoff constraints. This makes the model different from many other interpolation methods that only rely on spatial smoothing. For the above example, such methods would typically produce a prediction between 1000 and 2000 mm yr−1.
The full areal model is of course slightly more complicated than the simple example above, as prior distributions, covariance calculations and spatial ranges must be taken into account. However, the simple example illustrates the general idea of how the observation likelihood interprets the areal observations and constrains runoff. That the full areal model actually is able to conserve mass in practice is demonstrated for a real case example from Norway in Roksvåg et al. (2020).
The constraints in Eq. (13) also show how the areal model ensures consistent predictions over nested catchments: as the predicted runoff in the main catchment 𝒜1 can be expressed as a weighted sum of the predicted runoff in all its subcatchments depending on catchment areas, i.e. as , the water balance can not be violated for the predicted runoff for any of the catchments in Fig. 6. This means that the equations in Eq. (13) correspond to water balance constraints.
Compared to top-kriging, both top-kriging and the proposed method assume that the underlying variable is linearly aggregated and mass-conserved when performing covariance calculations. Top-kriging is also able to predict larger values than any of the observed values by allowing negative kriging weights. However, top-kriging does not use constraints to ensure that the mass balance is preserved over nested catchments, as in the above example. Consequently, the top-kriging predictions can more easily violate the water balance, which can have both benefits and drawbacks depending on the target variable and the problem we are trying to solve. Another hydrological model that uses water balance constraints, not unlike the proposed method, is the kriging approach in Sauquet et al. (2000), where mass balance constraints are introduced as additional constraints in the kriging system of equations.
4.3 Inference
In order to make the framework described in Sect. 4 computationally feasible, some simplifications of the suggested models are necessary. In general, statistical inference on models including GRFs is slow when the number of target locations is large because matrix operations on dense covariance matrices are required. The computational complexity is particularly large for the areal model, because each grid node in the discretization of the catchments can be regarded as a new target location, and because it includes soft constraints. To solve the computational issues for the centroid and areal models, we utilize the fact that a GRF with a Matérn covariance function can be expressed as the solution of a specific SPDE (Lindgren et al., 2011). This SPDE can be solved by using the finite-element method (see e.g. Brenner and Scott, 2008), and the result is a Gaussian Markov random field (GMRF). Working with GMRFs is convenient because GMRFs have precision matrices (inverse covariance matrices) that typically are sparse with many zero elements, and efficient algorithms are available for sparse matrix operations (see e.g Rue and Held, 2005). In this work, both GRFs xj(u) and c(u) are approximated by GMRFs.
Another challenge with the suggested models is that we suggest Bayesian models that include a large number of parameters for which the marginal distributions must be estimated. Traditionally, Bayesian inference is done by using Markov chain Monte Carlo (MCMC) methods, but inference can be slow when the dimension of the problem is large (Gamerman and Lopes, 2006). These challenges are met by modelling runoff as a latent Gaussian model (LGM). That is, the latent part x of the hierarchical model in Sect. 4.1.5 consists of only Gaussian distributions. More specifically, the prior distributions for c(u) and xj(u) are modelled as GRFs, and the prior distributions for βj and βc are Gaussian given the model parameters (see the equations in Eq. 4). This is convenient, because it allows us to use integrated nested Laplace approximations (INLAs) to make inference and predictions. INLA is a tool for making Bayesian inference for LGMs (Rue et al., 2009) and represents a fast and approximate alternative to MCMC algorithms. The INLA approach is based on approximating the Bayesian marginal distributions by using Laplace or other analytic approximations, and on numerical integration schemes. The main computational tool is the sparse matrix calculations described in Rue and Held (2005), such that in order to work quickly, the latent field of the LGM should be a GMRF with a sparse precision matrix. This requirement is fulfilled through the SPDE approach as already outlined.
INLA in general provides approximations of very high accuracy for most models (Rue et al., 2009; Martino et al., 2011; Eidsvik et al., 2012; Huang et al., 2017) but has faced problems for some (more extreme) models with binomial or Poisson data (Fong et al., 2009; Ferkingstad and Rue, 2015). For Gaussian likelihoods, however, INLA is exact up to numerical integration error. As we use Gaussian likelihoods in this work, we can thus expect INLA to give reliable approximations. The SPDE approach also provides accurate approximations (Lindgren et al., 2011; Huang et al., 2017), but it is important that the mesh involved in the finite-element method computations is sufficiently dense relative to the spatial variability and range in the study area.
Because of the high computational speed and accuracy, the INLA and SPDE framework has become quite common to use within different fields of science. See for example Khan and Warner (2018), Opitz et al. (2018), Yuan et al. (2017), Guillot et al. (2014), Ingebrigtsen et al. (2014), and Bakka et al. (2018). We refer to the R package r-inla for a user-friendly interface for applying INLA and the SPDE approach to spatial modelling. In particular, Moraga et al. (2017) is recommended for a description of how a model with (catchment) areal data can be implemented in r-inla. Furthermore, we have made code for the centroid model available on http://www.github.com/tjroksva/runoffinterpolation (last access: 29 January 2020; https://doi.org/10.5281/zenodo.3630348) with example data from the catchments in Fig. 1a.
The main objectives of this article are to (1) evaluate the new framework's ability to fill in missing annual runoff observations and to (2) predict mean annual runoff for catchments with varying record lengths. By this we also want to (3) demonstrate the potential added value of including short runoff records in the modelling compared to when not using them. In this section we present the experimental set-up and the evaluation criteria used to address our research questions.
5.1 Experimental set-up for infill of missing annual observations (1996–2005)
To assess the framework's ability to fill in missing values of annual runoff, we do interpolation of runoff for the 10 hydrological years 1996–2005 for the 180 fully gauged catchments shown in Fig. 1a. This is done both for series of annual runoff, and for the annual series of monthly runoff for January, April and June described in Sect. 2.
The annual time series of monthly runoff are included in the analysis in order to demonstrate the framework’s properties for hydrological variables or areas that are driven by more unstable hydrological processes. For the annual series of monthly runoff, the models from Sect. 4 are specified as before: considering predictions for January, Qj(𝒜i) in Eq. (5) represents the true runoff in January for catchment 𝒜i, year j, such that the GRF c(u) represents the long-term spatial variability in January. Likewise, the GRF xj(u) represents the annual discrepancy from the climate in January, and yij is the observed runoff in January for catchment 𝒜i year j. The models for June and April are specified similarly, and for simplicity we use the same prior distributions for all experiments.
In our assessment of the framework's predictive performance for infill of missing annual observations, the three following methods are compared.
-
Top-kriging. Spatial interpolation with top-kriging. For top-kriging each year (1996–2005) is interpolated independently of other years. Short records on an annual (or monthly) scale do not have an impact on years without data. The default covariance function (or variogram) in the R package
rtopwas fitted as this gave the most accurate results. This is a multiplication of a modified exponential and fractal variogram model, the same model as used in Skøien et al. (2006). -
Areal model. Spatial interpolation with the model defined in Sect. 4 with true annual runoff given by the areal model from Eq. (11). That is, the annual runoff in a catchment is interpreted as the average point runoff over the catchment area. All years are modelled simultaneously (1996–2005) such that short records of data can influence years without data.
-
Centroid model. Spatial interpolation with the model defined in Sect. 4 with true annual runoff given by the centroid model from Eq. (6). That is, annual runoff is interpreted as a process linked to point locations in space (the catchment centroids), and not to catchment areas. All years are modelled simultaneously (1996–2005) such that short records of data can influence years without data.
The predictive performance of the three methods is evaluated by cross-validation: the 180 catchments in Norway were divided into 20 groups or folds, each containing nine catchments. In turn each group was left out, and annual or monthly runoff predictions were performed for these so-called target catchments by using observations from the catchments in the other groups. That is, we predict runoff for 1996–2005 for 9 target catchments at once by using data from the remaining 171 fully gauged catchments and repeat the process for all 20 cross-validation folds. To evaluate and compare the three methods described above, we do the following two tests.
-
UG (ungauged). Assess the methods' ability to fill in missing values for ungauged catchments (denoted UG). That is, the target catchments are treated as totally ungauged, and all their observations are left out of the dataset when the predictions for 1996–2005 are performed.
-
PG (partially gauged). Assess the methods' ability to fill in missing values for partially gauged catchments (denoted PG). Each of the 9 target catchments in the cross-validation group is allowed to have one annual observation of runoff. That is, a short record of length 1 from the target catchment is included in the observation likelihood in addition to the full data series of runoff from the catchments in the other cross-validation folds. The short record is drawn randomly from the 10 years of observations available for each target catchment. We perform predictions for 9 partially gauged target catchments at once, for all 10 study years (for which 1 of them is observed for each catchment), and repeat the process for all 20 cross-validation folds.
To make the results comparable, we use the same cross-validation groups for both experiments (UG and PG) and methods (top-kriging, areal model and centroid model) and remove the same set of annual observations for PG across methods. For the PG case, we also compare our models to a method for exploiting short records from the target catchment. The method we choose for comparison is simple linear regression, and we perform linear regression for the PG case as follows.
-
Linear regression. The closest catchment in terms of catchment centroid is used as a donor catchment, and only catchments outside the target catchment's cross-validation group can be considered. Two annual observations between 1996 and 2005 are randomly drawn from the target catchment, and data from the donor catchment and target catchment are used to fit a linear regression model on the form . Next, the model is fitted as described in Sect. 3.4 and used to predict runoff for the target catchment for 1996–2005 (where two of the years are observed). The reason for using a short record of length 2 instead of 1 is that at least two observations are required to fit a linear regression model with uncertainty. Also note that we have omitted the intercept β0 in the regression model, such that we only have two unknown variables (β1 and σ2). We emphasize that estimating the variables statistically based on only two pairs of observations might not give the most reliable estimates, particularly when considering σ2. However, the linear regression results can provide an intuition about the target variable and how correlated the observation locations are over time. A good performance for linear regression in this study suggests that the spatial pattern for the target variable is very stable and that a fair prediction can be obtained by simply using the ratio of runoff between a target catchment and a donor catchment for any chosen year to develop a linear relationship between the two catchments. Hence, a short record can be very valuable. Motivated by this, linear regression is treated as an indicator for when our geostatistical method can be expected to perform particularly well rather than as a recommended method for record augmentation when having only two observations.
5.2 Experimental set-up for predictions of mean annual runoff (1981–2010)
To assess the framework's ability to estimate mean annual runoff, we use annual data from 1981 to 2010 from the 260 catchments in Fig. 5. Recall that these catchments have at least one observation of mean annual runoff between 1981 and 2010, but only 83 of them are fully gauged. This was different from the experiments described in Sect. 5.1, where all the test catchments were fully gauged before the cross-validation was performed.
For this experiment, we again compare the performances of top-kriging and the areal and centroid models. The areal model and the centroid model are fitted for several years of annual runoff simultaneously, as before. As a predictor for the mean annual runoff, we use the posterior distribution of the climatic part of the model. This is given by c(u𝒜)+βc for the centroid model, where u𝒜 is the centroid of the catchment 𝒜 of interest. For the areal model it is given by the average c(ui)+βc over the grid nodes ui in the discretization of the target catchment. Note that the climatic part of the model must be re-estimated for each experiment or cross-validation fold.
In order to interpolate mean annual runoff by using top-kriging, we have to compute the mean annual runoff based on the annual observations for all catchments before running the analysis. For catchments with less than 30 annual observations we use the average of the 1–29 available observations as an approximation for the mean annual runoff for 1981–2010. Next, the mean annual runoff is interpolated by using top-kriging where the uncertainty of the observations is specified as a function of record length. This is the suggested approach from Skøien et al. (2006) for including short records in the top-kriging framework. We set the observation variance for a catchment with record length m to , where is the average empirical standard deviation for the observed annual runoff taken over the 83 fully gauged catchments in our dataset, in this case mm yr−1. For the top-kriging experiments, we fit the same covariance model as in Sect. 5.1.
The areal and centroid models and top-kriging are again evaluated by cross-validation. The 83 fully gauged catchments from Fig. 5 were divided into four folds containing 20, 20, 20 and 23 catchments respectively, and in turn observations from each fold were removed and predicted. This was done for varying record lengths for the target catchments, more specifically when 0, 1, 3, 5 or 10 randomly drawn annual observations from the target catchments were included in the likelihood. We denote these settings UG, PG1, PG3, PG5 and PG10. Note that while we only are able to assess the predictive performance for the 83 fully gauged catchments in Fig. 5, data from the remaining 177 partially gauged catchments in Fig. 5 are used in the observation sample. This is in addition to the data from the fully gauged catchments from the other folds.
5.3 Evaluation scores
To evaluate the predictions we use the root mean squared error (RMSE) and the continuous rank probability score (CRPS). Having m pairs of observations and predictions, the RMSE is computed as
where is the observed value and is the corresponding predicted value. In our analysis, the posterior mean is used as the predicted value for the areal and centroid models.
The CRPS is defined as
where F() is the predictive cumulative distribution and y* is the actual observation (Gneiting and Raftery, 2007). For the methods we test (areal, centroid, top-kriging and linear regression), F() is a Gaussian distribution with mean equal to the predicted value and standard deviation equal to the standard deviation of the prediction.
For the experiments related to infill of individual years, the CRPS and RMSE are first computed for each of the 180 catchments in the dataset based on 10 pairs of predictions and observations. The average RMSE and CRPS over all catchments are used as a summary scores. For the experiments related to predictions of mean annual runoff, there is only one (mean annual) prediction for each catchment, and the RMSE and CRPS over all catchments are reported. Both the CRPS and the RMSE are negatively oriented such that low scores mean better predictions.
To be able to compare the RMSE and CRPS across methods, we use a paired Wilcoxon signed-rank test (Siegel, 1956). This is a non-parametric test that does not require normal distributed data. The null hypothesis of the test is that the median difference between pairs of data (in this case pairs of RMSE or CRPS values) follows a symmetric distribution around zero. The alternative hypothesis is that the difference between the data pairs does not follow a symmetric distribution around zero. If the null hypothesis is rejected, it indicates that one of the methods gives a significantly smaller RMSE or CRPS than another method.
In addition to the RMSE and the CRPS, we report the 95 % coverage of the experiments. The 95 % coverage is computed by calculating the amount of the actually observed runoff values that are within the corresponding 95 % posterior prediction intervals. Here, we make posterior prediction intervals for top-kriging and linear regression by assuming that the predictions are Gaussian. A 95 % coverage close to 0.95 is optimal and indicates that the model provides an accurate representation of the underlying uncertainty.
We also want to compare our mean annual runoff results with other studies of mean annual runoff, more specifically the studies collected in Blöschl et al. (2013). In Blöschl et al. (2013), the absolute normalized error (ANE) and the squared correlation coefficient (r2) are used as evaluation scores. The ANE is computed as
where y* and are the observed and predicted value as before. The ANE divides the absolute difference between the actual observation y* and corresponding prediction by the observed runoff and is therefore scale independent. An ANE close to zero corresponds to an accurate prediction.
Finally, the squared correlation coefficient between m pairs of observations and predictions is computed as
where Cor() denotes the Pearson correlation. An r2 close to 1 indicates a high correlation between the predicted and observed values.
6.1 Predictions for individual years (1996–2005)
We now present the results related to the framework's ability to predict runoff for individual, missing years for the annual time series of annual and monthly runoff for a 10-year period (1996–2005). First, we present the results for the ungauged catchments (UG), before we proceed to the partially gauged catchments (PG) that have short records of length 1.
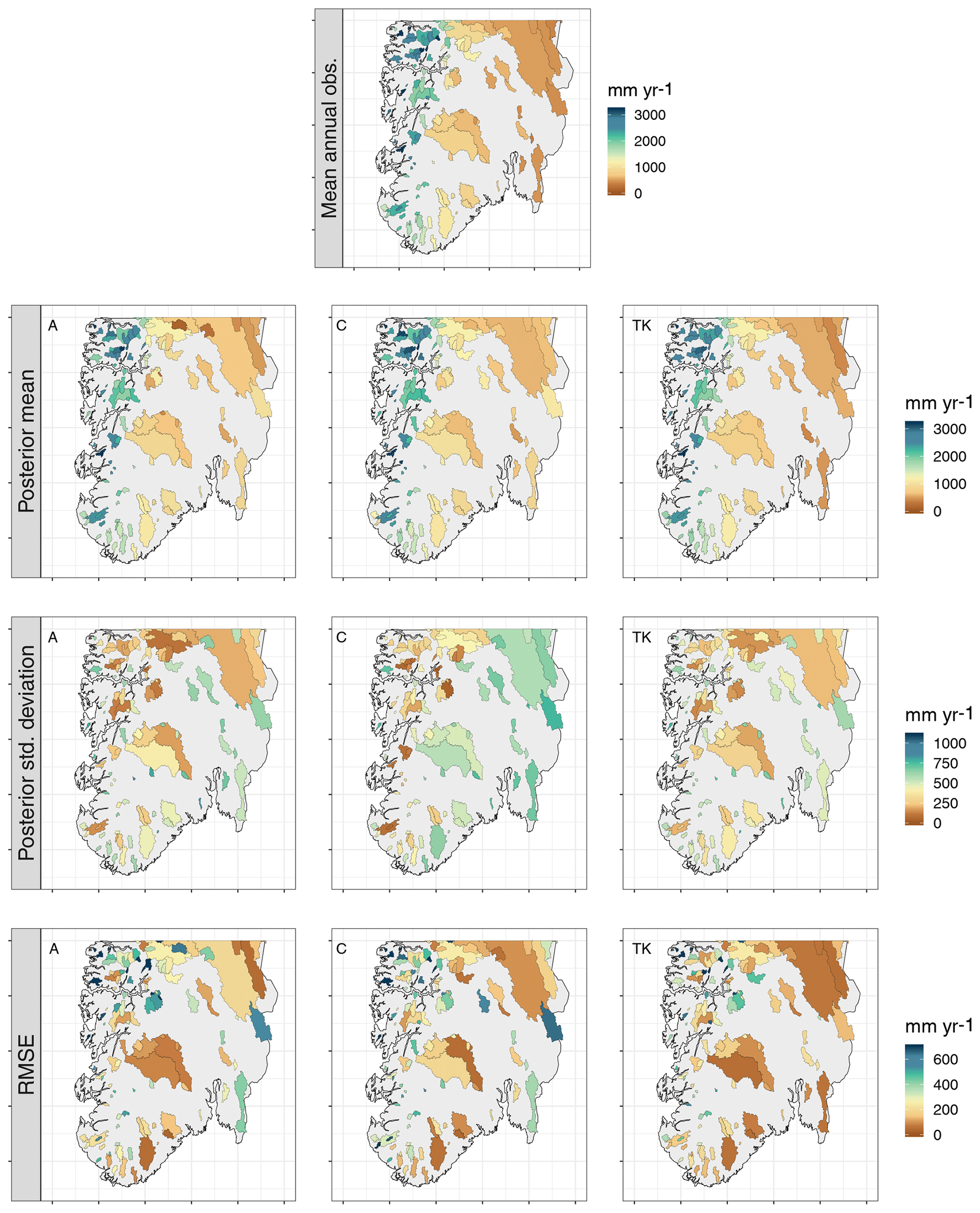
Figure 7Average posterior mean for Qj(𝒜), average posterior standard deviation for Qj(𝒜) and average RMSE for each catchment for predictions of missing annual observations in southern Norway for for the areal model (A, left), the centroid model (C, middle) and top-kriging (TK, right) when the target catchments are treated as ungauged (UG). The observed mean annual runoff is also included as a reference (first plot).
6.1.1 Infill for ungauged catchments (UG)
For the ungauged case (UG), the target catchments are treated as totally ungauged for the 10 study years 1996–2005, and missing values are predicted both for annual and monthly runoff. In Fig. 7 the resulting average predicted annual runoff in southern Norway is presented for top-kriging, the areal model and the centroid model. The three methods give similar results for the posterior mean, and all are able to reproduce the true spatial pattern of annual runoff. Furthermore, the RMSE plots in Fig. 7 show that the three methods succeed and fail for many of the same catchments. Here, we should keep in mind that the RMSE is scale dependent and might not give the best impression of the relative performance across the study area. However, we note that many of the catchments with high RMSE values typically are small catchments located in western Norway. We will come back to these catchments in Sect. 6.1.2 to see how the predictions here were affected when including a short record.
Table 1Predictive performance for predictions of missing annual values in ungauged catchments (UG) and partially gauged catchments (PG) for the areal model, centroid model, top-kriging (TK) and simple linear regression (LR). The best performance in each row is marked in bold. The RMSE and CRPS were compared across methods by using a one-sided paired Wilcoxon signed-rank test for assessing the significance of the results. Results that were significantly better than other results are marked with stars.
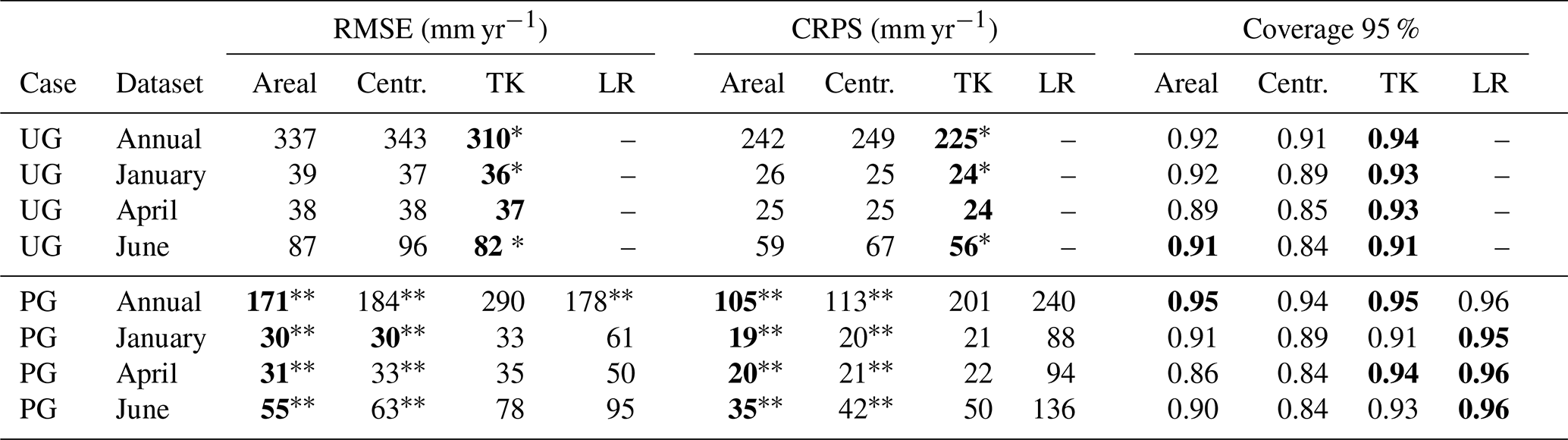
* The RMSE/CRPS is significantly lower than the RMSE/CRPS of the areal and centroid models on a 5 % significance level. The RMSE/CRPS is significantly lower than the RMSE/CRPS of top-kriging on a 5 % significance level.
Considering the posterior standard deviation in Fig. 7, we notice that top-kriging and the areal model provide a similar quantification of the predictive uncertainty. Top-kriging and the areal model take the nestedness of catchments into account by interpreting the runoff data as areal referenced, providing a predictive standard deviation of runoff that varies with the size of the target catchment: Fig. 7 shows that smaller catchments typically have a larger predictive uncertainty, which is reasonable. For the centroid model, runoff observations are point referenced and weighted independently of catchment size. Consequently, the predictive uncertainty only depends on how the centroids of the observed catchments are distributed in space, and decreases in areas where there are clusters of data. The predictive uncertainties provided by top-kriging and the areal method are thus more intuitive and realistic considering the process we are studying. The latter is also reflected in the coverage percentages presented in Table 1. The coverages show the amount of actual observations that were captured by the corresponding 95 % prediction intervals, and these are slightly closer to 0.95 for top-kriging and the areal model compared to the centroid model.
Table 1 also presents the summary scores for the predictive performance for infill of missing values for ungauged catchments for all methods. According to the RMSE and CRPS, top-kriging is a better interpolation method than our two suggested methods for ungauged catchments. However, the boxplots in Fig. 8 illustrate the distribution of RMSE for all catchments, and we see that on a monthly scale, the difference between top-kriging and the two other methods is quite low from a practical point of view. For January and April the differences are almost negligible.
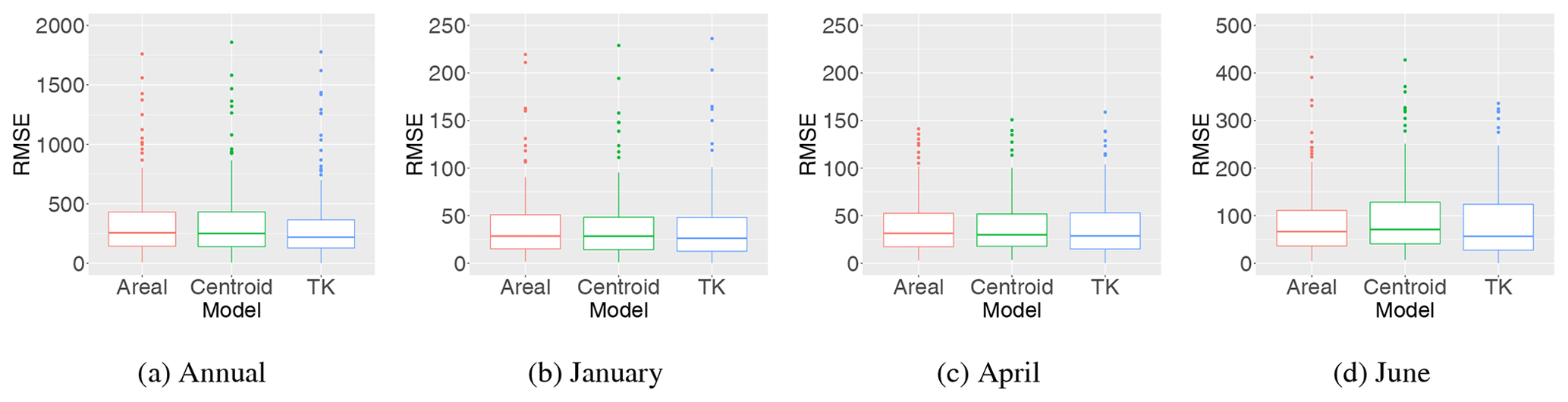
Figure 8Distribution of RMSE (mm yr−1 and mm month−1) for infill of missing values for all catchments and years (1996–2005) when the target catchments are treated as ungauged (UG) in the cross-validation for the areal, centroid and top-kriging methods. The lower and upper quartiles correspond to the first and third quartiles (the 25th and 75th percentiles), and the whiskers extend from the quartiles no further than 1.5⋅ IQR, where IQR is the distance between the first and third quartiles. The same applies for all boxplots presented in this paper.
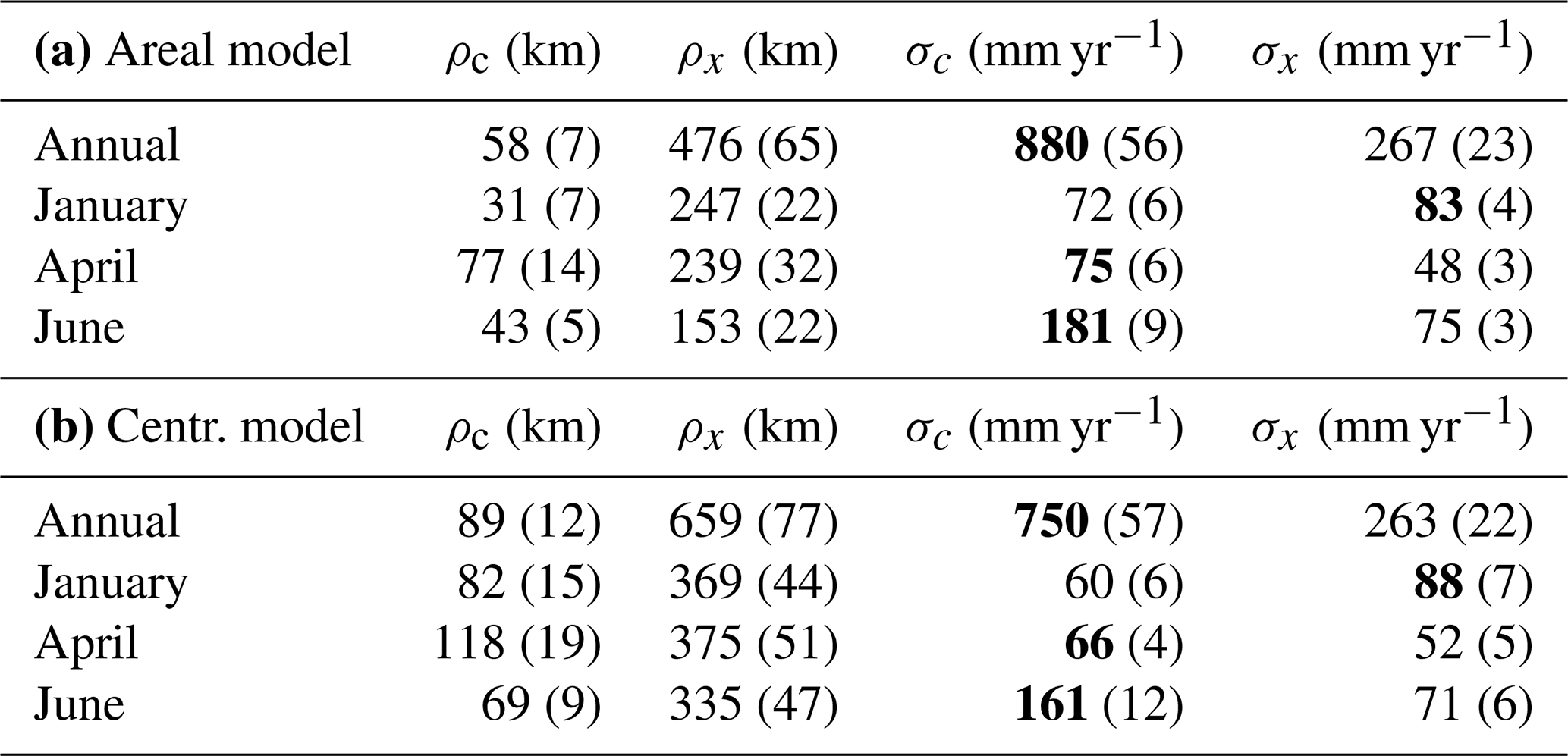
Table 2The posterior mode of the range parameters ρc and ρx and the marginal standard deviations σc and σx of the climatic and the annual GRFs c(u) and xj(u) for the areal model (a) and centroid model (b). The posterior standard deviations of the parameters are shown in parenthesis as a measure of the uncertainty. The mode and standard deviations vary between the experiments and groups in the cross-validation, and the values given here are the mean over all folds and experiments (UG and PG). The spatial effect that dominates (annual or climatic) is marked in bold.
6.1.2 Infill for partially gauged catchments (PG)
For the partially gauged (PG) case, each target catchment is allowed to have a short record of length 1 for top-kriging and the areal and centroid models and length 2 for linear regression. Before we comment the results from the cross-validation in Table 1 and Fig. 9, we consider the posterior estimates of the range parameters (ρx and ρc) and the marginal variance parameters (σx and σc) of the year-specific GRF xj(u) and the climatic GRF c(u) for our four datasets. These are shown in Table 2 and indicate how much of the spatial variability that is captured by the climatic GRF relative to the annual GRF. In particular, if σc dominates over σx, it suggests hydrological spatial stability.
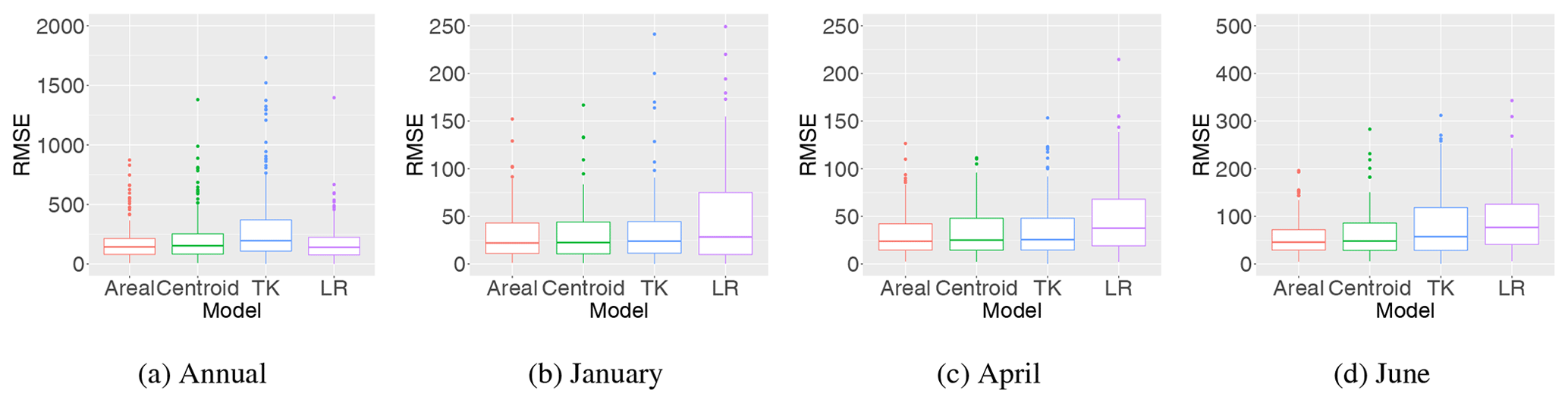
Figure 9Distribution of RMSE (mm yr−1 and mm month−1) for infill of missing values for all catchments and years (1996–2005) for the areal model, centroid model and top-kriging when the target catchments are treated as partially gauged (PG); i.e. a short record of length 1 from the target catchment is included in the observation likelihood in the cross-validation. Results for linear regression (LR) are also included here.
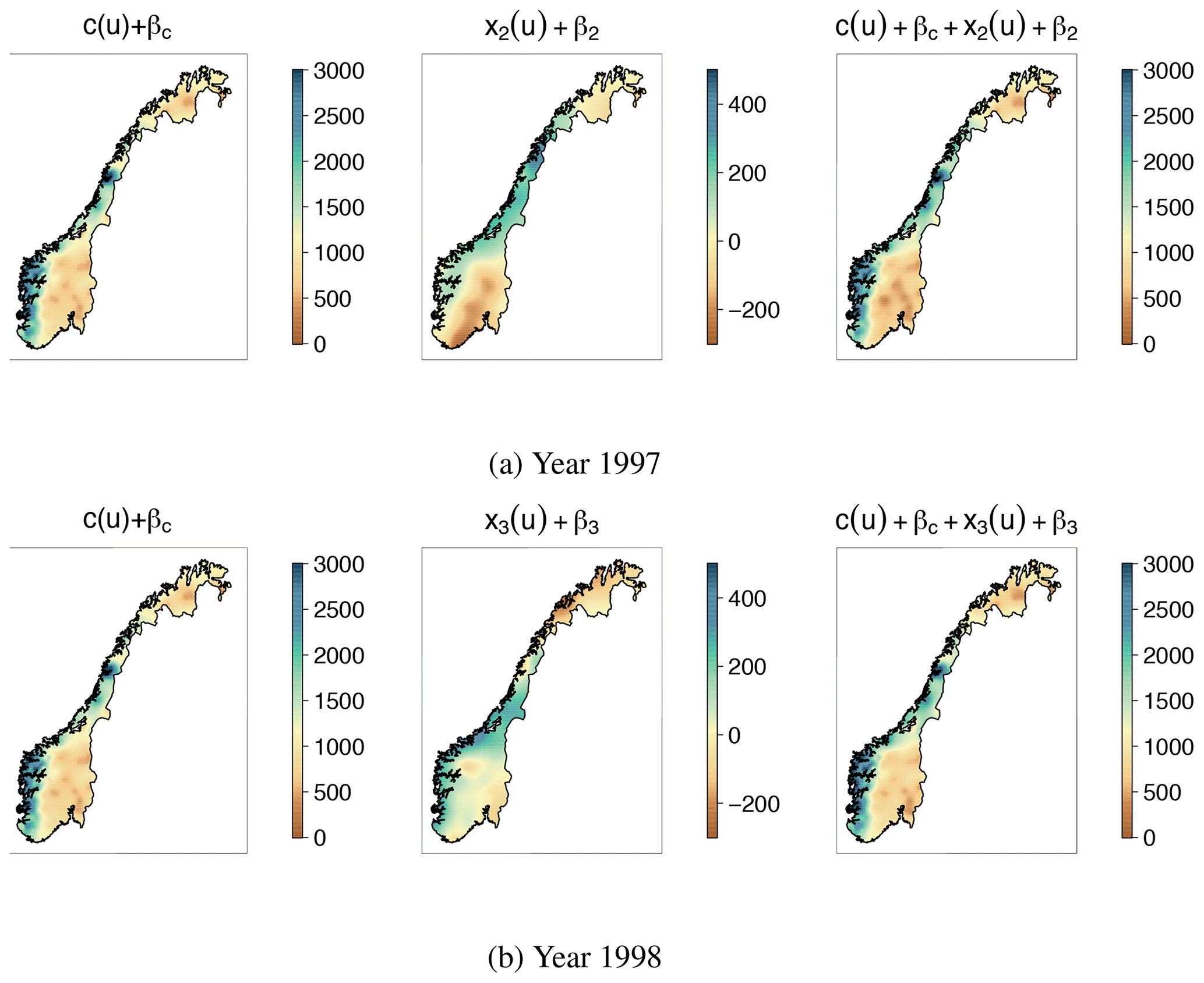
Figure 10From left to right: the climatic part of the model (common for all years), the annual (year-dependent) part of the model and the full model qj(u) for annual runoff in 1997 and 1998 (mm yr−1). Note that the scales of the middle plots only cover 25 % of the scale of the other plots. We see that most of the spatial variability of annual runoff for 1997 and 1998 can be explained by climatic effects and that the climatic range ρc is considerably smaller than the year-specific range ρx. The results above are produced by the centroid model, and plots similar to these are behind all results presented for the areal and centroid models in this article.
The estimates in Table 2 show that the hydrological spatial stability is largest for June and for annual runoff, as expected from the time series in Figs. 2b and 3. Here, the posterior mode for σc is more than twice as large as the posterior mode for σx for both the areal and centroid models. Furthermore, we see in Table 2 that the climatic range ρc is only around 12 % of the annual range ρx. In Fig. 10 we have illustrated the spatial pattern these parameters give for annual predictions in 1997 and 1998 for the whole study area. We see that the annual runoff for 1997 and 1998 have the same spatial pattern, and that this spatial pattern mostly originates from c(u), i.e. climatic conditions including catchment characteristics. The trend we see in Fig. 10 can also be seen for the remaining 8 years in the dataset (1996, 1999–2005) as well as for June. A spatial pattern like this, with σc≫σx and ρc<ρx, suggests that the information gain from neighbouring catchments further away is low for an ungauged catchment and that the potential information stored in short records is high.
For January however the situation is different: the posterior mode of σx is larger than the posterior mode of σc for both the areal and centroid model. The parameters show that for January, year-specific effects explain a larger part of the spatial variability. This can be due to a more unstable hydrological setting with runoff driven by snow accumulation and snowmelt. For April, we have that σc>σx, but σc is less dominant than for June and for the annual data.
In the areal and centroid models, the inclusion of a short record changes the climatic spatial field c(u), and hence the predictions can be considerably changed for the target catchment if the climatic effect is strong. The parameter values thus suggest that the gain of including short records is lower for April and January compared to the other two datasets. This is confirmed by comparing the RMSE and CRPS for the areal and centroid models for the partially gauged case (PG) to the RMSE and CRPS obtained for the ungauged case (UG) in Table 1. For all datasets, the RMSE and CRPS for our two models are reduced for PG compared to UG, but the reduction is lower for January and April than for June and the annual data. For the annual predictions, the RMSE and CRPS are reduced by more than 50 % when a short record of length 1 from the target catchment is included in the observation likelihood. The reduction for June is also remarkable (around 35 %–40 %), while the reduction for January and April is moderate (around 13 %–20 %). The results hold for both the areal and centroid models, but the areal model seems to be somewhat better than the centroid model in terms of exploiting short records of data from the target catchment. This is again related to the parameter estimates in Table 2, where we see that σc dominates more over σx in the areal model than in the centroid model.

Figure 11All observations for 1996–2005 compared to the corresponding predictions for the ungauged case (UG, left) and the partially gauged case (PG, right) for annual predictions (a) and for April (b). The predictions are performed by the areal model. The straight line represents a perfect correspondence between prediction and observation.
Considering the results for top-kriging in Table 1, we only obtain a small reduction in the RMSE and CRPS for the partially gauged case (PG) compared to the ungauged case (UG). This is because top-kriging treats each year of data independently when considering infill of missing annual data. A reduction in RMSE and CRPS is only seen for the specific year with extra data. This is different from our framework, where several years of data are modelled simultaneously. The evaluation scores in Table 1 and the boxplots in Fig. 9 clearly show that our two suggested methods outperform top-kriging for the partially gauged case for annual predictions and monthly predictions in June, which were the two timescales with the most hydrological spatial stability (σc≫σx). For January and April the three models are more similar in predictive performance.
For the PG case, we also compare the areal and centroid models to simple linear regression. According to Table 1 and Fig. 9 linear regression performs quite well for the annual data, which represent the most hydrologically spatially stable dataset. Linear regression actually provides the second lowest RMSE of all four methods for annual predictions. However, recall that a short record of length 2 from the target catchment is needed to use this method, while our areal model performs slightly better with a short record of length 1 (and observations from other neighbouring catchments). For January, April and June, linear regression is outperformed by the three other methods in terms of RMSE and CRPS (Table 1).
To illustrate the possible gain of including (very) short records of data from the target catchment, we present four scatter plots that compare the predicted values produced by the areal model to the actual observations of runoff (Fig. 11). For the annual predictions in Fig. 11a, the predictions for PG are considerably more concentrated around the straight line that indicates a perfect fit, than the predictions for UG. There are similar results for June, whereas the difference between the ungauged and partially gauged case is not that prominent for April (see Fig. 11b) and January. Furthermore, the April scatter plots demonstrate that (very) short records do not lead to a poorer predictive performance, even if April is a month driven by more unstable hydrological patterns. The predictions are simply not substantially affected by the new data points that are included in the likelihood, as we can see in Fig. 11b. In our model, the risk of including very short records is low because climatic effects c(u) are adjusted relative to year-specific effects xj(u) by statistical inference. This way short records can safely be included in the modelling regardless of the underlying weather patterns and the degree of hydrological spatial stability.

Figure 12Average posterior mean Qj(𝒜) (a, b), average posterior standard deviation (c, d) and RMSE (e, f) for for predictions of missing annual observations for the areal model for the ungauged case (UG, a, c, e) and the partially gauged case (PG, b, d, f).
In Fig. 7 we saw that all three interpolation methods were able to reproduce the true spatial pattern of annual runoff when filling in missing annual values for ungauged catchments (UG). However, all three methods produced high RMSE values for some of the catchments. These were typically small catchments located on the western coast of Norway. Figure 12 shows the impact of including a short record of length 1 for these catchments. It compares the annual predictions from the ungauged case (UG) to the annual predictions from the partially gauged case (PG) for the areal model. We see a large reduction in the RMSE for many of the catchments, and a (realistic) reduction of the posterior standard deviation. We also see that a few of the catchments obtain a decrease in predictive performance when short records are included, but the overall tendency is clear: the gain of including short records for annual predictions in Norway is high, and the suggested framework is able to exploit this property.
6.2 Predictions of mean annual runoff (1981–2010)
So far, we have presented an evaluation of the framework's ability to fill in missing annual observations of runoff for a 10-year period (1996–2005). We now present the evaluation of the framework's ability to predict mean annual runoff for a 30-year period as a whole (1981–2010), as described in Sect. 5.2.

Figure 13RMSE and CRPS as a function of record length (0, 1, 3, 5 and 10) for predictions of mean annual runoff for 1981–2010 for 83 fully gauged catchments in southern Norway.
Figure 13 shows the RMSE and CRPS for the predictions of mean annual runoff for top-kriging and the areal and centroid models as a function of record length (0, 1, 3, 5 and 10). The record length is the number of annual runoff observations available from the target catchment in the cross-validation. We find that top-kriging again performs best for the ungauged case (short record length 0), while the centroid model performs slightly better than the areal model for ungauged target catchments. Furthermore, the RMSE and CRPS decrease with increasing record length for all three methods. However, Fig. 13 shows that our areal and centroid models outperform top-kriging for record lengths larger than 0: the overall difference between our framework and top-kriging is around 30–60 mm yr−1 in terms of RMSE, which is a considerable difference when the RMSE values are around 100–200 mm yr−1.
Furthermore, we notice the large increase in predictive performance when including a (very) short record of length 1 (PG1 in Fig. 13). The reduction in RMSE and CRPS is 45 %–50 % from the UG to the PG1 case for the areal and centroid models. These results are thus comparable to the results we obtained for the experiments related to infill of missing annual values (Sect. 6.1).
To be able to compare our findings with other studies, we also included plots of the ANE and the squared correlation coefficient (r2) for the experiments. These can be found in Figs. 14 and 15, and are referred to in the discussion (Sect. 7.2). Also, according to these scale-independent evaluation criteria, the overall results are that for ungauged catchments top-kriging performs best, while when there are short records available, our framework performs better.
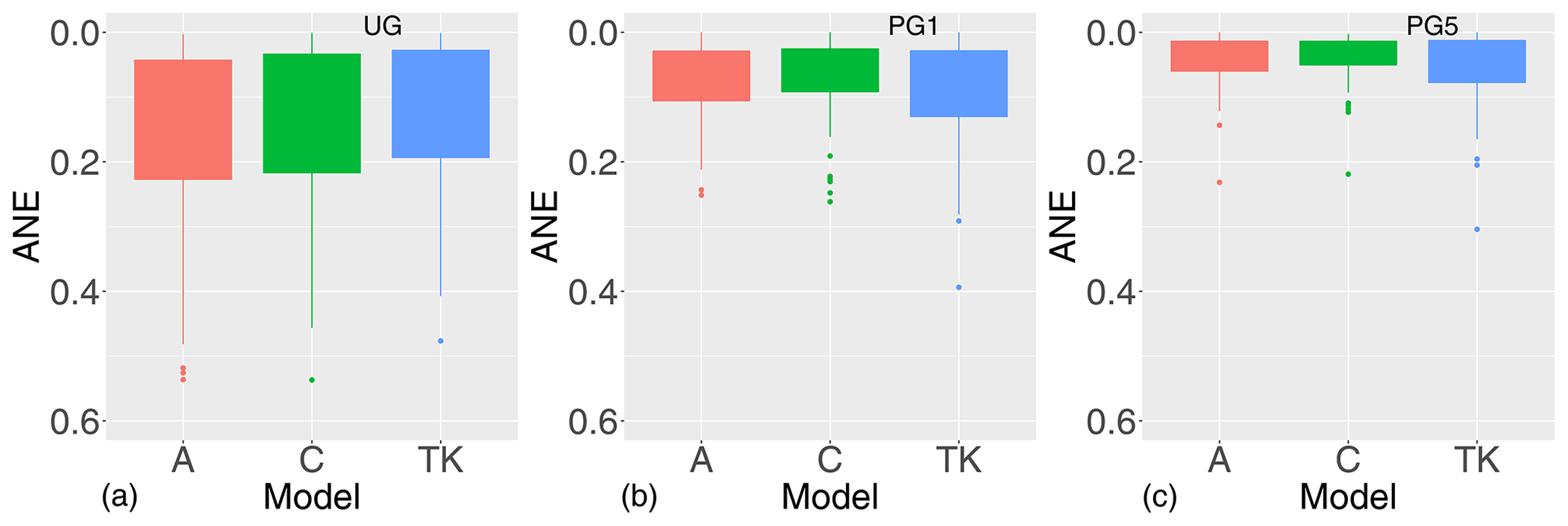
Figure 14Absolute normalized error (ANE) for the areal model (A), centroid model (C) and top-kriging (TK) for predictions of mean annual runoff in ungauged catchments (UG, a) and in partially gauged catchments with short records of length 1 (PG1, b) and length 5 (PG5, c).
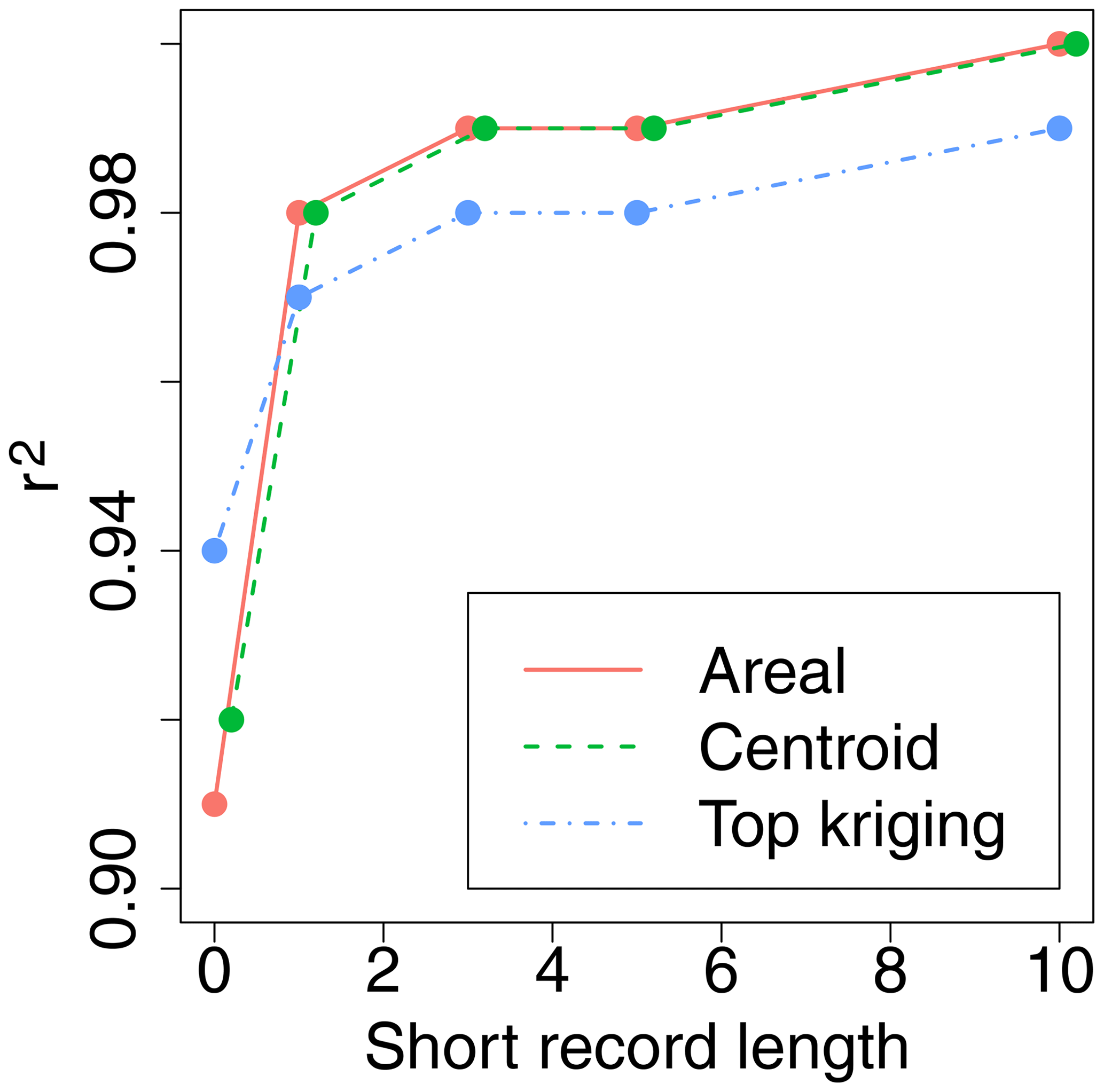
Figure 15The squared correlation coefficient (r2) for predictions of mean annual runoff for catchments in Norway with record length 0, 1, 3, 5 and 10.
In this article we have presented a geostatistical framework particularly suitable for hydrological datasets that include short records of data. Here, we highlight four points for discussion: (1) the difference in performance across methods and study areas, (2) comparing the findings with other studies, (3) shortcomings of the suggested framework and (4) suggested areas of use.
7.1 Difference in performance across methods and study areas
In our work, we evaluated two versions of our suggested framework by predicting annual runoff and mean annual runoff for Norway. The results showed that our areal-referenced method and our point- (or centroid-)referenced method gave very similar results in terms of posterior mean (see e.g. Figs. 7 and 13). We did not find a trend describing when one of the methods performed better than the others. In prior to the analysis, we would expect the areal model to perform better than the centroid model for ungauged, nested catchments since the areal model takes the water balance and the nested structure of catchments into account. However, these properties did not have a notable impact on the predicted posterior mean runoff for this particular dataset. This is not an extraordinary result as similar results have been obtained by other studies that have compared top-kriging (areal-referenced approach) to ordinary kriging (point-referenced approach): the point-referenced approaches often perform similarly to the areal-referenced approaches (Farmer, 2016; Skøien et al., 2014).
A possible explanation for the similar performance of the centroid and areal model in this study is that the proportion of nested catchments in our datasets was relatively low: only 30 % of the catchments in Fig. 1 were nested, while the percentage of nested catchments was 53 % among the fully gauged catchments in Fig. 5. Furthermore, most of the nested catchments only have one overlapping catchment. The water balance constraints of the areal model might be more important for datasets where there is a higher percentage of nested catchments in an area with high spatial variability. One example is shown in Roksvåg et al. (2020).
It is also possible that the water balance constraints of the areal model have some drawbacks. One example is if there is poor data quality for a subcatchment in the dataset. Then we impose an inaccurate but relatively strict constraint on the runoff in this catchment's drainage area. This will have an impact on the predictions for all overlapping catchments, and how the predicted runoff is distributed here. In this sense, the areal model is less flexible than the centroid model and requires better data quality.
The water balance constraints of the areal model also makes it computationally more expensive than the two other models. Top-kriging used around 1 min for the interpolation of mean annual runoff presented in Sect. 6.2 for one cross-validation fold. The centroid model used around 30–40 min for the interpolation, but provided results for both mean annual runoff and runoff for 30 individual years at the same time. Its run time is thus similar to the run time of top-kriging per year. The areal model on the other hand used around 6–7 h to do the calculations on the same computational server. Hence, from a practical point of view, the centroid model might be the most convenient version of our suggested framework for many applications. However, note that if the posterior uncertainty is important, the areal model gives a more realistic representation of uncertainty than the centroid model (see Fig. 7). The centroid model also treats small and large catchments equally, which can be problematic for some applications and study areas.
When considering predictions for ungauged catchments, the results showed that top-kriging provided better results than our two suggested models. Figure 7 showed that the three methods failed and succeeded for many of the same catchments, but that our models failed slightly more than top-kriging on average. We also see an indication that our models fail more than top-kriging for ungauged catchments that are located further away from other catchments. See for example the catchment that is located south-east in Fig. 7. For ungauged catchments located far away from other catchments (relative to the spatial range), the predicted value will go towards the intercept βc for our two Bayesian models. For top-kriging, the predicted value will always be a weighted sum of the observations from the neighbouring catchments. This can explain the difference in performance here. Apart from this, we do not find a pattern for which catchments top-kriging performs better (mean elevation, location and the magnitude of the observed value were investigated).
While top-kriging performed best for ungauged catchments, our framework outperformed top-kriging when there were some available data from the target catchment. This was the case both when predicting mean annual runoff, and runoff for individual years. The results showed that the potential gain of including (very) short records in the modelling in Norway was large. An explanation is that the annual runoff in Norway is mainly controlled by orographic precipitation. Since the orographic precipitation is driven by topography and westerly winds are dominating, the precipitation patterns are repeated each year and we obtain hydrological spatial stability with σc≫σx. The mountains in Norway also lead to rapid weather changes in space, here expressed through a low climatic spatial range ρc. Consequently, the information gain from neighbouring catchments is often low for ungauged catchments, and information from the target catchment can be very valuable. It is also convenient that Norway has a humid climate where only around 10 %–20 % of the annual precipitation evaporates.
The evaluation based on annual time series of monthly runoff gave us an indication of how the framework can be expected to behave for other climates and countries: for areas where the annual runoff is driven by unstable weather patterns and hydrological processes, short records can not be expected to contribute to as large improvements in the predictions as for the Norwegian annual data (see the predictions for April in Fig. 11b). This might be the case for countries and areas where most of the runoff can be explained by convective precipitation, where the aridity index is large or for variables for which storage effects are significant. However, the monthly predictions for January and April also illustrated that we safely can include (very) short records in the model, even if year-specific effects explain most of the spatial variability of runoff. By this we have demonstrated that our models represent a framework for safe use of short records regardless of record length and climate and with the benefit that we do not need to consider the choice of donor catchment as in other comparable methods.
Norway is a country with a moderate gauging density. The framework has not been tested for a denser gauging density. We suppose that there is less to gain from including short records if the gauging density is large relative to the spatial range: here the information obtained from neighbouring catchments could be sufficient. However, a high density of gauged catchments and a close distance to neighbouring catchments do not always guarantee good predictability at an ungauged catchment (Patil and Stieglitz, 2012). It is for example often difficult to predict runoff in ungauged catchments that are very small and/or located close to weather divides. We believe that for such catchments, our method for including short records can be useful regardless of gauging density (as long as the study area is characterized by repeated runoff patterns over time).
7.2 Comparing the findings of this study with other studies
There exist several other studies of mean annual runoff in the literature, and some of them are compared in terms of the ANE in the chapter about annual runoff in Blöschl et al. (2013). According to Figure 5.27 in Blöschl et al. (2013), an ANE between 0.05 and 0.5 is a typical result for regions like Norway where the potential evapotranspiration is less than 40 % of the mean annual precipitation. Figure 14 showed that the median ANE obtained for our suggested models is around 0.12 for ungauged catchments, i.e. in the lower range of ANE values in Blöschl et al. (2013). When a short record of length 1 or 5 was available (PG1 and PG5), the median ANE was as low as 0.05 and 0.03 for our methods.
In Fig. 5.30 in Blöschl et al. (2013) there is also a subplot showing the ANE for predictions of mean annual runoff for ungauged catchments in Austria. Here, geostatistical models (top-kriging) and process-based models (conceptual hydrological models) provided the best predictions according to the ANE, with a median ANE around 0.1. The results we obtain in Fig. 14 for the ungauged catchments are thus comparable to the results from Austria. This is reasonable as the Austrian climate is humid, like the Norwegian, and the western part of the country is dominated by mountains (the Alps) and has similar climate characteristics to Norway.
Furthermore, Blöschl et al. (2013) report an r2 (squared correlation coefficient) between 0.60 and 0.99 for studies done by cross-validation of around 250 catchments, or for studies using models based on spatial proximity like our suggested framework (Figure 5.25 and Figure 5.26 in Blöschl et al., 2013). The r2 for our two models was shown in Fig. 15, and we see that it lies between 0.91 and 0.99. This is in the higher range of values obtained by comparable studies.
7.3 Shortcomings
In this article, we proposed two models for runoff that are Gaussian. However, runoff is truncated at zero and typically not Gaussian distributed which we also can see from the histograms in Fig. 1b and 4. The consequence of the Gaussian assumptions is that there is nothing in the models that prevents them from predicting negative runoff. Negative values appear for both the areal and centroid models due to the uncertainty given by σy, but this is also a problem for the top-kriging technique. Another source of negative values is that the climatic part of the model (c(u)+βc) can be negative in some areas. This is a fully valid result because the other model components could still ensure positive predictions for most catchments and years. However, it can become a problem if we are unlucky and the year-specific GRF does not make up for the negative climatic GRF for one specific year. To avoid negative values, it is possible to log transform the data before performing an analysis. However, this is only valid for the centroid model, as the log transform is not compatible with the linear aggregation performed by the areal model (Eq. 11).
In the areal model, negative values also appear as a consequence of requiring preservation of water balance. If there are inconsistent or poor data over nested catchments, negative runoff in parts of a catchment can be the only option to fulfill the water balance requirements. To avoid negative runoff it is important that the discretization of the study area is fine enough to capture rapid changes in runoff over nested catchments. Catchments that are significantly influenced by human activities should also be removed from the analysis as these can influence both the water balance and the significance of the climatic field c(u) relative to the annual field xj(u).
In our study, some negative values were produced for the monthly predictions, as we can see in Fig. 11b. However, this is not common and happened for only 1.2 % of the predictions of missing monthly data and for a few data points for the missing annual data for the areal and centroid models. For predictions of mean annual runoff, negative values almost never appear as such effects typically are averaged out. Note that unphysical results also appear for top-kriging and other interpolation methods, either in terms of violating the water balance or in terms of negative values. These model weaknesses should be noted such that the modeller is able to choose what is most important in a real modelling setting. In this case it is a choice between (1) avoiding negative values by log transforming the data before using top-kriging or the centroid model or (2) imposing water balance constraints through the areal model.
7.4 Suggested areas of use
Finally, we want to highlight what we think are the main areas of use for our suggested framework. First, our results showed that our main benefit compared to top-kriging was connected to exploiting short records from the target catchment. For this reason, we think that our method is suitable as a pre-processing method for making inference about the (mean) annual runoff in partially gauged catchments before doing a further analysis with other statistical tools or process-based models. One possible approach for runoff estimation could for example be a two-step procedure where we (i) use the centroid or areal model as a record augmentation technique to predict runoff for the partially gauged catchments in the dataset and (ii) use top-kriging to predict runoff in ungauged catchments. Here, the results from step (i) can be used as observed values in top-kriging together with data from fully gauged catchments. Differences in observation uncertainty between fully gauged and partially gauged catchments should here be taken into account.
Secondly, we see that the parameter values of the suggested model provides interesting information about the study area. More specifically, if the marginal variance of the climatic GRF σc dominates over the marginal variance of the year-specific GRF σx, it suggests that the spatial variability is stable over time and that short records of runoff can have a large impact on the model, particularly if also ρc is small. This information can be used by decision makers to e.g. motivate the installation of a new (possibly temporary) gauging station as this might improve the long-term estimates only a year after installation for this catchment. Likewise can the model and its parameters be used to assess whether a gauging station is redundant and can be shut down. However, to exactly quantify the importance of a gauging station, all model variances (, , , ) and ranges (ρx, ρc) must be taken into account, as well as the distances between the donor catchments and the target catchment. Computing this gain is outside the scope of this article but an interesting topic for further research that is related to the field of decision theory and the value of information (Eidsvik et al., 2015).
We have presented a geostatistical framework for estimating runoff by modelling several years of runoff data simultaneously by using one (climatic) spatial field that is common for all years under study and one (annual) spatial field that is year-specific. By this, we obtain a framework that is particularly suitable for runoff interpolation when the available data originate from a mixture of gauged and partially gauged catchments, and that can be used to estimate runoff at ungauged and partially gauged locations. We evaluated the framework by (1) its ability to fill in missing values of annual runoff and (2) its ability to predict mean annual runoff for ungauged and partially gauged catchments. The case study from Norway showed that the suggested framework performs better than top-kriging for catchments that have short records of data, both for predictions of mean annual runoff and when filling in missing annual values. For totally ungauged catchments, top-kriging performed best. We also (3) demonstrated the potential value of including short records in the modelling and found that the value of (very) short records was high in Norway: an average reduction of 50 % in the RMSE was reported when a short record of length 1 was available from the target catchment, compared to when no annual observations were available. The reason for the large reduction is that the annual runoff in Norway is mainly driven by hydrological processes that are repeated each year. For such areas, our methodology has its main benefits, and we can use it as a tool for motivating the installation of new gauging stations: the new gauging stations might improve the long-term estimates at the target catchments only a year after installation. Furthermore, the results also show that the framework represents safe use of short records down to record lengths of 1 year, regardless of the underlying climatic conditions in the area of interest.
Example code for fitting the centroid model with example data is available on https://github.com/tjroksva/RunoffInterpolation (last access: 29 January 2020, https://doi.org/10.5281/zenodo.3630348, Roksvåg, 2020). The remaining data are available upon request.
TR was the main author, responsible for writing the majority of the paper, came up with initial ideas for experimental design, did the implementation, carried out the analysis and made figures. IS contributed to discussion throughout the work around ideas, analysis and discussion, suggested ideas for the experimental set-up and commented on the manuscript structure and content, and contributed to the writing of Sect. 6. KE provided the hydrological data, contributed to the discussion, particularly around the hydrological context and questions related to the data, contributed to the writing of Sects. 1 and 2, and commented on the structure and content of the rest of the paper.
The authors declare that they have no conflict of interest.
We would like to thank Gregor Laaha, Jon Olav Skøien, Joris Beemster and one anonymous referee for in-depth reviews and valuable comments. The review process improved the quality of the paper.
This research has been supported by the The Research Council of Norway (grant no. 250362).
This paper was edited by Harrie-Jan Hendricks Franssen and reviewed by Gregor Laaha, Jon Olav Skøien, and one anonymous referee.
Adamowski, K. and Bocci, C.: Geostatistical regional trend detection in river flow data, Hydrol. Process., 15, 3331–3341, https://doi.org/10.1002/hyp.1045, 2001. a
Bakka, H., Rue, H., Fuglstad, G.-A., Riebler, A., Bolin, D., Illian, J., Krainski, E., Simpson, D., and Lindgren, F.: Spatial modeling with R-INLA: A review, WIREs Computational Statistics, 10, e1443, https://doi.org/10.1002/wics.1443, 2018. a
Banerjee, S., Gelfand, A., and Carlin, B.: Hierarchical Modeling and Analysis for Spatial Data, vol. 101 of Monographs on Statistics and Applied Probability, Chapman & Hall, Boca Raton, Florida, 2004. a
Blöschl, G., Sivapalan, M., Wagener, T., Viglione, A., and Savenije, H.: Runoff Prediction in Ungauged Basins: Synthesis across Processes, Places and Scales, Camebridge University Press, Cambridge, 2013. a, b, c, d, e, f, g, h, i, j
Brenner, S. and Scott, L.: The Mathematical Theory of Finite Element Methods, 3rd Edition. Vol. 15 of Texts in Applied Mathematics, Springer, New York, 2008. a
Casella, G. and Berger, R.: Statistical Inference, Duxbury Press, Belmont, 1990. a
Cressie, N.: Statistics for spatial data, J. Wiley & Sons, New York, 1993. a, b, c
Eidsvik, J., Finley, A. O., Banerjee, S., and Rue, H.: Approximate Bayesian inference for large spatial datasets using predictive process models, Comput. Stat. Data An., 56, 1362–1380, https://doi.org/10.1016/j.csda.2011.10.022, 2012. a
Eidsvik, J., Mukerji, T., and Bhattacharjya, D.: Value of Information in the Earth Sciences: Integrating Spatial Modeling and Decision Analysis, Cambridge University Press, Cambridge, https://doi.org/10.1017/CBO9781139628785, 2015. a
Engeland, K. and Hisdal, H.: A Comparison of Low Flow Estimates in Ungauged Catchments Using Regional Regression and the HBV-Model, Water Resour. Manag., 23, 2567–2586, https://doi.org/10.1007/s11269-008-9397-7, 2009. a
Farmer, W. H.: Ordinary kriging as a tool to estimate historical daily streamflow records, Hydrol. Earth Syst. Sci., 20, 2721–2735, https://doi.org/10.5194/hess-20-2721-2016, 2016. a
Ferkingstad, E. and Rue, H.: Improving the INLA approach for approximate Bayesian inference for latent Gaussian models, Electron. J. Stat., 9, 2706–2731, https://doi.org/10.1214/15-EJS1092, 2015. a
Fiering, M.: Use of correlation to improve estimates of the mean and variance, USGS Publications Warehouse, Washington, 1963. a, b, c
Fong, Y., Rue, H., and Wakefield, J.: Bayesian inference for generalized linear mixed models, Biostatistics, 11, 397–412, https://doi.org/10.1093/biostatistics/kxp053, 2009. a
Fuglstad, G.-A., Simpson, D., Lindgren, F., and Rue, H.: Constructing Priors that Penalize the Complexity of Gaussian Random Fields, J. Am. Stat. Assoc., 114, 445–452, https://doi.org/10.1080/01621459.2017.1415907, 2019. a
Førland, E. J.: Nedbørens høydeavhengighet, Klima, 2, 3–24, 1979. a
Gamerman, D. and Lopes, H. F.: Markov chain Monte Carlo: stochastic simulation for Bayesian inference, 2 Edn., Chapman and Hall/CRC, Boca Raton, 2006. a
Gneiting, T. and Raftery, A. E.: Strictly Proper Scoring Rules, Prediction, and Estimation, J. Am. Stat. Assoc., 102, 359–378, https://doi.org/10.1198/016214506000001437, 2007. a
Gottschalk, L.: Correlation and covariance of runoff, Stoch. Hydrol. Hydraul., 7, 85–101, https://doi.org/10.1007/BF01581418, 1993. a, b
Gottschalk, L., Jensen, J. L., Lundquist, D., Solantie, R., and Tollan, A.: Hydrologic Regions in the Nordic Countries, Hydrol. Res., 10, 273–286, 1979. a
Guillot, G., Vitalis, R., le Rouzic, A., and Gautier, M.: Detecting correlation between allele frequencies and environmental variables as a signature of selection. A fast computational approach for genome-wide studies, Spat. Stat., 8, 145–155, https://doi.org/10.1016/j.spasta.2013.08.001, 2014. a
Guttorp, P. and Gneiting, T.: Studies in the history of probability and statistics XLIX On the Matérn correlation family, Biometrika, 93, 989–995, https://doi.org/10.1093/biomet/93.4.989, 2006. a
Hirsch, R. M.: A comparison of four record extension techniques, Water Resour. Res., 8, 1081–1088, 1982. a, b, c
Huang, J., Malone, B., Minasny, B., Mcbratney, A., and Triantafilis, J.: Evaluating a Bayesian modelling approach (INLA-SPDE) for environmental mapping, Sci. Total Environ., 609, 621–632, https://doi.org/10.1016/j.scitotenv.2017.07.201, 2017. a, b
Ingebrigtsen, R., Lindgren, F., and Steinsland, I.: Spatial models with explanatory variables in the dependence structure, Spat. Stat., 8, 20–38, https://doi.org/10.1016/j.spasta.2013.06.002, 2014. a
Ingebrigtsen, R., Lindgren, F., Steinsland, I., and Martino, S.: Estimation of a non-stationary model for annual precipitation in southern Norway using replicates of the spatial field, Spat. Stat., 14, 338–364, https://doi.org/10.1016/j.spasta.2015.07.003, 2015. a
Khan, D. and Warner, M.: A Bayesian spatial and temporal modeling approach to mapping geographic variation in mortality rates for subnational areas with r-inla, Journal of Data Science, 18, 147–182, 2018. a
Laaha, G. and Blöschl, G.: Low flow estimates from short stream flow records – a comparison of methods, J. Hydrol., 306, 264–286, https://doi.org/10.1016/j.jhydrol.2004.09.012, 2005. a, b, c, d
Lindgren, F., Rue, H., and Lindström, J.: An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach, J. Roy. Stat. Soc.-B, 73, 423–498, https://doi.org/10.1111/j.1467-9868.2011.00777.x, 2011. a, b, c
Martino, S., Akerkar, R., and Rue, H.: Approximate Bayesian Inference for Survival Models, Scand. J. Stat., 38, 514–528, https://doi.org/10.1111/j.1467-9469.2010.00715.x, 2011. a
Matalas, N. C. and Jacobs, B.: A correlation procedure for augmenting hydrologic data, U.S. Geol. Surv. Prof. Pap., 434-E, https://doi.org/10.3133/pp434E, 1964. a, b
Merz, R. and Blöschl, G.: Flood frequency regionalisation – spatial proximity vs. catchment attributes, J. Hydrol., 302, 283–306, https://doi.org/10.1016/j.jhydrol.2004.07.018, 2005. a, b, c
Moraga, P., Cramb, S. M., Mengersen, K. L., and Pagano, M.: A geostatistical model for combined analysis of point-level and area-level data using INLA and SPDE, Spat. Stat., 21, 27–41, https://doi.org/10.1016/j.spasta.2017.04.006, 2017. a
Opitz, T., Huser, R., Bakka, H., and Rue, H.: INLA goes extreme: Bayesian tail regression for the estimation of high spatio-temporal quantiles, Extremes, 21, 331–462, https://doi.org/10.1007/s10687-018-0324-x, 2018. a
Patil, S. and Stieglitz, M.: Controls on hydrologic similarity: role of nearby gauged catchments for prediction at an ungauged catchment, Hydrol. Earth Syst. Sci., 16, 551–562, https://doi.org/10.5194/hess-16-551-2012, 2012. a
Petersen-Øverleir, A.: Accounting for heteroscedasticity in rating curve estimates, J. Hydrol., 292, 173–181, https://doi.org/10.1016/j.jhydrol.2003.12.024, 2004. a
Roksvåg, T.: Code for implementing the centroid model, https://doi.org/10.5281/zenodo.3630348, last access: 29 January 2020.
Roksvåg, T., Steinsland, I., and Engeland, K.: A geostatistical two field model that combines point observations and nested areal observations, and quantifies long-term spatial variability – A case study of annual runoff predictions in the Voss area, arXiv:1904.02519v2, 2020. a, b, c, d, e
Rue, H. and Held, L.: Gaussian Markov Random Fields: Theory and Applications, vol. 104 of Monographs on Statistics and Applied Probability, Chapman & Hall, London, 2005. a, b
Rue, H., Martino, S., and Chopin, N.: Approximate Bayesian inference for latent Gaussian models using integrated nested Laplace approximations, J. Roy. Stat. Soc.-B, 71, 319–392, https://doi.org/10.1111/j.1467-9868.2008.00700.x, 2009. a, b
Sauquet, E., Gottschalk, L., and Lebois, E.: Mapping average annual runoff: A hierarchical approach applying a stochastic interpolation scheme, Hydrolog. Sci. J., 45, 799–815, https://doi.org/10.1080/02626660009492385, 2000. a, b, c
Siegel, S.: Non-parametric statistics for the behavioral sciences, McGraw-Hill, New York, 1956. a
Simpson, D., Rue, H., Riebler, A., Martins, T. G., and Sørbye, S. H.: Penalising Model Component Complexity: A Principled, Practical Approach to Constructing Priors, Stat. Sci., 32, 1–28, https://doi.org/10.1214/16-STS576, 2017. a
Skøien, J. O., Merz, R., and Blöschl, G.: Top-kriging - geostatistics on stream networks, Hydrol. Earth Syst. Sci., 10, 277–287, https://doi.org/10.5194/hess-10-277-2006, 2006. a, b, c, d, e
Skøien, J., Blöschl, G., Laaha, G., Pebesma, E., Parajka, J., and Viglione, A.: rtop: An R package for interpolation of data with a variable spatial support, with an example from river networks, Comput. Geosci., 67, 180–190, https://doi.org/10.1016/j.cageo.2014.02.009, 2014. a
Skøien, J. O. and Blöschl, G.: Spatiotemporal topological kriging of runoff time series, Water Resour. Res., 43, W09419, https://doi.org/10.1029/2006WR005760, 2007. a
Skøien, J. O., Blöschl, G., and Western, A. W.: Characteristic space scales and timescales in hydrology, Water Resour. Res., 39, 1304, https://doi.org/10.1029/2002WR001736, 2003. a, b
Stohl, A., Forster, C., and Sodemann, H.: Remote sources of water vapor forming precipitation on the Norwegian west coast at 60∘ N – a tale of hurricanes and an atmospheric river, J. Geophys. Res.-Atmos., 113, D05102, https://doi.org/10.1029/2007JD009006, 2008. a
Sælthun, N., Tveito, O., Bøsnes, T., and Roald, L.: Regional flomfrekvensanalyse for norske vassdrag, Tech. Rep., Oslo, NVE, 1997. a
Viglione, A., Parajka, J., Rogger, M., Salinas, J. L., Laaha, G., Sivapalan, M., and Blöschl, G.: Comparative assessment of predictions in ungauged basins – Part 3: Runoff signatures in Austria, Hydrol. Earth Syst. Sci., 17, 2263–2279, https://doi.org/10.5194/hess-17-2263-2013, 2013. a, b
Vogel, R. M. and Stedinger, J. R.: Minimum variance streamflow record augmentation procedures, Water Resour. Res., 21, 715–723, https://doi.org/10.1029/WR021i005p00715, 1985. a
Yuan, Y., Bachl, F., Lindgren, F., Borchers, D., Illian, J., Buckland, S., Rue, H., and Gerrodette, T.: Point process models for spatio-temporal distance sampling data from a large-scale survey of blue whales, Ann. Appl. Stat., 11, 2270–2297, https://doi.org/10.1214/17-AOAS1078, 2017. a
- Abstract
- Introduction
- Study area
- Statistical methodology
- A geostatistical framework for exploiting long-term averages and short records
- Model evaluation
- Results
- Discussion
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Study area
- Statistical methodology
- A geostatistical framework for exploiting long-term averages and short records
- Model evaluation
- Results
- Discussion
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References