the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 24 Oct 2025
| 24 Oct 2025
Synergistic identification of hydrogeological parameters and pollution source information for groundwater point and areal source contamination based on machine learning surrogate–artificial hummingbird algorithm
Chengming Luo
Y. Jun Xu
Shunqing Jia
Zejun Liu
Boyang Mao
Qinya Lv
Xuming Ji
Yanxin Rong
Yan Dai
Effectively remediating groundwater contamination relies on the precise determination of its sources. In recent years, a growing research focus has been placed on concurrently estimating hydrogeological characteristics and locating pollutant origins. However, the precise synergistic identification of point and areal contamination sources of groundwater and combined hydrogeological parameters has not been effectively solved. This study developed an inversion framework that integrates machine learning surrogates with the artificial hummingbird algorithm (AHA). The surrogate models approximating the simulation system were constructed using both backpropagation neural networks (BPNNs) and Kriging techniques. The AHA was then employed to solve the optimized model, and its performance was benchmarked against particle swarm optimization (PSO) and the sparrow search algorithm (SSA). The applicability of this inversion framework was assessed by application to point sources of contamination (PSC) and areal source contamination (ASC). The robustness of the framework was verified through application to scenarios with different noise levels. The results showed that the surrogate model constructed by the BPNN method provided estimates that were closer to those of the simulation model in comparison to the Kriging method. The coefficient of determination (R2) is 0.9994 and mean relative error (MARE) is 3.70 % in PSC, and the R2 is 0.9989 and MARE is 4.48 % in ASC. The performance of the AHA exceeded that of the PSO and the SSA. In PSC, the MARE of the identification result is 1.58 %. In ASC, the MARE of the identification result is 2.03 %, with the AHA able to rapidly and accurately identify the global optimum and improve the inversion efficiency. The proposed inversion framework was demonstrated to apply to both groundwater PSC and ASC problems with strong robustness, providing a reliable basis for groundwater pollution remediation and management.
- Article
(4042 KB) - Full-text XML
-
Supplement
(447 KB) - BibTeX
- EndNote




-
A highly adaptable inversion framework is adapted to different groundwater pollution scenarios.
-
Synergetic identification of source information, hydraulic conductivity, and boundary condition in PSC.
-
The artificial hummingbird algorithm is applied to solve the optimized model.
Groundwater pollution adversely affects human production and life (Wang et al., 2022; Liu et al., 2024). The remediation of groundwater contamination is important for ensuring human health and socioeconomic development. However, groundwater contamination is difficult to detect and treat due to its hidden nature, thereby complicating the assessment of groundwater pollution risk and contamination liability (Li et al., 2021). Remediation requires the identification of sources of groundwater contamination (location, number, release history, etc.) and hydrogeological conditions (Maliva et al., 2015; Daranond et al., 2020; Pan et al., 2022b; Medici et al., 2024). However, directly obtaining this information can pose a challenge, with a proven method being the identification of groundwater contamination by inversion of limited observational data.
The inversion of groundwater aquifer hydrogeologic parameters and pollution source information is a widely studied topic. In past studies on groundwater contamination identification (GCI), many researchers have focused on the separate identification of hydrogeological parameters or pollution source information. For example, Singh and Datta (2007) utilized backpropagation-based artificial neural network techniques specifically for the identification of groundwater pollution sources. Similarly, Mahar and Datta (2000) employed a non-linear optimization model to identify the location, duration, and magnitude of the contamination source. Liu et al. (2022) inverted hydrogeological parameters through a simulation–optimization approach, while Wang et al. (2024a) combined three different inversion algorithms and a Kriging surrogate model to invert hydraulic conductivity. While simplifying the problem, these methods allow researchers to focus on specific aspects. However, although the individual identification method can be effective in some cases, it often overlooks the inter-connectivity between hydrogeological parameters and pollution sources.
Currently, the simultaneous identification of hydrogeological parameters and pollution source information is gaining increasing attention in research. Researchers have employed various advanced technologies to achieve this goal. Wang et al. (2021) utilized a parallelized heuristic algorithm to concurrently determine aquifer characteristics and the groundwater pollution sources. Pan et al. (2021) integrated a Bayesian-regularized deep neural network surrogate to jointly infer pollution source details and hydraulic conductivity. Hou et al. (2021) integrated homotopy-based inverse optimization theory with a multi-kernel extreme learning machine to finish the co-identification of contamination sources and aquifer parameters. Luo et al. (2023) leveraged machine learning techniques to establish an inverse relationship between model outputs and inputs, enabling the fast and simultaneous retrieval of pollution source attributes and hydrogeological properties. Although these methods have advanced the field, improving recognition accuracy remains a major challenge in the simultaneous identification process.
The simulation–optimization method has been widely applied in GCI research because of its robust mathematical foundation (Mirghani et al., 2009) and its ability to identify multiple variables simultaneously. To enhance both identification accuracy and efficiency using simulation–optimization, two key approaches are employed: one is to optimize the model solution method for better performance, and the other is to construct a surrogate model with high approximation accuracy. Optimizing the model solution method is essential. Since heuristic optimization algorithms are more capable of identifying global optima, many have been applied to GCI. Mirghani et al. (2012) implemented a genetic algorithm in optimization to identify sources of contamination. Jiang et al. (2013) combined a harmony search algorithm with a contamination transport simulation model to characterize contamination sources. Additional methods, such as simulated annealing (Rao, 2006; Yeh et al., 2007; Jha and Datta, 2013) and the sparrow search algorithm (SSA; Pan et al., 2022b), have also been applied to GCI. However, increasing dimensionality and complexity in GCI problems make it difficult for many optimization algorithms to efficiently search for global optima. Constructing high-accuracy surrogate models is another crucial strategy. Surrogate models can significantly reduce computation time and improve inversion efficiency. Among these models, the widely used Kriging (Chugh et al., 2018; Zhang et al., 2019; Jiang et al., 2020) and backpropagation neural network (BPNN; Sargolzaei et al., 2012; Zhang et al., 2021; Wang et al., 2024b) methods offer high flexibility and strong non-linear fitting capabilities. Despite these advances, previous studies have overly focused on point source contamination (PSC) or areal source contamination (ASC) scenarios in isolation. However, the precise synergistic identification of PSC and ASC of groundwater and combined hydrogeological parameters has not been effectively solved.
Based on the above problems, this paper proposes an inversion framework integrating a machine learning surrogate model with the artificial hummingbird algorithm (AHA) using the simulation–optimization method (Fig. 1). Both BPNN and Kriging were utilized to develop surrogate models for the simulation model. The AHA was introduced to solve the optimization model, with its solution results compared against those of PSO and SSA. The applicability of this inversion framework was evaluated through its application to both PSC and ASC scenarios. The objectives of this study were to (1) develop a flexible groundwater pollution inversion scheme that can reliably invert parameters under various groundwater pollution scenarios, (2) adopt an integrated parameter identification strategy to achieve the simultaneous identification of multiple variables (including pollutant release characteristics and hydrogeological parameters) (3) design an optimization-based surrogate modeling method combining meta-heuristic search algorithms with neural network surrogate models to efficiently explore the solution space and reduce the risk of getting stuck in local optima during inversion calculations, and (4) evaluate the performance of the proposed scheme under various noise intensities and pollution patterns to validate its robustness and application potential in groundwater pollution inversion problems.
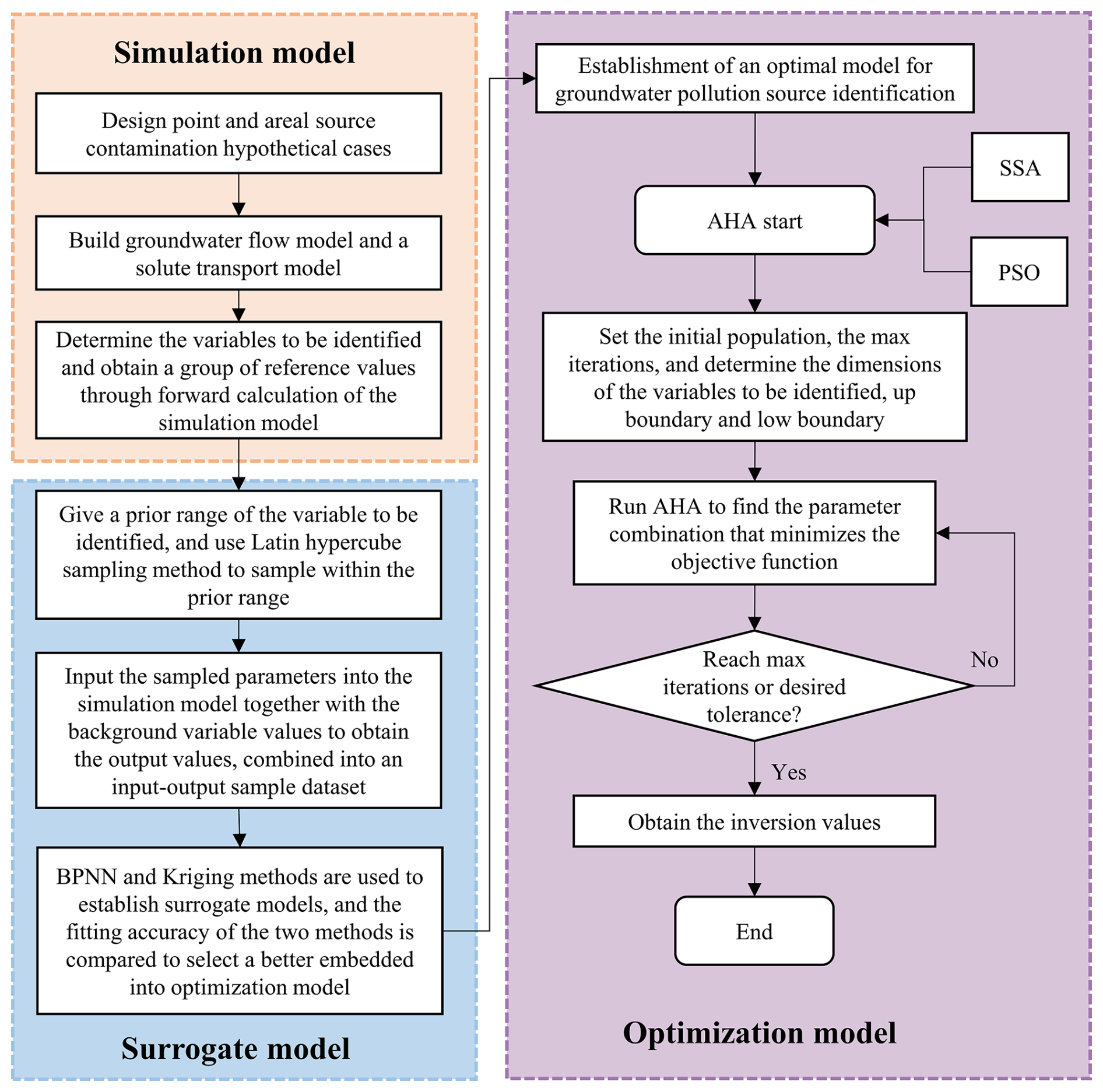
Figure 1The general process used in the present study to construct the machine learning surrogate model–artificial hummingbird algorithm framework.
The main innovations are as follows. (1) This study constructed an adaptive inversion framework that maintains high robustness in both PSC and ASC. (2) In the PSC case, the synergistic identification of source information, hydraulic conductivity, and boundary conditions is achieved. (3) Apply the AHA optimization model to solve the inverse problem of groundwater pollution to obtain the global optimal solution of the inverse problem and further improve the inversion accuracy. The good compatibility between the AHA and the BPNN surrogate model ensures the robustness and stability of the inversion process.
2.1 Simulation model
In this study, the numerical groundwater simulation framework comprised both a flow component and a solute transport module. The fundamental 2D partial differential equation governing groundwater flow is formulated as follows:
where Kij is hydraulic conductivity, W is the volumetric flux per unit volume, μ is the specific yield, H is the water-level elevation, z is the elevation of the aquifer floor, and S is the boundary of the spatial domain.
where C denotes the contaminant concentration in groundwater, t is the temporal variable, ui indicates the average flow velocity, R accounts for source and sink contributions, Dij refers to the hydrodynamic dispersion tensor, and ne represents the effective porosity of the medium. We used the MODFLOW-2005 (Harbaugh., 2005) and MT3DMS (Zheng et al., 2012) numerical models to obtain numerical solutions for groundwater flow and solute transport equations (Asher et al., 2015).
2.2 Kriging method
Kriging was employed to develop the underlying framework of the approach by capturing both the correlation and stochastic variability of variables within a confined spatial domain, thereby enabling the estimation of optimal regional values. The association between input and output variables is described through a regression-based expression, as shown below (Zhao et al., 2022a):
where is the estimated value of pollutant concentration y(x), is the basis function of the known regression model, and z(x) is the random part.
The following equations were satisfied:
where R(xixj) is the correlation function between the sampled point xi and xj .
The Gaussian model is commonly used:
where θk is a coefficient to be determined, which can be obtained by calculation.
2.3 The BPNN method
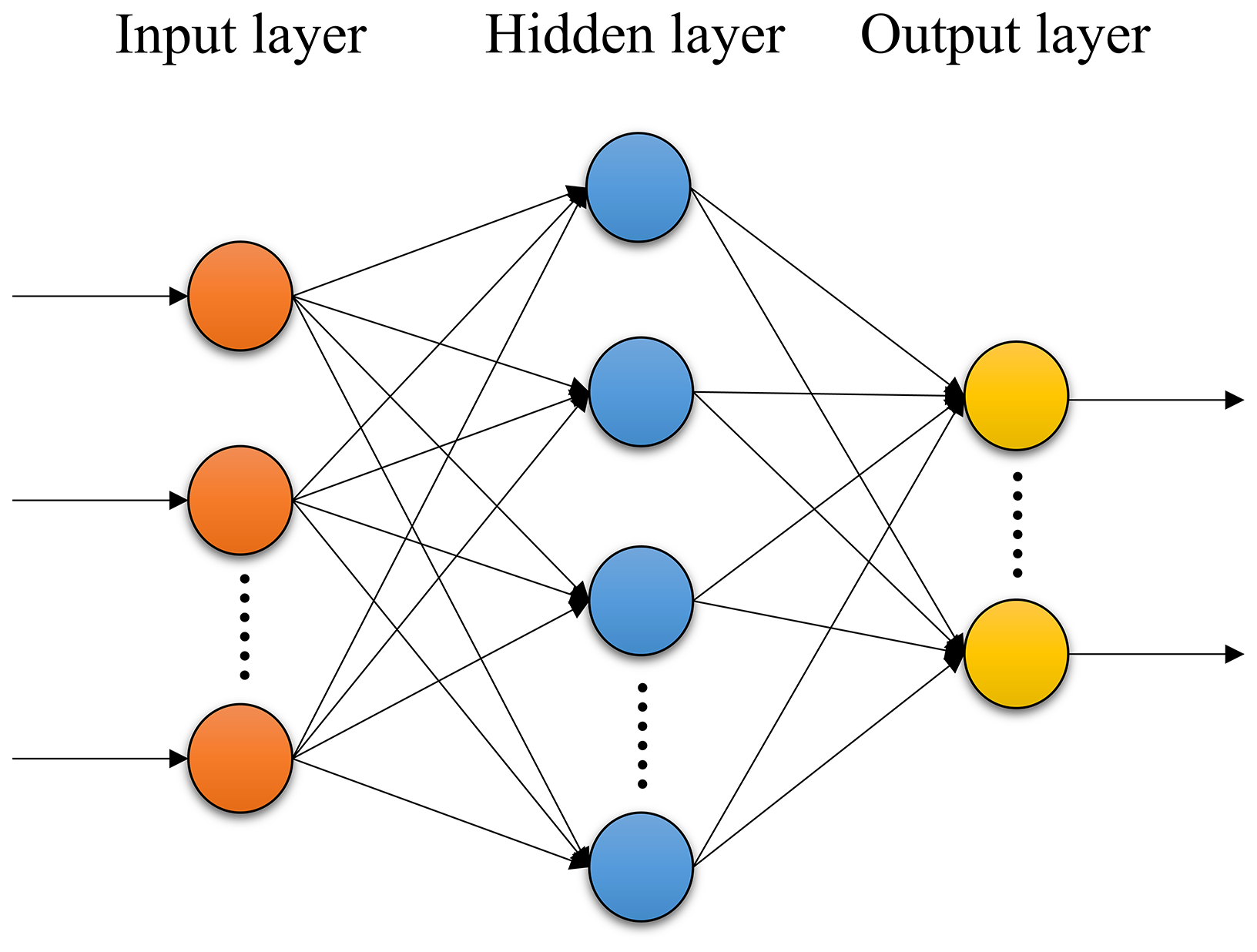
A typical backpropagation neural network (BPNN) is composed of three fundamental components (Fig. 2): (1) an input layer, (2) hidden layers, and (3) an output layer. The computation process proceeds in two main phases: forward propagation and backward propagation (Chen et al., 2010; Zhang et al., 2018).
-
During forward propagation, data are introduced into the network via the input layer and subsequently processed through successive layers to yield the final output. BPNNs frequently employ a non-linear sigmoid activation function:
The calculation of the forward transmission output layer is
where Oi represents the output of neuron i, Oj is the output of neuron j, b is the bias term, and Wij is the weight of the connection between neuron i and neuron j.
-
Backward propagation involves the random assignment of the weight of the first positive feedback process within the output layer. The adjustment of the parameters of the entire network is required. Network adjustment is performed by minimizing the discrepancy between the predicted output and the target category in the output layer. Specifically, for the output layer:
where Ej represents the error value at the jth node and Tj denotes the corresponding output. The hidden layers' output is determined by summing the weighted contributions from the errors of the lower nodes:
where Ek is the error gradient for the subsequent node k and Wjk is the weight connecting node j to node k. Following error calculation, the weight is adjusted according to the error gradient:
where η is the learning rate. In case 1, the BPNN architecture was configured as 19-30-45 and in case 2 as 15-20-50. The number of neurons in each layer was empirically optimized using a grid search combined with cross-validation to minimize the root mean square error (RMSE) and effectively prevent overfitting. The sigmoid function was employed as the activation function, and the network was trained using the Bayesian regularization algorithm. The maximum number of training iterations was set to 1000, and the learning rate was set to 0.01.
2.4 Artificial hummingbird algorithm (AHA)
The AHA consists of three main elements: food sources, hummingbirds, and the visit table. Hummingbirds typically assess food sources based on factors such as nectar quality, individual flower nectar content, and replenishment rates. For simplicity, it can be assumed that all food sources share the same flower type and number. Hummingbirds in a population can exchange information, be assigned to specific food sources, track nectar replenishment rates, and record the duration that each food source remains unvisited. The visit table records the time since a hummingbird last visited a food source and is used to assign visit levels; hummingbirds can harvest more nectar by first accessing food sources with higher access levels, following which food sources with the highest nectar replenishment rate are chosen (Zhao et al., 2022b). The AHA is algorithmically described below.
2.4.1 Initialization
First, n hummingbirds are randomly placed on n food sources:
The access table for the food source is then initialized:
where Low and Up are the lower and upper boundaries for a d-dimensional problem, respectively; r represents a random vector of [0,1]; and xi is the position of the ith food source. For i=j, indicates the sourcing of food from a specific source. For i≠j, indicates that the ith hummingbird has just visited the jth food source in the current iteration.
2.4.2 Guided foraging
Hummingbirds identify food sources in two steps: (1) identifying the food source with the highest access level and (2) selecting the food source with the highest nectar replenishment rate. After identifying the target food source, the hummingbird can fly to the target source to feed. During foraging, direction switching vectors used to control the availability of one or more directions in the d-dimensional space are introduced to model three flight skills: omnidirectional, diagonal, and axial flight. These flight models can be extended to the d-D space, and the mathematical model of axial flight is
Diagonal flight is defined as
Omnidirectional flight is defined as
where randi([1,d]) is a randomly generated integer from 1 to d, randperm(k) creates a random permutation of integers from 1 to k, and r1 is a random number in the range of 0 to 1.
Hummingbirds can access and obtain target food sources through these flight abilities. New food sources identified during the search are recorded along with previously identified food sources. The guided foraging behavior and candidate food sources can be represented as
where xi,tar(t) is the location of the food source that the ith hummingbird plans to visit, xi(t) represents the location of the ith food source at time t, and a is a leading factor obeying a normal distribution.
The location of the ith food source is updated as
where f(⋅) represents the function fitness value. The formula for updating the location can contribute to the preferential selection of food sources with a high nectar supply rate.
2.4.3 Territorial foraging
Since the quality of food sources in a foraging area may vary, hummingbirds actively search in that area. The regional foraging strategies and candidate food sources of hummingbirds can be represented as
where b is a territorial factor obeying a normal distribution. Equation (20) allows different hummingbirds to use their specific flight skills to identify new food sources near the target source.
2.4.4 Migration foraging
Migration coefficients are defined in the AHA to prevent the generation of local optimums. The exceedance of the number of iterations of the set migration coefficient results in the hummingbird located in the worst food source repeating a search for a new food source across the entire search range and the subsequent updating of the visit table:
where xwor is the food source with the worst nectar supply rate. The migration coefficient relative to population size can be defined as
The present study designed a groundwater PSC case study and an ASC case study to verify the applicability of the proposed GCI framework. Since the present study established two hypothetical examples, a set of variables to be identified and background variables for input into the groundwater contamination simulation model were established for each example for forward computation. The pollutant concentrations monitored at wells were used as observed data. The robustness of the inversion framework was verified by adding random noise to the observed data, expressed as
where α represents the observation data, α1 indicates observation data with added noise, l is the maximum disturbance range, and rand is a random number between −1 and 1.
3.1 Case study 1: groundwater PSC
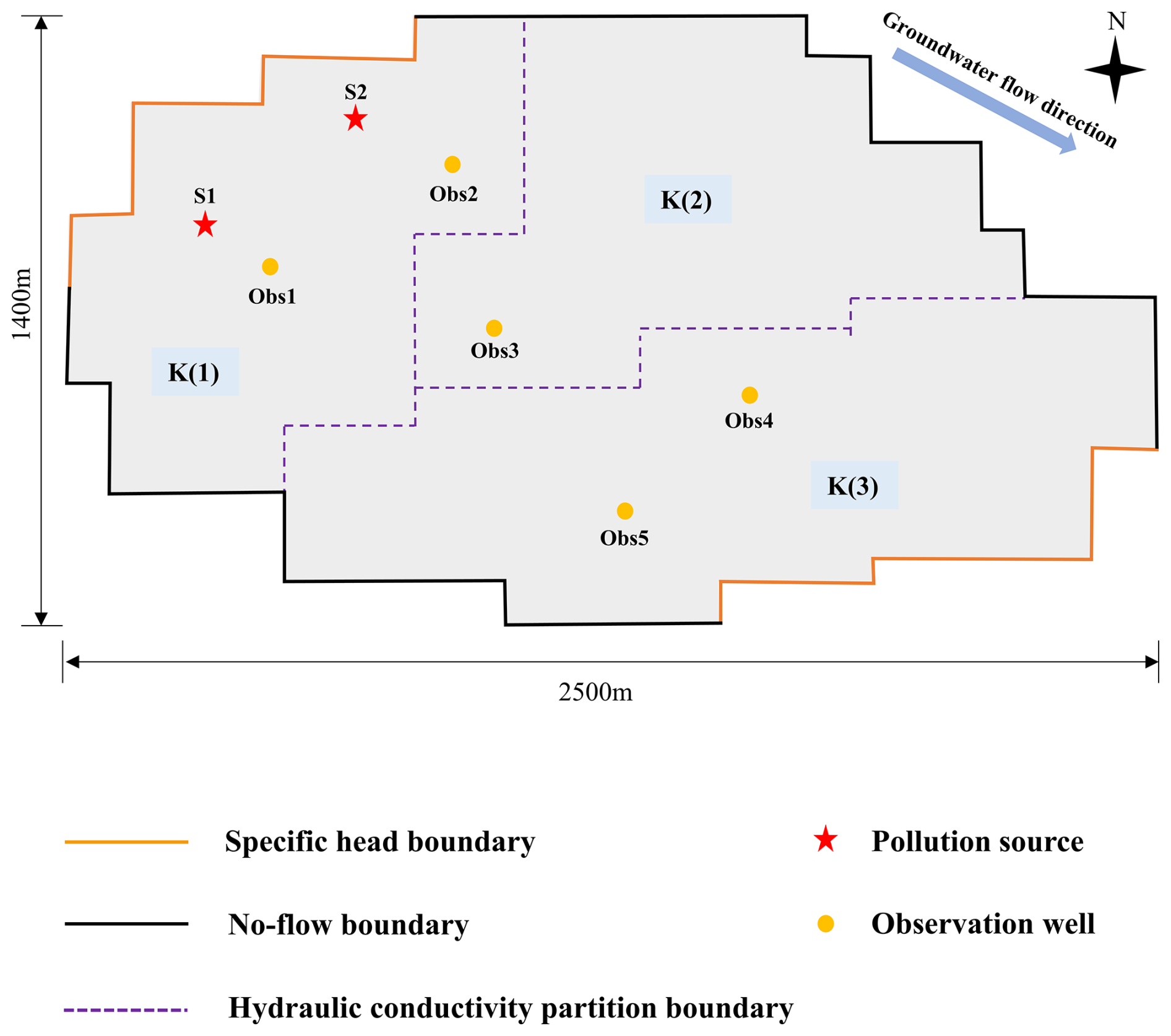
The study area is 2500 and 1400 m from east to west and north to south, respectively, with topography decreasing from west to east and groundwater flow from northwest to southeast. The study area contains a heterogeneous isotropic aquifer, and the present study focused on a layer of diving aquifer with a thickness of 10 m (Table 1). The aquifer comprises unconsolidated sediments, primarily well-sorted coarse sand and gravel. Groundwater flow was represented as a 2D steady flow, and the study area was divided into three areas according to differences in hydraulic conductivities. Since the northern and southern parts of the study area are very weakly permeable formations, they were generalized in the present study as no-flow boundaries. Rivers formed the boundaries of the western and eastern parts and were generalized as specific head boundaries (Fig. 3).
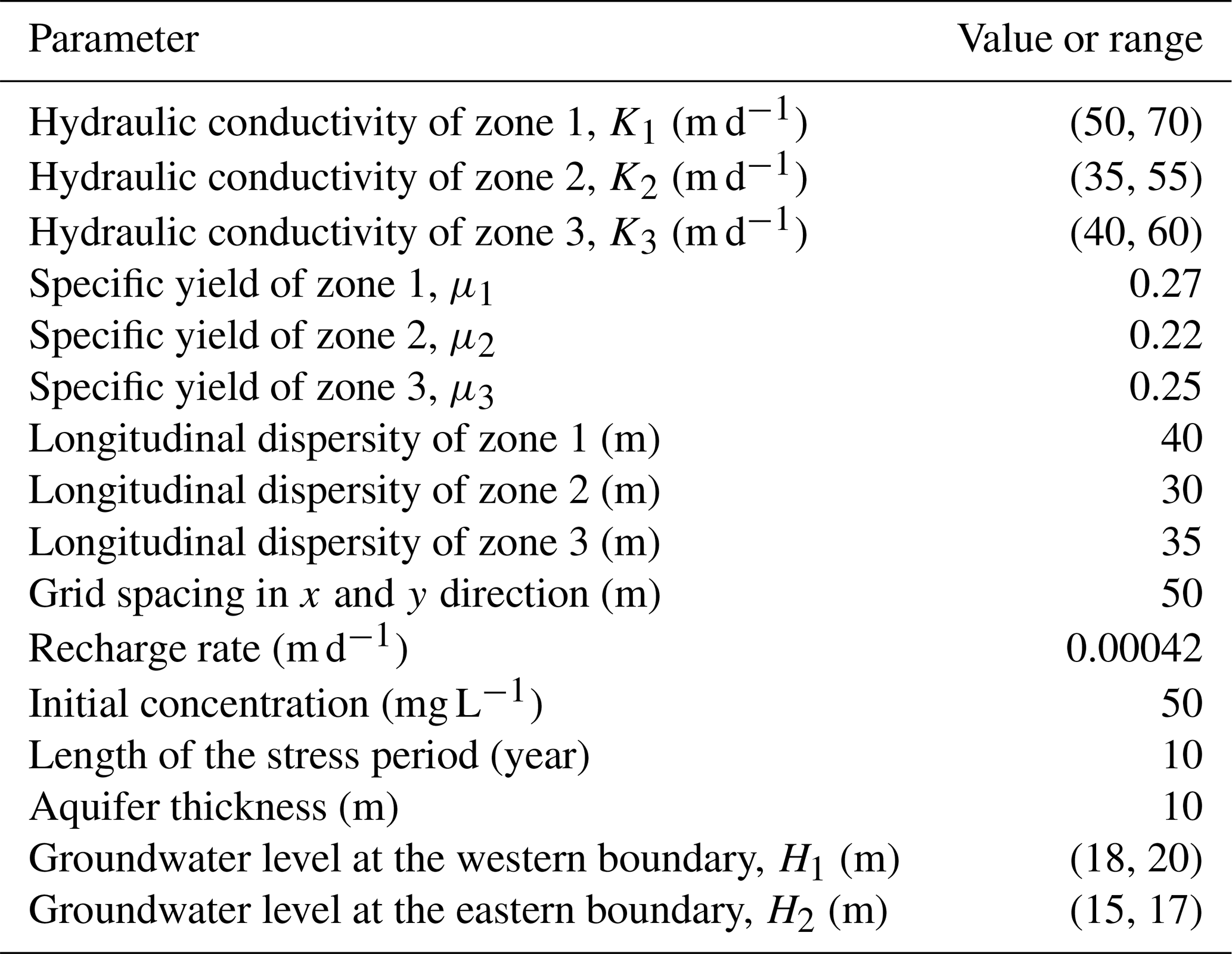
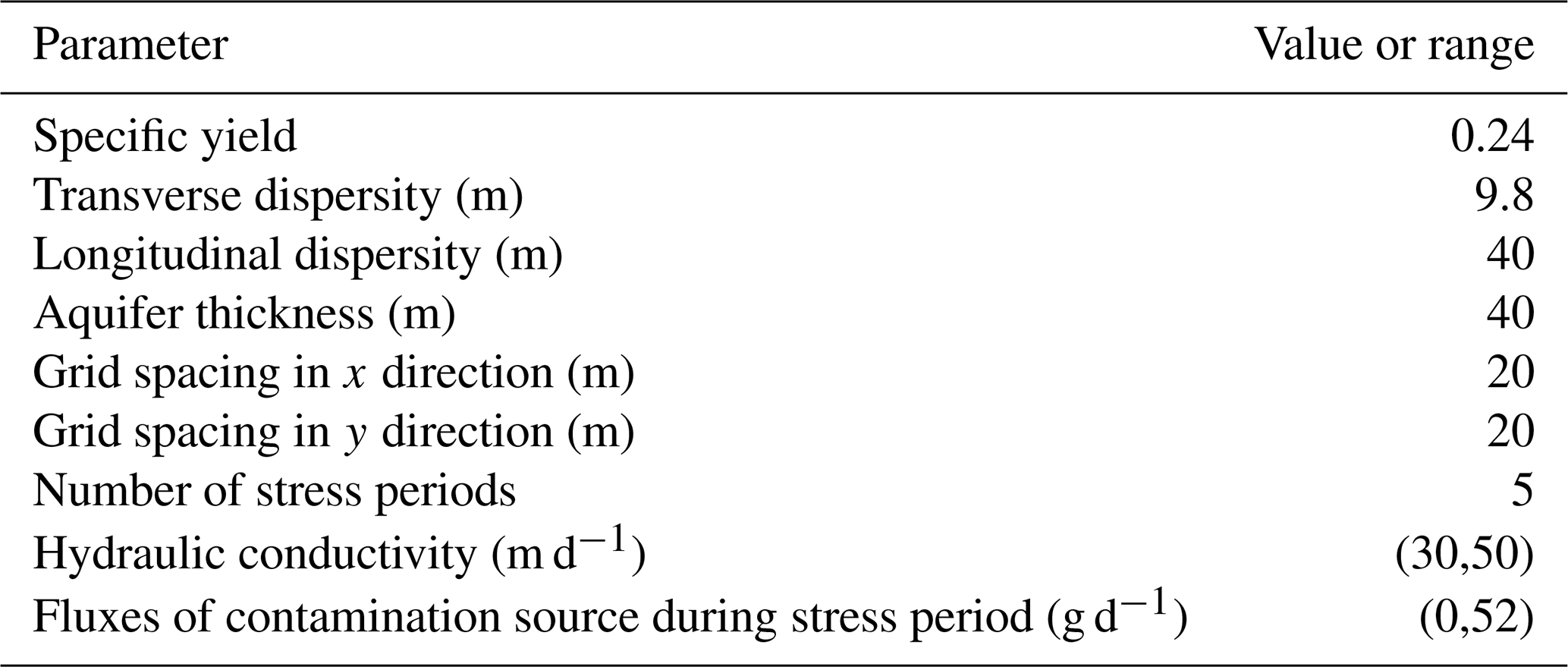
In this case study, the variables to be identified fell into three main categories: (1) head values at the specific head boundaries, including H1 and H2; (2) hydraulic conductivities for each part of the study area, including K1, K2, and K3; and (3) the intensities of the release of pollutants from the two sources during the release periods: S= SaTb; a=1, 2; and b=1, 2, 3, 4, 5 (Table S1 in the Supplement). SaTb represents the intensity of pollution source a during the bth stress period. This case study had a study period of 10 years (Table 1, Fig. 4), with both sources only releasing pollutants in the first 5 years (Table S2). Five wells were established to monitor the concentrations of groundwater contaminants once a year. The study area was spatially discretized into 50 m × 50 m grids (Table 1).
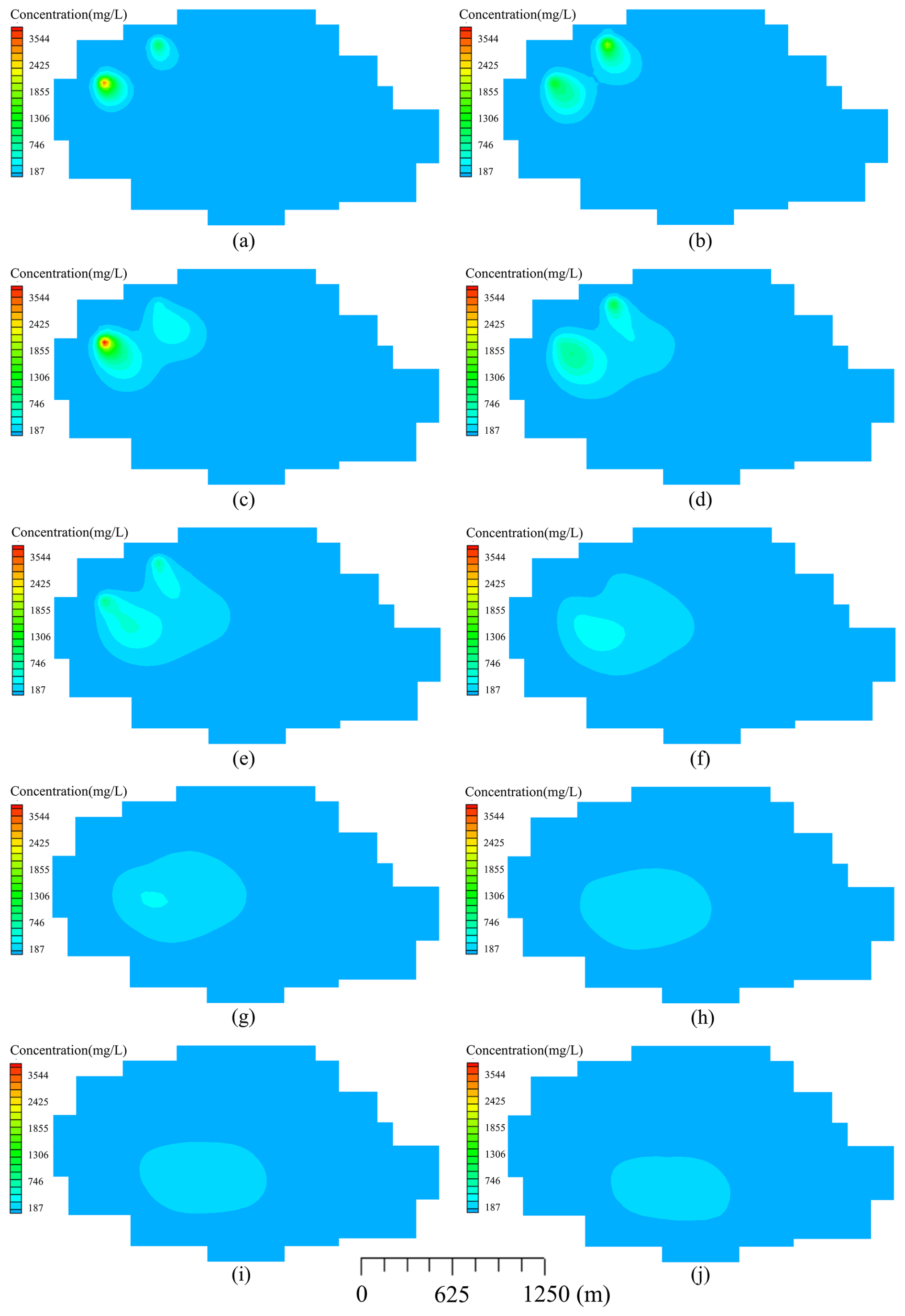
Figure 4Distributions of concentrations of groundwater pollutants over different periods: (a)–(j) represent 1–10 years.
3.2 Case study 2: groundwater ASC
The present study selected the hypothetical case study used by Pan et al. (2022a) as a case study. The site has an area of 5 km2, with a length of 2.5 km and a width of 2 km from east to west and south to north, respectively. Groundwater flows from northwest to southeast. The study area was conceptualized as a heterogeneous isotropic aquifer, and the current study focused on a diving aquifer, in which flow was represented as a 2D steady flow. The study area's aquifers were categorized into four zones based on hydraulic conductivity, labeled K1 to K4. The western and eastern river boundaries were modeled as specified head boundaries, while the northern and southern regions, characterized by low permeability granite, were treated as no-flow boundaries (Fig. 5, Table 2). The aquifer comprises unconsolidated sediments, primarily well-sorted coarse sand and gravel.
Table 2Fundamental values and ranges of aquifer parameters and pollution sources.
In this case study, the variables to be identified fell into two categories: (1) hydraulic conductivities of each part of the study area, includingK1 to K4, and (2) the intensities of pollutants released by three areal sources of contamination: S=SaTb; a=1, 2, 3; and b=1, 2, 3, 4, 5 (Table S3). SaTb indicates the intensity of pollution source a during the bth stress period. A total of nine monitoring wells were established to monitor the concentrations of groundwater contaminants once a year (Fig. 6). The study area was spatially discretized as 20 m × 20 m grids (Table 2).
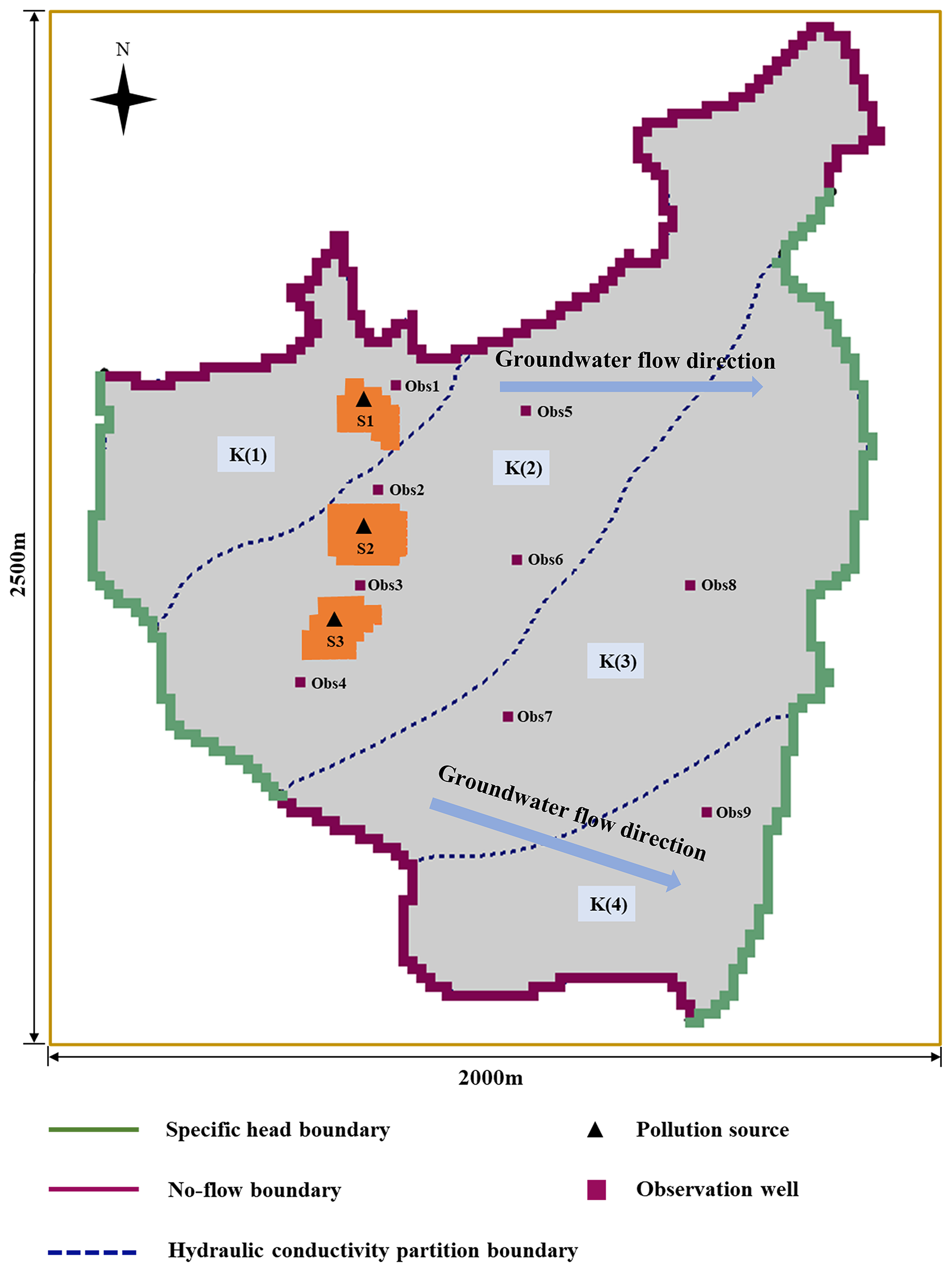
Figure 5Schematic diagram of case study 2.
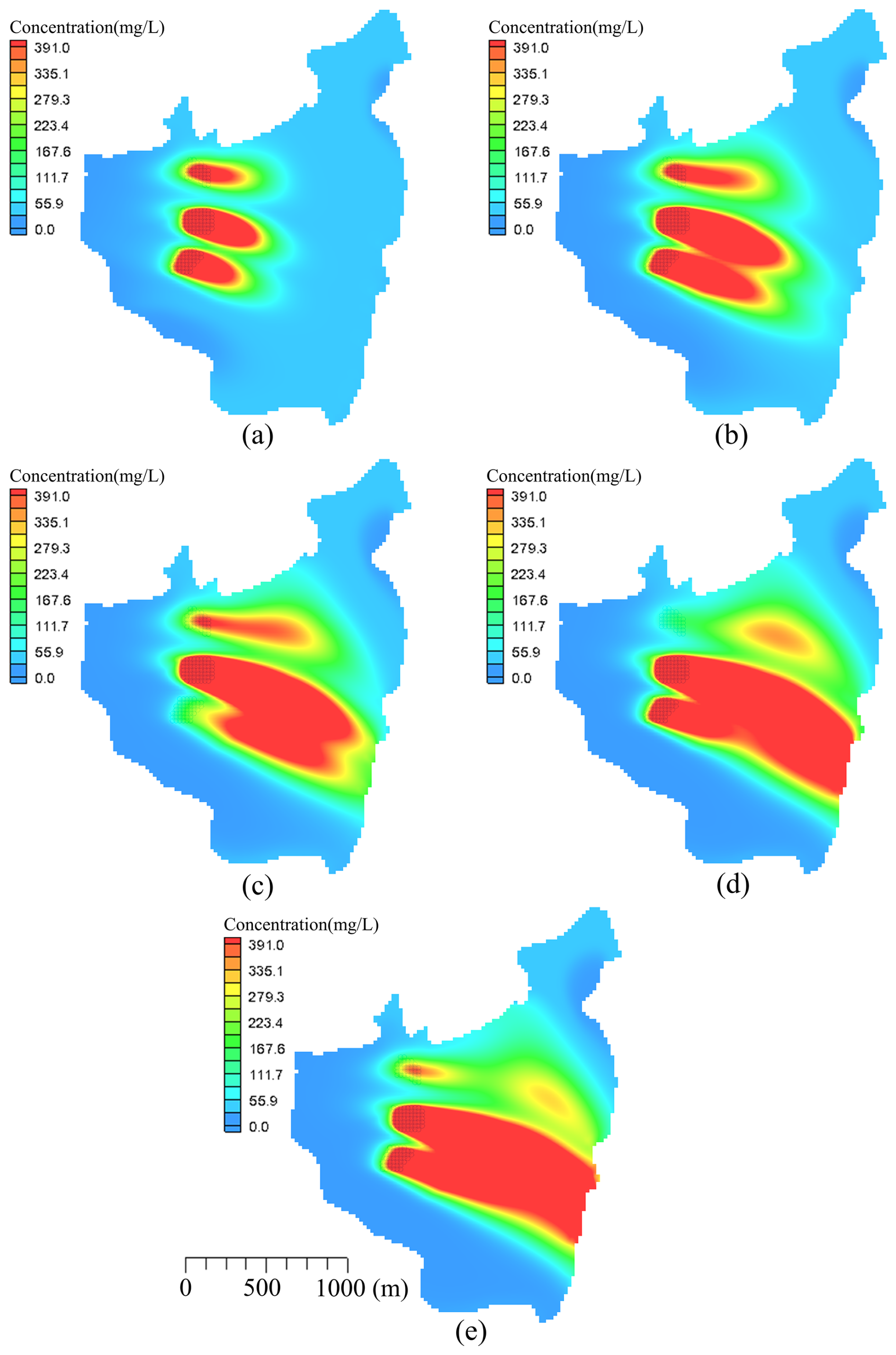
Figure 6Distributions of concentrations of groundwater pollutants over different periods: (a) 1 year, (b) 2 years, (c) 3 years, (d) 4 years, and (e) 5 years.
4.1 Establishment of surrogate models
The present study established two case studies: the PSC and the ASC. The variables to be identified for the PSC case study included three categories with 15 dimensions, whereas those to be identified for the ASC case study included two categories with 19 dimensions. The present study used the Latin hypercube method to sample within the feasible domain of the variables to be identified. This sampling process was implemented in MATLAB. Sample groups for the PSC and ASC case studies totaled 390 and 490, respectively, and the input sample dataset was generated by random combination.
The parameters obtained from the above sampling were input into the groundwater simulation model. The simulation model was then run to obtain the pollutant concentrations at the 390 and 490 monitoring groups in the PSC and ASC case studies, respectively. These simulated pollutant concentrations were used as the output sample dataset, and the output sample dataset was combined with the input sample dataset to form the input–output sample dataset. The Kriging and BPNN methods were used to establish the surrogate models of the simulation model. The first 350 and 440 groups of the PSC and ASC case input–output sample datasets, respectively, were used as training samples in each case study to construct surrogate models, while the remaining 40 and 50 groups were used as test samples to evaluate the accuracy of the surrogate models.
The present study applied the coefficient of determination (R2), the mean absolute relative error (MARE), and the root mean square error (RMSE) to assess the accuracy of the fit of the estimations of the surrogate models to the output of the simulation model.
-
R2: the closer R2 to 1, the more accurate the surrogate model is.
-
MARE: the average deviation between the outputs of the surrogate model and the outputs of the simulation model.
-
RMSE: the value of the RMSE is inversely proportional to the fitting accuracy of the surrogate model.
where is the average true value, n is the number of samples, is the output of the surrogate model, and yi is the true value of the variable to be identified.
4.2 Establishment of the optimization models
This study employed the GCI through the simulation–optimization method, which consists of two main components: a groundwater contaminant transport simulation model and an optimization model aimed at minimizing the least-squares error between the simulated and true values. To reduce the computational burden caused by repeated simulation calls, a surrogate model was used in place of the simulation model. While the same objective function was applied in both case studies, there were minor variations in the decision variables and constraints. The decision variables chosen for case study 1 included the boundary head values, the hydraulic conductivities of the site, and the release history of the contaminant source; those for case study 2 included the hydraulic conductivities of the site and the release history of the contaminant source. The constraint conditions were influenced by the decision variables. The optimization was expressed as
where z is the objective function, Cm is the monitored pollutant concentration in the mth monitoring well, is the simulated pollutant concentration in the mth monitoring well, C is the pollutant concentration, H is the head value at the boundary, s is the pollution source intensity, k represents the hydraulic conductivities of the site, CL and CU are the upper and lower bound values of pollutant concentration (respectively), and sl and su are the upper and lower bound values of pollution source intensity (respectively).
The AHA was used to identify the optimal combination of parameters according to the objective function through multiple iterative calculations, with this parameter set adopted as the result of inversion. The numbers of hummingbird populations and iterations were set to 500 and 1000, respectively.
5.1 Surrogate models
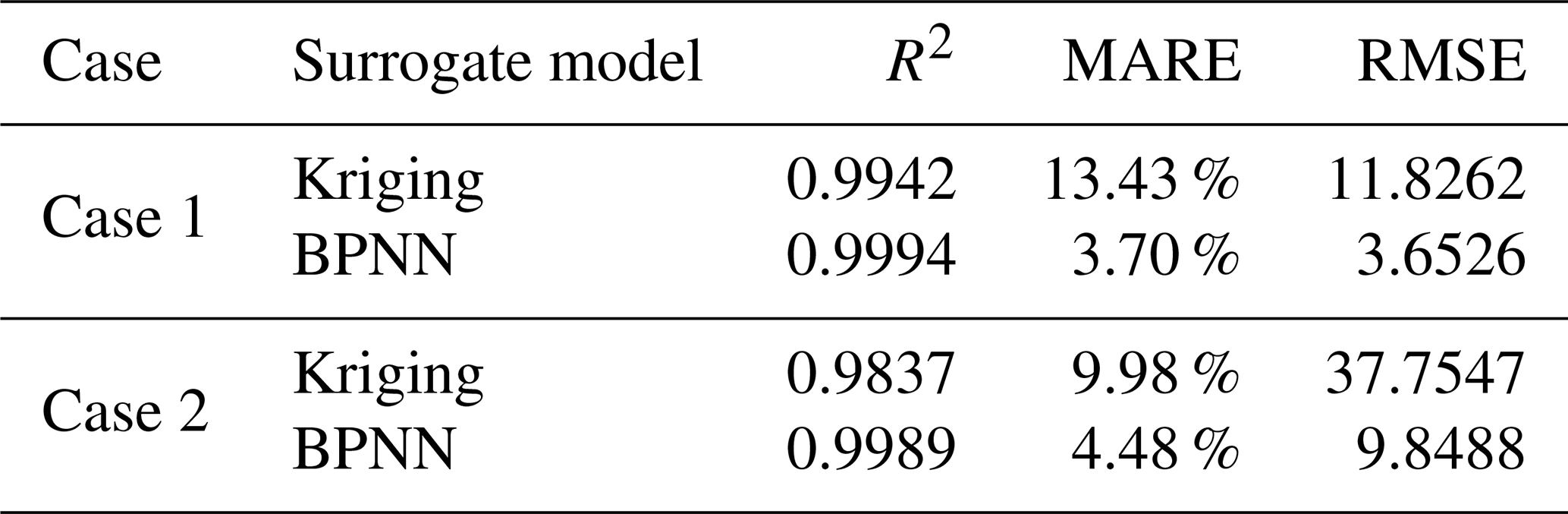
The surrogate model for case study 1 using the Kriging method achieved an R2 of 0.9942, a MARE of 13.43 %, and an RMSE of 11.8262 (Table 3), while the BPNN method produced values of 0.9994, 3.70 %, and 3.6526, respectively (Table 3). Similarly, for case study 2, the Kriging method yielded an R2 of 0.9837, a MARE of 9.98 %, and an RMSE of 37.7547, whereas the BPNN method provided corresponding values of 0.9989, 3.70 %, and 3.6526 (Table 3). The BPNN method demonstrated superior goodness-of-fit statistics compared to the Kriging method in both case studies. While the simulation model required 50 h for 1000 iterations, the BPNN surrogate model completed the same number of iterations in 67 s, significantly reducing the computation time.
Table 3A comparison of the accuracies of the assessed surrogate models.
5.2 Optimization algorithms
The BPNN surrogate model was embedded into the optimization model to optimize the parameter combination according to the objective function. This study employed AHA within the optimization process and compared its performance against SSA and PSO under the same population size and number of iterations. In the optimization of case study 1, PSO failed to converge after reaching the maximum number of iterations, while AHA and SSA converged after 120 and 350 iterations, respectively (Fig. 7a). For case study 2, both PSO and SSA failed to converge within the maximum number of iterations, whereas AHA converged after 150 iterations (Fig. 7b).
Given the results from case study 1, where both AHA and SSA converged, the subsequent analysis focused on these two algorithms. AHA achieved an optimal search value closer to the true value and reached the global optimum, while SSA settled at a local optimum (Fig. 8). These results demonstrate that AHA not only converged faster than SSA but also identified the global optimum, thereby improving the accuracy and efficiency of GCI.
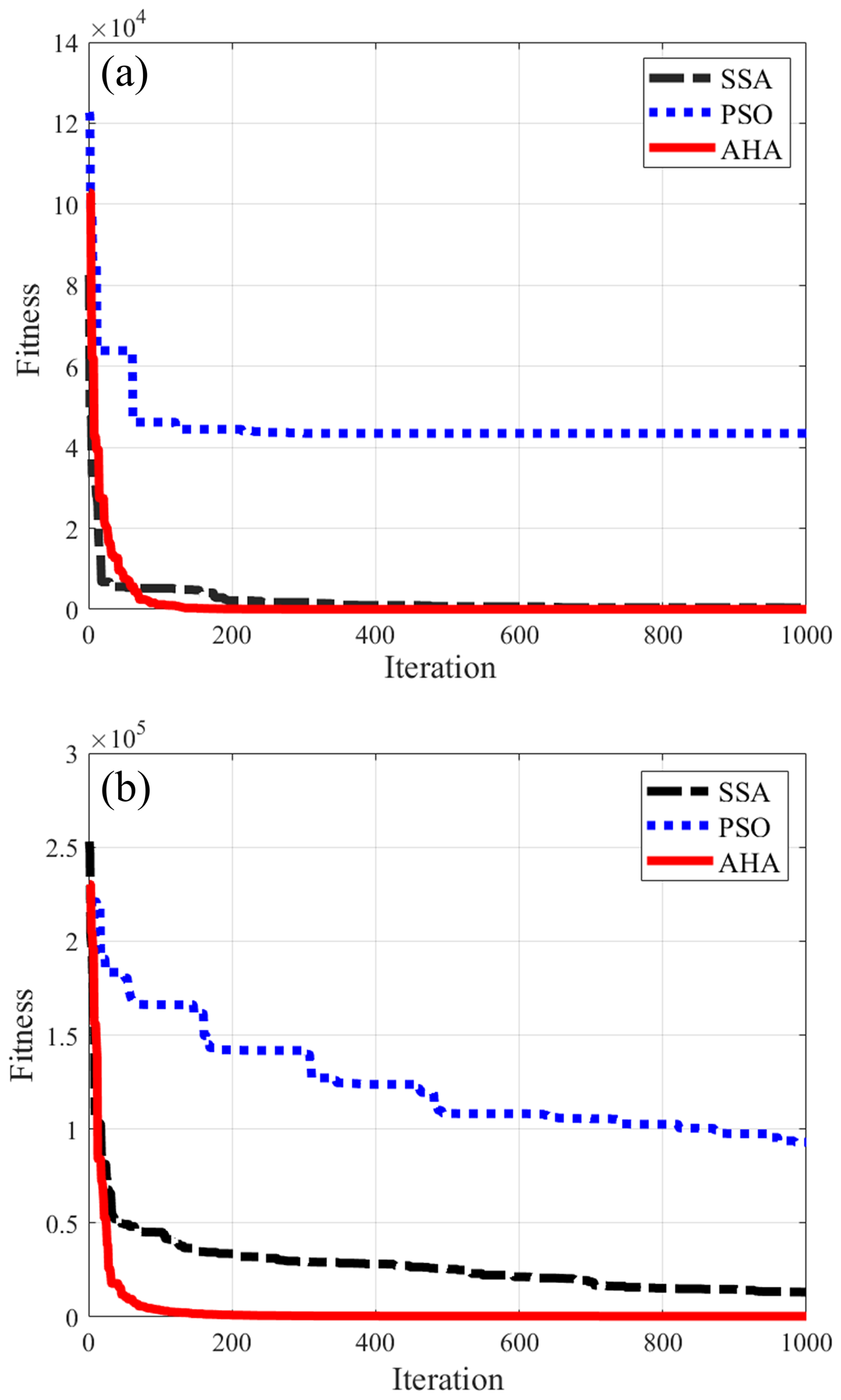
Figure 7Convergence curves of the sparrow search algorithm (SSA), particle swarm optimization (PSO), and artificial hummingbird algorithm (AHA) applied to the case studies: (a) case study 1 and (b) case study 2.
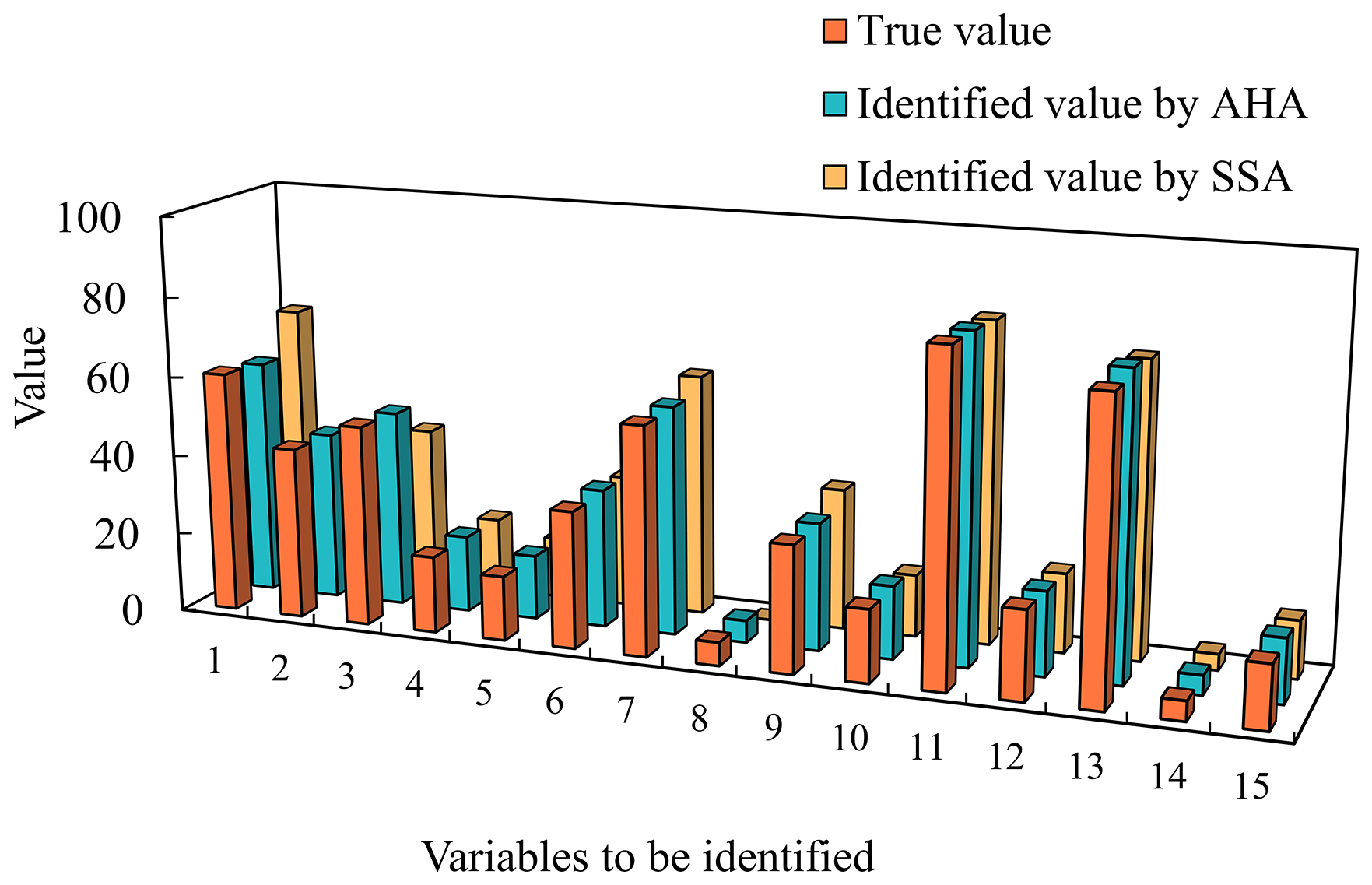
Figure 8Comparison between the true values and optimal values for the sparrow search algorithm (SSA) and artificial hummingbird algorithm (AHA).
5.3 Inversion results and robustness assessment
The BPNN–AHA inversion framework developed in this study was applied to identify groundwater PSC and ASC and to obtain inversion values. To verify the framework's robustness and reliability, random noise levels of 0.5 %, 1 %, and 2 % were added to the observed data. The average relative errors under each noise level were recorded (Tables 4 and 5). The highest inversion accuracy was achieved in the noise-free case for both case study 1 and case study 2, with average relative errors of 1.58 % and 2.03 %, respectively (Table S4). At a 0.5 % noise level, the average relative errors for case study 1 and case study 2 were 1.71 % and 2.3 %, respectively. At 1 % noise, they were 2.03 % and 2.33 %, while at 2 % noise, they increased to 2.55 % and 3.52 %, respectively. Although noise impacted the inversion accuracy, the framework maintained high performance, with the average relative errors for both case studies remaining below 5 % (Fig. 9). These results confirm the strong robustness and stability of the proposed inversion framework.
Table 4A comparison of inversion values under different noise levels for case study 1.
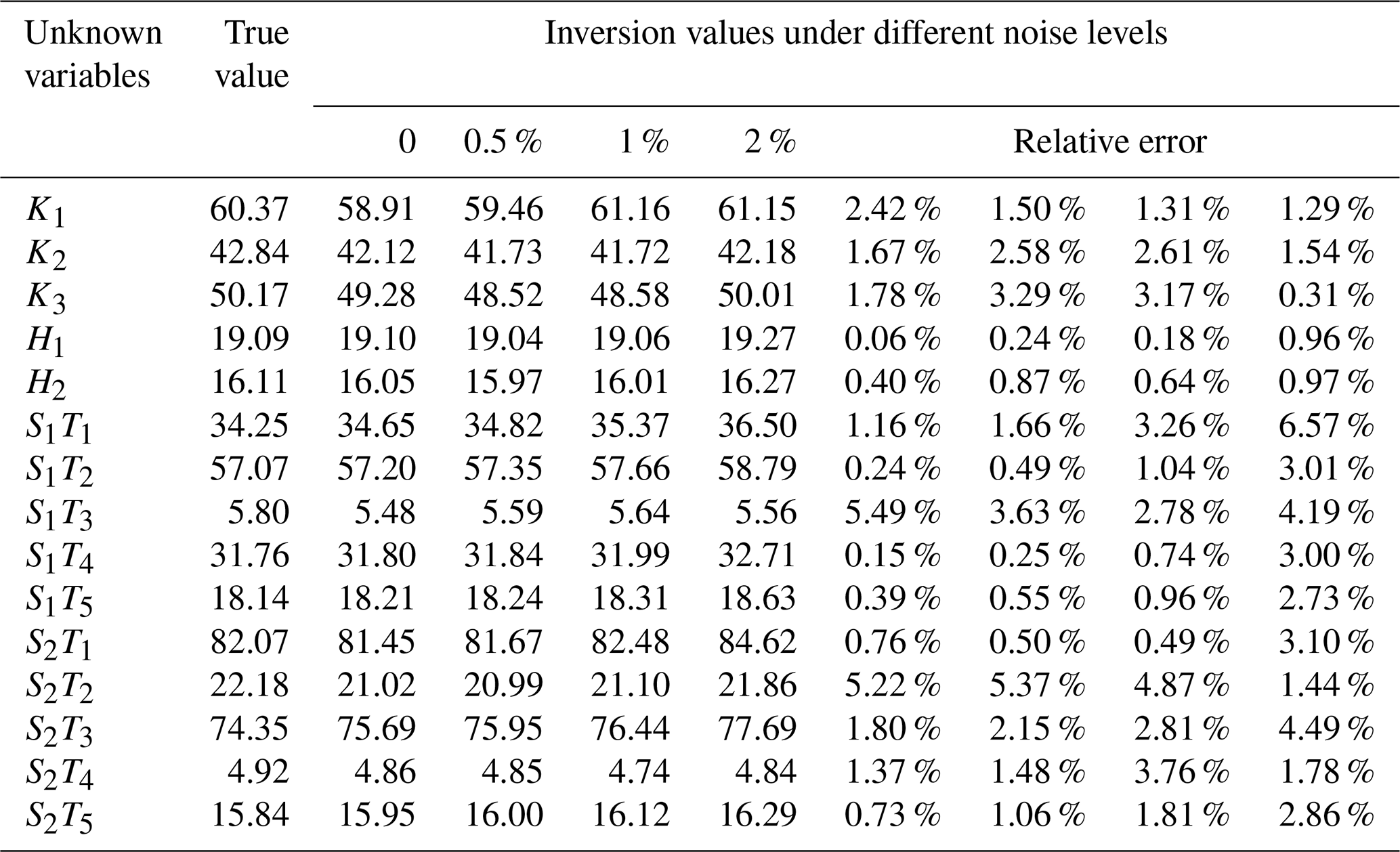
Table 5A comparison of inversion values under different noise levels for case study 2.
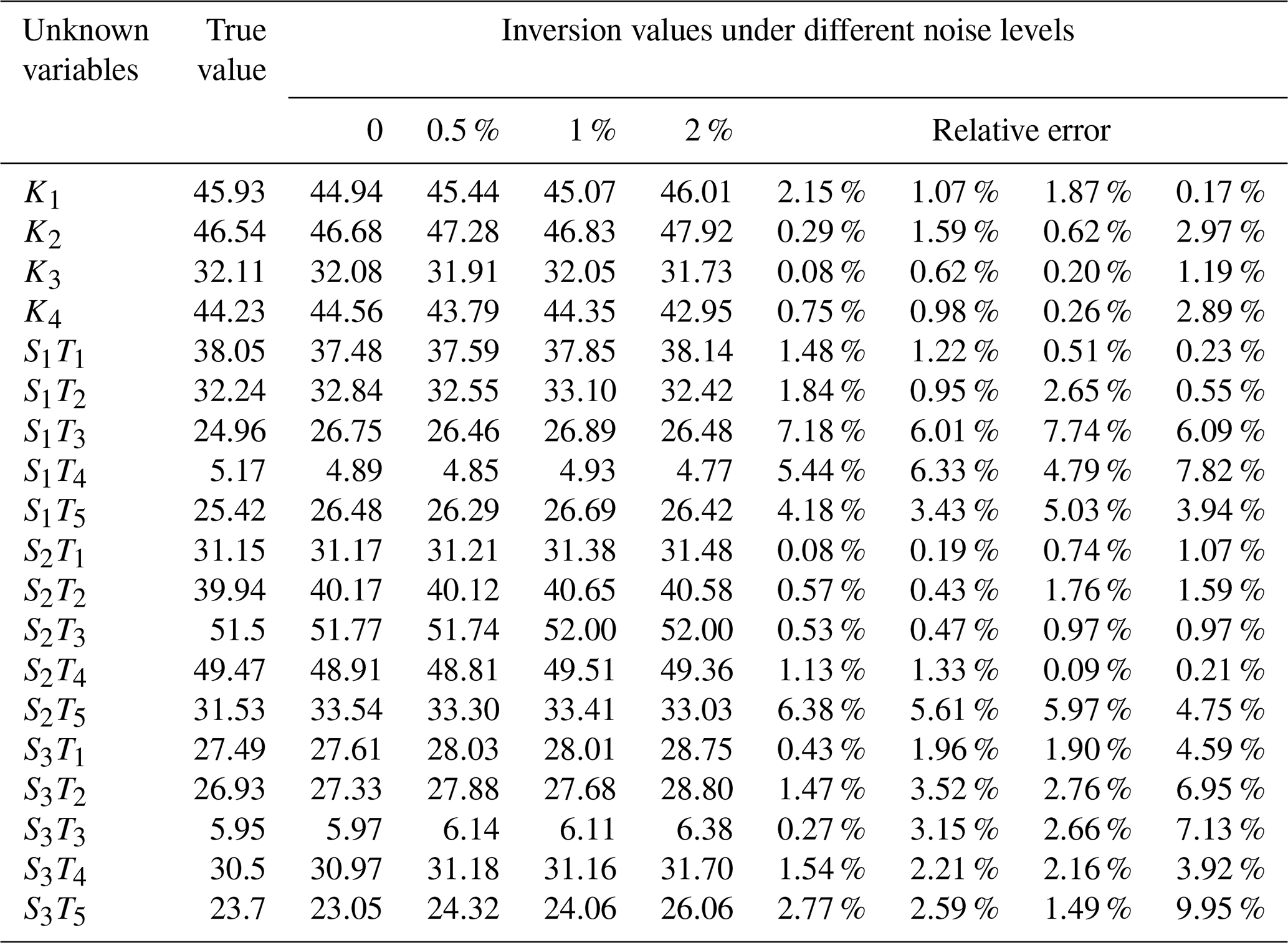
There are significant differences in sensitivity to noise among different parameter categories. Hydraulic conductivity: these parameters showed low sensitivity to noise, with relative errors remaining below 3 % in all scenarios for both PSC and ASC cases. Their errors increased gradually with noise but remained stable, indicating strong robustness. Boundary head values (PSC case only): these parameters also exhibited excellent noise resistance, with relative errors consistently below 1 % even at a 2 % noise level. Source release intensities: this group showed the highest sensitivity to noise. At a 2 % noise level, some source parameters (e.g., S1T1 in PSC and S1T3, S1T4, S3T2, S3T3, S3T5 in ASC) had relative errors exceeding 6 %–10 %, reflecting their higher inversion uncertainty under noisy conditions.
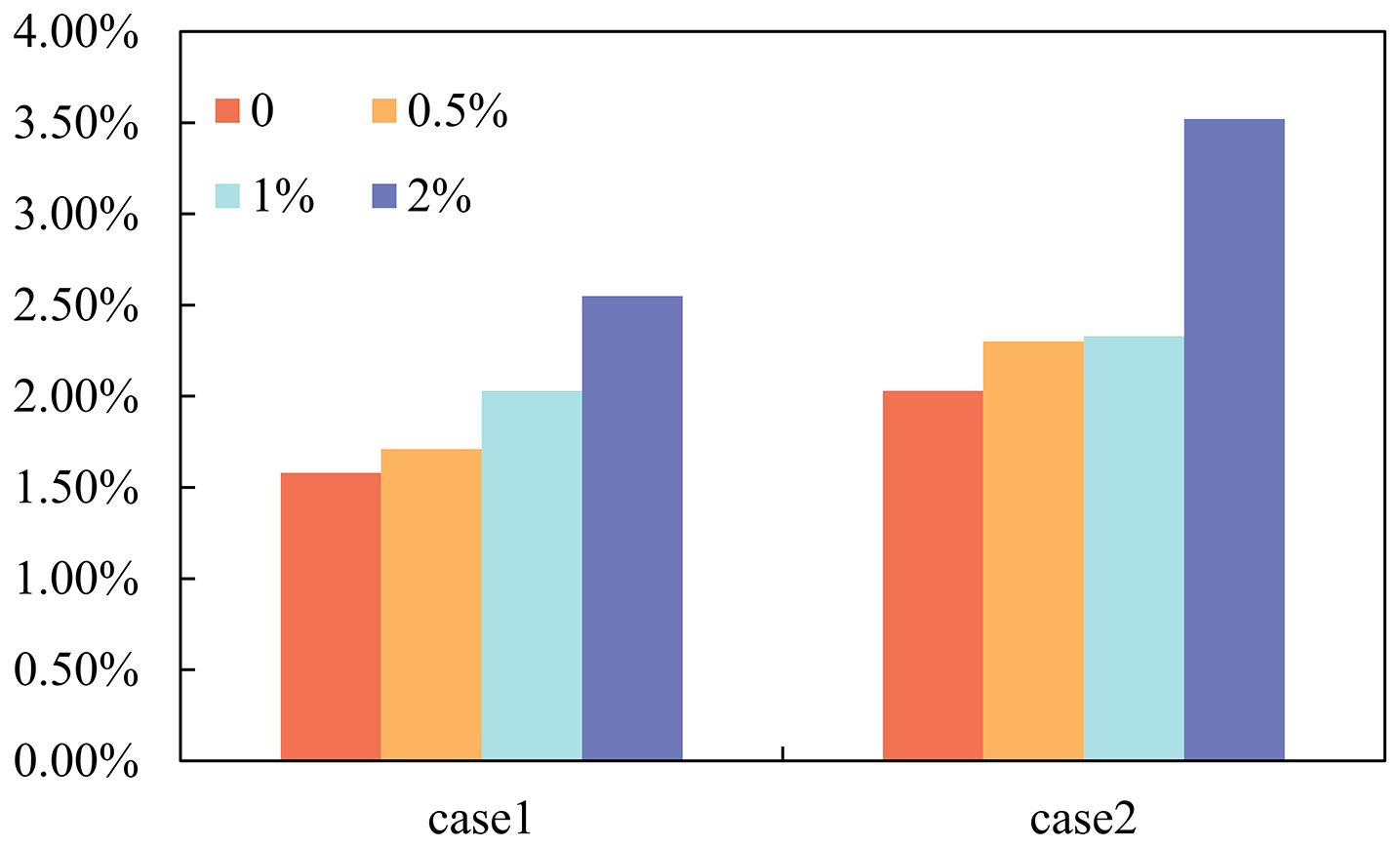
Figure 9Comparison of relative errors for case studies 1 and 2 under different noise levels.
6.1 Analysis of surrogate models
The results of this study show that the proposed BPNN–AHA framework achieves high accuracy, strong robustness, and efficient convergence in GCI tasks, performing consistently well in both the PSC and ASC scenarios, even under varying noise levels. In the PSC and ASC cases analyzed here, the R2 values reached 0.9994 and 0.9989, and the MARE values were 3.70 % and 4.48 %, respectively, demonstrating the model's excellent capability to approximate the input–output relationships of the simulation model. The BPNN surrogate model, with its simple structure, high flexibility, and broad adaptability, effectively balances accuracy and generalizability – characteristics that are essential for practical inversion applications. Compared to other surrogate modeling approaches reported in recent GCI research – such as long short-term memory neural networks (Li et al., 2021), light gradient boosting machines (Pan et al., 2023), and deep residual networks (Xu et al., 2024b) – the proposed framework leverages the adaptability of BPNN together with the global search and adaptive convergence mechanisms of the artificial hummingbird algorithm to deliver consistently accurate and stable inversion results. In this paper, the ASC is drawn from Pan et al. (2022a), which had been widely validated in other studies. For example, Li et al. (2023) used the same case to validate an inversion method, applying a multi-layer perceptron model to the simulation, achieving an R2 of 0.9999 and a MARE of 2.85 %. Similarly, Xu et al. (2024a) employed automatic machine learning methods for surrogate model construction, achieving an R2 of 0.9754 and a MARE of 4.154 %. Compared to the surrogate models developed by these researchers, the BPNN model constructed in this study also demonstrates excellent approximation accuracy, further validating the advantages of the proposed method. In summary, the proposed BPNN surrogate model has practical advantages in tasks related to GCI, thereby enhancing its applicability. Due to its relatively simple architecture and low computational requirements, the BPNN model can be trained and updated efficiently even under limited computational resources. Additionally, the model demonstrates strong generalization capabilities in both PSC and ASC scenarios, indicating that it is not specific to a particular case. This adaptability is crucial for practical groundwater inversion problems, as data availability and system complexity often vary significantly across different locations. These characteristics highlight the comprehensive advantages of the BPNN model in terms of accuracy, efficiency, and flexibility, making it a reliable and practical choice for surrogate modeling in groundwater simulation.
6.2 Analysis of optimization algorithms
This paper compares the AHA with PSO and SSA under the same preconditions and finds that the AHA offers clear advantages in both convergence speed and global optimization capability. Based on these results, the AHA was chosen to solve the optimization model, and its adaptability was further verified in two different cases. In the field of optimization algorithms, the “no free lunch” principle (Zhao et al., 2022b) emphasizes that no single algorithm performs well across all optimization problems. When addressing real-world problems, it is essential to understand the nature of the problem thoroughly before selecting the appropriate optimization algorithm. This principle encourages researchers to develop new and more effective algorithms from different perspectives, providing more options for optimization problem researchers. This insight also applies to groundwater pollution traceability. Given the diverse nature of pollution traceability problems, it is challenging for any single optimization algorithm to be universally applicable. As research deepens, these problems tend to become higher dimensional and non-linear, necessitating the exploration of algorithms with stronger global optimization capabilities and higher search efficiency. Additionally, it is important to consider alternative uses of optimization methods. One promising approach involves using optimization techniques to improve machine learning models by identifying optimal parameters (hyperparameters) during training, which can significantly enhance model accuracy (Jia et al., 2024).
6.3 Inversion analysis
Previous studies related to GCI employed a variety of methods to conduct either the single or simultaneous inversion characterization of pollution sources and to identify hydrogeological parameters of the model. Li et al. (2022) identified the number, location, and release history of pollution sources, while Li et al. (2008) focused on determining the hydraulic conductivities of a study site. Bai et al. (2022) utilized inversion techniques to simultaneously characterize pollution sources and identify the hydraulic conductivities in their simulation models. While some studies have applied inversion to the boundary conditions of the simulation model (Jiao et al., 2019), fewer studies have simultaneously characterized pollution sources and identified both hydrogeological parameters and boundary conditions of the model. Source information, model hydrogeological parameters, and boundary conditions are all critical components of groundwater contamination simulation models. Inaccuracies in any of these components can affect the overall results of inversion, making it essential to identify all components simultaneously. Therefore, in the PSC case of this study, the release history of the pollutant source, the hydraulic conductivity of the model, and the specific head boundary values were simultaneously identified. This simultaneous identification of multiple key parameters enhances the reliability and effectiveness of decision support systems.
In addition to the methods applied in this study, data assimilation methods are also widely used in the field of groundwater pollution inversion. They can combine observational data with numerical models to improve state estimation and parameter inversion (Zafarmomen et al., 2024). Many researchers have successfully applied data assimilation methods to the iterative optimization of pollutant transport states and related parameters, significantly improving inversion accuracy and reducing prediction uncertainty. For example, Pan et al. (2022a) proposed a refined particle filter with a deep learning method surrogate as an inverse framework for groundwater pollution source estimation. This framework was evaluated under different levels of observational error through estimation tasks for point source pollution cases and non-point source pollution cases. Wang et al. (2023) utilized an improved particle filter method for groundwater pollution source identification. Zhang et al. (2024) used an iterative local updating ensemble smoother method to simultaneously identify pollution source information and hydraulic conductivity fields. However, both the method proposed in this study and data assimilation methods have their own advantages and disadvantages. The method proposed in this study possesses strong fine-grained search capabilities, but its performance is highly dependent on the selection of initial points. Data assimilation methods can integrate multi-source data, significantly improving the spatiotemporal consistency of inversion results; however, their fine-grained search capabilities are somewhat limited. Future research could explore combining the real-time updating capabilities of data assimilation with the adaptability and optimization efficiency of the framework proposed in this study to further enhance the adaptability and performance of groundwater pollution inversion.
One of the main methodological motivations of this study is the integration of the BPNN surrogate model with the AHA for GCI. This choice is grounded in both the inherent characteristics of GCI problems and the complementary mechanisms of the two methods. GCI is a typical high-dimensional, non-linear, and ill-posed inverse problem. The mapping from observed contaminant concentrations to source characteristics and hydrogeological parameters is often multi-modal and non-convex. In such cases, surrogate models such as BPNN can provide a fast and flexible approximation to computationally demanding groundwater simulations, but their use inevitably introduces approximation errors into the inversion objective function. These errors may create local irregularities in the objective function landscape, which can mislead optimizers and cause premature convergence – particularly when the optimization algorithm lacks a mechanism to balance exploration and exploitation adaptively. The AHA offers notable advantages in addressing these issues. Its bio-inspired mode-switching strategy alternates dynamically between diversified search and focused search. In the early stages of optimization, the broad and varied exploration capability helps to survey the global search space and reduces the risk of becoming trapped in spurious local optima caused by surrogate-induced noise. As the search proceeds, the algorithm adaptively shifts toward more intensive exploitation, concentrating computational effort on promising regions and thereby accelerating convergence. This dynamic adjustment is particularly important in GCI problems, where the optimal parameter region is often narrow and embedded within a complex and noisy search space. In addition, the AHA's adaptive update mechanism adjusts search trajectories in response to population feedback, effectively mitigating the influence of local fluctuations in the surrogate-predicted objective function on the optimization process. This robustness to noisy or irregular fitness landscapes complements the BPNN's ability to generalize across diverse contamination scenarios. It is worth emphasizing that this integration is not a simple “algorithm replacement” but a targeted design choice based on the structural characteristics of the problem: BPNN provides broad adaptability to varying hydrogeological conditions, while the AHA contributes resilience and fine-tuning capability when the optimization landscape is distorted by surrogate approximation errors. This synergy allows the proposed framework to maintain both high accuracy and strong robustness under different contamination scenarios and noise levels. More importantly, the underlying design principle – matching the characteristics of the surrogate model with the search dynamics of the optimization algorithm – has broader applicability to other environmental inversion problems.
6.4 Limitations
The overall inversion framework in this paper combines BPNN and AHA and is validated under different noise scenarios to account for the effect of noise in the observed data. The results indicate that the inversion framework demonstrates high robustness. However, a limitation of this paper is that noise is not addressed, and its presence can contaminate the observed data, further impacting the accuracy of GCI. Noise elimination methods could be applied to the observed data in future studies. Another major limitation is the generalization of the actual aquifer system. Groundwater systems are often complex, necessitating model simplifications through assumptions (e.g., homogeneity, isotropy) that may not reflect the actual geological conditions, thereby affecting model accuracy. To address actual problems, the hydrogeological conditions of the study area should be thoroughly investigated, ensuring the model closely represents the actual situation – reducing errors, improving model accuracy, and ultimately enhancing inversion accuracy. In terms of computational time and efficiency, by integrating the agent model, we can avoid repeatedly calling the numerical simulation model during the optimization process, thereby significantly improving computational efficiency. In our current implementation, thousands of optimization iterations can be completed in just a few minutes. However, as the complexity of the inversion problem increases, the number of required samples and the training time for the surrogate model will also increase significantly. Additionally, the current BPNN surrogate model is relatively lightweight, while deeper networks or ensemble-based surrogate models may require more computational resources. To address these issues, potential future solutions include parallel computing, adaptive sampling, and hybrid surrogate strategies that balance accuracy and efficiency.
In this study, a BPNN–AHA inversion framework was developed to accurately and synergistically identify groundwater point and areal sources of contamination and combined hydrogeologic parameters. Among them, the BPNN surrogate model can well replace the simulation model, and the AHA had good global optimization capability and excellent solution accuracy. The robustness of the proposed methodology was verified by applying the inversion framework to scenarios with different noise levels. The conclusions of the present study are listed below:
-
The construction of a surrogate model to the simulation model satisfied the fitting accuracy requirement while also significantly reducing the computational time. The current study established BPNN and Kriging surrogate models, with a comparison of the outputs of the models illustrating that the former obtained a higher fitting accuracy, with R2 values of 0.9994 and 0.9989 for case 1 and case 2, respectively. Therefore, it can be applied to the inversion framework.
-
The present study applied the AHA in the model optimization, with the results compared to those of PSO and SSA optimization. Compared to PSO and SSA, the AHA rapidly reached convergence and identified the global optimum, and the MARE values for the inversion results of case 1 and case 2 were 1.58 % and 2.03 %, respectively.
-
The proposed inversion framework can realize the synergistic identification of PSC and ASC combined with hydrogeological parameters, which can ensure high identification accuracy, and the inversion framework has strong robustness under different noise levels. While individual identification simplifies the problem but may ignore correlations between parameters, synergistic identification improves the accuracy and consistency of identification by synchronizing the estimation of pollution sources and hydrogeological parameters. However, noise and parameter estimation uncertainties may still affect the reliability of the inversion results. Therefore, uncertainty analysis needs to be further considered in subsequent studies. Overall, the BPNN–AHA inversion framework has excellent inversion performance and strong practicability, which can provide a reliable basis for groundwater pollution remediation and management. For researchers working in groundwater contamination source identification, this study underscores the fact that the method selection should not be guided solely by algorithmic novelty but should be informed by the inherent complexity of the problem and the compatibility between the research question and the chosen approach. In groundwater contamination inversion, selecting a highly compatible method can substantially improve efficiency, while leveraging and organically integrating the strengths of different methods can greatly enhance robustness. This concept is equally applicable to a broader range of complex environmental inversion problems, offering valuable insights and practical potential.
The code used in this study can be found at https://doi.org/10.5281/zenodo.14568110 (Chengming, 2024).
The dataset for the point source contamination case in this study can be obtained from https://doi.org/10.5281/zenodo.17386323 (ming, 2025). The dataset for the areal source contamination case is sourced from Pan et al. (2022a).
The supplement related to this article is available online at https://doi.org/10.5194/hess-29-5719-2025-supplement.
CL: methodology, formal analysis, software, conceptualization, validation, and writing (original draft). XW: supervision, resources, funding acquisition, and writing (review and editing). YX: supervision and writing (review and editing). SJ, ZL, and BM: software and formal analysis. QL, XJ, YR, and YD: methodology and conceptualization.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
This research was supported by the Fundamental Research Funds for the Central Universities (02002150257) and the Overseas High-level Talents Program of Shanghai and Leading Talents (Overseas) Program of Shanghai.
This research has been supported by the Fundamental Research Funds for the Central Universities (grant no. 02002150257).
This paper was edited by Heng Dai and reviewed by two anonymous referees.
Asher, M. J., Croke, B. F. W., Jakeman, A. J., and Peeters, L. J. M.: A review of surrogate models and their application to groundwater modeling, Water Resour. Res., 51, 5957–5973, https://doi.org/10.1002/2015wr016967, 2015.
Bai, Y., Lu, W., Li, J., Chang, Z., and Wang, H.: Groundwater contamination source identification using improved differential evolution Markov chain algorithm, Environ. Sci. Pollut. Res., 29, 19679–19692, https://0.1007/s11356-021-17120-2, 2022.
Chen, D., Lu, J., and Shen, Y.: Artificial neural network modelling of concentrations of nitrogen, phosphorus and dissolved oxygen in a non-point source polluted river in Zhejiang Province, southeast China, Hydrol. Process., 24, 290–299, https://10.1002/hyp.7482, 2010.
Chengming, L.: Surrogate model-optimization algorithm, Zenodo [code], https://doi.org/10.5281/zenodo.14568110, 2024.
Chugh, T., Jin, Y., Miettinen, K., Hakanen, J., and Sindhya, K.: A Surrogate-Assisted Reference Vector Guided Evolutionary Algorithm for Computationally Expensive Many-Objective Optimization, IEEE Trans. Evol. Comput., 22, 129–142, https://10.1109/tevc.2016.2622301, 2018.
Daranond, K., Yeh, T.-C. J., Hao, Y., Wen, J.-C., and Wang, W.: Identification of groundwater basin shape and boundary using hydraulic tomography, J. Hydrol., 588, 125099, https://10.1016/j.jhydrol.2020.125099, 2020.
Harbaugh, A. W.: MODFLOW-2005, the U.S. Geological Survey modular ground-water model: the ground-water flow process, U.S. Geological Survey Techniques and Methods, Book 6, Chapter A16, https://doi.org/10.3133/tm6A16, 2005.
Hou, Z., Lao, W., Wang, Y., and Lu, W.: Hybrid homotopy-PSO global searching approach with multi-kernel extreme learning machine for efficient source identification of DNAPL-polluted aquifer, Comput. Geosci., 155, 104837, https://10.1016/j.cageo.2021.104837, 2021.
Jha, M. and Datta, B.: Three-Dimensional Groundwater Contamination Source Identification Using Adaptive Simulated Annealing, J. Hydrol. Eng., 18, 307–317, https://doi10.1061/(ASCE)HE.1943-5584.0000624, 2013.
Jiang, C., Qiu, H. B., Gao, L., Wang, D. P., Yang, Z., and Chen, L. M.: Real-time estimation error-guided active learning Kriging method for time-dependent reliability analysis. Appl. Math. Modell., 77, 82–98, https://doi.org/10.1016/j.apm.2019.06.035, 2020.
Jiang, S., Zhang, Y., Wang, P., and Zheng, M.: An almost-parameter-free harmony search algorithm for groundwater pollution source identification, Water Sci. Technol., 68, 2359–2366, https://doi.org/10.2166/wst.2013.499, 2013.
Jia, S., Wang, X., Xu, Y. J., Liu, Z., and Mao, B.: A New Data-Driven Model to Predict Monthly Runoff at Watershed Scale: Insights from Deep Learning Method Applied in Data-Driven Model, Water Resour. Manage., 38, 5179–5194, https://doi.org/10.1007/s11269-024-03907-8, 2024.
Jiao, J., Zhang, Y., and Wang, L.: A new inverse method for contaminant source identification under unknown solute transport boundary conditions. J. Hydrol., 577, 123911, https://doi.org/10.1016/j.jhydrol.2019.123911, 2019.
Li, J., Lu, W., and Luo, J.: Groundwater contamination sources identification based on the Long-Short Term Memory network, J. Hydrol., 601, 126670, https://doi.org/10.1016/j.jhydrol.2021.126670, 2021.
Li, J., Wu, Z., Lu, W., and He, H.: Simultaneous identification of the number, location and release intensity of groundwater contamination sources based on simulation optimization and ensemble surrogate model, Water Supply, 22, 7671–7689, https://doi.org 10.2166/ws.2022.339, 2022.
Li, W., Englert, A., Cirpka, O. A., and Vereecken, H.: Three-dimensional geostatistical inversion of flowmeter and pumping test data, Ground Water, 46, 193–201, https://doi.org/10.1111/j.1745-6584.2007.00419.x, 2008.
Li, Y., Lu, W., Pan, Z., Wang, Z., and Dong, G.: Simultaneous identification of groundwater contaminant source and hydraulic parameters based on multilayer perceptron and flying foxes optimization, Environ. Sci. Pollut. Res., 30, 78933–78947, https://doi.org/10.1007/s11356-023-27574-1, 2023.
Liu, Y., Luo, J., Xiong, Y., Ji, Y., and Xin, X.: Inversion of hydrogeological parameters based on an adaptive dynamic surrogate model, Hydrogeol. J., 30, 1513–1527, https://doi.org/10.1007/s10040-022-02493-6, 2022.
Liu, Z., Wang, X., Wan, X., Jia, S., and Mao, B.: Evolution origin analysis and health risk assessment of groundwater environment in a typical mining area: Insights from water-rock interaction and anthropogenic activities, Environ. Res., 252, 118792, https://doi.org/10.1016/j.envres.2024.118792, 2024.
Luo, C., Lu, W., Pan, Z., Bai, Y., and Dong, G.: Simultaneous identification of groundwater pollution source and important hydrogeological parameters considering the noise uncertainty of observational data, Environ. Sci. Pollut. Res., 30, 84267–84282, https://doi.org/10.1007/s11356-023-28091-x, 2023.
Mahar, P. S. and Datta, B.: Identification of pollution sources in transient groundwater systems, Water Resour. Manage., 14, 209–227, https://doi.org/10.1023/A:1026527901213, 2000.
Maliva, R. G., Herrmann, R., Coulibaly, K., and Guo, W.: Advanced aquifer characterization for optimization of managed aquifer recharge, Environ. Earth Sci., 73, 7759–7767, https://doi.org/10.1007/s12665-014-3167-z, 2015.
Medici, G., Munn, J. D., and Parker, B. L.: Delineating aquitard characteristics within a Silurian dolostone aquifer using high-density hydraulic head and fracture datasets, Hydrogeol. J., 32, 1663–1691, https://doi.org/10.1007/s10040-024-02824-9, 2024.
ming: PSC data, Zenodo [data set], https://doi.org/10.5281/zenodo.17386323, 2025.
Mirghani, B. Y., Mahinthakumar, K. G., Tryby, M. E., Ranjithan, R. S., and Zechman, E. M.: A parallel evolutionary strategy based simulation-optimization approach for solving groundwater source identification problems, Adv. Water Resour., 32, 1373–1385, https://doi.org/10.1016/j.advwatres.2009.06.001, 2009.
Mirghani, B. Y., Zechman, E. M., Ranjithan, R. S., and Mahinthakumar, G.: Enhanced Simulation-Optimization Approach Using Surrogate Modeling for Solving Inverse Problems, Environ. Forensics, 13, 348–363, https://doi.org/10.1080/15275922.2012.702333, 2012.
Pan, Z., Lu, W., Fan, Y., and Li, J.: Identification of groundwater contamination sources and hydraulic parameters based on bayesian regularization deep neural network, Environ. Sci. Pollut. Res., 28, 16867–16879, https://doi.org/10.1007/s11356-020-11614-1, 2021.
Pan, Z., Lu, W., and Bai, Y.: Groundwater contamination source estimation based on a refined particle filter associated with a deep residual neural network surrogate, Hydrogeol. J., 30, 881–897, https://doi.org/10.1007/s10040-022-02454-z, 2022a.
Pan, Z., Lu, W., Wang, H., and Bai, Y.: Recognition of a linear source contamination based on a mixed-integer stacked chaos gate recurrent unit neural network-hybrid sparrow search algorithm, Environ. Sci. Pollut. Res., 29, 33528–33543, https://doi.org/10.1007/s11356-022-18538-y, 2022b.
Pan, Z., Lu, W., and Bai, Y.: Groundwater contaminated source estimation based on adaptive correction iterative ensemble smoother with an auto lightgbm surrogate, J. Hydrol., 620, 129502, https://doi.org/10.1016/j.jhydrol.2023.129502, 2023.
Rao, S. V. N.: A computationally efficient technique for source identification problems in three-dimensional aquifer systems using neural networks and simulated annealing, Environ. Forensics, 7, 233–240, https://doi.org/10.1080/15275920600840560, 2006.
Sargolzaei, J., Asl, M. H., and Moghaddam, A. H.: Membrane permeate flux and rejection factor prediction using intelligent systems, Desalination, 284, 92–99, https://doi.org/10.1016/j.desal.2011.08.041, 2012.
Singh, R. M., and Datta, B.: Artificial neural network modeling for identification of unknown pollution sources in groundwater with partially missing concentration observation data, Water Resour. Manage., 21, 557–572, https://doi.org/10.1007/s11269-006-9029-z, 2007.
Wang, H., Lu, W., and Chang, Z.: Simultaneous identification of groundwater contamination source and aquifer parameters with a new weighted-average wavelet variable-threshold denoising method, Environ. Sci. Pollut. Res., 28, 38292–38307, https://doi.org/10.1007/s11356-021-12959-x, 2021.
Wang, X., Xu, Y. J., and Zhang, L.: Watershed scale spatiotemporal nitrogen transport and source tracing using dual isotopes among surface water, sediments and groundwater in the Yiluo River Watershed, Middle of China, Sci. Total Environ., 833, 155180, https://doi.org/10.1016/j.scitotenv.2022.155180, 2022.
Wang Z., Lu W., and Chang Z.: Joint inverse estimation of groundwater pollution source characteristics and model parameters based on an intelligent particle filter, J. Hydrol., 625, 129965, https://doi.org/10.1016/j.jhydrol.2023.129965, 2023.
Wang, Z., Yue, C., and Wang, J.: Evaluating parameter inversion efficiency in Heterogeneous Groundwater models using Karhunen-Loève expansion: a comparative study of genetic algorithm, ensemble smoother, and MCMC, Earth Sci. Inf., 17, 3475–3491, https://doi.org/10.1007/s12145-024-01361-z, 2024a.
Wang, X., Ji, X., Xu, Y. J., Mao, B., Jia, S., Wang, C., Liu, Z., and Lv, Q.: Multi-machine learning methods to predict spatial variation characteristics of total nitrogen at watershed scale: evidences from the largest watershed (yangtze river watershed), asian, Sci. Total Environ., 949, 175144, https://doi.org/10.1016/j.scitotenv.2024.175144, 2024b.
Xu, Y., Lu, W., Pan, Z., Luo, C., Bai, Y., and Qiu, S.: Groundwater contaminant source identification considering unknown boundary condition based on an automated machine learning surrogate, Geosci. Front., 15, 101732, https://doi.org/10.1016/j.gsf.2023.101732, 2024a.
Xu, Y., Lu, W., Pan, Z., Wang, Z., Luo, C., and Bai, Y.: Intelligent enhanced particle filter with deep residual network surrogate for accurate groundwater pollution source characterization, J. Hydrol., 642, 131904, https://doi.org/10.1016/j.jhydrol.2024.131904, 2024b.
Yeh, H.-D., Chang, T.-H., and Lin, Y.-C.: Groundwater contaminant source identification by a hybrid heuristic approach, Water Resour. Res., 43, W09420, https://doi.org/10.1029/2005WR004731, 2007.
Zafarmomen, N., Alizadeh, H., Bayat, M., Ehtiat, M., and Moradkhani, H.: Assimilation of Sentinel-Based Leaf Area Index for Modeling Surface-Ground Water Interactions in Irrigation Districts, Water Resour. Res., 60, e2023WR036080, https://doi.org/10.1029/2023WR036080, 2024.
Zhang, P., Cai, Y., and Wang, J.: A simulation-based real-time control system for reducing urban runoff pollution through a stormwater storage tank, J. Cleaner Prod., 183, 641–652, https://doi.org/10.1016/j.jclepro.2018.02.130, 2018.
Zhang, X., Wang, L., Sorensen, J. D.: REIF: A novel active-learning function toward adaptive Kriging surrogate models for structural reliability analysis, Reliab. Eng. Syst. Saf., 185: 440–454, https://doi.org/10.1016/j.ress.2019.01.014, 2019.
Zhang, X., Jiang, S., Zheng, N., Xia, X., Li, Z., Zhang, R., Zhang, J., and Wang, X.: Integration of DDPM and ILUES for Simultaneous Identification of Contaminant Source Parameters and Non-Gaussian Channelized Hydraulic Conductivity Field, Water Resour. Res., 60, e2023WR036893, https://doi.org/10.1029/2023WR036893, 2024.
Zhang, Y., Tang, J., Liao, R., Zhang, M., Zhang, Y., Wang, X., and Su, Z.: Application of an enhanced BP neural network model with water cycle algorithm on landslide prediction, Stochastic Environ. Res. Risk Assess., 35, 1273–1291, https://doi.org/10.1007/s00477-020-01920-y, 2021.
Zhao, Y., Fan, D., Li, Y., and Yang, F.: Application of machine learning in predicting the adsorption capacity of organic compounds onto biochar and resin, Environ. Res., 208, 112694, https://doi.org/10.1016/j.envres.2022.112694, 2022a.
Zhao, W., Wang, L., and Mirjalili, S.: Artificial hummingbird algorithm: A new bio-inspired optimizer with its engineering applications, Comput. Methods Appl. Mech. Eng., 388, 114194, https://doi.org/10.1016/j.cma.2021.114194, 2022b.
Zheng, C., Hill, M. C., Cao, G., and Ma, R.: MT3DMS: Model use, calibration, and validation, Trans. ASABE, 55, 1549–1559, 2012.