the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Sep 2025
| 30 Sep 2025
Statistical estimation of probable maximum precipitation
Anne Martin
Élyse Fournier
Jonathan Jalbert
Civil engineers design infrastructure exposed to hydrometeorological hazards, such as hydroelectric dams, using probable maximum precipitation (PMP) estimates. Current PMP estimation methods have several flaws: some required variables are not directly observable and rely on a series of approximations; uncertainty is not always accounted for and can be complex to quantify; climate change, which exacerbates extreme precipitation events, is difficult to incorporate; and subjective choices increase estimation variability. In this paper, we derive a statistical model from the World Meteorological Organization's PMP definition and use it for estimation. This novel approach leverages the Pearson Type-I distribution, a generalization of the Beta distribution over an arbitrary interval, allowing for uncertainty quantification and the incorporation of climate change effects. Multiple estimation procedures are considered, including the method of moments, maximum likelihood, and Bayesian estimation. However, statistical PMP estimation remains challenging because a short-tailed model is applied to typically heavy-tailed precipitation data. The performance of the proposed approach is assessed through a simulation study and applied to actual precipitation data from two nearby stations in Canada. Finally, we provide and discuss recommendations for best practices in PMP estimation.
- Article
(2306 KB) - Full-text XML
- BibTeX
- EndNote




Probable maximum precipitation (PMP) is used in the design of high-hazard infrastructure such as dams, nuclear facilities, or mine waste storage installations. Over-sizing these projects during construction or renovation can lead to unnecessary costs. Conversely, under-sizing them can pose safety risks to the environment and surrounding populations and may also result in excessive costs. Depending on the risk in case of breakage, various flood estimations are used, such as the millennial, decamillennial, or probable maximum flood (PMF). The latter is the greatest theoretically possible flood in a specific watershed and is computed based on, among other factors, the probable maximum precipitation (PMP). The World Meteorological Organization (WMO) defines PMP as “the maximum amount of water that can physically accumulate over a given time period and region, depending on the season and without considering long-term climate trends”. Several PMP estimation techniques have been developed, including moisture maximization, the empirical Hershfield approach, and approaches based on extreme-value theory. In general, PMP estimation is challenging and sensitive to the data. On the one hand, uncertainty and climate change effects are difficult to incorporate into non-statistical methods, and commonly used moisture maximization approaches involve several subjective judgements. On the other hand, statistical PMP estimation is challenging because its definition assumes a bounded tail, whereas precipitation data suggest an unbounded tail (see, e.g., Martins and Stedinger, 2000). The following sections summarize the different approaches to PMP estimation.
1.1 Estimation based on moisture maximization
In its 2009 manual, the WMO details several PMP estimation approaches, with hydrometeorological methods combining algorithms of storm selection, transposition, and maximization being the most popular in Canada. In regions where snow cover is important enough for floods to result from a combination of the PMP and snowmelt, the WMO typically recommends estimating both spring and summer–fall PMPs. Regarding storm selection, some authors use all rain events where the precipitation height exceeds a given threshold (Beauchamp et al., 2013), while others utilize all observed precipitation data over a given period (Ben Alaya et al., 2018). This selection process is usually carried out by meteorologists and depends on physical factors (CEHQ and SNC-Lavalin, 2004; DTN and MGS Engineering, 2020; Environmental Water Resources Group Ltd., 2020). Since the number of selected storms is small and varies from one calculation to another and among different meteorologists, this selection process introduces significant variability into the estimation of the PMP.
To increase the number of storms used in PMP estimation, a common practice is to include storms from neighbouring areas that are likely to also affect the region of interest. Over the past decades, meteorologists have developed various techniques considering the orography and other features of the areas to realistically transpose storms (WMO, 2009). This storm transposition can be incorporated into the storm selection process of PMP estimation methods. While it increases the sample size for PMP estimation, it also introduces additional sources of variability and subjectivity.
The moisture maximization approach estimates the PMP using the relationship between the amount of precipitation and the humidity of the air. Let Yi be the precipitation of storm among the n selected storms. The PMP estimation is based on moisture maximization (WMO, 2009) as follows:
where PWi corresponds to the precipitable water of storm i, and PWmax corresponds to the maximum precipitable water. The quantity is often referred to as the maximized precipitation of event i if the maximal precipitable water is available at the moment of the storm. The PMP then corresponds to the maximum of the maximized precipitation. The ratio is referred to as the maximization ratio and is sometimes arbitrarily set to a numerical value between 1.5 and 2.5 to avoid the overestimation of the PMP (Schreiner and Riedel, 1978; Hansen, 1988; WMO, 2009; Beauchamp et al., 2013). The use of this threshold is subjective and lacks physical or mathematical justification (Rouhani and Leconte, 2016).
A slightly different interpretation can be given for the moisture maximization equation expressed in Eq. (1) by rearranging the terms: the ratio corresponds to the ratio of precipitation to precipitable water and is referred to as the precipitation efficiency of storm i. The PMP occurs when the maximum precipitation efficiency coincides with the maximum precipitable water. Ben Alaya et al. (2018) utilize this definition to model the dependence between extreme values of precipitation efficiency and precipitable water. They demonstrate that the comonotonicity imposed by this interpretation leads to overestimation of the PMP in North America.
In practice, the precipitable water PWi at the moment of storm i and the maximum amount of precipitation for the considered region PWmax are unknown and must be estimated in order to use the moisture maximization approach. The amount of precipitable water can be estimated using the specific humidity of the air column above the area (WMO, 2009). However, for the majority of meteorological stations, specific humidity is neither observed nor recorded. The recommended estimation of precipitable water by the WMO (2009) uses the dew point, which is usually recorded and requires pseudo-adiabatic conditions (United States Weather Bureau, 1960; Miller, 1963). Viswanadham (1981) observed that the relation between surface dew point and precipitable water is greater when the latitude is over 25° than in lower-latitude zones. A study conducted by Chen and Bradley (2006) in the Chicago region indicates that the hypothesis of pseudo-adiabatic conditions could lead to overestimation of precipitable water, and Rouhani and Leconte (2020) noted that PMP estimates vary greatly depending on how the precipitable water was approximated. The uncertainty of these estimations is often neglected in PMP estimation. It is not uncommon for the uncertainty of PWi to lead to a precipitation efficiency larger than 1, which is physically impossible.
1.2 Estimation based on Hershfield's empirical approach
The Hershfield empirical method (Hershfield, 1961a, b, 1965) is an alternative to moisture maximization for PMP estimation. The method relies on a series of m precipitation annual maxima. The PMP estimate is as follows:
where and s correspond, respectively, to the mean and the standard deviation of the series of annual maxima, and K corresponds to the frequency factor for estimating PMP at that location. Hershfield (1961a) proposed a method to estimate this factor. This approach is widely employed for its simplicity and ease of use but can only estimate PMP over smaller watersheds (WMO, 2009). It also has the advantage of not requiring additional hydrometeorological data such as specific humidity or dew point. Only precipitation series from which annual maxima are extracted are required.
This method is often classified as a statistical technique, but, in this paper, it is considered to be empirical due to the nature of the link between the PMP and the sample moments. It should be noted that the PMP durations considered by Hershfield (1965) and available in WMO (2009) are all less than or equal to 24 h, which is inadequate for calculating longer-duration PMP.
1.3 Estimation based on extreme-value theory
The relevance of the Hershfield procedure can also be questioned. Equation (2) defines the PMP as an extreme quantile of the distribution, estimated using only the mean and standard deviation. This approach relies on the bulk of the distribution to extrapolate into the tail, which is inherently hazardous. Extreme-value theory (EVT; see, e.g., Coles, 2001) is a branch of statistics that focuses on extreme values. It provides asymptotic parametric distributions (the generalized extreme-value and the generalized Pareto distributions) and rigorous frameworks (block maxima and peaks over threshold) for extrapolating beyond the range of observations.
As a statistical approach, it is easier to incorporate non-stationarity induced by climate change and to provide uncertainty in the estimates. However, extreme-value analysis suggests that the precipitation distribution is unbounded, which is inconsistent with the PMP definition. To reconcile the PMP definition with extreme-value theory, some authors propose using a very large return period as the PMP estimate. For example, Koutsoyiannis (1999) shows that PMP estimates obtained through the Hershfield method correspond, on average, to return periods of 60 000 years when estimated using EVT. The National Academies of Sciences, Engineering, and Medicine (2024) also suggest using a quantile of an extreme-value distribution corresponding to an “extremely low annual probability of being exceeded”.
1.4 Estimation using simulated data
The methods for estimating PMP presented by the WMO (2009) rely solely on precipitation data observed at hydrometeorological stations. However, the scarcity of precipitation observations and the lack of direct measurements of precipitable water have driven the development of PMP estimation methodologies based on climate simulations from regional climate models in Canada (Beauchamp et al., 2013; Rousseau et al., 2014; Clavet-Gaumont et al., 2017; Rouhani and Leconte, 2018, 2020), North America (Kunkel et al., 2013; Ben Alaya et al., 2018, 2020a, b), and other parts of the world (Sarkar and Maity, 2020; Visser et al., 2022).
The use of these climate simulations not only allows for the consideration of a greater number of extreme rainfall events but also enables the estimation of future PMP. Indeed, the WMO (2009) defines the PMP as stationary values, and climate change (CC) is not taken into account in the calculations. However, it is widely acknowledged that CC has a direct impact on extreme precipitation events and should therefore be considered in their estimation. Using projected climate simulations, Kunkel et al. (2013) demonstrate a global increase in water vapour concentration in the atmosphere without a sufficient evolution in values of upward vertical motion or horizontal wind speed, factors that could counterbalance the rise in air humidity. This increase implies larger future values of PWmax and, consequently, an increase in PMP. Several papers conclude that PMP will generally increase under future climate (Beauchamp et al., 2013; Rousseau et al., 2014; Clavet-Gaumont et al., 2017; Rouhani and Leconte, 2018, 2020; Ben Alaya et al., 2018, 2020a, b; Sarkar and Maity, 2020; Visser et al., 2022).
1.5 Objectives of the paper
PMP estimations using the non-statistical approaches described in the previous sections are highly sensitive to arbitrary choices and are generally provided without accounting for uncertainty. Statistical approaches, on the other hand, provide uncertainty quantification and facilitate the inclusion of non-stationarity if needed. However, reconciling the PMP definition as the upper bound of an unbounded distribution remains particularly challenging. The objective of this paper is to develop a statistical model for PMP estimation based on the WMO definition, which assumes an upper bound. As a statistical approach, it offers two key advantages: (1) uncertainty is quantifiable, and (2) most subjective choices are eliminated, enhancing the reproducibility of the estimation.
In this section, a statistical model is developed for PMP estimation based on the definition expressed in Eq. (1). Statistical inference methods for this proposed model are also described.
2.1 Statistical model
Starting with the principles underlying moisture maximization (WMO, 2009), we develop a sensible statistical model that assumes an upper bound for precipitation. From Eq. (1), let denote the maximized daily precipitation on day i:
Factoring for the actual precipitation of day i gives the following expression:
where PWmax is the maximum of precipitable water. Hence, . Since the PMP corresponds to the maximum of the maximized precipitation , the maximized precipitation can be viewed as a fraction of the PMP; i.e., , where . It is then possible to express the actual daily precipitation as follows:
The ratio lies in (0,1] since each of the multiplicative factors is within (0,1]. This ratio can naturally be modelled using the Beta distribution, a flexible distribution for a random variable taking values in the unit interval. Actual precipitation Yi, which corresponds to this ratio multiplied by the PMP, can be modelled using the Beta distribution rescaled to the interval (0,PMP). The Beta distribution on the interval (a,b) for a<b is referred to as the Pearson Type-I distribution (Johnson et al., 1995, Chap. 24).
Therefore, we propose modelling the actual precipitation of day i with the Pearson Type-I distribution as follows:
where the Beta parameters α>0 and β>0 govern the ratio and where ψ>0 corresponds to the PMP. The lower bound is set at 0 because only non-zero precipitation events are considered. When and β≥1, the Pearson Type-I density is monotonically decreasing and convex, resembling the precipitation histogram shown in Fig. 5. With this proposed statistical model, the PMP constitutes a distribution parameter to be estimated with the data. Uncertainty can then be provided using the usual statistical methods, as described in the next section.
2.2 Parameter estimation
Three methods are considered for estimating the parameters of the proposed model: the method of moments, maximum likelihood estimation, and the Bayesian method.
2.2.1 Method of moments
The first four central moments, namely the mean m, the variance v, the skewness s, and the kurtosis k, of the Pearson Type-I distribution can be given by means of an analytical expression (Johnson et al., 1995, Chap. 24). As the skewness and kurtosis depend only on the shape parameters α and β and not on the upper bound ψ, it is possible to invert these expressions and retrieve equations for the distribution parameters (Johnson et al., 1995, Chap. 24). To estimate the parameters of the Pearson Type-I distribution using the method of moments from a random sample, the empirical moments of the sample – sample mean, sample variance, sample skewness, and sample kurtosis – are plugged into these equations. The uncertainty of the parameter estimates can be assessed through non-parametric bootstrapping (Efron, 1979).
2.2.2 Maximum likelihood
The density of precipitation Yi distributed as the is given as follows (Johnson et al., 1995):
Assuming that the n non-zero daily summer precipitation values are independent, the likelihood can be written as follows:
where denotes the vector of the n non-zero precipitations.
Maximizing the likelihood expressed in Eq. (8) is a non-regular problem (Wang, 2005). When β>1, a local maximum exists, allowing parameter estimates to be obtained. Additionally, parameter uncertainty can be estimated using the Fisher information matrix. However, when β≤1, no local maximum exists, causing the estimation procedure to fail. Several solutions have been proposed for this issue, but they are not relevant to the present paper since, for precipitation, the parameter β is expected to be greater than 1 as precipitation density decreases monotonically.
The Pearson Type-I distribution is continuous, as expressed in Eq. (7). However, precipitation measurements are discrete. For our data, the precipitation measurement resolution is 0.1 mm, and no precipitation less than 0.2 mm can be measured. This discretization of precipitation measurements has a larger impact on small amounts. Discrepancies appear between the continuous distribution and the discrete measurements, which places mass on points of measurement. One approach to tackle this problem, if needed, is to censor the likelihood function for small precipitation amounts below a given threshold u>0 (e.g., Naveau et al., 2016) as follows:
where Iy(α,β) denotes the regularized incomplete beta function of parameter (α,β) evaluated at y. Precipitation smaller than u still counts in the likelihood, but the actual values are not considered. Parameter estimates can be obtained by using this censored likelihood.
Another approach would be to set the lower bound of the Pearson Type-I distribution to (0.2−ϵ), where ϵ>0. This would maintain some mass at the measurement points but could sufficiently de-emphasize the issue, allowing the continuous likelihood to serve as a good approximation of the discrete measurements. One of these methods could be used if parameter estimation by maximum likelihood is affected by the discretization of precipitation measurements.
However, in our framework, approximating discrete precipitation measurements with a continuous model does not affect the fit. Therefore, we did not use either of the two methods.
2.2.3 Bayesian method
Estimation of the Pearson Type-I distribution can also be performed under the Bayesian paradigm. The benefit of using the Bayesian method lies in its ability to describe uncertainty. Unlike the non-parametric bootstrap and the asymptotic Gaussian convergence of maximum likelihood estimates, Bayesian inference directly provides parameter uncertainty based on the data at hand without relying on asymptotic arguments.
Bayesian methods require a prior distribution for the model parameters. For the Pearson Type-I distribution expressed in Eqs. (7) and (8), an improper non-informative prior distribution for the upper bound ψ>0 and the shape parameters α>0 and β>0 can be defined as follows:
The same prior distribution can be used with the censored likelihood expressed in Eq. (9) or with a positive lower bound.
If prior information on the upper bound (the PMP) is available, an improper semi-informative prior can be used as follows:
where the prior information on ψ is modelled with the proper density fψ. If β≤1, the problem is non-regular, and the informative prior proposed by Hall and Wang (2005) can be used to solve this issue.
The posterior distribution of the parameters is not available in analytical form for either of the proposed prior distributions. A sample from the posterior distribution can be obtained, for example, using a Gibbs sampling scheme, and inference can be performed using the generated sample.
2.3 Identifiability issues
When and β≥1, i.e., when the density is convex, a non-identifiability issue occurs between β and ψ. Indeed, these parameters can compensate for each other. For example, let and be two random variables with very different upper bounds – 10 for Z1 and 100 for Z2 – but whose moments are similar, as shown in Table 1. Both variables have the same mean and approximately the same variance. Although there are slight differences in skewness and kurtosis, these differences are not large enough to overcome the sampling uncertainty of these higher-order-moment estimates.

This non-identifiability issue is even more critical for parameter estimation using the model likelihood (both maximum likelihood and Bayesian methods). For example, consider the variable Z1 again and generate a large random sample of size 5000. The log-likelihood of the model evaluated at the true parameter vector is 35 678.3. The log-likelihood evaluated at another parameter vector is 35 678.0, which is practically the same, even though the parameters are quite different. The impact of this non-identifiability issue is assessed for parameter estimation with the method of moments, maximum likelihood, and Bayesian method with a simulation study provided in the following section.
In this section, a simulation study is conducted to assess the performance of parameter estimation methods for two different distribution behaviours: concave and convex density. The Pearson Type-I distribution with parameters is used for the concave distribution, while the Pearson Type-I distribution with parameters is used for the convex distribution. For each of these distributions, 100 random samples of various sizes were generated, and parameter estimation was performed on each sample.
3.1 Pearson Type I with concave density
For each of the 100 random samples, with sizes ranging from 100 to 8000, parameters were estimated using the method of moments, maximum likelihood, and Bayesian method. Figure 1 displays the mean of the 100 parameter estimates for the upper bound ψ as a function of the sample size, as well as the 95 % empirical confidence interval. For the Bayesian method, both a Gibbs sampling scheme and the No-U-Turn Sampler (NUTS) algorithm were implemented, yielding similar results.
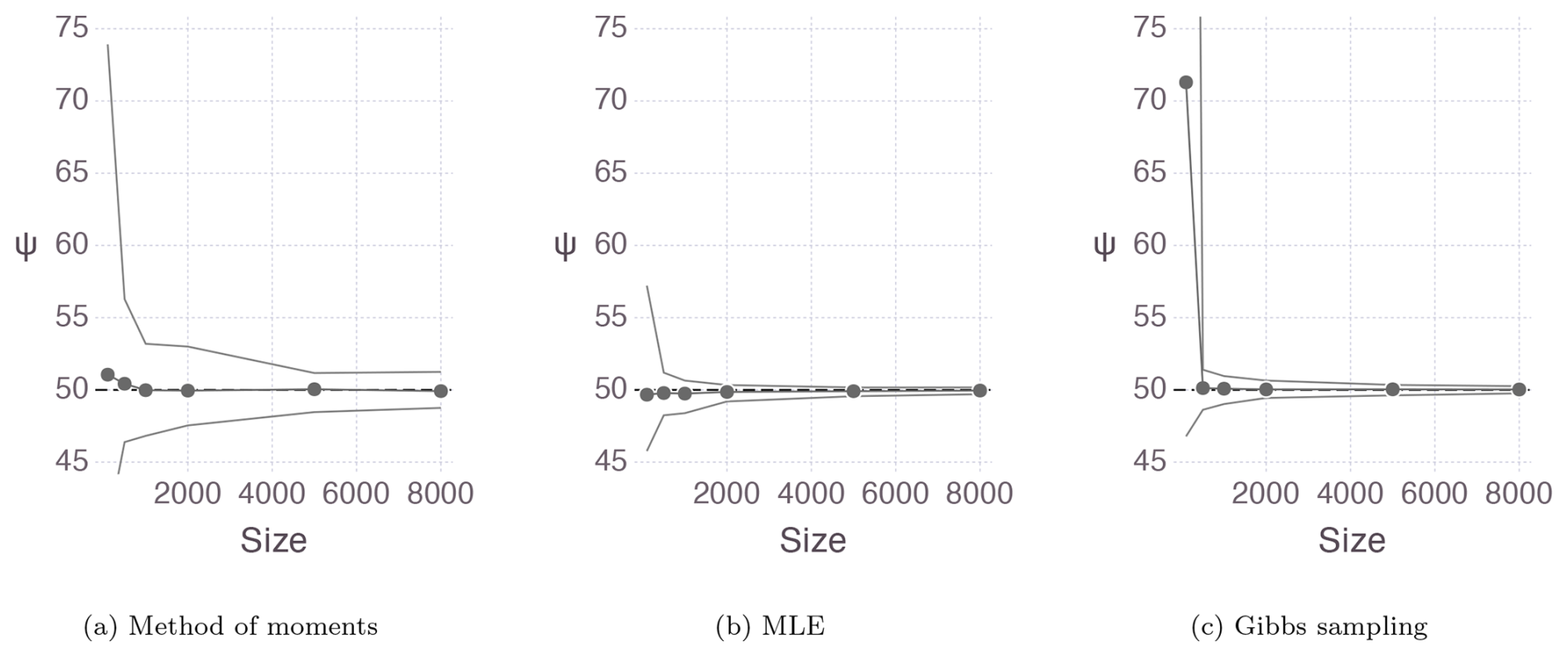
Figure 1Mean and 95 % empirical confidence interval for the ψ estimates of the 100 samples of the distribution obtained with (a) the method of moments, (b) the maximum likelihood, and (c) the Bayesian method using Gibbs sampling.
The three estimation procedures perform very well in estimating the upper bound, which is the parameter of interest in this paper. The mean estimate hovers around the true value of 50, and the confidence intervals include the true value. Estimation remains accurate even for relatively small sample sizes of 2000, which corresponds to approximately 20 years of precipitation data. However, the methods based on likelihood yield more precise results than the method of moments.
3.2 Pearson Type I with convex density
Figure 2 shows the mean and the 95 % empirical confidence intervals for the samples generated from the Pearson Type-I distribution with a convex density. For the method of moments, the estimation of the upper bound is close to the true value of 50. The confidence intervals, wider compared to those associated with the concave density, include the true value. However, estimation variability is very large. It is very sensitive to the sample. For example, for moderate sample sizes around 4000, the upper-bound estimate average is around 50, but for some samples, the estimate exceeds 100, which is 2 times larger than the true value. For other samples, the estimate is smaller than 25, which is half the true value.
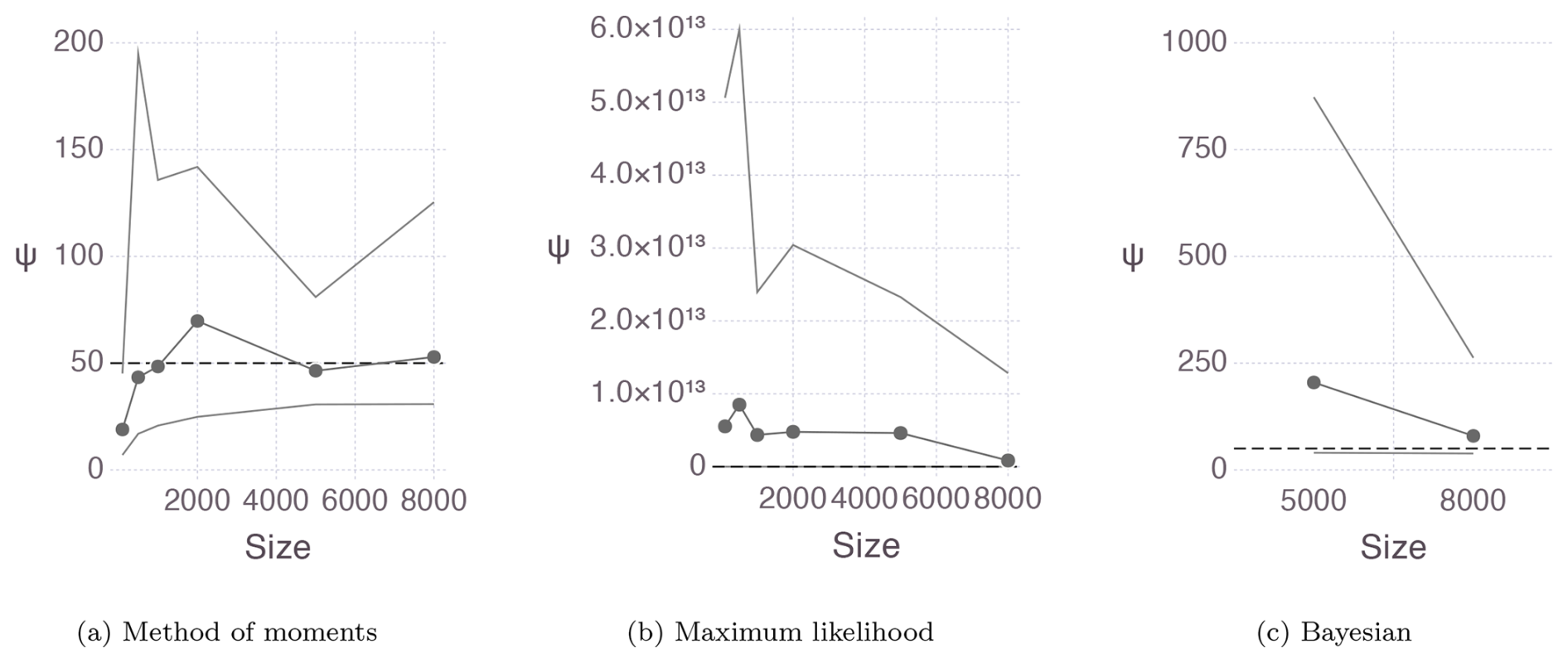
Figure 2Mean and 95 % empirical confidence interval for the ψ estimates of the 100 samples of the distribution obtained with (a) the method of moments, (b) the maximum likelihood, and (c) the Bayesian method using Gibbs sampling.
Upper-bound estimates using the maximum likelihood and Bayesian methods are not useful, as shown in Fig. 2. The non-identifiability issue arises because the shape parameter β compensates for the larger upper bound. While an informative prior for the upper bound could be introduced to control this issue, it would need to be highly informative. However, this approach was not pursued because using such a restrictive prior defeats the purpose of removing subjectivity in PMP estimation.
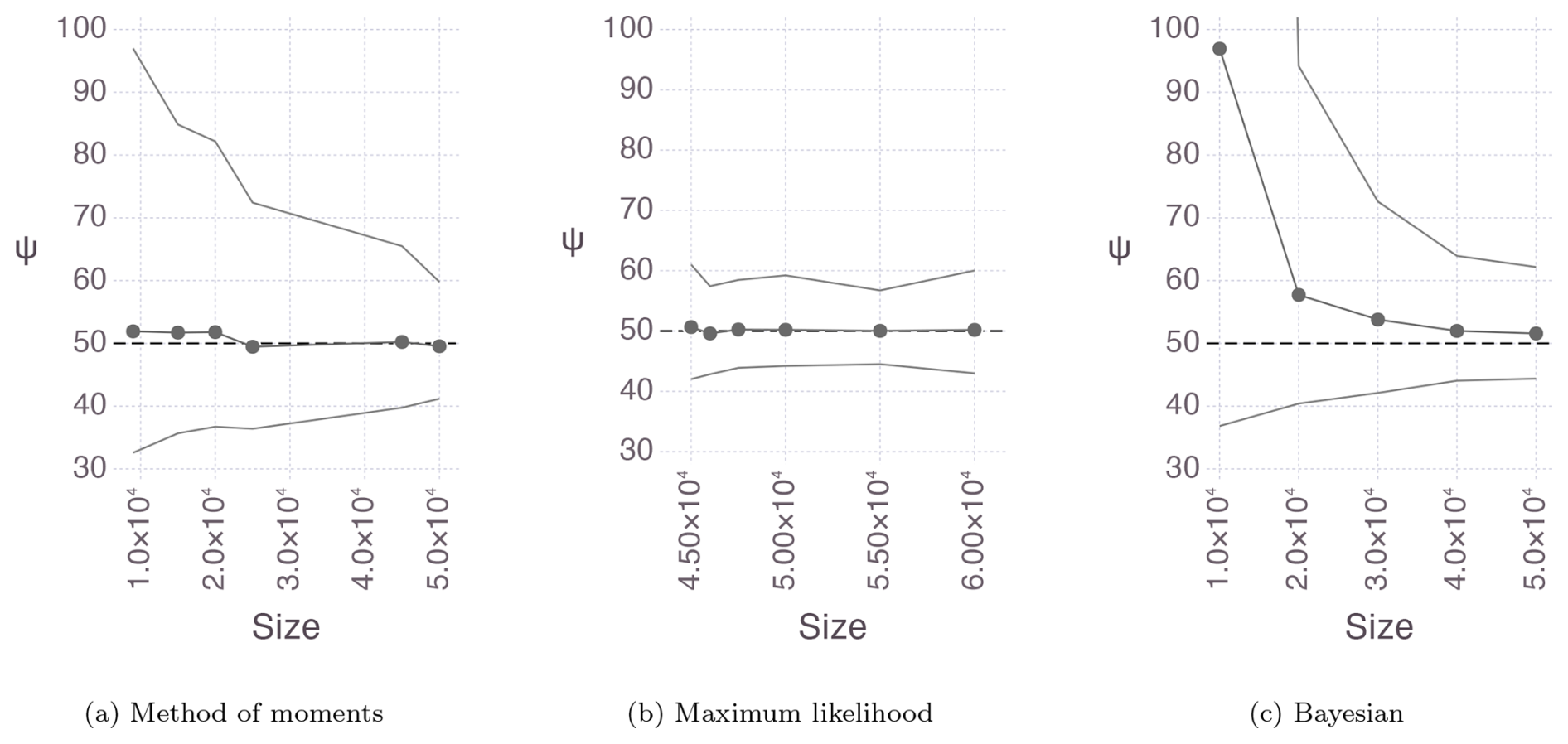
Figure 3Mean and 95 % empirical confidence interval for the ψ estimates of the 100 very large samples of the distribution obtained with (a) the method of moments, (b) the maximum likelihood, and (c) the Bayesian method using Gibbs sampling.
The sensitivity to the sample and the non-identifiability issue are resolved with very large sample sizes, as shown in Fig. 3. The estimates are well stabilized around a sample size of 40 000. For precipitation in Canada, this corresponds to approximately 400 years of data.
3.3 Key findings from the simulation study
For the Pearson Type-I distribution with a concave density, parameter estimates are precise with all three estimation methods considered. For a convex density, the non-identifiability issue in the likelihood is too severe to obtain usable upper-bound estimates for common sample sizes using the maximum likelihood and Bayesian methods. However, these two methods could be used with very large sample sizes.
Although the method of moments is sensitive to the data, it provides realistic estimates of the upper bound, even for common sample sizes. This method should be favoured for parameter estimation of non-concave Pearson Type-I distributions.
4.1 Observations
The proposed method for estimating the PMP is demonstrated using data from two meteorological stations in Quebec (QC), Canada, located 26 km apart: the Montréal Pierre-Elliott-Trudeau International Airport station (1953–2024) and the St. Hubert Airport station (1949–2024). The data are available from the Environment and Climate Change Canada (ECCC) website. Daily precipitation (in mm) and dew point (in degrees Celsius) were extracted from 1 May to 31 October each year to focus on liquid rainfall and to minimize the effect of seasonality. While it may still be present, it appears to be negligible compared to the natural variability of precipitation and precipitable water, as illustrated in Fig. 4 for the Montréal data. Descriptive statistics of recorded precipitation at these two stations are provided in Table 2. Figure 5 shows the histogram of non-zero daily rainfall for each station. Typically, for precipitation at the considered locations, autocorrelation exists in daily non-zero series but is very weak (0.0092 for Montréal and 0.0095 for St. Hubert) and short range.
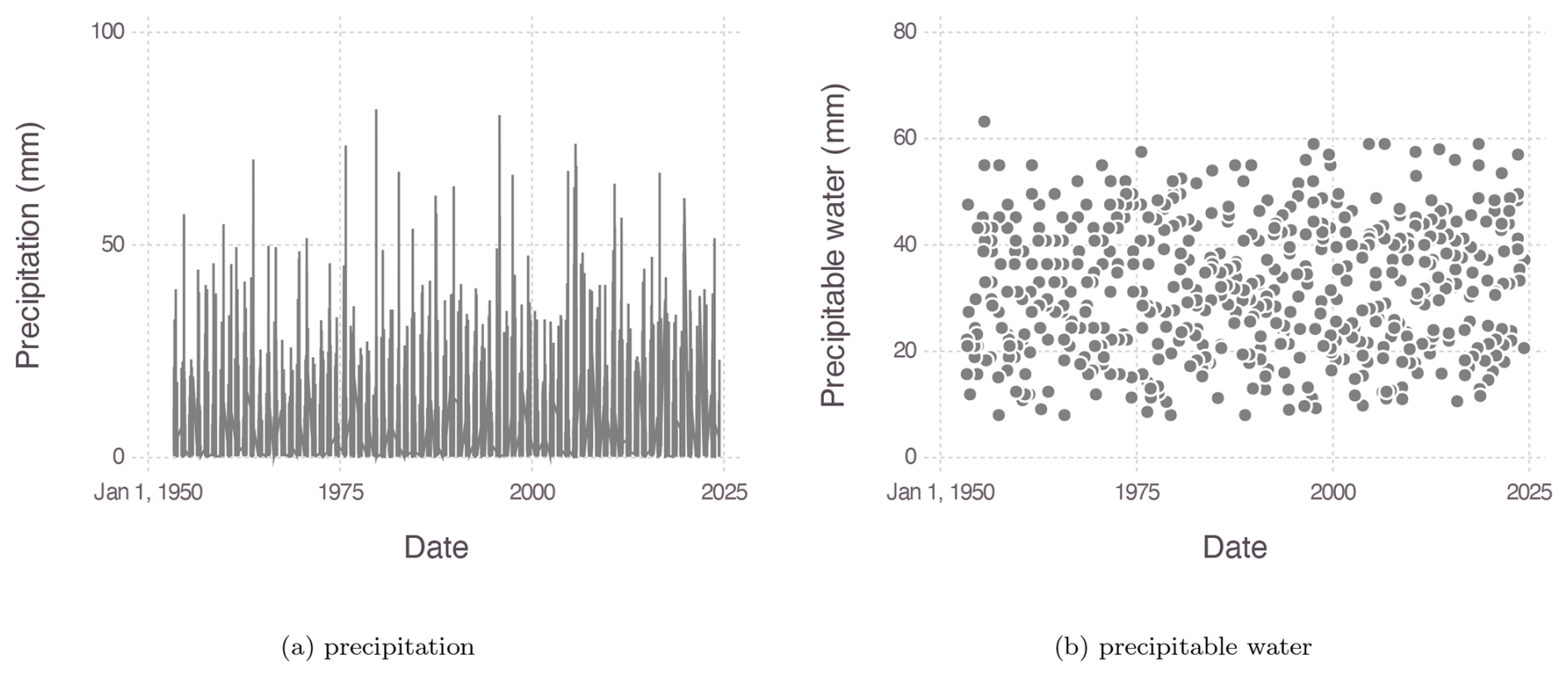
Figure 4Time series of (a) daily precipitation and (b) precipitable water for the top 10 % of storms recorded at the Montréal station.
Table 2Summer (May to October) daily precipitation statistics for the Montréal and St. Hubert stations.
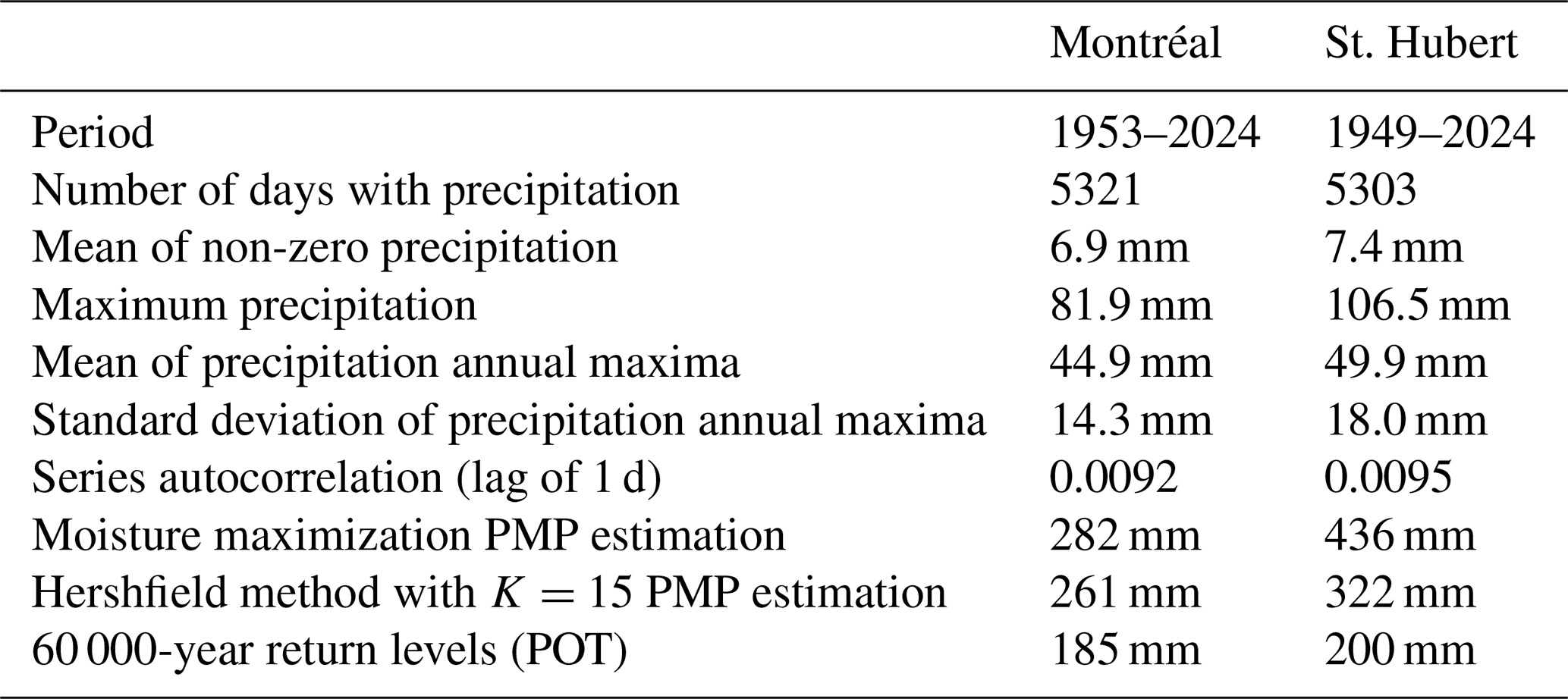
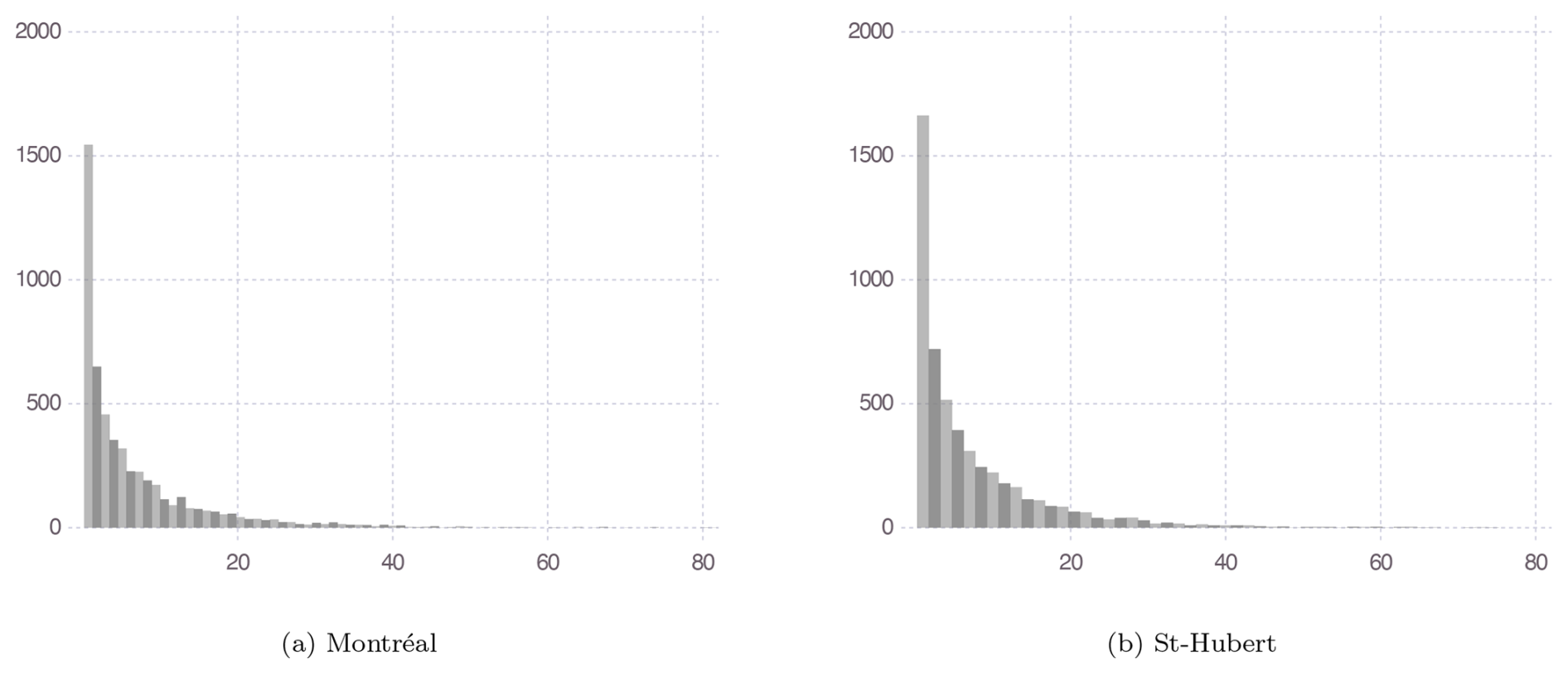
Figure 5Histogram of the non-zero summer precipitation in mm for (a) Montréal (QC) and (b) St. Hubert (QC).
4.2 PMP estimates using existing approaches
As a point of comparison, summer–fall PMP estimates for both stations are calculated using the moisture maximization method, Hershfield's approach, and the 60 000-year return level estimated with EVT. For the moisture maximization method, daily precipitation amounts from the top 10 % of storms for each year are selected, as proposed by Clavet-Gaumont et al. (2017). A sensitivity analysis was performed on the storm selection percentage (10 %, 1 %, or 0.1 %), but the PMP estimates remained unchanged because the maximized events were the same for both locations. Since precipitable water was not directly observed, it was estimated using the dew point over 12 h, as described by WMO (2009), which may have affected the quality of the PMP estimates. The corresponding PMP estimates for both stations are provided in Table 2. The PMP estimates are 282 and 436 mm for Montréal and St. Hubert, respectively, corresponding to maximization ratios of 4.4 and 4.9. Some authors suggest limiting this ratio to a value between 1.5 and 2.5 to constrain PMP estimation. Setting the maximization ratio to 2.0 would yield PMP estimates of 128 and 178 mm for Montreal and St. Hubert. While this would improve the moisture maximization results, it merely conceals the methodology's flaws, particularly its high variability, rather than addressing them.
Note that, for this approach, it is also possible to estimate the PMP using the 100-year return level of precipitable water instead of the sample maxima (e.g., Ben Alaya et al., 2018), but with our data, the estimated PMP values were similar: 284 mm and 427 mm for Montréal and St. Hubert, respectively.
For Hershfield's approach, the frequency factor of K=15 is employed as proposed by Hershfield (1961a). The adjustment based on the number of data points, as suggested by WMO (2009), is unnecessary. Hershfield's PMP estimates are 261 mm for Montréal and 322 mm for St. Hubert and are also provided in Table 2.
The 60 000-year return level was estimated using the peaks-over-threshold model (see, e.g., Coles, 2001; Davison and Smith, 1990), which adjusts the excesses over a high threshold to a generalized Pareto distribution (GPD). The threshold of 30 mm for both Montréal and St. Hubert is selected using the mean residual life plot as described by Coles (2001, Chap. 4). The estimated return levels are 185 mm (114, 363) and 200 mm (120, 385) for the Montréal and St. Hubert data, respectively, where the values in parentheses represent the 95 % confidence intervals for the 60 000-year return level estimates.
The Pearson Type-I distribution is fitted to the non-zero precipitation data recorded at Montréal and St. Hubert, with the upper-bound estimate assumed to represent the PMP. As shown in Fig. 5, the non-zero precipitation density appears to be convex, and so the model is fitted using the method of moments.
Table 3Parameter estimates for the Pearson Type-I distribution fitted on the non-zero precipitation data recorded at Montréal and St. Hubert. The values in parentheses correspond to the 95 % confidence intervals estimated by non-parametric bootstrapping using 10 000 samples.

The Pearson Type-I distribution has been fitted to the 5321 non-zero daily summer precipitation values observed at Montréal with the method of moments. The parameter estimates can be found in Table 3.
Figure 6 shows the upper-bound estimate for each bootstrap sample used to estimate the confidence interval based on the parameter estimations. The uncertainties of the second shape parameter β and the upper bound ψ are very large, which is expected given the simulation study results for a convex density. Note that using the maximum likelihood and Bayesian methods does not yield valid estimates due to identifiability issues.
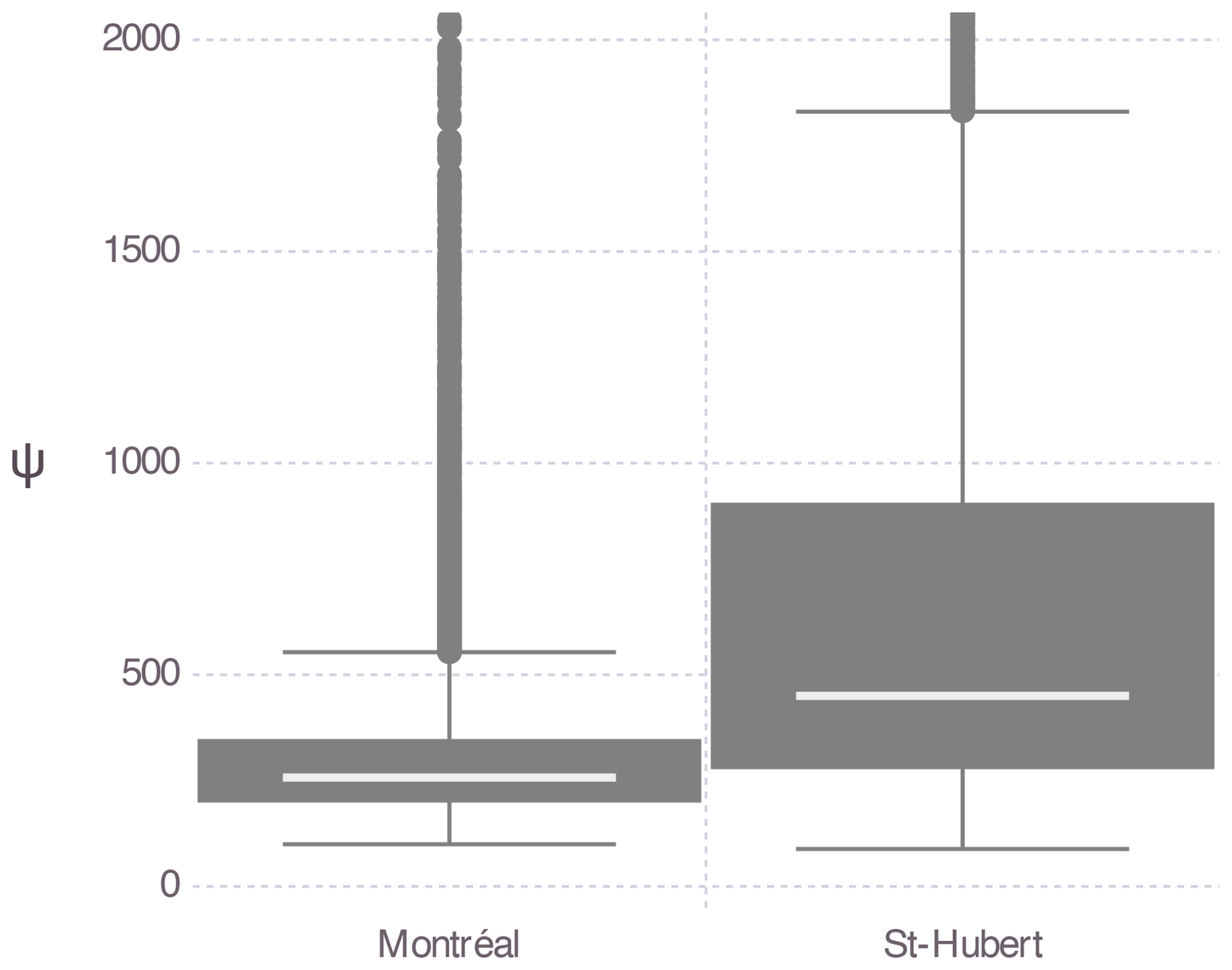
Figure 6PMP estimates (in mm) obtained by non-parametric bootstrapping in Montréal (QC) and St. Hubert (QC).
Figure 7Quantile–quantile (QQ) plots of the fitted Pearson Type-I model for (a) the Montréal data and (b) the St. Hubert data.
Figure 7 shows the Pearson Type-I distribution fitted to the Montréal data. The model fits the data very well. The PMP estimate obtained from the fitted Pearson Type-I distribution is consistent with the estimate derived using the moisture maximization method based on Eq. (1). The former estimates the PMP at 270 mm, while the latter estimates it at 284 mm. Unlike the proposed method, the moisture maximization method does not provide an uncertainty estimation.
For St. Hubert, the Pearson Type-I distribution has been fitted to the 5303 non-zero daily summer precipitation events, and the parameter estimates obtained with the method of moments are shown in Table 3. Uncertainties in the upper bound and the second shape parameter are exceedingly high, indicating that the non-identifiability issue is more pronounced for these data. Figure 6 shows the upper-bound estimates for each bootstrap sample.
Figure 7 shows that the model does not fit the St. Hubert data well. The PMP estimate given by the fitted Pearson Type-I distribution (417 mm) is consistent with the estimate obtained using the moisture maximization method (436 mm). This highlights the importance of using a statistical method, which allows for an assessment of estimation quality.
As with the Montréal data, maximum likelihood and Bayesian methods do not yield valid parameter estimates. It should be noted that the estimate for the first shape parameter α with the method of moments is larger than 1, which is inconsistent with the convex form of the distribution. However, the confidence interval includes values smaller than 1.
6.1 Pros and cons of the proposed approach
The proposed statistical approach to estimate the PMP translates the usual definition of the PMP into a statistical distribution for the recorded precipitation. The PMP constitutes one of the three parameters, and the remaining two concern the shape of the distribution. By estimating the parameters using standard statistical approaches, such as the moment, maximum likelihood, and Bayesian methods, it is possible to adequately describe the uncertainty, particularly for the PMP parameter. Additionally, the proposed approach uses all of the precipitation recorded at the station rather than only a subset from the stations and neighbouring stations. This reduces the subjectivity present in standard approaches.
In the simulation study, it is shown that the non-identifiability issue vanished with very large sample sizes. Figure 3 shows that the maximum likelihood estimation is stable with a sample size of 45 000. If we consider that 100 storms occur during a year, such a sample size would correspond to 450 years of observation. Of course, no meteorological record is that long, but it could be possible to have such a sample size of synthetic storms generated with a storm generator. However, such data augmentation should be carefully implemented to avoid overconfidence. For instance, if 40 000 daily precipitation data points generated from a weather generator are used to estimate the model, do these 40 000 data points contain 400 times more information than an actual recorded series of size 100? At this point, this is beyond the scope of the present paper, but it could be an interesting avenue for future investigation.
Another alternative to increase the sample size would be to include information from nearby stations. This could be achieved within the Bayesian framework described in Sect. 2.2.3 by replacing the parameter prior distribution with a spatial prior. However, the dependence between stations would need to be modelled in the likelihood as a single storm can generate precipitation across multiple stations. Accounting for this dependence would decrease the effective sample size of the pooled stations, and we believe that this effective sample size might not reach the level where the estimates are stable. However, we could be wrong.
PMP estimation, whether with the method proposed in this paper or with more standard approaches, is very sensitive to the data due to non-identifiability. For the two nearby meteorological stations considered, i.e., the Montréal Pierre-Elliott-Trudeau International Airport and the St. Hubert Airport stations, located 26 km apart, the PMP estimates are very different. However, these two stations do not experience significantly different climates and storms. Furthermore, in several estimates provided by engineering consulting firms, storms from even more distant stations are combined to estimate the PMP, a practice known as storm transposition. Moreover, the extreme-value analysis of the precipitation at these two stations, presented later in Sect. 6.2, yields consistent return level estimates. Therefore, the difference in the PMP for these two stations is more a numerical problem related to the PMP definition than a genuine difference in the PMP.
Another drawback is fitting the proposed short-tailed statistical model to heavy-tailed precipitation data, as shown in the following section. This inconsistency could explain why the model does not fit the St. Hubert data well, as shown in Fig. 7.
6.2 Comparison with extreme-value analysis
For the purpose of comparison, an extreme-value analysis has been performed on the precipitation data of Montréal and St. Hubert. As mentioned in Sect. 4.2, the peaks-over-threshold extreme-value model has been fitted by maximum likelihood to the Montréal data, with a 30 mm threshold. The estimated parameters of the generalized Pareto distribution modelling the excesses above the threshold can be found in Table 4. The model fits the data very well, as shown by the return level plot in Fig. 8. Note that the shape parameter estimate is positive, indicating an unbounded heavy-tailed distribution, which is typical for precipitation but inconsistent with the PMP existence assumption. Nevertheless, a short-tailed distribution cannot be excluded as the shape parameter confidence interval includes negative values. As an indication, the 60 000-year return level estimated with the POT model is 185 mm (114, 363), and the PMP value of 270 mm corresponds to a return period longer than 10×106 years.
Table 4Parameter estimates for the POT models fitted over Montréal and St. Hubert data. The values in parentheses correspond to the 95 % confidence intervals estimated using the Fisher information matrix.

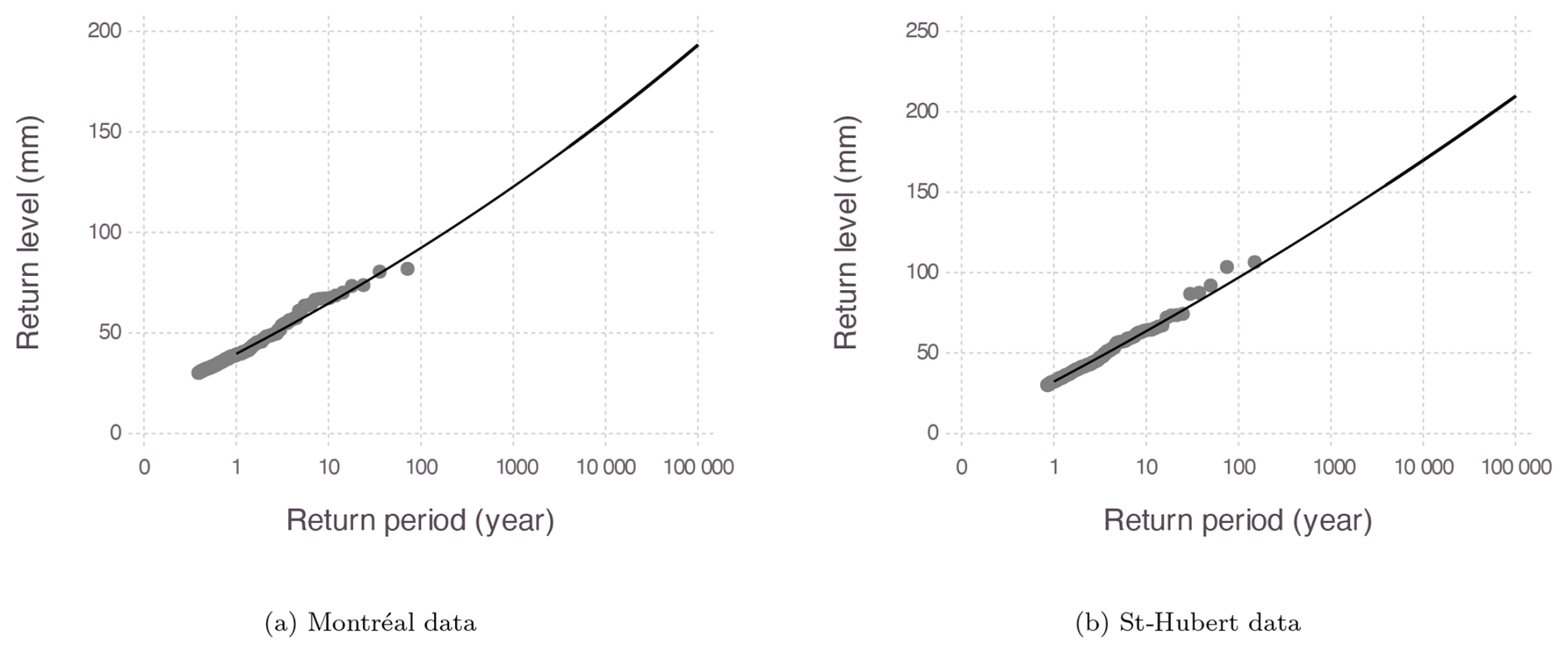
Figure 8Return level plot of the fitted peaks-over-threshold model for (a) the Montréal data and (b) the St. Hubert data.
The POT model has also been fitted to the St. Hubert data, and parameter estimates are shown in Table 4, and Fig. 8 shows the model fit to the data. Again, the model fits the data very well, and the shape estimate is positive, indicating a heavy-tailed distribution. Using the fitted POT model, the 60 000-year return level estimate is 200 mm (120, 385), which is consistent with the corresponding estimate of 185 mm for Montréal, located 26 km away. The PMP estimate of 416 mm corresponds to a return period longer than 1×109 years.
6.3 Possible modifications of the statistical model
To reduce the impact of model non-identifiability, we also developed a new parameterization for the Pearson Type-I distribution, replacing the shape parameters with a location parameter μ>0 and a concentration parameter ν>0:
We therefore have and . However, even with this parameterization, non-identifiability remained an issue for maximum likelihood and Bayesian inference.
Another approach to imposing a short-tailed model compliant with the PMP concept would be to consider the reverse Weibull distribution. The reverse Weibull is obtained by imposing a negative shape parameter on an extreme-value distribution. While this choice results in a short-tailed distribution, it is difficult to justify this constraint beyond the fact that it produces an upper bound. Moreover, we are concerned that using an extreme-value distribution in an inappropriate context, such as by imposing a negative shape parameter when the data suggest a positive one, could give practitioners a false sense of security. They might believe they are operating within the extreme-value framework when they are not.
The major drawback of the proposed approach lies in the issue of non-identifiability when the data distribution is convex, as is the case for precipitation. Maximum likelihood and Bayesian methods become highly unstable, and, although the method of moments is less affected, it is still impacted. Regularized maximum likelihood or informative priors could be employed to address non-identifiability. For example, a penalizing term corresponding to the log-density of an exponential distribution with parameter λ>0 can be introduced into the log-likelihood as a regularization term. This is equivalent to considering an exponential distribution with parameter λ as an informative prior for the PMP. When λ→0, the penalty vanishes and the regularized estimates converge to the maximum likelihood estimates. As λ increases, the penalty becomes more influential in the regularized likelihood. Choosing the penalty value λ involves a trade-off between bias and variance: λ should be small enough to minimize the added bias but large enough to help control non-identifiability.
For the Montréal data, the PMP estimate from the maximum likelihood exceeds 2×1013 mm, an absurd value explained by the non-identifiability issue, as demonstrated in the simulation study. Figure 9 shows the regularized maximum likelihood PMP estimate as a function of the penalty λ. If is selected using the subjective elbow method, the resulting PMP estimate is 272 mm. This value is more reasonable, but it is extremely sensitive to the choice of . We felt that this introduced too much subjectivity into the proposed approach and diminished its advantages over standard PMP estimation methods.
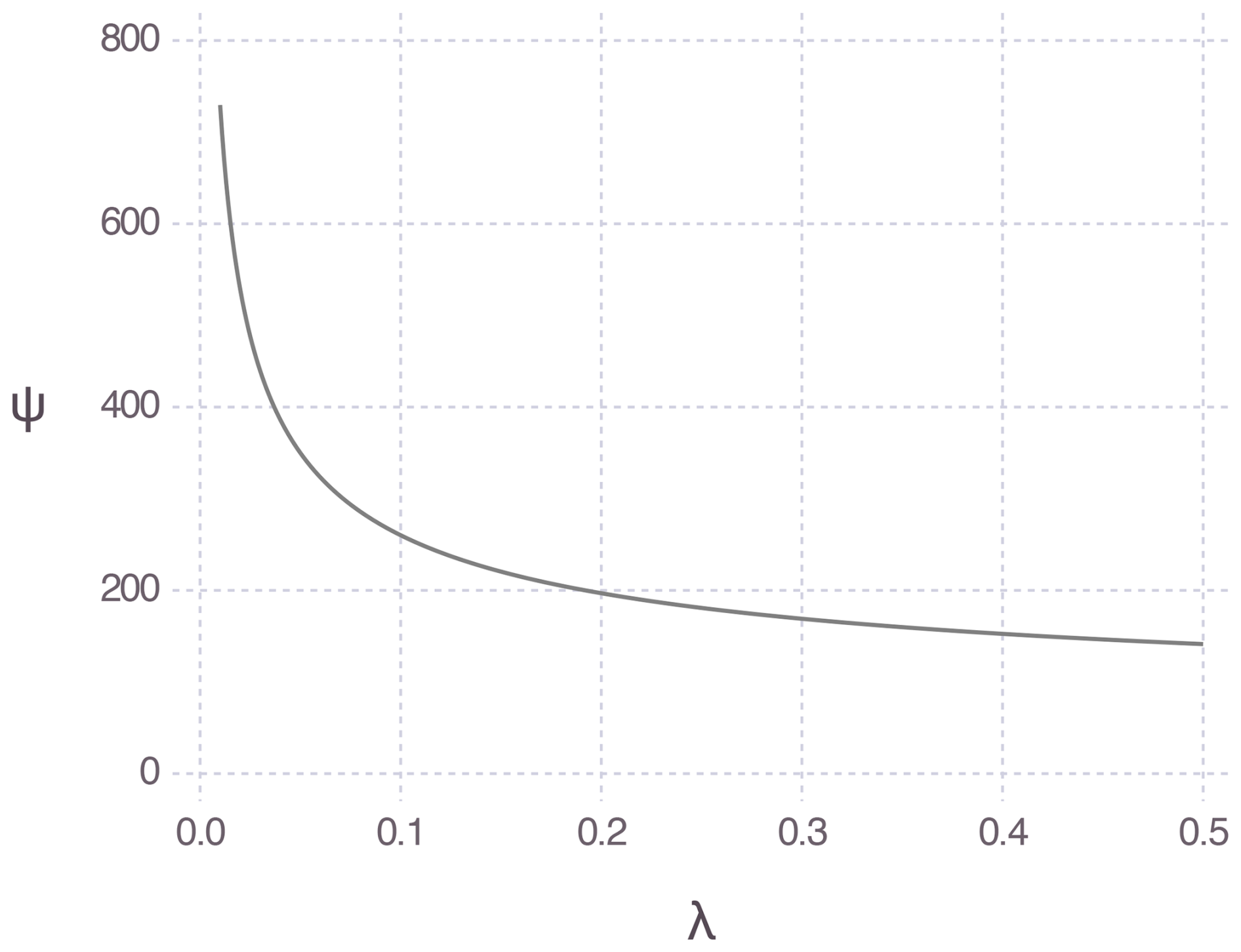
6.4 Non-stationarity
For the observed data considered, there is no evidence of a trend in either the precipitable water or precipitation, as shown in Fig. 4. Non-stationarity might be present in long series of simulated data from a climate model. In such cases, the proposed statistical model could easily be extended to account for non-stationarity and also for seasonality if needed. Equation (5) could be generalized to incorporate seasonality and non-stationarity by allowing either or both the PMP and the shape parameters to evolve over time. For example, precipitation Ytsi of year t, season s, and event i can be modelled as a function of the year and the event i as follows:
where the year t and season s could serve as covariates.
6.5 Recommendations
Although translating the definition of the PMP into a statistical model is interesting and despite the possibility of including non-stationarity and estimating uncertainty, we do not recommend using the Pearson Type-I distribution to estimate the PMP. The non-identifiability makes the model too sensitive to the data, and the PMP estimate becomes too volatile. This problem is also present in the standard moisture maximization method. Therefore, we align with the conclusions of the National Academies of Sciences, Engineering, and Medicine (2024), which recommends an extreme-value analysis instead. Additionally, the extreme-value theory allows for a genuine estimation of the uncertainty of extreme values, even when extrapolating to return periods that exceed the range of the data. Furthermore, it is easily generalizable to non-stationary cases, allowing the integration of the effects of climate change.
It should be noted that the recommendations of the National Academies of Sciences, Engineering, and Medicine (2024) address the North American context, but they stem from the broader observation that the definition and assumptions underlying PMP are outdated. This criticism is globally relevant as the definition and assumptions of PMP are consistent worldwide. Therefore, we believe that the recommendation can be considered to be general and not limited to the North American context.
More generally, the fact that PMP estimates using either moisture maximization, Hershfield's method, or the Pearson Type-I method are so sensitive to the data is a critical concern from an engineering standpoint. Specifically, for the Pearson Type-I method with a convex density, depending on the data, the PMP estimate can range from half to more than twice the true value. In the former case, using the estimate would result in under-dimensioning the infrastructure, putting the public at risk. In the latter case, using it would result in over-dimensioning the infrastructure, thereby increasing costs and environmental impacts. Although uncertainty estimates are not available with the moisture maximization and Hershfield's methods, the fact that the corresponding PMP estimates for Montréal and St. Hubert were so different is an important indication of the methods' sensitivity.
In the case of this article, we have seen that the POT model fits the data from both stations very well and that the estimates of the 60 000-year precipitation were consistent. Moreover, the extreme-value analysis indicates an unbounded and heavy-tailed distribution of precipitation, which is consistent with numerous results in the literature (e.g., Papalexiou and Koutsoyiannis, 2013). Therefore, it is better to design infrastructure by setting an appropriate level of risk and evaluating the uncertainty of the estimate.
In our opinion, EVT-based PMP estimates are preferable, but they do not resolve all challenges. Extrapolating beyond the data range, especially for large return periods associated with PMP estimates, remains difficult and introduces substantial uncertainty. Such return level estimates should be accompanied by uncertainty evaluations (e.g., confidence intervals) to clearly communicate to end-users that PMP estimates carry significant uncertainty inherent to extrapolation. The methodology based on simulated data, presented in Sect. 1.4 to address data scarcity, could also be adapted within the extreme-value framework to reduce uncertainty to some extent. However, a degree of uncertainty will always remain as it is inherent to extrapolation.
In this study, we developed a new statistical model for estimating the PMP based on its definition. The model involves modelling daily precipitation with the Pearson Type-I distribution, where the upper bound corresponds to the PMP. As a proper statistical model, parameter and uncertainty estimations can be derived using well-known statistical methods.
Our analysis demonstrates that, while the proposed statistical approach offers potential benefits, such as translating the PMP definition into a statistical model, incorporating non-stationarity, and providing uncertainty estimates, significant drawbacks limit its practical application. The major challenge lies in the non-identifiability issue, which renders the model highly sensitive to data and leads to volatile PMP estimates. This issue persists despite attempts at reparameterization and the use of regularized maximum likelihood or informative priors, which introduce subjectivity that undermines the model's advantages.
Given the inherent challenges and limitations of the Pearson Type-I distribution for precipitation modelling, we recommend using extreme-value analysis for PMP estimation. This approach aligns with the findings of the National Academies of Sciences, Engineering, and Medicine (2024), which advocate for extreme-value analysis due to its robustness and applicability, even in the context of non-stationary conditions brought about by climate change. With our data, the 60 000-year return level estimates of daily precipitation at the two considered locations were consistent, in contrast to the PMP estimates for those two locations. Moreover, the extreme-value analysis indicated a heavy-tailed distribution, consistent with existing literature, which invalidates the concept of PMP.
Future work may involve estimating the PMP of storms instead of daily precipitation. In this paper, we estimated the daily PMP, but precipitation accumulation over several days could also be a topic of interest. However, accumulation over several days would decrease the sample size and exacerbate the non-identifiability issue. Future work may also focus on PMP estimation based on a large sample of synthetic storms provided by a storm generator.
In conclusion, while innovative statistical methods offer promising avenues for PMP estimation, traditional extreme-value analysis remains, in our opinion, the most practical and reliable approach for assessing precipitation extremes and guiding infrastructure design.
The data and code for reproducing the results are provided in the following public repository: https://github.com/JuliaExtremes/PMP.jl (last access: 12 September 2025) (Martin and Jalbert, 2025).
This “Authors' contribution” statement was created using CRediT, with the degree of contribution:
-
AM – formal analysis (lead), investigation (lead), methodology (lead), software (equal), validation (equal), visualization (equal), writing (original draft preparation) (equal), writing (review and editing) (equal);
-
ÉF – conceptualization (equal), funding acquisition (equal), investigation (supporting), methodology (supporting), supervision (supporting), writing (original draft preparation) (supporting), writing (review and editing) (supporting);
-
JJ – conceptualization (equal), funding acquisition (equal), investigation (supporting), methodology (supporting), software (equal), validation (equal), visualization (equal), supervision (lead), writing (original draft preparation) (equal), writing (review and editing) (equal).
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
We would like to thank Gabriel Gobeil (Environment and Climate Change Canada) for his valuable assistance, Julie Carreau and Jean-Luc Martel for their insights, and the researchers of the ARRIMÉ project (https://arrime.escer.uqam.ca/, last access: 12 September 2025).
This research has been supported by the Natural Sciences and Engineering Research Council of Canada (NSERC, grant no. RGPIN-2018-04481), the MITACS Acceleration program (grant no. IT38510), the Alliance program of the NSERC (grant no. 576492–2022) and Hydro-Québec.
This paper was edited by Nadav Peleg and reviewed by three anonymous referees.
Beauchamp, J., Leconte, R., Trudel, M., and Brissette, F.: Estimation of the summer-fall PMP and PMF of a northern watershed under a changed climate, Water Resour. Res., 49, https://doi.org/10.1002/wrcr.20336, 2013. a, b, c, d
Ben Alaya, M. A., Zwiers, F., and Zhang, X.: Probable maximum precipitation: Its estimation and uncertainty quantification using bivariate extreme value analysis, J. Hydrometeorol., 19, 679–694, https://doi.org/10.1175/JHM-D-17-0110.1, 2018. a, b, c, d, e
Ben Alaya, M. A., Zwiers, F. W., and Zhang, X.: A bivariate approach to estimating the probability of very extreme precipitation events, Weather and Climate Extremes, 30, 100290, https://doi.org/10.1016/j.wace.2020.100290, 2020a. a, b
Ben Alaya, M. A., Zwiers, F. W., and Zhang, X.: Probable maximum precipitation in a warming climate over North America in CanRCM4 and CRCM5, Climatic Change, 158, 611–629, https://doi.org/10.1007/s10584-019-02591-7, 2020b. a, b
CEHQ and SNC-Lavalin: Estimation de conditions hydrométéorologiques conduisant aux crues maximales probables (CMP) au Québec: Rapport final, Tech. Rep. 014713-1000-40RT-001-00, Ministère de l'Environnement et de la Lutte contre les changements climatiques, 2004. a
Chen, L.-C. and Bradley, A. A.: Adequacy of using surface humidity to estimate atmospheric moisture availability for probable maximum precipitation, Water Resour. Res., 42, W09410, https://doi.org/10.1029/2005WR004469, 2006. a
Clavet-Gaumont, J., Huard, D., Frigon, A., Koenig, K., Slota, P., Rousseau, A., Klein, I., Thiémonge, N., Houdré, F., Perdikaris, J., Turcotte, R., Lafleur, J., and Larouche, B.: Probable maximum flood in a changing climate: An overview for Canadian basins, Journal of Hydrology: Regional Studies, 13, 11–25, https://doi.org/10.1016/j.ejrh.2017.07.003, 2017. a, b, c
Coles, S.: An introduction to statistical modeling of extreme values, Springer, https://doi.org/10.1007/978-1-4471-3675-0, 2001. a, b, c
Davison, A. C. and Smith, R. L.: Models for exceedances over high thresholds, J. Roy. Stat. Soc. B, 52, 393–425, https://doi.org/10.1111/j.2517-6161.1990.tb01796.x, 1990. a
DTN and MGS Engineering: Probable maximum precipitation guidelines for British Columbia, Tech. Rep. Bulletin 2020-3-PMP, British Columbia Ministry of Forests, Lands, Natural Resources Operations, and Rural Development, 2020. a
Efron, B.: Bootstrap methods: Another look at the jackknife, Ann. Stat., 7, 1–26, https://doi.org/10.1007/978-1-4612-4380-9_41, 1979. a
Environmental Water Resources Group Ltd.: Assessment of potential impact of climate change on probable maximum precipitation applicable to nuclear facilities in Canada, Tech. Rep. R723.1, Canadian Nuclear Safety Commission (CNSC), 2020. a
Hall, P. and Wang, J. Z.: Bayesian likelihood methods for estimating the end point of a distribution, J. Roy. Stat. Soc. B, 67, 717–729, https://doi.org/10.1111/j.1467-9868.2005.00523.x, 2005. a
Hansen, E. M.: Probable maximum precipitation estimates: United States between the Continental Divide and the 103rd meridian, Tech. Rep. 55A, United States Office of Hydrology, Hydrometeorological Branch; United States Army, Corps of Engineers, Washington D.C., https://repository.library.noaa.gov/view/noaa/7154 (last access: 12 September 2025), 1988. a
Hershfield, D. M.: Estimating the probable maximum precipitation, J. Hydr. Eng. Div., https://doi.org/10.1061/JYCEAJ.0000651, 1961a. a, b, c
Hershfield, D. M.: Rainfall frequency atlas of the United States, Tech. rep., United States Weather Bureau, 1961b. a
Hershfield, D. M.: Method for estimating probable maximum rainfall, J. Am. Water Works Ass., 57, 965–972, https://doi.org/10.1002/j.1551-8833.1965.tb01486.x, 1965. a, b
Johnson, N. L., Kotz, S., and Balakrishnan, N.: Continuous univariate distributions, 2nd edn., vol. 2, John Wiley & sons, ISBN 978-0-471-58494-0, 1995. a, b, c, d
Koutsoyiannis, D.: A probabilistic view of Hershfield's method for estimating probable maximum precipitation, Water Resour. Res., 35, 1313–1322, https://doi.org/10.1029/1999WR900002, 1999. a
Kunkel, K. E., Karl, T. R., Easterling, D. R., Redmond, K., Young, J., Yin, X., and Hennon, P.: Probable maximum precipitation and climate change, Geophys. Res. Lett., 40, 1402–1408, https://doi.org/10.1002/grl.50334, 2013. a, b
Martin, A. and Jalbert, J.: JuliaExtremes/PMP.jl, v0.1.0 (v0.1.1), Zenodo [data set and code], https://doi.org/10.5281/zenodo.17078642, 2025. a
Martins, E. and Stedinger, J.: Generalized maximum likelihood GEV quantile estimators for hydrologic data, Water Resour. Res., 36, 737–744, https://doi.org/10.1029/1999WR900330, 2000. a
Miller, J. F.: Probable maximum precipitation and rainfall-frequency data for Alaska for areas to 400 square miles, durations to 24 hours and return periods from 1 to 100 years, Technical paper 47, Weather Bureau, United States Department of Commerce Washington, D.C., 1963. a
National Academies of Sciences, Engineering, and Medicine: Modernizing Probable Maximum Precipitation estimation, Washington D.C., the national academies press edition, ISBN 978-0-309-71511-9, https://doi.org/10.17226/27460, 2024. a, b, c, d
Naveau, P., Huser, R., Ribereau, P., and Hannart, A.: Modeling jointly low, moderate, and heavy rainfall intensities without a threshold selection, Water Resour. Res., 52, 2753–2769, 2016. a
Papalexiou, S. M. and Koutsoyiannis, D.: Battle of extreme value distributions: A global survey on extreme daily rainfall, Water Resour. Res., 49, 187–201, https://doi.org/10.1029/2012WR012557, 2013. a
Rouhani, H., and Leconte, R.: A novel method to estimate the maximization ratio of the Probable Maximum Precipitation (PMP) using regional climate model output, Water Resour. Res., 52, 7347–7365, https://doi.org/10.1002/2016WR018603, 2016. a
Rouhani, H. and Leconte, R.: A methodological framework to assess PMP and PMF in snow-dominated watersheds under changing climate conditions – A case study of three watersheds in Québec (Canada), J. Hydrol., 561, 796–809, https://doi.org/10.1016/j.jhydrol.2018.04.047, 2018. a, b
Rouhani, H. and Leconte, R.: Uncertainties of precipitable water calculations for PMP estimates in current and future climates, J. Hydrol. Eng., 25, 04019066, https://doi.org/10.1061/(ASCE)HE.1943-5584.0001877, 2020. a, b, c
Rousseau, A. N., Klein, I. M., Freudiger, D., Gagnon, P., Frigon, A., and Ratté-Fortin, C.: Development of a methodology to evaluate probable maximum precipitation (PMP) under changing climate conditions: Application to southern Quebec, Canada, J. Hydrol., 519, 3094–3109, https://doi.org/10.1016/j.jhydrol.2014.10.053, 2014. a, b
Sarkar, S. and Maity, R.: Increase in probable maximum precipitation in a changing climate over India, J. Hydrol., 585, 124806, https://doi.org/10.1016/j.jhydrol.2020.124806, 2020. a, b
Schreiner, L.-C. and Riedel, J. T.: Probable maximum precipitation estimates, United States east of the 105th meridian, Tech. Rep. 51, United States, Office of Hydrology, Hydrometeorological Branch; United States, Army, Corps of Engineers, Washington D.C., https://repository.library.noaa.gov/view/noaa/6499 (last access: 12 September 2025), 1978. a
United States Weather Bureau: Generalized estimates of probable maximum precipitation for the United States west of the 105th meridian for areas to 400 square miles and durations to 24 hours, Technical paper 38, Weather Bureau, United States Department of Commerce Washington, D.C., https://www.weather.gov/media/owp/oh/hdsc/docs/TP38.pdf (last access: 12 September 2025), 1960. a
Visser, J. B., Kim, S., Wasko, C., Nathan, R., and Sharma, A.: The impact of climate change on operational probable maximum precipitation estimates, Water Resour. Res., 58, e2022WR032247, https://doi.org/10.1029/2022WR032247, 2022. a, b
Viswanadham, Y.: The relationship between total precipitable water and surface dew point, J. Appl. Meteorol. Clim., 20, 3–8, https://doi.org/10.1175/1520-0450(1981)020<0003:TRBTPW>2.0.CO;2, 1981. a
Wang, J. Z.: A note on estimation in the four-parameter Beta distribution, Commun. Stat. Simulat., 34, 495–501, https://doi.org/10.1081/SAC-200068514, 2005. a
WMO: Manual on estimation of Probable Maximum Precipitation (PMP), World Meteorological Organization (WMO), Geneva, ISBN 978-926-3103045-9, 2009. a, b, c, d, e, f, g, h, i, j, k, l
- Abstract
- Introduction
- Methodology
- Simulation study
- Data
- Probable maximum precipitation estimation using the proposed Pearson Type-I model
- Discussion
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methodology
- Simulation study
- Data
- Probable maximum precipitation estimation using the proposed Pearson Type-I model
- Discussion
- Conclusions
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References