the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 18 Oct 2023
| 18 Oct 2023
Accounting for precipitation asymmetry in a multiplicative random cascade disaggregation model
Kaltrina Maloku
Benoit Hingray
Guillaume Evin
Analytical multiplicative random cascades (MRCs) are widely used for the temporal disaggregation of coarse-resolution precipitation time series. This class of models applies scaling models to represent the dependence of the cascade generator on the temporal scale and the precipitation intensity. Although determinant, the dependence on the external precipitation pattern is usually disregarded in the analytical scaling models. Our work presents a unified MRC modelling framework that allows the cascade generator to depend in a continuous way on the temporal scale, precipitation intensity and a so-called precipitation asymmetry index.
Different MRC configurations are compared for 81 locations in Switzerland with contrasted climates. The added value of the dependence of the MRC on the temporal scale appears to be unclear, unlike what was suggested in previous works. Introducing the precipitation asymmetry dependence into the model leads to a drastic improvement in model performance for all statistics related to precipitation temporal persistence (wet–dry transition probabilities, lag-n autocorrelation coefficients, lengths of dry–wet spells). Accounting for precipitation asymmetry seems to solve this important limitation of previous MRCs.
The model configuration that only accounts for the dependence on precipitation intensity and asymmetry is highly parsimonious, with only five parameters, and provides adequate performances for all locations, seasons and temporal resolutions. The spatial coherency of the parameter estimates indicates a real potential for regionalisation and for further application to any location in Switzerland.
- Article
(7454 KB) - Full-text XML
-
Supplement
(3474 KB) - BibTeX
- EndNote





Multi-decadal time series of sub-daily precipitation at hourly or even higher temporal resolutions are necessary for many applications, e.g. assessment of soil erosion (Römkens et al., 2002; Jebari et al., 2012) or of flash floods due to intense precipitation (Rafieeinasab et al., 2015; Liang et al., 2016) or hydrological simulations of small catchments, such as those in mountainous regions (Sikorska and Seibert, 2018) or urban areas (Ochoa-Rodriguez et al., 2015; Cristiano et al., 2017). However, fine-scale precipitation data are scarce and usually cover limited periods of time, rarely predating the 1980s (Segond et al., 2006; Jennings et al., 2010). In contrast, daily precipitation observations are widely spread worldwide and cover much longer periods, even going back to the middle of the 19th century in some cases. To benefit from their much richer information, high-resolution precipitation data are often derived from coarse-resolution observations (especially at daily resolution) via some appropriate disaggregation process. For a given sequence of daily precipitation amounts, for instance, some disaggregation can be used to generate hourly precipitation scenarios, distributing the precipitation amount observed each day to its different hourly subdivisions. Disaggregation has been widely used to produce high-resolution time series scenarios from observed time series of daily precipitation, e.g. Molnar and Burlando (2005), or from low-resolution synthetic ones obtained in a first step with a so-called stochastic weather generator (e.g. Koutsoyiannis and Onof, 2001; Kang and Ramírez, 2010; Paschalis et al., 2014). Disaggregation models have also been used to generate high-resolution spatial precipitation (multi-site or spatial fields, see e.g. Mezghani and Hingray, 2009; Evin et al., 2018; Viviroli et al., 2022).
Many disaggregation models have been presented in the past (see, for example, Srikanthan and McMahon, 2001, and Koutsoyiannis, 2003, and the references within). A widely used method is the non-parametric method of fragments (MOF), where the disaggregation scheme for any target day is obtained from the high-resolution temporal (and spatial, if relevant) structure of a given analogue day selected in the archive of observations (e.g. Mezghani and Hingray, 2009; Breinl and Di Baldassarre, 2019; Park and Chung, 2020; Acharya et al., 2022). By construction, MOF methods preserve the sub-daily patterns of precipitation and the intermittency properties within each day. An alternative disaggregation method is provided by multiplicative random cascades (MRCs), inspired by the statistical theory of turbulent fields (Schertzer and Lovejoy, 1987; Tessier et al., 1993). Because of the simplicity of both parameter estimation and simulation processes, MRCs have been widely used in the past for many applications in hydrology, for the point temporal disaggregation of precipitation time series (e.g. Menabde and Sivapalan, 2000; Pui et al., 2012; Pohle et al., 2018) or for the spatial–temporal disaggregation of precipitation fields (e.g. Seed et al., 1999; Rupp et al., 2012; Schleiss, 2020).
MRC models are usually implemented with a so-called branching number equal to 2. In such a case, the amount of precipitation at any time step is partitioned into two parts, attributed respectively to the first and second subdivision of this time step. The partition is repeated throughout the cascade levels until the final temporal resolution is achieved (Olsson, 1998; Molnar and Burlando, 2005; Rupp et al., 2009). In the so-called micro-canonical MRC models, the partition of precipitation is conservative. The precipitation amounts R1 and R2 attributed respectively to the first and second subdivisions of the considered time step (with precipitation amount R0) are expressed as and , where . For a given time step, the disaggregation can be determined by the so-called breakdown coefficient (BDC) assigned to the first subdivision: W:=W1, which can take the values 0 with probability p01 (no precipitation is attributed to the first subdivision), 1 with probability p10 (R0 is fully attributed to the first subdivision) or any value between 0 and 1. When , follows a statistical distribution with a probability density function .
The probabilities p01 and p10 and the distribution define Γ, the statistical distribution of W, called the cascade generator. For a given location, they have been found to depend on different factors. They first depend on the temporal scale and on the precipitation intensity of the precipitation amount R0 to disaggregate (e.g. Molnar and Burlando, 2005; Rupp et al., 2009). For instance, p01 and p10 tend to significantly decrease with precipitation intensity and to be larger for higher time resolutions; they also often exhibit some seasonality (Molnar and Burlando, 2008). The cascade generator Γ also depends on the so-called external pattern of precipitation, i.e. on the temporal sequence of precipitation amounts Rt−1, Rt and Rt+1 around the precipitation amount Rt, to disaggregate (Ormsbee, 1989; Olsson, 1998; Güntner et al., 2001). For instance, p01 tends to be higher and p10 smaller in the case of a so-called ascending precipitation pattern (when ), and, conversely, p01 tends to be smaller and p10 higher with descending patterns ().
Different models have been proposed for the cascade generator Γ, i.e. for the estimation of p01, p10 and as a function of selected factors of variability. They are either empirical or analytical. Empirical models are usually obtained from the empirical cumulative distribution function (ECDF) of W estimated from time series of high-resolution observed data for a discrete number of dependency configurations. Parameter estimation is usually performed on a seasonal basis by considering the dependency on the temporal scales of interests and/or the dependency on the external pattern of precipitation (Olsson, 1998; Ormsbee, 1989; Güntner et al., 2001). The main drawback of empirical MRCs is the considerable number of parameters to be estimated, the large number of classes to be considered and, as a consequence, the lack of robustness in terms of parameter estimates. In practice, some dependencies of the ECDFs are thus often ignored.
Besides empirical MRC models, analytical models aim to represent in a synthetic way the dependency of p01 and p10 and of the distribution on important factors of variability. Most analytical models have focused on the dependency on the temporal scale and precipitation intensity. For instance, the symmetric beta distribution has been extensively used to model the distribution (Menabde and Sivapalan, 2000). The single parameter α of the symmetric beta distribution shows strong relationships with the temporal scale and the precipitation intensity and can be modelled with simple scaling analytical laws (Molnar and Burlando, 2005; Paulson and Baxter, 2007; Rupp et al., 2009). Analytical models typically use symmetric distribution models. Nevertheless, a few exceptions are worth mentioning. McIntyre et al. (2016) use a two-parameter asymmetric beta distribution and consider four external pattern classes for the estimation of its parameters (the so-called ending, starting, enclosed and isolated classes). Hingray and Ben Haha (2005) use an asymmetric piecewise linear distribution function, where the asymmetry of the distribution is estimated from a local precipitation asymmetry index defined from the deterministic model of Ormsbee (1989). In both cases, it was found that accounting for the asymmetry in the BDC distribution improved the reproduction of statistics related to precipitation persistence and intermittency, which are known to be difficult to reproduce with MRC models (e.g. Rupp et al., 2009; Paschalis et al., 2012, 2014; Müller and Haberlandt, 2018; Pohle et al., 2018). However, these MRC approaches did not include scaling models to account for the dependency of the parameters on the temporal scale and precipitation intensity, resulting in a rather large number of parameters to be estimated.
In this work, we present an analytical MRC modelling framework that allows the cascade generator Γ to depend in a continuous way on temporal scales, intensities and external patterns of precipitation. The possibility of merging into a single and unified analytical scaling framework all the principal Γ dependencies allows a minimal number of parameters while combining (1) scaling relationships with temporal scales and intensities and (2) scaling dependency on the external pattern. This approach aims to improve the model's relevance and performance. The following questions are considered:
-
To what extent can a continuous index of local precipitation asymmetry describe the way the cascade generator Γ depends on the external pattern of precipitation?
-
Is it possible to identify some scaling behaviour with respect to this asymmetry index? And is it possible to propose an analytical relationship to model this scaling behaviour?
-
What is the added value of including such an asymmetry dependency in the cascade generator Γ, especially with regard to statistics related to precipitation persistence and intermittency?
One important application of disaggregation models is for locations where only coarse-resolution data are available. In this case, the parameters of the model cannot be estimated from local data as such data are missing and are obtained with some regionalisation process based on data available from neighbouring locations and/or locations with similar precipitation regimes (e.g. Hingray et al., 2014). For such a work, analytical scaling MRCs are promising. They are very parsimonious, which is expected to ease model regionalisation and increase model robustness.
However, introducing precipitation asymmetry dependence is at the expense of model parsimony. In this work, we thus consider different MRC models of different complexities to find, if relevant, a compromise between model performance and parsimony. If the cascade generator is known to depict different types of scaling dependencies, not all are necessarily required to achieve fair model performance. Accounting for temporal scale dependence is widely considered to be beneficial. However, to our knowledge, the corresponding gain in performance is questionable (no improvement in Rupp et al. (2009) and loss of performance in Molnar and Burlando (2005)). Introducing dependence on intensity was conversely often found to significantly improve it (e.g. Rupp et al., 2009; Paschalis et al., 2014).
An additional objective of the present work is to investigate the loss of performance obtained when the cascade generator Γ disregards the dependency on temporal scales. In particular, a model configuration that only accounts for the dependence on precipitation intensity and asymmetry is assessed.
The paper is structured as follows. In Sect. 2, we introduce a precipitation asymmetry index used to model the dependency on asymmetry. Four different analytical MRC models are also presented in this section. They account for dependency on the temporal scale, precipitation intensity and/or precipitation asymmetry. The different models are used for the disaggregation of daily precipitation time series available for a large set of stations in Switzerland. Station locations and precipitation data are presented in Sect. 3. The models are evaluated on their ability to reproduce a number of characteristic statistics of precipitation at multiple temporal scales. The main performance evaluation results are presented in Sect. 4, while the interests of different model components are discussed in Sect. 5. Section 6 concludes the paper.
As mentioned previously, the cascade generator Γ used for the disaggregation of any precipitation amount R0 is defined by the probabilities p01 and p10 and the distribution of W+ denoted by . In the following, is modelled with a two-parameter beta distribution following e.g. McIntyre et al. (2016):
where the beta function B(α1, α2) is a normalisation constant. The two parameters α1 and α2 are related to the mean and the variance of the distribution as follows:
and
Note that when , the distribution is symmetric:
and
The MRCs compared in this study consider different ways of modelling their dependencies on the temporal scale, precipitation intensity and precipitation asymmetry. Four models are compared:
-
Model A accounts for the dependency on the temporal scale and precipitation intensity.
-
Model B is a simplification of model A. It disregards the dependency on the temporal scale.
-
Models A+ and B+ are refinements of models A and B, where the dependency on asymmetry is accounted for.
In the following, we describe the way the different models represent the scaling relationships for p01, p10, α1 and α2. We first present the MRC modelling framework of model A and the simplifications chosen for model B. Next, we introduce a precipitation asymmetry index further considered to account for the dependency of the cascade generator Γ on asymmetry. Finally, we describe how models A+ and B+ introduce this dependency.
To account for the seasonality of precipitation characteristics in the region, models are estimated and evaluated on a seasonal basis. Seasons are defined as follows: winter (December, January, February – DJF), spring (March, April, May – MAM), summer (June, July, August – JJA) and autumn (September, October, November – SON).
2.1 MRC models without asymmetry: models A and B
In models A and B, the dependency on precipitation asymmetry is disregarded, and the distribution of the cascade generator is assumed to be symmetric. The probabilities p01 and p10 are thus assumed equal to each other, and the distribution of the strictly positive BDCs, , is modelled with a symmetric beta distribution, i.e. .
The probabilities p01 and p10 are estimated from , where px is the non-zero subdivision probability, i.e. the probability that the precipitation amount is split into two non-zero amounts. As illustrated with data from the Zurich station in Fig. 1a, px generally increases with the intensity of the precipitation amount to disaggregate and is expected to increase for coarser temporal scales. In model A, following Rupp et al. (2009), the scaling dependency of px on the temporal scale τ and precipitation intensity I is modelled as follows:
where “erf” is the error function defined as and where μ and σ are assumed to be linearly dependent on the logarithm of the temporal scale:
In model B, the dependency on the temporal scale is disregarded. In this case, μ and σ are assumed to be constant, and Eq. (6) is simplified to the following:
The distribution in models A and B is a symmetric beta distribution. Its shape is defined by the value of its unique parameter α, which is related to the variance of W+ via Eq. (5). For α=1, the probability density function (pdf) is constant between 0 and 1; i.e. it corresponds to a uniform distribution. For α>1, the larger the value of α, the smaller the variance of W+, and the more the pdf is concentrated around its mean, 0.5. A roughly equal partition towards both sub-time steps becomes more likely in this case and leads to a stronger persistence of precipitation. For α<1, the smaller the value of α, the larger the variance of W+, and the more the pdf is concentrated close to 0 and 1, which leads to more variable and/or intermittent precipitation. In autumn, for the Zurich station, Fig. 1 shows that α increases (Var[W+] decreases) when precipitation intensity increases (Fig. 1b) and that α decreases (Var[W+] increases) when the temporal scale gets coarser (Fig. 1b and c).
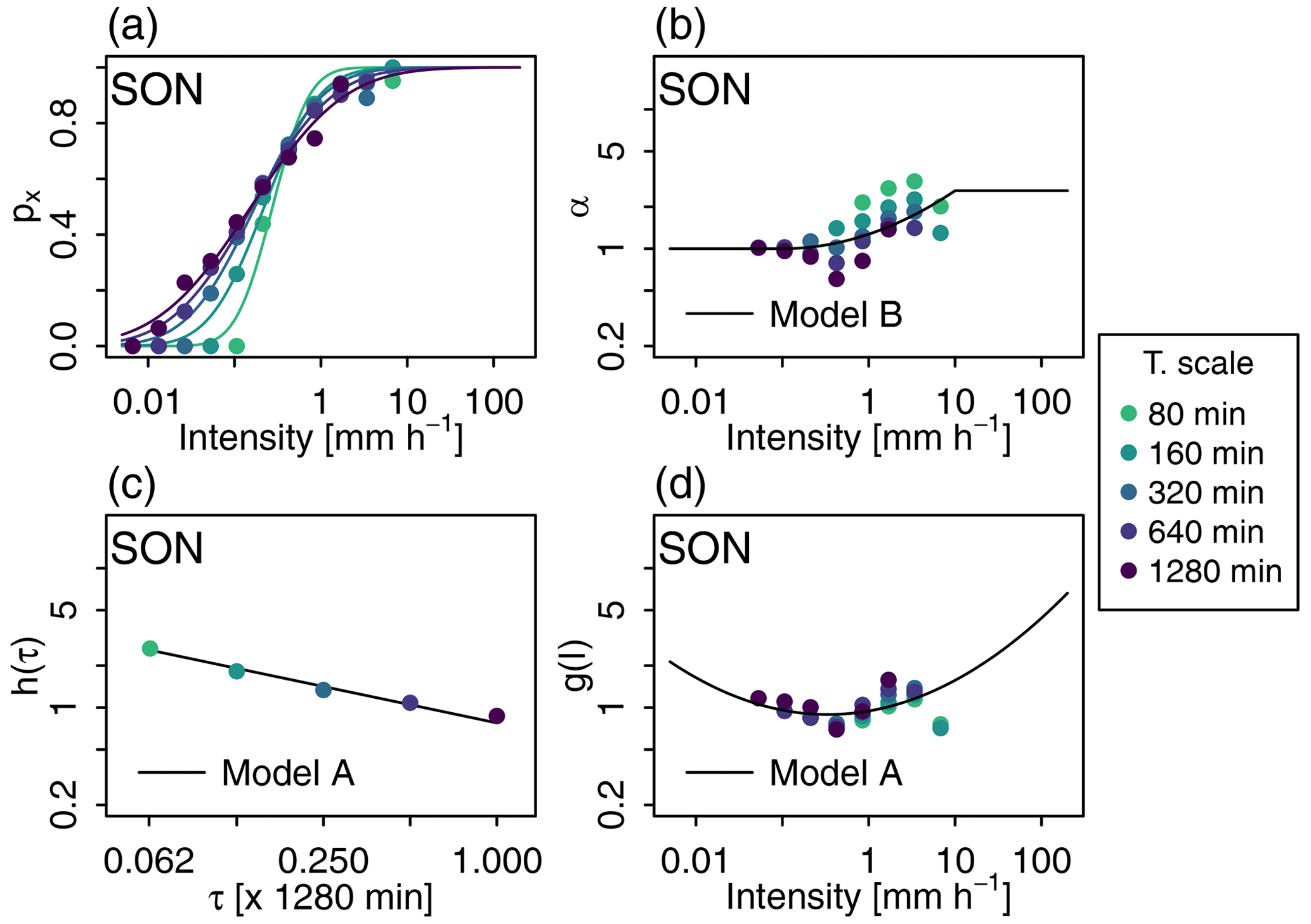
Figure 1(a, b) Two characteristics of the cascade generator Γ as a function of precipitation intensity I and temporal scale τ. (a) Non-zero subdivision probability px and (b) parameter α of the beta distribution for . In panel (a), the different lines correspond to the different px(I) models obtained for different scales according to the scaling model of model A (Eq. 6). In panel (b), the line corresponds to the scaling model for α in model B (Eq. 13). In both graphs, dots correspond to empirical estimates used for model fitting. They are obtained for different classes of intensity and different temporal scales. The colour indicates the temporal scale. (c, d) The two scaling sub-models for α in model A. (c) Model h(τ) (Eq. 11) and (d) model g(I) (Eq. 12). In panel (c), dots correspond to empirical estimates of α for the different temporal scales (all intensities included). In panel (d), dots correspond to empirical estimates of the ratio for different classes of intensity and different temporal scales. Data obtained from the Zurich station during the autumn season.
In model A, α is modelled as a function of precipitation intensity and temporal scale. Following Rupp et al. (2009), the model is the product of two functions of both variables, illustrated for Zurich data in Fig. 1c and d respectively:
where
and
In model B, the dependency of α on the temporal scale is disregarded. The dependency on intensity is modelled with the following function:
where I0=0.1 mm h−1 and I1=10 mm h−1, as illustrated for Zurich data in Fig. 1b. The distribution is thus uniform for very low intensities. For large intensities, α is bounded to the value obtained for I1. The higher the value for K, the higher the curvature of the scaling function log (α(I)). Positive K values lead to higher α values for larger intensities (and vice versa). Models A and B have, respectively, nine (aμ, bμ, aσ, bσ for px and α0, H, c0, c1, c2 for ) and three (μ, σ for px and K for ) invariant parameters to be estimated.
2.2 An asymmetry index of precipitation sequences
In models A+ and B+, the cascade generator can be asymmetric: the probabilities p01 and p10 are not necessarily equal, and the two-parameter Beta distribution used to model can be asymmetric. As we will explain in the following, the asymmetry of the cascade generator is assumed to depend in a continuous way on the asymmetry of the precipitation sequence {Rt−1, Rt, Rt+1}. In other words, we assume that the larger the asymmetry of the sequence is, the larger the asymmetry of the cascade generator is expected to be.
To characterise the asymmetry of {Rt−1, Rt, Rt+1}, we introduce an asymmetry index Zt, as in Hingray and Ben Haha (2005). Zt is defined as the hidden breakdown coefficient of the {Rt−1, Rt, Rt+1} sequence. It is estimated from the two hidden precipitation amounts and that would be respectively obtained for the first and second halves of the {Rt−1, Rt, Rt+1} sequence if Rt was split in half. Zt thus reads as follows:
While W is defined from the central precipitation and its subdivision amounts, Zt is fully determined from the central and its adjacent precipitation amounts. Details about the use of this index in the cascade generator are given in the following sections. Zt depends on the relative precipitation ratios and and varies from 0 to 1, as illustrated in Fig. 2.
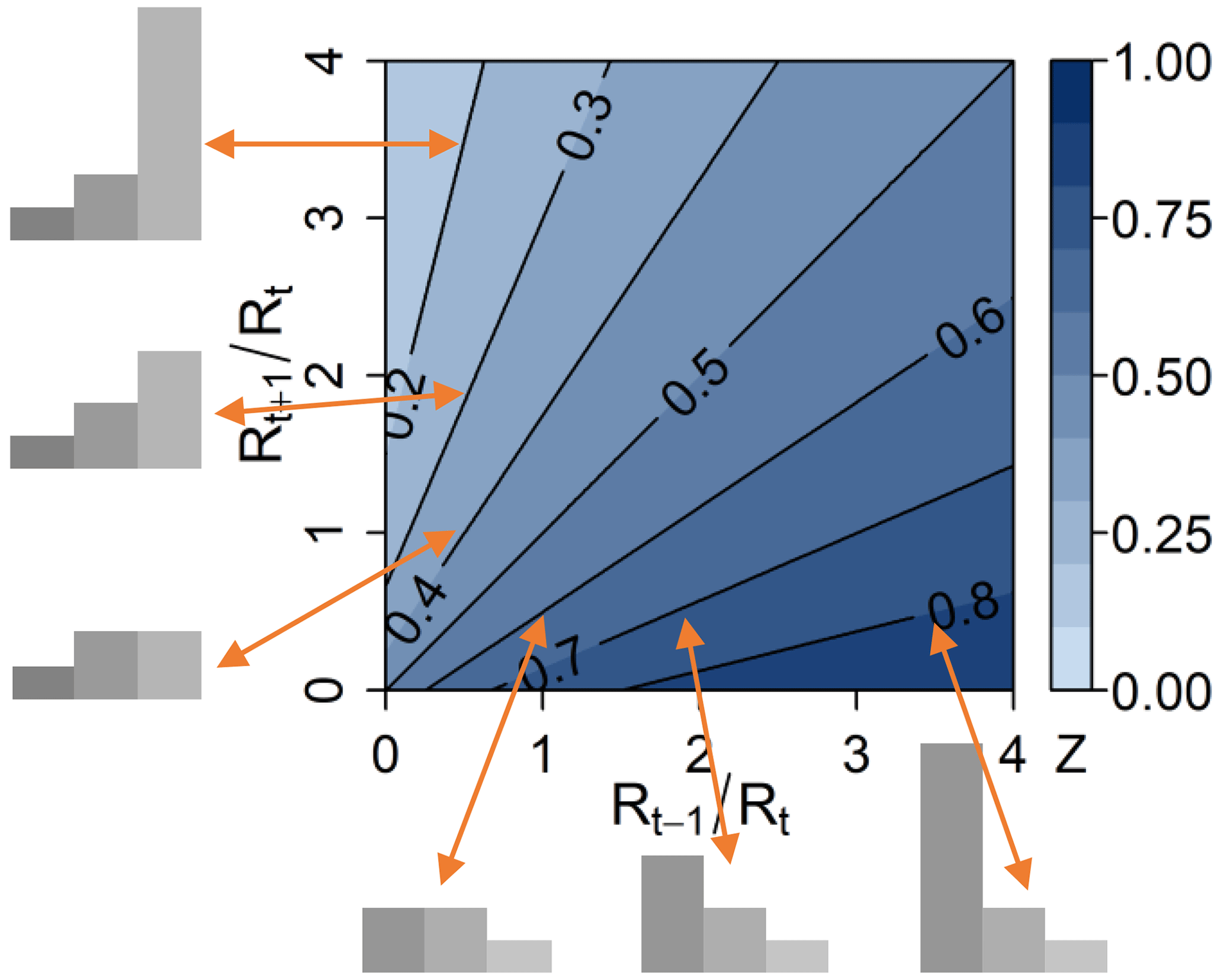
Figure 2Asymmetry index Zt of the {Rt−1, Rt, Rt+1} precipitation sequence as a function of the two precipitation ratios (x axis) and (y axis).
The following points can be noticed:
-
A symmetric precipitation sequence, i.e. when , leads to Zt=0.5 whatever the amount of precipitation in the central time step.
-
For sequences with central precipitation amounts much larger than the adjacent ones, Zt is close to 0.5.
-
Zt<0.5 indicates an increasing or right-valley sequence, i.e. a sequence where , while Zt>0.5 indicates a decreasing or left-valley sequence ().
-
The Zt asymmetry index characterises in a continuous way the intensity of the asymmetry; different decreasing precipitation sequences will have different Zt values depending on the steepness of the decrease. The larger the deviation from 0.5, the larger the asymmetry.
-
Zt values close to 0 indicate sequences with very little precipitation in the first two time steps when compared to the last one (very steep ascending sequences), whereas Zt values close to 1 indicate sequences with very little precipitation in the two last time steps when compared to the first one (very steep descending sequences).
2.3 ECDF dependency on precipitation asymmetry and scaling models
Figure 3a shows the ECDFs of observed weights W obtained for the Zurich station for 10 classes of precipitation asymmetry index, defined as , for l=1, …, 10. As expected, the ECDF depends a lot on the asymmetry class. The lower the value of Zt (i.e. corresponding to very steep ascending external patterns), the higher the value of p01 and the lower the value of p10 – in other words, the higher the probability that the whole of the Rt precipitation amount is attributed to the second subdivision and the lower the probability that the whole of Rt is attributed to the first subdivision. The exact opposite happens for high values of Zt (i.e. values corresponding to very steep descending external patterns).
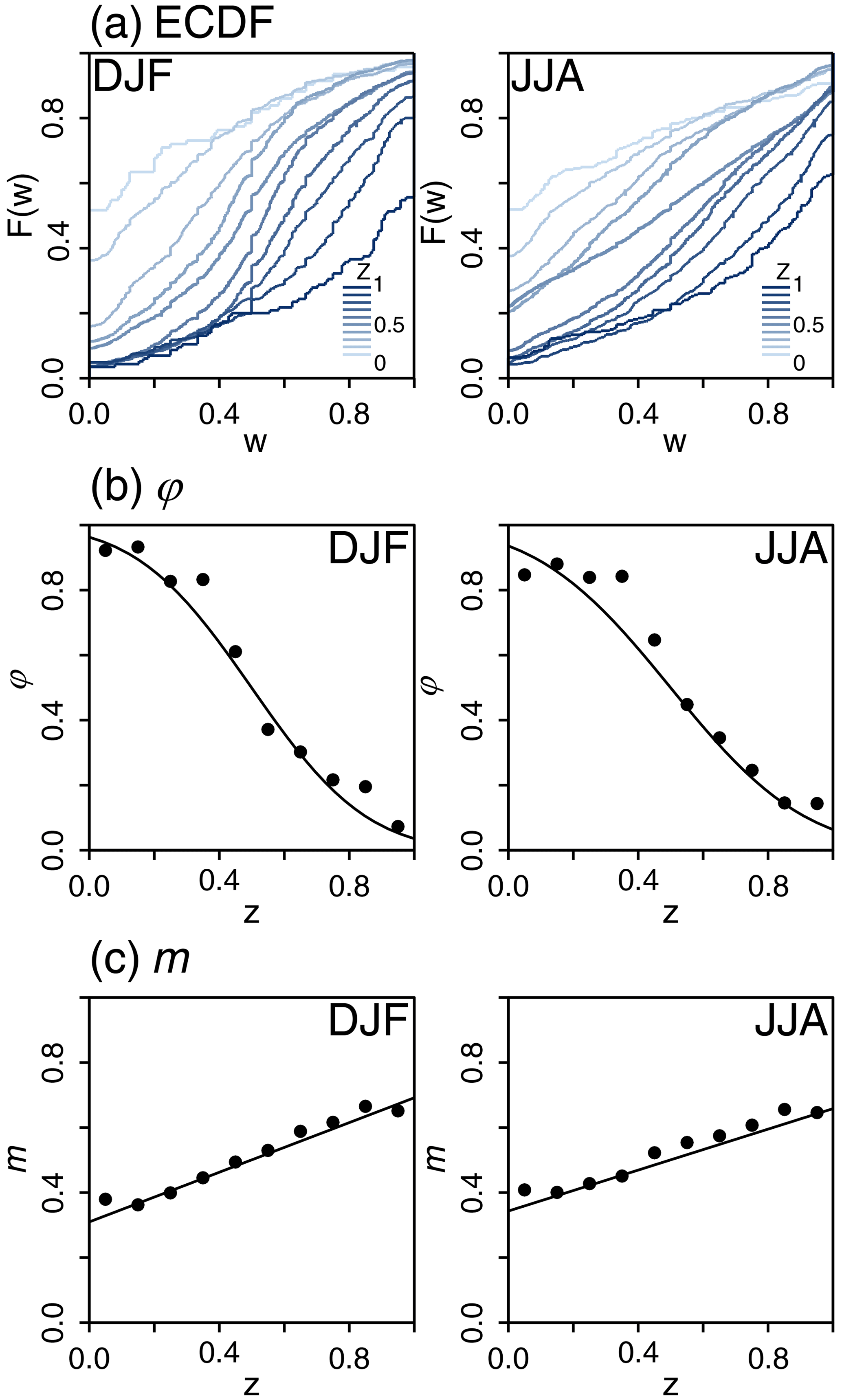
Figure 3Statistical characteristics of the breakdown coefficients W as a function of the asymmetry index Z for the Zurich station in winter (DJF, left column panels) and summer (JJA, right column panels). (a) ECDFs of W for 10 classes of Z. (b) Dry probability asymmetry ratio φ as a function of Z. The estimates φ obtained for different classes of Z are indicated with black dots, and the fitted model φ(Z) is indicated with a plain black line. (c) Estimated mean of W+ as a function of Z. Empirical means are indicated with black dots, and the fitted model m(Z) is indicated with a plain black line.
The asymmetry of the precipitation sequence directly translates to an asymmetry of the ECDF of W, namely to an asymmetry between p01 and p10 and to an asymmetry in the distribution . As shown in the following, the asymmetry of ECDF significantly depends on the value of the asymmetry index Z. For clarity, the temporal index t is omitted hereafter.
To quantify the asymmetry between p01 and p10, we introduce the probability asymmetry ratio, φ, defined as follows:
For φ values close to 0.5, the asymmetry between p10 and p01 is small. The case φ=0.5 corresponds to the symmetric case, i.e. p10=p01. The most asymmetrical configurations are obtained when φ=0 or φ=1. The case φ=0 (respectively, φ=1) corresponds to p01=0 and (respectively, and p10=0). The relationship between φ and Z is illustrated in Fig. 3b. As expected, when Z increases, φ decreases. The φ(Z) relationship is found to be roughly similar for all Swiss stations (results not shown) and can be modelled with an error function as follows:
where the single parameter ν is related to the strength of the φ(Z) relationship around the pivot point (Z=0.5, φ=0.5). The strength is found to depend on the station and on the season. It is, for instance, slightly higher in winter than in summer for Zurich station.
For asymmetric precipitation sequences, the distribution is also expected to be asymmetric. In particular, the mean of the distribution is expected to differ from 0.5. This is illustrated in Fig. 3c for Zurich observation data, where the mean of W+, denoted by m, is estimated for different classes of Z. As expected, the lower the value of Z, the lower the value of the mean. In terms of precipitation dynamics, this reflects the fact that, in an ascending precipitation sequence, the amount of precipitation tends to be smaller in the first time subdivision than in the second one. The reverse is true in the case of a descending sequence. The m(Z) relationship highlighted in Fig. 3c is found to be roughly linear for all Swiss stations (results not shown) and can be modelled as follows:
The model is centred on the pivot point (Z=0.5, m=0.5). Its unique parameter λ corresponds to the slope of this linear function and indicates the strength of the dependency on precipitation asymmetry Z. The strength is also found to depend on the season and station.
In models A+ and B+ described in the following section, the dependency of the cascade generator Γ on precipitation asymmetry is accounted for with the help of the scaling models φ(Z) and m(Z). Both scaling models have one single invariant parameter to estimate.
Table 1The four models compared and the parameters to be estimated for the scaling sub-models accounted for. The – symbol denotes a configuration where the scaling dependency is disregarded. The total number of parameters per season and station is given in the column “No. of params”.

2.4 MRC models with asymmetry: models A+ and B+
The introduction of asymmetry in model A, leading to model A+, is described hereafter. In model A+, the non-zero subdivision probability px is obtained for I and τ as in model A with the scaling model px(I,τ) presented in Sect. 2.1 (see Eq. 6). Contrarily to model A, probabilities p01 and p10 can be different and are obtained from Eq. (15) of the probability asymmetry ratio φ(Z) as follows:
In model A+, the Beta distribution can be asymmetric and its two parameters can be related to E[W+] and Var[W+] from Eqs. (4) and (5) as follows:
In model A+, we obtain E[W+] from the scaling model m(Z) of Eq. (17), and Var[W+] is assumed to be the same as in model A, i.e. in a configuration where the distribution is assumed symmetric. In practice, Var[W+] is thus simply derived from the value of α obtained with the scaling model α(I,τ) of model A as follows: . The parameters α1 and α2 are then derived from these representations of E[W+] and Var[W+].
Model B+ is derived from model B in the same way. The probabilities p01 and p10 are obtained from Eqs. (18) and (19) with the scaling model px(I) of Eq. (9). α1 and α2 are obtained from Eqs. (20) and (21), where E[W+] and Var[W+] are obtained respectively from the model m(Z) and from .
2.5 Estimation of scaling models
Table 1 summarises the dependencies of each MRC model on either temporal scale, intensity and/or asymmetry and indicates the parameters to be estimated for the corresponding scaling models.
Whatever the MRC model, the estimation of the different parameters required for the scaling model for px is independent of those related to α. The estimation of the scaling sub-model for the probability asymmetry index φ and for the mean m of the distribution is also independent of the estimation of the scaling models for the dependency on the intensity and/or temporal scale. In all cases, the estimation is also sequential: in a first step, the empirical value of the variable of interest (e.g. px, α, φ or m) is calculated for different classes of disaggregation configuration (e.g. different temporal scales, different classes of intensity or different classes of asymmetry index), and in a second step, the relevant scaling model is fitted to those empirical values by the method of least square errors.
This is illustrated in Fig. 3b and c for the asymmetry scaling model φ(Z) and m(Z). The models of Eqs. (16) and (17) are fitted (the plain black lines) to the empirical values of φ and m obtained for different asymmetry index classes (black dots). Empirical values of φ and m are calculated for each Z-index class by ignoring the intensity class and temporal scale. Estimation is also done on a seasonal basis. The estimation process for the parameters of the other scaling models is similar. It is described in detail for all models in Appendix A. An example of the model fit is given in Fig. 1a, c and d (plain lines) for the scaling models px(I,τ), g(I) and h(τ) used in model A. For the scaling model α(I) used in model B, an example is given in Fig. 1b.
Precipitation data aggregated at six temporal resolutions are considered for model estimation (40, 80, 160, 320, 640 and 1280 min). The 40 min precipitation data are obtained from the 10 min time series available for the stations. The 40 min time series are aggregated to 80 min time series to calculate the observed breakdown coefficients W using non-overlapping adjacent pairs of precipitation amounts for this cascade level. The aggregation procedure is repeated until the time series reaches the temporal resolution of 1280 min. These different series are used for the estimation of the BDCs relative to each temporal scale and are also used as a reference for the evaluation of the disaggregation models (see Sect. 2.6).
Note that the 1280 min aggregated temporal scale does not correspond to the daily resolution of 1440 min. Following Molnar and Burlando (2005), the first and last 80 min records of each day were thus discarded from the initial observed times series before aggregations. The resulting time series, with truncated days of 21.3 h, was used as a reference daily time series for model estimation and evaluation.
As reported in previous works, the precipitation measurement resolution, defined by the precipitation tipping bucket of automatic stations (0.1 mm here), is very likely to introduce artefacts and/or biases in different statistical characteristics of precipitation at fine temporal scales, especially sub-hourly ones, and can impact the empirical distributions of the breakdown coefficients W (e.g. Olsson, 1998; Rupp et al., 2009; Licznar et al., 2011; Paschalis et al., 2012).
Following previous works, the breakdown coefficients W obtained from precipitation amounts below a given precipitation threshold were discarded for the present study. A threshold of 0.8 mm is applied for the estimation of α in all models and for the estimation of px in models B and B+ (see Sect. 5.1 for further discussion on this issue).
2.6 Experimental setup
The 10 min observational records aggregated to the resolution of 1280 min are disaggregated back to the 40 min resolution using models A, B, A+ and B+. Since models are stochastic, the disaggregation is performed 30 times for each model.
The performance of a given model is evaluated by its ability to reproduce standard statistical metrics of precipitation, such as the standard deviation of precipitation amounts, the probability of precipitation occurrence and return levels of maximum precipitation amounts for given return periods. In addition, the temporal autocorrelation, wet–dry transition probabilities, and the duration of wet and dry spells are used to assess the ability of the models to reproduce the temporal persistence of precipitation. Evaluations are carried out on a seasonal basis for all available stations and for all temporal scales involved in the generation process (i.e. 40 to 640 min).
Different evaluation criteria are used. For most evaluation metrics, the variability between generated scenarios is small to very small. In this case, the evaluation criterion is the absolute error between the simulated and the observed metric, averaged over the different scenarios (and possibly temporal scales and seasons). To assess the performance of a given model across multiple sites, single-site performances are averaged over the different stations. We refer to this performance criterion as the mean absolute error (MAE). For some metrics, the percentage absolute relative error is considered (dividing for each station, season and temporal scale the absolute error by the observed value of the metric), giving the mean absolute percentage error (MAPE, Hyndman and Koehler, 2006).
For precipitation maxima, the variability between scenarios is often large. In this case, we apply the CASE evaluation framework proposed by Bennett et al. (2018) for which at-site model performances are categorised as “good”, “fair” and “bad”. For a single metric at a given site, 90 % and 99.7 % probability limits are obtained from the set of simulated metrics and are compared with the observed metric. Then, the performance is categorised as
-
“good” if the observed metric is inside the 90 % limits of simulated metrics,
-
“fair” if the observed metric is outside the 90 % limits of simulated metrics but within the 99.7 % limits of simulated metrics or absolute relative difference between the observed metric and the average simulated metrics is 5 % or less, and
-
“bad” otherwise.
To assess the performance of a given model across multiple sites, single-site performances are summarised as percentages of good, fair and bad cases among sites and seasons. The variables evaluated here are the return levels estimated for 5- and 20-year return periods. The 5- and 20-year return levels, respectively, are estimated empirically in a Gumbel plot from a linear interpolation between the two observed (or simulated) annual maxima which have the empirical return periods that are the closest to 5 and 20 years, respectively. The empirical return period of each observed (or simulated) annual maximum is simply obtained from its empirical non-exceedance probability estimated with the Gringorten plotting position formula (Gringorten, 1963).
The four models are applied to 81 stations of the Swiss meteorological observation network, a relatively dense network, with high-quality observational data (Fig. 4). The stations have at least 20 years of data available through the period 1980–2020 and use tipping-bucket rain gauges with a sampling resolution of 10 min and a tip volume of 0.1 mm. Switzerland has a complex topography, with 60 % of the territory covered by the Alps. Together with the Swiss Plateau and Jura mountains to the north, they are the main features of the landscape. The complex topography induces very different weather and precipitation regimes, as described in the precipitation climatology for the European Alps of Frei and Schär (1998). For instance, the main topographic slopes at the rim are responsible for enhanced precipitation and associated rain-shadowing of inner-Alpine sectors. The Swiss Plateau tends to be sheltered by the Jura mountains, resulting in less precipitation from northwestern fronts during winter than for the Jura mountains (Baeriswyl and Rebetez, 1997).
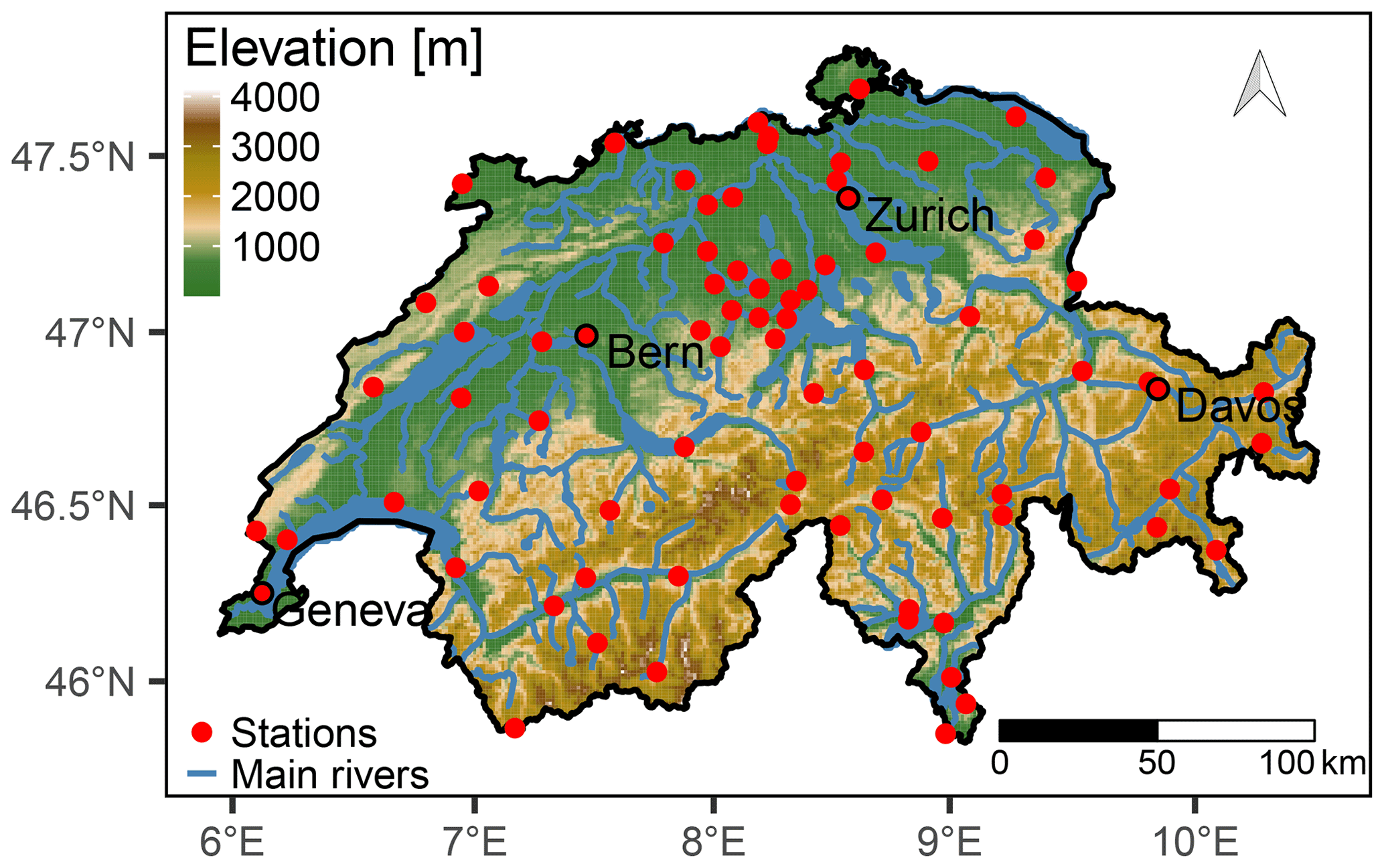
Figure 4Map of Switzerland and gauge locations.
If large precipitation amounts can be observed during winter and spring due to long stratiform and orographic precipitation events, intense precipitation events are often observed in summer and fall due to the topographically triggered convective events (Frei and Schär, 1998). Mediterranean cyclonic activity in autumn brings heavy precipitation in the region of Ticino, in the south of Switzerland, making autumn the main precipitation season in this region (Molnar and Burlando, 2008).
We first focus on results obtained for the target 40 min temporal resolution, namely for a set of standard statistics (Sect. 4.1) and for 5- and 20-year return levels of annual maxima (Sect. 4.2). Next, in Sect. 4.3, we present how results vary for intermediate disaggregation temporal resolutions and for the different seasons.
4.1 Standard statistics
Simulated values obtained for a set of standard statistics at a resolution of 40 min are compared to observed ones in Fig. 5. For the standard deviation and proportion of wet 40 min time steps, results are satisfying whatever the model. Slightly better results (i.e. smaller MAE values) are obtained with models B and B+ for standard deviation (Fig. 5a) and with models A and A+ for the proportion of wet steps (Fig. 5b).
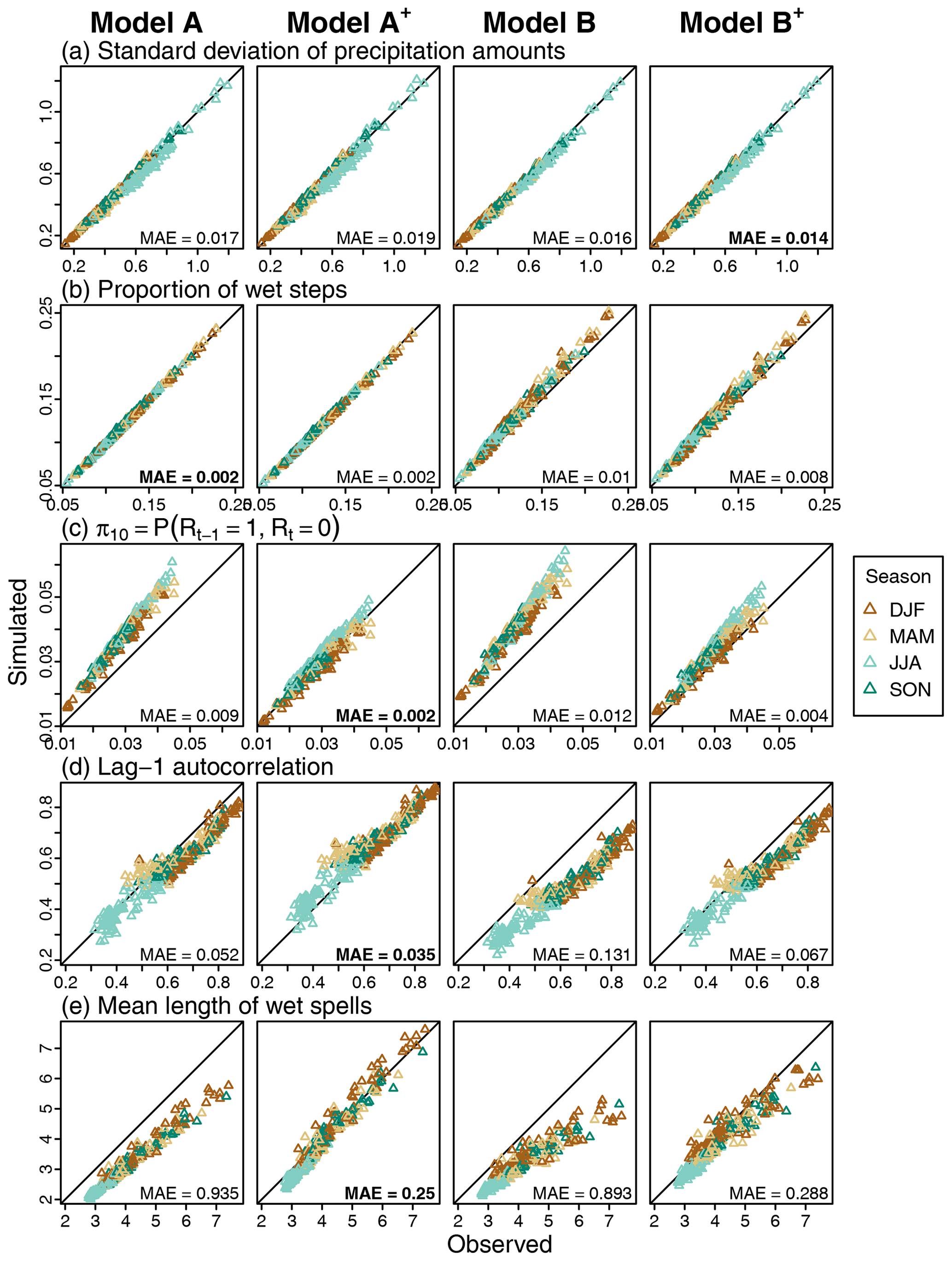
Figure 5Observed versus simulated statistics for each considered model at a 40 min temporal resolution for different metrics. Each triangle represents a site and a season. The triangles for the simulated metrics correspond to the median of the 30 statistics obtained from the corresponding 30 simulated scenarios. MAE values over all sites and seasons are indicated in the bottom-right corner, and the lowest MAE obtained over the four models is indicated in bold. Pearson's autocorrelation coefficients are estimated using the function acf implemented in R (R Core Team, 2022).
Differences between models are more important for statistics related to precipitation persistence and intermittency. The best-performing model depends on the statistic, but, whatever the statistic, the performance of the model is always drastically improved when precipitation asymmetry is accounted for (see model A+ vs. model A and model B+ vs. model B). At a 40 min resolution, this is illustrated with results obtained for the wet–dry transition probability, lag-1 autocorrelation and mean duration of wet spells in Fig. 5c–e respectively. For all stations and all seasons, the large over- or underestimation obtained with models A and B is largely reduced and even tends to disappear when asymmetry is accounted for (models A+ and B+). In the same manner, much better results are obtained for all other similar statistics and all other temporal scales, as indicated by the results obtained for lag-2 autocorrelation, mean duration of dry spells and all the other wet–dry transition probabilities (dry–dry, dry–wet, wet–wet) provided in the Supplement (see Figs. S3–S5 in the Supplement).
Some differences are also noticed depending on whether or not the dependency on the temporal scale is taken into account (i.e. model B vs. model A and model B+ vs. model A+). While these differences are sometimes non-negligible, they are much smaller than the obtained differences depending on whether or not the dependency on the asymmetry is included. For example, at the 40 min resolution, the observed autocorrelation coefficients are better reproduced with a dependency on the temporal scale (Fig. 5d for lag-1 and Fig. S3 for lag-2). For durations of wet and dry spells and the different wet–dry transition probabilities, the consideration of dependency on the temporal scale has a limited influence (Fig. 5c and f for the duration of wet spell and wet–dry transition probability and Figs. S4 and S5 for other statistics).
4.2 The 5- and 20-year return levels
The ability of the models to simulate relevant return levels for the 5- and 20-year return periods at the 40 min temporal resolution is presented in Fig. 6. The percentages of station–season configurations corresponding to the good, fair and poor CASE criteria are summarised with the horizontal green, yellow or red bar, respectively, in each graph.
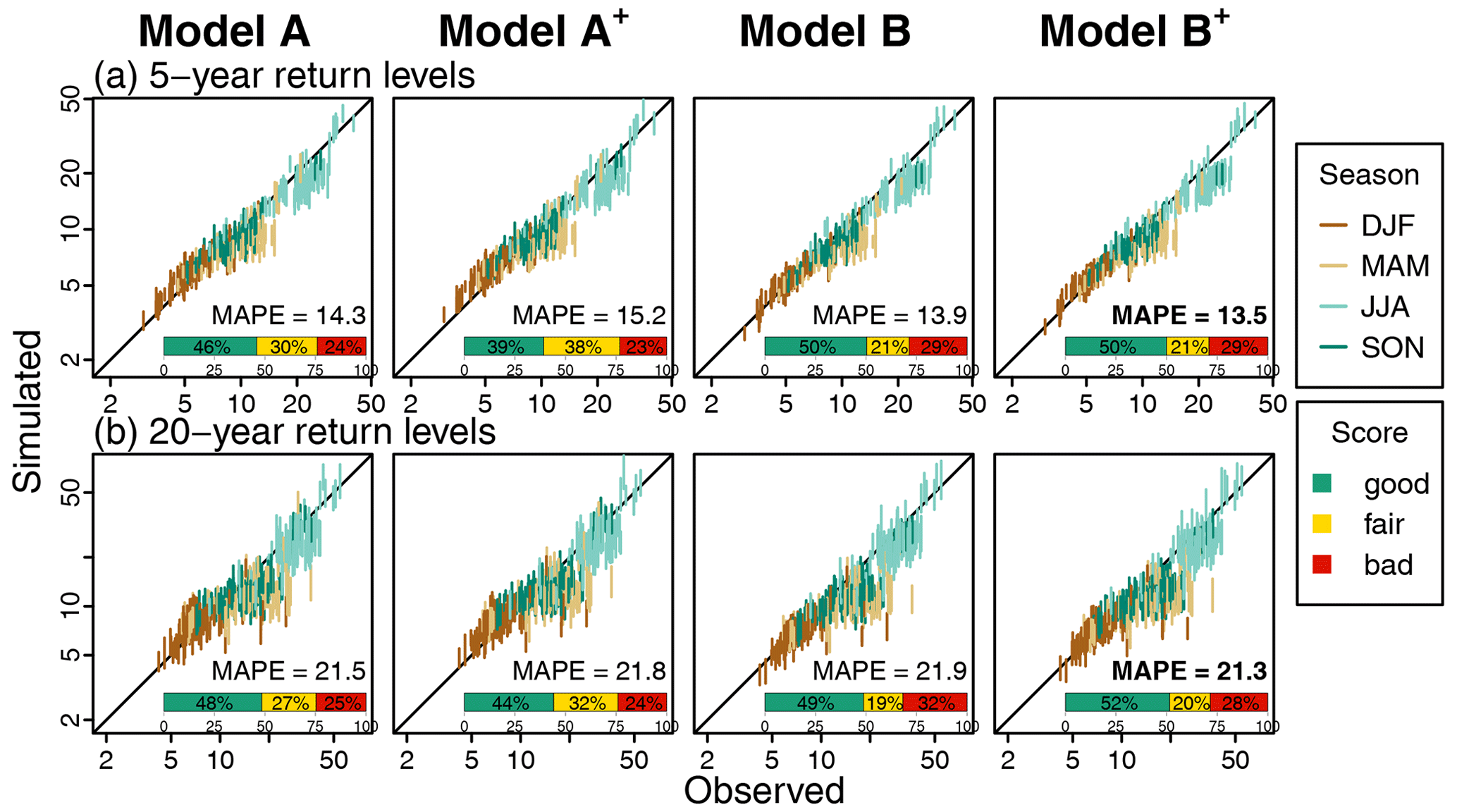
Figure 6Observed versus simulated return levels at the 40 min temporal resolution for (a) 5-year and (b) 20-year return periods for each model and at each site. Vertical bands indicate the 90 % CI limits obtained from the 30 simulated time series for each station and each season (one colour by season). Horizontal coloured bars indicate the percentage of good, fair and poor performance as assessed by the CASE framework for all sites and seasons ( cases). The return levels are estimated empirically using the Gringorten plotting position formula (Gringorten, 1963). MAPE values over all sites and seasons are indicated in the bottom-right corner, and the lowest MAPE obtained over the four models is indicated in bold.
Results are very similar from one model to the other. The percentage of sites with good performance is slightly higher for models B and B+, but MAPE values are very similar for all models. Contrarily to most of the other considered metrics, the consideration of asymmetry has almost no influence here.
All models are able to reproduce the large variety of 5- and 20-year return levels observed in Switzerland between sites and seasons. They also all perform rather well for both return periods. For most sites and seasons, however, return levels are slightly underestimated. At the 40 min resolution, the underestimation is stronger in spring and summer for some sites (Fig. 7). This point will be further discussed in Sect. 5.5.
4.3 Intermediate temporal scales and dependency on seasons
Figure 7 presents the performance of each model for the reproduction of the lag-1 autocorrelation, mean length of wet spells, and 5- and 20-year return levels at different temporal resolutions. Clearly, for almost all statistics, the performances depend on the temporal resolution. For the intermediate disaggregation resolutions, the best-performing models are not necessarily the same as those found at a 40 min resolution. For instance, between models A and B, with regard to the reproduction of the lag-1 autocorrelation, the best model at a 40 min resolution is model A, while model B is the best model at 160 min and coarser resolutions. For the mean length of wet (and dry) spells and for 5- and 20-year return levels, models A and B provide similar performances for 40 min, although model B tends to perform better at 160 min and at coarser resolutions.
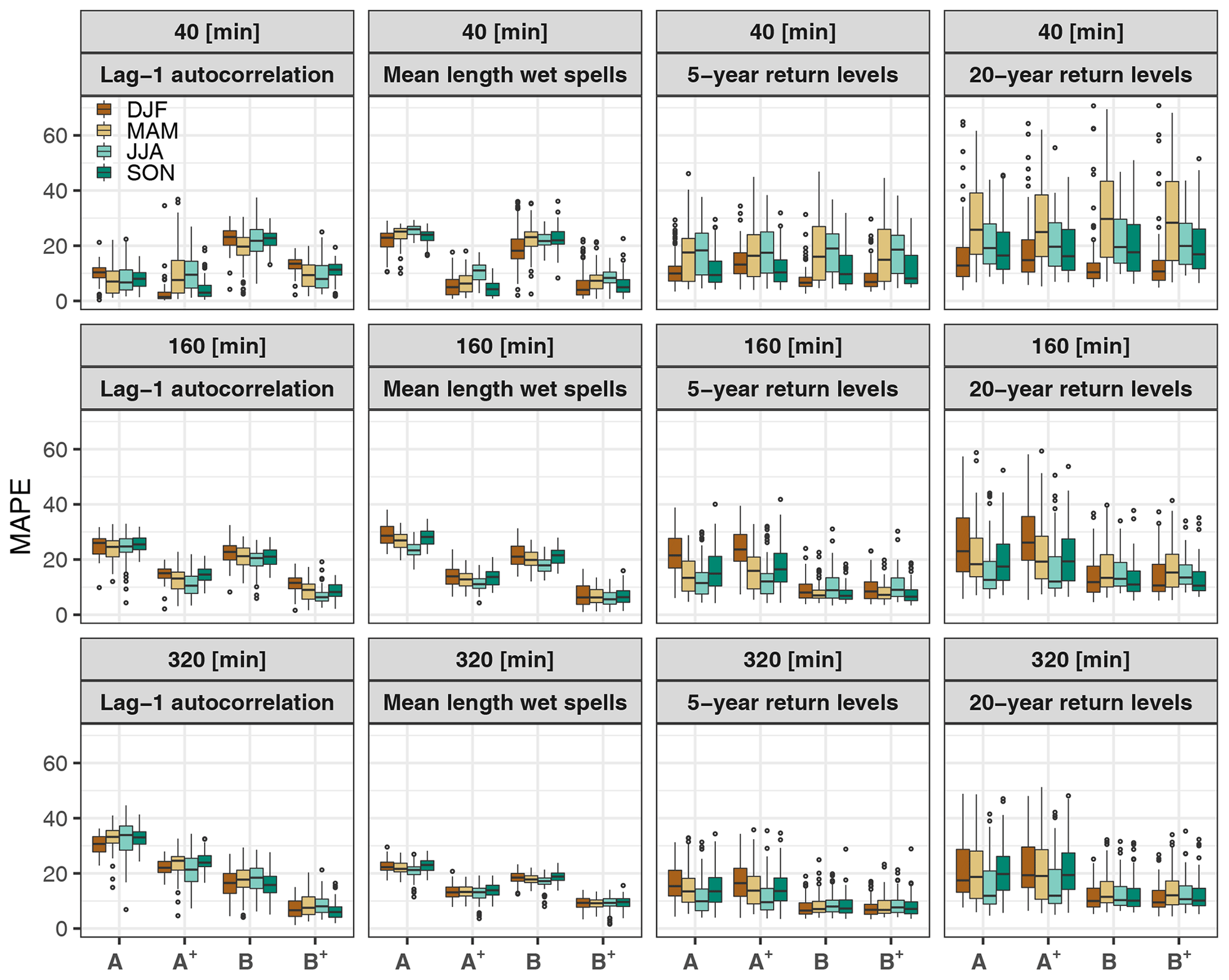
Figure 7Mean absolute percentage error (MAPE) as a function of the temporal aggregation level and season for lag-1 autocorrelation, mean length of wet spells, and 5- and 20-year return levels. Each boxplot summarises the single-site performances obtained for the 81 stations.
At 40 min resolution, accounting for asymmetry significantly improves the reproduction of all statistics related to precipitation persistence and intermittency, but it does not influence the reproduction of standard deviation, wet step probability and return levels. Similar results are obtained for the intermediate temporal resolutions.
As already mentioned previously, results can also depend on the season. Results for spring and summer are often similar and are in contrast with the results obtained for winter and autumn (Fig. 7).
5.1 Scaling MRC parameters with temporal scales
As highlighted in many previous works, the distribution of the breakdown coefficients W+ depends on the temporal scale, precipitation intensity, precipitation asymmetry and possibly other factors. Even though it was done in a discrete way by conditioning MRC parameters on a few external pattern classes, the dependency on the precipitation asymmetry has been widely accounted for in empirical approaches. However, to our knowledge, except for the pattern-based MRC model presented in Hingray and Ben Haha (2005), all analytical MRC developments have disregarded this dependency, most of them focusing on temporal scale and intensity dependencies.
According to the results shown in Sect. 4, the dependence on the temporal scale and its added value are not as pronounced, as is usually considered. In the present study, model A, which is the model considered by Rupp et al. (2009) and later by Paschalis et al. (2014), includes the dependency on the temporal scale and precipitation intensity. Model B, a simplification of model A, disregards temporal scale dependency. Besides the fact that it increases the number of parameters to be estimated (six additional parameters), model A is found to have similar performances to model B and even worse performances for coarse temporal scales. Note that Molnar and Burlando (2005) and Rupp et al. (2009) also show this limited advantage of the temporal scale dependency.
Two issues must be put into perspective with the preceding statements. The first one is related to the recording precision, which induces a relatively high frequency of , and and, to a lesser extent, of and . This precision artefact is actually detrimental for a relevant estimation of the cascade generator Γ characteristics for small temporal scales and low intensities (not for moderate to high intensities; see, e.g. Olsson, 1998; Rupp et al., 2009; Paschalis et al., 2012). Rupp et al. (2009) suggested that some of the dependency on intensity was the result of this artefact precision. We argue that a large part of the dependency on the temporal scale is also a result of this precision artefact. This is strongly suggested here concerning the probability px(I). As illustrated in Fig. 1a, the px(I) relationship for the Zurich station differs from one temporal scale to the other. The difference between the curves, which is mainly observed for small to very small intensities, depends a lot on the low precipitation threshold considered for selecting precipitation data (not shown). The differences between the curves almost disappear when precipitation amounts smaller than 0.8 mm are removed from the analysis (see Fig. S2 for the Zurich station). Without the small precipitation amounts, the scaling model for px(I) appears to not depend on the temporal scale anymore and motivates the simplification of model B considered here. Further investigations will be worthwhile to assess whether this holds true in other regions. This issue also calls for the development of a robust assessment framework (to be defined) that would be able to disentangle, if existent, the genuine dependence on the temporal scale from the one induced by the precision artefact.
Note that these conclusions were also obtained in auxiliary analyses we carried out on jittered high-resolution precipitation data (not shown). Random perturbations were added to the original observed 10 min time series before the model estimation procedure, as in Licznar et al. (2011). In our analysis, the jittering process was designed as an attempt to mimic the measurement process of the tipping-bucket rain gauge. In a tipping bucket with 0.1 mm precision device, one rainfall pulse is recorded within a given 10 min time step once the 0.1 mm rainfall bucket is filled, regardless of the duration required to fill the bucket. In reality, the recorded 0.1 mm measurement is likely to partially belong to the current time step and partially to the previous time steps. The jittering process reallocates the first recorded 0.1 mm of each time step to the current and previous time steps. This process results in the elimination of rounded quantities of precipitation (k×0.1 mm; k=1, 2, … n), especially small ones (0.1, 0.2, 0.3, … mm), and consequently, the removal of over-represented values of BDCs (, , , and ). In turn, this leads part of the scaling dependencies mentioned above to disappear.
Another issue concerns the parameter α of the distribution . For this parameter, the dependence on the temporal scale is poorly understood. For Zurich, rather large deviations are obtained between modelled and empirical estimates whether this dependence is taken into account (model A; see scaled parameter g(I) in Fig. 1d) or not (model B; see Fig. 1b). Deviations are mainly observed for large intensities in model A and for moderate intensities in model B. The temporal scale dependency assumption also seems to be detrimental for the disaggregation of large precipitation amounts. In all cases, neither of the two models (A and B) is fully satisfying for representing α, with similar results being obtained for all other stations considered in this work. The dependency on the temporal scale needs to be better characterised in future works along with alternative scaling models.
5.2 Scaling MRC parameters with precipitation asymmetry
The statistics related to precipitation persistence have always been found to be significantly underestimated by analytical MRC models (e.g. Hingray and Ben Haha, 2005; Rupp et al., 2009; Paschalis et al., 2012). Paschalis et al. (2014) actually suggest that analytical MRCs, by construction based on a symmetric cascade generator, are unable to account for the multiscale autocorrelation structure of precipitation. The results shown in Hingray and Ben Haha (2005) indicate that this issue could be at least partly fixed when the precipitation asymmetry is accounted for in the model. These insights are thus confirmed with the present work for a large variety of climate contexts found in Switzerland and for all seasons.
The dependence on precipitation asymmetry, acknowledged for a long time, was never accounted for in a fully analytical MRC framework. This study fills this methodological gap. We show that the dependency on the asymmetry can be modelled with a two-part analytical scaling sub-model, where the dry probability asymmetry ratio φ and the mean m of the positive BDC distribution depend on the precipitation asymmetry index Z. For Swiss stations, the dependence of the cascade generator properties on precipitation asymmetry seems to be much larger than that on temporal scales. The added value of introducing precipitation asymmetry into the model is clear: all statistics relative to precipitation persistence are much better reproduced, whatever the station, the season and the temporal scale.
Accounting for precipitation asymmetry seems to be of crucial importance to achieve the generation of a time series with relevant properties. This is also suggested by the results of some auxiliary evaluations described below. As shown previously in Sect. 2.3, the statistical distribution of W is expected to strongly depend on the external pattern of precipitation and more precisely on the value of the asymmetry index Z. When the asymmetry index Z is larger, the probability p01 (respectively, p10) is expected to be smaller (respectively, larger), and the mean of the distribution is expected to be larger (see the ECDFs of W for the Zurich data in Fig. 3).
Figures S12 and S13 demonstrate that the dependency of ECDF of BDCs on Z is almost perfectly reproduced with models A+ and B+ for Zurich data. Conversely, when the cascade generator does not account for precipitation asymmetry, as is the case with models A and B, the dependence of ECDF of W on Z is no longer reproduced, which is not surprising due to the inherent symmetric formulation of cascade generators.
Besides, the statistics of a precipitation time series, e.g. the standard statistics and the ECDF of W, are not expected to change when the time series is offset in time by a small time duration. This specific point is investigated here with an offset experiment similar to that presented by Rupp et al. (2009). Four 40 min time series are derived from the initial 10 min time series by aggregating 10 min data using four different time offsets: no offset, 10, 20 and 30 min. When the offset experiment is applied to observed data, the considered statistics estimated for the four time series are similar. Thus, the expected offset independence property is satisfied, as shown in Fig. S10 for standard statistics of 12 stations and in Figs. S12 and S13 for the ECDF of W for Zurich data. When the offset experiment is applied to times series generated with the disaggregation models, the offset independence property is not always satisfied. For illustration, the disaggregated 40 min time series were further disaggregated to 10 min time series (for the 20 and 10 min temporal scales, the parameters of the cascade generator are obtained with the scaling models). For each 10 min time series scenario, four offset 40 min time series were produced with four different offsets as for the observations. In general, the statistics obtained with disaggregated scenarios from models A and B (without asymmetry) are much more sensitive to temporal offset than those obtained from models A+ and B+. For models A and B, the estimates obtained for the three non-zero offsets (10, 20, 30 min) are often significantly different from the reference estimate (with the 0 min offset). This is the case for standard statistics, as highlighted in Fig. S11, and it is even more accentuated for the ECDFs of W, as illustrated in Figs. S12 and S13. Including the asymmetry in the generator makes the ECDFs rather insensitive to the offset.
As mentioned previously, the asymmetry of the cascade generator is mainly disregarded in analytical MRCs, but it is considered for a long time in empirical ones by estimation of the cascade generator for different external pattern classes. Conditioning the parameterisation of any analytical model on external pattern classes is also possible. Is our continuous asymmetry approach of interest when compared to a class-conditioned approach? To address this question, we considered two more models, namely A position and B position (Ap and Bp). These two models are based on models A and B respectively, but they are estimated by conditioning the estimation on four external pattern classes, i.e. the four position classes (starting, enclosed, ending, isolated) considered in McIntyre et al. (2016). Again, the observed quasi-daily amounts were disaggregated to time series of 40 min resolution with all models. Figures S14 and S15 show that the results depend on the considered statistics. Overall in our case, conditioning the analytical models to the position class improves the performance of classical unconditioned analytical models; nevertheless, it is less efficient than considering scaling laws with a continuous asymmetry index. These interesting results will be worth further investigation, especially in other climates. We believe that the better performance of models A+ and B+ over models Ap and Bp is due to the fact that they are additionally able to make a distinction between different starting sequences (or different ending sequences) as the asymmetry index is also a measure of the intensity of the asymmetry (i.e. steep decreasing intensity over the three consecutive precipitation amounts or only slow decreasing). As they are additionally highly parsimonious, models A+ and B+ appear to be promising alternatives to the class-conditioned models.
5.3 Spatial variability of parameters and the potential for a regional MRC model
In order to apply a MRC model in locations where only daily data are available, the possibility to develop a robust regional model for model parameters is necessary. The smaller the number of parameters, the more robust and easier the regionalisation is expected to be. In this regard, model B+ (5 parameters) is likely to be much more appropriate for regionalisation than model A+ (11 parameters).
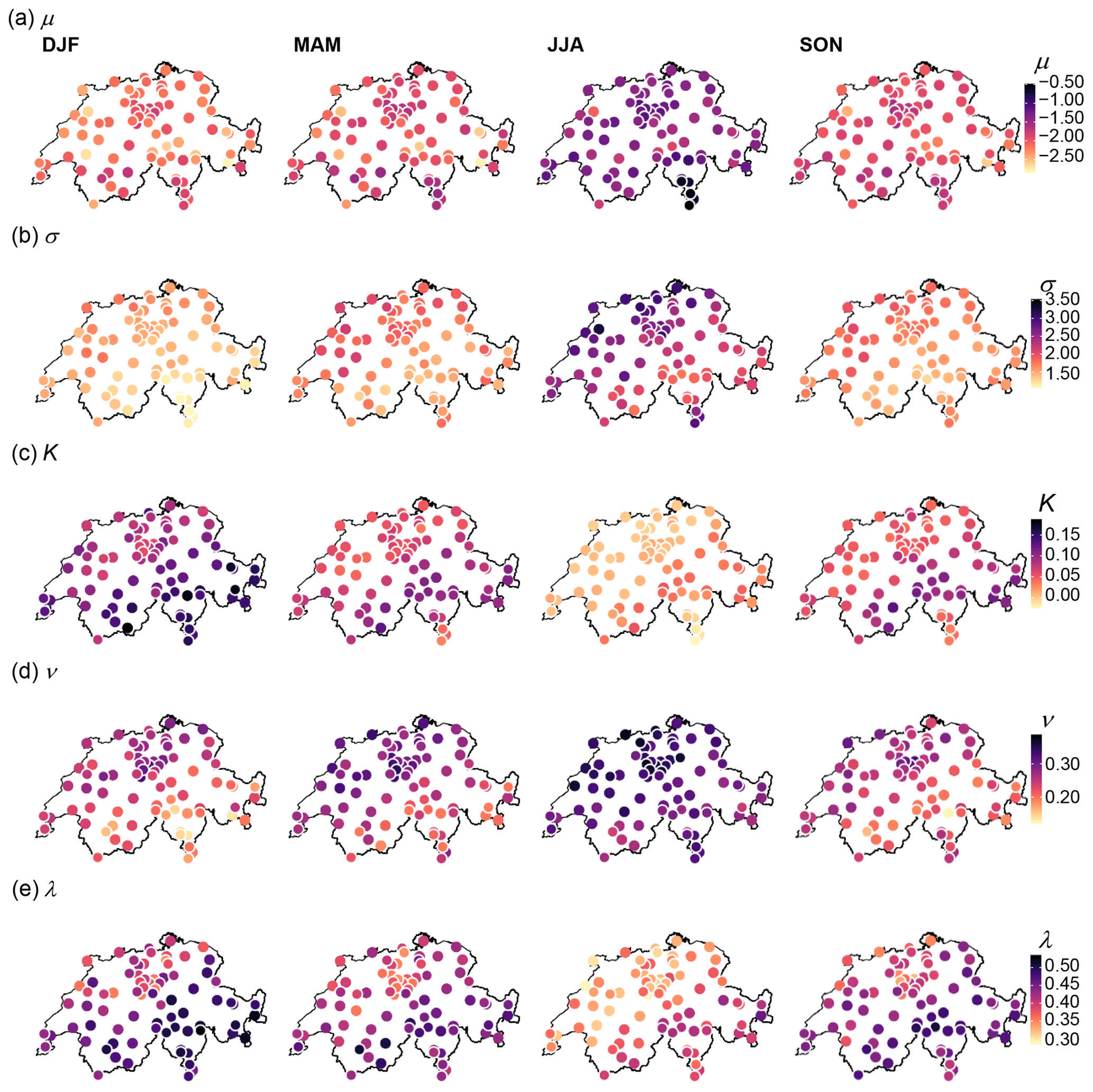
Figure 8Maps of Switzerland showing spatial and seasonal variations of the estimated parameters for model B+. Each row corresponds to one parameter of the model. Parameters representing the relationship between intermittency and intensity are those of the Eq. (9): (a) μ and (b) σ. (c) Parameter K, as in Eq. (13), is related to the dependency of the distribution of positive weights, , on the precipitation intensity and finally the parameters ν and λ in (d) and (e), respectively, hold the dependency of the cascade weights on the precipitation asymmetry through Eqs. (16) and (17). The colour of the circle indicates the value of the parameter estimate for the respective station and season.
Another important factor that can jeopardise the success of parameter regionalisation is the spatial variability of parameters. In the case of no evident relationship to some geographical features (e.g. topography), smooth spatial variations of parameters often help achieve robust regionalisation. The spatial variability of the five parameters of model B+ is shown in Fig. 8 where maps of estimates for μ, σ, K, ν and λ are presented for each season. Regardless of the parameters and throughout all seasons, the regional coherency is rather impressive. All parameters present significant spatial variability, reflecting the large variety of regional climates in Switzerland; nevertheless, the spatial variations are very smooth at sub-regional scales and from one region to the other. These results give increased confidence in the relevance of estimates and in the robustness of the model. They also suggest that a relevant regional model will be possible for all parameters, enabling the temporal disaggregation of coarse-resolution precipitation data anywhere in Switzerland. The performance of such a regional MRC model will be further investigated in future works.
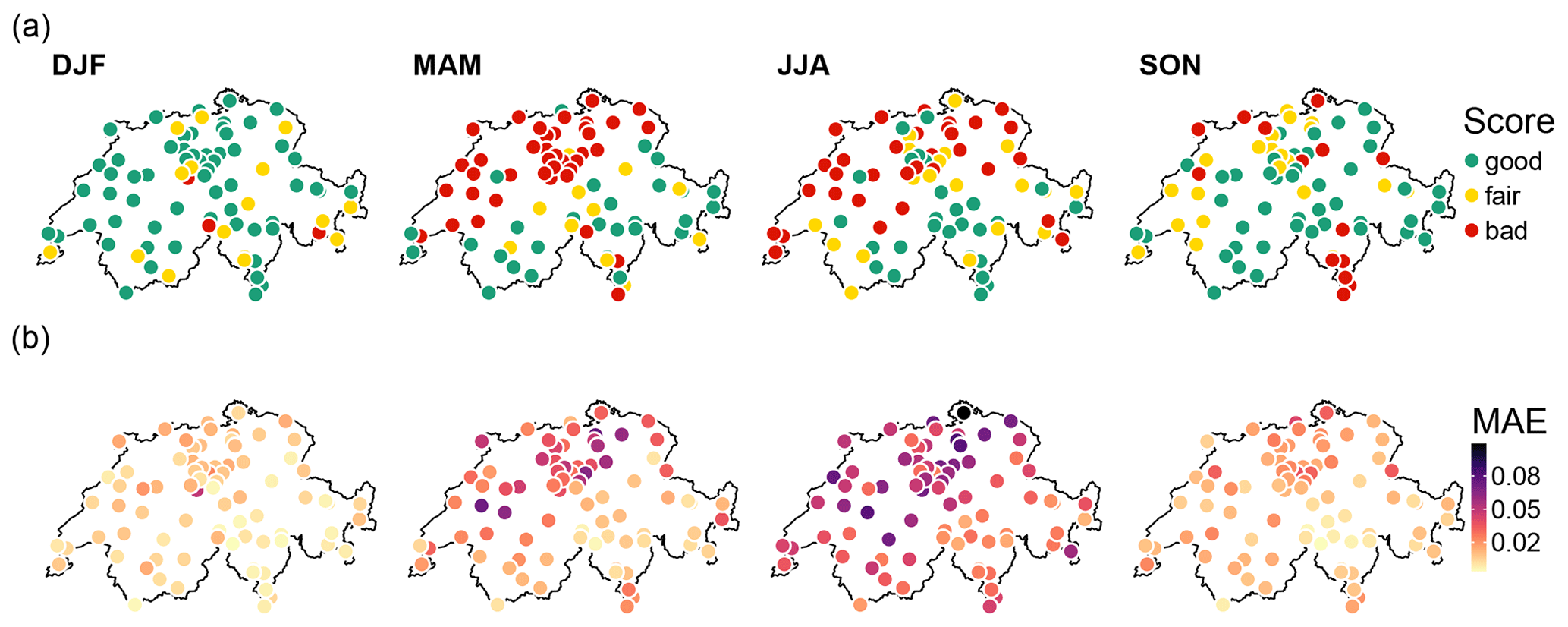
Figure 9(a) Scores as assigned by CASE framework for the reproduction of 5-year return levels at 40 min temporal resolution by model B for each site and each season. (b) Mean absolute errors (MAEs) between observed and modelled px values for precipitation intensities higher than 1 mm h−1 with model B; see Eq. (9).
5.4 Seasonal variability of parameters
Additionally, the maps presented in Fig. 8 depict the seasonal variations of the various parameters. As already shown in previous works (e.g. Molnar and Burlando, 2005), the season is actually a much larger factor of variability than the location. The contrast between winter and summer is particularly marked. Whatever the parameter, the values for spring and autumn are similar to each other. This seasonality reflects the different types of rainfall events throughout the year, with more stratiform events in winter, more convective ones in summer and mixed types in intermediate seasons. Stratiform events are generally persistent in time and with a large spatial extent, contrary to convective events which are often localised and with a short duration. The partition of any precipitation amount in two parts is thus expected to be smoother in winter, with more frequent partitions of similar rainfall amounts on the two subdivisions and more dependency on the external precipitation pattern. This is reflected by higher px values, higher α values, as well as higher sensitivity to precipitation asymmetry. This is also shown by the values of all scaling parameters in winter: lower values of μ and σ for the intermittency probability-scaling sub-model, higher values of K for the no-dry subdivision-scaling sub-model, and lower values of ν and higher values of λ for the asymmetry-scaling sub-models. As suggested by Rupp et al. (2009), an alternative to the seasonal stratification could consist of a parameterisation conditional on the type of precipitation events, especially for intermediate seasons where different types of events are observed.
These results suggest the importance of seasonal stratification for model parameter estimation. The interest of seasonal stratification is even more obvious when simulations are carried out with a model where parameter dependency on season was ignored. This is illustrated in Figs. S8 and S9, where the seasonal performances of all models are presented for a configuration where one single set of parameters has been estimated for all seasons together. The performance of the models without seasonal stratification degrades a lot for a number of statistics, especially in winter and summer seasons.
5.5 Asymptotic assumption of no-dry subdivision probability for high intensities
An opportunity for model improvement concerns the scaling sub-model for the no-dry subdivisions probability px. As shown in Sect. 4.2, all the models tend to underestimate spring and summer extreme events at some sites. Figure 9a shows that, for model B, this principally occurs in northern Switzerland for spring and summer seasons. Very similar maps are obtained for the other models (not shown). A plausible explanation is that the model used for px is not valid for very large intensities.
Following previous works, px is assumed to be related to precipitation intensity via the erf function of Eq. (6). By construction, for large precipitation intensities, this scaling model has an asymptotic value of 1, and p01 and p10 tend towards 0. In other words, very large precipitation amounts are systematically divided into two non-zero parts. However, the probability px has no reason to tend towards 1, especially at coarse temporal scales (see illustration in Fig. S2). For instance, large daily precipitation amounts in summer can result from intense convective events with short durations (less than 1 h). In this case, the daily amount must be neither subdivided nor spread over multiple high-resolution time steps. The BDCs for such events are either or , and the probability of having the configuration is expected for high resolutions only. When px is overestimated for large intensities, the configurations (no-dry subdivisions) are thus over-represented and lead to an underestimation of extreme values.
The misrepresentation of px for large intensities is illustrated with the mean deviation obtained between modelled and empirical px values for intensities larger than 1 mm h−1 in Fig. 9b. Whatever the season, the spatial pattern of these deviations fits very well with that obtained for the underestimation of the 5-year return level shown in Fig. 9a. The larger the deviation, the worse the underestimation. Relaxing the current asymptotic assumption for the px model may improve the simulation of extremes.
According to many previous works, the distribution of the breakdown coefficients (BDCs) used in MRC models depends on a number of factors, including the temporal scale, precipitation intensity and the external pattern of the local precipitation sequence.
In the present study, we compare different MRC models both with and without the scaling dependency on the temporal scales and with and without the scaling dependency on the external pattern of precipitation. Conversely to the scaling dependency on precipitation intensity and asymmetry, the scaling dependency on temporal scales is not obvious, and its added value in terms of model performance is less clear than what was suggested in previous works. Moreover, accounting for a dependency on the temporal scales drastically increases the number of parameters to be estimated (six more in the present case), which is especially expected to make the model much less robust and less appropriate for further regionalisation works.
The dependency on the external pattern of precipitation is shown to be important. In previous studies, it was mainly accounted for with empirical models where the BDC distribution was conditioned on different external pattern classes. To our knowledge, although determinant, it was never accounted for in an analytical scaling framework, which also accounts for temporal scale and intensity dependencies. Our work presents a unified analytical MRC modelling framework that allows the cascade generator to depend in a continuous way on the temporal scale, precipitation intensity and precipitation asymmetry. The continuous dependency of the cascade generator on the precipitation asymmetry index, which is introduced here, allows for the interpretation of the presented asymmetry sub-model as an extension of the position dependency approach already considered in several previous works. This sub-model could be easily assimilated in other multiplicative cascade models, either micro-canonical or canonical ones.
Initially, we demonstrate the feasibility of characterising the external precipitation pattern with a hidden BDC, the so-called precipitation asymmetry index. We show that the larger the deviation of this index from 0.5 (the index value for a symmetrical precipitation configuration), the larger the asymmetry of the distribution of the BDCs. The relationships with this asymmetry index are modelled with two scaling sub-models. The first sub-model represents the dry probability asymmetry ratio φ that quantifies the asymmetry between p10 and p01, i.e. the probabilities that the whole precipitation amount is attributed exclusively either to the first or to the second subdivision, respectively. The second sub-model is related to the mean m of the distribution of positive BDCs, , which is equal to 0.5 if the asymmetry is disregarded.
Accounting for precipitation asymmetry in the cascade generator preserves the good performances of MRCs concerning statistics related to precipitation distribution (standard deviations and precipitation extremes) and improves other aspects of the disaggregated precipitation time series. For the Swiss context considered in our work, we outline the following.
-
Accounting for precipitation asymmetry leads to significant model improvements for all statistics related to the temporal persistence and intermittency of precipitation, which are known to be difficult to simulate with standard MRC models.
-
The statistical distribution of BDCs is expected to strongly depend on the external pattern of precipitation. This dependency is well (respectively, is not) reproduced when precipitation asymmetry is included (respectively, not included) in the MRC.
-
The statistics of a precipitation time series are not expected to change when the time series is offset in time by a small time duration. This offset independence property is well (respectively, is not) satisfied when precipitation asymmetry is included (respectively, not included) in the MRC.
Among the four different MRC models considered here, the one that accounts only for precipitation intensity and asymmetry seems promising. It performs very well for all considered statistics, for all seasons and for all temporal resolutions. It is, moreover, very parsimonious, with only five parameters. The five parameters are almost all independent from each other and can be estimated in a robust way, which avoids equifinality issues (Beven, 2006; Bárdossy, 2007). Whatever the parameter, the regional coherency is rather impressive. While all parameters present significant spatial variability, reflecting the large variety of regional climates in Switzerland, the spatial variations of parameter estimates are very smooth. This suggests that a relevant regional model will be possible for all parameters, allowing in turn the temporal disaggregation of coarse-resolution precipitation data anywhere in Switzerland. This disaggregation modelling framework is promising and could also be suited to other climate contexts worldwide. Additional applications could help to better characterise its performance, its limitations and its potential for regionalisation in such other contexts.
The parameters of the scaling models of each MRC model are estimated as follows:
-
Model A. px(I,τ) is first estimated for different intensity classes I and temporal scales τ as the proportion of wet time steps where both subdivisions are wet (coloured dots in Fig. 1a). These estimates are used to fit the relationships of Eq. (7) for μ(τ) and Eq. (8) for σ(τ) using the method of least square errors, which leads to estimates of the parameters aμ, bμ, aσ and bσ. For α, this is first estimated for different classes of intensity I and different temporal scales τ (coloured dots in Fig. 1b) from the variance of the corresponding set of W+s by fitting a beta distribution of the W+ values with the method of moments (see Eq. 5). It is also estimated for different classes of temporal scales τ (all intensities included; coloured dots in Fig. 1c). The last estimates are used to fit the relationship (Eq. 12) for h(τ), which leads to estimates of the parameters α0 and H. In the third step, the ratio is estimated for different classes of intensity and different temporal scales (coloured dots in Fig. 1d). These estimates are used to fit the scaling model g(I) of Eq. (13), which leads to estimates of the parameters c0, c1 and c2. An example of model fit for px(I,τ), for g(I) and for h(τ), is given in Fig. 1a, c and d respectively (plain lines).
-
Model B. The estimation of model B follows a similar but more direct sequential process than for model A. In model B, px and α are assumed to only depend on the intensity I. In a first step, estimates of px (respectively, α) are thus simply obtained for different classes of intensity and temporal scales (coloured dots in Fig. S2c). These px (respectively, α) estimates are then used to fit the scaling relationship (Eq. 9) for px(I) (respectively, Eq.13 for α(I)) and to obtain estimates of μ and σ (respectively, K). An illustration is given in Fig. 1b for α.
-
Models A+ and B+. Estimating the additional parameters related to the asymmetry follows an independent estimation process. Different φ and m estimates are first obtained for different Z-index classes (all intensities and all temporal scales are merged for the estimation). For φ, these estimates are obtained from Eq. (15), while estimates of m are obtained as the mean of the W+ values for different Z-index classes. The scaling models Eq. (16) for φ(Z) and Eq. (17) for m(Z) are then fitted on these estimates, which leads to estimates of the parameters ν and λ, respectively. An example of fit is illustrated in Fig. 3b and c. The different steps necessary to obtain p01 and p01 and the two parameters α1 and α2 of the asymmetric beta distribution are described in Sect. 2.4.
The precipitation data used in this study are maintained by the Swiss Federal Office of Meteorology and Climatology, MeteoSwiss (MeteoSwiss, 2021). They are available upon request at https://www.meteoswiss.admin.ch/services-and-publications/service/weather-and-climate-products/data-portal-for-teaching-and-research.html (IDAWEB, 2021).
The open-source code with routines allowing the fitting and disaggregation of precipitation data based on the four MRC models presented in this study is available as an R package. It can be installed via Zenodo: https://doi.org/10.5281/zenodo.8435607 (Maloku, 2023).
The supplement related to this article is available online at: https://doi.org/10.5194/hess-27-3643-2023-supplement.
Funding acquisition: BH. Data acquisition: KM. Experimental design: KM, BH and GE. Script development: KM and GE. Model calibration, simulations and analyses: KM. Figure preparation: KM. Paper redaction: KM, BH and GE.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
We thank the editor, Hannes Müller-Thomy, and one anonymous reviewer for their constructive comments that helped us to improve the quality of this paper.
This research has been supported by the Bundesamt für Energie (grant no. SI/502150-01) and the Bundesamt für Umwelt (grant no. SI/502150-01), through the Extreme floods in Switzerland project.
This paper was edited by Nadav Peleg and reviewed by Hannes Müller-Thomy and one anonymous referee.
Acharya, S. C., Nathan, R., Wang, Q. J., and Su, C.-H.: Temporal disaggregation of daily rainfall measurements using regional reanalysis for hydrological applications, J. Hydrol., 610, 127867, https://doi.org/10.1016/j.jhydrol.2022.127867, 2022. a
Baeriswyl, P. A. and Rebetez, M.: Regionalization of precipitation in Switzerland by means of principal component analysis, Theor. Appl. Climatol., 58, 31–41, https://doi.org/10.1007/BF00867430, 1997. a
Bárdossy, A.: Calibration of hydrological model parameters for ungauged catchments, Hydrol. Earth Syst. Sci., 11, 703–710, https://doi.org/10.5194/hess-11-703-2007, 2007. a
Bennett, B., Thyer, M., Leonard, M., Lambert, M., and Bates, B.: A comprehensive and systematic evaluation framework for a parsimonious daily rainfall field model, J. Hydrol., 556, 1123–1138, https://doi.org/10.1016/j.jhydrol.2016.12.043, 2018. a
Beven, K.: A manifesto for the equifinality thesis, J. Hydrol., 320, 18–36, https://doi.org/10.1016/j.jhydrol.2005.07.007, 2006. a
Breinl, K. and Di Baldassarre, G.: Space-time disaggregation of precipitation and temperature across different climates and spatial scales, J. Hydrol. Reg. Stud., 21, 126–146, https://doi.org/10.1016/j.ejrh.2018.12.002, 2019. a
Cristiano, E., ten Veldhuis, M.-C., and van de Giesen, N.: Spatial and temporal variability of rainfall and their effects on hydrological response in urban areas – a review, Hydrol. Earth Syst. Sci., 21, 3859–3878, https://doi.org/10.5194/hess-21-3859-2017, 2017. a
Evin, G., Favre, A.-C., and Hingray, B.: Stochastic generation of multi-site daily precipitation focusing on extreme events, Hydrol. Earth Syst. Sci., 22, 655–672, https://doi.org/10.5194/hess-22-655-2018, 2018. a
Frei, C. and Schär, C.: A precipitation climatology of the Alps from high-resolution rain-gauge observations, Int. J. Climatol., 18, 873–900, https://doi.org/10.1002/(SICI)1097-0088(19980630)18:8<873::AID-JOC255>3.0.CO;2-9, 1998. a, b
Gringorten, I. I.: A plotting rule for extreme probability paper, J. Geophys. Res., 68, 813–814, https://doi.org/10.1029/JZ068i003p00813, 1963. a, b
Güntner, A., Olsson, J., Calver, A., and Gannon, B.: Cascade-based disaggregation of continuous rainfall time series: the influence of climate, Hydrol. Earth Syst. Sci., 5, 145–164, https://doi.org/10.5194/hess-5-145-2001, 2001. a, b
Hingray, B. and Ben Haha, M.: Statistical performances of various deterministic and stochastic models for rainfall series disaggregation, Atmos. Res., 77, 152–175, https://doi.org/10.1016/j.atmosres.2004.10.023, 2005. a, b, c, d, e
Hingray, B., Picouet, C., and Musy, A., eds.: Hydrology: A Science for Engineers, CRC Press, https://doi.org/10.1201/b17169, 2014. a
Hyndman, R. J. and Koehler, A. B.: Another look at measures of forecast accuracy, Int. J. Forecast., 22, 679–688, https://doi.org/10.1016/j.ijforecast.2006.03.001, 2006. a
IDAWEB: The data portal of MeteoSwiss for research and teaching, https://www.meteoswiss.admin.ch/services-and-publications/service/weather-and-climate-products/data-portal-for-teaching-and-research.html (last access: 10 December 2021), 2021. a
Jebari, S., Berndtsson, R., Olsson, J., and Bahri, A.: Soil erosion estimation based on rainfall disaggregation, J. Hydrol., 436-437, 102–110, https://doi.org/10.1016/j.jhydrol.2012.03.001, 2012. a
Jennings, S. A., Lambert, M. F., and Kuczera, G.: Generating synthetic high resolution rainfall time series at sites with only daily rainfall using a master–target scaling approach, J. Hydrol., 393, 163–173, https://doi.org/10.1016/j.jhydrol.2010.08.013, 2010. a
Kang, B. and Ramírez, J. A.: A coupled stochastic space-time intermittent random cascade model for rainfall downscaling, Water Resour. Res., 46, W10534, https://doi.org/10.1029/2008WR007692, 2010. a
Koutsoyiannis, D.: Rainfall disaggregation methods: Theory and applications, in: Proceedings, Workshop on Statistical and Mathematical Methods for Hydrological Analysis; Università di Roma “La Sapienza”, May 2003, Rome, Italy, 1–23, https://doi.org/10.13140/RG.2.1.2840.8564, 2003. a
Koutsoyiannis, D. and Onof, C.: Rainfall disaggregation using adjusting procedures on a Poisson cluster model, J. Hydrol., 246, 109–122, https://doi.org/10.1016/S0022-1694(01)00363-8, 2001. a
Liang, Q., Xia, X., and Hou, J.: Catchment-scale High-resolution Flash Flood Simulation Using the GPU-based Technology, Proced. Eng., 154, 975–981, https://doi.org/10.1016/j.proeng.2016.07.585, 2016. a
Licznar, P., Schmitt, T. G., and Rupp, D. E.: Distributions of microcanonical cascade weights of rainfall at small timescales, Acta Geophys., 59, 1013–1043, https://doi.org/10.2478/s11600-011-0014-4, 2011. a, b
Maloku, K.: disaggMRC: Temporal disaggregation of precipitation time series with microcanonical Random Cascade method (v1.0.0), Zenodo [code], https://doi.org/10.5281/zenodo.8435607, 2023. a
McIntyre, N., Shi, M., and Onof, C.: Incorporating parameter dependencies into temporal downscaling of extreme rainfall using a random cascade approach, J. Hydrol., 542, 896–912, https://doi.org/10.1016/j.jhydrol.2016.09.057, 2016. a, b, c
Menabde, M. and Sivapalan, M.: Modeling of rainfall time series and extremes using bounded random cascades and levy-stable distributions, Water Resour. Res., 36, 3293–3300, https://doi.org/10.1029/2000WR900197, 2000. a, b
MeteoSwiss: Federal Office of Meteorology and Climatology, https://gate.meteoswiss.ch/idaweb/more.do (last access: 12 December 2021), 2021. a
Mezghani, A. and Hingray, B.: A combined downscaling-disaggregation weather generator for stochastic generation of multisite hourly weather variables over complex terrain: Development and multi-scale validation for the Upper Rhone River basin, J. Hydrol., 377, 245–260, https://doi.org/10.1016/j.jhydrol.2009.08.033, 2009. a, b
Molnar, P. and Burlando, P.: Preservation of rainfall properties in stochastic disaggregation by a simple random cascade model, Atmos. Res., 77, 137–151, https://doi.org/10.1016/j.atmosres.2004.10.024, 2005. a, b, c, d, e, f, g, h
Molnar, P. and Burlando, P.: Variability in the scale properties of high-resolution precipitation data in the Alpine climate of Switzerland: Variability In Scale Properties, Water Resour. Res., 44, W10404, https://doi.org/10.1029/2007WR006142, 2008. a, b
Müller, H. and Haberlandt, U.: Temporal rainfall disaggregation using a multiplicative cascade model for spatial application in urban hydrology, J. Hydrol., 556, 847–864, https://doi.org/10.1016/j.jhydrol.2016.01.031, 2018. a
Ochoa-Rodriguez, S., Wang, L.-P., Gires, A., Pina, R. D., Reinoso-Rondinel, R., Bruni, G., Ichiba, A., Gaitan, S., Cristiano, E., van Assel, J., Kroll, S., Murlà-Tuyls, D., Tisserand, B., Schertzer, D., Tchiguirinskaia, I., Onof, C., Willems, P., and ten Veldhuis, M.-C.: Impact of spatial and temporal resolution of rainfall inputs on urban hydrodynamic modelling outputs: A multi-catchment investigation, J. Hydrol., 531, 389–407, https://doi.org/10.1016/j.jhydrol.2015.05.035, 2015. a
Olsson, J.: Evaluation of a scaling cascade model for temporal rain-fall disaggregation, Hydrol. Earth Syst. Sci., 2, 19–30, https://doi.org/10.5194/hess-2-19-1998, 1998. a, b, c, d, e
Ormsbee, L. E.: Rainfall Disaggregation Model for Continuous Hydrologic Modeling, J. Hydraul. Eng., 115, 507–525, https://doi.org/10.1061/(ASCE)0733-9429(1989)115:4(507), 1989. a, b, c
Park, H. and Chung, G.: A Nonparametric Stochastic Approach for Disaggregation of Daily to Hourly Rainfall Using 3-Day Rainfall Patterns, Water, 12, 2306, https://doi.org/10.3390/w12082306, 2020. a
Paschalis, A., Molnar, P., and Burlando, P.: Temporal dependence structure in weights in a multiplicative cascade model for precipitation, Water Resour. Res., 48, W01501, https://doi.org/10.1029/2011WR010679, 2012. a, b, c, d
Paschalis, A., Molnar, P., Fatichi, S., and Burlando, P.: On temporal stochastic modeling of precipitation, nesting models across scales, Adv. Water Resour., 63, 152–166, https://doi.org/10.1016/j.advwatres.2013.11.006, 2014. a, b, c, d, e
Paulson, K. S. and Baxter, P. D.: Downscaling of rain gauge time series by multiplicative beta cascade, J. Geophys. Res., 112, D09105, https://doi.org/10.1029/2006JD007333, 2007. a
Pohle, I., Niebisch, M., Müller, H., Schümberg, S., Zha, T., Maurer, T., and Hinz, C.: Coupling Poisson rectangular pulse and multiplicative microcanonical random cascade models to generate sub-daily precipitation timeseries, J. Hydrol., 562, 50–70, https://doi.org/10.1016/j.jhydrol.2018.04.063, 2018. a, b
Pui, A., Sharma, A., Mehrotra, R., Sivakumar, B., and Jeremiah, E.: A comparison of alternatives for daily to sub-daily rainfall disaggregation, J. Hydrol., 470-471, 138–157, https://doi.org/10.1016/j.jhydrol.2012.08.041, 2012. a
Rafieeinasab, A., Norouzi, A., Kim, S., Habibi, H., Nazari, B., Seo, D.-J., Lee, H., Cosgrove, B., and Cui, Z.: Toward high-resolution flash flood prediction in large urban areas – Analysis of sensitivity to spatiotemporal resolution of rainfall input and hydrologic modeling, J. Hydrol., 531, 370–388, https://doi.org/10.1016/j.jhydrol.2015.08.045, 2015. a
R Core Team: R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/ (last access: 12 October 2022), 2022. a
Römkens, M. J. M., Helming, K., and Prasad, S. N.: Soil erosion under different rainfall intensities, surface roughness, and soil water regimes, Catena, 46, 103–123, https://doi.org/10.1016/S0341-8162(01)00161-8, 2002. a
Rupp, D. E., Keim, R. F., Ossiander, M., Brugnach, M., and Selker, J. S.: Time scale and intensity dependency in multiplicative cascades for temporal rainfall disaggregation, Water Resour. Res., 45, W07409, https://doi.org/10.1029/2008WR007321, 2009. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p
Rupp, D. E., Licznar, P., Adamowski, W., and Leśniewski, M.: Multiplicative cascade models for fine spatial downscaling of rainfall: parameterization with rain gauge data, Hydrol. Earth Syst. Sci., 16, 671–684, https://doi.org/10.5194/hess-16-671-2012, 2012. a
Schertzer, D. and Lovejoy, S.: Physical modeling and analysis of rain and clouds by anisotropic scaling multiplicative processes, J. Geophys. Res., 92, 9693–9714, https://doi.org/10.1029/JD092iD08p09693, 1987. a
Schleiss, M.: A new discrete multiplicative random cascade model for downscaling intermittent rainfall fields, Hydrol. Earth Syst. Sci., 24, 3699–3723, https://doi.org/10.5194/hess-24-3699-2020, 2020. a
Seed, A. W., Srikanthan, R., and Menabde, M.: A space and time model for design storm rainfall, J. Geophys. Res., 104, 31623–31630, https://doi.org/10.1029/1999JD900767, 1999. a
Segond, M.-L., Onof, C., and Wheater, H.: Spatial–temporal disaggregation of daily rainfall from a generalized linear model, J. Hydrol., 331, 674–689, https://doi.org/10.1016/j.jhydrol.2006.06.019, 2006. a
Sikorska, A. E. and Seibert, J.: Appropriate temporal resolution of precipitation data for discharge modelling in pre-alpine catchments, Hydrolog. Sci. J., 63, 1–16, https://doi.org/10.1080/02626667.2017.1410279, 2018. a
Srikanthan, R. and McMahon, T. A.: Stochastic generation of annual, monthly and daily climate data: A review, Hydrol. Earth Syst. Sci., 5, 653–670, https://doi.org/10.5194/hess-5-653-2001, 2001. a
Tessier, Y., Lovejoy, S., and Schertzer, D.: Universal Multifractals: Theory and Observations for Rain and Clouds, J. Appl. Meteorol. Clim., 32, 223–250, https://doi.org/10.1175/1520-0450(1993)032<0223:UMTAOF>2.0.CO;2, 1993. a
Viviroli, D., Sikorska-Senoner, A. E., Evin, G., Staudinger, M., Kauzlaric, M., Chardon, J., Favre, A.-C., Hingray, B., Nicolet, G., Raynaud, D., Seibert, J., Weingartner, R., and Whealton, C.: Comprehensive space–time hydrometeorological simulations for estimating very rare floods at multiple sites in a large river basin, Nat. Hazards Earth Syst. Sci., 22, 2891–2920, https://doi.org/10.5194/nhess-22-2891-2022, 2022. a