the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 25 Apr 2022
| 25 Apr 2022
Spatially referenced Bayesian state-space model of total phosphorus in western Lake Erie
Craig A. Stow
Casey M. Godwin
Collecting water quality data across large lakes is often done under regulatory mandate; however, it is difficult to connect nutrient concentration observations to sources of those nutrients and to quantify this relationship. This difficulty arises from the spatial and temporal separation between observations, the impact of hydrodynamic forces, and the cost involved in discrete samples collected aboard vessels. These challenges are typified in Lake Erie, where binational agreements regulate riverine loads of total phosphorus (TP) to address the impacts from annual harmful algal blooms (HABs). While it is known that the Maumee River supplies 50 % of the nutrient load to Lake Erie, the details of how the Maumee River TP load changes Lake Erie TP concentration have not been demonstrated. We developed a hierarchical spatially referenced Bayesian state-space model with an adjacency matrix defined by surface currents. This was applied to a 2 km-by-2 km grid of nodes, to which observed lake and river TP concentrations were joined. The model generated posterior samples describing the unobserved nodes and observed nodes on unobserved days. We quantified the impact plume of the Maumee River by experimentally changing concentration data and tracking the change in in-lake predictions. Our impact plume represents the spatial and temporal variation of how river concentrations correlate with lake concentrations. We used the impact plume to scale the Maumee River spring TP load to an effective Maumee River TP spring load for each node in the lake. By assigning an effective load to each node, the relationship between load and concentration is consistent throughout our sampling locations. A linear model of annual lake node mean TP concentration and effective Maumee River load estimated that, in the absence of the Maumee River load, lake concentrations at the sampled nodes would be 23.1 µg L−1 (±1.75, 95 % CI, credible interval) and that for each 100 t of spring TP effective load delivered to Lake Erie, mean TP concentrations increase by 11 µg L−1 (±1, 95 % CI). Our proposed modeling technique allowed us to establish these quantitative connections between Maumee TP load and Lake Erie TP concentrations which otherwise would be masked by the movement of water through space and time.
- Article
(11385 KB) - Full-text XML
- BibTeX
- EndNote





In a collective response to the economic, human health, and environmental damage caused by pollution, assessing water quality is a regulatory mandate across many water bodies. In many aquatic ecosystems nutrient concentrations are a primary water quality analyte collected. Observed concentrations are driven by both point and non-point sources. For example, wastewater effluent and excessive nutrient export, primarily from agricultural watersheds, may lead to eutrophication and harmful algal blooms (HABs) and threatens drinking water contamination (Brooks et al., 2016; Mellios et al., 2020; Schneider and Bláha, 2020). Individual water bodies present data collection challenges, particularly large lakes. Even for those locations with well-funded sample collection schema, trying to describe the spatiotemporal heterogeneity in nutrients is difficult. Discernible trends are difficult to assess as samples represent discrete spatial data within a system of constantly moving water and asymmetrical spatial extents of riverine nutrient plumes.
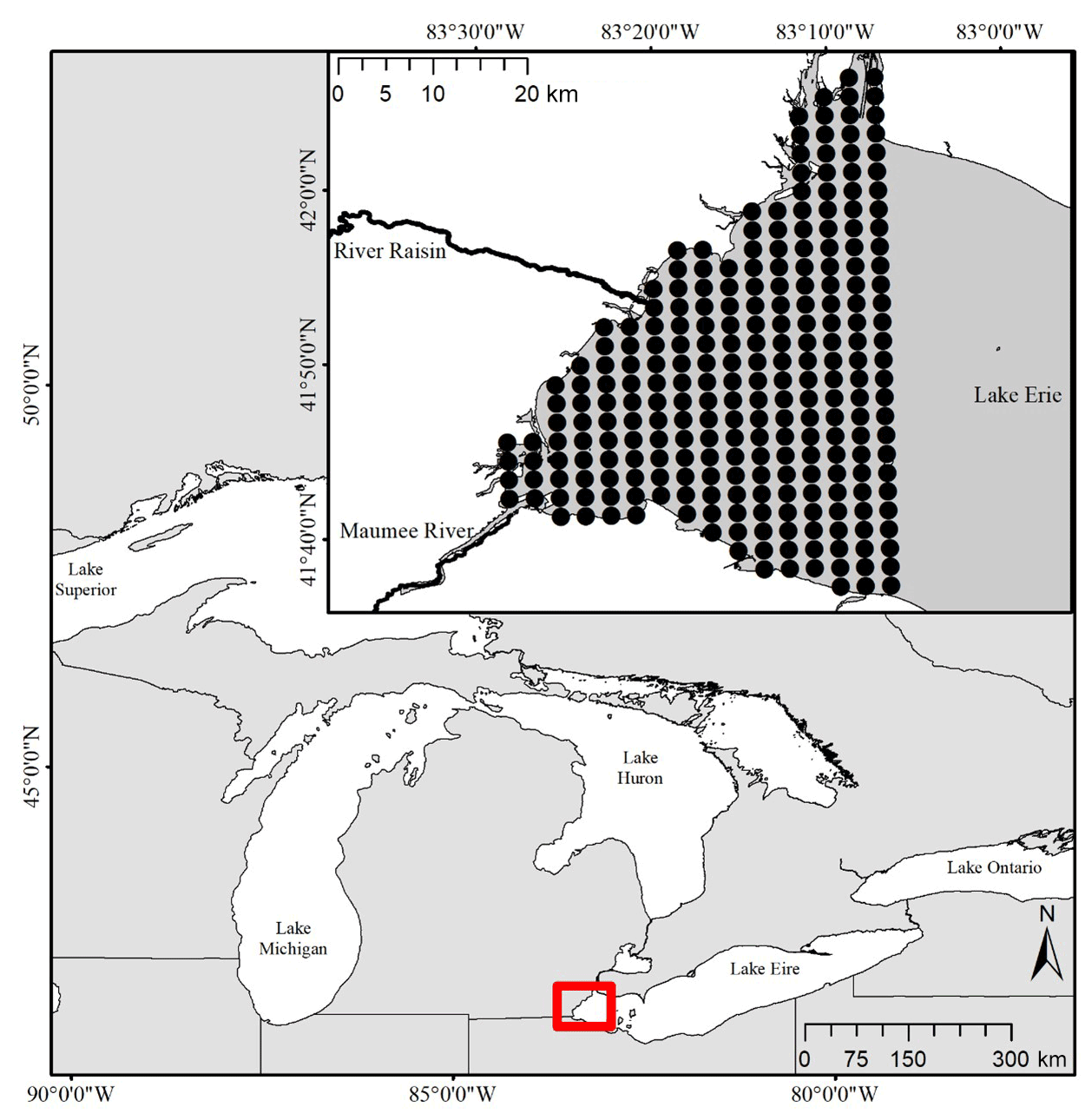
Figure 1Map showing the location of the study region in western Lake Erie. The inset map shows the tributaries and lake nodes that were included in the model. Our site boundary was defined by the western portions of Lake Erie. A grid of 2 km-by-2 km nodes was used to snap existing concentration data and define an adjacency matrix based on surface currents.
Lake Erie is an example of a water body that is challenging to model (Ho and Michalak, 2017; Steffen et al., 2017; Stow et al., 2015). While Lake Erie is large (25 700 km2), its western basin is relatively shallow (mean depth 6 m) (Bolsenga and Herdendorf, 1993), and intense nutrient export from the agriculturally dominated Maumee River watershed leads to episodic HABs (Watson et al., 2016). Commercial fisheries, drinking water, and human health within Lake Erie are all impacted because of the combination of nutrient addition, HABs, and physical lake properties (Wituszynski et al., 2017). Because of these intersecting concerns, a binational effort to regulate phosphorus entering Lake Erie has been active since 1978 (GLWQA, 2012). Nutrient concentration and physical lake data are pivotal in understanding the causes of western basin Lake Erie water quality issues and have been collected by a broad range of federal, state/province, and local agencies throughout western Lake Erie (Fig. 1). The goal has been to collect these data at a spatial and temporal scale, which should lead to a defined relationship of how river nutrient load affects lake nutrient concentration, understanding of the influence of riverine load through time and space, and ultimately the ability to predict how river load reductions would manifest as altered lake concentrations.
However, while western Lake Erie is routinely monitored and the nutrient concentration and flow are estimated daily in rivers, a generalizable connection between Maumee River phosphorus load and Lake Erie phosphorus concentrations remains undefined (i.e., if phosphorus load increases by 100 t, what is the response in lake concentration?) (Rowland et al., 2019). Spring Maumee River soluble reactive phosphorus export correlates with western Lake Erie HAB extent; this pattern has been observed since the soluble reactive phosphorus loads started to increase in the 1990s (Ho and Michalak, 2017; Michalak et al., 2013; Stow et al., 2015). The challenge is that nutrients in the lake move with the water currents, resulting in a complex relationship of upstream and downstream current dependence. Moreover, within-lake phosphorus cycling is dynamic and impacted by biological and physical processes (Li et al., 2021; Matisoff et al., 2016). Additionally, the time between sampling events within this time series and the size of the lake–river system where models need to be applied inherently adds uncertainty and reduces the predictive efficacy of transport models linked with hydrodynamic models (Schwab et al., 2009).
Bayesian state-space models have been used in ecology to incorporate temporal and spatial autocorrelation and quantify observation error separate from the error attributable to the modeled ecological process (Auger-Méthé et al., 2021; Durbin and Koopman, 2012; Shumway and Stoffer, 2019). State-space models are widely used in ecology to model animal populations (Buckland et al., 2004), movement (Royer et al., 2005), and fishery stocks (Meyer and Millar, 1999). Bayesian inference can quantify uncertainty in the effect of nutrient load on nutrient distribution within a dynamic system such as Lake Erie. Non-stationary time-series models have been used in the Great Lakes to model water levels (Lamon and Stow, 2010; Sellinger et al., 2008) and to predict polychlorinated biphenyl concentration in trout (Stow et al., 2004). The goal of this study was to use a spatially dependent time-series state-space model approach to define concentrations at unobserved locations and quantify the impact of river nutrient delivery across western Lake Erie. While spatial models have been used in the Great Lakes for predicting HAB biomass, HAB extent, and nutrient transport (Fang et al., 2019; Schwab et al., 2009), we proposed a Bayesian framework for similar spatial data. We showed that phosphorus concentration, along with an informed uncertainty, can be estimated by state-space models that incorporate concentration data from within the lake, the rivers, and lake surface currents. Although this approach is informed by the currents, it is does not include all the explicit biogeochemical and physical processes that are part of mechanistic models (Rowe et al., 2019). Our contribution to the ecological state-space model methodology is the incorporation of a surface-current-derived adjacency matrix, combined disparate agency field data, and inclusion of data from rivers as sources of information in fitting estimated values within a system dominated by missing values. Together our contribution will fit values in the absence of observations and allow experimentation in archival data previously not possible. Here, we quantified how well our model fits the data and generated predictions of total phosphorus (TP) concentrations across western Lake Erie. TP includes the dissolved and particulate forms of phosphorus. Additionally, we experimentally manipulated observed concentrations to estimate the spatial and temporal impact from the Maumee River plume. Using this delineated Maumee River impact in time and space, we tested the hypothesis that when water movement is incorporated, there is a linear relationship between river load and western Lake Erie water TP concentrations.
1.1 Study area and data curation
We limited the model spatial window to western Lake Erie (bounded by the portion of the lake west of −83.1∘ W, Fig. 1), which left ∼600 km2 to be defined. We gathered surface concentrations of TP (µg L−1) from publicly available databases through Environment Climate Change Canada's Offshore Water Quality Survey, the US Environmental Protection Agency's Great Lakes National Program Office, the Canadian Ministry of the Environment, the Conservation and Parks Great Lakes Intake program, the US National Oceanographic and Atmospheric Administration (NOAA) Great Lakes Environmental Research Laboratory (GLERL) Ecosystem Dynamics Long-Term Research program, and NOAA GLERL Western Lake Erie (WLE) Sampling (Table A1). The data used here extended from 2008 to 2018. For riverine TP concentrations from the Maumee River and Raisin River across the 2008–2018 interval, we downloaded data from the National Center for Water Quality Research (NCWQR) at Heidelberg University (Table A1). When multiple samples were collected from a node on a single day, the sample average was used.
1.2 Model description
We created a model where day t TP concentrations are predicted based on the concentrations “upstream” at day t−1. The spatial adjacency of “upstream” relationships was defined by the direction and magnitude of surface currents.
To build our adjacency matrix, we first defined a hypothetical distance and direction that surface water moved based on surface currents. We used surface current data retrieved from the NOAA Great Lakes Coastal Forecasting System (GLCFS, Table A1) database. These data are defined by hourly eastward and northward water velocity (m s−1) predicted across Lake Erie on a 2 km-by-2 km grid (Fig. 1). Hourly northward and eastward velocity (m d−1) for each node for the years 2008 to 2018 defined surface current direction in radians (dLat and dLon) using the node latitude (Lat0) and longitude (Lon0), the Earth's radius (R, 6 378 137 m), the northward velocity offset in meters (dN), and the eastward offset in meters (dE) (Eqs. 1 and 2). The direction the surface water travelled in radians was used to determine the latitude (Lat1) and longitude (Lon1) represented by each hourly movement (Eqs. 3 and 4) and was repeated for 24 h until the final position of the surface water movement from each node was determined (Fig. B1).
The limited model spatial window of western Lake Erie was represented by 254 nodes (Fig. 1). The Lake Erie surface water TP concentrations were associated with their closest nodes of the same 2 km-by-2 km grid nodes used in the surface current data sets. NCWQR concentration data were collected for the Maumee River (41.5∘ N, −83.712778∘ W) and the Raisin River (41.960556∘ N, −83.531111∘ W) locations ∼30 and ∼18 km, respectively, inland from Lake Erie. River concentrations were assigned to the node closest to the river mouth. The assumption that these concentrations represent the conditions at the terminus of the rivers adds uncertainty to our modeling; however, the spatial extent of this extra uncertainty should end where the Lake Erie TP concentration data begin to inform the model posterior samples.
1.2.1 State-space models
We constructed hierarchical, spatially referenced Bayesian state-space models (SSM) for each year to estimate TP concentrations for each node on each day. The data were logged prior to fitting the model, and MCMC samples remained in log space until exponentiated for plotting. The temporal range annually was 20 May to 2 October to coincide with the majority of the WLE sampling. The distance between each daily offset surface current location (Lat1, Lon1) and each 2 km-by-2 km concentration node was measured, and the node n with the shortest distance defined the adjacency matrix to associate each node n on day t with the node k on day t−1. The state-space model consists of two models, an observation model of data (y) and a latent state (x) process model.
Log-transformed TP concentration observations (y) at the nth node on the tth day of the yth year were estimated with a normal data model sampled from the unobserved latent state variable (x) at the nth node on the tth day of the yth year with standard deviation σ (Eq. 5). The process model is a first-order Markov, only depending on the value of the node at time t−1 which transported TP to node n at time t; that source node is denoted k. For nodes in the river, k=n, and for nodes in the lake, k is determined from the time t adjacency matrix.
where
The latent state (, Eq. 6) is sampled from a normal distribution of a predicted latent state (, Eq. 7) and standard deviation τ. was truncated by the detection limit of TP laboratory analysis (5 µg L−1, a, Eq. 6) and the maximum value observed in each year (y) within the Maumee River (b, Eq. 6). The maximum observed Maumee River concentration was used as the upper truncating value because no observation in the lake will exceed this value. Priors were uninformative and defined as
River model coefficients (βmau and βrai) were fit hierarchically () because the ecological and anthropogenic processes enacted on these watersheds are similar, if at different scales. The two lake models were fit with two independent β coefficients depending on whether the nearest adjacent node k is the same as the estimated node n (βself) or whether a different node k is nearest (βlake). Separate independent in-lake models were used to capture different potential drivers of TP concentration through time depending on whether each node was subject to little surface water movement (βself) or active surface water movement (βlake). In 2012 there were no Raisin River observations, and so the model in 2012 treats the Raisin River node as a lake node. The model was run in R (version 4.0.2) and JAGS (version 4.3.0) (Eddelbuettel, 2017; Microsoft Corporation and Weston, 2020; Plummer, 2019). Each year's model iteration count was 50 000 with a thin of 10, representing 5000 effective samples along three independent Markov chains. The chain convergence was monitored by Gelman and Rubin's convergence diagnostic. Scale factors less than 1.1 were used to define when chains had converged (Plummer, 2019). Initial conditions for the latent state were defined as the mean and variance of the previous year's first 20 d. The first year's (year 2008) initial conditions were estimated as N(12,5) (Rockwell et al., 2005). The goodness of fit of the models was described via posterior predictive p values (Gelman, 2013) and Bayesian R2 (Gelman et al., 2019), while the performance between years and across nodes was assessed with K-fold cross-validation (CV) utility (Geisser and Eddy, 1979; Piironen and Vehtari, 2017) (Eq. 8).
1.2.2 Fitting the SSM and diagnostics
Posterior predictive p values were calculated by model year with test statistic mean TP concentration to compare means of observations to the means of the model outputs. For each year, a posterior p-value distribution was described by 15 000 bootstraps of 100 resamples from the observed node posteriors. Bayesian R2 defined as the fitted variance (varfit) divided by the sum of varfit and the residual variance (varres) was calculated for each model year. Model varfit was the variance of the modeled predictive mean, while varres is estimated by squared standard deviation of the errors (Gelman et al., 2019).
K-fold CV utility compared model predictive performance across years and across nodes. The cross-validation via leave one node out was used to evaluate model predictions where observations are not available. This estimate of model performance is needed as our data set has far fewer observations than the product of nodes and time points, and estimates of R2 report how well the model does while given all the available data. Additionally, the cross-validation estimates aggregated by unobserved node (space) or by year (time) define how well the model estimates TP values irrespective of the node's proximity to the TP river sources or the number and location of annual in-lake observations. The cross-validated utility was applied by removing all d observations from a randomly selected node k with at least 10 observations collected during the model year. K-fold CV was calculated three times per year; for years that had fewer than three nodes with at least 10 observations, all nodes that satisfied the 10-observation cut-off were used. K-fold CV, the mean leave-one-node-out log-predictive density from posterior samples of the omitted d observation at node k, day t, and year y, were compared to observed concentrations at (Piironen and Vehtari, 2017) (Eq. 8).
Using a model that describes posterior predictive distributions of mean K-fold CV across years and nodes, we examined whether our state-space approach preferentially generated predictions for certain years or certain nodes that contain the observed values (Eqs. 9 and 10); 95 % credible differences between group means (for nodes μn or for years μy) that do not contain 0 were used to determine whether groups were different (e.g., if the 95 % credible difference from μ2018 to μ2017 contains 0, these means are not considered different).
μon and μoy were fit with normal priors , and σKFCV was defined as the standard deviation of the K-fold CVs. The μn and μy were given normal priors and σμ, which functions as the within-group variance has a gamma prior with rate and shape estimated from the mode and standard deviation of the K-fold CVs (Kruschke, 2015, p. 560). Finally, σn and σy, which represent the between-group variance, were fit with a uniform prior . ∑μn and ∑μy were constrained to 0 when fitting μon and μoy.
1.3 Model experimentation
Our state-space models were used to test the hypothesis that western Lake Erie TP concentrations are a linear function of Maumee River TP load when surface water movement is incorporated. We incorporate water movement into our linear model by first estimating the spatial impact of the Maumee River. The Maumee River impact plume was estimated by artificially reducing the Maumee River TP concentrations by 50 % (); each year's model was then refit (Eqs. 5–7). The model output for each node was examined, and the position of each node's concentration () 95 % PI (predictive interval) was compared to the original model (). The change from the original 95 % PI of , which we call the deflection, was interpreted as evidence that the Maumee River node was, at some time step, influencing node n. The annual mean root-squared sum of the 95 % PI change compared to the 95 % PI was then normalized by the largest value for that model year (y); this normalized estimate of PI change (dn,y) across the 254 nodes within our spatial window was used to define effective Maumee River spring TP impact within Lake Erie. We estimated Maumee River spring load estimates (ly, tons TP) by multiplying NCWQR daily flow and TP concentration data (Table A1) from 1 March to 31 July annually. Finally, we multiplied dn,y and ly to represent a spatially explicit effective Maumee River TP spring load at each node ().
A linear model of mean TP concentration () per year per node (n, where node n had at least one observation) as a function of effective spring Maumee River TP load () was used to test for a linear relationship between Maumee River load and Lake Erie surface water TP concentrations. The model was fit in a Bayesian framework, which allowed us to fit the heteroscedastic relationship of concentration and effective load by fitting a positive linear relationship to model variance and effective load (Eq. 11). β1,2 were given non-informative normal priors , while α1,2 were given non-informative log-normal priors because they must be positive random variables.
The annual data sets defined by TP concentration observations and riverine TP data on our 2 km-by-2 km grid in western Lake Erie contained an average of 99.1 % missing values. The number of nodes that contained observations ranged from 14 to 40 among years. The mean number of samples available at each observed lake node during the model year ranged from 2 to 9. Within the 252 Lake Erie nodes across the available 11 years, a total of 1218 observations were collected; our hierarchical spatially referenced Bayesian state-space model was then able to provide estimates for the 375 774 unobserved TP concentrations. Between the Maumee River and Raisin River, a total of 2258 observations were available in the data set, and the missing 734 values were also described by posterior distributions. The mean values of the observed TP concentrations within the Maumee River, Raisin River, and western Lake Erie were 170 µg L−1 (95 % interval, 3.5 to 438 µg L−1), 80 µg L−1 (95 %, 40 to 215 µg L−1), and 38 µg L−1 (95 %, 10 to 203 µg L−1), respectively.
2.1 State-space model fit
To assess the goodness of fit of the model, we determined annual Bayesian R2, posterior predictive p values, and k-fold CV utility. The 11 years of models had mean Bayesian R2 values from 0.84 to ∼1 and mean posterior predictive p values from 0.42 to 0.59 (Table 1). Posterior predictive p values of 0.5 indicate a good fit between model output and observations, and the 95 % CI of all our yearly posterior p-value distributions contains 0.5. Finally, the results of the k-fold cross-validation utility 95 % credible difference showed no difference across all pairwise comparisons of mean K-fold CV by year or node.
Table 1Bayesian model assessment via p value (posterior predictive p values of 0.5 are indicative of a good fit and 95 % CI (credible interval) of our yearly results, each containing 0.5), and R2 (each year > 0.8) showed the model-generated posterior samples similar in structure to the observations.

2.2 State-space model outputs
Posterior distributions for each node on each day provide estimates for TP concentrations where observations are present and in the absence of observations (2018 in Fig. 2, 2008–2017 in Appendix D). Mean and 95 % PI model posterior samples of each node at every day defined our predicted concentration. By example, the Maumee River node in 2018 shows the model following the data and widening PIs where observations are missing (Fig. 2a). For Lake Erie nodes that contained observations, the posterior samples follow the broad trend in the observed data (Fig. 2b). Nodes without any observations also follow the trend in downstream observed nodes, and while the uncertainty is larger at unobserved nodes, the PIs stay within expected values (Fig. 4c).
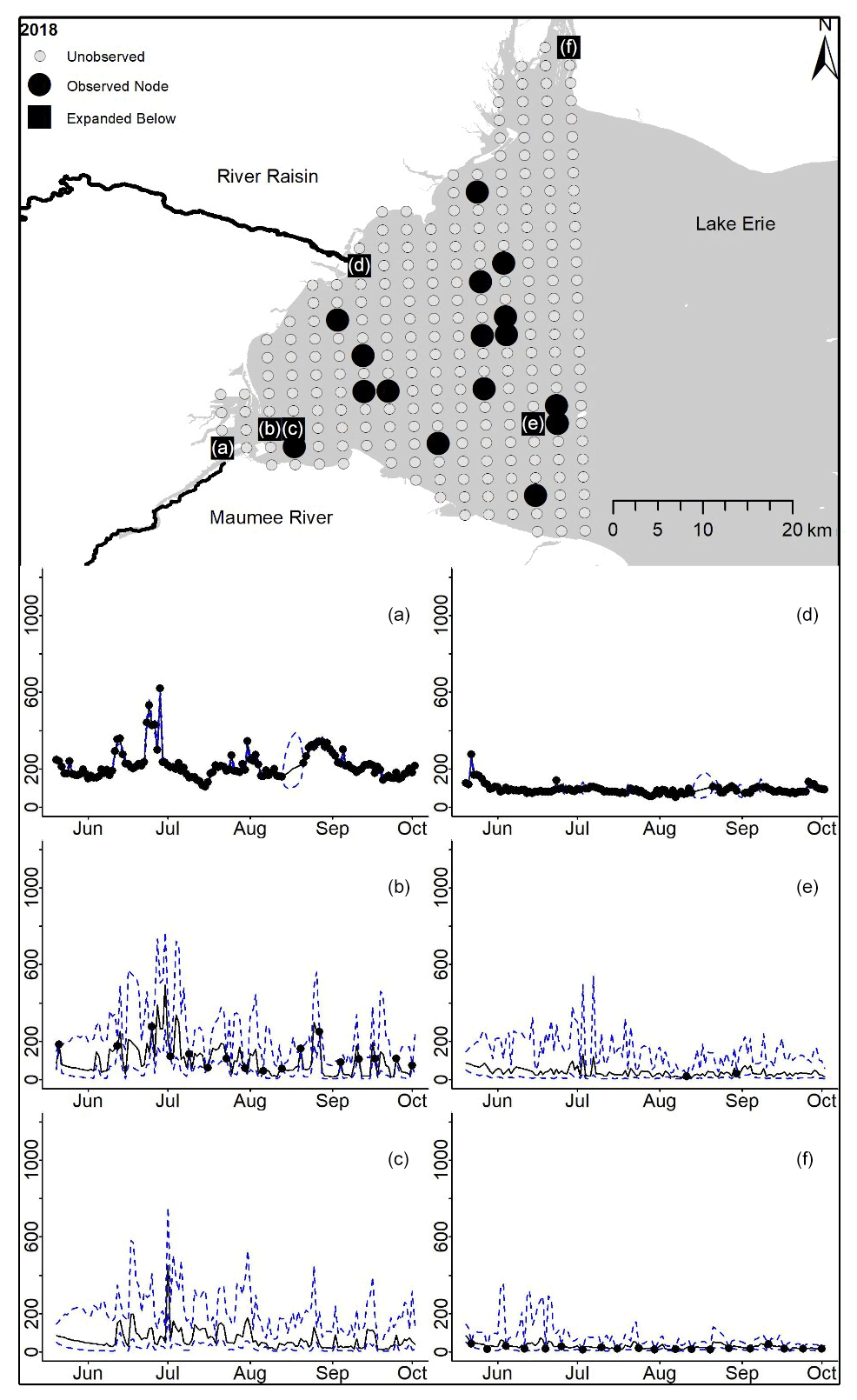
Figure 2For 2018 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
2.3 Model experimentation
After artificially reducing the Maumee River concentrations by 50 %, the nodes where TP concentration PIs were altered were defined as being within the Maumee River area of impact. The mean square root of each node's summed squared deflection annually normalized by the largest mean value (dn,y) in general was highest near the mouth of the Maumee. The impacted area spread south and east along the state of Ohio's coast most years, but some years were subject to larger plumes distributed further north (Fig. 3, Video Supplement 1).
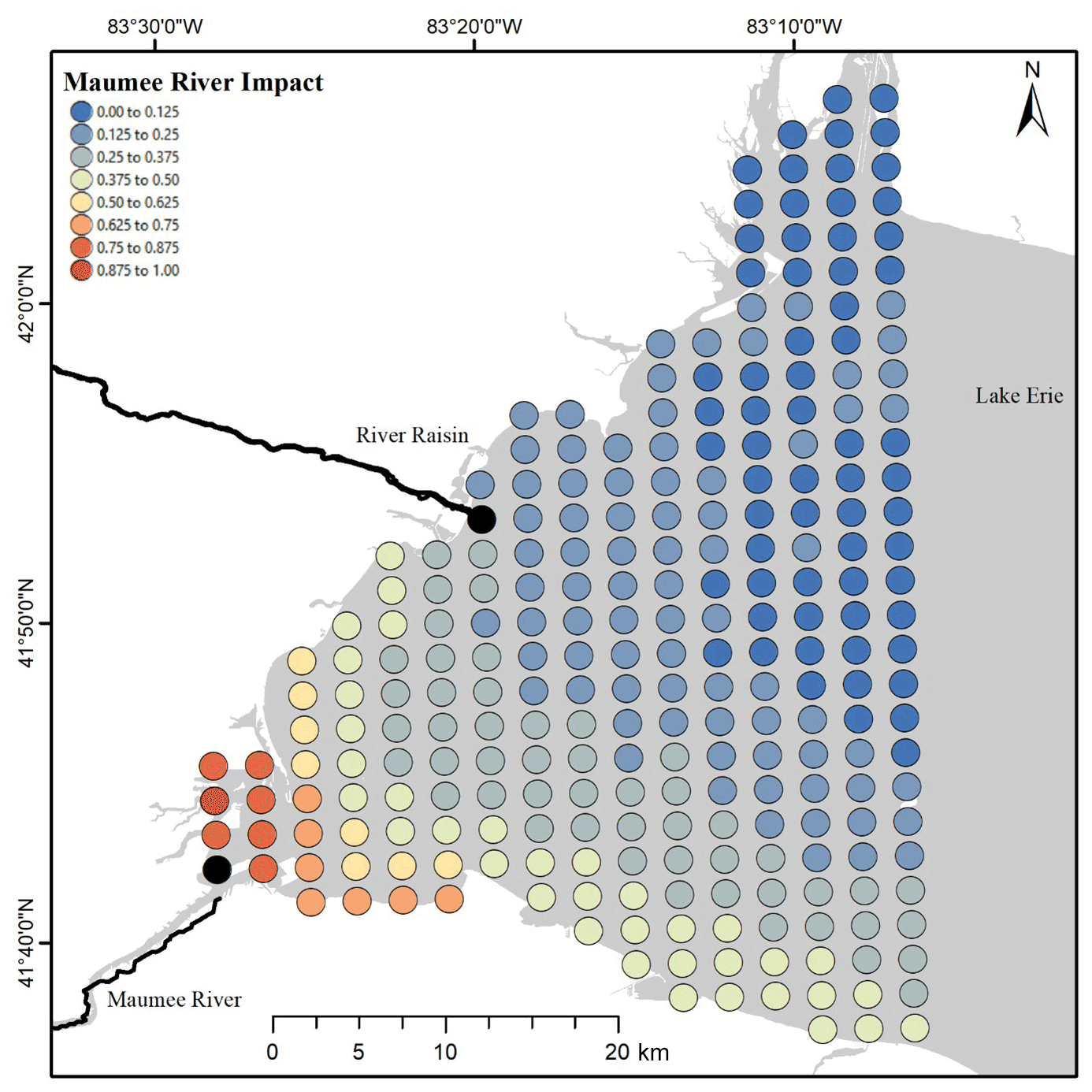
Figure 3Heatmap of the mean Maumee River impact plume from 2008 to 2018.
The normalized annual mean Maumee impact estimates (dn,y) generated per node were used to adjust spring load to an effective spring load () at each node where samples were collected. Lake Erie TP concentration was linearly correlated with the effective Maumee River TP spring load (mean node concentration = 23.1 (±1.75, 95 % CI) + 0.11 (±0.01, 95 % CI) × effective spring load (tons TP); Fig. 4). The heteroscedastic error in the mean concentration () and effective load () relationship was defined by a linear function (). α1 was estimated to be 2.9 (±1.4, 95 % CI), and α2 was 0.04 (±0.008, 95 % CI).
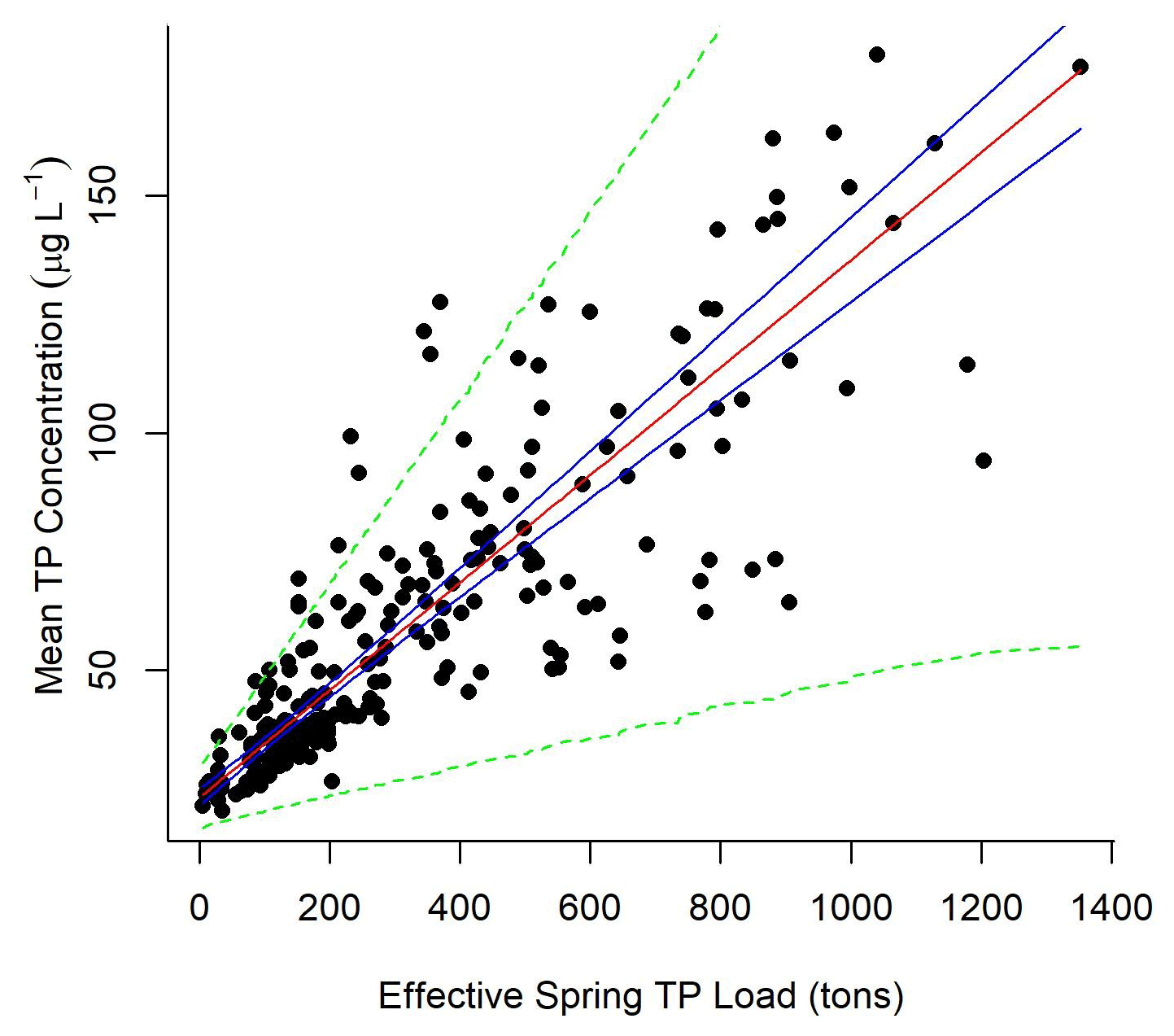
Figure 4Mean concentration at the observed nodes for each year was modeled as a function of the relative Maumee River spring TP load (mean concentration = 23.1 (±1.75, 95 % CI) + 0.11 (±0.01, 95 % CI) × effective load), where variance in concentration increased linearly with effective load. Effective load was defined by multiplying the normalized river impact generated by experimentally tracing the Maumee River's impact on Lake Erie nodes annually; 95 % predictive intervals of the data (green dotted lines) and 95 % credible intervals of the linear relationship (blue solid lines) were generated from the model output.
3.1 State-space model fit
By combining the western Lake Erie TP observations with riverine data and surface currents within a Bayesian model framework, we were able to generate estimates of TP across time and space. The models consistently generated plausible posterior samples for mean TP concentration as each 95 % CI of annual posterior predictive p values included 0.5, and annual Bayesian R2 95 % CI values ranged from 0.84 to 0.99 (Table 1). Annual posterior predictive p values indicate that our model framework is preforming well in predicting water quality within large water bodies, even with sparse observations within the data. While our high Bayesian R2 values appear to support the use of our model, it is likely that they represent an inappropriate model metric. The state-space framework forces the model to pass through the observed data, and the daily observations in the river data sets (Fig. 2a and d) are likely driving Bayesian R2 values higher with their constrained predictive intervals. Because of these elevated Bayesian R2 estimates, the k-fold CVs are important checks on the applicability of this state-space approach. The k-fold CV results generated by removing all the observations of a randomly selected lake node with at least 10 observations showed that model predictions were equally accurate across years and by node. Predicting equally well across the nodes and within any year provides strong support for this framework as being a useful application of Bayesian methods in water quality modeling.
TP is a conservative water quality constituent. TP observations are insensitive to biogeochemical transformations of phosphorus form because these data represent both the organic and inorganic forms of phosphorus occurring in the water column. βmau, βras, βlake, and βself fit in our models had 95 % predictive intervals encompassing a value of 1. Coefficients were close to 1 because, on our daily time step, the TP concentrations do not widely vary (e.g., the concentration today is similar to the concentration yesterday). The uncertainty in the process and data models allows the model predictions to trend toward the observations where available and be constrained where previous time steps passed through observations. Were these coefficients to exceed 1, this would be evidence of other inputs of P or less that 1 would indicate some internal loss such as settling or dilution. TP is conservative to processes within the water column because it accounts for the dissolved and particulate P; if our model was applied only to dissolved P, which is subject to strong assimilation pressure by phytoplankton, the model coefficients would likely be negative. While dilution, settling, and internal loading of TP are happening within our modeled extent in western Lake Erie, our model lacks the specificity to capture dilution, settling, and internal loading, and therefore their effect is being accumulated in our error terms. However, this state-space framework could be defined with a mechanistic process model that did capture these effects. Additionally, while our framework could be implemented with the coefficients (βMau, βRas, βLake, and βSelf) fit hierarchically by year potentially defining the overall effect of dilution, settling, and internal loading, current restrictions on computer memory prevented that use here. However, for smaller spatial and temporal models, it could be effective.
No identifiability issues were found: this was assessed by visually determining whether priors dominated the fit of coefficients (Auger-Méthé et al., 2021) (Fig. C1a and b). The lack of σ and τ correlation was also visually assessed (Fig. C1c). Fit process model or data model uncertainty was well identified (Fig. C1d). The apportionment of uncertainty between the process model and the data model varied from year to year (Table C1). This was driven by annual variation in the data model uncertainty. The 2012 Raisin River coefficient (βras) predictive interval was larger than other years because of a lack of data in that year. The proportion of uncertainty between process and data model also varied only slightly (Table C1), possibly because of the number of or spatial positions of observations. We propose that these annual differences were due to the combination of the number of samples collected and their relative positions to the surface currents. However, the uncertainty within our models did not prevent accurate outputs estimating TP concentrations at observed and unobserved nodes.
3.2 State-space model output
An important property of this modeling approach is that the surface-current-derived adjacency matrix we used to define our predicted spatially explicit latent state concentration () also produced estimates of TP concentration at nodes where no observations were available. This approach takes discrete measurements in western Lake Erie and establishes connections across the lake surface and through the model year. The model does this across 136 d and 254 2 km by 2 km nodes, yet model uncertainties are within the range of TP concentrations expected for western Lake Erie. Nodes along the eastern perimeter of the spatial window of our model have additional uncertainty inherent in their position. Occasionally, they will not be associated with the proper “down-gradient” node because the extent removes those nodes. Within our system there is little practical effect as these nodes are far from the Maumee River and are dominated by low concentrations. This is a potential problem in other systems and may necessitate wider spatial windows to eliminate.
Our model framework allows information from discrete grab samples to be shared across any water body where the movement pattern of water is available. Additionally, this model can generate estimates at unobserved nodes or at unobserved time steps of observed nodes without requiring defined biogeochemical processes of a mechanistic model. For our application, the 2 km-by-2 km grid was chosen to match the surface current data set. While we did not experiment with other discrete grid distances, any applicable configuration will work. Defining a reasonable grid distance could be based on the spatial distribution of the available data and the user's willingness to extrapolate or average surface current direction and magnitude. Similarly, our temporal time step was daily, but this could also be applied to monthly data in data-sparse systems or hourly data in data-rich applications. This spatial and temporal flexibility or using state-space frameworks gives users the capacity to tune the computational runtime and resolution of models to fit the hypothesis tested.
Within Lake Erie, having estimates for unobserved nodes and nodes that are infrequently sampled allows a connection between discrete point data collected by boat and data layers which cover large sections of a lake surface. The spatial distance and temporal disconnect between the data generated by multiple actors on the same water body often preclude the combined use of data from multiple projects. However, state-space models which explicitly incorporate time as well as space via water movement could harness more of the available data to make predictions beyond the spatial bounds of the original projects. For example, remotely sensed data layers would be especially useful in this model structure, both as predictor variables and as the response variables. Connecting estimates of TP concentrations to chlorophyll-a concentrations would enhance existing predictive models of cyanobacteria distribution and biomass (Fang et al., 2019).
The agencies and organizations collecting grab samples within Lake Erie would also be able to use the state-space model output to select sample locations specific to hypotheses. The model can be used to predict the movement of high nutrient water masses which investigators could target. Additionally, projects examining the impact of the Maumee River could sample in and out of the Maumee River impact plume. Beyond the impact on fieldwork, this modeling approach can also be used in model selection. Since this modeling approach is based entirely on observations in the absence of independent explanatory variables, it should be used as a benchmark model for future mechanistic or more complex models to be tested against.
3.3 Model experimentation
Having demonstrated the functional capacity of our hierarchical spatially referenced Bayesian state-space model predicting TP concentrations, our hypothesis was that a linear relationship exists between spring Maumee River load and observed Lake Erie concentrations. By experimentally reducing the concentrations for the Maumee River and rerunning the model, we were able to track the “downstream” repercussions for the lake-node-predicted values and to infer the Maumee River impact plume. Tracking a plume of TP impact using the grab samples was not previously possible because of the distances between sampling locations and the fact that the number of unobserved days outnumbers the observed days. Distance and direction across our model extent are wrapped up in the change observed in predictive intervals through time. In our framework distance and whether the water mass from the Maumee River physically moves toward a node combine. There are several days in which even the nodes closest to the Maumee River are bypassed because the currents take Maumee River water in a different direction. The dual complications of distance and movement have complicated previous attempts at defining a single relationship between Maumee River load and observed in-lake concentrations, which we overcome here.
The plume extent in general follows the southern coast (Fig. 3), which would be expected because of the movement associated with the Coriolis effect. Importantly, this is not a plume that displays a high concentration of TP; rather, this is the impact plume of the Maumee River. Concentrations outside the impact plume are not influenced, or are weakly influenced, by the Maumee River, and thus load reductions within the Maumee River would not impact lake concentrations in those areas. Our linear model (Eq. 11) estimated that when the effective load of the Maumee River was 0, the mean annual concentration in the area where samples were collected would be 23.1 µg L−1 ±1.75, 95 % CI.
Each year the Maumee River TP impact plume dimension and intensity changed. Rowland et al. (2019) demonstrated how a linear model of Lake Erie TP observations as a function of Maumee River spring loads defined positive relationships at the closest nodes. Here, we were able to fit parameters that define the load-to-concentration relationship across all of western Lake Erie. Much of the regulatory attention in addressing Lake Erie HABs has focused on Maumee River spring export, and providing this quantitative connection is important in furthering watershed TP reduction efforts. Our model estimated that for each 100 t of spring TP effective load delivered to Lake Erie, TP concentrations in the lake increase by 11 µg L−1 (±1, 95 % CI). We could use our defined linear relationship for hindcasting expected concentration reductions in western Lake Erie based on Maumee spring TP loads which were reduced by 40 % for all our model years. Additionally, given a mean concentration maximum, we could predict the load reductions required in previous years to meet that target. Using our linear relationship between lake concentration and spring load to make forecasts for future years is harder. The size and shape of the Maumee River impact (dn,y) change each year (Video Supplement 1), and our method defines the river impact from observations. Without being provided an estimate of dn,y, a forecast of mean western Lake Erie TP concentrations based on a proposed spring TP load is not achievable. An achievable next step for this modeling framework could be to link the size of the Maumee River plume and Lake Erie TP concentrations to HABs biomass and toxin production; the spatial aspect of such a model could explain why the relationship between bloom biomass and Maumee TP export is not linear (Obenour et al., 2014).
Our state-space model framework was shown to fit the data well, generated reasonable estimates of concentration at observed and unobserved locations, was modified experimentally to estimate a river impact plume, and used the experimentally derived plume to test a regulatory relevant hypothesis. Adequately characterizing water quality in a large water body is difficult. Sampling and laboratory analysis are expensive and excessively time-consuming for feasibly covering even a portion of Lake Erie with high temporal and spatial resolution. However, we demonstrate that a Bayesian state-space framework informed by an adjacency matrix defined by surface currents can generate daily TP concentrations which are constrained by uncertainties appropriate for lake conditions. By combining the data from two rivers entering the lake, our model (Eqs. 5–7) enables the rivers to inform the observed and unobserved lake nodes, the observed lake nodes inform the unobserved lake nodes, and unobserved lake nodes also inform unobserved and observed nodes. This information sharing across time and space empowers this model to connect sparse data across large distances. By experimenting with the model, we were able to estimate a plume of impact from the Maumee River and to apply the experimental results to hypothesis testing. The model is amenable to using remote sensing data and can effectively connect lake-wide data sets with discrete grab samples. The application here used TP, but any analyte could be modeled in this same structure to generate estimates through time and space, test hypotheses, or build baseline models to test process-based models against.
Table A1The data sources for total phosphorus concentrations and surface currents were all retrieved from publicly available online repositories.
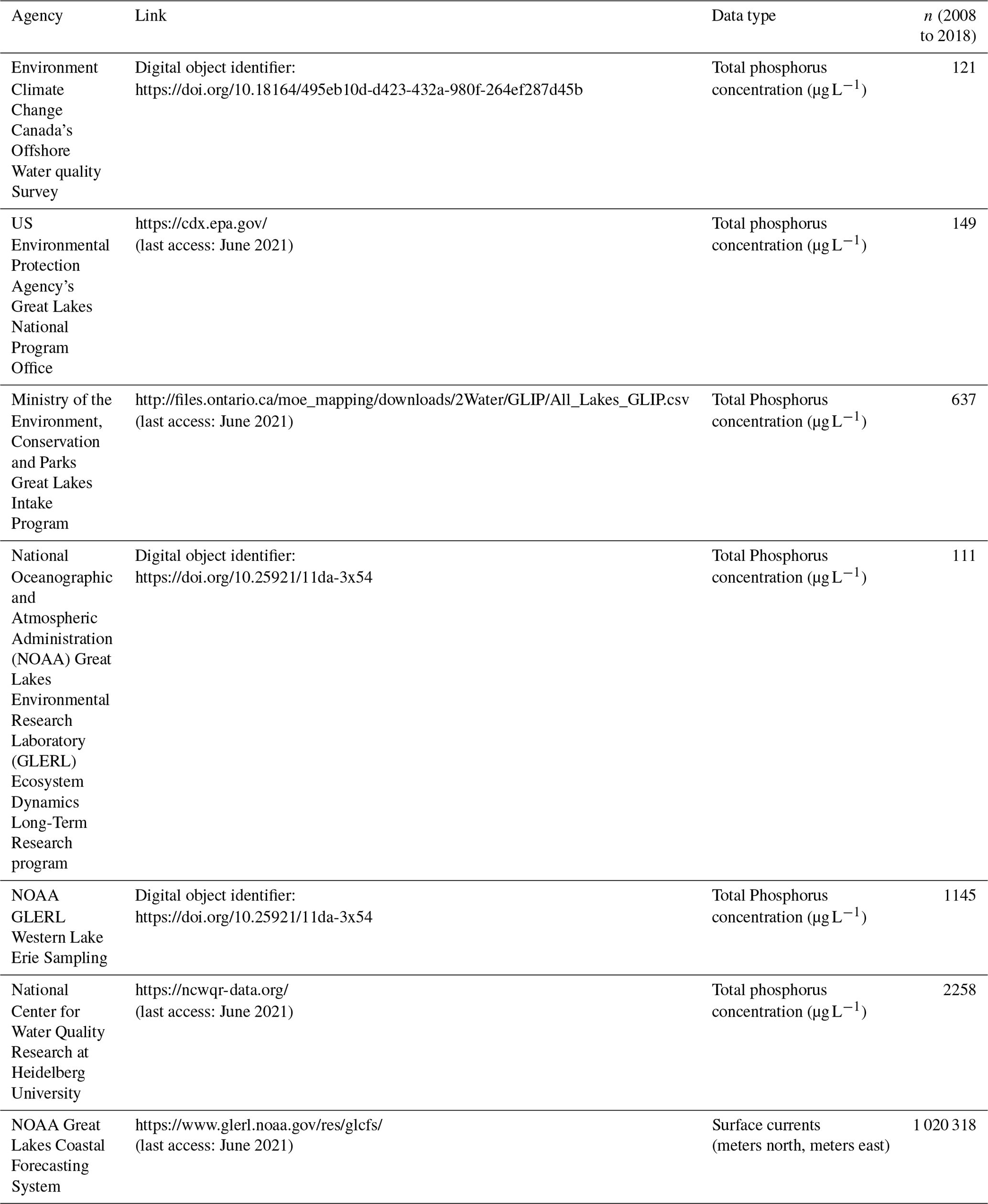
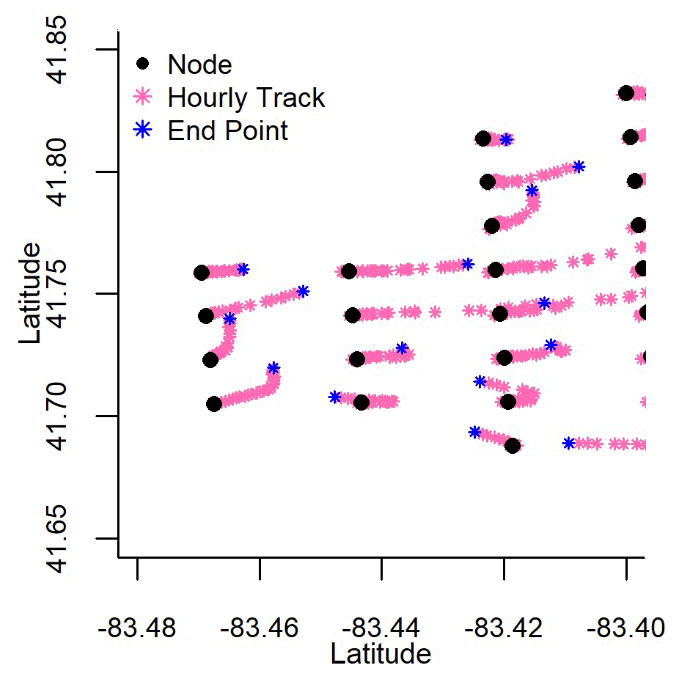
Figure B1Surface current data were available hourly within western Lake Erie. These 24 h data were used to track the daily movement of water from each node.
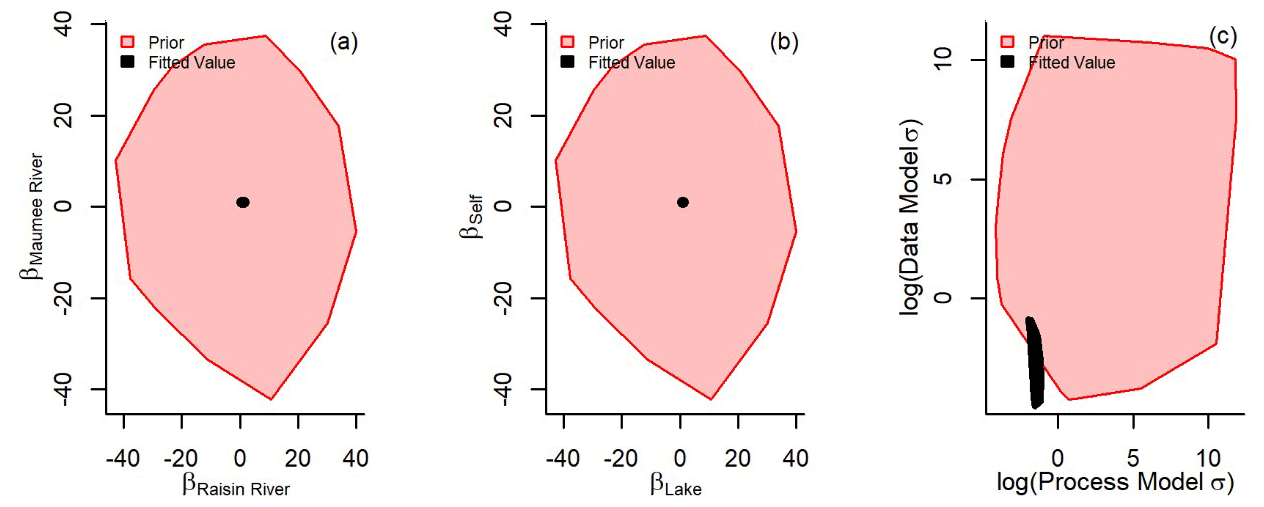
Figure C1Non-informative priors were used to fit the state-space coefficients of the Maumee River (βmau, a all values represented as red polygons), Raisin River (βras), the western Lake Erie nodes subject to movement (βlake, b red polygons), and those Lake Erie nodes which did not encounter sufficient water movement to associate with an “upstream” node (βself). The fitted values for every year (a and b, all values represented as black polygons) do not appear to be overly influenced by the uninformed priors. The log data model and process model uncertainty (c) for every year were also well identified (the uncertainty σ was logged to aid in visually comparing prior and fitted values).
Table C1State-space models in western Lake Erie fit coefficients predicting TP concentrations from the previous time step within the Maumee River, the Raisin River, Lake Erie, and lake locations where the current time step is informed by the same location, βmau, βrai, βlake, and βself, respectively. The 95 % PI (predictive interval) for each year and coefficient was examined. The same models fit the annual process model and data model precision.
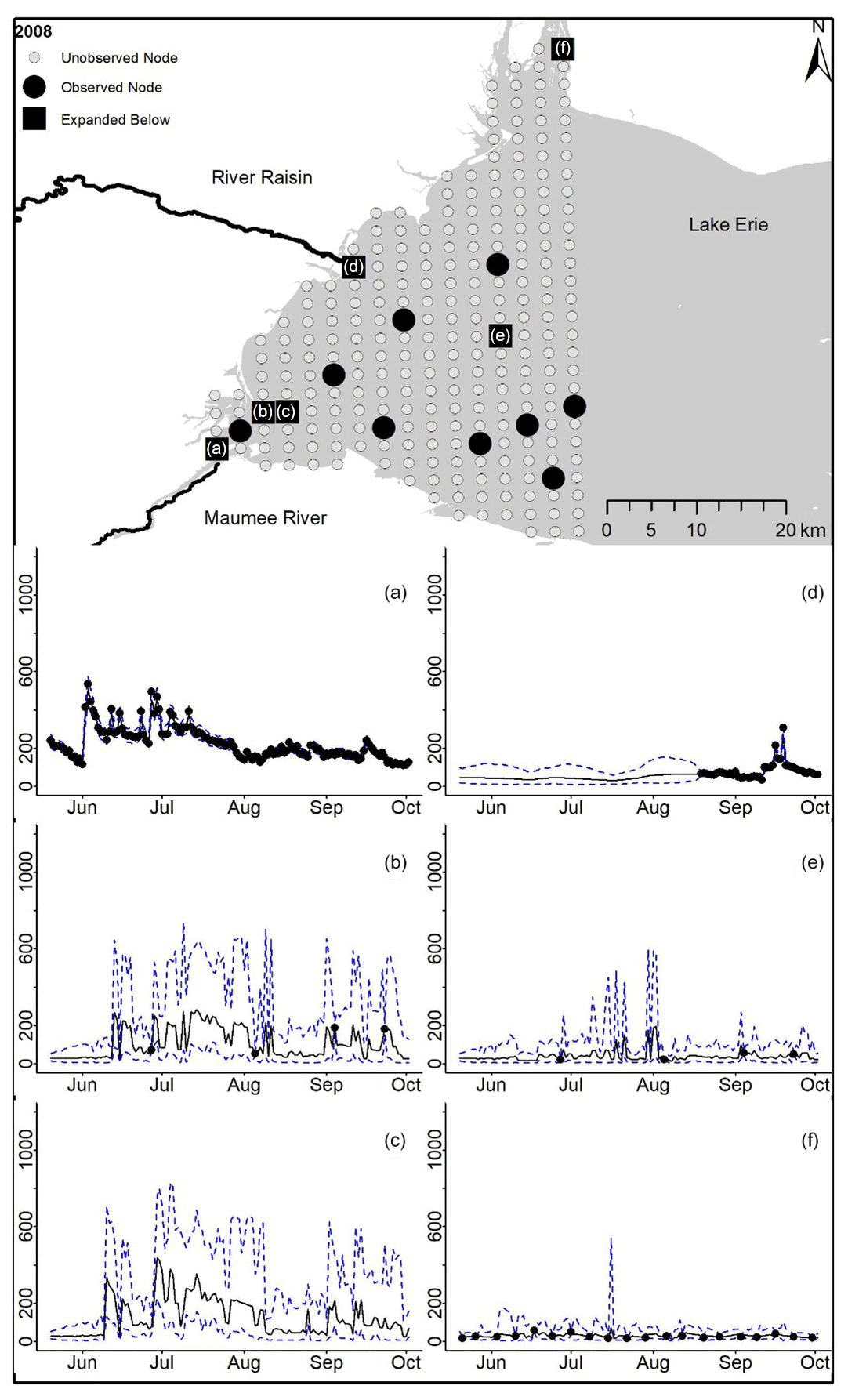
Figure D1For 2008 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
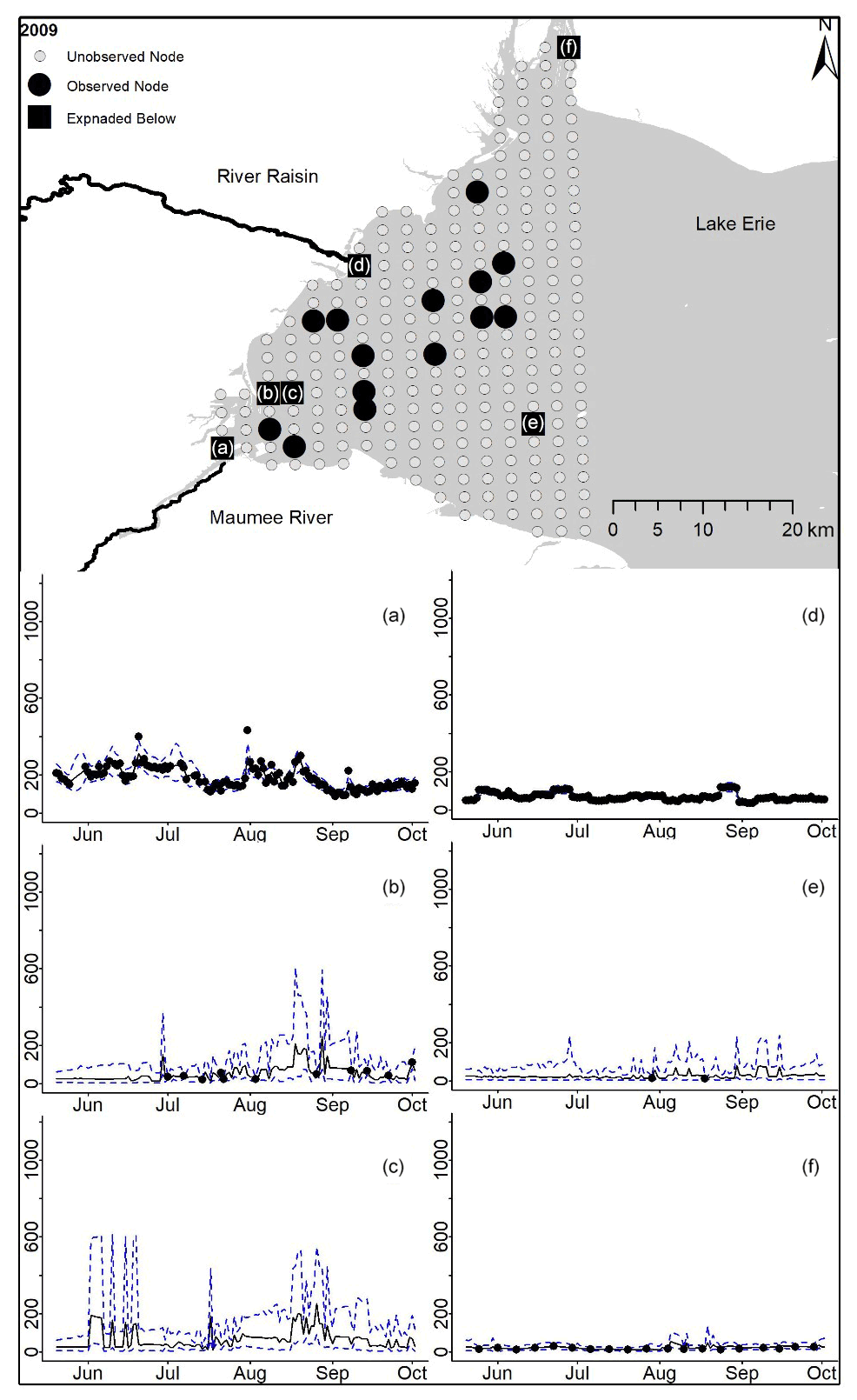
Figure D2For 2009 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
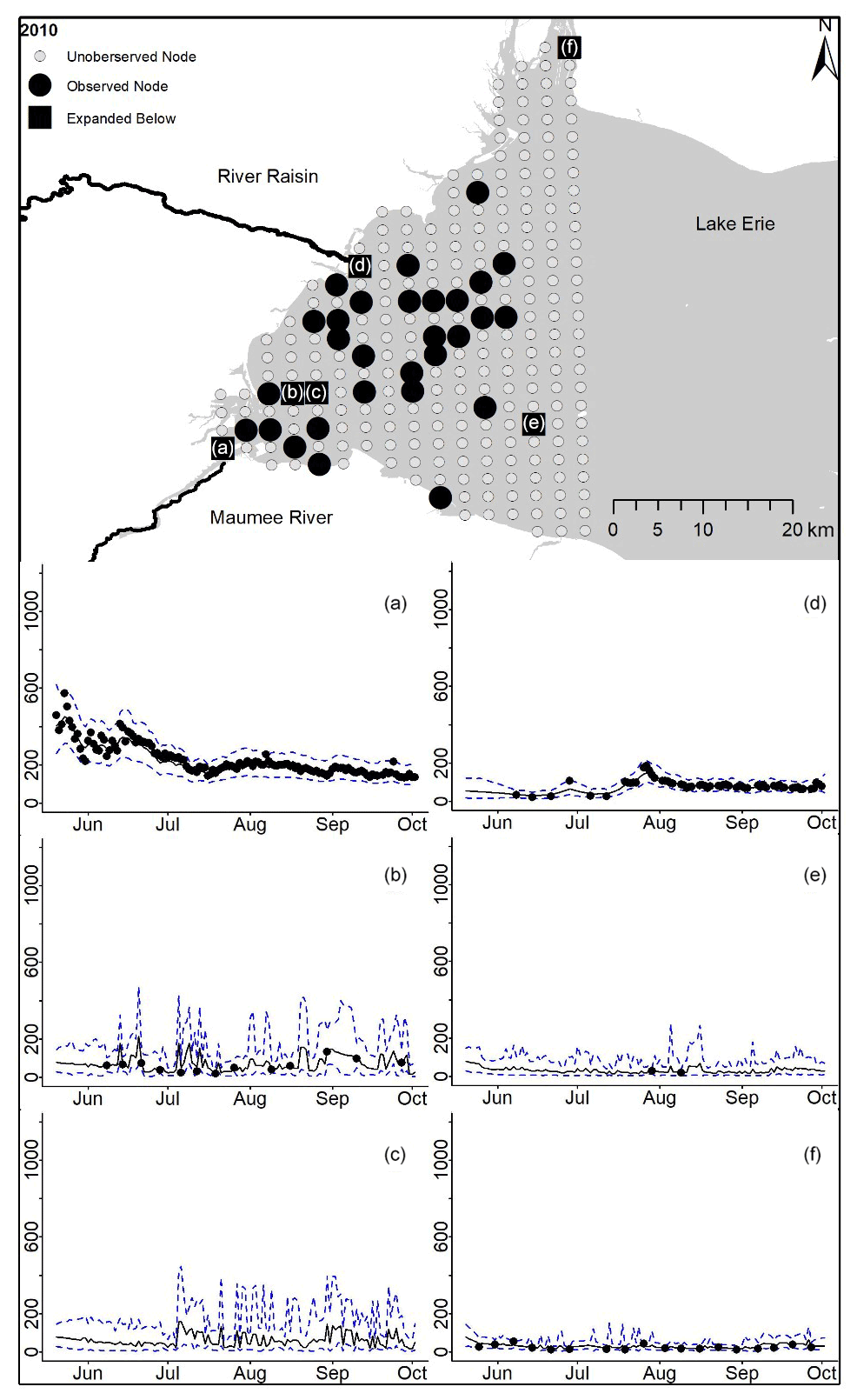
Figure D3For 2010 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
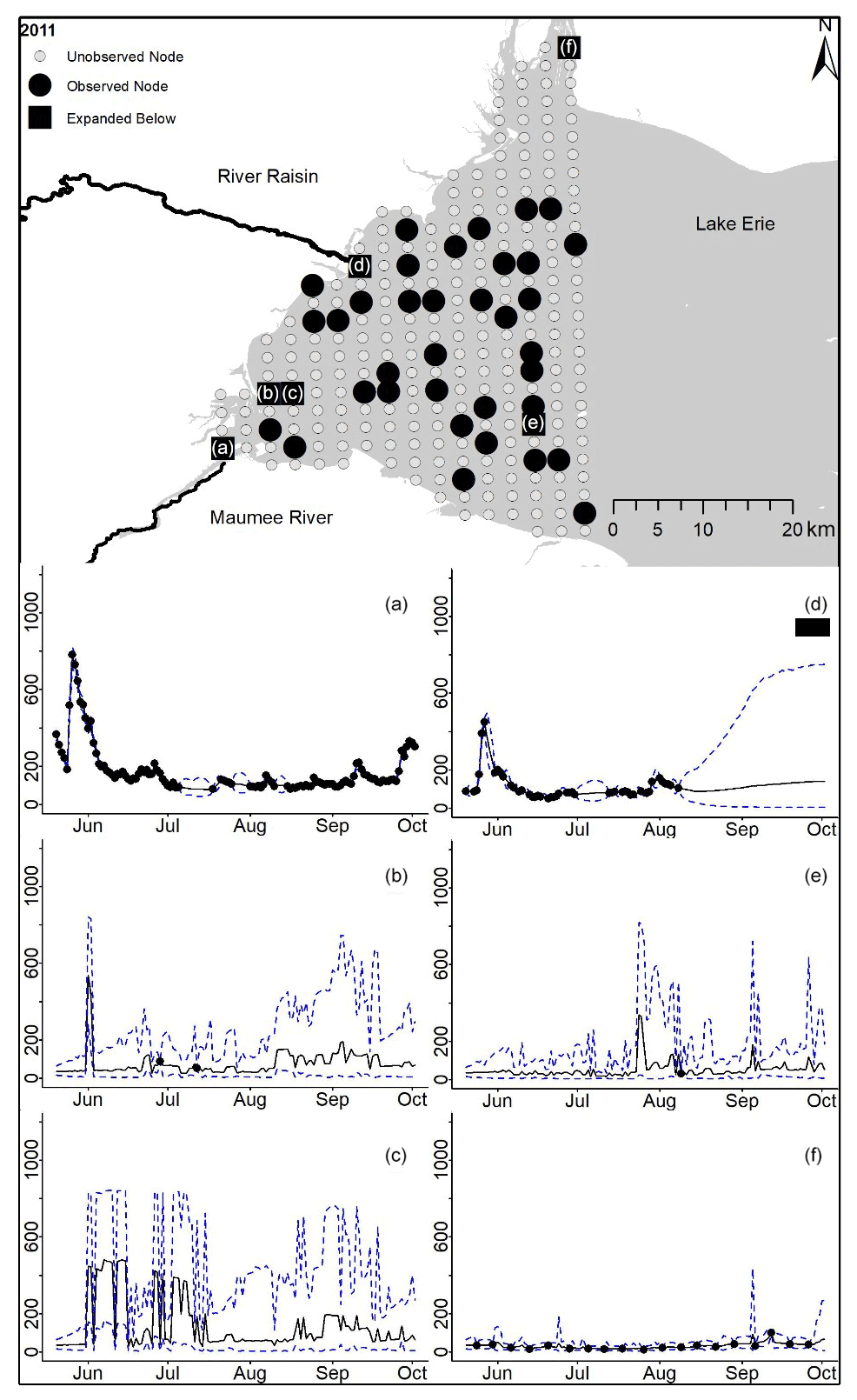
Figure D4For 2011 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
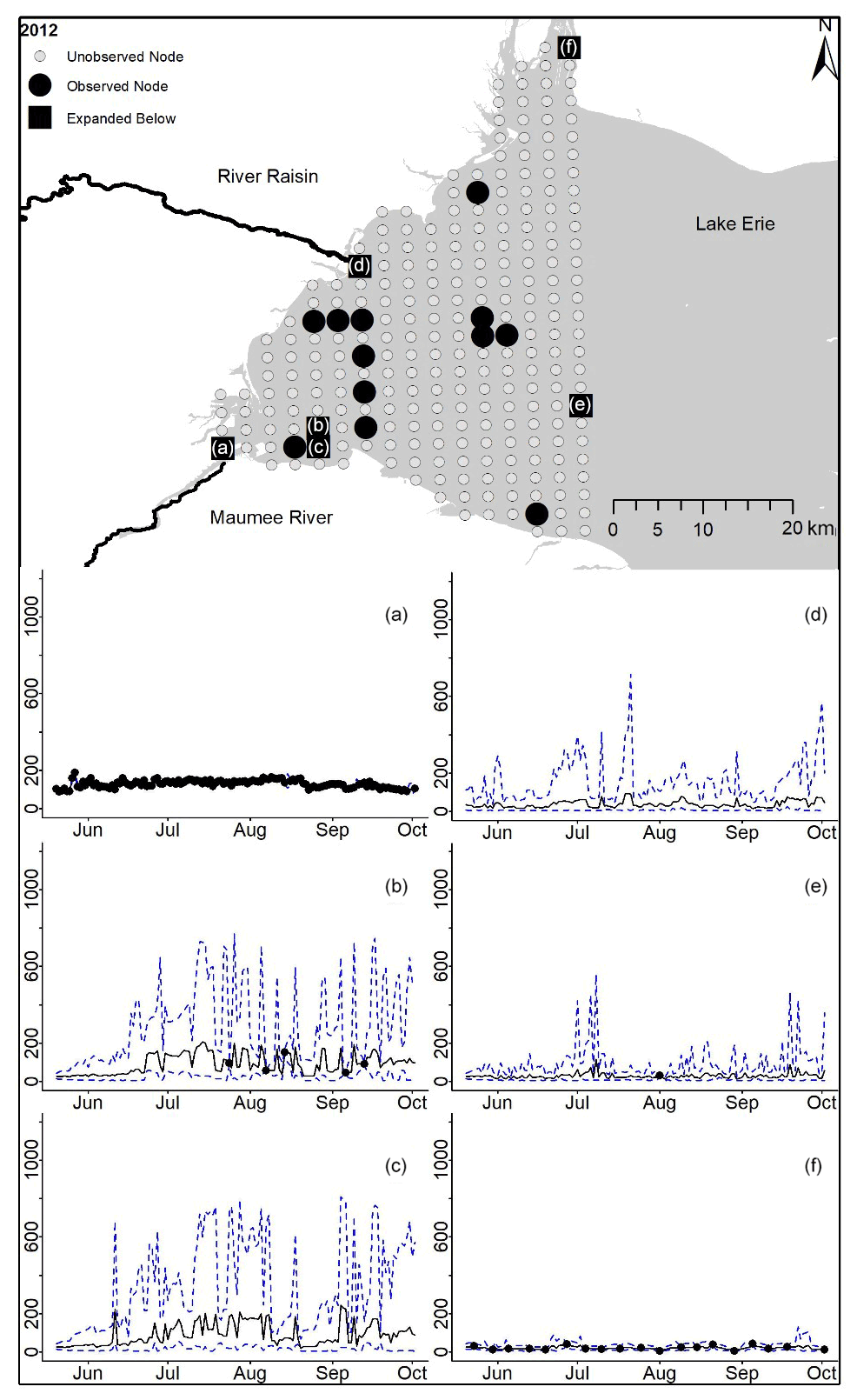
Figure D5For 2012 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
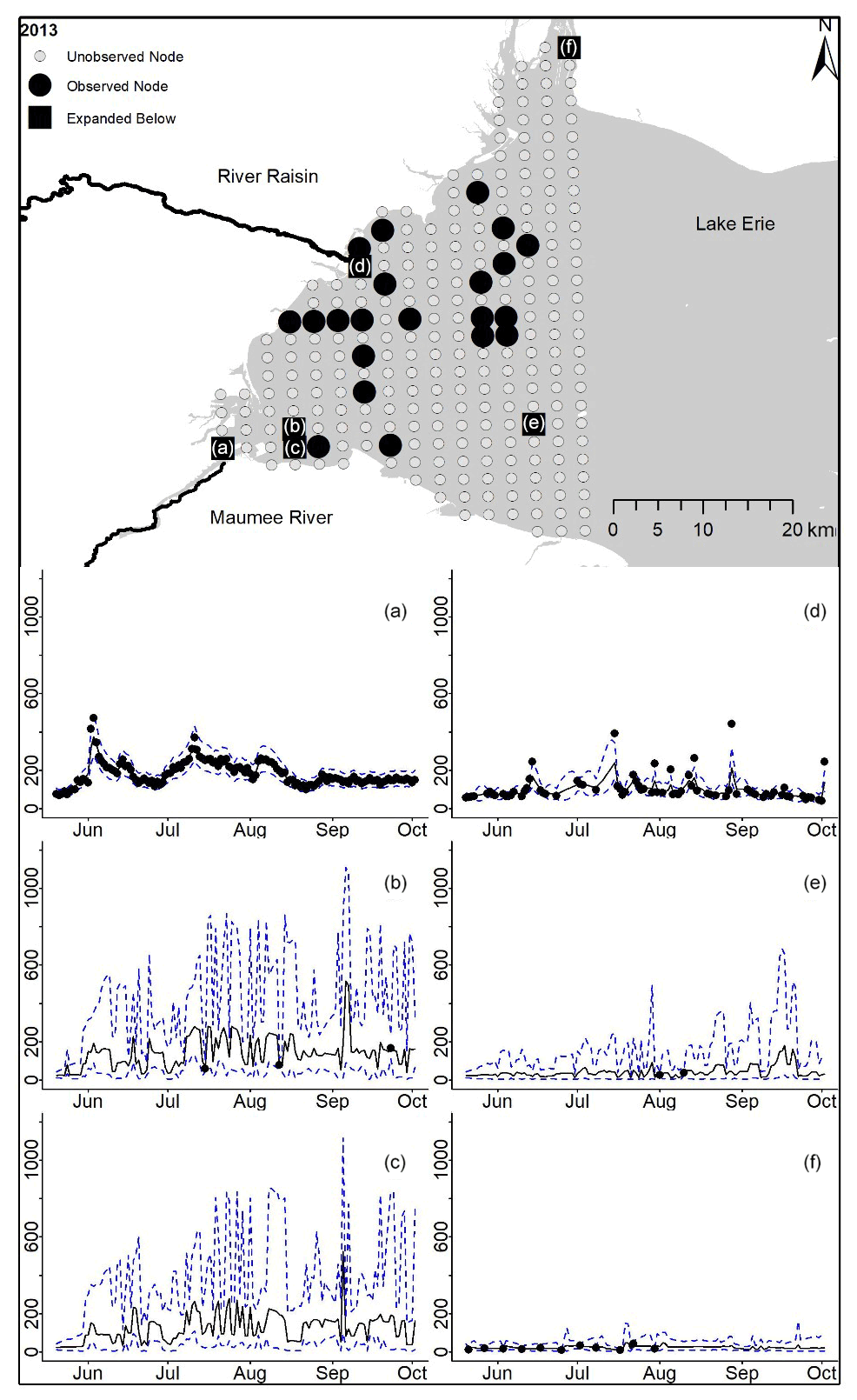
Figure D6For 2013 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
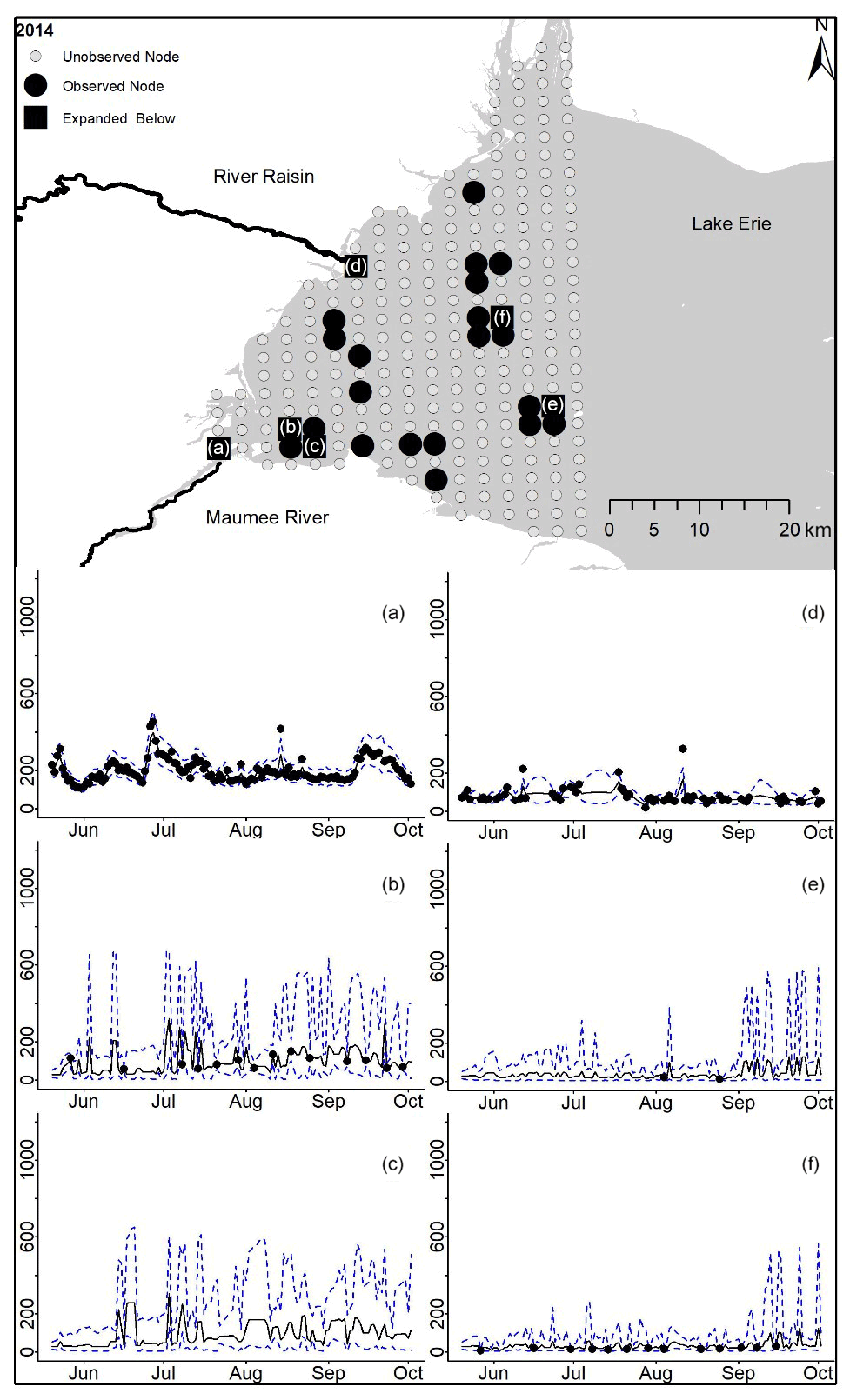
Figure D7For 2014 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
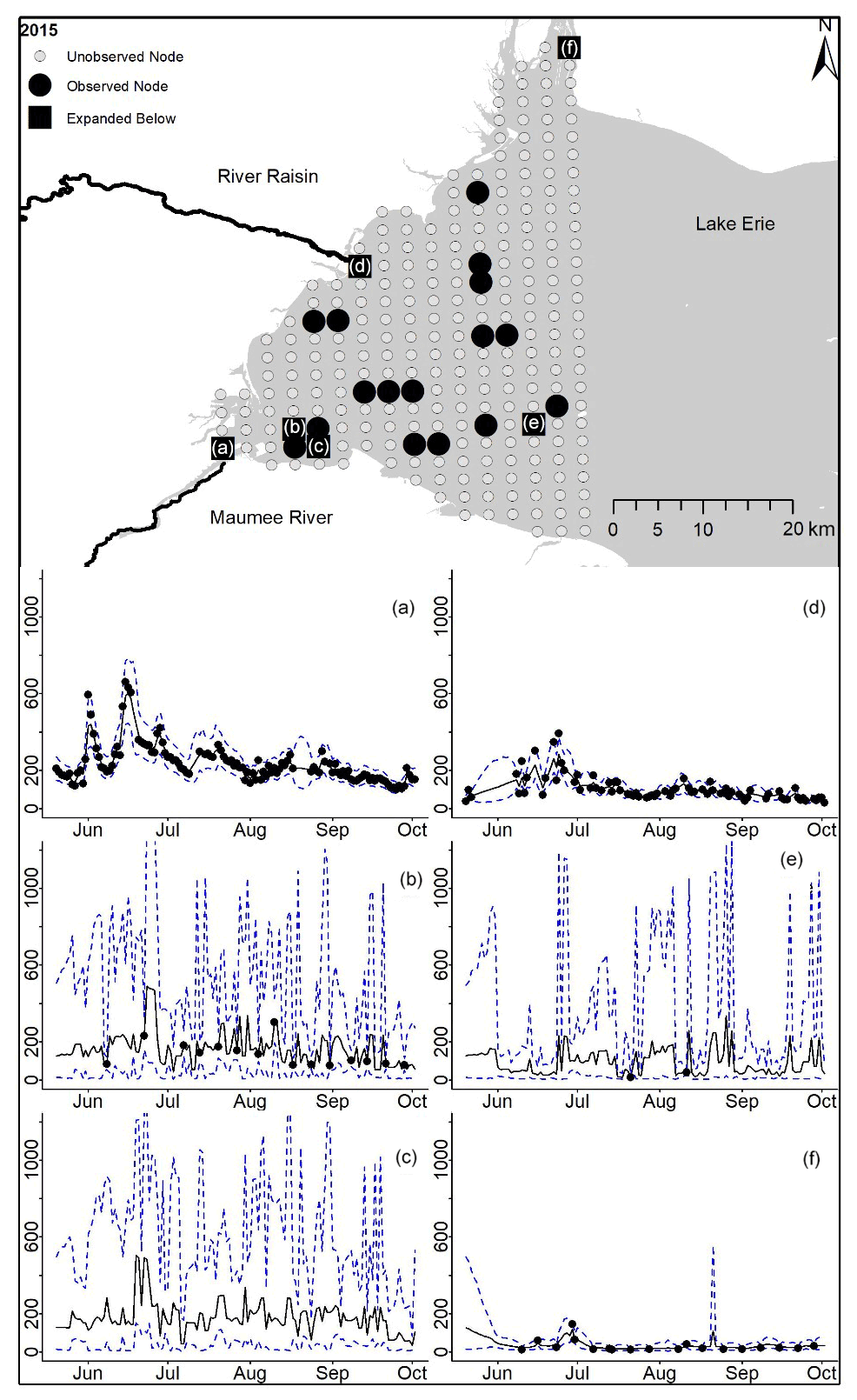
Figure D8For 2015 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
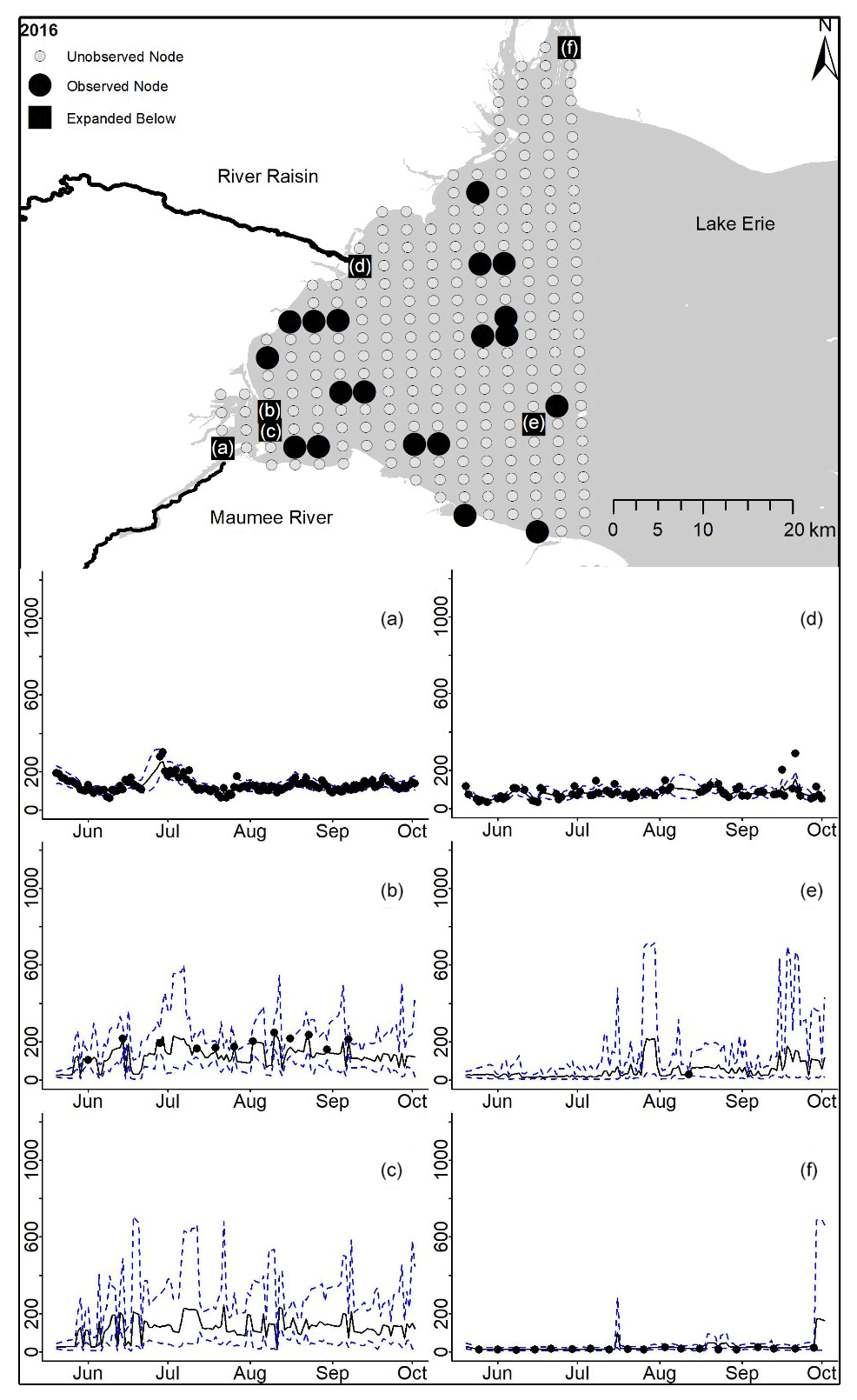
Figure D9For 2016 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.

Figure D10For 2017 the total phosphorus concentrations (µg L−1) at observed and unobserved nodes were estimated from the model posterior samples. Mean (solid black line) and 95 % PI (dashed blue line) for the model posterior samples of each node at every day for (a) the Maumee River, (b, c, e, f) western Lake Erie nodes, and (d) the Raisin River.
Template code for reproducing our model is available publicly on Zenodo at https://doi.org/10.5281/zenodo.5570508 (Maguire et al., 2021a). All the data used here were from publicly available sources which we provide in Appendix A. On the Zenodo site we made our curated data for 2018 available.
A supplemental video of Maumee River impact plume through time is available through https://doi.org/10.5446/53429 (Maguire et al., 2021b).
TJM, CAS, and CMG designed the models, the model fitting quality control, and the model experiments. TJM developed the model code and performed the simulations. TJM prepared the manuscript with contributions from CAS and CMG.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the special issue “Frontiers in the application of Bayesian approaches in water quality modelling”. It is a result of the EGU General Assembly 2020, 3–8 May 2020.
The authors would like to thank Peter Alsip of the University of Michigan Cooperative Institute for Great Lakes Research (CIGLR) for collating the data from sources listed in Appendix A. The authors would also like to thank the field personnel of CIGLR and National Oceanic and Atmospheric Administration (NOAA) Great Lakes Environmental Research Laboratory (GLERL) Western Lake Erie sampling captains and crews whose fieldwork inspired this paper. This publication is contribution no. 1188 from CIGLR and contribution no. 1992 from NOAA GLERL.
Funding was awarded to CIGLR through the NOAA Cooperative Agreement with the University of Michigan (NA17OAR4320152). Funding was provided by the Great Lakes Restoration Initiative.
This paper was edited by Miriam Glendell and reviewed by Ken Newman and two anonymous referees.
Auger-Méthé, M., Newman, K., Cole, D., Empacher, F., Gryba, R., King, A. A., Leos-Barajas, V., Mills Flemming, J., Nielsen, A., and Petris, G.: A guide to state–space modeling of ecological time series, Ecol. Monogr., 91, e01470, https://doi.org/10.1002/ecm.1470, 2021.
Bolsenga, S. J. and Herdendorf, C. E.: Lake Erie and Lake St. Clair Handbook, Wayne State University Press, ISBN 0-8143-2470-3, 1993.
Brooks, B. W., Lazorchak, J. M., Howard, M. D. A., Johnson, M. V, Morton, S. L., Perkins, D. A. K., Reavie, E. D., Scott, G. I., Smith, S. A., and Steevens, J. A.: Are harmful algal blooms becoming the greatest inland water quality threat to public health and aquatic ecosystems?, Environ. Toxicol. Chem., 35, 6–13, 2016.
Buckland, S. T., Newman, K. B., Thomas, L., and Koesters, N. B.: State-space models for the dynamics of wild animal populations, Ecol. Model., 171, 157–175, 2004.
Durbin, J. and Koopman, S. J.: Time series analysis by state space methods, Oxford University Press, ISBN 0-1996-4117-X, 2012.
Eddelbuettel, D.: random: True Random Numbers using RANDOM.ORG, https://cran.r-project.org/package=random (last access: June 2021), 2017.
Fang, S., Del Giudice, D., Scavia, D., Binding, C. E., Bridgeman, T. B., Chaffin, J. D., Evans, M. A., Guinness, J., Johengen, T. H., and Obenour, D. R.: A space-time geostatistical model for probabilistic estimation of harmful algal bloom biomass and areal extent, Sci. Total Environ., 695, 133776, https://doi.org/10.1016/j.scitotenv.2019.133776, 2019.
Geisser, S. and Eddy, W. F.: A predictive approach to model selection, J. Am. Stat. Assoc., 74, 153–160, 1979.
Gelman, A.: Two simple examples for understanding posterior p-values whose distributions are far from uniform, Electron. J. Stat., 7, 2595–2602, 2013.
Gelman, A., Goodrich, B., Gabry, J., and Vehtari, A.: R-squared for Bayesian regression models, Am. Stat., 73, 307–309, https://doi.org/10.1080/00031305.2018.154910, 2019.
GLWQA: Great Lakes Water Quality Agreement; Protocol Amending the Agreement Between Canada and the United States of America on Great Lakes Water Quality, 1978, as Amended on October 16, 1983 and on November 18, 1987, https://binational.net/2012/09/05/2012-glwqa-aqegl/ (last access: April 2022), 2012.
Ho, J. C. and Michalak, A. M.: Phytoplankton blooms in Lake Erie impacted by both long-term and springtime phosphorus loading, J. Great Lakes Res., 43, 221–228, 2017.
Kruschke, J.: Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan, 2nd Edn., Academic Press, Waltham, MA, USA, ISBN 0-1240-5916-3, 2015.
Lamon, E. C. and Stow, C. A.: Lake Superior water level fluctuation and climatic factors: A dynamic linear model analysis, J. Great Lakes Res., 36, 172–178, 2010.
Li, J., Ianaiev, V., Huff, A., Zalusky, J., Ozersky, T., and Katsev, S.: Benthic invaders control the phosphorus cycle in the world's largest freshwater ecosystem, P. Natl. Acad. Sci. USA, 118, e2008223118, https://doi.org/10.1073/pnas.2008223118, 2021.
Maguire, T. J., Stow, C. A., and Godwin, C. M.: Spatially Referenced Bayesian State-Space Model of Total Phosphorus in western Lake Erie, Zenodo [code and data set], https://doi.org/10.5281/zenodo.5570508, 2021a.
Maguire, T. J., Stow, C. A., and Godwin, C. M.: Impact of the Maumee River through Time, TIB AV-PORTAL [video supplement], https://doi.org/10.5446/53429, 2021b.
Matisoff, G., Kaltenberg, E. M., Steely, R. L., Hummel, S. K., Seo, J., Gibbons, K. J., Bridgeman, T. B., Seo, Y., Behbahani, M., and James, W. F.: Internal loading of phosphorus in western Lake Erie, J. Great Lakes Res., 42, 775–788, 2016.
Mellios, N. K., Moe, S. J., and Laspidou, C.: Using Bayesian hierarchical modelling to capture cyanobacteria dynamics in Northern European lakes, Water Res., 186, 116356, https://doi.org/10.1016/j.watres.2020.116356, 2020.
Meyer, R. and Millar, R. B.: Bayesian stock assessment using a state–space implementation of the delay difference model, Can. J. Fish. Aquat. Sci., 56, 37–52, 1999.
Michalak, A. M., Anderson, E. J., Beletsky, D., Boland, S., Bosch, N. S., Bridgeman, T. B., Chaffin, J. D., Cho, K., Confesor, R., and Daloğlu, I.: Record-setting algal bloom in Lake Erie caused by agricultural and meteorological trends consistent with expected future conditions, P. Natl. Acad. Sci. USA, 110, 6448–6452, 2013.
Microsoft Corporation and Weston, S.: doParallel: Foreach Parallel Adaptor for the “parallel” Package, https://cran.r-project.org/package=doParallel (last access: June 2021), 2020.
Obenour, D. R., Gronewold, A. D., Stow, C. A., and Scavia, D.: Using a Bayesian hierarchical model to improve L ake E rie cyanobacteria bloom forecasts, Water Resour. Res., 50, 7847–7860, 2014.
Piironen, J. and Vehtari, A.: Comparison of Bayesian predictive methods for model selection, Stat. Comput., 27, 711–735, 2017.
Plummer, M.: rjags: Bayesian Graphical Models using MCMC, https://cran.r-project.org/package=rjags (last access: June 2021), 2019.
Rockwell, D. C., Warren, G. J., Bertram, P. E., Salisbury, D. K., and Burns, N. M.: The US EPA Lake Erie indicators monitoring program 1983–2002: trends in phosphorus, silica, and chlorophyll a in the central basin, J. Great Lakes Res., 31, 23–34, 2005.
Rowe, M. D., Anderson, E. J., Beletsky, D., Stow, C. A., Moegling, S. D., Chaffin, J. D., May, J. C., Collingsworth, P. D., Jabbari, A., and Ackerman, J. D.: Coastal upwelling influences hypoxia spatial patterns and nearshore dynamics in Lake Erie, J. Geophys. Res.-Oceans, 124, 6154–6175, 2019.
Rowland, F. E., Stow, C. A., Johengen, T. H., Burtner, A. M., Palladino, D., Gossiaux, D. C., Davis, T. W., Johnson, L. T., and Ruberg, S.: Recent patterns in Lake Erie phosphorus and chlorophyll a concentrations in response to changing loads, Environ. Sci. Technol., 54, 835–841, 2019.
Royer, F., Fromentin, J., and Gaspar, P.: A state–space model to derive bluefin tuna movement and habitat from archival tags, Oikos, 109, 473–484, 2005.
Schneider, M. and Bláha, L.: Advanced oxidation processes for the removal of cyanobacterial toxins from drinking water, Environ. Sci. Eur., 32, 1–24, 2020.
Schwab, D. J., Beletsky, D., DePinto, J., and Dolan, D. M.: A hydrodynamic approach to modeling phosphorus distribution in Lake Erie, J. Great Lakes Res., 35, 50–60, 2009.
Sellinger, C. E., Stow, C. A., Lamon, E. C., and Qian, S. S.: Recent water level declines in the Lake Michigan-Huron System, Environ. Sci. Technol., 42, 367–373, 2008.
Shumway, R. H. and Stoffer, D. S.: Time Series: A Data Analysis Approach Using R: A Data Analysis Approach Using R, Chapman and Hall/CRC, ISBN 0-4292-7328-2, 2019.
Steffen, M. M., Davis, T. W., McKay, R. M. L., Bullerjahn, G. S., Krausfeldt, L. E., Stough, J. M. A., Neitzey, M. L., Gilbert, N. E., Boyer, G. L., and Johengen, T. H.: Ecophysiological Examination of the Lake Erie Microcystis Bloom in 2014: Linkages between Biology and the Water Supply Shutdown of Toledo, OH, Environ. Sci. Technol., 51, 6745–6755, 2017.
Stow, C. A., Lamon, E. C., Qian, S. S., and Schrank, C. S.: Will Lake Michigan lake trout meet the Great Lakes strategy 2002 PCB reduction goal?, Environ. Sci. Technol., 38, 359–363, https://doi.org/10.1021/es034610l, 2004.
Stow, C. A., Cha, Y., Johnson, L. T., Confesor, R., and Richards, R. P.: Long-term and seasonal trend decomposition of Maumee River nutrient inputs to western Lake Erie, Environ. Sci. Technol., 49, 3392–3400, 2015.
Watson, S. B., Miller, C., Arhonditsis, G., Boyer, G. L., Carmichael, W., Charlton, M. N., Confesor, R., Depew, D. C., Höök, T. O., and Ludsin, S. A.: The re-eutrophication of Lake Erie: Harmful algal blooms and hypoxia, Harmful Algae, 56, 44–66, 2016.
Wituszynski, D. M., Hu, C., Zhang, F., Chaffin, J. D., Lee, J., Ludsin, S. A., and Martin, J. F.: Microcystin in Lake Erie fish: risk to human health and relationship to cyanobacterial blooms, J. Great Lakes Res., 43, 1084–1090, 2017.