the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 19 Feb 2021
| 19 Feb 2021
Objective functions for information-theoretical monitoring network design: what is “optimal”?
Hossein Foroozand
Steven V. Weijs
This paper concerns the problem of optimal monitoring network layout using information-theoretical methods. Numerous different objectives based on information measures have been proposed in recent literature, often focusing simultaneously on maximum information and minimum dependence between the chosen locations for data collection stations. We discuss these objective functions and conclude that a single-objective optimization of joint entropy suffices to maximize the collection of information for a given number of stations. We argue that the widespread notion of minimizing redundancy, or dependence between monitored signals, as a secondary objective is not desirable and has no intrinsic justification. The negative effect of redundancy on total collected information is already accounted for in joint entropy, which measures total information net of any redundancies. In fact, for two networks of equal joint entropy, the one with a higher amount of redundant information should be preferred for reasons of robustness against failure. In attaining the maximum joint entropy objective, we investigate exhaustive optimization, a more computationally tractable greedy approach that adds one station at a time, and we introduce the “greedy drop” approach, where the full set of stations is reduced one at a time. We show that no greedy approach can exist that is guaranteed to reach the global optimum.
- Article
(3917 KB) - Full-text XML
- BibTeX
- EndNote





Over the last decade, a large number of papers on information-theory-based design of monitoring networks have been published. These studies apply information-theoretical measures on multiple time series from a set of sensors, to identify optimal subsets. Jointly, these papers (Alfonso et al., 2010a, b; Li et al., 2012; Ridolfi et al., 2011; Samuel et al., 2013; Stosic et al., 2017; Keum and Coulibaly, 2017; Banik et al., 2017; Wang et al., 2018; Huang et al., 2020; Khorshidi et al., 2020) have proposed a wide variety of different optimization objectives. Some have suggested that either a multi-objective approach or a single objective derived from multiple objectives is necessary to find an optimal monitoring network. These methods were often compared to other existing methods in case studies used to demonstrate that one objective should be preferred over the other based on the resulting networks.
In this paper, we do not answer the question “what is optimal?” with an optimal network. Rather, we reflect on the question of how to define optimality in a way that is logically consistent and useful within the monitoring network optimization context, thereby questioning the widespread use of minimum dependence between stations as part of the objectives. In fact, we argue that minimizing redundancy is a redundant objective.
The objective of a hydrological monitoring network depends on its purpose, which can usually be framed as supporting decisions. The decisions can be relating to management of water systems, as for example considered by Alfonso et al. (2010a), or flood warning and evacuation decisions in uncontrolled systems. Also purely scientific research can be formulated as involving decisions to accept or reject certain hypotheses, focus research on certain aspects, or collect more data (Raso et al., 2018). In fact, choosing monitoring locations is also a decision whose objective can be formulated as choosing monitoring locations to optimally support subsequent decisions.
The decision problem of choosing an optimal monitoring network layout needs an explicit objective function to be optimized. While this objective could be stated in terms of a utility function (Neumann and Morgenstern, 1953), this requires knowledge of the decision problem(s) at hand and the decision makers' preferences. These are often not explicitly available, for example, in the case of a government-operated monitoring network with a multitude of users. As a special case of utility, it is possible to state the objective of a monitoring network in terms of information (Bernardo, 1979). This can be done using the framework of information theory, originally outlined by Shannon (1948), who introduced information entropy H(X) as a measure of uncertainty or missing information in the probability distribution of random variable X, as well as many related measures.
Although ultimately the objective will be a more general utility, the focus of this paper is on information-theoretical methods for monitoring network design, which typically do not optimize for a specific decision problem supported by the network. Because information and utility (value of information) are linked through a complex relationship, this does not necessarily optimize decisions for all decision makers. Since we do not consider a specific decision problem, the focus in the present paper is on methods for maximization of information retrieved from a sensor network.
In this paper, the rationale behind posing various information-theoretical objectives is discussed in detail. While measures from information theory provide a strong foundation for mathematically and conceptually rigorous quantification of information content, it is important to pay attention to the exact meaning of the measures used. This paper is intended to shed some light on these meanings in the context of monitoring network optimization and provides new discussion motivated in part by recently published literature.
We present three main arguments in this paper. Firstly, we argue that objective functions for optimizing monitoring networks can, in principle, not be justified by analyzing the resulting networks from application case studies. Evaluating performance of a chosen monitoring network would require a performance indicator, which in itself is an objective function. Case studies could be helpful in assessing whether one objective function (the optimization objective) could be used as an approximation of another, underlying, objective function (the performance indicator). However, from results of case studies we should not attempt to draw any conclusions as to what objective function should be preferred. In other words: the objective function is intended to assess the quality of the monitoring network, as opposed to a practice in which the resulting monitoring networks are used to assess the quality of the objective function. Secondly, we argue that, in purely information-based approaches, the joint entropy of all signals together is in principle sufficient to characterize information content and can therefore serve as a single optimization objective. Notions of minimizing dependence between monitored signals through incorporation of other information measures in the objective function lack justification and are therefore not desirable. Thirdly, we could actually argue for maximizing redundancy as a secondary objective because of its associated benefits for creating a network robust against individual sensors' failures. The reason is that the undesirable information inefficiencies associated with high dependency or redundancy are already accounted for in maximizing joint entropy. Minimization of redundancy would mean that each sensor becomes more essential, and therefore the network as a whole would be more vulnerable to failures in delivering information. Adding a trade-off with maximum redundancy is outside the scope of this paper but serves to further illustrate the argument against use of minimum redundancy.
Choice of scope and role of the case study
The information-theoretical approach to monitoring network design is not the only option, and other objective functions have also been used for this problem. Examples are cost, geographical spread, and squared-error-based metrics. Some approaches use models describing spatial variability with certain assumptions, e.g., Kriging (Bayat et al., 2019). In the case of network expansion to new locations, models are always needed to describe what could be measured in those locations. These could vary from simple linear models to full hydrodynamic transport models, such as those used in Aydin et al. (2019), who compared performance of the sensor placement in a polder network based on a simple low-order PCA (principal component analysis) model and a detailed hydrodynamic and salt transport model.
In this paper, our main focus is to discuss the formulation of information-theoretical objective functions and previous literature. Therefore, we restrict our scope to those information-theory-based objective functions based on observed data on one single variable in multiple locations. Keeping this limited scope allows us to discuss the interpretation of these objective functions for monitoring network design, which formalize what we actually want from a network. Furthermore, we investigate whether the desired optimum in the objective function can be found by greedy approaches or whether exhaustive search is needed to prevent a loss of optimality.
Only after it is agreed on what is wanted from a network and this is captured as an optimization problem do other issues such as the solution or approximation of the solution to the problem become relevant. The numerical approach to this solution and calculation of information measures warrants independent discussion, which is outside our current scope and will be presented in a future paper. Our discussion is numerically illustrated by a case study using data from Brazos River in Texas, as presented in Li et al. (2012), to allow for comparisons. However, as we argue, the case study can only serve as an illustration and not be used for normative arguments for use of a particular objective function. Such an argument would be circular, as the performance metric will be one of the objective functions.
In this paper, since we are discussing the appropriate choice of objective function, there is no experimental setup that could be used to provide evidence for one objective version vs. the other. Rather, we must make use of normative theoretical reasoning and shine light on the interpretation of the objectives used and their possible justifications. The practical case studies in this paper therefore serve as an illustration but not as evidence for all the conclusions advocated in this paper, some of which are arrived at through interpretation and argumentation in the Results and discussion section.
The paper is organized as follows. In the following Methodology section, we introduce the methods used to investigate and illustrate the role of objective functions. In Sect. 3, we discuss the case study on the streamflow monitoring network of Brazos River. Section 4 introduces the results for the various methods and then discusses the need for multiple objectives, the interpretation of trade-offs between redundancy and total information, and the feasibility of greedy algorithms reaching the optimum. The article concludes with summarizing the key messages and raising important questions about the calculation of the measures to be addressed in future research.
2.1 Information theory terms
Shannon (1948) developed information theory (IT) based on entropy, the concept that explains a system's uncertainty reduction as a function of added information. To understand how, consider a set of N events for which possible outcomes are categorized into m classes. Uncertainty is a measure of our knowledge about which outcome will occur. Once an event is observed, and it is identified which of the m classes it belongs to, our uncertainty about the outcome decreases to 0. Therefore, information can be characterized as the decrease of an observer's uncertainty about the outcome (Krstanovic and Singh, 1992; Mogheir et al., 2006; Foroozand and Weijs, 2017; Foroozand et al., 2018; Konapala et al., 2020). For monitoring networks, we are interested in the information content of the observations from all stations. The information content is equal to the uncertainty about the observations before measuring. The uncertainty is quantified through probability distributions that describe the possible observations, based on the data.
In monitoring network design, IT has been applied in the literature to evaluate data collection networks that serve a variety of purposes, including rainfall measurement, water quality monitoring, and streamflow monitoring. These evaluations are then used to optimize the placement of sensors. In the monitoring network optimization literature, three expressions from IT are often used in monitoring network design: (1) entropy (H), to estimate the expected information content of observations of random variables; (2) mutual information, often called transinformation (T), to measure redundant information or dependency between two variables; and (3) total correlation (C), a multivariate analogue to mutual information, to measure the total nonlinear dependency among multiple random variables.
The Shannon entropy H(X) is a nonparametric measure, directly on the discrete probabilities, with no prior assumptions on data distribution. It is also referred to as discrete marginal entropy, to distinguish it both from continuous entropy and from conditional entropy. Discrete marginal entropy (Eq. 1), defined as the average information content of observations of a single discrete random variable X, is given by
where p(x)(0⩽p(x)⩽1) is the probability of occurrence of outcome x of random variable X. Equation (1) gives the entropy in the unit of “bits” since it uses a logarithm of base 2. The choice of the logarithm's base for entropy calculation is determined by the desired unit – other information units are “nats” and “Hartley” for the natural and base 10 logarithms, respectively. For monitoring network design, the logarithm of base 2 is common in the literature since it can be interpreted as the necessary number of answers to a series of binary questions and allows for comparisons with file sizes in bits; see, e.g., Weijs et al. (2013a). Joint entropy (Eq. 2), as an extension of entropy beyond a single variable, measures the number of questions needed to determine the outcome of a multivariate system.
where p(x1,x2) is the joint probability distribution of random variable X1 and X2. For a bivariate case, if two random variables are independent, then their joint entropy, H(X1,X2), is equal to the sum of marginal entropies H(X1)+H(X2). Conditional entropy (Eq. 3), H(X1|X2), explains the amount of information X1 delivers that X2 can not explain.
H(X1|X2) can have a range (Eq. 4) between zero when both variables are completely dependent and marginal entropy H(X1) when they are independent. Mutual information, in this field often referred to as transinformation (Eq. 5), T(X1,X2), explains the level of dependency and shared information between two variables by considering their joint distribution.
where p(x1) and p(x2) constitute the marginal probability distribution of random variable X1 and X2, respectively; and p(x1,x2) form their joint probability distribution. The assessment of the dependencies beyond three variables can be estimated by the concept of total correlation (Eq. 6) (proposed by McGill, 1954 and named by Watanabe, 1960).
Total correlation (C) gives the amount of information shared between all variables by taking into account their nonlinear dependencies. C can only be non-negative since the sum of all marginal entropies cannot be smaller than their multivariate joint entropy, though in the special case of independent variables, C would become zero.
2.2 Single-objective optimization
In this paper, we argue for the maximum joint entropy (maxJE) objective for maximizing the total information collected by a monitoring network. This is equivalent to the GR3 objective proposed by Banik et al. (2017), as part of six other objectives (see Appendix B for more detail) proposed in the same paper, which did not provide preference for its use. In the discussion, we argue that a single-objective optimization of the joint entropy of all selected sensors leads to a maximally informative sensor network, which minimizes total remaining uncertainty about the outcomes at all potential locations. Also, it should be noted that the maxJE objective function already penalizes redundant information through its network selection process, which aims to find a new station that produces maximum joint entropy when it is combined with already selected stations in each iteration. When applied in a greedy search, adding one new station at a time, this approach ranks stations based on growing joint information as quickly as possible. This is mathematically equivalent to adding to the selection, in each iteration, the new station FC that provides maximum conditional entropy H(FC|S) on top of an already selected set (S) of stations (see Fig. 1 for visual illustration).
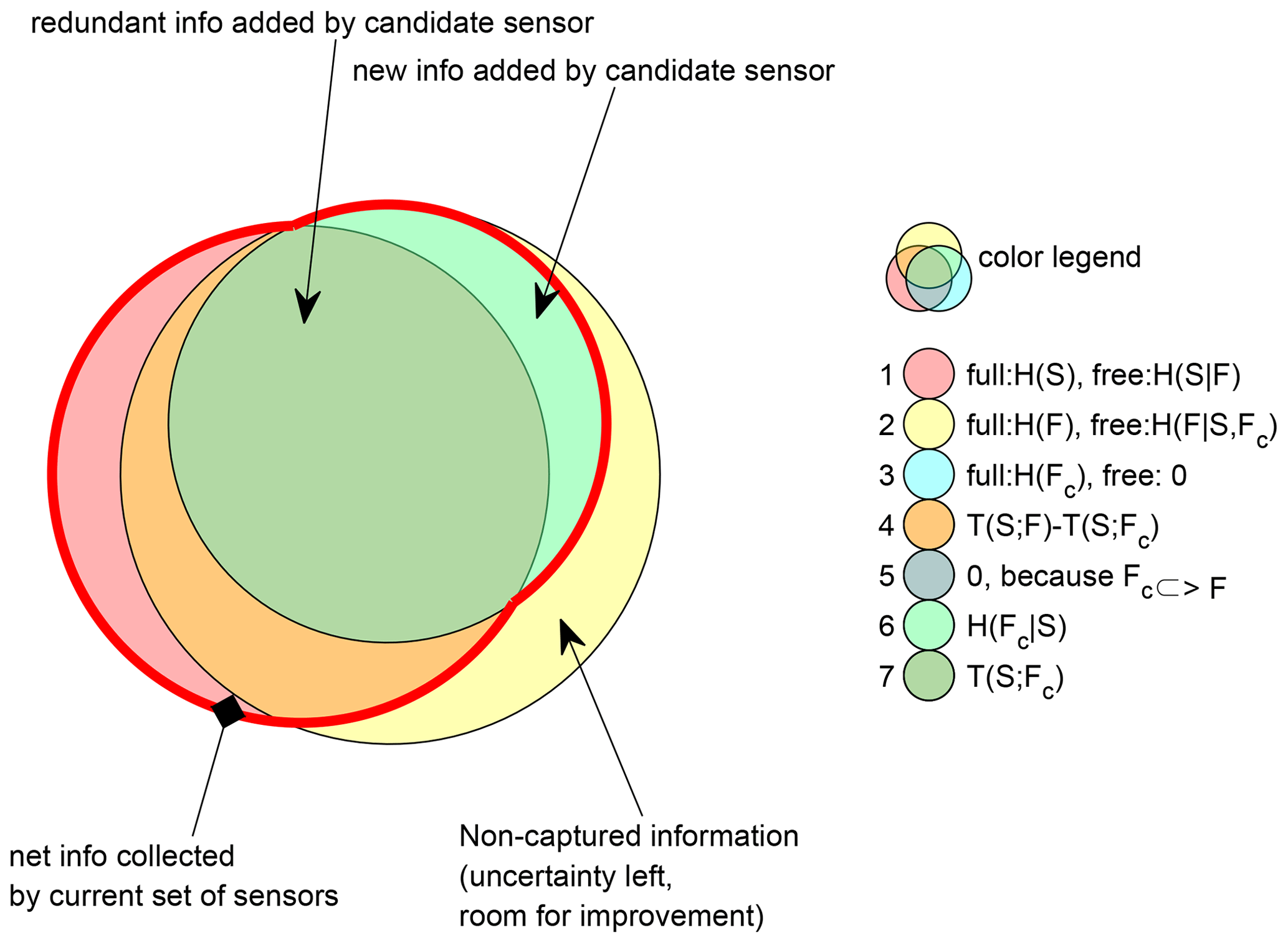
Figure 1Venn diagram illustrating the relations between the relevant information measures. In the legend, the joint and marginal information-theoretical quantities (joint) entropy H(X), conditional entropy H(X|Y), and transinformation T(X;Y) for the variable from sets of already selected sensors S, not yet selected sensors F, and the current candidate sensor FC are represented by the surfaces in the Venn diagram. For the three basic circle colors (first three circles in the legend), “free” gives the quantity represented by the non-covered part, and “full” gives the quantity represented by the entire circle surface. The joint entropy that is proposed to be maximized in this paper is the area enclosed in the thick red line.
2.3 Multi-objective optimization
Our research compares and contrasts a variety of objective functions from literature. Information-theory-based multi-objective optimization methods for monitoring networks have gained significant attention recently. Maximizing network information content, through either the sum of marginal entropy or joint entropy, is the common theme among existing methods (Alfonso et al., 2010b; Li et al., 2012; Samuel et al., 2013; Keum and Coulibaly, 2017; Wang et al., 2018; Huang et al., 2020). However, there is no consensus on whether to use total correlation or transinformation measures to minimize redundant information. Table 1 gives an overview of the large number of objectives and combinations of objectives used in the last decade. On the one hand, the water monitoring in polders (WMP) method (Alfonso et al., 2010a) and joint permutation entropy (JPE) method (Stosic et al., 2017) used normalized transinformation to minimize redundant information, while, on the other hand, the multi-objective optimization problem (MOOP) method (Alfonso et al., 2010b), combined regionalization and dual entropy multi-objective optimization (CRDEMO) method (Samuel et al., 2013), multivariable hydrometric networks (MHN) method (Keum and Coulibaly, 2017), and greedy-rank-based optimization (GR 5 and 6) method (Banik et al., 2017) adopted total correlation to achieve minimum redundancy. Interestingly, both C and T were used as competing objectives in the maximum information minimum redundancy (MIMR) method proposed by Li et al. (2012). They argued that transinformation between selected stations in the optimal set and non-selected stations should be maximized to account for the information transfer ability of a network. Meanwhile, recently proposed methods in the literature have attempted to improve monitoring network design by introducing yet more other additional objectives (Huang et al., 2020; Wang et al., 2018; Banik et al., 2017; Keum and Coulibaly, 2017). These additional objectives are further discussed in Appendix B.
Alfonso et al. (2010a)Alfonso et al. (2010a)Alfonso et al. (2010a)Alfonso et al. (2010b)Ridolfi et al. (2011)Li et al. (2012)Samuel et al. (2013)Stosic et al. (2017)Keum and Coulibaly (2017)Banik et al. (2017)Banik et al. (2017)Banik et al. (2017)Banik et al. (2017)Banik et al. (2017)Banik et al. (2017)Wang et al. (2018)Huang et al. (2020)Table 1Various information-theoretical objectives used by methods proposed in recent literature.

The table shows whether an objective is maximized (max) or minimized (min) or forms part of a weighted objective function that is maximized with weights λ1. SBM stands for the constraint whereby only stations are considered that are below the median score of all potential stations for that objective. D is detection time, and R is reliability. RDI stands for the ranking disorder index. SI is spatiotemporality information, and A is accuracy. WMP is the water monitoring in polders method, MOOP the multi-objective optimization problem, minT minimum transinformation, MIMR the maximum information minimum redundancy method, CRDEMO the combined regionalization and dual entropy multi-objective optimization, JPE the joint permutation entropy, MHN the multivariable hydrometric networks method, GR the greedy rank, DNEF the dynamic network evaluation framework, ISA the information content, spatiotemporality, and accuracy method, and maxJE the maximum joint entropy.
2.4 Exhaustive search vs. greedy add and drop
Apart from the objective function, the optimization of monitoring networks is also characterized by constraints. These constraints can either be implemented for numerical reasons or for the reflection of practical aspects of the real-world problem. The majority of existing literature listed in Table 1 often implicitly imposed a constraint by treating stations' selection as greedy optimization. Greedy optimization adds one station to the selected stations each time, without reconsidering the set's already selected stations. A practical reason for this is numerical efficiency; an exhaustive search of all subsets of k stations out of n possible stations will need to consider a large number of combinations, since the search space grows exponentially with the size n of the full set of sensors (2n combinations of sensors need to be considered).
In this paper, for the maximization of joint entropy that we advocate, we consider and compare three cases for constraints with a large influence on computational cost, with the purpose of investigating whether these influence the results. We also interpret the constraints as reflections of placement strategies. Firstly, the “greedy add” strategy is the commonly applied constraint that each time the network expands, the most favorable additional station is chosen, while leaving the already chosen network intact. The optimal network for k stations is found by expanding one station at a time. This approach can for example be useful in Alpine terrain, where relocating a sensor requires significant effort (Simoni et al., 2011). Secondly, “greedy drop” is the reverse strategy, not previously discussed in the literature, where the starting point is the full network with all n stations. The optimal network for k stations is found by reducing the full network one step at a time, each step dropping the least informative station. Since all of the discussed monitoring design strategies use recorded data and hence discuss networks whose stations are already established, network reduction is perhaps the more realistic application scenario for information-based design methods. Thirdly, “exhaustive search” is the strategy in which the optimal network of k stations is found by considering all subsets of k stations out of n. This unconstrained search is far more computationally expensive and may not be feasible in larger networks for computational reasons. It can therefore be seen as an optimality benchmark. Because all options are considered, this is guaranteed to find the optimal combination of selected sensors for each network size, given the objective function.
In this comparison, we investigate whether the exhaustive optimization yields a series of networks where an increase in network size may also involve relocating stations. This may not always be practically feasible or desired in actual placement strategies, where networks are slowly expanded one station at a time. Occurrence of relocation in the sequence of growing subsets would also show that no greedy algorithm could exist that guarantees optimality.

Figure 2Template illustrations of information interactions with (a) a Venn diagram and (b) a chord diagram. The green and red areas in both diagrams show a graphical representation of conditional entropy and mutual information respectively. The solid line circles in the Venn diagram depict single-variable entropy. *II is information interaction between three variables. The sector size in the outer circle in the chord diagram is composed of arcs whose relative lengths correspond to the sum of pairwise information interactions and conditional entropy of each variable and are best not interpreted.
2.5 Understanding and visualizing the measures of information
In this paper, we argue that, due to the additive relations of information measures (Eq. 6), the proposed objective functions in the literature are unnecessarily complicated, and a single-objective optimization of the joint entropy of all selected sensors will lead to a maximally informative sensor network. The additive relations between some of the information measures discussed in this paper are illustrated in Fig. 1. In this figure and later is this paper, we use a shorthand notation: we use the sets of stations directly in the information measures, as a compact notation for the multivariate random variable measured by that set of stations. Various types of information interactions for three variables are conceptually understandable using a Venn diagram (Fig. 2a. Although a Venn diagram can be used to illustrate information of more than three variables when they are grouped in three sets (Fig. 1), it cannot be used to illustrate pairwise information interactions beyond three variables. A chord diagram, on the other hand, can be useful to better understand pairwise information interaction beyond three variables. Figure 2 provides a simple template to interpret and compare Venn and chord diagrams.
There are two important caveats with these visualizations. In the general Venn diagram of three-variate interactions, the “interaction information”, represented by the area where three circles overlap, can become negative. Hence, the Venn diagram ceases to be an adequate visualization. For similar reasons, in the chord diagram, the sector size of outer arc lengths should not be interpreted as total information transferred (Bennett et al., 2019). Information that can contribute to interactions is a combination of unique, redundant, and synergistic components (Goodwell and Kumar, 2017; Weijs et al., 2018; Franzen et al., 2020). Their information entanglement is an active area of research in three or more dimensions. In this paper, the total size of the outer arc lengths is set to represent the sum of pairwise information interactions (used in Alfonso et al., 2010a) and conditional entropy of each variable. This size may be larger than the total entropy of the variable and does not have any natural or fundamental interpretation.
In this paper, we use Venn diagrams to illustrate information relations between three groups of variables. Group one is the set of all sensors that are currently selected as being part of the monitoring network, which we denote as S. Group two is the set of all sensors that are currently not selected, denoted as F, and group 3 is the single candidate sensor that is currently considered for addition to the network, FC; see Appendix A for an overview of notation. Since group 3 is a subset of group 2, one Venn circle is contained in the other, and there are only five distinct areas vs. seven in a general three-set Venn diagram. In this particular case, there is no issue arising from negative interaction information.
2.6 Objective functions used in comparison for this study
For the purpose of illustrating the main arguments of this study, we compare maxJE objective function (Eq. 7) with three other (sets of) objective functions from previously proposed methods: MIMR (Eq. 8), WMP (Eq. 9), and minT (Eq. 10). These methods were chosen since they are highly cited methods in this field, and more importantly, recent new approaches in the literature have mostly been built on one of these methods with additional objectives (Alfonso et al., 2010a, b; Ridolfi et al., 2011; Li et al., 2012; Samuel et al., 2013; Stosic et al., 2017; Keum and Coulibaly, 2017; Banik et al., 2017; Wang et al., 2018; Huang et al., 2020).
where refers to selected stations in the previous iterations. and H(FC) denote the variable at the current candidate station and its marginal entropy, respectively. FC is the station considered for addition to the current set in a greedy add approach. This formulation was chosen to allow for a uniform presentation between methods. The objectives for methods maxJE and MIMR can easily be modified to consider FC as part of S, so that the objective function evaluates the entire network rather than one candidate station for addition. This allows for greedy add, greedy drop and exhaustive search methods. λ1 is information-redundancy trade-off weight (Li et al., 2012). SBM (“select below median”) stands for the constraint whereby only stations are considered that are below the median score of all potential stations for that objective. m is equal to the number of non-selected stations in each iteration ( total number of stations). For the multi-objective approaches used in the case study, we used the same weights as the original authors to identify a single solution. It can be seen that a large number of different combinations of information-theoretical measures are used as objectives.
Table 2Resulting maximum joint entropy (bits) for the different network sizes found with different methods for the Brazos River case study (JE used exhaustive optimization).
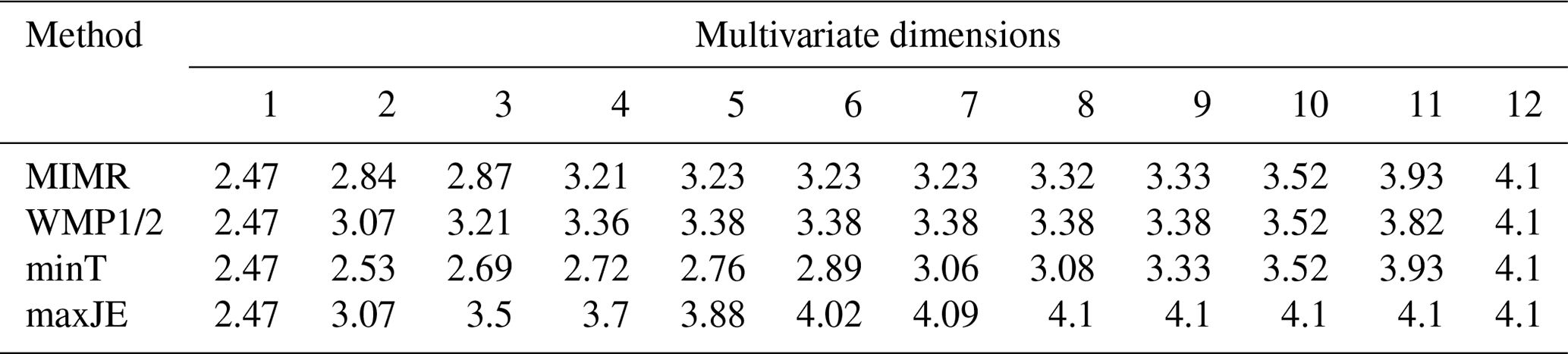
Table 3Optimal gauge orders found with different methods for the Brazos River case study.
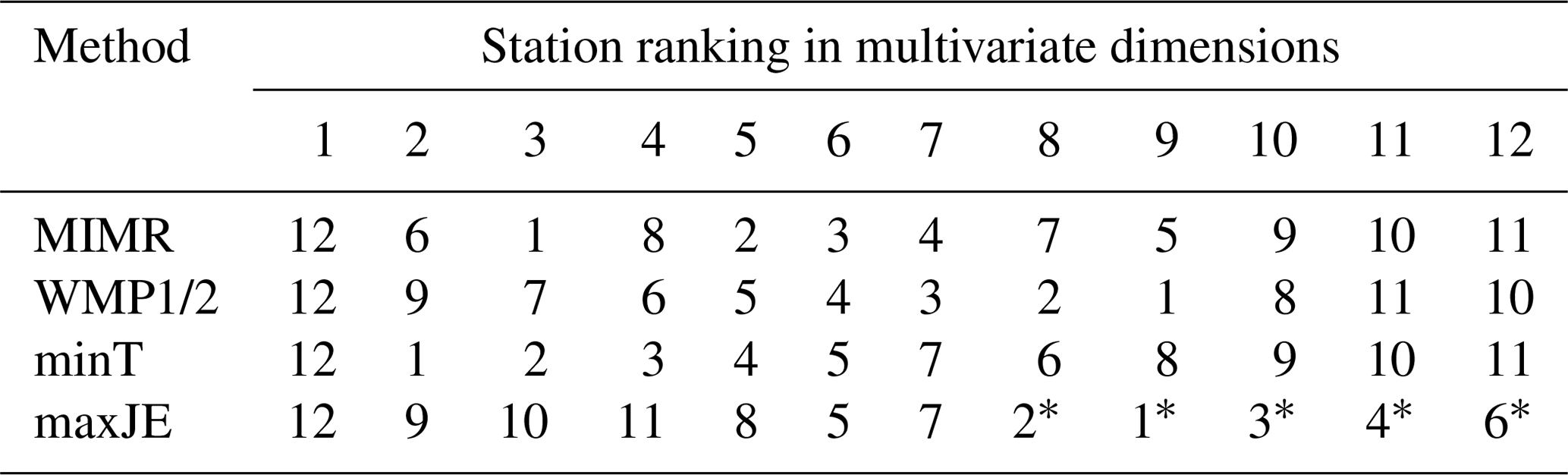
Note that for the last five stations, indicated with *, multiple optimal orders are possible.
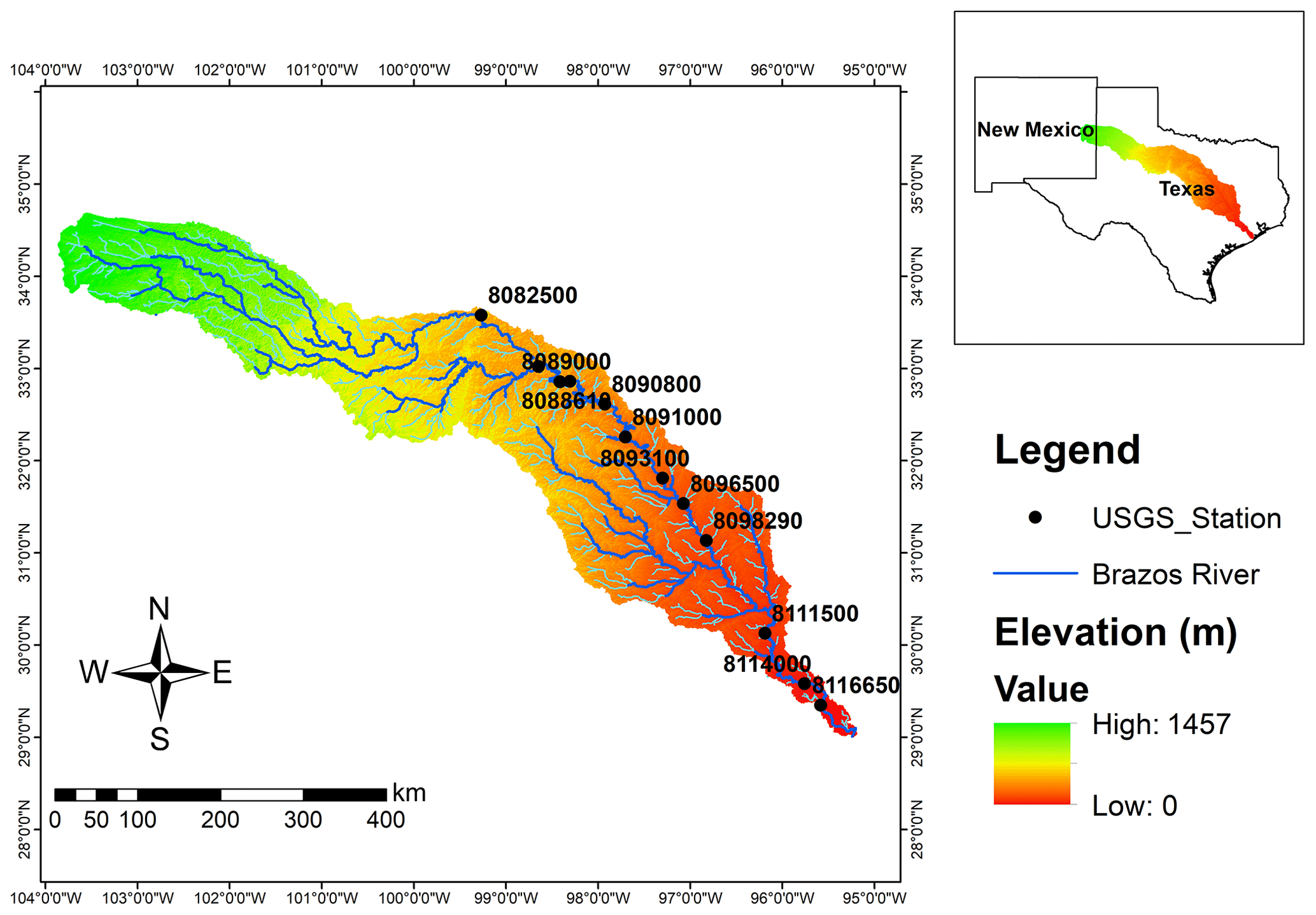
Figure 3Brazos streamflow network and USGS stream gauges' locations.
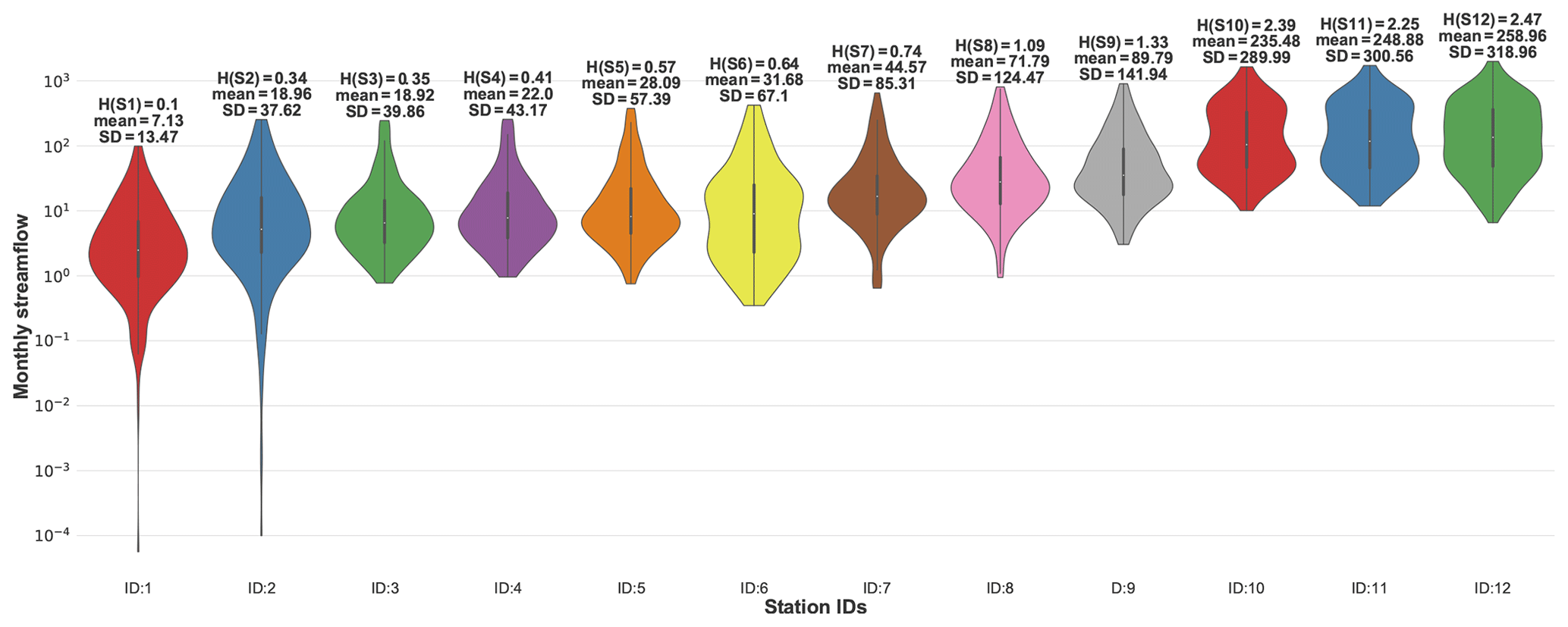
Figure 4Brazos River streamflow (m3 s−1) statistics and resulting entropy values (bits). The stations' IDs are organized from upstream to downstream gauges in the watershed. Entropy values are calculated by floor function and parameter .
In previous studies, the focus of the research has been on finding an optimal network for the subject case study with only little discussion on the theoretical justification of applying a new methodology. For this reason, the primary goal of this paper is critically discussing the rationale for use of several objective functions in monitoring network design. To illustrate differences between the methods, we decided to apply our methodology to the Brazos River streamflow network (Fig. 3) since this network was the subject of study for the MIMR method. This network is under-gauged, according to the World Meteorological Organization density requirement. However, using the exact same case study eliminates the effect of other factors besides the objective function on the comparison. Such factors could be initial network density, temporal variability, and spatial variability. To isolate our comparison from those effects, as well as from methodological choice such as resolution, time period considered, and quantization method, we used the same data period and floor function quantization (Eq. 11) proposed by Li et al. (2012).
Here, a is the histogram bin width for all intervals except the first one, for which the bin width is equal to . x is the station's streamflow value, and xq is its corresponding quantized value; and ⌊⌋ is the conventional mathematical floor function.
In Li et al. (2012), 12 USGS stream gauges on the Brazos River were selected for the period of 1990–2009 with monthly temporal resolution; some statistics of the data are presented in Fig. 4. For the discretization of the time series, they used a binning approach whereby they empirically optimized parameter a to satisfy three goals. (1) It must be guaranteed that all 12 stations have distinguishable marginal entropy. (2) To keep spatial and temporal variability of stations' time series, the bin width should be fine enough to capture the distribution of the values in the time series while being coarse enough so that enough data points are available per bin to have a representative histogram. (3) To prevent rank fluctuation due to the bin-width assumption, sensitivity analysis must be conducted. They carried out the sensitivity analysis and proposed for this case study; the resulting marginal entropy for each station is illustrated in Fig. 4.
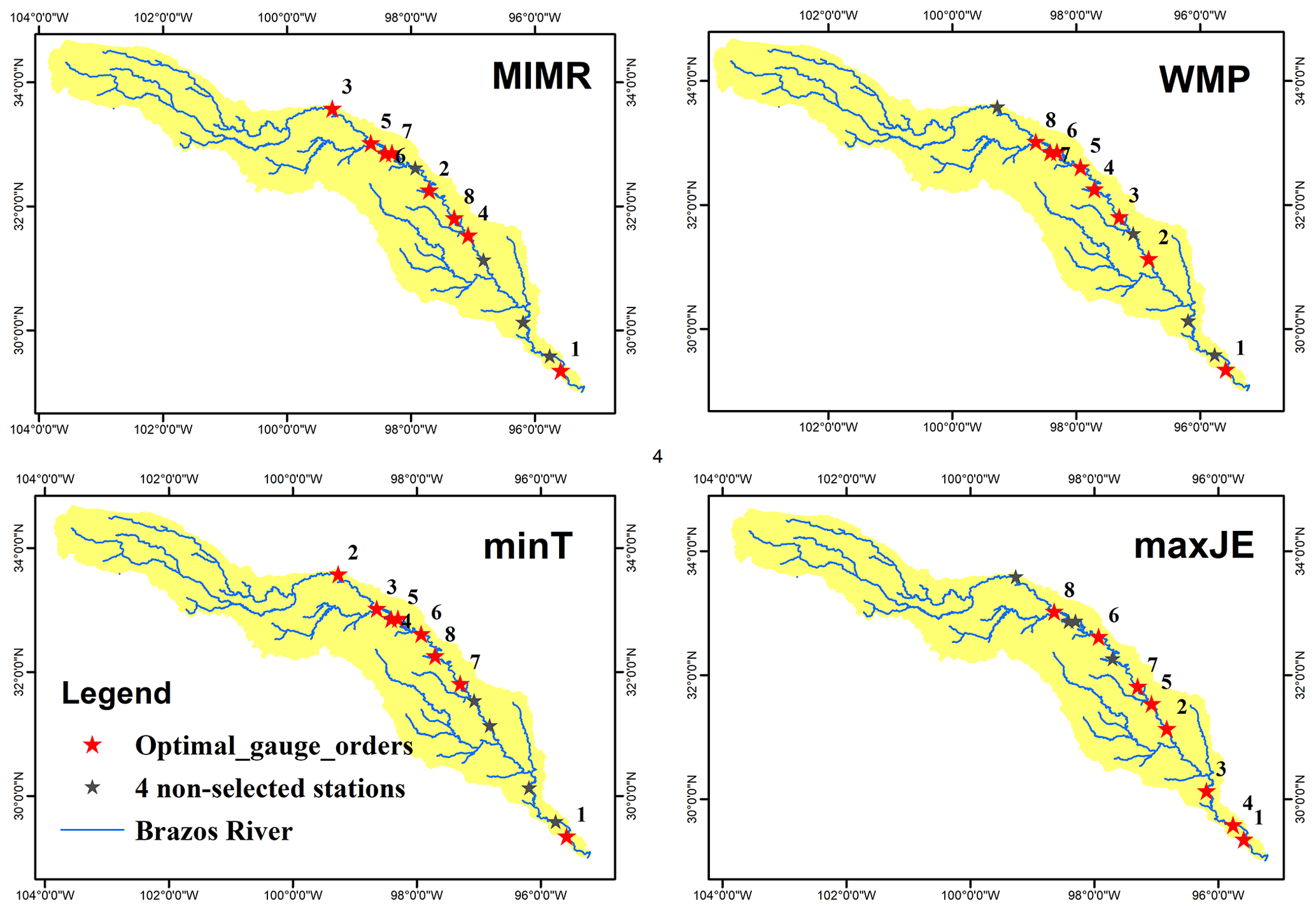
Figure 5Spatial distribution of the top eight streamflow gauges ranked by different objectives.

Figure 6Approximately proportional Venn diagrams showing the evolution of information measures when progressively (going down the rows) selecting stations (selected station for each step indicated by the numbers) using four different methods (in the different columns). The interpretation of the color-coded areas representing the information measures is the same as in Fig. 1. All methods select station 12 as the initial station (entropy given by pink circle in row 1). As can be seen from the diagram on the bottom right, the method maximizing joint entropy leaves almost no information unmeasured (yellow part) with just six stations, while the other methods still miss capturing this information. Exact numbers behind the Venn diagram can be found with the code available with this paper.
4.1 Comparison of the objectives for the Brazos River case
As indicated in the Introduction, we should not attempt to gauge the merits of the objective functions by the intuitive optimality of the resulting network. Rather, the merits of the networks should be gauged by the objective functions. Still, the case study can provide insight into some behaviors resulting from the objective functions.
To assess and illustrate the workings of the different objectives in retrieving information from the water system, we compared three existing methods with a direct maximization of the joint entropy of selected sensors, H(S,FC), indicated with maxJE in the results, such as Tables 2 and 3. The joint entropy results in Table 2 indicate that maxJE is able to find a combination of 8 stations that contains joint information of all 12 stations ranked by other existing methods. Figure 5 displays spatial distribution of the top eight stations chosen by different methods. Before any interpretation of the placement, we must note that the choices made in quantization and the availability of data play an important role in the optimal networks identified. Whether the saturation that occurs with eight stations has meaning for the real-world case study depends on whether the joint probability distribution can be reliably estimated. This is highly debatable and merits a separate detailed discussion which is out of the scope of this paper. We present this case study solely to illustrate behavior of the various objectives.
The most notable difference between maxJE and the other methods is the selection of all three of the stations located most downstream. While other methods would not select these together due to high redundancy between them, maxJE still selects all stations because despite the redundancy, there is still found to be enough new information in the second-most and third-most downstream station. This can be in part attributed to the quantization choice of equally sized bins throughout the network, leading to higher information contents downstream. While this quantization choice is debatable, it is important, in our opinion, to not compensate artifacts from quantization by modifying the objective function, even if the resulting network may seem more reasonable, but rather to address those artifacts in the quantization choices themselves. To repeat the key point: an objective function should not be chosen based on whether it yields a “reasonable network” but rather based on whether the principles that define it are reasonable.
Though already necessarily true from the formulation of the objective functions, we use the case study to illustrate how other methods with a separate minimum redundancy objective lead to the selection of stations with lower new information content (green area in Fig. 6). Reduction of the yellow area in each iteration (i.e., the information loss compared to the full network) in Fig. 6 corresponds to the growth of joint entropy values in Table 2 for each method. maxJE (by definition) has the fastest and minT the slowest rate of reduction of information loss. Methods' preference for reaching minimum redundancy or growing joint information (red area in Fig. 6) governs the reduction rate of information loss. Also, Fig. 7 provides auxiliary information about the evolution of pairwise information interaction between already selected stations in the previous iterations and new proposed station Xi. Figure 7 illustrates the contrast between the choice of the proposed stations in the first six iterations by different methods. For instance, the minT method aims to find a station that has minimum mutual information (red links in Fig. 7) with already selected stations. In contrast, the maxJE method tries to grow joint entropy, which translates to finding a station that has maximum conditional entropy (green segments in Fig. 7). Other methods opt to combine two approaches by either imposing a constraint (WMP) or having a trade-off between them (MIMR).
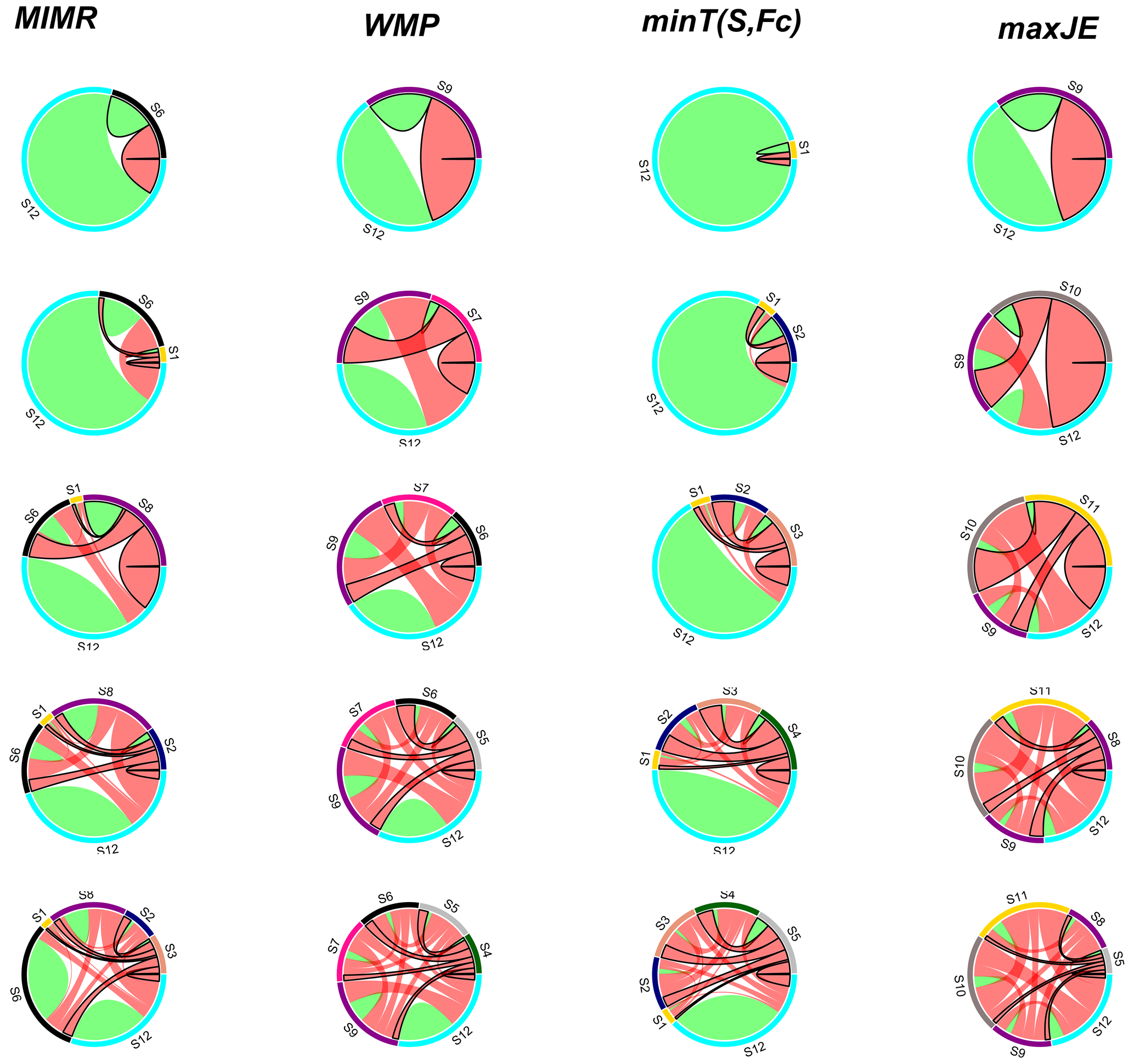
Figure 7Evolution of pairwise information interaction between already selected stations in the previous iterations and new proposed station. Green and red links represent proportional conditional entropy and mutual information, respectively. Links with black border emphasize the information interactions with the new proposed station in each iteration.
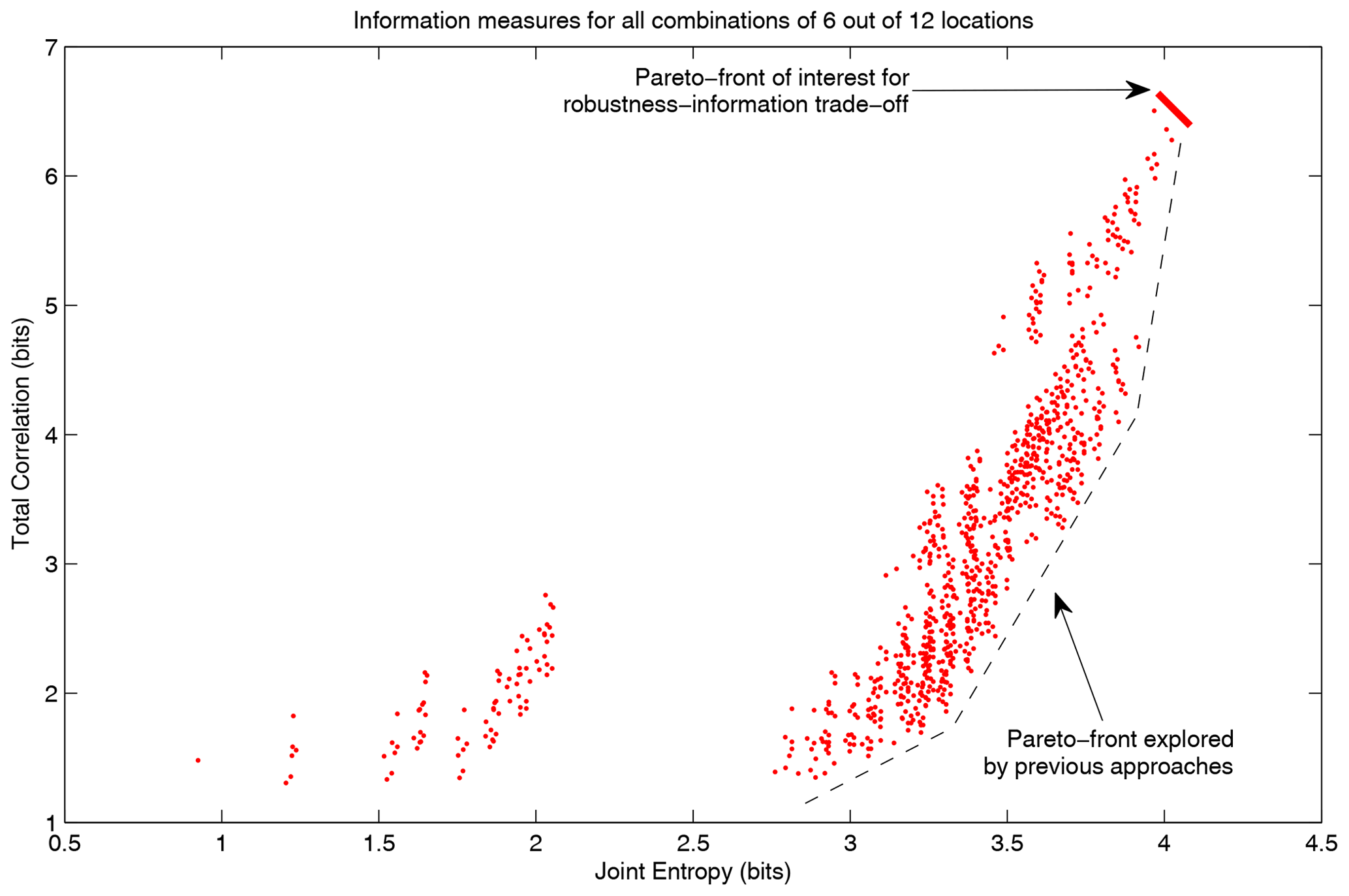
Figure 8The resulting total correlation and joint entropy for all 924 possible combinations of 6 out of 12 sensor locations. In some past approaches, a Pareto front in the lower right corner is given importance. In this paper, we argue that this trade-off is irrelevant, and information can be maximized with the horizontal direction only. If a trade-off with reliability needs to be considered, the Pareto front of interest is in the top-right corner instead of the lower right corner that is previously recommended in the literature.
4.2 Is minimization of dependence needed?
The existing approaches considered above have in common that they all involve some form of dependence criterion to be minimized. For example, the total correlation gives a measure of total redundant information within the selected set. This is information that is duplicated and therefore does not contribute to the total information content of the sensors, which is given by the joint entropy. Focusing fully on minimizing dependence, such as what is done in the minT objective optimization, makes the optimization insensitive to the amount of non-duplicated information added. This results in many low-entropy sensors being selected. It is important to note that the joint entropy already accounts for duplicated information and only quantifies the non-redundant information. This is exactly the reason why it is smaller than the sum of individual entropies. In terms of joint entropy, two completely dependent stations are considered to be exactly as informative as one of them. This means that the negative effect that dependency has on total information content is already accounted for by maximizing joint entropy only.
Mishra and Coulibaly (2009) stated that “the fundamental basis in designing monitoring networks based on the entropy approach is that the stations should have as little transinformation as possible, meaning that the stations must be independent of each other”. However, no underlying argument for this fundamental basis is given in the paper. The question is then whether there is another reason, apart from information maximization, why the total correlation should be minimized. In three of the early papers (Alfonso et al., 2010a, b; Li et al., 2012) introducing the approaches that employed or evaluated total correlation, no such reason was given other than the one by Mishra and Coulibaly (2009). Also in later citing research (Huang et al., 2020; Wang et al., 2018; Keum and Coulibaly, 2017; Stosic et al., 2017; Fahle et al., 2015), no such arguments have been found, except for effectiveness, which we argue is covered by looking at the total non-redundant information the network delivers. Traditional reasons for minimizing redundancy are reducing the burden of data storage and transmission, but these are not very relevant in monitoring network design, since those costs are often negligible compared to the costs of the sensor installation and maintenance (see Barrenetxea et al., 2008; Nadeau et al., 2009; Simoni et al., 2011). Moreover, information theory tells us that, if needed, redundant information can be removed before transmission and storage by employing data compression (Weijs et al., 2013b, a). The counter-side of minimal redundancy is less reliability, a far more relevant criterion for monitoring network design. Given that sensors often fail or give erroneous values, one could argue that redundancy (total correlation) should actually be maximized, given a maximum value of joint entropy. We might even want to gain more robustness at the cost of losing some information. One could for example imagine placing a new sensor directly next to another to gain confidence in the values and increase reliability, instead of using it to collect more informative data in other locations.
The Pareto front that would be interesting to explore in this context is the trade-off between maximum total correlation (robustness) vs. joint entropy (expected information gained from the network), indicated by the red line in Fig. 8. Different points on this Pareto front reflect different levels of trust in the sensors' reliability. Less trust requires more robustness and leads to a network design yielding more redundant information. Previous approaches, such as the MOOP approach proposed by Alfonso et al. (2010b), explore the Pareto front given by the dashed black line, where minimum total correlation is conflicting with maximizing joint entropy. As argued in this section, this trade-off is not fundamental in information-theoretical terms. Still, it results from the fact that there is usually redundant information as a by-product of new information, so highly informative stations also carry more redundant information. This redundant information does not reduce the utility of the new information so does not need to be included as a minimization objective in the optimization.
In summary, the maximization of joint entropy while minimizing redundancy is akin to maximizing effectiveness while maximizing a form of efficiency (i.e., bits of unique information/bits collected). However, bits do not have any significant associated cost. If installing and maintaining a monitoring location has a fixed cost, then efficiency should be expressed as unique information gathered per sensor installed, which could be found by maximizing joint entropy (effectiveness) for a given number of stations, as we suggest in this paper.
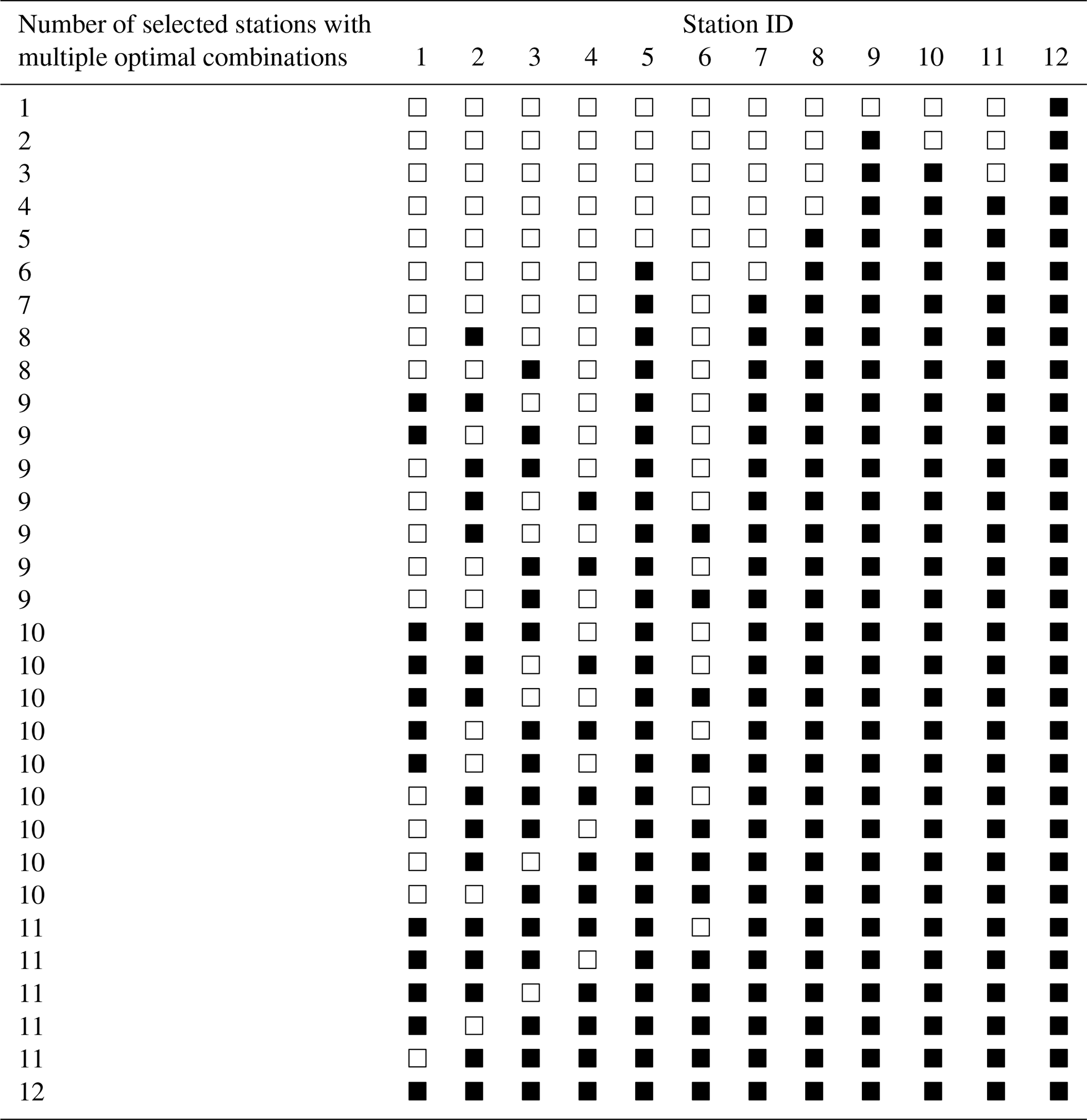
Table 4All optimal combinations of sensors for the joint entropy objective. For number of sensors above 7, multiple optimal combinations can be found due to saturation of joint entropy. Black squares are selected sensors.
4.3 Greedy algorithms vs. exhaustive optimization of maximum joint entropy
Different search strategies have been adopted in the literature for monitoring network design. The most commonly used greedy algorithms impose a constraint on exhaustive search space to reduce computational effort. We investigated three different search strategies to obtain the optimal network in the context of using maxJE as an objective function. We discuss the advantages and limitations of each search strategy in terms of optimality of the solution and computational effort.
The exhaustive optimization tests all possible new combinations, not restricted to those combinations containing the already selected set in a smaller network. Since the joint entropy of a set of locations does not depend on the order in which they are added, the number of possible combinations is (i.e., n choose k), where n is the number of potential stations in the pool, and k is the number of selected stations. The computational burden is therefore greatest when about half of the stations are selected. For a number of potential sensors under 20, this is still quite tractable (4 min on normal PC, implemented – by a hydrologist – in MATLAB), but for larger numbers, the computation time increases very rapidly. When considering all sub-network sizes, the number of combinations to consider is 2n, so an exponential growth. We could make an optimistic estimate, only considering the scaling from station combinations to evaluate but not considering the dimensionality of the information measures. For 40 stations, this estimate would yield a calculation time of more than 5 years, unless a more efficient algorithm can be found. Regardless of potential improvements in implementation, the exponential scaling will cause problems for larger systems.
Table 5Resulting station selections for the artificially permuted dataset with 860 data points.

* means a previously selected station is removed from the optimal set of selected stations.
Greedy approaches might be candidates for efficient algorithms. For the proposed joint entropy objective, we tested the optimality of greedy approaches against the benchmark of exhaustive optimization of all possible station combinations. For the Brazos River case study, both the “add” and “drop” greedy selection strategies resulted in the global optimum sets, i.e., the same gauge order and resulting joint entropy as was found by the exhaustive optimization. These results can be read from the last row of Tables 2 and 3. Therefore, for this case, the greedy approaches did not result in any loss of optimality. For the last few sensors, multiple different optimal sets could be identified, which are detailed in Table 4. Results in Table 4 show that multiple network layouts with equal network size and joint information exist. For this case, network robustness could be an argument to prefer the network with maximum redundancy.
In a further test, using artificially generated data, we experimentally falsified the hypothesis that greedy approaches can guarantee optimality. For this test, we generated a correlated random Gaussian dataset for 12 stations, based on the covariance matrix of the data from the case study. We increased the number of generated observations to 860 time steps, to get a more reliable multidimensional probability distribution. Table 5 shows the resulting orders for 12 stations for the three different approaches. Note how for the exhaustive optimization in this example, in some instances, one or two previously selected gauges are dropped in favor of selecting new stations. The resulting joint entropies for the selected sets are shown in Table 6. This means no greedy approach can exist that finds results equivalent to the exhaustive approach.
Based on our limited case study, the questions remain open: (1) whether faster algorithms can be formulated that yield guaranteed optimal solutions, and (2) in which cases the greedy algorithm provides a close approximation. It is also possible to formulate modified greedy methods with the ability of replacing a limited number of stations instead of just adding stations. This leads to a significantly reduced computational burden while reaching the optimum more often than when adding stations one at a time. In Table 5, it can be seen that allowing a maximum number of two relocated stations would already reach the optimal configurations for this specific case. Another limitation of this comparison is that we did not consider metaheuristic search approaches (Deb et al., 2002; Kollat et al., 2008), which fall in between greedy and exhaustive approaches in terms of computational complexity and could serve to further explore the optimality vs. computational complexity trade-off. It would be interesting to further investigate what properties in the data drive the suboptimality of greedy algorithms. Synergistic interactions (Goodwell and Kumar, 2017) are a possible explanation, although our generated data example shows that even when moving from one to two selected stations, a replacement occurs. Since there are only pairs of variables involved, synergy is not needed in the explanation of this behavior. Rather, the pair with maximum joint entropy does not always include the station with maximum entropy, which could perhaps be too highly correlated with other high entropy variables.
Table 6Resulting joint entropy for the artificially permuted dataset with 860 data points.

The aim of this paper was to contribute to better understanding the problem of optimal monitoring network layout using information-theoretical methods. Since using resulting networks and performance metrics from case studies to demonstrate that one objective should be preferred over the other would be circular, the results from our case study served as an illustration of the effects but not as arguments supporting the conclusions we draw about objective functions. We investigated the rationale for using various multiple-objective and single-objective approaches and discussed the advantages and limitations of using exhaustive vs. greedy search. The main conclusions for the study can be summarized as follows:
-
The purpose of the monitoring network governs which objective functions should be considered. When no explicit information about users and their decision problems can be identified, maximizing the total information collected by the network becomes a reasonable objective. Joint entropy is the only objective needed to maximize retrieved information, assuming that this joint entropy can be properly quantified.
-
We argued that the widespread notion of minimizing redundancy, or dependence between monitored signals, as a secondary objective is not desirable and has no intrinsic justification. The negative effect of redundancy on total collected information is already accounted for in joint entropy, which measures total information net of any redundancies.
-
When the negative effect on total information is already accounted for, redundant information is arguably beneficial, as it increases robustness of the network information delivery when individual sensors may fail. Maximizing redundancy as an objective secondary to maximizing joint entropy could therefore be argued for, and a trade-off between these objectives could be explored depending on the specific case.
-
The comparison of exhaustive and greedy search approaches shows that no greedy approach can exist that is guaranteed to give the true optimum subset of sensors for each network size. However, the exponential computational complexity, which doubles the number of sensor combinations to evaluate with every sensor added, makes exhaustive search prohibitive for large networks, illustrated by the following. During the COVID-19 response in March 2020, Folding@home, currently the world's largest distributed computing project, broke the exaFLOP barrier (1018 floating point operations per second). Even with that computational power, it would take more than 10 years to evaluate a network of 90 potential stations, under the impossibly optimistic assumption that evaluating one network were possible in one FLOP. The complexity of the greedy approach is quadratic in the number of locations and therefore feasible for large search spaces.
-
The constraints on the search space imposed by the greedy approach could also be interpreted as a logistical constraint. In a network expansion scenario, it disallows the replacement of stations already selected in the previous iteration.
-
We introduced the “greedy drop” approach that starts from the full set and deselects stations one by one. We have demonstrated that the two types of greedy approaches do not always lead to the same result, and neither approach guarantees the unconstrained true optimal solution. Synergistic interactions between variables may play a role, although this is not the only possible explanation. In our case study, the suboptimality of greedy algorithms was not visible in original data, but we demonstrated its existence with artificially generated data. In our specific case studies, differences between exhaustive and greedy approaches were small, especially when using a combination of the greedy add and greedy drop strategy. It remains to be demonstrated in further research how serious this loss of optimality is in a range of practical situations and how results compare to intermediate computational complexity approaches such as metaheuristic algorithms.
Further work
In this paper, we focused on the theoretical arguments for justifying the use of various objective functions and compared a maximization of joint entropy to other methods while using the same dataset and quantization scheme. Since the majority of previous research used greedy search tools to find optimal network configurations, we compared greedy and exhaustive search approaches to raise awareness in the scientific community that greedy optimization might fall into a local optimum, though its application can be justified considering the computation cost of the exhaustive approach. Banik et al. (2017) compared computation cost for greedy and metaheuristic optimization (Non-dominated Sorting Genetic Algorithm II). They reported that the greedy approach resulted in drastic reduction of the computational time for the same set of objective functions (metaheuristic computation cost was higher 58 times in one trial and 476 times in another). We recommend further investigation of these three search tools in terms of both optimality (for the maxJE objective) and computation cost.
Another important question that needs to be addressed in future research is to investigate how the choices and assumptions made (i.e., data quantization which influences probability distribution) in the numerical calculation of objective functions would affect network ranking. What many of these objective functions have in common is that they rely on multivariate probability distributions. For example, in our case study, the joint entropy is calculated from a 12-dimensional probability distribution. These probability distributions are hard to reliably estimate from limited data, especially in higher dimensions, since data requirements grow exponentially. Also, these probability distributions and the resulting information measures are influenced by multiple factors, including choices about the data's temporal scale and quantization. To have an unbiased comparison framework of objective functions, we kept data and quantization choices from a case study previously described in the literature. It is worth acknowledging that these assumptions, as well as data availability, can greatly influence station selection and require more attention in future research.
Numerically, the limited data size in the case study presents a problem for the calculation of multivariate information measures. Estimating multivariate discrete joint distributions exclusively from data requires quantities of data that exponentially grow with the number of variables, i.e., potential locations. When these data requirements are not met, and joint distributions are still estimated directly based on frequencies, independent data will be falsely qualified as dependent and joint information content severely underestimated. This can also lead to apparent earlier saturation of joint entropy, at a relatively low number of stations. For the case study presented here, we do not recommend interpreting this saturation as reaching the number of needed stations, since it could be a numerical artifact. This problem applies to all methods discussed in this paper. Before numerics can be discussed, clarity is needed on the interpretation and choice of the objective function. In other words, before thinking about how to optimize, we should be clear on what to optimize. We hope that this paper helped illuminate this.
- S
-
Set of indices of selected stations' locations
- F
-
Set of indices of potential monitoring locations not yet selected
- FC
-
The index of the monitoring station currently under consideration for addition
-
The (sets of) time series (variables) measured at the station(s) in the respective sets
- p(x1)
-
The marginal probability distribution of random variable X1
- p(x1,x2)
-
The joint probability distribution of variable X1 and X2
- H(FC)
-
A shorthand for ; in information measures, the set is used as shorthand for variables in that set
-
The entropy of the marginal distribution of time series in FC
- H(XF|XS)
-
The conditional joint entropy of variables in F, given knowledge of variables in S
- T(XF;XS)
-
Mutual information or transinformation between set of variables in F and set of variables in S
-
Total correlation, the amount of information shared between all variables
- λ1
-
Information-redundancy trade-off weight
- SBM
-
“select below median”, the constraint whereby only stations are considered that are below the median score of all potential stations
- a
-
Histogram bin width
- x
-
Station's streamflow value
- xq
-
Quantized value after discretization
- AE
-
Apportionment entropy
- RDI
-
Ranking disorder index
- SIz(X)
-
Local spatiotemporal information of the grid X in local window z in the time series
- p(σz)
-
Probability distribution of the standard deviation σz in time series
- Anetwork
-
Network accuracy
- Var
-
Kriging variance
- D
-
Detection time
- Dsp(γ)
-
The average of the shortest time among the detection times for monitoring station
- R
-
Reliability
- δs
-
Binary choice of 1 or 0 for whether the contamination is detected or not
Recent literature has expanded the information-theoretical objectives with additional objectives. For instance, (1) Wang et al. (2018) proposed the dynamic network evaluation framework (DNEF) method that follows the MIMR method for network configuration in different time windows, and optimal network ranking is determined by the maximum ranking disorder index (RDI) (Eq. B2), which is the normalized version of apportionment entropy (AE). RDI was proposed by Fahle et al. (2015) and named by Wang et al. (2018) to analyze the uncertainty of the rank assigned to a monitoring station under different time windows. (2) Huang et al. (2020) proposed the information content, spatiotemporality, and accuracy (ISA) method, which extends the MIMR method by adding two objectives: maximizing spatiotemporality information (SI) and maximizing accuracy (A). The SI (Eq. B4) objective is introduced to incorporate the spatiotemporality of satellite data into network design, and the A (Eq. B5) objective is proposed to maximize the interpolation accuracy of the network by minimizing the regional Kriging variance. (3) Banik et al. (2017) proposed six combinations (GR 1–6) of four objectives: detection time (D) (Eq. B6), reliability (R) (Eq. B7), H (Eq. 2), and C (Eq. 6) for locating sensors in sewer systems. (4) Keum and Coulibaly (2017) proposed to maximize conditional entropy as a third objective in dual entropy-multi-objective optimization to integrate multiple networks (in their case, rain gauge and streamflow networks). Although maximizing conditional entropy can indirectly be achieved with other objectives (joint entropy), this new objective gives more preference to maximizing unique information that one network can provide when another network cannot deliver. These multi-objective optimization problems are solved by either finding an optimal solution in a Pareto front (Alfonso et al., 2010b; Samuel et al., 2013; Keum and Coulibaly, 2017) or by merging multiple objectives with weight factors into a single-objective function (Li et al., 2012; Banik et al., 2017; Stosic et al., 2017).
where n is the number of possible ranks that a station can have (i.e., n is equal to the total number of stations). ratio is an occurrence probability of the outcome, where M is the number of ranks under different time windows, and ri is the number of a certain ith rank. Therefore, AE takes on its maximum value when the ranking probability of a station has an equally probable outcome, while minimum AE happens when the station's rank is constant. RDI ranges from 0 to 1, and higher RDI values indicate the ranking sensitivity of a station to temporal variability of the data.
where SIz(X) is the local spatiotemporal information of the grid X in local window z in the time series; and p(σz) is the probability distribution of the standard deviation σz in time series l. is spatiotemporal of the network, which is calculated by the average of spatiotemporal information of the already selected sites and a potential site . is network accuracy, and Var is Kriging variance over time series l and number of grids k in the study area.
where S is the total number of scenarios considered, Dsp(γ) is the average of the shortest time among the detection times for monitoring stations, and δs is the binary choice of 1 or 0 for whether the contamination is detected or not.
The code and data that were used to generate the results in this paper are available from https://doi.org/10.5281/zenodo.4323537 (Weijs and Foroozand, 2020), and flow data were originally retrieved from the USGS (https://waterdata.usgs.gov/nwis).
SVW conceptualized study, and HF and SVW jointly performed the analysis and wrote the paper. SVW supervised HF.
The authors declare that they have no conflict of interest.
This research was supported by funding from Hossein Foroozand's NSERC CGS – Doctoral award and Steven V. Weijs's NSERC discovery grant. The authors sincerely thank the four reviewers for their critical views and interesting discussion, which helped improve the paper.
This research has been supported by an NSERC discovery grant (grant no. RGPIN-2016-04256) and an NSERC CGS – Doctoral award (grant no. CGSD2-535466-2019).
This paper was edited by Nunzio Romano and reviewed by Heye Bogena and three anonymous referees.
Alfonso, L., Lobbrecht, A., and Price, R.: Information theory–based approach for location of monitoring water level gauges in polders, Water Resour. Res., 46, W03528, https://doi.org/10.1029/2009WR008101, 2010a. a, b, c, d, e, f, g, h, i
Alfonso, L., Lobbrecht, A., and Price, R.: Optimization of water level monitoring network in polder systems using information theory, Water Resour. Res., 46, W12553, https://doi.org/10.1029/2009WR008953, 2010b. a, b, c, d, e, f, g, h
Aydin, B. E., Hagedooren, H., Rutten, M. M., Delsman, J., Oude Essink, G. H. P., van de Giesen, N., and Abraham, E.: A Greedy Algorithm for Optimal Sensor Placement to Estimate Salinity in Polder Networks, Water, 11, 1101, https://doi.org/10.3390/w11051101 2019. a
Banik, B. K., Alfonso, L., Di Cristo, C., and Leopardi, A.: Greedy Algorithms for Sensor Location in Sewer Systems, Water, 9, 856, https://doi.org/10.3390/w9110856 2017. a, b, c, d, e, f, g, h, i, j, k, l, m, n
Barrenetxea, G., Ingelrest, F., Schaefer, G., and Vetterli, M.: The hitchhiker's guide to successful wireless sensor network deployments, in: Proceedings of the 6th ACM conference on Embedded network sensor systems, SenSys '08, 43–56, Association for Computing Machinery, Raleigh, NC, USA, https://doi.org/10.1145/1460412.1460418, 2008. a
Bayat, B., Hosseini, K., Nasseri, M., and Karami, H.: Challenge of rainfall network design considering spatial versus spatiotemporal variations, J. Hydrol., 574, 990–1002, https://doi.org/10.1016/j.jhydrol.2019.04.091, 2019. a
Bennett, A., Nijssen, B., Ou, G., Clark, M., and Nearing, G.: Quantifying Process Connectivity With Transfer Entropy in Hydrologic Models, Water Resour. Res., 55, 4613–4629, https://doi.org/10.1029/2018WR024555, 2019. a
Bernardo, J. M.: Expected Information as Expected Utility, Ann. Stat., 7, 686–690, https://doi.org/10.1214/aos/1176344689, 1979. a
Deb, K., Pratap, A., Agarwal, S., and Meyarivan, T.: A fast and elitist multiobjective genetic algorithm: NSGA-II, IEEE T. Evolut. Computat., 6, 182–197, https://doi.org/10.1109/4235.996017, 2002. a
Fahle, M., Hohenbrink, T. L., Dietrich, O., and Lischeid, G.: Temporal variability of the optimal monitoring setup assessed using information theory, Water Resour. Res., 51, 7723–7743, https://doi.org/10.1002/2015WR017137, 2015. a, b
Foroozand, H. and Weijs, S. V.: Entropy Ensemble Filter: A Modified Bootstrap Aggregating (Bagging) Procedure to Improve Efficiency in Ensemble Model Simulation, Entropy, 19, 520, https://doi.org/10.3390/e19100520, 2017. a
Foroozand, H., Radić, V., and Weijs, S. V.: Application of Entropy Ensemble Filter in Neural Network Forecasts of Tropical Pacific Sea Surface Temperatures, Entropy, 20, 207, https://doi.org/10.3390/e20030207, 2018. a
Franzen, S. E., Farahani, M. A., and Goodwell, A. E.: Information Flows: Characterizing Precipitation-Streamflow Dependencies in the Colorado Headwaters With an Information Theory Approach, Water Resour. Res., 56, e2019WR026133, https://doi.org/10.1029/2019WR026133, 2020. a
Goodwell, A. E. and Kumar, P.: Temporal information partitioning: Characterizing synergy, uniqueness, and redundancy in interacting environmental variables, Water Resour. Res., 53, 5920–5942, https://doi.org/10.1002/2016WR020216, 2017. a, b
Huang, Y., Zhao, H., Jiang, Y., and Lu, X.: A Method for the Optimized Design of a Rain Gauge Network Combined with Satellite Remote Sensing Data, Remote Sens.-Basel, 12, 194, https://doi.org/10.3390/rs12010194, 2020. a, b, c, d, e, f, g
Keum, J. and Coulibaly, P.: Information theory-based decision support system for integrated design of multivariable hydrometric networks, Water Resour. Res., 53, 6239–6259, https://doi.org/10.1002/2016WR019981, 2017. a, b, c, d, e, f, g, h, i
Khorshidi, M. S., Nikoo, M. R., Taravatrooy, N., Sadegh, M., Al-Wardy, M., and Al-Rawas, G. A.: Pressure sensor placement in water distribution networks for leak detection using a hybrid information-entropy approach, Inform. Sci., 516, 56–71, https://doi.org/10.1016/j.ins.2019.12.043, 2020. a
Kollat, J. B., Reed, P. M., and Kasprzyk, J. R.: A new epsilon-dominance hierarchical Bayesian optimization algorithm for large multiobjective monitoring network design problems, Adv. Water Resour., 31, 828–845, https://doi.org/10.1016/j.advwatres.2008.01.017, 2008. a
Konapala, G., Kao, S.-C., and Addor, N.: Exploring Hydrologic Model Process Connectivity at the Continental Scale Through an Information Theory Approach, Water Resour. Res., 56, e2020WR027340, https://doi.org/10.1029/2020WR027340, 2020. a
Krstanovic, P. F. and Singh, V. P.: Evaluation of rainfall networks using entropy: I. Theoretical development, Water Resour. Manag., 6, 279–293, https://doi.org/10.1007/BF00872281, 1992. a
Li, C., Singh, V. P., and Mishra, A. K.: Entropy theory-based criterion for hydrometric network evaluation and design: Maximum information minimum redundancy, Water Resour. Res., 48, W05521, https://doi.org/10.1029/2011WR011251, 2012. a, b, c, d, e, f, g, h, i, j, k, l
McGill, W. J.: Multivariate information transmission, Psychometrika, 19, 97–116, https://doi.org/10.1007/BF02289159, 1954. a
Mishra, A. K. and Coulibaly, P.: Developments in hydrometric network design: A review, Rev. Geophys., 47, RG2001, https://doi.org/10.1029/2007RG000243, 2009. a, b
Mogheir, Y., Singh, V. P., and de Lima, J. L. M. P.: Spatial assessment and redesign of a groundwater quality monitoring network using entropy theory, Gaza Strip, Palestine, Hydrogeol. J., 14, 700–712, https://doi.org/10.1007/s10040-005-0464-3, 2006. a
Nadeau, D. F., Brutsaert, W., Parlange, M. B., Bou-Zeid, E., Barrenetxea, G., Couach, O., Boldi, M.-O., Selker, J. S., and Vetterli, M.: Estimation of urban sensible heat flux using a dense wireless network of observations, Environ. Fluid Mech., 9, 635–653, https://doi.org/10.1007/s10652-009-9150-7, 2009. a
Neumann, J. v. and Morgenstern, O.: Theory of Games and Economic Behavior, Princeton University Press, Princeton, New Jersey, United States, 1953. a
Raso, L., Weijs, S. V., and Werner, M.: Balancing Costs and Benefits in Selecting New Information: Efficient Monitoring Using Deterministic Hydro-economic Models, Water Resour. Manag., 32, 339–357, https://doi.org/10.1007/s11269-017-1813-4, 2018. a
Ridolfi, E., Montesarchio, V., Russo, F., and Napolitano, F.: An entropy approach for evaluating the maximum information content achievable by an urban rainfall network, Nat. Hazards Earth Syst. Sci., 11, 2075–2083, https://doi.org/10.5194/nhess-11-2075-2011, 2011. a, b, c
Samuel, J., Coulibaly, P., and Kollat, J.: CRDEMO: Combined regionalization and dual entropy-multiobjective optimization for hydrometric network design, Water Resour. Res., 49, 8070–8089, https://doi.org/10.1002/2013WR014058, 2013. a, b, c, d, e, f
Shannon, C. E.: A mathematical theory of communication, Bell Syst. Tech. J., 27, 379–423, https://doi.org/10.1002/j.1538-7305.1948.tb01338.x, 1948. a, b
Simoni, S., Padoan, S., Nadeau, D. F., Diebold, M., Porporato, A., Barrenetxea, G., Ingelrest, F., Vetterli, M., and Parlange, M. B.: Hydrologic response of an alpine watershed: Application of a meteorological wireless sensor network to understand streamflow generation, Water Resour. Res., 47, W10524, https://doi.org/10.1029/2011WR010730, 2011. a, b
Stosic, T., Stosic, B., and Singh, V. P.: Optimizing streamflow monitoring networks using joint permutation entropy, J. Hydrol., 552, 306–312, https://doi.org/10.1016/j.jhydrol.2017.07.003, 2017. a, b, c, d, e, f
Wang, W., Wang, D., Singh, V. P., Wang, Y., Wu, J., Wang, L., Zou, X., Liu, J., Zou, Y., and He, R.: Optimization of rainfall networks using information entropy and temporal variability analysis, J. Hydrol., 559, 136–155, https://doi.org/10.1016/j.jhydrol.2018.02.010, 2018. a, b, c, d, e, f, g, h
Watanabe, S.: Information Theoretical Analysis of Multivariate Correlation, IBM J. Res. Dev., 4, 66–82, https://doi.org/10.1147/rd.41.0066, 1960. a
Weijs, S. and Foroozand, H.: hydroinfotheory/monitoring_network_objectives: v1.0.0 initial release with paper acceptance (Version v1.0.0), Zenodo, https://doi.org/10.5281/zenodo.4323537, 2020. a
Weijs, S. V., van de Giesen, N., and Parlange, M. B.: Data compression to define information content of hydrological time series, Hydrol. Earth Syst. Sci., 17, 3171–3187, https://doi.org/10.5194/hess-17-3171-2013, 2013a. a, b
Weijs, S. V., Van de Giesen, N., and Parlange, M. B.: HydroZIP: How Hydrological Knowledge can Be Used to Improve Compression of Hydrological Data, Entropy, 15, 1289–1310, https://doi.org/10.3390/e15041289, 2013b. a
Weijs, S. V., Foroozand, H., and Kumar, A.: Dependency and Redundancy: How Information Theory Untangles Three Variable Interactions in Environmental Data, Water Resour. Res., 54, 7143–7148, https://doi.org/10.1029/2018WR022649, 2018. a
- Abstract
- Introduction
- Methodology
- Study area and data description
- Results and discussion
- Conclusions
- Appendix A: Notation and definitions
- Appendix B: Additional objectives used in recent literature
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methodology
- Study area and data description
- Results and discussion
- Conclusions
- Appendix A: Notation and definitions
- Appendix B: Additional objectives used in recent literature
- Code and data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References