the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 21 Oct 2021
| 21 Oct 2021
Benchmarking data-driven rainfall–runoff models in Great Britain: a comparison of long short-term memory (LSTM)-based models with four lumped conceptual models
Marcus Buechel
Bailey Anderson
Louise Slater
Steven Reece
Gemma Coxon
Simon J. Dadson
Long short-term memory (LSTM) models are recurrent neural networks from the field of deep learning (DL) which have shown promise for time series modelling, especially in conditions when data are abundant. Previous studies have demonstrated the applicability of LSTM-based models for rainfall–runoff modelling; however, LSTMs have not been tested on catchments in Great Britain (GB). Moreover, opportunities exist to use spatial and seasonal patterns in model performances to improve our understanding of hydrological processes and to examine the advantages and disadvantages of LSTM-based models for hydrological simulation. By training two LSTM architectures across a large sample of 669 catchments in GB, we demonstrate that the LSTM and the Entity Aware LSTM (EA LSTM) models simulate discharge with median Nash–Sutcliffe efficiency (NSE) scores of 0.88 and 0.86 respectively. We find that the LSTM-based models outperform a suite of benchmark conceptual models, suggesting an opportunity to use additional data to refine conceptual models. In summary, the LSTM-based models show the largest performance improvements in the north-east of Scotland and in south-east of England. The south-east of England remained difficult to model, however, in part due to the inability of the LSTMs configured in this study to learn groundwater processes, human abstractions and complex percolation properties from the hydro-meteorological variables typically employed for hydrological modelling.
- Article
(3557 KB) - Full-text XML
-
Supplement
(5069 KB) - BibTeX
- EndNote





Rainfall–runoff models have evolved over many decades, reflecting a diversity of applications and purposes. These models range from physically based, spatially explicit models such as SHETRAN (Birkinshaw et al., 2010), CLASSIC (Crooks et al., 2014) and PARFLOW (Maxwell et al., 2009) to lumped conceptual models such as TOPMODEL (Beven and Kirkby, 1979) and VIC (Liang, 1994). Additionally, data-driven models have also been used for modelling rainfall–runoff processes (Reichstein et al., 2019; Elshorbagy et al., 2010; Wilby et al., 2003; Nourani et al., 2014; Le et al., 2019; Gauch et al., 2021b). The diversity of modelling approaches reflects the diversity of user objectives, uncertainty in terms of how to best represent the stores and fluxes of water and energy, and the trade-offs in terms of data requirements, degree of realism and computational costs (Beven, 2011).
Data-driven models range from simple regression models to large neural networks with thousands of parameters. These methods draw on empirical relationships between inputs and outputs to form a representation of how the hydrological system operates more generally (Beven, 2011). Other approaches from the class of data-driven models, such as statistical modelling and machine learning, include genetic programming (Chadalawada et al., 2020; Herath et al., 2021), random forests (Booker and Woods, 2014) and support vector regression models (Elshorbagy et al., 2010). Alternative empirical approaches also exist, including data-based mechanistic (DBM) modelling (Young, 1998, 2003). DBM approaches suggest that rather than imposing model structures from the outset hydrologists should in the first instance allow the data to suggest an appropriate model structure. Then, the modeller should see if there is a mechanistic interpretation of the learnt model structure (Young and Beven, 1994). Our modelling approach uses deep learning (DL) techniques, which have produced accurate predictions on a wide variety of tasks, including rainfall–runoff modelling (Huntingford et al., 2019), and represent a fruitful area of further exploration for hydrologists and Earth scientists (Reichstein et al., 2019). For a more complete picture on the uses of DL techniques in hydrology, an interested reader is referred to Shen (2018), Beven (2020), Nearing et al. (2020), and Kratzert et al. (2018).
DL methods have been used in hydrology and meteorology for decades (Daniell, 1991; Halff et al., 1993; Dawson and Wilby, 1998; Wilby et al., 2003; Peel and McMahon, 2020). However, one architecture explicitly designed for time series simulation, the long short-term memory (LSTM) network (Hochreiter et al., 2001; Hochreiter, 1991), has recently demonstrated credible performance for modelling hydrological signatures across the continental United States (CONUS) (Kratzert et al., 2018, 2019; Duan et al., 2020; Feng et al., 2020; Gauch et al., 2021b; Fang et al., 2018, 2020). More recent work has begun not only to explore the accuracy of forecasts but also to use LSTMs to (i) provide estimates of uncertainty (Klotz et al., 2020), (ii) explore the ability of the LSTM to integrate prior physical knowledge into DL model architectures (Hoedt et al., 2021; Jiang et al., 2020), and (iii) to use LSTMs to produce predictions at multiple timescales from a single model (Gauch et al., 2021a).
By contrast with the physically based, spatially explicit hydrological models, lumped conceptual models have relatively few parameters and simulate the stores and fluxes of water on a catchment scale, e.g. using a single store to represent the catchment-wide upper-soil water storage (Beven, 2011). Lumped conceptual models have lower data and computational requirements when compared to the spatially explicit, physically based, models, which is one reason why they are often used for operational purposes (Clark et al., 2008). There exist many lumped conceptual models, differing in their internal structures, the equations that govern fluxes of water and energy, and the processes that are included (Knoben et al., 2019). As an evidence-guided discipline, performance benchmarks provide hydrologists with an objective means for selecting between different models, instead of model selection by lineage or affiliation (Addor and Melsen, 2019). Furthermore, when applied over a large sample of catchments, differences in model performance can be instructive with regards to the hydrological conditions that are well simulated by one model compared with others (Gupta et al., 2014). Increasingly, “we need large-scale evaluations of model capability to identify which processes are important and which model structure(s) are most appropriate” (Lane et al., 2019, p. 4012).
This paper seeks to address three research gaps. First, there exists no large-sample performance benchmark of LSTMs in a Great Britain (GB) context. This is important because scientists and practitioners are interested in using LSTMs as hydrological models for hazard impact assessment, hazard early warning and rainfall–runoff modelling (Shen, 2018). Therefore, a rigorous assessment of LSTM performances is necessary to determine whether such a model choice is appropriate in the GB context. Furthermore, given that the data archives are rich in GB, there exists a very good opportunity to learn more about the capabilities and limitations of LSTM-based methods (Clark and Khatami, 2021). Second, there exists only one other comparison of the EA LSTM performance against the LSTM (Kratzert et al., 2019). Finally, there exist no studies that explore the relationship of performance differences (between conceptual and deep learning models) with the hydrological conditions in which those differences occur. The aim of studying the relationship between performance differences and hydrological conditions is to determine how best to improve our conceptual models. What information might be present in the underlying data that can help identify processes that are currently missing from our conceptual models?
The research questions that this study seeks to address are determined by the research gaps identified above.
-
How well do LSTM-based models (including the EA LSTM) simulate discharge in Great Britain?
-
How do LSTM-based model performances compare with the conceptual models used as a benchmark?
-
Can we extract information from the spatial and temporal patterns in diagnostic measures? For example, what is the relationship between LSTM performance and catchment attributes?
To address these questions, we have trained an ensemble of eight LSTMs and eight EA LSTMs on 669 catchments in Great Britain. We compare the results of the LSTM models with four deterministic lumped-conceptual models from a previous benchmarking study (Lane et al., 2019). This paper provides an evaluation of LSTM model ability across a large sample of GB catchments. We explore the association between catchment characteristics and the differences in model performances and present a data-driven benchmark that reflects the null-hypothesis of what information is present in a large-sample dataset (Nearing et al., 2020). Future modelling efforts may seek to assess whether hydrological theories encoded in conceptual and process-based models may contain more information than the benchmarks provided here (Nearing et al., 2021).
We believe that the research addresses the following needs of the hydrological community: (i) practitioners wishing to know whether the LSTM is a justifiable model choice in the GB context, (ii) scientists and practitioners interested in understanding under what hydrological conditions (e.g. catchment attributes) the LSTM performance differs from conceptual models, and (iii) as a reference for future GB-wide modelling studies.
2.1 Data – CAMELS-GB
All data employed in this analysis originate from the CAMELS-GB data (Coxon et al., 2020a). CAMELS-GB is a recently released, large-sample, long-term, daily dataset that offers the potential for GB-wide modelling studies. CAMELS-GB collates hydrologically relevant data for 671 GB catchments between the years of 1970 and 2015. The dataset includes daily time series for meteorology (dynamic data – Xt,n) and discharge (target data – yt,n). Also included are catchment attributes (static data – At,n) such as topography, climate, hydrologic signatures, soil and land cover, hydrogeology, and human influence. These features are, in reality, not static over time. However, for the purposes of this study we treat these features as time-invariant. Further information on the variables we used as input to our model can be found in Table 1. The reader is directed to Coxon et al. (2020b) for details of the source of the data, how the data were processed and a discussion of data limitations.
The dataset contains novel inputs compared with previous CAMELS (US, Chile, Brazil) datasets (Addor et al., 2017; Alvarez-Garreton et al., 2018; Chagas et al., 2020), such as human attributes, calculated potential evapotranspiration (pet) and uncertainty estimates. We do not use all of these features here. The static attributes we use to train the LSTM models are listed in Table 1. These static attributes were chosen to reproduce the experimental framework of Kratzert et al. (2019); however, the differences reflect the fact that the CAMELS-US and CAMELS-GB have slightly different attributes. These include both catchment properties and climate properties, describing the conditions relevant for rainfall–runoff modelling in different catchments.
Table 1Catchment attributes from the CAMELS-GB dataset (Coxon et al., 2020b) used to train the LSTM-based models and the static features included in A.

2.2 An overview of the LSTM and EA LSTM
In this paper, we test two neural network architectures used in other hydrological studies (Shen et al., 2018; Kratzert et al., 2019). The first is the LSTM, which has been used in a variety of time series modelling applications. The second model is the EA LSTM, which conditions the discharge response to meteorological forcings on time-invariant properties of river catchments, such as soil and topographic attributes, treating these time-invariant properties separately. For a summary of notation used throughout the paper, please refer to Table 2:
Table 2Table describing the notation used throughout the paper.

What follows is a brief introduction to the LSTM model architectures. For a more complete description of these models please refer to the Sect. S1 in the Supplement and Kratzert et al. (2018, 2019).
The LSTM has a strong inductive bias towards retaining information over long sequences (Hochreiter, 1991; Bengio et al., 1994). This means that the LSTM architecture is designed to retain information that is important over both long- and short-term time horizons. LSTMs do this by maintaining two state vectors: a cell memory vector that captures slowly evolving processes (Ct) and a more quickly evolving state vector, colloquially named the “hidden” vector (ht). Information flow is controlled by a series of gates which are neural network layers that determine what information is removed from ft (forget gate), what information is stored in it (input gate) and what information is passed to the ot (output gate) respectively.
The Entity Aware LSTM (EA LSTM) modifies the forget gate, so the output of the forget gate is a function of only the static catchment attributes (An) rather than both the catchment attributes and the dynamic data (). The EA LSTM was developed specifically for rainfall–runoff modelling (Kratzert et al., 2019). For the sake of clarity, it is important to note that both models receive the same information. The LSTM still receives the static catchment attributes. However, rather than affecting only the input gate the static data can influence all gates, since they are appended to a vector of dynamic inputs , and so the same information is given to the LSTM at each time step. The static attributes are used by the LSTM in the same way as the dynamic data. This offers extra flexibility for the LSTM compared with the EA LSTM, since the LSTM is able to modify the input gate based on information from time-varying data, whereas the EA LSTM is not. We are using the static nature of the data as a constraint on the EA LSTM to reflect the nature of the input data (separated into static and dynamic inputs).
2.3 Model training
We used the “neuralhydrology” codebase, written in Python 3.6 (Van Rossum et al., 2007), to train and evaluate the models, which is found at the following link: https://github.com/neuralhydrology/neuralhydrology (last access: 20 September 2021). The configuration files used to run the models can be found using the links at the end of this article. The predictions and error metrics for the fitted models can be found online at Zenodo (https://doi.org/10.5281/zenodo.4555819).
The goal of rainfall–runoff modelling is to predict time-varying specific discharge, (mm d−1) for time at measuring gauge n of N, given hydro-meteorological forcing data, , and catchment attributes (An – Table 1) within the catchment area upstream of the gauge. In the present case for GB, N=669. Although the underlying CAMELS-GB data have 671 station gauges, we trained on data from only 669 stations, because two basins have missing data in the static attributes; stations 18011 and 26006 have missing mean elevation (elev_mean) and mean drainage path slope (dpsbar).
Our task is to train a regional hydrological model, i.e. one model for all catchments in the dataset. This means that we learn a single set of parameters, θ, of a model, Mθ, that minimizes the loss function, , for all flow gauges and thus accurately simulates discharge () for all of the basins in our subset of CAMELS-GB:
We train our model using the Nash–Sutcliffe efficiency (NSE) loss as our objective function (ℓ), as described in Kratzert et al. (2019). Other objective functions could be used; however, we use the same objective function as the conceptual models we compare against, in order to control the possible sources of performance differences. The NSE describes the squared error loss normalized by the total variance of the observations. In order to account for the fact that some basins will have lower variance than others, we follow Kratzert et al. (2019) to normalize by basin-specific variance. This prevents the loss from being overly weighted towards high-variance catchments.
For this study, we trained the models on the days from 1 January 1988 to 31 December 1997 and tested on a hold-out sample using the days from 1 January 1998 to 31 December 2008 (4018 d of test data). We withheld the years 1975 to 1980 from the training process to check the performance of the model during training (our validation set). This means that we have separate time periods for calibration (1988–1997; train period) and evaluation (1998–2008; hold-out test period). These train and test periods were chosen to facilitate the comparison with the study whose published results for four lumped hydrological models we use as a benchmark (Lane et al., 2019). For further analysis of the train and test periods, please see Sect. S2.
Our input data were taken from CAMELS-GB, described above (Coxon et al., 2020b). We used precipitation, potential evapotranspiration and temperature as dynamic inputs (). We selected 21 individual features describing each catchment's topographic, soil, land-cover, and climatic properties as static inputs (An). These attributes were chosen to reflect hydrological information that the model can use to distinguish between catchment rainfall–runoff behaviours (Kratzert et al., 2019). These catchment attributes are described in Table 1. For both LSTM models, we pass the final hidden output through a fully connected (linear) layer. This final layer maps our hidden state vector to a scalar prediction () for discharge at that gauge on that day. We give the models 1 year of daily dynamic data (365 input time steps, ) to predict the final time step of specific discharge ().
All national results shown below are calculated for the 518 gauges that are found in both the CAMELS-GB data and the benchmark data. We then evaluate model performance on all of these basins for our test (evaluation) period (1998–2008). For each model (LSTM, EA LSTM), we also calculate the average of an ensemble of eight individually trained models with different random seeds. This strategy accounts for the random initialization of the network and the stochastic nature of the optimization algorithm. We used a hidden size (hs) of 64 and a final fully connected layer with a dropout rate of 0.4, which aims to avoid overfitting. Dropout works by randomly forcing certain weights in the network to zero (“dropping them out”), forcing the remaining weights to model the discharge without that extra information. This has been found to prevent weights “fixing” the erroneous outputs of other weights, preventing co-adaptation of weights and, ultimately, encouraging the model to use a simpler and more robust representation of rainfall–runoff processes (Srivastava et al., 2014). The hidden size determines the total number of parameters in the model. For the LSTM, there are 23 361 trainable parameters, whereas the EA LSTM has 14 593 trainable parameters. These are trained on data from 669 catchments over 4018 time steps (2 688 042 samples). Note that this is for a regional model and is independent of the number of catchments. Given that we train the LSTM on 669 catchments, we can interpret the LSTM as equivalent to using 35 parameters per catchment, with a median catchment area of 152 km2. The EA LSTM has of the order of 22 parameters per catchment. We chose the hyper-parameters (dropout rate, hidden size – hs) based on analysis of the NSE performances, finding that the improvement of further model complexity (increased hidden size) was negligible after a hidden size of 64. The hidden size was also consistent with the choices made in previous studies (Kratzert et al., 2019). We used the Adam optimization algorithm (Kingma and Ba, 2014) and stopped training after 30 epochs, after which there was no further improvement to the model. An epoch reflects a single pass of the training dataset through the model, such that every sample in the training dataset has been used to update the model weights. This reflects the fact that during the training of DL models, the data are often split into batches to allow large datasets to be read into memory. The LSTM ensemble took 10 h to train. The EA LSTM ensemble took 96 h to train. All models were trained on a machine with 188 GB of RAM and a single NVIDIA V100 GPU.
2.4 Model performance comparisons
The LSTMs learn to represent hydrological processes directly from data. When the LSTMs perform well on hold-out test samples, a necessary (but not sufficient) conclusion is that the data contain useful information about the hydrological processes that translate inputs (precipitation) into outputs (discharge). The differences in model performance between the LSTMs and the benchmark hydrological models can be used to determine hydrological processes that are described by the input data but not captured or under-represented by the benchmark hydrological models.
2.4.1 Benchmark models
In order to provide a reference for model performance statistics, we compare the performance of the LSTM-based models against four lumped conceptual models from the FUSE framework (Clark et al., 2008). To be unbiased on the model calibration, we used simulated discharge time series from Lane et al. (2019), who calibrated and evaluated these four conceptual models on 1000 catchments across Great Britain. The four conceptual models used are TOPMODEL (Beven and Kirkby, 1979), Variable Infiltration Capacity (VIC) (Liang, 1994), Precipitation-Runoff Modelling System (PRMS) (Leavesley et al., 1983) and SACRAMENTO (Burnash et al., 1973). These conceptual models are often used in operational settings, due to the relative ease of use and lower data requirements when compared with physically based models. These conceptual models all explicitly maintain mass balance and so assume no losses or gains of water other than flow from the catchment outlet or evaporation.
These conceptual models are all lumped models run at a daily time step. Each model is explicitly forced to close the water balance, limited by an upper limit of potential evapotranspiration for water losses. Every one of the conceptual models has a gamma distribution routing function. Furthermore, the four conceptual models do not include a snow routine nor a vegetation module (Clark et al., 2008). SACRAMENTO has 5 stores and 12 parameters per catchment, both VIC and TOPMODEL have 2 stores and 10 parameters, and PRMS has 3 stores and 11 parameters. A more complete description of these benchmark models and the processes that they include can be found in Table 3 of Lane et al. (2019) and in Sect. 4 of Clark et al. (2008).
The benchmark study provides an assessment of conceptual model simulation performances across a large sample of GB catchments, and it also quantifies uncertainty in hydrological simulations due to parameter uncertainty and model structural uncertainty (Lane et al., 2019). Parameter values for each conceptual model were selected from 10 000 simulations of multi-dimensional parameter space. The best-estimate model parameter values were selected from these 10 000 samples using the Nash–Sutcliffe efficiency score. These best-fit parameters are used as a benchmark against which to compare the LSTM performance. To place the intercomparison into context, we critically reflect on the consistencies and differences between the different model configurations here.
First, the selection of model parameters differs between the LSTM and the conceptual models. The experimental design of the benchmarking study produced 10 000 samples of parameter values, and Lane et al. (2019) provide the simulations given the best fitting parameters for future studies to employ as a benchmark. The LSTM parameters are optimized using stochastic gradient descent, choosing the best fitting set of parameters using the NSE score. While the method of choosing parameters differs, the objective function that determines the “best-fit” parameter values is the same for both the LSTMs and the conceptual models. Second, the calibration and evaluation data are the same. The calibration and evaluation of these models were performed using the same data from CAMELS-GB, i.e. the National River Flow Archive data (Centre for Ecology and Hydrology, 2016) for specific discharge (yt); the Centre for Ecology and Hydrology Gridded Estimates of Areal Rainfall, CEH-GEAR, for precipitation (Tanguy, 2014); and the Climate Hydrology and Ecology research Support System Potential Evapotranspiration (CHESS-PE) dataset for PET (Robinson et al., 2017). The benchmark experiment selected the best-fitting parameter values using data from the period 1988–2008 and then evaluated their performance on data from 1993–2008 (Lane et al., 2019). Instead, we calibrate the LSTMs on data from 1988–1998 and then evaluate the LSTM performances for our hold-out evaluation period of 1998–2008. We recalculate the performance statistics of the benchmark conceptual models for this evaluation period, 1998–2008, using the published simulated time series. Therefore, the LSTM is evaluated on out-of-sample (in time) data, whereas the conceptual model parameters were calibrated on data included in the evaluation period (in-sample evaluation). Finally, it is worth noting that Lane et al. (2019) focused not only on model performances but also on parameter uncertainty. Uncertainty is an essential component of any modelling study, and our approach of training an ensemble of eight models is one proposed method for dealing with uncertainty in LSTMs. For an analysis of model uncertainty with this method, see Sect. S4. For a more complete treatment and discussion of the different approaches for dealing with uncertainty using LSTMs, see Klotz et al. (2020).
As with any benchmarking study, there are important caveats to the intercomparison of model results. Ultimately, the purpose of the comparison is (i) to provide a reference for the diagnostic measures of LSTM performance, (ii) to identify the hydrological conditions where simulations differ, and (iii) to use these insights to diagnose missing representations in the conceptual models. We agree with Lane et al. (2019) that “benchmark [studies] provide a useful baseline for assessing more complex modelling strategies” (p. 4029), and we follow them in publishing the simulations and results of the LSTM models for future studies to use for comparison.
2.4.2 Evaluation metrics
Each model produces a daily simulated discharge value at each station. Three example hydrographs are shown in Sect. S3. The evaluation metrics described below evaluate the overall performance of each model to reproduce a specific aspect of the observed hydrograph. For the LSTM-based models, the evaluation metrics are calculated given the average discharge of the ensemble. Since no single evaluation metric can fully capture the performance of streamflow simulations across all flow-regimes (Gupta et al., 1998), we use a number of metrics to address the performance of models across the flow regime, outlined below.
We evaluate the goodness-of-fit metrics of the LSTM-based models and the conceptual models using six evaluation metrics. The Nash–Sutcliffe efficiency (NSE) (Nash and Sutcliffe, 1970) score has been used in numerous studies, and there is extensive literature discussing its strengths and weaknesses (Gupta et al., 2009). The NSE can be decomposed into three components: a correlation term, a bias term (BiasError) and a variability (SDError) term (Gupta et al., 2009). The bias term measures the error in predicting the mean flow. The variability term measures the error in predicting the standard deviation of discharge. We report results for the NSE and each of its three components.
To understand how well the LSTMs represent low, mean and high flows, we also consider the biases for different components of the flow duration curve. The low-flow bias (%BiasFLV) is the diagnostic signature measure for long-term base flow (Yilmaz et al., 2008), and low flows are defined as those which are exceeded 70 % of the time. For the middle of the flow duration curve, we use the bias of the midsection of the flow duration curve, between the 20th and 70th percentiles (%BiasFMS). Finally, we also look at the bias of the high flows, considering the top 2 % of flows (%BiasFHV).
3.1 National-scale model performance
The LSTM and EA LSTM models produce accurate simulations across Great Britain when evaluated using a variety of metrics, with differing levels of performance improvement over the benchmark conceptual models (See Table 3).
Table 3Summary of all goodness-of-fit metrics used to benchmark performance against the conceptual models for the validation period 1998–2008 on the 518 stations found in both CAMELS-GB data (Coxon et al., 2020a) and the FUSE conceptual models (Lane et al., 2019). We have shown the median catchment score for the metric given the mean simulated discharge of our ensemble. Values that are not significantly different from the best model are highlighted in bold (α=0.001).
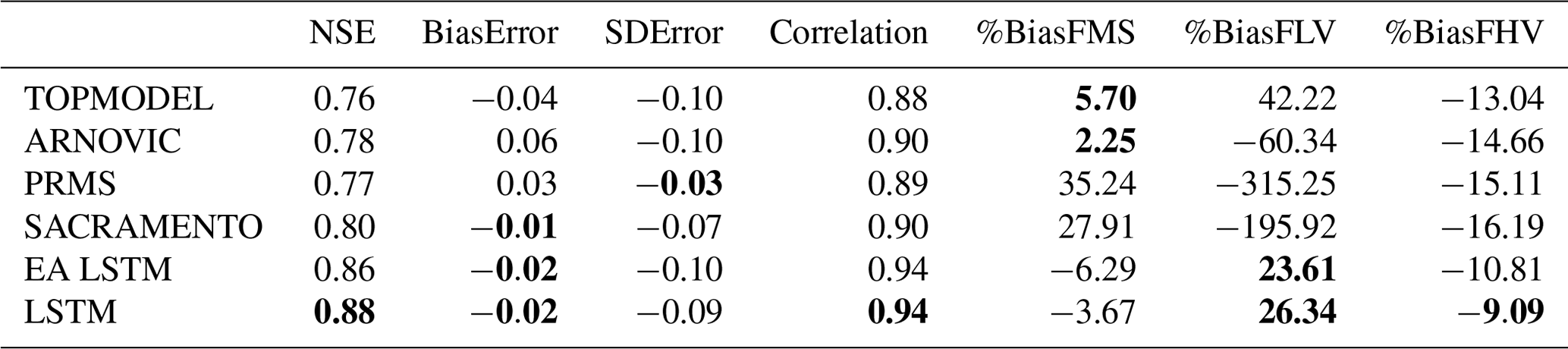
Comparing the median NSE for all catchments, the LSTM ensemble (0.88) outperforms all other models, including the EA LSTM ensemble (0.86). The slightly lower median NSE for the EA LSTM models is consistent with results from previous studies (Kratzert et al., 2019). The CDFs (cumulative distribution functions) of the NSE (Fig. 1a) show the entire distribution of LSTM scores is shifted towards better performances. The LSTM NSE scores are significantly different from all comparison models at α = 0.001 (paired Wilcoxon signed-rank test). We see the same pattern for the EA LSTM models. The performance improvement at the tails is particularly pronounced. Neither the LSTM nor the EA LSTM model have any station gauges with an NSE of less than zero.
As discussed in the methods, we can decompose the NSE into three components: bias (BiasError), correlation and error in predicting the variability of flows (SDError). The pattern of correlation scores closely follows the pattern of NSE, with the entire distribution of catchment correlation scores shifted towards improved performance. The CDFs in Fig. 1c show that the LSTM catchment bias scores are closer to zero than the benchmark models, which reflects the fact that the conceptual models are explicitly mass conserving, whereas the LSTM models are not. The median variability error is negative (Fig. 1d), showing that the LSTMs tend towards underpredicting the variability of flows.
The LSTM shows a large performance improvement for low-flow bias score (%BiasFLV – Fig. 1e). The LSTM has lower median bias in the slope of the midsection of the flow duration curve (%BiasFMS) than all models except ARNOVIC. When we consider the CDFs, both LSTMs have shorter tails than the conceptual models, showing that a greater proportion of catchments have biases closer to zero. The high-flow biases (%BiasFHV) are relatively similar for all models (as shown by Fig. 1g).
The biases at different flow exceedances suggest that the conceptual models produce good simulations for the high flows but are less able to simulate low flows. The LSTM shows a smaller performance decline at the low flows than the benchmark models and a competitive performance at high flows, suggesting that the LSTMs are robust to extreme conditions. We also note that the negative bias, for the midsection and the upper-section of the flow duration curve, demonstrates that the LSTM model is conservative in its flow predictions, particularly in comparison to the other models.
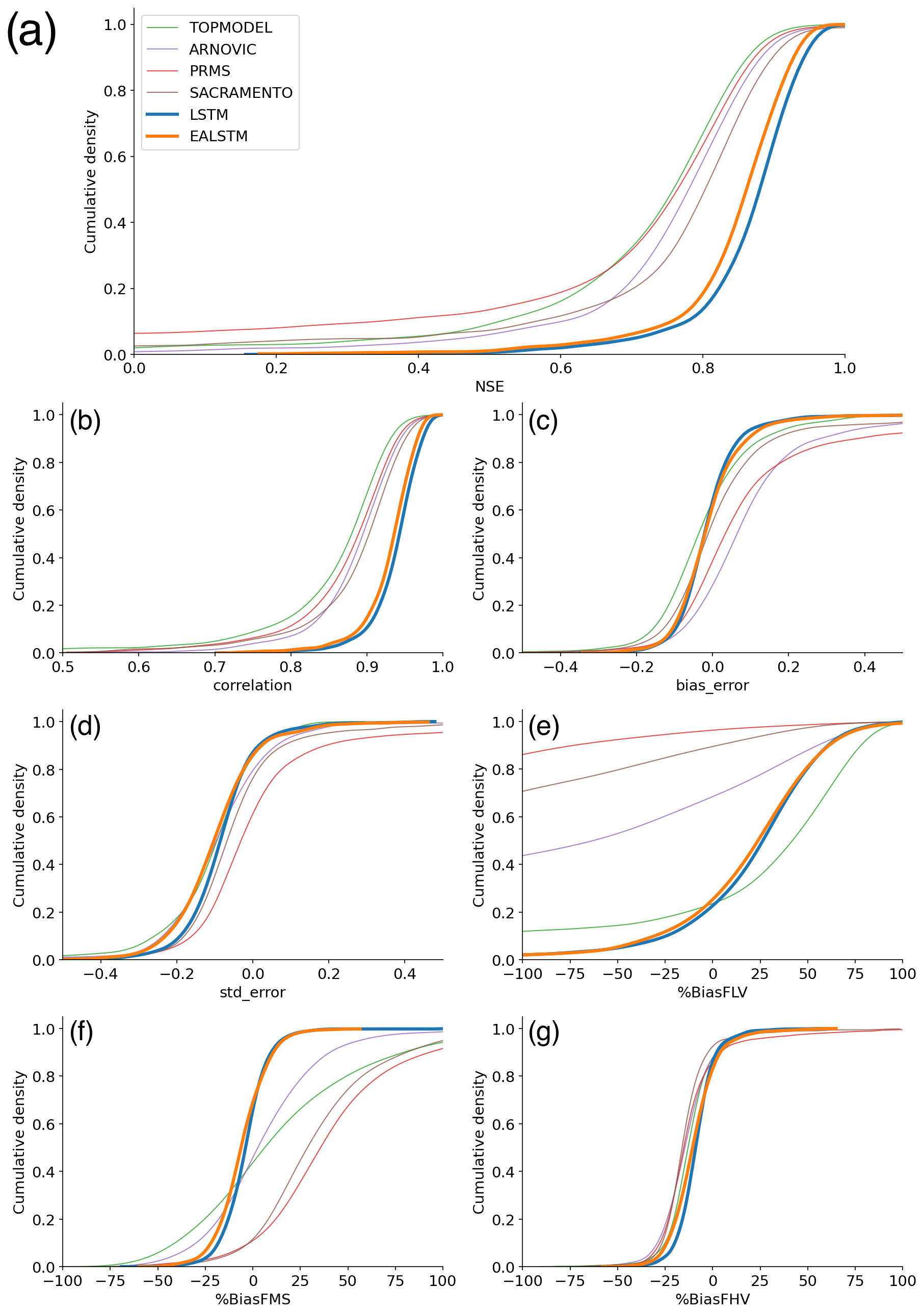
Figure 1Cumulative distribution functions (CDFs) of station goodness-of-fit metric scores for each model. EA LSTM (orange) and the LSTM (blue), as well as the conceptual models: TOPMODEL (green), VIC (red), PRMS (purple) and SACRAMENTO (brown) (Lane et al., 2019). Panels indicate the distribution of stations: (a) NSE scores, (b) correlation scores, (c) bias error scores, (d) variability error scores, (e) low-flow bias scores, (f) mid-range of flow bias scores and (g) high-flow bias scores.
3.2 Spatial patterns of performance
The LSTM demonstrates competitive simulation of discharge across Great Britain (see the spatial patterns of various performance metrics in Fig. S6). The EA LSTM has very similar spatial patterns to the LSTM but shows a consistently worse performance than the LSTM across GB.
The benchmark conceptual models struggled when simulating discharge in catchments on the permeable bedrock in the south-east of England and the mountainous catchments in the north-east of Scotland (Lane et al., 2019). Performance metrics in the south-east were lower due to poor simulation of variance and correlation and in north-eastern Scotland due to poor simulation of the mean flow conditions (Lane et al., 2019). We suggest that these differences in performance are due to the low rainfall and chalk aquifer in the south-east of England and to the lack of snow modules incorporated into the conceptual models for north-eastern Scotland.
Interestingly, the LSTM simulates discharge less well in the south-east of England relative to LSTM performance elsewhere in GB, particularly in the summer months (Fig. 2). Performances for all seasons are worse in the south-east of England. This pattern is stronger in the summer months (JJA). The east–west gradient in model performances can be seen for all models, particularly in JJA. However, the range of errors is smaller for the LSTM-based models when compared with the conceptual models.
The LSTM shows an underestimate of the variability and a cluster of high bias scores in the south-east (Fig. S6). The LSTM both overestimated and underestimated mean flows in catchments in the south-east region, explaining the relative underperformance in the composite metric (NSE) for the LSTM relative to the rest of GB.
Spatial patterns in the biases for different sections of the flow duration curve show that only the LSTMs demonstrate a consistent underprediction of the midsection slope of the flow duration curve (%BiasFMS). A steep slope in the midsection of the flow duration curve reflects a watershed having a “flashy” response (Yilmaz et al., 2008), potentially due to low soil moisture capacity. Therefore, an underprediction of the midsection reflects an underestimation of the “flashiness” of the catchment. The LSTM %BiasFMS is largest for the south-east of England. The LSTM shows improved performance compared to the benchmark models across GB, including these underperforming regions, the south-east of England and north-eastern Scotland.
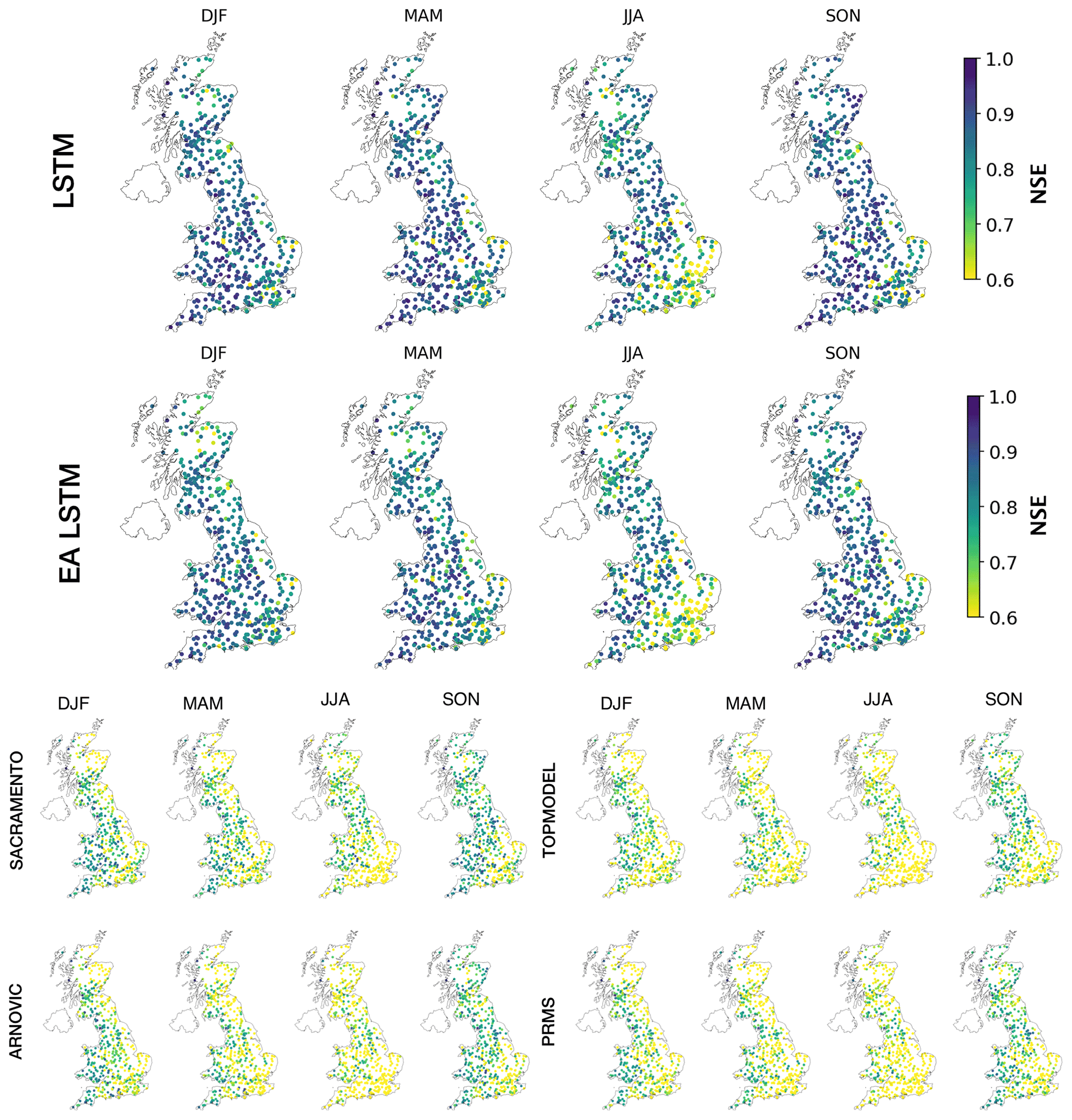
Figure 2Seasonal NSE patterns for the two LSTM-based models (above) and the conceptual models (below). Each station in the evaluation data is shown as a point. The colour of the point reflects the NSE score. Brighter colours reflect lower NSE values, currently capped at a minimum of 0.7 NSE.
3.3 In what hydrological conditions do model performances differ?
Large sample studies allow us to detect catchment attributes that our models are or are not able to represent. In order to determine what the LSTM is capable of representing well, we perform two analyses. Firstly, we directly calculate the difference in NSE scores. Secondly, we correlate catchment attributes with model diagnostic scores.
The ΔmeanNSE is the mean difference between a reference model (LSTM) and the comparison model. The ΔmedianNSE is the median difference. The mean differences between the LSTM station NSE and the other models is smallest for the EA LSTM (ΔmeanNSE =0.02). This is unsurprising given the very similar architectures of the two models. The differences for the conceptual models range from TOPMODEL (ΔmeanNSE =0.15), ARNOVIC (ΔmeanNSE =0.17), SACRAMENTO (ΔmeanNSE =0.20) and PRMS (ΔmeanNSE =0.43). While the mean performances show large differences, due to the presence of poorly performing stations, the median differences are smaller for SACRAMENTO (ΔmedianNSE =0.07), ARNOVIC (ΔmedianNSE =0.09), PRMS (ΔmedianNSE =0.10) and TOPMODEL (ΔmedianNSE =0.10). Both summaries (median, mean) demonstrate that the LSTM offers a single model architecture that offers more accurate simulations than traditional hydrological models in a variety of hydrological conditions.
Spatially, the benchmark conceptual models struggled to produce good simulations in two geographical regions. These were in the south-east of England and north-east of Scotland. The performance improvement (ΔNSE) of the LSTM over the conceptual model was indeed largest in the south-east of England and north-eastern Scotland (see Fig. 3).

Figure 3The performance improvement of the LSTM relative to the four conceptual models SACRAMENTO, ARNOVIC, TOPMODEL and PRMS. The difference in NSE is calculated by subtracting the conceptual model NSE from the LSTM NSE (). Each point represents a station, and the colour reflects the performance improvement (measured by NSE) of the LSTM compared with the conceptual models. Positive values reflect stations where the LSTM outperforms the conceptual models.
North-eastern Scotland is one of the most mountainous regions of GB. The Cairngorm National Park and the North Pennines are the only areas of GB where snow processes are consistently important, owing to catchments having a higher elevation. There are 36 catchments in the CAMELS-GB dataset with fraction of snow cover greater than 5 %, and 3 catchments are in the North Pennines; the other 33 catchments are in the Cairngorm National Park. The results in Fig. 3 show that the LSTM exhibits a large performance improvement in these catchments, since ΔNSE is high. This is most likely due to the cell state being able to represent longer-term stores and fluxes of water, therefore capturing the melting snow processes. The conceptual models lack a snow module and are therefore unable to capture snow melt or frozen ground processes, which are especially important in winter (DJF) and spring (MAM) (Lane et al., 2019). By contrast, what the LSTM performance shows is that data-driven models are able to flexibly incorporate snow processes in the catchments where they are required (NE Scotland) even when trained to produce one set of weights. This flexibility is an important asset of data-driven approaches, since these hydrological processes do not need to be specified prior to model training but can be learnt from the available data.
The south-east is a relatively dry area, with large chalk aquifers, contributing to a high baseflow index, and large urban and agricultural areas, contributing to a large anthropogenic signal in the hydrographs. Although the improvement in simulation accuracy compared to the conceptual models is large in the south-east, the pattern of raw LSTM NSE shows that the LSTM still underperforms in the south-east relative to elsewhere in GB. The seasonal patterns showed that the LSTMs performed worse in summer months, which is the drier period of the year. Consistent with this spatial pattern, the ratio of mean potential evapotranspiration to mean precipitation attribute (labelled “aridity” in the CAMELS-GB dataset; Coxon et al., 2020b) is negatively correlated with model performance for all models (Fig. 4), although the magnitude of this association is smaller for the LSTM-based models than the conceptual models.
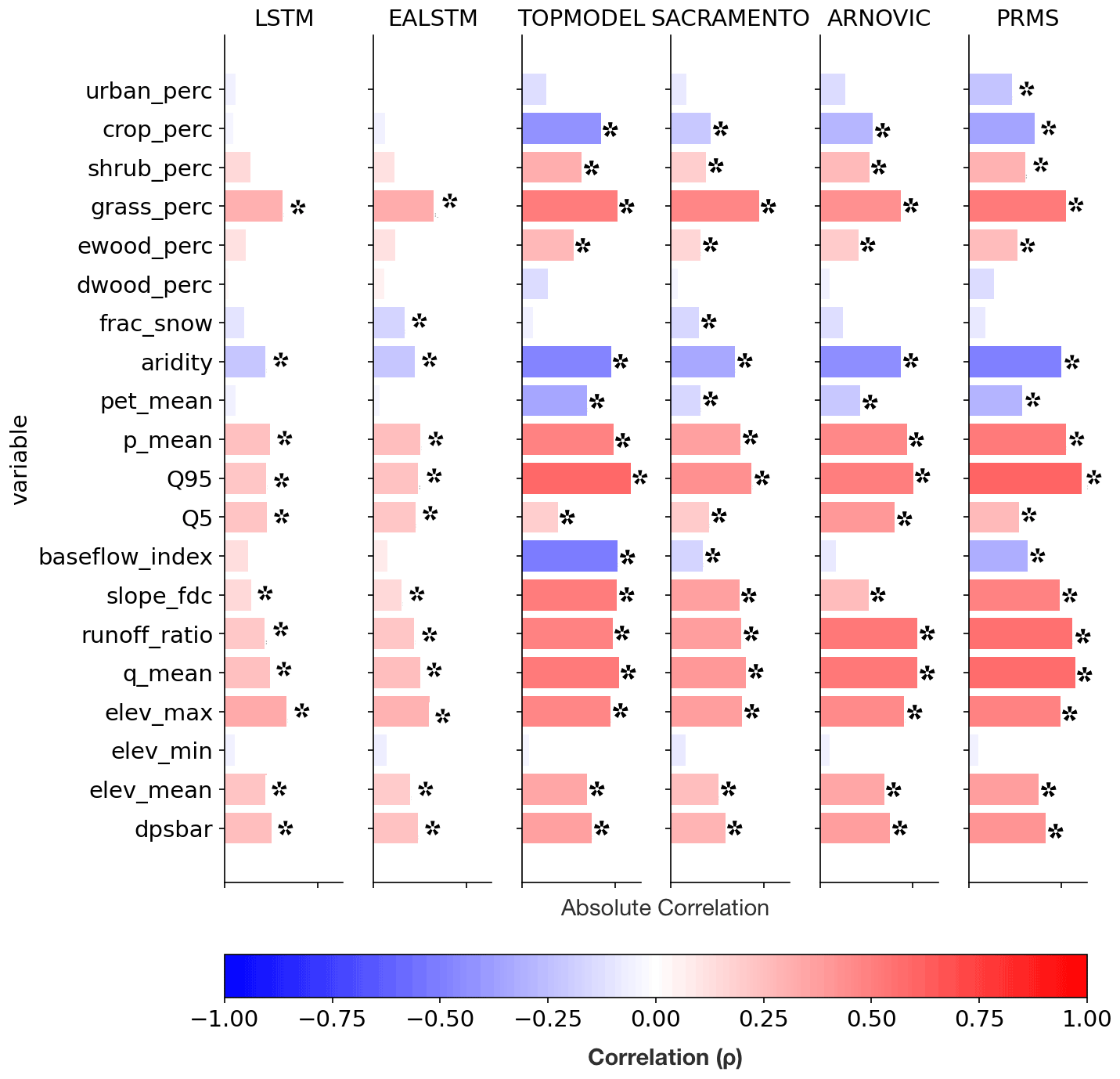
Figure 4Static features (rows) and their Spearman’s rank correlation coefficient with model (columns) NSE scores. The positive correlations are in blue, and the negative correlations are in red. Pale bars show very low correlations. Symbol “*” indicates that the correlation is significant at the α=0.001 level. The first six features can be classified as land cover features. The next four features are climatic indices. The next six features are hydrologic attributes and the final four are topographic features. “dpsbar” refers to the mean drainage path slope and reflects the average steepness of a catchment.
We observe consistently poorer performance across all models, including the LSTMs, in drier hydrological conditions. This can be seen by the negative correlations between catchment P PET (aridity) and model NSE scores (Fig. 4).
The LSTM-based models show no significant correlation between baseflow index and model performances, in contrast with the other models. ARNOVIC also shows no significant correlation. ARNOVIC's improved performance can be attributed to the non-linear relationship in the upper storage, which means that the model will only produce very fast responses when that storage is very close to full (Lane et al., 2019).
3.3.1 The impact of water balance closure on simulation accuracy
One of the key hydrological conditions that hydrological models struggle with is the lack of closure of the catchment water balance. The conceptual models we test here explicitly maintain mass balance. They define the topographic surface water catchment as the surface over which water is conserved; i.e. the surface water catchment is not expected to leak nor should any water enter the catchment other than through measured precipitation. This will not then capture water losses or gains from undercatch, drifting snow, advection of fog, groundwater, or anthropogenic transfers into or out of the topographic catchment. Consequently, we would not expect the conceptual models to take account of catchments where the water balance (defined in the data) does not close. The LSTM, in contrast, is free to adjust to account for patterns in these anomalies. It is not yet possible to diagnose the origin of any such anomalies using the LSTM alone: they may arise from inter-catchment transfers (either through anthropogenic or groundwater processes) or data errors, among other reasons that the water balance might not be closed based on observations at the catchment scale. In spite of this, we expect that the LSTM will show improved performance in these catchments where there is no closure of the catchment water balance in the underlying dataset. Since we are calculating performance on out-of-sample time steps, if the LSTM performance is improved, we can infer that the LSTM-based model has learnt to correct these inconsistencies in a way which is consistent between training and evaluation data and is therefore adjusting the catchment water balance to better simulate the hydrograph.
We plot catchments on two dimensions (Fig. 5), their wetness index (P PE) and the runoff coefficient (Q P), to identify catchments where water is not conserved. Points above the horizontal line reflect catchments where the observed discharge is greater than the precipitation input to the catchment. This area of the graph represents catchments where the data have too little water to generate the observed runoff. Points below the curved line are where runoff deficits exceed total PET in a catchment. This area of the graph represents catchments where PET is not large enough to describe the water remaining after runoff is accounted for; i.e. the data have “excess” water (Fig. 5).
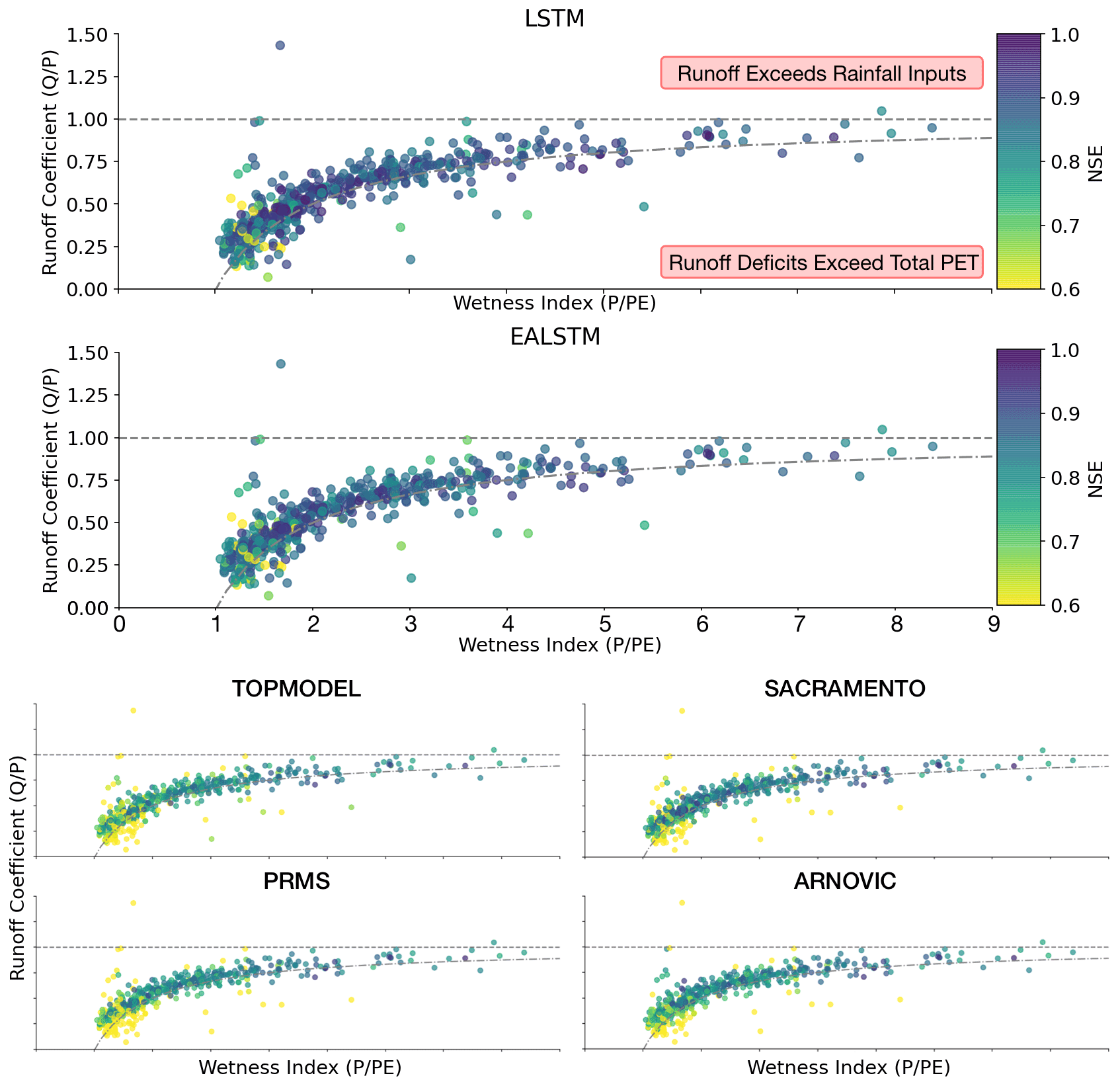
Figure 5Scatter plot for the relationship between the wetness index, runoff coefficient and the model NSE score. Each point is a catchment, coloured by the NSE score ranging from 0.8 (lighter) to 1.0 (darker). Points above the horizontal line reflect catchments where the observed discharge is greater than the precipitation input to the catchment. Points below the curved line are where runoff deficits exceed total PET in a catchment; therefore, there is excess water in the data, since PET cannot explain the leftover water after accounting for runoff.
We tested whether the LSTM was better able to simulate discharge in catchments with excess water (i.e. the points below the curved lines in Fig. 5, which are then represented by the orange kernel density estimate in Fig. 6). As hypothesized, we find that the LSTM is more robust to these conditions and produces NSE scores that are comparable to the stations where the conceptual models perform best.
Interestingly, despite the performance improvement over the benchmark conceptual models, the LSTMs continue to produce a performance decline in catchments with an imbalanced water balance (Fig. 6). This suggests that the LSTM models still struggle with water-limited and energy-limited (low runoff coefficient and low wetness index) catchments. This could be because human management decisions that lead to abstractions are unpredictable without further dynamic inputs, such as timings of abstractions and effluent returns, or else that the underlying data do not contain sufficient geological information to describe the complex percolation and surface or subsurface connectivity pathways that cause a surface water catchment to leak.
Ultimately, the performance decline is less pronounced for the LSTM. The LSTM continues to produce simulations with NSE scores greater than 0.6. This suggests that there remains information in the data that the LSTM is capable of using to maintain accurate simulations in out-of-sample conditions.
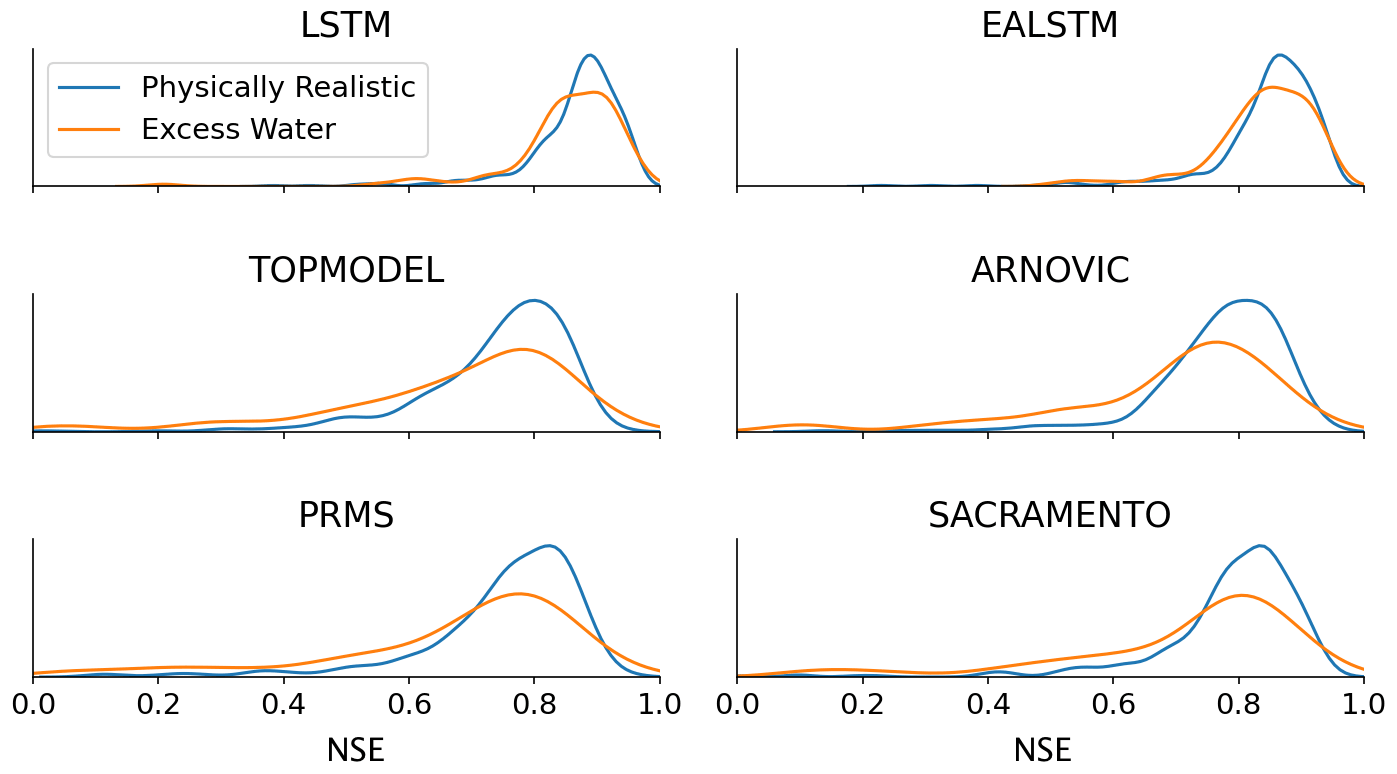
Figure 6Comparing the NSE results for catchments that have excess water, where runoff deficits exceed total PET (orange), to those catchments that have physically realistic conditions (blue). The orange line shows the histograms for stations that fall below the curved line in the Budyko analysis above (the runoff deficit exceeds total PET; therefore there is excess water in the model). The blue line shows the histograms for those stations between the two dashed lines.
This study benchmarks the performance of the LSTM using four commonly used conceptual models as a reference. The LSTM produced accurate simulations for a large number of catchments across Great Britain. The performance of the LSTM demonstrates that there is adequate information in the observational data to accurately simulate discharge behaviours across the various hydrological conditions found in Great Britain. The simulated time series and catchment error metrics can be found at https://doi.org/10.5281/zenodo.4555820.
In the discussion that follows we return to our three research questions. (i) How well do LSTM-based models simulate discharge in Great Britain? (ii) How do LSTM-based model performances compare with the conceptual models used as a benchmark? (iii) Can we extract information from the spatial and temporal patterns in diagnostic measures?
4.1 Inter-model performances
The LSTM-based models produce accurate simulations of discharge across GB, a temperate region. Two findings from this research confirm and extend the conclusions of previous work. First, the LSTM consistently outperforms the EA LSTM (Kratzert et al., 2019). Secondly, both LSTM-based models demonstrate improved simulation accuracy for discharge modelling compared with the conceptual models we use as benchmarks.
4.1.1 How well do LSTM-based models simulate discharge in Great Britain?
The EA LSTM is constrained to treat information that does not vary over time (catchment attributes) separately from information that varies over time (hydro-meteorological forcings). However, the constraint penalizes performance, which was also found by Kratzert et al. (2019). The EA LSTM, in contrast to LSTM, is forced to keep the input gate static through time. The input gate receives only information about catchment attributes. This means that no time-varying information is passed through the EA LSTM input gate. In contrast, the LSTM gates receive information from both time-varying meteorological inputs and static catchment attributes. The underperformance of the EA LSTM relative to the LSTM suggests that this regularization hurts performance in out-of-sample conditions.
It is worth noting that the LSTM and EA LSTM also differ in terms of practical computational requirements. The LSTM trains much faster than the EA LSTM. The LSTM will train 30 epochs in 1 h compared with 30 epochs in 10 h for the EA LSTM. This is due to the LSTM being an in-built PyTorch (v.1.7.1) function that makes use of CUDA-optimized code (for running the models on a GPU). In contrast, the EA LSTM relies on custom code without the CUDA-enabled optimizations.
4.1.2 How do the LSTM performances compare with the conceptual models used as a benchmark?
We have demonstrated that the LSTM is an effective model architecture for extracting information from hydro-meteorological data, providing a data-driven benchmark showing what is achievable given the information contained in available observation data from CAMELS-GB (Nearing et al., 2021). The LSTMs demonstrate better performance on out-of-sample times than in-sample performance from the benchmark conceptual models.
There are obvious challenges with direct comparison of LSTM performance against the benchmark developed by Lane et al. (2019). The first is that the LSTM is not constrained to maintain water mass balance, whereas the conceptual models discussed here are. Another challenge is that the method of optimization used for choosing parameters in the LSTM (stochastic gradient descent) is different to the random-sampling and NSE selection criteria used to select the “best” model parameters for the conceptual models. The sampling process used by Lane et al. (2019) is explicitly for estimating uncertainty as well as providing a reference of conceptual model performances. Another difference is that the LSTM diagnostic scores are calculated on out-of-sample predictions, compared with the in-sample predictions for the benchmark conceptual models.
Finally, the LSTM-based models are trained on all basins, with a single set of weights for the whole of GB. Therefore, these LSTM models are regional models that are able to reproduce behaviours across Great Britain. In contrast, most hydrological models perform best when calibrated on individual basins (Beven, 2006a). By contrast, LSTM-based models are most accurate when trained with as much data from as many catchments as possible (Gauch et al., 2021b). It is important to interpret the number of parameters for each model type in light of this fact.
The catchments where the comparative performance difference is small, i.e. where the conceptual models perform almost as well as the LSTM, reflect areas where the conceptual models capture the majority of the information from the data, and the conceptual model well represents the hydrological process. This is the case in western Scotland, north-western England and northern Wales, and north-eastern England (see Fig. S7). The benchmark results are valuable in providing a reference point for us to assess the value of LSTM-based approaches. We welcome future studies that use the LSTM simulations provided here and that further explore performance differences and the limitations of DL methods across GB.
4.1.3 Can we extract information from the spatial and temporal patterns in diagnostic measures?
The LSTM shows the largest performance improvement over the conceptual models in the north-west of Scotland and the south-east of England. The performance differences in north-western Scotland are very likely a result of the ability of the LSTM to learn a representation of snow processes from the input data, whereas the conceptual models were simulating these catchments without a snow module.
Despite the performance improvement over conceptual models in the south-east of England, the LSTM still struggles in the south-east relative to elsewhere in GB. The south-east is a relatively dry region compared to elsewhere in GB. It contains the highest proportion of catchments that fall below the dashed line in Fig. 5 and therefore stations where the surface water catchment is “leaky”. Furthermore, there are underlying chalk aquifers which provide water storage and lateral transfers. We outline three hypotheses for why the LSTM performance may be lower in the south-east compared with elsewhere in GB.
The first hypothesis is linked to the training of the LSTM-based models. The LSTM shows a performance decline in drier conditions (Fig. 4, see “aridity”). This confirms the findings of other DL studies in the USA, where the LSTM also struggled to reproduce hydrographs in drier conditions (Kratzert et al., 2019, 2018). Basins that have long periods of low flow contain little information, since changing meteorological inputs co-occurs with very little change in the target discharge. Therefore, the physical process relating meteorological inputs to river discharge can only be inferred from those catchments with varying discharge. There is some evidence for this hypothesis. NSE scores show positive correlations with increased discharge (at mean flow, Q5 and Q95), as well as increased NSE as rainfall increases (p_mean) (Fig. 4).
A related but separate hypothesis is that the use of NSE as an objective function fails to adequately weight performance in these low-flow regimes (the NSE was the objective function across both the conceptual models and the DL models).
A final hypothesis is that groundwater dynamics and human abstractions, which influence catchments in the south-east, are not well captured by the variables in CAMELS-GB. Hydrological processes are not simulated as effectively in leaky catchments compared to those catchments where the water balance can be closed with hydrometric data (Sect. 3.3.1), even using a very flexible and effective data-driven model that is not constrained to balance water (the LSTM). This suggests that the underlying data do not contain sufficient information to model the full range of processes that influence the hydrograph in these catchments, including groundwater and abstractions. The catchment-averaged information on soil texture (sand–silt–clay) provides a coarse proxy for catchment porosity. Furthermore, further data, such as groundwater time series, might be necessary to obtain more accurate discharge predictions. We suggest that different input datasets should be tested to try and improve LSTM performances, enabling the LSTM to more properly account for the complex percolation and infiltration dynamics in these catchments.
In terms of the seasonal patterns in LSTM performances and the worse performances in summer, the above hypotheses also apply, since the summer is the driest season in GB. Despite this, the LSTM-based models have been able to use the information in the available data to better model summer (JJA) discharge than the benchmark models. As in the data-based mechanistic modelling framework (Young, 2003), the next stage for hydrologists is to search for a mechanistic interpretation of the learnt model structure; also see Nearing et al. (2021). One possible mechanistic interpretation that warrants further exploration is the idea that the LSTM is capable of learning seasonally varying catchment “connectivity” (Bracken and Croke, 2007). In winter, when soils are saturated, there are a greater number of pathways for water to enter river channels, and connectivity is high. In summer, however, there is greater resistance to water flow, since water can be absorbed and stored in drier soils, as found in Swiss catchments by van Meerveld et al. (2019), and connectivity is lower. Connectivity information could be represented by the hidden state (ht) or cell state vectors (Ct). The proposed impact of catchment connectivity on the performance improvement of the LSTM-based models is ultimately speculative, and future work will explore whether the LSTM has learnt to represent the concept of connectivity and seasonally variable flow pathways.
In contrast with the benchmark conceptual models, the LSTM-based model NSE scores have no negative correlation with crop cover percentage (Fig. 4). It is possible that the LSTM has effectively used the cropland cover variable to improve its internal representation of hydrology in those catchments with a strong agricultural signal. In order to test this hypothesis, one could perform an ablation study, removing input features and determining the impact on model performances. Alternatively, sensitivity analysis could be used to determine the relative contribution of the input features to the discharge prediction, thus revealing what input features are important for the model simulations. We intend to pursue this idea in upcoming papers.
Ultimately, compared with the benchmark models, the LSTM shows robustness to catchment conditions associated with poor conceptual model performance. Dry catchments, catchments with a strong agricultural signal, and summer discharges are all strongly correlated with worse conceptual model performances. In contrast, the LSTM has good performance on out-of-sample times in these same conditions. There is therefore information that the LSTM has learnt to generalize from the CAMELS-GB dataset that the conceptual models are not utilizing. The experiments we present here demonstrate conditions in which we can (and cannot) improve our traditional hydrological models given the availability of high-quality, large-sample datasets (Nearing et al., 2020; Beven, 2006b).
In this study we have benchmarked the performance of two LSTM-based models trained on 669 catchments across Great Britain. We have demonstrated that LSTM-based models trained on a large sample of catchment-averaged hydro-meteorological time series produce accurate simulations across GB. There is clearly information available in CAMELS-GB for modelling diverse hydrological conditions, and the LSTM performances should be interpreted as a competitive reference for what simulation performance is possible for out-of-sample (in time) conditions. We trained an ensemble of LSTM-based models to account for random initialization during the training process of these deep learning models, which also provides an estimate of prediction uncertainty (Sect. S4). The ensemble mean simulation produces median NSE scores of 0.88 (LSTM) and 0.86 (EA LSTM), with no catchments scoring NSE below 0. These results are consistent with the findings from Kratzert et al. (2018) in a different geographical context.
We have explored the spatial and temporal patterns in LSTM and EA LSTM performances, using the large sample of catchments to better understand the conditions in which the LSTM-based models perform well compared to themselves (LSTM in catchment A vs. LSTM in catchment B) and compared with traditional conceptual models. The results show that LSTM-based model performances are more robust to hydro-climatic conditions in the south-east of England, in more arid catchments and in catchments where the water balance does not close. This suggests that there is more information in large-sample datasets such as CAMELS-GB than is captured by hydrological theory as encoded in the benchmark conceptual models. Further work remains to determine what information has been learnt by these LSTM-based models, to use that information to improve hydrological theories and to feed them back, if possible, into further developments in conceptual and physically based models.
Relative to the LSTM-based model performances elsewhere in GB, the LSTM-based models continue to underperform in south-eastern England relative to elsewhere in GB. Considering the catchment conditions that are associated with this pattern, it is clear that all models struggle with drier conditions and catchments where the water balance does not close. It also seems possible that the training process fails to capture hydrological behaviours in drier catchments. There are a number of possible reasons. Firstly, changing meteorological conditions in dry catchments lead to little or no change in discharge (as would be the case in ephemeral streams). Alternatively, the LSTM architecture may not be capable of simulating both dry catchments and those with a higher runoff ratio using just a single set of weights. Finally, the data may not contain sufficient information to capture the percolation and connectivity dynamics that drive hydrological behaviour in catchments with significant groundwater processes. Further studies will examine the internal representation of hydrological processes in these catchments to better understand what the LSTM has or has not learnt about connectivity and groundwater processes.
This paper benchmarks LSTM performance across Great Britain using a new large-sample dataset, i.e. CAMELS-GB (Coxon et al., 2020b), providing a reference for future hydrological modelling efforts. Furthermore, this article outlines the hydrological conditions in which the LSTM-based models perform well and those conditions which are more difficult to model. We encourage future benchmarking studies to include LSTMs as a competitive model choice for simulating rainfall–runoff processes.
CAMELS-GB data are available at https://doi.org/10.5285/8344e4f3-d2ea-44f5-8afa-86d2987543a9 (Coxon et al., 2020a). The FUSE benchmark model simulations are available at https://doi.org/10.5285/8344e4f3-d2ea-44f5-8afa-86d2987543a9 (Coxon et al., 2020a). The neuralhydrology package is available on Zenodo: https://doi.org/10.5281/zenodo.5541446 (Kratzert et al., 2021). The model simulations are freely available: https://doi.org/10.5281/zenodo.4555820 (Lees and Lane, 2021). The predictions and error metrics for the fitted models can be found online: https://doi.org/10.5281/zenodo.4555820 (Lees and Lane, 2021).
The supplement related to this article is available online at: https://doi.org/10.5194/hess-25-5517-2021-supplement.
TL designed and conducted all experiments and analysed results with advice from SD, LS and SR. MB performed preliminary geospatial analysis; GC guided the water balance analysis. All authors discussed and assisted with interpretation of the results and contributed to the article.
The authors declare that they have no conflict of interest.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors would like to thank the teams responsible for releasing CAMELS-GB (Coxon et al., 2020b), the FUSE benchmarking study (Lane et al., 2019), and the authors and maintainers of the neuralhydrology codebase for training machine learning models for rainfall–runoff modelling. Thomas Lees is supported by the NPIF award NE/L002612/1; Marcus Buechel is supported by NERC DTP studentship NE/L002612/1 and Bailey Anderson is supported by the Clarendon Scholarship. Simon J. Dadson is supported by NERC grant NE/S017380/1. We thank three anonymous reviewers for comments which have substantially improved this article.
This research has been supported by the Natural Environment Research Council (grant nos. NE/L002612/1 and NE/S017380/1).
This paper was edited by Nadav Peleg and reviewed by three anonymous referees.
Addor, N. and Melsen, L.: Legacy, rather than adequacy, drives the selection of hydrological models, Water Resour. Res., 55, 378–390, 2019. a
Addor, N., Newman, A. J., Mizukami, N., and Clark, M. P.: The CAMELS data set: catchment attributes and meteorology for large-sample studies, Hydrol. Earth Syst. Sci., 21, 5293–5313, https://doi.org/10.5194/hess-21-5293-2017, 2017. a
Alvarez-Garreton, C., Mendoza, P. A., Boisier, J. P., Addor, N., Galleguillos, M., Zambrano-Bigiarini, M., Lara, A., Puelma, C., Cortes, G., Garreaud, R., McPhee, J., and Ayala, A.: The CAMELS-CL dataset: catchment attributes and meteorology for large sample studies – Chile dataset, Hydrol. Earth Syst. Sci., 22, 5817–5846, https://doi.org/10.5194/hess-22-5817-2018, 2018. a
Bengio, Y., Simard, P., and Frasconi, P.: Learning Long-Term Dependencies with Gradient Descent is Difficult, IEEE T. Neural. Networ., 5, 157–166, 1994. a
Beven, K.: A manifesto for the equifinality thesis, J. Hydrol., 320, 18–36, 2006a. a
Beven, K.: Searching for the Holy Grail of scientific hydrology: as closure, Hydrol. Earth Syst. Sci., 10, 609–618, https://doi.org/10.5194/hess-10-609-2006, 2006b. a
Beven, K.: Deep learning, hydrological processes and the uniqueness of place, Hydrol. Process., 34, 3608–3613, https://doi.org/10.1002/hyp.13805, 2020. a
Beven, K. J.: Rainfall-runoff modelling: the primer, John Wiley & Sons, 2011. a, b, c
Beven, K. J. and Kirkby, M. J.: A physically based, variable contributing area model of basin hydrology/Un modèle à base physique de zone d'appel variable de l'hydrologie du bassin versant, Hydrolog. Sci. J., 24, 43–69, 1979. a, b
Birkinshaw, S. J., James, P., and Ewen, J.: Graphical user interface for rapid set-up of SHETRAN physically-based river catchment model, Environ. Modell. Softw., 25, 609–610, 2010. a
Booker, D. and Woods, R.: Comparing and combining physically-based and empirically-based approaches for estimating the hydrology of ungauged catchments, J. Hydrol., 508, 227–239, 2014. a
Bracken, L. J. and Croke, J.: The concept of hydrological connectivity and its contribution to understanding runoff-dominated geomorphic systems, Hydrol. Process., 21, 1749–1763, https://doi.org/10.1002/hyp.6313, 2007. a
Burnash, R., Ferral, R., and McGuire, R.: A generalised streamflow simulation system – conceptual modelling for digital computers, Joint Federal and State River Forecast Center, Tech. rep., Sacramento, Technical Report, 1973. a
Centre for Ecology and Hydrology: available at: https://nrfa.ceh.ac.uk/ (last access: 20 September 2021), 2016. a
Chadalawada, J., Herath, H., and Babovic, V.: Hydrologically Informed Machine Learning for Rainfall-Runoff Modeling: A Genetic Programming-Based Toolkit for Automatic Model Induction, Water Resour. Res., 56, e2019WR026933, https://doi.org/10.1029/2019WR026933, 2020. a
Chagas, V. B. P., Chaffe, P. L. B., Addor, N., Fan, F. M., Fleischmann, A. S., Paiva, R. C. D., and Siqueira, V. A.: CAMELS-BR: hydrometeorological time series and landscape attributes for 897 catchments in Brazil, Earth Syst. Sci. Data, 12, 2075–2096, https://doi.org/10.5194/essd-12-2075-2020, 2020. a
Clark, M. and Khatami, S.: The evolution of Water Resources Research, Eos, https://doi.org/10.1029/2021EO155644, 2021. a
Clark, M. P., Slater, A. G., Rupp, D. E., Woods, R. A., Vrugt, J. A., Gupta, H. V., Wagener, T., and Hay, L. E.: Framework for Understanding Structural Errors (FUSE): A modular framework to diagnose differences between hydrological models, Water Resour. Res., 44, W00B02, https://doi.org/10.1029/2007WR006735, 2008. a, b, c, d
Coxon, G., Addor, N., Bloomfield, J., Freer, J., Fry, M., Hannaford, J., Howden, N., Lane, R., Lewis, M., Robinson, E., Wagener, T., and Woods, R.: Catchment attributes and hydro-meteorological timeseries for 671 catchments across Great Britain (CAMELS-GB), NERC Environmental Information Data Centre [data set], https://doi.org/10.5285/8344e4f3-d2ea-44f5-8afa-86d2987543a9, 2020a. a, b, c, d
Coxon, G., Addor, N., Bloomfield, J. P., Freer, J., Fry, M., Hannaford, J., Howden, N. J. K., Lane, R., Lewis, M., Robinson, E. L., Wagener, T., and Woods, R.: CAMELS-GB: hydrometeorological time series and landscape attributes for 671 catchments in Great Britain, Earth Syst. Sci. Data, 12, 2459–2483, https://doi.org/10.5194/essd-12-2459-2020, 2020. a, b, c, d, e, f
Crooks, S. M., Kay, A. L., Davies, H. N., and Bell, V. A.: From Catchment to National Scale Rainfall-Runoff Modelling: Demonstration of a Hydrological Modelling Framework, Hydrology, 1, 63–88, https://doi.org/10.3390/hydrology1010063, 2014. a
Daniell, T.: Neural networks. Applications in hydrology and water resources engineering, in: National Conference Publication, Institute of Engineers, Australia, 1991. a
Dawson, C. W. and Wilby, R.: An artificial neural network approach to rainfall-runoff modelling, Hydrolog. Sci. J., 43, 47–66, 1998. a
Duan, S., Ullrich, P., and Shu, L.: Using Convolutional Neural Networks for Streamflow Projection in California, Front. Water, 2, 28, https://doi.org/10.3389/frwa.2020.00028, 2020. a
Elshorbagy, A., Corzo, G., Srinivasulu, S., and Solomatine, D. P.: Experimental investigation of the predictive capabilities of data driven modeling techniques in hydrology – Part 2: Application, Hydrol. Earth Syst. Sci., 14, 1943–1961, https://doi.org/10.5194/hess-14-1943-2010, 2010. a, b
Fang, K., Pan, M., and Shen, C.: The value of SMAP for long-term soil moisture estimation with the help of deep learning, IEEE T. Geosci. Remote, 57, 2221–2233, 2018. a
Fang, K., Kifer, D., Lawson, K., and Shen, C.: Evaluating the Potential and Challenges of an Uncertainty Quantification Method for Long Short-Term Memory Models for Soil Moisture Predictions, Water Resour. Res., 56, e2020WR028095, https://doi.org/10.1029/2020WR028095, 2020. a
Feng, D., Fang, K., and Shen, C.: Enhancing streamflow forecast and extracting insights using long-short term memory networks with data integration at continental scales, Water Resour. Res., 56, e2019WR026793, https://doi.org/10.1029/2019WR026793, 2020. a
Gauch, M., Kratzert, F., Klotz, D., Nearing, G., Lin, J., and Hochreiter, S.: Rainfall–runoff prediction at multiple timescales with a single Long Short-Term Memory network, Hydrol. Earth Syst. Sci., 25, 2045–2062, https://doi.org/10.5194/hess-25-2045-2021, 2021a. a
Gauch, M., Mai, J., and Lin, J.: The proper care and feeding of CAMELS: How limited training data affects streamflow prediction, Environ. Modell. Softw., 135, 104926, https://doi.org/10.1016/j.envsoft.2020.104926, 2021b. a, b, c
Gupta, H. V., Sorooshian, S., and Yapo, P. O.: Toward improved calibration of hydrologic models: Multiple and noncommensurable measures of information, Water Resour. Res., 34, 751–763, https://doi.org/10.1029/97WR03495, 1998. a
Gupta, H. V., Kling, H., Yilmaz, K. K., and Martinez, G. F.: Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling, J. Hydrol., 377, 80–91, 2009. a, b
Gupta, H. V., Perrin, C., Blöschl, G., Montanari, A., Kumar, R., Clark, M., and Andréassian, V.: Large-sample hydrology: a need to balance depth with breadth, Hydrol. Earth Syst. Sci., 18, 463–477, https://doi.org/10.5194/hess-18-463-2014, 2014. a
Halff, A. H., Halff, H. M., and Azmoodeh, M.: Predicting runoff from rainfall using neural networks, in: Engineering hydrology, ASCE, 760–765, 1993. a
Herath, H. M. V. V., Chadalawada, J., and Babovic, V.: Hydrologically informed machine learning for rainfall–runoff modelling: towards distributed modelling, Hydrol. Earth Syst. Sci., 25, 4373–4401, https://doi.org/10.5194/hess-25-4373-2021, 2021. a
Hochreiter, S.: Untersuchungen zu dynamischen neuronalen Netzen, Diploma, Technische Universität München, 91, 1991. a, b
Hochreiter, S., Bengio, Y., Frasconi, P., and Schmidhuber, J.: Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies, IEEE Press, 2001. a
Hoedt, P.-J., Kratzert, F., Klotz, D., Halmich, C., Holzleitner, M., Nearing, G. S., Hochreiter, S., and Klambauer, G.: MC-LSTM: MassConserving LSTM, in: Proceedings of the 38th International Conference on Machine Learning, vol. 139 of Proceedings of Machine Learning Research, edited by: Meila, M. and Zhang, T., 4275–4286, PMLR, available at: http://proceedings.mlr.press/v139/hoedt21a.html (last access: 1 October 2021), 2021. a
Huntingford, C., Jeffers, E. S., Bonsall, M. B., Christensen, H. M., Lees, T., and Yang, H.: Machine learning and artificial intelligence to aid climate change research and preparedness, Environ. Res. Lett., 14, 124007, https://doi.org/10.1088/1748-9326/ab4e55, 2019. a
Jiang, S., Zheng, Y., and Solomatine, D.: Improving AI system awareness of geoscience knowledge: Symbiotic integration of physical approaches and deep learning, Geophys. Res. Lett., 47, e2020GL088229, https://doi.org/10.1029/2020GL088229, 2020. a
Kingma, D. P. and Ba, J.: Adam: A method for stochastic optimization, arXiv [preprint], arXiv:1412.6980, 2014. a
Klotz, D., Kratzert, F., Gauch, M., Sampson, A. K., Klambauer, G., Hochreiter, S., and Nearing, G.: Uncertainty Estimation with Deep Learning for Rainfall-Runoff Modelling, arXiv [preprint], arXiv:2012.14295, 2020. a, b
Knoben, W. J. M., Freer, J. E., Fowler, K. J. A., Peel, M. C., and Woods, R. A.: Modular Assessment of Rainfall–Runoff Models Toolbox (MARRMoT) v1.2: an open-source, extendable framework providing implementations of 46 conceptual hydrologic models as continuous state-space formulations, Geosci. Model Dev., 12, 2463–2480, https://doi.org/10.5194/gmd-12-2463-2019, 2019. a
Kratzert, F., Klotz, D., Brenner, C., Schulz, K., and Herrnegger, M.: Rainfall–runoff modelling using Long Short-Term Memory (LSTM) networks, Hydrol. Earth Syst. Sci., 22, 6005–6022, https://doi.org/10.5194/hess-22-6005-2018, 2018. a, b, c, d, e
Kratzert, F., Klotz, D., Shalev, G., Klambauer, G., Hochreiter, S., and Nearing, G.: Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets, Hydrol. Earth Syst. Sci., 23, 5089–5110, https://doi.org/10.5194/hess-23-5089-2019, 2019. a, b, c, d, e, f, g, h, i, j, k, l, m, n
Kratzert, F., Lees, T., Gauch, M., Klotz, D., Jenkins, B., Nearing, G., and Visser, M.: tommylees112/neuralhydrology: Benchmarking Data Driven Rainfall-Runoff Models in Great Britain (benchmarking), Zenodo [code], https://doi.org/10.5281/zenodo.5541446, 2021. a
Lane, R. A., Coxon, G., Freer, J. E., Wagener, T., Johnes, P. J., Bloomfield, J. P., Greene, S., Macleod, C. J. A., and Reaney, S. M.: Benchmarking the predictive capability of hydrological models for river flow and flood peak predictions across over 1000 catchments in Great Britain, Hydrol. Earth Syst. Sci., 23, 4011–4032, https://doi.org/10.5194/hess-23-4011-2019, 2019. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s
Le, X.-H., Ho, H. V., Lee, G., and Jung, S.: Application of long short-term memory (LSTM) neural network for flood forecasting, Water, 11, 1387, https://doi.org/10.3390/w11071387, 2019. a
Leavesley, G., Lichty, R., Troutman, B., and Saindon, L.: Precipitation-runoff modelling system: user's manual, Report 83–4238, US Geological Survey Water Resources Investigations, 207, available at: https://pubs.usgs.gov/wri/1983/4238/report.pdf (last access: 1 October 2021), 1983. a
Lees, T. and Lane, R.: Benchmarking Data-Driven Rainfall-Runoff Models in Great Britain: A comparison of LSTM-based models with four lumped conceptual models, Zenodo [code], https://doi.org/10.5281/zenodo.4555820, 2021. a, b
Liang, X.: A two-layer variable infiltration capacity land surface representation for general circulation models, PhD Thesis, Harvard University, available at: https://ui.adsabs.harvard.edu/abs/1994PhDT.......137L/abstract (last access: 1 October 2021), 1994. a, b
Maxwell, R. M., Kollet, S. J., Smith, S. G., Woodward, C. S., Falgout, R. D., Ferguson, I. M., Baldwin, C., Bosl, W. J., Hornung, R., and Ashby, S.: ParFlow user's manual, International Ground Water Modeling Center Report GWMI, 1, 129, available at: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.721.6821&rep=rep1&type=pdf (last access: 1 October 2021) 2009. a
Nash, J. E. and Sutcliffe, J. V.: River flow forecasting through conceptual models part I – A discussion of principles, J. Hydrol., 10, 282–290, 1970. a
Nearing, G. S., Ruddell, B. L., Bennett, A. R., Prieto, C., and Gupta, H. V.: Does Information Theory Provide a New Paradigm for Earth Science? Hypothesis Testing, Water Resour. Res., 56, e2019WR024918, https://doi.org/10.1029/2019WR024918 2020. a, b, c
Nearing, G. S., Kratzert, F., Sampson, A. K., Pelissier, C. S., Klotz, D., Frame, J. M., Prieto, C. and Gupta, H. V.: What role does hydrological science play in the age of machine learning?, Water Resour. Res., 57, e2020WR028091, https://doi.org/10.31223/osf.io/3sx6g, 2021. a, b, c
Nourani, V., Baghanam, A. H., Adamowski, J., and Kisi, O.: Applications of hybrid wavelet–artificial intelligence models in hydrology: a review, J. Hydrol., 514, 358–377, 2014. a
Peel, M. C. and McMahon, T. A.: Historical development of rainfall-runoff modeling, Wiley Interdisciplinary Reviews: Water, 7, e1471, https://doi.org/10.1002/wat2.1471, 2020. a
Reichstein, M., Camps-Valls, G., Stevens, B., Jung, M., Denzler, J., Carvalhais, N., and Prabhat: Deep learning and process understanding for data-driven Earth system science, Nature, 566, 195–204, https://doi.org/10.1038/s41586-019-0912-1, 2019. a, b
Robinson, E., Blyth, E., Clark, D., Comyn-Platt, E., Finch, J., and Rudd, A.: Climate Hydrology and Ecology Research Support System Meteorology Dataset for Great Britain (1961–2015) [CHESS-met] v1.2, Centre for Environment and Hydrology [data set], https://doi.org/10.5285/b745e7b1-626c-4ccc-ac27-56582e77b900, 2017. a
Shen, C.: A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists, Water Resour. Res., 54, 8558–8593, https://doi.org/10.1029/2018WR022643, 2018. a, b
Shen, C., Laloy, E., Elshorbagy, A., Albert, A., Bales, J., Chang, F.-J., Ganguly, S., Hsu, K.-L., Kifer, D., Fang, Z., Fang, K., Li, D., Li, X., and Tsai, W.-P.: HESS Opinions: Incubating deep-learning-powered hydrologic science advances as a community, Hydrol. Earth Syst. Sci., 22, 5639–5656, https://doi.org/10.5194/hess-22-5639-2018, 2018. a
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R.: Dropout: A Simple Way to Prevent Neural Networks from Overfitting, J. Mach. Learn. Res., 15, 1929–1958, 2014. a
Tanguy, M., Dixon, H., Prosdocimi, I., Morris, D. G., and Keller, V. D. J.: Gridded estimates of daily and monthly areal rainfall for the United Kingdom (1890–2012) [CEH-GEAR], NERC Environmental Information Data Centre [data set], https://doi.org/10.5285/5dc179dc-f692-49ba-9326-a6893a503f6e, 2014. a
van Meerveld, H. J. I., Kirchner, J. W., Vis, M. J. P., Assendelft, R. S., and Seibert, J.: Expansion and contraction of the flowing stream network alter hillslope flowpath lengths and the shape of the travel time distribution, Hydrol. Earth Syst. Sci., 23, 4825–4834, https://doi.org/10.5194/hess-23-4825-2019, 2019. a
Van Rossum, G. et al.: Python programming language, in: USENIX annual technical conference, vol. 41, 36, 20 June 2007, Santa Clara, CA, USA, available at: https://www.usenix.org/conference/2007-usenix-annual-technical-conference/presentation/python-programming-language (last access: 1 October 2021) 2007. a
Wilby, R., Abrahart, R., and Dawson, C.: Detection of conceptual model rainfall–runoff processes inside an artificial neural network, Hydrolog. Sci. J., 48, 163–181, 2003. a, b
Yilmaz, K. K., Gupta, H. V., and Wagener, T.: A process-based diagnostic approach to model evaluation: Application to the NWS distributed hydrologic model, Water Resour. Res., 44, W09417, https://doi.org/10.1029/2007WR006716, 2008. a, b
Young, P.: Data-based mechanistic modelling of environmental, ecological, economic and engineering systems, Environ. Modell. Softw., 13, 105–122, 1998. a
Young, P.: Top-down and data-based mechanistic modelling of rainfall–flow dynamics at the catchment scale, Hydrol. Process., 17, 2195–2217, 2003. a, b
Young, P. C. and Beven, K. J.: Data-based mechanistic modelling and the rainfall-flow non-linearity, Environmetrics, 5, 335–363, 1994. a