the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 23 Sep 2021
| 23 Sep 2021
A novel method to identify sub-seasonal clustering episodes of extreme precipitation events and their contributions to large accumulation periods
Pauline Rivoire
S. Mubashshir Ali
Yannick Barton
Olivia Martius
Temporal (serial) clustering of extreme precipitation events on sub-seasonal timescales is a type of compound event. It can cause large precipitation accumulations and lead to floods. We present a novel, count-based procedure to identify episodes of sub-seasonal clustering of extreme precipitation. We introduce two metrics to characterise the prevalence of sub-seasonal clustering episodes and their contribution to large precipitation accumulations. The procedure does not require the investigated variable (here precipitation) to satisfy any specific statistical properties. Applying this procedure to daily precipitation from the ERA5 reanalysis data set, we identify regions where sub-seasonal clustering occurs frequently and contributes substantially to large precipitation accumulations. The regions are the east and northeast of the Asian continent (northeast of China, North and South Korea, Siberia and east of Mongolia), central Canada and south of California, Afghanistan, Pakistan, the southwest of the Iberian Peninsula, and the north of Argentina and south of Bolivia. Our method is robust with respect to the parameters used to define the extreme events (the percentile threshold and the run length) and the length of the sub-seasonal time window (here 2–4 weeks). This procedure could also be used to identify temporal clustering of other variables (e.g. heat waves) and can be applied on different timescales (sub-seasonal to decadal). The code is available at the listed GitHub repository.
- Article
(12605 KB) - Full-text XML
- BibTeX
- EndNote





Regional-scale extreme precipitation events can affect the entire catchment area of a river or a lake and result in flooding. Floods can have significant socio-economic impacts such as shortages of drinking water, water-borne diseases, and the displacement of people (e.g., IPCC, 2014). The impact of catchment-wide precipitation extremes is intensified when the events happen in close temporal succession, i.e. when they are serially clustered. The sub-seasonal serial clustering of extreme precipitation is a temporally compounding event (Zscheischler et al., 2020), and it is relevant for several reasons. First, it can lead to floods in rivers and catchment areas with a high retention capacity. Examples include several floods in Lake Maggiore in southern Switzerland (Barton et al., 2016), the floods in England in winter 2013/2014 (Priestley et al., 2017), the floods in Pakistan in 2010 (e.g., Lau and Kim, 2012; Martius et al., 2013), and the floods in China in summer 2020 (Guo et al., 2020). Second, the short recovery time between events can overburden rescue and response teams and prevent proper clean-up and efficient repairs to damaged protective structures (Raymond et al., 2020). Therefore, temporal dependence of precipitation and other extremes is of interest for insurance companies (Priestley et al., 2018) as floods are a major cause of financial loss from natural hazards (European Environment Agency, 2020).
A number of previous studies have analysed the statistical properties of the serial clustering of extreme events. Mailier et al. (2006), Vitolo et al. (2009) and Pinto et al. (2013) studied European winter storms (see Dacre and Pinto, 2020, for a review); Villarini et al. (2011) quantified clustering of extreme precipitation in the North American Midwest; and Villarini et al. (2012) focused on extreme flooding in Austria. In these studies, clustering in time was assessed using the index of dispersion (variance-to-mean ratio) of a one-dimensional homogeneous Poisson process model, i.e. a Poisson process with a constant rate of occurrence (Cox and Isham, 1980). Villarini et al. (2013) analysed flood occurrence in Iowa using a Cox regression model, i.e. a Poisson process with a randomly varying rate of occurrence (e.g., Cox and Isham, 1980; Smith and Karr, 1986). Yang and Villarini (2019) also used a Cox regression model to show that heavy precipitation events over Europe exhibit serial clustering. Their study also indicated that reanalysis products are skilful in reproducing serial clustering identified in observations. Barton et al. (2016) studied serial clustering of extreme precipitation events in southern Switzerland using Ripley's K function (Ripley, 1981) applied to a one-dimensional time axis (Dixon, 2002).
All studies discussed above used statistical models to identify significant serial clustering of extreme events. However, none of those methods are able to directly identify individual clustering episodes. According to the review of Dacre and Pinto (2020), there are no widely used impact metrics used as a proxy for precipitation-related damage, and only a recent study by Bevacqua et al. (2020) introduced a count-based procedure to identify individual cyclone clusters, combined with an impact metric based on precipitation accumulations. Here we propose a novel count-based procedure to study serial clustering of catchment-aggregated heavy precipitation using daily precipitation data from ERA5 (Hersbach et al., 2020). We investigate sub-seasonal serial clustering of extreme precipitation events in the mid-latitudes of the Northern Hemisphere and Southern Hemisphere. We also quantify the contribution of sub-seasonal serial clustering to large sub-seasonal precipitation accumulations at the catchment level. More specifically, we address the following questions. (1) Globally, what are the regions (catchments) where sub-seasonal serial clustering of extreme precipitation occurs frequently? (2) What is the contribution of sub-seasonal clustering to large sub-seasonal (14 to 28 d) precipitation accumulations? (3) Are the results affected by the choice of the parameters used to identify the extreme events and the length of the period (sensitivity analysis)?
The paper is organised as follows: the data and methods are introduced in Sect. 2. The results are presented and discussed in Sect. 3. Finally, general conclusions and future research avenues are presented in Sect. 4. All important quantities used in this study are listed in Table 1.

2.1 Catchment selection and precipitation aggregation
This study uses precipitation from the ERA5 reanalysis data set (Hersbach et al., 2020) by the European Centre for Medium-Range Weather Forecasts (ECMWF). The precipitation fields are interpolated to a spatial grid, and the hourly precipitation is aggregated to daily precipitation for the period 2 January 1979 to 31 March 2019. Precipitation is not directly constrained by observations in the ERA5 reanalysis data set as it stems from short-range numerical weather model forecasts. Consequently, the quality of the precipitation data depends on the forecast quality.
For catchment boundaries we use the HydroBASINS data set format 2 (with inserted lakes) (Lehner and Grill, 2013). HydroBASINS contains a series of polygon layers that delineate catchment area boundaries at a global scale. This dataset has a grid resolution of 15 arcsec, corresponding to approximately 500 m at the Equator. The HydroBASINS product provides 12 levels of catchment area delineations. The first three levels are assigned manually, with Level 1 distinguishing nine continental regions. From Level 4 onward, the breakdown follows a Pfafstetter coding, where a larger basin is sequentially subdivided into nine smaller units: the four largest tributaries and the five inter-basins. A basin is divided into two sub-basins at every location where two river branches meet and where they have an individual upstream area of at least 100 km2. We use Level 6 of HydroBASINS for our study. This choice is motivated further below.
Daily precipitation aggregated by catchment area was computed by taking the average of all ERA5 grid point values located within the catchment area (see Fig. 1 for an illustration). Computations were performed using the GeoPandas (version 0.6.0 and onward) Python library (Jordahl et al., 2019). Some small or elongated catchments had few or no grid points inside their boundaries. This is a consequence of the Pfafstetter coding used to construct the HydroBASINS division, where large differences can exist in the catchment areas for a given level. We retained only catchments containing at least five ERA5 grid points for our analyses. The choice of HydroBASINS Level 6 and the removal of the smallest catchments allow us to focus our analysis on relatively large catchments (90 % of the catchments are 3000 km2 or larger). Such large catchments are sensitive to extended periods of heavy rainfall lasting for several days or longer (Westra et al., 2014), and consequently the impact of subseasonal clustering is likely to be more important for those catchments.
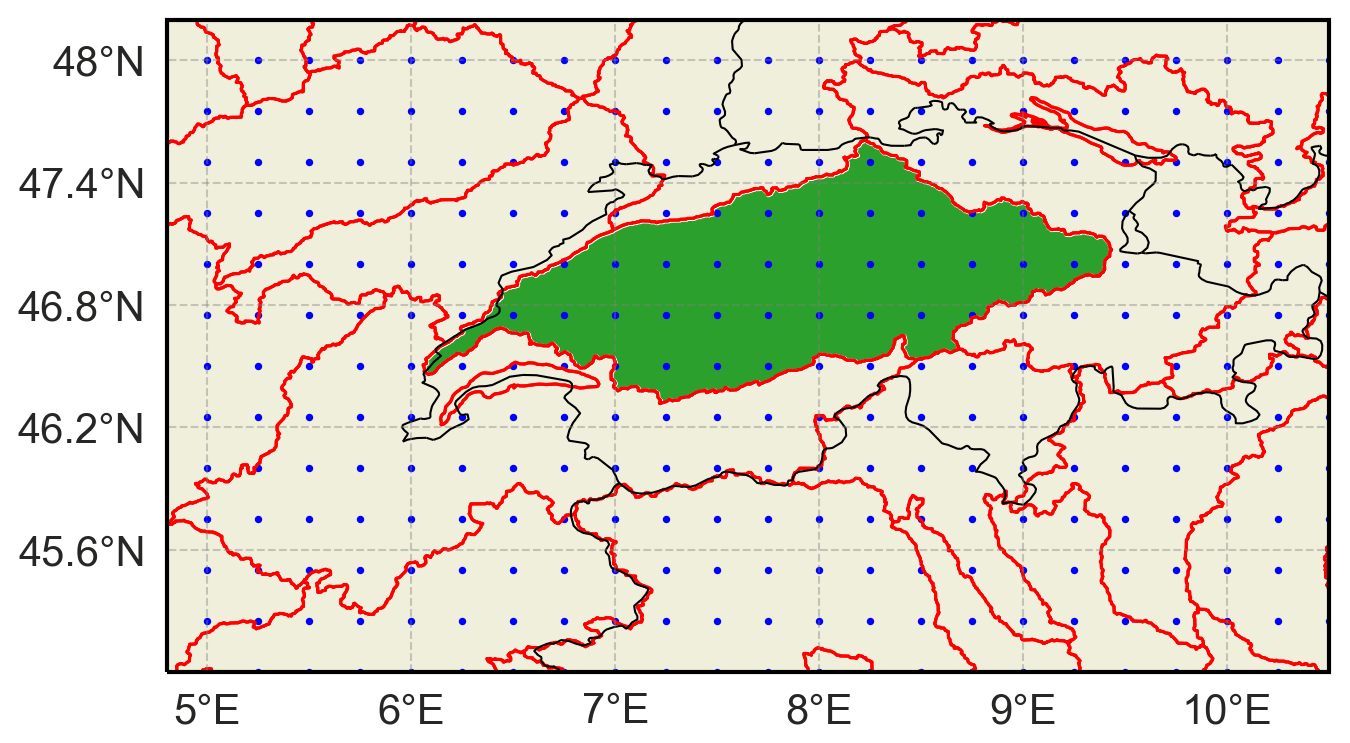
Figure 1Example of a catchment area (Aare basin, Switzerland in green). The red lines show the HydroBASINS Level 6 catchment area division. The blue dots indicate the ERA5 grid points. Country borders are indicated by black lines.
Further, we kept only catchments located in two latitudinal bands between 20 and 70∘ with a catchment 99th annual percentile (99 p) of daily precipitation above 10 mm (Fig. 2). Those criteria remove catchments from the tropics and the poles as well as dry areas and result in the selection of 6466 catchments. The timing of extreme precipitation (time of the year) is important for the present study because our method is based on counting how many extreme events happen in a certain time window (see Sect. 2.3). Rivoire et al. (2021) showed that this timing of extreme precipitation is well captured by ERA5 in the extratropics but less so in the tropics. Our choice of ERA5 was also motivated by its global coverage, its regular spatial and temporal resolution, and its consistency with the large-scale circulation (Rivoire et al., 2021).
Our method can be applied to any kind of dataset, independently of their spatial configuration and temporal resolution. Still, we do not expect our results to change significantly using other gridded datasets, surface station data or satellite observations. Indeed, previous studies have shown that precipitation extremes in gridded observational and reanalysis datasets correlated significantly (Donat et al., 2014) and that reanalysis products tended to agree in capturing the temporal clustering of heavy precipitation (Yang and Villarini, 2019). These studies used ERA-Interim, the predecessor of ERA5. More recently, Rivoire et al. (2021) compared moderate to extreme daily precipitation from ERA5 against two observational gridded datasets, EOBS (station-based) and CMORPH (satellite-based). Using the hit rate as a measure of co-occurrence, they found that for days exceeding the local 90th percentile, the mean hit rate is 65 % between ERA5 and EOBS (over Europe) and 60 % between ERA5 and CMORPH (globally). They also found that the differences between ERA5 and CMORPH are largest over NW America, central Asia, and land areas between 15∘ S and 15∘ N (the tropics). Another recent study by Tuel and Martius (2021) on sub-seasonal clustering compared ERA5 with three satellite-based datasets (TRMM, CMORPH and GPCP), as well as output from 25 CMIP6 global climate models (GCMs). They found a good agreement on the spatio-temporal clustering patterns across datasets.
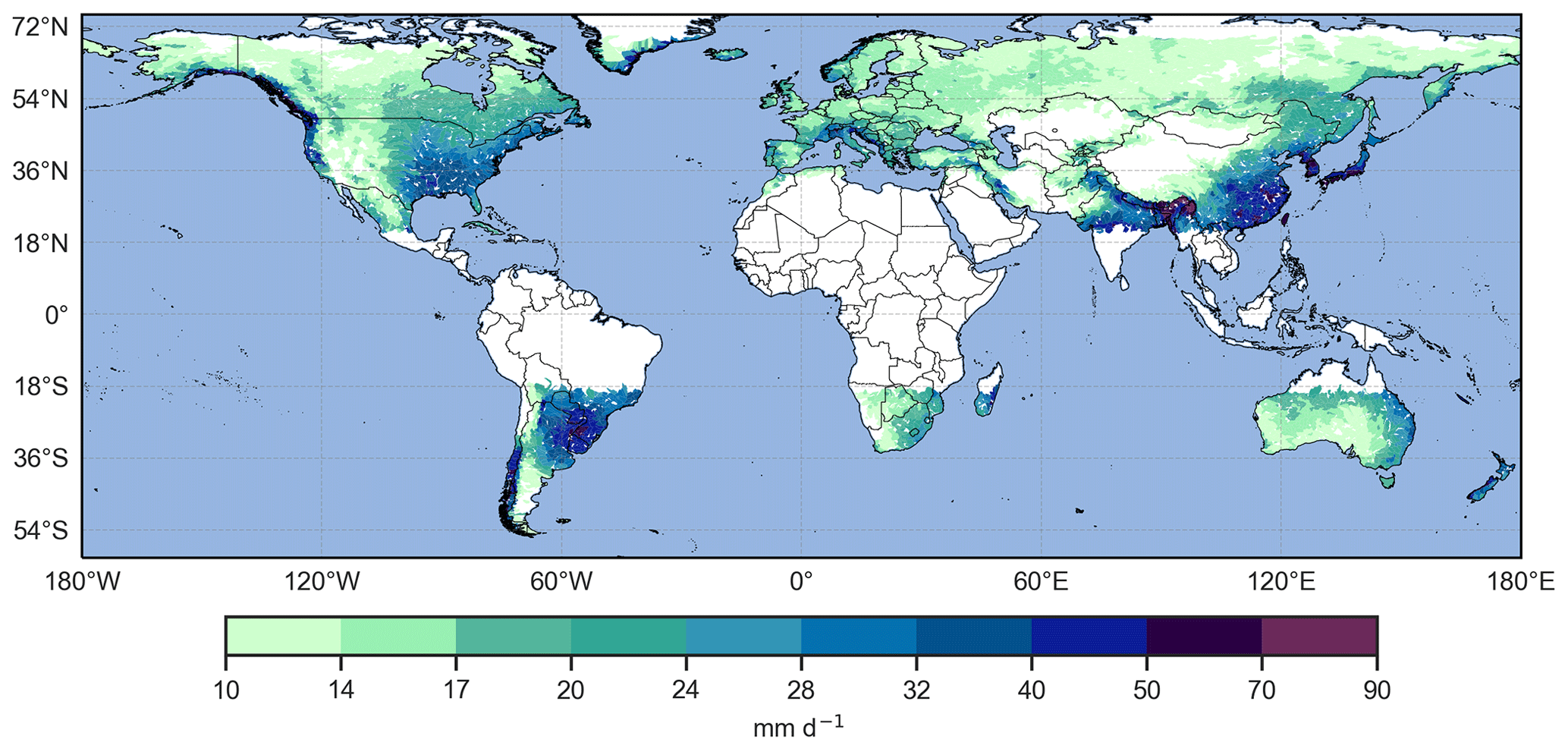
Figure 2The 99th annual percentile of daily precipitation per catchment (mm d−1). White areas correspond to the catchments that have been excluded from the analysis.
2.2 Identification of extreme precipitation events
We used a peak-over-threshold approach to identify extreme precipitation events from the time series of daily precipitation per catchment (Coles, 2001). We consider only the precipitation values exceeding the local annual 99th percentile. We use annual percentiles rather than seasonal percentiles because they are more impact relevant. To analyse sub-seasonal serial clustering, high-frequency clustering had to be removed from the daily precipitation time series. High-frequency clustering, i.e. successive days of extreme precipitation, can be caused by a stationary synoptic system (e.g., an extratropical cut-off cyclone). We employed the “runs declustering” method to account for the high-frequency clustering (Ferro and Segers, 2003). Thereby, given a run length r and a threshold t, days with precipitation exceeding t that are separated by fewer than r days with precipitation below t were grouped into one high-frequency cluster (see Fig. 3a for an illustration). The run declustering successively removes the short-term temporal dependence of extremes so as to focus exclusively on clustering at longer timescales (weekly and above). In this framework, a multi-day sequence of afternoon severe convective storms at the same grid point would be reduced to a single event, while being composed of multiple independent events. This is not an issue because the present research is more targeted at the larger-scale structures, such as mid-latitudes cyclones and cut-off lows. More importantly, the spatial (0.25∘ lat–long) and temporal (daily) resolutions of ERA-5 are too coarse to properly target convective-scale precipitation, and many convective extremes would be missed. Input data with a higher temporal and spatial resolution should be used to apply our approach to shorter timescales. After applying the declustering approach, a series of binary events of extreme daily precipitation was defined (Fig. 3a and b). In the case of a high-frequency cluster, the first day of the cluster was retained as the representative day for the event.
The choice of the two parameters (t and r) affects the distribution of independent extreme events (Coles, 2001). We followed the empirical approach of Barton et al. (2016) to determine reasonable values for the parameters. First, we selected two different thresholds: the 98th and 99th annual percentiles (further denoted as 98 p and 99 p) of the catchment area daily precipitation distribution. These thresholds have been used in previous studies (e.g. Fukutome et al., 2015).
The run length can either be determined with an objective method (Barton et al., 2016; Fukutome et al., 2015) or chosen based on meteorological process arguments (Lenggenhager and Martius, 2019). Following the approach of Lenggenhager and Martius (2019), we tested run lengths of both 1 and 2 d, corresponding to the influence time of a cyclone at one location (Lackmann, 2011).
The R package evd (Stephenson, 2002) was used for the computation of the yearly percentiles and the identification of independent peaks over the threshold, i.e. for the removal of the high-frequency clusters with the run declustering described above.
2.3 Identification of sub-seasonal clustering episodes
The identification of sub-seasonal clustering episodes is equivalent to searching for time periods (here 2 to 4 weeks) that contain several extreme precipitation events. The first step is to count the number of independent extreme precipitation events (nw) in a running (leading) time window of w days, after the run declustering has been applied to the time series. This count is computed for each day of the time series over the next w−1 d (not w, as the starting day is included in the time window length). In parallel, we calculate the running sum of daily precipitation (accw) over the same leading time window w. Time windows of w=14, 21 and 28 d were investigated. Figure 3c and d show the values of n21 and acc21, corresponding to the time series of Fig. 3a.
We then run an automated clustering episode identification algorithm that consists of the following steps: (i) isolate the days with the largest value of nw (highlighted in red in Fig. 3c). (ii) Among these days, retain the one with the largest accumulation accw (the purple bar in Fig. 3d). This selects a clustering episode which starts at the retained day and ends w−1 d later (shown by the red rectangle in Fig. 3a). The clustering episode identified in Fig. 3a contains four extreme events (n21=4), and the related accumulation acc21 is 275 [mm]. (iii) Reduce the time series by removing all days within w−1 d before and after the starting day of the selected episode (the purple window in Fig. 3d), to avoid further selected episodes from overlapping. (iv) Repeat steps (ii) and (iii) on the reduced time series to successively select the next episodes with the largest values of nw and accw until a predetermined number of episodes Nep=50 is reached. The choice of Nep is discussed below in greater detail, and at this stage we emphasise that limiting the selection to 50 episodes is sufficient for our method. This iterative selection results in the identification of 50 non-overlapping clustering episodes sorted by the number of extreme events (nw) and then by accumulations (accw). We denote this classification as Cln. The left panel of Table 2 shows the Cln classification obtained for a subcatchment of the Tagus river in the Iberian Peninsula (HydroBASINS ID: 2060654920). The Cln classification contains information about the frequency of sub-seasonal clustering. In a catchment where sub-seasonal clustering scarcely happens, Cln would typically be composed of a majority of episodes having a small number of extremes (e.g. nw≤2). However, for a catchment where sub-seasonal happens frequently, Cln would be composed of several episodes with more extreme events (e.g. ). Additional examples of catchments can be found in Appendix A.
In addition, we identify and classify the episodes with the largest precipitation accumulations as follows: we apply steps (ii) to (iv) of the automated identification algorithm to the accumulation time series. This is equivalent to selecting episodes using the sole criterion of maximising accw (the 21 d accumulations) at each iteration. This second selection results in the identification of 50 non-overlapping episodes sorted by accumulations (accw). We denote this classification as Clacc. The right half of Table 2 shows the Clacc classification obtained for the same catchment as the left half. All episodes listed in Table 2 are represented on the yearly timeline of Fig. 4 (in orange for Cln, in blue for Clacc and in grey when they overlap), along with the timing of all extreme events (black dots). We note that the choice of a centred or lagged window, instead of a leading window, does not change the values of nw and accw, except for the first and last w days of the time series. This has no significant impact on the results.
The degree of similarity between Cln and Clacc is the key point in our method to evaluate the contribution of clustering to large accumulations. This degree of similarity can be evaluated by doing a rank-by-rank comparison of the number of extreme events (nw) in the episodes of Cln with the episodes of Clacc. If the episodes composing Clacc and Cln have the same nw at each rank, then it means that the episodes with the largest number of extreme events are also leading to the largest accumulations. In this particular case, the contribution of clustering to accumulations is maximised. If an episode of Clacc has fewer extreme events than the episode with the same rank in Cln, then the contribution of clustering to accumulations is below the maximum contribution. The episodes selected in Cln and Clacc can be the same and ordered similarly or differently (they appear in grey in Fig. 4), but they can also differ (they appear in orange or blue in Fig. 4). The fifth columns of the left and right halves in Table 2 illustrate such a comparison, where the corresponding rank of each episode in the other classification is displayed. If the column is empty, it means that the episode is not present in the other classification. In this example, both classifications share the same first episode (nw=5), but their second and third episodes have different nw. We also note one episode without extreme events in Clacc at rank 11. The additional examples in Appendix A illustrate cases with different degrees of similarity between Cln and Clacc.
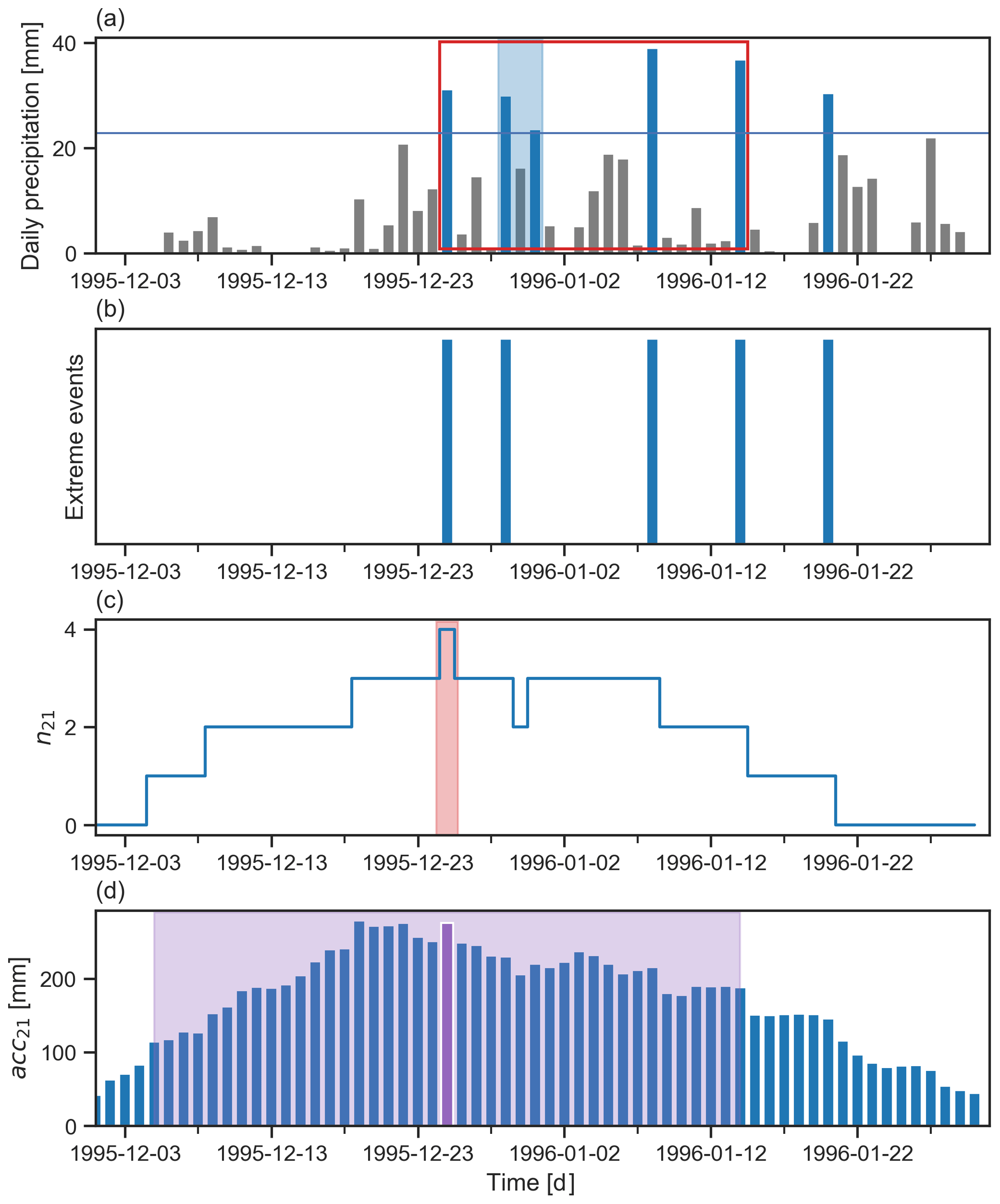
Figure 3Schematic illustration of the identification of a sub-seasonal clustering episode with w=21 d. (a) Time series of daily precipitation with extreme precipitation days marked by blue bars; the horizontal blue line represents the threshold t (e.g. the 99th percentile) defining the extreme events; the light blue shading highlights a high-frequency cluster (r=2 d), and the red rectangle denotes the clustering episode identified using the information of panels (c) and (d). (b) Series of binary events of extreme precipitation obtained after applying the declustering approach to the daily precipitation. (c) Number of extreme precipitation events in a running (leading) time window of 21 d (n21) based on the time series in panel (b); the light red shading indicates the day with the largest n21. (d) Precipitation accumulation in a running (leading) time window of 21 d (acc21) derived from the time series of panel (a); the purple bar denotes the day with the largest acc21 among the days with highest n21; this day is the starting day of the selected clustering episode; all days within the light purple shading are removed from the initial time series in the next step of the selection algorithm.

Figure 4For the catchment 2060654920, all extreme events are shown as black dots, and 21 d episodes are highlighted by the coloured rectangles. Episodes appearing in both classifications are shown in grey, and those appearing only in the Cln classification are shown in orange, whereas those only in the Clacc classification are shown in blue. Episodes containing two or more extreme events (nw≥2) are highlighted with a red edge. The clustering and contribution metrics (see Sect. 2.4) for this catchment are respectively Scl=43.63 and Scont=0.89, indicating prevalent sub-seasonal clustering with a substantial contribution to large accumulations (similar to the catchment of Appendix A1).
Table 2First 15 episodes of the Cln (left half) and Clacc (right half) classifications for the catchment with HydroBASINS ID 2060654920. Episodes of Cln (Clacc) are ranked according to their number of extreme events n21 (their accumulation acc21). The rightmost column of each panel indicates the corresponding rank of the episode in the other classification; if it is empty, the episode is not present in the other classification.

2.4 Metrics for sub-seasonal clustering
Next we define metrics that synthesise the properties of the two classifications to compare catchments. An intuitive choice for the metrics would be to average the number of extreme events; however such a choice would result in a loss of information (see Appendix C for a more detailed discussion on this). We take a different approach, equivalent to defining a scoring system, where each episode is given a weight qi depending on its rank in the classification, and this weight is used as a proportion factor for the number of extreme events in the episode. We have many options for defining the weights. For example, taking the average over the Nep episodes (as discussed in Appendix C) is the same as setting all weights equal to . Sitarz (2013) discusses a mathematical approach for defining a scoring system in sports, with two intuitively appealing properties. First, the first place should be rewarded more points than the second, and the second more than the third, and so on. In our case, rewarding more points is equivalent to giving a larger weight. Second, the difference between the ith place and the (i+1)th should be larger than the difference between the ith place and the (i+2)th. The second property means that someone gaining a place (or a rank) should be rewarded more if the initial rank is higher, as improving at upper ranks is more challenging than improving at lower ranks. We then follow the method of the incentre of a convex cone (Sitarz, 2013) to construct our weighting scheme (see Appendix B for a detailed description). The same weight qi is assigned to the ith episode of each classification (Cln and Clacc). We have tried two other weighting schemes, also satisfying the two required properties: the inverse of the rank () and the inverse of the square root of the rank (). The former gave slightly too much weight to the very first episodes of the classification, and the latter gave almost identical results to the incentre method. Our results are hence only slightly sensitive to the choice of the weighting scheme, as long as it satisfies the two desired properties.
We can now use each weight qi as a proportion factor for the corresponding number of extreme events in the ith episode for both classifications and derive the three following metrics.
The first metric Scl, called the clustering metric, is the weighted (qi) sum of the number of extreme events (nw(i)) over all episodes (i=1 to 50) in the Cln classification. Scl is proportional to the number of extreme events in the clustering episodes. It is most sensitive to the number of extreme events in the first clustering episodes, which are given the largest weight. In Sect. 2.5, we show that Scl correlates well with the index of dispersion – a widely used measure of clustering. Appendix A provides examples of catchments with high and low values of Scl for illustration.
The second metric Sacc, called the accumulation metric, is computed similarly to Scl, but using the episodes of the Clacc classification, where episodes were ranked according to their accumulations. As Scl and Sacc are computed using the same weights, their ratio Scont can be used to make a rank-by-rank comparison. Scont is equal to 1 when Sacc=Scl, i.e. when the two classifications have episodes with the same number of extreme events at identical ranks. Scont is equal to 0 when Sacc=0, i.e. when all episodes in the Sacc classification contain no extreme events (). In this particular case, subseasonal clustering does not contribute to large accumulation, and there is even no contribution of single extremes to large accumulations. In other cases, a proper assessment of the contribution of clustering to large accumulations is done by considering both Scl and Scont. Scont alone evaluates the similarity of the two classifications, and catchments can have low values of Scl (limited sub-seasonal clustering) and high values of Scont at the same time. The exact interpretation of intermediary values of Scont requires looking at both classifications (Cln and Clacc) in detail to see where they differ from each other. For example, if Scont=0.8, both classifications have a high degree of similarity, but it does not necessarily imply that 80 % of the episodes are ranked equally. Appendix A provides examples of catchments having high and low values of Scont as an illustration.
We now briefly address some technical points related to the definition of the metrics. First, we note that performing a regression between Cln and Clacc would be a more conservative approach in assessing their degree of similarity because it would require giving a unique identifier to each episode according to its starting day. In that case, the strength of the regression would be lowered when two episodes containing the same number of extreme events just swap their ranks in the two classifications. Such a change does not affect Scont.
Second, both scores depend on the number of clustering episodes considered (Nep). The choice of Nep is arbitrary but should be guided by some principles. The same value of Nep should be chosen for both Scl and Sacc and for all catchments to allow for comparisons. This implies that one cannot simply iterate over the precipitation time series until all non-overlapping episodes have been selected and classified. By doing so, one could end up with different values of Nep for each catchment. Moreover, the contribution of the ith term to the sums in Scl and Scont becomes smaller as Nep increases. We have tested several values of Nep ranging from 10 to 50 and found that the results with Nep ranging from 30 to 50 are comparable. Hence, we selected Nep=50 for our analysis.
Third, Scl and Sacc both increase with the number of extreme events per episode, so any parameter change which increases this number will also lead to an increase in Scl and Sacc. The variations in Scont with the parameters depend on the variations in both Scl and Sacc. This sensitivity to the parameters is assessed in Sect. 3.2.
2.5 Correlations with index of dispersion and significance test
We computed the index of dispersion ϕ for each catchment (Cox and Isham, 1980; Mailier et al., 2006) to compare our results to a more traditional method. For an homogeneous Poisson process, ϕ=1. When ϕ>1, the process is more clustered than random. When ϕ<1, the process is more regular than random (Mailier et al., 2006). To estimate ϕ for a given catchment, we separated the precipitation time series in successive intervals of w days and counted the number of extreme events in each interval. An estimator of ϕ is then given by (Mailier et al., 2006)
where is the sample mean and the sample variance of the number of extreme events in the intervals, where 14199 is the number of days in our time series.
We computed Scl and and calculated their Spearman rank correlation coefficient (Wilks, 2011) for all catchments and for each parameter combination (Table 3). All correlation coefficients are positive with values between 0.738 and 0.885 and significant with p values . Figure 5 displays a scatter plot of Scl versus for all catchments for the initial parameter combination () and illustrates this correlation. This significant positive correlation means that the use of Scl and leads to similar conclusions about the clustering of extreme precipitation events. This is further illustrated in Figs. 6a and E1, which respectively show a map of Scl and a map of for the initial parameter combination. A visual comparison of the two maps reveals that regions of high (low) Scl correspond to regions of high (low) .
An evident drawback of Scl compared to is the lack of a reference value above (below) which there is (no) clustering (e.g. ). While we cannot derive such a reference value, we can still use a bootstrap-based approach to assess how significant the value of Scl is for each catchment. More precisely, we tested the following hypothesis:
- H0
: The clustering episodes contain a number of extreme precipitation events (nw) which is not higher than for a distribution of those extremes without temporal structure (random).
- H1
: The clustering episodes contain a number of extreme precipitation events (nw) which is significantly higher than for a distribution of those extremes without temporal structure (random).
We reject H0 if the observed value of Scl is significantly greater than a given threshold. A rejection of H0 at a certain level of significance will be further noted as “significant sub-seasonal clustering” for simplicity. To this end, 1000 random samples were generated by doing permutations of the precipitation time series (i.e. each daily value is drawn only one time in each sample, without repetition; this way the distribution quantiles remain identical.). Scl was calculated for each sample, using the initial parameter combination and leading to an empirical distribution of Scl values. An empirical cumulative distribution function (ECDF) was calculated from the Scl empirical distribution, and an empirical p value was obtained by evaluating the ECDF at the observed Scl value: 1−ECDF(Scl(obs)). At a 1 % level, approx. 42 % of the catchments (2729 out of 6466) show significant sub-seasonal clustering (Fig. 6b, catchments in red).
Interestingly, the whole Scl empirical distribution based on the random samples is almost identical for all catchments, with a mean value around 31.42. This means that a selection of catchments based on a given level of significance can be well approximated by a selection based on relatively high observed Scl values. In Sect. 3, we select catchments which are either below the 25th percentile or above the 75th percentile of the observed Scl distribution for all catchments. It allows for a quick selection of catchments with rare or prevalent sub-seasonal clustering for each parameter combination, whereas the permutation/resampling approach would have required more computational time. We compared the two selection methods for the initial parameter combination and found only limited differences.
Many catchments have a very low p value because we take an annual percentile for defining the extreme precipitation events. With this definition, catchments with strong seasonality in the precipitation (e.g. with extremes occurring during a “wet” season) will have their extreme events occurring only during a few months. A random permutation of the daily precipitation will redistribute the extremes equally during the year in most cases, corresponding to much lower values of Scl. Taking seasonal percentiles would most likely result in fewer catchments having very low p values. The implications of seasonality and the choice of an annual percentile are further discussed in Sect. 4.
Table 3Spearman rank correlation coefficients between Scl and for all parameter combinations.

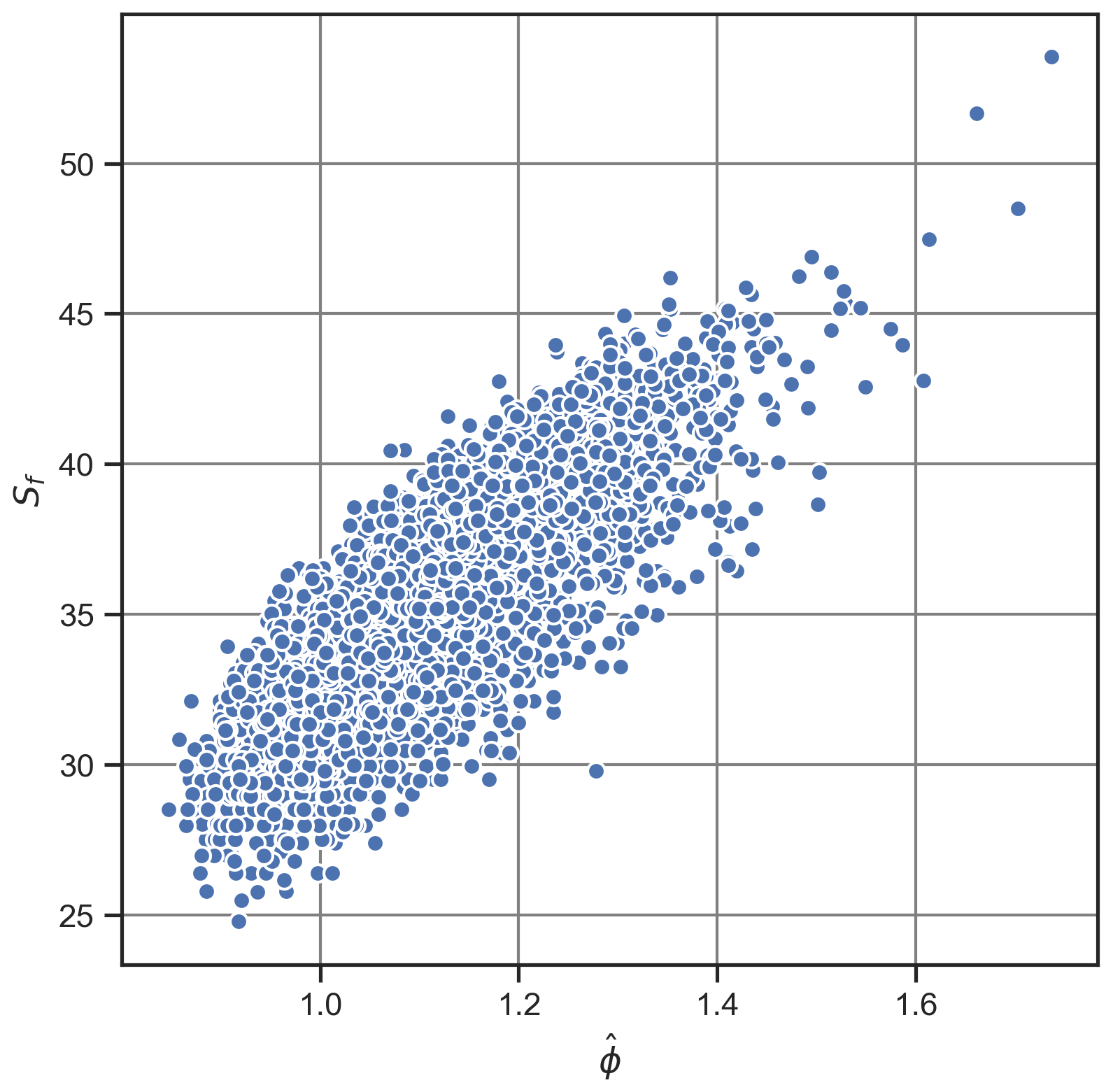
Figure 5Scatterplot of the index of dispersion versus the Scl metric for all selected catchments for the initial parameter combination ().

Figure 6Metric Scl (a) and sub-seasonal clustering significance (b) by catchment, for and w=21 d. In (a), high values of Scl denote catchments where sub-seasonal clustering is prevalent. In (b), catchments where Scl is significantly higher than for a distribution of extremes events without temporal structure are shown in red at the 1 % level.
3.1 Sub-seasonal clustering and its contribution to accumulations
Sub-seasonal clustering is prevalent in catchments having high values of Scl (see Sect. 2.5). Such catchments are located in the east and northeast of the Asian continent (northeast of Siberia, northeast of China, Korean Peninsula, south of Tibet), between the northwest of Argentina and the southwest of Bolivia, in the northeast and northwest of Canada as well as in Alaska, and in the southwestern part of the Iberian Peninsula (Fig. 6a). Regions with low values of Scl are located on the east coast of North America, on the east coast of Brazil, in central Europe, in South Africa, in central Australia, in New Zealand and in the north of Myanmar (Fig. 6a). Catchments with strongly contrasting values of Scl are rarely found in close proximity, except for a group of catchments located northeast of the Himalayas (south of Tibet) and another group located southeast of the Himalayas (Bangladesh and Myanmar). The catchments to the north have high values of Scl, whereas the neighbouring catchments to the south exhibit low values of Scl.

Figure 7(a) Catchments where Scl and Scont are both above their respective 75th percentile (pink areas). (b) Catchments where Scl<25 p and Scont>75 p (pink areas) and (c) catchments where Scl>75 p and Scont<25 p (pink areas). In all panels, catchments in grey do not satisfy the respective conditions, whereas catchments in white were excluded from the analysis according to the criteria defined in Sect. 2.1.
The contribution of sub-seasonal clustering to precipitation accumulations is analysed with both Scl and Scont. Catchments with high values of Scl and Scont are of special interest, because in these catchments, sub-seasonal clustering is prevalent and contributes substantially to large 21 d precipitation accumulations. We identify such catchments by considering those whose values of Scl and Scont are greater than the 75th percentile of their respective distribution for all catchments. The choice of the 75th percentile makes it possible to focus on the highest values, without being too restrictive, and follows the quick selection method mentioned in Sect. 2.5. Catchments where sub-seasonal clustering is prevalent and contributes substantially to large accumulations are mainly concentrated over eastern and northeastern Asia (Fig. 7a), in an area covering northeastern China, North and South Korea, Siberia, and east of Mongolia. Other areas with several catchments of interest are central Canada, south California, Afghanistan, Pakistan, the southwest of the Iberian Peninsula, the north of Argentina, and the south of Bolivia. Every continent includes groups of two to three or isolated catchments. Appendix A1 contains detailed information for an example catchment with a strong seasonality located in northeastern China (Scl=41.14, Scont=0.93). Almost all extreme events happen between June and August, which make clustering episodes and periods of large accumulations more likely to overlap.
We also identify catchments with values of Scl below the 25th percentile and values of Scont above the 75th percentile (Fig. 7b). Low values of Scl mean that the clustering episodes identified by our algorithm contain a small number or even no extreme events, and high values of Scont mean that those episodes lead to the largest accumulations. Such regions that exhibit rare clustering and where this rare clustering contributes substantially to large accumulations are the following: Taiwan, most of Australia, central Argentina, South Africa, south of Botswana and south of Greenland. Again, every continent includes groups of two to three or isolated catchments. Interestingly, the identified catchments are almost all located in the Southern Hemisphere. An example located in Australia is presented in detail in Appendix A1 (Scl=26.79, Scont=0.90). The extreme events are distributed throughout the whole year, and only a limited number of episodes contain two or more extreme events.
Finally, we identify regions with values of Scl above the 75th percentile and values of Scont below the 25th percentile (Fig. 7c). The high values of Scl mean that the clustering episodes identified by our algorithm contain a relatively large number of extreme events, whereas the low values of Scont mean that episodes leading to the largest accumulations contain a low number or even no extreme events. Such regions that exhibit prevalent clustering with a limited contribution to large accumulations are located in central China, the southwest of Japan and central Bolivia. Again, every continent includes groups of two to three or isolated catchments. Only a few catchments exhibit this combination of high Scl and low Scont values, highlighting the importance of the clustering of extreme events for generating the largest accumulations for the majority of the catchments. An example located in central China is presented in detail in Appendix A3 (Scl=43.23, Scont=0.59). The seasonality is present but less pronounced than in Appendix A1: almost all extreme events happen between mid-May and September. However, in this case, clustering episodes and periods of large accumulations tend not to overlap as much as in Appendix A1. This is a particularly interesting feature, especially because the two different patterns exemplified by Appendices A1 and A3 happen in neighbouring regions.
We investigated a potential link between the catchment size (in km2) and both the clustering (Scl) and contribution metric (Scont), by computing their Spearman rank correlation coefficient, but we found no significant correlations (not shown).
The physical drivers of the sub-seasonal clustering of extreme precipitation are numerous, and a detailed analysis of the identified clustering patterns is beyond the scope of the present research. Generally speaking, sub-seasonal clustering of extremes requires either very stationary or recurrent conditions that locally provide the ingredients for heavy precipitation (lifting and moisture) (Doswell et al., 1996). In some areas, large-scale patterns of variability were found to be relevant, such as the North Atlantic Oscillation (e.g., Villarini et al., 2011; Yang and Villarini, 2019), the El Niño–Southern Oscillation (Tuel and Martius, 2021) or the variability of the extratropical storm tracks (Bevacqua et al., 2020). However, in other areas the circulation patterns associated with clustering differ from the patterns of variability (Tuel and Martius, 2021). We direct the interested readers to the above-mentioned publications.
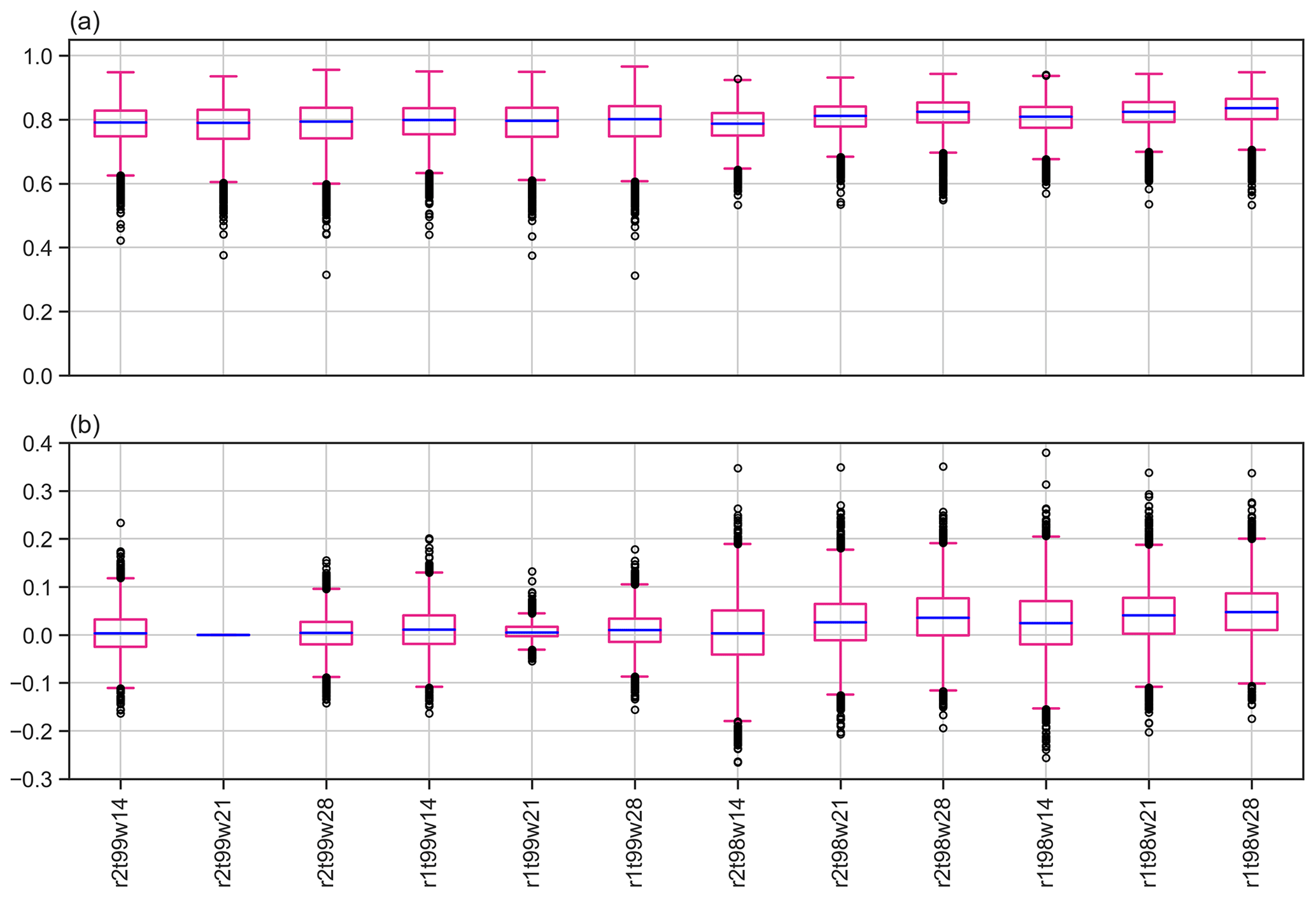
Figure 8Boxplots of (a) Scont for all catchments and parameter combinations and (b) of the differences in Scont between the initial parameter combination (the second boxplot from the left, i.e. ) and the other combinations. Boxes extend from the first (Q1) to the third (Q3) quartile values of the data, with a blue line at the median. The position of the whiskers is from the edges of the box. Outlier points past the end of the whiskers are shown with black circles.
3.2 Sensitivity analysis
The choice of the parameters will affect the values of Scl and Sacc. A lower (higher) threshold t and a shorter (longer) run length r both increase (decrease) the number of extreme events and lead to an increase (decrease) in Scl (Fig. D1 and Table D1). A longer (shorter) time window w increases (decreases) the likelihood of capturing more extreme events in a single episode and also leads to an increase in Scl (Fig. D1 and Table D1). Sacc will be impacted similarly to Scl. The sensitivity of Scl and Sacc to the parameters does not affect our general conclusions. Indeed, a change of parameters impacts all catchments, so while the scale of Scl (or Sacc) is changed, the comparison of two catchments will result in the same conclusion in almost all cases (not shown). That is, a catchment with a relatively low value of Scl compared to other catchments for one parameter combination will also have a relatively low value for other combinations and similarly for high values. However, the variations in Scont with the parameters depends on the variations in both Scl and Sacc. If the variations in Scl and Sacc are of the same order of magnitude, then Scont will change only slightly. It is therefore of interest to perform a sensitivity analysis on Scont by modifying the parameters used to define the clustering episodes to see whether the distribution of Scont remains similar.
Figure 8a shows the distributions of Scont for all parameter combinations, while Fig. 8b displays the distributions of the difference between the initial parameter combination () and the other combinations. The data used to draw the boxplots can be found in Tables F1 and F2 in the Appendix. The median value of Scont, indicated by the green lines in the boxplots, exhibits very low sensitivity to changes in the parameters with a minimum value of 0.79 (for ; see Fig. 8a) and a maximum value of 0.84 (). The same conclusion holds for the mean. In addition, the interquartile range and the position of the outliers are similar for all parameter combinations.
Examination of Fig. 8b reveals that the differences in Scont between the initial combination of parameters and the other combinations are relatively small for most catchments. For example, a change in r from 2 to 1 d, while keeping t and w constant (), results in an absolute difference in Scont smaller than 0.05 for almost all catchments. However, the variation can be more substantial for other parameter combinations. For example, a change in t from 99 to 98 p and in w from 21 to 14 d, while keeping r constant (e.g. ), leads to much larger absolute differences in Scont that can reach up to 0.35. Moreover, Scont at a given catchment can exhibit a wide range of variations when looking at all parameter combinations (not shown).
Taking into account the potential for high sensitivity to the parameters, we counted the number of parameter combinations where catchments are above the 75th percentile of both the Scl and Scont distributions to reach more robust conclusions. Areas with high counts, i.e. where catchments have been selected in several parameter combinations, are almost identical to the ones identified with the initial parameter combination (Fig. 9a). This means that the parameter selection does not have a substantial impact on the identified regions where sub-seasonal clustering occurs frequently and contributes substantially to large accumulations. This robustness with respect to variations in the parameters is also found for the catchments with Scl<25 p and Scont>75 p (rare clustering with substantial contribution) and Scl>75 p and Scont<25 p (frequent clustering with limited contribution),
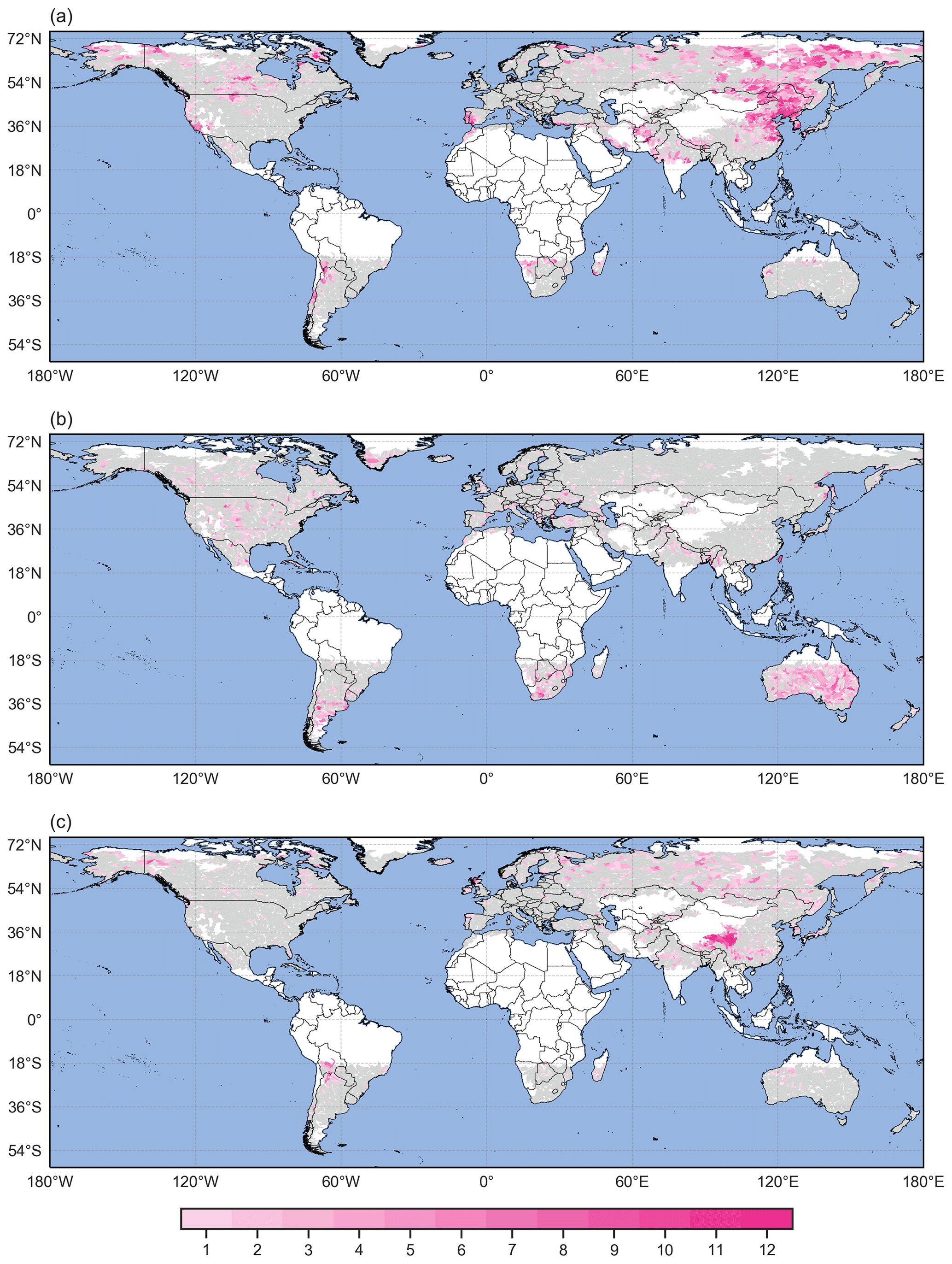
Figure 9(a) Count of parameter combinations where Scl>75 p and Scont>75 p (pink areas). (b) Count of parameter combinations where Scl<25 p and Scont>75 p (pink areas) and (c) count of parameter combinations where Scl>75 p and Scont<25 p (pink areas). In all panels, catchments in grey do not satisfy the respective conditions for any parameter combination, whereas catchments in white were excluded from the analysis according to the criteria defined in Sect. 2.1.
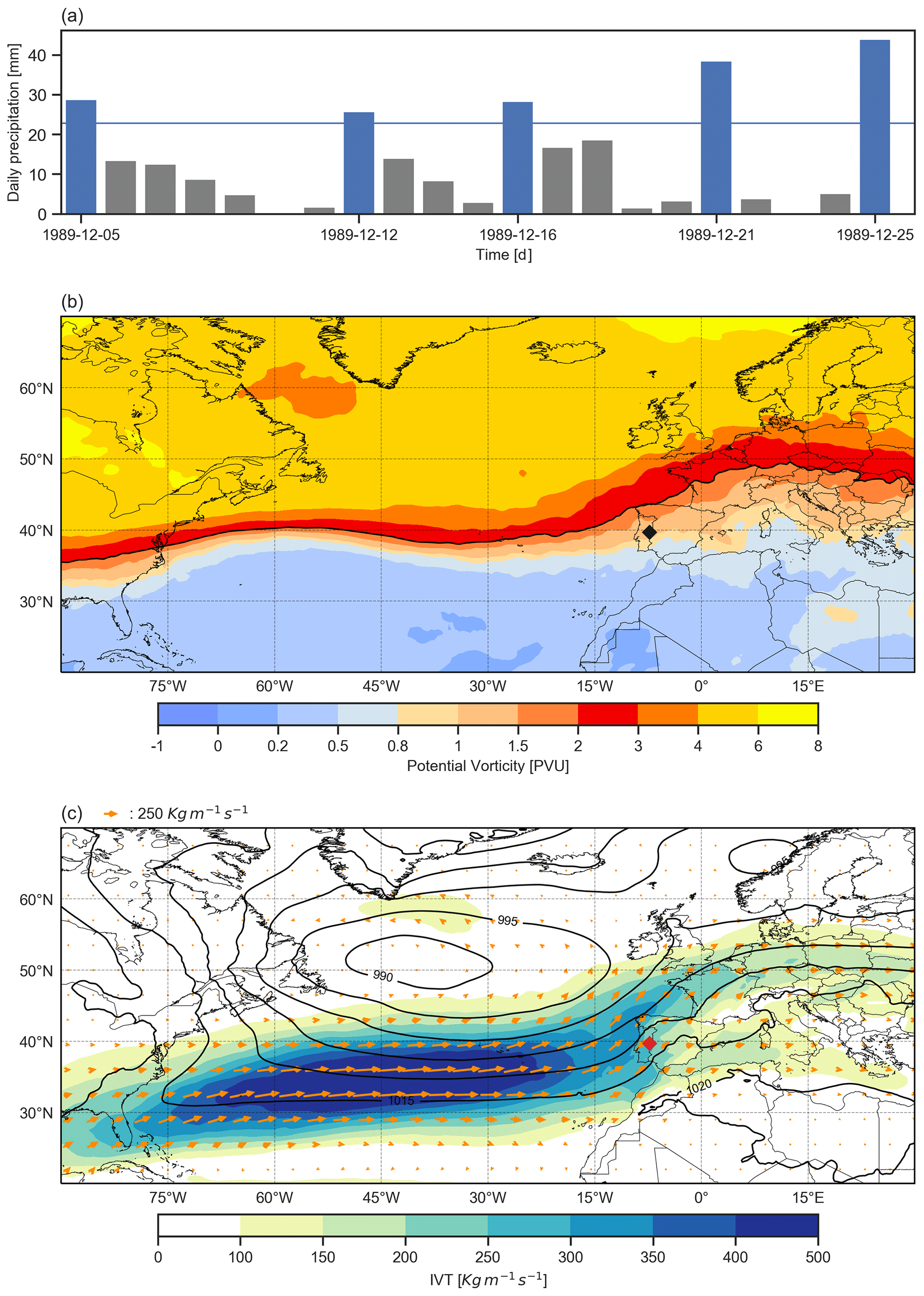
Figure 10Example of a sub-seasonal clustering episode identified with our procedure for catchment 2060654920 of HydroBASINS. (a) Daily precipitation with extreme precipitation events marked by blue bars. The horizontal blue line represents the 99 p of the catchment area daily precipitation distribution. (b) Potential vorticity composite in PVU on the 320 K isentropic level (colour shading) and dynamical tropopause identified by the 2 PVU contour (black line). (c) Integrated vapour transport composite magnitude (shading) and field in kg m−1 s−1 (arrows) and sea level pressure (SLP) composite in hPa (black contours). The black and red markers indicate the catchment location in panels (b) and (c) respectively. Both composites were calculated as the mean of the ERA5 6-hourly fields during the episode.
We present a novel count-based procedure to analyse sub-seasonal clustering of extreme precipitation events. The procedure identifies individual clustering episodes and introduces two metrics to characterise the frequency of sub-seasonal clustering episodes (Scl) and their relevance for large precipitation accumulations (Scont). Applying this procedure to the recent ERA5 dataset, we identify regions where sub-seasonal clustering of annual high precipitation percentiles occurs frequently and contributes substantially to large precipitation accumulations. Those regions are the east and northeast of the Asian continent, central Canada and the south of California, Afghanistan, Pakistan, the southwest of the Iberian Peninsula, and the north of Argentina and south of Bolivia. The method is robust with respect to changes in the parameters used to define the extreme events (the threshold t and the run length r) and the length of the episode (the time window w).
Conceptually, our approach differs from previously proposed methods to quantify sub-seasonal clustering that are based on parametric distributions with associated assumptions on the underlying distributions of the data. A major advantage of our method is that it does not require the investigated variable (here precipitation) to satisfy any specific statistical properties. This allowed us to study annual percentiles, which in most catchments exhibit a strong seasonal cycle. The seasonal cycle violates the independence assumptions underlying the parametric approaches. The seasonality issue is countered in the parametric approaches by either focusing on a single season (e.g., Mailier et al., 2006) or by including a seasonally varying occurrence rate in the models (Villarini et al., 2013). Working with annual percentiles allows us to focus on high-impact events. This comes at the cost of not being able to distinguish seasonal drivers from other drivers of sub-seasonal clustering. If precipitation in some regions occurs more often or with more intensity during a specific period of the year, then the use of an annual threshold will result in a more frequent detection of extremes during this specific period. Consequently, extremes will also be more likely to happen successively in a sub-seasonal time window. Hence, a catchment exhibiting a strong seasonality of extreme precipitation would likely show higher values of Scl than a catchment where precipitation shows no or weak seasonality. Finally, we note that our method can be applied using seasonally varying percentiles, by taking certain precautions in the identification of episodes to avoid edge effects at each season transition (Barton et al., 2016).
Our procedure introduces valuable practical refinements to the established methods. First, the identification of individual clustering episodes allows researchers to study the atmospheric conditions that prevailed before and during an episode and hence the processes leading to clustering. An illustration is given in Fig. 10a, which shows a 21 d clustering episode identified with our procedure for a catchment of the Iberian Peninsula (HydroBASINS ID no. 2060654920), with the corresponding potential vorticity and integrated vapour transport composites (Fig. 10b and c respectively). Second, knowing when clustering episodes happen enables researchers to study their medium range to seasonal predictability (see Webster et al., 2011 for an example). Third, the episode identification makes it possible to link the precipitation clustering to hydrological impacts (e.g., using disaster databases or hydrological models). And finally, the Scont metric allows the global assessment of the contribution of sub-seasonal clustering to high precipitation accumulations, which to our knowledge cannot be done with any existing method.
The objective of the present paper was to introduce a new methodology and to demonstrate its application to the study of sub-seasonal clustering of extreme precipitation. It paves the way for further research on several aspects. First, potential extensions of the method itself could be explored, such as integrating the magnitude of each extreme event within an episode and sequencing its variability. Second, possible trends in the contribution of clustering to accumulations could be studied by comparing values of Scl and Scont in the first half and the second half of the investigated period. Third, the method could provide insights into the physical drivers of clustering by looking at scaling between the two metrics and other environmental variables (such as temperature or pressure) during selected clustering episodes or globally. Regions that exhibit frequent clustering according to our approach could be studied with other methods to see whether the sub-seasonal clustering is due to seasonal effects such as monsoon circulations, changes in sea surface temperatures or seasonal variability of the extratropical storm tracks. We also think that our approach is very flexible and that it could also be used to identify serial clustering of other variables (e.g. heat waves) and can be applied on different timescales (e.g. for drought years). An example would be the classification of hurricane seasons using frequency and categories of hurricanes. For this reason, we have made our code available on the listed GitHub repository.
A1 Catchment with frequent sub-seasonal clustering contributing substantially to large accumulations
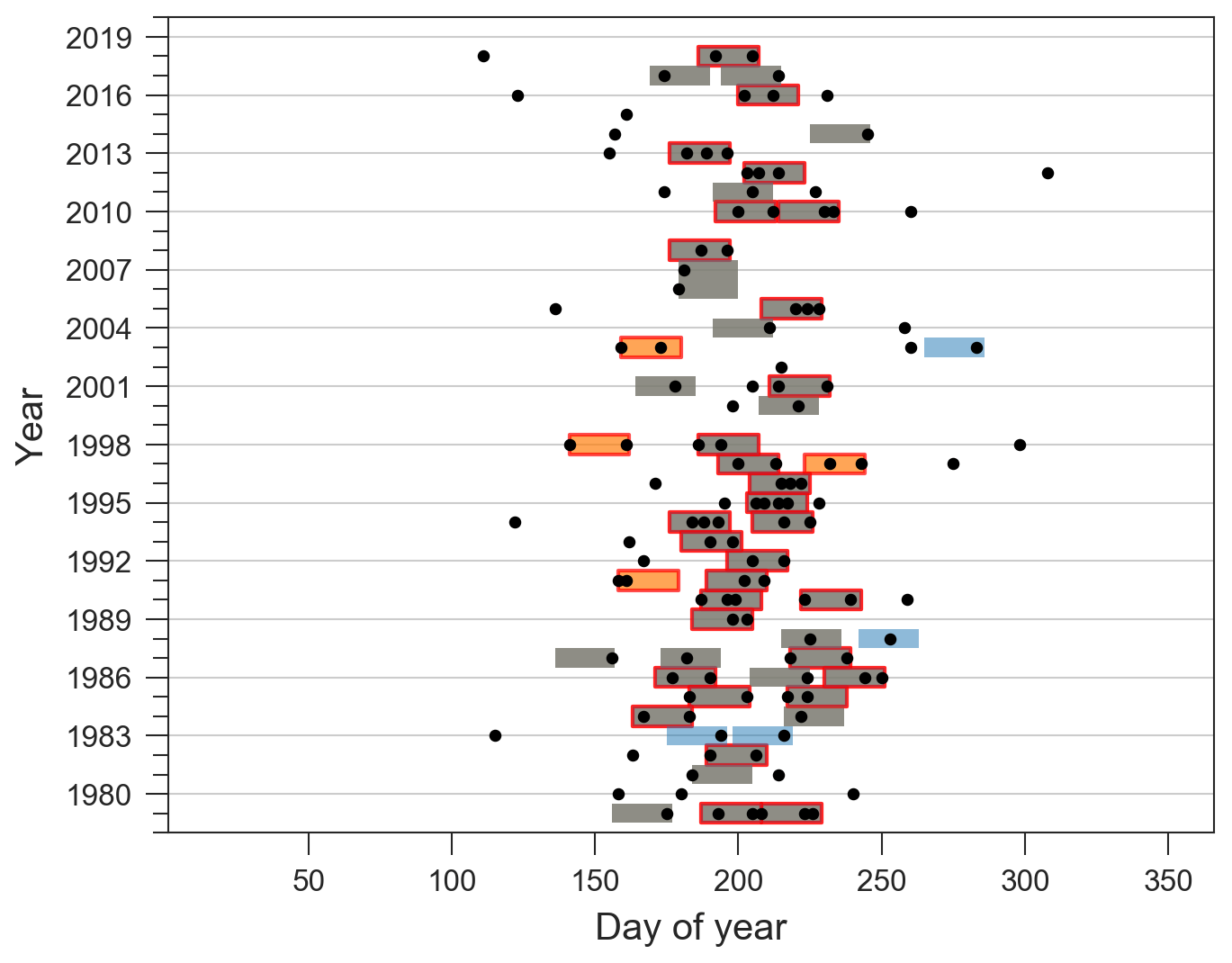
Figure A1Catchment 4060460860 located in northeastern China, with prevalent clustering (Scl=41.14) and a high degree of similarity between the classifications Cln and Clacc: Scont=0.93. All extreme events are shown as black dots, and 21 d episodes are highlighted by the coloured rectangles. Episodes appearing in both classifications are shown in grey, and those appearing only in the Cln classification are shown in orange, whereas those only in the Clacc classification are shown in blue. A total of 34 episodes contain two or more extreme events (nw>=2) and are highlighted with a red edge.
A2 Catchment with rare sub-seasonal clustering contributing substantially to large accumulations

Figure A2Catchment 5060089390 located in Australia, with rare clustering (Scl=26.79) and a high degree of similarity between the classifications Cln and Clacc: Scont=0.9. In that case, most of the contribution to precipitation accumulations is due to isolated extreme events. A total of 11 episodes contain two or more extreme events (nw>=2). Extreme events and episodes are shown as in Fig. A1.
A3 Catchment with frequent sub-seasonal clustering and limited contribution to large accumulations
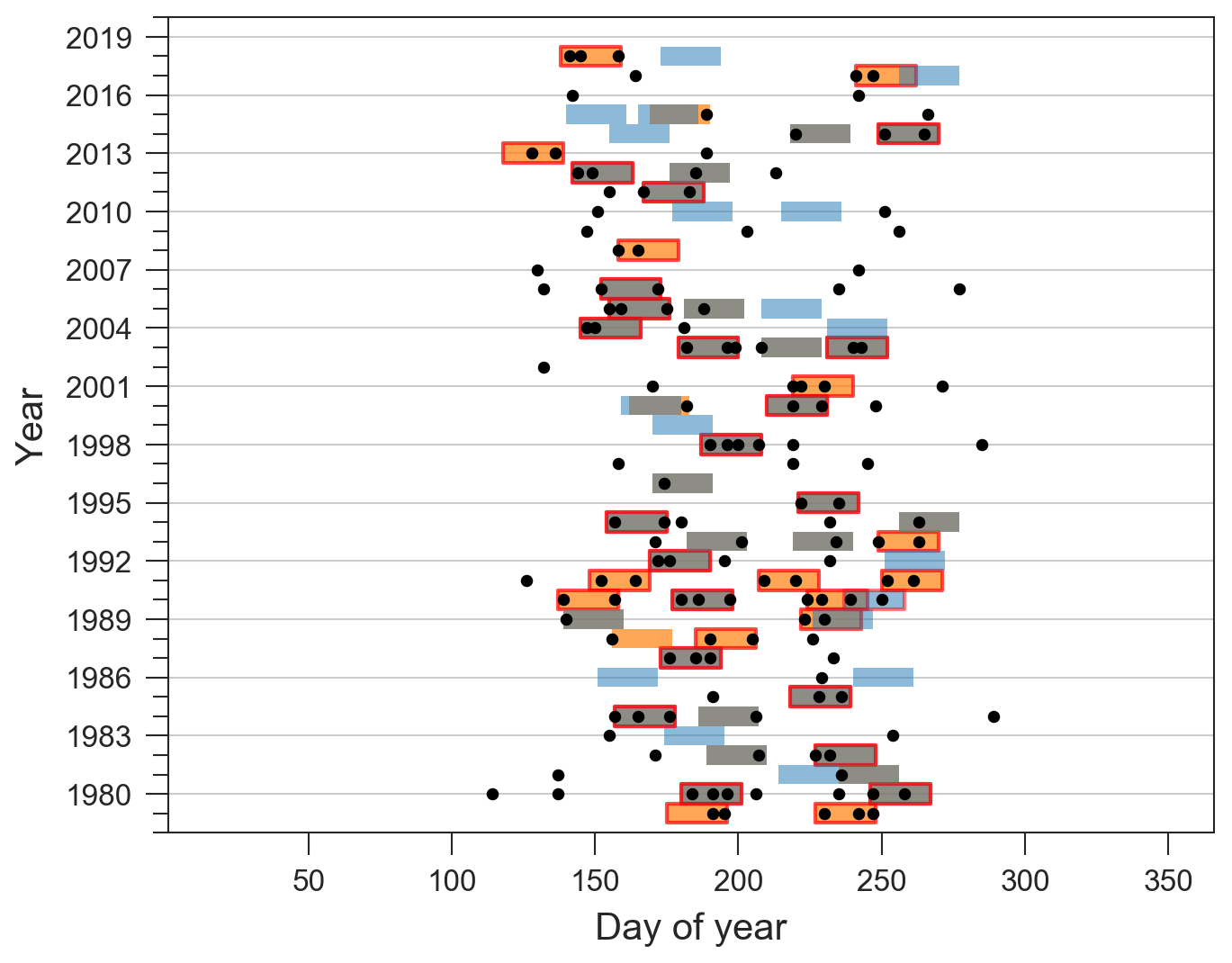
Figure A3Catchment 4060660750 located in central China, prevalent clustering (Scl=43.23) and a limited degree of similarity between the classifications Cln and Clacc: Scont=0.59. A total of 35 episodes contain two or more extreme events (nw>=2). Extreme events and episodes are shown as in Fig. A1.
Sitarz (2013) assume two intuitive conditions for a scoring system. First, more points are assigned to the first place than to the second place, more to the second than to the third and so on. Second, the difference between the ith place and the (i+1)th place should be larger than the difference between the (i+1)th place and the (i+2)th place. This is equivalent to considering the following set of points:
where x1 denotes the points for the first place, x2 the points for the second place, … and xN the points for the Nth place. Any choice of points in K would satisfy the two conditions for a scoring system; however we would like to have a unique and representative value. The option chosen by Sitarz (2013) is to look for the equivalent of a mean value: the incentre of K. Formally, the incentre is defined as an optimal solution of the following optimisation problem by Henrion and Seeger (2010):
where Sx denotes the unit sphere, ∂K denotes the boundary of set K and dist denotes the distance in the Euclidean space. By using the calculation presented in the Appendix of Sitarz (2013), and dividing the points of the first place () to get the weights (qi), we obtain
The weight q1 is always 1, but the values of weights q2 to qN depend on N, and in our case N is the number of clustering episodes Nep.
An intuitive choice to define the metrics (see Sect. 2.4) is to use the sum or average of the number of extreme events over all (or a subset of) the episodes of Cln and Clacc. However, such a choice would result in a loss of relevant information on how the episodes are ranked and preclude a rank-by-rank comparison between classifications. This can be illustrated with the following theoretical example: let us consider a catchment where Cln is composed of five episodes, each with three extreme events, and five other episodes, each with one extreme event (i.e. Nep=10). The average number of extreme events is two. If Clacc is composed of the same episodes, then the average remains identical whatever the order of the episodes in Clacc, and we cannot say anything about the contribution of clustering to accumulations by comparing the averages. For example, all episodes with one extreme event could have larger accumulations than those with three extreme events. There is a low contribution of clustering to accumulations in this case, and metrics based on averages would not be able to capture this feature. A metric based on average would also fail to capture some differences in the same classification between two catchments. This again can be illustrated with a theoretical example: let us consider catchment A where Cln is composed of five episodes, one with five extreme events, the four others without an extreme event, and catchment B, where Cln is composed of five episodes, each with one extreme event. In both cases the average number of extreme events is one but the clustering behaviour is different. Consequently, we need a way to properly account for the respective rank of each episode in both classifications.

Figure D1Boxplots of Scl for all catchments and parameter combinations. Boxes extend from the first (Q1) to the third (Q3) quartile values of the data, with a blue line at the median. The position of the whiskers is from the edges of the box. Outlier points past the end of the whiskers are shown with black circles.
Table D1Descriptive statistics of the Scl distributions for all parameter combinations. The measures are, from top to bottom, the mean value, the standard deviation, the minimum value, the first quartile, the median value, the third quartile and the maximum value.

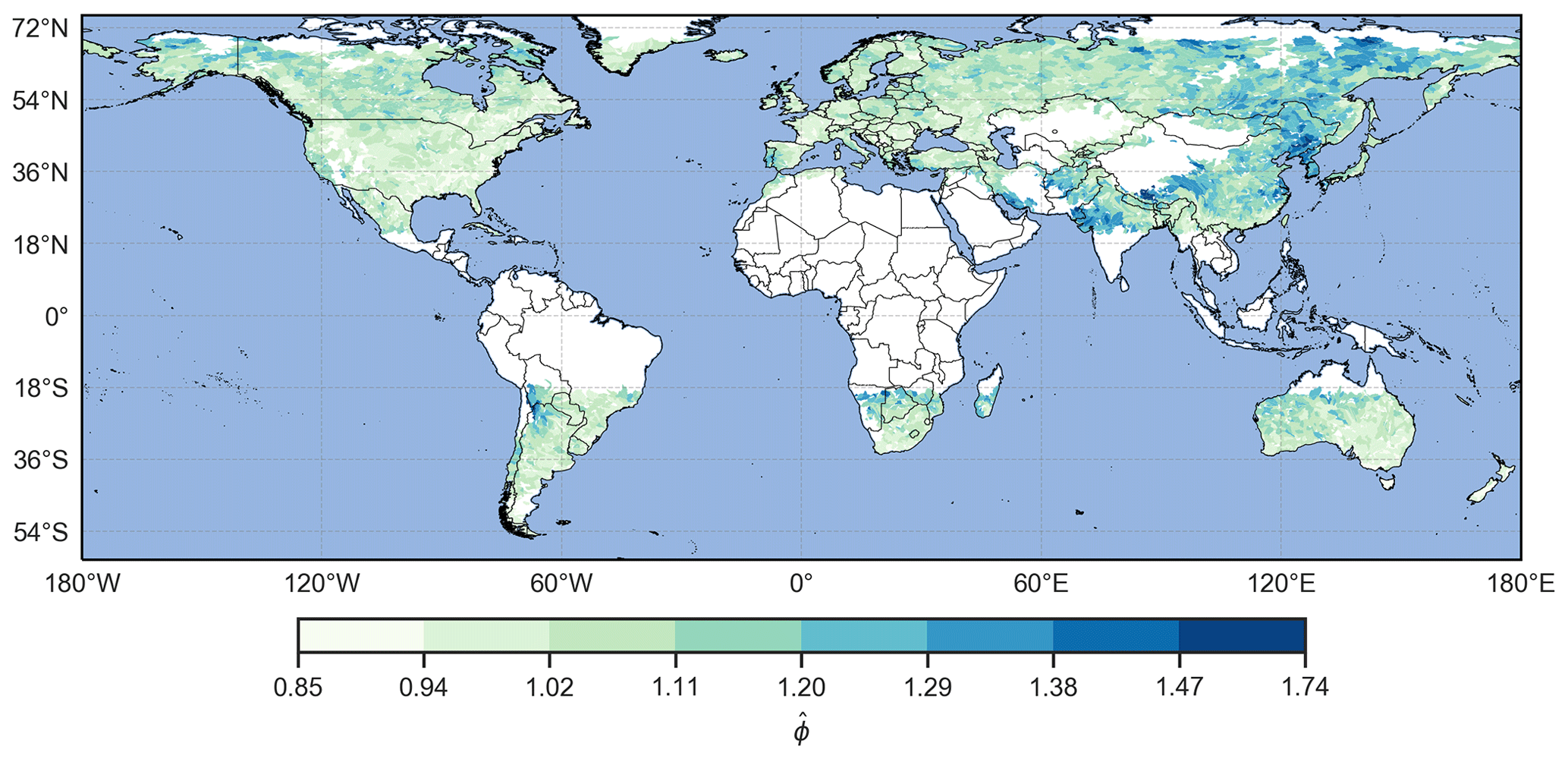
Figure E1Index of dispersion by catchment, for and w=21 d. denotes catchments where extreme precipitation events are more clustered than random.
Table F1Descriptive statistics of the Scont distributions for all parameter combinations. The measures are the same as in Table D1.

Table F2Descriptive statistics of the distributions of the difference between the initial parameter combination () and the other combinations. The measures are the same as in Table D1.

ERA5 data are available on the Copernicus Climate Change Service (C3S) Climate Data Store: https://doi.org/10.24381/cds.adbb2d47 (Hersbach et al., 2018).
HydroBASINS data are available on the HydroSHEDS website: https://www.hydrosheds.org/downloads (last access: 16 September 2021) (Lehner and Grill, 2013).
The complete code used to identify the clustering episodes, compute the metrics and generate all the figures is available on the following Zenodo page: https://doi.org/10.5281/zenodo.5330676 (Kopp, 2021b).
Datasets created in this study are available from the FAIR-aligned repository in the in-text data citation (https://doi.org/10.5281/zenodo.5330713; Kopp, 2021a.
JK developed the count-based procedure and metrics, carried out the data analyses, and wrote the paper. OM, PR and SMA developed the concept for the analysis, provided advice on the methodology and on data analysis, discussed the results, and contributed to the writing. YB supported the statistical analyses and contributed to the writing.
The authors declare that they have no conflict of interest.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the special issue “Understanding compound weather and climate events and related impacts (BG/ESD/HESS/NHESS inter-journal SI)”. It is not associated with a conference.
The authors thank Andrey Martynov for preparing the ERA5 reanalysis dataset and Alexandre Tuel for feedback on the draft.
Jérôme Kopp and Olivia Martius acknowledge support from the Swiss Mobiliar Insurance Company. Pauline Rivoire, Mubashshir Ali and Olivia Martius acknowledge support from the Swiss Science Foundation (grant no. 178751).
This paper was edited by Marie-Claire ten Veldhuis and reviewed by James Done and one anonymous referee.
Barton, Y., Giannakaki, P., von Waldow, H., Chevalier, C., Pfahl, S., and Martius, O.: Clustering of regional-scale extreme precipitation events in southern Switzerland, Mon. Weather Rev., 144, 347–369, https://doi.org/10.1175/MWR-D-15-0205.1, 2016. a, b, c, d, e
Bevacqua, E., Zappa, G., and Shepherd, T. G.: Shorter cyclone clusters modulate changes in European wintertime precipitation extremes, Environ. Res. Lett., 15, 124005, https://doi.org/10.1088/1748-9326/abbde7, 2020. a, b
Coles, S.: An Introduction to Statistical Modeling of Extreme Values, vol. 208, Springer, London, 2001. a, b
Cox, D. R. and Isham, V.: Point processes, vol. 12, Chapman & Hall, New York, 1980. a, b, c
Dacre, H. F. and Pinto, J. G.: Serial clustering of extratropical cyclones: a review of where, when and why it occurs, npj Climate and Atmospheric Science, 3, 1–10, https://doi.org/10.1038/s41612-020-00152-9, 2020. a, b
Dixon, P. M.: Ripley's K Function, Wiley StatsRef: Statistics Reference Online, 3, 1796–1803, https://doi.org/10.1002/9781118445112.stat07751, 2002. a
Donat, M. G., Sillmann, J., Wild, S., Alexander, L. V., Lippmann, T., and Zwiers, F. W.: Consistency of temperature and precipitation extremes across various global gridded in situ and reanalysis datasets, J. Climate, 27, 5019–5035, https://doi.org/10.1175/JCLI-D-13-00405.1, 2014. a
Doswell III, C. A., Brooks, H. E., and Maddox, R. A.: Flash flood forecasting: An ingredients-based methodology, Weather Forecast., 11, 560–581, https://doi.org/10.1175/1520-0434(1996)011<0560:FFFAIB>2.0.CO;2, 1996. a
European Environment Agency: Economic losses from climate-related extremes in Europe, available at: https://www.eea.europa.eu/data-and-maps/indicators/direct-losses-from-weather-disasters-4/assessment, (last access: 26 January 2021), 2020. a
Ferro, C. A. T. and Segers, J.: Inference for clusters of extreme values, J. R. Stat. Soc. B, 65, 545–556, https://doi.org/10.1111/1467-9868.00401, 2003. a
Fukutome, S., Liniger, M. A., and Süveges, M.: Automatic threshold and run parameter selection: a climatology for extreme hourly precipitation in Switzerland, Theor. Appl. Climatol., 120, 403–416, https://doi.org/10.1007/s00704-014-1180-5, 2015. a, b
Guo, Y., Wu, Y., Wen, B., Huang, W., Ju, K., Gao, Y., and Li, S.: Floods in China, COVID-19, and climate change, The Lancet Planetary Health, 4, e443–e444, https://doi.org/10.1016/S2542-5196(20)30203-5, 2020. a
Henrion, R. and Seeger, A.: On properties of different notions of centers for convex cones, Set-Valued Var. Anal., 18, 205–231, https://doi.org/10.1007/s11228-009-0131-2, 2010. a
Hersbach, H., Bell, B., Berrisford, P., Biavati, G., Horányi, A., Muñoz Sabater, J., Nicolas, J., Peubey, C., Radu, R., Rozum, I., Schepers, D., Simmons, A., Soci, C., Dee, D., and Thépaut, J.-N.: ERA5 hourly data on single levels from 1979 to present, Copernicus Climate Change Service (C3S), CDS – Climate Data Store [data set], https://doi.org/10.24381/cds.adbb2d47, 2018. a
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020. a, b
IPCC: Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change, edited by: Field, C. B., Barros, V. R., Dokken, D. J., Mach, K. J., Mastrandrea, M. D., Bilir, T. E., Chatterjee, M., Ebi, K. L., Estrada, Y. O., Genova, R. C., Girma, B., Kissel, E. S., Levy, A. N., MacCracken, S., Mastrandrea, P. R., and White, L. L., available at: https://www.ipcc.ch/report/ar5/wg2/ (last access: 15 September 2021), 2014. a
Jordahl, K., den Bossche, J. V., Wasserman, J., McBride, J., Gerard, J., Fleischmann, M., Tratner, J., Perry, M., Farmer, C., Hjelle, G. A., Gillies, S., Cochran, M., Bartos, M., Culbertson, L., Eubank, N., Maxalbert, Rey, S., Bilogur, A., Arribas-Bel, D., Ren, C., Wilson, J., Journois, M., Wolf, L. J., Wasser, L., Özak, Ö., Notoya, Y., Leblanc, F., Holdgraf, C., and Greenhall, A.: geopandas/geopandas: v0.6.0, https://doi.org/10.5281/zenodo.3463125, 2019. a
Kopp, J.: Dataset for “A novel method to identify sub-seasonal clustering episodes of extreme precipitation events and their contributions to large accumulation periods”, Zenodo [data set], https://doi.org/10.5281/zenodo.5330713, 2021. a
Kopp, J.: Subseasonal_clustering v1.1, Zenodo [code], https://doi.org/10.5281/zenodo.5330676, 2021. a
Lackmann, G.: Midlatitude Synoptic Meteorology: Dynamics, Analysis, and Forecasting, American Meteorological Society, Boston, MA, 2011. a
Lau, W. K. M. and Kim, K.-M.: The 2010 Pakistan Flood and Russian Heat Wave: Teleconnection of Hydrometeorological Extremes, J. Hydrometeorol., 13, 392–403, https://doi.org/10.1175/JHM-D-11-016.1, 2012. a
Lehner, B. and Grill, G.: Global river hydrography and network routing: baseline data and new approaches to study the world’s large river systems, Hydrol. Process., 27, 2171–2186, 2013. a
Lehner, B. and Grill, G.: HydroBASINS, available at: https://www.hydrosheds.org/downloads, last access: 16 September 2021. a
Lenggenhager, S. and Martius, O.: Atmospheric blocks modulate the odds of heavy precipitation events in Europe, Clim. Dynam., 53, 4155–4171, https://doi.org/10.1007/s00382-019-04779-0, 2019. a, b
Mailier, P. J., Stephenson, D. B., Ferro, C. A. T., Hodges, K. I., Mailier, P. J., Stephenson, D. B., Ferro, C. A. T., and Hodges, K. I.: Serial Clustering of Extratropical Cyclones, Mon. Weather Rev., 134, 2224–2240, https://doi.org/10.1175/MWR3160.1, 2006. a, b, c, d, e
Martius, O., Sodemann, H., Joos, H., Pfahl, S., Winschall, A., Croci-Maspoli, M., Graf, M., Madonna, E., Mueller, B., Schemm, S., Sedláček, J., Sprenger, M., and Wernli, H.: The role of upper-level dynamics and surface processes for the Pakistan flood of July 2010, Q. J. Roy. Meteor. Soc., 139, 1780–1797, https://doi.org/10.1002/qj.2082, 2013. a
Pinto, J. G., Bellenbaum, N., Karremann, M. K., and Della-Marta, P. M.: Serial clustering of extratropical cyclones over the North Atlantic and Europe under recent and future climate conditions, J. Geophys. Res.-Atmos., 118, 12476–12485, https://doi.org/10.1002/2013JD020564, 2013. a
Priestley, M. D., Pinto, J. G., Dacre, H. F., and Shaffrey, L. C.: The role of cyclone clustering during the stormy winter of 2013/2014, Weather, 72, 187–192, https://doi.org/10.1002/wea.3025, 2017. a
Priestley, M. D. K., Dacre, H. F., Shaffrey, L. C., Hodges, K. I., and Pinto, J. G.: The role of serial European windstorm clustering for extreme seasonal losses as determined from multi-centennial simulations of high-resolution global climate model data, Nat. Hazards Earth Syst. Sci., 18, 2991–3006, https://doi.org/10.5194/nhess-18-2991-2018, 2018. a
Raymond, C., Horton, R. M., Zscheischler, J., Martius, O., AghaKouchak, A., Balch, J., Bowen, S. G., Camargo, S. J., Hess, J., Kornhuber, K., Oppenheimer, M., Ruane, A. C., Wahl, T., and White, K.: Understanding and managing connected extreme events, Nat. Clim. Change, 10, 611–621, https://doi.org/10.1038/s41558-020-0790-4, 2020. a
Ripley, B. D.: Spatial Statistics, John Wiley & Sons, Hoboken, NJ, 1981. a
Rivoire, P., Martius, O., and Naveau, P.: A Comparison of Moderate and Extreme ERA-5 Daily Precipitation With Two Observational Data Sets, Earth and Space Science, 8, e2020EA001633, https://doi.org/10.1029/2020EA001633, 2021. a, b, c
Sitarz, S.: The medal points' incenter for rankings in sport, Appl. Math. Lett., 26, 408–412, https://doi.org/10.1016/j.aml.2012.10.014, 2013. a, b, c, d, e
Smith, J. A. and Karr, A. F.: Flood Frequency Analysis Using the Cox Regression Model, Water Resour. Res., 22, 890–896, https://doi.org/10.1029/WR022i006p00890, 1986. a
Stephenson, A. G.: evd: Extreme Value Distributions, R News, 2, 0, available at: https://CRAN.R-project.org/doc/Rnews/ (last access: 15 Septebmer 2021), 2002. a
Tuel, A. and Martius, O.: A global perspective on the sub-seasonal clustering of precipitation extremes, Weather Clim. Extrem., 33, 100348, https://doi.org/10.1016/j.wace.2021.100348, 2021. a, b
Villarini, G., Smith, J. A., Baeck, M. L., Vitolo, R., Stephenson, D. B., and Krajewski, W. F.: On the frequency of heavy rainfall for the Midwest of the United States, J. Hydrol., 400, 103–120, https://doi.org/10.1016/j.jhydrol.2011.01.027, 2011. a, b
Villarini, G., Smith, J. A., Serinaldi, F., Ntelekos, A. A., and Schwarz, U.: Analyses of extreme flooding in Austria over the period 1951-2006, International J. Climatol., 32, 1178–1192, https://doi.org/10.1002/joc.2331, 2012. a
Villarini, G., Smith, J. A., Vitolo, R., and Stephenson, D. B.: On the temporal clustering of US floods and its relationship to climate teleconnection patterns, Int. J. Climatol., 33, 629–640, https://doi.org/10.1002/joc.3458, 2013. a, b
Vitolo, R., Stephenson, D. B., Cook, I. M., and Mitchell-Wallace, K.: Serial clustering of intense European storms, Meteorologische Z., 18, 411–424, https://doi.org/10.1127/0941-2948/2009/0393, 2009. a
Webster, P. J., Toma, V. E., and Kim, H.-M.: Were the 2010 Pakistan floods predictable?, Geophys. Res. Lett., 38, L04806, https://doi.org/10.1029/2010GL046346, 2011. a
Westra, S., Fowler, H. J., Evans, J. P., Alexander, L. V., Berg, P., Johnson, F., Kendon, E. J., Lenderink, G., and Roberts, N. M.: Future changes to the intensity and frequency of short-duration extreme rainfall, Rev. Geophys., 52, 522–555, https://doi.org/10.1002/2014RG000464, 2014. a
Wilks, D. S.: Statistical Methods in the Atmospheric Sciences, vol. 100, Academic press, Oxford, Waltham, MA, 2011. a
Yang, Z. and Villarini, G.: Examining the capability of reanalyses in capturing the temporal clustering of heavy precipitation across Europe, Clim. Dynam., 53, 1845–1857, https://doi.org/10.1007/s00382-019-04742-z, 2019. a, b, c
Zscheischler, J., Martius, O., Westra, S., Bevacqua, E., Raymond, C., Horton, R. M., van den Hurk, B., AghaKouchak, A., Jézéquel, A., Mahecha, M. D., Maraun, D., Ramos, A. M., Ridder, N. N., Thiery, W., and Vignotto, E.: A typology of compound weather and climate events, Nat. Rev. Earth Environ., 1, 333–347, https://doi.org/10.1038/s43017-020-0060-z, 2020. a
- Abstract
- Introduction
- Data and methods
- Results
- Discussion and conclusions
- Appendix A: Examples of episodes by catchment
- Appendix B: Calculation of the weights
- Appendix C: Rationale behind the construction of the metrics
- Appendix D: Distributions of Scl and related data
- Appendix E: Map of (index of dispersion)
- Appendix F: Data of Fig. 8a and b
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Data and methods
- Results
- Discussion and conclusions
- Appendix A: Examples of episodes by catchment
- Appendix B: Calculation of the weights
- Appendix C: Rationale behind the construction of the metrics
- Appendix D: Distributions of Scl and related data
- Appendix E: Map of (index of dispersion)
- Appendix F: Data of Fig. 8a and b
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References