the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 23 Jul 2020
| 23 Jul 2020
A new discrete multiplicative random cascade model for downscaling intermittent rainfall fields
Marc Schleiss
Spatial downscaling of rainfall fields is a challenging mathematical problem for which many different types of methods have been proposed. One popular solution consists of redistributing rainfall amounts over smaller and smaller scales by means of a discrete multiplicative random cascade (DMRCs). This works well for slowly varying homogeneous rainfall fields but often fails in the presence of intermittency (i.e., large amounts of zero rainfall values). The most common workaround in this case is to use two separate cascade models, namely one for the occurrence and another for the intensity. In this paper, a new and simpler approach based on the notion of equal-volume areas (EVAs) is proposed. Unlike classical cascades where rainfall amounts are redistributed over grid cells of equal size, the EVA cascade splits grid cells into areas of different sizes, with each of them containing exactly half of the original amount of water. The relative areas of the subgrid cells are determined by drawing random values from a logit-normal cascade generator model with scale and intensity-dependent standard deviation (SD). The process ends when the amount of water in each subgrid cell is smaller than a fixed-bucket capacity, at which point the output of the cascade can be resampled over a regular Cartesian mesh. The present paper describes the implementation of the EVA cascade model and gives some first results for 100 selected events in the Netherlands. Performance is assessed by comparing the outputs of the EVA model to bilinear interpolation and to a classical DMRC model based on fixed grid cell sizes. Results show that, on average, the EVA cascade outperforms the classical method, producing fields with more realistic distributions, small-scale extremes and spatial structures. Improvements are mostly credited to the higher robustness of the EVA model in the presence of intermittency and to the lower variance of its generator. However, both approaches have their advantages and weaknesses. For example, while the classical cascade tends to overestimate small-scale variability and extremes, the EVA model tends to produce fields that are slightly too smooth and block shaped compared to the observations. The complementary nature of the two approaches, and the fact that they produce errors of opposite signs, opens up new possibilities for quality control and bias corrections of downscaled fields.
- Article
(12591 KB) - Full-text XML
- BibTeX
- EndNote





Stochastic rainfall downscaling algorithms are statistical methods designed to enhance the resolution of coarse-scale rainfall observations for use in hydrological modeling, weather prediction or flood-risk analyses. Their simplicity and low computational cost mean that large ensembles of possible realizations for a single input field can be generated. This leads to a better representation of measurement errors and model uncertainties compared to physical downscaling and a more realistic representation of small-scale variability. However, the statistical nature of the approach means that one needs to find a good balance between model complexity and performance (e.g., the realism of the distributions and spatial patterns that can be reproduced).
Popular statistical downscaling methods for global and regional climate models include various forms of transfer functions and quantile matching (Li et al., 2010; Teutschbein and Seibert, 2012; Langousis et al., 2016), machine learning (Jha et al., 2015; He et al., 2016), and a multitude of hybrid physical–statistical and autoregressive models (e.g., Lisniak et al., 2013; Bechler et al., 2015; Xu et al., 2015). Another important family revolves around the notion of self-similarity, generalized scale invariance and multiplicative random cascades (e.g., Lovejoy and Mandelbrot, 1985; Schertzer and Lovejoy, 1987; Gupta and Waymire, 1993; Menabde et al., 1997; Schertzer and Lovejoy, 2011). The main appeal of these techniques is that they require a very small number of model parameters, many of which can be inferred directly from the coarse-scale data. Also, the framework itself is very flexible, as it can apply to all kinds of rainfall inputs from time series to spatial and space–time fields (e.g., Deidda, 2000; Menabde and Sivapalan, 2000; Kang and Ramirez, 2010; Raut et al., 2018).
One long-standing and still-unresolved issue of random multiplicative cascade models applied to rainfall concerns the question of how to properly deal with zero rainfall values. Zeros are fundamentally incompatible with the notion of self-similarity and multiplicative random cascades (Gupta and Waymire, 1993). They must be artificially introduced into the cascade, for example, by setting a hard threshold on the minimum detectable intensity (e.g., Pathirana et al., 2003) or by modifying the cascade model in such a way that grid cells below a given intensity only have a finite, predetermined probability to survive at each cascade level (Gires et al., 2013). Another workaround consists of applying two separate cascade models for the occurrence and intensity (e.g., Over and Gupta, 1996; Olsson, 1998; Paulson and Baxter, 2007; Schmitt, 2014; Lombardo et al., 2017). However, this requires many additional model parameters to be estimated from the data, which can be challenging numerically and can increase the risk of overfitting. Regardless of how they are handled, zero rainfall values are likely to negatively impact the scaling properties of rainfall, making it difficult to retrieve reliable model parameters in the first place (Kedem and Chiu, 1987; Schmitt et al., 1998; Veneziano et al., 2006; de Montera et al., 2009; Gires et al., 2012; Veneziano and Lepore, 2012; Mascaro et al., 2013).
Given the numerous challenges mentioned above, there is a strong incentive to design new simple multiplicative cascade models capable of handling rainfall fields with high levels of intermittency. Particular attention is given to parsimonious models, with a maximum of three parameters, whose values can be inferred directly from the coarse-scale data. One promising avenue explored in this paper revolves around the notion of equal-volume areas (EVAs), a natural extension of the interamount times (IATs) concept introduced in the context of time-series analysis by Schleiss and Smith (2016). The theoretical foundation for this work is motivated by recent studies by Schleiss (2017) and ten Veldhuis and Schleiss (2017), who showed that intermittent rainfall and flow time series scale better when sampled adaptively rather than with a fixed frequency. The hope is that by switching to an adaptive sampling strategy, the mathematical challenges associated with the presence of zero rainfall values can be alleviated, thus leading to more robust cascades and more realistic rainfall fields after downscaling. The present study describes the implementation of this idea to the case of 2D rainfall fields and discusses its advantages and limitations with respect to traditional random cascades based on intensity.
The rest of this paper is structured as follows: Sect. 2 introduces the new EVA model, including the splitting rule, cascade generator and parameter estimation. In Sect. 3, the potential of the new cascade is demonstrated by applying it to radar rainfall snapshots collected over the Netherlands. First, the parameterization problem is discussed. Then, the performance is evaluated by means of controlled simulation experiments during which 100 high-resolution rainfall fields are aggregated to coarser scales and subsequently downscaled back to their original resolution. Results are compared to two alternative downscaling techniques (i.e., bilinear interpolation with local intensity rescaling and a classical random cascade based on intensity). The advantages and limitations of the model and possible extensions are discussed in Sect. 5, and the conclusions are given in Sect. 6.
2.1 A brief introduction to discrete multiplicative random cascades
Discrete multiplicative random cascades (DMRCs) are statistical downscaling techniques designed to enhance the resolution of a coarse-scale rainfall field to a desired fine-scale target resolution. For spatial cascades, this is done by successively splitting the dimensions of coarse-scale grid cells by two (or four, depending on the type of cascade) according to a predefined branching rule. For example, one large 16 × 16 grid cell might be divided into two subgrid cells of 8 km × 16 km at the first level of the cascade which, in turn, will be divided into four grid cells of 8 km × 8 km at the next level. The splitting process is repeated iteratively until the desired target resolution lx×ly is reached. During a split, each of the generated subgrid cells receives a random fraction of the total rainfall amount in the parent grid. Redistribution takes place according to some multiplicative weights, namely W1≥0 and W2≥0, drawn from a probability distribution Γ called the cascade generator. In microcanonical models, the sum of the weights associated with each split is forced to one, thus ensuring that the total rainfall amount in each grid cell is preserved. In contrast, in canonical cascades, only the average rainfall intensity over a large number of grid cells needs to be preserved. This has some advantages in terms of modeling but generally results in lower performance than microcanonical cascades (e.g., Hingray and Ben Haha, 2005). For the sake of completeness, it should also be mentioned that other types of cascades have been proposed to downscale rainfall, such as those based on continuous in-scale multifractal cascades (Lovejoy and Schertzer, 2010a, b). However, these are outside the scope of this paper which focuses on discrete microcanonical random cascades.
As pointed out by Rupp et al. (2009), differences in performances between cascade models primarily relate to which probability distribution is chosen for Γ and how rainfall amounts are reassigned to subgrid cells during the splits. In the simplest possible setup, the probability distribution of the generator remains the same across the entire cascade. However, rainfall fields downscaled with such an approach often exhibit unrealistically high small-scale variability and extremes. Consequently, many authors recommend using cascade generators whose distribution depends on the spatiotemporal dimensions of the grid cells that are being split or on the average rainfall intensity within them (Rupp et al., 2009; Licznar et al., 2011). In this paper, this is achieved by conditioning the variance of the generator on the spatial scale and the rainfall intensity.
2.2 Description of the EVA cascade model
Let R1−RN (in mm h−1) denote a coarse-scale rainfall intensity field over a regular Cartesian mesh composed of individual grid cells of (in km2), where and (in km) denote the horizontal and vertical dimensions, respectively, and N is the total number of grid cells in the field. Let denote the areas (in km2) of the individual grid cells. The relation between intensity Ri (in mm h−1), area Ai (in km2), volume Vi (in millions of liters), and temporal aggregation timescale Δt (in h) is given as follows:
In a classical cascade model, grid cells of area Ai are divided in two subgrid cells of equal areas, namely . The rainfall volumes V(i,1) and V(i,2) of the subgrid cells are determined by multiplying Vi by random weights W1≥0 and drawn from the cascade generator model Γ as follows:
The random quantities in this case are the rainfall volumes Vi (or, equivalently, the rainfall intensities) at each level, and the area of the grid cells plays the role of the scale λ. This is the most natural choice for downscaling applications and will be referred to as the classical approach in this paper. The main drawback of the classical approach is that the conditional probability distribution function of Vi, given Ai>0, has a mixed distribution with atom at zero as follows:
where ℙ denotes the probability. Moreover, the probability that Vi equals zero, knowing Ai>0, increases as the area tends to zero. To reproduce such behavior, the classical cascade generator model Γ must include a mechanism through which (some) of the weights can be set to zero during the splitting process (usually at the expense of additional model parameters). This is far from trivial as one needs to make sure that the cascade does not remove all rainy areas during the downscaling and does not introduce zeros immediately next to grid cells with very high rainfall intensities (Olsson, 1998).
The main contribution of this paper is to show that many of the issues associated with zero rainfall values can be avoided by adopting a slightly different representation of rainfall based on the notion of equal-volume areas. In the EVA framework, the scale λ is given by the total rainfall volume contained in a grid cell, and the random quantities that are being downscaled are the areas Ai needed to accumulate fixed volumes of water. At each split, the total volume of water Vi in a grid cell is divided by two and equally redistributed over two subgrid cells of different areas. The areas A(i,1) and A(i,2) of the two subgrid cells are determined by drawing random weights W1 and from a cascade generator ΓEVA with a predetermined probability distribution. A small diagram illustrating this process is provided in Fig. 1.
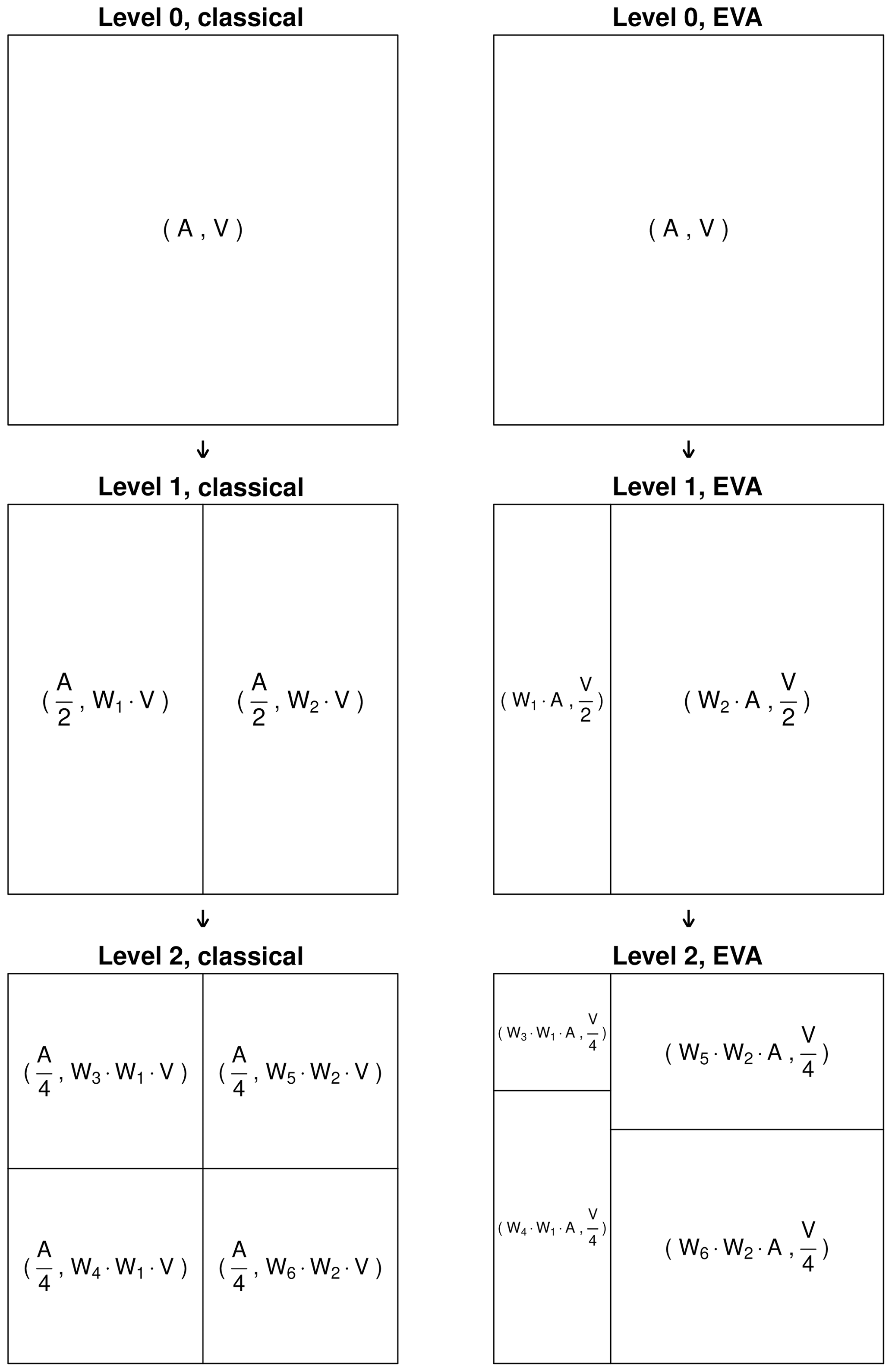
Figure 1Schematic of the branching rules for the classical and equal-volume area (EVA) random cascades. The area is denoted by A and the rainfall volume by V. The random weights are W1−W6.
Note that by convention, splits always occur perpendicular to the longest grid cell dimension; that is, splitting occurs horizontally if Lx≤Ly and vertically otherwise. Splitting is applied iteratively until the total rainfall volume in a grid cell is lower than a fixed-bucket capacity εV>0, which denotes the smallest rainfall volume that can be detected at the target resolution. The latter can be prescribed by end-user requirements or imposed to match known instrumental limitations, such as the capacity of a tipping-bucket rain gauge or the sensitivity of a weather radar. The smaller the bucket capacity, the larger the number of cascade levels and subgrid cells. Note that the rule above does not apply to grid cells for which Vi=0, as the latter do not contain any water and do not need to be split. These grid cells are kept “as is” until the end of the cascade. The main advantage of the EVA approach over the classical cascade is that the areas needed to accumulate a positive rainfall volume Vi>0 can never be zero, as follows:
Finally, note that, by construction, the EVA cascade described above implements an adaptive spatial sampling of the coarse-scale rainfall field, which is very similar to that of a quadtree (Shankar and Hutchinson, 1990). The cascade decomposes a regular 2D rainfall field into grid cells of variable sizes, with fewer and larger grid cells in areas of low rainfall intensity and more numerous and smaller grid cells in areas of large rainfall intensities. The redistribution rule ensures each of the generated subgrid cells contains a strictly positive rainfall amount, regardless of its size or at which level of the cascade it was produced. Zeros are not coded explicitly into the field, making it unnecessary to model their distribution and structure. The downside of the approach is that the output of the cascade consists of grid cells of variable sizes. From a practical point of view, it may therefore be necessary to resample the output of the EVA cascade onto a regular Cartesian mesh with a fixed spatial resolution, at which point the zero rainfall values will become apparent. This process, also known as “regridding”, is commonly encountered in geophysical image mapping, and various computationally efficient solutions have been proposed for it. Here, we consider the simple case of regridding an irregular rectilinear grid to a regular Cartesian mesh composed of square pixels of lx×ly in size centered around (xi,yi). The total rainfall amount V(xi,yi) in a target pixel centered around (xi,yi) is given by the sum of all rainfall amounts in the irregular source field times the ratio of overlapping areas with the target pixel, as follows:
where denotes the fractional area overlap of the target grid cell i with the source cell j, and m∈ℕ is the total number of grid cells generated by the cascade. Fractional overlaps for rectangular grid cells are easy to calculate, making this step very efficient. In the end, all resampled rainfall amounts V(xi,yi) below the minimum detectable threshold εV>0 are set to zero, similar to how they would appear in real measurements. Note that this threshold is not imposed on the cascade output itself (which does not contain any zeros) but only on the resampled quantities. Because of this, the frequency of zero rainfall values and their location in the domain will depend on the spatial scale at which the field is displayed. The latter can be changed at any time, depending on user requirements, without having to run another random cascade. In fact, an irregular grid combined with a final resampling step for visualization constitutes a very natural way of modeling a scale-dependent process like rainfall.
2.3 Splitting rule
The way grid cells are split at each level plays a crucial role in determining the spatial structure of the downscaled field. Independent of the used cascade generator, for any weight , there are only two possibilities for splitting a grid cell. In the case of vertical splits, the left subgrid cell can be assigned the area W⋅Ai (corresponding to an intensity of ) or, conversely, the complementary value . The splitting rule is a set of instructions for determining which side is assigned the lowest area or, equivalently, the highest rainfall intensity. To preserve the overall spatial structure and coherency of the rainfall field during downscaling, knowledge about the rainfall intensity in the surrounding grid cells is required. This is achieved by performing inverse distance interpolation of the coarse-scale rainfall intensity field on the left or right sides (for horizontal splits) or top or bottom (for vertical splits) of each grid cell. At each split, the side with the highest interpolated rainfall value is assigned the largest intensity (i.e., the smallest area). An example of this principle is shown in Fig. 2 for a single grid cell (in bold at the center of the figure) with area A surrounded by seven grid cells with different areas and intensities. Note that the splitting rule, as defined above, only takes into account the rainfall values in surrounding grid cells without influencing the cascade weights themselves. Its only purpose is to ensure that, as we go through the cascade, water is redistributed in a way that is spatially coherent with respect to the coarse-scale observations and all previously generated grid cells during the cascade. This is particularly important in the first stages of the cascade, when rainfall amounts can be redistributed very unevenly. The choice of the interpolation scheme is not critical as long as it provides a relatively smooth estimate of the rainfall distribution over the domain. In this study, inverse-distance weighting was used. To limit the computational time associated with interpolation, only the 100 nearest surrounding grid cells were used. Note that, since the spatial distribution of the rainfall intensity over the domain changes after each split, the interpolated values need to be updated regularly to take into account the newly generated fine-scale rainfall patterns. Without this update, downscaled fields would rapidly lose their spatial coherency. In theory, the interpolated rainfall values should be recalculated after each split. This is especially important at the beginning of the cascade when grid cells are still large. To save time at later stages, it is also acceptable, in practice, to update the interpolated values only once in a while, for example after a fixed number of splits or at the end of each new cascade level. Results show that this strategy can save precious time when the number of subgrid cells becomes large while only marginally affecting the small-scale structure of the downscaled fields.
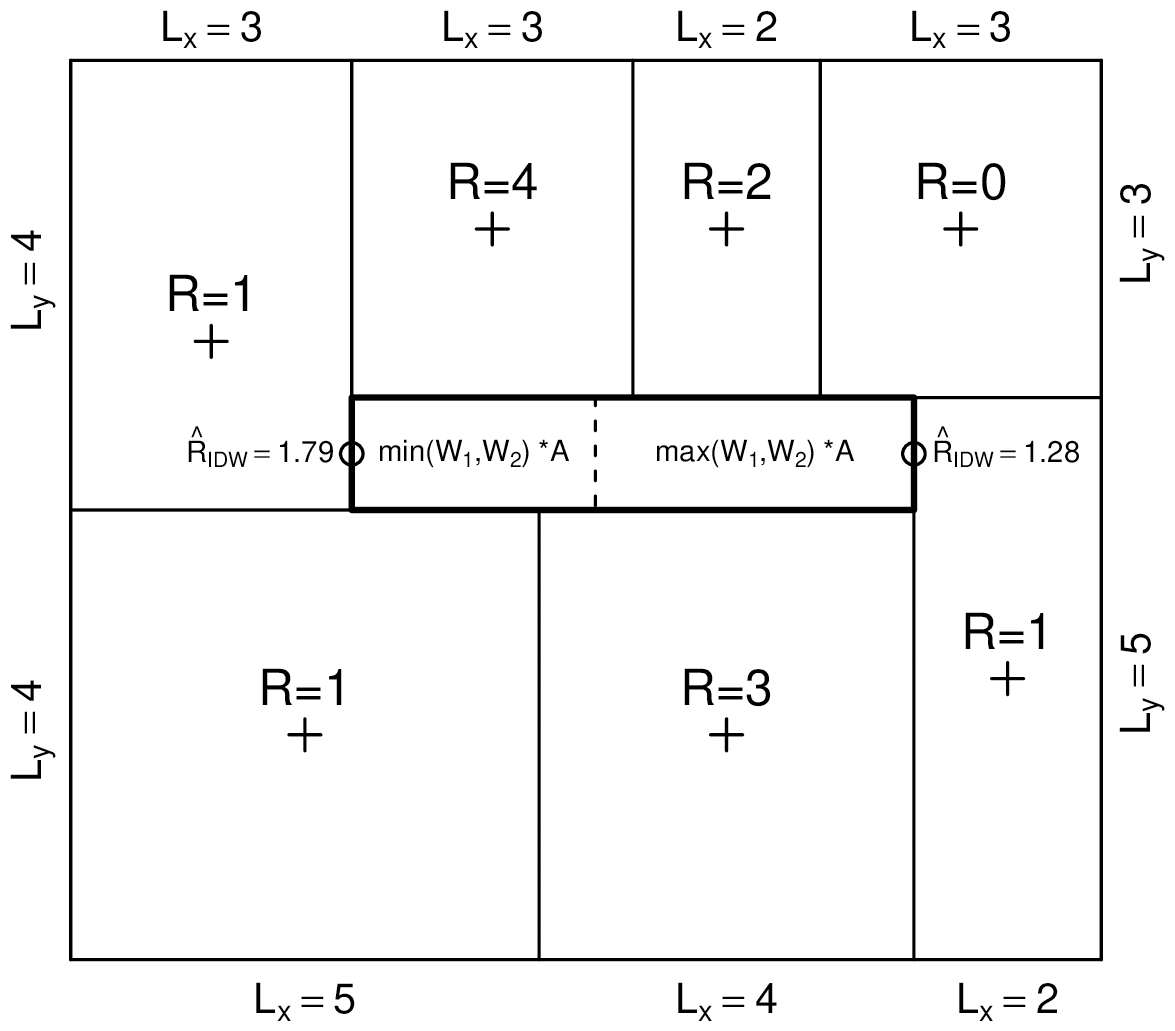
Figure 2Illustration of the splitting rule for a single grid cell (in bold at the center of the figure), with area A surrounded by seven grid cells with different areas and intensities. Grid cells are always split perpendicularly to their longest dimension (i.e., vertically in this case). The inverse-distance interpolated rainfall rates on the left and right sides of the grid cell (or equivalently, at the top and bottom for horizontal splits) are used to determine which side receives the highest rainfall intensity during the split (i.e., the left side in this case). The weights W1 and are drawn at random from a fixed distribution model.
2.4 The cascade generator
The probability distribution of the cascade generator is a crucial component of any discrete multiplicative random cascade (Over and Gupta, 1994; Ossiander and Waymire, 2000). Without any explicit physical law governing the redistribution of precipitation over scales, choosing an appropriate generator model can be a rather subjective task. Consequently, a wide range of possible distributions has been proposed so far, from uniform (Olsson, 1998) and log normal (Over and Gupta, 1996; Xu et al., 2015) to beta (Ahrens, 2003; Molnar and Burlando, 2005; Paulson and Baxter, 2007) and log Lévy (Gupta and Waymire, 1990; Menabde and Sivapalan, 2000; Pathirana et al., 2003; Schertzer and Lovejoy, 2011). Beyond the ability of the generator to reproduce observed scale invariance in data, other important factors to consider are simplicity and ease of interpretation. One distribution that satisfies all these criteria and will be used in this study is the following logit-normal distribution:
where μ∈ℝ and σ≥0 represent the mean and SD of an underlying Gaussian random variable. Further simplifications can be made by assuming that the cascade weights are symmetrically distributed around 0.5, which forces μ to be zero.
The logit-normal generator model is not necessarily optimal for all types of events and all spatiotemporal scales, but it is a fair enough approximation of empirical cascade weights to be useful in practice. Moreover, the distribution is continuous, supported over the open unit interval (0,1) and easy to simulate through its analytical link with the Gaussian distribution. The most important advantage of all, however, lies in the ease of interpretation of the parameter σ, which measures the spread of the underlying Gaussian and therefore directly relates to the subgrid variability (i.e., the intermittency) of the rainfall process within a given grid cell. Figure 3 illustrates this point by showing the density function of a logit-normal cascade generator W with μ=0 for four different values of σ. It can be seen that for small values of σ, the distribution tends to a delta function centered around 0.5. This corresponds to a case with low spatial variability and results in grid cells splitting up very evenly. On the other hand, as σ→∞, the density of W progressively moves away from 0.5 and tends to 0 almost everywhere, except for two small symmetric intervals near 0 and 1 (without ever reaching these limits). This corresponds to high spatial variability and high intermittency and means that grid cells split up very unevenly during the cascade.

Figure 3Theoretical distribution of the logit-normal cascade weights W in Eq. (7) for μ=0 and different values of SD σ.
Since μ=0 is fixed, the only parameter needed to define the full distribution of the cascade generator is σ. Previous research on discrete multiplicative random cascades has shown that the empirical distribution of W usually depends on both the intensity and spatial scale (e.g., Over and Gupta, 1994; Olsson, 1998; Marani, 2005; Rupp et al., 2009; De Luca, 2014). The analyses conducted within this study confirm these previous findings, showing that within the EVA framework, on average, the spread of the cascade weights increases with area A and decreases with intensity . Based on these empirical observations, a simple power law model for expressing the SD σ of the cascade generator W is proposed as follows:
where A (in km2) denotes the area of the grid cell to be split, R (in mm h−1) is the intensity (for a given area A and temporal resolution Δt), and a>0, b>0, are three model coefficients.
2.5 Convergence
Because the amount of water is halved at each split of the cascade, according to Eq. (8), the fate of individual grid cells in the EVA cascade will be determined by how quickly their area decreases with respect to their intensity. In fact, if we impose b>c and let the cascade run for a long enough time, only two possible outcomes can result, namely either σ→0 or σ→∞.
In the first case (σ→0), grid cells of area Ai are split in two almost equal areas . The cascade generator for the two subgrid cells after the split will therefore have SD as follows:
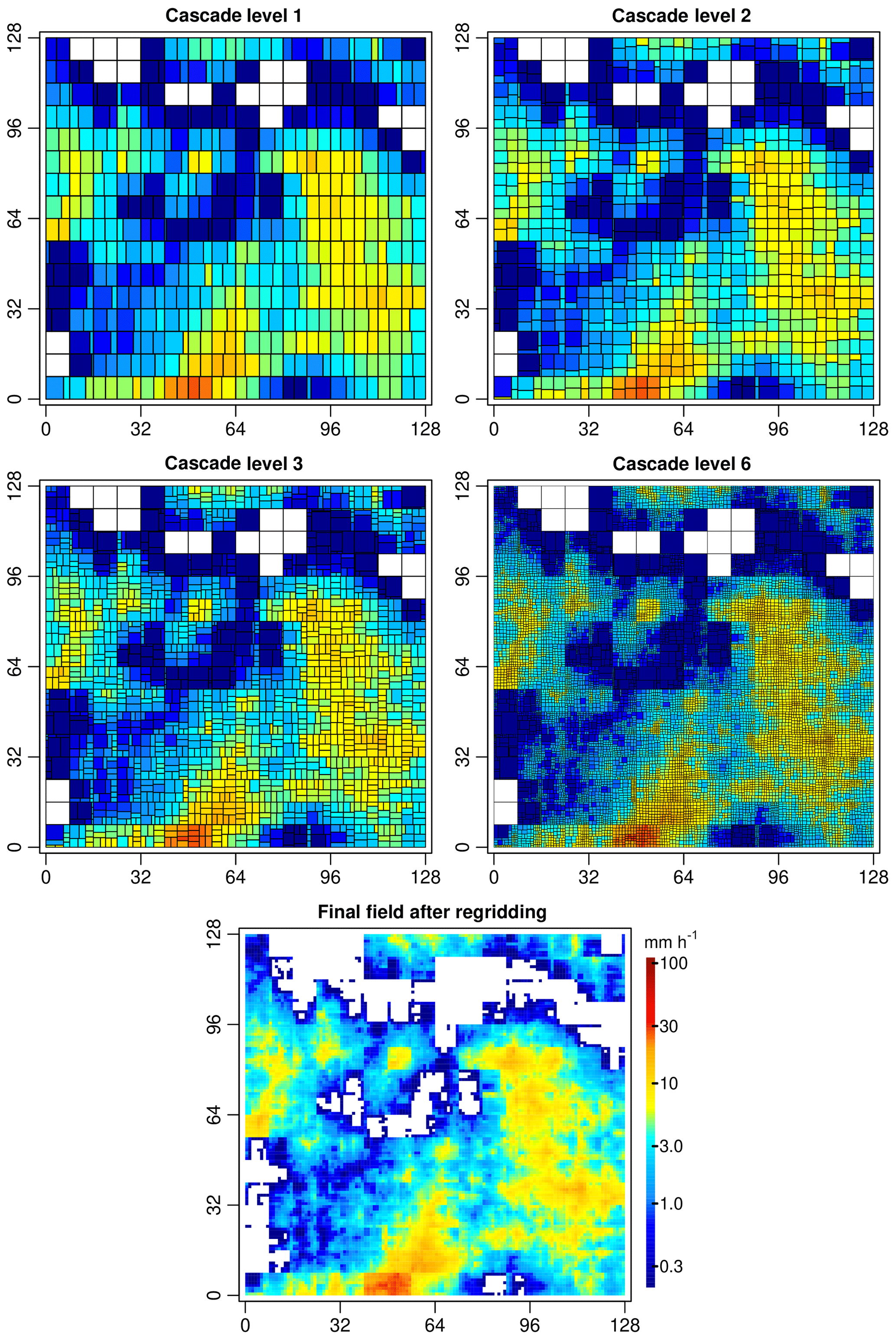
Figure 4Example of an EVA cascade for an 8 km × 8 km input field with the size of 128 km × 128 km. In this example, the cascade was stopped after a fixed number of levels equal to six. The output was then resampled over a regular 1 km × 1 km Cartesian grid. All rainfall rates below 0.1 mm h−1 (after resampling) are assumed to be undetectable and are therefore displayed in white. Note how some grid cells converge to a fixed area during the cascade while others converge to a fixed intensity.
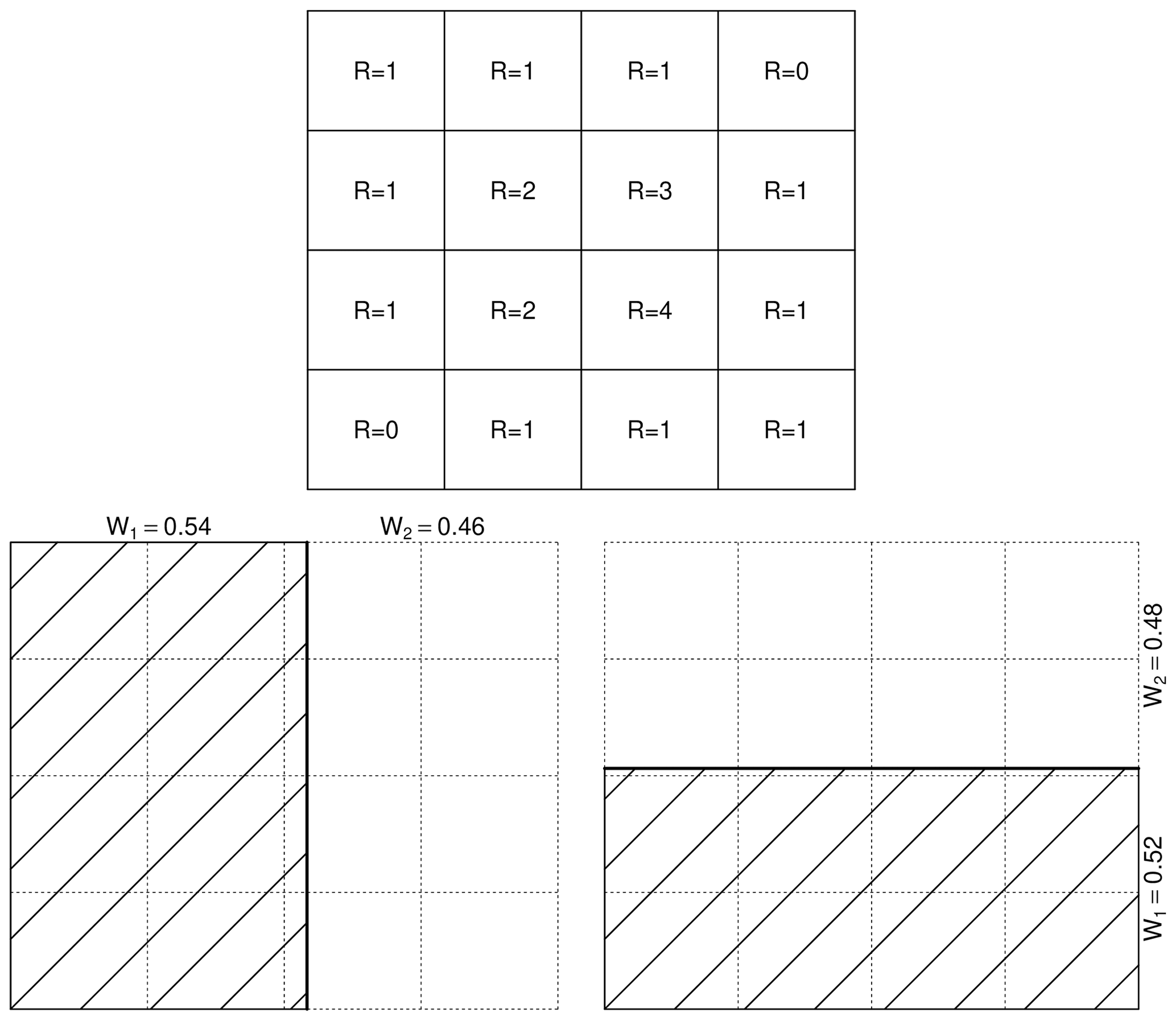
Figure 5Empirical breakdown coefficients for a 4 × 4 grid cell within the EVA framework (both for vertical and horizontal splits). The empirical weights W1 and W2, which split the rainfall volume in half, are determined by linear interpolation.
Therefore, grid cells at subsequent cascade levels will tend to split more and more evenly, eventually converging to a fixed rainfall intensity. In the second case (i.e., σ→∞), grid cells split up very unevenly. Without a loss of generality, we can assume that the first subgrid cell in this case will have area , while the second will have area . The SD of the cascade generator for the first subgrid cell is then given by the following:
while the SD of the second subgrid cell will be . At the next cascade level, the first subgrid cell will therefore split up very unevenly while the second subgrid cell will have a higher intensity and split up rather evenly (similar to the first case where σ→0). The final result of this process is a bounded cascade in which some grid cells have areas converging to a fixed value (or, equivalently, intensity converging to zero) while all other grid cells have rainfall rates converging to a strictly positive value. Figure 4 illustrates this process, showing how the area of some small grid cells become “stuck” during the cascade while all the others end up splitting more and more evenly. However, note that since the weights are drawn at random, the process only converges in a probabilistic sense, that is, on average, over a large number of cascade levels and splits. The condition b>c in Eq. (8) is used to ensure convergence by preventing any uncontrolled increases in rainfall intensities from one level to another in the cascade. Indeed, the generator is built in such a way that whenever the intensity in a grid cell increases, the SD of the generator decreases. This forces subsequent splits to be more even and reduces the probability of seeing any further increases in intensity at the next levels. This also means that the largest changes in rainfall intensities tend to occur at the earlier stages of the cascade when the variance of the generator is still large. The magnitude of the random fluctuations then progressively decreases (at a rate that depends on the values of a, b and c), and intensities quickly converge to a fixed value. This can be seen as a strength as it means that the cascade is very stable and can be stopped after a small number of iterations (i.e., as soon as the output has stabilized). However, it can also be a disadvantage as fast convergence means that the EVA cascade is more likely to underestimate small-scale variability (especially for large downscaling ratios).
2.6 Sample estimation of the cascade generator model
An important advantage of the microcanonical model is that the distribution of the cascade weights can be studied directly from the data through the calculation of empirical breakdown coefficients (Cârsteanu and Foufoula-Georgiou, 2016; Licznar et al., 2015). The latter are estimated by successively aggregating grid cells in the input field to larger spatial scales and by studying how the rainfall volumes in aggregated grid cells split up as a function of area and rainfall intensity. For example, an input field of a 1 km × 1 km resolution can be aggregated to blocks, with the sizes of 1 km × 2 km, 2 km × 1 km, 2 km × 2 km, and 4 km × 2 km etc., each of which can be split in two equal subareas to analyze the redistribution of rainfall volumes inside them. For the EVA framework, the procedure is similar, except that we are interested in determining the subarea needed to accumulate half of the rainfall amount in the parent grid cell. The main drawback compared to the classical approach is that, due to the fixed grid spacing, the subareas cannot be determined exactly but must be approximated by linear interpolation, similar to the procedure described in Eq. (4) of Schleiss (2017). Figure 5 shows an example of this for a single grid cell of 8 × 8 for both horizontal and vertical splits. For the vertical split, the two subgrid cells are 4.32 × 8 and 3.68 × 8. The first dimension (i.e., 4.32) is obtained by interpolating the rainfall amount contained in the smaller grid cell of 4 × 8 (containing slightly less than half the amount) and the one immediately above at a size of 5 × 8 (which contains more than half). The additional interpolation step means that the empirical breakdown coefficients of small grid cells will be affected by larger sampling uncertainties compared to large grid cells. In theory, one could calculate the local spatial autocorrelation structure of the rainfall field to estimate the uncertainty due to linear interpolation. However, the quantification of this uncertainty and its incorporation into the estimation process goes beyond the scope of this paper and will be ignored here.
In the classical cascade model, no linear interpolation is needed. However, some of the rainfall volumes in the subgrid cells may be zero (i.e., one size receives all the rain). Such splits are fundamentally incompatible with the logit-normal model prescribed in Eq. (7). To avoid numerical issues when evaluating ln (W), one can set the weights to a small positive value close to zero or simply ignore the problematic splits (which is the approach adopted in this paper). Because some splits are ignored during parameter estimation, the cascade generator model for the classical cascade model and highly intermittent rainfall fields is likely to be biased.
Once the empirical breakdown coefficients have been determined from the sample, the last step consists of estimating the three model parameters a, b and c in Eq. (8). To do this, the empirical breakdown coefficients are grouped in classes according to the total area A and rainfall intensity R of the parent grid cell that generated them. For the area A, the spacing between classes is imposed by the spatial resolution of the input field. For the intensity, the number of classes that can be formed depends on how many empirical breakdown coefficients are available at a given spatial scale. In this paper, 30 regularly spaced intensity classes were used for each value of A. Moreover, each class of (A, R) needed to contain at least 50 empirical breakdown coefficients in order to estimate the SD σ(A,R) of the underlying logit-normal distribution. In the end, once σ(A,R) has been estimated for all values of A and R, the coefficients a, b and c of the power law model in Eq. (8) can be estimated through nonlinear least square fitting (implemented in the nls() function in R).
2.7 Benchmarks
While the EVA downscaling technique is the main focus of this paper, two additional spatial downscaling techniques were considered for comparison purposes. The first is bilinear interpolation, implemented in the function “interp.surface()” of the R package “fields” (Douglas Nychka et al., 2017). Bilinear interpolation is a deterministic nonparametric downscaling method. It makes no assumption about the structure and distribution of the data, making it very robust. However, because it is an interpolation technique, it tends to generate fields that are too smooth compared to the observations. Note that, strictly speaking, bilinear interpolation is not a disaggregation technique because it does not conserve the total rainfall amount in each coarse-scale grid cell. However, the interpolated values can always be rescaled so that the average rainfall intensity over the whole domain is preserved, similar to a canonical cascade. This technicality is not crucial here since bilinear interpolation is not the main focus of the paper and is only used as a rough baseline against which the added value of the random cascade models can be assessed. Also note that other interpolation techniques, such as kriging, were explored. But the downscaled fields were still too smooth and no clear improvement in performance was observed compared to bilinear interpolation.
The second benchmark is a classical microcanonical discrete multiplicative random cascade based on rainfall intensity as described in Eq. (2). To ensure fair comparisons, the classical cascade model is set up to be a perfect replicate of the new EVA model. It uses the same logit-generator model, the same splitting rules and the same power law model as in Eq. (8), albeit with different a, b, and c coefficients. Note that the classical cascade is run without performing any separation between the occurrence and intensity process. Dry and rainy regions are delineated at the end by imposing a fixed threshold on the minimum detectable rainfall volume at the target resolution, similar to what is done in the EVA cascade. This may not be state of the art, but it ensures a fair comparison and makes it easier to outline the strengths and limitations of both approaches.
To assess performance, synthetic experiments on high-resolution radar rainfall fields were performed. During these experiments, 100 different 5 min radar rainfall snapshots from the operational Dutch national C-band radar composite over an area of 128 km × 128 km near Rotterdam were aggregated from their original spatial resolution of 1 km × 1 km to square blocks of 2 km × 2 km, 4 km × 4 km and 8 km × 8 km (see Fig. 6 for events 1–4). Then, the fields were downscaled back to their initial resolution of 1 km × 1 km. For each event, 100 different realizations of the random cascades were generated to have an estimate of the ensemble spread. The threshold used to distinguish dry from rainy grid cells at the target resolution was set to 0.1 mm h−1 (corresponding to a bucket capacity of εV=8333 L for each grid cell of 1 km × 1 km × 5 min) to match the minimum measurable rainfall intensity in the Dutch radar product. Performance is assessed both visually and quantitatively using a set of standard statistical metrics (e.g., bias, root mean square error, quantiles, coefficient of determination and variograms). Among the 100 radar snapshots used for performance evaluation, the first 4 were selected for in-depth analyses (see Fig. 6 and Table 1 for more details). Two of them (i.e., events 2 and 4) are characterized by widespread, predominantly stratiform and homogeneous rain with low rainfall intensities and low spatial variability. The other two are heavy convective storms with high rainfall intensities, spatial variability and a mixture of both stratiform and convective rainfall.
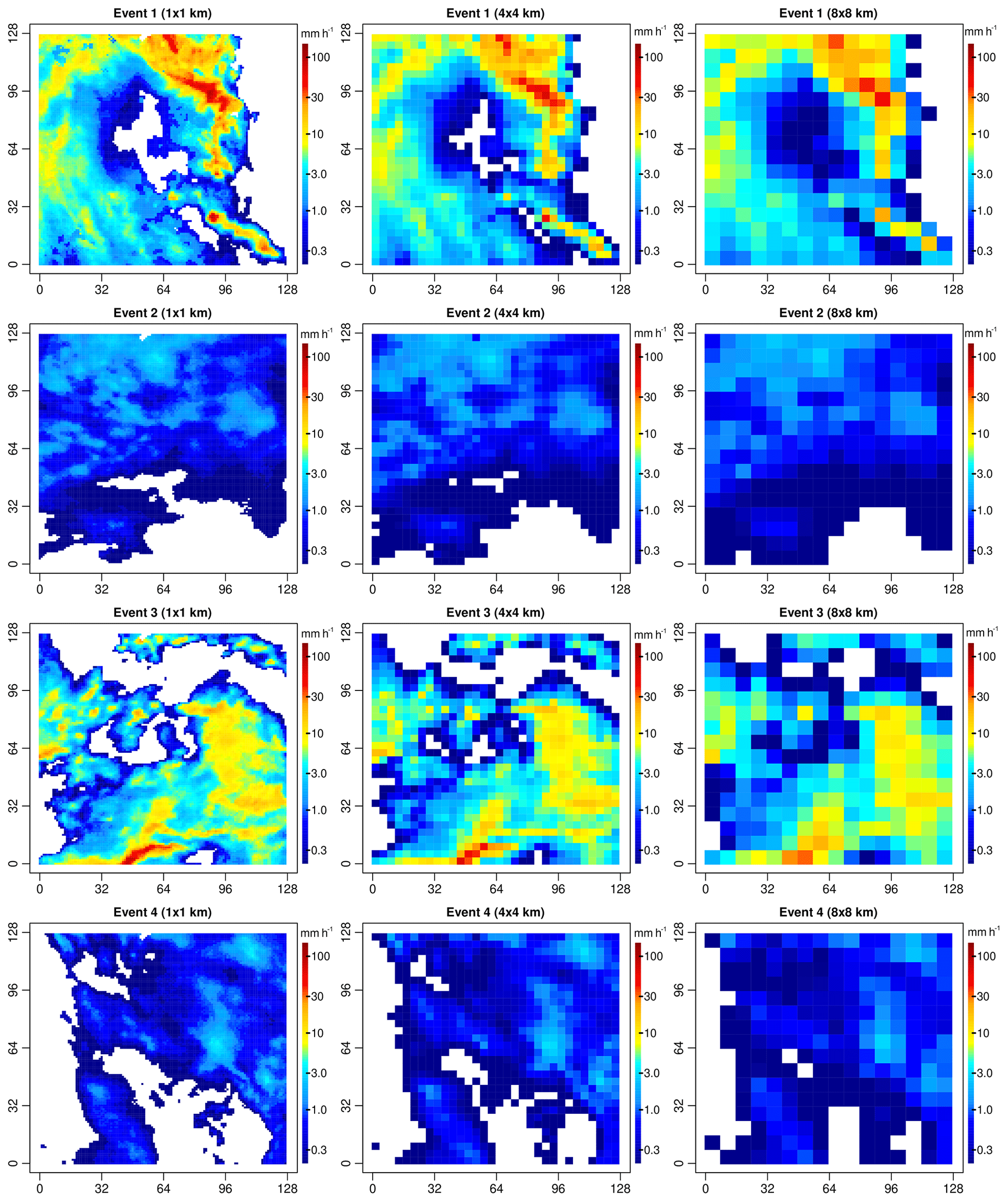
Figure 6Original 1 km × 1 km and upscaled (4 km × 4 km and 8 km × 8 km) 5 min radar rainfall snapshots for events 1 to 4.
Table 1Summary statistics for the four example events, namely time; proportion of zero rainfall values p0; average rainfall intensity (given occurrence); maximum rainfall intensity Rmax; variance of rainfall intensity (given occurrence); and spatial decorrelation range of the rainfall intensity field (given occurrence).

3.1 Parameterization
Table 2Model parameter estimates a, b and c for the first four events for input resolutions of 1 km × 1 km, 2 km × 2 km, 4 km × 4 km, and 8 km × 8 km.
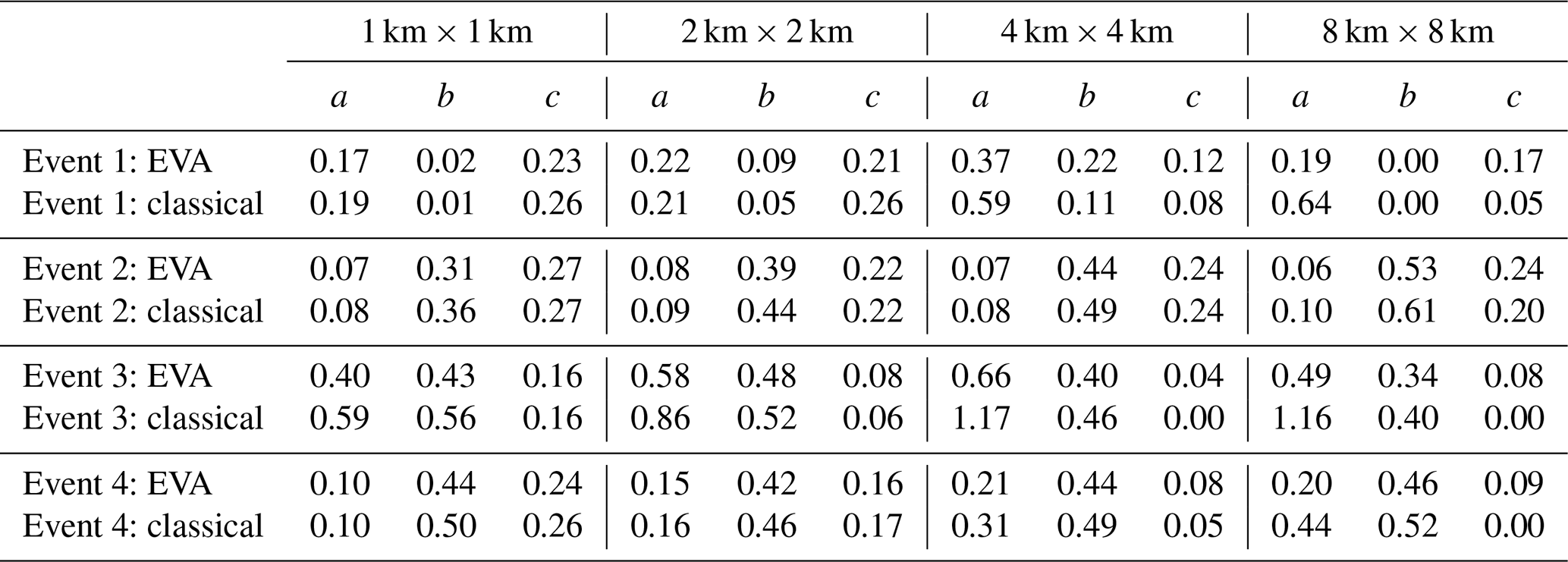
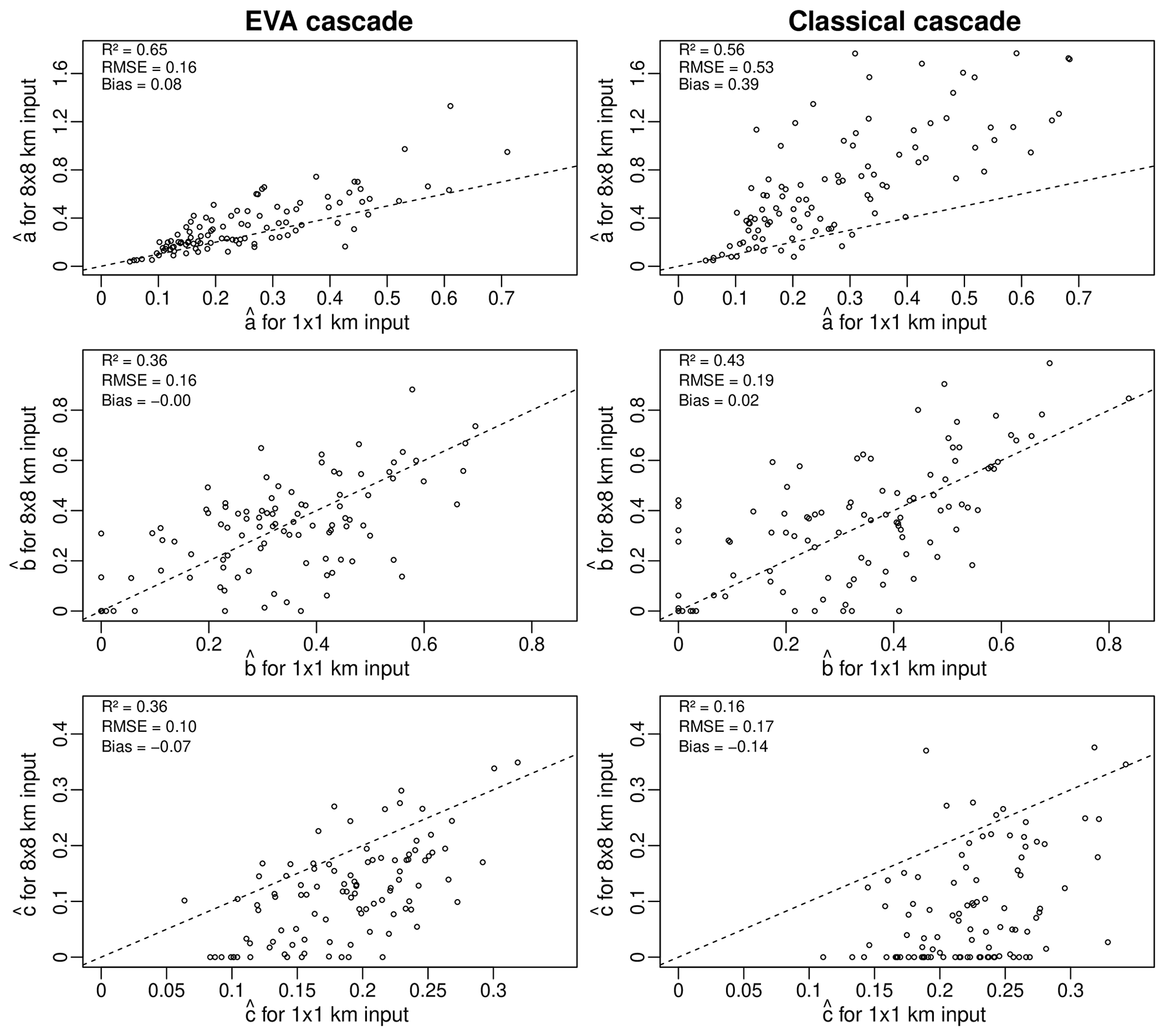
Figure 7Estimated coarse-scale generator parameters a, b and c for an input resolution of 8 km × 8 km versus the fine-scale parameter values derived using the 1 km × 1 km data for the 100 selected events.
In the following, the cascade generator models for the EVA and classical cascade models (for each of the 100 1 km × 1 km 5 min radar rainfall snapshots between 2008 and 2018) are derived. The procedure used to estimate the model parameters a, b and c for each event is described in Sect. 2.6. For completeness, two different approaches are considered. In the first, the values of a, b and c are estimated using the coarse-scale data only, as one would do in practice. In the second, the values of a, b and c are estimated using the high-resolution data at the target scale of 1 km × 1 km (which are unknown in practice). The latter represent the best possible estimates that we can make of the “true” underlying cascade generator parameters and will be used as a reference for assessing the bias in coarser-resolution estimates. Table 2 shows the obtained parameter estimates for the first four events in the database and four different input resolutions of 1 km × 1 km, 2 km × 2 km, 4 km × 4 km, and 8 km × 8 km. Retrieved model parameters are clearly sensitive to the spatial resolution of the input data, exhibiting different types of error patterns and biases as a function of the selected event and chosen cascade model. Figure 7 gives a more general overview of the problem, showing the estimated parameter values (denoted by , and ) for all 100 fields in the database for two different input resolutions of 8 km × 8 km and 1 km × 1 km. The large scatter and low coefficients of determination suggest that, in general, it is not possible to reliably infer the cascade generator parameters directly from coarse-scale data (both for the EVA and classical methods). Specifically, one can see that the a parameter tends to be overestimated while the c parameter tends to be underestimated. For b, there appears to be no systematic bias. However, the low coefficients of determination of 0.36 and 0.43 suggest that coarse-scale estimates are affected by a considerable sampling uncertainty. Also, the fact that is often zero when estimated from coarse-scale data is a statistical artifact caused by the lack of spatial resolution. It wrongly suggests that the size of a grid cell has no statistically significant effect on the variance of the generator, which is obviously not true as estimates of c obtained from the high-resolution 1 km × 1 km input data are never zero. The reason for this is the limited range of variation for A in the coarse-scale input data, which makes it impossible to correctly estimate the variance of the generator when A→0. In contrast, the behavior of the generator when R→0 (i.e., the b parameter) is much easier to guess, as both low and large rainfall intensities remain possible even at coarser spatial scales. Comparing the root mean square errors for the EVA and classical cascade models in Fig. 7, one can see that parameters estimated via the EVA framework tend to be slightly more robust to changes in the input resolution. Nevertheless, both methods suffer from estimation biases and neither of them is capable of perfectly recovering the “true” generator from coarse-scale data, even for relatively modest downscaling ratios (i.e., 64 in this case). Sampling effects obviously play an important role in this but also the fact that rainfall fields are not perfectly scale invariant. Therefore, the splitting and scaling information retrieved from the coarse-scale fields may not reflect what happens at smaller scales or specific areas in the field, especially if the rainfall is highly heterogeneous and intermittent. The conclusion is that in applications involving downscaling ratios larger than approximately 64, it is generally not possible to retrieve reliable cascade generator parameters directly from coarse-scale data. However, good results might still be possible with the help of climatological generator models or, alternatively, by combining multiple successive time steps together to increase sample size and obtain less noisy sample estimates of σ(A,R).
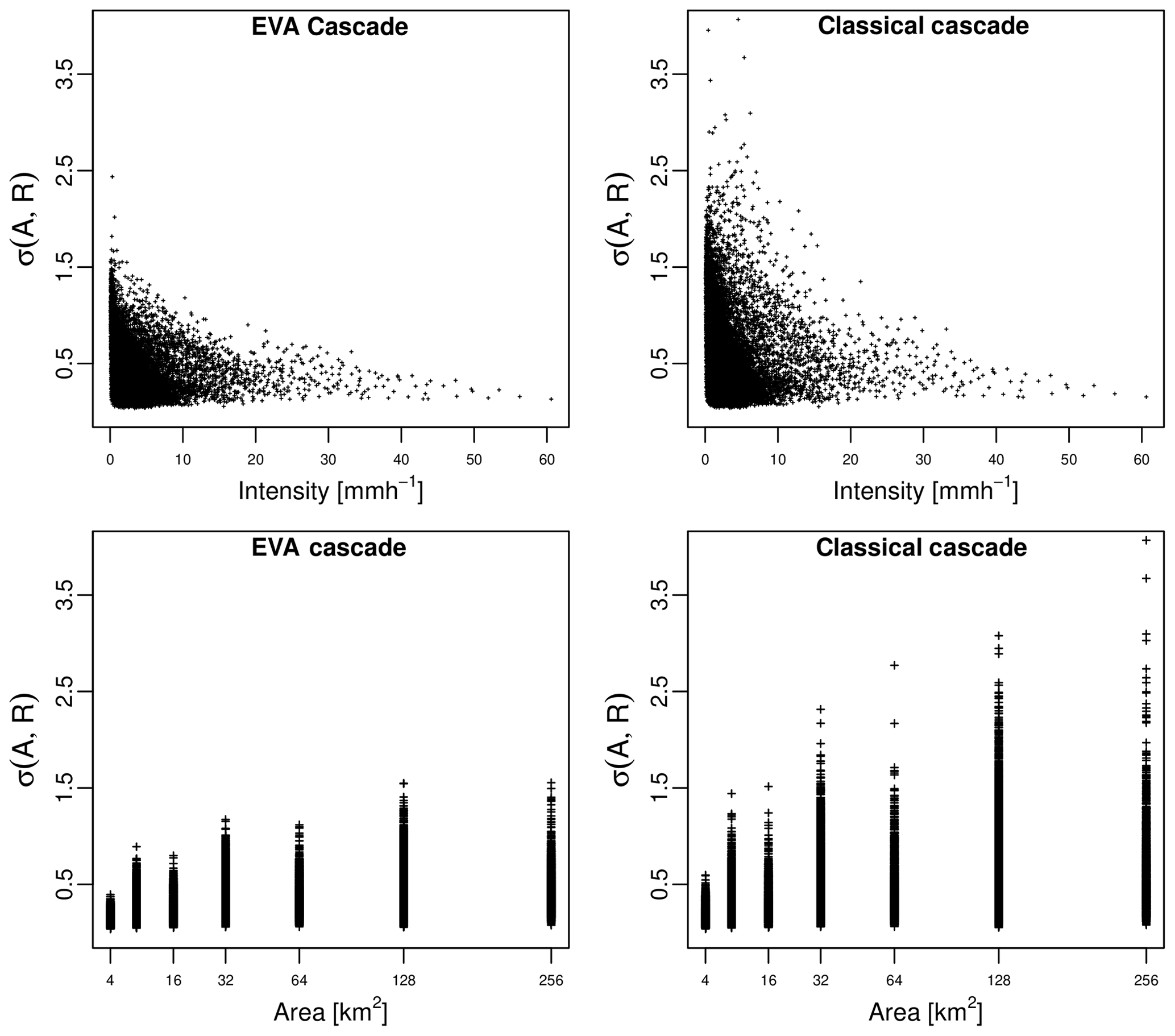
Figure 8Standard deviation of empirical breakdown coefficients for the 100 radar snapshots in the database as a function of the rainfall intensity R and area A of grid cells.
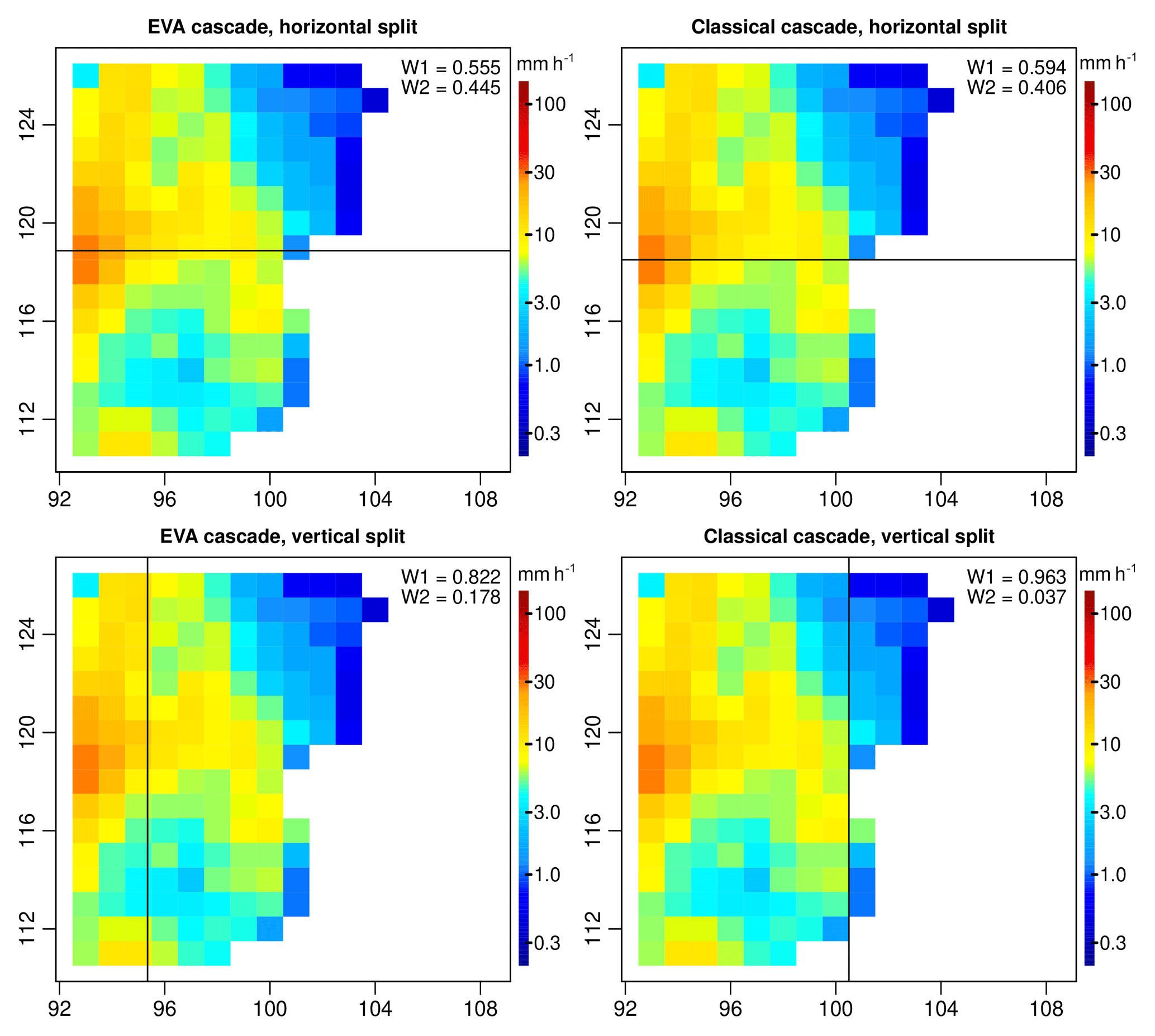
Figure 9Example of empirical breakdown coefficients W1 and W2 for a 16 km × 16 km grid cell in event 1 (convective). The splits corresponding to the EVA model are shown on the left. The ones for the classical model are shown on the right.
Another important observation that can be made concerns the variance of the generator for the EVA and classical models. Figure 8 shows the SD σ(A,R) of the empirical breakdown coefficients for all 100 radar snapshots as a function of area A and rainfall intensity R. The left column shows the results for the EVA cascade, while the classical model is depicted on the right. One can see that empirical cascade weights in the EVA model tend to have slightly lower variance compared to the classical framework (0.409 versus 0.535), especially for larger values of A. This is the consequence of the way grid cells are split in the EVA approach, i.e., through integration of the rainfall amount rather than splitting grid cells in two equal parts. Figure 9 illustrates this point by showing the empirical breakdown coefficients W1 and W2 for a 16 km × 16 km subdomain belonging to event 1. Since in this case most of the rainfall is concentrated in the left part of the domain, splitting grid cells vertically results in a very uneven redistribution of rainfall rates. In the classical cascade, the left part receives 96.3 % of the total rainfall volume while the right part only receives 3.7 % (W1=0.963 and W2=0.037). The EVA model also produces an uneven split, with half of the total rainfall amount being assigned to an area 82.2 % the size of the parent grid cell to the right of the domain while the other half is assigned to the remaining 17.8 % (W1=0.822 and W2=0.178). Overall, however, the EVA split is more balanced. The same conclusion applies to horizontal splits, with the EVA method producing slightly more balanced weights (55.5 %–44.5 %) than the classical framework (59.4 %–40.6 %). Of course, in reality, many more grid cells must be taken into account when calculating the variance of the generator around 0.5. But the key point here is to understand that the generator of the EVA cascade tends to have lower overall variance, making it easier to estimate from a limited number of sample splits. Also, the adaptive sampling strategy in the EVA model reduces sensitivity to the input resolution, resulting in a slightly better power law fit in Eq. (8; i.e., R2 of 0.66 for EVA versus 0.61 for the classical method). Nevertheless, improvements are not systematic and differences between the two methods can be rather subtle. For very homogeneous rainfall fields, for example, both approaches will essentially be identical, and the classical way of splitting might even be better. But for strongly variable and intermittent fields, the EVA model is likely to provide a significant practical advantage over the classical approach (see the next section).
3.2 Visual assessment of downscaled fields
Figure 10 shows some examples of downscaled rainfall fields obtained using the EVA and classical cascade models for the first four events in the database. In all four cases, the downscaling ratio was 64. In other words, the original radar rainfall snapshots were first aggregated (i.e., block averaged) to 8 km × 8 km before being downscaled back to their original resolution of 1 km × 1 km. The cascade generator models needed to run the downscaling schemes were estimated directly from the coarse-scale 8 km × 8 km resolution data, as one would do in practice.
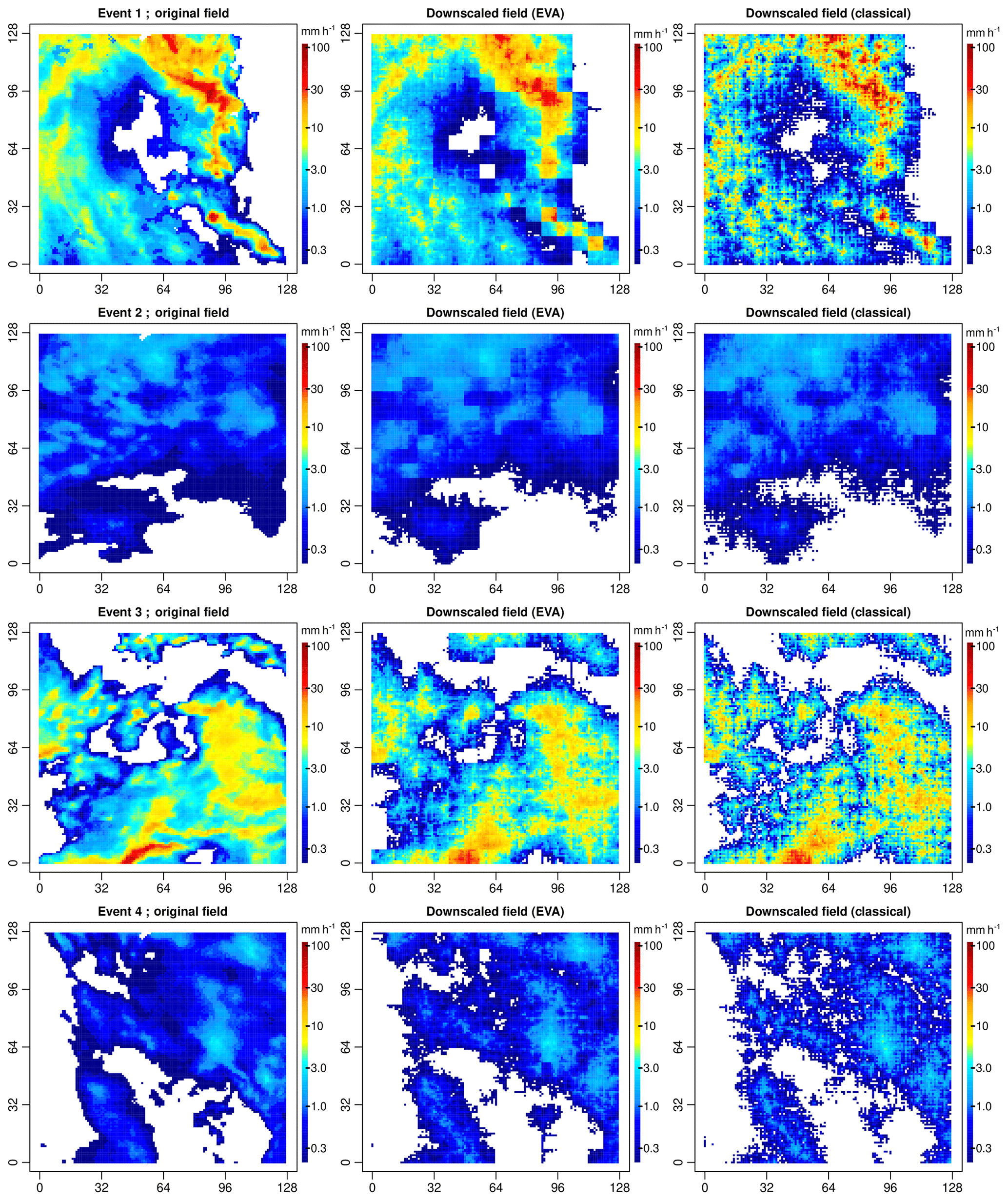
Figure 10Downscaled rainfall fields for events 1–4 and a downscaling factor of 64 (i.e., input resolution of 8 km × 8 km and target resolution of 1 km × 1 km). The left column shows the original radar rainfall snapshots at 1 km × 1 km. The middle and right columns show the outputs of the EVA and classical cascade models for the (biased) coarse-scale sample generator. Only the first of 100 different random realizations for each field and cascade model is shown.
Comparing the outputs of the EVA and the classical cascade, one can see that the EVA cascade tends to produce smoother fields with lower overall variance and peak intensities. Visually, the fields appear to be in better agreement with the original radar snapshots, both in terms of distribution and spatial structure (see Sect. 3.3 for more quantitative comparisons). Visually speaking, one of the biggest disadvantages of the EVA cascade appears to be the fact that the resulting fields look slightly block shaped, with some of the initial coarse-scale grid cells still visible. The block shape can be attributed to biased parameter estimates a, b and c caused by the limited range of spatial scales available for studying the splitting behavior of grid cells. In particular, the previous section has shown that the c parameter, which controls the splitting of grid cells with respect to area, tends to be underestimated when derived from coarse-scale data, causing the cascade to converge too quickly. The classical model does not appear to produce these block-shaped patterns. On the contrary, downscaled fields appear to be too variable compared to the observations. Again, the discrepancies can be attributed to biased cascade generator parameters. But in this case, the main problem appears to be the strongly overestimated a parameter which controls the overall variability of the splits and compensates for the underestimated c parameter. As shown by these four examples, none of the downscaled methods appears to be able to perfectly reproduce the small-scale properties of the underlying rainfall field. However, the fact that one method tends to underestimate the total variability while the other tends to overestimate it is interesting. It highlights the complementary nature of the two approaches and, perhaps, could be exploited during further postprocessing steps and/or quality control steps.
Before moving on to more quantitative assessments, there is another important point that needs to be made here concerning the individual performances of the two random cascade models. The problem with Fig. 10 is that it only shows the performance of the two cascade models for the suboptimal cascade generators estimated from coarse-scale data. While this might be representative of the actual performance in real-life conditions, it is not really a fair comparison of the two methods. Indeed, a large part of the differences between EVA and the classical cascade in Fig. 10 can be attributed to the biased cascade generator parameters and not the model itself. Therefore, to compare the two methods on a truly fair basis, one also needs to say something about the performance under optimal conditions (i.e., unbiased parameter estimates). To do this, additional experiments were performed in which the same four rainfall fields were downscaled with the help of the best possible generator model derived from the 1 km × 1 km data (see Fig. 11). When comparing Fig. 10 to Fig. 11, a big improvement in the performance of the classical cascade model can be observed. This shows that both models are capable, in theory, of producing similarly good results. However, since in practice the optimal cascade generator model is likely to be unknown and model parameters must be estimated from coarse-scale data, the more robust EVA cascade is the preferable method as it is more likely to stay close to the optimal performance on average.
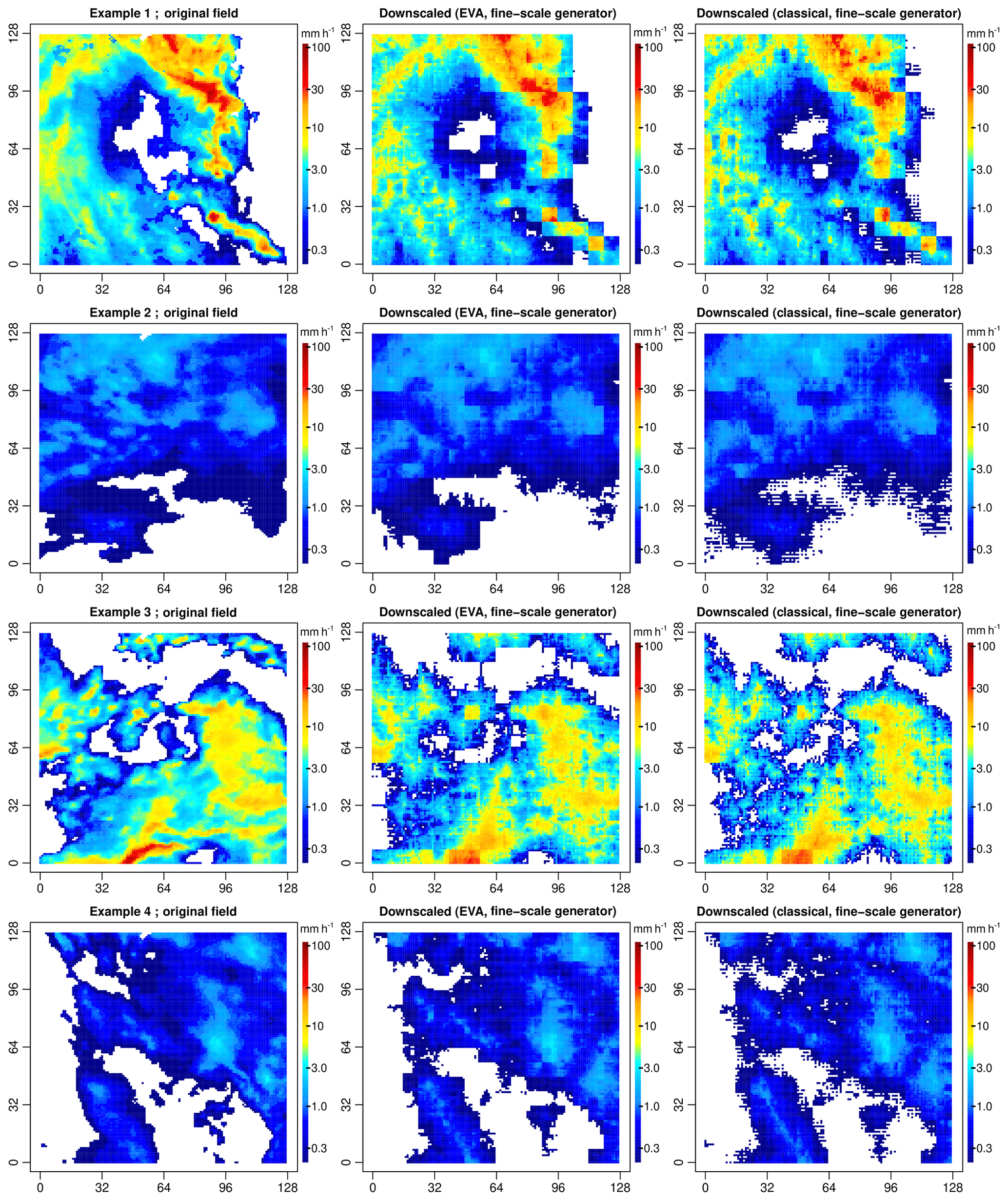
Figure 11Downscaled rainfall fields for events 1–4 and a downscaling ratio of 64 (i.e., input resolution of 8 km × 8 km and target resolution of 1 km × 1 km). Similar format to Fig. 10 except that the generator model was derived from the 1 km × 1 km data.
3.3 Quantitative assessment of downscaled fields
Next, the probability distribution functions of the downscaled rainfall rates generated by the random cascades are assessed. Figure 12 shows the quantiles of observed and downscaled rainfall rates for the first four events and a downscaling ratio of 64 (8 km × 8 km to 1 km × 1 km; 100 random realizations for each event). Each cascade model is represented by two boxplots in which the first shows the quantiles of rainfall rate obtained when the generator is derived from the coarse-scale data while the second shows the results for when the generator is derived using the 1 km × 1 km data. The second generator is unknown in practice but provides further insight into the sensitivity of the performance to parameterization issues. It also gives a good idea of the best possible achievable performance for each model. To provide further insight into the performance of the cascade models, Fig. 12 also shows the quantiles obtained when applying bilinear interpolation, which is well known for producing fields that are too smooth compared to the observations, thus strongly underestimating small-scale extremes.
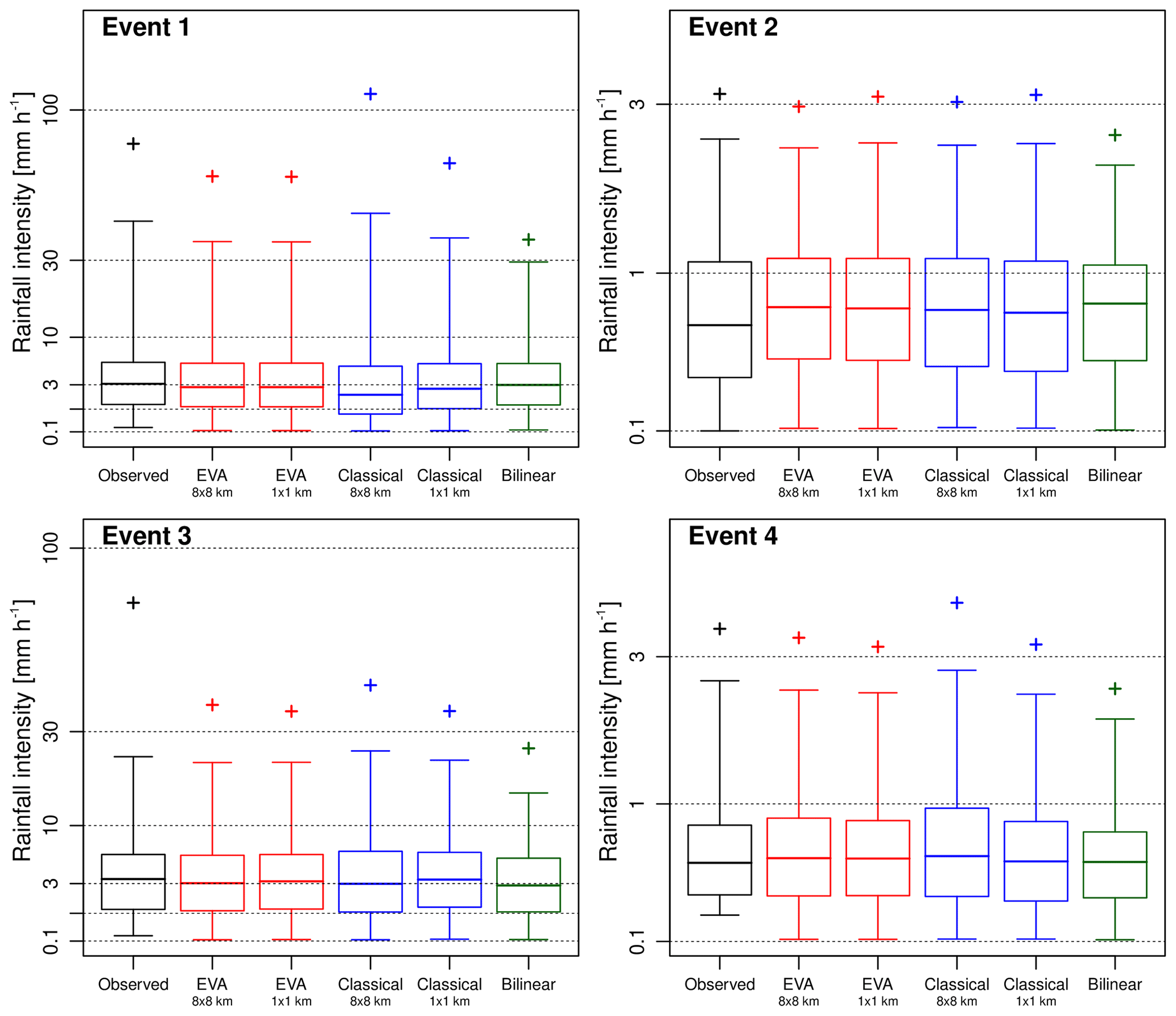
Figure 12Observed versus downscaled rainfall rates for the first four events in the database and a downscaling ratio of 64 (i.e., input resolution of 8 km × 8 km and target resolution of 1 km × 1 km). The boxplots denote the 1 %, 25 %, 50 %, 75 %, and 99 % quantiles of rainfall rates (given occurrence). The crosses represent the 99.9 % quantiles among 100 different random realizations. The labels of 8 × 8 km and 1 × 1 km denote the resolution of the input data used to estimate the sample cascade generator.
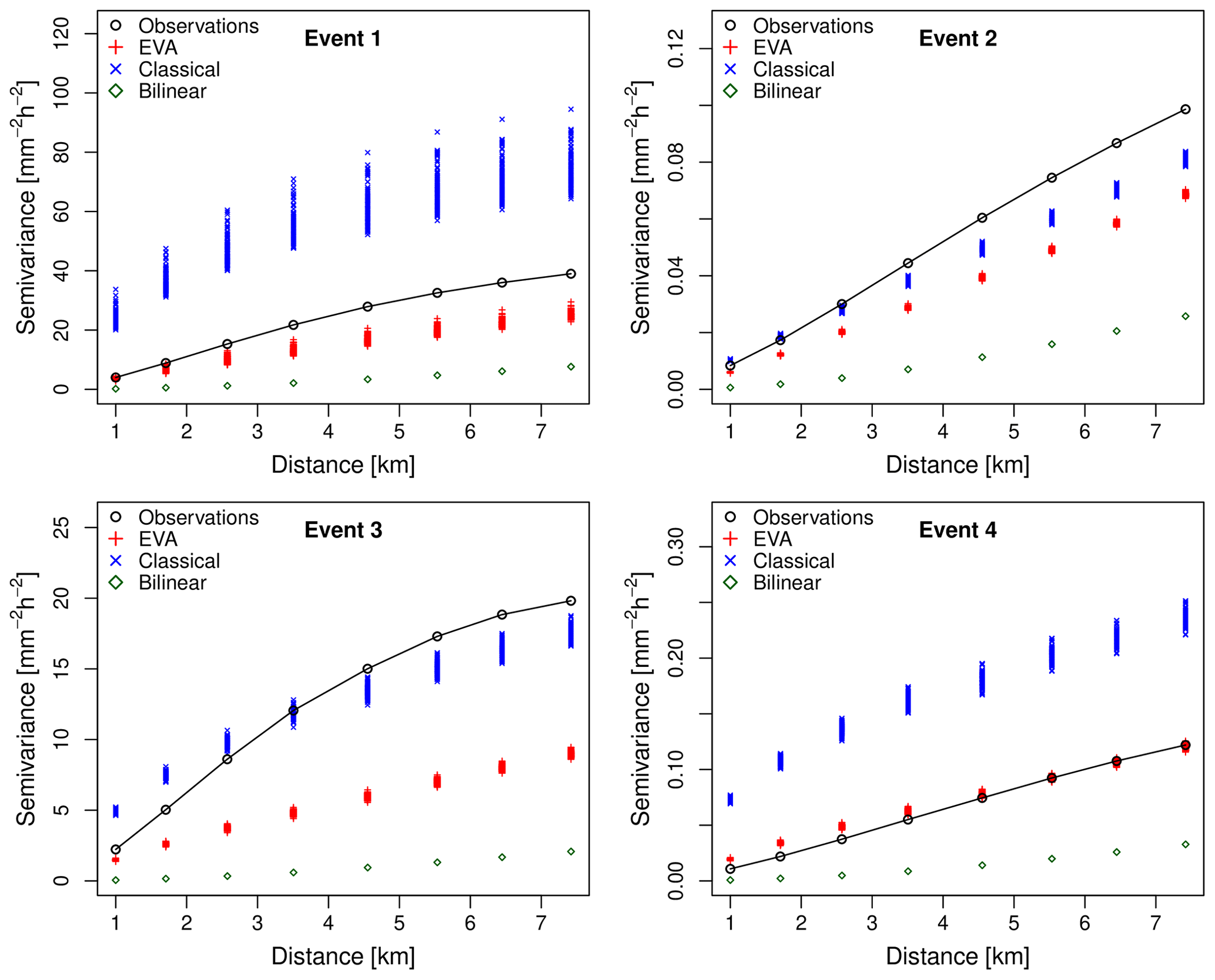
Figure 13Sample variograms of rainfall intensity (given occurrence) for events 1–4 and spatial displacements up to 8 km. The downscaling factor is 64 (i.e., input resolution of 8 km × 8 km and target resolution of 1 km × 1 km). For each cascade model, 100 different realizations were generated. The generator model was estimated from the coarse-scale data at an 8 km × 8 km resolution.
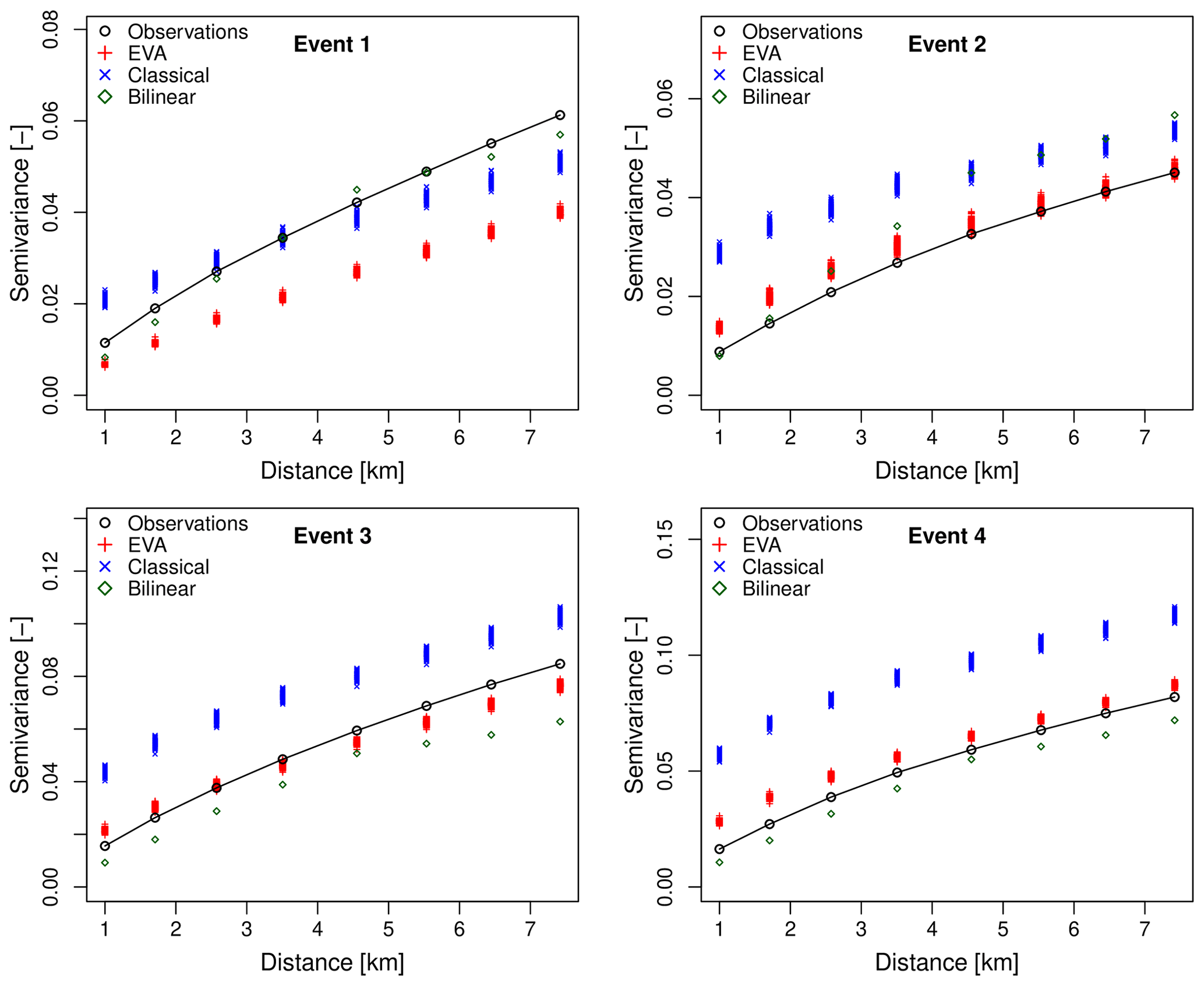
Figure 14Sample variograms of rainfall occurrence for events 1–4 and spatial displacements up to 8 km. The downscaling factor is 64 (i.e., input resolution of an 8 km × 8 km and target resolution of 1 km × 1 km). For each cascade model, 100 different realizations were generated. The generator model was estimated from the coarse-scale data at an 8 km × 8 km resolution.
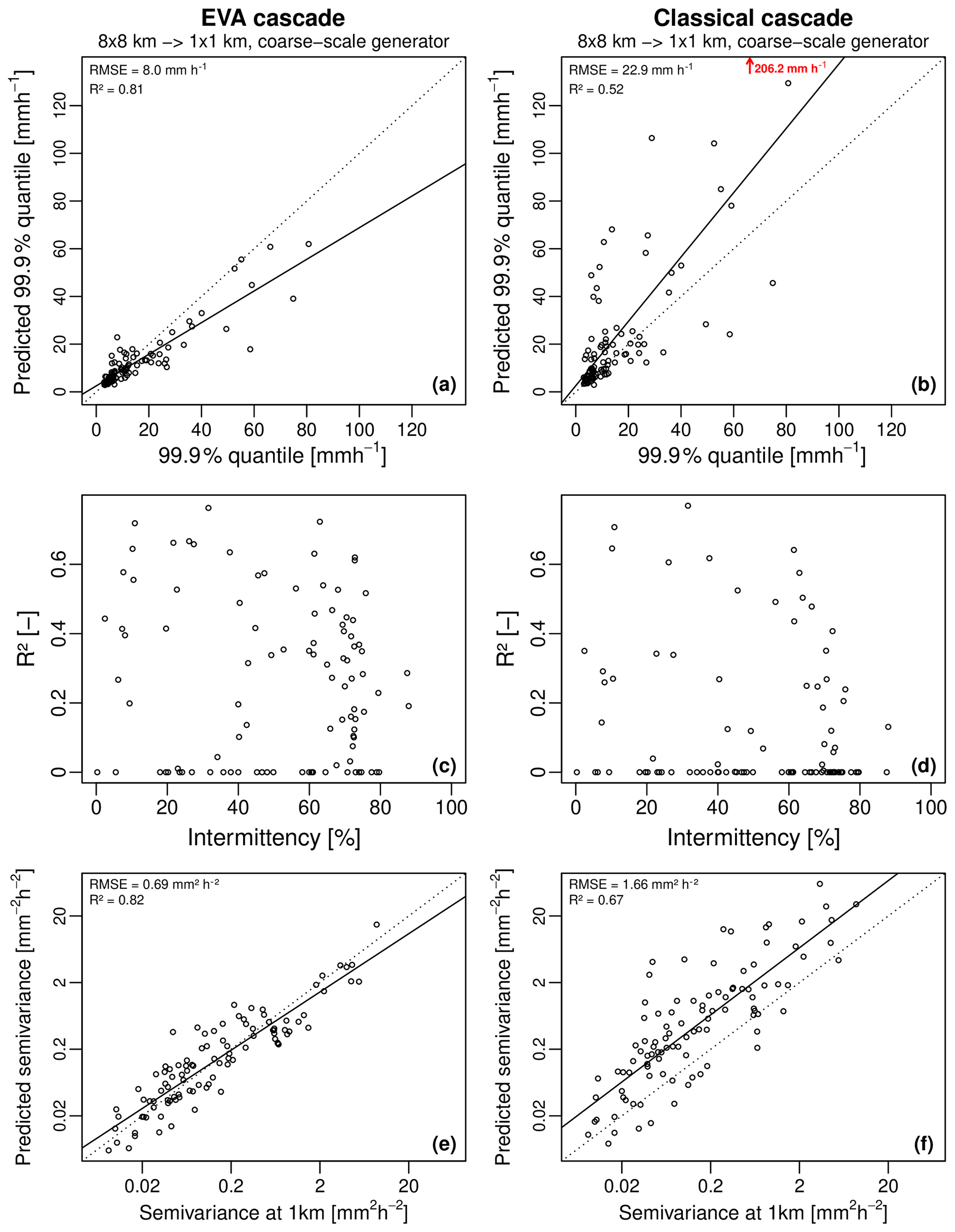
Figure 15Overall performance of the random cascade models for 100 high-resolution radar rainfall fields, coarse-scale sample generator estimate and downscaling factor of 64 (i.e., input resolution of 8 km × 8 km and target resolution of 1 km × 1 km). Panels (a) and (b) show the predicted versus observed 99.9 % quantile of rainfall intensity, (c) and (d) the coefficient of determination R2 between downscaled and observed rainfall rates as a function of intermittency (i.e., the fraction of zero rainfall values in the domain), and (e) and (f) show the predicted versus observed semivariance values for a 1 km spatial displacement. The EVA cascade is shown on the left and the classical cascade on the right.
First, the rainfall rates generated by the classical random cascade model are analyzed. The distributions appear to be in relatively good agreement with the observations. However, some important discrepancies remain, especially for the very high quantiles. Performance is clearly sensitive to parameterization issues, which vary a lot depending on the type of event and chosen generator model. Homogeneous, low-intensity events such as event 2 are reproduced rather well. But, in events 1 and 4, extremes are clearly overestimated. In fact, in the majority of the 100 considered events, the classical cascade overestimates rainfall extremes when the coarse-scale generator is used. However, there are also a few interesting exceptions to this rule. For example, in event 3, the classical cascade underestimates the 99.9 % quantile compared to the observations. The problem with event 3 is that the rainfall field is highly heterogeneous, consisting of multiple convective and stratiform areas of different sizes, shapes and orientations. Therefore, big local differences in scaling behavior exist within the field, making it hard to derive a meaningful cascade generator model that applies to the entire domain. This is highlighted by the fact that the coarse-scale generator actually produces better results than the fine-scale generator, which is highly unusual and points to serious problems during parameter estimation.
When looking at the results for the EVA model, there appears to be no obvious, substantial improvement in terms of the model's ability to reproduce higher rainfall rates and small-scale extremes. The only clear advantage, compared to the classical approach, is that the outcomes of the EVA cascade are more consistent with each other (i.e., they have a lower ensemble spread). However, the downscaled rainfall distributions are clearly too narrow compared to the observations, meaning that the model underestimates higher rainfall quantiles and small-scale extremes. Still, the underestimation is much less severe than for bilinear interpolation. The systematic underestimation of higher rain rates is a problem but can be explained by the fact that the variance of empirical EVA cascade weights for small values of A tends to be underestimated due to the additional interpolation step (see Sect. 2.6 for more details). Figure 13 provides more insight into this by showing the empirical semivariance values of rainfall intensities for distances of 1 km up to 8 km (i.e., the subgrid variability generated during the downscaling). It confirms that the EVA cascade produces fields that are slightly too smooth, while the classical cascade tends to overestimate small-scale variability. Figure 14 makes a similar comparison in terms of the spatial structures of the rainfall occurrence fields (0∕1 fields). Overall, the EVA model produces small-scale structures that are closer to the observations than the classical cascade and bilinear interpolation. However, improvements are not systematic, and occasionally, the classical cascade will be better at reproducing some of the small-scale features. In event 1 for example, the classical cascade appears to be better at reproducing the spatial structure of the occurrence field, while the EVA cascade produces outputs that are too smooth. Moreover, the ensemble spread for the EVA model appears to be slightly lower than for the classical cascade on average. This can be explained by the rapid convergence of the EVA cascade model, as explained in Sect. 2.5, and means that, for a fixed generator model, the EVA cascade produces rainfall fields with almost identical distributions and spatial structures. Individual realizations may still look different on a pixel-by-pixel basis, but their average statistical properties (e.g., histograms and variograms) will be almost identical. This stability can be an advantage but also means that, in order to produce truly representative ensembles that capture a large enough range of possible scenarios, it is better to run the EVA cascade several times with slightly perturbed model parameters a, b and c rather than generating a large number of fields with the same generator.
Figure 15 gives a broader overview of the performance over the 100 selected events for a downscaling ratio of 64 and coarse-scale sample generator. It confirms what has been pointed out before, namely that the classical cascade model tends to overestimate high rainfall rates while the EVA model tends to underestimate them. Nevertheless, the higher coefficient of determination R2 between observations and downscaled rainfall rates and the better agreement in terms of reproduced semivariance values show that the new EVA cascade model tends to outperform the classical approach, both in terms of the reproduced spatial correlation structure and also in terms of its ability to reproduce consistent small-scale extremes. In both cases, systematic biases remain, which were attributed to difficulties in getting reliable generator estimates from coarse-scale data. Also, Fig. 15c–d show that performance clearly decreases with intermittency (i.e., the fraction of dry pixels in the 1 km × 1 km input data). This can be explained by the fact that the number of samples available for estimating the generator decreases with the fraction of dry pixels but also because highly intermittent rainfall fields tend to be more heterogeneous, making them more likely to exhibit deviations from scale invariance than their homogeneous counterparts. Because it is more robust for sampling uncertainty, the EVA model tends to produce more reliable results in those difficult cases characterized by low sample sizes and high heterogeneity. However, improvements are not systematic and many issues remain. In particular, more development is needed to overcome the drop in performance at intermittency levels above 60 % and to mitigate the underestimation of small-scale rainfall extremes, which is a fundamental requirement in downscaling for hydrological applications (Molnar and Burlando, 2005).
Next, the performance of the cascade models as a function of the downscaling ratio is analyzed. Figure 16 shows the 10 %, 25 %, 50 %, 75 %, and 90 % quantiles of the coefficient of determination R2 between observed and downscaled rainfall rates for three different downscaling factors (i.e., 4, 16 and 64). Figure 16a and b show the performance for the coarse-scale sample generator, while Fig. 16c and d show the best possible performance for the generator derived from 1 km × 1 km data (unknown in practice). The values corresponding to Fig. 16a and b are given in Table 3. It shows that, in practical applications where the generator must be estimated from the coarse-scale data, the EVA model outperforms the classical cascade across all three downscaling ratios. As expected, differences between the two methods increase as we move towards larger ratios. However, the EVA model tends to remain much closer to the best theoretical achievable performance compared to the classical cascade. Again, the small differences between Fig. 16c and d confirm that, in theory, both cascade models are capable of achieving a similarly good performance, provided that the optimum generator model can be guessed from the data. Even so, the EVA model still appears to have a slight edge over the classical approach, with median R2 values of 0.94, 0.83 and 0.54 against 0.93, 0.81 and 0.52 for the classical method, which makes sense given that even the “best” generator model at 1 km × 1 km was inferred from a limited number of samples and might therefore still be slightly biased. Unfortunately, the relatively small domain size of 128 km × 128 km meant that no reliable estimates of the generator could be obtained for an input resolution of 16 km × 16 km or higher. However, this is an issue related to the choice of the domain size in this study rather than a theoretical limit on the maximum downscaling ratio. Additional experiments on larger domains (not shown here) suggest that decent results can still be obtained for downscaling ratios up to about 256, making the technique applicable to satellite data or global numerical weather models with grid sizes up to 10 kilometers. However, the accuracy of downscaled rainfall fields for scale ratios of 256 or higher is likely to be low given that it is not always possible to reliably estimate the cascade generator from such coarse-scale inputs.

Figure 1610 %, 25 %, 50 %, 75 %, and 90 % quantiles of the coefficient of determination R2 between observed and downscaled rainfall fields for the 100 selected rain events. The values corresponding to the coarse-scale generator are given in Table 3.
Table 310 %, 25 %, 50 %, 75 %, and 90 % quantiles of the coefficient of determination R2 between observed and downscaled rain rates for the EVA and classical method and three different downscaling factors (coarse-scale sample generator only).

While this research mainly focused on the description of the EVA cascade model, the underlying generator and its application to a few selected case studies, there are numerous complementary research lines that can be pursued. One of them revolves around possible ways to overcome biases in cascade generator parameters and correct for systematic errors as a function of the intermittency and downscaling ratio. Diagnostic tools for detecting potentially problematic cases based on plausible ranges for each parameter need to be developed. Alternatively, one could apply both an EVA and a classical cascade and compare the obtained results. If they are wildly inconsistent, the EVA model is likely to be closer to the radar observations. Another possibility would be to design flexible climatological generator values that can be adjusted depending on rainfall type and large-scale properties (e.g., intensity, intermittency and range), which is an approach that may be more flexible while limiting sampling issues. Preliminary work performed within this study (not shown) suggests that this may be promising for larger downscaling ratios as cascade parameters often tend to be correlated with each other or to large-scale rainfall properties (Guntner et al., 2001; McIntyre et al., 2016). Also, different cascade distribution models could be used with various degrees of interpretation for the parameters. In this work, the logit-normal model was chosen because it was the easiest and most convenient while providing a reasonable fit to empirical cascade weights. However, other more flexible distribution models could be used (e.g., the beta distribution).
The second point that is worth discussing concerns the complementary nature of the EVA framework compared to the classical representation in terms of intensity over fixed grid cell sizes. The main advantage of the EVA framework lies in its adaptive sampling strategy. By flipping the problem around and focusing on the areas for fixed amounts of water, rather than the opposite, additional insight into the spatial variability of rainfall within grid cells can be gained. Most importantly, occurrence and intensity are not viewed separately anymore but combined together into a single continuous process. All quantities are strictly positive, which reduces model complexity, improves the scaling and lowers sampling uncertainty. If rainfall fields were perfectly homogeneous and the sensors used to measure them had unlimited precision, the two representations would be equivalent. However, since rainfall fields can be highly variable in space and time, and measurements are affected by sampling uncertainties, one of the two representations is likely to be more appropriate or useful in practice. A better understanding of these cases and how to choose the best framework depending on sampling resolution, intermittency and measurement accuracy is key for improving our understanding of the space–time variability of rainfall and its representation in models.
The third issue that needs to be mentioned relates to the assumption that the cascade generator model is stationary and, in particular, location invariant (i.e., that the same splitting rules apply to all pixels independent of their location). This may not necessarily be valid for highly heterogeneous fields, as highlighted by the poor performance and inconsistent behavior of the cascade models during event 3. The key point here is that there might be specific areas within a rainfall field where the scaling properties are different from the rest (e.g., stratiform versus convective areas). Similarly, the scaling properties and spatial variability within individual rainfall cells might be very different from the average variability observed over a large collection of rain cells. Also, elements belonging to larger-scale structures might evolve together in a more coherent and predictable way than expected based on their size and intensity. One possible solution for overcoming this problem would be to define multiple local generators instead of a single universal one. But this is a very challenging problem that requires more research, including the ability to automatically detect strong local variations in scaling properties to help pinpoint problematic regions and come up with a better approach. Also, the use of multiple generators would require additional model parameters, which is not necessarily desirable and should only be considered when absolutely necessary (e.g., to account for strong orographic effects). On a more theoretical level, one should also point out that even if the cascade generator is perfectly stationary, the final disaggregated fields (or time series) obtained after applying the cascade are likely to be nonstationary with location and time-dependent autocorrelation structures (Lombardo et al., 2012).
The fourth point of discussion concerns possible extensions of the EVA model. Similar to classical multiplicative random cascades, the EVA cascade can be applied to downscale time series, spatial and space–time data. For time series, the equivalent formalism is given by the notion of equal-volume times, also known as interamount times (IATs; Schleiss and Smith, 2016; Schleiss, 2017). Future work will therefore be directed at exploiting the superior scaling properties of interamount times to downscale the time series of intermittent rainfall and combining IATs with EVAs to design more general downscaling schemes for space–time data. Another interesting and possible extension concerns the possibility of including spatial anisotropy into the downscaling process. One way to do this is by using two different generator models, namely one for vertical and another for horizontal splits. For example, an additional model parameter characterizing the ratio between the SD of the generator for horizontal and vertical split could be introduced. More generally, one could also define a full set of different model parameters (aH, bH and cH) and (aV, bV and cV) for each type of split. Grid cells could also be rotated and realigned along the principal direction of variability, allowing for splits along spatial directions other than H and V. This could help in the case of highly elongated rainfall cells.
One last point that is worth mentioning concerns the computational complexity of the EVA model. One crucial difference between the EVA and the classical cascade is that the classical cascade stops as soon as the target resolution has been reached. The EVA cascade on the other hand tends to run over more levels, producing many grid cells that are smaller than the target resolution. The total number of cascade levels and grid cells depends on (1) the initial rainfall volumes contained in the coarse-scale grid cells and (2) the bucket capacity prescribed by the user. This means that for large rainfall fields (e.g., several hundreds of km) with high rainfall intensities, the number of generated grid cells can be of the order of several millions. As a result, both the run time and memory usage will be larger than for a classical cascade. However, there are various ways to limit the computational burden. The easiest is to stop splitting grid cells once they are about 3–4 times smaller than the target resolution, regardless of how much water they contain. Similarly, grid cells that are entirely contained within a target resolution pixel do not need to be split up further (regardless of their size and amount) as these additional splits would not be visible after the resampling anyway. Similarly, there is no need to split up grid cells once they have converged to a fixed rainfall intensity, i.e., when , as this would only result in a higher number of subgrid cells with identical intensities and would not add any new information. The obvious downside to these numerical tricks is a loss of flexibility as users need to decide on a fixed target resolution before running the cascade.
A new multiplicative random cascade for downscaling intermittent rainfall fields based on the concept of equal-volume areas (EVAs) has been proposed. Downscaling experiments on 100 high-resolution radar rainfall snapshots in the Netherlands have shown that, on average, the EVA cascade outperforms its competitors, both in terms of the reproduced rainfall distributions and spatial structures. Improvements are mainly attributed to the adaptive sampling strategy in the EVA formalism, which avoids zero rainfall values and leads to more accurate and robust model estimates in the presence of intermittency. The new proposed logit-normal cascade generator model with scale- and intensity-dependent variance ensures that every grid cell in the EVA cascade eventually converges to a fixed intensity or a fixed area, putting the new model in the category of bounded microcanonical cascades. Despite the encouraging results, improvements are not systematic and many challenges remain. The most important is that the EVA cascade tends to underestimate small-scale extremes, producing fields that are slightly too smooth and block shaped compared to the observations. This is attributed to biased model parameters and, more generally, to the difficulty of retrieving the true cascade generator from coarse-scale data. The fact that cascade weights in the EVA framework must be estimated using linear interpolation is also a clear weakness, causing σ(A,R) to be underestimated when A→0 (i.e., small grid cells tend to split too evenly). On the other hand, one also needs to be aware of the fact that the classical cascade model based on fixed grid cells suffers from the opposite problem as it strongly overestimates the small-scale variability and magnitude of rainfall extremes. The complementary nature of the two approaches, and the fact that they tend to produce opposite errors, opens new possibilities for quality control and bias corrections of downscaled fields.
Apart from introducing a new model, the present study also clearly highlighted the outstanding challenges associated with downscaling intermittent rainfall fields. The most important issue concerns the estimation of cascade generator models from coarse-scale data. Sensitivity analyses performed within the framework of this study clearly showed that two of the cascade model parameters (i.e., a and c) tend to be biased when estimated from coarse-scale data. However, the EVA model seems to be more robust for these sampling issues. This is the single most important advantage of the EVA model compared to the classical approach and also the main factor responsible for the higher performance. However, it is also worth mentioning that, in principle, good performance remains possible for both cascade models for downscaling ratios up to 128–256, provided that the optimal cascade generator can be guessed from the data. While interesting from a theoretical point of view, this last result may be of limited usefulness in practice as the optimal generator is likely to be unknown. Also, for large domains of several hundreds of kilometers and highly heterogeneous fields, it might not always be possible to adequately describe the complex redistribution of water across scales using a single location-invariant cascade generator. Event 3 is a good example of such a case, with both cascade models struggling to reproduce realistic small-scale patterns. Obviously, one can always improve the performance by introducing more model parameters or tuning them to individual cases. Similarly, one could easily increase the performance of the classical cascade by performing a separation between dry and wet components before disaggregation. There is little doubt that such a state-of-the-art model with six to seven parameters would outperform the simple EVA cascade proposed in this paper. At the same time, such comparisons are not really fair or helpful at this stage, as optimization was not the primary objective of this paper, and the EVA model should not be seen as a competitor designed to replace traditional cascades but rather as a new complementary tool for modelers to deal with intermittency and have new insight into the complex spatiotemporal organization of rainfall across scales.
All data used in this study can be downloaded free of charge from the KNMI data center (https://data.knmi.nl/datasets, KNMI, 2017).
The author declares that there is no conflict of interest.
We extend our special thanks to the Royal Netherlands Meteorological Institute (KNMI) for collecting and providing the radar data used in this study.
This research has been supported by the Netherlands Organisation for Scientific Research NWO (grant no. ALWWW.2014.3). The funding for this work has also been provided by Water JPI Europe, an ERA-NET Cofund WaterWorks2014 project, entitled Multi-scale Urban Flood Forecasting (MUFFIN): From Local Tailored Systems to a Pan-European Service.
This paper was edited by Carlo De Michele and reviewed by Katarzyna Siekanowicz and one anonymous referee.
Ahrens, B.: Rainfall downscaling in an alpine watershed applying a multiresolution approach, J. Geophys. Res.-Atmos., 108, 1–12, https://doi.org/10.1029/2001JD001485, 2003. a
Bechler, A., Vrac, M., and Bel, L.: A spatial hybrid approach for downscaling of extreme precipitation fields, J. Geophys. Res.-Atmos., 120, 4534–4550, https://doi.org/10.1002/2014JD022558, 2015. a
Cârsteanu, A. and Foufoula-Georgiou, E.: Assessing dependence among weights in a multiplicative cascade model of temporal rainfall, J. Geophys. Res.-Atmos., 101, 26363–26370, https://doi.org/10.1029/96JD01657, 2016. a
De Luca, D. L.: Analysis and modelling of rainfall fields at different resolutions in southern Italy, Hydrolog. Sci. J., 59, 1536–1558, https://doi.org/10.1080/02626667.2014.926013, 2014. a
de Montera, L., Barthès, L., Mallet, C., and Golé: The Effect of Rain–No Rain Intermittency on the Estimation of the Universal Multifractals Model Parameters, J. Hydrometeorol., 10, 493–506, https://doi.org/10.1175/2008JHM1040.1, 2009. a
Deidda, R.: Rainfall downscaling in a space-time multifractal framework, Water Resour. Res., 36, 1779–1794, https://doi.org/10.1029/2000WR900038, 2000. a
Gires, A., Tchiguirinskaia, I., Schertzer, D., and Lovejoy, S.: Influence of the zero-rainfall on the assessment of the multifractal parameters, Adv. Water Resour., 45, 12–25, https://doi.org/10.1016/j.advwatres.2012.03.026, 2012. a
Gires, A., Tchiguirinskaia, I., Schertzer, D., and Lovejoy, S.: Development and analysis of a simple model to represent the zero rainfall in a universal multifractal framework, Nonlin. Processes Geophys., 20, 343–356, https://doi.org/10.5194/npg-20-343-2013, 2013. a
Güntner, A., Olsson, J., Calver, A., and Gannon, B.: Cascade-based disaggregation of continuous rainfall time series: the influence of climate, Hydrol. Earth Syst. Sci., 5, 145–164, https://doi.org/10.5194/hess-5-145-2001, 2001. a
Gupta, V. K. and Waymire, E. C.: Multiscaling properties of spatial rainfall and river flow distributions, J. Geophys. Res., 95, 1999–2009, https://doi.org/10.1029/JD095iD03p01999, 1990. a
Gupta, V. K. and Waymire, E. C.: A statistical analysis of mesoscale rainfall as a random cascade, J. Appl. Meteorol., 32, 251–267, https://doi.org/10.1175/1520-0450(1993)032<0251:ASAOMR>2.0.CO;2, 1993. a, b
He, X., Chaney, N. W., Schleiss, M., and Sheffield, J.: Spatial downscaling of precipitation using adaptable random forests, Water Resour. Res., 52, 8217–8237, https://doi.org/10.1002/2016WR019034, 2016. a
Hingray, B. and Ben Haha, M.: Statistical performances of various deterministic and stochastic models for rainfall series disaggregation, Atmos. Res., 77, 152–175, https://doi.org/10.1016/j.atmosres.2004.10.023, 2005. a
Jha, S. K., Mariethoz, G., Evans, J., McCabe, M. F., and Sharma, A.: A space and time scale-dependent nonlinear geostatistical approach for downscaling daily precipitation and temperature, Water Resour. Res., 51, 6244–6261, https://doi.org/10.1002/2014WR016729, 2015. a
Kang, B. and Ramirez, J.: A coupled stochastic space-time intermittent random cascade model for rainfall downscaling, Water Resour. Res., 46, W10534, https://doi.org/10.1029/2008WR007692, 2010. a
Kedem, B. and Chiu, L. S.: Are rain rate processes self-similar?, Water Resour. Res., 23, 1816–1818, 1987. a
KNMI: Precipitation – 5-min precipitation accumulations from climatological gauge-adjusted radar dataset for The Netherlands (1 km), available at: https://data.knmi.nl/datasets (last access: 20 July 2020), 2017. a
Langousis, A., Mamalakis, A., Deidda, R., and Marrocu, M.: Assessing the relative effectiveness of statistical downscaling and distribution mapping in reproducing rainfall statistics based on climate model results, Water Resour. Res., 52, 471–494, https://doi.org/10.1002/2015WR017556, 2016. a
Li, H., Sheffield, J., and Wood, E. F.: Bias correction of monthly precipitation and temperature fields from Intergovernmental Panel on Climate Change AR4 models using equidistant quantile matching, J. Geophys. Res.-Atmos., 115, 1–20, https://doi.org/10.1029/2009JD012882, 2010. a
Licznar, P., Lomotowski, J., and Rupp, D. E.: Random cascade driven rainfall disaggregation for urban hydrology: An evaluation of six models and a new generator, Atmos. Res., 99, 563–578, https://doi.org/10.1016/j.atmosres.2010.12.014, 2011. a
Licznar, P., De Michele, C., and Adamowski, W.: Precipitation variability within an urban monitoring network via microcanonical cascade generators, Hydrol. Earth Syst. Sci., 19, 485–506, https://doi.org/10.5194/hess-19-485-2015, 2015. a
Lisniak, D., Franke, J., and Bernhofer, C.: Circulation pattern based parameterization of a multiplicative random cascade for disaggregation of observed and projected daily rainfall time series, Hydrol. Earth Syst. Sci., 17, 2487–2500, https://doi.org/10.5194/hess-17-2487-2013, 2013. a
Lombardo, F., Volpi, E., and Koutsoyiannis, D.: Rainfall downscaling in time: theoretical and empirical comparison between multifractal and Hurst-Kolmogorov discrete random cascades, Hydrolog. Sci. J., 57, 1052–1066, https://doi.org/10.1080/02626667.2012.695872, 2012. a
Lombardo, F., Volpi, E., Koutsoyiannis, D., and Serinaldi, F.: A theoretically consistent stochastic cascade for temporal disaggregation of intermittent rainfall, Water Resour. Res., 53, 4586–4605, https://doi.org/10.1002/2017WR020529, 2017. a
Lovejoy, S. and Mandelbrot, B. B.: Fractal properties of rain, and a fractal model, Tellus A, 37A, 209–232, 1985. a
Lovejoy, S. and Schertzer, D.: On the simulation of continuous in scale universal multifractals, part I: Spatially continuous processes, Comput. Geosci., 36, 1393–1403, https://doi.org/10.1016/j.cageo.2010.04.010, 2010a. a
Lovejoy, S. and Schertzer, D.: On the simulation of continuous in scale universal multifractals, part II: Space–time processes and finite size corrections, Comput. Geosci., 36, 1404–1413, https://doi.org/10.1016/j.cageo.2010.07.001, 2010b. a
Marani, M.: Non-power-law-scale properties of rainfall in space and time, Water Resour. Res., 41, https://doi.org/10.1029/2004WR003822, 2005. a
Mascaro, G., Deidda, R., and Hellies, M.: On the nature of rainfall intermittency as revealed by different metrics and sampling approaches, Hydrol. Earth Syst. Sci., 17, 355–369, https://doi.org/10.5194/hess-17-355-2013, 2013. a
McIntyre, N., Shi, M., and Onof, C.: Incorporating parameter dependencies into temporal downscaling of extreme rainfall using a random cascade approach, J. Hydrol., 542, 896–912, https://doi.org/10.1016/j.jhydrol.2016.09.057, 2016. a
Menabde, M. and Sivapalan, M.: Modeling of rainfall time series and extremes using bounded random cascades and levy-stable distributions, Water Resour. Res., 36, 3293–3300, https://doi.org/10.1029/2000WR900197, 2000. a, b
Menabde, M., Seed, A., Harris, D., and Austin, G.: Self-similar random fields and rainfall simulation, J. Geophys. Res., 102, 13509–13515, 1997. a
Molnar, P. and Burlando, P.: Preservation of rainfall properties in stochastic disaggregation by a simple random cascade model, Atmos. Res., 77, 137–151, https://doi.org/10.1016/j.atmosres.2004.10.024, 2005. a, b
Nychka, D., Furrer, R., Paige, J., and Sain, S.: fields: Tools for spatial data, https://doi.org/10.5065/D6W957CT, available at: https://www.image.ucar.edu/~nychka/Fields (last access: 15 July 2020), r package version 9.6, 2017. a
Olsson, J.: Evaluation of a scaling cascade model for temporal rain- fall disaggregation, Hydrol. Earth Syst. Sci., 2, 19–30, https://doi.org/10.5194/hess-2-19-1998, 1998. a, b, c, d
Ossiander, M. and Waymire, E. C.: Statistical Estimation for Multiplicative Cascades, Ann. Stat., 28, 1533–1560, 2000. a
Over, T. M. and Gupta, V. K.: Statistical Analysis of Mesoscale Rainfall: Dependence of a Random Cascade Generator on Large-Scale Forcing, J. Appl. Meteorol., 33, 1526–1542, https://doi.org/10.1175/1520-0450(1994)033<1526:SAOMRD>2.0.CO;2, 1994. a, b
Over, T. M. and Gupta, V. K.: A space-time theory of mesoscale rainfall using random cascades, J. Geophys. Res.-Atmos., 101, 2156–2202, https://doi.org/10.1029/96JD02033, 1996. a, b
Pathirana, A., Herath, S., and Yamada, T.: Estimating rainfall distributions at high temporal resolutions using a multifractal model, Hydrol. Earth Syst. Sci., 7, 668–679, https://doi.org/10.5194/hess-7-668-2003, 2003. a, b
Paulson, K. S. and Baxter, P. D.: Downscaling of rain gauge time series by multiplicative beta cascade, J. Geophys. Res.-Atmos., 112, https://doi.org/10.1029/2006JD007333, 2007. a, b
Raut, B. A., Seed, A. W., Reeder, M. J., and Jakob, C.: A Multiplicative Cascade Model for High-Resolution Space-Time Downscaling of Rainfall, J. Geophys. Res.-Atmos., 123, 2050–2067, https://doi.org/10.1002/2017JD027148, 2018. a
Rupp, D. E., Keim, R. F., Ossiander, M., Brugnach, M., and Selker, J. S.: Time scale and intensity dependency in multiplicative cascades for temporal rainfall disaggregation, Water Resour. Res., 45, https://doi.org/10.1029/2008WR007321, 2009. a, b, c
Schertzer, D. and Lovejoy, S.: Physical modeling and analysis of rain and clouds by anisotropic scaling multiplicative processes, J. Geophys. Res.-Atmos., 92, 9693–9714, https://doi.org/10.1029/JD092iD08p09693, 1987. a
Schertzer, D. and Lovejoy, S.: Multifractals, Generalized Scale Invariance and Complexity in Geophysics, Int. J. Bifurcat. Chaos, 21, 3417–3456, https://doi.org/10.1142/S0218127411030647, 2011. a, b
Schleiss, M.: Scaling and Distributional Properties of Precipitation Interamount Times, J. Hydrometeorol., 18, 1167–1184, https://doi.org/10.1175/JHM-D-16-0221.1, 2017. a, b, c
Schleiss, M. and Smith, J. A.: Two simple metrics for quantifying rainfall intermittency: the burstiness and memory of inter-amount times, J. Hydrometeorol., 17, 421–436, https://doi.org/10.1175/JHM-D-15-0078.1, 2016. a, b
Schmitt, F., Vannitsem, S., and Barbosa, A.: Modeling of rainfall time series using two-state renewal processes and multifractals, J. Geophys. Res., 103, 2156–2202, https://doi.org/10.1029/98JD02071, 1998. a
Schmitt, F. G.: Continuous multifractal models with zero values: a continuous beta-multifractal model, J. Stat. Mech.-Theory E., 2014, P02008, https://doi.org/10.1088/1742-5468/2014/02/P02008, 2014. a
Shankar, S. U. and Hutchinson, P. D.: Quadtrees in Hydrological Research, New Zeal. Geogr., 46, 29–32, https://doi.org/10.1111/j.1745-7939.1990.tb01944.x, 1990. a
ten Veldhuis, M.-C. and Schleiss, M.: Statistical analysis of hydrological response in urbanising catchments based on adaptive sampling using inter-amount times, Hydrol. Earth Syst. Sci., 21, 1991–2013, https://doi.org/10.5194/hess-21-1991-2017, 2017. a
Teutschbein, C. and Seibert, J.: Bias correction of regional climate model simulations for hydrological climate-change impact studies: Review and evaluation of different methods, J. Hydrol., 456-457, 12–29, https://doi.org/10.1016/j.jhydrol.2012.05.052, 2012. a
Veneziano, D. and Lepore, C.: The scaling of temporal rainfall, Water Resour. Res., 48, https://doi.org/10.1029/2012WR012105, 2012. a
Veneziano, D., Furcolo, P., and Iacobellis, V.: Imperfect scaling of time and space-time rainfall, J. Hydrol., 322, 105–119, https://doi.org/10.1016/j.jhydrol.2005.02.044, 2006. a
Xu, G., Xu, X., Liu, M., Sun, Y. A., and Wang, K.: Spatial Downscaling of TRMM Precipitation Product Using a Combined Multifractal and Regression Approach: Demonstration for South China, Water, 7, 3083–3102, https://doi.org/10.3390/w7063083, 2015. a, b