the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Aug 2019
| 02 Aug 2019
Technical note: Stochastic simulation of streamflow time series using phase randomization
Manuela I. Brunner
András Bárdossy
Reinhard Furrer
Stochastically generated streamflow time series are widely used in water resource planning and management. Such series represent sets of plausible yet unobserved streamflow realizations which should reproduce the main characteristics of observed data. These characteristics include the distribution of daily streamflow values and their temporal correlation as expressed by short- and long-range dependence. Existing streamflow generation approaches have mainly focused on the time domain, even though simulation in the frequency domain provides good properties. These properties comprise the simulation of both short- and long-range dependence as well as extension to multiple sites. Simulation in the frequency domain is based on the randomization of the phases of the Fourier transformation. We here combine phase randomization simulation with a flexible, four-parameter kappa distribution, which allows for the extrapolation to as yet unobserved low and high flows. The simulation approach consists of seven steps: (1) fitting the theoretical kappa distribution,
(2) normalization and deseasonalization of the marginal distribution,
(3) Fourier transformation, (4) random phase generation, (5) inverse Fourier transformation, (6) back transformation, and (7) simulation. The simulation approach is applicable to both individual and multiple sites. It was applied to and validated on a set of four catchments in Switzerland. Our results show that the stochastic streamflow generator based on phase randomization produces realistic streamflow time series with respect to distributional properties and temporal correlation. However, cross-correlation among sites was in some cases found to be underestimated. The approach can be recommended as a flexible tool for various applications such as the dimensioning of reservoirs or the assessment of drought persistence.
Highlights.
-
Stochastic simulation of streamflow time series for individual and multiple sites by combining phase randomization and the kappa distribution.
-
Simulated time series reproduce temporal correlation, seasonal distributions, and extremes of observed time series.
-
Simulation procedure suitable for use in water resource planning and management.
- Article
(4497 KB) - Full-text XML
- BibTeX
- EndNote





Stochastically generated streamflow time series are used in various applications of water resource planning and management. These applications include water and reservoir management, the determination of the dimensions of hydraulic structures such as reservoirs, and the estimation of hydrological extremes such as droughts and floods. Stochastically generated time series mimic the characteristics of observed data and represent sets of plausible realizations of streamflow sequences (Ilich, 2014; Borgomeo et al., 2015; Tsoukalas et al., 2018b). They are essential for many uncertainty studies in hydrology because they can serve as input for deterministic water system models in which they allow for the propagation of natural variability and uncertainty (Tsoukalas et al., 2018b).
Stochastic models for the generation of synthetic streamflow time series need to fulfil certain requirements. They should reproduce both the marginal distribution of observed streamflow time series as well as their temporal dependence structure (Sharma et al., 1997; Salas and Lee, 2010). Temporal dependence encompasses both short- and long-range dependence. While short-range dependence typically refers to the dependence of daily streamflow values measured within a few days, long-range dependence refers to dependencies across months or years. This temporal dependence has been found to depend on magnitude, in that low values have stronger dependence than high values (Lee and Salas, 2011). A proper representation of this long-range dependence is of particular importance in studies where storage in reservoirs is of interest (Tsoukalas et al., 2018b). If one is interested in extreme events, the model should allow for the generation of values that go beyond the magnitude of those observed (Herman et al., 2016). This requires the choice of a suitable theoretical marginal distribution. Streamflow typically exhibits a skewed distribution, which requires the use of a three- or more-than-three-parameter distribution (Koutsoyiannis, 2000; Blum et al., 2017). Studies looking at individual hydrological events such as floods or droughts require a daily resolution. Therefore, the stochastic model should allow for outputs at such a fine temporal resolution. Often, study regions encompass several sites whose streamflows are correlated. Consequently, the model ideally not only allows for the simulation of streamflow at individual sites, but also for the joint simulation of streamflow at multiple sites, taking into account their spatio-temporal dependence. From a practitioner's point of view, the model should not only reproduce the characteristics of the observed data, but it should also be simple (Sharma et al., 1997).
Many different approaches have been proposed for the stochastic simulation of streamflow time series, each able to fulfil some but usually not all of the desired properties listed above. One commonly used approach is the use of a synthetic weather generator in combination with a rainfall–runoff model (Pender et al., 2015). This approach is affected by uncertainties due to hydrological model selection and calibration, which can be avoided by using direct synthetic streamflow generation approaches (Herman et al., 2016). According to Stedinger and Taylor (1982), the development of such direct approaches consists of the following steps: (1) selection of a model for seasonal marginal distributions, (2) selection of a model for spatial and temporal dependence, and (3) validation of the model. Different groups of direct approaches exist which are distinct in terms of their flexibility regarding marginal distributions and temporal dependence structures.
A first group of models consists of parametric models such as autoregressive moving average (ARMA) models and their modifications. While these models are commonly used in stochastic hydrology, they only allow for modelling of short-range dependence because their autocorrelation decreases strongly with increasing lag time (Sharma et al., 1997). This means they guarantee neither the reproduction of observed persistence of annual flows nor the correlation structure among flows in different months (Stedinger and Taylor, 1982). This makes them unsuitable for applications where long-range dependence is important (Koutsoyiannis, 2000). However, AR models can be used to generate seemingly long-memory processes if a parametric autocorrelation structure is used to fit the data (Papalexiou, 2018). A second group of parametric models is based on the temporal disaggregation of annual series and enables the representation of long-range dependence (Stedinger and Taylor, 1982; Salas and Lee, 2010). These models include fractional Gaussian noise models (Mandelbrot, 1965), fast fractional Gaussian noise models (Mandelbrot, 1971), broken line models (Mejia et al., 1972), and fractional autoregressive integrated moving average models (Hosking, 1984). Disaggregation models can be extended to multi-site applications (Grygier and Stedinger, 1988). However, this group of models has been shown to exhibit parameter estimation problems and only allows for the representation of a narrow range of autocorrelation functions (Koutsoyiannis, 2000). A third group of models is nonparametric in its approach and includes kernel density estimation (Lall and Sharma, 1996; Sharma et al., 1997) and various bootstrap approaches. The latter include simple bootstrap, which is only useful if data are uncorrelated, moving block-bootstrap, nearest-neighbour bootstrap (Salas and Lee, 2010; Herman et al., 2016), matched-block bootstrap (Srinivas and Srinivasan, 2006), and maximum-entropy bootstrap (Srivastav and Simonovic, 2014), which also take lagged correlations into account. These nonparametric techniques resample from the data with perturbations and directly reproduce the characteristics of the original data (Sharma et al., 1997). However, the reproduction of long-range dependence is difficult, and variance can be underestimated or overestimated (Salas and Lee, 2010). To allow for values that go beyond the observed distribution, Salas and Lee (2010) proposed a model employing k-nearest-neighbour resampling with a gamma kernel perturbation. A further group of models consists of models that employ Markov chains and their variations. These models account for transition probabilities between different hydrological states (Stagge and Moglen, 2013; Bracken et al., 2014; Pender et al., 2015) and can be combined with nonparametric approaches such as k-nearest neighbours (Prairie et al., 2008). They can be extended to multiple sites by scaling the simulated values at individual sites with spatially correlated random numbers (Mehrotra and Sharma, 2006).
Several alternatives to these well-established simulation procedures have been proposed, which allow for a flexible choice of marginal distributions. These include models where the temporal dependence structure is modelled with copula functions, which are, however, difficult to apply for higher orders of autocorrelation (Lee and Salas, 2011). Examples of new simulation procedures based on the Autoregressive to Anything (ARTA) model proposed by Cario and Nelson (1996) following Li and Hammond (1975) are the SMARTA model by Tsoukalas et al. (2018b) or the SPARTA model by Tsoukalas et al. (2018a), which employ Nataf's joint distribution model for the simulation of stochastic time series, representing both short- and long-range dependence. In addition, simulation schemes based on wavelet decomposition, which avoid assumptions about the temporal dependence structure, have been proposed by Kwon et al. (2007), Wang et al. (2010), and Erkyihun et al. (2016). Borgomeo et al. (2015) have shown how simulated annealing can be used to generate synthetic streamflow time sequences that represent possible climate-induced changes in user-specified streamflow properties.
All these previously mentioned models are based on the time domain. An alternative to time-domain models is frequency-domain models (Shumway and Stoffer, 2017), which allow for the simulation of surrogate data with the same Fourier spectra as the raw data (Theiler et al., 1992). Such methods are based on the randomization of the phases of the Fourier transformation and have been commonly applied in hypothesis testing, when identifying nonlinearity in time series (Schmitz and Schreiber, 1996; Kugiumtzis, 1999; Venema et al., 2006; Maiwald et al., 2008), and in trend detection (Radziejewski et al., 2000). We hereafter refer to such methods, which are also known as amplitude-adjusted Fourier transformations (AAFTs) (Lancaster et al., 2018), as phase randomization simulations. Serinaldi and Lombardo (2017) used an iterative AAFT method to generate binary series of rainfall occurrence and non-occurrence. An extension of the amplitude-adjusted Fourier transformation has been presented by Keylock (2007), who applied randomization procedures to wavelet-decomposed signals to generate surrogate data. In hydrology, phase randomization simulation has rarely been applied for purposes other than hypothesis testing (Fleming et al., 2002) even though it has desirable properties which make it suitable for a wider range of applications. Indeed, its implementation is relatively simple, it can simulate time series with both short- and long-range dependence, and it can be extended to multiple sites. However, its application is often limited to the reproduction of the empirical distribution of the data. We here propose the use of phase randomization simulation for the stochastic generation of streamflow time series at individual and multiple sites. To allow for non-empirical distributions, we combine the data simulated by phase randomization with the flexible, four-parameter kappa distribution introduced by Hosking (1994) as a generalization of the three-parameter kappa distribution suggested by Mielke (1973). The stochastic streamflow generation approach shall represent a flexible tool which is easy to apply and generalizable to different contexts. This is enabled by combining a nonparametric time dependence model with a flexible four-parameter distribution. The simulation approach can be tailored to the specific problem at hand and be used for various water resource management applications.
We now turn to some theoretical background on Fourier transformation and phase randomization. For a more detailed introduction to the Fourier transformation, the reader is referred to textbooks by Morrison (1994) or Shumway and Stoffer (2017). We then discuss the use of phase randomization for the stochastic generation of streamflow time series. For illustration purposes, we apply and validate the approach on a set of four catchments in Switzerland. Finally, we discuss potential applications of the simulation approach.
The basic idea behind all surrogate methods is to randomize the Fourier phases of the underlying (hydrological) process. The Fourier transformation converts a time-domain signal into a frequency-domain signal, which is complex-valued. This transformation may be depicted as a decomposition of the time series into sine and cosine waves of different amplitude, phase, and period (Fleming et al., 2002; Shumway and Stoffer, 2017). In the frequency domain, the power spectral density (power spectrum) expresses the same information in cycles as the autocovariance function expresses in lags in the time domain. The periodogram, the empirical counterpart of the power spectrum, shows high values at those frequencies which correspond to strong periodic components (Shumway and Stoffer, 2017).
The surrogate approach utilizes the property that realizations of linear Gaussian processes differ only in their Fourier phases and not their power spectrum. It preserves the autocorrelation structure of the raw series by conserving its power spectrum through phase randomization. The procedure consists of three main steps (Radziejewski et al., 2000; Maiwald et al., 2008; Kim et al., 2010). In the first step, the streamflow series is converted from the time domain to the frequency domain by Fourier transformation (Morrison, 1994). In this frequency domain, the data are represented by the phase angle and the power spectrum, as represented by the periodogram. The phase angle θ of the power spectrum is uniformly distributed over the range of −π to π. In the second step, the phases in the phase spectrum are randomized while the power spectrum is preserved. In the third step, the inverse Fourier transformation is applied to transform the data from the frequency domain back to the temporal domain (Maiwald et al., 2008).
The Fourier transformation of a given time series x=(x1, …, xt, …, xn) of length n is
where is the imaginary unit. The original time series can be recovered by the back transformation
if the transformation is calculated for discrete frequencies , j=1, 2, …, n. The Fourier transformation surrogate method constructs a new time series yt with the same periodogram as the observations. Apart from this, the new series are statistically independent of xt. This can be achieved by fixing the Fourier amplitudes and replacing the Fourier phases ϕ(ωj)=arg(f(ωj)) with uniformly distributed random numbers , π]. A new realization is given by
The surrogate data consist of the same values as the original data in another temporal order but with the same time dependence structure as the original data (Schreiber and Schmitz, 2000). The approach can be extended to multiple sites by multiplying the phases of each site by the same set of random phases. This is possible because the cross-spectrum, which describes the cross-correlation of the data in the frequency domain, reflects relative phases only (Prichard and Theiler, 1994; Schreiber and Schmitz, 2000).
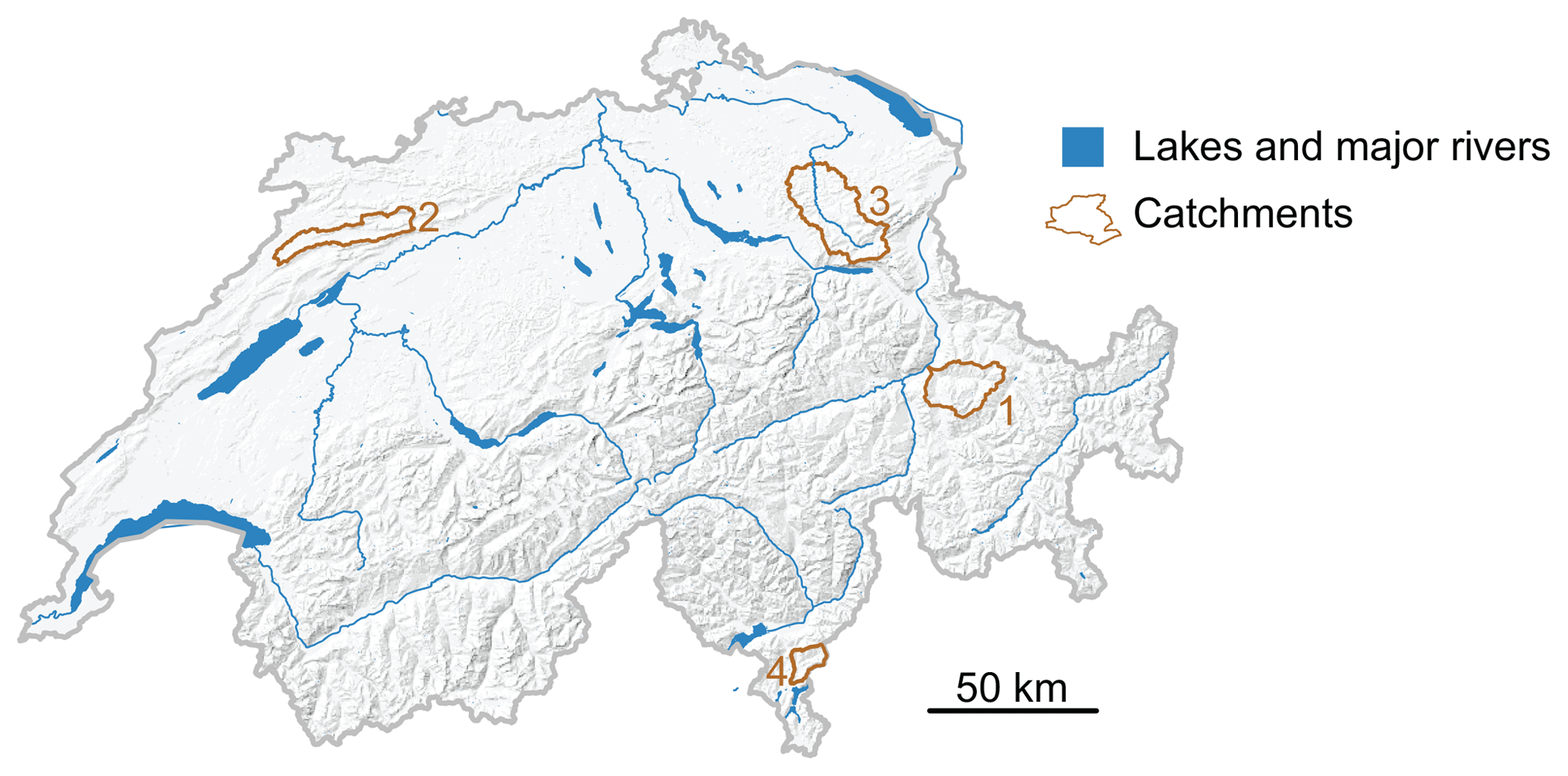
Figure 1Map showing the four Swiss catchments: (1) Plessur, (2) Birse, (3) Thur, and (4) Cassarate.
3.1 Stochastic streamflow simulation
Here, we use phase randomization to simulate stochastic streamflow time series to be used in various water resource management studies. The stochastic series generated using phase randomization are combined with a theoretical distribution to allow extrapolation to unobserved values which still realistically represent daily streamflow values. The observed streamflow time series require pre-treatment before phase randomization can be applied. First, they need to be normalized because phase randomization assumes Gaussianity (Maiwald et al., 2008). Second, they need to be deseasonalized in order to remove monthly/daily fluctuations (Pender et al., 2015). The stochastic simulation procedure consists of the following seven steps.
-
Fitting of theoretical kappa distribution: the four-parameter kappa distribution (Hosking, 1994) is fitted to the daily values of the observed input time series using L moments. This distribution will be used for the back transformation in Ste 7 and permits extreme values going beyond the empirical distribution to be obtained. It has four parameters and its cumulative distribution function is expressed as
where ξ is the location parameter, α is the scale parameter which must be positive, and k and h are the shape parameters.
The kappa distribution was found to be suitable for fitting observed streamflow data in US catchments (Blum et al., 2017). A suitable fit was also found for our data as confirmed by the Kolmogorov–Smirnov and Anderson–Darling tests which did not reject the null hypothesis at α=0.05 for most catchments. We fitted a separate distribution for each day to take into account seasonal differences in the distribution of daily streamflow values. To do so, we used the daily values in a 30 d window around the day of interest. This procedure guarantees a large enough sample for the parameter fitting procedure, and allows for smoothly changing distributions along the year. For leap years, flows from 29 February were removed to maintain constant sample sizes across years as in Blum et al. (2017).
-
Normalization and deseasonalization of the marginal distribution: the input time series are normalized using the normal transform, i.e. values corresponding to a certain rank are replaced with respective values from a standard normal distribution. The normal transform is applied to each day of the year separately, which results in the deseasonalization of the marginal distribution of the data.
-
Fourier transformation: the normalized and deseasonalized data are transferred to the frequency domain using the Fourier transformation (Eq. 1). The Fourier phases (i.e. the arguments of the Fourier transformation) are computed.
-
Random phase generation: random phase series are generated by sampling from the uniform phase distribution. The observed spectrum (i.e. the modulus of the Fourier transformation) is preserved.
-
Inverse Fourier transformation: the random phases are combined with the observed spectrum and inverse Fourier transformation is applied (Eq. 2) to transform the data back to the time domain.
-
Back transformation: the data are back transformed from the normal to the kappa domain using the fitted daily kappa distributions (Eq. 4), which achieves reseasonalization. This is done by generating a sample of length n (length of observed time series) and reassigning values according to the ranks in the simulated series. Negative simulated values are replaced by values sampled from a uniform distribution in the interval [0, min(x)], where min(x) represents the minimum of the observed values corresponding to the day under consideration. Using the empirical distribution instead of the kappa distribution would prevent us from obtaining values that go beyond the range of observed data (Srinivas and Srinivasan, 2006). Depending on the input time series, other suitable theoretical distributions than the kappa distributions could be used for back transformation.
-
Simulation: steps 4–7 are repeated m times to generate m time series of the same length as the observed time series.
The method is extended to the simulation of stochastic streamflow time series at multiple sites. To model the cross-correlation between sites, the phase randomization performed in Step 4 of the procedure is performed in the same way for all the stations in the data set (Prichard and Theiler, 1994). In contrast, the parameters of the monthly kappa distributions and the power spectrum are calculated for each individual site separately.
3.2 Model validation
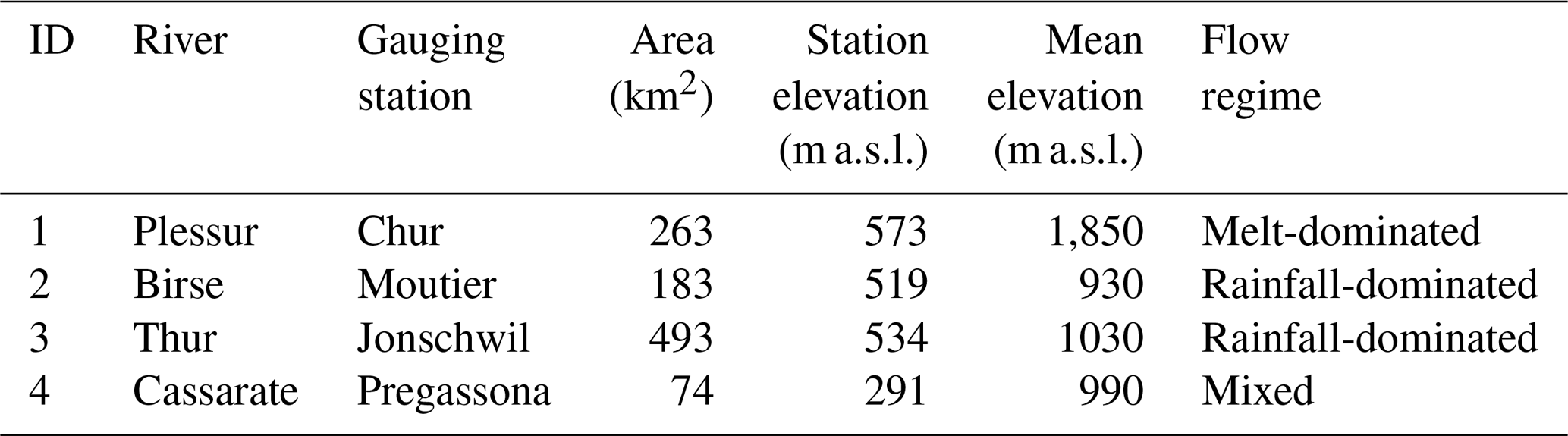
The simulation was validated on the observed streamflow time series of a set of four catchments in Switzerland (Fig. 1), namely, Plessur–Chur, Birse–Moutier, Thur–Jonschwil, and Cassarate–Pregassona. The catchments are characterized by diverse catchment characteristics and flow regimes (Table 1). Their catchment areas range between 74 and 493 km2 and their mean elevations between 930 and 1850 m a.s.l. Plessur represents a catchment with a melt-dominated flow regime with high flows in summer but low flows in winter. In contrast, the flow regimes of Birse and Thur are dominated by precipitation with high flows in winter and low flows in summer. The regime of Cassarate shows two peaks, one in spring due to melt processes and one in autumn due to precipitation.
Table 1List of catchments and catchment summary including ID, river name, gauging station, catchment area, station elevation, mean elevation, and flow regime.
The model outlined in the previous section was fitted to the observed time series over 50 years (1960–2009) for each individual catchment. The application of this approach is only recommended for records longer than 30 years to reduce uncertainty in the estimation of the parameters of the kappa distribution. The model was then run, on the one hand, for each individual catchment and, on the other hand, for the four sites jointly. In both cases, 100 sets of stochastic streamflow time series of the same length as the observed series were generated as in Salas and Lee (2010) and Pender et al. (2015).
Both the temporal correlation structure and seasonal streamflow statistics were used to compare observed and simulated streamflow time series in order to assess the validity of the stochastic streamflow generation model. As in Kim et al. (2010), we used the autocorrelation function on daily values to represent the short-range temporal correlation. Further, we also used the partial autocorrelation function (Stedinger and Taylor, 1982). In addition to short-range dependence, long-range dependence was assessed by looking at the autocorrelation function of annual discharge sums. The seasonal statistics were validated with respect to the seasonal distributions (winter: December–February, spring: March–May, summer: June–August, and autumn: September–November) and the monthly means, maxima, minima, and standard deviations. In addition to general distribution characteristics, the approach was validated for low and high flows because these characteristics are often of interest in hydrological simulation studies (Borgomeo et al., 2015). High and low flows were defined as above or below threshold values, respectively. For high flows, the 95th percentile was used as a threshold, while the 5th percentile was used for low flows.
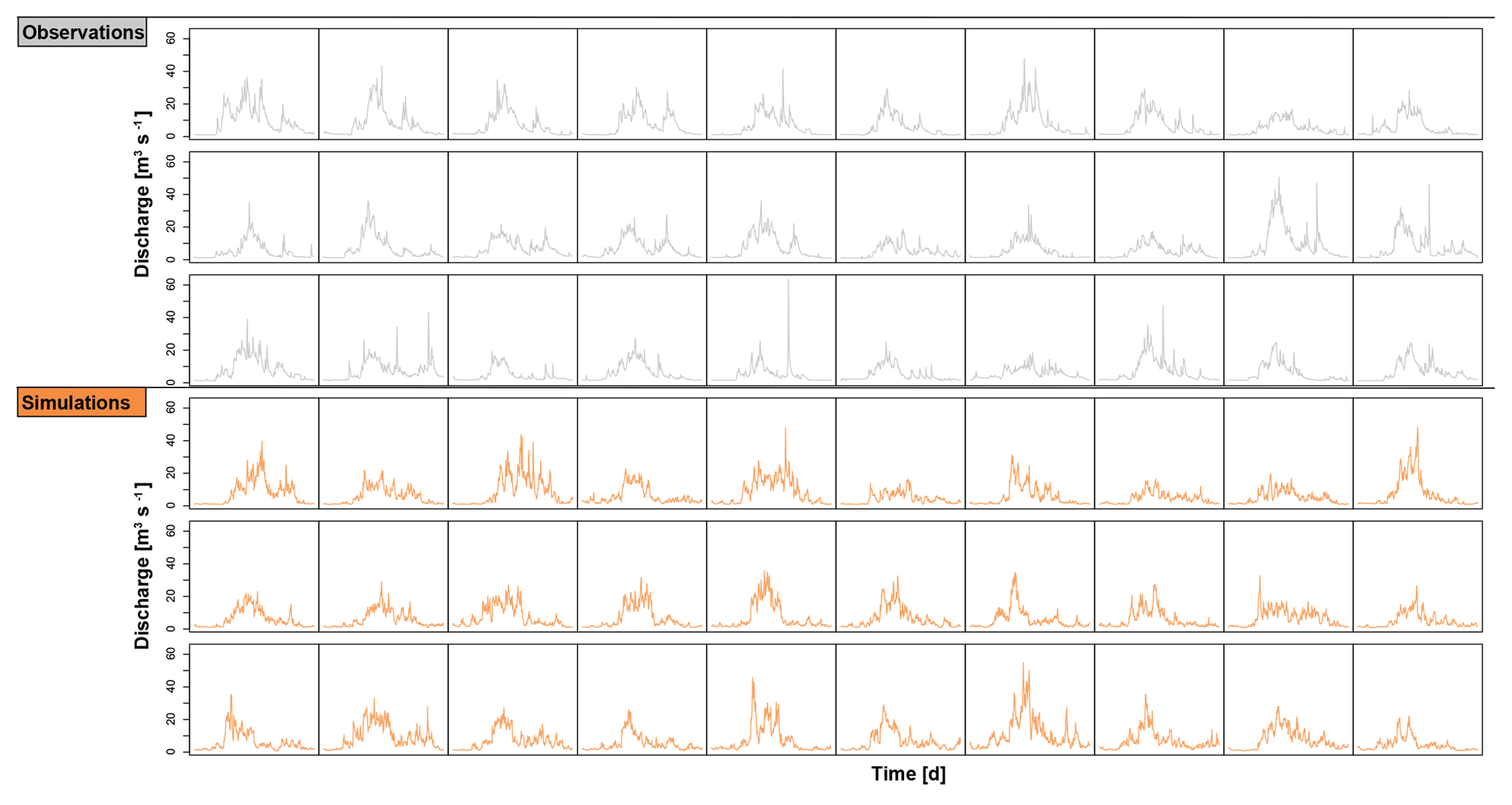
Figure 2Observed (grey) and stochastically generated (orange) annual hydrographs at daily resolution over 30 years for the Plessur catchment.

Figure 3Comparison of observed and stochastically generated time series for the melt-dominated Plessur catchment (upper two rows) and the rainfall-dominated Birse catchment (lower two rows) for the following characteristics: mean hydrograph over 50 years, autocorrelation function, partial autocorrelation function, seasonal distributions, monthly means, monthly maxima, monthly minima, and monthly standard deviations. Black lines represent observations, while orange lines represent simulations.
4.1 Simulation at individual sites
The stochastic streamflow generator was found to produce realistic annual hydrograph realizations as illustrated in Fig. 2 for the Plessur catchment (Fig. 1). This is confirmed visually by observing the temporal correlation structure as well as the seasonal statistics (see Fig. 3 for Thur and Plessur).
The stochastic generator produces time series with mean regimes similar to the observed mean regime, and reproduces both the autocorrelation (ACF) and partial autocorrelation functions (PACF). Seasonal distributions match well thanks to the good fit of the kappa distribution to the data. Monthly means and standard deviations match particularly well, while monthly maxima and minima show some deviations from the observed maxima and minima, as was intended by using a theoretical instead of an empirical distribution. The suitability of the kappa distribution for producing realistic high and low flows is confirmed in Fig. 4. The distribution produces low flows similar to observed low flows, but with different outliers. In two catchments (Thur and Cassarate), however, observed low flows were rather overestimated. High flow distributions match well in all catchments, and values exceeding observed values are generated. The four-parameter kappa distribution (Houghton, 1978; Griffiths, 1989) was found to be more suitable for representing daily streamflow values compared to distributions with even more parameters, which are rather prone to over-fitting. Similarly, tests on distributions with only three parameters (e.g. Burr type XII; Burr, 1942 and generalized Gamma distributions; Stacy and Mihram, 1965) were here not satisfactory because the distributions were not flexible enough. In cases where distributions with fewer parameters provide a satisfactory fit, they could, however, be used instead of the kappa distribution to ensure model parsimony.
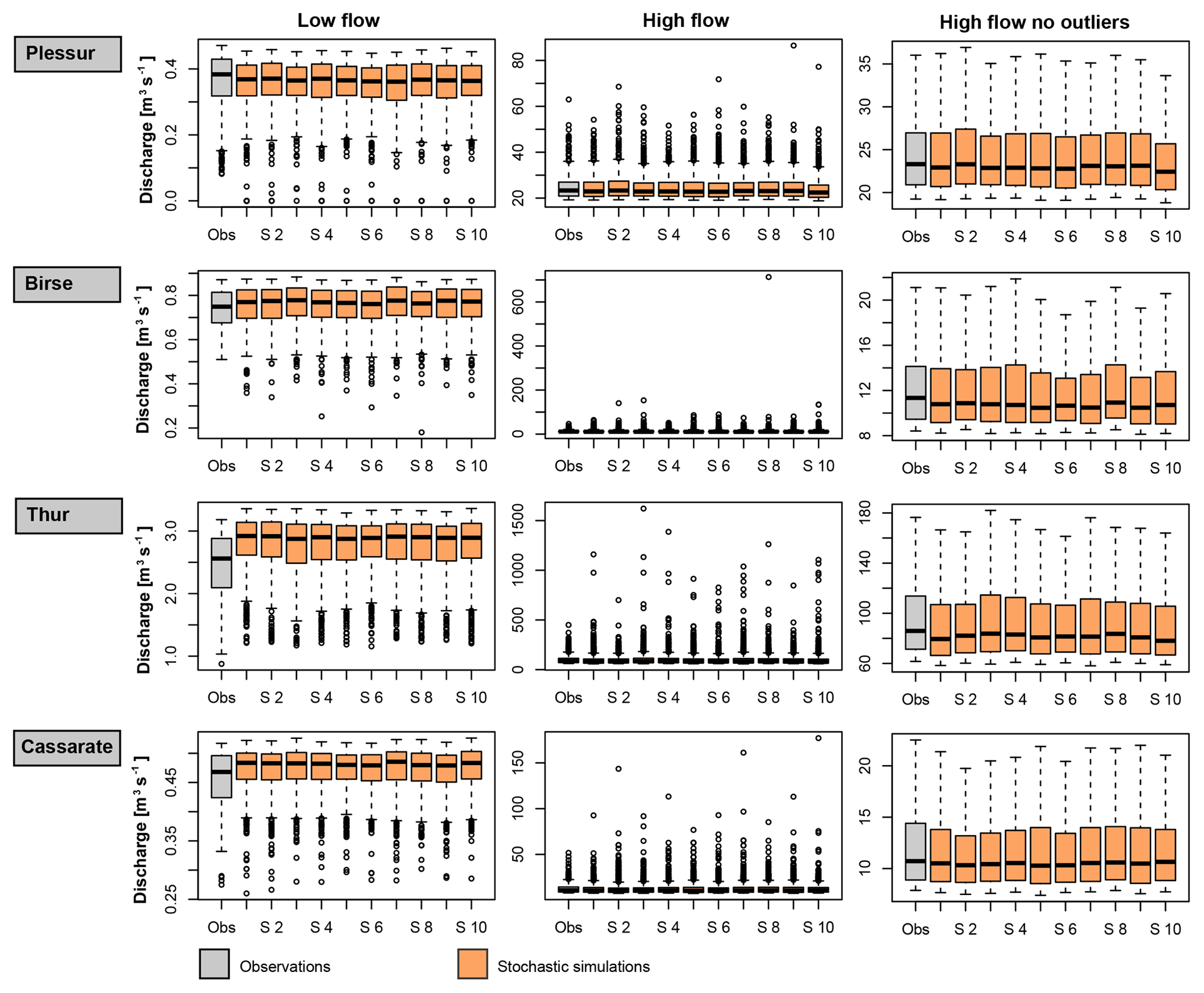
Figure 4Low and high flows for observed (grey) and simulated (orange) time series for the four catchments Plessur, Birse, Thur, and Cassarate. The results are given for 10 simulation runs (S1–S10), and high flows are plotted with (middle column) and without (right column) outliers. Whiskers extend to the lowest/highest data point, which is still within 1.5 times the interquartile range.
The stochastic streamflow generator is able to reproduce not only the streamflow distribution and the short-range dependence in the data, but also the long-range dependence over several years (Fig. 5). Both the rapid decrease in the ACF at short lags (up to 5 years) and the cyclical behaviour at lags longer than 5 years are reproduced as well.
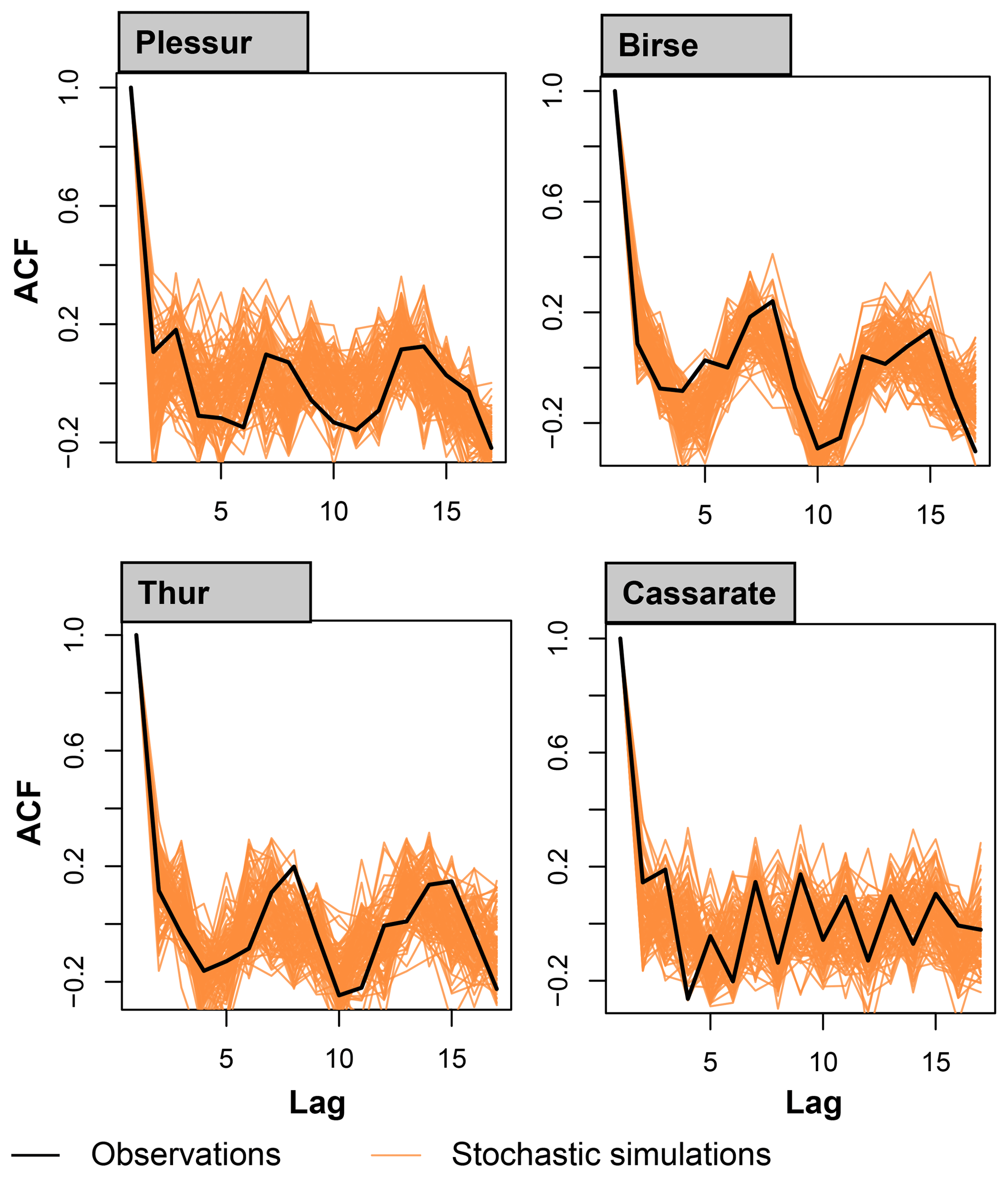
Figure 5Autocorrelation (ACF) of annual streamflow sums of the observed and simulated streamflow time series for the catchments Plessur, Birse, Thur, and Cassarate.
The good performance of the stochastic streamflow generator with respect to streamflow distribution and temporal correlation – both short and long range – is not limited to these four example catchments, but generalizes to other data sets used as input.
4.2 Simulation at multiple sites
The stochastic streamflow generator can be extended from the simulation at individual sites to the joint simulation at multiple sites. In addition to reproducing distribution and temporal correlation at individual sites, it should then be able to reproduce the cross-correlation among sites, which describes the similarity of time series at two sites. Figure 6 shows the cross-correlation function (CCF) for pairs of stations among the example catchments for the observed time series and the 100 simulation runs. Cross-correlation is already generally low for observations because the selected sample catchments are characterized by diverse discharge regimes and seasonality. The shape of the cross-correlation is reproduced for all pairs of stations. However, the magnitude of cross-correlation is underestimated for certain pairs of stations in the simulated time series compared to the observed series independently of the simulation run considered. For the catchment pair Birse–Thur, whose discharge behaviour is rainfall-dominated, the simulated cross-correlation is much lower than the observed one. In the observations, spatially consistent rainfall events lead to a joint rise in discharge at both stations. This behaviour is not captured by the stochastic discharge generator. The underestimation of cross-correlation is also visible when looking at the cross-correlation of below- or above-threshold events (not shown).
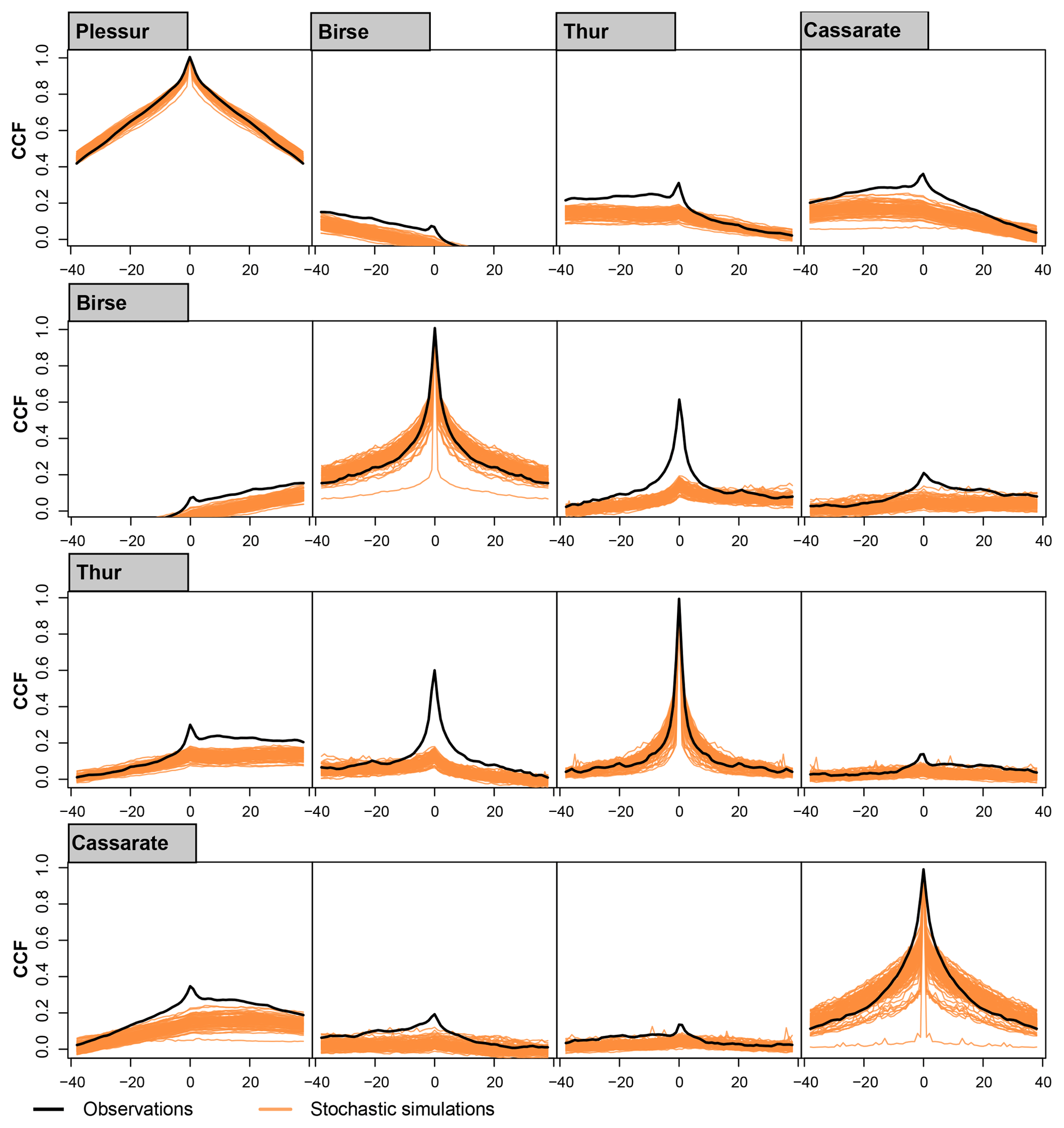
Figure 6Cross-correlation function (CCF) of observed (black line) and simulated (orange lines) daily streamflow for pairs of stations at Plessur, Birse, Thur, and Cassarate.
The stochastic streamflow generator based on phase randomization has been shown to produce realistic streamflow time series with respect to both distributional properties and temporal correlation. Compared to models commonly used for the stochastic generation of streamflow time series, such as autoregressive moving average models, the simulation approach presented here reproduces not only short-range, but also long-range dependence. However, the representation of this dependence is limited to ranges within the length of the observed time series. Instead of producing one long time series, the simulation procedure allows for the simulation of multiple series of the same length as the original series. The use of ensembles of the same length as the observed time series might not be equivalent to using a long time series. Still, long-range dependence features may not be generated in either case since the model is fitted based on a limited number of years of observations. While the reproduction of the temporal dependence was well reproduced here, this is not necessarily the case under all conditions. Embrechts et al. (2010) have shown that any nonlinear transformation of a Gaussian time series, which is done during back transformation, reduces the strength of the linear correlations in the time series as expressed by Pearson's correlation coefficient and preserves only rank correlations. If one is working with heavy-tailed and zero inflated marginals (as present when looking at intermittent processes), it can happen that autocorrelations are reduced during back transformation (Papalexiou, 2018).
Phase randomization was here combined with the flexible four-parameter kappa distribution, which was found to effectively represent daily streamflow values. The distribution of daily flows was found to be modelled well in all seasons. However, the use of one distribution per day has the disadvantage of introducing a lot of parameters, which makes the model non-parsimonious (Koutsoyiannis, 2016). If the user is not reliant on the generation of unobserved values, he/she might use the empirical instead of theoretical kappa distribution for back transformation instead. The use of the kappa distribution allows us to generate values that go beyond the range of observed values, which would not be the case if the empirical distribution was used. This ability of the generator to extrapolate extremes makes it suitable for applications where extreme events such as floods and droughts are of interest.
The generator can, on the one hand, be used to simulate streamflow at individual sites, and, on the other, to simulate jointly at multiple sites, which is not necessarily the case for other existing models. Its application to the example catchments, however, resulted in somewhat underestimated cross-correlations between stations. This underestimation can be explained by the fact that phase randomization preserves the cross-correlation in the normal domain but not necessarily in the domain of the original distribution. This cannot be overcome even if the simulation run which best reproduces these cross-correlations is extracted from a large set of simulations. However, Stedinger and Taylor (1982) showed that estimators of the autocorrelation and cross-correlation of flows which do not match the historical sample estimates often provide more accurate estimates of the true but unknown correlations. Still, there are several potential avenues for improving the representation of cross-correlation. A first possibility would be the use of phase annealing (Hörning and Bárdossy, 2018). Phase annealing modifies the Fourier phases in an iterative way in order to optimize certain statistics, such as the cross-correlation function, and makes it possible to take covariates into consideration for the generation of time series. However, using phase annealing increases the computational effort. A second possibility was presented by Keylock (2012), who only randomized the phases corresponding to the wavelet coefficients lying above a certain threshold. He suggested fixing the large wavelet scales if one wanted to ensure that the low-frequency behaviour between the observations and simulated series remains the same. This can indeed be a solution for retaining the cross-correlation between two series. However, it comes with the disadvantage that the temporal structure of the simulated series is not very variable from the one of the observed series anymore. A third possibility is the introduction of functions correcting for the phase differences between two series as done by Nguyen et al. (2019), who applied this approach to correct for biases across multiple atmospheric variables derived from global circulation models. Another possibility for addressing the underestimation of cross-correlation would be the inflation of the cross-spectrum in the original domain in order to allow for a certain target cross-correlation after back transformation. To do so, transformation approaches have been introduced, which inflate the original process, which should after the back transformation to the original domain result in a process with a target distribution and correlation structure (Papalexiou, 2018; Tsoukalas et al., 2018b). An additional disadvantage of the method presented here (and of most other approaches presented in the literature) is that time irreversibility, which has been shown to be significant at a daily scale (Koutsoyiannis, 2019), is not explicitly modelled.
The streamflow generator was here used on observed streamflow time series. The input time series, however, do not necessarily need to consist of observed values. One could also use the generator on streamflow simulated with a hydrological model. This extends its application to climate impact studies where a hydrological model is driven by meteorological time series generated with global and/or regional climate models. Alternatively, the representation of non-stationary conditions in the properties of the marginal distribution or the temporal dependence structure could also be achieved by adjusting the parameters of the marginal distribution or the frequency spectrum, respectively. Phase randomization simulation can potentially accommodate not only changing climate conditions, but also changes in land use or water extractions. The approach is not limited to the simulation of streamflow time series, but extends to other hydro-meteorological variables such as precipitation, evapotranspiration, or snowmelt. This would require the test and identification of a suitable marginal distribution. In the case of intermittent processes, mixed-type marginal distributions would need to be used (Papalexiou, 2018). Distributions other than the kappa distribution can be used in PRSim by specifying a suitable (mixture) distribution. Spatio-temporal modelling of precipitation fields, for example, may be performed using a technique based on phase randomization. However, it must be noted that due to the large number of zero observations (specifically with fine temporal resolution), the normal score transformation can become non-unique. In this case, additional efforts are needed to preserve the spatial structure of precipitation.
The stochastic streamflow generator presented here represents a flexible tool for streamflow simulation at individual or multiple sites. It can be used for various applications such as the design of hydropower reservoirs, the assessment of flood risk, or the assessment of drought persistence and the estimation of the risk of multi-year droughts.
The stochastic simulation procedure for a single site using the empirical, kappa, or any other distribution and some of the functions used to generate the validation plots are provided in R package PRSim. The stable version can be found in the CRAN repository https://cran.r-project.org/web/packages/PRSim/index.html (Brunner and Furrer, 2019), and the current development version is available at https://git.math.uzh.ch/reinhard.furrer/PRSim-devel.
The observational discharge data were provided by the Federal Office for the Environment (FOEN) and can be ordered from http://www.bafu.admin.ch/wasser/13462/13494/15076/index (FOEN, 2009).
AB and MIB jointly developed the concept and methodology of the study. MIB and RF set up the simulation approach. MIB did the data analysis, produced the figures, and wrote the first draft of the manuscript. The manuscript was revised by RF and AB and edited by MIB.
The authors declare that they have no conflict of interest.
We thank the reviewers Ashish Sharma, Demetris Koutsoyiannis, and Simon Papalexiou for their constructive comments.
This research has been supported by the Swiss Federal Office for the Environment (FOEN) (grant no. 15.0003.PJ/Q292-5096), the Deutsche Forschungsgemeinschaft (DFG) (grant no. Ba-1150/13-1), and the Swiss National Science Foundation (SNF) (grant no. 175529).
This paper was edited by Nadav Peleg and reviewed by Demetris Koutsoyiannis, Ashish Sharma, and Simon Michael Papalexiou.
Blum, A. G., Archfield, S. A., and Vogel, R. M.: On the probability distribution of daily streamflow in the United States, Hydrol. Earth Syst. Sci., 21, 3093–3103, https://doi.org/10.5194/hess-21-3093-2017, 2017. a, b, c
Borgomeo, E., Farmer, C. L., and Hall, J. W.: Numerical rivers: A synthetic streamflow generator for water resources vulnerability assessments, Water Resour. Res., 51, 5382–5405, https://doi.org/10.1002/2014WR016259, 2015. a, b, c
Bracken, C., Rajagopalan, B., and Zagona, E.: A hidden Markov model combined with climate indices for multidecadal streamflow simulation, Water Resour. Res., 50, 7836–7846, https://doi.org/10.1002/2014WR015567, 2014. a
Brunner, M. I. and Furrer, R.: PRSim: Stochastic Simulation of Streamflow Time Series using Phase Randomization, CRAN, available at: https://cran.r-project.org/web/packages/PRSim/index.html, last access: July 2019. a
Burr, I. W.: Cumulative frequency functions, Ann. Math. Stat., 13, 215–232, 1942. a
Cario, M. C. and Nelson, B. L.: Autoregressive to anything: Time-series input processes for simulation, Operat. Res. Lett., 19, 51–58, https://doi.org/10.1016/0167-6377(96)00017-X, 1996. a
Embrechts, P., McNeil, A. J., and Straumann, D.: Correlation and dependence in risk management: Properties and pitfalls, chap. 7, in: Risk Management, edited by: Dempster, M. A. H., Cambridge University Press, Cambridge, 176–223, https://doi.org/10.1017/cbo9780511615337.008, 2010. a
Erkyihun, S. T., Rajagopalan, B., Zagona, E., Lall, U., and Nowak, K.: Wavelet-based time series bootstrap model for multidecadal streamflow simulation using climate indicators, Water Resour. Res., 52, 4061–4077, https://doi.org/10.1002/2016WR018696, 2016. a
Fleming, S. W., Marsh Lavenue, A., Aly, A. H., and Adams, A.: Practical applications of spectral analysis of hydrologic time series, Hydrol. Process., 16, 565–574, https://doi.org/10.1002/hyp.523, 2002. a, b
FOEN – Federal Office for the Environment: Hydrological Data Service for watercourses and lakes, Hydrol. Data Serv., available at: https://www.bafu.admin.ch/bafu/en/home/topics/water/state/data/obtaining-monitoring-data-on-the-topic-of-water/hydrological-data-service-for-watercourses-and-lakes.html (last access: July 2019), 2009. a
Griffiths, G. A.: A theoretically based Wakeby distribution for annual flood series, Hydrolog. Sci. J., 34, 231–248, https://doi.org/10.1080/02626668909491332, 1989. a
Grygier, J. A. N. C. and Stedinger, J. R.: Condensed disaggregation procedures and conservation corrections for stochastic hydrology, Water Resour. Manage., 24, 1574–1584, 1988. a
Herman, J. D., Reed, P. M., Zeff, H. B., Characklis, G. W., and Lamontagne, J.: Synthetic drought scenario generation to support bottom-up water supply vulnerability assessments, J. Water Resour. Pl. Manage., 142, 1–13, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000701, 2016. a, b, c
Hörning, S. and Bárdossy, A.: Phase annealing for the conditional simulation of spatial random fields, Comput. Geosci., 112, 101–111, https://doi.org/10.1016/j.cageo.2017.12.008, 2018. a
Hosking, J. R. M.: Modeling persistence in hydrological time series using fractional differencing, Water Resour. Res., 20, 1898–1908, https://doi.org/10.1029/WR020i012p01898, 1984. a
Hosking, J. R. M.: The four-parameter kappa distribution, IBM J. Res. Dev., 38, 251–258, 1994. a, b
Houghton, J. C.: Birth of a parent: The Wakeby Distribution for modeling flood flows, Water Resour. Res., 14, 1105–1109, https://doi.org/10.1029/WR014i006p01105, 1978. a
Ilich, N.: An effective three-step algorithm for multi-site generation of stochastic weekly hydrological time series, Hydrolog. Sci. J., 59, 85–98, https://doi.org/10.1080/02626667.2013.822643, 2014. a
Keylock, C. J.: A wavelet-based method for surrogate data generation, Physica D, 225, 219–228, https://doi.org/10.1016/j.physd.2006.10.012, 2007. a
Keylock, C. J.: A resampling method for generating synthetic hydrological time series with preservation of cross-correlative structure and higher-order properties, Water Resour. Res., 48, 1–18, https://doi.org/10.1029/2012WR011923, 2012. a
Kim, J. S., Huh, Y., and Suh, M. W.: A method to generate autocorrelated stochastic signals based on the random phase spectrum, J. Text. Inst., 101, 471–479, https://doi.org/10.1080/14685240802528443, 2010. a, b
Koutsoyiannis, D.: A generalized mathematical framework for stochastic simulation and forecast of hydrologic time series, Water Resour. Res., 36, 1519–1533, 2000. a, b, c
Koutsoyiannis, D.: Generic and parsimonious stochastic modelling for hydrology and beyond, Hydrolog. Sci. J., 61, 225–244, https://doi.org/10.1080/02626667.2015.1016950, 2016. a
Koutsoyiannis, D.: Time's arrow in stochastic characterization and simulation of atmospheric and hydrological processes, Hydrolog. Sci. J., 64, 1013–1037, https://doi.org/10.1080/02626667.2019.1600700, 2019. a
Kugiumtzis, D.: Test your surrogate data before you test for nonlinearity, Phyd. Rev. E, 60, 2808–2816, https://doi.org/10.1103/PhysRevE.60.2808, 1999. a
Kwon, H. H., Lall, U., and Khalil, A. F.: Stochastic simulation model for nonstationary time series using an autoregressive wavelet decomposition: Applications to rainfall and temperature, Water Resour. Res., 43, 1–15, https://doi.org/10.1029/2006WR005258, 2007. a
Lall, U. and Sharma, A.: A nearest neighbor bootstrap for resampling hydrologic time series, Water Resour. Res., 32, 679–693, 1996. a
Lancaster, G., Iatsenko, D., Pidde, A., Ticcinelli, V., and Stefanovska, A.: Surrogate data for hypothesis testing of physical systems, Phys. Rep., 748, 1–60, https://doi.org/10.1016/j.physrep.2018.06.001, 2018. a
Lee, T. and Salas, J. D.: Copula-based stochastic simulation of hydrological data applied to Nile River flows, Hydrol. Res., 42, 318–330, https://doi.org/10.2166/nh.2011.085, 2011. a, b
Li, S. T. and Hammond, J. L.: Generation of Pseudorandom Numbers with Specified Univariate Distributions and Correlation Coefficients, IEEE T. Syst. Man Cybernet., SMC-5, 557–561, https://doi.org/10.1109/TSMC.1975.5408380, 1975. a
Maiwald, T., Mammen, E., Nandi, S., and Timmer, J.: Surrogate data – A qualitative and quantitative analysis, in: Mathematical methods in time series analysis and digital image processing, chap. 2, edited by: Dahlhaus, R., Kurths, J., Maass, P., and Timmer, J., 41–74, Springer, Berlin, Heidelberg, 2008. a, b, c, d
Mandelbrot, B. B.: Une classe de processus stochastiques homothetiques a soi: Application a la loi climatologique de H. E. Hurst, Comptes rendus de l'Académie des sciences, 260, 3274–3276, 1965. a
Mandelbrot, B. B.: A fast fractional Gaussian noise generator, Water Resour. Res., 7, 543–553, 1971. a
Mehrotra, R. and Sharma, A.: A nonparametric stochastic downscaling framework for daily rainfall at multiple locations, J. Geophys. Res.-Atmos., 111, 1–16, https://doi.org/10.1029/2005JD006637, 2006. a
Mejia, J. M., Rodriguez-Iturbe, I., and Dawdy, D. R.: Streamflow simulation: 2. The broken line process as a potential model for hydrologic simulation, Water Resour. Res., 8, 931–941, https://doi.org/10.1029/WR008i004p00931, 1972. a
Mielke, P. W.: Another family of distributions for describing and analyzing precipitation data, J. Appl. Meteorol., 12, 275–280, 1973. a
Morrison, N.: Introduction to Fourier analysis, 3rd Edn., John Wiley & Sons, Inc, New York, 1994. a, b
Nguyen, H., Mehrotra, R., and Sharma, A.: Correcting systematic biases across multiple atmospheric variables in the frequency domain, Clim. Dynam., 52, 1283–1298, https://doi.org/10.1007/s00382-018-4191-6, 2019. a
Papalexiou, S. M.: Unified theory for stochastic modelling of hydroclimatic processes: Preserving marginal distributions, correlation structures, and intermittency, Adv. Water Resour., 115, 234–252, https://doi.org/10.1016/j.advwatres.2018.02.013, 2018. a, b, c, d
Pender, D., Patidar, S., Pender, G., and Haynes, H.: Stochastic simulation of daily streamflow sequences using a hidden Markov model, Hydrol. Res., 47, 75–88, https://doi.org/10.2166/nh.2015.114, 2015. a, b, c, d
Prairie, J., Nowak, K., Rajagopalan, B., Lall, U., and Fulp, T.: A stochastic nonparametric approach for streamflow generation combining observational and paleoreconstructed data, Water Resour. Res., 44, 1–11, https://doi.org/10.1029/2007WR006684, 2008. a
Prichard, D. and Theiler, J.: Generating surrogate data for time series with several simultaneously measured variables, Phys. Rev. Lett., 73, 951–954, 1994. a, b
Radziejewski, M., Bardossy, A., and Kundzewicz, Z.: Detection of change in river flow using phase randomization, Hydrolog. Sci. J., 45, 547–558, https://doi.org/10.1080/02626660009492356, 2000. a, b
Salas, J. D. and Lee, T.: Nonparametric simulation of single-site seasonal streamflows, J. Hydrol. Eng., 15, 284–296, https://doi.org/10.1061/(ASCE)HE.1943-5584.0000189, 2010. a, b, c, d, e, f
Schmitz, A. and Schreiber, T.: Improved surrogate data for nonlinearity tests, Phys. Rev. Lett., 77, 635–638, https://doi.org/10.1103/PhysRevLett.77.635, 1996. a
Schreiber, T. and Schmitz, A.: Surrogate time series, Physica D, 142, 346–382, https://doi.org/10.1016/S0167-2789(00)00043-9, 2000. a, b
Serinaldi, F. and Lombardo, F.: General simulation algorithm for autocorrelated binary processes, Phys. Rev. E, 95, 1–9, https://doi.org/10.1103/PhysRevE.95.023312, 2017. a
Sharma, A., Tarboton, D. G., and Lall, U.: Streamflow simulation: a nonparametric approach, Water Resour. Res., 33, 291–308, 1997. a, b, c, d, e
Shumway, R. H. and Stoffer, D. S.: Time series analysis and its applications. With R examples, 4th Edn., Springer International Publishing AG, Cham, https://doi.org/10.1007/978-1-4419-7865-3, 2017. a, b, c, d
Srinivas, V. V. and Srinivasan, K.: Hybrid matched-block bootstrap for stochastic simulation of multiseason streamflows, J. Hydrol., 329, 1–15, https://doi.org/10.1016/j.jhydrol.2006.01.023, 2006. a, b
Srivastav, R. K. and Simonovic, S. P.: An analytical procedure for multi-site, multi-season streamflow generation using maximum entropy bootstrapping, Environ. Model. Softw., 59, 59–75, https://doi.org/10.1016/j.envsoft.2014.05.005, 2014. a
Stacy, E. W. and Mihram, G. A.: Parameter estimation for a generalized Gamma distribution, Technometrics, 7, 349–358, https://doi.org/10.1080/00401706.1965.10490268, 1965. a
Stagge, J. H. and Moglen, G. E.: A nonparametric stochastic method for generating daily climate-adjusted streamflows, Water Resour. Res., 49, 6179–6193, https://doi.org/10.1002/wrcr.20448, 2013. a
Stedinger, J. R. and Taylor, M. R.: Synthetic Streamflow Generation. 1. Model verification and validation, Water Resour. Res., 18, 909–918, 1982. a, b, c, d, e
Theiler, J., Eubank, S., Longtin, A., Galdrikian, B., and Farmer, J. D.: Testing for nonlinearity in time series: the method of surrogate data, Physica D, 58, 77–94, https://doi.org/10.1016/0167-2789(92)90102-S, 1992. a
Tsoukalas, I., Efstratiadis, A., and Makropoulos, C.: Stochastic periodic autoregressive to anything (SPARTA) modeling and simulation of cyclostationary processes with arbitrary marginal distributions, Water Resour. Res., 54, 161–185, https://doi.org/10.1111/j.1752-1688.1969.tb04897.x, 2018a. a
Tsoukalas, I., Makropoulos, C., and Koutsoyiannis, D.: Simulation of stochastic processes exhibiting any-range dependence and arbitrary marginal distributions, Water Resour. Res., 54, 9484–9513, https://doi.org/10.1029/2017WR022462, 2018b. a, b, c, d, e
Venema, V., Bachner, S., Rust, H. W., and Simmer, C.: Statistical characteristics of surrogate data based on geophysical measurements, Nonlin. Processes Geophys., 13, 449–466, https://doi.org/10.5194/npg-13-449-2006, 2006. a
Wang, W., Hu, S., and Li, Y.: Wavelet transform method for synthetic generation of daily streamflow, Water Resour. Manage., 25, 41–57, https://doi.org/10.1007/s11269-010-9686-9, 2010. a