the Creative Commons Attribution 3.0 License.
the Creative Commons Attribution 3.0 License.
Precipitation pattern in the Western Himalayas revealed by four datasets
Hong Li
Jan Erik Haugen
Chong-Yu Xu
Data scarcity is the biggest problem for scientific research related to hydrology and climate studies in the Great Himalayas region. High-quality precipitation data are difficult to obtain due to a sparse network, cold climate and high heterogeneity in topography. In this paper, we examine four datasets in northern India of the Western Himalayas: interpolated gridded data based on gauge observations (IMD, , and APHRODITE, ), reanalysis data (ERA-Interim, ) and high-resolution simulation by a regional climate model (WRF, ). The four datasets show a similar spatial pattern and temporal variation during the period 1981–2007, though the absolute values vary significantly (497–819 mm year−1). The differences are particularly large in July and August at the windward slopes and high-elevation areas. Overall, the datasets show that the summer is getting wetter and the winter is getting drier, though most of the trends in monthly precipitation are not significant. Trend analysis of summer and winter precipitation at every grids confirms the changes. Wetter summers will result in more and bigger floods in the downstream areas. Warmer and drier winters will result in less glacier accumulation. All the datasets show consistency in the period 1981–2007 and can give a spatial overview of the precipitation in the region. Comparing with the Bhuntar gauge data, the WRF dataset gives the best estimates of extreme precipitation. To conclude, we recommend the APHRODITE dataset and the WRF dataset for hydrological studies for their improved spatial variation which match the scale of hydrological processes as well as accuracy in extreme precipitation for flood simulation.
- Article
(4358 KB) - Full-text XML
-
Supplement
(21322 KB) - BibTeX
- EndNote





The Great Himalayas region is the largest cryosphere outside the polar areas and the source of many rivers which supply water to more than 800 million people (H. Li et al., 2016; Hegdahl et al., 2016). The local population depends mainly on rivers for drinking water, hygiene, industry, fishing, but also for hydro-power generation and agriculture, which is one of main sectors of local economy (Ménégoz et al., 2013). Therefore, precipitation is very important to the local society and welfare of the local people. Climate change has significant impacts on water security, where mitigation and adaption to climate change are more challenging in this area due to poverty.
Precipitation is one of the most important elements in meteorology and hydrology. Precipitation measurements at gauges are usually used as benchmark data to compare with other datasets. They are often believed to be the most reliable and accurate data. However, there are fewer gauges available in this area compared to other areas in the world. Therefore, it is tricky to look at spatial variability based on gauge data. Besides, quality of measurements is rarely high due to harsh climate and complex environment. Additionally, manual errors are very common in developing countries. These errors include, for example, error in gauge location, missing the unit of data as well as wrong position of the decimal point. Last but not least, gauge data are usually hard to obtain due to data policy and political conflict in some countries.
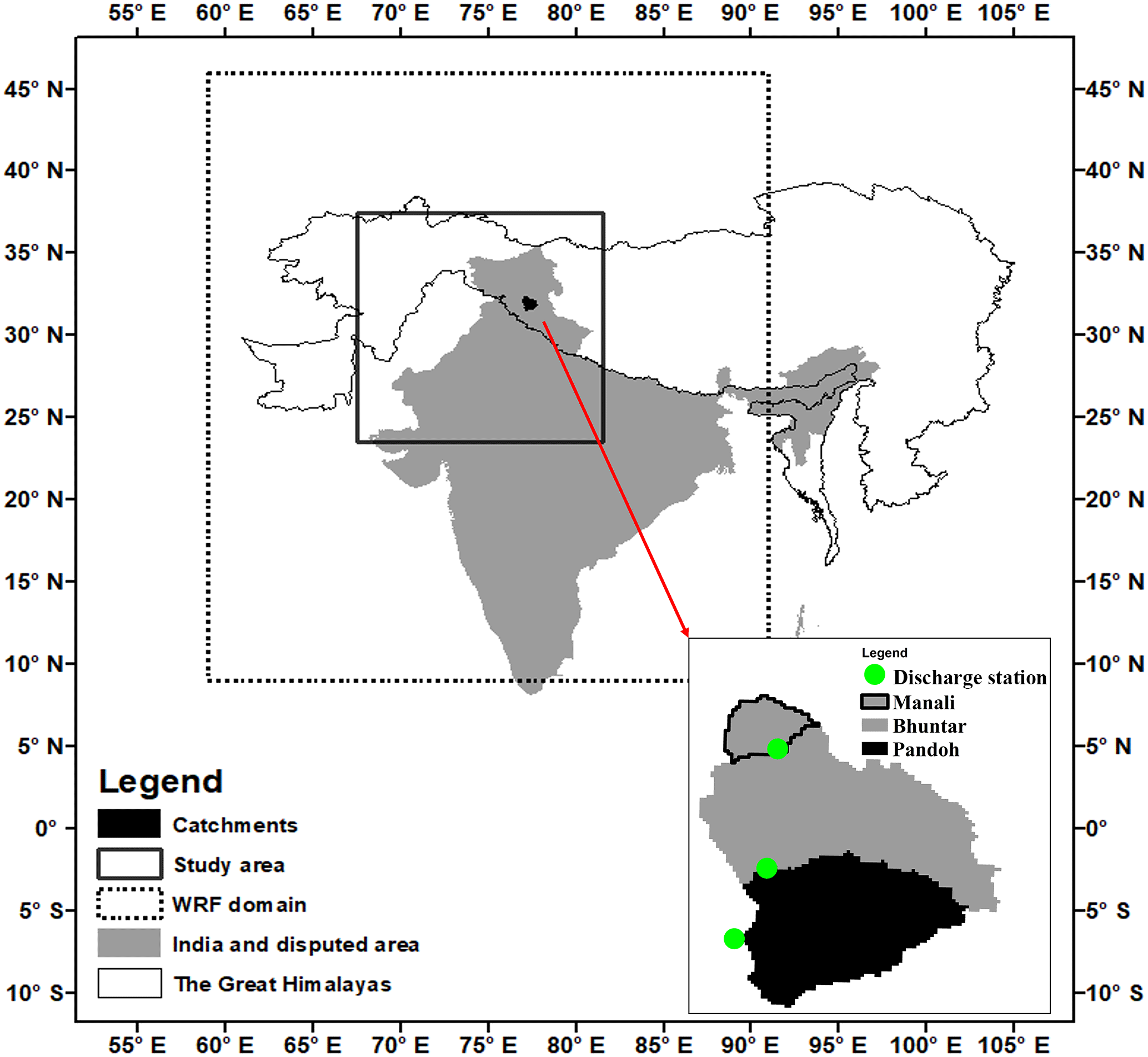
Figure 1Location map of the study area, the Bhuntar rain gauge and three discharge stations.

Figure 2Mean annual precipitation (1981–2007) of the four datasets (from a IMD gridded observations, ERA-Interim reanalysis, APHRODITE gridded observations and WRF regional climate model simulation) and terrain height of the study area (e).
In recent years, with development of space-borne measurements and computing technologies, gridded precipitation datasets have been widely generated and attract much interest. Compared to measurements at traditional gauge, gridded data can cover a large area, sometimes even the globe, and disclose spatial variability at a continuous surface. Additionally, gridded data are usually produced by researchers for scientific purposes and they are free accessible to scientific research. Therefore, gridded data have been extensively used, particularly where high-quality in situ measurements are not available.

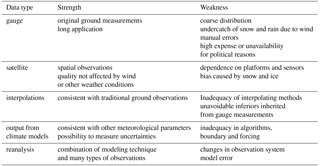
There have been quite a few studies on precipitation over the Great Himalayas region (Ménégoz et al., 2013; Palazzi et al., 2013; Yatagai et al., 2012). The available gridded data fall into four types: satellite data, interpolation of gauge observations, reanalysis and model simulation. However, all estimates are generally very uncertain due to the complex climate dynamics and local topography, and precipitation rates differ widely among the four types, even among different products of the same type. The satellite images show discrepancies due to platforms and characteristics of sensors. Reflectance from land surface, particularly snow and ice, can cause distinctive biases (Yin et al., 2008). The interpolated observations are usually believed the most reliable. However, great cautions have to be paid when using such data due to inadequacy of interpolating methods and unavoidable inferiors inherited from gauge measurements. For example, underestimation of precipitation could be 58 % of annual total precipitation in the cold Alaska region due to wind, wetting loss and trace precipitation (Yang et al., 1998). High-resolution climate models provide an alternative perspective and the models are competitive in the aspects of high spatio-temporal resolution, identification of precipitation forms (Ménégoz et al., 2013), and internal consistency between climate parameters. On the other hand, the simulated data may misrepresent the reality and suffer from inadequacy of boundary and forcing conditions. Reanalysis data are a combination of observations from many sources and dynamic models, but users should be cautious because of continuous changes in observing systems and systematic model errors (Dee et al., 2011). Additionally, uncertainties in reanalysis data are difficult to understand and quantify (Dee et al., 2011). The weaknesses and strength of each type are summarized in Table 1.
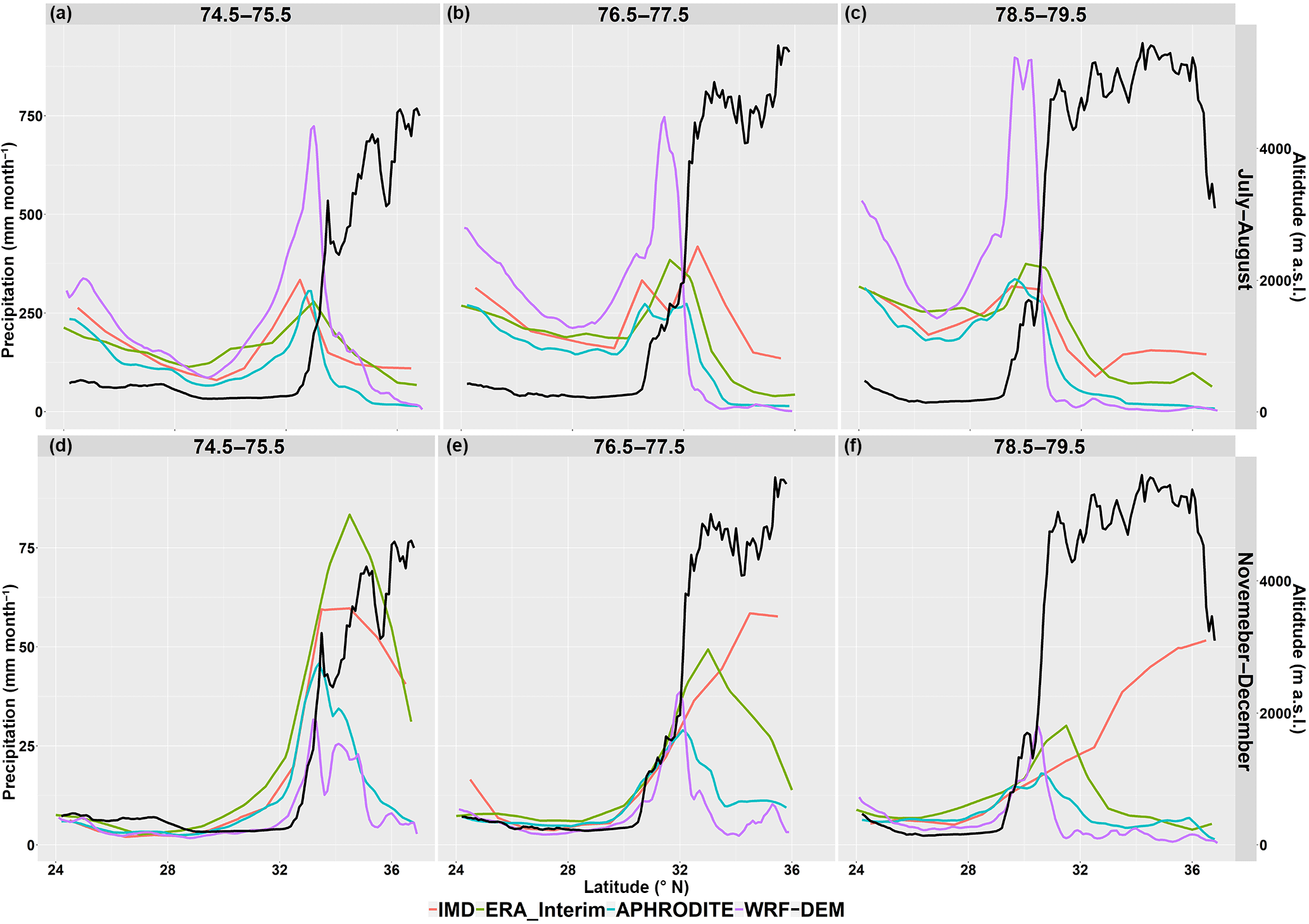
Figure 4Precipitation (mm month−1) for July–August (a, b, c) and November–December (d, e, f) and in three selected longitude bands from west to east (left to right) plotted against latitude. The longitude value of each band is indicated above the figures. The corresponding terrain height (m) in black is displays at the right axis.
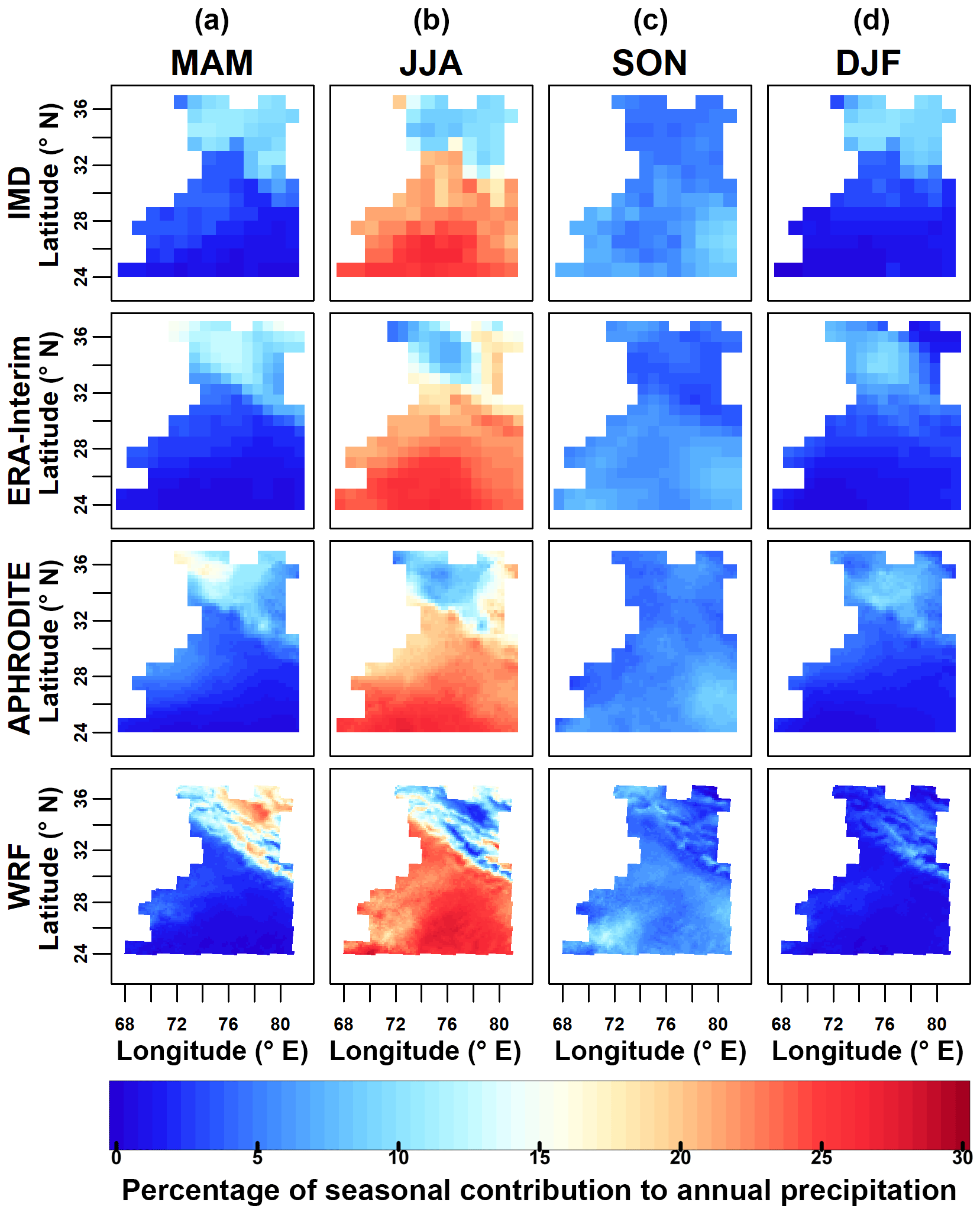
Figure 5Seasonal contributions (in %) to annual precipitation. (a) spring (MAM), (b) summer (JJA), (c) autumn (SON) and (d) winter (DJF). From bottom to top: WRF regional climate model, APHRODITE gridded observations, ERA-Interim reanalysis and IMD gridded observations.
Table 1Summary of weaknesses and strength of four types of gridded precipitation data.
In this study, we select four datasets from various sources, i.e., interpolation of gauge observations, reanalysis and model simulations in northern India of the Western Himalayas as well as measurements at one rain gauge. Due to differences in availability, a common analysis is based on daily data in a long period of 27 years (1981–2007). To our knowledge, this is the first of its kind in this region in terms of number of datasets and data length. The purpose is to compare the datasets and to find their similarity and difference, as well as implications for further use in hydrological studies.
The study area lies in the western part of the Indian Himalayan region (Fig. 1). The highest point is 7677 m above sea level (m a.s.l.), located in the northeastern region. The low-elevation part lies in the southwestern region, which adjoins Pakistan. The climate is affected by monsoon and western disturbance. In summer, warm moisture from the Indian Ocean moves northwards and turns westward when it hits the high mountains. This interaction brings plenty of precipitation and daily precipitation can be more than 200 mm (Purohit and Kau, 2016). Precipitation in high mountains usually falls as snow in winter. Along the course of the moist wind, precipitation decreases from east to west. In winter, the climate is controlled by western turbulence. The mid-latitude low-pressure systems bring some snowfall (Ménégoz et al., 2013), but winter is generally quite dry, especially in the coldest region. In this study, seasons are referred based on northern meteorological seasons (spring: March to May; summer: June to August; autumn: September to November; winter: December to February).

This area is the headwater of the Indus River and the Ganges River, which are transboundary among China, India, Pakistan and Bangladesh. Additionally, these two rivers have very high hydropower potential. How to explore hydropower is continuously negotiated among the involved countries, which makes the study area very political sensitive.
3.1 IMD dataset
The IMD dataset is produced by the India Meteorological Department for the whole India. The time period is 1951–2007 and the spatial resolution is . The data are interpolated from gauge measurements by using the Shepard method (Shepard, 1968). Rajeevan et al. (2006) compare the IMD dataset with the Variability Analysis of Surface Climate Observations (VASClimo) dataset and conclude that the IMD dataset is more accurate in terms of spatial variation. The IMD dataset has been extensively used in climate related research and applications, such as validation of climate models (Bollasina et al., 2011; Wiltshire, 2014) and monsoon variability and predictions (Goswami et al., 2006).
The number of used gauges varies during the period as well as spatially across the region. The average number of gauges per grid point is 2.99 ranging from 0.2 to 4.4 (Rajeevan et al., 2006). Spatially, more gauges are used in the central south; less gauges near the borders of India and in the northern part. No gauge measurements are available near the latitude of 35.5∘ N and northward.
3.2 APHRODITE dataset
The APHRODITE (Asian Precipitation – Highly Resolved Observational Data Integration Towards Evaluation of Water Resources) dataset is interpolated by the Sphere map method based on data collected at 5000–12 000 gauges (Yatagai et al., 2012). The interpolated parameter is the precipitation anomaly or ratio, instead of the precipitation amount (Yatagai et al., 2012). Elevation corrections are considered by a weighting function, which is based on the angular distance when considering topography (Yatagai et al., 2012). The dataset covers Asia over the period of 1951–2007. Different versions of the APHRODITE dataset have been used to determine Asian monsoon precipitation change, hydrological modeling (Pechlivanidis and Arheimer, 2015; Xu et al., 2016), verification of high-resolution model simulations and satellite precipitation estimates (Kamiguchi et al., 2010). In this research, we use the latest version (V1101) for monsoon Asia at a spatial resolution of (Dimri et al., 2013). The APHRODITE dataset uses the largest number of gauge observations among interpolated products, and is believed to be one of the most realistic precipitation datasets for Asia (Ménégoz et al., 2013).
3.3 ERA-Interim dataset
The ERA-Interim dataset is the precipitation product of ERA-Interim (Dee et al., 2011), which is a spatially and temporally complete dataset of multiple climate variables at high spatial and temporal resolution. The data we use here are on a Gaussian grid (with a resolution of at the Equator) with a 3 h time resolution, and aggregated to daily time step. ERA-Interim is a global atmospheric reanalysis dataset produced by the ECMWF (European Center for Medium-Range Weather Forecasts)1. The dataset dates back to 1979 and is updated with approximately 1-month delay from real time. The data assimilation system is based on a 2006 release of the IFS (Cy31r2) (Dee et al., 2011). This dataset has been widely used as boundary and forcing conditions for regional climate models (Dimri et al., 2013; Katragkou et al., 2015).
3.4 WRF dataset
The WRF dataset is generated by using a regional climate model, the Weather Research & Forecasting Model (v3.7.1). The climate model is a limited-area, non-hydrostatic, primitive-equation model with multiple options for various physical parameterization schemes. The model has been used in climate simulation in Asia and other areas (Li et al., 2016; Maussion et al., 2011). Here we use the Thompson scheme for microphysics, CAM for short- and long-wave radiation, the Noah Land-Surface scheme, Mellor–Yamada–Janjic TKE for the planetary boundary layer and Kain–Fritsch (new Eta) for convection. The model is forced by 6-hourly ERA-Interim reanalysis data. To avoid error at boundary edges and to facilitate further hydrological modeling work, we set up the model at a very large domain (59–91∘ E, 9–46∘ N). The spatial resolution is around 16 km, where topography and land use are aggregated from data with an accuracy of 10 m. They are preprocessed by using the WRF Preprocessing System (WPS). We divide the atmosphere into 30 vertical layers with model top pressure 50 hPa. The height of the lowest model level varies between 15 and 27 m depending on the surface pressure. The whole simulation period is from 1979 to 2007, and the period 1979–1980 is used as model spinup. Due to the long model running time, we restart the model around every 5 years. Model setup is summarized in Table 2 and the whole setting is a file in the Supplement.
3.5 Gauge data
Rain gauge Bhuntar lies in a valley at a small town in the state of Himachal Pradesh, India (Fig. 1). The Bhuntar gauge is only 400 m down the confluence of the Parvati River with the Beas River. The altitude of the gauge is 1080 m a.s.l., and both precipitation and discharge data are used in this study. Annual precipitation is 921 mm year−1 based on data from 1981 to 2007, with most rainfall in July and August. Temperature is rarely below 0 ∘C, and only minimum temperature is occasionally below 0 ∘C in winters. The precipitation data have been used in hydrological modeling research for the Beas Basin (Li et al., 2015).
Table 2The main settings of the WRF regional climate model. The complete setting are shown in the Supplement.
Table 3P value of the tailed Kolmogorov–Smirnov test on differences of on annual precipitation (mm year−1) among the datasets. The p value indicates strong evidence against the null hypothesis. It is typically to reject the null hypothesis, which is two datasets are the same here, when the p value is not greater than 0.05.

3.6 Discharge
Three discharge series are selected to cross validate water balance. They are respectively Pandoh (downstream), Bhuntar (middle stream) and Manali (upstream). These stations are operated by Central Water Commission regional office in India. The catchments are located in the Beas Basin, which is a main tributary of the Indus River in northern India (Fig. 1). The catchments are nested from upstream to downstream. The purpose is to reflect precipitation data at various elevations within a hydrological scale. Runoff is considerably influenced from glacier melting (Li et al., 2015). According to the 0.5 km MODIS-based Global Land Cover Climatology by the USGS Land Cover Institute (https://landcover.usgs.gov/global_climatology.php, last access: 1 May 2017), coverage of snow and ice is 16 % in the Pandoh catchment, 24 % in the Bhuntar catchment and 21 % in the Manali catchment. The discharge data have been manually quality controlled and missing data are filled by discharge anomaly. Discharge measurements are more qualified than precipitation in the snow and ice dominated area (Henn et al., 2015; Kretzschmar et al., 2016). Therefore, the quality of runoff simulation can infer by the forcing precipitation data. Li et al. (2016) use the WRF-Hydro (v3.5.1) modeling system in the Beas Basin, and they find that the distribution of simulated daily discharge values agrees well with observations, which reversely confirms the precipitation simulations.
3.7 Evaporation
The MODIS Global Evapotranspiration Project (MOD16) (http://www.ntsg.umt.edu/project/modis/mod16.php, last access: 1 May 2017) is selected to reveal actual evaporation. The MODIS project is started in 2000, and has a short overlap period with the study period. Additionally, part of the catchments is covered by permanent snow and ice and the sensors cannot work well on this type surface. Therefore, we use annual mean amounts of 2000 to 2013 to reduce uncertainties. The missing ratios of annual mean actual evaporation are 22 % for the Pandoh catchment, 32 % for the Bhuntar catchment and 31 % for the Manali catchment.
4.1 Spatial variations
The four datasets show similar spatial pattern of mean annual precipitation (Fig. 2). The highest precipitation is located at the foothill of the mountains and stretched from southeast to northwest. Visually, the high precipitation belt (the foothills of the mountains and the southeastern corner) is most clearly shown by the WRF dataset. The spatial variability increases from the IMD dataset to the WRF dataset. Their coefficients of variation are respectively 0.5 for the IMD data, 0.6 for the ERA-Interim data, 0.7 for the APHRODITE data and 1.1 for the WRF data. The density curves of mean annual precipitation values in all grid points (Fig. 3) and the statistics of the Kolmogorov–Smirnov test (Table 3) show the variabilities and the differences among the datasets more clearly.
Both the IMD and APHRODITE datasets are interpolated from observations at gauges. However, the APHRODITE dataset shows a rain belt at the mountains' foothills much better. Additionally, the APHRODITE dataset shows much lower estimates (less than 300 mm year−1) in the northeastern corner. This area is quite high, with mean elevation at 4650 m a.s.l. and elevation ranges from 906 to 7677 m a.s.l. The temperature is −2.35 ∘C of annual mean and as low as −16.81 ∘C in January (Yatagai et al., 2012). The reason for this low-precipitation area is that the APHRODITE dataset uses more gauges, particularly also observations from Nepal, Bhutan and China (Yatagai et al., 2012). These gauges have undercatch problems, which means rain gauges could only catch part of snowfall due to wind and disturbance. In contrast, the IMD dataset uses only the gauges in the low-valley area of India and extends north by interpolation (Rajeevan et al., 2006). Eventually, the APHRODITE dataset has the lowest annual amount, only 61 % of the IMD dataset.
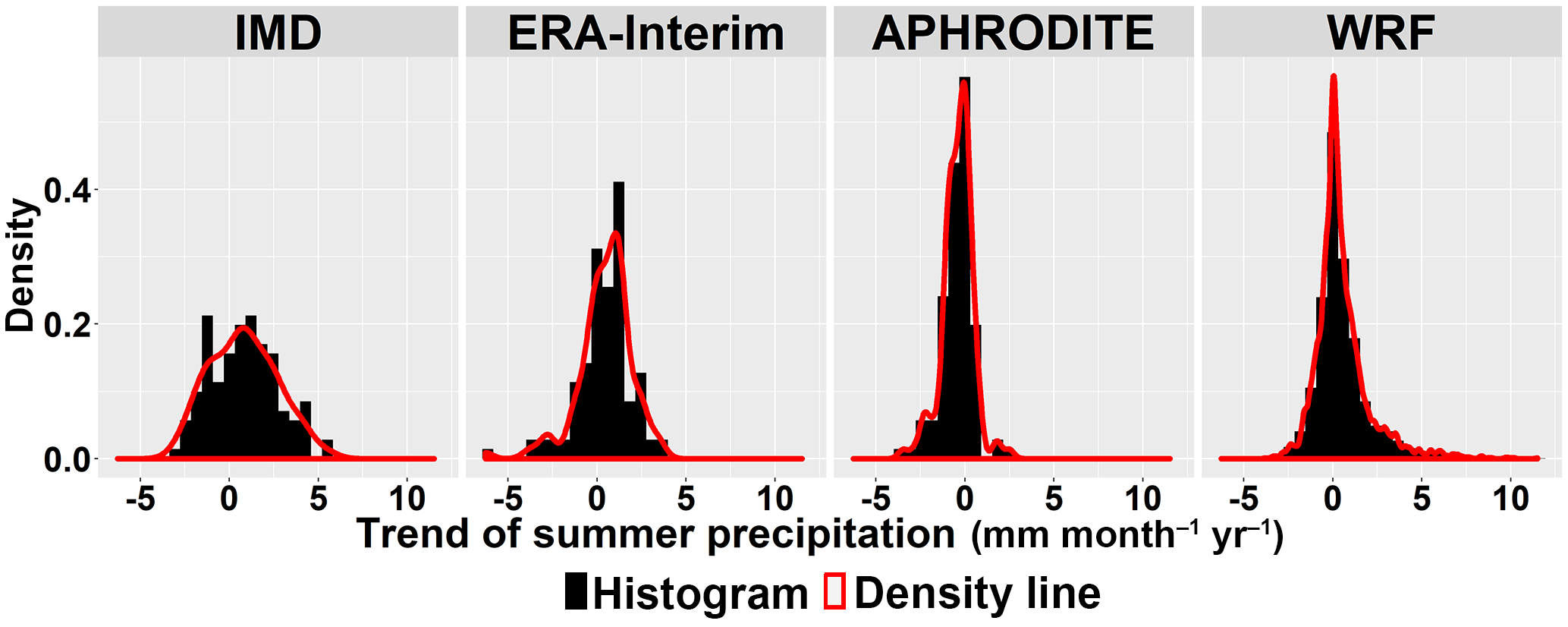
Figure 8Density curves of trends (mm month−1 year−1) of summer precipitation in all grid points.
The ERA-Interim and WRF datasets are products with different dynamical models. The ERA-Interim data and the WRF data are similar in terms of annual total amount (ERA-Interim: 718 mm year−1, WRF: 688 mm year−1) and spatial pattern, partially due to the fact that in this area the observations that are assimilated into the data assimilation system are sparse and unevenly distributed. The WRF data are more realistic than the ERA-Interim data due to finer spatial resolution, especially in complex topography areas (Dimri et al., 2013; Ménégoz et al., 2013).
The effects of location and topography are shown in Fig. 4. The summer precipitation changes dramatically. Over the high flat plateau, precipitation decreases with latitude since the strength of the monsoon decreases with distance from its source. As the monsoon gets closer to the mountains, precipitation starts to increase. As the air parcel is lifted to high elevation, climate gets dry and cold. The winter precipitation occurs mainly along the upslope. The magnitude is also small and decreased along the path of the winter monsoon. The highest precipitation occurs in the windward of the upslope region, but it is 0.5 or 1.5∘ (around 55–110 km) far away from the mountains in summer. Bookhagen and Burbank (2006) analyze a decade of TRMM data and also find the highest annual precipitation is offset by a few 10 s of km south of either high topography or relief. This offset has been found only over tall and broad mountain regions rather than narrow mountain peaks (Dimri and Niyogi, 2013).
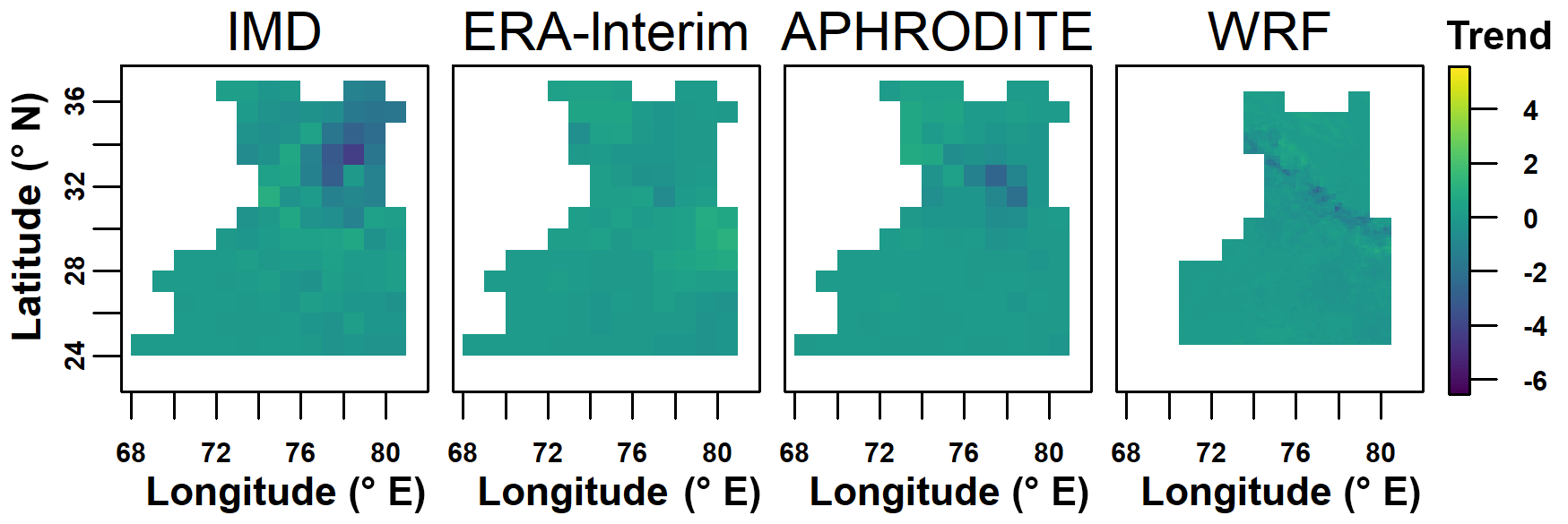
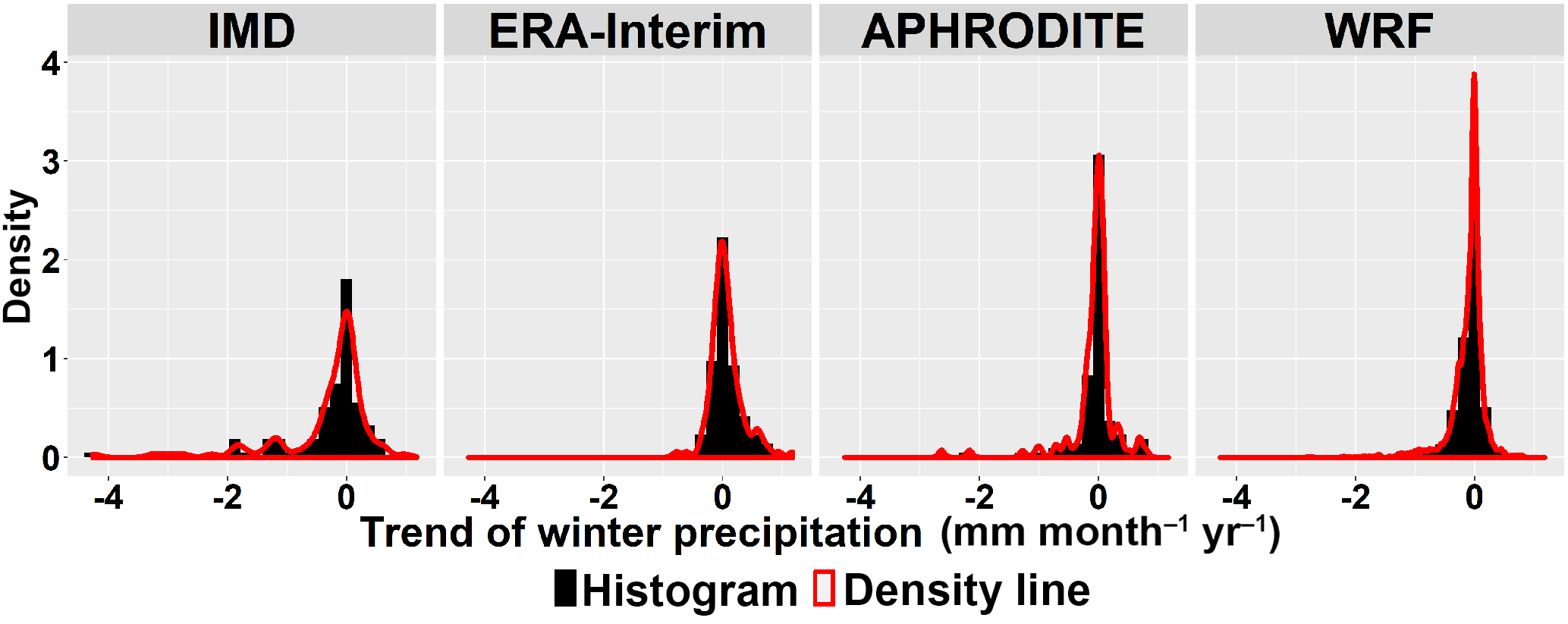
Figure 10Density curves of trends (mm month−1 year−1) of winter precipitation in all grid points.
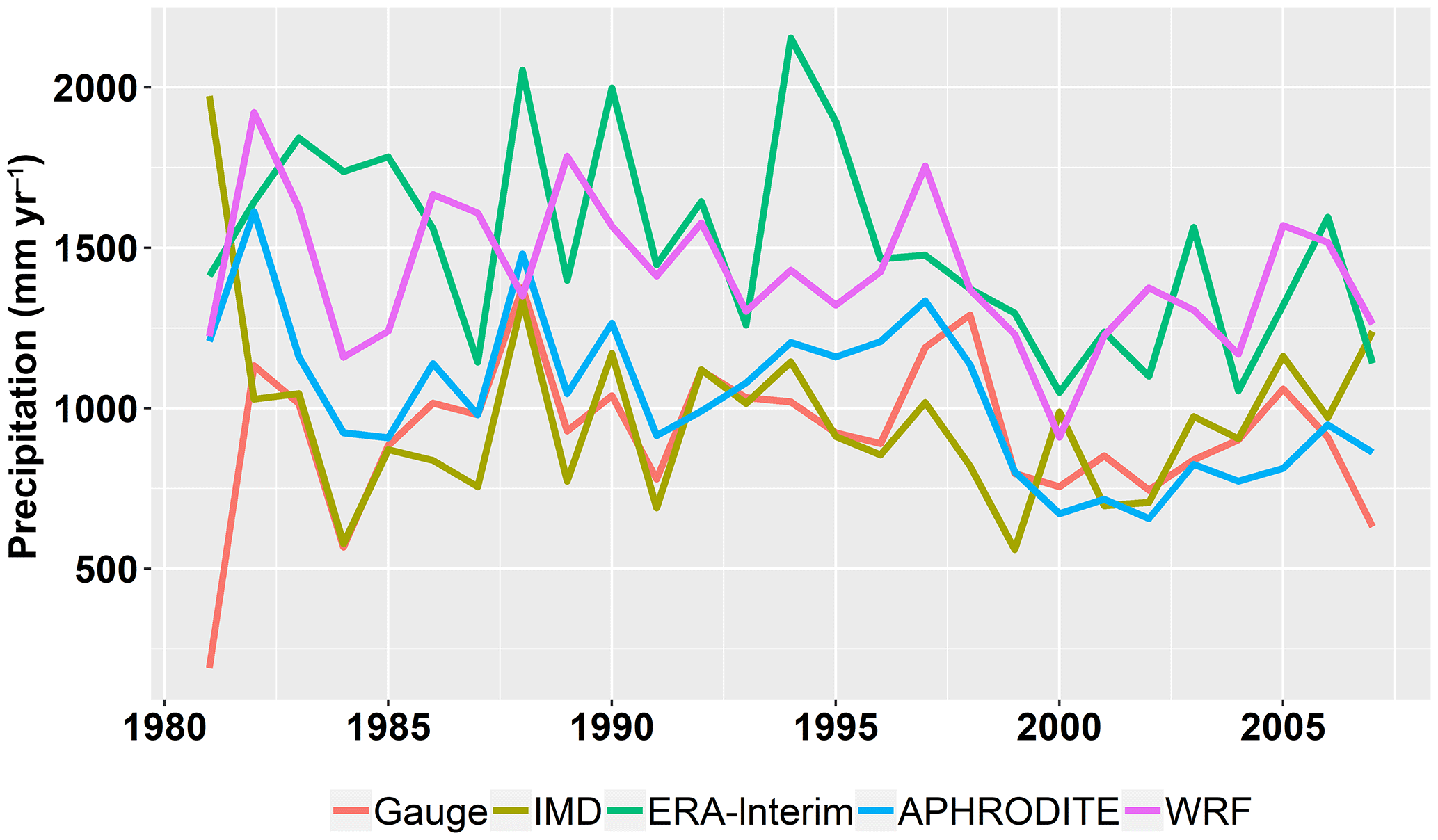
Figure 11Annual precipitation at the Bhuntar gauge. Data at the nearest point to the Bhuntar gauge are extracted from the gridded datasets.
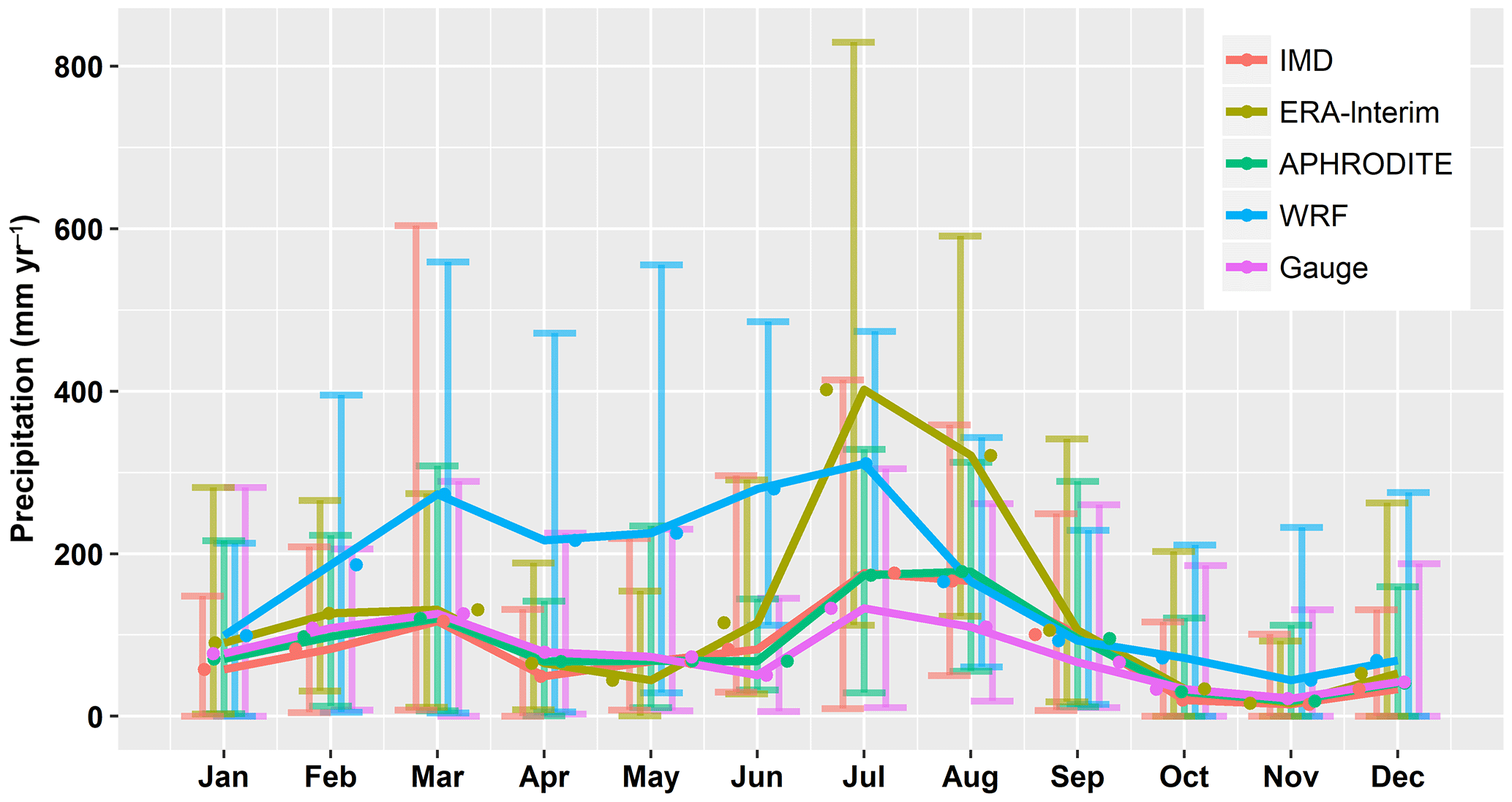
Figure 12Monthly anomaly at the Bhuntar gauge. Data at the nearest point to the Bhuntar gauge are extracted from the gridded datasets.
The differences among the datasets are more obvious in summer at the mountain foot. The WRF dataset gives much more precipitation (700 mm month−1) in July and August at the mountain foot, almost 2 times that of other datasets (300 mm month−1). This is reported as a moisture bias in summer (Li et al., 2016; Srinivas et al., 2013). It is often cited as orographic bias which describes as strong overprediction of precipitation rates along windward slopes while predicted snowfall lies under measured values along leeward slopes (Maussion et al., 2011).
4.2 Temporal variations and changes
The inter-annual patterns are very similar as indicated by high correlations between pairs of datasets, shown in Table 4. The correlation between the IMD and APHRODITE datasets is the highest, reaching 0.91. The WRF dataset has low correlation with all other datasets. Spatially, the four datasets show a similar seasonal distribution, and the WRF dataset has the highest variability (Fig. 5). The intra-annual cycle is also similar as shown in Fig. 6. The WRF and APHRODITE datasets have respectively the highest and lowest precipitation in summer.
Table 4Pearson's correlation of annual precipitation series. The italics indicate the minimum values by row and by column.

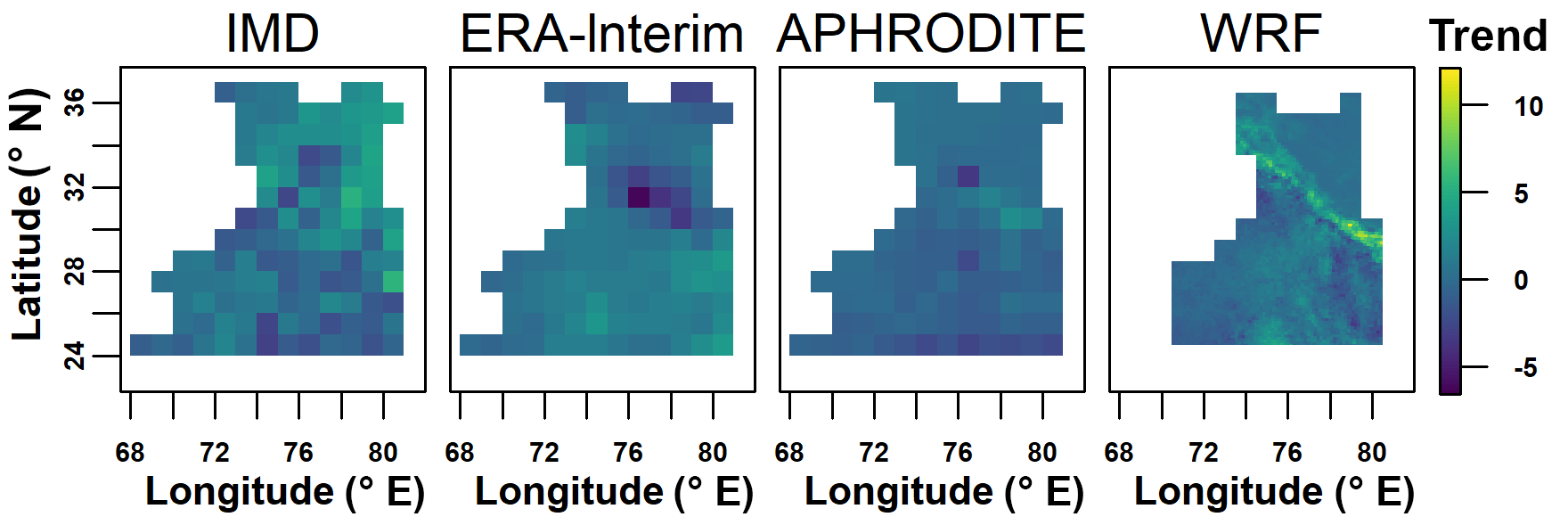
To look at changes over time, we select the Theil–Sen median method to calculate trends due to its robustness and the non-parametric Mann–Kendall test for the significance test. The trend analysis and significance test are done for the areal mean of each month (Fig. 6), and every individual grid for summer (Figs. 7 and 8) and winter (Figs. 9 and 10). The figures show an increase in summer precipitation and a decrease in winter precipitation, although both increase and decrease exist in each dataset. Three of the areal mean trends (May by the WRF dataset; June by the IMD and ERA-Interim datasets) are statistically significant at the 95 % confidence level. The spatial distribution of trends in summer precipitation varies a lot. Most decreasing trends of winter precipitation occur in the northern part. Approximately 10 % of grids are significant at the 10 % confidence level.
Table 5Statistics of annual maximum daily precipitation (mm day−1) at the Bhuntar gauge. Data of the nearest point are extracted from the gridded datasets. Bold indicates the value closest to the data of the Bhuntar gauge.
It is difficult to conclude why northern India of the Western Himalayas shows an increase in summer precipitation. However, Bollasina et al. (2011) find the same increasing monsoon precipitation in northern India but decreasing monsoon precipitation in central Asia. They use a series of climate model experiments, and conclude that such pattern is a robust outcome of a slowdown of the tropical meridional overturning circulation, which could be attributed mainly to human-influenced aerosol emissions. The trends will continue and become more significant with time if greenhouse gas emission continues as usual. Such trends would lead to strong negative mass balance conditions of glaciers, which is discussed in the next section.
5.1 Comparison of gridded precipitation datasets with gauge data
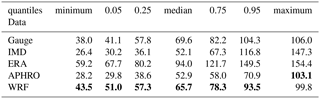
To compare the gridded datasets with measurements at the Bhuntar gauge, we extract the time series at the nearest point to the Bhuntar gauge. We look at annual precipitation (Fig. 11), monthly anomaly (Fig. 12) as well as extreme precipitation, i.e., annual maximum daily precipitation (Table 5). As shown in Fig. 11, all gridded datasets are comparable with the Bhuntar gauge data. The interpolated datasets, IMD and APHRODITE are quantitatively closest to the Bhuntar gauge data. The ERA-Interim and WRF datasets generally give 2 or 3 times higher precipitation than the Bhuntar gauge data. Figure 12 shows the differences are mainly from March to July in the WRF dataset, and from July and August in the ERA-Interim dataset. In addition, the WRF dataset shows large variations from February to June, and the ERA-Interim dataset shows large variations in July and August. Table 5 shows the statistics of annual maximum daily precipitation. Notably, the WRF dataset gives the closest estimate to the Bhuntar data in five quantiles, and the APHRODITE dataset gives the best estimate of the maximum precipitation over the whole period.
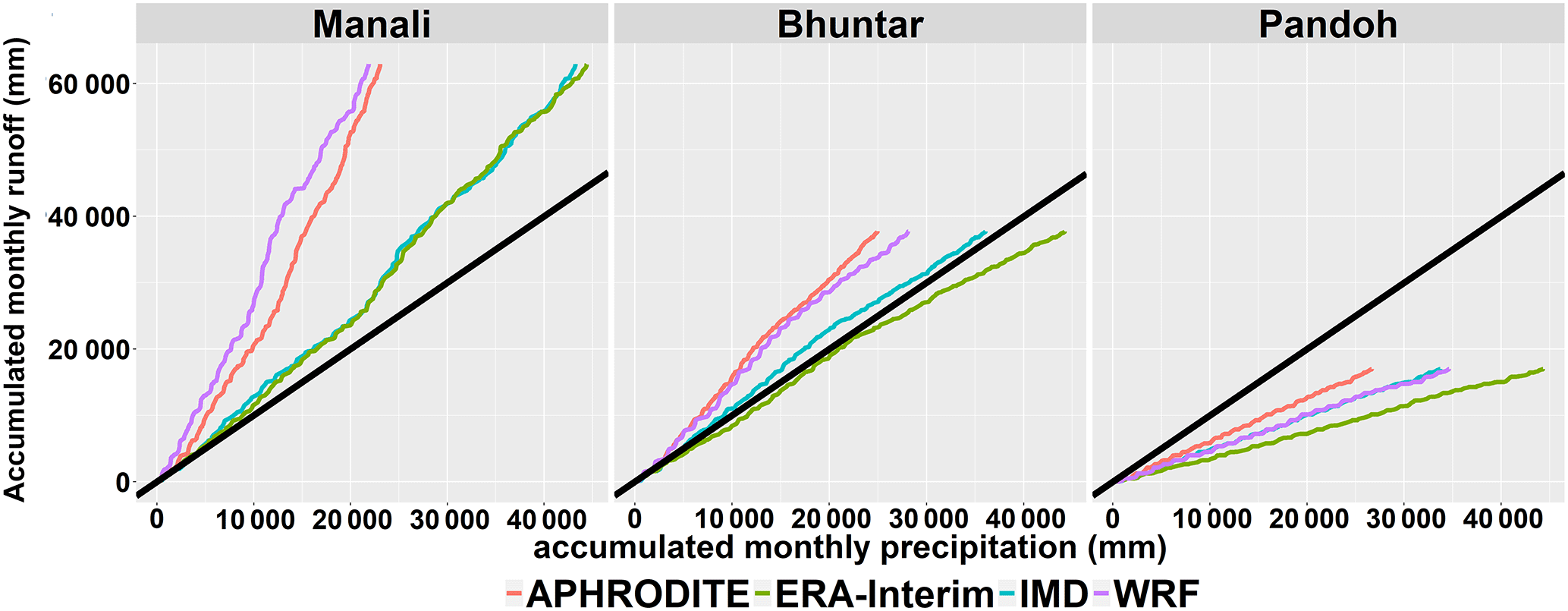
5.2 Comparison of gridded precipitation datasets with runoff data
The annual actual evaporation from MODIS data is 614 mm year−1 at the Pandoh catchment, 639 mm year−1 at the Bhuntar catchment and 649 mm year−1 at the Manali catchment. The values are too high compared with 64 mm year−1 at the Pandoh catchment for the period from 1990 to 2004 calculated by Kumar et al. (2007) using potential evaporation, mean and maximum temperature. The Pandoh catchment covers the lower and middle parts, and should have the highest evaporation due to warm climate among three catchments. The MODIS data are not qualified at the catchments and at small catchment scales for the study period.
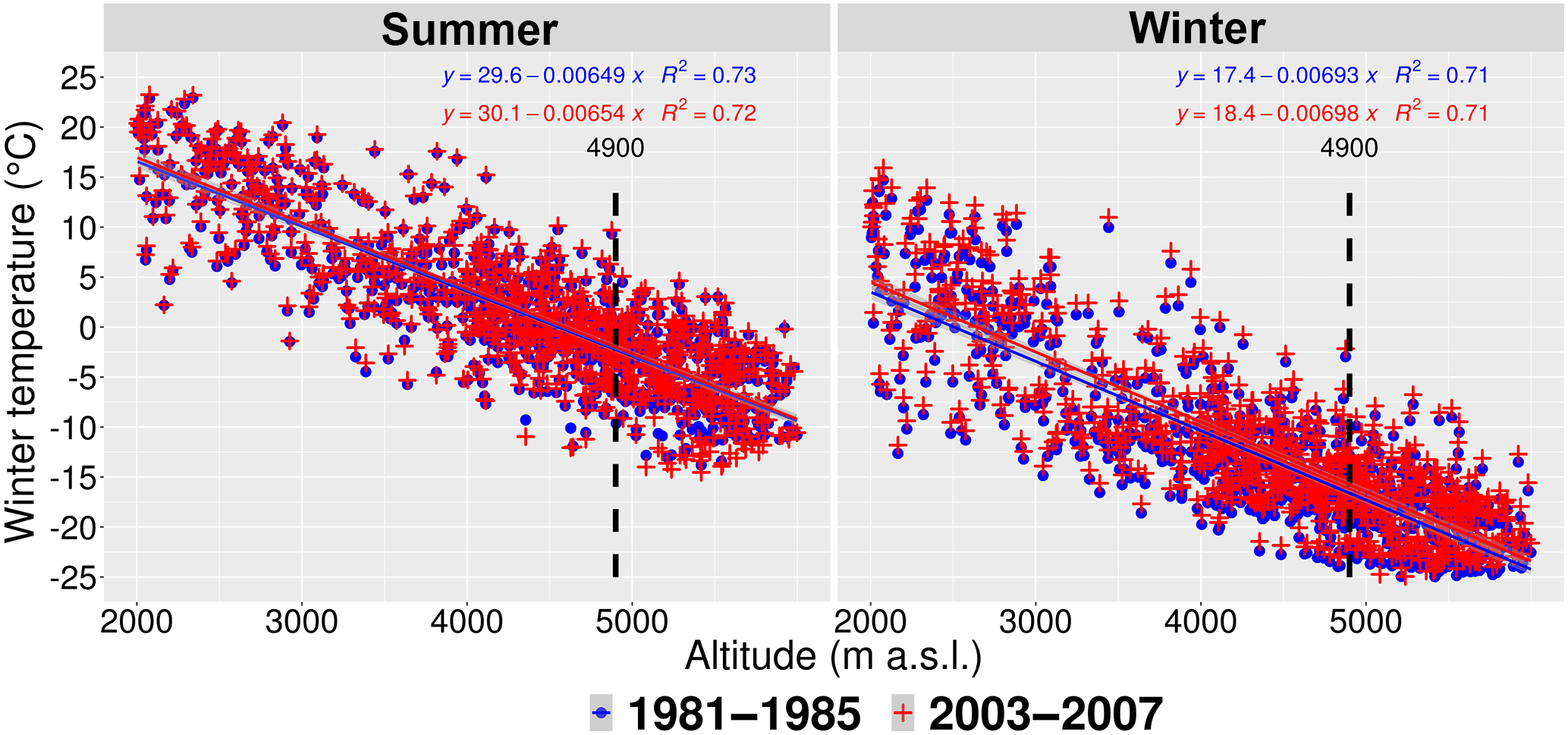
Figure 14Mean temperature and its regression lines for the periods of 1981–1985 and 2003–2007 by the WRF simulation.
The precipitation and runoff relationship is shown in Fig. 13 as accumulation of monthly precipitation and runoff. Though the lines have different slopes, but they share very similar linear relationships. They are consistent in terms of temporal changes. Errors are systematic within each dataset. Runoff is generally less than precipitation due to evaporation loss. However, runoff could possibly exceed precipitation at glacierized catchments due to glacier melting. In the Manali catchment, runoff is much more than precipitation. In the Bhuntar catchment, only the ERA-Interim data show less runoff than precipitation. All datasets show less runoff than precipitation in the Pandoh catchment. Precipitation is definitely underestimated in higher-elevation areas, especially in the Manali catchment. Azam et al. (2014) reconstruct annual mass balance of Chhota Shigri glacier since 1969. The Chhota Shigri glacier lies in the Western Himalayas, India and it is representative in terms of mass balance for the Western Himalayas glaciers (Azam et al., 2014). The mass loss rates are 0.36±0.36 for 1969 to 1985 and 0.57±0.36 m water equivalent per year (m w.e. a−1) for 2001 to 2015. The runoff contribution from glacier melting is only 3306 mm within 29 years with assumptions of 20 % glacier coverage and −0.57 m w.e. a−1.
5.3 Implications for glaciers
In the Great Himalayas region, there are many glaciers, and they are key indicators of regional climate change and water resources. Temperature in combination with precipitation controls survival of glaciers. Therefore, we also look at changes in temperature by comparing the temperature results by the same simulation of the WRF precipitation dataset for the first and last 5 years, namely 1981–1985 and 2003–2007. We skip the trend analysis and significance test, because it is already well known that temperature has been increasing quickly in the Great Himalayas region since the 1980s (Ren et al., 2017). Temperature is well measured and simulated. Therefore, there is no need to go through many datasets. We are particularly interested in temperature at the equilibrium line altitude (ELA). As the slope of the regression lines shown in Fig. 14, the WRF model is able to reproduce the lapse rates. Between the two 5-year periods, temperature increases by 0.91 ∘C in winter and by 0.26 ∘C in summer. Such changes lead to an increase in the elevation of the freezing point (0 ∘C) of 125 m in winter and 32 m in summer. As shown in Sect. 4.2, precipitation overall decreases in winter. In combination with increasing temperature, this is an unfavourable condition for the glaciers with less accumulation and faster melting. Moreover, the area between 4900 m a.s.l., which is the equilibrium line altitude (ELA) of the Chhota Shigri glacier (Azam et al., 2012), and 5200 m a.s.l. is large. Therefore, as the climate gets warmer, the ELA will further move up. Such a nonlinear characteristic of elevation distribution results in a potential large reduction in the accumulation area and small storage buffer of permanent snow and ice.
Data scarcity is a major problem for hydrological research in the Great Himalayas region. High-quality precipitation data are difficult to obtain due to the sparse network, cold climate and high heterogeneity in topography. This paper investigates the spatial and temporal pattern of precipitation in this region based on four datasets: interpolated gridded data based on gauge observations (IMD, and APHRODITE, ), reanalysis data (ERA-Interim, ) and high-resolution simulation by a regional climate model (WRF, ) in northern India of the Western Himalayas during the period 1981–2007.
The four datasets are similar in terms of spatial pattern and temporal variation and changes, though the absolute values vary a lot (497–819 mm year−1) due to the data source and the methods of data generation. The differences are particularly large in July and August and at the windward slopes and the high-elevation areas. The datasets reveal that summer gets wetter and winter gets drier, though most of the trends are not statistically significant. Wetter summer results in more and bigger floods at the downstream areas. Warmer and drier winter results in less glaciers accumulation. The four datasets are able to give a good overview of spatial pattern and temporal changes. Comparison with measurements at the Bhuntar gauge shows that the WRF and APHRODITE datasets give the best estimate of extreme precipitation amounts. To conclude, the APHRODITE and WRF datasets are recommended for hydrological studies due to their improved spatial variations which match the scale of hydrological processes as well as accuracy in extreme precipitation for flood simulation. However, careful local correction is definitely required.
The ERA-Interim and APRODITE data are available from the data provider sites. The WRF data are available via https://archive.norstore.no/pages/public/about.jsf (last access: 1 May 2017).

Figure A1Precipitation of the gridded datasets and terrain height of the study area resampled to the IMD grid by bilinear interpolation.
Table A1Statistics of the non-parametric Mann–Kendall test of precipitation.

The supplement related to this article is available online at: https://doi.org/10.5194/hess-22-5097-2018-supplement.
HL: model simulation, data analysis and writing. JEH: model simulation, analysis of results, review and revision. CYX: review and revision.
The authors declare that they have no conflict of interest.
This article is part of the special issue “The changing water cycle of the Indo-Gangetic Plain”. It is not associated with a conference.
This study is funded by the Research Council of Norway through research
program NORKLIMA under grant project 216546. We thank the India
Meteorological Department and Sonia Grover at the Water Resources Division at
TERI (India), the European Centre for Medium-Range Weather Forecasts and
APHRODITE (http://www.chikyu.ac.jp/precip/english/products.html, last
access: 1 May 2017), and research program JOINTINDNOR under grant project
203867 for provision of data. We thank Oskar Landgren at the Norwegian
Meteorological Institute for help in modeling and data analysis as well as
review of the manuscript. The model simulation was done when the first author
worked at the Norwegian Meteorological Institute.
Edited by: Ian Holman
Reviewed by: four
anonymous referees
Azam, M. F., Wagon, P., Ramanathan, A., Vincent, C., Sharma, P., Arnaud, Y., Linda, A., Pottakkal, J. G., Chevallier, P., Singh, V. B., and Berthier, E.: From balance to imbalance: a shift in the dynamic behaviour of Chhota Shigri glacier, western Himalaya, India, J. Glaciol., 58, 315–324, https://doi.org/10.3189/2012JoG11J123, 2012. a
Azam, M. F., Wagnon, P., Vincent, C., Ramanathan, A., Linda, A., and Singh, V. B.: Reconstruction of the annual mass balance of Chhota Shigri glacier, Western Himalaya, India, since 1969, Ann. Glaciol., 55, 69–80, https://doi.org/10.3189/2014AoG66A104, 2014. a, b
Bollasina, M. A., Ming, Y., and Ramaswamy, V.: Anthropogenic Aerosols and the Weakening of the South Asian Summer Monsoon, Science, 334, 502–505, 2011. a, b
Bookhagen, B. and Burbank, D. W.: Topography, relief, and TRMM-derived rainfall variations along the Himalaya, Geophys. Res. Lett., 33, L08405, https://doi.org/10.1029/2006GL026037, 2006. a
Dee, D. P., Uppala, S. M., Simmons, A. J., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Balmaseda, M. A., Balsamo, G., Bauer, P., Bechtold, P., Beljaars, A. C. M., van de Berg, L., Bidlot, J., Bormann, N., Delsol, C., Dragani, R., Fuentes, M., Geer, A. J., Haimberger, L., Healy, S. B., Hersbach, H., Hólm, E. V., Isaksen, L., Kållberg, P., Köhler, M., Matricardi, M., McNally, A. P., Monge-Sanz, B. M., Morcrette, J.-J., Park, B.-K., Peubey, C., de Rosnay, P., Tavolato, C., Thépaut, J.-N., and Vitart, F.: The ERA-Interim reanalysis: configuration and performance of the data assimilation system, Q. J. Roy. Meteor. Soc., 137, 553–597, https://doi.org/10.1002/qj.828, 2011. a, b, c, d
Dimri, A. P. and Niyogi, D.: Regional climate model application at subgrid scale on Indian winter monsoon over the western Himalayas, Int. J. Climatol., 33, 2185–2205, https://doi.org/10.1002/joc.3584, 2013. a
Dimri, A. P., Yasunari, T., Wiltshire, A., Kumar, P., Mathison, C., Ridley, J., and Jacob, D.: Application of regional climate models to the Indian winter monsoon over the western Himalayas, Sci. Total Environ., 468–469, 36–47, https://doi.org/10.1016/j.scitotenv.2013.01.040, 2013. a, b, c
Goswami, B. N., Venugopal, V., Sengupta, D., Madhusoodanan, M. S., and Xavier, P. K.: Increasing Trend of Extreme Rain Events Over India in a Warming Environment, Science, 314, 1442–1445, 2006. a
Hegdahl, T. J., Tallaksen, L. M., Engeland, K., Burkhart, J. F., and Xu, C.-Y.: Discharge sensitivity to snowmelt parameterization: a case study for Upper Beas basin in Himachal Pradesh, India, Hydrol. Res., https://doi.org/10.2166/nh.2016.047, 2016. a
Henn, B., Clark, M. P., Kavetski, D., and Lundquist, J. D.: Estimating mountain basin-mean precipitation from streamflow using Bayesian inference, Water Resour. Res., 51, 8012–8033, https://doi.org/10.1002/2014WR016736, 2015. a
Kamiguchi, K., Arakawa, O., Kitoh, A., Yatagai, A., Hamada, A., and Yasutomi, N.: Development of APHRO_JP, the first Japanese high-resolution daily precipitation product for more than 100 years, Hydrological Research Letters, 4, 60–64, https://doi.org/10.3178/hrl.4.60, 2010. a
Katragkou, E., García-Díez, M., Vautard, R., Sobolowski, S., Zanis, P., Alexandri, G., Cardoso, R. M., Colette, A., Fernandez, J., Gobiet, A., Goergen, K., Karacostas, T., Knist, S., Mayer, S., Soares, P. M. M., Pytharoulis, I., Tegoulias, I., Tsikerdekis, A., and Jacob, D.: Regional climate hindcast simulations within EURO-CORDEX: evaluation of a WRF multi-physics ensemble, Geosci. Model Dev., 8, 603–618, https://doi.org/10.5194/gmd-8-603-2015, 2015. a
Kretzschmar, A., Tych, W., Chappell, N. A., and Beven, K. J.: Reversing hydrology: quantifying the temporal aggregation effect of catchment rainfall estimation using sub-hourly data, Hydrol. Res., 47, 630–645, 2016. a
Kumar, V., Singh, P., and Singh, V.: Snow and glacier melt contribution in the Beas River at Pandoh Dam, Himachal Pradesh, India, Hydrolog. Sci. J., 52, 376–388, https://doi.org/10.1623/hysj.52.2.376, 2007. a
Li, H., Beldring, S., Xu, C.-Y., Huss, M., Melvold, K., and Jain, S. K.: Integrating a glacier retreat model into a hydrological model – Case studies of three glacierised catchments in Norway and Himalayan region, J. Hydrol., 527, 656–667, https://doi.org/10.1016/j.jhydrol.2015.05.017, 2015. a, b
Li, H., Xu, C.-Y., Beldring, S., Tallaksen, L. M., and Jain, S. K.: Water Resources under Climate Change in Himalayan Basins, Water Resour. Manag., 30, 843–859, 2016. a
Li, L., Gochis, D. J., Sobolowski, S., and Mesquita, M. d. S.: Evaluating the present annual water budget of a Himalayan headwater river basin using a high-resolution atmosphere-hydrology model, in: EGU General Assembly Conference Abstracts, vol. 18, p. 2480, 2016. a, b, c
Maussion, F., Scherer, D., Finkelnburg, R., Richters, J., Yang, W., and Yao, T.: WRF simulation of a precipitation event over the Tibetan Plateau, China – an assessment using remote sensing and ground observations, Hydrol. Earth Syst. Sci., 15, 1795–1817, https://doi.org/10.5194/hess-15-1795-2011, 2011. a, b
Ménégoz, M., Gallée, H., and Jacobi, H. W.: Precipitation and snow cover in the Himalaya: from reanalysis to regional climate simulations, Hydrol. Earth Syst. Sci., 17, 3921–3936, https://doi.org/10.5194/hess-17-3921-2013, 2013. a, b, c, d, e, f
Palazzi, E., von Hardenberg, J., and Provenzale, A.: Precipitation in the Hindu-Kush Karakoram Himalaya: Observations and future scenarios, J. Geophys. Res.-Atmos., 118, 85–100, https://doi.org/10.1029/2012JD018697, 2013. a
Pechlivanidis, I. G. and Arheimer, B.: Large-scale hydrological modelling by using modified PUB recommendations: the India-HYPE case, Hydrol. Earth Syst. Sci., 19, 4559–4579, https://doi.org/10.5194/hess-19-4559-2015, 2015. a
Purohit, M. K. and Kau, S.: Rainfall Statistics of India – 2016, Tech. rep., India Meteorological Department, available at: http://hydro.imd.gov.in/hydrometweb/(S(0ymurl55bikbhgzupnyvnny0))/PRODUCTS/Publications/Rainfall Statistics of India - 2016/Rainfall Statistics of India - 2016.pdf (last access: 26 September 2018), 2016. a
Rajeevan, M., Bhate, J., Kale, J. D., and Lal, B.: High resolution daily gridded rainfall data for the Indian region: Analysis of break and active monsoon spells, Curr. Sci., 91, 296–306, 2006. a, b, c
Ren, Y.-Y., Ren, G.-Y., Sun, X.-B., Shrestha, A. B., You, Q.-L., Zhan, Y.-J., Rajbhandari, R., Zhang, P.-F., and Wen, K.-M.: Observed changes in surface air temperature and precipitation in the Hindu Kush Himalayan region over the last 100-plus years, Advances in Climate Change Research, 8, 148–156, https://doi.org/10.1016/j.accre.2017.08.001, 2017. a
Shepard, D.: A two-dimensional interpolation function for irregularly-spaced data, in: Proceedings of the 1968 23rd ACM national conference, 517–524, ACM, New York, USA, 1968. a
Srinivas, C. V., Hariprasad, D., Bhaskar Rao, D. V., Anjaneyulu, Y., Baskaran, R., and Venkatraman, B.: Simulation of the Indian summer monsoon regional climate using advanced research WRF model, Int. J. Climatol., 33, 1195–1210, https://doi.org/10.1002/joc.3505, 2013. a
Wiltshire, A. J.: Climate change implications for the glaciers of the Hindu Kush, Karakoram and Himalayan region, The Cryosphere, 8, 941–958, https://doi.org/10.5194/tc-8-941-2014, 2014. a
Xu, H., Xu, C.-Y., Chen, S., and Chen, H.: Similarity and difference of global reanalysis datasets (WFD and APHRODITE) in driving lumped and distributed hydrological models in a humid region of China, J. Hydrol., 542, 343–356, https://doi.org/10.1016/j.jhydrol.2016.09.011, 2016. a
Yang, D., Goodison, B. E., Ishida, S., and Benson, C. S.: Adjustment of daily precipitation data at 10 climate stations in Alaska: Application of World Meteorological Organization intercomparison results, Water Resour. Res., 34, 241–256, https://doi.org/10.1029/97WR02681, 1998. a
Yatagai, A., Kamiguchi, K., Arakawa, O., Hamada, A., Yasutomi, N., and Kitoh, A.: APHRODITE: Constructing a Long-Term Daily Gridded Precipitation Dataset for Asia Based on a Dense Network of Rain Gauges, B. Am. Meteorol. Soc., 93, 1401–1415, https://doi.org/10.1175/BAMS-D-11-00122.1, 2012. a, b, c, d, e, f
Yin, Z.-Y., Zhang, X., Liu, X., Colella, M., and Chen, X.: An Assessment of the Biases of Satellite Rainfall Estimates over the Tibetan Plateau and Correction Methods Based on Topographic Analysis, J. Hydrometeorol., 9, 301–326, https://doi.org/10.1175/2007JHM903.1, 2008. a