the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 05 Jan 2026
| 05 Jan 2026
Comparison of ensemble assimilation methods in a hydrological model dedicated to agricultural best management practices
Emilie Rouzies
Claire Lauvernet
Hydrological models are valuable tools for understanding the movement of water and contaminants in agricultural catchments. They are particularly useful for assessing the impact of landscape organization on pesticide transfers and for developing effective mitigation strategies. However, using these models in an operational context requires reducing uncertainties in their outputs, which can be achieved through data assimilation methods. In this study, we aim to integrate surface moisture images into the PESticide and Hydrology Modelling at the catchment scale (PESHMELBA) water and pesticide transfer model using data assimilation techniques. Twin experiments are conducted on a virtual catchment consisting of vineyard plots and vegetative filter strips. We compare the performance of the ensemble Kalman filter (EnKF), the ensemble smoother with multiple data assimilation (ES-MDA), and the iterative ensemble Kalman smoother (iEnKS) in jointly estimating vertical moisture profiles and van Genuchten soil water retention properties of all soil horizons. Results indicate that the ES-MDA performs the best in estimating surface moisture and saturated water contents, while all methods show similar results for subsurface moisture variables and parameters. Furthermore, we examine the sensitivity of the methods to observation error magnitude, observation frequency, and ensemble size to establish an effective assimilation setup. This study paves the way for future operational applications of data assimilation in PESHMELBA.
- Article
(2193 KB) - Full-text XML
- BibTeX
- EndNote




Understanding the transfer of water and pesticides is critically important for protecting aquatic and human life. To do so, numerical simulations effectively support risk assessment studies at the catchment scale. These studies particularly benefit from distributed hydrological models as they can accurately describe the relevant processes and transfer pathways that influence pesticide fate (Gassmann et al., 2013; Djabelkhir et al., 2017; Branger et al., 2010; Rouzies et al., 2019; Wendell et al., 2024).
Such hydrological models simulate several interacting physical processes in order to properly capture the complex reality of the field, such as surface and subsurface hydrological transfer, sediment, and pollutants, among different units of the catchment. They need large sets of input parameters, potentially varying in space (such as soil hydraulic characteristics, land cover, and atmospheric boundary conditions), which may be hard to properly define. Uncertainties in parameters, such as in model structure, can thus result in significant errors in model simulations (Liu and Gupta, 2007; Fatichi et al., 2016; Herrera et al., 2022).
Data assimilation (DA) is an interesting approach used to quantify and reduce these uncertainties. It consists of combining complementary information from observations distributed in time and space and a numerical model while accounting for uncertainties from both sources. Stochastic ensemble methods derived from the Kalman filter (Kalman, 1960), such as the ensemble Kalman filter (EnKF; Evensen, 2003, 2009) or the ensemble smoother (ES; van Leeuwen and Evensen, 1996), are broadly used in geophysics. They consist of Monte Carlo algorithms and linear solutions of the estimation problem. Dimension reduction is performed by approximating the state probability distribution by an ensemble of vectors. Such approximation makes these methods particularly suitable for high-dimension problems (Katzfuss et al., 2016). Observations are integrated as they arrive, either one at a time (filter) or in batches, within a temporal window (smoother). Although the EnKF and its variants are based on the assumption of Gaussian statistics, they have been successfully applied to nonlinear, non-Gaussian problems in many fields over the last few decades (e.g. Bertino et al., 2003; Crow and Wood, 2003; Moradkhani et al., 2005; Rochoux et al., 2014; Kurtz et al., 2016; Devers et al., 2020).
In many of these studies, DA is used to jointly correct state variables and estimate model parameters. A classical approach to performing joint estimation consists of augmenting the state vector by including the parameters to be estimated. Parameters are mostly unobserved, and their posterior distributions are deduced from the covariances built to perform DA between them and the state variables (Bocquet and Sakov, 2013). In hydrology, wrong parameter values are often identified as the dominant source of error (Hendricks Franssen and Kinzelbach, 2008; Nie et al., 2011), and joint estimation can significantly improve simulation accuracy. Recent studies have demonstrated the potential of joint estimation in groundwater flow or integrated surface–subsurface hydrological models at the catchment or hillslope scale (e.g. Hendricks Franssen and Kinzelbach, 2008; Baatz et al., 2017; Botto et al., 2018). Among them, Pasetto et al. (2015) examine the potential of the EnKF in the integrated surface–subsurface hydrological model CATHY (Paniconi and Putti, 1994; Camporese et al., 2010) to estimate the field of saturated hydraulic conductivity on a virtual hillslope. Xie and Zhang (2010) also demonstrate the EnKF's capability to estimate the runoff curve number empirical parameter in addition to various prognostic variables in the conceptual hydrological SWAT model (Arnold et al., 1998). The ES scheme's capability to perform joint estimation is also investigated as this scheme is easier to implement and less computationally demanding than the EnKF. In Crestani et al. (2013), the performances of the EnKF and the ES are compared to deduce the spatial distribution of hydraulic conductivity using a groundwater flow and transport model. Bailey and Baù (2012) also retrieve conductivity distributions based on the ES, both on its original version and on an iterative version. More recently, Emerick and Reynolds (2013a) introduced the ensemble smoother with multiple data assimilation (ES-MDA), an iterative scheme based on the ES that allows the same observations to be assimilated several times. This scheme has been shown to outperform both the EnKF and the ES for parameter estimation in reservoir history-matching problems (Emerick and Reynolds, 2013a, b). Cui et al. (2020) also use the ES-MDA to estimate soil hydraulic parameters from Hydrus one-dimensional simulations (Šimůnek et al., 1998) and water content observations. These studies focus solely on parameter estimation, but the ES-MDA scheme could easily be extended to joint estimation in a hydrological modelling context.
Ensemble methods have also percolated into the variational DA community, which defines the data assimilation problem as a cost function to be minimized. Ensemble variational methods, such as the iterative ensemble Kalman smoother (iEnKS; Bocquet and Sakov, 2013), have recently been developed and have also demonstrated their ability to solve joint estimation problems. The iEnKS for joint estimation consists of iteratively minimizing a cost function that depends on the augmented state. In contrast to classical variational problems, the cost function is defined in the ensemble space, which limits the required computational effort. This DA method has so far been tested on simple oceanic models (Bocquet and Sakov, 2013) and atmospheric chemistry models (Defforge et al., 2018) and has been shown to outperform the EnKF in some cases. In Bocquet and Sakov (2013), the authors argue that this method may be able to successfully deal with nonlinearities. The iEnKS has not yet been applied to hydrological models, but it may be worth exploring for dealing with the complex structures and physical processes implemented in such models.
The above references show that there has been a wealth of studies dedicated to DA in catchment-scale hydrological models, both conceptual and physically based. However, during the last decade, a novel approach to modelling has been emerging in hydrology. This approach consists of building physically based and distributed models with a modular structure, relying, for example, on flexible modelling frameworks (Buytaert et al., 2008). Resulting models are then composed of distinct code units representing various physical processes that are coupled in the modelling framework. The motivation behind this innovative philosophy is to provide model structures that are flexible enough to evolve according to the targeted application. Several tools already exist in the hydrological field, and they show promising results for risk assessment applications (Tortrat, 2005; Moussa et al., 2010; Branger et al., 2010; Kraft et al., 2012; Rouzies et al., 2019). However, these modular models are often characterized by a highly interactive structure and numerous parameters, which complicates uncertainty quantification and reduction (Rouzies et al., 2023). As a result, the application of DA to these models may lead to different results from those of classical models, warranting an in-depth study and comparison of the available DA algorithms.
Within this context, the objectives of this study are twofold. First, we aim to propose first examples of a DA framework in a process-oriented, modular model used for risk assessment applications. Second, we propose a comparison of three DA algorithms (namely the EnKF, the iEnKS, and the ES-MDA) that are representative of the three main types of DA ensemble methods: a filter, a hybrid variational/ensemble smoother that is efficient over short data assimilation windows, and an ensemble smoother that is efficient over long data assimilation windows. For this purpose, we apply these DA schemes to the PESticide and Hydrology Modelling at the catchment scale (PESHMELBA; Rouzies et al., 2019) model. PESHMELBA aims to simulate different landscape configuration scenarios and rank them in terms of pesticide transfer mitigation. Such a model could thus greatly benefit from joint estimation as it could contribute to identifying consistent parameter distributions for scenario exploration. In this paper, we focus on the joint estimation of moisture variables and input parameters θsat (water content at saturation) for different soil types by assimilating surface soil moisture images. We do so on the basis of synthetic experiments, and we compare the performance of the EnKF, the ES-MDA, and the iEnKS. The outline of the paper is as follows: after a short description of the PESHMELBA model in Sect. 2.1, the different DA methods are introduced in Sect. 2.2. The case study and the DA setup are presented in Sect. 2.3 and 2.4. The capabilities of the tested methods in retrieving variables and input parameters for both surface and subsurface compartments are explored in Sect. 3.1. Sensitivities to error prescription, ensemble size, and observation frequency are investigated in Sect. 3.2.
2.1 Model description
The PESHMELBA model is a physically based and spatialized model that simulates the transfer of water and pesticides at the scale of small agricultural catchments (Rouzies et al., 2019). It is designed to compare different landscape management scenarios and to identify an optimal configuration regarding pesticide transfer mitigation. As PESHMELBA aims to assess the impact of landscape composition, the hydrodynamical impact of various landscape elements, such as vegetative filter strips (VFSs), hedges, or ditches, is explicitly simulated in model units that interact with each other. PESHMELBA meshing is based on the landscape organization as one mesh element represents one landscape feature. As a result, physical process representation and coupling are adapted to this heterogeneous, element-scale meshing.
In this study, we use a version of PESHMELBA that simulates surface/subsurface hydrological fluxes within vineyard plots, VFSs, and river reaches. The discretization of each landscape element and the physical processes integrated in this code version are summarized in Fig. 1. Each plot or VFS is simulated as a single column of soil discretized vertically into numerical cells of heterogeneous thickness. Each soil column is composed of one or several soil layers, also called soil horizons, which are characterized by distinct hydrodynamical behaviours. Within a time step, vertical infiltration is solved on each column in the catchment, using the one-dimensional Richards equation for flows in variably saturated porous media (Richards, 1931). Once vertical infiltration has been solved, the overland flow is sequentially computed from ponding height resulting from solving the Richards equation. Overland flow toward downstream elements is simulated using a pseudo-one-dimensional kinematic wave (Lighthill and Whitham, 1955). Channel flow routing in the river is also simulated using a kinematic wave approximation in a network of reaches with trapezoidal sections. For both overland and channel flows, a finer time step is used compared with that for vertical infiltration calculations. Finally, at the end of the time step, subsurface lateral flows in the saturated zone between plots or VFSs are calculated based on Darcy's law (Darcy, 1857). Lateral saturated exchanges between water tables and the river are computed from Miles' equation (Miles, 1985) adapted by Dehotin (2007). As a result, PESHMELBA is able to simulate the hydrological variables and their dynamics in three dimensions.
All physical processes are integrated in PESHMELBA in independent code units. The different code units are coupled in the OpenPALM coupler (Fouilloux and Piacentini, 1999; Buis et al., 2006) that ensures variable exchanges and synchronization. It is worth emphasizing that PESHMELBA's final structure is characterized by strong interactions, nonlinearities, and threshold effects. It makes any attempt at DA particularly challenging and justifies studying several approaches in depth in order to identify the most appropriate one.
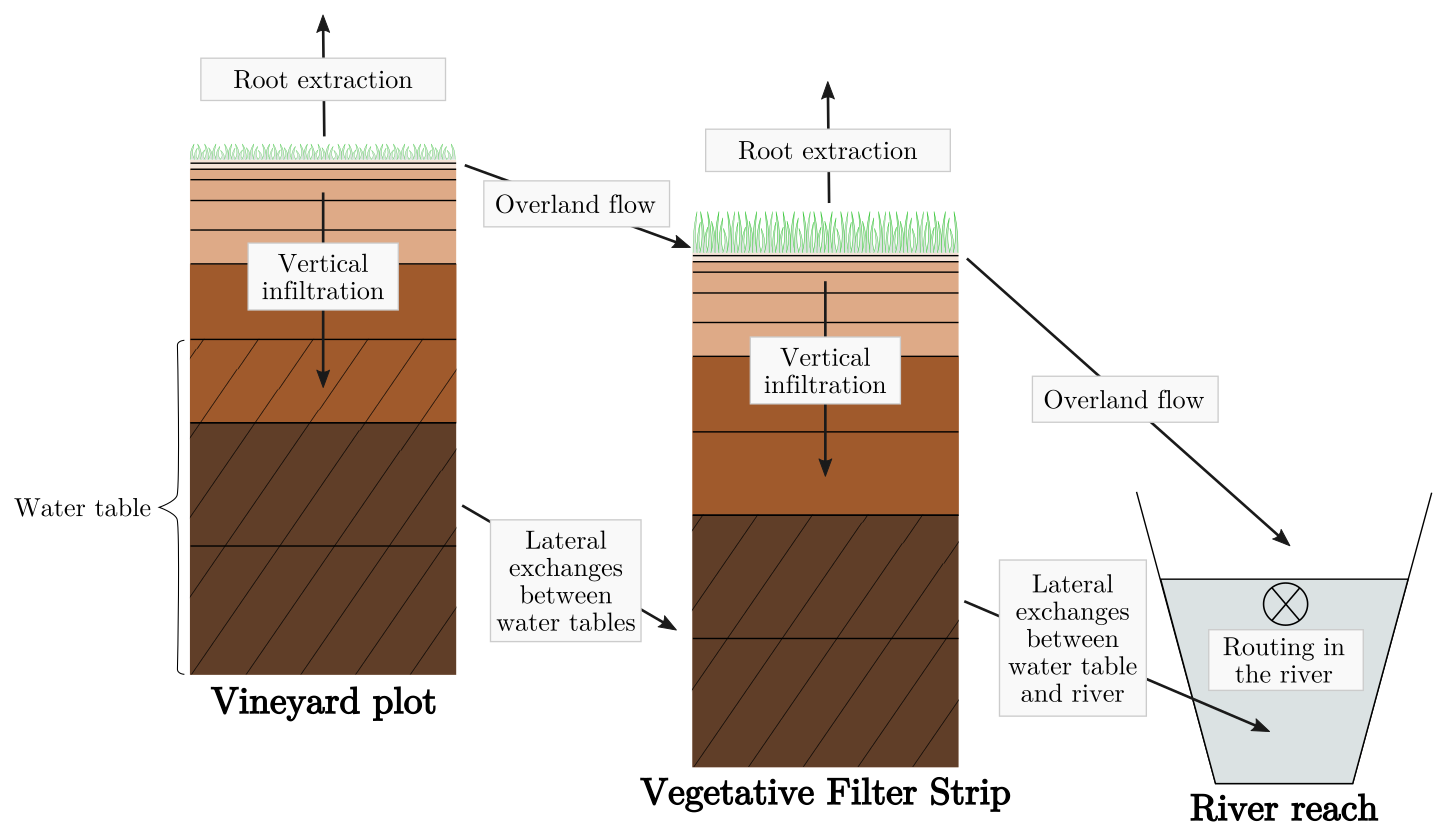
Figure 1Discretization of landscape elements and physical processes included in the PESHMELBA version of this study. The horizontal black lines in the left and middle soil columns delimit the numerical cells, while the hatched areas represent the water tables. In these columns, the different brown fillings delimit the different soil horizons.
2.2 Data assimilation methods
The following sections introduce the ensemble Kalman filter, the ensemble smoother with multiple data assimilation, and the iterative ensemble Kalman smoother with multiple data assimilation. These methods aim to estimate the probability density function (PDF) of a state vector conditional on available observations. In this case study, we aim to estimate three-dimensional moisture profiles and some input parameters of the PESHMELBA model. The corresponding system state vector at time tk with is denoted xk∈ℝn in what follows. We assume available observations of mean moisture in the top 5 cm of the soil, and the corresponding observation vector at time tk is denoted .
The model propagates the state vector from time tk to time tk+1 (Eq. 1), and is the observation operator that maps the state variable space onto the observation space at each time step (Eq. 2):
where vk and zk are the state error and the observation error respectively. They are assumed to be unbiased and to follow a Gaussian distribution:
where (resp. ) is the model error covariance matrix (resp. observation error covariance matrix).
In the case of joint estimation, the state vector xk is augmented with the model parameters to be estimated, and the model also includes an evolution law for the estimated parameters in addition to the state dynamical evolution. As soil characteristics are not expected to change over time at the scale of interest, we have chosen a persistence law to represent the (non-)evolution of the parameters.
The DA methods introduced in the next sections are sequential and consist of an alternation of a forecast step and an analysis step. During the forecast step, the model propagates a background state xk−1 from tk−1 to tk, resulting in a forecast state vector . This prior state is updated during the analysis step based on the available measurements. The analysis results in a posterior state at time tk that becomes the background for the next forecast step between tk and tk+1. Accordingly, any given vector a or matrix A derived from the forecast step is denoted af or Af in what follows, while it is denoted aa or Aa if it is calculated at the analysis step. Although they aim to solve the same problem derived from the Bayes theorem, the methods tested in this study differ in the time window that is considered in the forecast step and the number of measurements simultaneously used in the analysis step. The distinct approximations and assumptions they are based on may lead to significantly different solutions that are analysed in this study. Their common structure and characteristics are summarized in Fig. 2.
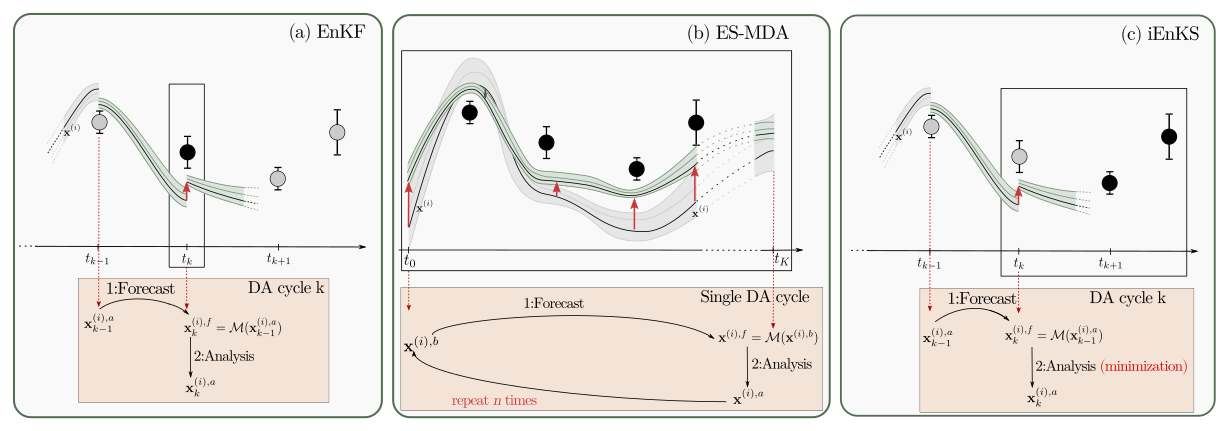
Figure 2Schematic view of one DA cycle for the EnKF (a), the ES-MDA (b), and the iEnKS (c). The lines depict trajectories for some members of the ensemble, and the coloured envelop represents the ensemble uncertainty. The dots depict the available observations. The black dots in the black window are the observations that are used for the current DA cycle, whereas the grey dots are unused observations.
2.2.1 Ensemble Kalman filter
The ensemble Kalman filter (EnKF; Evensen, 1994) extends the Kalman filter resolution of the Bayesian estimation problem to nonlinear, high-dimensional contexts. The state distribution is approximated by an ensemble of M state vectors . Each vector is sequentially propagated during the forecast step by applying the nonlinear model ℳ and updated during the analysis step using the current observations (see Fig. 2, left). This study is based on the ensemble transform Kalman filter (ETKF; Bishop et al., 2001; Hunt et al., 2007). At each time tk, we consider , the matrix of normalized perturbations whose columns are expressed as
with
During the analysis step, one looks for a state vector in the affine subspace spanned by the anomalies: . The analysis is then expressed as
where wk∈ℝM is a weight vector in the ensemble subspace. The optimal weight vector is obtained from the Kalman filter equation:
where the Kalman gain is computed with the forecast error covariance matrix expressed from the ensemble: . Identification of terms using the Sherman–Morrison–Woodbury formula allows us to express the optimal weight vector wk in the ensemble subspace:
where δ is the innovation vector that contains the observations and where contains the observation normalized perturbations:
with
The posterior ensemble of perturbations is generated so as to be representative of the posterior uncertainty that can be factorized as . The analysis normalized anomalies are then derived:
This leads to the following expression for the analysed members :
The ETKF is favoured for high-dimension problems as it alleviates the computational cost of the analysis. Indeed, most of the algebraic calculations are performed in the ensemble subspace, which is generally of a smaller dimension than the state or observation space.
2.2.2 Ensemble smoother with multiple data assimilation
The above section has introduced a filtering approach that is a sequential scheme based on incremental updates of the state vector x. For each update, the present system state PDF is corrected by Eq. (12) using present observations only. In contrast, the ensemble smoother (ES; van Leeuwen and Evensen, 1996) aims to estimate a posterior distribution for the state vector in an assimilation window , relying on all observations available in that window. First, the ensemble is integrated over the whole assimilation window in a single forecast step. The augmented state vector x is composed of temporal trajectories for each state variable at each point of the model grid along with input parameters. The same analysis as for EnKF is then carried out, using all the observations at the same time (see Fig. 2, middle). The state variable trajectories are updated in space and time through space–time covariances estimated from the ensemble (Crestani et al., 2013).
More recently, Emerick and Reynolds (2013a) introduced the ensemble smoother with multiple data assimilation (ES-MDA), an “iterative version” that consists of iteratively performing the ES-like sequence: ensemble model integration over the whole assimilation window followed by an analysis step. It should be noted that the number of iterations is prescribed before launching the DA procedure and does not depend on a convergence criterion. At iteration (j), the analysis step from Eq. (12) is replaced by
where the notation (resp. and ) for time tk has been simplified to Xa (resp. Xf and Yf) and where the weight α(j) is an inflation term for the observation error covariance matrix R. Considering J, the predefined total number of iterations in the ES-MDA full scheme, the weights must satisfy
In this study, we set (Emerick and Reynolds, 2013a; Cui et al., 2020).
The model integration at iteration (j+1) is then initialized with the posterior distribution of parameters obtained from the analysis at iteration (j). This scheme replaces a single abrupt analysis by several smaller analyses.
2.2.3 Iterative ensemble Kalman smoother with multiple data assimilation
As with the EnKF, the iEnKS alternates forecast and analysis steps to perform incremental updates of the state. However, in this fixed-lag smoothing context, each analysis aims to update a state vector at time tk using observations between tk+1 and tk+L, where L is the length of the data assimilation window (DAW; see Fig. 2, right). Moreover, in contrast to the EnKF and the ES-MDA, the iEnKS fundamentally belongs to the category of variational methods. As such, the iEnKS analysis step consists of minimizing a cost function deduced from the Bayesian estimation problem formulation:
where . Like the EnKF and the ES, the iEnKS is an ensemble-based method, and the calculations rely on M members: . X denotes the perturbation matrix (see Eq. 5).
At time tk, the analysed state vector is expressed as an incremental correction , and the minimization consists of finding the weight vector that minimizes the cost function expressed in the ensemble subspace. Again, the forecast error covariance matrix is expressed from the ensemble: , leading to the following expression for the cost function:
where .
The minimization of the cost function ℐ is performed in the ensemble subspace by a Gauss–Newton algorithm:
where (j) is the iteration index, A is an approximation of the Hessian of ℐ, and ∇ is the gradient operator. Such minimization actually corresponds to a nonlinear update.
The approximated Hessian and the gradient are expressed using the tangent linear of the operator transporting from the ensemble space to the observation space
In this study and as proposed in Bocquet and Sakov (2013), this tangent linear operator is estimated using finite differences (“bundle” iEnKS version). Both A and ∇ℐ are then computed from the ensemble:
where values are inflation weights for the observation error. As the ensemble size is generally rather small, A(j) can be inverted using direct exact methods. As with the ES-MDA, the iEnKS implementation chosen in this paper allows each observation to be used several times. The weights αl then merely measure the impact of each observation in the DAW. The sum of the weights for an assimilation cycle respects
In Bocquet and Sakov (2014), a heuristic justification of this MDA scheme is given. The reader should refer to this paper for more details about this scheme. In this study, we choose a uniform scheme so that .
The minimization takes place until a convergence criterion is reached. Then, the analysed members are deduced at time tk using the minimized vector w* and the associated state vector :
This way, the iEnKS offers to perform the nonlinear update of the state as in standard variational DA (Carrassi et al., 2018).
2.3 Case study
In this study, we aim to investigate the accuracy and the robustness of the aforementioned DA methods in a simulation exercise based on PESHMELBA. To do so, we perform synthetic (or twin) DA experiments on a simplified, virtual catchment. DA experiments are conducted on the Morcille-like virtual catchment described in Rouzies et al. (2023). This size-limited catchment is inspired from the La Morcille catchment, situated in the Beaujolais vineyard region east of France. A comprehensive description of the setup can be found in their study, and its main characteristics are reported in what follows. The virtual catchment is composed of 10 vineyard plots, 4 VFSs, and a portion of river that delimits two hillslopes. All soil columns are 4 m deep. They are vertically discretized into 25 numerical cells whose thickness ranges from 0.05 m at the top to 1 m at the bottom. Three soil units (SUs), mainly sandy, compose the catchment, in accordance with the soil composition of the La Morcille catchment. Each soil type is made up of the vertical succession of three or four soil horizons. Each soil horizon is characterized by its own hydrodynamical behaviour that results in distinct sets of parameters. Figure 3 summarizes the scenario composition, the different SUs, and their vertical constitution. Vineyard plots and VFSs from the same SU are parameterized identically except for the first soil horizon. The first soil horizon is chosen to extend to the first 15 cm in VFSs, while it can vary on vineyard plots. Its main parameters are set in order to account for the effect of increased soil structuring and dense vegetation that mitigate surface runoff on VFSs. This way, the saturated hydraulic conductivity, the ponding height, and the roughness are increased compared with vineyard plots.
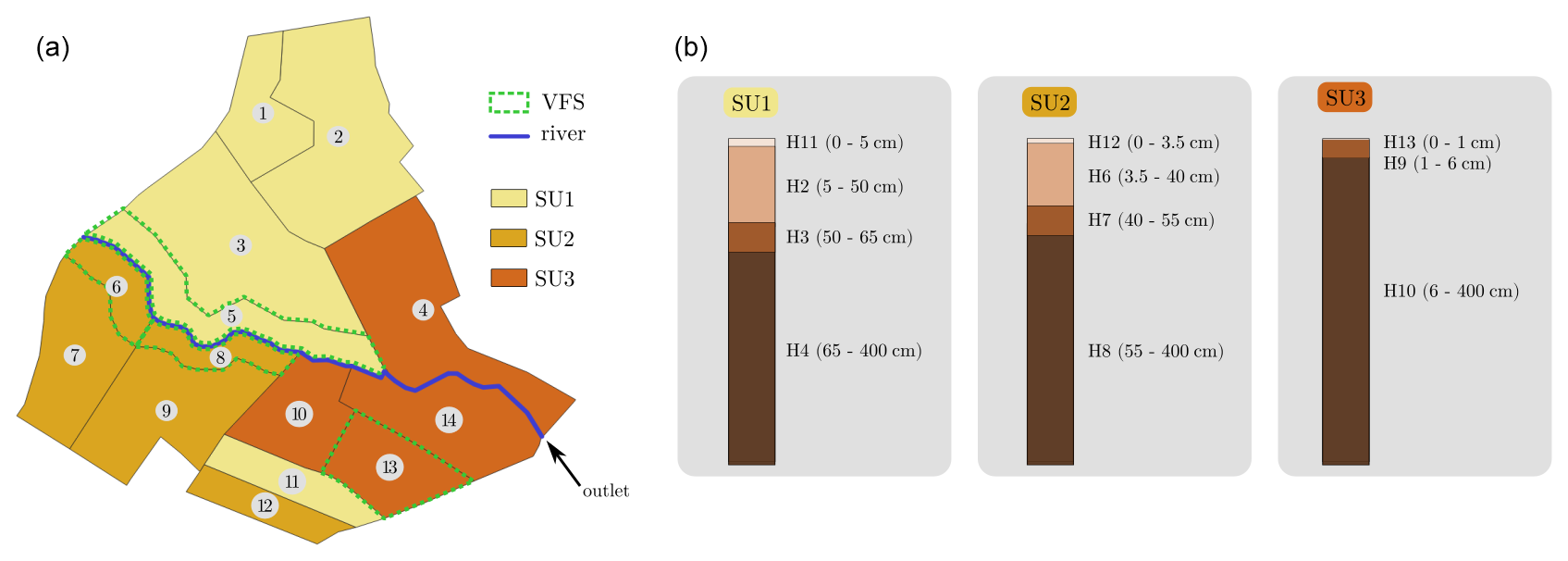
Figure 3(a) Composition and spatial distribution of SUs in the virtual catchment. VFSs are bounded with the dashed green line, while the remaining mesh units are vineyard plots. (b) Details of SU constitution in terms of succession of soil horizons on vineyard plots. SU constitutions for VFSs are the same except for the surface horizon that is 15 cm deep.
Vineyard plot and VFS pressure profiles are initialized considering hydrostatic equilibrium and initial water table levels that are consistent with field data for the given time period. Realistic rain and potential evapotranspiration forcings that correspond to a typical winter period in the area are used. Except for atmospheric forcings, all boundary conditions are zero fluxes. Two vegetation types are set in this scenario. A vineyard cover is considered on plots, while a permanent, mature grassland is parameterized on VFSs. Root depth and root density are supposed to be constant all over the simulation for both of them, while the leaf area index (LAI) evolves over the simulation period for vineyard cover. LAI remains constant on grassland.
The full scenario results in 128 parameters whose nominal values and meaning are described in Appendix A. Some input parameters may seem redundant from one soil horizon to another, but we explicitly distinguish between several horizons in order to prepare setups that include pesticide transfers. In such an application, parameters will need to vary from one horizon to the other.
As a reference for result interpretation, Fig. 4 shows an example of nominal time series of moisture at different depths (surface, intermediate, and deep). At the surface, soil moisture dynamics are strongly driven by rain forcings all over the simulation. In contrast, moisture varies significantly only after 1200 h of simulation at 0.2 m depth, when stronger rain events occur. Finally, at 4 m depth, the system is not affected by the dynamics from superficial cells or climate forcings. It remains in a steady state that corresponds to the presence of a water table, leading to a constant moisture value.
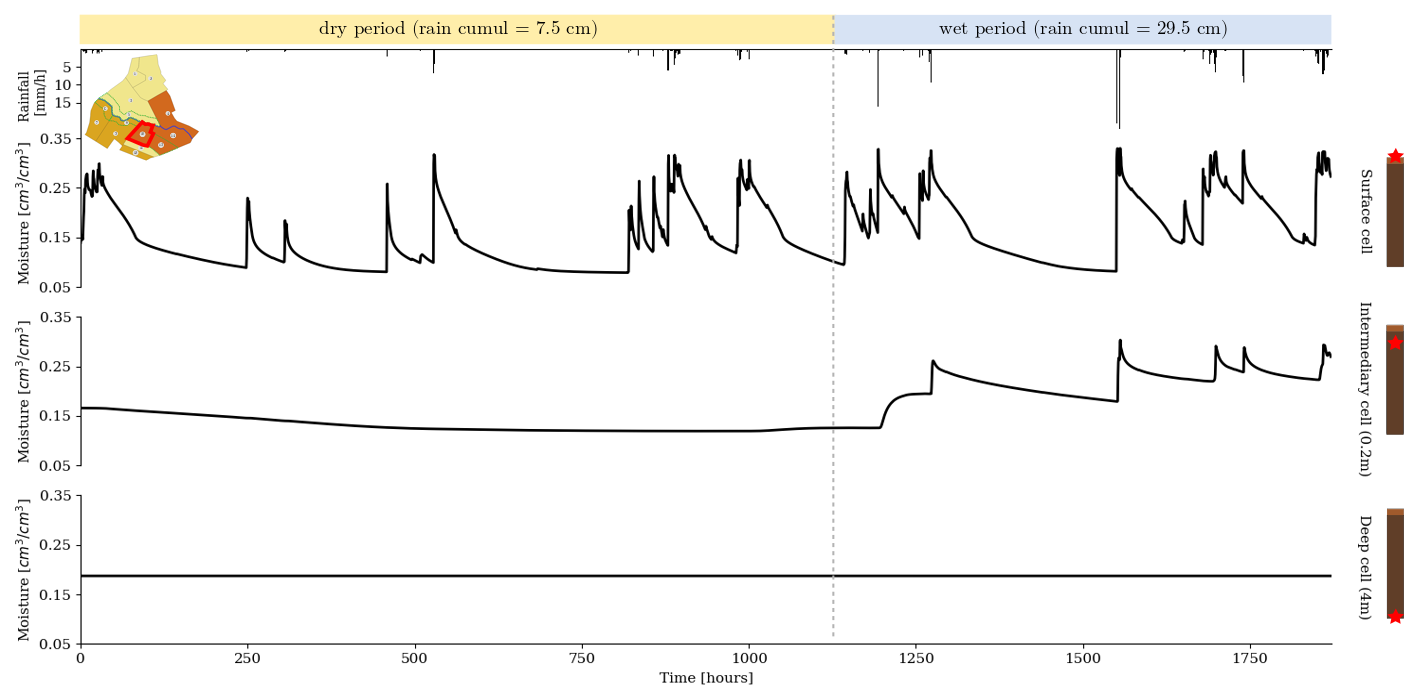
Figure 4Soil moisture time series for the nominal simulation on plot 10 at the surface (top), 0.2 m depth (middle), and 4 m depth (bottom). Rain forcings are shown in the top black histogram, while the position of plot 10 in the catchment is denoted by a red line in the top-left pictogram. The soil composition of plot 10 is shown in the soil columns depicted on the right, with red stars showing the corresponding depths.
2.4 DA setup
As this study focuses on twin experiments, we use synthetic images that mimic satellite moisture data in the top 5 cm. Such data are supposed to come from the synergistic use of optical and radar signals from Sentinel-1 and Sentinel-2 satellites (Bousbih et al., 2018), which in turn can be converted into maps of surface soil moisture in agricultural areas (El Hajj et al., 2017; Gao et al., 2017). The synthetic images are generated from a “true” reference run of PESHMELBA and are perturbed with Gaussian, non-biased noise. Observation errors are supposed to be uncorrelated in time and space, and the standard deviation for error is set to 0.02 cm3 cm−3 at the first step. It should be noted that this approximate for observation error is underestimated compared with values found in Bousbih et al. (2018). In this paper, the authors conducted experiments on cereal crops. To our knowledge, similar experiments on vineyards have not been performed yet. Observation error for such soil cover may differ greatly, and sensitivity to the observation error magnitude is thus investigated in this study. We assume a time series is available for mean moisture in the top 5 cm for each vineyard plot and VFS in the catchment. The observation operator ℋ is accordingly built as a matrix so as to relate each observation to the weighted mean of moisture over the six numerical cells that compose the top 5 cm of the soil column:
where θj and dzj are the soil moisture and the thickness of numerical cell j respectively.
For the sake of simplicity, we consider that the input parameters are the only sources of uncertainty in the model. The ensemble is initialized by independently perturbing the 128 input parameters. Perturbations are set according to each input parameter PDF. Such a PDF has been defined from field measurements, the literature, and expert knowledge in a previous study (Rouzies et al., 2023). They are detailed in Appendix A.
Joint estimation is performed in order to estimate both vertical moisture profiles and relevant uncertain input parameters. The global sensitivity analysis of PESHMELBA in this case study showed that parameters that influence moisture profiles the most are mainly θs (water contents at saturation) for the different soil horizons (Radišić et al., 2023). The augmented state vector thus includes these 14 parameters for both surface and deeper soil horizons, and a bias is added to their PDFs when generating the initial ensemble.
For the iEnKS, the number of Gauss–Newton iterations in the cost function minimization is set to three, which, from experience, can limit the cost and is considered enough (Eq. 18 being solved exactly). A preliminary sensitivity study also allowed us to set the iEnKS optimal DAW length L so as to assimilate observations by a batch of five. Similarly, from preliminary trials, the number of iterations is set to three for the ES-MDA.
The nominal scenario consists of a 78 d simulation with 6 d observation frequency, a standard deviation for observation error equal to 0.02 cm3 cm−3, and an ensemble size of 50 members. Then, a series of experiments is set up in order to assess the robustness of the DA methods and to test their sensitivity to the (1) observation error magnitude, (2) observation frequency, and (3) ensemble size. To do so, each factor (observation error magnitude, observation frequency, and ensemble size) is varied individually, while the others are set up to nominal values. Tested values are reported in Table 1.
Table 1Scenarios explored to assess the sensitivity of DA methods to the (i) observation error (standard deviation), (ii) frequency of observation, and (iii) ensemble size. Nominal values are in bold.
The performances of the DA methods in the different setups are assessed by computing the continuous ranked probability score (CRPS; Brown, 1974) on the moisture time series, on each vineyard plot, and the VFS at the surface and at 0.2 and 4 m depths. The CRPS expresses the distance between the cumulative density function (CDF) of the probabilistic forecast and the CDF of a reference. In this case, the reference is the “true” run of PESHMELBA that is supposed to be free of error. Its CDF is built using the Heaviside function, and the CRPS consists of building the quadratic distance between the two functions:
where FY is the CDF of the one-dimensional ensemble of moisture values Y, is the deterministic value of moisture from the PESHMELBA “true” run, and H(x) is the Heaviside function. It is a positive error criterion variable: the closer it is to 0, the better is the ensemble forecast. The CRPS is expressed in the same unit as the evaluated variable. It is averaged over time/space in the case of a multidimensional forecast Y. In this study, CRPS scores are estimated following Hersbach (2000), and the corresponding formulation is detailed in Appendix B. In order to better capture the impact of DA on the simulation, we also use the continuous ranked probability skill score (CRPSS), which is the ratio between the CRPS of the analysis and the CRPS of the free run (i.e. the unassimilated state):
where CRPSDA (resp. CRPSfree) is the CRPS score of the analysis (resp. the free run). When positive, the closer the CRPSS is to 1, the more the DA process improves the estimation. When negative, the assimilation process degrades the estimation compared with the free run.
As pointed out in Bocquet and Sakov (2014), it is crucial to remind the reader that the performances of a DA scheme depend on the metrics chosen to assess its quality. We chose the CRPS because it rigorously generalizes the notion of mean absolute error (MAE) to stochastic predictions. In addition, the decomposition of the average CRPS can also provide information on the reliability and the resolution of the posterior ensemble (Hersbach, 2000).
3.1 Comparison of methods
3.1.1 Performances on moisture variable correction
The three DA methods are first tested on the nominal setup presented in Sect. 2.4. Figure 5 compares the CRPS time series of moisture variables assimilated by the three DA methods with the free run simulation on plot 10. The evolution of the CRPS for both the free run and the assimilated state is highly correlated to the precipitation time series. Rainfall events and the following recession periods lead to peaks in the CRPS chronicle, showing an increased level of uncertainty in the system in wet conditions. During the first three assimilation cycles (up to 576 h), the iEnKS and the EnKF decrease the error to a limited extent compared with the free run. More precisely, in this first part of the simulation, the corrections from their analysis steps have nearly no effect after each rainfall event that follows an analysis. Until 576 h, the ES-MDA is then the only method that allows for a clear reduction in the CRPS, during both rainfall events and dry periods. The second part of the simulation is characterized by longer and more intense rainfall events. In this time period, all methods allow for an effective decrease in the model error. Broadly speaking, the ES-MDA leads to lower CRPS values and smaller discrepancies between dry and wet periods, showing comparable performances for both hydrological regimes.
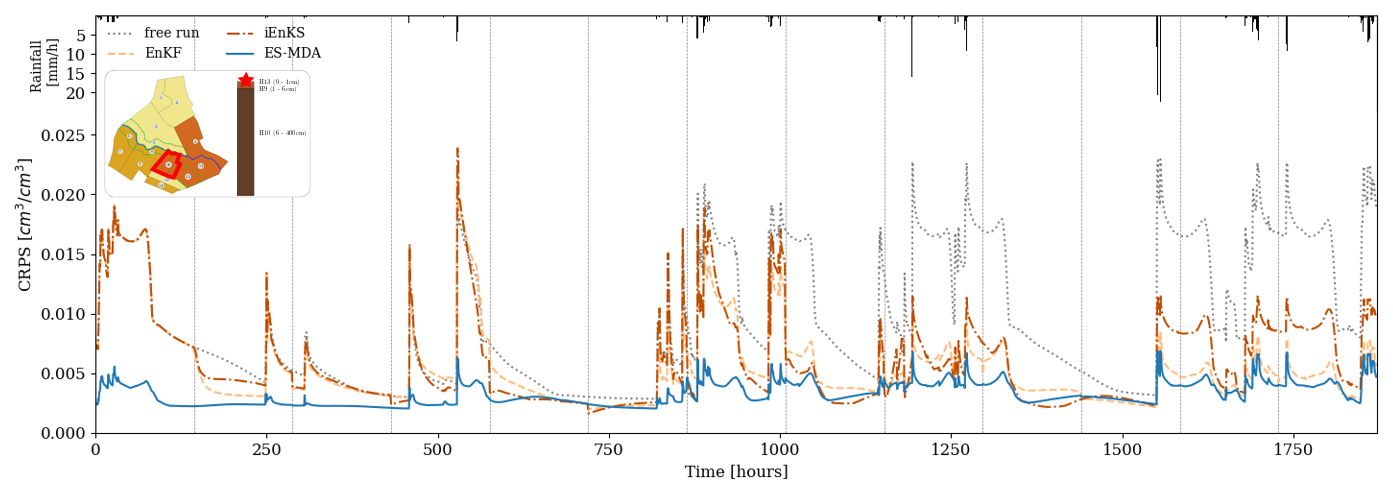
Figure 5Comparison of CRPS time series for the free run and the different DA methods on plot 10's surface compartment. The position of plot 10 is depicted by the red line in the top-right map, while the position of the surface cell in the associated soil column is depicted by the red star. The rainfall chronicle is shown in the top histogram, while vertical grey lines correspond to times when surface moisture observations are available.
Unlike surface moisture estimation, the three methods exhibit much more limited performances in the subsurface, as shown in Fig. 6. At 0.2 m depth, the soil only reacts to stronger rain events from 1200 h, once again leading to peaks in the CRPS series within this time period. Again, the ES-MDA performs the best in decreasing the error, although the gain from the free run is much more limited than for surface estimation. The iEnKS generally degrades the moisture estimation, especially between 1000 and 1250 h. The iEnKS is the only method that is characterized by moving DA windows. During each analysis, the current state is corrected using the next L observations (L=5 in this case). The change in the model dynamics between the analysis time step and the following observation time steps observed in the intermediary cell after 1200 h (see Fig. 4, middle) may explain such poor correction of the state by the iEnKS.
In the deeper cell, the CRPS remains constant between each analysis step (see Fig. 4, bottom). The EnKF and the ES-MDA also achieve a limited decrease in CRPS compared with the free run, whereas the iEnKS once again degrades the estimation. Note that from 1152 h, the iEnKS no longer performs analysis because there are not enough observations available in the DAW. The system is no longer corrected from this moment onwards.
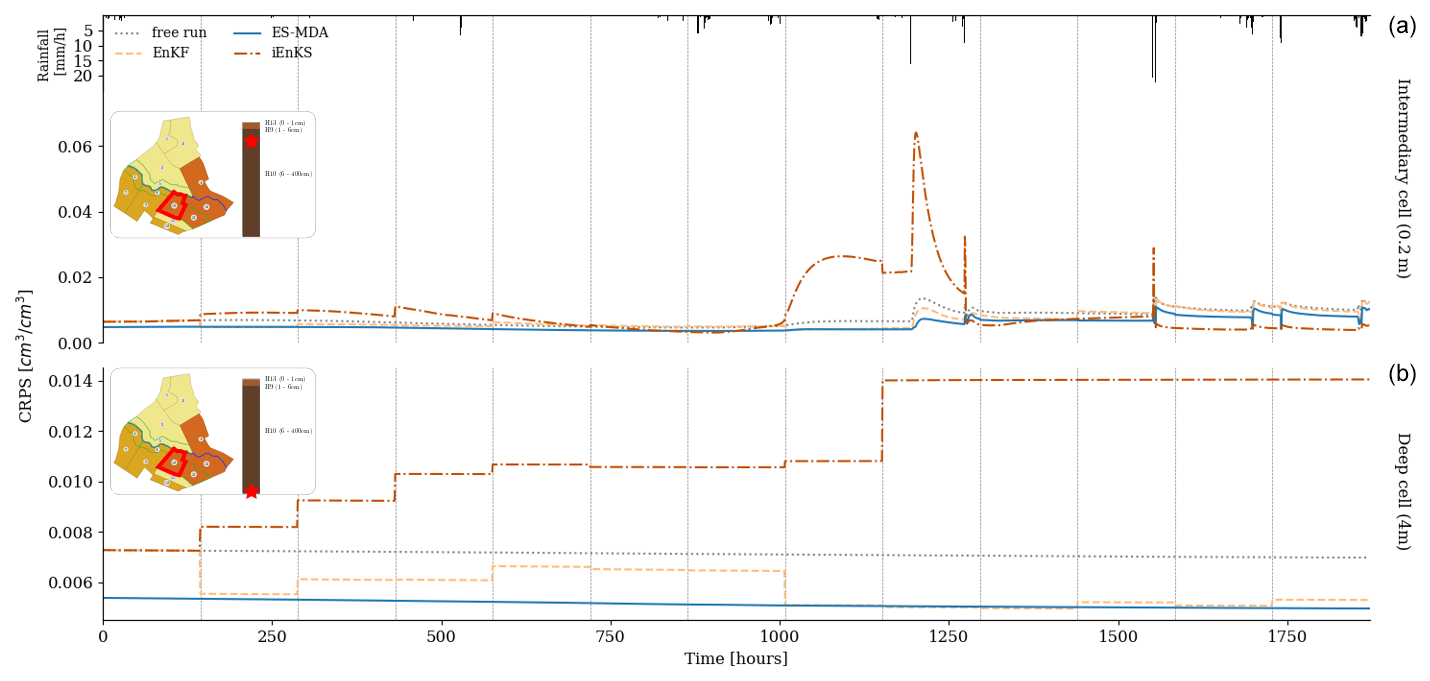
Figure 6Comparison of CRPS time series for the free run and the different DA methods in the intermediary cell (0.2 m depth, a) and the deeper cell (4 m depth, b) for plot 10. The position of plot 10 is depicted by the red line in the top-right map, while the position of the cell in the associated soil column is depicted by the red star. The rainfall chronicle is shown in the top histogram, while vertical grey lines correspond to time steps when surface moisture observations are available.
The average CRPSSs over the whole temporal period and the whole catchment at the scrutinized depths are computed for the three methods in order to quantitatively identify the most appropriate DA method for the PESHMELBA model. All methods significantly improve moisture estimation at the surface, with CRPSSs being superior, with an average value of 0.38. The ES-MDA almost always outperforms the EnKF and the iEnKS at the surface and, to a lesser extent, at the subsurface (Fig. 7). Conversely, the EnKF significantly degrades the state estimate in the middle cells for most of the HUs (Hydrological Units) (negative CRPSS value). In the deeper cell, the ES-MDA also outperforms the EnKF on average (0.15 vs. 0.06), while the iEnKS leads to significantly increased error compared to the free run. However, when looking locally, better CRPSSs are performed by the ES-MDA on 9 out of the 14 UHs, which makes it impossible to generalize. Indeed, the contribution of assimilation is much more limited in the intermediary compartment, which is not observed and not significant in the deep compartment.
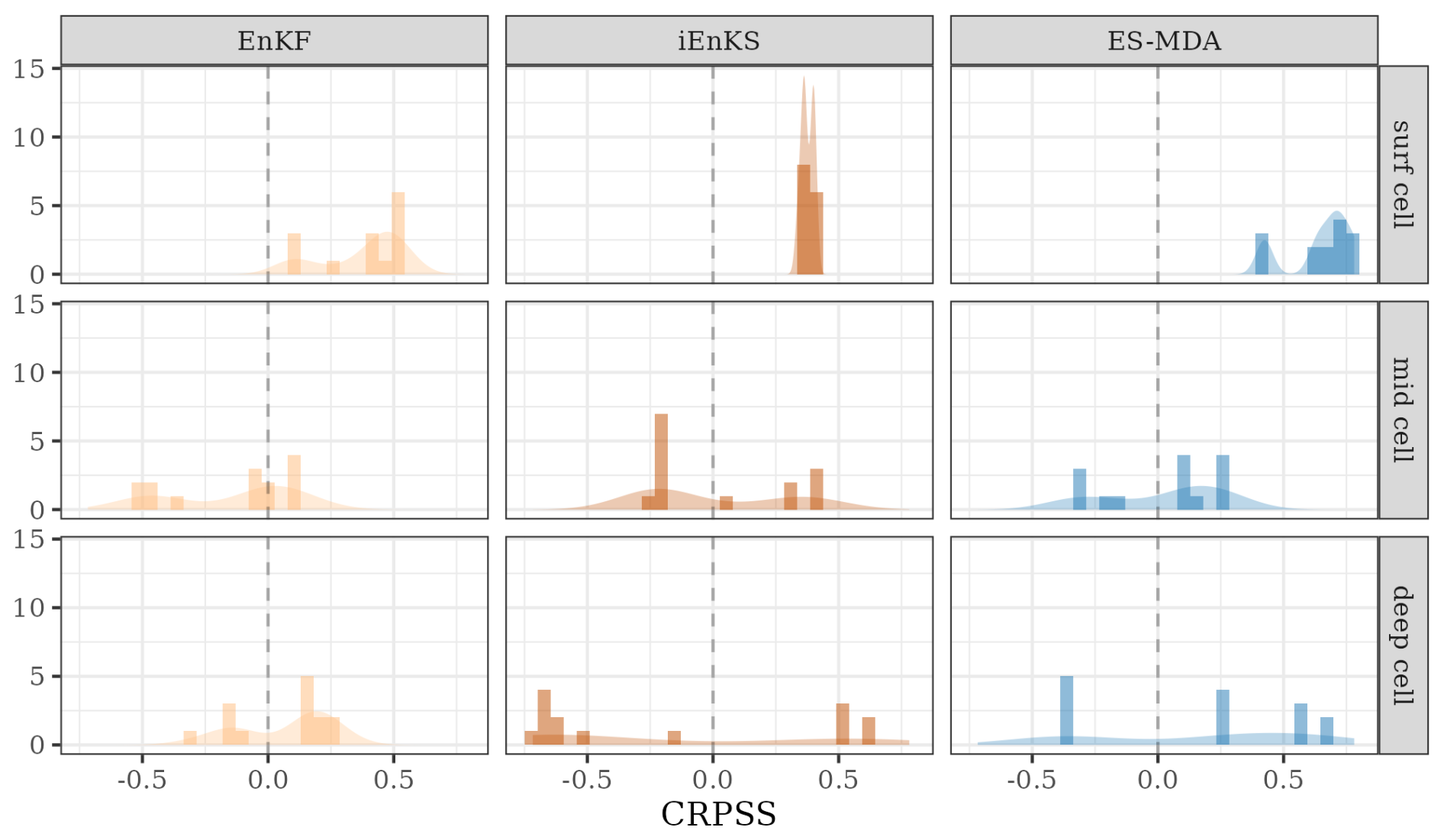
Figure 7Distribution over the 14 HUs (Hydrological Units) of CRPSS averaged over time. The vertical line at a CRPSS of 0 highlights a decrease in error compared with the free run (positive values) or an increase in error compared to the free run (negative values).
3.1.2 Performances on parameter estimation
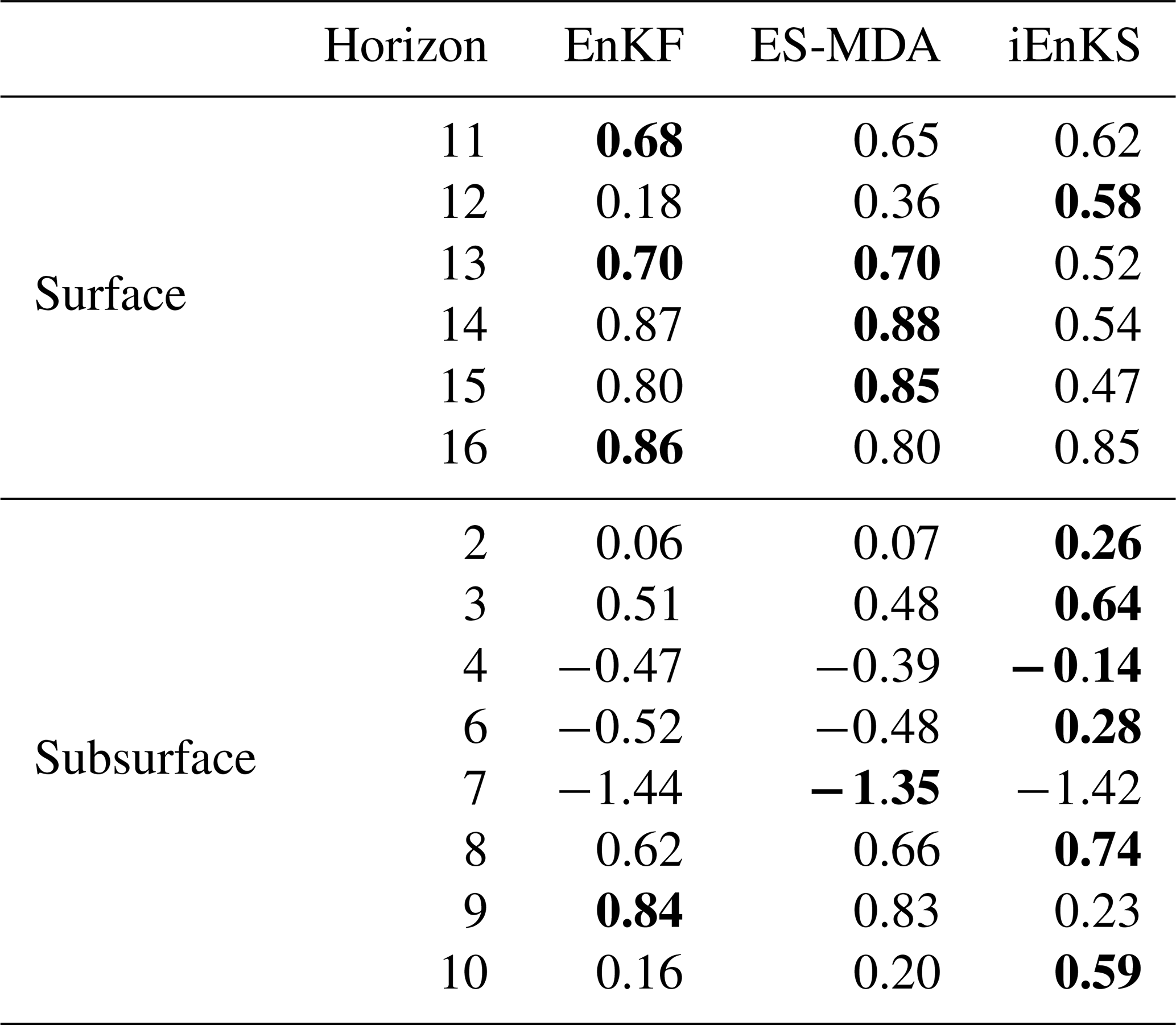
Performances on parameter estimation are also assessed, and Fig. 8 shows the posterior PDFs of the estimated water contents at saturation θs, while Table 2 summarizes the associated CRPSS values. Estimation of θs for surface horizons is significantly improved by the three methods as CRPSS values exceed 0.58 in all cases. Still based on CRPSS values, the EnKF and the ES-MDA perform the best. Results are less clear-cut for the estimation of subsurface parameters. Indeed, CRPSS values are far lower than for the surface, and the DA process even degrades θs estimation for horizons 4, 7, and 6, except for the iEnKS. For subsurface parameters, the iEnKS tends to perform the best, although it once again achieves limited performances compared with surface parameter estimation. While the EnKF and the ES-MDA rely on the correlation matrix to estimate unobserved parameters, the iEnKS builds a cost function that explicitly relates to the input parameters. The full correlation matrix (not shown here) shows that there is little to no correlation between the moisture in the upper 5 cm and the parameters in the subsurface, which may explain why the iEnKS performs better in such compartments. Finally, for both surface and subsurface parameters, the posterior PDF and the associated CRPSS values obtained from the EnKF and the ES-MDA are quite close. It shows that assimilating observations one by one or all at once, using an ensemble-Kalman-filter-based method, leads to comparable performances for parameter estimation, whereas significant differences are noticed for variable correction.
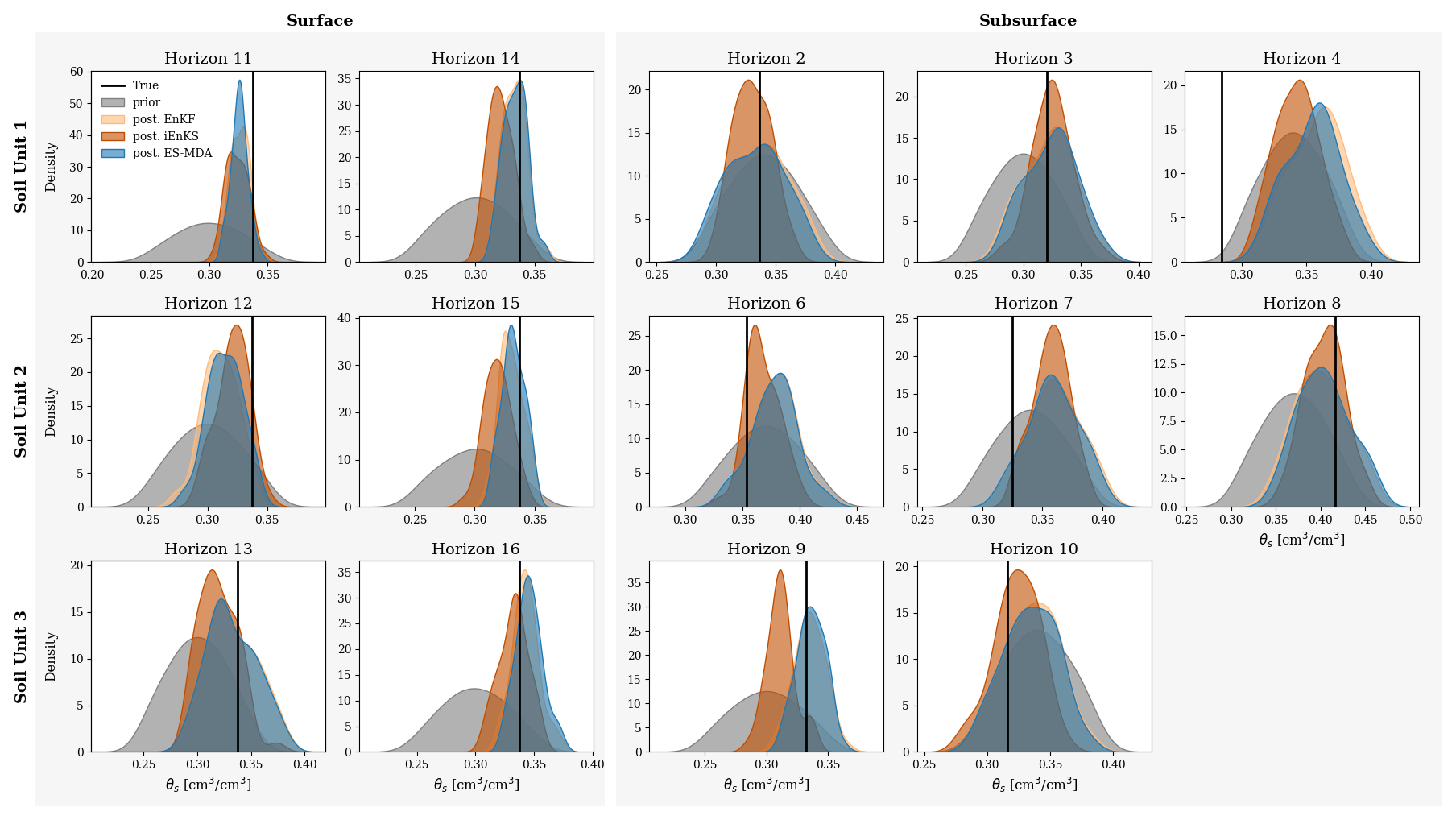
Figure 8Empirical PDFs for estimated surface parameters for SU1 (top line), SU2 (middle line), and SU3 (bottom line). The first column shows PDFs of surface θs on vineyard plots, while the second column refers to surface parameters on VFSs. The remaining columns represent parameters for subsurface horizons. The true values of the parameters are indicated by the vertical black line in each plot.
Table 2CRPSS values associated with parameter estimation for the three DA methods. Positive values indicate a decrease in error compared with the free run, while negative values indicate an increase in error compared with the free run. For each line, the bold value refers to the best estimate.

3.1.3 Computational cost
The computational costs of the three methods are differ considerably. The EnKF is the fastest method (277 CPU hours), followed by the ES-MDA (558 CPU hours) and the iEnKS (2143 CPU hours). Compared with the EnKF, both the ES-MDA and the iEnKS perform incremental corrections, leading to higher computational costs. Furthermore, in the case of the iEnKS, using an assimilation window of size L implies that the model must be integrated up to times to perform each analysis. As PESHMELBA integration is the most costly step in the assimilation process, the iEnKS computational cost ends up being much more significant than for the other methods.
3.2 Sensitivity of the methods to DA setup
In this section, the sensitivity of the different methods to observation error prescription, assimilation frequency, and ensemble size is investigated. As the tested DA methods have shown limited performance in retrieving subsurface moisture from satellite surface moisture images, the analysis focuses on surface moisture estimation, following several scenarios (Table 1). Furthermore, as mentioned in the previous section, the high computational cost of the iEnKS is prohibitive for performing intensive exploration of the method in this case study. Sensitivity analysis is then only performed for the two methods with the highest potential in this application, EnKF and ES-MDA.
3.2.1 Observation error
The sensitivity to the observation error magnitude is tested on a setup with a frequency of assimilation of 6 d (144 h) and an ensemble size of 50 on a 78 d long simulation and evaluated on averaged CRPSS (Fig. 9). As expected, for both methods, the CRPSS is the highest for small observation errors and regularly decreases for larger observation errors. In the case of the EnKF, no significant correction of the state can be obtained from error values higher than 0.1 cm3 cm−3. In the case of the ES-MDA, moisture is noticeably corrected for error values up to 0.2 cm3 cm−3.
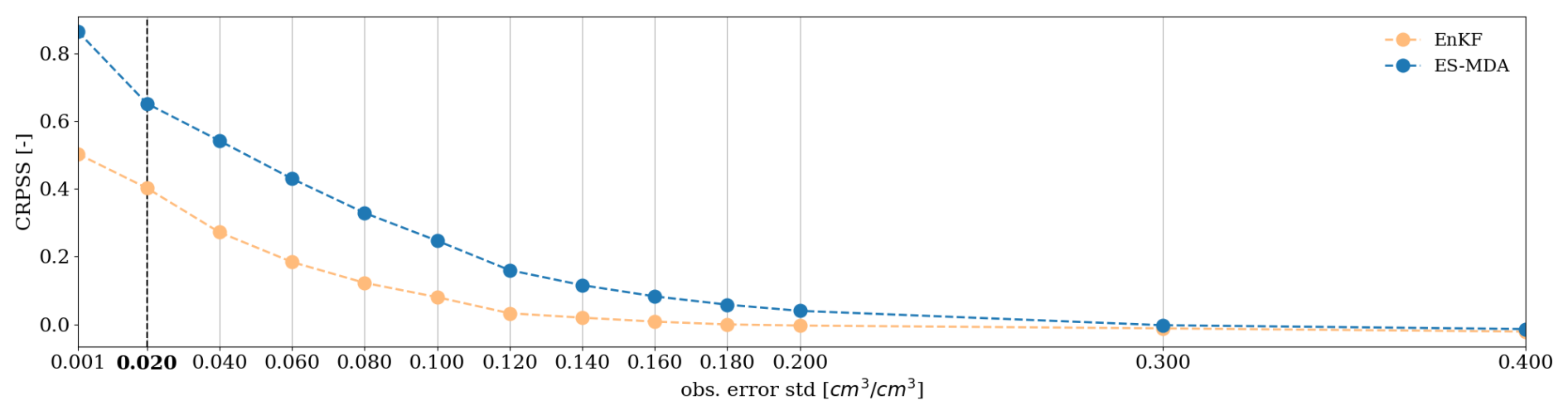
Figure 9CRPSS sensitivity to the standard deviation of the observation error for the surface cell with the EnKF and ES-MDA. The CRPSS is computed as an average over the whole time series and over the whole catchment. The bold label and vertical dashed line denote the nominal value of the observation error used in this case study.
3.2.2 Frequency of observation
The averaged CRPSS in the surface compartment for the EnKF and the ES-MDA is also evaluated as a function of the observation frequency (Fig. 10). The observation error magnitude is set to 0.02 cm3 cm−3, and the ensemble size is set to 50. In the case of the EnKF, the CRPSS is relatively stable for observation frequencies (meaning analysis frequencies) up to 72 h and decreases regularly for lower frequencies. ES-MDA performances are rather stable for frequencies of observation less than 144 h (6 d). Performances are slightly worse for frequencies of 192 and 216 h (even if they are still higher than the best-performing EnKF setup) and drop significantly if observations are available only every 240 h (10 d).
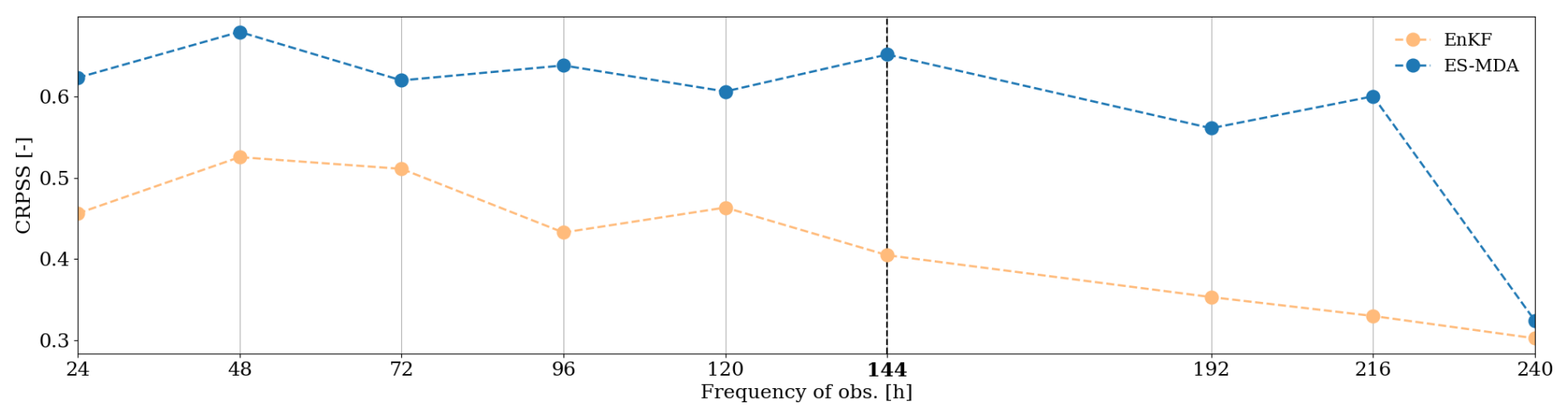
Figure 10Comparison of the CRPSS sensitivity to observation frequency for the surface cell. The CRPSS is computed as an average over the whole time series and over the whole catchment. The bold label and vertical dashed line denote the nominal frequency of the observation. This value also corresponds to a realistic frequency of observation for surface moisture images used in this case study.
3.2.3 Ensemble size
While the observation error magnitude and the observation frequency are intrinsic properties of the observation set in practice, the ensemble size is a parameter of the DA setup that can be tuned by the user. Its choice also critically impacts the numerical cost of the data assimilation and should be chosen to reach a satisfying trade-off between limited computational cost and sufficient accuracy of the analysis. In this experiment, the sensitivity to the ensemble size is tested on a scenario with an observation error of 0.02 cm3 cm−3 and with a frequency of observations of 144 h (Fig. 11).
For both methods, the lower CRPSS value is reached for an ensemble size of 20. The EnKF performances stabilize for an ensemble size higher than 50 members, while 100 members are necessary for the ES-MDA, partly due to its higher state vector size that includes a temporal dimension.
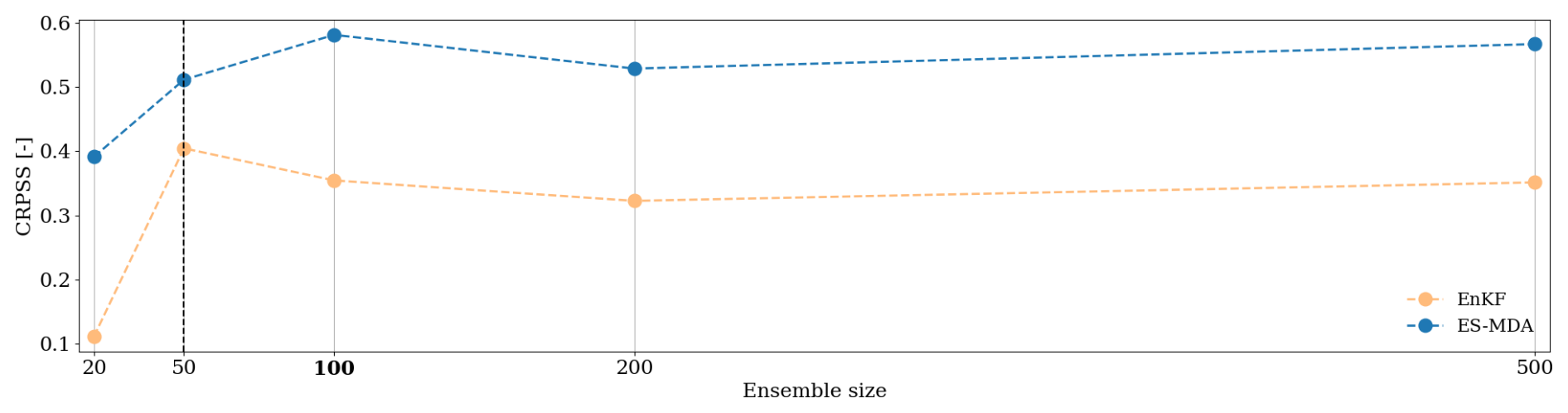
Figure 11CRPSS sensitivity to the ensemble size for the surface cell. The CRPSS is computed as an average over the whole time series and over the whole catchment. The bold label and vertical dashed line denote the nominal value of the ensemble size used in this case study.
4.1 On the choice of the DA method
Results from the above section indicate that in this case study, assimilating observations one at a time is sufficient for estimating input parameters. However, integrating several observations simultaneously is more efficient for correcting moisture trajectories, particularly when using the ensemble smoother with multiple data assimilation. The ES-MDA better constrains the system as it incorporates information from all observations and the system dynamics, making it especially effective in coping with nonlinearity, as noted by Emerick and Reynolds (2013a). The ES-MDA ensures that corrections can propagate from observed to unobserved times, particularly from rainy periods to inter-event periods, given sufficient temporal correlations. In contrast, during the initial dry hydrological regime, saturated water contents (θs) are unobservable, limiting the performances of the EnKF and the iEnKS, which correct the augmented state vector at a specific time. The global and iterative correction of the ES-MDA allows the impact of accurate observations during wet periods to extend to unobservable dry periods. In addition, although the iEnKS demonstrates potential for parameter estimation, it is clear that the additional computational cost for moisture correction is not worth it. This is likely because the PESHMELBA modular approach results in the linear coupling of the one-dimensional vertical Richards equation through lateral Darcy's law, rather than employing the nonlinear full three-dimensional Richards equation. Such linear coupling reduces the potential benefits of using iEnKS on highly nonlinear systems.
From the above, the ES-MDA is identified as the best compromise for assimilating moisture images for the joint estimation of moisture profiles and θs parameters in the PESHMELBA model. The ES-MDA performs the best for moisture correction and achieves performances comparable to those of the EnKF for parameter estimation. This method is also straightforward to implement and does not require frequent interruptions of the calculation code to perform the analysis. Additionally, although the ES-MDA is an iterative method, its computational cost remains reasonable, as only a few iterations are necessary to optimize its performances.
4.2 On the real-case DA implementation
The exploration of DA implementation scenarios (Sect. 3.2) allows us to suggest some practical guidelines to best adapt the setup to the PESHMELBA model. First, the quality of assimilated data plays a crucial role: the results provide users of moisture data obtained from Sentinel-1/Sentinel-2 synergistic inversion with guidelines on the required quality of future observations over vineyard cover. For example, one could keep in mind that an error in observations less than 0.05 cm3 cm−3 with the EnKF (resp. 0.1 cm3 cm−3 with the ES-MDA) will be required to reach significant improvements (higher than 20 % compared with the free run) in surface moisture estimation. Regarding the frequency of data, it is set to 144 h on average for surface moisture images computed from the Sentinel-1 and Sentinel-2 satellites. In this application, this frequency is nearly optimal, all other factors being equal, for maximizing the performances of the ES-MDA for DA window lengths of around 3 months, as all observations are integrated at the same time. In the case of the EnKF, a frequency of 72 h would be necessary to optimize its performances.
Finally, an ensemble size of 100 members is advised for both methods to ensure a stable performance, as this size is often chosen in studies that describe their DA experiment setup in hydrology (Camporese et al., 2009; Nie et al., 2011; Lei et al., 2020).
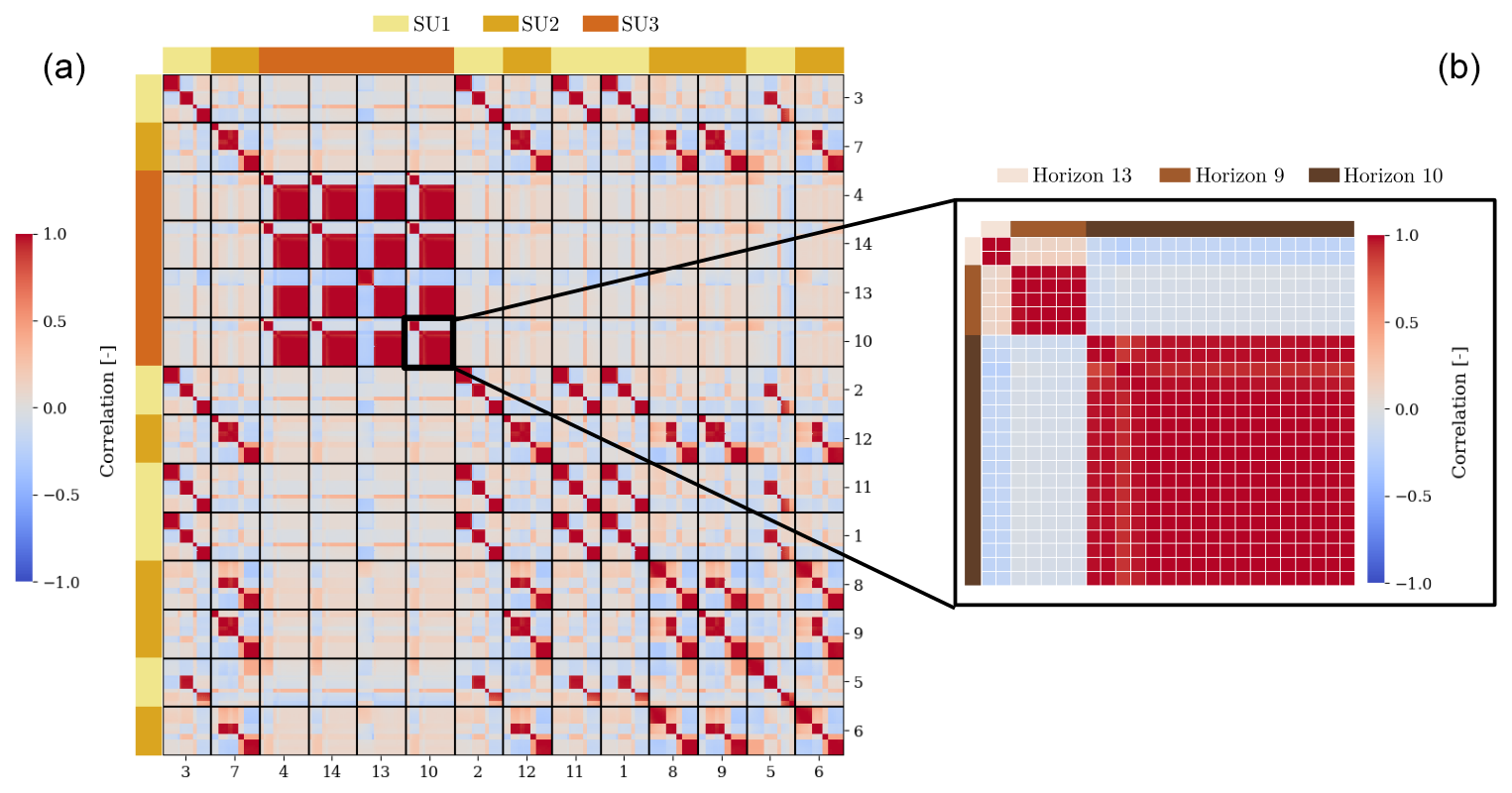
Figure 12(a) Correlation matrix of the ensemble after 144 h of simulation in the free run. Vertical and horizontal lines delimit the numerical cells from the same plot. The top and left colours indicate the soil type for each plot, while the bottom and right indices are the plot indices. (b) Portion of the correlation matrix that relates to plot 10. Each square outlined in white refers to a numerical cell in the vertical profile of plot 10. The top and left colours refer to the soil horizon for each numerical cell.
4.3 On the limitations of the methods
Even if the different DA methods succeed in estimating surface variables and parameters, the gain is limited to retrieving subsurface variables and parameters. Moisture observations only cover the top 5 cm, and none of the tested methods properly retrieve deeper values. In theory, both the iEnKS and the ES-MDA, which are characterized by longer DAW lengths, may have been able to capture the subsurface dynamics if they had remained correlated to the surface dynamics. However, the correlation matrices extracted at some time steps, such as those shown in Fig. 12, and for the whole time series (not shown here) show that there are nearly no correlations between the surface and the subsurface, even when considering potential time lags. In this case study, the composition of each soil type with distinct horizons, as well as the vertical discretization, which is much more refined at the surface than at the subsurface, may explain the lack of correlation. It should be noted that such a lack of correlation has also been observed in Bonan et al. (2020) (in arid contexts only).
We conclude that assimilating observations of topsoil moisture cannot properly correct subsurface variables or parameters. However, from the correlation matrix (Fig. 12), we see that the moisture in a given soil horizon is highly correlated to the moisture in this same soil horizon in other plots that also contain this specific soil horizon. This means that observations of a full soil column in some points in the catchment may be sufficient to correct all plots with the same soil type. This option must be further investigated, for example, by assimilating measurements from electronic magnetic interference that can provide punctual pseudo-observations of soil moisture vertical profiles. In this case, we would need to introduce a new observation error model since the moisture profiles would be deduced from resistivity measurements. Figure 12 also highlights the absence of spatial correlations between soil units of different soils, advocating the use of a scheme with a local domain DA in the ES-MDA (Asch et al., 2016) to alleviate the computational cost of this method that uses high-dimension matrices.
In this study, we set a rigorous data assimilation framework for a modular model that is specifically built for water quality management. The conducted experiments were aimed not only at retrieving vertical moisture profiles but also at estimating certain input parameters, based on synthetic surface moisture satellite images. To do so, we implemented several stochastic ensemble methods, namely the ensemble Kalman filter, the ensemble smoother with multiple data assimilation, and the iterative ensemble Kalman smoother. These three methods are representative of the spectrum of available ensemble methods (ensemble filters, hybrid ensemble/variational smoothers, and long-window ensemble smoothers). They solve the DA problem differently, and, in particular, they use the available observations in different ways. We then assessed and compared their performances for joint estimation so as to choose the most appropriate method for the PESHMELBA model.
Results of the comparison showed that all methods performed well in retrieving moisture and parameters at the surface, but the ES-MDA significantly outperformed the EnKF and the iEnKS. The ES-MDA is indeed the only method that can fully integrate the system dynamics in its analysis step. Results for the subsurface, however, showed that all methods failed in retrieving the rest of the vertical moisture profiles and associated saturated water content parameters. The analysis of the correlation matrices showed that the surface and the subsurface compartments are poorly correlated, meaning that one should not expect surface moisture data alone to improve moisture estimates in deeper compartments. Furthermore, the results of analyses on the sensitivity to observation error, observation frequency, and ensemble size provided practical guidelines to implement an adapted DA setup in future operational applications.
As the proposed setup has been shown to be limited in retrieving subsurface moisture, further research could extend this study to multi-source data assimilation. For instance, the joint assimilation of surface moisture images and punctual observations of vertical moisture profiles obtained from electronic magnetic interference should be further investigated to improve moisture estimation in deep soil compartments. In addition, when setting up any stochastic DA experiment, the ensemble must be generated so as to represent the model error as accurately as possible. In this study, only the parameter values were considered a source of uncertainty, which is certainly too simplistic. Future experiments should then integrate uncertainty in initial conditions and climate forcings.
Systematically taking into account and reducing the uncertainties in risk assessment models is a major issue, especially when these models have an operational impact. This study paves the way for further applications in risk assessment models, even based on a complex structure, to assess both water and pollutant transfers in agricultural landscapes.
Assuming an ensemble of M moisture values Y1,…,YM sorted from the smallest to the largest so that
and so that is the deterministic reference value, the CRPS for the ensemble is evaluated as follows (Hersbach, 2000):
where , and αi and βi are defined as follows:
The cases where i=0 and i=M only apply to the CRPS when the reference value is an outlier, meaning it is less than Y1 or more than YM. In this case, Table B3 must be modified with the following:
The PESHMELBA model is an open-source model coded in Python (version 2.7.17) and Fortran 90 and embedded in the OpenPALM coupler (version 4.3.0). The code for the OpenPALM coupler is available from http://www.cerfacs.fr/globc/PALM_WEB/user.html#download (Buis et al., 2006) after registration. The exact version of PESHMELBA, as well as Python (version 3.7) and Bash scripts used for data assimilation, is provided in the following Zenodo repository: https://doi.org/10.5281/zenodo.6782073 (Rouzies et al., 2022).
All authors contributed to writing the text and to all stages of editing. Data curation, formal analysis, and software implementation were conducted by ER with extensive support from CL and AV with respect to the conceptualization, investigation, methodology, resources, and supervision.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
The authors kindly acknowledge Jérémy Verrier for his support on HIICS cluster usage.
This paper was edited by Harrie-Jan Hendricks Franssen and reviewed by Benjamin Mary and one anonymous referee.
Arnold, J. G., Srinivasan, R., Muttiah, R. S., and Williams, J. R.: Large area hydrologic modeling and assessment – Part 1: Model development, J. Am. Water Resour. A., 34, 73–89, https://doi.org/10.1111/j.1752-1688.1998.tb05961.x, 1998. a
Asch, M., Bocquet, M., and Nodet, M.: Data assimilation: methods, algorithms, and applications, in: Fundamentals of Algorithms, v1, SIAM, xviii + 306, halID hal-01402885, 2016. a
Baatz, D., Kurtz, W., Hendricks Franssen, H. J., Vereecken, H., and Kollet, S. J.: Catchment tomography – An approach for spatial parameter estimation, Adv. Water Resour., 107, 147–159, https://doi.org/10.1016/j.advwatres.2017.06.006, 2017. a
Bailey, R. T. and Baù, D.: Estimating geostatistical parameters and spatially-variable hydraulic conductivity within a catchment system using an ensemble smoother, Hydrol. Earth Syst. Sci., 16, 287–304, https://doi.org/10.5194/hess-16-287-2012, 2012. a
Bertino, L., Evensen, G., and Wackernagel, H.: Sequential Data Assimilation Techniques in Oceanography, Int. Stat. Rev., 71, 223–241, https://doi.org/10.1111/j.1751-5823.2003.tb00194.x, 2003. a
Bishop, C. H., Etherton, B. J., and Majumdar, S. J.: Adaptive sampling with the ensemble transform Kalman filter. Part I: Theoretical aspects, Mon. Weather Rev., 129, 420–436, https://doi.org/10.1175/1520-0493(2001)129<0420:ASWTET>2.0.CO;2, 2001. a
Bocquet, M. and Sakov, P.: Joint state and parameter estimation with an iterative ensemble Kalman smoother, Nonlin. Processes Geophys., 20, 803–818, https://doi.org/10.5194/npg-20-803-2013, 2013. a, b, c, d, e
Bocquet, M. and Sakov, P.: An iterative ensemble Kalman smoother, Q. J. Roy. Meteor. Soc., 140, 1521–1535, https://doi.org/10.1002/qj.2236, 2014. a, b
Bonan, B., Albergel, C., Zheng, Y., Barbu, A. L., Fairbairn, D., Munier, S., and Calvet, J.-C.: An ensemble square root filter for the joint assimilation of surface soil moisture and leaf area index within the Land Data Assimilation System LDAS-Monde: application over the Euro-Mediterranean region, Hydrol. Earth Syst. Sci., 24, 325–347, https://doi.org/10.5194/hess-24-325-2020, 2020. a
Botto, A., Belluco, E., and Camporese, M.: Multi-source data assimilation for physically based hydrological modeling of an experimental hillslope, Hydrol. Earth Syst. Sci., 22, 4251–4266, https://doi.org/10.5194/hess-22-4251-2018, 2018. a
Bousbih, S., Zribi, M., El Hajj, M., Baghdadi, N., Lili-Chabaane, Z., Gao, Q., and Fanise, P.: Soil moisture and irrigation mapping in a semi-arid region, based on the synergetic use of Sentinel-1 and Sentinel-2 data, Remote Sens., 10, 1953, https://doi.org/10.3390/rs10121953, 2018. a, b
Branger, F., Braud, I., Debionne, S., Viallet, P., Dehotin, J., Henine, H., Nedelec, Y., and Anquetin, S.: Towards multi-scale integrated hydrological models using the LIQUID® framework. Overview of the concepts and first application examples, Environ. Model. Softw., 25, 1672–1681, https://doi.org/10.1016/j.envsoft.2010.06.005, 2010. a, b
Brown, T. A.: Admissible scoring systems for continuous distributions, Tech. rep., The Rand Corporation, 1974. a
Buis, S., Piacentini, A., and Déclat, D.: PALM: a computational framework for assembling high-performance computing applications, Concurrency and Computation: Practice and Experience, 18, 231–245, https://doi.org/10.1002/cpe.914, 2006 (code available at: http://www.cerfacs.fr/globc/PALM_WEB/user.html#download, last access: December 2023). a, b
Buytaert, W., Reusser, D., Krause, S., and J.-P., R.: Why can't we do better than Topmodel?, Hydrol. Process., 22, 4175–4179, https://doi.org/10.1002/hyp.7125, 2008. a
Camporese, M., Paniconi, C., Putti, M., and Salandin, P.: Ensemble Kalman filter data assimilation for a process-based catchment scale model of surface and subsurface flow, Water Resour. Res., 45, https://doi.org/10.1029/2008WR007031, 2009. a
Camporese, M., Paniconi, C., Putti, M., and Orlandini, M.: Surface-subsurface flow modeling with path-based runoff routing, boundary condition-based coupling, and assimilation of multisource observation data, Water Resour. Res., 46, https://doi.org/10.1029/2008WR007536, 2010. a
Carrassi, A., Bocquet, M., Bertino, L., and Evensen, G.: Data assimilation in the geosciences: An overview of methods, issues, and perspectives, Wiley Interdisciplinary Reviews: Climate Change, 9, e535, https://doi.org/10.1002/wcc.535, 2018. a
Crestani, E., Camporese, M., Baú, D., and Salandin, P.: Ensemble Kalman filter versus ensemble smoother for assessing hydraulic conductivity via tracer test data assimilation, Hydrol. Earth Syst. Sci., 17, 1517–1531, https://doi.org/10.5194/hess-17-1517-2013, 2013. a, b
Crow, W. T. and Wood, E. F.: The assimilation of remotely sensed soil brightness temperature imagery into a land surface model using Ensemble Kalman filtering: a case study based on ESTAR measurements during SGP97, Adv. Water Resour., 26, 137–149, https://doi.org/10.1016/S0309-1708(02)00088-X, 2003. a
Cui, F., Bao, J., Cao, Z., Li, L., and Zheng, Q.: Soil hydraulic parameters estimation using ground penetrating radar data via ensemble smoother with multiple data assimilation, J. Hydrol., 583, 124552, https://doi.org/10.1016/j.jhydrol.2020.124552, 2020. a, b
Darcy, H.: Recherches expérimentales relatives au mouvement de l'eau dans les tuyaux, Mallet – Bachelier, 1857. a
Defforge, C. L., Carissimo, B., Bocquet, M., Armand, P., and Bresson, R.: Data assimilation at local scale to improve CFD simulations of atmospheric dispersion: application to 1D shallow-water equations and method comparisons, Int. J. Environ. Pollut., 64, 90–109, https://doi.org/10.1504/IJEP.2018.099151, 2018. a
Dehotin, J.: Prise en compte de l'hétérogénéité des surfaces continentales dans la modélisation hydrologique spatialisée. Application sur le haut-bassin de la Saône., Ph.D. thesis, Institut National Polytechnique de Grenoble, 2007. a
Devers, A., Vidal, J.-P., Lauvernet, C., Graff, B., and Vannier, O.: A framework for high-resolution meteorological surface reanalysis through offline data assimilation in an ensemble of downscaled reconstructions, Q. J. Roy. Meteor. Soc., 146, 153–173, https://doi.org/10.1002/qj.3663, 2020. a
Djabelkhir, K., Lauvernet, C., Kraft, P., and Carluer, N.: Development of a dual permeability model within a hydrological catchment modeling framework: 1D application, Sci. Total Environ., 575, 1429–1437, https://doi.org/10.1016/j.scitotenv.2016.10.012, 2017. a
El Hajj, M., Baghdadi, N., Zribi, M., and Bazzi, H.: Synergic use of Sentinel-1 and Sentinel-2 images for operational soil moisture mapping at high spatial resolution over agricultural areas, Remote Sens., 9, 1292, https://doi.org/10.3390/rs9121292, 2017. a
Emerick, A. A. and Reynolds, A. C.: Ensemble Smoother with Multiple Data Assimilation, Comput. Geosci., 55, 3–15, https://doi.org/10.1016/j.cageo.2012.03.011, 2013a. a, b, c, d, e
Emerick, A. A. and Reynolds, A. C.: History-matching production and seismic data in a real field case using the ensemble smoother with multiple data assimilation, in: SPE Reservoir Simulation Symposium, 18–20 February 2013, The Woodlands, Texas, USA, OnePetro, https://doi.org/10.2118/163675-MS, 2013b. a
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res.-Oceans, 99, 10143–10162, https://doi.org/10.1029/94JC00572, 1994. a
Evensen, G.: The ensemble Kalman filter: Theoretical formulation and practical implementation, Ocean Dynam., 53, 343–367, https://doi.org/10.1007/s10236-003-0036-9, 2003. a
Evensen, G.: The ensemble Kalman filter for combined state and parameter estimation, IEEE Contr. Syst. Mag., 29, 83–104, https://doi.org/10.1109/MCS.2009.932223, 2009. a
Fatichi, S., Vivoni, E. R., Ogden, F. L., Ivanov, V. Y., Mirus, B., Gochis, D., Downer, C. W., Camporese, M., Davison, J. H., Ebel, B., Jones, N., Kim, J., Mascaro, G., Niswonger, R., Restrepo, P., Rigon, R., Shen, C., Sulis, M., and Tarboton, D.: An overview of current applications, challenges, and future trends in distributed process-based models in hydrology, J. Hydrol., 537, 45–60, https://doi.org/10.1016/j.jhydrol.2016.03.026, 2016. a
Fouilloux, A. and Piacentini, A.: The PALM Project: MPMD Paradigm for an Oceanic Data Assimilation Software, in: Euro-Par’99 Parallel Processing: 5th International Euro-Par Conference Toulouse, France, 31 August–3 September , 1999 Proceedings, 1423–1430, 1999. a
Gao, Q., Zribi, M., Escorihuela, M., and Baghdadi, N.: Synergetic Use of Sentinel-1 and Sentinel-2 Data for Soil Moisture Mapping at 100 m Resolution, Sensors, 17, 1966, https://doi.org/10.3390/s17091966, 2017. a
Gassmann, M., Stamm, C., Olsson, O., Lange, J., Kümmerer, K., and Weiler, M.: Model-based estimation of pesticides and transformation products and their export pathways in a headwater catchment, Hydrol. Earth Syst. Sci., 17, 5213–5228, https://doi.org/10.5194/hess-17-5213-2013, 2013. a
Hendricks Franssen, H. J. and Kinzelbach, W.: Real-time groundwater flow modeling with the Ensemble Kalman Filter: Joint estimation of states and parameters and the filter inbreeding problem, Water Resour. Res., 44, https://doi.org/10.1029/2007WR006505, 2008. a, b
Herrera, P. A., Marazuela, M. A., and Hofmann, T.: Parameter estimation and uncertainty analysis in hydrological modeling, WIREs Water, 9, e1569, https://doi.org/10.1002/wat2.1569, 2022. a
Hersbach, H.: Decomposition of the Continuous Ranked Probability Score for Ensemble Prediction Systems, Weather Forecast., 15, 559–570, https://doi.org/10.1175/1520-0434(2000)015<0559:DOTCRP>2.0.CO;2, 2000. a, b, c
Hunt, B. R., Kostelich, E. J., and Szunyogh, I.: Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter, Physica D, 230, 112–126, https://doi.org/10.1016/j.physd.2006.11.008, data Assimilation, 2007. a
Kalman, R. E.: A New Approach to Linear Filtering and Prediction Problems, Transactions of the ASME–Journal of Basic Engineering, 82, 35–45, https://doi.org/10.1115/1.3662552, 1960. a
Katzfuss, M., Stroud, J. R., and Wikle, C. K.: Understanding the ensemble Kalman filter, Am. Stat., 70, 350–357, https://doi.org/10.1080/00031305.2016.1141709, 2016. a
Kraft, P., Vache, K. B., Frede, H.-G., and Breuer, L.: CMF: A Hydrological Programming Language Extension For Integrated Catchment Models, Environ. Model. Softw., 26, 828–830, https://doi.org/10.1016/j.envsoft.2010.12.009, 2012. a
Kurtz, W., He, G., Kollet, S. J., Maxwell, R. M., Vereecken, H., and Hendricks Franssen, H.-J.: TerrSysMP–PDAF (version 1.0): a modular high-performance data assimilation framework for an integrated land surface–subsurface model, Geosci. Model Dev., 9, 1341–1360, https://doi.org/10.5194/gmd-9-1341-2016, 2016. a
Lei, F., Crow, W. T., Kustas, W. P., Dong, J., Yang, Y., Knipper, K. R., Anderson, M. C., Gao, F., Notarnicola, C., Greifeneder, F., McKee, L. M., Alfieri, J. G., Hain, C., and Dokoozlian, N.: Data assimilation of high-resolution thermal and radar remote sensing retrievals for soil moisture monitoring in a drip-irrigated vineyard, Remote Sens. Environ., 239, 111622, https://doi.org/10.1016/j.rse.2019.111622, 2020. a
Lighthill, M. J. and Whitham, G. B.: On kinematic waves I. Flood movement in long rivers, P. Roy. Soc. Lond. A, 229, 281–316, https://doi.org/10.1098/rspa.1955.0088, 1955. a
Liu, Y. and Gupta, H. V.: Uncertainty in hydrologic modeling: Toward an integrated data assimilation framework, Water Resour. Res., 43, https://doi.org/10.1029/2006WR005756, 2007. a
Miles, J. C.: The representation of flows to partially penetrating rivers using groundwater flow models, J. Hydrol., 82, 341–355, https://doi.org/10.1016/0022-1694(85)90026-5, 1985. a
Moradkhani, H., Sorooshian, S., Gupta, H. V., and Houser, P. R.: Dual state–parameter estimation of hydrological models using ensemble Kalman filter, Adv. Water Resour., 28, 135–147, https://doi.org/10.1016/j.advwatres.2004.09.002, 2005. a
Moussa, R., Colin, F., Dagès, C., Fabre, J.-C.and Lagacherie, P., Louchart, X., Rabotin, M., Raclot, D., and Voltz, M.: Distributed hydrological modelling of farmed catchments (MHYDAS): assessing the impact of man-made structures on hydrological processes, in: International Conference on Integrative Landscape Modelling, LANDMOD2010, Symposcience – Éditions Quae, Section 2. Modelling the biophysical components of landscapes, https://hal.inrae.fr/hal-02753016 (last access: 5 January 2026), 2010. a
Nie, S., Zhu, J., and Luo, Y.: Simultaneous estimation of land surface scheme states and parameters using the ensemble Kalman filter: identical twin experiments, Hydrol. Earth Syst. Sci., 15, 2437–2457, https://doi.org/10.5194/hess-15-2437-2011, 2011. a, b
Paniconi, C. and Putti, M.: A comparison of Picard and Newton iteration in the numerical solution of multidimensional variably saturated flow problems, Water Resour. Res., 30, 3357–3374, https://doi.org/10.1029/94WR02046, 1994. a
Pasetto, D., Niu, G.-Y., Pangle, L., Paniconi, C., Putti, M., and Troch, P. A.: Impact of sensor failure on the observability of flow dynamics at the Biosphere 2 LEO hillslopes, Adv. Water Resour., 86, 327–339, https://doi.org/10.1016/j.advwatres.2015.04.014, 2015. a
Radišić, K., Rouzies, E., Lauvernet, C., and Vidard, A.: Global sensitivity analysis of the dynamics of a distributed hydrological model at the catchment scale, Socio-Environmental Systems Modelling, 5, 18570, https://doi.org/10.18174/sesmo.18570, 2023. a
Richards, A. L.: Capillary conduction of liquids in porous mediums, Physics 1, 1, 318–333, https://doi.org/10.1063/1.1745010, 1931. a
Rochoux, M. C., Ricci, S., Lucor, D., Cuenot, B., and Trouvé, A.: Towards predictive data-driven simulations of wildfire spread – Part I: Reduced-cost Ensemble Kalman Filter based on a Polynomial Chaos surrogate model for parameter estimation, Nat. Hazards Earth Syst. Sci., 14, 2951–2973, https://doi.org/10.5194/nhess-14-2951-2014, 2014. a
Rouzies, E., Lauvernet, C., Barachet, C., Morel, T., Branger, F., Braud, I., and Carluer, N.: From agricultural catchment to management scenarios: A modular tool to assess effects of landscape features on water and pesticide behavior, Sci. Total Environ., 671, 1144–1160, https://doi.org/10.1016/j.scitotenv.2019.03.060, 2019. a, b, c, d
Rouzies, E., Lauvernet, C., and Vidard, A.: Code availability for: Comparison of different ensemble assimilation methods for joint estimation in a pesticide transfer model, Zenodo [code], https://doi.org/10.5281/zenodo.6782073, 2022. a
Rouzies, E., Lauvernet, C., Sudret, B., and Vidard, A.: How is a global sensitivity analysis of a catchment-scale, distributed pesticide transfer model performed? Application to the PESHMELBA model, Geosci. Model Dev., 16, 3137–3163, https://doi.org/10.5194/gmd-16-3137-2023, 2023. a, b, c
Šimůnek, J., Van Genuchten, M. T., and Šejna, M.: HYDRUS-1D - Simulating the one-dimensional movement of water, heat, and multiple solutes in variably-saturated media, Tech. rep., U.S. Salinity Lab., Riverside, CA., 1998. a
Tortrat, F.: Modélisation orientée décision des processus de transfert par ruissellement et subsurface des herbicides dans les bassins versants agricoles., Ph.D. thesis, Ecole nationale supérieure d'agronomie de Rennes, 2005. a
van Leeuwen, P. J. and Evensen, G.: Data Assimilation and Inverse Methods in Terms of a Probabilistic Formulation, Mon. Weather Rev., 124, 2898–2913, https://doi.org/10.1175/1520-0493(1996)124<2898:DAAIMI>2.0.CO;2, 1996. a, b
Wendell, A.-K., Guse, B., Bieger, K., Wagner, P. D., Kiesel, J., Ulrich, U., and Fohrer, N.: A spatio-temporal analysis of environmental fate and transport processes of pesticides and their transformation products in agricultural landscapes dominated by subsurface drainage with SWAT+, Sci. Total Environ., 945, 173629, https://doi.org/10.1016/j.scitotenv.2024.173629, 2024. a
Xie, X. and Zhang, D.: Data assimilation for distributed hydrological catchment modeling via ensemble Kalman filter, Adv. Water Resour., 33, 678–690, https://doi.org/10.1016/j.advwatres.2010.03.012, 2010. a