the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Dec 2025
| 01 Dec 2025
Ensembling differentiable process-based and data-driven models with diverse meteorological forcing datasets to advance streamflow simulation
Yalan Song
Kathryn Lawson
Streamflow simulations produced by different hydrological models exhibit distinct characteristics and can provide valuable information when ensembled. However, few studies have focused on ensembling simulations from models with significant structural differences and evaluating them under both temporal and spatial tests. Here we systematically evaluated and utilized the simulations from two highly different models with great performances: a purely data-driven long short-term memory (LSTM) network and a physics-informed machine learning (“differentiable”) HBV (Hydrologiska Byråns Vattenbalansavdelning) model (δHBV). To effectively display the features of the two models, multiple forcing datasets are employed. The results show that the simulations of LSTM and δHBV have distinct features and complement each other well, leading to better Nash-Sutcliffe model efficiency coefficients (NSE) and improved high-flow and low-flow metrics across all spatiotemporal tests, compared to within-class ensembles. Ensembling models trained on a single forcing outperformed a single model using fused forcings, challenging the paradigm of feeding all available data into a single data-driven model. Most notably, δHBV significantly enhanced spatial interpolation when incorporated into LSTM, and provided even more prominent benefits for spatial extrapolation where the LSTM-only ensembles degraded significantly, attesting to the value of the structural constraints in δHBV. These advances set new benchmark records on the well-known CAMELS (Catchment Attributes and Meteorology for Large-sample Studies) hydrological dataset, reaching median NSE values of ∼ 0.83 for the temporal test (densely trained scenario), ∼ 0.79 for the ungauged basin test (PUB, Prediction in Ungauged Basins), and ∼ 0.70 for the ungauged region test (PUR, Prediction in Ungauged Regions). This study advances our understanding of how various model types, each with distinct mechanisms, can be effectively leveraged alongside multi-source datasets across diverse scenarios.
- Article
(11080 KB) - Full-text XML
- BibTeX
- EndNote




-
Combining LSTM and δHBV with diverse forcings sets new accuracy benchmarks
-
Ensembling models with one forcing outperforms merging forcings as an input
-
δHBV and LSTM together always increase NSEs, especially spatial generalization
-
δHBV provides valuable spatial constraints in the deterministic ensemble simulations
-
δHBV and LSTM have different error characteristics that can be offset in an ensemble
Streamflow, a critical component of the global hydrosphere, profoundly influences both human society and natural ecosystems (Lins and Slack, 1999). Accurate simulation and prediction of streamflow yield numerous benefits, including improved flood prevention strategies (Brunner et al., 2021). Hydrological models serve as indispensable tools for achieving this objective and can be traditionally categorized into two types: data-driven models (Feng et al., 2020; Kratzert et al., 2018; Liu et al., 2024; Nearing et al., 2024) and process-based (or physically-based) models (Newman et al., 2017; Paul et al., 2021). Data-driven models, exemplified by long short-term memory (LSTM) (Feng et al., 2020; Kratzert et al., 2018) and transformer (Liu et al., 2024) networks, excel in learning patterns from multi-source data (Li et al., 2023b, 2024; Liu et al., 2022; Nearing et al., 2024) and generally achieve high performance. However, they often lack interpretability and may not resolve extreme values very well (Li et al., 2020a; Song et al., 2025b). Conversely, process-based models, derived deductively from physical laws or conceptualized views of natural systems, offer insights into internal hydrological processes but may exhibit weaker performance due to structural inadequacies (Li et al., 2020a, 2022; Zhang et al., 2019).
To combine the benefits and counteract the weaknesses of these two kinds of models, many efforts have been made to incorporate physical constraints and structures into data-driven models to align with fundamental physical principles, such as mass and water balances (Bandai and Ghezzehei, 2021; Wang et al., 2020; Xie et al., 2021). The most seamless integration uses neural networks to provide parameterizations or missing process representations for process-based models (Aboelyazeed et al., 2023; Bindas et al., 2024; Feng et al., 2022; Jiang et al., 2020; Kraft et al., 2022; Rahmani et al., 2023; Song et al., 2024; Tsai et al., 2021). These differentiable models (Shen et al., 2023) connect (flexible amounts of) prior physical knowledge to neural networks, and have displayed many advantages, including improved computational efficiency and prediction of untrained variables (Tsai et al., 2021), spatial generalization (Feng et al., 2023b), and representation of extremes (Song et al., 2025b). However, it is also unclear whether current differentiable models, e.g., δHBV, the Hydrologiska Byråns Vattenbalansavdelning (HBV) model implemented within a differentiable framework (Feng et al., 2023b; Ji et al., 2025; Shen et al., 2023; Song et al., 2025b), have unique bias characteristics that are associated with the process-based parts of their structures that cannot be reduced once the equations are prescribed.
Orthogonal to such efforts are ensemble simulations (Yu et al., 2024), which combine many members with different biases and uncertainties to mitigate their respective biases in deterministic predictions. Many previous studies have tried ensemble methods to improve streamflow (Clark et al., 2016; Zounemat-Kermani et al., 2021) based on many factors, like initial conditions (e.g., initial weights and biases in LSTM; Kratzert et al., 2018), data used for parameterization (Feng et al., 2021), and objective functions (Lin et al., 2024). These studies generally use one model to generate the differences among the ensemble members. Furthermore, some studies (Dion et al., 2021; Solanki et al., 2025) have utilized simulations from multiple different models but are limited to process-based models, resulting in ensemble simulations that are better than each individual member. Thus far, however, most studies have focused on simulations from only similar models or model types, and little work has tested an ensemble across the boundary of model types, particularly between data-driven, process-based, and hybrid models, especially on a large number of samples. Presumably, if each model has its own unique bias, data-driven and process-based models are likely to exhibit greater differences due to their inherently distinct characteristics. It remains unclear whether ensembling across model types should bring benefits to deterministic predictions. Furthermore, grounded in the process-based model, the differentiable process-based hydrological model, such as δHBV, significantly enhances performance compared to traditional process-based models, while on the other hand introducing greater uncertainty regarding its potential benefits when ensembled. Moreover, previous studies have primarily focused on evaluating ensemble simulations for temporal predictions. However, streamflow simulation under spatial extrapolation scenarios presents greater challenges, and findings from temporal tests may not be directly applicable in this context.
It is known that the performance of any type of hydrologic model heavily depends on the quality of input data, particularly meteorological forcing data (Bell and Moore, 2000; Yao et al., 2020), and other inputs, like the uncertainties of initial conditions, can be mitigated via warming up (Yu et al., 2019). While independent forcing datasets excel in certain aspects, they each carry different error characteristics (Beck et al., 2017; Behnke et al., 2016; Newman et al., 2019) and accordingly affect the hydrological models in different ways. In order to fully display the different features between LSTM and δHBV, multiple forcing datasets could be considered. Given the utilization of multiple forcing datasets, one could choose to use data fusion to combine them into a single coherent model input (Kratzert et al., 2021; Sawadekar et al., 2025), or to pass each forcing dataset through a model and then afterwards combine the multiple outputs in an ensemble. It is not clear which approach is more beneficial.
Considering the knowledge gaps discussed above, we sought to answer several research questions:
-
Will a cross-model-type ensemble of LSTM and δHBV improve deterministic streamflow prediction more than a within-class ensemble?
-
Is it better to use multiple forcings in one model or to ensemble multiple models, each with a different forcing input?
-
Do process-based equations bring unique value to an ensemble, especially in terms of spatial generalizability?
The remainder of this paper is structured as follows: Sect. 2 outlines the hydrological data and models used in this study, as well as the experimental design. Results and discussions are presented in Sect. 3, with conclusions provided in Sect. 4.
2.1 CAMELS hydrologic dataset
The Catchment Attributes and Meteorology for Large-sample Studies (CAMELS) dataset (Addor et al., 2017) is widely employed for hydrological model evaluation and community benchmarking. The CAMELS dataset encompasses 671 basins distributed across the conterminous United States, with basin sizes ranging from 1 to 25 800 km2 (median: 335 km2). This standardized and publicly available dataset serves as a benchmark for evaluating various hydrological models, with LSTM models trained on this dataset often serving as a reference point for comparing other models (Kratzert et al., 2021). CAMELS provides basin-scale data, including streamflow observations and static basin attributes, as well as forcing datasets from three independent sources: Daymet (Thornton et al., 1997), North American Land Data Assimilation System (NLDAS) (Xia et al., 2012), and Maurer (Maurer et al., 2002). Each of the three meteorological forcing datasets operates at a daily temporal resolution, encompassing precipitation, temperature, vapor pressure, and surface radiation variables, with daily temperature extrema of NLDAS and Maurer supplemented from Kratzert et al. (2021). These three meteorological forcing datasets have methodological distinctions in spatial resolution, data generation approaches, and temporal processing (Behnke et al., 2016; Kratzert et al., 2021). Exemplary plots illustrating the differences among the three meteorological forcing datasets are provided in Appendix B. These features can lead to dataset-specific error characteristics and make them valuable for displaying the distinct features of different model types. All model inputs used in this study are detailed in Table C1 in Appendix C.
2.2 Long short-term memory
As one kind of deep learning algorithm, long short-term memory (LSTM) (Hochreiter and Schmidhuber, 1997) has unique structures like hidden states and gates activated by the tanh and sigmoid functions (Li et al., 2023a), respectively. These features enable LSTM to excel in streamflow simulation tasks (Feng et al., 2020; Kratzert et al., 2018; Nearing et al., 2024). In the current benchmark framework, LSTM models are trained using dynamic atmospheric forcings and static basin attributes as inputs, with streamflow as the target output, making it perform well in both temporal and spatial tests (Fig. 1a). In this work, for cross-group comparability, we used the LSTM model and its hyperparameters as reported in Kratzert et al. (2021).
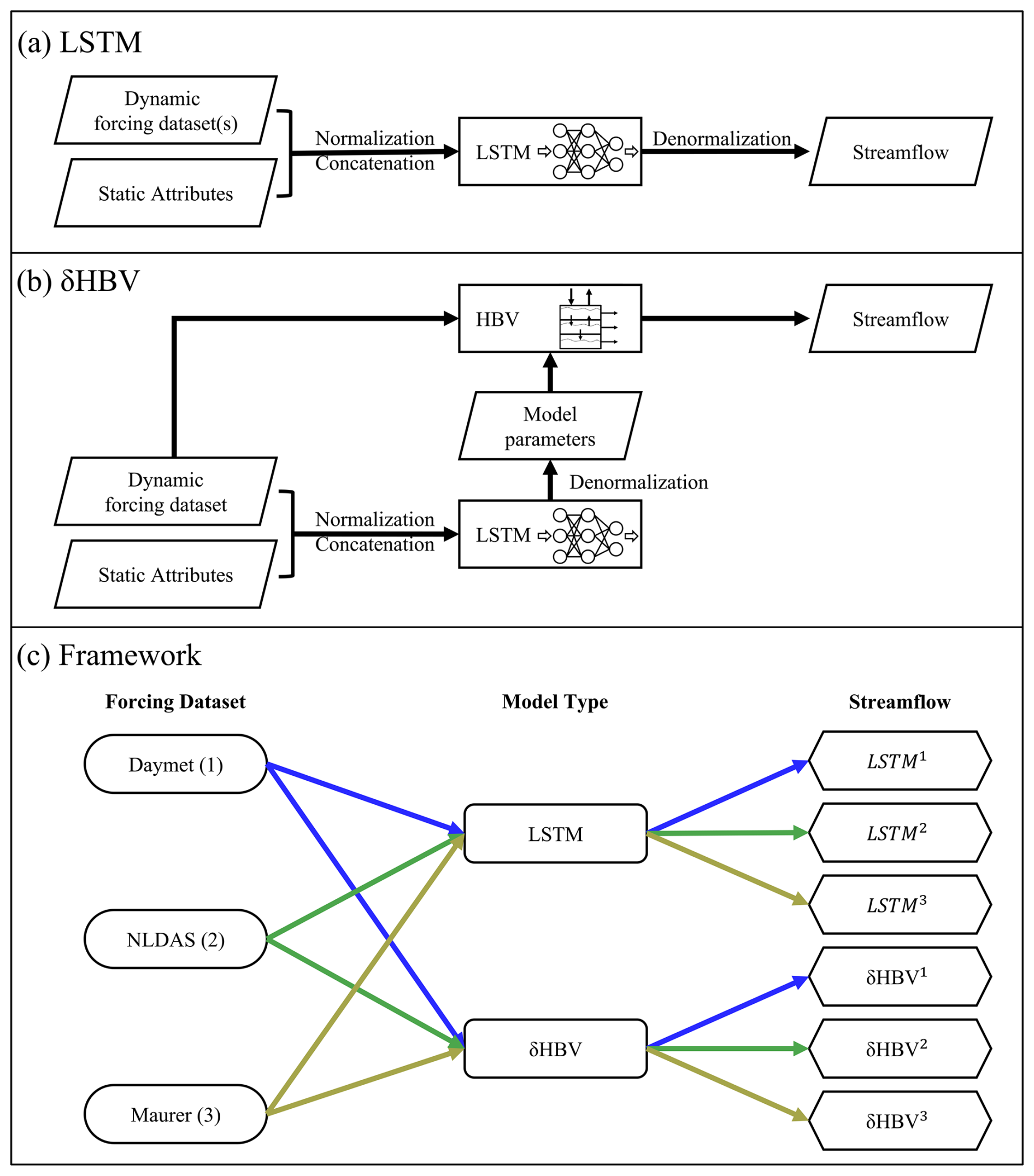
Figure 1(a) The LSTM structure, (b) the δHBV structure, and (c) the framework to generate the six individual ensemble members of the streamflow simulations, in which different colors of arrow lines denote the different meteorological forcing datasets (also denoted as 1, 2, 3), respectively.
2.3 Differentiable HBV model (δHBV)
The Hydrologiska Byråns Vattenbalansavdelning (HBV) model is a parsimonious bucket-type hydrologic model that simulates various hydrological variables, including snow water equivalent, soil water, groundwater storage, evapotranspiration, quick flow, baseflow, and total streamflow (Aghakouchak and Habib, 2010; Beck et al., 2020; Bergström, 1976, 1992). Recently demonstrated differentiable HBV (δHBV) model (Feng et al., 2023b; Ji et al., 2025; Shen et al., 2023; Song et al., 2024) incorporates deep neural networks for both regionalized parameterization and missing process representations within a differentiable programming framework that supports “end-to-end” training (Fig. 1b). This innovation enables δHBV to effectively learn from data while obeying physical laws, resulting in high-level performance for streamflow simulations. From the perspective of process-based modeling, LSTM is a regionalized parameter provider that leverages the autocorrelated nature of its inputs to impose an implicit spatial constraint on the generated parameters.
In this study, we used δHBV1.1p (Song et al., 2024, 2025b), which is an updated version of δHBV1.0 (Feng et al., 2022, 2023b). The main improvement is the addition of a capillary rise module, which enhances the characterization of low flows. Three additional modifications are included to address high-flow simulation challenges: the use of three dynamic parameters (γ, β, k0) (Song et al., 2025b); the removal of log-transform normalization for precipitation; and the adoption of the normalized squared-error loss function (Table C2) (Frame et al., 2022; Kratzert et al., 2021; Song et al., 2025a, b; Wilbrand et al., 2023). We also maintain dynamic parameters during warm-up periods. Although this provides only marginal benefits and increases computational costs, it yields a more realistic representation and reduces uncertainties associated with initial conditions. The basic equations in δHBV are as follows:
where θ are the dynamic or static physical parameters, w denotes the weights and biases of LSTM, x includes the basin-averaged meteorological forcings, such as precipitation, mean temperature, and potential evapotranspiration, with representing their normalized versions. Similarly, consists of normalized observable basin-averaged attributes, encompassing basin area, topography, climate, soil texture, land cover, and geology (Table C1). Precipitation and mean temperature are from CAMELS, while potential evapotranspiration is calculated using the Hargreaves (1994) method based on maximum and minimum temperatures along with basin latitudes, all from data described in Sect. 2.1. Q and Q∗ are the streamflow simulations (model outputs) and observations (as provided in CAMELS), respectively. HBV is implemented on PyTorch so it is programmatically differentiable: all steps store information related to gradient calculations during backpropagation, allowing this model to be trained together with neural networks in an end-to-end fashion. More details about differentiable HBV can be found in previous studies (Feng et al., 2022; Song et al., 2024). The details of some particularly relevant HBV processes are described in Appendix A.
2.4 Experimental design
In this study, we trained the two models of very different types (LSTM and δHBV), each with one of three meteorological forcing datasets (Daymet, NLDAS, and Maurer), resulting in six corresponding streamflow simulations (Fig. 1c) for each different test scenario (see Sect. 2.5 for additional information). The training processes of LSTM and δHBV followed Kratzert et al. (2021) and Feng et al. (2023b), respectively. Test results and performance metrics for all models are reported for the 531-basin subset that excludes those with areas larger than 2000 km2 or with more than a 10 % discrepancy between different basin area calculation methods (Newman et al., 2017).
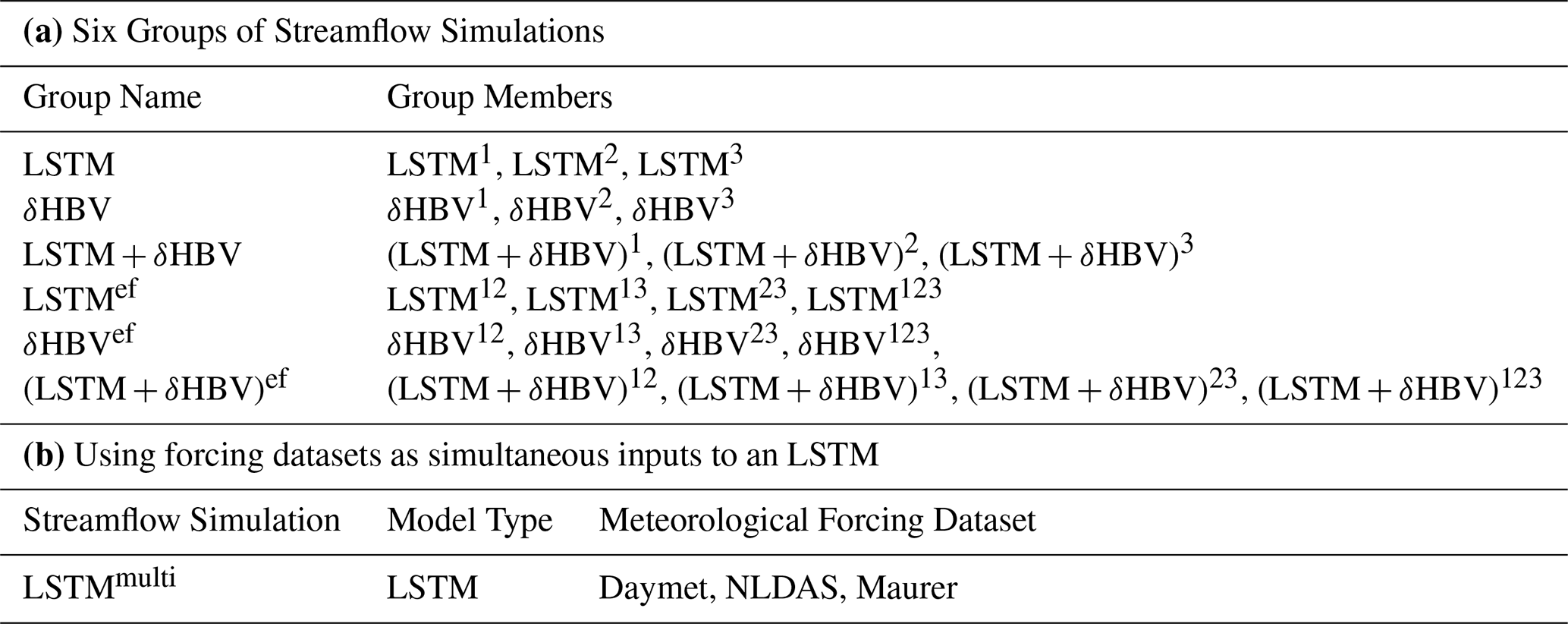
To generate ensembles, we tested various weighting strategies and ultimately employed averaging to combine the six single-forcing, single-model-type simulations, as it yielded the best performance. To better describe various combinations including cross-model ensembles, these simulations were categorized into six groups (Table 1). A shorthand notation is used throughout the remainder of this work to describe the forcing datasets and ensembles. Daymet, NLDAS, and Maurer are abbreviated as superscripts 1, 2, and 3, respectively. The + symbol is used to group model types being ensembled, while superscript clustering (e.g., 12 or 123) is used to group the meteorological forcing types being ensembled, with parentheses indicating that the superscripts apply to all model types within. For example, (LSTM+δHBV)123 could be explicitly written as . To compare two different strategies to utilize the multiple meteorological forcing datasets and to benchmark against the previously highest performance, we additionally trained a single LSTM model using all three forcing datasets as simultaneous inputs as done by Kratzert et al. (2021), referred to as LSTMmulti (the last row in Table 1).
Table 1(a) The six groups of streamflow simulations, and (b) the streamflow simulation via LSTM based on a different strategy, in which three meteorological forcing datasets were combined as a single set of inputs (Kratzert et al., 2021). Superscripts 1, 2, and 3 denote Daymet, NLDAS, and Maurer, respectively. The ensemble across forcings (“ef”) superscript indicates an ensemble of model simulations, each of which uses a different single meteorological forcing, e.g., LSTM12 means the average of LSTM1 and LSTM2.
2.5 Evaluation scenarios and criteria
The above cases were comprehensively evaluated for performance in temporal extrapolation (Feng et al., 2022; Kratzert et al., 2018), as well as two types of spatial generalization: prediction in ungauged basins (PUB) (Feng et al., 2023b; Kratzert et al., 2019), and prediction in ungauged regions (PUR) (Feng et al., 2021, 2023b):
-
Temporal Test: Models were trained using data from all basins and tested across different periods.
-
PUB Test: Models were trained on randomly selected subsets from all basins and tested on the remaining basins during the same time period.
-
PUR Test: Different from the PUB test, basins were grouped into continuous regions, one of which was selected to comprise the group of testing basins while the others were used for training.
Temporal generalization is generally considered to be the easiest of these tests. In terms of spatial generalization, which approximates data-sparse scenarios, the PUB test is an example of spatial interpolation, whereas the PUR test involves spatial extrapolation. The PUR test is widely regarded as the most challenging and may therefore produce findings that differ significantly from those in other scenarios. In this study, all basins were divided into 10 spatially stratified groups for the PUB test and 7 fully disjoint regional groups for the PUR test (Table 2) in the same way as Feng et al. (2023b). The spatial extent of the 7 regions for the PUR test is also shown in Fig. 3c1–c2. Therefore, we conducted 10 rounds for the PUB test and 7 rounds for the PUR test, with a different group held out for testing in each round. Model performance was evaluated after concatenating the test results for all basins.
Table 2Differences of temporal, PUB, and PUR tests.
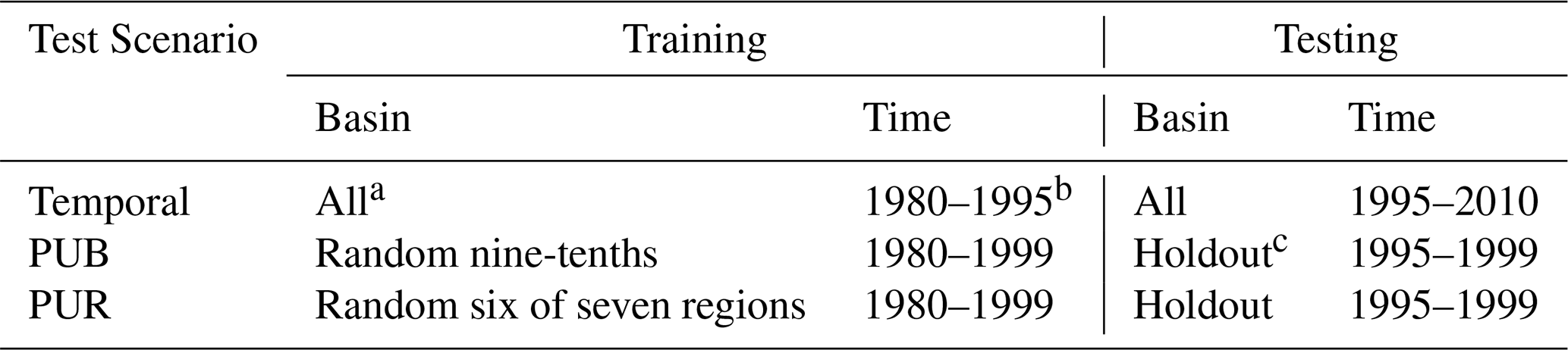
a δHBV training followed Feng et al. (2023b) using all 671 CAMELS basins, while LSTM training followed Kratzert et al. (2021) using the selected 531-basin subset. Test results and performance metrics for all models are reported for the 531 basins. b Each hydrological year spans from 1 October to 30 September of the following year. c In the PUB and PUR tests, models are run for 10 and 7 rounds, respectively, with the group held out for testing changed in each round. The simulation performance was evaluated after concatenating the test results for all basins.
We repeated all the simulations with three different random seeds. Therefore, all the simulations come from a total of trained models. The first factor represents the models: two model types (LSTM and δHBV) trained separately with each of the three forcing datasets, along with LSTMmulti, a single model instance trained using all three forcing datasets simultaneously. The second factor accounts for the three types of tests (temporal, PUB, and PUR tests), and the last for the three random seeds. With respect to random seeds, we present two variations in the results, which are visually depicted in Fig. C1 in Appendix C. The results without “seed” as a subscript represent the average metric values from multiple streamflow simulations, each generated from a single model implementation, along with the corresponding uncertainties, visualized using error bars. The results marked with “seed” as a subscript are based on the average of multiple streamflow simulations conducted with different random seeds. In terms of computational cost, training LSTM (30 epochs) and δHBV (50 epochs) for temporal testing under a single meteorological forcing dataset takes approximately 5 and 21 h, respectively, using a single NVIDIA Tesla V100 GPU.
We calculated several well-established performance metrics: Nash-Sutcliffe model efficiency coefficient (NSE) (Nash and Sutcliffe, 1970), Kling-Gupta model efficiency coefficient (KGE) (Kling et al., 2012), percent bias (PBIAS), and root-mean-square error (RMSE). We also considered RMSE values for high (top 2 % “peak” flow, highRMSE), low (bottom 30 % “low” flow, lowRMSE), and mid-range (the remaining flow, midRMSE) flow conditions (Yilmaz et al., 2008). These metrics were computed for each basin and aggregated into error bars and cumulative density functions (CDFs). For brevity, the main text primarily reports NSE values, and other metric values are provided in Appendices D and E. Furthermore, we use the spread values (Li et al., 2021; Reichle and Koster, 2003) to investigate ensemble variability and explore model complementarity. Detailed descriptions of these metrics and their calculations are available in Table C2.
3.1 Temporal extrapolation
For the temporal test, in which models were trained and tested on the same basins but in different time periods, we found that cross-model-type ensembles noticeably surpassed the within-class ensembles when other conditions were the same, with small uncertainties as shown by the error bars in Fig. 2. With a single forcing dataset, the median NSE was elevated from ∼ 0.735 for LSTM to ∼ 0.79 with δHBV added, though δHBV performance was similar to LSTM (∼ 0.74 under Daymet). Even after LSTM achieved very high performance when its simulations, each derived separately from different meteorological forcing datasets, were ensembled (ef = 123, ∼ 0.808), adding δHBV still improved the results to ∼ 0.818. This finding was robust for all different combinations of the tested meteorological forcing datasets. Conversely, adding LSTM also helped to improve δHBV ensembles. These results highlight the benefits of the cross-model-type ensemble framework and indicate distinct simulation features for each model type. LSTM is a data-driven method that has low bias and large variance. Data errors (Li et al., 2020b), different sampling strategies (Nai et al., 2024), or even different weight initializations (Narkhede et al., 2022) can lead to substantively different outcomes. Conversely, δHBV may have a smaller variance but a larger bias due to the fixed HBV formulation (Moges et al., 2016) for some scenarios like low flows (Feng et al., 2023b; Song et al., 2024) or in basins with significant water uses (Song et al., 2025a). These errors with varying characteristics from different model classes can partially offset each other in an ensemble. On a side note, δHBV models seem more reliant on the quality of the forcing data, as shown in Fig. 2. δHBV with the Maurer and NLDAS forcing datasets generally performs worse than it does with Daymet, which has lower biases. However, even in those cases, the combination of LSTM and δHBV was still better than LSTM alone, attesting to the robustness of these benefits.
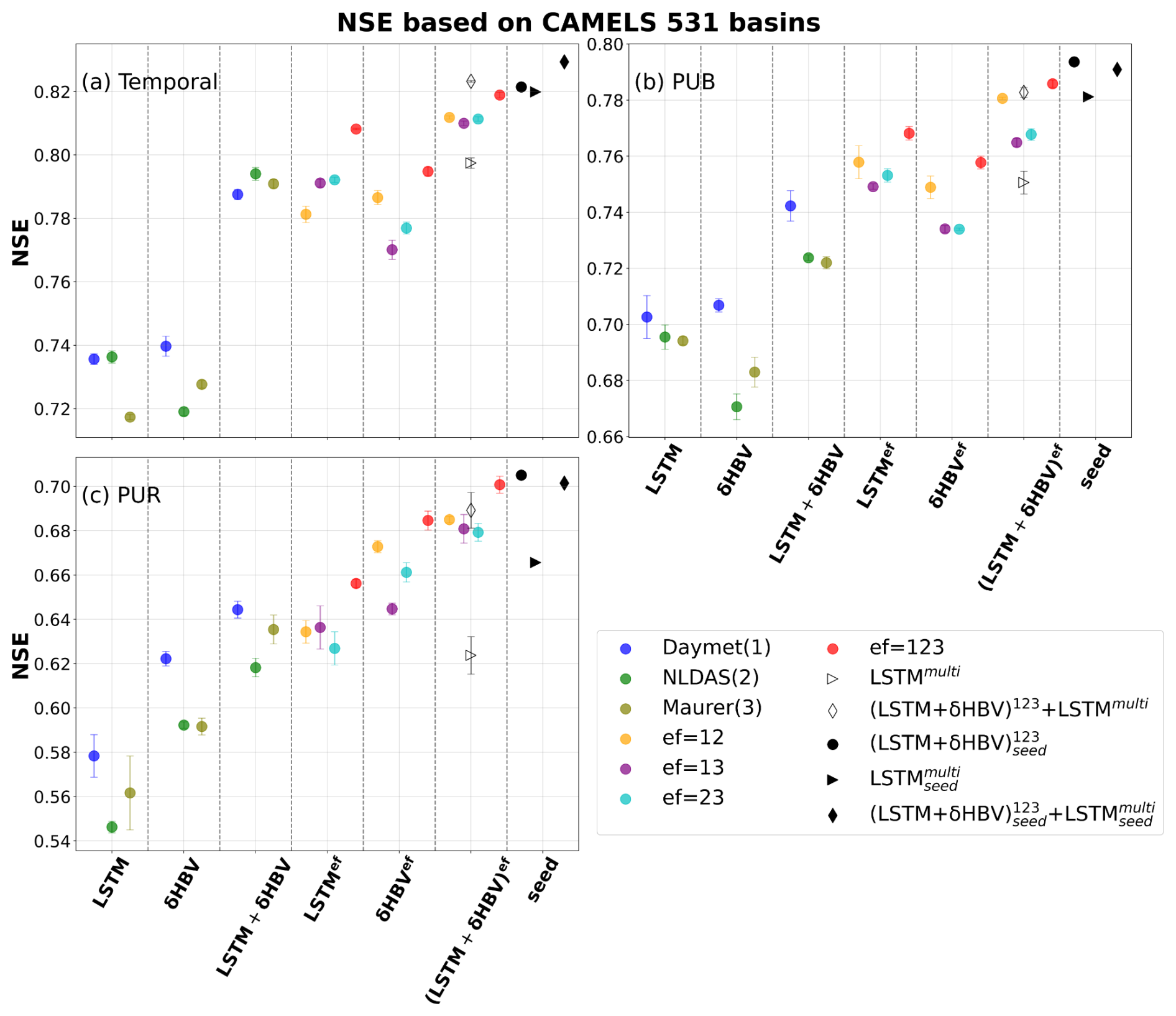
Figure 2Median NSE values for 531 CAMELS basins, indicating model and ensemble performances for (a) temporal, (b) prediction in ungauged basin (PUB), and (c) prediction in ungauged region (PUR) tests. Different simulations are represented by variously-shaped and -colored points, and are organized by ensemble group, listed along the x-axis: LSTM, δHBV, LSTM + δHBV, and their “ensemble forcing” counterparts, LSTMef, δHBVef, and (LSTM+δHBV)ef. LSTMmulti is a single LSTM model trained directly on all three forcing datasets at once. The superscript “ef” denotes the forcing datasets involved in each ensemble (choices of 1 for Daymet, 2 for NLDAS, and 3 for Maurer), while the “+” connects the model types used within an ensemble. The x-axis group and subscript “seed” indicate that simulation results were averaged based on three different random seeds (see Fig. C1). Other points without “seed”, along with their corresponding error bars, are derived from the averages of metrics computed over repeated runs with three different random seeds. The error bar indicates one standard deviation above and below the average value for each simulation.
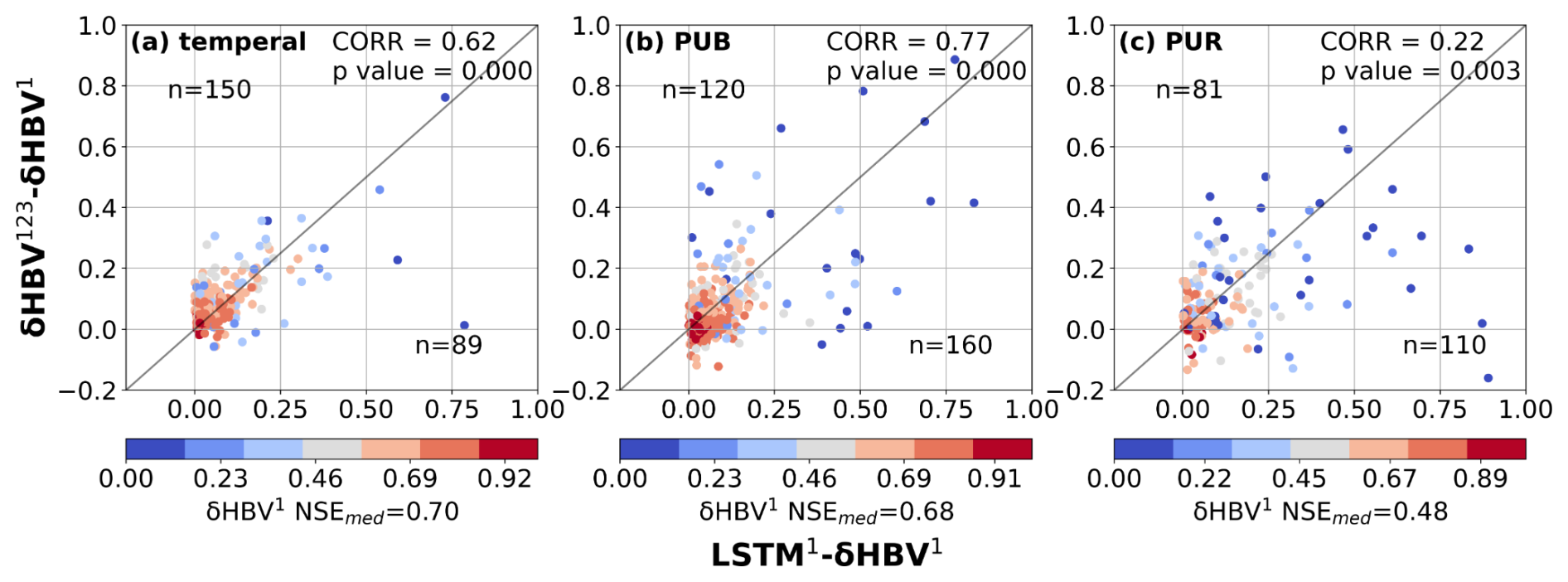
Figure 3Scatter plots comparing the performance differences between hydrological models for the basins where LSTM outperformed δHBV (the basins where δHBV outperformed are not shown in this plot). The x-axis represents the NSE differences between LSTM1 and δHBV1 (LSTM1−δHBV1), while the y-axis shows the NSE differences between δHBV123 and δHBV1 (δHBV123−δHBV1). Points are color-coded according to the NSE values of δHBV1. The correlation coefficient (CORR) and p values between the x-axis values and the y-axis values, along with the median NSE value of δHBV1 (NSEmed) on these basins, are also noted. We note that NSE is not additive and should generally not be subtracted. Here the purpose is only to confirm that basins where LSTM outperforms δHBV also tend to be those that benefit from the ensemble of forcings.
In the lower-performing basins where LSTM1 had advantages over δHBV1, the ensemble of meteorological forcings δHBV123 also tended to be higher than δHBV1 (Fig. 3), suggesting that forcing quality was a significant reason behind the underperformance of δHBV1 in these basins. Similar patterns were also observed when analyzing δHBV2 and δHBV3 values (Figs. D1 and D2 in Appendix D). These basins previously contributed to LSTM's cumulative distribution function of NSE diverging from that of δHBV1 at the low end (Feng et al., 2022). Forcing errors can exist in the form of systematic timing errors, low or high bias for larger events, etc., which can be difficult for the mass-balanced conceptual HBV1 structure to adapt to these errors. Because the ensemble of forcings tends to suppress the errors in each forcing source, part of the advantages of δHBV123 over δHBV1 can be attributed to reducing forcing bias or timing errors. Since the advantages of LSTM1 over δHBV1 also tend to occur with these same basins, this also explains how LSTM1 surpasses δHBV1 in some basins with poorer-quality forcings. In contrast to δHBV, LSTM has the innate ability to shift information in time and moderately adjust the input scale. Moving from temporal validation to PUB to PUR scenarios, the advantages of diverse forcing datasets appear to diminish, as evidenced by the decreasing ratio of points above versus below the diagonal line, since the forcing error patterns remembered by LSTM may not generalize well in space (discussed in more detail in Sect. 3.2).
Ensembling streamflow simulations from different meteorological forcing datasets demonstrates certain advantages over the previous approach of simultaneously sending multiple forcings into a data-driven model like LSTM (Kratzert et al., 2021). Ensembling LSTM simulations each using a single forcing dataset (LSTM123) resulted in an NSE value of 0.8082, higher than that of 0.7974 from feeding multiple forcing datasets into a single LSTM (LSTMmulti). This difference was more pronounced in the cross-model-type ensemble, after including δHBV, compared to the previous within-class ensemble, and particularly notable for the spatial generalization tests (to be discussed in more detail in Sect. 3.2). The corresponding specific performance metrics are summarized in Tables D1–D5 in Appendix D, with seasonal evaluations provided in Fig. D3. These results indicate that the trained LSTM in LSTMmulti may be overfit to the significant redundant information in these three forcing datasets, and that LSTM models alone cannot fully exploit the information hidden in the multiple forcing datasets. Training separate ensemble members via different nonlinear hydrological processes, on the other hand, seems to allow different bias features to emerge with separate forcing datasets, accordingly mitigating them during the subsequent ensembling process.
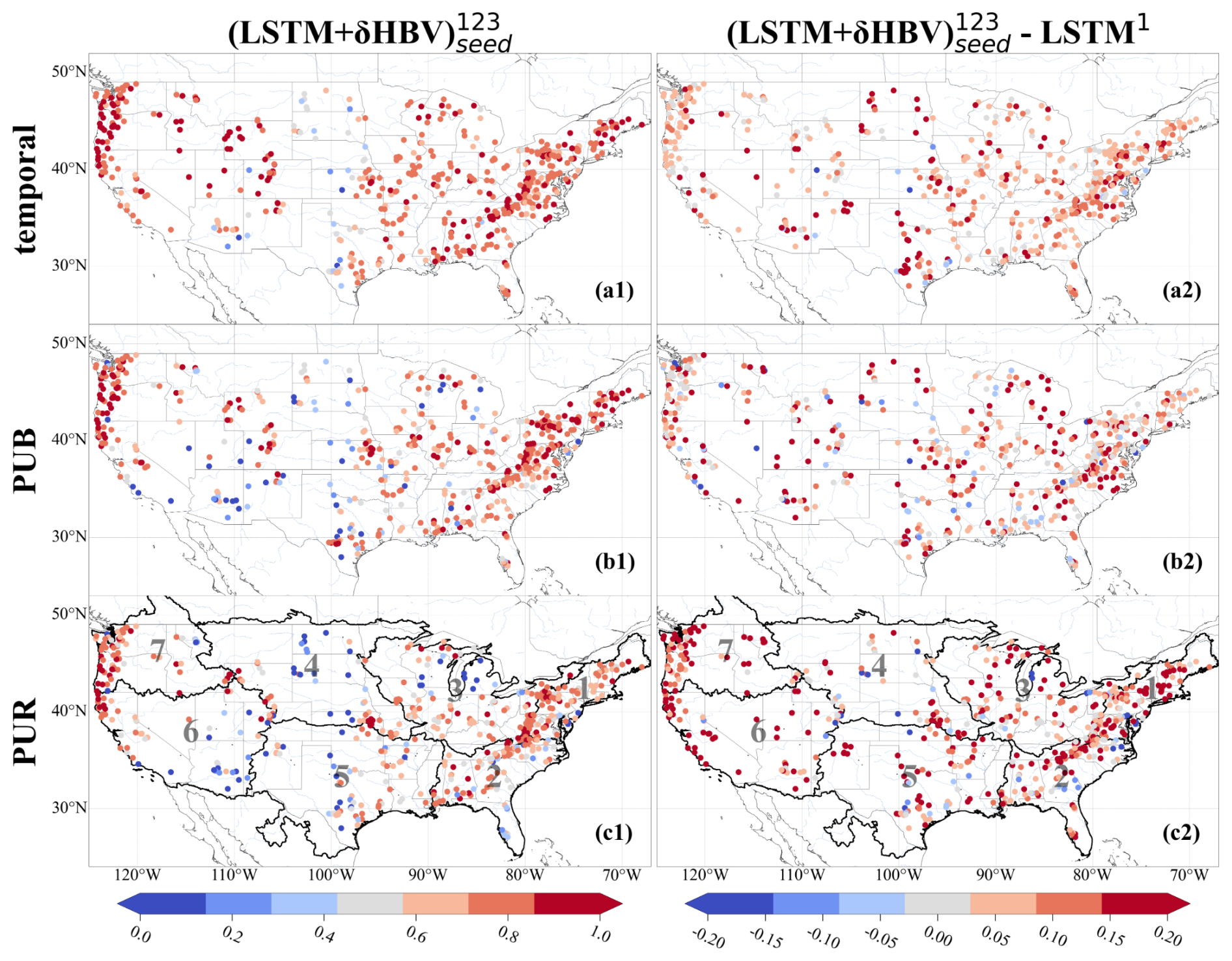
Figure 4Spatial distributions of NSE values over 531 basins. Subplots are arranged in rows, indicating (a) temporal, (b) PUB, and (c) PUR test results, and columns, denoting (1) NSE values from and (2) the differences between these NSE values and those of LSTM1 (models using only forcing 1, Daymet). For LSTM1 each NSE value reported was the average of three NSE values from three simulations using three different random seeds. The seven continuous regions used to divide up basins for the PUR test are outlined and numbered in the PUR test maps.
Our most diverse ensemble, , achieved a median NSE value of ∼ 0.83, surpassing the ∼ 0.82 benchmark set by (Table D4). This advancement was achieved through random seed variation and cross-model-type ensembling. The performance of (LSTM+δHBV)123 ensemble proved more robust than LSTMmulti, with only a slight boost when we incorporated random seeds, i.e., . Notably, the derived ensemble outperformed LSTM1 across almost all basins (Fig. 4). Further incorporation of LSTMmulti into this framework, especially when using multiple random seeds, , yielded the best overall performance. Here, the margin over the previous benchmark was small in the temporal test. However, as we will show in Sect. 3.2, the previous benchmark, , lacked robustness, exhibited greater deficiencies in spatial generalization, and negatively impacted ensemble simulations.
When we changed the number of random seeds from 3 to 10, we found that although all model and ensemble performances slightly improved, the gaps between them did not change much (Fig. 5; Table D5 for 10 seeds, Table D4 for 3 seeds). In particular, the gap between and or remained unchanged. This indicates that the benefits from more random seeds rapidly become marginal, and our results based on 3 random seeds were sufficiently robust. For LSTMs alone, different random seeds displayed higher variation, and ensembling them led to greater improvement than ensembling (LSTM+δHBV)123 with additional random seeds. It was noteworthy that while the (LSTM+δHBV)123 ensemble generally showed the lowest RMSE values, it did not always show the best high flow performance, as indicated by highRMSE (Tables D1–D4). After incorporating the variant into , overall RMSE and highRMSE both improved. Nevertheless, this ensemble did not always obtain the best values in other metrics like low flow (lowRMSE) and requires further improvement.
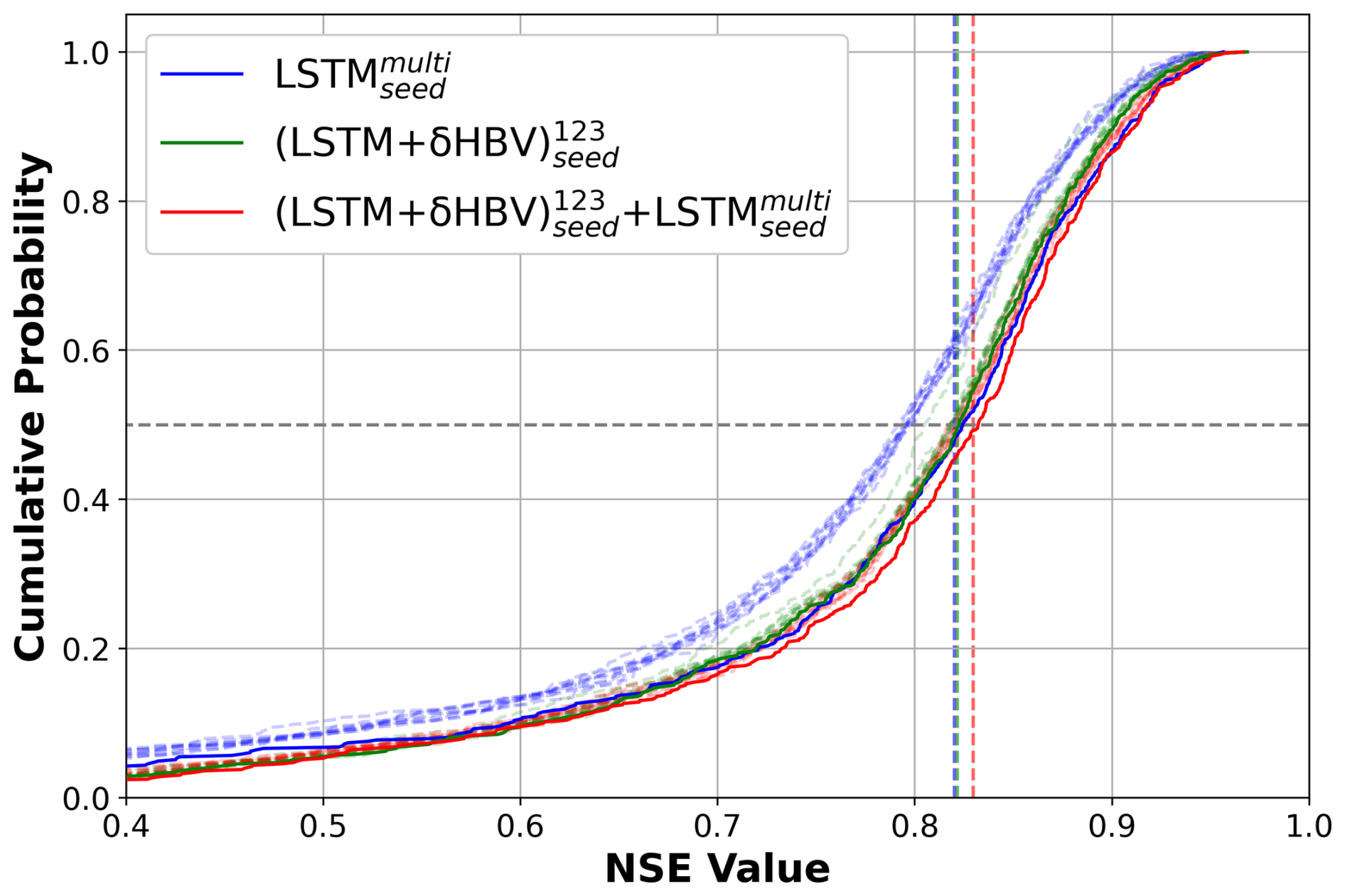
Figure 5Cumulative distribution function (CDF) curves based on temporal test results for LSTMmulti, (LSTM+δHBV)123, and . The solid lines (with “seed”) denote the results with 10 random seeds while the corresponding dashed and translucent lines denote the performances of their individual members each based on one random seed. The median NSE values computed with 3 random seeds are also indicated by vertical dashed and translucent lines in the corresponding colors.
3.2 Spatial generalization
It is clear that cross-model-type ensembling and the incorporation of δHBV significantly improved prediction in ungauged basins (PUB) or regions (PUR), mitigating the difficulty of spatial generalization (Fig. 2b–c). In particular, the previous record-holder for temporal test performance, , incurred large drops in the PUB and PUR tests, once again reminding us of the limitations of LSTM in spatial generalization. Given the same forcings, δHBV-only individual simulations or ensembles consistently outperformed LSTM-only counterparts in the PUR test. Furthermore, adding δHBV to the same-model-type LSTM ensembles improved median NSE by 0.02–0.03 for PUB. The role of δHBV became even more prominent in the harder PUR tests, with an increased gap (0.04–0.07), e.g., LSTM123 (median NSE ∼ 0.656) and (LSTM+δHBV)123 (median NSE ∼ 0.701). The increased significance of δHBV is also illustrated by the optimized weights shown in Fig. E1 in Appendix E, which were estimated using a genetic algorithm with streamflow observations from the test periods. These weights are presented solely to illustrate the relative contributions of the different ensemble components. The significantly different spatial distribution patterns of these weights among different test scenarios also indicate the differences among temporal, PUB, and PUR tests (Figs. E2–E3). The performance of (LSTM+δHBV)123 improved compared to LSTMmulti regardless of whether multiple random seeds were employed to form an ensemble. As such, we can conclude that the inclusion of a differentiable process-based model like δHBV in an ensemble is a systematic way to reduce the risks of failed generalizations of LSTM.
Utilizing a cross-model-type ensemble led to widespread improvements over LSTM-only ensembles, with the exception of a few scattered basins for each temporal (Fig. 4a2), PUB (Fig. 4b2), and PUR (Fig. 4c2) test. The most significant improvements due to the ensemble were concentrated on the center of the Great Plains along with the midwestern US, while the eastern US was moderately improved, suggesting data uncertainty is a larger issue in the central and midwestern US. The Great Plains have historically had poor performance for all kinds of models (Mai et al., 2022) and even the ensemble model had NSE values of only 0.3–0.4 for many of the basins there, although this still marked significant improvements over LSTM1 (Fig. 4a2, b2, c2). Some western basin NSE values were elevated by more than 0.15 for the temporal test (Fig. 4a2) and even more for PUB and PUR. Meteorological stations are generally sparse on the Great Plains, and an ensemble seems to be an effective way to leverage the different forcing datasets that are available. The poor performances in some basins highlight some remaining deficiencies in current models, which clearly cannot fully consider the heterogeneities of different basins; thus, multiscale formulations that resolve such heterogeneities may have advantages (Song et al., 2025a).
To investigate why ensembles outperformed single-model, single-forcing approaches, we compared their temporal, PUB, and PUR test simulation time series against observations for 531 basins (Fig. 6). Analysis of averaged hydrological year data revealed that while individual ensemble members using single-source forcing datasets performed similarly for easily simulated periods, they showed significant divergence during challenging periods, particularly peak flows. This divergence stems from distinct systematic errors inherent to different model types and forcing datasets. Notably, LSTM-based simulations alone proved insufficient in generating adequate spread to capture these divergent points. By averaging individual model outputs and stabilizing uncertainties, ensemble simulations achieved effective and robust performance across all conditions, which can be shown via the metric highRMSE and lowRMSE values in Tables D1–D4. This highlights the critical importance of comprehensive training for each ensemble member, including diverse forcing inputs, full-period model calibration, and rigorous hyperparameter tuning, to ensure that each member develops distinct simulation behaviors. These differences allow the ensemble to better represent a range of hydrological responses, particularly under extreme or uncertain conditions. By capturing complementary strengths and compensating for individual weaknesses, such well-trained ensemble members collectively enhance the robustness and accuracy of streamflow simulations.
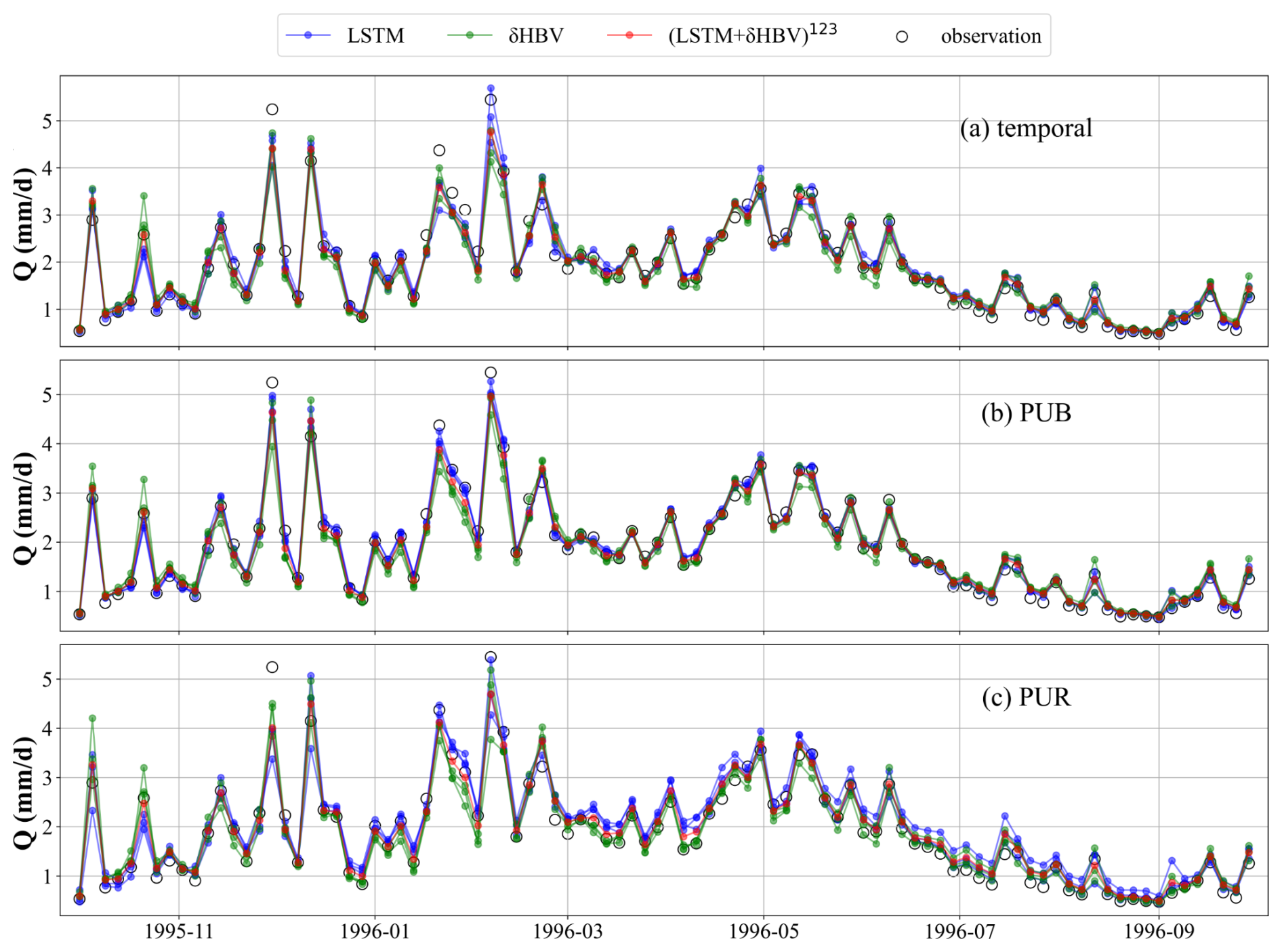
Figure 6Comparisons between multi-basin-averaged streamflow observations and simulations across 531 basins. The time series points are displayed at four-day intervals for clarity and conciseness. Ensemble members based on the same model (LSTM or δHBV) but driven by different forcing datasets are shown in the same color to highlight the differences between models more clearly.
3.3 Ensemble variability and robustness analysis
Although δHBV (median spread 0.61) exhibits lower spreads than LSTM (mean spread 0.72), their combination increases the ensemble spreads, thereby enhancing diversity (Fig. 7). This pattern holds across the temporal, PUB, and PUR tests. Ensemble effectiveness depends on the diversity of model behaviors and their distinct error characteristics. Consequently, larger spreads are generally associated with greater ensemble benefits. Figure D4 further demonstrates that δHBV + LSTM exhibits larger spreads than LSTM in most basins.
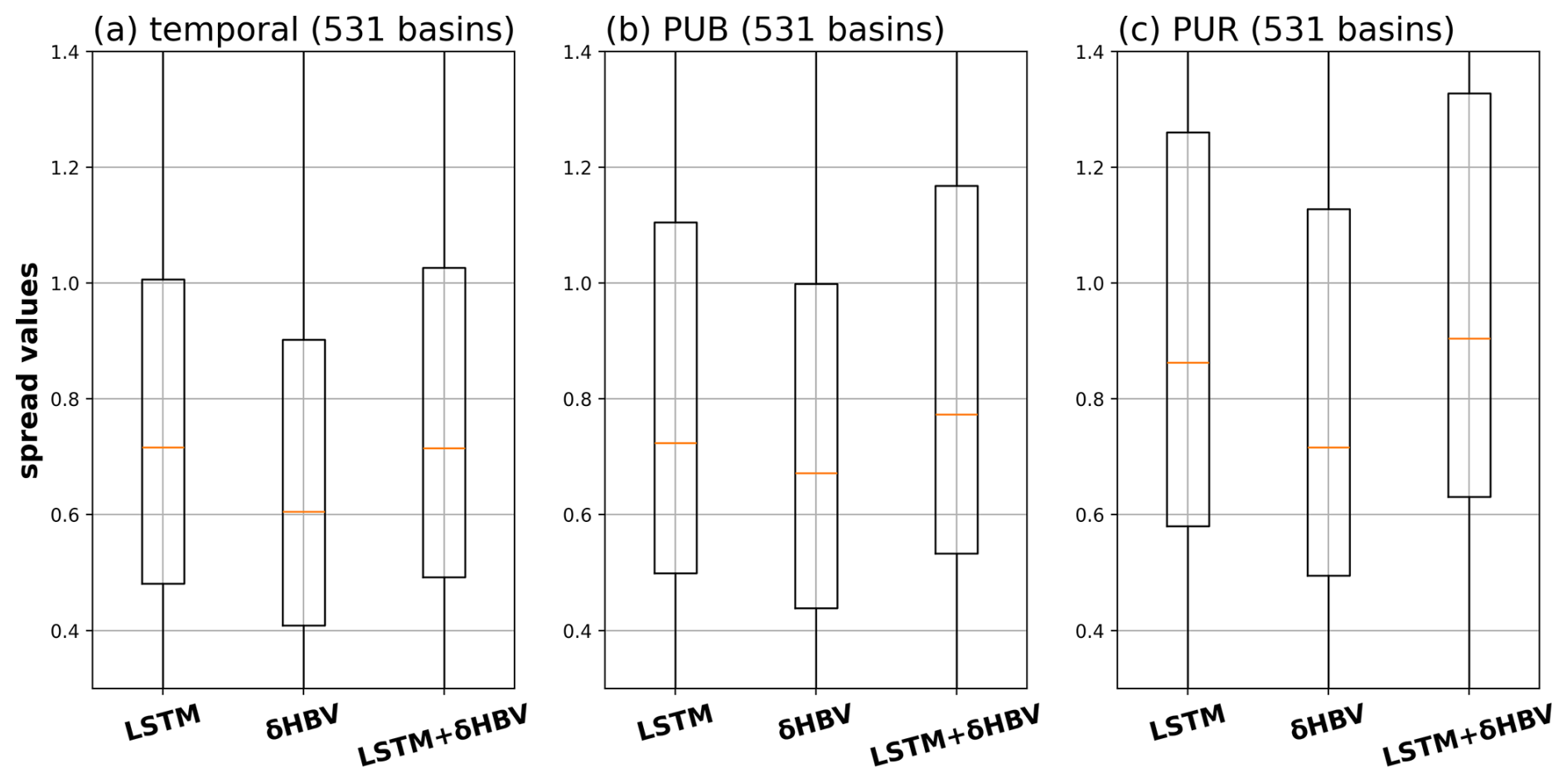
Figure 7Spread values (Table C2) of each model for LSTM, δHBV, and LSTM + δHBV due to different meteorological forcings and random seeds across temporal, PUB, and PUR tests.
As the warming signal is already clear across most basins under any forcing across the periods of simulation (Fig. D5), the models' strong performance in the temporal test suggests decent extrapolation capability under warming scenarios. It is often questioned whether data-driven models like LSTM lose accuracy under stronger climate drift, but no substantially warmed dataset is available to test this. Benchmarks suggest LSTM captures 15-year trends well in temporal tests, but less so in data-sparse scenarios (Feng et al., 2023b). Introducing a 10 % precipitation perturbation (multiplying precipitation by 1.1) slightly reduced performance for both models as expected (Fig. D6a and b), but ensemble benefits remained robust across models despite the perturbation.
Training sample size, dynamic parameter choices, and lookback windows exert only a limited impact on our conclusions. δHBV shows limited sensitivity to sample size, with similar results when trained on 531 versus 671 basins (Fig. D6c). Regarding parameter uncertainties, fixing one δHBV parameter (k0) as static increased structural errors and reduced performance (Fig. D6d), yet ensemble benefits remained robust. For LSTM, alternative window sizes of 182 and 730 d were tested, with the default 365 d window yielding optimal performance (Fig. D6e). Importantly, variations in the lookback window had only minor effects on model performance, underscoring the robustness of ensemble benefits.
3.4 Further discussion
Based on our results, we identified several avenues for future research. First, while we have explored various weighting strategies and found that averaging yields the best performance yet, we believe that dynamic or adaptive weighting schemes could further enhance performance in future studies. It is also demonstrated by Table E1 that estimated uneven weights can significantly improve simulation performance. Moreover, within specific basins, the estimated weights of different components are often highly imbalanced, as evidenced by the spatial distribution of optimized weights (Figs. E2–E3). Some potential feasible ways include using the simulations from these individually-trained models as inputs of a data-driven model (Solanki et al., 2025), and making the weight estimation and the ensemble member training simultaneously.
Both LSTM and δHBV models exhibit limitations in regions with significant anthropogenic impacts, such as dam presence, as well as arid climatic and highly heterogeneous geological conditions. These regions are mainly located in the midwestern and western CONUS, where high evaporation conditions (Heidari et al., 2020) and numerous dams (Bellmore et al., 2017) coincide with complex water use processes (Wada et al., 2016) that current models cannot simulate well. Together, these factors suggest that anthropogenic influence is likely an important driver of poor model performance. Further improvements may include incorporating additional data that capture these factors like capacity-to-runoff ratio (Ouyang et al., 2021) or integrating specialized modules, such as reservoirs (Hanazaki et al., 2022; West et al., 2025). Compared with LSTM, δHBV is more sensitive to precipitation biases. For example, the differences between δHBV simulations under different forcing datasets were generally larger than those for LSTM, and δHBV using the Daymet forcing dataset showed largely better performance than with the other two forcing datasets, which indicates that δHBV may not be able to fit different forcing datasets well. Therefore, many potential structural optimizations can be implemented to improve δHBV. Our analysis provided corroborating evidence that forcing error is an important reason why LSTM can outperform δHBV in the temporal test for some basins, although such patterns may not generalize well in space. A meteorological forcing data correction module can be developed in the future to account for timing and magnitude errors in precipitation. Ensemble simulations may face challenges when computational resources are constrained, particularly for large-scale or real-time applications. Nevertheless, we remain optimistic about overcoming these challenges due to several promising solutions. These include tailoring the hydrological model by simplifying less relevant components to specific simulation objectives (Clark et al., 2015; Kraft et al., 2022) and cloud-based computing infrastructures that offer scalable, on-demand resource allocation (He et al., 2024; Leube et al., 2013). Importantly, the majority of computational costs are incurred during model training. In practice, ensemble members are typically pre-trained by different research or application groups (Bodnar et al., 2025; Nearing et al., 2024; Song et al., 2025a), enabling direct reuse of these well-trained models and significantly improving computational efficiency.
For this work, we did not create a δHBVmulti model (in the same vein as LSTMmulti) using all forcings as an input to a single model, since a similar experiment has already been conducted by Sawadekar et al. (2025). We also did not examine “seed” combinations of a δHBVmulti as we believed they would not result in a significant performance boost (unlike that seen with LSTMmulti), because LSTM has high variability and low bias, while δHBV has lower variance and potentially higher bias. As a result, random seeds would likely not create large enough perturbations for δHBV and wouldn't bring the benefits seen with . To achieve an equivalent perturbation level for δHBV, it may be necessary to incorporate multiple distinct hydrological models, such as SAC-SMA, PRMS, and GR4J, similar to the approach implemented in the Framework for Understanding Structural Errors (FUSE) (Clark et al., 2008). Work is ongoing to create a combination of a series of differentiable process-based models, which is expected to produce a further improved ensemble with great interpretability. Given the success of cross-model-type ensembles shown in this work, we also encourage further exploration of ensemble simulations involving models with other distinct mechanisms.
This study comprehensively analyzes ensemble combinations of two advanced model types (LSTM and δHBV), each with distinct mechanisms, for streamflow simulation across 531 basins in the US. Three meteorological forcing datasets (Daymet, NLDAS, and Maurer) are employed to fully capture the characteristics of the two models. Their applications are also tested in two distinct ways: (1) by feeding all diverse forcing datasets simultaneously into a single LSTM model, and (2) by ensembling the outputs of multiple LSTM models, each trained separately using a single forcing dataset. The performance of ensemble simulations was evaluated under three distinct testing scenarios (temporal, PUB, and PUR tests), surpassing the previous highest performances. Our findings enhance the understanding of how to effectively utilize diverse model types and multi-source datasets to improve streamflow simulations. The principal conclusions are:
-
Cross-model-type ensembles (LSTM + δHBV) consistently outperformed single-model approaches across all test scenarios, setting new performance benchmarks on the CAMELS dataset. These ensembles demonstrated the complementarity of data-driven (LSTM) and physics-informed (δHBV) approaches in capturing diverse hydrological behaviors.
-
Ensembling models trained on different forcing datasets proved more effective than using multiple forcing datasets as simultaneous inputs to a single model. This suggests that separate training allows each model to capture unique features contained in each forcing dataset, which can then be effectively leveraged in the ensemble.
-
δHBV provided significant benefits to ensemble simulations on spatial generalization. Ensembling LSTM with δHBV showed increasing benefits as generalization challenges increased, from temporal to spatial interpolation (PUB) to spatial extrapolation (PUR) tests. This underscores the value of physics-informed constraints in improving model transferability to ungauged basins and regions.
-
While ensemble methods significantly improved overall performance, they did not fully mitigate consistent deficiencies in certain challenging areas (e.g., regions with high dam density or heterogeneous hydrogeological conditions). This indicates areas for future model development.
These findings have important implications for hydrological modeling and water resources management. The improved accuracy and spatial generalization of our ensemble approach can enhance streamflow predictions, benefiting water resources planning and management, particularly in data-scarce regions. Our results also suggest that future hydrological model development should focus on combining data-driven and physics-based approaches to improve model generalizability across diverse conditions. The superior performance of ensembling models with different forcing datasets over using merged forcings as a single input highlights the risk of indiscriminately feeding all available data into one data-driven model. While computational demands certainly require consideration, the potential improvements in prediction accuracy offer significant value for both research and operational applications. Future work should focus on refining these ensemble techniques, addressing model limitations in challenging regions, and exploring ensemble implementation in operational settings.
The Hydrologiska Byråns Vattenbalansavdelning (HBV) model (Aghakouchak and Habib, 2010; Beck et al., 2020; Bergström, 1976, 1992) is a simple yet effective bucket-type hydrologic model that simulates hydrologic components including snow water equivalent, soil moisture, groundwater storage, evapotranspiration, quick flow, baseflow, and total streamflow.
In the following, we describe these processes in detail with their corresponding equations. Uppercase letters denote state variables, while lowercase letters denote parameters. The overall water balance is expressed as Eq. (A1).
where EP is effective precipitation, AE is actual evapotranspiration, Qt is total simulated runoff, SN is snow storage, SM is soil moisture storage, SUZ and SLZ are the upper and lower groundwater storages, respectively, and LAKE represents lake storage (omitted in this study).
First, effective precipitation (EP) is partitioned into rain (RN) and snow (SN) components based on the air temperature (T) relative to a threshold temperature (tt):
Snow (SN) accumulates in the snowpack (SNP), while snowmelt (SNM) happens when T≥tt, which is calculated based on a melt factor (cfm) and the temperature difference (T−tt). The computed snowmelt (SNM) is constrained by the available snowpack (SNP).
The snowmelt (SNM) contributes to meltwater (MW), while the snowpack (SNP) is updated as:
A portion of the meltwater (MW) may refreeze when T<tt, controlled by the refreezing parameter (cfr):
The remaining meltwater (MW) exceeding the snowpack's liquid water holding capacity (cwh⋅SNP) infiltrates into the soil (IF), with the remainder retained in MW:
The fraction of soil moisture (SM) relative to the field capacity (fc), raised to the power index β, modulates shallow seepage (SP) according to the available water (IF+RN):
Excess soil water above the field capacity contributes to direct infiltration (IFdir):
Actual evapotranspiration (AE) is estimated as the product of potential evapotranspiration (PE) and an evapotranspiration coefficient (PEC). The PEC depends on soil moisture storage (SM), field capacity (fc), a shape parameter (λ), and a threshold parameter (lp).
Capillary rise (CP) from the lower zone (SLZ) replenishes SM, controlled by a coefficient (c) and constrained by the soil moisture deficit:
Recharge from the soil, consisting of shallow seepage (SP) and direct infiltration (IFdir), enters the upper groundwater zone (SUZ). Water in the upper zone either percolates to the lower groundwater zone (SLZ) at a constant percolation rate (prc) or contributes to direct runoff (Q0) when the upper zone (SUZ) exceeds a threshold (uzl). Flow from the upper and lower zones is computed using linear reservoir formulations, with parameters k0, k1, k2 controlling the respective runoff components Q0, Q1, Q2. The total simulated streamflow (Qt) is then computed as the sum of these components.
Finally, a routing module (Feng et al., 2022) is used to process Qt to produce the final streamflow output (). This module with two parameters (θα, θτ) assumes a gamma function for the unit hydrograph and convolves the unit hydrograph with the runoff as,
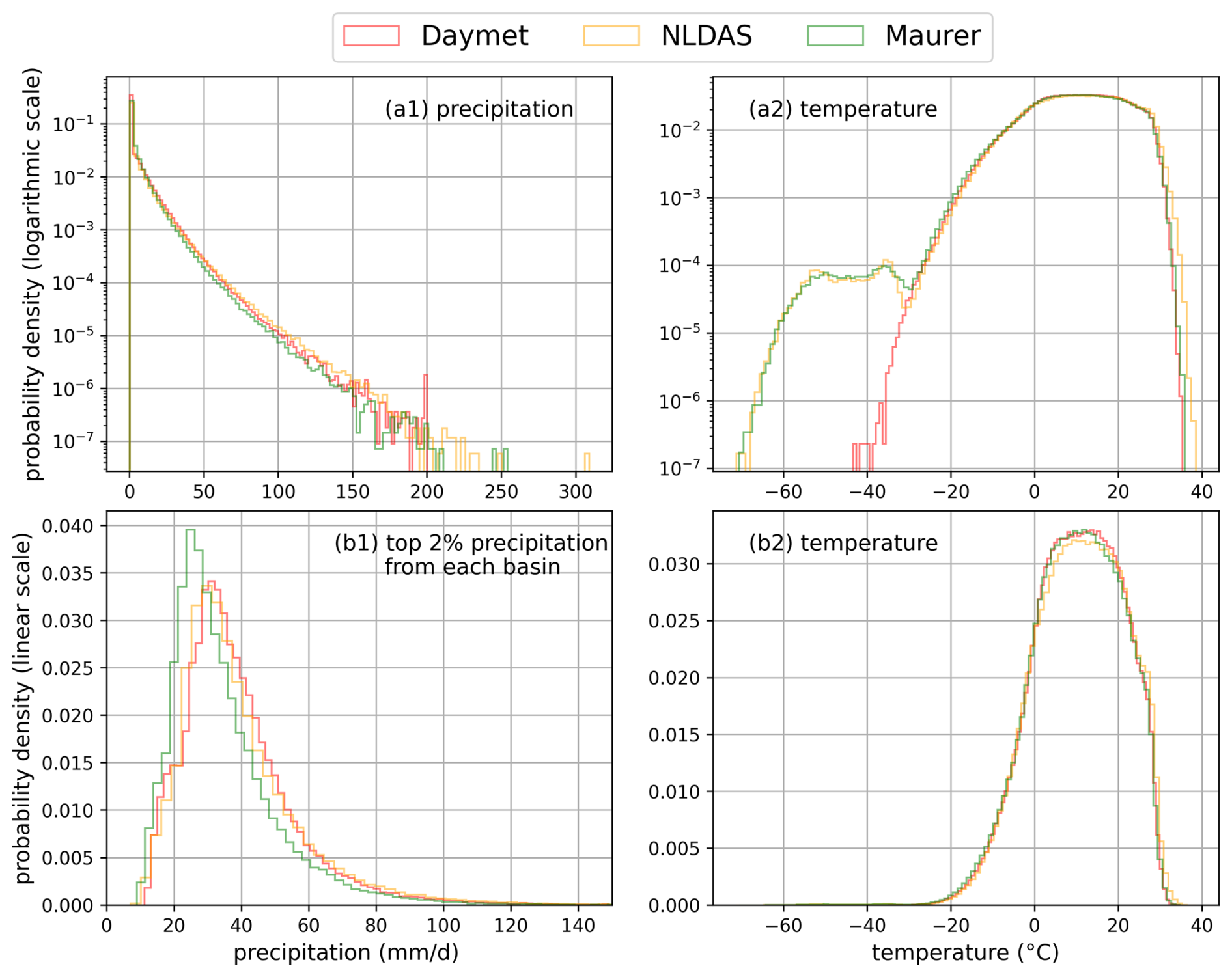
Figure B1Probability density distributions (top panel in logarithmic scale, bottom panel in linear scale) of precipitation and temperature across three meteorological forcing datasets.
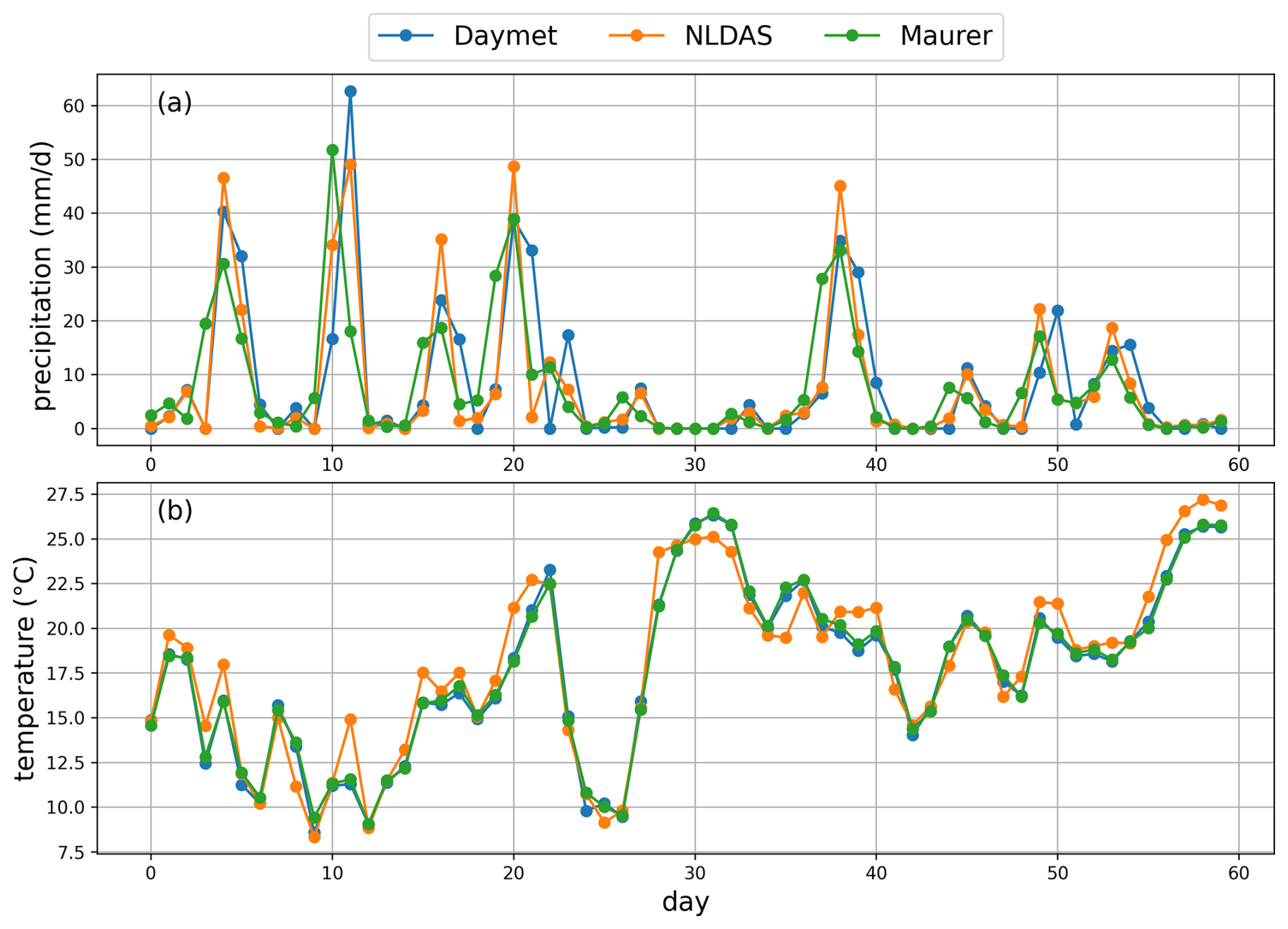
Figure B2Illustrated temporal variations of precipitation and temperature in a basin across three meteorological forcing datasets.
Table C1Full names for the abbreviations of dynamic data (all but streamflow are “forcings”) and static basin attributes used as model inputs and outputs. All variables and their values are provided in the CAMELS dataset (Addor et al., 2017) except for the NLDAS and Maurer daily temperature extrema, which are from Kratzert et al. (2021). Potential evapotranspiration and normalized streamflow were calculated in this work, using CAMELS data. The number in parentheses specifies model usage: 1 denotes use in the LSTM model, and 2 denotes use in the δHBV model.
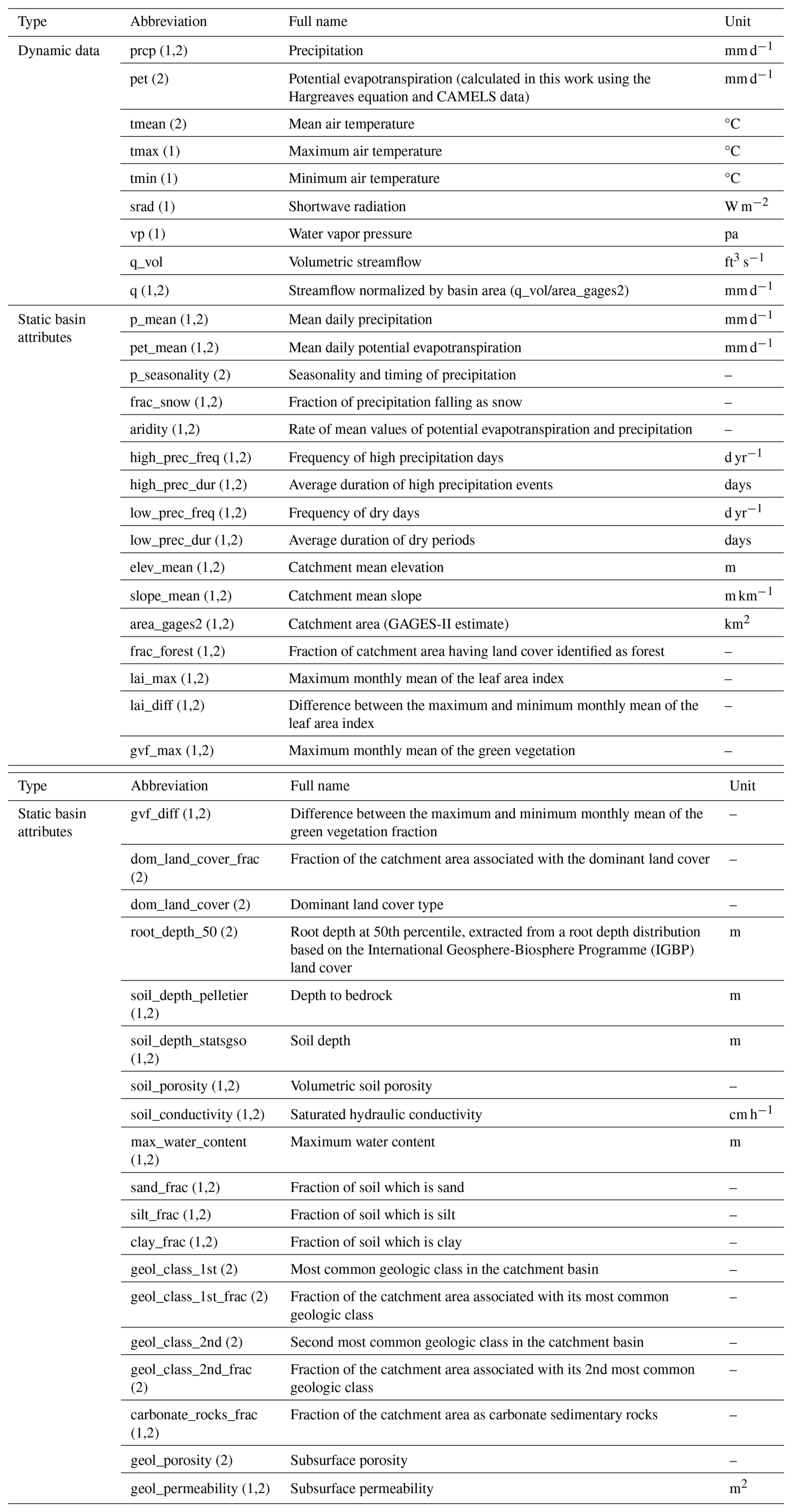
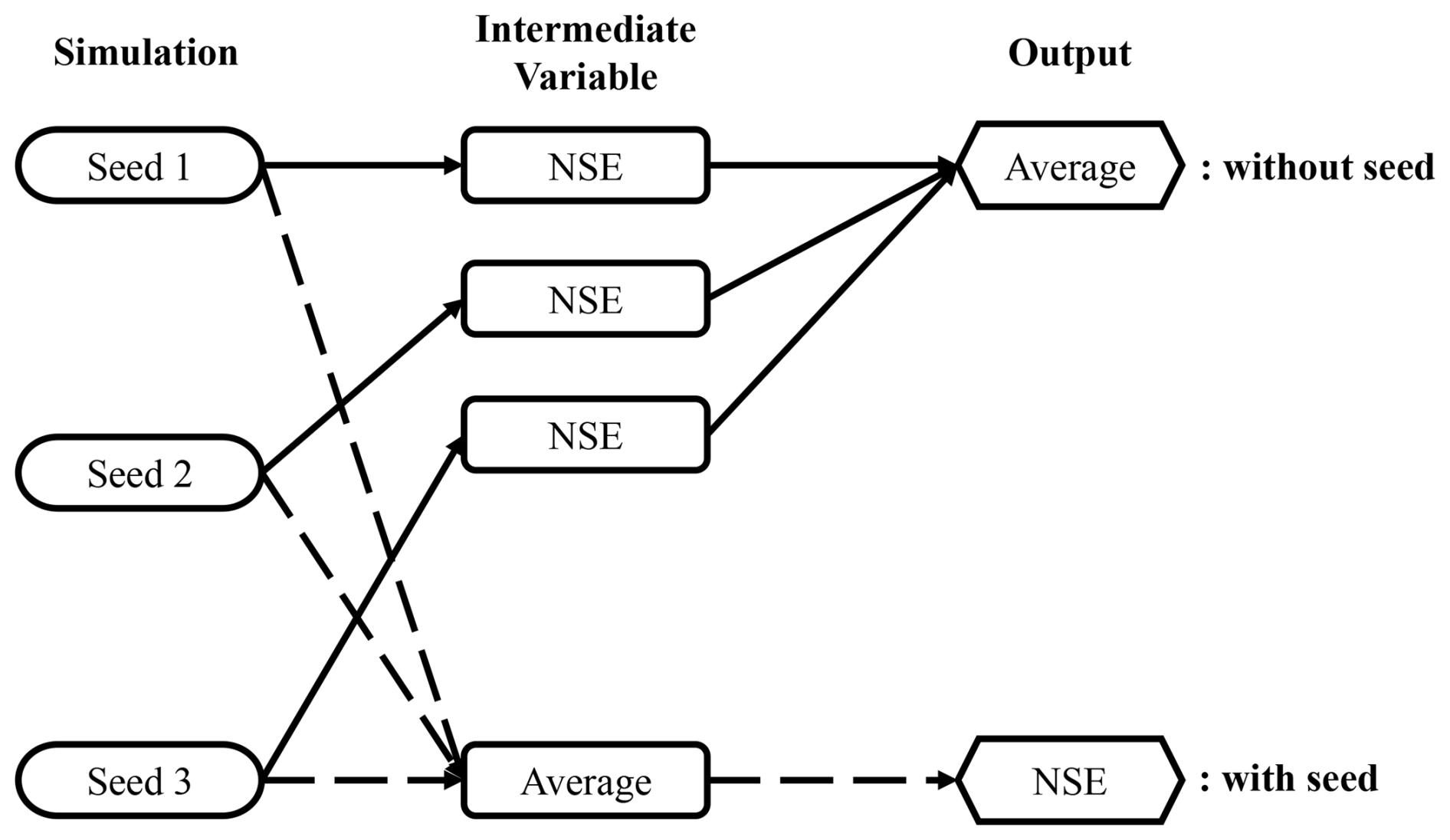
Figure C1Ensemble frameworks to generate metrics for ensembles named without (solid arrows) and with (dashed arrows) “seed” as a subscript.
Table C2Loss function and evaluation metrics.
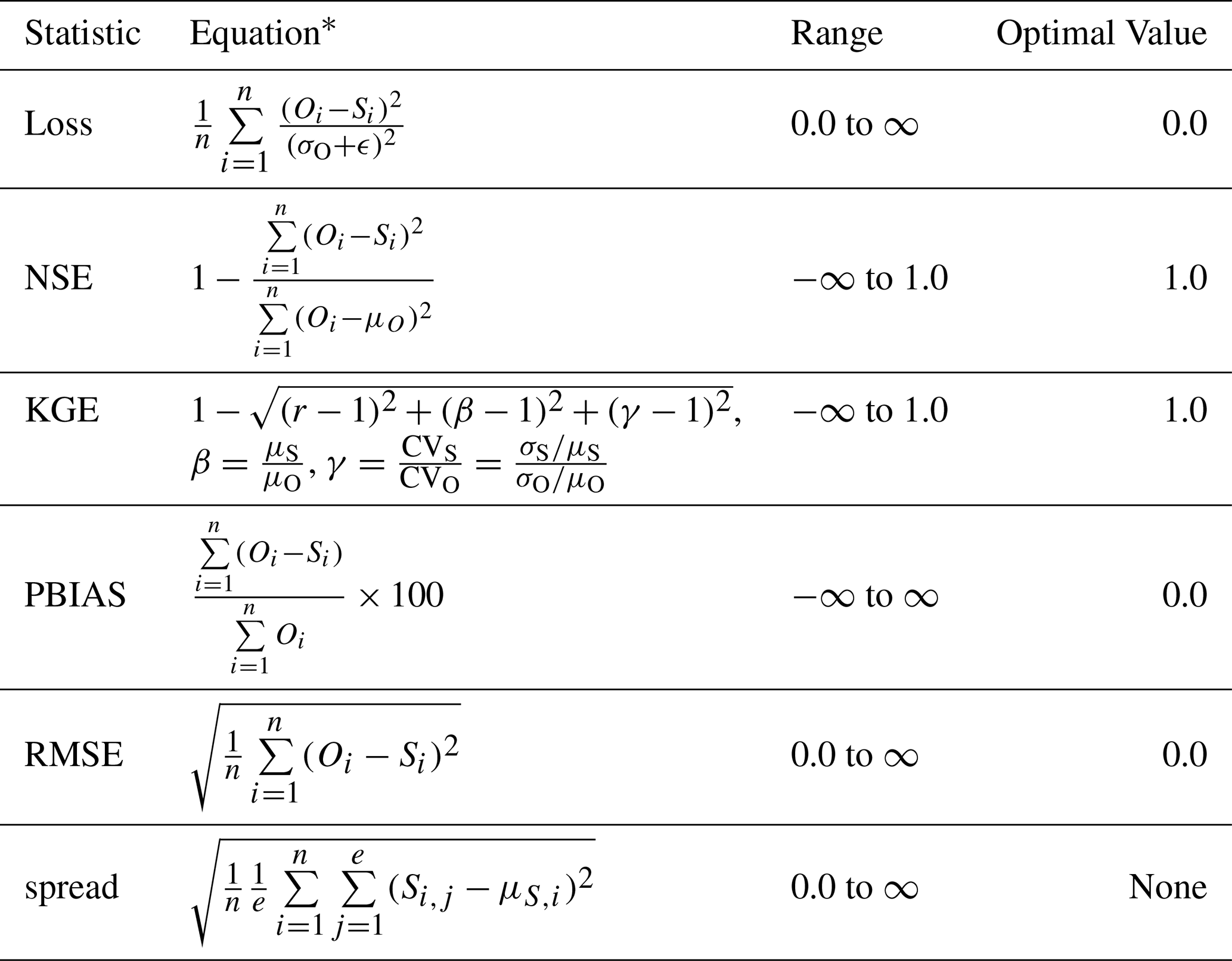
* S is a streamflow simulation; O is the corresponding observation; n is the number of total S or O; ϵ is a numerical stabilizer, with a default value of 0.1; e is the number of ensemble members; r is the linear Pearson correlation between S and O; β is the mean bias; and γ is the variability bias. The mean and standard deviation of simulations are denoted as μS and σS, respectively, and μO and σO are the mean and standard deviation of the observations.
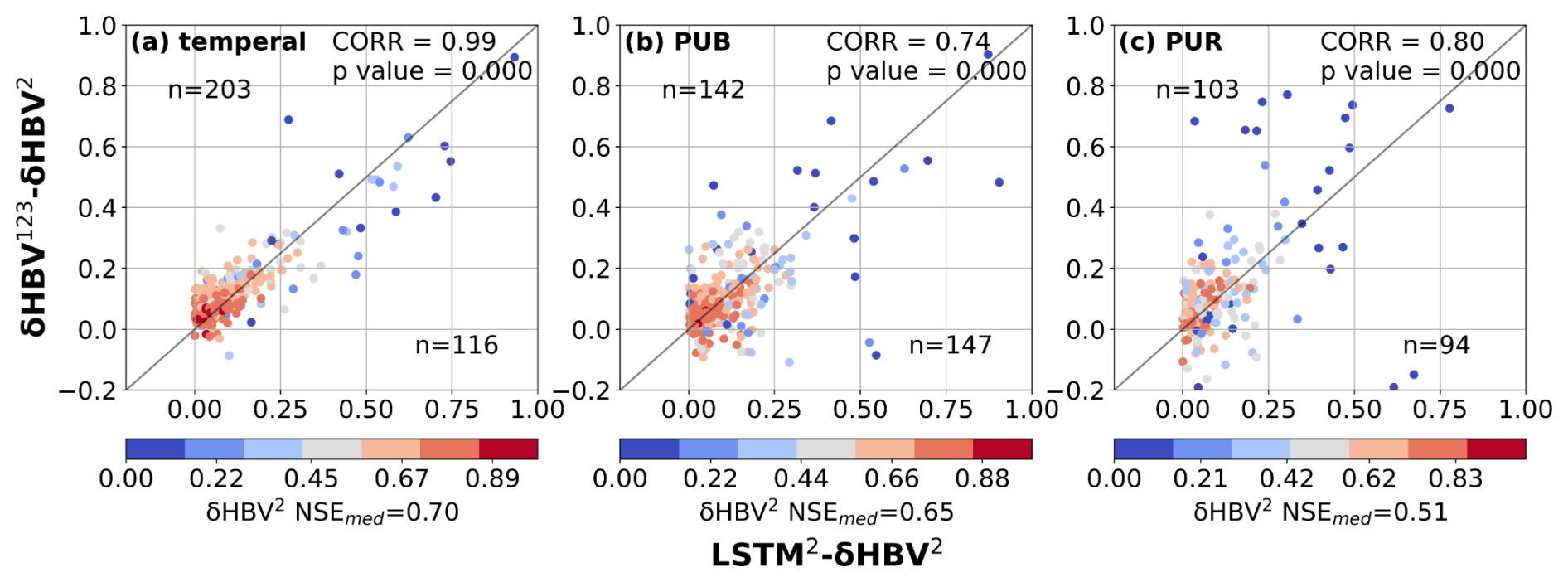
Figure D1Scatter plots comparing the performance differences between hydrological models for the basins where LSTM outperformed δHBV (the basins where δHBV outperformed are not shown in this plot). The x-axis represents the NSE differences between LSTM2 and δHBV2 (LSTM2−δHBV2), while the y-axis shows the NSE differences between δHBV123 and δHBV2 (δHBV123−δHBV2). Points are color-coded according to the NSE values of δHBV2. The correlation coefficient (CORR) and p values between the x-axis values and the y-axis values, along with the median NSE value of δHBV2 (NSEmed) on these basins, are also noted.
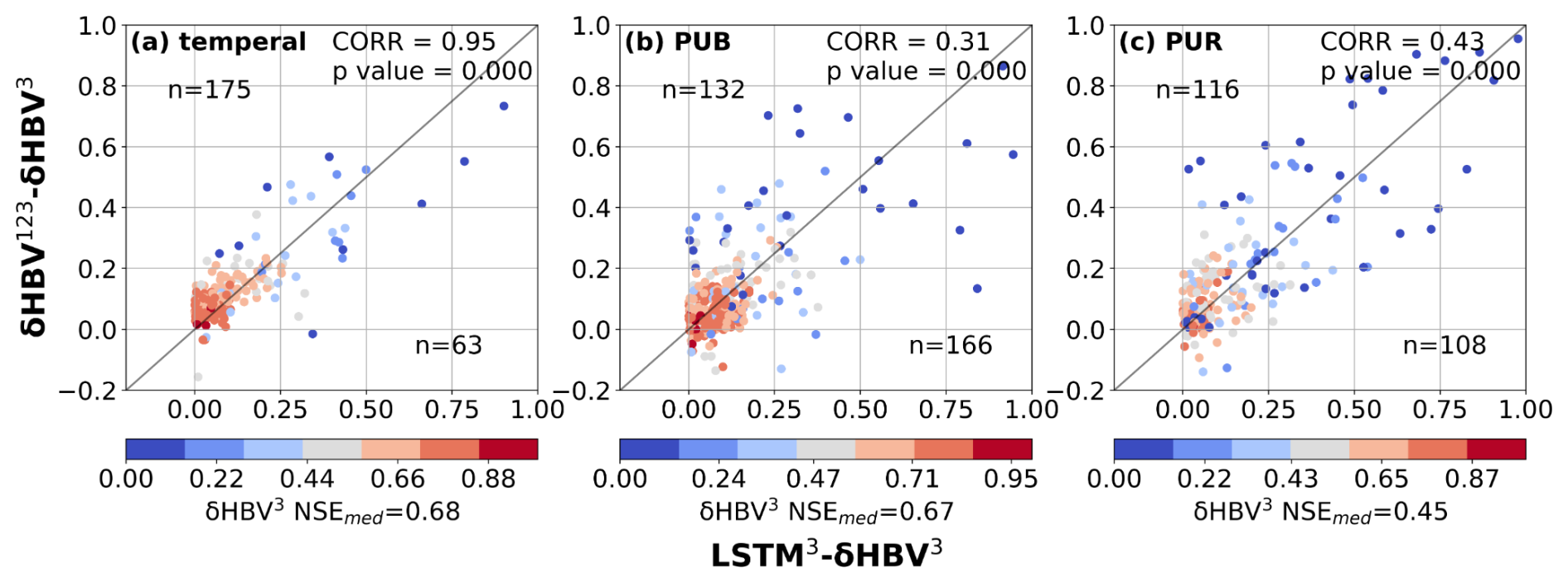
Figure D2Scatter plots comparing the performance differences between hydrological models for the basins where LSTM outperformed δHBV (the basins where δHBV outperformed are not shown in this plot). The x-axis represents the NSE differences between LSTM3 and δHBV3 (LSTM3−δHBV3), while the y-axis shows the NSE differences between δHBV123 and δHBV3 (δHBV123−δHBV3). Points are color-coded according to the NSE values of δHBV3. The correlation coefficient (CORR) and p values between the x-axis values and the y-axis values, along with the median NSE value of δHBV3 (NSEmed) on these basins, are also noted.
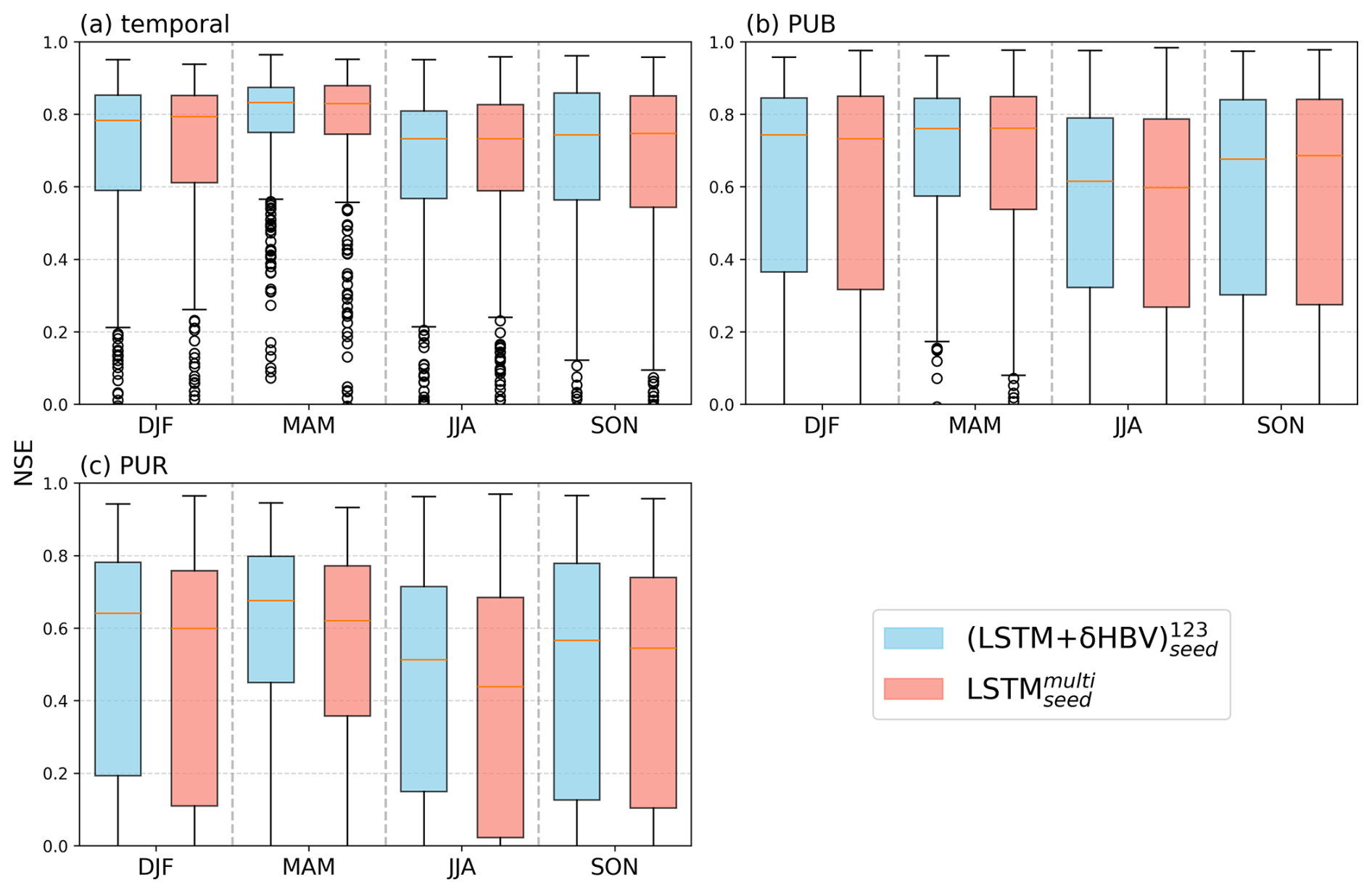
Figure D3Seasonal comparison of Nash–Sutcliffe efficiency (NSE) values for (blue) and (red) in (a) temporal, (b) PUB, and (c) PUR tests. Each box represents the distribution of NSE values across 531 basins for a given season (DJF: December–February, MAM: March–May, JJA: June–August, SON: September–November). Vertical dashed lines separate different seasons. performs better than in most cases, especially during MAM, likely due to differences in snowmelt representation.
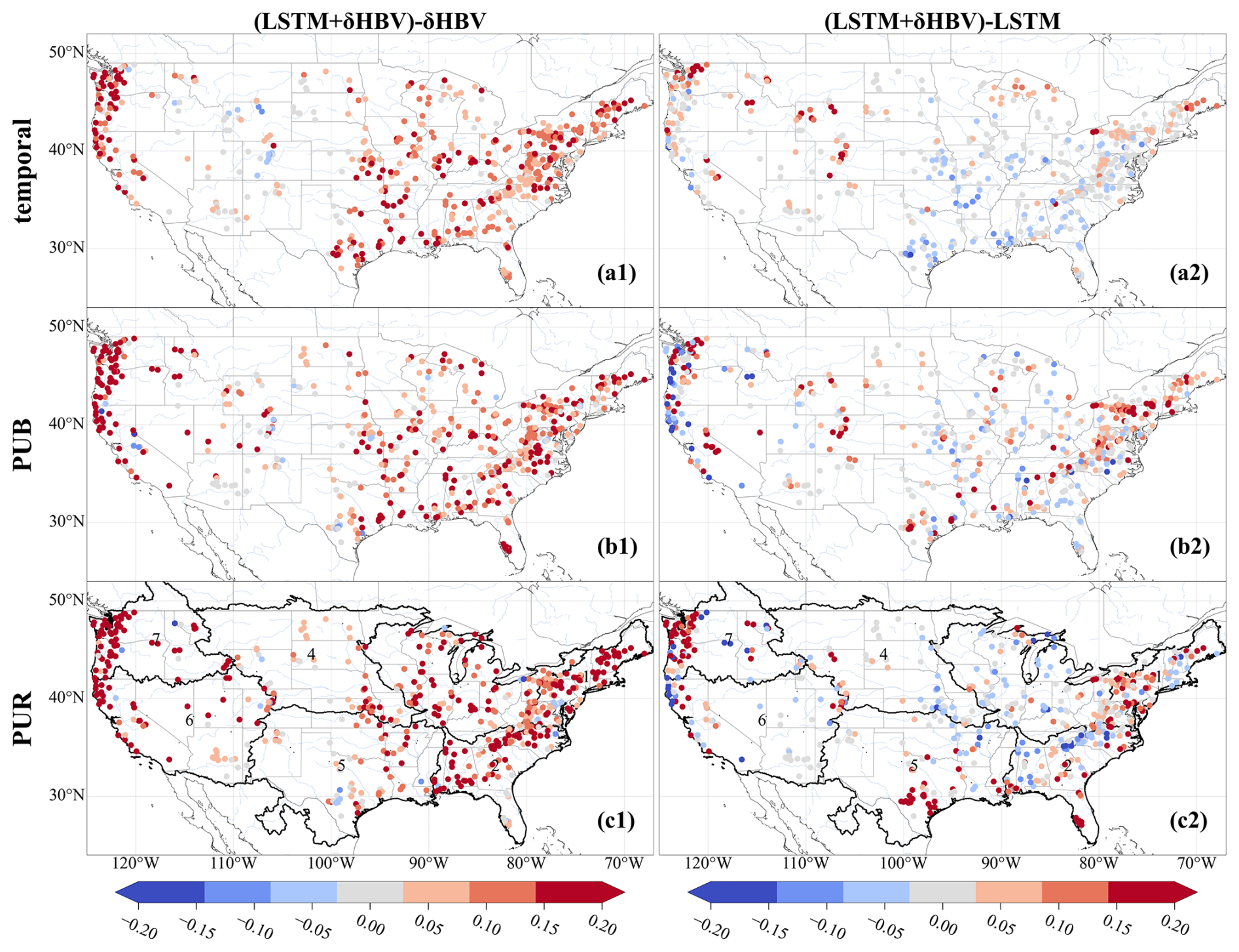
Figure D4Spatial distributions of model spread values increase from δHBV and LSTM to the LSTM + δHBV ensemble across temporal, PUB, and PUR tests.
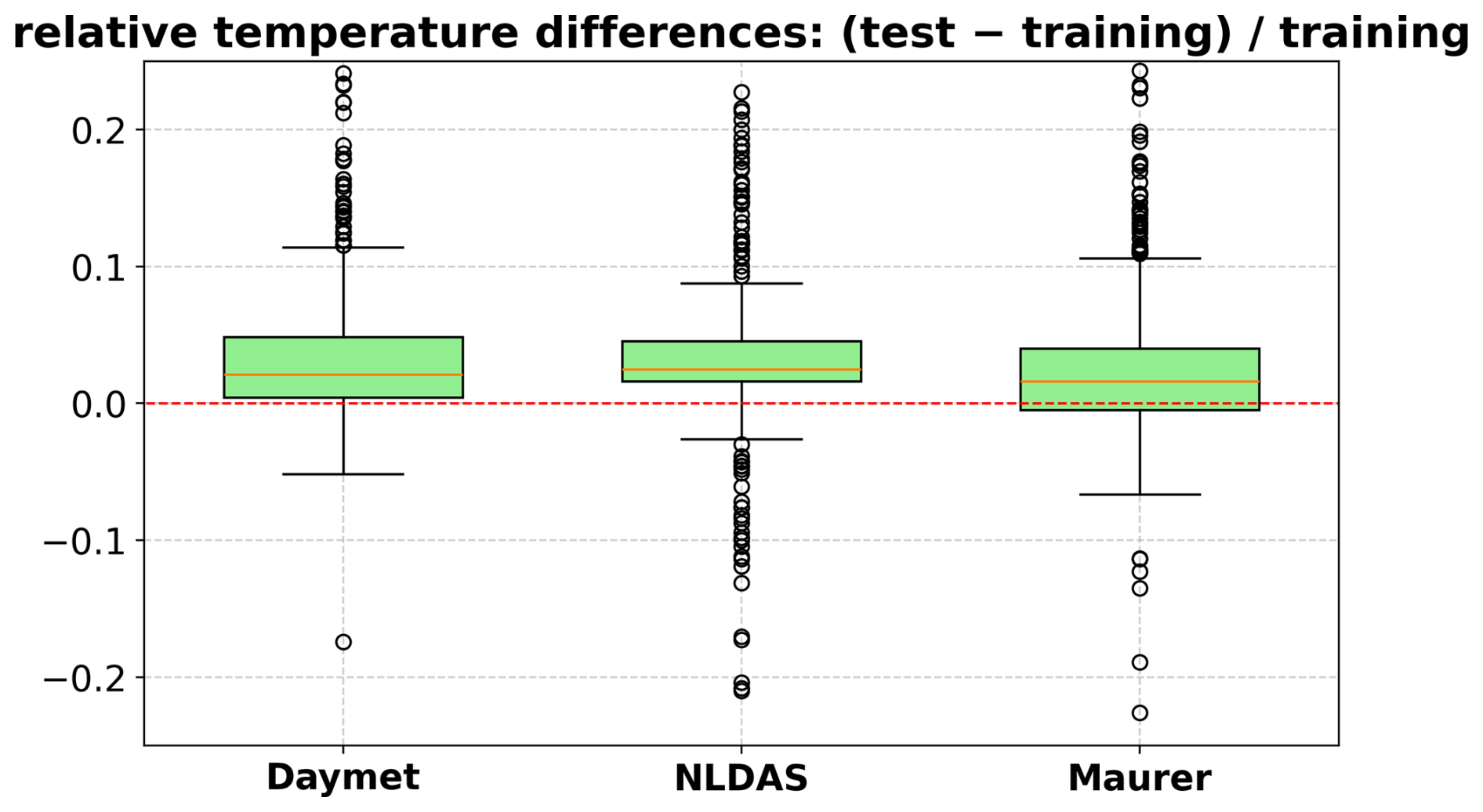
Figure D5Boxplot of relative temperature differences between the test and training periods, calculated as (test − training)training. Each box represents the distribution of normalized temperature changes across basins for a specific meteorological forcing dataset: Daymet, NLDAS, and Maurer. Positive values indicate warming in the test period relative to the training period.
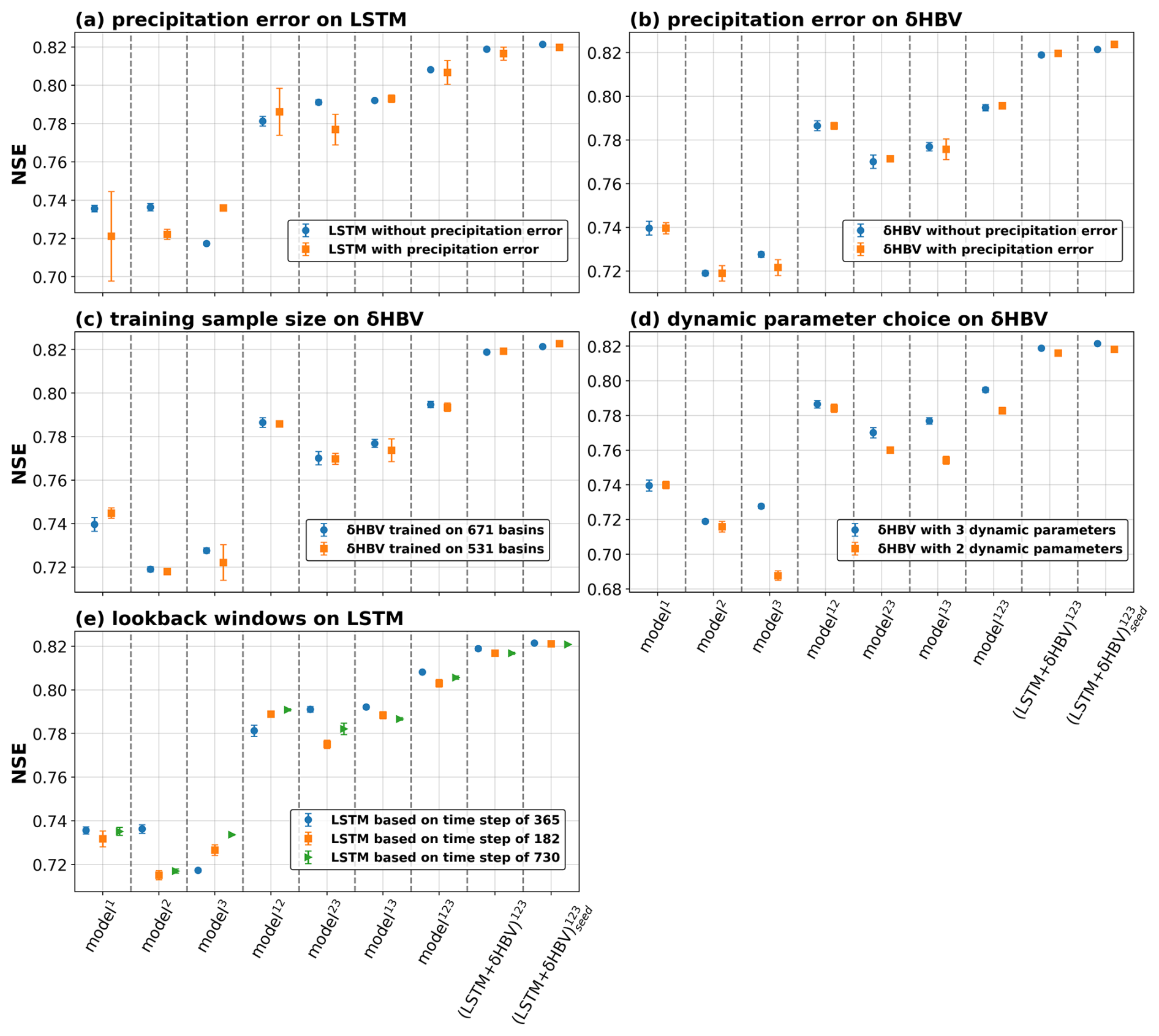
Figure D6Simulation performance (NSE) under the temporal test: (a) LSTM model with and without a 10 % precipitation error (precipitation × 1.1); (b) δHBV model with and without a 10 % precipitation error; (c) δHBV model trained on 671 versus 531 basins; (d) δHBV model with 3 versus 2 dynamic parameters; (e) δHBV model using time steps of 365, 182, and 730 d. Individual and ensemble groups are distinguished along the x-axis. Ensemble benefits are indicated by the gap between columns of the same color within each panel–columns 1–7 correspond to individual LSTM or δHBV groups, and the last two columns correspond to LSTM + δHBV ensembles.
Table D1Median NSE, KGE, RMSE, PBIAS, and RMSE values under low (lowRMSE), high (highRMSE), and middle (midRMSE) flows based on 531 basins under the temporal test. The values are the mean of three simulations run with different random seeds.
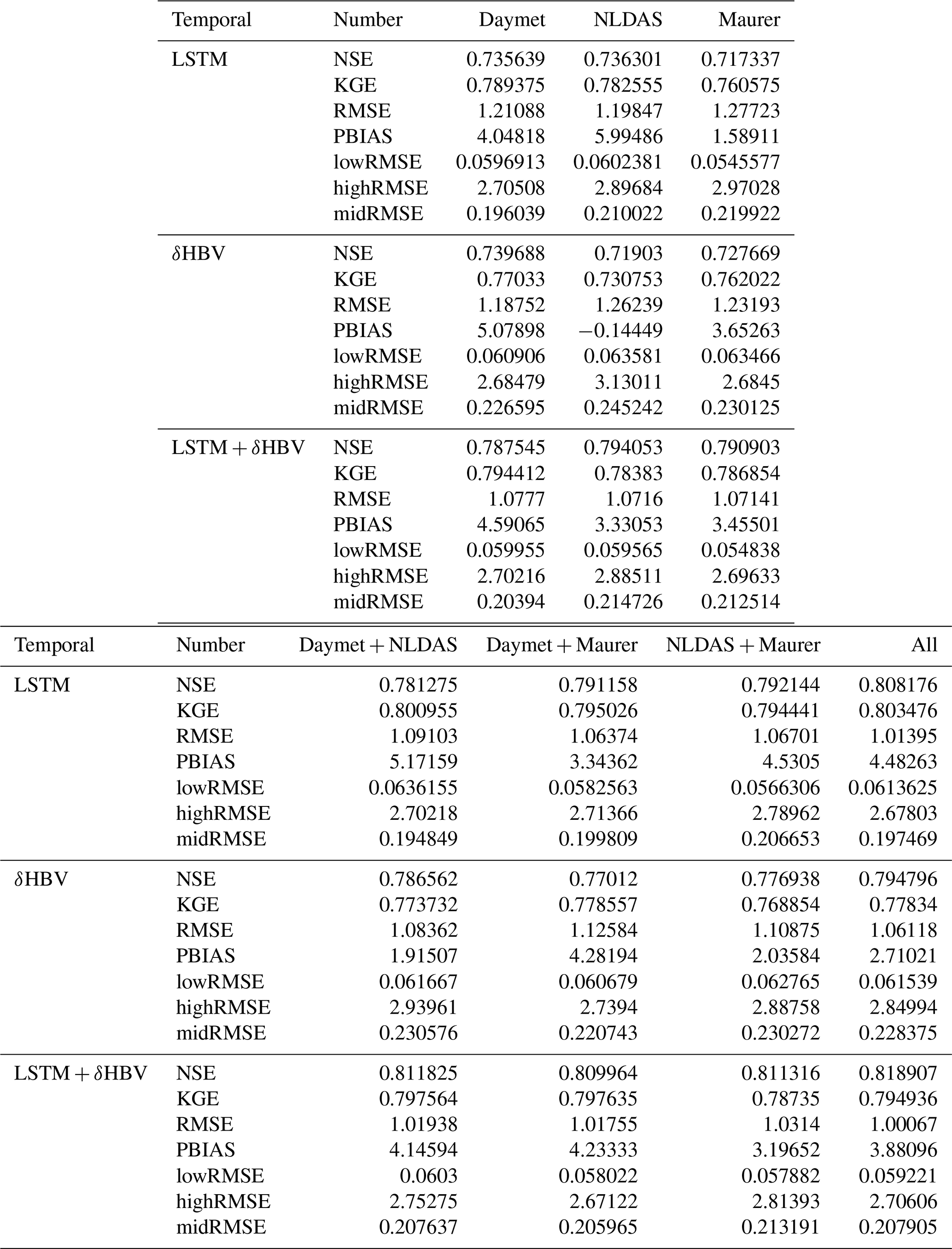
Table D2Median NSE, KGE, RMSE, PBIAS, and RMSE values under low (lowRMSE), high (highRMSE), and middle (midRMSE) flows based on 531 basins under the PUB test. The values are the mean of three simulations run with different random seeds.
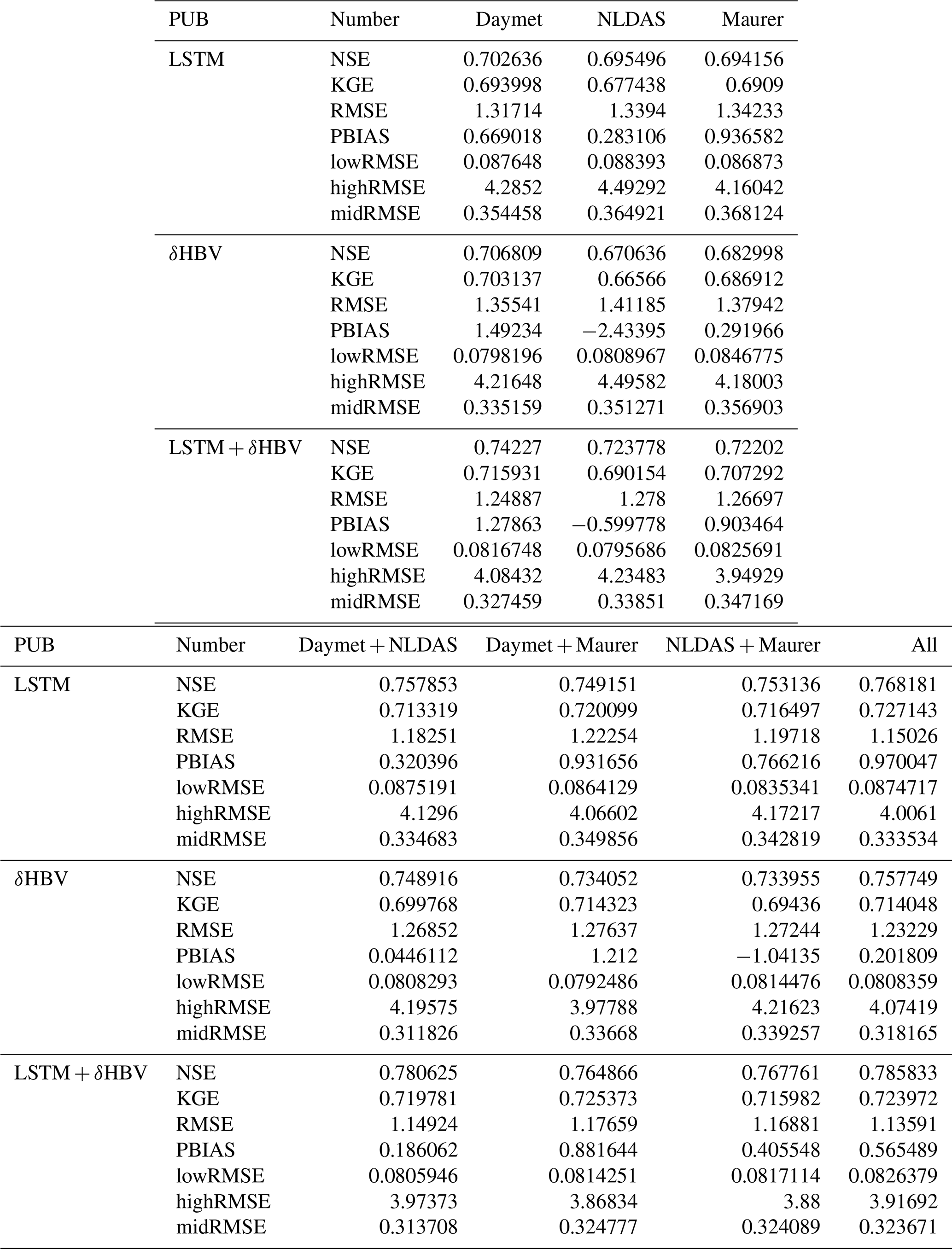
Table D3Median NSE, KGE, RMSE, PBIAS, and RMSE values under low (lowRMSE), high (highRMSE), and middle (midRMSE) flows based on 531 basins under the PUR test. The values are the mean of three simulations run with different random seeds.
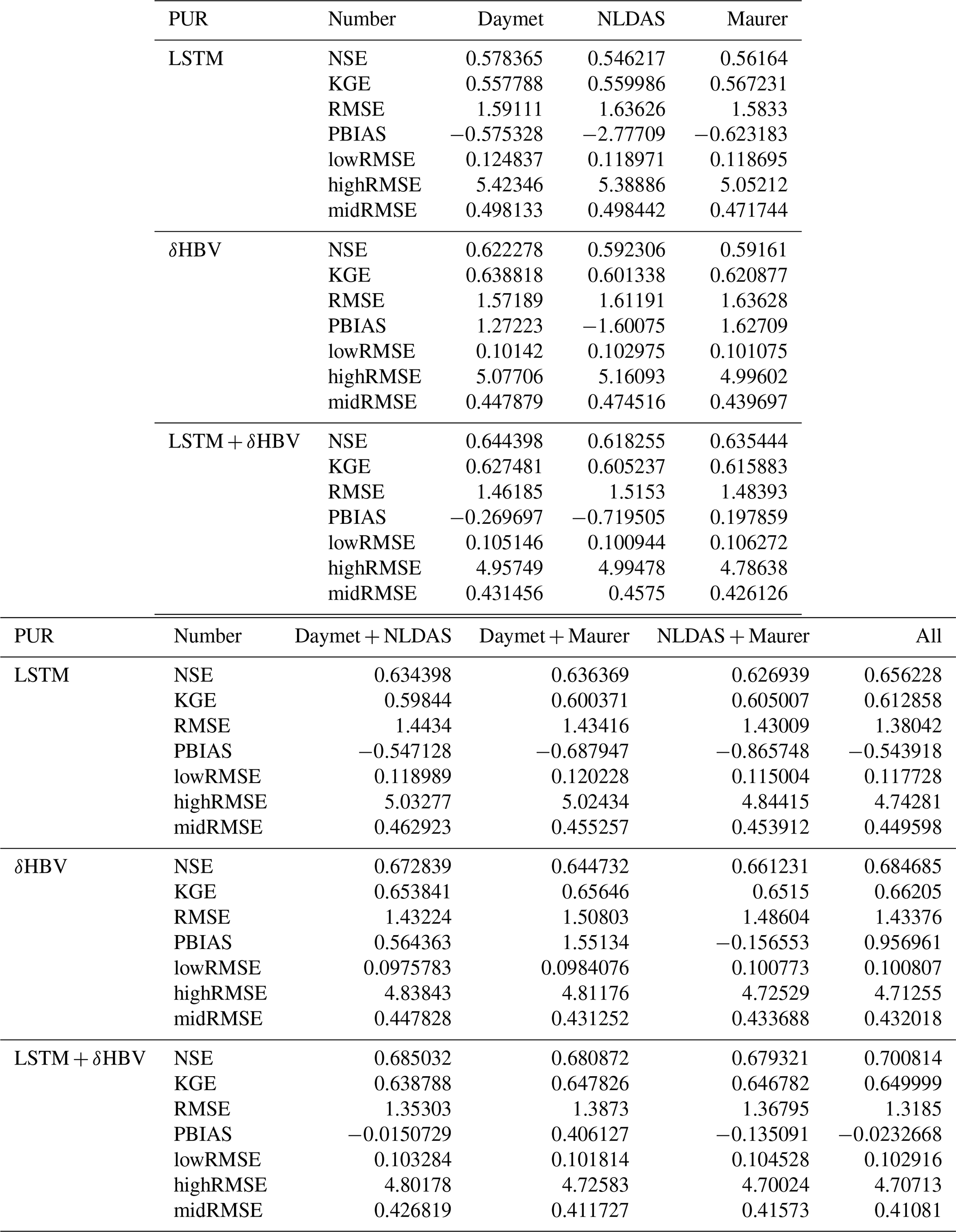
Table D4Median NSE, KGE, RMSE, PBIAS, and RMSE values under low (lowRMSE), high (highRMSE), and middle (midRMSE) flows based on 531 basins under the temporal, PUB, and PUR tests of LSTMmulti, , their “seed” version, and .
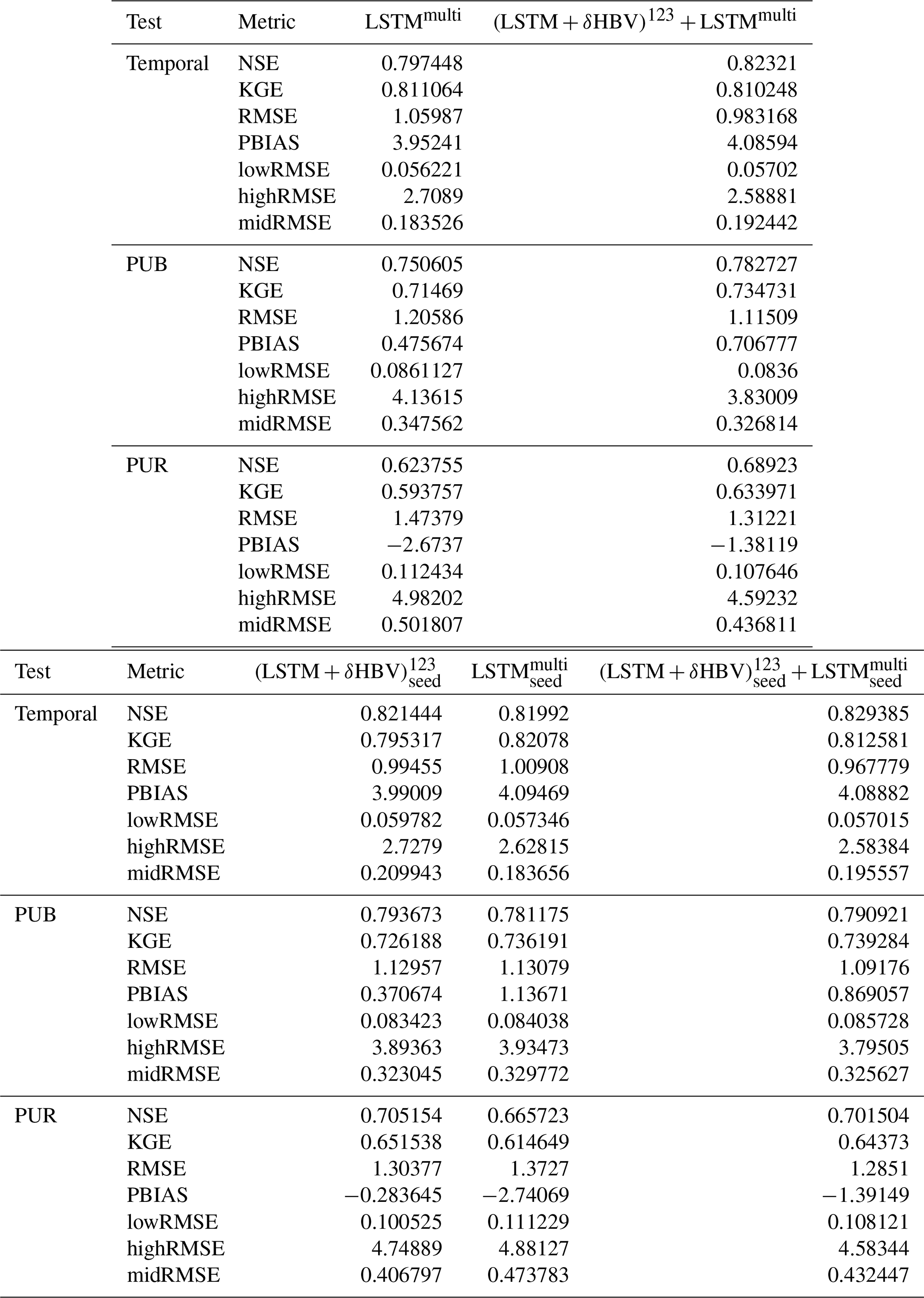
Table D5Median NSE values based on ten different random seeds during the temporal test. Each number (1 through 10) represents metric values calculated for an individual simulation based on only one random seed. “Seed” indicates metric values calculated by averages of these ten simulations based on different random seeds, while “mean” denotes the average of metrics from 1–10 individual simulations (visualized in Fig. C1).
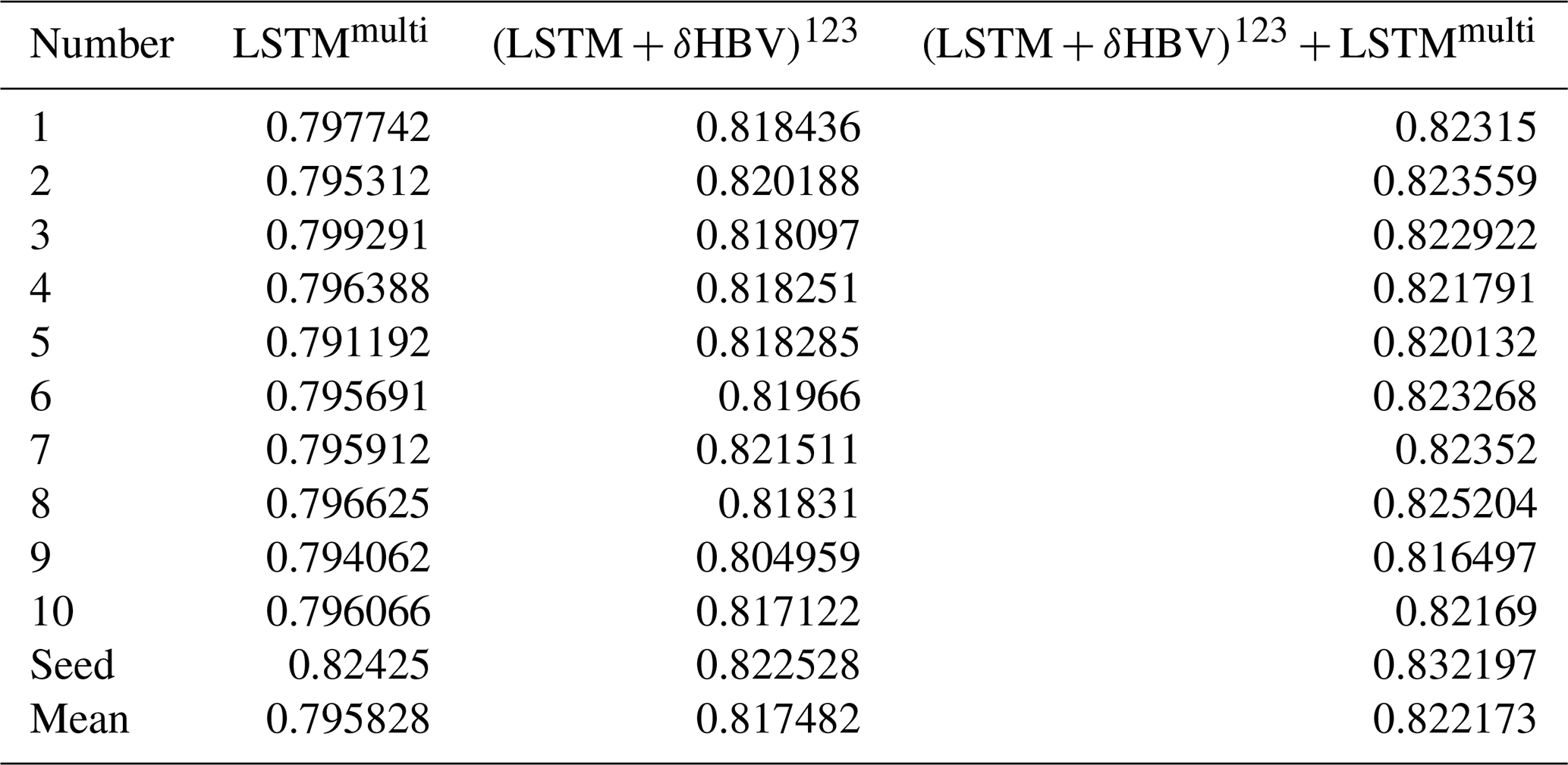
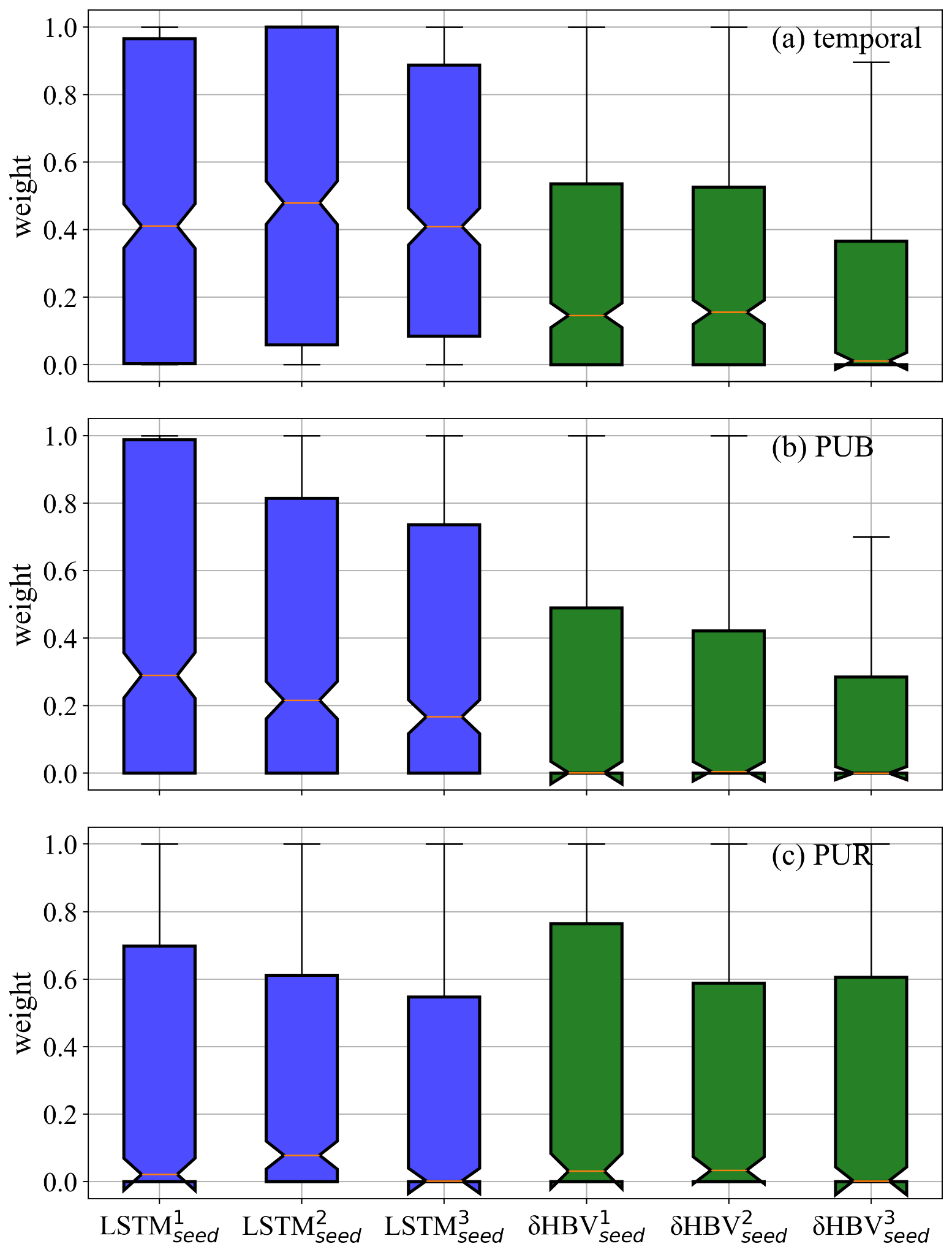
Figure E1Weights of six components across 531 basins, estimated basin-by-basin using a genetic algorithm based on streamflow observations during the test periods. The weights are normalized by the maximum weight within each ensemble group. These weights are used exclusively for qualitatively analyzing the relative contributions of different ensemble members, with higher values indicating larger relative contributions.
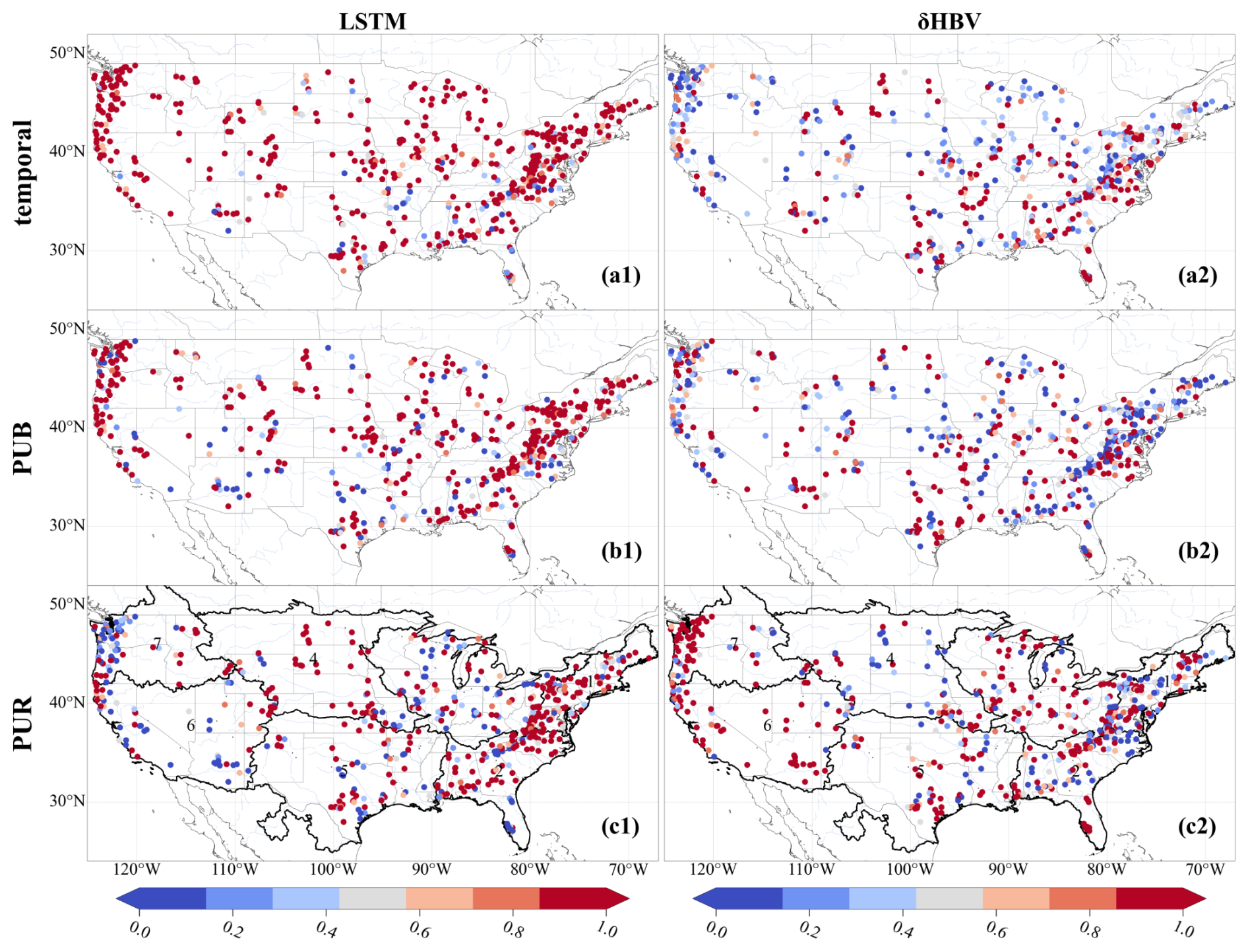
Figure E2Spatial distributions of weights of the LSTM and δHBV models, estimated by a genetic algorithm based on streamflow observations during the test periods. The weights are normalized by the maximum weight within each ensemble group. These weights are used exclusively for qualitatively analyzing the relative contributions of different ensemble members, with higher values indicating larger relative contributions.
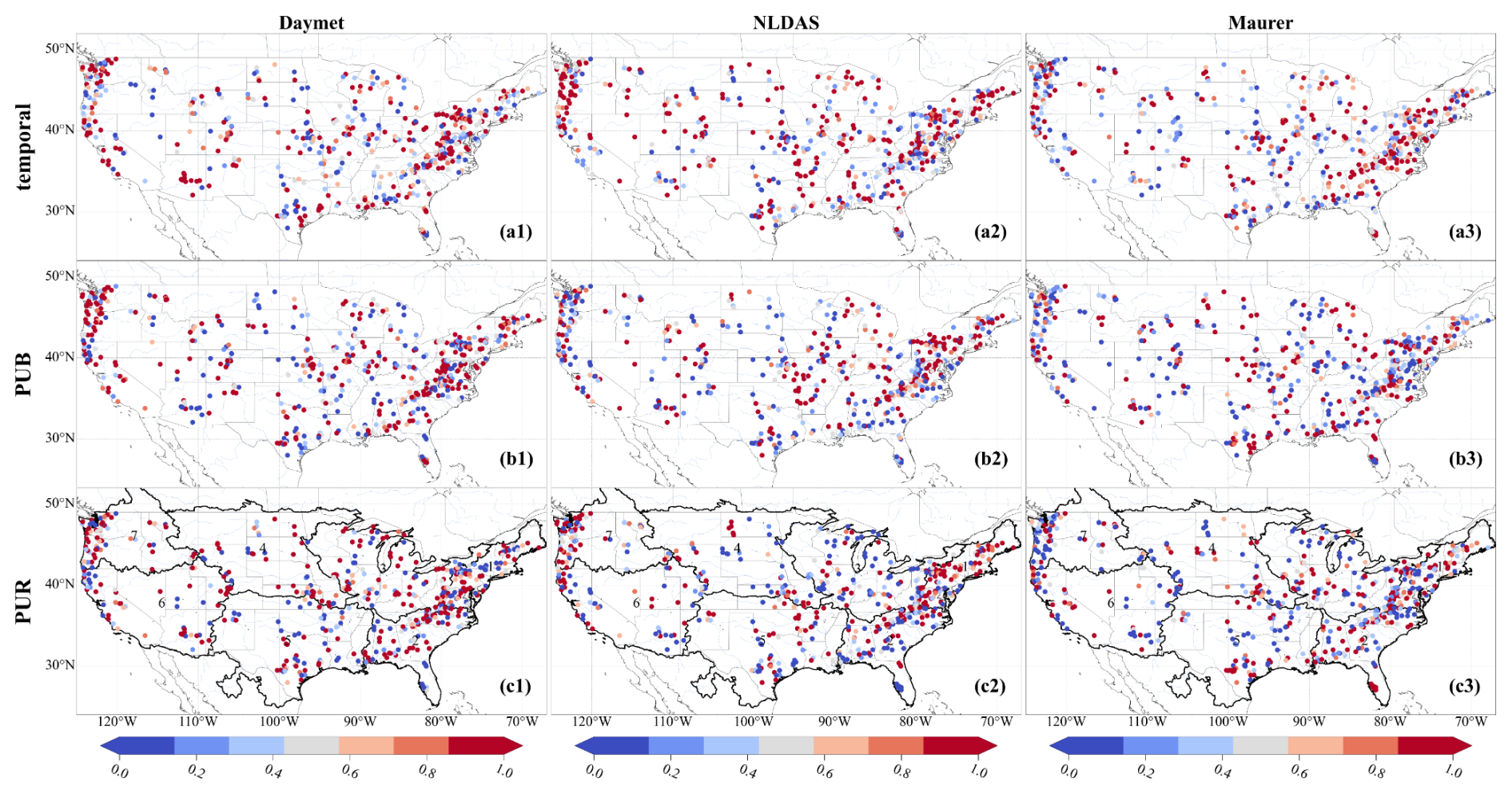
Figure E3Spatial distributions of weights of the Daymet, NLDAS, and Maurer meteorological forcing datasets, estimated by a genetic algorithm based on streamflow observations during the test periods. The weights are normalized by the maximum weight within each ensemble group. These weights are used exclusively for qualitatively analyzing the relative contributions of different ensemble members, with higher values indicating larger relative contributions.
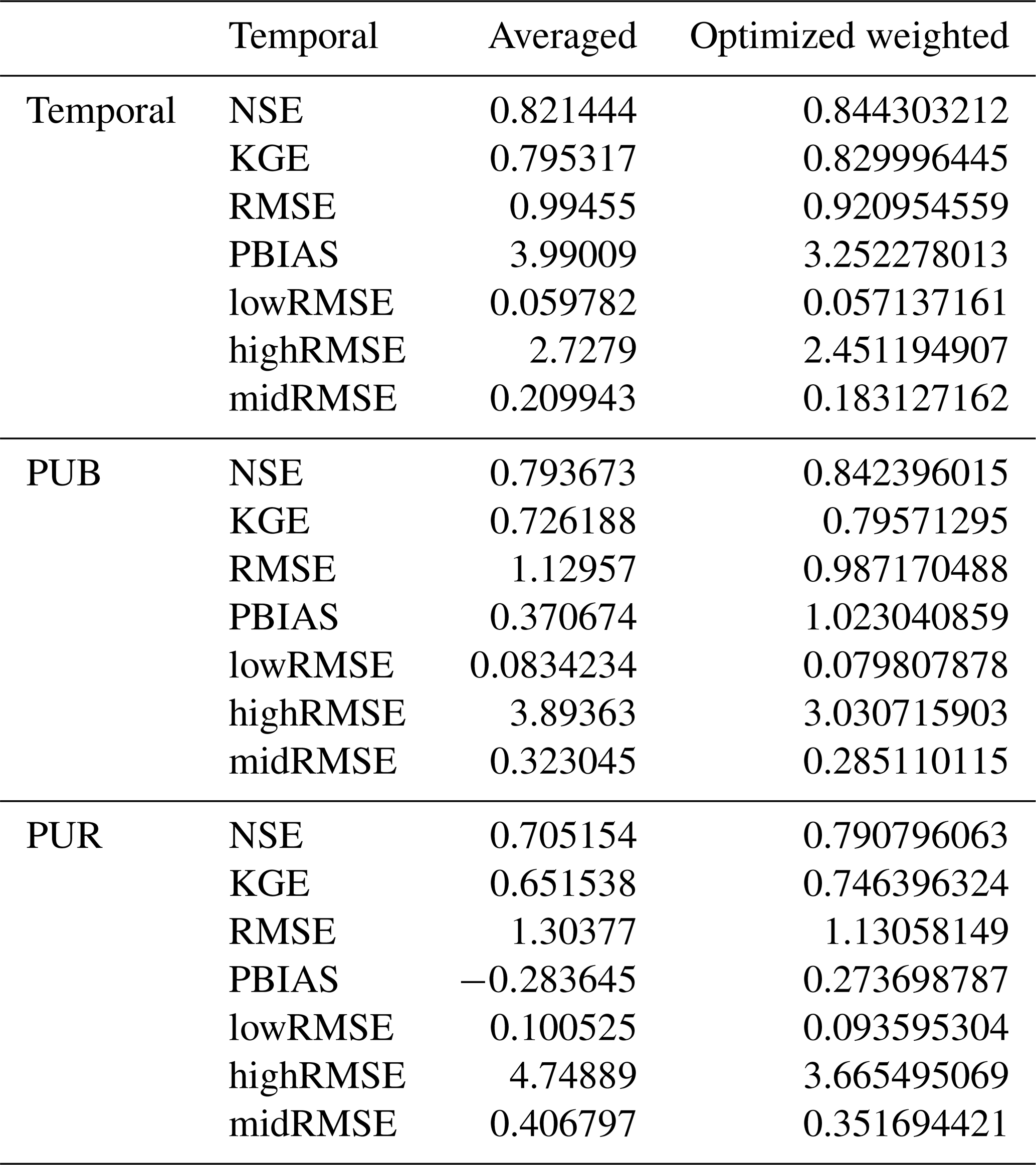
Table E1Comparisons of metric values between averaged ensemble simulations and optimized weighted simulations, estimated using a genetic algorithm based on streamflow observations during the test periods. The results highlight the potential for further improvements in ensemble simulations.
The source codes and datasets utilized in this study are publicly accessible through the following repositories: The δHBV modeling framework, including all computational scripts and documentation, is hosted on Zenodo (https://doi.org/10.5281/zenodo.7943626) (Feng et al., 2023a), with an updated version and comprehensive software release scheduled upon manuscript acceptance. The implementation of the LSTM architecture is accessible through Zenodo (https://doi.org/10.5281/zenodo.6326394) (Kratzert et al., 2022). The CAMELS hydrometeorological dataset, which provides the foundational basin characteristics and time series data used in our analysis, can be obtained via https://doi.org/10.5065/D6MW2F4D (Newman et al., 2022; Addor et al., 2017). The streamflow simulations produced in this study can be downloaded at https://doi.org/10.5281/zenodo.16895228 (Li et al., 2025).
PL and CS designed the experiments and PL carried them out. YS developed the modified δHBV code. PL prepared the manuscript with contributions from all co-authors.
Chaopeng Shen and Kathryn Lawson have financial interests in HydroSapient, Inc., a company that could potentially benefit from the results of this research. This interest has been reviewed by the Pennsylvania State University in accordance with its individual conflict of interest policy for the purpose of maintaining the objectivity and the integrity of research. The other authors have no competing interests to declare.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
PL, CS, and KL were supported by the Office of Biological and Environmental Research of the U.S. Department of Energy (contract no. DESC0016605). PJ and MP were also partially supported by California Department of Water Resources Atmospheric River Program Phase III (Grant 4600014294). YS and CS were partially supported by subaward A23-0252-S002 from the Cooperative Institute for Research to Operations in Hydrology (CIROH) through the National Oceanic and Atmospheric Administration (NOAA) Cooperative Agreement (Grant no. NA22NWS4320003).
Financial support. This research has been supported by the Biological and Environmental Research (grant no. DESC0016605), the Department of Water Resources (grant no. 4600014294), and the National Oceanic and Atmospheric Administration (grant no. A23-0252-S002).
This paper was edited by Thomas Kjeldsen and reviewed by Aggrey Muhebwa and one anonymous referee.
Aboelyazeed, D., Xu, C., Hoffman, F. M., Liu, J., Jones, A. W., Rackauckas, C., Lawson, K., and Shen, C.: A differentiable, physics-informed ecosystem modeling and learning framework for large-scale inverse problems: demonstration with photosynthesis simulations, Biogeosciences, 20, 2671–2692, https://doi.org/10.5194/bg-20-2671-2023, 2023.
Addor, N., Newman, A. J., Mizukami, N., and Clark, M. P.: The CAMELS data set: catchment attributes and meteorology for large-sample studies, Hydrol. Earth Syst. Sci., 21, 5293–5313, https://doi.org/10.5194/hess-21-5293-2017, 2017.
Aghakouchak, A. and Habib, E.: Application of a Conceptual Hydrologic Model in Teaching Hydrologic Processes, International Journal of Engineering Education, 26, 963–973, 2010.
Bandai, T. and Ghezzehei, T. A.: Physics-informed neural networks with monotonicity constraints for Richardson-Richards equation: Estimation of constitutive relationships and soil water flux density from volumetric water content measurements, Water Resources Research, 57, e2020WR027642, https://doi.org/10.1029/2020wr027642, 2021.
Beck, H. E., van Dijk, A. I. J. M., de Roo, A., Dutra, E., Fink, G., Orth, R., and Schellekens, J.: Global evaluation of runoff from 10 state-of-the-art hydrological models, Hydrol. Earth Syst. Sci., 21, 2881–2903, https://doi.org/10.5194/hess-21-2881-2017, 2017.
Beck, H. E., Pan, M., Lin, P., Seibert, J., van Dijk, A. I. J. M., and Wood, E. F.: Global fully distributed parameter regionalization based on observed streamflow from 4,229 headwater catchments, Journal of Geophysical Research: Atmospheres, 125, e2019JD031485, https://doi.org/10.1029/2019JD031485, 2020.
Behnke, R., Vavrus, S., Allstadt, A., Albright, T., Thogmartin, W. E., and Radeloff, V. C.: Evaluation of downscaled, gridded climate data for the conterminous United States, Ecological Applications, 26, 1338–1351, https://doi.org/10.1002/15-1061, 2016.
Bell, V. A. and Moore, R. J.: The sensitivity of catchment runoff models to rainfall data at different spatial scales, Hydrol. Earth Syst. Sci., 4, 653–667, https://doi.org/10.5194/hess-4-653-2000, 2000.
Bellmore, J. R., Duda, J. J., Craig, L. S., Greene, S. L., Torgersen, C. E., Collins, M. J., and Vittum, K.: Status and trends of dam removal research in the United States, Wiley Interdisciplinary Reviews: Water, 4, e1164, https://doi.org/10.1002/wat2.1164, 2017.
Bergström, S.: Development and application of a conceptual runoff model for Scandinavian catchments, PhD Thesis, Swedish Meteorological and Hydrological Institute (SMHI), Norköping, Sweden, urn:nbn:se:smhi:diva-5738, 1976.
Bergström, S.: The HBV model – its structure and applications, SMHI, urn:nbn:se:smhi:diva-2672, 1992.
Bindas, T., Tsai, W.-P., Liu, J., Rahmani, F., Feng, D., Bian, Y., Lawson, K., and Shen, C.: Improving river routing using a differentiable Muskingum-Cunge model and physics-informed machine learning, Water Resources Research, 60, e2023WR035337, https://doi.org/10.1029/2023WR035337, 2024.
Bodnar, C., Bruinsma, W. P., Lucic, A., Stanley, M., Allen, A., Brandstetter, J., Garvan, P., Riechert, M., Weyn, J. A., Dong, H., Gupta, J. K., Thambiratnam, K., Archibald, A. T., Wu, C.-C., Heider, E., Welling, M., Turner, R. E., and Perdikaris, P.: A foundation model for the Earth system, Nature, 641, 1180–1187, https://doi.org/10.1038/s41586-025-09005-y, 2025.
Brunner, M. I., Slater, L., Tallaksen, L. M., and Clark, M.: Challenges in modeling and predicting floods and droughts: A review, WIREs Water, 8, e1520, https://doi.org/10.1002/wat2.1520, 2021.
Clark, M. P., Slater, A. G., Rupp, D. E., Woods, R. A., Vrugt, J. A., Gupta, H. V., Wagener, T., and Hay, L. E.: Framework for Understanding Structural Errors (FUSE): A modular framework to diagnose differences between hydrological models, Water Resources Research, 44, https://doi.org/10/chvc6k, 2008.
Clark, M. P., Nijssen, B., Lundquist, J. D., Kavetski, D., Rupp, D. E., Woods, R. A., Freer, J. E., Gutmann, E. D., Wood, A. W., Brekke, L. D., Arnold, J. R., Gochis, D. J., and Rasmussen, R. M.: A unified approach for process-based hydrologic modeling: 1. Modeling concept, Water Resources Research, 51, 2498–2514, https://doi.org/10/f7db99, 2015.
Clark, M. P., Wilby, R. L., Gutmann, E. D., Vano, J. A., Gangopadhyay, S., Wood, A. W., Fowler, H. J., Prudhomme, C., Arnold, J. R., and Brekke, L. D.: Characterizing uncertainty of the hydrologic impacts of climate change, Curr. Clim. Change Rep., 2, 55–64, https://doi.org/10.1007/s40641-016-0034-x, 2016.
Dion, P., Martel, J.-L., and Arsenault, R.: Hydrological ensemble forecasting using a multi-model framework, Journal of Hydrology, 600, 126537, https://doi.org/10.1016/j.jhydrol.2021.126537, 2021.
Feng, D., Fang, K., and Shen, C.: Enhancing streamflow forecast and extracting insights using long-short term memory networks with data integration at continental scales, Water Resources Research, 56, e2019WR026793, https://doi.org/10.1029/2019WR026793, 2020.
Feng, D., Lawson, K., and Shen, C.: Mitigating prediction error of deep learning streamflow models in large data-sparse regions with ensemble modeling and soft data, Geophysical Research Letters, 48, e2021GL092999, https://doi.org/10.1029/2021GL092999, 2021.
Feng, D., Liu, J., Lawson, K., and Shen, C.: Differentiable, learnable, regionalized process-based models with multiphysical outputs can approach state-of-the-art hydrologic prediction accuracy, Water Resources Research, 58, e2022WR032404, https://doi.org/10.1029/2022WR032404, 2022.
Feng, D., Shen, C., Liu, J., Lawson, K., and Beck, H.: differentiable parameter learning (dPL) + HBV hydrologic model, Zenodo [code, data set], https://doi.org/10.5281/zenodo.7943626, 2023a.
Feng, D., Beck, H., Lawson, K., and Shen, C.: The suitability of differentiable, physics-informed machine learning hydrologic models for ungauged regions and climate change impact assessment, Hydrol. Earth Syst. Sci., 27, 2357–2373, https://doi.org/10.5194/hess-27-2357-2023, 2023b.
Frame, J. M., Kratzert, F., Klotz, D., Gauch, M., Shalev, G., Gilon, O., Qualls, L. M., Gupta, H. V., and Nearing, G. S.: Deep learning rainfall–runoff predictions of extreme events, Hydrol. Earth Syst. Sci., 26, 3377–3392, https://doi.org/10.5194/hess-26-3377-2022, 2022.
Hanazaki, R., Yamazaki, D., and Yoshimura, K.: Development of a reservoir flood control scheme for global flood models, JAMES, 14, e2021MS002944, https://doi.org/10.1029/2021MS002944, 2022.
Hargreaves, G. H.: Defining and using reference evapotranspiration, Journal of Irrigation and Drainage Engineering, 120, 1132–1139, https://doi.org/10.1061/(ASCE)0733-9437(1994)120:6(1132), 1994.
He, Y., Chen, M., Wen, Y., Duan, Q., Yue, S., Zhang, J., Li, W., Sun, R., Zhang, Z., Tao, R., Tang, W., and Lü, G.: An open online simulation strategy for hydrological ensemble forecasting, Environmental Modelling & Software, 174, 105975, https://doi.org/10.1016/j.envsoft.2024.105975, 2024.
Heidari, H., Arabi, M., Warziniack, T., and Kao, S.-C.: Assessing shifts in regional hydroclimatic conditions of U.S. river basins in response to climate change over the 21st century, Earth's Future, 8, e2020EF001657, https://doi.org/10.1029/2020EF001657, 2020.
Hochreiter, S. and Schmidhuber, J.: Long Short-Term Memory, Neural Computation, 9, 1735–1780, https://doi.org/10.1162/neco.1997.9.8.1735, 1997.
Ji, H., Song, Y., Bindas, T., Shen, C., Yang, Y., Pan, M., Liu, J., Rahmani, F., Abbas, A., Beck, H., Lawson, K., and Wada, Y.: Distinct hydrologic response patterns and trends worldwide revealed by physics-embedded learning, Nat. Commun., 16, 9169, https://doi.org/10.1038/s41467-025-64367-1, 2025.
Jiang, S., Zheng, Y., and Solomatine, D.: Improving AI system awareness of geoscience knowledge: Symbiotic integration of physical approaches and deep learning, Geophys. Res. Lett., 47, e2020GL088229, https://doi.org/10.1029/2020GL088229, 2020.
Kling, H., Fuchs, M., and Paulin, M.: Runoff conditions in the upper Danube basin under an ensemble of climate change scenarios, Journal of Hydrology, 424–425, 264–277, https://doi.org/10.1016/j.jhydrol.2012.01.011, 2012.
Kraft, B., Jung, M., Körner, M., Koirala, S., and Reichstein, M.: Towards hybrid modeling of the global hydrological cycle, Hydrol. Earth Syst. Sci., 26, 1579–1614, https://doi.org/10.5194/hess-26-1579-2022, 2022.
Kratzert, F., Klotz, D., Brenner, C., Schulz, K., and Herrnegger, M.: Rainfall-Runoff modelling using Long-Short-Term-Memory (LSTM) networks, Hydrology and Earth System Sciences, 22, 6005–6022, https://doi.org/10.17605/OSF.IO/QV5JZ, 2018.
Kratzert, F., Klotz, D., Herrnegger, M., Sampson, A. K., Hochreiter, S., and Nearing, G. S.: Toward improved predictions in ungauged basins: Exploiting the power of machine learning, Water Resources Research, 55, 11344–11354, https://doi.org/10/gg4ck8, 2019.
Kratzert, F., Klotz, D., Hochreiter, S., and Nearing, G. S.: A note on leveraging synergy in multiple meteorological data sets with deep learning for rainfall–runoff modeling, Hydrol. Earth Syst. Sci., 25, 2685–2703, https://doi.org/10.5194/hess-25-2685-2021, 2021.
Kratzert, F., Gauch, M., Nearing, G., and Klotz, D.: NeuralHydrology – A Python library for Deep Learning research in hydrology, Zenodo [data set], https://doi.org/10.5281/zenodo.6326394, 2022.
Leube, P. C., de Barros, F. P. J., Nowak, W., and Rajagopal, R.: Towards optimal allocation of computer resources: Trade-offs between uncertainty quantification, discretization and model reduction, Environmental Modelling & Software, 50, 97–107, https://doi.org/10.1016/j.envsoft.2013.08.008, 2013.
Li, P., Zha, Y., Shi, L., Tso, C. H. M., Zhang, Y., and Zeng, W.: Comparison of the use of a physical-based model with data assimilation and machine learning methods for simulating soil water dynamics, Journal of Hydrology, 584, 124692, https://doi.org/10.1016/j.jhydrol.2020.124692, 2020a.
Li, P., Zha, Y., Tso, C. H. M., Shi, L., Yu, D., Zhang, Y., and Zeng, W.: Data assimilation of uncalibrated soil moisture measurements from frequency-domain reflectometry, Geoderma, 374, 114432, https://doi.org/10.1016/j.geoderma.2020.114432, 2020b.
Li, P., Zha, Y., Shi, L., and Zhong, H.: Identification of the terrestrial water storage change features in the North China Plain via independent component analysis, Journal of Hydrology: Regional Studies, 38, 100955, https://doi.org/10.1016/j.ejrh.2021.100955, 2021.
Li, P., Zha, Y., Shi, L., and Zhong, H.: Assessing the Global Relationships Between Teleconnection Factors and Terrestrial Water Storage Components, Water Resources Management, 36, 119–133, https://doi.org/10.1007/s11269-021-03015-x, 2022.
Li, P., Zha, Y., Zuo, B., and Zhang, Y.: A family of soil water retention models based on sigmoid functions, Water Resources Research, 59, e2022WR033160, https://doi.org/10.1029/2022WR033160, 2023a.
Li, P., Zha, Y., and Tso, C.-H. M.: Reconstructing GRACE-derived terrestrial water storage anomalies with in-situ groundwater level measurements and meteorological forcing data, Journal of Hydrology: Regional Studies, 50, 101528, https://doi.org/10.1016/j.ejrh.2023.101528, 2023b.
Li, P., Zha, Y., Zhang, Y., Michael Tso, C.-H., Attinger, S., Samaniego, L., and Peng, J.: Deep learning integrating scale conversion and pedo-transfer function to avoid potential errors in cross-scale transfer, Water Resources Research, 60, e2023WR035543, https://doi.org/10.1029/2023WR035543, 2024.
Li, P., Song, Y., Pan, M., Lawson, K., and Shen, C.: Streamflow Simulation Data from Differentiable HBV and LSTM Models Using CAMELS Datasets, Zenodo [data set], https://doi.org/10.5281/zenodo.16895228, 2025.
Lin, Y., Wang, D., Zhu, J., Sun, W., Shen, C., and Shangguan, W.: Development of objective function-based ensemble model for streamflow forecasts, Journal of Hydrology, 632, 130861, https://doi.org/10.1016/j.jhydrol.2024.130861, 2024.
Lins, H. F. and Slack, J. R.: Streamflow trends in the United States, Geophysical Research Letters, 26, 227–230, https://doi.org/10/d5zbbd, 1999.
Liu, J., Rahmani, F., Lawson, K., and Shen, C.: A multiscale deep learning model for soil moisture integrating satellite and in situ data, Geophysical Research Letters, 49, e2021GL096847, https://doi.org/10.1029/2021GL096847, 2022.
Liu, J., Bian, Y., Lawson, K., and Shen, C.: Probing the limit of hydrologic predictability with the Transformer network, Journal of Hydrology, 637, 131389, https://doi.org/10.1016/j.jhydrol.2024.131389, 2024.
Mai, J., Craig, J. R., Tolson, B. A., and Arsenault, R.: The sensitivity of simulated streamflow to individual hydrologic processes across North America, Nat. Commun., 13, 455, https://doi.org/10.1038/s41467-022-28010-7, 2022.
Maurer, E. P., Wood, A. W., Adam, J. C., Lettenmaier, D. P., and Nijssen, B.: A long-term hydrologically based dataset of land surface fluxes and states for the conterminous United States, Journal of Climate, 15, 3237–3251, https://doi.org/10.1175/1520-0442(2002)015<3237:ALTHBD>2.0.CO;2, 2002.
Moges, E., Demissie, Y., and Li, H.-Y.: Hierarchical mixture of experts and diagnostic modeling approach to reduce hydrologic model structural uncertainty, Water Resources Research, 52, 2551–2570, https://doi.org/10.1002/2015WR018266, 2016.
Nai, C., Liu, X., Tang, Q., Liu, L., Sun, S., and Gaffney, P. P. J.: A novel strategy for automatic selection of cross-basin data to improve local machine learning-based runoff models, Water Resources Research, 60, e2023WR035051, https://doi.org/10.1029/2023WR035051, 2024.
Narkhede, M. V., Bartakke, P. P., and Sutaone, M. S.: A review on weight initialization strategies for neural networks, Artificial Intelligence Review, 55, 291–322, https://doi.org/10.1007/s10462-021-10033-z, 2022.
Nash, J. E. and Sutcliffe, J. V.: River flow forecasting through conceptual models part I – A discussion of principles, Journal of Hydrology, 10, 282–290, https://doi.org/10.1016/0022-1694(70)90255-6, 1970.
Nearing, G., Cohen, D., Dube, V., Gauch, M., Gilon, O., Harrigan, S., Hassidim, A., Klotz, D., Kratzert, F., Metzger, A., Nevo, S., Pappenberger, F., Prudhomme, C., Shalev, G., Shenzis, S., Tekalign, T. Y., Weitzner, D., and Matias, Y.: Global prediction of extreme floods in ungauged watersheds, Nature, 627, 559–563, https://doi.org/10.1038/s41586-024-07145-1, 2024.
Newman, A. J., Mizukami, N., Clark, M. P., Wood, A. W., Nijssen, B., Nearing, G., Newman, A. J., Mizukami, N., Clark, M. P., Wood, A. W., Nijssen, B., and Nearing, G.: Benchmarking of a Physically Based Hydrologic Model, Journal of Hydrometeorology, 18, 2215–2225, https://doi.org/10/gbwr9s, 2017.
Newman, A. J., Clark, M. P., Longman, R. J., and Giambelluca, T. W.: Methodological intercomparisons of station-based gridded meteorological products: Utility, limitations, and paths forward, Journal of Hydrometeorology, 20, 531–547, https://doi.org/10.1175/JHM-D-18-0114.1, 2019.
Newman, A. J., Sampson, K., Clark, M., Bock, A., Viger, R., Blodgett, D., Addor, N. and Mizukami, M.: CAMELS: Catchment Attributes and MEteorology for Large-sample Studies (1.2), Zenodo [data set], https://doi.org/10.5065/D6MW2F4D, 2022.
Ouyang, W., Lawson, K., Feng, D., Ye, L., Zhang, C., and Shen, C.: Continental-scale streamflow modeling of basins with reservoirs: Towards a coherent deep-learning-based strategy, Journal of Hydrology, 599, 126455, https://doi.org/10.1016/j.jhydrol.2021.126455, 2021.
Paul, P. K., Zhang, Y., Ma, N., Mishra, A., Panigrahy, N., and Singh, R.: Selecting hydrological models for developing countries: Perspective of global, continental, and country scale models over catchment scale models, Journal of Hydrology, 600, 126561, https://doi.org/10.1016/j.jhydrol.2021.126561, 2021.
Rahmani, F., Appling, A., Feng, D., Lawson, K., and Shen, C.: Identifying structural priors in a hybrid differentiable model for stream water temperature modeling, Water Resources Research, 59, e2023WR034420, https://doi.org/10.1029/2023WR034420, 2023.
Reichle, R. H. and Koster, R. D.: Assessing the impact of horizontal error correlations in background fields on soil moisture estimation, Journal of Hydrometeorology, 4, 1229–1242, https://doi.org/10.1175/1525-7541(2003)004<1229:ATIOHE>2.0.CO;2, 2003.
Sawadekar, K., Song, Y., Pan, M., Beck, H., McCrary, R., Ullrich, P., Lawson, K., and Shen, C.: Improving differentiable hydrologic modeling with interpretable forcing fusion, J. Hydrol., 659, 133320, https://doi.org/10.1016/j.jhydrol.2025.133320, 2025.
Shen, C., Appling, A. P., Gentine, P., Bandai, T., Gupta, H., Tartakovsky, A., Baity-Jesi, M., Fenicia, F., Kifer, D., Li, L., Liu, X., Ren, W., Zheng, Y., Harman, C. J., Clark, M., Farthing, M., Feng, D., Kumar, P., Aboelyazeed, D., Rahmani, F., Song, Y., Beck, H. E., Bindas, T., Dwivedi, D., Fang, K., Höge, M., Rackauckas, C., Mohanty, B., Roy, T., Xu, C., and Lawson, K.: Differentiable modelling to unify machine learning and physical models for geosciences, Nat. Rev. Earth Environ., 4, 552–567, https://doi.org/10.1038/s43017-023-00450-9, 2023.
Solanki, H., Vegad, U., Kushwaha, A., and Mishra, V.: Improving streamflow prediction using multiple hydrological models and machine learning methods, Water Resources Research, 61, e2024WR038192, https://doi.org/10.1029/2024WR038192, 2025.
Song, Y., Knoben, W. J. M., Clark, M. P., Feng, D., Lawson, K., Sawadekar, K., and Shen, C.: When ancient numerical demons meet physics-informed machine learning: adjoint-based gradients for implicit differentiable modeling, Hydrol. Earth Syst. Sci., 28, 3051–3077, https://doi.org/10.5194/hess-28-3051-2024, 2024.
Song, Y., Bindas, T., Shen, C., Ji, H., Knoben, W. J. M., Lonzarich, L., Clark, M. P., Liu, J., van Werkhoven, K., Lamont, S., Denno, M., Pan, M., Yang, Y., Rapp, J., Kumar, M., Rahmani, F., Thébault, C., Adkins, R., Halgren, J., Patel, T., Patel, A., Sawadekar, K. A., and Lawson, K.: High-resolution national-scale water modeling is enhanced by multiscale differentiable physics-informed machine learning, Water Resour. Res., 61, e2024WR038928, https://doi.org/10.1029/2024WR038928, 2025a.
Song, Y., Sawadekar, K., Frame, J. M., Pan, M., Clark, M., Knoben, W. J. M., Wood, A. W., Lawson, K. E., Patel, T., and Shen, C.: Physics-informed, differentiable hydrologic models for capturing unseen extreme events, ESS Open Archive, https://doi.org/10.22541/essoar.172304428.82707157/v2, 2025b.
Thornton, P. E., Running, S. W., and White, M. A.: Generating surfaces of daily meteorological variables over large regions of complex terrain, Journal of Hydrology, 190, 214–251, https://doi.org/10.1016/S0022-1694(96)03128-9, 1997.
Tsai, W.-P., Feng, D., Pan, M., Beck, H., Lawson, K., Yang, Y., Liu, J., and Shen, C.: From calibration to parameter learning: Harnessing the scaling effects of big data in geoscientific modeling, Nat. Commun., 12, 5988, https://doi.org/10.1038/s41467-021-26107-z, 2021.
Wada, Y., de Graaf, I. E. M., and van Beek, L. P. H.: High-resolution modeling of human and climate impacts on global water resources, Journal of Advances in Modeling Earth Systems, 8, 735–763, https://doi.org/10/f8wgpv, 2016.
Wang, N., Zhang, D., Chang, H., and Li, H.: Deep learning of subsurface flow via theory-guided neural network, Journal of Hydrology, 584, 124700, https://doi.org/10.1016/j.jhydrol.2020.124700, 2020.
West, B. D., Maxwell, R. M., and Condon, L. E.: A scalable and modular reservoir implementation for large-scale integrated hydrologic simulations, Hydrol. Earth Syst. Sci., 29, 245–259, https://doi.org/10.5194/hess-29-245-2025, 2025.
Wilbrand, K., Taormina, R., ten Veldhuis, M.-C., Visser, M., Hrachowitz, M., Nuttall, J., and Dahm, R.: Predicting streamflow with LSTM networks using global datasets, Front. Water, 5, https://doi.org/10.3389/frwa.2023.1166124, 2023.
Xia, Y., Mitchell, K., Ek, M., Sheffield, J., Cosgrove, B., Wood, E., Luo, L., Alonge, C., Wei, H., Meng, J., Livneh, B., Lettenmaier, D., Koren, V., Duan, Q., Mo, K., Fan, Y., and Mocko, D.: Continental-scale water and energy flux analysis and validation for the North American Land Data Assimilation System project phase 2 (NLDAS-2): 1. Intercomparison and application of model products, Journal of Geophysical Research: Atmospheres, 117, https://doi.org/10.1029/2011JD016048, 2012.
Xie, K., Liu, P., Zhang, J., Han, D., Wang, G., and Shen, C.: Physics-guided deep learning for rainfall-runoff modeling by considering extreme events and monotonic relationships, Journal of Hydrology, 603, 127043, https://doi.org/10.1016/j.jhydrol.2021.127043, 2021.
Yao, L., Libera, D. A., Kheimi, M., Sankarasubramanian, A., and Wang, D.: The roles of climate forcing and its variability on streamflow at daily, monthly, annual, and long-term scales, Water Resources Research, 56, e2020WR027111, https://doi.org/10.1029/2020WR027111, 2020.
Yilmaz, K. K., Gupta, H. V., and Wagener, T.: A process-based diagnostic approach to model evaluation: Application to the NWS distributed hydrologic model, Water Resources Research, 44, https://doi.org/10/fpvsgb, 2008.
Yu, D., Yang, J., Shi, L., Zhang, Q., Huang, K., Fang, Y., and Zha, Y.: On the uncertainty of initial condition and initialization approaches in variably saturated flow modeling, Hydrol. Earth Syst. Sci., 23, 2897–2914, https://doi.org/10.5194/hess-23-2897-2019, 2019.
Yu, M., Huang, Q., and Li, Z.: Deep learning for spatiotemporal forecasting in Earth system science: a review, International Journal of Digital Earth, 17, 2391952, https://doi.org/10.1080/17538947.2024.2391952, 2024.
Zhang, Q., Shi, L., Holzman, M., Ye, M., Wang, Y., Carmona, F., and Zha, Y.: A dynamic data-driven method for dealing with model structural error in soil moisture data assimilation, Advances in Water Resources, 132, 103407, https://doi.org/10.1016/j.advwatres.2019.103407, 2019.
Zounemat-Kermani, M., Batelaan, O., Fadaee, M., and Hinkelmann, R.: Ensemble machine learning paradigms in hydrology: A review, Journal of Hydrology, 598, 126266, https://doi.org/10.1016/j.jhydrol.2021.126266, 2021.
- Abstract
- Highlights
- Introduction
- Materials and methods
- Results and discussion
- Summary and conclusions
- Appendix A: Detailed processes of HBV employed in this study
- Appendix B: Illustrated differences among the three meteorological forcing datasets
- Appendix C: Details of model inputs, ensemble frameworks, and evaluations
- Appendix D: Additional details on model performance
- Appendix E: Intuitive visualization of the relative contributions of ensemble members based on optimized weights
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Highlights
- Introduction
- Materials and methods
- Results and discussion
- Summary and conclusions
- Appendix A: Detailed processes of HBV employed in this study
- Appendix B: Illustrated differences among the three meteorological forcing datasets
- Appendix C: Details of model inputs, ensemble frameworks, and evaluations
- Appendix D: Additional details on model performance
- Appendix E: Intuitive visualization of the relative contributions of ensemble members based on optimized weights
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References