the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Sep 2025
| 01 Sep 2025
Toward merging MOPEX and CAMELS hydrometeorological datasets: compatibility and statistical comparison
Katharine Sink
Tom Brikowski
This study compares two large hydrometeorological datasets, the Model Parameter Estimation Experiment (MOPEX) and the Catchment Attributes and Meteorology for Large-sample Studies (CAMELS), with the aim of quantifying differences that might impact their mergers. This comparison focuses on 47 shared watersheds within the continental United States spanning daily, monthly, seasonal, and annual scales for the overlapping water years of 1981 to 2000. Results indicate significant differences between the datasets at daily time steps, highlighting the challenge of high-temporal-resolution data reconciliation; however, compatibility markedly improves with temporal aggregation at monthly, seasonal, and annual scales. Systematic biases are evident, with MOPEX showing a warm bias for temperature and CAMELS displaying a wet bias for precipitation. For future studies analyzing monthly or annual runoff trends, no corrections to the raw data are necessary, as the biases do not significantly affect large-scale temporal analyses. Studies focusing on fine-scale hydrological characteristics, such as daily precipitation events, the frequency of wet and dry days per month, or single-basin dynamics, may require a statistical bias correction to ensure accuracy. Uncertainty is inherent in all climate datasets due to differences in data sources, interpolation methods, and spatial coverage. The transition from MOPEX to CAMELS does not notably introduce additional uncertainty beyond what is already present in the original datasets. The variability between the datasets is comparable to the inherent variability within each individual dataset and is neither a useful criterion for dataset selection nor a barrier to potential merger. As a result, the overall uncertainty in annual or decadal modeling outcomes remains essentially the same, regardless of which dataset is used. That said, model outputs should be calibrated against observational reference data to account for systematic errors. Statistical analyses demonstrate that both datasets are representative of climatic conditions, trends, and extreme events. Our findings validate the results of previous research employing either dataset. Furthermore, this study serves as a foundation for the merging and extension of MOPEX and CAMELS datasets without any alterations, providing a comprehensive, long-term dataset suitable for hydrological modeling and climate analyses while maintaining comparability across basin and temporal scales.
- Article
(7489 KB) - Full-text XML
- BibTeX
- EndNote




Comprehensive historical datasets are crucial for investigating and projecting surface water availability given the complex response of watersheds to natural and anthropogenic forcings. In particular, comparative hydrology and large-sample hydrology (LSH) rely on large datasets comprised of numerous catchments to derive relationships, develop new models and uncertainty estimates, and classify locations that span different climatic and physiographic regions (Addor et al., 2020; Gupta et al., 2014), yet significant discrepancies make combining and comparing such datasets difficult. Indeed, Addor et al. (2020) state that the “lack of common standards impedes the comparison of basins from different datasets”.
This paper explores and attempts to resolve the principal issues confronting the merger of two of the most commonly used LSH datasets for the continental United States, (CONUS), the Model Parameter Estimation Experiment, MOPEX (Duan et al., 2006; Schaake et al., 2006), and the Catchments Attributes and Meteorology for Large-sample Studies, CAMELS (Addor et al., 2017; Newman et al., 2015). In general, there is an abundance of data available for climate variables, streamflow, and catchment characteristics, including ground and remotely sensed parameters; however, varying spatial and temporal resolutions among variables such as precipitation and temperature often hinder intercomparison and merging of datasets (Guo, 2017). A wide range of data sources with varying analysis and derivation methods can introduce uncertainty, especially when metadata (Kelleher and Braswell, 2021) or uncharacterized anthropogenic influences are excluded (Addor et al., 2020).
MOPEX and CAMELS are two prominent datasets that encompass a combination of daily temperature, precipitation, potential evapotranspiration, and streamflow values for selected catchments. Additionally, these datasets provide essential catchment characteristics such as area, elevation, vegetation, and soil texture, employing the United States Geological Survey (USGS) hydrologic unit code (HUC) subbasin classification (Seaber et al., 1987). While the consolidation of attributes and hydroclimatic data simplifies the acquisition process, challenges arise due to differences in spatial coverage and data sources, which currently limit the opportunity to effectively utilize both the MOPEX and CAMELS datasets simultaneously or confirm findings and expand on studies employing either dataset.
Researchers often face the necessity of choosing one dataset over the other, leading to a situation where the unique strengths and limitations of each dataset influence the selection process. Numerous studies have engaged in the generalization and categorization of watersheds within the CONUS using either the MOPEX or CAMELS dataset, which underscores the widespread impact and influence of these two large-sample datasets, making them arguably the most prolific resources within hydrological studies focused on the CONUS. Their prevalence in hydrologic studies is reflected in the citation count data derived from Clarivate Web of Science (certain data included herein are derived from ClarivateTM – Web of ScienceTM – © Clarivate 2024, all rights reserved), with MOPEX (Duan et al., 2006) currently cited in 489 scientific papers and CAMELS (Addor et al., 2017) cited in 352. Here we undertake a unique comparative study between the MOPEX and CAMELS datasets using exploratory data analysis to evaluate their comparability, accuracy, and implications for past, present, and future research. The results aim to bolster confidence in analytical and modeling outcomes derived from either dataset, thereby fostering robust hydrological research and supporting effective water resource management in the CONUS.
This study compares daily precipitation and temperature data derived from land surface stations across the country. MOPEX includes data for 431 watersheds from 1948 to 2003 and CAMELS covers 671 basins from 1980 to 2014. There are 52 overlapping basins between the two datasets. This evaluation is conducted over water years common to both datasets (1981–2000), emphasizing 47 common subbasins. Many previous dataset comparison studies have addressed global climate datasets (Essou et al., 2016; Newman et al., 2019), precipitation (Buban et al., 2020; Levy et al., 2017; Muche et al., 2020; Prat and Nelson, 2015; Sitterson et al., 2020; Sun et al., 2018), temperature (Oubeidillah et al., 2014), and evapotranspiration products (Carter et al., 2018; Chao et al., 2021; Han et al., 2015). These studies contribute to the ongoing efforts to advance the understanding of hydrological processes and improve the reliability of hydrologic models (Gupta et al., 2014); however, there has yet to be a study comparing these two large-sample watershed-based datasets. Our findings show that while MOPEX and CAMELS exhibit systematic biases, they can still be merged or reliably compared without requiring corrections beyond smaller timescales (i.e., a single day, month, or season). Statistical adjustments to daily data depend on study objectives, as no single method fits all needs. Raw data or direct model outputs typically require bias correction, and we intend for our results to help researchers determine necessary adjustments using appropriate methods, such as equidistant quantile matching (EDCDFm) for temperature and quantile delta mapping (QDM) or PresRATe for precipitation (Lehner et al., 2023; Pierce et al., 2015). To support long-term hydrological analyses, all basins will be extended to 2023 using Daymet, yielding a combined dataset of up to 1050 basins (Sink, 2025). When MOPEX is extended using Daymet, slight shifts in these biases are expected, but the dataset's overall reliability remains intact.
2.1 MOPEX
The MOPEX intercomparison project was conceived by several organizations including the World Meteorological Organization (WMO), the International Association of Hydrogeologists (IAH) Predictions in Ungauged Basins (PUB) initiative, and the Global Energy and Water Cycle Experiment (GEWEX) in 1996 (Duan et al., 2006). Its aim was to establish guidelines for parameter estimation techniques while simultaneously decreasing uncertainty (Schaake et al., 2006). MOPEX contains precipitation, minimum and maximum temperature, and streamflow data for 431 CONUS basins on a daily time step for 1948–2003. MOPEX variables are based on weather station observations from the National Climatic Data Center (NCDC) and Natural Resources Conservation Service (NRCS) SNOTEL network, which were then averaged by catchment area using an inverse distance weighting method. For more details regarding data selection and processing, refer to Duan et al. (2006) and Schaake et al. (2006).
2.2 CAMELS
CAMELS, sponsored by the US Bureau of Reclamation and the US Army Corps of Engineers, consists of three daily forcing datasets from Daymet Version 2 (Thornton et al., 2013), Maurer (Maurer et al., 2002), and the North American Land Data Assimilation System (NLDAS) (Xia et al., 2012), along with benchmark model performance results using the coupled Snow-17 snow model and the Sacramento Soil Moisture Accounting Model (SAC-SMA), using each of the three forcing datasets, for 671 basins within the CONUS covering the years 1980–2014 (Newman et al., 2015). CAMELS contains precipitation, temperature, and streamflow data on daily time steps in addition to detailed soil characterizations and geology. The CAMELS Daymet Version 2 forcing dataset is used in this study and interpolates observations to a 1 km × 1 km grid using a Gaussian weighting process (Thornton et al., 2021), which are simply averaged over the catchment area in CAMELS. For an in-depth discussion regarding data selection and processing for CAMELS, refer to Addor et al. (2017) and Newman et al. (2015).
2.3 Dataset comparison
Both datasets select basins with apparently minimal anthropogenic impacts, highlight processing methods, and provide access to basin characteristics including boundary files, fractional spatial coverage of soil type, vegetation type, land cover, area, and elevation (Table 1). The documentation of catchment attributes, along with daily data for streamflow, temperature, precipitation, and potential evapotranspiration, significantly streamlines the initial phases of data investigation, consolidation, and processing, making the datasets exceptionally valuable for research and analysis.
Table 1Comparisons between MOPEX and CAMELS. Acronyms are Hydro-Climatic Data Network (HCDN), National Climatic Data Center (NCDC), Cooperative Observer Program (COOP), Snow Telemetry Network (SNOTEL), Parameter-elevation Regressions on Independent Slopes Model (PRISM), North American Land Data Assimilation System (NLDAS), National Oceanic and Atmospheric Administration (NOAA), Sacramento Soil Moisture Accounting Model (SAC-SMA), State Soil Geographic (STATSGO) database, Global Lithological Map (GLiM), Global Hydrogeology Maps (GLHYMPS) of permeability and porosity, Moderate Resolution Imaging Spectroradiometer (MODIS), International Geosphere–Biosphere Programme (IGBP), University of Maryland (UMD), and normalized difference vegetation index (NDVI).
For this study, temperature and precipitation values from the datasets were evaluated on daily, monthly, seasonal, and annual temporal scales between 1981 and 2000, based on water years spanning 1 October 1980 to 30 September 2000. Derived variables were omitted for most analyses in this study because evapotranspiration, when calculated using the water balance, will only differ based on the precipitation since both MOPEX and CAMELS obtain the other balance component, streamflow, from the USGS National Water Information System (NWIS). Potential evapotranspiration values are highly dependent on the estimation method used and require additional information such as wind speed, solar radiation, and temperature (Andréassian et al., 2004; Lemaitre-Basset et al., 2022; Pimentel et al., 2023). Potential evapotranspiration values can also be estimated during modeling.
This study provides researchers with detailed analyses regarding the uncertainties within the datasets and between them for a 20-year period through quantitative measurements of dispersion, distribution, central tendency, interval estimates, and statistical tests. To obtain a longer record, the datasets will be extended to the present using Daymet (Thornton et al., 2021), and the results from this study can be applied to additional basins by climate region. The merged MOPEX and CAMELS datasets will incorporate up to 1050 watersheds, temporally extended from 1948 to 2023 (Sink, 2025).
2.4 Study area
MOPEX contains 431 catchments and CAMELS contains 671 (red and blue points, respectively, Fig. 1) within the CONUS. The spatial coverage differs between the two, with CAMELS deliberately incorporating more basins within the Great Plains and southwestern US (Addor et al., 2017; Newman et al., 2015). Each catchment is identified based on the USGS NWIS stream gauge identification number (Table 2), representing its downstream outlet.
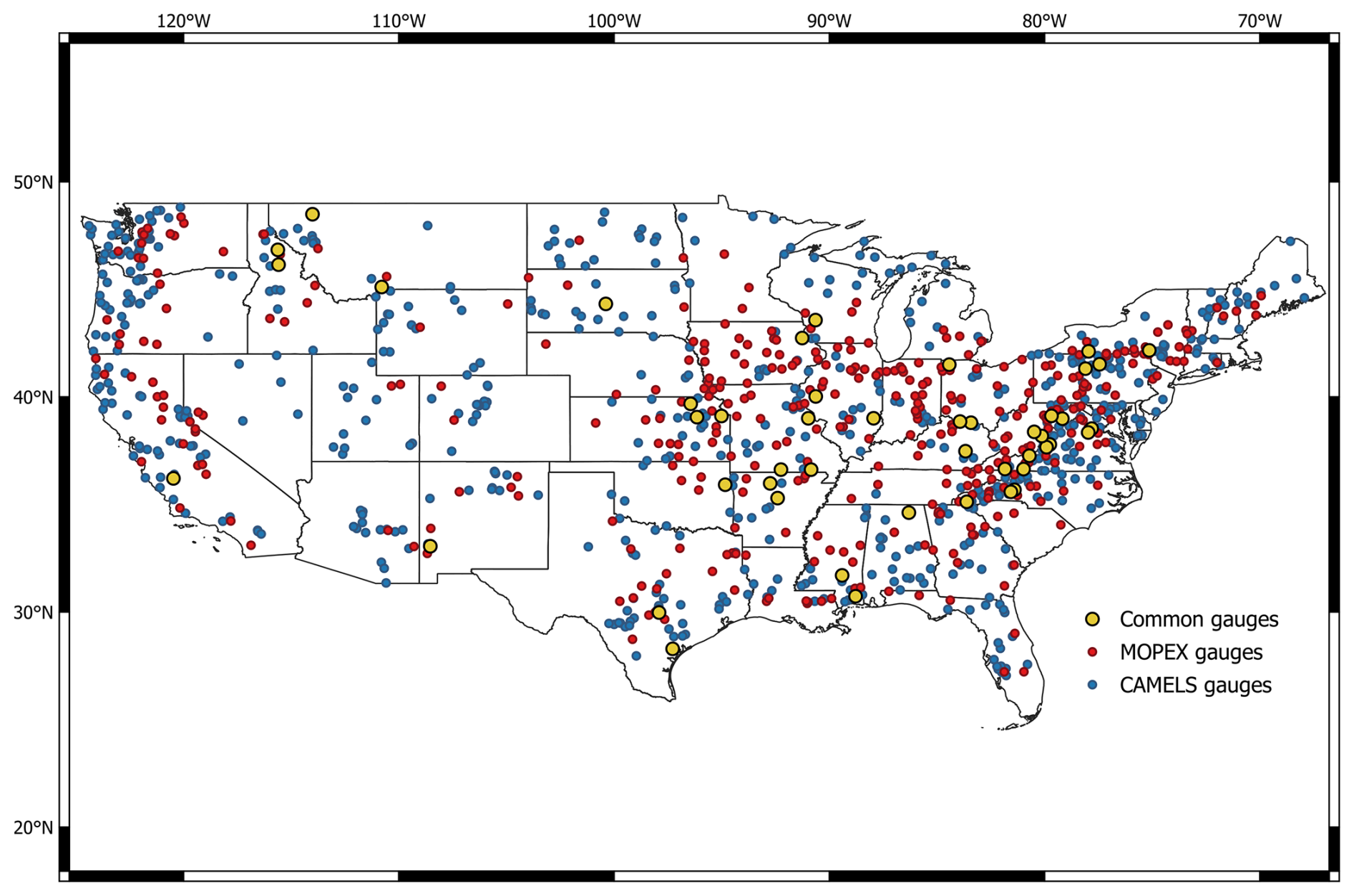
Figure 1Locations of the 431 USGS NWIS stream gauges in MOPEX (red points), 671 gauges in CAMELS (blue points), and 47 common gauges (yellow points) within the CONUS that appear in both the MOPEX and CAMELS datasets.
The datasets have 52 basins in common, 47 of which were used in this study (yellow points, Fig. 1). Five watersheds were omitted from this study because of incomplete streamflow records, or the gauge catchment was only a portion of the watershed. The catchment climate variables precipitation (PRCP) and temperature (TAIR) were area-weighted (average of observation values over the area of the basin) using the Hydro-Climatic Data Network (HCDN) basin delineations (Slack and Landwehr, 1994).
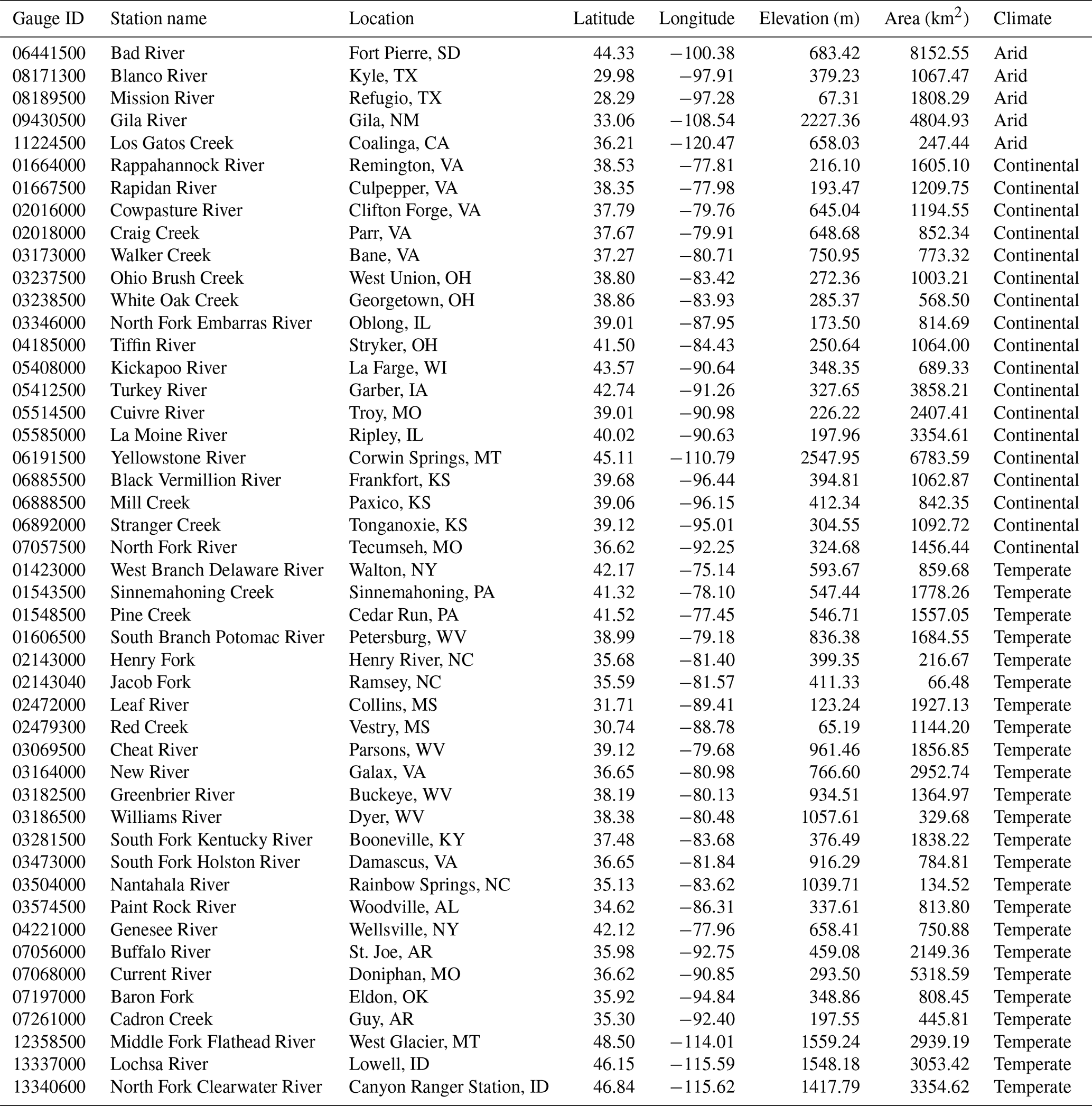
Table 2Common watersheds between MOPEX and CAMELS. Basins are described by the gauge ID (NWIS identification) along with the station name, location (city, state), latitude (decimal degrees), longitude (decimal degrees), elevation (meters), area (square kilometers), and climate. Basins are grouped by climate type and then sorted by increasing gauge identification number.
3.1 Climate characterization of the watersheds
Understanding how catchments partition annual precipitation into runoff and evapotranspiration under varying climatic conditions is crucial for hydrological modeling and water resource management. The Budyko function describes the long-term water and energy balance using annual evaporative (evapotranspiration/precipitation) and aridity (potential evapotranspiration/precipitation) indices (Budyko, 1974). The annual indices were determined for both datasets and subsequently combined during K-means clustering to obtain the overall climate representation for each basin. K-means clustering, an unsupervised machine learning algorithm that seeks to minimize the within cluster sum of squares (Hartigan and Wong, 1979), was utilized to divide the 47 selected MOPEX–CAMELS shared basins into three climate groups based on their annual evaporative and aridity indices, with a classification accuracy of 84 %. The arid (aridity index > 1.5), continental (aridity index 1.5 to 0.82), and temperate (aridity index < 0.82) zones represent the three K-means groups. For this study, the basin climate region classifications (arid, continental, temperate) are based on the K-means clustering results, which agree closely (but not perfectly) with the Köppen–Geiger (Beck et al., 2018) climate classification (Fig. 2).
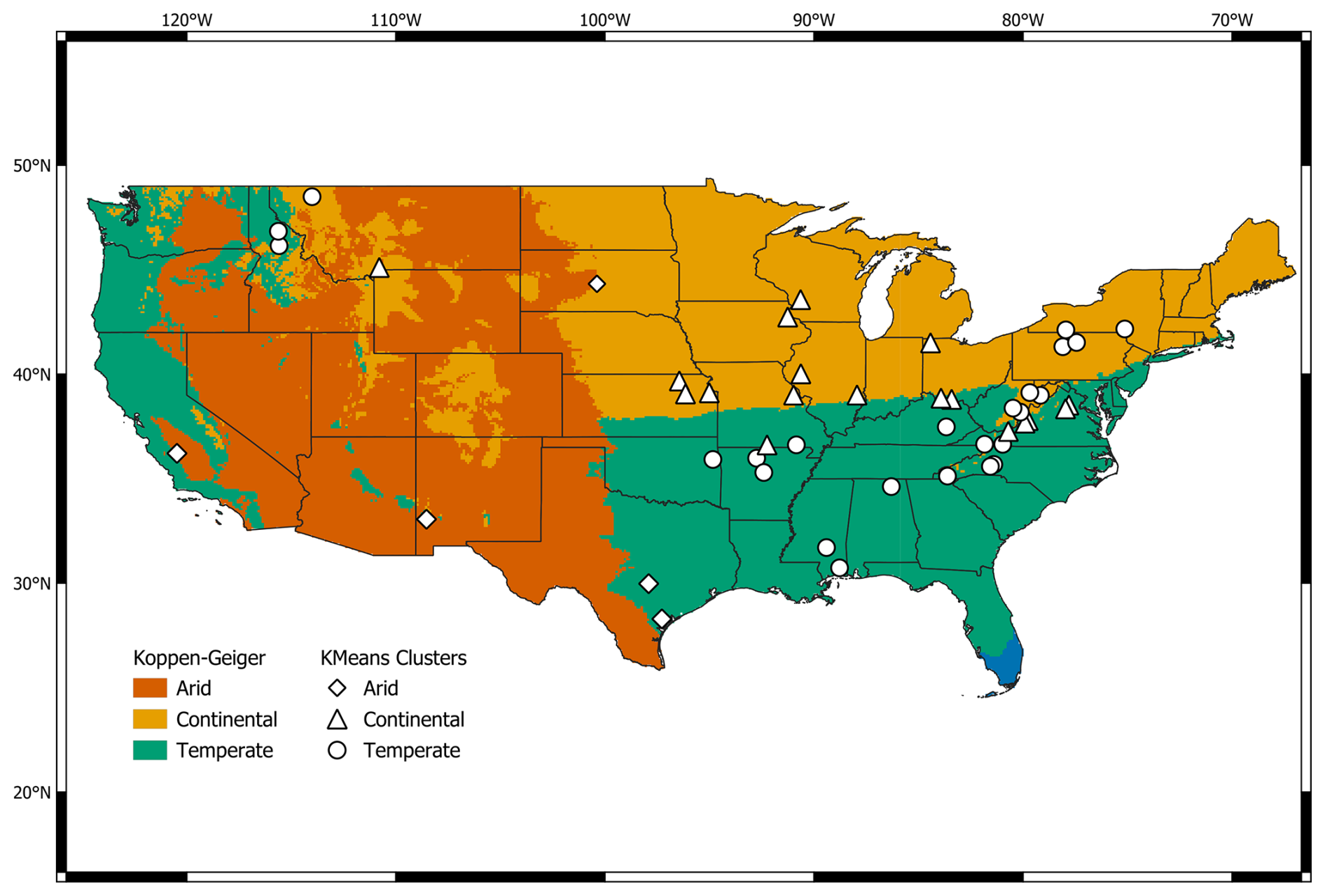
Figure 2Regions of the CONUS divided into Köppen–Geiger climate classification (arid, continental, temperate) are represented by vermillion, orange, and bluish green, respectively. The blue colors in southern Florida represent regions within the tropical climate group, which is not represented in this study. The results of K-means clustering are based on the annual aridity and evaporative indices for MOPEX and CAMELS shared basins shown by point symbols (diamond, triangle, circle). Climate groupings for analyses are represented by K-means clusters which agree closely but imperfectly with the Köppen–Geiger classification.
Terrestrial evapotranspiration (ET) is difficult to measure directly but can be evaluated using lysimeters or eddy covariance towers on small, local scales. ET can be estimated on a larger scale using satellite remote sensing or land surface models, but these carry with them inherent biases due to varying algorithms, spatial resolutions, calibration, and input data (Long et al., 2014). Many studies have shown that derived ET products fail to reconcile the terrestrial water budget on multiple temporal scales (Carter et al., 2018). A water balance approach is commonly used on a catchment scale, with observed streamflow obtained from a measured outlet (Han et al., 2015). A water balance sets ET (mm) equal to the precipitation (mm) minus basin runoff (mm), with water storage assumed to be zero on an annual scale.
The MOPEX dataset does not contain daily ET. Studies that have made use of MOPEX data obtain ET via the water balance approach using the precipitation and observed runoff (Berghuijs et al., 2014; Coopersmith et al., 2012; Sawicz et al., 2014). As mentioned previously, CAMELS provides three different daily forcing datasets (Daymet, Maurer, NLDAS), which do not contain ET, in addition to three Sacramento Soil Moisture and Accounting Model (SAC-SMA)-generated time series from each of the forcing datasets. Daily ET values from the model output time series using Daymet forcing variables (CAMELS SAC-SMA) were compared to the water-balance-derived ET using CAMELS catchment-averaged Daymet precipitation and USGS runoff values (CAMELS WB) to evaluate any notable differences between methods and facilitate comparison of MOPEX and CAMELS. The CAMELS SAC-SMA-derived ET values are typically greater than the values derived from the CAMELS WB, which will become more prominent at an annual scale, as plotted in Fig. 3.
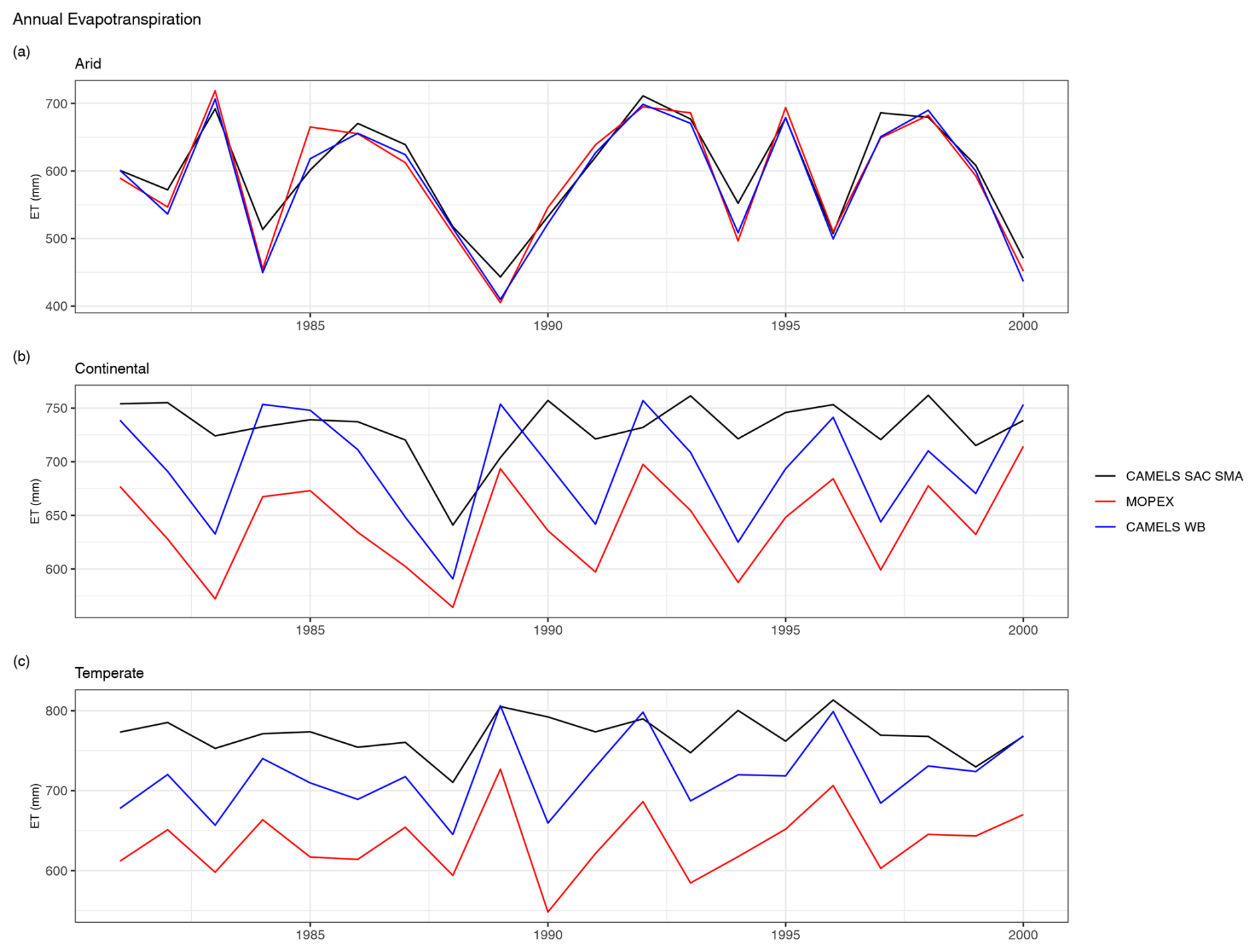
Figure 3Total annual evapotranspiration for (a) arid, (b) continental, and (c) temperate regions. The annual values are the overall mean of all basin totals in a region. The model-output ET (CAMELS SAC-SMA, black line), water-balance-derived MOPEX ET (MOPEX, red line), and water-balance-derived CAMELS ET (CAMELS WB, blue line) are shown in each plot.
When annual differences between CAMELS SAC-SMA-estimated ET and CAMELS WB-estimated ET are averaged, SAC-SMA estimations are approximately 13 mm larger in arid regions (Fig. 3a), 36 mm larger in continental regions (Fig. 3b), and 50 mm larger in temperate regions (Fig. 3c). Higher ET values lead to reduced runoff. As shown in Fig. 4, estimated ET values from the CAMELS SAC-SMA were subtracted from the provided CAMELS (Daymet) precipitation data to calculate estimated runoff (SAC_RUN), which was then compared to observed runoff (OBS_RUN). Incorporating ET values from the model output time series as an input variable to a hydrologic model may result in slightly lower discharge estimates, primarily reflecting the influence of ET values rather than actual runoff conditions.
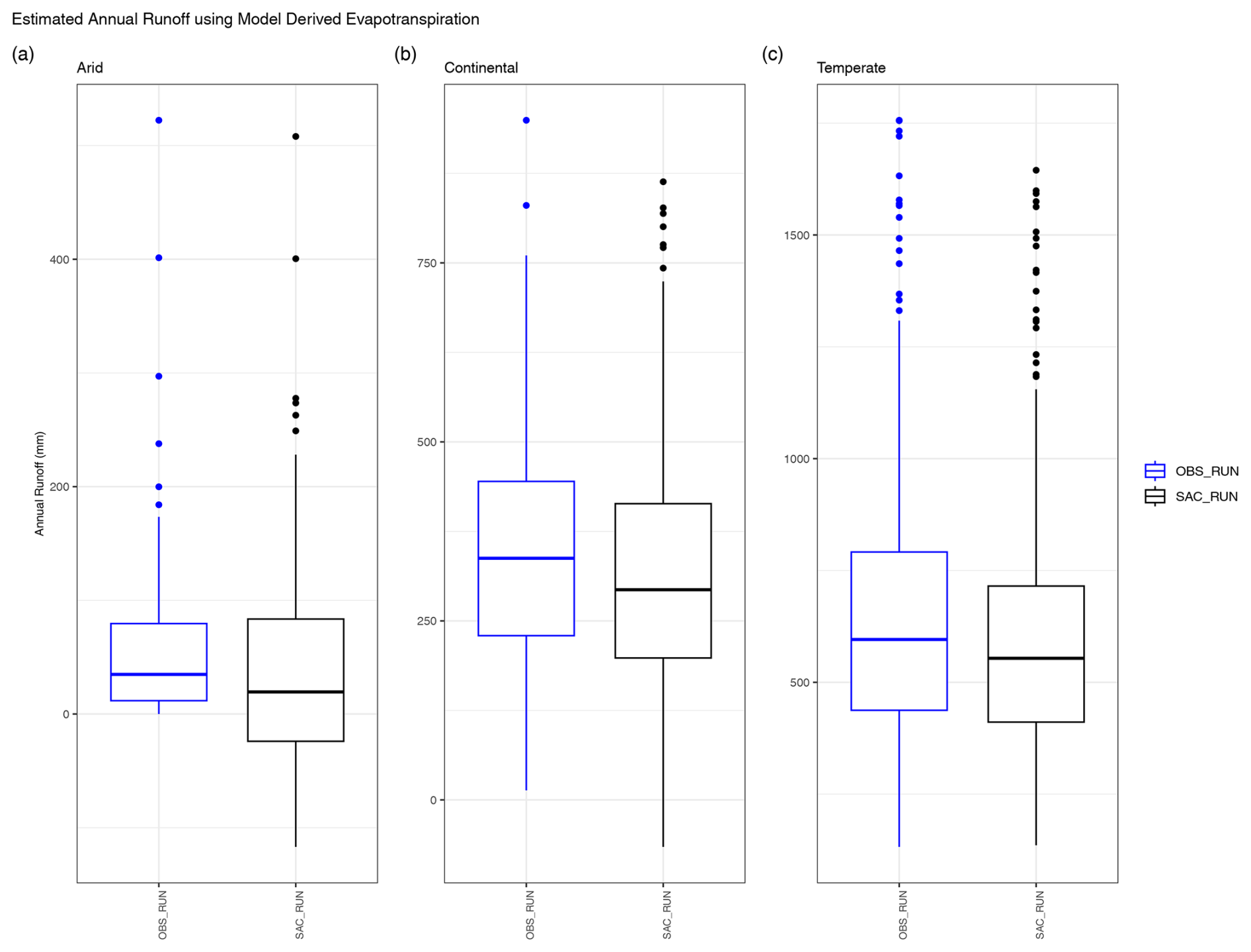
Figure 4Total annual runoff for (a) arid, (b) continental, and (c) temperate regions. The box plots represent the annual totals for all basins in a region, with measured observed runoff (OBS_RUN, blue) and water-balance-calculated runoff (PRCP minus ET) using CAMELS SAC-SMA-output ET (SAC_RUN, black).
A Budyko diagram, plotting evaporative versus aridity indices, clarifies the predominant hydrologic processes versus climate type (Fig. 5) for the common basins. The CAMELS SAC-SMA evapotranspiration (solid symbols, Fig. 5) exhibits large discrepancies from CAMELS WB (open symbols, Fig. 5) and MOPEX ET values for most catchments (arrows, Fig. 5). Furthermore, several CAMELS SAC-SMA gauges plotted above the water limit (i.e., to extreme values in the Budyko context) and were 10 % to 12 % larger than the water-balance-calculated evapotranspiration indices. The higher model-derived ET for CAMELS could reflect additional non-precipitation sources of water to the catchment, but that was not evaluated in this study. The largest discrepancies between model-derived ET/P and water-balance-derived ET/P for CAMELS for each climate region are 46 %, 12 %, and 60 % for arid, continental, and temperate regions, respectively. Average discrepancies between CAMELS evapotranspiration values are largest in arid regions at 12 %, followed by average discrepancies of 11 % in temperate regions and 5 % in continental regions.
Differences between water-balance-calculated ET for MOPEX versus CAMELS vary by climate type and may partly result from variations in sample distribution. Most of the shared watersheds fall into temperate and continental climates, but the western US is not as heavily represented based on the distribution of the catchments and the restriction to shared basins. Only eight shared catchments lie west of the 100th meridian (Fig. 1). The arid region basins lie close to the water limit (ET/P = 1, Fig. 5), while the temperate region basins are close to the energy limit (PET/P = 1). The continental region catchments can be seen as located in a transitional climate, which can be either energy- or water-limited. Annual MOPEX and CAMELS evaporative and aridity indices are plotted separately to highlight the improvements when utilizing the water balance evapotranspiration values for CAMELS. The largest difference between MOPEX and CAMELS evaporative indices using evapotranspiration water balance values is 16.2 % in temperate regions with an overall average difference of 4.6 % for all 47 basins. The mean difference between MOPEX and CAMELS evaporative indices, with water-balance-calculated evapotranspiration, is 1.89 %, 2.53 %, and 7.14 % for arid, continental, and temperate regions, respectively.
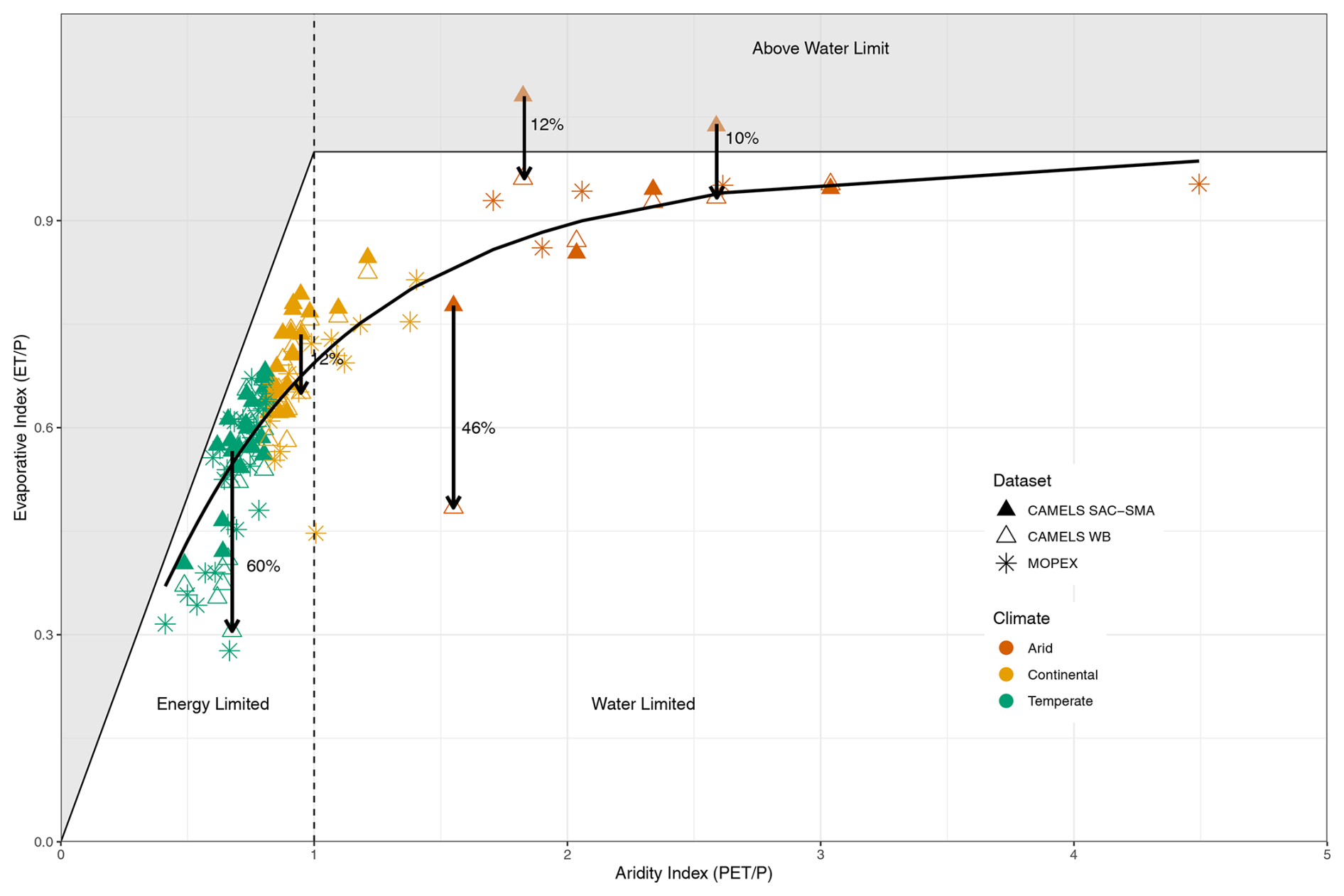
Figure 5Budyko diagram with the aridity and evaporative indices plotted for each of the 47 catchments (1981–2000). The overall aridity index and evaporative index are plotted for each catchment for the three ET values, resulting in 141 points. The three ET values include MOPEX (asterisk), CAMELS (solid triangle) with SAC-SMA-derived ET, and CAMELS WB (open triangle) with water-balance-calculated evapotranspiration. The colors represent the climate region. Evaporative index values > 1 are nonphysical.
Further research using the CAMELS dataset should apply the water balance approach instead of SAC-SMA-derived ET to avoid decreased runoff and vertical displacement in Budyko space that are artifacts of model-derived ET values. The water balance ET values were calculated using precipitation that does not include snowmelt; however, most of the larger discrepancies are present in arid regions (vermillion, Fig. 5) where snowmelt is negligible.
3.2 Exploratory data analysis
All statistical analyses were conducted using R Statistical Software (v. 4.3.3; R Core Team, 2024). When basins are consolidated by climate region, the number of values used in calculations are dependent on the number of gauges unless otherwise specified (Table 3). Each gauge has 7305 daily observations beginning on 1 October 1980 and ending on 30 September 2000. Monthly values are based on water years which begin in October of the previous calendar year and end in September of the current calendar year. Seasons are winter (December, January, February), spring (March, April, May), summer (June, July, August), and fall (September, October, November), and the months are grouped by water year, resulting in all four seasons within each water year.
Table 3Number of observations used for various statistical analyses on temporal scales per dataset.

3.2.1 Uncertainty and variability within datasets
The central tendency (mean, median), variability (variance, standard deviation, coefficient of variation), and distribution (skewness) of precipitation and temperature were independently evaluated for MOPEX and CAMELS. Uncertainty for the mean value was determined using two-sided confidence intervals computed via the bootstrap method. Bootstrapping is a statistical technique that estimates the sampling distribution of a statistic by iteratively resampling, with replacement, from the observed data when the population or sample distribution is unknown (Helsel et al., 2020). This nonparametric method utilizes the observed data to derive robust estimates and sampling distributions. In this study, bootstrapping was implemented using the Hmisc R package (Harrell, 2024) to calculate the mean value for daily, monthly, seasonal, and annual precipitation and temperature for MOPEX and CAMELS separately. Analyses involved 10 000 resamples, and the two-sided 95 % confidence intervals were determined by the 0.025 and 0.975 quantiles. This approach provides a robust method for estimating the uncertainty and variability associated with the mean values on different temporal scales.
3.2.2 Uncertainty and variability between datasets
Several hypothesis tests were conducted to compare observations between MOPEX and CAMELS. The nonparametric (binomial) sign test is used to compare two groups and assess whether one group is consistently higher than the other (Helsel et al., 2020). For a two-sided test, the null hypothesis posits that about half of the differences will be positive and half will be negative, resulting in a median difference of zero between paired observations. For context, paired observations compare the same date (day), month, season, or water year from each dataset. To conduct this test, MOPEX values were subtracted from CAMELS values, where a positive (negative) difference indicates that the CAMELS value is greater than (less than) the MOPEX value, with no consideration for the magnitude. The differences were computed for daily (7305 pairs), monthly (240 pairs), seasonal (80 pairs), and annual (20 pairs) precipitation and temperature values for each basin (“Per gauge” column, Table 3). Given that temperature may include negative instances, strict inequalities were applied. Subsequently, the outcomes were assigned a positive (n+), negative (n−), or zero value, and the values were tallied. A binomial distribution was used to calculate the probability of observing a value of n, which is 0.5. A 95 % confidence interval results in a significance level of p<0.05. Hypothesis testing and significance make use of the rstatix (Kassambara, 2023) and stats R packages.
Independent difference hypothesis tests included the Fligner–Killeen test (Fligner and Killeen, 1976) and the t test. The nonparametric Fligner–Killeen test was conducted to check whether MOPEX and CAMELS have equal variances, with the null hypothesis assuming variances are equal across all samples. It is less sensitive to departures from normality compared to the Bartlett and Levene tests (Helsel et al., 2020). The absolute value of the residuals (AVR) is calculated in Eq. (1) from each group median for j=1 to k groups and i=1 to nj observations, where
The AVR is ranked and weighted, resulting in a set of scores. A linear-rank test is then computed on the set of scores (Helsel et al., 2020).
Welch's t test (Welch, 1951) is a modification of the Student's t test that does not assume equal variance. The null hypothesis posits that the two group means are identical. The test statistic, t, is calculated as shown in Eq. (2):
where SA and SB are the standard deviation of the two groups A and B, along with the means mA and mB. And the degrees of freedom, df, are calculated as shown in Eq. (3).
Statistical significance for the Fligner–Killeen test and t test is based on a p value less than 0.05.
Bias, the mean absolute error (MAE), and standard error (SE) were also used to assess the variability within each group. The standard error provides an estimate of the standard deviation of the sampling distribution of the difference between means. The margin of error (MOE) was also determined based on a 95 % confidence interval with a critical value (α) of 1.96. The critical value is multiplied by the standard error of the difference of the means, which provides the confidence interval for the true difference between the means. The nonparametric Spearman rank correlation coefficient (ρ) was also employed to assess the strength of association between variables. This method is robust to the distribution of data and is less influenced by outliers.
3.3 Validation
Machine learning (ML) techniques, such as linear regression, random forest, gradient boosting, and support vector regression, offer a valuable alternative to physically based models by capturing relationships between input and output variables. While they do not rely on detailed hydrological processes, these models can still provide robust predictions and allow for comparative analysis of different datasets (Herrera et al., 2022). Using ML models as a proxy is increasingly common in hydrological research, as these models can efficiently handle high-dimensional data and learn intricate patterns without explicitly modeling physical processes (Kratzert et al., 2019). ML models have been shown to perform well in a range of hydrological applications, especially in data-rich contexts. For this study, we employed ML models to evaluate the potential influences of MOPEX and CAMELS precipitation and temperature biases on predicted runoff.
Hydrologic models rely on parameterization and assumptions about physical processes, while ML models learn directly from data, reducing dependence on prior assumptions and allowing for a purely data-driven evaluation (Nearing et al., 2021). ML models can highlight inconsistencies or biases in input datasets by comparing their predictive performance across datasets. If one dataset consistently leads to better predictions, it may indicate better representativeness or higher quality. Traditional hydrologic models typically require extensive calibration and long run times, especially for larger-scale applications, but ML models, once trained, can make predictions rapidly and do not require manual calibration (Kratzert et al., 2019). ML models can also be trained separately on different temporal scales, allowing for direct comparisons without modifying model structures. By evaluating performance metrics across datasets, ML provides an objective assessment of whether precipitation and temperature inputs are sufficient to capture runoff variability (Yokoo et al., 2022).
Four different ML models were implemented in R to estimate runoff from precipitation and mean air temperature using the e1071 (Meyer et al., 2024), gbm (Ridgeway et al., 2024), randomForest (Breiman et al., 2024), and caret (Kuhn et al., 2024) packages. Linear regression models the relationship between a dependent variable and one or more independent variables by fitting a linear equation (Xu and Liang, 2021). Random forest is an ensemble learning method that constructs multiple decision trees and averages their predictions to improve accuracy and reduce overfitting (Breiman, 2001). Gradient boosting builds models sequentially, optimizing for errors in previous iterations by combining weak learners to create a stronger predictive model (Xu and Liang, 2021). Support vector regression (SVR) maps input data into a higher-dimensional space and finds the ideal hyperplane, separating the data points into different classes, and minimizes prediction error while maintaining generalization (Shmilovici, 2023). These models provide a diverse approach to estimating runoff, ranging from simple linear relationships to more complex, nonlinear learning techniques.
MOPEX and CAMELS precipitation and temperature values were used as input to predict runoff at daily, monthly, seasonal, and annual timescales. Precipitation and temperature data were transformed into common scales using min–max normalization. Datasets were then split into training and test sets, with 80 % of the data allotted to training and 20 % to testing. Rather than partitioning the data into multiple subsets, each ML model was run 10 times, resampling and randomly splitting into testing and training sets (Domingos, 2012). Predicted runoff values were then compared to actual observed runoff to assess model accuracy using root mean square error (RMSE), MAE, R2, and bias as performance metrics. Model results were then compared across MOPEX and CAMELS datasets to determine their consistency, assess whether they provide compatible inputs for runoff estimation, and determine the influence of potential systematic biases in the input data.
SVR was also able to compare MOPEX and CAMELS datasets as a simple binary classification problem using the e1071 (Meyer et al., 2024) R package. The two datasets were merged into a composite dataset for each climate region and temporal aggregation, and each was identified by either a zero (CAMELS) or 1 (MOPEX), representing the target variable. The composite dataset was then split into training and test sets, with 75 % of the data allotted to training and 25 % to testing. Data were randomly selected to avoid any potential bias due to formatting, for example. SVR models were trained on the composite datasets to classify the binary label (MOPEX or CAMELS) using precipitation, temperature, and evapotranspiration values as predictor variables. Classification was performed separately for all three climate regions at daily, monthly, seasonal, and water year aggregations. If the datasets are similar, then the model should have difficulty differentiating between them, yielding a classification probability near 50 %, akin to a random guess. A double mass curve was also used to check the consistency of the data by plotting the cumulative annual precipitation of CAMELS versus MOPEX. If the data are proportional, then the points will plot as a straight line (Searcy et al., 1960).
Evaluation and comparison of the internal uncertainty and variability of individual dataset parameters are key to understanding the consistency between the MOPEX and CAMELS datasets and the potential for merging and extending these datasets. For each dataset, climate parameter variability primarily depends on level of aggregation (daily, monthly, seasonal, annual) and secondarily on climate type. Between datasets, potentially important biases in climate variables are evident, varying by climate type and aggregation level. This paper presents a thorough exploratory data analysis and supports the main finding that the two datasets exhibit similar uncertainty and variability, both within and between them. By considering multiple statistics, we can evaluate the representativeness of each dataset and identify any systematic differences that may need further investigation. If both datasets exhibit similar means and variability within a climate region, it suggests that their distributions are comparable. Differences in variance and skewness, on the other hand, highlight potential biases between the datasets. Though there are consistent biases, they are minimal for aggregations beyond a daily time step, making them suitable for combined application in climate studies and hydrologic modeling at monthly, seasonal, or annual aggregations. Although efforts were made to distinguish results for internal analyses within datasets and intercomparisons between datasets, the results are often presented together to provide a clearer understanding of how each dataset behaves independently, while also enabling direct cross-dataset evaluation. Consequently, some overlap does occur.
4.1 Uncertainty and variability within datasets
The internal uncertainty and variability of the MOPEX and CAMELS datasets were assessed using median, mean, variance, standard deviation, skewness, coefficient of variation, and confidence intervals for each climate region at daily, monthly, seasonal, and annual scales. Precipitation statistics shown in Table 4 were determined for each individual basin, with minimum and maximum values representing all basins within each climate region (number of observations, Table 3). Due to the large differences between temporal precipitation totals, the ranges for each statistic were normalized by finding the difference between the maximum and minimum values and then dividing the difference by the mean of the maximum and minimum values. The normalized ranges (NRs) were then used to assess the variability of each statistic within the dataset across the different temporal aggregations and are summarized in Table 4. When calculating the normalized range, a minimum value of zero or close to zero (i.e., median or skew) will conflate the range, making it appear larger than it truly is. For this reason, normalized daily median ranges and normalized skew values are ignored.
Table 4Minimum (min), maximum (max), and normalized range (NR) of median, mean, variance, standard deviation, and skewness for MOPEX and CAMELS total daily, monthly, seasonal, and annual precipitation (PRCP) in millimeters (mm). Values are based on all basins within a climate region. The normalized ranges are based on the maximum and minimum values (maximum − minimum mean (maximum + minimum)), except for daily median and skewness values.
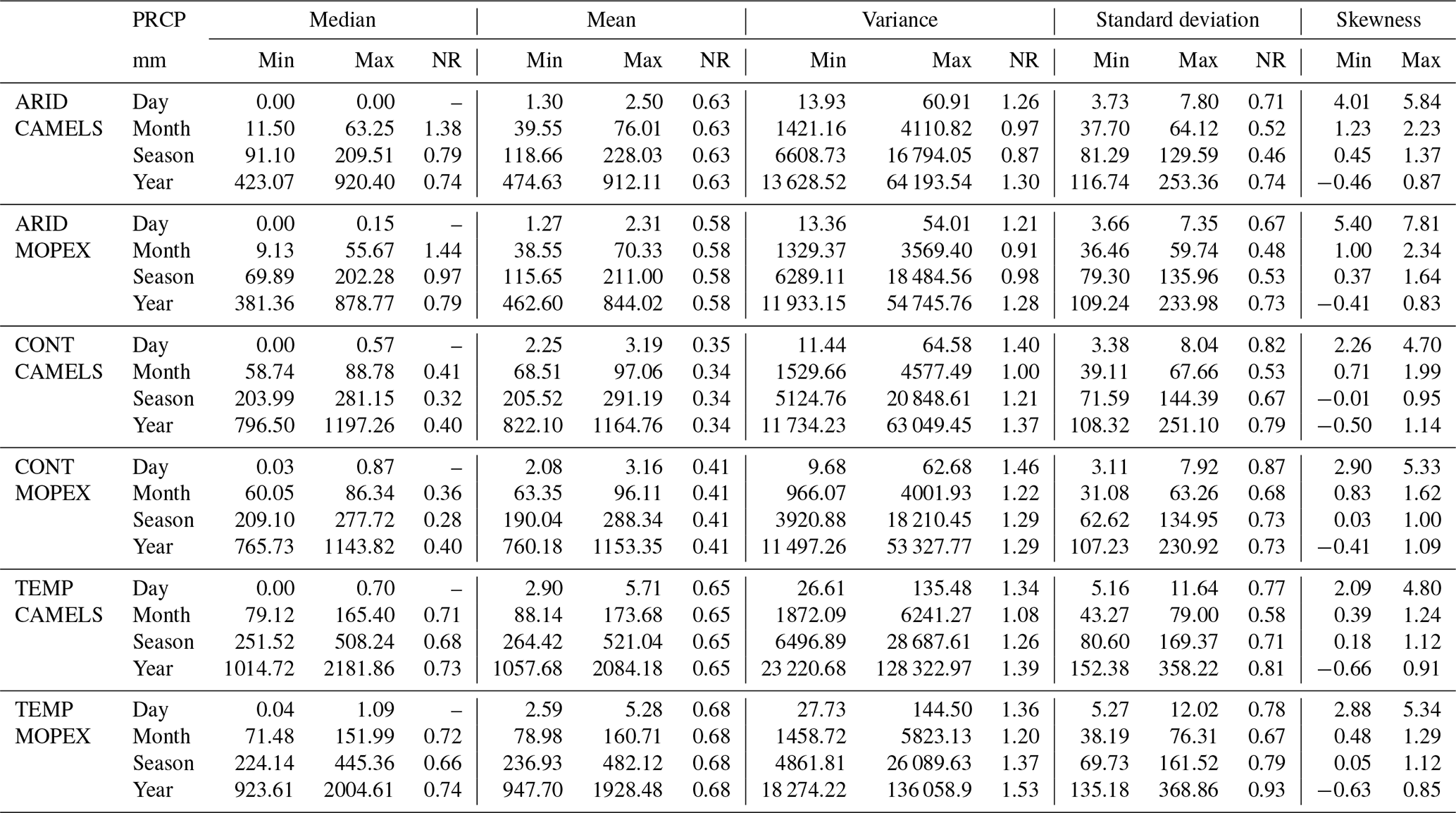
The range in median values decreases in all regions when moving from a monthly aggregation to seasonal (CAMELS arid 1.38 to 0.79, CAMELS continental 0.41 to 0.32, CAMELS temperate 0.71 to 0.68, MOPEX arid 1.44 to 0.97, MOPEX continental 0.36 to 0.28, MOPEX temperate 0.72 to 0.66). Median ranges continue to contract in arid regions at an annual scale (CAMELS 0.74, MOPEX 0.79). Continental and temperate regions show a slight expansion in median ranges between seasonal and annual aggregations. The range in mean values is uniform in each region over all temporal scales (CAMELS arid 0.63, CAMELS temperate 0.65, MOPEX arid 0.58, MOPEX continental 0.41, MOPEX temperate 0.68), with a minor change of 0.35 to 0.34 in CAMELS continental daily to monthly. All basins within each region demonstrate minimal variability in the mean and proportional aggregation. The range in variance is slightly wider for daily and annual aggregations in all regions for both CAMELS and MOPEX. The range in annual variance increases when moving to an annual aggregation except for MOPEX continental, which remains at a normalized value of 1.29 between seasonal and annual. This suggests that interannual variability may be more pronounced than intra-seasonal fluctuations, attributed to the accumulation of extreme precipitation events or shifting between wet and dry. The range of standard deviation values mimics the variability in variance values, with the smallest ranges for monthly and seasonal aggregations and minor increases at daily and annual aggregations for all regions except MOPEX continental (seasonal and annual 0.73). Differences in precipitation patterns can become more apparent over longer periods of time. Precipitation variability has been shown to increase over longer timescales under a warming climate (Pendergrass et al., 2017; Zhang et al., 2021). The distribution in all regions tends to become more Gaussian as the aggregation increases from daily to annual, which is to be expected.
The minimum and maximum median, mean, variance, standard deviation, and skewness values for mean temperature in degrees Celsius along with the range values are shown in Table 5. Overall, temperature variability in each climate region decreases with temporal aggregation, with daily values showing the highest variability and annual values the lowest for both CAMELS and MOPEX datasets. There is minimal variability in the central tendency in all climate regions, with a slightly narrower spread in the mean values compared to the median values. In continental regions, the minimum seasonal median value for all CAMELS basins is 0.81 and 0.96 °C for MOPEX basins, which is due to a few colder-than-average winters in a watershed located in Montana. Variance in mean temperature is smallest in annual aggregations for all regions because it is based on annual averages, which smooths the extreme values. In contrast, the variability in skewness is greatest at annual aggregations in both CAMELS and MOPEX. Aggregation at an annual scale reduces variance among mean temperature values, but at the same time, fewer data points increase the sensitivity to extremes, which can shift the distribution.
Table 5Minimum (min), maximum (max), and range of median, mean, variance, standard deviation, and skewness for MOPEX and CAMELS mean daily, monthly, seasonal, and mean temperature (TAIR) in degrees Celsius. Values are based on all basins within a climate region. Range is maximum minus minimum.
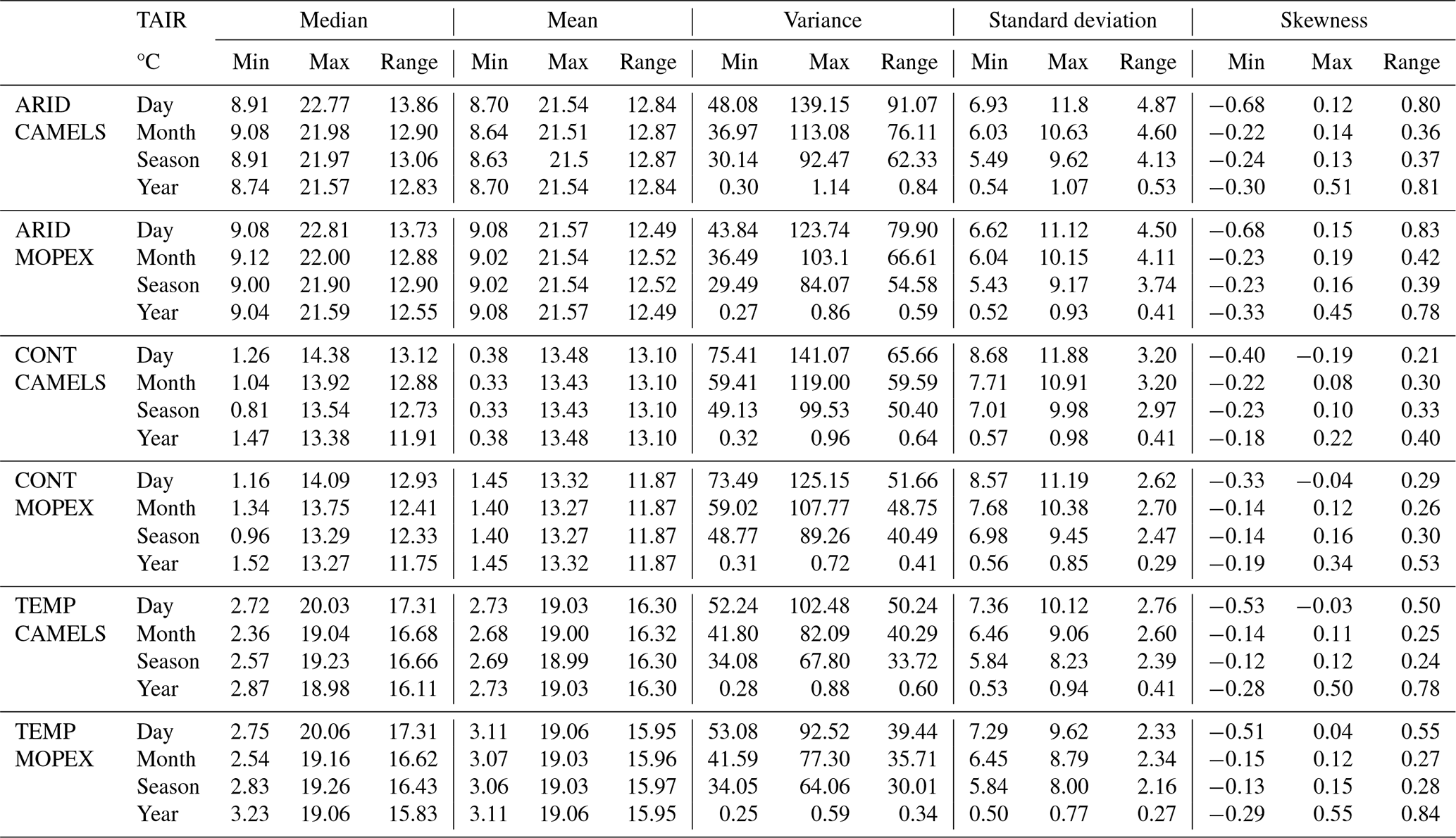
The coefficient of variation (CV) was calculated for each catchment on all temporal scales for precipitation (Fig. 6). Daily precipitation shows considerably high variation, with CAMELS mean CV values of 3.28, 2.39, and 2.12 and MOPEX mean CV values of 3.23, 2.42, and 2.22 in arid, continental, and temperate regions, respectively (Fig. 6a). Considerably high variation is still observed on monthly scales (Fig. 6b) but decreases to moderate variability for seasonal temporal aggregations for all regions and low variability, less than 1, on an annual scale. The normalized ranges for precipitation variance in Table 4 indicate that annual totals are the most variable, while the CV demonstrates decreasing variability from a daily to annual scale. While both are measures of variability, they differ in how they express dispersion and their sensitivity to scale. Variance is unit-dependent and sensitive to magnitude, while the CV is normalized relative to the mean. This suggests that at short timescales, precipitation is more event-driven, whereas at longer scales, climate patterns dominate. Temperature demonstrates a consistent decrease in variability from daily to annual temporal aggregation for all regions and is not shown.
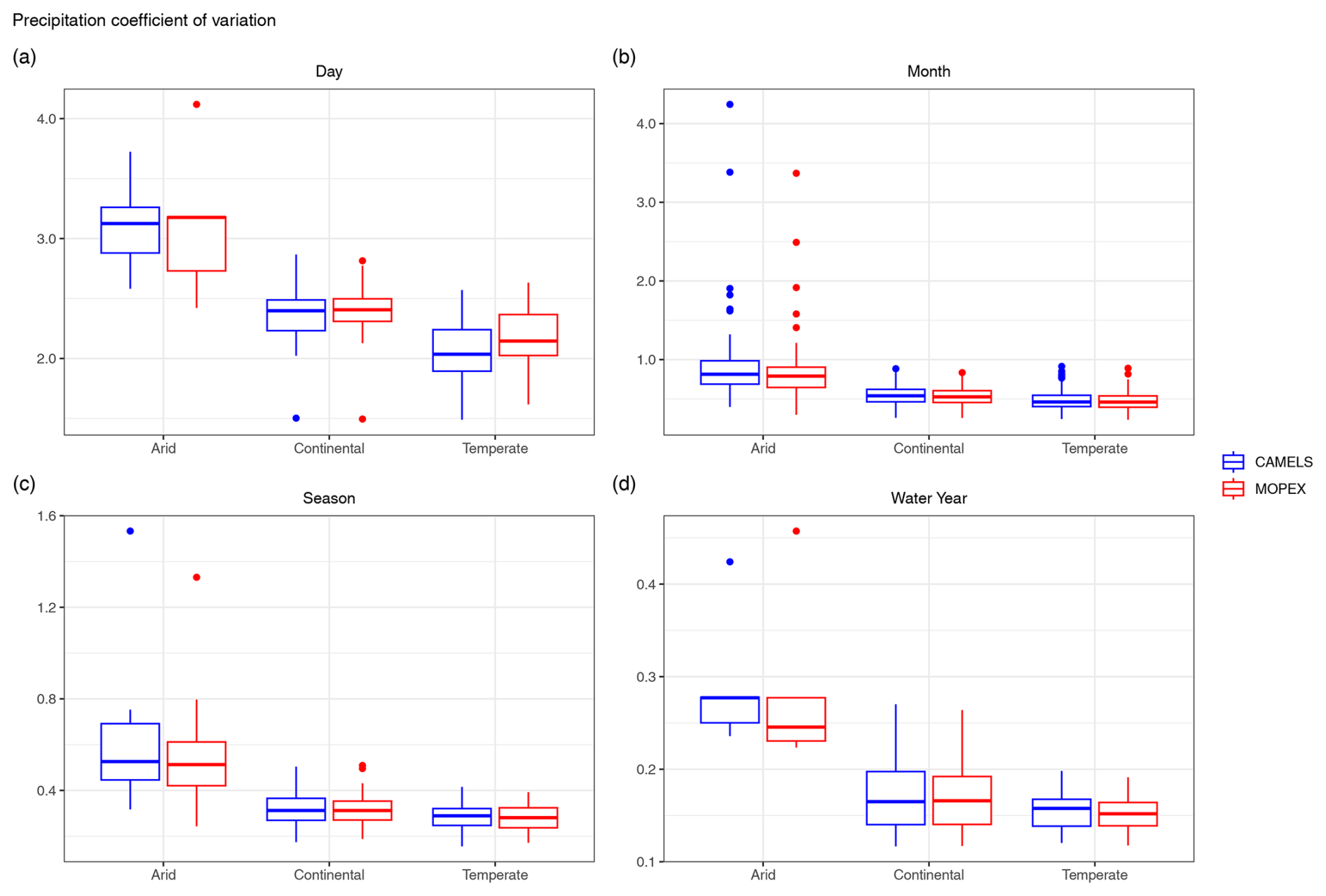
Figure 6Coefficient of variation of precipitation for CAMELS (blue) and MOPEX (red) for each climate region, shown by temporal aggregation (a) day, (b) month, (c) season, and (d) water year. Each box plot represents the value of all basins within the climate region based on total precipitation (mm). Note the progressively declining y-axis range from (a) to (d).
Two-sided interval estimates were computed to determine the uncertainty within each dataset. The daily mean precipitation and temperature were calculated for each basin, and the corresponding 95 % confidence intervals were established by bootstrapping using 10 000 samples with replacement. The results in Table 4 illustrate that overall daily precipitation means are larger for CAMELS than for MOPEX (except for arid regions); however, it is noteworthy that the confidence intervals, shown in Table 7, exhibit overlap for most regions, suggesting similar degrees of uncertainty. The most pronounced divergence in precipitation means, a difference of 7 %, is observed in temperate catchments where the overall CAMELS daily mean is 3.73 mm d−1 and MOPEX is 3.50 mm d−1.
When examining total mean monthly precipitation, both datasets exhibit comparable monthly fluctuations (Fig. 7), but CAMELS exhibits a small positive bias in non-arid climate regions. Arid regions display the most variability, with the largest confidence intervals (±13.74 mm month−1 for CAMELS and ±12.93 mm month−1 for MOPEX) observed in June and the smallest (±7.00 mm month−1 for CAMELS and ±7.73 mm month−1 for MOPEX) observed in November. Despite this variability, these regions show the greatest temporal consistency between MOPEX and CAMELS values, with total precipitation highest in May and June and lowest in April (Fig. 7a). Additionally, arid regions demonstrate the most notable overlap of the mean values and confidence intervals of the two datasets. Continental regions show an increase in total monthly precipitation in May, June, and July (Fig. 7b). There is the least amount of variation in February (±4.12 mm month−1 for CAMELS and ±3.79 mm month−1 for MOPEX), contrasting with the largest in July (±6.31 mm month−1 for CAMELS and ±6.08 mm month−1 for MOPEX). Temperate regions show decreased precipitation in August, September, and October with less overlap between dataset confidence intervals (Fig. 7c). The smallest confidence intervals differ between datasets, with April (±4.92 mm month−1) for CAMELS and July (±4.54 mm month−1) for MOPEX, but both share the largest amount of variability in December (±8.19 mm month−1 for CAMELS and ±10.21 mm month−1 for MOPEX).
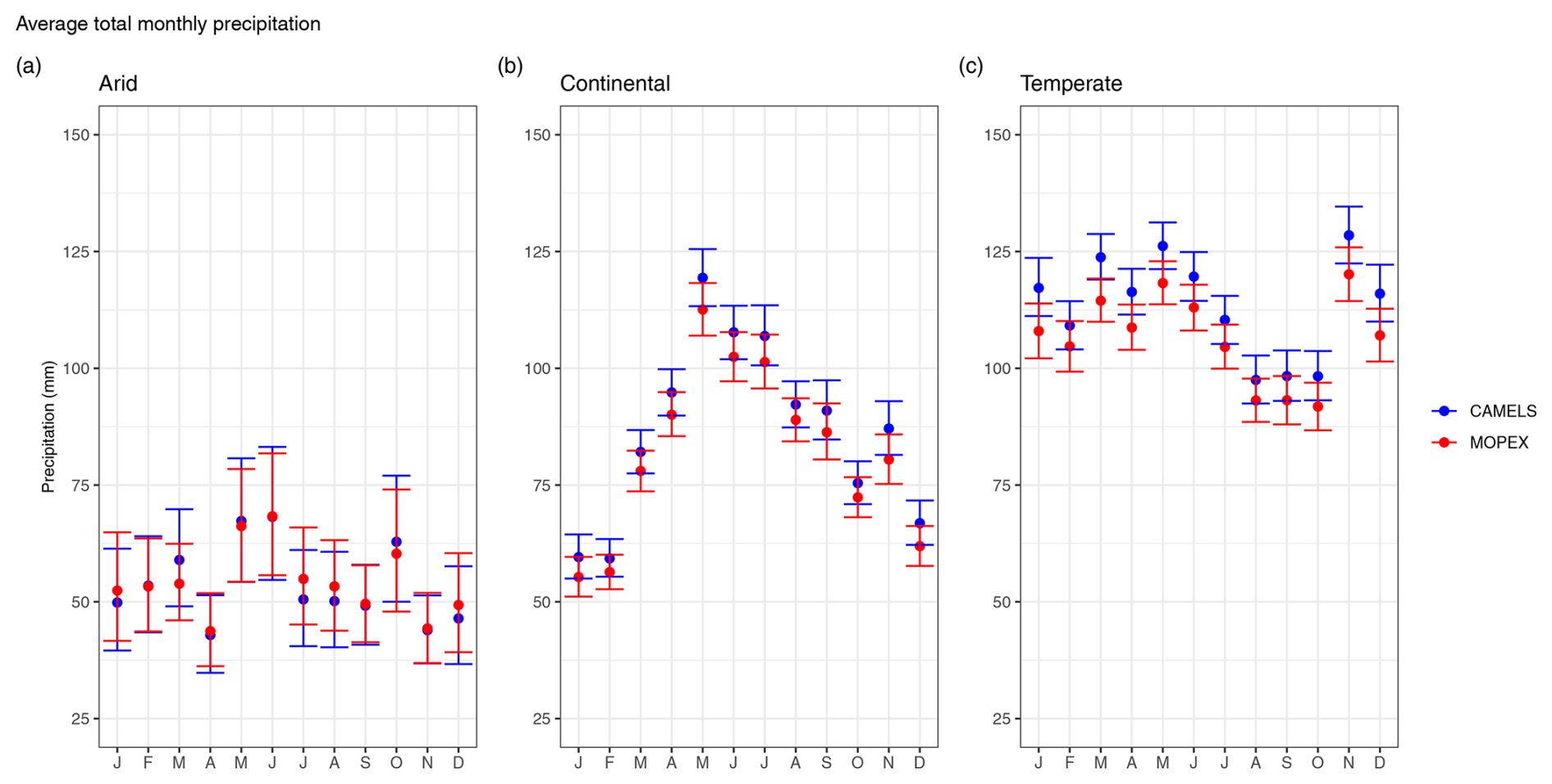
Figure 7Average total monthly precipitation for CAMELS (blue) and MOPEX (red) by (a) arid, (b) continental, and (c) temperate climate region in millimeters. The mean value is determined using all basins within the climate region and each corresponding month for 1981–2000. Error bars represent two-sided 95 % confidence intervals, derived from bootstrapping with replacement for 10 000 replicates.
Seasonal precipitation confidence intervals exhibit the most variability yet also the greatest consistency in arid regions (Fig. 8), which coincides with monthly precipitation analyses (Fig. 7). The range of potential values decreases in continental and temperate regions. MOPEX values are larger than CAMELS in arid regions in the summer and winter seasons (which corresponds to larger monthly values in December, January, June, July, and August). For arid regions (Fig. 8a), the greatest variance is in the winter season (±25.24 mm season−1 for CAMELS and ±25.37 mm season−1 for MOPEX). Continental regions (Fig. 8b) show the greatest uncertainty in summer for CAMELS (±10.58 mm season−1) and fall for MOPEX (±10.24 mm season−1). Temperate regions (Fig. 8c) have the largest differences in variance between datasets with little to no overlap of confidence intervals, notably in the spring. Winter has the greatest confidence intervals for CAMELS (±17.69 mm season−1) and MOPEX (±22.89 mm season−1).
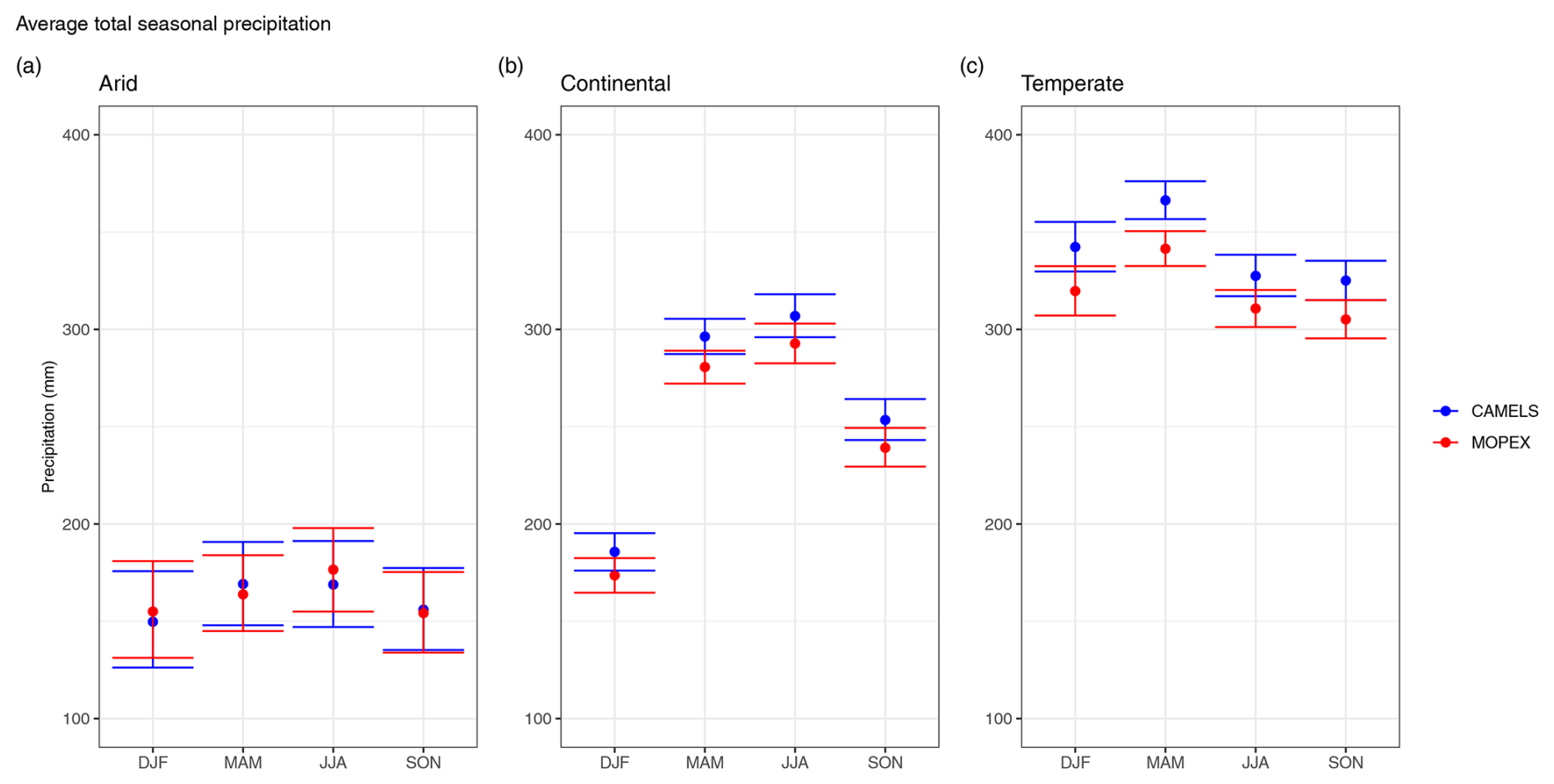
Figure 8Average total seasonal precipitation for CAMELS (blue) and MOPEX (red) by (a) arid, (b) continental, and (c) temperate climate region in millimeters. The mean value is determined using all basins within the climate region and each corresponding season for 1981–2000. Error bars represent two-sided 95 % confidence intervals, derived from bootstrapping with replacement for 10 000 replicates.
For average total annual precipitation, arid regions exhibit the highest variability within each individual dataset; however, their mean values remain similar between the two datasets (Fig. 9a). Other climate regions exhibit a small positive precipitation bias for CAMELS. Arid region confidence intervals are greater for CAMELS (between ± 70.91 mm yr−1 in 1996 and ± 326.94 mm yr−1 in 1987) than MOPEX (between ± 33.96 mm yr−1 in 1996 and ± 298.17 mm yr−1 in 1985). Annual means in continental (Fig. 9b) and temperate regions (Fig. 9c) are consistently higher in CAMELS, but confidence intervals do overlap with MOPEX. The smallest uncertainty is in continental regions with intervals slightly larger for CAMELS (± 48.03 mm yr−1 in 1986 to ± 136.19 mm yr−1 in 1996) compared to MOPEX (± 43.57 mm yr−1 in 1992 to ± 126.91 mm yr−1 in 1996). Temperate regions have greater uncertainty associated with MOPEX values (± 92.22 mm yr−1 in 1992 to ± 221.13 mm yr−1 in 1982) than CAMELS (± 72.39 mm yr−1 in 1981 to ± 152.43 mm yr−1 in 1995).
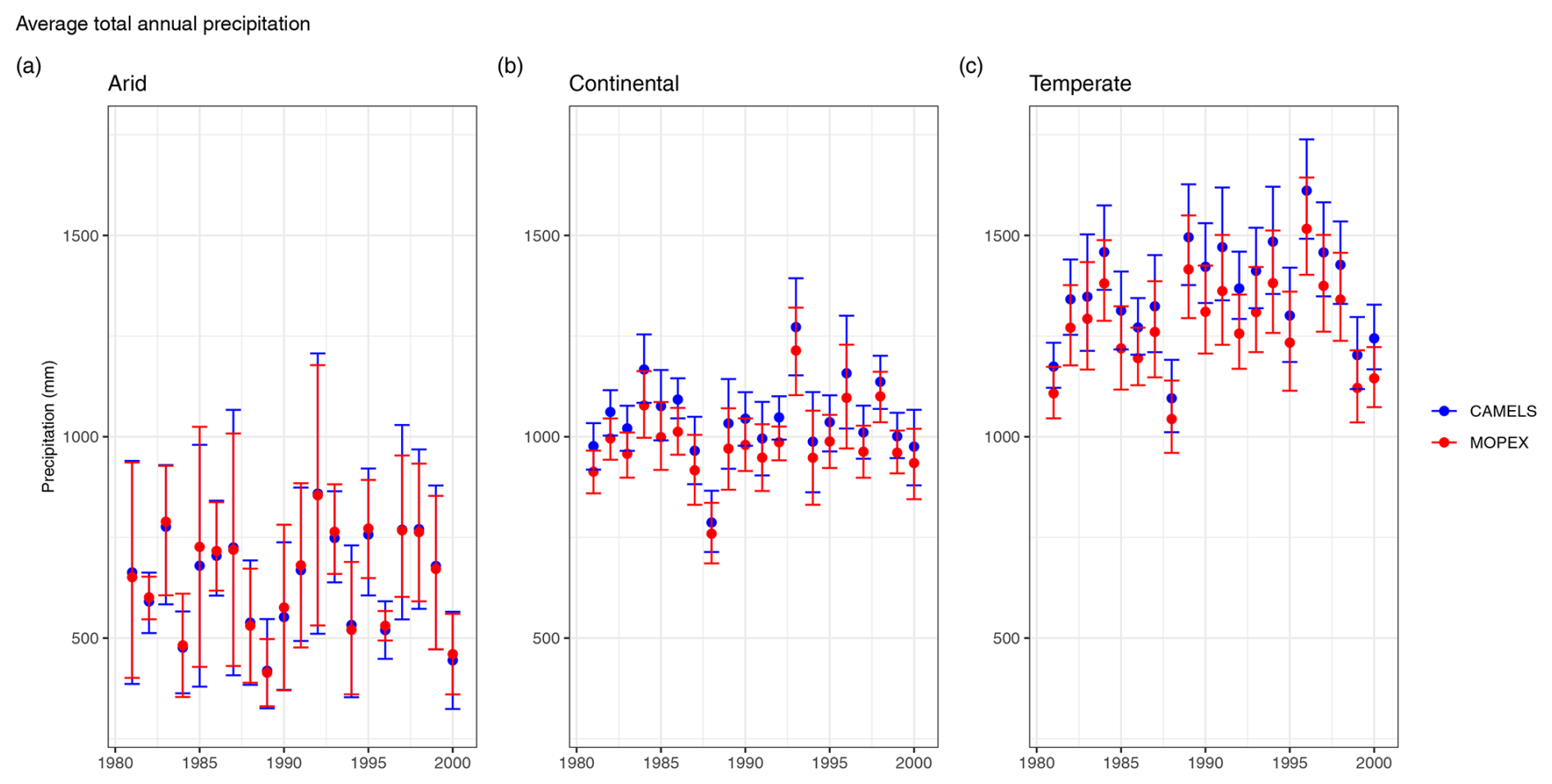
Figure 9Average total annual precipitation for CAMELS (blue) and MOPEX (red) by (a) arid, (b) continental, and (c) temperate climate region in millimeters. The mean value is determined using all basins within the climate region and each corresponding water year for 1981–2000. Error bars represent two-sided 95 % confidence intervals, derived from bootstrapping with replacement for 10 000 replicates.
Evaluation of daily temperature indicates a consistent pattern discerned in Tables 5 and 8. The means for daily temperature are consistently larger for MOPEX, with the largest differences (mean difference of 0.62 °C d−1) observed in arid regions. Monthly temperatures show consistent trends in both datasets, with higher temperatures in July and August and lower temperatures in January and December in all regions. MOPEX and CAMELS are quite similar in their mean values and monthly variability (Fig. 10). Akin to precipitation, arid regions contain the most variability, followed by temperate regions. The largest uncertainty is in December for CAMELS (± 1.37 °C month−1) and MOPEX (± 1.32 °C month−1) in arid and continental regions (CAMELS ± 0.46 °C month−1, MOPEX ± 0.40 °C month−1) and in February for temperate regions (CAMELS ± 0.45 °C month−1, MOPEX ± 0.43 °C month−1). The smallest uncertainty is in July (CAMELS ± 0.80 °C month−1, MOPEX ± 0.71 °C month−1) for arid regions, October (CAMELS ± 0.32 °C month−1, MOPEX ± 0.31 °C month−1) for continental regions, and August (CAMELS ± 0.36 °C month−1, MOPEX ± 0.33 °C month−1) for temperate regions.
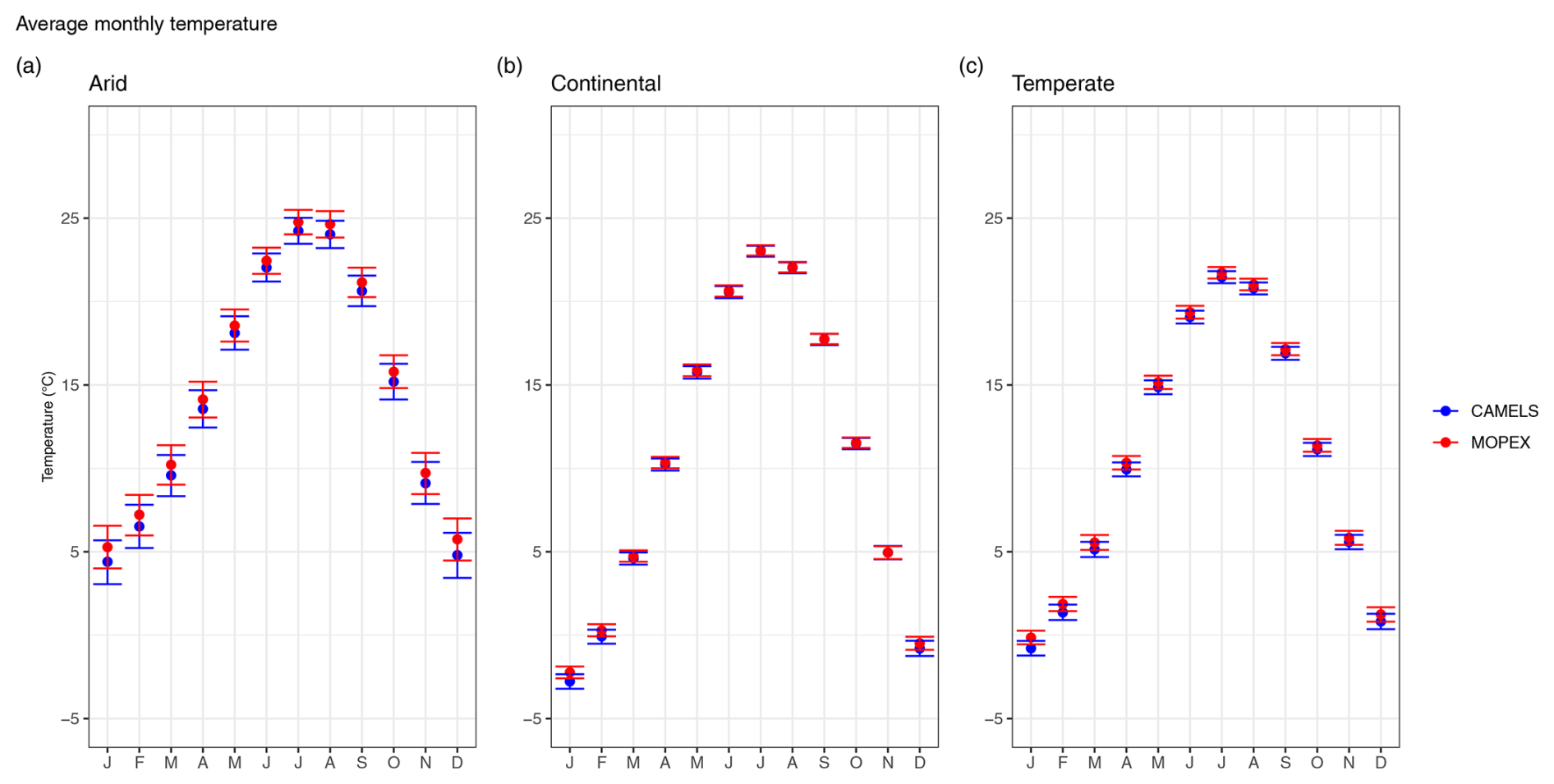
Figure 10Average monthly mean temperature for CAMELS (blue) and MOPEX (red) by (a) arid, (b) continental, and (c) temperate climate region in degrees Celsius. The mean value is determined using all basins within the climate region and each corresponding month for 1981–2000. Error bars represent two-sided 95 % confidence intervals, derived from bootstrapping with replacement for 10 000 replicates.
Seasonal temperature is also the most variable in arid regions, with confidence intervals ranging from ± 0.77 to ± 1.28 °C season−1 compared to intervals ranging from ± 0.30 to ± 0.40 °C season−1 for continental and temperate regions (Fig. 11). Winter is consistently the most variable season among all regions, resulting in the largest confidence intervals.
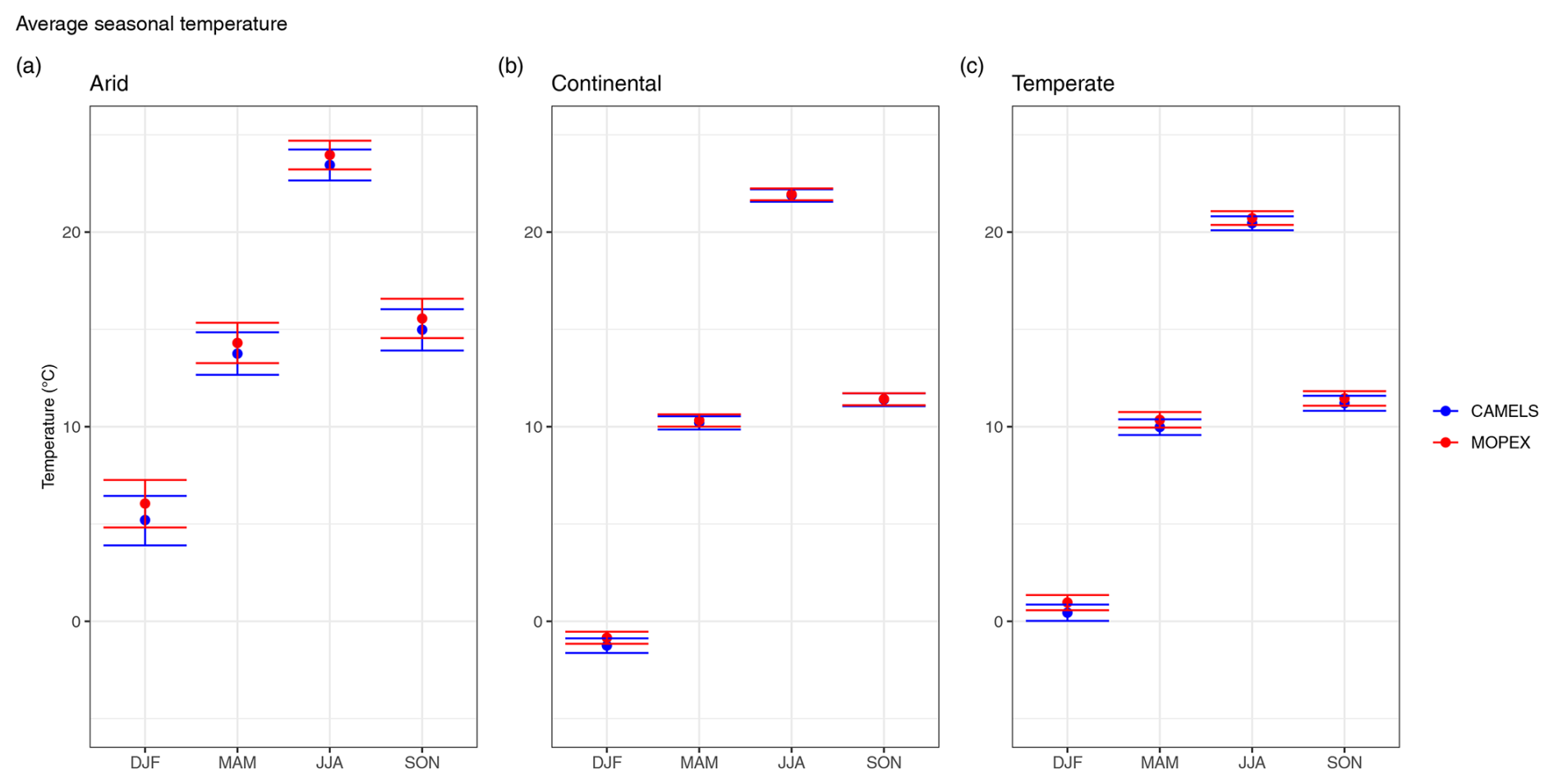
Figure 11Average mean seasonal temperature for CAMELS (blue) and MOPEX (red) by (a) arid, (b) continental, and (c) temperate climate region in degrees Celsius. The mean value is determined using all basins within the climate region and each corresponding season for 1981–2000. Error bars represent two-sided 95 % confidence intervals, derived from bootstrapping with replacement for 10 000 replicates.
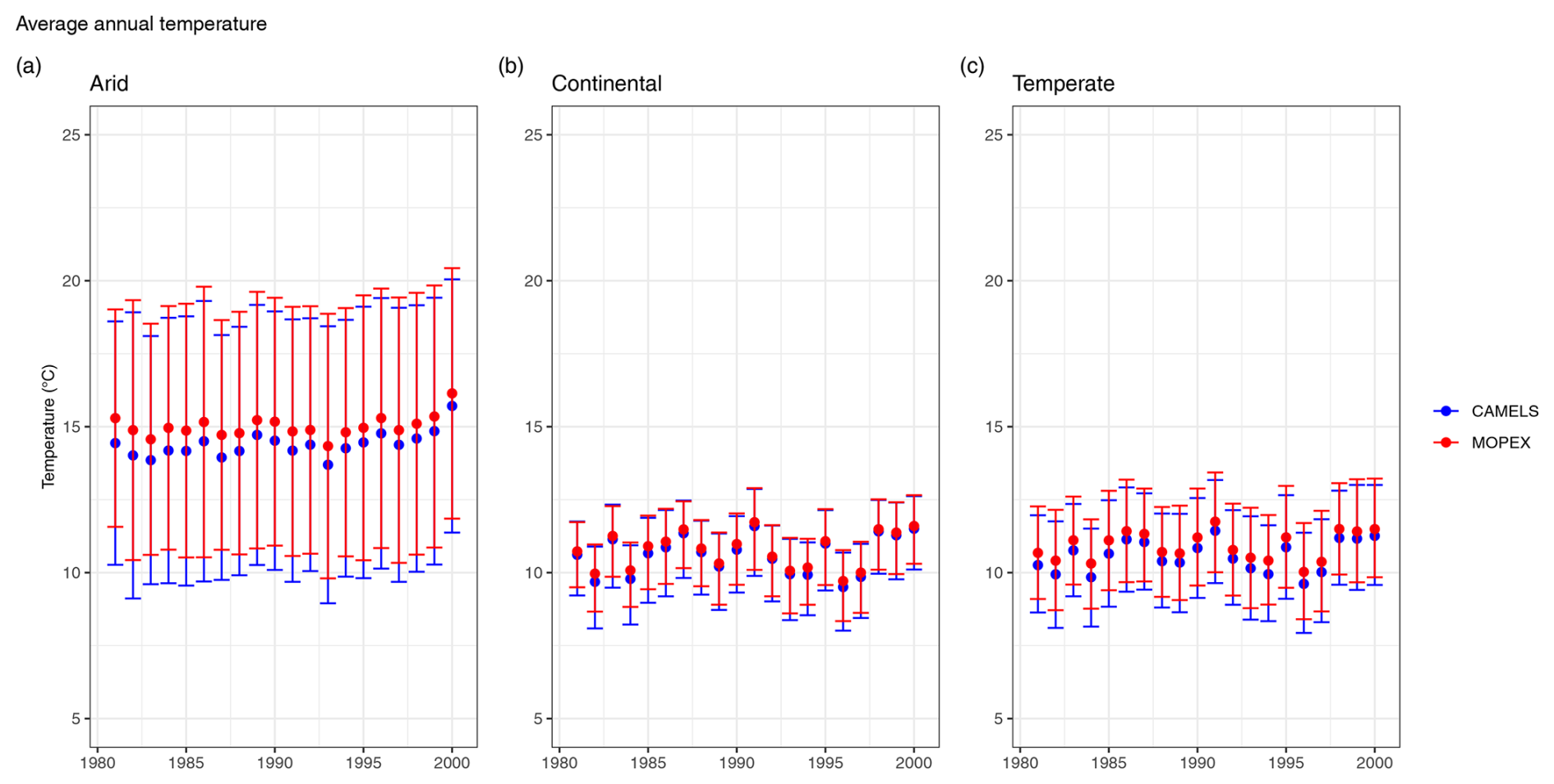
Figure 12Average annual temperature for CAMELS (blue) and MOPEX (red) by (a) arid, (b) continental, and (c) temperate climate region in degrees Celsius. The mean value is determined using all basins within the climate region and each corresponding water year for 1981–2000. Error bars represent two-sided 95 % confidence intervals, derived from bootstrapping with replacement for 10 000 replicates.
Annually, for temperature, arid confidence intervals are more than double the range of those found in continental and temperate regions (Fig. 12), strongly influenced by the small number of arid sites (Table 3). MOPEX means are consistently larger than CAMELS, indicating a warm bias with the largest bias in arid regions (Fig. 12a). Continental regions have the most similarity between mean values and the smallest amount of uncertainty, with confidence intervals ranging from ± 1.24 to ± 1.47 °C yr−1 for CAMELS and from ± 1.10 to ± 1.31 °C yr−1 for MOPEX (Fig. 12b). For temperate regions, MOPEX has a slightly smaller variance compared to CAMELS (Fig. 12c), with confidence intervals ranging from ± 1.44 to ± 1.73 °C yr−1 (MOPEX) versus ± 1.47 to ± 1.82 °C yr−1 (CAMELS).
4.2 Uncertainty and variability between datasets
Important differences between the datasets are detailed below, but in general in time-aggregated values MOPEX exhibits higher temperature, while CAMELS exhibits higher precipitation. Statistical and bootstrapping results from Sect. 4.1 support these findings. The comparison of paired observations via a binomial sign test, CAMELS values minus MOPEX, indicates that individual daily MOPEX values for precipitation and temperature are generally larger than CAMELS; in contrast, when CAMELS precipitation values are aggregated monthly, seasonally, or annually, they are typically larger than MOPEX in continental and temperate regions (Fig. 13). This analysis is based solely on the counts of negative (MOPEX > CAMELS), positive (CAMELS > MOPEX), and zero values (CAMELS = MOPEX). The magnitudes of the differences are not incorporated. Out of the 7305 d recorded for each basin, precipitation values for MOPEX surpass CAMELS 48 % (62 638 d out of 131 490 total days) and 49 % (86 496 d out of 175 320 total days) of the time in continental and temperate climates, respectively, and 40 % of the time in arid regions (Fig. 13a). In arid climates, MOPEX and CAMELS precipitation values are equal 46 % of total days, while in continental and temperate climates, they are equal 28 % and 22 % of total days. The same binomial test was conducted to analyze total monthly precipitation for each catchment. Direct comparisons were made for each month across all water years (i.e., January 1981, January 1982), tallying negative and positive differences, resulting in 240 months per catchment. When aggregated on a monthly scale, CAMELS typically exhibits greater total monthly precipitation, particularly in continental (66 %) and temperate (69 %) regions. Identical (“SAME”, Fig. 13b) total values are negligible. In contrast, arid regions indicate larger MOPEX values in 55 % of all months and only 3.25 % of all months have the same total value (Fig. 13b). Seasonal comparisons, based on 80 seasons per catchment, indicate the same pattern, with total precipitation greater in MOPEX for 52 % of all seasons in arid regions and CAMELS greater in continental and temperate regions for 76 % and 78 % of all seasons, respectively (Fig. 13c). On an annual scale, 20 years per watershed, the comparison reveals that total precipitation for arid regions is evenly split, with CAMELS and MOPEX dominating 51 % and 49 % of all years, respectively. In contrast, continental and temperate regions are largely dominated by CAMELS, constituting 88 % of all years (Fig. 13d). All comparisons, except for arid seasonal and annual, failed to reject the null hypothesis, which expects a median difference of zero between paired observations.
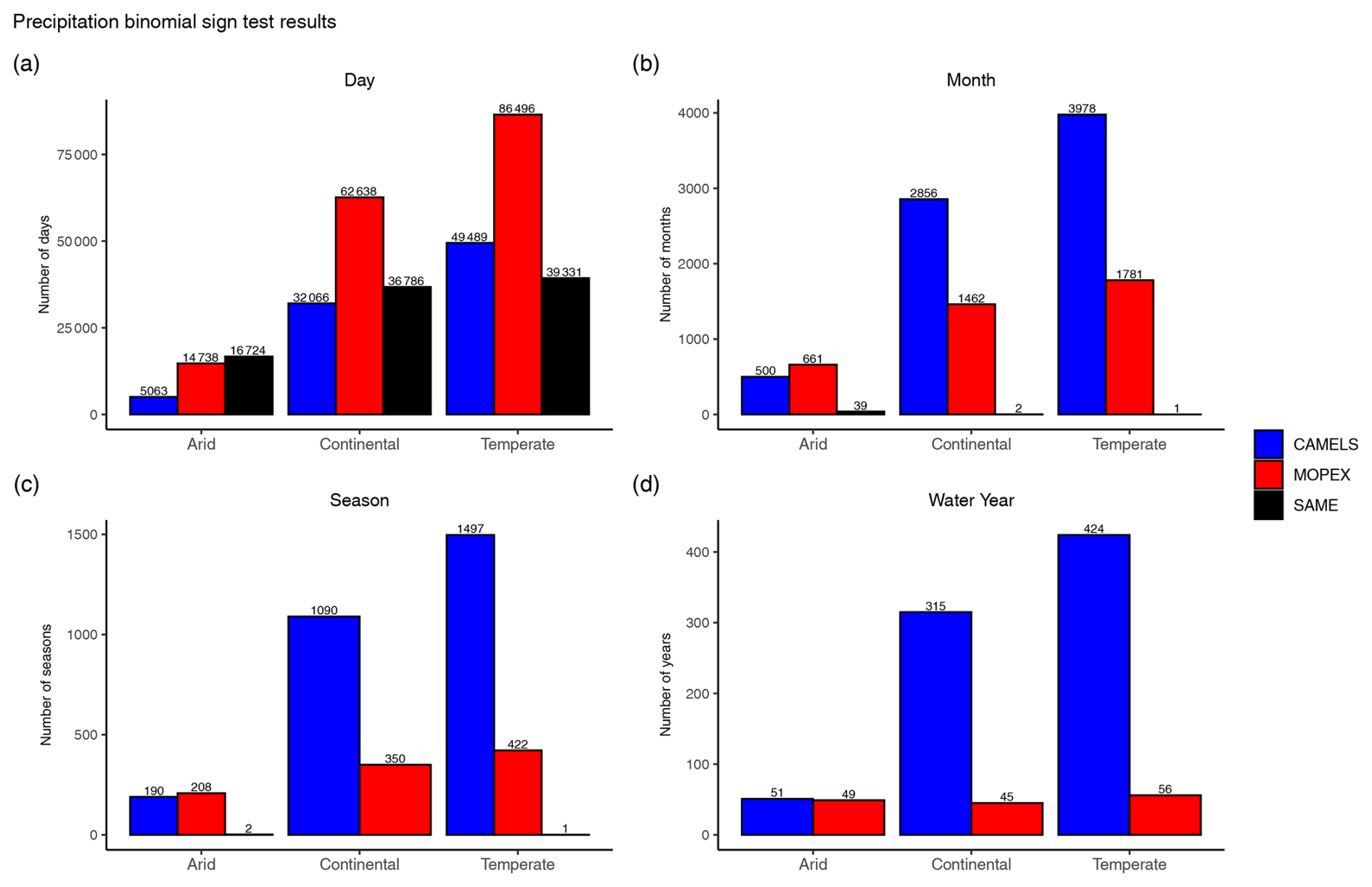
Figure 13Sign tally results from nonparametric binomial sign for (a) daily, (b) monthly, (c) seasonal, and (d) annual precipitation values. Counts on the y axis reflect the number of basins (gauges) within each climate region times the number of temporal periods. All results are based on CAMELS minus MOPEX values. Positive values (CAMELS) indicate that CAMELS > MOPEX (blue bars), negative (MOPEX) values indicate MOPEX > CAMELS (red bars), and zero (SAME) indicates CAMELS = MOPEX (black bars).
Regarding temperature, MOPEX exceeds CAMELS 72 % of total days in arid, 58 % in continental, and 65 % in temperate regions (Fig. 14a). These regions all exhibit the same mean daily temperature values (CAMELS = MOPEX) only 0.03 % of total days. On a monthly scale, MOPEX mean temperature values are larger for all regions, with arid at 81 %, continental at 58 %, and temperate at 74 % of total months with no equal values (Fig. 14b). Seasonal temperature is greater for MOPEX values 85 %, 58 %, and 77 % of all seasons for arid, continental, and temperate regions (Fig. 14c). As for annual mean temperatures, MOPEX values are greater for arid regions in 91 % of all years, while continental and temperate regions show MOPEX dominance in 65 % and 79 % of all years, respectively (Fig. 14d). All temperature differences were statistically significant.
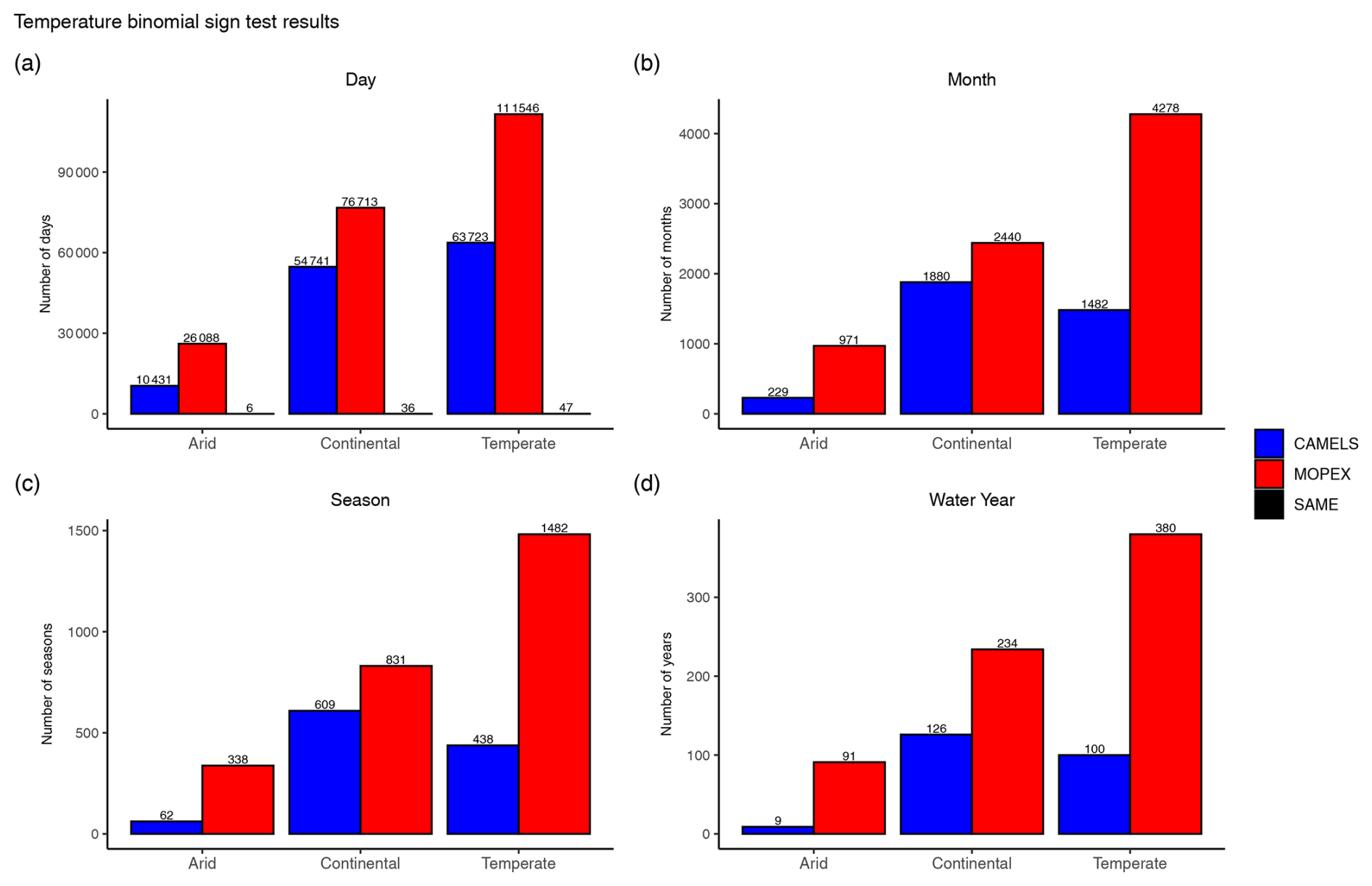
Figure 14Sign tally results from nonparametric binomial sign for (a) daily, (b) monthly, (c) seasonal, and (d) annual temperature values. Counts on the y axis reflect the number of basins (gauges) within each climate region times the number of temporal periods. All results are based on CAMELS minus MOPEX values. Positive values (CAMELS) indicate that CAMELS > MOPEX (blue bars), negative (MOPEX) values indicate MOPEX > CAMELS (red bars), and zero (SAME) indicates CAMELS = MOPEX (black bars).
The numerical differences between each pair of same-day precipitation values, CAMELS minus MOPEX, reveal substantial differences for extreme events. Specifically, there are 20 instances of daily precipitation values differing by more than 100 mm in separate comparisons across all catchments. This indicates notable variations in daily precipitation values between the two datasets. Daily values do not consistently coincide, as exemplified by the comparison of the same maximum precipitation events for each climate region between 1981 and 2000 (Table 6). In the temperate region, for instance, CAMELS reports the maximum precipitation (181.04 mm d−1) occurring on 7 April 1983 for gauge 02479300, while MOPEX, for the same date, reports a precipitation total of 64.07 mm. MOPEX reports the maximum precipitation (183.25 mm d−1) as occurring on 20 January 1993 at the same gauge (while CAMELS shows a precipitation value of 59.73 mm d−1). Consequently, this study does not recommend direct daily comparisons between MOPEX and CAMELS due to discrepancies in single precipitation events.
Table 6Largest precipitation event on record for each climate region in millimeters. Max indicates the maximum daily measurement on record for that dataset between 1981–2000 along with the corresponding value in the other dataset on that date for comparison.

A positive precipitation bias for CAMELS is visible for all watersheds within a climate region for all temporal aggregations (positive values, Fig. 15). Monthly, precipitation biases for arid regions range from −52.57 to 99.28 mm month−1, continental regions range from −57.60 to 103.22 mm month−1, and temperate regions are between −102.68 and 117.29 mm month−1, comparing 240 months per catchment (Fig. 15a). Seasonal precipitation biases for arid, continental, and temperate regions are −92.21 to 94.65, −64.04 to 137.32, and −123.50 to 174.88 mm season−1 (Fig. 15b). Total annual precipitation bias ranges are −174.43 to 160.03, −111.77 to 315.40, and −256.88 to 405.25 mm yr−1 based on 20 years per catchment (Fig. 15c).
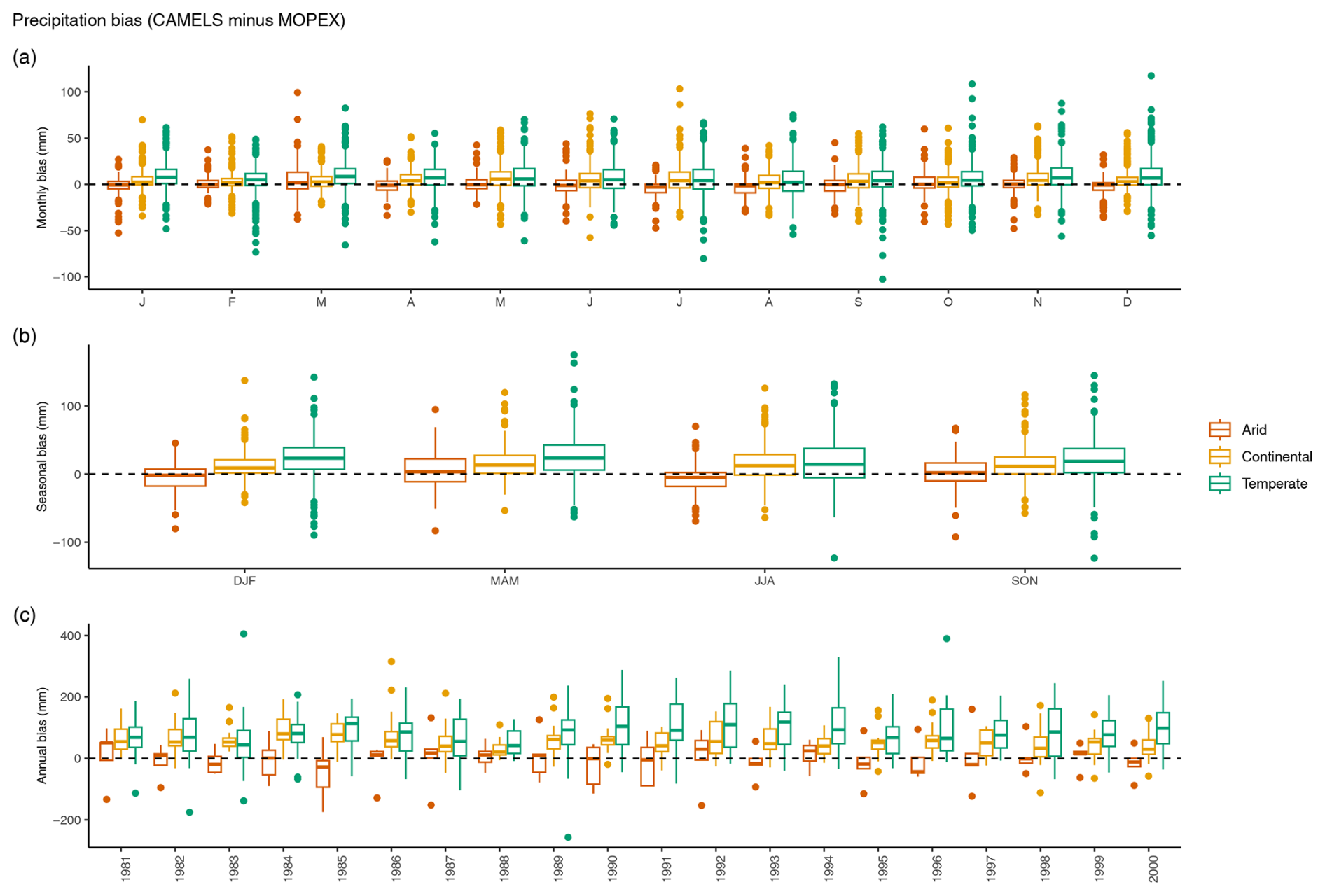
Figure 15Monthly (a), seasonal (b), and annual (c) precipitation biases in millimeters. All basins are combined by climate region (arid, continental, and temperate) and box plots represent the number of observations indicated in Table 3. Precipitation biases are based on total values of CAMELS minus MOPEX. Positive values indicate CAMELS > MOPEX and negative values indicate MOPEX > CAMELS.
A negative temperature bias for CAMELS vs. MOPEX is visible for all watersheds in a climate region for all temporal aggregations (negative values, Fig. 16). Daily temperature values differ between the datasets by as much as ± 28 °C d−1, with MOPEX demonstrating a greater positive bias (Fig. 14a). Monthly temperature biases for arid regions range from −5.29 to 2.00 °C month−1, continental regions range from −6.43 to 0.70 °C month−1, and temperate regions range from −5.51 to 2.26 °C month−1 (Fig. 16a). Seasonal temperature biases range from −2.71 to 1.70, −4.24 to 0.53, and −2.84 to 0.85 °C season−1 (Fig. 16b) and mean annual temperature biases decrease to −2.17 to 0.09, −2.44 to 0.39, and −1.89 to 0.36 °C yr−1 (Fig. 16c) for arid, continental, and temperate regions, respectively.
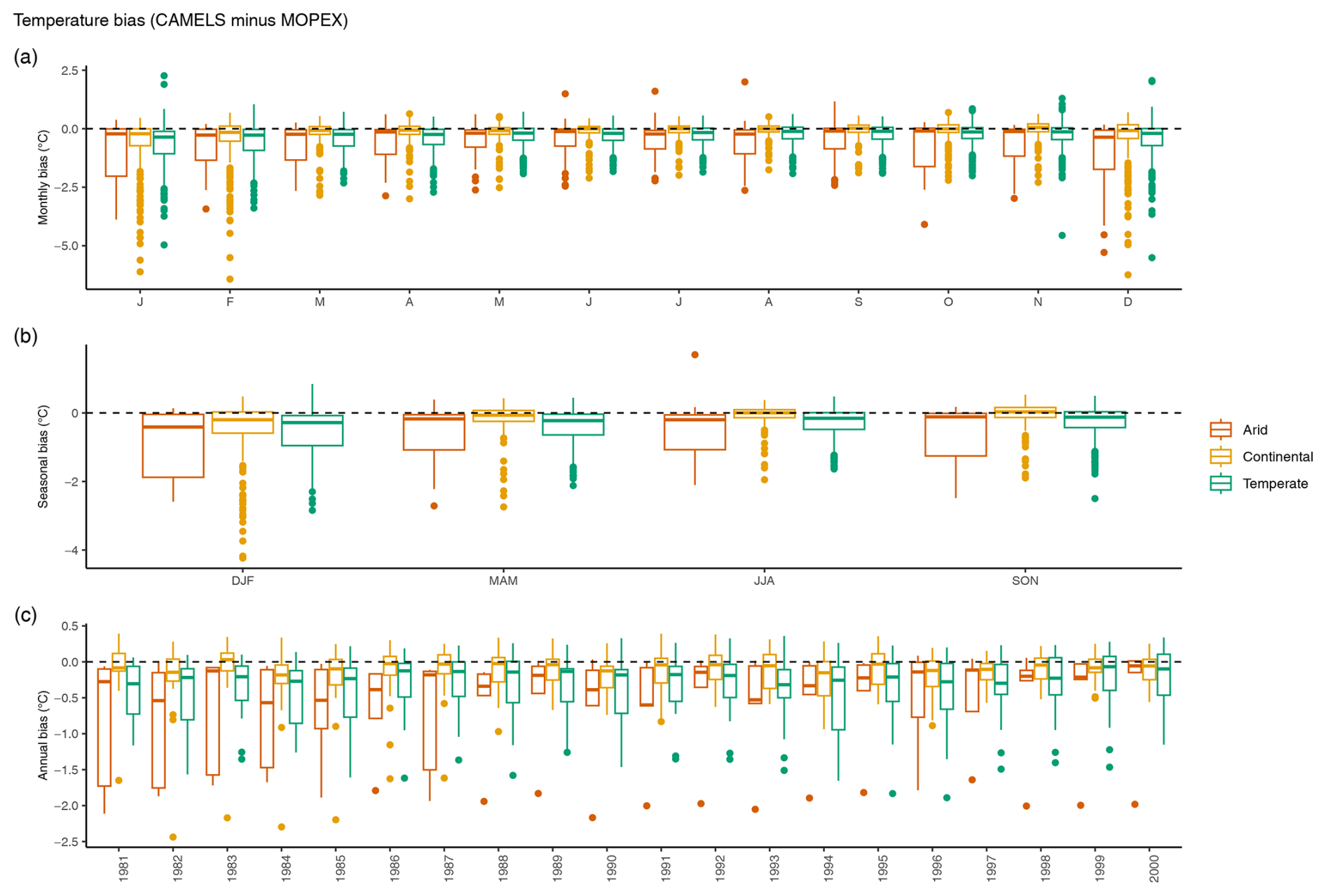
Figure 16Monthly (a), seasonal (b), and annual (c) temperature biases in degrees Celsius. All basins are combined by climate region (arid, continental, and temperate) and box plots represent the number of observations indicated in Table 3. Temperature biases are based on mean values of CAMELS minus MOPEX. Positive values indicate CAMELS > MOPEX and negative values indicate MOPEX > CAMELS.
While the ranges of biases for precipitation and temperature are shown in Figs. 15 and 16, respectively, the magnitude of differences between MOPEX and CAMELS precipitation and temperature values is clarified by averaging biases over all basins in a climate region for daily, monthly, seasonal, and annual time aggregations for 1981–2000 (Fig. 17). Given that the differences are either negative (MOPEX > CAMELS) or positive (CAMELS > MOPEX), the mean reflects the overall bias since equal differences will negate each other. In direct pairwise comparisons, MOPEX daily precipitation values tend to be larger than CAMELS; however, when CAMELS values exceed MOPEX, the numerical difference is greater. Daily averages (not shown) for precipitation bias are −0.02 mm d−1 (MOPEX > CAMELS) for arid regions, 0.15 mm d−1 (CAMELS > MOPEX) for continental, and 0.23 mm d−1 (CAMELS > MOPEX) for temperate regions, indicating a wet bias in arid regions for MOPEX and a wet bias for CAMELS in continental and temperate regions. When precipitation values are aggregated on a monthly scale (Fig. 17a), CAMELS values exceed MOPEX values by 2.94 mm month−1 (February) to 6.79 mm month−1 (May) in continental regions and by 4.41 mm month−1 (August) to 9.31 mm month−1 (March) in temperate regions. In arid climates, CAMELS exceeds MOPEX by 0.18 mm month−1 (February), 5.07 mm month−1 (March), 1.11 mm month−1 (May), and 2.56 mm month−1 (October), while MOPEX exceeds CAMELS (negative values) by 2.58 mm month−1 (January), 0.84 mm month−1 (April), 0.14 mm month−1 (June), 4.38 mm month−1 (July), 3.16 mm month−1 (August), 0.42 mm month−1 (September), 0.36 mm month−1 (November), and 2.88 mm month−1 (December). Average seasonal precipitation differences are larger for CAMELS in continental regions (Fig. 17b), ranging between 12.13 mm season−1 (DJF) and 15.66 mm season−1 (MAM), and temperate regions, ranging between 16.78 mm season−1 (JJA) and 24.88 mm season−1 (MAM). Average arid precipitation differences are larger in JJA and DJF by 7.68 and 5.27 mm season−1 for MOPEX values and larger in SON and MAM by 1.79 and 5.34 mm season−1 for CAMELS. Mean annual differences mirror the biases observed in monthly aggregations (Fig. 17c). Annual CAMELS precipitation values are 1.62 to 12.05 mm yr−1 larger (1981, 1987, 1988, 1989, 1992, 1994, 1997, 1998, 1999) than MOPEX, while MOPEX values are 5.63 to 46.91 mm yr−1 larger than CAMELS for annual totals (1982, 1983, 1984, 1985, 1986, 1990, 1991, 1993, 1995, 1996, 2000) in arid regions. CAMELS values in continental regions are 27.84 to 89.23 mm yr−1 larger, and temperate regions are 51.46 to 112.03 mm yr−1 larger than MOPEX values.
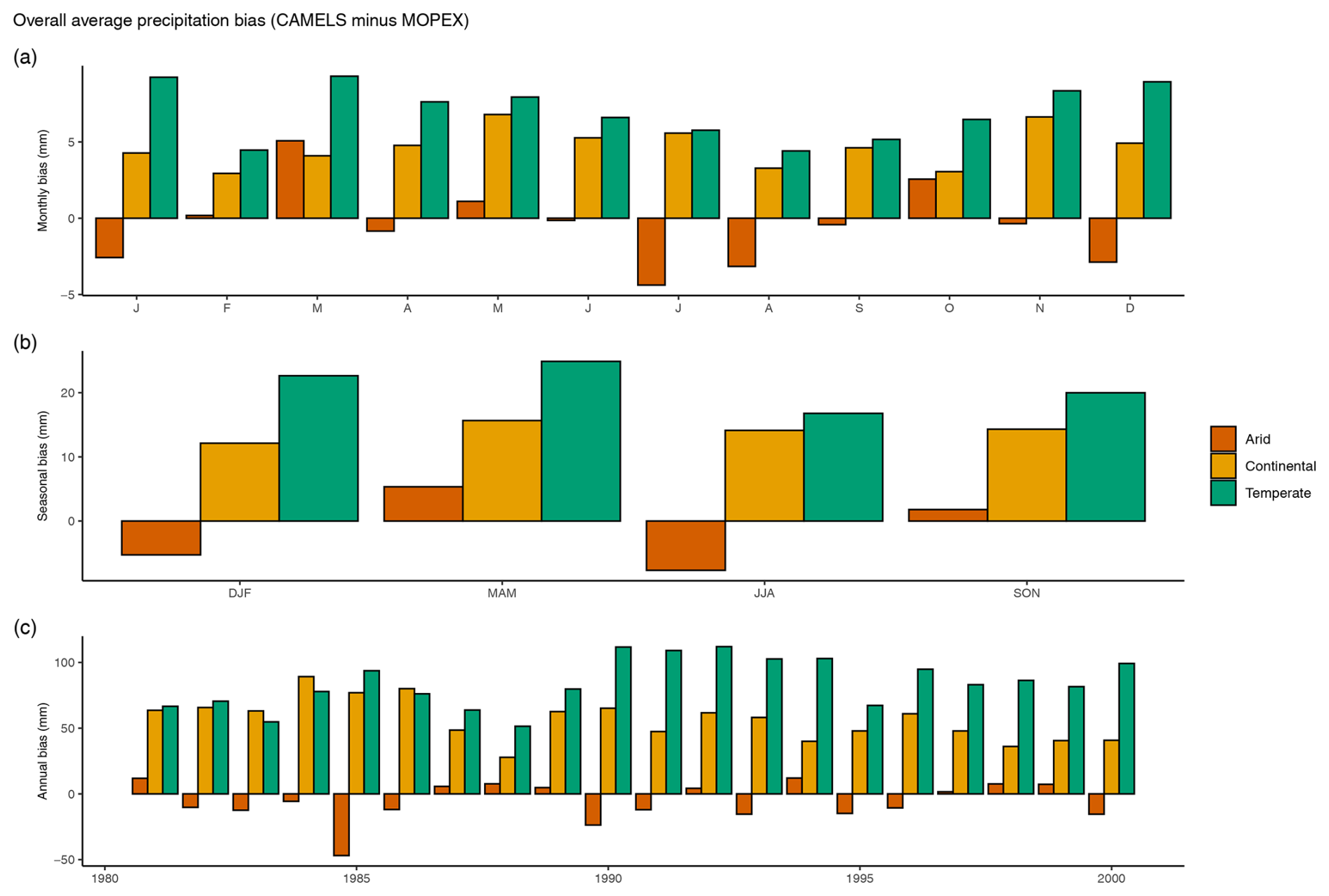
Figure 17Magnitude of precipitation bias averaged over all watersheds in a climate region (arid, continental, and temperate) based on (a) monthly, (b) seasonal, and (c) annual totals in millimeters. All differences are CAMELS minus MOPEX values. Positive bias indicates CAMELS >MOPEX, while negative bias indicates MOPEX > CAMELS.
The average of daily temperature differences indicated that MOPEX values were greater than CAMELS by 0.62 °C d−1 for arid basins, 0.15 °C d−1 for continental basins, and 0.35 °C d−1 for temperate basins, suggesting a warmer bias in all MOPEX values. For monthly aggregations, temperature exhibits larger values for MOPEX by 0.41 to 0.95, 0.01 to 0.54, and 0.24 to 0.64 °C month−1 in arid, continental, and temperate regions, respectively (Fig. 18a). Seasonally, temperature differences indicate a warm MOPEX bias with average differences of 0.51 to 0.85 °C season−1 in arid, 0.03 to 0.41 °C season−1 in continental, and 0.25 to 0.52 °C season−1 in temperate regions (Fig. 18b). Mean annual temperature differences indicate that MOPEX is greater than CAMELS by 0.43 to 0.86, 0.07 to 0.29 °C, and 0.23 to 0.47 °C yr−1 for arid, continental, and temperate regions, respectively (Fig. 18c).
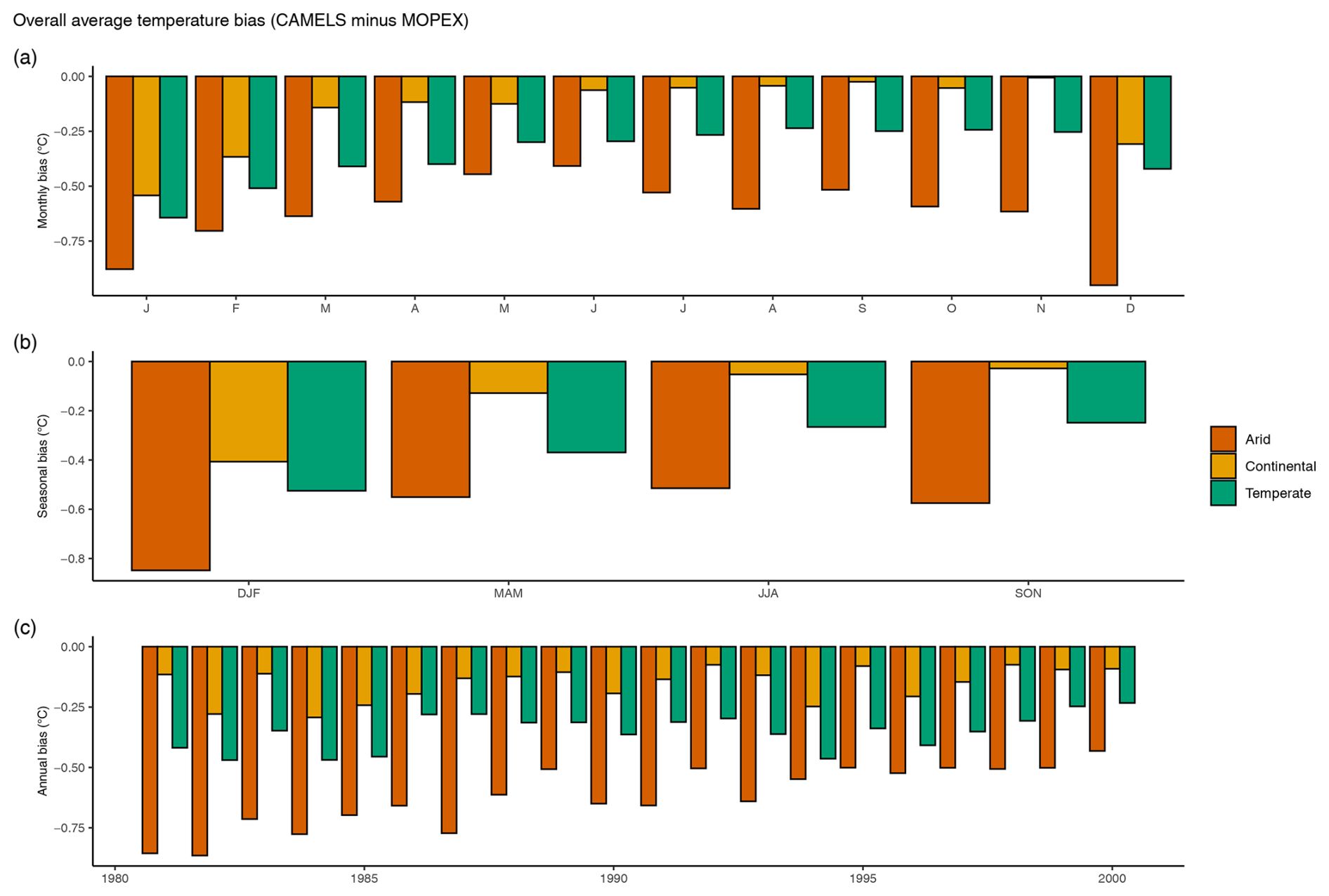
Figure 18Magnitude of temperature bias averaged over all watersheds in a climate region (arid, continental, and temperate) based on (a) monthly, (b) seasonal, and (c) annual totals in degrees Celsius. All differences are CAMELS minus MOPEX values. Positive bias indicates CAMELS > MOPEX, while negative bias indicates MOPEX > CAMELS.
The spatial distribution of precipitation and temperature mean biases between the two datasets shows some geographic concentration, especially of positive (CAMELS) bias for precipitation in the eastern US (Fig. 19a). Arid regions show an overall wet bias for MOPEX (two watersheds have a slight wet bias for CAMELS), while continental and temperate regions have a wet bias for CAMELS for all temporal aggregations. Temperature biases in Fig. 19b show an overall warm bias for MOPEX for all regions with the exception of four continental watersheds and two temperate watersheds.
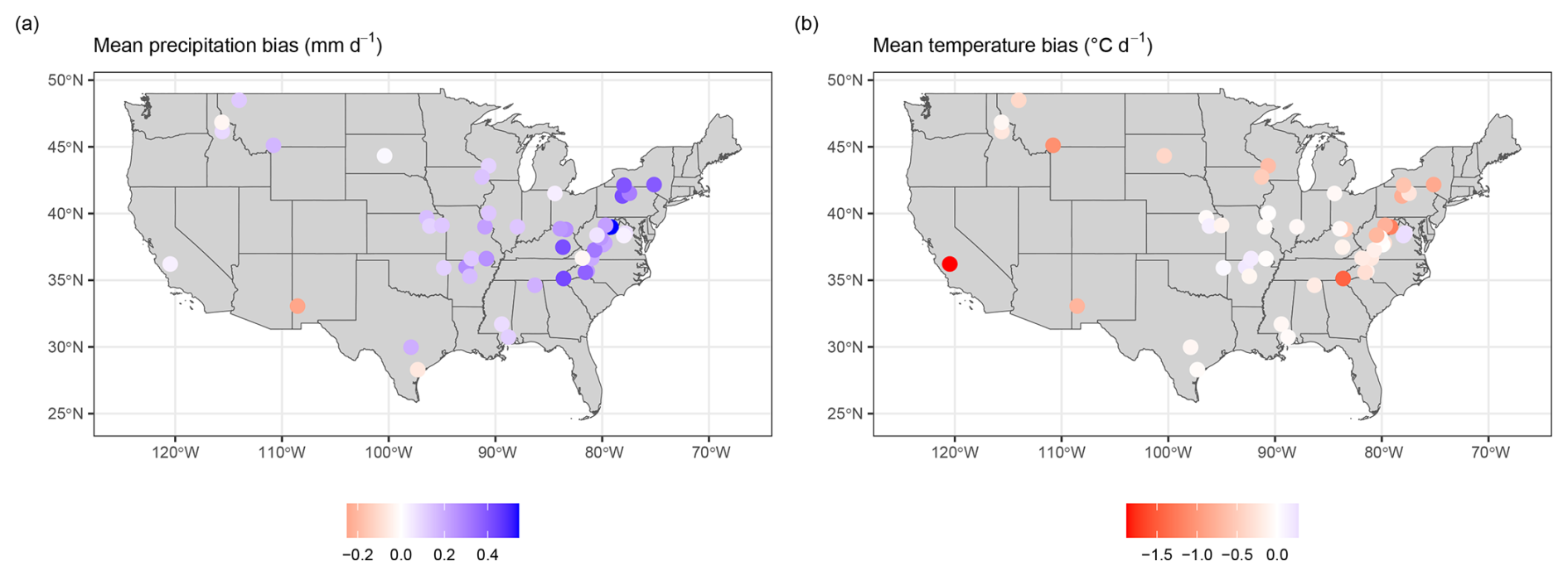
Figure 19Overall bias for (a) mean precipitation at each gauge location based on CAMELS minus MOPEX. The color bar represents bias in millimeters per day, where negative values (red) indicate a MOPEX wet bias and positive values (blue) indicate a CAMELS wet bias. Overall bias for (b) mean temperature at each gauge location based on CAMELS minus MOPEX. The color bar represents bias in degrees Celsius per day, where negative values (red) indicate a MOPEX warm bias and positive values (blue) indicate a CAMELS warm bias.
Overall statistics for precipitation are shown in Table 7 and were calculated over all shared basins within a climate region. Temperature statistics are shown in Table 8. The mean values and corresponding confidence intervals are based on the averages derived from bootstrapping results, shown in Figs. 7–9 for monthly, seasonal, and annual precipitation values and Figs. 10–12 for monthly, seasonal, and annual temperature values. The tables highlight the commensurate central tendencies, variabilities, and dispersion values within the datasets and provide insight into the comparisons between the datasets.
Table 7Overall statistics for MOPEX (M) and CAMELS (C) precipitation totals by climate region in millimeters. Bootstrapping mean values for each climate region and the lower and upper confidence limits are based on a two-sided 95 % confidence interval (CI) and 10 000 replicates with replacement. Median, variance, standard deviation, and skewness are based on the average of all values for each basin within a region.
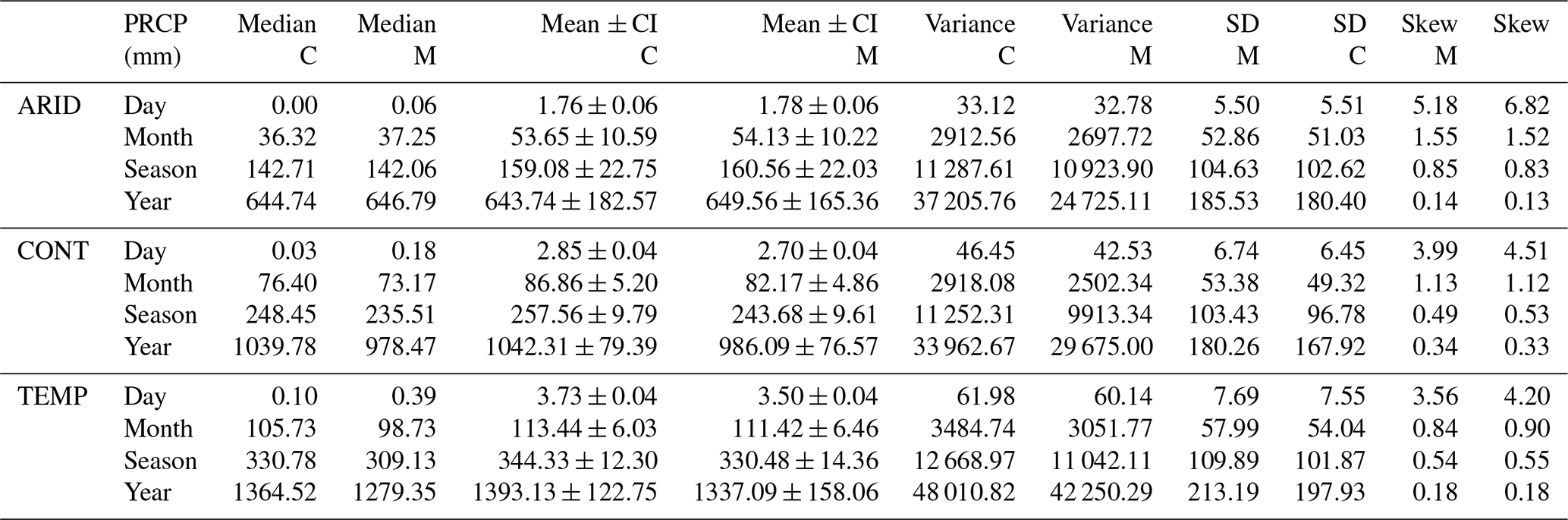
Table 8Overall statistics for MOPEX (M) and CAMELS (C) temperature by climate region in degrees Celsius. Bootstrapping mean values for each climate region and the lower and upper confidence limits are based on a two-sided 95 % confidence interval (CI) and 10 000 replicates with replacement. Median, variance, standard deviation, and skewness are based on the average of all values for each basin within a region.
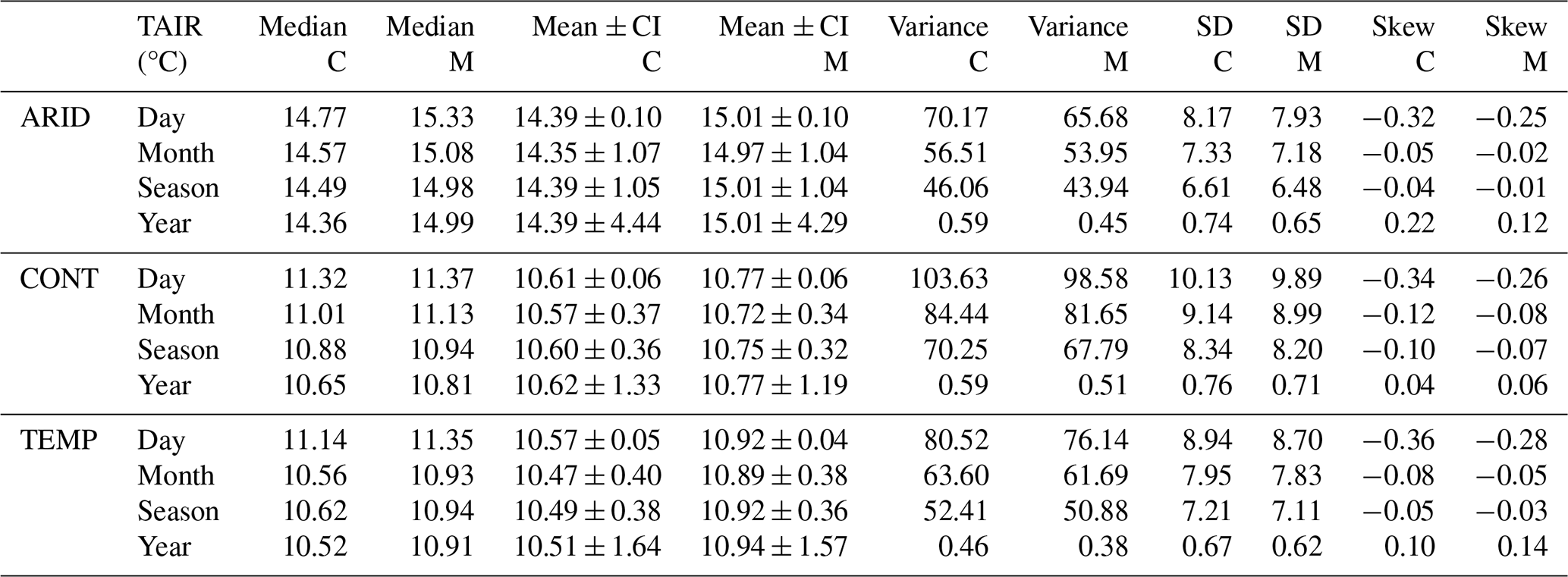
To assess the magnitude of disparities between CAMELS and MOPEX, we also examined the mean absolute error (MAE), with temperate regions exhibiting the greatest MAE for precipitation (Fig. 20) and arid regions the greatest values for temperature (Fig. 21). The overall error considers both positive and negative differences equally, with the magnitude increasing from 1.30 mm d−1 in arid regions to 2.70 mm d−1 in continental and 3.19 mm d−1 in temperate regions for daily precipitation. Monthly precipitation MAE ranges from 2.37 to 5.72 mm month−1 in arid regions, 3.74 to 6.80 mm month−1 for continental regions, and 5.48 to 9.62 mm month−1 in temperate regions (Fig. 20a). Seasonal MAE ranges from 1.79 to 7.68, 12.13 to 15.66, and 16.78 to 24.88 mm season−1 for arid, continental, and temperate regions (Fig. 20b). Annual MAE ranges from 1.62 to 46.91, 27.84 to 89.23, and 51.46 to 112.03 mm yr−1 for arid, continental, and temperate regions (Fig. 20c).
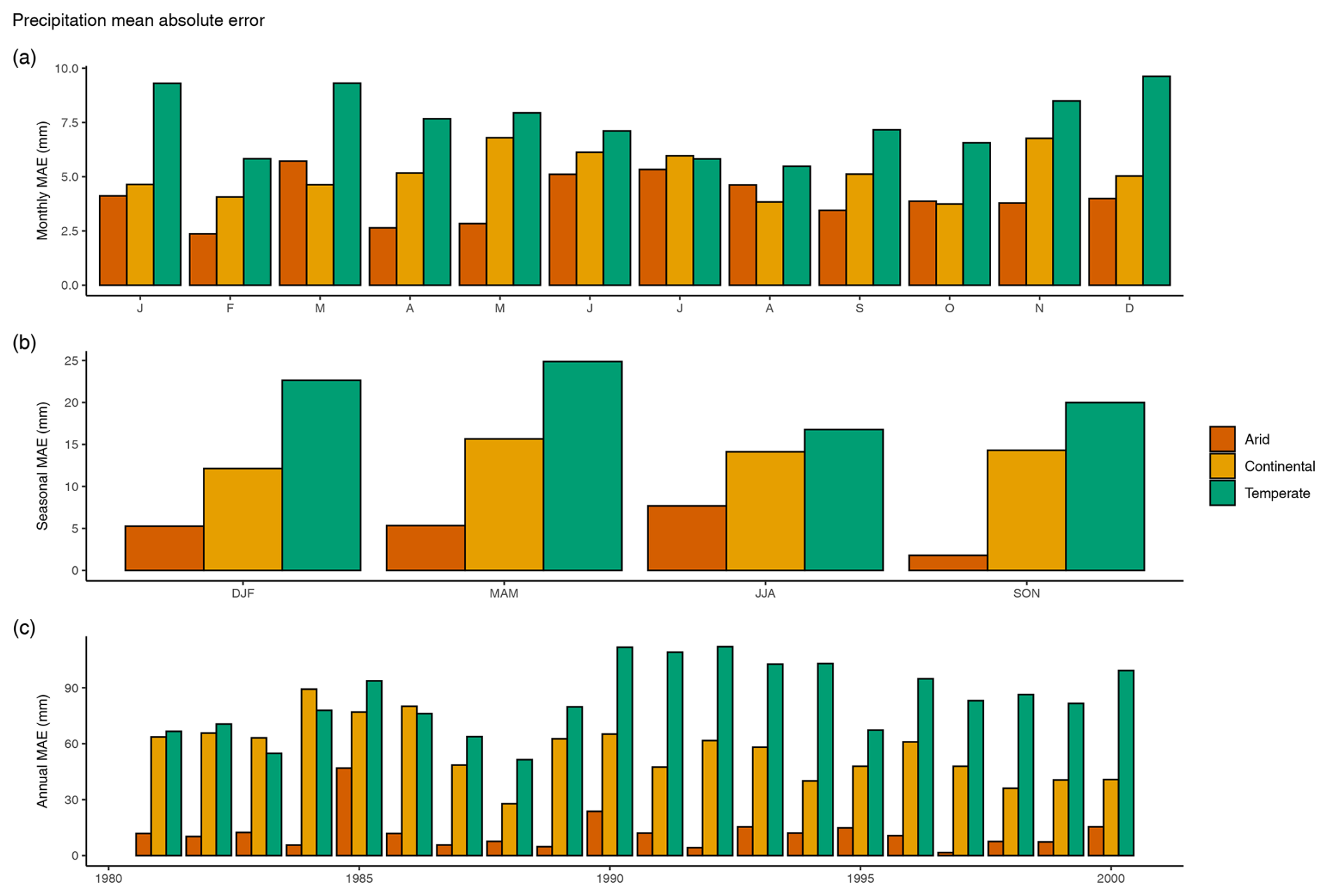
Figure 20Mean absolute error for (a) monthly, (b) seasonal, and (c) annual precipitation in millimeters. MAE is based on mean totals between all basins within a climate region (arid, continental, and temperate).
Daily temperature MAE averages 1.01 °C d−1 in arid regions, 0.87 °C d−1 in continental regions, and 0.82 °C d−1 in temperate regions. Monthly temperature MAE ranges from 0.41 to 0.95, 0.04 to 0.54, and 0.24 to 0.64 °C month−1 for arid, continental, and temperate regions, respectively (Fig. 21a). Seasonal MAE for temperature ranges from 0.51 to 0.85, 0.03 to 0.41, and 0.25 to 0.52 °C season−1 for arid, continental, and temperate regions (Fig. 21b). Annual temperature MAE ranges from 0.43 to 0.86, 0.07 to 0.29, and 0.23 to 0.47 °C yr−1 for arid, continental, and temperate regions (Fig. 21c).
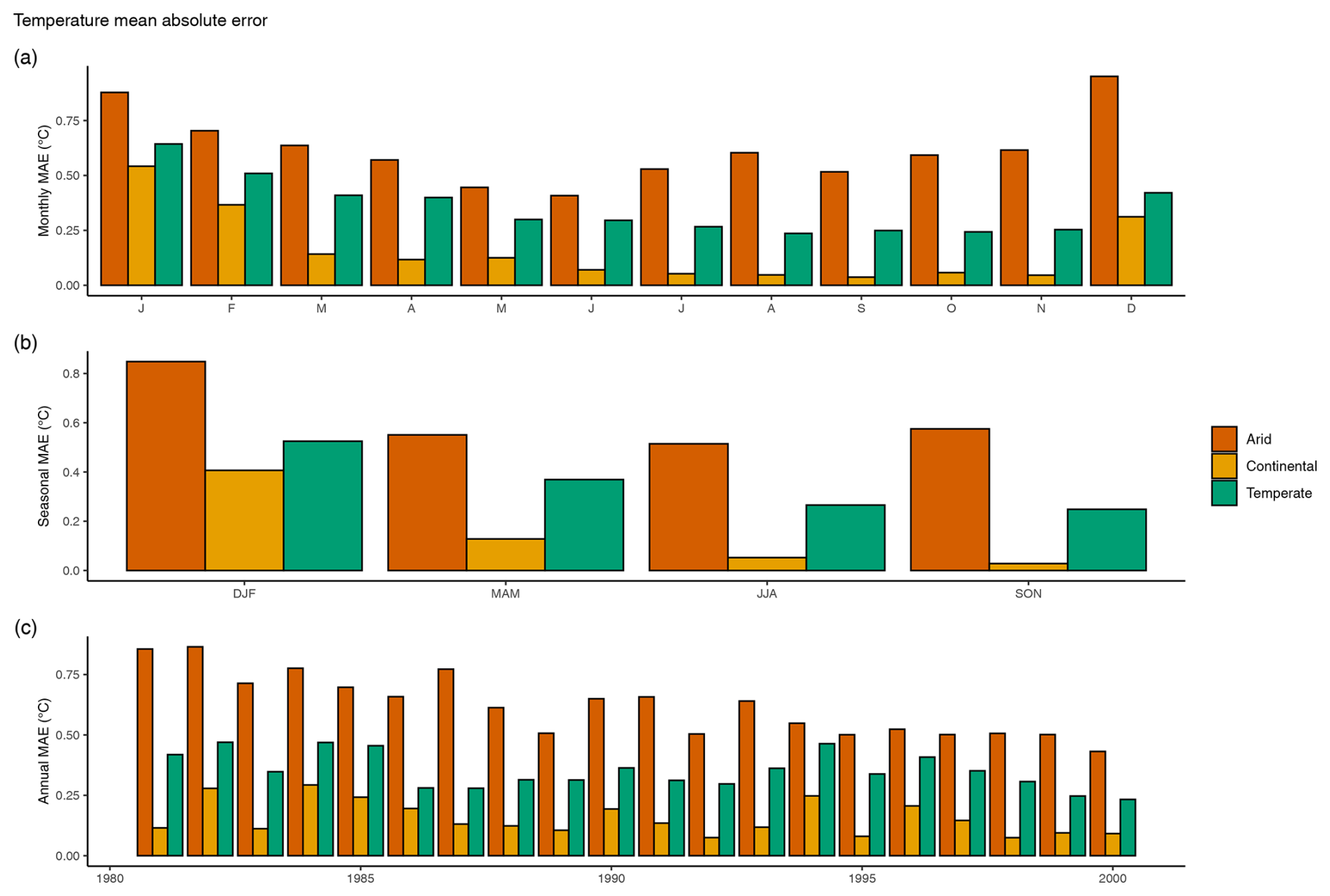
Figure 21Mean absolute error for (a) monthly, (b) seasonal, and (c) annual temperature in degrees Celsius. MAE is based on means between all basins within a climate region (arid, continental, and temperate).
The statistical results for all regions are summarized in Table 9 and are calculated over all days, months, seasons, and water years (refer to Table 3). Overall statistics remove the observed fluctuations in monthly, seasonal, and annual data but provide a generalized value by climate region. The margin of error (MOE) was derived from the standard error (SE) of the difference of the means and coincides with the bootstrapping results. Arid regions have the largest MOE for precipitation and temperature.
Table 9Statistical results for comparisons between CAMELS and MOPEX values for all basins within a climate region. Analyses were conducted over the total number of values. Bias represents mean CAMELS minus mean MOPEX. Standard error (SE), margin of error (MOE), mean absolute error (MAE), and Spearman rank (R2) are also based on mean values.
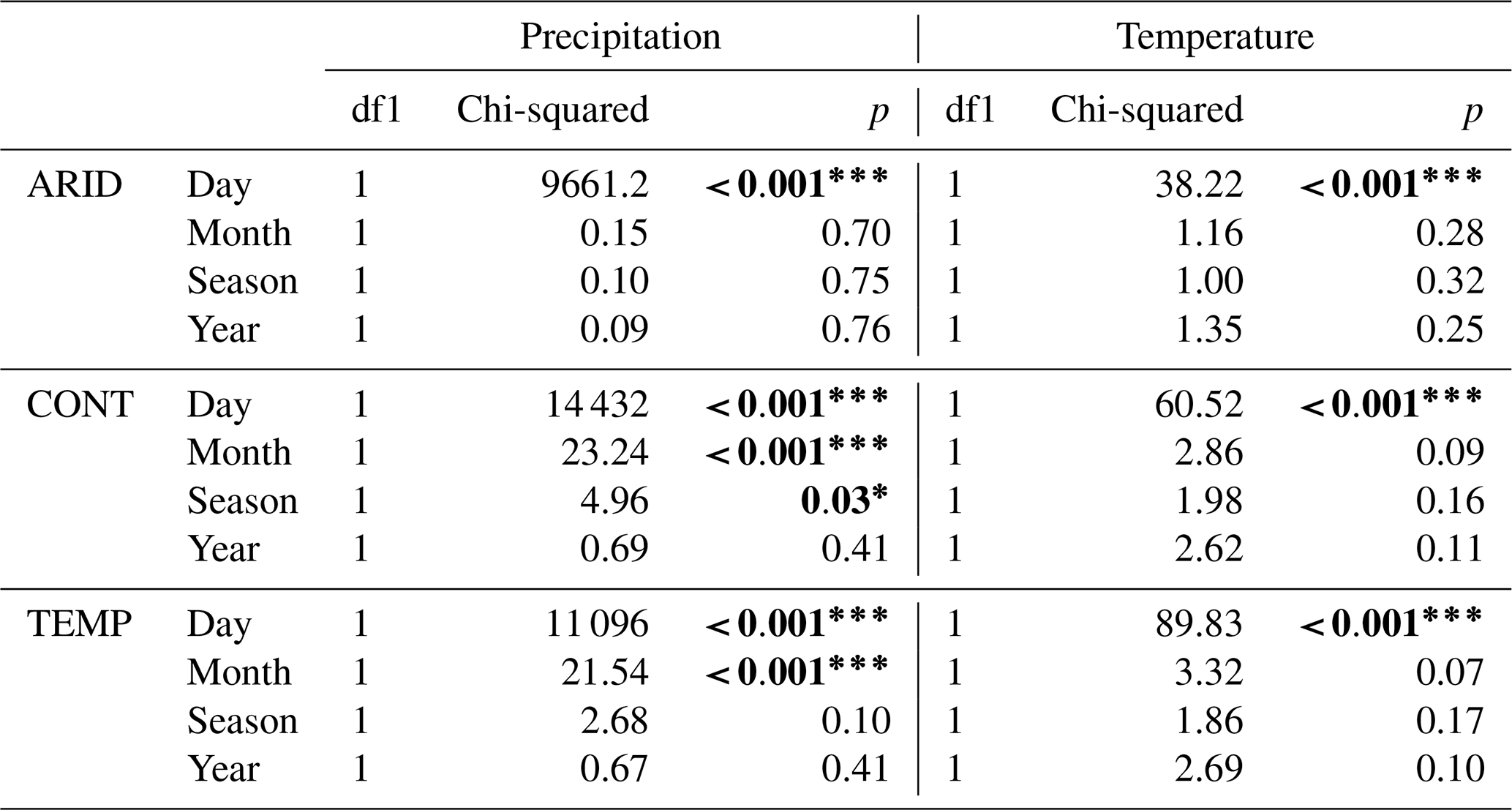
The Fligner–Killeen test for equality of variances indicated that arid regions are the most similar in precipitation variance for all temporal aggregations except daily (Table 10). Statistically significant differences between variances were found for continental regions (daily, monthly, seasonally) and temperate regions (daily and monthly) but not on an annual basis. Temperature values are more consistent, with statistically significant differences between variances indicated for daily values only. These results are corroborated by observations previously presented and outlined in Sect. 4.1, as shown in Tables 4 and 5 and Figs. 7 through 12.
Table 10The results of the Fligner–Killeen test for homogeneity of variance. The df1 value is the number of groups minus 1, and the statistic is χ2. The p values are reported as * p<0.05, p<0.01, and p<0.001. Bolded values are statistically significant.
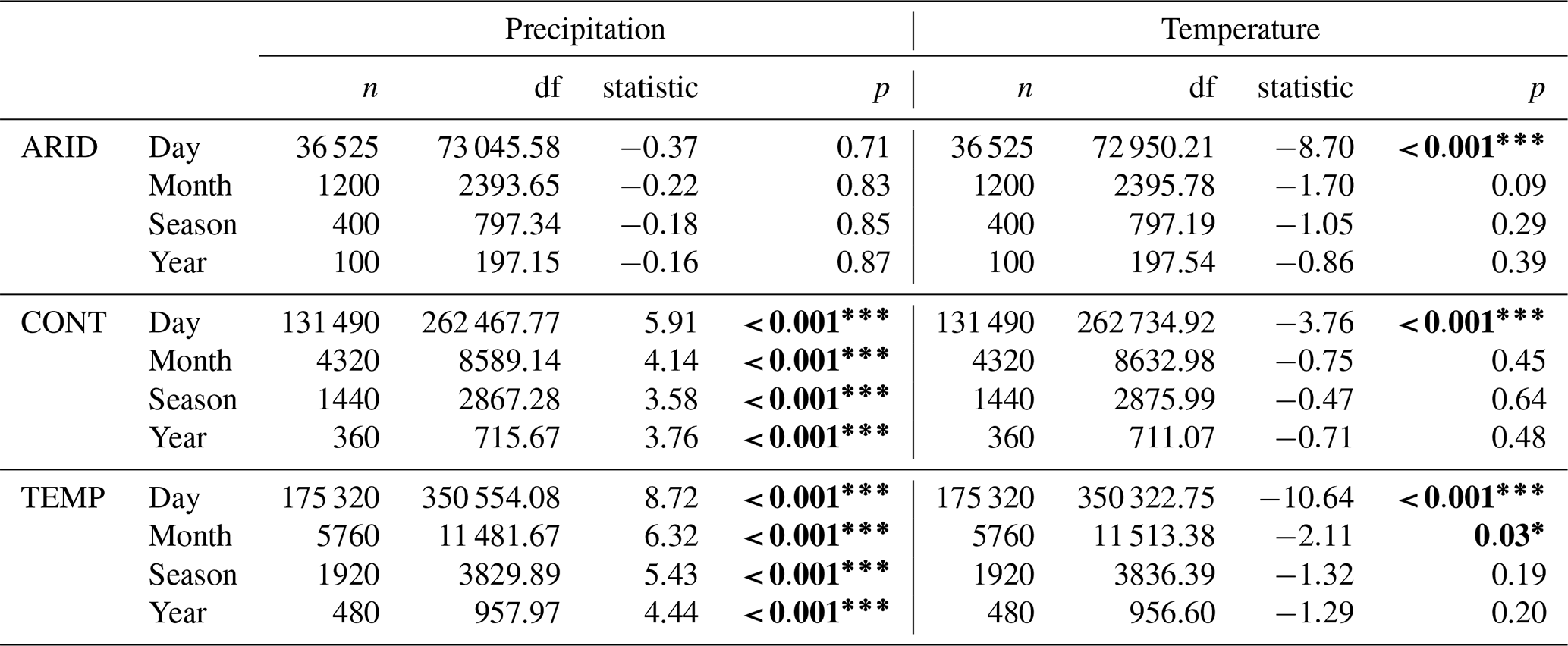
Differences in the mean values, evaluated by Welch's t test, indicated that there were no statistically significant differences in the mean for daily, monthly, seasonal, and annual arid precipitation (Table 11). Despite the largest variance, arid regions are the most similar with the smallest amount of bias between means. Differences in mean precipitation values in continental and temperate regions are statistically significant on all temporal scales; however, the largest difference between mean values is only 6.36 % (daily temperate). Temperature mean differences are only statistically significant at daily aggregations for all climate regions, with the exception of monthly temperature.
Table 11The results of Welch's t test for comparison of means with unequal variance. Here, n represents the number of values, df is calculated degrees of freedom, and the statistic calculated is t. The p values are reported as * p<0.05, p<0.01, and p<0.001. Bolded values are statistically significant.
The nonparametric Wilcoxon signed-rank test (Helsel et al., 2020) was also conducted to evaluate the median differences, and the results indicated statistically significant differences for daily precipitation in all regions and for monthly, seasonal, and annual precipitation in continental and temperate regions. Temperature median differences were only statistically significant for daily values.
As previously noted, there are no discrepancies in runoff between MOPEX and CAMELS datasets because both contain identical daily streamflow values sourced from the USGS. However, evapotranspiration estimates derived from the water balance approach will differ due to variations in precipitation, since runoff remains consistent across the datasets. Runoff and water-balance-derived evapotranspiration were included in correlation analyses to evaluate the relationships among all variables for both datasets and to determine consistency in the strength and direction of their associations.
Daily precipitation Spearman rank correlation values between CAMELS (_C) and MOPEX (_M) ranged from 0.58 to 0.74, 0.48 to 0.86, and 0.46 to 0.88 for arid, continental, and temperate regions, respectively (Fig. 22a, e, i). The highest precipitation correlation values were observed for monthly (Fig. 22b, f, j) and seasonal aggregations (red cells, Fig. 22c, g, k), with annual values following closely (Fig. 22d, h, l). Monthly precipitation correlations are the lowest in July and August for all regions (0.84 to 0.91). Monthly and seasonal aggregations are the most consistent between MOPEX and CAMELS, followed by annual and then daily for precipitation and temperature. Temperature shows a high similarity between MOPEX and CAMELS for all temporal aggregations and regions, ranging from 0.99 to 1.0. Correlations between runoff and precipitation are positive for all regions and temporal aggregations in both datasets, with the largest difference of 0.08 in daily continental (0.14 for MOPEX, 0.22 for CAMELS). Water balance evapotranspiration values show improved agreement, greater than 0.90, for monthly, seasonal, and annual aggregations. Daily evapotranspiration coefficients are between 0.59 and 0.64, indicating less consistency between MOPEX and CAMELS.
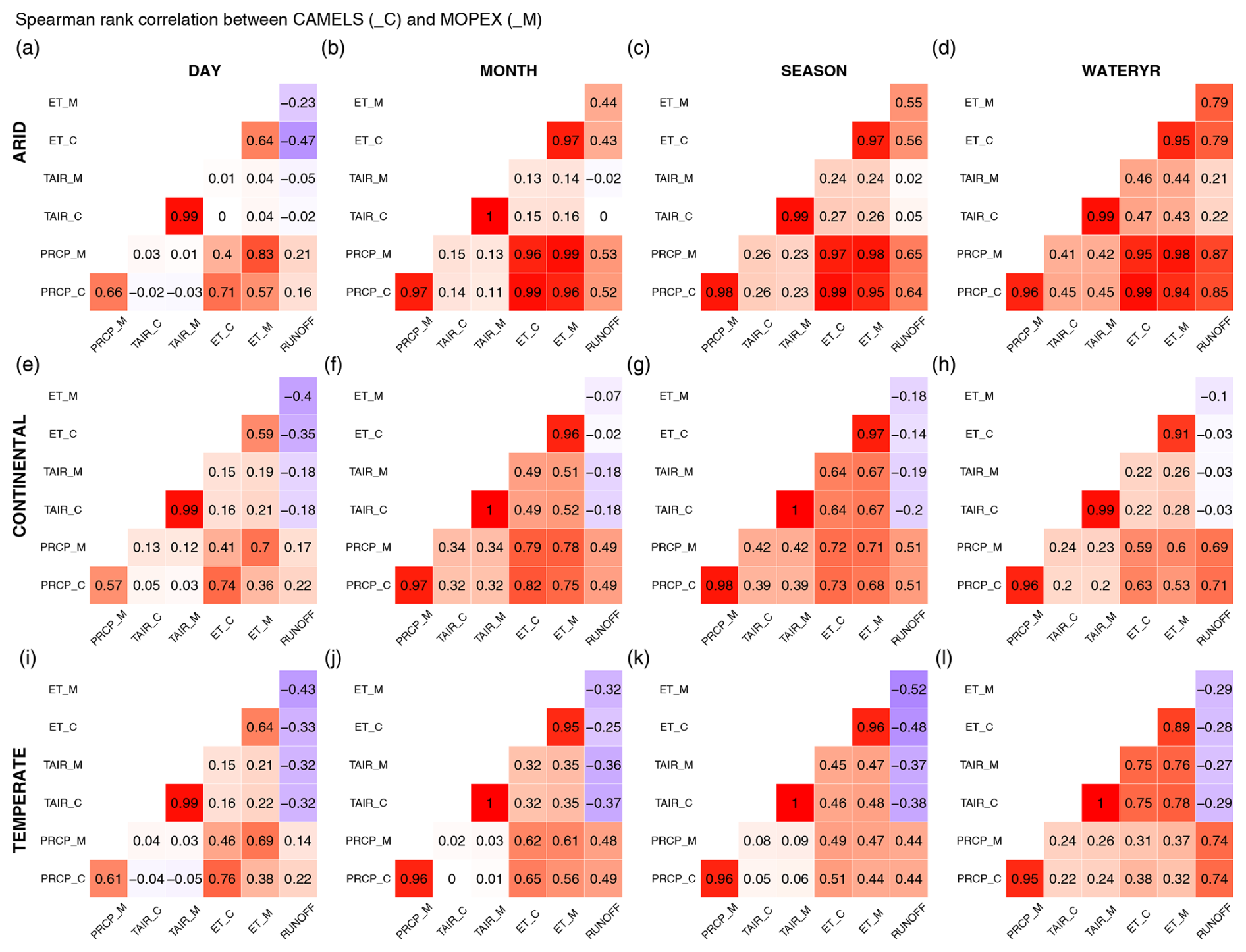
Figure 22Spearman rank correlation values between CAMELS (_C) and MOPEX (_M) datasets for precipitation (PRCP) in millimeters, temperature (TAIR) in degrees Celsius, and water-balance-calculated evapotranspiration (ET) in millimeters. Runoff, in millimeters, represents both datasets. Arid correlations are between (a) daily values, (b) monthly values, (c) seasonal values, and (d) annual water year values. Continental correlations are between (e) daily values, (f) monthly values, (g) seasonal values, and (h) annual water year values. Temperate correlations are between (i) daily values, (j) monthly values, (k) seasonal values, and (l) annual water year values.
Runoff efficiency is the amount of precipitation that becomes runoff and can be used to evaluate trends and climate impact. This coefficient provides an additional metric of dataset compatibility. The annual efficiency for each basin was determined for CAMELS and MOPEX using total precipitation and total runoff and then plotted, resulting in an R2 value of 0.988 for all climate regions combined (Fig. 23). This correlation was calculated to illustrate the annual compatibility of the datasets and the ability of both to convey consistent attributes among watersheds for derived parameters, such as runoff efficiency.
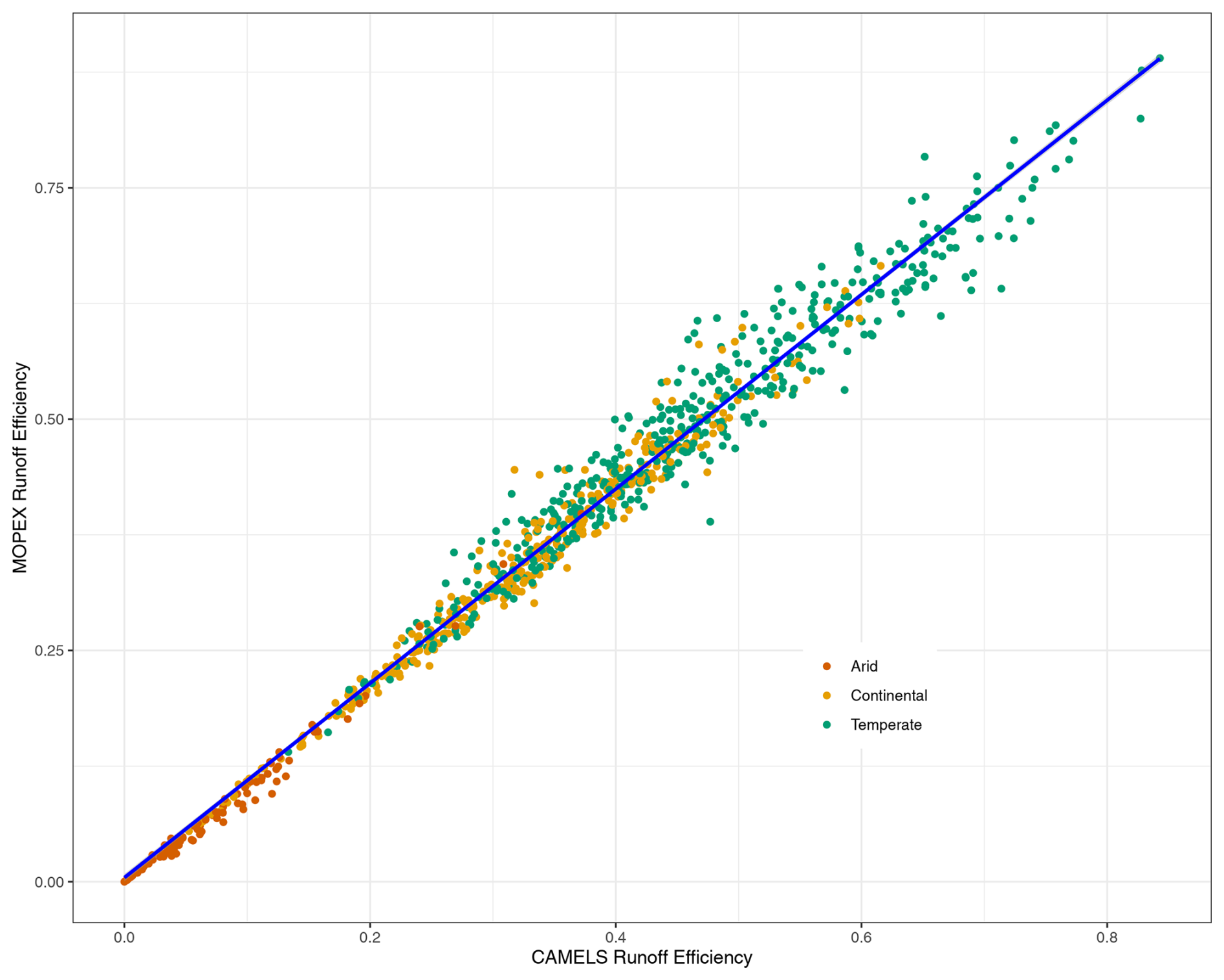
Figure 23Annual runoff coefficient (runoff precipitation) for each basin. Colored points represent climate region (arid, continental, and temperate). The blue line indicates the best linear fit.
4.3 Evaluation of precipitation and temperature extremes between datasets
While data extremes were not the focus of this study, a few precipitation and temperature extreme indices were evaluated for CAMELS and MOPEX values. Heavy precipitation days, where daily precipitation is greater than or equal to 10 mm, are more prolific in CAMELS, consistent with the wet bias (Fig. 24a). Despite the difference in the number of days, the two datasets show the same trends over time from 1981 to 2000. The number of dry days (precipitation < 1 mm) per year is greater in CAMELS for all climate regions, with the largest discrepancies in arid regions (Fig. 24b). This study has shown that CAMELS has a wet bias for continental and temperate regions and MOPEX has a wet bias for arid regions (Fig. 17). The differences in the number of dry days show that CAMELS daily precipitation values are overall larger than MOPEX values (Fig. 24b).
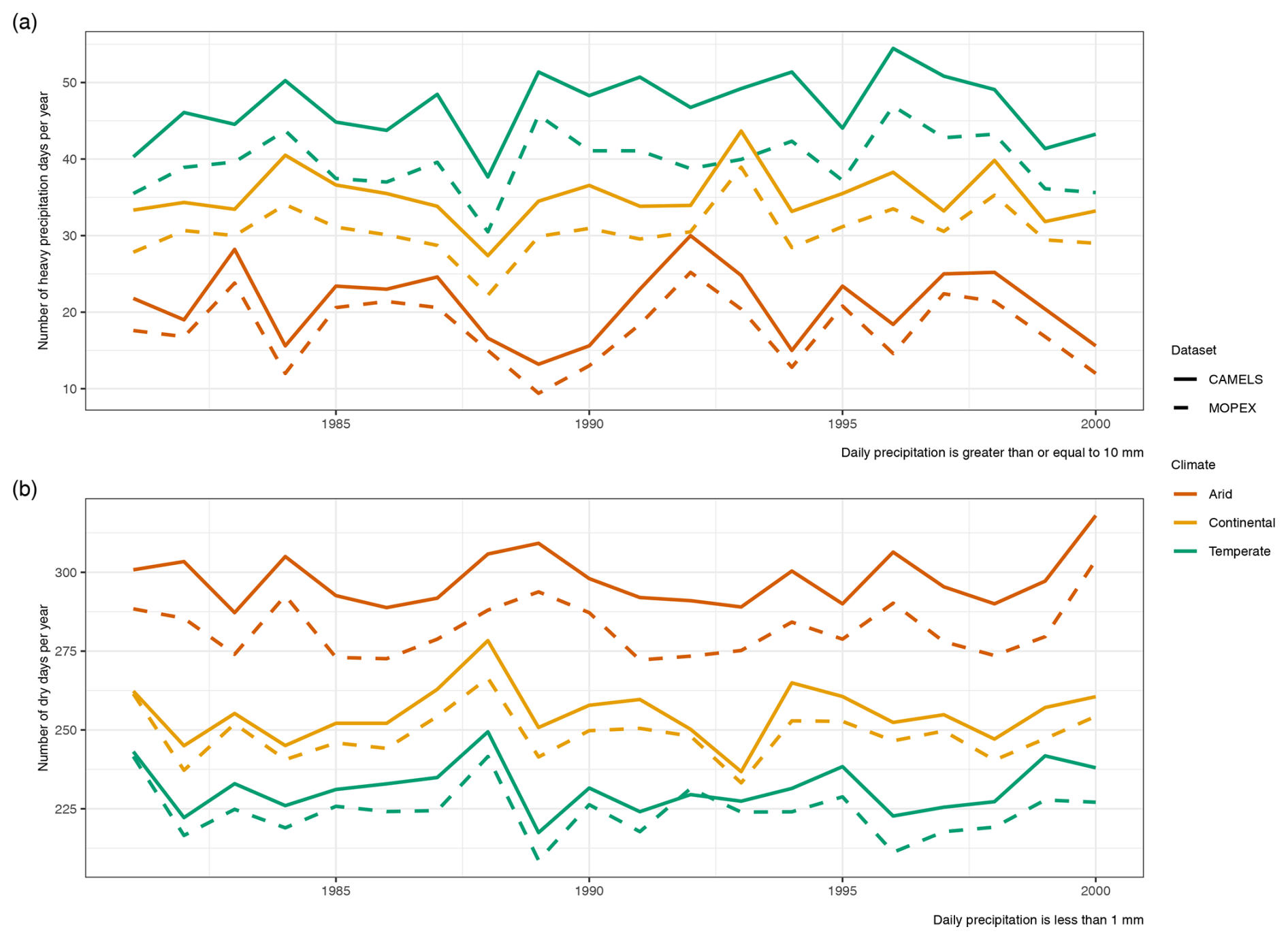
Figure 24Precipitation indices which show the (a) annual count of heavy precipitation days where precipitation is ≥ 10 mm and (b) annual count of dry days where the precipitation amount is <1 mm. Colors represent the climate region (arid, continental, and temperate), dashed lines represent MOPEX, and solid lines represent CAMELS.
The extreme wet-day rainfall, R99p, represents the annual total precipitation when daily rainfall is greater than the 99th percentile; when plotted for both datasets by climate region, very similar trends are observed (Fig. 25). In a broad temporal context, analysis consistently shows that precipitation values tend to be larger in CAMELS, regardless of the temporal scale considered beyond paired daily values. This pattern is observed in monthly, seasonal, and annual aggregations as well as summarized daily mean for continental and temperate regions.
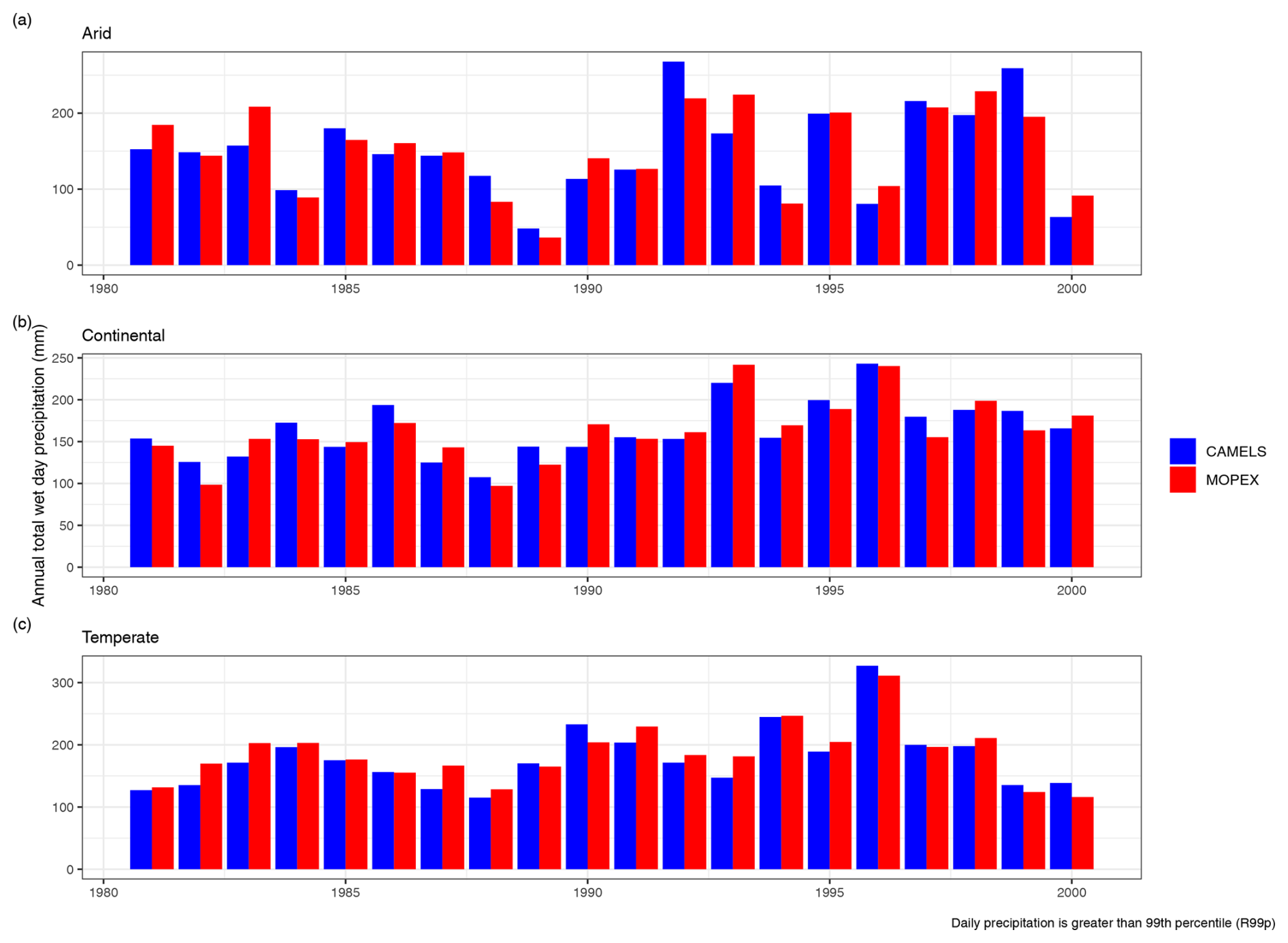
Figure 25Annual total precipitation when the daily precipitation amount on a wet day (≥ 1 mm) is greater than the 99th percentile for (a) arid, (b) continental, and (c) temperate regions. Colors (blue and red) represent the dataset.
In contrast, temperature values exhibit a different trend, with MOPEX consistently showing larger values irrespective of the temporal aggregation or climate region (Fig. 18). The number of frost days (Fig. 26a) indicates the annual count per year when temperature falls below 0 °C. CAMELS has a greater number of cold days, which corresponds to a warmer MOPEX bias. The warm MOPEX bias is most prevalent in arid regions when evaluating the number of summer days per year, which is the annual count of days with temperatures above 25 °C (Fig. 26b).
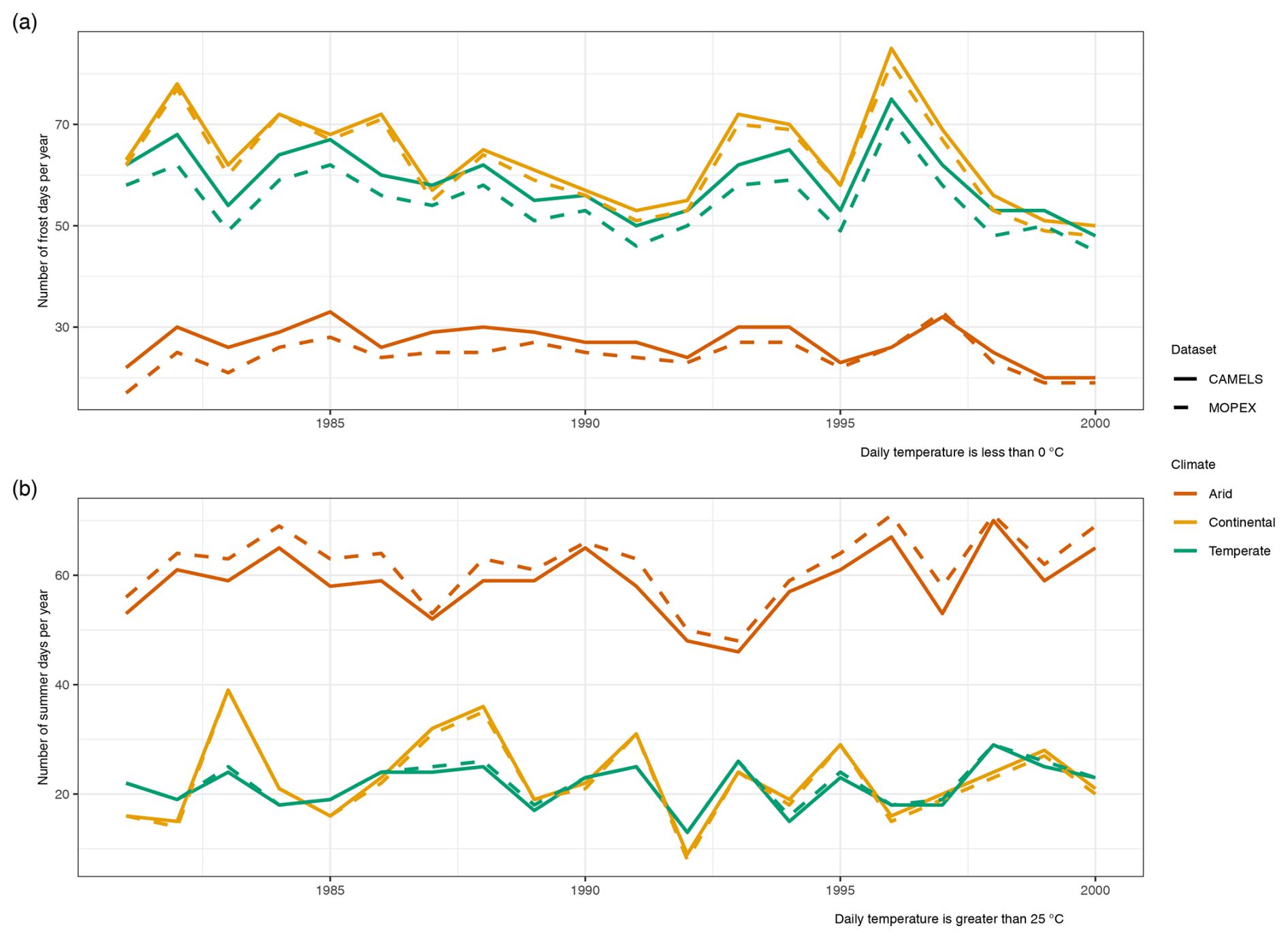
Figure 26Temperature indices which show the (a) annual count of frost days where temperature is <0 °C and (b) annual count of summer days where temperature is >25 °C. Colors represent the climate region (arid, continental, and temperate), dashed lines represent MOPEX, and solid lines represent CAMELS.
4.4 Validation
Hydrologic models are used to simulate real-world processes and range from simple conceptual models to complex physically based models. Choosing a suitable model is highly dependent on the purpose and scale. The input data required depend on the spatial and temporal distributions evaluated in a model, but precipitation and temperature are fundamental. Inherent biases in input data can skew modeling results. Machine learning (ML) was used instead of hydrologic models (i.e., SWAT, VIC, SAC-SMA) because ML models provide a data-driven, model-agnostic approach that focuses on the relationships between inputs and outputs without relying on predefined process-based assumptions (Herrera et al., 2022). Four machine learning models were used to predict runoff at daily, monthly, seasonal, and annual scales for MOPEX and CAMELS. The objective is not to determine model suitability but rather to evaluate the performance of each dataset. The RMSE, MAE, R2, and bias of predicted versus observed runoff serve as dataset comparisons.
On a daily scale, CAMELS has a slightly lower RMSE and MAE than MOPEX for all regions and a better R2, although the values are quite low, less than 0.3, shown in Table 12. A good fit is not expected with daily data which will have multiple zero values for precipitation.
Table 12Machine learning model metrics for predicted versus observed total daily runoff using total daily precipitation and mean daily temperature data as inputs for CAMELS (C) and MOPEX (M).
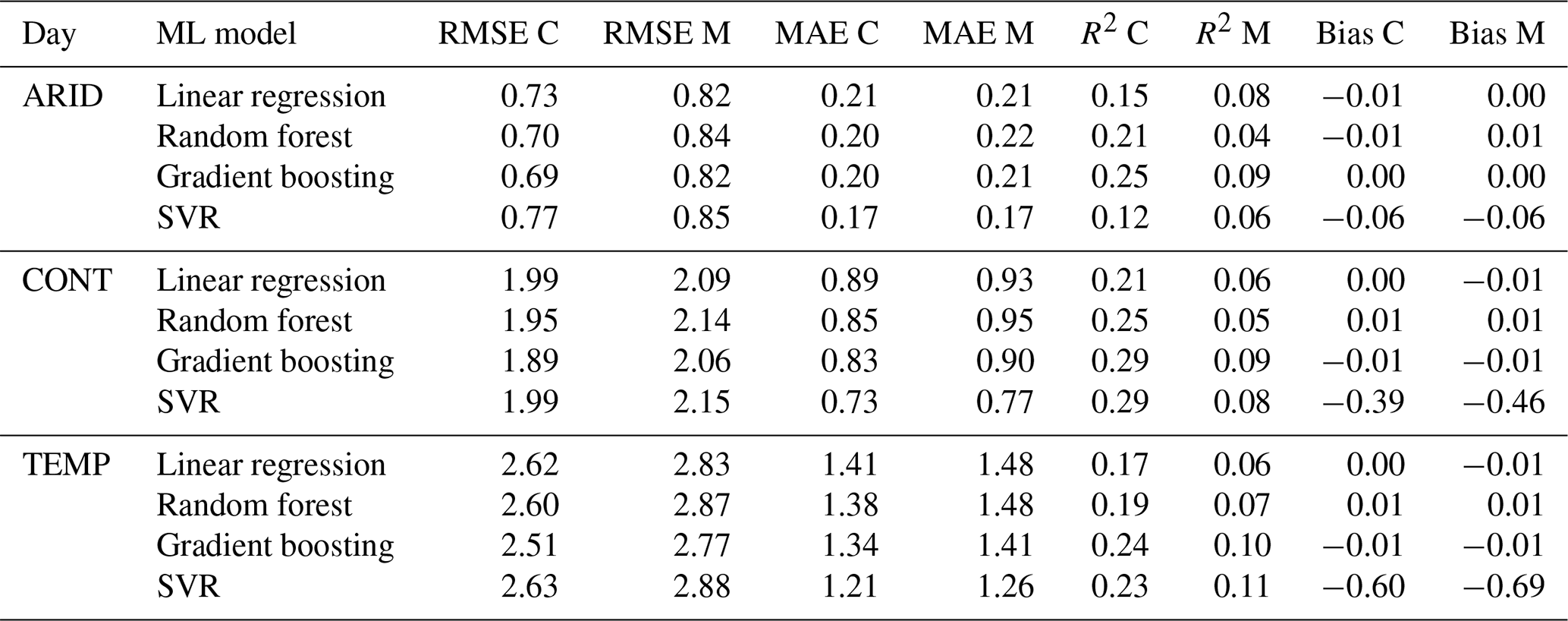
At the monthly aggregation, shown in Table 13, CAMELS narrowly outperforms MOPEX with lower RMSE and MAE values. The R2 values are extremely similar between datasets in all regions, and both exhibit the same positive biases with all ML models except for SVR, which underpredicts runoff and results in negative biases for both datasets. The results indicate that the predictive performance of the models is very similar across both datasets, suggesting a high degree of consistency between them.
Table 13Machine learning model metrics for predicted versus observed total monthly runoff using total monthly precipitation and mean monthly temperature data as inputs for CAMELS (C) and MOPEX (M).
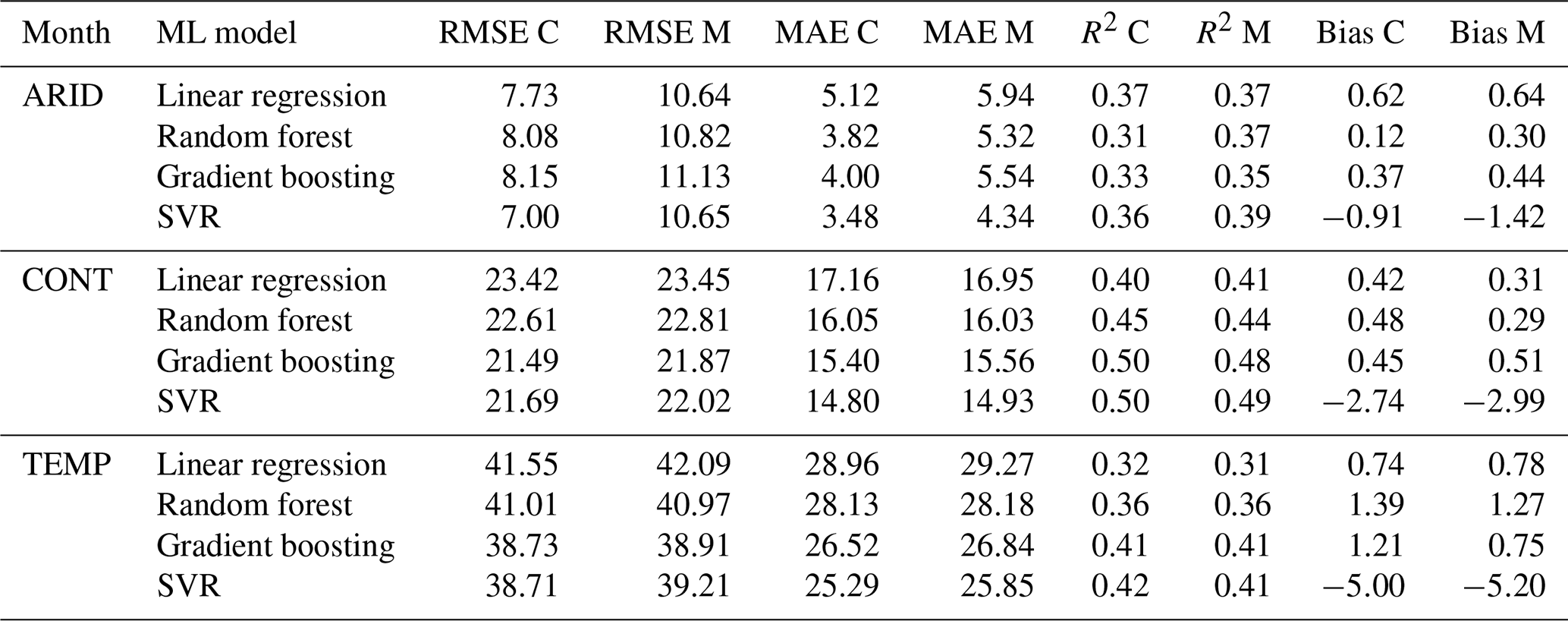
Seasonally, as shown in Table 14, the main discrepancies between the datasets are in continental regions, where CAMELS runoff predictions are lower than those from MOPEX by approximately 4 to 5 mm. This difference, while evident, is relatively small and may not have significant implications for broader regional or long-term studies. For instance, seasonal runoff values in continental regions range from 0.3 mm in one basin (JJA 1988) to 423.88 mm (MAM 1996) in another basin. This effect of these biases would be more pronounced for basins with very little runoff in a specific season, but this issue is not unique to these datasets. Any dataset used on such a fine, basin-specific scale may exhibit similar biases.
Table 14Machine learning model metrics for predicted versus observed total seasonal runoff using total seasonal precipitation and mean seasonal temperature data as inputs for CAMELS (C) and MOPEX (M).
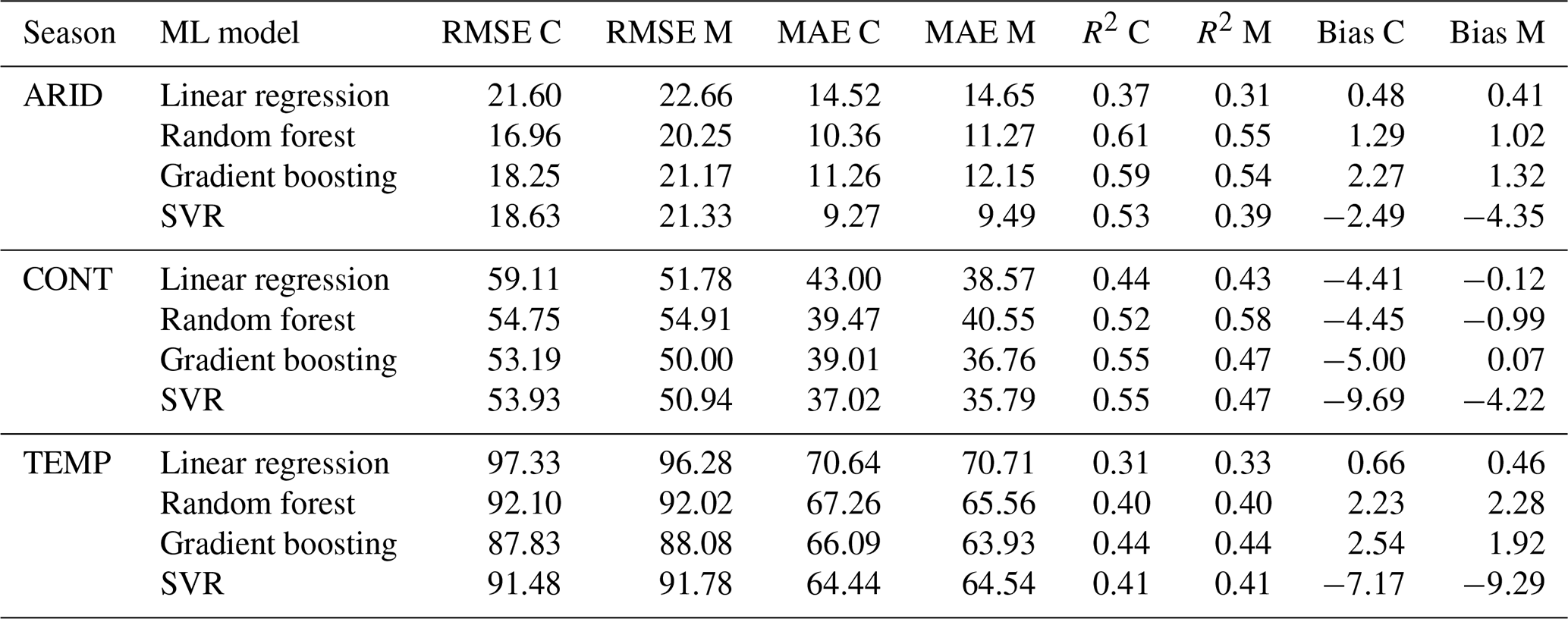
The differences in precipitation and temperature between MOPEX and CAMELS become more relevant depending on the scale and objective of the study. For daily or single-month analyses, as well as for very specific seasons, the datasets may not be directly comparable. However, as with any modeling approach, results come with inherent uncertainty, which should be acknowledged when presenting findings. Model results should be accompanied by an uncertainty estimate, reflecting potential biases or discrepancies. Bias correction is an essential part of any modeling process, typically done during the calibration phase (Lehner et al., 2023). In this context, the warm bias in MOPEX and the wet bias in CAMELS are important only when focusing on very fine, basin-specific scales. On larger temporal or spatial scales, these biases are less likely to significantly affect the conclusions, making these two datasets comparable for general hydrological or climate studies. At an annual scale, as shown in Table 15, MOPEX and CAMELS have improved R2 and the same predicted runoff biases despite the overall warm MOPEX temperature biases and wet CAMELS precipitation biases present in the data. The similarity in predicted runoff demonstrates the compatibility between the two datasets and that no corrections to the raw data are required at an annual scale.
Table 15Machine learning model metrics for predicted versus observed total annual runoff using total annual precipitation and mean annual temperature data as inputs for CAMELS (C) and MOPEX (M).
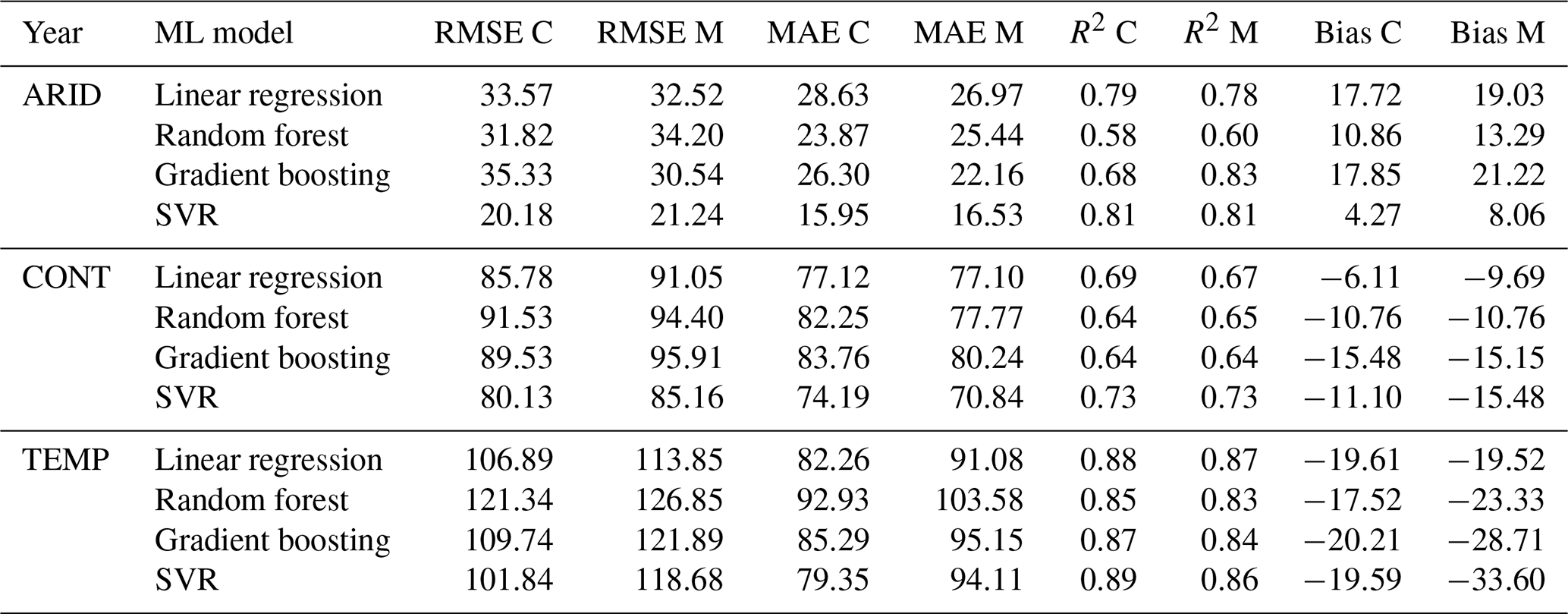
Total annual observed runoff is plotted against the predicted runoff for all four ML models in Fig. 27 with a 1 : 1 reference line. In all regions, MOPEX and CAMELS exhibit similar visual patterns and alignment of the points. In arid regions (Fig. 27a, b), both datasets show distinct clusters of low and high runoff values, reflecting greater variability and defined wet and dry periods. In contrast, continental (Fig. 27c, d) and temperate regions (Fig. 27e, f) display a more even distribution of runoff throughout the year, with both datasets capturing this behavior.
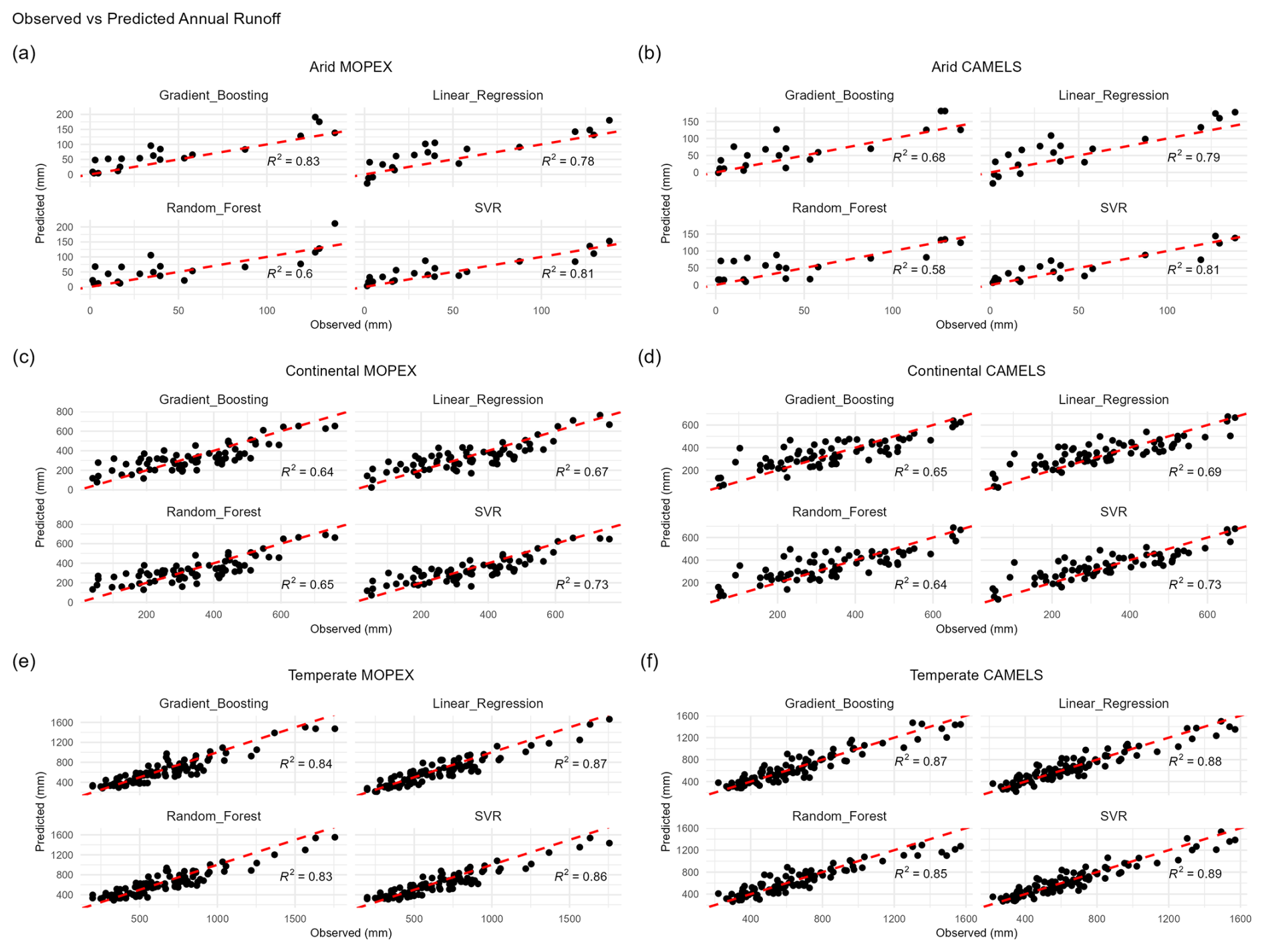
Figure 27Observed versus predicted total annual runoff (mm) for each ML model and each climate region. The dashed red line represents the 1 : 1 reference line. MOPEX correlations are (a) arid, (c) continental, and (e) temperate. CAMELS correlations are (b) arid, (d) continental, and (f) temperate.
In addition to predicting runoff, machine learning was used to differentiate between MOPEX and CAMELS. Data were separated by climate region, and then daily, monthly, seasonal, and annual precipitation, temperature, and water-balance-derived evapotranspiration were used for classifications. The support vector machine performed binary classification, assigning the standardized values to either MOPEX or CAMELS. The classification accuracy values shown in Table 16 represent the model's ability to identify which dataset the values belong to. If both datasets are considered equal, then the probability of choosing the correct dataset based on a selection of precipitation, temperature, and evapotranspiration values would be 0.5. Accuracy ranges from 49 % to 53 %, with most classifications close to 50 %. The model's difficulty in successfully classifying the data demonstrates the relative similarity of MOPEX and CAMELS for all climate regions and temporal aggregations.
Table 16Classification accuracy results for support vector models.
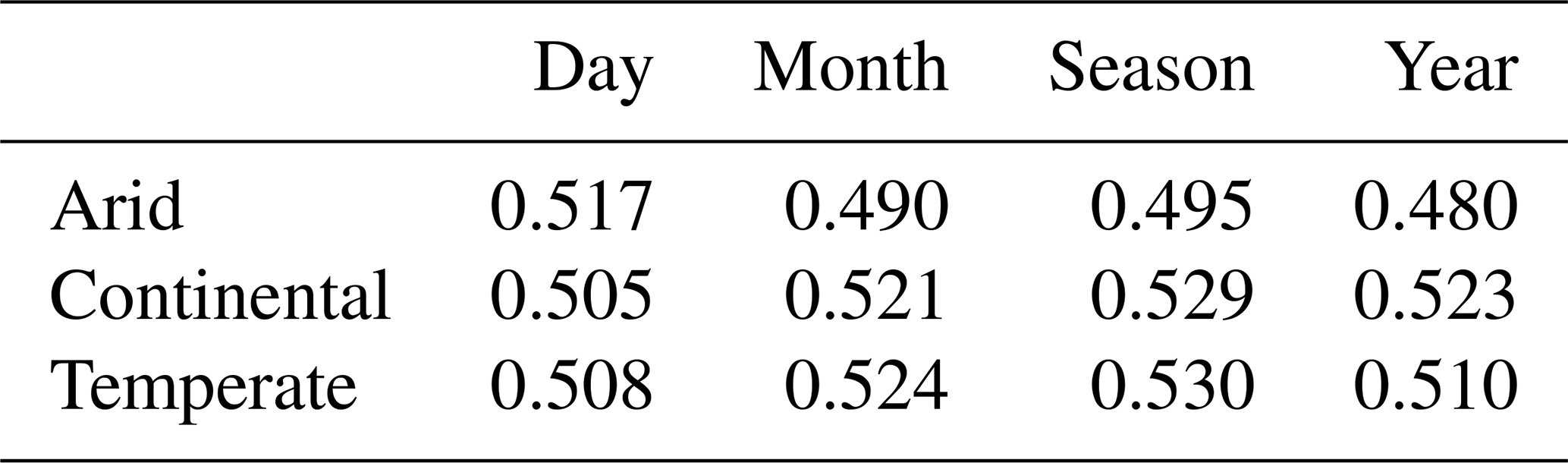
Annual precipitation similarity was evaluated using the double mass curve (Searcy et al., 1960), a comparative analysis that can identify changes in values over time, examine data consistency, and provide validation (Gao et al., 2017). Cumulative values of two variables plotted against each other should display a linear relationship if the ratio between them is constant. Breaks in the slope can indicate changes in the data and the time they occurred. When cumulative precipitation values are plotted for CAMELS and MOPEX, the slopes are 0.99, 1.06, and 1.07 for arid (Fig. 28a), continental (Fig. 28b), and temperate regions (Fig. 28c), respectively. There are apparent trends in the residuals for continental (Fig. 28e) and temperate (Fig. 28f) regions which could be due to bias; however, the residuals are small, within ± 60 mm.
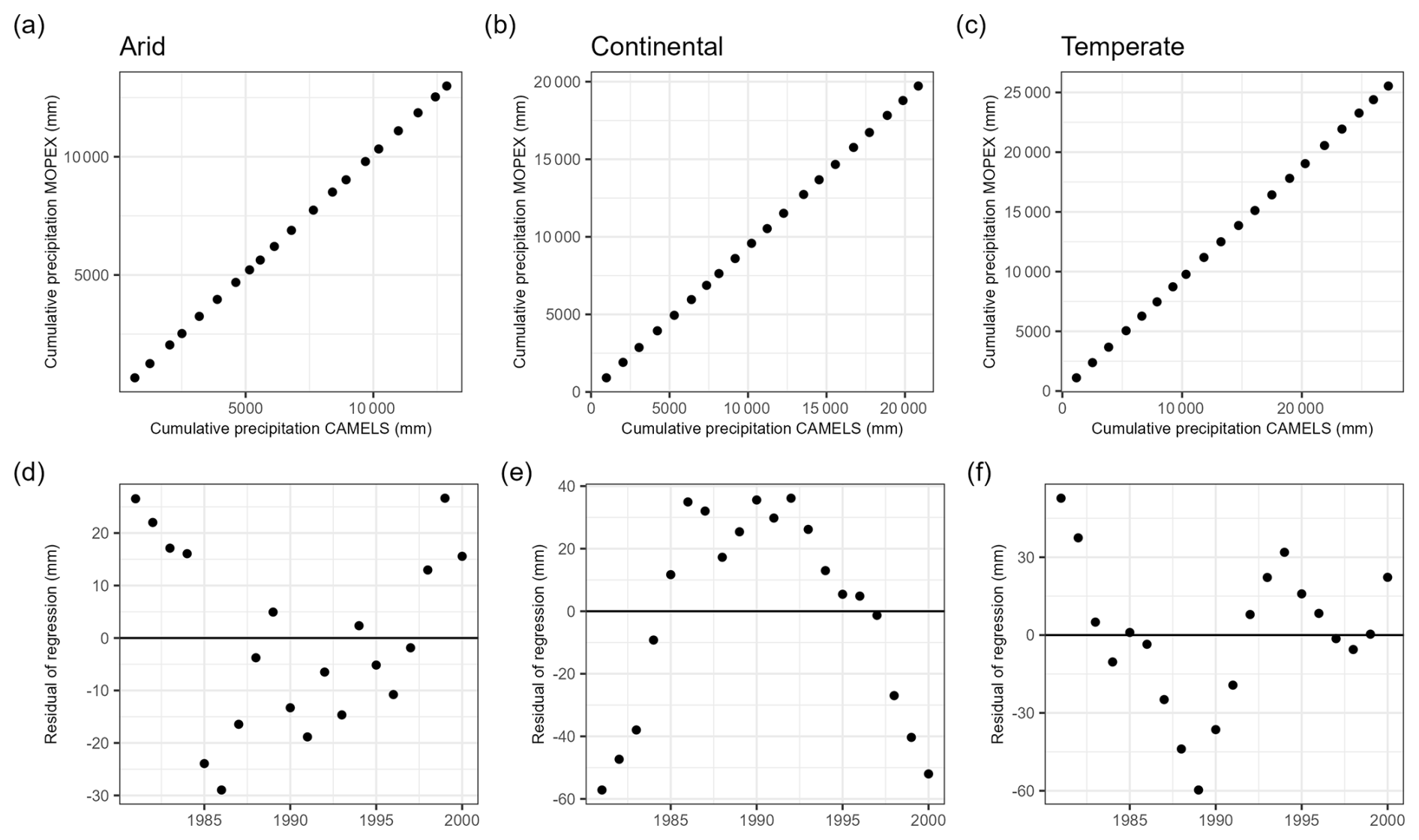
Figure 28Cumulative annual precipitation of CAMELS versus MOPEX for each climate region: (a) arid, (b) continental, and (c) temperate for all water years 1981–2000. Residuals of regression are shown for each double mass curve: (d) arid, (e) continental, and (f) temperate.
The comprehensive results above indicate important biases between the CAMELS and MOPEX datasets which vary in potential importance by climate region, geographic location, and degree of temporal aggregation. The findings underscore the need for careful consideration of dataset disparities, acknowledging the impact of temporal scale and methodology. As one would expect, comparability between CAMELS and MOPEX increases with greater temporal aggregation. The uncertainty and variability within each dataset were evaluated independently by calculating variance, standard deviation, and mean confidence intervals with bootstrapping (Tables 4–5, 7–8). The uncertainty and variability between the datasets were evaluated by paired tests, bias, MAE, MOE, R2, and hypothesis tests. With these measures, monthly, seasonal, and annual precipitation and temperature values are comparable for MOPEX and CAMELS (Table 9). “Magnitudes of difference or trends within data products may be comparable to the magnitude of difference between data products” (Levy et al., 2017). Essentially, the datasets share similar uncertainties and variances.
Statistically significant differences between variance and mean were more prevalent for precipitation than temperature; however, bootstrapping results indicate that both datasets have similar uncertainties for their mean values, with frequent overlap of the confidence intervals (Tables 7–8). The most substantial differences in mean values are observed in daily aggregations, with discrepancies of 1.13 %, 5.41 %, and 6.36 % for arid, continental, and temperate regions, respectively. At the annual scale, these differences decrease to 0.87 % for arid regions and 4.11 % for temperate regions. Continental regions unexpectedly show an increased difference of 5.54 % at the annual scale, which could be attributed to higher interannual variability or spatial heterogeneity. Median differences in precipitation show significant improvement with temporal aggregation: arid regions decrease from 200 % to 4.88 %, continental regions from 142.86 % to 5.70 %, and temperate regions from 118.37 % to 5.63 %.
Arid regions have the largest margin of error for precipitation but the smallest percent difference between their daily, monthly, seasonal, and annual mean values. Conversely, for temperature, arid regions have the largest percent difference between mean values in addition to the largest margins of error compared to continental and temperate regions. Correlations improve from 0.57 to 0.67 for daily precipitation values to greater than 0.90 for monthly, seasonal, and annual totals. Temperature correlation values are 0.99 for all regions. Positive correlation between temperature/evapotranspiration and runoff in arid regions is possibly due to increased rates of soil drying and decreased soil moisture retention, which then leads to greater runoff. Intense precipitation events with higher temperatures can also lead to less infiltration and more runoff. Climate patterns, such as rainy or dry seasons, are captured similarly in both datasets, and the more consistent pattern may contribute to higher monthly and seasonal correlations compared to annual.
MOPEX has an overall warm bias for all climate regions and a wet bias for arid regions. CAMELS has an overall wet bias for temperate and continental regions. MOPEX is approximately 0.62, 0.16, and 0.35 °C warmer than CAMELS for arid, continental, and temperate regions, respectively, on all temporal scales. For precipitation, MOPEX is larger than CAMELS by 0.02 mm d−1, 0.48 mm month−1, 1.45 mm season−1, and 5.82 mm yr−1 for arid regions. CAMELS shows a wet bias for continental, ranging from 0.15 mm d−1 to 56.21 mm yr−1, and temperate, with biases of 0.23 mm d−1 to 84.27 mm yr−1. Other comparison studies have also shown a warm MOPEX bias when compared to Daymet and a wet Daymet bias compared to MOPEX (Essou et al., 2016) and PRISM (Muche et al., 2020). Arid regions have the largest variance and uncertainty, which could be due to high evaporation rates, diverse landscapes, or the limited number of stations influencing bootstrapping results, incorporating fewer values compared to temperate or continental landscapes.
Precipitation exhibits a more pronounced positive bias on an annual scale (Fig. 15c), primarily due to the accumulation of small positive biases observed on monthly and seasonal scales. On finer temporal scales, these individual biases may partially offset each other due to seasonality, leading to less noticeable discrepancies, yet when data are aggregated annually, consistent overestimations are amplified, resulting in a more evident positive bias. This pattern highlights the presence of a systematic wet bias, where precipitation is consistently overestimated across temporal scales. The effect becomes more apparent at larger aggregation intervals, particularly due to increasing precipitation totals.
For temperature, although larger biases are observed in the 1980s, this pattern is limited to arid regions. Even in later years, the outliers for arid regions remain close to −2 °C. The medians for 1981, 1983, and 1987 are near zero, indicating minimal central tendency bias for those years. When averaged over time, as shown in Fig. 18, there is a slight improvement in biases for arid regions, with a reduction of approximately 0.25 °C from 1981 to 2000. An increase in station density could also contribute to the observed improvement in biases. The GHCNd database, accessed via the National Centers for Environmental Information (NCEI), indicates a noticeable rise in the number of precipitation and temperature stations during the late 1990s and early 2000s. This increased station coverage likely enhanced the spatial representation of observations, reducing biases and improving the accuracy of aggregated data.
Biases have potential consequences for dependent variables like evapotranspiration and runoff. A wet bias in daily precipitation could propagate and inflate the estimates of evapotranspiration and runoff, with hydrological models possibly predicting higher water availability across the system than actually present. Precipitation and temperature data sources differ between MOPEX and CAMELS, resulting in the observed biases; however, statistical analyses and validation in this study demonstrate that the datasets closely resemble one another. Precipitation biases are between −0.25 and 0.54 mm d−1 and temperature biases are between −1.88 and 0.27 °C d−1. These biases exhibit little influence on general hydrologic indices such as runoff efficiency (Fig. 23). Paired same-day comparisons of CAMELS versus MOPEX indicate that the largest discrepancies are between daily values for precipitation and temperature. Combining these datasets is not recommended for evaluating daily events such as maximum 1 d precipitation; however, both datasets exhibit the same general trends for seasonality and climatic indices (Sect. 4.3).
Climate data inherently carry a degree of uncertainty, and the biases described above derive from varying data sources and interpolation of those data to the watershed footprint. Factors such as heterogeneity, gaps in coverage, and interpolation methods contribute to deviations from precision. Data sources can include gauges, satellites, or a combination of both. No two datasets will be identical, as discrepancies occur across various scales. The primary objective is to choose the most appropriate, quality-controlled, accurate, and representative dataset for the research at hand. Previous comparison studies have highlighted the inconsistencies and biases between data products (Levy et al., 2017; Mallakpour and Villarini, 2016; Prat and Nelson, 2015; Sun et al., 2018).
Differences are expected between the datasets based on their sources and processing. Essou et al. (2016) compared three gridded datasets that interpolated daily temperature and precipitation values from the same observation network and noted that “the differences between gridded products may largely be attributed to the interpolation schemes which differ substantially from one dataset to another”. A key distinction between the MOPEX and CAMELS datasets lies in their methodological foundations. While both rely on ground-based weather stations as their primary source of meteorological input, they differ in how these observations were processed and spatially interpolated. Daily observations from a network of weather stations are made available by NOAA's National Centers for Environmental Information (NCEI). These data undergo quality assurance checks and processing prior to dissemination. However, uncertainties inherent to station observations remain due to limitations in instrumentation, despite adhere to established standards and calibration protocols, such as those outlined by the National Weather Service (https://www.weather.gov/coop/standards, last access: 24 April 2025).
MOPEX used observed, gauge-based inputs of precipitation and temperature from Cooperative Observer Program (COOP) and Snowpack Telemetry Network (SNOTEL) weather stations to estimate mean areal values at the catchment scale (Schaake et al., 2006). For precipitation, MOPEX employed the mean areal precipitation (MAP) methodology developed by the National Weather Service River Forecast Systems (NWSRFS), which combined an inverse distance weighting algorithm with monthly climatological means from PRISM to enhance spatial representativeness (Daly et al., 1993). In contrast, CAMELS derived its meteorological forcing data, specifically precipitation and temperature, from Daymet version 2, a gridded dataset that interpolates and extrapolates surface observations from Global Historical Climatology Network (GHCN) stations, including those from COOP (Wuertz et al., 2018). Daymet version 2 employs a Gaussian convolution kernel interpolation method to produce spatially and temporally consistent values across the CONUS. These gridded values were then spatially averaged to the catchment scale within CAMELS (Newman et al., 2015).
Evapotranspiration values in CAMELS are estimated via the SAC-SMA hydrological model, and as our results highlight, these model-based ET values can sometimes produce implausible behavior – such as overestimation or ET demand exceeding available precipitation. As MOPEX does not provide ET data, it can be calculated as a water balance residual. This approach benefits from empirical grounding, particularly in well-instrumented basins, but may suffer in regions with poor data quality or significant anthropogenic influences that are not explicitly accounted for in the water balance in addition to the uncertainties present in precipitation and runoff estimates (Carter et al., 2018).
MOPEX provides a longer historical record, which is valuable for evaluating long-term trends and hydroclimate variability. CAMELS is particularly well-suited for regional-scale hydrological analyses and climate sensitivity studies, especially in areas where gauge coverage is minimal or where spatial variability in meteorology is high (Addor et al., 2017; Newman et al., 2015). For spatially extensive or gridded analyses where consistency and meteorological realism are priorities, CAMELS offers advantages. Thus, when using daily data, the choice between CAMELS and MOPEX depends on the application.
In this study, we evaluated two large-sample datasets, MOPEX and CAMELS, comparing precipitation and temperature. The current MOPEX dataset contains data for 431 watersheds within the CONUS, while CAMELS includes data for 671 watersheds. The datasets were combined for this study and 47 common basins were compared for water years 1981 through 2000 on daily, monthly, seasonal, and annual scales. Precipitation, temperature, and streamflow data are areally weighted by delineated boundaries available as shapefiles. The main conclusions from the statistical comparison between CAMELS and MOPEX at daily, monthly, seasonal, and annual scales are summarized as follows.
-
The relevance of differences between MOPEX and CAMELS depends on the study's scale and purpose.
-
Daily pairwise comparisons are not recommended due to the variability in extreme precipitation event measurements. However, both datasets capture similar patterns and basin behavior, for example, when evaluating the number of rainy days or dry days per year.
-
Comparison improves significantly with monthly, seasonal, and annual aggregations. Despite temperature and precipitation biases, MOPEX and CAMELS show similar predicted runoff at the annual scale, requiring no raw data corrections. Monthly, seasonal, and annual values are comparable, as their differences are within expected uncertainty ranges.
-
Compatibility is constrained by basin water balance and requires basin-averaged values; i.e., ET values from model-output CAMELS time series must be used with caution and often cannot be reconciled with MOPEX or other water-balance-based estimates
-
All modeling results should include uncertainty estimates. Bias correction is typically performed during calibration, addressing dataset-specific biases.
The comparative analysis of the MOPEX and CAMELS datasets reveals distinct biases and variability patterns across climate regions and temporal scales. CAMELS generally exhibits a positive precipitation bias at monthly, seasonal, and annual aggregations in continental and temperate regions, while MOPEX shows higher daily precipitation values, particularly in arid regions. Temperature analysis highlights a consistent warm bias in MOPEX across all regions and timescales, with notable disparities in daily values. Despite these differences, the datasets show overlapping confidence intervals for many metrics, suggesting similar levels of uncertainty.
The observed variations, particularly for extreme precipitation events, underscore the necessity for cautious interpretation of dataset-specific results. For applications requiring precision, such as hydrological modeling or climate analysis, direct substitution of daily values between MOPEX and CAMELS is not advisable without considering these biases. Instead, leveraging insights from both datasets can provide a more comprehensive understanding of regional and temporal climate characteristics.
Ongoing research aims to extend the MOPEX dataset from 2003 to 2023 and the CAMELS dataset from 2014 to 2023, leveraging the Daymet dataset (Thornton et al., 2021). MOPEX and CAMELS will be integrated into a cohesive resource that combines catchment attributes and human impact classifications based on the GAGESII framework (Falcone et al., 2010). The enhanced dataset will support model calibration and freshwater balance studies at the watershed scale (Sink, 2025). Basin-scale analyses and forecasts are expected to benefit from more precise water balance constraints, improving their accuracy and predictive power.
A repository with R code used for analyses and resulting data is available from https://github.com/k-sink/Toward_merging (last access: 27 December 2024). Colors are based on https://jfly.uni-koeln.de/color/#pallet (last access: 6 December 2024) by Okabe-Ito (2008). Although the MOPEX dataset (Schaake et al., 2006) was publicly available at the time of analysis, recent attempts to access the data at http://hydrology.nws.noaa.gov/pub/gcip/-mopex/US_Data were unsuccessful. The CAMELS dataset (Addor et al., 2017) is available from https://gdex.ucar.edu/dataset/camels.html. Streamflow data and attributes are available from https://waterdata.usgs.gov/nwis/inventory (last access: 6 December 2024).
KS and TB conceptualized the research project. KS developed and performed the formal analysis. KS prepared the paper with contributions from the co-author.
The contact author has declared that neither of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
Data processing and visualization were performed with R (R Core Team, 2024). UTD SESS contribution #1728.
This paper was edited by Lelys Bravo de Guenni and reviewed by two anonymous referees.
Addor, N., Newman, A. J., Mizukami, N., and Clark, M. P.: The CAMELS data set: catchment attributes and meteorology for large-sample studies, Hydrol. Earth Syst. Sci., 21, 5293–5313, https://doi.org/10.5194/hess-21-5293-2017, 2017 (data available at: https://gdex.ucar.edu/dataset/camels.html, last access: 25 June 2024).
Addor, N., Do, H. X., Alvarez-Garreton, C., Coxon, G., Fowler, K., and Mendoza, P. A.: Large-sample hydrology: recent progress, guidelines for new datasets and grand challenges, Hydrolog. Sci. J., 65, 712–725, https://doi.org/10.1080/02626667.2019.1683182, 2020.
Andréassian, V., Perrin, C., and Michel, C.: Impact of imperfect potential evapotranspiration knowledge on the efficiency and parameters of watershed models, J. Hydrol., 286, 19–35, https://doi.org/10.1016/j.jhydrol.2003.09.030, 2004.
Beck, H. E., Zimmermann, N. E., McVicar, T. R., Vergopolan, N., Berg, A., and Wood, E. F.: Present and future köppen-geiger climate classification maps at 1-km resolution, Sci. Data, 5, 1–12, https://doi.org/10.1038/sdata.2018.214, 2018.
Berghuijs, W. R., Sivapalan, M., Woods, R. A., and Savenije, H. H. G.: Patterns of similarity of seasonal water balances: A window into streamflow variability over a range of time scales, Water Resour. Res., 50, 5638–5661, https://doi.org/10.1002/2014WR015692, 2014.
Breiman, L.: Random Forests, Mach. Learn., 45, 5–32, 2001.
Breiman, L., Cutler, A., Liaw, A., and Wiener, M.: randomForest: Breiman and Cutlers Random Forests for Classification and Regression, R package version 4.7-1.2, https://CRAN.R-project.org/package=randomForest, 2024.
Buban, M. S., Lee, T. R., and Baker, C. B.: A comparison of the U.S. climate reference network precipitation data to the parameter-elevation regressions on independent slopes model (PRISM), J. Hydrometeorol., 21, 2391–2400, https://doi.org/10.1175/JHM-D-19-0232.1, 2020.
Budyko, M. I.: Climate and life, Academic Press, New York, 508 pp., ISBN 0121394506, 1974.
Carter, E., Hain, C., Anderson, M., and Steinschneider, S.: A water balance-based, spatiotemporal evaluation of terrestrial evapotranspiration products across the contiguous United States, J. Hydrometeorol., 19, 891–905, https://doi.org/10.1175/JHM-D-17-0186.1, 2018.
Chao, L., Zhang, K., Wang, J., Feng, J., and Zhang, M.: A comprehensive evaluation of five evapotranspiration datasets based on ground and grace satellite observations: Implications for improvement of evapotranspiration retrieval algorithm, Remote Sens., 13, 2414, https://doi.org/10.3390/rs13122414, 2021.
Coopersmith, E., Yaeger, M. A., Ye, S., Cheng, L., and Sivapalan, M.: Exploring the physical controls of regional patterns of flow duration curves – Part 3: A catchment classification system based on regime curve indicators, Hydrol. Earth Syst. Sci., 16, 4467–4482, https://doi.org/10.5194/hess-16-4467-2012, 2012.
Daly, C., Neilson, R. P., and Phillips, D. L.: A Statistical-Topographic Model for Mapping Climatological Precipitation over Mountainous Terrain, J. Appl. Meteorol., 33, 140–158, 1993.
Domingos, P.: A few useful things to know about machine learning, Commun. ACM, 55, 78–87, https://doi.org/10.1145/2347736.2347755, October 2012.
Duan, Q., Schaake, J., Andréassian, V., Franks, S., Goteti, G., Gupta, H. V., Gusev, Y. M., Habets, F., Hall, A., Hay, L., Hogue, T., Huang, M., Leavesley, G., Liang, X., Nasonova, O. N., Noilhan, J., Oudin, L., Sorooshian, S., Wagener, T., and Wood, E. F.: Model Parameter Estimation Experiment (MOPEX): An overview of science strategy and major results from the second and third workshops, J. Hydrol., 320, 3–17, https://doi.org/10.1016/j.jhydrol.2005.07.031, 2006.
Essou, G. R. C., Arsenault, R., and Brissette, F. P.: Comparison of climate datasets for lumped hydrological modeling over the continental United States, J. Hydrol., 537, 334–345, https://doi.org/10.1016/j.jhydrol.2016.03.063, 2016.
Falcone, J. A., Carlisle, D. M., Wolock, D. M., and Meador, M. R.: GAGES: A stream gage database for evaluating natural and altered flow conditions in the conterminous United States, Ecology, 91, 621, https://doi.org/10.1890/09-0889.1, 2010.
Farnsworth, R. K. and Thompson, E. S.: Evaporation Atlas for the Contiguous 48 United States, NOAA Technical Report NWS 33, Washington, D. C., 1982.
Fligner, M. A. and Killeen, T. J.: Distribution-free two-sample tests for scale, J. Am. Stat. Assoc., 71, 210–213, https://doi.org/10.1080/01621459.1976.10481517, 1976.
Gao, P., Li, P., Zhao, B., Xu, R., Zhao, G., Sun, W., and Mu, X.: Use of double mass curves in hydrologic benefit evaluations, Hydrol. Process., 31, 4639–4646, https://doi.org/10.1002/hyp.11377, 2017.
Guo, H.: Big Earth data: A new frontier in Earth and information sciences, Big Earth Data, 1, 4–20, https://doi.org/10.1080/20964471.2017.1403062, 2017.
Gupta, H. V., Perrin, C., Blöschl, G., Montanari, A., Kumar, R., Clark, M., and Andréassian, V.: Large-sample hydrology: a need to balance depth with breadth, Hydrol. Earth Syst. Sci., 18, 463–477, https://doi.org/10.5194/hess-18-463-2014, 2014.
Han, E., Crow, W. T., Hain, C. R., and Anderson, M. C.: On the use of a water balance to evaluate interannual terrestrial ET variability, J. Hydrometeorol., 16, 1102–1108, https://doi.org/10.1175/JHM-D-14-0175.1, 2015.
Harrell, F. E.: Harrell Miscellaneous, R package version 5-2.0, https://CRAN.R-project.org/package=Hmisc, 2024.
Hartigan, J. A. and Wong, M. A.: Algorithm AS 136: A K-Means Clustering Algorithm, J. R. Stat. Soc. C-App., 38, 100–108, 1979.
Helsel, D. R., Hirsch, R. M., Ryberg, K. R., Archfield, S. A., and Gilroy, E. J.: Statistical Methods in Water Resources Techniques and Methods 4 – A3, USGS Techniques and Methods, https://doi.org/10.3133/tm4A3, 2020.
Herrera, P. A., Marazuela, M. A., and Hofmann, T.: Parameter estimation and uncertainty analysis in hydrological modeling, WIRes Water, 9, e1569, https://doi.org/10.1002/wat2.1569, 2022.
Kassambara, A.: rstatix: Pipe-friendly framework for basic statisical tests, R package version 0.7.2, https://CRAN.R-project.org/package=rstatix, 2023.
Kelleher, C. and Braswell, A.: Introductory overview: Recommendations for approaching scientific visualization with large environmental datasets, Environ. Modell. Softw., 143, 105113, https://doi.org/10.1016/j.envsoft.2021.105113, 2021.
Kratzert, F., Klotz, D., Herrnegger, M., Sampson, A. K., Hochreiter, S., and Nearing, G. S.: Toward Improved Predictions in Ungauged Basins: Exploiting the Power of Machine Learning, Water Resour. Res., 55, 11344–11354, https://doi.org/10.1029/2019WR026065, 2019.
Kuhn, M., Wing, J., Weston, S., Williams, A., Keefer, C., Engelhardt, A., Cooper, T., Mayer, Z., Kenkel, B., Benesty, M., Lescarbeau, R., Ziem, A., Scrucca, L., Tang, Y., Candan, C., and Hunt, T.: caret: Classification and Regression Training, R package version 7.0-1, https://CRAN.R-project.org/package=caret, 2024.
Lehner, F., Nadeem, I., and Formayer, H.: Evaluating skills and issues of quantile-based bias adjustment for climate change scenarios, Adv. Stat. Climatol. Meteorol. Oceanogr., 9, 29–44, https://doi.org/10.5194/ascmo-9-29-2023, 2023.
Lemaitre-Basset, T., Oudin, L., Thirel, G., and Collet, L.: Unraveling the contribution of potential evaporation formulation to uncertainty under climate change, Hydrol. Earth Syst. Sci., 26, 2147–2159, https://doi.org/10.5194/hess-26-2147-2022, 2022.
Levy, M. C., Cohn, A., Lopes, A. V., and Thompson, S. E.: Addressing rainfall data selection uncertainty using connections between rainfall and streamflow, Sci. Rep., 7, 219, https://doi.org/10.1038/s41598-017-00128-5, 2017.
Lins, H. F.: USGS Hydro-Climatic Data Network 2009 (HCDN-2009): U.S. Geological Survey Fact Sheet 2012–3047, 4, https://pubs.usgs.gov/fs/2012/3047/, 2012.
Long, D., Longuevergne, L., and Scanlon, B. R.: Uncertainty in evapotranspiration from land surface modeling, remote sensing, and GRACE satellites, Water Resour, Res,, 50, 1131–1151, https://doi.org/10.1002/2013WR014581, 2014.
Mallakpour, I. and Villarini, G.: A simulation study to examine the sensitivity of the Pettitt test to detect abrupt changes in mean, Hydrolog. Sci. J., 61, 245–254, https://doi.org/10.1080/02626667.2015.1008482, 2016.
Maurer, E. P., Wood, A. W., Adam, J. C., Lettenmaier, D. P., and Nijssen, B.: A Long-Term Hydrologically Based Dataset of Land Surface Fluxes and States for the Conterminous United States*, J. Climate, 15, 3237–3251, https://doi.org/10.1175/1520-0442(2002)015<3237:ALTHBD>2.0.CO;2, 2002.
Meyer D., Dimitriadou E., Hornik K., Weingessel A., and Leisch F.: e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), R package version 1.7-14, https://CRAN.R-project.org/package=e1071, 2024.
Miller, D. A. and, White, R. A.: A conterminous United States multi-layer soil characteristics data set for regional climate and hydrology modeling, Earth Interactions, 2, https://doi.org/10.1175/1087-3562(1998)002<0001:ACUSMS>2.3.CO;2, 1998.
Muche, M. E., Sinnathamby, S., Parmar, R., Knightes, C. D., Johnston, J. M., Wolfe, K., Purucker, S. T., Cyterski, M. J., and Smith, D.: Comparison and Evaluation of Gridded Precipitation Datasets in a Kansas Agricultural Watershed Using SWAT, J. Am. Water Resour. As., 56, 486–506, https://doi.org/10.1111/1752-1688.12819, 2020.
Nearing, G. S., Kratzert, F., Sampson, A. K., Pelissier, C. S., Klotz, D., Frame, J. M., Prieto, C., and Gupta, H. V.: What Role Does Hydrological Science Play in the Age of Machine Learning?, Water Resour. Res., 57, e2020WR028091, https://doi.org/10.1029/2020WR028091, 2021.
Newman, A. J., Clark, M. P., Sampson, K., Wood, A., Hay, L. E., Bock, A., Viger, R. J., Blodgett, D., Brekke, L., Arnold, J. R., Hopson, T., and Duan, Q.: Development of a large-sample watershed-scale hydrometeorological data set for the contiguous USA: data set characteristics and assessment of regional variability in hydrologic model performance, Hydrol. Earth Syst. Sci., 19, 209–223, https://doi.org/10.5194/hess-19-209-2015, 2015.
Newman, A. J., Clark, M. P., Longman, R. J., and Giambelluca, T. W.: Methodological intercomparisons of station-based gridded meteorological products: Utility, limitations, and paths forward, J. Hydrometeorol., 20, 531–547, https://doi.org/10.1175/JHM-D-18-0114.1, 2019.
Okabe, M. and Ito, K.: Color universal design (CUD): How to make figures and presentations that are friendly to colorblind people, https://jfly.uni-koeln.de/color/#pallet, 2008.
Oubeidillah, A. A., Kao, S.-C., Ashfaq, M., Naz, B. S., and Tootle, G.: A large-scale, high-resolution hydrological model parameter data set for climate change impact assessment for the conterminous US, Hydrol. Earth Syst. Sci., 18, 67–84, https://doi.org/10.5194/hess-18-67-2014, 2014.
Pelletier, J. D., Broxton, P .D., Hazenberg, P., Zeng, X., Troch, P. A., Niu, G., Williams, Z., Brunke, M. A., and Gochis, D.: A gridded global data set of soil, intact regolith, and sedimentary deposit thicknesses for regional and global land surface modeling, J. Adv. Model. Earth Syst., 8, 41–65, 2016.
Pendergrass, A. G., Knutti, R., Lehner, F., Deser, C., and Sanderson, B. M.: Precipitation variability increases in a warmer climate, Sci. Rep., 7, 17966, https://doi.org/10.1038/s41598-017-17966-y, 2017.
Pierce, D. W., Cayan, D. R., Maurer, E. P., Abatzoglou, J. T., and Hegewisch, K. C.: Improved Bias Correction Techniques for Hydrological Simulations of Climate Change*, J. Hydrometeorol., 16, 2421–2442, https://doi.org/10.1175/JHM-D-14-0236.s1, 2015.
Pimentel, R., Arheimer, B., Crochemore, L., Andersson, J. C. M., Pechlivanidis, I. G., and Gustafsson, D.: Which Potential Evapotranspiration Formula to Use in Hydrological Modeling World-Wide?, Water Resour. Res., 59, e2022WR033447, https://doi.org/10.1029/2022WR033447, 2023.
Prat, O. P. and Nelson, B. R.: Evaluation of precipitation estimates over CONUS derived from satellite, radar, and rain gauge data sets at daily to annual scales (2002–2012), Hydrol. Earth Syst. Sci., 19, 2037–2056, https://doi.org/10.5194/hess-19-2037-2015, 2015.
R Core Team: R: A language and environment for statistical computing, R Foundation for Statistical Computing, Vienna, Austria, R version 4.3.3, https://www.R-project.org/, 2024.
Ridgeway, G.: gbm: Generalized Boosted Regression Models, R package version 2.2.2, https://CRAN.R-project.org/package=gbm, 2024.
Sawicz, K. A., Kelleher, C., Wagener, T., Troch, P., Sivapalan, M., and Carrillo, G.: Characterizing hydrologic change through catchment classification, Hydrol. Earth Syst. Sci., 18, 273–285, https://doi.org/10.5194/hess-18-273-2014, 2014.
Schaake, J., Cong, S., and Duan, Q.: The US mopex data set, IAHS-AISH Publication, 307, 9–28, 2006 (data available at: http://hydrology.nws.noaa.gov/pub/gcip/-mopex/US_Data, last access: 4 May 2021).
Seaber, P. R., Kapinos, F. P., and Knapp, G. L.: USGS Watershed Delineation, United States Geological Survey Water Supply Paper, 2294, 1987.
Searcy, J. K., Hardison, C. H., and Langbein, W. B.: Double-Mass Curves With a section Fitting Curves to Cyclic Data Manual of Hydrology: Part 1. General Surface-Water Techniques, https://doi.org/10.3133/wsp1541B, 1960.
Shmilovici, A.: Machine Learning for Data Science Handbook, edited by: Rokach, L., Maimon, O., and Shmueli, E., Springer International Publishing, https://doi.org/10.1007/978-3-031-24628-9, 2023.
Sink, K.: MACH Hydrometeorological dataset for 1,014 catchments in the United States (1.0), Zenodo [data set], https://doi.org/10.5281/zenodo.15311986, 2025.
Sitterson, J., Sinnathamby, S., Parmar, R., Koblich, J., Wolfe, K., and Knightes, C. D.: Demonstration of an online web services tool incorporating automatic retrieval and comparison of precipitation data, Environ. Modell. Softw., 123, 104570, https://doi.org/10.1016/j.envsoft.2019.104570, 2020.
Slack, J. R. and Landwehr, J. M.: HYDRO-CLIMATIC DATA NETWORK (HCDN): A U. S. GEOLOGICAL SURVEY STREAMFLOW DATA SET FOR THE UNITED STATES FOR THE STUDY OF CLIMATE VARIATIONS, 1874-1988 Open-File Report 92-129, https://doi.org/10.3133/ofr92129, 1992.
Sun, Q., Miao, C., Duan, Q., Ashouri, H., Sorooshian, S., and Hsu, K. L.: A Review of Global Precipitation Data Sets: Data Sources, Estimation, and Intercomparisons, Rev. Geophys., 56, 79–107, https://doi.org/10.1002/2017RG000574, 2018.
Thornton, P. E., Shrestha, R., Thornton, M., Kao, S. C., Wei, Y., and Wilson, B. E.: Gridded daily weather data for North America with comprehensive uncertainty quantification, Sci. Data, 8, 1–17, https://doi.org/10.1038/s41597-021-00973-0, 2021.
Thornton, P. E., Thornton, M. M., Mayer, B. W., Wilhelmi, N., Wei, Y., Devarakonda, R., and Cook, R. B.: Daymet: Daily Surface Weather Data on a 1-km Grid for North America, Version 2., https://www.osti.gov/biblio/1148868, 2013.
Welch, B. L.: On the comparison of several mean values: an alternative approach, Biometrika, 38, 330–336, https://doi.org/10.1093/biomet/38.3-4.330, 1951.
Wuertz, D., Lawrimore, J., and Koreniewski, B.: Cooperative observer program (COOP) Hourly precipitation data (HPD), NOAA National centers for environmental information, https://doi.org/10.25921/p7j8-2170, 2018.
Xia, Y., Mitchell, K., Ek, M., Cosgrove, B., Sheffield, J., Luo, L., Alonge, C., Wei, H., Meng, J., Livneh, B., Duan, Q., and Lohmann, D.: Continental-scale water and energy flux analysis and validation for North American Land Data Assimilation System project phase 2 (NLDAS-2): 2. Validation of model-simulated streamflow, J. Geophys. Res.-Atmos., 117, 1–23, https://doi.org/10.1029/2011JD016051, 2012.
Xu, T. and Liang, F.: Machine learning for hydrologic sciences: An introductory overview, WIRes Water, 8, e1533, https://doi.org/10.1002/wat2.1533, 2021.
Yokoo, K., Ishida, K., Ercan, A., Tu, T., Nagasato, T., Kiyama, M., and Amagasaki, M.: Capabilities of deep learning models on learning physical relationships: Case of rainfall-runoff modeling with LSTM, Sci. Total Environ., 802, 149876, https://doi.org/10.1016/j.scitotenv.2021.149876, 2022.
Zhang, W., Furtado, K., Wu, P., Zhou, T., Chadwick, R., Marzin, C., Rostron, J., and Sexton, D.: Increasing precipitation variability on daily-to-multiyear time scales in a warmer world, Sci. Adv., 7, eabf8021, https://doi.org/10.1126/sciadv.abf8021, 2021.