the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 25 Aug 2020
| 25 Aug 2020
Predicting discharge capacity of vegetated compound channels: uncertainty and identifiability of one-dimensional process-based models
Adam Kiczko
Kaisa Västilä
Adam Kozioł
Janusz Kubrak
Elżbieta Kubrak
Marcin Krukowski
Despite the development of advanced process-based methods for estimating the discharge capacity of vegetated river channels, most of the practical one-dimensional modeling is based on a relatively simple divided channel method (DCM) with the Manning flow resistance formula. This study is motivated by the need to improve the reliability of modeling in practical applications while acknowledging the limitations on the availability of data on vegetation properties and related parameters required by the process-based methods. We investigate whether the advanced methods can be applied to modeling of vegetated compound channels by identifying the missing characteristics as parameters through the formulation of an inverse problem. Six models of channel discharge capacity are compared in respect of their uncertainty using a probabilistic approach. The model with the lowest estimated uncertainty in explaining differences between computed and observed values is considered the most favorable. Calculations were performed for flume and field settings varying in floodplain vegetation submergence, density, and flexibility, and in hydraulic conditions. The output uncertainty, estimated on the basis of a Bayes approach, was analyzed for a varying number of observation points, demonstrating the significance of the parameter equifinality. The results showed that very reliable predictions with low uncertainties can be obtained for process-based methods with a large number of parameters. The equifinality affects the parameter identification but not the uncertainty of a model. The best performance for sparse, emergent, rigid vegetation was obtained with the Mertens method and for dense, flexible vegetation with a simplified two-layer method, while a generalized two-layer model with a description of the plant flexibility was the most universally applicable to different vegetative conditions. In many cases, the Manning-based DCM performed satisfactorily but could not be reliably extrapolated to higher flows.
- Article
(9435 KB) - Full-text XML
- BibTeX
- EndNote





Compound channels consisting of a main channel and vegetated floodplains are commonly observed in both natural and engineered settings. For instance, vegetated compound (two-stage) channels have been recently proposed as an environmentally preferable alternative to conventional dredging in flood and agricultural water management (e.g., Västilä and Järvelä, 2011). Such a nature-based solution (NBS) is expected to allow combination of the technical needs, e.g., flow conveyance and channel bed stability, and the environmental requirements, e.g., improved water quality and biodiversity (Rowiński et al., 2018), but requires reliable predictions of the discharge capacity. Herein, the difficulty results from the complex cross-sectional geometry and the composite roughness resulting from parts of channels with highly different flow resistance. Floodplain vegetation is the main factor complicating the predictions, particularly in small- to medium-sized channels, where up to 90 % of the flow resistance can be caused by plants (e.g., Västilä et al., 2016). With an increase in computing power, two- and even three-dimensional models are gaining popularity in flood assessments (Teng et al., 2017; Liu et al., 2019). In practice, one-dimensional models, on which the present study focuses, still play an important role, especially in tasks requiring long-term or large spatial-scale simulations (e.g., Yu et al., 2019; Chaudhary et al., 2019). In one-dimensional flow-routing models the most widely used technique for predicting the discharge capacity of compound channels is the divided channel method (DCM) with the Manning formula, defined in 1960 (Posey, 1967). In this approach flow is computed separately in channel zones with differing flow resistance, usually the main channel and floodplains. The momentum exchange between areas of the higher and lower stream velocity, the so-called kinematic effect, is represented by rough imaginary walls at the interfaces (Sellin, 1964; Kubrak et al., 2019a, b). Despite the well-known limitations of the DCM (Myers, 1978; Fread, 1989; Soong and DePue, 1996; Pasche, 2007), the Manning formula is presently the basis for the majority of practical models for flood hazard assessments, design of hydraulic structures, and water management (Shields et al., 2017).
To improve the reliability of practical discharge capacity estimation in vegetated channels, the key vegetation properties controlling the reach-scale flow resistance should be incorporated into the calculations (e.g., Yen, 2002; Luhar and Nepf, 2013). One of the most sophisticated models of the channel capacity can be attributed to Shiono and Knight (1991), who on the basis of a turbulent flow theory, derived equations for depth-averaged velocities in the cross-sectional plane. Accompanied by an additional drag term, the method was successfully used to model flow in a channel with composite roughness consisting of vegetated and non-vegetated zones (e.g., Zhang et al., 2018; Abril and Knight, 2004; Zinke et al., 2011; Tang and Knight, 2008; Kalinowska et al., 2020). However, for a typical practical case, the Shiono and Knight (1991) model is too complex, requiring much of modelers' efforts, especially in the presence of efficient two-dimensional solutions.
Several approaches providing a physically based characterization of vegetation and the flow–vegetation interactions are available for straightforward one-dimensional discharge capacity assessments in small- to medium-sized vegetated channels. In these models, vegetation can be represented as rigid or flexible, interacting with water streams as submerged and emergent (Shields et al., 2017). There are many methods explaining each of these types of vegetation, and a comprehensive review can be found in Aberle and Järvelä (2013). Some of the most recognized methods include, e.g., those developed by Pasche (1984) and simplified by Mertens (1989) to describe the flow in zones with unsubmerged (emergent) vegetation; by Arcement and Schneider (1989), who presented empirical relationships for Manning roughness coefficients and vegetation parameters; by Klopstra et al. (1997), who derived a process-based model for rigid, submerged vegetation; by Järvelä (2004), who provided a process-based approach for emergent rigid and flexible vegetation; by Baptist et al. (2007), who introduced a two-layer model for rigid vegetation; and by Luhar and Nepf (2013), who developed a two-layer model for submerged vegetation. Despite the recent developments of these process-based methods, there is a lack of knowledge on whether the state-of-the-art methods with a significant number of parameters are reliable in common practical applications characterized by insufficient information on vegetative properties and related model parameters.
An important drawback of vegetation models for hydraulic resistance, from the practical (modeler's) point of view, is that they require much more data than traditional methods. For example, with the DCM, in terms of roughness, the river cross section can be usually characterized using three values of the Manning coefficient, for the main channel and two floodplains. The vegetation models would require specific data on plant features, such as density, spacing, shape or species, and leaf area indices. An exception may be channel design assignments, where it is possible to assume a future character of a plant cover after an intended intervention, and necessary data on vegetation can be obtained through field surveys, which noticeably increase costs of a model application. A promising way for a more effective determination of vegetation features might be remote sensing, and many studies were devoted to the use of these techniques in flood routing. For example, Casas et al. (2010), Forzieri et al. (2010), Abu-Aly et al. (2014), and Wolski et al. (2018) investigated the use of airborne laser scanning for determining vegetation classes, which corresponds to hydraulic features. The obtained values of plant properties are however affected by a strong uncertainty, resulting from classification itself but also generalization and variation within a class, as demonstrated by Straatsma and Huthoff (2011). Forzieri et al. (2012) argued that airborne laser scanning itself is not suitable for measuring plant characteristics without extensive field reference data. Therefore more recent attempts focused on application of terrestrial laser scanning (e.g., Antonarakis et al., 2009; Jalonen and Järvelä, 2014; Jalonen et al., 2015; Kałuza et al., 2018). However, the use of the remote sensing data in vegetation models requires extensive field measurements to establish a link between obtained data and hydraulic properties.
The aforementioned Straatsma and Huthoff (2011) study showed that even with field measurements of vegetation properties, generalization of acquired parameters is rather unavoidable, especially when dealing with larger areas. Values characterizing vegetation, obtained in the field, have to be attributed to a spatial unit usually representing a vegetation class. On the one hand, together with the nonlinear form of the vegetation resistance models, such a generalization introduces significant uncertainty. On the other hand, it weakens the link between measured values and model parameters, which reflect the lumped hydraulic effect instead of representing physical quantities. Such quantities are not measurable and depend on the structure of the flow model, such as the governing equations or the simplification of the flow dynamics made in the model. In still scarce studies where flood routing is analyzed with the use of vegetation-roughness models, some researchers tend to consider plant properties to be model parameters that should be calibrated, i.e., identified with respect to observations. So, treating them similarly to Manning coefficients, which are usually obtained by the model calibration, where their values are adjusted, ensures an agreement between computed and observed, e.g., water levels, stream velocities, or flow rates – by solving the inverse problem (e.g., Khatibi et al., 1997; Marcinkowski et al., 2018, 2019; Yu et al., 2019). The example is given by Dalledonne et al. (2019), who identified vegetation parameters describing, e.g., stem diameters, their heights, drag coefficients, and a leaf area index in the two-dimensional flow model. Berends et al. (2019) directly addressed the problem of parameter identifiability of vegetation-roughness models, also using the two-dimensional model. It seems that when vegetation resistance methods become more popular in practical codes for flood routing, this approach will become more common.
Performing model calibration using parameters of vegetation-roughness models raises at least four implications.
-
Is it possible to identify models for vegetation roughness on the basis of the inverse task? The problem arises from the larger number of parameters in vegetation-roughness models, compared to traditional approaches, based, e.g., on the Manning formula. The problem was well demonstrated by Werner et al. (2005), who investigated the uncertainty and sensitivity of a hybrid two-/one-dimensional model for a varying number of parameters used to describe a channel and floodplain roughness. Analyzing the parameter identification using a probabilistic approach, they showed that with an increasing number of parameters, the obtained parameter distributions become less specific, suggesting the same level of probability over a wide range of values. Moreover, the obtained parameter distributions were different from values suggested in the literature. Although the Werner et al. (2005) study did not account for vegetation-roughness models, the same effect was observed in the case of these methods by Berends et al. (2019) and Kiczko et al. (2017). This leads to the second point.
-
Is it reasonable to apply process-based vegetation-roughness models if the identification of their parameters results in values differing from the real values measured at the field (Werner et al., 2005; Kiczko et al., 2017; Berends et al., 2019)? Such a calibration procedure gives an impression of using process-based methods as data-driven, black-box models common, e.g., in rating curve assessments (Kiang et al., 2018). From this perspective, the process-based methods with other than measured parameters act as functions with a large number of parameters compared to traditional approaches like the Manning-based DCM. The effect can probably be mitigated by applying constraints on the parameter values to ensure that they are within their physical bands. With additional information on channel vegetation, using, e.g., remote sensing or land use maps, it might be possible to restrict their variability ranges further. The advantage of process-based approaches might come from the physical interpretability of their parameters. For instance, too large stem diameters of plants are easier to spot than too high values of Manning roughness coefficients. However, still there is a lack of evidence on whether it is beneficial to apply process-based models instead of purely data-driven approaches.
-
The choice of the vegetation-roughness model, e.g., for rigid or flexible vegetation, depends on the type of vegetation present in the channel. Is it then possible to choose an appropriate model without knowledge of the plant type? This issue should be considered in respect of point 3 by analyzing whether it is possible to choose an appropriate model structure by solving the inverse problem.
-
Are the process-based models beneficial compared to, e.g., the DCM-based Manning approach when there is a need to extrapolate to higher flows? This is an issue well recognized in hydrology (Kuczera and Mroczkowski, 1998), that identification of simpler models is much more straightforward, but because process-based models incorporate casual interrelationships, they provide a better basis for the extrapolation. It is of special importance in flood assessments, where the calibrated models need to be extrapolated to higher flood flows.
The overall goal of the present paper is to investigate the implications of the use of one-dimensional state-of-the-art process-based methods in discharge capacity estimation of small- to medium-sized vegetated compound channels. These common practical applications are typically characterized by insufficient data on vegetative properties, so that models are identified in terms of the inverse problem. We compare the model identifiability, uncertainty, and physical interpretation of the parameters of discharge capacity methods characterized by different levels of parameterization. The following methods were investigated: Manning-based DCM, Pasche (Pasche, 1984), and Mertens (1989) methods designed for emergent rigid vegetation, and three versions of the two-layer model proposed by Luhar and Nepf (2013) as modified by Västilä and Järvelä (2018), designed for flexible submerged or emergent vegetation. All the models were applied to vegetation conditions differing in relative submergence (covering both submerged and emergent conditions) and density, as motivated by real cases where it is possible that, e.g., a “rigid” vegetation model is applied for flexible vegetation because of a lack of information on the vegetation properties. Parameter identification was conditioned on water depths instead of discharges to make the problem more similar to practical cases, such as flood assessments, where a model outcome is usually the water level. It is out of the scope of the paper to provide a summary of all available methods.
This section provides an overall description of the applied methodology. In Sect. 2.2.2 the Pasche (1984) and Mertens (1989) models for rigid emergent vegetation are presented. Flexible vegetation models based on the two-layer assumption of Luhar and Nepf (2013), generalized by Västilä and Järvelä (2018), are provided in Sect. 2.2.3–2.2.4. Computations were performed for steady-state conditions by applying vegetation-roughness models to find water levels in a channel cross section.
Two experimental data sets collected from vegetated compound channels were used: flume measurements with rigid vegetation (Koziol, 2010; Kozioł, 2013, Sect. 2.3.1) and field measurements with natural mostly grassy vegetation at Ritobacken Brook (Västilä et al., 2016, Sect. 2.3.2). The process-based models of vegetation roughness were compared with the traditional DCM with Manning roughness coefficients. For the purpose of the identification task it was necessary to assume that parameters are constant and, for that reason, the experimental data were divided into sets, where vegetation features were as constant as possible. Therefore, the model identification for the field data was performed separately for each season.
Similarly to Werner et al. (2005) and Berends et al. (2019), the parameter identification problem is defined in the probabilistic manner, on the basis of Bayesian estimation (Sect. 2.1). The adapted assumption is that the methods can be compared in terms of assessed uncertainty: i.e., the more appropriate the method is, the lower the uncertainty of its predictions is. At this point it should be noted that with a such problem statement the goal is the model identification rather than parameter identification (Mantovan and Todini, 2006), as without knowledge of true parameter values, only measures for model outputs are used in the calibration process. The model identifiability in a probabilistic manner is understood as the ability to determine the parameter distribution that explains the model uncertainty in relation to observations. An effort was made to ensure that uncertainty analysis is objective and repeatable, despite different assumptions about initial a priori parameter distributions for each method.
The identification was performed for a different number of observations, similarly to hydrological studies of Her and Chaubey (2015) and Her and Seong (2018). For calibration the points of rating curves were used and the effect of different possible combinations of observations in the identification task was also investigated; e.g., the model was calibrated for a set of five lower flows but also for a set of five higher and all intermediate sets. To address the issue of using simpler and more complex, process-based models for extrapolation of the rating curve, a special focus was placed on predictions of maximum flows with a model identified using only lower flows.

Figure 1Two ways to define the parameter identification problem for process-based methods of channel discharge: (a) traditional approach; (b) adapted in the present study.
2.1 Parameter identification and uncertainty analysis
River assessments using one-dimensional models with DCM, based on the Manning formula, are usually performed without detailed knowledge of vegetation properties. The Manning roughness coefficients are considered model parameters, identified in the inverse problem, where their values are adjusted to ensure a satisfactory fit between model outputs and observations, e.g., computed and measured water depths H at given discharge Q. The vegetation-roughness models provide a relationship between plant features and the water flow. Vegetation characteristics that can be obtained by field measurements or, e.g., design assumptions, are considered model input. In discharge calculations, the use of such models can be illustrated with Fig. 1a, where vegetation properties are one of the model inputs. It is still necessary to specify remaining parameters like roughness coefficients for bed or drag coefficients for plants. The present study investigates the approach given in Fig. 1b, where vegetation characteristics in vegetation-roughness models are also considered model parameters that have to be identified without knowledge of channel vegetation. This makes the application of vegetation-roughness models similar to the way Manning-based approaches are used. From the practical point of view, the difference, apart the model structure, comes from the number of parameters that have to be identified.
In the probabilistic parameter identification approach, parameters are assumed to be random variables explaining the model uncertainty (Werner et al., 2005; Berends et al., 2019). The model identification is performed along with the uncertainty analysis and consists in a determination of parameter distributions that translates to using the model for probabilistic distributions of model outputs, here water depths H. The results of parameter identification and uncertainty estimation are usually presented in the form of confidence intervals for model outputs and parameter marginal distributions. The problem was defined on the basis of Bayes estimation using the generalized likelihood uncertainty estimation (GLUE) approach (Beven and Binley, 1992; Romanowicz and Beven, 2006). Parameter distributions are obtained using the Bayes formula:
where θ stands for parameters, H water depths, P(θ) a priori parameter distribution, P(θ∕H) a posteriori parameter distribution, and L(H∕θ) the likelihood function. The equation is solved using Monte Carlo sampling of parameters within the adapted a priori distributions P(θ) and model simulations for given flow rates Q.
The choice of the likelihood function L(H∕θ) depends on the assumptions about the character of model errors. In the present study it was assumed that models are unbiased and errors between computed and observed water levels ζ are independent and normally distributed: , where σ2 is unknown variance. The relationship between observed water levels and the computed H for a given flow rate Q and parameters θ can be given as follows:
The error ζ explains all discrepancies between the model and observations, as well as the measurement and model uncertainty. Therefore the performed uncertainty analysis accounts for the total uncertainty. When comparing different models for the same observation set, the measurement uncertainty is constant and differences result from the model uncertainty. For independent and normally distributed errors ζ the likelihood function is given by (Romanowicz et al., 1996; Romanowicz and Beven, 2006)
with m standing for the number of observation points with discharges Qi used in the parameter identification. It should be noted that with the likelihood function given with Eq. (3) the selection of a so-called behavioral set, common in GLUE approaches, is not necessary.
The variance σ2 is unknown and in GLUE approaches it is usually estimated using model residuals (Romanowicz and Beven, 2006; Stedinger et al., 2008). In the present study, σ2 is determined on the basis of observations by ensuring that the appropriate share is enclosed in confidence intervals (Blasone et al., 2008) of modeled water depths H. The optimization problem is defined in terms of scaling factor κ for the variance of model residuals , used commonly in GLUE:
The variance of model residuals is calculated using the Monte Carlo sample (Romanowicz and Beven, 2006):
The purpose of Eq. (4) is to provide an initial guess on σ2. The κ scaling factor is computed on the basis of the minimization task:
where and denote the lower and upper quantiles (qL, qU) of the calculated water levels from the a posteriori distribution (Eq. 1), obtained with the likelihood function (Eq. 3); p stands for confidence interval, defined as . In the present study 95 % confidence intervals (p=0.95) were used, with qL=0.025 and qU=0.975. ϵ is a small number as a penalty for too wide confidence intervals of water levels H. The minimum of the function given with Eq. (6) should be the smallest value of κ for which the last term in Eq. (6) equals zero:
This is true when exactly p⋅m observations fall within the confidence intervals. For p=0.95 and relatively small observation sets of m∼10 in the present study, a minimum is found when all observations are enclosed by intervals. In such a case, the sum term in Eq. (8) is equal to 1 and the difference becomes negative. The procedure given with Eqs. (6)–(8) allows for determination of the minimal value of σ2 (Eqs. 2 and 3), sufficient to explain model uncertainty with respect to observations. It should be noted that for a poor model and/or inappropriate variability ranges of a priori parameter distributions, such a solution might not exist. The term given with Eq. (8) was therefore a criterion for the model identifiability. The model was considered identifiable if Eq. (8) was fulfilled.
The assumption of a priori parameter distributions P(θ) has a significant effect on the a posteriori solution (Freni and Mannina, 2010; Tang et al., 2016). In the present study, to obtain objective uncertainty estimates for different methods and parameters, it was decided to apply uninformative and relatively wide a priori distributions, assuming no knowledge of channel vegetation, maintaining however physically interpretable ranges (Table 1). The parameter ranges of uniform distribution were chosen to ensure that the high-probability region is enclosed by the Monte Carlo sample. The span of this region links with confidence intervals comprising 95 % of the a posteriori distribution, so it was assumed that the sample should be noticeably larger. It was obtained by testing whether it is possible to make confidence intervals wider by increasing the κ coefficient determined using Eqs. (6)–(8). This way it was possible to check whether confidence intervals are not directly affected by the span of the Monte Carlo sample. When confidence intervals were insensitive to increasing values of κ, it was necessary to extend ranges of a priori parameter distributions. It should be noted that it was necessary only in the case of unsuitable models, where the condition given by Eq. (8) was usually not fulfilled.
Table 1Parameter variability ranges (uniform P(θ) distribution) for the Ritobacken and flume experiments; numerals in parameter symbols are used to distinguish properties on the left (1) and right (1) channel sides.
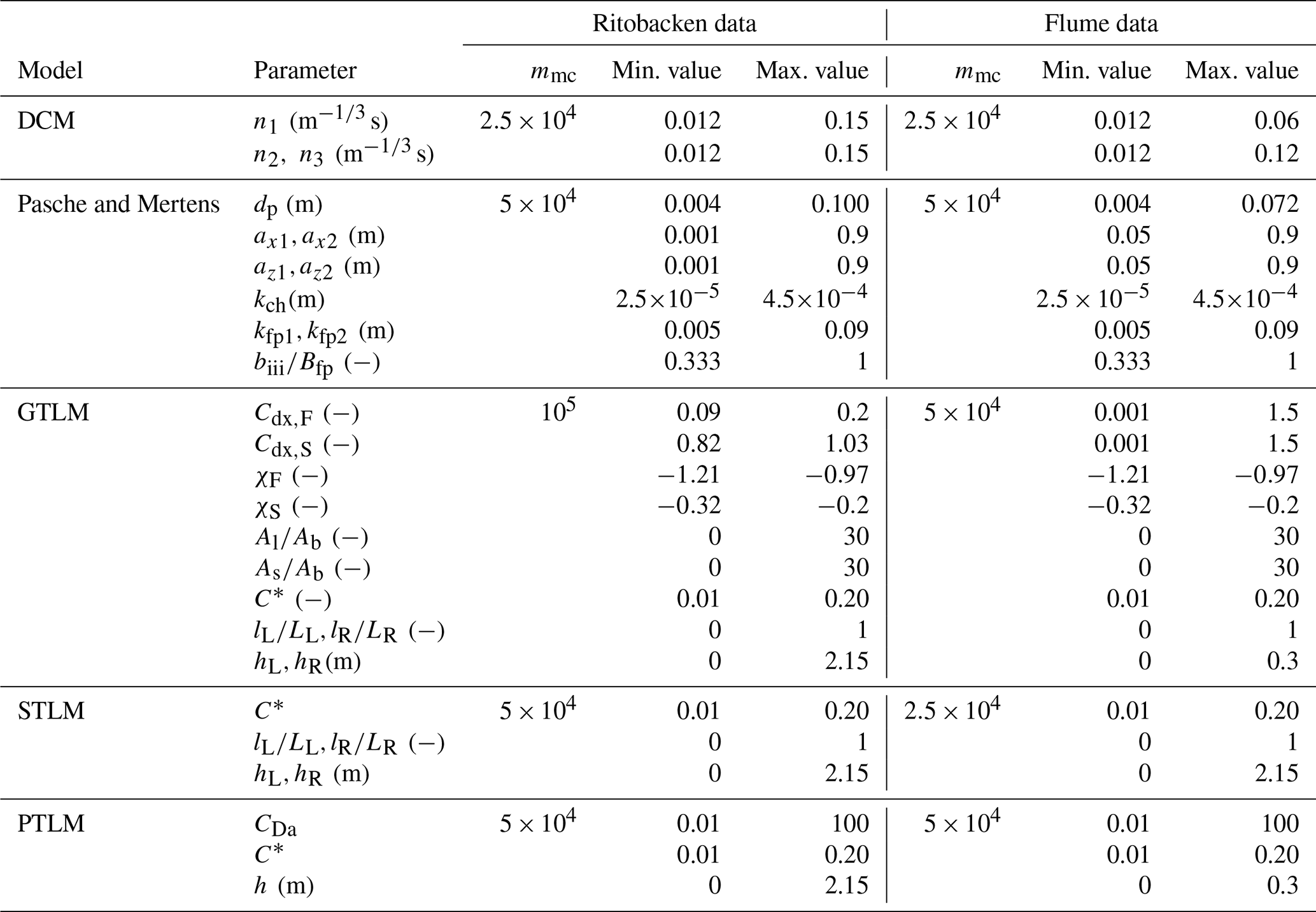
Note that in flume experiments the cross section was symmetric and that the same parameter values were used for the following parameters: , hL=hR, ax1=ax2, and az1=az2.
It is acknowledged that the parameter identification and associated uncertainty depend on the size of the observation data set. To address this issue, the model identification (Eq. 1) was performed for a varying number m of observation points: and the corresponding flow rates as the input. The m included values from 1 to the total number of available observations M: . The calculations included all possible combinations of observations with the given m, i.e., . The number of all combinations is then 2M−1, excluding the empty set (m=0). Such an approach allows us to eliminate the effect of non-representative observation samples. The method was discussed previously by Kiczko et al. (2017).
Observation points not used for identification M−m act as a verification set. In this analysis, both the proportion of verification points that fall within estimated confidence intervals and the width of confidence intervals are used as measures of model performance. The narrower the confidence bands and the fewer observation points falling outside them, the better a model is. On the opposite end, a less adequate model requires a larger spread of the solution to enclose observations, as it wrongly explains their variability. Because the different combinations of m points resulted in multiple uncertainty estimates, the results were presented in terms of statistical moments as a function of m. For a detailed description of results box-plots were used, where the median is given as a horizontal line within a box that spans over the 25 % and 75 % quantiles and whiskers indicate the result extent, excluding extreme values given with cross marks.
As was mentioned before, it should be noted that by applying the Bayesian concept, the objective is the model identification (see the comment on the purpose of the Bayesian identification of Mantovan and Todini, 2006). Parameter variability is used to describe the uncertainty, specifically the error ζ defined with Eq. (2). This comes from the form of the inverse problem, where likelihood measures depend only on measured model outputs, here water depths, and it is possible that parameters that are different from real ones but provide a good model fit are considered likely (Werner et al., 2005; Kiczko et al., 2017; Berends et al., 2019). To demonstrate this effect and to discuss possible implications, the obtained marginal a posteriori distributions of parameters P(θ∕H) were compared with values obtained by direct measurements in analyzed case studies. A special focus was placed on extrapolation capabilities of vegetation models with parameters determined on the basis of the inverse problem, assuming a lack of knowledge of channel vegetation properties.
Latin hypercube sampling (Budiman, 2017) was applied to improve the performance of the Monte Carlo technique. The size of the Monte Carlo sample (mmc, Table 1) was determined in each case by trial and error to satisfy the convergence of the solution. As the criterion for the convergence the difference of estimated average water depth was used. The number of simulations was considered sufficient when the difference in subsequent ensembles stabilized below 10−5–10−4 m.
2.2 Discharge capacity formulas
2.2.1 Divided channel method
In the DCM approach (Posey, 1967), the channel cross section is divided into flow zones of similar hydraulic conditions, typically the main channel and floodplain. The interactions between the zones of significantly different mean velocities are reproduced with a rough imaginary wall applied to the zone with the higher velocity, i.e., the main channel. In the present study, the roughness of the interface was assumed to be equal to the roughness of the channel banks next to the interface. Parameters of the method are the roughness coefficients for each flow zone. In the present study, DCM was based on the Manning formula, with the common approach of having separate Manning coefficients for the main channel (nc) and left (nL) and right floodplains (nR). The parameter bands with mmc Monte Carlo sample sizes are provided in Table 1 separately for flume and field experiments. For flume data sets calculations were performed for a symmetric channel, which allowed us to reduce the number of parameters, as the same values were used for the left and right floodplains.
2.2.2 Pasche and Mertens methods
A brief concept of the Pasche method is provided by Pasche (1984) and Pasche and Rouvé (1985), and a detailed description of the algorithm used herein is provided in Kozioł et al. (2004). The model describes the discharge capacity of the compound cross section with rigid vegetation, derived for steady flow conditions. Similarly to DCM, the model divides the compound cross section into regions of the main channel and floodplains, dominated by bottom and vegetation roughness, respectively. It accounts additionally for the transition region between these two main zones. As in the DCM, the interactions between the main channel and floodplains are modeled using an imaginary rough wall. For the resistance of the imaginary wall, bed, and also vegetation stems, the Darcy–Weisbach formula is used.
The Darcy–Weisbach friction coefficients are determined using a set of semi-empirical equations for each zone and the imaginary wall, including transitional regions. The method explains the extent of the transition region within the vegetated region, affected by the higher flow velocity of the unvegetated main channel. The flow in the main channel depends on the apparent resistance of the imaginary wall. There is no general expression for the span of the transition region in the main channel, and it has to be established for each case.
Velocities in the flow zones and transitional regions are interrelated by the apparent resistance. Equations describing these dependencies have an implicit form that requires iterative methods for solving, so that the Pasche method has a very complex numerical solution and may be affected by a lack of convergence for unfeasible parameter sets. Mertens (1989) attempted to improve the numerical efficiency of the Pasche concept by simplifying most of the demanding implicit formulas to less accurate but explicit ones, reducing the number of terms requiring iterative numerical solving.
In the Pasche and Mertens methods, a detailed parameterization of the channel, including plant properties, surface roughness, and the extent of the interaction zone in the main channel, is used. Assuming that the modeler has only knowledge of the geometry of the cross section, the following parameters have to be identified: ax and ay, longitudinal and horizontal spacing of plant stems; dp, average diameter of the stems; kf and kc, roughness heights of the floodplain and the main channel bed; and bIII∕Bc, ratio of the interaction region width in the main channel (bIII) to the main channel width (Bc). Assuming that the channel is symmetric, the total number of parameters is six. Modeling different properties of vegetation on the left (subscript L) and right (subscript R) floodplains (, , , kf,L:kf,R) increases the number of parameters up to 10.
2.2.3 Generalized and simplified two-layer model
In the present study, the two-layer model of Luhar and Nepf (2013), generalized by Västilä and Järvelä (2018) for more complex cross sections, is considered to be the state-of-the-art approach for submerged vegetation. This generalized two-layer model (GTLM) is based on the momentum balance with drag coefficients at the interfaces between vegetated and unvegetated areas of the channel cross section. Generalization proposed to the original model (Luhar and Nepf, 2013) by Västilä and Järvelä (2018) consists in assuming a non-rectangular cross section, so that the channel width is replaced by the wetted perimeter (P) and water depth by the hydraulic radius (R).
The channel discharge capacity is computed on the basis of equations for mean velocities in the unvegetated (u0) and vegetated (uv) parts of the cross section (Västilä and Järvelä, 2018):
where g is the gravitational constant, S the energy slope, the dimensionless velocity in the unvegetated zone, C* the drag coefficient for shear stresses at the channel bed and at the interface between the vegetated and unvegetated zones, and Lb and Lv the wetted lengths of the unvegetated channel margin and of the interface between the vegetated and vegetated zones, respectively. BX denotes the vegetative blockage factor in the cross section, defined as the vegetated flow area divided by a total flow area. Physically, there might be different values of drag coefficients for the bed and interface of the vegetation zone. Following Luhar and Nepf (2013); Västilä and Järvelä (2018), it was herein assumed that the same value of C* can be used for both regions.
Cda is the vegetative drag per unit water volume, expressed conventionally as the product of a drag coefficient Cd and the frontal projected plant area per unit water volume a, assuming that plants are rigid simple-shaped objects. To account for the presence of foliage and the flexibility of the plants inducing bending and streamlining, the vegetative drag per unit water volume can be parameterized as (Västilä and Järvelä, 2018)
where uC is a characteristic approach velocity, taken here as equal to the velocity in a vegetation layer: uC≈uv. AS denotes total frontal projected areas of the plant stems and AL the total one-sided leaf area per unit ground area AB. and represent constant coefficients for the drag of stems and foliage, respectively. The effect of streamlining and reconfiguration on the drag is described using exponents χS and χF for stems and foliage, respectively. uX,F and uX,S are reference velocities needed for determining the drag and reconfiguration coefficients.
Equations (9) and (11) implicitly depend on each other and require numerical solving. In the conservative approach vegetation parameters have to be known (Fig. 1a). The blockage factor BX requires knowledge of the vegetation distribution and/or height in the cross section. and ratios characterizing the plant structure can be measured or typical values for certain plant communities can be adopted. Drag coefficients , , and F and reconfiguration exponents χS and χF, along with their reference velocities (uX,F, and uX,S), are factors specific for plant species or plant type and can be determined on the basis of laboratory measurements. Their values have been published for common plant species (Västilä and Järvelä, 2014; Jalonen and Järvelä, 2015; Västilä and Järvelä, 2018).
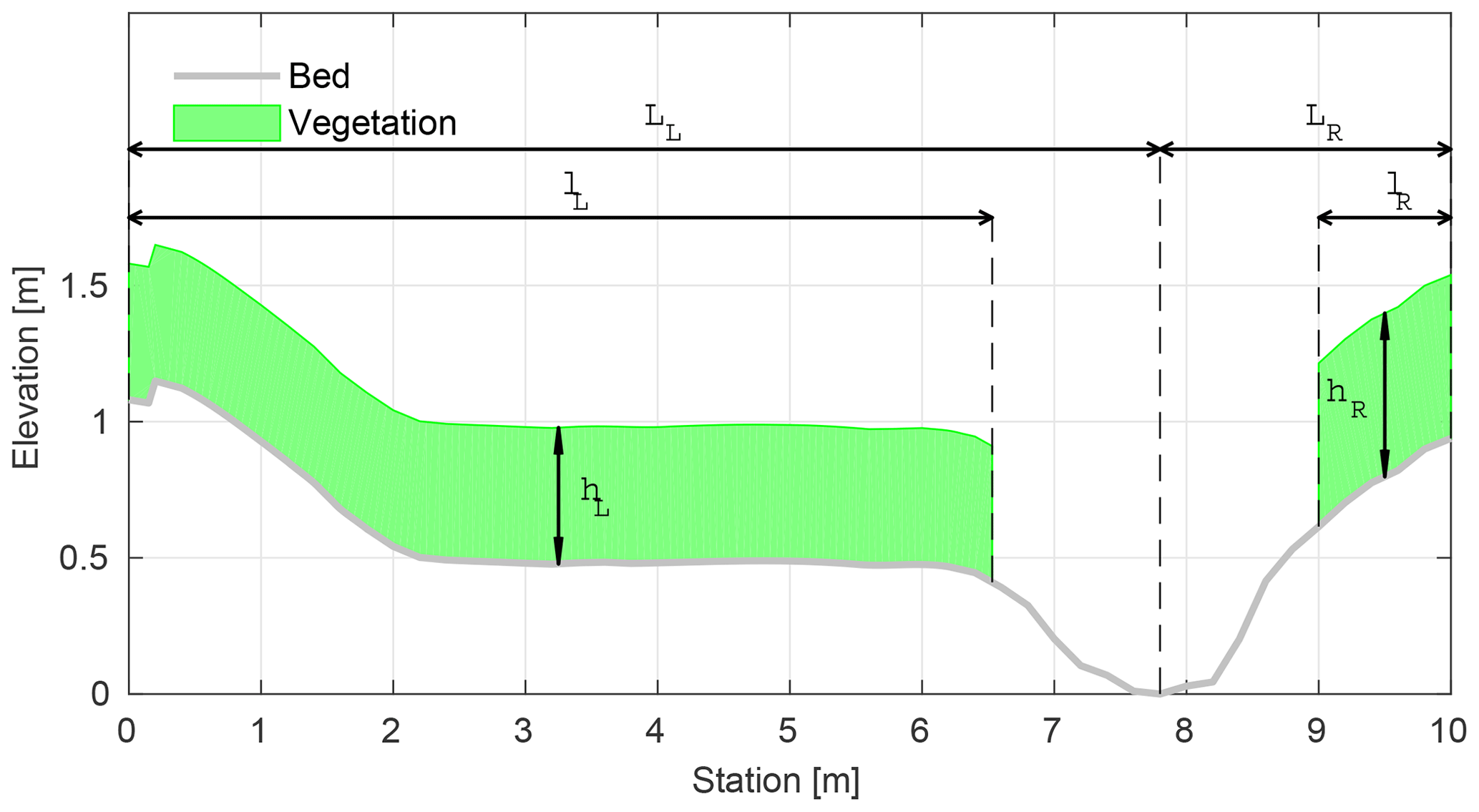
Figure 2Parameterization of the blockage factor BX; the cross section for Ritobacken Brook (Västilä and Järvelä, 2014).
For channel flows with dense vegetation for which over 80 % of the discharge is conveyed in the unvegetated regions, the GTLM approach can be simplified by assuming that discharge in the vegetation layer is negligible with respect to the total discharge: uv≈0 m s−1 (Luhar and Nepf, 2013; Västilä et al., 2016). The remaining Eq. (9) does not require numerical solving. In the present study the above approach is referred to as the simplified two-layer model (STLM). It has to be noted that, with this approach, up to 20 % of the discharge is neglected, depending on the density and cross-sectional blockage of vegetation. By neglecting Eq. (10), the STLM requires five and the GTLM nine parameters.
Parameters of GTLM and STLM resulting from Eq. (9) are the drag coefficient for shear stresses C* and blockage factor BX. BX depends on the area occupied by the vegetation in the cross section. It changes with the water level and therefore should not be represented as a constant value but rather as the vegetation share in the cross-sectional area in the function of the depth. In the present study, to obtain a general parameterization, BX was described in terms of left–right extents lL∕LL, lR∕LR and the height hL, hR of vegetation. LL, LR stand for the cross section width from the left and right banks, respectively, to the lowest elevation in the main channel. lL and lR denote vegetation extents, from banks towards the main channel (Fig. 2). lL∕LL is the vegetation extent on the left side, starting form the top of the left bank towards the channel middle point: 0 stands for clean bank, while 1 means that the vegetation cover extends over the entire left side. The same applies for lR∕LR, where it is assumed that vegetation zones start from the top of the right bank. The vertical range of the vegetation in the cross section is obtained by adding hL or hR to the value of the ground elevation. The adopted parameterization for BX was verified with field estimates for Ritobacken Brook (Västilä and Järvelä, 2018) and allowed to obtain a fit with the linear correlation coefficient of 0.88.
It should be noted that by parameterizing the blockage factor, the parameter identification task is much more complicated than in the conventional approaches. In the DCM the vegetation extent is equivalent to the division into the main channel and floodplains, which is known on the basis of the cross-sectional geometry. Here, for GTLM and STLM it was considered a part of the parameter identification problem.
2.2.4 Practical two-layer model
Luhar and Nepf (2013) derived a formula for the Manning coefficient n for shallow channels lined with vegetation, where the blockage factor can be approximated as :
where h stands for the vegetation height and K=1 m1∕3 s−1 to ensure correct dimensions of the equation. In the presented form of Eq. (12), following Västilä and Järvelä (2018), the water depth H was replaced with the hydraulic radius R.
Equation (12) has a convenient form to be easily applied in practical cases, where usually the Manning equation is used. In the present study, this approach is called the practical two-layer model (PTLM) as it requires fewer parameters influenced by vegetation. In the present study this approach is named the PTLM and is applied as a three-parameter model, with the drag coefficient C*, average vegetation height h in the cross section and CDa.
2.3 Case studies
The analyses were conducted for a flume data set (Koziol, 2010) and a field data set (Västilä et al., 2016) collected from vegetated compound channels, interpreted herein as five distinct case studies, as detailed below. To our knowledge, the field cases are one of the most thorough characterizations of the dependency between vegetation properties and discharge capacity in natural compound channels, including spatially averaged values for vegetation height, blockage factor, and frontal area density in different seasons and flow conditions. The flume cases are representative of typical experimental arrangements where vegetation is simulated by rigid cylindrical elements at a uniform spacing.
2.3.1 Flume experiments
The experiments were conducted at the Warsaw University of Life Sciences (WULS-SGGW) using a physical model of a compound channel with rigid cylinders simulating vegetation. A detailed description of the data set can be found in Kozioł and Kubrak (2015), Kozioł (2013), Kubrak et al. (2019a), and Kubrak et al. (2019b).
The modeled channel was straight and 16 m long with a slope of . The cross section was trapezoidal and wide for 2.10 m (Fig. 3). The main channel bottom was made of smooth concrete with estimated roughness height . Floodplain vegetation was simulated with rigid cylinders of a diameter dp=0.008 m and spacing m. There were two experimental variants of vegetation layout and floodplain roughness. In the first one (1) the floodplain bottom was made of the same smooth concrete as the main channel, with a single row of vegetation present also on the channel bank (Fig. 3a). In the second one (2), vegetation was constrained on the floodplain by removing the channel bank stems, while floodplain surfaces were made rougher using a layer of terrazzo concrete of grain sizes of 0.5 to 1 cm (Fig. 3b).

Experiments were performed for steady and quasi-uniform flow conditions (Kubrak et al., 2019a, b). The water surface was kept parallel using a pressure gauge, measuring the differences in depths at cross sections located 4.8 and 12 m from the flume inflow and a weir localized at the outflow. Water discharge was measured using a circular weir and water levels were recorded in the middle of the channel.
The data set used in the present study consisted of discharge and water-level observations (Appendix A1) within the range of 0.037–0.060 m3 s−1 (mean velocities: 0.2–0.4 m s−1) and 0.2–0.3 m, respectively, which includes only overbank flows. The number of observation points in the first variant was 9 (M=9) and in the second one 10 (M=10). The uncertainty calculations were performed for a symmetric channel, which allowed us to reduce the number of parameters, as the same values were used for the left and right floodplains.
2.3.2 Ritobacken field experiment
The field data with seasonally and annually varying vegetation were obtained from an 11 m wide compound channel, Ritobacken Brook (Finland, Fig. 4), where the floodplain was excavated on one side of the existing channel in February 2010 (Västilä et al., 2016). Measurement series with vegetated floodplain flows (Appendix A2) were available for three seasons, with the number of observations given in brackets: spring 2011 (M=6), autumn 2011 (M=12), and spring 2012 (M=11). Vegetation consisted mainly of different grassy species, with both stems and foliage, while sparse woody vegetation covered 10 % of the total wetted ground area.

The respective mean floodplain vegetation heights were h=9, 47, and 24 cm, while the vegetative blockage factor ranged at BX=0.13–0.53. The taller vegetation in spring 2012 compared to spring 2011 was explained by the ongoing succession phase after the floodplain excavation. Vegetation was submerged under all examined flows in spring 2011 and under 42 % and 64 % of the flows in autumn 2011 and spring 2012, respectively.

Figure 5Exemplary rating curves for m=5, Ritobacken case study (spring 2012): (a) GTLM, (b) STLM, (c) PTLM; the flume data set, case 2: (d) Pasche, (e) Mertens, (f) DCM. Confidence intervals and the median of the probabilistic solution are given with dashed lines; red line denotes the best simulation in the Monte Carlo ensemble. Observation points used for parameter identification are marked with squares (□), while verification data points are marked with circles (∘).
The discharge capacity at different flow conditions was obtained from water-level data recorded at 5–15 min intervals with pressure transducers at the upstream and downstream ends of a 190 m long test reach. The discharge was obtained from a rating curve determined for a culvert at the downstream end of the test reach. The stream is free flowing and there are no hydraulic structures affecting the flow or water levels at the investigated discharges. Flow conditions were gradually varied, and therefore the energy slope S was used instead of the bed slope in determining the flow resistance.
At floodplain flows, discharge and floodplain water depth ranged at 0.19–1.59 m3 s−1 and 0.10–0.67 m, respectively, with cross-sectional mean velocities of 0.11–0.30 m s−1. The Manning coefficient of the narrow main channel as obtained from the highest flows not inundating the floodplain was due to irregular main channel geometry, woody debris, and some aquatic vegetation.
The calculations in the present study were performed for the channel geometry and water depths, averaged over 190 m of the stream reach.
2.3.3 Analysis of the numerical results
The numerical results were analyzed from four perspectives: (1) identifiability of the model for the given vegetation conditions; (2) width of estimated confidence intervals as a function of the number of observation points; (3) representation of high flows with models identified for low overbank flows; (4) the physical interpretation of the obtained parameter values.
The obtained parameter distributions were compared with measured values, as in Berends et al. (2019), but using several vegetation-roughness models. This way it was possible to analyze the problem of parameter identifiability. In the second step, the applicability of models, which parameters differ from measured values, was discussed.
The obtained uncertainty estimates of computed water levels allowed us to compare the efficiency of each model in explaining the rating curve. The same output was used to measure the selectivity of models when applied for inappropriate cases, e.g., modeling of the rigid vegetation with the model for flexible vegetation. It should be expected that the solution for the model used for the inappropriate type of vegetation should be characterized by the relatively high uncertainty.
The obtained results were also compared with other studies on vegetation model identification and uncertainty estimation, like already mentioned studies by Werner et al. (2005), Dalledonne et al. (2019), and Berends et al. (2019), but also Warmink et al. (2013), who compare the uncertainty of a two-dimensional model for chosen methods of bed and vegetation resistance.
3.1 Computational output and general observations
The basic output of the computations which included Monte Carlo simulations using channel discharge models and parameter identification on the basis of Eqs. (1)–(7) were rating curves. They were derived with a different number of observation points m for the parameter identification, for all possible combinations (see Sect. 2.1).
Exemplary curves are presented to highlight some general observations (Fig. 5). We show chosen solutions for m=5 of observation points used in the parameter identification for the two-layer approaches (GTLM, STLM, and PTLM in Fig. 5a–c) developed for dense, submerged vegetation corresponding to the Ritobacken case study and for the Pasche, Mertens, and Manning-based DCM models for rigid emergent vegetation corresponding to the flume conditions (Fig. 5d–f). In this example, chosen to provide a background for the analysis of extrapolation capabilities of models (Sect. 3.3), the parameters for discharge curves were identified at lower overbank flows, while the verification was conducted for the highest flows. This represents the common practical way of using hydraulic models to assess flood hazard at flows higher than the ones the models were calibrated with. In terms of parameter identification results are considered successful, as all m observation points were enclosed by the confidence intervals. Except for the DCM model in the flume case study (Fig. 5f), all the remaining points, i.e., the verification set with M−m points, given in Fig. 5 as circles (∘), are enclosed, indicating good quality of the solutions. For the DCM (Fig. 5f) the points used in the model identification are within confidence intervals (the condition given by Eq. 8), but the verification points are outside despite the wide confidence intervals. The reason is that for the flume data with rigid vegetation, the Manning formula with constant values of roughness coefficients is unable to correctly reproduce the rating curve and fulfill the constraint given by Eq. (8), which is only possible by extending the confidence intervals.
Along with the probabilistic solution, Fig. 5 presents a deterministic solution obtained as a computed rating curve with the highest value of likelihood measure (Eq. 3). The deterministic solution often deviates from the median of the probabilistic one, as in the case of the GTLM and STLM (Fig. 5a–b).
On the basis of the rating curves computed for each combination of m observation points, it is possible to analyze the estimated average widths of confidence intervals in a function of m observation points used in the identification. The averaged confidence widths were provided for a given m in relative sizes as W:
where and stand for the estimates of lower and upper confidence intervals for the calculated water level, normalized for each i point of the rating curve by the median of the probabilistic solution for the ith point: median(H)i. From m rating curve points a mean value is computed with the term for all possible combinations of m observations in the full set of size M. In the last step, mean values of confidence interval widths were again averaged over sets where the model was identified using m observations.
Chosen results on the influence of the number of observations used for identification of the widths of the confidence intervals and the percentage of verification points included within the intervals are provided in Figs. 6–8. In Fig. 6 for GTLM applied for the Ritobacken case study for spring 2012 and also in Fig. 9 with the Pasche model used for the flume data set in case 1, it can be noticed that (1) the relative confidence interval widths (Figs. 6a, 7a) are high for a small m as a result of the ill-posed inverse problem; i.e., the number of observations is insufficient for unequivocal model identification; (2) with additional data points, the solution converges by reducing the span of intervals but also its variability due to different combinations of observation points; (3) the width of confidence intervals for the full data set m=M in both cases is below 5 %; (4) the confidence intervals estimated for a low number of observations (m<4) have poor predictive performance, as most of the observations in the verification sets fall outside (Figs. 6b, 7b); (5) in both cases for m>4 more than 50 % of the verification set is enclosed with the estimated confidence intervals. Figure 8 shows an example of a model with a poor performance, indicating the model's inadequacy for the given case. The confidence intervals are extended with m (Fig. 8a), which for m>4 allows enclosure of most of the verification set (Fig. 8b).
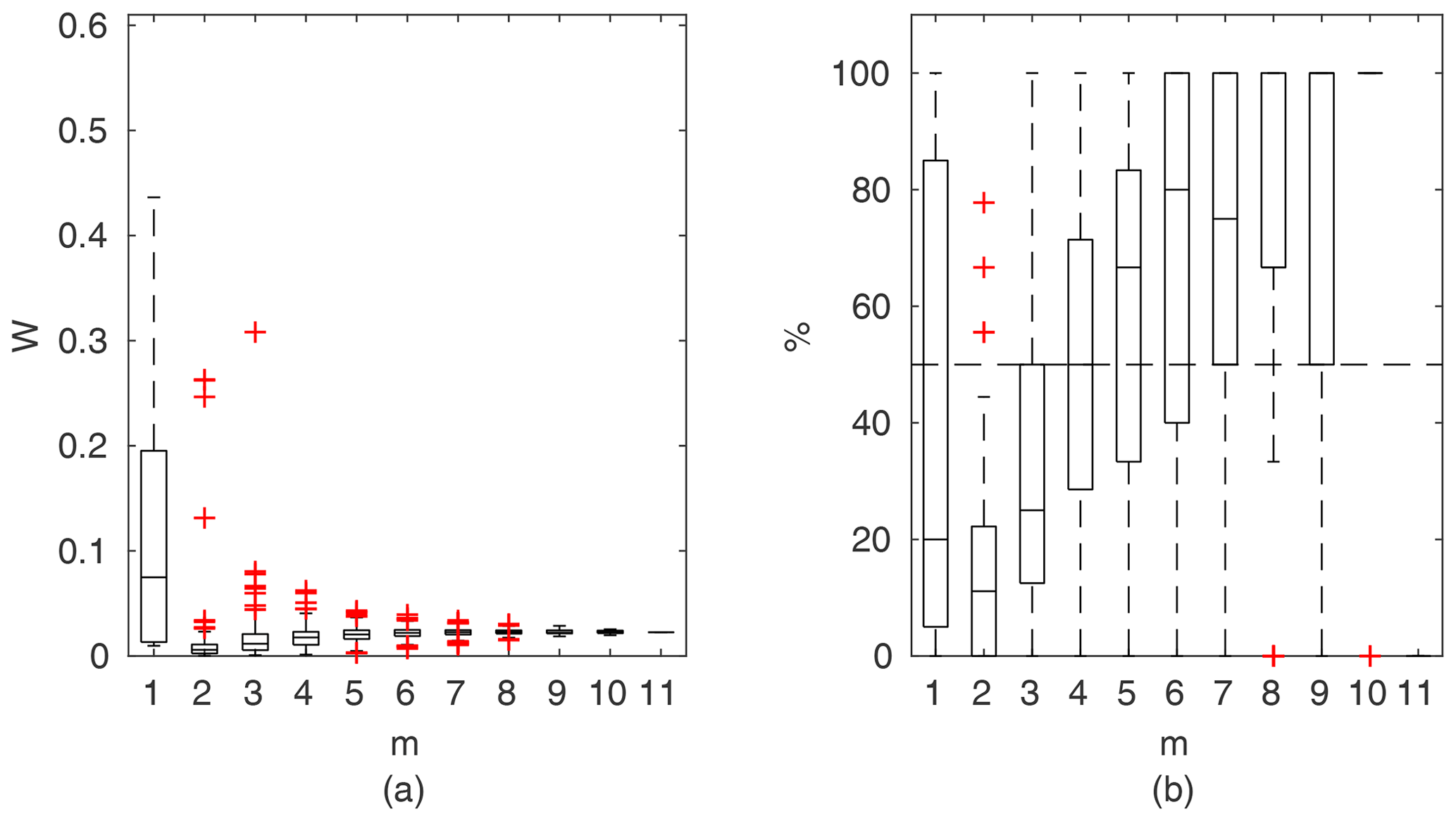
Figure 6GTLM results for the Ritobacken case study, spring 2012: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
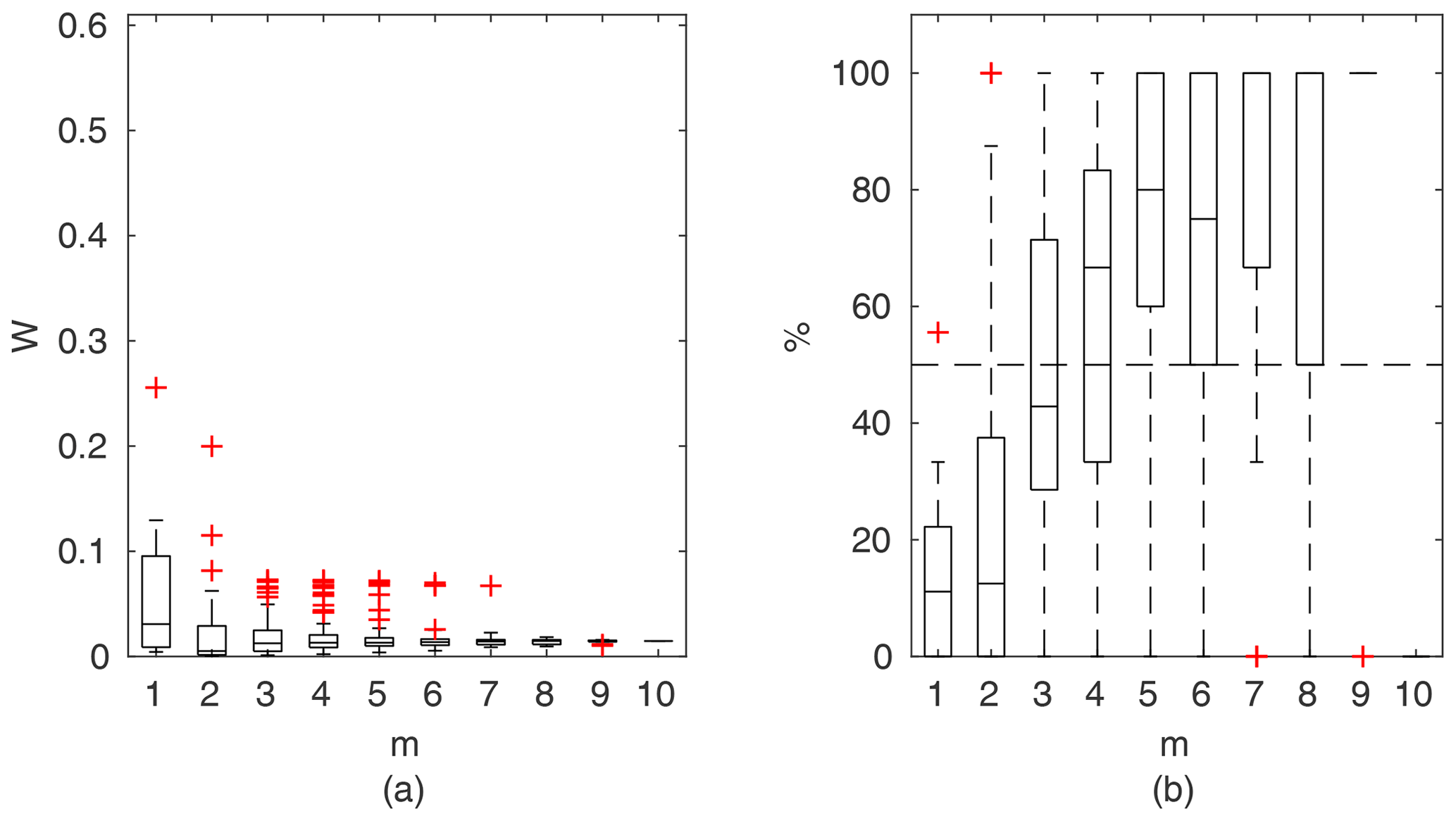
Figure 7Pasche results for the flume data set, case 2: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
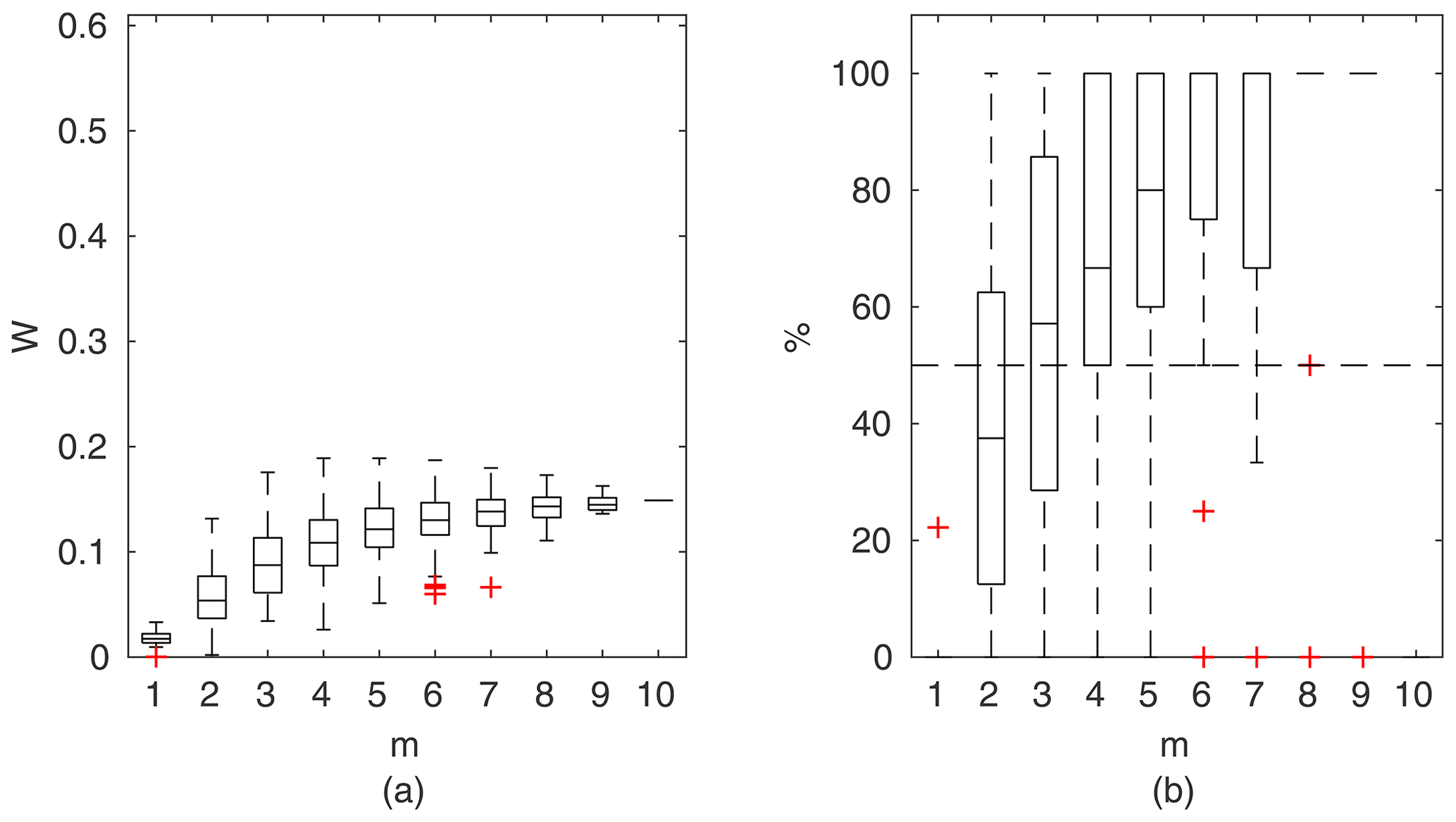
Figure 8Manning-based DCM results for the flume data set, case 2: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
3.2 Model identifiability
Model identifiability is understood here as the ability to determine the parameter a posteriori distribution that explains the model uncertainty in relation to observations (see Sect. 2.1). This is satisfied by meeting the constraint given in Eq. (8) as for cases presented in Fig. 5. The criterion of Eq. (8) might be fulfilled even for a poor model by extending the parameter variability ranges (Table 1), specified with a priori distribution P(θ). The only limitation could be the physical meaning of the parameters.
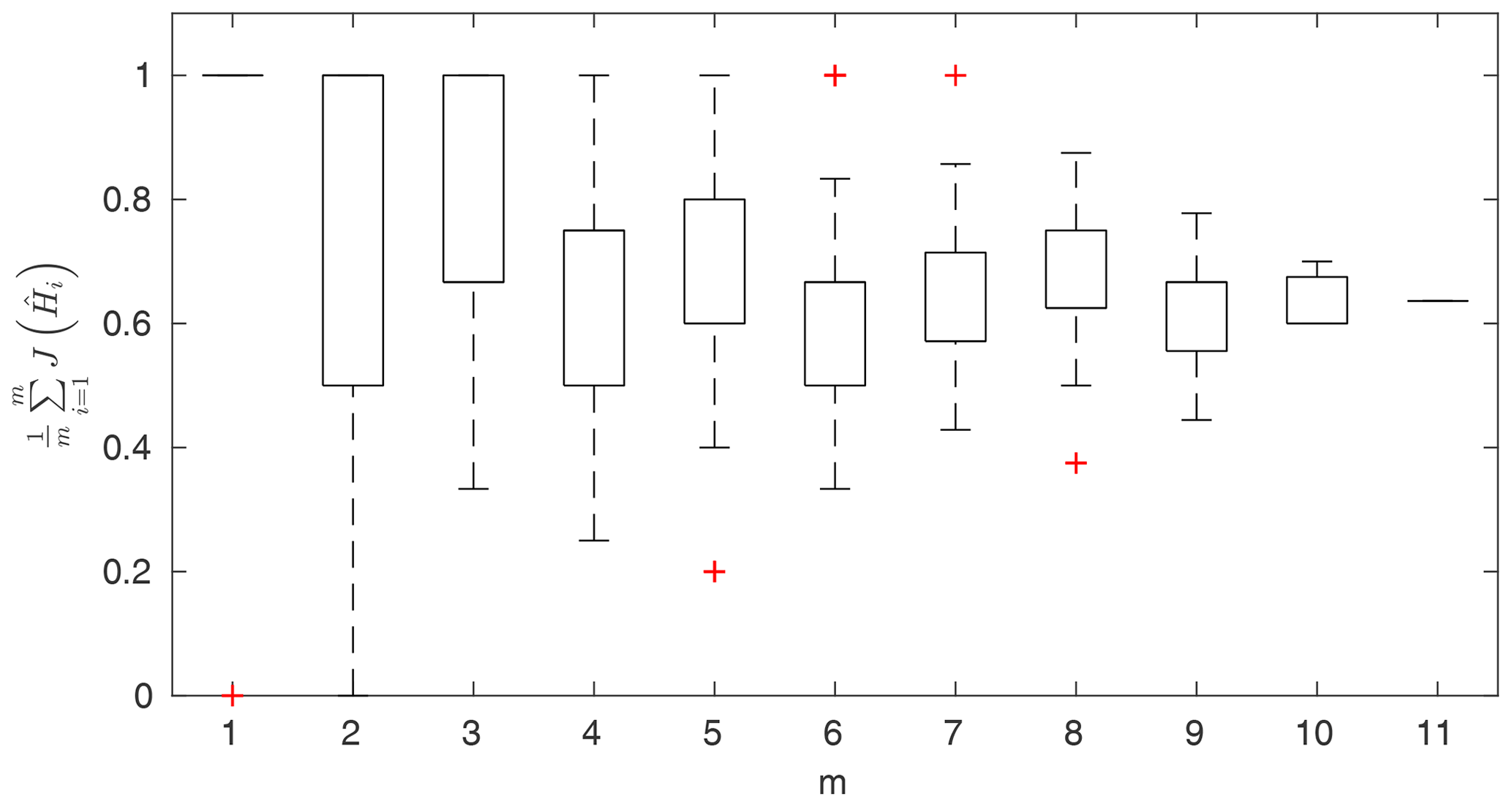
Figure 9Portion of observation points within 95 % confidence intervals for the Pasche method as a function of observation points used in parameter identification, presented in the form of box-plots; results for the unsuitable data set for the Pasche method of Ritobacken, spring 2012.
Figure 9 shows exemplary results for a model that could not be identified for a given data set. Values of J (Eq. 7) were computed for observation points used in the parameter identification and averaged in respect of their count m. This model was unable to correctly reproduce the rating curve over the whole Monte Carlo ensemble of parameters. The computed water levels did not follow the observed shape of the rating curve, and as a result it was not possible to find such a solution of Eq. (1) where identification data points would be enclosed by the confidence intervals (Eq. 8). The constraint given with Eq. (8) was fulfilled only for m=1, but not for all points, as indicated with the single red cross in Fig. 9. This indicates that not all observed water levels were covered by the Monte Carlo sample of computed water levels. With an increasing number of m, the number of observation points enclosed by the confidence intervals depends on the combination of observation points. Some beneficial effects allow us to fulfill the constraint given with Eq. (8), such as an extreme value of 1 for m=6, whereas others enclose only a small share of observations. For , there is a single solution, in which about 60 % of observations were enclosed by confidence intervals. For an identifiable model, Fig. 9 would consist of single horizontal lines between 0.95 and 1, indicating fulfillment of the constraint of Eq. (8) for all simulations.
The Pasche and Mertens models applied to the Ritobacken case study were not identifiable even with relatively large variability ranges of the parameters (Fig. 9). This is likely explained by the fact that these methods were developed for rigid emergent vegetation, whereas the Ritobacken had mostly dense submerged flexible vegetation. The PTLM could be identified for the field site in spring 2011 and spring 2012 but not in autumn 2011. This result is likely explained by the fact that the assumption of noticeably overestimates BX in compound channels with an unvegetated main channel and high floodplain vegetation, as in autumn 2011 conditions.
By applying large parameter variability for the GTLM and PTLM models, it was possible to meet Eq. (8) for the flume case study, although these methods were not originally designed for such emergent vegetation. The STLM model failed for flume experiments, likely because the assumption that >80 % of flow should be conveyed in the non-vegetated zones was not fulfilled. The rest of the models, including DCM for all cases, were identifiable.
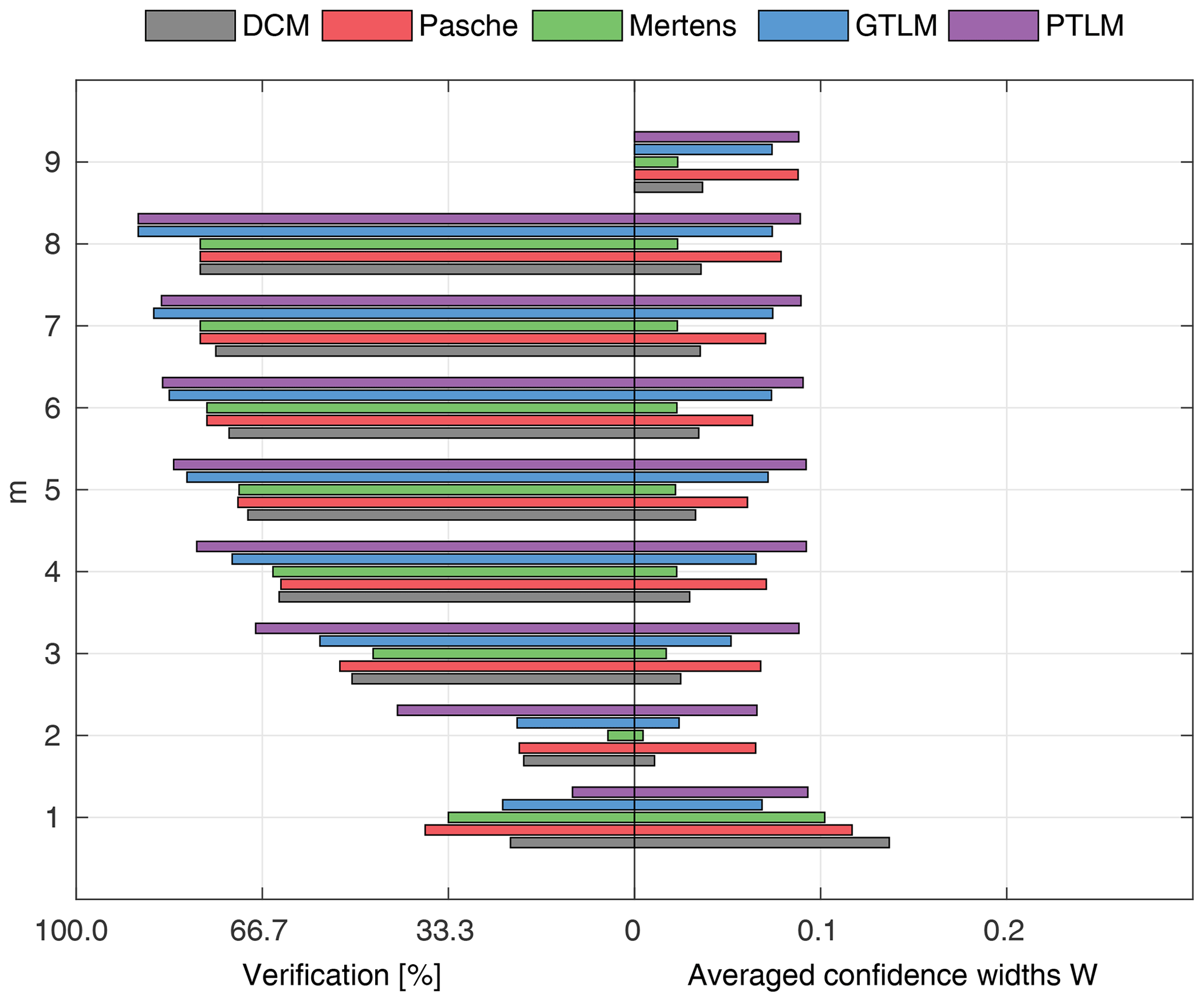
Figure 10Percentage of the verification set (M−m) enclosed by confidence intervals and average width of confidence intervals for different numbers of data points for model identification (m); flume data set, case 1.

Figure 11Percentage of the verification set (M−m) enclosed by confidence intervals and average width of confidence intervals for different numbers of data points for model identification (m); flume data set, case 2.
To compare the performance of the applied identifiable discharge prediction methods, we show bar plots of the average percentage of verification set points enclosed by confidence intervals and their relative widths as a function of observation points used in the model identification m (Figs. 10–14). The averaged values correspond to the mean values of the box-plots in Figs. 6–8.
3.3 Widths of confidence intervals and quality of uncertainty estimation
The values presented in Figs. 10–14 are averaged over all uncertainty estimates at a given number of observations m. Therefore, for , where there was always only one verification point, the percentage for verification points can be any value between 0 % and 100 %, not only 0 % or 100 %. An averaged ratio of verification points enclosed within confidence intervals, together with their relative width W, should be considered a two-criterion measure of how well the obtained model reproduces the discharge curve. Narrow confidence intervals indicate that the model uncertainty, estimated using m observations, is small. The percentage of observations from the verification set enclosed within these intervals informs how the estimated uncertainty is representative for other data sets than these used for identification. The low percentage suggests that the model uncertainty for the verification set is incorrectly predicted. Therefore, narrow confidence intervals for small m numbers, enclosing a small amount of observations, should be considered unsuccessful, as the uncertainty analysis appears to be too optimistic. On the other hand, for larger m, good ratios might be obtained with very wide confidence intervals, indicating a poor model. The best solution is that one which has the narrowest confidence intervals with a satisfactory percentage of the verification set enclosed within it. We interpret the results by analyzing both those criteria together.
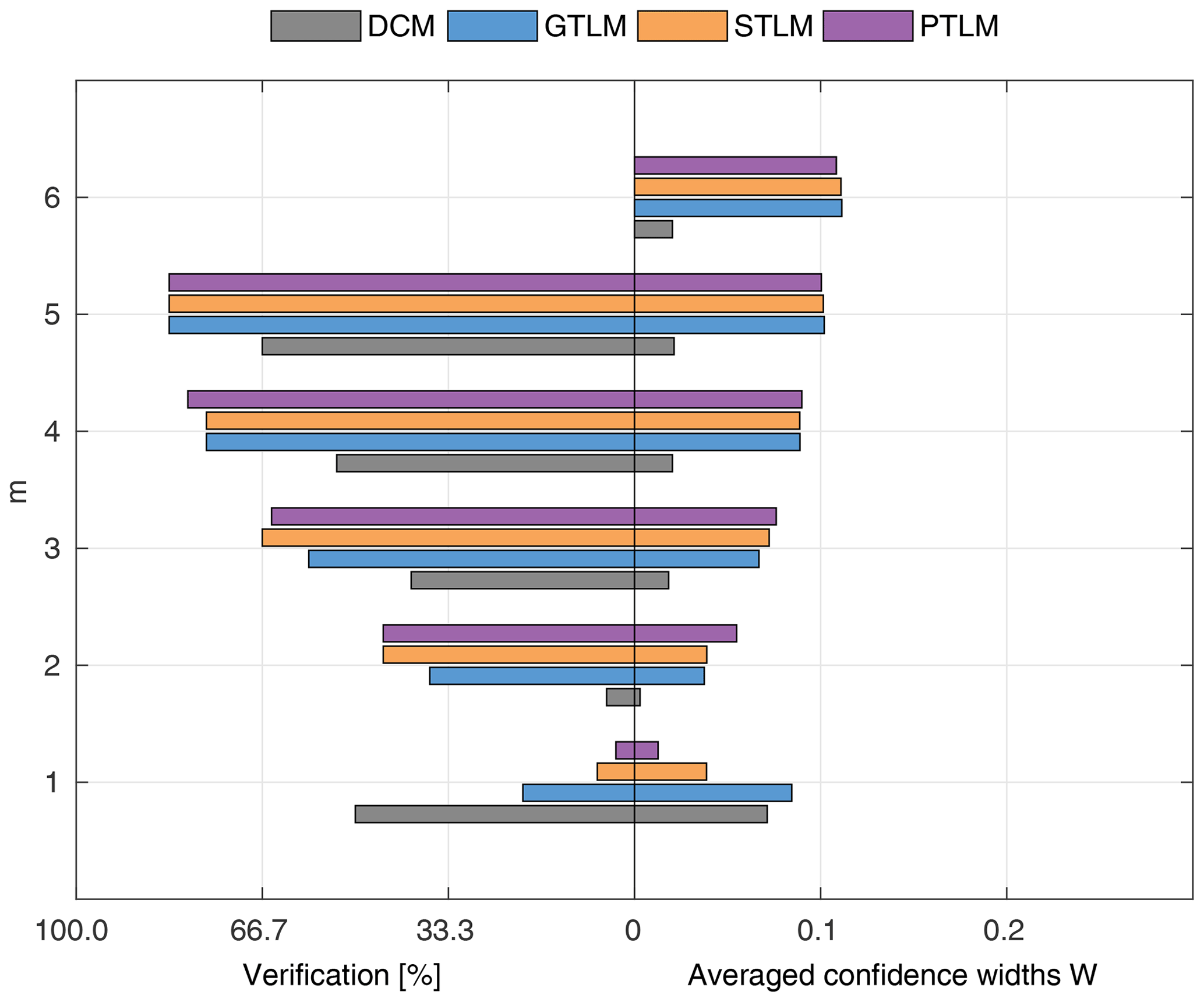
Figure 12Percentage of the verification set (M−m) enclosed by confidence intervals and average width of confidence intervals for different numbers of data points for model identification (m); results shown for the identifiable models for Ritobacken, spring 2011.
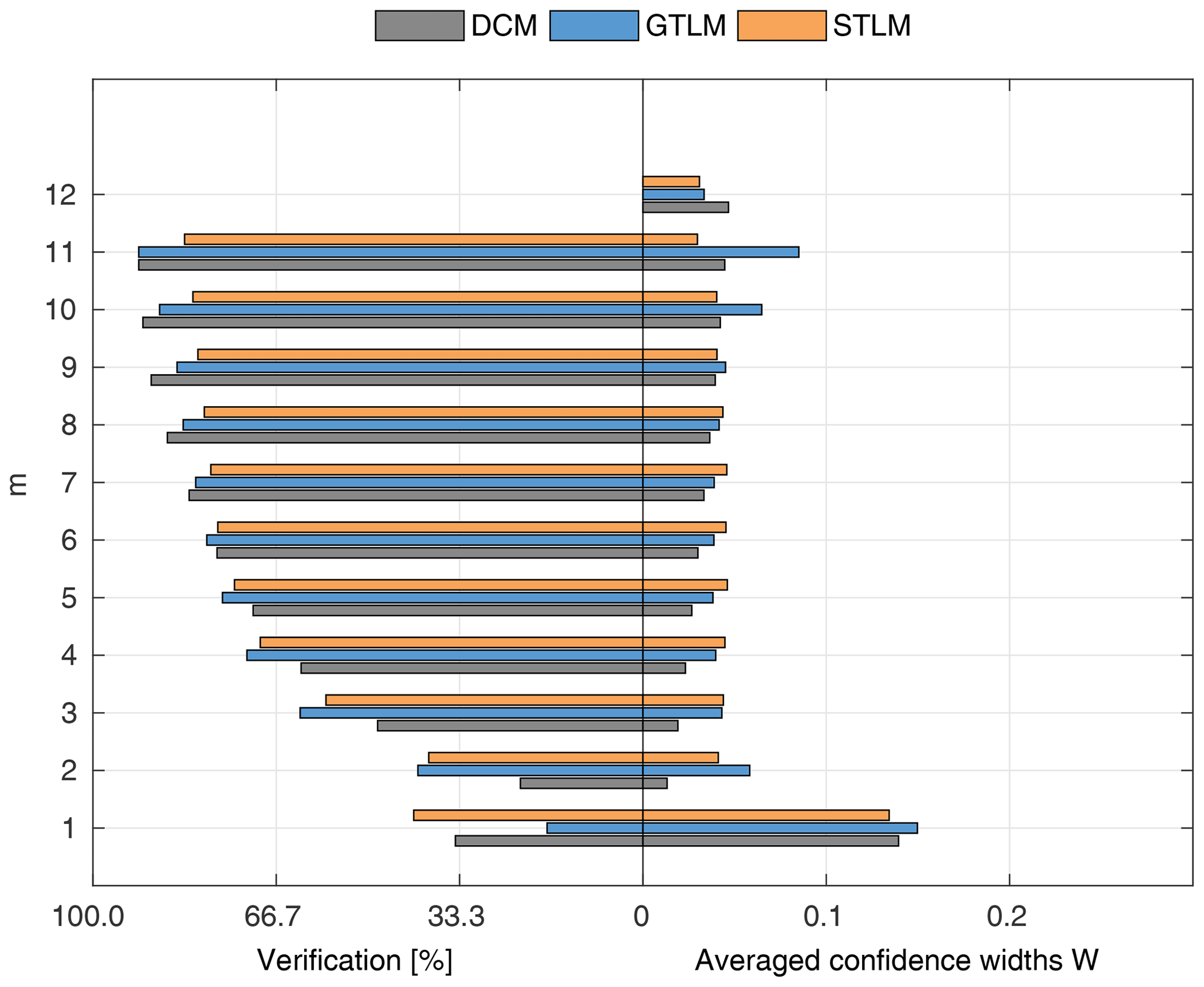
Figure 13Percentage of the verification set (M−m) enclosed by confidence intervals and average width of confidence intervals for different numbers of data points for model identification (m); results shown for the identifiable models for Ritobacken, autumn 2011.
Widths of confidence intervals in a function of the number m of observation points used in the model identification (Figs. 10–14) allow for a qualitative analysis of the uncertainty, resulting from the insufficient data for calibration. Wide confidence intervals and their spread for the small observation number m=1 should be attributed to the ill-posed inverse problem. Additional data points allow narrow confidence intervals and reduce their spread. The number of observations m at which the widths of confidence intervals stabilize, in some cases obtaining minimal values, suggests the point where the effect of the ill-posed inverse problem becomes a less significant source of uncertainty for computed water levels. In these qualitative analyses, its effect cannot be excluded but rather should be considered less important.
General investigations of discharge models in respect of obtaining confidence intervals were supplemented with the analysis of their extrapolation capabilities for higher flows. Figures 10–14 present averaged outcomes for models identified using all possible combinations of m observations. This includes sets with only low or high but also mixed flow rates (note that only overbank flows are considered). In Fig. 5 widths of confidence intervals and the percentage of the enclosed verification set are presented for models identified only for the lowest m=5 flow rates. The number of m=5 observations used for the model identification was chosen arbitrarily, following the impressions that this size is sufficient to minimize the uncertainty due to an insufficient number of observations for the model identification (ill-posed inverse problem), and for all case studies with m=5 a reasonable number (M−m) of observations for verification was available.

Figure 14Percentage of the verification set (M−m) enclosed by confidence intervals and average width of confidence intervals for different numbers of data points for model identification (m); results shown for the identifiable models for Ritobacken, spring 2012.
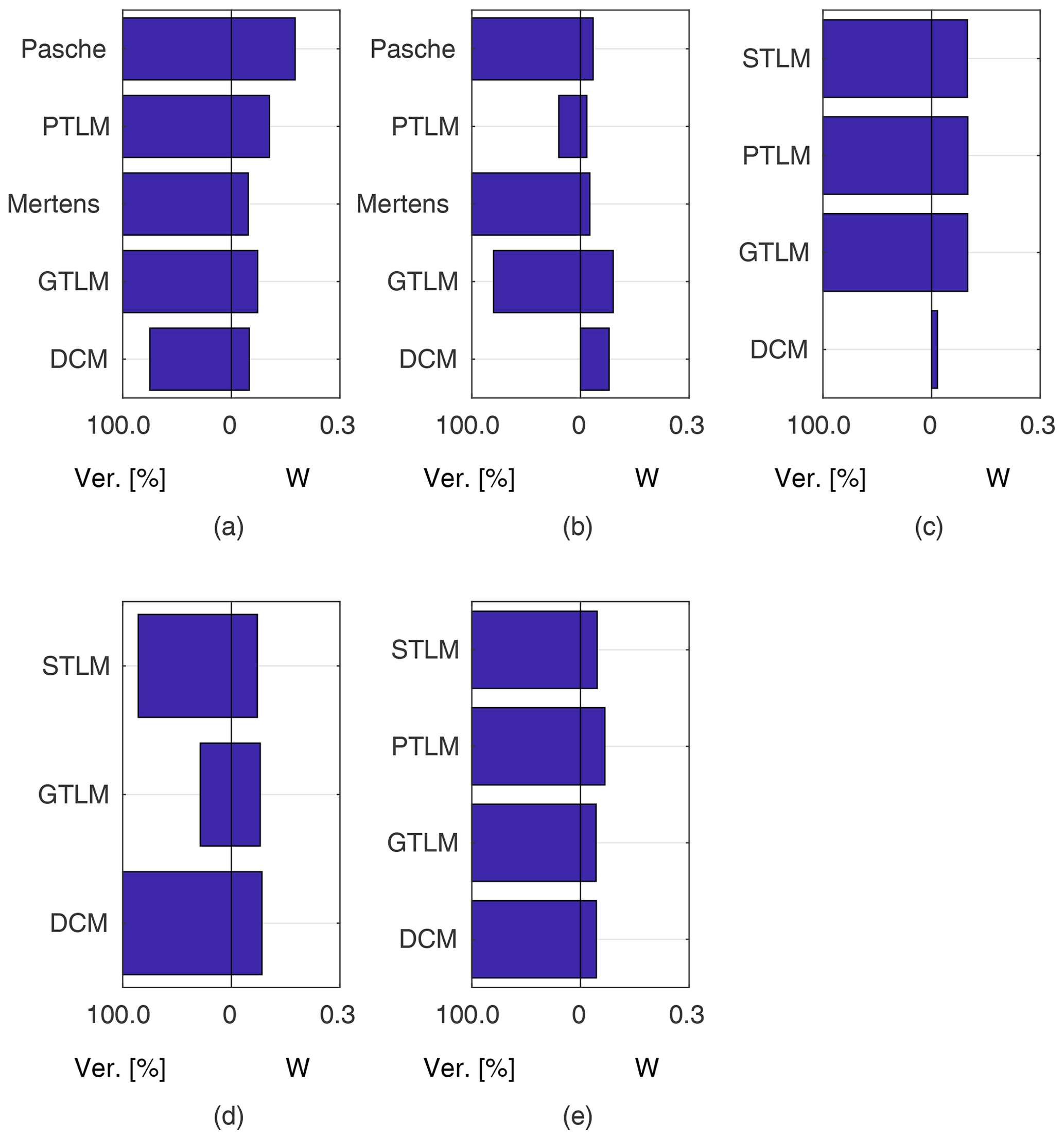
Figure 15Percentage of verification points for higher flows enclosed within confidence intervals obtained with models identified for five (m=5) lower flows (note that only overbank flows were considered): (a) flume experiment, case 1 (M=9); (b) flume experiment, case 2 (M=10); (c) Ritobacken, spring 2011 (M=6); (d) Ritobacken, autumn 2011 (M=12); (e) Ritobacken, spring 2012 (M=11).
3.3.1 Flume data set, case 1
For the flume data in case 1 (Fig. 10), with rigid-high vegetation in floodplains and also channel banks, the best results were obtained with the Mertens method. It is characterized by the narrowest confidence intervals W with a good predictive performance. Confidence intervals for m>1 were below 5 %, and for m>3 they already enclosed more than 50 % of the verification points. Almost similar performance was found for the DCM method, with slightly wider confidence intervals.
Surprisingly, both methods outperformed the Pasche model that is a very similar approach to the Mertens method but with a much more detailed description of the vegetation-induced resistance. Estimated confidence intervals widths were about 3 times larger than for the Mertens method and DCM but included a similar number of verification points. The reason could be the susceptibility of the Pasche method to numerical instabilities. Because of vegetation present on the channel banks, the floodplain region was extended above geometrical channel banks. This introduces discontinuity to the hydraulic radius in floodplains, as water levels slightly exceed geometrical banks. Probably, this might lead to numerical instability of implicit formulas used in the Pasche method but not present in the Mertens method. GTLM and PTLM confidence intervals were similar to the Pasche ones but enclosed even more observations than Mertens. However, confidence intervals for Mertens are almost 3 times narrower, and this method should be considered to be the most appropriate in this case.
Figure 15a presents the results for models identified using the lowest m=5 flow rates. The Mertens model with the smallest estimated uncertainty was capable of explaining the rating curve for all verification points. Other models, except the DCM, allowed us to enclose the whole verification set but with much wider confidence intervals.
3.3.2 Flume data set, case 2
For flume case 2 (Fig. 11), both the Pasche and Mertens methods appear to be the most effective. Estimated widths of confidence intervals do not exceed 4 %–5 % for m>1 and fell below 1 %–2 % for a sufficient number of observations (m>5). The predictive skills of the identified models are high, with around 70 % of the verification set enclosed by the confidence intervals at m>4. GTLM has a similar uncertainty performance to the DCM, while PTLM provides noticeably much narrower uncertainty estimates. For the GTLM and DCM, the final confidence widths for m=M are about 15 % and, for PTLM, 5 %. Because of their larger extent, the estimated intervals enclose a slightly larger number of verification points than with the Pasche and Mertens methods. The DCM has 3 times wider confidence intervals than for flume case 1. The main difference between flume cases 1 and 2 was the rough floodplain surface with grain sizes of 0.5–1 cm for case 2 compared to the smooth floodplain of case 1, indicating that the DCM was not able to perform reliably for the combination of rough surface and emergent vegetation.
Figure 11 highlights the specific dependency of DCM, GTLM, and PTLM on m. For a small number of data points for a model identification at m=1, confidence widths are high, because of the ill-posed inverse problem. With additional points, the effect is reduced, and for m=2 the confidence interval widths are at their smallest but with poor predictive skills. With increasing m the uncertainty estimates are corrected by additional data points. The same pattern is present but less noticeably for the Pasche and Mertens methods and for the other cases.
As in general output, the Pasche and Mertens models provided the best results when identified for m=5 lower flows (Fig. 15b). Their confidence intervals, narrower for the Mertens model, enclosed 100 % of the verification set. Performances of the Manning-based DCM are poor here, as despite relatively wide confidence intervals it appeared impossible to explain any of verification points. In Fig. 5d–f rating curves for the Pasche, Mertens, and Manning-based DCMs were presented for this specific calibration case.
3.3.3 Ritobacken, spring 2011 case
The spring 2011 case study refers to flow conditions with poorly developed vegetation 1 year after the floodplain excavation. These conditions with low vegetation with a mean relative submergence (floodplain water depth divided by vegetation height) of 3.3 are reflected in the computational output (Fig. 12), with process-based methods for vegetation resistance characterized by a relatively poor fit.
All three two-layer models (GTLM, STLM, and PTLM) have very similar performances but with noticeably wider confidence intervals than the DCM, with W of 12 % to 3 %. The percentage of enclosed verification points at m>2 is better for two-layer approaches, although the difference is small (single observation point). The picture is different in the case of Fig. 15c presenting the extrapolation capabilities of the methods. Widths of confidence intervals of two-layer models are similar to averaged values at m=5 given in Fig. 12 and enclose all verification points (note that for spring 2011, M=6). The DCM's narrow confidence intervals were unable to enclose the verification points.
3.3.4 Ritobacken, autumn 2011 and spring 2012 cases
The Ritobacken autumn 2011 and spring 2012 case studies reflect the influence of seasonal differences of vegetation on the flow conditions. In autumn 2011 vegetation was higher and denser than before and at the beginning of the growing season in spring 2012. This can be seen in the performance of the applied discharge methods. For the fully vegetated conditions of autumn 2011 (Fig. 13), all the identified methods enclosed over 70 % of the observations at m>5 with M=12. STLM has the narrowest confidence intervals (4 %) when all data were used for model identification. STLM had a slightly lower percentage of enclosed verification points compared to DCM with also very narrow confidence intervals and GTLM with somewhat wider ones. For autumn 2011, it was not possible to identify the PTLM.
For spring 2012 (Fig. 14), DCM, STLM, and GTLM have almost equal confidence widths and ratios of enclosed verification points, while PTLM has very wide confidence intervals. The overall measures are similar to those from autumn 2011. The confidence widths for DCM, GTLM, and STLM are about 3 % and for m>5, and more than 70 % of points fall within confidence intervals. PTLM has a slightly higher ratio of verification data enclosed compared to the other methods because of notably wider confidence intervals of 8 %–9 %.
In the calibration case with the lowest m=5 flow rates, for autumn 2011 (Fig. 15d), a high explanation of the rating curve was obtained with the STLM and Manning DCM. Poorer results for the autumn 2011 set were obtained for the GTLM, with a low percentage of verification points enclosed. For spring 2012 all two-layer models (GTLM, PTLM, and STLM) and also the Manning DCM allowed us to obtain a very good explanation of the rating curve when identified for the lowest m=5 flow rates (Fig. 15e). The rating curves of the GTLM, STLM, and PTLM in this calibration case for spring 2012 were presented in Fig. 5a–c.
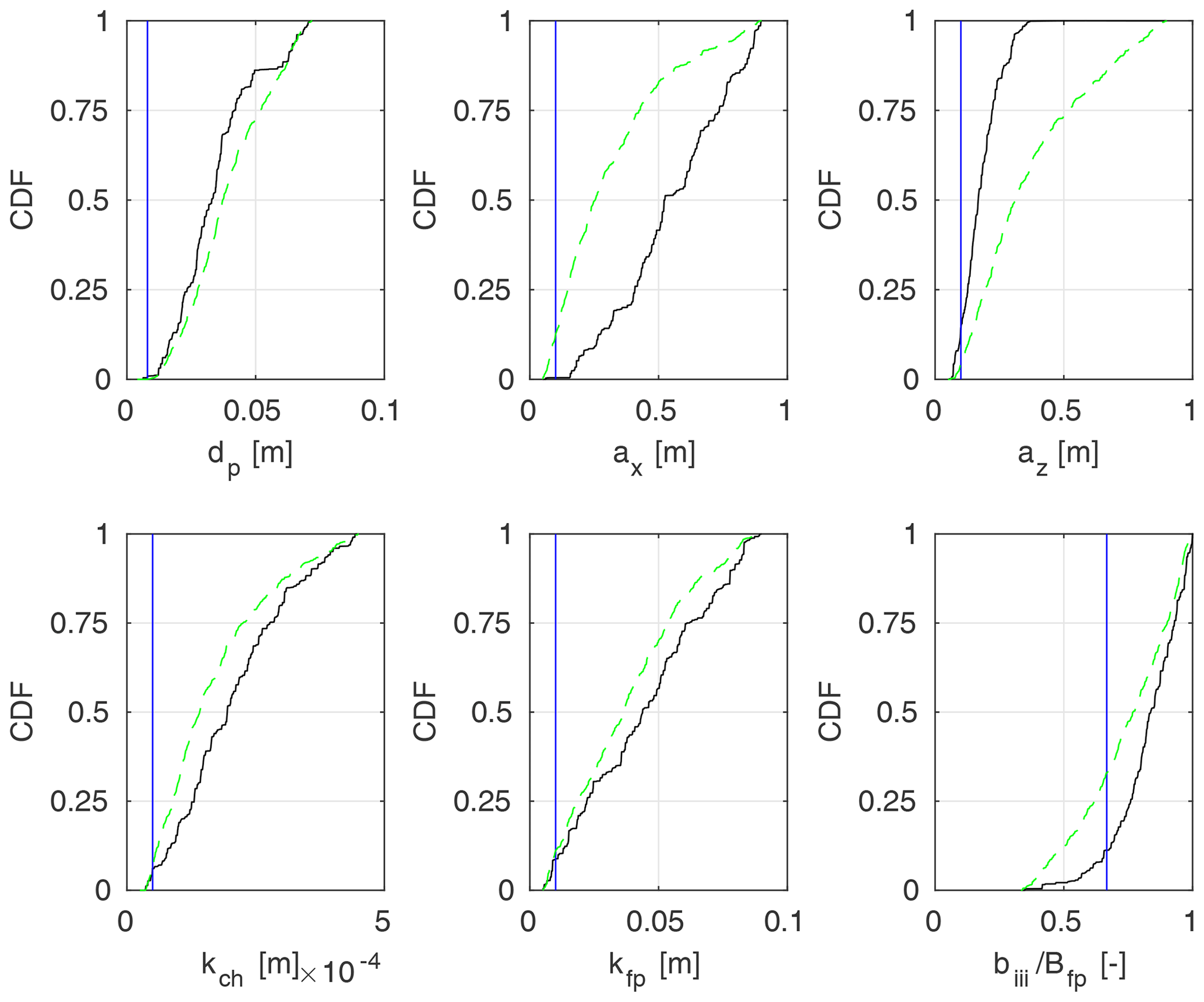
Figure 16Marginal a posteriori distributions of Pasche (black lines) and Mertens (green lines) model parameters, identified using m=M observation points for the flume experiment, case 2; measured parameter values were provided with blue lines.
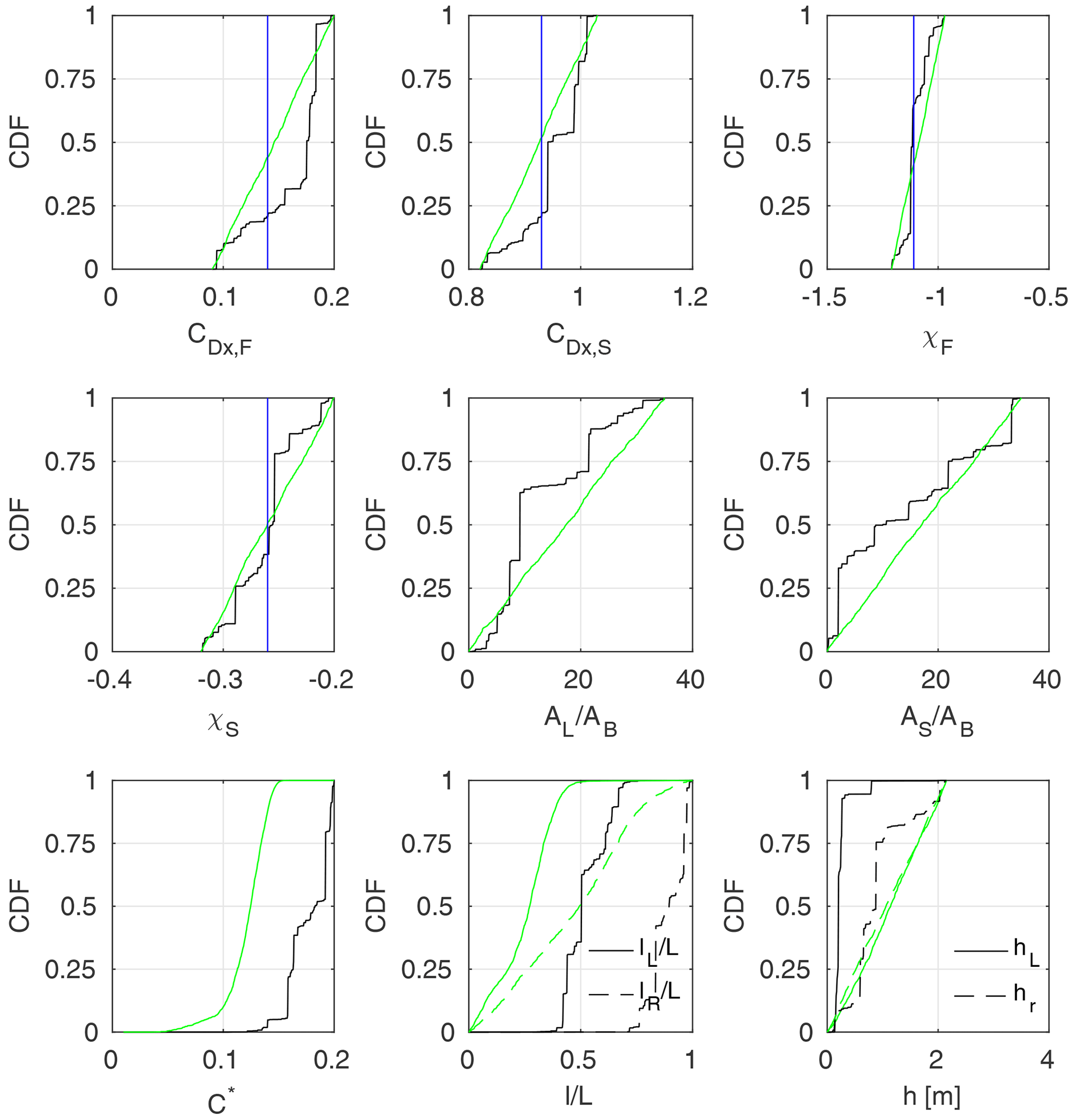
Figure 17Marginal a posteriori distributions of GTLM model parameters, identified using m=M observation points in the Ritobacken case study; black lines stand for the autumn 2011 set and green for spring 2012; parameter values given by Västilä and Järvelä (2014) for woody vegetation were provided with blue vertical lines.
3.4 Physical interpretation of identified parameters
A posteriori parameter distributions P(θ∕H) can be presented in a form of marginal cumulative distribution functions (CDFs). The CDF is plotted over the sampled parameter range, given in Table 1. The shape of the marginal CDF indicates the likelihood of given parameter values. The linear dependency would mean that all values are equally likely in respect of the likelihood function (Eq. 3). On the other hand, a strong CDF skewness characterizes regions of a high probability and larger model sensitivity on the parameter. The a posteriori marginal CDFs of parameters were presented for four vegetation-roughness models: Pasche, Mertens, GTLM, and STLM. Parameters of the Pasche and Mertens models (Fig. 16) were given for flume case 2, where both models explained the rating curve very well. GTLM and STLM parameter estimates (Figs. 17–18) were compared for the Ritobacken autumn 2011 and spring 2012 sets, as both models were found here to be appropriate and, additionally, it was possible to analyze the seasonal vegetative differences on parameter estimates (see Sect. 3.3.4). In all cases, solutions for all observation points m=M were used.
In Fig. 16 the CDF for Pasche parameters for flume case 2 is given with black lines and green lines for Mertens. Measured values of parameters are provided with blue lines. The steep shape of the CDF for the Pasche az indicates a strong model sensitivity to the parameter and that the values above ∼0.3 m are unlikely. For the Mertens model, a similar effect but with smoother CDF is present for both ax and az. The differences in the case of these particular parameters come from the more complex structure of the Pasche model, restricting values of az, due to a lack of a numerical convergence for its implicit formulas. For both models (Fig. 16) bIII∕Bfp appears to be a sensitive parameter, while the response for the remaining parameters is more uniform.
The strongest discrepancies between measured and identified values of parameters of the Pasche and Mertens models (Fig. 16) are present for the stem diameter dp and longitudinal stem spacing ax. A median (at CDF 0.5) of the probabilistic solution for dp is close to 0.04 m, while the real diameter was 0.008 m. In the case of ax it is 0.6 m for Pasche and 0.25 m for Mertens to 0.1 m. This has a clear physical sense, as in terms of the model identification, small stem diameters dp at dense spacing with small ax were equivalent to larger dp and smaller ax. This finding is supported by much smaller discrepancies in other parameters. It should be noted that the measured parameter values provide a fit close to the best one in a deterministic sense (Kiczko et al., 2017).
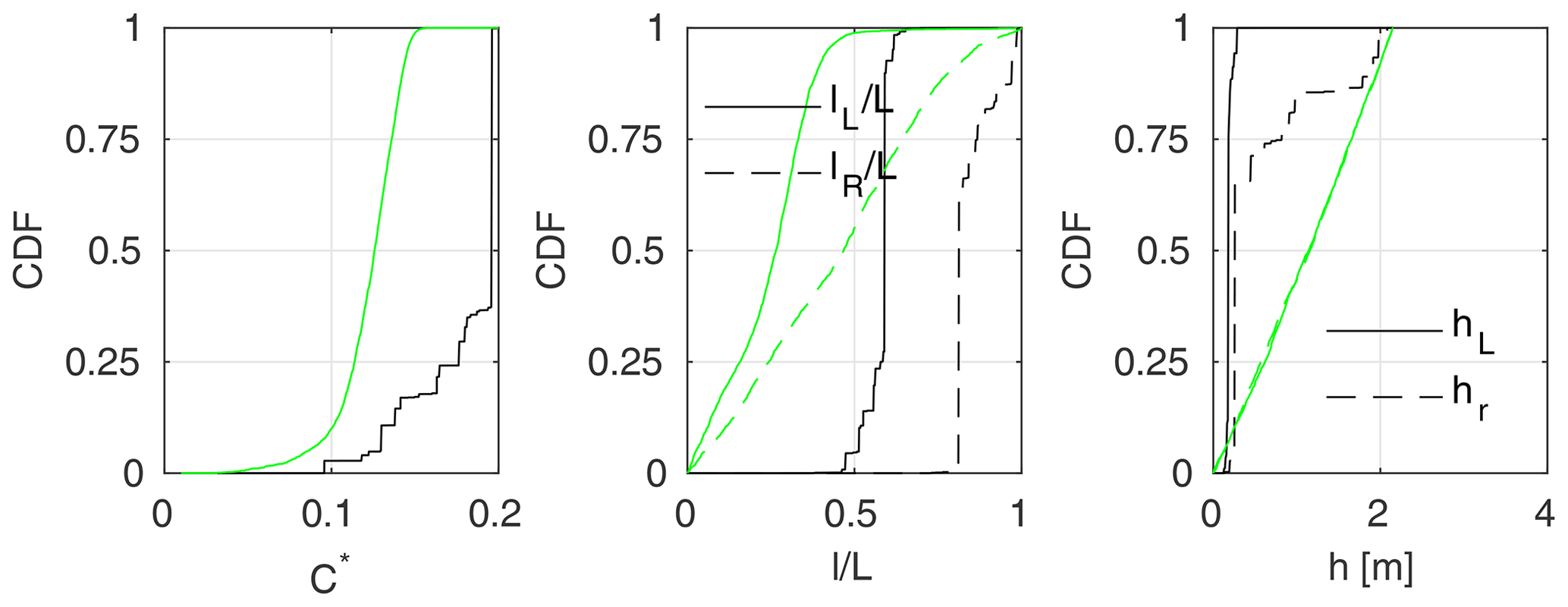
Figure 18Marginal a posteriori distributions of STLM model parameters, identified using m=M observation points in the Ritobacken case study; black lines stand for the autumn 2011 set and green lines for spring 2012.
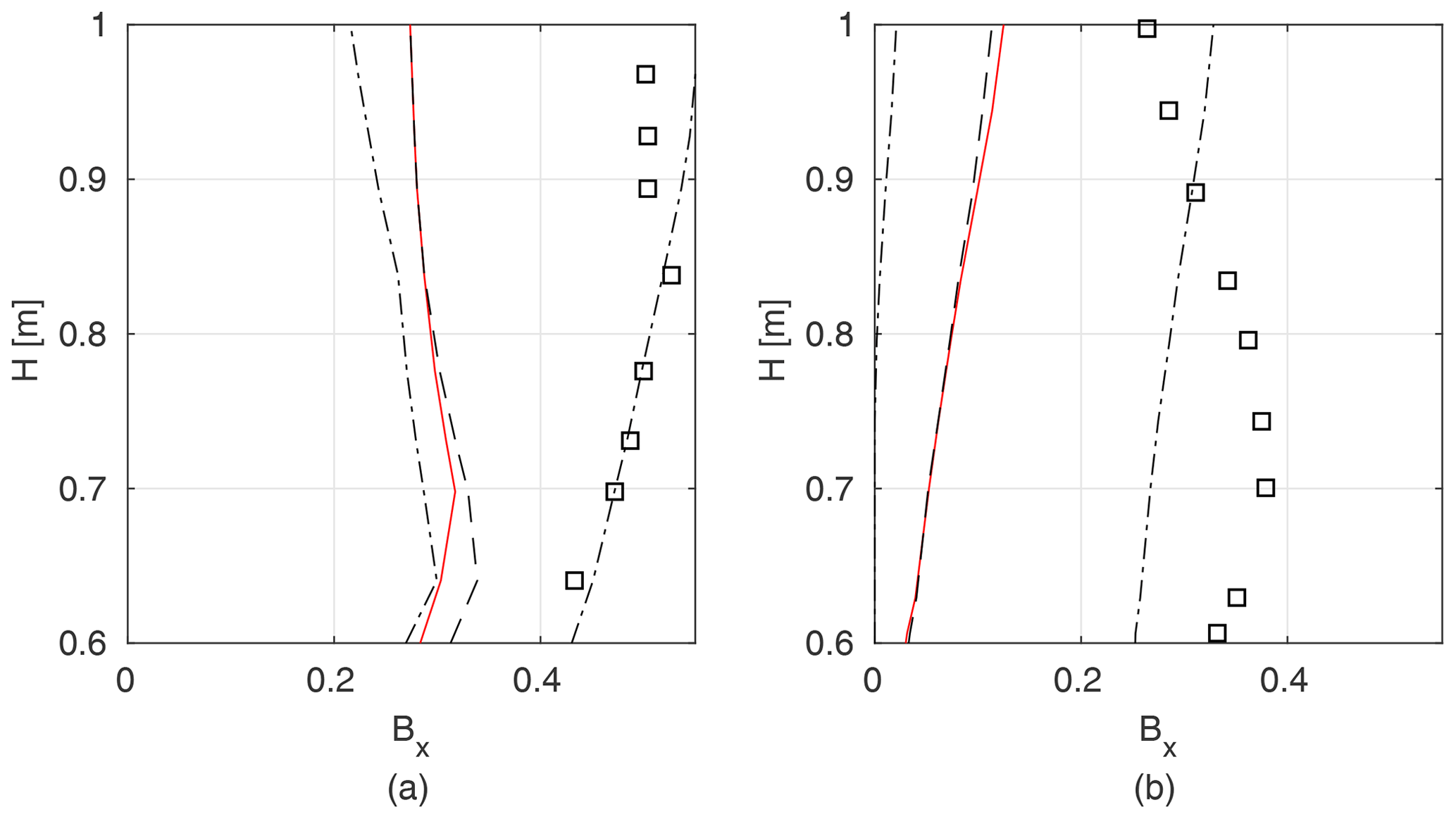
Figure 19Blockage factor BX measured in the field and determined as an inverse solution of GTLM for the Ritobacken autumn 2011 (a) and spring 2012 (b) case studies; squares denote measured values, dashed lines confidence intervals and the median of a probabilistic solution, and red line the best simulation in the Monte Carlo ensemble.
In Fig. 17 results for the GTLM model identified for the Ritobacken autumn 2011 (black lines) and spring 2012 (green lines) are provided. It can be seen that in both cases the identified values of the parameterization for flexible vegetation (Eq. 11) had a fairly narrow distribution for the reconfiguration (χ) of the foliage, which fell close to the values observed for willows and other woody species (e.g., Västilä and Järvelä, 2018). In the case of remaining parameters it can be noticed that for the autumn 2011 set, the CDFs have a step shape, clearly indicating more likely regions. For example, the most probable values of the steam reconfiguration coefficient χS for autumn 2011 are very close to the observed ones. The same applies to CDx,S and CDx,F. In all these cases, CDFs also suggest other highly probable regions, different from expected ones; e.g., for χS values close to 0.3 were also considered very likely. The effect, also seen clearly for AS∕AB, AL∕AB, C*, CDx,S, hL, and hR, is an example of parameter equifinality. Distributions obtained for the spring 2012 set are much more uniform, without values that can be considered highly probable.
Similarly to the Pasche method, not all distributions follow the expected values. The CDF for C* in autumn 2011 shows notably larger values than experimentally derived ones (–0.08, Västilä et al., 2016). For spring 2012 C* values are much closer to the expected ones, but it is hard to find an explanation for the differences when the autumn 2011 case is considered, other than the effect of an ill-posed inverse problem, where water depths are insufficient for identification of this parameter.
Wider ranges for the vegetation heights h, extents l∕L, and frontal projected areas of stems AS∕AB and leafs AL∕AB in the spring 2012 set may be associated with lower vegetation roughness in that period (Västilä et al., 2016). The solution providing a good representation of water depths might be obtained for different combinations of these parameters, such as too small h with too large l∕L. Higher autumn flow resistance, resulting in a different shape of the rating curve, appeared to be more restrictive for these parameters.
Parameters of the STLM are given in Fig. 18. As in this approach flow in the vegetation layer is neglected, it includes fewer parameters than the GTLM: lL∕L, lR∕L, hL, and hR used for parameterization of the blockage factor BX. The obtained CDFs are very similar to those for the GTLM (Fig. 17). As previously, parameters of autumn 2011 are much better defined. Again a noticeable shift in C* can be observed for autumn 2011. Such good agreement between obtained parameters for GTLM and STLM, together with very similar uncertainty estimates (Figs. 13–14), suggests that flow within the vegetation layer was not significant for the shape of the discharge curve under the analyzed conditions. Otherwise, the shape of GTLM CDFs would be noticeably different as a result of interactions with parameters characterizing flow in the vegetation layer.
Studies by Västilä and Järvelä (2018) provided estimates of the blockage factor BX which allow comparison to the results of model identification by calculating confidence intervals for modeled BX on the basis of identified parameters lL∕LL, lR∕LL, hL, and hR for autumn 2011 and spring 2012 (Fig. 19). The confidence intervals for BX are wide and the observed values are shifted from the median of a probabilistic solution towards the 0.9 quantile. The noticeable underestimation of BX by the model identification likely decreases the performance of GTLM for the field case, since under partly vegetated conditions the cross-sectional vegetative blockage has been found to be the most important property in determining the flow resistance (e.g., Green, 2005; Luhar and Nepf, 2013). A large spread of values for BX with very small variation of water levels for that solution (Fig. 13) suggests a moderate model sensitivity to BX affected by interactions with other parameters.
The present study is according to our knowledge the first one where different discharge capacity methods were compared in respect of their uncertainty and estimated along with model parameters using a probabilistic formulation of the problem of the parameter identification. The noticeable focus was made to ensure that the uncertainty analysis was objective and repeatable. The novelty of the proposed approach includes the analysis of obtained confidence widths together with the percentage of independent observations explained by them with respect to the number of observations used in the model identification. The results confirm previous findings of Kiczko and Mirosław-Świa̧tek (2018), Kiczko et al. (2018), and Romanowicz and Kiczko (2016) that for discharge formulas the probabilistic solution differs from the deterministic one. This is evident from Fig. 5 for calculated rating curves. This obvious behavior of nonlinear models highlights the need for such uncertainty analyses.
Our results show that the number of parameters seems not to be a factor precluding the identifiability of vegetation-roughness models. It was possible to identify a model with more than 10 parameters (i.e., GTLM accompanied by a parameterization of complex reconfiguring vegetation) almost as well as three-parameter ones (DCM). In most cases, the ill-posed inverse problem appears to affect the uncertainty estimates only when the number of observation points was very small, independent of the number of parameters. Widths of confidence intervals stabilized close to the final extent at about three to four observation points (m>3, Figs. 10–14). The process-based methods have more parameters than the required number of observations necessary for the identification. This suggests the ill-posed problem but might be explained by a low model sensitivity to groups of parameters seen in the marginal CDF of the a posteriori parameter distributions (Figs. 16–18) and in the result that the model fit depends on only several parameters. The observations are however different for the field case with the most developed vegetation, Ritobacken in autumn 2011, where the uncertainty estimated for the GTLM, with the largest number of parameters, falls below levels obtained for the DCM only for the full set of observations used for the model identification. In this case the GTLM was found to be very sensitive to parameters characterizing flow in the vegetation layer (Sect. 3.4), and a noticeably larger number of observations was necessary to restrict variability of parameters.
Our findings indicated that the performance of a model depends on its adequacy for the given vegetative and flow conditions. For emergent sparse rigid vegetation, the most reliable method was the Mertens model with mostly explicit formulas. Because of a simpler numerical form than in the Pasche method, the Mertens method was less vulnerable to numerical instabilities, which probably affected the outcomes of the Pasche uncertainty estimation. In the case of dense mostly grassy vegetation typically observed on natural floodplains (Fig. 4), the most reliable performance with respect to uncertainty estimates was obtained with the simplified two-layer approach (STLM), which neglects the flow in the vegetation layer (Figs. 12–14). The full two-layer model (GTLM) also provided a reasonable representation of the rating curve for flexible vegetation, although with higher estimated uncertainty, probably because of a larger number of parameters. For all cases, except Ritobacken spring 2011 with the least developed vegetation, the best-performing process-based method produced narrower confidence intervals than the DCM, when the models were identified with all observation points. Further, for the field conditions, the predictions of the validation data set were notably better with the process-based models compared to DCM when the number of data points used for model identification was low (2–4), while the confidence intervals were reasonable for practical applications.
An important aspect when comparing the different methods is their general applicability for different channel conditions. Despite the larger number of parameters, the process-based methods were less generally applicable than the Manning-based DCM approach, which could be identified and thus applied in all cases. The Pasche and Mertens methods were only applicable for the sparse rigid emergent flume vegetation for which they were derived. By contrast, the two-layer approaches GTML and PTML, although it was possible to identify them, had a less favorable performance when applied to the flume vegetation (Fig. 3). Further, our findings appeared to confirm that the STLM is strict about the assumption that less than 20 % of the flow is conveyed within vegetation (Sect. 3.2). The STLM could not be identified for the flume conditions with sparse vegetation likely resulting in substantial flow on the floodplain. The results for the DCM with constant values of the Manning coefficient were quite good except for flume case 2, indicating that the process-based methods are expected to perform better and more reliably than the DCM when several important sources of flow resistance, such as rough floodplain surface and sparse emergent vegetation, are present. These methodological findings suggest that it could be possible to choose an appropriate method on the basis of its goodness-of-fit measures and uncertainty estimates.
For practical channel design or flood inundation estimation cases, the capability to extend the model calibrated with observations at low flows to high flows is crucial. Of the six models, none provided good extrapolation results under all tested cases. GTLM was the most reliable model as it performed reasonably in four of five cases and thus across a wide range of vegetative conditions (Fig. 15). The GTLM parameterized at low flows successfully predicted the more rapid increase in discharge at water levels exceeding vegetation height (Fig. 5a), except for the autumn 2011 data set. For instance, the DCM was in two of the five cases unable to reliably predict the water levels at higher discharges when optimized based on observations at lower discharges (Fig. 15). The overestimation of channel flows (Fig. 5f) is a known feature of the DCM with constant Manning coefficients, as it does not account for the momentum transfer between the main channel and floodplains (Myers, 1978).
The GTLM was in this paper amended with a vegetation parameterization (Eq. 11) that describes the influence of the plant streamlining and reconfiguration on flow resistance. Although Eq. (11) has been developed for woody vegetation, it was applicable to the predominantly grassed vegetation at the field site. Field surveys indicated that much of the plants consisted of a main stem and more flexible leaves, conceptually similar in behavior to foliated woody vegetation. Equation (11) describes the drag from stem and leaves and allows us to set different values for the flexibility-induced reconfiguration for the stem and foliage. By setting the reconfiguration parameters to 0, the model can be used for rigid vegetation, which might explain the applicability of the model in flume cases with rigid vegetation.
Further justification of the wide applicability of the two-layer modeling concept is not straightforward with the obtained results. Shields et al. (2017) suggested that two-layer models based on the Luhar and Nepf (2013) concept allow for a better representation of the transition from the submerged to emergent flows, in which case the cross-sectional vegetative blockage and the bulk flow resistance typically start to decrease. Obtained CDF of a posteriori parameter distributions for STLM and GTLM suggest that this effect might be important. For the autumn 2011 case, with well-developed vegetation, the most probable solution included moderated vegetation heights and larger extents (hL and hR, Fig. 17), which ensures that transition from submerged to emerged vegetation is present. On the other hand, this effect was not observed for other cases.
Put together, our various analyses show the advantages of the more complex process-based methods over the Manning-based DCM. The results agree with Dalledonne et al. (2019), who obtained the narrowest uncertainty estimates for the more complex models. Besides being applicable to flood water-level estimation, the described process-based models allow prediction of the influence of different channel management scenarios on water levels. The methods are expected to be helpful in planning common practical management measures for vegetated compound channels, such as cutting of the floodplain and bank vegetation as well as maintaining the channel by dredging the main channel or lowering the floodplain. Improved reliability of the discharge capacity estimates may help in decreasing unnecessary, environmentally disruptive management actions and allow planning of more sustainable alternatives, such as partial cutting.
We found that the differences between the one-dimensional methods were notably larger than for the study of Dalledonne et al. (2019) focusing on a two-dimensional model. Further, the Warmink et al. (2013) study did not consider the choice of the flow resistance parameterization method to be crucial. The presently investigated flume and field cases had a notable portion of the cross section covered by the floodplain vegetation, with Manning's n ranging at 0.017–0.150 . Thus, our results indicate that the choice of the resistance formula is important for cases where vegetative resistance dominates. On the other hand, one-dimensional models may be more sensitive to uncertainty related to the identification of the resistance parameters than are two-dimensional models.
The most important issue is the physical interpretation of parameters obtained by the model identification. As expected, on the basis of previous studies of Werner et al. (2005) and Berends et al. (2019), the obtained values, shown in a form of CDF of marginal a posteriori distributions in Figs. 16–18, differs from measured ones. This results from the parameter equifinality. One of the reasons might be insufficient observation sets used in model identification. The likelihood function, conditioned only on water levels, is not capable of restricting variability of parameters in more complex vegetation-roughness models. It can be seen in the shape of the marginal CDF of parameters, presented in Figs. 16–18, suggesting small sensitivity of the model to given parameters, except only the Ritobecken autumn 2011 case. Their variability can be probably reduced by additional data sources, as discussed in hydrological studies of Her and Chaubey (2015) and Her and Seong (2018). For channel flows it could be velocity measurements, used, e.g., by Berends et al. (2019) for model identification. It should be however noted that in practical assignments on a flood hazard such data are rarely available. The other reason for parameter equifinality and therefore discrepancies with measured values of parameters are parameter interactions. The shift in a given parameter is compensated by others; e.g., the large stem diameter dp, observed for the Pasche and Mertens models, comes along with too large spacing of plants ax and az. Such an effect is probably present in all process-based models identified in terms of an inverse problem.
The inability to specify parameters of process-based methods by model identification is an argument against such an approach, already signalized by Werner et al. (2005). Moreover, with parameters different from real values, the use of these complex models gives the impression of black-box modeling, as the identification goal is only to obtain a satisfactory fit and uncertainty estimate. With outcomes of the present study, it is hard to address this problem directly, as it would require comparison of process-based methods with a pure data-based model. However, the overall impression is that the application of models with numerous parameters seems to be inseparably connected with the problem of the equifinality. A similar behavior is known, e.g., for the Shiono–Knight model by Knight et al. (2007). For vegetation-roughness models, it will apply not only in the cases where parameters are identified purely in terms of the inverse task, but also when available measurements of vegetation properties are uncertain and have to be generalized over larger areas (Straatsma and Huthoff, 2011). In such cases it will always be necessary to find values characterizing hydraulic conditions rather than true vegetation features. The difference is that even with very uncertain data, the identification problem will be limited to relatively narrow parameter ranges.
The parameter identification is expected to result in more physically realistic values if at least some of the required vegetation properties or the channel bed roughness can be directly measured and used as the input. For instance, the vegetation extents of the two-layer models (Fig. 2) are straightforward to obtain at the field, or vegetation can be assumed to cover all channel perimeters above the bankfull level. Typical heights of grassy floodplain vegetation in a given geographical area can be obtained through remote sensing coupled with information on channel geometry, and these values may be extrapolated to other sites where such information is not available.
Process-based models introduce however physical constraints, providing, as mentioned before, a better basis for extrapolation than purely data-driven approaches and, in this study, better than a simpler model. In most of the cases analyzed here, vegetation-roughness models, when applied for the vegetation conditions they were originally developed for, provided better predictions of higher flow than the Manning-based DCM (Fig. 15). Some advantages of using the process-based models, even without knowledge of parameters, might also be their clear physical interpretation compared for example with Manning coefficients. Nonphysical stem diameters are more obvious to large values of the Manning coefficient. A modeler aware of parameter interactions can decide whether, e.g., given discrepancies in vegetation characteristics are important in an analyzed case.
Discharge formulas analyzed in the study are usually only a part of the one-dimensional model. The uncertainty of such models depends also on additional elements, like spatial variability of resistance and simplification of the channel geometry. It should also be noted that the investigated cases had a fairly regular cross section and homogeneous vegetation. Therefore, care should be taken when attempting to generalize the presented findings to all one-dimensional approaches. In complex real-world cases, it might be beneficial to include several discharge formulas through an ensemble approach, which is also used in other fields, such as climate modeling.
This study investigated the application of advanced process-based methods for the discharge capacity estimation of vegetated compound channels in practical cases with limited information on the vegetation properties. We compared five process-based methods with a physically based vegetation characterization to the conventional Manning-based divided channel method (DCM), focusing on their uncertainty. The developed probabilistic approach and the used data covering a range of conditions on floodplain vegetation submergence, density, flexibility, and flow hydraulics allowed us to draw the following conclusions.
-
The calculations showed that it is possible to identify process-based models with a large number of parameters on the basis of the inverse problem with narrower or similar uncertainty bands compared to the Manning-based DCM.
-
The uncertainty related to the ill-posed inverse problem, resulting from the insufficient number of observations, is in most cases noticeable only when a small number (three to four) of observations is used in the model identification. However, in the cases where the shape of the rating curve is more sensitive to model parameters, the results suggest that methods with more parameters have wider uncertainty bands when identified with a small number of observations.
-
The model identification resulted in some parameters differing from their measured physical values, raising doubts about the physical interpretation of obtained models.
-
Despite unrealistic values of parameters, the process-based models for vegetation roughness revealed good extrapolation capabilities to high floodplain flows when identified using only low floodplain flows.
-
Uncertainty estimates clearly indicate the applicability of a given model to the analyzed case. Unsuitable models, e.g., those developed for non-submerged vegetation but applied to submerged vegetation, have relatively wide uncertainty estimates or lack a probabilistic solution. Therefore, the results showed that it is possible to choose an appropriate model without prior knowledge of vegetation properties in the channel, by comparing obtained uncertainty widths.
-
The best results in terms of the lowest uncertainty estimates were obtained with the Mertens method for the emergent, rigid vegetation case. For the dense flexible vegetation, the simplified two-layer method (STLM) neglecting the flow in the vegetation layer, had the most reliable performance across different seasons, functioning under submerged and emergent conditions. The generalized two-layer model (GTLM), of the process-based approaches, amended with a vegetation parameterization describing the flexibility and reconfiguration of the plants was the most universally applicable to different vegetative conditions.
-
In most cases, the Manning-based DCM also had satisfactory performance, but results suggest it had poorer capabilities for extrapolation to high floodplain flows when calibrated with only low floodplain flows, in comparison to process-based models.
-
An open issue is the generalizability of the obtained results to spatially distributed one-dimensional models.
-
The proposed approach with the novelty of comparing different models in terms of their uncertainty along with the quality of the uncertainty estimation might be useful in other similar studies.
A1 Flume experiments
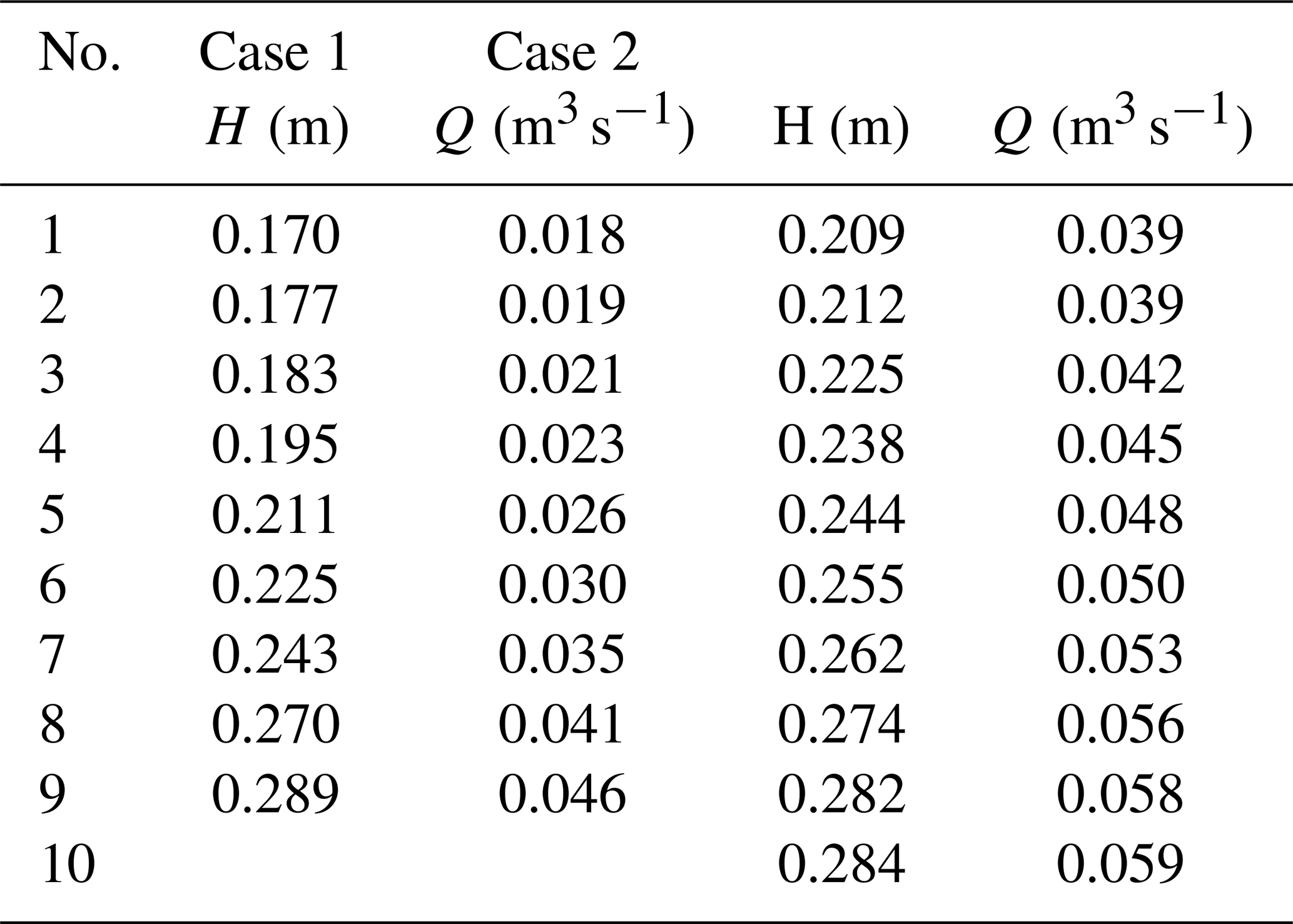
A2 Ritobacken field experiment
Table A2Cross section for the Ritobacken Brook. Original data collected by Västilä et al. (2016).

Obtained from field surveys for 2010–2012 for a 190 m river reach and averaged to obtain a single cross section; the number of measurement points was reduced using the algorithm of recursive Douglas–Peucker polyline simplification (Schwanghart, 2010), with a tolerance of 0.01 m.
Table A3Data for the Ritobacken case study used in calculations: water depth H, flow rate Q, energy grade slope S, inundated vegetation height , and blockage factor BX. Water depths H were obtained by averaging upstream and downstream depths. Original data collected by Västilä et al. (2016).
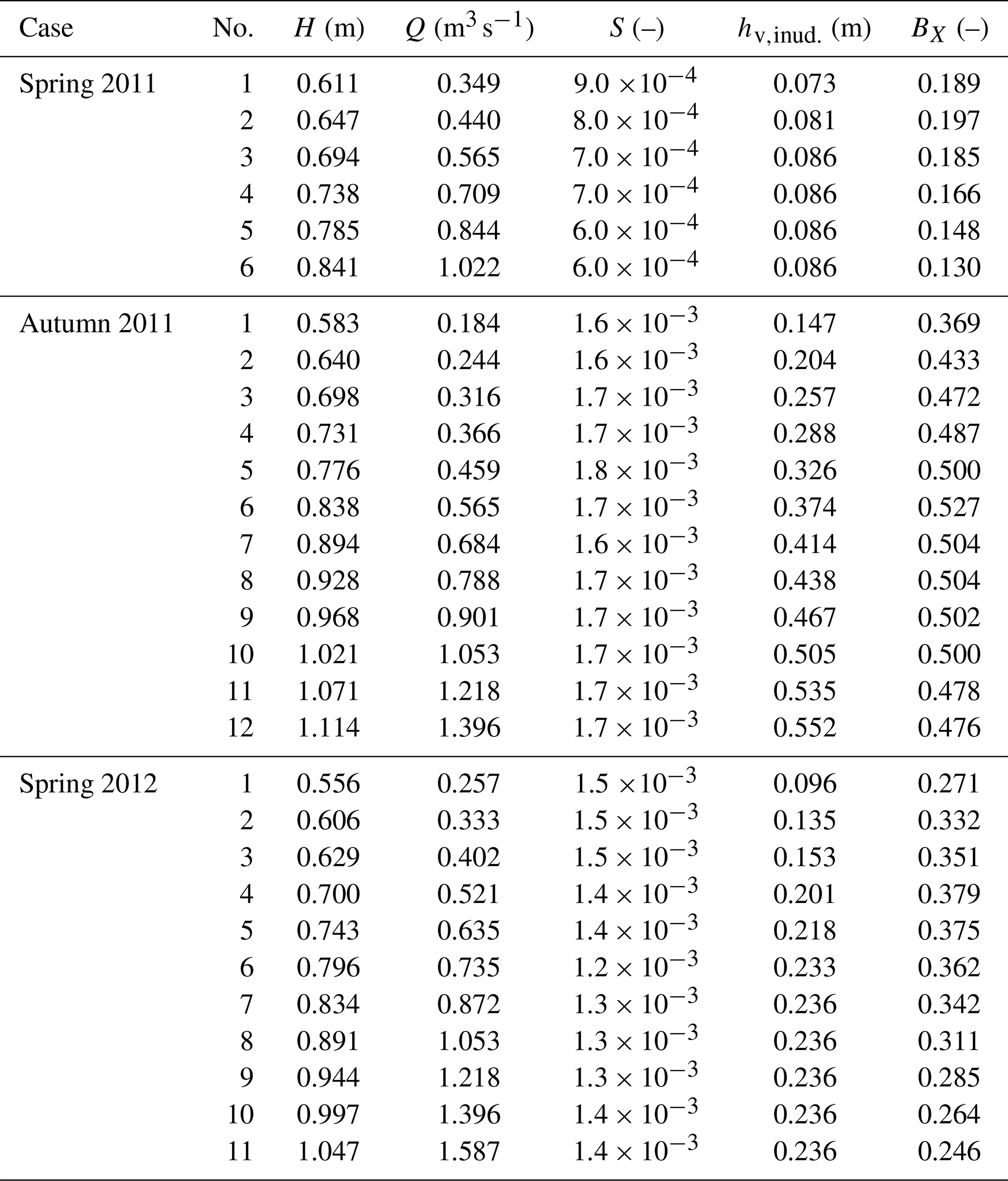
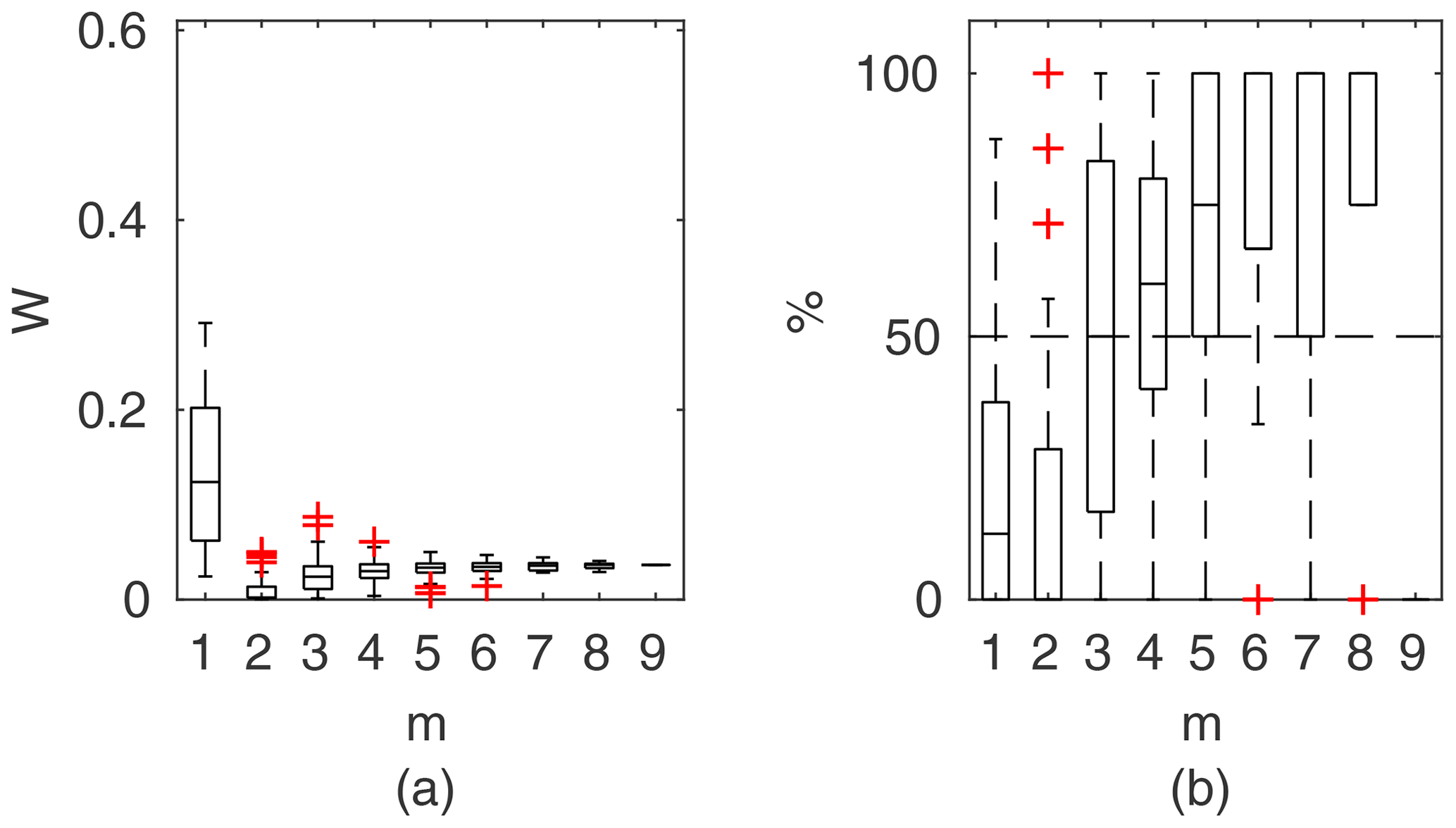
Figure B1DCM Manning results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).

Figure B2Pasche results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
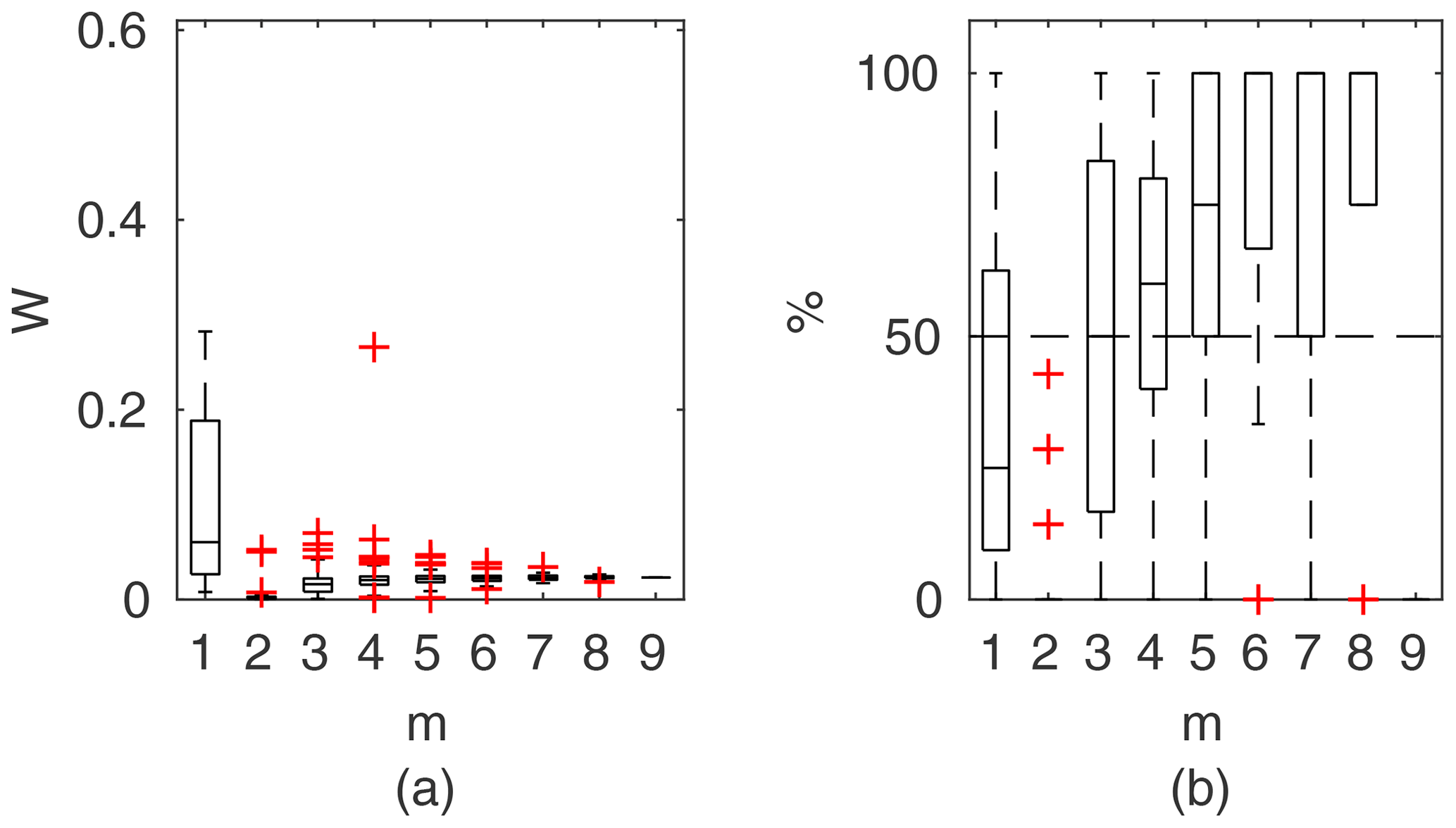
Figure B3Mertens results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
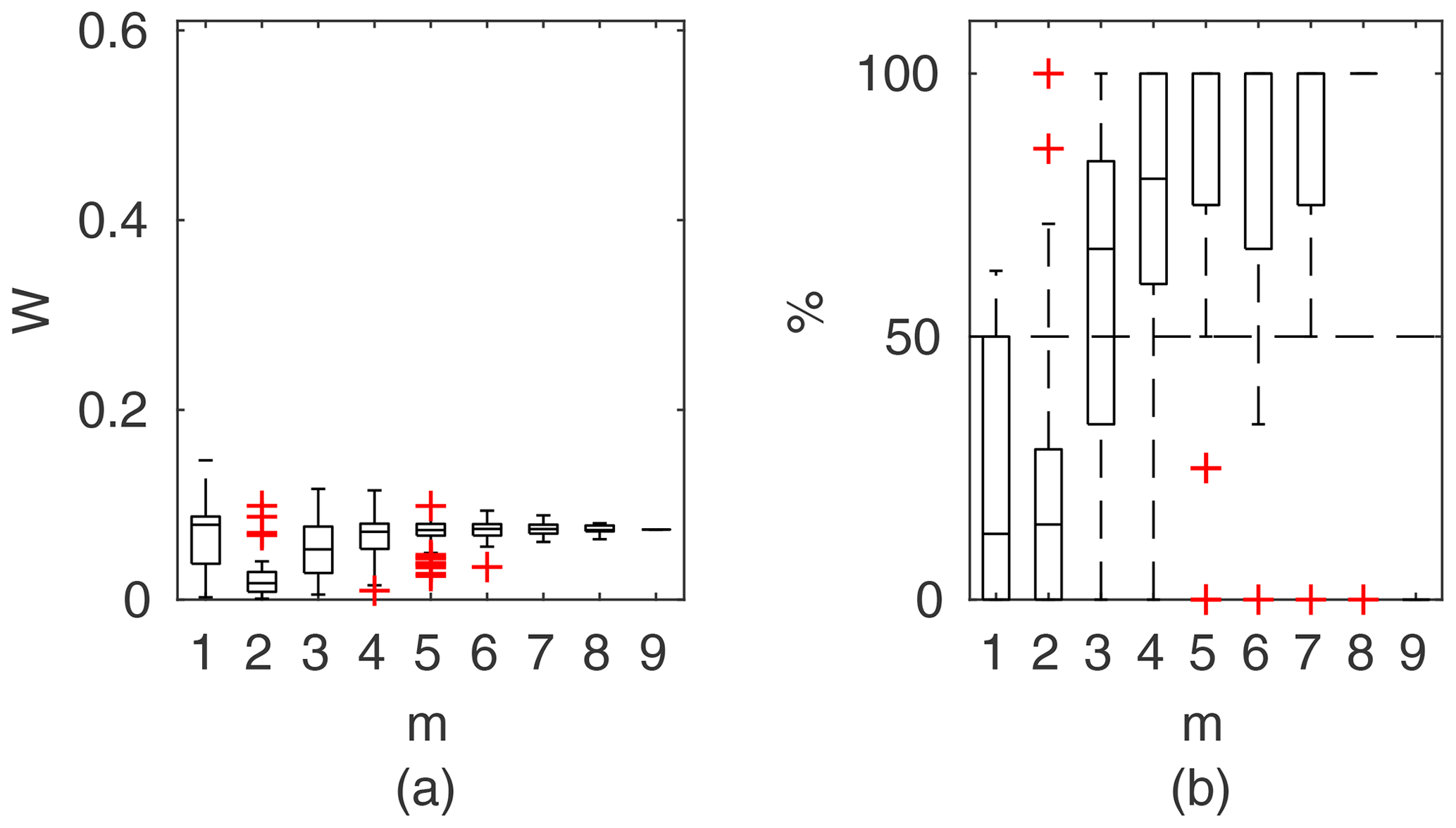
Figure B4GTLM results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).

Figure B5PTLM results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
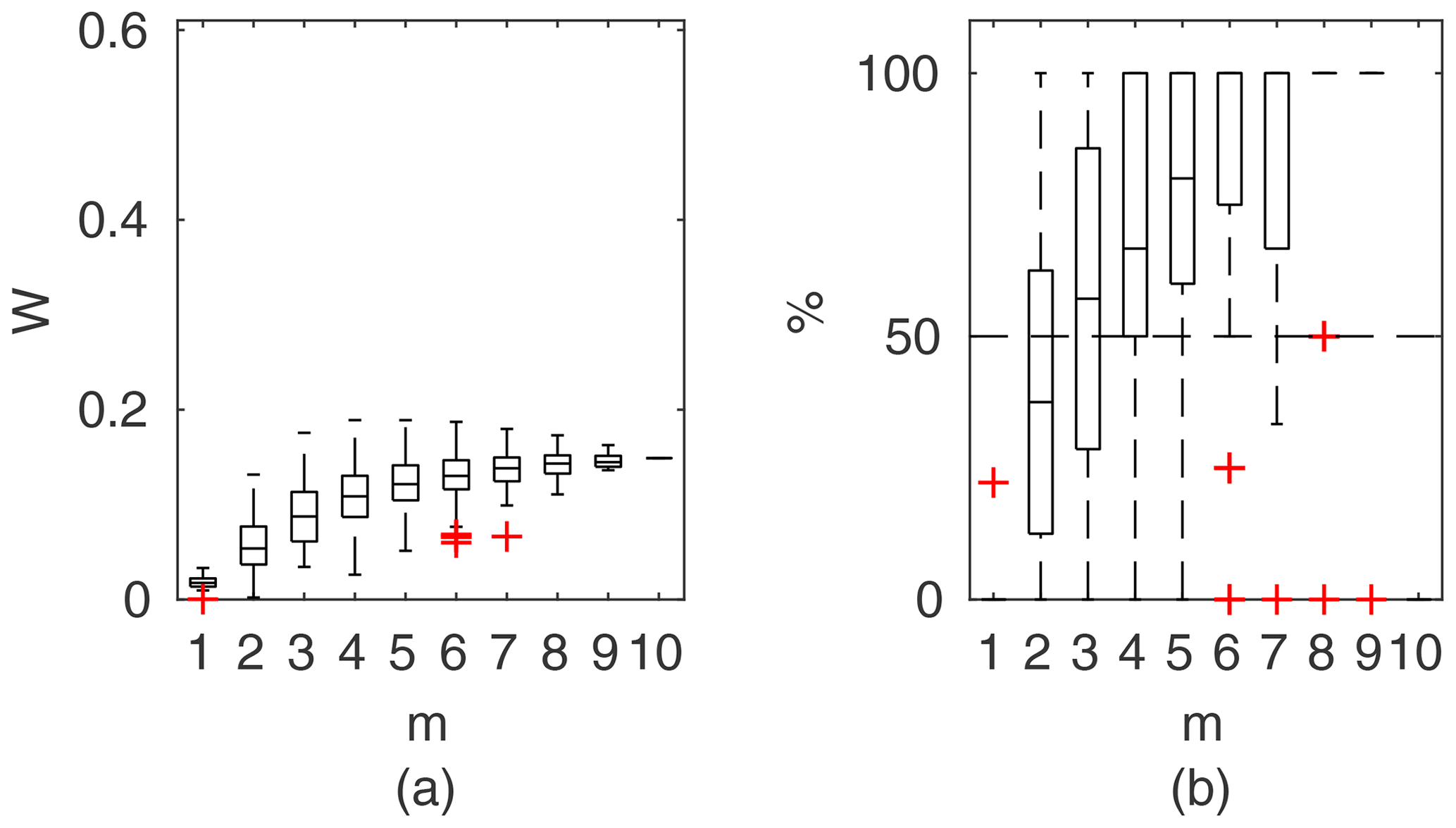
Figure B6DCM Manning results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).

Figure B7Pasche results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
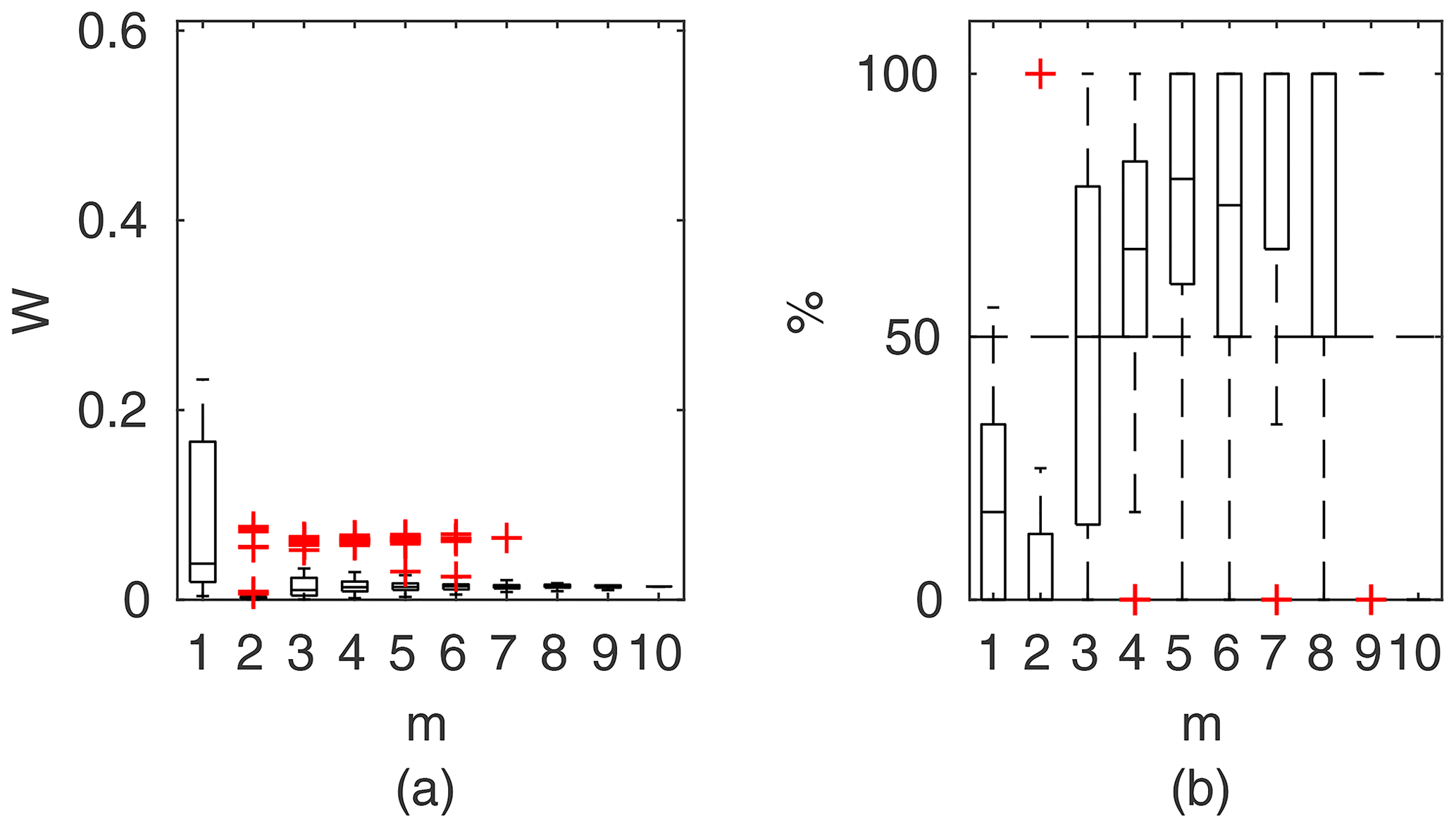
Figure B8Mertens results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
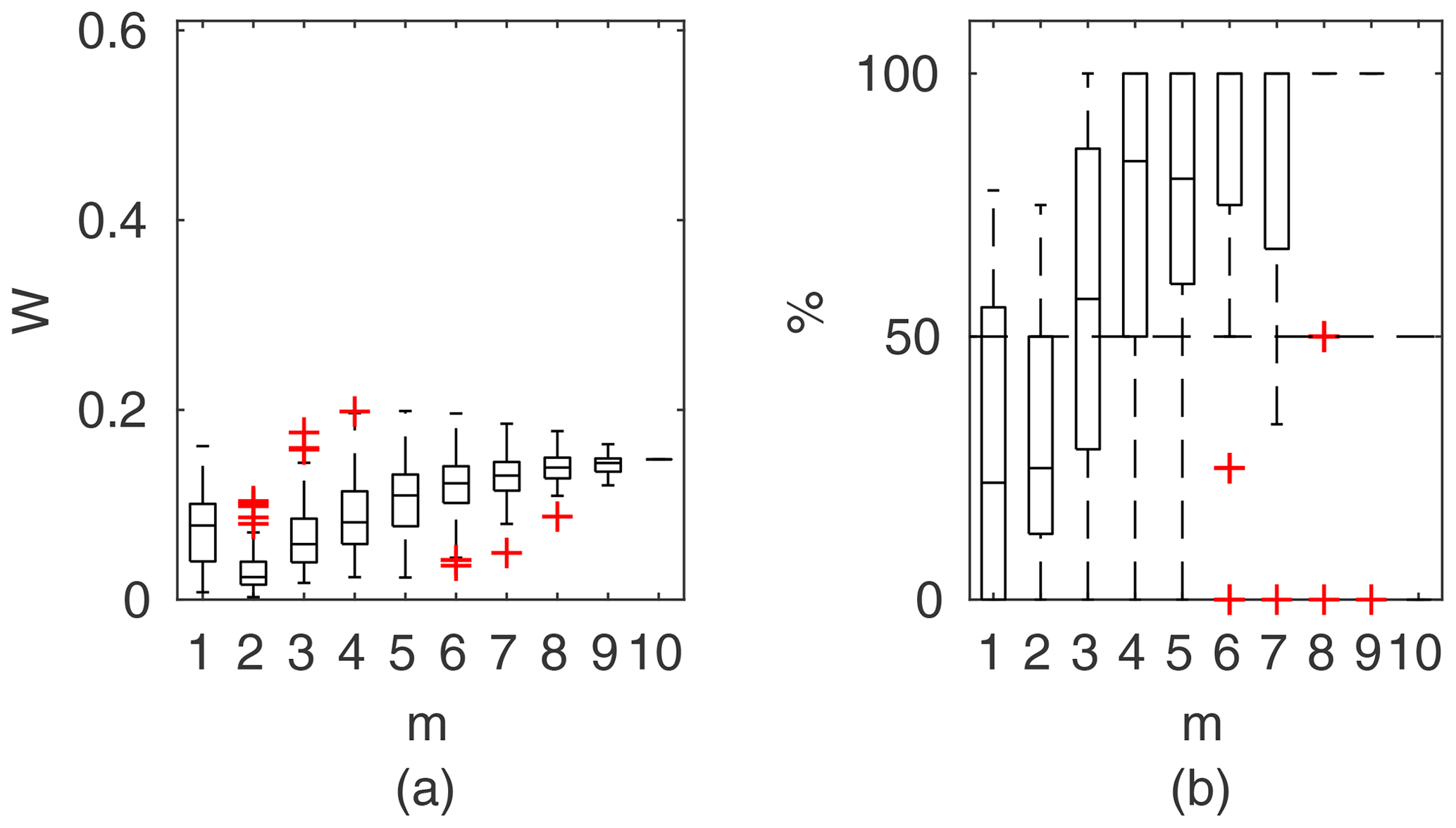
Figure B9GTLM results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
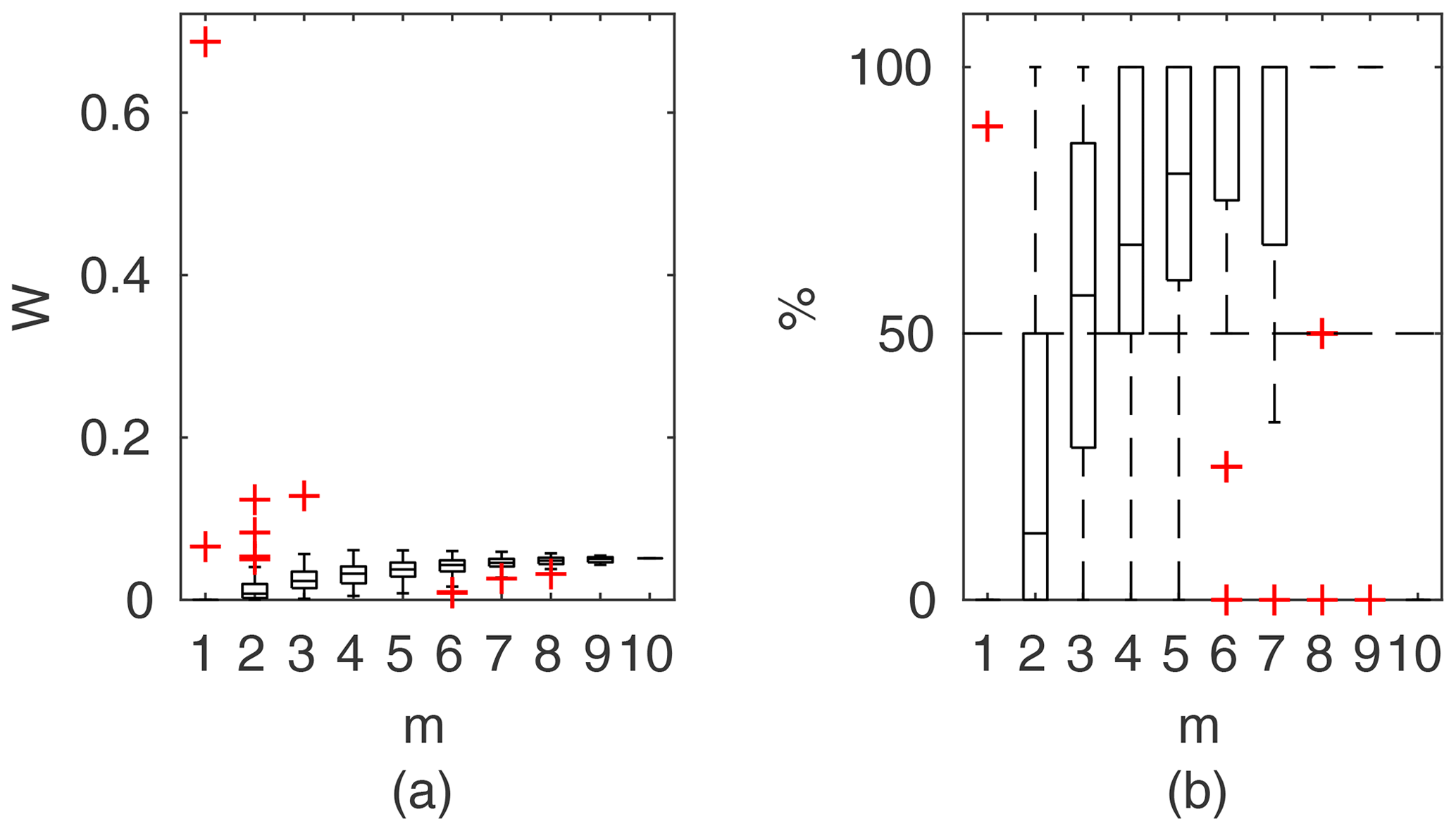
Figure B10PTLM results for flume case 1: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
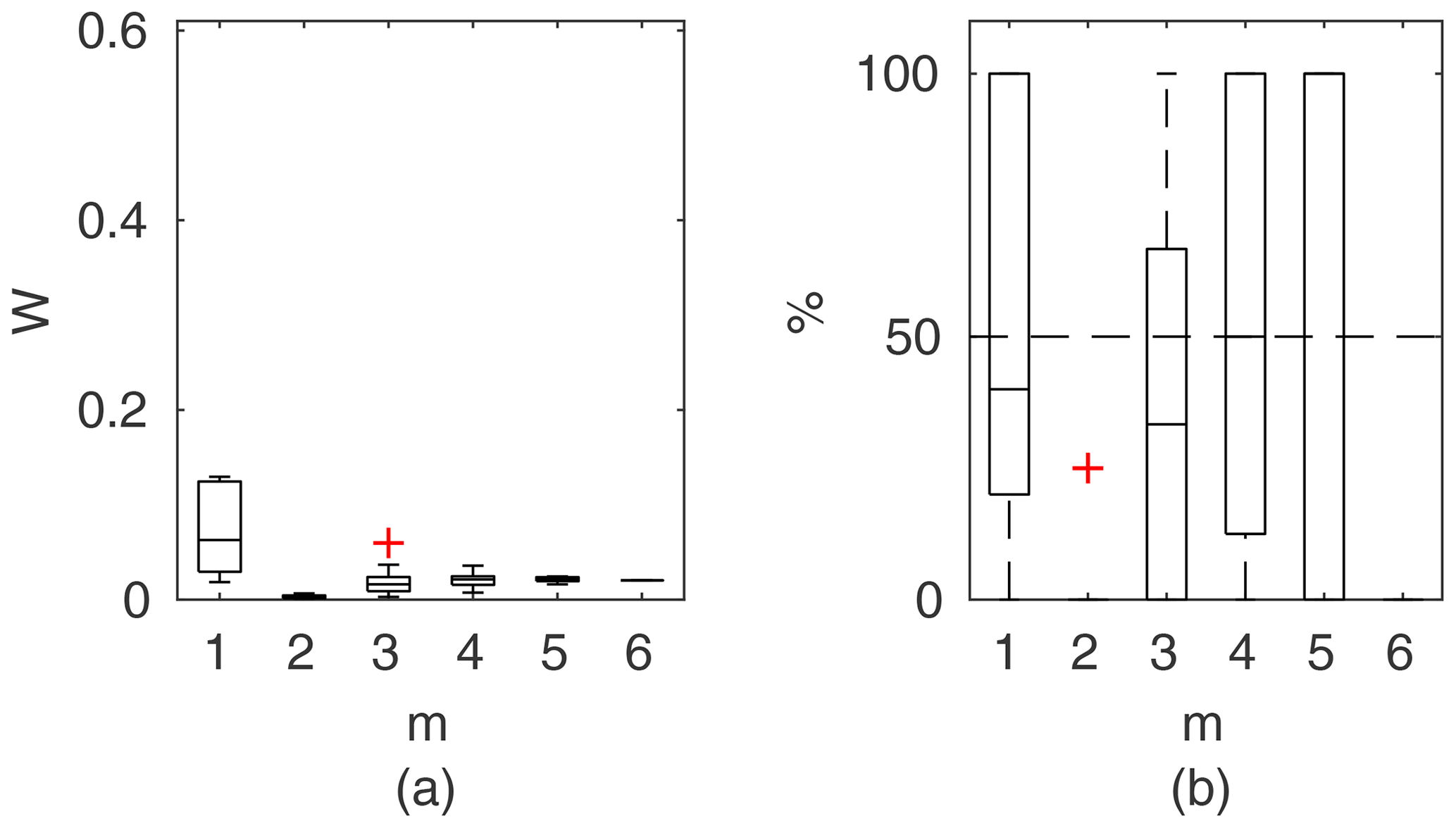
Figure B11Manning DCM results for the Ritobacken case study, spring 2011: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
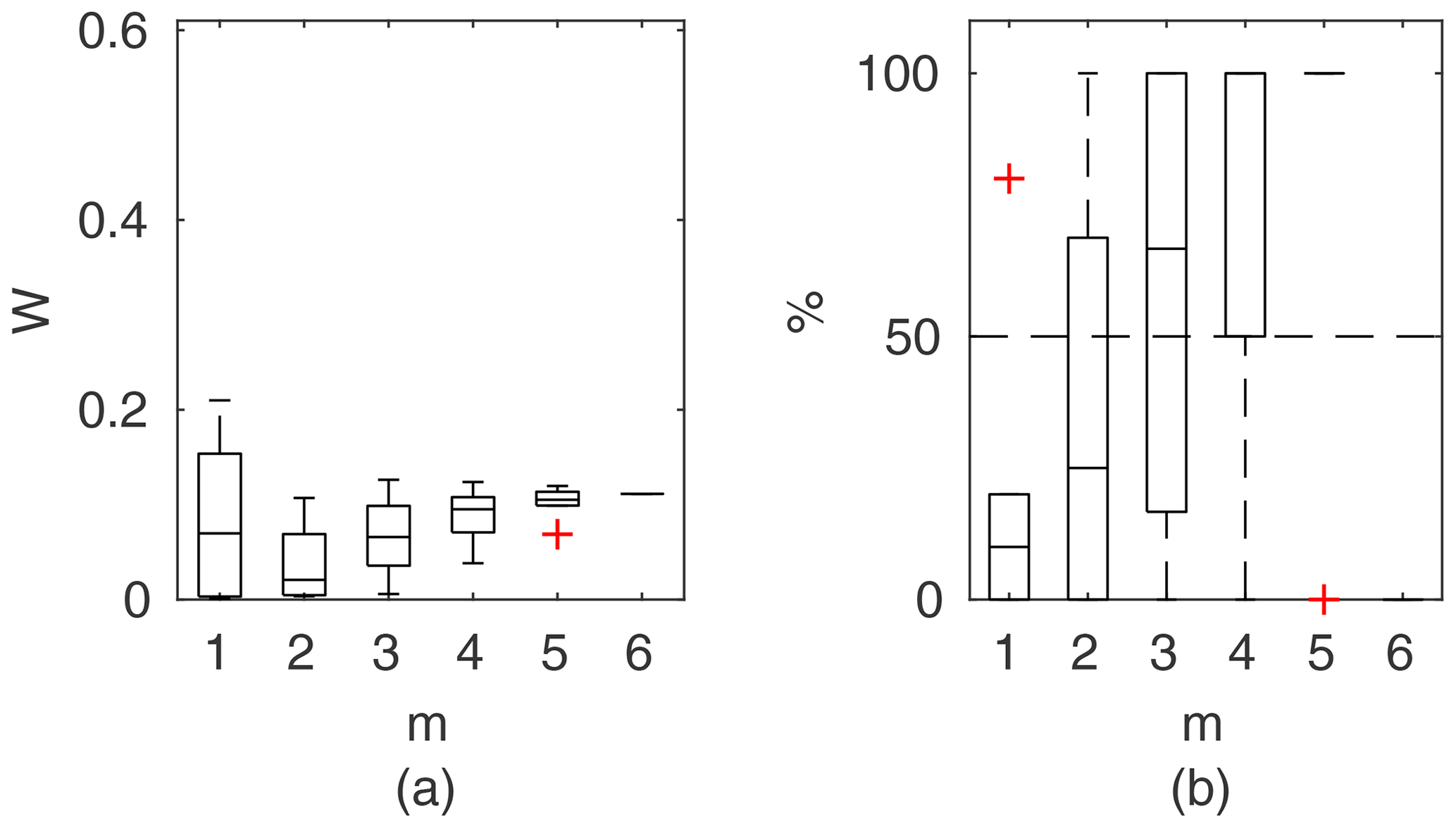
Figure B12GTLM results for the Ritobacken case study, spring 2011: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
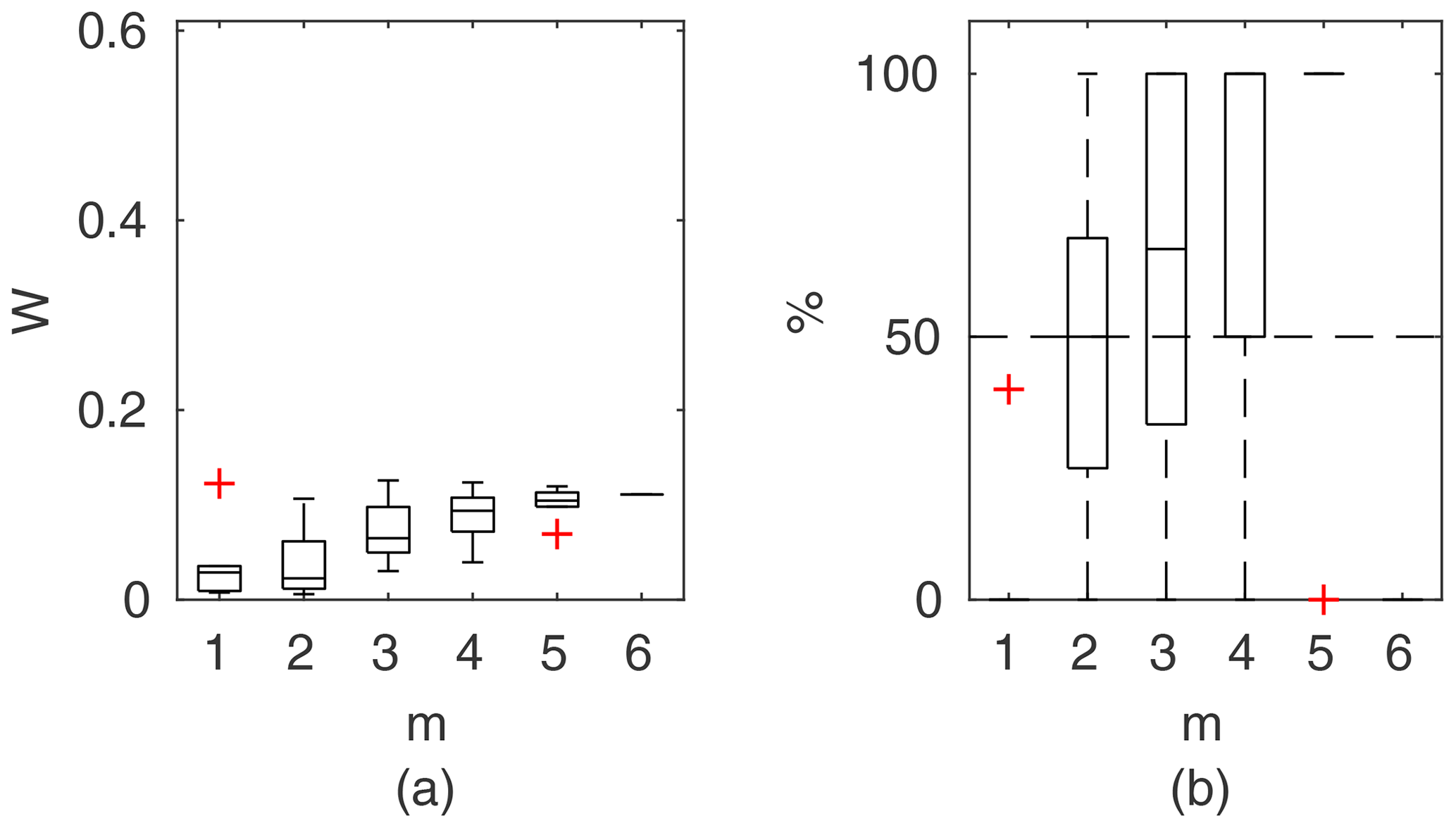
Figure B13STLM results for the Ritobacken case study, spring 2011: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
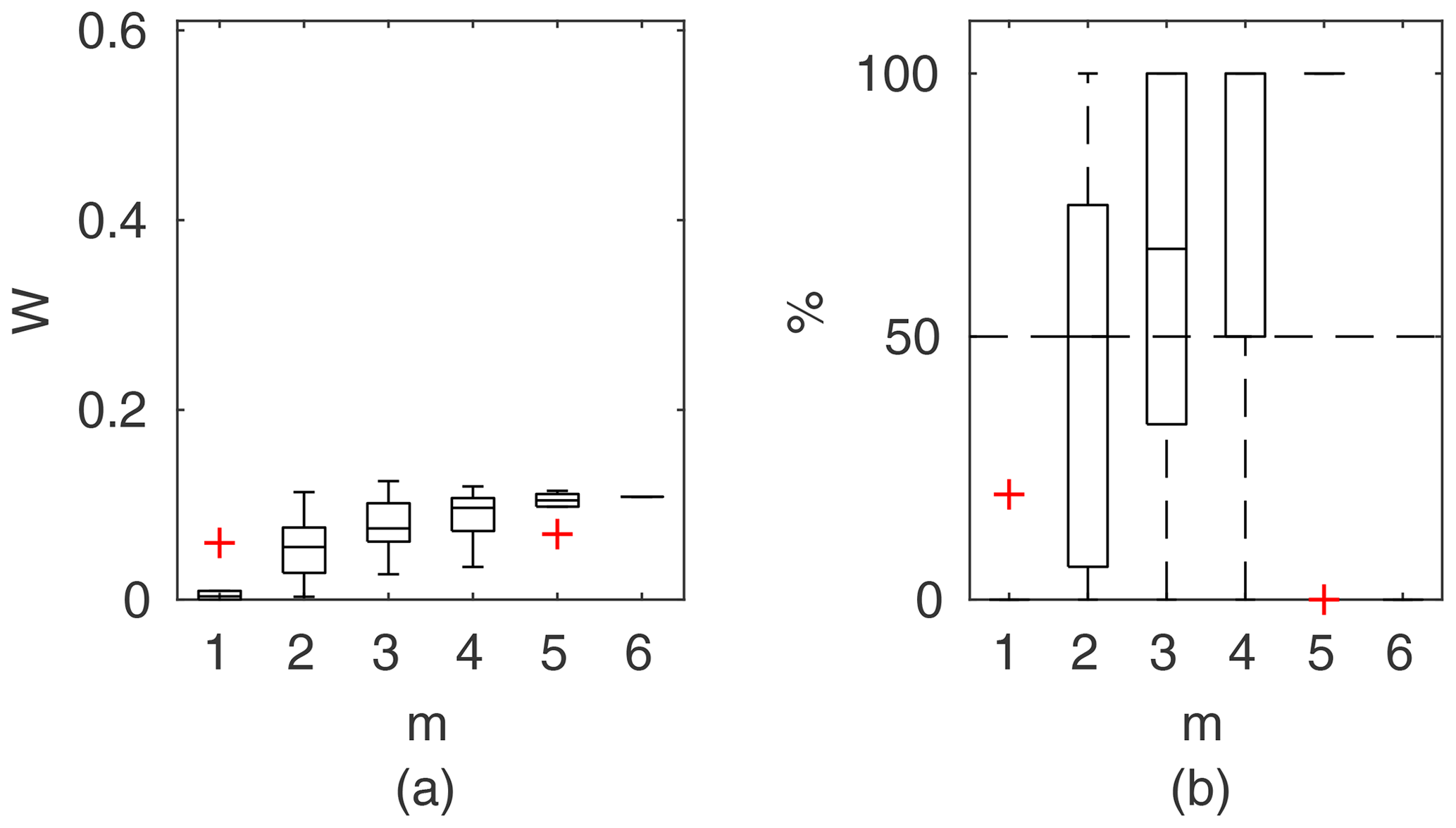
Figure B14PTLM results for the Ritobacken case study, spring 2011: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
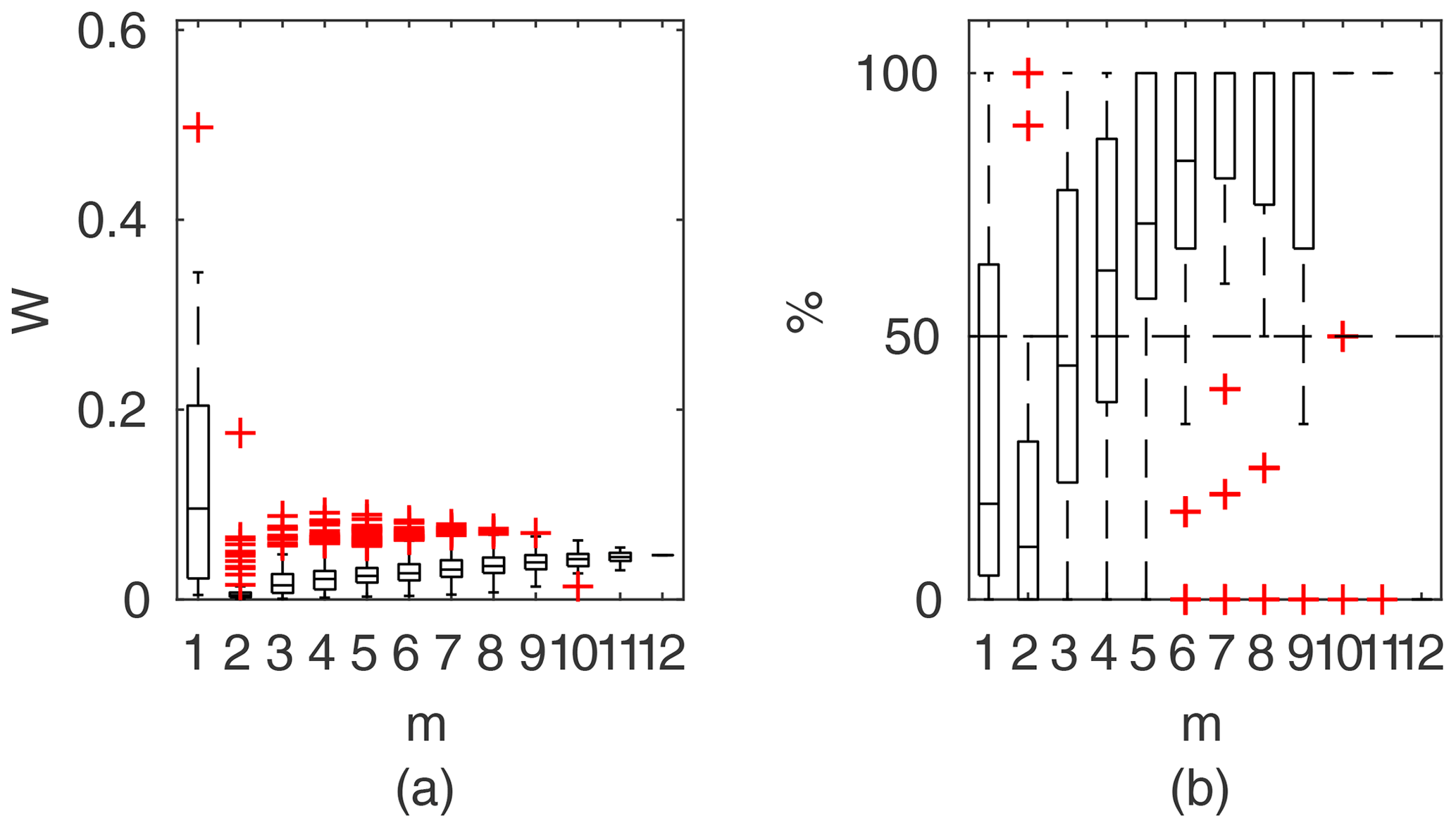
Figure B15Manning DCM results for the Ritobacken case study, autumn 2011: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
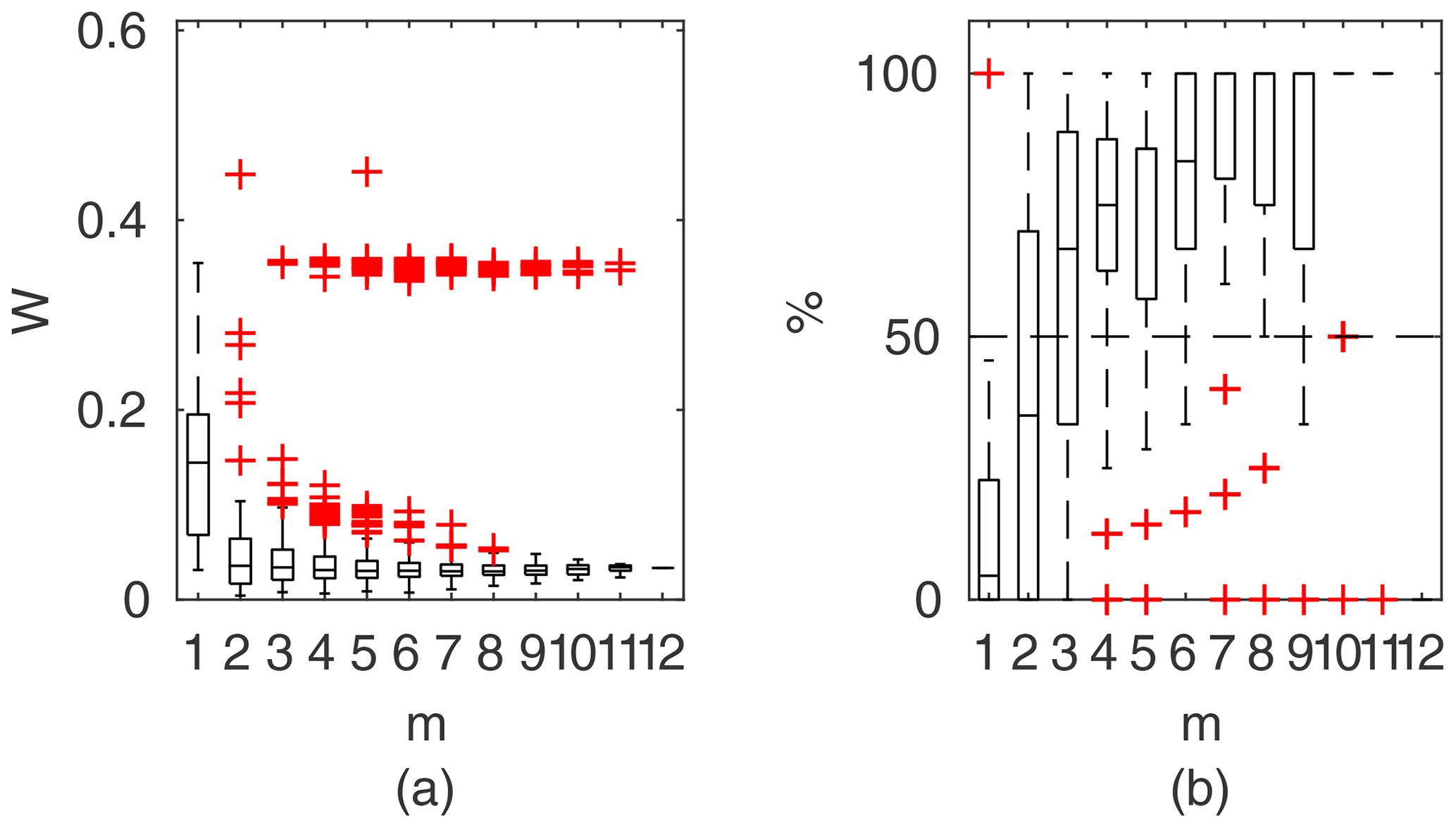
Figure B16GTLM results for the Ritobacken case study, autumn 2011: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).

Figure B17STLM results for the Ritobacken case study, autumn 2011: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
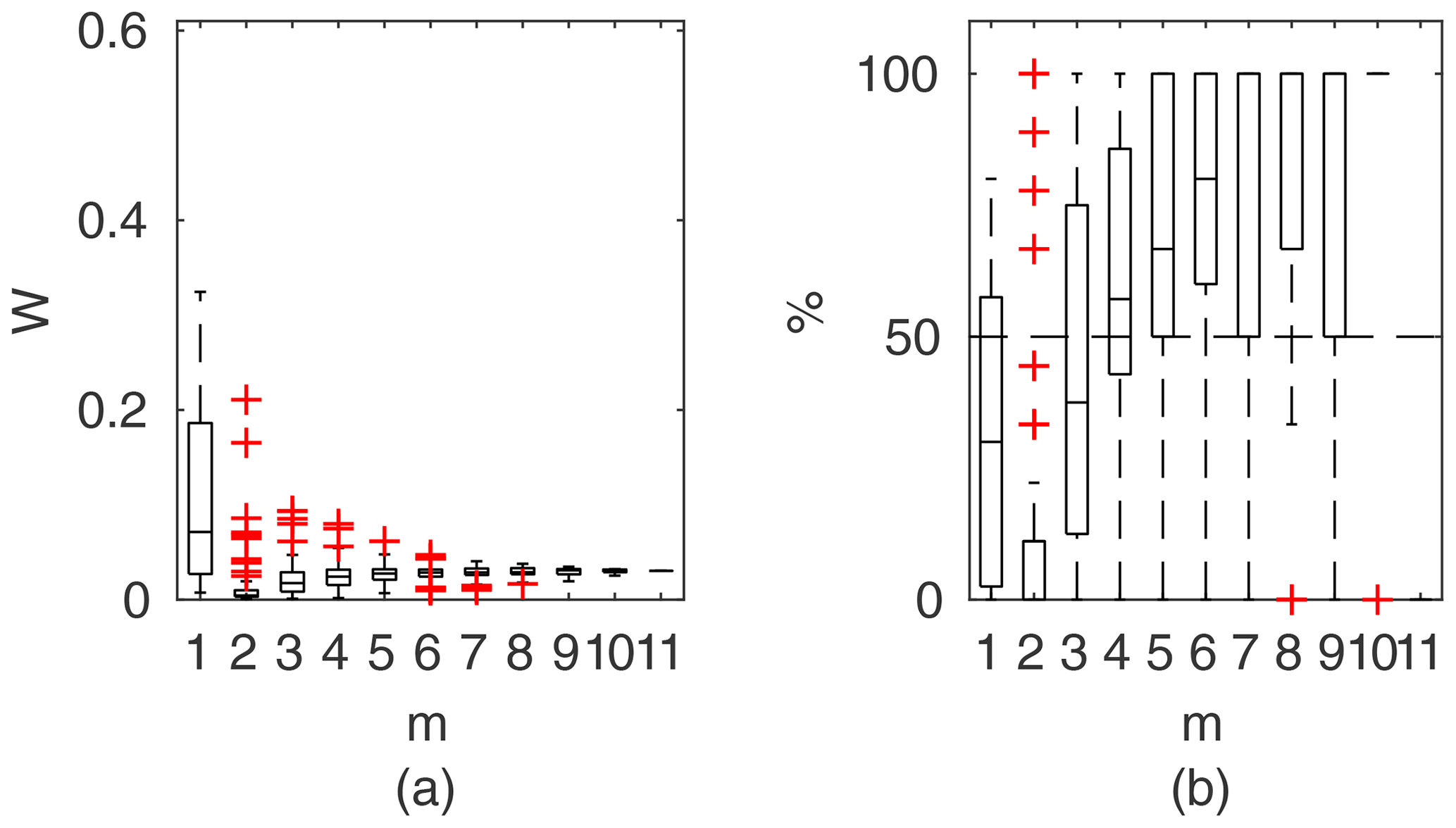
Figure B18Manning DCM results for the Ritobacken case study, spring 2012: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).

Figure B19GTLM results for the Ritobacken case study, spring 2012: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
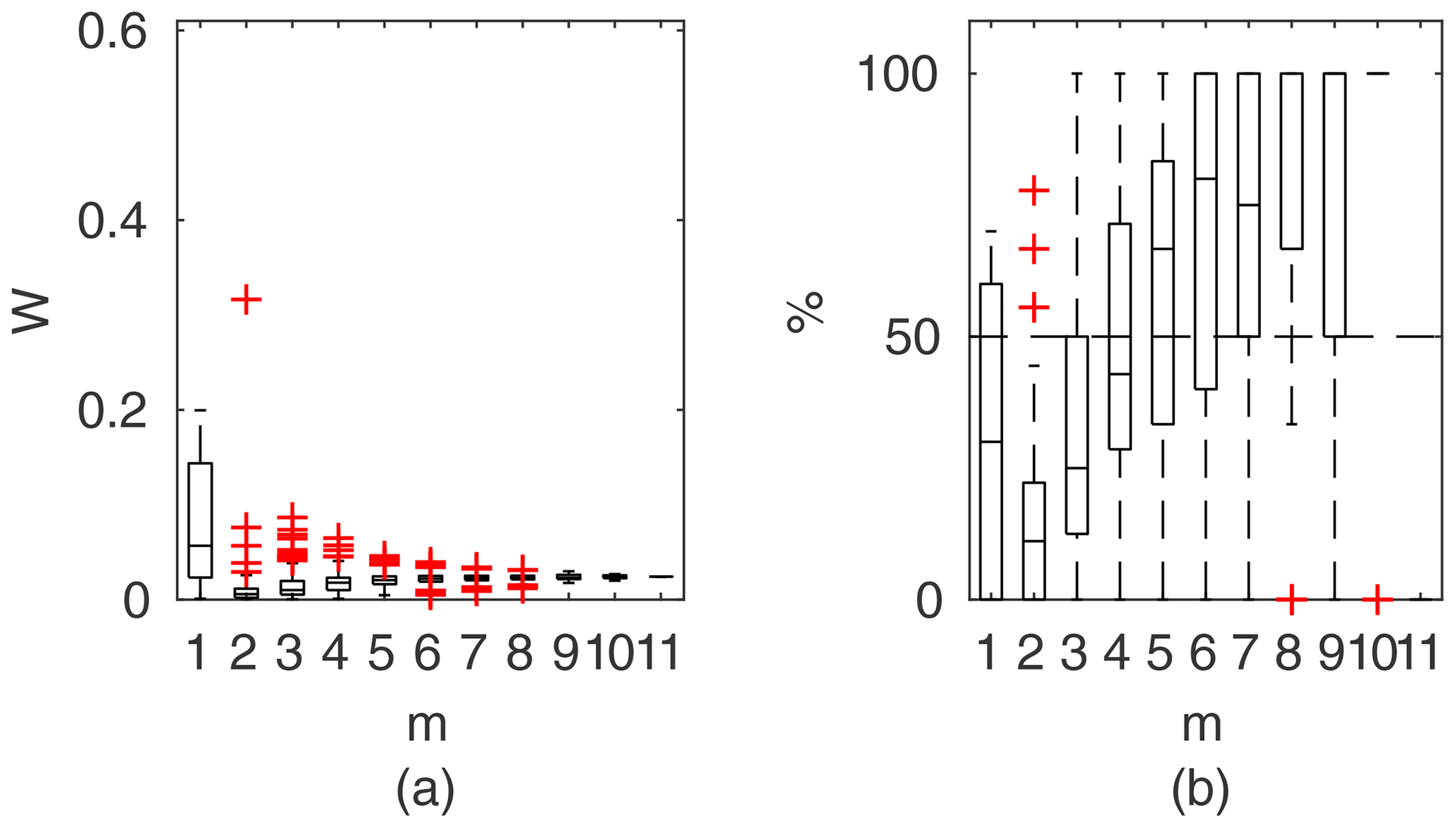
Figure B20STLM results for the Ritobacken case study, spring 2012: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
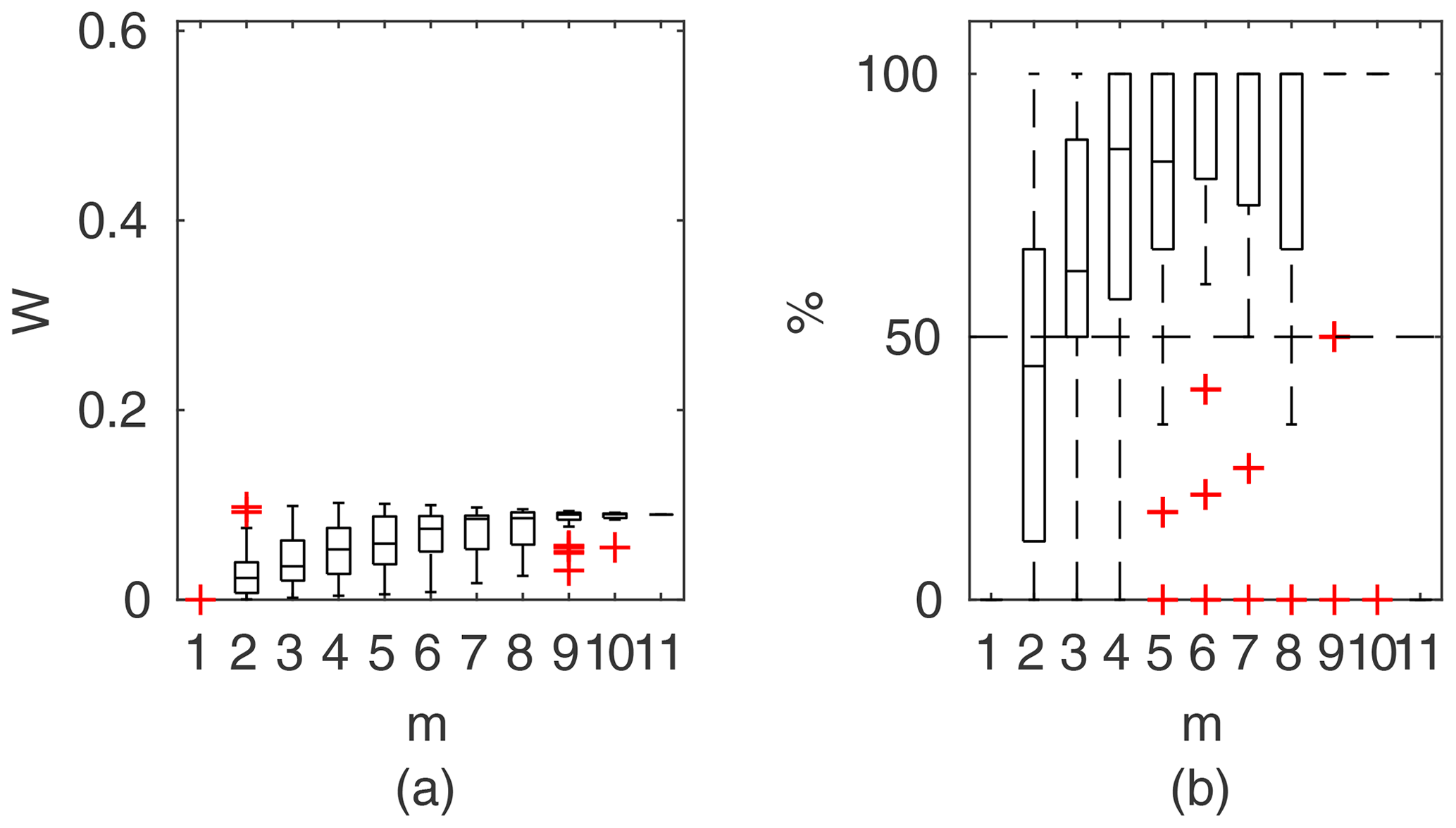
Figure B21PTLM results for the Ritobacken case study, spring 2012: (a) averaged relative confidence widths W as a function of observation set size m used for model identification; (b) percentage of verification points enclosed by the confidence intervals (100 % denotes all points within intervals, box spans over the 25 % and 75 % quantiles, the median is given with horizontal line, whiskers indicate the result extent, and cross marks are for extreme values).
Measurement data used in this research are provided in the Appendix.
AK was responsible for the manuscript text, implementation of discharge formulas in Matlab, and the numerical experiments; KV was responsible for the manuscript text, the methodology for two-layer models, the Ritobacken field experiment, and analysis of numerical outputs; AK was responsible for the flume experiments and, together with JK, the Pasche and Martens methodology including the computation algorithm; EK and MK were responsible for the flume experiments, measurement data analysis, and improving the article's text.
The authors declare that they have no conflict of interest.
We acknowledge the Academy of Finland (grant no. 133113), Maa- ja vesitekniikan tuki ry, and the Finnish Ministry of Agriculture and Forestry for funding the collection of the original field data.
This research has been supported by the National Science Centre (Poland) (Miniatura 1, grant no. 2017/01/X/ST10/00987), the Maa- ja vesitekniikan tuki ry (Finland) (grant no. 33271), the Maj and Tor Nessling Foundation (grant no. 201800045), and the National Centre for Research and Development (Poland) (grant no. 347837/11/NCBR/2017, “Technical innovations and system of monitoring, forecasting and planning of irrigation and drainage for precise water management on the scale of drainage/irrigation system”).
This paper was edited by Insa Neuweiler and reviewed by three anonymous referees.
Aberle, J. and Järvelä, J.: Flow resistance of emergent rigid and flexible floodplain vegetation, J. Hydraul. Res., 51, 33–45, 2013. a
Abril, J. B. and Knight, D. W.: Stage-discharge prediction for rivers in flood applying a depth-averaged model, J. Hydraul. Res., 42, 616–629, 2004. a
Abu-Aly, T. R., Pasternack, G. B., Wyrick, J. R., Barker, R., Massa, D., and Johnson, T.: Effects of LiDAR-derived, spatially distributed vegetation roughness on two-dimensional hydraulics in a gravel-cobble river at flows of 0.2 to 20 times bankfull, Geomorphology, 206, 468–482, https://doi.org/10.1016/j.geomorph.2013.10.017, 2014. a
Antonarakis, A. S., Richards, K. S., Brasington, J., and Bithell, M.: Leafless roughness of complex tree morphology using terrestrial lidar, Water Resour. Res., 45, W10401, https://doi.org/10.1029/2008WR007666, 2009. a
Arcement, G. J. and Schneider, V. R.: Guide for selecting Manning's roughness coefficients for natural channels and flood plains, vol. 2339, United States Geological Survey Water-Supply Paper 2339, https://doi.org/10.3133/wsp2339, 1989. a
Baptist, M. J., Babovic, V., Rodriguez Uthurburu, J., Keijzer, M., Uittenbogaard, R. E., Mynett, A., and Verwey, A.: On inducing equations for vegetation resistance, J. Hydraul. Res., 45, 435–450, 2007. a
Berends, K. D., Straatsma, M. W., Warmink, J. J., and Hulscher, S. J. M. H.: Uncertainty quantification of flood mitigation predictions and implications for interventions, Nat. Hazards Earth Syst. Sci., 19, 1737–1753, https://doi.org/10.5194/nhess-19-1737-2019, 2019. a
Berends, K. D., Ji, U., Penning, W., and Warmink, J. J.: Inverse modelling for vegetation parameters estimation, Human intervention in rivers: quantifying the uncertainty of hydraulic model predictions, PhD thesis, 106–127, https://doi.org/10.3990/1.9789036548823, 2019. a, b, c, d, e, f, g, h, i
Beven, K. and Binley, A.: The future of distributed models: model calibration and uncertainty prediction, Hydrol. Process., 6, 279–298, 1992. a
Blasone, R.-S., Vrugt, J. A., Madsen, H., Rosbjerg, D., Robinson, B. A., and Zyvoloski, G. A.: Generalized likelihood uncertainty estimation (GLUE) using adaptive Markov Chain Monte Carlo sampling, Adv. Water Resour., 31, 630–648, 2008. a
Budiman, M.: Latin Hypercube Sampling, available at: https://www.mathworks.com/matlabcentral/fileexchange/4352-latin-hypercube-sampling, last access: 16 January 2017. a
Casas, A., Lane, S. N., Yu, D., and Benito, G.: A method for parameterising roughness and topographic sub-grid scale effects in hydraulic modelling from LiDAR data, Hydrol. Earth Syst. Sci., 14, 1567–1579, https://doi.org/10.5194/hess-14-1567-2010, 2010. a
Chaudhary, H. P., Isaac, N., Tayade, S. B., and Bhosekar, V. V.: Integrated 1D and 2D numerical model simulations for flushing of sediment from reservoirs, ISH J. Hydraul. Eng., 25, 19–27, https://doi.org/10.1080/09715010.2018.1423580, 2019. a
Dalledonne, G. L., Kopmann, R., and Brudy-Zippelius, T.: Uncertainty quantification of floodplain friction in hydrodynamic models, Hydrol. Earth Syst. Sci., 23, 3373–3385, https://doi.org/10.5194/hess-23-3373-2019, 2019. a, b, c, d
Forzieri, G., Moser, G., Vivoni, E. R., Castelli, F., and Canovaro, F.: Riparian vegetation mapping for hydraulic roughness estimation using very high resolution remote sensing data fusion, J. Hydraul. Eng., 136, 855–867, 2010. a
Forzieri, G., Castelli, F., and Preti, F.: Advances in remote sensing of hydraulic roughness, Int. J. Remote Sens., 33, 630–654, 2012. a
Fread, D.: Flood routing models and the Manning n, in: International Conference for Centennial of Manning's Formula and Kuichling's Rational Formula, 699–708, 1989. a
Freni, G. and Mannina, G.: Bayesian approach for uncertainty quantification in water quality modelling: The influence of prior distribution, J. Hydrol., 392, 31–39, https://doi.org/10.1016/j.jhydrol.2010.07.043, 2010. a
Green, J. C.: Comparison of blockage factors in modelling the resistance of channels containing submerged macrophytes, River Res. Appl., 21, 671–686, 2005. a
Her, Y. and Chaubey, I.: Impact of the numbers of observations and calibration parameters on equifinality, model performance, and output and parameter uncertainty, Hydrol. Process., 29, 4220–4237, https://doi.org/10.1002/hyp.10487, 2015. a, b
Her, Y. and Seong, C.: Responses of hydrological model equifinality, uncertainty, and performance to multi-objective parameter calibration, J. Hydroinform., 20, 864–885, https://doi.org/10.2166/hydro.2018.108, 2018. a, b
Jalonen, J. and Järvelä, J.: Estimation of drag forces caused by natural woody vegetation of different scales, J. Hydrodyn., 26, 608–623, 2014. a
Jalonen, J. and Järvelä, J.: Erratum to Estimation of drag forces caused by natural woody vegetation of different scales, J. Hydrodyn., 27, p. 319, https://doi.org/10.1016/S1001-6058(15)60487-5, 2015. a
Jalonen, J., Järvelä, J., Virtanen, J.-P., Vaaja, M., Kurkela, M., and Hyyppä, H.: Determining characteristic vegetation areas by terrestrial laser scanning for floodplain flow modeling, Water, 7, 420–437, 2015. a
Järvelä, J.: Determination of flow resistance caused by non-submerged woody vegetation, International Journal of River Basin Management, 2, 61–70, https://doi.org/10.1080/15715124.2004.9635222, 2004. a
Kalinowska, M. B., Västilä, K., Kozioł, A. P., Rowinski, P. M., Kiczko, A., and Kubrak, J.: Modelling of velocity distribution in a channel partly covered by submerged vegetation, in: Recent Trends in Environmental Hydraulics, edited by: Kalinowska, M. B., Mrokowska, M. M., and Rowinski, P. M., GeoPlanet: Earth and Planetary Sciences. Springer, Cham, 91–101, https://doi.org/10.1007/978-3-030-37105-0_8, 2020. a
Kałuza, T., Sojka, M., Strzeliński, P., and Wrózyński, R.: Application of terrestrial laser scanning to tree trunk bark structure characteristics evaluation and analysis of their effect on the flow resistance coefficient, Water, 10, 753, https://doi.org/10.3390/w10060753, 2018. a
Khatibi, R. H., Williams, J. J. R., and Wormleaton, P. R.: Identification Problem of Open-Channel Friction Parameters, J. Hydraul. Eng. ASCE, 123, 1078–1088, https://doi.org/10.1061/(ASCE)0733-9429(1997)123:12(1078), 1997. a
Kiang, J. E., Gazoorian, C., McMillan, H., Coxon, G., Le Coz, J., Westerberg, I. K., Belleville, A., Sevrez, D., Sikorska, A. E., Petersen-Øverleir, A., Reitan, T., Freer, J., Renard, B., Mansanarez, V., and Mason, R.: A comparison of methods for streamflow uncertainty estimation, Water Resour. Res., 54, 7149–7176, 2018. a
Kiczko, A. and Mirosław-Świa̧tek, D.: Impact of Uncertainty of Floodplain Digital Terrain Model on 1D Hydrodynamic Flow Calculation, Water, 10, 1308, https://doi.org/10.3390/w10101308, 2018. a
Kiczko, A., Kozioł, A., Kubrak, J., Krukowski, M., Kubrak, E., and Brandyk, A.: Identification of vegetation parameters for compound channel discharge as inverse problem, Annals of Warsaw University of Life Sciences – SGGW, Land Reclamation, 49, 255–267, https://doi.org/10.1515/sggw-2017-0020, 2017. a, b, c, d, e
Kiczko, A., Szela̧g, B., Kozioł, A., Krukowski, M., Kubrak, E., Kubrak, J., and Romanowicz, R. J.: Optimal Capacity of a Stormwater Reservoir for Flood Peak Reduction, J. Hydrol. Eng., 23, 4018008, https://doi.org/10.1061/(ASCE)HE.1943-5584.0001636, 2018. a
Klopstra, D., Barneveld, H. J., Van Noortwijk, J. M., and Van Velzen, E. H.: Analytical model for hydraulic roughness of submerged vegetation, in: Proceedings of the 27th Congress of the International Association for Hydraulic Research, Theme A, Managing Water: Coping with Scarcity and Abundance, San Francisco, 775–780, 1997. a
Knight, D. W., Omran, M., and Tang, X.: Modeling depth-averaged velocity and boundary shear in trapezoidal channels with secondary flows, J. Hydraul. Eng., 133, 39–47, 2007. a
Koziol, A.: Czasowa i przestrzenna makroskala turbulencji strumienia w dwudzielnym trapezowym korycie z drzewami na terenach zalewowych, Acta Scientiarum Polonorum, Formatio Circumiectus, 9, 25–34, 2010. a, b, c, d
Kozioł, A. P.: Three-dimensional turbulence intensity in a compound channel, J. Hydraul. Eng., 139, 852–864, 2013. a, b, c
Kozioł, A. P. and Kubrak, J.: Measurements of Turbulence Structure in a Compound Channel, in: Rivers–Physical, Fluvial and Environmental Processes, Springer, 229–254, https://doi.org/10.1007/978-3-319-17719-9_10, 2015. a, b
Kozioł, A. P., Kubrak, J., and Ciepielowski, A.: A hydraulic model of discharge capacity for rivers with forest vegetation on flood lowland, in: Model application for wetlands hydrology and hydraulics, edited by: Kubrak, J., Okruszko, T., and Ignar, S., Center of Excellence in Wetland Hydrology Wethydro, Warsaw, Warsaw Agricultural University Press, Warsaw, 103–111, 2004. a
Kubrak, E., Kubrak, J., Kozioł, A., Kiczko, A., and Krukowski, M.: Apparent Friction Coefficient Used for Flow Calculation in Straight Compound Channels, Water, 11, 745, https://doi.org/10.3390/w11040745, 2019a. a, b, c
Kubrak, E., Kubrak, J., Kuśmierczuk, K., Kozioł, A. P., Kiczko, A., Rowiński, P. M., Kozioł Adam Paweł, Kiczko, A., Kozioł, A. P., Kiczko, A., and Rowiński, P. M.: Influence of stream interactions on the carrying capacity of two-stage channels, J. Hydraul. Eng., 145, 6019003, https://doi.org/10.1061/(ASCE)HY.1943-7900.0001585, 2019b. a, b, c
Kuczera, G. and Mroczkowski, M.: Assessment of hydrologic parameter uncertainty and the worth of multiresponse data, Water Resour. Res., 34, 1481–1489, https://doi.org/10.1029/98WR00496, 1998. a
Liu, Z., Merwade, V., and Jafarzadegan, K.: Investigating the role of model structure and surface roughness in generating flood inundation extents using one- and two-dimensional hydraulic models, J. Flood Risk Manag., 12, e12347, https://doi.org/10.1111/jfr3.12347, 2019. a
Luhar, M. and Nepf, H. M.: From the blade scale to the reach scale: A characterization of aquatic vegetative drag, Adv. Water Resour., 51, 305–316, 2013. a, b, c, d, e, f, g, h, i, j, k
Mantovan, P. and Todini, E.: Hydrological forecasting uncertainty assessment: Incoherence of the GLUE methodology, J. Hydrol., 330, 368–381, https://doi.org/10.1016/J.JHYDROL.2006.04.046, 2006. a, b
Marcinkowski, P., Kiczko, A., and Okruszko, T.: Model-based analysis of macrophytes role in the flow distribution in the anastomosing river system, Water, 10, 953, https://doi.org/10.3390/w10070953, 2018. a
Marcinkowski, P., Kiczko, A., and Okruszko, T.: Model-based evaluation of restoration measures efficiency in the anastomosing section of the River Narew, Ecol. Eng., 130, 213–227, https://doi.org/10.1016/J.ECOLENG.2019.02.022, 2019. a
Mertens, W.: Zur frage hydraulischer berechnungen naturnaher fliessgewasser, Wasserwirtschaft, 79, 170–179, 1989. a, b, c, d
Myers, W.: Momentum Transfer In A Compound Channel, J. Hydraul. Res., 16, 139–150, https://doi.org/10.1080/00221687809499626, 1978. a, b
Pasche, E.: Turbulenzmechanismen in naturnahen Fließgewässern und die Möglichkeit ihrer mathematischen Erfassung, Institut fur Wasserbau und Wasserwirtschaft, TH Aachen, Heft 52, 1984. a, b, c, d
Pasche, E.: Flood Modelling in Urban Rivers–the State-of-the-Art and Where to Go, in: Advances in Urban Flood Management, edited by: Ashley, R., Garvin, S., Pasche, E., Vassilopoulos, A., and Zevenbergen, C., CRC Press, available at: https://www.routledge.com/Advances-in-Urban-Flood-Management/Ashley-Garvin-Pasche-Vassilopoulos-Zevenbergen/p/book/9780367389512 (last access: 14 April 2020), 71–102, 2007. a
Pasche, E. and Rouvé, G.: Overbank Flow with Vegetatively Roughened Flood Plains, J. Hydraul. Eng., 111, 1262–1278, 1985. a
Posey, C. J.: Computation of discharge including over-bank flow, Civil Eng., 37, 62–63, 1967. a, b
Romanowicz, R., Beven, K. J., and Tawn, J.: Bayesian Calibration of Flood Inundation Models, Floodplain Processes, edited by: Anderson, M. G., Walling, D. E., and Bates, P. D., Wiley, 333–360, 1996. a
Romanowicz, R. J. and Beven, K. J.: Comments on generalised likelihood uncertainty estimation, Reliab. Eng. Syst. Safe., 91, 1315–1321, 2006. a, b, c, d
Romanowicz, R. J. and Kiczko, A.: An event simulation approach to the assessment of flood level frequencies: risk maps for the Warsaw reach of the River Vistula, Hydrol. Process., 30, 2451–2462, https://doi.org/10.1002/hyp.10857, 2016. a
Rowiński, P., Västilä, K., Aberle, J., Järvelä, J., and Kalinowska, M. B.: How vegetation can aid in coping with river management challenges: A brief review, Ecohydrology & Hydrobiology, 18, 345–354, 2018. a
Schwanghart, W.: Recursive Douglas-Peucker Polyline Simplification, available at: https://github.com/wschwanghart/topotoolbox/blob/master/GIStools/dpsimplify.m, last access: 1 December 2010. a
Sellin, R. H. J.: A laboratory investigation into the interaction between the flow in the channel of a river and that over its flood plain, Houille Blanche, 20, 793–802, https://doi.org/10.1371/journal.pone.0116943, 1964. a
Shields, J. F. D., Coulton, K. G., and Nepf, H.: Representation of vegetation in two-dimensional hydrodynamic models, J. Hydraul. Eng., 143, 2517002, https://doi.org/10.1061/(ASCE)HY.1943-7900.0001320, 2017. a, b, c
Shiono, K. and Knight, D. W.: Turbulent open-channel flows with variable depth across the channel, J. Fluid Mech., 222, 617–646, 1991. a, b
Soong, T. W. and DePue, P. M.: Variation of Manning's Coefficient with Channel Stage, Water Resources Center, University of Illinois, USA, 1996. a
Stedinger, J. R., Vogel, R. M., Lee, S. U., and Batchelder, R.: Appraisal of the generalized likelihood uncertainty estimation (GLUE) method, Water Resour. Res., 44, W00B06, https://doi.org/10.1029/2008WR006822, 2008. a
Straatsma, M. and Huthoff, F.: Uncertainty in 2D hydrodynamic models from errors in roughness parameterization based on aerial images, Phys. Chem. Earth, Parts A/B/C, 36, 324–334, https://doi.org/10.1016/j.pce.2011.02.009, 2011. a, b, c
Tang, X. and Knight, D. W.: Lateral depth-averaged velocity distributions and bed shear in rectangular compound channels, J. Hydraul. Eng.., 134, 1337–1342, 2008. a
Tang, Y., Marshall, L., Sharma, A., and Smith, T.: Tools for investigating the prior distribution in Bayesian hydrology, J. Hydrol., 538, 551–562, https://doi.org/10.1016/J.JHYDROL.2016.04.032, 2016. a
Teng, J., Jakeman, A. J., Vaze, J., Croke, B. F., Dutta, D., and Kim, S.: Flood inundation modelling: A review of methods, recent advances and uncertainty analysis, Environ. Modell. Softw., 90, 201–216, https://doi.org/10.1016/j.envsoft.2017.01.006, 2017. a
Västilä, K. and Järvelä, J.: Environmentally preferable two-stage drainage channels: considerations for cohesive sediments and conveyance, International Journal of River Basin Management, 9, 171–180, 2011. a
Västilä, K. and Järvelä, J.: Modeling the flow resistance of woody vegetation using physically based properties of the foliage and stem, Water Resour. Res., 50, 229–245, 2014. a, b, c
Västilä, K. and Järvelä, J.: Characterizing natural riparian vegetation for modeling of flow and suspended sediment transport, J. Soil. Sediment., 18, 3114–3130, https://doi.org/10.1007/s11368-017-1776-3, 2018. a, b, c, d, e, f, g, h, i, j, k, l
Västilä, K., Järvelä, J., and Koivusalo, H.: Flow-Vegetation-Sediment Interaction in a Cohesive Compound Channel, J. Hydraul. Eng., 142, 4015034, https://doi.org/10.1061/(ASCE)HY.1943-7900.0001058, 2016. a, b, c, d, e, f, g, h, i
Warmink, J. J., Straatsma, M. W., Huthoff, F., Booij, M. J., and Hulscher, S. J. M. H.: Uncertainty of design water levels due to combined bed form and vegetation roughness in the Dutch River Waal, J. Flood Risk Manag., 6, 302–318, 2013. a, b
Werner, M. G., Hunter, N. M., and Bates, P. D.: Identifiability of distributed floodplain roughness values in flood extent estimation, J. Hydrol., 314, 139–157, https://doi.org/10.1016/j.jhydrol.2005.03.012, 2005. a, b, c, d, e, f, g, h, i
Wolski, K., Tyminski, T., and Dabek, P. B.: Assessment of the effect of vegetation on the transition of the flood wave using hydraulic 2D models, in: E3S Web of Conferences, EDP Sciences, vol. 44, p. 195, 2018. a
Yen, B. C.: Open Channel Flow Resistance, J. Hydraul. Eng., 128, 20–39, 2002. a
Yu, K., Chen, Y., Zhu, D., Variano, E. A., and Lin, J.: Development and performance of a 1D–2D coupled shallow water model for large river and lake networks, J. Hydraul. Res., 57, 852–865, https://doi.org/10.1080/00221686.2018.1534286, 2019. a, b
Zhang, J., Zhong, Y., and Huai, W.: Transverse distribution of streamwise velocity in open-channel flow with artificial emergent vegetation, Ecol. Eng., 110, 78–86, 2018. a
Zinke, P., Olsen, N. R. B., and Bogen, J.: Three-dimensional numerical modelling of levee depositions in a Scandinavian freshwater delta, Geomorphology, 129, 320–333, 2011. a