the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 05 Mar 2020
| 05 Mar 2020
Using hydrological and climatic catchment clusters to explore drivers of catchment behavior
Florian U. Jehn
Konrad Bestian
Lutz Breuer
Philipp Kraft
Tobias Houska
The behavior of every catchment is unique. Still, we seek for ways to classify them as this helps to improve hydrological theories. In this study, we use hydrological signatures that were recently identified as those with the highest spatial predictability to cluster 643 catchments from the CAMELS dataset. We describe the resulting clusters concerning their behavior, location and attributes. We then analyze the connections between the resulting clusters and the catchment attributes and relate this to the co-variability of the catchment attributes in the eastern and western US. To explore whether the observed differences result from clustering catchments by either climate or hydrological behavior, we compare the hydrological clusters to climatic ones. We find that for the overall dataset climate is the most important factor for the hydrological behavior. However, depending on the location, either aridity, snow or seasonality has the largest influence. The clusters derived from the hydrological signatures partly follow ecoregions in the US and can be grouped into four main behavior trends. In addition, the clusters show consistent low flow behavior, even though the hydrological signatures used describe high and mean flows only. We can also show that most of the catchments in the CAMELS dataset have a low range of hydrological behaviors, while some more extreme catchments deviate from that trend. In the comparison of climatic and hydrological clusters, we see that the widely used Köppen–Geiger climate classification is not suitable to find hydrologically similar catchments. However, in comparison with novel, hydrologically based continuous climate classifications, some clusters follow the climate classification very directly, while others do not. From those results, we conclude that the signal of the climatic forcing can be found more explicitly in the behavior of some catchments than in others. It remains unclear if this is caused by a higher intra-catchment variability of the climate or a higher influence of other catchment attributes, overlaying the climate signal. Our findings suggest that very different sets of catchment attributes and climate can cause very similar hydrological behavior of catchments – a sort of equifinality of the catchment response.
- Article
(10943 KB) - Full-text XML
-
Supplement
(62 KB) - BibTeX
- EndNote





Every hydrological catchment is composed of a unique combination of topography and climate, which makes their discharge heterogeneous. This, in turn, makes it hard to generalize behavior beyond individual catchments (Beven, 2000). Catchment classification is used to find patterns and laws in the heterogeneity of landscapes and climatic inputs (Sivapalan, 2003). Historically, this classification was often done by simply using geographic, administrative or physiographic considerations. However, those regions proved to be not sufficiently homogenous (Burn, 1997). Therefore, it was proposed to use seasonality measures with physiographic and meteorological characteristics, but it was deemed difficult to obtain this information for a large number of catchments (Burn, 1997), even if only simple catchment attributes (e.g., aridity) are used (Wagener et al., 2007). Nonetheless, in the last decade datasets with hydrologic and geological data were made available, comprising information on hundreds of catchments around the world (Addor et al., 2017; Alvarez-Garreton et al., 2018; Newman et al., 2014; Schaake et al., 2006). This is a significant step forward as those large-sample datasets can generate new insights, which are impossible to obtain when only a few catchments are considered (Gupta et al., 2014). Different attributes have been used to classify groups of catchments in those kind of datasets: flow duration curve (Coopersmith et al., 2012; Yaeger et al., 2012), catchment structure (McGlynn and Seibert, 2003), hydro-climatic regions (Potter et al., 2005), function response (Sivapalan, 2005) and, more recently, a variety of hydrological signatures (Kuentz et al., 2017; Sawicz et al., 2011; Toth, 2013). Quite often, climate has been identified as the most important driving factor for different hydrological behavior (Berghuijs et al., 2014; Kuentz et al., 2017; Sawicz et al., 2011). Still, it is also noted that this does not hold true for all regions and scales (Ali et al., 2012; Singh et al., 2014; Trancoso et al., 2017). In addition, a recent large study of Addor et al. (2018) has shown that many of the hydrological signatures often used for classification are easily affected by data uncertainties and cannot be predicted using catchment attributes. Another recent study by Kuentz et al. (2017) used an extremely large datasets of 35 000 catchments in Europe and classified them using hydrological signatures. For their classification, they used hierarchical clustering and evaluated the result of the clustering by comparing variance between different numbers of clusters. They were able to find 10 distinct classes of catchments. However, Kuentz et al. (2017) used some of the signatures identified to have a low spatial predictability by Addor et al. (2018). In addition, one-third of their catchments was aggregated in one large class with no distinguishable attributes. Overall, we conclude that no large-sample study exists that uses only hydrological signatures with a good spatial predictability. In addition, if the climate is the dominant driver of catchment behavior, clustering catchments based on their hydrological behavior should result in clusters with a similar climate.
Therefore, we selected the best six hydrological signatures with spatial predictability to classify catchments of the CAMELS (Catchment Attributes and MEteorology for Large-Sample Studies) dataset (Addor et al., 2017). Those six hydrological signatures are evaluated together with the 16 catchment attributes that were shown to have a large influence on hydrological signatures (Addor et al., 2018). The connection between the hydrological signatures and the catchment attributes is determined by using quadratic regression of the principal components (of the hydrological signatures) and the catchment attributes. This will help to explore whether a clustering with hydrological signatures that have a high predictability in space provides hydrologically meaningful clusters and how those are related to catchment attributes. In addition, we compare the hydrologically derived clusters with climatic clusters and determine the spatial distance between the most hydrologically similar catchments. This will determine whether grouping catchments by climate or by hydrologic behavior will yield the same results and whether the signatures identified by Addor et al. (2018) as having the highest spatial predictability can be used to delineate hydrologically meaningful clusters, even though they do not consider low flows.
2.1 Database
This work is based on a detailed analysis of catchment attributes and information contained in hydrological signatures. The CAMELS dataset contains 671 catchment in the continental United States (Addor et al., 2017) with additional meta information such as slope and vegetation parameters. For our study, we used a selection of the available metadata. We excluded all catchments that had missing data, which left us with 643 catchments. Those catchments come from a wide spectrum of characteristics like different climatic regions, elevations ranging from 10 to almost 3600 m a.s.l. and catchment areas ranging from 4 to almost 26 000 km2. We used the following attributes per class:
-
climate: aridity, frequency of high-precipitation events, fraction of precipitation falling as snow, precipitation seasonality;
-
vegetation: forest fraction, green vegetation fraction maximum, leaf area index (LAI) maximum;
-
topography: mean slope, mean elevation, catchment area;
-
soil: clay fraction, depth to bedrock, sand fraction;
-
geology: dominant geological class, subsurface porosity, subsurface permeability.
Those catchment attributes were chosen due to their ability to improve the prediction of hydrological signatures (Addor et al., 2018) and because they are relatively easy to obtain, which will allow a transfer of this method to other groups of catchments worldwide.
Hydrological signatures cover different behaviors of catchments. However, many of the published signatures have large uncertainties (Westerberg and McMillan, 2015) and lack in predictive power (Addor et al., 2018). Therefore, we used the six hydrological signatures with the best predictability in space (Table 1) (Addor et al., 2018). Those signatures were calculated for all catchments. Due to this selection, no signatures that capture low flow behavior were used, as those signatures have a very low spatial predictability.
Table 1Applied hydrological signatures on the discharge data of the CAMELS (Addor et al., 2018).
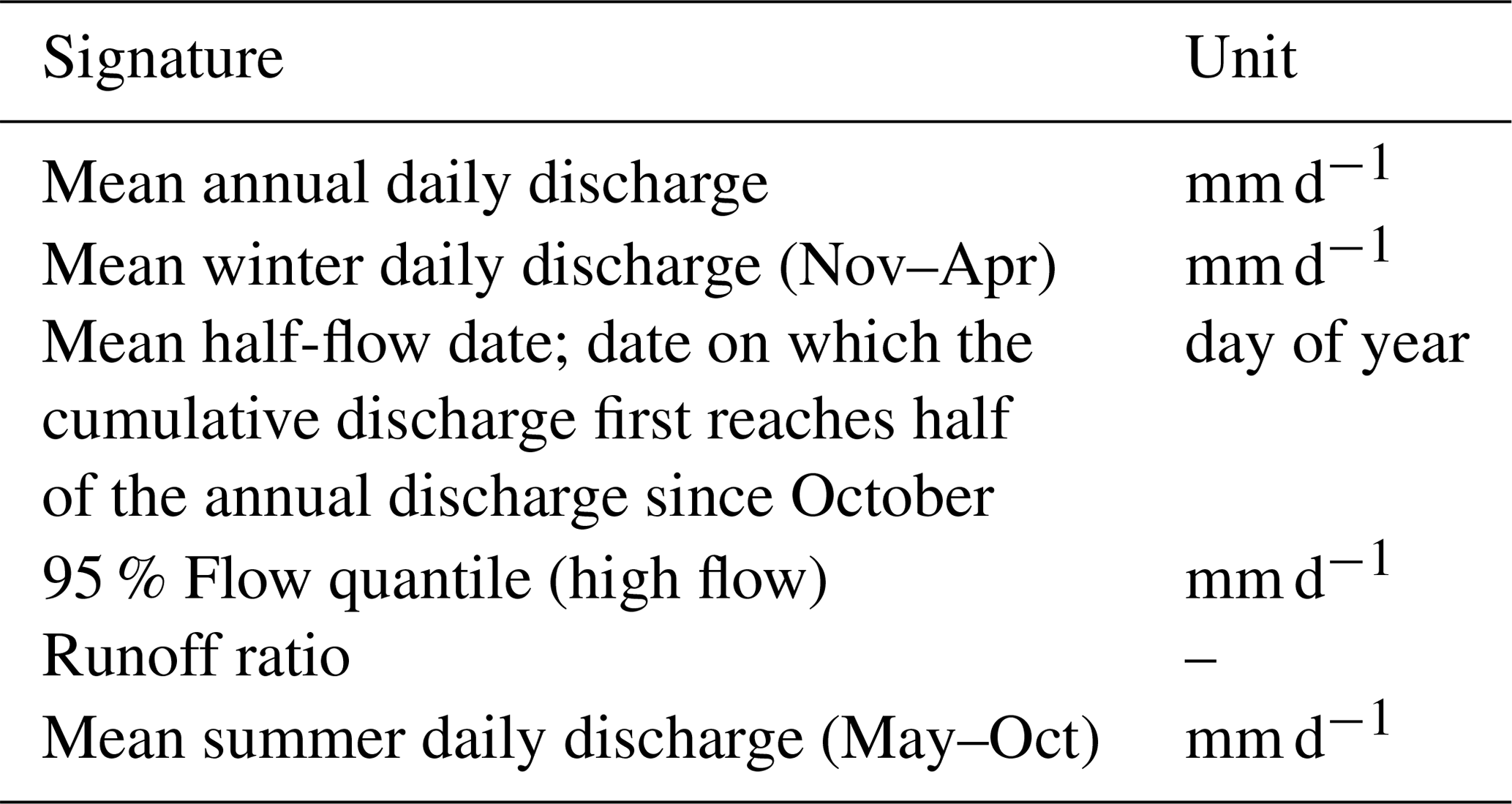
2.2 Data analysis
The workflow of the data analysis considers a data reduction approach with a principal component analysis and a subsequent clustering of the principal components, similar to Kuentz et al. (2017) and McManamay et al. (2014). For the principal component analysis and the clustering, we used the Python package sklearn (0.19.1). The code is available at GitHub (Jehn, 2020). Validity was checked by also clustering a random selection of 50 % and 75 % of all catchments. This showed that the clustering stayed the same, independently of the number of catchments used (not shown). In all further analysis, we used all catchments to get a sample as large as possible to be able to make statements that are more general.
2.2.1 Calculation of the principal component analysis
The principal components were calculated from the six hydrological signatures described above (Table 1). We used a principal component analysis on the hydrological signatures to remove correlations between the single hydrological signatures. We only used principal components that together account for at least 80 % of the total variance of the hydrological signatures, which resulted in two principal components. Those two principal components contain the uncorrelated information of all hydrological signatures used and thus can be seen as describers of the hydrological behavior in regard to the overall amount of discharge, its distribution throughout the year, high flows and runoff ratio. Therefore, catchments with similar principal components have similar hydrological behavior along those signatures.
2.2.2 Evaluating the connection between the principal components and the catchment attributes
-
First, we calculated quadratic regressions between the two principal components and the catchment attributes (with the principal component as the dependent variable). This resulted in one coefficient of determination (R2) for each pair of principal component and catchment attribute (e.g., PC 1 and aridity).
-
We then weighted the R2 by the explained variance of the principal components. This addresses the differences in the explained variance of the principal components (e.g., PC 1 explained 75 % of the variance, PC 2 explained 19 % of the variance).
-
The weighted coefficients of determination of the two principal components were subsequently added to obtain one coefficient of determination for every catchment attribute.
Quadratic regression was selected as interactions in natural hydrological systems are known to have unclear patterns and can therefore often not be fitted with a simple straight line (Addor et al., 2017; Costanza et al., 1993). This was done first for the whole dataset and then for all clusters separately. This procedure captures the pattern on the catchment attributes in the PCA space of the hydrological signatures (for examples of this pattern see Appendix Fig. A1).
2.2.3 Clustering the principal components
The principal components of the hydrological signatures were clustered following agglomerative hierarchical clustering with ward linkage (Ward, 1963), similar to previous studies (Kuentz et al., 2017; Li et al., 2018; Yeung and Ruzzo, 2001). Therefore, the clusters are based on the hydrological signatures of the catchments. From the previous studies, Kuentz et al. (2017) provides the largest set with over 35 000 catchments. They also clustered their catchments in a PCA space of a range of hydrological signatures. To select the number of clusters, they used the elbow method (and two other methods to validate their results) and found that 10 or 11 clusters (depending on the method) were most appropriate for their data. Due to the similarity in the clustered data and the larger database of Kuentz et al. (2017), we also used 10 clusters (Berghuijs et al., 2014) also found that 10 clusters captured the distinct hydrological behaviors for the continental US. Those 10 clusters represent groups of catchments with distinctly different hydrological behavior.
3.1 Catchment attribute correlations in the CAMELS dataset
Usually the 100th meridian is seen as the dividing climatic line in the US, splitting the country into a semiarid west and a humid east. We assume that this difference in climate also has implications for the hydrology and the overall catchment attributes in those regions. To quantify this we split the CAMELS dataset into a western and an eastern part, based on the 100th meridian (Figs. 1 and 4). This shows that many of the catchment attribute correlations do not differ much between the east and the west. In most cases (> 80 %), Spearman rank correlation coefficients vary by less than 0.4 (Fig. 1c). Still, there are some catchment attributes with larger differences of up to 0.8 between both regions. Most striking are the mean elevation and the fraction of the precipitation falling as snow as well as the vegetation attributes LAI maximum and green vegetation fraction maximum. Even though these attributes are directly related to each other through temperature gradients, they differ substantially in both parts of the country. In the mountainous western US, elevation is highly correlated with the fraction of precipitation falling as snow (r=0.8), while it is not in the eastern US (r=0.4). This and the different correlations between vegetation and elevation are probably caused by the fact that the temperature gradients differ in both regions. The western US is much more mountainous and thus temperatures typically change with elevation. In the more level eastern US, the change in temperature is mainly linked to the latitude. Striking are also the changes of correlation with regard to the fraction of precipitation falling as snow. Here we find altered directions of the correlation; i.e., positive correlations with LAI maximum and frequency of high-precipitation events in the east turn to negative ones in the west. The change in the LAI maximum might be linked to the higher elevations in the west, as in higher elevations less vegetation is growing, but more snow falls. It also becomes obvious that all three measures of vegetation seem to track similar characteristics in the catchments, as they correlate highly with each other (especially in the eastern US with r=0.9). In addition, all vegetation attributes depict a large negative correlation with aridity. Hence, the vegetation attributes considered are likely good proxies for aridity. Overall, we see that the relations between the catchment attributes are quite similar for the eastern and western US, with the exception of the mean elevation, snow and the LAI maximum.
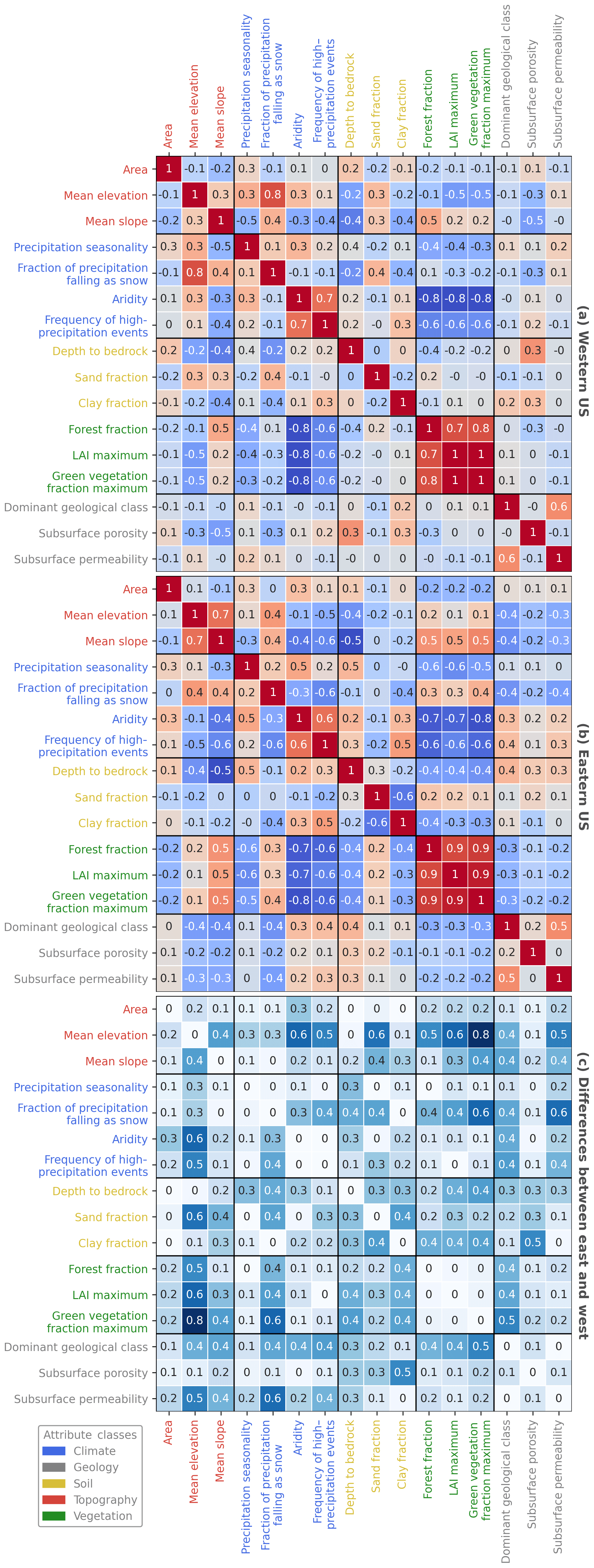
Figure 1Spearman rank correlation coefficients given for all catchment attributes in the western (a) and eastern (b) US. Absolute differences of the correlation coefficients between the eastern and western US are given in (c). Eastern and western is defined by the 100th meridian. Due to rounding effects, correlations with the same Spearman rank correlation coefficient might show slightly varying color codes.
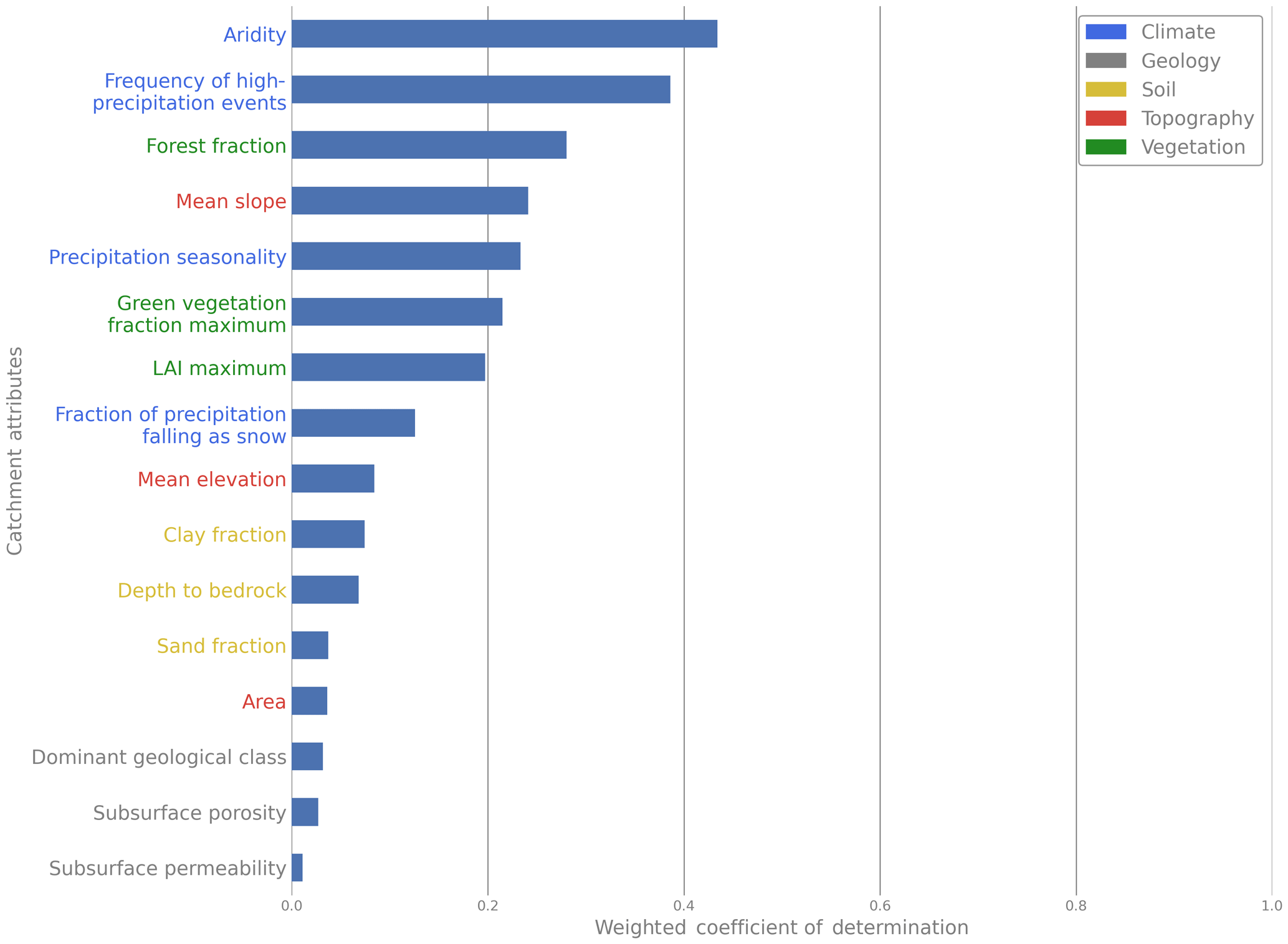
Figure 2Importance of catchment attributes evaluated by quadratic regression for all considered catchments. Attributes colored according to their catchment attribute class.
3.2 Impacts of catchment attributes on discharge characteristics in the whole dataset
Next we examined the weighted R2 of the catchment attributes for the whole dataset. This analysis shows not only differences in their score between the single attributes, but also between the different classes of catchment attributes (Fig. 2). Attributes related to climate (aridity) and vegetation (forest fraction) get the highest scores. However, it should be noted that all vegetation catchment attributes show a strong correlation with the aridity (Fig. 1) and thus capture similar trends, in both the east and the west. With the exception of the mean slope, the first seven catchment attributes are all related to climate and vegetation. The last seven attributes on the other hand are all related to soil and geology, except the catchment area. They also show much lower scores of the weighted R2. This indicates that soil and geology are less important for the chosen hydrological signatures. Similar patterns were also found by Yaeger et al. (2012). They stated climate as the most important driver for the hydrology. As the correlations between the catchment attributes showed that the climate and the vegetation attributes are highly correlated (Fig. 1), it can be assumed that climate is the most important factor overall, with aridity and high-precipitation events being most important within the climate attributes.
However, Yaeger et al. (2012) also unraveled that low flows are mainly controlled by soil and geology. The minor importance of soil and geology in our study might therefore be biased by the choice of hydrological signatures, which excluded low flow signatures due to their low predictability in space. Nevertheless, our study probably captures a more general trend as we used a larger dataset and hydrological signatures that vary more gradually in space (Addor et al., 2018). Addor et al. (2018) also explored the influence of different catchment attributes in the CAMELS dataset on discharge characteristics. They found that climate has the largest influence on discharge characteristics, well in agreement with Coopersmith et al. (2012). The latter also used a large group of catchments in the continental United States from the MOPEX dataset. They conclude that the seasonality of the climate is the most important driver of discharge characteristics. While the seasonality is still important in our analysis, the aridity is an even stronger factor. However, Coopersmith et al. (2012) only analyzed the flow duration curve, which has a mediocre predictability in space, and it is therefore less clear what it really depicts (Addor et al., 2018). Overall, this study here is in line with other literature in the field. Using the weighted R2 reliably detects climatic forcing as the most important of the discharge characteristics for a large group of catchments.
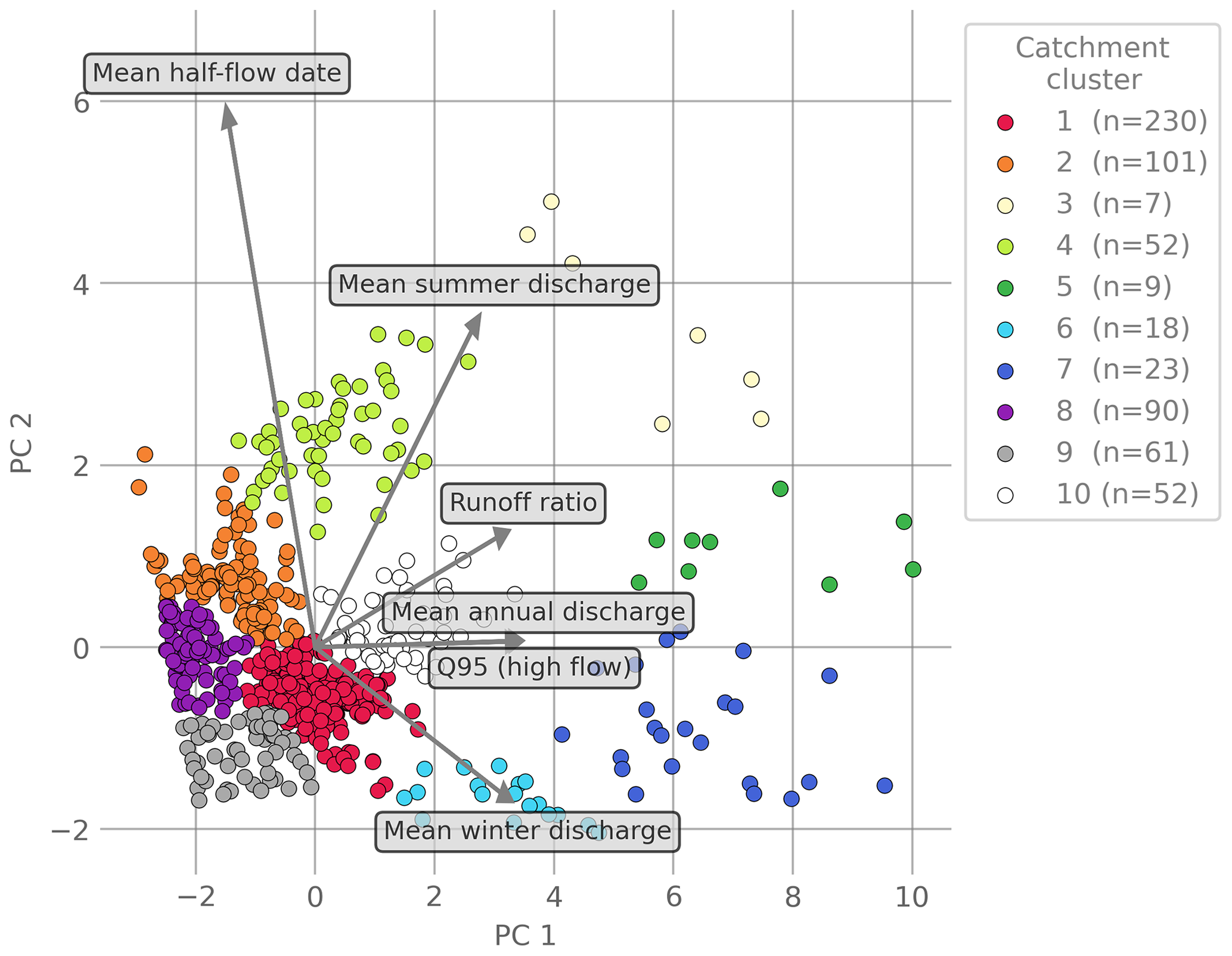
Figure 3Biplot of the principal components (PCs). Colors indicate the cluster of the catchment. Grey arrows indicate the loadings of the original catchment attributes in the PCA space.
3.3 Relation of the principal components and the hydrological signatures
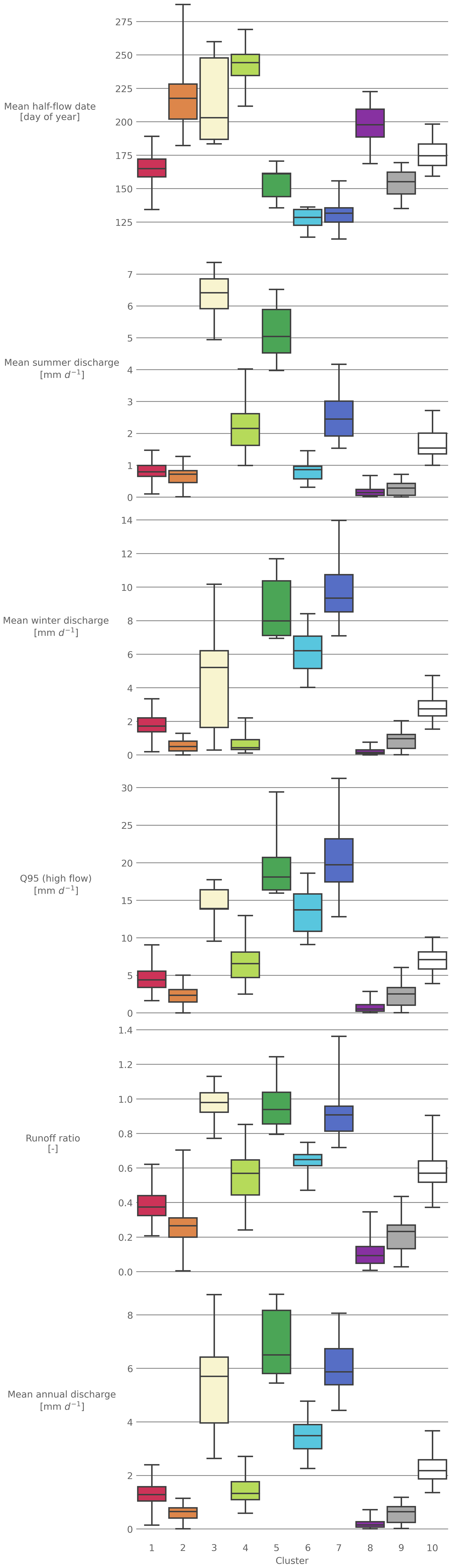
The rivers considered in this study show a wide range of hydrological signatures. This is visible in the clusters of principal components of the hydrological signatures (Fig. 3). Most of the rivers are opposite to the loading vectors (the loading vectors are shown as arrows). This shows that most rivers have relatively low values for all hydrological signatures and only some more extreme rivers have higher values for specific hydrological signatures. Most typical for the overall behavior of the river are the hydrological signatures mean annual discharge and Q95 (high flows), as they have a strong correlation with the first principal component. For the second principal component, the mean half-flow date has the highest correlation. Therefore, the first principal component can be seen as a measure of overall discharge and amount of high flows. Overall, it can also be seen that most of the rivers show a relatively similar behavior (Clusters 1, 2, 8, 9, 10), while smaller groups of rivers tend to deviate from that by having a more extreme behavior (Clusters 3, 5, 7). The remaining Clusters 4 and 6 are located between those extremes. This pattern also explains the different sizes of the clusters. While most catchments behave relatively similar, only some show extreme behavior and thus the clusters with extreme catchments are smaller.
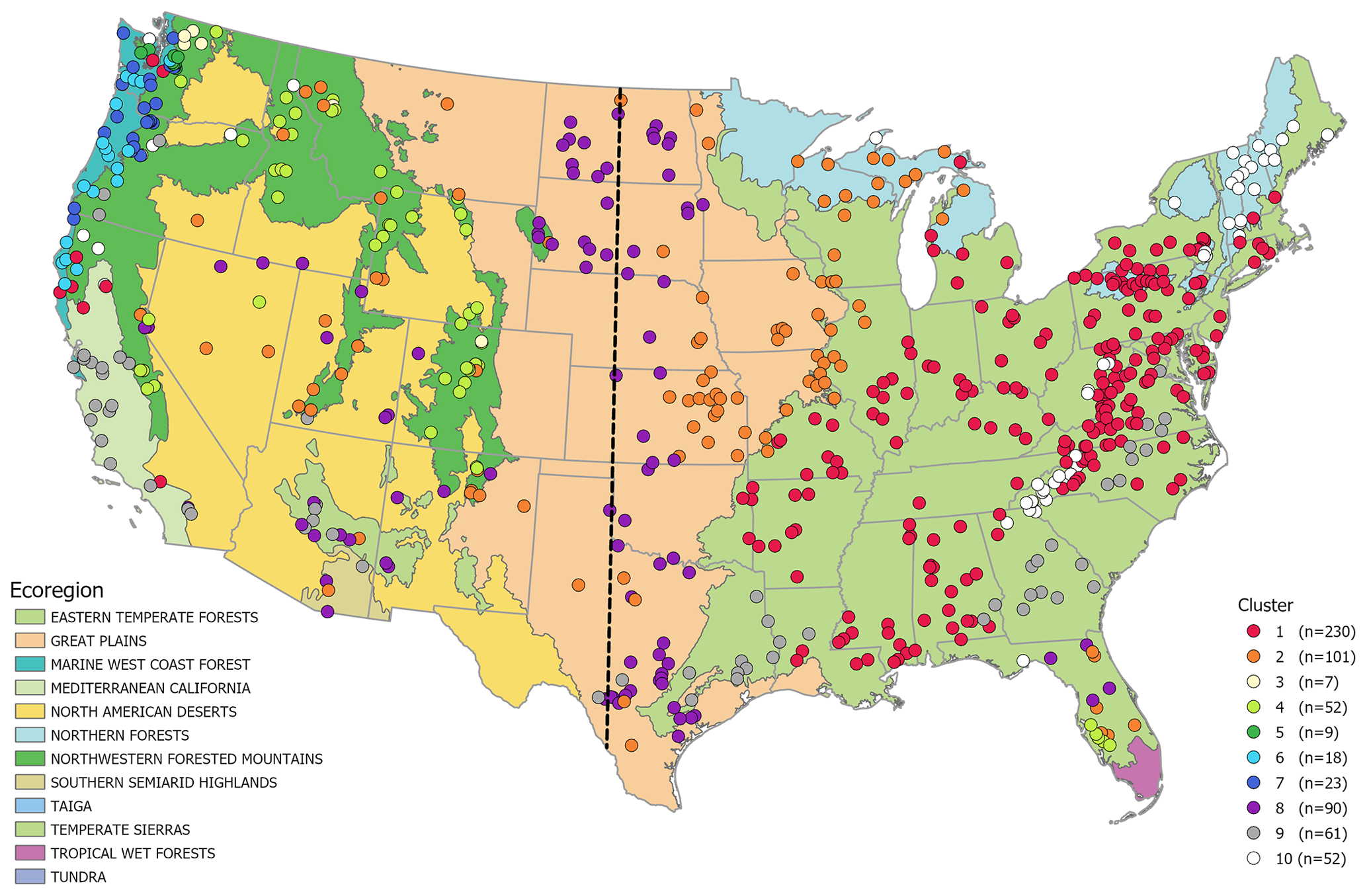
Figure 4Locations of the clustered CAMELS catchments and level I ecoregions (Omernik and Griffith, 2014) in the continental US. Dotted line marks the 100th meridian. An interactive version of this map can be found at https://florianjehn.github.io/Catchment-Classification/map.html (last access: 16 September 2024).
3.4 Location and properties of the catchment clusters
The catchment attributes in the CAMELS and similar large-scale datasets often show a pattern that resembles climatic zones (Addor et al., 2018; Coopersmith et al., 2012; Yaeger et al., 2012). For the catchment clusters presented here, we can see that most of the clusters roughly follow ecoregions in the US (Fig. 4). Clusters 1, 4, 6 and 7 in particular are almost entirely located within one ecoregion. Cluster 2, 8 and 9 on the other hand follow those ecological boundaries to a lesser degree.
We can see a split of the clusters along the 100th meridian. Clusters 3, 4, 5, 6 and 7 are located mainly in the west, while Clusters 1 and 10 are mainly found in the east. However, the remaining Clusters 2, 8 and 9 have roughly similar numbers of catchments in both regions. Overall, the catchments in the eastern half of the United States form large spatial patterns of similar behavior, while the catchments in the west are patchier. This same pattern can also be seen in some of the signatures used by Addor et al. (2018). In particular, the runoff ratio and mean annual discharge form very similar patterns to the clusters in this study.

Figure 5Swarm plot of the real-world distances of all catchments to the most hydrologically similar catchment (based on their distance in the PCA space of the hydrological signatures).
In addition, similar catchments can be quite far away from each other (Fig. 5). Sometimes, the catchment with the most similar signature was found as far as 4000 km away (almost the entire longitudinal distance of the continental US). This explains why spatial proximity seems to be important in some studies that look into explanations of catchment behavior (Andréassian et al., 2012; Sawicz et al., 2011), but not in others (Trancoso et al., 2017). This also indicates that clustering by using spatial proximity might only work in regions like the eastern US, where the behavior of rivers changes only gradually, due to uniform climate that only changes gradually as well. The finding that the most similar catchment (based on their hydrological signatures) can be far away also explains the behavior of clusters that contain catchments quite distant from each other (e.g., Cluster 4). Even though the catchments might be far away from each other, the interplay of different catchment attributes and driving factors, including sometimes very different climates, can lead to similar (equifinal) discharge behavior, concerning the overall amount of discharge, its distribution in the year, the high flows and the runoff ratio. This was also found by several other studies (e.g., Berghuijs et al., 2014; Knoben et al., 2018; Kuentz et al., 2017).
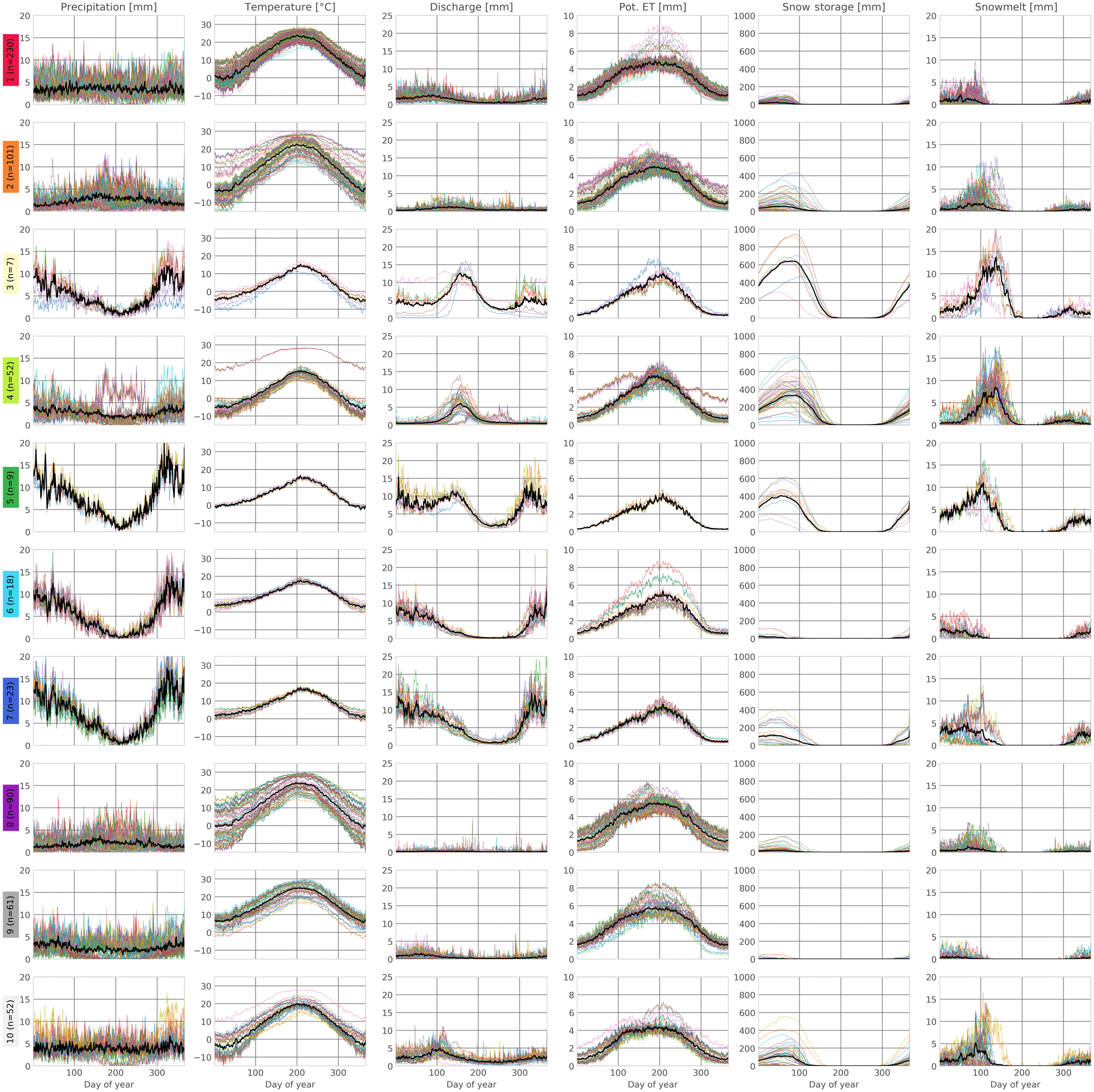
Figure 6Meteorological attributes of the clustered CAMELS catchments averaged by day of the year. Potential evapotranspiration (Pot. ET) was calculated with Hargreaves–Samani (Samani, 2000). Snow storage and melting was calculated using a temperature-based approach described in Massmann (2019). Black lines indicate the mean of all cluster members. Colored lines represent the individual catchments.
In the following, we describe the catchment clusters in regard to their characteristics in meteorology (Fig. 6), attributes (Fig. 7), hydrology (Fig. 8) and location (Fig. 4). The main points of this description are summarized in Table 2. A list of all catchments with index, position, cluster classification and climate indices is given in the Supplement.
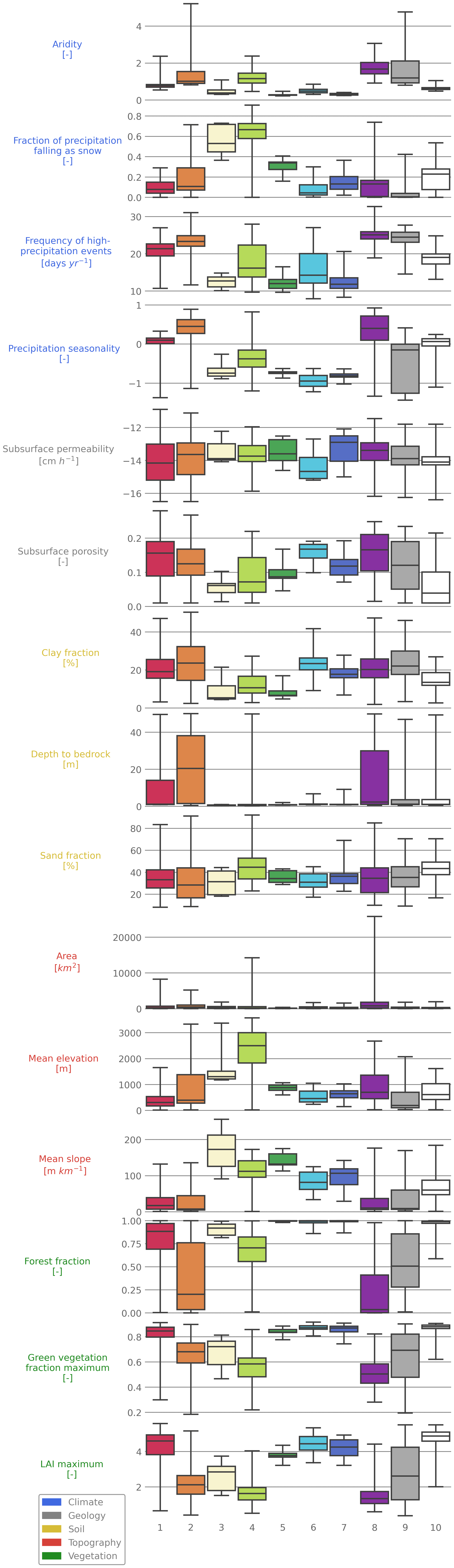
Cluster 1 is defined by a dense vegetation cover (Fig. 7). The low elevation of those catchments results in little annual snowfall. They are mainly located in the southeastern and central plains and therefore get relative high rainfall (> 1000 mm per year) (Fig. 4), almost uniformly distributed over the year (Fig. 6). Still, they produce only a small amount of discharge. This cluster contains the highest number of catchments (n=230). So over one-third of the catchments in CAMELS show a relatively similar behavior when it comes to the amount of water fluxes and their distribution throughout the year. This is particular visible when we look at the annual supply of discharge (Fig. 6). Even though the cluster contains a large number of catchments that also partly differ a lot in their potential evapotranspiration, there is only a minor difference in the amount of discharge and its seasonality.
Cluster 2's most typical attribute is its high-precipitation seasonality. However, concerning most other catchment attributes, Cluster 2 is undefined as it contains catchments of most regions of the continental US (with a concentration in the eastern Great Plains) (Fig. 4). The hydrological signatures on the other hand show a clearer pattern. Here, the mean winter discharge, Q95 and the mean annual discharge have a narrow range (Fig. 8). This shows that catchments with very different attributes can produce similar discharge characteristics. The different attributes seem to cancel each other out in their influence on the discharge. This might be enhanced by the high-precipitation seasonality with higher precipitation in the summer, which creates a strong climatic forcing and thus a narrow range for the hydrological signatures (Fig. 6). This cluster differs from the first one, by having even lower discharge, with almost no peaks and a higher influence of snowmelt.
Cluster 3 is the smallest cluster, with only seven catchments. Those are all located in the Northwestern Forested Mountains. Their most distinct feature is their strong negative precipitation seasonality (indicating a strong precipitation peak in the winter) (Figs. 6, 7). They also experience high-precipitation events (mostly as snow). Hydrologically, their most distinct features is the very high mean summer discharge and high runoff ratio (Fig. 8). This is probably caused by the large amounts of snowmelt in late spring and early summer. The catchments of Cluster 3 have the largest snow storage in the dataset, with a mean maximum value of over 600 mm. Overall, the catchments in this cluster seem to be, from a hydrological point of view, the most extreme in the overall CAMELS dataset. This can be seen in their varying discharge patterns. The uniting pattern is their large peak discharge during summer and their extreme values in the PCA space (indicating much higher values for the hydrological signatures in comparison with the other catchments) (Fig. 3).
Cluster 4 is, like Cluster 3, located in the Northwestern Forested Mountains, with the exception of four catchments that are located in Florida (Fig. 4). This cluster is another example of different catchment attributes being able to create similar discharge characteristics concerning the signatures used, while having very different catchment attributes (Fig. 6). The catchments have overall low discharge and few high flow events, except one large peak in the middle of the summer, which is caused by melting snow in the northern catchments and strong rainfalls in Florida. Their catchment attributes vary widely, especially in all attributes that are related to elevation (e.g., fraction of precipitation falling as snow) (Fig. 7), which is to be expected when some of the catchments are located close to the sea in the southeast, while others are mountainous.
Cluster 5 includes only few catchments (n=9), which are all located at regions in the northern part of the Marine West Coast Forests (Fig. 4). This is the region in the continental US that receives the highest precipitation (> 2000 mm year), which is reflected in its discharge characteristics (Figs. 6, 8). These catchments have the highest discharge in the whole dataset, especially in the early summer, due to a combination of high precipitation and snowmelt. They also experience only few high-precipitation events as they receive large amounts of rain and snow most of the year, with a distinct very high peak in the winter months. They further depict an additional discharge peak in late spring–early summer that separates them from the other catchments found at the west coast. The catchments are almost 100 % covered by forest.
Cluster 6 is located in the Marine West Coast Forest, but in contrast to Cluster 5, it covers the whole region and not only the northern part (Fig. 4). The catchments are very similar in their attributes and discharge characteristics to Cluster 5, with the exception of lower discharges and runoff ratios (Fig. 7, 8). This is caused by slightly lower precipitation in comparison with Cluster 5. Cluster 6 experiences the most negative precipitation seasonality across all clusters, with almost all precipitation falling in the winter month. Due to this seasonality and the lower precipitation in the summer, the catchments of this cluster uniformly dry out almost completely in late summer (Fig. 6).
Cluster 7 is also located in the same region as Clusters 5 and 6 (Marine West Coast Forests) (Fig. 4). In terms of the catchment attributes and the discharge characteristics, it is between Clusters 5 and 6. So, Clusters 5 to 7 all cover the same region and differ in their mean summer discharge, which is caused by variations in elevation and location (Fig. 7). Cluster 7 has higher subsurface permeabilities than Cluster 6, which might explain the differences in hydrological behavior, even though the overall attributes of both clusters are rather similar. For example, Cluster 7 has an overall lower discharge than Cluster 5, but does not dry out during the summer as Cluster 6 does (Fig. 6). This might be due to the larger amount of snow it receives in comparison with Cluster 6 and its lower evapotranspiration.
Cluster 8 is the most arid cluster (Fig. 7). All of the catchments are located in western parts of the Great Plains and in the North American deserts (Fig. 4). They are characterized by an overall low water availability and high evaporation, which is shown in the very low mean annual discharge and runoff ratio (Figs. 6, 8). This also results in low values for the LAI. Yet, the frequency of high-precipitation events is high. However, those high-precipitation events are only high in comparison with the mean precipitation for those catchments and not the overall range of precipitation in the entire CAMELS dataset.
Cluster 9 covers all southern states of the United States (Fig. 4). The catchments here are quite similar to Cluster 8, but show a lower precipitation seasonality and a higher forest cover and green vegetation (Fig. 7). In addition, all catchments of this cluster are in relative close proximity to the sea. The uniting factor in this cluster seems to be the very low snow fraction and the high evapotranspiration (Figs. 6, 7).
Cluster 10 catchments are all located in the Appalachian Mountains (Fig. 4). The mean elevation is higher than that of most other clusters and the catchments have a low aridity and a very high forest cover (Fig. 7). Their discharge characteristics are similar to that of the Marine West Coast Forests (Clusters 5 to 7; Figs. 6, 8). However, they receive less water than those catchments. Cluster 10 covers the same ecoregion as Cluster 1, but has a distinct behavior due to its mountainous character, which can be seen in the higher seasonality of the discharge. This is probably caused by the larger snow cover, with a discharge peak in spring due to snowmelt.
Overall, we can see similar trends for some of the clusters. The general similarities of the clusters are also represented by their distance and position in the PCA space (Fig. 3). We identified four distinct groups:
-
Group 1 (Clusters 1, 2, 8, 9): low seasonality in precipitation and discharge; located in the eastern US; due to low slope inclinations, water takes a long time to reach the outlet.
-
Group 2 (Clusters 3, 4): dominant summer peak of discharge caused by rapid snowmelt; mostly located in the mountains of the western US; differ in precipitation inputs.
-
Group 3 (Clusters 5, 6, 7): located in the Northwestern Forested Mountains; characterized by high-precipitation amount and seasonality, but more or less extreme versions.
-
Group 4 (Cluster 10): located in the Appalachian mountains; share characteristics with Group 1, though influenced by higher elevations and steeper slopes.
Those groups of clusters are similar to the ones found by Berghuijs et al. (2014), even though they used a very different method to derive them. The main difference in the groups is probably caused by how we structure the clusters and groups in the eastern US, due our clusters being more influenced by the Appalachian Mountains. However, both approaches deliver similar results overall.
The question remains: what is the right numbers of clusters? Though we did find four distinct groups, having only four clusters would probably be too little, as the clusters in the groups show a wide range of behaviors (Figs. 3, 7, 8, Table 2). There are catchment attributes which we did not take into account but which could further split up the clusters (e.g., the shape of the catchments). However, this study considered the catchment attributes that are usually considered to be important. The fact that the clusters contain different numbers of catchments can be explained by their distances in the PCA space (Fig. 3). Many of the catchments are rather similar. This produces some clusters which contain most of the catchments. However, we also have some extreme catchments (e.g., Clusters 3 and 5), which are very different to the bulk of the catchments in the CAMELS dataset. Thus, even though some of our presented clusters are quite small in number, they are needed to capture their extreme hydrological behavior. It can also be seen that for most of the clusters there is no clear dividing line to neighboring clusters. Therefore, it might be useful to use fuzzy clustering approaches in future research, to avoid those strict boundaries in a continuous space. Our results show that some of the clusters follow the boundaries of the ecoregions in the US very directly (Cluster 1), while others do not (Cluster 9). The worlds of ecology and hydrology are sometimes shaped by the same forcing, but not always.
Table 2Properties of the catchment clusters. Typical signatures and attributes refers to the signature and attribute of the cluster with the lower coefficient of variation scaled by the mean coefficient of variation of the whole dataset. Dominating attribute refers to the catchment attribute that has the highest weighted R2.
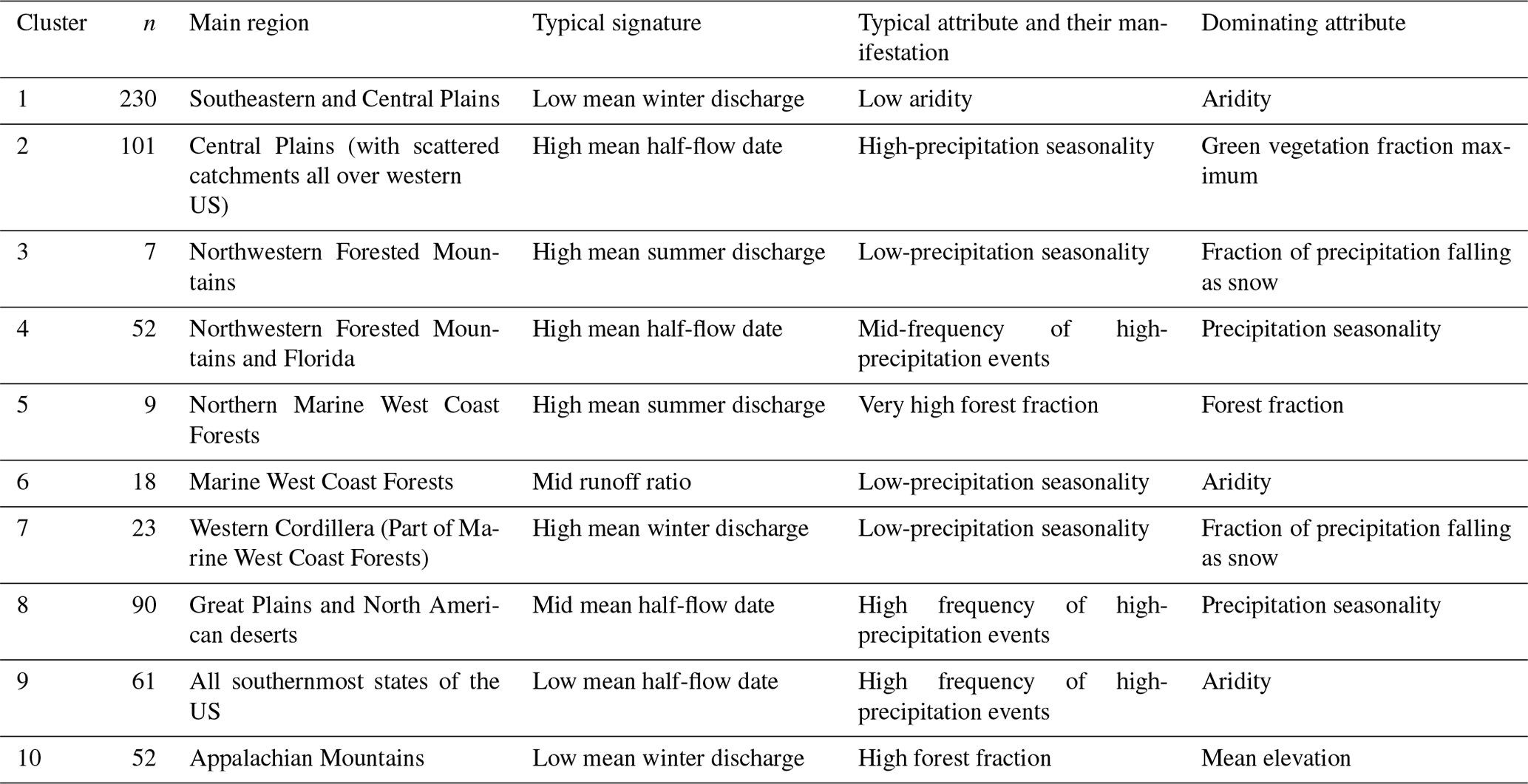
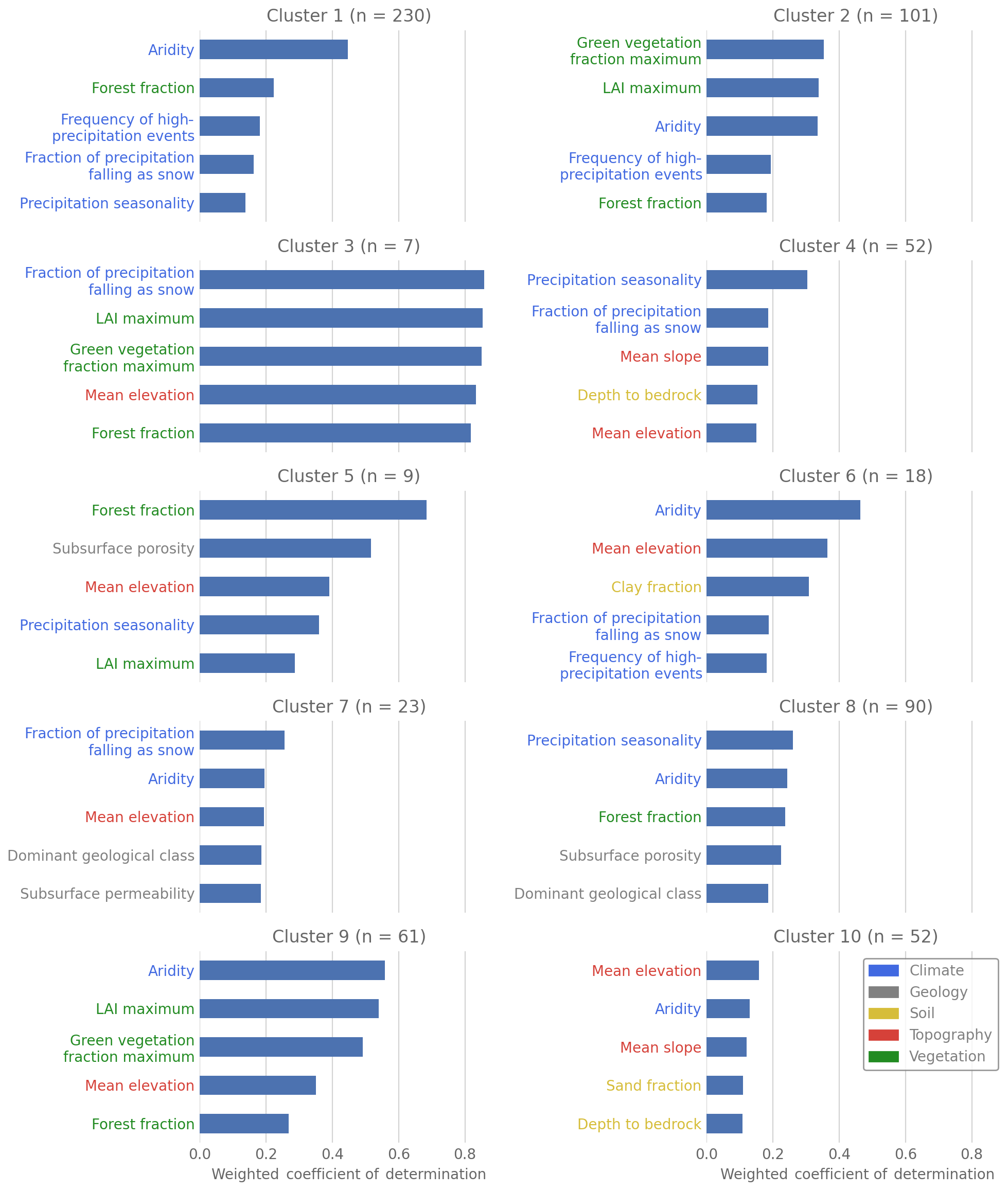
Figure 9Importance of the catchment attributes evaluated by the quadratic regression for the catchment clusters. Attributes colored according to their catchment attribute class.
3.5 Importance of the catchment attributes in the clusters
The individual importance of the catchment attributes in the clusters is variable and partly deviates from the order of importance in the overall dataset (compare Figs. 2 and 9). For Clusters 1 (Southeastern and Central Plains), 6 (Marine West Coast Forests) and 9 (coastal states) aridity has the highest weighted coefficient of determination in the clusters. For Clusters 3 (Northwestern Forested Mountains) and 7 (Western Cordillera) the highest relevance is found for the fraction of precipitation falling as snow. For the remaining clusters it is precipitation seasonality (Cluster 4, Northwestern Forested Mountains, and Cluster 8, Great Plains and Deserts), the green vegetation fraction maximum (Cluster 2, Central Plains) and the mean elevation (Cluster 10, Appalachian Mountains). We can also see that some clusters have one dominating catchment attribute (investigated by the coefficient of determination, e.g., aridity in Cluster 1; see Fig. 9), while for other clusters, all attributes seem equally important (e.g., Cluster 8). Overall, the western clusters (west of the 100th meridian) display the highest weighted R2 with the following:
-
fraction of precipitation falling as snow (Clusters 3, 7),
-
precipitation seasonality (Cluster 4),
-
forest fraction (Cluster 5),
-
aridity (Cluster 6).
Eastern clusters (east of the 100th meridian) display the highest weighted R2 with the following:
-
aridity (Cluster 1),
-
mean elevation (Cluster 10).
Clusters equally present in west and east display the highest weighted R2 with the following:
-
green vegetation fraction maximum (Cluster 2),
-
aridity (Cluster 9),
-
precipitation seasonality (Cluster 8).
Keeping the correlation coefficients displayed in Fig. 1 in mind, we see that climate is the most important factor in almost all clusters, as the vegetation attributes are highly correlated with the climate attributes. The only exception is Cluster 10, in which mean elevation is the most important catchment attribute. However, the catchment attributes in Cluster 10 have overall low R2 values and the mean elevation is directly followed by the aridity. This again shows that climate seems to be the dominating factor for catchment behavior, as found in other large-sample studies (e.g., Berghuijs et al., 2014; Kuentz et al., 2017). Nevertheless, if one takes a closer look at the dataset, more detailed, regional correlations with regard to individual climate variables can be determined. For example, Cluster 1 is defined by the aridity, while Cluster 4 seems to be much more influenced by the precipitation seasonality. Overall, it is feasible to link dominating catchment attributes to the hydrological behavior. While it is straightforward in some regions of the US, it is more challenging in others. We link this to the signal of the climatic forcing being more superimposed by other catchment attributes, which results in a less clear connection between its hydrological behavior and the climate. This hints that climate and catchment attributes are more intertwined in those areas and indicates regions where different types of hydrological runoff generation processes exist. Furthermore, it indicates regions where hydrological predictions in ungauged basins (Hrachowitz et al., 2013) can become very challenging, as the interplay of the available meteorological data and catchment attributes cannot sufficiently explain the hydrological characteristics. Those findings also highlight one current discrepancy between large-sample and single-catchment studies. While large-sample studies, especially the very large ones, identify climate as being most important for the hydrological behavior (e.g., Addor et al., 2018; Kuentz et al., 2017), smaller-sample studies (e.g., Chiverton et al., 2015; Pfister et al., 2017) and single-catchment studies (e.g., Floriancic et al., 2018) often identify the geology or soils as being very important. This might be linked to the overall problem of scales in hydrology, as different scales of soil/geology and climate have different effects and varying data accuracy (Addor et al., 2018; Blöschl, 2001). In addition to this, the overall scale might also come into play. Smaller sample studies often compare catchments that are not far away from each other and probably have similar climate forcings. Thus, the differences in hydrological behavior can only be caused by catchment attributes other than climate. Therefore, larger and smaller sample studies might be looking at different things. While very large-sample studies capture what drives catchments on large scales (the climate), smaller studies look at how this climatic signal is transferred to discharge by the catchment attributes.
3.6 Differences in clusters in comparison with other hydrological clustering studies
The results of this study show some similarities with the clustering results of Kuentz et al. (2017), who derived their cluster from European catchments by an analogous method. Like them, this study here also found one cluster (Cluster 2) that does not have any distinct character. However, only around one-sixth of the CAMELS catchments belongs to this Cluster 2, while one-third of the catchments in the study by Kuentz et al. (2017) were in a cluster without distinct features. Therefore, our selection of hydrological signatures seems to allow a better identification of hydrological similarities. However, all catchments in CAMELS are mostly without human impact (Addor et al., 2017), while many catchments in the study of Kuentz et al. (2017) are under human influence. This human influence might mask otherwise apparent patterns. Kuentz et al. (2017) also found two clusters that contain mostly mountainous catchments. These show a similar behavior to Cluster 3 (Northwestern Forested Mountains) and Cluster 10 (Appalachian Mountains) (Fig. 4). The main difference between their findings and this study here is Cluster 8, as it contains very arid catchments (with some being located in deserts). Obviously, this cluster cannot be found in Europe as Europe has no real deserts. Still, there is some similarity with their cluster of Mediterranean catchments as both are dominated by aridity. Summarizing, in their study and this study catchments are mainly clustered in groups of desert/arid catchments, mountainous catchments, medium-height mountains with high forest fraction, wet lowland catchments, and one cluster of catchments that does not show a very distinct behavior and therefore does not fit in the other clusters (Table 2). One possible explanation for this unspecific behavior might be that many catchments have one or two important attributes that dictate most of their behavior, but which are different from other cluster members. For example, desert catchments are relatively easy to identify, as they are dominated by high energy and little precipitation. A European upland catchment on the other hand has several more influences such as snow in the winter, high energy in the summer, varying land use and a strong impact of seasonality. Here, many influences overlap each other and thus make it difficult to identify a single cause; see also the discussion by Trancoso et al. (2017) that goes in a similar direction. Those overlapping influences are probably also the reason why catchment classification studies often find one or two clusters that include a large number of catchments, while most other clusters only contain a few catchments (Coopersmith et al., 2012; Kuentz et al., 2017). Therefore, it is quite difficult to confirm the “wish” of the hydrological community to have homogenous catchment groups with only a few outliers (e.g., Burn, 1997), because catchments are complex systems with a high level of self-organization arising from co-evolution of climate and landscape properties, including vegetation (Coopersmith et al., 2012). Accordingly, it requires many separate clusters to separate those multi-influence catchments into homogenous groups. This hints that for future research a fuzzy clustering approaches might provide less ambiguous results, as it respects the continuous nature of hydrological behavior. Still, the cluster found here might capture much of the variety present in the United States, as they roughly follow ecological regions (McMahon et al., 2001), which has been stated as a sign of a good classification (Berghuijs et al., 2014). In addition, this study shows that using clusters derived from principal components of hydrological signatures creates meaningful groups of catchments with similar attributes (Figs. 6, 7, 8). Those clusters also show distinct spatial patterns (Fig. 4). Similar results were also found in other studies that used the same method (Kuentz et al., 2017; McManamay et al., 2014) but based them on partly different hydrological signatures. Therefore, the principal components of hydrological signatures can be used as a measure of similarity between catchments. They represent the “essence” of all hydrological signatures used. Our results also show that it is difficult to link those catchment clusters to simple averaged measures of catchment attributes. While some clusters have very clear connections to the attributes, others have no catchment attribute that could easily explain the behavior of the catchments. This hints that some catchments are easier to explain (in a hydrological sense) than others. Those difficulties might be an artifact of the averaged catchment attributes or be caused by a complex catchment reaction, forced by intertwined climate and catchment attributes, which in turn might indicate an equifinality of catchment response.
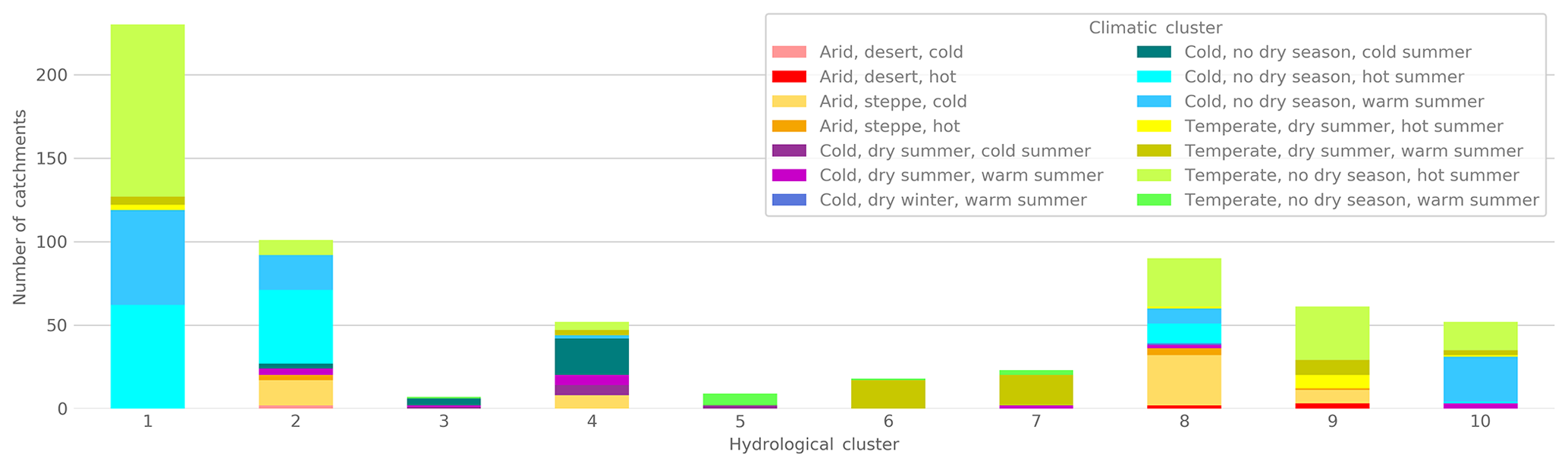
Figure 10Membership of Köppen–Geiger clusters (Beck et al., 2018) in the hydrological clusters.
3.7 Comparing catchment clusters based on hydrological behavior and climate
Besides hydrological behavior, climate is often used to sort catchments into similar groups (e.g., Berghuijs et al., 2014; Knoben et al., 2018). Therefore, we are interested if both approaches deliver comparable results. To evaluate this, we contrasted our results to the commonly used Köppen–Geiger climate classification (Beck et al., 2018) (Fig. 10) and recently published approach of Knoben et al. (2018), who sorted climate along three continuous axes of aridity, seasonality and fraction of precipitation falling as snow (Fig. 11). The resulting clusters based on climate and hydrology should be the same, if climate is the dominating driver of hydrological behavior in every catchment. Yet, this is not the case for the Köppen–Geiger classification. In every hydrological cluster are at least two different climates regarding the Köppen–Geiger classification, ranging up to eight different climatic regions for Clusters 2 and 8 (those even include deserts and very cold regions). Thus, the Köppen–Geiger classification seems unable to capture the essential drivers of hydrological behavior, a critique also raised in other studies (e.g., Haines et al., 1988; Knoben et al., 2018).
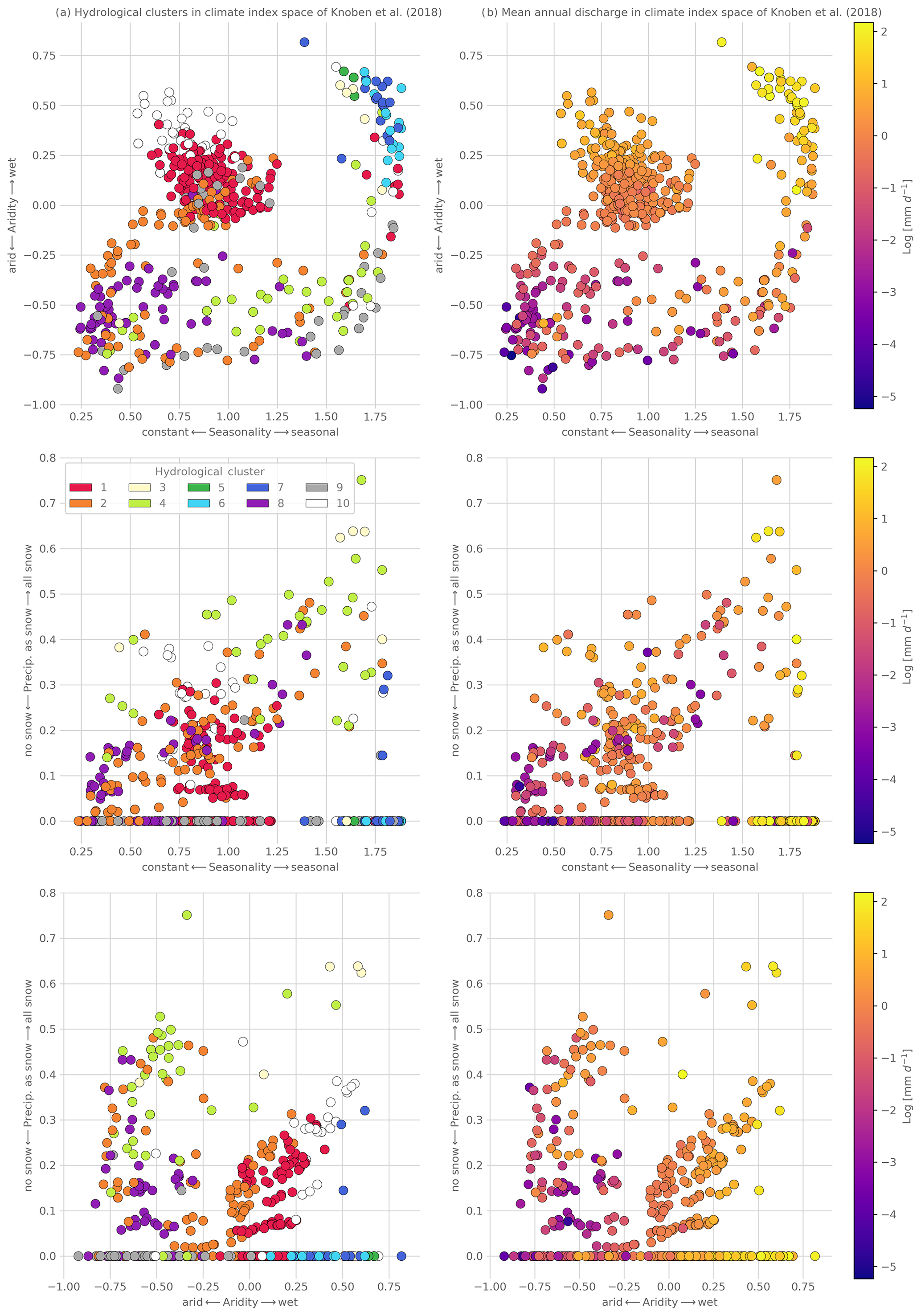
Figure 11(a) Comparison of the hydrological clustering of this study with the climate index space of Knoben et al. (2018). Single dots show the catchments and are colored by their hydrological clusters. (b) Mean annual discharge for all catchments in the climate index space of Knoben et al. (2018). Single dots show the catchments and are colored according to the value of the mean annual discharge. The log of the mean annual discharge is used to show the relative differences between the catchments. For a depiction of all hydrological signatures used, see Fig. A2.
The picture is less clear concerning the climatic index space of Knoben et al. (2018) (Fig. 11a). Due to the continuous nature of the approach of Knoben et al. (2018), there are no clear boundaries as in the Köppen–Geiger classification. Still, there are some emerging patterns. For example, according to the approach of Knoben et al. (2018) Cluster 1 is mainly defined by a relatively arid climate, with some seasonal variability and little to no snow. This is in line with our analysis of the most influential catchment attributes for this cluster, as we identified aridity as the main driver. There seem to be regions where the forcing signal of the climate is transferred more directly to a streamflow response than in others. However, this does not mean that climate is unimportant in those regions. Either the climate forcing signal is changed more through other attributes of the catchment, or the mean values describing the climate do not properly reflect the variability of the climate in the single catchments. This leads to a less clear correlation between the climate and the hydrological behavior. Interestingly, when we look at the single hydrological signatures in the climate index space (Figs. 11b, A2) we see a very clear connection between the single hydrological signatures and the climate. This direct connection of the signatures used was also found by Addor et al. (2018). Our results and the comparison show that the complex hydrological behavior, captured in a range of hydrological signatures, does not simply follow the climate only, even though the individual signatures do. Still, all signatures combined seem to capture a dynamic which is climatic in origin but is shaped through the attributes of the catchments (like vegetation and soils Berghuijs et al., 2014). Therefore, to find truly similar catchments, using climate characteristics only is probably not sufficient (see also Addor et al., 2018; Knoben et al., 2018; Kuentz et al., 2017).
This study explored differences in the catchment characteristics between the eastern and western US, the properties and location of catchment clusters based on hydrological signatures, the importance of catchment attributes for those clusters, and how this study relates to other clustering studies and methods. We found that the correlations between catchment characteristics are quite similar for the eastern and western US with the exception of mean elevation, snow, geology and the leaf area index. For the overall CAMELS dataset climate seems to be the most important factor for the hydrological behavior. However, depending on the location either aridity, snow or seasonality were most important. The clusters derived from the hydrological signatures partly follow the ecological regions in the US and can combined into four groups of general behavior trends. Still, similar catchments can be quite far away from each other. We also found that most of the catchments have a rather similar discharge behavior, while only some more extreme catchments deviate from that main trend. This might be a hint as to why it is so difficult to cluster catchments, as those single extreme catchments are quite unique and do not fit together well with other catchments. We also found that there are differences of how directly the signal of forcing climate can be found again in the hydrological behavior. This explains why catchments often show a surprisingly similar behavior across many different climate and landscape properties (Troch et al., 2013) and why the most hydrologically similar catchment can be hundreds of kilometers away. Those findings also relate to the paradox that small-scale and single-catchment studies identify geology/soils as most important for the hydrological behavior, while large-sample studies usually find the climate to be most important. This might simply be influenced by spatial proximity. Small-scale studies look at catchments which all have a similar climatic forcing, and thus only the other catchment attributes can be the cause of differences in hydrological behavior. Large-sample studies on the other hand consider catchments with a wider area and thus attribute the differences in behavior to climate.
The aggregated data used in this study might level out the variability of the catchment attributes in the single catchment, but they also indicate that there is a kind of equifinality in the behavior of catchments. Different sets of intertwined climate forcing and catchment attributes could lead to a very similar overall behavior, not unlike hydrological models that produce the same discharge with different sets of parameters.
We acknowledge that the results are dependent on the amount and size of the clusters, the catchment attributes considered and the hydrological signatures used. Still, we think that the CAMELS dataset offers an excellent overview of different kinds of catchments in contrasting climatic and topographic regions. In addition, this study shows that using hydrological signatures with high spatial predictability results in hydrological meaningful clusters, which show consistent low flow behavior, even though those low flows were not explicitly considered. However, it seems that even a comprehensive dataset like CAMELS does not allow an easy way to find a conclusive set of clusters for catchments. For future research, we recommend including measures of spatial variability of the climate in the single catchments and to look into the single clusters in more depth. This might help to prove whether a less clear climatic signal is caused by intra-catchment variability of the climate or a larger influence from other catchment attributes.
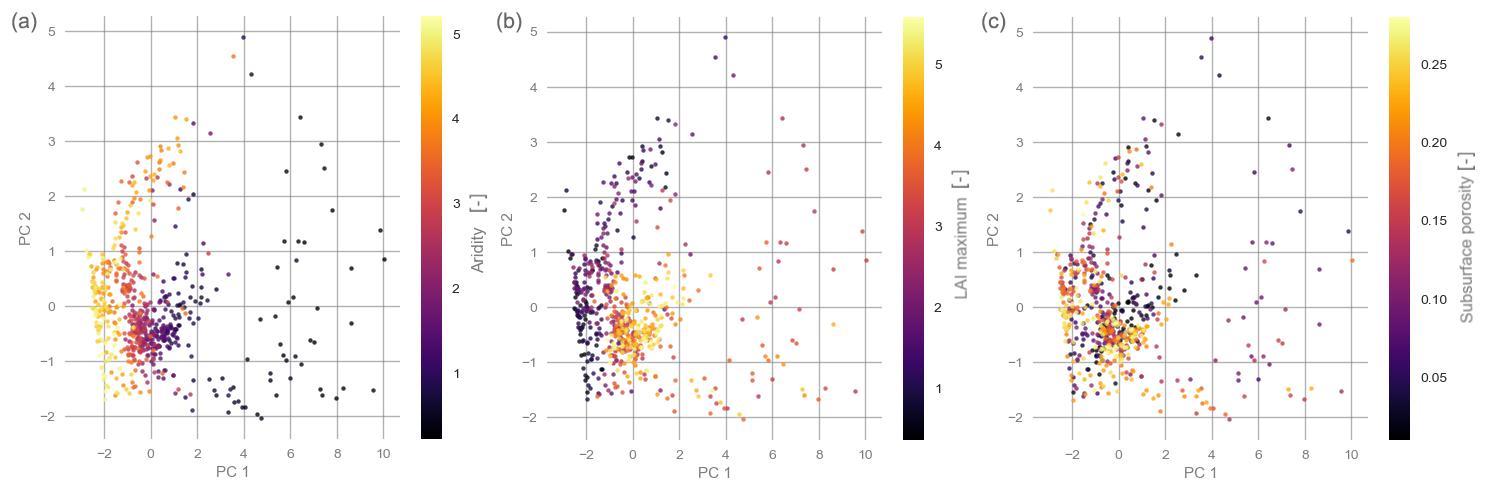
Figure A1Patterns of catchment attributes in the PCA space of the hydrological signatures, with decreasing strength of the observed pattern from left (aridity) to right (subsurface porosity).

Figure A2Hydrological signatures for all catchments in the climate index space of Knoben et al. (2018). Single dots show the catchments and are colored according to the value of the mean annual discharge. The log of the signatures is used to show the relative differences between the catchments.
The code used for this study can be found in Jehn (2020; https://doi.org/10.5281/zenodo.3630303).
The CAMELS dataset can be found at https://doi.org/10.5065/D6MW2F4D (Newman et al., 2014) and is described in Addor et al. (2017; https://doi.org/10.5194/hess-21-5293-2017). The cluster numbers together with the CAMELS catchment ID and the climatic indices can be found in the Supplement of this paper.
The supplement related to this article is available online at: https://doi.org/10.5194/hess-24-1081-2020-supplement.
FUJ, LB, TH and PK conceived and designed the study. FUJ did the data analysis. All authors aided in the interpretation and discussion of the results and the writing of the paper.
The authors declare that they have no conflict of interest.
We would like to thank Ina Pohle, Marc Vis, Jan Seibert, Wouter Knoben, Andrew Newman and two anonymous reviewers for giving valuable and important feedback on the creation of this paper. We would also like to thank all the people who helped create the CAMELS dataset. Thank you for your work! We further would like to thank the DFG for generously funding the project HO 6420/1-1.
This paper was edited by Daniel Viviroli and reviewed by Andrew Newman and two anonymous referees.
Addor, N., Newman, A. J., Mizukami, N., and Clark, M. P.: The CAMELS data set: catchment attributes and meteorology for large-sample studies, Hydrol. Earth Syst. Sci., 21, 5293–5313, https://doi.org/10.5194/hess-21-5293-2017, 2017.
Addor, N., Nearing, G., Prieto, C., Newman, A. J., Le Vine, N., and Clark, M. P.: A ranking of hydrological signatures based on their predictability in space, Water Resour. Res., 54, 8792–8812, https://doi.org/10.1029/2018WR022606, 2018.
Ali, G., Tetzlaff, D., Soulsby, C., McDonnell, J. J., and Capell, R.: A comparison of similarity indices for catchment classification using a cross-regional dataset, Adv. Water Resour., 40, 11–22, https://doi.org/10.1016/j.advwatres.2012.01.008, 2012.
Alvarez-Garreton, C., Mendoza, P. A., Boisier, J. P., Addor, N., Galleguillos, M., Zambrano-Bigiarini, M., Lara, A., Puelma, C., Cortes, G., Garreaud, R., McPhee, J., and Ayala, A.: The CAMELS-CL dataset: catchment attributes and meteorology for large sample studies – Chile dataset, Hydrol. Earth Syst. Sci., 22, 5817–5846, https://doi.org/10.5194/hess-22-5817-2018, 2018.
Andréassian, V., Lerat, J., Le Moine, N., and Perrin, C.: Neighbors: Natures own hydrological models, J. Hydrol., 414–415, 49–58, https://doi.org/10.1016/j.jhydrol.2011.10.007, 2012.
Beck, H. E., Zimmermann, N. E., McVicar, T. R., Vergopolan, N., Berg, A., and Wood, E. F.: Present and future Köppen-Geiger climate classification maps at 1-km resolution, Scientific Data, 5, 180214, https://doi.org/10.1038/sdata.2018.214, 2018.
Berghuijs, W. R., Sivapalan, M., Woods, R. A., and Savenije, H. H. G.: Patterns of similarity of seasonal water balances: A window into streamflow variability over a range of time scales, Water Resour. Res., 50, 5638–5661, https://doi.org/10.1002/2014WR015692, 2014.
Beven, K. J.: Uniqueness of place and process representations in hydrological modelling, Hydrol. Earth Syst. Sci., 4, 203–213, https://doi.org/10.5194/hess-4-203-2000, 2000.
Haines, A. T., Finlayson, B. L., and McMahon, T. A.: A global classification of river regimes, Appl. Geogr., 8, 255–272, https://doi.org/10.1016/0143-6228(88)90035-5, 1988.
Blöschl, G.: Scaling in hydrology, Hydrol. Process., 15, 709–711, https://doi.org/10.1002/hyp.432, 2001.
Burn, D. H.: Catchment similarity for regional flood frequency analysis using seasonality measures, J. Hydrol., 202, 212–230, https://doi.org/10.1016/S0022-1694(97)00068-1, 1997.
Chiverton, A., Hannaford, J., Holman, I., Corstanje, R., Prudhomme, C., Bloomfield, J., and Hess, T. M.: Which catchment characteristics control the temporal dependence structure of daily river flows?: TEMPORAL DEPENDENCE IN RIVER FLOW, Hydrol. Process., 29, 1353–1369, https://doi.org/10.1002/hyp.10252, 2015.
Coopersmith, E., Yaeger, M. A., Ye, S., Cheng, L., and Sivapalan, M.: Exploring the physical controls of regional patterns of flow duration curves – Part 3: A catchment classification system based on regime curve indicators, Hydrol. Earth Syst. Sci., 16, 4467–4482, https://doi.org/10.5194/hess-16-4467-2012, 2012.
Costanza, R., Wainger, L., Folke, C., and Mäler, K.-G.: Modeling Complex Ecological Economic Systems: Toward an Evolutionary, Dynamic Understanding of People and Nature, in Ecosystem Management, Springer New York, New York, NY, 148–163, 1993.
Floriancic, M. G., Meerveld, I., Smoorenburg, M., Margreth, M., Naef, F., Kirchner, J. W., and Molnar, P.: Spatio-temporal variability in to low flows in the high Alpine Poschiavino catchment, Hydrol. Process., 32, 3938–3953, https://doi.org/10.1002/hyp.13302, 2018.
Gupta, H. V., Perrin, C., Blöschl, G., Montanari, A., Kumar, R., Clark, M., and Andréassian, V.: Large-sample hydrology: a need to balance depth with breadth, Hydrol. Earth Syst. Sci., 18, 463–477, https://doi.org/10.5194/hess-18-463-2014, 2014.
Hrachowitz, M., Savenije, H. H. G., Blöschl, G., McDonnell, J. J., Sivapalan, M., Pomeroy, J. W., Arheimer, B., Blume, T., Clark, M. P., Ehret, U., Fenicia, F., Freer, J. E., Gelfan, A., Gupta, H. V., Hughes, D. A., Hut, R. W., Montanari, A., Pande, S., Tetzlaff, D., Troch, P. A., Uhlenbrook, S., Wagener, T., Winsemius, H. C., Woods, R. A., Zehe, E., and Cudennec, C.: A decade of Predictions in Ungauged Basins (PUB)a review, Hydrolog. Sci. J., 58, 1198–1255, https://doi.org/10.1080/02626667.2013.803183, 2013.
Jehn, F. U.: Repository for all code related to this paper, https://doi.org/10.5281/zenodo.3630303, 2020.
Knoben, W. J. M., Woods, R. A., and Freer, J. E.: A Quantitative Hydrological Climate Classification Evaluated With Independent Streamflow Data, Water Resour. Res., 54, 5088–5109, https://doi.org/10.1029/2018WR022913, 2018.
Kuentz, A., Arheimer, B., Hundecha, Y., and Wagener, T.: Understanding hydrologic variability across Europe through catchment classification, Hydrol. Earth Syst. Sci., 21, 2863–2879, https://doi.org/10.5194/hess-21-2863-2017, 2017.
Li, C., Cao, J., Nie, S.-P., Zhu, K.-X., Xiong, T., and Xie, M.-Y.: Serum metabolomics analysis for biomarker of Lactobacillus plantarum NCU116 on hyperlipidaemic rat model feed by high fat diet, J. Funct. Foods, 42, 171–176, https://doi.org/10.1016/j.jff.2017.12.036, 2018.
Massmann, C.: Modelling Snowmelt in Ungauged Catchments, Water, 11, 301, https://doi.org/10.3390/w11020301, 2019.
McGlynn, B. L. and Seibert, J.: Distributed assessment of contributing area and riparian buffering along stream networks: TECHNICAL NOTE, Water Resour. Res., 39, https://doi.org/10.1029/2002WR001521, 2003.
McMahon, G., Gregonis, S. M., Waltman, S. W., Omernik, J. M., Thorson, T. D., Freeouf, J. A., Rorick, A. H., and Keys, J. E.: Developing a Spatial Framework of Common Ecological Regions for the Conterminous United States, Environ. Manage., 28, 293–316, https://doi.org/10.1007/s0026702429, 2001.
McManamay, R. A., Bevelhimer, M. S., and Kao, S.-C.: Updating the US hydrologic classification: an approach to clustering and stratifying ecohydrologic data: US HYDROLOGIC CLASSIFICATION, Ecohydrology, 7, 903–926, https://doi.org/10.1002/eco.1410, 2014.
Newman, A., Sampson, K., Clark, M. P., Bock, A., Viger, R. J., and Blodgett, D.: A large-sample watershed-scale hydrometeorological dataset for the contiguous USA, Boulder, CO: UCAR/NCAR, https://doi.org/10.5065/D6MW2F4D, 2014.
Omernik, J. M. and Griffith, G. E.: Ecoregions of the Conterminous United States: Evolution of a Hierarchical Spatial Framework, Environ. Manage., 54, 1249–1266, https://doi.org/10.1007/s00267-014-0364-1, 2014.
Pfister, L., Martínez-Carreras, N., Hissler, C., Klaus, J., Carrer, G. E., Stewart, M. K., and McDonnell, J. J.: Bedrock geology controls on catchment storage, mixing, and release: A comparative analysis of 16 nested catchments, Hydrol. Process., 31, 1828–1845, https://doi.org/10.1002/hyp.11134, 2017.
Potter, N. J., Zhang, L., Milly, P. C. D., McMahon, T. A., and Jakeman, A. J.: Effects of rainfall seasonality and soil moisture capacity on mean annual water balance for Australian catchments: WATER BALANCE OF AUSTRALIAN CATCHMENTS, Water Resour. Res., 41, https://doi.org/10.1029/2004WR003697, 2005.
Samani, Z.: Estimating solar radiation and evapotranspiration using minimum climatological data, J. Irrig. Drain. Eng., 126, https://doi.org/10.1061/(ASCE)0733-9437(2000)126:4(265), 2000.
Sawicz, K., Wagener, T., Sivapalan, M., Troch, P. A., and Carrillo, G.: Catchment classification: empirical analysis of hydrologic similarity based on catchment function in the eastern USA, Hydrol. Earth Syst. Sci., 15, 2895–2911, https://doi.org/10.5194/hess-15-2895-2011, 2011.
Schaake, J., Cong, S. Z., and Duan, Q. Y.: The US MOPEX data set, IAHS-AISH, 307, 9–28, 2006.
Singh, R., Archfield, S. A., and Wagener, T.: Identifying dominant controls on hydrologic parameter transfer from gauged to ungauged catchments – A comparative hydrology approach, J. Hydrol. 517, 985–996, https://doi.org/10.1016/j.jhydrol.2014.06.030, 2014.
Sivapalan, M.: Prediction in ungauged basins: a grand challenge for theoretical hydrology, Hydrol. Process., 17, 3163–3170, https://doi.org/10.1002/hyp.5155, 2003.
Sivapalan, M.: Pattern, Process and Function: Elements of a Unified Theory of Hydrology at the Catchment Scale, in: Encyclopedia of Hydrological Sciences, edited by: Anderson, M. G. and McDonnell, J. J., John Wiley & Sons, Ltd, Chichester, UK, 2005.
Toth, E.: Catchment classification based on characterisation of streamflow and precipitation time series, Hydrol. Earth Syst. Sci., 17, 1149–1159, https://doi.org/10.5194/hess-17-1149-2013, 2013.
Trancoso, R., Phinn, S., McVicar, T. R., Larsen, J. R., and McAlpine, C. A.: Regional variation in streamflow drivers across a continental climatic gradient, Ecohydrology, 10, e1816, https://doi.org/10.1002/eco.1816, 2017.
Troch, P. A., Carrillo, G., Sivapalan, M., Wagener, T., and Sawicz, K.: Climate-vegetation-soil interactions and long-term hydrologic partitioning: signatures of catchment co-evolution, Hydrol. Earth Syst. Sci., 17, 2209–2217, https://doi.org/10.5194/hess-17-2209-2013, 2013.
Wagener, T., Sivapalan, M., Troch, P., and Woods, R.: Catchment Classification and Hydrologic Similarity, Geography Compass, 1, 901–931, https://doi.org/10.1111/j.1749-8198.2007.00039.x, 2007.
Ward, J. H.: Hierarchical Grouping to Optimize an Objective Function, J. Am. Stat. Assoc., 58, 236–244, https://doi.org/10.1080/01621459.1963.10500845, 1963.
Westerberg, I. K. and McMillan, H. K.: Uncertainty in hydrological signatures, Hydrol. Earth Syst. Sci., 19, 3951–3968, https://doi.org/10.5194/hess-19-3951-2015, 2015.
Yaeger, M., Coopersmith, E., Ye, S., Cheng, L., Viglione, A., and Sivapalan, M.: Exploring the physical controls of regional patterns of flow duration curves – Part 4: A synthesis of empirical analysis, process modeling and catchment classification, Hydrol. Earth Syst. Sci., 16, 4483–4498, https://doi.org/10.5194/hess-16-4483-2012, 2012.
Yeung, K. Y. and Ruzzo, W. L.: Principal component analysis for clustering gene expression data, Bioinformatics, 17, 763–774, https://doi.org/10.1093/bioinformatics/17.9.763, 2001.