the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 20 Mar 2019
| 20 Mar 2019
Geostatistical interpolation by quantile kriging
Henning Lebrenz
András Bárdossy
The widely applied geostatistical interpolation methods of ordinary kriging (OK) or external drift kriging (EDK) interpolate the variable of interest to the unknown location, providing a linear estimator and an estimation variance as measure of uncertainty. The methods implicitly pose the assumption of Gaussianity on the observations, which is not given for many variables. The resulting “best linear and unbiased estimator” from the subsequent interpolation optimizes the mean error over many realizations for the entire spatial domain and, therefore, allows a systematic under-(over-)estimation of the variable in regions of relatively high (low) observations. In case of a variable with observed time series, the spatial marginal distributions are estimated separately for one time step after the other, and the errors from the interpolations might accumulate over time in regions of relatively extreme observations.
Therefore, we propose the interpolation method of quantile kriging (QK) with a two-step procedure prior to interpolation: we firstly estimate distributions of the variable over time at the observation locations and then estimate the marginal distributions over space for every given time step. For this purpose, a distribution function is selected and fitted to the observed time series at every observation location, thus converting the variable into quantiles and defining parameters. At a given time step, the quantiles from all observation locations are then transformed into a Gaussian-distributed variable by a 2-fold quantile–quantile transformation with the beta- and normal-distribution function. The spatio-temporal description of the proposed method accommodates skewed marginal distributions and resolves the spatial non-stationarity of the original variable. The Gaussian-distributed variable and the distribution parameters are now interpolated by OK and EDK. At the unknown location, the resulting outcomes are reconverted back into the estimator and the estimation variance of the original variable. As a summary, QK newly incorporates information from the temporal axis for its spatial marginal distribution and subsequent interpolation and, therefore, could be interpreted as a space–time version of probability kriging.
In this study, QK is applied for the variable of observed monthly precipitation from raingauges in South Africa. The estimators and estimation variances from the interpolation are compared to the respective outcomes from OK and EDK. The cross-validations show that QK improves the estimator and the estimation variance for most of the selected objective functions. QK further enables the reduction of the temporal bias at locations of extreme observations. The performance of QK, however, declines when many zero-value observations are present in the input data. It is further revealed that QK relates the magnitude of its estimator with the magnitude of the respective estimation variance as opposed to the traditional methods of OK and EDK, whose estimation variances do only depend on the spatial configuration of the observation locations and the model settings.
- Article
(5047 KB) - Full-text XML
- BibTeX
- EndNote





Many environmental variables (e.g., precipitation, ore grades) are only measured at some distinct observation locations, but possess a highly variable and unknown spatial distribution (Armstrong, 1998). The regionalization of the variable, i.e., the interpolation of the variable to the unknown locations, attempts the full description of its spatial distribution as a prerequisite for practical objectives (e.g., hydrological modeling, efficient exploitation of resources). However, a deterministic description of the spatial distribution is severely hampered for many variables since they incorporate a complex genesis which is neither fully known nor understood.
Therefore, the assessment of the distribution by geostatistical models arose, whose theoretical fundamentals were firstly laid out by Matheron (1962). The theory regards the (observed) values of a variable z as one realization z(x) of a random variable (RV) Z at the specific location x for ℝ2). Since the variable is often only partially known at a few distinct measurement locations xi, ergodicity is assumed and the intrinsic hypothesis for ordinary kriging (OK, Matheron, 1965) is given as
in which γ(h) is the semi-variogram. The increment is assumed as a stationary random function and its variance only depends on the translation vector h. The set of outcomes by the interpolation to the unknown location x is described by the linear estimator Z∗(x) as a measure of their centrality and by the estimation (or kriging) variance as a measure of the associated uncertainty.
The stated hypothesis entails three implications: the first condition of the intrinsic hypothesis (Eq. 1) demands the variable to be spatially stationary and yields an unbiased estimation error in the entire domain (Chilès and Delfiner, 1999). Therefore, a systematic under-(over-)estimation is induced for regions of high (low) observations. Secondly, the marginal distribution of the observed data should ideally be Gaussian in order to be adequately described. Unfortunately, the distribution often departs from the ideal case (Journal and Alabert, 1989), necessitating an a priori transformation of the marginal distribution. And last, the second condition (Eq. 2) implies that the magnitude of the kriging variance only depends on the spatial configuration of the observation locations, the a priori variance of all observations and on the selected variogram model, but not on the magnitude of the linear estimator Z∗(x) itself (Goovaerts, 2000).
The theoretical extension of external drift kriging (EDK, Ahmed and deMarsily, 1987) addresses the first implication. EDK can be attributed to the non-stationary geostatistical interpolation methods and has been frequently applied in various disciplines of practice and science (e.g., Bourennane et al., 2000, van de Kassteele et al., 2009, Motaghian and Mohammadi, 2011). It incorporates additional information from external variables (or drifts) Yj(x) for the estimation of the variable at the unknown location. The mean m(x) is non-stationary but linearly depends on the external variables. Thus, the first condition (Eq. 1) is reformulated to
where k is the number of the incorporated external drifts Yi(x), while a, bi are the unknown constants. The drifts are required to be known prior to interpolation at all relevant locations. Ideally, EDK still requires a marginal Gaussian distribution.
The non-parametric methods of indicator kriging and probability kriging (Journel, 1983) are further derivatives and allow an a priori transformation of the skewed marginal distribution. Indicator kriging transforms the variable z into a binary variable by defining a threshold value zth and restates the first condition (Eq. 1) of the random function to
This nonlinear transformation is relatively robust and limits the effect of high values on the description of the variable at the unknown location. However, a loss of information comes along by the transformation into a binary variable. Therefore, probability kriging defines multiple thresholds and uses the order relation of the observed variable (Carr and Mao, 1993), being implemented by using co-kriging in the derived multi-variate context. Both non-parametric methods have been subject to research, especially for detection limit problems of groundwater contamination (e.g., Goovaerts et al., 2005; Lee et al., 2007; Adhikary et al., 2011).
In summary, geostatistical methods have been derived in the past in order to address the stated shortfalls of the intrinsic hypothesis. However, all present methods only regard the observations from the one respective time step for the estimation of their marginal spatial distribution, but do not incorporate observations from other time steps. The inclusion of a temporal behavior into the geostatistical models is mostly irrelevant for the original geological variables. However, the temporal variability of a variable becomes more prominent for other sciences, e.g., hydrology, where observations from raingauges over several time steps are implemented into the geostatistical models in order to generate spatial precipitation estimates. These estimates subsequently serve as input to the hydrological modeling (e.g., Syed et al., 2003; Basistha et al., 2008; Cole and Moore, 2008) over multiple time steps. Associated errors in the precipitation estimates may ultimately lead to greater errors in the subsequent discharge modeling (Kobold and Sušelj, 2005). These errors strongly depend on the spatial and temporal distribution of the input precipitation (Gabellani et al., 2007; Moulin et al., 2009) and may limit the accuracy of rainfall–runoff simulations. There are geostatistical space–time models in order to incorporate the temporal variability of the variable, but they are primarily aiming on the extrapolation of the variable in time (Snepvangers et al., 2003). Therefore, they require a strong dependence of the variable over time, suited, e.g., for groundwater modeling where temporal changes occur relative slowly. This temporal dependence might be absent for other variables, e.g., monthly precipitation.
In the following section, we introduce quantile kriging as a spatio-temporal description of the variable Z, addressing the three shortfalls: non-stationary variables, skewed marginal distributions over space and the independence of the error distribution from the magnitude of the observation.
The theory of quantile kriging (QK) is outlined along with the major theoretical implications, followed by a general discussion of the underlying geostatistical model and a case study for the variable of monthly precipitation is presented.
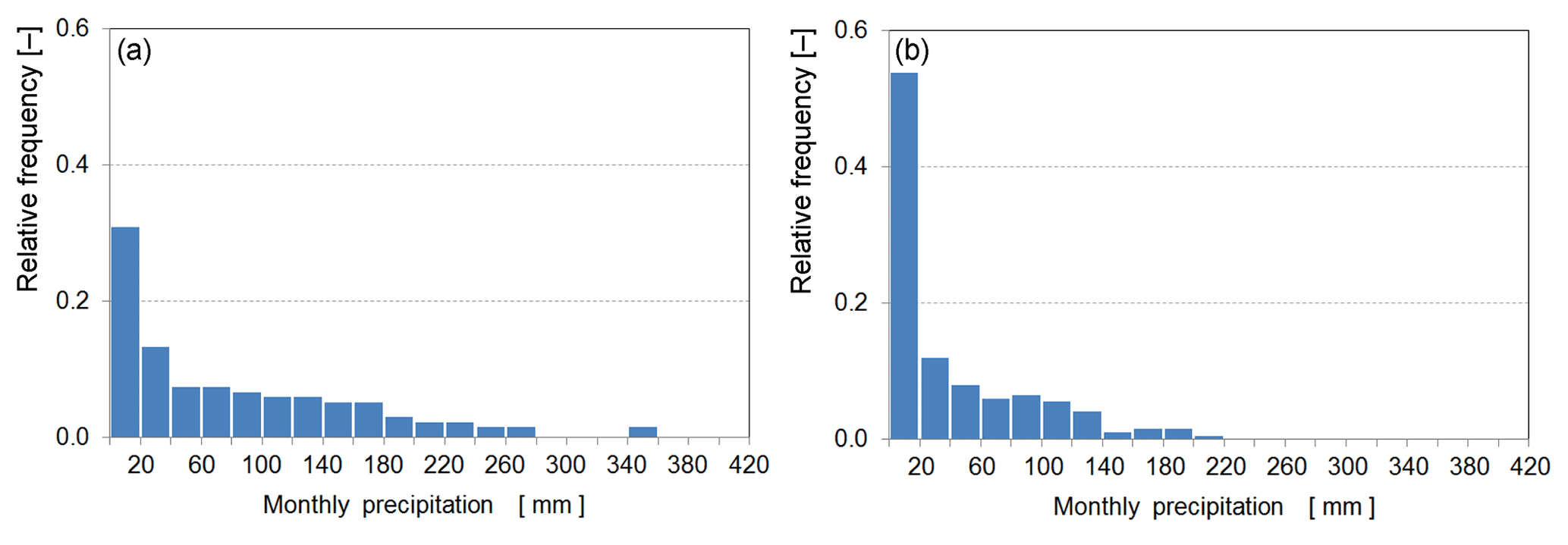
Figure 1Histogram from the times series of observed monthly precipitation for two random stations: “Laingsnek”, x57 with mm (a) and “Tambotieboom”, x29 with mm (b).
A preliminary analysis of the selected variable exemplary reveals (Fig. 1) the non-Gaussianity within the data and that the first assumption of the intrinsic hypothesis (see Eq. 1) is not fulfilled since, e.g., .
2.1 Theory of quantile kriging
QK presumes the existence of observations of the variable z over consecutive time steps t at every observation location xi (for the two-dimensional space ℝ2), providing an observed time series z(xi,t) at every observation location i . QK proceeds first with a two-step procedure prior to interpolation (see Sect. 2.1.1) and second with the interpolation itself (see Sect. 2.1.2).
2.1.1 Estimation of the temporal and the spatial marginal distribution
At first, the distribution over time is estimated at every observation location location xi: an appropriate theoretical cumulative distribution function (cdf) F is selected and fitted to the corresponding time series of observations z(xi,t), yielding ni specific distributions F(z(xi,t)). The distributions are defined by their corresponding parameter sets Θ(xi) (= ϑk(xi) with ) of the K-parametric distribution function F. The quantiles w(xi,t) (= ) are calculated from the observed values of the variable z(xi,t) and the defining parameter set Θ(xi). The quantiles w(xi,t) possess a uniform distribution over time on the interval [0,1] for a given observation location xi. However, their empirical distribution in space is not uniform on [0,1]. In order to profit from the optimality of kriging, it requires a transformation into a Gaussian distribution as a prerequisite of the subsequent interpolation.
The marginal spatial distribution corresponding to a time step t is, therefore, estimated by a 2-fold quantile–quantile conversion as the second step: the two-parametric beta distribution is fitted to the quantiles w(xi,t) of a given time step t, whose cdf is defined as
on the interval [0,1] by the two parameters α>0 and β>0. The quantiles from Eq. (5) are finally transformed by a normal score transformation into the standard Gaussian variable u(xi,t) with Nu[0|1], which ultimately serves as spatial marginal distribution to the subsequent geostatistical interpolation.
The transformation via the quantiles into the variable u accounts for spatially non-stationary distributions of the original variable z with and exchanges the two conditions of Eqs. (1) and (2) to
resolving the problem of spatial non-stationarity. QK can accommodate skewed marginal distributions of the original variable Z, which is similar to probability kriging, but it newly incorporates the temporal behavior of Z into its estimation of the spatial marginal distribution.
2.1.2 Interpolation to the unknown location
The outlined conversion of the variable z(xi,t) into the variable u(xi,t) and its corresponding parameter set Θ(xi) entails separate interpolations to the unknown location x.
The inherent assumption of second-order stationarity implies the existence of a constant spatial mean for the variable u within the domain for every time step t. The transformed quantiles are implicitly assumed to be more homogeneously distributed over space than the original variable z. The variable u is subject to a stationary geostatistical interpolation method (e.g., OK), providing a linear estimator and the estimation variance . They jointly describe the Gaussian distribution of the random variable U(x,t) with .
The defining parameters ϑk (for ) of the K-parametric distribution function F are independent from the time step t and they are separately interpolated to the unknown location x. The separate interpolation, however, requires the independence of the parameters ϑk from each other. Therefore, a principal component analysis examines the “observed” parameters ϑk(xi) in the Cartesian coordinate system () and determines the corresponding rotation angle α and translation vector k. The coordinate system is then rotated and translated accordingly prior to interpolation in order to ensure independence. A possible spatial non-stationarity of the parameters can be accounted for by the choice of an appropriate non-stationary interpolation method (e.g., EDK). The interpolation of the independent parameters yields their estimators at the unknown location x, which are rotated and translated back to the original coordinate system. Thus, the estimators are defining the distribution function at the unknown location x.
At last, the resulting Gaussian distribution of the random variable U(x,t) is reconverted into a distribution of the original variable Z(x,t) by the outlined steps of conversion (Sect. 2.1.1), but in reverse order: first the distribution of the quantiles of the beta distribution is calculated by the inverse of the normal score transformation. The distribution of the quantiles W(x,t) are calculated next using the inverse of Eq. (5) and last, the distribution of the original variable Z(x,t) is estimated by using the inverse of the selected cdf, being defined by the estimators of its parameters . The reconversion of the distribution of U(x,t) to the distribution of Z(x,t) can be implemented by the simple numerical Rosenblueth point estimation method (Rosenblueth, 1975). The resulting distribution of the original variable Z is then described by the expectation value and the variance . Note that the resulting asymmetrical distribution of Z(x,t) is non-Gaussian due to the conversion with the nonlinear but monotonic theoretical cdf F.
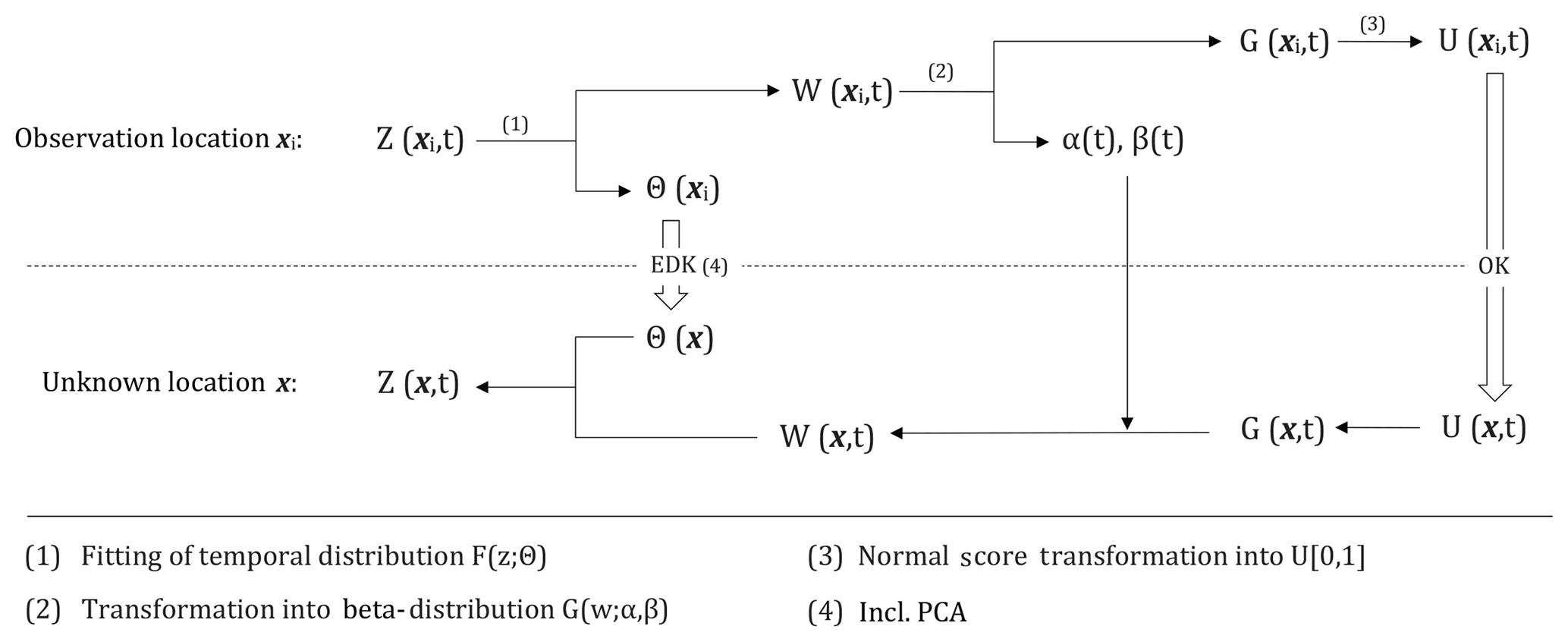
The basic methodology of the proposed QK is illustrated in Fig. 2.
2.2 Discussion of the geostatistical model
Since the proposed method of QK is applied for the variable of monthly precipitation (see Sect. 2.3), the discussion of the underlying process model is based on the following properties of precipitation fields:
-
The monthly (and even daily) precipitation amounts z(x,t) for a given time step t often show a skewed distribution and cannot be considered as stationary over space. The differences in expected precipitation amounts become especially obvious for long time accumulations.
-
The meteorological processes, which are generating precipitation, are usually of large spatial extent: if one location receives heavy precipitation, it is likely that other locations also receive heavy precipitation.
-
Correlations between time series of precipitation indicate a strong spatial dependence, while the spatial dependence of precipitation at one given time step (e.g., day, month) usually show a much weaker spatial dependence.
A possible process model reflecting the above properties can be described as follows.
Let U(x,t) be independent (for each different time step t) normal stationary spatial fields with E[U]=0 and D2(U)=1 for each time step t. Now, the process M(t) is introduced in order to reflect large-scale meteorological processes. High M(t) values correspond to heavy precipitation covering the area, while low values correspond to dry conditions, as it is reflected by seasonal variations of precipitation amounts. The introduced M modifies the spatial process to
where M(t) is a process (only in time) with a mean of zero. We may assume that the distribution of M(t) is normal and, therefore, G(x,t) would be normally distributed with N(0,d) (with ) at every location x.
For each individual time step t, the distribution of G(x,t) is N(M(t),1) and the resulting spatial field W is the temporal non-exceedance probability at location x being confined to and formally described as
where Φ0,d is the distribution function of N(0,d). The precipitation is then generated as
where Fx is the distribution function of precipitation at the location x. The distribution functions Fx may vary between different locations x due to topography and other influencing factors, and they could be subject to interpolation (e.g., Mosthaf and Bárdossy, 2017).
We use W(x,t) for each time step t and assume that it follows a beta distribution. In fact, its distribution depends on M(t). If M(t)=0 for all time steps t, then monthly precipitation can be fully characterized by independent realizations over space. In this case, the distribution of W is uniform for each t.
However, this is not the case with observed data because wet and dry conditions occur simultaneously over the entire domain. This is controlled by M(t), which can be taken, e.g., as an independent random variable or to follow an ARMA process. If M(t)≠0 then the distribution of W(x,t) is not uniform for this specific time step t. The exact form of the corresponding distribution would be something like
However, the use of Eq. (11) would require the estimation of M(t) for each time step t. We decided to use a simple beta distribution instead. The reason for assuming a beta distribution is due to their flexibility and their ability to describe distributions well within the interval [0,1].
The introduction of M(t) is reasonable as it explains the difference between the correlation between stations and the spatial correlation calculated using a variogram type approach for a given time step. The later correlations are usually lower (smaller ranges), which are increased by the common large-scale weather described by M(t). Note that the introduction of M(t) leads to a correlation of the precipitation time series even if the individual snapshots of U(x,t) are independent in space.
We estimate and subsequently interpolate Fx within the proposed methodology by the preceding conversion of the variable Z(xi,t). In addition, we calculate W(xi,t) for the observation locations xi and interpolate it to the unknown location x in order to come back to Z(x,t). In here, spatial variograms are calculated for W for each time step t, assuming W to be spatially stationary. Non-Gaussian and non-stationary distributions only occur for the precipitation amounts (i.e., the variable Z).
Non-Gaussianity should be considered due to the usually skewed distribution of precipitation amounts and it only applies to the marginal distribution at a given time step t. The suggested model should enable a simulation of the precipitation amounts. The spatial dependencies are considered to correspond to a multi-Gaussian copula, being a type of transformation frequently used (e.g., for lognormal kriging).
The distributions Fx, fitted to the individual locations, are supposed to have a spatial dependence. They are further assumed to follow the same distribution (e.g., Γ or Weibull distribution) and are subsequently interpolated. In here, we assume that the large-scale meteorological processes, generating precipitation, are better reflected by the distributions than by a single monthly (or daily) realization. Therefore, the use of external covariates, e.g., elevation, is deemed more appropriate for their interpolation. The usage of these distributions transforms the process into a stationary one, which is then interpolated using the beta distribution of the non-exceedance probabilities.
2.3 Application of quantile kriging
The proposed method of QK is applied for the variable of monthly precipitation in South Africa and the outcomes are compared to those from OK and EDK.
2.3.1 Study area and data
The rectangular study area (, Fig. 3) covers approx. 132 000 km2 and is located within the Republic of South Africa. The second release of the digital elevation model from the Shuttle Radar Topography Mission (USGS, 2003) serves as elevation input. The original resolution was upscaled from 3 arcsec (approx. 92 m) to 2 arcmin (approx. 3700 m) by spatial averaging, resulting in a mean of 1442 m and ranging from 669 to 2197 m (a.m.s.l.). The upscaled elevation ultimately serves as external drift for EDK of the parameters within QK and for the reference EDK with the original variable.
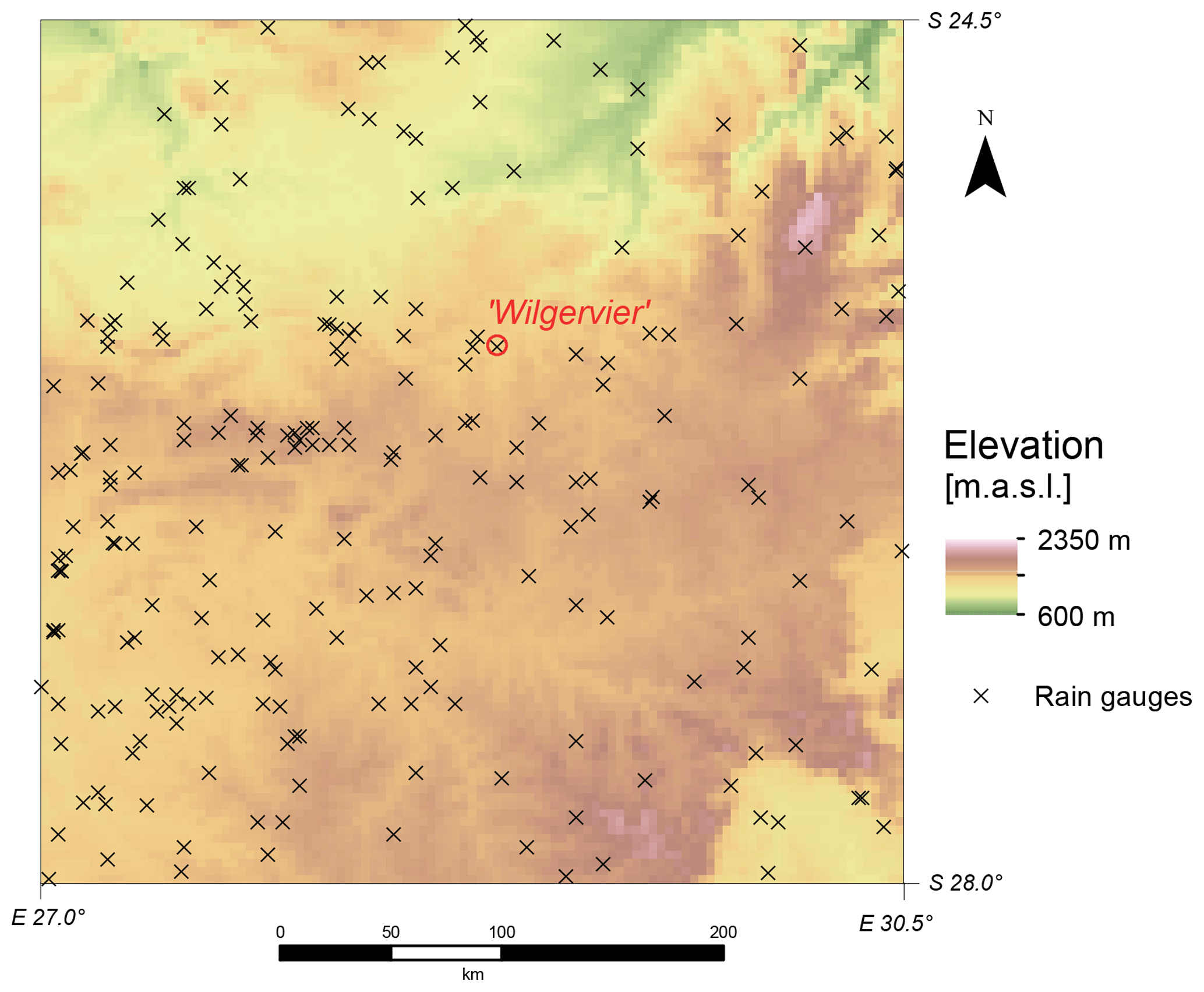
The observations of monthly precipitation were retrieved from raingauges of four different sources: the Department of Water Affairs (DWA, 2008), the Global Historical Climatology Network (Vose et al., 1992), the Climate Research Unit (Mitchell and Jones, 2005) and the internal database of the University of KwaZulu-Natal (Lynch, 2004). Accumulation of daily recordings yield monthly values for the 264 (=J) consecutive months from January 1986 to December 2007. A total of 226 (=ni) raingauges (Fig. 3) provided 32 226 (=N) monthly precipitation values, which ultimately serve as input data.
The observed average monthly precipitation over the 12 calendar months c is illustrated in Fig. 4 along with the percentage of zero-value observations over all observations of the specific calender month c (hereafter referred to as the dry ratio), revealing a seasonal variation. High precipitation is typically encountered in the calendar months from October to March, being characterized by a low dry ratio <3 %. The study area receives relatively low precipitation amounts during the calender months from April (dry ratio = 11 %) to September (dry ratio = 25 %).
2.3.2 Adaptation to monthly precipitation
At first, we subdivided the observations of monthly precipitation into the corresponding calendar month c prior to the fitting of the selected distribution function due to two reasons: the seasonal variation in monthly precipitation (Fig. 4) and to ensure independence of the individual sample members as a theoretical requirement for the fitting method. We used the maximum likelihood estimation method for fitting the selected distribution function to the respective measurements values z(xi,tc) of every calender month c and every measurement location xi, resulting in a total of 2712 () fittings. In this context, the two-parametric Γ and Weibull distribution were selected, whose cdf F(z;Θ) are defined as
where Γ(μ) is the gamma function and is the lower incomplete gamma function. The parameter set Θc(xi) is composed for the Γ distribution out of and and for the Weibull distribution out of and . All parameters are restrained to values greater than zero and both cdfs are defined for .

Figure 4Average monthly precipitation (in mm) and dry ratio (in %) from 226 raingauges. Note that the dry ratio (dashed brown line) is indicated on the right axis.
Thus, the original observations of monthly precipitation z(xi,t) are converted by Eq. (12) or Eq. (13) into the corresponding quantiles w(xi,t) (= ) and their defining parameter set Θc(xi). As outlined in Sect. 2.1, the quantiles w(xi,t) were further converted into the standard Gaussian variable u(xi,t), ultimately subject to the subsequent OK as our chosen geostatistical interpolation method. Note that the stationary assumption of more homogeneously distributed quantiles in space appear more plausible in the case of monthly precipitation. In total, the variable u(xi,t) was interpolated 264 times by OK to the unknown location x. The corresponding variograms are calculated using Kendall's tau for a robust interpolation (Lebrenz and Bárdossy, 2017).
We further selected EDK as non-stationary interpolation method for the defining parameters ϑ1,c and ϑ2,c. Elevation data (Sect. 2.3.1) are taken as external drift since the distributions of monthly precipitation are assumed to depend on the altitude of the terrain. However, it was revealed that the direct use of the parameters may lead to negative or zero estimators at locations of extreme external drifts. Therefore, the sample mean and the sample variance are estimated instead, using the two statistical moments of the selected distribution functions, defined as
The dependence of the two derived parameters and σ2 on each other appears obvious in the case of monthly precipitation: a high mean is likely to be associated with a high variance and vice versa. Their dependence is exemplary illustrated for the calender month “May” in Fig. 5.

Figure 5Scatterplot of sample mean and sample variance of calendar month “May” along with the principle components s5 and r5.
The principal component analysis allows for the transformation into the new Cartesian coordinate system with the new coordinates rc(xi) and sc(xi). They are now independent and subject to a separate interpolation by EDK. A total of 24 () interpolations by EDK to the unknown location x is performed for each selected type of distribution.
The proposed interpolation method of QK, using either a Γ distribution (QK-Γ) or a Weibull distribution (QK-Wei), is implemented and compared to the traditional geostatistical interpolation methods of OK and EDK. The respective performances are evaluated by cross-validation for the resulting estimators Z∗ and the associated kriging variances . In here, cross-validation eliminates all values z(xi,t) in turns from the input data, and subsequently calculates the estimator Z∗(xi) and the associated kriging variance from the remaining data. Only the 32 226 data points of the actually recorded values were considered for the cross-validation and the resulting outcomes are compared to the actual observations.
3.1 Implementation of quantile kriging
The outcomes from the interpolation by OK, EDK and QK-Γ are exemplary displayed and examined for a month with low precipitation and a high dry ratio (August 1993) and a month with high precipitation and a low dry ratio (January 1996). The respective spatial patterns of the estimator Z∗(x) and the associated standard deviation σK(x) are illustrated in Figs. 6 and 7.
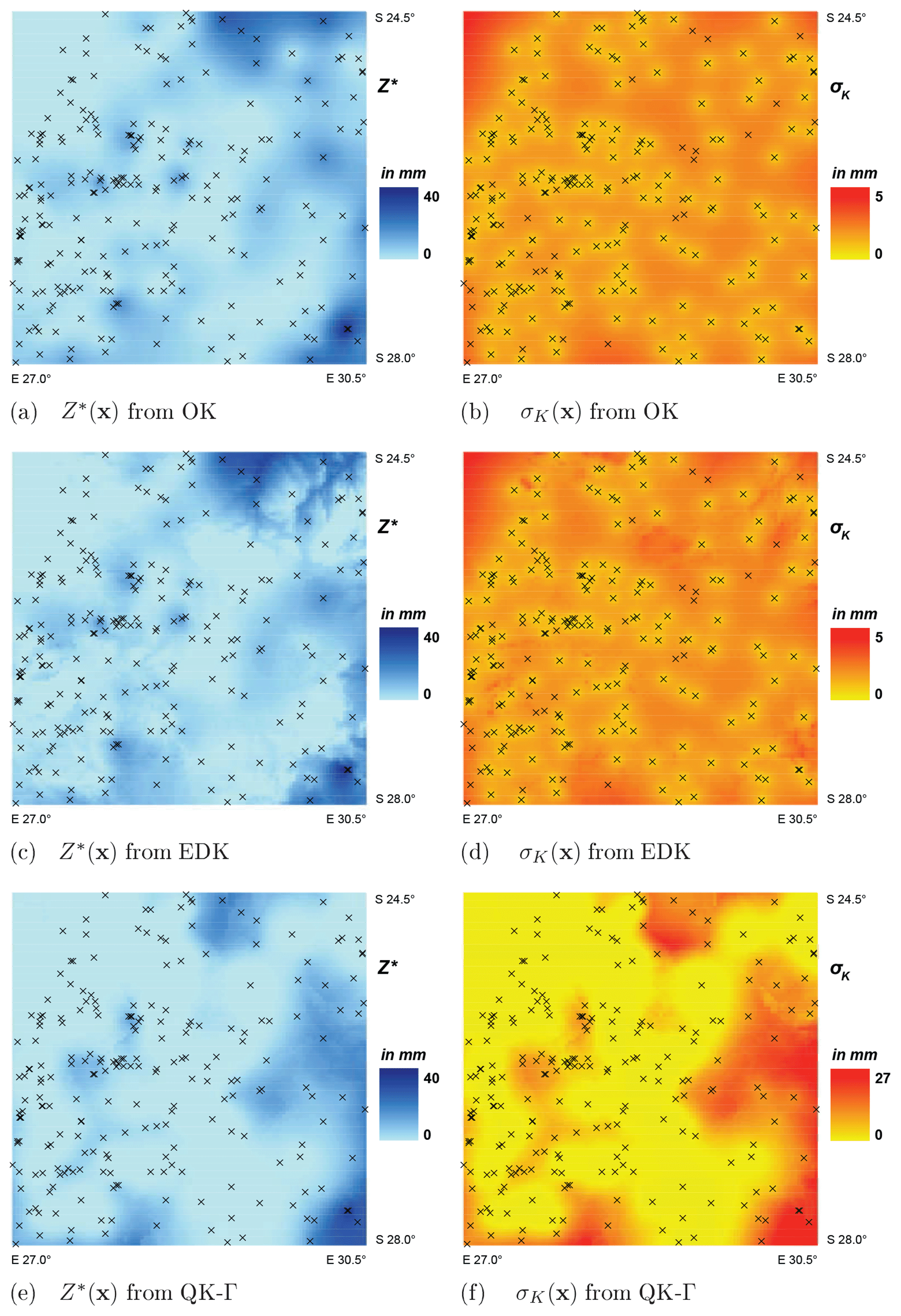
Figure 6Spatial patterns of the estimator Z∗(x) and the standard deviation σK(x) from OK, EDK and QK-Γ for August 1993. Note that crosses indicate positions of raingauges.
The estimator Z∗ displays similar spatial patterns and value ranges for all the interpolation methods. However, the local contours of the isohyets are more rugged for QK-Γ (Figs. 6e and 7e) than for OK (Figs. 6a and 7a), but smoother than for EDK (Figs. 6c and 7c).
QK utilizes elevation for the interpolation of the two distribution parameters ϑ1,c and ϑ2,c. The two parameters incorporate information from all time steps tc of the specific calendar month c and, thus, transfer information over time. They are further combined with the ordinary kriged quantiles W(x,t), leading to more smooth contours of the isohyets than EDK (compare Fig. 3). We regard the resulting spatial patterns of QK as more plausible, assuming that the accumulated monthly precipitation is hardly affected by local features in elevation.
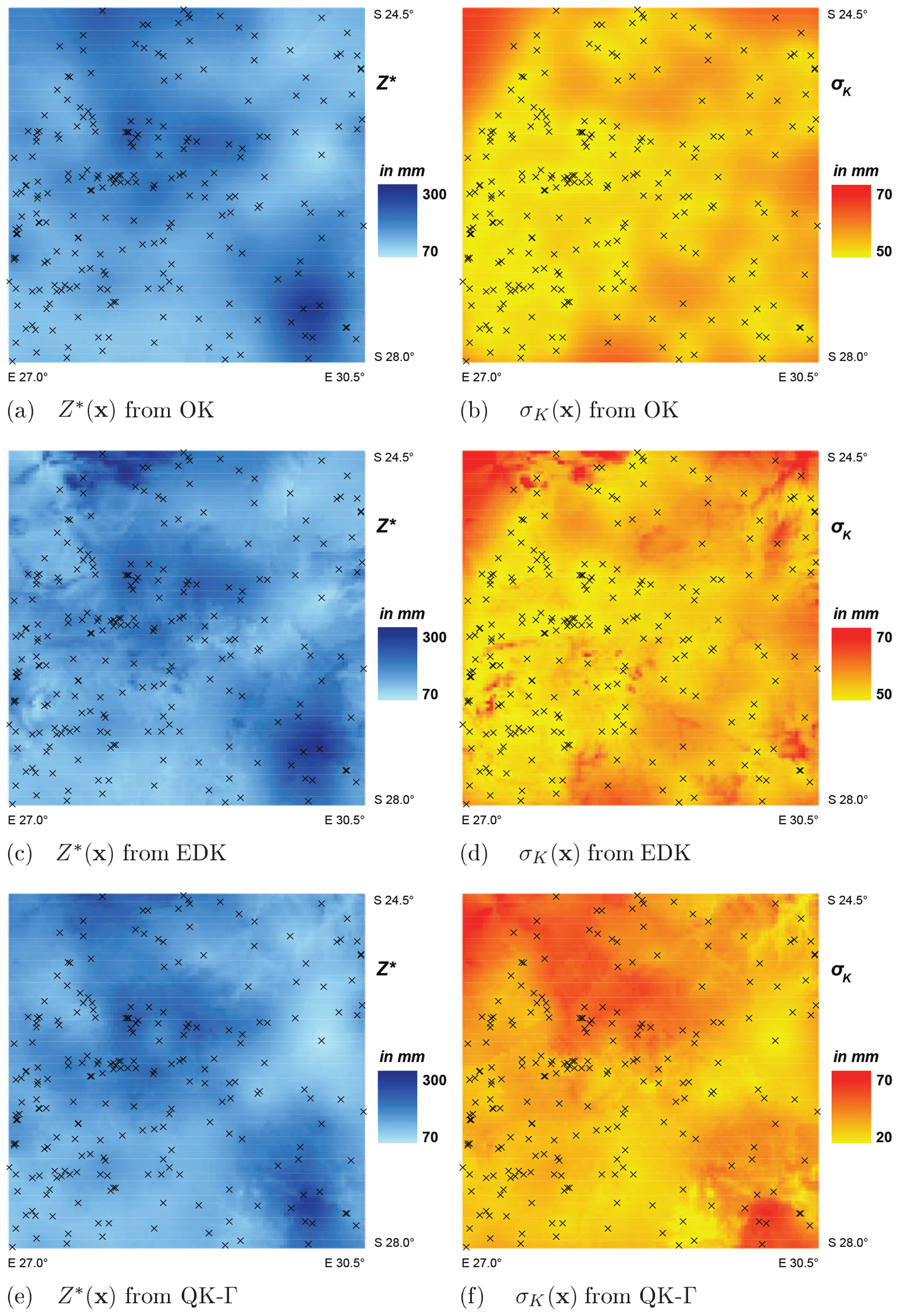
Figure 7Spatial patterns of the estimator Z∗(x) and the standard deviation σK(x) from OK, EDK and QK-Γ for January 1996. Note that crosses indicate positions of raingauges.
The standard deviations σK of the associated estimation error show notable deviations in spatial pattern for the implemented interpolation methods. The range of error is notably higher for QK (Figs. 6f and 7f) and its spatial patterns deviates from the typical, bull-eye-shaped patterns of OK (Figs. 6b and 7b) or EDK (Figs. 6d and 7d).
The estimation error from OK and EDK depends on the spatial configuration of the observation locations xi, their global variance and the selected variogram model. This typical spatial pattern of the error distribution from the ordinary kriged quantiles W(x) is converted within QK by the monotonic cdf (Eq. 12). The resulting σK(x) of the original variable Z(x) is, therefore, increased by relatively flat slopes of the cdfs, which are encountered for relatively high values of W(x). A relationship between the magnitude of the estimator Z∗ and the magnitude of the associated standard deviation σK is suggested by Figs. 6 and 7.
3.1.1 Relationship between estimator and standard deviation
A relationship between the magnitude of the estimator Z∗ and the associated standard deviation σK would be possibly an improvement to geostatistical interpolation and is, therefore, examined next by cross-validation. The Spearman rank correlation coefficient ρS is chosen for its description, being defined as
where and rg(σK(xi,t)) are the ranks of the estimator Z∗ and the associated standard deviation σK within a set of data, while and are the respective average ranks. The non-parametric Spearman rank correlation ρS describes the monotonic relation between the estimator Z∗ and estimation standard deviation σK, ranging from −1 (negative) to +1 (positive) with 0 indicating its absence. A set of data consists of all n values of the corresponding calendar month c. The evolution of the Spearman rank correlation coefficient ρS over all 12 calendar months is displayed in Fig. 8.
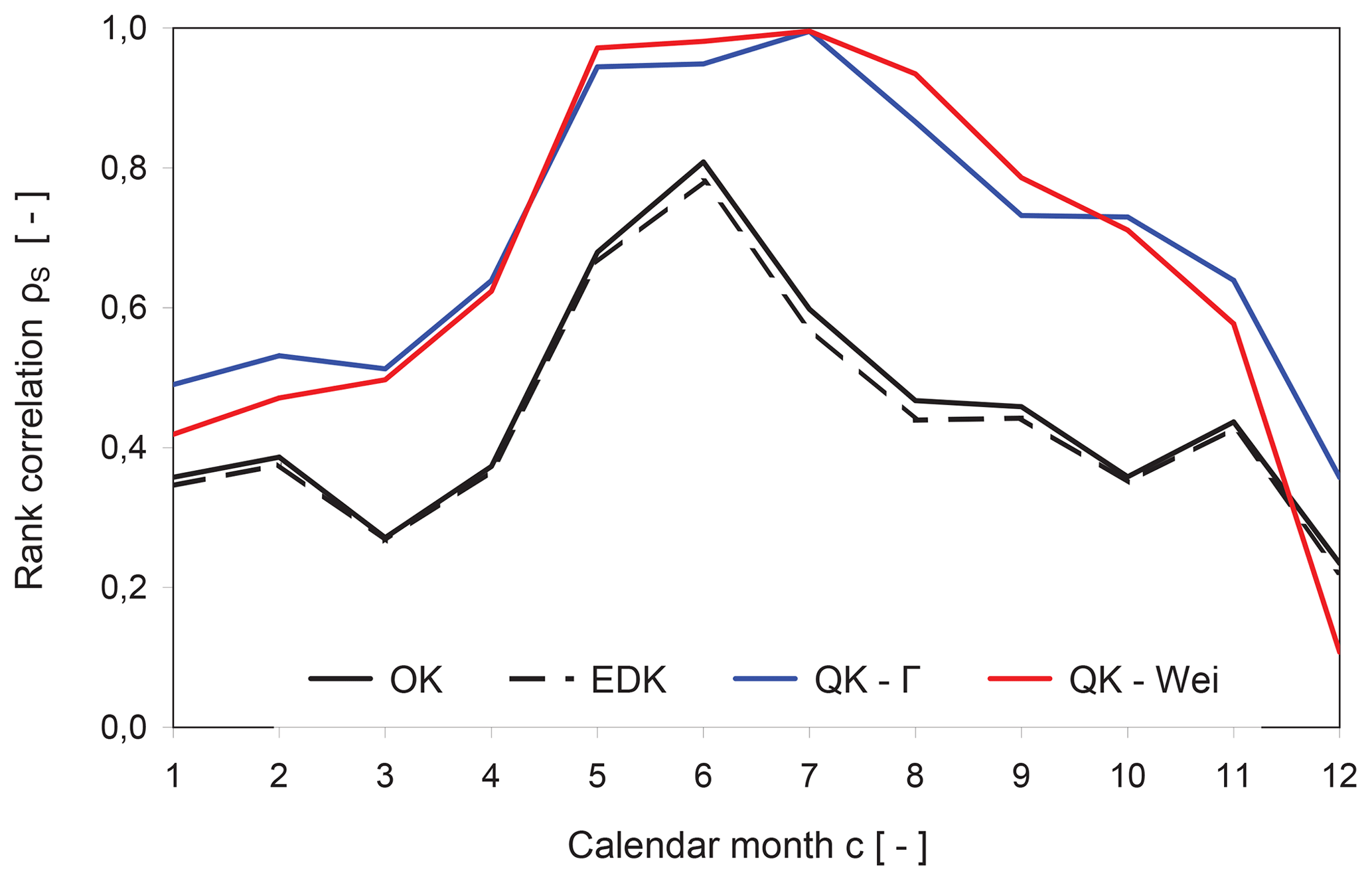
Figure 8Evolution of the Spearman rank correlation coefficient ρS between the estimator Z∗ and the standard deviation σK.
The rank correlation varies over the calendar months for all implemented interpolation methods and reach their seasonal maximums in June or July (Fig. 8), being characterized by a high dry ratio and low precipitation.
An improvement in the relationship between the estimator Z∗ and the associated standard deviation σK can be observed for QK-Γ and QK-Wei, exhibiting superior rank correlation coefficients for all calender months with the exception of QK-Wei in December (Fig. 8). QK-Γ deploys the strongest relation during the wetter months from October to March, while QK-Wei is superior from May to September. The resulting spread of the error distribution is increased by decreasing slopes of the theoretical cdfs (Eqs. 12 and 13) and vice versa. The slope is effectively the probability density function (pdf). Both selected theoretical distributions imply a monotonic decrease in their respective pdfs for small parameters, being typically encountered during the dry season, and evoke a higher spread of the error distribution for higher monthly precipitation. Thus, the almost perfect rank correlation ρS(c) of QK during the months of low precipitation can be explained. The rank correlation between the estimator and the standard deviation is weakened for the months with higher precipitation due to the departure from the strict monotonic decrease in the pdfs, which is induced by increasing distribution parameters.
The inferior correlation coefficients of OK and EDK are nearly congruent due to their inherent geostatistical definition: although the kriging weights are altered by the drift, they influence the linear estimator Z∗ and the standard deviation σK by the same extent. Therefore, the non-parametric Spearman descriptor hardly differentiates between OK and EDK.
3.2 Cross-validation of the estimator
The estimator from the cross-validation is evaluated by six objective functions: the Pearson correlation coefficient ρ, the Nash–Sutcliffe efficiency coefficient NSE (Nash and Sutcliffe, 1970), the overall bias B1 and the root mean square error (RMSE) are complemented by the temporal bias B2 and the spatial bias B3 (Bárdossy and Pegram, 2012), which are defined as
where J is the number of time steps, ni is the number of observation locations and ntot is the total number of cross-validated observations. Note that the cross-validation for only one time step (J=1) would yield the following relations: and B2=RMSE2.
3.2.1 Summary results
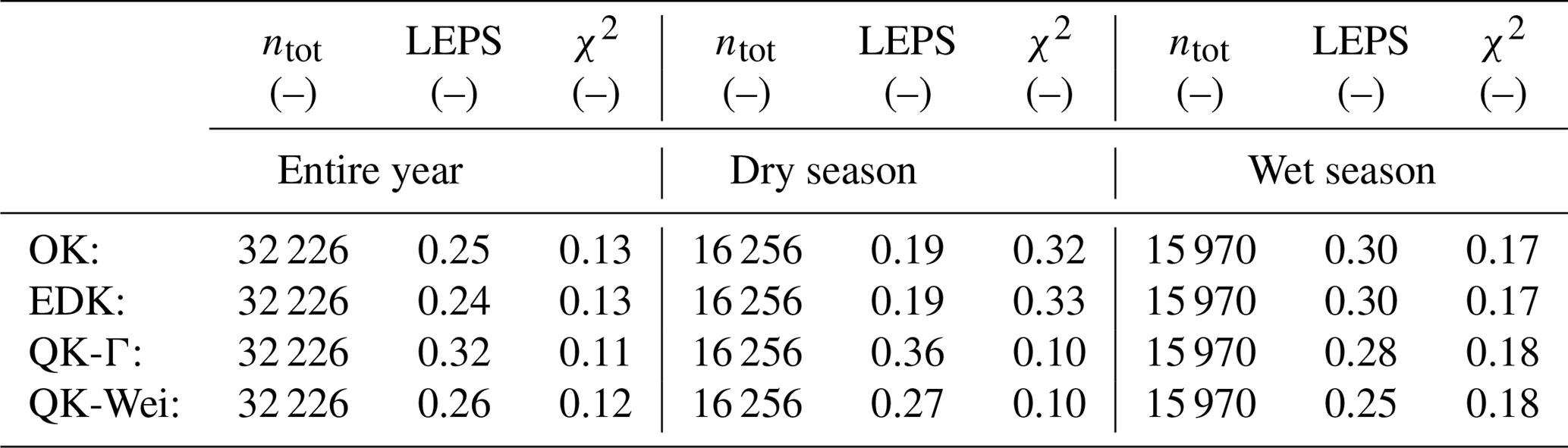
The overall values of the six objective functions from all 32 226 original observations, along with a separation into dry season (calender months: 4–9) and wet season (calender months: 1–3 and 10–12) are given in Table 1.
Table 1Summary results from the cross-validation of the estimator Z∗ for the 12 calender months of the entire year, and split into dry (calender months: 4–9) and wet (calender months: 1–3 and 10–12) season.


Figure 9Errors of the estimator Z∗(x125) at raingauge “Wilgervier”: evolution of temporal bias B2 over the study period (a) and smoothed distribution of the relative estimation error ϵr (b).
The total values of the correlation coefficient ρ, the NSE coefficient, the temporal bias B2 and the RMSE are better for QK-Γ and QK-Wei than for OK and EDK, evoking from a superior performance especially during the wet season when not many of many zero values are present (see Table 1).
Complementary, OK and EDK have superior values for the biases B1 and B3 as a result of the implicit definition as best linear and unbiased estimator. OK (and to some extent EDK) optimize the spatial bias B3 for a given month by adapting their global mean to the observed mean, according to Eq. (1) (Eq. 3). However, this evokes a systematic underestimation in regions of high precipitation and a systematic overestimation in regions of low precipitation. Therefore, a temporal bias B2 accumulates for a location, which consistently experiences extreme precipitation over time. Especially during the wet season, QK outperforms OK and EDK with respect to the temporal bias. The following investigations on raingauge “Wilgervier” exemplary serve as illustration for the evolution of a temporal bias.
3.2.2 Temporal bias at raingauge “Wilgervier”
Raingauge “Wilgervier” (i=125, see Fig. 3) records a relatively high monthly precipitation of 70.1 mm in average compared to the average monthly precipitation of 54.7 mm in the entire domain.
Table 2Summary results from the cross-validation of the estimation error for the entire year, and split into dry (calender months: 4–9) and wet (calender months: 1–3 and 10–12) season.
The evolution of the temporal bias B2 at raingauge “Wilgervier” is calculated from cross-validation according to Eq. 20 and illustrated in Fig. 9 (left). In addition, the relative estimation error ϵr is estimated from the 218 (out of the 264 possible) original observations at “Wilgervier”, being defined as
The 218 values of ϵr(x125) are smoothed by a Gaussian kernel with a defined range dG (=0.35). The distribution of the relative estimation errors should ideally be symmetrical around zero. However, the respective distributions are truncated due the confinement to for the variable of monthly precipitation. The smoothed distributions are factually a summary of the estimation errors and are illustrated in Fig. 9 (right).
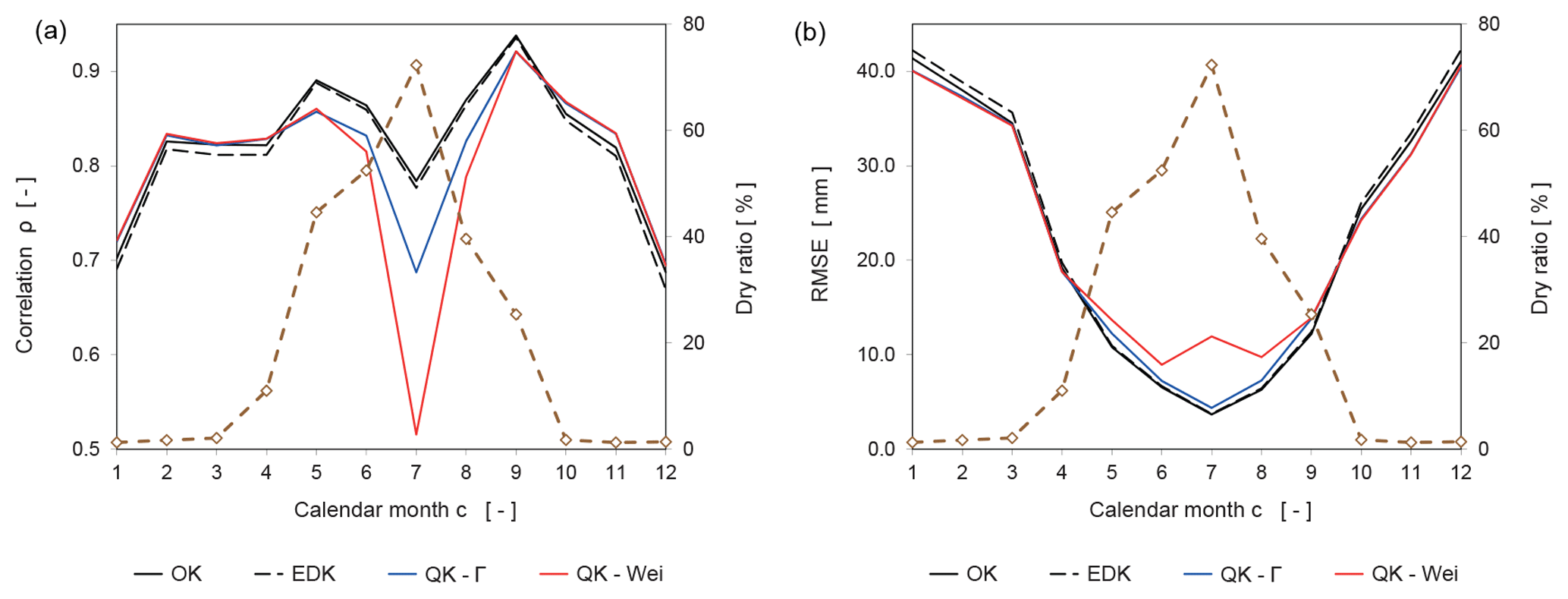
Figure 10Evolution of two objective functions for the estimator over the 12 calendar months: Correlation coefficient ρ (a) and RMSE (b). Note that the dry ratio (dashed brown line) is indicated as a percentage on the right axis.
OK displays the highest systematic underestimation over time (Fig. 9 left) and the relative estimation errors have a mode of −20 % (Fig. 9 right). EDK slightly improves the systematic bias of the interpolation, but the relative error distribution still possess a mode of −15 %. QK-Γ and QK-Wei can further improve the systematic underestimation over time and exhibit error distributions with modes of −12 %, and −10 % respectively.
Raingauge “Wilgervier” illustrates that OK and EDK might optimize the spatial bias (Table 1), but they are hampered to minimize the temporal bias in locations of extreme observations. QK, as a spatio-temporal interpolation method, is capable of reducing the temporal bias within regions of relatively high (or low) precipitation, which is potentially important for possible successive water balance considerations.
3.2.3 Cross-validation for different calendar months
The effects of the increased occurrence of zero-value observations on the Pearson correlation coefficient ρ (Eq. 17) and the RMSE (Eq. 22) is exemplary examined next. The respective values are calculated for each calender month from the cross-validation and are illustrated in Fig. 10 along with the dry ratio (Fig. 4).
QK-Γ and QK-Wei display improved values in comparison to OK and EDK for the two selected objective functions from October to March (Fig. 10). However, their performance deteriorates from May to September, when many zero-value observations are present, indicated by a dry ratio of at least 25 % or above. The correlation coefficient ρ plunges in July for both versions of QK (Fig. 10 left) and the respective RMSE shows a similar qualitative behavior (Fig. 10 right).
The performance of QK is considerably influenced by the dry ratio. The presence of many zero values in the data leads to very steep or nearly vertical theoretical cdfs, hampering the allocation of the quantiles to the respective precipitation values.
3.3 Cross-validation of the uncertainty
The estimated error distribution of the estimator Z∗(x) is described by the associated standard deviation σK(x) as a measure of associated uncertainty. The quality of the uncertainty from the cross-validation is assessed by two objective functions: the adapted linear error in the probability space LEPS (Ward and Folland, 1991) and a test on uniformity (Bárdossy and Li, 2008).
LEPS compares the values of the estimator and the observation z(xi,t) within the estimated cdf of the error distribution as
LEPS is defined on the interval [0,1]: low values indicate a higher probability for the observation to originate from the estimated probability density distribution and vice versa. The average over the differences of all observations ntot yields the overall LEPS value.
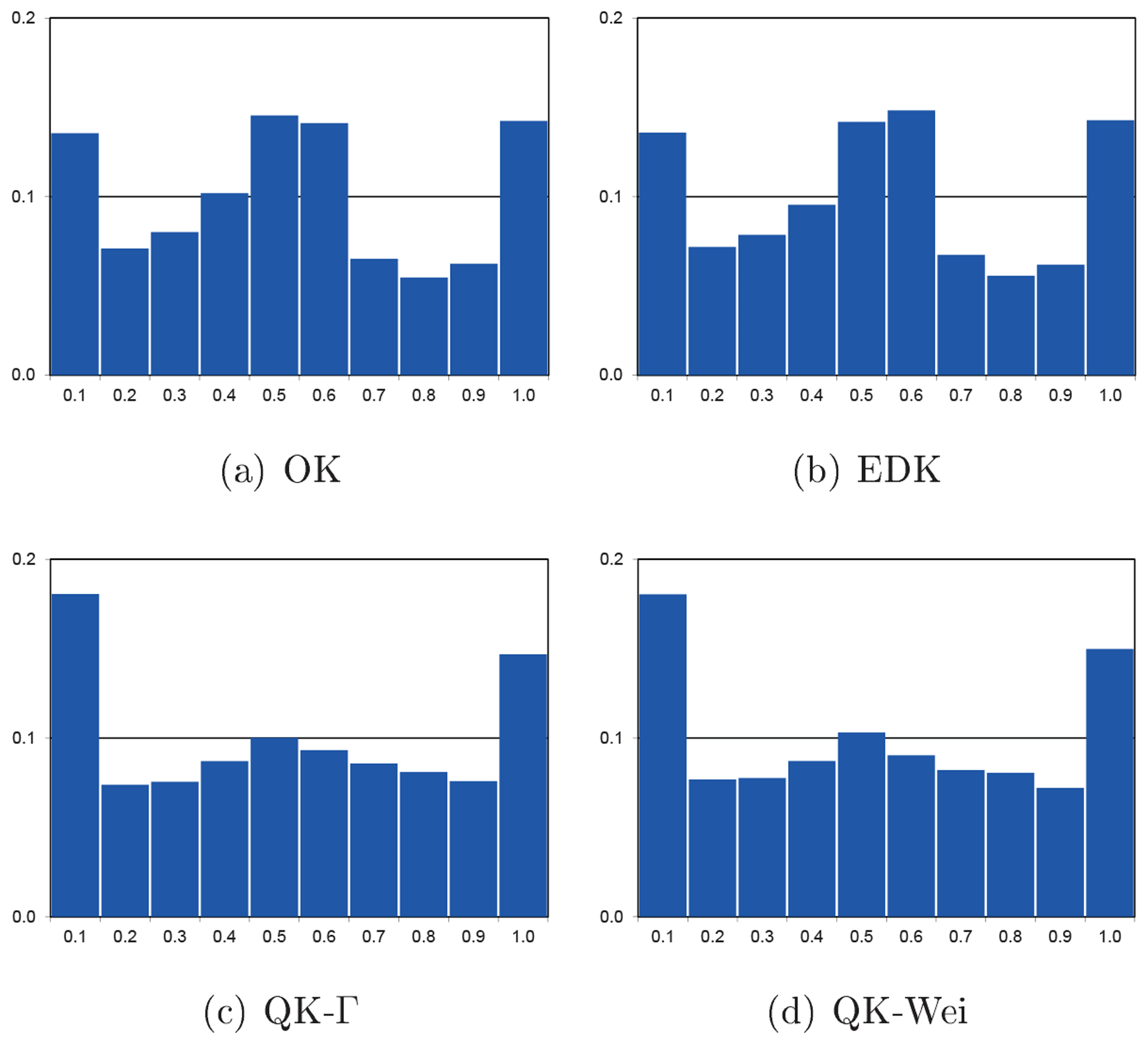
The test on uniformity verifies the estimated, conditional distribution by calculating its value for every original observation z(xi,t). The resulting values (or quantiles) should be uniformly distributed on the interval [0,1] (Bárdossy and Li, 2008). We defined 10 classes of equal width, which should have the same resulting relative frequency. The deviation from uniformity is quantified by the χ2- test variable as the sum of the relative squared differences between uniformity and empirical distribution, ranging from zero (perfect) to nine (improper).
3.3.1 Summary results
The values of the two objective functions from cross-validation of all 32 226 original observations of the entire year, and divided into dry (calender months: 4–9) and wet season (calender months: 1–3 and 10–12) are displayed in Table 2.
The best overall LEPS values are received from the traditional EDK and OK (Table 2). QK-Wei is superior to QK-Γ, but both versions of QK are displaying higher LEPS values than OK or EDK, originating from the dry season when many zero values are present in the data.
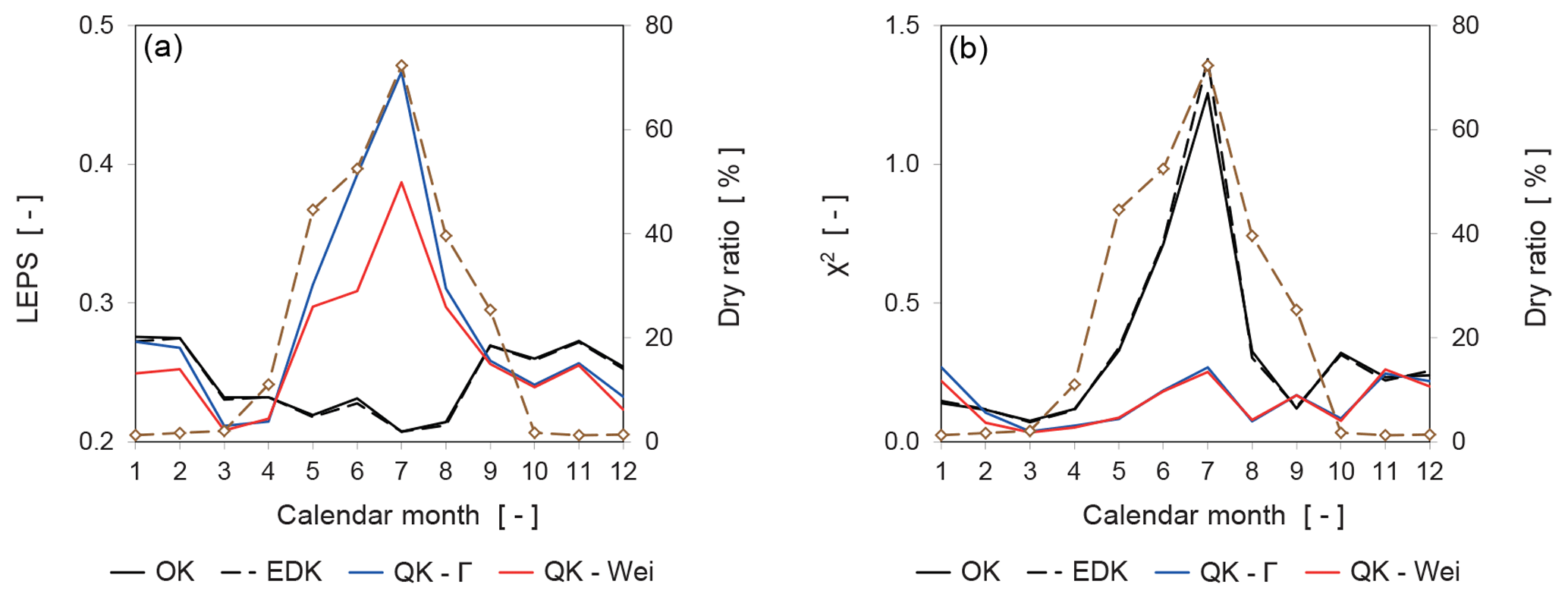
Figure 12Evolution of the two objective functions for the error distribution over 12 calendar months: LEPS (a) and χ2 (b). Note that the dry ratio (dashed brown line) is indicated as a percentage on the right axis.
However, the χ2-test variables (Table 2) exhibit a reverse hierarchy among the implemented interpolation methods: QK is superior during the dry season and similar during the wet season. The χ2-test variables should be read in conjunction with the corresponding histograms of the values (Fig. 11). Note that the outer classes of the histograms host all the observations z(xi,t), which are situated outside the estimated distribution. These classes exhibit the largest deviation from the ideal uniform distribution.
QK-Γ and QK-Wei provide in general a more uniform distribution of than OK and EDK (Table 2), which possess the same value of the χ2-test variable and similar histograms (Table 2 and Fig. 11) due to their implicit affinity in definition.
3.3.2 Cross-validation for different calendar months
The effect of many zero-value observations on the error distribution is investigated by the differentiation into calendar months. The objective functions are recalculated accordingly and illustrated in Fig. 12.
The temporal evolution of the LEPS values for the two versions of QK is influenced by the presence of many zero-value observations. QK-Γ and QK-Wei exhibit LEPS values superior to OK and EDK from September to April, characterized by a dry ratio of less than 26 % (Fig. 12, left). However, the performance of QK deteriorates from May to August when many zero-value observations are present. This dependence explains the overall inferior LEPS values for QK in Table 2. The LEPS values for OK and EDK are hardly influenced by the dry ratio (Fig. 12 left) and show a congruent behavior.
The temporal evolution of the χ2 test variable (Fig. 12 right) shows better values for QK-Γ and QK-Wei than for OK or EDK during most calender months. QK maintains a more uniform distribution of the values even for the months with a high dry ratio when OK and EDK deteriorate.
The cross-validation for the uncertainty suggests an improvement by QK under the prerequisite of a low dry ratio within the input data. This improvement is attributed to the wider range of the error distribution and the increased relation between the magnitude of the estimator and the spread of the distribution (see Sect. 3.1).
The geostatistical interpolation method of QK addresses the spatial non-stationarity of a variable of interest by its conversion into quantiles and defining distribution parameters. The spatial–temporal description of the variable by QK is a novelty in applied geostatistics and can be regarded as a temporal extension of probability kriging. Therefore, the proposed method could be extended to spatially aggregated variables of streamflows, requiring, however, further investigations. The proposed method accommodates skewed marginal distributions and converts them into an ideal Gaussian distribution prior to interpolation as a major theoretical advantage over the traditional OK or EDK. QK describes an asymmetrical distribution of the random variable Z(x) by the nonlinear estimator Z∗(x) and the estimation variance of the error. QK further establishes a relation between the magnitude of both descriptors.
The variable of monthly precipitation, observed at 226 raingauges over 264 consecutive time steps, serves as input data. We selected the two-parametric Γ distribution and Weibull distribution, because they are defined on the interval [0,∞] and are suitable to describe the variable of monthly precipitation. The selected distributions are fitted to the observations of a specific calendar month, implying an absence of temporal dependence between two sample members (e.g., between the monthly precipitation of December 2002 and December 2003). However, QK does accommodate temporal independence between consecutive observations, unlike existing spatio-temporal kriging methods. In general, other types of distributions, with a higher number of parameters could be selected, especially in case of other variables of interest. Finally, we used elevation as external drift, both for the interpolation of the parameters within QK as well as for the reference EDK.
The cross-validation of the estimator revealed an improvement for most of the selected objective functions. In particular, QK addresses the temporal bias, which remains unattended by the traditional geostatistical methods, which only optimize the mean spatial bias. In case of the estimator, QK-Γ performs slightly better than QK-Wei for most of the selected objective functions. The cross-validation of the associated uncertainty shows an improvement by QK in the description of the distribution of the estimation errors in comparison to the traditional geostatistical interpolation methods. However, its performance depends on the percentage of zero values in the input data and declines when many zero values are present. In general, QK-Wei shows a superior estimation of the associated uncertainty than QK-Γ.
Respective codes can be obtained from the corresponding author.
Precipitation and elevation data can be obtained from the respective sources mentioned in Sect. 2.3.1
HL and AB set up, collaborated and designed the study. HL performed the computational work and wrote the paper. AB and HL interpreted the results and replied to the comments from the reviewers.
The authors declare that they have no conflict of interest.
This research was executed at the Institute for Modeling Hydraulic and Environmental Systems of the University of Stuttgart.
This paper was edited by Sally Thompson and reviewed by Marc F. Muller and two anonymous referees.
Adhikary, P. P., Dash, C. J., Bej, R., and Chandrasekharan, H.: Indicator and probability kriging methods for delineating Cu, Fe, and Mn contamination in groundwater of Najafgarh Block, Delhi, India, Environ. Monit. Assess., 176, 663–676, https://doi.org/10.1007/s10661-010-1611-4, 2011. a
Ahmed, S. and deMarsily, G.: Comparison of geostatistical methods for estimating transmissivity using data on transmissivity and specific capacity, Water Resour. Res., 23, 1717–1737, 1987. a
Armstrong, M.: Basic Linear Geostatistics, Springer, available at: http://books.google.de/books?id=-9vp1lVuMCsC, Springer Berlin Heidelberg, 1998. a
Basistha, A., Arya, D. S., and Goel, N. K.: Spatial Distribution of Rainfall in Indian Himalayas – A Case Study of Uttarakhand Region, Water Resour. Manag., 22, 1325–1346, https://doi.org/10.1007/s11269-007-9228-2, 2008. a
Bourennane, H., King, D., and Couturier, A.: Comparison of kriging with external drift and simple linear regression for predicting soil horizon thickness with different sample densities, Geoderma, 97, 255–271, https://doi.org/10.1016/S0016-7061(00)00042-2, 2000. a
Bárdossy, A. and Li, J.: Geostatistical interpolation using copulas, Water Resour. Res., 44, 1–15, 2008. a, b
Bárdossy, A. and Pegram, G.: Interpolation of precipitation under topographic influence at different time scales, Water Resour. Res., 49, 4545–4565, https://doi.org/10.1002/wrcr.20307, 2012. a
Carr, J. R. and Mao, N.-H.: A general form of probability kriging for estimation of the indicator and uniform transforms, Math. Geol., 25, 425–438, https://doi.org/10.1007/BF00894777, 1993. a
Chilès, J.-P. and Delfiner, P.: Geostatistics: modeling spatial uncertainty, Wiley, New York, 1999. a
Cole, S. J. and Moore, R. J.: Hydrological modelling using raingauge- and radar-based estimators of areal rainfall, J. Hydrol., 358, 159–181, https://doi.org/10.1016/j.jhydrol.2008.05.025, 2008. a
DWA: Hydrological Information System (HIS), available at: http://www.dwa.gov.za/Hydrology/ (last access: 5 October 2008), 2008. a
Gabellani, S., Boni, G., Ferraris, L., von Hardenberg, J., and Provenzale, A.: Propagation of uncertainty from rainfall to runoff: A case study with a stochastic rainfall generator, Adv. Water Resour., 30, 2061–2071, https://doi.org/10.1016/j.advwatres.2006.11.015, 2007. a
Goovaerts, P.: Geostatistical approaches for incorporating elevation into the spatial interpolation of rainfall, J. Hydrol., 228, 113–129, https://doi.org/10.1016/S0022-1694(00)00144-X, 2000. a
Goovaerts, P., AvRuskin, G., Meliker, J., Slotnick, M., Jacquez, G., and Nriagu, J.: Geostatistical modeling of the spatial variability of arsenic in groundwater of southeast Michigan, Water Resour. Res., 41, w07013, https://doi.org/10.1029/2004WR003705, 2005. a
Journal, A. and Alabert, F.: Non-Gaussian data expansion in the Earth Sciences, Terra Nova, 1, 123–134, https://doi.org/10.1111/j.1365-3121.1989.tb00344.x, 1989. a
Journel, A. G.: Nonparametric estimation of spatial distributions, Journal of the International Association for Mathematical Geology, 15, 445–468, https://doi.org/10.1007/BF01031292, 1983. a
Kobold, M. and Sušelj, K.: Precipitation forecasts and their uncertainty as input into hydrological models, Hydrol. Earth Syst. Sci., 9, 322–332, https://doi.org/10.5194/hess-9-322-2005, 2005. a
Lebrenz, H. and Bárdossy, A.: Estimation of the Variogram Using Kendall's Tau for a Robust Geostatistical Interpolation, J. Hydrol. Eng., 22, 04017038, https://doi.org/10.1061/(ASCE)HE.1943-5584.0001568, 2017. a
Lee, J.-J., Jang, C.-S., Wang, S.-W., and Liu, C.-W.: Evaluation of potential health risk of arsenic-affected groundwater using indicator kriging and dose response model, Sci. Total Environ., 384, 151–162, https://doi.org/10.1016/j.scitotenv.2007.06.021, 2007. a
Lynch, S.: Development of a Raster Database of Annual, Monthly and Daily Rainfall for Southern Africa, Report 1156/1/03, Water Research Commission, Pretoria, RSA, 2004. a
Matheron, G.: Traité de Géostatistique Appliquée, Mémoires du Bureau de Recherches Géologiques et Minières, vol. I, p. 333, Paris, 1962. a
Matheron, G.: Les variables régionalisées et leur estimation: une application de la théorie des fonctions aléatoires aux sciences de la nature, PhD thesis, Université de Paris, Paris, 1965. a
Mitchell, T. D. and Jones, P. D.: An improved method of constructing a database of monthly climate observations and associated high-resolution grids, Int. J. Climatol., 25, 693–712, https://doi.org/10.1002/joc.1181, 2005. a
Mosthaf, T. and Bárdossy, A.: Regionalizing nonparametric models of precipitation amounts on different temporal scales, Hydrol. Earth Syst. Sci., 21, 2463–2481, https://doi.org/10.5194/hess-21-2463-2017, 2017. a
Motaghian, H. and Mohammadi, J.: Spatial Estimation of Saturated Hydraulic Conductivity from Terrain Attributes Using Regression, Kriging, and Artificial Neural Networks, Pedosphere, 21, 170–177, https://doi.org/10.1016/S1002-0160(11)60115-X, 2011. a
Moulin, L., Gaume, E., and Obled, C.: Uncertainties on mean areal precipitation: assessment and impact on streamflow simulations, Hydrol. Earth Syst. Sci., 13, 99–114, https://doi.org/10.5194/hess-13-99-2009, 2009. a
Nash, J. and Sutcliffe, J.: River flow forecasting through conceptual models part I – A discussion of principles, J. Hydrol., 10, 282–290, https://doi.org/10.1016/0022-1694(70)90255-6, 1970. a
Rosenblueth, E.: Point estimates for probability moments, P. Natl. Acad. Sci. USA, 72, 3812–3814, 1975. a
Snepvangers, J., Heuvelink, G., and Huisman, J.: Soil water content interpolation using spatio-temporal kriging with external drift, Geoderma, 112, 253–271, https://doi.org/10.1016/S0016-7061(02)00310-5, 2003. a
Syed, K. H., Goodrich, D. C., Myers, D. E., and Sorooshian, S.: Spatial characteristics of thunderstorm rainfall fields and their relation to runoff, J. Hydrol., 271, 1–21, https://doi.org/10.1016/S0022-1694(02)00311-6, 2003. a
USGS: NASA Shuttle Radar Topography Mission Global Version 2, SRTM Topography, United States Geological Survey, USGS EROS Data Center, 2003. a
van de Kassteele, J., Stein, A., Dekkers, A. L. M., and Velders, G. J. M.: External drift kriging of NOx concentrations with dispersion model output in a reduced air quality monitoring network, Environ. Ecol. Stat., 16, 321–339, https://doi.org/10.1007/s10651-007-0052-x, 2009. a
Vose, R. S., Schmoyer, R. L., Steurer, P. M., Peterson, T. C., Heim, R. R., Thomas, R. K., and Eischeid, J. K.: The Global Historical Climatology Network: Long-term monthly temperature, precipitation, sea-level pressure, and station pressure data, Rep. ornl/cdiac-53, Carbon Dioxide Inf. Anal. Cent., Oak Ridge Natl. Lab., Oak Ridge, TN, 25 pp., 1992. a
Ward, M. N. and Folland, C. K.: Prediction of seasonal rainfall in the north nordeste of Brazil using eigenvectors of sea-surface temperature, Int. J. Climatol., 11, 711–743, https://doi.org/10.1002/joc.3370110703, 1991. a
quantile kriging, providing an improved estimator and associated uncertainty. It can also host variables, which would not fulfill the implicit presumptions of the traditional geostatistical interpolation methods.