the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 19 Feb 2019
| 19 Feb 2019
Identifying rainfall-runoff events in discharge time series: a data-driven method based on information theory
Stephanie Thiesen
Paul Darscheid
Uwe Ehret
In this study, we propose a data-driven approach for automatically identifying rainfall-runoff events in discharge time series. The core of the concept is to construct and apply discrete multivariate probability distributions to obtain probabilistic predictions of each time step that is part of an event. The approach permits any data to serve as predictors, and it is non-parametric in the sense that it can handle any kind of relation between the predictor(s) and the target. Each choice of a particular predictor data set is equivalent to formulating a model hypothesis. Among competing models, the best is found by comparing their predictive power in a training data set with user-classified events. For evaluation, we use measures from information theory such as Shannon entropy and conditional entropy to select the best predictors and models and, additionally, measure the risk of overfitting via cross entropy and Kullback–Leibler divergence. As all these measures are expressed in “bit”, we can combine them to identify models with the best tradeoff between predictive power and robustness given the available data.
We applied the method to data from the Dornbirner Ach catchment in Austria, distinguishing three different model types: models relying on discharge data, models using both discharge and precipitation data, and recursive models, i.e., models using their own predictions of a previous time step as an additional predictor. In the case study, the additional use of precipitation reduced predictive uncertainty only by a small amount, likely because the information provided by precipitation is already contained in the discharge data. More generally, we found that the robustness of a model quickly dropped with the increase in the number of predictors used (an effect well known as the curse of dimensionality) such that, in the end, the best model was a recursive one applying four predictors (three standard and one recursive): discharge from two distinct time steps, the relative magnitude of discharge compared with all discharge values in a surrounding 65 h time window and event predictions from the previous time step. Applying the model reduced the uncertainty in event classification by 77.8 %, decreasing conditional entropy from 0.516 to 0.114 bits. To assess the quality of the proposed method, its results were binarized and validated through a holdout method and then compared to a physically based approach. The comparison showed similar behavior of both models (both with accuracy near 90 %), and the cross-validation reinforced the quality of the proposed model.
Given enough data to build data-driven models, their potential lies in the way they learn and exploit relations between data unconstrained by functional or parametric assumptions and choices. And, beyond that, the use of these models to reproduce a hydrologist's way of identifying rainfall-runoff events is just one of many potential applications.
- Article
(2109 KB) - Full-text XML
- BibTeX
- EndNote





Discharge time series are essential for various activities in hydrology and water resources management. In the words of Chow et al. (1988), “[…] the hydrograph is an integral expression of the physiographic and climatic characteristics that govern the relations between rainfall and runoff of a particular drainage basin.” Discharge time series are a fundamental component of hydrological learning and prediction, since they (i) are relatively easy to obtain, being available in high quality and from widespread and long-existing observation networks; (ii) carry robust and integral information about the catchment state; and (iii) are an important target quantity for hydrological prediction and decision-making.
Beyond their value in providing long-term averages aiding water balance considerations, the information they contain about limited periods of elevated discharge can be exploited for baseflow separation; water power planning; sizing of reservoirs and retention ponds; design of hydraulic structures such as bridges, dams or urban storm drainage systems; risk assessment of floods; and soil erosion. These periods, essentially characterized by rising (start), peak and recession (ending) points (Mei and Anagnostou, 2015), will hereafter simply be referred to as “events”. They can have many causes (rainfall, snowmelt, upstream reservoir operation, etc.) and equally as many characteristic durations, magnitudes and shapes. Interestingly, while for a trained hydrologist with a particular purpose in mind, it is usually straightforward to identify such events in a time series, it is hard to identify them automatically based on a set of rigid criteria. One reason for this is that the set of criteria for discerning events from non-events typically comprises both global and local aspects, i.e., some aspects relate to properties of the entire time series and some to properties in time windows. And to make things worse, the relative importance of these criteria can vary over time, and they strongly depend on user requirements, hydroclimate and catchment properties.
So why not stick to manual event detection? Its obvious drawbacks are that it is cumbersome, subject to handling errors and hard to reproduce, especially when working with long-term data. As a consequence, many methods for objective and automatized event detection have been suggested. The baseflow separation, and consequently the event identification (since the separation allows the identification of the start and end time of the events), has a long history of development. Theoretical and empirical methods for determining baseflow are discussed since 1893, as presented in Hoyt et al. (1936). One of the oldest techniques according to Chow et al. (1988) dates back to the early 1930s, with the normal depletion curve from Horton (1933). As stated by Hall (1968), fairly complete discussions of baseflow equations, mathematical derivations and applications were already present in the 1960s. In the last 2 decades, more recent techniques embracing a multitude of approaches (graphical-, theoretical-, mathematical-, empirical-, physical- and data-based) aim to automate the separation.
Ehret and Zehe (2011) and Seibert et al. (2016) applied a simple discharge threshold approach with partly unsatisfactory results; Merz et al. (2006) introduced an iterative approach for event identification based on the comparison of direct runoff and a threshold. Merz and Blöschl (2009) expanded the concept to analyze runoff coefficients and applied it to a large set of catchments. Blume et al. (2007) developed the “constant k” method for baseflow separation, employing a gradient-based search for the end of event discharge. Koskelo et al. (2012) presented the physically based “sliding average with rain record” – SARR – method for baseflow separation in small watersheds based on precipitation and quick-flow response. Mei and Anagnostou (2015) suggested a physically based approach for combined event detection and baseflow separation, which provides event start, peak and end times.
While all of these methods have the advantage of being objective and automatable, they suffer from limited generality. The reason is that each of them contains some kind of conceptualized, fixed relation between input and output. Even though this relation can be customized to a particular application by adapting parameters, it remains to a certain degree invariant. In particular, each method requires an invariant set of input data, and sometimes it is constrained to a specific scale, which limits its application to specific cases and to where these data are available.
With the rapidly increasing availability of observation data, computer storage and processing power, data-based models have become increasingly popular as an addition or alternative to established modeling approaches in hydrology and hydraulics (Solomatine and Ostfeld, 2008). According to Solomatine and Ostfeld (2008) and Solomatine et al. (2009), they have the advantage of not requiring detailed consideration of physical processes (or any kind of a priori known relation between model input and output); instead, they infer these relations from data, which however requires that there are enough data to learn from. Of course, including a priori known relations among data into models is an advantage as long as we can assure that they really apply. However, when facing undetermined problems, i.e., for cases where system configuration, initial and boundary conditions are not well known, applying these relations may be over-constraining, which may lead to biased and/or overconfident predictions. Predictions based on probabilistic models that learn relations among data directly from the data, with few or no prior assumptions about the nature of these relations, are less bias-prone (because there are no prior assumptions potentially obstructing convergence towards observed mean behavior) and are less likely to be overconfident compared to established models (because applying deterministic models is still standard hydrological practice, and they are overconfident in all but the very few cases of perfect models). This applies if there are at least sufficient data to learn from, appropriate binning choices are made (see the related discussion in Sect. 2.2) and the application remains within the domain of the data that was used for learning.
In the context of data-based modeling in hydrology, concepts and measures from information theory are becoming increasingly popular for describing and inferring relations among data (Liu et al., 2016), quantifying uncertainty and evaluating model performance (Chapman, 1986; Liu et al., 2016), estimating information flows (Weijs, 2011; Darscheid, 2017), analyzing spatio-temporal variability in precipitation data (Mishra et al., 2009; Brunsell, 2010), describing catchment flow (Pechlivanidis et al., 2016), and measuring the quantity and quality of information in hydrological models (Nearing and Gupta, 2017).
In this study, we describe and test a data-driven approach for event detection formulated in terms of information theory, showing that its potential goes beyond event classification, since it enables the identification of the drivers of the classification, the choice of the most suitable model for an available data set, the quantification of minimal data requirements, the automatic reproduction classifications for database generation and the handling of any kind of relation between the data. The method is presented in Sect. 2. In Sect. 3, we describe two test applications with data from the Dornbirner Ach catchment in Austria. We present the results in Sect. 4 and draw conclusions in Sect. 5.
The core of the information theory method (ITM) is straightforward and generally applicable; its main steps are shown in Fig. 1 and will be explained in the following.
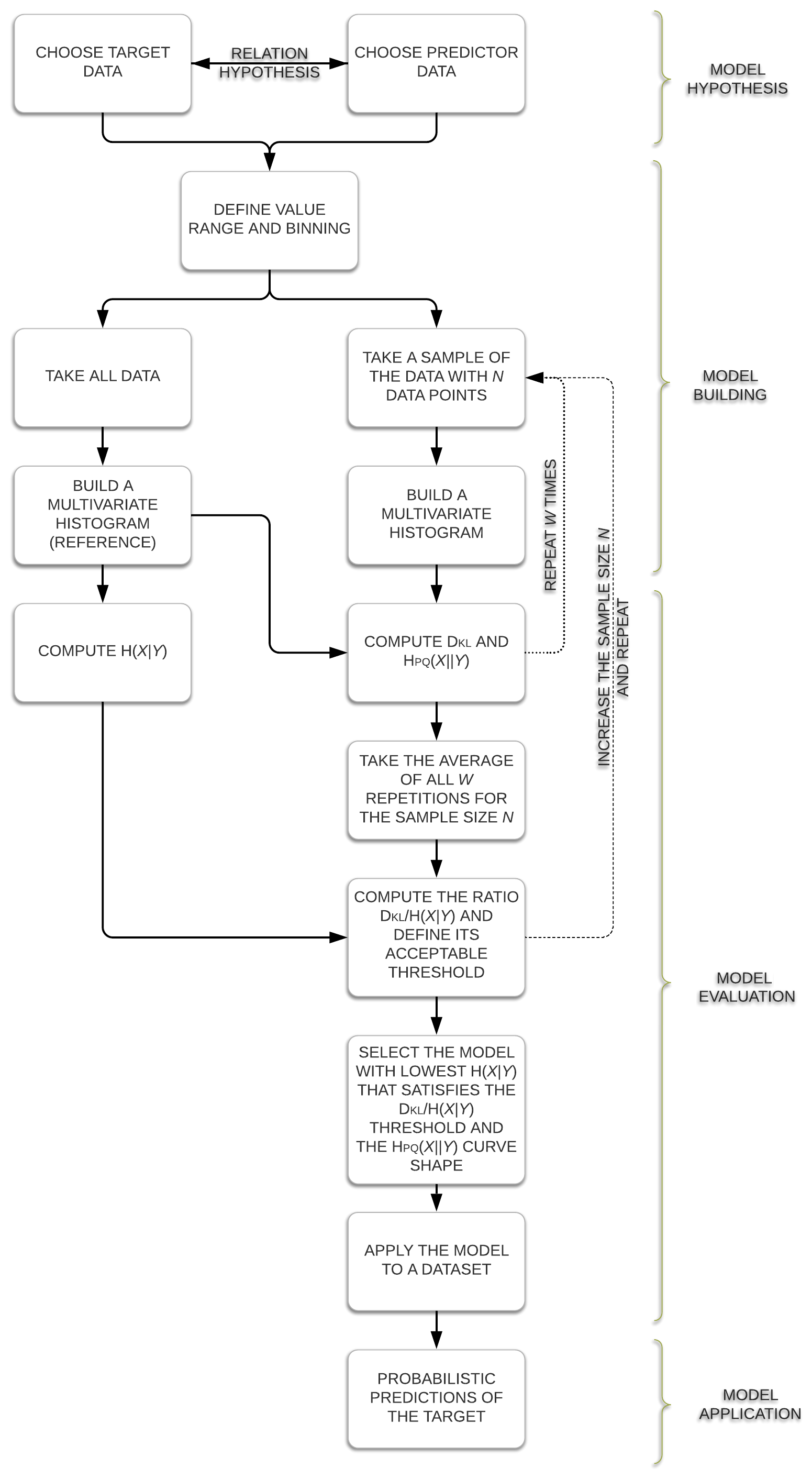
2.1 Model hypothesis step
The process starts by selecting the target (what we want to predict) and the predictor data (that potentially contain information about the target). Choosing the predictors constitutes the first and most important model hypothesis, and there are almost no restrictions to this choice. They can be any kind of observational or other data, transformed by the user or not; they can be part of the target data set themselves, e.g., time lagged or space shifted; and they can even be the output of another model. The second choice and model hypothesis is the mapping between items in the target and the predictor data set, i.e., the relation hypothesis. It is important for the later construction of conditional histograms that a 1 : 1 mapping exists between target and predictor data, i.e., one particular value of the target is related to one particular value of predictor (in contrast to 1 : n or n : m relationships). Often, the mapping relation is established by equality in time.
2.2 Model building step
The next step is the first part of model building. It consists of choosing the value range and binning strategy for target and predictor data. These choices are important, as they will frame the estimated multivariate probability mass functions (PMFs) constituting the model and directly influence the statistics we compute from them for evaluation. Generally, these choices are subjective and reflect user-specific requirements and should be made while taking into consideration data precision and distribution, the size of the available data sets, and required resolution of the output. According to Gong et al. (2014), when constructing probability density functions (PDFs) from data via the simple bin-counting method, “[...] too small a bin width may lead to a histogram that is too rough an approximation of the underlying distribution, while an overly large bin width may result in a histogram that is overly smooth compared to the true PDF.” Gong et al. (2014) also discussed the selection of an optimal bin width by balancing bias and variance of the estimated PDF. Pechlivanidis et al. (2016) investigated the effect of bin resolution on the calculation of Shannon entropy and recommended that bin width should not be less than the precision of the data. Also, while equidistant bins have the advantage of being simple and computationally efficient (Ruddell and Kumar, 2009), hybrid alternatives can overcome weaknesses of conventional binning methods to achieve a better representation of the full range of data (Pechlivanidis et al., 2016).
With the binning strategy fixed, the last part of the model building is to construct a multivariate PMF from all predictors and related target data. The PMF dimension equals the number of predictors plus one (the target), and the way probability mass is distributed within it is a direct representation of the nature and strength of the relationship between the predictors and the target as contained in the data. Application of this kind of model for a given set of predictor values is straightforward; we simply extract the related conditional PMF (or PDF) of the target, which, under the assumption of system stationarity, is a probabilistic prediction of the target value.
If the system is non-stationary, e.g., when system properties change with time, the inconsistency between the learning and the prediction situation will result in additional predictive uncertainty. The problems associated with predictions of non-stationary systems apply to all modeling approaches. If a stable trend can be identified, a possible countermeasure is to learn and predict detrended data and then reimpose the trend in a post-processing step.
2.3 Model evaluation step
2.3.1 Information theory – measures
In order to evaluate the usefulness of a model, we apply concepts from information theory to select the best predictors (the drivers of the classification) and validate the model. With this in mind, this section provides a brief description of the information theory concepts and measures applied in this study. The section is based on Cover and Thomas (2006), which we recommend for a more detailed introduction to the concepts of information theory. Complementarily, for specific applications to investigate hydrological data series, we refer the reader to Darscheid (2017).
Entropy can be seen as a measure of the uncertainty of a random variable; it is a measure of the amount of information required on average to describe a random variable (Cover and Thomas, 2006). Let X be a discrete random variable with alphabet χ and probability mass function p(x), x ∈ χ. Then, the Shannon entropy H(X) of a discrete random variable X is defined by
If the logarithm is taken to base two, an intuitive interpretation of entropy is the following: given prior knowledge of a distribution, how many binary (yes or no) questions need to be asked on average until a value randomly drawn from this distribution is identified?
We can describe the conditional entropy as the Shannon entropy of a random variable conditional on the (prior) knowledge of another random variable. The conditional entropy H(X|Y) of a pair of discrete random variables (X, Y) is defined as
The reduction in uncertainty due to another random variable is called mutual information I(X,Y), which is equal to H(X)−H(X|Y). In the study, both measures, Shannon entropy and conditional entropy, are used to quantify the uncertainty of the models (univariate and multivariate probability distributions, respectively). The first is calculated as a reference and measures the uncertainty of the target data set. The latter is applied to the probability distributions of the target conditional on predictor(s), and it corroborates to select the more informative predictors, i.e., the ones which lead to the most significant reduction of uncertainty of the target.
It is also possible to compare two probability distributions p and q. For measuring the statistical “distance” between the distributions p and q, it is common to use relative entropy, also known as Kullback–Leibler divergence DKL(p||q), which is defined as
The Kullback–Leibler divergence is also a measure of the inefficiency of assuming that the distribution is q when the true distribution is p (Cover and Thomas, 2006). The Shannon entropy H(p) of the true distribution p plus the Kullback–Leibler divergence DKL(p||q) of p with respect to q is called cross entropy Hpq(X||Y). In the study, we use these related measures to validate the models and to avoid overfitting by measuring the additional uncertainty of a model if it is not based on the full data set p but is only based on a sample q thereof.
Note that the uncertainty measured by Eqs. (1) to (3) depends only on event probabilities, not on their values. This is convenient, as it allows joint treatment of many different sources and types of data in a single framework.
2.3.2 Information theory – model evaluation
As a benchmark, we can start with the case where no predictor is available, but only the unconditional probability distribution of the target is known. As seen in Eq. (1), the associated predictive uncertainty can be measured by the Shannon entropy H(X) of the distribution (where X indicates the target). If we introduce a predictor and know its value in a particular situation a priori, predictive uncertainty is the entropy of the conditional probability function of the target given the particular predictor value. Conditional entropy H(X|Y), where Y indicates the predictor(s), is then simply the probability-weighted sum of entropies of all conditional PMFs. Conditional entropy, like mutual information, is a generic measure of statistical dependence between variables (Sharma and Mehrotra, 2014), which we can use to compare competing model hypotheses and select the best among them.
Obviously, advantages of setting up data-driven models in the described way are that it involves very few assumptions and that it is straightforward when formulating a large number of alternative model hypotheses. However, there is an important aspect we need to consider: from the information inequality, we know that conditional entropy is always less than or equal to the Shannon entropy of the target (Cover and Thomas, 2006). In other words, information never hurts, and consequently adding more predictors will always either improve or at the least not worsen results. In the extreme, given enough predictors and applying a very refined binning scheme, a model can potentially yield perfect predictions if applied to the learning data set. However, besides the higher computational effort, in this situation, the curse of dimensionality (Bellman, 1957) occurs, which “covers various effects and difficulties arising from the increasing number of dimensions in a mathematical space for which only a limited number of data points are available” (Darscheid, 2017). This means that with each predictor added to the model, the dimension of the conditional target–predictor PMF will increase by 1, but its volume will increase exponentially. For example, if the target PMF is covered by two bins and each predictor by 100, then a single, double and triple predictor model will consist of 200, 20 000 and 2 000 000 bins, respectively. Clearly, we will need a much larger data set to populate the PMF mentioned last than the first. This also means that increasing the number of predictors for a fixed number of available data increases the risk of creating an overfitted or non-robust model in the sense that it will become more and more sensitive to the absence or presence of each particular data point. Models overfitted to a particular data set are less likely to produce good results when applied to other data sets than robust models, which capture the essentials of the data relation without getting lost in detail.
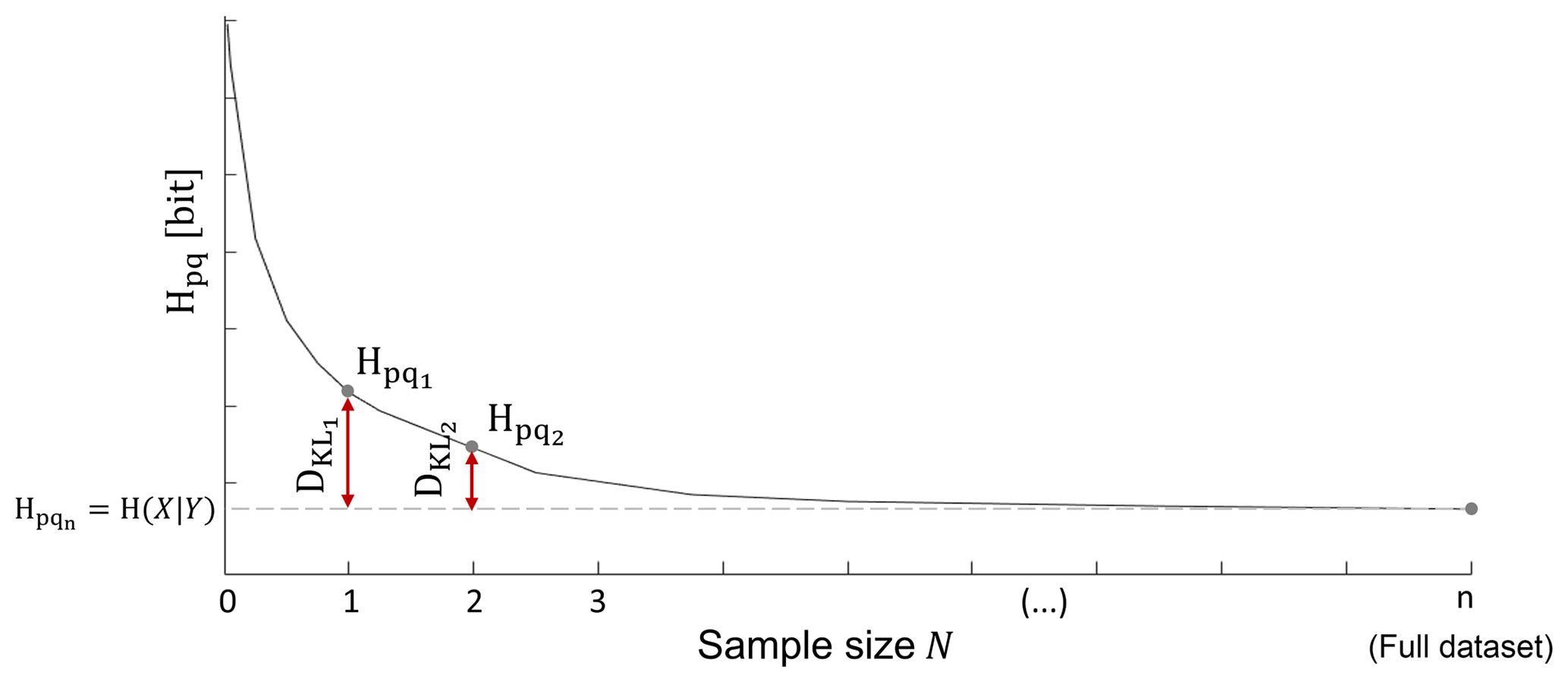
Figure 2Investigating the effect of sample size through cross entropy and Kullback–Leibler divergence.
We consider this effect with a resampling approach: from the available data set, we take samples of various sizes and construct the model from each sample (see repetition statement regarding N in Fig. 1). Obviously, since the model was built from just a sample, it will not reflect the target–predictor relation as well as a model constructed from the entire data set. It has been shown (Cover and Thomas, 2006; Darscheid, 2017) that the total uncertainty of such an imperfect model is the sum of two components: the conditional entropy H(X|Y) of the “perfect” model constructed from all data and the Kullback–Leibler divergence DKL between the sample-based and the perfect model. In this sense, DKL quantifies the additional uncertainty due to the use of an imperfect model. For a given model (selection of target and predictors), the first summand is independent of the sample size, as it is calculated from the full data set, but the second summand varies: the smaller the sample, the higher DKL. Another important aspect of DKL is that for a fixed amount of data, it strongly increases with the dimension of the related PMF, in other words, it is a measure of the impact of the curse of dimensionality. In information terms, the sum of conditional entropy and Kullback–Leibler divergence is referred to as cross entropy Hpq(X||Y). A typical example of cross entropy as a function of sample size is, for a single model, shown in Fig. 2.
The curve represents the mean of several repetitions, which were randomly taken with replacement among these repetitions. Note that, comparable to the Monte Carlo cross-validation, the analysis presented in Fig. 2 summarizes a large number of training and testing splits performed repeatedly, and, in addition, were also performed in different split proportions (subsets of various sizes). The difference here is that, in contrast to a standard split where data sets for training and testing are mutually exclusive, we build the model in the training set and apply it in the full data set, where one part of the data has not been seen yet and another part has. In other words, we use the training subsets for building the model (a supervised learning approach), and the resulting model is then applied to and evaluated on the full data set. If, on the one hand, the use of the full data set for the application includes data of the training set, on the other hand, the procedure favors the comparison of the results always with the same model. Thus, the stated procedure allows a robust and holistic analysis, in the sense that it works with the mean of W repetition for each subset and compares different sizes of training subset with a unique reference, the model built from the full data set.
Particularly, Fig. 2 shows that for small sample sizes, DKL is the main contributor to total uncertainty, but when the sample approaches the size of the full data set, it disappears, and total uncertainty equals conditional entropy. From the shape of the curve in Fig. 2 we can also infer whether the available data are sufficient to support the model; when DKL approaches zero (cross entropy approaches its minimum), this indicates that the model can be robustly estimated from the data, or, in other words, the sample size is enough to represent the full data set. In an objective manner, we can also do a complementary analysis by calculating the ratio DKL∕H(X|Y), which is a measure of the relative contribution of DKL to total uncertainty. We can then compare this ratio to a defined tolerance limit (e.g., 5 %) to find the minimally required sample size.
Another application for Fig. 2 is to use these kinds of plots to select the best among competing models with different numbers of predictors. Typically, for small sample sizes, simple models will outperform multi-predictor models, as the latter will be hit harder by the curse of dimensionality; but with increasing data availability, this effect will vanish, and models incorporating more sources of information will be rewarded.
In order to reduce the effect of chance when taking random samples, we repeat the described resampling and evaluation procedure many times for each sample size (see repetition statement W in Fig. 1) and take the average of the resulting DKL's and Hpq's. Based on these averaged results, we can identify the best model for a set of available data.
The proposed cross entropy curve contains a joint visualization of model analysis and model evaluation and, at the same time, provides the opportunity to compare models with different numbers of predictors, being a support tool to decide, for a given amount of data, which number of predictors is optimal in the sense of avoiding both ignoring the available information (by choosing too few predictors) and overfitting (by choosing too many predictors). And since it incorporates a sort of cross-validation in its construction, one of the advantages of this approach is that it avoids splitting the available data into a training and a testing set. Instead, it makes use of all available data for learning and provides measures of model performance across a range of sample sizes.
2.4 Model application step
Once a model has been selected, the ITM application is straightforward; from the multivariate PMF that represents the model, we simply extract the conditional PMF of the target for a given set of predictor values. The model returns a probabilistic representation of the target value. If the model was trained on all available data, and is applied within the domain of these data, the predictions will be unbiased and will be neither overconfident nor underconfident. If instead a model using deterministic functions is trained and applied in the same manner, the resulting single-value predictions may also be unbiased, but due to their single-value nature they will surely be overconfident.
For application in a new time series, if its conditions are outside of the range of the empirical PMF or if they are within the range but have never been observed in the training data set, the predictive distribution of the target (event yes or no) will be empty and the model will not provide a prediction. Several methods exist to guarantee a model answer, however they come with the cost of reduced precision. The solutions range from (i) coarse graining, where the PMF can be rebuilt with fewer, wider bins and an extension of the range until the model provides an answer to the predictive setting, as have been proposed by Darbellay and Vajda (1999), Knuth (2013) and Pechlivanidis et al. (2016), to (ii) gap filling, where the binning is maintained and the empty bins are filled with non-zero values based on a reasonable assumption. Gap-filling approaches comprise adding one counter to each zero-probability bin of the sample histogram, adding a small probability to the sample PDF, smoothing methods such as kernel density smoothing (Blower and Kelsall, 2002; Simonoff, 1996) or Bayesian approaches based on the Dirichlet and multinomial distribution or a maximum-entropy method recently suggested by Darscheid et al. (2018), the latter being applied in the present study.
In this section, we describe the hydroclimatic properties of the data and the two performed applications. For demonstration purposes, the first test application was developed according to the Sect. 2 in order to explain which additional predictors we derived from the raw data and their related binning and to present our strategy for the model setup, classification and evaluation. For benchmarking purposes, the second application compares the proposed data-driven approach (ITM) with the physically based approach proposed by Mei and Anagnostou (2015), the characteristic point method (CPM), and applies the holdout method (splitting the data set into training and testing set) for the cross-validation analysis.
3.1 Data and site properties
We used quality-controlled hourly discharge and precipitation observations from a 9-year period (31 October 1996–1 November 2005, 78 912 time steps). Discharge data are from the gauge Hoher Steg, which is located at the outlet of the 113 km2 Alpine catchment of the Dornbirner Ach in northwestern Austria (GMT+1). Precipitation data are from the station Ebnit located within the catchment.
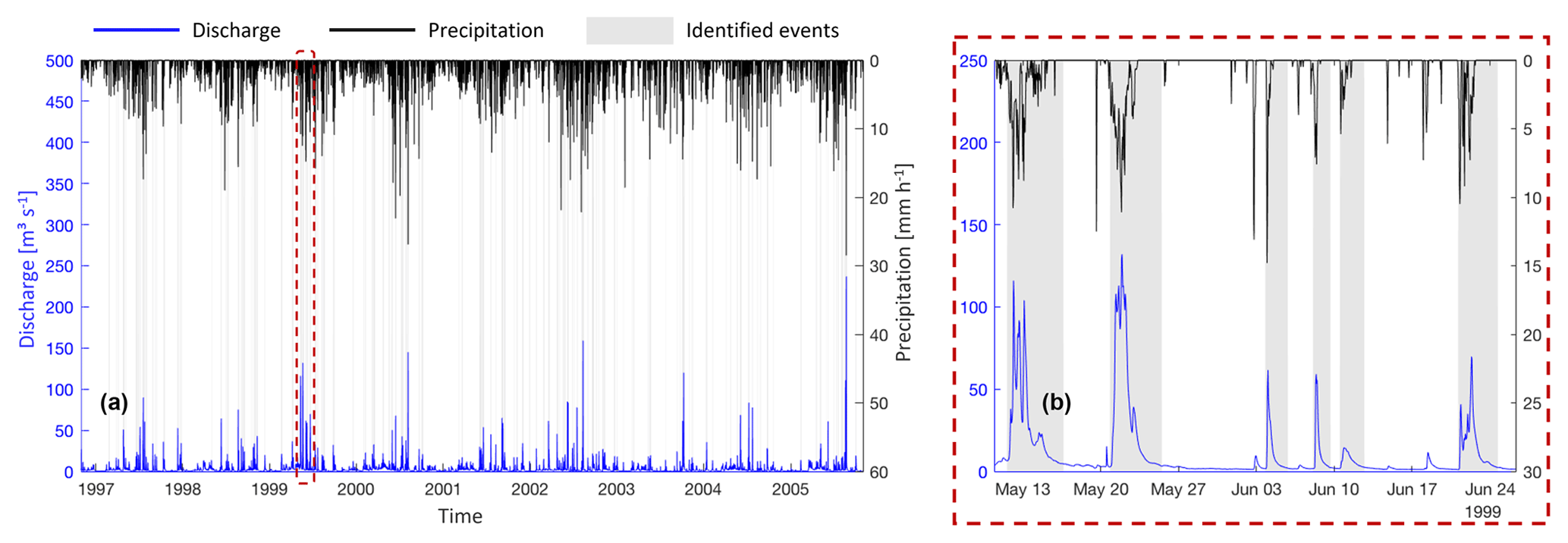
Figure 3Input data of discharge, precipitation and user-based event classification. Overview of the time series (a) and detailed view (b).
For the available period, we manually identified hydrological events by visual inspection of the discharge time series. To guide this process, we used a broad event definition, which can be summarized as follows: “an event is a coherent period of elevated discharge compared to the discharge immediately before and after and/or a coherent period of high discharge compared to the data of the entire time series.” We suggest that this is a typical definition if the goal is to identify events for hydrological process studies such as analysis of rainfall-runoff coefficients, baseflow separation or recession analysis. Based on this definition, we classified each time step of the time series as either being part of an event (value 1) or not (value 0). Altogether, we identified 177 individual events covering 9092 time steps, which is 11.5 % of the time series. For the available 9-year period, the maximum precipitation is 28.5 mm h−1, and the maximum and minimum discharge values are 237.0 and 0.037 m3 s−1, respectively. A preliminary analysis revealed that all times with discharge exceeding 15.2 m3 s−1 were classified as an event, and all times with discharge below 0.287 m3 s−1 were always classified as a non-event.
Both the input data and the event classification are shown in Fig. 3.
3.2 Application I – ITM
3.2.1 Predictor data and binning
Since we wanted to build and test a large range of models, we not only applied the raw observations of discharge and precipitation but also derived new data sets. The target and all predictor data sets with the related binning choices are listed in Table 1; additionally, the predictors are explained in the text below. For reasons of comparability, we applied uniform binning (fixed-width interval partitions) to all data used in the study, except for discharge; here we grouped all values exceeding 15.2 m3 s−1 (the threshold beyond which an event occurred for sure) into one bin to increase computational efficiency. For each data type, we selected the bin range to cover the range of observed data and chose the number of bins with the objective of maintaining the overall shape of the distributions with the least number of bins.
Table 1Target and predictors – characterization and binning strategy.

* Bins identified by their central values [leftmost center value : step : rightmost center value].
Discharge Q (m3 s−1)
This is the discharge as measured at Hoher Steg. In order to predict an event at time step t, we tested discharge at the same time step as a predictor, Q(t), and at time steps before and after t, such as Q(t−2), Q(t−1), Q(t+1), and Q(t+2).
Natural logarithm of discharge ln Q (ln(m3 s−1))
We also used a log transformation of discharge to evaluate whether this non-linear conversion preserved more information in Q when mapped into the binning scheme than the raw values. Note that the same effect could also be achieved by a logarithmic binning strategy, but as mentioned we decided to maintain the same binning scheme for reasons of comparability. As for Q, we also applied the log transformation to time-shifted data.
Relative magnitude of discharge QRM (–)
This is a local identifier of discharge magnitude at time t in relation to its neighbors within a time window. For each time step, we normalized discharge into the range [0, 1] using Eq. (4), where Qmax is the largest value of Q within the window and Qmin is the smallest:
A value of QRM=0 indicates that Q(t) is the smallest discharge within the analyzed window, and a value of QRM=1 indicates that it is the largest. We calculated these values for many window sizes and for windows with the time step under consideration in the center (QRMC), at the right end (QRMR) and at the left end (QRML) of the window. The best results were obtained for a time-centered window of 65 h. For further details see Sect. 3.2.2.
Slope of discharge Qslope (m3 s−1 h−1)
This is the local inclination of the hydrograph. This predictor was created to take into consideration the rate and direction of discharge changes. We calculated both the slope from the previous to the current time step applying Eq. (5) and the slope from the current to the next time step applying Eq. (6), where positive values always indicate rising discharge:
Precipitation P (mm h−1)
This is the precipitation as measured at Ebnit.
Model-based event probability ep (–)
In general, information about a target of interest can be encoded in related data such as the predictors introduced above, but it can also be encoded in the ordering of data. This is the case if the processes that are shaping the target exhibit some kind of temporal memory or spatial coherence. For example, the chance of a particular time step to be classified as being part of an event increases if the discharge is on the rise, and it declines if the discharge declines. We can incorporate this information by adding to the predictors discharge from increasingly distant time steps, but this comes at the price of a rapidly increasing impact of the curse of dimensionality. To mitigate this effect, we can use sequential or recursive modeling approaches; in a first step, we build a model using a set of predictors and apply it to predict the target. In a next step, we use this prediction as a new, model-derived predictor, combine it with other predictors in a second model, use it to make a second prediction of the target and so forth. Each time we map information from the multi-dimensional set of predictors onto the one-dimensional model output, we compress data and reduce dimensionality while hoping to preserve most of the information contained in the predictors. Of course, if we apply such a recursive scheme and want to avoid iterations, we need to avoid circular references, i.e., the output of the first model must not depend on the output of the second. In our application, we assured this by using the output from the first model at time step t−1 as a predictor in the second model to make a prediction at time step t. Comparable to a Markov model, this kind of predictor helps the model to better stick to a classification after a transition from event to non-event or vice versa.
3.2.2 Selecting the optimal window size for the QRM predictor
To select the most informative window size when using relative magnitude of discharge as a predictor, we calculated conditional entropy of the target given discharge and the QRMC, QRML and QRMR predictors for a range of window sizes on the full data set. The definition of the window sizes for the different window types and the conditional entropies are shown in Fig. 4.
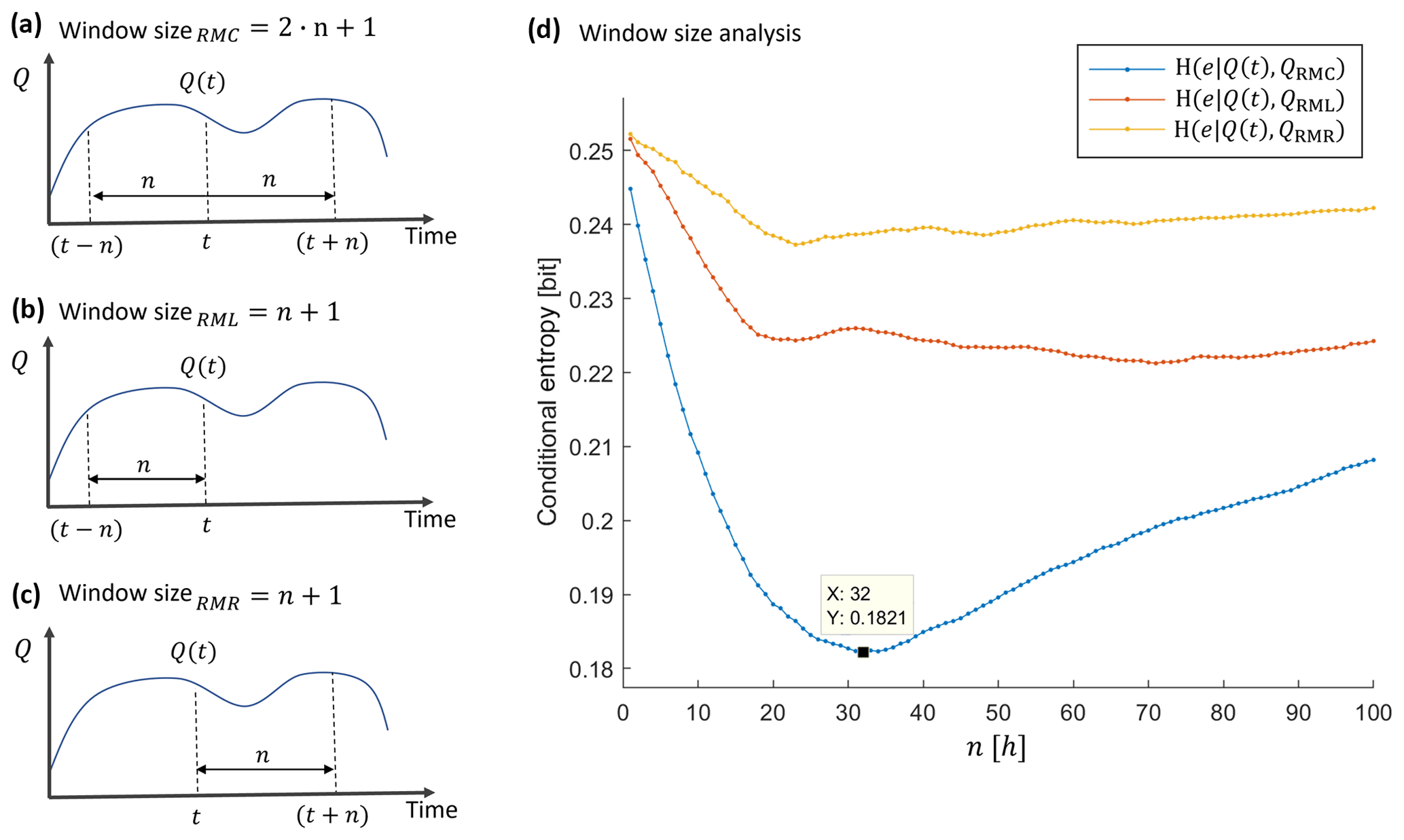
Figure 4Window size definitions for window types. (a) QRMC, (b) QRML and (c) QRMR window definitions and (d) window size analysis.
The best (lowest) value of conditional entropy was obtained for a time-centered window (QRMC) with h of total width. We used this value for all further analyses.
3.2.3 Model classification, selection and evaluation
Model classification
All the models we set up and tested in this study can be assigned to one of three distinct groups. The groups distinguish both typical situations of data availability and the use of recursive and non-recursive modeling approaches. Models in the Q-based group apply exclusively discharge-based predictor(s). For models in the P-based group, we assumed that in addition to discharge, precipitation data are also available. This distinction was made, because in the literature two main groups of event detection methods exist: one relying solely on discharge data the other using precipitation data additionally. Finally, models in the model-based group all apply a two-step recursive approach as discussed in Sect. 3.2.1. In this case, the first model is always from the Q- or P-based group. Later, event predictions at time step t−1 of the first model application are then, together with additional predictors from the Q- or P-based group, used as a predictor in the second model.
Model selection
In order to streamline the model evaluation process, we applied an approach of supervised model selection and gradually increasing model complexity, we started by setting up and testing all possible one-predictor models in the Q- and P-based group. From these, we selected the best-performing model and combined it with each remaining predictor into a set of two-predictor models. The best-performing two-predictor model was then expanded to a set of three-predictor models using each remaining predictor and so forth. For the model-based group, the strategy was to take the best-performing models from both the Q- and the P-based group as the first model and then combine it with an additional predictor. In the end, we stopped at four-predictor models, since beyond it, the uncertainty contribution due to limited sample size became dominant.
Model evaluation
Among models with the same number of predictors, we compared model performance via the conditional entropy (target given the predictors), calculated from the full data set. However, when comparing models with different numbers of predictors, the influence of the curse of dimensionality needs to be taken into account. To this end, we calculated sample-based cross entropy and Kullback–Leibler divergence as described in Sect. 2.3.2 for samples of size of 50 up to the size of the full data set, using the following sizes: 50, 100, 500, 1000, 1500, 2000, 2500, 5000, 7500, 10 000, 15 000, 20 000, 30 000, 40 000, 50 000, 60 000, 70 000 and 78 912. To eliminate effects of chance, we repeated the resampling 500 times for each sample size and took their averages. In Appendix A, the resampling strategy and the choice of repetitions are discussed in more detail.
3.3 Application II – ITM and CPM comparison
The second application aims to compare the performances of the ITM and another automatic event identification method from a more familiar perspective. The predictions were performed in a separate data set, and, as a measure of diagnostic, concepts from the receiver operating characteristic (ROC) curve quantified the hits and misses of the predictions of both models according to a time series of user-classified events (considered the true value). More about the ROC analysis can be found in Fawcett (2005).
For the comparison, the characteristic point method (CPM) was chosen, because, in contrast with the data-driven ITM, it is a physically based approach for event identification, which is applicable to and recommended for the characteristics of the available data set (hourly timescale data on catchment precipitation and discharge) and open source. The essence of the method is to characterize flow events with three points (start, peak(s) and end of the event) and then associate the event to a corresponding rainfall event (Mei and Anagnostou, 2015). For the event identification, a baseflow separation is previously needed and proposed by coupling the revised constant k method (Blume et al., 2007) and the recursive digital filter proposed by Eckhardt (2005). More about the CPM can be attained in Mei and Anagnostou (2015).
Since the outcome of the CPM is dichotomous, classified as either event or non-event, the probabilistic outcome of the ITM must be converted into a binary solution. The binarization was reached in the study by choosing an optimum threshold of the probabilistic prediction (pthreshold), where all time steps with probabilities equal to or greater than it were classified as being part of an event. The objective function of the optimization was based on the ROC curve and sought to minimize the distance to the top-left corner of the ROC curve, i.e., the Euclidean distance between the true positive rate (RTP, proportion of events correctly identified in relation to the total of true events) and false positive rate (RFP, proportion of false events in relation to the total of true non-events) to the perfect model (where and ), as expressed in Eq. (7)1:
Even though the physically based CPM method theoretically does not require a calibration step, for avoiding misleading comparison, the parameter Rnc (rate of no change, used to quantify null-change ratio in recession coefficient k) was optimized by Eq. (7). Thus, RTP and RFP ϵ [0,1] are calculated as a function of the optimized parameter pthreshold (for the ITM) and Rnc (for the CPM).
Due to the pthreshold and Rnc optimization and to enable the cross-validation of the models in a new data set, the available data were divided into training and testing sets. And, since the ITM model requires a minimum data set size to guarantee the model robustness, the holdout split was based on the data requirement of the selected ITM model obtained according to application I, Sect. 3.2. Therefore, the training data set was used to build the ITM model and to calibrate the pthreshold (needed for the binarization) and Rnc.
After that, the calibrated models (ITM and CPM) were applied to a new data set (testing data set), and measures of quality based on the ROC curve were computed in order to evaluate and compare their performance, such as (i) the true positive rate (RTP), which represents the percentage of event classification hits (counting of events correctly classified by the model, PT, divided by the amount of the true events in the testing data set, P); (ii) the false positive rate (RFP), which represents the percentage of false events identified by the model (counting of events misclassified by the model, PF, divided by the amount of the true non-events in the testing data set, N); (iii) the accuracy, which reflects the total proportion of events (PT) and non-events (or true negative, NT) that were correctly predicted by the model; and (iv) the distance to the perfect model given by the Eq. (7), which represents the norm between the results obtained by the method and a perfect prediction.
4.1 Results for application I
4.1.1 Model performance for the full data set
Here we present and discuss the model results when constructed and applied to the complete data set. As we stick to the complete data set, Kullback-Leibler divergence will always be zero, and model performance can be fully expressed by conditional entropy (see Sect. 3.2.3; Model Evaluation), with the (unconditional) Shannon entropy of the target data H(e)=0.516 bits as an upper limit, which we use as a reference to calculate the relative uncertainty reduction for each model. In Table 2, conditional entropies and their relative uncertainty reductions are shown for each Q- and P-based one-predictor model.
One-predictor models based on Q and ln Q reduced uncertainty to about 50 % (models no. 1–10 in Table 2, fourth column), with a slight advantage of Q over ln Q. Interestingly, both show their best results for the time offset t+2, i.e., future discharge is a better predictor of event detection than discharge at the current time step. As we were not sure whether this also applies to two-predictor models, we decided to test both the t+2 and t predictors of Q and ln Q in the next step. Compared to Q and ln Q, relative magnitude of discharge QRMC and discharge slope Qslope performed poorly, and so did P, the only model in the P-based group. This is most likely because for a certain time step, being part of an event is not as dependent on precipitation at this particular time step but is rather dependent on the accumulated rainfall in a period preceding it. Despite its poor performance, we decided to use it in higher-order models to see whether it becomes more informative in combination with other predictors.
Table 2Conditional entropy and relative uncertainty reduction of one-predictor models.
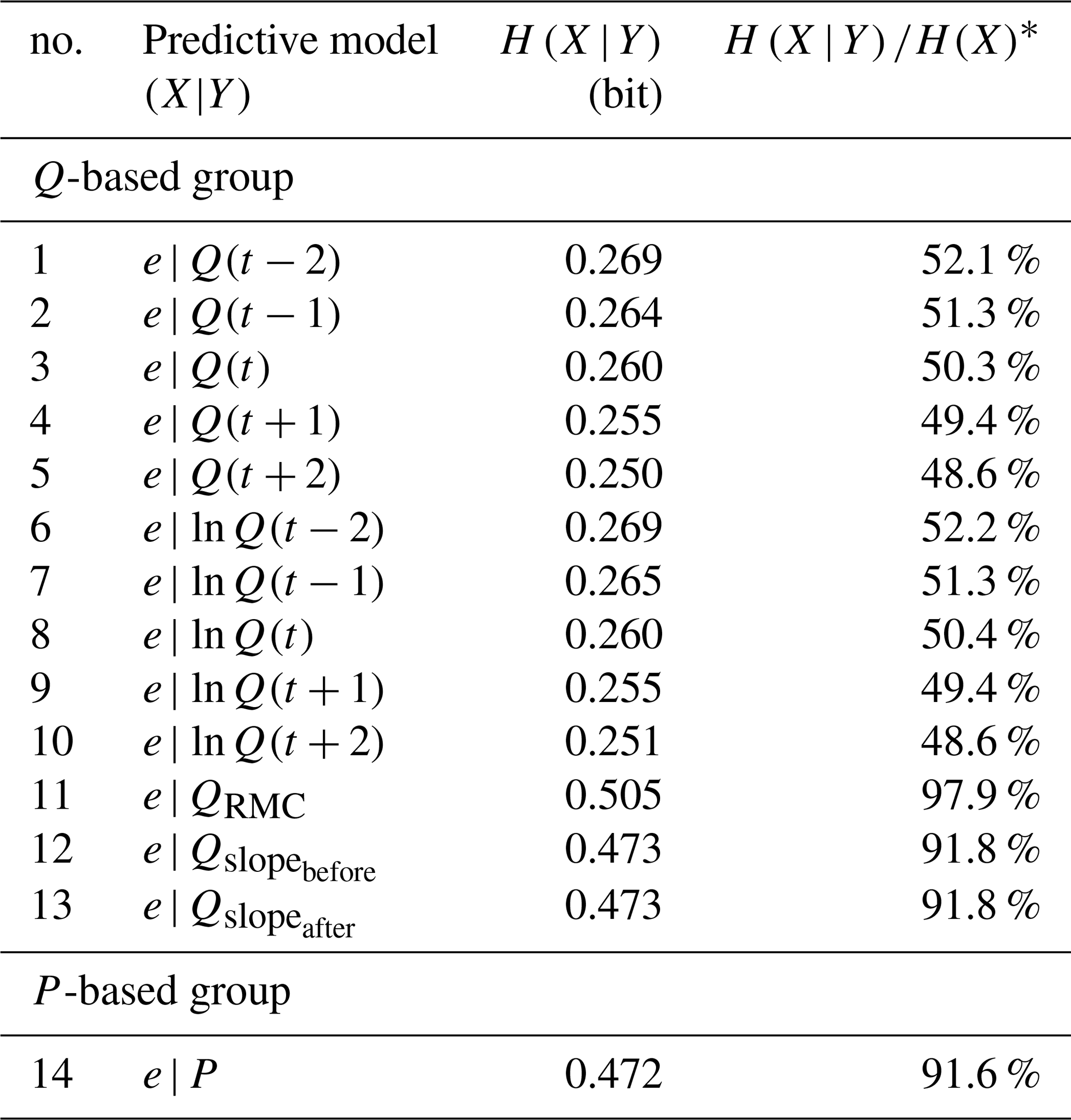
∗ bits.
Based on these considerations and the model selection strategy described in Sect. 3.2.3, we built and evaluated all possible two-predictor models. The models and results are shown in Table 3.
As could be expected from the information inequality, adding a predictor improved the results, and for some models (no. 16 and no. 20), the t predictors outperformed their t+2 counterparts (no. 17 and no. 21, respectively). Once more, Q predictors performed slightly better than ln Q such that for all higher-order models, we only used Q(t) and ignored Q(t+2), ln Q(t) and ln Q(t+2).
In the P-based group, adding any predictor greatly improved results by about 50 %, but not a single P-based model outperformed even the worst of the Q-based group.
Table 3Conditional entropy and relative uncertainty reduction of two-predictor models.
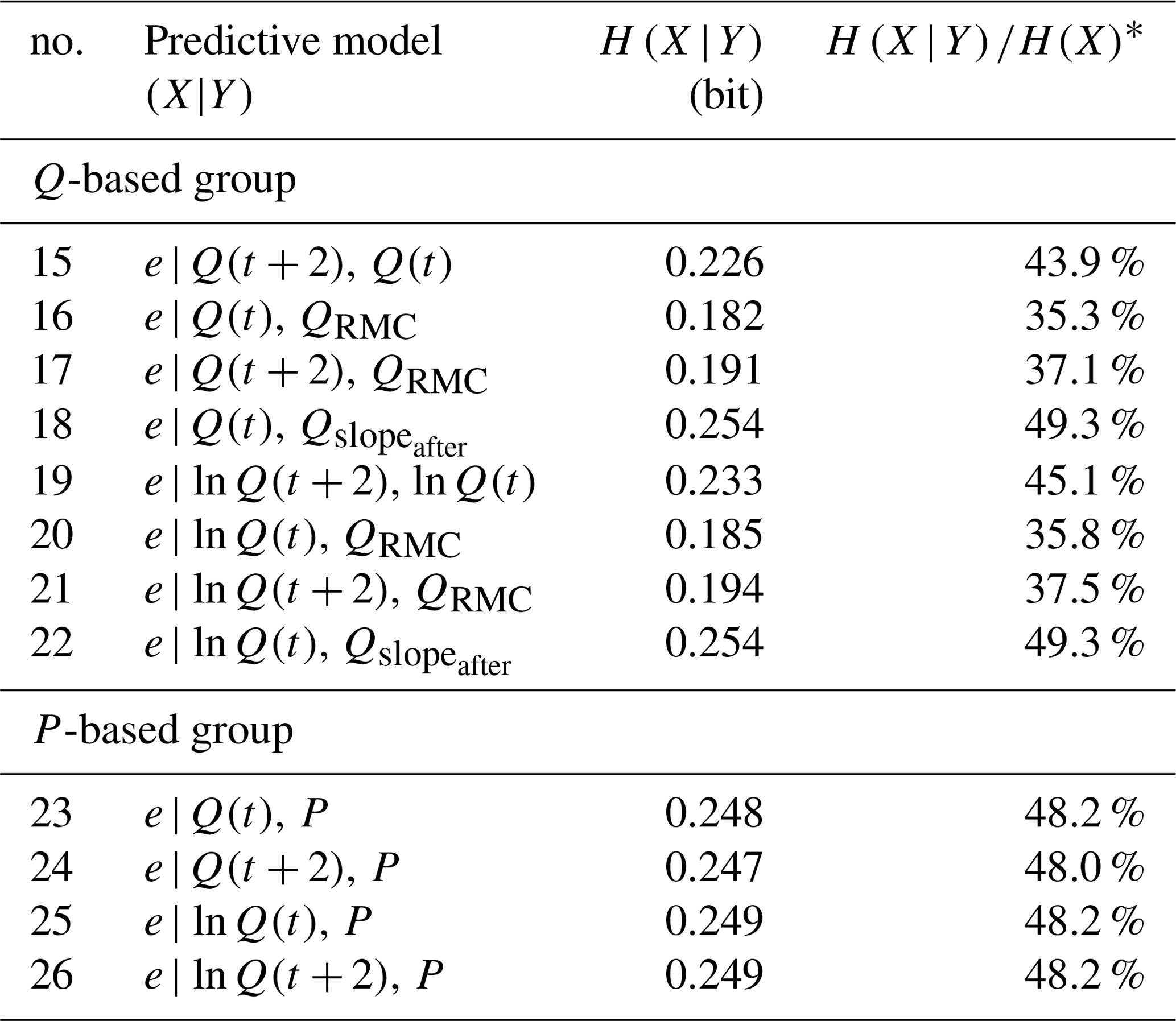
∗ bits.
Finally, from both the Q- and P-based group, we selected the best model using t predictors (no. 16 and no. 23, respectively) and extended them to three-predictor models with the remaining predictors. The models and results are shown in Table 4.
Again, for both models, the added predictor improved results considerably, and we used both of them to build a recursive four-predictor model as described in Sect. 3.2.3. The new predictor, ep(t−1) is simply the probabilistic prediction of a model (no. 27 or no. 28, in this case) for time step t−1 of being part of an event, with a value range of [0, 1]. This means that carries the memory from the previous predictions of model no. 27 (and from model no. 28, accordingly), and the new four-predictor models no. 29 and no. 30 as shown in Table 5 are simply copies of these models, extended by a memory term: ep(t−1).
Table 4Conditional entropy and relative uncertainty reduction of three-predictor models.
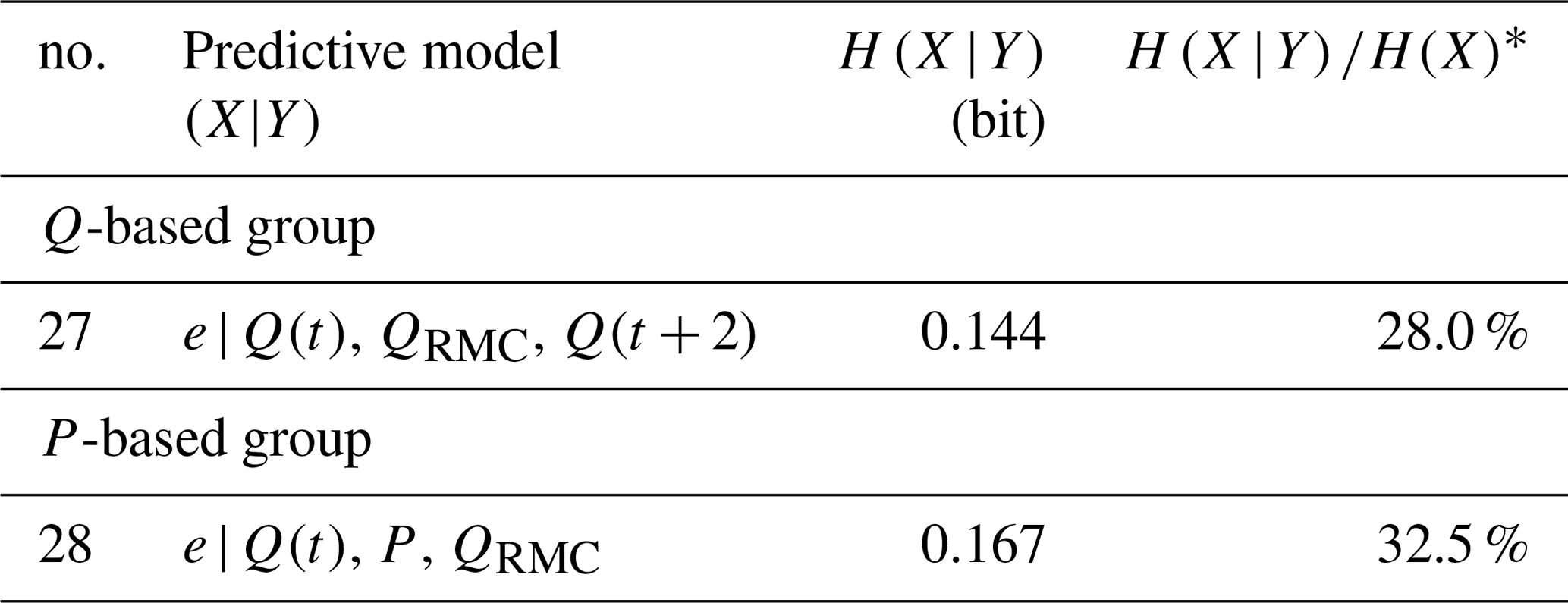
∗ bits.
Table 5Conditional entropy and relative uncertainty reduction of recursive four-predictor models.

∗ bits.
Again, model performance improved, and model no. 29 was the best among all tested models, though so far the effect of sample size was not considered, which might have a strong impact on the model rankings. This is investigated in the next section.
Table 6Models selected for sample-based tests.
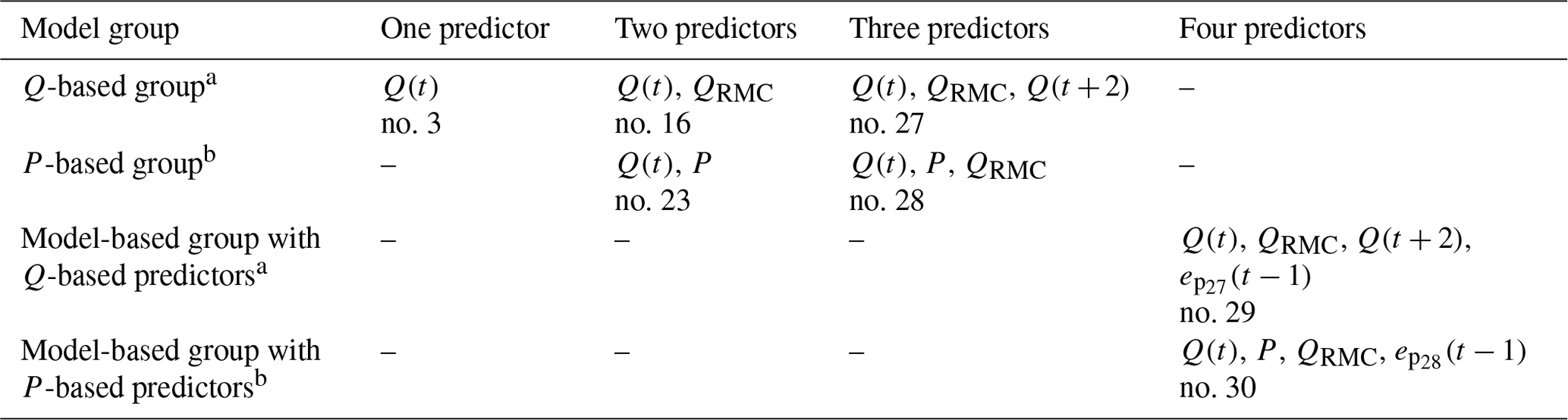
a Models which apply exclusively discharge-based predictor(s). b Models which apply discharge- and precipitation-based predictor(s).
4.1.2 Model performance for samples
The sample-based model analysis is computationally expensive, so we restricted these tests to a subset of the models from the previous section. Our selection criteria were to (i) include at least one model from each predictor group, (ii) include at least one model from each dimension of predictors and (iii) choose the best-performing model. Altogether we selected the seven models shown in Table 6. Please note that despite our selection criteria, we ignored the one-predictor model using precipitation due to its poor performance.
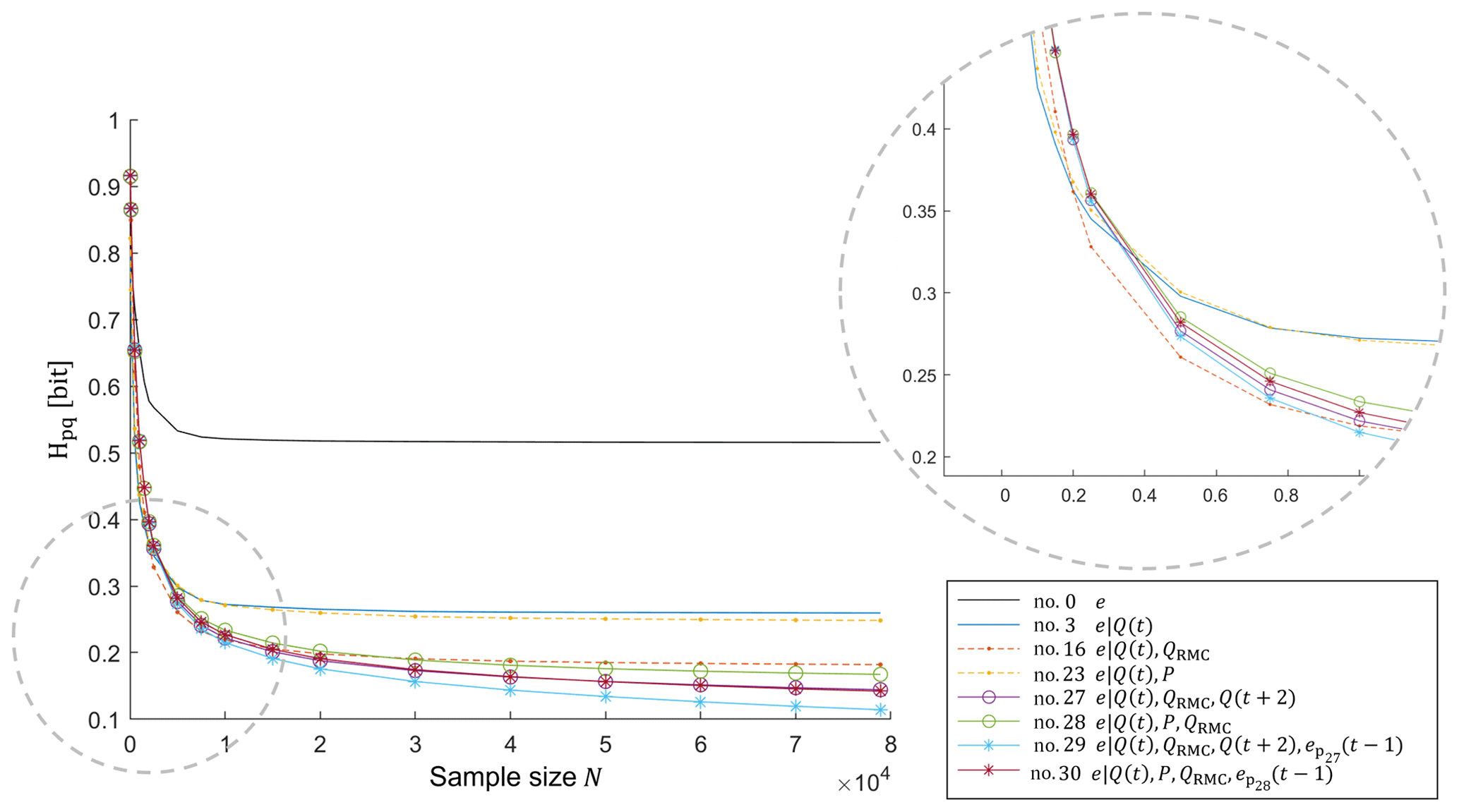
For these models, we computed the cross entropies between the full data set and each sample size N for W repetitions, and in the end, for each sample size N, we took the average of the W repetitions. The results are shown in Fig. 5. For comparison, the cross entropies between the target data set and samples thereof are also included and labeled as model no. 0.
In Fig. 5, the cross entropies at the right end of the x axis, where the sample contains the entire data set, equal the conditional entropies, as the effect of sample size is zero. However, with decreasing sample size, cross entropy grows in a non-linear fashion as DKL starts to grow. If we walk through the space of sample sizes in the opposite direction, i.e., from left to right, we can see that as the samples grow, the rate of change of cross entropy decreases, the reason being that the rate of change of DKL decreases, which means that the model learns less and less from new data points. Thus, by visually exploring these “learning curves” of the models we can make two important statements related to the amount of data required to inform a particular model: we can state how large a training data set should be to sufficiently inform a model, and we can compare this size to the size of the actually available data set. If the first is much smaller than the latter, we gain confidence that we have a well-informed, robust model. If not, we know that it may be beneficial to gather more data, and if this is not possible, we should treat model predictions with caution.
As mentioned in Sect. 2.3.2, besides Fig. 5 informing the amount of data needed to have a robust model (implying that sample size is enough to represent the full data set), it allows the comparison of competing models with different dimensions and selection of the optimal number of predictors (taking advantage of the available information and avoiding overfitting). In this sense, in the P-based group and for sample sizes smaller 5000, the two-predictor model no. 23 performs best, but for larger samples sizes, the four-predictor model no. 30 takes the lead. Likewise, in the Q-based group and for sample sizes smaller than 2500, the single-predictor model no. 3 is the best but is outperformed by the two-predictor model no. 16 from 2500 until 10 000, which in turn is outperformed by the four-predictor model no. 29 from 10 000 to the end. Across all groups, models no. 3, no. 16 and no. 29 form the lower envelope curve in Fig. 5, which means that one of them is always the best model choice, depending on the sample size.
Interestingly, the best-performing model for large sample sizes (no. 29) includes predictors which reflect the definition criteria that guided manual event detection (Sect. 3.1): Q(t) and Q(t+2) contain information about the absolute magnitude of discharge, QRMC expresses the magnitude of discharge relative to its vicinity, and relates it to the requirement of events to be coherent.
Table 7Application I – curse of dimensionality and data size validation for models in Table 6.
a bits. b Size of the full data set: 78 912 data points (9 years).
We also investigated the contribution of sample size effects to total uncertainty by analyzing the ratio of DKL and H(X|Y) as described in Sect. 2.3.2. As expected, for all models the contribution of sample size effects to total uncertainty decreases with increasing sample size, but the absolute values and the rate of change strongly differ. For the one-predictor model no. 3, the DKL contribution is small already for small sample sizes (circa 65 % for a sample size equal to 50), and it quickly drops to almost zero with increasing sample size. For multi-predictor models such as no. 29, the DKL contribution to uncertainty exceeds that of H(X|Y) by a factor of 7 for small samples (circa 700 % for sample size equal 50), and it decreases only slowly with increasing sample size.
In Table 7 (fifth column), we show the minimum sample size to keep the DKL contribution below a threshold of 5 % for each model.
As expected, the models with few predictors require only small samples to meet the 5 % requirement (starting from a subset of 12.6 % of the full data set for the one-predictor model to 37.3 % for the two-predictor model), but for multi-predictor models such as models no. 29 and no. 30, more than 60 000 data points are required (87.6 % and 79.4 % of the full data set, respectively). This happens because the greater the number of predictors, the greater the number of bins in the model. This means that we need a much larger data set to populate the PMF with the largest number of bins; for example, model no. 29 has 279 752 bins and requests 7.9 years of data. Considering that the amount of data available in the study is limited, this also means that increasing the number of predictors and/or bins also increases the risk of creating an overfitted or non-robust model. Thus, the ratio DKL∕H(X|Y) and visual inspection of the curve in Fig. 5 orientate the user when to stop adding new predictors to avoid overfitting. In this fashion, Table 7 shows that each of the models tested meets the 5 % requirement, claiming up to 87.6 % of the available data set (69 102 out of 78 912 data points for model no. 29), which indicates that all of them are robustly supported by the data. In this case, we can confidently choose the best-performing model among them (no. 29, with uncertainty equal to 0.114 bits) for further use. Interestingly, with this analysis, it was also possible to identify the drivers of the user classification, which, in the case of model no. 29, were the predictors Q(t), QRMC, Q(t+2) and ep(t−1).
4.1.3 Model application
In the previous sections, we developed, compared and validated a range of models to reproduce subjective, manual identification of events in a discharge time series. Given the available data, the best model was a four-predictor recursive model built with the full data set and Q(t), QRMC, Q(t+2) and ep(t−1) as predictors (no. 29; Table 7). This model reduced the initial predictive uncertainty by 77.8 %, decreasing conditional entropy from 0.516 to 0.114 bits. This sounds reasonable, but what do the model predictions actually look like? As an illustration, we applied the model to a subset of the training data, from 22 April to 22 June 2001. For this period, the observed discharge, the manual event classification by the user and the model-based prediction of event probability are shown in Fig. 6.
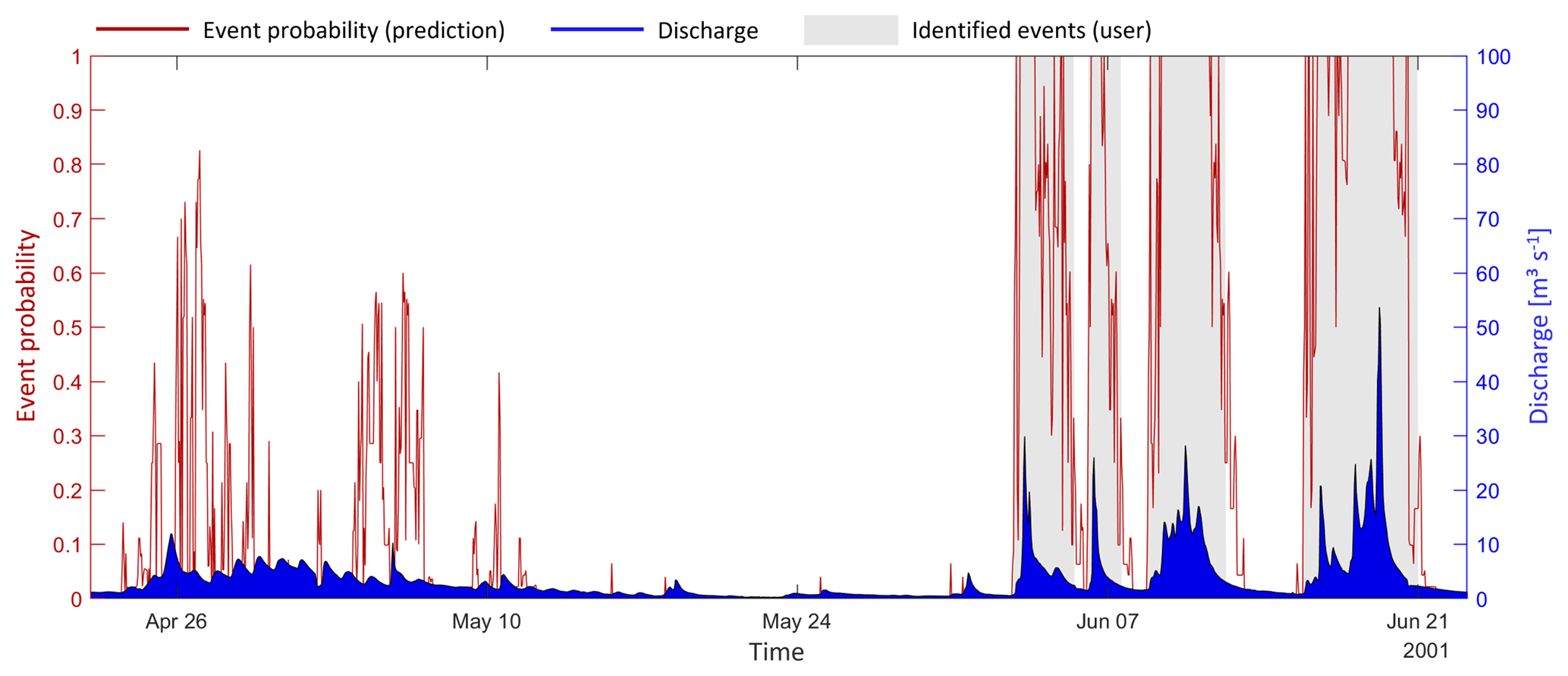
Figure 6Application I – probabilistic prediction of four-predictor model no. 29 (Table 5) for a subset of the training data.
In the period from 1 to 21 June, four distinct rainfall-runoff events occurred which were also classified as such by the user. During these events, the model-based predictions for event probability remained consistently high, except for some times at the beginning and end of events or in times of low flow during an event. Obviously, the model here agrees with the user classification, and if we wished to obtain a binary classification from the model, we could get it by introducing an appropriate probability threshold (as further described in Sect. 4.2).
Things look different, though, in the period of 26 April to 10 May, when snowmelt induced diurnal discharge patterns. During this time, the model identified several periods with reasonable (above 50 %) event probability, but the user classified the entire period as a non-event. Arguably, this is a difficult case for both manual and automated classification, as the overall discharge is elevated, but it is not elevated by much, and diurnal events can be distinguished but are not pronounced. In such cases, both the user-based and the model-based classifications are uncertain and may disagree.
To identify snowmelt events or potentially improve the information contained in the precipitation set, other predictors could have been used in the analysis (such as aggregated precipitation, snow depth, air temperature, nitrate concentrations, moving average of discharge, etc.), or the target could have been classified according to it type (rainfall, snowmelt, upstream reservoir operation, etc.), instead of having a dichotomous outcome, i.e., event and non-event. The choice of target and potential predictors occurs according to user interest and data availability.
Another point that may be of interest to the user is the improvement of the consistency of the event duration. This can be reached by selection of predictors or through a post-processing step. As previously discussed in Sect. 3.2.1, by applying a recursive predictor ep(t−1), a memory effect is incorporated into the model, bringing some inertia for the transition from event to non-event or vice versa. If it is in the user's interest, the memory effect could be further enhanced by adding more recursive predictors, such as ep(t−2), ep(t−3) and so on. An alternative option for clearing very short discontinuous time steps or very short events would be to increase event coherence in a post-processing step with an autoregressive model, with model parameters found by maximizing agreement with the observed events.
Finally, in contrast to the evaluation approach presented, where the subsets are compared to the full data set (subset data plus data not seen during training), the next section will present the evaluation of the ITM and CPM applied for mutually exclusive training and testing sets.
4.2 Results for application II
Section 4.1 showed that, for the full data set, the best model was the recursive one with Q(t), QRMC, Q(t+2) and ep(t−1) as the drivers of the user classification (model no. 29, Table 7), which could be robustly built with a sample size of 69 102. Thus, to assure its robustness for the second application, since we are creating a new PMF based only on the training set, the split of the data (discharge, precipitation and user event classification) divided the 78 912 time steps into two periods composed of (i) 87.6 % of the full data set (69 102 time steps) forming the training data set (from 31 October 1996 at 01:00 to 18 September 2004 at 06:00 GMT+1) and (ii) the remaining 12.4 % (9810 time steps) forming the testing data set (from 18 September 2004 at 07:00 to 1 November 2005 at 00:00 GMT+1). The characteristics of the user event classification data set, used as the true classification for accounting the hits and misses of the ITM and CPM, is presented in Table 8.
Table 8Cross-validation data set – characteristics of the user event classification set.

For model training, input data from both models, the ITM and CPM, were smoothed. First, a 24 h moving average was applied to the discharge of the CPM (this was recommended by the first author of the method, Yiwen Mei, during personal communications in 2018), and to avoid misleading comparison, it was then applied to the probabilities of the ITM right before the binarization. The smoothing improved the results of both models and worked as a post-processing filter which removed some noise (events with a very short duration) and attenuated effects from snowmelt. Note that this is a feature of our training data set, and it is therefore not necessarily applicable to other similar problems and neither is a required step.
Table 9Application II – ITM and CPM performance.

a P=942, N=8868 (Table 8). b . c Distance to the perfect model of the ROC curve.
Following the data smoothing, we proceeded with the optimization of the following parameters: the threshold for the probability output of the ITM and rate of no change for the CPM (Sect. 3.3). The results of the two models also improved with the optimization performed. The optimum parameters obtained were pthreshold=0.26 and . For these values, the final distances in the training data set given by Eq. (7) were 0.05 and 0.23 for the ITM and CPM, respectively.
After the model training, the calibrated models were applied to the testing data set to predict binary events. The event predictions were then compared to the true classification (Table 8, testing row), and their hits and misses were calculated in order to evaluate and compare their performance. The results are compiled in Table 9.
The quality parameters presented in Table 9 show that the ITM true positive rate equals 97.5 %, i.e., it is 13.0 % higher than the CPM RTP). In contrast, the CPM false negative rate is equal to 9.9 %, while the ITM RFP is equal to 12.6 % (2.7 % higher). These results indicate that the ITM is more likely to predict events than the CPM but at the cost of increasing the false positive rate. Combining these two rates into a single success criterion according to Eq. (7) showed that the ITM is slightly superior to the CPM (Table 9, last column).
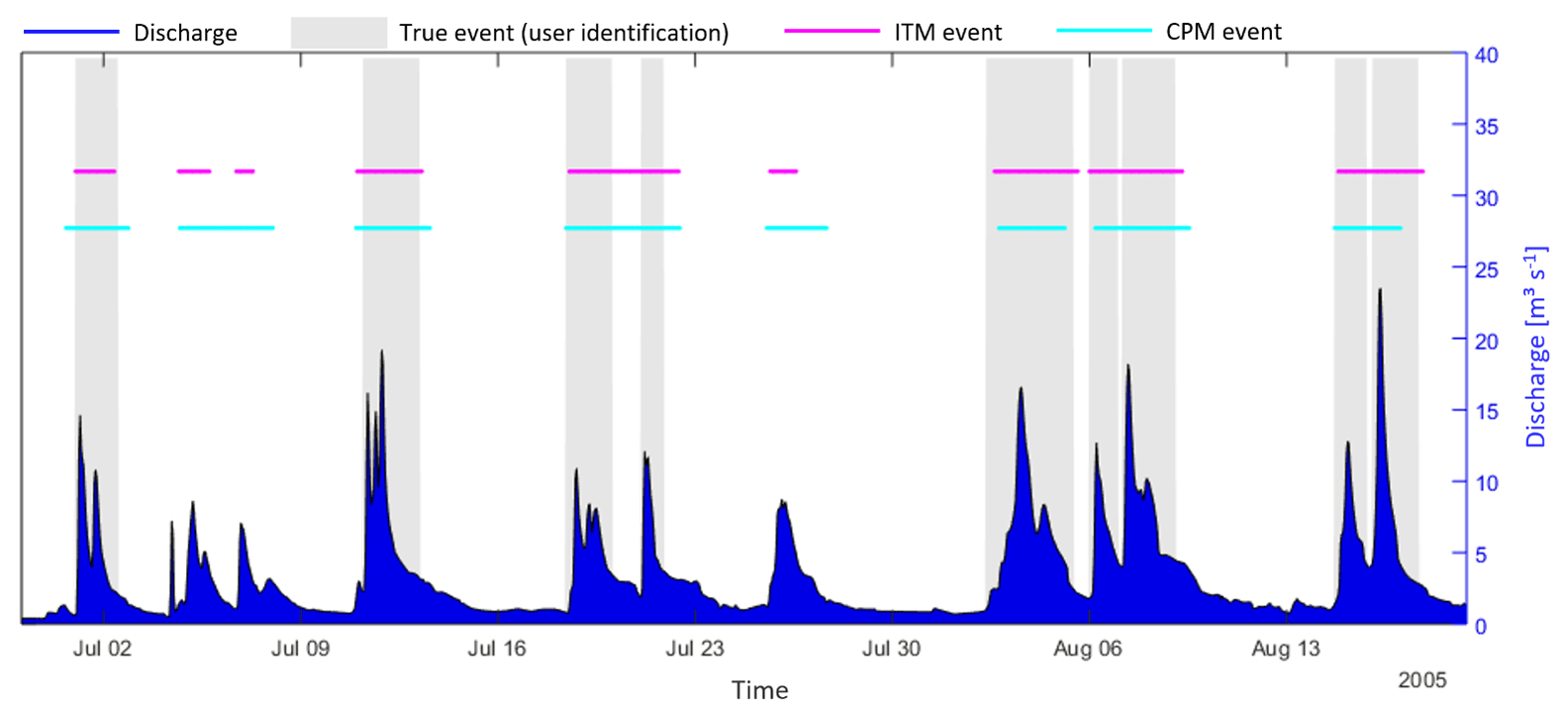
Figure 7Application II – binary prediction of ITM and CPM for a subset of the testing data set.
Considering only the hits of the models, both methods performed similarly, reaching almost 90 % accuracy, with the CPM being slightly better than the ITM. However, it should be emphasized that although the accuracy of the model gives a good notion of the model hits, it was not used as a criterion for success because it is a myopic criterion for the false event classifications. False positives are essential in the context of event prediction, since most of the data are non-events (88.2 % of the training data set; Table 8), and a blind classification of all time steps as being non-event, for example, would overcome the accuracy obtained by both models (90.4 % of the testing data set; Table 8), even though it is not a useful model.
As an illustration, in the context of the binary analysis, the observed discharge, the true event classification (manually made by an expert), the ITM-predicted events and CPM-predicted events are shown in Fig. 7 for a subset of the testing data, from 29 June to 19 August 2005.
For the analyzed subset, nine distinct rainfall-runoff events occurred and were identified as such by the ITM and CPM. However, different from the true identification, both models grouped some of these events (20 July, 7 and 16 August) with events with longer duration. False events were also observed in both models, where three false events were identified by the ITM (5, 7 and 26 July), and two (but contemplating the same period as the ITM) were identified by the CPM. It should be noted that they are false in relation to the user classification; however, we can not exclude the possibility of false classification by the visual inspection process. A further criticism is that the holdout cross-validation involves a single run, which is not as robust as multiple runs. Nevertheless, the way that the split was proposed recognizes the logical order of obtaining the data. Thus, despite the subjectivity of event selection by a user and the application of a simplified method of cross-validation, it is possible to conclude that, overall, the ITM and CPM behaved similarly and provided reasonable predictions, as seen numerically in Table 9 and qualitatively through Fig. 7.
An interesting conclusion is that the ITM was able to overcome the CPM while requiring only discharge data and a training data set of classified events (also based on the discharge set), whereas the CPM demanded precipitation, catchment area and discharge as inputs. It is important to note that the CPM can be modified to be used without precipitation data; however in our case it resulted in a considerably higher false positive rate, since the rainfall event-related filters cannot be applied. In contrast, since the CPM is a physically based approach, it does not require a training data set with identified events (although the optimization in the calibration step has representatively improved its results), and there are no limitations in terms of data set size, which eliminates the robustness analysis, being then a method more easily implemented for binary classification. The binarization of the ITM predictions and parameter optimization in the CPM are not included in the original methods, however, they were essential adaptations to allow a fair comparison of the models. Finally, the suitability or not of the existing event detection techniques depends mainly on the user's interest and the data available for application.
Typically, it is easy to manually identify rainfall-runoff events due to the high discriminative and integrative power of the brain–eye system. However, this is (i) cumbersome for long time series; (ii) subject to handling errors; and (iii) hard to reproduce, since it dependents on acuity and knowledge of the event identifier. To mitigate these issues, this study has proposed an information theory approach to learn from data and to choose the best predictors, via uncertainty reduction, for creating predictive models that automatically identify rainfall-runoff events in discharge time series.
The method was established in four main steps: the model hypothesis, building, evaluation and application. Each association of predictor(s) to the target is equivalent to formulating a model hypothesis. For the model building, non-parametric models constructed discrete distributions via bin-counting, requiring at least a discharge time series and a training data set containing a yes or no event identification as target. In the evaluation step, we used Shannon entropy and conditional entropy to select the more informative predictors and Kullback–Leibler divergence and cross entropy to analyze the model in terms of overfitting and curse of dimensionality. Finally, the best model was applied to its original data set to compare the predictability of the events. For the purpose of benchmarking, a holdout cross-validation and a comparison of the proposed data-driven method with an alternative physically based approach were performed.
The approach was applied to discharge and precipitation data from the Dornbirner Ach catchment in Austria. In this case study, 30 models based on 16 predictors were built and tested. Among these, seven predictive models with a number of predictors varying from one to four were selected. Interestingly, across these models, the three best-performing ones were obtained using only discharge-based predictors. The overall best model was a recursive one applying four predictors: discharge from two different time steps, the relative magnitude of discharge compared to all discharge values in a surrounding 65 h time window and event predictions from the previous time step. When applying the best model, the uncertainty of event classification was reduced by 77.8 %, decreasing conditional entropy from 0.516 to 0.114 bits. Since the conditional entropy reduction of the models with precipitation was not higher than the ones exclusively based on discharge information, it was possible to infer that (i) the information coming from precipitation was likely already contained in the discharge data series and (ii) the event classification is not so much dependent on precipitation at a particular time step but rather on the accumulated rainfall in the period preceding it. Furthermore, precipitation data are often not available for analysis, which makes the model exclusively based on discharge data even more attractive.
Further analysis using cross entropy and Kullback–Leibler divergence showed that the robustness of a model quickly dropped with the number of predictors used (an effect known as the curse of dimensionality) and that the relation between number of predictors and sample size was crucial to avoid overfitting. Thus, the model choice is a tradeoff between predictive power and robustness, given the available data. For our case, the minimum amount of data to build a robust model varied from 9952 data points (one-predictor model with 0.260 bits of uncertainty) to 69 102 data points (four-predictor model with 0.114 bits of uncertainty). Complementarily, the quality of the model was verified in a more traditional way, by a cross-validation analysis (where the model was built in a training data set and validated in a testing data set), and a comparative investigation between our data-driven approach and a physically based model. As a result, in general, both models presented reasonable predictions and reached similar quality parameters, with almost 90 % of accuracy. In the end, the comparative analysis and cross-validation reinforced the quality of the method, previously validated in terms of robustness using measures from information theory.
In the end, the data-driven approach based on information theory is a consolidation of descriptive and experimental investigations, since it allows one to describe the drivers of the model through predictors and investigates the similarity of the model hypothesis with respect to the true classification. In summary, it presents advantages such as the following: (i) it is a general method that involves a minimum of additional assumptions or parameterizations; (ii) due to its non-parametric approach, it preserves the full information of the data as much as possible, which might get lost when expressing the data relations with functional relationships; (iii) it obtains data relations from the data itself; (iv) it is flexible in terms of data requirement and model building; (v) it allows one to measure the amount of uncertainty reduction via predictors; (vi) it is a direct way to account for uncertainty; (vii) it permits explicitly comparing information from various sources in a single currency, the bit; (viii) it allows one to quantify minimal data requirements; (ix) it enables one to investigate the curse of dimensionality; (x) it is a way of understanding the drivers (predictors) of the model (also useful in machine learning, for example); (xi) it one permits to choose the most suitable model for an available data set; and (xii) the predictions are probabilistic, which compared to a binary classification, additionally provides a measure of the confidence of the classification.
Although the procedure was employed to identify events from a discharge time series, which for our case were mainly triggered by rainfall and snowmelt, the method can be applied to reproduce user classification of any kind of event (rainfall, snowmelt, upstream reservoir operation, etc.) and even identify them separately. Moreover, one of the strengths of the data-based approach is that it potentially accepts any data to serve as predictors, and it can handle any kind of relation between the predictor(s) and the target. Thus, the proposed approach can be conveniently adapted to another practical application.
The event detection program, containing the functions to develop multivariate histograms and calculate information theory measures, is published alongside this manuscript via GitHub: https://github.com/KIT-HYD/EventDetection (last access: 12 February 2019) (Thiesen et al., 2018). The repository also includes scripts for exemplifying the use of the functions and the data set of identified event, discharge and precipitation time series from the Dornbirner Ach catchment in Austria used in the case study.
In the study, samples of size N from the data set were obtained through bootstrapping, i.e., they were taken randomly but continuously in time, with replacement among the W repetitions. For each sample size, we repeated draws W times and took the average cross entropy and DKL to eliminate effects of chance (see repetition statements N and W in Fig. 1).
Thus, in order to find the value of W which balances statistical accuracy and computational efforts, we did a dispersion analysis through calculating the Shannon entropy (as a measure of dispersion) of the cross entropy distribution of the (unconditional) target model (model no. 0 in Table 7). Sixty-one bins ranging from 0 to 6 in steps of 0.1 bits were used; this contemplates the range of all possible cross entropy values among the tested pairs of N and W. Figure A1 presents the Shannon entropy applied as a dispersion parameter to analyze the effect of the number of repetitions W for different sample sizes N.
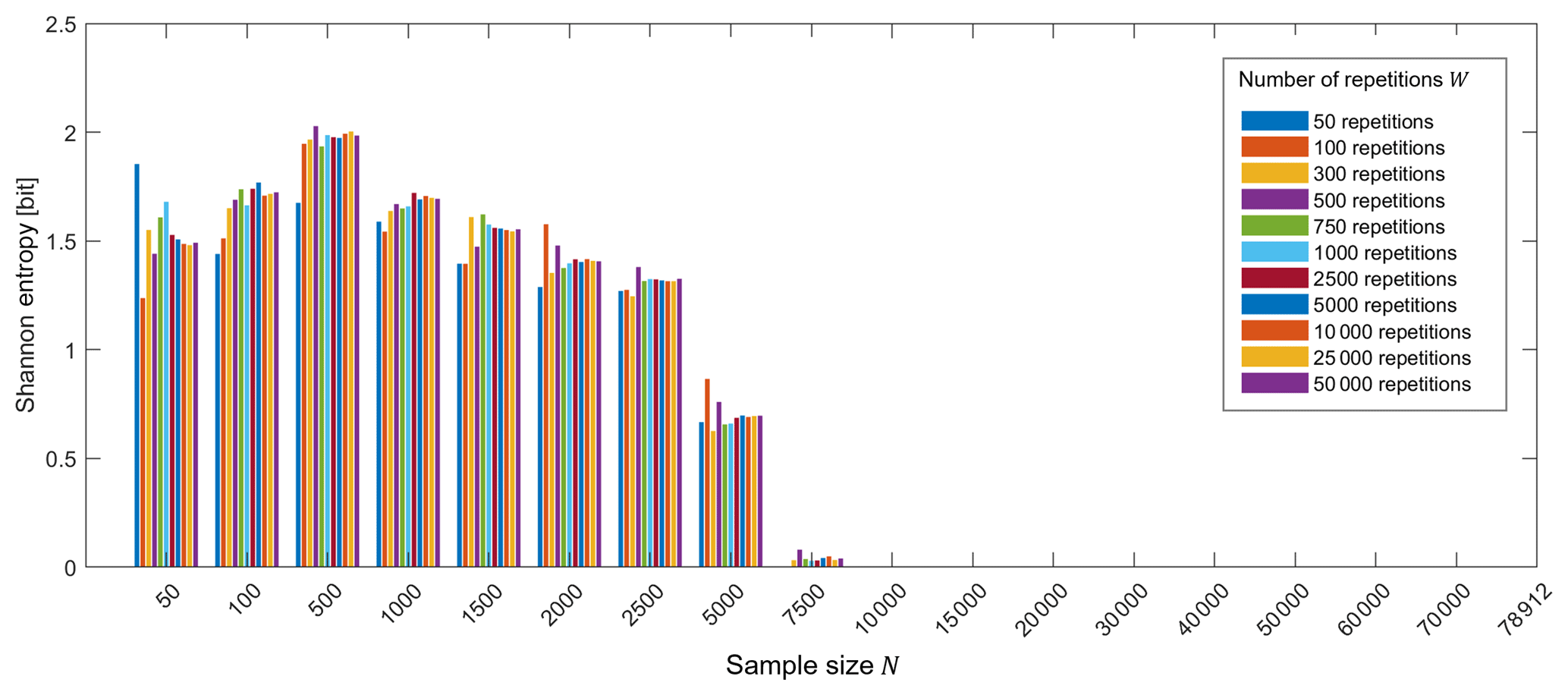
Figure A1Dispersion analysis of the cross entropy. The effect of the number of repetitions in the target model (no. 0 in Table 7).
Considering the graph in Fig. A1, in general, the behavior of the Shannon entropy among the repetitions is similar for each sample size analyzed, indicating that the dispersion of the results according to the number of repetitions does not vary too much, i.e., the bins are similarly filled. However, it is possible to see that, as the sample size increases, the Shannon entropy for the different number of repetitions approaches that for the 50 000 repetitions. For sample sizes up to 7500, the bars from 50, 100 and 300 repetitions present some peaks and troughs, indicating some dispersion in filling the bins. Thus, in this case study, the minimum of 500 repetitions was assumed as a reasonable number of repetitions for computing the mean of the cross entropy in the sample size investigation. This number of repetitions was also validated considering the smoothness and logical behavior of the curves obtained during the data size validation and curse of dimensionality analyses (Fig. 5 in Sect. 4.1.2).
UE and PD developed the model program (calculation of information theory measures, multivariate histograms operations and event detection) and developed a method for avoiding infinitely large values of DKL (Darscheid et al., 2018). ST performed the simulations, cross-validation, parameter optimization, comparative analysis to a second model and the justification of the number of repetitions of the resampling stage. ST and UE directly contributed to the design of the method and test application and the analysis of the performed simulations and wrote the paper.
The authors declare that they have no conflict of interest.
Stephanie Thiesen and Uwe Ehret acknowledge support from the Deutsche
Forschungsgemeinschaft (DFG) and Open Access Publishing Fund of the Karlsruhe
Institute of Technology (KIT). We thank Clemens Mathis from Wasserwirtschaft
Vorarlberg, Austria, for providing the case study data.
The article processing charges for this open-access
publication were covered by a research
center of the Helmholtz Association.
Edited by: Bettina Schaefli
Reviewed by: Yiwen Mei and one anonymous referee
Bellman, R.: Dynamic Programming, Princeton University Press, Princeton, USA, 1957.
Blower, G. and Kelsall, J. E.: Nonlinear Kernel Density Estimation for Binned Data: Convergence in Entropy, Bernoulli, 8, 423–449, 2002.
Blume, T., Zehe, E., and Bronstert, A.: Rainfall-runoff response, event-based runoff coefficients and hydrograph separation, Hydrolog. Sci. J., 52, 843–862, https://doi.org/10.1623/hysj.52.5.843, 2007.
Brunsell, N. A.: A multiscale information theory approach to assess spatial-temporal variability of daily precipitation, J. Hydrol., 385, 165–172, https://doi.org/10.1016/j.jhydrol.2010.02.016, 2010.
Chapman, T. G.: Entropy as a measure of hydrologic data uncertainty and model performance, J. Hydrol., 85, 111–126, https://doi.org/10.1016/0022-1694(86)90079-X, 1986.
Chow, V. T., Maidment, D. R., and Mays, L. W.: Applied Hydrology, McGraw-Hill, New York, USA, 1988.
Cover, T. M. and Thomas, J. A.: Elements of Information Theory, 2nd ed., John Wiley & Sons, New Jersey, USA, 2006.
Darbellay, G. A. and Vajda, I.: Estimation of the information by an adaptive partitioning of the observation space, IEEE T. Inform. Theory, 45, 1315–1321, 1999.
Darscheid, P.: Quantitative analysis of information flow in hydrological modelling using Shannon information measures, Karlsruhe Institute of Technology, Karlsruhe, Germany, 73 pp., 2017.
Darscheid, P., Guthke, A., and Ehret, U.: A Maximum-Entropy Method to Estimate Discrete Distributions from Samples Ensuring Nonzero Probabilities, Entropy, 20, 601, https://doi.org/10.3390/e20080601, 2018.
Eckhardt, K.: How to construct recursive digital filters for baseflow separation, Hydrol. Process., 19, 507–515, https://doi.org/10.1002/hyp.5675, 2005.
Ehret, U. and Zehe, E.: Series distance – an intuitive metric to quantify hydrograph similarity in terms of occurrence, amplitude and timing of hydrological events, Hydrol. Earth Syst. Sci., 15, 877–896, https://doi.org/10.5194/hess-15-877-2011, 2011.
Fawcett, T.: An introduction to ROC analysis Tom, Irbm, 35, 299–309, https://doi.org/10.1016/j.patrec.2005.10.010, 2005.
Gong, W., Yang, D., Gupta, H. V., and Nearing, G.: Estimating information entropy for hydrological data: One dimensional case, Water Resour. Res., 1, 5003–5018, https://doi.org/10.1002/2014WR015874, 2014.
Habibzadeh, F., Habibzadeh, P., and Yadollahie, M.: On determining the most appropriate test cut-off value: The case of tests with continuous results, Biochem. Medica, 26, 297–307, https://doi.org/10.11613/BM.2016.034, 2016.
Hall, F. R.: Base-Flow Recessions – A Review, Water Resour. Res., 4, 973–983, 1968.
Horton, R. E.: The role of infiltration in the hydrologic cycle, Trans. Am. Geophys. Union, 14, 446–460, 1933.
Hoyt, W. G. and others: Studies of relations of rainfall and run-off in the United States, Geol. Surv. of US, US Govt. Print. Off., Washington, 301 pp., available at: https://pubs.usgs.gov/wsp/0772/report (last access: 12 February 2019), 1936.
Knuth, K. H.: Optimal Data-Based Binning for Histograms, 2, 30, arXiv 2013, available at: https://arxiv.org/pdf/physics/0605197 (last access: 12 February 2019), 2013.
Koskelo, A. I., Fisher, T. R., Utz, R. M., and Jordan, T. E.: A new precipitation-based method of baseflow separation and event identification for small watersheds (<50 km2), J. Hydrol., 450–451, 267–278, https://doi.org/10.1016/j.jhydrol.2012.04.055, 2012.
Liu, D., Wang, D., Wang, Y., Wu, J., Singh, V. P., Zeng, X., Wang, L., Chen, Y., Chen, X., Zhang, L., and Gu, S.: Entropy of hydrological systems under small samples: Uncertainty and variability, J. Hydrol., 532, 163–176, https://doi.org/10.1016/j.jhydrol.2015.11.019, 2016.
Mei, Y. and Anagnostou, E. N.: A hydrograph separation method based on information from rainfall and runoff records, J. Hydrol., 523, 636–649, https://doi.org/10.1016/j.jhydrol.2015.01.083, 2015.
Merz, R. and Blöschl, G.: A regional analysis of event runoff coefficients with respect to climate and catchment characteristics in Austria, Water Resour. Res., 45, 1–19, https://doi.org/10.1029/2008WR007163, 2009.
Merz, R., Blöschl, G., and Parajka, J.: Spatio-temporal variability of event runoff coefficients, J. Hydrol., 331, 591–604, https://doi.org/10.1016/j.jhydrol.2006.06.008, 2006.
Mishra, A. K., Özger, M., and Singh, V. P.: An entropy-based investigation into the variability of precipitation, J. Hydrol., 370, 139–154, https://doi.org/10.1016/j.jhydrol.2009.03.006, 2009.
Nearing, G. S. and Gupta, H. V.: Information vs. Uncertainty as the Foundation for a Science of Environmental Modeling, eprint arXiv:1704.07512, 1–23, available at: http://arxiv.org/abs/1704.07512 (last access: 12 February 2019), 2017.
Pechlivanidis, I. G., Jackson, B., Mcmillan, H., and Gupta, H. V.: Robust informational entropy-based descriptors of flow in catchment hydrology, Hydrol. Sci. J., 61, 1–18, https://doi.org/10.1080/02626667.2014.983516, 2016.
Ruddell, B. L. and Kumar, P.: Ecohydrologic process networks: 1. Identification, Water Resour. Res., 45, 1–23, https://doi.org/10.1029/2008WR007279, 2009.
Seibert, S. P., Ehret, U., and Zehe, E.: Disentangling timing and amplitude errors in streamflow simulations, Hydrol. Earth Syst. Sci., 20, 3745–3763, https://doi.org/10.5194/hess-20-3745-2016, 2016.
Sharma, A. and Mehrotra, R.: An information theoretic alternative to model a natural system using observational information alone, Water Resour. Res., 50, 650–660, https://doi.org/10.1002/2013WR013845, 2014.
Simonoff, J. S.: Smoothing Methods in Statistics, Springer, Berlin/Heidelberg, Germany, 1996.
Solomatine, D., See, L. M., and Abrahart, R. J.: Data-Driven Modelling: Concepts, Approaches and Experiences, in: Practical hydroinformatics, Springer, Berlin, Heidelberg, Germany, 17–31, 2009.
Solomatine, D. P. and Ostfeld, A.: Data-driven modelling: some past experiences and new approaches, J. Hydroinform., 10, 3–22, https://doi.org/10.2166/hydro.2008.015, 2008.
Thiesen, S., Darscheid, P., and Ehret, U.: Event Detection Method Based on Information Theory, Zenodo, https://doi.org/10.5281/zenodo.1404638, 2018.
Weijs, S. V.: Information Theory for Risk-based Water System Operation, Technische Universiteit Delft, Delft, the Netherlands, 210 pp., 2011.
A detailed discussion about the cut-off values of the ROC curve can be found in Habibzadeh et al. (2016).