the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Oct 2018
| 02 Oct 2018
Technical note: An improved Grassberger–Procaccia algorithm for analysis of climate system complexity
Chongli Di
Tiejun Wang
Xiaohua Yang
Siliang Li
Understanding the complexity of natural systems, such as climate systems, is critical for various research and application purposes. A range of techniques have been developed to quantify system complexity, among which the Grassberger–Procaccia (G-P) algorithm has been used the most. However, the use of this method is still not adaptive and the choice of scaling regions relies heavily on subjective criteria. To this end, an improved G-P algorithm was proposed, which integrated the normal-based K-means clustering technique and random sample consensus (RANSAC) algorithm for computing correlation dimensions. To test its effectiveness for computing correlation dimensions, the proposed algorithm was compared with traditional methods using the classical Lorenz and Henon chaotic systems. The results revealed that the new method outperformed traditional algorithms in computing correlation dimensions for both chaotic systems, demonstrating the improvement made by the new method. Based on the new algorithm, the complexity of precipitation, and air temperature in the Hai River basin (HRB) in northeastern China was further evaluated. The results showed that there existed considerable regional differences in the complexity of both climatic variables across the HRB. Specifically, precipitation was shown to become progressively more complex from the mountainous area in the northwest to the plain area in the southeast, whereas the complexity of air temperature exhibited an opposite trend, with less complexity in the plain area. Overall, the spatial patterns of the complexity of precipitation and air temperature reflected the influence of the dominant climate system in the region.
- Article
(1262 KB) - Full-text XML
- BibTeX
- EndNote





There are increasing interests in understanding system complexity, ranging from natural phenomena to social behaviors (Bras, 2015; Lin et al., 2015; Wang et al., 2016). As an open system with random external forcings and nonlinear dissipation, climate systems are highly complex (Nicolis and Nicolis, 1984; Jayawardena and Lai, 1994; Rind, 1999; Wang et al., 2015). Owing to nonlinear interactions among atmosphere, hydrosphere, and biosphere, climatic variables exhibit highly nonlinear and dynamic characteristics, which reflect the complexity of climate systems (Palmer, 1999; Rial et al., 2004; Sivakumar, 2005; Wu et al., 2010). It is thus imperative to quantitatively measure the complexity of climatic variables for understanding underlying processes. However, no common definition of system complexity exists in scientific communities, particularly from a mathematical perspective (Carbone et al., 2016). To resolve this issue, numerous concepts and methods, including chaos theory, wavelet analysis, and dynamical analysis, have been proposed to describe the complexity of climate systems (Lorenz, 1963; Di et al., 2014; Feldhoff et al., 2015; Sivakumar, 2017; Meseguer-Ruiz et al., 2017). For instance, the chaos theory has been extensively used to characterize the chaotic and nonlinear features of climate systems (Sivakumar, 2001). Overall, previous studies based on the chaos theory revealed that the time series of air temperature and precipitation is nonstationary with abundant information. The complexity of rainfall and temperature dynamics has been widely used to indicate the extent of the complexity of climate systems (Dhanya and Kumar, 2010; Gan et al., 2002).
One of the important parameters in the chaos theory is correlation dimension, which can be used to measure the complexity and chaotic properties of variables, including precipitation and streamflow (Sivakumar et al., 2002; Dhanya and Kumar, 2011; Kyoung et al., 2011; Lana et al., 2016). Conceptually, the correlation dimension of a variable indicates the number of primary controls of the variable and thus determines the degree of freedom of the underlying process (Sivakumar and Singh, 2012). Despite the wide applications in various scientific fields, the use of the correlation dimension method is still hindered by certain limitations. For instance, the dimension method proposed by Grassberger and Procaccia (1983b) (denoted as the G-P method hereafter) is commonly used in the fields of hydrology and atmospheric science; however, its calculation procedures are still problematic (Ji et al., 2011). Specifically, the G-P method utilizes phase space reconstruction (Packard et al., 1980) and the embedding theorem (Takens, 1981) to compute correlation dimensions, which requires selection of an appropriate scaling region. The scaling region is a domain, over which an object exhibits self-similarity across a range of scales. However, the G-P method relies on visual inspections for choosing scaling regions, which is subject to human errors (Sprott and Rowlands, 2001). To tackle this problem, alternative methods have been developed to improve the original G-P method (Maragos and Sun, 1993). For example, Jothiprakash and Fathima (2013) utilized empirical equations to calculate the upper limit of scaling regions. Ji et al. (2011) applied the clustering analysis technique to determine scaling regions. However, these existing methods for identifying scaling regions are still not adaptive and the choice of scaling regions relies heavily on subjective criteria, and the use of the least squares method for fitting straight lines to determine correlation exponents can include outliers (Cantrell, 2008) and thus is not optimal. Therefore, studies are still warranted to seek more objective and adaptive algorithms for identifying scaling regions to obtain more accurate estimates of correlation dimensions.
The primary aims of this study were twofold. First, a new algorithm was proposed to improve the original G-P method, which integrated the methods of normal estimation, K-means clustering (Lloyd, 1982) and random sample consensus (RANSAC; Fischler and Bolles, 1981). The classical Lorenz and Henon chaotic systems were chosen to test the effectiveness of the proposed algorithm for estimating correlation dimensions. Afterwards, the newly developed algorithm was utilized to investigate the nonlinear characteristics of precipitation and air temperature across the Hai River basin (HRB) in northeastern China. The HRB has been facing serious water shortage issues due to climate change and increasing water demand. Although previous studies have investigated climate variability (e.g., precipitation, air temperature, and evaporation) in the HRB from different perspectives (Bao et al., 2012; Sang et al., 2012; Chu et al., 2010a), to our best knowledge, there have been no attempts made so far to quantify the nonlinear characteristics of climatic variables, especially regarding their chaotic behaviors in the HRB, which is essential for understanding the nonlinearity of the climate system in the region. Furthermore, the HRB is a diverse hydroclimatic region with many subwatersheds of varying geographical and hydroclimatic conditions, which makes the region ideal for understanding the climate system complexity. The rest of this paper is organized as follows: Sect. 2 describes the calculation procedures of the proposed algorithm, which is then tested using classical mathematical models in Sect. 3. Section 4 describes the data obtained from the HRB and presents the results and analysis. Conclusions are made in the last part of this paper.
2.1 Algorithm for computing correlation dimension
Correlation dimensions can be used to identify the complexity of dynamical systems with varying complexity degrees (e.g., low-dimensional vs. high-dimensional systems). A wealth of algorithms have been developed for computing correlation dimensions, among which the G-P algorithm has been used most and is also adopted in this study. The G-P algorithm uses the concept of phase space reconstruction (Packard et al., 1980) from a single-variable time series. Here, the method of delays (Takens, 1981) was employed for reconstructing phase space. Given a time series Xi (i=1, ), a multi-dimensional phase space can be reconstructed as follows:
where , m is the dimension of Yj called embedding dimension, τ is delay time, and Xj is the reconstructed phase space vector.
For the m-dimensional reconstructed phase space, the correlation function C(r, m) is defined as follows:
where ∥Yi−Yj∥ is the Euclidean distance between the vectors Yi and Yj. H(x) is the Heaviside function with H(x)=1 for x>0 and H(x)=0 for x≤0, where and r is the vector norm (i.e., radius of a sphere) centered on Yi or Yj; rmin and rmax were set as the minimum and maximum distances between points, respectively (Ji et al., 2011; Lai and Lerner, 1998). If r≤rmin, none of the vector points falls within the volume element and . Otherwise, if r≥rmax, all vector points fall within the volume element and . If there exists an attractor in the reconstructed system, C(r, m) and r are related through the following relationship:
where α is a constant and D2(m) is the correlation exponent.
D2(m) is usually estimated using the least squares method by fitting a straight line through ln r vs. ln C(r, m). According to the relationship between D2(m) and m, the saturation value of D2(m) is defined as the correlation dimension. If the saturation value is low (e.g., a low correlation dimension), the system is considered to exhibit low-dimensional deterministic dynamics (i.e., a chaotic system); otherwise, the system is a stochastic one. The range over which the straight line is fitted through ln r vs. ln C(r, m) is called the scaling region, where the slope is defined. Clearly, choosing an appropriate scaling region is critical for computing correlation dimensions. In previous studies, scaling regions are usually determined by visual inspections, and this will be prone to individual preferences and thus not objective. Therefore, an objective method with adaptive procedures for computing correlation dimensions is still desired.
2.2 Scaling region identification
To overcome the limitation of the original G-P algorithm for selecting scaling regions, we propose an adaptive identification algorithm of scaling regions, which utilizes the normal-based K-means clustering technique and the RANSAC algorithm. The use of the normal-based K-means clustering technique is to partition all normals of the scatter points into K clusters with high similarity and to remove the points that are outside of the range of the scaling region. The RANSAC algorithm was introduced to fit a straight line through the log-transformed points obtained by the normal-based K-means clustering technique, which had been shown to outperform the traditional least squares method for fitting straight lines (Kyoung, 2011; Ji et al., 2011). To illustrate the advantages of using the RANSAC algorithm for linear fitting, a hypothetical example is shown in Fig. 1, which compares the fitting results obtained from the RANSAC algorithm and the traditional least squares method. The input data are sampled from a line y=0.5x, with added noises and outliers. Here, for the RANSAC algorithm, the inliers are the points used to fit the line, whereas the outliers are removed from the line fitting. It can be seen from Fig. 1 that the fitting line (; R2=0.854) obtained from the least squares method is seriously affected by outliers and deviated from the original line y=0.5x. By contrast, the RANSAC method is able to distinguish the inliers from outliers effectively and results in a satisfactory fitting line (; R2=0.990), demonstrating the advantage of using the RANSAC algorithm for linear fitting.
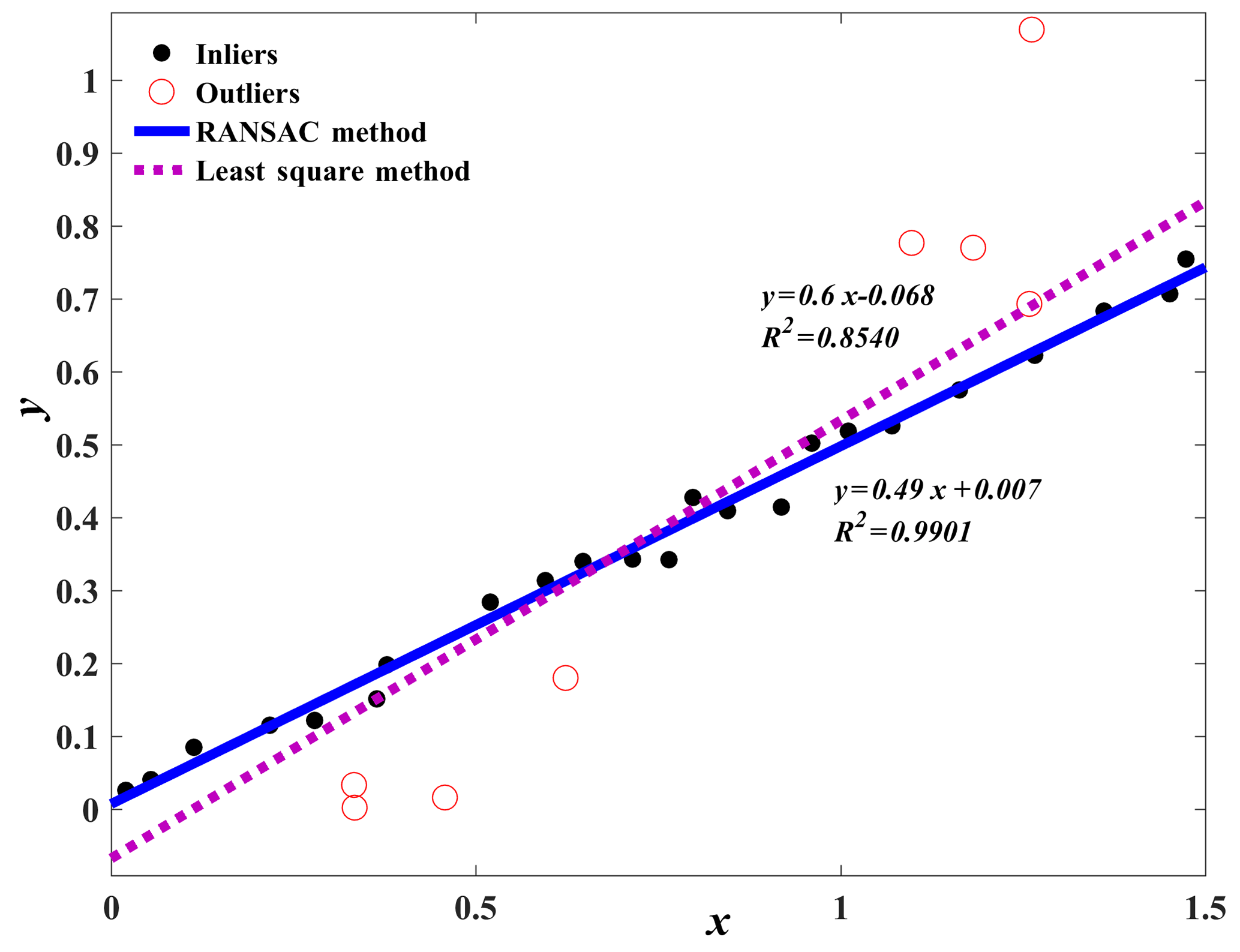
Figure 1Comparison of the fitted lines obtained from the RANSAC algorithm and the least squares method.
The flow chart of the proposed procedures for calculating correlation dimensions is given in Fig. 2, which consists of five major steps:
-
For the time series x(t), the time delay τ is computed by an autocorrelation function (Liebert and Schuster, 1989). Then the minimum embedding dimension mmin=2 was set and the phase space was reconstructed by increasing m to obtain the correlation exponent function C(r, m).
-
The normals of the scatter points on the ln r ∼ ln C(r, m) line are estimated via principal component analysis (Mitra et al., 2004).
-
The K-means clustering technique is performed on the normal set N with K=2 to obtain two different clusters. Set a threshold value T to determine the angle α between the two clusters. If α>T, the data set with larger differences in normals is discarded. Then, the K-means clustering technique is repeated on the remaining data set until α≤T.
-
The RANSAC algorithm is used to fit a straight line through the set of remaining scatter points.
-
The slope of the line obtained from the RANSAC method is computed to acquire the correlation dimension D2(m) for each m. Finally, the saturation correlation dimension is determined using the plot D2(m) vs. m.
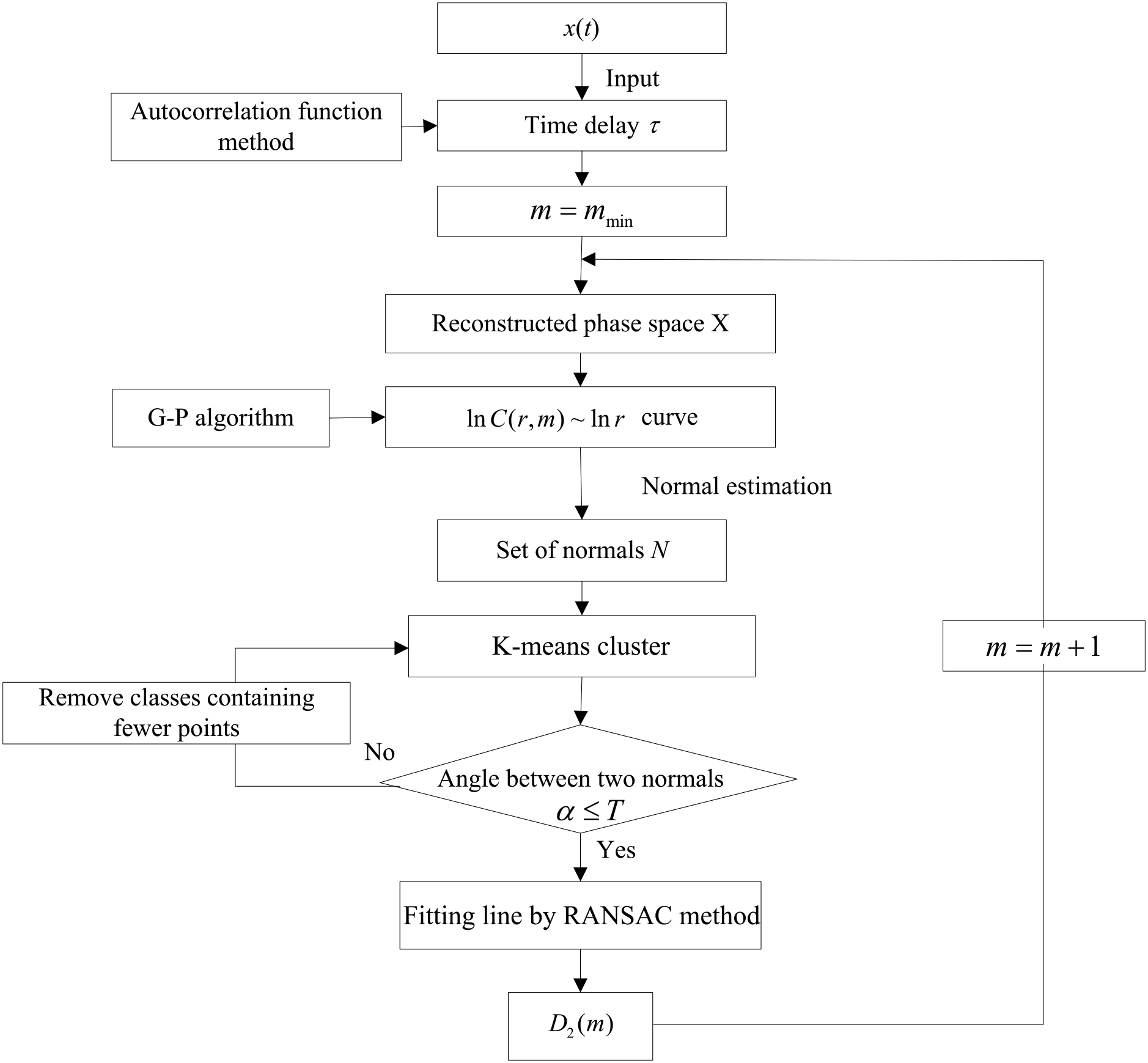
Figure 2Flow chart of the proposed algorithm for computing correlation dimensions (the details are listed in the text).
To test the effectiveness of the proposed algorithm, the classical chaotic models of Lorenz (1963) in Eq. (4) and Henon (1976) in Eq. (5) were used. The Lorenz and Henon systems with existing theoretical correlation dimensions have been studied the most in the past and thus widely used to analyze the chaotic behavior in climate systems and to test the effectiveness of algorithms for computing climate system complexity (e.g., Grassberger and Procaccia, 1983a; Lai and Lerner, 1998; Ji et al., 2011).
where σ=10, b=28, and in Eq. (4), and a=1.4 and b=0.3 in Eq. (5). The theoretical dimensions of the Lorenz and the Henon systems are 2.05±0.01 and 1.25±0.02, respectively (Grassberger and Procaccia, 1983a). As a comparison, the results obtained by our proposed method were compared with the theoretical dimensions and the values obtained by another two commonly used algorithms, including the intuitive judgment method (IJM) and the point-based K-means clustering method (PKC).
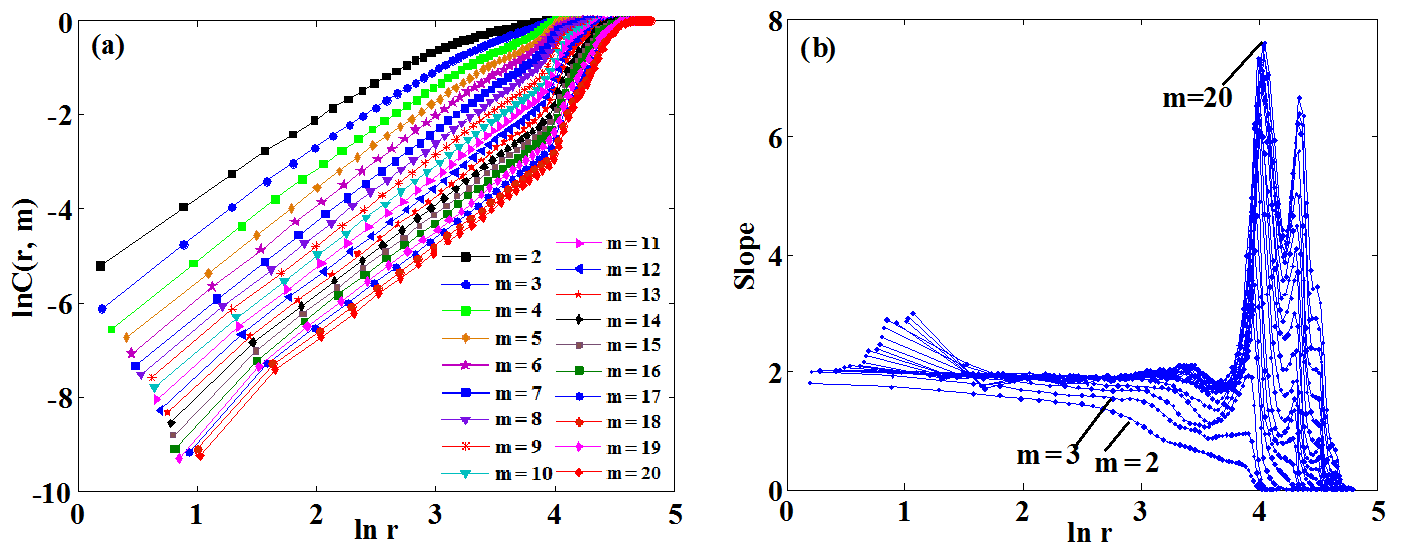
Figure 3Correlation integral as a function of r, with embedding dimension m ranging from 2 to 20 for the Lorenz attractor: (a) ln C(r, m) vs. ln r, (b) the slopes of ln C(r, m) vs. ln r.
According to the autocorrelation function, the time delay τ was determined to be 10 for the Lorenz system, with m varying from 2 to 20. Figure 3a shows the relationship between ln C(r, m) and ln r, with m ranging from 2 to 20. Figure 3b shows the slopes of ln C(r, m) against ln r by increasing the embedding dimension m (i.e., the bottom curves are associated with smaller m values in Fig. 3b). The threshold value T was set as 5∘ and K was set as 2. The scaling regions of the curves in Fig. 3a were determined using the normal-based K-means clustering technique. As an example, an arbitrary curve was first selected from Fig. 3a, and the results are presented in Fig. 4. It can be seen from Fig. 4 that the process of the proposed method for determining the scaling region is adaptive. Specifically, for the selected curve shown in Fig. 4a, the normals of the curve were first computed based on Step 2 and the results are plotted in Fig. 4b. Different from previous K-means methods (e.g., the point-based K-means clustering method), we measured the similarity of points using the diversity between normals of different points. The reason for using the normal-based method is that the directions of normals for different points may vary considerably (see Fig. 4b), whereas for the point-based K-means method, the distance between different points might be small, making it difficult to separate the points into different clusters (Fig. 3a). The obtained two separate clusters of the normals (in red and blue) are shown in Fig. 4c. If the angle α between the two clusters was larger than T, the one with larger differences in normals was discarded. Then, the K-means clustering technique was performed again on the remaining data set. This process was usually repeated for 2–3 times until α≤T (e.g., Fig. 4c to e). The final scaling region was determined as shown in Fig. 4f.
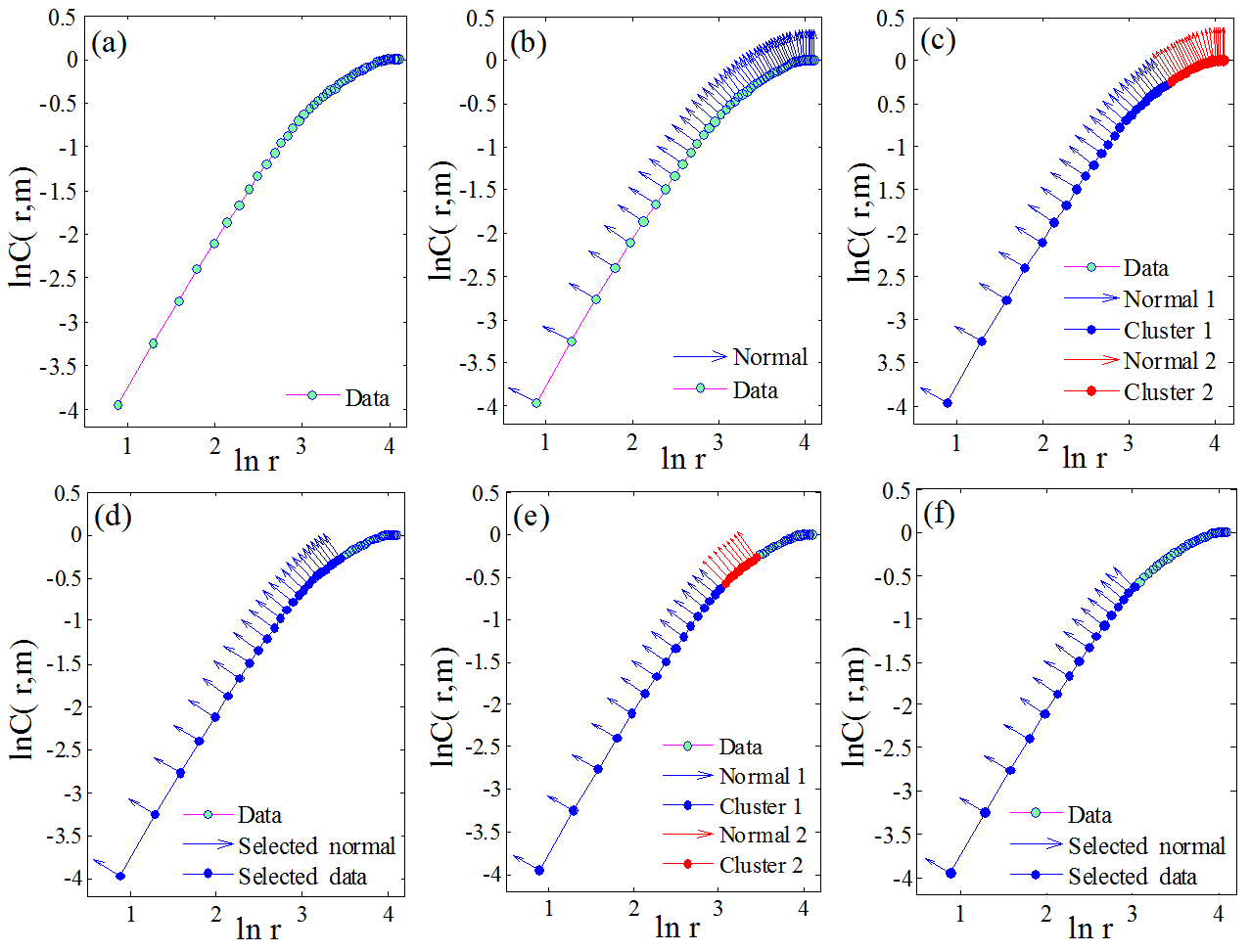
Figure 4Illustration of using the normal-based K-means clustering technique for determining the scaling region. The curve shown here was randomly selected from Fig. 3.
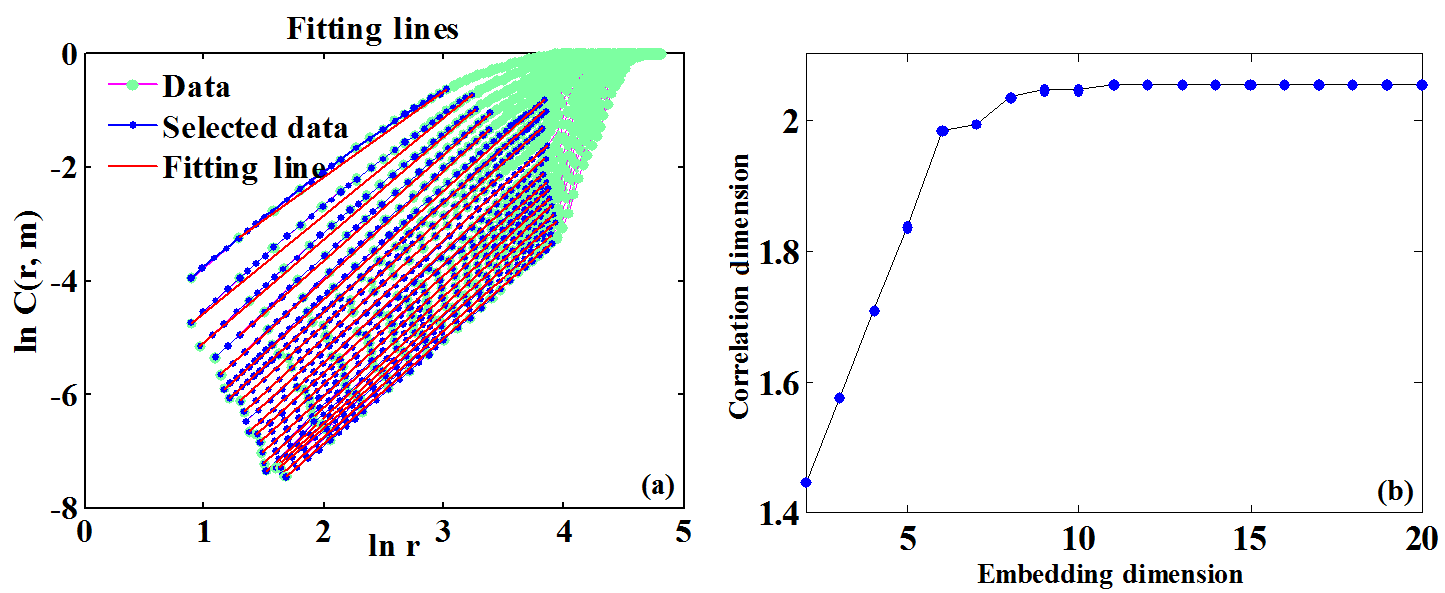
Figure 5The final fitted lines and the correlation dimension of the Lorenz system: (a) the final fitted lines through the scaling regions and (b) correlation dimensions as a function of embedding dimension.
Figure 5a shows the final fitted lines through the scaling regions using the RANSAC method. The slope of the fitted line is the correlation dimension for each corresponding m. Figure 5b presents the graph of D2(m) against m with the value of m varying from 2 to 20. From Fig. 5b, we can see that D2(m) was saturated when m>5 with the saturation value approximately equal to 2.054, which was comparable to the theoretical value of the correlation dimension for the Lorenz attractor (i.e., 2.05±0.01). Following the same procedures, the obtained correlation dimension for the Henon attractor was 1.243, which was also close to its theoretical value (i.e., 1.25±0.02).
To verify the accuracy of our algorithm for computing correlation dimensions, the results derived from the proposed algorithm were compared with the ones obtained from the IJM and PKC methods. The IJM method was based on visual inspections to determine scaling regions (Jothiprakash and Fathima, 2013), while the PKC method integrated the K-means algorithm and the point-slope-error technique to determine scaling regions (Ji et al., 2011). The obtained correlation dimensions are reported in Table 1. For the Lorenz system, the differences in the correlation dimensions between the theoretical value and the ones obtained from IJM and PKC were 0.18±0.01 and 0.014±0.01, respectively, whereas the difference was much smaller for the newly proposed algorithm (i.e., 0.004±0.01). Similar conclusions can be also made for the Henon system, demonstrating the improved performance of the proposed algorithm for determining correlation dimensions. It should be stressed that despite the improvement made by our proposed algorithm, further studies are still needed to address the issues in the computation of correlation dimensions. For example, estimation of correlation dimensions is partly dependent on the proper selection of time delay and embedding dimension; therefore, the impacts of their uncertainties should be further assessed.
Table 1Comparison of the correlation dimensions derived from different methods. TCD: theoretical correlation dimension; IJM: intuitive judgment method; PKC: point-based K-means clustering; NPA: newly proposed algorithm.

The correlation dimension method is an important diagnostic tool for understanding the complexity of natural systems with chaotic characteristics. In this section, a case study is presented to illustrate the use of the newly developed algorithm for studying the complexity of climate systems. Specifically, the algorithm was first utilized to compute the correlation dimensions of precipitation and air temperature using time series obtained from the HRB. Afterwards, the regional patterns of correlation dimensions for precipitation and air temperature in the HRB were analyzed.
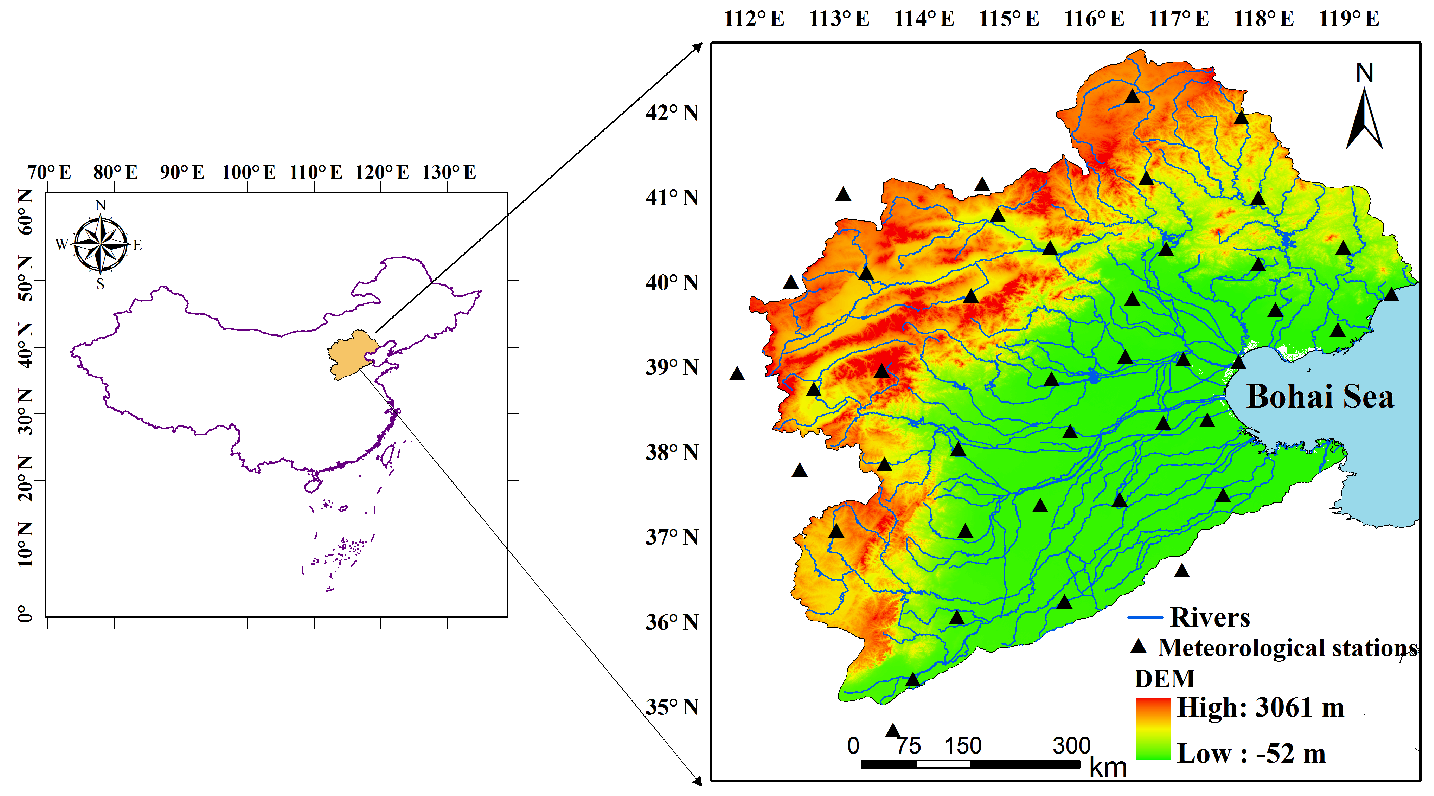
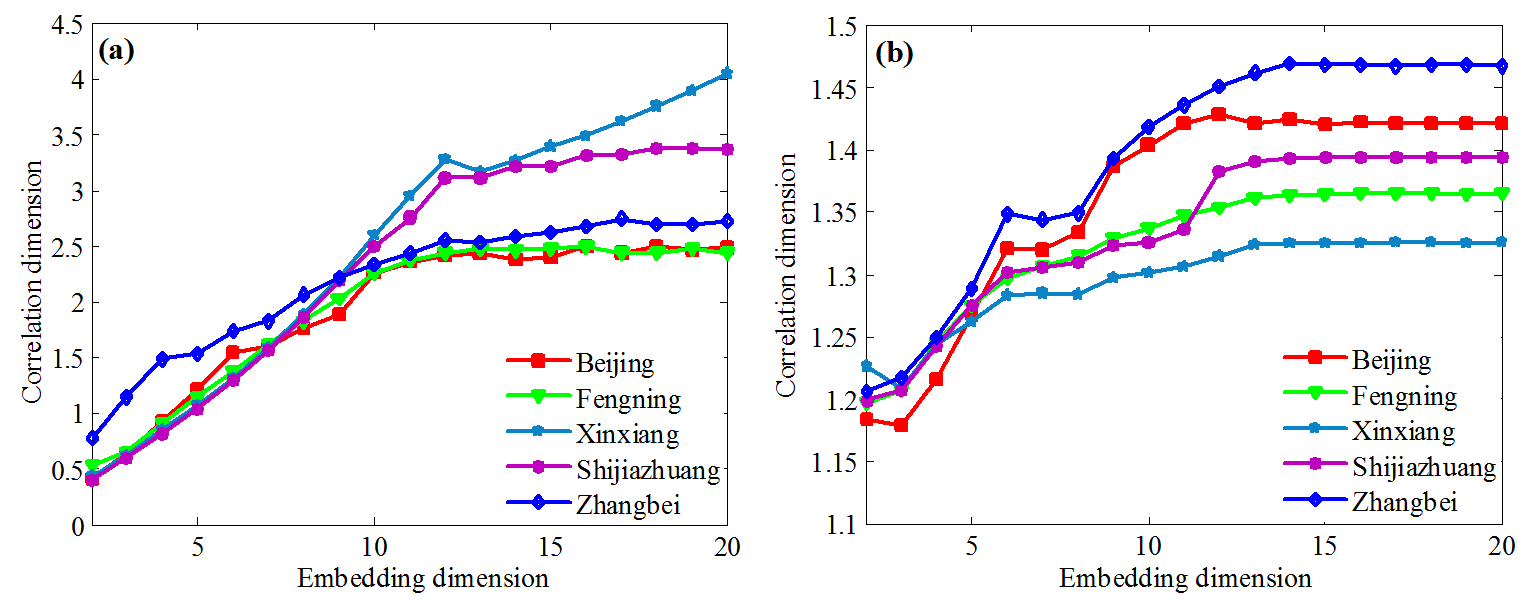
Figure 7Variation of correlation dimension vs. embedding dimension of climate variables: (a) precipitation and (b) air temperature.
4.1 Study area and data
The HRB is located in northeastern China (112–120∘ E, 35–43∘ N; Fig. 6), which hosts one of the most important economic zones in China (White et al., 2015). Under the influences of climate change and human activities, complex water issues have become increasingly prominent in the HRB (Liu and Xia, 2004). Topography varies considerably across the area, with 22 % of the total area for mountains in the western and northern parts, 40 % for plains in the eastern and southern parts, and 38 % for hilly areas in the central part. The regional climate in the HRB is of a semiarid or subhumid type, with mean annual precipitation of 539.0 mm year−1 and mean annual temperature of 10.2 ∘C. Mean annual precipitation increases from the mountainous areas in the west to the plains in the east, while mean annual temperature decreases from south to north. In addition, precipitation in the HRB exhibits significant interdecadal and interannual variations. To apply the proposed algorithm for computing correlation dimensions, monthly precipitation and air temperature data spanning from 1951 to 2016 were retrieved from 40 meteorological stations in the HRB and nearby areas (Fig. 6), which were operated by the China Meteorological Administration (http://data.cma.cn/site/index.html, last access: 28 September 2018).
4.2 Results and analysis
The correlation dimensions of precipitation and air temperature at all 40 meteorological stations were computed using the algorithm proposed in this study. Figure 7 shows the relationships between correlation dimension and embedding dimension for precipitation and air temperature at five representative stations across the HRB (i.e., Beijing, Fengning, Shijiazhuang, Xinxiang, and Zhangbei). The embedding dimensions of precipitation and air temperature for the five stations varied between 10 and 12. It is evident that the relationship between correlation dimension and embedding dimension for precipitation and air temperature differed among the selected stations. In general, correlation dimensions for precipitation showed gradual saturation processes with respective saturation values of 2.378, 2.407, 3.055, and 2.550 for Beijing, Fengning, Shijiazhuang, and Zhangbei stations, respectively (Fig. 7a), indicating chaotic dynamical characteristics of precipitation. By comparison, the correlation dimension for precipitation at the Xinxiang station increased with increasing embedding dimensions, suggesting random characteristics of precipitation. For air temperature, the correlation dimensions at the five stations also showed gradual saturation processes (Fig. 7b), suggesting low dimensional chaotic characteristics for air temperature.
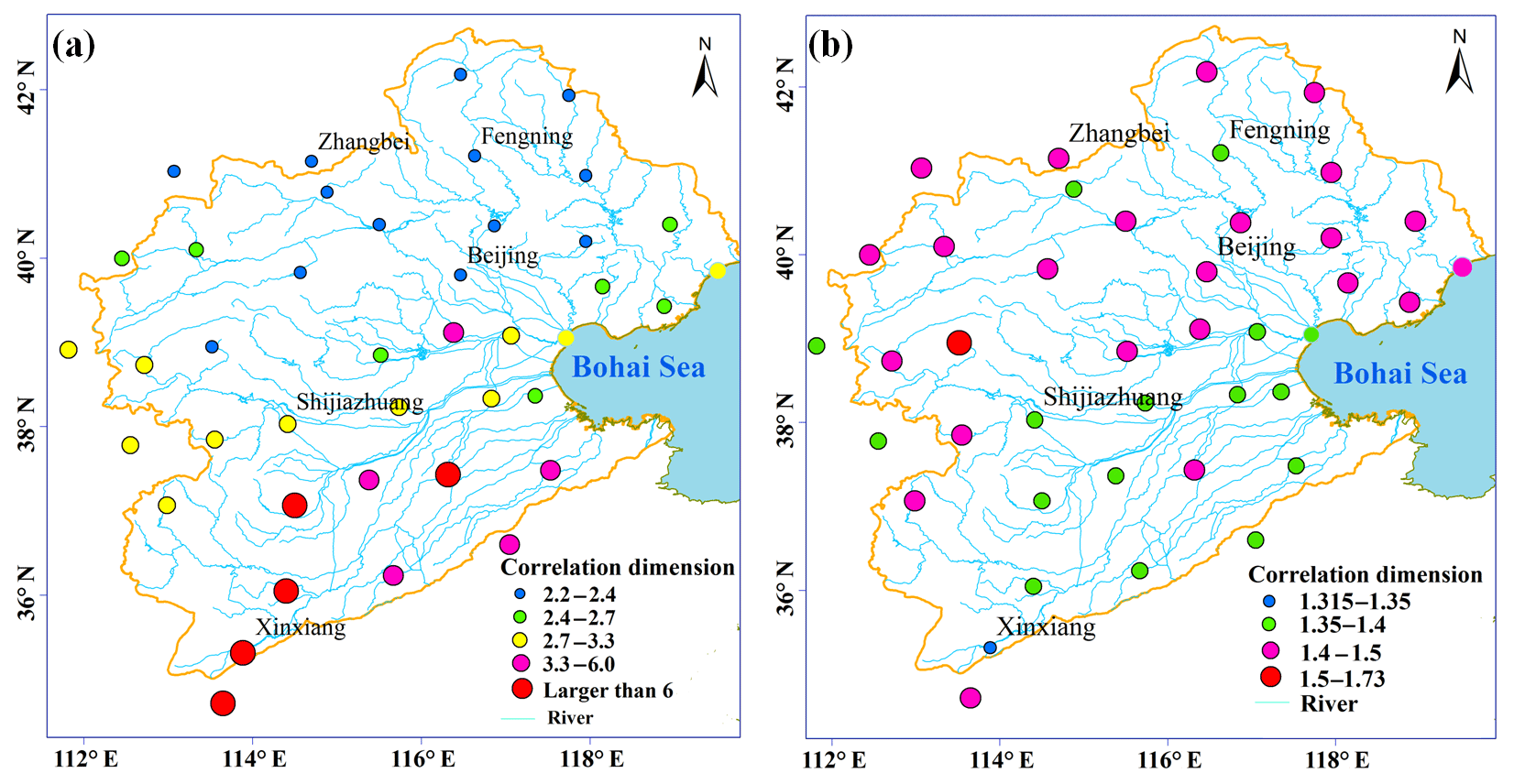
Figure 8The spatial distribution of the correlation dimension values for all the 40 stations: (a) precipitation and (b) temperature.
Figure 8 presents the spatial distributions of the saturated correlation dimensions at the 40 meteorological stations for precipitation and air temperature in the HRB. For both precipitation and air temperature, the correlation dimensions varied markedly across the area. The correlation dimension for precipitation ranged from less than 3 to more than 6, while the correlation dimension was much lower for temperature (i.e., less than 2). Overall, the ranges of the correlation dimensions for precipitation and air temperature were comparable to previously reported values in other regions with similar climatic conditions (Kyoung et al., 2011; Sivakumar and Singh, 2012; Sivakumar et al., 2014). More importantly, the considerable spatial variations in the dimensionality for both climatic variables suggest the regional differences in the complexity of the climate system in the HRB. Specifically, the correlation dimension for precipitation tended to be smaller in the northwestern mountainous area, with values of less than 2.5. In the central area, the correlation dimension for precipitation became larger, with values of greater than 3, while precipitation in the southeastern plain area showed very high correlation dimensions, with values of larger than 6. Given that correlation dimensions indicate the number of controls on the underlying process (Sivakumar and Singh, 2012), Fig. 8a suggests that precipitation processes become progressively more complex from the mountainous area to the plain area in the HRB. Interestingly, the regional pattern of the correlation dimension for air temperature showed an opposite trend with smaller values mainly located in the northern HRB, indicating more complex temporal dynamics of air temperature in the area.
The spatial pattern of the correlation dimension for precipitation in the HRB may be largely attributed to the regional flow pathway of moisture flux, which is mainly controlled by the East Asian Summer Monsoon (EASM). The HRB is located in a monsoon-dominated region, where the EASM plays a leading role in the regional meteorological system. Chen et al. (2013) showed that the EASM had significant impacts on the spatiotemporal distribution of precipitation in eastern China. Li et al. (2017) further suggested that there was a significant correlation between precipitation and the EASM index in the HRB. Wang et al. (2011) revealed that large-scale atmospheric circulations had close relationships with precipitation patterns in the HRB by analyzing the moisture flux derived from NCAR/NCEP reanalysis data. Influenced by the large-scale atmospheric circulation, precipitation in the middle and southeast parts of the HRB is more sensitive to climate variability due to their locations closer to the ocean. This leads to the decreasing trend of precipitation from the southeast to the northwest in the HRB, suggesting that the supply of moisture for precipitation in the region mainly comes from the ocean.
Partly owing to the closer geographical proximity to the ocean (Fig. 8), the EASM has a stronger impact on precipitation in the southern and central areas than in the northern part of the HRB. Furthermore, at the north corner of the HRB, the westerlies primarily affect the hydrometeorological system and thus weaken the impact of the EASM on precipitation (Li et al., 2017). In addition, other factors (e.g., topography, vegetation distribution, and human activity) may also have impacts on regional patterns of climate variables. In particular, the Yan and Taihang mountain range located in the northwestern HRB obstructs the vapor transport driven by the EASM, resulting in lower spatiotemporal variability in precipitation in the northern part of the HRB. As a result, precipitation had higher degrees of complexity in the southern HRB, while its complexity was lower in the mountainous area in the northwestern HRB. As for air temperature, the orographic effect on air temperature might be stronger in the mountainous area (Chu et al., 2010b), resulting in the higher complexity of temperature in this area. However, it should be noted that the range of the correlation dimension for air temperature from 1.0 to 2.0 suggests that two primary controls on temperature exist at all stations across the region.
In this study, the original G-P algorithm for calculating correlation dimensions was modified by incorporating the normal-based K-means clustering technique and the RANSAC algorithm. Using the proposed method, the spatial patterns of the complexity of precipitation and air temperature in the HRB were analyzed. The following conclusions were reached:
-
The effectiveness of the proposed method for calculating correlation dimensions was illustrated using the classical Lorenz and Henon chaotic systems. The results showed that the new method outperformed the traditional intuitive judgment and point-based K-means clustering method for computing correlation dimensions.
-
Except for few stations in the northern region, precipitation at most of the meteorological stations in the HRB showed chaotic behaviors. Specifically, the correlation dimension for precipitation showed an increasing trend from the mountainous region in the northwest to the plain area in the southeast, indicating that precipitation processes became progressively more complex from the mountainous area to the plain area. The spatial pattern of the complexity of precipitation reflected the influence of the dominant climate system in the region. Meanwhile, air temperature at all meteorological stations showed chaotic characteristics. In contrast to precipitation, the complexity of air temperature exhibited an opposite trend, with less complexity in the plain area.
The modified G-P algorithm proposed in this study can be used more objectively to characterize the complexity of climate systems (and other hydrological systems, such as streamflow, soil moisture, and groundwater) and thus provide a more reliable estimate of the number of dominant factors governing climate systems. Theoretically, it can provide valuable information for optimizing the number of parameters in climate models to reduce computational demands and model parameter uncertainties. Furthermore, the findings of this study can be used for the regionalization of hydrometeorological systems in the HRB, which has important significance in prediction in ungaged areas (Lebecherel et al., 2016). It should be noted that more studies are still required to verify the present results using other nonlinear techniques, such as the Lyapunov exponent (Wolf et al., 1985) and approximate entropy (Pincus, 1995), which might provide additional insights into climate complexity analysis.
The data sets used in this study are publicly available. The monthly precipitation and temperature data can be downloaded from the China Meteorological Administration Network (http://data.cma.cn/site/index.html, last access: 28 September 2018). The code for computing correlation dimension can be acquired from the first author, Chongli Di.
CD performed the improved method, experiments and algorithm coding. CD and TW conceived the framework and analysis of the paper. XY contributed to data collection. SL took part in the data analysis. All the authors contributed to writing and revising the paper.
The authors declare that they have no conflict of interest.
The work was supported by the National Key R&D Program of China (no. 2016YFA0601002, no. 2016YFC0401305, and no. 2017YFC0506603), and by the
National Natural Scientific Foundation of China (no. 51679007 and no.
U1612441). The authors would also like to acknowledge the financial support
from the Tianjin University, and Tiejun Wang also acknowledges the financial
support from the Thousand Talent Program for Young Outstanding Scientists
for this study.
Edited by: Dimitri Solomatine
Reviewed by: Nagesh Kumar Dasika and one anonymous referee
Bao, Z. X., Zhang, J. Y., Wang, G. Q., Fu, G. B, He, R. M., Yan, X. L., Jin, J. L., Liu, Y. L., and Zhang, A. J.: Attribution for decreasing streamflow of the Haihe River basin, northern China: Climate variability or human activities?, J. Hydrol., 460, 117–129, https://doi.org/10.1016/j.jhydrol.2012.06.054, 2012.
Bras, R. L.: Complexity and organization in hydrology: A personal view, Water Resour. Res., 51, 6532–6548, https://doi.org/10.1002/2015WR016958, 2015.
Cantrell, C. A.: Technical Note: Review of methods for linear least-squares fitting of data and application to atmospheric chemistry problems, Atmos. Chem. Phys., 8, 5477–5487, https://doi.org/10.5194/acp-8-5477-2008, 2008.
Carbone, A., Jensen, M., and Sato, A. H.: Challenges in data science: a complex systems perspective, Chaos Soliton. Fract., 90, 1–7, https://doi.org/10.1016/j.chaos.2016.04.020, 2016.
Chen, F., Yuan, Y. J., Wei, W. S., Fan, Z. A., Yu, S. L., Zhang, T. W., Zhang, R. B., Shang, H. M., and Qin, L.: Reconstructed precipitation for the north-central China over the past 380 years and its linkages to East Asian summer monsoon variability, Quat. Int., 283, 36–45, https://doi.org/10.1016/j.quaint.2012.05.047, 2013.
Chu, J. T., Xia, J., Xu, C. Y., Li, L., and Wang, Z. G.: Spatial and temporal variability of daily precipitation in Haihe River basin, 1958–2007, J. Geogr. Sci., 20, 248–260, https://doi.org/10.1007/s11442-010-0248-0, 2010a.
Chu, J. T., Xia, J., Xu, C. Y., and Singh, V. P.: Statistical downscaling of daily mean temperature, pan evaporation and precipitation for climate change scenarios in Haihe River, China, Theor. Appl. Climatol., 99, 149–161, https://doi.org/10.1007/s00704-009-0129-6, 2010b.
Dhanya, C. T. and Kumar, D. N.: Nonlinear ensemble prediction of chaotic daily rainfall, Adv. Water Resour., 33, 327–347, https://doi.org/10.1016/j.advwatres.2010.01.001, 2010.
Dhanya, C. T. and Kumar, D. N.: Multivariate nonlinear ensemble prediction of daily chaotic rainfall with climate inputs, J. Hydrol., 403, 292–306, https://doi.org/10.1016/j.jhydrol.2011.04.009, 2011.
Di, C. L., Yang, X. H., and Wang, X. C.: A four-stage hybrid model for hydrological time series forecasting, Plos One, 9, e104663, https://doi.org/10.1371/journal.pone.0104663, 2014.
Feldhoff, J. H., Lange, S., Volkholz, J., Donges, J. F., Kurths, J., and Gerstengarbe, F.: Complex networks for climate model evaluation with application to statistical versus dynamical modeling of South American climate, Clim. Dynam., 44, 1567–1581, https://doi.org/10.1007/s00382-014-2182-9, 2015.
Fischler, M. A. and Bolles, R. C.: Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography, Commun. ACM, 24, 381–395, 1981.
Gan, T. Y., Wang, Q., and Seneka, M.: Correlation dimensions of climate sub-systems and their geographic variability, J. Geophys. Res.-Atmos., 107, 4728, https://doi.org/10.1029/2001JD001268, 2002.
Grassberger, P. and Procaccia, I.: Characterization of strange attractors, Phys. Rev. Lett., 50, 346–349, https://doi.org/10.1103/PhysRevLett.50.346, 1983a.
Grassberger, P. and Procaccia, I.: Measuring the strangeness of strange attractors, Physica D, 9, 189–208, https://doi.org/10.1016/0167-2789(83)90298-1, 1983b.
Henon, M.: A two-dimensional mapping with a strange attractor, Commun. Math. Phys., 50, 69–77, https://doi.org/10.1007/BF01608556, 1976.
Jayawardena, A. W. and Lai, F.: Analysis and prediction of chaos in rainfall and stream flow time series, J. Hydrol., 153, 23–52, https://doi.org/10.1016/0022-1694(94)90185-6, 1994.
Ji, C. C., Zhu, H., and Jiang, W.: A novel method to identify the scaling region for chaotic time series correlation dimension calculation, Chinese Sci. Bull., 56, 925–932, https://doi.org/10.1007/s11434-010-4180-6, 2011.
Jothiprakash, V. and Fathima, T. A.: Chaotic analysis of daily rainfall series in Koyna reservoir catchment area, India, Stoch. Env. Res. Risk A., 27, 1371–1381, https://doi.org/10.1007/s00477-012-0673-y, 2013.
Kyoung, M. S., Kim, H. S., Sivakumar, B., Singh, V. P., and Ahn, K. S.: Dynamic characteristics of monthly rainfall in the Korean Peninsula under climate change, Stoch. Env. Res. Risk A., 25, 613–625, https://doi.org/10.1007/s00477-010-0425-9, 2011.
Lai, Y. C. and Lerner, D.: Effective scaling regime for computing the correlation dimension from chaotic time series, Physica D, 115, 1–18, https://doi.org/10.1016/S0167-2789(97)00230-3, 1998.
Lana, X., Burgueno, A., Martinez, M. D., and Serra, C.: Complexity and predictability of the monthly Western Mediterranean Oscillation index, Int. J. Climatol., 36, 2435–2450, https://doi.org/10.1002/joc.4503, 2016.
Lebecherel, L., Andreassian, V., and Charles, P.: On evaluating the robustness of spatialproximity-based regionalization methods, J. Hydrol., 539, 196–203, https://doi.org/10.1016/j.jhydrol.2016.05.031, 2016.
Li, F. X., Zhang, S. Y., Chen, D., He, L., and Gu, L. L.: Inter-decadal variability of the east Asian summer monsoon and its impact on hydrologic variables in the Haihe River Basin, China, J. Resour. Ecol., 8, 174–184, https://doi.org/10.5814/j.issn.1674-764X.2017.02.008, 2017.
Liebert, W. and Schuster, H. G.: Proper choice of the time delay for the analysis of chaotic time series, Phys. Lett. A, 142, 107–111, https://doi.org/10.1016/0375-9601(89)90169-2, 1989.
Lin, H., Vogel, H., Phillips, J., and Fath, B. D.: Complexity of soils and hydrology in ecosystems, Ecol. Model., 298, 1–3, https://doi.org/10.1016/j.ecolmodel.2014.11.016, 2015.
Liu, C. and Xia, J.: Water problems and hydrological research in the Yellow River and the Huai and Hai River basins of China, Hydrol. Process., 18, 2197–2210, https://doi.org/10.1002/hyp.5524, 2004.
Lloyd, S. P.: Least squares quantization in PCM, IEEE Trans. Inf. Theory, 28, 129–137, https://doi.org/10.1109/TIT.1982.1056489, 1982.
Lorenz, E. N.: Deterministic nonperiodic flow, J. Atmos. Sci., 20, 130–141, https://doi.org/10.1175/1520-0469(1963)020<0448:TMOV<2.0.CO;2, 1963.
Maragos, P. and Sun, F.: Measuring the fractal dimension of signals: Morphological covers and iterative optimization, IEEE Trans. Signal Process., 41, 108–121, https://doi.org/10.1109/TSP.1993.193131, 1993.
Meseguer-Ruiz, O., Olcina Cantos, J., Sarricolea, P., and Martin-Vide, J.: The temporal fractality of precipitation in mainland Spain and the Balearic Islands and its relation to other precipitation variability indices, Int. J. Climatol., 37, 849–860, https://doi.org/10.1002/joc.4744, 2017.
Mitra, N. J., Nguyen, A. N., and Guibas, L.: Estimating surface normals in noisy point cloud data, J. Comput. Geom. Appl., 14, 261–276, https://doi.org/10.1145/777792.777840, 2004.
Nicolis, C. and Nicolis, G.: Is there a climatic attractor?, Nature, 311, 529–532, https://doi.org/10.1038/311529a0, 1984.
Packard, N. H., Crutchfield, J. P., Farmer, J. D., and Shaw, R. S.: Geometry from a time series, Phys. Rev. Lett., 45, 712–716, https://doi.org/10.1103/PhysRevLett.45.712, 1980.
Palmer, T. N.: A Nonlinear Dynamical Perspective on Climate Prediction, J. Climate, 12, 575–591, https://doi.org/10.1175/1520-0442(1999)012<0575:ANDPOC>2.0.CO;2, 1999.
Pincus, S.: Approximate entropy (ApEn) as a complexity measure, Chaos, 5, 110–117, https://doi.org/10.1063/1.166092, 1995.
Rial, J. A., Pielke, R. A., Beniston, M., Claussen, M., Canadell, J., Cox, P., Held, H., De Noblet-Ducoudre, N., Prinn, R., Reynolds, J. F., and Salas, J. D.: Nonlinearities, feedbacks and critical thresholds within the Earth's climate system, Climate Change, 65, 11–38, https://doi.org/10.1023/B:CLIM.0000037493.89489.3f, 2004.
Rind, D.: Complexity and climate, Science, 284, 105–107, https://doi.org/10.1126/science.284.5411.105, 1999.
Sang, Y., Wang, Z., and Li, Z.: Discrete wavelet entropy aided detection of abrupt change: A case study in the haihe river basin, china, Entropy-Switz., 14, 1274–1284, https://doi.org/10.3390/e14071274, 2012.
Sivakumar, B.: Rainfall dynamics at different temporal scales: A chaotic perspective, Hydrol. Earth Syst. Sci., 5, 645–652, https://doi.org/10.5194/hess-5-645-2001, 2001.
Sivakumar, B.: Chaos in rainfall: variability, temporal scale and zeros, J. Hydroinform., 7, 175–184, https://doi.org/10.2166/hydro.2005.0015, 2005.
Sivakumar, B.: Chaos in Hydrology: Bridging determinism and stochasticity, Springer, the Netherlands, https://doi.org/10.1007/978-90-481-2552-4, 2017.
Sivakumar, B. and Singh, V. P.: Hydrologic system complexity and nonlinear dynamic concepts for a catchment classification framework, Hydrol. Earth Syst. Sci., 16, 4119–4131, https://doi.org/10.5194/hess-16-4119-2012, 2012.
Sivakumar, B., Persson, M., Berndtsson, R., and Uvo, C. B.: Is correlation dimension a reliable indicator of low-dimensional chaos in short hydrological time series?, Water Resour. Res., 38, 3–1, https://doi.org/10.1029/2001WR000333, 2002.
Sivakumar, B., Woldemeskel, F. M., and Puente, C. E.: Nonlinear analysis of rainfall variability in Australia, Stoch. Env. Res. Risk A., 28, 17–27, https://doi.org/10.1007/s00477-013-0689-y, 2014.
Sprott, J. C. and Rowlands, G.: Improved correlation dimension calculation, Int. J. Bifurcat. Chaos, 11, 1865–1880, https://doi.org/10.1142/S021812740100305X, 2001.
Takens, F.: Detecting strange attractors in turbulence. Dynamical Systems and Turbulence, Warwick 1980, Springer, Berlin, Heidelberg, 366–381, 1981.
Wang, W. G., Shao, Q. X., Peng, S. Z., Zhang, Z. X., Xing, W. Q., An, G. Y., and Yong, B.: Spatial and temporal characteristics of changes in precipitation during 1957–2007 in the Haihe River basin, China, Stoch. Env. Res. Risk A., 25, 881–895, https://doi.org/10.1007/s00477-011-0469-5, 2011.
Wang, W., Wei, J., Shao, Q., Xing, W., Yong, B., Yu, Z., and Jiao, X.: Spatial and temporal variations in hydro-climatic variables and runoff in response to climate change in the Luanhe River basin, China, Stoch. Env. Res. Risk A., 29, 1117–1133, https://doi.org/10.1007/s00477-014-1003-3, 2015.
Wang, W., Lai, Y., and Grebogi, C.: Data based identification and prediction of nonlinear and complex dynamical systems, Phys. Rep., 644, 1–76, https://doi.org/10.1016/j.physrep.2016.06.004, 2016.
White, D. J., Feng, K. S., Sun, L. X., and Hubacek, K.: A hydro-economic MRIO analysis of the Haihe River Basin's water footprint and water stress, Ecol. Model., 318, 157–167, https://doi.org/10.1016/j.ecolmodel.2015.01.017, 2015.
Wolf, A., Swift, J. B., and Swinney, H. L.: Determining Lyapunov exponents from a time series, Physica D, 16, 285–317, https://doi.org/10.1016/0167-2789(85)90011-9, 1985.
Wu, C. L., Chau, K. W., and Fan, C.: Prediction of rainfall time series using modular artificial neural networks coupled with data-preprocessing techniques, J. Hydrol., 389, 146–167, https://doi.org/10.1016/j.jhydrol.2010.05.040, 2010.