the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 27 May 2026
| 27 May 2026
A novel classifier-guided ensemble framework for global terrestrial evapotranspiration estimates
Le Ni
Weiguang Wang
Jianyu Fu
Mingzhu Cao
Evapotranspiration (ET) is a key hydrological and meteorological variable, serving as the critical nexus between water and energy exchanges. However, accurate estimation of global ET remains a challenging task, as process-based ET algorithms are often inadequate to capture the nonlinear relationship among environmental factors, and the application of data-driven ET algorithms is hindered by sparse and uncertain ET observations. In this study, we developed a novel ensemble framework that integrates three existing ET models (process-based algorithm, machine learning-based ET model, and hybrid model), aiming to provide high-precision terrestrial ET estimates. The framework is guided by an additional classifier that can achieve dynamic per-pixel model selection, thus fully utilizing the spatiotemporal dynamics of each model's distinct advantages in mapping global ET and avoiding the typical underestimation of high values by ensemble methods. Comprehensive validation of the model was carried out using in situ ET observations from the FLUXNET2015 dataset, catchment-scale water balance ET dataset, and six global-scale ET products, including comparisons to individual base models and another Attention-Based ensemble model. The quantitative comparisons across statistical metrics (RMSE, MAE, R2, KGE) indicate that our ensemble model outperforms other evaluated models, especially in extreme samples. Meanwhile, the introduction of classifier can not only significantly enhance the algorithmic robustness and generalizability, but also allow us to gain a basic understanding of the mechanisms behind model selection by interpretability analysis. The study demonstrated the effectiveness of the proposed framework in enhancing ET estimation robustness, thereby providing a valuable reference for the estimation of other similar variables.
- Article
(13262 KB) - Full-text XML
- BibTeX
- EndNote




Evapotranspiration (ET) plays a crucial role in both global water and energy cycles (Fisher et al., 2017; Good et al., 2015; Milly et al., 2005), transferring over 60 % of terrestrial precipitation back into the atmosphere (Oki and Kanae, 2006), and concurrently consuming a significant amount of energy (Trenberth et al., 2009). Particularly in the context of global warming, changes in ET will not only alter the distribution of global available freshwater resources (Greve and Seneviratne, 2015; Huntington, 2006; Purdy et al., 2018), but also significantly impact the frequency and severity of hydroclimatic extremes (Miralles et al., 2019; Schwalm et al., 2017). Therefore, reliable ET monitoring at the global scale is of great importance in studying the potential changes in the water cycle and energy budget under climate change conditions (Jung et al., 2011; Milly et al., 2005; Wang and Alimohammadi, 2012; Wang and Dickinson, 2012; Xie et al., 2015; Zhang et al., 2019).
Flux towers can provide reliable in situ ET observations at hourly to sub-hourly timesteps based on the eddy covariance method (Williams et al., 2004; Wilson et al., 2001), but their limited spatial representativeness hinders the acquisition of regional ET. Although regional ET can be measured indirectly through assessing the water balance of catchments, the method is only suitable for catchment ET measurements over annual or longer timescales (Reitz et al., 2023). As none of existing methods can provide direct global ET measurements with both high precision and continuous spatial coverage (Fisher et al., 2017; Reitz et al., 2023; Teuling et al., 2009), remote sensing ET algorithms tend to be used to quantify global ET based on temporally and spatially continuous satellite data (e.g., Bastiaanssen et al., 1998; Jung et al., 2011; Kustas and Norman, 1997; Mu et al., 2011).
The existing remote sensing ET algorithms can be divided into two categories: process-based algorithms and data-driven algorithms (Fu et al., 2022; Shang et al., 2023). Process-based algorithms (e.g., Monteith, 1965; Penman, 1948; Priestley and Taylor, 1972; Su, 2002) employ flux equations to estimate ET based on physically-founded methods, such as the Monin–Obukhov similarity theory, energy balance method and aerodynamic method (Monteith, 1965; Penman, 1948; Allen et al., 1998). However, uncertainties remain in process-based ET algorithms, arising from the insufficient theoretical bases on the complex physical and biological factors involved in ET processes (Mu et al., 2011; Polhamus et al., 2013). With the influx of satellite and in situ observations, data-driven algorithms, especially the machine learning (ML) methods, have become popular in large-scale ET estimation (e.g., Xu et al., 2018; Zhang et al., 2022; Granata, 2019; Lyu and Yong, 2024). ML-based ET models can characterize the nonlinear relationship between different ET-related variables and efficiently capture the spatiotemporal dynamics features of ET from meteorological data streams (Reichstein et al., 2019), thus providing overall more accurate ET estimation than process-based algorithms in data-dense regions. However, due to the lack of global-scale ET observations, these ML-based ET models have to be trained based on in situ observations (Jung et al., 2010). The density of in situ observations is insufficient to represent global ET information, particularly in heterogeneous and data-sparse regions, hindering the use of these ML-based ET models at the global scale (Zhao et al., 2019).
Combining ML-based ET models with process-based algorithms may be a feasible way to improve the generalizability of ML-based ET models (e.g., Brenowitz and Bretherton, 2018; Karpatne et al., 2017; Reichstein et al., 2019; Willard et al., 2022). In these hybrid models, ML methods can be employed for improving parameterizations, or replacing a sub-model of physical model (Reichstein et al., 2019). For example, ML models can be used to estimate the parameters with high uncertainty, such as surface resistance (rs) in Penman–Monteith (PM) equation (Chen et al., 2022; Shang et al., 2023), or to estimate both aerodynamic resistance (ra) and rs (ElGhawi et al., 2023). ML models can also be coupled to stress-based ET models by replacing the formulation of transpiration stress (St) (Koppa et al., 2022). However, hybrid models still rely on sufficient availability of training data; therefore, they cannot take the place of process-based algorithms, especially in data-sparse regions and heterogeneous surfaces (Shang et al., 2023). On the other hand, due to the uncertainties in the coupling of machine learning and physical laws (Shang et al., 2023), hybrid models cannot consistently outperform pure ML-based ET models in the data-dense regions.
Given the different characteristics of process-based algorithms, ML-based ET models, and hybrid models, it is essential to explore a method to utilize the distinct advantages of the three models. Ensemble learning, a common approach to integrate multiple ML models to achieve better performance (Ganaie et al., 2022; Mohammed and Kora, 2023), may have the potential to address this issue. Several existing ensemble frameworks have been demonstrated to have the capability to achieve better performance than single model (e.g., Pérez-Rodríguez et al., 2023; Tseng, 2023). For example, genetic algorithm can be employed to determine the weights for the ensemble of multiple different ML models Ayan et al., 2020). Similarly, the attention mechanism in neural network can dynamically assign weights to provide effective model integration Liu et al., 2022). Statistical methods, such as Bayesian model averaging, can utilize the probability distributions of each model to assess their relative prediction performance, thereby assigning ensemble weights (Huang and Merwade, 2023). However, these approaches exhibit limitations in global ET estimation, either due to the sparse distribution of in situ observations, similar to the challenges encountered by pure ML-based ET models, or due to the non-dynamic weight assignments that cannot reflect the spatiotemporal distribution of distinct model advantages. Previous studies have demonstrated the significantly superior performance of observation-calibrated ML-based models over process-based algorithms at the site scale (Shang et al., 2023), thus when only site-observed ET is the most reliable data source, existing data-driven ensemble methods may not fully utilize the advantages of process-based algorithms. In addition, the existing ensemble models mainly focus on the integration between ML models and whether they are efficient to the integration among ML models, process-based algorithms and hybrid models have not been substantially validated.
Hence, we proposed a novel ensemble framework and developed a model called Classifier-Guided Ensemble model to utilize the individual advantages of three base models (process-based algorithms, ML-based ET models, and hybrid models) by decomposing the ET estimation process into two steps, that is, the classification of input data and the regression of ET. An additional explainable ML classifier was trained to dynamically select the “dominant model” to be used at each pixel. Since the ML classifier is used for classification rather than directly calculating ET, both in situ ET observations and global ET datasets can serve as reference datasets for deriving classifier training labels, resulting in improved classification accuracy and generalizability of the ensemble framework. In this study, the main objectives are to (a) use the proposed ensemble framework to generate global ET estimation based on in situ observations, satellite retrievals, reanalysis data, and multiple ET products; (b) carry out comprehensive evaluation of the model across multiple spatial scales to analyze model's robustness and generalizability; (c) assess the impact of introducing ML classifier; (d) analyze the interpretability of the ML classifier to gain insights into the implicit meteorological and vegetation features suitable for different ET models. In doing so, our framework offers a reference for ET estimation and contributes to the understanding of the mechanisms behind ET estimation.
The same input covariates for all ML model used were selected: International Geosphere-Biosphere Programme (IGBP) land cover types, leaf area index (LAI), normalized difference vegetation index (NDVI), atmospheric pressure (P), incident solar radiation (Rs), soil moisture (SM), air temperature (Ta), soil temperature (Ts), vapor pressure deficit (VPD), wind speed (WS), with a monthly temporal scale. These variables comprehensively represent energy, water, and vegetation conditions, and have been proven effective for ET estimation in previous studies (Monteith, 1965; Mu et al., 2007, 2011; Penman, 1948; Priestley and Taylor, 1972; Chen et al., 2026; Shang et al., 2023; Zhang et al., 2025). Specifically, the selected covariates integrate not only the variables in process-based algorithms (e.g., Penman–Monteith and Priestley–Taylor equations) but also the high-contribution variables identified in established machine learning and hybrid frameworks. The calculation process and the models used are as follows:
2.1 Machine learning model
We chose to use Autogluon for all machine learning components in this study. Autogluon is an open-source AutoML framework that can automatically conduct the selection, combination, and parameterization of multiple ML methods, allowing us to achieve high-accuracy results without manual intervention (Erickson et al., 2020).
Several ML algorithms are provided by Autogluon, including CatBoost boosted trees (Dorogush et al., 2018), Extremely Randomized Trees, k-Nearest Neighbors, LightGBM boosted trees (Ke et al., 2017), Random Forests (Breiman, 2001) and neural networks. These models have been widely used with their own distinct characteristics and advantages (Fan et al., 2019; da Silva Júnior et al., 2019; Zhangzhong et al., 2023). Autogluon combined all the algorithms mentioned above using methods known as stacking and bagging (Erickson et al., 2020), and can achieve better performance than individual models. More detailed algorithm information can be found in Erickson et al. (2020).
2.2 Hybrid model
The original PM equation (Monteith, 1965; Penman, 1948) is as follows:
where λEPM is the latent heat flux (W m−2), Δ is the slope of the saturated vapor pressure vs. temperature curve (k Pa °C−1), Rn is the net radiation (W m−2), G is the soil heat flux (W m−2), ρ is the air density (kg m−3), Cp is the specific heat capacity of air at constant pressure (), VPD is the vapor pressure deficit of the air (Pa), γ is the psychrometric constant (k Pa °C−1), ra and rs are the aerodynamic resistance and surface resistance (s m−1).
Although some studies have optimized the estimation of parameter rs (Wang et al., 2010a, b), estimating parameter rs remains a challenging task. So in hybrid model, we replaced the empirical expression of rs with ML model, similar to the surface conductance-based ML model as proposed by Shang et al. (2023). The target label rs in ML model is obtained by inverting the Eq. (1), due to the lack of observations for parameter rs. As the other variables in Eq. (1) can be calculated based on the covariates for ML model, the estimated ET can be computed by Eq. (1) after obtaining the parameter rs from the ML model.
2.3 Process-based ET algorithms
We chose to use a MODIS global terrestrial ET algorithm from Mu et al. (2011, 2007) based on the PM equation. They improved the methods to estimate some parameters in traditional PM algorithms and included additional ET sources into the algorithm. They divided ET into three main components: wet canopy evaporation, plant transpiration, and soil evaporation, with soil evaporation further divided into the saturated surface and the moist surface. Some of the main formulas are listed below:
where is evaporation from wet canopy surface, λEtrans is plant transpiration, and are evaporation from soil surface and potential soil evaporation, respectively.
Additionally, they improved the method to estimate vegetation cover fraction, soil heat flux, and parameters such as rs, ra, etc., and calculated ET as the sum of daytime and nighttime components, thereby enhancing accuracy. The distinction between daytime and nighttime periods was determined based on incoming shortwave radiation (Rs). Specifically, hours with Rs>10.0 (W m−2) were classified as daytime, while the remainder were defined as nighttime. Although the general framework remained consistent for both periods, distinct parameterization equations were applied for surface conductance (Gs) and soil heat flux (Gsoil) to account for the differences:
where and are daytime and nighttime stomatal conductance, respectively; Gsoil is soil heat flux for bare soil without vegetation, rcorr is the total aerodynamic resistance to vapor transport corrected for atmospheric temperature and pressure, Tann,avg is annual average daily temperature. CL, m(Tmin), m(VPD) and Tmin,close are empirical parameters based on vegetation cover types.
Subsequently, the daily total ET was computed by aggregating the hourly estimates:
where N is the number of valid hourly observations in a day. More detailed information on the algorithms and the parameters can be found in Mu et al. (2011, 2007). In applying this algorithm, we mainly used input variables LAI, IGBP, P, Rs, Ta, VPD, etc., all of which were also employed by the ML models, without introducing any additional data.
2.4 Classifier-Guided Ensemble model
The Classifier-Guided Ensemble model aims to integrate three base models (process-based algorithm, ML-based ET model, and Hybrid model) to optimize the global ET estimation by dividing the ET estimation process into two sub-problems: (a) training a ML classifier to identify the “dominant model” at each pixel, and (b) using the corresponding “dominant model” at each pixel to estimate ET (Fig. 1).
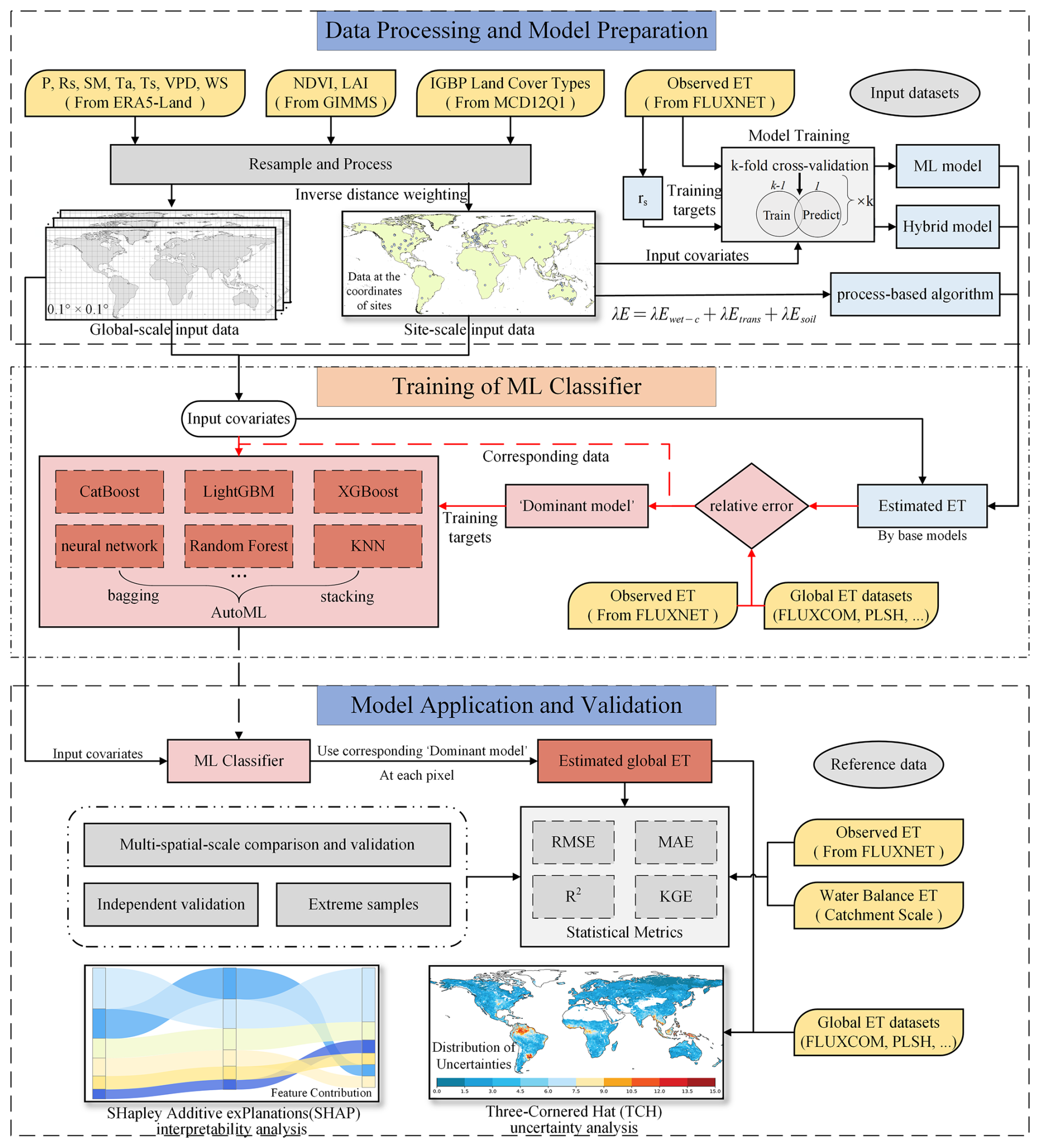
Figure 1Schematic of the Classifier-Guided Ensemble model. The red arrows indicate the modeling steps of the ML Classifier. P is atmospheric pressure, Rs is incident solar radiation, SM is soil moisture, Ta is air temperature, Ts is soil temperature, VPD is vapor pressure deficit, WS is wind speed, LAI is leaf area index, NDVI is normalized difference vegetation index.
Before training the ML classifier, we needed to first use the three base models to estimate ET at both site and global scales. The estimated ET, in situ ET observations and other global ET products were processed for classification task, in order to obtain the training target. At the site scale, we classified the data at each site for every time point into three types (“ML model-dominated”, “hybrid model-dominated”, and `process-based algorithm-dominated') based on the relative errors between the model-estimated ET and the observed ET. The model with the smallest relative error was the “dominant model” for the corresponding site and time. Specifically, at the site scale, we conducted ten-fold cross-validation on three base models and used ET estimates from the validation sets for classification task, to avoid abnormally high accuracy resulting from model overfitting.
At the global scale, due to the lack of reliable ET observations, we used six widely used global ET products, including FLUXCOM, PLSH, GLEAM a, GLEAM b, GLDAS and ERA5-Land (refer to Sect. 3.3 for details), as references to extract some relatively reliable data for the training dataset. Specifically, we calculated the relative errors between estimated ET of base models and global ET products at each pixel for every time point, obtaining six error values for each base model. If a base model yielded relative errors consistently lower than the other two models across all six products, data of this specific pixel and time point was identified as relatively reliable training data. Data from these specific spatiotemporal points were added into the training data, and the model yielding the lowest relative errors was considered to be the “dominant model” of these specific spatiotemporal points. In contrast, data from the remaining spatiotemporal points were excluded to reduce uncertainty.
In the training phase, we utilized the classification results (i.e., the identified dominant model) as the training target for the ML classifier, using the same input covariates as the other ET models in this study. Through this process, the classifier learned the relationship between input covariates and the dominant model labels. Notably, after the training phase was completed, the classifier could operate independently of ET data. Therefore, during validation and application, we employed the classifier to identify the corresponding dominant model label at each spatiotemporal point based on the input covariates without requiring observed ET data. Subsequently, the identified dominant model at each spatiotemporal point was utilized to generate the ET estimates.
2.5 Other ensemble models used for comparison
We use the Attention-Based ensemble technique used by Liu et al. (2022) as a comparison. The Attention Mechanism is similar to human selective attention and is a method to mimic the human visual and cognitive systems. This technique utilizes the focusing ability of the self-attention mechanism (Zhang et al., 2021), which allows the neural network to focus on what it considers important. It can improve model performance by automatically assigning higher weights to sub-models with higher accuracy. The core formula of this model is as follows:
where fAE(x) is the output of Attention-Based ensemble network, is the output of ith base model, Wi is attention coefficient, N is the number of base models (N=3 in this study). More detailed algorithm information can be found in Liu et al. (2022).
We used the site-scale ET estimation from three base models as input variables, and ground observed ET as the training target to train a neural network model with attention mechanism which was then used to estimate the global ET as a comparison.
3.1 In situ observations
In this study, we take ground observed surface latent heat flux (LE) to calculate the ET values for training and validation. We used data from 129 flux tower sites (Table A1 and Fig. 2a) in the FLUXNET2015 dataset (https://fluxnet.org/, last access: 24 April 2026) (Pastorello et al., 2020) with the sampling frequency of half-hourly or hourly. These selected sites represent a wide range of major IGBP land cover types: cropland (CRO, 15 sites), deciduous broadleaf forests (DBF, 14 sites), evergreen broadleaf forests (EBF, 10 sites), evergreen needleleaf forests (ENF, 28 sites), grasslands (GRA, 28 sites), mixed forests (MF, 5 sites), open shrublands (OSH, 7 sites), savannas (SAV, 13 sites) and permanent wetlands (WL, 9 sites).
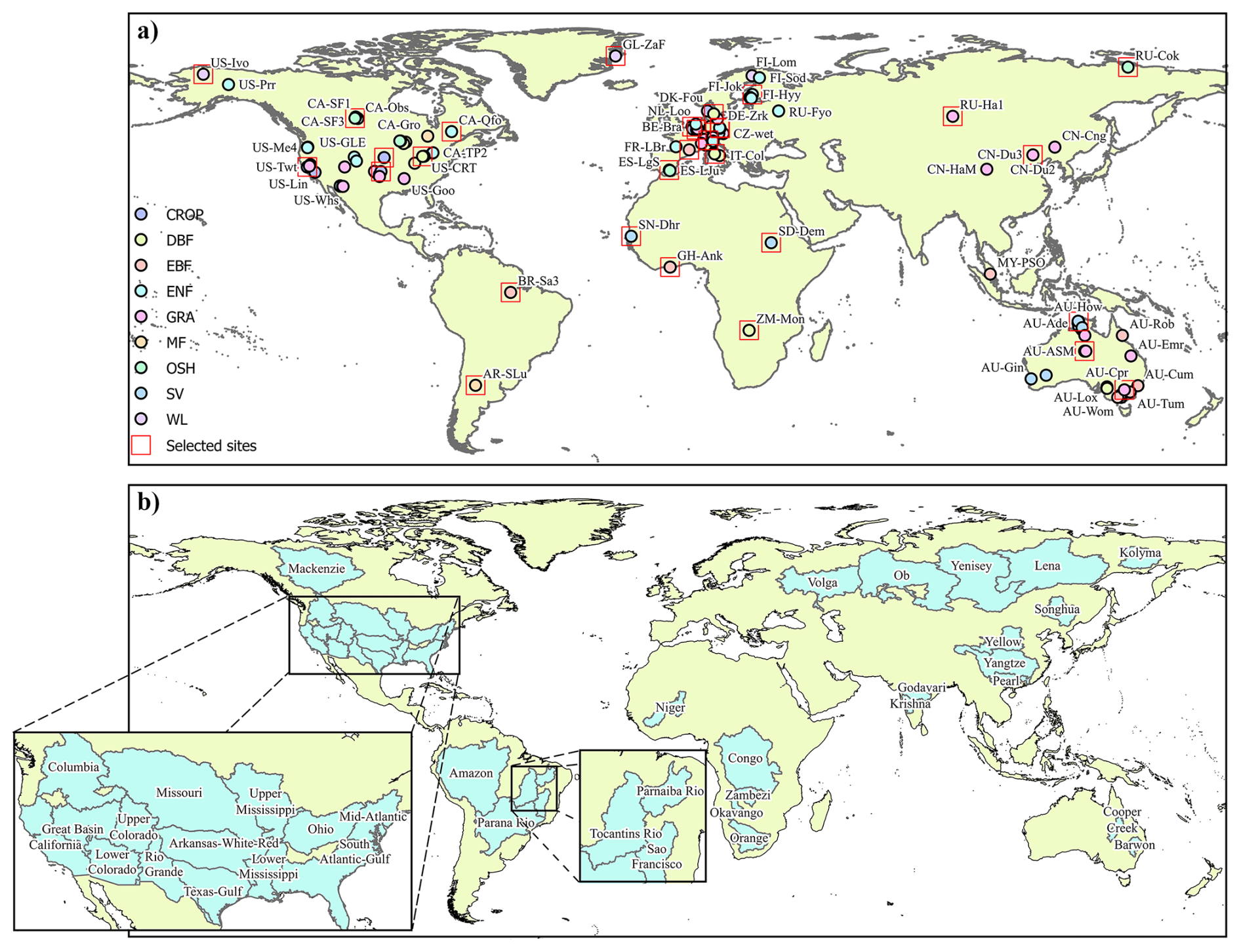
Figure 2Locations of (a) the 129 Flux sites and (b) the 38 global catchments chosen for analysis in this study. The land cover types are identified based on the International Geosphere-Biosphere Programme (IGBP) biome classification. The red boxes indicate the locations of the 30 sites used in the independent validation.
To mitigate the effects of the uncertainty from data, we only chose the sites with high-quality data and rejected the non-observed data, missing values and data with energy closure less than 70 % in the original dataset. Due to potential issues with eddy covariance technology and measurements under rainy conditions (Medlyn et al., 2011), we excluded rainy day samples to avoid errors. We also applied the Bowen ratio closure method to address the issue of energy imbalance in original observations (Foken, 2008; Twine et al., 2000). If the filtered data had more than 20 % missing values in a month, the data for that month was removed. The remaining data were then processed using linear interpolation and averaging to generate monthly-scale data.
3.2 Catchment-scale ET
At the catchment scale, the water balance method can be used to obtain a more reliable ET data (Pascolini-Campbell et al., 2020). The catchment-scale ET can be calculated as:
where P is precipitation, Q is runoff at the basin outlet, and is the change in total water storage. We used the dataset of the water-balance-based evapotranspiration of global typical large river basins published by Ma et al. (2024). This dataset spans a 34 year period from 1983–2016 and can be downloaded from the National Tibetan Plateau Data Center (Ma, 2024). This data is derived from water balance methods combined with four different precipitation data sources (P), three types of terrestrial water storage change estimates () and observed flow data from control sites (Q). We selected 38 major catchments (>200 000 km2) in this dataset as our validation data (Fig. 2b and Table A2).
3.3 Global- scale datasets
At the global scale, given the current lack of reliable direct global ET observations for validation, we collected six widely used ET products derived from diverse data sources, forcing data, and calculation methods to conduct a comprehensive validation. (1) FLUXCOM (Jung et al., 2019; Tramontana et al., 2016) provides a latent heat dataset, with 0.0833°×0.0833° resolution and time spanning a 75 year period from 1950 onwards generated, from energy flux measurements from FLUXNET eddy covariance towers and meteorological data utilizing only machine learning methods. (2) Process-based Land Surface Evapotranspiration/Heat Fluxes (PLSH) (Zhang et al., 2015) is a product with 0.0833°×0.0833° resolution and time spanning a 32 year period from 1982–2013. The dataset is driven by satellite observations of photosynthetic canopy cover and surface meteorology inputs. (3) Global Land Evaporation Amsterdam Model (GLEAM) version 3.8a (Martens et al., 2017; Miralles et al., 2011) is an established ET product based on satellite and reanalysis data with 0.25°×0.25° resolution and time spanning the 44 year period from 1980–2022. (4) GLEAM version 3.8b (Martens et al., 2017; Miralles et al., 2011) is also selected because of its different forcing data. It is based on only satellite data with 0.25°×0.25° resolution and time spanning the 20 year period from 2003–2022. (5) Global Land Data Assimilation System (GLDAS) version 2.1 (Rodell et al., 2004; Beaudoing and Rodell, 2020), a product with 0.25°×0.25° resolution and time spanning a 24 year period from 2001 onwards, is generated by combining data assimilation techniques with satellite and ground-based observations. (6) European Centre for Medium-range Weather Forecasts (ECMWF)-ERA5-Land product (Muñoz Sabater, 2019) is a reanalysis product based on multi-source data with 0.1°×0.1° and time spanning a 75 year period from 1950 onwards.
Input covariates for all models described in Sect. 2 were derived from the same source to ensure consistency in the training process. In the input training data, variables P, Rs, SM, ST, Ta, VPD, WS are sourced from the ERA5-land product. Since the ERA5-Land dataset only provides dew point temperature data, we used the following formula for calculation (Abbott and Tabony, 1985):
Here, T and Td represent temperature and dew point temperature respectively (°C). Although these data are also available in the in situ observations, we chose to use the global-scale dataset instead to avoid issues caused by inconsistencies in spatial scales between the training data and the calculation data (Xiao et al., 2008). We employed an inverse distance weighting method to extract data at the coordinates of the corresponding sites for training data.
Other variables LAI and NDVI are sourced from the Global Inventory Modeling and Mapping Studies (GIMMS) NDVI and LAI products (Cao et al., 2023; Li et al., 2023), which are half-month products with 0.0833°×0.0833° resolution. We averaged the two values for the month to obtain the monthly average data. The IGBP variables are sourced from the MODIS Land Cover Climate Modeling Grid Product (MCD12C1) (Friedl and Sulla-Menashe, 2015), which is a spatially aggregated and reprojected version of the tiled MCD12Q1 product with 0.05°×0.05° resolution. We resampled all these data to 0.1° spatial resolution, the same as the ERA5-Land product that contains the most input variables.
3.4 Model validation
3.4.1 Site and catchment scale validation
Given that both in situ observations and the total catchment ET calculated by the water balance method are relatively reliable datasets, we can directly compare the ET generated by our model with these datasets at site and catchment scale. At the site scale, we conducted k-fold cross-validation with k=10. In each fold we selected 10 % of the data at each site as the validation set and the remaining data as the training set. In addition, we carried out independent validation by selecting 30 independent sites excluded from the training data (Table A3 and Fig. 2a) to evaluate the spatial simulation performance of our Classifier-Guided Ensemble model. The selected independent validation sites cover multiple land cover types and most of the major regions. Also, we evaluated the ET estimation performance of our model on extreme samples sorted in ascending order within the 0th–1st percentiles and 99th–100th percentiles for six variables (LAI, NDVI, Rs, SM, Ta, VPD) to verify the extrapolation performance of the model. At the catchment scale, we used calculated catchment ET to compare with the total catchment ET estimated by our model and other global ET products.
To quantitatively validate the performance of our model, we used several statistical metrics: Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Coefficient of Determination (R2), and Kling–Gupta Efficiency (KGE) (Table 1). MAE and RMSE are used to measure the closeness between the model results and observations. R2 can be used to assess the correlations. KGE comprehensively considers the relative error, correlation coefficient and variance of the model results, providing a comprehensive assessment of the model's overall performance.
Table 1The explanation of statistical metrics used to evaluate model performance in this study. n/a: not applicable.

Note: yi and represent observations and estimations, respectively, α is the bias ratio, β is the variability ratio, σ represents the standard deviation, μ represents the average.
3.4.2 Global scale validation
Taking into account the available years of each product, we analyzed the data for the period from 2003–2013, with the data of 2003 and 2004 serving as the training set and the data of remaining years as the validation set. At global scale, due to the lack of reliable ET observations, conventional validation methods are not feasible. Therefore, we used the three-cornered hat (TCH) method (Tavella and Premoli, 1994) to quantify the uncertainties of ET estimation. TCH is a reliable method for estimating the uncertainty of various time series products and has been used for validation of multiple datasets (Liu et al., 2021). We used the same formula as in (Xie et al., 2024). The time series of ET at each pixel can be expressed as:
where k represents the index of the corresponding ET product, N is the total number of ET products included in the validation, Xt represents the true value and εk represents the error term.
The truth value of ET cannot be obtained, so we need to get the εk without Xt. To solve this problem, the TCH algorithm defines a product as a reference product to get a matrix Yk,m as:
where XR is the arbitrarily selected reference product, Yk,m is an matrix, M is the length of the time series of X. S, the covariance matrix of Y, is related to the unknown M×N covariance matrix of the individual noise Q as (Galindo and Palacio, 2003):
Since the number of equations is still less than the number of unknowns, it is impossible to solve the equation. They used the Kuhn–Tucker theorem proposed by Galindo and Palacio (1999) to solve the constrained minimization problem. The definition of the objective function and constraint function is:
where are the elements of the corresponding Q. They also used the initial conditions for the iteration proposed by Torcaso et al. (1998):
Finally, the Q value is obtained by minimizing the objective function. More detailed information can be found in their paper (Galindo and Palacio, 1999, 2003; Torcaso et al., 1998; Xie et al., 2024).
3.4.3 ML model interpretability analysis
We used SHAP (SHapley Additive exPlanations) to analyze the interpretability of the ML classifier we used. SHAP was originally proposed in game theory (Shapley, 1952) and was used as a method to equitably distribute benefits by calculating each member's marginal contribution. Subsequently, it was used to compute the marginal contribution of each input variables to enhance the interpretability of machine learning (Lundberg and Lee, 2017).
The Python library of SHAP was used to calculate the SHAP values for each input feature. SHAP library is applicable for interpretability analysis of ensemble models that integrate multiple ML models. In this study, SHAP values were employed to enhance our understanding of how our ML classifier selects the “dominant model”.
4.1 Model evaluation with in situ observations
4.1.1 Model Evaluation using EC observations
To evaluate the model simulation performance, we conducted a ten-fold cross-validation at all selected EC sites (Fig. 3). First, we check whether the integrated base models could accurately estimate ET at site scale (Fig. 3b, c and e). It is found that both ML model and Hybrid model perform well with R2 and KGE nearing 0.9, ensuring the reliability of ensemble model while process-based algorithm exhibits relatively lower performance, with a KGE of 0.65, R2 of 0.48, MAE of 17.41 mm per month, RMSE of 26.45 mm per month. Despite the lower accuracy of process-based algorithm at site scale, it is also integrated as the employed physically-founded equations enable process-based algorithm to maintain acceptable performance in data-sparse regions.
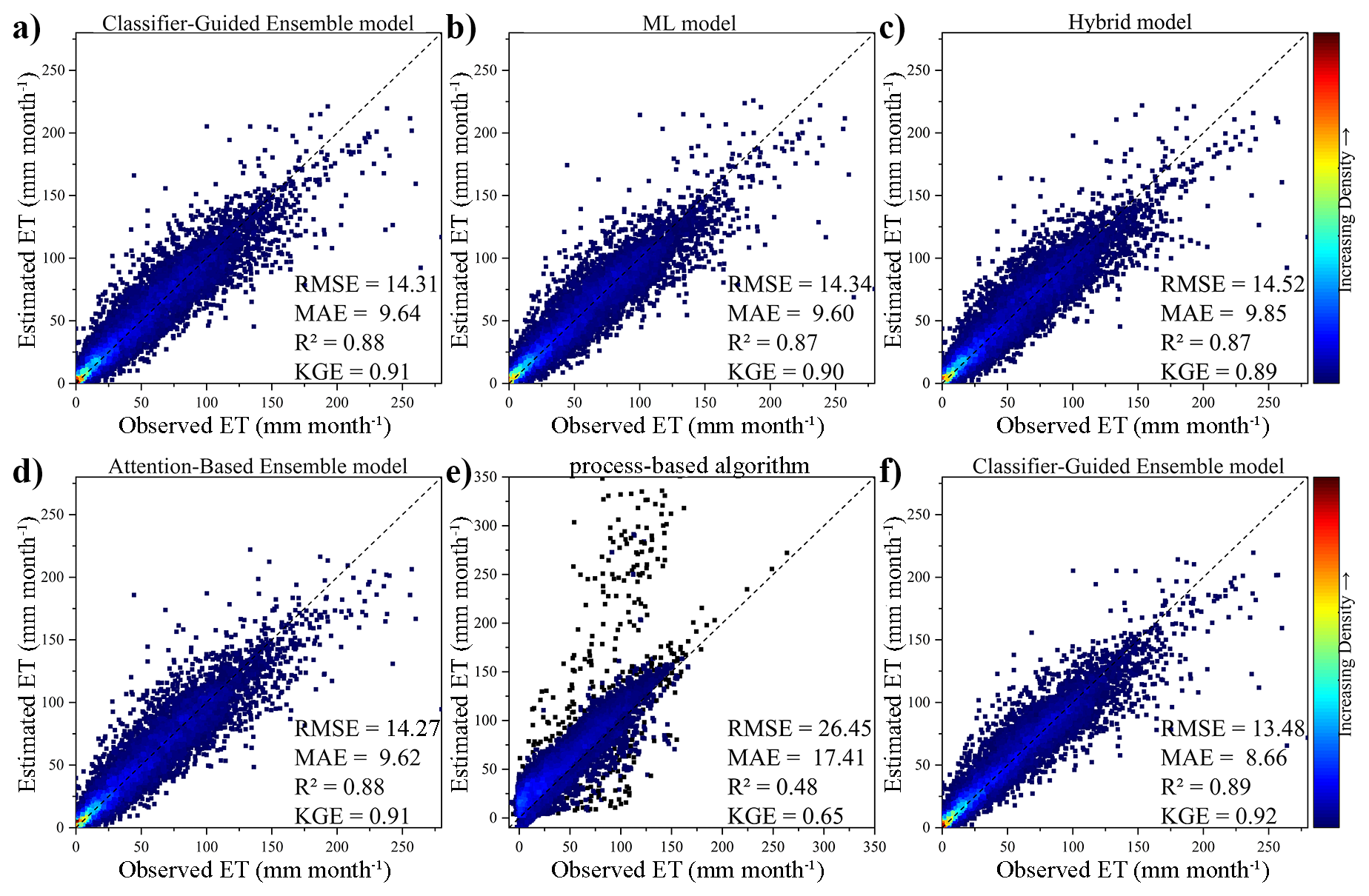
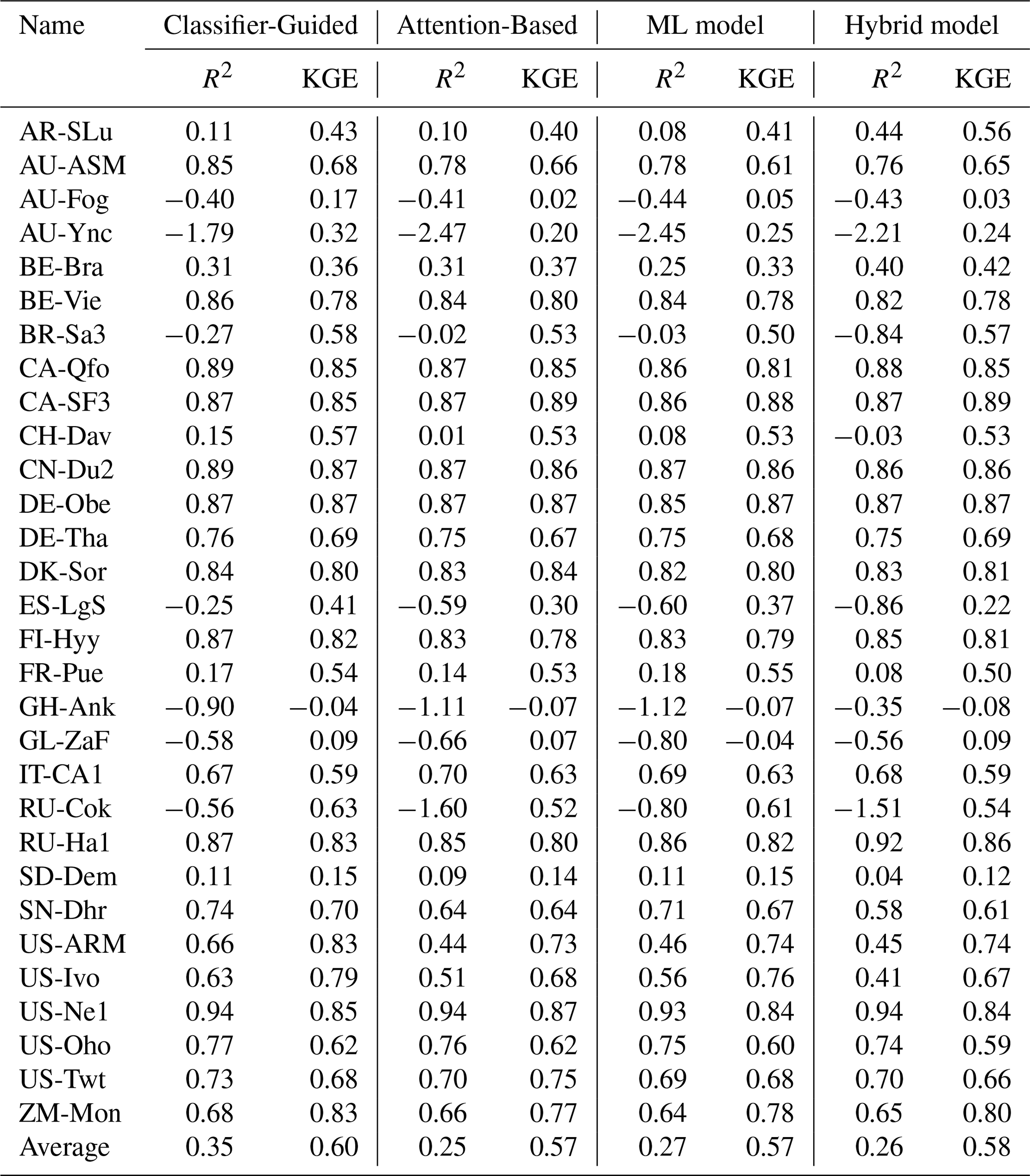
Figure 3Performance of (a) Classifier-Guided Ensemble model, (b) ML model, (c) Hybrid model, (d) Attention-Based Ensemble model, (e) process-based algorithm and (f) Classifier-Guided Ensemble model (enhanced by additional global-scale training data) in ten-fold cross-validation.
The performance of our Classifier-Guided Ensemble model and the model with more training data are shown in Fig. 3a and f. Although when trained using only site-scale data, our Classifier-Guided Ensemble model performs well with a KGE of 0.91, R2 of 0.88, MAE of 9.64 mm per month, RMSE of 14.31 mm per month, showing clear advantages over base models, it cannot significantly outperform the Attention-Based Ensemble model with the same KGE and R2, lower RMSE of 14.27 mm per month and lower MAE of 9.62 mm per month (Fig. 3d). As illustrated in Fig. 3e, the process-based algorithm exhibits inferior performance to data-driven models at the site scale, resulting in its near exclusion from the classifier when trained only on in situ observations. Expanding the training dataset with global datasets enables the classifier to better recognize the scenarios where each base model performs best, with accuracy improving from 70 %–90 %, particularly for process-based algorithm. Therefore, our model can achieve the best performance among all of the models used for comparison in the validation dataset, with a KGE of 0.92, R2 of 0.89, MAE of 8.66 mm per month, RMSE of 13.48 mm month−1.
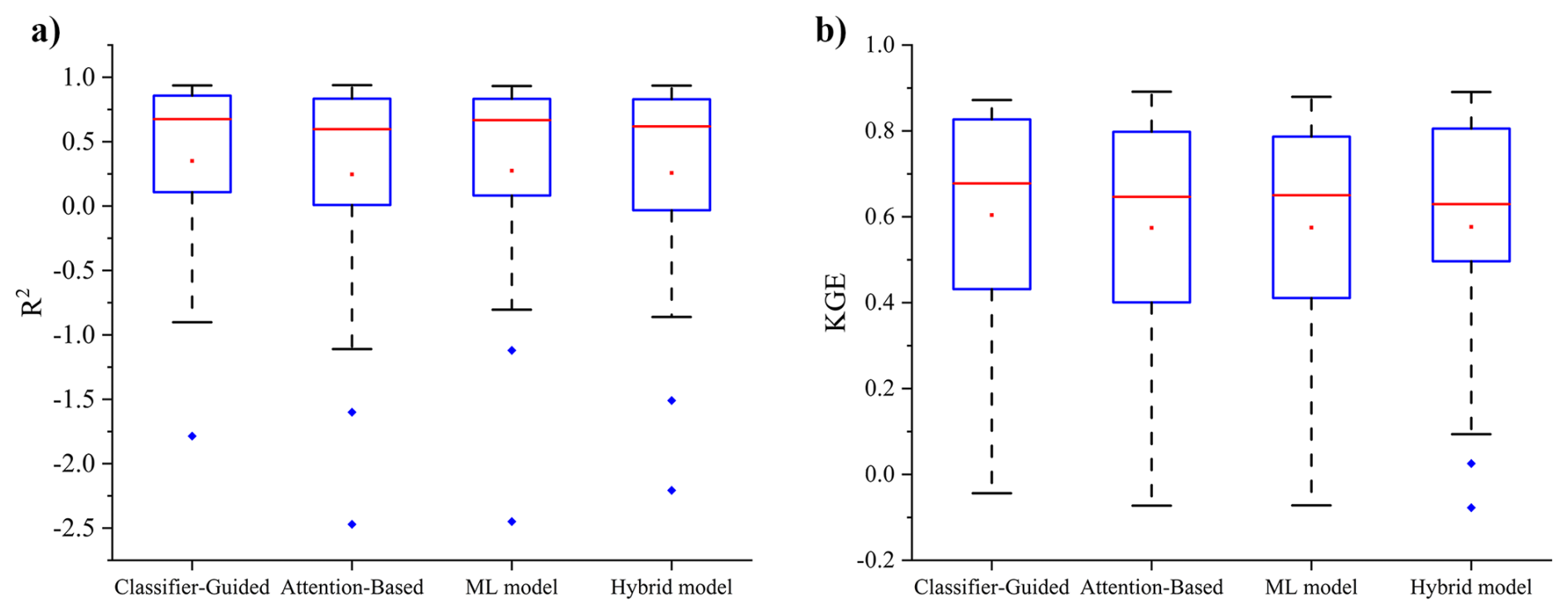
Figure 4The (a) R2 and (b) KGE of the Classifier-Guided Ensemble model, Attention-Based Ensemble model, ML model, and Hybrid model in independent validation. The red lines represent the median of the validation metrics, and the red dots represent the average values of the validation metrics.
The independent validation results shown in Fig. 4 and Table A4 also indicate that our model exhibits excellent generalizability in these independent sites. The ET estimation from Classifier-Guided Ensemble model achieves the best performance among all compared models, with a higher average R2 of 0.35 and a higher average KGE of 0.60. The Classifier-Guided Ensemble model performs well in most of the selected independent sites, especially at the CH-Dav and US-ARM sites, as it can make better use of the process-based algorithm's extrapolation strengths, yielding better outcomes even when ML model and Hybrid model struggle, while the Attention-Based Ensemble model's results are closer to those of the ML model at most sites, resulting in poorer performance in independent validation.
The results from the k-fold cross-validation and independent validation indicate that our Classifier-Guided Ensemble model performs well in estimating ET at site scale, exhibiting better stability and generalizability, and the inclusion of global-scale data makes our model perform better.
4.1.2 Model Evaluation under different sites and vegetation cover conditions
In situ observations were also used to evaluate the performance of models across different sites and land cover types, thereby validating the models' spatial simulation performance. The Taylor diagram is used to compare the performance of the models, where the two axes represent the root mean square error (RMSE, in mm per month), and the curves indicate the Pearson's correlation coefficient (r).
As Fig. 5a and Table 2 demonstrates, Classifier-Guided Ensemble model performs the best among the four models in the majority of the site, with lower average RMSE of 14.55 mm per month (Attention-Based Ensemble model: 15.41 mm per month, Hybrid model: 15.52 mm per month, ML model: 15.46 mm per month), and higher average correlation coefficient (r) of 0.90 (Attention-Based Ensemble model: 0.88, Hybrid model: 0.88, ML model: 0.87). Specifically, the best-performing sites for multiple models include “CA-Obs” (RMSE: Classifier-Guided Ensemble model: 3.92 mm per month, Attention-Based Ensemble model: 3.91, Hybrid model: 5.27 mm per month, ML model: 3.90 mm per month) and “CA-SF1” (RMSE: Classifier-Guided Ensemble model: 3.75 mm per month, Attention-Based Ensemble model: 4.83 mm per month, Hybrid model: 4.08 mm per month, ML model: 5.75 mm per month). Furthermore, Classifier-Guided Ensemble model significantly outperformed the other models at “US-Me4” and “DE-Zrk”, achieving RMSE below 4.0, whereas all other models exceeded 8.0 at these sites.
Table 2Performance of different ET models as indicated by averaged RMSE and R2 for all sites, based on the cross-validation dataset.
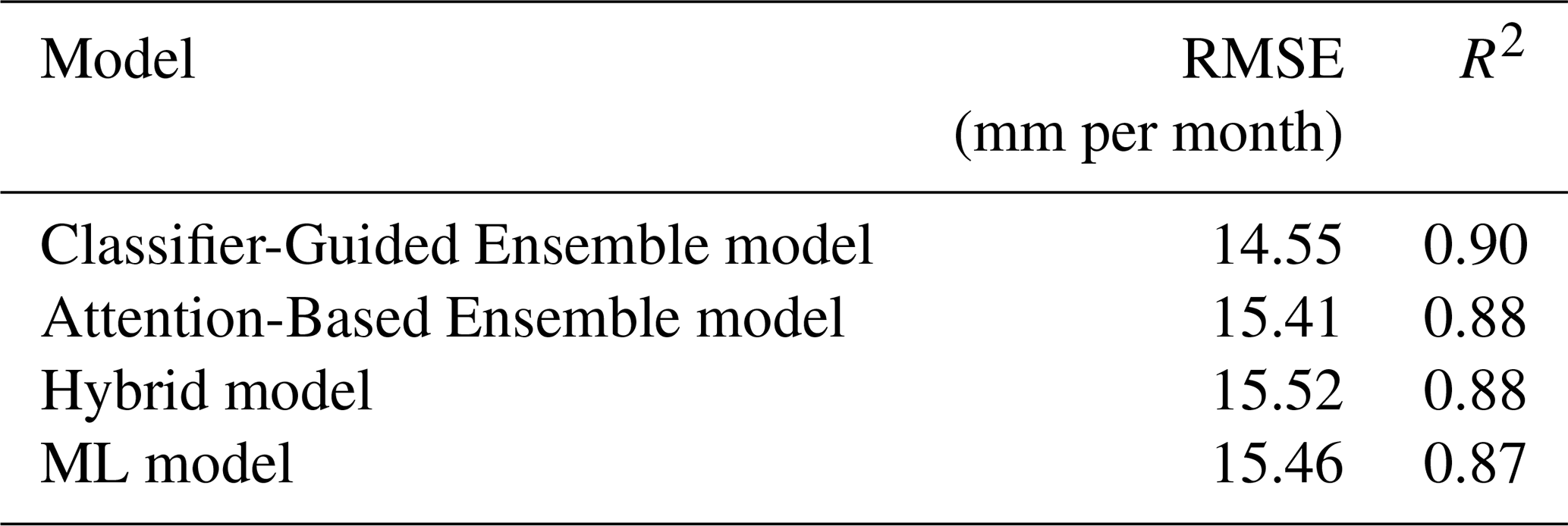
Figure 5Taylor diagram that compares the performance of the four models with ground observations for (a) different sites and (b) different land cover types, based on the cross-validation dataset.
Classifier-Guided Ensemble model also demonstrates greater performance than the other three models in the majority of land cover types (Fig. 5b and Table 3), with lower average RMSE of 16.88 mm per month (Attention-Based Ensemble model: 17.40 mm per month, Hybrid model: 17.38 mm per month, ML model: 17.94 mm per month), and higher average correlation coefficient (r) of 0.93 (Attention-Based Ensemble model: 0.92, Hybrid model: 0.93, ML model: 0.92). Classifier-Guided Ensemble model outperforms other models across most land cover types, with the exception of the CSH, where its performance is slightly inferior to Attention-Based Ensemble model and Hybrid model. For CSH, the limitation to a single site (“US-ZS2”) with sparse data resulted in lower accuracy for all models. In this specific case, although Classifier-Guided Ensemble model yielded better results than both the ML model and the Attention-Based Ensemble model, it did not outperform the Hybrid model.
Table 3Performance of different ET models as indicated by RMSE and R2 for all IGBP land cover types, based on the cross-validation dataset.
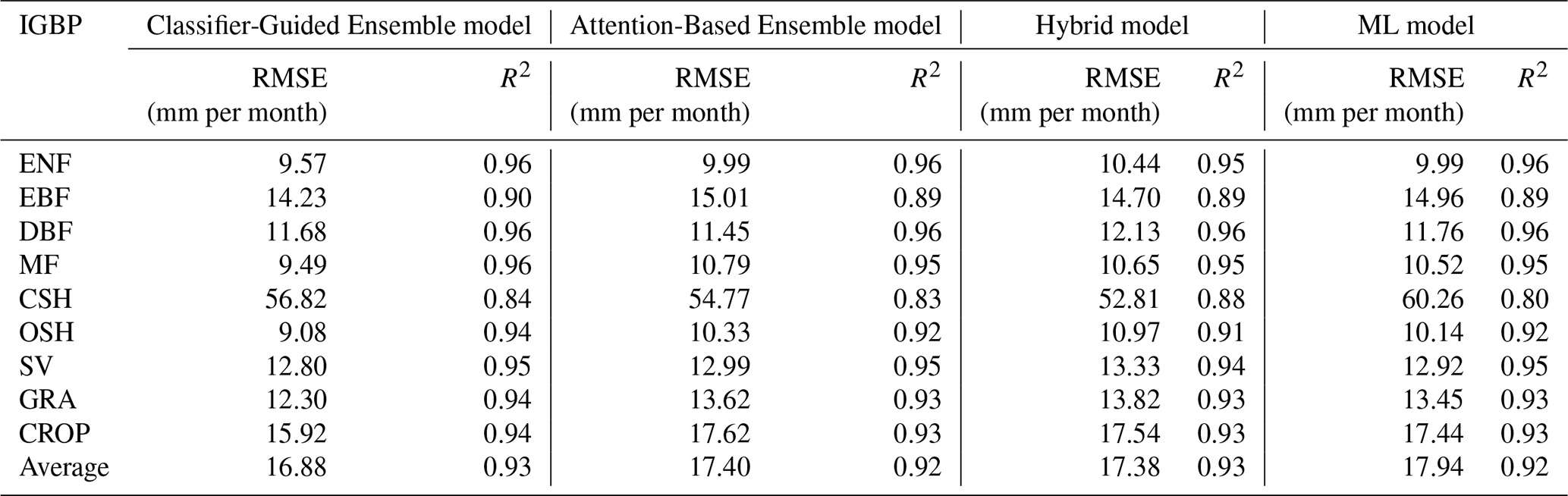
Further, we notice that the Attention-Based Ensemble model assigns more “attention” to the ML model, since the ML model performs best at the site scale among the three base models. Therefore, the Attention-Based Ensemble model yields results similar to the ML model across sites and land cover types, and at certain sites, such as “CA-SF1”, the Attention-Based Ensemble model is significantly outperformed by the Hybrid model, while Classifier-Guided Ensemble model can fully utilize the characteristics of the base models and get better results, which is consistent with the conclusion from independent validation. In summary, the proposed model better fits the data from different sites and different land cover types, which demonstrates the effectiveness of our ensemble method.
4.1.3 Model Evaluation using extreme samples
In order to verify the extrapolation performance of the models for extreme samples, we compared the performance of these models for multiple extreme samples. The heatmaps in Fig. 6 indicate that for the majority of these extreme samples, our Classifier-Guided Ensemble model can accurately estimate ET.
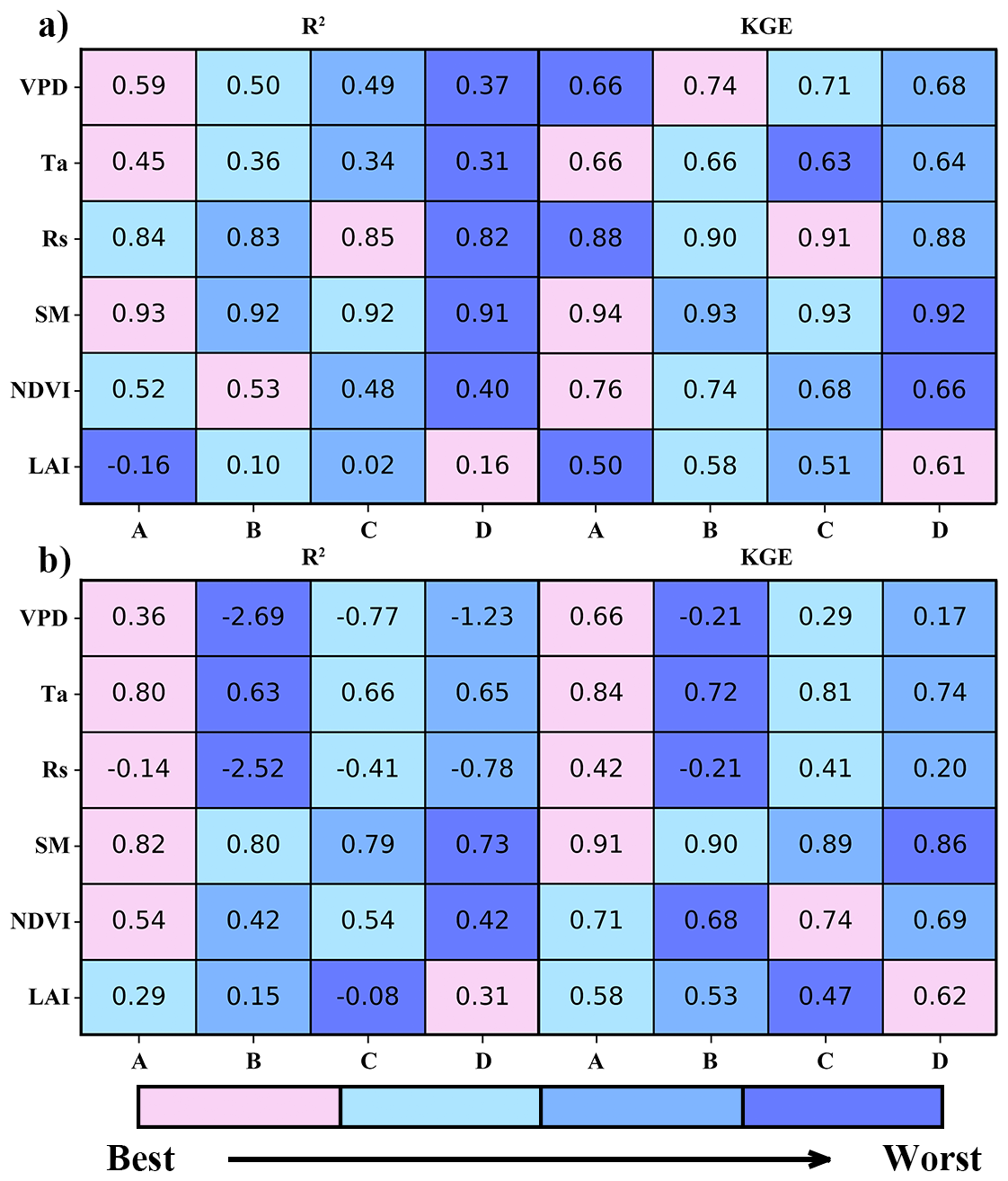
Figure 6The comparison of different models (A Classifier-Guided Ensemble model, B Attention-Based Ensemble model, C ML model, D Hybrid model) under extreme conditions in the form of heatmaps. (a) and (b) represent the extreme samples sorted in ascending order within the 0th–1st percentiles and 99th–100th percentiles, respectively.
For the 99th–100th percentiles of the VPD in particular, Classifier-Guided Ensemble model performs significantly better than the other models, with a KGE of 0.66, R2 of 0.36, while the KGE of other models is below 0.3 and the R2 is less than 0. This shows that Classifier-Guided Ensemble model has the potential to efficiently select the “dominant model” to achieve good results even when these existing ML models perform poorly. Under the cases of high Ta, high Rs and low Ta, Classifier-Guided Ensemble model performs significantly better than the other models. Only under the three cases of low VPD, low Rs and low LAI, Classifier-Guided Ensemble model is not as good as the other models and the difference is not significant, with the KGE being 0.08, 0.02 and 0.08 lower than that of the Attention-Based Ensemble model, respectively. In most extreme cases, Classifier-Guided Ensemble model can yield stronger extrapolation performance than individual base models or other ensemble models, providing more accurate ET estimates under extreme weather events.
4.2 Model evaluation at catchment scale
To validate the model performance for the catchment-scale application, we used six ET products, Classifier-Guided Ensemble model, and Attention-Based Ensemble model to estimate ET in each catchment and compare them to the water balance ET dataset. The results show that Classifier-Guided Ensemble model performs better than other comparison models and products (Fig. 7), with a KGE of 0.94, R2 of 0.92, MAE of 6.17 mm per month, RMSE of 7.73 mm per month and the slope of the regression of estimated ET versus water balance ET for our model (0.99) is closer to 1 than that of the other ET products and models. The Attention-Based Ensemble model also performs better than most of the ET products used, with a KGE of 0.89, but the results are not as good as those of our model, ERA5-Land, and GLDAS ET products as it exhibits higher RMSE and MAE. This proves that our model is in better agreement with the catchment water balance ET.
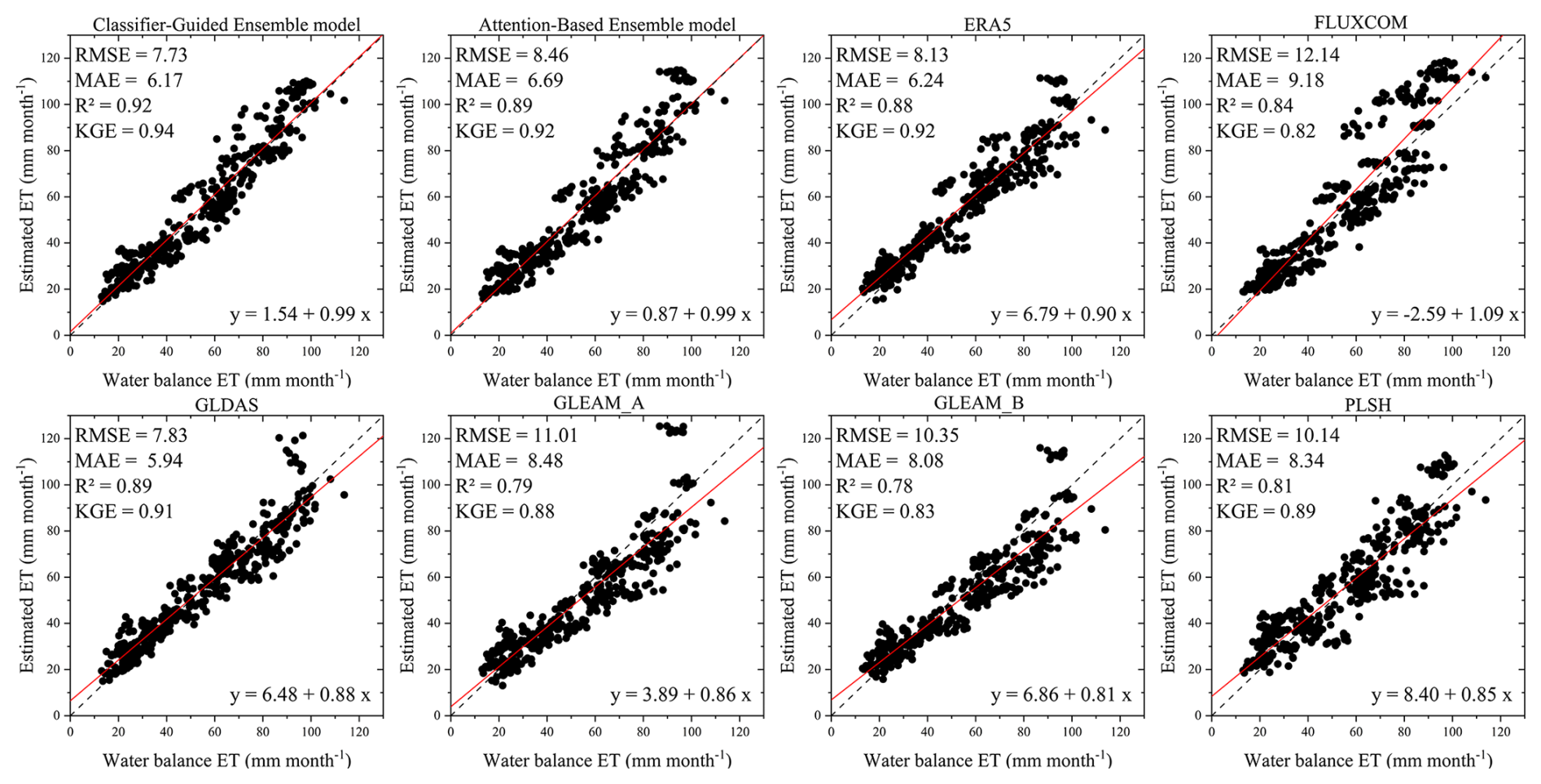
Figure 7Scatterplot for the relationship between estimated ET and water balance ET (each point represents a catchment over a one-year period).
The spatial distribution of RMSE across 38 catchments (Fig. 8) further demonstrate the superior performance of our model. Compared to the Attention-Based Ensemble model, our model shows significant improvement in RMSE for catchment “Mackenzie”, “Rio Grande”, “Lower Colorado”, “Amazon”, “Kolyma ”, “Godavari”, “Krishna”, “Orange”, “Cooper Creek” and “Barwon”, with a reduction in RMSE of over 20 %. Especially in catchment “Godavari”, the RMSE of our model is 5.59 mm per month and the RMSE of Attention-Based Ensemble model is 12.02 mm per month, with a difference of more than 50 %. In some other catchments (“Mid-Atlantic”, “Ohio”, “Upper Colorado”, “Ob” and “Yellow”), the RMSE of the Attention-Based Ensemble model is over 20 % lower than that of our model. Compared to another well-performing GLDAS product, there are large differences between our model and GLDAS due to the difference in calculation methods, with each of these two methods having lower RMSE in 19 catchments. In summary, while there are some differences in ET estimation among our model, the Attention-Based Ensemble model, and other products in different catchments, our model is in better agreement with the catchment water balance ET in the majority of catchments.
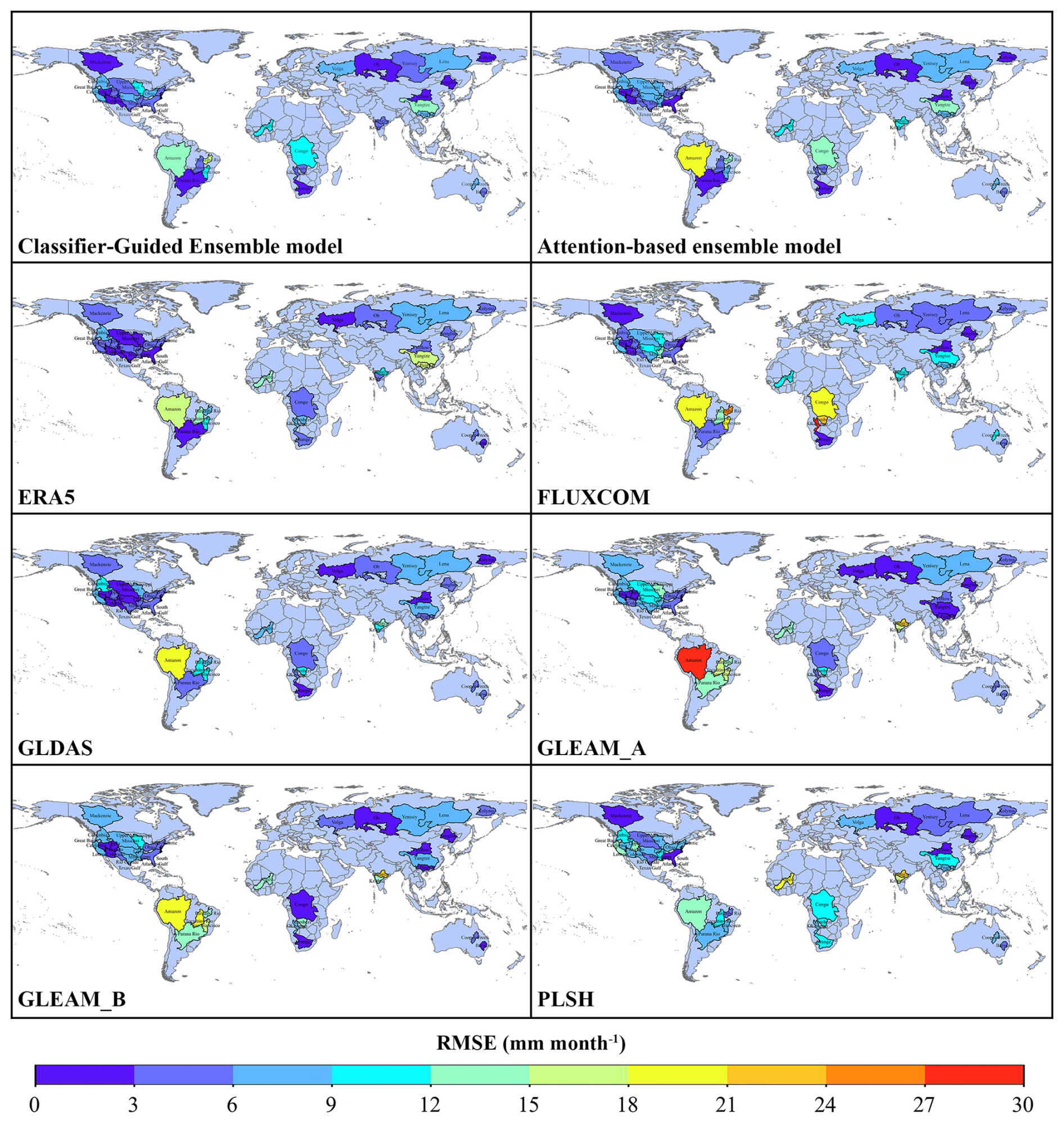
Figure 8Distributions of the root-mean-square error (RMSE) for the 38 catchments.
4.3 Model evaluation at global scale
To further validate the performance of our model on larger spatial scales, we compared the multi-year average ET estimated by Classifier-Guided Ensemble model and Attention-Based Ensemble model, and other ET products. We primarily compared our Classifier-Guided Ensemble model with Attention-Based Ensemble model to validate the performance of our ensemble method and with FLUXCOM, which is an ET product generated based on pure ML models, to evaluate the differences between ensemble model and pure ML models. Additionally, other ET products were included as reference for the analysis. Some ET products, like FLUXCOM, contain missing values in certain regions, and these regions were excluded from the comparison.
4.3.1 Evaluation of multi-year average ET estimates
Figure 9 shows the spatial distribution of the multiyear (2005–2013) mean global ET estimates for the ET models and products. Our Classifier-Guided Ensemble model shows expected global patterns of ET and all of these ET models and products generally show similar spatial pattern. ET values are relatively higher in mid-latitude regions near the equator, including the Amazon Basin, the Congo Basin, and Southeast Asia, while lower ET values are shown in some arid regions, including the Sahara Desert and Central Asia, as well as in high-latitude alpine regions, including northern Russia, and northern Canada. The multiyear mean ET ranges from 46.99–49.69 mm per month, with FLUXCOM having the highest average ET and GLEAM_B having the lowest average ET.
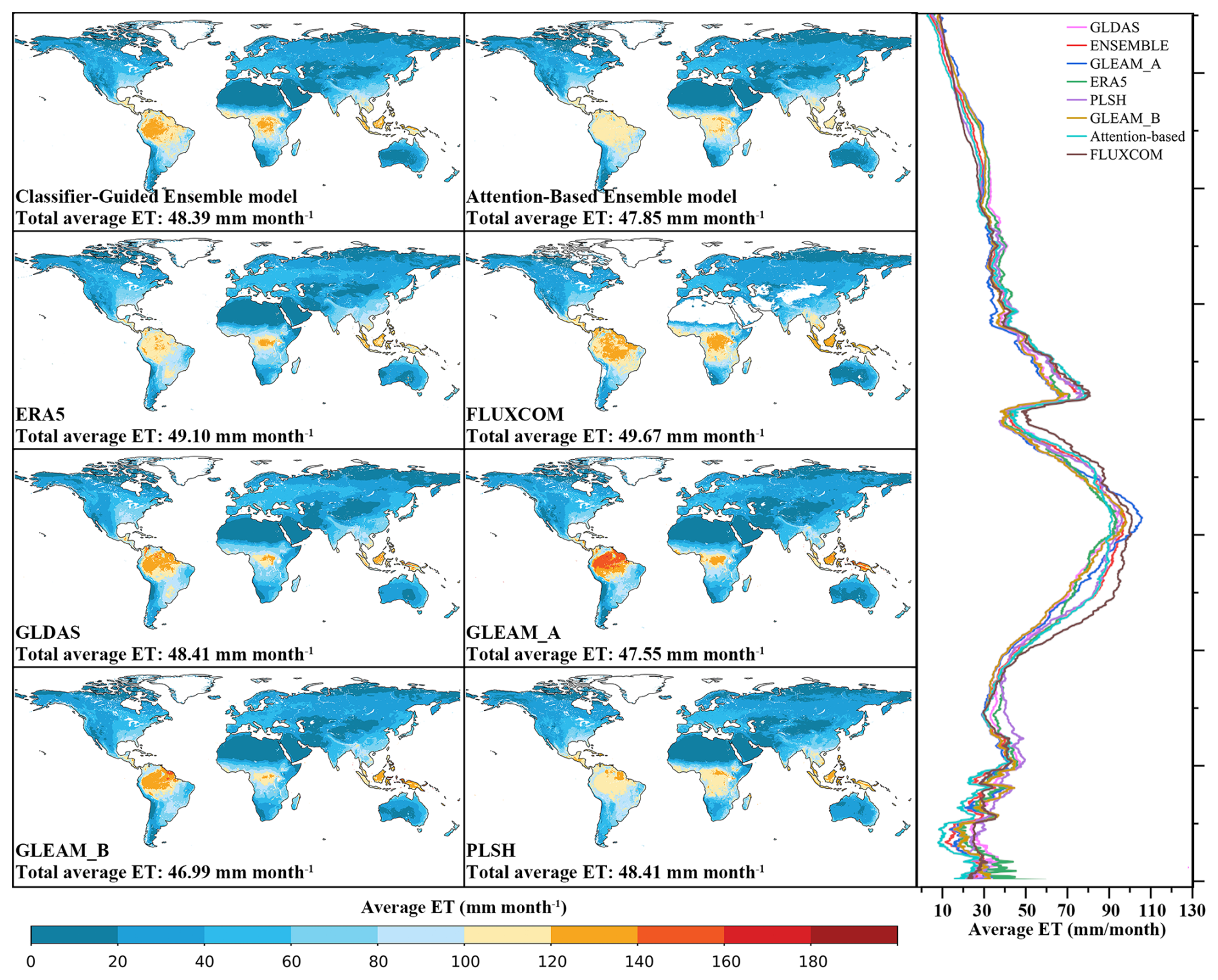
Figure 9Average annual land evapotranspiration from 2005–2013 for Classifier-Guided Ensemble model, Attention-Based Ensemble model and other ET products. The latitudinal profiles of these datasets are shown in the right panel.
Despite their great consistency in spatial patterns, there are still some regional discrepancies detected among these datasets. Compared with other products, the Attention-Based Ensemble model shows the largest discrepancy in tropical regions, as it provides lower ET estimates, with almost no regions exhibiting ET exceeding 120 mm per month. This may be attributed to the ML model's limited ability to estimate extreme high values, as well as the potential underestimation of ET by the ensemble model (Cai et al., 2024). Compared with the Attention-Based Ensemble model, our Classifier-Guided Ensemble model shows better spatial consistency with other ET products and avoids the underestimation of high values. The latitudinal average ET distribution for each dataset also confirms this conclusion. The Attention-Based Ensemble model shows lower ET estimates in both high-ET and low-ET regions and the FLUXCOM product tends to overestimate ET in low-latitude regions, particularly in areas slightly below the peak values, while the ET profile estimated by our model shows improvement in these areas. Overall, our model generally performs well and provides a reasonable global ET estimate, indicating a distinct improvement in generalizability with the introduction of ML classifier.
4.3.2 Uncertainty analysis at global scale
The proposed model also demonstrates strong stability in the uncertainty analysis. Figure 10 illustrates the uncertainty distribution estimated from the TCH method for eight global ET estimates during the period from 2005–2013. All of these datasets exhibit high stability, with less than 5 mm per month mean uncertainty in most areas. The lowest mean uncertainty is achieved by Classifier-Guided Ensemble model (1.45), followed by FLUXCOM (1.54), Attention-Based Ensemble model (1.63), GLEAM_A (1.84), GLEAM_B (1.88), PLSH (1.93), ERA5 (2.25), GLDAS (3.08). The uncertainty distribution of these datasets also shows a similar spatial pattern and typically high uncertainty is found in low-latitude areas. Many studies have investigated the uncertainty of these ET products. Xie et al. (2024) used the TCH method to assess the uncertainty of several products from 2003–2015 and found that FLUXCOM had the lowest uncertainty. Zhu et al. (2022) and Li et al. (2022) also evaluated several products and found that the GLEAM product exhibited lower uncertainty. The uncertainty of these products we calculated is consistent with the results of these previous studies.
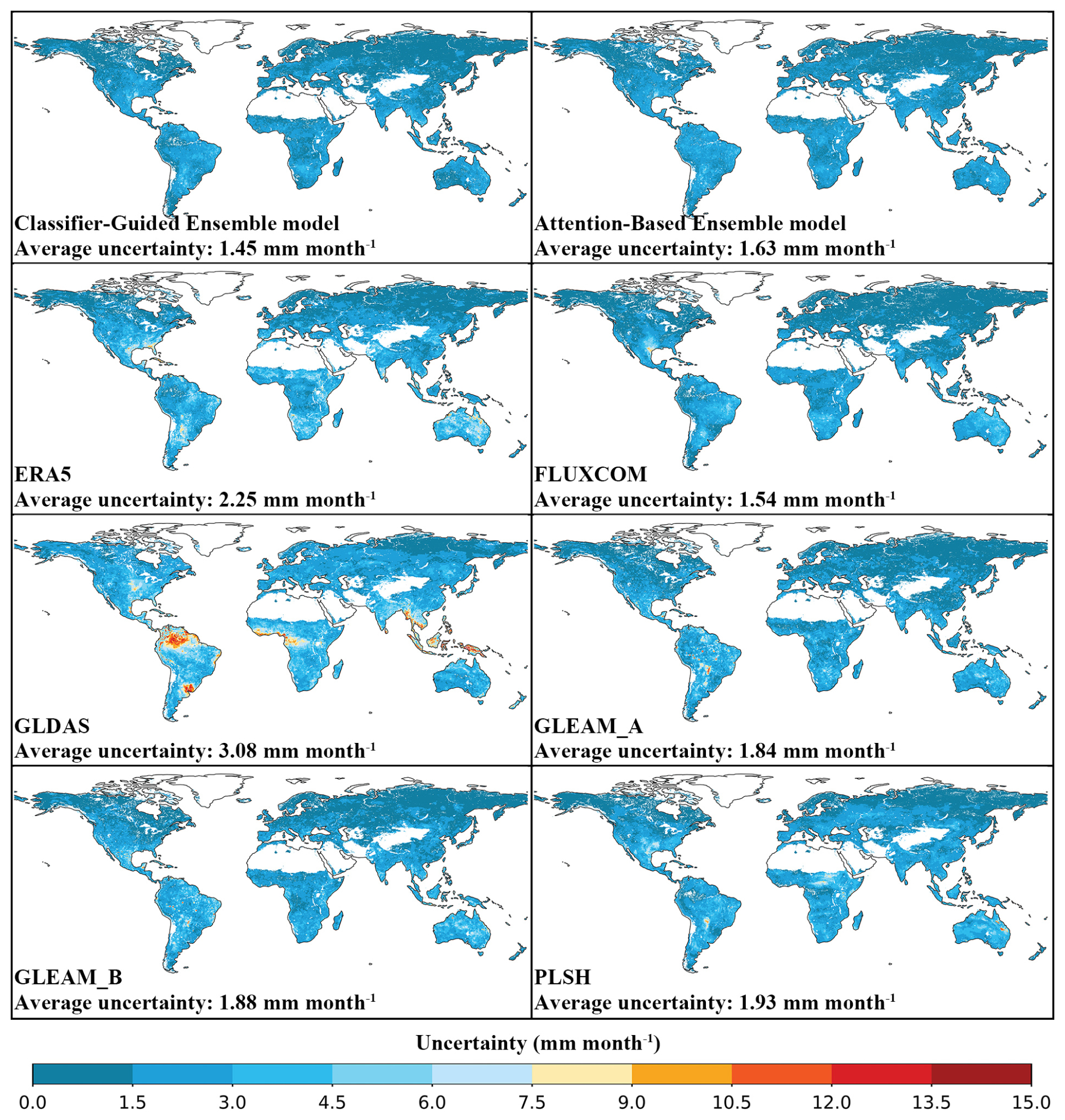
Figure 10Average monthly uncertainty from 2005–2013 for Classifier-Guided Ensemble model, Attention-Based Ensemble model and other ET products.
Compared to Attention-Based Ensemble model, our model shows lower uncertainty in high ET regions near the equator and shows lower uncertainty compared to FLUXCOM in the southern North America and Australia. These results confirm preceding analysis that our Classifier-Guided Ensemble model consistently perform well at global scale, showcasing the potential of our ensemble method to enhance the generalizability.
In this work, by developing a novel ML Classifier-Guided Ensemble ET model, we provide a simple but effective way to integrate different base models (process-based algorithm, ML-based ET model, and hybrid model) to estimate ET or similar variables lacking reliable global observations. Through the introduction of ML classifier, Classifier-Guided Ensemble model can utilize the distinct advantages of the three base models with better performance at multiple spatial scales. Compared with individual base models and Attention-Based Ensemble model, Classifier-Guided Ensemble model fit ET observations better, especially in extreme samples and under different sites and vegetation cover conditions, demonstrating improved generalizability and avoiding the underestimation of high values compared to traditional ensemble models. At catchment scale, ET estimates from Classifier-Guided Ensemble model show a greater agreement with catchment ET calculated from water balance, with performance comparable to other widely used ET products (ERA5, FLUXCOM, GLDAS, GLEAM_A, GLEAM_B, and PLSH). At global scale, the evaluation of multi-year average ET estimates and uncertainty analysis indicate that Classifier-Guided Ensemble model can provide a reasonable and stable global ET estimate. The main advantage of Classifier-Guided Ensemble model is the improved generalizability, which is primarily attributed to the introduction of ML classifier due to the ML Classifier's capacity to include a broader range of training data and to select the appropriate model at each pixel, especially for process-based algorithm.
5.1 Evaluation of the Effectiveness of ML classifier
As the additionally incorporated ML classifier is the core of the proposed ensemble framework, we further validated its effectiveness at both site and global scales. Figure 11a shows that in “process-based algorithm-dominated” type derived from in situ observations, our Classifier-Guided Ensemble model achieves better results than other models, with a KGE of 0.94, R2 of 0.94, MAE of 5.07 mm per month, RMSE of 8.71 mm per month. As demonstrated by the results in Sect. 4.1.1, the process-based algorithm has a poor accuracy of ET estimation at site scale, with a KGE of 0.65, so ensemble model based on in situ observations cannot take good advantage of the process-based algorithm. In Attention-Based Ensemble model, the process-based algorithm contributes much less than the other two models, so neither ML model nor Attention-Based Ensemble model can outperform our Classifier-Guided Ensemble model when the ET estimated by process-based algorithm is the closest to the observed ET.
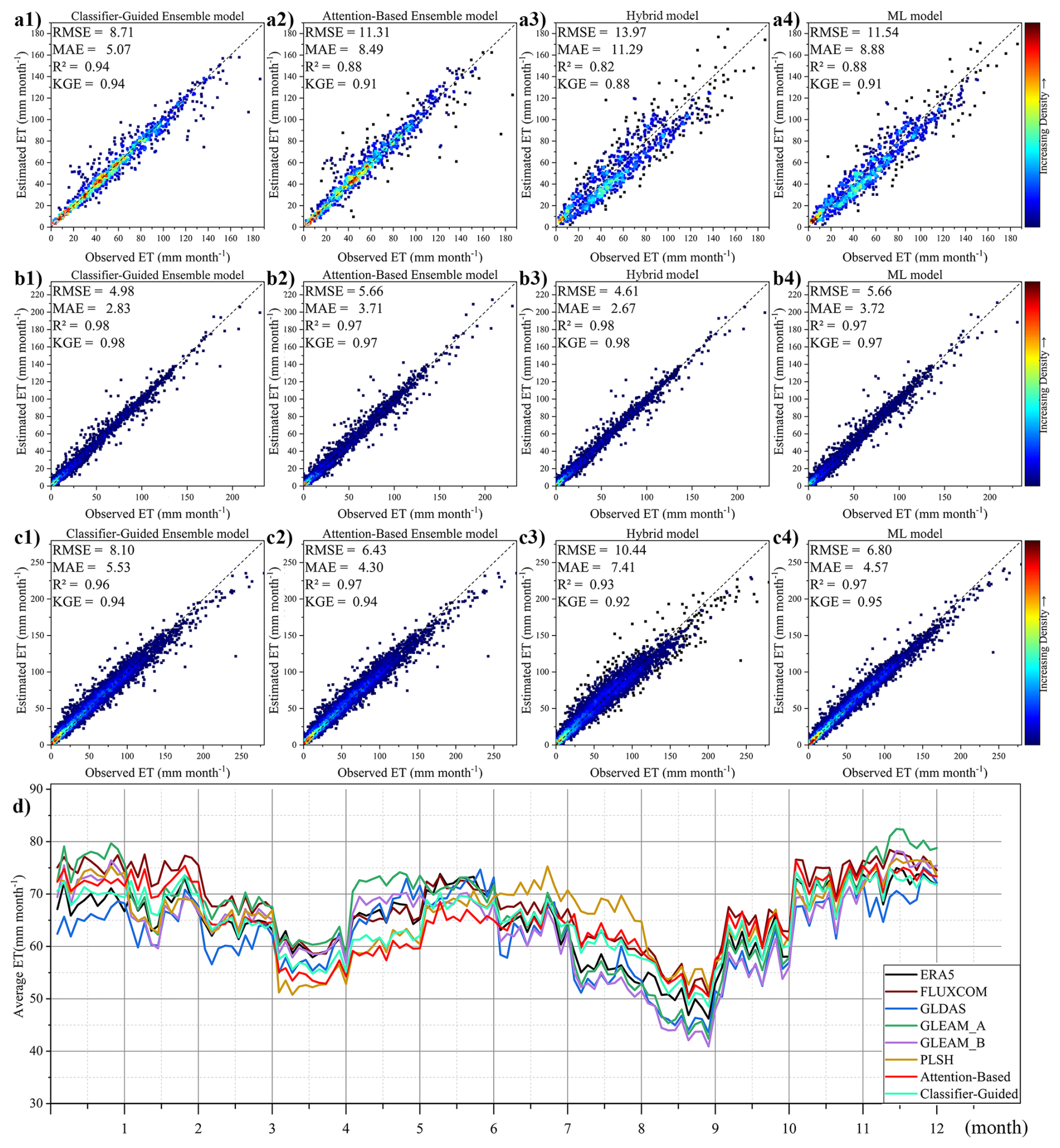
Figure 11The comparison of model performance among (1) Ensemble model, (2) Attention-Based Ensemble model, (3) Hybrid model and (4) ML model under (a) “process-based algorithm-dominated” type, (b) “Hybrid model-dominated” type, (c) “ML model-dominated” type based on in situ observations. (d) The comparison of global average monthly land evapotranspiration from 2005–2013 under “process-based algorithm-dominated” type.
We also analyzed the case of two other types: “hybrid model-dominated” and “ML model-dominated” derived from in situ observations. In “hybrid model-dominated” type (Fig. 11b), the hybrid model performs the best as expected, with a KGE of 0.98, R2 of 0.98, MAE of 2.66 mm per month, RMSE of 4.61 mm per month. Classifier-Guided Ensemble model also performs better in this case compared to Attention-Based Ensemble models, with a KGE of 0.98, R2 of 0.98, MAE of 2.83 mm per month, RMSE of 4.92 mm month−1. The Attention-Based Ensemble model pays more “attention” to the ML model which has higher accuracy at site scale, so in “hybrid model-dominated” type, its results are closer to the ML model, while our model can use hybrid model in most points based on the results of the ML classifier, leading to better results for our models. However, in “ML model-dominated” type (Fig. 11c), Attention-Based Ensemble model performs better than Classifier-Guided Ensemble model, with a higher R2 of 0.97, lower RMSE of 6.43 mm per month and MAE of 4.30 mm per month. Classifier-Guided Ensemble model cannot perform as well as the ML model because the accuracy of ML classifier is not 100 %, while the Attention-Based Ensemble model gets better performance by combining the results of the three models.
Therefore, although our model performs well in estimating ET at various scales, there are still some limitations. The core of our model is to select the potential optimal model as “dominant model” for each pixel as determined by the ML classifier, so in regions where a single model already achieves the best results, Classifier-Guided Ensemble model does not improve performance. In this case, other ensemble model, such as Attention-Based Ensemble model, performs better, as they can improve performance by integrating multiple models.
At global scale, we also conducted additional analysis and validation of the results of the ML classifier within our model. Since ML model and Hybrid model perform well at global scale, while process-based algorithm has lower overall accuracy, we focused on whether the ML classifier can identify pixels where the process-based algorithm performs well and use it to improve the estimation robustness in these areas. Figure 11d shows the line chart of the monthly mean ET series for all datasets at the points corresponding to “process-based algorithm-dominated” type derived from the ML classifier. It is found that the Attention-Based model yields the lowest ET estimation among all datasets around May and FLUXCOM overestimates ET around February, September, October and November, while our Classifier-Guided Ensemble model shows improvements in these cases. In comparison to the Attention-Based Ensemble model's performance (R2 with the various products as follows, ERA5: 0.60, FLUXCOM: 0.71, GLDAS: 0.29, GLEAM_A: 0.54, GLEAM_B: 0.51, and PLSH: 0.73), our model's results are closer to these widely used ET products (R2 with the various products as follows, ERA5: 0.85, FLUXCOM: 0.72, GLDAS: 0.60, GLEAM_A: 0.67, GLEAM_B: 0.71, and PLSH: 0.84). This also demonstrates that using the process-based algorithm instead of ML models in these regions has led to an improvement in the reliability of the ET estimation. Overall, the introduction of the ML classifier did improve the performance of our model at both site and global scale.
5.2 Interpretability of machine learning used in Classifier-Guided Ensemble model
For machine learning-based models, improvement of the model performance is important, but the interpretability of the model is equally crucial. Especially for our model, the explanation of ML classifier can give us more insight into how it selects the “dominant model”, and under which meteorological conditions a particular model is preferred to be selected at both global and site scales, providing valuable support for future research. Interpretable machine learning models are gaining increasing attention, and various methods, such as LIME and SHAP, have been widely used to explain various machine learning models (e.g. Chakraborty et al., 2021; Chu et al., 2024; Eskandari et al., 2024). In this study, we used SHAP values to analyze the interpretability of the ML classifier within Classifier-Guided Ensemble model and we used both site-scale and global-scale data to calculate SHAP values.
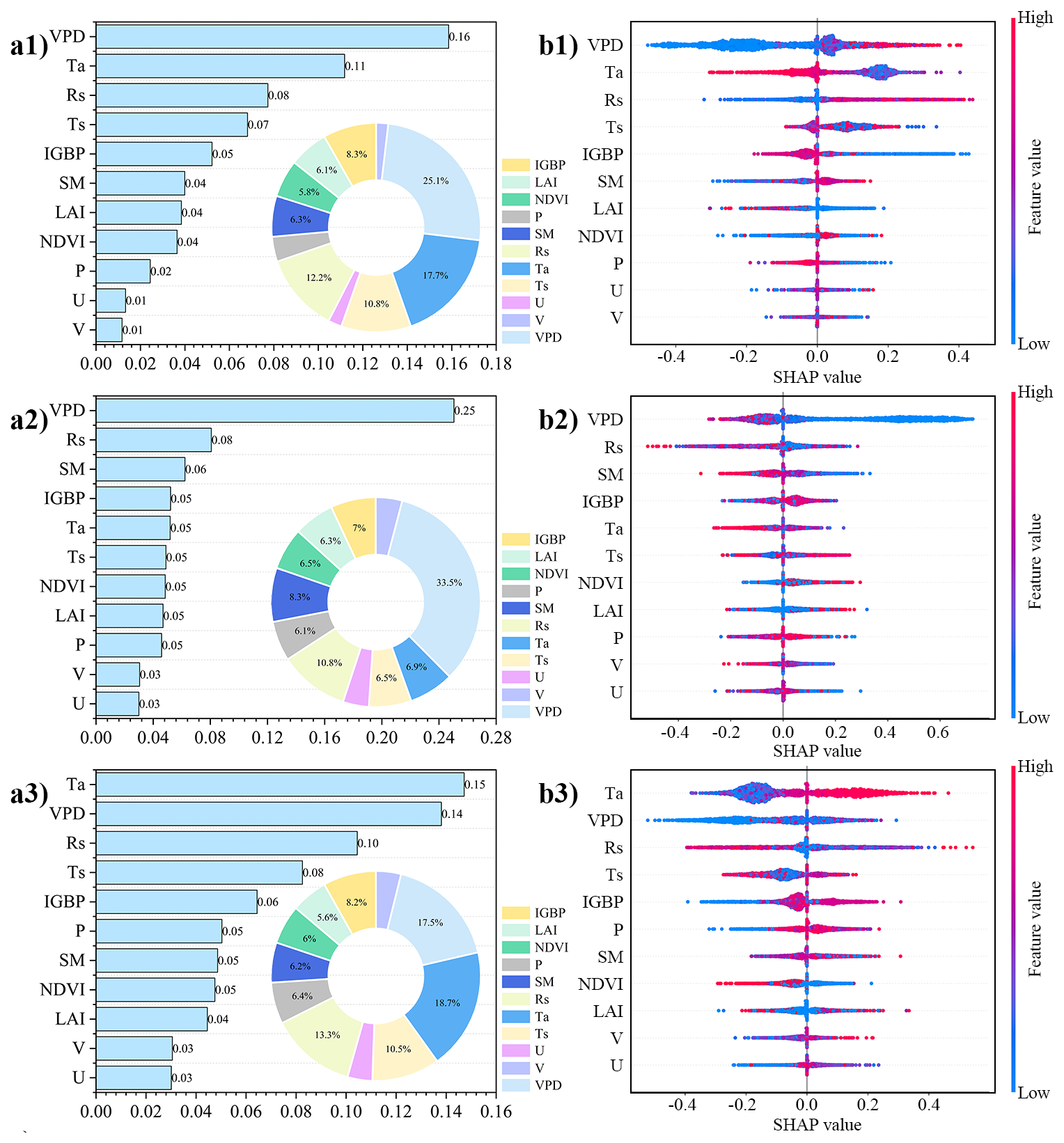
Figure 12(a) The bar plot and (b) summary plot of the SHAP values for (1) “process-based algorithm-dominated” type, (2) “Hybrid model-dominated” type and (3) “ML model-dominated” type. The bar plot exhibits the mean absolute SHAP values for each covariate and the summary plot exhibits the distribution of SHAP values.
The contribution of different covariates to the results varies across the different classes (Fig. 12a). As Fig. 13a shows, the covariates VPD, Ta, and Rs have a higher contribution, while NDVI, LAI, P, U, and V have a lower contribution. For “process-based algorithm-dominated” type, the contribution of VPD accounts for 25.09 %, followed by Ta (17.68 %), Rs (12.22 %), Ts (10.78 %), IGBP (8.25 %), SM (6.31 %), LAI (6.08 %), NDVI (5.77 %), P (3.86 %), U (2.10 %), V (1.85 %). For “ML model-dominated” type, the distribution of SHAP values shows some similarity to “process-based algorithm-dominated” type (Fig. 13b), with Ta having the highest contribution (18.67 %) and VPD the second highest (17.52 %). Previous studies have demonstrated that variables VPD, Ta, and Rs make significant contributions to the estimation of ET, whether using machine learning methods or the process-based algorithm (Mu et al., 2011; Shang et al., 2023). The similarity in the contribution distribution of ML model and process-based algorithm may be attributed to the fact that they directly estimate ET, while differences may result from their different algorithms.
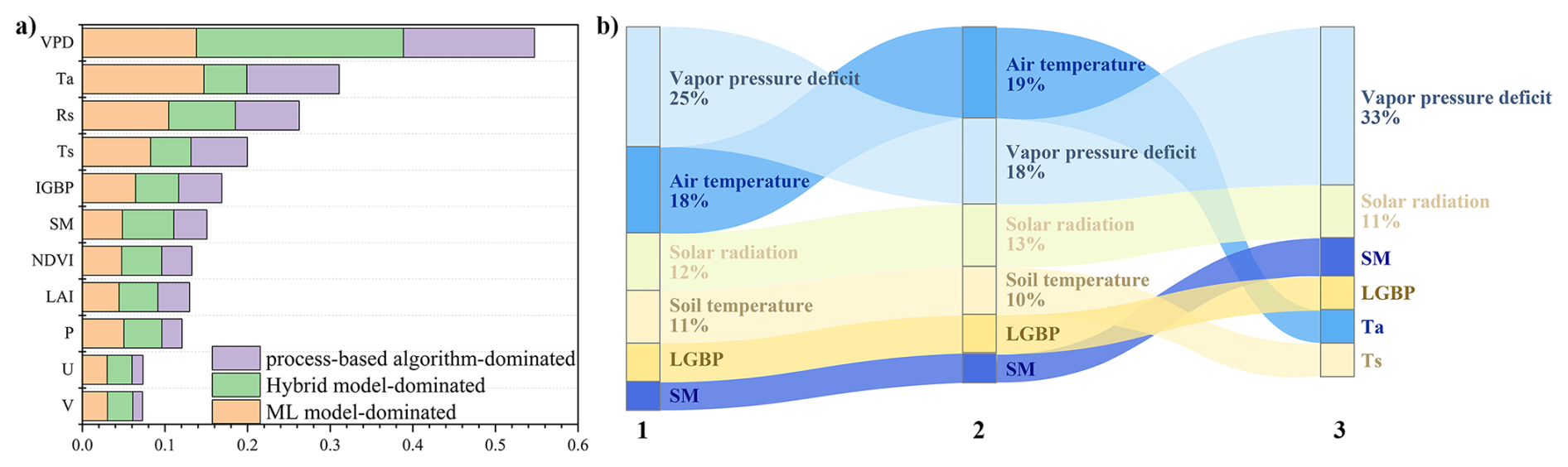
Figure 13(a) The bar plot of the mean absolute SHAP values for three types and (b) the changes in variable contributions across (1) “process-based algorithm-dominated” type, (2) “ML model-dominated” type, (3) “Hybrid model-dominated” type.
For “Hybrid model-dominated” type, it is still VPD that dominates the feature contribution, with its proportion rising to 33.39 %. The distribution of covariates under “Hybrid model-dominated” type is somewhat distinct from “process-based algorithm-dominated” type and “ML model-dominated” type, with a higher contribution from SM and a slightly reduced contribution from Ta (Fig. 13b). Machine learning was used in the hybrid model for the estimation of rs, and it was strongly correlated with water content (VPD, SM), and temperature (Ta) (Gan et al., 2018; Leuning et al., 2008; Mallick et al., 2015). In the hybrid model ML-GS developed by Shang et al. (2023), the distribution of SHAP values for their input variables is similar to that in our “Hybrid model-dominated” type. Therefore, it can be seen that the variables with a higher contribution when selecting the `dominant model' in the ML classifier have a certain correlation with those having a higher contribution when estimating ET.
The Fig. 12b shows the summary plot, where the horizontal axis represents the SHAP values, indicating the contribution of each covariate and color represents the magnitude of the variable values, with redder colors indicating larger variable values. The summary plot illustrates that, in certain conditions, a specific base model may have higher SHAP values, indicating its greater likelihood of being selected. For instance, under high VPD, low Ta and high Rs conditions, process-based algorithm is more likely to be selected. Also, there is a tendency to select Hybrid model under conditions of low VPD and low SM, while the ML model tends to be selected under high Ta conditions. The results in the summary plot show some correlation to the extreme samples analysis (Sect. 4.1.3) that for the 0th–1st percentiles of the VPD and SM, hybrid model outperforms ML model, making hybrid model the preferred choice. Despite these clear conditions, model selection remains unclear in some cases, particularly for ML model and Hybrid model, possibly due to their inter-correlation as both of them are based on ML method.
In summary, the interpretability analysis provides insights into the covariates with the high contribution to model selection, as well as scenarios where the three base models are more likely to be selected. However, the model selection for some cases such as high VPD, low radiation, etc. is not fully determined and further research is needed to explore the deeper mechanisms of model selection.
5.3 Uncertainties of Classifier-Guided Ensemble model
Despite better performance than other models in estimating ET at multiple spatial scales, there are still uncertainties in our model. First, the inclusion of a ML classifier in our ensemble model may introduce uncertainties. Although we used multiple global ET products as references when adding global-scale training data, these are not as reliable as ET observations, so we are still unsure of the accuracy of classification. Moreover, the classification results of machine learning model are not completely accurate, leading to the fact that the ML classifier does not guarantee optimal model selection. To minimize the impact of this issue, we have chosen models that have been shown to be excellent for global ET estimation in previous studies, so even if the ML classifier does not accurately choose the optimal model as “dominant model” at some pixels, the results of the other models will not differ significantly.
Second, the base models selected may introduce uncertainties. We chose to integrate ML-based ET models, process-based algorithms, and hybrid models. Although process-based algorithms have been widely used for ET estimation, there is still no widely recognized optimal method for the parameterization of some ET processes (Jiménez et al., 2018; Mu et al., 2011). While ML-based ET models perform well in regions with sufficient data, they tend to have poor generalizability in regions with limited data and may suffer from local optima or overfitting problems (Koppa et al., 2022; Yuan et al., 2020). For hybrid model, there are also uncertainties in the synergy between physical laws and machine learning (Shang et al., 2023).
Lastly, our model contains many input variables that incorporate multiple data sources including: satellite data, reanalysis data, and in situ observations, which may introduce uncertainty. At site scale, water flux observations obtained by the eddy covariance method have inherent random errors from the measuring instruments (Mizoguchi et al., 2009). According to the previous study, the biases between the reanalysis data and the satellite meteorological data (Rienecker et al., 2011) and the inconsistency between in situ observations and global-scale data also introduces uncertainty (Cao et al., 2021). We have made efforts to reduce uncertainties caused by data inconsistencies by replacing in situ covariate observations with the corresponding data from global-scale datasets at the same coordinates, but the uncertainties remain unavoidable.
5.4 Future perspectives
Despite the uncertainties and limitations, our model offers a new perspective on integrating multiple models and utilizing the complementarity between ML models and physical models, and there remains potential for further improvement. First, various alternatives still exist for the selection of base models. For example, there are many other ML models that can be chose and have their own advantages, such as some deep learning models (LSTM, CNN, etc.). These deep learning models or their improved forms have been shown to effectively estimate ET in previous studies (Guo et al., 2024; Karbasi et al., 2022; de Oliveira e Lucas et al., 2020). There are also some ET estimation methods based on other frameworks without using the three base models we chose, such as a Bayesian-driven ensemble learning method (Ochege et al., 2024). Better results might be obtained by choosing different models or by integrating more models, which could be a potential direction for future research.
Second, more rigorous and reasonable methods are needed for model integration. One of the advantages of the proposed framework is that we can add global data as training data even when there are no global-scale observations, which offers a novel approach to improving the generalizability of model, but how to identify the “dominant model” from additional data remains a problem. If there is a more rigorous and reasonable method to optimize the model selection, it can not only improve the reliability of the final ET estimation, but also contribute to the study of the regions where each base model demonstrates its advantages. Additionally, after the ML classifier has selected the “dominant model” at each pixel, if we discard the simple use of the selected model and adopt more advanced methods for model integration, the results of Classifier-Guided Ensemble model may be further improved. We have tried optimizing the results under three different classes using both genetic algorithms and machine learning models, but the results were not as good as expected. Since these methods are still limited by in situ observations, they do not perform as well as using the original models directly when upscaled to a global scale. It is still worth exploring how to better utilize these models.
Finally, more effective integration of machine learning and physical models has the potential to further improve ET estimation. Since physical models have higher interpretability and extrapolation capabilities, while machine learning can utilize data more effectively, how to better integrate the complementary advantages of them is a topic worthy of in-depth investigation. Moreover, ML models, especially deep learning models, are data-driven, but the available data cannot provide sufficient information for ML models to achieve better results. Leveraging physical models to extract more meaningful information from limited data is a viable way to enhance model performance.
The poor generalizability is a common limitation across ML-based global ET models due to the sparse distribution of in situ observations. In this study, we developed a novel ensemble framework for combining the distinct advantages of process-based algorithms (extrapolation performance in data-sparse regions), ML-based ET models (data adaptability in data-dense regions), and hybrid models (overall performance) by introducing an additional ML classifier. Taking advantage of the ML classifier's capacity for automatic model selection, we are able to improve the generalizability of ML-based ET models by employing physically-founded process-based algorithm and hybrid model at appropriate pixel and avoid the typical underestimation of high values by ensemble methods.
The evaluation results across site and catchment scales indicate that our Classifier-Guided Ensemble model is overall more accurate than the individual base models, Attention-Based Ensemble model and other widely used global terrestrial ET products (ERA5, FLUXCOM, GLDAS, GLEAM_A, GLEAM_B, and PLSH) with lower RMSE and MAE and higher R2 and KGE, especially in extreme samples where existing ML models perform poorly. At global scale, our model also exhibits higher stability, as well as greater consistency with these global ET products in both spatial patterns and latitude-averaged values.
In addition, the analysis of ML classifier's effectiveness demonstrates that the ML classifier can reasonably select the base models used at both global and site scales, highlighting the potential to further enhance the model's generalizability. Moreover, by further analyzing the SHAP values of different input covariates when the ML classifier select the “dominant model”, we gained a simple understanding of the mechanisms behind the selection of “dominant model” that just as VPD, Ta, and Rs are critical for ET estimation, these variables also play a crucial role in model selection and identified some specific scenarios in which each model is most suitable. However, we chose to introduce global-scale training data to enhance the generalizability of the ML classifier, which has indeed led to improvements in ET estimation, but since these data were not obtained from ET observations, this may introduce uncertainties. Therefore, while our framework demonstrates significant potential to advance global ET estimation, further in-depth analysis and investigation are required, especially for the introduction of the ML classifier.
Table A1Information for the 129 EC Flux Tower Sites, including the Site Name, Latitude (Lat), Longitude (Lon), International Geosphere-Biosphere Programme Land Cover Types (IGBP).

Table A3Information for the 30 Selected EC Flux Tower Sites in Independent Validation.
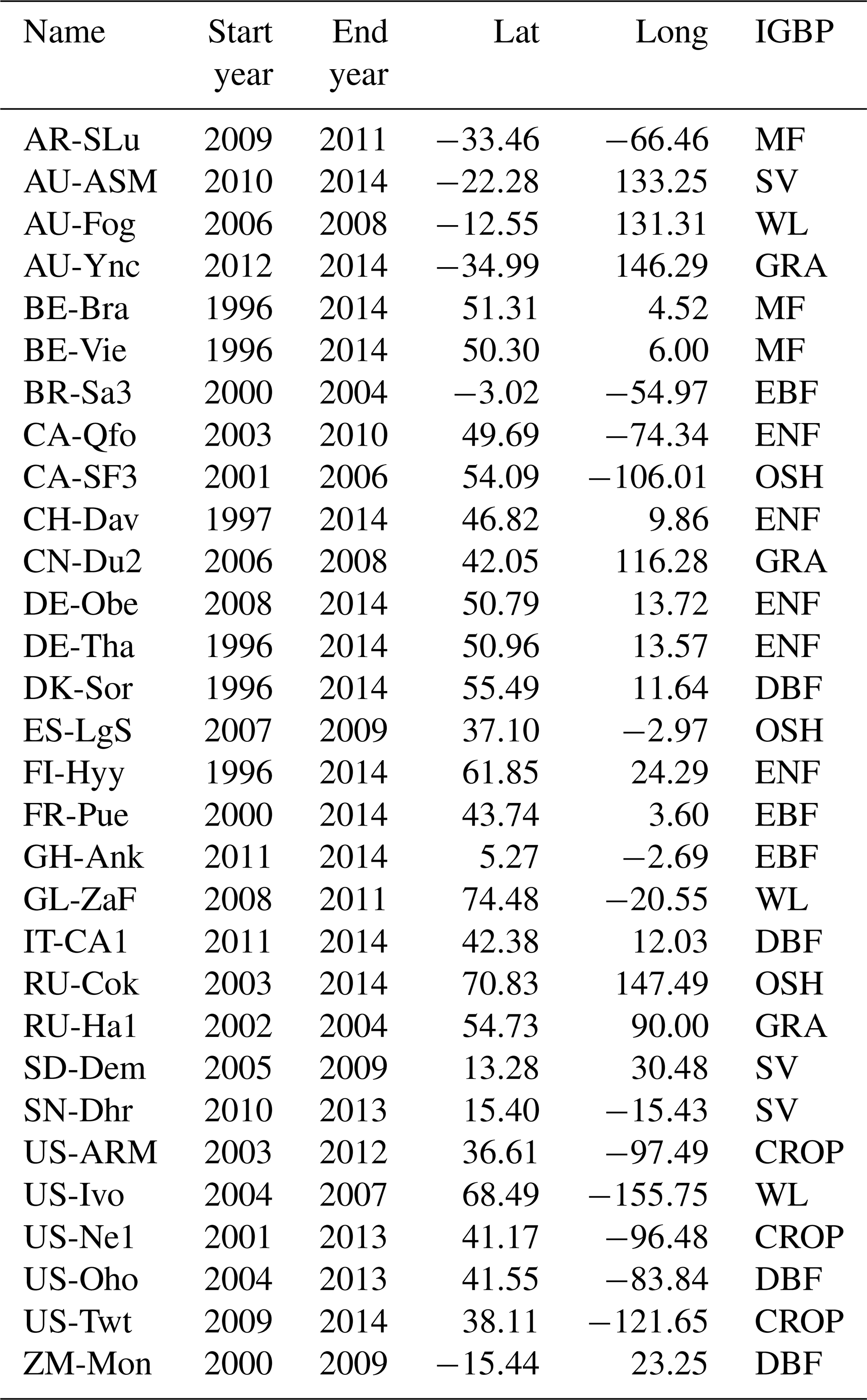
Table A4Performance of Different ET Models in Independent Validation.
All dataset used are publicly available from data sources cited throughout the paper. The in-situ datasets were obtained from the FLUXNET2015 dataset via https://fluxnet.org/ (last access: 24 April 2026). The ERA5-Land reanalysis products were obtained from the ECMWF via https://cds.climate.copernicus.eu/ (last access: 24 April 2026). The water-balance-based evapotranspiration product was downloaded from the National Tibetan Plateau Data Center via https://doi.org/10.11888/Atmos.tpdc.300493 (Ma, 2024). The FLUXCOM product was obtained via http://www.fluxcom.org/ (last access: 24 April 2026). The PLSH product was obtained via http://files.ntsg.umt.edu/data/ (last access: 24 April 2026). The GLEAM product version 3.8a and 3.8b was obtained via https://www.gleam.eu/ (last access: 24 April 2026). The GLDAS product was obtained via https://doi.org/10.5067/SXAVCZFAQLNO (Beaudoing and Rodell, 2020). The NDVI and LAI data was obtained from GIMMS product (Cao et al., 2023; Li et al., 2023). The MODIS Land Cover Climate Modeling Grid Product (MCD12C1) was obtained via https://doi.org/10.5067/MODIS/MCD12C1.006 (Friedl and Sulla-Menashe, 2015). The machine learning models were trained using AutoGluon version 0.8.2 (Erickson et al., 2020). The code supporting this study is available upon reasonable request from the corresponding author. The global evapotranspiration dataset estimated in this study is openly available online in a Zenodo repository (https://doi.org/10.5281/zenodo.18543737, Ni et al., 2026).
Conceptualization: LN, WW; Investigation: LN, WW, JF, MC; Supervision: WW; Visualization: LN; Writing–original draft: LN; Writing–review and editing: WW, JF, MC.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
Cordial thanks are extended to the editor, the associate editor, and reviewers for their critical and constructive comments, which highly improve the quality of the manuscript.
This work was jointly supported by the National Natural Science Foundation of China (grant nos. U25A20752 and 52479010). Jianyu Fu is supported by the National Natural Science Foundation of China (grant no. 42401020), National Key Laboratory of Water Disaster Prevention (grant no. 2022nkms05).
This paper was edited by Elham R. Freund and reviewed by two anonymous referees.
Abbott, P. F. and Tabony, R. C.: The estimation of humidity parameters, Meteorol. Mag., 114, 49–56, 1985.
Allen, R. G., Pereira, L. S., Raes, D., and Smith, M.: Crop evapotranspiration-Guidelines for computing crop water requirements-FAO Irrigation and drainage paper 56, Fao, Rome, 300, D05109, ISBN 92-5-104219-5, 1998.
Ayan, E., Erbay, H., and Varçın, F.: Crop pest classification with a genetic algorithm-based weighted ensemble of deep convolutional neural networks, Comput. Electron. Agr., 179, 105809, https://doi.org/10.1016/j.compag.2020.105809, 2020.
Bastiaanssen, W. G. M., Menenti, M., Feddes, R. A., and Holtslag, A. A. M.: A remote sensing surface energy balance algorithm for land (SEBAL). 1. Formulation, J. Hydrol., 212–213, 198–212, https://doi.org/10.1016/S0022-1694(98)00253-4, 1998.
Beaudoing, H. and Rodell, M.: GLDAS Noah Land Surface Model L4 monthly 0.25 x 0.25 degree V2.1, NASA/GSFC/HSL, Greenbelt, Maryland, USA, Goddard Earth Sciences Data and Information Services Center (GES DISC) [data set], https://doi.org/10.5067/SXAVCZFAQLNO, 2020.
Beaudoing, H., Rodell, M., and NASA/GSFC/HSL: GLDAS Noah Land Surface Model L4 3 hourly 0.25×0.25 degree V2.1, Goddard Earth Sciences Data and Information Services Center (GES DISC) [data set], https://doi.org/10.5067/E7TYRXPJKWOQ, 2020.
Breiman, L.: Random Forests, Mach. Learn., 45, 5–32, https://doi.org/10.1023/A:1010933404324, 2001.
Brenowitz, N. D. and Bretherton, C. S.: Prognostic Validation of a Neural Network Unified Physics Parameterization, Geophys. Res. Lett., 45, 6289–6298, https://doi.org/10.1029/2018GL078510, 2018.
Cai, Y., Xu, Q., Bai, F., Cao, X., Wei, Z., Lu, X., Wei, N., Yuan, H., Zhang, S., Liu, S., Zhang, Y., Li, X., and Dai, Y.: Reconciling Global Terrestrial Evapotranspiration Estimates From Multi-Product Intercomparison and Evaluation, Water Resour. Res., 60, e2024WR037608, https://doi.org/10.1029/2024WR037608, 2024.
Cao, M., Wang, W., Xing, W., Wei, J., Chen, X., Li, J., and Shao, Q.: Multiple sources of uncertainties in satellite retrieval of terrestrial actual evapotranspiration, J. Hydrol., 601, 126642, https://doi.org/10.1016/j.jhydrol.2021.126642, 2021.
Cao, S., Li, M., Zhu, Z., Wang, Z., Zha, J., Zhao, W., Duanmu, Z., Chen, J., Zheng, Y., Chen, Y., Myneni, R. B., and Piao, S.: Spatiotemporally consistent global dataset of the GIMMS leaf area index (GIMMS LAI4g) from 1982 to 2020, Earth Syst. Sci. Data, 15, 4877–4899, https://doi.org/10.5194/essd-15-4877-2023, 2023.
Chakraborty, D., Başağaoğlu, H., and Winterle, J.: Interpretable vs. noninterpretable machine learning models for data-driven hydro-climatological process modeling, Expert Syst. Appl., 170, 114498, https://doi.org/10.1016/j.eswa.2020.114498, 2021.
Chen, H., Good, S., Caylor, K., Fiorella, R. P., and Wang, L.: A hybrid Penman–Monteith and machine learning model for simulating evapotranspiration and its components, J. Hydrol., 134985, https://doi.org/10.1016/j.jhydrol.2026.134985, 2026.
Chen, H., Huang, J. J., Dash, S. S., Wei, Y., and Li, H.: A hybrid deep learning framework with physical process description for simulation of evapotranspiration, J. Hydrol., 606, 127422, https://doi.org/10.1016/j.jhydrol.2021.127422, 2022.
Chu, W., Zhang, C., Li, H., Zhang, L., Shen, D., and Li, R.: SHAP-powered insights into spatiotemporal effects: Unlocking explainable Bayesian-neural-network urban flood forecasting, Int. J. Appl. Earth Obs., 131, 103972, https://doi.org/10.1016/j.jag.2024.103972, 2024.
Dorogush, A. V., Ershov, V., and Gulin, A.: CatBoost: gradient boosting with categorical features support, arXiv [preprint], https://doi.org/10.48550/arXiv.1810.11363, 2018.
ElGhawi, R., Kraft, B., Reimers, C., Reichstein, M., Körner, M., Gentine, P., and Winkler, A. J.: Hybrid modeling of evapotranspiration: inferring stomatal and aerodynamic resistances using combined physics-based and machine learning, Environ. Res. Lett., 18, 034039, https://doi.org/10.1088/1748-9326/acbbe0, 2023.
Erickson, N., Mueller, J., Shirkov, A., Zhang, H., Larroy, P., Li, M., and Smola, A.: AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data, arXiv [preprint], https://doi.org/10.48550/arXiv.2003.06505, 2020.
Eskandari, H., Saadatmand, H., Ramzan, M., and Mousapour, M.: Innovative framework for accurate and transparent forecasting of energy consumption: A fusion of feature selection and interpretable machine learning, Appl. Energ., 366, 123314, https://doi.org/10.1016/j.apenergy.2024.123314, 2024.
Fan, J., Ma, X., Wu, L., Zhang, F., Yu, X., and Zeng, W.: Light Gradient Boosting Machine: An efficient soft computing model for estimating daily reference evapotranspiration with local and external meteorological data, Agr. Water Manage., 225, 105758, https://doi.org/10.1016/j.agwat.2019.105758, 2019.
Fisher, J. B., Melton, F., Middleton, E., Hain, C., Anderson, M., Allen, R., McCabe, M. F., Hook, S., Baldocchi, D., Townsend, P. A., Kilic, A., Tu, K., Miralles, D. D., Perret, J., Lagouarde, J.-P., Waliser, D., Purdy, A. J., French, A., Schimel, D., Famiglietti, J. S., Stephens, G., and Wood, E. F.: The future of evapotranspiration: Global requirements for ecosystem functioning, carbon and climate feedbacks, agricultural management, and water resources, Water Resour. Res., 53, 2618–2626, https://doi.org/10.1002/2016WR020175, 2017.
Foken, T.: The Energy Balance Closure Problem: An Overview, Ecol. Appl., 18, 1351–1367, https://doi.org/10.1890/06-0922.1, 2008.
Friedl, M. and Sulla-Menashe, D.: MCD12C1 MODIS/Terra+Aqua Land Cover Type Yearly L3 Global 0.05Deg CMG V006, NASA Land Processes Distributed Active Archive Center [data set], https://doi.org/10.5067/MODIS/MCD12C1.006, 2015.
Fu, J., Wang, W., Shao, Q., Xing, W., Cao, M., Wei, J., Chen, Z., and Nie, W.: Improved global evapotranspiration estimates using proportionality hypothesis-based water balance constraints, Remote Sens. Environ., 279, 113140, https://doi.org/10.1016/j.rse.2022.113140, 2022.
Galindo, F. J. and Palacio, J.: Estimating the Instabilities of N Correlated Clocks, https://api.semanticscholar.org/CorpusID:92985051 (last access: 24 April 2026), 1999.
Galindo, F. J. and Palacio, J.: Post-processing ROA data clocks for optimal stability in the ensemble timescale, Metrologia, 40, S237, https://doi.org/10.1088/0026-1394/40/3/301, 2003.
Gan, R., Zhang, Y., Shi, H., Yang, Y., Eamus, D., Cheng, L., Chiew, F. H. S., and Yu, Q.: Use of satellite leaf area index estimating evapotranspiration and gross assimilation for Australian ecosystems, Ecohydrology, 11, e1974, https://doi.org/10.1002/eco.1974, 2018.
Ganaie, M. A., Hu, M., Malik, A. K., Tanveer, M., and Suganthan, P. N.: Ensemble deep learning: A review, Eng. Appl. Artif. Intel., 115, 105151, https://doi.org/10.1016/j.engappai.2022.105151, 2022.
Good, S. P., Noone, D., and Bowen, G.: Hydrologic connectivity constrains partitioning of global terrestrial water fluxes, Science, 349, 175–177, https://doi.org/10.1126/science.aaa5931, 2015.
Granata, F.: Evapotranspiration evaluation models based on machine learning algorithms – A comparative study, Agr. Water Manage., 217, 303–315, https://doi.org/10.1016/j.agwat.2019.03.015, 2019.
Greve, P. and Seneviratne, S. I.: Assessment of future changes in water availability and aridity, Geophys. Res. Lett., 42, 5493–5499, https://doi.org/10.1002/2015GL064127, 2015.
Guo, X., Yao, Y., Tang, Q., Liang, S., Shao, C., Fisher, J. B., Chen, J., Jia, K., Zhang, X., Shang, K., Yang, J., Yu, R., Xie, Z., Liu, L., Ning, J., and Zhang, L.: Multimodel ensemble estimation of Landsat-like global terrestrial latent heat flux using a generalized deep CNN-LSTM integration algorithm, Agr. Forest Meteorol., 349, 109962, https://doi.org/10.1016/j.agrformet.2024.109962, 2024.
Huang, T. and Merwade, V.: Improving Bayesian Model Averaging for Ensemble Flood Modeling Using Multiple Markov Chains Monte Carlo Sampling, Water Resour. Res., 59, e2023WR034947, https://doi.org/10.1029/2023WR034947, 2023.
Huntington, T. G.: Evidence for intensification of the global water cycle: Review and synthesis, J. Hydrol., 319, 83–95, https://doi.org/10.1016/j.jhydrol.2005.07.003, 2006.
Jiménez, C., Martens, B., Miralles, D. M., Fisher, J. B., Beck, H. E., and Fernández-Prieto, D.: Exploring the merging of the global land evaporation WACMOS-ET products based on local tower measurements, Hydrol. Earth Syst. Sci., 22, 4513–4533, https://doi.org/10.5194/hess-22-4513-2018, 2018.
Jung, M., Reichstein, M., Ciais, P., Seneviratne, S. I., Sheffield, J., Goulden, M. L., Bonan, G., Cescatti, A., Chen, J., de Jeu, R., Dolman, A. J., Eugster, W., Gerten, D., Gianelle, D., Gobron, N., Heinke, J., Kimball, J., Law, B. E., Montagnani, L., Mu, Q., Mueller, B., Oleson, K., Papale, D., Richardson, A. D., Roupsard, O., Running, S., Tomelleri, E., Viovy, N., Weber, U., Williams, C., Wood, E., Zaehle, S., and Zhang, K.: Recent decline in the global land evapotranspiration trend due to limited moisture supply, Nature, 467, 951–954, https://doi.org/10.1038/nature09396, 2010.
Jung, M., Reichstein, M., Margolis, H. A., Cescatti, A., Richardson, A. D., Arain, M. A., Arneth, A., Bernhofer, C., Bonal, D., Chen, J., Gianelle, D., Gobron, N., Kiely, G., Kutsch, W., Lasslop, G., Law, B. E., Lindroth, A., Merbold, L., Montagnani, L., Moors, E. J., Papale, D., Sottocornola, M., Vaccari, F., and Williams, C.: Global patterns of land–atmosphere fluxes of carbon dioxide, latent heat, and sensible heat derived from eddy covariance, satellite, and meteorological observations, J. Geophys. Res.-Biogeo., 116, https://doi.org/10.1029/2010JG001566, 2011.
Jung, M., Koirala, S., Weber, U., Ichii, K., Gans, F., Camps-Valls, G., Papale, D., Schwalm, C., Tramontana, G., and Reichstein, M.: The FLUXCOM ensemble of global land–atmosphere energy fluxes, Scientific Data, 6, 74, https://doi.org/10.1038/s41597-019-0076-8, 2019.
Karbasi, M., Jamei, M., Ali, M., Malik, A., and Yaseen, Z. M.: Forecasting weekly reference evapotranspiration using Auto Encoder Decoder Bidirectional LSTM model hybridized with a Boruta-CatBoost input optimizer, Comput. Electron. Agr., 198, 107121, https://doi.org/10.1016/j.compag.2022.107121, 2022.
Karpatne, A., Atluri, G., Faghmous, J. H., Steinbach, M., Banerjee, A., Ganguly, A., Shekhar, S., Samatova, N., and Kumar, V.: Theory-Guided Data Science: A New Paradigm for Scientific Discovery from Data, IEEE T. Knowl. Data En., 29, 2318–2331, https://doi.org/10.1109/TKDE.2017.2720168, 2017.
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., and Liu, T.-Y.: LightGBM: A Highly Efficient Gradient Boosting Decision Tree, in: Neural Information Processing Systems, https://api.semanticscholar.org/CorpusID:3815895 (last access: 24 April 2026), 2017.
Koppa, A., Rains, D., Hulsman, P., Poyatos, R., and Miralles, D. G.: A deep learning-based hybrid model of global terrestrial evaporation, Nat. Commun., 13, 1912, https://doi.org/10.1038/s41467-022-29543-7, 2022.
Kustas, W. P. and Norman, J. M.: A two-source approach for estimating turbulent fluxes using multiple angle thermal infrared observations, Water Resour. Res., 33, 1495–1508, https://doi.org/10.1029/97WR00704, 1997.
Leuning, R., Zhang, Y. Q., Rajaud, A., Cleugh, H., and Tu, K.: A simple surface conductance model to estimate regional evaporation using MODIS leaf area index and the Penman–Monteith equation, Water Resour. Res., 44, https://doi.org/10.1029/2007WR006562, 2008.
Li, C., Yang, H., Yang, W., Liu, Z., Jia, Y., Li, S., and Yang, D.: Error characterization of global land evapotranspiration products: Collocation-based approach, J. Hydrol., 612, 128102, https://doi.org/10.1016/j.jhydrol.2022.128102, 2022.
Li, M., Cao, S., Zhu, Z., Wang, Z., Myneni, R. B., and Piao, S.: Spatiotemporally consistent global dataset of the GIMMS Normalized Difference Vegetation Index (PKU GIMMS NDVI) from 1982 to 2022, Earth Syst. Sci. Data, 15, 4181–4203, https://doi.org/10.5194/essd-15-4181-2023, 2023.
Liu, G., Tang, Z., Qin, H., Liu, S., Shen, Q., Qu, Y., and Zhou, J.: Short-term runoff prediction using deep learning multi-dimensional ensemble method, J. Hydrol., 609, 127762, https://doi.org/10.1016/j.jhydrol.2022.127762, 2022.
Liu, J., Chai, L., Dong, J., Zheng, D., Wigneron, J.-P., Liu, S., Zhou, J., Xu, T., Yang, S., Song, Y., Qu, Y., and Lu, Z.: Uncertainty analysis of eleven multisource soil moisture products in the third pole environment based on the three-corned hat method, Remote Sens. Environ., 255, 112225, https://doi.org/10.1016/j.rse.2020.112225, 2021.
Lundberg, S. M. and Lee, S.-I.: A unified approach to interpreting model predictions, arXiv [preprint], https://doi.org/10.48550/arXiv.1705.07874, 2017.
Lyu, Y. and Yong, B.: A Novel Double Machine Learning Strategy for Producing High-Precision Multi-Source Merging Precipitation Estimates Over the Tibetan Plateau, Water Resour. Res., 60, e2023WR035643, https://doi.org/10.1029/2023WR035643, 2024.
Ma, N.: Dataset of the water-balance-based evapotranspiration of global typical large river basins (1983–2016), National Tibetan Plateau Data Center [data set], https://doi.org/10.11888/Atmos.tpdc.300493, 2024.
Ma, N., Zhang, Y., and Szilagyi, J.: Water-balance-based evapotranspiration for 56 large river basins: A benchmarking dataset for global terrestrial evapotranspiration modeling, J. Hydrol., 630, 130607, https://doi.org/10.1016/j.jhydrol.2024.130607, 2024.
Mallick, K., Boegh, E., Trebs, I., Alfieri, J. G., Kustas, W. P., Prueger, J. H., Niyogi, D., Das, N., Drewry, D. T., Hoffmann, L., and Jarvis, A. J.: Reintroducing radiometric surface temperature into the Penman–Monteith formulation, Water Resour. Res., 51, 6214–6243, https://doi.org/10.1002/2014WR016106, 2015.
Martens, B., Miralles, D. G., Lievens, H., van der Schalie, R., de Jeu, R. A. M., Fernández-Prieto, D., Beck, H. E., Dorigo, W. A., and Verhoest, N. E. C.: GLEAM v3: satellite-based land evaporation and root-zone soil moisture, Geosci. Model Dev., 10, 1903–1925, https://doi.org/10.5194/gmd-10-1903-2017, 2017.
Medlyn, B. E., Duursma, R. A., Eamus, D., Ellsworth, D. S., Prentice, I. C., Barton, C. V. M., Crous, K. Y., De Angelis, P., Freeman, M., and Wingate, L.: Reconciling the optimal and empirical approaches to modelling stomatal conductance, Glob. Change Biol., 17, 2134–2144, https://doi.org/10.1111/j.1365-2486.2010.02375.x, 2011.
Milly, P. C. D., Dunne, K. A., and Vecchia, A. V.: Global pattern of trends in streamflow and water availability in a changing climate, Nature, 438, 347–350, https://doi.org/10.1038/nature04312, 2005.
Miralles, D. G., Holmes, T. R. H., De Jeu, R. A. M., Gash, J. H., Meesters, A. G. C. A., and Dolman, A. J.: Global land-surface evaporation estimated from satellite-based observations, Hydrol. Earth Syst. Sci., 15, 453–469, https://doi.org/10.5194/hess-15-453-2011, 2011.
Miralles, D. G., Gentine, P., Seneviratne, S. I., and Teuling, A. J.: Land–atmospheric feedbacks during droughts and heatwaves: state of the science and current challenges, Ann. NY Acad. Sci., 1436, 19–35, https://doi.org/10.1111/nyas.13912, 2019.
Mizoguchi, Y., Miyata, A., Ohtani, Y., Hirata, R., and Yuta, S.: A review of tower flux observation sites in Asia, J. Forest Res.-Jpn., 14, 1–9, https://doi.org/10.1007/s10310-008-0101-9, 2009.
Mohammed, A. and Kora, R.: A comprehensive review on ensemble deep learning: Opportunities and challenges, Journal of King Saud University – Computer and Information Sciences, 35, 757–774, https://doi.org/10.1016/j.jksuci.2023.01.014, 2023.
Monteith, J. L.: Evaporation and environment, Sym. Soc. Exp. Biol., 19, 205–234, 1965.
Mu, Q., Heinsch, F. A., Zhao, M., and Running, S. W.: Development of a global evapotranspiration algorithm based on MODIS and global meteorology data, Remote Sens. Environ., 111, 519–536, https://doi.org/10.1016/j.rse.2007.04.015, 2007.
Mu, Q., Zhao, M., and Running, S. W.: Improvements to a MODIS global terrestrial evapotranspiration algorithm, Remote Sens. Environ., 115, 1781–1800, https://doi.org/10.1016/j.rse.2011.02.019, 2011.
Muñoz Sabater: ERA5-Land monthly averaged data from 1950 to present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/cds.68d2bb30, 2019.
Ni, L., Wang, W., Fu, J. and Cao, M.: ET Dataset for paper “A Novel Classifier-Guided Ensemble Framework for Global Terrestrial Evapotranspiration Estimates”, Zenodo [data set], https://doi.org/10.5281/zenodo.18543737, 2026.
Ochege, F. U., Yuan, X., Ezekwe, I. C., Ling, Q., Nzabarinda, V., Kayiranga, A., Xie, M., Shi, H., and Luo, G.: Reconstructing monthly 0.25° terrestrial evapotranspiration data in a remote arid region using Bayesian-driven ensemble learning method, J. Hydrol., 634, 131115, https://doi.org/10.1016/j.jhydrol.2024.131115, 2024.
Oki, T. and Kanae, S.: Global Hydrological Cycles and World Water Resources, Science, 313, 1068–1072, https://doi.org/10.1126/science.1128845, 2006.
de Oliveira e Lucas, P., Alves, M. A., de Lima e Silva, P. C., and Guimarães, F. G.: Reference evapotranspiration time series forecasting with ensemble of convolutional neural networks, Comput. Electron. Agr., 177, 105700, https://doi.org/10.1016/j.compag.2020.105700, 2020.
Pascolini-Campbell, M. A., Reager, J. T., and Fisher, J. B.: GRACE-based Mass Conservation as a Validation Target for Basin-Scale Evapotranspiration in the Contiguous United States, Water Resour. Res., 56, e2019WR026594, https://doi.org/10.1029/2019WR026594, 2020.
Pastorello, G., Trotta, C., Canfora, E., et al.: The FLUXNET2015 dataset and the ONEFlux processing pipeline for eddy covariance data, Sci. Data, 7, 225, https://doi.org/10.1038/s41597-020-0534-3, 2020.
Penman, H. L.: Natural evaporation from open water, bare soil and grass, P. R. Soc. Lond. A-Conta., 193, 120–145, https://doi.org/10.1098/rspa.1948.0037, 1948.
Pérez-Rodríguez, J., Fernández-Navarro, F., and Ashley, T.: Estimating ensemble weights for bagging regressors based on the mean–variance portfolio framework, Expert Syst. Appl., 229, 120462, https://doi.org/10.1016/j.eswa.2023.120462, 2023.
Polhamus, A., Fisher, J. B., and Tu, K. P.: What controls the error structure in evapotranspiration models?, Agr. Forest Meteorol., 169, 12–24, https://doi.org/10.1016/j.agrformet.2012.10.002, 2013.
Priestley, C. H. B. and Taylor, R. J.: On the Assessment of Surface Heat Flux and Evaporation Using Large Scale Parameters, Mon. Weather Rev., 100, 81–92, 1972.
Purdy, A. J., Fisher, J. B., Goulden, M. L., Colliander, A., Halverson, G., Tu, K., and Famiglietti, J. S.: SMAP soil moisture improves global evapotranspiration, Remote Sens. Environ., 219, 1–14, https://doi.org/10.1016/j.rse.2018.09.023, 2018.
Reichstein, M., Camps-Valls, G., Stevens, B., Jung, M., Denzler, J., Carvalhais, N., and Prabhat: Deep learning and process understanding for data-driven Earth system science, Nature, 566, 195–204, https://doi.org/10.1038/s41586-019-0912-1, 2019.
Reitz, M., Sanford, W. E., and Saxe, S.: Ensemble Estimation of Historical Evapotranspiration for the Conterminous U. S., Water Resour. Res., 59, e2022WR034012, https://doi.org/10.1029/2022WR034012, 2023.
Rienecker, M. M., Suarez, M. J., Gelaro, R., Todling, R., Bacmeister, J., Liu, E., Bosilovich, M. G., Schubert, S. D., Takacs, L., Kim, G.-K., Bloom, S., Chen, J., Collins, D., Conaty, A., Silva, A. da, Gu, W., Joiner, J., Koster, R. D., Lucchesi, R., Molod, A., Owens, T., Pawson, S., Pegion, P., Redder, C. R., Reichle, R., Robertson, F. R., Ruddick, A. G., Sienkiewicz, M., and Woollen, J.: MERRA: NASA's Modern-Era Retrospective Analysis for Research and Applications, J. Climate, 24, 3624–3648, https://doi.org/10.1175/JCLI-D-11-00015.1, 2011.
Rodell, M., Houser, P. R., Jambor, U., Gottschalck, J., Mitchell, K., Meng, C.-J., Arsenault, K., Cosgrove, B., Radakovich, J., Bosilovich, M., Entin, J. K., Walker, J. P., Lohmann, D., and Toll, D.: The Global Land Data Assimilation System, B. Am. Meteorol. Soc., 85, 381–394, https://doi.org/10.1175/BAMS-85-3-381, 2004.
Schwalm, C. R., Anderegg, W. R. L., Michalak, A. M., Fisher, J. B., Biondi, F., Koch, G., Litvak, M., Ogle, K., Shaw, J. D., Wolf, A., Huntzinger, D. N., Schaefer, K., Cook, R., Wei, Y., Fang, Y., Hayes, D., Huang, M., Jain, A., and Tian, H.: Global patterns of drought recovery, Nature, 548, 202–205, https://doi.org/10.1038/nature23021, 2017.
Shang, K., Yao, Y., Di, Z., Jia, K., Zhang, X., Fisher, J. B., Chen, J., Guo, X., Yang, J., Yu, R., Xie, Z., Liu, L., Ning, J., and Zhang, L.: Coupling physical constraints with machine learning for satellite-derived evapotranspiration of the Tibetan Plateau, Remote Sens. Environ., 289, 113519, https://doi.org/10.1016/j.rse.2023.113519, 2023.
Shapley, L. S.: A Value for N-Person Games, RAND Corporation, Santa Monica, CA, https://doi.org/10.7249/P0295, 1952.
da Silva Júnior, J. C., Medeiros, V., Garrozi, C., Montenegro, A., and Gonçalves, G. E.: Random forest techniques for spatial interpolation of evapotranspiration data from Brazilian's Northeast, Comput. Electron. Agr., 166, 105017, https://doi.org/10.1016/j.compag.2019.105017, 2019.
Su, Z.: The Surface Energy Balance System (SEBS) for estimation of turbulent heat fluxes, Hydrol. Earth Syst. Sci., 6, 85–100, https://doi.org/10.5194/hess-6-85-2002, 2002.
Tavella, P. and Premoli, A.: Estimating the Instabilities of N Clocks by Measuring Differences of their Readings, Metrologia, 30, 479, https://doi.org/10.1088/0026-1394/30/5/003, 1994.
Teuling, A. J., Hirschi, M., Ohmura, A., Wild, M., Reichstein, M., Ciais, P., Buchmann, N., Ammann, C., Montagnani, L., Richardson, A. D., Wohlfahrt, G., and Seneviratne, S. I.: A regional perspective on trends in continental evaporation, Geophys. Res. Lett., 36, https://doi.org/10.1029/2008GL036584, 2009.
Torcaso, F., Ekstrom, C. R., Burt, E., and Matsaki, D.: Estimating Frequency Stability and Cross-Correlations, in: Proceedings of the 30th Annual Precise Time and Time Interval Systems and Applications Meeting, Reston, Virginia, December 1998, 69–82, https://www.ion.org/publications/abstract.cfm?articleID=14124 (last access: 24 April 2026), 1998.
Tramontana, G., Jung, M., Schwalm, C. R., Ichii, K., Camps-Valls, G., Ráduly, B., Reichstein, M., Arain, M. A., Cescatti, A., Kiely, G., Merbold, L., Serrano-Ortiz, P., Sickert, S., Wolf, S., and Papale, D.: Predicting carbon dioxide and energy fluxes across global FLUXNET sites with regression algorithms, Biogeosciences, 13, 4291–4313, https://doi.org/10.5194/bg-13-4291-2016, 2016.
Trenberth, K. E., Fasullo, J. T., and Kiehl, J.: Earth's Global Energy Budget, B. Am. Meteorol. Soc., 90, 311–324, https://doi.org/10.1175/2008BAMS2634.1, 2009.
Tseng, M.-H.: GA-based weighted ensemble learning for multi-label aerial image classification using convolutional neural networks and vision transformers, Mach. Learn.: Sci. Technol., 4, 045045, https://doi.org/10.1088/2632-2153/ad10cf, 2023.
Twine, T. E., Kustas, W. P., Norman, J. M., Cook, D. R., Houser, P. R., Meyers, T. P., Prueger, J. H., Starks, P. J., and Wesely, M. L.: Correcting eddy-covariance flux underestimates over a grassland, Agr. Forest Meteorol., 103, 279–300, https://doi.org/10.1016/S0168-1923(00)00123-4, 2000.
Wang, D. and Alimohammadi, N.: Responses of annual runoff, evaporation, and storage change to climate variability at the watershed scale, Water Resour. Res., 48, W05546, https://doi.org/10.1029/2011WR011444, 2012.
Wang, K. and Dickinson, R. E.: A review of global terrestrial evapotranspiration: Observation, modeling, climatology, and climatic variability, Rev. Geophys., 50, https://doi.org/10.1029/2011RG000373, 2012.
Wang, K., Dickinson, R. E., Wild, M., and Liang, S.: Evidence for decadal variation in global terrestrial evapotranspiration between 1982 and 2002: 1. Model development, J. Geophys. Res.-Atmos., 115, https://doi.org/10.1029/2009JD013671, 2010a.
Wang, K., Dickinson, R. E., Wild, M., and Liang, S.: Evidence for decadal variation in global terrestrial evapotranspiration between 1982 and 2002: 2. Results, J. Geophys. Res.-Atmos., 115, https://doi.org/10.1029/2010JD013847, 2010b.
Willard, J., Jia, X., Xu, S., Steinbach, M., and Kumar, V.: Integrating Scientific Knowledge with Machine Learning for Engineering and Environmental Systems, ACM Comput. Surv., 55, 66:1–66:37, https://doi.org/10.1145/3514228, 2022.
Williams, D. G., Cable, W., Hultine, K., Hoedjes, J. C. B., Yepez, E. A., Simonneaux, V., Er-Raki, S., Boulet, G., Bruin, H. A. R. de, Chehbouni, A., Hartogensis, O. K., and Timouk, F.: Evapotranspiration components determined by stable isotope, sap flow and eddy covariance techniques, Agr. Forest Meteorol., 125, 241–258, https://doi.org/10.1016/j.agrformet.2004.04.008, 2004.
Wilson, K. B., Hanson, P. J., Mulholland, P. J., Baldocchi, D. D., and Wullschleger, S. D.: A comparison of methods for determining forest evapotranspiration and its components: sap-flow, soil water budget, eddy covariance and catchment water balance, Agr. Forest Meteorol., 106, 153–168, https://doi.org/10.1016/S0168-1923(00)00199-4, 2001.
Xiao, J., Zhuang, Q., Baldocchi, D. D., Law, B. E., Richardson, A. D., Chen, J., Oren, R., Starr, G., Noormets, A., Ma, S., Verma, S. B., Wharton, S., Wofsy, S. C., Bolstad, P. V., Burns, S. P., Cook, D. R., Curtis, P. S., Drake, B. G., Falk, M., Fischer, M. L., Foster, D. R., Gu, L., Hadley, J. L., Hollinger, D. Y., Katul, G. G., Litvak, M., Martin, T. A., Matamala, R., McNulty, S., Meyers, T. P., Monson, R. K., Munger, J. W., Oechel, W. C., Paw U, K. T., Schmid, H. P., Scott, R. L., Sun, G., Suyker, A. E., and Torn, M. S.: Estimation of net ecosystem carbon exchange for the conterminous United States by combining MODIS and AmeriFlux data, Agr. Forest Meteorol., 148, 1827–1847, https://doi.org/10.1016/j.agrformet.2008.06.015, 2008.
Xie, X., Liang, S., Yao, Y., Jia, K., Meng, S., and Li, J.: Detection and attribution of changes in hydrological cycle over the Three-North region of China: Climate change versus afforestation effect, Agr. Forest Meteorol. 203, 74–87, https://doi.org/10.1016/j.agrformet.2015.01.003, 2015.
Xie, Z., Yao, Y., Tang, Q., Liu, M., Fisher, J. B., Chen, J., Zhang, X., Jia, K., Li, Y., Shang, K., Jiang, B., Yang, J., Yu, R., Zhang, X., Guo, X., Liu, L., Ning, J., Fan, J., and Zhang, L.: Evaluation of seven satellite-based and two reanalysis global terrestrial evapotranspiration products, J. Hydrol., 630, 130649, https://doi.org/10.1016/j.jhydrol.2024.130649, 2024.
Xu, T., Guo, Z., Liu, S., He, X., Meng, Y., Xu, Z., Xia, Y., Xiao, J., Zhang, Y., Ma, Y., and Song, L.: Evaluating Different Machine Learning Methods for Upscaling Evapotranspiration from Flux Towers to the Regional Scale, J. Geophys. Res.-Atmos., 123, 8674–8690, https://doi.org/10.1029/2018JD028447, 2018.
Yuan, Q., Shen, H., Li, T., Li, Z., Li, S., Jiang, Y., Xu, H., Tan, W., Yang, Q., Wang, J., Gao, J., and Zhang, L.: Deep learning in environmental remote sensing: Achievements and challenges, Remote Sens. Environ., 241, 111716, https://doi.org/10.1016/j.rse.2020.111716, 2020.
Zhang, C., Brodylo, D., Rahman, M., Rahman, M. A., Douglas, T. A., and Comas, X.: Using an object-based machine learning ensemble approach to upscale evapotranspiration measured from eddy covariance towers in a subtropical wetland, Sci. Total Environ., 831, 154969, https://doi.org/10.1016/j.scitotenv.2022.154969, 2022.
Zhang, C., Zhou, C., Luo, G., Ye, S., and Shi, Z.: Physics-constrained machine learning for satellite-derived evapotranspiration in China, J. Hydrol., 660, 133512, https://doi.org/10.1016/j.jhydrol.2025.133512, 2025.
Zhang, K., Kimball, J. S., Nemani, R. R., Running, S. W., Hong, Y., Gourley, J. J., and Yu, Z.: Vegetation Greening and Climate Change Promote Multidecadal Rises of Global Land Evapotranspiration, Sci. Rep.-UK, 5, 15956, https://doi.org/10.1038/srep15956, 2015.
Zhang, K., Zhu, G., Ma, J., Yang, Y., Shang, S., and Gu, C.: Parameter Analysis and Estimates for the MODIS Evapotranspiration Algorithm and Multiscale Verification, Water Resour. Res., 55, 2211–2231, https://doi.org/10.1029/2018WR023485, 2019.
Zhang, Z., Qin, H., Li, J., Liu, Y., Yao, L., Wang, Y., Wang, C., Pei, S., Li, P., and Zhou, J.: Operation rule extraction based on deep learning model with attention mechanism for wind-solar-hydro hybrid system under multiple uncertainties, Renewable Energy, 170, 92–106, https://doi.org/10.1016/j.renene.2021.01.115, 2021.
Zhangzhong, L., Gao, H., Zheng, W., Wu, J., Li, J., and Wang, D.: Development of an evapotranspiration estimation method for lettuce via mobile phones using machine vision: Proof of concept, Agr. Water Manage., 275, 108003, https://doi.org/10.1016/j.agwat.2022.108003, 2023.
Zhao, W. L., Gentine, P., Reichstein, M., Zhang, Y., Zhou, S., Wen, Y., Lin, C., Li, X., and Qiu, G. Y.: Physics-Constrained Machine Learning of Evapotranspiration, Geophys. Res. Lett., 46, 14496–14507, https://doi.org/10.1029/2019GL085291, 2019.
Zhu, W., Tian, S., Wei, J., Jia, S., and Song, Z.: Multi-scale evaluation of global evapotranspiration products derived from remote sensing images: Accuracy and uncertainty, J. Hydrol., 611, 127982, https://doi.org/10.1016/j.jhydrol.2022.127982, 2022.