the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 24 Feb 2026
| 24 Feb 2026
Sensitivity of hydrological machine learning prediction accuracy to information quantity and quality
Minhyuk Jeung
Younggu Her
Sang-Soo Baek
Kwangsik Yoon
Machine learning (ML) is now commonly employed as a tool for hydrological prediction due to recent advances in computing resources and increases in data volume. The prediction accuracy of ML (or data-driven) modeling is known to be improved through training with additional data; however, the improvement mechanism needs to be better understood and documented. This study explores the connection between the amount of information contained in the data used to train an ML model and the model's prediction accuracy. The amount of information was quantified using Shannon's information theory, including marginal and transfer entropy. Three ML models were trained to predict the flow discharge, sediment, total nitrogen, and total phosphorus loads of four watersheds. The amount of information contained in the training data was increased by sequentially adding weather data and the simulation outputs of uncalibrated and/or calibrated mechanistic (or theory-driven) models. The reliability of training data was considered a surrogate of information quality, and accuracy statistics were used to measure the quality (or reliability) of the uncalibrated and calibrated theory-driven modeling outputs to be provided as training data for ML modeling. The results demonstrated that the prediction accuracy of hydrological ML modeling depends on the quality and quantity of information contained in the training data. The use of all types of training data provided the best hydrological ML prediction accuracy. ML models trained only with weather data and calibrated theory-driven modeling outputs could most efficiently improve accuracy in terms of information use. This study thus illustrates how a theory-driven approach can help improve the accuracy of data-driven modeling by providing quality information about a system of interest.
- Article
(8313 KB) - Full-text XML
-
Supplement
(2955 KB) - BibTeX
- EndNote




Machine learning (ML) techniques have become commonly employed for hydrological prediction due to the availability of large hydrological data repositories and advances in computing resources and techniques (Sun et al., 2020; Xu and Liang, 2021). Studies have demonstrated that ML techniques can predict hydrological variables as accurately or even better than other statistical methods and mechanistic (or theory-driven) modeling (Panidhapu et al., 2020). The prediction accuracy of ML modeling is known to increase with the volume of data used to train the models (Jha et al., 2018); as such, the accuracy is expected to improve further as hydrological observations and records accumulate over time. However, it remains unclear how prediction accuracy is associated with the characteristics of training data: can any data added to a training set improve the accuracy?
Information theory has served as a mathematical tool to measure the amount of information contained in data and its transfer to another set of data (Shannon, 1948). This tool can help us understand the correlations or dependencies among multiple interconnected data sets (Pechlivanidis et al., 2018), which helps determine whether the training data contains information that could improve the accuracy of the model (Nearing et al., 2020). Shannon's entropy, often called marginal entropy, is one of the most commonly used information theories that can quantify information content in a set of data (Silva et al., 2017). The concept of transfer entropy was proposed to measure the amount of information transferred from one variable to another (Schreiber, 2000). Previous studies have employed marginal entropy to quantify the amount of information in hydrological datasets (Silva et al., 2017) and transfer entropy to qualify the interactions between input and output data in hydrological analyses (Bennett et al., 2019; Konapala et al., 2020). Both marginal and transfer entropies have great potential as concepts and methods to evaluate the informatic characteristics of training data and their impacts on hydrological ML model performance.
Data-driven methods, including ML modeling, rely on historical records and estimates from other analyses, while theory-driven approaches employ existing hydrological concepts and knowledge for prediction. Mechanistic modeling can be classified as a theory-driven method even when its parameter calibration has the nature of a data-driven approach. Mechanistic models employ different assumptions, knowledge, and methods to conceptualize a hydrological system of interest, which is why they provide unique predictions. For example, streamflow hydrographs predicted using Hortonian and Dunne's concepts might be substantially different from each other even after parameter calibration (Loague et al., 2010). Information embedded in hydrological theories and models can help improve the performance of data-driven modeling, and the information is considered in the predictions of mechanistic modeling. Weather records are one of the data sets commonly used to train hydrological ML models (Chen et al., 2020). Previous studies have demonstrated that ML models trained only with meteorological data provide limited accuracy; this is unsurprising given that hydrological processes are usually complicated by many other factors, including topography, soil, land use and cover, geological features, and management practices (Srinivasan et al., 2010; Srivastava et al., 2020). Hence, mechanistic model predictions can be an alternative source of data for the training of hydrological ML models.
Mechanistic modeling often or always requires parameter calibration to consider the hydrological characteristics of an area of interest. In a technical sense, parameter calibration is an effort to improve the statistical similarity between observed and predicted variables of interest. The prediction accuracy of mechanistic modeling is usually improved through the calibration process. As a result, the amount and/or quality of information in a relatively accurate prediction may be greater and/or higher than that of information in a relatively inaccurate one. When the prediction accuracy of mechanistic modeling is improved by calibrating its parameters, the calibrated model may have more and/or better-quality information than the uncalibrated model. Thus, a pair of uncalibrated and calibrated mechanistic models for a watershed can be a useful tool to create training data sets with different amounts and/or qualities of information for hydrological ML modeling.
Recent advancements in hydrological modeling highlight the importance of combining ML approaches with diverse data sources and process-based models to improve prediction accuracy. Kratzert et al. (2021) demonstrated how deep learning models could leverage the synergy among multiple meteorological datasets to enhance rainfall-runoff predictions, emphasizing the role of data integration in improving model performance. Similarly, Razavi et al. (2022) advocated for the coevolution of machine learning and process-based models, suggesting that their combined use can address limitations inherent to each approach and revolutionize Earth and environmental sciences. Reichstein et al. (2019) explored the intersection of data-driven methods and process understanding, illustrating how deep learning can advance Earth system science by extracting insights from complex datasets while maintaining a connection to fundamental physical principles. These studies underscore the critical interplay between information quantity, quality, and model design, which is central to this study.
This study attempted to relate the quantity and quality of information contained in sets of training data to the prediction accuracy of hydrological ML models, with the goal of understanding how to improve the accuracy efficiently. Information quantity and quality were quantified using information theory, including marginal and transfer entropies statistics. The research question that this study tried to answer was how the quantity and quality of information in training datasets, as measured by marginal and transfer entropies, can affect the prediction accuracy of hydrological ML models. We hypothesized that both higher information quantity and quality in training datasets, as reflected by increased marginal and transfer entropies values, would together positively correlate with improved model prediction accuracy. Three different ML algorithms (or models) were tested in the evaluation. The quantity of information was systematically increased by adding weather records and uncalibrated and calibrated theory-driven (or mechanistic) model outputs to training data sets. This study employed a mechanistic model commonly used to predict flow and water quality to represent a theory-driven approach. The data-driven (i.e., ML) and theory-driven (i.e., mechanistic) modeling approaches were applied to predict the flow discharge, suspended solid (SS), total nitrogen (TN), and total phosphorus (TP) loads of four watersheds. Then, the implications of the evaluation results and the limitations of this study were discussed, and the future direction of hydrological ML modeling was suggested based on the findings.
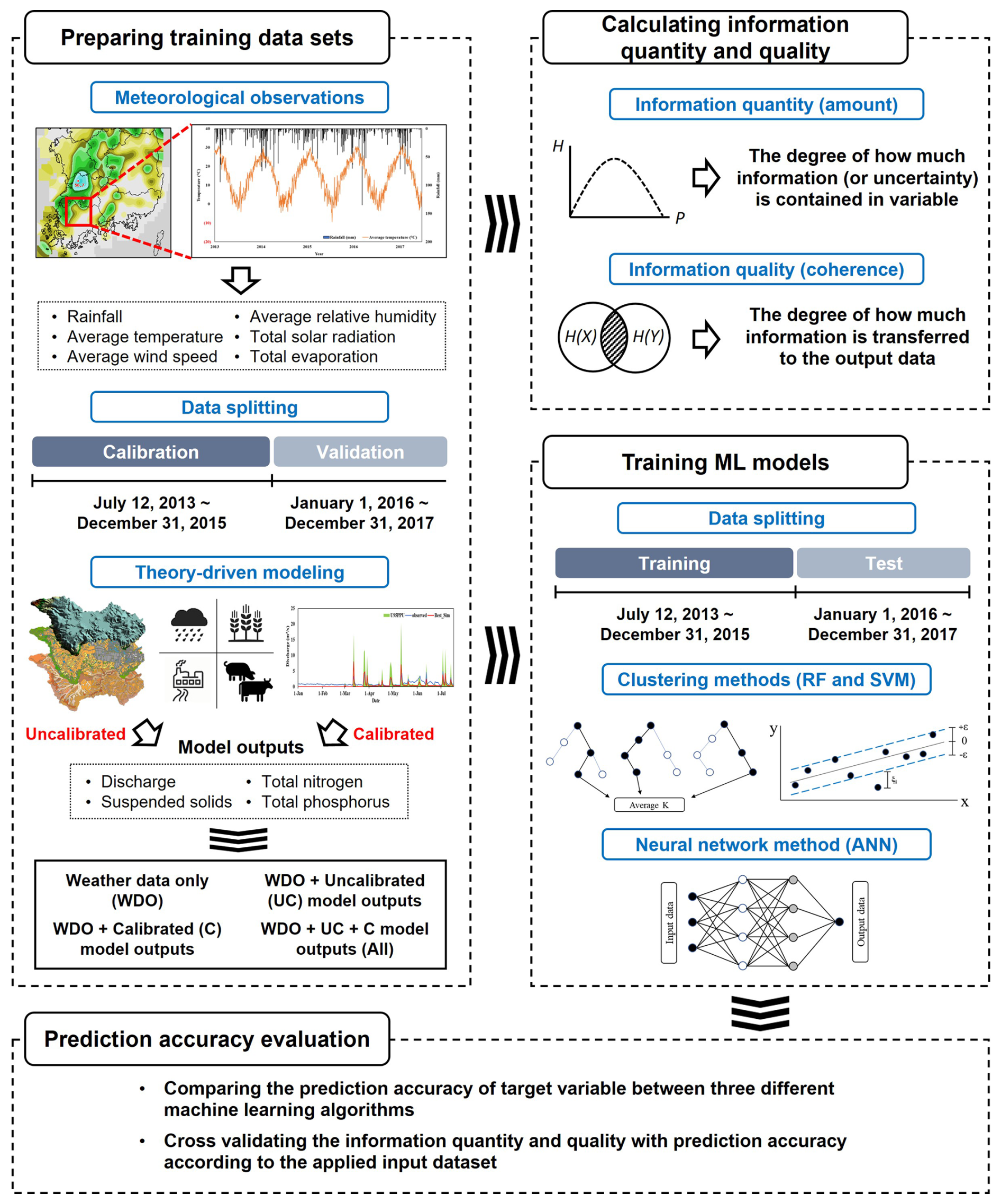
Figure 1Overall procedure to investigate the contribution of information quantity and quality to the prediction accuracy of hydrological machine learning (ML) modeling.
2.1 Overall procedure
Three ML models, including Random Forest (RF), Support Vector Machine (SVM), and Artificial Neural Network (ANN), were employed in this study (Fig. 1). The ML models were first trained using data sets collected from four study watersheds, including weather data observed at weather stations within or close to the watersheds and flow discharge, SS, TN, and TP measured at the outlets of the four study watersheds. The Soil and Water Assessment Tool (SWAT) model was selected to represent a mechanistic (or theory-driven) model. The SWAT model was used to produce additional data sets to which the ML models would be trained. The SWAT models were calibrated to flow (or streamflow discharges), SS, TN, and TP loads measured at the outlets. Then, the outputs (i.e., flow discharge, SS, TN, and TP loads) of the uncalibrated (i.e., SWAT models with the default parameter values) and calibrated SWAT models were used as additional data sets for the training of the three ML models. Before model training, we carefully separated the ML training and testing datasets to match the SWAT model's calibration and validation periods and to prevent data leakage. For example, we evaluated the ML models using the same validation window used for SWAT, 1 January 2016 to 31 December 2017. Here, we assumed there would be a difference in the quality of information contained in the uncalibrated and calibrated outputs of the SWAT model, and we employed the marginal and transfer entropy based on Shannon's information theory, to quantify the amount and quality of information contained in the training data sets. Finally, the weather data and uncalibrated and calibrated SWAT model outputs were sequentially fed to the three ML models.
Specifically, four datasets were prepared using different types of hydrological data, including weather records and outputs from theory-driven (or mechanistic) models. The first dataset consisted solely of weather data, serving as the baseline. The second and third datasets incorporated uncalibrated and calibrated hydrological model outputs into the baseline, respectively, to evaluate how integrating hydrological knowledge from mechanistic models improves predictions. Additionally, we compared how variations in input data quality influenced model performance. The final dataset combined all input variables, including weather data and both uncalibrated and calibrated model outputs. The baseline model in our study was not intended to replicate a fully developed nutrient model; rather, it was purposefully designed as a foundational benchmark for systematically assessing the effects of incorporating additional information – particularly theory-driven outputs from uncalibrated and calibrated mechanistic models. This framework allowed us to isolate and quantify the incremental gains in ML prediction accuracy as the training data increased in both informational quantity and quality. The use of calibrated mechanistic model outputs as ML training data was a deliberate methodological choice to evaluate how improvements in data reliability influence prediction performance. By excluding nutrient inputs and management practices from the baseline model, we established a consistent reference point for evaluating the added value of such variables when subsequently introduced through mechanistic model outputs. To rigorously assess these effects, we applied Shannon's marginal and transfer entropy to quantify the amount and quality of information embedded in each training dataset. This structured approach enabled a theory-grounded evaluation of how ML model accuracy responds to changes in both data quantity and quality (Fig. 1 and Table 1). Furthermore, we calculated information use efficiency (IUE) to measure how effectively each ML model leveraged added information, based on the improvement in prediction accuracy per unit increase in entropy across the four training data sets.
Table 1Combinations of data sets used to train hydrological ML models.
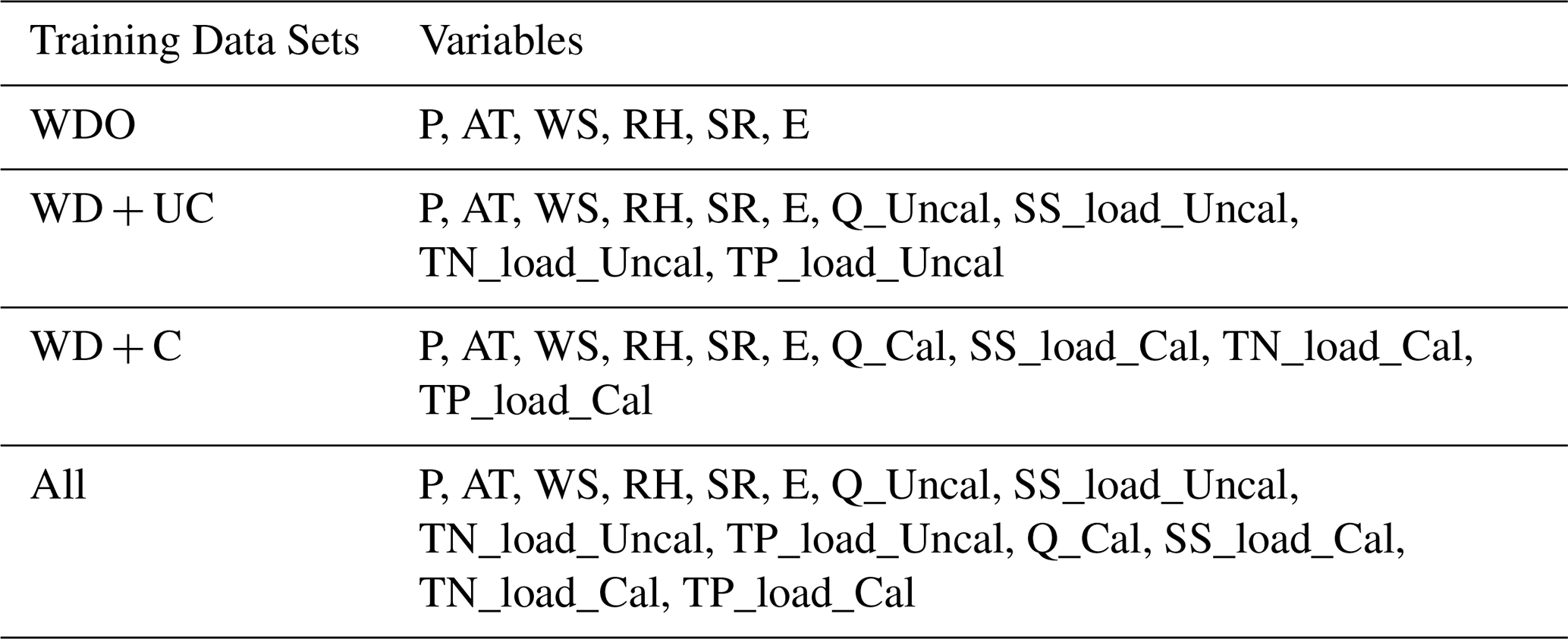
P, AT, WS, RH, SR, and E represent precipitation, average temperature, wind speed, relative humidity, solar radiation, and evaporation, respectively. The SWAT outputs, including Q, SS load, TN load, and TP load, were used to train ML models separately depending on the target variables. For example, SWAT's SS load simulation results were used only when predicting SS load using ML models.
2.2 Data-driven (or machine learning) models
The RF model is based on a regression tree, but it differs as it does not grow with a single tree but rather an entire forest of numerous trees using the bootstrap aggregating technique or bagging technique to help decrease model variance (Breiman et al., 1984; Breiman, 2001). The RF model is known for its ability to be used when there are more variables than observation data, and it does not result in overfitting due to the pruning process (Díaz-Uriate and de Andrés, 2006). The RF model was also reported to offer excellent performance even when predictive variables are irregular (Díaz-Uriate and de Andrés, 2006). In RF modeling, a decision tree grows by splitting a tree node, and it is pruned by removing tree nodes or sections with relatively low explanatory power compared to others (Hasanipanah et al., 2017).
The SVM model divides a high- or infinite-dimensional space using hyperplanes until all data points are separated (Vapnik, 1995, 1998). The SVM model is known to be able to avoid overfitting and produces highly accurate predictions (Aktan, 2011). The goal of the SVM procedures is to identify the optimal hyperplane separating two classes in the high-dimensional space that maximizes the distance between the two data point groups (Ahmed et al., 2017). SVM modeling transforms training data using the kernel function so that a linear hyperplane can separate the data points in high dimensions. Three kernel functions are commonly used: radial basis function (RBF), linear function, and polynomial function. This study employed the RBF, which is the most widely used kernel function (Tao et al., 2008).
The ANN model has been widely used to solve various modeling problems (Khashei and Bijari, 2010). The structure of the ANN model was inspired by the biological structure of the human brain, which is composed of many interconnected processing elements called neurons (Tosun et al., 2016). The structure is characterized by a network of three layers: input, hidden, and output. The number of input and hidden layers is determined by the number of input variables and the complexity of the problem (Yilmazkaya et al., 2018). Neurons are a critical parameter used in interconnected processing, which is characterized by weights (Tosun et al., 2016). The weights of individual neurons determine how input values are transferred to other values on the output nodes. The weights of connections between layers are calculated by the backpropagation process, which calculates the gradient of prediction error with respect to weights (Siddique and Tokhi, 2001).
The optimization of three machine learning models (i.e., RF, SVM, and ANN) was carried out using Bayesian optimization, a method that improves decision-making efficiency by iteratively identifying the most promising hyperparameter configurations (Jones, 2001). Compared to traditional grid or random search methods, Bayesian optimization is notably more efficient in finding optimal hyperparameters (Yu and Zhu, 2020). For the RF model, key parameters such as the maximum number of splits, the number of predictors per split, and the number of trees were optimized. In the case of the SVM model, the kernel scale, epsilon, and cost parameters were fine-tuned. For the ANN model, optimization focused on activation functions and layer sizes. These optimizations were designed to enhance each model's performance by leveraging input variables, including precipitation, temperature, and watershed characteristics that were carefully selected to align with the study's objectives.
2.3 Data normalization and accuracy evaluation
ML modeling is known to have low learning rates when some types of training data have value ranges substantially different from those of others (Ioffe and Szegedy, 2015). Data normalization techniques are commonly used to rescale the training data from their original ranges into a common value range so that the ML models can be efficiently and quickly trained. Several data normalization methods are available; linear scaling is one of the most widely used, presumably due to its simplicity and efficacy (Raju et al., 2020; Eq. 1).
where χ′ is the normalized value of the data set (ranges from 0 to 1), and x is an original value.
The prediction accuracy of the three ML models was evaluated using the Kling-Gupta efficiency coefficient (KGE; Gupta et al., 2009). The KGE considers the strength of the correlation between observed and predicted variables while also comparing the variables' biases and variances. Thus, compared to the Nash-Sutcliffe efficiency and the coefficient of determination, the KGE is less sensitive to relatively large values that lead to biases toward such values (Nash and Sutcliffe, 1970; Gupta et al., 2009; Eq. 2).
where σobs and σsim are the standard deviations of observations and simulation results, respectively, and μobs and μobs are the averages of observed and simulated variables, respectively.
A KGE of 1 indicates perfect agreement between observations and predictions (Andersson et al., 2017). Knoben et al. (2019) mathematically demonstrated that the KGE value approaches −0.41 when the predicted (or simulated) values of a variable are equal to the average value of its observations. Thus, a KGE value of −0.41 can be interpreted similarly to an NSE value of 0.00, meaning that the predictions may not be a better than the observed mean (Schaefli and Gupta, 2007). In this study, we assumed that predictions would be acceptable or satisfactory when the differences between observed and simulated averages of a variable (or percentage biases) and the variances of the differences are less than 25 % for flow, 55 % for SS, and 70 % for TN TP (Moriasi et al., 2007), which correspond to KGEs of 0.54, 0.17, and −0.03 for flow, SS, and TN TP, respectively, with an arbitrarily selected threshold correlation of 0.30.
2.4 Theory-driven (or mechanistic) model
The SWAT model was designed to predict watershed processes based on theories and known mechanisms that control the generation and transport processes of water, sediment, and nutrients (Nietsch et al., 2002). The SWAT model is popularly used to predict water and nutrient loadings at the watershed and basin scales due to its proven applicability to a variety of landscapes and climate zones as well as its simple but defendable modeling strategies. Moreover, the SWAT model can consider various management practices, including application rates and timing of fertilizers and herbicides/pesticides; tillage and low-impact development practices; and agricultural conservation practices such as filter strips, nutrient management plans, terraces, and tile drainage (Her et al., 2017; Her and Jeong, 2018; Li et al., 2021). Several studies have attempted to improve the prediction accuracy of SWAT modeling by coupling it with ML techniques, for example, to predict peak flow (Senent-Aparicio et al., 2019), water quality (Noori et al., 2020), and aquifer vulnerability (Jang et al., 2020).
Two versions of the SWAT model, namely uncalibrated and calibrated mechanistic modeling outputs, were prepared to generate two sets of training data for the ML models. The agricultural management practices, including fertilizer application, planting and harvest dates, compiled from the study watersheds were incorporated into both models (RDA, 2014; Table S2). The values of all parameters of the uncalibrated SWAT model remained unchanged; thus, the uncalibrated SWAT models do not necessarily represent the hydrological processes of the study watersheds, and they are not likely to reproduce the observed flow, SS, TN, and TP at an acceptable accuracy level. Accordingly, the quality of information contained in the outputs of the uncalibrated SWAT models may be relatively low compared to that of the calibrated SWAT models. The parameter values of the SWAT models were calibrated to flow, SS, TN, and TP observations made at the study watersheds' outlets (Table S3). While the SWAT model includes many parameters, previous studies (Arnold et al., 2012; Douglas-Mankin et al., 2010; El-Sadek and Irvem, 2014) have identified key parameters that relatively substantially influence model outputs. In this study, we focused on these parameters for each target variable and calibrated each watershed independently. Calibration was performed sequentially; upstream watersheds were calibrated first, and their calibrated parameter values remained unchanged while calibrating the corresponding parameters for their downstream watersheds. For example, the WJ watershed (which is nested by the HN watershed) was calibrated prior to the HN watershed, and then the parameters for areas that are not included in the WJ watershed but only in the HN watershed were calibrated to observations made at the outlet of the HN watershed. For the target variable, previous studies (Arnold et al., 2012; Engel et al., 2007; Santhi et al., 2001) have recommended that streamflow should be calibrated first, followed by SS, and then TN and TP, due to the interdependencies among these constituents resulting from shared transport processes. The flow, SS, TN, and TP loads predicted using the calibrated SWAT models were assumed to have relatively high-quality information compared to those of the uncalibrated SWAT model. The quantity and quality of information were quantified using the marginal and transfer entropies described in the following section.
The SUFI-2 algorithm, widely used for SWAT model calibration, was used to explore the multi-dimensional parameter spaces of the SWAT models and locate a solution (or a parameter set) close to the global optimum in this study (Sao et al., 2020). The simulation period was split into three: a warm-up period from 1 January 2008 to 11 July 2013; a calibration period from 12 July 2013 to 31 December 2015; and a validation period from 1 January 2016 to 31 December 2017. The types and value ranges of the calibration parameters were determined based on the previous SWAT modeling experience, the understanding of the calibration parameters, and the literature (Tobin and Bennett, 2017; Tang et al., 2021).
2.5 Marginal and transfer entropy
This study measured the quantity and quality of information contained in the training data using marginal and transfer entropies. In general, a data set that is spread out has relatively high entropy, while another data set that is concentrated on a small range of values has relatively small entropy. The marginal entropy is defined as the information content of a variable and used to calculate randomness in time series using Eq. (3) (Shannon, 1948; Cover and Thomas, 2006; Silva et al., 2017):
where H(X) is a measure of information of a discrete random variable X, and P(x) is the probability mass function of variable x in the ith step. The base-2 logarithm is used in the entropy calculation to express information content in bits (Shannon, 1948).
While the amount of information contained in a variable can be calculated using the marginal entropy, we can also calculate the amount of information shared between two variables based on mutual information theory using Eq. (4) (Cover and Thomas, 2006):
where I(XY) is the quantified value between X and Y. The mutual information I(XY) represents the expected information gained in Y from measuring X, or vice versa. From these definitions, we can calculate the conditional entropy by subtracting the amount of information shared between X and Y from H(X), which indicates how much information remains about the entire time series X in case we already know the information content of Y.
These quantities are all symmetrical and do not explain the amount of information exchanged between variables (Bennett et al., 2019). The transfer entropy was devised to consider the asymmetric transfer of information between any two-time series X and Y (the information flow from one to another variable), and can be defined as conditional mutual information (Schreiber, 2000):
where TX→Y is the transfer entropy from X to Y, and Xt or Yt denotes the variables X and Y in time t. The lag parameter, which defines the time delay between variables X and Y, was set to zero because the ML models used in this study are standard regression models without explicit temporal memory (e.g., no long-short term memory model); accordingly, we quantified synchronous information-use between inputs and outputs (i.e., the lag time or time delay between X and Y is zero), which aligns with our primary objective.
Transfer entropy was calculated using a quantile-based discretization scheme provided by the RTransferEntropy package (Behrendt et al., 2019) for R software. This method enhances robustness to outliers and better captures information transfer associated with relatively high and low values (Nie, 2021; Zhang and Zhao, 2022). Once the marginal and transfer entropies were calculated for the modeling experiments with the unique combinations of the ML models and the training data sets (Fig. 1 and Table 1), the prediction accuracy gain was divided by the increases in the quantity (marginal entropy) and quality (transfer entropy) of information contained in the training data to calculate IUE:
where PWD→ID is the prediction accuracy gain or increase from using additional straining data sets, as compared to the case of only using weather data for the training. The H(xWD→xID) and denotes the marginal entropy and transfer entropy gain or increase from using additional straining data sets, compared to the case of only using weather data for the training.
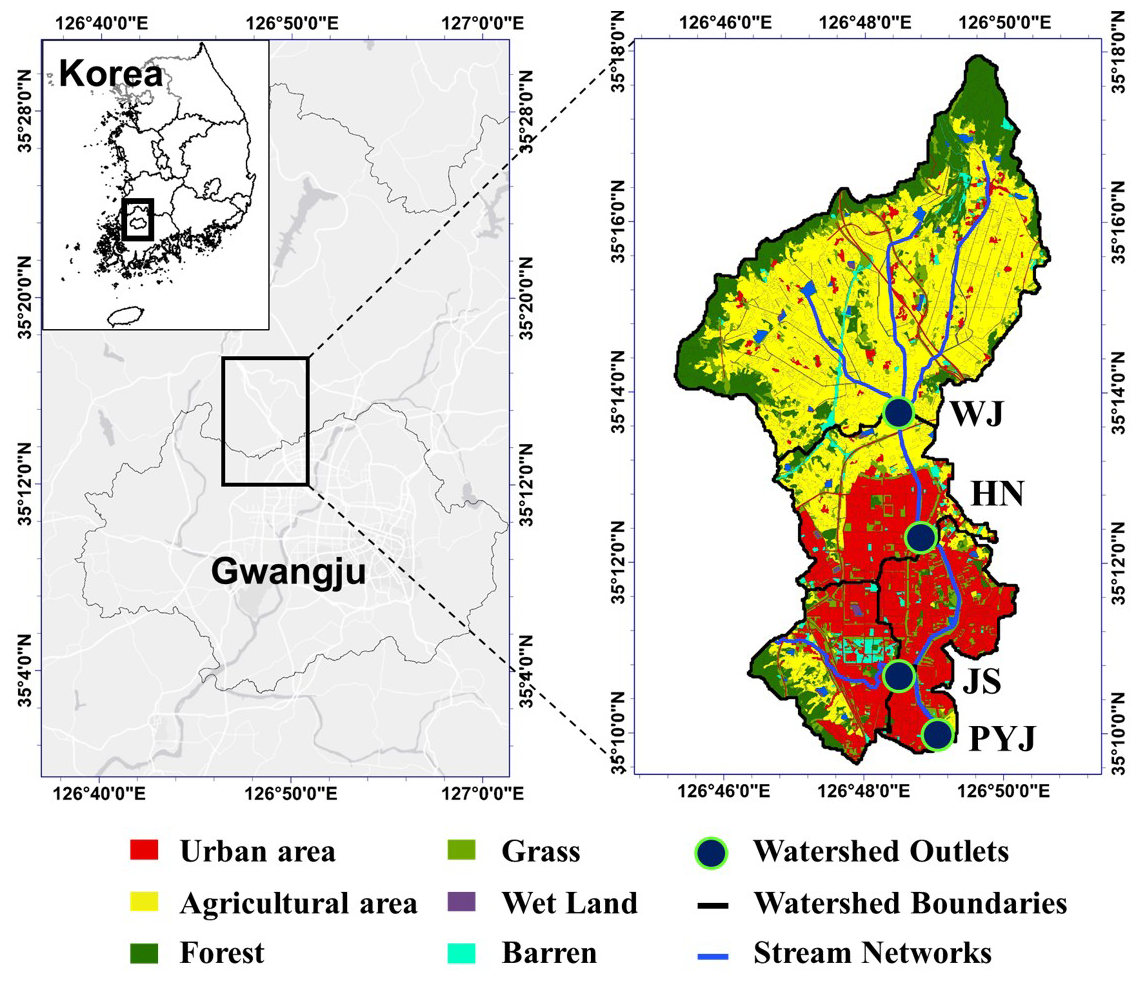
Figure 2Location of the study watersheds and their land uses and covers.
2.6 Study watersheds and training data acquisition
The Pung-Yeong-Jung (PYJ) river watershed was selected for the modeling experiment of this study. The PYJ watershed can be divided into three sub-watersheds from upstream to downstream: the Wall-Jeong (WJ), Ha-Nam (HN), and Jang-Su (JS) watersheds (Fig. 2 and Table S1 in the Supplement). The WJ watershed is nested by the HN watershed, and the HN and JS watersheds are nested by the PYJ watershed. Thus, all direct runoff drained from the three nested watersheds passes the outlet (35°09′58.87′′ N, 126°49′08.93′′ E) of the PYJ watershed. The streamflow, SS, TN, and TP concentrations were monitored at the outlets of the four study watersheds for four years and six months, from 12 July 2013 to 31 December 2017. Most of the drainage areas were covered by agricultural land uses, including upland and rice paddy fields (covering 41 % of the JS watershed and 62 % of the WJ watershed) and forest. Urbanized areas cover 5 % (WJ watershed) to 31 % (JS watershed) of the watersheds.
Streamflow, SS, TN, and TP concentrations were monitored at the outlets of the four study watersheds over a period of four years and six months, from 12 July 2013 to 31 December 2017. These monitoring data were divided into two non-overlapping subsets: one for model training and the other for testing. To prevent potential data leakage, we applied a consistent temporal split such that the training and testing periods for the ML models matched the calibration and validation periods of the mechanistic model (i.e., SWAT), respectively. In this setup, the three ML models were trained on data corresponding to the SWAT model calibration period (12 July 2013 to 31 December 2015), while their prediction accuracy of the ML models was evaluated using the testing dataset from the SWAT validation period (1 January 2016 to 31 December 2017), ensuring a clear separation between the data used for model training and for model evaluation (Fig. 1). To ensure the integrity of the experiment, observed discharge and concentration data were used solely for the calibration and validation of the SWAT model and were not reused in training the ML models. This separation of data sources was a deliberate aspect of the study design to maintain the independence of the ML training process and to avoid any unintended data leakage.
The Korean Meteorological Administration monitors weather variables, including daily AT, P, E, WS, RH, and SR, at a weather station located approximately 7 km away from the study watersheds. Water pressure sensors and data loggers (OTT Orpheus Mini, Germany) were deployed at the monitoring sites close to the watershed outlets. The cross-sections of the streams were surveyed at the monitoring sites, and the velocity of streamflow was then measured using a flow meter (VALEPORT model 002, UK) across the sections to estimate flow discharge rates. Water quality samples were manually collected every one or two weeks. During a rainfall event, stream water was collected using an automatic sampler (ISCO portable sampler 6712, USA), and the sampling interval was reduced to 1 h to catch the expected large variations of flow rates and the corresponding water quality concentrations for improved observation accuracy. During the monitoring period, a total of 17 large rainfall events were sampled.
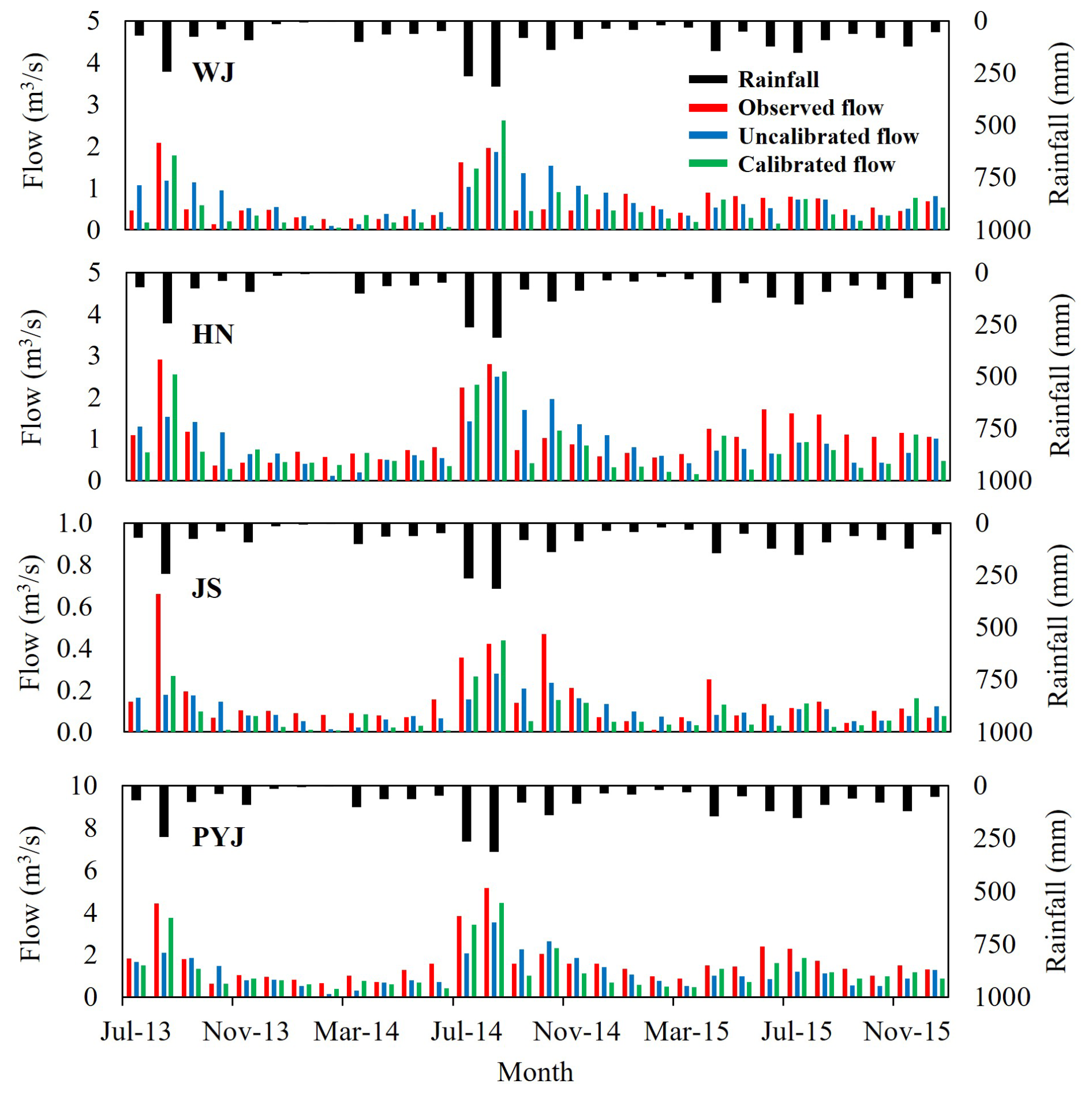
Figure 3Comparison of monthly streamflow predicted using the mechanistic models (i.e., uncalibrated and calibrated SWAT models) and observed during the training period (12 July 2013 to 31 December 2015). The daily-scale comparisons can be found in the Supplement (Figs. S1–S4).
3.1 Training data: Weather records and monitoring data
Sets of training data were prepared using the daily weather records, the watershed monitoring data, and SWAT modeling results (uncalibrated and calibrated outputs; Figs. 3 and S1–S4). The watersheds have four seasons, with relatively short springs and falls. The watersheds are fairly wet in the summer and dry in the spring. For example, the watersheds receive precipitation of 831–1333 mm annually, with more than half (59 % on average) of the precipitation occurring in the summer (from June to September). In spring, the stream might dry up due to the small amount of precipitation and warm air. In the case of the PYJ watershed, streamflow discharges can be large, with as much as 2.64 m3 s−1 on average in summer, but they are limited (e.g., 1.21 m3 s−1) enough to reveal the bottom of the stream in spring (from March to May).
The PYJ and JS watersheds had the largest and smallest average daily discharge of 1.69 and 0.16 m3 s−1, respectively (Table S4). The JS watershed had relatively higher SS concentrations compared to the other watersheds as it includes large construction sites (Adeola-Fashae et al., 2019; Mendie, 2005; Pullanikkatil et al., 2015). In addition, the first flush effects of the urbanized watersheds (e.g., the JS watershed; Table S1) led to higher peak SS, TN, and TP concentrations (Chaudhary et al., 2022). The WJ and HN watersheds had relatively higher TN and TP concentrations, presumably due to agricultural management activities such as fertilizer application and livestock farming in their large agricultural areas (Liu et al., 2012; Table S4).
Table 2Accuracy statistics (KGEs) of a theory-driven (or SWAT) model in the training period. The KGE scores that satisfy the acceptable accuracy criteria (i.e., 0.54 for flow, 0.17 for SS, −0.03 for TN TP) are in bold.
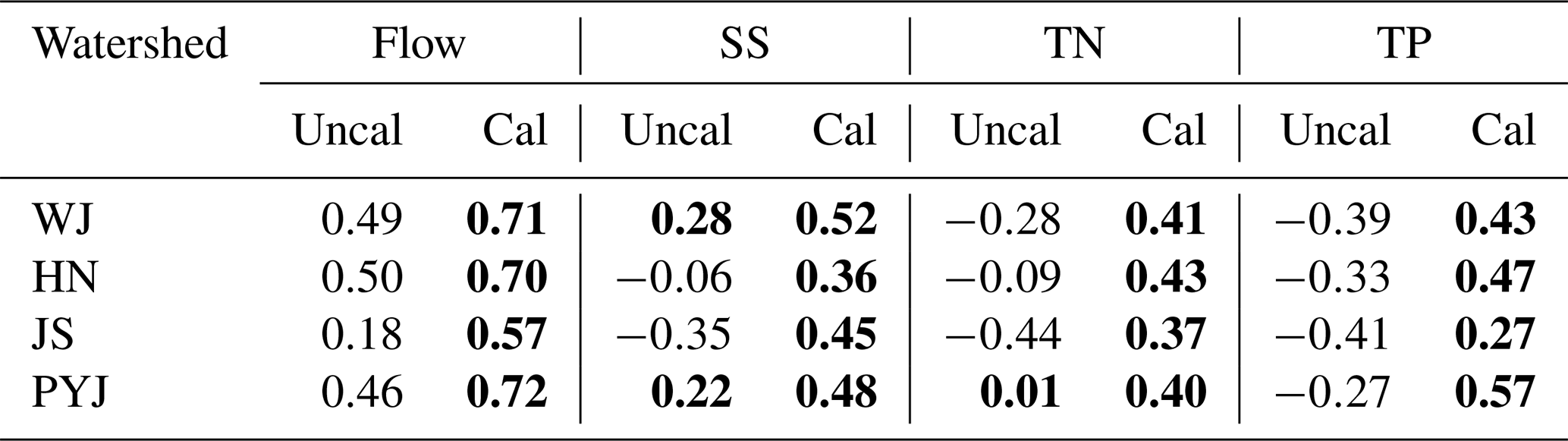
3.2 Training data: Outputs of the mechanistic modeling
The calibrated SWAT model provided acceptable performance in all watersheds (e.g., KGEs equal to or greater than 0.54 for flow, 0.17 for SS, and −0.03 for TN TP). The average KGE values for all watersheds were 0.68 for flow, 0.45 for SS, 0.40 for TN, and 0.44 for TP (Table 2). However, as expected, the uncalibrated model could not accurately predict the variables; average KGEs for all watersheds were less than 0.41 for flow, 0.02 for SS, −0.20 for TN, and −0.35 for TP. As such, the information quality of the outputs of the calibrated SWAT modeling may be greater than that of the uncalibrated modeling. The quantity and quality of information were evaluated with marginal and transfer entropies.
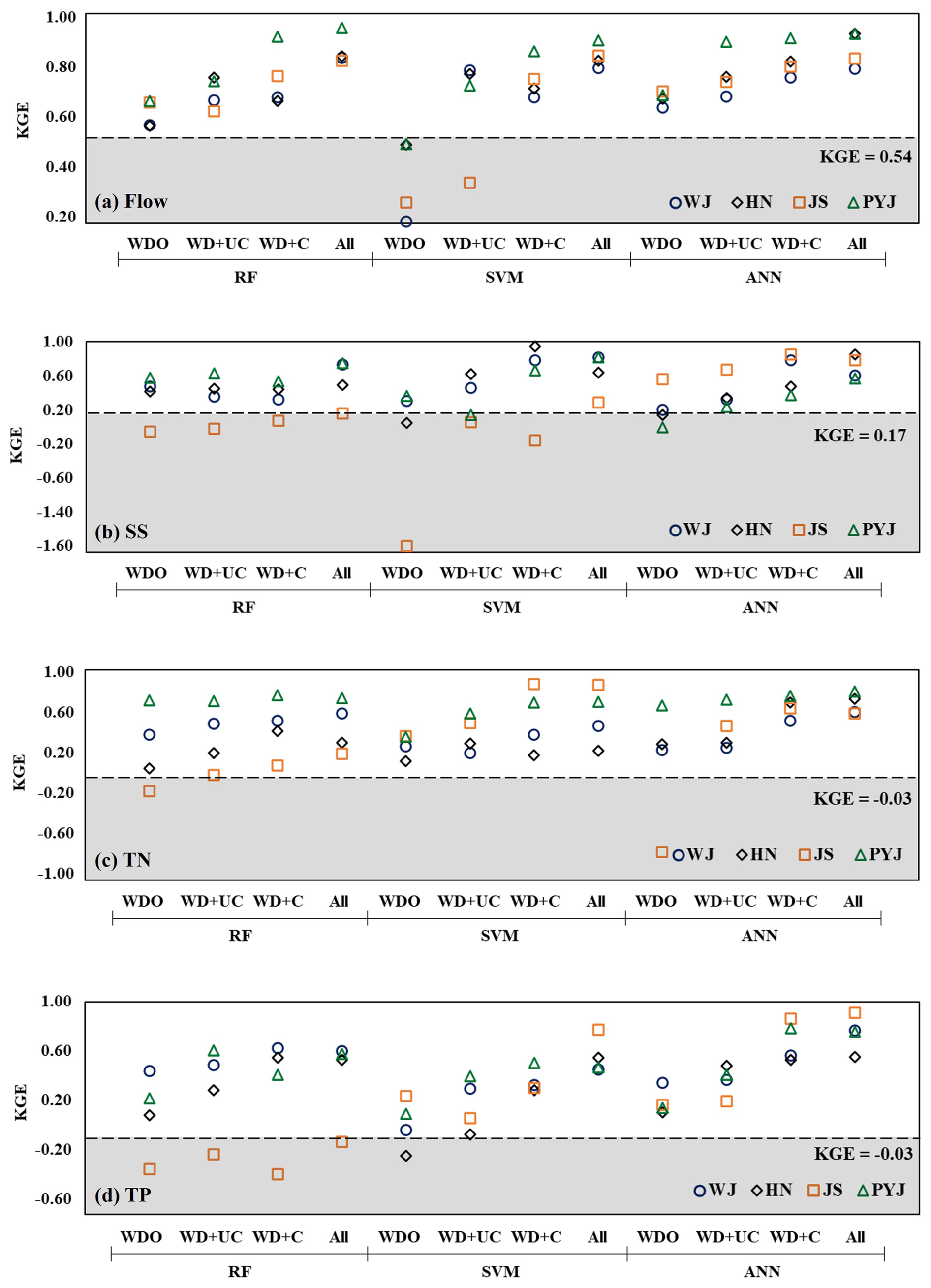
Figure 4Prediction accuracy (KGE) of hydrological ML models trained with the different training data set combinations. The KGE values that do not satisfy the acceptable accuracy levels (e.g., i.e., 0.54 for flow, 0.17 for SS, and −0.03 for TN TP) are included in gray areas.
3.3 Prediction accuracy of machine learning modeling
The four ML models were trained with different sets of training data: weather data only (WDO), the uncalibrated SWAT modeling outputs added to WDO (WD + UC), the calibrated SWAT modeling outputs added to WDO (WD + C), and all training data (All or WD + UC + C). The trained ML models yielded unique performances in the predictions depending on the training data set types (Fig. 4). Overall, the ML models' prediction accuracy consistently improved as additional data sets were added to the training data, including WDO to WD + UC, WDO + C, and All (Fig. S5a). For example, the WDO case provided acceptable accuracy (KGE of 0.67 greater than the threshold of 0.54) in the prediction of flow using the RF algorithm at the outlet of the PYJ watershed. When the outputs of the uncalibrated and/or calibrated SWAT modeling were added to the training data, the accuracy of the ML modeling was increased to KGEs of 0.74 (11.6 % increase with WD + UC) and 0.91 (37.2 % increase with WD + C) in the case of using the RF model. The additional training data sets also improved the accuracy of the water quality ML modeling. However, ML models trained only using the weather data and uncalibrated mechanistic modeling outputs failed to meet the acceptable accuracy levels (i.e., 0.17 for SS and −0.03 for TN TP; Fig. 4). In Fig. 4, the KGE scores overall increase from left to right. Negative KGE scores are frequently found in the JS watershed, indicating the models relatively poorly performed for the watershed.
None of the ML models consistently provided more accurate predictions than the others (Figs. 4 and S5b). This finding aligns with other studies that identified no ML model that is universally applicable to all data sets or problems (Alzubi et al., 2018; Domingos, 2012). A study has demonstrated that the RF model is more accurate compared to the SVM and ANN models (Al-Mukhtar, 2019). Conversely, another study has determined that the SVM or ANN model outperform the RF model (Ahmad et al., 2018). In this study, the RF model provided relatively better accuracy than other ML models when predicting the streamflow of the PYJ watershed using all training data sets (the All case). The ANN model was the only one that could provide acceptable accuracy (KGE of 0.84, which is greater than the threshold of 0.17 for SS) in the prediction of SS loads in the JS watershed with the WD + C training data. The SVM model provided a relatively greater KGE score than the other models when predicting the SS loads of the HN watersheds using the WD + UC training data.
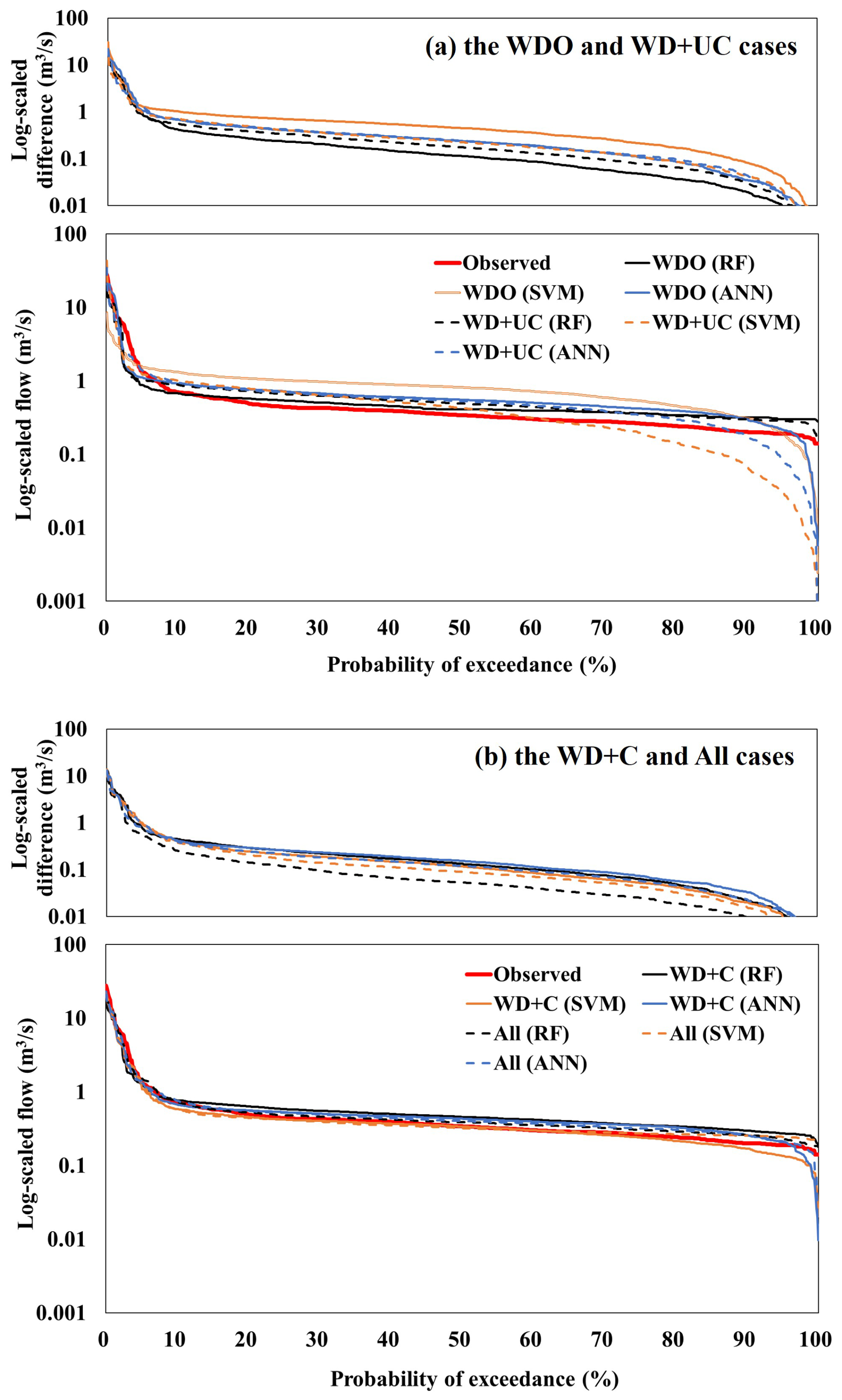
Figure 5Comparison between observed and ML-predicted FDCs at the outlet of the WJ watershed.
A flow duration curve (FDC) provides a graphical way of investigating the frequency of extreme events, such as floods and droughts. The FDCs were derived from the observed and predicted flow hydrographs and compared to evaluate prediction accuracy in the frequency domain (Figs. 5 and S6). The FDCs created from flow predictions made using the ML models trained with all training data (the All case) were the closest to the observed FDC in both high (e.g., flooding) and low (e.g., drought) exceedance probability regions. The WDO and WD + UC cases created relatively large differences (under- and over-estimations) between the predicted and observed FDCs, especially for extreme events (i.e., flooding and drought). For example, the differences between the ANN predictions and observations for the 5 % (flooding) and 95 % (drought) exceedance probabilities of the WJ watershed were 18.1 % and 13.8 % in the All case respectively, and they increased to 28.8 % and 77.9 % in the WD + UC case. The findings indicate that the ML models trained with all available training data sets (the All case) can more accurately predict the extremes than the relatively less trained ML models (the WDO and WD + UC cases).
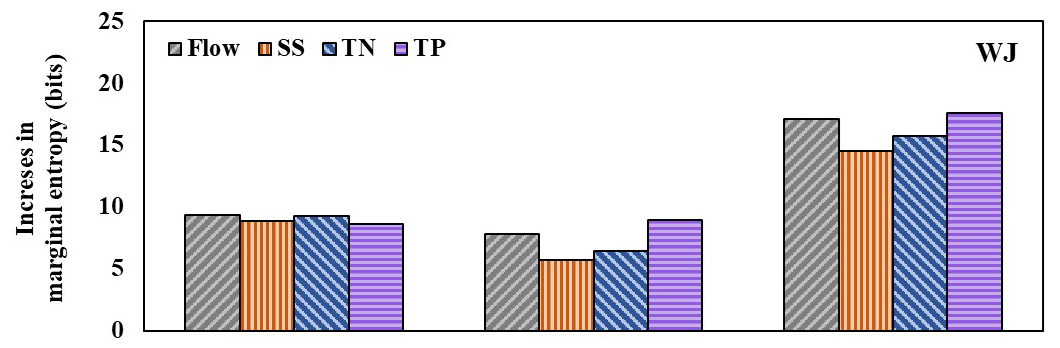
Figure 6Increases in marginal entropy due to the addition of additional training data sets in the case of the WJ watershed. The WDO training data set serves as the baseline for this comparison.
3.4 Information quantity and quality
The amount and quality of information contained in the training data sets for the ML training were quantified using the marginal and transfer entropy concepts, respectively. Then, IUE scores were calculated to understand how efficiently information quantity and quality can improve the prediction accuracy of hydrological ML modeling. marginal entropy of the training data sets generally increased as additional data (i.e., the outputs of the uncalibrated and calibrated mechanistic or SWAT modeling) were added to the weather data (i.e., WDO case; Figs. 6 and S7–S8). In the case of predicting the flow of the WJ watershed, for example, marginal entropy increased by 7.8 to 17.1 bits when the uncalibrated and/or calibrated SWAT modeling outputs were added to the training data respectively, compared to the WDO case (Fig. 6). The All cases increased marginal entropy more substantially than the WD + UC and WD + C cases, regardless of the watersheds and variables. The WD + C cases did not always increase marginal entropy more than the WD + UC cases, and the marginal entropy increases were negligible even when they did occur (e.g., in the case of predicting TP loads); this confirms that marginal entropy does not consider the association between two variables (i.e., watershed responses observed and simulated using the calibrated mechanistic models) in the training data sets, which is one of the features that marginal entropy has. Thus, marginal entropy does not change depending on the types of ML models as marginal entropy only counts information in the training data.
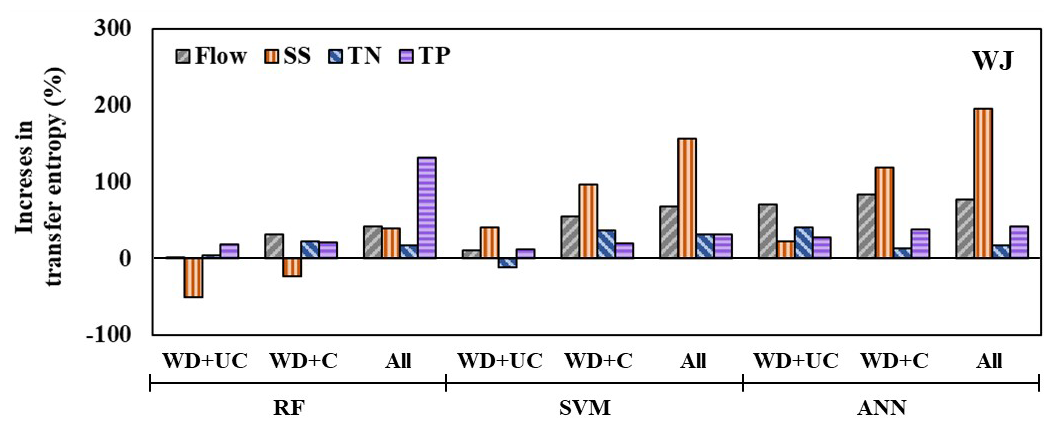
Figure 7Increases in transfer entropy due to the addition of training data sets in the case of the WJ watershed. The WDO training data set serves as the baseline for this comparison.
Transfer entropy did not always increase with additional training data (Figs. 7 and S9, Table S6). For example, in the case of the RF modeling trained with the WDO data set for the WJ watershed, the transfer entropy of SS loads decreased from 0.385 to 0.190 and 0.294 when adding uncalibrated and calibrated mechanistic modeling outputs, respectively (Fig. 7); this indicates that a loss of information was commonly found in the target and training data sets when adding additional data, such as uncalibrated and calibrated modeling outputs, to the training data set. The amount of precipitation information (0.174 bits) was transferred to the SS prediction for the WJ watershed in the case of WDO. However, when adding the uncalibrated mechanistic (i.e., SWAT) modeling output to the training data set, the amount of transferred precipitation information decreased to 0.066 bits, whereas only 0.044 bits were transferred from the uncalibrated SWAT modeling output. Here, the information loss of 0.064 bits can be calculated by subtracting 0.110 bits (amount of information on precipitation and uncalibrated mechanistic modeling output when applying WD + UC training data set) from 0.174 bits. Transfer entropy quantifies the amount of information contained in the training data sets that is effectively transferred into the predictions made using the trained ML models. It captures not only the shared information between input and output variables but also the directional flow of information from one variable to another (Schreiber, 2000). Thus, transfer entropy depends on the types of training data sets, prediction variables, and ML models (Fig. S8 vs. S10).
3.5 Information use efficiency
The IUE represents the relative improvement of prediction accuracy compared to the baseline per unit change of information quantity (Eqs. 7 and 8). IUE was calculated by dividing the increases in KGEs (the WDO training data set serves as the baseline) by the differences between the amount of information quantified using marginal entropy (IUE-ME) or transfer entropy (IUE-TE) contained in the training data sets (Fig. 8).
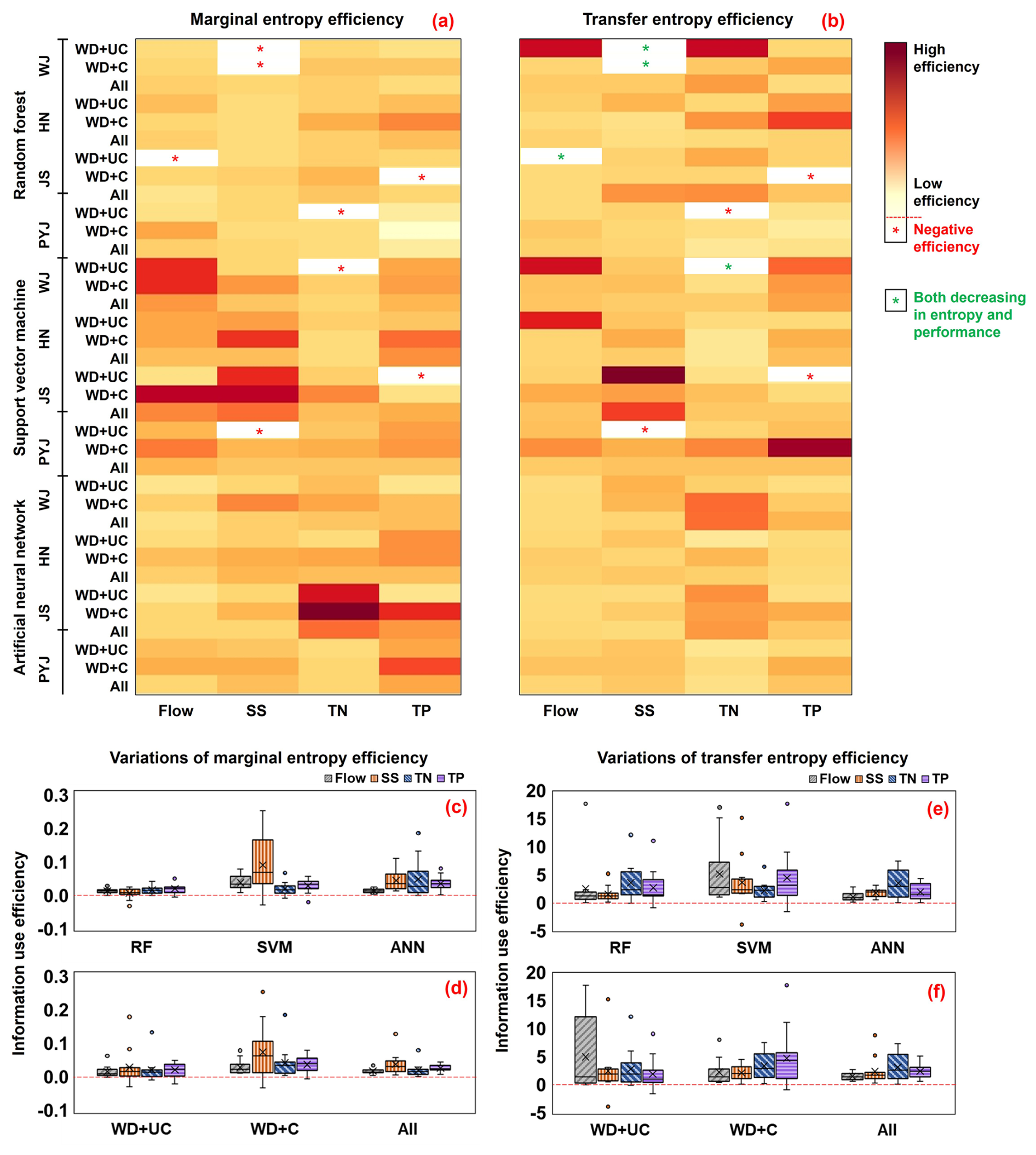
Figure 8Comparison of changes in information use efficiency (IUE) calculated from the entropy (marginal and transfer entropies) and accuracy (KGE) statistics provided by using the different training sets. (a) and (b) exhibit relative changes in information use efficiency (IUE-ME and IUE-TE) across all factors, including the ML models, watersheds, training datasets, and predicted variables. Red asterisks marks represent “Negative efficiency” describing the case where prediction accuracy decreased with increases in entropy, and green asterisks marks indicate the cases where both IUE and KGE decrease. (c) and (d) summarize, with box-whisker plots, the variations of changes in IUE-ME for the watersheds and training datasets (c) and for the watersheds and ML models (d), respectively; (e) and (f) show the variations of changes in IUE-TE for the watersheds and training datasets (e) and for the watersheds and ML models (f), respectively.
The case of WD + C provided a relatively higher IUE-ME compared to the other training data cases (Fig. 8d and Table S5). This means that the prediction accuracy of ML modeling can be most efficiently improved when the outputs of the calibrated mechanistic modeling are added to the training data sets (i.e., WD + C). Interestingly, WD + C may be more efficient than the All case, which added the uncalibrated theory-driven modeling outputs to WD + C. This finding implies that information quality can more efficiently improve the prediction accuracy of hydrological ML modeling than information quantity. However, it is worth noting that the All case still provided the best prediction accuracy (or the highest KGE), but its IUE in increasing KGE scores was lower than that of WD + C when considering the relative accuracy improvement to the amount of added information.
IUE-ME were often negative, especially in the WD + UC case, indicating that prediction accuracy decreased even when entropy increased (red star in Fig. 8a); this is because marginal entropy always increases with additional input variables, regardless of their quality or association with the target variables. IUE-TE also showed negative efficiency, which means the KGE decreased with increases in the transfer entropy. Model performance might not necessarily relate to transfer entropy because of complicated associations among weather forcings, management practices, watershed feathers, and responses (Konapala et al., 2020). KGEs also decreased when transfer entropy decreased (green star in Fig. 8b), which implies that transfer entropy can capture the decrease in information flow between independent (i.e., weather data, uncalibrated and calibrated modeling outputs) and dependent (or target) variables that may lead to decreased prediction accuracy (or decreased KGEs). This inverse relationship was primarily detected when adding uncalibrated mechanistic modeling outputs to the training data set, demonstrating the role of information quality in ML modeling training.
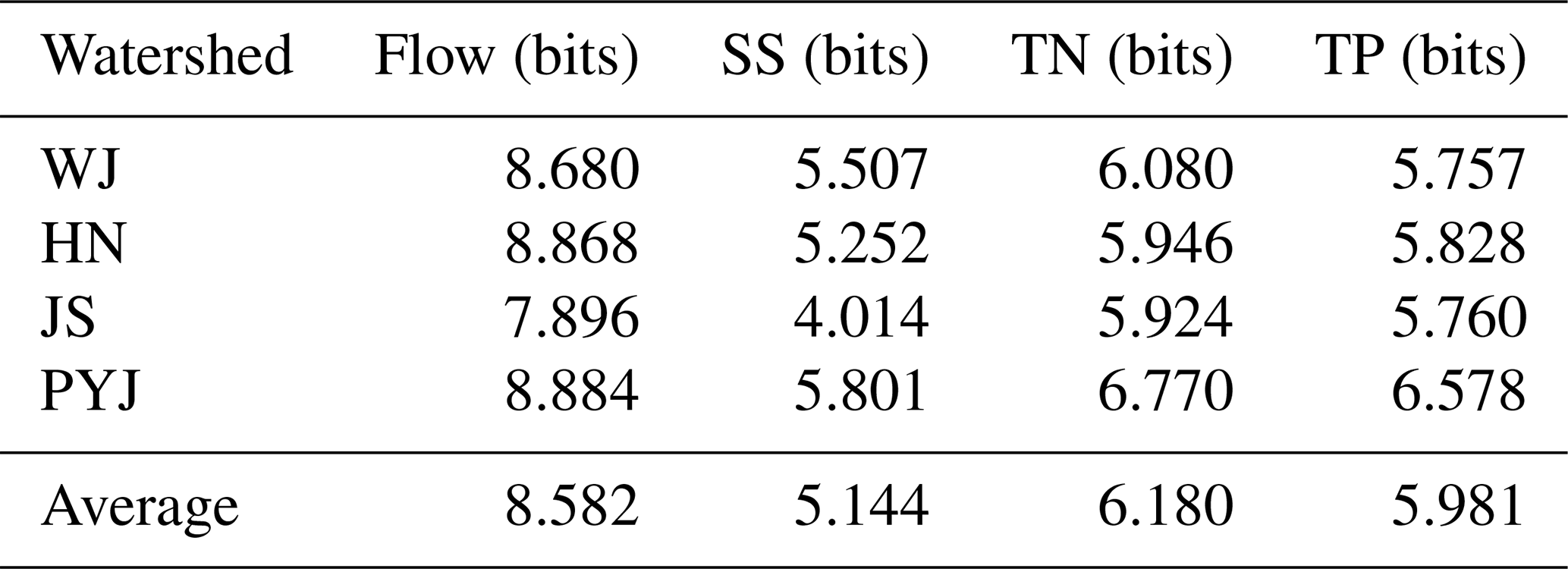
Table 3Marginal entropy quantified for target variables observed at the watershed outlets in the training period.
4.1 Influence of target variables and watershed characteristics on ML performance
The prediction accuracy of the ML models varied according to the variables of interest (flow, SS, TN, and TP). The RF, SVM, and ANN ML models were best at predicting the flow of the study watersheds compared to the other variables (Figs. 4 and S5). For example, the ML models provided KGEs of 0.557 (WDO) to 0.854 (All) when predicting flow versus KGEs of 0.093 (WDO) to 0.607 (All) for SS loads. This variance is presumably because of the previously described differences in the amount of information contained in the watershed responses or target variables. For example, the flow hydrographs commonly have relatively higher marginal entropies (8.582 on average) than the other variables' hydrographs (5.144 for SS, 6.180 for TN, and 5.981 for TP on average) for all study watersheds (Table 3). In the frequency domain, normalized SS load data have the most biased distributions toward low values (small SS loads) and the highest frequencies among the watershed responses or target variables, leading to relatively low entropy in the SS data (Fig. S11). The SS, TN, and TP concentrations observed at the watershed outlets have relatively small variations compared to the flow (Table S4), which might be attributed to the fact that water quality variables were much less frequently measured (or sampled) than flow (Table S4, the number of observations); thus, potentially large concentration variations might not be apparent in the observations. These comparison results imply that the frequency of water quality sampling can affect the amount of information in training data and the accuracy of hydrological ML model prediction.
The accuracy of the ML modeling also varied by the watersheds. Regardless of the training data sets, the ML models provided the best prediction accuracy for the PYJ watershed, which has the largest drainage area, while they did the worst for the JS watershed, which has the smallest drainage area; this implies the potential impact of watershed features and responses (flow, SS, TN, and TP) on ML prediction accuracy. For example, entropy in the watershed responses of the PYJ watershed was consistently higher than that of the JS watershed (Table 3). In the case of WDO, the amount of information contained in the independent variables (i.e., only weather records observed at a single station) of the training data set should be the same for the PYJ and JS watersheds. However, their responses (dependent or target variables) differ and thus have different entropy (or information) scores. The responses of the PYJ watershed are spread out over wide value ranges, which means relatively high entropies compared to those of the other watersheds, especially the JS watershed (Fig. S11). The flow observed at the outlet of the JS watershed are relatively highly biases toward low flow ranges. ML model prediction accuracy was found to be associated with the entropy in the watershed responses (Fig. 9). The results indicated that the KGE (i.e., prediction accuracy) scores of the ML models generally increased with increases in the amount of information contained in the target variables (Fig. 9).
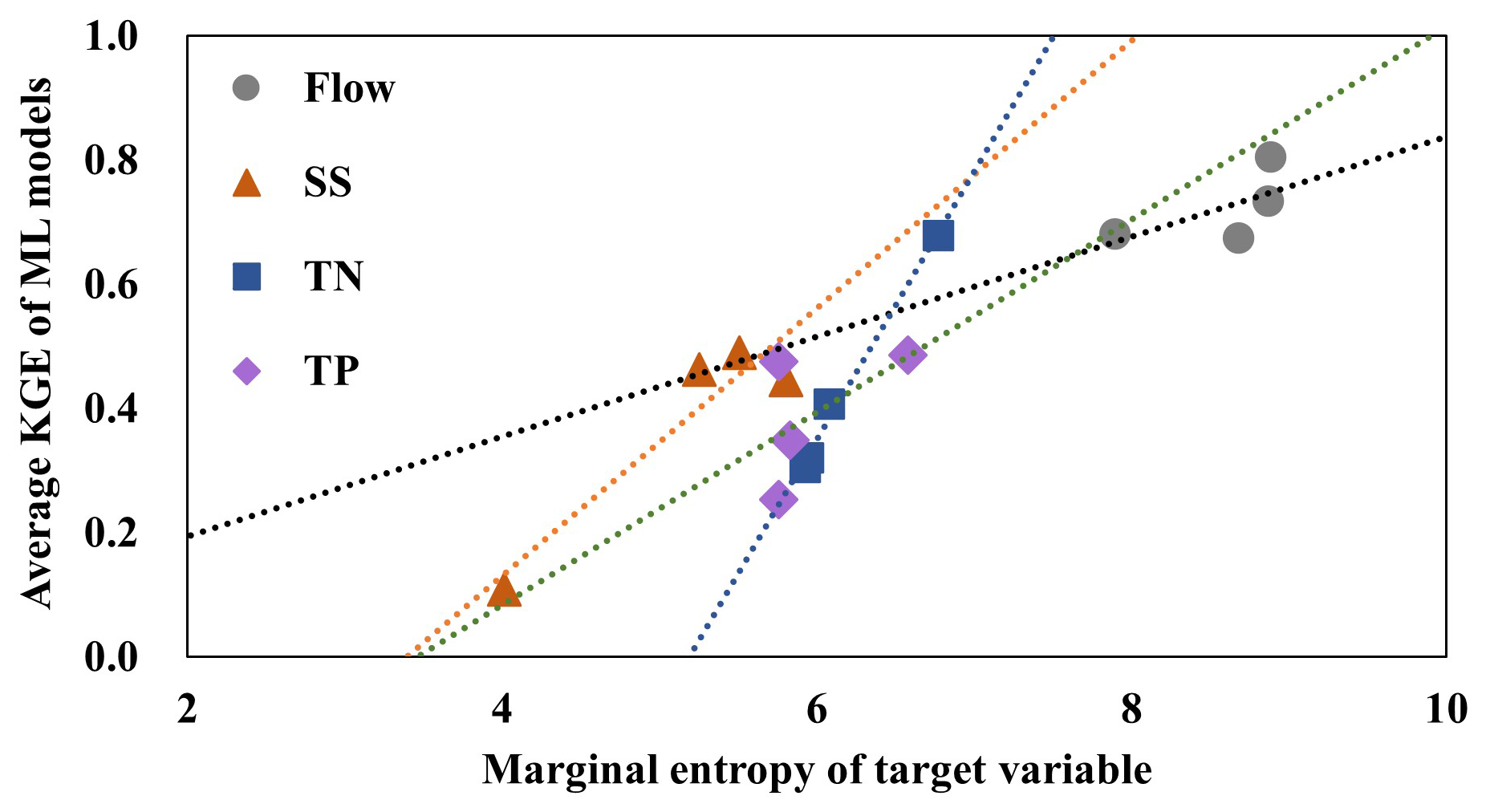
Figure 9Linear relationship between the average KGE scores of three ML models trained using the four training data sets and the marginal entropy of the target variables.
4.2 Influence of model structure on ML performance across information quantity and quality
Despite being trained on identical datasets, ML models exhibited different predictive abilities in response to increases in information quantity and quality. The ANN and SVM models could improve their predictions more efficiently in terms of the amount of information (i.e., marginal entropy) added to the training data compared to the RF model (Fig. 8c). The RF model uses a random sampling method to select the feature subspace for each node in growing the trees (Breiman, 2001), which is a model parameter called the “number of variables”. Previous studies (Wang and Xia, 2016; Ye et al., 2013) have argued that when applying the random sampling method to a high-dimension data set, model may select many subspaces that do not include informative features and will increase error bounds for the RF model. This study agrees with previous studies: RF performed relatively poorly when dimension of a training data set was higher (i.e., the large number of independent variables) than SVM and ANN. A traditional ANN model with one or two hidden layers is known to suffer performance degradation due to its rapid growth in the number of connection weights (Krenker et al., 2011). However, one study demonstrated that a deep neural network that employs numerous hidden layers, such as the one used in this study, could yield promising performance with high-dimensional training data (Liu et al., 2017).
In addition, negative IUE-TE values were observed when watershed responses were predicted using RF and SVM models (red star in Fig. 8b), particularly in the WD + UC case, suggesting challenges in leveraging additional information from training data. While SVM models use kernel function to transform non-linear decision spaces into linear ones, and RF models employ non-linear decision boundaries, prior studies indicate that such methods are not always effective in resolving high-dimensionality issues, often sampling less informative features (Wang and Xia, 2016; Ye et al., 2013). Despite the radial basis kernel function and Bayesian optimization employed in this study to enhance SVM performance (Shawe-Taylor and Sun, 2011), the model's predictive accuracy remained inconsistent. Conversely, the ANN model avoided negative IUE scores, demonstrating its robustness by effectively exploiting additional information even when lower-quality data (WD + UC) were added to the training dataset (Fig. 8b and e). This indicates that the ANN model excels at handling high-dimensional, non-linear data, making it more effective than RF and SVM for this study's hydrological predictions. With diverse features such as precipitation, temperature, and watershed characteristics contributing to accurate predictions, the ANN model utilized the rich, high-dimensional data from calibrated and uncalibrated SWAT outputs to achieve strong performance. Unlike clustering methods, which primarily group data without a predictive function, neural networks improve prediction accuracy through learning from labelled data and adapting to input quality. The absence of negative IUE scores for ANN underscores its flexibility and robustness. These findings affirm the ANN model's suitability for high-dimensional hydrological modeling, highlighting its advantage over other methods in tasks requiring predictive precision and adaptability to data complexity.
4.3 Implications, limitations, and future directions for integrating ML with mechanistic models
The quantitative evaluation of data quality and quantity in relation to model performance provides actionable insights for future modeling efforts. Our findings highlight the importance of prioritizing high-quality, high-relevance inputs to improve prediction accuracy. This suggests feature selection techniques, informed by our results, could help identify the most impactful variables, reducing the risk of overfitting and computational inefficiencies. The demonstrated sensitivity of ML models to data quality suggests the need for rigorous preprocessing steps, such as outlier detection, imputation of missing data, and validation of sensor measurements. For example, ensuring consistent and accurate data collection at critical watershed locations can enhance model reliability. Our results could guide the development of benchmarks or thresholds for data quality metrics (e.g., measurement error limits) to ensure datasets meet the minimum requirements for effective modeling.
Our findings also have implications for hybrid modeling approaches, particularly guiding the integration of ML with mechanistic models. These results can help select variables where mechanistic models provide better physical realism (e.g., water and nutrient transport) while leveraging ML for complementary predictions (e.g., extreme event responses or data gap interpolation). Improving the quality of key inputs can also help reconcile discrepancies between data-driven and theory-driven predictions, enhancing overall model accuracy. Expanding beyond standalone ML applications, this study provides a foundation for adaptive modeling frameworks that dynamically assess and adjust data inputs based on their predictive contributions.
Future studies could build on our quantitative evaluation by applying these insights to develop guidelines or workflows for selecting and preparing datasets tailored to specific hydrological and water quality objectives. The study underscores the need to refine hydrological ML prediction models by emphasizing the connection between training data quantity, quality, and prediction accuracy. These results suggest that higher-quality training data improved the IUE of ML models, enabling them to maintain or improve prediction accuracy while using a reduced number of inputs. The integration of theory-driven and data-driven approaches will not only improve prediction accuracy but also streamline model training by ensuring that the data used contains both sufficient quantity and quality. Moreover, a deeper understanding of the interaction between different data types will inform more effective training strategies for ML models, leading to more accurate and reliable hydrological predictions.
While this study provides valuable insights into the relationship between ML prediction accuracy and the quality and quantity of input data in hydrological modeling, several limitations and uncertainties must be acknowledged. The study's findings are based on a specific set of watersheds with unique hydrological, climatic, and geographical characteristics. The variability in watershed conditions across different regions may limit the generalizability of the results. The study assumes that the available datasets accurately represent real-world hydrological processes. However, biases, errors, and inconsistencies in the input data, such as measurement inaccuracies or missing values, could influence the results. The study evaluates model performance at specific temporal and spatial scales. Fine temporal resolutions (e.g., daily predictions) may introduce additional complexities not captured in coarser scales (e.g., monthly or annual). Despite optimization efforts, ML models remain susceptible to overfitting, particularly when trained on small datasets or when irrelevant features are included. By acknowledging these limitations and uncertainties, this study provides a helpful starting point for future work to build upon, with the goal of enhancing the reliability of ML models in hydrological applications.
This study provides clear evidence that the predictive accuracy of hydrological ML models is intricately linked to both the quantity and the quality of information embedded within the training datasets. The highest overall accuracy was achieved when the full suite of available data sources was used to train the models (i.e., the All case). However, the most efficient improvements in predictive accuracy – relative to the amount of information added – were realized when high-quality outputs from calibrated mechanistic models were incorporated (i.e., the WD + C case).
To better characterize the nature of these improvements, we employed metrics from information theory, specifically marginal entropy and transfer entropy, to quantify the amount and relevance of information in each training dataset. Furthermore, we introduced IUE as a novel indicator to evaluate how effectively additional information contributes to gains in prediction accuracy.
The findings underscore the critical role of information quality in hydrological ML modeling. In particular, augmenting training datasets with low-relevance or low-accuracy data (as in the WD + UC case) did not necessarily improve – and in some cases degraded – model performance. This highlights the potential risks associated with increasing data volume without due consideration of informational relevance.
Importantly, the combined application of marginal entropy, transfer entropy, and IUE offers a robust and interpretable framework for evaluating and optimizing training data. These metrics facilitate a more rigorous assessment of how data characteristics influence model performance, providing actionable insights for both model development and data acquisition strategies. By leveraging this framework, hydrologists and modelers can more effectively select and structure training datasets that balance both informational quantity and quality, ultimately improving the robustness and generalizability of hydrological ML predictions.
The weather dataset used in this study is available from the Korea Meteorological Administration (KMA). For access, visit the KMA weather data service website: https://data.kma.go.kr/ (last access: 16 February 2026). The codes developed for this study are available from the authors upon reasonable request.
The supplement related to this article is available online at https://doi.org/10.5194/hess-30-1077-2026-supplement.
MJ: Conceptualization, Software, Validation, Formal analysis, Writing – Original Draft; YH: Conceptualization, Methodology, Supervision, Writing – Review & Editing; SB: Validation, Formal analysis, Data Curation; KY: Conceptualization, Supervision, Writing – Review & Editing.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
The KY acknowledge funding by the Yeongsan and Seomjin River Water Management Committee.
This work was supported by the Yeongsan and Seomjin River Water Management Committee through the project “A Long-term Monitoring for the Nonpoint Sources Discharge”.
This paper was edited by Fuqiang Tian and reviewed by two anonymous referees.
Adeola Fashae, O., Abiola Ayorinde, H., Oludapo Olusola, A., and Oluseyi Obateru, R.: Landuse and surface water quality in an emerging urban city, Appl. Water Sci., 9, 25, https://doi.org/10.1007/s13201-019-0903-2, 2019.
Ahmad, I., Basheri, M., Iqbal, M. J., and Rahim, A.: Performance Comparison of Support Vector Machine, Random Forest, and Extreme Learning Machine for Intrusion Detection, IEEE Access, 6, 33789–33795, https://doi.org/10.1109/ACCESS.2018.2841987, 2018.
Ahmed, S., Khalid, M., and Akram, U.: A method for short-term wind speed time series forecasting using Support Vector Machine Regression Model, 2017 6th International Conference on Clean Electrical Power (ICCEP), 27–29 June 2017, 190–195, https://doi.org/10.1109/ICCEP.2017.8004814, 2017.
Aktan, S.: Application of machine learning algorithms for business failure prediction, Invest. Manage. And Financial Inno., 8, 52–65, 2011.
Al-Mukhtar, M.: Random forest, support vector machine, and neural networks to modelling suspended sediment in Tigris River-Baghdad, Environ. Monit. Assess., 191, 673, https://doi.org/10.1007/s10661-019-7821-5, 2019.
Alzubi, J., Nayyar, A., and Kumar, A.: Machine Learning from Theory to Algorithms: An Overview, J. Phys. Conf. Ser., 1142, 012012, https://doi.org/10.1088/1742-6596/1142/1/012012, 2018.
Andersson, J. C. M., Arheimer, B., Traoré, F., Gustafsson, D., and Ali, A.: Process refinements improve a hydrological model concept applied to the Niger River basin, Hydrol. Process., 31, 4540–4554, https://doi.org/10.1002/hyp.11376, 2017.
Arnold, J. G., Moriasi, D. N., Gassman, P. W., Abbaspour, K. C., White, M. J., Srinivasan, R., Santhi, C., Harmel, R. D., Van Griensven, A., and Van Liew, M. W.: SWAT: Model Use, Calibration, and Validation, Transactions of the ASABE, 55, 1491–1508, https://doi.org/10.13031/2013.42256, 2012.
Behrendt, S., Dimpfl, T., Peter, F. J., and Zimmermann, D. J.: RTransferEntropy – Quantifying information flow between different time series using effective transfer entropy, SoftwareX, 10, 100265, https://doi.org/10.1016/j.softx.2019.100265, 2019.
Bennett, A., Nijssen, B., Ou, G., Clark, M., and Nearing, G.: Quantifying Process Connectivity With Transfer Entropy in Hydrologic Models, Water Resour. Res., 55, 4613–4629, https://doi.org/10.1029/2018WR024555, 2019.
Breiman, L.: Random Forests, Mach. Learn., 45, 5–32, https://doi.org/10.1023/A:1010933404324, 2001.
Breiman, L., Friedman, J., Olshen, R. A., and Stone, C. J.: Classification and Regression Trees, CRC press, Wadsworth, ISBN 9780412048418, 1984.
Chaudhary, S., Chua, L. H., and Kansal, A.: Event mean concentration and first flush from residential catchments in different climate zones, Water Res., 219, 118594, https://doi.org/10.1016/j.watres.2022.118594, 2022.
Chen, Z., Zhu, Z., Jiang, H., and Sun, S.: Estimating daily reference evapotranspiration based on limited meteorological data using deep learning and classical machine learning methods, J. Hydrol., 591, 125286, https://doi.org/10.1016/j.jhydrol.2020.125286, 2020.
Cover, T. M. and Thomas, J. A.: Elements of Information Theory, John Wiley & Sons, Inc., Hoboken, ISBN 9780471062592, 2006.
Díaz-Uriarte, R. and Alvarez de Andrés, S.: Gene selection and classification of microarray data using random forest, BMC Bioinformatics, 7, 3, https://doi.org/10.1186/1471-2105-7-3, 2006.
Domingos, P.: A few useful things to know about machine learning, Commun. ACM, 55, 78–87, https://doi.org/10.1145/2347736.2347755, 2012.
Douglas-Mankin, K., Srinivasan, R., and Arnold, G. J.: Soil and Water Assessment Tool (SWAT) Model: Current Developments and Applications, Transactions of the ASABE, 53, 1423–1431, https://doi.org/10.13031/2013.34915, 2010.
El-Sadek, A. and Irvem, A.: Evaluating the impact of land use uncertainty on the simulated streamflow and sediment yield of the Seyhan River basin using the SWAT model, Turkish Journal of Agriculture and Forestry, 38, 515–530, https://doi.org/10.3906/tar-1309-89, 2014.
Engel, B., Storm, D., White, M., Arnold, J., and Arabi, M.: A Hydrologic/Water Quality Model Application, JAWRA Journal of the American Water Resources Association, 43, 1223–1236, https://doi.org/10.1111/j.1752-1688.2007.00105.x, 2007.
Gupta, H. V., Kling, H., Yilmaz, K. K., and Martinez, G. F.: Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling, J. Hydrol., 377, 80–91, https://doi.org/10.1016/j.jhydrol.2009.08.003, 2009.
Hasanipanah, M., Faradonbeh, R. S., Amnieh, H. B., Armaghani, D. J., and Monjezi, M.: Forecasting blast-induced ground vibration developing a CART model, Eng. Comput., 33, 307–316, https://doi.org/10.1007/s00366-016-0475-9, 2017.
Her, Y. and Jeong, J.: SWAT+ versus SWAT2012: Comparison of Sub-Daily Urban Runoff Simulations, Transactions of the ASABE, 61, 1287–1295, https://doi.org/10.13031/trans.12600, 2018.
Her, Y., Jeong, J., Arnold, J., Gosselink, L., Glick, R., and Jaber, F.: A new framework for modeling decentralized low impact developments using Soil and Water Assessment Tool, Environ. Model. Softw., 96, 305–322, https://doi.org/10.1016/j.envsoft.2017.06.005, 2017.
Ioffe, S. and Szegedy, C.: Batch Normalization: Acceleration Deep Network Training by Reducing Internal Covariate Shift, arXiv [preprint], https://doi.org/10.48550/arXiv.1502.03167, 2015.
Jang, W. S., Engel, B., and Yeum, C. M.: Integrated environmental modeling for efficient aquifer vulnerability assessment using machine learning, Environ. Model. Softw., 124, 104602, https://doi.org/10.1016/j.envsoft.2019.104602, 2020.
Jha, D., Ward, L., Paul, A., Liao, W.-K., Choudhary, A., Wolverton, C., and Agrawal, A.: ElemNet: Deep Learning the Chemistry of Materials From Only Elemental Composition, Sci. Rep., 8, 17593, https://doi.org/10.1038/s41598-018-35934-y, 2018.
Jones, D. R.: A Taxonomy of Global Optimization Methods Based on Response Surfaces, J. Glob. Optim., 21, 345–383, https://doi.org/10.1023/A:1012771025575, 2001.
Khashei, M. and Bijari, M.: An artificial neural network (p,d,q) model for timeseries forecasting, Expert Syst Appl., 37, 479–489, https://doi.org/10.1016/j.eswa.2009.05.044, 2010.
Knoben, W. J. M., Freer, J. E., and Woods, R. A.: Technical note: Inherent benchmark or not? Comparing Nash–Sutcliffe and Kling–Gupta efficiency scores, Hydrol. Earth Syst. Sci., 23, 4323–4331, https://doi.org/10.5194/hess-23-4323-2019, 2019.
Konapala, G., Kao, S.-C., and Addor, N.: Exploring Hydrologic Model Process Connectivity at the Continental Scale Through an Information Theory Approach, Water Resour. Res., 56, e2020WR027340, https://doi.org/10.1029/2020WR027340, 2020.
Kratzert, F., Klotz, D., Hochreiter, S., and Nearing, G. S.: A note on leveraging synergy in multiple meteorological data sets with deep learning for rainfall–runoff modeling, Hydrol. Earth Syst. Sci., 25, 2685–2703, https://doi.org/10.5194/hess-25-2685-2021, 2021.
Krenker, A., Bester, J., and Kos, A.: Introduction to the Artificial Neural Networks, in: Artificial Neural Networks – Methodological Advances and Biomedical Applications, edited by: Suzuki, K., IntechOpen, London, https://doi.org/10.5772/15751, 2011.
Li, S., Liu, Y., Her, Y., Chen, J., Guo, T., and Shao, G.: Improvement of simulating sub-daily hydrological impacts of rainwater harvesting for landscape irrigation with rain barrels/cisterns in the SWAT model, Sci. Total Environ., 798, 149336, https://doi.org/10.1016/j.scitotenv.2021.149336, 2021.
Liu, B., Wei, Y., Zhang, Y., and Yang, Q.: Deep Neural Networks for High Dimension, Low Sample Size Data, In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI), 2287–2293, https://doi.org/10.24963/ijcai.2017/318, 2017.
Liu, Z. A., Yang, J., Yang, Z., and Zou, J.: Effects of rainfall and fertilizer types on nitrogen and phosphorus concentrations in surface runoff from subtropical tea fields in Zhejiang, China, Nutr. Cycl. Agroecosyst., 93, 297–307, https://doi.org/10.1007/s10705-012-9517-x, 2012.
Loague, K., Heppner, C. S., Ebel, B. A., and VanderKwaak, J. E.: The quixotic search for a comprehensive understanding of hydrologic response at the surface: Horton, Dunne, Dunton, and the role of concept-development simulation, Hydrol. Process., 24, 2499–2505, https://doi.org/10.1002/hyp.7834, 2010.
Mendie, U. E.: The theory and practice of clean water production for domestic and industrial use: Purified and package water, Lacto-Medal Ltd, Lagos, ISBN 9798300766955, 2005.
Moriasi, D. N., Arnold, J. G., Van Liew, M. W., Bingner, R. L., Harmel, R. D., and Veith, T. L.: Model Evaluation Guidelines for Systematic Quantification of Accuracy in Watershed Simulations, Transactions of the ASABE, 50, 885–900, https://doi.org/10.13031/2013.23153, 2007.
Nash, J. E. and Sutcliffe, J. V.: River flow forecasting through conceptual models part I – A discussion of principles, J. Hydrol., 10, 282–290, https://doi.org/10.1016/0022-1694(70)90255-6, 1970.
Nearing, G. S., Ruddell, B. L., Bennett, A. R., Prieto, C., and Gupta, H. V.: Does Information Theory Provide a New Paradigm for Earth Science? Hypothesis Testing, Water Resour. Res., 56, e2019WR024918, https://doi.org/10.1029/2019WR024918, 2020.
Nie, C. X.: Dynamics of the price-volume information flow based on surrogate time series, Chaos, 31, 013106, https://doi.org/10.1063/5.0024375, 2021.
Nietsch, S. L., Arnold, J. G., Kiniry, J. R., Srinivasan, R., and Williams, J. R.: SWAT: Soil and water assessment tool user's manual. Texas Water Resources Institute, USDA Agricultural Research Service, College Station, TX, 2002.
Noori, N., Kalin, L., and Isik, S.: Water quality prediction using SWAT-ANN coupled approach, J. Hydrol., 590, 125220, https://doi.org/10.1016/j.jhydrol.2020.125220, 2020.
Panidhapu, A., Li, Z., Aliashrafi, A., and Peleato, N. M.: Integration of weather conditions for predicting microbial water quality using Bayesian Belief Networks, Water Res., 170, 115349, https://doi.org/10.1016/j.watres.2019.115349, 2020.
Pechlivanidis, I. G., Gupta, H., and Bosshard, T.: An Information Theory Approach to Identifying a Representative Subset of Hydro-Climatic Simulations for Impact Modeling Studies, Water Resour. Res., 54, 5422–5435, https://doi.org/10.1029/2017WR022035, 2018.
Pullanikkatil, D., Palamuleni, L. G., and Ruhiiga, T. M.: Impact of land use on water quality in the Likangala catchment, southern Malawi, Afr. J. Aquat. Sci., 40, 277–286, https://doi.org/10.2989/16085914.2015.1077777, 2015.
Raju, V. N. G., Lakshmi, K. P., Jain, V. M., Kalidindi, A., and Padma, V.: Study the Influence of Normalization/Transformation process on the Accuracy of Supervised Classification, 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), 20–22 August 2020, 729–735, https://doi.org/10.1109/ICSSIT48917.2020.9214160, 2020.
Razavi, S., Hannah, D. M., Elshorbagy, A., Kumar, S., Marshall, L., Solomatine, D. P., Dezfuli, A., Sadegh, M., and Famiglietti, J.: Coevolution of machine learning and process-based modelling to revolutionize Earth and environmental sciences: A perspective, Hydrol. Process., 36, e14596, https://doi.org/10.1002/hyp.14596, 2022.
Reichstein, M., Camps-Valls, G., Stevens, B., Jung, M., Denzler, J., Carvalhais, N., and Prabhat: Deep learning and process understanding for data-driven Earth system science, Nature, 566, 195–204, https://doi.org/10.1038/s41586-019-0912-1, 2019.
Rural Development Administration (RDA): Agricultural work schedule – Machine transplanting cultivation, http://www.nongsaro.go.kr (last access: 16 February 2026), 2014.
Santhi, C., Arnold, J. G., Williams, J. R., Dugas, W. A., Srinivasan, R., and Hauck, L. M.: VALIDATION OF THE SWAT MODEL ON A LARGE RWER BASIN WITH POINT AND NONPOINT SOURCES, J. Am. Water Resour. Assoc., 37, 1169–1188, https://doi.org/10.1111/j.1752-1688.2001.tb03630.x, 2001.
Sao, D., Kato, T., Tu, L. H., Thouk, P., Fitriyah, A., and Oeurng, C.: Evaluation of Different Objective Functions Used in the SUFI-2 Calibration Process of SWAT-CUP on Water Balance Analysis: A Case Study of the Pursat River Basin, Cambodia, Water, 12, 2901, https://doi.org/10.3390/w12102901, 2020.
Schaefli, B. and Gupta, H. V.: Do Nash values have value?, Hydrol. Process., 21, 2075–2080, https://doi.org/10.1002/hyp.6825, 2007.
Schreiber, T.: Measuring Information Transfer, Phys. Rev. Lett., 85, 461–464, https://doi.org/10.1103/PhysRevLett.85.461, 2000.
Senent-Aparicio, J., Jimeno-Sáez, P., Bueno-Crespo, A., Pérez-Sánchez, J., and Pulido-Velázquez, D.: Coupling machine-learning techniques with SWAT model for instantaneous peak flow prediction, Biosys. Eng., 177, 67–77, https://doi.org/10.1016/j.biosystemseng.2018.04.022, 2019.
Shannon, C. E.: A Mathematical Theory of Communication, Bcl Syst. Tech. J., 27, 379–423, https://doi.org/10.1002/j.1538-7305.1948.tb01338.x, 1948.
Shawe-Taylor, J. and Sun, S.: A review of optimization methodologies in support vector machines, Neurocomputing, 74, 3609–3618, https://doi.org/10.1016/j.neucom.2011.06.026, 2011.
Siddique, M. H. and Tokhi, M. O.: Training neural networks: backpropagation vs. genetic algorithms, IJCNN'01. International Joint Conference on Neural Networks. Proceedings (Cat. No.01CH37222), vol. 2674, 4, 2673–2678, 2001.
Silva, V. D. P. R. D., Belo Filho, A. F., Singh, V. P., Almeida, R. S. R., Silva, B. B. D., de Sousa, I. F., and Holanda, R. M. D.: Entropy theory for analysing water resources in northeastern region of Brazil, Hydrol. Sci. J., 62, 1029–1038, https://doi.org/10.1080/02626667.2015.1099789, 2017.
Srinivasan, R., Zhang, X., and Arnold, J.: SWAT Ungauged: Hydrological Budget and Crop Yield Predictions in the Upper Mississippi River Basin, Transactions of the ASABE, 53, 1533–1546, https://doi.org/10.13031/2013.34903, 2010.
Srivastava, A., Kumari, N., and Maza, M.: Hydrological Response to Agricultural Land Use Heterogeneity Using Variable Infiltration Capacity Model, Water Resour. Manag., 34, 3779–3794, https://doi.org/10.1007/s11269-020-02630-4, 2020.
Sun, W., Lv, Y., Li, G., and Chen, Y.: Modeling River Ice Breakup Dates by k-Nearest Neighbor Ensemble, Water, 12, 220, https://doi.org/10.3390/w12010220, 2020.
Tang, X., Zhang, J., Wang, G., Jin, J., Liu, C., Liu, Y., He, R., and Bao, Z.: Uncertainty Analysis of SWAT Modeling in the Lancang River Basin Using Four Different Algorithms, Water, 13, 341, https://doi.org/10.3390/w13030341, 2021.
Tao, J., Chen, W., Wang, B., Jiezhen, X., Nianzhi, J., and Luo, T.: Real-Time Red Tide Algae Classification Using Naive Bayes Classifier and SVM, 2008 2nd International Conference on Bioinformatics and Biomedical Engineering, 16–18 May 2008, 2888–2891, https://doi.org/10.1109/ICBBE.2008.1054, 2008.
Tobin, K. J. and Bennett, M. E.: Constraining SWAT Calibration with Remotely Sensed Evapotranspiration Data, J. Am. Water Resour. Assoc., 53, 593–604, https://doi.org/10.1111/1752-1688.12516, 2017.
Tosun, E., Aydin, K., and Bilgili, M.: Comparison of linear regression and artificial neural network model of a diesel engine fueled with biodiesel-alcohol mixtures, Alex. Eng. J., 55, 3081–3089, https://doi.org/10.1016/j.aej.2016.08.011, 2016.
Vapnik, V.: The nature of statistical learning theory, Springer, Berlin, ISBN 9780387945590, 1995.
Vapnik, V.: Statistical learning theory, John Wiley & Sons, New York, ISBN 9780471030034, 1998.
Wang, Y. and Xia, S. T.: A novel feature subspace selection method in random forests for high dimensional data, 2016 International Joint Conference on Neural Networks (IJCNN), 24–29 July 2016, 4383–4389, https://doi.org/10.1109/IJCNN.2016.7727772, 2016.
Xu, T. and Liang, F.: Machine learning for hydrologic sciences: An introductory overview, WIREs Water, 8, e1533, https://doi.org/10.1002/wat2.1533, 2021.
Ye, Y., Wu, Q., Zhexue Huang, J., Ng, M. K., and Li, X.: Stratified sampling for feature subspace selection in random forests for high dimensional data, Pattern Recognit., 46, 769–787, https://doi.org/10.1016/j.patcog.2012.09.005, 2013.
Yilmazkaya, E., Dagdelenler, G., Ozcelik, Y., and Sonmez, H.: Prediction of mono-wire cutting machine performance parameters using artificial neural network and regression models, Eng. Geol., 239, 96–108, https://doi.org/10.1016/j.enggeo.2018.03.009, 2018.
Yu, T. and Zhu, H.: Hyper-parameter optimization: A review of algorithms and applications, arXiv [preprint], arXiv:2003.05689, https://doi.org/10.48550/arXiv.2003.05689, 2020.
Zhang, N. and Zhao, X.: Quantile transfer entropy: Measuring the heterogeneous information transfer of nonlinear time series, Commun. Nonlinear Sci. Numer. Simul., 111, 106505, https://doi.org/10.1016/j.cnsns.2022.106505, 2022.