the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 10 Jan 2025
| 10 Jan 2025
Review of gridded climate products and their use in hydrological analyses reveals overlaps, gaps, and the need for a more objective approach to selecting model forcing datasets
Kyle R. Mankin
Sushant Mehan
Timothy R. Green
David M. Barnard
Climate forcing data accuracy drives performance of hydrologic models and analyses, yet each investigator needs to select from among the numerous gridded climate dataset options and justify their selection for use in a particular hydrologic model or analysis. This study aims to provide a comprehensive compilation and overview of gridded datasets (precipitation, air temperature, humidity, wind speed, solar radiation) and considerations for historical climate product selection criteria for hydrologic modeling and analyses based on a review and synthesis of previous studies conducting dataset intercomparisons. All datasets summarized here span at least the conterminous US (CONUS), and many are continental or global in extent. Gridded datasets built on ground-based observations (G; n= 20), satellite imagery (S; n= 20), and/or reanalysis products (R; n= 23) are compiled and described, with focus on the characteristics that hydrologic investigators may find useful in discerning acceptable datasets (variables, coverage, resolution, accessibility, and latency). We provide best-available-science recommendations for dataset selection based on a thorough review, interpretation, and synthesis of 29 recent studies (past 10 years) that compared the performance of various gridded climate datasets for hydrologic analyses. No single best source of gridded climate data exists, but we identified several common themes that may help guide dataset selection in future studies:
-
Gridded daily temperature datasets improved when derived over regions with greater station density.
-
Similarly, gridded daily precipitation data were more accurate when derived over regions with higher-density station data, when used in spatially less-complex terrain, and when corrected using ground-based data.
-
In mountainous regions and humid regions, R precipitation datasets generally performed better than G when underlying data had a low station density, but there was no difference for higher station densities.
-
G datasets were generally more accurate in representing precipitation and temperature data than S or R datasets, although this did not always translate into better streamflow modeling.
We conclude that hydrologic analyses would benefit from guided dataset selection by investigators, including justification for selecting a specific dataset, and improved gridded datasets that retain dependencies among climate variables and better represent small-scale spatial variability in climate variables in complex topography. Based on this study, the authors' overall recommendations to hydrologic modelers are to select the gridded dataset (from Tables 1, 2, and 3) (a) with spatial and temporal resolutions that match modeling scales, (b) that are primarily (G) or secondarily (SG and RG) derived from ground-based observations, (c) with sufficient spatial and temporal coverage for the analysis, (d) with adequate latency for analysis objectives, and (e) that includes all climate variables of interest (so as to better represent interdependencies).
- Article
(581 KB) - Full-text XML
- BibTeX
- EndNote





Hydrologists are faced with a dizzying variety of options when selecting climate data for water resource analyses. Climate drives hydrological processes, and accurate climate forcing data are essential for meaningful water resource investigations and modeling. However, it is arguable that no single source of climate data is universally appropriate, leading to a dearth of studies that make an effort to justify their dataset selection. Over recent decades, while ground-based observations from weather stations have decreased (Sun et al., 2018; Strangeways, 2006), gridded datasets built on ground-based observations, satellite imagery, and reanalysis products have increased.
A well-maintained, long-term weather station, although not error-free (Gebremichael, 2010; Strangeways, 2006), provides direct, in situ point measurements for a location. However, most hydrologic analyses address processes at locations and scales for which the point weather station data may not be representative. Gridded datasets offer several advantages over point station data (Essou et al., 2016a): gridded datasets are relatively easy to use, have uniform spatial coverage, provide consistent coverage over time (avoids the problem of non-reporting stations), and rarely have missing data. Uniform grids with temporal consistency allow simple averaging across a domain. However, gridded datasets often are not available in real time (i.e., data latency), which might pose limitations for some hydrologic analyses (e.g., snowmelt and runoff forecasting as well as operational water resource decision-making).
Many studies (29 of which are reviewed in Sect. 4 of this article) have intercompared the accuracy of particular subsets of these gridded climate datasets for various regions, settings, and time frames across the globe with various insights and conclusions. However, no cataloguing or synthesis of these studies has been completed to date, presenting an important knowledge gap that may hinder well-informed dataset selection. To address this need, we completed a search of “intercomparison” AND “gridded AND climate AND data”, which yielded 202 documents using Scopus. Excluding “climate change” reduced this to 100 documents, and excluding “CMIP” produced 77 documents. Even with these filters, most studies focus on a limited number of datasets, lack generalizable recommendations, and do not consider the functional implications of dataset limitations on end users' hydrologic analysis. The present study aims to provide a comprehensive compilation, overview, and considerations for selection of gridded datasets with an emphasis on selection for hydrologic modeling and analyses. Our focus is on historical datasets (not climate projections) at the conterminous US (CONUS) to global extents.
Gridded historical climate datasets can be categorized as ground-based (G), satellite-based (S), or reanalysis-based (R) according to the sources of data and methods used in their derivation. Many datasets integrate multiple data sources and methods in deriving the dataset; in this article, the primary data source/method for integrated datasets is listed first, followed by secondary method(s) (e.g., SR, RG, and RSG). We focus on gridded datasets available for five climatological variables that are essential to hydrological analyses: precipitation (P), air temperature (T), atmospheric moisture (relative humidity, rh; specific humidity, sh; dew-point T, Tdp; or vapor pressure, Vp), wind speed (u), and solar radiation (Rs) or associated metrics (cloud cover, cc, or sky cover, sc). Particular emphasis is on datasets that provide gridded P, a highly variable and critical driver in hydrological analyses. For more details, the reader is directed to an informative review of global P datasets, including a discussion of these dataset sources and estimation procedures (Sun et al., 2018).
Although the grid resolution of each data product is clear, the support scale is generally vague. That is, the grid centroid is often treated as a point, which is then interpolated or regionalized to obtain area-averaged values at the scale of hydrologic model resolution (e.g., a hydrologic response unit – HRU). However, if the gridded data represent grid-scale (e.g., 4 km × 4 km) areal averages, this should be considered during interpolation to the HRU scale. Scaling within and across grid cells has been explored for gridded soil moisture (Hoehn et al., 2017), but it remains an issue for gridded climate products. In this study, we mention this as a precaution but do not offer scaling solutions.
2.1 Ground-based (G) datasets
Ground-based gridded datasets (Table 1) are derived directly from observational data, typically from weather station networks. Various methods are used to interpolate data between stations and may account for orographic effects, lake effects, and other mesoscale meteorologic phenomena. These datasets benefit from direct application of data with relatively well-defined biases and uncertainty inherited from the instrumentation characteristics and errors. For example, P data collection has well-known errors at the station level from sources such as wind, evaporation, wetting, splashing, site location, instrument error, spatiotemporal variation in drop-size distribution, and frozen vs. liquid P (Sun et al., 2018). Interpolating these data to a grid adds additional uncertainty to the extent to which station density inadequately captures spatial variability in the climatic variable across the domain. Minimum recommended station densities vary by physiographic unit (e.g., mountains and plains) from one to four stations per 1000 km2 (WMO, 2008). Essou et al. (2017) noted that most of the 316 watersheds in their comprehensive Canadian study had less than one station per 1000 km2, indicating a wider global concern. Increased station density generally improves gridded dataset quality, but it may be impractical to adequately cover regions with complex topography, localized convective storms, heat islands, blowing snow, or other micrometeorological heterogeneity. For example, snow gauge undercatch due to high wind speeds is an especially pronounced phenomenon that challenges accurate characterization of water storage in snow-dominated basins (Fassnacht, 2004; Panahi and Behrangi, 2020). Station density and coverage also change over time as old stations are deprecated or new stations added, complicating interpolation schemes and often disproportionately diminishing coverage in remote areas. Sun et al. (2018) noted that the number of global stations in the GPCC v7 dataset changed from 10 900 stations in 1901 to a maximum of 49 470 in 1970, decreasing to 30 000 in 2005, and decreasing again to only 10 000 in 2012. This recent decline in station data not only impacts G datasets but also S and R datasets that rely on station data in their dataset development. Uncertainties associated with these temporal changes in sampling density are further complicated by the nonstationarity of climate and accelerated climate change in recent decades.
Table 1Summary of ground-based (G) gridded datasets.
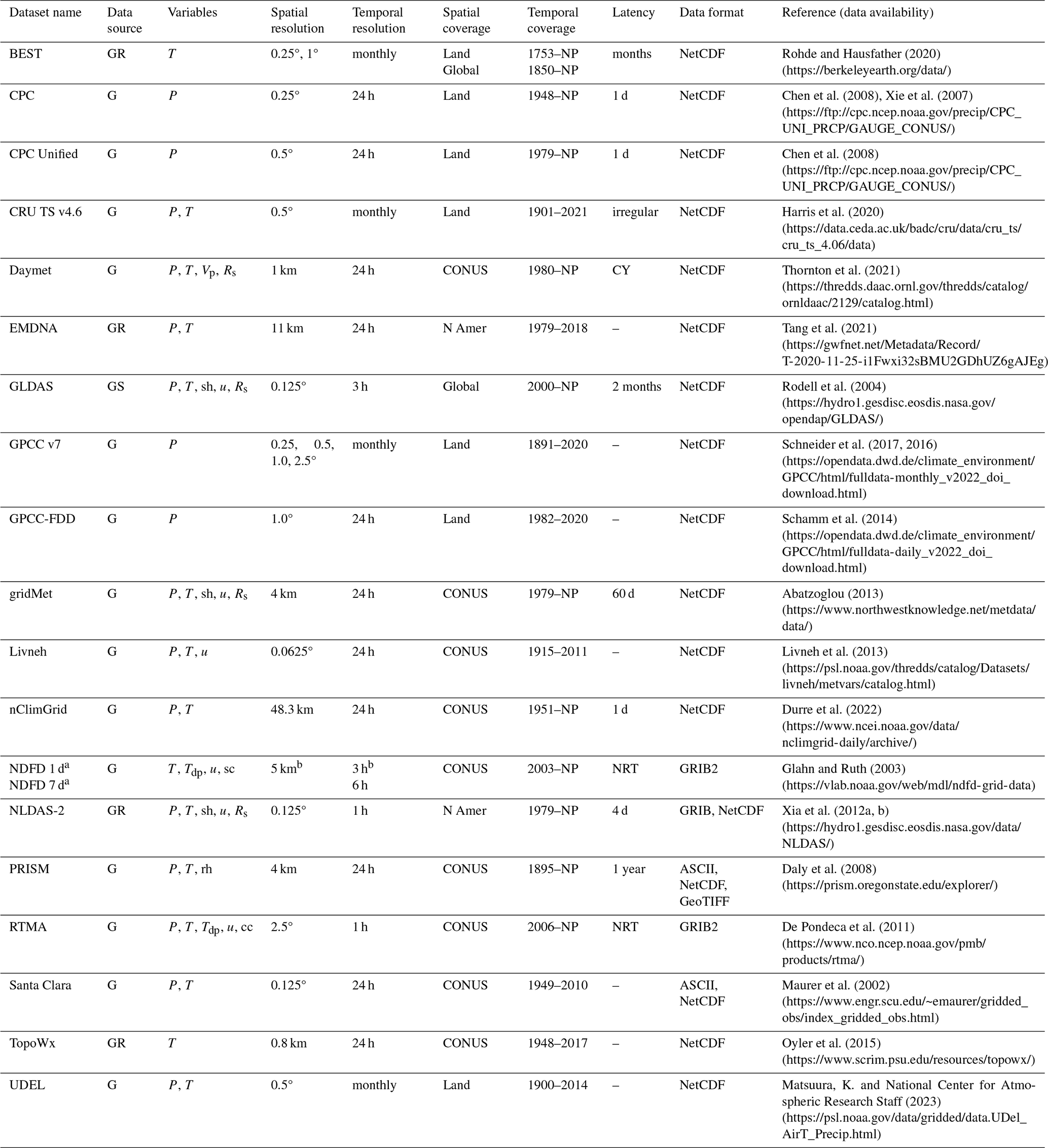
Data source: G – ground-based observations (with interpolation); S – satellite; R – reanalysis. Variables: P – precipitation; T – air temperature; rh – relative humidity; sh – specific humidity; Tdp - dew-point T; Vp – vapor pressure; u – wind speed; Rs – solar radiation; sc – sky cover; cc – cloud cover. Spatial resolution: 1.0° latitude = 111 km; 1.0° longitude = 111 km at 0° latitude and 85 km at 40° latitude. Spatial coverage: CONUS – conterminous US; N Amer – North America; Land – global land surfaces only (not ocean surfaces); Global – global land and ocean surfaces. Temporal coverage: NP – near present. Latency: NRT – near-real time; CY – available each calendar year; “–” – static dataset. Data format: NetCDF – Network Common Data Form; ASCII – American Standard Code for Information Interchange; GRIB – Gridded Binary; GeoTIFF – Georeferenced Tagged Image File Format. a NDFD provides 1–7 d lead-time forecasts. b NDFD spatial resolution changes to 2.5 km and 1 d forecast temporal resolution changes to 1 h after 19 August 2014. All links listed in the table were last accessed on 29 November 2024.
2.2 Satellite-based (S) datasets
Satellite-based gridded datasets (Table 2) are derived from various sensors aboard geostationary satellites (visible/infrared, IR, sensors) with rapid sampling frequency (30 min or less) and low-Earth-orbit satellites (visible/IR; passive microwave, MW; and active MW) with a lower temporal sampling frequency (Sun et al., 2018). Compared to G datasets, S datasets provide spatially homogenous coverage (the entire area within the coverage field has similar data density) and temporally continuous records, but they are limited in temporal coverage to the satellite era, with the first Television and IR Observation Satellite (TIROS) launched in 1960. Visible/IR methods detect cloud-top surface conditions and correlate colder/brighter cloud tops to greater convection and more P. Passive MW methods detect precipitation-sized particles, thereby providing a more-direct measure of P. Active MW methods allow measurement of the instantaneous three-dimensional structure of rainfall. Methods have been developed to merge these datasets to capitalize on the higher accuracy of MW methods and greater temporal frequency of visible/IR methods and increase overall product accuracy (Sun et al., 2018).
A review by Maggioni et al. (2016) described satellite instruments and compared many of the algorithms used in current satellite P datasets. They found that S datasets have a larger overestimation bias in the warm season and a lower positive bias in the cold season. Satellite datasets have high probability of capturing warm-season convective events; as a result, in the central US, for example, S datasets have better agreement with ground-radar products than rain gauge stations, which can miss localized convective storms. Satellite-based products tend to underestimate intense rainfall during extreme hurricane events; S also tends to underestimate light P at high elevations and overestimate P at low elevations in regions of complex topography in northwestern Mexico and the Appalachian Mountains, all of which may be attributed to IR sensors' lack of discrimination between raining and non-raining clouds.
Table 2Summary of satellite-based (S) gridded datasets.
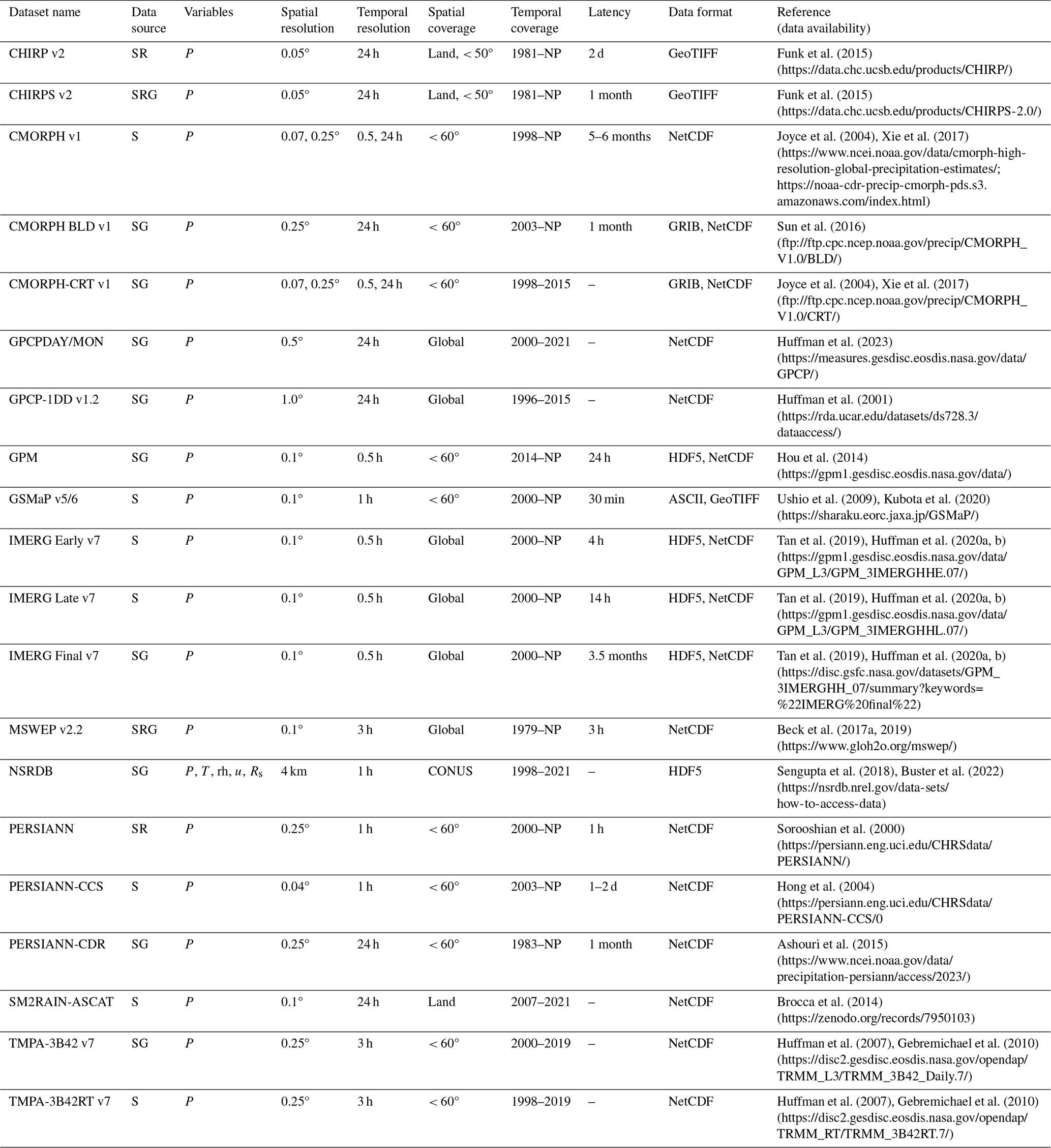
Data source: G – ground-based observations (with interpolation); S – satellite; R – reanalysis. Variables: P – precipitation; T – air temperature; rh – relative humidity; u – wind speed; Rs – solar radiation. Spatial resolution: 1.0° latitude = 111 km; 1.0° longitude = 111 km at 0° latitude and 85 km at 40° latitude. Spatial coverage: CONUS – conterminous US; N Amer – North America; Land – global land surfaces only (not ocean surfaces); Global – global land and ocean surfaces. Temporal coverage: NP – near present. Latency: “–” – static dataset. Data format: NetCDF – Network Common Data Form; HDF5 – Hierarchical Data Format 5; ASCII – American Standard Code for Information Interchange; GRIB – Gridded Binary; GeoTIFF – Georeferenced Tagged Image File Format. All links listed in the table were last accessed on 29 November 2024.
2.3 Reanalysis-based (R) datasets
Reanalysis-based gridded datasets (Table 3) are synthesized from process-based climate models, often together with G and/or S observational data, with the goal of generating gridded datasets with spatially homogenous data density that are temporally continuous. A precipitation forecast is generated from complex interactions of a priori predictions from a physically based, dynamical process model (that can often account for orographic effects in topographically complex regions) and ingested observational data. Reanalysis systems use various models, observational datasets, and assimilation methods; can generate many climate variables with interdependent variable consistency; and provide near-real-time datasets with latency periods from hours to months. Accuracy of R methods may be limited by the changing availability of observational data and biases in observations and models.
Reanalysis datasets have been found to better capture winter P resulting from large-scale systems than summer P with a greater influence of localized convective storms (Massmann, 2020; Beck et al., 2019). Similarly, Beck et al. (2017b) confirmed the conclusions of several other studies (Barrett et al., 1994; Xie and Arkin, 1997; Adler et al., 2001; Ebert et al., 2007; Massari et al., 2017) which demonstrated that reanalysis underperformed MW- and IR-based datasets in the tropics and outperformed them in colder regions (> 40° latitude). Reanalysis demonstrated reduced bias compared with S datasets, with greater ranges of bias among all datasets in areas with complex topography (the Rockies, Andes, and Hindu Kush) and arid regions (the Saharan, Arabian, and Gobi deserts) (Beck et al., 2017b).
Table 3Summary of reanalysis-based (R) gridded datasets.
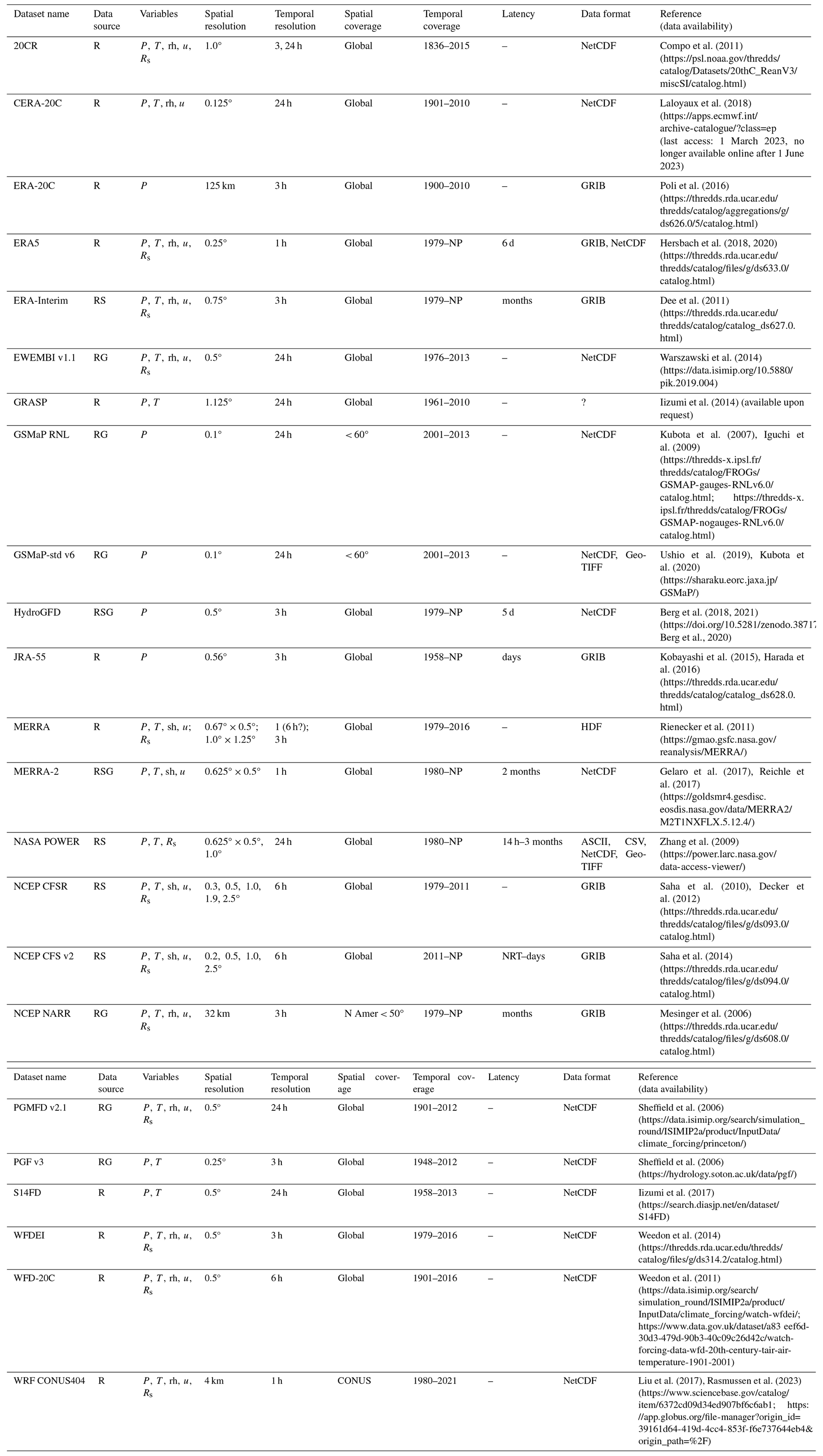
Data source: G – ground-based observations (with interpolation); S – satellite; R – reanalysis. Variables: P – precipitation; T – air temperature; rh – relative humidity; sh – specific humidity; u – wind speed; Rs – solar radiation. Spatial resolution: 1.0° latitude = 111 km; 1.0° longitude = 111 km at 0° latitude and 85 km at 40° latitude. Spatial coverage: CONUS – conterminous US; N Amer – North America; Land – global land surfaces only (not ocean surfaces); Global – global land and ocean surfaces. Temporal coverage: NP – near present. Latency: “–” – static dataset. Data format: NetCDF – Network Common Data Form; HDF5 – Hierarchical Data Format 5; ASCII – American Standard Code for Information Interchange; GRIB – Gridded Binary; GeoTIFF – Georeferenced Tagged Image File Format; CSV – comma-separated values; ? – unknown. All links listed in the table were last accessed on 29 November 2024.
2.4 Integrated products
Inherent limitations of individual data sources (G, S, or R) can be reduced by merging other data sources with complementary advantages to reduce errors or biases. Some reanalysis datasets are used independently or merge multiple reanalysis products (denoted by R in Table 3). Reanalysis datasets commonly ingest ground-based observational data (RG), satellite data (RS), or both (RSG). Some S datasets also integrate G data (denoted by SG in Table 2), reanalysis data (SR), or both (SRG) to enhance accuracy and reduce bias. Several data sources, such as CHIRP, CMORPH, IMERG, PERSIANN, and TMPA, offer multiple products with increasing data source complexity, often with increased latency and different spatial and temporal resolutions. Each dataset follows a different workflow in developing the integrated product; in general, the primary method (in this article, the first abbreviation letter) is enhanced somewhat sequentially with various interpolation or bias correction schemes using the secondary dataset(s).
The gridded datasets summarized in Tables 1, 2, and 3 span 0.8 to 278 km spatial resolutions, 0.5 to 720 h (monthly) temporal resolutions, 0.02 (30 min) to 365 d latencies, CONUS to global spatial coverage, and 10- to 271-year periods of record, starting as early as 1753 (Fig. 1). Differences have emerged in the representation of G, S, and R datasets across many of these categories. G datasets have the finest spatial resolutions (1 km) and longest periods of record (> 240 years) and tend to have the longest latency (average for G = 86 d, compared with S = 29 d and R = 36 d). A greater proportion of G datasets have less-extensive spatial coverage (CONUS to North American continental in this study), whereas S and R datasets were typically global in extent. S datasets start no earlier than 1979 and comprise no greater than a 45-year period of record (through 2023). More R and S datasets have finer temporal resolution than G datasets, with average resolutions of 10 h for R and 9 h for S compared with 158 h for G.
No single best source of gridded climate data exists. Many characteristics of gridded datasets influence the best product for a given application or research question. We highlight several of the most important considerations in differentiating among the many possible gridded datasets. Most of these characteristics are detailed for each gridded dataset in Tables 1, 2, and 3.
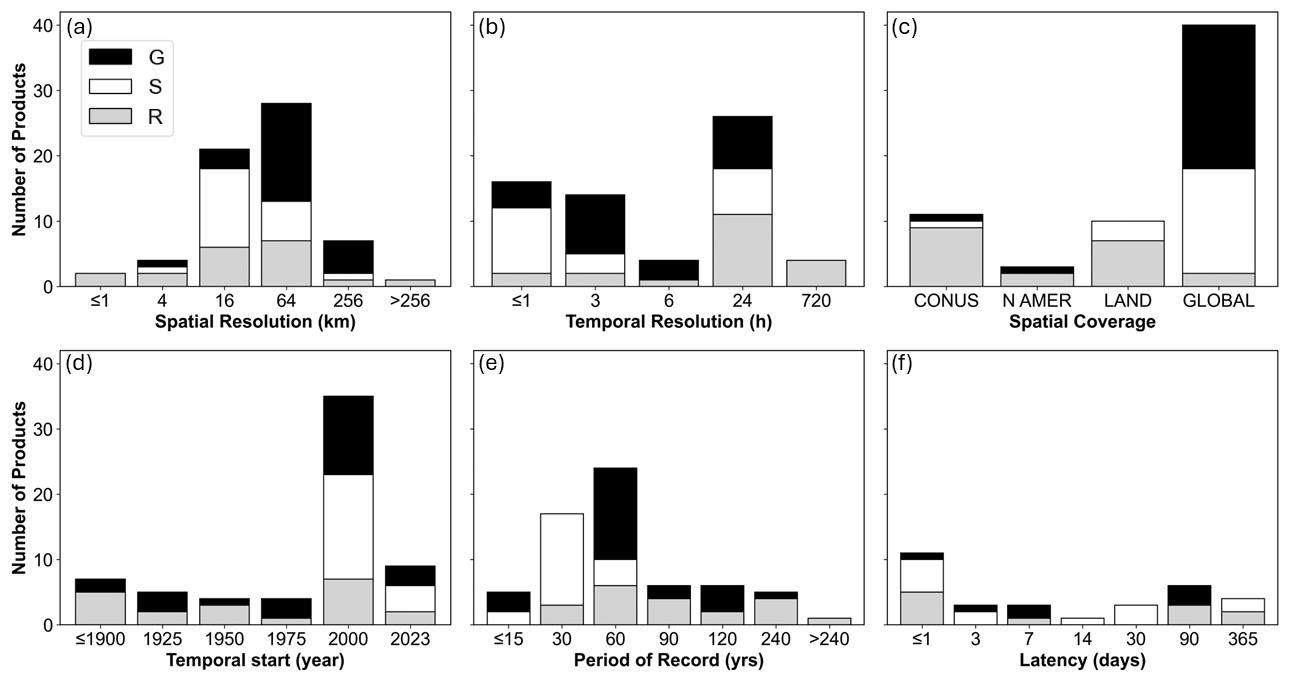
Figure 1Distribution of (a) spatial resolution, (b) temporal resolution, (c) latency, (d) period start date, (e) period of record, and (f) spatial coverage for assessed ground-based (G), satellite-based (S), and reanalysis-based (R) gridded precipitation data sources. x-axis labels are the upper limits of each categorical bin, exclusive of other bins. The abbreviations used in the figure are as follows: CONUS – conterminous US; N AMER – North America; LAND – global land surfaces only (not ocean surfaces); GLOBAL – global land and ocean surfaces.
3.1 Variables and interdependencies
Hydrological investigations typically begin with selecting datasets for each important climate variable. Tables 1, 2, and 3 summarize the variables included in each gridded dataset. Datasets that include all climate variables of interest may inherently represent appropriate interdependencies or cross-correlations among the variables. For example, periods of time with P are associated with cloud cover; decreased Rs; and, often, higher humidity. Other types of dependency-related dilemmas may also occur in gridded datasets. Cold-air drainage can invert the minimum T (Tmin)–elevation relationship in montane foothills, and daily Tmin may not equal daily average Tdp in semiarid regions (Tmin decoupled from 100 % rh), thus invalidating an assumption of commonly used schemes to spatially interpolate gridded Tdp data (McEvoy et al., 2014). Often the accurate representation of these interdependencies is important in hydrologic analyses.
3.2 Coverage
Gridded datasets have a range of spatial and temporal extents. All datasets summarized in this article span at least the CONUS, and many are continental or global in extent. General guidelines by the World Meteorological Organization require a 30-year minimum period of record to reasonably represent climate variability. Non-stationarity of climate makes it even more important to consider whether longer periods representing climatic trends or periods more heavily weighted toward recent data are preferable for a given hydrologic study. Periods of record may be dictated by investigations focused on specific events or periods, such as studies of the hydrologic effects of wildfire or other disturbance events, calculations of the recurrence interval of a flood of a given severity, or studies assessing hydrologic responses over specific periods.
3.3 Resolution
The spatial and temporal resolution of the dataset should be adequate to represent the variability in the climate variable given the representational scale of the hydrologic model. The simulated spatial and temporal resolution of evapotranspiration (ET), runoff, and other hydrological elements in hydrologic models can be relatively fine (< 1 km, subdaily), and model resolution is increasing in ways that capitalize on increasing computational power, process understanding, and data availability (Melsen et al., 2016). Hydrologic model output resolution and uncertainty are often limited by the spatial and temporal resolution of climate datasets. As such, the resolution of gridded climate datasets should be an important criterion to consider, especially in mountainous areas within complex terrain driving spatial heterogeneity in climate variables. Some gridded datasets sacrifice the representation of extremes, both wet and dry, to better represent mean climatic conditions. Alternatively, increased temporal resolution may come at the cost of reduced spatial resolution. Creation of spatially continuous and consistent gridded response surfaces can result in point data extremes being smoothed during interpolation. Gridded data interpolation schemes can also influence the representation of meteorologic variability; for example, Daymet uses a strict T–elevation relationship that limits its ability to represent T inversions relative to PRISM, which includes “climatologically aided interpolation” (McEvoy et al., 2014). Methods that create ensembles of multiple gridded datasets often better represent mean conditions across a domain at the expense of representing the full range of possible conditions within the domain.
3.4 Format and accessibility
Data format and accessibility dictate how easily and effectively a dataset can be accessed, processed, and analyzed for a specific hydrologic application. Several common data formats are described in Table A1. The data format must be compatible with software and tools used in the hydrologic analysis. Formats such as NetCDF and HDF5 are widely used in climate research because they are consistent with various processing tools and can efficiently store large multidimensional datasets. Adequate metadata are essential for understanding the dataset, including its origin, methodology, and any processing it has undergone. Investigators may consider the importance of datasets that can be compressed without significant data loss, are interoperable with the other datasets, and are freely available and easily accessible online. Some datasets have application programming interfaces (APIs) for automated data retrieval that can be useful.
3.5 Site and event characteristics
Preference may be given to datasets that reflect characteristic spatial and temporal dimensions of climatic processes in the domain, such as cool-air drainage patterns, orographic or convective P events, lake effects, and effects of altitude. Priority may be given to datasets that capture the most important aspects of climate variable magnitude and variability at appropriate scales, including daily/seasonal/annual averages, extreme event (high or low) magnitudes, or event sequences (continuous dry days, CDDs; continuous wet days, CWDs; etc.). For example, datasets with fine temporal resolution (∼1 h) may be required to capture hydrological functioning when P is dominated by high-intensity but short-duration convective events. In hydrologic models, spatiotemporal scales are interdependent, and source data should be considered in watershed delineation.
3.6 Process and model sensitivity and latency
Hydrologic processes are differentially sensitive to climatic variables and characteristics. For example, a snowmelt runoff modeling study may prioritize a dataset with accurate, fine-spatial-resolution T and accurate Rs, whereas a small-basin study of soil moisture or erosion dynamics may prioritize a fine-scale P dataset that maintains a full range of extreme events. A study focused on ET dynamics may prioritize a dataset that includes T, rh, u, and Rs and maintains appropriate inter-variable dependencies. Flood simulation may prioritize fine-temporal-resolution P data at a resolution matching the domain heterogeneity. Long-term water balance studies or large-scale river basin studies may prefer daily or monthly datasets with coarse spatial resolution. Often, the selected model formulation will constrain the required variables, their characteristics, and the preferred data format.
Latency, or the time lag in dataset availability, may also be an important consideration. Some modeling applications may require real-time or near-real-time results. Other applications designed to analyze historical trends or prior conditions can tolerate long data latency periods. Gridded datasets may implement additional processing steps intended to increase accuracy or resolution but that increase the latency before data become available for use. In the gridded datasets summarized in Tables 1–3, S datasets averaged the shortest latency periods (29 d), followed by R (36 d) and G (86 d).
3.7 Time zone considerations
When using climate and other hydrologic data from different sources, the data time period consistency is critical and too often overlooked. Particularly for data in a “daily” format, users must be cognizant of the zonal time period for each dataset. Station data vary with respect to the reporting period for G data (e.g., daily periods beginning at midnight, 07:00, or 08:00 standard time or local time, i.e., with spring and fall daylight savings time shifts). Gridded datasets may provide data for a standard time period (e.g., 24 h period from 00:00 GMT) or adjusted for a user-defined time zone. Hydrologic comparison datasets (e.g., streamflow) may be reported for 24 h starting at midnight standard or local time or for some other 24 h period. Mismatched datasets may lead to systematic analysis errors.
Appropriate selection from among the many available gridded meteorological datasets requires an understanding of how these datasets impact hydrologic modeling. To assist with the selection process, we conducted a thorough review and synthesis of the recent (past 10 years) literature comparing gridded meteorological datasets, with specific consideration of their influence on hydrologic modeling (Table 4). Studies were selected that (a) compared multiple gridded datasets, preferably including comparisons with different resolutions, scales, spatial contexts (topography, climate), goals, or hydrologic models; (b) compared the accuracy of those datasets to observed meteorological data; and (c) compared the performance of those datasets as forcing data for hydrologic model(s) or analyses. Most studies assessed and compared P datasets; some also assessed T datasets; and very few assessed rh, u, or Rs datasets. This relates, in equal measures, to the relative importance of P data in hydrologic analysis; the relative complexity of representing P in gridded datasets; and the relative availability of P, T, and other data across G, S, and R datasets (Tables 1, 2, 3).
Table 4Summary of recent (10 years, 2014–2023) literature on gridded dataset comparisons for hydrologic modeling.

Reference (location): general region of study. Data source: G – ground-based observations (with interpolation); S – satellite; R – reanalysis; D – downscaling.
4.1 Humidity, wind, and solar radiation dataset assessment
A total of 2 of the 29 studies summarized in Table 4 assessed and compared humidity (rh, sh, Tdp, or Vp), wind speed (u), and/or solar radiation (Rs, sc, or cc) to station data or their effects on hydrologic analyses. Mourtzinis et al. (2017) assessed and compared G gridded datasets for rh (Daymet, derived from Vp, and PRISM derived from Tmin and Tmax) and Rs (Daymet, G; NASA POWER, RS) to observed data from 45 stations in the US Midwest. They found good agreement between daily Rs and station data (RMSE = 8 % for both datasets), with 98 % of data within 15 % of the measured data. However, daily rh agreement was poor for both Daymet (RMSE = 13 %) and PRISM (RMSE = 18 %). Blankenau et al. (2020) compared six G datasets to 3 years of data at 103 weather stations across the US, Guam, and Puerto Rico. For Vp, u, and Rs, performance was best for RTMA and NDFD 1 d forecasts and worst for NLDAS. High spatial resolution did not necessarily confer accuracy, as coarser GLDAS (28 km) and NCEP CFS v2 (22 km) datasets outperformed finer NLDAS (14 km). Bandaru et al. (2017) compared four gridded datasets (three G and one RG) to observed monthly data from five flux towers in the northwestern US and found different results for humidity (Tdp) and Rs. For Tdp, performance decreased in the following order: NCEP NARR (RG) to PRISM to Daymet to NLDAS (G). Conversely, for Rs, performance decreased in the following order: from NLDAS to Daymet (both with negative bias) to NCEP NARR (positive bias). McEvoy et al. (2014) compared P, T, and rh data from four G datasets to 14 stations in Nevada. Gridded datasets, particularly Daymet, had difficulty representing cold-air drainage in this mountainous terrain; PRISM incorporates methods to represent inversions and performed better across the 1-year comparison study. Finer resolution (PRISM: 800 m; Daymet: 1 km) had less bias than coarser resolution (PRISM and gridMet: 4 km) datasets. Also, the common assumption that daily Tmin approximates Tdp (used by Daymet) was unrealistic in this semiarid environment.
Current literature is too limited to provide a consensus for humidity, u, or Rs gridded dataset selection. More studies are needed, both to assess the accuracy of available humidity, u, or Rs gridded datasets (Tables 1, 2, 3) and to assess their impacts on hydrologic model performance. A key conclusion was that analyses in which rh, u, and Rs are primary forcing variables (e.g., ET, airshed, snowpack, or surface soil moisture dynamic analyses) would benefit from an assessment of available dataset suitability (e.g., comparison of the gridded dataset to reference, ground-based weather stations in or around the study area) and a sensitivity analysis of the model (how responsive is the response variable to the noted gridded climate dataset uncertainty) prior to dataset selection. Hybrid data sources (station and gridded) need to be considered regarding both model skill for simulating hydrology and optimal model parameter sets, because effects of mixing data sources are generally unknown. Dependencies among climate variables (such as those discussed in Sect. 4.4 for P−T dependencies) may also be an important consideration for humidity, u, and Rs and lead to prioritizing a gridded dataset that represents covariances among variables of concern. As such, methods to retain coupling of climate variables in gridded datasets are needed.
4.2 Temperature (T) dataset assessment
Accuracy and agreement of gridded datasets of air temperature (T) at 2 m above the ground (Table 4), about crop canopy height, were dependent on many factors, including the spatial region of interest and topography. Essou et al. (2016b) found that T data from six R datasets were generally comparable to station data in 370 basins across the CONUS. Behnke et al. (2016) evaluated eight G datasets and found gridded T data to be highly correlated (r>0.9) with station data, although biased towards cooler T, across the CONUS; the best dataset differed by region, and spatial resolution was not an important factor. Massmann (2020) analyzed three datasets (two R and one G) with long (century) periods of record in 168 basins throughout the CONUS and found that T datasets were generally adequate across the US but were less adequate (lower daily rank correlation and higher long-term bias) in the Rocky Mountains. In the Rockies, Shuai et al. (2022) found a strong correlation (r>0.95) with measured station data in Colorado for G datasets (PRISM, Daymet, and NLDAS-2). In the US Midwest, Mourtzinis et al. (2017) found good agreement (RMSE < 5 %) for both PRISM and Daymet. Tercek et al. (2021) revealed a characteristic of G datasets tending to underrepresent higher-elevation point locations (e.g., mountain tops), which corresponded to gridded monthly maximum T data. McEvoy et al. (2014) found that G datasets (PRISM, Daymet, and gridMet) in montane regions underestimated inversion strength and Tmin in foothills. As expected, datasets resulting from downscaling methods were constrained by the inherent inaccuracies of the original gridded T dataset (Gupta and Tarboton, 2016).
Several studies have specifically addressed the contribution of gridded T datasets to hydrologic model performance. A consensus across many studies was that T dataset selection was less influential on hydrologic simulation accuracy than P dataset selection (Dembélé et al., 2020; Essou et al., 2016a; Mei et al., 2022; Shuai et al., 2022). Laiti et al. (2018) evaluated five gridded daily T datasets covering a basin in the Italian Alps, with elevations ranging from 185 to 3500 m. They found that G datasets with higher resolution produced the best streamflow (Q) simulation and also suggested that T datasets from various sources (G, S, and R) can be used interchangeably, with negligible impacts on simulation results. The consensus from these nine studies (discussed in this section and cited in Table 4) suggests that gridded T datasets can generally be used interchangeably for hydrologic analyses in most parts of the CONUS or globally, although differences in hydrologic response may arise in areas of more complex (i.e., mountain) topography.
4.3 Precipitation (P) dataset assessment
Precipitation (P) datasets were less reliable than T datasets, both with respect to their accuracy and their performance forcing hydrologic models. P data often lack accuracy and spatial variability in complex, mountainous topography (Hafzi and Sorman, 2022; Henn et al., 2018) and need to be gauge-corrected (Raimonet et al., 2017; Mazzoleni et al., 2019; Laiti et al., 2018; Essou et al., 2017; Hafzi and Sorman, 2022). In mountainous regions and humid regions, R datasets generally performed better than G in areas with a low station density (less than one station per 1000 km2), but there was no difference in performance for higher station densities (more than three stations per 1000 km2) (Essou et al., 2017). Gampe and Ludwig (2017) and Essou et al. (2016b) found that R datasets show a great potential to provide reasonable P data in areas where the station location and density cause high errors and uncertainty, especially at higher elevations and in topographically complex regions. Ang et al. (2022) found that P data from G (APHRODITE), SG (TMPA-3B42 and IMERG), and R (ERA5) datasets all performed well (r>0.75) in a data-sparse region (less than three stations per 1000 km2) of Southeast Asia. Essou et al. (2016b) judged that differences between R and observed G data across the CONUS were small enough to allow direct use of R-based P and T data for hydrologic modeling without bias correction. Satellite datasets corrected with either R or G datasets increased P accuracy (Hafzi and Sorman, 2022). In hydrologic models, inputs of daily or hourly P are partitioned into rain (liquid) and snow (solid) based primarily on T (daily Tmin), but little information exists on the relative accuracy of P for rain, snow, and rain–snow mixes. See Sect. 4.4 and 4.6 for P–T interactions and the estimation of the snow-water equivalent (SWE).
The G methods provided the most accurate gridded P data (Kouakou et al., 2023; Massmann, 2020), although performance of G datasets deteriorate in gauge-sparse regions (Beck et al., 2017b). With adequate station density, weather-station network data were superior at local to regional scales (Tarek et al., 2020; Meng et al., 2014; Yang et al., 2014). Datasets that directly integrated higher-temporal-resolution gauge data performed best, with decreasing performance from those incorporating daily gauge data (CPC Unified and MSWEP v1.2 and v2) compared with 5 d gauge data (CHIRPS v2), monthly gauge data (GPCP-1DD v1.2, TMPA-3B42 v7, and WFDEI CRU), or a monthly SG GPCP product (PERSIANN) (Beck et al., 2017b).
Global R datasets often were good proxies for P data (Essou et al., 2016b). Massmann (2020) found that R datasets were more appropriate for short-term P in the northwestern US, with some difficulties in representing P in the southern and eastern US. From a comparison of 18 gridded datasets, Mazzoleni et al. (2019) found no single best P dataset. The R datasets performed better than G datasets for a low station density (less than one station per 1000 km2); otherwise, little difference was observed (Essou et al., 2017; Tarek et al., 2020). Gampe and Ludwig (2017) found that higher-resolution P data performed better, but coarse-resolution data provided a close representation of overall, longer-term climate characteristics. Raimonet et al. (2017) demonstrated the importance of accounting for the impacts of high-resolution topography on P gridded data and that low-altitude, less-complex topographies were less sensitive to the choice of gridded dataset. Similar results were reported by Laiti et al. (2018), who added that simple bias correction cannot overcome P dataset deficiencies.
Overall, the literature suggests that the interaction of station density and basin characteristics, primarily topography, is of central importance and can drive performance. In regions with a high station density (more than three stations per 1000 km2), G datasets or those corrected using G data (SG, RG, SRG, and RSG) perform similarly. However, in areas with a lower station density (less than one station per 1000 km2), at higher elevations, and in topographically complex regions, R datasets perform better. Unadjusted S datasets, without G or R correction, were generally the least reliable. Other site and dataset considerations may also be important for specific hydrologic modeling applications and are discussed in the following sections.
4.4 P–T dependency
Climatological dependencies can exist between P and T. Gridded datasets decouple P and T, which can cause problems with hydrologic simulation (Singh and Najafi, 2020). For example, Singh and Najafi (2020) noted the failure of gridded datasets to represent warm–wet dependencies in north and southwest Canada and hot–dry dependencies in the spring and summer seasons in the Canadian Prairies that were present in the observed data. This led to inaccurate modeling of hydrologic processes (rain–snow partitioning and extreme events), which may be particularly important in representing hydrological reality under a changing climate. In response to this need for coupled P and T data, Raimonet et al. (2017) suggested a process for dynamically calibrating a conceptual hydrological model on meteorological datasets, which was able to assess the consistency of the meteorological datasets, including the covariance of P and T, as well as improve streamflow simulation performance. Again, these results suggest that methods to retain coupling of climate variables in gridded datasets are needed.
4.5 Streamflow (Q) modeling
Not surprisingly, as noted above, Q was more responsive to P than T (Dembélé et al., 2020; Essou et al., 2016a; Mei et al., 2022; Shuai et al., 2022). Most gridded P datasets were adequate for Q simulation at the monthly scale and at spatial scales ranging from 3000 to 122 000 km2 (Ray et al., 2022; Meng et al., 2014; Muche et al., 2020; Setti et al., 2020). Some studies found that G-based P datasets were generally better than S or R datasets for hydrological modeling (Ray et al., 2022; Meng et al., 2014; Kouakou et al., 2023; Massmann, 2020), especially for high-spatial-resolution datasets (Laiti et al., 2018). In addition, hydrologic performance using G datasets was not affected by basin size, but the performance of the G datasets did improve slightly as the weather station density of their source data increased (Essou et al., 2017). However, total basin size did not influence Q performance (Tarek et al., 2020). In a study of eight large-scale basins globally, Mazzoleni et al. (2019) found that Q simulation was affected by the basin scale, human footprint, and climate: S datasets had the poorest performance and were the most variable; SG datasets were the best performers in tropical and arid temperate climates; and RG datasets were the best performers in temperate and cold temperate climates and within basins with densely gauged P.
In a study of nine gridded datasets applied with a conceptual hydrologic model to simulate streamflow in 9053 basins (< 50 000 km2) worldwide, Beck et al. (2017b) found that the MSWEP v2 P dataset provided consistently better performance than other products across North America, Europe, Japan, Australia, New Zealand, and southern and western Brazil, whereas CHIRPS v2 performed better than other products in Central America, and central and eastern Brazil, but no one dataset performed best everywhere. They also concluded, based on the good performance of CPC-United, CHIRPS v2, and MSWEP v1.2 and v2, that the incorporation of sub-monthly gauge data improved Q simulation.
Interestingly, the best P dataset was not always the best for Q modeling (Yang et al., 2014), and lower P and T performance did not always translate into lower Q performance (Essou et al., 2016a; Hafzi and Sorman, 2022). Similarly, Ang et al. (2022) found that S datasets corrected with G observations had better Q performance than other G or R datasets that performed similarly in comparison to observed P data.
Datasets with the best representation of temporal dynamics did not necessarily align with those with the best representation of spatial patterns, with more hydrologic uncertainty associated with misrepresenting spatial patterns than temporal dynamics (Dembélé et al., 2020). Hafzi and Sorman (2022) found that most gridded P datasets had low performance with respect to representing daily P over space and time, but some still had accurate Q simulation. Mazzoleni et al. (2019) found that the best P dataset for a basin outlet was not necessarily the best for its subbasins, which reflects the influence of scale and suggests a benefit to distributed hydrologic modeling over lumped modeling approaches.
Hydrologic model calibration approaches were also sensitive to the selection of gridded dataset. Ray et al. (2022) found that model parameter uncertainty decreased when calibrating the SWAT model using G-based P datasets. In addition, hydrologic models calibrated using one gridded dataset did not work as well when applied using forcings from other datasets (Zhu et al., 2018; Hafzi and Sorman, 2022).
Dependency between P and T did not appear to affect Q simulation. Shuai et al. (2022) found that intermixing T datasets among PRISM, Daymet, and NLDAS P datasets had little effect on Q.
4.6 ET and SWE modeling
Few studies were found that compared the effects of gridded datasets on the simulation of other spatially distributed hydrologic variables, such as ET or SWE. Mourtzinis et al. (2017) found that Daymet outperformed PRISM with respect to calculating the FAO Penman–Monteith reference ET (ET0) in the US Midwest. Although both were similar in comparisons of P and T, ET0 bias was less for Daymet (−4 mm) than for PRISM (+253 mm), and both had poor agreement in the high and low ranges of measured ET0. Errors were related to poor agreement with rh, especially for PRISM. Similarly, ET0 was generally overestimated (relative to ET0 from weather station data) by all six G datasets evaluated by Blankenau et al. (2020), with median biases from 12 % to 31 %, consistent with the overestimation of T, u, and Rs and the underestimation of Vp. In a comparison of different gridded datasets forcing ET simulation in SWAT, Ang et al. (2022) found that using P from TRMM and IMERG with T from a Southeast Asia observational network (SA-OBS) outperformed other gridded datasets (P: Aphrodite, ERA5, and NCEP CFS v2; T: CPC) in this tropical region. Poor performance of gridded dataset P and T was credited to the poor ET simulation. Shuai et al. (2022) found little difference between the simulation of ET from PRISM, Daymet, and NLDAS in Colorado and assumed that the similarity was related to using the same Rs forcing. Shuai et al. (2022) also evaluated the effects of G datasets on SWE in Colorado. They found that a fine spatial scale helped PRISM (0.8 km) and Daymet (1 km) outperform NLDAS (12 km) with respect to simulating spatial SWE, with the highest correlation from PRISM. Gupta and Tarboton (2016) used spatially downscaled R datasets (MERRA data for T, rh, u, and Rs; RFE v2 data for P) and found good SWE simulation compared to SNOTEL data (mean NSE = 0.67 across eight sites). Key sources of discrepancies were from P and Rs data uncertainty. These results indicate that accuracy in climate data translated into accuracy in ET and SWE simulation and suggest that all gridded data be scrutinized, as well as possibly bias-corrected, before use in ET and SWE modeling.
4.7 P ensembles
Ensembles of gridded datasets have often been recommended to account for gridded dataset uncertainty and better represent overall climatology (Gampe and Ludwig, 2017; Pokorny et al., 2020), although with some caveats. For example, Gampe and Ludwig (2017) found that R data (compared with station data) showed fewer consecutive dry days (CDDs, P < 1 mm), more consecutive wet days (CWDs, P > 1 mm), and a lower contribution of heavy-P events (i.e., more low- but steady-P events) to annual P, which has the potential to impact hydrologic simulation (more infiltration, less streamflow, greater baseflow, fewer floods, etc.). They recommended identification and removal of such nonrepresentative datasets from ensembles. Pokorny et al. (2020) suggested that data should be assessed in relation to the target hydrologic model's spatiotemporal scale. Notably, ensembles dampen extreme events and decrease the frequency of low-P/high-P events, which can lead to nonrepresentative hydrological simulations (Pokorny et al., 2020). Laiti et al. (2018) demonstrated a hydrologic coherence test (HyCoT), essentially a metric-independent method of comparing gridded datasets according to their performance in a hydrologic model, to exclude meteorological data less capable of reproducing a hydrologic outcome.
4.8 Latency
The latency with which gridded datasets become available for use may be a critical factor in gridded dataset selection. Few studies have assessed latency effects. Hafzi and Sorman (2022) found that some real-time datasets that were available with short latency (e.g., 1 h lag, PERSIANN-CSS with 0.04°) sacrificed accuracy compared with coarser, longer-latency datasets, such as IMERG Late v6 (14 h lag, 0.1°), MSWEP v2.8 (a few months lag, 0.1°), and CHIRPS v2 (1-month lag, 0.05°).
This study summarized characteristics, primary references, and data availability of 63 gridded datasets from a CONUS to a global extent to assist with dataset selection by hydrologic investigators. Our review of information from 29 recent (past 10 years) intercomparison studies spans a wide range of gridded datasets, study settings and scales, and hydrologic modeling objectives. Readers are referred to these studies for a wealth of detail on their results and recommendations; we encourage a particular focus on studies with similar climatic setting and hydrologic objectives to the planned investigation. From this review and synthesis, we formulated interpretations and, where appropriate, guidelines that are outlined in the following.
No single gridded climate dataset or data source was universally superior for hydrologic analyses. Several common themes arose among the 29 studies reviewed. Gridded daily temperature (T) datasets improved when derived from greater station density, although they were relatively interchangeable in hydrologic analyses. Gridded daily precipitation (P) data were more accurate when derived from higher-density station data, when used in spatially less-complex terrain, and when corrected using ground-based (G) data. In mountainous or humid regions, reanalysis-based (R) gridded datasets generally performed better than G gridded datasets when the underlying station density was low; however, when station densities were higher, there was no difference. Ground-based (G) gridded P datasets generally performed better than satellite-based (S) or R datasets, although better P and T datasets did not always translate into better streamflow modeling. Hydrologic analyses would benefit from advances in creating gridded datasets that retain climate variable interdependencies and better represent climate variables in complex topography. The caveat that some studies were insensitive to using independent sources of P and T may not be a good rationale for ignoring possible cross-correlations between climate variables. Rather, this result may point to the insensitivity of hydrologic models that do not necessarily capture spatiotemporal process interactions within a watershed. Use of hybrids of gridded datasets and station data for a particular region remains a topic for further investigation, as there can be substantial differences between data at a particular station and the corresponding grid cell data.
Hydrologic studies rarely defend their selection of a particular dataset to address research questions, but investigators should justify their selection of a particular gridded dataset with full consideration of both the climatologic setting and the hydrologic analysis type and objectives. Via a thorough review of the recent literature, this study provides general consensus recommendations for dataset selection, although characteristics of a given hydrologic analysis or study may warrant more specific selection processes and criteria. The authors' overall recommendations to hydrologic modelers are to select the gridded dataset (from Tables 1, 2, and 3) (a) with spatial and temporal resolutions that match modeling scales; (b) that are primarily (G) or secondarily (SG and RG) derived from ground-based observations, especially in areas of high topographic relief; (c) with sufficient spatial and temporal coverage for the analysis; (d) with adequate latency for analysis objectives; and (e) that includes all climate variables of interest, so as to better represent interdependencies.
Table A1Summary of different data formats, descriptions, and processing approaches for gridded climate datasets using programming languages and software.

All links listed in the table were last accessed on 29 November 2024.
The data that support the findings of this study are available from the corresponding author upon reasonable request.
KRM conceptualized the study and prepared original draft. SM compiled the data and contributed to preparing the original draft, KRM and SM developed methodologies and interpreted data. TRG and DMB provided manuscript critical review and revisions.
The contact author has declared that none of the authors has any competing interests.
The findings and conclusions in this publication are those of the author(s) and should not be construed to represent any official USDA or US government determination or policy. Mention of trade names or commercial products in this publication is solely for the purpose of providing specific information and does not imply recommendation or endorsement by the USDA.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
USDA is an equal opportunity employer and provider. This research was supported by the USDA Agricultural Research Service.
This paper was edited by Jan Seibert and reviewed by three anonymous referees.
Abatzoglou, J. T.: Development of gridded surface meteorological data for ecological applications and modelling, Int. J. Climatol., 33, 121–131, https://doi.org/10.1002/joc.3413, 2013.
Adler, R. F., Kidd, C., Petty, G., Morissey, M., and Goodman, H. M.: Intercomparison of global precipitation products: The third precipitation intercomparison project (PIP-3), B. Am. Meteorol. Soc., 82, 1377–1396, 2001.
Ang, R., Kinouchi, T., and Zhao, W.: Evaluation of daily gridded meteorological datasets for hydrological modeling in data-sparse basins of the largest lake in Southeast Asia, J. Hydrol., Regional Studies, 42, 101135, https://doi.org/10.1016/j.ejrh.2022.101135, 2022.
Ashouri, H., Hsu, K. L., Sorooshian, S., Braithwaite, D. K., Knapp, K. R., Cecil, L. D., Nelson, B. R., and Prat, O. P.: PERSIANN-CDR: Daily precipitation climate data record from multisatellite observations for hydrological and climate studies, B. Am. Meteorol. Soc., 96, 69–83, https://doi.org/10.1175/BAMS-D-13-00068.1, 2015.
Bandaru, V., Pei, Y., Hart, Q., and Jenkins, B. M.: Impact of biases in gridded weather datasets on biomass estimates of short rotation woody cropping systems, Agr. Forest Meteorol., 233, 71–79, https://doi.org/10.1016/j.agrformet.2016.11.008, 2017.
Barrett, E. C., Adler, R. F., Arpe, K., Bauer, P., Berg, W., Chang, A., Ferraro, R., Ferriday, J., Goodman, S., Hong, Y., Janowiak, J., Kidd, C., Kniveton, D., Morrissey, M., Olson, W., Petty, G., Rudolf, B., Shibata, A., Smith, E., and Spencer, R.: The first WetNet precipitation intercomparison project (PIP-1): Interpretation of results, Remote Sens. Reviews, 11, 303–373, https://doi.org/10.1080/02757259409532268, 1994.
Beck, H. E., van Dijk, A. I. J. M., Levizzani, V., Schellekens, J., Miralles, D. G., Martens, B., and de Roo, A.: MSWEP: 3-hourly 0.25° global gridded precipitation (1979–2015) by merging gauge, satellite, and reanalysis data, Hydrol. Earth Syst. Sci., 21, 589–615, https://doi.org/10.5194/hess-21-589-2017, 2017a.
Beck, H. E., Vergopolan, N., Pan, M., Levizzani, V., van Dijk, A. I. J. M., Weedon, G. P., Brocca, L., Pappenberger, F., Huffman, G. J., and Wood, E. F.: Global-scale evaluation of 22 precipitation datasets using gauge observations and hydrological modeling, Hydrol. Earth Syst. Sci., 21, 6201–6217, https://doi.org/10.5194/hess-21-6201-2017, 2017b.
Beck, H. E., Wood, E. F., Pan, M., Fisher, C. K., Miralles, D. M., van Dijk, A. I. J. M., McVicar, T. R., and Adler, R. F.: MSWEP V2 global 3-hourly 0.1° precipitation: methodology and quantitative assessment, B. Am. Meteorol. Soc., 100, 473–500, 2019.
Behnke, R., Vavrus, S., Allstadt, A., Albright, T., Thogmartin, W. E., Radeloff, V. C.: Evaluation of downscaled, gridded climate data for the conterminous United States, Ecol. Appl., 26, 1338–1351, 2016.
Berg, P., Almén, F., and Bozhinova, D.: HydroGFD3.0 (Hydrological Global Forcing Data): A 25 km global precipitation and temperature data set updated in near-real time, Earth Syst. Sci. Data, 13, 1531–1545, https://doi.org/10.5194/essd-13-1531-2021, 2021.
Berg, P., Donnelly, C., and Gustafsson, D.: Near-real-time adjusted reanalysis forcing data for hydrology, Hydrol. Earth Syst. Sci., 22, 989–1000, https://doi.org/10.5194/hess-22-989-2018, 2018.
Berg, P., Almén, F., and Bozhinova, D.: HydroGFD3.0 (v3.0), Zenodo [data set], https://doi.org/10.5281/zenodo.3871707, 2020.
Blankenau, P. A., Kilic, A., and Allen, R.: An evaluation of gridded weather data sets for the purpose of estimating reference evapotranspiration in the United States, Agr. Water Manage., 242, 106376, https://doi.org/10.1016/j.agwat.2020.106376, 2020.
Brocca, L., Ciabatta, L., Massari, C., Moramarco, T., Hahn, S., Hasenauer, S., Kidd, R., Dorigo, W., Wagner, W., and Levizzani, V.: Soil as a natural rain gauge: Estimating global rainfall from satellite soil moisture data, J. Geophys. Res.-Atmos., 119, 5128–5141, 2014.
Buster, G., Bannister, M., Habte, A., Hettinger, D., Maclaurin, G., Rossol, M., Sengupta, M., and Xie, Y.: Physics-guided machine learning for improved accuracy of the National Solar Radiation Database, Sol Energy, 232, 483–492, https://doi.org/10.1016/j.solener.2022.01.004, 2022.
Chen, M., Shi, W., Xie, P., Silva, V. B., Kousky, V. E., Wayne Higgins, R., and Janowiak, J. E.: Assessing objective techniques for gauge-based analyses of global daily precipitation, J. Geophys. Res.-Atmos., 113, D04110, https://doi.org/10.1029/2007JD009132, 2008.
Compo, G. P., Whitaker, J. S., Sardeshmukh, P. D., Matsui, N., Allan, R. J., Yin, X., Gleason, B. E., Vose, R. S., Rutledge, G., Bessemoulin, P., Brönnimann, S., Brunet, M., Crouthamel, R. I., Grant, A. N., Groisman, P. Y., Jones, P. D., Kruk, M. C., Kruger, A. C., Marshall, G. J., Maugeri, M., Mok, H. Y., Nordli, Ø., Ross, T. F., Trigo, R. M., Wang, X. L., Woodruff, S. D., and Worley, S. J.: The Twentieth Century Reanalysis project, Q. J. Roy. Meteor. Soc., 137, 1–28, https://doi.org/10.1002/qj.776, 2011.
Daly, C., Halbleib, M., Smith, J. I., Gibson, W. P., Doggett, M. K., Taylor, G. H., Curtis, J., and Pasteris, P. P.: Physiographically sensitive mapping of climatological temperature and precipitation across the conterminous United States, Int. J. Climatol., 28, 2031–2064, https://doi.org/10.1002/joc.1688, 2008.
Decker, M., Brunke, M. A., Wang, Z., Sakaguchi, K., Zeng, X., and Bosilovich, M. G.: Evaluation of the Reanalysis Products from GSFC, NCEP, and ECMWF Using Flux Tower Observations, J. Climate, 25, 1916–1944, https://doi.org/10.1175/JCLI-D-11-00004.1, 2012.
Dee, D. P., Uppala, S. M., Simmons, A. J., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Balmaseda, M. A., Balsamo, G., Bauer, D. P., and Bechtold P.: The ERA-Interim reanalysis: Configuration and performance of the data assimilation system, Q. J. Roy. Meteor. Soc., 137, 553–597, https://doi.org/10.1002/qj.828, 2011.
Dembélé, M., Schaefli, B., van de Giesen, N., and Mariéthoz, G.: Suitability of 17 gridded rainfall and temperature datasets for large-scale hydrological modelling in West Africa, Hydrol. Earth Syst. Sci., 24, 5379–5406, https://doi.org/10.5194/hess-24-5379-2020, 2020.
De Pondeca, M. S. F. V., Manikin, G. S., DiMego, G., Benjamin, S. G., Parrish, D. F., Purser, R. J., Wu, W.-S., Horel, J. D., Myrick, D. T., Lin, Y., Aune, R. M., Keyser, D., Colman, B., Mann, G., and Vavra, J.: The real-time mesoscale analysis at NOAA's national centers for environmental prediction: current status and development, Weather Forecast., 26, 593–612, https://doi.org/10.1175/WAF-D-10-05037.1, 2011.
Durre, I., Arguez, A., Schreck III, C. J., Squires, M. F., and Vose, R. S.: Daily high-resolution temperature and precipitation fields for the Contiguous United States from 1951 to Present, J. Atmos. Ocean. Tech., 39, 1837–1855, https://doi.org/10.1175/JTECH-D-22-0024.1, 2022.
Ebert, E. E., Janowiak, J. E., and Kidd, C.: Comparison of near-real-time precipitation estimates from satellite observations and numerical models, B. Am. Meteorol. Soc., 88, 47–64, 2007.
Essou, G. R. C., Arsenault, R., and Brissette, F. P.: Comparison of climate datasets for lumped hydrological modeling over the continental United States, J. Hydrol., 537, 334–345, https://doi.org/10.1016/j.jhydrol.2016.03.063, 2016a.
Essou, G. R. C., Sabarly, F., Lucas-Picher, P., Brissette, F., and Poulin, A.: Can Precipitation and Temperature from Meteorological Reanalyses be used for Hydrological Modeling?, J. Hydrometeorol., 17, 1929–1950, https://doi.org/10.1175/JHM-D-15-0138.1, 2016b.
Essou, G. R. C., Brissette, F., and Lucas-Picher, P.: The Use of Reanalyses and Gridded Observations as Weather Input Data for a Hydrological Model: Comparison of Performances of Simulated River Flows Based on the Density of Weather Stations, J. Hydrometeorol., 18, 497–513, https://doi.org/10.1175/JHM-D-16-0088.1, 2017.
Fassnacht, S. R.: Estimating Alter-shielded gauge snowfall undercatch, snowpack sublimation, and blowing snow transport at six sites in the coterminous USA, Hydrol. Process., 18, 3481–3492, 2004.
Funk, C., Peterson, P., Landsfeld, M., Pedreros, D., Verdin, J., Shukla, S., Husak, G., Rowland, J., Harrison, L., Hoell, A., and Michaelsen, J.: The climate hazards infrared precipitation with stations – a new environmental record for monitoring extremes, Sci. Data, 2, 1–21, https://doi.org/10.1038/sdata.2015.66, 2015.
Gampe, D. and Ludwig, R.: Evaluation of Gridded Precipitation Data Products for Hydrological Applications in Complex Topography, Hydrology, 4, 53, https://doi.org/10.3390/hydrology4040053, 2017.
Gebremichael, M.: Framework for satellite rainfall product evaluation, Rainfall: State of the Science, 191, 265–275, 2010.
Gelaro, R., McCarty, W., Suárez, M. J., Todling, R., Molod, A., Takacs, L., Randles, C. A., Darmenov, A., Bosilovich, M. G., Reichle, R., and Wargan, K.: The modern-era retrospective analysis for research and applications, version 2 (MERRA-2), J. Climate, 30, 5419–5454, https://doi.org/10.1175/JCLI-D-16-0758.1, 2017.
Glahn, H. R., and Ruth, D. P.: The new digital forecast database of the national weather service, B. Am. Meteorol. Soc., 84, 195–202, https://doi.org/10.1175/BAMS-84-2-195, 2003.
Gupta, A. S., and Tarboton, D. G.: A tool for downscaling weather data from large-grid reanalysis products to finer spatial scales for distributed hydrological applications, Environ. Modell. Softw., 84, 50e69, https://doi.org/10.1016/j.envsoft.2016.06.014, 2016.
Hafzi, H. and Sorman, A. A.: Assessment of 13 Gridded Precipitation Datasets for Hydrological Modeling in a Mountainous Basin, Atmosphere, 13, 143, https://doi.org/10.3390/atmos13010143, 2022.
Harada, Y., Kamahori, H., Kobayashi, C., Endo, H., Kobayashi, S., Ota, Y., Onoda, H., Onogi, K., Miyaoka, K., and Takahashi, K.: The JRA-55 Reanalysis: Representation of atmospheric circulation and climate variability, J. Meteorol. Soc. Jpn., 94, 269–302, https://doi.org/10.2151/jmsj.2016-015, 2016.
Harris, I., Osborn, T. J., Jones, P., and Lister, D.: Version 4 of the CRU TS monthly high-resolution gridded multivariate climate dataset, Sci. Data, 7, 109, https://doi.org/10.1038/s41597-020-0453-3, 2020.
Henn, B., Newman, A. J., Livneh, B., Daly, C., and Lundquist, J. D.: An assessment of differences in gridded precipitation datasets in complex terrain, J. Hydrol., 556, 1205–1219, https://doi.org/10.1016/j.jhydrol.2017.03.008, 2018.
Hersbach, H., de Rosnay, P., Bell, B., Schepers, D., Simmons, A. J., Soci, C., Abdalla, S., Balmaseda, M. A., Balsamo, G., Bechtold, P., Berrisford, P., Bidlot, J., de Boisséson, E., Bonavita, M., Browne, P., Buizza, R., Dahlgren, P., Dee, D. P., Dragani, R., Diamantaki, M., Flemming, J., Forbes, R., Geer, A. J., Haiden, T., Hólm, E. V., Haimberger, L., Hogan, R., Horányi, A., Janisková, M., Laloyaux, P., Lopez, P., Muñoz Sabater, J., Peubey, C., Radu, R., Richardson, D., Thépaut, J.-N., Vitart, F., Yang, X., Zsótér, E., and Zuo, H.: Operational global reanalysis: progress, future directions and synergies with NWP, ERA Report Series no. 27, ECMWF, Reading, UK, https://doi.org/10.21957/tkic6g3wm, 2018.
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlin, Q., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J. N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020.
Hoehn, D. C., Niemann, J. D., Green, T. R., Jones, A. S., and Grazaitis, P. J.: Downscaling soil moisture over regions that include multiple coarse-resolution grid cells, Remote Sens. Environ., 199, 187–200, https://doi.org/10.1016/j.rse.2017.07.021, 2017.
Hong, Y., Hsu, K. L., Sorooshian, S., and Gao, X. G.: Precipitation estimation from remotely sensed imagery using an artificial neural network cloud classification system, J. Appl. Meteorol., 43, 1834–1852, 2004.
Hou, A. Y., Kakar, R. K., Neeck, S., Azarbarzin, A. A., Kummerow, C. D., Kojima, M., Oki, R., Nakamura, K., and Iguchi, T.: The global precipitation measurement mission, B. Am. Meteorol. Soc., 95, 701–722, https://doi.org/10.1175/BAMS-D-13-00164.1, 2014.
Huffman, G. J., Adler, R. F., Morrissey, M. M., Bolvin, D. T., Curtis, S., Joyce, R., McGavock, B., and Susskind, J.: Global precipitation at one-degree daily resolution from multi-satellite observations, J. Hydrometeorol., 2, 36–50, https://doi.org/10.1175/1525-7541(2001)002<0036:GPAODD>2.0.CO;2, 2001.
Huffman, G. J., Bolvin, D. T., Nelkin, E. J., Wolff, D. B., Adler, R. F., Gu, G., Hong, Y., Bowman, K. P., and Stocker, E. F.: The TRMM multi-satellite precipitation analysis (TMPA): Quasi-global, multiyear, combined-sensor precipitation estimates at fine scales, J. Hydrometeorol., 8, 38–55, 2007.
Huffman, G. J., Bolvin, D. T., Braithwaite, D., Hsu, K. L., Joyce, R. J., Kidd, C., Nelkin, E. J., Sorooshian, S., Stocker, E. F., Tan, J., and Wolff, D. B.: Integrated multi-satellite retrievals for the global precipitation measurement (GPM) mission (IMERG), Satellite Precipitation Measurement: Volume 1, 343–353, https://doi.org/10.1007/978-3-030-24568-9_19, 2020a.
Huffman, G. J., Bolvin, D. T., Braithwaite, D., Hsu, K., Joyce, R., Kidd, C., Nelkin, E. J., Sorooshian, S., Tan, J., and Xie, P.: NASA Global Precipitation Measurement (GPM) Integrated Multi-satellite Retrievals for GPM (IMERG), Algorithm Theoretical Basis Document (ATBD), version 06, https://gpm.nasa.gov/sites/default/files/2020-05/IMERG_ATBD_V06.3.pdf (last access: 7 December 2024), 2020b.
Huffman, G. J., Adler, R. F., Behrangi, A., Bolvin, D. T., Nelkin, E. J., Gu, G., and Ehsani, M. R.: The new version 3.2 Global Precipitation Climatology Project (GPCP) monthly and daily precipitation products, J. Climate, 36, 7635–7655, 2023.
Iguchi, T., Kozu, T., Kwiatkowski, J., Meneghini, R., Awaka, J., and Okamoto, K.: A Kalman filter approach to the Global Satellite Mapping of Precipitation (GSMaP) from combined passive microwave and infrared radiometric data, J. Meteorol. Soc. Jpn., 87, 137–151, 2009.
Iizumi, T., Okada, M., and Yokozawa, M.: A meteorological forcing data set for global crop modeling: Development, evaluation, and intercomparison, J. Geophys. Res.-Atmos., 119, 363–384, https://doi.org/10.1002/2013JD020130, 2014.
Iizumi, T., Takikawa, H., Hirabayashi, Y., Hanasaki, N., and Nishimori, M.: Contributions of different bias-correction methods and reference meteorological forcing data sets to uncertainty in projected temperature and precipitation extremes, J. Geophys. Res.-Atmos., 122, 7800–7819, https://doi.org/10.1002/2017JD026613, 2017.
Joyce, R. J., Janowiak, J. E., Arkin, P. A., and Xie, P.: CMORPH: A method that produces global precipitation estimates from passive microwave and infrared data at high spatial and temporal resolution, J. Hydrometeorol., 5, 487–503, 2004.
Kobayashi, S., Ota, Y., Harada, Y., Ebita, A., Moriya, M., Onoda, H., Onogi, K., Kamahori, H., Kobayashi, C., Endo, H., Miyaoka, K., and Takahashi, K.: The JRA-55 reanalysis: General specifications and basic characteristics, J. Meteorol. Soc. Jpn. Ser. I, 93, 5–48, https://doi.org/10.2151/jmsj.2015-001, 2015.
Kouakou, C., Paturel, J. E., Stage, F., Tramblay, Y., Defrance, D., and Rouche, N.: Comparison of gridded precipitation estimates for regional hydrological modeling in West and Central Africa, J. Hydrol.-Regional Studies, 47, 101409, https://doi.org/10.1016/j.ejrh.2023.101409, 2023.
Kubota, T., Shige, S., Hashizume, H., Aonashi, K., Takahashi, N., Seto, S., Hirose, M., Takayabu, Y. N., Ushio, T., Nakagawa, K., Iwanami, K., Kachi, M., and Okamoto, K.: Global precipitation map using satellite-borne microwave radiometers by the GSMaP project: Production and validation, IEEE T. Geosci. Remote, 45, 2259–2275, https://doi.org/10.1109/TGRS.2007.895337, 2007.
Kubota, T., Aonashi, K., Ushio, T., Shige, S., Takayabu, Y. N., Kachi, M., Arai, Y., Tashima, T., Masaki, T., Kawamoto, N., Mega, T., Yamamoto, M. K., Hamada, A., Yamaji, M., Liu, G., and Oki, R.: Global Satellite Mapping of Precipitation (GSMaP) products in the GPM era, Satellite Precipitation Measurement, Springer, https://doi.org/10.1007/978-3-030-24568-9_20, 2020.
Laiti, L., Mallucci, S., Piccolroaz, S., Bellin, A., Zardi, D., Fiori, A., Nikulin, G., and Majone, B.: Testing the hydrological coherence of high-resolution gridded precipitation and temperature data sets, Water Resour. Res., 54, 1999–2016, https://doi.org/10.1002/2017WR021633, 2018.
Laloyaux, P., de Boisseson, E., Balmaseda, M. A., Bidlot, J.-R., Broennimann, S., Buizza, R., Dalhgren, P., Dee, D. P., Haimberger, L., Hersbach, H., Kosaka, Y., Martin, M., Poli, P., Rayner, N., Rustemeier, E., and Schepers, D.: CERA-20C: a coupled reanalysis of the twentieth century, J. Adv. Model. Earth Sy., 10, 1172–1195, https://doi.org/10.1029/2018MS001273, 2018.
Liu, C., Ikeda, K., Rasmussen, R., Barlage, M., Newman, A., Prein, A., Chen, F., Chen, L., Clark, M., Dai, A., Dudhia, J., Eidhammer, T., Gochis, D., Gutman, E., Kurkute, S., Li, Y., Thompson, G., and Yates, G.: Continental-Scale Convection-Permitting Modeling of the Current and Future Climate of North America, Clim. Dynam., 49, 71–95, https://doi.org/10.1007/s00382-016-3327-9, 2017.
Livneh, B., Rosenberg, E. A., Lin, C., Nijssen, B., Mishra, V., Andreadis, K. M., Maurer, E. P., and Lettenmaier, D. P.: A long-term hydrologically based dataset of land surface fluxes and states for the conterminous United States: Update and extensions, J. Climate, 26, 9384–9392, https://doi.org/10.1175/JCLI-D-12-00508.1, 2013.
Maggioni, V., Meyers, P. C., and Robinson, M. D.: A review of merged high resolution satellite precipitation product accuracy during the Tropical Rainfall Measuring Mission (TRMM)-era, J. Hydrometeorol., 17, 1101–1117, https://doi.org/10.1175/JHM-D-15-0190.1, 2016.
Massari, C., Crow, W., and Brocca, L.: An assessment of the performance of global rainfall estimates without ground-based observations, Hydrol. Earth Syst. Sci., 21, 4347–4361, https://doi.org/10.5194/hess-21-4347-2017, 2017.
Massmann, C.: Evaluating the Suitability of Century-Long Gridded Meteorological Datasets for Hydrological Modeling, J. Hydrometeorol., 21, 2565–2580, https://doi.org/10.1175/JHM-D-19-0113.1, 2020.
Matsuura, K. and National Center for Atmospheric Research Staff (Eds.): The Climate Data Guide: Global (land) precipitation and temperature: Willmott & Matsuura, University of Delaware (last modified 2023-11-27), https://climatedataguide.ucar.edu/climate-data/global-land-precipitation-and-temperature-willmott-matsuura-university-delaware last access: 3 December 2023), 2023.
Maurer, E. P., Wood, A. W., Adam, J. C., Lettenmaier, D. P., and Nijssen, B.: A long-term hydrologically based dataset of land surface fluxes and states for the conterminous United States, J. Climate, 15, 3237–3251, https://doi.org/10.1175/1520-0442(2002)015%3C3237:ALTHBD%3E2.0.CO;2, 2002.
Mazzoleni, M., Brandimarte, L., and Amaranto, A.: Evaluating precipitation datasets for large-scale distributed hydrological modelling, J. Hydrol., 578, 124076, https://doi.org/10.1016/j.jhydrol.2019.124076, 2019.
McEvoy, D. J., Mejia, J. F., and Huntington, J. L.: Use of an observation network in the Great Basin to evaluate gridded climate data, J. Hydrometeorol., 15, 1913–1931, https://doi.org/10.1175/JHM-D-14-0015.1, 2014.
Mei, X., Smith, P. K., Li, J., and Li, B.: Hydrological evaluation of gridded climate datasets in a Texas urban watershed using soil and water assessment tool and artificial neural network, Front. Environ. Sci., 10, 90577, https://doi.org/10.3389/fenvs.2022.905774, 2022.
Melsen, L. A., Teuling, A. J., Torfs, P. J. J. F., Uijlenhoet, R., Mizukami, N., and Clark, M. P.: HESS Opinions: The need for process-based evaluation of large-domain hyper-resolution models, Hydrol. Earth Syst. Sci., 20, 1069–1079, https://doi.org/10.5194/hess-20-1069-2016, 2016.
Meng, J., Li, L., Hao, Z., Wang, J., and Shao, Q.: Suitability of TRMM satellite rainfall in driving a distributed hydrological model in the source region of Yellow River, J. Hydrol., 509, 320–332, https://doi.org/10.1016/j.jhydrol.2013.11.049, 2014.
Mesinger, F., DiMego, G., Kalnay, E., Mitchell, K., Shafran, P. C., Ebisuzaki, W., Jović, D., Woollen, J., Rogers, E., Berbery, E. H., and Ek, M. B.: North American regional reanalysis, B. Am. Meteorol. Soc., 87, 343–360, https://doi.org/10.1175/BAMS-87-3-343, 2006.
Mourtzinis, S., Rattalino Edreira, J. I., Conley, S. P., and Grassini, P.: From grid to field: Assessing quality of gridded weather data for agricultural applications, Eur. J. Agron., 82, 163–172, https://doi.org/10.1016/j.eja.2016.10.013, 2017.
Muche, M. E., Sinnathamby, S., Parmar, R., Knightes, C. D., Johnston, J. M., Wolfe, K., Purucker, S. T., Cyterski, M. J., and Smith, D.: Comparison and Evaluation of Gridded Precipitation Datasets in a Kansas Agricultural Watershed Using SWAT, J. Am. Water Resour. As., 56, 486–506, https://doi.org/10.1111/1752-1688.12819, 2020.
National Oceanic and Atmospheric Administration, National Centers for Environmental Information (NOAA-NCEI): Global Historical Climatology Network (GHCN), https://www.ncei.noaa.gov/pub/data/ghcn/daily/ (last access: 13 December 2024), 2018.
Oyler, J. W., Ballantyne, A., Jencso, K., Sweet, M., and Running, S. W.: Creating a topoclimatic daily air temperature dataset for the conterminous United States using homogenized station data and remotely sensed land skin temperature, Int. J. Climatol., 35, 2258–2279, https://doi.org/10.1002/joc.4127, 2015.
Panahi, M. and Behrangi, A.: Comparative analysis of snowfall accumulation and gauge undercatch correction factors from diverse data sets: In situ, satellite, and reanalysis, Asia-Pac. J. Atmos. Sci., 56, 615–628, 2020.
Pokorny, S., Stadnyk, T. A., Lilhare, R., Ali, G., Dery, S. J., and Koening, K.: Use of Ensemble-Based Gridded Precipitation Products for Assessing Input Data Uncertainty Prior to Hydrologic Modeling, Water, 12, 2751, https://doi.org/10.3390/w12102751, 2020.
Poli, P., Hersbach, H., Dee, D. P., Berrisford, P., Simmons, A. J., Vitart, F., Laloyaux, P., Tan, D. G. H., Peubey, C., Thépaut, J.-N., Trémolet, Y., Hólm, E. V., Bonavita, M., Isaksen, L., and Fisher, M.: ERA-20C: An atmospheric reanalysis of the twentieth century, J. Climate, 29, 4083–4097, 2016.
Radcliffe, D. E. and Mukundan, R.: PRISM vs. CFSR Precipitation Data Effects on Calibration and Validation of SWAT Models, J. Am. Water Resour. As., 53, 89–100, https://doi.org/10.1111/1752-1688.12484, 2017.
Raimonet, M., Ouden, L., Thieu, V., Silvestre, M., Vautard, R., Rabouille, C., and Le Moigne, P.: Evaluation of Gridded Meteorological Datasets for Hydrological Modeling, J. Hydrometeorol., 18, 3027–3041, https://doi.org/10.1175/JHM-D-17-0018.1, 2017.
Rasmussen, R. M., Chen, F., Liu, C. H., Ikeda, K., Prein, A., Kim, J., Schneider, T., Dai, A., Gochis, D., Dugger, A., Zhang, Y., Jaye, A., Dudhia, J., He, C., Harrold, M., Xue, L., Chen, S., Newman, A., Dougherty, E., Abolafia-Rosenzweig, R., Lybarger, N. D., Viger, R., Lesmes, D., Skalak, K., Brakebill, J., Cline, D., Dunne, K. , Rasmussen, K., and Miguez-Macho G.: CONUS404: The NCAR–USGS 4-km Long-Term Regional Hydroclimate Reanalysis over the CONUS, B. Am. Meteorol. Soc., 104, E1382–E1408, https://doi.org/10.1175/BAMS-D-21-0326.1, 2023.
Ray, R. L., Sishodia, R. P., and Tefera, G. W.: Evaluation of Gridded Precipitation Data for Hydrologic Modeling in North-Central Texas, Remote Sens., 14, 3860, https://doi.org/10.3390/rs14163860, 2022.
Reichle, R. H., Draper, C. S., Liu, Q., Girotto, M., Mahanama, S. P. P., Koster, R. D, and De Lannoy, G. J. M.: Assessment of MERRA-2 Land Surface Hydrology Estimates, J. Climate, 30, 2937–2960, https://doi.org/10.1175/JCLI-D-16-0720.1, 2017.
Rienecker, M. M., Suarez, M. J., Gelaro, R., Todling, R., Bacmeister, J., Liu, E., Bosilovich, M. G., Schubert, S. D., Takacs, L., Kim, G. K., and Bloom, S.: MERRA: NASA's modern-era retrospective analysis for research and applications, J. Climate, 24, 3624–3648, https://doi.org/10.1175/JCLI-D-11-00015.1, 2011.
Rodell, M., Houser, P. R., Jambor, U., Gottschalck, J., Mitchell, K., Meng, C.-J., Arsenault, K., Cosgrove, B., Radakovich, J., Bosilovich, M., Entin, J. K., Walker, J. P., Lohmann, D., and Toll, D.: The Global Land Data Assimilation System, B. Am. Meteorol. Soc., 85, 381–94, 2004.
Rohde, R. A. and Hausfather, Z.: The Berkeley Earth Land/Ocean Temperature Record, Earth Syst. Sci. Data, 12, 3469–3479, https://doi.org/10.5194/essd-12-3469-2020, 2020.
Saha, S., Moorthi, S., Pan, H. L., Wu, X., Wang, J., Nadiga, S., Tripp, P., Kistler, R., Woollen, J., Behringer, D., and Liu, H.: The NCEP climate forecast system reanalysis, B. Am. Meteorol. Soc., 91, 1015–1058, https://doi.org/10.1175/2010BAMS3001.1, 2010.
Saha, S., Moorthi, S., Wu, X., Wang, J., Nadiga, S., Tripp, P., Behringer, D., Hou, Y. T., Chuang, H. Y., Iredell, M., and Ek, M.: The NCEP climate forecast system version 2, J. Climate, 27, 2185–2208, https://doi.org/10.1175/JCLI-D-12-00823.1, 2014.
Schamm, K., Ziese, M., Becker, A., Finger, P., Meyer-Christoffer, A., Schneider, U., Schröder, M., and Stender, P.: Global gridded precipitation over land: a description of the new GPCC First Guess Daily product, Earth Syst. Sci. Data, 6, 49–60, https://doi.org/10.5194/essd-6-49-2014, 2014.
Schneider, U., Ziese, M., Meyer-Christoffer, A., Finger, P., Rustemeier, E., and Becker, A.: The new portfolio of global precipitation data products of the Global Precipitation Climatology Centre suitable to assess and quantify the global water cycle and resources, Proc. IAHS, 374, 29–34, https://doi.org/10.5194/piahs-374-29-2016, 2016.
Schneider, U., Finger, P., Meyer-Christoffer, A., Rustemeier, E., Ziese, M., and Becker, A.: Evaluating the hydrological cycle over land using the newly-corrected precipitation climatology from the Global Precipitation Climatology Centre (GPCC), Atmosphere, 8, 52, https://doi.org/10.3390/atmos8030052, 2017.
Sengupta, M., Xie, Y., Lopez, A., Habte, A., Maclaurin, G., and Shelby, J.: The national solar radiation data base (NSRDB), Renewable Sustainable Energy Reviews, 89, 51–60, https://doi.org/10.1016/j.rser.2018.03.003, 2018.
Setti, S., Maheswaran, R., Sridhar, V., Barik, K. K., Merz, B., and Agarwal, A.: Inter-Comparison of Gauge-Based Gridded Data, Reanalysis and Satellite Precipitation Product with an Emphasis on Hydrological Modeling, Atmosphere, 11, 1252, https://doi.org/10.3390/atmos11111252, 2020.
Sheffield, J., Goteti, G., and Wood, E. F.: Development of a 50-year high-resolution global dataset of meteorological forcings for land surface modeling, J. Climate, 19, 3088–3111, 2006.
Shuai, P., Chen, X., Mital, U., Coon, E. T., and Dwivedi, D.: The effects of spatial and temporal resolution of gridded meteorological forcing on watershed hydrological responses, Hydrol. Earth Syst. Sci., 26, 2245–2276, https://doi.org/10.5194/hess-26-2245-2022, 2022.
Singh, H., and Najafi, M. R.: Evaluation of gridded climate datasets over Canada using univariate and bivariate approaches: Implications for hydrological modelling, J. Hydrol., 584, 124673, https://doi.org/10.1016/j.jhydrol.2020.124673, 2020.
Sorooshian, S., Hsu, K. L., Gao, X., Gupta, H. V., Imam, B., and Braithwaite, D.: Evaluation of PERSIANN system satellite-based estimates of tropical rainfall, B. Am. Meteorol. Soc., 81, 2035–2046, https://doi.org/10.1175/1520-0477(2000)081<2035:EOPSSE>2.3.CO;2, 2000.
Strangeways, I.: Precipitation: Theory, measurement and distribution, Cambridge: Cambridge University Press, ISBN 9780521851176, 2006.
Sun, Q., Miao, C., Duan, Q., Ashouri, H., Sorooshian, S., Hsu, K. L.: A review of global precipitation data sets: Data sources, estimation, and intercomparisons, Rev. Geophys., 56, 79–107, https://doi.org/10.1002/2017RG000574, 2018.
Sun, R., Yuan, H., Liu, X., and Jiang, X.: Evaluation of the latest satellite–gauge precipitation products and their hydrologic applications over the Huaihe River basin, J. Hydrol., 536, 302–319, 2016.
Tan, J., Huffman, G. J., Bolvin, D. T., and Nelkin, E. J.: IMERG V06: Changes to the morphing algorithm. J. Atmos. Ocean. Tech., 36, 2471–2482, 2019.
Tang, G., Clark, M. P., Papalexiou, S. M., Newman, A. J., Wood, A. W., Brunet, D., and Whitfield, P. H.: EMDNA: an Ensemble Meteorological Dataset for North America, Earth Syst. Sci. Data, 13, 3337–3362, https://doi.org/10.5194/essd-13-3337-2021, 2021.
Tarek, M., Brissette, F. P., and Arsenault, R.: Evaluation of the ERA5 reanalysis as a potential reference dataset for hydrological modelling over North America, Hydrol. Earth Syst. Sci., 24, 2527–2544, https://doi.org/10.5194/hess-24-2527-2020, 2020.
Tercek, M. T., Rodman, A., Woolfolk, S., Wilson, Z., Thoma, D., and Gross, J.: Correctly applying lapse rates in ecological studies: Comparing temperature observations and gridded data in Yellowstone, Ecosphere 12, e03451, https://doi.org/10.1002/ecs2.3451, 2021.
Thornton, P. E., Shrestha, R., Thornton, M., Kao, S. C., Wei, Y., and Wilson, B. E.: Gridded daily weather data for North America with comprehensive uncertainty quantification, Sci. Data, 8, 190, https://doi.org/10.1038/s41597-021-00973-0, 2021.
Ushio, T., Sasashige, K., Kubota, T., Shige, S., Okamoto, K., Aonashi, K., and Kawasaki, Z. I.: A Kalman Filter Approach to the Global Satellite Mapping of Precipitation (GSMaP) from Combined Passive Microwave and Infrared Radiometric Data, J. Meteorol. Soc. Jpn., 87, 137–151, 2009.
Ushio, T., Mega, T., and Kubota, T.: Multi-satellite Global Satellite Mapping of Precipitation (GSMaP)-Design and Products, in: 2019 URSI Asia-Pacific Radio Science Conference (APRASC), New Delhi, India, 1, https://doi.org/10.23919/URSIAP-RASC.2019.8738594, 2019.
Warszawski, L., Frieler, K., Huber, V., Piontek, F., Serdeczny, O., and Schewe, J.: The inter-sectoral impact model intercomparison project (ISI–MIP): Project framework, P. Natl. Acad. Sci. USA, 111, 3228–3232, https://doi.org/10.1073/pnas.1312330110, 2014.
Weedon, G. P., Gomes, S. S., Viterbo, P. P., Shuttleworth, W. J., Blyth, E. E., Österle, H. H., Adam, J. C., Bellouin, N. N., Boucher, O. O., and Best, M. M.: Creation of the WATCH Forcing Data and Its Use to Assess Global and Regional Reference Crop Evaporation over Land during the Twentieth Century, J. Hydrometeorol., 12, 823–848, https://doi.org/10.1175/2011JHM1369.1, 2011.
Weedon, G. P., Balsamo, G., Bellouin, N., Gomes, S., Best, M. J., and Viterbo, P.: The WFDEI meteorological forcing data set: WATCH Forcing Data methodology applied to ERA-Interim reanalysis data, Water Resour. Res., 50, 7505–7514, https://doi.org/10.1002/2014WR015638, 2014.
World Meteorological Organization (WMO): Density of stations for a network. Hydrology – From Measurement to Hydrological Information, Vol. 1, Guide to Hydrological Practices, 6th edn., WMO-168, World Meteorological Organization, I.2-24–I.2-28, https://www.hydrology.nl/images/docs/hwrp/WMO_Guide_168_Vol_I_en.pdf (last access: 7 December 2024), 2008.
Xia, Y., Mitchell, K., Ek, M., Sheffield, J., Cosgrove, B., Wood, E., Luo, L., Alonge, C., Wei, H., Meng, J., and Livneh, B.: Continental-scale water and energy flux analysis and validation for the North American Land Data Assimilation System project phase 2 (NLDAS-2): 1. Intercomparison and application of model products, J. Geophys. Res.-Atmos., 117, D03109, https://doi.org/10.1029/2011JD016048, 2012a.
Xia, Y., Mitchell, K., Ek, M., Cosgrove, B., Sheffield, J., Luo, L., Alonge, C., Wei, H., Meng, J., Livneh, B., and Duan, Q.: Continental-scale water and energy flux analysis and validation for North American Land Data Assimilation System project phase 2 (NLDAS-2): 2. Validation of model-simulated streamflow, J. Geophys. Res.-Atmos., 117, D03110, https://doi.org/10.1029/2011JD016051, 2012b.
Xie, P. and Arkin, P. A.: Global precipitation: A 17-year monthly analysis based on gauge observations, satellite estimates, and numerical model outputs, B. Am. Meteorol. Soc., 78, 2539–2558, 1997.
Xie, P., Chen, M., Yang, S., Yatagai, A., Hayasaka, T., Fukushima, Y., and Liu, C.: A gauge-based analysis of daily precipitation over East Asia, J. Hydrometeorol., 8, 607–626, https://doi.org/10.1175/JHM583.1, 2007.
Xie, P., Joyce, R., Wu, S., Yoo, S.-H., Yarosh, Y., Sun, F., and Lin, R.: Reprocessed, bias-corrected CMORPH global high-resolution precipitation estimates from 1998, J. Hydrometeorol., 18, 1617–1641, https://doi.org/10.1175/JHM-D-16-0168.1, 2017.
Yang, Y., Wang, G., Wang, L., Yu, J., and Xu, Z.: Evaluation of gridded precipitation data for driving SWAT model in area upstream of three gorges reservoir, PLoS One, 9, e112725, https://doi.org/10.1371/journal.pone.0112725, 2014.
Zhang, T., Chandler, W. S., Hoell, J. M., Westberg, D., Whitlock, C. H., and Stackhouse, P. W.: A global perspective on renewable energy resources: NASA's prediction of worldwide energy resources (power) project, in: Proceedings of ISES World Congress 2007 (Vol. I–Vol. V) Solar Energy and Human Settlement, Springer Berlin Heidelberg, 2636–2640, https://ntrs.nasa.gov/api/citations/20070031737/downloads/20070031737.pdf (last access: 7 December 2024), 2009.
Zhu, H., Li, Y., Huang, Y., Li, Y., Hou, C., and Shi, X.: Evaluation and hydrological application of satellite-based precipitation datasets in driving hydrological models over the Huifa river basin in Northeast China, Atmos. Res., 207, 28–41, https://doi.org/10.1016/j.atmosres.2018.02.022, 2018.