the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 18 Feb 2025
| 18 Feb 2025
Training deep learning models with a multi-station approach and static aquifer attributes for groundwater level simulation: what is the best way to leverage regionalised information?
Sivarama Krishna Reddy Chidepudi
Nicolas Massei
Abderrahim Jardani
Bastien Dieppois
Abel Henriot
Matthieu Fournier
In this study, we use deep learning models with advanced variants of recurrent neural networks, specifically long short-term memory (LSTM), gated recurrent unit (GRU), and bidirectional LSTM (BiLSTM), to simulate large-scale groundwater level (GWL) fluctuations in northern France. We develop multi-station collective training for GWL simulations, using dynamic variables (i.e. climatic) and static basin characteristics. This large-scale approach can incorporate dynamic and static features to cover more reservoir heterogeneities in the study area. Further, we investigated the performance of relevant feature extraction techniques such as clustering and wavelet transform decomposition to simplify network learning using regionalised information. Several modelling performance tests were conducted. Models specifically trained on different types of GWL, clustered based on the spectral properties, performed significantly better than models trained on the whole dataset. Clustering-based modelling reduces complexity in the training data and targets relevant information more efficiently. Applying multi-station models without prior clustering can lead the models to preferentially learn the dominant behaviour, ignoring unique local variations. In this respect, wavelet pre-processing was found to partially compensate for clustering, bringing out common temporal and spectral characteristics shared by all available GWL time series even when these characteristics are “hidden” (e.g. if their amplitude is too small). When employed along with prior clustering, using wavelet decomposition as a pre-processing technique significantly improves model performances, particularly for GWLs dominated by low-frequency interannual to decadal variations. This study advances our understanding of GWL simulation using deep learning, highlighting the importance of different model training approaches, the potential of wavelet pre-processing, and the value of incorporating static attributes.
- Article
(7869 KB) - Full-text XML
-
Supplement
(580 KB) - BibTeX
- EndNote




Understanding the large-scale hydrological functioning of a hydrological system is the best approach for grasping a global view of water reserves and implementing appropriate long-term management strategies (Kingston et al., 2020; Massei et al., 2020; Muñoz-Carpena et al., 2023). However, this approach typically requires constructing a large-scale hydrological model capable of capturing interactions over large areas, while respecting hydraulic continuity across the hydrological system. The model must be able to analyse and test, for example, the effects of different modes of exploitation or any other human interventions, as well as the effects of climate change over the long term. Building a large-scale model implies collecting and processing a massive database to accurately capture all the geological, oceanic, climatic, and anthropogenic forcings that drive groundwater flow. In addition, the numerical, physics-based representation of all hydrological processes occurring between the surface, sub-surface, and groundwater remains extremely complex, particularly in large-scale modelling (Paniconi and Putti, 2015). For these reasons, although progress has been made in this field, applications of physics-based models are still mainly focused on aquifers in relatively small watersheds (Massei et al., 2020; Muñoz-Carpena et al., 2023).
Under these conditions, data-driven tools have emerged as a valuable, or complements, for capturing the complex interactions across various spatio-temporal scales. These tools leverage large datasets without relying on physical representations of the non-linear processes linking climatic and hydrological signals (Hauswirth et al., 2021). Instead, they approximate these processes using simple weight matrices that replicate observed hydrological signals, whether at the scale of an aquifer or a river (Vu et al., 2023). Notably, the application of artificial intelligence (AI) algorithms, especially deep learning (DL), is expanding in hydrological sciences (Nourani et al., 2014, 2023; Rajaee et al., 2019), a trend driven by increased computational resources and the growing availability of global datasets covering hydrological and catchment attributes (Addor et al., 2017; Kratzert et al., 2023). Recent studies further highlight the potential of DL for hydrological modelling (Fang et al., 2022; Klotz et al., 2022; Kratzert et al., 2019, 2021; Nourani et al., 2021) and forecasting (Jahangir et al., 2023; Momeneh and Nourani, 2022; Jahangir and Quilty, 2023; Vu et al., 2023).
Data-driven approaches have been widely applied to rainfall-runoff modelling due to the availability of extensive runoff data. However, their application in groundwater studies is more challenging. The high cost of installing piezometers and the geological complexity of underground reservoirs, which exhibit diverse hydrodynamic behaviours across scales, make it difficult to obtain representative data. Additionally, linking groundwater data to specific locations is challenging, as aquifer delineation is more complex than catchment delineation for surface water. Groundwater systems also respond more slowly to changes, often requiring long-term data series, and are uniquely sensitive to human activities, such as pumping, which differ from influences on runoff, like river straightening or dam construction. Consequently, deep learning (DL) applications in groundwater modelling are generally limited to local scales, often using single-station data for simulation or forecasting (Chidepudi et al., 2023b; Bai and Tahmasebi, 2023; Vu et al., 2023).
In groundwater studies, the term “global models” is sometimes used to describe models trained on data from multiple wells or stations. However, this can be misleading, as it implies a broader scope than is usually intended. In the present study, we use the term “multi-station approach” to more accurately describe models that integrate data from various wells alongside external input variables. Although some studies have explored multi-station approaches for groundwater level (GWL) simulations, they are typically limited to forecasting or reconstruction using data from nearby wells. For example, Vu et al. (2021) reconstructed GWLs at single stations based on nearby station data, and Patra et al. (2023) developed “global models” focused on GWL forecasting. In another study, Gholizadeh et al. (2023) demonstrated the potential of LSTM combined with static attributes to simulate both streamflow and GWL.
Furthermore, clustering methods have shown promise in groundwater modelling, often used in hybrid models alongside AI techniques such as self-organising maps (Nourani et al., 2015, 2016; Wunsch et al., 2022b), K-means (Ahmadi et al., 2022; Kardan Moghaddam et al., 2021; Kayhomayoon et al., 2021, 2022; Nourani et al., 2023), and fuzzy C-means (Jafari et al., 2021; Nourani and Komasi, 2013; Rajaee et al., 2019; Zare and Koch, 2018). However, most of these studies focus on autoregressive approaches that depend on past GWL data. The regionalisation of GWLs through clustering and non-autoregressive DL models, which learn from comprehensive datasets with external variables, remains underexplored. Multi-station approaches that integrate both static and dynamic data or incorporate clustering have shown potential for runoff modelling (Fang et al., 2022; Hashemi et al., 2022; Klotz et al., 2022), but their utility for GWL simulations across varied hydrogeological settings requires further investigation.
To address these gaps, this study aims to provide a comprehensive evaluation of regional modelling approaches for GWL simulations compared with local models, guided by the following research questions:
- a.
How do generalised (multi-station) models compare with specialised (single-station) models in simulating GWLs?
- b.
Can wavelet pre-processing improve the performance of models trained on data from multiple stations across different types of GWLs?
- c.
To what extent do static attributes or one-hot encoding techniques enhance model generalisation across varied GWL behaviours, and is their combined use more effective than individual applications? How do these models compare to those trained on stations grouped by similar spectral and temporal characteristics?
- d.
What are the key variables influencing model learning, particularly for capturing low-frequency variability within high-frequency-dominated explanatory signals?
By investigating these questions, this study seeks to advance the understanding of regional GWL modelling and to compare multi-station and local approaches. This study focuses on “simulation” rather than “forecasting” in the context of DL applications in groundwater modelling, following the framework developed by Beven and Young (2013), where “simulation” aims to reproduce system behaviour without observed outputs, and “forecasting” predicts future states based on past observations. Our approach centres on simulating GWL dynamics to improve understanding rather than forecasting future levels. To this end, we evaluate multi-station models, incorporating static attributes and wavelet pre-processing, and compare results with local models. All experiments are conducted in a gauged setting, similar to Li et al. (2022).
The remainder of this paper is structured as follows: Sect. 2 presents the study area along with the datasets used, and Sect. 3 outlines the methodology and experimental design. Section 4 assesses the models' ability to capture variations in GWLs under different scenarios, followed by discussions on result interpretability. Section 5 presents our main conclusions and future perspectives.
The study area is approximately 80 000 km2 of northern France, as depicted in Fig. 1. The available GWLs of climate-sensitive wells (i.e. not strongly affected by human activities) were obtained between 1968 and 2022 from the ADES (Accès aux Données sur les Eaux Souterraines) database (https://ades.eaufrance.fr/, last access: 8 September 2023; Winckel et al., 2022). The dataset consists of 35 mixed, 23 inertial, and 18 annual stations. All the wells considered in the study are in unconfined aquifers. In addition, the GWL data were clustered into three different types following the methodology outlined by Baulon et al. (2022b), which is based on spectral properties (i.e. characteristic timescales of variability inherent to each cluster). These clusters are identified as annual, mixed, and inertial, as depicted in Fig. 1. Specifically, the first cluster exhibits a GWL pattern predominantly influenced by the annual cycle, indicating an annual behaviour. The second cluster, the mixed, shows characteristics of both annual and interannual GWL variability. The third cluster, the inertial, is mainly characterised by its low-frequency GWL variability. In this study, low frequency refers to interannual to decadal timescales; from now in this paper, the term low frequency will be used to refer to such timescales. A comprehensive list of all analysed wells, including their identifiers, GWL types, and coordinates, is available in the Supplement (Table S1).
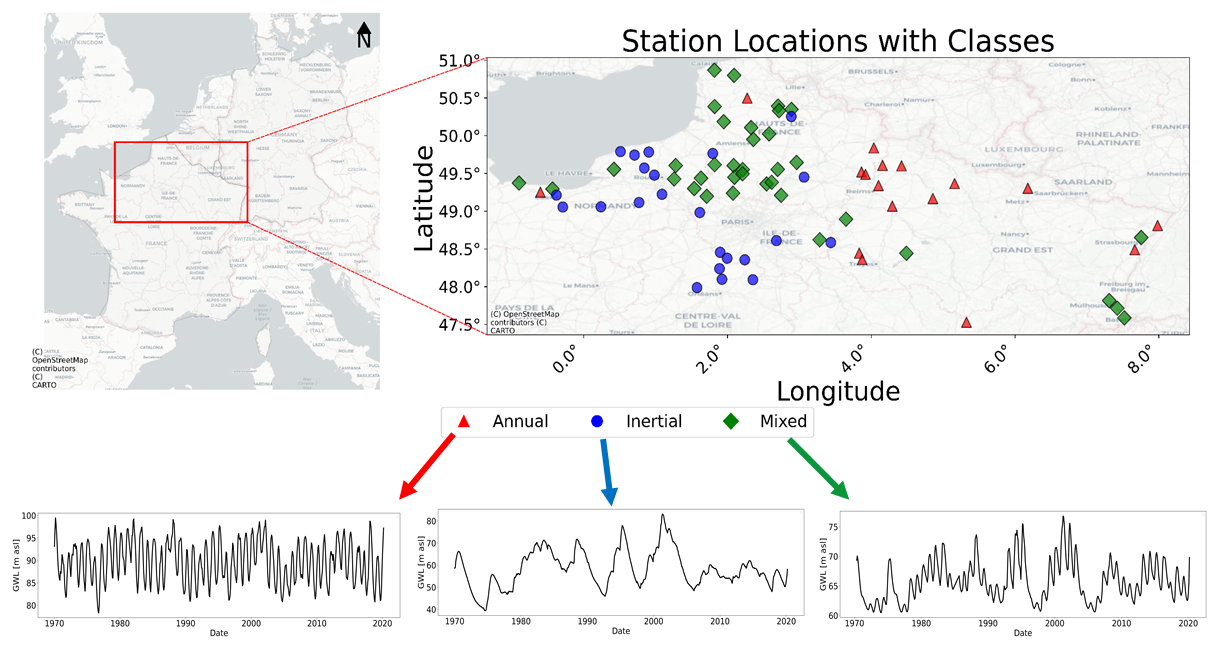
Figure 1Clustering of GWL time series data (background layer: © OpenStreetMap contributors 2023. Distributed under the Open Data Commons Open Database License (ODbL) v1.0.) based on the spectral statistical properties (Baulon et al., 2022b): station locations (top) and representative GWL time series for each groundwater type (bottom).
We used the forcing data from ERA5, with a spatial resolution of 0.25°, to obtain the dynamic climate variables (Hersbach et al., 2020). In particular, we extract seven atmospheric variables: 10 m zonal (W–E) u-wind component (u10), 10 m meridional (S–N) v-wind component (v10), 2 m air temperature (t2m), evaporation (e), mean sea level pressure (msl), surface net solar radiation (ssr), and total precipitation (tp). These variables are among the most commonly used inputs for hydrological and land surface models, representing atmospheric conditions, circulation, moisture fluxes and radiative forcing (Kratzert et al., 2023). ERA5 is the best available global reanalysis with the data available from 1940 and is generally considered adequate for capturing regional and global hydrometeorological variations (Chidepudi et al., 2024). Addressing the uncertainty issue of ERA5 is beyond the scope of this paper and can be considered a complete research work. ERA5 Reanalysis data have uncertainty related to potential regional biases; this and their use for hydrological modelling is still ongoing research. Particularly in “large-sample hydrology”, precipitation is considered to have more bias than temperature (Clerc-Schwarzenbach et al., 2024). Nevertheless, studies conducted recently concluded that ERA5 temperature and precipitation biases had been consistently reduced compared to ERA-Interim and were found to be quite accurate for hydrological modelling, for instance, in the case of the conterminous US (Tarek et al., 2020). Gualtieri (2022) highlighted that ERA5 uncertainties are greatest in mountainous and coastal locations (in the study presented herein, only 1 station out of 76 is located within the 10–15 km from the coast). Finally, one recent study concluded that the use of ERA5 precipitation was recommended for all extra-tropical regions (Lavers et al., 2022). Nevertheless, we evaluated different alternative reanalysis products, such as the SAFRAN (Système d'Analyse Fournissant des Renseignements Atmosphériques à la Neige) reanalysis developed specifically for France (Vidal et al., 2010). ERA5 and SAFRAN precipitation appeared to have the same low-frequency timescales of variability as our GWL time series, as displayed in Fig. 3 (this paper) and in Fig. 11 in Chidepudi et al. (2023b). ERA 5, then, is suitable for our purpose.
Table 1Summary of the static attributes used in the current study. A comprehensive explanation of all descriptions can be found at the URLs provided in the third column.

All links in this table were accessed on 19 July 2023.
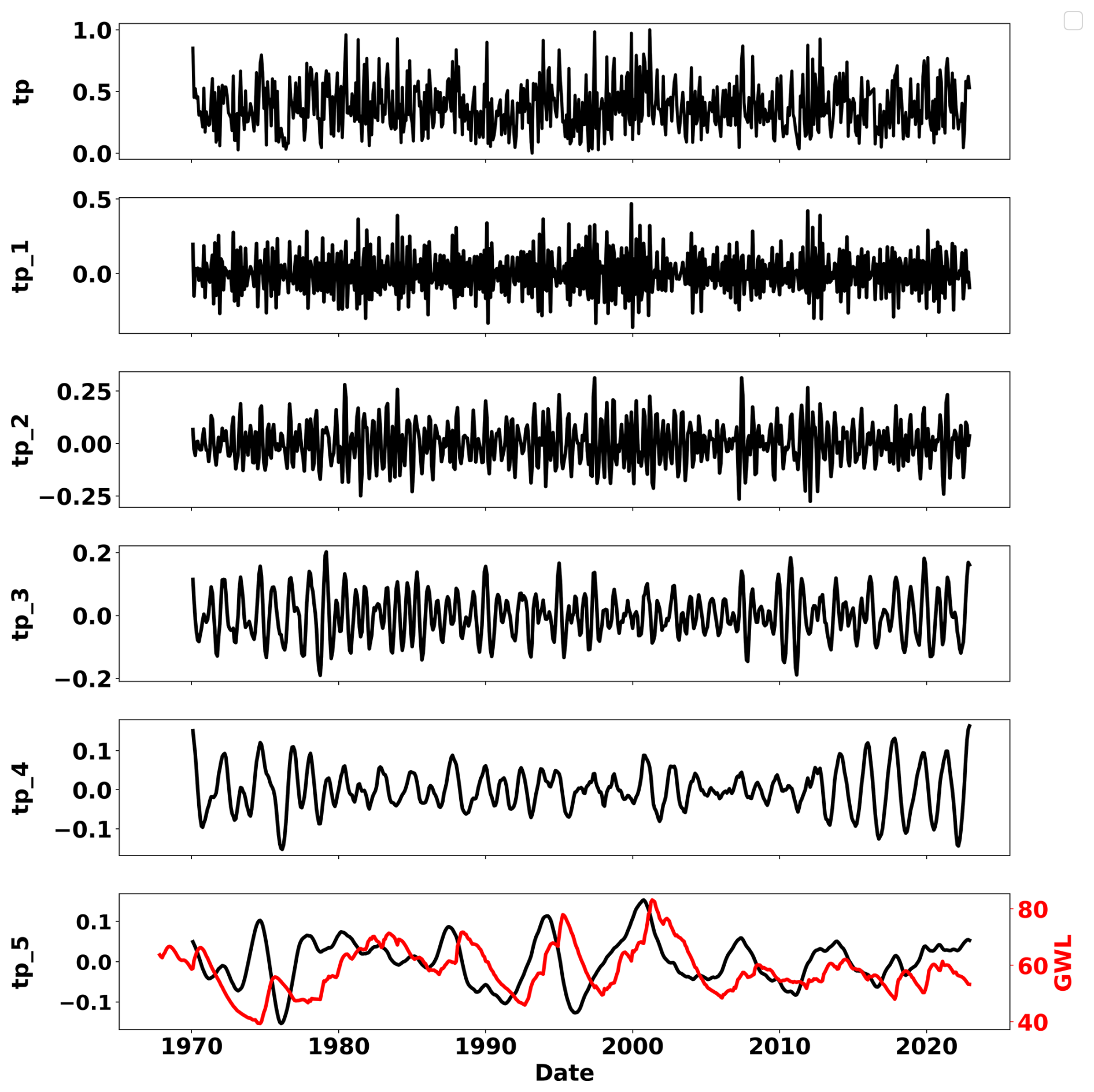
Figure 3Total precipitation (tp) and its wavelet components: high (tp_1) to low frequency (tp_5) and GWL (in red).
In this work, we also included static attributes (Table 1 and Fig. 2) to assess whether such informative data would help to better represent small differences between GWL time series owing to different contexts (e.g. type of porosity, overall geological context, lithology, location). Static attributes are available for different ranges of aquifer classes with different resolutions. We took the static attribute's value corresponding to each well's location. Static attributes were extracted from the BDLISA (Base de Donnée des Limites des Systèmes Aquifères) (https://bdlisa.eaufrance.fr/, last access: 19 July 2023) database, which provides point-scale information. BDLISA is based on a mix of information from geological maps, piezometric maps, and hydrochemistry at a scale of 25 km. For our study, we kept information coming from BDLISA at its original scale (25 km), which means aquifer static attributes have a resolution of 25 km. This information from BDLISA should be understood as a local–regional description of aquifers. Exact details of static attributes for each GWL station can be found in Table S1.
The decision to include the relevant static attributes comes from a trade-off between the transposability of models and the availability of attributes, as we need to ensure that all those variables are widely available at the required resolution. For instance, hydraulic conductivity might not be easily available everywhere, and high spatial heterogeneity that would not be accounted for owing to available spatial resolution may lead to inconsistent results (a 25 km resolution might not be relevant when aquifers are highly heterogeneous). Exploring the role of static attributes in more detail would require much further work than what was conducted in this study.
3.1 Theoretical modelling background
In the present study, we explored the use of recurrent-based deep learning models to simulate GWLs across multiple stations using different approaches as described in Sect. 3.2. We apply three types of recurrent neural networks: long short-term memory (LSTM; Hochreiter and Schmidhuber, 1997), gated recurrent unit (GRU; Cho et al., 2014), and bidirectional LSTM (BiLSTM; Graves and Schmidhuber, 2005), alongside a wavelet pre-processing strategy (BC-MODWT). Each of these methods is designed to process data that changes over time, capturing patterns and dependencies that occur over extended periods. In brief, LSTM has a single memory cell and three gates (forget, input, and output) to manage the flow of information. GRU simplifies this design, with only two gates (reset and update), to increase computational efficiency by reducing the number of parameters compared to LSTM. BiLSTM further optimises data analysis by simultaneously processing sequences in both forward and backward directions. These models are particularly good at identifying various patterns in data sequences, making them ideal for simulating GWLs that change over time (Vu et al., 2023).
We also explored the potential of wavelet decomposition (BC-MODWT) to decompose the data into components of varying frequencies (Fig. 3), from high to low, to provide more detailed input to the DL models to better simulate the GWLs. As explained in Chidepudi et al. (2023b), decomposition depth (i.e. the choice of the number of components) was constrained by the trade-off between (1) achieving a sufficient high level of decomposition to ensure the low-frequency variability is properly reached and (2) keeping the number of coefficients affected by boundary conditions as low as possible since these have to be ultimately removed from the input time series. All input time series were decomposed using BC-MODWT, with a decomposition depth of 4 as in Chidepudi et al. (2023b). Figure 3 illustrates the decomposition result for the precipitation time series. A four-level decomposition efficiently extracted the first four so-called wavelet details (tp_1 to tp_4), while the last fifth (so-called smooth) tp_5 component remains of sufficiently low frequency. It is visible that tp_5, almost invisible in the original tp precipitation time series, corresponds well to the variability of the most inertial GWL types (Fig. 3, in red, with a few months' time lag with respect to tp).
3.1.1 Model training and evaluation
To maintain consistent comparison criteria across all methods evaluated in the study, Bayesian optimisation was used for hyperparameter tuning. Details of the range of hyperparameters used are shown in Table 2. Furthermore, the range of hyperparameters used for optimisation was standardised across all methods, following the best practices outlined for both standalone and wavelet-assisted models, as detailed in Chidepudi et al. (2023b) and Quilty and Adamowski (2018).
Table 2Hyperparameter details (modified and adapted from Chidepudi et al., 2023b).
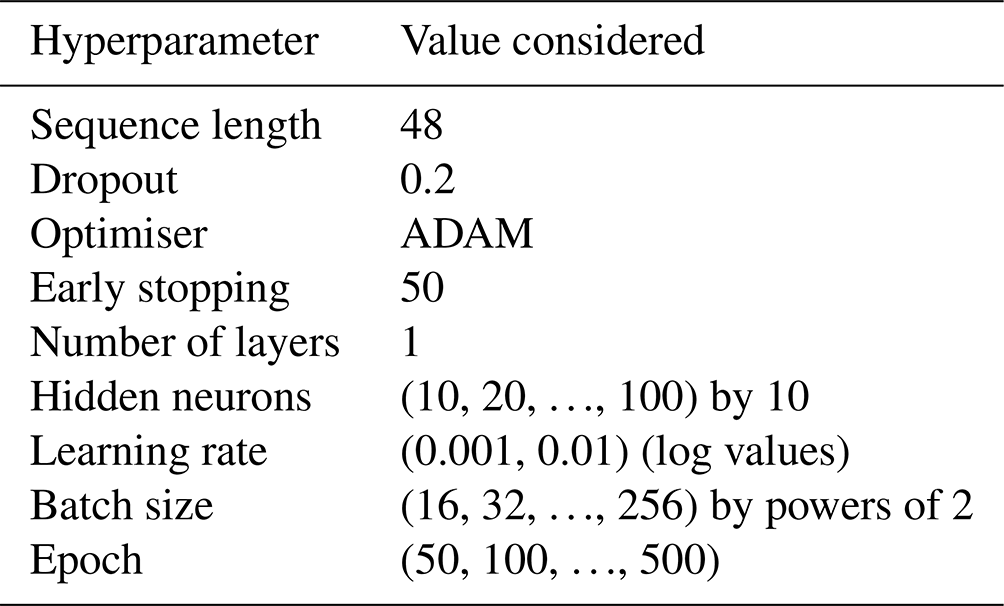

Figure 4Comparison of performance of single-layer DL models (a, c, e) and multiple-layer DL models (b, d, f) with respect to single-station models as a reference. SA represents standalone models, while Wav represents wavelet-assisted models.
However, we made an important update to the model architecture by setting the number of layers to one for all models, rather than optimising it. This decision was based on findings from Fig. 4, which suggested that optimising the number of layers did not significantly improve performance, in line with recent studies in related fields like rainfall-runoff modelling (Kratzert et al., 2019, 2021). Other adjustments included reducing the number of initialisations to 10 and setting the number of trials in the Bayesian optimisation to 30. These changes were aimed at reducing the computational requirements of our approach, making it more efficient without significantly affecting the quality of our results, and are consistent with recent studies (Wunsch et al., 2022a).
The intricacies and specific technical details of the architectures of these models are well documented in the existing body of deep learning research applied to hydrological simulations, as detailed in several studies (Chidepudi et al., 2023b, 2024; Fang et al., 2022; Kratzert et al., 2021; Li et al., 2022; Vu et al., 2023).
To further interpret and decrypt the results, we used the SHAP or Shapley Additive Explanations approach (Lundberg and Lee, 2017), which is an increasingly popular game-centric approach for explaining the outcomes of deep learning models. SHAP explains how each input feature influences the model's simulations. It does this by highlighting two key aspects: the importance of each variable, where a higher mean absolute SHAP value indicates a greater impact, and the nature of that impact, whether positive or negative.
3.2 Experimental design
This section details the experimental design used to assess the effectiveness of training models using data from all available stations. Our study uses different strategies to incorporate numerical and categorical data into the models. The aim is to improve the accuracy of GWL simulations by exploring ways of incorporating regional variability into the models. The experimental setup is structured to test different modelling strategies, as described below and visualised in Figs. 5 and 6.
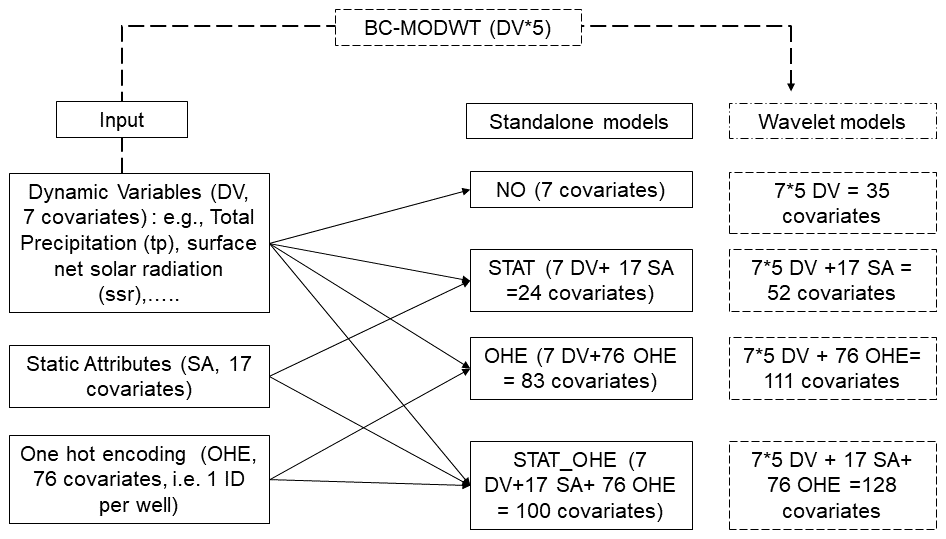
Figure 5Construction of the different multi-station approaches for standalone and wavelet models and associated covariates (input features).

Figure 6Comparison of different approaches adopted in the current study: single station (top), multi-station without clustering (middle), and multi-station with clustering based on spectral properties (bottom). (Background layer: © OpenStreetMap contributors 2023. Distributed under the Open Data Commons Open Database License (ODbL) v1.0.)
-
Single-station or local models (models trained and tested individually per station). These models are trained and evaluated on data from individual stations. As a baseline, their performance provides a benchmark for evaluating the effectiveness of more generalised models. This approach is dominant in developing data-driven models for GWL simulations and is discussed in detail in Chidepudi et al. (2023b, 2024). The optimal hyperparameters for all standalone and wavelet models in the single-station approach are presented in Tables S3 and S4.
-
Multi-station models (models trained and tested together on many stations). These models are trained using data aggregated from multiple stations and tested with different input configurations. In the first configuration (NO), models are trained on all stations using dynamic variables only, excluding static attributes and one-hot encoding. In the second configuration (OHE), models are trained using one-hot encoding to represent individual station ID information as binary vectors to ensure that the specific information is obtained from collective training. Li et al. (2022) also showed that one-hot vector (one-hot encoding using basin ID) could produce similar results to using catchment attributes in gauged basin scenarios. One-hot encoding serves as an alternative to incorporating static attributes directly into the model (Table 3). In the third configuration (STAT: static attributes and dynamic variables), models include both static attributes (e.g. latitude, longitude) and dynamic variables as inputs, with categorical variables encoded similarly to one-hot encoding but represented in separate columns for each unique value or class (Table 4). In the fourth configuration (STAT_OHE), we combine static attributes, one-hot encoding for well IDs, and dynamic variables to provide a comprehensive dataset for model training. In other words, it is a combination of the two input strategies above. The covariates and input shapes for various multi-station approaches are summarised in Fig. 5, and the exact shapes of 3D tensors are provided in Table S5.
Table 3Example of one-hot encoding based on different wells. The ellipses denote the usual time series data of dynamic variables.
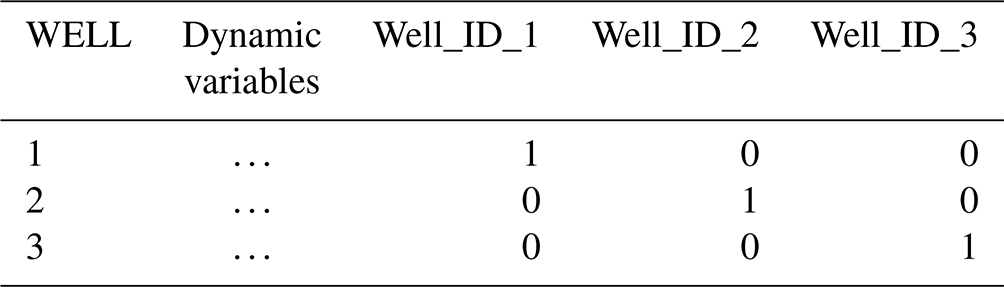
Table 4Example with static attributes of numeric and categorical types.

In addition to these configurations, we investigated the performance of multi-station models trained on GWLs with similar spectral statistical properties. This approach assesses the effectiveness of models tailored to specific GWL behaviours compared to more generalised models using the aforementioned strategies. For validation purposes, in this study, the Kling–Gupta efficiency (KGE; Gupta et al., 2009) is preferred over the Nash–Sutcliffe efficiency (NSE) and other metrics because it offers a more comprehensive evaluation by integrating three aspects of model error: correlation, bias, and the ratio of standard deviations.
For the single-station approach, the data were split into training (80 %) and testing sets (20 %) as described in Chidepudi et al. (2023b). Furthermore, to facilitate hyperparameter tuning, the last 20 % of the training data were used as a validation set. For the multi-station approach, the train–test split was also performed at each station, following the same procedure as the single-station approach. However, the data from all stations were then collectively combined during the training. The rationale behind the specific train–test split is to ensure that the models capture the multi-annual to decadal variability in observed GWLs. To achieve this, data spanning a minimum of 34 years (1970–2014) were used for training, while data spanning the most recent 8.66 years (January 2015–August 2023) were reserved for testing. The testing period was chosen to be the most recent years, allowing for an evaluation of the model's performance on the latest available data. The specific dates and periods used for training and testing at each station are detailed in Table S2.
Our methodology for comparing single-station and multi-station approaches, both with and without prior clustering based on spectral properties, is consistent with the research conducted in rainfall-runoff modelling by Hashemi et al. (2022), where the catchments were divided into five subsets according to hydrological regimes. This comprehensive experimental design aims to identify the most effective strategies for using multi-station data in the simulation of groundwater level variations. Detailed hyperparameters for all the multi-station standalone and wavelet models can be found in Tables S6–S9.
4.1 Different strategies for multi-station approach
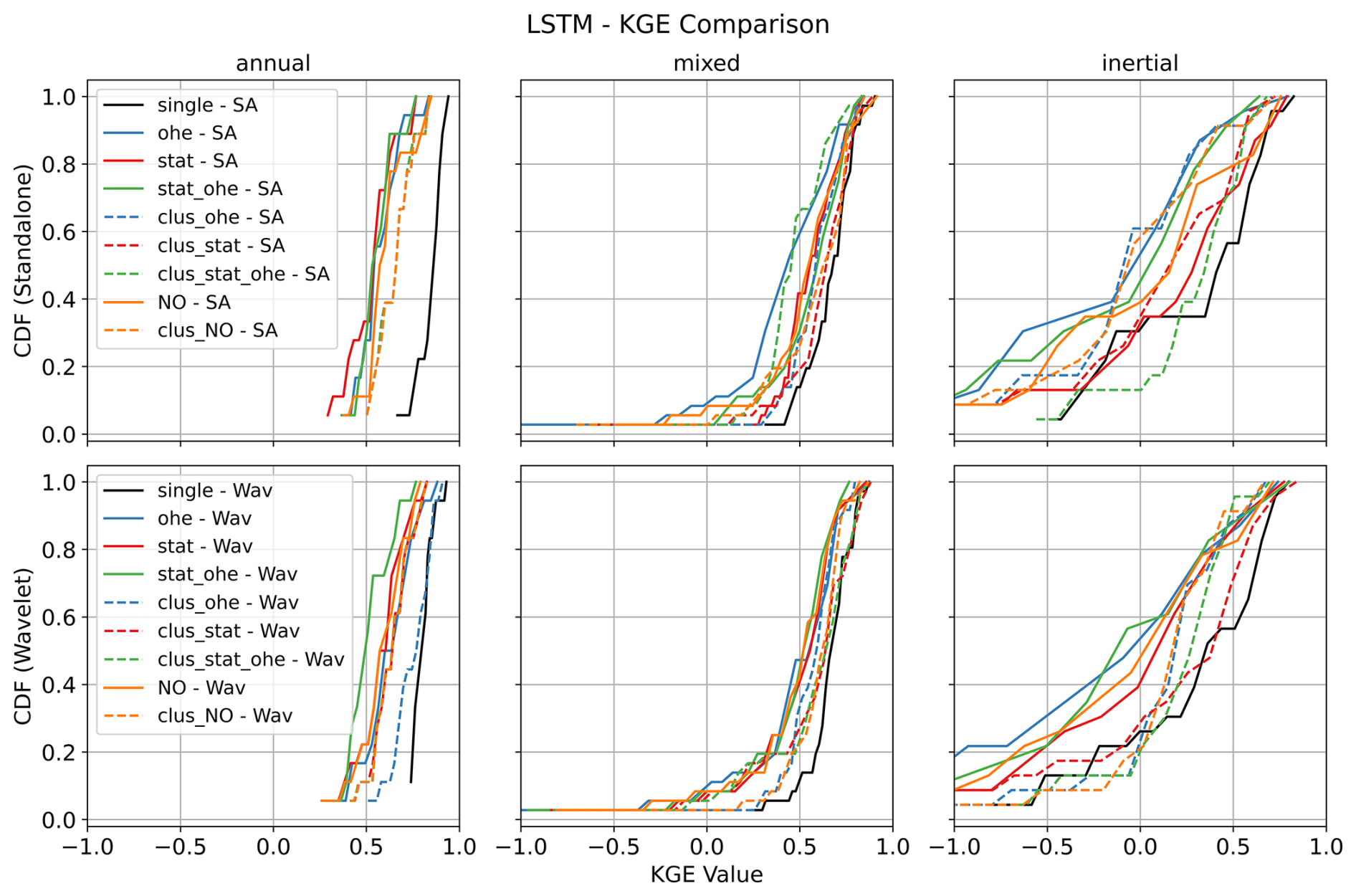
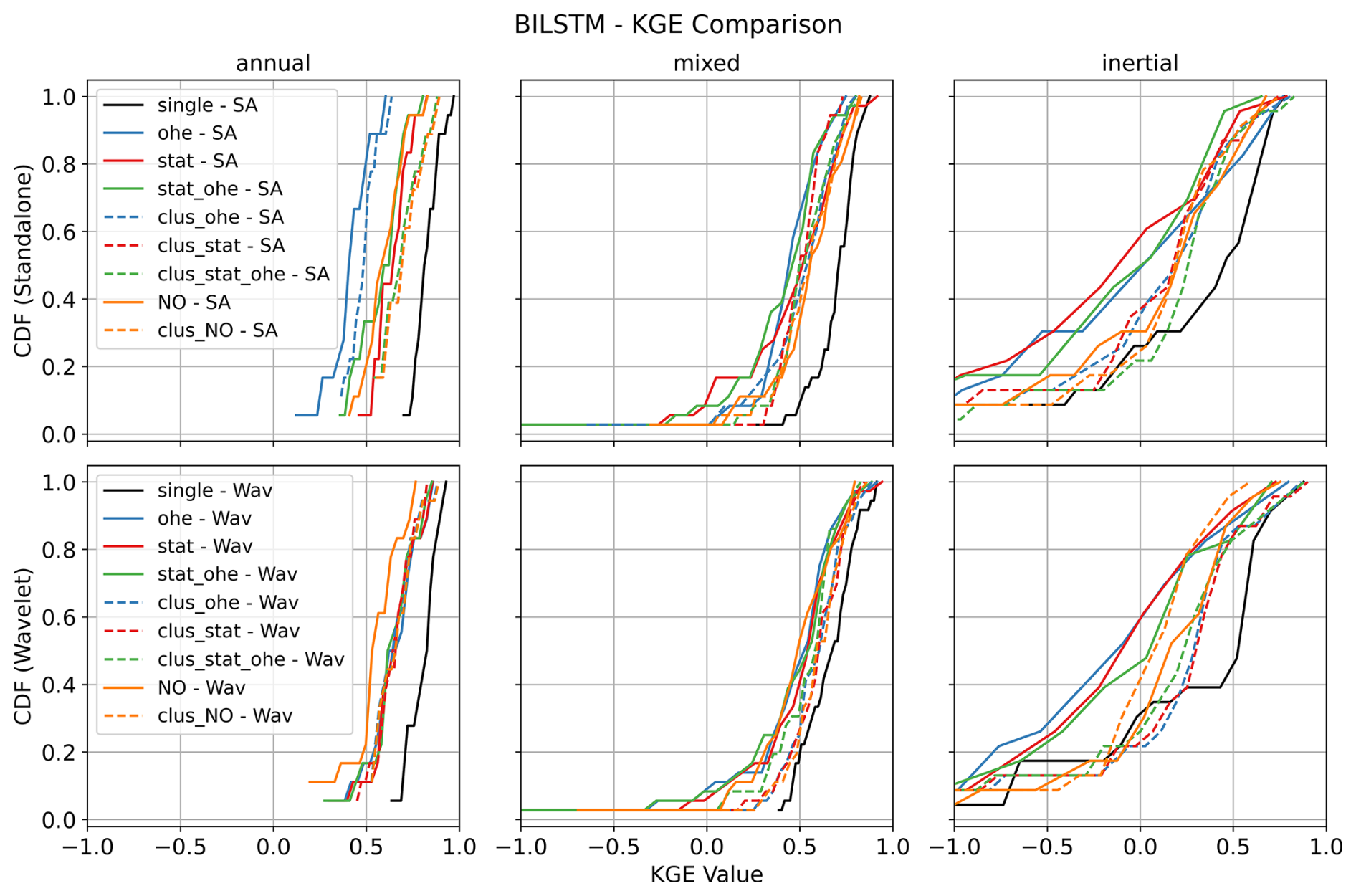
All models tested in the case of this study performed more or less equivalently and eventually yielded very satisfactory results. This can be attested by the performance comparison shown in Fig. 4 (comparison of the three model types in single-station mode) and by comparing Fig. 7 (GRU multi-station) with Figs. A1 (LSTM multi-station) and A2 (BiLSTM multi-station). We finally decided to favour the GRU architecture, owing to its recognised computational efficiency over more traditional LSTM-based architectures (Cho et al., 2014; Cai et al., 2021; Chidepudi et al., 2023b, 2024)
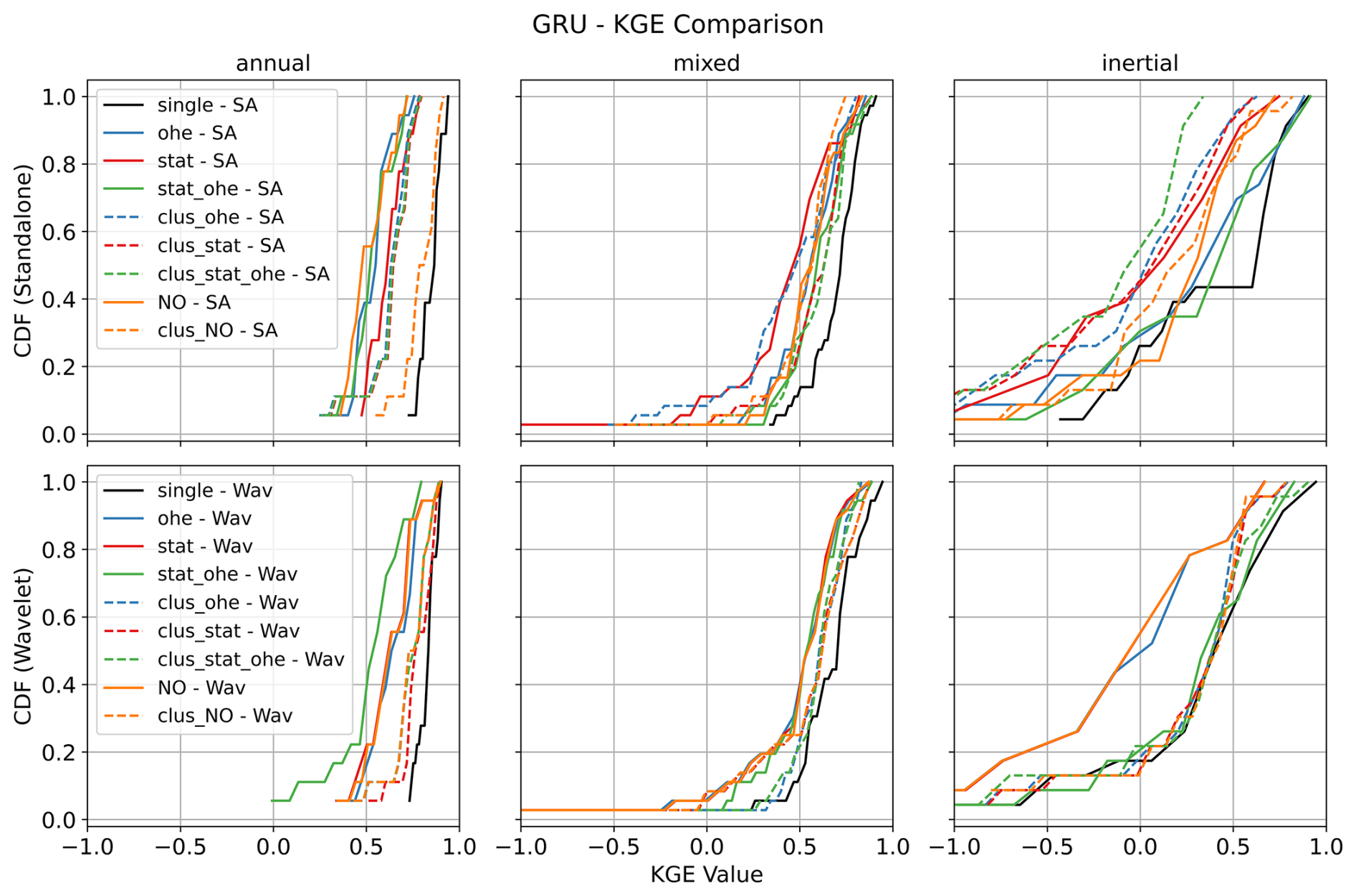
Figure 7 shows the results of different GRU model configurations for simulating GWLs. The first row shows the performance of the standalone GRU model for different GWL categories, while the second row shows the wavelet-assisted GRU results.
Several observations can be made from Fig. 7. Wavelet pre-processing generally improves model performance, especially in the inertial GWL category, where cumulative distribution functions (CDFs) are steeper and shifted to the right, indicating a higher proportion of simulations with high performance. This is in line with previous findings as already reported in our previous works (Chidepudi et al., 2023a, 2024). This demonstrates the wavelet decomposition ability to extract “hidden” inertial dynamics features which facilitate their assimilation by the model in the learning process. In other words, the improvement attributed to wavelet pre-processing becomes more pronounced as we move from annual to mixed and then further to inertial behaviour. This is because in the case of annual-type GWL, the dominant variability (annual cycle) is already well expressed in several input variables (e.g. t2m, msl, ssr). In the case of mixed- and inertial GWL types, the dominant low-frequency variability, while also present, is barely expressed, almost “hidden”, in the input data and becomes prominent in GWL due to the low-pass filtering action of aquifers (Baulon et al., 2022a; Schuite et al., 2019). Wavelet decomposition allows the unravelling of such hidden information, helping the neural networks to reach it for enhanced learning. This is illustrated in Fig. 3 with the low-frequency component of precipitation (tp5) matching the variations of one inertial-type GWL (in red, with a few months' lag time), whereas it is masked by other higher-frequency components in the original precipitation time series (tp). The combination of static attributes and OHE gives competitive results, particularly in the inertial category, demonstrating the effectiveness of this method without the need for prior clustering of GWL behaviour. Multi-station models, when trained separately for each GWL cluster, generally outperform those trained on aggregated data. This is reflected in higher KGE values for cluster-specific models, suggesting a better representation of the unique characteristics of each GWL type. However, this advantage diminishes for mixed GWLs, which are the majority in the study area. Although single-station models perform best for all GWL types, some multi-station models approach or match their performance, highlighting their potential for regional-scale GWL simulations. For the annual GWL category, models trained on mixed GWL data without wavelet pre-processing and relying solely on static attributes do not show significant performance improvements, suggesting that static features alone may not adequately represent the dynamic nature of groundwater behaviour.
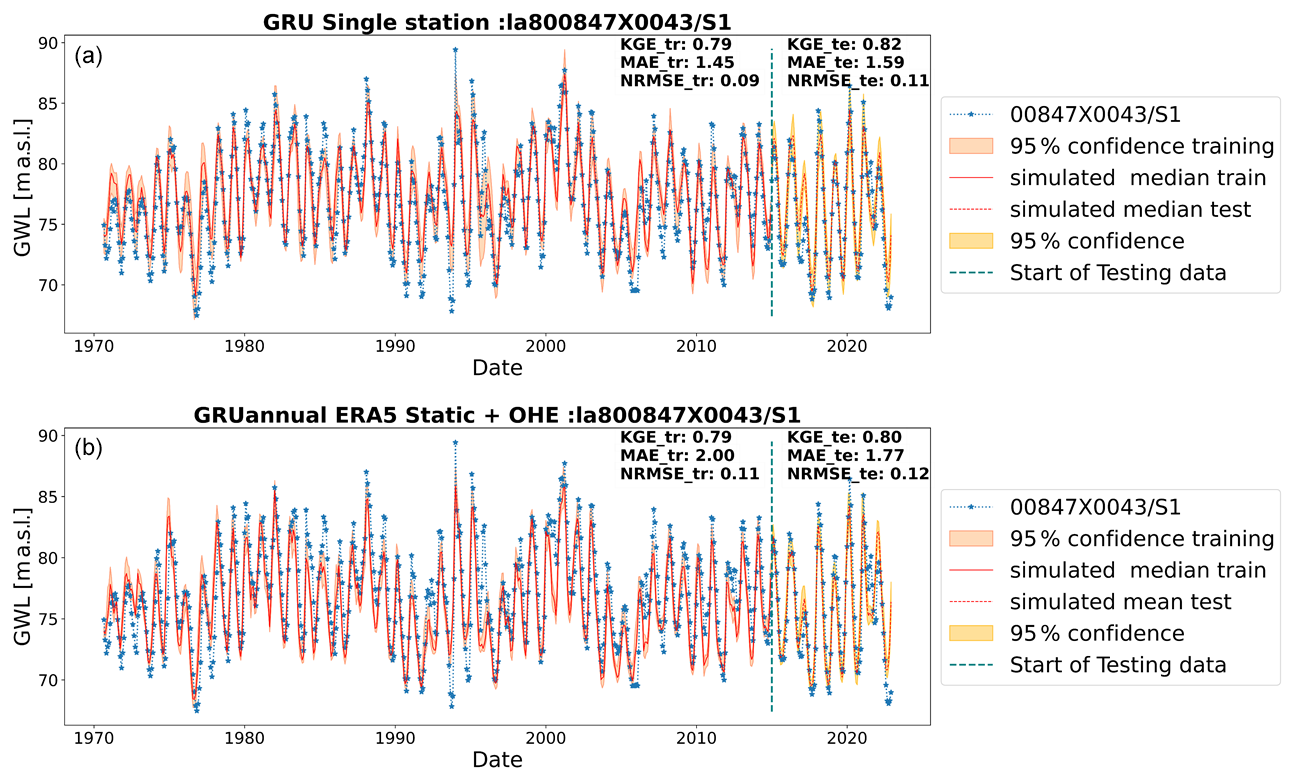
Figure 8Results with wavelet-assisted GRU in the annual type of GWLs through (a) single-station and (b) multi-station models trained on the annual type of GWLs with static attributes and OHE.
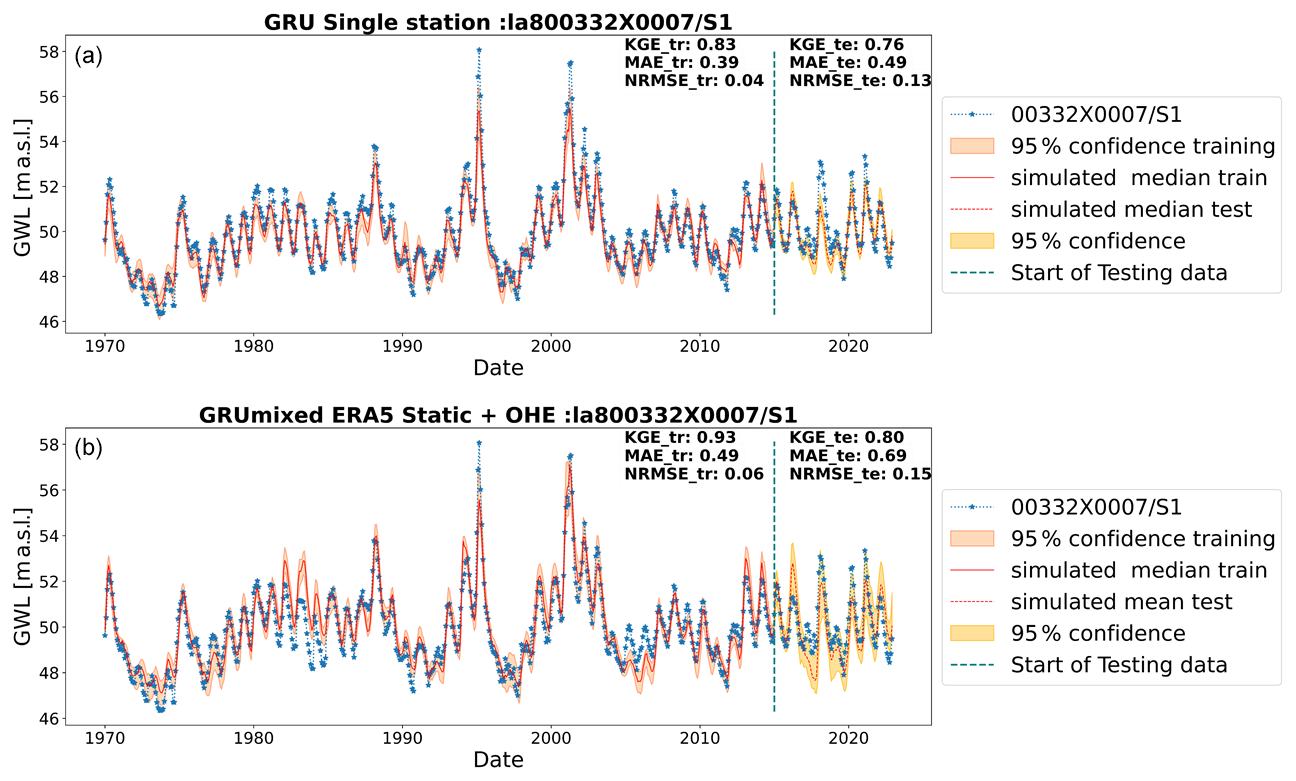
Figure 9Results with wavelet-assisted GRU in the mixed type of GWLs through (a) single-station and (b) multi-station models trained on the mixed type of GWLs with static attributes and OHE.
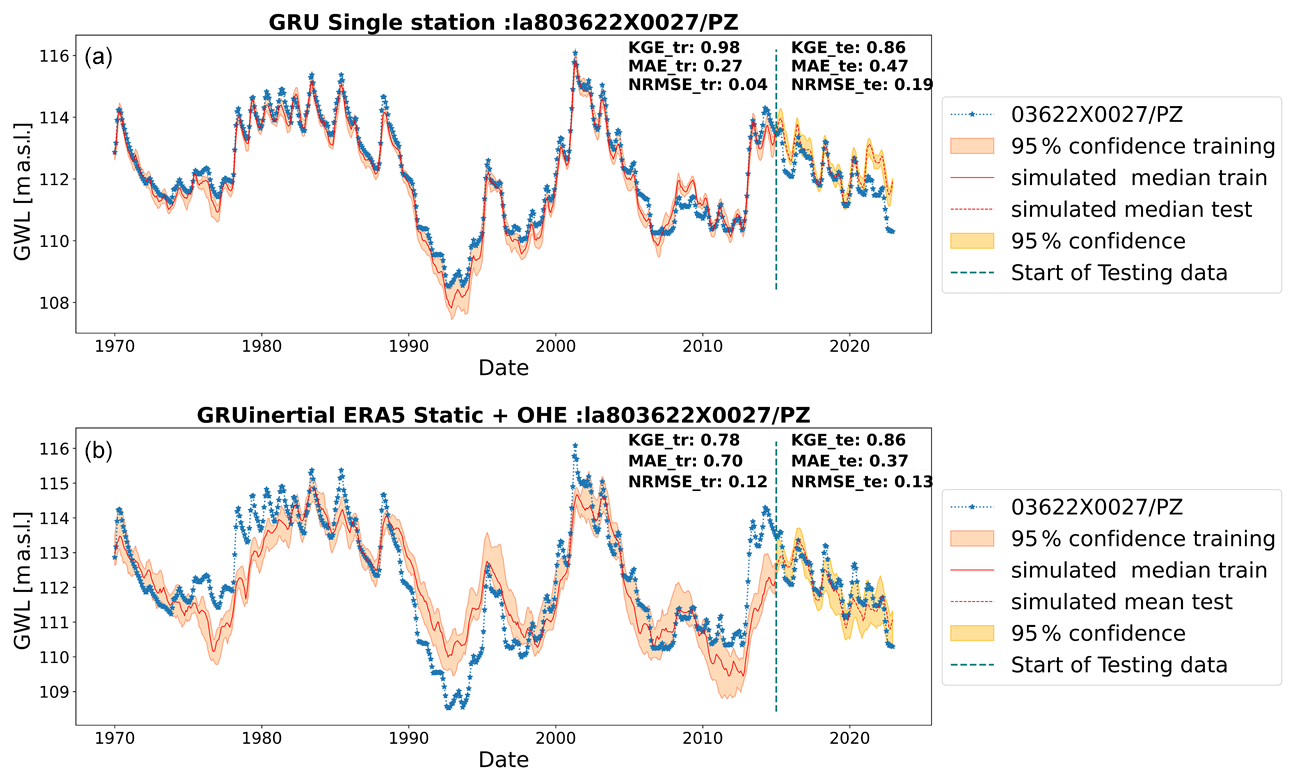
Figure 10Results with wavelet-assisted GRU in the inertial type of GWLs through (a) single-station and (b) multi-station models trained inertial type of GWLs with static attributes and OHE.
Figures 8–10 show the best GWL simulations obtained of different types (annual, mixed, and inertial) for single and multi-station models. For those particular cases, both approaches perform similarly and lead to good performance. However, the single-station modelling seems to perform best for inertial GWL type for training by simple visual assessment, and it is clear from the comparison of KGE values of all stations (Fig. 7) that the more specialised single-station models generally gave the best results overall, although not significantly. This is more specifically true for inertial GWL, where regional model performances reach the same level as single-station models. While single-station models perform well, multi-station models are valuable when single-station modelling is impractical due to data limitations or computational requirements. For instance, for inertial types where the length of training data might be an issue (e.g. Chidepudi et al., 2024), the performance of the wavelet multi-station models was completely comparable to single-station models (Fig. 7, wavelet models/inertial types), showing that in the case of data limitation, the regional approach seems to compensate for the lack of temporal depth of available time series.
In summary, wavelet-assisted GRU models are particularly effective, especially for low-frequency dominated GWL behaviour, and multi-station models designed for specific GWL types (i.e. training over specific pre-clustered datasets) generally outperform generalised models. The multi-station approach is sensitive to the dominant GWL type in the training dataset, with the best results identified in models trained for the predominant mixed GWL type. To address the issue of models learning dominant behaviour in the collective training of multi-station approaches, future investigations may involve generating synthetic time series with randomised amplitude changes of constituting frequencies to increase the dataset while balancing all the important behaviours. This could also help in understanding the influence of the size of the dataset on using multi-station approaches.
4.2 Understanding GWL simulations through SHAP interpretability
This section deals with a deeper understanding of the simulations from the insights obtained from the SHAP analysis on the model's interpretability. Here, we investigated the key contributing factors for GWL simulations in different approaches that were previously evaluated above in terms of accuracy.
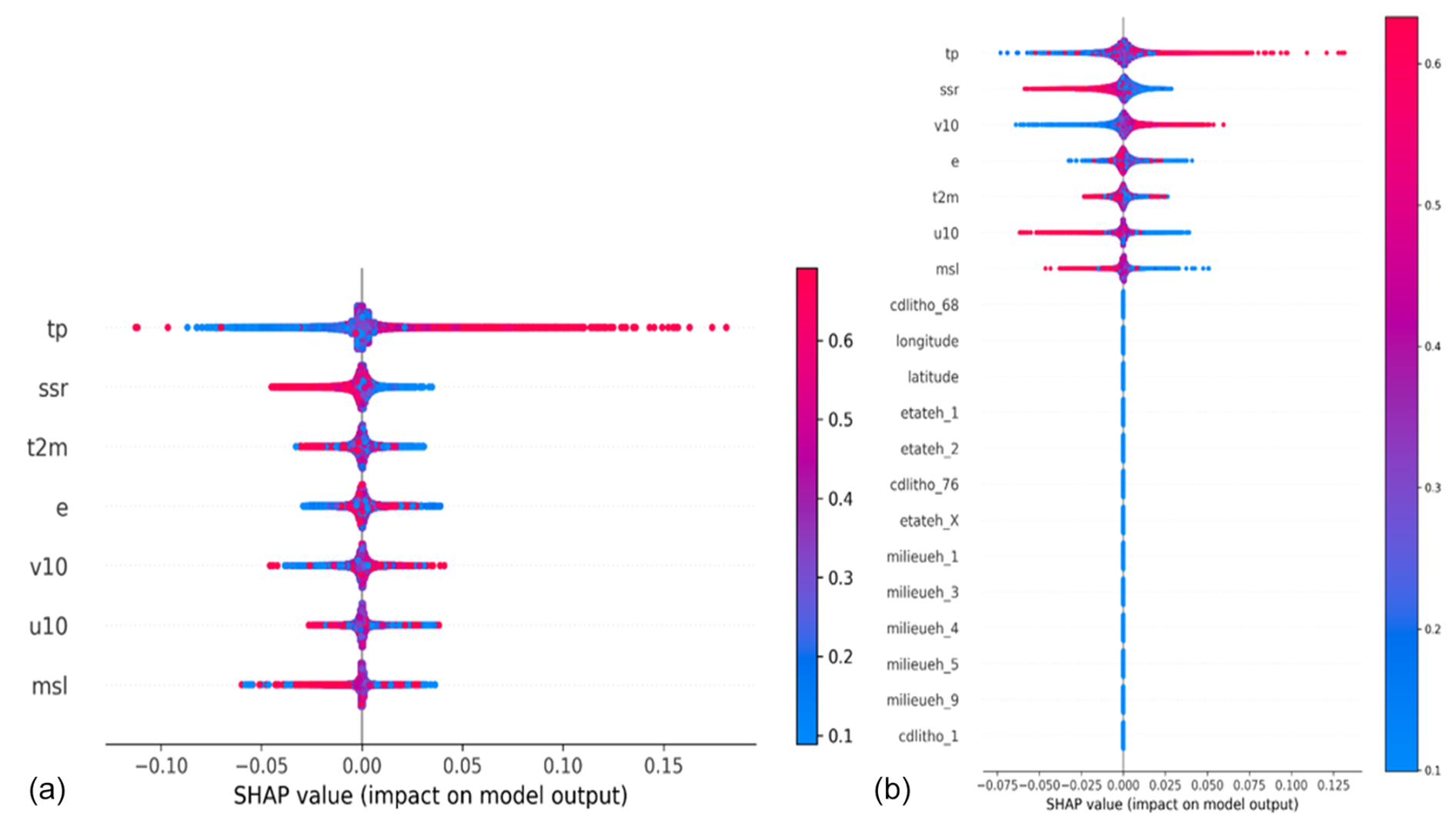
Figure 11SHAP summary plot examples for single-station models (a) and multi-station models with static attributes (b). The colour bar shows the range of feature values, with red depicting larger values and blue referring to smaller ones.
Figure 11a shows the SHAP representative summary plot for the standalone models using a single-station approach. These plots highlight the influence of different variables/attributes on the final simulation. In particular, the distribution of data points on the SHAP diagram indicates either a positive (right side on the x axis) or negative (left side on the x axis) impact on the output variable. In contrast, the colour scale indicates the range of feature values in which red represents large values, and blue represents small ones of the corresponding feature. Features (input variables) are organised from the most to the least influencing, from top to bottom, based on each feature's mean absolute SHAP values. For instance, in Fig. 11a, total precipitation (tp) is the most influencing feature on the GWL output, and the large feature values on the right (red) correspond to a positive influence on GWL (high GWL with high total precipitation). On the left side, negative tp SHAP values indicate lower precipitation values contributing to the low GWLs.
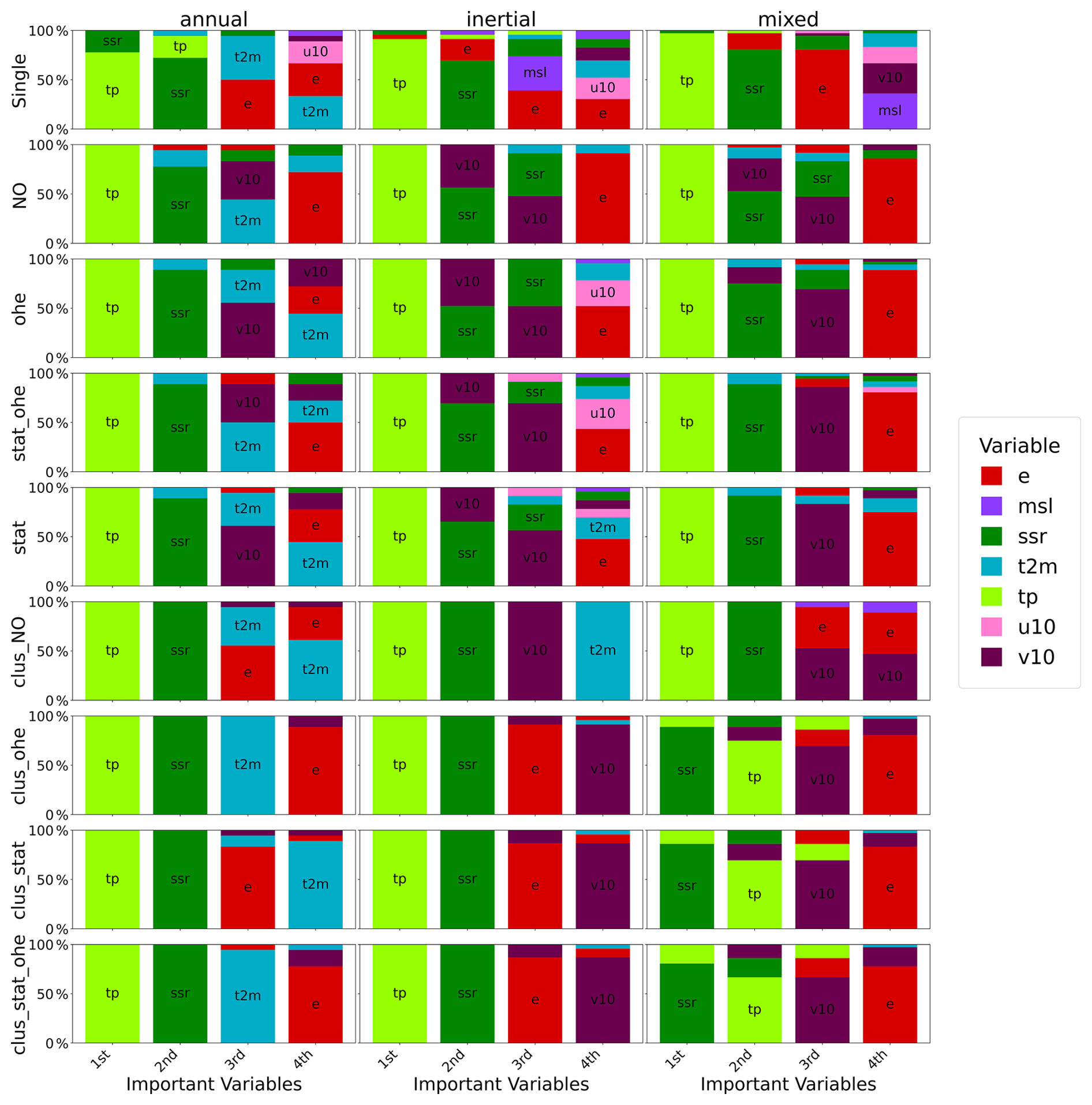
Figure 12Top four important variables by cluster for standalone GRU models with different approaches. On the y axis, percentage of stations for each variable within the cluster.
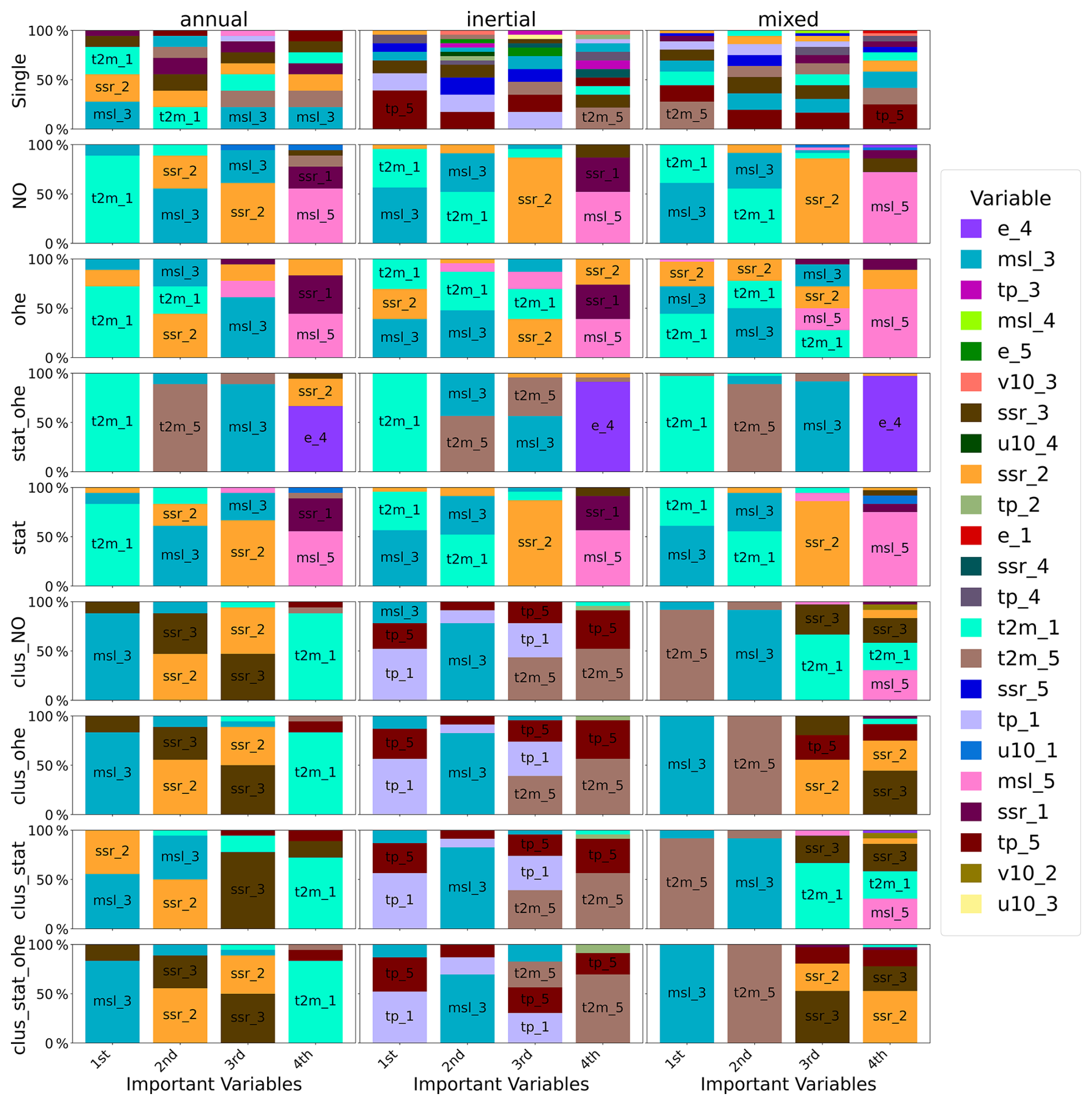
Figure 13Top four important variables in regional GRU wavelet-assisted models trained with different approaches for different classes: wavelet components of each variable are denoted by the numbers 1 to 5, where 1 represents highest frequency and 5 represents the lowest.
From the analysis of Figs. 12 and 13, several notable patterns emerge regarding the contribution of different variables to GWL simulations using standalone models and those with wavelet pre-processing and the impact of clustering as well as pre-clustering based on spectral statistical properties.
In single-station standalone models, SHAP analysis shows that certain variables consistently influence GWL simulations, although their order of importance can change. Total precipitation (tp) emerges as the key factor, with surface net solar radiation (SSR) occasionally overtaking tp in importance, particularly in mixed GWL clusters. This is especially evident in models trained on clusters, along with static features, or one-hot encoding (OHE). Nonetheless, tp and SSR are the primary drivers in these simulations.
In multi-station standalone models without clustering, tp and SSR lead in importance among all variables, followed by wind speed at 10 m (v10), evaporation (e), and air temperature close to the ground (2 m temperature, t2m), which vary in their influence. Notably, v10 plays a bigger role in models in multi-station approaches. When models are trained on clusters, evaporation becomes more significant, yet the impact of clustering on variable importance is generally minor.
The spectral statistical characteristics (amplitude of high and low frequencies) were used for the pre-clustering of GWLs. These characteristics are related to the filtering of the input signal by the physical properties of the hydrological system. This highlights the importance of pre-clustering in capturing the physical characteristics of basins and suggests that it may be preferable to cluster based on these properties rather than relying on static attributes, especially when the relevance of static attributes is uncertain.
SHAP analyses show that standalone models maintain similar variable importance rankings even after clustering with static attributes and OHE. However, wavelet pre-processing shifts the importance towards dynamic components, reducing the contributions of static features or OHE. When clustering is combined with wavelet pre-processing, low-frequency precipitation components emerge as key contributors, improving model performance.
When models are trained after clustering, low-frequency components (e.g. tp_5, t2m_5) are prioritised in mixed and inertial clusters: components not seen without clustering. Annual types prioritise relevant frequencies (1 to 3), consistent with single-station model patterns. The addition of static attributes to the OHE does not significantly alter the contributions, suggesting a dominance of dynamic variables after decomposition. Also, differences among multi-station approaches after clustering are minimal for both standalone and wavelet models.
Wavelet pre-processing performs a similar function to pre-clustering based on spectral properties by revealing information across all frequencies, including low-amplitude frequencies that may be obscured. The order of best approaches is based on the results: wavelet and pre-clustering, followed by pre-clustering only, then wavelet only, and finally standalone, highlighting the effectiveness of this approach.
There is a clear pattern when clustering is applied; without clustering the high-frequency component of the 2 m temperature (T2m_1) is dominant. Multi-station models show less diversity in variable contributions than single-station models. The exception is the Stat_OHE without clustering approach, which uniquely captures low-frequency information from T2m_5 and e_4. Otherwise, the static and NO approaches gave similar results.
The influence of static attributes or OHE appears to be minimal, possibly due to the high dimensionality introduced by numerous dynamic and static attributes. This observation suggests that future research could investigate alternative methods, such as target encoding, to address this dimensionality issue. It is also true that deeper investigation on the most relevant static attributes linked to hydrologic response could be conducted. Yet the purpose of this study was not to determine the forcing factors of GWL variations; in this aim, a more comprehensive evaluation of such links would require specific approaches that have been undertaken and presented in several previous works (Lee et al., 2019; Heudorfer et al., 2019; Liesch and Wunsch, 2019; Haaf et al., 2020; Giese et al., 2020). In some of our previous works (albeit for the Normandy region only), the linkages between GWL variability and potential forcing factors, such as the thickness and lithology of surficial formations, aquifer thickness, vadose zone thickness, upstream/downstream location along the flow path, distance to the river, and presence of karst, were investigated using dedicated approaches combining multivariate analysis, clustering, and spectral analysis of GWL time series (Slimani et al., 2009; El Janyani et al., 2012, 2014). These studies showed that GWL dynamics could be related to some basin and aquifer properties, although these relationships remained rather complex. In a recent study, Haaf et al. (2023) developed an innovative methodological approach for modelling GWL at unmonitored locations using basin properties and machine learning on a daily time-step basis for alluvial aquifers with hydraulic conductivity that is quite high overall (median around 10−2 m s−1). Their models performed quite well in representing GWL variations at both intra- and interannual timescales using physiographic, land cover and geological characteristics. However, the amplitude of low-frequency, interannual to decadal variability of the dataset used in their study was much lower than what could be encountered in our monthly time-step database. The specific type of aquifer that Haaf et al. (2023) investigated likely explains their high sensitivity to many surface processes. In our study, alluvial aquifers only represented approximately 10 % of the GWL stations (8 over 76 stations) and were only of annual (3 stations) or mixed (4 stations) types. Almost all other wells were located in chalk or limestones.
In the framework of our study, we decided to exclude characteristics such as vadose or saturated zone thickness. Such variables have been used in previous studies (El Janyani et al., 2012, 2014; Haaf et al., 2023) and considered static (averaged over long periods of time) to investigate the impact of (hydro)geological and geomorphologic characteristics on GWL behaviours. However, in our study, it was not relevant to consider such characteristics as “static” since they are linked to the varying GWL which we aim to simulate. Other types of static characteristics reflecting the hydraulic properties of the aquifers, such as hydraulic conductivity, transmissivity, porosity, or storativity, were also discarded. While informative in terms of hydrological knowledge, it is likely that (1) their availability may not be guaranteed over large areas, hence limiting their usefulness, and (2) their representativeness as numeric values might be questionable in contexts where spatial heterogeneity is high: in such cases, more general qualitative descriptors such as “fissured” or “porous” might be preferable, as using precise values of hydraulic conductivity, etc., would likely make the models very sensitive to hydraulic heterogeneity, which can not be accounted for so precisely. In addition, in a recent and relevant study on “entity-aware deep learning models with static attributes,” Heudorfer et al. (2024) highlighted that the models developed did not actually show any entity awareness and eventually utilised static attributes as simple identifiers (almost similar to the OHE approach presented herein), meaning that the models did not make use of relevant and precise (hydro)geological information.
Although the added value of static variables was found to be marginal in the present study, they may prove useful in settings where no measurement is available. Further research is required to determine their utility in simulating such ungauged hydro systems. The approaches presented (except OHE) may apply to ungauged aquifers but require validation in a pseudo-ungauged environment. The use of data from multiple stations can enrich the dataset, improving the representation of groundwater systems and the robustness of the models. This multi-station approach also allows the model to be applied to areas without GWL monitoring, thereby capturing regional dynamics. However, single-station modelling remains important for understanding local interactions. The choice of method should, therefore, be guided by research objectives, data availability, and the hydrogeological context. Where clustering results in too many groups, future studies should consider fine-tuning the general model for each cluster, following the approach of Anderson and Radić (2022).
This study has explored different multi-station approaches to GWL simulations with emphasis on the use of static attributes, one-hot encoding, and the combination of both while training on all available data or by training on each GWL type based on the clustering. Our results highlight the potential of these approaches compared to the traditional single-station approach with and without the use of BC-MODWT. Key findings from this research highlight the advantages of clustering based on spectral properties, which significantly improve the results of multi-station models, surpassing those of general models. As highlighted above, clustering should be preferred over the use of static attributes, as the use of static attributes alone may not be sufficient to effectively distinguish different behaviours. Wavelet pre-processing is very effective at extracting relevant information at all timescales, allowing low-frequency dominated GWLs to be handled with increased accuracy. The combination of clustering and wavelet pre-processing produced the most accurate simulations, indicating that wavelet pre-processing likely captured key information needed for accurate modelling.
The study also showed that a multi-station approach, without clustering, should be used cautiously, as models tend to adopt dominant behaviour, which may not always be desirable. In scenarios where wavelet pre-processing is not applied, the combination of static attributes and OHE demonstrated promising results, particularly for GWLs dominated by low-frequency variability. However, the minimal effect of static attributes or OHE observed in wavelet-assisted models may be due to the high-dimensional nature of these variables (due to wavelet decomposition that increases the number of covariates), suggesting a potential avenue for future research to explore alternative encoding strategies, such as target encoding. SHAP analyses consistently identified key contributors across models, with clustered models highlighting the pivotal role of low-frequency components, especially precipitation and temperature, in achieving superior simulations for inertial and mixed types of GWL.
In this article, we introduced the following question: “what is the best way to leverage regionalised information?”. Our results suggest that this is highly dependent on the specific characteristics of the dataset, particularly the quantity and types of static attributes. It is generally expected that a much higher number of static attribute types would allow for a much better improvement of the multi-station simulation approach. However, our findings indicate that the most significant improvements in multi-station simulation approaches come from wavelet analysis and clustering techniques. The inclusion of static attributes provides minor additional enhancements, which can be valuable but are not the primary drivers of improvement. These findings align with those of Heudorfer et al. (2024), who found no substantial improvements using around 28 static features (including 18 environmental and 10 time-series-based). Also, as pointed out by these authors, employing static attributes for model training might be more relevant in applications involving larger scales (i.e. a spatial case that compasses variety of geological contexts as in continental or global) and/or more extensive datasets. Moreover, one must remember that a trade-off must be found between the number of static attributes required and data availability, especially for applications at ungauged sites. However, the use of static attributes and OHE yielded similar results in the gauged scenario and proved efficient in accounting for local station information, which aligns with the findings of Heudorfer et al. (2024). On the other hand, in the study presented herein, wavelet pre-processing allowed for deciphering the “hidden” dynamic components of GWL variability (i.e. by separating low-frequency variations from annual or intra-annual variability), which eventually corresponded to taking into account the influence of (hydro)geological, geomorphological and physiographic properties. Ultimately, the latter, which varies across the study region, operates a differential filtering effect of the input signals. Pre-clustering the dataset also yielded significant improvements that were even more noticeable when combined with wavelet pre-processing. However, owing to its capability of leveraging pre-processing the different frequency components in the time series of the whole dataset, wavelet pre-processing somehow acts in the same way as pre-clustering, which consists of grouping inertial (i.e. low-frequency dominated), mixed, and annual time series in different clusters.
In summary, although the study has led to a better understanding of GWL simulation approaches with limited static attributes, further research is needed to explore the potential influence of other physical basin properties, such as the thickness of overlying formations, altitude, and distance from the sea. It should also be pointed out that clustering can be a source of information on the physical properties of the basin. Indeed, the three groups determined in this study based on spectral properties indirectly carry information on the modalities of water transfer in the shallow formations and aquifer, which are controlled by the hydraulic properties of the basin. The study of the importance of using static data in groundwater modelling using deep learning tools needs to be extended to cover level prediction at sites with no piezometers. The insights gained here pave the way for future efforts to simulate GWLs in unmonitored or new locations, taking advantage of the robustness offered by multi-station models while recognising the value of single-station models for capturing local-scale interactions. Finally, it is noticeable through our study that the overall approach is compatible with a frugal AI approach (keeping in mind that our datasets are very small compared to classical big datasets from other fields like natural language processing): compact networks were tested and preferred (one layer), and Bayesian optimisation was used instead of grid search for hyperparameter tuning. In addition, multi-station approaches pave the way for transfer learning, reducing the need for specialised models and retraining new models. The way forward is clear: to improve the GWL simulations efficiently, we may need to adopt a nuanced mix of efficient input signal pre-processing, potentially new encoding strategies or a more straightforward way like physics-informed neural networks to incorporate all possible additional knowledge of the system, and possibly clustering. Yet, we would recommend using advanced pre-processing over clustering, which would allow for leveraging the same type of information while preventing the dataset from being separated and its size from being reduced.
All this work was conducted in Python version 3.8.13, and the code necessary for reproducing the results is provided at https://doi.org/10.5281/zenodo.14866126 (Chidepudi, 2025a) and in the GitHub repository at https://github.com/sivaramakrishnareddyc/GWL-DLMultistationApproaches (Chidepudi, 2025b).
All the data used in this study are publicly available. The ERA5 reanalysis data can be accessed from https://doi.org/10.24381/cds.f17050d7 (Hersbach et al., 2023). Groundwater level data were obtained from the ADES (Accès aux Données sur les Eaux Souterraines) database (https://ades.eaufrance.fr/, ADES Eaufrance, 2024; Winckel et al., 2022).
The supplement related to this article is available online at https://doi.org/10.5194/hess-29-841-2025-supplement.
SKRC: data curation, formal analysis, writing and conceptualisation of original draft, model development, model runs, and investigation. NM: funding acquisition, supervision, writing and co-conceptualisation of the original draft (review and editing), and project administration. AJ: supervision, writing (review and editing), and project administration. BD: review and editing. AH: supervision, review and editing, and project administration. MF: review and editing.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
We acknowledge the computational resources provided by CRIANN to carry out the experiments as part of our ongoing project. DL models were built using TensorFlow (Abadi et al., 2015) and Keras (Chollet, 2015). All figures were prepared using Matplotlib (Hunter, 2007), pandas (McKinney, 2010), and NumPy (Harris et al., 2020). Bayesian optimisation was performed using Optuna software (Akiba et al., 2019). All background maps in the figures are from OpenStreetMap.
This research has been supported by the Région Normandie and the Bureau de Recherches Géologiques et Minières.
This paper was edited by Monica Riva and reviewed by two anonymous referees.
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., Irving, G., Isard, M., Jia, Y., Jozefowicz, R., Kaiser, L., Kudlur, M., Levenberg, J., Mané, D., Monga, R., Moore, S., Murray, D., Olah, C., Schuster, M., Shlens, J., Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V., Viégas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., and Zheng, X.: Large-Scale Machine Learning on Heterogeneous Systems, https://www.tensorflow.org (last access: 1 March 2024), 2015.
Addor, N., Newman, A. J., Mizukami, N., and Clark, M. P.: The CAMELS data set: catchment attributes and meteorology for large-sample studies, Hydrol. Earth Syst. Sci., 21, 5293–5313, https://doi.org/10.5194/hess-21-5293-2017, 2017.
ADES Eaufrance: France groundwater reference dataset, https://ades.eaufrance.fr/ (last access: 8 September 2023), 2024.
Ahmadi, A., Olyaei, M., Heydari, Z., Emami, M., Zeynolabedin, A., Ghomlaghi, A., Daccache, A., Fogg, G. E., and Sadegh, M.: Groundwater Level Modeling with Machine Learning: A Systematic Review and Meta-Analysis, Water, 14, 949, https://doi.org/10.3390/w14060949, 2022.
Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M.: Optuna: A Next-generation Hyperparameter OptimizationFramework, in: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD '19, Association for Computing Machinery, New York, NY, USA, 2623–2631, ISBN 978-1-4503-6201-6, https://doi.org/10.1145/3292500.3330701, 2019.
Anderson, S. and Radić, V.: Evaluation and interpretation of convolutional long short-term memory networks for regional hydrological modelling, Hydrol. Earth Syst. Sci., 26, 795–825, https://doi.org/10.5194/hess-26-795-2022, 2022.
Bai, T. and Tahmasebi, P.: Graph neural network for groundwater level forecasting, J. Hydrol., 616, 128792, https://doi.org/10.1016/j.jhydrol.2022.128792, 2023.
Baulon, L., Allier, D., Massei, N., Bessiere, H., Fournier, M., and Bault, V.: Influence of low-frequency variability on groundwater level trends, J. Hydrol., 606, 127436, https://doi.org/10.1016/j.jhydrol.2022.127436, 2022a.
Baulon, L., Massei, N., Allier, D., Fournier, M., and Bessiere, H.: Influence of low-frequency variability on high and low groundwater levels: example of aquifers in the Paris Basin, Hydrol. Earth Syst. Sci., 26, 2829–2854, https://doi.org/10.5194/hess-26-2829-2022, 2022b.
Beven, K. and Young, P.: A guide to good practice in modeling semantics for authors and referees, Water Resour. Res., 49, 5092–5098, https://doi.org/10.1002/wrcr.20393, 2013.
Cai, H., Shi, H., Liu, S., and Babovic, V.: Impacts of regional characteristics on improving the accuracy of groundwater level prediction using machine learning: The case of central eastern continental United States, J. Hydrol., 37, 100930, https://doi.org/10.1016/j.ejrh.2021.100930, 2021.
Chidepudi, S. K. R.: sivaramakrishnareddyc/GWL-DLMultistationApproaches: Scripts (Dlmodels), Zenodo [code], https://doi.org/10.5281/zenodo.14866126, 2025a.
Chidepudi, S. K. R.: GWL-Multistation Approaches, GitHub [code], https://github.com/sivaramakrishnareddyc/GWL-DLMultistationApproaches (last access: 14 February 2025), 2025b.
Chidepudi, S. K. R., Massei, N., Henriot, A., Jardani, A., and Allier, D.: Local vs. regionalised deep learning models for groundwater level simulations in the Seine basin, EGU General Assembly 2023, Vienna, Austria, 24–28 Apr 2023, EGU23-3535, https://doi.org/10.5194/egusphere-egu23-3535, 2023a.
Chidepudi, S. K. R., Massei, N., Jardani, A., Henriot, A., Allier, D., and Baulon, L.: A wavelet-assisted deep learning approach for simulating groundwater levels affected by low-frequency variability, Sci. Total Environ., 865, 161035, https://doi.org/10.1016/j.scitotenv.2022.161035, 2023b.
Chidepudi, S. K. R., Massei, N., Jardani, A., and Henriot, A.: Groundwater level reconstruction using long-term climate reanalysis data and deep neural networks, J. Hydrol., 51, 101632, https://doi.org/10.1016/J.EJRH.2023.101632, 2024.
Cho, K., van Merrienboer, B., Bahdanau, D., and Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches, in: Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, Association for Computational Linguistics, arXiv [preprint], 103–111, https://doi.org/10.48550/arXiv.1409.1259, 2014.
Chollet, F.: Keras, GitHub [code], https://github.com/keras-team/keras (last access: 1 March 2024), 2015.
Clerc-Schwarzenbach, F., Selleri, G., Neri, M., Toth, E., van Meerveld, I., and Seibert, J.: Large-sample hydrology – a few camels or a whole caravan?, Hydrol. Earth Syst. Sci., 28, 4219–4237, https://doi.org/10.5194/hess-28-4219-2024, 2024.
El Janyani, S., Massei, N., Dupont, J., Fournier, M., and Dörfliger, N.: Hydrological responses of the chalk aquifer to the regional climatic signal, J. Hydrol., 464–465, 485–493, https://doi.org/10.1016/j.jhydrol.2012.07.040, 2012.
El Janyani, S., Dupont, J. P., Massei, N., Slimani, S., and Dörfliger, N.: Hydrological role of karst in the Chalk aquifer of Upper Normandy, France, Hydrogeol. J., 22, 663–677, https://doi.org/10.1007/s10040-013-1083-z, 2014.
Fang, K., Kifer, D., Lawson, K., Feng, D., and Shen, C.: The Data Synergy Effects of Time-Series Deep Learning Models in Hydrology, Water Resour. Res., 58, e2021WR029583, https://doi.org/10.1029/2021WR029583, 2022.
Gholizadeh, H., Zhang, Y., Frame, J., Gu, X., and Green, C. T.: Long short-term memory models to quantify long-term evolution of streamflow discharge and groundwater depth in Alabama, Sci. Total Environ., 901, 165884, https://doi.org/10.1016/j.scitotenv.2023.165884, 2023.
Giese, M., Haaf, E., Heudorfer, B., and Barthel, R.: Comparative hydrogeology – reference analysis of groundwater dynamics from neighbouring observation wells, Hydrolog. Sci. J., 65, 1685–1706, https://doi.org/10.1080/02626667.2020.1762888, 2020.
Graves, A. and Schmidhuber, J.: Framewise phoneme classification with bidirectional LSTM and other neural network architectures, Neural Networks, 18, 602–610, 2005.
Gualtieri, G.: Analysing the uncertainties of reanalysis data used for wind resource assessment: A critical review, Renew. Sust. Energ. Rev., 167, 112741, https://doi.org/10.1016/j.rser.2022.112741, 2022.
Gupta, H. V., Kling, H., Yilmaz, K. K., and Martinez, G. F.: Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling, J. Hydrol., 377, 80–91, https://doi.org/10.1016/j.jhydrol.2009.08.003, 2009.
Haaf, E., Giese, M., Heudorfer, B., Stahl, K., and Barthel, R.: Physiographic and climatic controls on regional groundwater dynamics, Water Resour. Res., 56, e2019WR026545, https://doi.org/10.1029/2019WR026545, 2020.
Haaf, E., Giese, M., Reimann, T., and Barthel, R.: Data-driven estimation of groundwater level time-series at unmonitored sites using comparative regional analysis, Water Resour. Res., 59, e2022WR033470, https://doi.org/10.1029/2022WR033470, 2023.
Harris, C. R., Millman, K. J., J., S., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., Van Kerkwijk, M. H., Brett, M., Haldane, A., Del Río, J. F., Wiebe, M., Peterson, P. Gérard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., and Oliphant, T. E.: Array programming with NumPy, Nature, 585, 357–362, https://doi.org/10.1038/s41586-020-2649-2, 2020.
Hashemi, R., Brigode, P., Garambois, P.-A., and Javelle, P.: How can we benefit from regime information to make more effective use of long short-term memory (LSTM) runoff models?, Hydrol. Earth Syst. Sci., 26, 5793–5816, https://doi.org/10.5194/hess-26-5793-2022, 2022.
Hauswirth, S. M., Bierkens, M. F. P., Beijk, V., and Wanders, N.: The potential of data driven approaches for quantifying hydrological extremes, Adv. Water Resour., 155, 104017, https://doi.org/10.1016/J.ADVWATRES.2021.104017, 2021.
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020.
Hersbach, H., Bell, B., Berrisford, P., Biavati, G., Horányi, A., Muñoz Sabater, J., Nicolas, J., Peubey, C., Radu, R., Rozum, I., Schepers, D., Simmons, A., Soci, C., Dee, D., and Thépaut, J.-N.: ERA5 monthly averaged data on single levels from 1940 to present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/cds.f17050d7, 2023.
Heudorfer, B., Haaf, E., Stahl, K., and Barthel, R.: Index-based characterization and quantification of groundwater dynamics, Water Resour. Res., 55, 5575–5592, https://doi.org/10.1029/2018WR024418, 2019.
Heudorfer, B., Liesch, T., and Broda, S.: On the challenges of global entity-aware deep learning models for groundwater level prediction, Hydrol. Earth Syst. Sci., 28, 525–543, https://doi.org/10.5194/hess-28-525-2024, 2024.
Hochreiter, S. and Schmidhuber, J.: Long Short-Term Memory, Neural Comput., 9, 1735–1780, https://doi.org/10.1162/neco.1997.9.8.1735, 1997.
Hunter, J. D.: Matplotlib: a 2D graphics environment, Comput. Sci. Eng., 9, 90–95, https://doi.org/10.1109/MCSE.2007.55, 2007.
Jafari, M. M., Ojaghlou, H., Zare, M., and Schumann, G. J. P.: Application of a novel hybrid wavelet-anfis/fuzzy c-means clustering model to predict groundwater fluctuations, Atmosphere, 12, 1–15, https://doi.org/10.3390/atmos12010009, 2021.
Jahangir, M. S. and Quilty, J.: Generative deep learning for probabilistic streamflow forecasting: conditional variational auto-encoder, J. Hydrol., 629, 130498, https://doi.org/10.1016/J.JHYDROL.2023.130498, 2023.
Jahangir, M. S., You, J., and Quilty, J.: A quantile-based encoder-decoder framework for multi-step ahead runoff forecasting, J. Hydrol., 619, 129269, https://doi.org/10.1016/J.JHYDROL.2023.129269, 2023.
Kardan Moghaddam, H., Ghordoyee Milan, S., Kayhomayoon, Z., Rahimzadeh Kivi, Z., and Arya Azar, N.: The prediction of aquifer groundwater level based on spatial clustering approach using machine learning, Environ. Monit. Assess., 193, 1–20, https://doi.org/10.1007/s10661-021-08961-y, 2021.
Kayhomayoon, Z., Ghordoyee Milan, S., Arya Azar, N., and Kardan Moghaddam, H.: A New Approach for Regional Groundwater Level Simulation: Clustering, Simulation, and Optimization, Natural Resources Research, 30, 4165–4185, https://doi.org/10.1007/s11053-021-09913-6, 2021.
Kayhomayoon, Z., Ghordoyee-Milan, S., Jaafari, A., Arya-Azar, N., Melesse, A. M., and Kardan Moghaddam, H.: How does a combination of numerical modeling, clustering, artificial intelligence, and evolutionary algorithms perform to predict regional groundwater levels?, Comput. Electron. Agr., 203, 107482, https://doi.org/10.1016/J.COMPAG.2022.107482, 2022.
Kingston, D. G., Massei, N., Dieppois, B., Hannah, D. M., Hartmann, A., Lavers, D. A., and Vidal, J. P.: Moving beyond the catchment scale: Value and opportunities in large-scale hydrology to understand our changing world, Hydrol. Process., 34, 2292–2298, https://doi.org/10.1002/hyp.13729, 2020.
Klotz, D., Kratzert, F., Gauch, M., Keefe Sampson, A., Brandstetter, J., Klambauer, G., Hochreiter, S., and Nearing, G.: Uncertainty estimation with deep learning for rainfall–runoff modeling, Hydrol. Earth Syst. Sci., 26, 1673–1693, https://doi.org/10.5194/hess-26-1673-2022, 2022.
Kratzert, F., Klotz, D., Shalev, G., Klambauer, G., Hochreiter, S., and Nearing, G.: Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets, Hydrol. Earth Syst. Sci., 23, 5089–5110, https://doi.org/10.5194/hess-23-5089-2019, 2019.
Kratzert, F., Klotz, D., Hochreiter, S., and Nearing, G. S.: A note on leveraging synergy in multiple meteorological data sets with deep learning for rainfall–runoff modeling, Hydrol. Earth Syst. Sci., 25, 2685–2703, https://doi.org/10.5194/hess-25-2685-2021, 2021.
Kratzert, F., Nearing, G., Addor, N., Erickson, T., Gauch, M., Gilon, O., Gudmundsson, L., Hassidim, A., Klotz, D., Nevo, S., Shalev, G., and Matias, Y.: Caravan – A global community dataset for large-sample hydrology, Scientific Data, 10, 1–11, https://doi.org/10.1038/s41597-023-01975-w, 2023.
Lavers, D. A., Simmons, A., Vamborg, F., and Rodwell, M. J.: An evaluation of ERA5 precipitation for climate monitoring, Q. J. Roy. Meteor. Soc., 148, 3152–3165, https://doi.org/10.1002/qj.4351, 2022.
Lee, S., Lee, K. K., and Yoon, H.: Using artificial neural network models for groundwater level forecasting and assessment of the relative impacts of influencing factors, Hydrogeol. J., 27, 567–579, https://doi.org/10.1007/s10040-018-1866-3, 2019.
Li, X., Khandelwal, A., Jia, X., Cutler, K., Ghosh, R., Renganathan, A., Xu, S., Tayal, K., Nieber, J., Duffy, C., Steinbach, M., and Kumar, V.: Regionalization in a Global Hydrologic Deep Learning Model: From Physical Descriptors to Random Vectors, Water Resour. Res., 58, e2021WR031794, https://doi.org/10.1029/2021WR031794, 2022.
Liesch, T. and Wunsch, A.: Aquifer responses to long-term climatic periodicities. J. Hydrol., 572, 226–242, https://doi.org/10.1016/j.jhydrol.2019.02.060, 2019.
Lundberg, S. M. and Lee, S.-I.: A Unified Approach to Interpreting Model Predictions, in: Advances in Neural Information Processing Systems, arXiv [perprint], 4765–4774, https://doi.org/10.48550/arXiv.1705.07874, 2017.
Massei, N., Kingston, D. G., Hannah, D. M., Vidal, J.-P., Dieppois, B., Fossa, M., Hartmann, A., Lavers, D. A., and Laignel, B.: Understanding and predicting large-scale hydrological variability in a changing environment, Proc. IAHS, 383, 141–149, https://doi.org/10.5194/piahs-383-141-2020, 2020.
McKinney, W.: Data structures for statistical computing in python, in: Proceedings of the 9th Python in Science Conference, Austin, TX, 445, 51–56, https://doi.org/10.25080/Majora-92bf1922-00a, 2010.
Momeneh, S. and Nourani, V.: Forecasting of groundwater level fluctuations using a hybrid of multi-discrete wavelet transforms with artificial intelligence models, Hydrol. Res., 53, 914–944, https://doi.org/10.2166/NH.2022.035, 2022.
Muñoz-Carpena, R., Carmona-Cabrero, A., Yu, Z., Fox, G., and Batelaan, O.: Convergence of mechanistic modeling and artificial intelligence in hydrologic science and engineering, PLOS Water, 2, e0000059, https://doi.org/10.1371/journal.pwat.0000059, 2023.
Nourani, V. and Komasi, M.: A geomorphology-based ANFIS model for multi-station modeling of rainfall–runoff process, J. Hydrol., 490, 41–55, https://doi.org/10.1016/J.JHYDROL.2013.03.024, 2013.
Nourani, V., Hosseini Baghanam, A., Adamowski, J., and Kisi, O.: Applications of hybrid wavelet-Artificial Intelligence models in hydrology: A review, J. Hydrol., 514, 358–377, https://doi.org/10.1016/j.jhydrol.2014.03.057, 2014.
Nourani, V., Alami, M. T., and Vousoughi, F. D.: Wavelet-entropy data pre-processing approach for ANN-based groundwater level modeling, J. Hydrol., 524, 255–269, https://doi.org/10.1016/J.JHYDROL.2015.02.048, 2015.
Nourani, V., Mohammad, A. T., and Daneshvar Vousoughi, F.: Hybrid of SOM-Clustering Method and Wavelet-ANFIS Approach to Model and Infill Missing Groundwater Level Data, J. Hydrol. Eng., 21, 05016018, https://doi.org/10.1061/(ASCE)HE.1943-5584.0001398, 2016.
Nourani, V., Gökçekuş, H., and Gichamo, T.: Ensemble data-driven rainfall-runoff modeling using multi-source satellite and gauge rainfall data input fusion, Earth Sci. Inform., 14, 1787–1808, https://doi.org/10.1007/s12145-021-00615-4, 2021.
Nourani, V., Ghareh Tapeh, A. H., Khodkar, K., and Huang, J. J.: Assessing long-term climate change impact on spatiotemporal changes of groundwater level using autoregressive-based and ensemble machine learning models, J. Environ. Manage., 336, 117653, https://doi.org/10.1016/J.JENVMAN.2023.117653, 2023.
Paniconi, C. and Putti, M.: Physically based modeling in catchment hydrology at 50: Survey and outlook, Water Resour. Res., 51, 7090–7129, https://doi.org/10.1002/2015WR017780, 2015.
Patra, S. R., Chu, H. J., and Tatas: Regional groundwater sequential forecasting using global and local LSTM models, J. Hydrol., 47, 101442, https://doi.org/10.1016/j.ejrh.2023.101442, 2023.
Quilty, J. and Adamowski, J.: Addressing the incorrect usage of wavelet-based hydrological and water resources forecasting models for real-world applications with best practices and a new forecasting framework, J. Hydrol., 563, 336–353, https://doi.org/10.1016/j.jhydrol.2018.05.003, 2018.
Rajaee, T., Ebrahimi, H., and Nourani, V.: A review of the artificial intelligence methods in groundwater level modeling, J. Hydrol., 572, 336–351, https://doi.org/10.1016/j.jhydrol.2018.12.037, 2019.
Schuite, J., Flipo, N., Massei, N., Rivière, A., and Baratelli, F.: Improving the Spectral Analysis of Hydrological Signals to Efficiently Constrain Watershed Properties, Water Resour. Res., 55, 4043–4065, https://doi.org/10.1029/2018WR024579, 2019.
Slimani, S., Massei, N., Mesquita, J., Valdés, D., Fournier, M., Laignel, B., and Dupont, J. P.: Combined climatic and geological forcings on the spatio-temporal variability of piezometric levels in the chalk aquifer of Upper Normandy (France) at pluridecennal scale, Hydrogeol. J., 17, 1823–1832, https://doi.org/10.1007/s10040-009-0488-1, 2009.
Tarek, M., Brissette, F. P., and Arsenault, R.: Evaluation of the ERA5 reanalysis as a potential reference dataset for hydrological modelling over North America, Hydrol. Earth Syst. Sci., 24, 2527–2544, https://doi.org/10.5194/hess-24-2527-2020, 2020.
Vidal, P., Martin, E., Franchistéguy, L., Baillon, M., and Soubeyroux, M.: A 50 year high-resolution atmospheric reanalysis over France with the Safran system, Int. J. Climatol., 30, 1627–1644, https://doi.org/10.1002/joc.2003, 2010.
Vu, M. T., Jardani, A., Massei, N., and Fournier, M.: Reconstruction of missing groundwater level data by using Long Short-Term Memory (LSTM) deep neural network, J. Hydrol., 597, 125776, https://doi.org/10.1016/j.jhydrol.2020.125776, 2021.
Vu, M. T., Jardani, A., Massei, N., Deloffre, J., Fournier, M., and Laignel, B.: Long-run forecasting surface and groundwater dynamics from intermittent observation data: An evaluation for 50 years, Sci. Total Environ., 880, 163338, https://doi.org/10.1016/j.scitotenv.2023.163338, 2023.
Winckel, A., Ollagnier, S., and Gabillard, S.: Managing groundwater resources using a national reference database: the French ADES concept, SN Applied Sciences, 4, 1–12, https://doi.org/10.1007/s42452-022-05082-0, 2022.
Wunsch, A., Liesch, T., and Broda, S.: Deep learning shows declining groundwater levels in Germany until 2100 due to climate change, Nat. Commun., 13, 1–13, https://doi.org/10.1038/s41467-022-28770-2, 2022a.
Wunsch, A., Liesch, T., and Broda, S.: Feature-based Groundwater Hydrograph Clustering Using Unsupervised Self-Organizing Map-Ensembles, Int. Ser. Prog. Wat. Res., 36, 39–54, https://doi.org/10.1007/s11269-021-03006-y, 2022b.
Zare, M. and Koch, M.: Groundwater level fluctuations simulation and prediction by ANFIS- and hybrid Wavelet-ANFIS/Fuzzy C-Means (FCM) clustering models: Application to the Miandarband plain, J. Hydro-Environ. Res., 18, 63–76, https://doi.org/10.1016/J.JHER.2017.11.004, 2018.
- Abstract
- Introduction
- Study area and data
- Methodology: from single-station to multi-station training
- Capabilities, performances, and interpretability of multi-station approaches
- Concluding remarks
- Appendix A: Results from LSTM and BiLSTM
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Study area and data
- Methodology: from single-station to multi-station training
- Capabilities, performances, and interpretability of multi-station approaches
- Concluding remarks
- Appendix A: Results from LSTM and BiLSTM
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement