the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 01 Jun 2022
| 01 Jun 2022
Performance-based comparison of regionalization methods to improve the at-site estimates of daily precipitation
Abubakar Haruna
Juliette Blanchet
Anne-Catherine Favre
In this article, we compare the performance of three regionalization approaches in improving the at-site estimates of daily precipitation. The first method is built on the idea of conventional RFA (regional frequency analysis) but is based on a fast algorithm that defines distinct homogeneous regions relying on their upper-tail similarity. It uses only the precipitation data at hand without the need for any additional covariate. The second is based on the region-of-influence (ROI) approach in which neighborhoods, containing similar sites, are defined for each station. The third is a spatial method that adopts generalized additive model (GAM) forms for the model parameters. In line with our goal of modeling the whole range of positive precipitation, the chosen marginal distribution model is the extended generalized Pareto distribution (EGPD) to which we apply the three methods. We consider a dense network composed of 1176 daily stations located within Switzerland and in neighboring countries. We compute different criteria to assess the models' performance in the bulk of the distribution and the upper tail. The results show that all the regional methods offered improved robustness over the local EGPD model. While the GAM method is more robust and reliable in the upper tail, the ROI method is better in the bulk of the distribution.
- Article
(2131 KB) - Full-text XML
- BibTeX
- EndNote





Flood events occurring at different timescales pose hazards that are of enormous consequences for life and property. Even though necessary for risk assessments and safe design, reliable prediction remains a challenge and a difficult task. Usually, in the context of risk assessment, river flows are simulated via hydrological models. These models take as inputs, among others, meteorological data such as temperature and precipitation. However, whatever the complexity of the model and how it represents the underlying hydrological behavior of the catchment, the accuracy, robustness, and reliability of the flood predictions rely on the quality of the input data.
Precipitation intensities, the key input signal, are modeled using probabilistic methods. Within this framework, a good probabilistic model should predict rainfall intensities of any return level, whether low, medium, or extreme, with reliable accuracy. Gamma distribution, a common choice over models such as log-normal, Weibull, and exponential, fails in this respect, as the tail is too light to model heavy intensities (Katz et al., 2002). Models based on the classical extreme value theory (EVT), such as generalized Pareto (GP), can model the upper tail, but one has to choose another model for the other intensities below the chosen threshold.
Since generalized Pareto distribution (GPD) has been favored in hydrological applications (see, e.g., Langousis et al., 2016), many authors in the framework of modeling the full range of observations have considered different approaches to adding flexibility to this model. A common approach is the use of mixture models where GPD is combined with another appropriate model for the bulk of the distribution (see the review in Scarrot and MacDonald, 2012). Mixture models, however, have the drawback of inflating the number of parameters to estimate (Naveau et al., 2016) and thus complexify statistical inference.
As an alternative, Naveau et al. (2016) proposed a model which is an extension of the GP (afterward called extended generalized Pareto distribution – EGPD). It has the advantage of avoiding the need for threshold selection (a drawback of GP) while being parsimonious by avoiding the use of mixtures. The model is Gamma-like in the lower tail and heavy-tailed (GP) in the upper tail, with a smooth transition in between. It is able to model adequately the entire range of positive precipitation, and many authors within the framework of rainfall modeling have used this model (e.g., Blanchet et al., 2015; Evin et al., 2018; Tencaliec et al., 2020; Le Gall et al., 2022).
Modeling the whole range of precipitation has various practical applications. For instance, in flood risk assessments, where stochastic precipitation generators are used to simulate long series of positive precipitation, extremes included (e.g., in Evin et al., 2018). The simulated precipitation is then used as input to conceptual hydrological models for the simulation of long series of river flows. Other practical applications are in the evaluation of numerical weather simulations or investigation of the climatology of rainfall events as outlined by Blanchet et al. (2019).
Although EGPD uses all the data to estimate the parameters, the shape parameter which controls the upper-tail behavior remains difficult to estimate based on a few decades of data, the usual length of precipitation data. This is because there are usually few extremes exhibiting much variability. As precipitation is spatial by nature, several studies (Cunnane, 1988; Burn, 1990; Hosking and Wallis, 2005) proposed the use of observations surrounding the local station to increase the number of data available for estimation, thereby reducing the uncertainty involved in the estimation.
Different methods exist in the literature to use information surrounding the station at hand (see Cunnane, 1988; Hosking and Wallis, 2005). Methods based on regional homogeneity (e.g., the method of Hosking and Wallis, 2005) pool all observations in hydrologically similar sites to increase the sample size and so yield more accurate estimates of the parameters. Hydrologically similar sites are first defined using cluster analysis and are then subjected to some statistical homogeneity tests on the scaled observations. Thereafter, a chosen distribution is fitted to the scaled observations in the identified region, and all stations within this region would share the same regional parameters. Station-specific parameters and quantiles can then be inferred by appropriate scaling. This method has been applied by various authors (e.g., Gaál and Kyselý, 2009; Malekinezhad and Zare-Garizi, 2014) and to various distributions such as the GEV and GP. Variants of this method exist, such as the region of influence (ROI) proposed by Burn (1990), which avoids defining fixed regions but assigns homogeneous regions (neighborhood of different shapes according to the method) for each site. Scaled observations within the neighborhood of each station are then used to estimate the regional parameters of that station. This method has been applied by various authors (see Gaál et al., 2008; Kyselý et al., 2011; Carreau et al., 2013; Evin et al., 2016; Das, 2017, 2019).
In contrast to the aforementioned methods that generally rely on some covariates such as spatial coordinates to define the homogeneous regions, another variant, recently developed by Le Gall et al. (2022), defines homogeneous regions based on the similarity of their upper-tail behavior. This method avoids the use of any covariate but relies completely on the precipitation data at hand. The upper-tail behavior for each station is summarized based on a ratio of probability-weighted moments (PWMs) (refer to Eq. 4). Subsequently, a clustering algorithm is used to partition these ratios into distinct homogeneous regions, and then regional parameters can be estimated.
Spatial methods exist in which all the observations from all the stations are pooled and then used to estimate the spatial surface for each of the model parameters. The surface for each of the model parameters is defined as a function of some well-chosen covariates such as longitude, latitude, or altitude. Estimating the parameters involves simply the estimation of the coefficients of these relationships. From the fitted surfaces, station-specific model parameters can be inferred as a function of the covariates at that specific location. Surfaces that are smooth and flexible can be obtained by fitting generalized additive models (GAMs) to the relationships (see Chavez-Demoulin and Davison, 2005; Blanchet and Lehning, 2010; Youngman, 2019, 2020). Other alternatives to the classical RFA include the Bayesian spatial modeling (see Madsen et al., 1995; Cooley et al., 2007) and those discussed in Cunnane (1988).
Recent analyses have been done to compare the performance of regional approaches with a particular interest in distributions allowing one to model extremes only. Gaál et al. (2008) compared different versions of the ROI method against the classical RFA method of Hosking and Wallis (2005). The ROI versions were distinguished by the choice of the distance metric and the maximum threshold to delineate neighborhoods. For all the methods, GEV distribution was assumed to be the underlying distribution. The authors, through a Monte Carlo simulation study, concluded that the ROI approach was superior to the classical RFA involving distinct clusters. In an interpolation framework, Carreau et al. (2013) compared three methods: spatial interpolation of locally estimated parameters, the ROI method, and a rainfall generator called SHYPRE. For the first two methods, GEV distribution was assumed. The authors found comparable performance between the ROI and SHYPRE and a lack of robustness in the method based on interpolation of local parameters. Deidda et al. (2021) also used GEV to compare the classical RFA of Hosking and Wallis (2005) and geostatistical interpolation of locally estimated parameters. They highlighted the limitation of the former in yielding distinct regions and being of less accuracy compared to the latter. Other comparisons include those of Gaál and Kyselý (2009), Kyselý et al. (2011), and Das (2019).
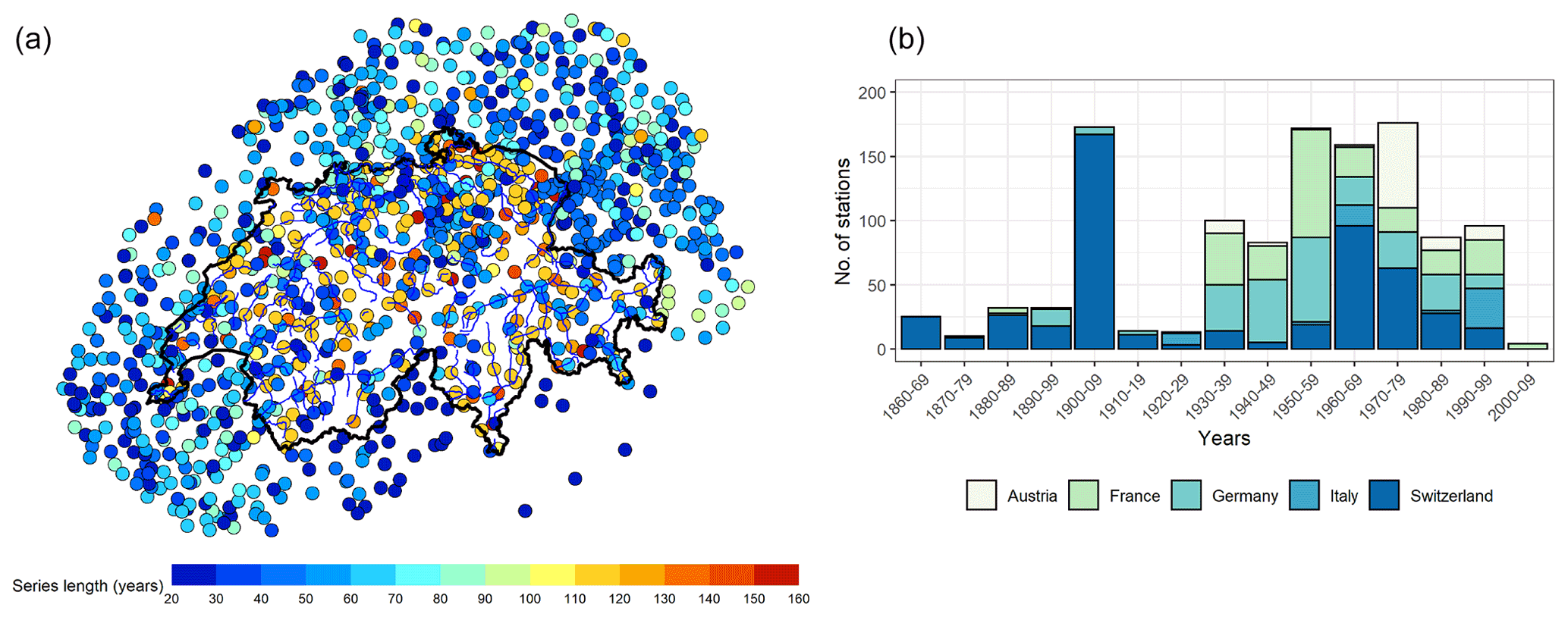
Figure 1Description of the data used for the study. (a) Map of Switzerland and the neighboring areas showing the locations of the 1176 daily stations. The color indicates the length of the series, a minimum of 20 years and a maximum of 156 years. (b) Bar plot showing the number of stations installed in each country for each decade.
Our approach differs from the aforementioned studies in the following respects. First, in contrast to the case where the underlying distributions are basically for modeling only extremes (e.g., Burn, 1990; Gaál et al., 2008; Gaál and Kyselý, 2009; Kyselý et al., 2011; Carreau et al., 2013; Evin et al., 2016; Das, 2019; Deidda et al., 2021), we consider the EGPD that models low, medium, and extreme precipitations. This is in line with our goal of having a robust and reliable model that can model the whole distribution and not only the extremes. Secondly, our comparison approach is more general and is based on Garavaglia et al. (2011) and Renard et al. (2013), focusing on the predictive ability of the models in a cross-validation framework similar to the case of authors such as Blanchet et al. (2015) and Evin et al. (2016) rather than simply based on quality of fit (e.g., Gaál et al., 2008; Kyselý et al., 2011; Deidda et al., 2021). Finally, in our contribution, we compare new methods not previously compared viz-a-viz. The first method defines distinct homogeneous regions based on their similarity in upper-tail behavior (Le Gall et al., 2022). The second method is based on the ROI approach framework of Evin et al. (2016). The last method is a spatial approach that assumes the GAM forms for the model parameters. For all the methods, we assume the EGPD to be the underlying marginal distribution. We apply this comparison to a dense network of over 1100 daily stations located within Switzerland and in the neighboring countries.
The paper is organized as follows: Sect. 2 presents the data and the study area. Section 3 introduces the competing models, while Sect. 4 describes the comparison methodology as well as the criteria used. The results are presented in Sect. 5. Finally, we discuss the conclusion and the relevant perspectives in Sect. 6.
The comparison is made considering daily precipitation observations from 1176 stations shown in Fig. 1. Of this total, 500 are located within Switzerland and 676 in the neighboring countries. The data have a variable length ranging from a minimum of 20 years to a maximum of 156 years, from 1863 to 2019. The bar plot in Fig. 1 shows the number of stations installed in each country during each decade of the study period. While the main study area is Switzerland, we use the data in the neighboring countries simply to improve the estimates of the stations located around the border of Switzerland. Consequently, although we use all the stations (both within and outside) for regionalization and model fitting, we apply the performance criteria only to the stations located in Switzerland.
Daily precipitation in Switzerland is characterized by seasonality arising from multiple moisture sources brought by prevailing winds (Sodemann and Zubler, 2009; Umbricht et al., 2013; Giannakaki and Martius, 2015). It is also characterized by spatial variability in both intensity and occurrence resulting from the complex topography (Sevruk, 1997; Sevruk et al., 1998; Frei and Scha, 1998; Molnar and Burlando, 2008; Isotta et al., 2014). Winter receives the least precipitation, and summer is the main season of precipitation all over Switzerland. An exception is in the case of Ticino in the south, where fall is the main season. This region is also subject to the heaviest precipitation. In the north of the country, the topography plays an important role: the northern rim and the Jura mountains receive heavier precipitation compared to the plateau.
As a result of the marked seasonality and the importance of taking it into account (Leonard et al., 2008; Garavaglia et al., 2011), we apply a seasonally based analysis approach. We divide the data into the four distinct seasons of 3 months each: winter (December, January, February), spring (March, April, May), summer (June, July, August), and fall (September, October, November).
In this section, we start by presenting the marginal distribution (EGPD). We then give a brief description of three different methods of regionalization that we will use to improve the local estimates of the EGPD. They are (i) regional frequency analysis based on the upper-tail behavior, (ii) the ROI approach, and (iii) the spatial method using GAM forms. Finally, we summarize the regional models that are developed based on the three outlined methods of regionalization as applied to the EGPD.
3.1 Marginal distribution of positive rainfall
We use the marginal distribution of rainfall proposed by Naveau et al. (2016), which is able to model sufficiently the full spectrum of positive (non-zero) rainfall. The model is EVT compliant in the upper and lower tails while providing a smooth transition in between. It provides an alternative to the light-tailed distributions such as Gamma, which can underestimate extremes (Katz et al., 2002). Four parametric families of this model have been proposed by Naveau et al. (2016) and more recently a non-parametric scheme of the transition function by Tencaliec et al. (2020). However, the simplest of the parametric family is parsimonious and can adequately model precipitation intensities without the need for GPD threshold selection (Naveau et al., 2016; Evin et al., 2018; Le Gall et al., 2022). We therefore use this model in our study.
Let X be a random variable representing positive daily precipitation intensity that is distributed according to the EGPD; then, the cumulative distribution function (CDF) is given by
where G is any CDF that ensures a smooth transition between the EVT-compliant upper and lower tails, and
with .
For the parsimonious model we use, the function G is simply defined as G(v)=vk. Therefore, the model is given as
The model has three parameters. k>0 controls the lower tail, ξ≥0 controls the upper tail, and σ>0 is the scale parameter.
Inference of the model parameters can be done through maximum likelihood estimation (MLE) or through the method of PWMs.
3.2 Methods of regionalization
3.2.1 RFA based on upper-tail behavior
Classical regional frequency analysis (Hosking and Wallis, 2005) defines regions that are homogeneous up to a scaling factor. To identify the regions, covariates have to be carefully chosen, which usually include at-site characteristics such as geographical and atmospheric characteristics. However, this information might not be generally available at each station. Homogeneity tests then have to be applied to confirm that the regions are sufficiently similar.
Le Gall et al. (2022) proposed a fast and efficient method to delineate regions based on the homogeneity of their upper-tail behavior. The method relies on the precipitation data at hand, only without the need for additional covariates. More so, regions identified are inherently homogeneous, thereby avoiding the need for the application of some homogeneity tests. For each station i, a ratio ω given in Eq. (4) that is based on PWMs is obtained.
where denotes the PWM of order j.
The authors showed that ω summarizes the upper-tail behavior of the data at hand, and for the EGPD model, this depends mainly on the ξ parameter (the effect of k is not very significant; see Le Gall et al., 2022). Stations with high values of ω have high intense extremes, and those with low values have less intense extremes. The idea is to classify or form regions with similar values of ω, which is possible using any of the clustering algorithms, such as K-means, hierarchical clustering, or partitioning around medoids (PAM). For details of these clustering methods, see Kaufman and Rousseeuw (2005).
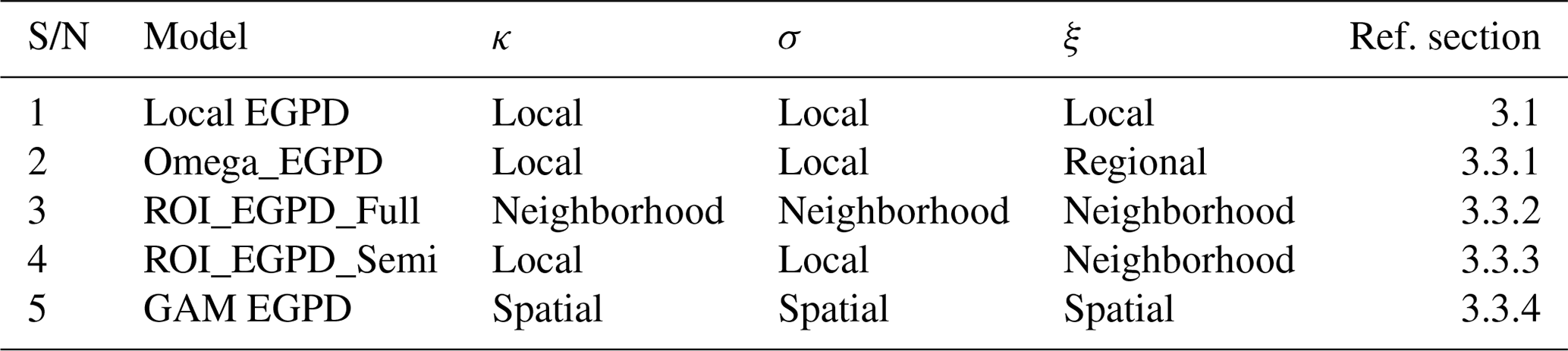
Table 1Summary of the regional models that are compared in this study. The first model is the local EGPD model, the next three models are based on regional homogeneity, and the last model is a spatial method based on GAM. The second column gives the name of the model. The next three columns are the parameters of the EGPD model and indicate whether the parameter is estimated locally (from the data of the station at hand only) or through regionalization. The last column gives a reference to the section where the method is described.
3.2.2 RFA based on the ROI approach
The ROI method (Burn, 1990) is similar in concept to the classical RFA method. It circumvents the drawback of having contiguous regions separated by distinct boundaries that result in “undesirable step changes of the variables and estimated quantiles” (Gaál et al., 2008). Instead of defining distinct homogeneous regions separated by some boundaries, a region of influence is assigned to each station. All the scaled observations in the identified ROI are used to estimate its regional parameters. To apply this method, several choices have to be made. These involve the choice of the scale factor, distance metric, radius delimitation, and homogeneity test. The choices influence the application of the method and have to be carefully and objectively decided on. Different authors in the application of the methods have explored some or all of these factors, starting from Burn (1990) and in Gaál et al. (2008).
In this work, we follow the objectively selected steps and choices similarly to Evin et al. (2016) in the application of the method in the southeastern part of France. The authors applied the method by considering peaks over threshold (POT) (exceedances of a 70 % quantile) of central rainfalls (largest observations in 3 d rainfall events) and of some distributions (exponential, GPD, and Weibull). We apply the same procedure but to positive rainfall and the EGPD model.
3.2.3 Spatial method based on the GAM
In contrast to the previous methods where regionalization is based on homogeneity of normalized data or upper-tail similarity, this is a regression-based method for fitting the parameters of models by allowing for spatial non-stationarity of the parameters. Accordingly, we pool all the observations from all the stations to estimate flexible and smooth spatial surfaces for each parameter, relying on the basis that pooling of spatial information can help improve the at-site estimates and hence the extreme quantiles. In particular, we let the parameters have a GAM form, represented by smoothing splines. In effect, we assumed them to have some form of flexible relationship with some covariates x, which can be explained by GAM forms.
3.3 Regional models
This section summarizes the regional models that are compared in the study. The models are built based on the concepts of the three regionalization methods outlined in Sect. 3.2. Table 1 presents the four models plus the local EGPD model.
3.3.1 Omega_EGPD model
This model is built based on the regionalization method described in Sect. 3.2.1, i.e., RFA based on upper-tail behavior. To build this model that relies on regionalization of the shape parameter, the following steps are followed.
-
For each station i, use the positive data to estimate the ratio .
-
Identification of homogeneous regions: use an appropriate clustering algorithm alongside an internal validation criterion to decide on the optimal number of homogeneous clusters based on the estimated . In our case, after doing a simulation study (result not shown), we settled on the PAM algorithm and three criteria, silhouette (Rousseeuw, 1987), Davies–Bouldin (DB) (Davies and Bouldin, 1979), and S_Dbw (Halkidi and Vazirgiannis, 2001).
-
For each homogenous region C,
- a.
fit EGPD locally to find (ki, σi, and ξi),
- b.
find the regional shape parameter ξr as the average of all ξi in that region, and
- c.
fit EGPD locally again to find new estimates and , given the estimated ξr.
- a.
We have also explored other options to estimate ξr after obtaining the homogeneous regions.
-
The first method involves pooling all the observations in a homogeneous region (cluster) after scaling them by their mean and then fitting a regional EGPD to estimate the regional parameters (k(R), σ(R), and ξ(R)). We then retain ξ(R) and then refit an EGPD locally to estimate ki and σi. Every station in that cluster will have similar ξ(R) but locally estimated ki and σi.
-
The second approach is similar to the main method, where we take the average of the locally estimated ξ, but here we take a weighted average. The idea is that, for each cluster, the locally estimated ξ for the medoid station (the station with the least average dissimilarity to all the other stations in the same cluster) should be assigned the highest weight in the average. All other stations should then have weights as a function of their dissimilarity to this medoid. Thus, very similar stations to the medoid should have higher weights, while those that are less similar should have smaller weights. The dissimilarity is measured by the Manhattan distance |ωm−ωi|, where ω is given in Eq. (4), while the indices m and i denote, respectively, the medoid and the station i.
After testing these three approaches to estimate ξr, by measuring the accuracy of the resulting quantile–quantile plot according to the normalized root mean square error (NRMSE) (see Sect. 4 for details of this criterion), results (not shown here) showed that the first method, where we simply take the average of the locally estimated ξ, resulted in the least error. We thus retain this approach in our subsequent analysis.
3.3.2 ROI EGPD full model
This model is based on the method of ROI described in Sect. 3.2.2.
Let be the random variable of daily positive rainfall at station i which is distributed according to EGPD. We also assume that is the daily positive rainfall normalized by a scale factor mi. If we consider several stations (whose data have been normalized as well) that have a similar distribution to Yi and use the data to estimate the regional parameters k(R), σ(R), and ξ(R), then Yi will have parameters . Accordingly, by back transformation, the unnormalized random variable Xi will have the parameters . This shows that for a random variable that is distributed according to EGPD, after regionalization, the parameters k and ξ are those obtained regionally, while the scale parameter σ has to be multiplied by the scale factor for that station.
The general procedure of application is summarized below, and the details can be found in Evin et al. (2016).
-
For each station and season, exceedances of a threshold of 95 % quantile (POT) are selected and scaled by a factor. The scale factor is the mean of all positive daily precipitation.
-
We start the search from a radius of 2 km starting from the current station. If we find other stations within this radius, we apply the homogeneity test to the scaled POT found in step 1. If the test is positive, we increase the radius by another 2 km and repeat the test. We stop the search when the test fails or when we reach a maximum radius beyond which we doubt the existence of homogeneity. We use 100 km as the upper bound.
-
The distance metric we use is the “crossing distance” (Gottardi et al., 2012) given in Eq. (5). This distance takes into account the effect of elevation and is summed over all the pixels along a straight line between two targeted stations. We use a weight on elevation equal to 20 similarly to Evin et al. (2016) to account for the effect of relief. Again, following the same authors, we use the test of Hosking and Wallis (2005) on mean and L coefficient of variation (L CV).
-
We estimate the regional parameters by a weighted MLE on the scaled positive observations in the ROI. The target station has the highest weights, and the closer the station, the higher the weights.
The full regional model is such that . We call this model ROI_EGPD_Full afterward.
3.3.3 ROI_EGPD_Semi model
This model follows exactly as ROI_EGPD_Full in the preceding section. The only difference is that here we retain the regional shape parameter ξ(R) obtained from the neighborhood and then estimate the two other parameters locally, i.e., from only the data at station i. We refer to this model as ROI_EGPD_Semi.
The semi-regional model is such that .
3.3.4 GAM EGPD model
For this spatial EGPD model, we have , where x denotes some covariate and each of the model parameters depends on some form of x. The relationship between the model parameter (say α) and the covariate x is through an identity link:
where βkd and bkd are, respectively, the basis coefficients and the basis functions. K is the number of smooths and Dk is the dimension (number of knots) for smooth k.
For the choice of spatial covariates, we use longitude, latitude, and mean daily precipitation because they give a better Akaike information criterion (AIC) (Akaike, 1974). To fit EGPD with the GAM, we extended the functions already available in the evgam R package
(Youngman, 2020).
This section presents the comparison framework and the performance criteria used to compare the regional models.
4.1 Comparison framework
The evaluation framework and criteria are as proposed by Garavaglia et al. (2011) and Renard et al. (2013). Garavaglia et al. (2011) and the references therein argued that the classical statistical goodness-of-test fits such as the Kolmogorov–Smirnov test (Kolmogoroff, 1941; Sminorv, 1944), the Anderson–Darling test (Anderson and Darling, 1952), and the Cramer–von Mises criterion (Cramer, 1928; Darling, 1957) lack the ability to assess the models' ability to predict unobserved values and that they are also not very efficient for three-parameter distributions.
Accordingly, we follow a split sampling procedure and a cross-validation framework. For each station i, we used of the data by choosing every third observation to reduce temporal dependence. Then, we divide the non-zero observations into two equal sub-samples of the same length but in different years that are randomly chosen. We call the first and second sub-samples and . We then fit models and on sub-samples and , respectively. We then compute the criterion at station i by comparing vs. (i.e., a model fitted on sub-sample 1 vs. observations in sub-sample 2). In the same way, we compute the criterion . Given that we have N stations, and so N values of both and , the regional score is obtained as the average of these scores. This procedure is repeated 50 times to obtain 50 regional averages of these indices.
4.2 Evaluation criteria
For each method, four (4) criteria C are computed. We first judge the methods based on how they accurately fit all the observations at each site. Next, we compare them in terms of their robustness in extrapolation, i.e., how stable a high quantile estimate is, depending on which sub-sample is used in the estimate. We finally judge the performance based on the reliability to predict rainfall maxima.
In the following paragraphs, we describe the four criteria used for the comparison.
4.2.1 Accuracy of the whole distribution
The accuracy of the model in predicting the positive observations at a given station is given by the NRMSE (Blanchet et al., 2019). For each site i, the positive observed values in are associated with their empirical return periods. We then use the fitted model on , i.e., , to estimate the modeled quantiles associated with these return levels and finally to compute the NRMSE associated with these quantiles. The normalization is by the average daily rainfall. This score is given as
where is the score computed at station i, is the kth observation of return period T in , and is the corresponding T return level estimated from . The denominator is the average daily rainfall at site i. Details on the score are given in Blanchet et al. (2019).
Finally, the regional score computed over the N stations, i.e., , is given as
is computed in a similar way. We thus finally have 2 × 50 values of NRMSEreg resulting from the cross-validation in both periods. NRMSEreg=1 means a perfect model, and the closer the value is to 1, the more accurate the model is.
4.2.2 Continuous ranked probability score (CRPS)
The CRPS has been used as a metric to compare the performance of two competing probabilistic forecast models (Jordan et al., 2018). It gives a combined measure of both the spread and reliability of a forecast distribution, given the observation or outcome that is observed.
For a given observation xi,t at station i and time step t that is contained in , we have 50 of its quantile estimates coming from the 50 fitted models (models fitted with data not containing xi,t). If the method used to estimate all 50 models is accurate enough, then these 50 quantile estimates should be similar (low spread) and very close to the observed value xi,t. The same applies to an observation xi,t contained in when compared to its quantile estimates from the 50 models of . Thus, the CRPS of xi,t should be low, and when applied to all the observations at station i, the average, , should also be low.
The averaged over the observed data from time steps t=1 to t=Ti at station i is given as
where H(z) denotes the Heaviside function that is 0 if z≤0 and 1 otherwise. Fi,t(y) and xi,t are the CDF of the 50 estimates and the observed value at time step t of station i, respectively. Note that, for the cross-validation, if xi,t belongs to (), then Fi,t(y) will be the CDF of the 50 quantile estimates of the 50 models (). The smaller the score, the better the model.
Given that we have N stations, in the end, we will have N values of computed for each of the competing models. This is different from the other criteria, with 50 or 100 values per model.
4.2.3 Stability of the high quantile estimate
The robustness of a model is measured by the stability of a high quantile estimated from two sub-samples. A robust model should have a similar estimate of, say, a 100-year event, when the sub-sample/calibration data are changed. The SPAN criteria (Garavaglia et al., 2011; Blanchet et al., 2019) give the measure of the stability of a chosen quantile estimated from two sub-samples.
The score is computed as the absolute difference between the two quantile estimates divided by their average and is given as
where and are the T-year return levels estimated from and , respectively, at station i.
The score is computed for all the N stations, and the regional score SPANreg,T is computed as
In the end, we have 50 values of SPAN. A robust model should have a SPANreg,T of 1; therefore, the closer the value is to 1, the more stable/robust the model is.
4.2.4 Reliability in predicting the maximum observed value
The reliability of a model is defined as its ability to associate the correct probability with a given observation. Specifically, the FF criteria measure the reliability of the model in predicting the maximum value in a given sample. The score is defined as
where are the cross-validation criteria computed at station i by predicting the probability of the maximum value in sub-sample 2, , of sample size using the model fitted on sub-sample 1, .
According to Renard et al. (2013) and Blanchet et al. (2015), if the model is reliable, then is the realization of a uniform distribution. Accordingly, if we compute the score for all the stations, i.e., , we should end up with a set FF(12) of N realizations of a uniform distribution. Blanchet et al. (2015) therefore concluded that the area between the density of FF(12) and a uniform density should be close to zero.
The regional score is computed as 1−AREA(FF(12)), and is computed in a similar way. The closer the value is to 1, the more reliable the model is in prediction of the maxima. We have at the end 2 × 50 values of FFreg.
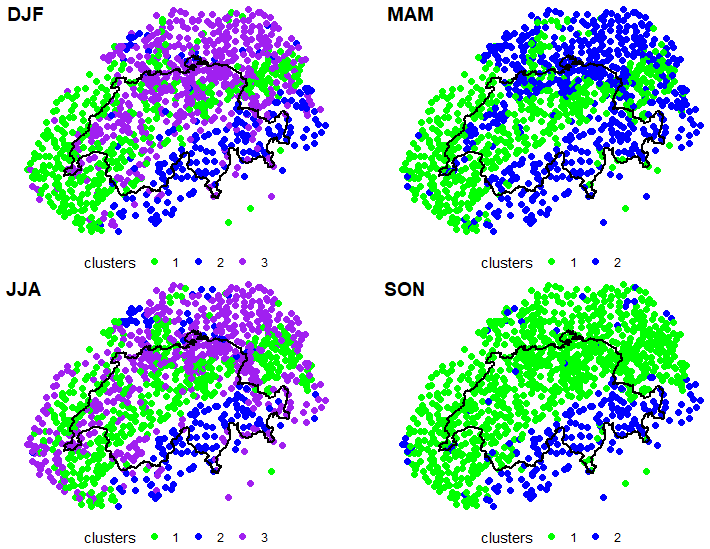
Figure 2Maps of Switzerland showing the optimal number of clusters identified with the PAM algorithm for each season. For each season, the regions identified are color-coded. From top left, going clockwise, DJF (two clusters), MAM (two clusters), JJA (three clusters) and SON (three clusters).
5.1 Estimated regions with RFA by upper-tail behavior
Figure 2 shows the optimal number of clusters identified for each season. We have three clusters in the case of winter (DJF), two in spring (MAM), three in summer (JJA), and two in fall (SON). Notably, although the spatial coordinates are not used, the identified clusters are somehow spatially plausible for each season. Stations in the south are generally in the same cluster. In the north, the stations located in the northern rim and the Jura generally fall in the same cluster. This is partly according to our knowledge of the spatial pattern of heavy precipitation in the respective seasons. A few stations for each season, however, appeared in clusters different from their neighbors.
5.2 Estimated regions with the ROI method
Figure 3 presents the neighborhoods found for each station. In panel a is the map of Switzerland showing the stations with the size corresponding to the size of the radius identified and the color indicating a local fit will be done (for stations without any neighbors) or a regional fit (for stations with at least one neighbor). For those without neighbors, the search sometimes terminated at a very small distance. This means that, although they have proximate neighbors according to the crossing distance, the homogeneity test failed. For some stations, however, no neighbors are found. These are stations whose closest neighbors are at large crossing distances, and the test failed after application.
In Fig. 3b, the histogram of the neighborhood size, as well as the average number of neighbors identified for each class, is shown. Only a few stations reach the bound of 100 km. The observed seasonal differences are due to the seasonality and spatial variability of daily precipitation in Switzerland. We recall that the identification of the regions for each station is based on the homogeneity of the scaled extremes. The occurrence of these extremes and their quantity, which affects the test of homogeneity (Evin et al., 2016), depends on the season and hence the observed seasonal differences.
In our subsequent experiments, we keep these neighborhoods and fit accordingly the model versions described in Sects. 3.3.2 and 3.3.3, i.e., ROI_EGPD_Full and ROI_EGPD_Semi. For all the stations without any neighborhood, we simply fit a local EGPD model.
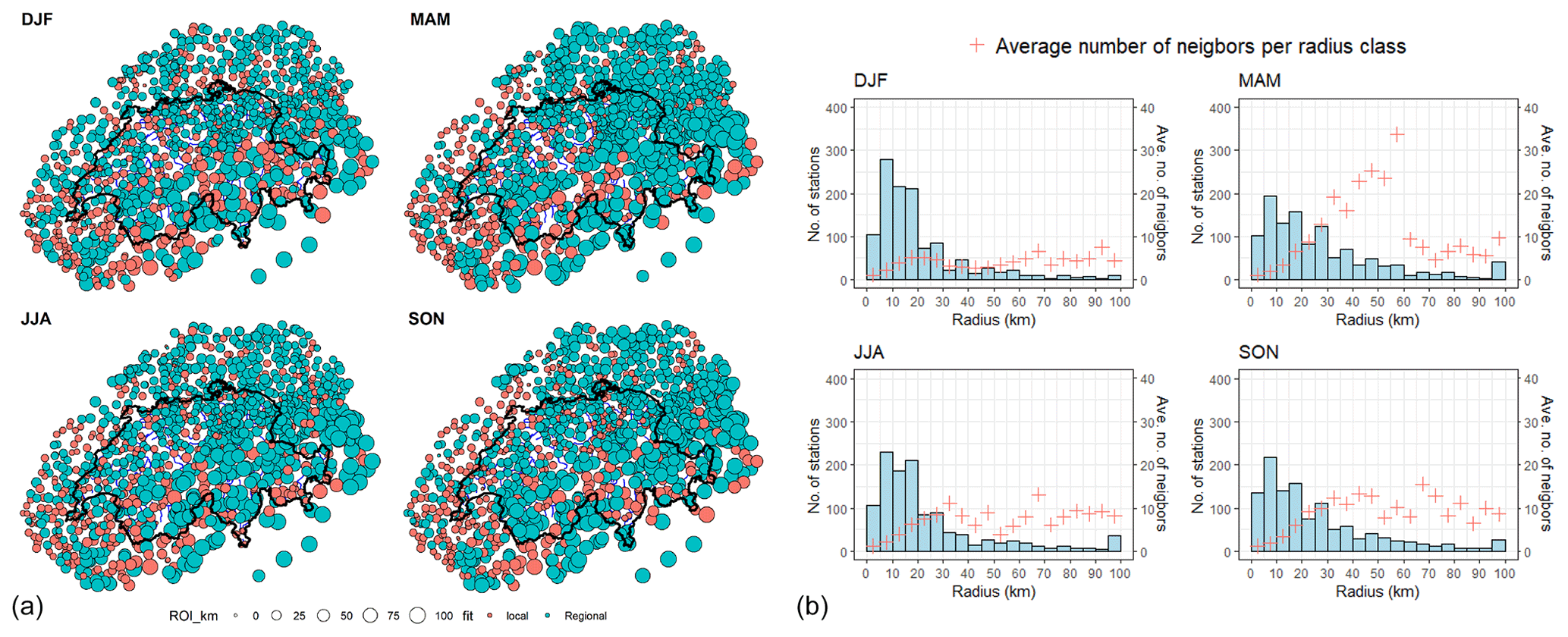
Figure 3Properties of the ROI identified for each station. (a) Seasonal maps showing the size of the ROI per station. For each season, the size of the circle is proportional to the ROI size: the smallest is 0 (km), and the largest is 100 (km). The color of the circle indicates whether a local fit is done or a regional fit. (b) Histogram of the size of the ROI identified. The red points indicate the average number of neighbors identified for each ROI class.
5.3 Choice of covariates in the GAM
Following the outlined methodology for the spatial model in Sect. 3.2.3, we present in this part the choice of covariate combinations made for the EGPD model.
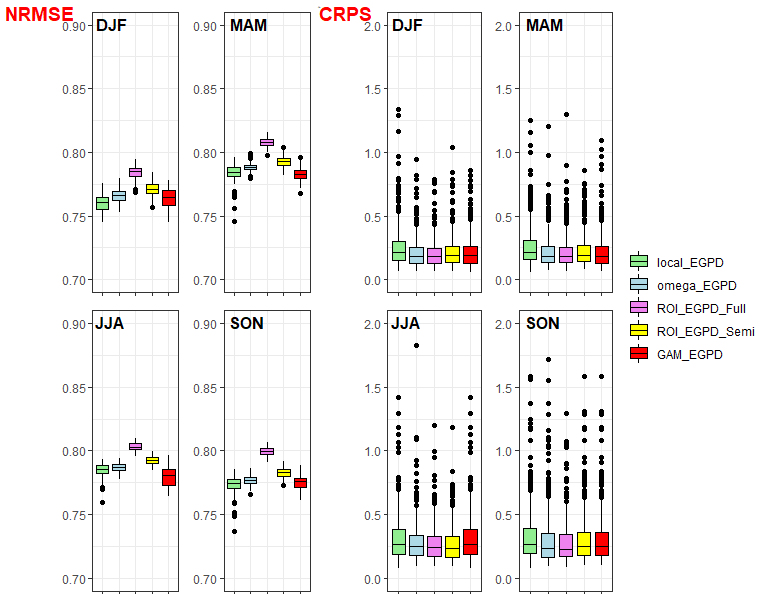
Figure 4Criteria applied to the bulk of the distribution for each season. Left: accuracy of the whole distribution as measured by the NRMSE; each box plot contains 100 values. Right: CRPS score; each box plot contains 500 points, 1 per station.
We use longitude, latitude, and the mean daily precipitation to explain the parameters of EGPD, that is, k, σ, and ξ. Other covariates would be possible, but we use these ones because they are readily available, and so estimation at ungauged locations would be possible. After testing different combinations of the covariates, we use the following forms for the relationships
where s(lon,lat) means a thin plate spline smooth s on the longitude lon and latitude lat, and s(m) means a cubic spline on the mean daily precipitation (m).
Although all three model parameters have to be positive, we still used the identity link function to reduce the complexity in the generation of the gradients of the negative likelihood function of the EGPD model (necessary for model fitting in GAM; see Wood et al., 2016). We, however, imposed constraints on the likelihood function to ensure that the parameters remain positive.
5.4 Model comparison
In this section, we present the results of the comparison between the competing models, as judged by the criteria introduced in Sect. 4. We remind the reader that the sampling was repeated 50 times for all the models, and so, for clarity, we show the box plots of the criteria. Each box plot contains 50 values of the criteria obtained per run in the case of SPAN, 100 in the case of FF and NRMSE, and 500 in the case of CRPS (500 corresponds to the number of stations in Switzerland which the criteria were computed on).
First, the accuracy/reliability of the models in the bulk of the distribution as measured by the NRMSE is shown on the left of Fig. 4. The results are shown per season, and the closer the value is to 1, the more accurate the model is. From this result we can clearly see that, for all seasons, the two models based on ROI are the most reliable. The ROI_EGPD_Full model (where we regionalize according to the ROI method, all three parameters of the EGPD model) is the best model compared to ROI_EGPD_Semi model 4 (where only the shape parameter is regionalized but the other two parameters are locally estimated). The performance of the other regional models is similar, and there is no large improvement in these models over the local EGPD model according to these criteria.
The CRPS score gives a combined measure of the spread and reliability of the competing models. A model should not only assign the correct probabilities to the observations, but the spread of the probabilities estimated from the different sub-samples (100 in our case) should also be low as well. We computed this score for all the positive observations at every station. The best model should have the smallest score.
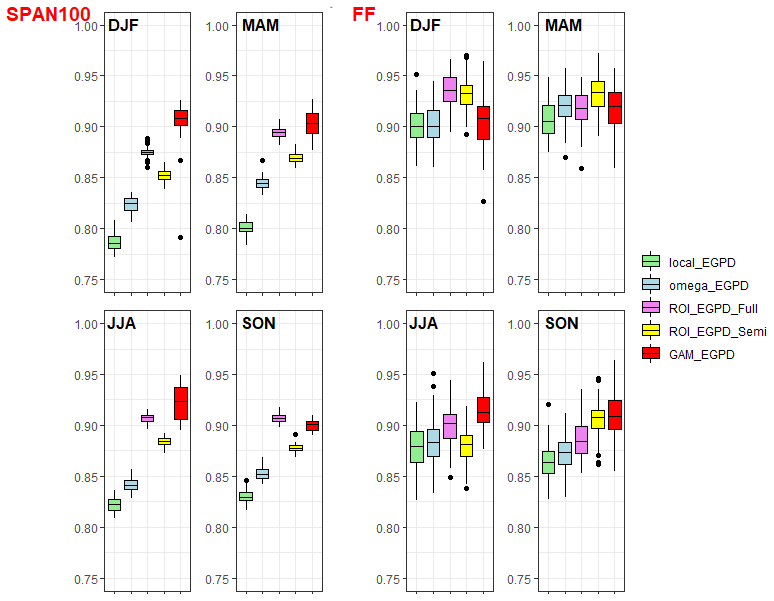
Figure 5Criteria applied to the upper tail for each season. Left: robustness of the local EGPD and the four candidate models, as measured by the SPAN criteria. The stability is measured with respect to a 100-year return-level estimate. Each box plot contains 50 values. Right: reliability in prediction of the maxima as measured by the FF criteria; each box plot contains 100 values.
The plot on the right of Fig. 4 presents the seasonal box plots for the CRPS of the five models. Each box plot consists of 500 points, 1 per station (recall the scores are computed for only the 500 stations located within Switzerland). From the box plots and the medians, it is clear that ROI_EGPD_Full has the smallest value of this score. For all seasons (except summer), the local model has the largest score, showing that the models offer improvement over the local model.
The stability/robustness of the estimate of a 100-year return level in between two periods as measured by the SPAN criteria is shown on the left of Fig. 5. Obviously, all the regional models show clear improvement in robustness over the local EGPD model. The spatial model (GAM_EGPD) shows the highest robustness over all the models, except in fall, when it is slightly overtaken by the ROI_EGPD_Full model. The results also show that, of all four regional models, the RFA model based on the upper tail (Omega_EGPD) has the smallest robustness. In the case of the two ROI models, ROI_EGPD_Full is more robust compared to the ROI_EGPD_Semi model. The former involves regionalizing all three model parameters, while the latter involves only the shape parameter regionalization. Looking at the two models where only the shape parameter is regionalized, the model based on ROI (ROI_EGPD_Semi) is more robust in all the seasons compared to the model based on upper-tail behavior that involves clustering (Omega_EGPD).
Finally, the FF score measures the reliability of the models in the upper tail, more precisely in the prediction of the maximum observed value. This criterion is also optimized at a value of 1. The plot on the right of Fig. 5 shows generally high values of this score for all the models, indicating that they are generally reliable in the prediction of the maximum observed value. For all the seasons, all the regional models appear to be more reliable compared to the local model. An exception is however in the case of Omega_EGPD in winter and ROI_EGPD_Semi in summer (looking at the median). In fall and summer, the GAM_EGPD model emerges as the most reliable. While in winter ROI_EGPD_Full is the most reliable, ROI_EGPD_Semi is the most reliable in spring.
Table 2Summary of the comparison results from the four criteria used. For each season and criterion, the model with the highest median is shown. In the case of the CRPS score, however, the model with the smallest median CRPS is shown.

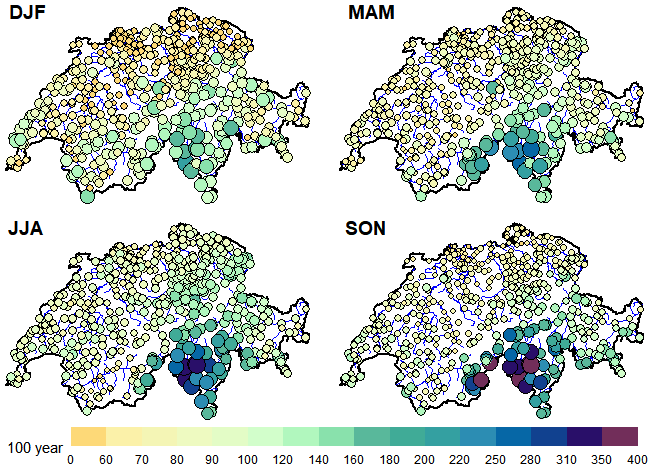
Figure 6Map of Switzerland showing the 100-year return level for the four seasons as predicted with the ROI_EGPD_Full model.
To conclude, we present an overall summary of the results in Table 2 by focusing on the median of the box plots. We also show the map of the seasonal 100-year return level predicted with the ROI_EGPD_Full model in Fig. 6. The maps reveal a clear seasonality and spatial pattern. Ticino in the south is subject to the highest levels, especially in the fall, where up to 400 mm can be expected.
The objective of this contribution was to compare three methods to improve the at-site estimates of daily precipitation. By considering a dense network of 1176 stations mainly located in Switzerland, we compared methods based on different philosophies to regionalize the estimation of daily precipitation. The first method defines homogeneous regions based on their upper-tail similarity. No covariate is used in the delineation of regions, but only the precipitation data at hand. The second method avoids defining “hard” clusters but assumes that every station has its homogeneous region that can be identified using homogeneity tests. The third method is spatially based, so all the data are used to estimate smooth and flexible surfaces for the model parameters. Pooling the data to estimate the surfaces thus ensures sharing of information between stations. Using these methods, we built four regional EGPD models and compared them. The comparison is based on the accuracy, robustness, and reliability of the models in a cross-validation framework. More precisely, we assessed the performance in both the bulk of the distribution (NRMSE and CRPS) and the upper tail (SPAN and FF).
In contrast to most comparative studies of regionalization approaches that focused on extreme distributions (GEV or POT), we assumed the daily data to follow the EGPD. This distribution can adequately model the full spectrum of precipitation intensities. It has the elegant property of being EVT compliant in both the upper and lower tails while providing for a smooth transition in between.
The results showed that regionalization offers improvement in robustness and reliability even in the case of a full-scale model (EGPD) that includes all the data in the estimation of its parameters.
From the four criteria used, the performance depends on the season, but we can still draw the following conclusions.
-
In terms of the reliability/accuracy over the whole distribution, the ROI model (ROI_EGPD_Full), with all parameters regionalized, emerged as the most accurate.
-
Reliability in the prediction of the maxima, as measured by FF, indicated that the GAM is the most reliable, especially in the seasons with the heaviest rainfall (summer and fall).
-
The GAM emerged as the most robust (SPAN) and is followed closely by the ROI model (ROI_EGPD_Full).
In conclusion, two models compete hand in hand: the ROI model (ROI_EGPD_Full) and the GAM. When we focus on the bulk of the distribution (NRMSE and CRPS), ROI_EGPD_Full is the best model. When we however focus on the far tail (FF and SPAN), the GAM is the best. As Garavaglia et al. (2011) pointed out, the two properties of reliability and robustness are complementary. For two models of similar reliability, the model with the best robustness should be preferred. Given this, the GAM on EGPD, combining both properties in the upper tail, can be said to be the preferred method. We note, however, a major drawback of the GAM. It requires significant computational time as compared to the ROI, especially in our case, where we have a dense network (1176 stations) with long series (up to 156 years for some stations), and we use all the positive precipitation. In practice, thus, it would be much easier to use ROI compared to the GAM, given that the performance of both is similar and the former is more reliable when we consider the whole distribution (a feature of interest in our case), not only maxima.
It is worth noting that, in the course of the present study, we focused our evaluation at the station level, where we have observations. A further step will be to assess the models more generally by looking at their performance at ungauged locations in spatial cross-validation as done by Blanchet and Lehning (2010), Carreau et al. (2013) or more generally the framework proposed by Blanchet et al. (2019). In this respect, the spatial model based on the GAM offers a key advantage over the other methods since it inherently results in a regional model that can be applied everywhere. In the case of the other methods, however, the step of choosing the appropriate interpolation technique has to be considered. It is also worth mentioning the inherent drawback of conventional RFA approaches involving “hard” clustering, in this case the Omega_EGPD model. They are known to produce abrupt parameter shifts (in our case, the shape parameter) along the boundaries of the contiguous regions. Again, estimation at ungauged locations between two homogeneous regions with a significant difference in the regional shape parameter will be a difficult decision. The method of ROI however circumvents some of the drawbacks of the conventional RFA approach.
Finally, our approach also assumed the spatial independence of the observations. This assumption will however not be true, especially since we have considered all the positive precipitation. We however expect the benefit of the regional approach to outweigh the consequences of ignoring the spatial dependence (Hosking and Wallis, 1988), especially since our interest is in the marginal distribution only (Zheng et al., 2015). An interesting aspect is also to improve the method based on omega (see 3.2.1) to take into account both the margins and the dependence between sites.
The French data used in this paper are maintained by MétéoFrance and can be downloaded from http://publitheque.meteo.fr/ (MeteoFrance, 2021) and those of Switzerland from MeteoSwiss (https://gate.meteoswiss.ch/idaweb/more.do; MeteoSwiss, 2021), German Weather Service (https://opendata.dwd.de; DWD, 2021), Federal Ministry of Agriculture, Regions and Tourism, Austria (https://ehyd.gv.at/; Federal Ministry for Agriculture, 2021), and for the Italian regions (https://www.arpalombardia.it/; ARPA, 2021a, http://www.arpa.piemonte.it/; ARPA, 2021b, https://www.arpa.vda.it/fr/; Aosta Valley Environmental Protection Agency, 2021). However, not all these agencies allow sharing of the data with third parties or publishing them on the Internet. Hence, we cannot offer direct access to the data used in this study.
AH performed the numerical computations and prepared the paper. All the authors participated in the discussions, results analysis and paper writing.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors would like to thank the editor and two anonymous referees for their fruitful suggestions.
This research has been supported by the Bundesamt für Energie (grant no. SI/502150-01) and the Bundesamt für Umwelt (grant no. SI/502150-01), through the Extreme floods in Switzerland project.
This paper was edited by Thomas Kjeldsen and reviewed by two anonymous referees.
Akaike, H.: A new look at the statistical model identification, IEEE T. Automat. Contr., 19, 716–723, https://doi.org/10.1109/TAC.1974.1100705, 1974. a
Anderson, T. W. and Darling, D. A.: Asymptotic theory of certain “goodness of fit” criteria based on stochastic processes, Ann. Math. Stat., 23, 193–212, 1952. a
Aosta Valley Environmental Protection Agency: http://www.arpa.vda.it/it/, last access: 12 March 2021. a
ARPA: Lombardia, https://www.arpalombardia.it/ (last access: 12 March 2021), 2021a. a
ARPA: Piemonte, https://www.arpa.piemonte.it/ (last access: 12 March 2021), 2021b. a
Blanchet, J. and Lehning, M.: Mapping snow depth return levels: smooth spatial modeling versus station interpolation, Hydrol. Earth Syst. Sci., 14, 2527–2544, https://doi.org/10.5194/hess-14-2527-2010, 2010. a, b
Blanchet, J., Touati, J., Lawrence, D., Garavaglia, F., and Paquet, E.: Evaluation of a compound distribution based on weather pattern subsampling for extreme rainfall in Norway, Nat. Hazards Earth Syst. Sci., 15, 2653–2667, https://doi.org/10.5194/nhess-15-2653-2015, 2015. a, b, c, d
Blanchet, J., Paquet, E., Vaittinada Ayar, P., and Penot, D.: Mapping rainfall hazard based on rain gauge data: an objective cross-validation framework for model selection, Hydrol. Earth Syst. Sci., 23, 829–849, https://doi.org/10.5194/hess-23-829-2019, 2019. a, b, c, d, e
Burn, D. H.: Evaluation of regional flood frequency analysis with a region of influence approach, Water Resour. Res., 26, 2257–2265, https://doi.org/10.1029/WR026i010p02257, 1990. a, b, c, d, e
Carreau, J., Neppel, L., Arnaud, P., and Cantet, P.: Extreme Rainfall Analysis at Ungauged Sites in the South of France: Comparison of Three Approaches, Journal de la société franȩaise de statistique, 154, 119–138, http://www.numdam.org/item/JSFS_2013__154_2_119_0/ (last access: 21 April 2021), 2013. a, b, c, d
Chavez-Demoulin, V. and Davison, A. C.: Generalized additive modelling of sample extremes, J. R. Stat. Soc.-Appl., 54, 207–222, https://doi.org/10.1111/j.1467-9876.2005.00479.x, 2005. a
Cooley, D., Nychka, D., and Naveau, P.: Bayesian Spatial Modeling of Extreme Precipitation Return Levels, J. Am. Stat. Assoc., 102, 824–840, https://doi.org/10.1198/016214506000000780, 2007. a
Cramer, H.: On the composition of elementary errors, Scand. Actuar. J., 1, 141–180, 1928. a
Cunnane, C.: Methods and merits of regional flood frequency analysis, J. Hydrol., 100, 269–290, https://doi.org/10.1016/0022-1694(88)90188-6, 1988. a, b, c
Darling, D. A.: The kolmogorov-smirnov, cramer-von mises tests, Ann. Math. Stat., 28, 823–838, 1957. a
Das, S.: Performance of region-of-influence approach of frequency analysis of extreme rainfall in monsoon climate conditions, Int. J. Climatol., 37, 612–623, https://doi.org/10.1002/joc.5025, 2017. a
Das, S.: Extreme rainfall estimation at ungauged sites: Comparison between region-of-influence approach of regional analysis and spatial interpolation technique, Int. J. Climatol., 39, 407–423, https://doi.org/10.1002/joc.5819, 2019. a, b, c
Davies, D. L. and Bouldin, D. W.: A Cluster Separation Measure, IEEE T. Pattern Anal., PAMI-1, 224–227, https://doi.org/10.1109/TPAMI.1979.4766909, 1979. a
Deidda, R., Hellies, M., and Langousis, A.: A critical analysis of the shortcomings in spatial frequency analysis of rainfall extremes based on homogeneous regions and a comparison with a hierarchical boundaryless approach, Stoch. Env. Res. Risk A., 35, 2605–2628, https://doi.org/10.1007/s00477-021-02008-x, 2021. a, b, c
DWD: Climate Data Center – Climate observations in Germany, DWD [data set], https://opendata.dwd.de/, last access: 10 March 2021. a
Evin, G., Blanchet, J., Paquet, E., Garavaglia, F., and Penot, D.: A regional model for extreme rainfall based on weather patterns subsampling, J. Hydrol., 541, 1185–1198, https://doi.org/10.1016/j.jhydrol.2016.08.024, 2016. a, b, c, d, e, f, g, h
Evin, G., Favre, A.-C., and Hingray, B.: Stochastic generation of multi-site daily precipitation focusing on extreme events, Hydrol. Earth Syst. Sci., 22, 655–672, https://doi.org/10.5194/hess-22-655-2018, 2018. a, b, c
Federal Ministry for Agriculture: Regions and Tourism, Federal Ministry for Agriculture [data set], https://ehyd.gv.at/, last access: 12 March 2021. a
Frei, C. and Scha, C.: A precipitation climatology of the Alps from high-resolution rain-gauge observations, Int. J. Climatol., 18, 873–900, https://doi.org/10.1002/(SICI)1097-0088(19980630)18:8<873::AID-JOC255>3.0.CO;2-9, 1998. a
Gaál, L. and Kyselý, J.: Comparison of region-of-influence methods for estimating high quantiles of precipitation in a dense dataset in the Czech Republic, Hydrol. Earth Syst. Sci., 13, 2203–2219, https://doi.org/10.5194/hess-13-2203-2009, 2009. a, b, c
Gaál, L., Kyselý, J., and Szolgay, J.: Region-of-influence approach to a frequency analysis of heavy precipitation in Slovakia, Hydrol. Earth Syst. Sci., 12, 825–839, https://doi.org/10.5194/hess-12-825-2008, 2008. a, b, c, d, e, f
Garavaglia, F., Lang, M., Paquet, E., Gailhard, J., Garçon, R., and Renard, B.: Reliability and robustness of rainfall compound distribution model based on weather pattern sub-sampling, Hydrol. Earth Syst. Sci., 15, 519–532, https://doi.org/10.5194/hess-15-519-2011, 2011. a, b, c, d, e, f
Giannakaki, P. and Martius, O.: Synoptic-scale flow structures associated with extreme precipitation events in northern Switzerland, Int. J. Climatol., 36, 2497–2515, https://doi.org/10.1002/joc.4508, 2015. a
Gottardi, F., Obled, C., Gailhard, J., and Paquet, E.: Statistical reanalysis of precipitation fields based on ground network data and weather patterns: Application over French mountains, J. Hydrol., 432, 154–167, https://doi.org/10.1016/j.jhydrol.2012.02.014, 2012. a
Halkidi, M. and Vazirgiannis, M.: Clustering validity assessment: finding the optimal partitioning of a data set, in: Proceedings 2001 IEEE International Conference on Data Mining, IEEE Comput. Soc., San Jose, CA, USA, 187–194, https://doi.org/10.1109/ICDM.2001.989517, 2001. a
Hosking, J. R. M. and Wallis, J. R.: The effect of intersite dependence on regional flood frequency analysis, Water Resour. Res., 24, 588–600, https://doi.org/10.1029/WR024i004p00588, 1988. a
Hosking, J. R. M. and Wallis, J. R.: Regional frequency analysis: an approach based on L-moments, Cambridge University Press, Cambridge, New York, 2005. a, b, c, d, e, f, g
Isotta, F. A., Frei, C., Weilguni, V., Perčec Tadić, M., Lassègues, P., Rudolf, B., Pavan, V., Cacciamani, C., Antolini, G., Ratto, S. M., Munari, M., Micheletti, S., Bonati, V., Lussana, C., Ronchi, C., Panettieri, E., Marigo, G., and Vertačnik, G.: The climate of daily precipitation in the Alps: development and analysis of a high-resolution grid dataset from pan-Alpine rain-gauge data: Climate of daily precipitation in the Alps, Int. J. Climatol., 34, 1657–1675, https://doi.org/10.1002/joc.3794, 2014. a
Jordan, A., Krüger, F., and Lerch, S.: Evaluating probabilistic forecasts with scoringRules, arXiv:1709.04743 [stat], arXiv:1709.04743, 2018. a
Katz, R. W., Parlange, M. B., and Naveau, P.: Statistics of extremes in hydrology, Adv. Water Resour., 25, 1287–1304, https://doi.org/10.1016/S0309-1708(02)00056-8, 2002. a, b
Kaufman, L. and Rousseeuw, P. J.: Finding groups in data: an introduction to cluster analysis, Wiley Series in Probability and Mathematical Statistics, Wiley, Hoboken, NJ, 2005. a
Kolmogoroff, A.: Confidence limits for an unknown distribution function, Ann. Math. Stat., 12, 461–463, 1941. a
Kyselý, J., Gaál, L., and Picek, J.: Comparison of regional and at-site approaches to modelling probabilities of heavy precipitation, Int. J. Climatol., 31, 1457–1472, https://doi.org/10.1002/joc.2182, 2011. a, b, c, d
Langousis, A., Mamalakis, A., Puliga, M., and Deidda, R.: Threshold detection for the generalized Pareto distribution: Review of representative methods and application to the NOAA NCDC daily rainfall database, Water Resour. Res., 52, 2659–2681, https://doi.org/10.1002/2015WR018502, 2016. a
Le Gall, P., Favre, A.-C., Naveau, P., and Prieur, C.: Improved regional frequency analysis of rainfall data, Weather Clim. Extrem., 36, 100456, https://doi.org/10.1016/j.wace.2022.100456, 2022. a, b, c, d, e, f
Leonard, M., Metcalfe, A., and Lambert, M.: Frequency analysis of rainfall and streamflow extremes accounting for seasonal and climatic partitions, J. Hydrol., 348, 135–147, https://doi.org/10.1016/j.jhydrol.2007.09.045, 2008. a
Madsen, H., Rosbjerg, D., and Harremoöes, P.: Application of the Bayesian approach in regional analysis of extreme rainfalls, Stoch. Hydrol. Hydraul., 9, 77–88, https://doi.org/10.1007/BF01581759, 1995. a
Malekinezhad, H. and Zare-Garizi, A.: Regional frequency analysis of daily rainfall extremes using L-moments approach, Atmósfera, 27, 411–427, https://doi.org/10.1016/S0187-6236(14)70039-6, 2014. a
MeteoFrance: Publitheque, https://publitheque.meteo.fr/, last access: 10 March 2021. a
MeteoSwiss: Federal Office of Meteorology and Climatology, https://gate.meteoswiss.ch/idaweb/login.do, last access: 12 May 2021. a
Molnar, P. and Burlando, P.: Variability in the scale properties of high-resolution precipitation data in the Alpine climate of Switzerland, Water Resour. Res., 44, W10404, https://doi.org/10.1029/2007WR006142, 2008. a
Naveau, P., Huser, R., Ribereau, P., and Hannart, A.: Modeling jointly low, moderate, and heavy rainfall intensities without a threshold selection, Water Resour. Res., 52, 2753–2769, https://doi.org/10.1002/2015WR018552, 2016. a, b, c, d, e
Renard, B., Kochanek, K., Lang, M., Garavaglia, F., Paquet, E., Neppel, L., Najib, K., Carreau, J., Arnaud, P., Aubert, Y., Borchi, F., Soubeyroux, J.-M., Jourdain, S., Veysseire, J.-M., Sauquet, E., Cipriani, T., and Auffray, A.: Data-based comparison of frequency analysis methods: A general framework, Water Resour. Res., 49, 825–843, https://doi.org/10.1002/wrcr.20087, 2013. a, b, c
Rousseeuw, P. J.: Silhouettes: A graphical aid to the interpretation and validation of cluster analysis, J. Comput. Appl. Math., 20, 53–65, https://doi.org/10.1016/0377-0427(87)90125-7, 1987. a
Scarrot, C. and MacDonald, A.: A review of extreme value threshold es-timation and uncertainty quantification, REVSTAT – Stat. J., 10, 33–60, https://www.ine.pt/revstat/pdf/rs120102.pdf (last access: 10 June 2021), 2012. a
Sevruk, B.: Regional dependency of precipitation-altitude relationship in the Swiss Alps, in: Climatic change at high elevation sites, edited by: Diaz, H. F., Springer, 123–137, https://doi.org/10.1007/978-94-015-8905-5_7, 1997. a
Sevruk, B., Matokova-Sadlonova, K., and Toskano, L.: Topography effects on small-scale precipitation variability in the Swiss pre-Alps, IAHS Publications-Series of Proceedings and Reports–Intern Assoc. Hydrological Sciences, 248, 51–58, 1998. a
Sminorv, N. V.: Approximate laws of distribution of random variables from empirical data, Uspekhi Matematicheskikh Nauk, 10, 179–206, 1944. a
Sodemann, H. and Zubler, E.: Seasonal and inter-annual variability of the moisture sources for Alpine precipitation during 1995–2002, Int. J. Climatol., 30, 947–961, https://doi.org/10.1002/joc.1932, 2009. a
Tencaliec, P., Favre, A., Naveau, P., Prieur, C., and Nicolet, G.: Flexible semiparametric generalized Pareto modeling of the entire range of rainfall amount, Environmetrics, 31, e2582, https://doi.org/10.1002/env.2582, 2020. a, b
Umbricht, A., Fukutome, S., Liniger, M. A., Frei, C., and Appenzeller, C.: Seasonal Variation of Daily Extreme Precipitation in Switzerland, Tech. Rep. 97, Scientific Report MeteoSwiss, https://www.meteosuisse.admin.ch/content/dam/meteoswiss/en/Ungebundene-Seiten/Publikationen/Scientific-Reports/doc/sr97umbricht.pdf (last access: 1 May 2021), 2013. a
Wood, S. N., Pya, N., and Säfken, B.: Smoothing Parameter and Model Selection for General Smooth Models, J. Am. Stat. Assoc., 111, 1548–1563, https://doi.org/10.1080/01621459.2016.1180986, 2016. a
Youngman, B. D.: Generalized Additive Models for Exceedances of High Thresholds With an Application to Return Level Estimation for U. S. Wind Gusts, J. Am. Stat. Assoc., 114, 1865–1879, https://doi.org/10.1080/01621459.2018.1529596, 2019. a
Youngman, B. D.: evgam: An R package for Generalized Additive Extreme Value Models, arXiv [stat], arXiv:2003.04067, 2020. a, b
Zheng, F., Thibaud, E., Leonard, M., and Westra, S.: Assessing the performance of the independence method in modeling spatial extreme rainfall, Water Resour. Res., 51, 7744–7758, https://doi.org/10.1002/2015WR016893, 2015. a