the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 09 May 2022
| 09 May 2022
Karst spring discharge modeling based on deep learning using spatially distributed input data
Tanja Liesch
Guillaume Cinkus
Nataša Ravbar
Zhao Chen
Naomi Mazzilli
Hervé Jourde
Nico Goldscheider
Despite many existing approaches, modeling karst water resources remains challenging as conventional approaches usually heavily rely on distinct system knowledge. Artificial neural networks (ANNs), however, require only little prior knowledge to automatically establish an input–output relationship. For ANN modeling in karst, the temporal and spatial data availability is often an important constraint, as usually no or few climate stations are located within or near karst spring catchments. Hence, spatial coverage is often not satisfactory and can result in substantial uncertainties about the true conditions in the catchment, leading to lower model performance. To overcome these problems, we apply convolutional neural networks (CNNs) to simulate karst spring discharge and to directly learn from spatially distributed climate input data (combined 2D–1D CNNs). We investigate three karst spring catchments in the Alpine and Mediterranean region with different meteorological–hydrological characteristics and hydrodynamic system properties. We compare the proposed approach both to existing modeling studies in these regions and to our own 1D CNN models that are conventionally trained with climate station input data. Our results show that all the models are excellently suited to modeling karst spring discharge (NSE: 0.73–0.87, KGE: 0.63–0.86) and can compete with the simulation results of existing approaches in the respective areas. The 2D models show a better fit than the 1D models in two of three cases and automatically learn to focus on the relevant areas of the input domain. By performing a spatial input sensitivity analysis, we can further show their usefulness in localizing the position of karst catchments.
- Article
(7409 KB) - Full-text XML
- BibTeX
- EndNote





Karst aquifers and karst springs are crucial for freshwater supply in many regions, and 9 % of the global population partly or fully relies on karst water resources (Stevanović, 2019). Karst systems in general are characterized by high structural heterogeneity due to the at least in large parts unknown conduit network, which controls the highly variable groundwater flow. These factors make modeling difficult; nevertheless, different approaches exist, which Jeannin et al. (2021) classify as hydrological models (fully distributed models), pipe flow models (semi-distributed models), and data-driven models (including reservoir models). Artificial neural networks (ANNs) or their subgroup of deep learning (DL) models are part of the last group. In contrast to the other two categories, which usually require detailed system knowledge in order to achieve high-quality results, DL approaches offer an alternative possibility of modeling by being able to establish an input–output relationship automatically, without detailed system knowledge necessary. Even though ANNs are not a standard method in karst modeling yet, different types of ANNs have been applied in modeling karst water resources for quite a long time. As one of the first applications (Johannet et al., 1994) showed, karst spring discharge modeling is possible with ANNs. Since then, application of ANNs in hydrology in general has received ever-growing research attention (e.g., Maier and Dandy, 2000; Maier et al., 2010). This has amplified even more in the last years, mainly because of the recent success of DL models (e.g., Kratzert et al., 2018). Rajaee et al. (2019) more recently reviewed applications of ANNs to groundwater; Sit et al. (2020) summarize applications to hydrology and water resources in general. Recurrent neural networks (RNNs), such as long short-term memory (LSTM) (Hochreiter and Schmidhuber, 1997), are standard models for time series modeling, because they possess explicit or implicit memory to remember past time steps, which helps to infer the future. A consequence is that they are trained sequentially, which can make them computationally expensive. Convolutional neural networks (CNNs) (LeCun et al., 2015) on the other hand use convolutions along the time axis (1D CNNs) to learn temporal features and can be trained batch-wise, which therefore usually makes them computationally favorable over RNNs. One example of this fact exists in the related domain of groundwater-level forecasting, where Wunsch et al. (2021) showed that 1D CNNs are considerably faster than RNNs in the case of single-site model application. CNNs at the same time exhibited more stable results through less dependency on the random network initialization and achieved some of the highest performances in this specific study (better than LSTM). Other authors similarly applied CNNs successfully for either groundwater-level forecasting (Afzaal et al., 2020; Lähivaara et al., 2019; Müller et al., 2020) or rainfall–runoff modeling (Van et al., 2020; Hussain et al., 2020). Müller et al. (2020) find in contrast to Wunsch et al. (2021) that CNNs take a considerably longer time to optimize than LSTMs, yet both studies agree that they outperform LSTMs in terms of accuracy. Given these favorable properties of CNNs, we choose 1D CNNs for karst spring discharge modeling for our study. To our best knowledge, Jeannin et al. (2021) is the only study applying CNNs for karst spring discharge modeling in some first experiments, and they also find CNNs to be superior over LSTMs in terms of testing performance.
Data-driven approaches in general are considered to be black boxes. A way to still build confidence in a model's decisions is to understand what the model is doing (ideally, even why) by using explainable artificial intelligence (XAI). There are different approaches, which are potentially suited for this purpose, depending on the specific goal. Such approaches not only are useful for gaining trust, but also help during model building to debug the model and to check which aspects it is focusing on (McGovern et al., 2019). The class of wrapper methods (Kohavi and John, 1997) incorporates both the data and the trained model to interpret what a model has learned. Methods from this class are, for example, impurity importance for determining feature importance in random forest (RF) models (Louppe et al., 2013), permutation importance (Breiman, 2001) both for RF and DL models, and partial dependence plots (Friedman, 2001) that also reveal why a predictor is important. See McGovern et al. (2019) for an overview of these and several other model interpretation and visualization methods. Especially for image-alike data, input sensitivity approaches seem suitable, as focus regions of the model on the image can be visualized. Two well-known approaches are occlusion sensitivity (Zeiler and Fergus, 2014) and RISE (Randomized Input Sampling for Explanation) (Petsiuk et al., 2018). Both methods show how relevant each pixel or area is to the decision of the model (image classification) and can generate an importance heat map (saliency map) for visualization. The idea behind both algorithms is to use masked versions of an input image and, by obtaining the respective model output, to learn the focus regions. A very closely related approach to generate a saliency map was recently proposed by Anderson and Radić (2022), which in contrast to RISE and occlusion takes the physical meaning of the absolute value of each variable at each pixel into account during the perturbation of the input data.
One drawback of the 1D CNN approach, as well as most other data-driven approaches, is the dependency on high data availability and quality. However, climate stations are often not available within the catchment itself, do not match the data availability of the discharge time series (period or temporal resolution), or are more distant and thus do not truly represent the climatic conditions within the catchment. Gridded climate data can provide a solution to such data availability problems. Several openly available products exist (e.g., ERA5-Land, Muñoz Sabater, 2019; E-OBS, Cornes et al., 2018), which provide climate data for several decades and with, in terms of karst spring modeling, appropriate temporal (hourly or daily) and spatial () resolution. However, especially for karst springs, it is not straightforward to extract relevant time series from the gridded data, because the spatial extent of the grid cell containing the location of the spring usually does not coincide well with the associated spring catchment position. Moreover, especially for karst springs, the catchment is often not well known, and, for larger springs, can stretch over several grid cells. If the exact position of the catchment is unknown, using gridded data has the advantage that a broader region can be taken into account as input to let the model learn the relevant grid cells automatically.
Besides such modeling aspects, the delineation of karst catchments is generally important for sustainably exploiting but also protecting karst water resources by establishing protection zones accordingly. Malard et al. (2015) explain that only a few generalizable methods based on models in general for karst spring catchment delineation have been proposed. Instead, delineations usually rely on classical hydrogeological methods such as assessing geology, topography, hydrology, water balance, elaborate tracer tests and geophysical investigations. These methods usually are complex and costly, and thus for many karst springs, exact catchment delineations are not available at all or at least contain some uncertainties. Where no information about the catchment is available at all, an approximate localization is advantageous as a first step towards an exact delineation, since it facilitates the application of more elaborate methods like tracer tests. There has already been an attempt by Longenecker et al. (2017) to semi-automatically derive approximate catchment boundaries by correlating karst spring discharge events with global precipitation measurement (GPM) gridded data (NASA, 2016). The authors were able to achieve reasonable results with their method but also noticed that they could not replace conventional methods.
Anderson and Radić (2022) already applied gridded meteorological data to streamflow modeling in western Canada and used a coupled 2D CNN–LSTM model to directly process spatially distributed input data. They showed that such models learn the relevant parts of the large-scale gridded input data for each local or regional streamflow automatically. We adapt and extend this approach to karst spring discharge modeling, however, purely based on CNNs by replacing the LSTM part with a 1D CNN. Similar to the approach of Anderson and Radić (2022), in our proposed methodology the 2D CNN part learns the spatial features of the input data, while the 1D CNN part extracts the temporal features, both necessary for simulating the spring discharge time series. With this combined 2D–1D approach (for the sake of simplicity in the following 2D-only approach), we can now directly use gridded meteorological data to potentially overcome the common data availability problems when using climate station data for modeling. This approach further no longer depends on a prior description of the catchment area, other than a very rough estimation of its approximate size to make the gridded data section large enough. Moreover, we investigate the potential of this approach to identifying the approximate catchment location based on a modified spatial input sensitivity analysis from Anderson and Radić (2022). Deriving recharge areas based on rainfall–discharge event correlation, as previously done by Longenecker et al. (2017), requires (i) heterogeneous rainfall at catchment scale, (ii) precipitation data with sufficient spatial resolution that capture this heterogeneity and (iii) a karst system without too much dampening of the precipitation signals. These requirements hold for our proposed methodology as well, but a potential advantage of ANNs is their nonlinearity, which may better capture the nonlinear relationships between rainfall and discharge.
We explore the applicability of our proposed deep learning approaches with spatially distributed input data in modeling karst spring discharge in three different study areas in Austria (Aubach spring), France (Lez spring) and Slovenia (Unica springs). All three associated karst areas are well studied and, for Austria and France, several modeling publications are available as benchmarks. Discharge of Lez spring in France was extensively studied in the past, including several ANN studies. Please refer to Kong A Siou et al. (2011) for an overview of older modeling studies at Lez spring with approaches other than ANNs. We omit three newer ANN studies because they either do not focus on modeling discharge (Kong-A-Siou et al., 2015) or train models not on the complete annual cycle (September–August in this region) but on flash-flood events (Darras et al., 2015, 2017). The other ANN studies all use classical multilayer perceptrons (MLPs) or recurrent MLPs for discharge modeling, and we introduce them shortly in the following. Kong A Siou et al. (2011, 2012) and Kong-A-Siou et al. (2013) use precipitation from three or six gauges, respectively, and all use a similar but slightly varying data basis of 12 to 13 full annual cycles between 1988 and 2006. The testing period is either the single cycle 2002/03 (Kong A Siou et al., 2012; Kong-A-Siou et al., 2013) or two cycles roughly in the same period (2002–2004) (Kong A Siou et al., 2011). Kong-A-Siou et al. (2014) use data from 1987 to 2007, however, this time additionally including evapotranspiration and pumping from the Lez aquifer. For Aubach spring in Austria no ANN studies exist; however, other modeling studies are available. Three studies (Chen and Goldscheider, 2014; Chen et al., 2017b, 2018) based on three successive and improved versions of a combined lumped parameter (SWMM) and distributed model investigate and simulate three springs of this karst system simultaneously. They all achieve high performance in terms of NSE (>0.8), but none of them covered a complete annual cycle as a contiguous test period. Additionally, they differ considerably in terms of their individual data basis for modeling (number and position of climate stations used as input data) as well as their testing periods. The shortest test set only had 40 d (in fall), and the longest (Chen et al., 2017b) used 1 year of data for model calibration and performed a split-sample test on the same dataset. This makes a comparison of modeling results among these studies difficult. For the third spring (Slovenia), several earlier modeling studies are available (e.g., Kaufmann et al., 2016; Mayaud et al., 2019; Kaufmann et al., 2020; Kovačič et al., 2020), even including ANNs (Sezen et al., 2019), but none of these directly modeled Unica springs discharge but rather focused on other aspects like cave hydraulics or polje modeling. Besides existing studies, we compare the results of the 2D model with our own 1D CNN models using climate station input data to assess the usefulness and possible advantages of the direct use of spatially distributed input data. As spatially distributed inputs, we use either hourly ERA5-Land reanalysis data (Muñoz Sabater, 2019), hourly RADOLAN precipitation data (DWD Climate Data Center, 2020), or daily E-OBS data (Cornes et al., 2018), depending on the temporal resolution of spring discharge data. We selected these datasets among all openly accessible datasets (e.g., via the Copernicus Climate Data Store) because of their available variable set and their spatial and temporal resolution. We introduce them in more detail in the following data section. Finally, we explore the potential of the 2D approach for karst spring catchment localization by investigating the spatial input sensitivity of the trained CNN models.

Figure 1Overview of all three study areas, the simulated springs (red star), and their catchments (red lines). Black squares indicate the locations of climate stations used for 1D modeling (some are outside the shown maps), and blue shadings in the upper map show karst areas based on WOKAM (Chen et al., 2017a). (a) Hochifen-Gottesacker karst area and Aubach spring; black lines depict minor contributing subcatchments; (b) Unica River springs and Javorniki karst plateau (B); (c) Lez spring catchment, Lirou overflow spring (black star), and major fault Corconne-Les Matelles (grey line).
2.1 Overview
In this study, we investigate three different karst springs: Aubach spring in the Hochifen-Gottesacker area in Austria (Fig. 1a), springs of the Unica River in Slovenia (Fig. 1b) and Lez spring in southern France (Fig. 1c). All springs show different characteristics regarding relevant system properties (e.g., catchment size, complexity of the hydrological system), environmental conditions (e.g., dominant climate, anthropogenic forcing) and data availability (see also Table A1). All areas are well studied, and existing data were easily accessible. Further, several previous modeling approaches are available for comparison, except for the Slovenian spring.
2.2 Aubach spring, Austria
Aubach spring is a major karst spring in the Hochifen-Gottesacker karst area in the northern Alps at the border between Germany and Austria. The southern border of the area is the Schwarzwasser Valley, which geologically forms the contact zone between the Helvetic Säntis nappe in the north and sedimentary rocks of the flysch zone in the south (Goldscheider, 2005). In the northern part, the dominant karst formation is the Schrattenkalk formation, a cretaceous limestone with a thickness of about 100 m. The Schrattenkalk is structured in folds, which hydrogeologically form parallel subcatchments (Fig. 1a) that contribute to different proportions to the several springs in the valley (Goldscheider, 2005; Chen and Goldscheider, 2014). In this study we focus on one large, non-permanent spring called Aubach spring (1080 m a.s.l., discharge up to 10 m3 s−1). The Hochifen-Gottesacker area is largely influenced by seasonal snow accumulation and melting in the elevated regions (>1600 m a.s.l.), which is also clearly reflected in the discharge of Aubach spring by increased baseflow and diurnal snowmelt-induced variations, especially in the months of April to June. Earlier studies by Goldscheider (2005) and Chen and Goldscheider (2014) have identified one major catchment area of Aubach spring with approximately 9 km2 (Fig. 1a); still, in smaller proportions upstream catchments can also contribute to Aubach spring discharge depending on the flow conditions. This applies also to the non-karstified flysch area directly in the south (southernmost subcatchment in Fig. 1a), where precipitation events are only relevant during low-flow conditions. Then, the surface runoff from this area sinks into an upstream estavelle and contributes via an underground connection to the discharge of Aubach spring. During high-flow conditions, the estavelle itself acts as an overflow spring, and no contribution from surface runoff at Aubach spring occurs. Generally, the climate in the area can be described as cooltemperate and humid, and the mean annual precipitation at the closest used climate station in this study (Walmendinger Horn) is about 2000 mm (2003–2019).
For this study we select Aubach spring because of the good data availability and use 8 years of hourly discharge data provided by the office of the federal state of Vorarlberg, division of water management. Further precipitation and temperature data from three surrounding climate stations are available: Oberstdorf, Walmendinger Horn (shown in Fig. 1a) and Diedamskopf. Additionally, due to the high importance of snow in the area, we run a snowmelt routine as preprocessing of the meteorological input data as described in Chen et al. (2018). This routine is a slightly modified version (after Hock, 1999) of the HBV hydrological model snow routine (e.g., Bergström, 1975, 1995; Kollat et al., 2012; Seibert, 2000), which redistributes the precipitation time series in accordance with probable snow accumulation and snowmelt.
2.3 Unica springs, Slovenia
The Unica springs (450 m a.s.l.) are located on the southern edge of a karst polje in southwestern Slovenia and are important from a biodiversity and water supply perspective. There are two permanent and several temporary springs that feed the Unica River. The joint discharge during 1989–2018 ranged from 1 to 90 m3 s−1, while the mean discharge was 21 m3 s−1 (ARSO, 2020a). The springs are fed by three clearly distinguishable subcatchments covering an area of about 820 km2. The main recharge area is the highly karstified Javorniki plateau (up to 1800 m a.s.l., marked B in Fig. 1b), whose predominant lithology is Cretaceous rocks, mainly limestones, changing in places to dolomites and breccias. To a lesser extent, Jurassic and Palaeogene carbonate rocks are also present. The thickness of the unsaturated zone is estimated to be up to several hundred meters (Petrič et al., 2018, and references therein). To the east, a strike–slip fault zone controls the hydrology of the area, along which a chain of karst poljes developed (between 500 and 700 m a.s.l., marked C in Fig. 1b). Upper Triassic dolomites predominate, changing to Jurassic limestones and dolomites in the south and west, forming aquifers with fracture porosity which in places have very low to moderate permeability, and in some parts a superficial river network forms. As the karst poljes follow each other in a downward series, they are connected in a common hydrological system with transitions between surface and groundwater flows and frequent flooding (Mayaud et al., 2019). In the west, the Pivka River basin (between 500 and 700 m a.s.l., marked A in Fig. 1b) consists of poorly permeable Eocene flysch in the north, which conditions a surface river network. The southern part consists of Cretaceous and Jurassic carbonate rocks forming a shallow karst aquifer. Surface flow occurs during high water levels, receiving additional water from intermittent springs on the western foothills of the Javorniki plateau. The water flow of the sinking rivers in the subsurface from regions A and C is of the channel flow type. We select the springs for this study because they drain a complex binary karst system of the so-called classical karst, they are well studied with long records of hydro-meteorological data and their hydrology is influenced by substantial snow accumulation and melting. The catchment belongs to the moderate continental climate and is mostly covered with forests. For this study we use daily discharge data from the Unica–Hasberg gauging station (in the following called Unica) (ARSO, 2020a) and daily meteorological data from the Postojna and Cerknica climate stations ranging from 1981 to 2018 (ARSO, 2020b). These climate stations (squares in Fig. 1b) are located in the western (Postojna) and eastern (Cerknica) parts of the catchment, representing different climate regimes, and are separated by the karst massif in between. For Postojna station the following variables are available: precipitation (P), temperature (T), potential evapotranspiration (PET), relative humidity (RH), snow (S) and new snow (nS). For Cerknica station, only P, S and nS exist. Average annual precipitation during 1989–2018 is about 1500 mm, and on average 33 d of snow cover occur in Postojna (530 m a.s.l.) per year, while even longer snow cover is expected on the plateau.
2.4 Lez spring, France
Our third study area is located 15 km north of Montpellier in southern France, within a large and complex karst system delimited by rivers and marly terrains. Eastern and western borders are the Vidourle and Hérault river valleys, and northern and southern borders are piezometric limits. At a larger scale, northern and southern boundaries are structural boundaries due to the Cévennes and Montpellier faults, respectively. The dominant karst formations are Argovian to Kimmeridgian and Berriasian massive limestones with 650 m to 1000 m thickness. Infiltration occurs mostly diffuse but also localized through fractures and sinkholes along the basin and through the major geologic fault of Corconne-Les Matelles in the northern part of the basin (indicated by a grey line in Fig. 1c).
The hydrogeological basin associated with Lez spring has a size of about 240 km2 (Fig. 1c), which is estimated on the basis of the hydrodynamic response to high-discharge continuous pumping into the saturated zone of the aquifer (Thiéry and Bérard, 1983). However, the effective recharge catchment of Lez spring, which corresponds to the extent of Jurassic limestone outcrops, has been estimated to be about 130 km2 (Fleury et al., 2009; Jourde et al., 2014). The Lez karst aquifer is under anthropogenic pressure (i.e., aquifer exploitation for water supply), with pumping performed directly within the karst conduit. The discharge is measured at the spring pool and is regularly null during low water periods, when the pumping rate exceeds the natural spring discharge. Ecological water discharge towards the Lez River (160 L s−1 then 230 L s−1 after 2018) is ensured during such periods by a partial deviation of the pumped water to the river. Lirou spring (Fig. 1c) is the main one of several overflow springs that activate during high-flow periods (Jourde et al., 2014).
The Lez catchment is exposed to a Mediterranean climate characterized by hot and dry summers, mild winters and wet falls. Analyses by MeteoFrance show that on average 40 % of the annual precipitation occurs between September and November, with a high variability across years (Bicalho et al., 2012). The average annual rainfall rate for the 2008–2018 period is 904 mm.
For this study, we use nearly 10 years of daily discharge data provided by SNO KARST (Jourde et al., 2018; SNO KARST, 2021). The temperature data are from the Prades-le-Lez climate station; we use, however, an interpolated precipitation data series that is derived from a weighted average of four rainfall stations (Fig. 1c) (similar to Fleury et al., 2009; Mazzilli et al., 2011), three of them being located on the Lez catchment (Prades-le-Lez, Valflaunès, Sauteyrargues). The fourth station (Saint-Martin-de-Londres) is located a few kilometers west of the catchment. Interpolation is in principle possible in this area due to the existing topography; at the same time, interpolation based on Thiessen polygons (compare Appendix B) also allows compensation for data gaps at single stations. We decided to apply this preprocessing, because all but Saint-Martin-de-Londres climate station show such gaps from time to time, which explains the benefit of including within-catchment precipitation. We do not use pumping data as input in this study, because these were only available for a shorter period of time and such data would also not be available for a real forecast in the future (in contrast to weather and climate data).
2.5 Spatial climate data
Besides climate station data, we explored raster data from the E-OBS (Cornes et al., 2018), the ERA5-Land (Muñoz Sabater, 2019) and the RADOLAN (DWD Climate Data Center, 2020) as spatially distributed model inputs. E-OBS provides daily gridded meteorological data for Europe from 1950 to the present, derived from in situ observations, and ERA5-Land provides hourly reanalysis data from 1981 to the present. Both are available with a spatial resolution of (approximately 8 km × 11 km for all study areas). Depending on the dataset, different sets of variables are available. In the case of E-OBS we initially provide our models with precipitation (P), mean, minimum and maximum temperature (T, Tmin, Tmax), relative humidity (RH) and surface shortwave downwelling radiation (Rad). For ERA5-Land, where a substantially larger set of variables is available, the following were used as initial inputs: total precipitation (P), 2 m temperature (T), total evaporation (E), snowmelt (SMLT), snowfall (SF) and volumetric soil water of all four available layers (SWVL1: 0–7 cm, SWVL2: 7–28 cm, SWVL3: 28–100 cm, SWVL4: 100–289 cm). Relevant input variables from both datasets are later selected through Bayesian optimization (see Sect. 3.3). The spatial extent of the input data is chosen very generously for each spring, so that between six and eight additional cells are available as input data around the respective catchments. This prevents a predefinition of the area that needs to be identified as relevant and reduces the influence of possible border effects due to the CNN approach using 3×3 filters (compare the methodology section). The resolution of ERA5-Land and E-OBS data corresponds to the grid cell size shown in the catchment plots in Fig. 1a–c, although each shows a slightly different absolute position of their grid center points. Depending on the temporal resolution of the available spring discharge measurements, we choose the spatial input data in accordance, i.e., E-OBS for Unica and Lez spring and ERA5-Land for Aubach spring.
Compared with the catchment size of Aubach spring (about 9 km2), the spatial resolution (approximately 8 km × 11 km) of the gridded input data is extremely coarse. We therefore additionally explore a combination of ERA5-Land input variables (except P) with radar-based precipitation data (RADOLAN) that offer a spatial resolution of 1 km × 1 km (DWD Climate Data Center, 2020). The higher resolved precipitation data from RADOLAN are thus augmented with climate variable values from ERA5-Land (for T, RH, etc.), which were downscaled and re-gridded to match the 1×1 km2 RADOLAN grid. Compared with the ERA5-Land section around Aubach spring, for this additional analysis we reduce the spatial extent of the 2D input data to save calculation time but still considerably increase the total number of cells due to the higher resolution of the RADOLAN grid.
3.1 Modeling approach
In this study, we simulate karst spring discharge with deep learning models using meteorological input data. As proof of feasibility, we use meteorological data from surrounding climate stations as inputs to 1D CNN models. However, data from such stations are often limited to precipitation and temperature, rarely more, and often exhibit data gaps and limited record length or coarse sampling intervals. Also, the proximity to the catchment is often not sufficient, which especially in mountainous regions can introduce a distinct error in representing the true conditions within the catchment. This applies especially to variables with higher spatial variability such as precipitation.
Gridded meteorological data can be a solution to these issues, as they usually provide good temporal coverage and sampling intervals, a good spatial resolution as well as large-scale availability (e.g., continental – E-OBS – or even global – ERA5-Land; see Bandhauer et al., 2021, for a comparison of both products). Further, especially reanalysis data include a larger variable set. When the catchment of the spring is unknown, it remains unclear which cells of the gridded data should be selected to best represent the climate conditions in the catchment, because the actual location of the spring is only a very rough indicator of the location of the catchment. Based on our revised version of the approach of Anderson and Radić (2022), we demonstrate a solution by processing 2D inputs and letting the model decide automatically which parts of the input data are relevant to modeling the spring discharge.
3.2 CNNs
Convolutional neural networks (LeCun et al., 2015) are widely applied in several domains such as object recognition (e.g., Cai et al., 2016), image classification (e.g., Li et al., 2014), and signal or natural language processing (e.g., Yin et al., 2017; Kiranyaz et al., 2019). The structure of most CNN models is based on the repetition of blocks that are made up of several layers, typically at least one convolutional layer followed by a pooling layer. The former matches the dimension of the input data (e.g., 2D for image-alike data, 1D for sequences such as time series) and uses filters with a fixed size (receptive field) to produce feature maps of the input. The latter performs downsampling of the produced feature maps and summarizes the features detected in the input. This decreases the total number of parameters of the model and makes it approximately invariant to small translations of the input (Goodfellow et al., 2016). A large variety of model structures based on such blocks in combination with additional layers in between to prevent exploding gradients (e.g., batch normalization layers; Ioffe and Szegedy, 2015) or model overfitting (e.g., dropout layers; Srivastava et al., 2014) is possible; however, CNNs usually end with one or several fully connected dense layers to produce a meaningful output.
From earlier studies (Wunsch et al., 2021; Jeannin et al., 2021) we know that 1D CNNs are fast, reliable and excellently suited for modeling hydrogeological time series, such as groundwater levels or spring discharge. We have shown that they are faster compared with LSTMs, which are often the method of choice for time series modeling, and even outperform them or at least show similar performance (Wunsch et al., 2021). This is in agreement with the findings of Van et al. (2020) in the domain of rainfall–runoff modeling. In Wunsch et al. (2021) we further show that, for the closely related application of groundwater-level forecasting, CNNs are less sensitive to the random initialization procedure and thus provide more stable results. Based on these findings, we choose CNNs for predicting karst spring discharge in this study and establish two different setups. One setup uses 1D meteorological input data from surrounding climate stations and applies a 1D CNN for forecasting. The second approach consistently uses a 1D CNN to learn temporal features for discharge prediction but combined with a time-distributed 2D CNN to learn spatial features directly from gridded climate input data. Compared with the approach in Anderson and Radić (2022), we replace the LSTM with a 1D CNN to make both setups methodologically consistent. Using CNNs in both setups further helps to assess the influence of using spatially distributed input data in terms of model accuracy, as we do not have to speculate whether higher or lower performance might be due to the LSTM model rather than the input data. The general model structures of both setups are shown in Fig. 2. They basically use the same 1D model except for the position of the dropout layer. We use Bayesian hyperparameter optimization to select the 1D filter number, batch size and input sequence length of each model in both setups.
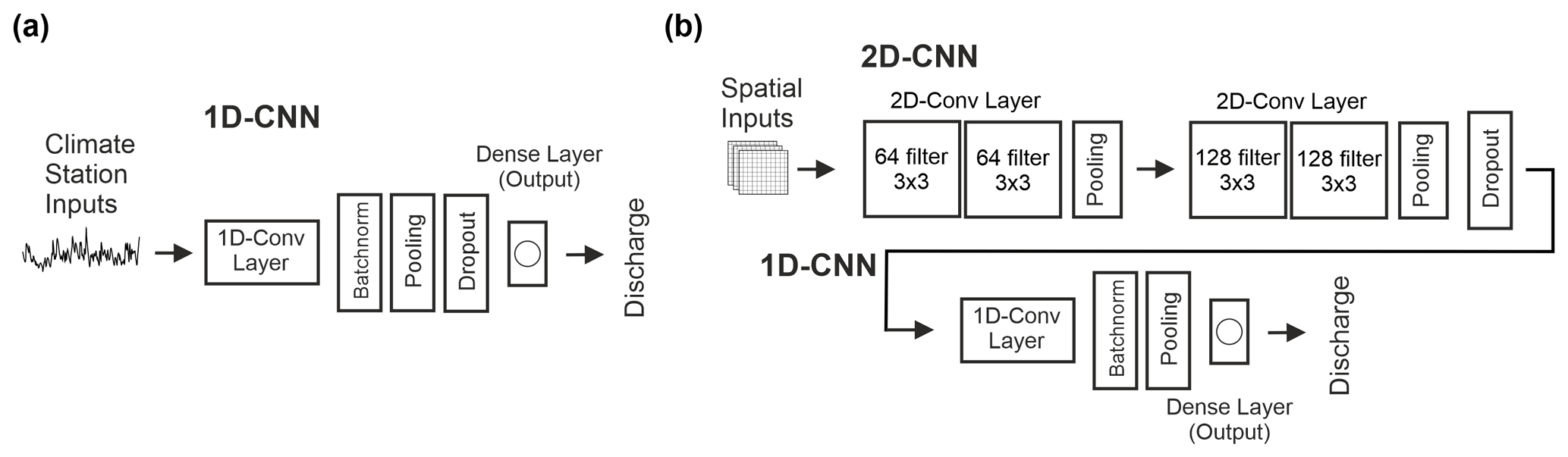
Figure 2Model structures applied for modeling karst spring discharge based on climate station data (a) and gridded meteorological input data (b). Flatten layers are not displayed.
To reduce the dependency on the random initialization of the models, we use an ensemble with 10 members, each based on a different pseudo-random seed. Further, we implement Monte Carlo dropout to estimate the model uncertainty from a distribution of 100 results for each of the 10 realizations of each model in this study. We derived the 95 % confidence interval from these 100 realizations by using 1.96 times the standard deviation of the resulting distribution for each time step. Each uncertainty was propagated while calculating the overall ensemble mean value for final evaluation in the test set. This uncertainty is shown as the confidence interval for each of our simulation results in the following. We want to point out that this uncertainty does not include other sources (such as input data uncertainty) but the random number dependency. All our models are implemented in Python 3.8 (van Rossum, 1995), and we use the following libraries and frameworks: Numpy (van der Walt et al., 2011), Pandas (McKinney, 2010; The pandas development team, 2020), Scikit-Learn (Pedregosa et al., 2011), Unumpy (Lebigot, 2010), Matplotlib (Hunter, 2007), BayesOpt (Nogueira, 2014), TensorFlow and its Keras API (Abadi et al., 2015; Chollet, 2015).
3.3 Model calibration and evaluation
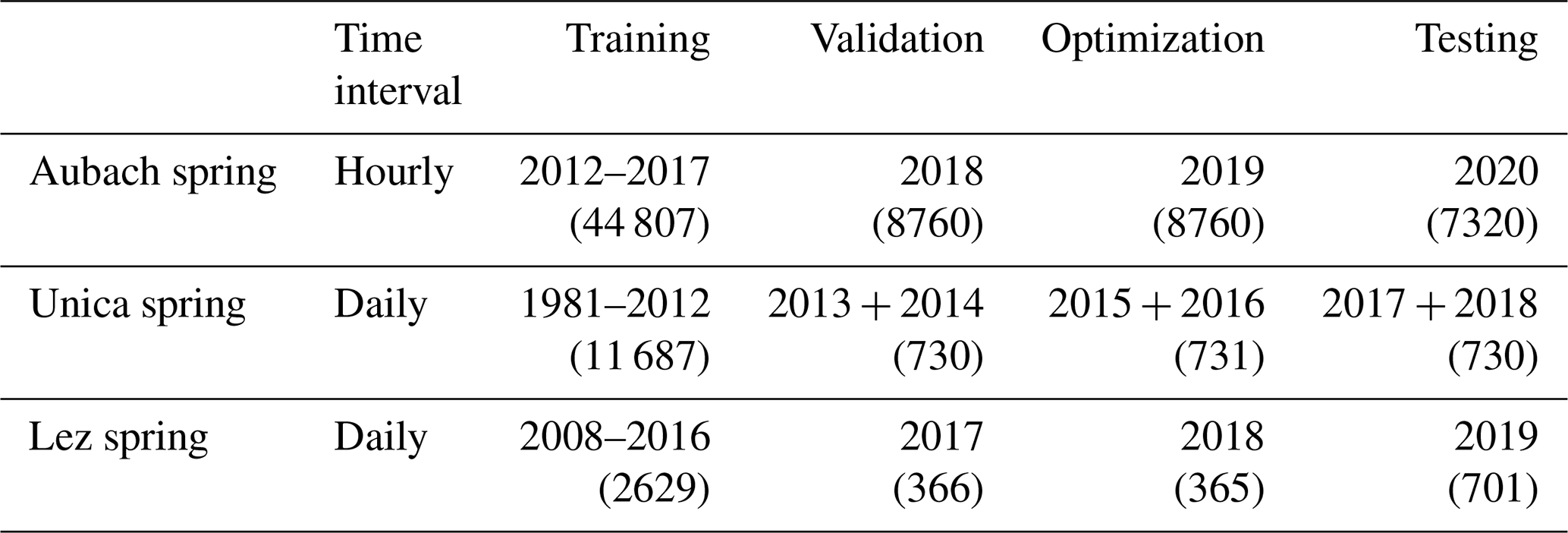
We split the time series data for each site into four parts according to Table 1. While the first part is used for training, the second part (validation) is simultaneously used to prevent the model from overfitting via early stopping. The model's hyperparameters are optimized according to its performance on the optimization set, while the last set is used as a completely independent test set for final evaluation of the model performance without data leakage from training or optimization.
Table 1Data splitting schemes for all study areas (number of values in parentheses).
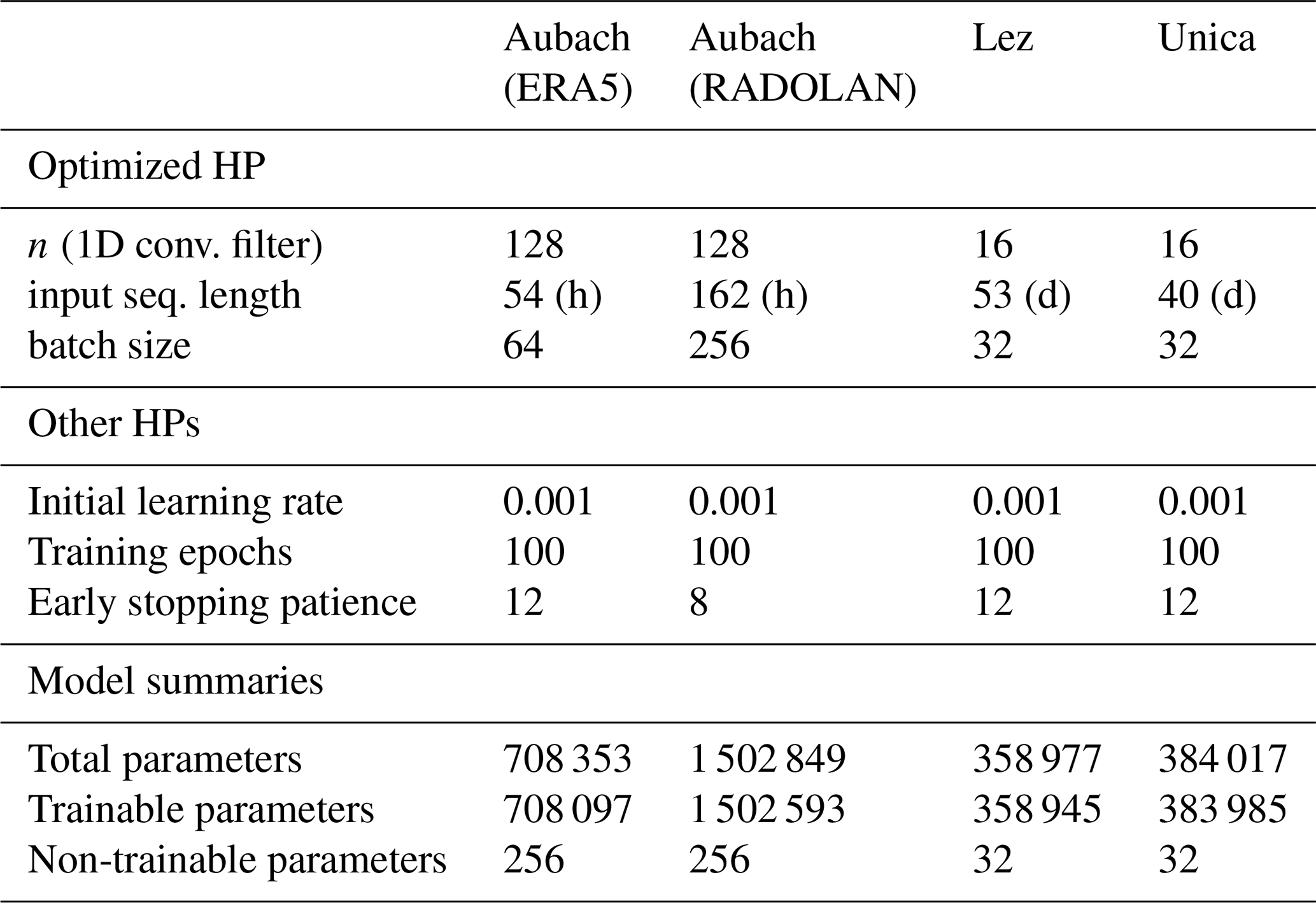
Training epoch number and early stopping patience are varied manually for each model at each test site. Hyperparameters for the 1D CNNs of both setups are optimized on the respective optimization set as stated above, maximizing the sum of Nash–Sutcliffe efficiency and R2 (calculated as explained below). The number of optimization steps is also varied manually for each model and is always a trade-off between accuracy and computational costs. In case of many available input variables, we treat input variable selection equally as a global optimization problem and use Bayesian optimization to simultaneously select a proper set of input variables and hyperparameters. Thus, input optimization is used for each 2D model, as ERA5-Land and E-OBS offer several different climate variables, as well as for the 1D model of Unica springs, where the climate station records provide additional climate variables such as snow cover. For Lez spring and Aubach spring, only a smaller input variable set is available (mainly precipitation and temperature) and hence fully used. For all models we use an additional input (Tsin), which is a sine curve fitted to the temperature data. This variable can provide the model with noise-free information on seasonality and on the current position in the annual cycle (Kong-A-Siou et al., 2014). Precipitation is the only variable that is not optimized but that is fixed as input, because it undoubtedly has a major influence on the discharge of a karst spring. The optimized hyperparameters, information on some fixed hyperparameters, and a summary of the number of parameters in each model are given in Table D1.
We calculate several metrics to evaluate the performance of our models: Nash–Sutcliffe efficiency (NSE) (Nash and Sutcliffe, 1970), squared Pearson r (R2), root mean squared error (RMSE), bias (Bias) as well as Kling–Gupta efficiency (KGE) (Gupta et al., 2009). For squared Pearson r we use the notation of the coefficient of determination (R2), because we compare the linear fit between simulated and observed discharge and thus of a simple linear model, which makes them equal in this case.
3.4 Spatial input sensitivity and catchment localization
Anderson and Radić (2022) show in their study that combined 2D CNN–LSTM models can learn to focus on specific areas of the spatially distributed input data and that these make physical sense. We modify this approach and transfer it to karst spring modeling, where we demonstrate that this approach is suited to approximating the location of karst catchments.
We use the Gaussian spatial perturbation approach from Anderson and Radić (2022), which is similar to other input sensitivity algorithms such as occlusion (Zeiler and Fergus, 2014) or RISE (Petsiuk et al., 2018), but in contrast to these methods, it takes into account the physical meaning of the absolute value of each variable at each pixel during the perturbation. We modify this approach so that only a single input channel (e.g., precipitation) is perturbed at a time for the sensitivity analysis. For details of this approach, we refer to the original study. In short, it works by perturbing spatial fractions of the input data by adding or subtracting a 2D Gaussian curve from the input data at a certain location. Both the perturbed and unperturbed data are passed through the trained model to determine the resulting simulation error between them. In this way, after many iterations, heat maps are created that show how sensitive the trained model is to perturbations of certain areas of the input data.
The considered input variables in our study show different properties in terms of spatial heterogeneity and variability. Temperature, for example, usually exhibits a distinct spatial autocorrelation, meaning that temperature information from outside the catchment area may be used to infer temperature within the catchment area. In contrast, precipitation is less spatially autocorrelated, meaning that precipitation information from outside the catchment area is less related to precipitation from inside the catchment area. Therefore, we hypothesize that the within-catchment precipitation fields will be most important for the model's prediction, and we will test this hypothesis by visually inspecting the sensitivity maps produced by the modified approach of Anderson and Radić (2022). Compared with the original approach by Anderson and Radić (2022), we therefore perturb only single channels at a time, instead of all channels at once, to separate the influence of each channel on the model output.
4.1 Aubach spring
Figure 3a shows the simulation results of the 1D CNN model for the test period 2020, using only available climate station input data. Error measures indicate a high accuracy of the model simulation: NSE and R2 values are both 0.74, and KGE is 0.79. We observe that peaks in winter and spring are underestimated. The snowmelt period, clearly visible in increased baseflow and diurnal variations from April to June, is nicely fitted, as well as the following summer peaks. A short series of discharge peaks in the end of September/beginning of October is not captured. We assume that these were caused by small-scale precipitation events that are not represented in the data of the climate stations used as inputs. Interestingly, diurnal variations, which might be learned during the snowmelt period, are also visible in periods not influenced by snow (e.g., in August). From Chen et al. (2017b) we know the high relevance of snow in this area and, by coupling the CNN model with snow routine data preprocessing, we are able to further improve the model performance (Fig. 3b). We can now achieve a fit with 0.77 for both NSE and R2, and KGE increases to 0.84. Our model is able to better fit the second-largest peak of the whole dataset, which occurs in February, though the peak is slightly overestimated, whereas other peaks still tend to be underestimated. The snowmelt period remains well simulated but shows increasing deviations close to the end of the period. The earlier noticed diurnal variations in summer and fall are now diminished, which is presumably an effect of the snowmelt preprocessing.
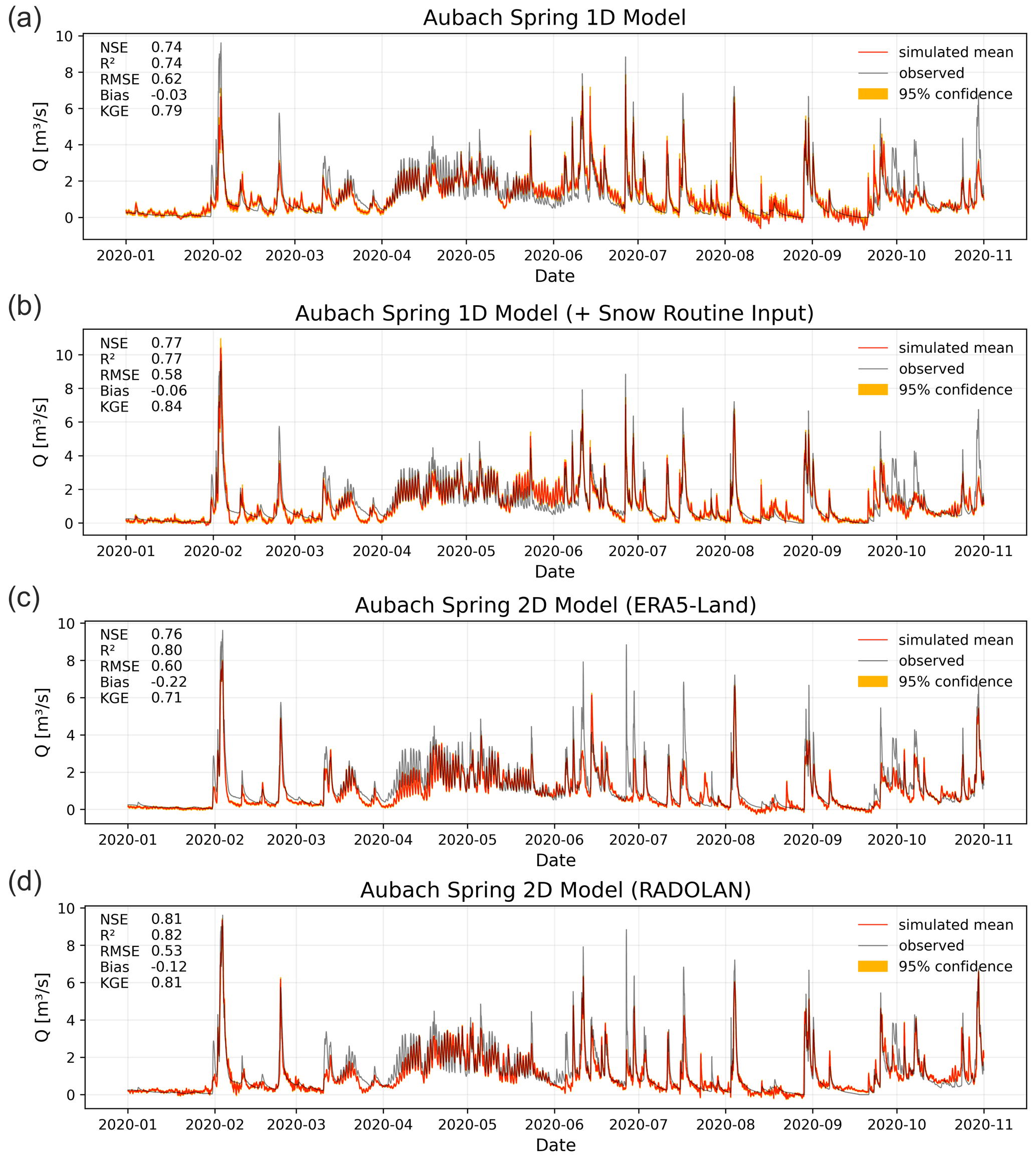
Figure 3Simulation results for the year 2020 at Aubach spring: (a) 1D model based on climate station inputs, (b) 1D model with additional snow routine preprocessing, (c) 2D model based on ERA5-Land gridded data and (d) 2D model with combination of ERA5-Land data and RADOLAN precipitation input.
Please note that the 95 % model uncertainty from random number dependency, estimated from 10 differently initialized models with a Monte Carlo dropout distribution from 100 runs each (i.e., 1000 simulations in total), is very low for both modeling results (a + b) compared with the overall variability of the discharge. We assume the spatially limited input data to be the major source of error in the complete modeling procedure, because all climate stations are located outside of the catchment area and thus introduce distinct uncertainty about the true conditions within the catchment. Other modeling approaches (Chen and Goldscheider, 2014; Chen et al., 2017b, 2018) based on combined lumped parameter (SWMM) and distributed models achieve similar or higher NSE values for the simulation of Aubach spring discharge (0.92, 0.83, and 0.80, respectively). As mentioned, the results are, however, hardly comparable with each other nor with this study. Reasons are (i) different input data (number and position of climate stations), (ii) different simulation periods, and (iii) very different test set lengths. One reason for the slightly lower performance of our model could be that none of the previous studies covered a complete annual cycle as a contiguous test period, including high peaks in late winter and strong snowmelt influence in spring and early summer.
Figure 3c shows the results of the 2D modeling setup using (only) ERA5-Land input data. Based on the described optimization procedure, the model uses the following inputs: P, T, E, SMLT, SWVL2 and SWVL4 (for a comparison of selected input variables with other study areas, see also Table A1). The performance of the 2D model is similar to that of the 1D models, showing a NSE (0.76) and RMSE in between both: a larger R2 (0.8) but a lower KGE (0.71). This performance is still high considering that the major catchment is extremely small (about 9 km2) compared with one ERA5-Land grid cell and that a large grid section of 14×14 ERA5-Land cells () was used as input. We see that the major peak in February is slightly underestimated as well as the beginning of the snowmelt period in April; however, the end of this period in May/June has improved now compared with (b). Both 1D models are superior in estimating the peaks, especially during summer, except the already mentioned peaks in September/October, which have improved using the 2D input data. This supports the assumption that the climate stations do not represent these precipitation events but that the 2D data do due to their spatial nature.

Figure 4Simulation results for 2017–2018 at Unica springs in Slovenia using climate station input data (a) and E-OBS gridded data (b).
To account for the small area of the catchment of Aubach spring, Fig. 3d shows the results of the 2D input data, using the spatially higher-resolved RADOLAN precipitation data in combination with downscaled ERA5-Land data. We have reduced the spatial extent of the 2D input but still have a reasonable buffer around the catchments and, compared with the former 2D model, increase the grid cell number considerably (22×22 or 222 km2). The optimized model uses P, T, Tsin, SMLT, SF, and SWVL1/2/4 as inputs and thus omits E and SWVL3. This model shows the best performance of all four models by reaching a NSE of 0.81, R2 of 0.82 and KGE of 0.81. Similar to the model in Fig. 3c, the beginning of the snowmelt period in April remains slightly underestimated and, compared with the 1D models, the peaks in summer are less well fitted. Nevertheless, we generally see an accurate fit: especially the largest peak in February is well reproduced. Compared with the 1D approach, the main source of uncertainty for both 2D models should be the uncertainty of ERA5-Land variables. Their values originate from large grid cells in comparison with the catchment size, and thus it is not clear how well they represent the true conditions at catchment scale. A more elaborate downscaling of ERA5 data or other high-resolved climate data for a combination with RADOLAN precipitation data might be a promising approach for simulating small catchments like this one. Model uncertainty derived from random number effects and Monte Carlo dropout is (equal to the 1D models) satisfyingly small. In total, we think that both the 1D and 2D approaches for this catchment bear substantial shortcomings in terms of how well the input data represent the true conditions in the catchment, even though the simulation results are generally very accurate. On the one hand the climate stations represent the true observed climate, and on the other hand this is true only for a very specific point, which is in this case outside the catchment and embedded in a highly variable topography. The 2D data have a too coarse spatial resolution compared with the size of the Aubach spring catchment and are themselves modeled (in the case of ERA5-Land). We therefore do not think that one approach is superior for this study area, but we can show that even in this case with relatively coarsely gridded input data compared with the catchment size, the 2D approach offers a decent alternative in case of missing climate station data.
4.2 Unica springs
Figure 4 summarizes the 1D and 2D model performance on the years 2017 and 2018 for Unica springs in Slovenia. The simulation of this quite large catchment area (820 km2) is based on the data of only two climate stations (Postojna and Cerknica). All available input variables from both stations except relative humidity from Postojna station and new snow from Cerknica station were used as inputs as selected by the Bayesian optimization model. The 1D model shows good performance overall (NSE: 0.73, R2: 0.79, KGE: 0.63), including a response for all major discharge events. However, recession slopes, especially in 2017, are underestimated substantially, and the plateau shapes of the large peaks (e.g., January 2018) are not well captured but rather simulated as multiple peaks. In general, many of the high-flow events at this gauge have a quite long duration of days to even weeks, resulting in such plateau-like shapes. This is due to the regular flooding of the polje. After the drainage areas of the polje are completely flooded, there is a progressive back-flooding and a steady rise in the water level, which makes it impossible to accurately monitor the flow conditions under these conditions. Therefore, during the plateau-like peaks, when we cannot observe the true flow, the peaks simulated by the ANN might be conceptually true, which is however not possible to evaluate. The peak in April 2018 is quite clearly underestimated, whereas the following low-flow period (summer 2018) is slightly overestimated. Such overestimation might be due to small-scale meteorological events that are detected by the climate stations but that do not well represent the conditions in the whole catchment area. It is also important to notice that during 2014 and 2018 substantial environmental changes occurred in the catchment (Kovačič et al., 2020). During this period a considerable amount of vegetation was destroyed by a series of large-scale forest disturbances. We expect the evapotranspiration changed due to changes in canopy interception, water use and soil moisture. As a result, spring behavior has likely changed, because vegetation cover is an important element of the water balance and recharge events may have resulted in higher infiltration rates and more intense spring response as well as more pronounced droughts. The effect of this environmental change on the model performance is hard to evaluate, because it is not part of the training data. However, the model was optimized and validated (early stopping) on a part of the period with environmental changes, which means that the model may infer some information on the changes from these periods (2014–2016). It is not expedient to exclude this change from model building, since this would require shortening the time series to the period after 2018, thus losing almost the complete data basis. Due to highly complex hydraulic behavior in this study area, which is, for example, related to the already mentioned polje flooding and to a strongly variable water level in the system that also varies the catchment area, extracting the highly nonlinear precipitation discharge is especially challenging. We generally observe fewer dynamics in terms of the number of flood pulse events compared with Aubach spring. In terms of intensity of hydrologic variability, discharge rates can vary by about 2 orders of magnitude. This is primarily due to the large size of the catchment area, the very high degree of karstification of the carbonate rocks, and the fact that the main spring may act as an overflow spring.
By using the 2D input data from 18×21 E-OBS grid cells, we were able to improve the model performance substantially (Fig. 4b), reaching now a NSE of 0.83, a R2 of 0.84 and a KGE of 0.80. Model input variables are P, Tmax, RH and Rad. We generally observe a similar shape of the simulation to the 1D model but with overall reduced errors. Still, the plateau shapes of some peaks are not well captured, but the same conceptual understanding as for the 1D model seems to be learned, which means the model mainly simulates peaks instead of plateau-shaped high-flow events. The slopes of the recessions are still generally underestimated, especially the simulation of low-flow periods, and minor discharge events improve clearly though. The improved results are plausible, because we can expect precipitation events to be represented more accurately in the gridded data that in the point data of only two climate stations, especially considering the size of the catchment. As for Aubach spring, both models show a comparably low model uncertainty based on random number variation and Monte Carlo dropout, and the model uncertainty of the 2D simulation is even a bit lower than for the 1D model. Again, we assume the spatially limited climate station data to be the main source of data uncertainty in the 1D model, because meteorological stations are located on the western and eastern sides of the karst massif. The massif itself represents the orographic barrier with different temperature and precipitation regimes that are certainly not captured by the considered meteorological stations. Concerning the 2D data, the grid resolution is sufficiently high to adequately represent the climatic conditions in this large-sized catchment.
4.3 Lez spring
Lez spring represents a third class of study area, as the catchment size (around 240 km2) is somewhere in between the two others, the climate is Mediterranean and the spring runs dry for a considerable amount of time during the annual cycle due to a constant exploitation of the karst aquifer through pumping. Figure 5 shows both the results for the 1D (a) and 2D (b) models. Despite comparably short training (daily data, starting in 2008), we observe a very high fit of the 1D model above 0.86 for NSE, R2 and KGE as well as the timing of the peaks and the absolute height of the peaks, as the dry periods are simulated accurately, except for some deviations in early 2019.
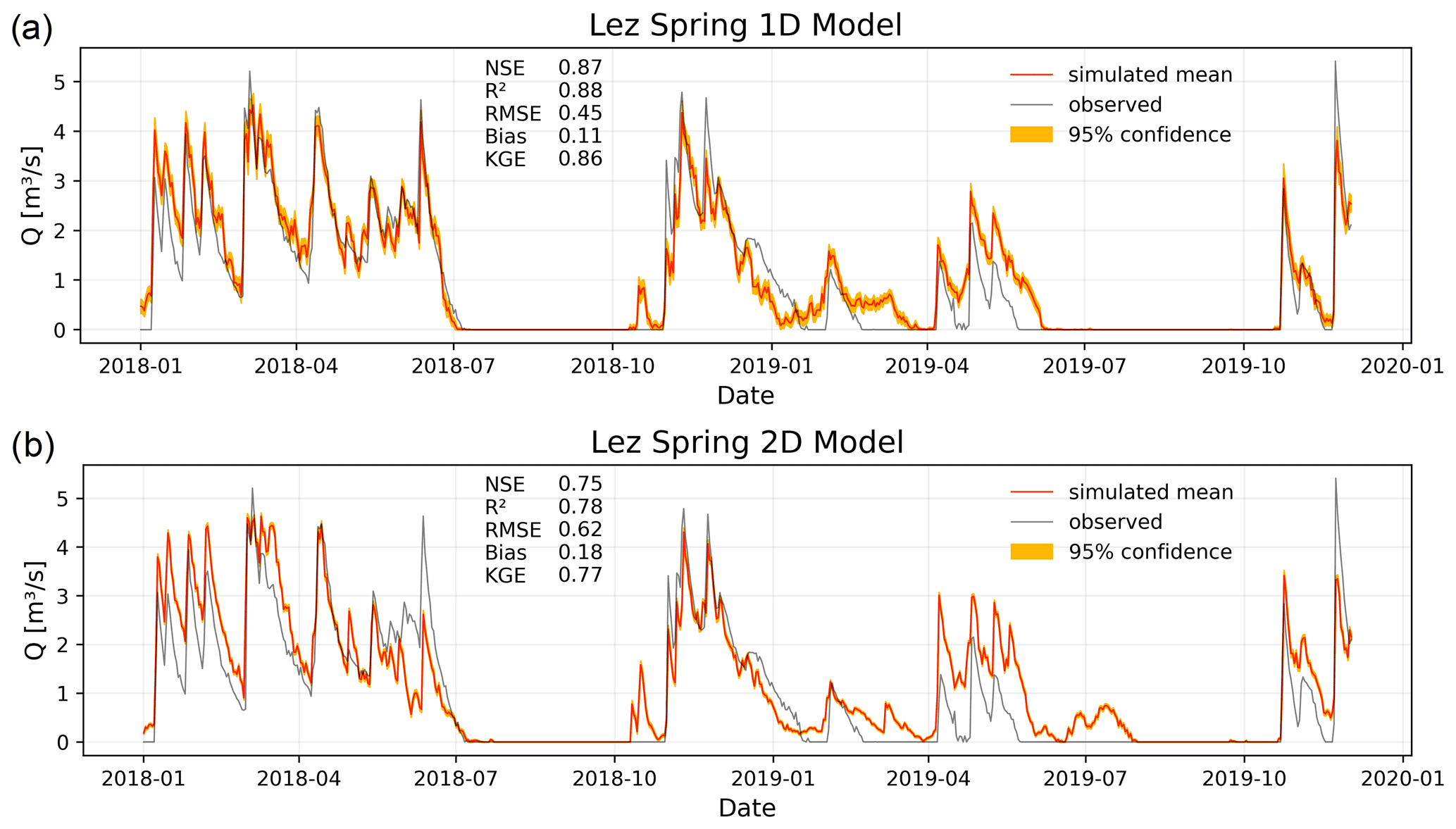
Figure 5Simulation results for 2018–2019 at Lez spring in France using climate station input data (a) and E-OBS gridded data (b).
For the 2D model we use input data from 19×18 E-OBS grid cells, and the Bayesian model selects only RH and Rad as inputs besides the fixed input P. Considering the high relevance of potential evapotranspiration (PET) in the Mediterranean, it is a bit surprising that temperature, as a major driver of PET, is not selected (neither T, Tmin nor Tmax). However, relative humidity is also important for calculating PET (King et al., 2015) (e.g., low RH favors high evaporation), and the information on seasonality well encoded in a temperature time series is presumably deducible from the radiation data (higher in summer than in winter). The performance of the model is very good but clearly lower compared with the 1D model, showing NSE, R2, and KGE between 0.75 and 0.78. Generally, the simulation is better in 2018 than in 2019, which is, however, also a tendency of the 1D model. The model simulated some non-existent peaks in the dry sections: after all, one of them (in October 2018) clearly also occurs in the 1D model's simulation. Presumably, the input data are accountable for the general performance differences between both modeling approaches. The climate stations, from which the interpolated precipitation time series is derived, are mainly located inside the catchment and additionally represent a good spatial coverage. Compared with both other study areas, the 1D input data here best represent the climatic conditions within the catchment. Based on the lower performance of the 2D model, we conclude that it seems to be harder to extract the relevant relationships between climate forcing and spring discharge from the gridded data. This may be related to a less favorable ratio of grid cell size to catchment size than for the Unica catchment, for example. The model uncertainty based on initializations and derived from Monte Carlo dropout again is small for both model setups, especially during dry periods.
The results of our models (1D NSE: 0.87, 2D NSE: 0.75) can compete with the results from several earlier studies (NSE: 0.76–0.88, Kong A Siou et al., 2011; NSE: 0.76–079, Kong-A-Siou et al., 2014); however, we do not beat the maximum performance reported by Kong A Siou et al. (2012) (NSE: 0.69–0.95) and Kong-A-Siou et al. (2013) (NSE: 0.96). Generally, all studies, including ours, achieve high performance, and it is hard to conclude reasons for the superiority of one or other study, as several factors differ among them, such as model types, training and testing periods, or set of input variables. For our study, we chose not to include pumping data (as used in Kong-A-Siou et al., 2014) due to the data availability reasons elaborated in Sect. 2.4 as well as to be consistent in the 2D modeling approach, which would need an update of the model structure due to the 1D time series character of the pumping data. The 2D approach still shows very good performance in general; however, in comparison among all mentioned NSE values, its performance is rather low. Nevertheless, we conclude that if no climate station data are available to apply a 1D model, the 2D approach still offers a reasonable substitute.

Figure 6Heat maps of spatial input sensitivity for Aubach spring based on ERA5-Land gridded data (a) and for Aubach spring based on RADOLAN precipitation data (b), Unica springs (c) and Lez spring (d), both based on E-OBS gridded data. In the case of (c) and (d), light-grey lines indicate the coastlines for orientation.
4.4 Spatial input sensitivity results
The most important results of the spatial input sensitivity analysis from all catchments are shown in Fig. 6. In the case of Aubach spring modeled with ERA5-Land data (Fig. 6a), we can see that the catchment is smaller than one grid cell. Hence, despite the quite good discharge modeling, we see no clear spatial meaning of the precipitation channel heat map. We also find a border effect with an almost uniform decrease in sensitivity toward the edges, which is an important reason to make the spatial extent of the data large enough. This effect could be related to the size of the filter in the convolutional layer (3×3), as it sometimes only occurs in the one or two outermost pixels (e.g., Fig. 6c). In combination with zero-padding, which we apply to improve the informative value of the edges and to maintain the data size throughout the convolutions, this may result in such an error halo, as also illustrated by Innamorati et al. (2020). Yet its origin remains unclear, and not all heat maps show this pattern (Fig. 6d), which questions the hypothesis of this being a purely technical issue. For Aubach spring, precipitation shows only the fourth-highest sensitivity (S) in terms of absolute values, while the second-most sensitive variable is snowmelt, which also shows the best spatial agreement with the catchment area. This is plausible insofar as the discharge for a large part of the time is dominated by snowmelt and to a lesser extent directly by precipitation. We conclude that even though the modeling results are satisfying, not much meaning can be extracted from the spatial sensitivity analysis for such a small catchment, given the existing spatial resolution of the gridded data. Please find heat maps of all other variables in Fig. C1. The combined approach of RADOLAN and ERA5-Land data (Fig. 6b) shows the heat map in more detail in relation to the size of the catchment. We show only the precipitation heat map, because it is the only variable with a native resolution of 1 km × 1 km, and we do not consider the spatial patterns of the remaining ERA5-Land-based variables to be meaningful to interpret. We observe that the most sensitive cells are identified close to the spring and at the border between the main catchment and the southern adjacent subcatchment. Due to the small scale of the spatial extent shown in Fig. 6b in relation to the spatial extent of precipitation events, the model is not able to sharply distinguish between precipitation inside and outside the catchment. This is presumably also related to the data, as precipitation is not directly measured but is estimated from radar signals and subsequently adjusted according to measured values from nearby climate stations. It remains unclear whether precipitation is spatially resolved with sufficient accuracy in such alpine valleys on a kilometer scale. No plausible reasoning exists for the two separate sensitive areas in the southwestern and northeastern corners; however, they are less sensitive than the center cells of the map.
Heat maps of all four selected E-OBS variables at the Unica catchment are shown in Fig. 6c. In accordance with our expectation for karst areas, we see the highest sensitivity for precipitation, which visually also identifies the catchment area very well. Especially Tmax and RH show high sensitivities in larger areas; however, they are usually highly spatially autocorrelated and do not show a strong spatial heterogeneity like precipitation, which makes it plausible that the model learns from larger areas and does not concentrate strongly on the catchment itself. The model further identifies an area in the north as most sensitive for radiation.
Heat maps of the 2D Lez spring model are shown in Fig. 6d. In this area the model very strongly ignores large parts of the input data (dark blue, no visible border effects) and comparably sharply identifies the relevant area for the spring. This might be related to the higher spatial heterogeneity of precipitation in a Mediterranean climate (Fresnay et al., 2012), which in this specific region has a special importance (severe flash floods known as Cévenol episodes; Kong A Siou et al., 2011). Generally, we observe a slight southerly and easterly shift of the highest sensitivity compared with the catchment position. This might be related to the performance of the 2D approach, which could not compete with the 1D models. Maybe the model did not exactly learn the most relevant spatial features. The most sensitive variable is precipitation, while the RH channel shows the best spatial fit. We furthermore see that the size of the catchment is about the minimum size to produce meaningful heat maps based on this given grid resolution, which also corresponds to our interpretation of the 2D model performance shortcomings in comparison with the 1D approach.
Given the spatial resolution of the used input data, the obtained heat maps, and the simulation results of all three catchments, the Unica springs catchment seems to be most appropriate for further investigating the usefulness for catchment localization. It has the highest ratio of catchment size to data resolution and exhibits both generally high performance of the ANN models and especially a considerably improved performance when using spatially distributed inputs compared with climate station input data. Thus, we used Unica springs to conduct additional experiments to investigate the sensitivity of our approach to the absolute catchment location within the considered area of the input data. Figure 7 shows the results of these experiments, where we shifted the 2D input data boundaries in such a way that the catchment is located in one of the four corners or edges, leading to eight additional modeling results, named by the position of the catchment in the considered area of the input data (e.g., upleft: catchment in the upper left corner). First of all, we find that all models successfully model the spring discharge curve and similarly learn the relevant grid cells of the considered input area; i.e., they are able to learn the approximate position of the catchment. The NSE values vary moderately between 0.80 and 0.85 among all models. The heat maps of the precipitation input channel visually well identify the location of the catchment for each of the different considered areas of the input data. We find that, regardless of the catchment's position within the considered areas of the input data, the resulting highly sensitive area in the P channel well indicates the true catchment position. For the heat maps of the other input channels, we see that usually larger areas are identified as relevant and that more variations between the models occur. Two things are particularly noticeable here. First, the identified sensitive input areas are generally slightly smaller for the up* models, which is possibly related to the fact that the considered area of the input data is shifted towards the Mediterranean Sea, where no input data are available in the E-OBS dataset (compare the grey coastline). These areas contain zeros or mean values and show no temporal variation that could be used to model the spring discharge. Second, the noticeably best-performing model (downleft, NSE of 0.85) is the model with the least fraction of no-data cells (due to the sea). Intuitively, we would not have expected the best performance here but rather with the upright model, since there it is almost predetermined where the model has to learn. So, the model seems to be able to use the larger amount of “useful data”, even outside the catchment, to improve the overall performance. To possibly delineate a catchment from these results, a strategy has to be developed regarding the sensitivity contrast between the catchment and its surroundings. From our results we conclude that focusing on the precipitation channel is the most promising approach for potential catchment delineation. This however only makes sense if (i) precipitation is sufficiently heterogeneous at the scale of investigation, (ii) if conceptually spring discharge is mainly driven by precipitation (not snowmelt, for example) and (iii) the gridded climate data are provided at a relatively high spatial resolution compared with the catchment size. Please find the precipitation channel heat maps for Aubach spring and Lez spring in Figs. C2 and C3.
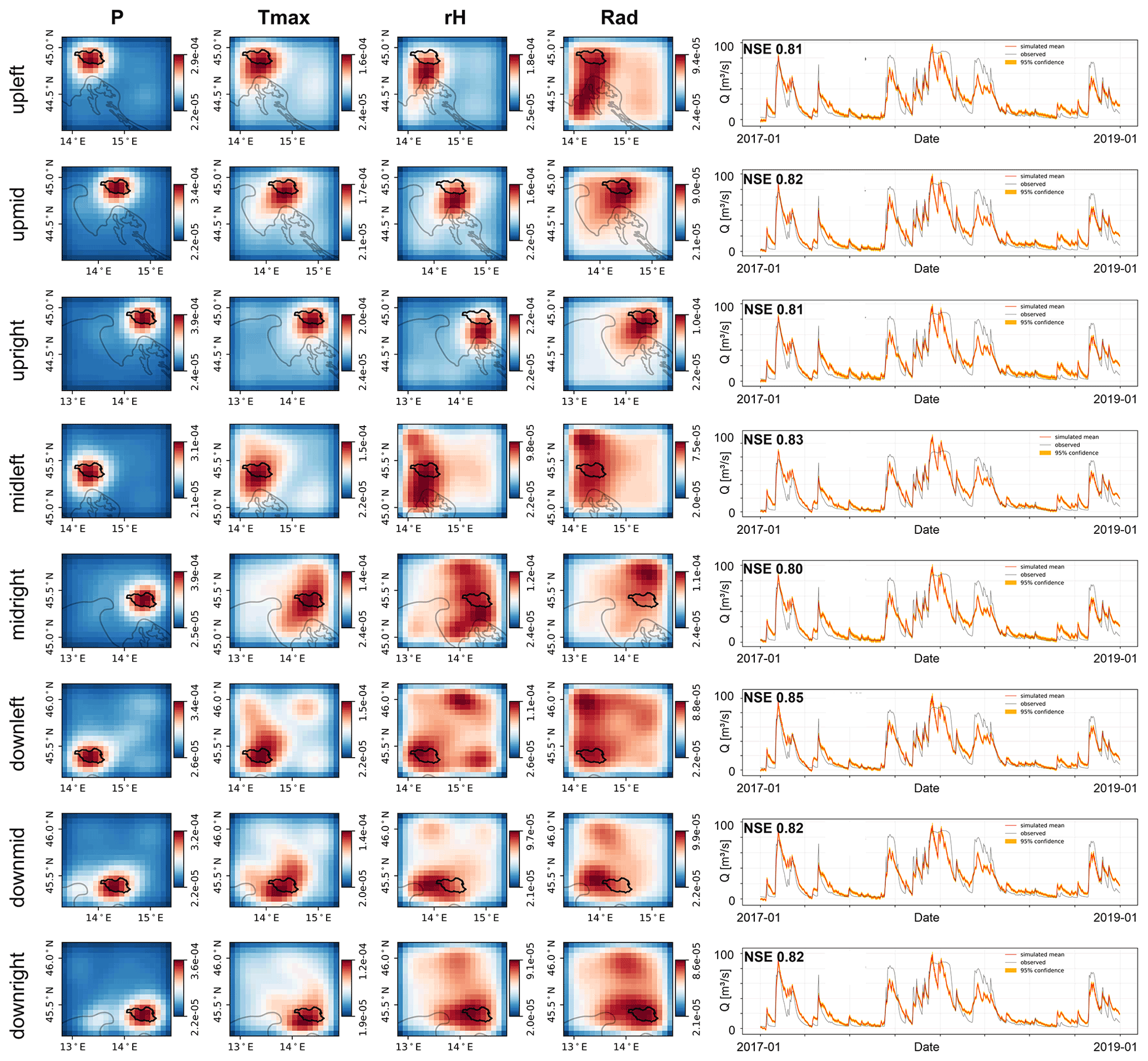
Figure 7Heat maps of spatial input sensitivity for the Unica springs catchment based on E-OBS gridded data. The considered area of the gridded input data is shifted to demonstrate the spatial learning capabilities of the models.
In summary, we observe that the approach in its current form can produce meaningful heat maps for at least roughly locating karst spring catchments. At least for the precipitation channel, we showed that the location of the catchment is successfully learned, regardless of the position within the considered area of the input data, if the ratio of catchment size to grid cell size is favorable (as for Unica springs). We notice that it generally works better the larger the catchment area, especially in relation to the grid cell size, but the absolute size of the catchment itself appears to also be important. For small catchments it seems harder to extract precise catchment locations, even if spatially finer-resolved data are available. This might be related to the fact that, at small scales, even precipitation has a distinct spatial correlation, which can lead to higher sensitivity also in areas outside the catchment. However, one should keep in mind that these conclusions are only tendencies as we only investigated a small number of catchments. To develop a catchment delineation strategy, future investigations should analyze more catchments with adequate ratios of size to grid cell resolution, such as the Unica catchment. Moreover, it can be expected that more and better gridded meteorological data products will be available in the future, which might lead to better results with the proposed methodology, also for catchments with varying sizes.
From the obtained insights we can conclude that karst spring discharge can be predicted accurately with the presented 1D and 2D approaches. Their performance competes with that of existing models in the three study areas. One main advantage compared with conventional modeling approaches in karst is that, in order to obtain precise discharge simulations, far less prior knowledge of the system under consideration is required. Thus, using ANNs can generally reduce the amount of preliminary work that would be required to gain such sufficient system knowledge. We can further show that gridded climate data can provide an excellent substitute for non-existent or patchy climate station data. This does not require knowledge of the exact catchment area, which is a critical component, especially for karst springs. Rather, coupled 2D–1D CNNs can be used to generate a first approximation of the catchment location. However, as was shown, this approach still needs further development to more accurately localize the catchment, for example by modifying the input sensitivity approach and by defining a routine to infer the catchment location from the sensitivity data other than visual inspection. An important factor in achieving more accurate catchment localization is 2D meteorological input data with a finer spatial resolution in relation to the catchment size, because we found the approach to work best for the largest catchment. Additionally, a sufficient heterogeneity of precipitation in comparison with the catchment size is necessary, which, however, cannot be controlled but possibly limits the application in some karst areas. Given these developments and conditions, the approach's capabilities to delineate karst catchments should be further investigated, ideally including an evaluation against tracer tests and hydrogeological studies. In terms of accuracy, we do not find that one of the tested model setups (1D and 2D) is fundamentally superior. A key benefit of the 2D approach, which uses spatially discretized input data, is the spatially and temporally complete nature of the data and the number of variables available for study. Furthermore, for many areas the openly available 2D climate data are more easily accessible than climate station data, which still have to be collected from various different authorities if accessible or existent at all. A weak spot of the 2D approach is a substantially higher computational effort due to the large number of model parameters and the larger amount of data that has to be processed during training and optimization. In summary, gridded meteorological data are useful for overcoming missing climate station data and getting quite a good idea of the spatial extent of larger catchments, given sufficiently small grid cell sizes.
Table A1Summary and comparison of different aspects of all three study areas.

The Thiessen polygon interpolation method consists of calculating a weighted average of the precipitation data by allocating a contribution percentage to each meteorological station, based on its influence area in the catchment. These influence areas are calculated through geometric operations. First, we draw straight-line segments between each adjacent station, and then we add the perpendicular bisectors of each segment, which will define the edges of the polygons. Each meteorological station thus corresponds to a particular polygon, for which the precipitation over the surface is assumed to be the same as the measured precipitation at the station.
The weighted average of the precipitation Pwa at each time step is calculated as follows:
with n the number of meteorological stations, Ai the area (over the catchment) of the polygon corresponding to the ith station, Pi the precipitation measured at the ith station and A the area of the catchment.
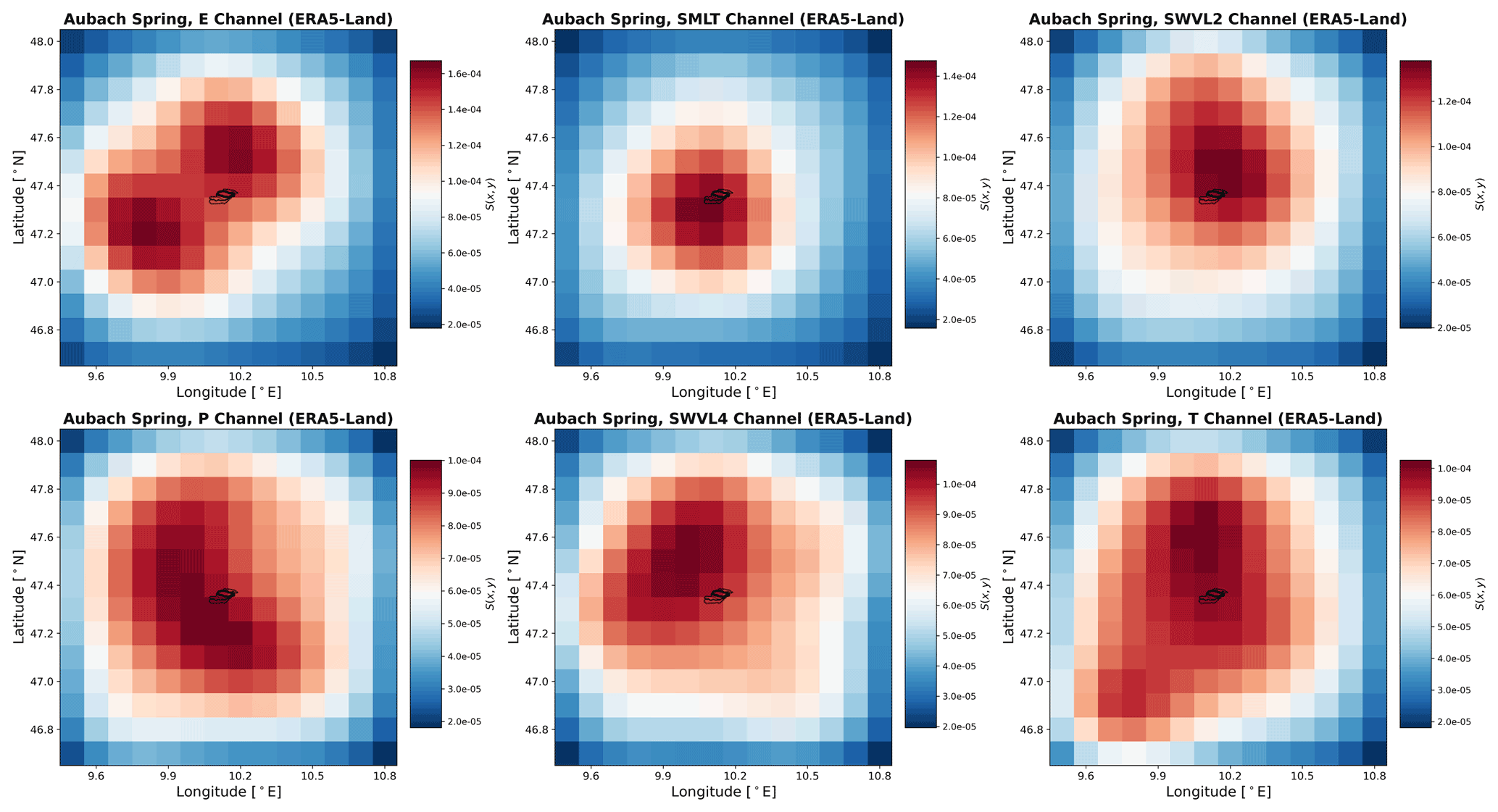
Figure C1Spatial input sensitivity heat maps for Aubach spring based on ERA5-Land gridded data.
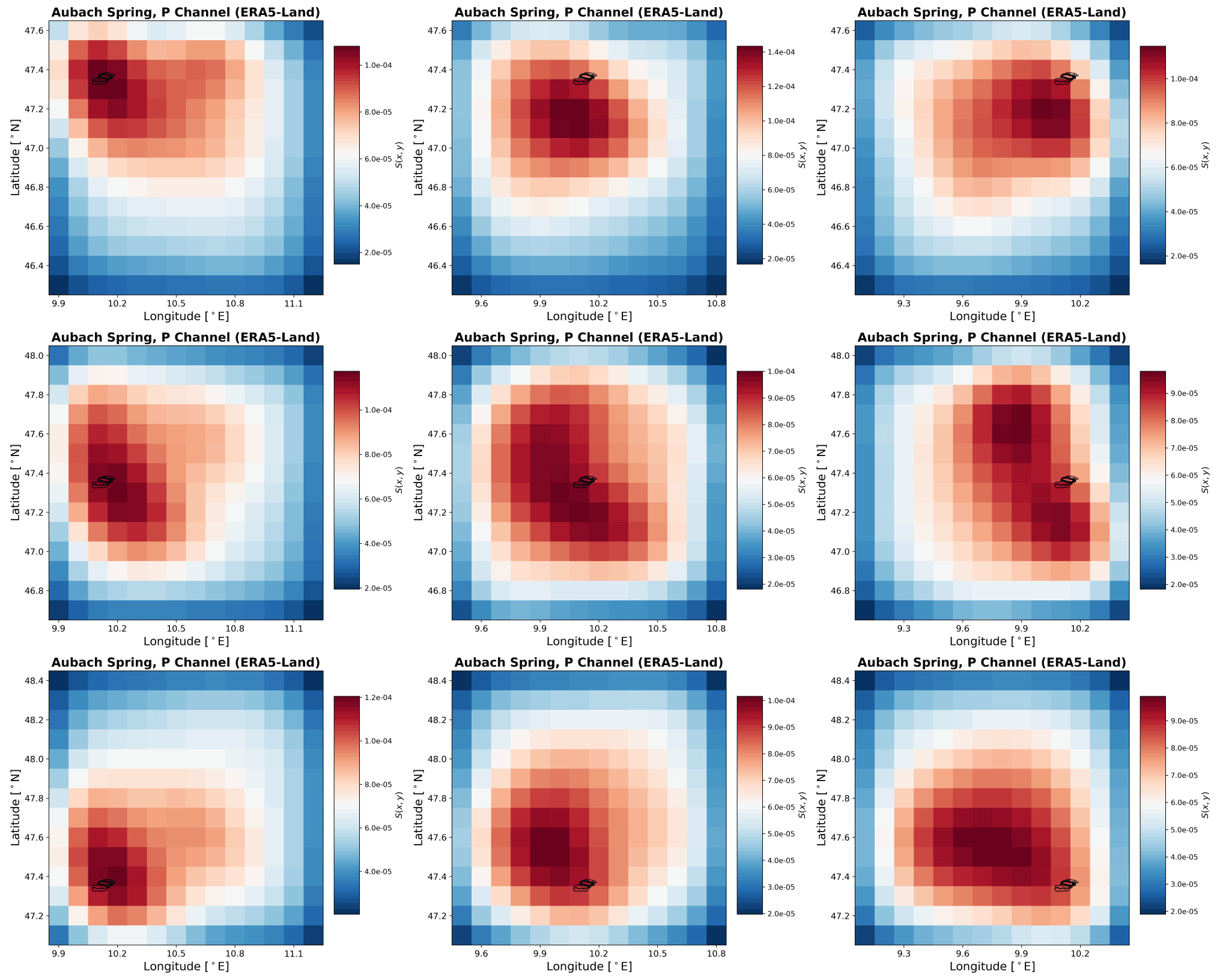
Figure C2P-channel heat maps based on ERA5-Land gridded data for Aubach spring with shifted area of the spatial input data in relation to the catchment position.
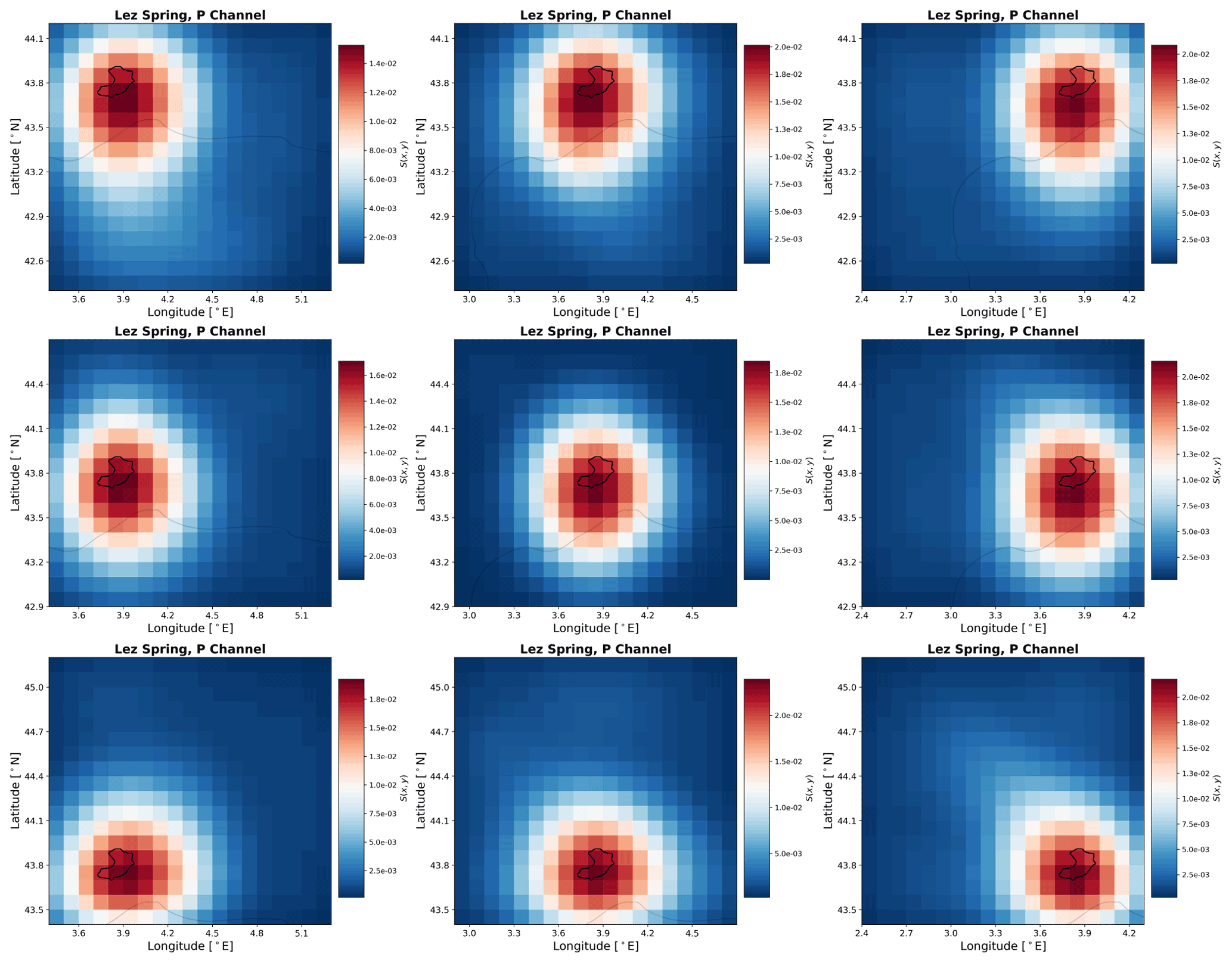
Figure C3P-channel heat maps based on E-OBS gridded data for Lez spring with shifted area of the spatial input data in relation to the catchment position.
We provide complete model codes on Github (https://doi.org/10.5281/zenodo.5184692) (Wunsch, 2021). Due to redistribution restrictions from several parties, we cannot provide a dataset. Nevertheless, the data are available from the respective local authorities listed in the main text and in the following: 2D datasets are fully accessible online: E-OBS (https://doi.org/10.24381/CDS.151D3EC6; Copernicus Climate Change Service, 2020), ERA5-Land (https://doi.org/10.24381/CDS.E2161BAC; Muñoz Sabater, 2019). Aubach spring discharge and climate data from surrounding climate stations in Austria are available on request from the office of the federal state of Vorarlberg, division of water management, and Oberstdorf station data (German Meteorological Service) are available via the DWD Open Data Server (https://opendata.dwd.de/; DWD, 2022). Data from Slovenia can be retrieved from ARSO (Slovenian Environment Agency) (http://vode.arso.gov.si/hidarhiv/, ARSO, 2020a and http://www.meteo.si, ARSO, 2020b). Lez spring discharge was provided by SNO KARST (2021) (https://doi.org/10.15148/CFD01A5B-B7FD-41AA-8884-84DBDDAC767E), and climate data are available on request from MeteoFrance.
AW, TL and NG conceptualized the study. AW and TL developed the methodology and software code and validated the results. AW performed the experiments and investigated and visualized the results. GC and ZC performed formal analysis. NR and GC contributed to data curation activities. AW wrote the original paper draft with contributions from GC and NR. All the authors contributed to interpretation of the results and review and editing of the paper draft. TL and NG supervised the work.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The financial support of KIT through the German Federal Ministry of Education and Research (BMBF) and the European Commission through the Partnership for Research and Innovation in the Mediterranean Area (PRIMA) program under Horizon 2020 (KARMA project, grant agreement no. 01DH19022A) is greatly appreciated. We thank the French Ministry of Higher Education and Research for the thesis scholarship of Guillaume Cinkus as well as the European Commission and the Agence Nationale de la Recherche (ANR) for its support of HSM and UMR through the Partnership for Research and Innovation in the Mediterranean Area (PRIMA) program under Horizon 2020 (KARMA project, ANR-18-PRIM-0005). We were further financially supported by the Slovenian Research Agency within the project Infiltration processes in forested karst aquifers under changing environment (no. J2-1743). The authors were supported by the state of Baden-Württemberg through bwHPC. Muñoz Sabater (2019) was downloaded from the Copernicus Climate Change Service (C3S) Climate Data Store. The results contain modified Copernicus Climate Change Service information 2020. Neither the European Commission nor ECMWF is responsible for any use that may be made of the Copernicus information or data it contains. We acknowledge the E-OBS dataset (v23.1) from the EU-FP6 project UERRA and the Copernicus Climate Change Service, and the data providers in the ECA&D project. Lez spring discharge data were provided by the KARST observatory network (SNO KARST) initiative from the INSU/CNRS (FRANCE), which aims to strengthen knowledge sharing and to promote cross-disciplinary research on karst systems. The authors were also supported by the KIT Publication Fund of the Karlsruhe Institute of Technology.
This research has been supported by the European Commission, Horizon 2020 Framework Programme (4PRIMA – grant no. 724060).
The article processing charges for this open-access publication were covered by the Karlsruhe Institute of Technology (KIT).
This paper was edited by Yue-Ping Xu and reviewed by two anonymous referees.
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., Irving, G., Isard, M., Jia, Y., Jozefowicz, R., Kaiser, L., Kudlur, M., Levenberg, J., Mane, D., Monga, R., Moore, S., Murray, D., Olah, C., Schuster, M., Shlens, J., Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V., Viegas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., and Zheng, X.: TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems, p. 19, https://www.tensorflow.org/ (last access: 6 May 2022), 2015. a
Afzaal, H., Farooque, A. A., Abbas, F., Acharya, B., and Esau, T.: Groundwater Estimation from Major Physical Hydrology Components Using Artificial Neural Networks and Deep Learning, Water, 12, 5, https://doi.org/10.3390/w12010005, 2020. a
Anderson, S. and Radić, V.: Evaluation and interpretation of convolutional long short-term memory networks for regional hydrological modelling, Hydrol. Earth Syst. Sci., 26, 795–825, https://doi.org/10.5194/hess-26-795-2022, 2022. a, b, c, d, e, f, g, h, i, j
ARSO – Slovenian Environment Agency: Archive of Hydrological Data, ARSO [data set], http://vode.arso.gov.si/hidarhiv/ (last access: 5 December 2020), 2020a. a, b, c
ARSO – Slovenian Environment Agency: Archive of Meteorological Data, ARSO [data set], http://www.meteo.si (last access: 5 December 2020), 2020b. a, b
Bandhauer, M., Isotta, F., Lakatos, M., Lussana, C., Båserud, L., Izsák, B., Szentes, O., Tveito, O. E., and Frei, C.: Evaluation of Daily Precipitation Analyses in E-OBS (V19.0e) and ERA5 by Comparison to Regional High-Resolution Datasets in European Regions, Int. J. Climatol., 42, 727–747, https://doi.org/10.1002/joc.7269, 2021. a
Bergström, S.: The Development of a Snow Routine for the HBV-2 Model, Hydrol. Res., 6, 73–92, https://doi.org/10.2166/nh.1975.0006, 1975. a
Bergström, S.: The HBV Model, in: Computer Models of Watershed Hydrology, edited by: Singh, V. P., Water Resources Publications, Colorado, USA, 443–476, ISBN 0-918334-91-8, 1995. a
Bicalho, C. C., Batiot-Guilhe, C., Seidel, J. L., Van Exter, S., and Jourde, H.: Hydrodynamical Changes and Their Consequences on Groundwater Hydrochemistry Induced by Three Decades of Intense Exploitation in a Mediterranean Karst System, Environ. Earth Sci., 65, 2311–2319, https://doi.org/10.1007/s12665-011-1384-2, 2012. a
Breiman, L.: Random Forests, Mach. Learn., 45, 5–32, https://doi.org/10.1023/A:1010933404324, 2001. a
Cai, Z., Fan, Q., Feris, R. S., and Vasconcelos, N.: A Unified Multi-Scale Deep Convolutional Neural Network for Fast Object Detection, in: Computer Vision – ECCV 2016, edited by: Leibe, B., Matas, J., Sebe, N., and Welling, M., Springer International Publishing, Cham, 354–370, ISBN 978-3-319-46493-0, 2016. a
Chen, Z. and Goldscheider, N.: Modeling Spatially and Temporally Varied Hydraulic Behavior of a Folded Karst System with Dominant Conduit Drainage at Catchment Scale, Hochifen–Gottesacker, Alps, J. Hydrol., 514, 41–52, https://doi.org/10.1016/j.jhydrol.2014.04.005, 2014. a, b, c, d
Chen, Z., Auler, A. S., Bakalowicz, M., Drew, D., Griger, F., Hartmann, J., Jiang, G., Moosdorf, N., Richts, A., Stevanovic, Z., Veni, G., and Goldscheider, N.: The World Karst Aquifer Mapping Project: Concept, Mapping Procedure and Map of Europe, Hydrogeol. J., 25, 771–785, https://doi.org/10.1007/s10040-016-1519-3, 2017a. a
Chen, Z., Hartmann, A., and Goldscheider, N.: A New Approach to Evaluate Spatiotemporal Dynamics of Controlling Parameters in Distributed Environmental Models, Environ. Model. Softwa., 87, 1–16, https://doi.org/10.1016/j.envsoft.2016.10.005, 2017b. a, b, c, d
Chen, Z., Hartmann, A., Wagener, T., and Goldscheider, N.: Dynamics of water fluxes and storages in an Alpine karst catchment under current and potential future climate conditions, Hydrol. Earth Syst. Sci., 22, 3807–3823, https://doi.org/10.5194/hess-22-3807-2018, 2018. a, b, c
Chollet, F.: Keras, https://github.com/keras-team/keras (last access: 22 May 2020), 2015. a
Copernicus Climate Change Service: E-OBS daily gridded meteorological data for Europe from 1950 to present derived from in-situ observations, Copernicus Climate Change Service [data set], https://doi.org/10.24381/CDS.151D3EC6, 2020. a
Cornes, R. C., van der Schrier, G., van den Besselaar, E. J. M., and Jones, P. D.: An Ensemble Version of the E-OBS Temperature and Precipitation Data Sets, J. Geophys. Res.-Atmos., 123, 9391–9409, https://doi.org/10.1029/2017jd028200, 2018. a, b, c
Darras, T., Borrell Estupina, V., Kong-A-Siou, L., Vayssade, B., Johannet, A., and Pistre, S.: Identification of spatial and temporal contributions of rainfalls to flash floods using neural network modelling: case study on the Lez basin (southern France), Hydrol. Earth Syst. Sci., 19, 4397–4410, https://doi.org/10.5194/hess-19-4397-2015, 2015. a
Darras, T., Kong-A-Siou, L., Vayssade, B., Johannet, A., and Pistre, S.: Karst Flash Flood Forecasting Using Recurrent and Nonrecurrent Artificial Neural Network Models: The Case of the Lez Basin (Southern France), in: EuroKarst 2016, Neuchâtel, Advances in Karst Science, Springer International Publishing, Cham, https://doi.org/10.1007/978-3-319-45465-8, 2017. a
DWD: DWD Opendata, https://opendata.dwd.de/, last access: 6 May 2022. a
DWD Climate Data Center: Historical and Current Hourly RADOLAN Grids of Precipitation Depth (Binary), Version V001, https://opendata.dwd.de/climate_environment/CDC/grids_germany/hourly/radolan/, last access: 11 December 2020. a, b, c
Fleury, P., Ladouche, B., Conroux, Y., Jourde, H., and Dörfliger, N.: Modelling the Hydrologic Functions of a Karst Aquifer under Active Water Management – The Lez Spring, J. Hydrol., 365, 235–243, https://doi.org/10.1016/j.jhydrol.2008.11.037, 2009. a, b
Fresnay, S., Hally, A., Garnaud, C., Richard, E., and Lambert, D.: Heavy Precipitation Events in the Mediterranean: Sensitivity to Cloud Physics Parameterisation Uncertainties, Nat. Hazards Earth Syst. Sci., 12, 2671–2688, https://doi.org/10.5194/nhess-12-2671-2012, 2012. a
Friedman, J. H.: Greedy Function Approximation: A Gradient Boosting Machine, Ann. Stat., 29, 1189–1232, https://doi.org/10.1214/aos/1013203451, 2001. a
Goldscheider, N.: Fold Structure and Underground Drainage Pattern in the Alpine Karst System Hochifen-Gottesacker, Eclogae Geol. Helv., 98, 1–17, https://doi.org/10.1007/s00015-005-1143-z, 2005. a, b, c
Goodfellow, I., Bengio, Y., and Courville, A.: Deep Learning, Adaptive Computation and Machine Learning, The MIT Press, Cambridge, Massachusetts, ISBN 978-0-262-03561-3, 2016. a
Gupta, H. V., Kling, H., Yilmaz, K. K., and Martinez, G. F.: Decomposition of the Mean Squared Error and NSE Performance Criteria: Implications for Improving Hydrological Modelling, J. Hydrol., 377, 80–91, https://doi.org/10.1016/j.jhydrol.2009.08.003, 2009. a
Hochreiter, S. and Schmidhuber, J.: Long Short-Term Memory, Neural Comput., 9, 1735–1780, https://doi.org/10.1162/neco.1997.9.8.1735, 1997. a
Hock, R.: A Distributed Temperature-Index Ice- and Snowmelt Model Including Potential Direct Solar Radiation, J. Glaciol., 45, 101–111, https://doi.org/10.3189/s0022143000003087, 1999. a
Hunter, J. D.: Matplotlib: A 2D Graphics Environment, Comput. Sci. Eng., 9, 90–95, https://doi.org/10.1109/mcse.2007.55, 2007. a
Hussain, D., Hussain, T., Khan, A. A., Naqvi, S. A. A., and Jamil, A.: A Deep Learning Approach for Hydrological Time-Series Prediction: A Case Study of Gilgit River Basin, Earth Sci. Inform., 13, 915–927, https://doi.org/10.1007/s12145-020-00477-2, 2020. a
Innamorati, C., Ritschel, T., Weyrich, T., and Mitra, N. J.: Learning on the Edge: Investigating Boundary Filters in CNNs, Int. J. Comput. Vis., 128, 773–782, https://doi.org/10.1007/s11263-019-01223-y, 2020. a
Ioffe, S. and Szegedy, C.: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, arXiv preprint: 1502.03167 [cs], http://arxiv.org/abs/1502.03167 (last access: 14 November 2021), 2015. a
Jeannin, P.-Y., Artigue, G., Butscher, C., Chang, Y., Charlier, J.-B., Duran, L., Gill, L., Hartmann, A., Johannet, A., Jourde, H., Kavousi, A., Liesch, T., Liu, Y., Lüthi, M., Malard, A., Mazzilli, N., Pardo-Igúzquiza, E., Thiéry, D., Reimann, T., Schuler, P., Wöhling, T., and Wunsch, A.: Karst Modelling Challenge 1: Results of Hydrological Modelling, J. Hydrol., 600, 126508, https://doi.org/10.1016/j.jhydrol.2021.126508, 2021. a, b, c
Johannet, A., Mangin, A., and D'Hulst, D.: Subterranean Water Infiltration Modelling by Neural Networks: Use of Water Source Flow, in: Volume 1, Parts 1 and 2, ICANN '94: Proceedings of the International Conference on Artificial Neural Networks, 26–29 May 1994, Sorrento, Italy, Springe, Berlin, Heidelberg, Sorrento, Italy, 1033–1036, ISBN 978-3-540-19887-1, 1994. a
Jourde, H., Lafare, A., Mazzilli, N., Belaud, G., Neppel, L., Dörfliger, N., and Cernesson, F.: Flash Flood Mitigation as a Positive Consequence of Anthropogenic Forcing on the Groundwater Resource in a Karst Catchment, Environ. Earth Sci., 71, 573–583, https://doi.org/10.1007/s12665-013-2678-3, 2014. a, b
Jourde, H., Massei, N., Mazzilli, N., Binet, S., Batiot-Guilhe, C., Labat, D., Steinmann, M., Bailly-Comte, V., Seidel, J. L., Arfib, B., Charlier, J. B., Guinot, V., Jardani, A., Fournier, M., Aliouache, M., Babic, M., Bertrand, C., Brunet, P., Boyer, J. F., Bricquet, J. P., Camboulive, T., Carrière, S. D., Celle-Jeanton, H., Chalikakis, K., Chen, N., Cholet, C., Clauzon, V., Soglio, L. D., Danquigny, C., Défargue, C., Denimal, S., Emblanch, C., Hernandez, F., Gillon, M., Gutierrez, A., Sanchez, L. H., Hery, M., Houillon, N., Johannet, A., Jouves, J., Jozja, N., Ladouche, B., Leonardi, V., Lorette, G., Loup, C., Marchand, P., de Montety, V., Muller, R., Ollivier, C., Sivelle, V., Lastennet, R., Lecoq, N., Maréchal, J. C., Perotin, L., Perrin, J., Petre, M. A., Peyraube, N., Pistre, S., Plagnes, V., Probst, A., Probst, J. L., Simler, R., Stefani, V., Valdes-Lao, D., Viseur, S., and Wang, X.: SNO KARST: A French Network of Observatories for the Multidisciplinary Study of Critical Zone Processes in Karst Watersheds and Aquifers, Vadose Zone J., 17, 180094, https://doi.org/10.2136/vzj2018.04.0094, 2018. a
Kaufmann, G., Mayaud, C., Kogovšek, B., and Gabrovšek, F.: Understanding the Temporal Variation of Flow Direction in a Complex Karst System (Planinska Jama, Slovenia), Acta Carsolog., 49, 213–228, https://doi.org/10.3986/ac.v49i2-3.7373, 2020. a
Kaufmann, G., Gabrovšek, F., and Turk, J.: Modelling Flow of Subterranean Pivka River in Postojnska Jama, Slovenia, Acta Carsolog., 45, 57–70, https://doi.org/10.3986/ac.v45i1.3059, 2016. a
King, D. A., Bachelet, D. M., Symstad, A. J., Ferschweiler, K., and Hobbins, M.: Estimation of Potential Evapotranspiration from Extraterrestrial Radiation, Air Temperature and Humidity to Assess Future Climate Change Effects on the Vegetation of the Northern Great Plains, USA, Ecol. Model., 297, 86–97, https://doi.org/10.1016/j.ecolmodel.2014.10.037, 2015. a
Kiranyaz, S., Ince, T., Abdeljaber, O., Avci, O., and Gabbouj, M.: 1-D Convolutional Neural Networks for Signal Processing Applications, in: ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 12–17 May 2019, Brighton, UK, 8360–8364, https://doi.org/10.1109/ICASSP.2019.8682194, 2019. a
Kohavi, R. and John, G. H.: Wrappers for Feature Subset Selection, Artific. Intel., 97, 273–324, https://doi.org/10.1016/S0004-3702(97)00043-X, 1997. a
Kollat, J. B., Reed, P. M., and Wagener, T.: When Are Multiobjective Calibration Trade-Offs in Hydrologic Models Meaningful?, Water Resour. Res., 48, W03520, https://doi.org/10.1029/2011wr011534, 2012. a
Kong A Siou, L., Johannet, A., Borrell, V., and Pistre, S.: Complexity Selection of a Neural Network Model for Karst Flood Forecasting: The Case of the Lez Basin (Southern France), J. Hydrol., 403, 367–380, https://doi.org/10.1016/j.jhydrol.2011.04.015, 2011. a, b, c, d, e
Kong A Siou, L., Johannet, A., Valérie, B. E., and Pistre, S.: Optimization of the Generalization Capability for Rainfall–Runoff Modeling by Neural Networks: The Case of the Lez Aquifer (Southern France), Environ. Earth Sci., 65, 2365–2375, https://doi.org/10.1007/s12665-011-1450-9, 2012. a, b, c
Kong-A-Siou, L., Cros, K., Johannet, A., Borrell-Estupina, V., and Pistre, S.: KnoX Method, or Knowledge eXtraction from Neural Network Model. Case Study on the Lez Karst Aquifer (Southern France), J. Hydrol., 507, 19–32, https://doi.org/10.1016/j.jhydrol.2013.10.011, 2013. a, b, c
Kong-A-Siou, L., Fleury, P., Johannet, A., Borrell Estupina, V., Pistre, S., and Dörfliger, N.: Performance and Complementarity of Two Systemic Models (Reservoir and Neural Networks) Used to Simulate Spring Discharge and Piezometry for a Karst Aquifer, J. Hydrol., 519, 3178–3192, https://doi.org/10.1016/j.jhydrol.2014.10.041, 2014. a, b, c, d
Kong-A-Siou, L., Johannet, A., Borrell Estupina, V., and Pistre, S.: Neural Networks for Karst Groundwater Management: Case of the Lez Spring (Southern France), Environ. Earth Sci., 74, 7617–7632, https://doi.org/10.1007/s12665-015-4708-9, 2015. a
Kovačič, G., Petrič, M., and Ravbar, N.: Evaluation and Quantification of the Effects of Climate and Vegetation Cover Change on Karst Water Sources: Case Studies of Two Springs in South-Western Slovenia, Water, 12, 3087, https://doi.org/10.3390/w12113087, 2020. a, b
Kratzert, F., Klotz, D., Brenner, C., Schulz, K., and Herrnegger, M.: Rainfall–Runoff Modelling Using Long Short-Term Memory (LSTM) Networks, Hydrol. Earth Syst. Sci., 22, 6005–6022, https://doi.org/10.5194/hess-22-6005-2018, 2018. a
Lähivaara, T., Malehmir, A., Pasanen, A., Kärkkäinen, L., Huttunen, J. M. J., and Hesthaven, J. S.: Estimation of Groundwater Storage from Seismic Data Using Deep Learning, Geophys. Prospect., 67, 2115–2126, https://doi.org/10.1111/1365-2478.12831, 2019. a
Lebigot, E. O.: Uncertainties: A Python Package for Calculations with Uncertainties, https://pythonhosted.org/uncertainties/numpy_guide.html (last access: 18 February 2021), 2010. a
LeCun, Y., Bengio, Y., and Hinton, G.: Deep Learning, Nature, 521, 436–444, https://doi.org/10.1038/nature14539, 2015. a, b
Li, Q., Cai, W., Wang, X., Zhou, Y., Feng, D. D., and Chen, M.: Medical Image Classification with Convolutional Neural Network, in: 2014 13th International Conference on Control Automation Robotics Vision (ICARCV), 10–12 December 2014, Singapore, 844–848, https://doi.org/10.1109/ICARCV.2014.7064414, 2014. a
Longenecker, J., Bechtel, T., Chen, Z., Goldscheider, N., Liesch, T., and Walter, R.: Correlating Global Precipitation Measurement Satellite Data with Karst Spring Hydrographs for Rapid Catchment Delineation, Geophys. Res. Lett., 44, 4926–4932, https://doi.org/10.1002/2017GL073790, 2017. a, b
Louppe, G., Wehenkel, L., Sutera, A., and Geurts, P.: Understanding Variable Importances in Forests of Randomized Trees, in: Advances in Neural Information Processing Systems, vol. 26, Curran Associates, Inc., https://papers.nips.cc/paper/2013/hash/e3796ae838835da0b6f6ea37bcf8bcb7-Abstract.html (last access: 30 January 2022), 2013. a
Maier, H. R. and Dandy, G. C.: Neural Networks for the Prediction and Forecasting of Water Resources Variables: A Review of Modelling Issues and Applications, Environ. Model. Softw., 15, 101–124, https://doi.org/10.1016/s1364-8152(99)00007-9, 2000. a
Maier, H. R., Jain, A., Dandy, G. C., and Sudheer, K.: Methods Used for the Development of Neural Networks for the Prediction of Water Resource Variables in River Systems: Current Status and Future Directions, Environ. Model. Softw., 25, 891–909, https://doi.org/10.1016/j.envsoft.2010.02.003, 2010. a
Malard, A., Jeannin, P.-Y., Vouillamoz, J., and Weber, E.: An Integrated Approach for Catchment Delineation and Conduit-Network Modeling in Karst Aquifers: Application to a Site in the Swiss Tabular Jura, Hydrogeol. J., 23, 1341–1357, https://doi.org/10.1007/s10040-015-1287-5, 2015. a
Mayaud, C., Gabrovšek, F., Blatnik, M., Kogovšek, B., Petrič, M., and Ravbar, N.: Understanding Flooding in Poljes: A Modelling Perspective, J. Hydrol., 575, 874–889, https://doi.org/10.1016/j.jhydrol.2019.04.092, 2019. a, b
Mazzilli, N., Jourde, H., Guinot, V., Bailly-Comte, V., and Fleury, P.: Hydrological Modelling of a Karst Aquifer under Active Groundwater Management Using a Parsimonious Conceptual Model, in: H2Karst, Besançon, France, https://hal.archives-ouvertes.fr/hal-01844603 (last access: 28 July 2021), 2011. a
McGovern, A., Lagerquist, R., John Gagne, D., Jergensen, G. E., Elmore, K. L., Homeyer, C. R., and Smith, T.: Making the Black Box More Transparent: Understanding the Physical Implications of Machine Learning, B. Am. Meteorol. Soc., 100, 2175–2199, https://doi.org/10.1175/BAMS-D-18-0195.1, 2019. a, b
McKinney, W.: Data Structures for Statistical Computing in Python, in: Python in Science Conference, Austin, Texas, 56–61, https://doi.org/10.25080/majora-92bf1922-00a, 2010. a
Müller, J., Park, J., Sahu, R., Varadharajan, C., Arora, B., Faybishenko, B., and Agarwal, D.: Surrogate Optimization of Deep Neural Networks for Groundwater Predictions, J. Global Optim., 81, 203–231, https://doi.org/10.1007/s10898-020-00912-0, 2020. a, b
Muñoz Sabater, J.: ERA5-Land hourly data from 2001 to present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS) [data set], https://doi.org/10.24381/CDS.E2161BAC, 2019. a, b, c, d, e
NASA: GPM – Global Precipitation Measurement, http://www.nasa.gov/mission_pages/GPM/main/index.html (last access: 8 June 2021), 2016. a
Nash, J. E. and Sutcliffe, J. V.: River Flow Forecasting through Conceptual Models Part I – A Discussion of Principles, J. Hydrol., 10, 282–290, https://doi.org/10.1016/0022-1694(70)90255-6, 1970. a
Nogueira, F.: Bayesian Optimization: Open Source Constrained Global Optimization Tool for Python, GitHub, https://github.com/fmfn/BayesianOptimization (last access: 15 April 2020) 2014. a
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., and Cournapeau, D.: Scikit-Learn: Machine Learning in Python, J. Mach. Learn. Res., 12, 2825–2830, 2011. a
Petrič, M., Kogovšek, J., and Ravbar, N.: Effects of the Vadose Zone on Groundwater Flow and Solute Transport Characteristics in Mountainous Karst Aquifers – the Case of the Javorniki–Snežnik Massif (SW Slovenia), Acta Carsolog., 47, 35–51, https://doi.org/10.3986/ac.v47i1.5144, 2018. a
Petsiuk, V., Das, A., and Saenko, K.: RISE: Randomized Input Sampling for Explanation of Black-box Models, arXiv preprint: 1806.07421 [cs], http://arxiv.org/abs/1806.07421 (last access: 13 November 2021), 2018. a, b
Rajaee, T., Ebrahimi, H., and Nourani, V.: A Review of the Artificial Intelligence Methods in Groundwater Level Modeling, J. Hydrol., 572, 336–351, https://doi.org/10.1016/j.jhydrol.2018.12.037, 2019. a
Seibert, J.: Multi-criteria calibration of a conceptual runoff model using a genetic algorithm, Hydrol. Earth Syst. Sci., 4, 215–224, https://doi.org/10.5194/hess-4-215-2000, 2000. a
Sezen, C., Bezak, N., Bai, Y., and Šraj, M.: Hydrological Modelling of Karst Catchment Using Lumped Conceptual and Data Mining Models, J. Hydrol., 576, 98–110, https://doi.org/10.1016/j.jhydrol.2019.06.036, 2019. a
Sit, M., Demiray, B. Z., Xiang, Z., Ewing, G. J., Sermet, Y., and Demir, I.: A Comprehensive Review of Deep Learning Applications in Hydrology and Water Resources, Water Sci. Technol., 82, 2635–2670, https://doi.org/10.2166/wst.2020.369, 2020. a
SNO KARST: Time Series of Type Hydrology-Hydrogeology in Le Lez (Méditerranée) Basin – MEDYCYSS Observatory – KARST Observatory Network – OZCAR Critical Zone Network Research Infrastructure, SNO KARST [data set], https://doi.org/10.15148/CFD01A5B-B7FD-41AA-8884-84DBDDAC767E, 2021. a, b
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R.: Dropout: A Simple Way to Prevent Neural Networks from Overfitting, J. Mach. Learn. Res., 15, 1929–1958, 2014. a
Stevanović, Z.: Karst Waters in Potable Water Supply: A Global Scale Overview, Environ. Earth Sci., 78, 662, https://doi.org/10.1007/s12665-019-8670-9, 2019. a
The pandas development team: Pandas-Dev/Pandas: Pandas 1.0.3, Zenodo [code], https://doi.org/10.5281/zenodo.3509134, 2020. a
Thiéry, D. and Bérard, P.: Alimentation en eau de la ville de Montpellier – captage de la source du Lez – études des relations entre la source et son réservoir aquifère, Tech. rep., BRGM No. 83, SNG 167 LRO, BRGM, http://infoterre.brgm.fr/rapports/83-SGN-167-LRO.pdf (last access: 30 June 2021), 1983. a
Van, S. P., Le, H. M., Thanh, D. V., Dang, T. D., Loc, H. H., and Anh, D. T.: Deep Learning Convolutional Neural Network in Rainfall–Runoff Modelling, J. Hydroinform., 22, 541–561, https://doi.org/10.2166/hydro.2020.095, 2020. a, b
van der Walt, S., Colbert, S. C., and Varoquaux, G.: The NumPy Array: A Structure for Efficient Numerical Computation, Comput. Sci. Eng., 13, 22–30, https://doi.org/10.1109/mcse.2011.37, 2011. a
van Rossum, G.: Python Tutorial, https://ir.cwi.nl/pub/5008/05008D.pdf (last access: 4 May 2022), 1995. a
Wunsch, A.: AndreasWunsch/CNN_KarstSpringModeling: v0.1 (v0.1), Zenodo [code], https://doi.org/10.5281/zenodo.5184692, 2021. a
Wunsch, A., Liesch, T., and Broda, S.: Groundwater Level Forecasting with Artificial Neural Networks: A Comparison of Long Short-Term Memory (LSTM), Convolutional Neural Networks (CNNs), and Non-Linear Autoregressive Networks with Exogenous Input (NARX), Hydrol. Earth Syst. Sci., 25, 1671–1687, https://doi.org/10.5194/hess-25-1671-2021, 2021. a, b, c, d, e
Yin, W., Kann, K., Yu, M., and Schütze, H.: Comparative Study of CNN and RNN for Natural Language Processing, arXiv preprint: 1702.01923 [cs], http://arxiv.org/abs/1702.01923 (last access: 29 January 2022), 2017. a
Zeiler, M. D. and Fergus, R.: Visualizing and Understanding Convolutional Networks, in: Computer Vision – ECCV 2014, edited by: Fleet, D., Pajdla, T., Schiele, B., and Tuytelaars, T., Springer International Publishing, Cham, 818–833, ISBN 978-3-319-10590-1, 2014. a, b
- Abstract
- Introduction
- Data and study areas
- Methodology
- Results and discussion
- Conclusions
- Appendix A: Study area comparison table
- Appendix B: Lez catchment precipitation interpolation
- Appendix C: Heat maps
- Appendix D: Model overview
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Data and study areas
- Methodology
- Results and discussion
- Conclusions
- Appendix A: Study area comparison table
- Appendix B: Lez catchment precipitation interpolation
- Appendix C: Heat maps
- Appendix D: Model overview
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References