the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 22 Apr 2022
| 22 Apr 2022
A data-driven method for estimating the composition of end-members from stream water chemistry time series
Esther Xu Fei
End-member mixing analysis (EMMA) is a method of interpreting stream water chemistry variations and is widely used for chemical hydrograph separation. It is based on the assumption that stream water is a conservative mixture of varying contributions from well-characterized source solutions (end-members). These end-members are typically identified by collecting samples of potential end-member source waters from within the watershed and comparing these to the observations. Here we introduce a complementary data-driven method (convex hull end-member mixing analysis – CHEMMA) to infer the end-member compositions and their associated uncertainties from the stream water observations alone. The method involves two steps. The first uses convex hull nonnegative matrix factorization (CH-NMF) to infer possible end-member compositions by searching for a simplex that optimally encloses the stream water observations. The second step uses constrained K-means clustering (COP-KMEANS) to classify the results from repeated applications of CH-NMF and analyzes the uncertainty associated with the algorithm. In an example application utilizing the 1986 to 1988 Panola Mountain Research Watershed dataset, CHEMMA is able to robustly reproduce the three field-measured end-members found in previous research using only the stream water chemical observations. CHEMMA also suggests that a fourth and a fifth end-member can be (less robustly) identified. We examine uncertainties in end-member identification arising from non-uniqueness, which is related to the data structure, of the CH-NMF solutions, and from the number of samples using both real and synthetic data. The results suggest that the mixing space can be identified robustly when the dataset includes samples that contain extremely small contributions of one end-member, i.e., samples containing extremely large contributions from one end-member are not necessary but do reduce uncertainty about the end-member composition.
- Article
(1935 KB) - Full-text XML
- BibTeX
- EndNote





End-member mixing analysis (EMMA) has been used to interpret observed stream water chemical concentration variability in terms of time-varying contributions from unknown end-member sources, each supplying water with a constant concentration profile. This method has been applied in many different hydro-climatic and geology settings (e.g., Bernal et al., 2006; Hooper et al., 1990; Li et al., 2019; Liu et al., 2008a, 2017; Lv et al., 2018; Jung et al., 2009; Neill et al., 2011). EMMA has also been used to distinguish sources of dissolved organic matter in natural streams (Hur et al., 2006; Yang and Hur, 2014), specific conductance (Kronholm and Capel, 2015), and other combinations of stream water attributes that can be assumed to mix conservatively (Barthold et al., 2011).
EMMA assumes that the chemical solute composition of stream water can be explained by the conservative mixing of a finite set of end-members (Hooper et al., 1990). These end-members, therefore, are the most extreme points of a simplex within which all stream water samples must lie (if the assumptions of the method are valid). End-members are identified by collecting samples of candidate source water from within the watershed, i.e., in addition to the mixture samples collected in the stream. The EMMA method assumes that (1) solutes used in the mixing model are conservative, (2) stream water consists of an identifiable number of end-member sources, (3) end-member compositions are distinct for at least one tracer, and (4) end-member compositions are spatiotemporally constant (or their variations are known or can be reduced by adding additional end-members; Hooper et al., 1990).
Christophersen and Hooper (1992) suggested that “[u]nambiguous identification of the source solution compositions from the mixture alone is impossible”. In a strict sense, this is likely true in that the underlying assumption (streamflow as a conservative mixture of invariant sources) is unlikely to be adhered to in a real watershed. However, recent advances in statistical learning methods suggest that some utility may exist in attempting to identify (perhaps not free of ambiguity) a potential source solution composition from the observed mixture alone (without additional candidate source water samples; Ding et al., 2008; Hyvärinen and Oja, 2000; Thurau et al., 2011). Here we propose a method, the convex hull end-member mixing analysis (CHEMMA), which can in fact identify source solution compositions from the mixture alone. We will also present an analysis of the ambiguity, or uncertainty, in the identified end-members.
It is worth distinguishing CHEMMA from previous applications of statistical learning methods (such as maximum likelihood estimation, Bayesian inference, and Markov chain Monte Carlo, MCMC) to estimate uncertainties of end-member mixing analysis. Genereux (1998) presented a linear estimator for uncertainties in end-member concentration and mixing ratios. Carrera et al. (2004) achieved a similar approach by using the maximum likelihood method. By combining likelihood methods, Bayesian inferences, or probabilistic linear models with the MCMC algorithm, Barbeta and Peñuelas (2017), Beria et al. (2020), Delsman et al. (2013), and Popp et al. (2019) were able to acquire time-evolving uncertainty estimation. These contributions focus on quantifying uncertainty resulting from the use of field-sampled candidate end-members. In contrast, CHEMMA aims to infer the end-members themselves.
Stream water concentrations of different conservative solutes are naturally correlated. EMMA uses principal component analysis (PCA) to convert the naturally correlated stream water concentrations into a set of linearly uncorrelated variables (Christophersen and Hooper, 1992). Each new variable, which is called a principal component (PC), is a linear combination of the observed stream water attributes. For a set of n variables, PCA first requires standardized observations (Xobs) by subtracting the mean and dividing by the standard deviation. Then it calculates a projection matrix Pobs (rows of which are eigenvectors of the correlation matrix), which transforms from observation space to the PC space, by decomposing correlation matrix of Xobs. The transformed columns of Yobs (representing the n observations in the PC space) are uncorrelated, each of which accounts for a portion of total variance as follows (Christophersen and Hooper, 1992):
Standardized end-member candidates Xem can be projected into the PC space by the same projection matrix Pobs and then converted in the transformed space as Yem, as follows (Christophersen and Hooper, 1992):
To find the parsimonious subset of appropriate end-members, EMMA subsequently takes the information provided by PCA to determine the approximate dimensionality of the stream water mixture and to screen end-members (Hooper, 2003; Liu et al., 2008a). In the PC space, appropriate end-member candidates (Yem) are selected by choosing ones that tightly bound the transformed observations (Yobs; Christophersen and Hooper, 1992; Hooper et al., 1990; Hooper, 2003). Christophersen and Hooper (1992) mathematically proved that one end-member more than the number of PCs is required to describe the rank of the stream water observation. However, the number of retained PCs is usually determined using a heuristic, such as using the number of PCs that explain at least the proportion of the total variance because of the need to capture the variance (Hooper, 2003). In addition, Hooper (2003) suggests examining the residual distribution pattern as an auxiliary technique for determining the dimensionality revealed by the data.
Limitations to this approach exist, which can result in spurious or incomplete source identification (Delsman et al., 2013; Hooper, 2003; Valder et al., 2012; Yang and Hur, 2014). Specifically, the composition of a source cannot be determined unless candidate end-member measurements are obtained that are representative of it. In addition, determining the number of significant PCs , or the number of end-members, is subjective to some degree, even with the aid of diagnostic tool of mixing models (DTMMs). EMMA is not able to deal with non-conservative mixing if a nonlinear structure is not provided to replace the current simplex structure (Christophersen and Hooper, 1992); therefore, only tracers that are believed to be approximately conservative should be included because they entered the stream, thereby altering their concentrations primarily by dilution rather than other mechanisms. Finally, another limitation involves uncertainties introduced by spatial and temporal variability in end-member concentrations that may cause additional difficulties (Delsman et al., 2013).
Here we focus on the first of these issues. In spite of EMMA's wide application (Ali et al., 2010; Bernal et al., 2006; Burns et al., 2001; Delsman et al., 2013; Hooper and Christophersen, 1992; James and Roulet, 2006; Jung et al., 2009; Li et al., 2019; Lv et al., 2018; Neal et al., 1992; Neill et al., 2011; Valder et al., 2012), no method exists to characterize missing or unmeasured end-members purely based on stream water observations, other than using baseflow to characterize groundwater (Liu et al., 2008b). Popp et al. (2019) came close, introducing a residual end-member that represents collective behavior of all other unobserved end-members, though it still requires some a priori knowledge of observed end-members to initiate a Bayesian mixing model. In contrast, CHEMMA aims to identify the entire suite of end-member compositions and their associated uncertainties.
The CHEMMA method depends on the idea inherited from EMMA that the end-members are located near the most extreme points in the mixing space of stream water samples. Note that this does not imply that the concentration of any particular solute is extreme in an end-member or that the end-member composition is even distinct for all solutes. Rather, it only implies that the linear combination of concentrations in PC space is extremal at the end-member. This suggests that we may be able to interrogate the observational data projected in the end-member space to locate such extremal end-members, even if no individual samples fully represent that end-member. The approach we propose, CHEMMA, is a data-driven method to exploit this possibility and to characterize the end-members' chemical composition and the associated uncertainty. The capabilities of this method are demonstrated by an application to the 1986 to 1988 Panola Mountain Research Watershed dataset published in Hooper and Christophersen (1992). We will further explore the robustness of this method using synthetic datasets generated with three end-members.
Convex hull end-member mixing analysis (CHEMMA) applies the matrix factorization method, convex hull nonnegative matrix factorization (CH-NMF), along with the classification method, constrained K-means clustering (COP-KMEANS), to determine end-member compositions under EMMA assumptions. The CH-NMF method provides a numerical iterative algorithm to search for end-member compositions that optimally enclose the stream water observations in the PC space. The CH-NMF algorithm is run many times because each iteration of the search can result in highly non-unique optima. We apply the COP-KMEANS method to classify the CH-NMF numerical outputs into clusters. The centroid of each represents our best estimate of an end-member.
2.1 Adaption of CH-NMF to the EMMA problem
The concepts of convex combination and convex hull connect CH-NMF with the idea of end-member mixing. A convex combination is equivalent to a weighted sum. It is a linear combination of vectors where the weight associated with each vector varies between zero and one, and the weights sum to one. If we construct a simplex, which means a highly dimensional polytope, with some distinct vectors at its vertices, then this simplex is a convex hull that encloses points within the hull to be a convex combination of the vertices. Similarly, if we conservatively mixed distinct end-members, then the stream water chemical concentration observations can be a weighted sum of end-members with their contributions. The ideas of convex combination and convex hull are mathematically identical to end-member mixing.
The CH-NMF method describes a general methodology of finding the most extreme points (end-members) that form a simplex with k vertices around the n-dimensional observation data cloud by searching for a convex hull that encloses the data (Thurau et al., 2011). CH-NMF requires the rank k−1 of the data to be determined independently first. PCA can help with this. The top k−1 PCs are retained, as with EMMA, using standardized (zero mean and unit variance) observations. The CHEMMA algorithm does not entirely avoid this subjective choice of the number of end-members retained and so does not resolve this criticism of EMMA. The DTMMs can also be used in conjunction with EMMA to determine the rank of the data. Next, the standardized data are projected into the 2D subspace spanned by two of the PCs (i.e., PCi vs. PCj, where i≠j, i<j). Qualified points forming a convex hull around the projected data are marked at each pairwise 2D subspace. Finally, we interpolate between convex hull vertices in each subspace to find k vertices that define a (k−1-)dimensional mixing simplex. This simplex forms a convex hull, such that all the data points can be optimally approximated as convex linear combinations of them. The algorithm is summarized as follows:

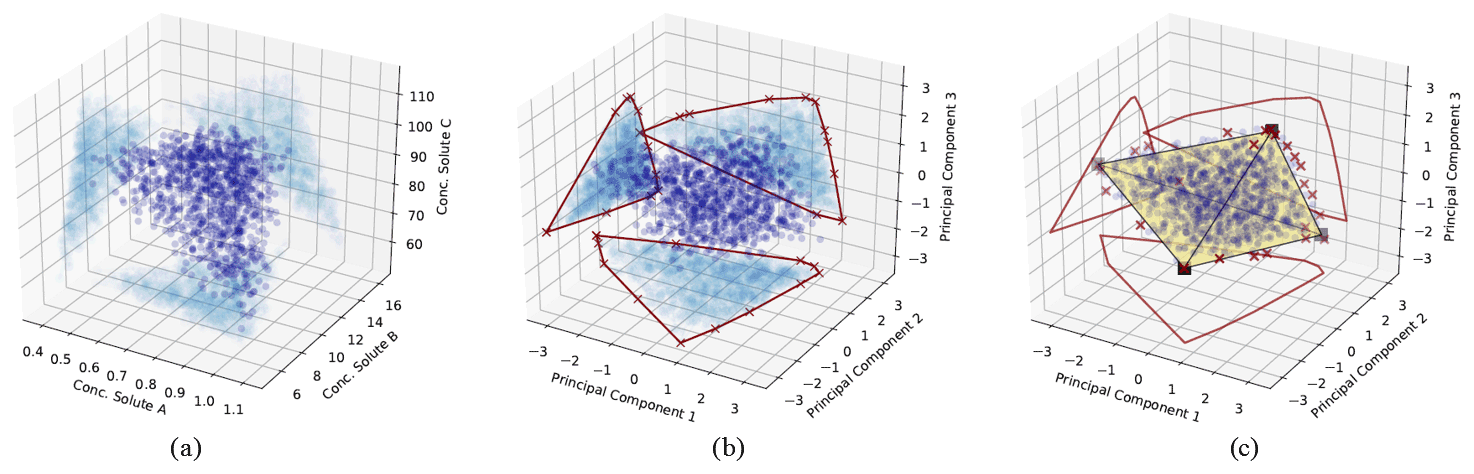
Figure 1Illustration of the CH-NMF algorithm using a three-dimensional space with four end-members. (a) The standardized observations (dark blue) and its projection (light blue) on the observational space. (b) The projected observations (dark blue) and its projection (light blue) on PC subspaces. The red crosses are the marked extreme points (S) that form a convex hull (the red polygons) in each PC subspace. (c) Find the convex hull (the black simplex) and its associated vertices (the k vectors xemi) in the PC space, such that the vertices are convex combinations of the extreme points S, and the distance between the simplex and S is minimized. The red crosses are the same extreme points marked in (b) but are projected back in the three-dimensional PC space.
Given the m standardized stream water samples, each with n measured attributes and k desired end-members (Step 1; Fig. 1a), CH-NMF decomposes the correlation matrix of the observations to obtain at most d PCs (d is the maximum number of linearly uncorrelated variables), which is the same linear orthogonal projection as the PCA method (in Step 2, from Fig. 1a to b, note the changing distribution of the blue points). Instead of immediately reducing the dimensionality by discarding some PCs (as with EMMA), CH-NMF examines the distribution of Xobs in all of the subspaces spanned by PC pairs (Step 3; Fig. 1b; light blue points) and marks the most extreme points (Fig. 1b; red crosses) that construct the convex hull (Fig. 1b; red lines) to store in S (Step 4). Then, a subset of S, SI=Xem, is found as a convex combination of S (Step 5; Fig. 1c; square vertices of the simplex) that minimizes the Frobenius norm (the entry-wise Euclidean norm of the matrix). Inasmuch as SI may be any possible points within the convex hull constructed using S, J is needed to force SI to be chosen close to the convex hull boundary. In practice, I and J are estimated iteratively, using an optimization procedure, until they converge (Eqs. 1 and 2 from Thurau et al., 2011). Finally, the contribution H is found by locating the convex combination of end-members that reproduces the data with minimal error (again using the Frobenius norm; Step 6).
Step 5 is the essential step of the CH-NMF theory, and it is a modification of convex nonnegative matrix factorization (C-NMF) by adding a convexity constraint on J that ensures each component contributes a fraction between zero and one, with the sum of all fractions being one (Ding et al., 2008; Thurau et al., 2011). In the original setting of C-NMF, the I and J are naturally sparse if the vertex search is in PC subspaces (Ding et al., 2008). Adding the convexity constraint on J makes J an interpolation between each column of SI (i.e., each end-member composition xem); however, the sparse nature of I remains (Thurau et al., 2011).
We could interpret the objective function of Step 5 (minimize ) in three steps. First , the sparsity of I results in the end-member composition Xem close to a subset of the extreme observations (S) projected in the PC subspace. Second, J means that other extreme observations in S are expressed as a convex combination (interpolation) of Xem. Third, minimizing the Frobenius distance between S and XemJ guarantees that end-member compositions Xem will be convex hull vertices because all other extreme points can be written as convex combinations of vertices but not vice versa. As a consequence, a well-supported set of convex hull vertices tightly bound the observations and are as unique as possible, which satisfies the original EMMA assumption of the finite set of distinct end-members. The sparse nature of I helps prevent overfitting because noise will tend to be concentrated on superfluous vertices without degrading identification of the others. The noisy end-members can be identified in the classification step given in the next section.
The constraint requiring that the end-members be a convex combination of the extreme observations implies that CH-NMF may not accurately identify end-members that are not a large fraction of any observation in the dataset. As the synthetic example shown in Fig. 1 illustrates, the simplex formed by joining the CH-NMF end-members lies inside the shell formed by connecting the extreme points (red crosses in Fig. 1c). Consequently, it is easier to identify end-members when more points lie on or near the hull itself so that the shape of the hull is clearly defined. In addition, if no samples are anywhere close to being pure representatives of an end-member, the apparent end-member identified by CH-NMF may lie closer to the data centroid than the true end-member. Methods to relax the constraint on Step 5 and better identify end-members distant from the data in the mixing space will be investigated in future work.
2.2 Quantifying the intrinsic uncertainty using COP-KMEANS
Each run of CH-NMF may yield different end-member estimates. This is because the complex structure of the high-dimensional stream water data results in a rough objective function surface (Step 5). CH-NMF runs with different initial search locations may fall into different local minima.
Depending on the structure of the data cloud, each run's end-members may be nearly identical (if the end-member is well-constrained by the dataset) or may vary widely. Poor identification may result if the data cloud lacks the clear planar boundaries that the CH-NMF algorithm looks for. It may also occur if more end-members are sought than the data can support or if an end-member is variable in time. The time-varying end-member blurs the planar boundaries and vertices. Alternatively, the observations may not sample the true mixing space sufficiently to identify an end-member in the space as a convex hull vertex, perhaps because it never represents more than a small fraction of variance.
Even in the absence of these issues, the variability and uncertainty of the stream concentration observations will contribute to uncertainty in end-member identification. The variation in the CH-NMF-identified end-members can be assessed by running the CH-NMF analysis a large number of times and then using a clustering algorithm to extract the centroid and spread of areas consistently identified as an end-member. We use the COP-KMEANS variant of the K-means clustering algorithm, which allows us to require that end-members predicted from the same CH-NMF run must not be placed in the same cluster (Wagstaff et al., 2001). This is achieved by assigning a “cannot link” constraint between every pair of candidate end-members generated by the same CH-NMF run. Apart from the cannot link constraints, COP-KMEANS works identically to normal k-means clustering (Wagstaff et al., 2001). For each cluster identified by COP-KMEANS, we can qualitatively examine the spatial distribution of the associated end-members and quantitatively calculate the centroid and variance of the cluster.
2.3 Assessing the goodness of fit
There are several metrics that arise naturally from the CHEMMA framework that could be used to assess the goodness of fit of the inferred mixing subspace. The first and second are the centroid and within-cluster variance of each inferred end-member, which will tend to increase as the number of end-members increases. The third is the orthogonal projection distance from the observation space to the mixing subspace, which will be smaller when the end-member lies closer to the linear subspace where the rest of the data live. In this paper, we consider a new cluster to be tenable as a proper end-member if (1) the spread of the previously identified clusters remains similar or decreases, (2) the cluster itself has a reasonable variance, and 3) the orthogonal projection distances of previously identified end-members do not significantly increase after adding a new end-member.
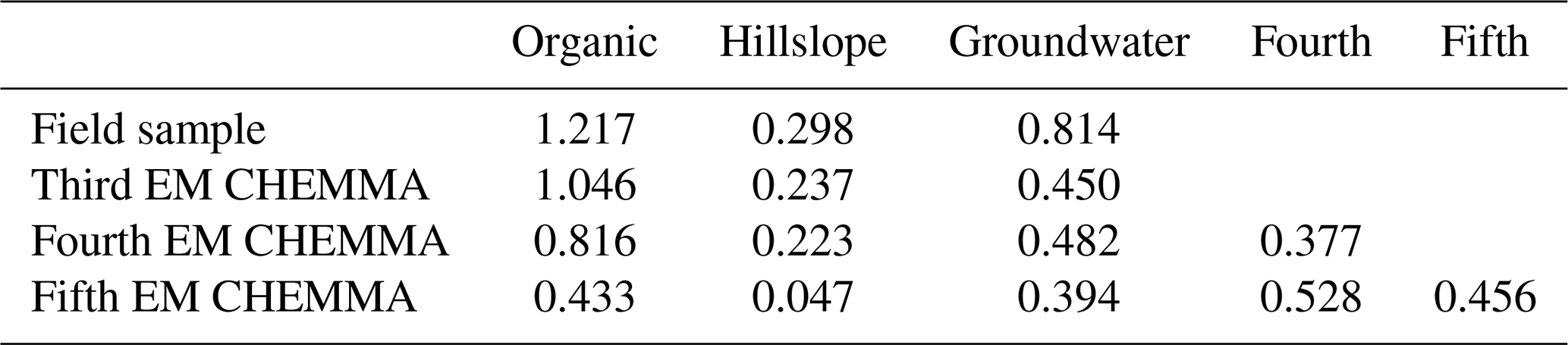
We can also assess the degree to which CHEMMA and field-sampled end-members are similar to the stream chemical signatures. Field end-member candidate samples typically rely on a few grab samples (for example, in Hooper et al., 1990, the groundwater was based on samples from a single well), which may insufficiently sample the overall source variability. CHEMMA end-members may provide a better idea of the time–space-averaged chemical signature of a source than the field samples. One way to examine this is to look at the difference between an end-member's composition and its composition when projected into the reduced rank k−1 principal component subspace. This can be done for both field-sampled and CHEMMA end-members. A summary measure of that difference is the Euclidean distance of the end-member from the reduced rank subspace. Where that distance is shorter, the end-member has a chemical profile that is aligned with that which is typically found in the stream. This distance can be calculated from the loadings on the remaining principal components.
2.4 Example Python implementation
An example Python implementation of CHEMMA, including the application to Panola Mountain data, is presented in the next section. The code is available in a Jupyter Notebook on GitHub (https://github.com/Estherrrrrxu/CHEMMA/blob/master/CHEMMA.ipynb, last access: 16 March 2022). Updates can also be found from the GitHub page. The CH-NMF section uses a Python package, pymf.chnmf, detailed in Thurau et al. (2011). The COP-KMEANS section uses a Python package, COP-Kmeans, presented in Babaki (2017).
We applied CHEMMA to a test dataset of 905 samples of six solutes (alkalinity, sulfate, sodium, magnesium, calcium, and dissolved silica) collected from the stream in the Panola Mountain research catchment, Georgia, USA, and described in Hooper et al. (1990). The six solutes were specifically selected to meet EMMA's assumption that their concentrations vary significantly across the watershed (Hooper et al., 1990). Hooper et al. (1990) suggested that the stream chemistry could be interpreted as a mixture of hillslope, groundwater, and organic soil horizon (organic) end-members, which are identified by sampling within the watershed. Hooper (2003) suggested that the rank of the data (lower gauge in Hooper, 2003 dataset) is at least three. There was considerable evolution over time in the interpretation of these end-members (Hooper, 2001), but we will use the terminology from Hooper et al. (1990) to avoid confusion. Here we ask the following questions: (1) does CHEMMA recover the same three end-members as Hooper et al. (1990) identified in field-sampling? (2) Do the data support the existence of additional end-members?
3.1 Results
We ran CHEMMA for three, four, and five end-member cases (k=3, 4, and 5) because two and three PCs account for 94 % and 97 % of the total variance, respectively. In order to capture the intrinsic uncertainty associated with the identified clusters, we calculated the mean and standard deviation (SD) for each case based on 100 CH-NMF runs (Table 1). CHEMMA was able to recover the three field-measured end-members reported by Hooper et al. (1990, Fig. 2; three green diamonds). The mean of the three CHEMMA identified clusters (Fig. 3 and Table 1) are very similar to the median concentration of the field-measured end-members (Table 2). The median concentration of the hillslope field sample (Table 2) has much lower alkalinity concentration compared with the mean concentration of the CHEMMA-identified green cluster (Fig. 3 and Table 1); however, it is still within the cluster spread provided in Table 1.
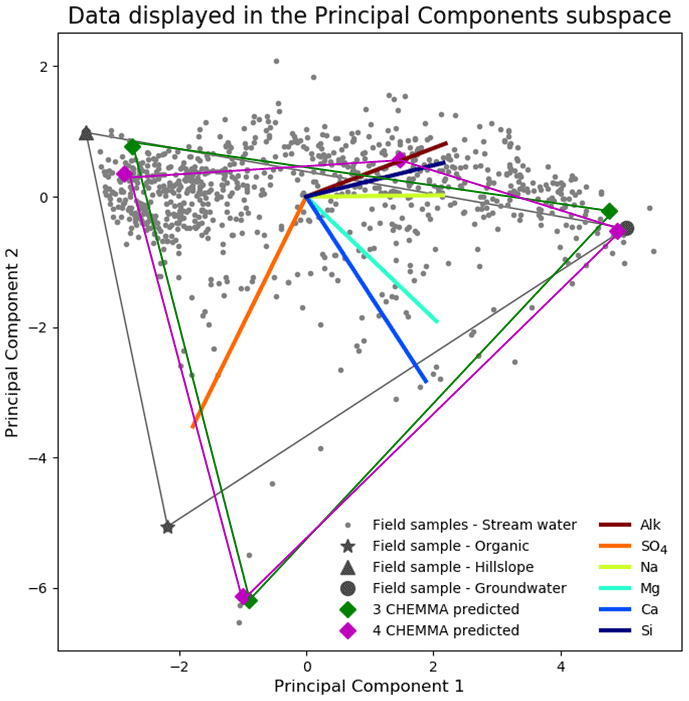
Figure 2CHEMMA prediction (cluster centroids) for three end-member (blue diamonds) and four end-member (red diamonds) cases plotted in the PC2 vs. PC1 subspace. The colored lines that connect those predicted end-members indicate the convex hull projected into the two-dimensional PC subspace formed by those end-members. The observations (gray dots) inside of the convex hull can be explained as linear combinations of the end-members. The colored lines in the center of the plot are the projected original solute axes in this PC subspace. Note that a three-dimensional subspace is required for four end-members.
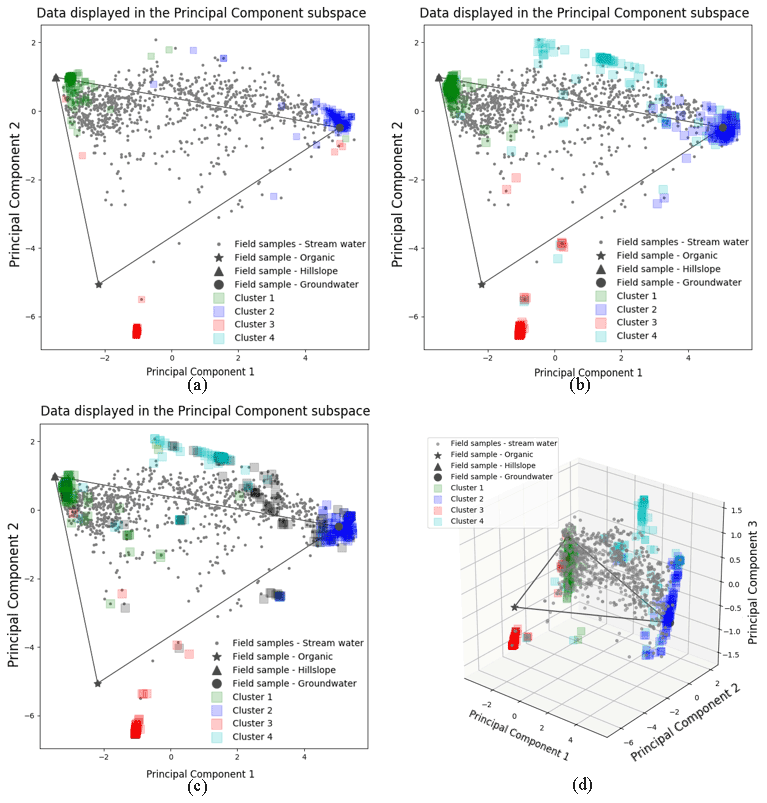
Figure 3The 100 random initialized CH-NMF run results for three (a), four (b, d), and five (c) end-member cases. Panels (a)–(c) are in the 2D PC2 vs. PC1 subspaces. Panel (d) is in the 3D PC3 vs. PC2 vs. PC1 subspace. The color shade of each cluster reflects the concentration of the vertices at its location.
Table 1The mean and standard deviation (SD) of each end-member cluster based on 100 random initialized CH-NMF runs. All values are in micromoles per liter. The cluster color indications correspond to Fig. 3a to c.
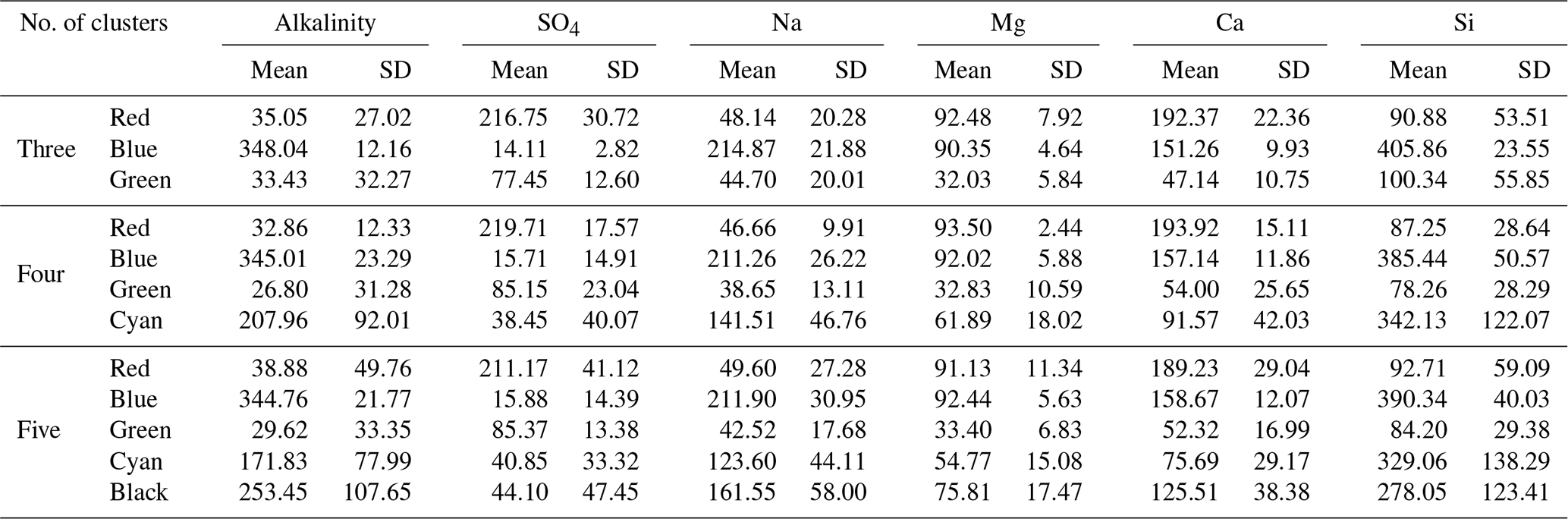
Table 2The median concentration of individual field-measured end-members from Hooper and Christophersen (1992). All units are in micromoles per liter.
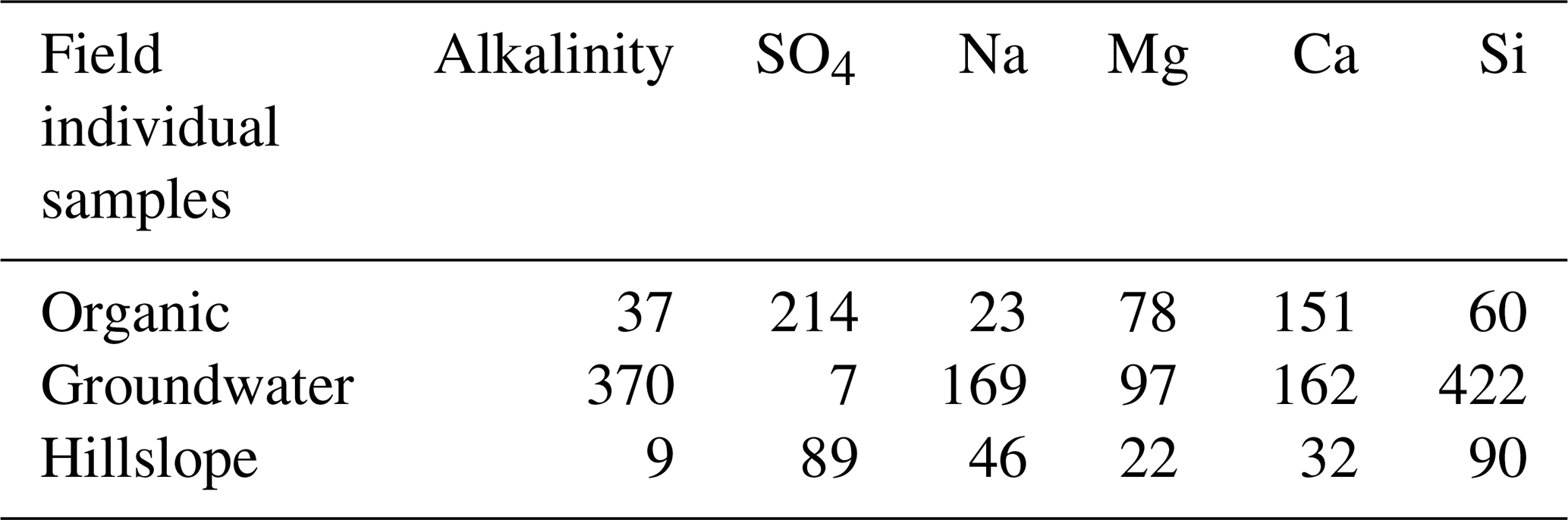
The three CHEMMA end-members are also located closer to the subspace spanned by the k−1 PC than the original three field-sampled end-members. The orthogonal projection distances are given in Table 3 and show that the CHEMMA end-members are more similar to the stream chemistry than the field samples, particularly for the groundwater end-member (field sample distance is 0.814; CHEMMA sample distance is 0.450). The differences in the chemical signatures of the groundwater end-members and their projections in the data subspace are shown in Fig. 4 (with concentrations given in standardized units, with the left side for field samples and right side for CHEMMA predictions). The CHEMMA end-member's alkalinity, SO4, and Ca values, in particular, are much closer to those of the data subspace than the field-sampled end-member, which is indicated by the shorter distance from the original 6D chemical profile in dots (blue for field samples and red for CHEMMA predictions) to the 2D mixing space profile in flat caps (orange for field samples and green for CHEMMA predictions). Only for Si is the field-sampled value closer. After PCA dimension reduction, both field-sampled and CHEMMA-predicted profiles are close in the standardized solute space. It is worth noting that CHEMMA does not require dimensional reduction; PCA is only needed to determine the number of end-members.
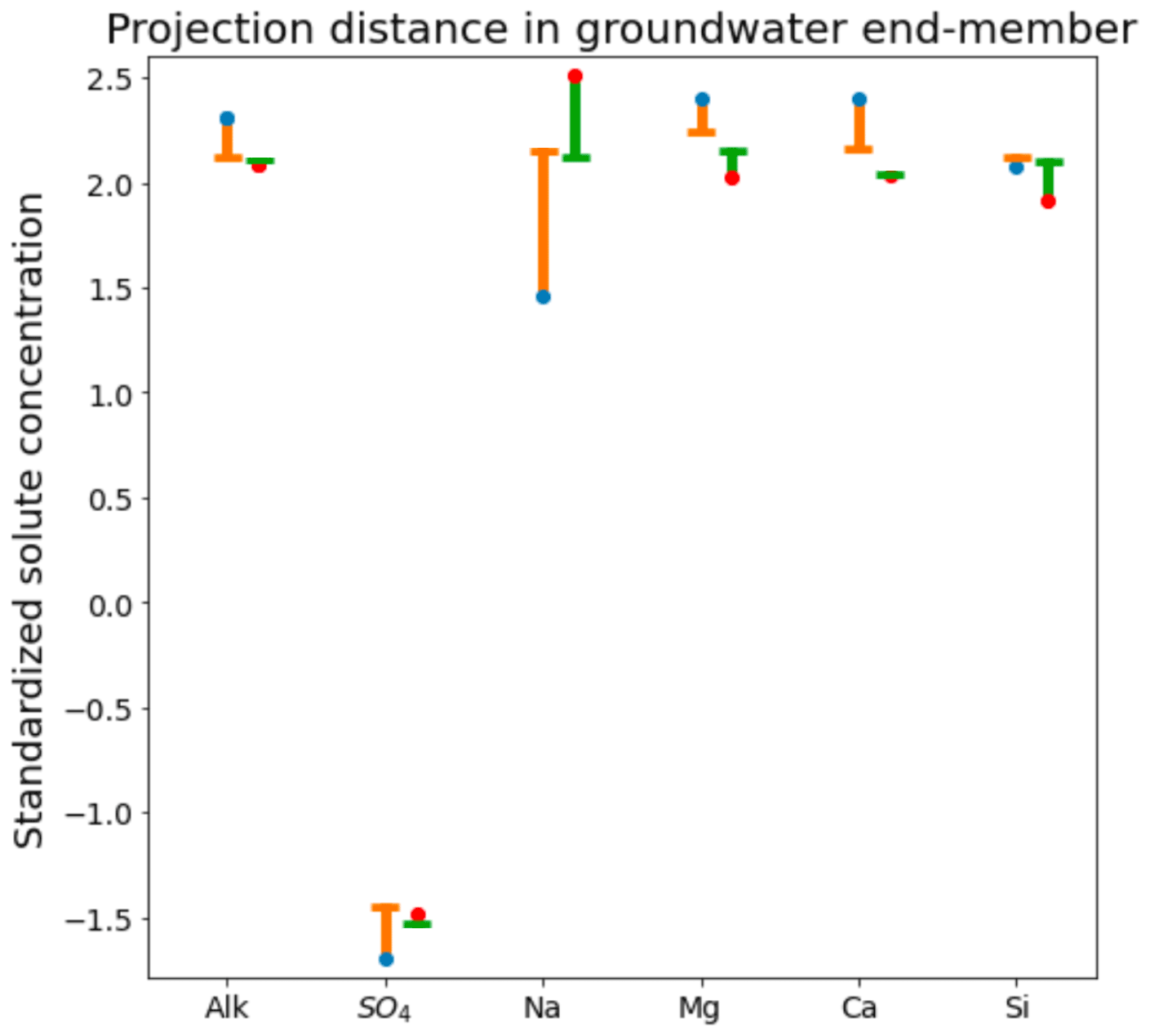
Figure 4Comparison of orthogonal projection distance for field-measured and CHEMMA-predicted groundwater end-member solute concentrations (in standardized units). For each solute, the blue and red dots are the observed and CHEMMA-estimated end-member concentrations, respectively. The orange and green bars show how these concentrations change when the end-members are projected in the 2D subspace (formed by retaining only the first two PC). The CHEMMA end-members lie closer to the 2D subspace that PCA analysis suggests the data principally occupy, so their projection distances are smaller.
Table 3End-member distance from observational plane to Principal Component subspace.
A fourth end-member could be robustly identified (Fig. 2; four magenta diamonds), which explained more of the data variability. Hooper (2003) also suggested the existence of a fourth end-member. This end-member appeared to be a mixture of hillslope and groundwater in some ways but had a relatively high alkalinity and silica concentration compared to those end-members (Fig. 2; brown and navy axes). The fourth end-member captures variations along the third PC axis (Fig. 3d), which are not apparent in the 2D view (Fig. 3b).
The spread of all end-member clusters (generated by 100 runs of CH-NMF) was small when four were sought, but a fifth could not be clearly identified. As the number of end-members was increased from three (Fig. 3a) to four (Fig. 3b), the new cluster (cyan Cluster 4) was dense, while the other three clusters (green, blue, and red) remained at similar locations to those clusters identified in the third end-member case. Adding the fourth end-member reduced the spread of the previously identified three clusters in the PC subspace (Fig. 3a and b and Table 1), suggesting that they could now be identified with less uncertainty. However, the inclusion of the fifth end-members (Fig. 3c) did not further tighten the previously identified clusters; indeed, the fifth cluster was poorly defined (black Cluster 5). Except for the cyan cluster that generally decreased within cluster variation, the standard deviations of other clusters increased for both the third and fourth end-member cases (Table 1).
The results in Fig. 2 imply that identification of end-members from the mixture alone may not be as impossible as Hooper and Christophersen (1992) suggested. CHEMMA is able to reproduce the three end-members that were identified in Hooper et al. (1990) and a fourth end-member, which explains more variation in the data.
This is not to say that the estimates provided by CHEMMA are unambiguous or even a complete set of contributing sources. CHEMMA identifies sources that can be found through their control on the boundary of the sample space. For example, sources that never supply the plurality of water but also that are never absent (or nearly never) may not be identified by CHEMMA, in that they never produce a vertex-like structure in the data cloud, nor do they constrain the location of a face. Further work is needed to determine the limits of end-member identification for a given dataset.
3.2 Dimensionality and DTMMs
For four CHEMMA end-member case in Table 3, the orthogonal projection distances of organic, hillslope, and groundwater end-members decrease/remain similar with the third CHEMMA end-member case. Adding a fifth end-member significantly increases the projection distance of identified fourth end-member. In addition, the dispersed cluster distributions in Fig. 3c suggest that a fifth end-member may be spurious. We cannot rule out the possibility that it reflects only the noisy edges of the sample space and so cannot be supported by the data. Indeed, CHEMMA does not come equipped with an objective criteria for determining how many end-members can be supported by the data. There are many mathematical methods, such as factor analysis and diffusion map spectral gaps, that could be used in parallel with CHEMMA to estimate data dimensions (Ashley and Lloyd, 1978; Coifman et al., 2008). It may be possible to use the k-fold cross-validation of CHEMMA itself to try to determine the best number of end-members. CHEMMA can also be used in conjunction with the approach already developed for EMMA to assess dimensionality, i.e., the DTMM presented in Hooper (2003)), which suggests choosing the smallest possible number of end-members that gives uncorrelated residuals resembling random noise. Any correlation structure in the residuals suggests a lack of fit in the model, which could be caused by (among other things) outliers and nonconservative solutes. An additional dimensionality (additional eigenvector to be retained) can be added until the residual structure is unseen or is not improved.
3.3 Uncertainty analysis
Because CHEMMA extracts end-members from the observations, the accuracy of the end-member's composition is influenced by a range of sources of variability and uncertainty, including how much noise exists from sample analysis error, how well the collected samples represent the full range of sources in the catchment, how many end-members we assume (as discussed above), how unique the CH-NMF and COP-KMEANS analyses are, and how valid the assumptions are that end-members are conservatively mixed and time invariant. For example, rare contributions from an end-member may result in the dispersion of Cluster 3 (Fig. 3b). Temporal variations of the end-member composition could produce the kind of variations seen in PC 3 in Fig. 3d (Inamdar et al., 2013). Fortunately, CHEMMA itself may be a basis for exploring the effects of time variability. For example, by partitioning the dataset into time periods (or hydrologic state, etc.), the apparent temporal variability of end-members could be explored.
Sampling uncertainty is a more tractable issue for the present analysis. We can estimate the magnitude of this error using bootstrapping (resampling with replacement; Efron and Tibshirani, 1994). We generated 1000 bootstrapped sets of the original Panola data and ran CHEMMA on each of them. The end-members identified in these bootstrapped datasets showed relatively little scatter compared to the overall variance in the stream water concentrations (Fig. 5), suggesting that they are robust with respect to the sampling error. Even the organic end-member, which dominates a limited number of stream water samples (Fig. 2; the few gray points towards the organic end-member) could still be identified with considerably small variance compared with the original solute variation (as shown in Fig. 5). However, this poorly represented end-member shows many more outliers (end-member compositions substantially different from the best estimate) than the other two. Figure 5 also re-emphasizes that CHEMMA identifies end-members that collectively exhibit unusual combinations of concentrations (i.e., vertex-like structures in the overall data cloud). While many solute concentrations of CHEMMA-predicted end-members are located towards extremal values of the observations, they need not be all individually extremes (e.g., the sulfate concentration of end-member 3 corresponding to the hillslope end-member; Fig. 5; upper middle plot).
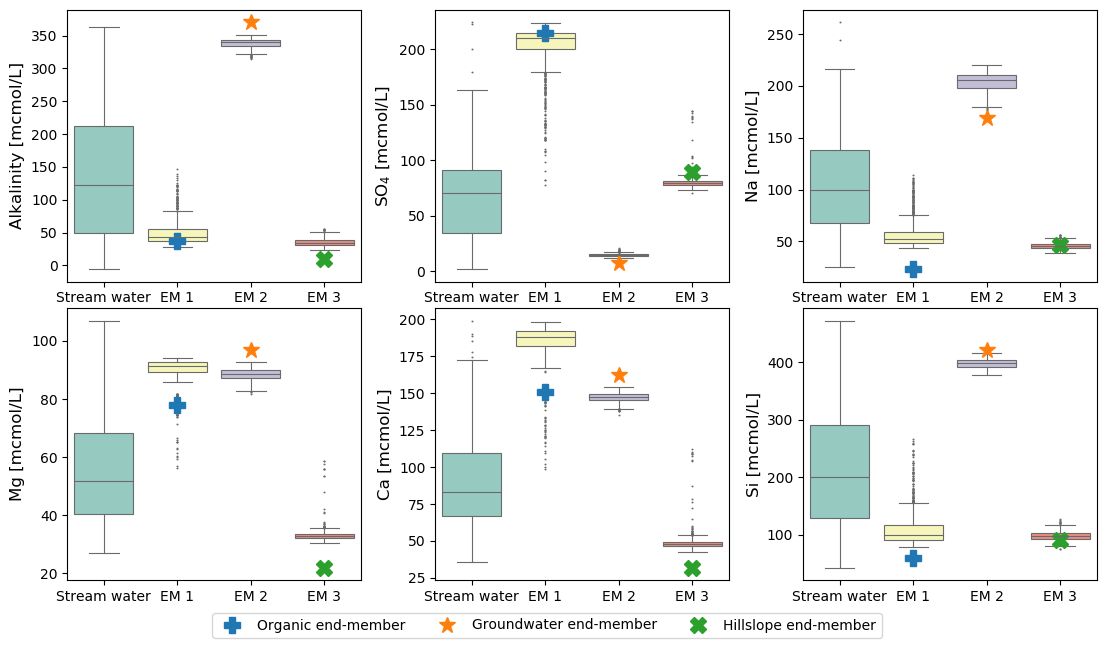
Figure 5Uncertainties of CHEMMA-predicted end-members (EM 1 to EM 3) compared with the total solute variances (stream water). The four columns represent the stream water samples and three CHEMMA-identified end-members. Each CHEMMA end-member (EM 1 to EM 3, predicted without using the field end-member samples) is matched with a field-measured end-member, based on the similarity of the concentration profile. The six subplots represents six stream water solute space.
To see how robustly the end-members could be identified with a smaller number of observations, we ran CHEMMA on bootstrapped subsets of the original data. These subsets represented from 5 % to 100 % of the original data size (905), and each subsetting experiment was repeated 1000 times. Results are shown in Fig. 6. For this particular dataset, the uncertainty is substantial when less than 40 % (362) of the original data are used, decreasing greatly from 40 % (362) to 60 % (543). Further improvements in the robust identification with more samples are mainly in the less well-constrained organic end-member (Fig. 6).

Figure 6CHEMMA end-members predicted with varying sample size grouped by the corresponding three field measured end-members. Each sample size box is drawn from 1000 bootstrap samples with the size of the number of sample used.
In addition, the overall number of samples may matter less than the number of samples that are dominated by one end-member or in which an end-member is entirely absent. Of the varying effects of sampling uncertainty on CHEMMA, four are illustrated in Fig. 6, where (1) some end-member constitutes, such as SO4 in the groundwater end-member (EM 2), and alkalinity, Na, and Si in the hillslope end-member (EM 3), are well identified regardless of whether 5 % (45) or 100 % (905) of the total available sample size is used. (2) For the well-represented groundwater and hillslope end-members, the uncertainty bounds do not vary as dramatically with sample size as they do for the organic end-member, which is less frequently important. (3) Even when using the full dataset, some of the end-member constituents are not very well-constrained (e.g., SO4 of the organic end-member/EM 1 has a larger variance than the well-constrained end-members with a sample size as small as 45. (4) Clusters of outliers (or multi-modality in the bootstrapped replicates) may suggest poorly constrained end-members. For example, SO4, Mg, and Ca in hillslope end-member/EM 3, identified with sample sizes 45 and 90, exhibit clusters of outliers in their tails. These clusters are within the range identified with EM 1 using larger sample sizes.
3.4 A synthetic exploration on model robustness
We also examined uncertainties arising from the potential non-uniqueness of the CH-NMF and COP-KMEANS analyses. Intuitively, we can expect these to be the greatest when the dataset lacks the vertex-like structures that the algorithm seeks to identify. In Fig. 7, the algorithm standard deviation denotes the variability amongst 100 CH-NMF runs (in one CHEMMA run), and the data standard deviation represents the variability amongst 100 bootstrapped CHEMMA runs. The variability induced by the instability of these algorithms is small compared to the overall variability of the dataset but is much greater than that introduced by the sampling alone.
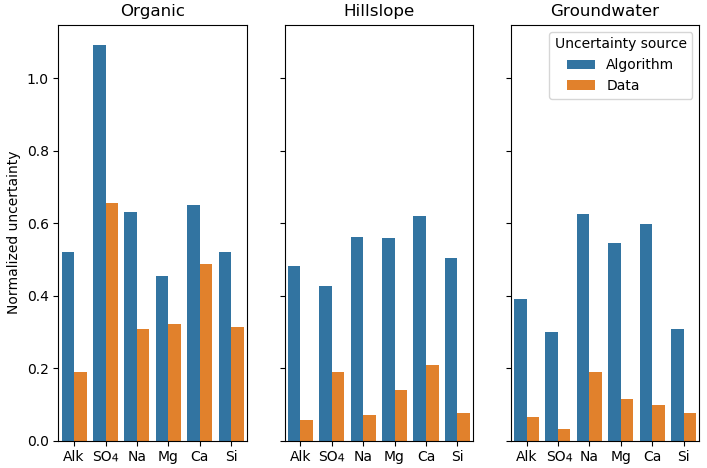
Figure 7The normalized uncertainty of predicted end-members, where the uncertainty sources are from algorithm and data groups using the Panola data. The algorithm and the data are two groups that used the bootstrap method. Normalized uncertainties are estimated by dividing standard deviation of bootstrapped dataset over the standard deviation of stream water solute measurements.
To explore this source of uncertainty further, we created a relatively simple synthetic dataset of observations of two Gaussian-distributed independent variables (X and Y) that can be represented as conservative mixtures of three true end-members. As Fig. 8 shows, X and Y are chosen to center on the conservative mixing triangle's inner center. The variance in the Gaussian distributions used to generate these data increases from case 1 to 6 in Fig. 8. All marked estimated end-members are outputs from 100 CH-NMF runs, which represent the end-member variation during one CHEMMA run (Fig. 8).
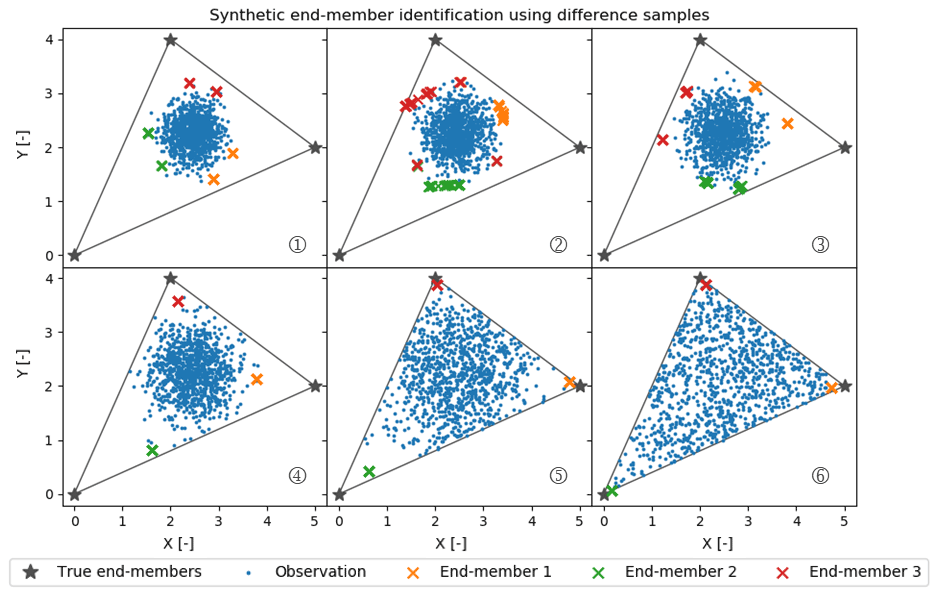
Figure 8Synthetic random mixture (blue dots) generated by three fixed true end-members (gray stars). All cases (1 to 6) have the same number of samples (1000 samples) and are normally distributed around the inner center of the gray triangle. From case 1 to 6, the mixture occupies more of the convex mixing space, as the standard deviation of the normal distribution used to generate those synthetic points increases.
As expected, when the observations have a low variance compared to the spread of the end-members, CHEMMA does a poor job at identifying the end-members. In the case with the tightest cluster, case 1, the estimated end-members are actually less variable than in the less tightly clustered case 2. This suggests that variations between applications of CH-NMF are sensitive to the particularities of a dataset's extremal observations.
Between case 3 and case 4, the stability of the end-members identified by CH-NMF becomes much better, even though the distribution of observations in case 4 seems to have been barely constrained by the mixing space. There is a sufficient structure for the algorithm to anchor three unique end-members (Figs. 8 and 9). However, the estimated end-members are biased toward the centroid of the dataset and do not accurately characterize the end-members. As the observations fill more of the conservative mixing space within the triangle (i.e. the convex hull), the CHEMMA-identified end-members are closer to the true end-members.

Figure 9Standard deviation of the predicted end-members, with sources separated into algorithm and data groups using the synthetic data. Component X and Y represent the two synthetic measures, X [–] and Y [–], in Fig. 8. The X-axis percent end-member-limited values are corresponding to the synthetic case numbers in Fig. 8. A percent end-member-limited value is a measure of the degree to which the synthetic data were constrained by the mixing space (it is the proportion of randomly generated normally distributed samples that fell outside of the triangular constraint of the end-members and which were discarded). In each case, samples were continuously generated from the normal distribution with the given variance until 1000 samples fell within the triangular constraint.
Figure 9 confirms and expands the observations from Figs. 7 and 8 in that the major uncertainty of CHEMMA predicted end-members comes from sampling errors when the dataset has sufficient structure. For the synthetic dataset, the algorithmic uncertainty becomes insignificant when the data cloud just begins to be constrained by the end-members. In case 4 in Fig. 8), less than 1 % of the random samples generated fell outside the mixing space (and were, thus, discarded). Note that it is the edges, not the vertices, that have affected the shape of the data cloud at this stage. This suggests that the CHEMMA algorithm does not require that there be extreme samples containing large contributions from only one end-member (i.e., samples close to a vertex in the mixing space). Rather, it can detect the mixing structure robustly when the dataset includes samples containing very small contributions of one end-member and intermediate contributions of another (i.e., samples close to an edge/face of the mixing space, but far from a vertex). However, an end-member whose contribution is consistently low may not be effectively detected because it does not sufficiently affect the shape of the data cloud boundary to justify increasing the number of end-members sought (i.e., the number of principal components retained in the analysis plus one).
Here we have advanced a method of the end-member mixing analysis that challenges Christophersen and Hooper (1992)'s assertion that source solution compositions cannot be unambiguously determined from the mixture alone. The traditional EMMA method requires potential end-member source waters to be sampled in the field and compared to the data.
The method presented, convex hull end-member mixing analysis, or CHEMMA, uses a combination of recently developed statistical learning techniques to infer streamflow end-members from the stream water solute concentration data structure. The end-members are estimated by fitting a simplex (k-dimensional polyhedron) to the data cloud and identifying the end-members with the vertices of the simplex. The method was tested by applying it to the Panola dataset of Hooper et al. (1990). CHEMMA was able to accurately reproduce the field-sampled end-members identified in the original study solely from the stream water samples.
In total, two sources of uncertainty in the chemical profile of the identified end-members were evaluated. The algorithmic error (variations between applications of the CHEMMA algorithm) was estimated by re-running the algorithm multiple times on the same dataset. A sample error was estimated by bootstrapping the original dataset and re-running the CHEMMA analysis 1000 times. The results demonstrated that the end-members in the Panola dataset were identified with relatively little variance compared to the overall variance of the data. More of the error was due to algorithmic error rather than sampling error.
Subsampling of the Panola dataset demonstrated the sensitivity of the CHEMMA method to the number of samples. The results suggested that estimates of the end-members may be uncertain when too few samples are available or when an end-member is the major component of only a small proportion of the sample set (as is the case with the organic end-member in the Panola dataset). Some end-member constituents were reliably identified with as few as 45 samples (e.g., SO4 in the groundwater end-member and alkalinity, Na, and Si in the hillslope end-member), while others needed more than ∼500 samples to be identified with similar robustness (e.g., all the constituents of the organic end-member).
A synthetic dataset was used to examine how uncertainty in the end-member identification was related to the data structure. This showed that algorithmic uncertainty could be large when the fringes of the data cloud were far from the edges and constrained by the need to be a mixture of the end-members. That is, when all the samples contained a non-trivial portion of all the end-members, and no end-member dominated any one sample, then the shape of the data cloud did not provide usable information about the end-members. This uncertainty dropped dramatically once the boundaries of the data cloud contacted the boundaries of the mixing space, and so at least a few samples contained a near-zero contribution from at least one end-member. Notably, it was not necessary for some minimum number of samples to contain the majority of contributions from each end-member. However, estimates of the end-member composition were biased toward the data cloud centroid unless such extremal samples (i.e., ones that were almost entirely composed of one end-member) were present in the dataset.
CHEMMA makes it possible to investigate stream chemical dynamics in terms of end-members, even when the samples of candidate source waters are not available. However, even where such samples are available (or could be collected in the future) CHEMMA may be a useful tool to augment the traditional approach in the following ways: (1) reducing subjectivity when selecting from field-measured end-member candidates by comparing them to CHEMMA-identified end-members, (2) serving as a check on missing sources by characterizing end-members that are not represented in field samples, and (3) helping target candidate end-member field sampling by suggesting source characteristics. However, the usefulness of CHEMMA is limited by the structure of the data in mixing space. As Fig. 9 suggests, CHEMMA will fail for datasets in which all end-members are present in all samples to some non-trivial degree. Samples in which an end-member is absent provide critical information and strongly control the location of the face of the convex hull used to identify the other end-members.
It should be noted that CHEMMA itself does not establish a systematic way to determine the appropriate number of end-members k for which to search. This choice must be made independently. However, it is compatible with the DTMM method, presented by Hooper (2003), that has been used to make this judgment in the past. DTMM (Hooper, 2003) was used to conclude that (1) the dimensionality of the Panola dataset is at least 3 (i.e., at least four end-members are required) and (2) the possible fourth source (end-member) may be weathering products containing calcium and magnesium. CHEMMA was able to identify a fourth end-member with such a characteristic without running through DTMM analysis.
This method can be improved in a wide range of ways. Future work should focus on (1) applying quantitative methods to eliminate the subjective choice of k, such as the Akaike information criterion (AIC) or Bayesian information criterion (BIC or Schwarz information criterion; see Kuha, 2004), (2) relaxing the constraints on the CH-NMF algorithm (e.g., forcing algorithm 1, Step 5 to construct a perfect convex hull) so that extreme points in S also lie inside the simplex, thereby allowing the method to better characterize end-members that are never a large fraction of any samples, (3) further exploring the data requirements and uncertainty of the method, including a better understanding of the relationship between the stability of COP-KMEANS clusters, the temporal variability of end-members, and the number of samples, and (4) pre-conditioning a Bayesian CHEMMA with priors based on field end-member measurements.
Both the example code and data are available in a Jupyter Notebook on Zenodo https://doi.org/10.5281/zenodo.4116082 (Xu Fei, 2020).
EXF and CJH were responsible for conceptualization, methodology, and visualization. EXF was responsible for investigation, formal analysis, and writing (original draft). CJH was responsible for the funding acquisition, supervision, and writing (review and editing).
The contact author has declared that neither they nor their co-author has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Panola stream solute chemistry data from Hooper and Christophersen (1992) were collected with the support of the United States Geological Survey and are available at http://hiscentral.cuahsi.org/pub_network.aspx?n=385 (last access: 7 May 2020). Thanks to Rick Hooper, for providing thoughtful feedback on the draft paper, and to Joost Delsman and three anonymous reviewer, for their careful reading. This work has been supported by the NSF (grant no. EAR-1654194).
This research has been supported by the National Science Foundation, Directorate for Geosciences (grant no. EAR-1654194).
This paper was edited by Genevieve Ali and reviewed by Joost Delsman and three anonymous referees.
Ali, G. A., Roy, A. G., Turmel, M. C., and Courchesne, F.: Source-to-stream connectivity assessment through end-member mixing analysis, J. Hydrol., 392, 119–135, https://doi.org/10.1016/j.jhydrol.2010.07.049, 2010. a
Ashley, R. and Lloyd, J.: An example of the use of factor analysis and cluster analysis in groundwater chemistry interpretation, J. Hydrol., 39, 355–364, 1978. a
Babaki, B.: COP-Kmeans version 1.5, Zenodo, https://doi.org/10.5281/zenodo.831850, 2017. a
Barbeta, A. and Peñuelas, J.: Relative contribution of groundwater to plant transpiration estimated with stable isotopes, Scient. Rep., 7, 1–10, https://doi.org/10.1038/s41598-017-09643-x, 2017. a
Barthold, F. K., Tyralla, C., Schneider, K., Vaché, K. B., Frede, H.-G., and Breuer, L.: How many tracers do we need for end member mixing analysis (EMMA)? A sensitivity analysis, Water Resour. Res., 47, 1–14, https://doi.org/10.1029/2011WR010604, 2011. a
Beria, H., Larsen, J. R., Michelon, A., Ceperley, N. C., and Schaefli, B.: HydroMix v1.0: A new Bayesian mixing framework for attributing uncertain hydrological sources, Geosci. Model Dev., 13, 2433–2450, https://doi.org/10.5194/gmd-13-2433-2020, 2020. a
Bernal, S., Butturini, A., and Sabater, F.: Inferring nitrate sources through end member mixing analysis in an intermittent Mediterranean stream, Biogeochemistry, 81, 269–289, https://doi.org/10.1007/s10533-006-9041-7, 2006. a, b
Burns, D. A., Mcdonnell, J. J., Hooper, R. P., Peters, N. E., Freer, J. E., Kendall, C., and Beven, K.: Quantifying contributions to storm runoff through end-member mixing analysis and hydrologic measurements at the Panola Mountain Research Watershed (Georgia, USA), Hydrol. Process., 15, 1903–1924, https://doi.org/10.1002/hyp.246, 2001. a
Carrera, J., Vázquez-Suñé, E., Castillo, O., and Sánchez-Vila, X.: A methodology to compute mixing ratios with uncertain end-members, Water Resour. Res., 40, 1–11, https://doi.org/10.1029/2003WR002263, 2004. a
Christophersen, N. and Hooper, R. P.: Multivariate analysis of stream water chemical data: the use of Principal Components Analysis for the end-member mixing problem, Water Resour. Res., 28, 99–107, 1992. a, b, c, d, e, f, g, h
Coifman, R. R., Kevrekidis, I. G., Lafon, S., Maggioni, M., and Nadler, B.: Diffusion maps, reduction coordinates, and low dimensional representation of stochastic systems, Multisc. Model. Simul., 7, 842–864, 2008. a
Delsman, J. R., Oude Essink, G. H., Beven, K. J., and Stuyfzand, P. J.: Uncertainty estimation of end-member mixing using generalized likelihood uncertainty estimation (GLUE), applied in a lowland catchment, Water Resour. Res., 49, 4792–4806, https://doi.org/10.1002/wrcr.20341, 2013. a, b, c, d
Ding, C. H., Li, T., and Jordan, M. I.: Convex and semi-nonnegative matrix factorizations, IEEE T. Pattern Anal. Mach. Intel., 32, 45–55, 2008. a, b, c
Efron, B. and Tibshirani, R. J.: An introduction to the bootstrap, CRC Press, ISBN 9780412042317, 1994. a
Genereux, D.: Quantifying uncertainty in tracer-based hydrograph separations, Water Resour. Res., 34, 915–919, https://doi.org/10.1029/98WR00010, 1998. a
Hooper, R. P.: Applying the Scientific Method to Small Catchment Studies: A Review of the Panola Mountain Experience, Hydrol. Process., 15, 2039–2050, https://doi.org/10.1002/hyp.255, 2001. a
Hooper, R. P.: Diagnostic tools for mixing models of stream water chemistry, Water Resour. Res., 39, 1055, https://doi.org/10.1029/2002WR001528, 2003. a, b, c, d, e, f, g, h, i, j, k
Hooper, R. P. and Christophersen, N.: Predicting episodic stream acidification in the southeastern United States: combining a long‐term acidification model and the end‐member mixing concept, Water Resour. Res., 28, 1983–1990, https://doi.org/10.1029/92WR00706, 1992. a, b, c, d, e
Hooper, R. P., Christophersen, N., and Peters, N. E.: Modelling streamwater chemistry as a mixture of soilwater end-members – an application to the Panola Mountain Catchment, Georgia, U.S.A., J. Hydrol., 116, 321–343, 1990. a, b, c, d, e, f, g, h, i, j, k, l, m
Hur, J., Williams, M. A., and Schlautman, M. A.: Evaluating spectroscopic and chromatographic techniques to resolve dissolved organic matter via end member mixing analysis, Chemosphere, 63, 387–402, https://doi.org/10.1016/j.chemosphere.2005.08.069, 2006. a
Hyvärinen, A. and Oja, E.: Independent component analysis: algorithms and applications, Neural Netw., 13, 411–430, 2000. a
Inamdar, S., Dhillon, G., Singh, S., Dutta, S., Levia, D., Scott, D., Mitchell, M., Van Stan, J., and McHale, P.: Temporal variation in end-member chemistry and its influence on runoff mixing patterns in a forested, Piedmont catchment, Water Resour. Res., 49, 1828–1844, 2013. a
James, A. L. and Roulet, N. T.: Investigating the applicability of end-member mixing analysis (EMMA) across scale: A study of eight small, nested catchments in a temperate forested watershed, Water Resour. Res., 42, 1–17, https://doi.org/10.1029/2005WR004419, 2006. a
Jung, H. Y., Hogue, T. S., Rademacher, L. K., and Meixner, T.: Impact of wildfire on source water contributions in Devil Creek, CA: evidence from end-member mixing analysis, Hydrol. Process., 23, 183–200, https://doi.org/10.1002/hyp.7132, 2009. a, b
Kronholm, S. C. and Capel, P. D.: A comparison of high-resolution specific conductance-based end-member mixing analysis and a graphical method for baseflow separation of four streams in hydrologically challenging agricultural watersheds, Hydrol. Process., 29, 2521–2533, https://doi.org/10.1002/hyp.10378, 2015. a
Kuha, J.: AIC and BIC: Comparisons of assumptions and performance, Sociolog. Meth. Res., 33, 188–229, 2004. a
Li, X., Ding, Y., Han, T., Kang, S., Yu, Z., and Jing, Z.: Seasonal controls of meltwater runoff chemistry and chemical weathering at Urumqi Glacier No. 1 in central Asia, Hydrol. Process., 33, 3258–3281, https://doi.org/10.1002/hyp.13555, 2019. a, b
Liu, F., Bales, R. C., Conklin, M. H., and Conrad, M. E.: Streamflow generation from snowmelt in semi-arid, seasonally snow-covered, forested catchments, Valles Caldera, New Mexico, Water Resour. Res., 44, W12443, https://doi.org/10.1029/2007WR006728, 2008a. a, b
Liu, F., Parmenter, R., Brooks, P. D., Conklin, M. H., and Bales, R. C.: Seasonal and interannual variation of streamflow pathways and biogeochemical implications in semi-arid, forested catchments in Valles Caldera, New Mexico, Ecohydrology: Ecosystems, Land and Water Process Interactions, Ecohydrogeomorphology, 1, 239–252, 2008b. a
Liu, F., Conklin, M. H., and Shaw, G. D.: Insights into hydrologic and hydrochemical processes based on concentration-discharge and end-member mixing analyses in the mid-Merced River Basin, Sierra Nevada, California, Water Resour. Res., 53, 832–850, 2017. a
Lv, Y., Gao, L., Geris, J., Verrot, L., and Peng, X.: Assessment of water sources and their contributions to streamflow by end-member mixing analysis in a subtropical mixed agricultural catchment, Agr. Water Manage., 203, 411–422, https://doi.org/10.1016/j.agwat.2018.03.013, 2018. a, b
Neal, C., Robson, A., Reynolds, B., and Jenkins, A.: Prediction of future short-term stream chemistry – a modelling approach, J. Hydrol., 130, 87–103, https://doi.org/10.1016/0022-1694(92)90105-5, 1992. a
Neill, C., Chaves, J. E., Biggs, T., Deegan, L. A., Elsenbeer, H., Figueiredo, R. O., Germer, S., Johnson, M. S., Lehmann, J., Markewitz, D., and Piccolo, M. C.: Runoff sources and land cover change in the Amazon: An end-member mixing analysis from small watersheds, Biogeochemistry, 105, 7–18, https://doi.org/10.1007/s10533-011-9597-8, 2011. a, b
Popp, A. L., Scheidegger, A., Moeck, C., Brennwald, M. S., and Kipfer, R.: Integrating Bayesian Groundwater Mixing Modeling With On-Site Helium Analysis to Identify Unknown Water Sources, Water Resour. Res., 55, 10602–10615, https://doi.org/10.1029/2019WR025677, 2019. a, b
Thurau, C., Kersting, K., Wahabzada, M., and Bauckhage, C.: Convex non-negative matrix factorization for massive datasets, Knowledge Inform. Syst., 29, 457–478, https://doi.org/10.1007/s10115-010-0352-6, 2011. a, b, c, d, e, f
Valder, J. F., Long, A. J., Davis, A. D., and Kenner, S. J.: Multivariate statistical approach to estimate mixing proportions for unknown end members, J. Hydrol., 460-461, 65–76, https://doi.org/10.1016/j.jhydrol.2012.06.037, 2012. a, b
Wagstaff, K., Cardie, C., Rogers, S., and Schroedl, S.: Constrained k-means clustering with background knowledge, in: Proceedings of the Eighteenth International Conference on Machine Learning, vol. 1, 577–584, https://web.cse.msu.edu/~cse802/notes/ConstrainedKmeans.pdf (last access: 6 May 2020), 2001. a, b
Xu Fei, E.: Example CHEMMA application code for the technical note, Zenodo [data set, code], https://doi.org/10.5281/zenodo.4116082, 2020. a
Yang, L. and Hur, J.: Critical evaluation of spectroscopic indices for organic matter source tracing via end member mixing analysis based on two contrasting sources, Water Res., 59, 80–89, https://doi.org/10.1016/j.watres.2014.04.018, 2014. a, b