the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 03 Jan 2020
| 03 Jan 2020
Significant spatial patterns from the GCM seasonal forecasts of global precipitation
Tongtiegang Zhao
Wei Zhang
Yongyong Zhang
Zhiyong Liu
Xiaohong Chen
Fully coupled global climate models (GCMs) generate a vast amount of high-dimensional forecast data of the global climate; therefore, interpreting and understanding the predictive performance is a critical issue in applying GCM forecasts. Spatial plotting is a powerful tool to identify where forecasts perform well and where forecasts are not satisfactory. Here we build upon the spatial plotting of anomaly correlation between forecast ensemble mean and observations to derive significant spatial patterns to illustrate the predictive performance. For the anomaly correlation derived from the 10 sets of forecasts archived in the North America Multi-Model Ensemble (NMME) experiment, the global and local Moran's I are calculated to associate anomaly correlations at neighbouring grid cells with one another. The global Moran's I associates anomaly correlation at the global scale and indicates that anomaly correlation at one grid cell relates significantly and positively to anomaly correlation at surrounding grid cells. The local Moran's I links anomaly correlation at one grid cell with its spatial lag and reveals clusters of grid cells with high, neutral, and low anomaly correlation. Overall, the forecasts produced by GCMs of similar settings and at the same climate centre exhibit similar clustering of anomaly correlation. In the meantime, the forecasts in NMME show complementary performances. About 80 % of grid cells across the globe fall into the cluster of high anomaly correlation under at least 1 of the 10 sets of forecasts. While anomaly correlation exhibits substantial spatial variability, the clustering approach serves as a filter of noise to identify spatial patterns and yields insights into the predictive performance of GCM seasonal forecasts of global precipitation.
- Article
(1690 KB) - Full-text XML
-
Supplement
(5268 KB) - BibTeX
- EndNote





Global climate models (GCMs) have been steadily improved over the past decades and are being employed by major climate centres around the world to generate operational long-range forecasts (Doblas-Reyes et al., 2013; Saha et al., 2014; Bauer et al., 2015; Hudson et al., 2017; Kushnir et al., 2019), providing physically based forecasts in comparison to conventional statistical forecasts (Mason and Goddard, 2001; Wu et al., 2009; Schepen et al., 2012). In particular, the fully coupled GCMs assimilate world-wide observational information to predict the global hydrological cycle (Merryfield et al., 2013; Saha et al., 2014; Jia et al., 2015). Equipped with physical and dynamical laws, GCMs can potentially make forecasts of longer lead time and higher skill than statistical models (Kirtman et al., 2014; Becker et al., 2014; Chen et al., 2017). In terms of computation, global climate forecasting is as complex as the simulation of the human brain and of the evolution of the early universe (Bauer et al., 2015). Advances in super-computing facilitate the forecasting and make GCM forecasts readily available for hydrological, environmental, and agricultural modelling (Sheffield et al., 2014; Vecchi et al., 2014; Bellprat et al., 2019; Pappenberger et al., 2019; Zhao et al., 2019a).
GCMs generate a vast amount of high-dimensional forecast data, including retrospective forecasts of past climate and real-time forecasts (Kirtman et al., 2014; Saha et al., 2014; Jia et al., 2015). Due to the complexity of atmospheric processes and model physics, the predictive performance of GCM forecasts is not uniform, but varies considerably across the globe (Yuan et al., 2013; Tian et al., 2017; Zhao et al., 2018). Therefore, interpreting and understanding the predictive performance is a critical issue in the applications of GCM forecasts (Doblas-Reyes et al., 2013; Saha et al., 2014; Jia et al., 2015; Hudson et al., 2017; Wang et al., 2019a). There are various metrics to verify the attributes of forecasts (Murphy, 1993). For example, bias in percentage indicates the extent to which the forecasts are persistently higher, or lower, than the corresponding observations; probability integral transform (PIT) evaluates the reliability of the spread of ensemble forecasts in capturing the distribution of observations; and the continuous ranked probability score (CRPS) is a probability-weighted measure of the errors of ensemble members in relation to the observations (Murphy, 1993; Hersbach, 2000; Gneiting et al., 2007; Tian et al., 2018; Wang et al., 2019b). The anomaly correlation that indicates how well large (small) values of forecasts correspond to large (small) values of observations is one of the most popular metrics (e.g. Yuan et al., 2011; Saha et al., 2014; Crochemore et al., 2016; Hudson et al., 2017; Zhao et al., 2017a). Compared to PIT that requires a diagnostic plot and CRPS that relies on numerical integration, anomaly correlation is conceptually simple, easy to implement, and also robust to missing and censored values (Yuan et al., 2011; Luo et al., 2013; Slater et al., 2017).
Spatial plotting with latitude and longitude has been extensively used to handle the dimensionality for the verification of GCM forecasts (Kirtman et al., 2014; Hudson et al., 2017; Slater et al., 2017). The fact that forecasts are commonly generated by GCMs as grid-based data makes spatial plotting a particular tool of choice for verification (Merryfield et al., 2013; Saha et al., 2014; Jia et al., 2015). As to anomaly correlation, spatial plotting overcomes tedious eyeball search by grid cell and is effective in locating where there is a good correspondence between forecasts and observations and where the correspondence is not satisfactory (Luo et al., 2013; Saha et al., 2014; Crochemore et al., 2016; Zhao et al., 2018, 2019b). Similarly, spatial plotting applies to other verification metrics, such as bias and CRPS, and facilitates the examination of forecast attributes (Hersbach, 2000; Gneiting et al., 2007; Kirtman et al., 2014).
The extensive use of spatial plotting underlines the importance of testing the significance of spatial patterns. In spatial statistics, one of the fundamental issues is “are the spatial patterns displayed by the spatial plots significant in some sense and therefore worth interpreting?” (Cliff and Ord, 1981; Anselin, 1995; Getis, 2007). However, the test of significance is commonly missing in the spatial plotting of GCM forecasts. In other words, verification metrics, such as anomaly correlation, are calculated for each grid cell and then shown as they are. To some extent, the interpretation of predictive performance depends on the colour schemes, which are selected subjectively to represent the scale of verification metrics. There is the first law of geography – “everything is related to everything else, but near things are more related than distant things” (Tobler, 1970). As to spatial plotting, the indication is that when verifying forecasts at one grid cell, attention also needs to be paid to forecasts at surrounding grid cells. For anomaly correlation, a grid cell with high correlation between forecasts and observations can be surrounded by grid cells with similarly high correlation or by grid cells with low correlation. In the former case, the grid cell is located in a region where the GCM forecasts tend to perform well. But in the latter case, the high correlation can be a suspicious outlier. Moreover, previous studies observed grid cells with negative anomaly correlation; i.e. large (small) values of forecasts correspond to small (high) values of observations (Zhao et al., 2017b, 2018, 2019b). In such a case, forecasts are cautiously wrong. Therefore, it is critical to characterize the different cases in spatial plotting and test whether the spatial patterns are significant and worth further attention.
In this paper, we are motivated to introduce spatial statistics (e.g. Di Luzio et al., 2008; Lu and Wong, 2008; Woldemeskel et al., 2013) to investigate the spatial plotting of anomaly correlation at the global scale. As will be shown later in this paper, the technique of spatial clustering facilitates the identification of significant patterns of high, neutral, and low anomaly correlation and provides an objective approach to interpreting the predictive performance of GCM forecasts. For the purpose of inter-comparison, the examination of significant patterns in spatial plotting has been conducted for 10 sets of GCM seasonal precipitation forecasts in the North American Multi-Model Ensemble (NMME) experiment (Kirtman et al., 2014; Ma et al., 2016; Zhang et al., 2017). In the remainder of the paper, the dataset of GCM seasonal forecasts is illustrated in Sect. 2; the spatial clustering using global and local Moran's I is detailed in Sect. 3; the results of anomaly correlation at the global scale and its clustering are shown in Sect. 4; the discussion and conclusions are respectively presented in Sects. 5 and 6.
The NMME builds on existing GCMs in North America to provide quality-controlled forecast data to the community of climate research and applications. More than 10 sets of GCM precipitation forecasts have been spatially regridded and temporally aggregated to form a consistent dataset (Kirtman et al., 2014). Each set of forecasts overall has five dimensions. They are (1) start time s, when the forecasts are initialized; (2) lead time l, whose unit is month for the forecasts; (3) ensemble member n, which is meant to represent forecast uncertainty; (4) latitude y; and (5) longitude x. Taking the precipitation forecasts of the Climate Forecast System version 2 (CFSv2, Saha et al., 2014) in NMME as an example, s is the beginning of each month, and its value represents the number of months since January 1960; l is 0, 1, …, 9; i.e. the forecasts are for month 0 head (current month), month 1 ahead, …, and month 9 ahead; n is numbered from 1 to 24, i.e. 24 ensemble members; y is from −90 to 90, while x is from 0 to 359; i.e. the spatial resolution is 1∘ by 1∘ (approximately 100 km). In the meantime, NMME provides precipitation observations corresponding to the forecasts. Specifically, the Climate Prediction Center (CPC)'s merged analysis of precipitation (CMAP; Xie and Arkin, 1997; Xie et al., 2007), which is monthly, has been regridded to 1∘ resolution to verify GCM forecasts (Kirtman et al., 2014; Chen et al., 2017; Zhao et al., 2018).
Ten sets of precipitation forecasts, as well as CMAP observations, in the NMME are downloaded from the International Research Institute at Columbia University (https://iridl.ldeo.columbia.edu/SOURCES/.Models/.NMME/, last access: 2 January 2020). Their retrospective forecasts are complete in the period from 1982 to 2010 (Merryfield et al., 2013; Saha et al., 2014; Jia et al., 2015). In the meantime, their real-time forecasts are updated periodically in a slightly different setting; for example, CFSv2 forecasts have been generated since January 2011 using initial conditions of the last 30 d, with four runs from each day (https://www.cpc.ncep.noaa.gov/products/CFSv2/CFSv2_body.html, last access: 2 January 2020). Basic information on the forecasts is provided in Table 1. In the analysis, the attention is paid to the retrospective forecasts:
In Eq. (1), f represents forecast values that are specified by the five dimensions; F, which is the set of forecasts, is marked by the GCM that generates the forecasts. It is noted that, in NMME, FGCM are raw forecasts generated by GCMs and are not bias-corrected or downscaled.
Table 1Basic information on the 10 sets of GCM forecasts from the NMME experiment.

The observed precipitation corresponding to the forecasts is denoted as
As shown in Eq. (2), the observation in total has three dimensions: time t, whose value is the addition of lead time l to start time s in the alignment of observations with forecasts; latitude y; and longitude x. It is pointed out that while F differs by GCM, O is the same across the 10 sets of forecasts.
The start time s in Eqs. (1) and (2) comprises year k, i.e. 1982, 1983, …, 2010, and month m, i.e. January, February, …, and December. The predictive performance of GCM forecasts exhibits seasonality (Zhao et al., 2017a, b, 2018). Accordingly, in the analysis, forecasts are selected by fixing m while varying k, e.g. pooling forecasts initialized in June 1982, June 1983, …, June 2010. The anomaly correlation is calculated by relating forecasts to the corresponding observations:
The above formulation deals with k and omits other dimensions, including m, l, y, and x, for the sake of simplicity. In Eq. (3), rfk (rok) is the rank of year k's forecast ensemble mean (observation) in the 29 years' ensemble mean (observations); and () is the mean value of rfk (rok). In general, the anomaly correlation characterizes how well large (small) values of the ensemble mean correspond to large (small) values of observations. Good (poor) correspondence makes r tend towards 1 (−1).
With Eq. (3), the set of anomaly correlation between FGCM and O is evaluated:
in which r and R are respectively the correlation coefficients and the set of correlation. R, which differs by GCM, has four dimensions: (1) month m, which substitutes start time s in Eq. (1); (2) lead time l; (3) latitude y; and (4) longitude x. Comparing Eq. (4) to Eq. (1), the dimension n of the ensemble member is eliminated since the forecast ensemble mean is taken in the calculation of anomaly correlation (Eq. 3).
For selected GCM forecasts in month m and at lead time l, the anomaly correlation between ensemble mean and observation forms a two-dimensional array by latitude and longitude. Here, spatial plotting applies to the presentation of anomaly correlation at the global scale. Following Eq. (4), the set of anomaly correlation is denoted as
In Eq. (5), y and x specify the location of grid cells. Denoting a grid cell as i, the subscripts of latitude y and longitude x are merged into i for the purpose of simplicity:
in which ri represents the anomaly correlation at grid cell i, of which the latitude is yi and the longitude is xi.
The spatial plotting employs certain pre-selected colour schemes to represent the value of anomaly correlation and show the grid cell-wise anomaly correlation as it is (e.g. Yuan et al., 2011; Kirtman et al., 2014; Ma et al., 2016). Spatial patterns that represent clusters of grid cells with high anomaly correlation have been observed and highlighted in peer studies (e.g. Saha et al., 2014; Jia et al., 2015; Slater et al., 2017). The spatial clustering associates anomaly correlation at neighbouring grid cells with one another and tests the significance of the patterns by random permutation (Anselin, 1995: Anselin et al., 2006; Rey and Anselin, 2010). Following the standard formulations of spatial statistics, the global Moran's I is calculated to examine the association among anomaly correlation at the global scale:
in which N is the number of grid cells indexed by i and j across the globe; is the mean value of anomaly correlation; and wi,j is the spatial weighting coefficient that usually decays with the distance between i and j (Miller, 2004; Hao et al., 2016; Schmal et al., 2017). On the right-hand side of Eq. (7), the denominator is the variance of ri across all the grid cells; and the numerator is the spatially weighted and averaged covariance between ri and rj. Generally, the value of the global Moran's I ranges from −1 to 1. The similarity (dissimilarity) of ri to the surrounding rj makes I tend toward 1 (−1), while the random distribution of anomaly correlation makes I close to 0.
The spatial weight wi,j plays an important part in the calculation of I (Rey and Anselin, 2010). Following the inverse distance weighting (IDW) interpolation in the geosciences (Di Luzio et al., 2008; Lu and Wong, 2008; Woldemeskel et al., 2013), wi,j is formulated as follows:
in which d(i, j) is the Euclidean distance between grid cells i and j, i.e. . In addition, the cut-off threshold for d(i, j) is set as 10∘ (approximately 1000 km) to reduce the computational burden. That is, wi,j is set as 0 if d(i, j) exceeds 10.
Adding to the global Moran's I, the local Moran's I is obtained to test whether ri at a certain grid cell i significantly relates to the surrounding rj at the local scale (Anselin et al., 2006; Hao et al., 2016; Yuan et al., 2018):
As shown in the above formulation, Ii is positive when ri and the surrounding rj are similarly high or similarly low. On the other hand, Ii is negative when a high (low) value of ri corresponds to low (high) values of the neighbouring rj. Also, Ii can be close to zero when ri or the surrounding rj is close to the mean value. The significance of Ii is tested by random permutations (Rey and Anselin, 2010). For each permutation, the values of rj are randomly rearranged, and then the local Moran's I is re-calculated. The permutations obtained a reference distribution for Ii under the null hypothesis of randomly distributed anomaly correlation (Anselin, 1995; Anselin et al., 2006; Rey and Anselin, 2010). Given a significance level α, the quantiles Iα∕2 and are retrieved from the reference distribution. Therefore, the two-tailed test of Ii along with the anomaly correlation ri facilitates spatial clustering and derives five cases:
As illustrated in Eq. (9), the first case HH, which is short for high–high, indicates that a high value of ri is surrounded by high values of rj; the second case is HL – high–low – a high value of ri surrounded by low values of rj; the third case is NS – not significant – the local association of ri with surrounding rj is not significant; the fourth case is LH – low–high – a low value of ri surrounded by high values of rj; and the fifth case is LL – low–low – a low value of ri surrounded by low values of rj. In this way, the significance of patterns, which generally represent clusters of grid cells with high (low) anomaly correlation, is examined for spatial plotting of anomaly correlation. α is set to be 0.05 in this paper.
The spatial clustering is performed for the anomaly correlation across the 10 sets of forecasts in NMME. In the analysis, the attention is mainly paid to June, July, and August (JJA), which are generally boreal summer and austral winter. Specifically, the start time of the forecasts is June, and the forecasts at the lead times of 0, 1, and 2 months are aggregated to form the seasonal forecasts. In the meantime, forecasts initialized in September of total precipitation in September, October, and November (SON), forecasts initialized in December of total precipitation in December, (the next) January, and (the next February) (DJF), and forecasts initialized in March of total precipitation in March, April, and May (MAM) are also investigated, with the results presented in the Supplement.
4.1 Anomaly correlation in JJA
The anomaly correlation between ensemble mean and observation is evaluated for the 10 sets of seasonal precipitation forecasts. In Fig. 1, the spatial plots employ a diverging red–blue colour scheme to represent the value of anomaly correlation. Red pixels indicate positive correlation, while blue pixels indicate negative correlation. For each set of forecasts, many instances of red pixels can be observed. That is, forecasts exhibit promising performance, with ensemble mean positively correlated with observation in many instances. Meanwhile, there also exist instances of blue pixels. In those instances, forecasts are generally not right because large (small) values of ensemble mean coincide with small (large) values of observation. While an inter-comparison of the 10 sets of GCM forecasts in terms of anomaly correlation is presented in Fig. 1, the anomaly correlation exhibits considerable spatial variability that hinders the analysis across the different sets of forecasts. As a result, it is none too easy to identify regions where the forecasts persistently exhibit promising predictive performance.
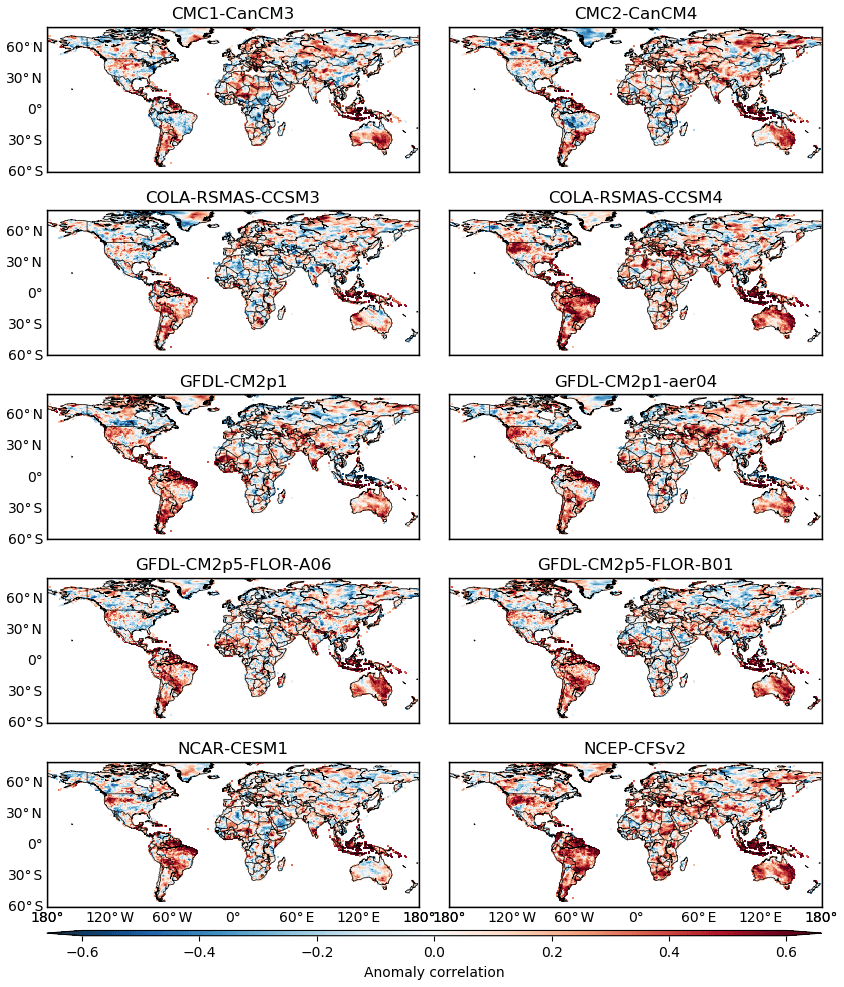
Figure 1Anomaly correlation between forecast ensemble mean and observation for 10 sets of GCM forecasts of seasonal precipitation. The forecasts are initialized in June and are for the total precipitation in June, July, and August.
The first row of Fig. 1 is for the forecasts generated by two Canadian GCMs. Although CanCM3 and CanCM4 share the ocean components and have slightly different atmospheric components (Merryfield et al., 2013), their anomaly correlation shows differences. For example, in Asia and Africa, the clusters of red pixels do not seem to overlap, but differ instead; and in Australia, the anomaly correlation is high in south-eastern Australia and part of Western Australia for CanCM3, while it is high in eastern Australia for CanCM4. These results are in accordance with a previous finding that CanCM3 and CanCM4 tend to complement each other (Merryfield et al., 2013). The second row of Fig. 1 shows the performance of two sets of forecasts by COLA-RSMAS GCMs. Complementary performance is no longer seen. Instead, CCSM4 forecasts show higher anomaly correlation and largely outperform CCSM3 forecasts in North and South America, Africa, and Australia. The outperformance can be attributed to the developments in ocean, atmospheric, and land components and the new coupling infrastructure of CCSM4 (Gent et al., 2011).
The third and fourth rows of Fig. 1 are for the forecasts produced by four GFDL GCMs. In the third row, CM2p1 and CM2p1-aer04 forecasts seem to exhibit similar anomaly correlation, which tends to be high in north-eastern South America, western Africa, and south-eastern Australia. In the fourth row, CM2p5-FLOR-A06 and CM2p5-FLOR-B01 forecasts show similarly high anomaly correlation in north-eastern and south-eastern South America, north-eastern Australia, and part of West Australia. On the other hand, the anomaly correlation differs from the CM2p1/CM2p1-aer04 forecasts to the CM2p5-FLOR-A06/CM2p5-FLOR-B01 forecasts. Jia et al. (2015) illustrated that CM2p5-FLOR GCMs have higher-resolution atmospheric and land components but coarser-resolution ocean components than CM2p1 GCMs. It is likely that the changes in the setting of GCMs lead to the difference in predictive performance. The fifth row of Fig. 1 is for NCAR-CESM1 and NCEP-CFSv2 forecasts. Compared to CESM1 forecasts, CFSv2 forecasts tend to exhibit similar anomaly correlation in South America and show higher anomaly correlation in Asia, Africa, and Australia.
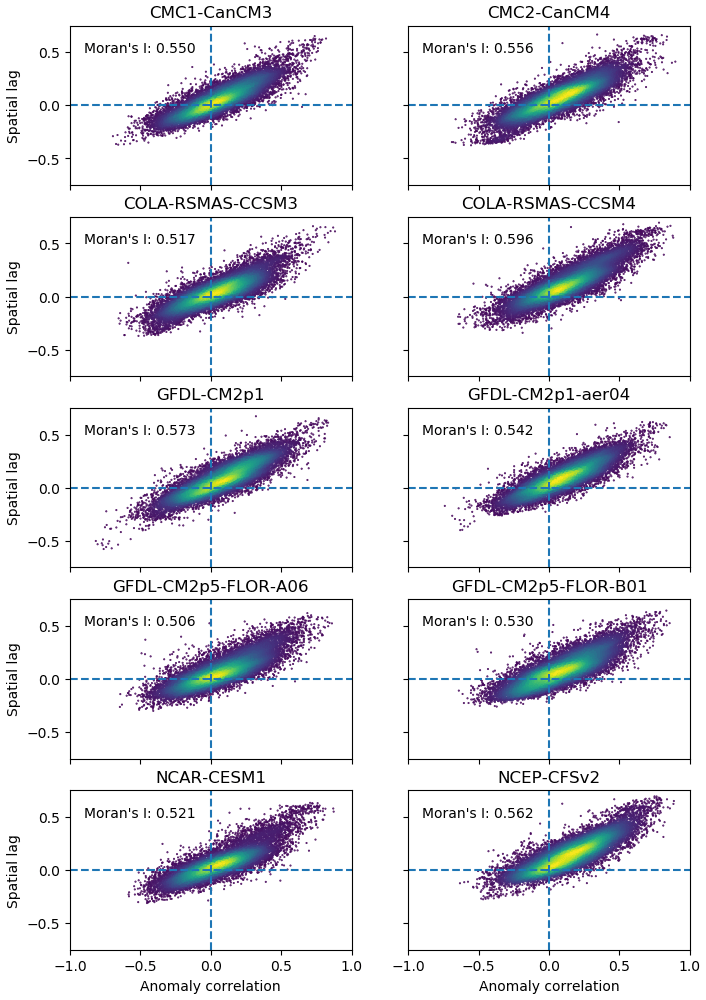
Figure 2Scatter plots of anomaly correlation at one grid cell against the corresponding spatial lag, i.e. spatially weighted and averaged anomaly correlation at surrounding grid cells. The density of points is estimated by the kernel density function and shown by the viridis heatmap, with yellow (blue) colour indicating high (low) density.
4.2 Anomaly correlation and its spatial lag in JJA
In spatial analysis, one critical issue is how an attribute at one location relates to the attribute at neighbouring locations (Cliff and Ord, 1981; Anselin, 1995; Getis, 2007). For anomaly correlation, the subplots of Fig. 1 imply the existence of some relationships as there are clusters of red pixels and of blue pixels. As for the clusters, Fig. 2 presents a statistical test of the relationships using the global Moran's I. Specifically, for all the grid cells across the globe, the anomaly correlation at each grid cell is plotted against the spatially weighted and averaged anomaly correlation, i.e. spatial lag (Miller, 2004; Hao et al., 2016; Schmal et al., 2017), at the surrounding grid cells.
Figure 2 uses a viridis heatmap to indicate the density of scatter points. It can be observed that the points frequently fall in the first quadrant under all 10 sets of forecasts. In accordance with clusters of red pixels in Fig. 1, this result suggests that many grid cells have positive anomaly correlation and that they tend to be surrounded by grid cells with positive anomaly correlation. Meanwhile, some points are in the third quadrant. This is due to the fact that some grid cells have negative anomaly correlation and are surrounded by grid cells with negative anomaly correlation. This outcome corresponds to the existence of clusters of blue grid cells in Fig. 1. Also, there are a few points in the second and fourth quadrants. Overall, anomaly correlation at one grid cell positively relates to anomaly correlation at the neighbouring grid cells. The global Moran's I is above 0.500, with the p value far smaller than 0.01, for all 10 sets of NMME seasonal forecasts. Therefore, it is statistically verified that at the global scale, a grid cell with high (neutral, or low) anomaly correlation tends to be surrounded by grid cells with high (neutral, or low) anomaly correlation.
4.3 Spatial clustering in JJA
Furthermore, the local Moran's I classifies the grid cells across the globe into five cases under each of the 10 sets of forecasts. In Fig. 3, the five cases are marked by different colours. Specifically, case HH is in orange, case HL in red, case NS in grey, case LH in green, and case LL in blue. A prominent finding from the subplots of Fig. 3 is that the three cases of HH, NS, and LL have more instances than the other two cases of HL and LH. This result agrees with the spatial clustering of anomaly correlation in Fig. 1 and with the distribution of scatter points in Fig. 2. Comparing Fig. 3 to Fig. 1, it can be observed that orange regions generally correspond to clusters of red pixels, which represent positive anomaly correlation, and that blue regions coincide with clusters of blue pixels, which show negative anomaly correlation. In the meantime, in-between orange and blue regions are grey regions. The implication is that regions with high and low anomaly correlation tend to be separated by regions with neutral anomaly correlation. While the spatial variability of anomaly correlation in Fig. 1 complicates the analysis of predictive performance, the classification in Fig. 3 facilitates effective analysis across the 10 sets of GCM forecasts.
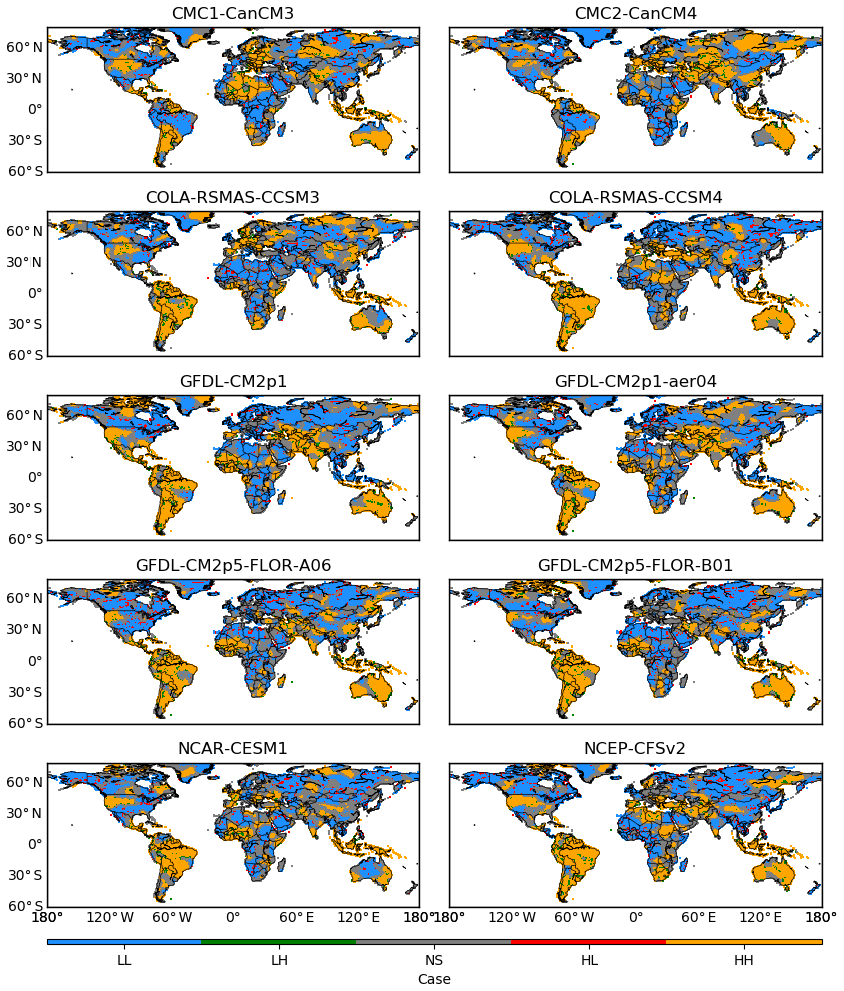
Figure 3Classification of grid cells across the globe into five cases based on spatial clustering of anomaly correlation. Case HH is marked in orange, case HL in red, case NS in grey, case LH in green, and case LL in blue. H and L are respectively short for high and low; case HH (HL, LH, and LL) indicates that a grid cell with high (high, low, and low) anomaly correlation is surrounded by grid cells with high (low, high, and low) anomaly correlation. NS is short for not significant; case NS means that the anomaly correlation at a grid cell or surrounding grid cells is neutral.
The orange regions that correspond to clusters of grid cells with high anomaly correlation are of particular interest. Three findings are made from the spatial extent of orange regions. First of all, they tend to be similar under forecasts generated by the same climate centre. For example, orange regions exist in a large part of South America for the 10 sets of forecasts. On the other hand, they are not as extensive in the Amazon Basin under the CMC1-CanCM3 and CMC2-CanCM4 forecasts, while they tend to cover the Amazon under the COLA-RSMAS-CCSM3 and COLA-RSMAS-CCSM4 forecasts. The similarity versus difference could be due to the fact that GCMs developed at the same climate centre tend to share certain ocean, atmospheric, and land components (Gent et al., 2011; Merryfield et al., 2013; Jia et al., 2015). Secondly, orange regions seem to be affected by the setting of GCMs. There are four sets of forecasts by the GFDL. In the western US, orange regions are extensive under the GFDL-CM2p1 and GFDL-CM2p1-aer04 forecasts, but tend to be limited under the GFDL-CM2p5-FLOR-A06 and GFDL-CM2p5-FLOR-B01 forecasts. This drastic difference can be due to the setting of FLOR, i.e. forecast-oriented low ocean resolution (Vecchi et al., 2014; Jia et al., 2015). Thirdly, there are substantial regional variations, possibly due to the predictability of seasonal precipitation (Doblas-Reyes et al., 2013; Becker et al., 2014; Zhang et al., 2017). For example, orange regions cover large parts of Australia, in particular south-western and south-eastern Australia. However, they are not as extensive in Europe, Asia, and Africa. This is possibly due to the fact that the climate in Australia is strongly affected by ENSO (Schepen et al., 2012; Wang et al., 2012; Hudson et al., 2017) and that the 10 GCMs in NMME tend to capture the effect of ENSO on the total precipitation in JJA.
The blue regions correspond to clusters of grid cells with low anomaly correlation. They are generally indicative of locations where forecasts are not satisfactory. Under the 10 sets of forecasts, blue regions can be observed in large parts of Europe, Asia, Africa, Canada, and the eastern US. While orange regions show some relationships with the source and setting of GCMs, blue regions are more varying. In addition, they tend to mix with grey regions, which are indicative of neutral anomaly correlation, and also with red and green regions. Generally, this outcome implies the difficulty of generating skilful climate forecasts at the global scale as there are complex land–ocean–atmosphere processes (Bauer et al., 2015; Kapnick et al., 2018; Kushnir et al., 2019). It is noted that some red regions that represent case HL are observed to be located inside blue regions. The implication is that some grid cells may happen to exhibit high anomaly correlation but that their surrounding grid cells are of low anomaly correlation. From the perspective of spatial statistics, the high correlation is not trustworthy and can be an outlier.
4.4 Frequency of case HH in JJA
While the orange regions of case HH are indicative of promising predictive performance, grid cells classified as this case differ across the 10 sets of forecasts. To deal with the spatial variation of case HH, the frequency that a grid cell falls into orange regions is counted for Fig. 3. For one grid cell, the frequency ranges from 0 to 10. That is, across the 10 sets of forecasts, one grid cell has a high anomaly correlation and is surrounded by grid cells with high anomaly correlation at the minimum for 0 times and at the maximum for 10 times. Figures 4 and 5 illustrate the spatial and statistical distributions of the frequency respectively.
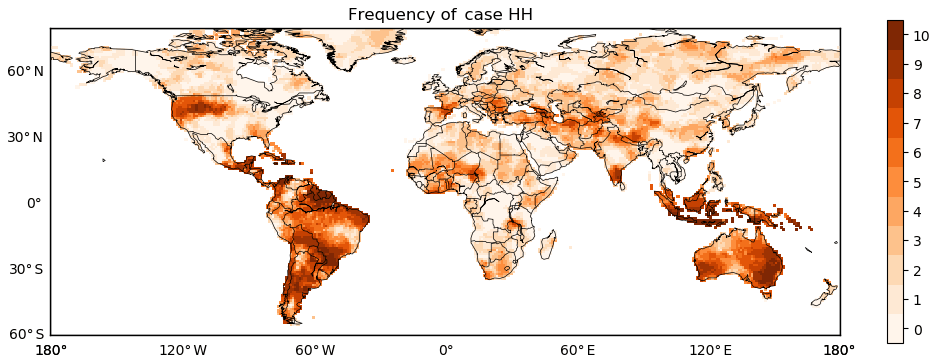
Figure 4The spatial distribution of the frequency of case HH across the globe for the 10 sets of GCM forecasts of the total precipitation in JJA.
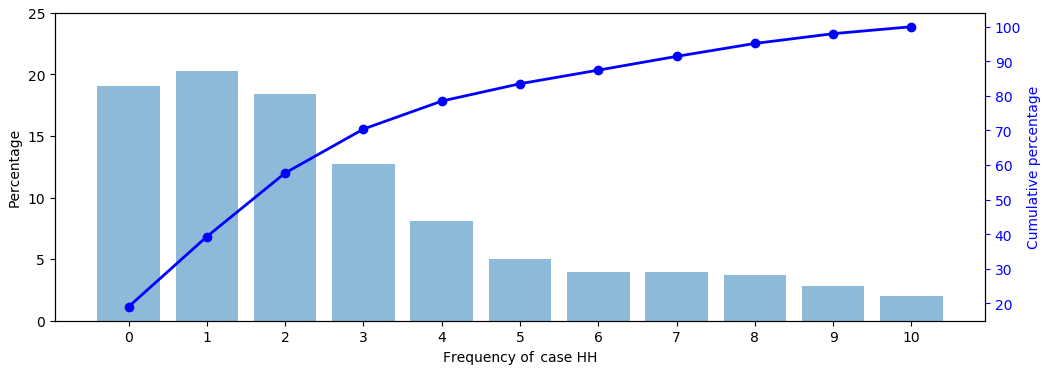
Figure 5Percentage (bar plot) and cumulative percentage (line plot) of the frequency of case HH under the 10 sets of GCM forecasts of the total precipitation in JJA.
Substantial regional variation can be observed for the frequency of case HH from Fig. 4. In North America, the frequency is evidently higher in the western US than in the eastern US, Canada, and Mexico. Globally, the frequency is higher in South America than in Europe, Asia, and Africa. Also, the frequency is high in Australia and South-east Asia. Mason and Goddard (2001) elaborated on the relationship between ENSO and global seasonal precipitation anomalies: for the total precipitation in JJA, El Niño was shown to coincide with above-normal precipitation in parts of South and North America and below-normal precipitation in parts of Australia and South-east Asia; by contrast, the impact of El Niño is not prominent for large parts of Europe, Asia, and Africa. With Mason and Goddard's finding, it is speculated that the results in Fig. 4 to some extent reflect the impact of ENSO at the global scale.
The percentage and cumulative percentage of the frequency of case HH are shown by bar and line plots in Fig. 5 respectively. The frequency of 0 corresponds to a percentage of nearly 20 %. This outcome means that about 20 % of the grid cells across the globe do not fall into case HH in any of the 10 sets of forecasts. Another interpretation of this result is that about 80 % of the grid cells fall into case HH in at least 1 of the 10 sets of forecasts. This result is in contrast to Fig. 3, suggesting that orange regions are limited under each of the 10 sets of forecasts. It highlights the spatial complementarity among the multiple sets of GCM forecasts (Doblas-Reyes et al., 2013; Merryfield et al., 2013; Jia et al., 2015). In the meantime, the percentages corresponding to the frequencies of 5, 6, …, 10 are all below 5 % and the cumulative percentage reaches 80 % at the frequency of 4. This result is due to the performances of the different sets of forecasts not being the same. In other words, for certain regions, some sets of GCM forecasts may be not satisfactory, while some other sets of GCM forecasts can be promising. Overall, Fig. 5 suggests that GCM forecasts in NMME can complement each other (Wang et al., 2012; Becker et al., 2014; Kirtman et al., 2014).
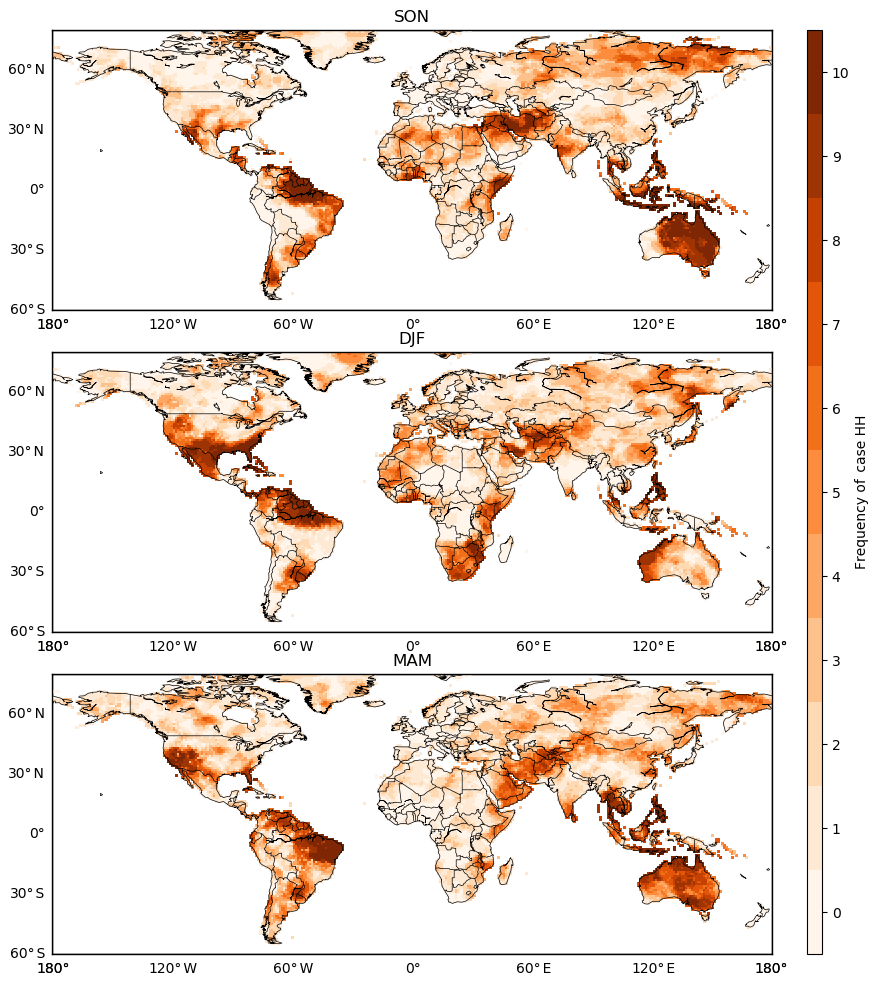
Figure 6As for Fig. 4 but for SON, DJF, and MAM.
4.5 Frequency of case HH in SON, DJF, and MAM
Besides JJA, spatial clustering has been performed for the anomaly correlation of GCM seasonal forecasts of total precipitation in SON, DJF, and MAM. Similarly, it is observed that the anomaly correlation varies across the globe (Figs. S1, S4, and S7 in the Supplement), correlates with its spatial lag (Figs. S2, S5, and S8), and exhibits significant spatial patterns (Figs. S3, S6, and S9). In addition to Figs. 4 and 5, the frequency of case HH is counted for the other three seasons and shown in Figs. 6 and 7.

ENSO is one of the most important drivers of global climate (Mason and Goddard, 2001; Saha et al., 2014; Bauer et al., 2015), and the CPC of NOAA has summarized the correlation between ENSO and global precipitation in different seasons (https://www.cpc.ncep.noaa.gov/products/precip/CWlink/ENSO/regressions/geplr.shtml, last access: 1 January 2020). In this paper, the results in Fig. 6 are associated with the global effects of ENSO. In SON, the CPC shows that ENSO correlates negatively with precipitation in eastern Australia and South-east Asia and positively with precipitation in parts of the Middle East and eastern Africa. From the upper part of Fig. 6, it is observed that the frequency of case HH is high in these regions. In DJF, ENSO is shown to correlate positively with precipitation in southern North America and negatively with precipitation in northern South America. In these two regions, the frequency of case HH is high (middle part of Fig. 6). In MAM, ENSO is illustrated to correlate negatively with precipitation in parts of South-east Asia, eastern Brazil, and eastern Australia. Therein, the frequency of case HH seems to be high (lower part of Fig. 6). Therefore, as previous studies found that GCMs in NMME generate skilful forecasts of ENSO (e.g. Kirtman et al., 2014; Saha et al., 2014; Zhang et al., 2017), Fig. 6 suggests that the skill, as is indicated by anomaly correlation, of GCM forecasts in NMME can also be related to ENSO. In Fig. 7, the percentage and cumulative percentage of the frequency of case HH are illustrated for SON, DJF, and MAM. Similarly to Fig. 5, the results show the complementarity among the 10 sets of forecasts.
Besides ENSO, there are other drivers of global climate. For example, North Atlantic Oscillation (NAO) and Arctic Oscillation (AO) extensively affect the climate in Europe, Asia, and North America (Hurrell et al., 2001; Ambaum et al., 2002). Several sea surface temperature indices of the Atlantic and Indian oceans and ENSO jointly impact the climate in Africa (Rowell, 2013). As can be observed from Figs. 4 to 7, there is still substantial room for improvement of seasonal precipitation forecasts for large parts of Europe, Asia, and Africa. The overall neutrally skilful precipitation forecasts in these regions can possibly be due to GCM formulations of other climate drivers not being as effective as the formulations of ENSO. In the meantime, the difficulty of global climate forecasting due to spatially–temporally varying teleconnections between regional precipitation and global climate drivers is noted (Merryfield et al., 2013; Saha et al., 2014; Jia et al., 2015; Hudson et al., 2017; Kushnir et al., 2019).
This paper proposes to use spatial clustering to identify significant spatial patterns (Anselin, 1995; Miller, 2004; Schmal et al., 2017) from spatial plots of anomaly correlation, which have been widely used to illustrate the predictive performance of GCM forecasts. The test of significance is based on global and local Moran's I. The global Moran's I indicates that at the global scale anomaly correlation at one grid cell significantly relates to anomaly correlation at neighbouring grid cells, and the local Moran's I reveals clusters of grid cells with high anomaly correlation. Across the 10 sets of GCM forecasts in NMME, the clusters are observed in different regions across the globe, which suggests that the skill of forecasts differs from region to region; in the meantime, the clusters vary by season owing to the seasonality of the skill of GCM forecasts (Doblas-Reyes et al., 2013; Becker et al., 2014; Yuan et al., 2015; Hudson et al., 2017; Kushnir et al., 2019). To test whether the spatial patterns are robust, the observations of precipitation are also sourced from the Global Precipitation Climatology Centre (GPCC) (Becker et al., 2011; Schamm et al., 2014). The anomaly correlation is re-calculated, and the spatial clustering is re-conducted. The results of GPCC precipitation, which are shown in Figs. S10 to 25, are overall similar to the results of CMAP precipitation. In particular, as to the two datasets of precipitation observations, the spatial distributions of case HH resemble those in JJA (Figs. 4 and S10) and also in SON, DJF, and MAM (Figs. 6 and S12). This outcome highlights the existence of significant spatial patterns and confirms that the spatial clustering can serve as an effective tool to yield insights into the predictive performance of GCM forecasts.
The spatial clustering ties anomaly correlations at neighbouring grid cells to one another and converts the continuous anomaly correlations into five categorical cases. Similarly to the technique of a moving average in time-series analysis, the categorical cases serve as a filter to reduce noise for the identification of spatial patterns. They handle the spatial variability of anomaly correlation and facilitate analysis across the 10 sets of forecasts. It is illustrated that the forecasts produced by the same climate centre tend to exhibit similar predictive performance and that changes in the setting of GCMs lead to changes in the predictive performance. Given that the global and local Moran's I are flexible and easy to compute, they are ready to be extended in future analysis to other datasets of forecasts, such as forecasts generated by GCMs in Europe and Asia or by regional climate models (RCMs) (Alfieri et al., 2013; Bellprat et al., 2019; Kushnir et al., 2019). Also, the forecasts can be verified using global and regional datasets of precipitation (Funk et al., 2015; Zhao et al., 2017a, b). A more extensive investigation would contribute to better understanding of the predictive performance and illustrate the advantages of different sets of forecasts. Of particular interest is to explore which forecasts achieve promising predictive performance in large parts of Europe, Asia, and Africa. In the meantime, it is meaningful to account for the dynamics of global climate and investigate the model physics that leads to the improved performance.
The spatial clustering is a popular approach to geographical, ecological, and environmental modelling (e.g. Anselin, 1995; Anselin et al., 2006; Miller, 2004; Hao et al., 2016; Schmal et al., 2017). Meanwhile, its use appears to be unpopular in the forecasting field. A possible cause is that the objective of forecasting is usually location-specific. In other words, forecasts are produced for a certain site/watershed and then verified using the corresponding observations, of which the process does not involve other sites/watersheds. In this paper, the analysis of GCM forecasts in NMME reveals that forecasts at neighbouring locations positively relate to one another. The indication is that the skill at one location can to some extent be inferred from adjacent locations. This result facilitates a new perspective for the verification of GCM forecasts. If a grid cell with high anomaly correlation is surrounded by grid cells with high anomaly correlation, then the promising predictive performance at that grid cell can be confirmed. On the other hand, if the surrounding grid cells have low, or even negative, anomaly correlation, then the high anomaly correlation is identified as a suspicious outlier. Under that circumstance, further examination of the predictive performance is required to avoid undue optimism.
Fully coupled GCMs perform physically based forecasting of the global climate and generate a vast amount of spatial–temporal forecast data. The predictive performance is of both societal and scientific importance in the applications of these GCM forecasts. Focusing on the anomaly correlation between forecast ensemble mean and observation, we have conducted in-depth spatial analysis for 10 sets of GCM forecasts in NMME and identified significant patterns from the spatial plotting of anomaly correlation. In the analysis of spatial clustering, grid cells across the globe are classified into five categories – HH, HL, NS, LH, and LL – depending on the anomaly correlation at that grid cell and the surrounding grid cells. The regions of grid cells with high, neutral, and low anomaly correlation are effectively identified. Further, effective inter-comparison across multiple sets of GCM forecasts is facilitated. While the analysis is concentrated on the spatial plotting of anomaly correlation, the framework readily applies to other metrics of GCM forecasts, such as bias, reliability, and skill. Moreover, the framework can be extended to GCM forecasts of other climate variables, for example temperature and wind speed, serving as a tool to explore GCM forecasts and interpret the predictive performance.
Both the forecasts and the observations can be downloaded from the International Research Institute for Climate and Society, Earth Institute, Columbia University (https://iridl.ldeo.columbia.edu/SOURCES/.Models/.NMME/, https://doi.org/10.1175/bams-d-12-00050.1, Kirtman et al., 2014).
The supplement related to this article is available online at: https://doi.org/10.5194/hess-24-1-2020-supplement.
The authors declare that they have no conflict of interest.
TZ, WZ, and YZ designed the experiment and performed the data analysis. TZ, ZL, and XC collected the data. TZ prepared the manuscript with contributions from all the co-authors.
The authors are grateful to the editor and the two anonymous reviewers for the constructive comments, which led to major improvements of the paper.
The work is supported by the Ministry of Science and Technology of China (2017YFC0405900 and 2016YFC0400902), the Natural Science Foundation of China (51979295, 51861125203, and U191120010), and the Guangdong Provincial Department of Science and Technology (2019ZT08G090).
This paper was edited by Xing Yuan and reviewed by two anonymous referees.
Alfieri, L., Burek, P., Dutra, E., Krzeminski, B., Muraro, D., Thielen, J., and Pappenberger, F.: GloFAS – global ensemble streamflow forecasting and flood early warning, Hydrol. Earth Syst. Sci., 17, 1161–1175, https://doi.org/10.5194/hess-17-1161-2013, 2013.
Ambaum, M. H. P., Hoskins, B. J., and Stephenson, D. B.: Arctic oscillation or North Atlantic oscillation? (vol 14, pg 3495, 2001), J. Climate, 15, 3495–3507, https://doi.org/10.1175/1520-0442(2002)015<0553:c>2.0.co;2, 2002.
Anselin, L.: Local Indicators Of Spatial Association – LISA, Geogr. Anal., 27, 93–115, https://doi.org/10.1111/j.1538-4632.1995.tb00338.x, 1995.
Anselin, L., Syabri, I., and Kho, Y.: GeoDa: An introduction to spatial data analysis, Geogr. Anal., 38, 5-22, https://doi.org/10.1111/j.0016-7363.2005.00671.x, 2006.
Bauer, P., Thorpe, A., and Brunet, G.: The quiet revolution of numerical weather prediction, Nature, 525, 47–55, https://doi.org/10.1038/nature14956, 2015.
Becker, A., Finger, P., Meyer-Christoffer, A., Rudolf, B., and Ziese, M.: GPCC full data reanalysis version 6.0 at 1.0: monthly land-surface precipitation from rain-gauges built on GTS-based and historic data, Global Precipitation Climatology Centre (GPCC), Berlin, Germany, https://doi.org/10.5065/D6000072, 2011.
Becker, E., van den Dool, H., and Zhang, Q.: Predictability and Forecast Skill in NMME, J. Climate, 27, 5891–5906, https://doi.org/10.1175/jcli-d-13-00597.1, 2014.
Bellprat, O., Guemas, V., Doblas-Reyes, F., and Donat, M. G.: Towards reliable extreme weather and climate event attribution, Nat. Commun., 10, 1732, https://doi.org/10.1038/s41467-019-09729-2, 2019.
Chen, L.-C., Van den Dool, H., Becker, E., and Zhang, Q.: ENSO Precipitation and Temperature Forecasts in the North American Multimodel Ensemble: Composite Analysis and Validation, J. Climate, 30, 1103–1125, https://doi.org/10.1175/jcli-d-15-0903.1, 2017.
Cliff, A. D., and Ord, J. K.: Spatial processes: models & applications, Pion Ltd, https://doi.org/10.1086/412797, 1981.
Crochemore, L., Ramos, M. H., and Pappenberger, F.: Bias correcting precipitation forecasts to improve the skill of seasonal streamflow forecasts, Hydrol. Earth Syst. Sci., 20, 3601–3618, https://doi.org/10.5194/hess-20-3601-2016, 2016.
Di Luzio, M., Johnson, G. L., Daly, C., Eischeid, J. K., and Arnold, J. G.: Constructing retrospective gridded daily precipitation and temperature datasets for the conterminous United States, J. Appl. Meteorol. Clim., 47, 475–497, https://doi.org/10.1175/2007jamc1356.1, 2008.
Doblas-Reyes, F. J., Garcia-Serrano, J., Lienert, F., Biescas, A. P., and Rodrigues, L. R. L.: Seasonal climate predictability and forecasting: status and prospects, Wiley Interdisciplin. Rev.-Clim. Change, 4, 245–268, https://doi.org/10.1002/wcc.217, 2013.
Funk, C., Peterson, P., Landsfeld, M., Pedreros, D., Verdin, J., Shukla, S., Husak, G., Rowland, J., Harrison, L., and Hoell, A.: The climate hazards infrared precipitation with stations – a new environmental record for monitoring extremes, Scient. Data, 2, 150066, https://doi.org/10.1038/sdata.2015.66, 2015.
Gent, P. R., Danabasoglu, G., Donner, L. J., Holland, M. M., Hunke, E. C., Jayne, S. R., Lawrence, D. M., Neale, R. B., Rasch, P. J., Vertenstein, M., Worley, P. H., Yang, Z. L., and Zhang, M. H.: The Community Climate System Model Version 4, J. Climate, 24, 4973–4991, https://doi.org/10.1175/2011jcli4083.1, 2011.
Getis, A.: Reflections on spatial autocorrelation, Reg. Sci. Urban Econ., 37, 491–496, https://doi.org/10.1016/j.regsciurbeco.2007.04.005, 2007.
Gneiting, T., Balabdaoui, F., and Raftery, A. E.: Probabilistic forecasts, calibration and sharpness, J. Roy. Stat. Soc. B, 69, 243–268, https://doi.org/10.1111/j.1467-9868.2007.00587.x, 2007.
Hao, Y., Liu, Y. M., Weng, J. H., and Gao, Y. X.: Does the Environmental Kuznets Curve for coal consumption in China exist? New evidence from spatial econometric analysis, Energy, 114, 1214–1223, https://doi.org/10.1016/j.energy.2016.08.075, 2016.
Hersbach, H.: Decomposition of the continuous ranked probability score for ensemble prediction systems, Weather Forecast., 15, 559–570, https://doi.org/10.1175/1520-0434(2000)015<0559:dotcrp>2.0.co;2, 2000.
Hudson, D., Alves, O., Hendon, H. H., Lim, E.-P., Liu, G., Luo, J.-J., MacLachlan, C., Marshall, A. G., Shi, L., Wang, G., Wedd, R., Young, G., Zhao, M., and Zhou, X.: ACCESS-S1: The new Bureau of Meteorology multi-week to seasonal prediction system, J. South. Hemis. Earth Syst. Sci., 67, 132–159, https://doi.org/10.22499/3.6703.001, 2017.
Hurrell, J. W., Kushnir, Y., and Visbeck, M.: Climate – The North Atlantic oscillation, Science, 291, 603–605, https://doi.org/10.1126/science.1058761, 2001.
Jia, L. W., Yang, X. S., Vecchi, G. A., Gudgel, R. G., Delworth, T. L., Rosati, A., Stern, W. F., Wittenberg, A. T., Krishnamurthy, L., Zhang, S. Q., Msadek, R., Kapnick, S., Underwood, S., Zeng, F. R., Anderson, W. G., Balaji, V., and Dixon, K.: Improved Seasonal Prediction of Temperature and Precipitation over Land in a High-Resolution GFDL Climate Model, J. Climate, 28, 2044–2062, https://doi.org/10.1175/jcli-d-14-00112.1, 2015.
Kapnick, S. B., Yang, X., Vecchi, G. A., Delworth, T. L., Gudgel, R., Malyshev, S., Milly, P. C. D., Shevliakova, E., Underwood, S., and Margulis, S. A.: Potential for western US seasonal snowpack prediction, P. Natl. Acad. Sci. USA, 115, 1180–1185, https://doi.org/10.1073/pnas.1716760115, 2018.
Kirtman, B. P., Min, D., Infanti, J. M., Kinter, J. L., Paolino, D. A., Zhang, Q., van den Dool, H., Saha, S., Mendez, M. P., Becker, E., Peng, P. T., Tripp, P., Huang, J., DeWitt, D. G., Tippett, M. K., Barnston, A. G., Li, S. H., Rosati, A., Schubert, S. D., Rienecker, M., Suarez, M., Li, Z. E., Marshak, J., Lim, Y. K., Tribbia, J., Pegion, K., Merryfield, W. J., Denis, B., and Wood, E. F.: The North American Multimodel Ensemble Phase-1 Seasonal-to-Interannual Prediction; Phase-2 toward Developing Intraseasonal Prediction, B. Am. Meteorol. Soc., 95, 585–601, https://doi.org/10.1175/bams-d-12-00050.1, 2014.
Kushnir, Y., Scaife, A. A., Arritt, R., Balsamo, G., Boer, G., Doblas-Reyes, F., Hawkins, E., Kimoto, M., Kolli, R. K., Kumar, A., Matei, D., Matthes, K., Muller, W. A., O'Kane, T., Perlwitz, J., Power, S., Raphael, M., Shimpo, A., Smith, D., Tuma, M., and Wu, B.: Towards operational predictions of the near-term climate, Nat. Clim. Change, 9, 94–101, https://doi.org/10.1038/s41558-018-0359-7, 2019.
Lu, G. Y. and Wong, D. W.: An adaptive inverse-distance weighting spatial interpolation technique, Comput. Geosci., 34, 1044–1055, https://doi.org/10.1016/j.cageo.2007.07.010, 2008.
Luo, L., Tang, W., Lin, Z., and Wood, E. F.: Evaluation of summer temperature and precipitation predictions from NCEP CFSv2 retrospective forecast over China, Clim. Dynam., 41, 2213–2230, https://doi.org/10.1007/s00382-013-1927-1, 2013.
Ma, F., Ye, A., Deng, X., Zhou, Z., Liu, X., Duan, Q., Xu, J., Miao, C., Di, Z., and Gong, W.: Evaluating the skill of NMME seasonal precipitation ensemble predictions for 17 hydroclimatic regions in continental China, Int. J. Climatol., 36, 132–144, https://doi.org/10.1002/joc.4333, 2016.
Mason, S. J. and Goddard, L.: Probabilistic precipitation anomalies associated with ENSO, B. Am. Meteorol. Soc., 82, 619–638, https://doi.org/10.1175/1520-0477(2001)082<0619:ppaawe>2.3.co;2, 2001.
Merryfield, W. J., Lee, W. S., Boer, G. J., Kharin, V. V., Scinocca, J. F., Flato, G. M., Ajayamohan, R. S., Fyfe, J. C., Tang, Y. M., and Polavarapu, S.: The Canadian Seasonal to Interannual Prediction System. Part I: Models and Initialization, Mon. Weather Rev., 141, 2910–2945, https://doi.org/10.1175/mwr-d-12-00216.1, 2013.
Miller, H. J.: Tobler's First Law and spatial analysis, Ann. Assoc. Am. Geogr., 94, 284–289, https://doi.org/10.1111/j.1467-8306.2004.09402005.x, 2004.
Murphy, A. H.: What is a good forecast? An essay on the nature of goodness in weather forecasting, Weather Forecast., 8, 281–293, https://doi.org/10.1175/1520-0434(1993)008<0281:WIAGFA>2.0.CO;2, 1993.
Pappenberger, F., Cloke, H. L., and Baugh, C. A.: Cartograms for Use in Forecasting Weather-Driven Natural Hazards, Cartogr. J., 56, 134–145, https://doi.org/10.1080/00087041.2018.1534358, 2019.
Rey, S. J. and Anselin, L.: PySAL: A Python library of spatial analytical methods, in: Handbook of applied spatial analysis, Springer, 175–193, https://doi.org/10.1007/978-3-642-03647-7_11, 2010.
Rowell, D. P.: Simulating SST Teleconnections to Africa: What is the State of the Art?, J. Climate, 26, 5397–5418, https://doi.org/10.1175/jcli-d-12-00761.1, 2013.
Saha, S., Moorthi, S., Wu, X. R., Wang, J., Nadiga, S., Tripp, P., Behringer, D., Hou, Y. T., Chuang, H. Y., Iredell, M., Ek, M., Meng, J., Yang, R. Q., Mendez, M. P., Van Den Dool, H., Zhang, Q., Wang, W. Q., Chen, M. Y., and Becker, E.: The NCEP Climate Forecast System Version 2, J. Climate, 27, 2185–2208, https://doi.org/10.1175/jcli-d-12-00823.1, 2014.
Schamm, K., Ziese, M., Becker, A., Finger, P., Meyer-Christoffer, A., Schneider, U., Schroeder, M., and Stender, P.: Global gridded precipitation over land: a description of the new GPCC First Guess Daily product, Earth Syst. Sci. Data, 6, 49–60, https://doi.org/10.5194/essd-6-49-2014, 2014.
Schepen, A., Wang, Q. J., and Robertson, D.: Evidence for Using Lagged Climate Indices to Forecast Australian Seasonal Rainfall, J. Climate, 25, 1230–1246, https://doi.org/10.1175/jcli-d-11-00156.1, 2012.
Schmal, C., Myung, J., Herzel, H., and Bordyugov, G.: Moran's I quantifies spatio-temporal pattern formation in neural imaging data, Bioinformatics, 33, 3072–3079, https://doi.org/10.1093/bioinformatics/btx351, 2017.
Sheffield, J., Wood, E. F., Chaney, N., Guan, K. Y., Sadri, S., Yuan, X., Olang, L., Abou, A., Ali, A., Demuth, S., and Ogallo, L.: A Drought Monitoring and Forecasting System For Sub-Sahara African Water Resources And Food Security, B. Am. Meteorol. Soc., 95, 861–882, https://doi.org/10.1175/bams-d-12-00124.1, 2014.
Slater, L. J., Villarini, G., and Bradley, A. A.: Weighting of NMME temperature and precipitation forecasts across Europe, J. Hydrol., 552, 646–659, https://doi.org/10.1016/j.jhydrol.2017.07.029, 2017.
Tian, D., Wood, E. F., and Yuan, X.: CFSv2-based sub-seasonal precipitation and temperature forecast skill over the contiguous United States, Hydrol. Earth Syst. Sci., 21, 1477–1490, https://doi.org/10.5194/hess-21-1477-2017, 2017.
Tian, F. Q., Li, Y. L., Zhao, T. T. G., Hu, H. C., Pappenberger, F., Jiang, Y. Z., and Lu, H.: Evaluation of the ECMWF System 4 climate forecasts for streamflow forecasting in the Upper Hanjiang River Basin, Hydrol. Res., 49, 1864–1879, https://doi.org/10.2166/nh.2018.176, 2018.
Tobler, W. R.: A computer movie simulating urban growth in the Detroit region, Econ. Geogr., 46, 234–240, 1970.
Vecchi, G. A., Delworth, T., Gudgel, R., Kapnick, S., Rosati, A., Wittenberg, A. T., Zeng, F., Anderson, W., Balaji, V., Dixon, K., Jia, L., Kim, H. S., Krishnamurthy, L., Msadek, R., Stern, W. F., Underwood, S. D., Villarini, G., Yang, X., and Zhang, S.: On the Seasonal Forecasting of Regional Tropical Cyclone Activity, J. Climate, 27, 7994–8016, https://doi.org/10.1175/jcli-d-14-00158.1, 2014.
Wang, Q. J., Schepen, A., and Robertson, D. E.: Merging Seasonal Rainfall Forecasts from Multiple Statistical Models through Bayesian Model Averaging, J. Climate, 25, 5524–5537, https://doi.org/10.1175/jcli-d-11-00386.1, 2012.
Wang, Q. J., Shao, Y., Song, Y., Schepen, A., Robertson, D. E., Ryu, D., and Pappenberger, F.: An evaluation of ECMWF SEAS5 seasonal climate forecasts for Australia using a new forecast calibration algorithm, Environ. Model. Softw., 122, 104550, https://doi.org/10.1016/j.envsoft.2019.104550, 2019a.
Wang, Q. J., Zhao, T., Yang, Q., and Robertson, D.: A Seasonally Coherent Calibration (SCC) Model for Postprocessing Numerical Weather Predictions, Mon. Weather Rev., 147, 3633–3647, https://doi.org/10.1175/mwr-d-19-0108.1, 2019b.
Woldemeskel, F. M., Sivakumar, B., and Sharma, A.: Merging gauge and satellite rainfall with specification of associated uncertainty across Australia, J. Hydrol., 499, 167–176, https://doi.org/10.1016/j.jhydrol.2013.06.039, 2013.
Wu, Z., Wang, B., Li, J., and Jin, F.-F.: An empirical seasonal prediction model of the east Asian summer monsoon using ENSO and NAO, J. Geophys. Res.-Atmos., 114, D18120, https://doi.org/10.1029/2009jd011733, 2009.
Xie, P. and Arkin, P. A.: Global Precipitation: A 17-Year Monthly Analysis Based on Gauge Observations, Satellite Estimates, and Numerical Model Outputs, B. Am. Meteorol. Soc., 78, 2539–2558, https://doi.org/10.1175/1520-0477(1997)078<2539:gpayma>2.0.co;2, 1997.
Xie, P., Arkin, P. A., and Janowiak, J. E.: CMAP: The CPC merged analysis of precipitation, in: Measuring precipitation from space, Springer, 319–328, https://doi.org/10.1007/978-1-4020-5835-6, 2007.
Yuan, X., Wood, E. F., Luo, L., and Pan, M.: A first look at Climate Forecast System version 2 (CFSv2) for hydrological seasonal prediction, Geophys. Res. Lett., 38, L13402, https://doi.org/10.1029/2011GL047792, 2011.
Yuan, X., Wood, E. F., Roundy, J. K., and Pan, M.: CFSv2-based seasonal hydroclimatic forecasts over the conterminous United States, J. Climate, 26, 4828–4847, https://doi.org/10.1175/JCLI-D-12-00683.1, 2013.
Yuan, X., Wood, E. F., and Ma, Z.: A review on climate-model-based seasonal hydrologic forecasting: physical understanding and system development, Wiley Interdisciplin. Rev.: Water, 2, 523–536, https://doi.org/10.1002/wat2.1088, 2015.
Yuan, Y. M., Cave, M., and Zhang, C. S.: Using Local Moran's I to identify contamination hotspots of rare earth elements in urban soils of London, Appl. Geochem., 88, 167–178, https://doi.org/10.1016/j.apgeochem.2017.07.011, 2018.
Zhang, W., Villarini, G., Slater, L., Vecchi, G. A., and Bradley, A. A.: Improved ENSO Forecasting Using Bayesian Updating and the North American Multimodel Ensemble (NMME), J. Climate, 30, 9007–9025, https://doi.org/10.1175/jcli-d-17-0073.1, 2017.
Zhao, T. T. G., Bennett, J. C., Wang, Q. J., Schepen, A., Wood, A. W., Robertson, D. E., and Ramos, M. H.: How Suitable is Quantile Mapping For Postprocessing GCM Precipitation Forecasts?, J. Climate, 30, 3185–3196, https://doi.org/10.1175/jcli-d-16-0652.1, 2017a.
Zhao, T. T. G., Liu, P., Zhang, Y. Y., and Ruan, C. Q.: Relating anomaly correlation to lead time: Clustering analysis of CFSv2 forecasts of summer precipitation in China, J. Geophys. Res.-Atmos., 122, 9094–9106, https://doi.org/10.1002/2017jd027018, 2017b.
Zhao, T. T. G., Chen, X. H., Liu, P., Zhang, Y. Y., Liu, B. J., and Lin, K. R.: Relating Anomaly Correlation to Lead Time: Principal Component Analysis of NMME Forecasts of Summer Precipitation in China, J. Geophys. Res.-Atmos., 123, 6039–6052, https://doi.org/10.1029/2018jd028267, 2018.
Zhao, T. T. G., Wang, Q. J., Schepen, A., and Griffiths, M.: Ensemble forecasting of monthly and seasonal reference crop evapotranspiration based on global climate model outputs, Agr. Forest Meteorol., 264, 114–124, https://doi.org/10.1016/j.agrformet.2018.10.001, 2019a.
Zhao, T. T. G., Zhang, Y. Y., and Chen, X. H.: Predictive performance of NMME seasonal forecasts of global precipitation: A spatial-temporal perspective, J. Hydrol., 570, 17–25, https://doi.org/10.1016/j.jhydrol.2018.12.036, 2019b.