the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 25 Mar 2025
| 25 Mar 2025
Optimising ensemble streamflow predictions with bias correction and data assimilation techniques
Michael Eastman
Amulya Chevuturi
Eugene Magee
Elizabeth Cooper
Robert H. B. Johnson
Katie Facer-Childs
Jamie Hannaford
This study evaluates the efficacy of bias correction (BC) and data assimilation (DA) techniques in refining hydrological model predictions. Both approaches are routinely used to enhance hydrological forecasts, yet there have been no studies that have systematically compared their utility. We focus on the application of these techniques to improve operational river flow forecasts in a diverse dataset of 316 catchments in the United Kingdom (UK), using the ensemble streamflow prediction (ESP) method applied to the (Génie Rural à 4 paramètres Journalier) (GR4J) hydrological model. This framework is used in operational seasonal forecasting, providing a suitable test bed for method application. Assessing the impacts of these two approaches on model performance and forecast skill, we find that BC yields substantial and generalised improvements by rectifying errors after simulation. Conversely, DA, adjusting model states at the start of the forecast period, provides more subtle enhancements, with the biggest effects seen at short lead times in catchments impacted by snow accumulation or melting processes in winter and spring and catchments with a high baseflow index (BFI) in summer. The choice between BC and DA involves trade-offs considering conceptual differences, computational demands, and uncertainty handling. Our findings emphasise the need for selective application based on specific scenarios and user requirements. This underscores the potential for developing a selective system (e.g. a decision tree) to refine forecasts effectively and deliver user-friendly hydrological predictions. While further work is required to enable implementation, this research contributes insights into the relative strengths and weaknesses of these forecast enhancement methods. These could find application in other forecasting systems, aiding the refinement of hydrological forecasts and meeting the demand for reliable information by end-users.
- Article
(9794 KB) - Full-text XML
- BibTeX
- EndNote




Hydrological forecasts are a critical tool for water resource management, flood forecasting, and drought mitigation. In a warming world, we expect to see an increase in both high-flow and low-flow extremes, which will cause a wide range of impacts on society and the environment (Kreibich et al., 2022). Therefore, the need for reliable hydrological forecasts is more critical than ever, such that proactive action can be taken to mitigate these impacts.
There are different approaches to operational hydrological forecasting, ranging from process-based models to fully data-driven approaches. In the United Kingdom (UK), the Hydrological Outlook UK (HOUK) provides operational forecasts which are used by a range of stakeholders to support their decision-making (Hannaford et al., 2019). The HOUK uses three different approaches to produce its forecasts (Prudhomme et al., 2017). For the first approach, hydrological models are driven with seasonal weather forecasts produced by the UK Met Office (UKMO) to derive river flow forecasts (Bell et al., 2013). A second, dual approach, which is purely data-driven and based on statistical methods, generates “persistence” forecasts using flow anomalies in the most recent month and “historical analogue” forecasts using the most similar historical sequences (Svensson, 2016). The third approach, which is the one we are focusing on in this paper, is ensemble streamflow prediction (ESP), where a hydrological model is driven by an ensemble of historical climate time series to generate probabilistic streamflow forecasts (Harrigan et al., 2018). The operational ESP uses all available years of historical meteorological data from 1961 onwards to generate forecasts, i.e. currently the period 1961–2024. Each year, a new ensemble is added as more data become available. The initial hydrological conditions (IHCs) are calculated by driving the hydrological model (currently GR6J; previously GR4J until November 2023) with observed meteorological data from UKMO in near real time. These data include provisional, non-quality-controlled precipitation and temperature grids (HadUK; Hollis et al., 2019). Potential evapotranspiration (PET) is calculated using the calibrated McGuinness–Bordne equation as outlined by Tanguy et al. (2018).
Alternative approaches include long-term average scenarios, where catchment hydrological models are driven by rainfall scenarios assuming specific percentages of long-term average rainfall (e.g. 60 %, 80 %, or 100 %). This method is used in monthly water situation reports by the Environment Agency (e.g. Environment Agency, 2022). Additionally, emerging approaches like the use of storylines and large ensembles to explore plausible worst-case scenarios for upcoming months are gaining popularity in water resource management (e.g. Chan et al., 2024; Kay et al., 2024).
This study will focus on enhancing hydrological predictions using the ESP method, which has long been used worldwide and forms the basis for many operational seasonal forecasting systems (Wood et al., 2016). The UK provides a test bed for application given the existence of the operational HOUK, but the results of this study could resonate in many other settings. The ESP method, as utilised in this paper, employs historical sequences of climate data (precipitation and potential evapotranspiration) to drive hydrological models, generating a range of possible future streamflow conditions. The source of the forecasting skill of the ESP method is accurate estimation of the IHCs, which, depending on the model, can include antecedent stores of soil moisture, groundwater, snowpacks, and channel streamflow (Wood et al., 2016; Wood and Lettenmaier, 2008), rather than skilful atmospheric forecasts. ESP therefore offers an ideal environment for testing forecast enhancement techniques since it isolates the skill associated with IHCs from that stemming from accurate meteorological forcings. The IHCs can be detected up to a year in advance (Staudinger and Seibert, 2014), depending on the catchment characteristics. Harrigan et al. (2018) show that, in the UK, ESP is particularly skilful in catchments with a long “memory” due to its great groundwater influence. These catchments are concentrated in the south-east of the country, where ESP shows forecasting skill for lead times of up to 6 months. In the north-west of the country, however, the skill of ESP is limited. This part of the country is dominated by “flashy” fast-responding catchments with steeper orography and little groundwater storage where the IHCs have less predictive power, and it highlights the limitations of the ESP method. Despite its simplicity, ESP outperforms other hydrological forecasting approaches in many cases and remains a hard-to-beat reference in terms of both skill and value (Peñuela et al., 2020).
The ability of ESP to produce skilful forecasts, as with any model-based forecasting approach, is also inherently linked to the capability of the hydrological models used to produce accurate streamflow simulations. Streamflow simulations produced by hydrological models contain multiple sources of uncertainties, including the model structure, parameterisation, forcing data, and initial conditions (Renard et al., 2010).
The GR4J (Génie Rural à 4 paramètres Journalier)1 hydrological model was used in this study and has been shown to reliably simulate the hydrology of a diverse set of catchments (Perrin et al., 2003), including the temporal transition between wet and dry periods (Broderick et al., 2016). Smith et al. (2019) demonstrated the good performance of the GR4J model over 303 UK catchments, enabling historic streamflow data reconstruction. However, GR4J is a simple lumped catchment with only four parameters: (i) a soil moisture accounting reservoir, (ii) a water exchange function, (iii) a non-linear routing store to represent baseflow, and (iv) rainfall-runoff time lags controlled by two-unit hydrographs. This simple model has the advantages of being very quick to run and being computationally inexpensive, which are essential criteria for an operational service, but it might not be able to capture the complexity of some of the hydrological systems, resulting in some biases, particularly towards the extremes.
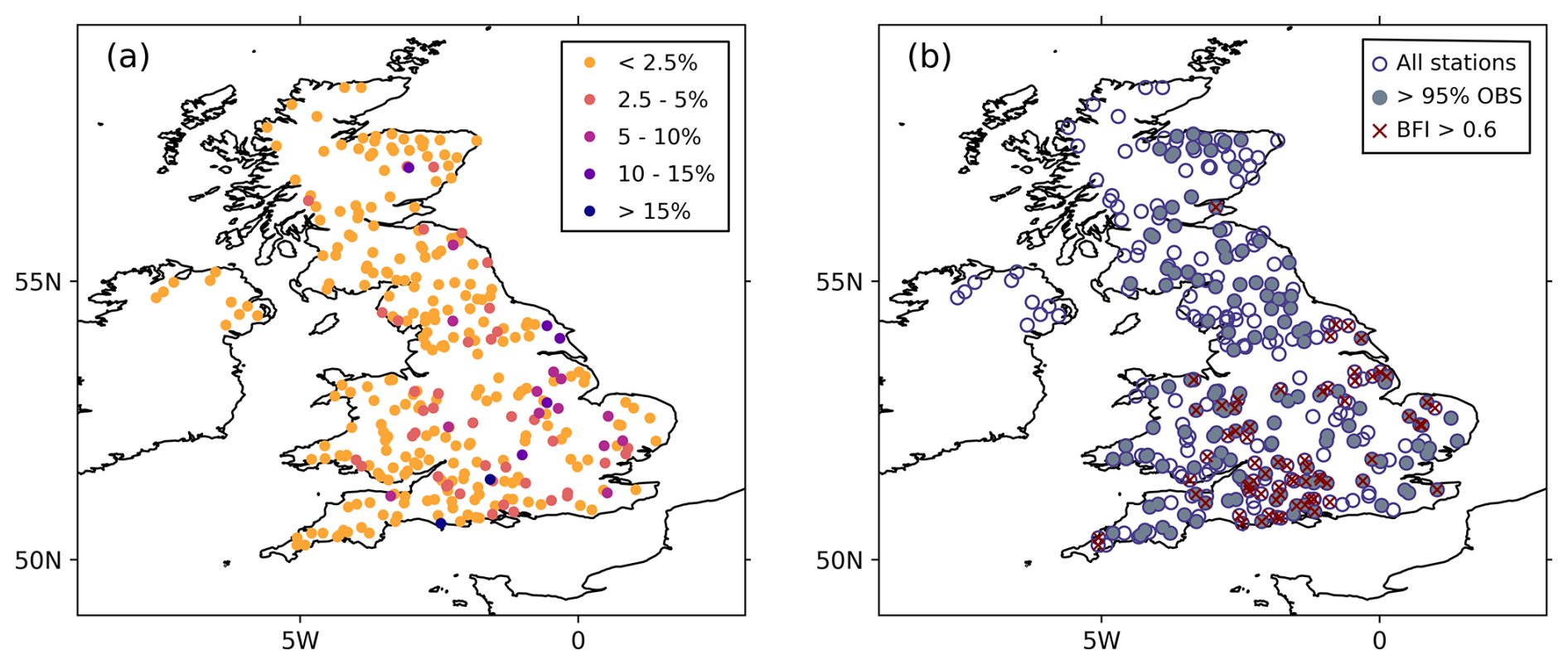
Figure 1(a) Absolute percent bias (absPBIAS) in the 316 study catchments for streamflow simulated with the GR4J model, calculated based on the current analysis. (b) Locations of the gauging stations for the 316 NRFA catchments used in this study and their categories based on the amount of missing data and the value of the BFI.
While Lane et al. (2019) did not include GR4J in their study, they demonstrated a common challenge in hydrological modelling: systematic biases, which are particularly evident in regions with inadequate snowpack simulation, inter-catchment groundwater exchange, or significant human influence on the basin. Figure 1a illustrates the scale of the model bias for GR4J. Figures A4 and A5 show that the bias is generally greater for low flows when measured as a percent bias, whereas it is greater for high flows when considering raw bias values. To address this issue of hydrological model biases impacting predictions, researchers have developed various approaches to refining forecasts. Two prominent techniques are bias correction (BC; e.g. Bum Kim et al., 2021) and data assimilation (DA; e.g. Piazzi et al., 2021). While both methods share the common goal of enhancing forecast accuracy, they diverge fundamentally in their approaches. BC is a statistically based post-processing step that adjusts the forecast based on past performance, whereas DA improves the IHCs and corrects the internal model states. This fundamental difference may explain why there has been no prior attempt to compare the efficacy of these approaches in operational settings. However, from a user perspective, where the emphasis lies on the reliability of the final product to aid decision-making, such a comparison holds significant value. Ultimately, it can lead to the creation of more reliable end-products for users.
Several previous studies have shown the advantages of using BC as a post-processing technique to enhance the skill of hydrological forecasts (e.g. Chevuturi et al., 2023; Tiwari et al., 2022). Some operational systems, such as the GEOGloWS ECMWF Streamflow Service, apply BC to generate their forecasts (Sanchez Lozano et al., 2021). Hashino et al. (2007) conducted a study in which they compared various BC methods for ensemble streamflow forecasts and found that the quantile mapping (QM) method outperformed other techniques, resulting in a significant improvement in forecast skill. QM stands out as the most frequently employed approach in prior studies using bias correction to improve streamflow simulations (e.g. Chevuturi et al., 2023; Farmer et al., 2018; Usman et al., 2022). While some researchers opt to bias-correct precipitation and temperature prior to input into hydrological models, Tiwari et al. (2022) found that directly bias-correcting streamflow leads to superior results. Li et al. (2017) present a comprehensive review of forecast post-processing methods. QM stands out as one of the most popular options in hydrological forecasting due to its simplicity and efficiency (e.g. Hashino et al., 2007; Wood and Schaake, 2008). However, as an unconditional method, QM uses the cumulative distribution function (CDF) to perform the correction, and so it does not preserve the connection between each pair of simulated and observed values. Thus, QM may adjust the raw forecasts in the wrong direction for some forecast values (Madadgar et al., 2014). Note that, in our study, we apply QM BC using flow duration curves (FDCs) instead of CDFs. While statistically distinct, FDCs are better suited to hydrology due to their focus on flow exceedance probabilities. We view this as an extension of the QM framework tailored to hydrological data and have retained the term “quantile mapping” for consistency with the broader QM literature.
Unlike BC, which is applied as a post-processing step, the aim of DA is to improve the IHCs by combining models with observed data to improve the estimation of the target variable during the forecast period (e.g. Carrassi et al., 2018). In this way, DA can be seen as an effort to provide a more physically based improvement of the model predictions rather than as a statistically based post hoc correction. DA has a long history of application in meteorological (e.g. Navon, 2009) and hydrological (e.g. Liu et al., 2012) forecasting, but in the latter case it has tended to be focused on short lead times (typically of the order of days for flood forecasting applications; e.g. Piazzi et al., 2021). There have been relatively few studies of DA for sub-seasonal to seasonal forecasts in hydrology.
DA can be performed sequentially, using observed data as they become available, to update the model states and/or parameters. In this study, sequential DA of streamflow observations is performed during the model spin-up period to better approximate the IHCs at the start of the forecast period and to update the model parameter values. Previous research has demonstrated the potential of sequential DA approaches to improve model performance by reducing initial condition uncertainty (e.g. Piazzi et al., 2021). Two of the most popular methods are Kalman filters (e.g. Maxwell et al., 2018; Thiboult et al., 2016) and particle filters (e.g. DeChant and Moradkhani, 2011; Jin et al., 2013).
Kalman filter approaches for non-linear systems, such as the extended Kalman filter, are often limited by their high computational demand, unbounded error growth, and instability in the error covariance equation (Evensen, 1992). Ensemble Kalman filter (EnKf) approaches can be used to overcome some of these issues but rely on the assumption of Gaussian errors (Evensen, 1994). In contrast, particle filters do not make any assumptions regarding error distributions. However, particle filters may struggle in high-dimensional cases, requiring very large ensemble sizes to avoid “particle weight collapse”, where most particles end up with similar weights, failing to represent the full range of system states (Snyder et al., 2008).
For hydrological forecasts, Piazzi et al. (2021) show the potential effect of DA on skill improvement for a short lead time (2 d). Other work has shown that the impact of data assimilation and alternative approaches used to improve model skill, such as precipitation forcing, varies with lead times. However, the majority of the research in this area focuses on short- to medium-range forecasts (1–31 d lead times; e.g. Boucher et al., 2020; Clark et al., 2008; Piazzi et al., 2021; Randrianasolo et al., 2014; Seo et al., 2009; Sun et al., 2015; Thiboult et al., 2016). This is despite the improvements in hydrological forecasting making the production of skilful longer-term forecasts possible (e.g. Harrigan et al., 2018). Only a handful of studies have investigated the impact of initial condition estimates on longer lead times in hydrological forecasts in the United States (DeChant and Moradkhani, 2011; Shukla and Lettenmaier, 2011), showing generally improved seasonal predictions with DA but little added value beyond a 1-month forecast. However, beyond this, research into the potential of DA to improve seasonal and sub-seasonal hydrological forecast skill is limited. Therefore, there may be potential to improve skill at longer lead times by updating model parameters and initial streamflow states.
Note that other approaches, such as multi-model blending, have been used by others to improve forecasts (e.g. Chevuturi et al., 2023; Roy et al., 2020; Shamseldin, 1997) but will not be considered in this study.
The overall objective of this paper is to evaluate and compare the utility and effectiveness of the BC and DA approaches for optimising hydrological forecast outputs over a range of different lead times. This is achieved through application to a dataset of 316 UK catchments, representing a diverse range of catchment properties. We aim to provide guidance on the relative performance of these methods and how this varies according to location and catchment type, lead time, and time of year. As this is based on an operational seasonal forecasting product, i.e. the Hydrological Outlook UK ESP forecasts, it will enable users to make informed decisions and will provide insights into the most effective strategies for enhancing UK hydrological forecasting. More generally, these results can find application in other hydrological seasonal forecasting systems in other regions and can underpin future research in improving operational hydrological forecasts.
Table 1Glossary of the abbreviations commonly used in this study.
A glossary of the key abbreviations used in this study is provided in Table 1 for reference.
2.1 Data
2.1.1 River flow data
Observed daily river flow data were obtained for 316 catchments (Fig. 1) from the National River Flow Archive (NRFA, https://nrfa.ceh.ac.uk/, last access: 18 March 2025) database. For the full metadata of these catchments, see the Supplement of Harrigan et al. (2018). The catchment observations were used to calibrate the model (see Sect. 2.2), bias-correct the streamflow simulations (see Sect. 2.3), evaluate the model performance evaluation (see Sect. 2.5), and assess the forecast skill (see Sect. 2.6). The study period used was from 1 January 1961 to 31 December 2015.
For the forecast skill assessment, complete observed time series were needed (see Sect. 2.6), so gap-filling using simple linear interpolation was applied to the missing data in the observed river flow time series (the limitations of this method are discussed in Sect. 4.4). The gap-filled version of the dataset was only used for the forecast skill assessment, not for the other applications (model calibration, BC, and model performance evaluation).
Considering the amount of missing data in the observational dataset and the diverse hydrological characteristics of the catchments, we defined four different subsets of catchments (see Fig. 1b):
- i.
The full set of catchments (316 catchments).
- ii.
Catchments with less than 5 % missing observed river flow data (139 catchments).
- iii.
Catchments with a BFI greater than 0.6 (70 catchments). The BFI is a measure of the proportion of the river runoff that derives from stored sources: the more permeable the rock, superficial deposits, and soils in a catchment, the higher the baseflow and the more sustained the river's flow during periods of dry weather (Gustard, 1992). In other words, the higher the BFI, the longer the catchment memory, and therefore improving the IHCs in these catchments has the potential to improve the hydrological forecasts for longer lead times.
- iv.
Catchments with a BFI greater than 0.6 and missing observed river flow data of less than +5 % (29 catchments).
2.1.2 Meteorological data
To run the hydrological model (see Sect. 2.2), precipitation (P) and PET data are needed. For the P data, we used CEH-GEAR daily rainfall data (Keller et al., 2015; Tanguy et al., 2019). For the PET data, we used the CHESS-PET data (Robinson et al., 2017, 2020) for the UK and the Historic PET dataset (Tanguy et al., 2017) for Northern Ireland, where CHESS-PET is not available. Tanguy et al. (2018) describe how the Historic PET dataset was derived using a temperature-based PET equation calibrated using CHESS-PET. Consequently, these two datasets can be regarded as almost equivalent and sufficiently similar for our purposes. The meteorological data used also covered the period from 1961 to 2015.
2.2 Hydrological model, river flow simulations, and ESP hindcasts
2.2.1 Simulated observed river flows
The hydrological model used to simulate river flow was the GR4J model (Perrin et al., 2003), which served as the operational model for producing ESP forecasts in the HOUK until September 2023. The calibration approach adopted was consistent with Harrigan et al. (2018), where the modified Kling–Gupta efficiency (KGEmod; Gupta et al., 2009; Kling et al., 2012), applied to root-squared transformed flows (KGEmod[sqrt]), was used as the objective function for automatic fitting. This approach places weight evenly across the flow regime rather than focusing on high or low flows, a decision made considering that ESP forecasts are generated throughout the year, encompassing both dry and wet conditions.
Daily river flow simulations were produced for the period 1 January 1964 to 31 December 2015. The initial 3 years (1961–1963) served as a spin-up period to allow the internal stores to transition from an initial state of unusual conditions to one of equilibrium (Rahman et al., 2016).
2.2.2 ESP hindcasts from the historical climate
Three versions of ESP hindcasts were used for the period 1964–2014: (i) the hindcasts produced by Harrigan et al. (2018), referred to as the “Original ESP” (OR-ESP) in the rest of the paper; (ii) a bias-corrected version of these hindcasts using the method described in Sect. 2.3, referred to as the “Bias-corrected ESP” (BC-ESP); and (ii) new hindcasts where the initial conditions at the start of the forecast are corrected using the DA method described in Sect. 2.4, referred to as the “Data assimilation ESP” (DA-ESP). Note that what we call “Original” (OR) is the model simulations with no correction (neither BC nor DA); this is often referred to as an “open loop” in the literature related to DA (e.g. Boucher et al., 2020).
Each set of hindcasts comprised a 51-member ensemble of streamflow predictions initiated on the first of each month. These predictions were generated by forcing GR4J with 54 historic climate sequences (P and PET pairs) extracted for each historic year from 1961 to 2014 and projected out to a 12-month lead time at a daily time step. As in Harrigan et al. (2018), to ensure that historic climate sequences did not artificially inflate skill (Robertson, 2016), we used a leave-3-years-out cross-validation (L3OCV) approach, whereby the 12-month forecast window and the 2 succeeding years were not used as climate forcings, resulting in a final count of 51 ensembles. This was done to account for persistence from known large-scale climate–streamflow teleconnections such as the North Atlantic Oscillation with influences lasting from several seasons to years (Dunstone et al., 2016). Each of the 51 generated hindcast time series (54 years minus 3 years for model spin-up) was then temporally aggregated to provide a forecast of mean streamflow over seamless lead times of 1 d to 12 months, resulting in 365 lead times per forecast (leap days were removed). Following the convention in the HOUK, “lead time” in this paper refers to the streamflow (expressed as the mean daily streamflow) over the period from the forecast initialisation date to n days (or months) ahead in time. So, for example, a January ESP forecast with a 1-month lead time is the mean daily streamflow from 1 January to the end of January and a January ESP forecast with a 2-month lead time is the mean daily streamflow from 1 January to the end of February. A total of 612 forecasts (51 years × 12 initialisation dates) with simulations for 365 d were therefore generated for our analysis.
The main differences between the operational ESP and experimental set-ups in this paper are that (i) the ESP model in the experimental set-up is constructed from 54 years of historical meteorological data (1961–2014), whereas the operational ESP currently uses 1961–2024, with a new ensemble added every year; (ii) the GR4J model is used in our analysis, as it was the operational model at the time, whereas the operational ESP has used GR6J since November 2023; and (iii) in our experiments, PET is derived from the Penman–Monteith CHESS-PE, except in Northern Ireland, where the McGuinness–Bordne PET was used due to its data availability. For the operational ESP, the McGuinness–Bordne PET is used over the whole of the UK. Since the McGuinness–Bordne equation is calibrated against CHESS-PE, we do not expect significant biases between the two PET calculation methods.
2.3 Bias correction
The BC methodology applied in this study is a QM approach similar to that employed by Farmer et al. (2018). This method was selected for its simplicity of implementation and its popularity in hydrological applications. QM BC is applied by Sanchez Lozano et al. (2021) to operationally bias-correct the GEO Global Water Sustainability (GEOGloWS) streamflow forecasts. Farmer et al. (2018) recommend 14 complete years of observed data to apply this method. This condition is satisfied in our dataset, where the shortest record has 23 years of complete data.
BC was applied separately to each of the 12 months using the observed distribution specific to that month, aiming to capture seasonality in flow. The decision to apply BC on a monthly basis was motivated by the seasonal variability in the UK Hydrological System with wet winters, drier summers, and transitional spring and autumn periods. Monthly BC effectively captures these seasonal changes while avoiding overfitting to short-term fluctuations. While more frequent corrections could improve short-term forecasts, the high variability in the UK climate suggests that weekly or biweekly BC might introduce noise rather than enhance accuracy. Monthly BC provides a balanced approach by adjusting for seasonality without overreacting to short-term extremes.
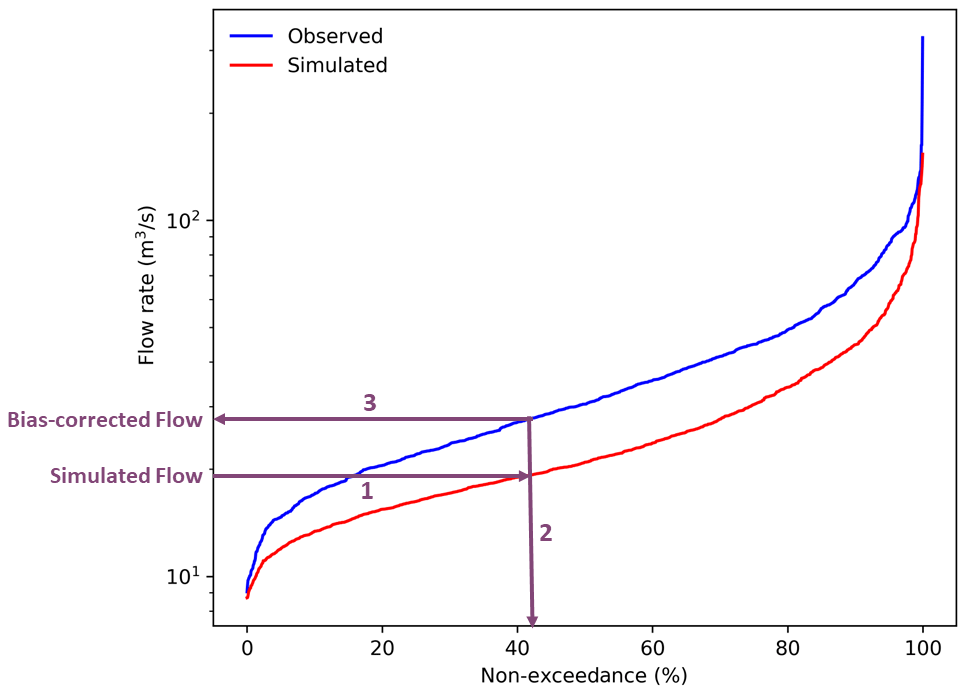
Figure 2Conceptual diagram of quantile mapping bias correction (QM BC), showing the percentage of non-exceedance against the streamflow rate for observed (blue) and simulated (red) streamflow for GR4J an example catchment (NRFA catchment ID 12001) for the month of May. The purple arrows show the steps involved in the bias correction process: (1) for a given native simulated flow, the point on the simulated FDC (red line) is identified; (2) the non-exceedance corresponding to that simulated flow is determined; and (3) the observed flow for that same non-exceedance is determined from the observed FDC (blue line), and this value corresponds to the bias-corrected flow.
Figure 2 shows a conceptual diagram of how QM BC works. Each flow value on the simulated FDC is replaced with the flow value of the observed FDC for the corresponding non-exceedance level.
2.4 Data assimilation
DA is a group of mathematical methods which can be used to combine information from a numerical model (here a hydrological model) with available observations to generate an improved estimate of the system's state and, consequently, more accurate forecasts. DA methods can account for uncertainties associated with model structures, initial conditions, and observations and provide a probabilistic representation of the hydrological state. Here we used a particle filter (PF) technique, which uses a set of computational particles (representing possible states of the hydrological system) to estimate the most likely current state of the system.
The PF works by simulating multiple potential scenarios (particles) of the hydrological system based on the underlying model but with different sets of model parameters. The method then assigns probabilities to these scenarios based on how well they match the observed data. As new observations become available, the PF updates the particle set, giving more weight to scenarios that align with the most recent data. We updated the model parameters (production store, routing store, unit hydrograph-1 level, and unit hydrograph-2 level) in GR4J, following the implementation of Piazzi et al. (2021). We applied the particle filter approach to daily data throughout the model spin-up period (4 years) in order to improve the IHCs for the seasonal forecast. A sequential importance sampling approach was used to assign weights to individual particle states according to their likelihoods. This method is explained in more detail in Piazzi et al. (2021). We chose a PF method over a Kalman filter approach to avoid the restriction of assumed Gaussian errors and so that no mass constraints needed to be applied (see e.g. Piazzi et al., 2021). To generate the simulated observed river flows, the PF was applied once a day during the full evaluation period (1964–2015), i.e. using daily streamflow observations. Then the IHCs produced in this way at the start of each month were used to run our 612 ESP forecasts (DA-ESP).
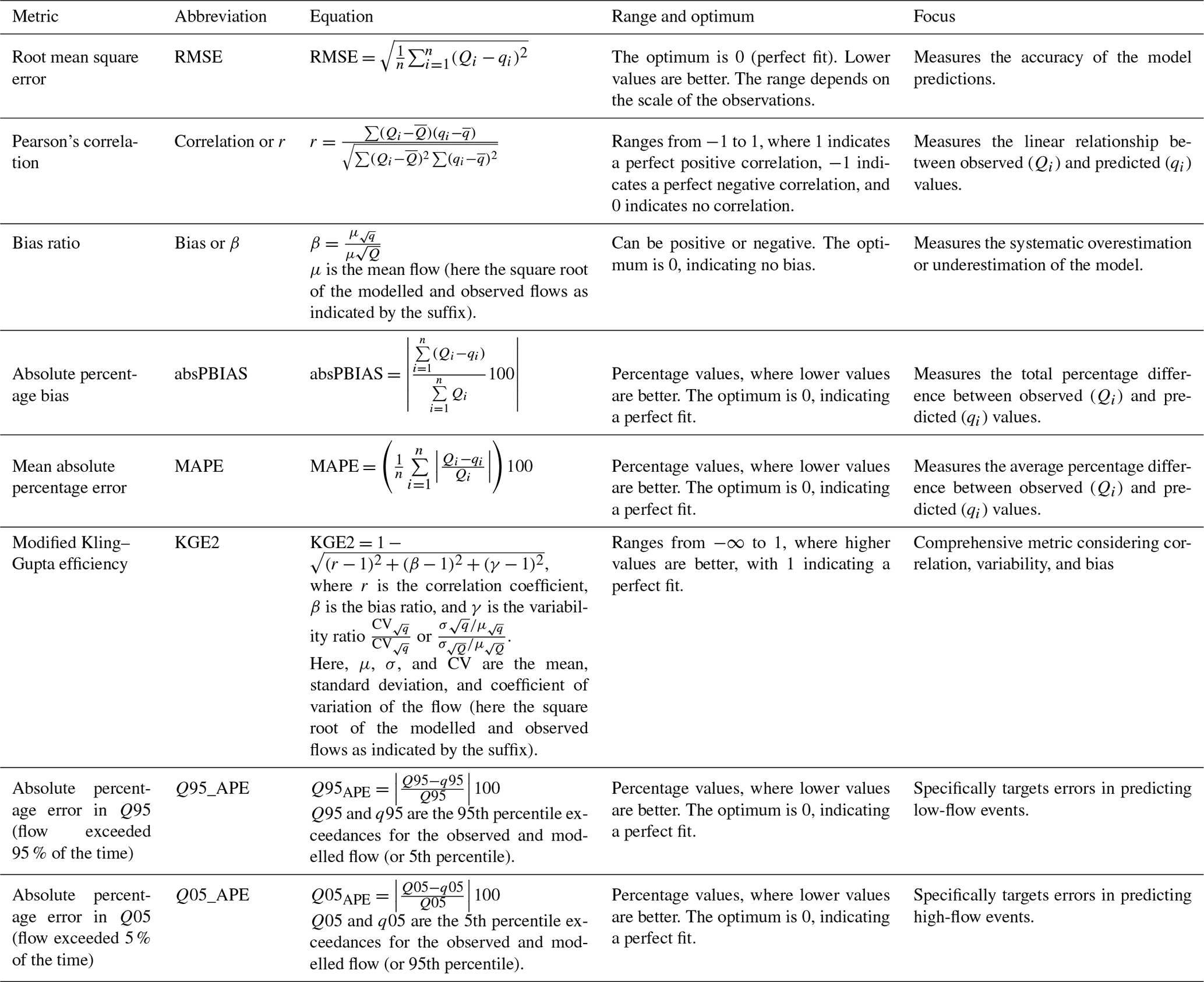
Table 2List of performance metrics calculated with their corresponding equations. Qi and qi are observed and modelled flows for day i of an n daily record. and are the mean observed and modelled flows.
2.5 Model performance evaluation
To assess the model performance and in particular compare the improvement in the simulated observed flows provided by BC and DA, we computed a range of performance metrics detailed in Table 2. These are all metrics commonly used in hydrological assessments (e.g. Hannaford et al., 2023).
2.6 Forecast skill assessment
Forecast skill refers to the relative accuracy of a set of forecasts with respect to some set of standard reference forecasts (Wilks, 2019). Even if the model performance metrics (presented in Sect. 2.5) improve with BC and DA, this is not necessarily going to translate into direct improvement in forecasting skill. This is because the enhancement achieved through DA focuses on improving IHCs, whose impact decays over lead times. Conversely, while BC is expected to enhance simulations across all lead times, its effectiveness is constrained by the inherent limitations linked to the lack of skill in the meteorological forcings, particularly in the case of ESP, which relies on climatological data.
The continuous ranked probability skill score (CRPSS; Hersbach, 2000) was used in our study to evaluate the probabilistic skill of OR-ESP, DA-ESP, and BC-ESP, using the climatology as our reference forecast like in Harrigan et al. (2018).
The CRPSS measures the relative skill of the forecast compared to a benchmark, in this case climatology. It is defined as
-
CRPSforecast is the continuous ranked probability score (CRPS) of the forecast ensemble, calculated by comparing the cumulative distribution function (CDF) of the forecast to the observed data over the evaluation period.
-
CRPSclimatology is the CRPS of the climatology (our benchmark), calculated by comparing the CDF of the climatology (our benchmark) to the observed data over the same period.
The CRPSS values are interpreted as follows:
-
CRPSS = 1 – the forecast has perfect skill.
-
CRPSS = 0 – the forecast has no skill compared to the climatology (the forecast is as good as using the climatology).
-
CRPSS < 0 – the forecast is less accurate than the climatology (the forecast is misleading and has no skill).
The CRPSS penalises biased forecasts and those with low sharpness (Wilks, 2019). The Ferro et al. (2008) ensemble size correction for the CRPS was applied to account for differences between the number of members in the hindcasts (51 members, corresponding to the historic period from 1961 to 2015 with the L3OCV approach) and the benchmark (47 members, corresponding to the period of 1965–2015 with the L3OCV approach and with 4 years removed for the spin-up period), as done in the evaluation of hydrological ensemble forecasting elsewhere (e.g. Crochemore et al., 2017). Calculation of the skill scores was undertaken using the open-source easyVerification package v0.4.2 in R (MeteoSwiss, 2017).
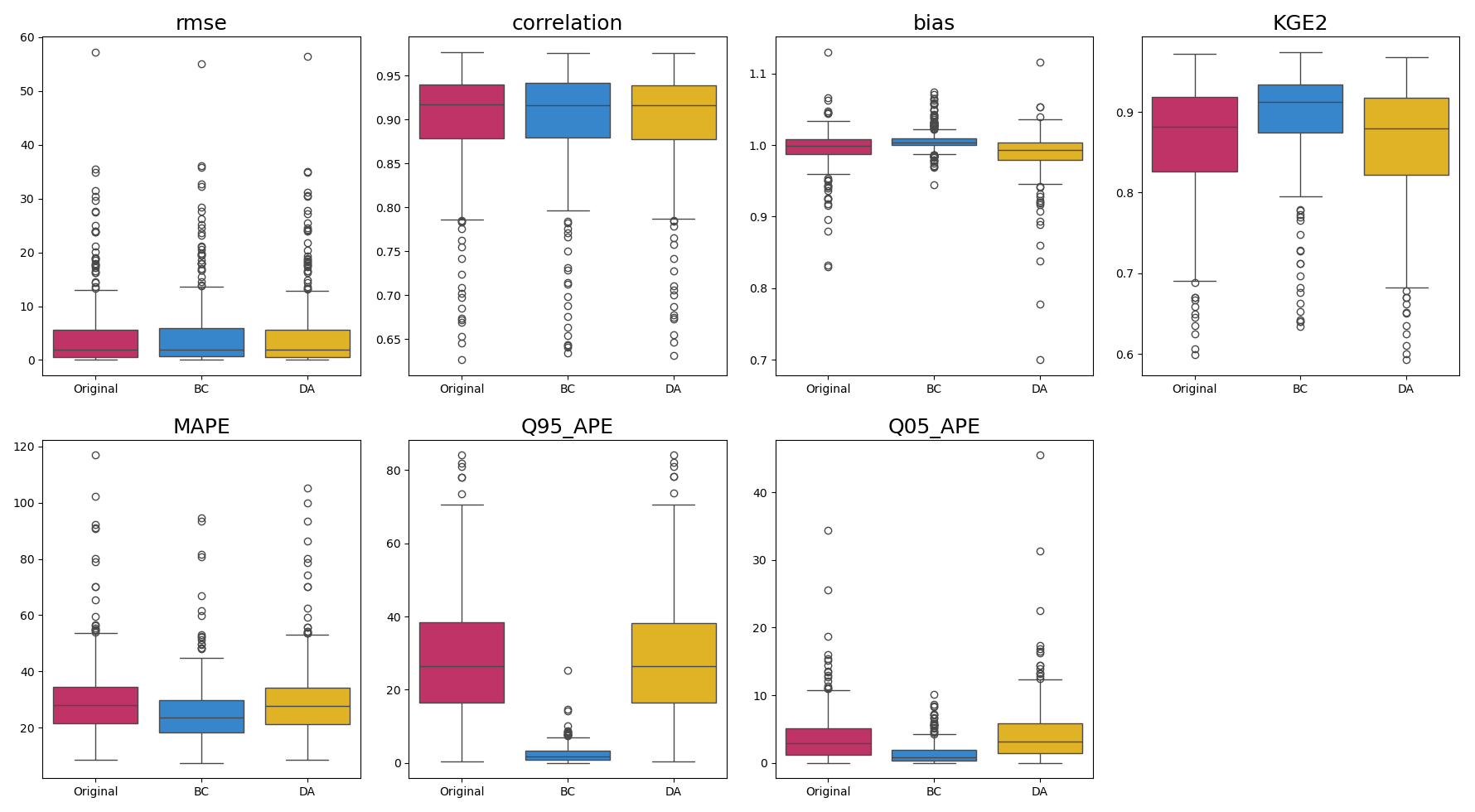
Figure 3Model performance metrics for river flow simulations produced by the GR4J model with no additional processing (dark pink), GR4J with BC (blue), and GR4J with DA (orange) for all 316 catchments (Fig. 1b). For almost all of the performance metrics, the GR4J with BC and GR4J with DA differ significantly from GR4J model with no additional processing at the 5 % significance level, based on a Student’s t test.
To construct the time series for the CRPSS calculation, the model forecast is initialised on the first day of each month, after which the model runs freely for a lead time of up to 365 d, producing a forecast for each subsequent day at progressively longer lead times. For that month, no further initialisations are performed beyond the first day. Thus, all lead times (e.g. 1 d, 3 d, or 7 d) are calculated relative to the first day of the month. The CRPSS is then calculated based on the accumulated flow over the full forecast period rather than point values on specific days. For example, for the 7 d forecast horizon, the skill score is based on the total flow accumulated over the first 7 d of the forecast, not the streamflow value at precisely day 7. This approach better reflects the overall forecast performance for each lead time by considering the cumulative discharge over the given period.
The calculation of the CRPSS requires selection of a benchmark against which the forecasting system is evaluated. A forecasting system is considered “skilful” if its performance surpasses that of the chosen benchmark. Common benchmarks for hydrological forecast evaluation include climatology (long-term average flows), persistence forecasts (assuming the current state remains constant and commonly used for short-range forecasts), and gain-based benchmarks (using simpler models to quantify the added value of more complex models; Pappenberger et al., 2015). In this study, we selected climatology as the benchmark for evaluation, as it is a widely used reference for assessing sub-seasonal to seasonal forecasts.
Unlike Harrigan et al. (2018), who employed simulated observed river flows as the “truth” for skill evaluation, our study relies on observed flows. This choice ensures a fair comparison between OR-ESP, DA-ESP, and BC-ESP. Considering DA's objective of using observations to enhance models, using simulated observed data as the reference would have adversely affected the skill assessment of DA.
The performance metrics (Sect. 2.5) were calculated for the simulated observed flows produced by the three methods (OR, BC, and DA), and skill scores (Sect. 2.6) were calculated for all three versions of the hindcasts (OR-ESP, BC-ESP, and DA-ESP). To assess whether the differences in performance metrics and forecast skills are statistically significant, we applied a paired t test to the performance metrics and CRPSS values calculated across the 316 catchments. In all of the cases, we compared the OR simulations with the DA and BC simulations to evaluate the overall improvements introduced by the new approaches relative to the original method and to determine whether these differences are statistically significant.
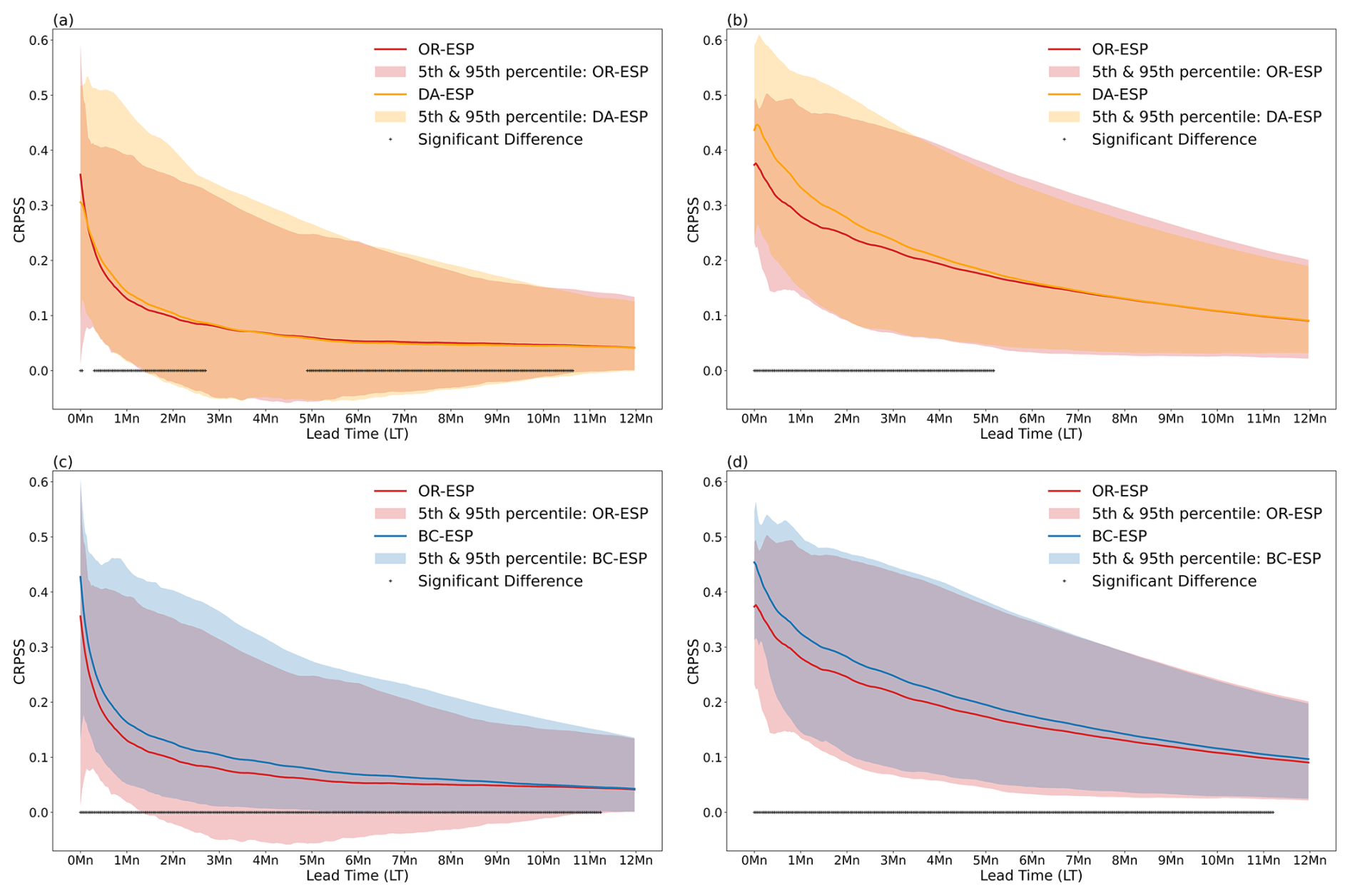
Figure 4(a) CRPSS for all stations with < 5 % missing observations for OR-ESP (red) and DA-ESP (orange) simulations over lead times. (b) CRPSS for all stations with < 5 % missing observations and BFI > 0.6 for OR-ESP (red) and DA-ESP (orange) simulations over lead times. (c) CRPSS for all stations with < 5 % missing observations for OR-ESP (red) and BC-ESP (blue) simulations over lead times. (d) CRPSS for all stations with < 5 % missing observations and BFI > 0.6 for OR-ESP (red) and BC-ESP (blue) simulations over lead times. The solid lines show the median CRPSS, whereas the shaded areas show the catchment spread of the 5th–95th percentiles. The black plus markers indicate the lead times where BC-ESP or DA-ESP differs significantly from OR-ESP at the 5 % significance level, based on a Student's t test.
We have also calculated other skill scores, i.e. the mean absolute error skill score (MAESS) and the mean square error skill score (MSESS). However, these are deterministic skill scores and therefore less suited than the CRPSS to ensemble forecast verification. Hence, we only show CRPSS results in the following sections for brevity. The results were very similar to the ones presented here when using alternative skill scores.
3.1 Model performance
BC and DA both improve the overall model performance in the simulated observed flows (Fig. 3), though in DA the improvement is only marginal and not for all metrics, whereas for BC the difference is more substantial and is generalised for all of the metrics considered.
The greater impact on model performance observed in BC compared to DA is unsurprising given the fundamental differences in their approaches. In BC, observations serve as the absolute truth, guiding adjustments to align simulations with the observed FDCs. As its name implies, BC is explicitly designed to rectify predictions by conforming them to observations, thus naturally yielding improvement in overall performance. Conversely, DA endeavours to enhance predictions through a mechanistic, physically informed approach during model simulation. In DA, both model-generated and observed values are weighed, aiming to refine the model's alignment with observed data while preserving the hydrological model's structural integrity. Consequently, it is expected that DA may exhibit comparatively lower performance due to the complex interplay between model fidelity and alignment with observed data.
3.2 Forecast skill improvement with data assimilation
Figure 4a shows the evolution of the skill score (CRPSS) with lead times for OR-ESP and DA-ESP for all catchments with less than 5 % missing data. We can see in this figure that, overall, there is no big improvement in skill with DA (no difference in the median skill score). However, the envelope is wider at the top end, especially for very short lead times, suggesting that DA does make a difference for some catchments.
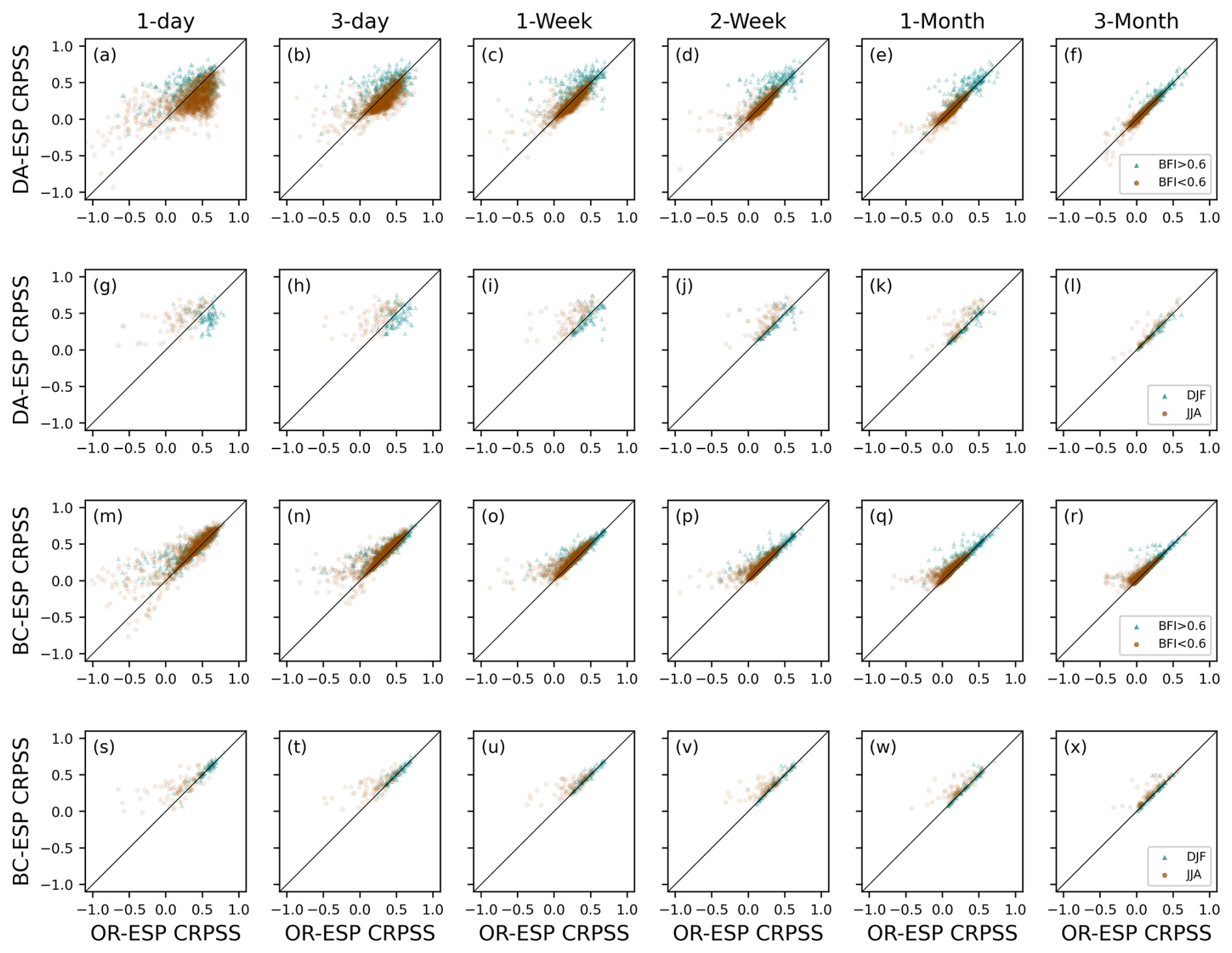
Figure 5(a–f) Scatterplots of the CRPSS between OR-ESP and DA-ESP for all catchments with less than 5 % missing observation data, broken down according to the BFI of the station, with a low BFI < 0.6 (brown dots) and a high BFI > 0.6 (green triangles). (g–l) Scatterplots of the CRPSS between OR-ESP and DA-ESP for all stations with < 5 % missing observations and a BFI > 0.6, broken down according to season: December, January, and February start months (DJF, winter; green triangle) and June, July, and August start months (JJA, summer; brown dots). (m–r) Same as panels (a–f) but for BC-ESP instead of DA-ESP. (s–x) Same as panels (g–l) but for BC-ESP instead of DA-ESP. Forecasts are initialised on the first day of each month. The subplots within each category show increasing lead times (d).
If we look at the same comparison for catchments with BFI > 0.6 only (Fig. 4b), the improvement with DA is more notable. This improvement is observed for lead times of up to a season (∼ 3 months). After that, the effect of improved initial conditions diminishes.
Figure 5a–f show differences in skill (comparing skill for the OR-ESP on the x axis and skill for the DA-ESP on the y axis) in more detail for different types of catchments (low and high BFI values) and different lead times. The improvement in skill with DA is more apparent for higher-BFI catchments, especially for lead times of 3 to 30 d (as there are more green triangles above the 1:1 line). We also observe that catchments with a high BFI exhibit greater overall skill, which is reflected in higher CRPSS values for both OR-ESP and DA-ESP, which is in line with findings of Harrigan et al. (2018). Figure 5g–l show results for high-BFI catchments only and with a breakdown between seasons: winter (green triangles) and summer (brown dots), with forecasts initialised on the first day of each month within these seasons. We can see that the improvement brought by DA is much stronger in summer, especially at short lead times.
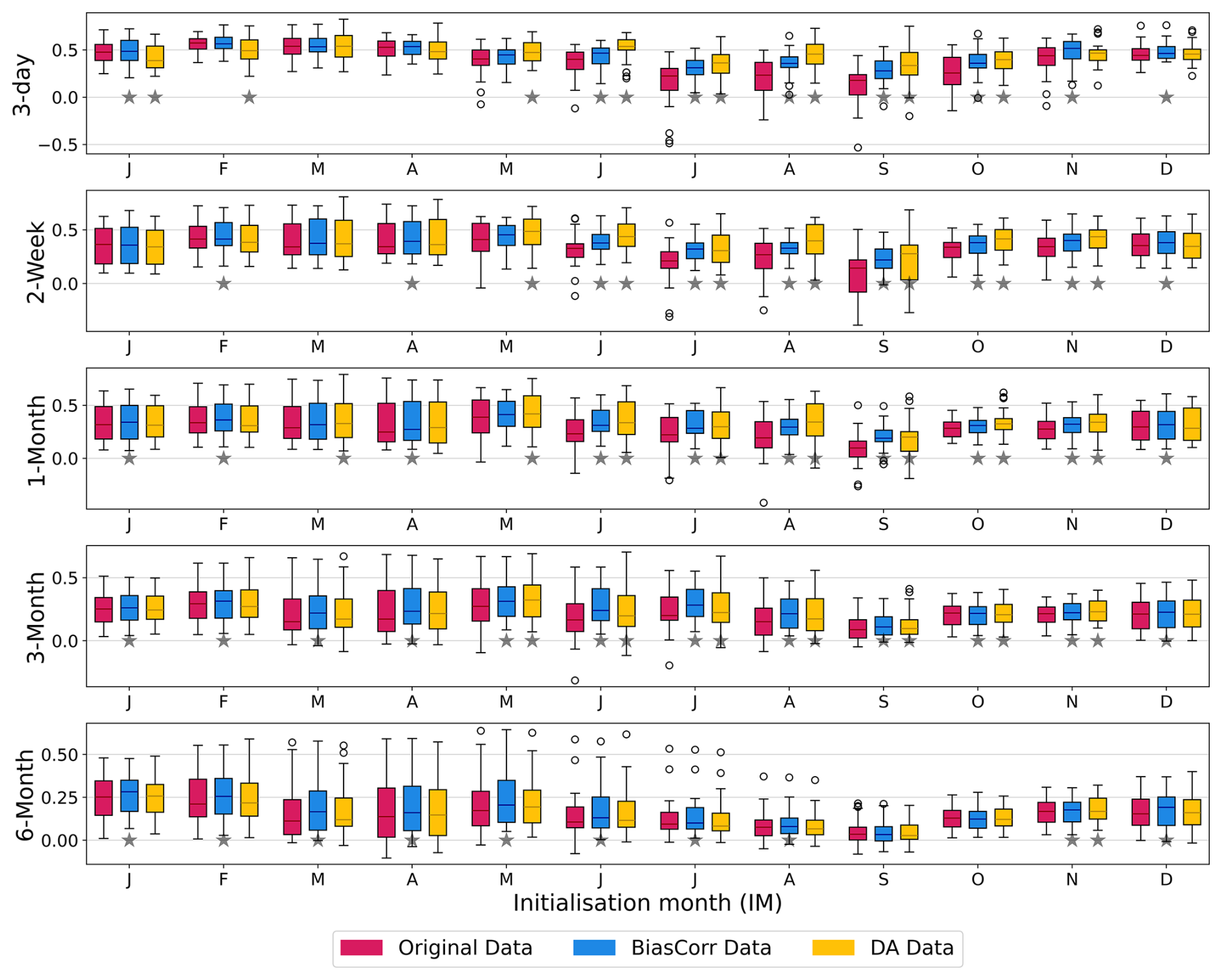
Figure 6CRPSS values of OR-ESP, BC-ESP, and DA-ESP forecasts at different lead times and initialisation months for catchments with < 5 % of missing data and BFI > 0.6. Grey stars indicate where BC-ESP or DA-ESP differs significantly from OR-ESP at the 5 % significance level, based on a Student's t test. The “initialisation month” here refers to the month when the forecast was launched. This month marks the beginning of the forecast period, and it coincides with the start of the forecast time series data. The equivalent figure for all catchments with < 5 % of missing data can be found in Appendix Fig. A6.
3.3 Forecast skill improvement with bias correction
In the case of BC, the improvement in skill is longer-lasting and more generalised (Fig. 4c). Moreover, there is not such a clear difference in improvement between catchments with BFI > 0.6 and the rest (Fig. 4c versus Fig. 4d). Notably, BC improves the skill of even the most poorly performing catchments, as evidenced by the upward shift of the lower bound of the skill envelope (Fig. 4c), ensuring that all catchments achieve positive skill scores, in contrast to the performance of DA.
Figure 5m–x mirror Fig. 5a–l but focus on BC instead of DA, comparing the skill of OR-ESP and BC-ESP across various catchment types (Fig. 5m–r) and seasons (Fig. 5s–x). In this case, no discernible difference in skill improvement between high- and low-BFI catchments is evident with BC (Fig. 5m–r). However, we can see that the improvement in skill is greater for catchments with poor original performance. When narrowing our focus to high-BFI catchments alone (Fig. 5s–x) and investigating the seasonal effect, we observe that, similarly to DA, skill enhancements are more prominent in summer with BC as well, although to a lesser extent than with DA. This general tendency of better skill in summer is also true for all catchments in the case of BC (not shown).
The greater predictive ability of the bias-corrected forecast compared to the climatology can be attributed to the role of initial conditions in hydrological forecasting. The GR4J model is initialised using hydrological simulations driven by observed meteorological data, providing a strong foundation for the forecast. This accurate initialisation, combined with the hydrological memory of the system, enhances forecast skill, even at longer lead times. In contrast, climatological forecasts do not adjust initial conditions and lack this model-based foundation, which is why the bias-corrected model outperforms the climatology despite being driven by the historical meteorology.
3.4 Data assimilation versus bias correction
In comparing forecast skills for DA and BC at different lead times and seasons for catchments with BFI > 0.6 (Fig. 6), distinctive patterns emerge: in summer, up to a 1-month lead time, DA-ESP outperforms OR-ESP and BC-ESP, whereas BC exhibits higher improvement in skill over winter and at longer lead times. The notable suitability of DA for summer months in high-BFI catchments (i.e. with a high hydrological memory) underscores the importance of accurate IHCs during drier periods. During such periods, precipitation tends to be closer to the climatology, which is what is used to drive ESP. Getting IHCs right through DA in these situations will have a long-lasting effect.
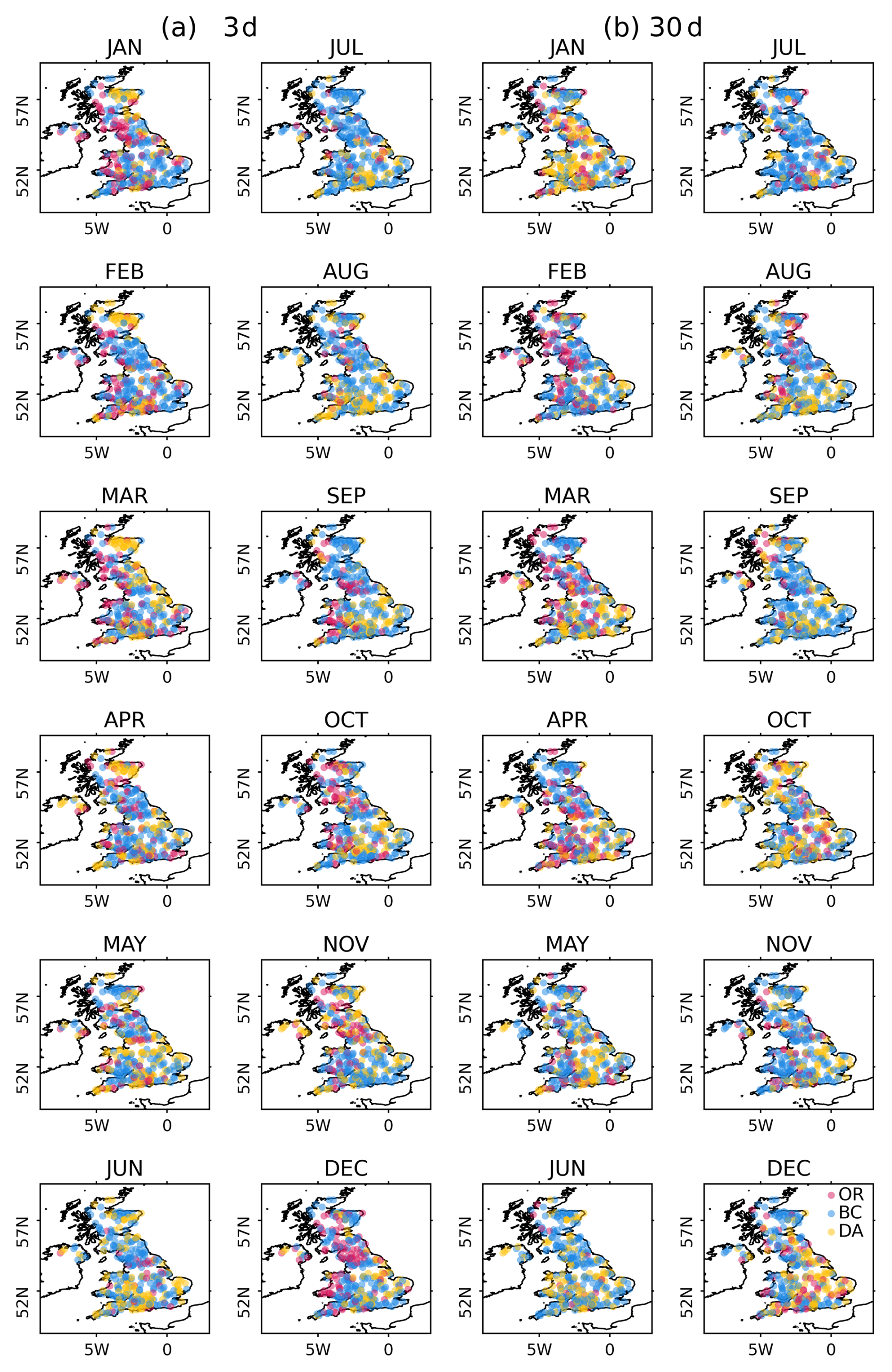
Figure 7Each catchment showing the best-performing method (OR-ESP in red, BC-ESP in blue, and DA-ESP in yellow) based on the CRPSS for each month at lead times of (a) 3 d and (b) 30 d.
Figure 7 (which displays all 316 catchments) shows spatial differences, notably with DA showing better performance in snow-dominated catchments during winter and spring, especially for short lead times in north-eastern Scotland (Fig. 7a). Figure A7 shows the fraction of precipitation falling as snow for catchments across the UK. The version of GR4J used in this study lacks the capability to model snow accumulation and snowmelt processes, making it less reliable in catchments affected by them. DA is especially effective at adjusting the IHCs during seasons influenced by snow, such as winter accumulation and spring melting, when errors in IHCs can be large. However, for longer lead times (Fig. 7b), while no distinct patterns emerge, BC generally exhibits better performance across the majority of the catchments over most months. This observation suggests a nuanced interplay of factors influencing forecast skill, with BC showing a more consistent advantage in extended lead times across diverse catchment conditions. As mentioned previously, this can be attributed to the fundamental differences in both methodologies.
It is also interesting to note that there are cases where OR-ESP is better than both DA-ESP and BC-ESP (magenta points in Fig. 7), especially in autumn, in winter, and at the beginning of spring (October to March) in the western part of the country for short lead times (Fig. 7a) and in spring for longer lead times (Fig. 7b) with no clear spatial pattern.
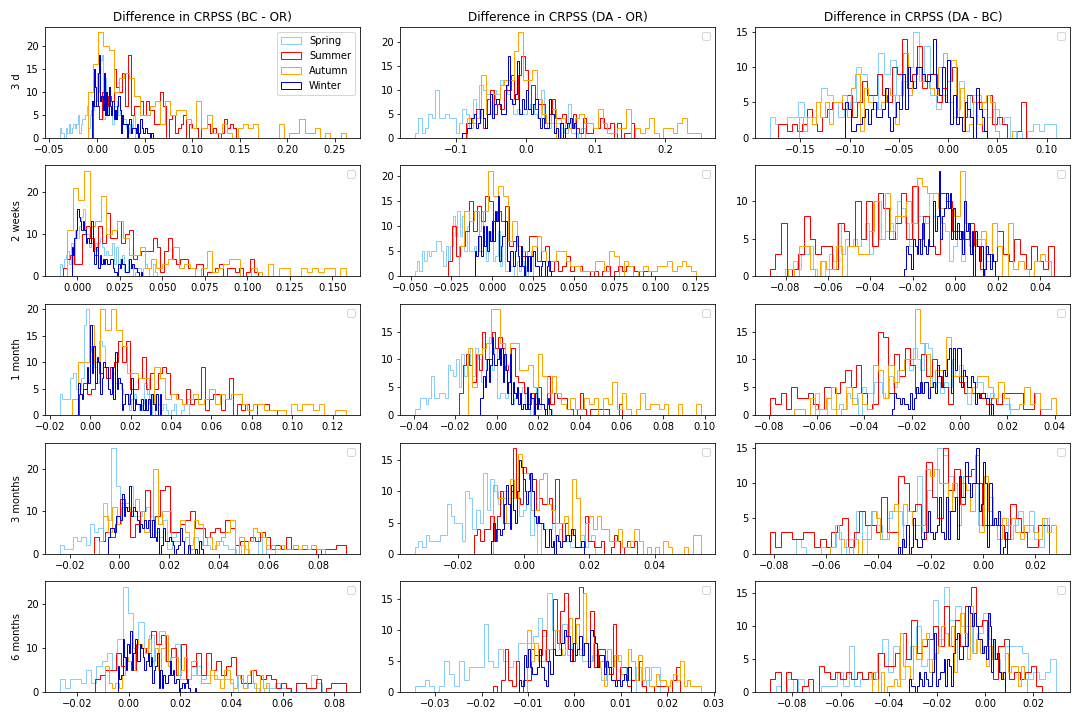
Figure 8Histogram showing the difference in CRPSS values across 316 catchments between BC-ESP and OR-ESP (first column), DA-ESP and OR-ESP (second column), and DA-ESP and BC-ESP (third column) for various lead times (rows) and seasons (colours). Positive values indicate that the CRPSS value of the first ESP version in each pair is greater than the second (indicating higher skill).
Figure 8 presents a series of histograms illustrating the differences in the CRPSS across various versions of ESP for all 316 catchments, showcasing the extent and variations in improvement offered by BC and DA across different seasons and lead times. Examining the first two columns of subplots (the first column comparing BC-ESP and OR-ESP and the second column comparing DA-ESP and OR-ESP), we observe some similarities: (i) the range of differences between the corrected (BC or DA) and original (OR) ESPs is narrower in winter (dark blue) and widest in autumn (orange); (ii) spring (light blue) exhibits the most cases where OR-ESP outperforms both BC-ESP and DA-ESP (indicated by the negative values in the histograms); (iii) for both methods (BC and DA), the greater gains in skill are achieved in summer and autumn; and (iv) for lead times longer than 3 months, the differences between the different ESP versions are minimal, with absolute values < 0.08 for BC-ESP versus OR-ESP and < 0.03 for DA-ESP versus OR-ESP, suggesting negligible improvement beyond this point. Therefore, the gain achieved beyond 3 months using either technique is marginal.
Focusing now on the differences between DA and BC, we can see that, in general, BC presents fewer negative instances compared to DA, indicating that BC-ESP outperforms OR-ESP more frequently than DA-ESP. However, the magnitudes of improvement are typically comparable for lead times of less than 3 months for both methods. Directly comparing the CRPSS of DA-ESP and BC-ESP (third column of subplots in Fig. 8), we observe a skew towards negative values, indicating more instances where BC outperforms DA. Nonetheless, beyond a 2-week lead time, the absolute differences are negligible (< 0.08), suggesting that both methods yield similar outcomes.
4.1 Bias correction versus data assimilation
Despite their shared goal of enhancing forecast accuracy, it is important to recognise the fundamental and conceptual differences between the DA and BC methodologies. As already mentioned, BC operates as a post-processing technique, rectifying model errors after simulations, while DA intervenes during model initialisations, adjusting model internal states to nudge simulations towards observed data. DA, as used here, primarily focuses on refining initial conditions and hence yields more significant impacts on catchments with a high BFI due to the extended hydrological memory. DA also proves superior at short lead times for snow-dominated catchments, where the IHCs can be widely wrong due to the lack of explicit representation of snow accumulation and snowmelt processes in the hydrological modelling used in this study. Although the GR4J model does not include a dedicated snow module, snowmelt and accumulation processes are likely captured indirectly through other model dynamics. Data assimilation updates the model state, improving the simulation of these processes even without explicit representation. As Cooper et al. (2021) note, updated parameters in models like JULES can implicitly correct for processes not directly included in the model, such as groundwater dynamics. Similarly, GR4J may implicitly account for snow-related processes through data assimilation, provided there are sufficient observational signals. One future improvement would be to explicitly include snow processes, e.g. by using GR4J-CemaNeige. This would enable a comparison of updated parameters and provide insight into how snow processes influence parameter values.
In contrast to these enhancements at short lead times yielded by DA, BC extends its improvement beyond the initial conditions, improving the quality of the simulations throughout the entire time series. However, it is noteworthy that the DA and BC methods also fundamentally differ in their handling of uncertainties. DA methodologies based on Bayesian statistics, such as PF, account for uncertainties associated with model structures, initial conditions, and observations, providing a probabilistic representation of the hydrological state. This probabilistic nature enables a more thorough understanding of the forecast, acknowledging the inherent uncertainty in predicting natural systems. Additionally, DA offers the advantage of maintaining the structural integrity of the hydrological model. In other words, a model with DA-updated initial conditions preserves the relationships between the model state and the target variable, while BC can alter them. Moreover, BC, while effectively aligning model outputs with observations, may inadvertently mask or underestimate the uncertainties in the hydrological model and observational data. The deterministic nature of BC can oversimplify the complex interplay of factors influencing streamflow predictions and uncertainties in observations, potentially leading to an overconfident representation of forecast accuracy.
While the handling of uncertainties distinguishes DA from BC, it is imperative to consider the associated computational demands and implementation complexities, especially if they are to be implemented operationally. This introduces a pragmatic dimension into the comparison, as the choice between DA and BC necessitates a nuanced evaluation of their distinct features and trade-offs. DA's computational demands and implementation complexity starkly contrast with the simplicity and ease of implementation offered by BC, positioning the latter as an accessible “easy win” for swiftly enhancing forecasting products. Our results reveal an absence of universal superiority of one method over another, underscoring their dependency on catchment characteristics, seasonal dynamics, and lead times. Interestingly, there are cases where the uncorrected OR-ESP outperforms both DA-ESP and BC-ESP, even at shorter lead times (Fig. 7). Therefore, based on our findings, for the UK, we recommend selectively applying DA for short lead times in summer and catchments with a high BFI and for catchments affected by snow accumulation and snowmelt in winter and spring at short lead times, which is where the greatest benefit of DA was observed (Fig. 6). In the rest of the cases, BC is the recommended method. Alternatively, the exclusive use of BC is advocated as a pragmatic, efficient solution, particularly where computational costs pose a limitation. Figure 8 shows that, even in the rare cases where OR-ESP outperforms BC-ESP, it does so with only marginal differences in the CRPSS. This ensures that the hydrological post-processing is not “doing any harm” to the inherent skill of the raw model outputs (Hopson et al., 2020).
It should be noted that applying both BC and DA simultaneously to harness their combined effect is not straightforward. This complexity arises from the fact that the FDC used for quantile mapping relies on observed flow data without incorporating data assimilation. Thus, introducing data assimilation would disrupt the established relationships that underpin the quantile mapping method. However, the two methods are not mutually exclusive, and combining them could be evaluated in future work. This would require a different experimental setting to ensure the applicability of QM BC in simulations that have undergone data assimilation.
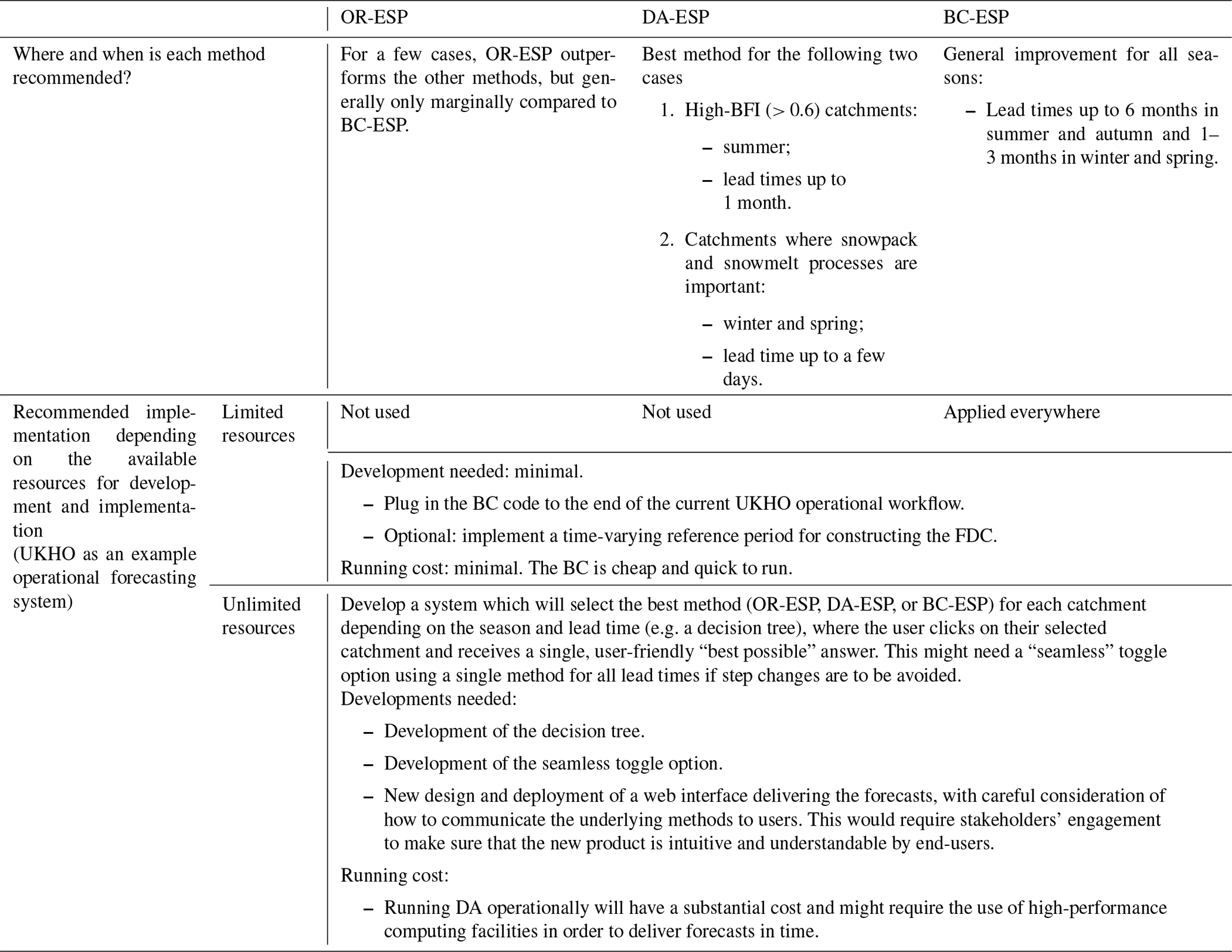
Table 3“Best” method and recommended implementation based on the available resources.
4.2 Model improvements versus practical needs: a fine balance
Many argue that science should focus on enhancing hydrological models rather than correcting their errors by post-processing (BC) or “nudging” their parameters through data assimilation (Refsgaard et al., 2023). While such advancement is undoubtedly crucial for deepening our comprehension of the physical world (Beven, 2019), this type of research is much slower to conduct, and incremental improvements take time to translate into impact for users. We could even argue that no model will ever perfectly simulate the physical world. For example, human influence is notoriously difficult to account for in hydrology. This slowly evolving advancement of the models is asynchronous with the urgent need of end-users to have reliable outputs that they can trust to base their decision-making on (e.g. Cassagnole et al., 2021; Li et al., 2019; Pappenberger, 2024). It is worth noting the practical implications of improving hydrological forecasts (Lopez and Haines, 2017; Neumann et al., 2018), particularly in the context of operational use by decision-makers, whereby the difference between correcting or not correcting a forecast – regardless of the method being used – can determine whether they are deemed useful and consequently used by stakeholders or not (Hopson et al., 2020). The Hydrological Outlook UK, which is the subject of this case study, serves as a pertinent example of the real-world application of forecast products.
Moreover, incremental refinements in hydrological models often result in only marginal enhancements to forecast skill, as illustrated by plots in the Appendix comparing the GR4J and GR6J models (Fig. A1). Notably, the difference in forecasting skill between these models is minimal, highlighting the challenge of achieving substantial gains through model enhancements alone. In contrast, our assessment demonstrates that methods like BC yield more significant and immediate improvements in forecast accuracy. Therefore, in parallel with the ongoing efforts to enhance the cores of hydrological models, exploring methods – such as BC and DA – to refine existing forecasting products becomes justified. This paper consistently assesses and compares two of these methods, offering evidence of the benefits they deliver and providing a pragmatic solution to refine existing forecasting products, meeting the pressing demand from end-users for reliable outputs that inform their decision-making.
4.3 Post-processing methods in hydrological forecasting
In the broader context of hydrological research, our study's exploration of BC and DA methods contributes to the ongoing dialogue surrounding hydrological forecast post-processing techniques. While machine learning (ML) methods like convolutional neural networks (CNNs) and support vector regression (SVR) have shown promise in enhancing forecast accuracy (Liu et al., 2022), their computational demands present challenges. Notably, our study employs QM for BC, a computationally efficient method, distinguishing it from more resource-intensive ML approaches.
In similar work, Matthews et al. (2022) adopt a post-processing method derived from the Multi-Temporal Model Conditional Processor (MT-MCP; Coccia and Todini, 2011). They find a pronounced impact in catchments with a long hydrological memory. A key difference with our work lies in their use of numerical weather prediction (NWP) as the driving data, contrasting with our reliance on climatological weather input for the ESP method. This distinction implies that their hydrological forecasts, particularly in dynamic or “flashy” catchments, are sensitive to the skill of NWP input, potentially diminishing the relative effectiveness of post-processing compared to our experimental setting in those catchments. In that sense, ESP serves as an ideal test case to isolate the value of the DA and BC methods given the absence of skill from the meteorological forecast to “take over” from the IHCs.
Additionally, we acknowledge the challenge of non-stationarity in QM, a concern highlighted by Ceola et al. (2014). To address this, in an operational setting, incorporating real-time updates by dynamically adding the newest observed data would be done, allowing the FDC to adapt monthly. A potential refinement could be explored by changing reference periods, such as the most recent 30-year period, offering a dynamic approach to account for non-stationarity, albeit with the associated risk of overlooking rarer extreme events.
To the best of our knowledge, no prior study has undertaken a direct comparison between BC and DA, a gap that might be attributed, in part, to the inherent disparities between these two methodologies, as mentioned already. Nevertheless, from a users' standpoint, such a comparative analysis holds significant value. It facilitates the selection of the optimal forecasting product tailored to distinct situations, offering valuable insights for decision-makers seeking to enhance the reliability of their hydrological forecasts.
4.4 Limitations and future work
The present study naturally has some limitations given the practicalities of applying multiple approaches across many catchments, lead times, and seasons. Firstly, the gap-filling approach employed to address missing data in the observed river flow time series is quite rudimentary, relying on a simple linear interpolation method. While this method is commonly used for gap-filling (Niedzielski and Halicki, 2023), it comes with inherent limitations, such as its sensitivity to outliers and oversimplification of the underlying hydrological processes, especially when gap-filling longer time periods. Note that both techniques (BC and DA) can be applied even if the observed data have some missing data (DA is not applied where no data are available, and BC uses whatever data are available to construct the FDC). Full time series were only needed to calculate the CRPSS used to carry out the comparative analysis. While more sophisticated techniques for handling missing data, such as data-driven methods or advanced statistical approaches, could have been considered to enhance the accuracy of the reconstructed time series (e.g. Dembélé et al., 2019; Luna et al., 2020), such methods would have significantly increased the complexity of the analysis. To mitigate this limitation, the study has focused much of its analysis on a subset of the dataset, where less than 5 % of the data were missing (Fig. 1b), minimising in that way the effect of the gap-filling (Arriagada et al., 2021). Consequently, using an alternative gap-filling method would likely have yielded comparable conclusions.
Secondly, the DA methodology implemented in this study, the PF technique, is used in a deterministic manner (where we have used the PF ensemble mean to avoid having an ensemble of ensembles) to ensure comparability with BC results. However, the PF method inherently provides valuable information on uncertainty associated with the hydrological state (e.g. Moradkhani et al., 2012). In the current study, this information on uncertainty is not fully exploited, as the analysis primarily focuses on the comparison with BC. Future investigations could explore more sophisticated approaches within DA that capitalise on the uncertainty estimates provided by the PF technique.
Building on our analysis of the comparative strengths of DA and BC, our study identified the specific scenarios where each method improves the forecasts the most. Depending on the resources available for implementation, we summarise our recommendations based on our findings in Table 3. This lays the groundwork for a prospective user-friendly hydrological forecasting system in the future that could be implemented in the operational HOUK setting. Recognising that end-users and non-specialists often prioritise a simplified and trustworthy message (Hannaford et al., 2019), we envision the implementation of a flexible, combinatory (e.g. decision-tree-based) forecasting system that would dynamically choose the most effective method based on specific factors such as catchment characteristics, time of year, and lead time. For end-users seeking “the best answer” without delving into the intricacies of the methodology, this streamlined approach aims to provide the most reliable forecast available in a clear and simple manner. While this concept would require rigorous testing and development first, it highlights a potential avenue for future research in tailoring hydrological forecasts to meet the practical needs and expectations of end-users. The cheaper, more immediate solution would be to blanket-apply BC to improve all catchments indiscriminately.
Furthermore, future studies could explore alternative post-processing methods (Li et al., 2017), such as copula-based approaches and machine learning techniques (Liu et al., 2022), or statistical and empirical post-processing methods, such as using the Hydrological Uncertainty Processor (HUP; Krzysztofowicz, 1999) and its variants such as the Model Conditional Processor (MCP, Todini, 2008). All of these options, while potentially offering improved forecast accuracy, come with varying computational expenses. Investigations into diverse post-processing methodologies can enhance our understanding of their applicability and effectiveness in different hydrological contexts, providing valuable options for refining forecasting products in the future.
In this study, we have explored the effectiveness of quantile mapping (QM), bias correction (BC), particle filter (PF), and data assimilation (DA) techniques in enhancing hydrological model performance and forecast skill, specifically focusing on improving hydrological forecasts using the ensemble streamflow prediction (ESP) method with the GR4J model for the Hydrological Outlook UK operational service. Our findings reveal that both BC and DA contribute to improvements, yet their impacts vary across different metrics and catchment characteristics.
BC, operating as a post-processing method, demonstrates substantial and generalised improvements across various performance metrics. It rectifies model errors after simulations, extending its positive influence beyond initial conditions throughout the entire time series. However, while QM BC effectively aligns statistical properties, it may oversimplify the complexity of hydrological systems by neglecting to capture the physical processes and interactions, consequently leading to an underestimation of uncertainties.
On the other hand, DA, which adjusts model internal states during initialisations to align simulations with observed data, exhibits more subtle and marginal improvements. The positive effects of DA are particularly notable in catchments with a high baseflow index (BFI) and up to the seasonal scale, and DA often yields more improvement than BC at short lead times (up to 1 month) in summer. DA also outperforms BC for catchments where snow processes are important, mainly in north-eastern Scotland in winter (snow accumulation) and spring (snowmelt) at short lead times. The probabilistic nature of DA, considering uncertainties associated with model structures, initial conditions, and observations, provides a comprehensive representation of the hydrological state.
The choice between BC and DA involves trade-offs, considering their conceptual differences, computational demands, and handling of uncertainties. While DA offers a more sophisticated approach, BC presents a pragmatic and computationally efficient solution, especially when computational costs pose a limitation. The absence of universal superiority of one method over another emphasises the importance of selectively applying these techniques based on specific scenarios, user requirements, and operational constraints. Future work could explore the combined use of both techniques, though it would need to first address the challenge of constructing the flow duration curve used in the QM method for flow simulations modified by data assimilation.
In the broader context of hydrological research, our study contributes valuable insights to the body of literature on forecast enhancement techniques. Our findings can pave the way for a more objective, on-the-fly selective forecasting system tailored to catchment characteristics, time of year, and lead time, which would be a step towards user-friendly and practical hydrological forecasting systems.
In conclusion, this research provides a novel intercomparison of QM BC and PF DA, offering an assessment of their strengths and limitations when applied to UK streamflow forecasting. By recognising the diverse contexts where each method excels, hydrologists and decision-makers can make informed choices to refine forecasting products, aligning with the ever-growing demand for reliable and actionable hydrological information.
Figure A1Change in forecasting skill (CRPSS) at different lead times when transitioning from GR4J to GR6J to produce ESP forecasts in the different UK hydroclimate regions. Blue signifies improved forecast skill with GR6J compared to GR4J, while orange represents the reverse.
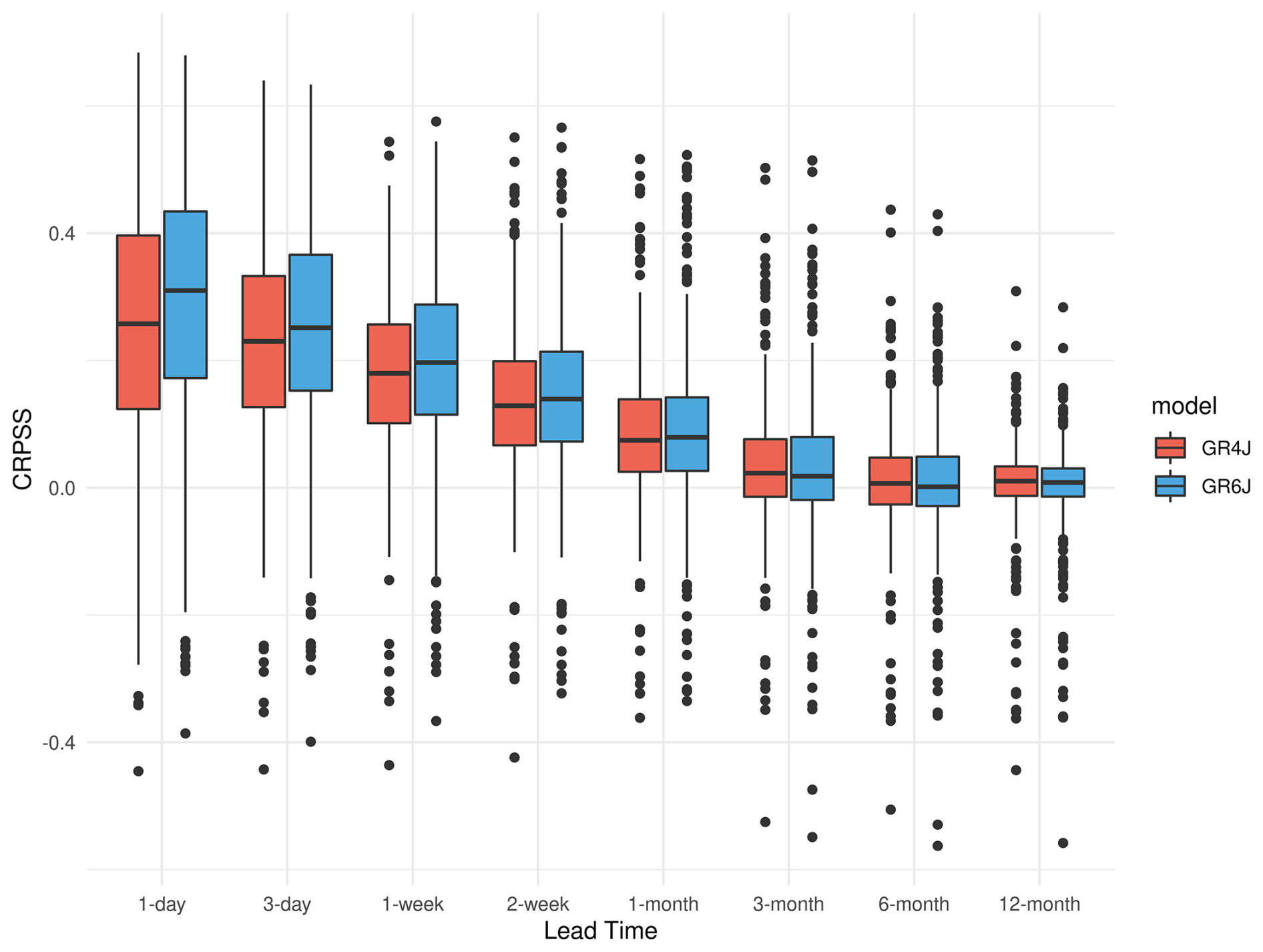
Figure A2Boxplots showing the range of the CRPSS for all catchments used in the UKHO at different lead times in ESP forecasts generated using GR4J (in red) and GR6J (in blue).
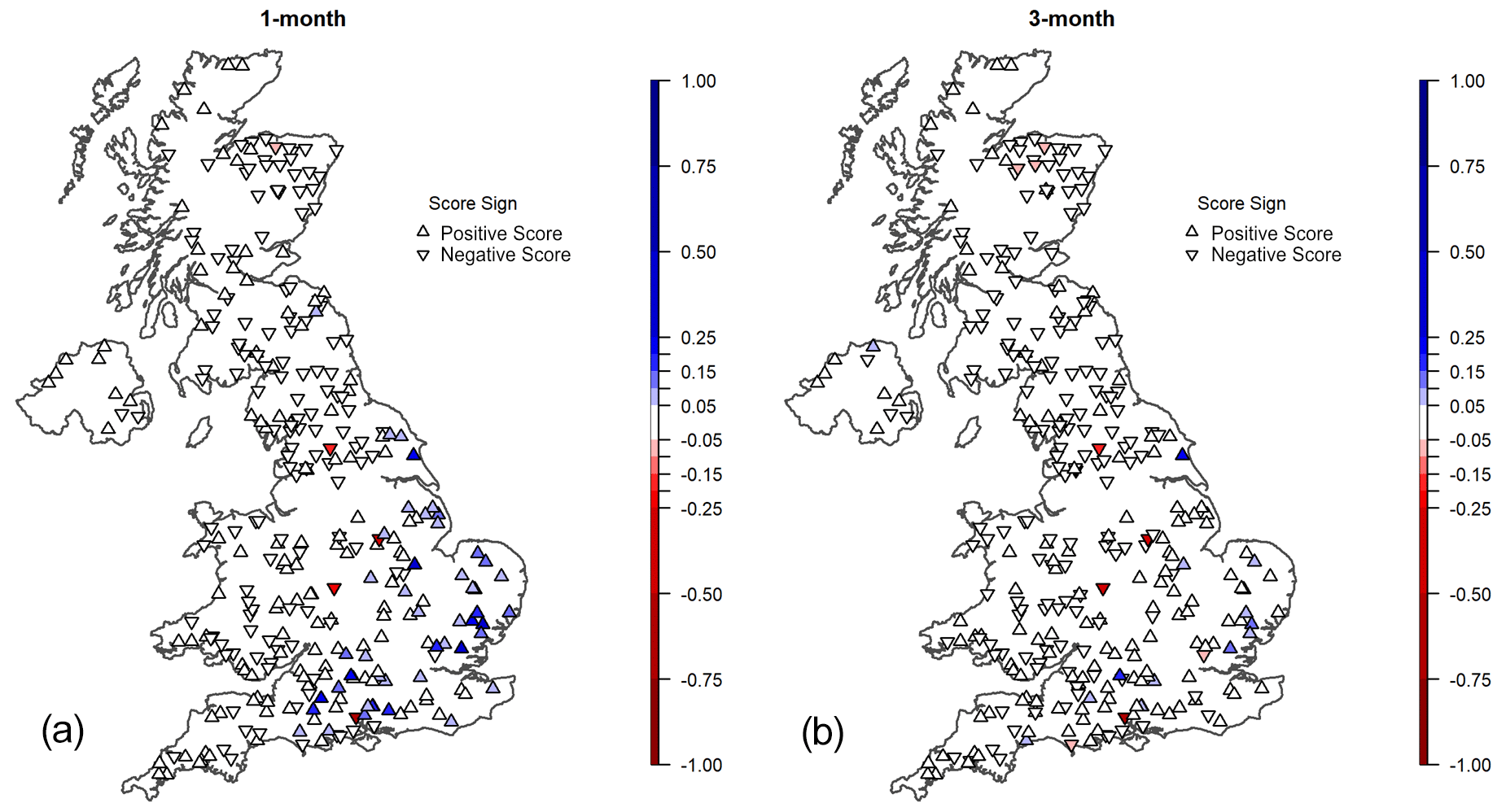
Figure A3Map of the difference in skill (CRPSS) between ESP forecasts generated using GR6J and GR4J at (a) a 1-month lead time and (b) a 3-month lead time. Blue shades signify improved forecast skill with GR6J compared to GR4J, red shades represent the reverse, and white shades signify negligible differences (source: https://hydoutuk.net/about/methods/river-flows, last access: 18 March 2025).
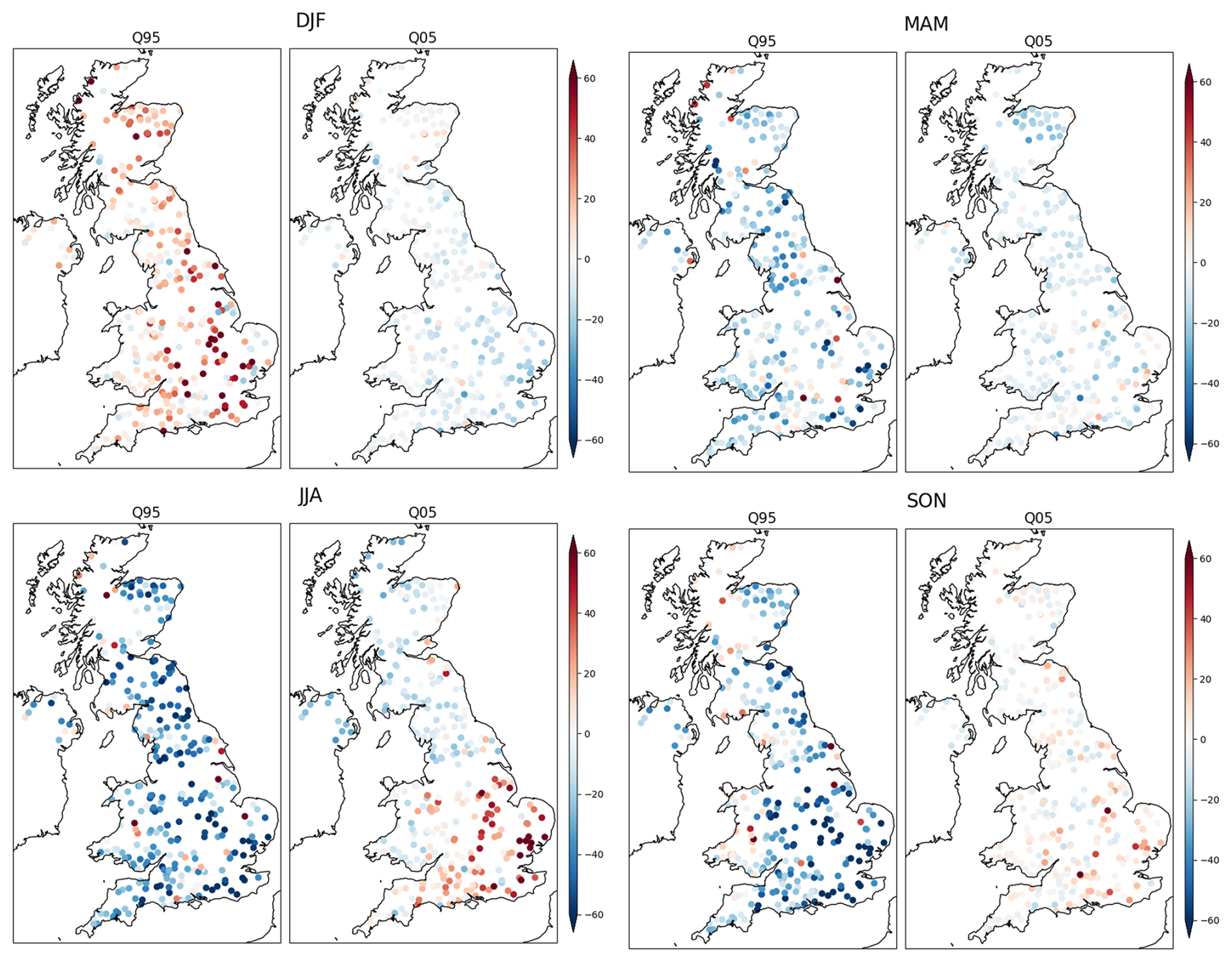
Figure A4Percent bias for each season for low flows (Q95) and high flows (Q05) in streamflow simulated by GR4J. The percent bias is calculated as for the low flows (Q95) and high flows (Q05), where q is the simulated flow and Q is the observed flow. The percent bias can be negative when the simulated flow is lower than the observed flow.
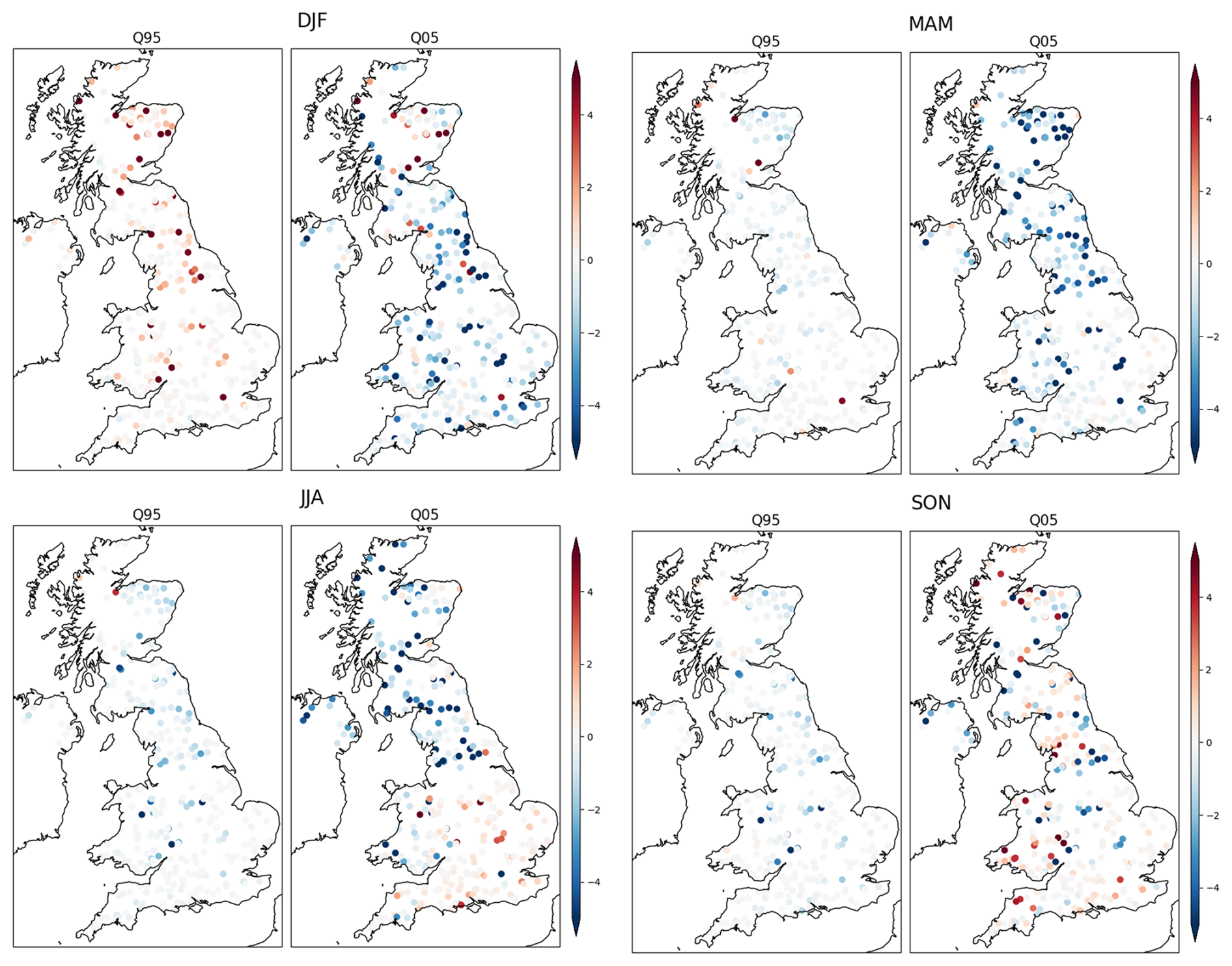
Figure A5Bias (m3 s−1) for each season for low flows (Q95) and high flows (Q05) in streamflow simulated by GR4J. The bias shown here is the raw bias, defined as (q−Q), for the low flows (Q95) and high flows (Q05), where q is the simulated flow and Q is the observed flow. The bias can be negative when the simulated flow is lower than the observed flow.
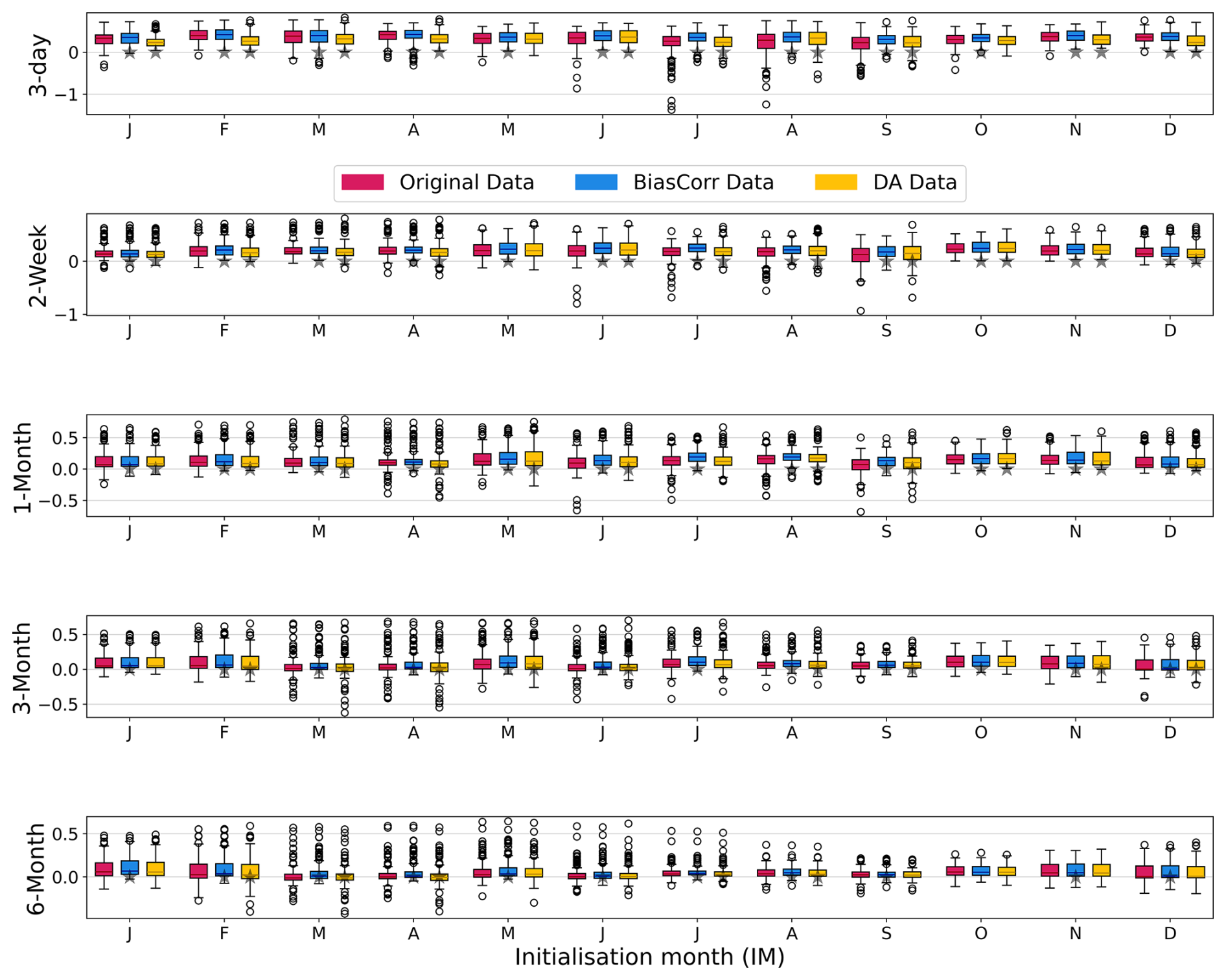
Figure A6The CRPSS of OR-ESP, BC-ESP, and DA-ESP forecasts at different lead times and initialisation months for catchments with < 5 % of missing data. The grey stars indicate where BC-ESP or DA-ESP differ significantly from OR-ESP at the 5 % significance level, based on a Student's t test.
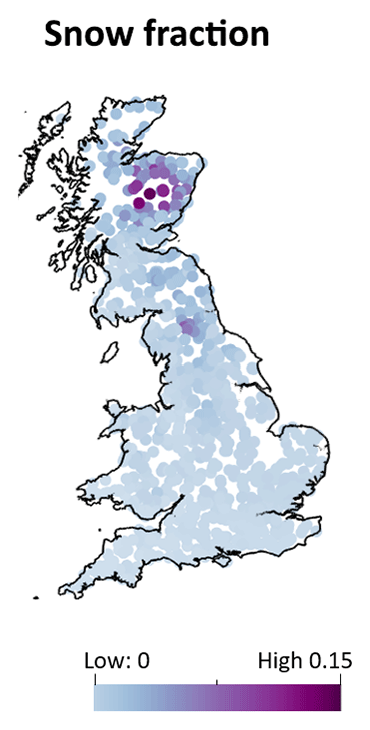
Figure A7Fraction of precipitation falling as snow for catchments across the UK, where a value of 0.15 indicates that 15 % of the catchment precipitation falls on days when the temperature is below zero (source: Lane et al., 2019).
All the code used in this study was based on open-source libraries. The hydrological model GR4J was based on R package airGR (https://cran.r-project.org/web/packages/airGR/index.html, Coron et al., 2025). Verification was done with R package easyVerification (https://cran.r-project.org/web/packages/easyVerification/index.html, MeteoSwiss et al., 2025). The data used in this study are also from open-source datasets: river flow is from the NRFA at https://nrfa.ceh.ac.uk/data (last access: 18 March 2025), and precipitation from the GEAR dataset is downloadable at https://catalogue.ceh.ac.uk/documents/dbf13dd5-90cd-457a-a986-f2f9dd97e93c (Tanguy et al., 2021). Potential evapotranspiration from CHESS for the UK and the historical PET for Northern Ireland are downloadable at https://catalogue.ceh.ac.uk/documents/9116e565-2c0a-455b-9c68-558fdd9179ad (Robinson et al., 2020) and https://catalogue.ceh.ac.uk/documents/17b9c4f7-1c30-4b6f-b2fe-f7780159939c (Tanguy et al., 2017).
MT led the overall analysis, experimental design, and manuscript preparation and supervised the team. ME led the data assimilation analysis and contributed to the manuscript preparation. AC conducted the bias correction analysis, supervised the junior staff, and contributed to the manuscript. EM performed the analyses to compare the models and approaches and produced the figures for the paper. EC supervised the data assimilation work and contributed to the manuscript. RHBJ developed the code and conducted the bias correction analysis. KFC contributed to the experimental design, supervision, and manuscript preparation. JH secured the funding, supervised the work, and contributed to the experimental design and manuscript preparation.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
This work was undertaken through the Hydro-JULES research programme (grant no. NE/S017380/1), the CANARI project (grant no. NE/W004984/1), the NC International programme (grant no. NE/X006247/1), and the UK-SCAPE programme (grant no. NE/R016429/1) of the UK Natural Environment Research Council (NERC). The authors would also like to thank Matthieu Chevallier at ECMWF, who carried out an internal review and provided valuable feedback on the paper. During the preparation of this paper, the authors used generative AI (ChatGPT) with the exclusive aim of enhancing the readability and language. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
This research has been supported by the Natural Environment Research Council (grant nos. NE/S017380/1, NE/W004984/1, NE/X006247/1, and NE/R016429/1).
This paper was edited by Nadia Ursino and reviewed by two anonymous referees.
Arriagada, P., Karelovic, B., and Link, O.: Automatic gap-filling of daily streamflow time series in data-scarce regions using a machine learning algorithm, J. Hydrol. (Amst), 598, 126454, https://doi.org/10.1016/J.JHYDROL.2021.126454, 2021.
Bell, V. A., Davies, H. N., Kay, A. L., Marsh, T. J., Brookshaw, A., and Jenkins, A.: Developing a large-scale water-balance approach to seasonal forecasting: application to the 2012 drought in Britain, Hydrol. Process., 27, 3003–3012, https://doi.org/10.1002/hyp.9863, 2013.
Beven, K.: How to make advances in hydrological modelling, Hydrol. Res., 50, 1481–1494, https://doi.org/10.2166/nh.2019.134, 2019.
Boucher, M.-A., Quilty, J., and Adamowski, J.: Data Assimilation for Streamflow Forecasting Using Extreme Learning Machines and Multilayer Perceptrons, Water Resour. Res., 56, e2019WR026226, https://doi.org/10.1029/2019WR026226, 2020.
Broderick, C., Matthews, T., Wilby, R. L., Bastola, S., and Murphy, C.: Transferability of hydrological models and ensemble averaging methods between contrasting climatic periods, Water Resour. Res., 52, 8343–8373, https://doi.org/10.1002/2016WR018850, 2016.
Bum Kim, K., Kwon, H.-H., and Han, D.: Bias-correction schemes for calibrated flow in a conceptual hydrological model, Hydrol. Res., 52, 196–211, https://doi.org/10.2166/nh.2021.043, 2021.
Carrassi, A., Bocquet, M., Bertino, L., and Evensen, G.: Data assimilation in the geosciences: An overview of methods, issues, and perspectives, WIREs Clim. Change, 9, e535, https://doi.org/10.1002/wcc.535, 2018.
Cassagnole, M., Ramos, M.-H., Zalachori, I., Thirel, G., Garçon, R., Gailhard, J., and Ouillon, T.: Impact of the quality of hydrological forecasts on the management and revenue of hydroelectric reservoirs – a conceptual approach, Hydrol. Earth Syst. Sci., 25, 1033–1052, https://doi.org/10.5194/hess-25-1033-2021, 2021.
Ceola, S., Montanari, A., and Koutsoyiannis, D.: Toward a theoretical framework for integrated modeling of hydrological change, WIREs Water, 1, 427–438, 2014.
Chan, W. C. H., Arnell, N. W., Darch, G., Facer-Childs, K., Shepherd, T. G., and Tanguy, M.: Added value of seasonal hindcasts to create UK hydrological drought storylines, Nat. Hazards Earth Syst. Sci., 24, 1065–1078, https://doi.org/10.5194/nhess-24-1065-2024, 2024.
Chevuturi, A., Tanguy, M., Facer-Childs, K., Martínez-de la Torre, A., Sarkar, S., Thober, S., Samaniego, L., Rakovec, O., Kelbling, M., Sutanudjaja, E. H., Wanders, N., and Blyth, E.: Improving global hydrological simulations through bias-correction and multi-model blending, J. Hydrol. (Amst), 621, 129607, https://doi.org/10.1016/j.jhydrol.2023.129607, 2023.
Clark, M. P., Rupp, D. E., Woods, R. A., Zheng, X., Ibbitt, R. P., Slater, A. G., Schmidt, J., and Uddstrom, M. J.: Hydrological data assimilation with the ensemble Kalman filter: Use of streamflow observations to update states in a distributed hydrological model, Adv. Water Resour., 31, 1309–1324, https://doi.org/10.1016/j.advwatres.2008.06.005, 2008.
Coccia, G. and Todini, E.: Recent developments in predictive uncertainty assessment based on the model conditional processor approach, Hydrol. Earth Syst. Sci., 15, 3253–3274, https://doi.org/10.5194/hess-15-3253-2011, 2011.
Cooper, E., Blyth, E., Cooper, H., Ellis, R., Pinnington, E., and Dadson, S. J.: Using data assimilation to optimize pedotransfer functions using field-scale in situ soil moisture observations, Hydrol. Earth Syst. Sci., 25, 2445–2458, https://doi.org/10.5194/hess-25-2445-2021, 2021.
Coron, L., Delaigue, O., Thirel, G., Dorchies, D., Perrin, C., Michel, C., Andréassian , V., Bourgin, F., Brigode, P., Le Moine, N., Mathevet, T., Mouelhi, S., Oudin, L., Pushpalatha, R., and Valéry, A.: Suite of GR Hydrological Models for Precipitation-Runoff Modelling, airGR [code], https://cran.r-project.org/web/packages/airGR/index.html (last access: 18 March 2025), 2025.
Crochemore, L., Ramos, M.-H., Pappenberger, F., and Perrin, C.: Seasonal streamflow forecasting by conditioning climatology with precipitation indices, Hydrol. Earth Syst. Sci., 21, 1573–1591, https://doi.org/10.5194/hess-21-1573-2017, 2017.
DeChant, C. M. and Moradkhani, H.: Improving the characterization of initial condition for ensemble streamflow prediction using data assimilation, Hydrol. Earth Syst. Sci., 15, 3399–3410, https://doi.org/10.5194/hess-15-3399-2011, 2011.
Dembélé, M., Oriani, F., Tumbulto, J., Mariéthoz, G., and Schaefli, B.: Gap-filling of daily streamflow time series using Direct Sampling in various hydroclimatic settings, J. Hydrol. (Amst), 569, 573–586, https://doi.org/10.1016/j.jhydrol.2018.11.076, 2019.
Dunstone, N., Smith, D., Scaife, A., Hermanson, L., Eade, R., Robinson, N., Andrews, M., and Knight, J.: Skilful predictions of the winter North Atlantic Oscillation one year ahead, Nat. Geosci., 9, 809–814, https://doi.org/10.1038/ngeo2824, 2016.
Environment Agency: Monthly Water Situation Report: England, Environment Agency, https://assets.publishing.service.gov.uk/media/63bed442e90e0771b293c82a/Water_Situation_Report_for_England_December_2022.pdf (last access: 18 March 2025), 2022.
Evensen, G.: Using the extended Kalman filter with a multilayer quasi-geostrophic ocean model, J. Geophys. Res.-Oceans, 97, 17905–17924, https://doi.org/10.1029/92JC01972, 1992.
Evensen, G.: Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics, J. Geophys. Res.-Oceans, 99, 10143–10162, https://doi.org/10.1029/94JC00572, 1994.
Farmer, W. H., Over, T. M., and Kiang, J. E.: Bias correction of simulated historical daily streamflow at ungauged locations by using independently estimated flow duration curves, Hydrol. Earth Syst. Sci., 22, 5741–5758, https://doi.org/10.5194/hess-22-5741-2018, 2018.
Ferro, C. A. T., Richardson, D. S., and Weigel, A. P.: On the effect of ensemble size on the discrete and continuous ranked probability scores, Meteorol. Appl., 15, 19–24, https://doi.org/10.1002/met.45, 2008.
Gupta, H. V, Kling, H., Yilmaz, K. K., and Martinez, G. F.: Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling, J. Hydrol. (Amst), 377, 80–91, https://doi.org/10.1016/j.jhydrol.2009.08.003, 2009.
Gustard, A., Bullock, A., and Dixon, J. M.: Low flow estimation in the United Kingdom, IH Report No.108, Institute of Hydrology, Wallingford, https://nora.nerc.ac.uk/id/eprint/6050 (last access: 18 March 2025), 88 pp., 1992.
Hannaford, J., Collins, K., Haines, S., and Barker, L. J.: Enhancing Drought Monitoring and Early Warning for the United Kingdom through Stakeholder Coinquiries, Weather Clim. Soc., 11, 49–63, https://doi.org/10.1175/WCAS-D-18-0042.1, 2019.
Hannaford, J., Mackay, J. D., Ascott, M., Bell, V. A., Chitson, T., Cole, S., Counsell, C., Durant, M., Jackson, C. R., Kay, A. L., Lane, R. A., Mansour, M., Moore, R., Parry, S., Rudd, A. C., Simpson, M., Facer-Childs, K., Turner, S., Wallbank, J. R., Wells, S., and Wilcox, A.: The enhanced future Flows and Groundwater dataset: development and evaluation of nationally consistent hydrological projections based on UKCP18, Earth Syst. Sci. Data, 15, 2391–2415, https://doi.org/10.5194/essd-15-2391-2023, 2023.
Harrigan, S., Prudhomme, C., Parry, S., Smith, K., and Tanguy, M.: Benchmarking ensemble streamflow prediction skill in the UK, Hydrol. Earth Syst. Sci., 22, 2023–2039, https://doi.org/10.5194/hess-22-2023-2018, 2018.
Hashino, T., Bradley, A. A., and Schwartz, S. S.: Evaluation of bias-correction methods for ensemble streamflow volume forecasts, Hydrol. Earth Syst. Sci., 11, 939–950, https://doi.org/10.5194/hess-11-939-2007, 2007.
Hersbach, H.: Decomposition of the Continuous Ranked Probability Score for Ensemble Prediction Systems, Weather Forecast., 15, 559–570, https://doi.org/10.1175/1520-0434(2000)015<0559:DOTCRP>2.0.CO;2, 2000.
Hollis, D., McCarthy, M., Kendon, M., Legg, T., and Simpson, I.: HadUK-Grid—A new UK dataset of gridded climate observations, Geosci. Data J., 6, 151–159, https://doi.org/10.1002/gdj3.78, 2019.
Hopson, T. M., Wood, A., and Weerts, A. H.: Motivation and Overview of Hydrological Ensemble Post-processing, in: Handbook of Hydrometeorological Ensemble Forecasting, edited by: Duan, Q., Pappenberger, F., Wood, A., Cloke, H. L., and Schaake, J. C., Springer Berlin Heidelberg, Berlin, Heidelberg, https://doi.org/10.1007/978-3-642-40457-3_36-3, 1–11, 2020.
Jin, N. S., Yasuto, T., Michiharu, S., and Sunmin, K.: Ensemble Kalman Filtering and Particle Filtering in a Lag-Time Window for Short-Term Streamflow Forecasting with a Distributed Hydrologic Model, J. Hydrol. Eng., 18, 1684–1696, https://doi.org/10.1061/(ASCE)HE.1943-5584.0000751, 2013.
Kay, A. L., Dunstone, N., Kay, G., Bell, V. A., and Hannaford, J.: Demonstrating the use of UNSEEN climate data for hydrological applications: case studies for extreme floods and droughts in England, Nat. Hazards Earth Syst. Sci., 24, 2953–2970, https://doi.org/10.5194/nhess-24-2953-2024, 2024.
Keller, V. D. J., Tanguy, M., Prosdocimi, I., Terry, J. A., Hitt, O., Cole, S. J., Fry, M., Morris, D. G., and Dixon, H.: CEH-GEAR: 1 km resolution daily and monthly areal rainfall estimates for the UK for hydrological and other applications, Earth Syst. Sci. Data, 7, 143–155, https://doi.org/10.5194/essd-7-143-2015, 2015.
Kling, H., Fuchs, M., and Paulin, M.: Runoff conditions in the upper Danube basin under an ensemble of climate change scenarios, J. Hydrol. (Amst), 424–425, 264–277, https://doi.org/10.1016/j.jhydrol.2012.01.011, 2012.
Kreibich, H., Van Loon, A. F., Schröter, K., Ward, P. J., Mazzoleni, M., Sairam, N., Abeshu, G. W., Agafonova, S., AghaKouchak, A., Aksoy, H., Alvarez-Garreton, C., Aznar, B., Balkhi, L., Barendrecht, M. H., Biancamaria, S., Bos-Burgering, L., Bradley, C., Budiyono, Y., Buytaert, W., Capewell, L., Carlson, H., Cavus, Y., Couasnon, A., Coxon, G., Daliakopoulos, I., de Ruiter, M. C., Delus, C., Erfurt, M., Esposito, G., François, D., Frappart, F., Freer, J., Frolova, N., Gain, A. K., Grillakis, M., Grima, J. O., Guzmán, D. A., Huning, L. S., Ionita, M., Kharlamov, M., Khoi, D. N., Kieboom, N., Kireeva, M., Koutroulis, A., Lavado-Casimiro, W., Li, H.-Y., LLasat, M. C., Macdonald, D., Mård, J., Mathew-Richards, H., McKenzie, A., Mejia, A., Mendiondo, E. M., Mens, M., Mobini, S., Mohor, G. S., Nagavciuc, V., Ngo-Duc, T., Thao Nguyen Huynh, T., Nhi, P. T. T., Petrucci, O., Nguyen, H. Q., Quintana-Seguí, P., Razavi, S., Ridolfi, E., Riegel, J., Sadik, M. S., Savelli, E., Sazonov, A., Sharma, S., Sörensen, J., Arguello Souza, F. A., Stahl, K., Steinhausen, M., Stoelzle, M., Szalińska, W., Tang, Q., Tian, F., Tokarczyk, T., Tovar, C., Tran, T. V. T., Van Huijgevoort, M. H. J., van Vliet, M. T. H., Vorogushyn, S., Wagener, T., Wang, Y., Wendt, D. E., Wickham, E., Yang, L., Zambrano-Bigiarini, M., Blöschl, G., and Di Baldassarre, G.: The challenge of unprecedented floods and droughts in risk management, Nature, 608, 80–86, https://doi.org/10.1038/s41586-022-04917-5, 2022.
Krzysztofowicz, R.: Bayesian theory of probabilistic forecasting via deterministic hydrologic model, Water Resour. Res., 35, 2739–2750, https://doi.org/10.1029/1999WR900099, 1999.
Lane, R. A., Coxon, G., Freer, J. E., Wagener, T., Johnes, P. J., Bloomfield, J. P., Greene, S., Macleod, C. J. A., and Reaney, S. M.: Benchmarking the predictive capability of hydrological models for river flow and flood peak predictions across over 1000 catchments in Great Britain, Hydrol. Earth Syst. Sci., 23, 4011–4032, https://doi.org/10.5194/hess-23-4011-2019, 2019.
Li, W., Duan, Q., Miao, C., Ye, A., Gong, W., and Di, Z.: A review on statistical postprocessing methods for hydrometeorological ensemble forecasting, WIREs Water, 4, e1246, https://doi.org/10.1002/wat2.1246, 2017.
Li, W., Chen, J., Li, L., Chen, H., Liu, B., Xu, C.-Y., and Li, X.: Evaluation and Bias Correction of S2S Precipitation for Hydrological Extremes, J. Hydrometeorol., 20, 1887–1906, https://doi.org/10.1175/JHM-D-19-0042.1, 2019.
Liu, S., Wang, J., Wang, H., and Wu, Y.: Post-processing of hydrological model simulations using the convolutional neural network and support vector regression, Hydrol. Res., 53, 605–621, https://doi.org/10.2166/nh.2022.004, 2022.
Liu, Y., Weerts, A. H., Clark, M., Hendricks Franssen, H.-J., Kumar, S., Moradkhani, H., Seo, D.-J., Schwanenberg, D., Smith, P., van Dijk, A. I. J. M., van Velzen, N., He, M., Lee, H., Noh, S. J., Rakovec, O., and Restrepo, P.: Advancing data assimilation in operational hydrologic forecasting: progresses, challenges, and emerging opportunities, Hydrol. Earth Syst. Sci., 16, 3863–3887, https://doi.org/10.5194/hess-16-3863-2012, 2012.
Lopez, A. and Haines, S.: Exploring the Usability of Probabilistic Weather Forecasts for Water Resources Decision-Making in the United Kingdom, Weather Clim. Soc., 9, 701–715, https://doi.org/10.1175/WCAS-D-16-0072.1, 2017.
Luna, A. M., Lineros, M. L., Gualda, J. E., Giráldez Cervera, J. V., and Madueño Luna, J. M.: Assessing the Best Gap-Filling Technique for River Stage Data Suitable for Low Capacity Processors and Real-Time Application Using IoT, Sensors, 20, 6354, https://doi.org/10.3390/s20216354, 2020.
Madadgar, S., Moradkhani, H., and Garen, D.: Towards improved post-processing of hydrologic forecast ensembles, Hydrol. Process., 28, 104–122, https://doi.org/10.1002/hyp.9562, 2014.
Matthews, G., Barnard, C., Cloke, H., Dance, S. L., Jurlina, T., Mazzetti, C., and Prudhomme, C.: Evaluating the impact of post-processing medium-range ensemble streamflow forecasts from the European Flood Awareness System, Hydrol. Earth Syst. Sci., 26, 2939–2968, https://doi.org/10.5194/hess-26-2939-2022, 2022.
Maxwell, D. H., Jackson, B. M., and McGregor, J.: Constraining the ensemble Kalman filter for improved streamflow forecasting, J. Hydrol. (Amst), 560, 127–140, https://doi.org/10.1016/j.jhydrol.2018.03.015, 2018.
MeteoSwiss: easyVerification: Ensemble Forecast Verification for Large Data Sets, R package version 0.4.2, CRAN.R-project [code], http://CRAN.R-project.org/package=easyVerification (last access: 10 June 2024), 2017.
MeteoSwiss, Bhend, J., Ripoldi, J., Mignani, C., Mahlstein, I., Hiller, R., Spirig, C., Liniger, M., Weigel, A., Bedia Jimenez, J., De Felice, M., Siegert, S., and Sedlmeier, K.: Ensemble Forecast Verification for Large Data Sets, easyVerification [code], https://cran.r-project.org/web/packages/easyVerification/index.html (last access: 18 March 2025)
Moradkhani, H., DeChant, C. M., and Sorooshian, S.: Evolution of ensemble data assimilation for uncertainty quantification using the particle filter-Markov chain Monte Carlo method, Water Resour. Res., 48, W12520, https://doi.org/10.1029/2012WR012144, 2012.
Navon, I. M.: Data Assimilation for Numerical Weather Prediction: A Review, in: Data Assimilation for Atmospheric, Oceanic and Hydrologic Applications, edited by: Park, S. K. and Xu, L., Springer Berlin Heidelberg, Berlin, Heidelberg, https://doi.org/10.1007/978-3-540-71056-1_2, 21–65, 2009.
Neumann, J. L., Arnal, L., Emerton, R. E., Griffith, H., Hyslop, S., Theofanidi, S., and Cloke, H. L.: Can seasonal hydrological forecasts inform local decisions and actions? A decision-making activity, Geosci. Commun., 1, 35–57, https://doi.org/10.5194/gc-1-35-2018, 2018.
Niedzielski, T. and Halicki, M.: Improving Linear Interpolation of Missing Hydrological Data by Applying Integrated Autoregressive Models, Water Resour. Manag., 37, 5707–5724, https://doi.org/10.1007/s11269-023-03625-7, 2023.
Pappenberger, F.: A Crescendo in Hydro-Forecasting: Moving Beyond Incremental Gains, HEPEX Blog, HEPEX, https://hepex.org.au/a-crescendo-in-hydro-forecasting (last accessed: 11 June 2024), 2024.
Pappenberger, F., Ramos, M. H., Cloke, H. L., Wetterhall, F., Alfieri, L., Bogner, K., Mueller, A., and Salamon, P.: How do I know if my forecasts are better? Using benchmarks in hydrological ensemble prediction, J. Hydrol. (Amst), 522, 697–713, https://doi.org/10.1016/j.jhydrol.2015.01.024, 2015.
Peñuela, A., Hutton, C., and Pianosi, F.: Assessing the value of seasonal hydrological forecasts for improving water resource management: insights from a pilot application in the UK, Hydrol. Earth Syst. Sci., 24, 6059–6073, https://doi.org/10.5194/hess-24-6059-2020, 2020.
Perrin, C., Michel, C., and Andréassian, V.: Improvement of a parsimonious model for streamflow simulation, J. Hydrol. (Amst), 279, 275–289, https://doi.org/10.1016/S0022-1694(03)00225-7, 2003.
Piazzi, G., Thirel, G., Perrin, C., and Delaigue, O.: Sequential Data Assimilation for Streamflow Forecasting: Assessing the Sensitivity to Uncertainties and Updated Variables of a Conceptual Hydrological Model at Basin Scale, Water Resour. Res., 57, e2020WR028390, https://doi.org/10.1029/2020WR028390, 2021.
Prudhomme, C., Hannaford, J., Harrigan, S., Boorman, D., Knight, J., Bell, V., Jackson, C., Svensson, C., Parry, S., Bachiller-Jareno, N., Davies, H., Davis, R., Mackay, J., McKenzie, A., Rudd, A., Smith, K., Bloomfield, J., Ward, R., and Jenkins, A.: Hydrological Outlook UK: an operational streamflow and groundwater level forecasting system at monthly to seasonal time scales, Hydrolog. Sci. J., 62, 2753–2768, https://doi.org/10.1080/02626667.2017.1395032, 2017.
Pushpalatha, R., Perrin, C., Le Moine, N., Mathevet, T., and Andréassian, V. A.: Downward structural sensitivity analysis of hydrological models to improve low-flow simulation, J. Hydrol., 411, 66–76, https://doi.org/10.1016/j.jhydrol.2011.09.034, 2011.
Rahman, M. M., Lu, M., and Kyi, K. H.: Seasonality of hydrological model spin-up time: a case study using the Xinanjiang model, Hydrol. Earth Syst. Sci. Discuss. [preprint], https://doi.org/10.5194/hess-2016-316, in review, 2016.
Randrianasolo, A., Thirel, G., Ramos, M. H., and Martin, E.: Impact of streamflow data assimilation and length of the verification period on the quality of short-term ensemble hydrologic forecasts, J. Hydrol. (Amst), 519, 2676–2691, https://doi.org/10.1016/j.jhydrol.2014.09.032, 2014.
Refsgaard, J. C., Mai, J., Hrachowitz, M., Jain, S. K., and Stisen, S.: Towards more credible models in catchment hydrology to enhance hydrological process understanding: Preface, Hydrol. Process., 37, e14995, https://doi.org/10.1002/hyp.14995, 2023.
Renard, B., Kavetski, D., Kuczera, G., Thyer, M., and Franks, S. W.: Understanding predictive uncertainty in hydrologic modeling: The challenge of identifying input and structural errors, Water Resour. Res., 46, W05521, https://doi.org/10.1029/2009WR008328, 2010.
Robertson, D., Bennett, J., and Schepen, A.: How good is my forecasting method? Some thoughts on forecast evaluation using cross-validation based on Australian experiences, HEPEX Blog, HEPEX, https://hepex.org.au/how-good-is-my-forecasting-method-some-thoughts-on-forecast-evaluation-using-cross-validation-based-on-australian-experiences/ (last accessed: 18 March 2025) 2016.
Robinson, E. L., Blyth, E. M., Clark, D. B., Finch, J., and Rudd, A. C.: Trends in atmospheric evaporative demand in Great Britain using high-resolution meteorological data, Hydrol. Earth Syst. Sci., 21, 1189–1224, https://doi.org/10.5194/hess-21-1189-2017, 2017.
Robinson, E. L., Blyth, E. M., Clark, D. B., Comyn-Platt, E., and Rudd, A. C.: Climate hydrology and ecology research support system potential evapotranspiration dataset for Great Britain (1961–2017) [CHESS-PE], NERC Environmental Information Data Centre [data set], 2020.
Roy, T., Valdés, J. B., Serrat-Capdevila, A., Durcik, M., Demaria, E. M. C., Valdés-Pineda, R., and Gupta, H. V.: Detailed overview of the multimodel multiproduct streamflow forecasting platform, Journal of Applied Water Engineering and Research, 8, 277–289, https://doi.org/10.1080/23249676.2020.1799442, 2020.
Sanchez Lozano, J., Romero Bustamante, G., Hales, R. C., Nelson, E. J., Williams, G. P., Ames, D. P., and Jones, N. L.: A Streamflow Bias Correction and Performance Evaluation Web Application for GEOGloWS ECMWF Streamflow Services, Hydrology, 8, 71, https://doi.org/10.3390/hydrology8020071, 2021.
Seo, D.-J., Cajina, L., Corby, R., and Howieson, T.: Automatic state updating for operational streamflow forecasting via variational data assimilation, J. Hydrol. (Amst), 367, 255–275, https://doi.org/10.1016/j.jhydrol.2009.01.019, 2009.
Shamseldin, A. Y.: Application of a neural network technique to rainfall-runoff modelling, J. Hydrol. (Amst), 199, 272–294, https://doi.org/10.1016/S0022-1694(96)03330-6, 1997.
Shukla, S. and Lettenmaier, D. P.: Seasonal hydrologic prediction in the United States: understanding the role of initial hydrologic conditions and seasonal climate forecast skill, Hydrol. Earth Syst. Sci., 15, 3529–3538, https://doi.org/10.5194/hess-15-3529-2011, 2011.
Smith, K. A., Barker, L. J., Tanguy, M., Parry, S., Harrigan, S., Legg, T. P., Prudhomme, C., and Hannaford, J.: A multi-objective ensemble approach to hydrological modelling in the UK: an application to historic drought reconstruction, Hydrol. Earth Syst. Sci., 23, 3247–3268, https://doi.org/10.5194/hess-23-3247-2019, 2019.
Snyder, C., Bengtsson, T., Bickel, P., and Anderson, J.: Obstacles to High-Dimensional Particle Filtering, Mon. Weather Rev., 136, 4629–4640, https://doi.org/10.1175/2008MWR2529.1, 2008.
Staudinger, M. and Seibert, J.: Predictability of low flow – An assessment with simulation experiments, J. Hydrol. (Amst), 519, 1383–1393, https://doi.org/10.1016/j.jhydrol.2014.08.061, 2014.
Sun, L., Nistor, I., and Seidou, O.: Streamflow data assimilation in SWAT model using Extended Kalman Filter, J. Hydrol. (Amst), 531, 671–684, https://doi.org/10.1016/j.jhydrol.2015.10.060, 2015.
Svensson, C.: Seasonal river flow forecasts for the United Kingdom using persistence and historical analogues, Hydrolog. Sci. J., 61, 19–35, https://doi.org/10.1080/02626667.2014.992788, 2016.
Tanguy, M., Prudhomme, C., Smith, K., and Hannaford, J.: Historic Gridded Potential Evapotranspiration (PET) based on temperature-based equation McGuinness-Bordne calibrated for the UK (1891–2015), NERC Environmental Information Data Centre [data set], https://doi.org/10.5285/17b9c4f7-1c30-4b6f-b2fe-f7780159939c, 2017.
Tanguy, M., Prudhomme, C., Smith, K., and Hannaford, J.: Historical gridded reconstruction of potential evapotranspiration for the UK, Earth Syst. Sci. Data, 10, 951–968, https://doi.org/10.5194/essd-10-951-2018, 2018.
Tanguy, M., Dixon, H., Prosdocimi, I., Morris, D. G., and Keller, V. D. J.: Gridded estimates of daily and monthly areal rainfall for the United Kingdom (1890–2017) [CEH-GEAR], NERC Environmental Information Data Centre, 2019.
Tanguy, M., Dixon, H., Prosdocimi, I., Morris, D. G., and Keller, V. D. J.: Gridded estimates of daily and monthly areal rainfall for the United Kingdom (1890–2019) [CEH-GEAR], NERC EDS Environmental Information Data Centre [data set], https://doi.org/10.5285/dbf13dd5-90cd-457a-a986-f2f9dd97e93c, 2021.
Thiboult, A., Anctil, F., and Boucher, M.-A.: Accounting for three sources of uncertainty in ensemble hydrological forecasting, Hydrol. Earth Syst. Sci., 20, 1809–1825, https://doi.org/10.5194/hess-20-1809-2016, 2016.
Tiwari, A. D., Mukhopadhyay, P., and Mishra, V.: Influence of Bias Correction of Meteorological and Streamflow Forecast on Hydrological Prediction in India, J. Hydrometeorol., 23, 1171–1192, https://doi.org/10.1175/JHM-D-20-0235.1, 2022.
Todini, E.: A model conditional processor to assess predictive uncertainty in flood forecasting, International Journal of River Basin Management, 6, 123–137, https://doi.org/10.1080/15715124.2008.9635342, 2008.
Usman, M., Manzanas, R., Ndehedehe, C. E., Ahmad, B., Adeyeri, O. E., and Dudzai, C.: On the Benefits of Bias Correction Techniques for Streamflow Simulation in Complex Terrain Catchments: A Case-Study for the Chitral River Basin in Pakistan, Hydrology, 9, 188, https://doi.org/10.3390/hydrology9110188, 2022.
Wilks, D. S.: Chapter 9 – Forecast Verification, in: Statistical Methods in the Atmospheric Sciences (Fourth Edition), edited by: Wilks, D. S., Elsevier, https://doi.org/10.1016/B978-0-12-815823-4.00009-2, 369–483, 2019.
Wood, A. W. and Lettenmaier, D. P.: An ensemble approach for attribution of hydrologic prediction uncertainty, Geophys. Res. Lett., 35, L14401, https://doi.org/10.1029/2008GL034648, 2008.
Wood, A. W. and Schaake, J. C.: Correcting Errors in Streamflow Forecast Ensemble Mean and Spread, J. Hydrometeorol., 9, 132–148, https://doi.org/10.1175/2007JHM862.1, 2008.
Wood, A., Pagano, T., and Roos, M.: Tracing the Origin of ESP, HEPEX blog, HEPEX, https://hepex.org.au/tracing-the-origins-of-esp/ (last access: 18 March 2025), 2016.
When this study was carried out, the GR4J model (Perrin et al., 2003) was used in the HOUK to produce the ESP forecasts, having been used operationally for 5 years. This was subsequently updated to GR6J (Génie Rural à 6 paramètres Journalier; Pushpalatha et al., 2011) in October 2023. However, the difference in skill between the two model structures is minimal (Appendix Figs. A1–A3), except for some catchments in the south-east for a short lead time. The mean difference in skill (measured by the continuous ranked probability skill score – CRPSS) between the two models is less than 0.03. In this study, we used GR4J, but given the marginal discrepancy in performance between the two models, we anticipate that the findings and conclusions of this study will remain largely applicable when employing GR6J.